Embed Size (px)
Citation preview

Supliment 2008Reproducerea cvasiintegralǎ a cursului
COS 598A, Parallel Architecture and Programming,predat la Princeton University, Princeton N.J., U.S.A.Traducerea (nu fǎrǎ defecte): Gheorghe M.Panaitescu
1

Introducere
Paginile care urmeazǎ sunt reproducerea cursului COS 598A, Parallel Architecture and Programming, tinut la Universitatea Princeton din Statele Unite în primǎvara anului 2007 pentru studenti de profiluri diverse interesati de calculul paralel. Am gǎsit multe idei noi, proaspete în acel curs si am considerat potrivit a le aduce în zona de interes a studentilor ca o utilǎ completare la materialul existent deja, afisat încǎ în anul scolar precedent.
Versiunea în limba românǎ care poate fi cititǎ în continuare pleacǎ de la prezentǎrile sustinute vizual si verbal în fata studentilor de la universitatea amintitǎ si este în oarecare mǎsurǎ dezvoltatǎ prin consultarea altor câteva surse ajutǎtoare.
Figurile sunt preluate aproape în totalitate din sursa COS 598A: în graba de a aduce studentilor de la Calculatoare material de studiu nou, numai o micǎ parte din diagrame si figuri a fost re-fǎcutǎ si înzestratǎ cu comentarii în limba românǎ. Aceastǎ carentǎ este pe alocuri suplinitǎ prin comentarii suplimentare în text si prin note de subsol.
Acest supliment de informatii tehnico-stiintifice din domeniu ar putea capta, credem, interesul studentilor cǎrora le este destinat.
2

Generalitǎti asupra arhitecturilor paralel si asupra modelelor de programare
Ce este un calculator paralel?
Un calculator paralel este o reuniune de elemente procesoare care coopereazǎ la rezolvarea rapidǎ, acceleratǎ a unor probleme de amploare.Câteva aspecte majore care fac din calculatoarele paralel o specie aparte de sisteme de calcul: • Alocarea de resurse: cât de cuprinzǎtoare este reuniunea de elemente, cât de
puternice sunt elementele componente, câtǎ memorie este implicatǎ.• Accesul la date, comunicarea si sincronizarea: cum coopereazǎ si cum
comunicǎ componentele, cum se transmit datele între procesoare, care sunt în esentǎ formele primare de coperare (acele abstractions si primitives).
• Performantele si scalabilitatea: cum se traduc toate aceste elemente de structurǎ în performante, cum se pot (dacǎ se pot) scala1 performantele.
De ce este necesar paralelismul?
• Paralelismul furnizeazǎ o alternativǎ în ceea ce priveste performanta la ceasul (clock) dorit a fi mai rapid si mai rapid. Admitând o dublare a performantei efective pe nod la fiecare 2 ani, un sistem cu 1024 de unitǎti procesoare centrale (CPU) poate produce o perfomantǎ pe care o poate avea un singur CPU în 20 de ani.
• Paralelismul se aplicǎ la toate nivelurile de proiectare a sistemului.• Paralelismul este din ce în ce mai în centrul problemelor mari de procesare
a informatiei. Câteva exemple: calculele stiintifice: simularea, analiza datelor, managementul si stocarea informatiei etc.; calculele de interes comercial: procesarea tranzactiilor, exploatarea bazelor de date; aplicatiile Internet: operatii de cǎutare, Google opereazǎ cu cel putin 50.000 de procesoare, multe din ele ca parte a unor mari sisteme paralel.
Cum se pot studia sistemele paralel?
1 Scalabil – scalabilitate. Cuvinte populare printre specialistii IT, care se referǎ la cât de bine se poate adapta un sistem hardware sau software la cerinte în crestere. De pildǎ, un sistem în retea scalabil este un sistem care poate fi alcǎtuit la început din câteva noduri dar care poate fi extins cu usurintǎ la mii de noduri. Scalabiltatea poate fi o caracteristicǎ foarte importantǎ deoarece ea aratǎ cǎ se poate face o investitie într-un sistem cu siguranta cǎ cresterea lui ulterioarǎ este deplin posibilǎ.
3

Istoric: diverse structuri organizationale inovatoare legate adesea de modele noi de programare. Solutiile s-au maturizat rapid sub puternice influente si restrictii tehnologice: microprocesoarele sunt de-acum omniprezente, iar laptop-urile si supercalculatoarele sunt în esentǎ similare, trendul tehnologic face ca tratǎrile diverse sǎ fie convergente. Aceleasi tendinte tehnologice fac calculul paralel inevitabil, îl aduc pe curentul principal al preocupǎrilor din domeniu.Apare necesitatea întelegerii nu numai a clasificǎrilor/ierarhizǎrilor ci si a principiilor fundamentale si a compromisurilor urmǎrite în proiectare: identificare, ordonare, multiplicare, performatele în comunicare.
Fortele motoare ale calculului paralel
Necesitǎtile aplicative, pofta de calcul generalǎ si insatiabilǎ: calcule stiintifice (în mecanica fluidelor, în biologie, în chimie, în fizicǎ …), calcule de uz general (video, graficǎ, CAD, baze de date, procesarea tranzactiilor…), aplicatii de Internet (cǎutare, comert electronic, clustering…)Trendul tehnologic.Trendul arhitecturilor.Aspectele economice.Tendintele curente:Toate microprocesoarele au suport pentru multiprocesare (MP) externǎ.Serverele si statiile de lucru sunt fǎrǎ exceptie MP-uri: Sun, SGI, Dell, COMPAQ…Microprocesoarele sunt ele însesi multiprocesoare.S-a realizat cu deplin succes multiprocesarea pe acelasi cip (SMP – Symmetric MultiProcessors).
Trendul aplicatiilor
Frecventa ceasului si (implicit) durata unui ciclu sunt caracteristici fundamental determinante în ceea ce priveste performanta sistemelor de calcul. Cererea de cicluri în numǎr cât mai mare în unitatea de timp alimenteazǎ progresele hardware si reciproc. Numǎrul în crestere de cicluri la secundǎ provoacǎ o crestere exponentialǎ a performantelor microprocesoarelor.Existǎ totodatǎ o presiune puternicǎ pe arhitecturile paralel, prin aparitia unor aplicatii foarte pretentioase.Cererea de amplificare a performantelor: sunt cerute performante ale sistemelor la un cost progresiv crescǎtor; se poate vorbi de o piramidǎ a platformelor de calcul.Telul în alicatiile care utilizeazǎ masini parelel este accelerarea (speedup):
)1()()(
procesoraPerformantprocesoarepaPerformantprocesoarepSpeedup =
Pentru o problemǎ de dimensiune fixǎ, performanta = 1/timp.
4

)()1()(
procesoarepTimpulprocesorTimpulprocesoarepSpeedup fixaproblema =
Cerintele calculelor stiintifice
Cerintele calculelor stiintifice sunt si acestea permanent în crestere: precizie mai mare, modelare pe niveluri superioare, cunostinte pe niveluri superioare, analiza unor cantitǎti de datemari la modul exploziv.Exemple din domeniul nr.1: modelarea climaticǎ si ecologicǎ.Aproximativ în 2010: rezolutia actualǎ mai curând simplǎ, timpul acoperit prin simulare si indicatiile fizice îmbogǎtite duc la o crestere a pretentiilor cu factori de la 104 la 107. Predictia mai sigurǎ (more reliable) a încǎlzirii globale, a dezastrelor naturale, a vremii vor fi de actualitate la sfârsitul deceniului curent.Aproximativ în 2015: vor fi implementate modele predictive ale distrugerii pǎdurilor tropicale, modele de sustenabilitate a pǎdurilor terrei, vor fi cuprinse efectele schimbǎrilor climatice asupra ecosistemelor si asupra surselor de alimente, se vor modela tendintele globale în sǎnǎtate.Aproximativ în 2020: modele verificate si verificabile ale ecosistemelor si epidemice globale, integrarea efectelor macro cu efectele locale si apoi cu micro efectele, efectele predictive ale activitǎtilor umane asupra suportului vietii pe pǎmânt, întelegerea sistemelor vii de pe pǎmânt.Exemple din domeniul nr.2: teme din biologie.Aproximativ în 2010: diagnoza molecularǎ computerizatǎ ex vivo si apoi in vivo.Aproximativ în 2015: vaccinuri pe bazǎ de model, medicina individualizatǎ, integrarea cuprinzǎtoare a datelor biologice (cele mai multe co-analizabile), modelul complet al unei celule.Aproximativ în 2020: modelul complet al tesuturilor/organismelor multicelulare, medicamente dezvoltate pur in-silico, medicamente inteligente personalizate, întelegerea sistemelor biologice complexe, celulele si organismele în ecosisteme, modele predictive verificabile ale sistemelor biologice.
Cerinte de calcul ingineresc
Masini paralele mari devin pǎrti principale în multe industrii: analiza rezervelor de petrol, simularea coliziunilor între vehicole de diferite tipuri, analiza de aderentǎ la frânare, eficienta combustiei în automobile, analiza deplasǎrii, eficienta motoarelor, mecanica structurilor, electromagnetismul în aeronauticǎ, proiectarea asistatǎ de calculator (CAD), modelarea molecularǎ în industria farmaceuticǎ, vizualizarea în domeniile deja mentionate dar si în industria de entertainment (cinematografie), arhitecturǎ (deplasǎri virtuale, interpretare), modelarea financiarǎ (randamente si analize derivate) etc.
5

Curbe de învǎtare pentru aplicatii paralele
Programul AMBER de simulare a dinamicii moleculare.Punctul de plecare a fost codul vectorial pentru masina Cray-1.Pe masina Cray90 – 145 Mflops, pe Paragon cu 128 de procesoare – 406 Mflops în versiunea finalǎ, pe Cray T3D cu 128 de procesoare – 891 Mflops.
Calcule de interes comercial
Calculele de interes comercial se bazeazǎ de asemenea, pentru scopuri înalte pe paralelism. Scara calculelor nu este asa de mare dar utilizarea este mult mai larg rǎspânditǎ. Puterea de calcul determinǎ scara la care se poate actiona pe o afacere.Bazele de date, procesarea tranzactiilor în timp real, suportul decizional, data mining, data warehousing s.a.Transaction Processing Performance Council (TPC) benchmarks (TPC-C order entry, TPC-D decision support): sunt furnizate criterii de scalare explicite (dimensiunea întreprinderii se scaleazǎ cu sistemul), dimensiunea problemei nu mai este fixatǎ/limitatǎ asa încât capacitatea de prelucrare este o mǎsurǎ a performantei (tranzactii pe minut, tpm).Comert electronic (e-commerce), cǎutare si alte servicii internet scalabile: aplicatii paralel care sunt executate pe clustere, dezvoltarea de noi modele si primitive software paralel.Examinare a analizei automate a datelor disparate de mare cuprindere.
6

Paralelismul este penetrant în domenii variate.Este foarte important atât paralelismul la scarǎ micǎ cât si cel la scarǎ moderatǎ.Este dificil a obtine instantanee (snapshot) pentru a compara platforme produse de producǎtori diferiti.
Sumar al tendintelor aplicative
Trecerea la calculul paralel s-a produs în zona stiintificǎ si inginereascǎ.De asemenea a apǎrut în calculul comercial: tranzactii cu bazele de date, zona financiarǎ; serviciile internet scalabile (cel putin paralelismul de granulatie grosierǎ).Programele pentru calculatoarele de birou utilizeazǎ si ele mai multe fire care sunt în mare mǎsurǎ asemenea programelor paralele.Cererea de capacitate mai mare pentru sarcinile secventiale: foarte largǎ utilizare a multiprocesoarelor de scarǎ micǎ.Cererea de aplicatii solide îsi mentine cresterea în timp.
Performance(tpmC)
Price-performance($/tpmC)
PerformancPerformanc Price-Price- 342K
19K 40K 57K
165K234K
12K7K0
50,0100,0150,0200,0250,0300,0350,0400,0
1996 1997 1998 1999 2000 2001 200 2003 $$1$2$3$4$5$6$7$8$9$10
7
4-wayCpq PL 5000
Pentium Pro 200 MHz
6,751 tpmC$89.62/tpmC
Avail: 12-1-96TPC-C v3.2(withdrawn)
4-wayCpq PL 5000
Pentium Pro 200 MHz
6,751 tpmC$89.62/tpmC
Avail: 12-1-96TPC-C v3.2(withdrawn)
8-wayDell PE 8450PIII Xeon 700
MHz57,015 tpmC$14.99/tpmC
Avail: 1-15-01TPC-C v3.5(withdrawn)
32-wayUnisys ES7000
Xeon MP 2 GHz234,325 tpmC$11.59/tpmC
Avail: 3-31-03TPC-C v5.0
32-wayNEC Express5800
Itanium2 1GHz342,746 tpmC$12.86/tpmC
Avail: 3-31-03TPC-C v5.0
6-wayUnisys AQ HS6Pentium Pro 200
MHz12,026 tpmC$39.38/tpmC
Avail: 11-30-97TPC-C v3.3(withdrawn)
8-wayCpq PL 8500PIII Xeon 550
MHz40,369 tpmC$18.46/tpmC
Avail: 12-31-99TPC-C v3.5(withdrawn)
32-wayUnisys ES7000PIII Xeon 900
MHz165,218 tpmC$21.33/tpmC
Avail: 3-10-02TPC-C v5.0

Provocarea majorǎ pentru toatǎ lumea este de a face programarea paralel mai usoarǎ: a profita de paralelismul penetrant cu sisteme multi-core.
Trendul tehnologic: cresterea microprocesoarelorP
erfo
rman
ce
0.1
1
10
100
1965 1970 1975 1980 1985 1990 1995
Supercomputers
Minicomputers
Mainframes
Microprocessors
Blocul de multiprocesoare este acum practic si cel mai rapid.
Performantele microprocesoarelor cresc anual cu 50-100%.Frecventa ceasurilor se dubleazǎ la fiecare trei ani.Numǎrul de tranzistoare se multiplicǎ cu patru la fiecare trei ani. Legea lui Moore: xtors pe cip = 1,59anul – 1959 (initial 2anul – 1959).Investitia imensǎ pe fiecare generatie este antrenatǎ de o piatǎ de commodity imensǎ.Cu fiecare scalare cu n a dimensiunii caracteristice (a unui element de cip) se obtin O(n2) tranzistori si frecventa posibilǎ a ceasului creste de O(n).Ar trebui sǎ obtinem o crestere a performantelor de O(n3). Se obtine? Sǎ vedem trendul arhitecturilor.
8

Scalarea cipului (die) si a dimensiunii caracteristice (feature size): cipul creste cu 7% pe an, dimensiunea caracteristicǎ scade cu 25-30%
Frecventa ceasului (familia Intel) creste anual cu o ratǎ de 30%.
9

Numǎrul de tranzistori (familia Intel) creste mai rapid decât frecventa ceasului, 40% pe an, o contributie mai mare cu un ordin de mǎrime în circa douǎ decenii.Lǎrgime/spatiu (width/space) are un potential mai mare decât viteza pe unitate.
Cum se pot utiliza mai multi tranzistori?
Sporirea performantei pe un singur fir prin arhitecturǎ: nu tine pasul cu potentialul dat de tehnologie.Utilizarea tranzistorilor pentru structuri de memorie pentru cresterea localismului datelor: nu aduce prea mari avantaje (de douǎ ori la de patru ori dimensiunea cahe-ului).Utilizarea paralelismului la nivel de instructiune, la nivel de fir.
Performantele microprocesoarelor
10

Limita de jos: nu pentru cǎ performanta pe un singur fir s-a plafonat, ci pentru cǎ paralelismul este natural pentru a rǎmâne pe o curbǎ mai bunǎ.
O poveste similarǎ pentru memorare (numǎr de tranzistori)
Povestea este cam aceeasi pentru memoria DRAM
11

Divergenta dintre capacitatea de memorare si viteza de calcul mai pronuntatǎ. Capacitatea a crescut de 1000 de ori între 1980 si 1995 si creste în continuare cu 50% pe an. Latenta se reduce cu numai 3% pe an (numai de douǎ ori în cei 15 ani mentionati). Banda de trecere pentru cipul de memorie creste de douǎ ori mai repede decât se reduce latenta.
Memoriile mai mari sunt mai lente în timp ce procesoarele sunt în crestere de vitezǎ. Apare necesitatea transferului de date în paralel. Ierarhia memoriilor cache se adânceste. Cum se organizeazǎ memoria cache?Paralelismul creste dimensiunea eficientǎ a fiecǎrui nivel al ierarhiei fǎrǎ a creste timpul de acces.Paralelismul si localismul în memoria sistemului, asemenea: conceptiile noi regǎsesc multi biti în cipul de memorie, urmeazǎ un transfer rapid în sistemul pipeline prin interfete mai înguste. Bufferele debiteazǎ (caches) datele accesate cele mai recent.Cu discurile la fel: discuri paralele si sectiuni cache.În general, cresterea dramaticǎ a vitezelor de care sunt capabile procesoarele, capacitatea de memorare si banda de trecere fatǎ de latente (în special) si fatǎ de viteza ceasurilor aratǎ spre paralelism ca directie de urmat din punct de vedere arhitectural.
Trendul arhitectural
Arhitectura traduce oferta tehnologiei în performante si abilitǎti.Rezolvǎ echilibrul între paralelism si localism. Microprocesoarele recent confectionate calculeazǎ 1/3 din timp, opereazǎ cache 1/3 din timp, se conecteazǎ cu alte echipamente 1/3 din timp. Echilibrul se poate negocia încǎ o datǎ cu scara si cu progresele tehnologice.Patru generatii în istoria arhitecturilor: tubul, tranzistorul, circuitele integrate si circuitele integrate pe scarǎ largǎ (VLSI). Ne concentrǎm aici numai pe generatia VLSI.
12

Cea mai importantǎ delimitare în VLSI a fost în ceea ce priveste scara/tipul de paralelism exploatat.
Trendul arhitectural în paralelism
Pânǎ în 1985: paralelismul la nivel de biti: 4 biti → 8 biti → 16 biti. Încetineste dupǎ 32 de biti. Adoptarea arhitecturii pe 64 de biti este în derulare mai mult decât promitǎtoare. Adoptarea arhitecturii pe 128 de biti este îndepǎrtatǎ si nu din motive de performante. Marea schimbare a adus-o structura cu 32 de biti când microprocesorul si memoria cache au încǎput, s-au potrivit pe un acelasi cip. Pipeline-ul de bazǎ, suportul hardware pentru operatii complexe cum este multiplicarea FP (floating point) etc. au adus cresteri de performate de O(n3). Intel: 4004 la 386.Între anii ’80 mijlocii si anii ’90 mijlocii se dezvoltǎ paralelismul la nivel de instructiune. Sistemul pipeline si seturile de instructiuni simple plus dezvoltarea compilatoarelor (RISC). Memorii cache mai mari pe cip, dar o ratǎ de ratǎri de numai pe jumǎtate la o cvadruplare a dimensiunii memoriei cache. Mai multe unitǎti functionale, executii superscalare, dar scalarea performantelor limitatǎ. Crestere în performante de O(n2). Intel: 486 la Pentium III/IV.Dupǎ mijlocul deceniului ultim al secolului trecut, rafinament mai mare: executii în afara ordinei (out-of-order), executie speculativǎ, executie predictivǎ. Toate acestea pentru a rezolva problemele de transfer al controlului si de latenţǎ. Procesoare de foarte mare cuprindere (issue): în multe aplicatii nu ajutǎ prea mult, necesitǎ exploatarea firelor multiple (SMT – Simultaneous Multi-Threading). Complexitatea sporitǎ si cresterea geometriei duce la o încetinire: fire globale lungi, timp de acces la date în crestere, timp pentru market.Pasul urmǎtor: paralelismul la nivel de fire (threads).
Ne poate duce nivelul instructiunilor acolo?
Accelerǎri (speedups) pentru procesoare superscalare publicate în literaturǎ:• Horst, Harris si Jardine [1990] ............................ 1,37• Wang si Wu [1988] ............................................. 1,70• Smith, Johnson si Horowitz [1989] ..................... 2,30• Murakami si altii [1989] ...................................... 2,55• Chang si altii [1991] ............................................ 2,90• Jouppi si Wall [1989] .......................................... 3,20• Lee, Kwok si Briggs [1991] ................................ 3,50• Wall [1991] .......................................................... 5• Melvin si Patt [1991] ........................................... 8• Butler si altii [1991] ............................................. 17+
13

O gamǎ mare de valori din cauza diferenţelor între domeniile aplicaţiilor studiate (numerice sau non-numerice), din cauza capabilitǎţilor diferite ale procesoarelor modelate.
Potentialul ideal al paralelismului la nivel de instructiune (ILP)
0 1 2 3 4 5 6+0
5
10
15
20
25
30
●
●
●● ●
0 5 10 150
0.5
1
1.5
2
2.5
3
Frac
tion
of to
tal c
ycle
s (%
)
Number of instructions issuedS
peed
upInstructions issued per cycle
Banda de trecere la regǎsire (fetch) si resurse infinite, predicţia perfectǎ a ramificaţiilor, redenumire perfectǎ. Memorii cache reale si latenţe nule pentru ratǎri.
Rezultatele studiilor de paralelism la nivelul instructiunilor
Studiile acestea s-au concentrat asupra paralelismului în masinile 4 issue.
1 x
2 x
3 x
4 x
J o u p p i _ 8 9 S m i t h _ 8 9 M u r a k a m i _ 8 9 C h a n g _ 9 1 B u t l e r _ 9 1 M e l v i n _ 9 1
1 b r a n c h u n i t / r e a l p r e d i c t i o n
p e r f e c t b r a n c h p r e d i c t i o n
14

Studiile realiste aratǎ o accelerare nu mai mare decât dublǎ. Mai de curând se cerceteazǎ ILP (Instruction Level Parallelism) care priveste la fire pentru paralelism.
Banda de trecere a bus-ului: sistemul Intel
Bus-urile scaleazǎ?
Bus-urile sunt o cale convenabilǎ de a extinde arhitectura la paralelism, dar nu sunt scalabile. Banda de trecere nu creste pe mǎsurǎ ce sunt adǎugate CPU-uri.Sistemele scalabile utilizeazǎ memorii fizic distribuite.
Switch
P$
XY
Z
External I/O
Memctrl
and NI
Mem
15

Aspecte economice
Costurile de fabricatie sunt grosier de O(1/dimensiunea caracteristicǎ). Produsele de 90 nm costǎ circa 1-2 milarde de dolari. Astfel, fabricatia procesoarelor este costisitoare.Numǎrul de proiectanti sunt, tot asa, de O(1/dimensiunea caracteristicǎ). Procesorul 4004 de 10 microni are 3 proiectanti. Procesoarele recente de 90 nm beneficiazǎ de 300. Proiectele noi sunt foarte costisitoare.Existǎ o presiune spre consolidarea tipurilor de procesoare.Complexitatea procesoarelor este din ce în ce mai costisitoare.Partea de bazǎ (cores) se reutilizeazǎ dar dezvoltarea este si ea costisitoare.
Complexitatea proiectǎrii si productivitatea
Complexitatea proiectului depǎseste productivitatea umanǎ.
Microprocesoarele obisnuite (commodity price) sunt nu numai rapide dar sunt si ieftine. Costul dezvoltǎrii este de zeci de milioane de dolari. Dar sunt vândute mult mai multe comparativ cu supercalculatoarele. Acesta este un fapt crucial pentru a profita de investiţie si de a uza de blocul constructiv “community”. Arhitecturile paralel exotice nu se fac decât pentru scopuri speciale.Multiprocesoarele sunt opţiunea presantǎ a producǎtorilor de software (de pildǎ pentru baze de date) dar si a producǎtorilor de hardware.Standardizarea de la Intel genereazǎ SMP-uri mici, bazate pe bus, de natura “commodity”.
16

Dar ce se poate spune despre proiectarea perocesorului pe cip?
Reluǎm: numǎrul de tranzistori creste rapid; metodele de utilizat pentru performatele la rularea uni-fir sunt pe cale de a pierde din avânt; problemele cu memoria pledeazǎ si ele pentru paralelism; paralelismul la nivel de instructiune este limitat si necesitǎ trecerea la nivelul de fire; consolidarea este o fortǎ redutabilǎ; totul pare a indica spre mai multe cores mai simple si nu spre un core unic mare si complex; argumente cheie suplimentare: fire (wires), putere (power), cost.
Întârzierea pe fire
Scǎderea/prǎbusirea întârzierii portilor, cresterea întârzierii interconectǎrii globale au condus la fire locale scurte.
Puterea
17

Puterea disipatǎ în procesoarele Intel de-a lungul timpului
Puterea si performanţele
Puterea
Puterea creste odatǎ cu numǎrul de tranzistoare si cu frecventa ceasului.Puterea creste cu tensiunea: P = CV2f.Trecând de la 12 V la 1,1 V se reduce consumul de putere de 120 de ori în 20 de ani.Se preconizeazǎ ca în 2018 voltajul sǎ fie 0,7 V. Asta micsoreazǎ puterea de numai 2,5 ori,
18

Vârful de putere pe cip în proiect: Itanium II a fost de 130 W, Montecito de 100 W. Puterea este o restrictie în proiectare de prim ordin.Tehnicile de alimentare la nivelul circuitelor practic aproape de ceea ce trebuie: porti pentru ceas, praguri multiple, tranzistori transversali (clock gating, multiple thresholds, sleeper transistors)
Puterea si frecvenţa ceasului
Douǎ generatii de procesoare; douǎ dimensiuni caracteristice
Implicatiile arhitecturǎ-putere
Mai puţini tranzistori în “core”, eficienţǎ mai mare la putere. Editare (de instrucţiuni) mai scurtǎ, pipeline mai scurt, ferestre OOO (Object Oriented Operations) mai mici; readuce performanţele procesoarelor pe curba O(n3); dar scad performanţele firului unic.Care complexitate este de eliminat? Speculaţia, multifirele, …? Toate sunt bune sub un aspect, dar trebuie avut grijǎ de raportul putere/beneficii.
19

Previziuni ITRS (International Technology Roadmap for Semiconductors)
Numǎrul mai mare de procesoare pe cip va duce la depǎsirea performantele procesorului individual
20

Costul dezvoltǎrii unui cip
Inginerie non-recursivǎ, costuri repede crescǎtoare pe mǎsurǎ ce complexitatea depǎseste productivitatea
Costurile recurente pe piesǎ (die) (1994)
21

Sumarul a ceea ce este/poate fi pe un cip
Dincolo de argumentele în favoarea paralelismului bazat pe procesoarele “commodity” în general: întârzierea pe conexiuni, puterea si aspectele economice toate aduc argumente pentru “cores” simple dar multiple pe un cip si nu “cores” unice din ce în ce mai complexe.Provocarea software (cum sǎ se programeze masinile paralele).
De ce arhitecturǎ paralel? (sumar)
Din ce în ce mai atractivǎ. Aspectele economice, tehnologia, ahitectura, cererea motivatǎ de/prin aplicatii.Se aflǎ deja de ceva timp în curentul principal.Paralelismul se exploateazǎ la mai multe niveluri: la nivel de instructiune, la nivel de fire în cazul multiprocesǎrii pe cip, pe serverele multiprocesoare, pe multiprocesoarele la scarǎ mare (MPP-uri – Massively Parallel Processing).Focalizare pe aceastǎ clasǎ: paralelismul la nivelul multiprocesare.Aceeasi poveste si din perspectiva sistemului de memorare: cresterea benzii de trecere, reducerea latentei medii cu multe memorii locale.Existǎ natural o gamǎ mare de arhitecturi paralele. Costuri, performante si scalabilitate diferite.
Tendinte în supercalculul stiintific
Supercalculul stiintific oferǎ teren fertil pentru arhitecturi si tehnici înnoitoare. Piata ocupatǎ de supercalculul stiintific este redusǎ fatǎ de cea comercialǎ desi MP-urile devin de interes principal. Începând din anii 70 dominante sunt masinile vectoriale. Microprocesoarele au câstigat imens în performantele în virgulǎ mobilǎ: viteze ale ceasului mari, unitǎti de virgulǎ mobilǎ pe principiul pipeline (exemplu: mult-add), paralelismul la nivel de instructiune, utilizarea eficientǎ a memoriilor cache. Plus o seamǎ de aspecte economice.Multiprocesoarele la scarǎ largǎ înlocuiesc supercalculatoarele vectoriale.
22

Performantele brute ale sistemelor uniprocesor: LINPACK
LIN
PAC
K (M
FLO
PS
)
▲
▲
▲
▲
▲
▲
◆
◆
◆
◆◆
◆
◆◆
◆
◆ ◆
1
10
100
1,000
10,000
1975 1980 1985 1990 1995 2000
▲ CRAY n = 100■
■
CRAY n = 1,000
◆ Micro n = 100●
●
Micro n = 1,000
CRAY 1s
Xmp/14se
Xmp/416Ymp
C90
T94
DEC 8200
IBM Power2/990MIPS R4400
HP9000/735DEC Alpha
DEC Alpha AXPHP 9000/750
IBM RS6000/540
MIPS M/2000
MIPS M/120
Sun 4/260
■
■■
■
■
■
●
●
●
● ●
●●●
●●
●
LIN
PAC
K (G
FLO
PS
)
■ CRAY peak● MPP peak
Xmp /416(4)
Ymp/832(8) nCUBE/2(1024)iPSC/860
CM-2CM-200
Delta
Paragon XP/S
C90(16)
CM-5
ASCI Red
T932(32)
T3D
Paragon XP/S MP(1024)
Paragon XP/S MP(6768)
■
■
■
■
●
●
■●
●
●
●●
●
●●
0.1
1
10
100
1,000
10,000
1985 1987 1989 1991 1993 1995 1996
Chiar si masinile Cray devin paralele: X-MP (2-4), Y-MP (8), C-90 (16), T94(32).Din 1993, Cray produce de asemenea MPP-uri (T3D, T3E)
23

Un alt unghi de vedere
Topul celor mai rapide 10 calculatoare (Linpack)
Rank Site Computer Processors/Year/Rmax1 DOE/NNSA/LLNL USA IBM BlueGene 131072 2005 2806002 NNSA/Sandia Labs, USA Cray Red Storm, Opteron 26544 2006 1014003 IBM Research, USA IBM Blue Gene Solution 40960 2005 912904 DOE/NNSA/LLNL, USA ASCI Purple - IBM eServer p5 12208 2006 757605 Barcelona Center, Spain BM JS21 Cluster, PPC 970 10240 2006 626306 NNSA/Sandia Labs, USA Dell Thunderbird Cluster 9024 2006 530007 CEA, France Bull Tera-10 Itanium2 Cluster 9968 2006 528408 NASA/Ames, USA SGI Altix 1.5 GHz, Infiniband 10160 2004 518709 GSIC Center, Japan NEC/Sun Grid Cluster (Opteron) 11088 2006 4738010 Oak Ridge Lab, USA Cray Jaguar XT3, 2.6 GHz dual 10424 2006 43480
Stiluri arhitecturale în Top 500
Tipuri de procesoare în Top 500
24

Tipuri de instalǎri în Top 500
Observatii speciale asupra Top-ului 500 din noiemrie 2006
• Calculatorul NEC Earth Simulator (la vârf în 5 liste succesive) a cǎzut pe locul 14.
• Sistemul de pe locul 10 si-a dublat performantele într-un singur an.• Numǎrul 359 de acum sase luni a ajuns pe locul 500 în aceastǎ listǎ.• Performanta totalǎ din Top 500 creste de la 2,3 Pflops acum un an, la 3,5
Pflops.• Clusterele sunt dominante la aceastǎ scarǎ: 359 de structuri din 500 sunt
calificate drept clustere.• Procesoarele dual core cresc în popularitate: 75 utilizeazǎ Opteron dual core
si 31 Intel Woodcrest.• IBM este producǎtorul principal cu aproape 50% din sisteme, HP este pe
locul secund.
25

• IBM si HP au 237 din cele 244 instalǎri comerciale si industriale.• Statele Unite au 360 din cele 500 de instalǎri, Marea Britanie 32, Japonia
30, Germania 19, china 18.
Performantele Linpack în timp, în Top 500
Un alt unghi de vedere asupra cresterii performantelor
26

27

Tipuri de procesoare în Top 500 (2002)
Sisteme distribuite si paralel
Evolutia si convergenta arhitecturilor paralele
Istoric
Din punct de vedere istoric, arhitecturile paralel sunt legate strâns de modelele de programare. Arhitecturi divergente, cu pattern de crestere impredictibil.
28

Incertitudinea în directia de urmat a paralizat dezvoltarea de software paralel!
Azi
Extindere a “arhitecturii calculatorului” pentru a suporta comunicarea si cooperarea. În trecut: arhitectura setului de instructiuni. Mai nou: arhitectura comunicǎrii.Se definesc abstractiile critice, limitele si primitivele (interfetele), structurile organizationale care implementeazǎ interfetele (hw si sw).Compilatoarele, bibliotecile si sistemele de operare sunt azi punti importante între aplicatii si arhitecturi.
Cadrul stratificat modern
Modelul de programare paralel
Ceea ce programatorul foloseste la scrierea aplicatiilor.Specificǎ comunicarea si sincronizarea.Exemple:• Multiprogramare: nu existǎ comunicare sau sincronizare la nivel de
program
Application Software
SystemSoftware SIMD
Message Passing
Shared MemoryDataflow
SystolicArrays
Architecture
29

• Spatiu de adresare partajat: ca un panou de afisaj (bulletin board).• Transfer de mesaje: ca srisorile sau ca apelurile telefonice, explicite si punct
la punct.• Paralel pe date: mai regimentat, actiuni globale asupra datelor. Implementat
si cu spatiu de adresare partajat si cu transfer de mesaje.
Abstractii (preocupǎri) de comunicare
Primitive de comunicare la nivel de utilizator furnizate de sistem. Realizeazǎ modelul de programare. Existǎ o asociere (mapping) între primitivele de limbaj ale modelului de programare si aceste primitive.Suportate direct de hardware sau via OS sau via software de utilizator.Dezbateri intense asupra a ceea ce se suportǎ software si asupra spatiului (gap) între straturi (layers).Azi: interfetele hardware/software tind a fi plate, adicǎ complexitatea este în linii mari uniformǎ. Compilatoarele si sofware-ul joacǎ roluri importante ca punti de legǎturǎ. Trendul tehnologic exercitǎ o influentǎ puternicǎ.Rezultatul este convergenta în structura organizationalǎ. Primitive relativ simple pentru scopul de a facilita comunicarea generalǎ.Arhitectura de comunicare
Este interfata utilizator/sistem la care se adaugǎ implementarea.Interfata utilizator/sistem: primitivele de comunicare expuse la nivelul utilizatorului de hardware si la nivel de sistem de software (uneori poate exista un nivel utilizator software între acesta si modelul de programare).Implementarea: structuri organizationale care implementeazǎ primitivele (hardware sau OS – Operating System). Cât de optimizate sunt acestea? Cât de integrate în nodul de procesare sunt? Structura retelei.Scopurile urmǎrite: performante, aplicabilitate largǎ, programabilitate, scalabilitate, cost redus.
Evolutia modelelor arhitecturale
Istoric, masinile au fost croite pe modelele de programare. Modelele de programare, abstractiunile de comunicare si organizarea masinii se întrunesc în “arhitecturǎ”.Întelegerea evolutiei lor ajutǎ întelegerea convergentelor. Identificǎ conceptul de “core”.Evolutia modelelor arhitecturale:• Spatiu de adresare partajat (SAS – Shared Address Space).• Transfer de mesaje.• Paralel pe date.• Altele (nediscutate aici): Dataflow, Systolic Arrays.Se examineazǎ modelul de programare, motivatia si convergentele.
30

Spatiu de adresare partajat (SAS)
Orice procesor poate accesa direct orice locatie de memorie. Comunicarea este implicitǎ, se produce odatǎ cu operatiile de încǎrcare si descǎrcare.Convenabilǎ: transparenţa locatiilor. Model de programare similar partajǎrii temporale pe sistemele uniprocesor, cu deosebirea cǎ procesele se deruleazǎ pe porcesoare diferite, randament (throughput) bun pe sarcini de lucru multiprogramate.Furnizate natural pe o varietate largǎ de platforme. Istoria consemneazǎ cel putin precursori de mainframes în anii 60 timpurii. O mare varietate de scarǎ: câteva procesoare la câteva sute de procesoare.Cunoscute popular ca masini sau modele cu memorie partajatǎ. Ambiguitate: memoria poate fi distribuitǎ fizic între procesoare.Procesul: spatiul de adresare partajat plus unul sau mai multe fire de control.Portiuni din spatiul de adresare al proceselor sunt partajate. Scrierile se fac în locatii de memorie vizibile si altor fire (si altor procese). O extensie naturalǎ a modelelor uniprocesor: pentru comunicare – operatii conventionale cu memoria, operatii atomice speciale pentru sincronizare. Sistemul de operare (OS) utilizeazǎ memoria partajatǎ pentru a coordona procesele.
Comunicarea hardware pentru SAS
Este si ea o extensie naturalǎ a uniprocesǎrii.Avem deja procesorul, unul sau mai multe module de memorie si controlere de I/O conectate toate la o (inter)conexiune hardware de un tip anumit. Capacitatea de memorare creste prin adǎugarea de module suplimentare, capacitatea I/O prin adǎugarea de controllere.
31

Se adaugǎ procesoare pentru procesare!
Istoria arhitecturilor SAS
Solutia “Mainframe”. Motivatǎ de multiprogramare. Extinde sistemul crossbar utilizat pentru lǎrgime de bandǎ cu memoria si dispozitivele I/O. La început costul procesoarelor a limitat structurile la mic, ulterior costul sistemului crossbar. Banda de trecere scaleazǎ cu numǎrul de procesoare. Costul incremental mare; se utilizeazǎ în loc schemele multietajate (multistage).
Solutia “minicomputer”. Aproape toate sistemele cu microprocesoare au un bus. Motivatǎ de multiprogramare, procesarea tranzactiilor (TP). Utilizatǎ din plin pentru calculul paralel. Denumitǎ multiprocesor simetric (SMP – Symmetric MultiProcessor). Latenţa mai mare decât la sistemele uniprocesor. Bus-ul este strangulant în ceea ce priveste banda de trecere: utilizarea memoriilor cache ridicǎ problema coerentei. Cost incremental scǎzut.
P
CI/
M MCI/
$
32

Exemplu: Intel Pentium Pro Quad
Toatǎ aderenţa de coerenţǎ si multiprocesare este integratǎ în modulul procesorului. Integrare înaltǎ, orientatǎ pe volum extins. Latentǎ si bandǎ mici.
33

Exemplu: SUN Enterprise
Gigaplane bus (256 data, 41 addr ess, 83 MHz)
SB
US
SB
US
SB
US
2 Fi
berC
hann
el
100b
T, S
CS
I
Bus interface
CPU/memcardsP
$2
$P
$2
$
Mem ctrl
Bus interface/switch
I/O cards
Memoria plasatǎ chiar pe plǎcile procesorului. 16 plǎci (cards) de fiecare tip (procesor + memorie sau dispozitive I/O).Toatǎ memoria accesatǎ pe bus, deci simetricǎ.Bandǎ mai largǎ, bus cu latentǎ mai înaltǎ.
34

Scalarea
Probleme cu interconectarea: costul (crossbar) sau banda (bus).Schema Dance-hall: banda de trecere este încǎ scalabilǎ, dar este mai ieftinǎ decât sistemul crossbar, latentele cu memoria sunt uniforme dar uniform de mari.Schema cu memorie distribuitǎ sau NUMA (Non-Uniform Memory Access): un construct de spatiu de adresare partajat din tranzactii prin mesaje simple pe o retea de utilitate generalǎ (de exemplu: read-request, read-response); caching pentru datele partajate (uzual nonlocale).
Exemplu: Cray T3E
Switch
P$
XY
Z
External I/O
Memctrl
and NI
Mem
Scalare posibilǎ pânǎ la 1024 de procesoare, legǎturi de 480 MB/secundǎ.Controllerul memoriei genereazǎ cererile de comunicare pentru referiri nonlocale. Arhitectura comunicǎrii strict integratǎ în nod.
M M M° ° °
° ° ° M ° ° °M M
N e t w o r kN e t w o r k
P
$
P
$
P
$
P
$
P
$
P
$
“Dance hall” Distributed memory
35

Nu existǎ vreun mecanism hardware pentru coerenţǎ (sistemel SGI Oeigin etc. asigurǎ aceasta).
Memoriile cache si coerenţa de cache
Memoriile cache joacǎ un rol cheie în toate cazurile. Reduc timpul mediu de acces la date, reduc cererea de bandǎ de trecere formulatǎ pentru interconectarea partajatǎ.Dar memoriile cache private ale procesoarelor creeazǎ o problemǎ. Copiile unei variabile pot fi prezente în mai multe cache-uri. O scriere fǎcutǎ de un procesor poate sǎ nu fie vizibilǎ celorlalte procesoare: ele vor pǎstra accesul la valorile depǎsite din cache-urile lor. Apare problema coerentei de cache. Trebuie luate mǎsuri pentru asigurarea vizibilitǎtii.
Exemplu de problemǎ de coerentǎ de cache
Procesoarele vǎd valori diferite ale lui u dupǎ evenimentul 3.Cu rescrierea cache-urilor, valoarea rescrisǎ în memorie depinde de circumstanta în care cache-ul evacueazǎ sau rescrie valoarea când procesul care accede la memoria principalǎ poate vedea chiar valoarea veche.Situaţie inacceptabilǎ pentru programe dar frecventǎ!
Coerenţa de cache
Citirea une locatii trebuie sǎ returneze cea mai recentǎ valoare scrisǎ de oricare dintre procese.Facil în sistemele uniprocesor. Exceptie: I/O; coerenta între dispozitivele I/O si procesoare. Aceste situatii sunt rare si solutiile software sunt acoperitoare.Ar fi de dorit ca si în cazul în care procesele ruleazǎ pe procesoare diferite lucrurile sǎ se petreacǎ la fel. De pildǎ ca atunci când procesele sunt intercalate pe un singur procesor.Dar problema coerentei cache-urilor este mult mai criticǎ în cazul multiprocesǎrii. Difuzǎ si criticǎ sub aspectul performantelor. A asigura un
36

suport eficient pentru modelul de programare este o problemǎ fundamentalǎ la proiectare.Este încǎ mai rǎu decât atât: ce înseamnǎ “cel mai recent” pentru procese independente? Se cer modele ale consistenţei de memorie.
SGI Origin2000
L2 cache
P
(1-4 MB)L2 cache
P
(1-4 MB)
Hub
Main Memory(1-4 GB)
Direc-tory
L2 cache
P
(1-4 MB)L2 cache
P
(1-4 MB)
Hub
Main Memory(1-4 GB)
Direc-tory
Interconnection Network
SysAD busSysAD bus
Masinile cu spatiu de adresare partajat (SAS) contemporane
Masinile bazate pe bus, cache coerente la scarǎ micǎ.Sistemele cu memorie distribuitǎ, cache coerente la scarǎ mare. Fǎrǎ coerenţǎ de cache, sunt în esenţǎ sisteme cu transmitere (rapidǎ) de mesaje.Clusterele acestora sunt la scarǎ încǎ mai mare.
Modelul de programare cu transmitere de mesaje (MP)
Send spune cǎ bufferul de date trebuie transmis la procesul receptor.Recv spune despre procesul expeditor si memoria de aplicatie în care se face primirea; o etichetǎ (tag) optionalǎ la trimitere si o regulǎ de potrivire-identificare la receptie.Copiere de la o memorie la alta, cu necesitatea numirii proceselor.
37

Procesul utilizator numeste numai datele si entitǎtile locale în spatiul proces/etichetǎ (tag).În forma ceam mai simplǎ, potrivirea send/recv face sincronizarea unor evenimente perechi. Mai sunt si alte variante.Multe overheaduri: cu copierea, cu mangementul bufferelor, cu protecţia.
Arhitecturi cu transfer de mesaje
Calculatorul complet ca bloc constructiv, inclusiv I/O. Comunicare prin operatii I/O explicite.Modelul de programare: acces direct numai la spatiul de adresare privat (memoria localǎ), comunicare prin mesaje explicite (send/receive).Diagrama bloc la nivel superior este similarǎ cu aceea a sistemului cu memorie partajatǎ (SAS) dar distribuitǎ. Dar comunicarea nu trebuie sǎ fie integratǎ în sistemul de memorare, ci numai ca I/O. Istoria integrǎrii mai stricte evolueazǎ cǎtre un spectru care include clusterele. Sistemele acestea sunt mai usor de construit decât SAS-urile scalabile. Pot fi folosite clustere de PC-uri, de SMP-uri pe o retea localǎ (LAN).Modelul de programare mult independent de operatiile hardware de bazǎ. Interventii ale bibliotecii sau ale sistemului de operare (OS).
Evolutia masinilor cu transfer de mesaje
000001
010011
100
110
101
111
Primele masini erau de tipul FIFO (First In First Out) pe fiecare legǎturǎ. Hardware aproape de modelul de programare; operatii sincrone. Înlocuit de DMA (Direct Memory Access), care abiliteazǎ operatiuni fǎrǎ blocare, bufferizare de cǎtre sistem la destinatie pânǎ când este pregǎtitǎ receptia (recv).
38

Diminuarea rolului topologiei. În rutarea store&forward topologia este importantǎ. Introducerea rutǎrii pipeline face topologia mai putin importantǎ. Costul este în interfata nod-retea. Programarea se simplificǎ.
Exemplu: IBM SP-2
Memory bus
MicroChannel bus
I/O
i860 NI
DMA
DR
AM
IBM SP-2 node
L2 $
Power 2CPU
Memorycontroller
4-wayinterleaved
DRAM
General inter connectionnetwork formed fr om8-port switches
NIC
În esentǎ, sistemul este alcǎtuit din statii de lucru RS6000 complete.Interfata de retea integratǎ în bus-ul I/O (bandǎ de trecere limitatǎ de bus-ul I/O). Nu este necesar a vedea referirile la memorie.
Exemplu: Intel Paragon
Interfata de retea integratǎ în bus-ul de memorie pentru performante.
39

Spre o convergentǎ arhitecturalǎ
Evolutia si rolul software-lui au estompat granitele. Send/recv suportate pe masini SAS via buffere. Se poate construi un spatiu de adresare global pe sistemele MP prin utilizarea metodei hashing2. Software-ul pe memorie partajatǎ (de pildǎ, utilizarea de pagini ca unitǎti de comunicare).Organizarea hardware converge si ea. Integrarea mai strictǎ a NI (Network Interface) chiar pentru sisteme MP (latenţǎ redusǎ, bandǎ mai largǎ). La nivelul mai de jos, chiar hardware-ul SAS transferǎ mesaje hardware. Suport hardware pentru comunicatie fin granulatǎ face si software-ul MP mai rapid.Chiar clusterele de statii de lucru sau SMP-urile sunt sisteme paralel. Sisteme de retele zonale (SAN – System Area Network) rapide.Modele de programare distincte dar organizǎrile converg. Noduri conectate prin retele generale si comunicare asistatǎ. Asistarea se regǎseste în gradul de integrare, pe tot parcursul spre clustere.
Sisteme paralel pe date
Modelul de programare. Operatii executate în paralel pe fiecare element al structurii de date. Logic, un singur fir de control. Acesta executǎ secvential pasi paraleli. Conceptual, un procesor asociat fiecǎrui articol-datǎ.
PE PE PE° ° °
PE PE PE° ° °
PE PE PE° ° °
° ° ° ° ° ° ° ° °
Controlprocessor
Modelul arhitectural. Masive de multe procesoare simple fiecare cu putinǎ memorie. Procesoarele nu trec secvential prin instructiuni.Atasat la un procesor controlor care genereazǎ instructiuni.Comunicare specializatǎ si generalǎ, sincronizare globalǎ ieftinǎ.
2 Hashing – a produce valori hash pentru accesarea datelor sau pentru securitate. O valoare hash (sau simplu un hash), denumit si un digest de mesaj este un numǎr generat dintr-un sir/text. Hash-ul este substantial mai mic decât textul însusi si este generat printr-o formulǎ într-o asa manierǎ încât este extrem de improbabil ca vreun alt text sǎ producǎ aceeasi valoare hash.
40

Motivatia initialǎ. Se potrivesc cu rezolvarea ecuatiilor diferentiale simple. Se centreazǎ pe costul ridicat al regǎsirii instructiunii si al secventierii.
Aplicatii ale paralelismului pe date
Un stat de functiuni contine o înregistrare pentru fiecare salariat care reprezintǎ salariul.
if salariu > 1000 then salariu = salariu *1.05else salariu = salariu *1.10
Logic, întreaga operatie constǎ dintr-un singur pas. Unele procesoare sunt abilitate pentru operatii aritmetice, altele nu.Alte exemple: diferente finite, algebra liniarǎ, cǎutarea de documente, graficǎ, procesarea de imagini, …Câteva masini recente: Thinking Machines CM-1, CM-2 (si CM-5), masiv paralelele MP-1 si MP-2.
Evoluţie si convergenţǎ
Structurǎ de control rigidǎ (SIMD în clasificarea Flynn). SISD pentru uniprocesoare, MIMD pentru multiprocesoare.Populare când reducerile de costuri ale secventiatorului centralizat vor fi mari. În anii ’60 când un CPU era un dulap. Înlocuit de vectori la mijlocul anilor ’70: mai flexibile în ceea ce priveste dispunerea memoriei si mai usor de administrat.Revitalizat în anii ’80 mijlocii când cǎile de date de 32 de biti s-au potrivit pe cip. Ceea ce nu mai este adevǎrat pentru microprocesoarele moderne.Alte ratiuni pentru disparitie. Aplicatiile obisnuite, simple au un bun localism, pot lucra bine oricum. Pierdere în aplicabilitate din cauza circulatiei pe fire în paralelismul de date: masinile MIMD sunt la fel de eficiente si pentru paralelismul pe date si în general.Modelul de programare este convergent cu SPMD (Single Program Multiple Data). Contributii necesare pentru sincronizarea globalǎ rapidǎ. Spatiul de adresare global este structurat, implementat fie cu SAS, fie cu MP.
Convergenţǎ: arhitectura paralel genericǎ
Mem
° ° °
Network
P
$
Communicationassist (CA)
41

Un sistem multiprocesor generic modern.
Nodul: procesor/procesoare, sistem de memorie, plus asistenţa la comunicare. Controller al interfetei de retea si al comunicǎrii. Retea scalabilǎ. Asistentul de comunicare furnizeazǎ primitive cu profil perfect. Se construieste modelul de comunicare pe acesta. Convergenta permite multe inovatii, acum în cadru. Integrarea asistentului cu nodul, care operatii, cât de eficace…
Contractul model-sistem
Modelul specificǎ o interfatǎ (contractul) cǎtre programator:• Numirea: cum sunt partajate logic datele si/sau procesele la care se face
referire.• Operatii: ce operatii sunt furnizate pe aceste date.• Ordonarea: cum sunt ordonate si coordonate accesǎrile la date.• Replicarea: cum sunt replicate datele pentru a reduce comunicarea.Implementarea realizatǎ face obilgatoriu referiri la aspecte de performantǎ. Costul comunicǎrii: latentǎ, bandǎ de trecere, overhead, gradul de ocupare.Se vor prezenta aceste aspecte prin exemple.
Suportul contractului
Fiind dat un model de programare, acesta poate avea suport în modalitǎti variate în straturi variate.
În fapt, fiecare strat are o pozitie în toate privintele (numirea, operatiile, performantele etc.) si orice set de pozitii poate fi asociat (mapped) altui set prin software.Elementele cheie pentru a oferi suport modelelor de perogramare:• Ce primitive sunt furnizate în stratul abstractiilor de comunicare.• Cât de eficient sunt ele suportate (hardware/software).• Cum sunt sociate (mapped) modelele de programare cu ele.
42

Recapitulare asupra arhitecturilor paralele
Arhitecturile paralele reprezintǎ un fir important în evolutia generalǎ a arhitecturilor. La toate nivelurile, cu nivelul procesoarelor multiple pe curentul principal din domeniul calculului.Proiectele exotice au contribuit mult, dar s-a renuntat la ele de dragul convergentei. Presiunea tehnologicǎ, a costurilor si a performantelor aplicative. Arhitectura de bazǎ procesoare-memorie este în linii mari aceeasi. Elementele arhitecturale cheie sunt în arhitectura comunicǎrii: cum este integratǎ comunicarea în memorie si în sistemul I/O din nod.Probleme de proiectare fundamentale:• Functionale: numirea, operatiile, ordonarea• Performante: organizare, replicare, caracteristicile de performantǎDeciziile de proiectare sunt dictate de evaluǎri dirijate de încǎrcare. Parte integrantǎ a focalizǎrii ingineriei.
Credinte vechi cu fata la zid
Puterea este gratuitǎ, tranzistorii sunt scumpi
Zidul puteriiPuterea este scumpǎ, tranzistorii sunt gratuiti
Multiplicarea este lentǎ, accesul la memorie este rapid
Zidul memorieiMultiplicarea este rapidǎ si accesul la memorie este lent
Paralelismul la nivel de instructiune (ILP – Instruction Level Parallelism) trebuie crescut prin compilatoare, prin inovatii (out-of-order, speculatii, VLIW – Very Long Instruction Word, …)
Zidul ILPSatisfactii în diminuare de la mai mult ILP
Conceptia veche: performantele uniprocesoarelor cresc de 2 ori la fiecare 1,5 ani.Mai nou: performantele uniprocesoarelor cresc de 2 ori la fiecare 5 ani.
Din nou despre tendintele tehnologice
43

Performantele uniprocesoarelor (SPECint3)
• VAX: 25% pe an din 1978 pânǎ în 1986• RISC + x86: 52% pe an din 1986 pânǎ în 2002• RISC + x86: ??% pe an din 2002 pânǎ azi
3 SPECint este o specificatie de testare standard (benchmark) pentru puterea de procesare în întregi a unitǎtii centrale. Norma este întretinutǎ de Standard Performance Evaluation Corporation (SPEC).
44

Sistemele multi-core sunt din ce în ce mai prezente
“We are dedicating all of our future product development to multicore designs. … This is a sea change in computing”
Paul Otellini, Intel (2005)(“Toatǎ activitatea de dezvoltare a produselor noastre viitoare o dedicǎm proiectǎrii sistemelor multicore. … Acestea reprezintǎ un val imens de schimbare în calcul,”).
Intel a fǎcut demonstratii cu un chip în faza de cercetare cu 80 de cores.Cipul metro-chip CISCO are 188 de cores.
Programe paralel
De ce ne preocupǎ programele?
Ele sunt acelea care sunt executate pe masinile pe care le proiectǎm. Asadar ajutǎ deciziile de proiectare, ajutǎ evaluarea concesiilor (trade-offs) din sisteme.
45

Au condus la progresele cheie din arhitectura uniprocersor. Memoriile cache si proiectarea setului de instructiuni.Mai importante în sistemele multiprocesor. Grade de libertate noi, penalitǎti mai mari pentru nepotriviri între programe si arhitecturi.
Importante pentru cine?
Pentru proiectantii de algoritmi. Proiectarea de algoritmi care vor rula pe sisteme reale.Pentru programatori. Întelegerea problemelor cheie si obtinerea celor mai bune performante.Pentru arhitecti. Întelegerea încǎrcǎrilor, a interactiunilor, a importantei gradelor de libertate. Valoroase pentru proiectare si pentru evaluare.
Lectii despre programe în acest curs
• Programe paralel• Procesul de paralelizare• Cum aratǎ programele paralel în modelele de programare majore• Programarea pentru performante• Evaluǎri arhitecturale dictate de încǎrcare• Beneficiile pentru arhitecti dar si pentru utilizatori la procurarea de masini.Spre deosebire de masinile secventiale, nu se poate lua ca garantie sarcina (workload).Baza software nu este maturǎ; evolueazǎ odatǎ cu arhitecturile cu obiectivul performante.Asa cǎ trebuie deschisǎ cutia.Sǎ începem cu programele paralel…
Outline
Probleme motivante (studii de cazuri aplicative).Pasi în crearea unui program paralel.Cum aratǎ un program paralel simplu. Trei modele majore de programare. Primitivele necesitǎ suport în sistem.Mai târziu: interactiunea aspectelor de performantǎ cu arhitectura.
Probleme motivante
Simularea curentilor oceanici. Structurǎ regulatǎ, calcul stiintific.Simularea evolutiilor galactice. Structurǎ neregulatǎ, calcul stiintific.Interpretarea scenelor prin urme/efecte ale razelor (Raytrace). Structurǎ neregulatǎ, graficǎ computerizatǎ.Filtrare (paralelism pipeline).
46

Data mining. Structurǎ neregulatǎ, procesarea informatiei (subiect aparte, studii speciale).
Simularea curentilor oceanici
Model pe grilǎ bidimensionalǎ.Se discretizeazǎ în spatiu si în timp. Rezolutii spatiale si temporale mai fine înseamnǎ precizii mai bune, solutii mai exacte.Multe si diferite calcule la fiecare pas de timp. Constituirea si rezolvarea de ecuatii.Calcule la concurentǎ între si în grile.
Simularea evolutiilor galactice
Se simuleazǎ interactiunile multor stele care evolueazǎ în timp.Calculul fortelor este costisitor.Tratarea brutǎ a fortelor – cost cam de ordinul O(n2).Metodele ierarhice profitǎ de legea universalǎ a fortelor G = m1m2/r2.
Pasi temporali numerosi, concurentǎ bogatǎ între stele în cadrul fiecǎrui pas.
Interpretarea scenelor prin urme/efecte ale razelor (Raytrace)
Se trimit raze într-o scenǎ prin pixeli de imagine planǎ. Se urmǎreste drumul lor: ele se împrǎstie în jur când lovesc obiecte, genereazǎ raze noi, un arbore de raze la fiecare razǎ incidentǎ.
47

Rezultatul este culoarea si transparenta/opacitatea acelui pixel.Paralelism pe raze.Toate cazurile studiate aratǎ o concurentǎ4 abundentǎ.
Crearea unui program paralel
Se admite cǎ este cunoscut un algoritm secvential. Uneori este necesar un algoritm foarte diferit, dar asta este dincolo de preocupǎrile de fatǎ.Pǎrtile lucrǎrii:• Identificarea lucrului care poate fi fǎcut în paralel.• Partitionarea lucrului si probabil a datelor între procese.• Se gestioneazǎ accesul la date, comunicarea si sincronizarea.• De notat: lucrul include calcul, accesul la date si operatiile I/O.Telul principal: accelerarea (speedup) la care se adaugǎ efortul de programare redus si necesarul de resurse.
)1()()(
eperformancpeperformancpspeedup =
4 Concurenţa (concurrency). În stiinta calculatoarelor concurenta este o proprietate a sistemelor conform cǎreia mai multe procese de calcul se deruleazǎ concomitent si interferǎ adesea între ele. Studiul concurentei cuprinde o categorie largǎ de sisteme, de la cele strâns cuplate, puternic sincrone în sistemele de calcul paralel, la cele slab cuplate, vǎdit asincrone, întâlnite în sistemele distribuite. Procesele concurente se pot derula realmente simultan în cazul în care ele ruleazǎ pe procesoare separate sau pasi din derularea lor pot fi intercalati pentru a produce aparenta concurentei ca în cazul proceselor separate care ruleazǎ într-un sistem multi-task. Deoarece procesele într-un sistem concurent pot interactiona în timpul derulǎrii, numǎrul de cǎi de executie posibile pe sistem poate fi extrem de mare si comportarea rezultantǎ poate fi foarte complexǎ. Dificultǎtile asociate concurentei au fost si sunt rezolvate atât prin construirea de limbaje si concepte pentru a face complexitatea executiei concurente gestionabilǎ cât si prin dezvoltarea de teorii potrivite rationamentelor asupra proceselor concurente care mai si interactioneazǎ.Diferenta dintre sistemele secventiale si cele concurente constǎ în faptul cǎ procesele care fac un sistem concurent pot interactiona. Utilizarea concurentǎ de resurse partajate este sursa multor dificultǎti. Conditiile “race” care implicǎ resurse partajate pot produce comportǎri inprevizibile ale sistemului. Introducerea excluderii mutuale poate preveni conditiile “race” dar pot conduce la probleme de genul blocajelor deadlock si de înfometare (starvation).În afara interactiunilor interne, multe sisteme concurente, cum sunt sistemele de operare si bazele de date sunt gândite sǎ participe si la interactiuni curente cu utilizatorii si cu alte sisteme. Notiunile traditionale de corectitudine a programelor care sunt bazate pe punerea în relatie a unor intrǎri initiale cu iesirile asteptate sǎ aparǎ la terminarea programului nu mai sunt realmente aplicabile. Sunt necesare modalitǎti diferite de definire a ceea ce înseamnǎ un sistem concurent care opereazǎ corect.Proiectarea unui sistem concurent implicǎ adesea stabilirea de tehnici cât mai sigure pentru coordonarea executǎrii, pentru schimbul de date, pentru alocarea de memorie si pentru esalonarea executiei cu scopul de a minimiza durata de rǎspuns si de a maximiza capacitatea de prelucrare (throughput).Teoria concurentei a fost si este un câmp activ de cercetare în stiinta calculatoarelor în latura ei teoreticǎ de când în anii 1960 timpurii Carl Adam Petri a publicat lucrarea fundamentalǎ despre retelele Petri. În anii care au urmat s-a dezvoltat o varietate cuprinzǎtoare de formalisme destinate modelǎrii si rationamentelor relative la concurentǎ.
48

Pentru o problemǎ fixǎ:
)()1()(
ptimetimepspeedup =
Pasii creǎrii unui program paralel
Sunt patru pasi: descompunerea, atribuirea, orchestrarea, associere (mapping). Pasii sunt executati de programator sau de software-ul de sistem (la compilare, la executie…). Problemele sunt aceleasi asa cǎ mai departe se admite cǎ programatorul face totul în mod explicit.
Câteva concepte importante
Task: o bucatǎ arbitrarǎ a unei lucrǎri nedescompuse în calculul paralel; se executǎ secvential cu concurentǎ numai între taskuri; exemple: o particulǎ/celulǎ în metoda Barnes-Hut, o razǎ sau un grup de raze în Raytrace; taskuri fin granulate, taskuri grosier granulate.Proces (fir): o entitate abstractǎ care executǎ taskurile atribuite proceselor; procesele comunicǎ si se sincronizeazǎ pentru a executa taskurile lor.Procesor: suportul fizic pe care se executǎ procesul; procesele virtualizeazǎ masina pentru programator: se scrie mai întâi programul ca reuniune de procese si apoi se aplicǎ (to map) pe procesoare.
Descompunerea
Spargerea calculului în taskuri pentru a fi împǎrtite între procese. Taskurile pot fi distribuite dinamic. Numǎrul de taskuri disponibile poate varia în timp. Altfel spus, se identificǎ concurenta si se decide nivelul la care aceasta este exploatatǎ.Telul: suficiente taskuri pentru a tine procesele ocupate, dar nu prea multe.Numǎrul de taskuri disponibile la un moment dat este limita suprioarǎ a accelerǎrii (speedup) obtenabile.
49

Concurenta limitatǎ: legea lui Amdahl
Limitarea fundamentalǎ în accelerarea prin paralelism.Dacǎ fractia de lucru serial/secvential inerent este s atunci speedup ≤ 1/s.Exemplu: calculul în douǎ faze: traversarea unei grile nxn si executarea unor calcule independente, traversarea a doua oarǎ si adunarea fiecǎrei valori într-o sumǎ globalǎ. Timpul consumat în prima fazǎ este n2/p. Timpul pentru faza a doua serializatǎ într-o variabilǎ globalǎ este n2.Accelerarea este
22
22
np
nnspeedup+
=
si nu poate depǎsi valoarea 2.Artificiu de calcul, truc: faza a doua se divide în douǎ. Se acumuleazǎ în suma privatǎ în timpul traversǎrii, apoi se adunǎ sumele private per-proces în suma globalǎ. Timpul paralel este n2/p + n2/p + p si accelerarea este în cel mai bun caz
22
2
22
pnnspeedup+
=
Descrierea graficǎ
Profilele concurentiale
Uzual, divizarea în partea serialǎ si partea paralelǎ nu poate fi fǎcutǎ.
50

Aria de sub curbǎ este lucrul total sau timpul cu un procesor. Extinderea orizontalǎ este limita inferioarǎ a timpului consumat (cu procesoare în numǎr nelimitat)Accelerarea este raportul
∑
∑∞
=
∞
=
1
1
kk
kk
pkf
kf
în cazul de bazǎ
pss −+ 1
1
Legea lui Amdahl se aplicǎ la orice overhead, nu numai la concurentǎ limitatǎ.
Tipuri de paralelism
Paralelism de taskuri. Paralelism care apare explicit în algoritm. Între filtre fǎrǎ relatii producǎtor/consumator.
51
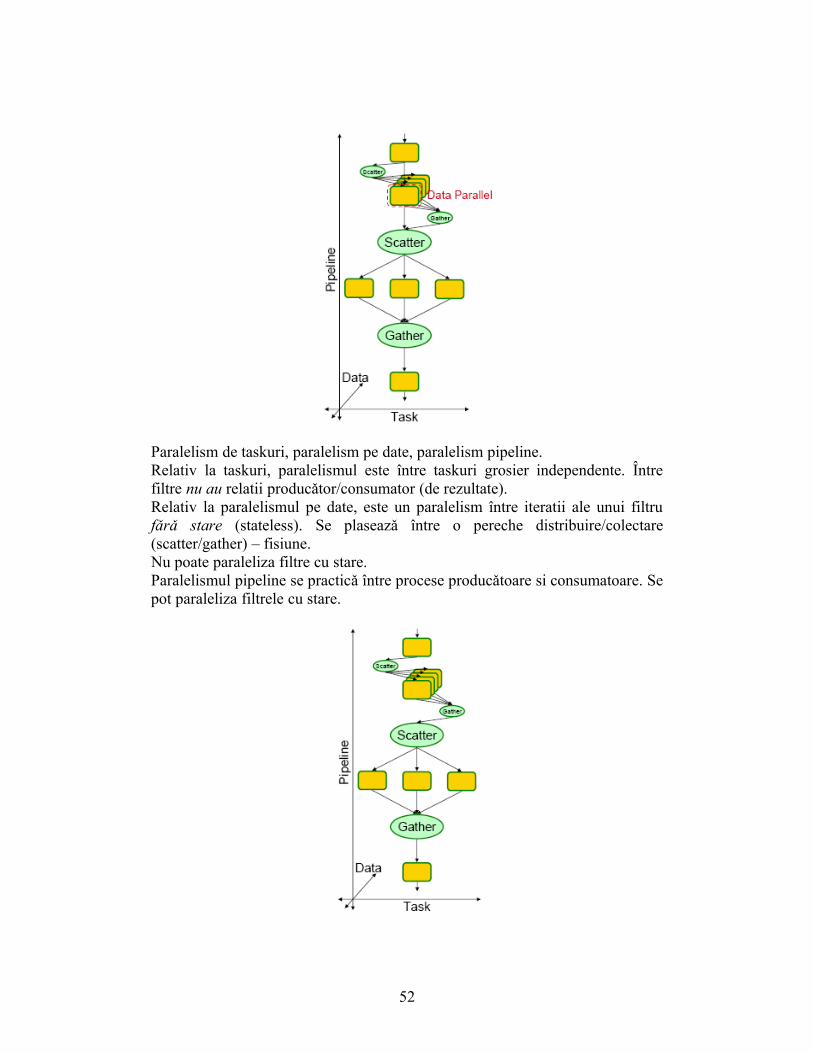
Paralelism de taskuri, paralelism pe date, paralelism pipeline.Relativ la taskuri, paralelismul este între taskuri grosier independente. Între filtre nu au relatii producǎtor/consumator (de rezultate).Relativ la paralelismul pe date, este un paralelism între iteratii ale unui filtru fǎrǎ stare (stateless). Se plaseazǎ între o pereche distribuire/colectare (scatter/gather) – fisiune.Nu poate paraleliza filtre cu stare. Paralelismul pipeline se practicǎ între procese producǎtoare si consumatoare. Se pot paraleliza filtrele cu stare.
52

Paralelism de taskuri, paralelism pe date, paralelism pipeline.Relativ la taskuri, paralelismul este de tipul pe fire, adicǎ ramificǎ/recompune (fork/join).Relativ la paralelismul pe date, este de tipul forall (bucle paralel pe date).Paralelismul pipeline se practicǎ în programele multor servere. Manipularea cozilor (queues) prin bufferizare între etape. Unul sau mai multe fire în fiecare etapǎ pipeline.
Asignarea
Specificarea mecanismului prin care se divizeazǎ lucrul între procese. De pildǎ, care proces evalueazǎ fortele asupra unei anumite stele sau care razǎ este în evaluare a unui proces. Împreunǎ cu descompunerea, denumitǎ si partitionare. Echilibreazǎ încǎrcarea, reduce costul comunicǎrii si managementului.Tratarea structuratǎ lucreazǎ de regulǎ bine. Inspectarea codului (bucle paralel) sau întelegerea aplicatiei. Euristicile binecunoscute. Asignarea poate fi staticǎ sau dinamicǎ.Programatorii sunt preocupati mai întâi de partiţionare. Uzual este independentǎ de arhitecturǎ sau de modelul de programare. Dar costul si complexitatea utilizǎrii primitivelor pot afecta deciziile.Arhitecţii presupun cǎ programul face o treabǎ raţionalǎ din ea.
Orchestrarea
• Numirea datelor• Structurarea comunicǎrii• Sincronizarea• Organizarea structurilor de date si planificarea temporalǎ a taskurilorTeluri• Reducerea costului comunicǎrii si sincronizǎrii cu vedere dinspre
procesoare• Prezervarea localismului datelor de referinţǎ (inclusiv organizarea
strucutralǎ a datelor)• Planificarea taskurilor pentru a satisface timpuriu dependenţele• Reducerea overheadului managementului paralelApropierea foarte clarǎ de arhitecturǎ (si de modelul si limbajul de programare)• Alegerile depind mult de abstractiile de comunicare, de eficienta
primitivelor• Arhitecţii trebuie sǎ furnizeze eficient primitive adecvate.
Mapping
Dupǎ orchestare, existǎ deja un program paralel.Douǎ aspecte ale asocierii (mapping):
53

• Care procese vor rula pe acelasi procesor dacǎ este necesar• Care proces ruleazǎ pe un procesor particularAsocierea cu o topologie de retea.O extremǎ: spatiu partajat. Masina este divizatǎ în subseturi, pe un subset la fiecare moment o singurǎ aplicatie. Procesele pot fi prinse (pinned) de procesoare sau lǎsate în seama sistemului de operare (OS).Altǎ extremǎ: OS are controlul complet al administrǎrii resurselor. Sistemul de operare utilizeazǎ tehnici de performantǎ care vor fi discutate mai departe.Lumea realǎ se încadreazǎ între aceste extreme. Utilizatorul specificǎ dorinţele sale în anumite privinţe, sistemul le poate ignora.Se adoptǎ uzual punctul de vedere: proces ↔ procesor.
Paralelizarea calculului fatǎ-n fatǎ cu paralelizarea pe date
Vederea de mai sus este centratǎ pe calcul. Calculul este descompus si asignat (partiţionat).O vedere la fel de naturalǎ este adesea partitionarea datelor. Calculul îsi urmeazǎ datele: proprietarul calculeazǎ. Exemplul pe grilǎ; data mining; HPF – High Performance Fortran.Dar în general nu este suficient. Distinctia între calcul si date este mai accentuatǎ în multe aplicatii (Barnes-Hut, Raytrace). Rǎmâne de retinut punctul de vedere centrat pe calcule. Accesul la date si comunicarea este parte din orchestrare.
Ţinte de nivel înalt
Performanţe înalte (accelerarea faţǎ de programul secvential)
Dar efort redus pentru utilizarea resurselor si dezvoltare.
54

Implicaţii pentru proiectanţii de algoritmi si pentru arhitecţi. Proiectanţii de algoritmi: performanţe ridicate, necesitǎţi reduse de resurse. Arhitecţii: performante ridicate, cost redus, efort de programare redus. Ca exemplu, cresterea gradualǎ a performantelor cu effort de programare pe mǎsurǎ poate fi de preferat unui salt brusc dupǎ un effort de programare considerabil.
Cum aratǎ un program paralel
Paralelizarea unui program (exemplu)
Problemele motivante toate duc la programe ample si complexe.Sǎ examinǎm o versiune simplificatǎ a unui fragment din simularea oceanicǎ. Un program-solutie iterativ.Se ilustreazǎ cu un program paralel într-un limbaj paralel de nivel scǎzut. Un pseudocod asemǎnǎtor C-ului cu extensii simple pentru paralelism. Sunt expuse primitivele de bazǎ pentru comunicare si sincronizare care trebuie sǎ aibe suportul necesar. Aceasta este starea celor mai multe programe paralel reale de azi.
Exemplu cu program-solutie pe grilǎ
Expresia pentru actualizarea punctelor interioareA[I, J]=0.2*(A[I, J] + A[I, J – 1] + A[I – 1, J] + A[I, J + 1] + A[I + 1, J])
O versiune simplificatǎ de program-solutie pentru simularea oceanicǎ.Metoda Gauss-Seidel (vecinii apropiati) merge la convergentǎ.Punctele interioare, nxn din cele (n + 2)x(n + 2) sunt actualizate la fiecare pas în fiecare parcugere a grilei.Actualizǎrile sunt fǎcute pe loc în grilǎ si sunt diferite de valorile calculate anterior.Se acumuleazǎ diferentele partiale într-o diferentǎ globalǎ la finalul fiecǎrei parcurgeri.Se verificǎ dacǎ eroarea este la convergentǎ (într-o limitǎ de tolerantǎ); dacǎ da calculul înceteazǎ, dacǎ nu se reia parcurgerea grilei.
55

1. int n; /*dimensiunile matricei: (n + 2)x(n + 2) elemente*/2. float **A, diff = 0;3. main()4. begin5. read(n); /*se citeste parameterul de intrare: dimensiunea matricei*/6. A ← malloc (a 2-d array of size n + 2 by n + 2 doubles);7. initialize(A); /*se initializeazǎ cumva matricea A*/8. Solve (A); /*se apeleazǎ rutina de rezolvare a ecuatiei*/9. end main10. procedure Solve (A) /*rezsolvǎ sistemul de ecuatii*/11. float **A; /*A este un masiv de (n + 2)-pe-(n + 2) elemente*/12. begin13. int i, j, done = 0;14. float diff = 0, temp;15. while (!done) do /*bucla ultimǎ în toate parcurgerile*/16. diff = 0; /*se initializeazǎ diferenta maximǎ la 0*/17. for i ← 1 to n do/*se parcurge grila pe toate punctele care nu sunt pe frontierǎ*/18. for j ← 1 to n do19. temp = A[i,j]; /*de salveazǎ vechea valoare a elementului*/20. A[i,j] ← 0.2 * (A[i,j] + A[i,j-1] + A[i-1,j] + A[i,j+1] + A[i+1,j]); /*se calculeazǎ media*/21. diff += abs(A[i,j] - temp);22. end for23. end for24. if (diff/(n*n) < TOL) then done = 1;25. end while26. end procedure
Descompunerea
Calea simplǎ de a identifica concurenta constǎ în examinarea iteratiilor din buclǎ: analiza concurentei, dacǎ nu este suficientǎ concurentǎ.Aici, la acest nivel nu-i prea multǎ concurentǎ (toate buclele sunt secventiale).Se examineazǎ dependentele fundamentale ignorând structura buclelor.
56

Concurenta este de O(n) în lungul antidiagonalelor, serializarea este de O(n) pe diagonale. De retinut structura buclei, utilizarea sincronizǎrilor punct-la-punct; probleme? Restructurarea sincronizǎrilor globale; probleme?
Exploatarea cunostintelor asupra aplicatiei
Reordonarea traversǎrii grilei: ordonarea rosu-negru.
Ordonarea diferitǎ a actualizǎrilor: poate duce la o convergentǎ mai rapidǎ sau mai lentǎ.Parcursul pe rosu si parcursul pe negru sunt fiecare deplin paralele: sincronizare globalǎ între ele (conservativǎ dar convenabilǎ. Simularea oceanicǎ utilizezǎ rosu-negru; utilizǎm ilustrativ una mai simplǎ, asincronǎ. Nu rosu-negru ci, simplu, ignorǎm dependentele în parcurs. Ordinea rǎmâne secventialǎ ca altǎdatǎ, programul paralel este nondeterminist.
Numai descompunere
15. while (!done) do /*o buclǎ secventialǎ*/16. diff = 0;
17. for_all i ← 1 to n do /*o buclǎ paralel continentǎ*/18. for_all j ← 1 to n do19. temp = A[i,j];20. A[i,j] ← 0.2 * (A[i,j] + A[i,j-1] + A[i-1,j] +
A[i,j+1] + A[i+1,j]);21. diff += abs(A[i,j] - temp);22. end for_all23. end for_all24. if (diff/(n*n) < TOL) then done = 1;25. end while
Descompunerea în elemente: gradul de concurentǎ n2.Descompunerea în linii, face bucla din linia 18 a programului secventialǎ; de gradul n.for_all lasǎ asignarea în seama sistemului; sincronizarea este globalǎ si implicitǎ la finalul buclei for_all.
57

Asignarea
Asignarea staticǎ (fiind datǎ descompunerea în linii).
Asignarea pe blocuri de linii: linia i este atribuitǎ procesului
pi
.
Asignarea de linii ciclicǎ: procesului i îi sunt atribuite liniile i, i + p s.a.m.d.
Asignarea dinamicǎ: se preia un indice de linie, se lucreazǎ pe acea linie, se preia o linie nouǎ, s.a.m.d.Asignarea staticǎ pe linii reduce concurenta (de la n la p); asignarea în blocuri reduce comunicarea prin retinerea laolaltǎ de linii adiacente.Sǎ adâncim problema orchestrǎrii din punct de vedere al modelelor de programare.
Programul-solutie paralel pe date
1. int n, nprocs;/*dimensiunea grilei (n + 2-pe-n + 2) si numǎrul de procese*/
2. float **A, diff = 0;3. main()4. begin5. read(n); read(nprocs);
/*se citesc dimensiunea grilei si numǎrul de procese */6. A ← G_MALLOC (a 2-d array of size n+2 by n+2 doubles);7. initialize(A); /*se initializeazǎ cumva matricea A*/8. Solve (A); /*se apeleazǎ rutina de rezolvare a ecuatiei*/9. end main10. procedure Solve(A) /*se rezolvǎ sistemul de ecuatii*/11. float **A; /*A este un masiv de (n + 2-pe-n + 2)*/12. begin13. int i, j, done = 0;14. float mydiff = 0, temp;14a. DECOMP A[BLOCK,*, nprocs];15. while (!done) do /*bucla exterioarǎ pe toate parcurgerile*/16. mydiff = 0; /*se initializeazǎ diferenta maximǎ la 0*/17. for_all i ← 1 to n do
58

/*parcurgere pe punctele grilei care nu sunt pe frontierǎ*/18. for_all j ← 1 to n do19. temp = A[i,j]; /*se salveazǎ vechea valoare a elementului*/20. A[i,j] ← 0.2 * (A[i,j] + A[i,j-1] + A[i-1,j] +
A[i,j+1] + A[i+1,j]); /*se calculeazǎ media*/21. mydiff += abs(A[i,j] - temp);22. end for_all23. end for_all23a. REDUCE (mydiff, diff, ADD);24. if (diff/(n*n) < TOL) then done = 1;25. end while26. end procedure
Programul-solutie în varianta SAS
Program unic date multiple (SPMD – Single Program Multiple Data)
Asignarea este controlatǎ de valori ale variabilelor utilizate ca limite ale buclelor.
1. int n, nprocs;/*dimensiunea matricei si numǎrul de procesoare utilizate*/
2a. float **A, diff;/*A este un masiv global (partajat) care reprezintǎ grila*//*diff este diferenta maximǎ globalǎ (partajatǎ) pentru parcurgerea curentǎ*/
2b. LOCKDEC(diff_lock);/*declaratie de lock/lacǎt pentru a introduce excluderea mutualǎ*/
2c. BARDEC (bar1);/*declaratie de barierǎ pentru sincronizarea globalǎ între parcurgeri*/
3. main()4. begin5. read(n); read(nprocs);
/*se citesc dimensiunea matricei de intrare si numǎrul de procese*/
59

6. A ← G_MALLOC;/*un masiv bidimensional de mǎrimea n + 2 pe n + 2 în dublǎ precizie*/
7. initialize(A); /*se initializeazǎ A într-un mod neprecizat*/8a. CREATE (nprocs–1, Solve, A);8. Solve(A); /*procesul principal devine si el un proces lucrǎtor*/8b. WAIT_FOR_END (nprocs–1);
/*se asteaptǎ ca toate procesele descendente create sǎ finalizeze*/9. end main10. procedure Solve(A)11. float **A;
/*A este masivul partajat integral n + 2-pe-n + 2 ca în programulsecvential*/
12. begin13. int i,j, pid, done = 0;14. float temp, mydiff = 0; /*variabile private*/14a. int mymin = 1 + (pid * n/nprocs);
/*pentru simplitate, se presupune cǎ n este divizibilcu numǎrul de procese*/
14b. int mymax = mymin + n/nprocs – 1;15. while (!done) do /*bucla exterioarǎ pe toate elementele diagonale*/16. mydiff = diff = 0;
/*se pune la zero diferenta globalǎ diff (OK pentru tot ce-i de fǎcut)*/16a. BARRIER(bar1, nprocs);
/*ne asigurǎm cǎ toate procesele ajung aici înainte cavreunul sǎ modifice diff*/
17. for i ← mymin to mymax do/*pentru fiecare din liniile atribuite unui proces*/
18. for j ← 1 to n do/*pentru toate elementele acelei linii care nu sunt pe frontierǎ*/
19. temp = A[i,j];20. A[i,j] = 0.2 * (A[i,j] + A[i,j-1] + A[i-1,j] +
A[i,j+1] + A[i+1,j]);21. mydiff += abs(A[i,j] - temp);22. endfor23. endfor24a. LOCK(diff_lock);
/*dacǎ este necesar se actualizeazǎ diferenta globalǎ diff */24b. diff += mydiff;24c. UNLOCK(diff_lock);24d. BARRIER(bar1, nprocs);
/*ne asigurǎm cǎ toate procesele ajung aici înainte deverificarea conditiei done*/
24e. if (diff/(n*n) < TOL) then done = 1;/*se verificǎ convergenta; toate procesele obtin acelasi rǎspuns*/
24f. BARRIER(bar1, nprocs);25. endwhile26. end procedure
60

Observatii asupra programului SAS
SPMD: nu existǎ lockstep5 sau nici mǎcar în mod necesar aceleasi instructiuni.Asignarea este controlatǎ de valorile variabilelor utilizate ca limite pentru bucle. Pid (process identificator) unic pe fiecare proces utilizat pentru asignarea controlului.Conditia “done” evaluatǎ redundant de toate procesele.Codul nu face updatarea identicǎ cu aceea a unui program secvential. Fiecare proces detine o variabilǎ privatǎ mydiff.Cele mai interesante operatii speciale sunt cele de sincronizare. Acumulǎrile în variabila diff partajatǎ trebuie sǎ fie mutual exclusive. De ce sunt necesare bariere pentru toate procesele?
Necesitatea excluderii mutuale
Codul pe care-l executǎ fiecare procesor:
load the value of diff into register r1add the register r2 to register r1store the value of register r1 into diff
O posibilǎ intercalare (procesoarele P1 si P2):
r1 ← diff {P1 primeste 0 în registrul sǎu r1}r1 ← diff {P2 primeste de asemenea 0}r1 ← r1+r2 {P1 seteazǎ registrul sǎu r1 la 1}r1 ← r1+r2 {P2 seteazǎ registrul sǎu r1 la 1}diff ← r1 {P1 seteazǎ cell_cost la 1}diff ← r1 {P2 seteazǎ cell_cost la 1}
Este necesar ca operatiunile de setare sǎ fie atomice (mutual exclusive – Mutex).
Excluderea mutualǎ
5 Sistemele lockstep sunt sisteme de calcul redundante care executǎ acelasi set de operatii în acelasi timp în paralel. Iesirea din operatiile lockstep poate fi comparatǎ pentru a determina dacǎ s-a produs o eroare.Pentru a rula în lockstep, fiecare sistem este pus sǎ treacǎ de la o stare bine definitǎ la urmǎtoarea stare bine definitǎ. Când un set nou de intrǎri ajung la sistem, acesta le proceseazǎ, genereazǎ iesiri noi si updateazǎ starea sa. Acest set de schimbǎri (intrǎri noi, iesiri noi, stare nouǎ) este consideratǎ definitorie pentru acel pas si trebuie tratatǎ ca o tranzactie atomicǎ; cu alte cuvinte, fie de se produc toate sau nu se produce nici una, dar nimic între ele.Termenul lockstep are originea în limbajul puscǎriilor si se referǎ la mersul sincronizat în care cei care mǎrsǎluiesc sunt atât de aproape unul de altul pe cât este posibil fizic.
61

Excluderea mutualǎ este furnizatǎ de perechea LOCK-UNLOCK din jurul sectiunii critice. Set de operatii pe care îl dorim executat atomic. Implementarea perechii LOCK-UNLOCK trebuie sǎ garanteze excluderea mutualǎ.
Use Pthreads:#include <stdio.h>#include <pthread.h>pthread_mutex_t mutex1 = PTHREAD_MUTEX_INITIALIZER;...pthread_mutex_lock( &mutex1 );diff += mydiff;pthread_mutex_unlock( &mutex1 );
Probleme cu Mutex pe masini mari?
Sincronizarea evenimentelor globale
BARRIER(nprocs): asteaptǎ aici pânǎ cele nprocs procese ating acest punct. Se construieste din primitive de nivel scǎzut.Exemplu cu suma globalǎ: asteaptǎ pentru ca toate sǎ acumuleze înaintea utilizǎrii sumei sum. Adesea utilizatǎ pentru a separa fazele calculului.
Global Event Synchronization
O formǎ conservatoare de a pǎstra dependentele, dar usor de utilizat.WAIT_FOR_END (nprocs – 1).
Sincronizarea evenimentelor de grup
Este implicat un subset de procese. Poate utiliza flag-uri sau bariere (care implicǎ numai subsetul). Conceptele de producǎtor si de consumator.Tipuri principale: producǎtor unic, consumatori multipli; producǎtori multipli consumator unic; producǎtori multipli, consumatori multipli.
Sincronizarea evenimentelor punct-la-punct
62

Un proces face o notificare altuia despre un eveniment, astfel încât notificatul poate continua. Un exemplu comun: producǎtor-consumator (buffer limitat).
Programele concurente pe un sistem uniprocesor: semafoare. Programele paralel cu spatiul de adresare partajat: semafoare sau variabile obisnuite utilizate ca flag-uri.
Sincronizarea si cozile
Paralelismul pipeline.Cozile între etapele unei pipeline producǎtor-consumator.Firele multiple pot coopera pe o etapǎ pipeline; de exemplu, în schema paralel pe date sau în modalitatea taskuri-paralele.Numai firele care coopereazǎ într-o etapǎ trebuie sǎ se sincronizeze (lock, barrier etc.) în acea etapǎ.Dar accesul la aceeasi coadǎ necesitǎ a fi sincronizat.
Programarea cu fire:
Creare si jonctiune
#include <pthread.h>void *parallel_work( void *ptr );main(){pthread_t threads[N];int i;...for (i=1; i < N; i++ )pthread_create( &threads[i], NULL,
63

parallel_work, (void*) &input[i]);parallel_work( &input[0] ); /* optional */for (i=1; i < N; i++ )pthread_join( threads[i], NULL);}void *parallel_work( void *ptr ){... /* work here */}
Mai multe despre programarea cu fire
Este numǎrul de fire diferit de numǎrul de procesoare? În ce conditii e de dorit a fi egale? În ce conditii e de dorit a fi diferite?Firul “master” trebuie sǎ execute sau nu lucru paralel? Face lucru paralel: creazǎ N – 1 fire. Firul master este special: coordoneazǎ si vegheazǎ.Creazǎ N fire.
Mai mult despre programarea cu p-fire (Pthreads)
Transfer de date. Transferǎ intrǎri/ieisiri prin pointeri I/O. Transfer prin date partajate.Caracteristicile firelor. Controlate prin atribute struct, similar unui obiect C++. Preferintele se seteazǎ înaintea creǎrii firelor cum ar fi alternativa uniprocesor-multiprocesor.Încheierea firelor. Firele se isprǎvesc când functia lor revine (returns). Firul se poate termina mai devreme prin apelul la functia pthread_exit(). Celelalte fire pot fi oprite (kill) prin apelul la functia pthread_cancel().
Monitor în stilul Mesa (un limbaj de programare de nivel înalt – Xerox)
#include <stdio.h>#include <pthread.h>pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
64

...
Este aici o relatie consumator-producǎtor? Este vreo problemǎ cu codul?
Consumator-producǎtor cu monitor stilul Mesa.
#include <stdio.h>#include <pthread.h>pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;pthread_cond_t full = PTHREAD_COND_INITIALIZER;pthread_cond_t empty = PTHREAD_COND_INITIALIZER;
Insert(Buf_t buffer,item_t item)
{pthread_mutex_lock(&mutex);if (count==N)
pthread_cond_wait(&full, &mutex);
insert item into buffercount++;pthread_cond_signal(empty);pthread_mutex_unlock(&mutex);}
Item_t Remove(Buf_t buffer){
pthread_mutex_lock(&mutex);if (!count)
pthread_cond_wait(&empty, &mutex);
remove item from buffercount--;pthread_cond_signal(&full);pthread_mutex_unlock(&mutex);}
Vreo problemǎ cu asta?
#include <stdio.h>#include <pthread.h>pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;pthread_cond_t full = PTHREAD_COND_INITIALIZER;pthread_cond_t empty = PTHREAD_COND_INITIALIZER;
Insert(Buf_t buffer,item_t item)
{pthread_mutex_lock(&mutex);while (count==N)
pthread_cond_wait(&full, &mutex);
insert item into buffercount++;pthread_cond_signal(empty);
pthread_mutex_unlock(&mutex);}Item_t Remove(Buf_t buffer){
pthread_mutex_lock(&mutex);while (!count)
pthread_cond_wait(&empty, &mutex);
remove item from buffer
65

count--;pthread_cond_signal(&full);pthread_mutex_unlock(&mutex);}
Acesta este idiomul monitorului în stil Mesa
Programul-solutie pentru grilǎ, cu transfer de mesaje
Masivul A nu mai poate fi declarat ca fiind partajat. Masivul trebuie compus si recompus logic din masive private per-proces: alocat uzual în concordantǎ cu asignarea lucrului, procesul a asignat un set de linii alocate local.Transfer de linii întregi între transversale.Structural este similar cu SAS (de pildǎ SPMD), dar orchestrarea este diferitǎ. Structura datelor si accesul/numirea datelor, comunicarea, sincronizarea.
1. int pid, n, b;/*identificator al procesului, dimensiunea matricei si numǎrul deprocesoare care vor fi utilizate*/
2. float **myA;3. main()4. begin5. read(n); read(nprocs);
/*se citeste dimensiunea matricei de intrare si numǎrul de procese*/8a. CREATE (nprocs-1, Solve);8b. Solve(); /*procesul principal devine el însusi lucrǎtor*/8c. WAIT_FOR_END (nprocs–1);
/*asteptare pentru ca toate procesele descendente create sǎ se încheie*/9. end main10. procedure Solve()11. begin13. int i,j, pid, n’ = n/nprocs, done = 0;14. float temp, tempdiff, mydiff = 0; /*variabile private*/6. myA ← malloc(a 2-d array of size [n/nprocs + 2] by
n+2); /*liniile din A asignate acestui proces*/7. initialize(myA);
/*se initializeazǎ liniile din A asignate, într-o manierǎ nespecificatǎ*/15. while (!done) do16. mydiff = 0; /*se pune variabila localǎ diff egalǎ cu 0*/16a. if (pid != 0) then SEND(&myA[1,0],n*sizeof(float),pid-1,ROW);16b. if (pid = nprocs-1) thenSEND(&myA[n’,0],n*sizeof(float),pid+1,ROW);16c. if (pid != 0) then RECEIVE(&myA[0,0],n*sizeof(float),pid-1,ROW);16d. if (pid != nprocs-1) thenRECEIVE(&myA[n’+1,0],n*sizeof(float), pid+1,ROW);
66

/*liniile de frontierǎ ale vecinilor sunt copiate aici în myA[0,*] si în myA[n’+1,*]*/
17. for i ← 1 to n’ do/*pentru fiecare din liniile din myA (nonghost)*/
18. for j ← 1 to n do/*pentru toate elementele acelei linii care nu sunt pe frontierǎ*/
19. temp = myA[i,j];20. myA[i,j] = 0.2 * (myA[i,j] + myA[i,j-1] + myA[i-1,j] +21. myA[i,j+1] + myA[i+1,j]);22. mydiff += abs(myA[i,j] - temp);23. endfor24. endfor
/*se comunicǎ valorile locale diff si se determinǎ dacǎ “done = true”;poate fi înlocuitǎ cu operatii de reducere si broadcast*/
25a. if (pid != 0) then/*procesul 0 detine valoarea globalǎ totalǎ diff*/
25b. SEND(mydiff,sizeof(float),0,DIFF);25c. RECEIVE(done,sizeof(int),0,DONE);25d. else /*se executǎ de cǎtre procesul cu pid 0*/25e. for i ← 1 to nprocs-1 do /*pentru toate celelalte procese*/25f. RECEIVE(tempdiff,sizeof(float),*,DIFF);25g. mydiff += tempdiff; /*se acumuleazǎ într-un total*/25h. endfor25i if (mydiff/(n*n) < TOL) then done = 1;25j. for i ← 1 to nprocs-1 do /*pentru toate celelalte procese*/25k. SEND(done,sizeof(int),i,DONE);25l. endfor25m. endif26. endwhile27. end procedure
Note asupra programului cu transfer de mesaje
Sunt în program câteva linii fantomatice…Receive nu transferǎ date, send transferǎ. Spre deosebire de programul SAS care este initiat uzual ca primitor (receiver – încarcǎ date localizate).Comunicarea se executǎ la începutul unei iteratii, deci nu existǎ asincronism.Comunicarea se face în linii întregi, nu element cu element.Miezul este similar dar indicii/limitele lor sunt evidentiate ca variabile locale si nu globale.Sincronizarea se face prin send-uri si receive-uri. Actualizarea variabilei globale diff si evenimentul sincronizǎrii pentru conditiile îndeplinite. Se pot implementa lacǎte si bariere (locks and barriers) cu mesaje.Se pot utiliza apelurile la functiile de bibiliotecǎ REDUCE si BROADCAST pentru a simplifica codul.
67

/*se comunicǎ valorile locale diff si se determinǎ dacǎ “done = true”;poate fi înlocuitǎ cu operatii de reducere si broadcast*/
25b. REDUCE(0,mydiff,sizeof(float),ADD);25c. if (pid == 0) then25i. if (mydiff/(n*n) < TOL) then done = 1;25k. endif25m. BROADCAST(0,done,sizeof(int),DONE);
Variante de send si receive
Functionalitatea poate fi extinsǎ: stride (a merge cu pasi mari), scatter-gather (împrǎstie-adunǎ), groups (pe grupe).Arome semantice: pe baza momentului când este returnat controlul.Efect atunci când structurile de date sau bufferele pot fi reutilizate la ambele extremitǎti.
Afecteazǎ evenimentul sincronizare (excludere mutualǎ prin ordin (fiat): numai un proces detine accesul la date).Afecteazǎ usurinta programǎrii si performantele. Mesajele sincrone asigurǎ sincronizarea prin ele însesi, prin potrivire (match).Pentru mesajele asincrone, este necesarǎ sincronizarea separatǎ a evenimentelor. Cu mesaje de sincronizare, codul de mai sus este blocat (deadlocked). Cum se reparǎ?
Orchestratia: sumar
Pentru spatiu de adresare partajat. Datele private si cele partajate sunt separate explicit. Comunicarea este implicitǎ în pattern-uri de acces. Pentru distribuirea datelor nu este necesarǎ corectitudinea. Sincronizarea prin operatii atomice pe datele partajate. Sincronizarea este explicitǎ si distinctǎ de comunicarea datelor.
Pentru transferul de mesaje. Sunt necesare spatii de adresare locale pentru distribuirea datelor. Nu existǎ structuri de partajare explicite (sunt implicite în patternurile de comunicare). Comunicarea este explicitǎ. Sincronizarea este implicitǎ în comunicare (cel putin în cazul sincron). Excluderea mutualǎ prin ordin (fiat).
68

Corectitudinea programelor-solutie pentru grilǎ
Descompunerea si asignarea sunt similare în SAS si MP.Orchestratia este diferitǎ pe: structurile de date, accesul/numirea datelor, comunicare, sincronizare.
Cerintele privind performantele sunt o altǎ poveste …
69

Sisteme multiprocesor cu memorie partajatǎ
70

Exemplu privind problema coerentei memoriei cache
Dupǎ evenimentul 3, procesoarele vǎd pentru variabila u valori diferite.Cu rescrierea memoriilor cache, valoarea rescrisǎ în memorie depinde de secventa de întâmplǎri mai mult sau mai putin aleatoare în care memoriile sunt evacuate sau rescrise când procesoarele care au acces la memoria principalǎ pot vedea valori depǎsite, ceea ce este inacceptabil pentru un program!
Un sistem coerent de memorii (discutie intuitivǎ)
La lectura unei locatii trebuie sǎ se vadǎ cea mai recentǎ valoare scrisǎ de vreunul dintre procesoare. Pe sistemele uniprocesor nu apar probleme între procese: existǎ o coerentǎ între operatiile DMA (Direct Memory Access) si memoria cache a procesorului. În sistemele cu mai multe procesoare: problema coerentei apare ca si când procesele ar fi intercalate pe un sistem uniprocesor.
Probleme cu rationamentul intuitiv
Valoarea returnatǎ de o operatie de citire ar trebui sǎ fie ultima valoare scrisǎ, dar adjectivul “ultima” nu este binedefinit. În cazul secvential, “ultima” se defineste în raport cu ordinea datǎ de program, nu ca o ordine temporalǎ ci ca ordine a operatiilor prezentate procesorului în limbajul-masinǎ.În cazul paralel, ordinea programatǎ este definitǎ în cadrul unui program. Trebuie gǎsit un sens pentru ordinea generalǎ, pe toate procesele.
Câteva definitii de bazǎ
Operatie cu memoria: un singur acces la memorie de tipurile read (load), write (store) sau readmodify-read. Operatiile acestea sunt presupuse a fi executate atomic una în raport cu alta.
71

Issue: o operatie cu memoria se editeazǎ (issues) când pǎrǎseste ambianta internǎ a procesorului si este prezentatǎ sistemului de memorie (cache, buffer, …)Perform: operatia se considerǎ cǎ a avut loc, decât când procesorul poate “vorbi” de alte operatii cu memoria pe care le genereazǎ/editeaǎ (issues).Un write face un perform în raport cu procesorul când un read urmǎtor al procesorului returneazǎ valoarea acelui write sau a unui write ulterior.Un read face un perform în raport cu procesorul când write-uri urmǎtoare generate de procesor nu pot afecta valoarea returnatǎ de read.În sistemele multiprocesor definitia rǎmâne, dar se înlocuieste “procesorul” cu “un procesor”. De asemenea, perform complet: o operatie perform în raport cu toate procesoarele.Este încǎ necesar a da sens termenului de ordine în operatiile din diferite procese.
Ascutind intuitia
Sǎ ne imaginǎm o singurǎ memorie partajatǎ fǎrǎ vreun cache. Fiecare read si write adresate unei locatii are acces la aceeasi locatie fizicǎ. Operatia este completǎ când:• Memoria impune o ordine serialǎ sau totalǎ pe operatiile cu locatia• Operatiile cu locatia de la un procesor anumit sunt în ordinea din program• Ordinea operatiilor cu locatia de la procesoare diferite este un gen de
intercalare care prezervǎ ordinile individuale de program.“Last” înseamnǎ acum cel mai recent într-o ordine serialǎ ipoteticǎ care mentine aceste proprietǎti.Pentru ca ordinea serialǎ sǎ fie consistentǎ, toate procesoarele trebuie sǎ vadǎ scrierile (the writes) în locatie în aceeasi ordine (dacǎ au intentia sǎ vadǎ adicǎ sǎ facǎ o citire).De observat cǎ ordinea totalǎ nu este realmente niciodatǎ construitǎ în sistemele reale. Nici mǎcar memoria sau vreun hardware nu doreste sǎ vadǎ toate operatiile. Dar programul ar trebui sǎ se comporte ca si când se forteazǎ (enforced) o anumitǎ ordine serialǎ. Ordinea în care lucrurile par a se produce, nu cea în care realmente se produc.
Definitia formalǎ a coerentei
Rezultatele unui program: valorile returnate de operatiile lui de citire (read).Un sistem de memorii este coerent dacǎ rezultatele oricǎrei executii a unui program sunt astfel ca (pentru) fiecare locatie este posibil a construi o ordine serialǎ ipoteticǎ a tuturor operatiilor cu o locatie, care sunt consistente cu rezutatele executiei si în care:1. Operatiile generate (issued) de orice proces apar în ordinea generatǎ
(issued) de acel proces si
72

2. Valoarea returnatǎ de un read este valoarea scrisǎ (written) de ultimul write în acea locatie în ordinea serialǎ ipoteticǎ.
Sunt necesare douǎ proprietǎti:• Propagarea scrierilor: valoarea scrisǎ trebuie sǎ devinǎ vizibilǎ tuturor
imediat• Serializarea scrierilor: operatiile write într-o locatie, oricare, sǎ fie vizibile
în aceeasi ordine de toti.Dacǎ un procesor vede w1 dupǎ w2, nici un alt procesor nu trebuie sǎ vadǎ invers. Nu este necesarǎ o serializare similarǎ pentru operatiile read deoarece citirile nu sunt vizibile altora.
Solutii potentiale de coerentǎ hardware
Solutia detectivisticǎ (snooping):Toate cererile de date se trimit tuturor procesoarelor. Procesoarele cautǎ si detecteazǎ dacǎ au o copie proprie a detelor solicitate si rǎspund în consecintǎ.Solutia cere o difuzare (broadcast) deoarece informatia cache-atǎ este plasatǎ la procesoare.Solutia snooping lucreazǎ bine cu bus-ul (este un mediu de broadcast natural).Este solutie dominantǎ pe masinile relativ mici (cea mai mare parte din piatǎ).Scheme/solutii bazate pe director:Un director tine evidenta a ceea ce este partajat într-un loc logic centraliza(n)t.Pentru sistemele cu memorie distribuitǎ si directorul este distribuit din ratiuni de scalabilitate (se evitǎ astfel locurile înguste – bottleneck).Se trimit solicitǎri punct-la-punct la procesoare prin retea.Se scaleazǎ mai bine decât snooping-ul.Ideea a existat înainte de schemele bazate pe actiunea detectivisticǎ (snooping).
Topologia pentru snooping-ul pe bus
Memoria: centralizatǎ cu acces uniform (UMA – Uniform Memory Access) si interconectare pe bus.Exemple timpurii: Firefly, Encore, Sequent, …Un exemplu curent: Unisys.
73

Protocoale de bazǎ pentru Snoopy
Protocolul Write InvalidateCitiri multiple, scriere unicǎScrierea în zona de date partajatǎ: o instructiune de invalidare este expediatǎ cǎtre toate cache-urile, care detecteazǎ si invalideazǎ orice (altǎ) copie.Ratare de citire (read miss):• Write-through (scrie complet, pânǎ la capǎt): memoria este tot timpul
actualǎ (up-to-date)• Write-back: sondeazǎ (snoop) în cache-uri pentru a afla copia cea mai
recentǎ.Protocolul Write Broadcast (este tipic un write-through):Scriere la date partajate: broadcast pe bus, supravegherea (snoop) procesoarelor si actualizarea oricǎrei cópii.Ratare de read: memoria este totdeauna up-to-date.Serializarea scrierilor: bus-ul serializeazǎ cererile!Bus-ul este singurul punct de arbitraj.Write Invalidate fatǎ-n fatǎ cu Write Broadcast:Varianta Invalidate cere o tranzactie constând într-o executie de write.Varianta Invalidate utilizeazǎ localismul spatial: o tranzactie pe un bloc de memorie.Varianta Broadcast are latenţǎ mai micǎ între write si read.
Un exemplu de protocol Snoopy
Protocolul cu invalidare, rescrierea memoriei cache. Fiecare bloc de memorie este în una din stǎrile:• Curat în toate memoriile cache si actualǎ în memorie (partajatǎ)• SAU exact un cache murdar (dirty) (exclusiv)• SAU nu în nici un cache.Fiecare bloc de cache este în una din stǎrile:• Partajat: blocul poate fi citit• SAU exclusiv cache-ul are o copie exclusivǎ, ea se poate citi si este murdarǎ• SAU invalid: blocul nu contine date (de luat în considerare).Ratǎri la citire (read miss): produce o documentare (snoop) a tuturor cache-urilor pe bus.Scrierile (writes) pentru a curǎta o linie sunt tratate ca ratǎri (miss).
74

Masina de stare cu snoopy-cache (I)
Masina de stare cu snoopy-cache (II)
Masina de stare cu snoopy-cache (III)
75

Exemplu
Se admite cǎ starea initialǎ a cache-ului este invalidǎ si A1 si A2 se asociazǎ (map) aceluiasi bloc de cache, dar A1 ≠ A2
Exemplu: pasul 1
Arcul orientat activ este încadrat într-un paralelogram.
Exemplu: pasul 2
76

Exemplu: pasul 3
Exemplu: pasul 4
Exemplu: pasul 5
77

Paşi
Proc.1 (P1) Proc.2 (P2) Bus Mem.
Star
e
Adr
esa
Val
oare
Star
e
Adr
esa
Val
oare
Act
iune
Proc
esor
Adr
esa
Val
oare
Adr
esa
Val
oare
1. P1 scrie 10 în A1 E
xclu
siv
A1 10
WrM
s
P1 A1
2. P1 citeste pe A1 E
xclu
siv
A1 10
3. P2 citeste pe A1 Pa
rtaj
at
A1R
dMs
P2 A1
Part
ajat
A1 10
WrB
k
P1 A1 10 A1 10
Part
ajat
A1 10
RdD
a
P2 A1 10 A1 10
4. P2 scrie 20 în A1 In
valid
Exc
lusi
v
A1 20
WrM
s
P2 A1 A1 10
5. P2 scrie 40 în A2 W
rMs
P2 A2 20 A1 10
Exc
lusi
v
A2 40
WrB
k
P2 A1 20 A1 20
78

Variante de cache cu snooping
Protocolul de bazǎ
Protocolul Berkeley Protocolul Illinois Protocolul MESI
ExclusivePartajatInvalid
Proprietate exclusivǎ
Proprietate partajatǎPartajatInvalid
Privat şi murdarPrivat şi curat
PartajatInvalid
Modificat (privat, ≠ memorie)
Exclusiv (privat, = memorie)
Partajat (partajat, = memorie)
Invalid
Proprietarul poate updata prin bus operatiile invalidate.Proprietarul trebuie sǎ re-scrie când înlocuieste în cache.Dacǎ citirea (read) are sursa în memorie, atunci este vorba de “privat si curat”.Dacǎ citirea are sursa în alt cache, atunci este vorba de “partajat”.Se poate scrie (write) în cache dacǎ se mentine “privat curat” sau “privat murdar”.Se tin sub observatie (snoop) si extensiile de cache.
Complicatii la implementare
Competitia pentru scriere (Write Races): nu se poate updata cache-ul pânǎ când nu se obtine accesul la bus. Altminteri, un alt procesor poate prelua bus-ul primul si apoi scrie în acelasi bloc de cache!Un proces în douǎ etape: arbitrajul de bus, plasare de “miss” pe bus si completarea operatiei. Dacǎ apare “miss” pentru a bloca în timp ce este asteptat bus-ul, se manipuleazǎ “miss”-ul (poate fi necesarǎ invalidarea) si apoi se reia.
79

Bus cu tranzactii divizate (split): tranzactia pe bus nu este atomicǎ; poate avea tranzactii importante multiple pentru un bloc. “Miss”-urile multiple se pot intercala, permitând ca douǎ cache-uri sǎ acapareze blocul în starea Exclusiv. “Miss”-urile multiple pentru un bloc trebuie urmǎrite si prevenite. Este necesar suport pentru interventii si invalidǎri.
Implementarea de cache-uri snooping
Procesoarele multiple trebuie sǎ fie pe bus, acces atât la adrese cât si la date. Se adaugǎ câteva comenzi noi pentru a executa operatii legate de coerentǎ, suplimentar la read si write.Procesoarele spioneazǎ continuu pe bus-ul de adrese. Dacǎ adresa se potriveste la etichetǎ (tag) atunci fie se face invalidarea fie updatarea.Deoarece fiecare tranzactie pe bus verificǎ etichetele de cache, ar putea interfera cu accesul CPU la cache:Solutia 1: duplicarea setului de etichete pentru cache-urile de nivelul L1 tocmai pentru a permite verificǎri în paralel cu CPU.Solutia 2: cache-ul de nivelul L2 deja este un duplicat dat fiind cǎ nivelul 2 se supune regulii incluziunii cu nivelul L1. În ceea ce priveste dimensiunea blocului, asociativitatea din L2 afecteazǎ nivelul L1.Bus-ul serializeazǎ scrierile, asigurând prin aceasta cǎ nici un alt procesor nu poate executa operatii cu memoria.La un “miss” într-un cache de rescriere (write back cache), s-ar putea avea copia doritǎ si varianta ei murdarǎ asa încât trebuie rǎspuns/replicare.Se adaugǎ la cache un bit suplimentar pentru a determina dacǎ este partajat sau nu.Se adaugǎ a patra stare (MESI – Modified, Exclusive, Shared, Invalid)
Multiprocesoare extinse
Memorie separatǎ pe fiecare procesor.Accesul local sau la distantǎ printr-un controller de memorie.Alternativǎ: director pe fiecare cache care tine evidenta (tracks) stǎrii fiecǎrui bloc din fiecare cache.Care cache-uri au o copie a blocului, curatǎ sau murdarǎ, …Informatii pe bloc de memorie si pe bloc de cache?PLUS: în memorie protocol mai simplu (centralizat/o locatie)MINUS: în memorie directorul este functie de dimensiunea memoriei sau functie de dimensiunea cache-ului.Prevenirea strangulǎrii pe director? Distribuirea articolelor din director cu memoria, fiecare detinând informatia privitoare la care procesoare au cópii în blocurile lor.
80

Multiprocesoare ccNUMA
ccNUMA = Cache Coherent Non-Uniform Memory Access.
Protocol cu/pe director
Este similar protocolului snoopy: se disting trei stǎriShared: mai mult de un procesor detine data, memorie up-to-date.Uncached: nici un procesor nu detine data; invalidǎ în orice cache.Exclusive: un procesor (proprietar) are data; memoria depǎsitǎ (out-of-
date).Directorul trebuie sǎ urmǎreascǎ starea cache-ului, care procesoare au data când starea este shared.• Vector de biti, bitul este 1 dacǎ un procesor anumit are o copie.• Combinatie de ID si vector de biti.Mentinerea simplitǎtii:Scriere pe date non-exclusive, write miss.Procesorul blocheazǎ pânǎ când accesul se încheie.Se presupune cǎ asupra mesajelor primite se actioneazǎ în ordinea în care au fost trimise.În cazul lipsei de bus si a lipsei intentiei de broadcast:Interconectarea nu mai are un singur punct de arbitraj, toate mesajele au rǎspuns explicit.Termeni: o situatie tipicǎ cu implicarea a trei procesoare.Nod local (local node) – nodul de unde provine cererea.Nodul de bastinǎ (home node) – locul în memorie de rezidentǎ a unei adrese.Nodul la distantǎ (remote node) – are o copie a blocului de cache, fie exclusiv, fie partajat.Exemple de mesaje:P = numǎrul procesorului, A = adresa.Mesaje prin protocolul cu director
81

ReadMiss(P, A): de la cache-ul local la directorul HomeProcesorul P citeste data din A, îl face pe P partajant la citire si cere
retur al datei (data back).WriteMiss(P, A): de la cache-ul local la directorul HomeProcesorul P scrie data în A, îl face pe P proprietar exclusiv si cere retur
al datei (data back).Invalidate(P, A): din directorul Home la cache-ul îndepǎrtatInvalideazǎ o copie partajatǎ a lui A la procesorul P.Fetch(P, A): din directorul Home la cache-ul îndepǎrtat (remote)Localizeazǎ si aduce data la adresa A din cache-ul lui P.Fetch&Invalidate(P, A): din directorul Home la cache-ul îndepǎrtatLocalizeazǎ si aduce data din directorul Home din cache-ul lui P si
invalideazǎ directorul cache-ului din nod.DataReply(P, A): din directorul Home la cache-ul îndepǎrtatReturneazǎ data din directorul Home (read miss).
Implemetarea unui director
Probleme:Operatiile nu sunt atomice, de ce?Putem avea blocǎri (deadlocks), de ce?Solutii:Douǎ retele, una pentru cereri si una pentru rǎspunsuri.Cum poate fi de ajutor o astfel de schemǎ?Optimizǎri:Pentru read miss sau pentru write miss în Exclusive, se transmite data direct la cel care a cerut-o de la proprietar la memorie si apoi de la memorie la cel care a cerut-o.Nodul Exclusive este totdeauna proprietarul, este treaba aceasta dificilǎ?
Sincronizare
De ce sincronizare? Trebuie stiut când este sigur pentru procese diferite a utiliza date partajate.Probleme cu sincronizarea:Instructiuni care nu pot fi întrerupte pentru a regǎsi si a updata memoria (operatii atomice); operatii de sincronizare la nivelul utilizatorului care utilizeazǎ aceastǎ primitivǎ; pentru MP-uri de mare capacitate sincronizarea poate fi un loc îngust (o strangulare); tehnici de a reduce controversele si latenta de sincronizare.
Instructiuni atomice pentru lucrul cu memoria
Schimbarea mutualǎ de continut între un registru si o locatie de memorie este atomicǎ.
82

0 ⇒ variabilǎ de sincronizare liberǎ1 ⇒ variabilǎ de sincronizare blocatǎ (locked) sau indisponibilǎSe pune registrul la 1 si se face schimbul.Noua valoare din registru determinǎ succesul în obtinerea blocǎrii (lock)
0 dacǎ blocarea este un succes (procesorul este primul venit)1 dacǎ alt procesor a obtinut deja accesul
Testeazǎ-si-seteazǎ (test-and-set)Testeazǎ o valoare si seteaz-o dacǎ valoarea trece testul.Regǎseste-si-opereazǎ (fetch-and-op): returneazǎ valoarea unei locatii de memorie si executǎ atomic o operatie.0 ⇒ variabilǎ de sincronizare liberǎ
Încarcǎ blocat si memoreazǎ conditional (Load Locked and Store Conditional)
Pe un multiprocesor de mare cuprindere este dificil de implementat o instructiune atomicǎ.Load linked (or load locked) + store conditional.Load linked returneazǎ valoarea initialǎ.Store conditional returneazǎ 1 dacǎ reuseste (nimeni altcineva nu depune în aceeasi locatie de memorie de la precedentul load) si 0 altminteri.Exemplu de schimbare (swap) atomicǎ cu LL (Load Linked) si SC (Store conditional):
try: mov R3,R4 ; mov exchange valuell R2,0(R1) ; load linkedsc R3,0(R1) ; store conditionalbeqz R3,try ; branch store fails (R3 = 0)mov R4,R2 ; put load value in R4
Exemplu de fetch & increment cu LL si SC:
try: ll R2,0(R1) ; load linkedaddi R2,R2,#1 ; increment (OK if reg–reg)sc R2,0(R1) ; store conditionalbeqz R2,try ; branch store fails (R2 = 0)
Blocare ca regulǎ (Always Block)
Acquire(lock) { while (!TAS(lock.value)) Block(lock); }
Release(lock) { lock.value = 0; Unblock(lock); }
Care sunt problemele acestui mod de tratare?
83

Împletire ca regulǎ (Always Spin)
Acquire(lock) { while (!TAS(lock.value)) while(lock.value) ; }
Release(lock) { lock.value = 0; }
Douǎ bucle împletite (spinning) în Acquire()?Probleme cu aceastǎ tratare?
Algoritmi optimali
Care este solutia optimǎ între spin si block?Cunoasterea viitorului. Exact când sǎ se facǎ spin si când sǎ se facǎ block. Dar viitorul nu ne este cunoscut. Nu existǎ un algoritm optimal online.
Algoritm optimal offline.Dupǎ o executie, se poate deduce exact când sǎ se apeleze la block si când la spin (“what if”).Util pentru a face comparatii cu algoritmii online.
Algoritmi competitivi
Un algoritm este c-competitiv dacǎ pentru orice secventǎ de intrare σCA(σ) ≤ c × Copt(σ) + k
84

cu c o constantǎ, CA(σ) costul cerut de algoritmul A în procesarea secventei σ si Copt(σ) costul cerut de algoritmul optim în procesarea aceleiasi secvente σ.Este de dorit o valoare pentru c cât mai micǎ posibil.Determinist. Randomizat.
Algoritmi constant competitivi
Acquire(lock, N) {int i;while (!TAS(lock.value))for (i = 0; i < N; i++)if (!lock.value) break;if (lock.value)Block(lock);}
Dacǎ N este numǎrul recurgeri la spin egal cu timpul de comutare contextual (context-switch), care este factorul competitiv al algoritmului?
Algoritmi optimali online aproximativi
Ideea principalǎ: utilizeazǎ trecutul pentru a prezice viitorul.Tratarea: cea mai simplǎ metodǎ este random walk.• Descreste pe N cu o unitate dacǎ ultimul Acquire() a blocat• Incrementeazǎ pe N cu o unitate dacǎ ultimul Acquire() n-a blocatRecalculeazǎ pe N de fiecare datǎ pentru fiecare Acquire() bazat pe o anumitǎ distributie a asteptǎrii (E) de lock (lock-waiting) pentru fiecare lock.Rezultate teoretice:
E {CA(σ(P))} ≤ (e/(e – 1)) × E{Copt(σ(P))}Factorul de competitie este de circa 1,58.
Rezultate empirice
Tabelul 1. Costurile sincronizǎrii pentru fiecare programraportat la algoritmul off-line optimal
85

Tabelul 3. Timpul consumat al Regsim utilizând strategii variate de spinning
Tabelele conform A. Karlin, K. Li, M. Manasse, and S. Owicki, “Empirical Studies of Competitive Spinning for a Shared-Memory Multiprocessor” în Proceedings of the 13th ACM Symposium on Operating Systems Principle, 1991.
Bariere în arbori combinativi
Sumar
Memoria cache este cheia implementǎrii unui sistem multiprocesor.Coerenta de cache este centralǎ în proiectare.Protocoalele snooping si directory sunt similare: bus-ul faciliteazǎ snooping-ul din cauza broadcast-ului (snooping ⇒ acces uniform la memorie).Directory are o structurǎ suplimentarǎ care retine stǎrile tuturor blocurilor de cache.Director distribuit, sisteme multiprocesor scalabile cu adrese partajate: ccNUMA (cache coherent, Non Uniform Memory Access).
86

Sincronizarea.Necesitǎ suport hardware: instructiuni atomice.Necesitatea de prudentǎ în folosirea primitivelor de sincronizare pe sistemele multiprocesoare mari.
87

Paralelismul la nivel de fire pe întelesul tuturor
Autor: Kunle Olukotun Computer Systems Lab.Stanford University2007
Traducerea si adaptarea: Gheorghe M.Panaitescu
Lumea s-a schimbat si este în schimbare
Procesul tehnologic a încetat sǎ mai progreseze. Se face referire le legea lui Moore, dar… Tranzistoarele nu merg mai repede si au pierderi mai mari (65 nm fatǎ-n-fatǎ cu 45 nm). Firele, legǎturile sunt într-o situatie si mai rea.Performantele firului de control/executie unic s-au plafonat. Complexitatea proiectǎrii si verificǎrilor este coplesitoare. Consumul de putere creste dramatic. Paralelismul la nivel de instructiune (ILP – Instruction-level parallelism) a fost epuizat.Viraj la dreapta: îndepǎrtarea de performanta prin frecventǎ, pretutindeni apare prefixul “multi” (MT – Multi-Threading, CMP – Cellular MultiProcessing).Informatii recente de la Intel Developer Forum (septembrie 2004).
Era multiprocesoarelor pe cip unic
Multiprocesoarele pe cip unic furnizeazǎ o alternativǎ scalabilǎ. Se bazeazǎ pe forme de paralelism scalabile. Paralelism la nivel de solicitare (request), paralelism la nivelul datelor. Proiectare modularǎ cu tolerantǎ la defecte inerentǎ si potrivitǎ tehnologiei VLSI.Multiprocesoarele pe cip unic sunt deja prezente. Toti producǎtorii de procesoare urmeazǎ calea aceasta, în sisteme încorporate, în servere, chiar în sistemele desktop.Cum se creazǎ arhitecturi de CMP pentru a exploata cât mai bine paralelismul la nivel de fire? În aplicatiile server: capacitatea de prelucrare (throughput). În aplicatiile stiintifice si de uz general: latenţa.
Liniile generale ale discutiei
Motivatie: era multiprocesoarelor pe cip unic.Capacitate de prelucrare (throughput) si putere micǎ: Sun Niagara.Latenţa: Stamford TCC (Transactional Coherence and Consistency).
88

TLP (Thread-Level Parallelism) pe întelesul tuturor (Google)
Trei platforme hardware (cf. Luiz Barroso, ACM Queue, sept.2005)
CAGR (Cumulative Average Growth Rate)
89

TCO (Total Cost of Operations) este dominat de costul energiei. Un ciclu de viatǎ de 4 ani al unui server la 0,09 $ kWh. Performanta/watt trebuie crescutǎ. (cf. Luiz Barroso, ACM Queue, sept.2005)
Încǎrcarea serverelor comerciale
Capacitatea de prelucrare proiectatǎ a serverelor
Aplicatiile comerciale ale serverelor. Multimea de taskuri atrage folosirea firelor multiple. ILP scǎzut si întârzieri mari cu memoria.Foarte bune performante (throughput) obtinute cu fire multiple. O formǎ scalabilǎ de paralelism. Se face un compromis sub aspectul latentei pentru productivitatea (throughput) firelor multiple. Se renuntǎ la un CPU OOO6 unic si mare pentru mai multe CPU simple. Memorii cache de la medii la mari. Banda de trecere spre si dinspre memorie mare.
Maximizarea productivitǎtii (throughput) CMP (cellular multiprocessors) cu cores simple
Se recomandǎ articolul semnat de J. Davis, J. Laudon si K. Olukotun PACT 2005.Sunt examinate mai multe proiecte UltraSPARC II, III, IV si Niagara bazate pe tehnologii diferite.
6 OOO: out of order (scris uneori si O-O-O). Pentru cresterea performantelor, unele microprocesoare pot executa instructiunile date prin program altfel decât în ordinea lor originarǎ din sirul de instructiuni înainte de a extrage rezultate în ordine.
90

S-a construit un model pentru arie bazat pe aceste explorǎri.S-a presupus o suprafatǎ ocupatǎ de cip (die) de arie fixǎ (400 mm2) si s-a tinut seamǎ de overheadul datorat monturii, pinilor, rutǎrii.S-au urmǎrit performantele pentru o gamǎ largǎ de proiecte de core cu procesoare scalare si superscalare ordonate (in-order).
Cores mai simple oferǎ performante mai înalte
Pentru detalii a se vedea articolul mentionat mai devreme (PACT 2005).Optimizarea dupǎ IPC-ul (Instruction Per Cycle) cipului. Arhitecturi de 4-20 cores pe o arie de 400 mm2. Memorii cache de nivelul 2 de la 1,5 MB la 2,5 MB. Importante firele multiple si pipes-urile multiple. Pipes-urile scalare sunt cu 37% la 46% mai bune decât pipes-urile superscalare (12 fatǎ de 7 cores).
Importanta echilibrului procesor-cache
Dimensiunea cache-ului secundar
Performante pe TPC-C.
91

C1: 64 kB cache de nivelul 1, C2: 32 kB cache de nivelul 1, ambele variante cu cores 2p4t.
Cores mai simple oferǎ putere mai redusǎ
Sursa: Tilak Agerwala Micro May-June 2005
Cores simple fac peformante mai bune per watt. Aceleasi performante la 20% putere. Opt cores simple consumǎ aceeasi putere ca si douǎ cores complexe.
Principii de proiectare la Niagara 1
Sun Microsystems a ahizitionat în 2003 Afara Websystems apǎrutǎ în 2002.Proiectat pentru productivitate si putere micǎ în aplicatii comerciale server. Niagara 1 (UltraSPARC T1) 2005.Multe cores simple în opozitie cu putine cores complexe. Exploateazǎ paralelismul la nivel de fire (request) în opozitie cu ILP (Instruction Level Parallelism). O crestere a eficientei raportatǎ la putere (MIPS/watt). Cost de dezvoltare scǎzut, risc de planificare (schedule risk) cu pipeline simplu. Randament sporit prin vânzare de pǎrti non-perfect.Proiectat pentru performante bune cu ratǎri de cache (cache missis). Bandǎ mare de trecere cu memoria per cip. Executǎ aplicatii reale mai bine chiar decât reperele standard (benchmarks). Ascunde cache, ramificǎ stagnǎrile cu fire, în opozitie cu ILP.
Niagara CMP overview
Implementare de SPARC V9.Opt cores a câte patru fire = 32 de fire.Comutare crossbar de 90 GB/secundǎ.Bandǎ de trecere înaltǎ, patru cǎi partajeazǎ cache de nivelul 2 de 3 MB pe cip.
92

Patru canale DDR2.Circa 300 M de tranzistori.Suport (die) de 378 mm2.
Pipeline SPARC
Pipeline cu generare simplǎ (single issue).Patru fire, comutare în fiecare ciclu.Registre repartizate pe fiecare fir, buffere de instructiuni si buffere de memorare. Overhead de arie 20%.
93

Sistemul de memorie Niagara
Cache-ul de instructiuni. 16 kB, asociativ pe seturi în patru moduri, dimensiunea liniei 32 B.Cache-ul de date. 8 kB, asociativ pe seturi în patru moduri, dimensiunea liniei 16 B. Cache write-through, write-around la miss.Cache-ul de nivel 2. 3 MB, asociativ pe seturi în 12 moduri, dimensiunea liniei 64 B. Write-through. Bancat (banked) pe linii în patru moduri.Coerentǎ. Liniile cache de date au douǎ stǎri: validǎ sau invalidǎ. Când cache-ul de date este scris în maniera write-through atunci nu are loc vreo modificare de stare. Cache-ul este mentinut coerent prin linii de evidentǎ (tracking) în directoare în cache-ul de nivelul 2.Consistentǎ. TSO asigurat prin crossbar. Punctul de consistentǎ este nivelul 2, firele care folosesc partajat cache-ul de nivelul 1 trebuie sǎ astepte pentru a avea vedere spre memorii.
Performantele sistemului de memorare
Latenţe. Încǎrcare pentru utilizare: 3 cicluri. Latenţa la descǎrcare pentru nivelul 2: 22 de cicluri. Latenţa la descǎrcare a memoriei: ~90 ns.Banda de trecere (bandwidth). Pentru nivelul 2: 76,8 GB/s, pentru memorie: 25,6 GB/s.
Performanţele multifir TPC-C
O crestere la triplu a productivitǎtii (throughput) pentru o crestere a ariei de 20%. O crestere a latenţei de 33%.
94

Fotografia suportului fizic (die) pentru Niagara 1
O unitate de virgulǎ mobilǎ (FPU).90 nm.279 M de tranzistori.378 mm2.
Comparatie pentru microprocesorul de 90 nm
95

Performantele de productivitate (throughput)
Performanţele/watt
Strangulǎri la Niagara 1
96

Strangulǎri în pipeline si la interfaţa DRAM.Bandǎ de trecere cu rezerve în cache-uri.
Transformarea de Niagara 1 în Niagara 2
Scopul: dublarea productivitǎtii la aceeasi putere. Dublarea numǎrului de cores?Dublarea numǎrului de fire de la 4 la 8. S-au ales 2 fire din 8 pentru a fi executate în acelasi ciclu.Dublarea unitǎtilor de executie de la 1 la 2 si adǎugarea de FPU.Dublarea asociativitǎtii în seturi pentru cache-ul de instructiuni de nivelul 1 la 8 cǎi.Dublarea dimensiunii pentru DTLB total asociativ de la 64 la 128 de intrǎri.Dublarea bǎncilor la nivelul L2 de la 4 la 8. Pierdere de performantǎ de 15% cu numai 4 bǎnci si 64 de fire.
Niagara 2 dintr-o privire
97

Opt cores a câte patru fire. Douǎ pipes/core, douǎ grupe de fire.Un FPU per core.Procesor Crypto per core. DES, 3DES, AES, RC4 etc.Nivelul 2 de cache de 4 MB, 8 bǎnci, 16 cǎi/moduri S.A.De patru ori porturi FBDIMM dublu canal (60+ GB/s).Productivitatea si productivitatea/watt mai mult decât dublǎ fatǎ de cele pentru Niagara 1.De 1,4 ori Niagara 1 la întregi.De 10 ori Niagara 1 la FP.
Suportul fizic (die) pentru Niagara 2
98

65 nm.342 mm2.
Crizǎ din imaginatie (looming)
Prin 2010, dezvoltatorii de software vor fi în fata unor structuri noi.CPU-uri cu (Niagara 2 si cele ce vor urma): peste 20 de cores, peste 100 de fire hardware, cores eterogene si acceleratori specifici de aplicatie.CPU-uri cu capacitǎti de calcul generale.Gaura (gap) din programarea paralel: o uimitoare separare între capacitǎtile programatorilor de azi, a limbajelor de programare, a modelelor si instrumentelor si provocǎrile viitoarelor arhitecturi si aplicatii paralele.
Provocǎri în programrea paralel
Stabilirea de taskuri independente.Asocierea taskurilor cu firele.Definirea si implementarea protocoalelor de sincronizare.Conditiile de competitie (race).Evitarea blocajelor (deadlock).Model al memoriei.Compunerea de taskuri.Scalabilitatea.
99

Analiza performantelor paralel.Recuperarea din eroare.Tranzactiile reclamǎ un numǎr mare de probleme de programare paralel.
Coerenta si consistenta tranzactiilor (TCC – Transactional Coherence & Consistency)
A se urmǎri lucrǎrile lui Christos Kozyrakis (Stanford University).Ţelul: a aduce programarea paralel pe memorie în indiviziune (partajatǎ) la îndemâna dezvoltatorilor medii.Programarea paralel pe memorie în indiviziune (partajatǎ) cu tranzactii. Nu fire, nu locks, numai tranzactii…Tranzactiile definite de programator sunt singurele abstractii (the only abstraction): lucru paralel, comunicare si sincronizare, coerenta si consistenta memoriei, atomicitatea esecurilor si recuperarea, optimizarea performantelor.
Definirea memoriei tranzactionale
Tranzactie cu memoria: o secventǎ de operatii cu memoria care fie se executǎ complet (commit) sau nu au nici un efect (abort).O secventǎ de operatii “totul sau nimic”. La commit, toate operatiile cu memoria apar ca având efect unitar (toate deodatǎ). La abort, nici una din operatiile de depozitare (store) nu apare a avea efect.Executarea tranzactiilor în izolare. Efectele de depozitare nu sunt vizibile pânǎ când tranzactia nu se încheie (commits). Nu existǎ acces concurent conflictual din partea altor tranzactii.Similare proprietǎtilor bazelor de date ACID.
Limbajul memoriilor tranzactionale
Construct
Constructul de bazǎ atomic: lock(L); x++; unlock(L) ⇒ atomic {x++}Declarativ – utilizatorul specificǎ pur si simplu, sistemul implementeazǎ “sub acoperire”.Constructul atomic de bazǎ universal propus. Limbajele HPCS (Fortress, X10, Chapel) furnizeazǎ atomic în loc de locks. Cercetǎri extise la alte limbaje – Java, C#, Haskell, …Recent, activitate de cercetare sustinutǎ. Constructe de limbaj pentru memorii tranzactionale. Compilare si optimizare atomicǎ. Implementǎri hardware si software de memorii tranzactionale.
100

Programarea tranzactionalǎ Atomos
Limbajul
Atomos a derivat din Java.Memorie tranzactionalǎ pentru concurentǎ. Blocuri atomice definesc bazele tranzactiilor una-în-alta. Eliminare sincronizatǎ si volatilǎ.Tranzactia bazatǎ pe asteptare conditionatǎ. Derivatǎ din regiuni critice conditionate (Conditional Critical Regions) si revenirea (retry) Harris. Eliminarea de wait, notify si notifyAll. Seturi de veghe (Watch sets) pentru implementare eficientǎ. Tranzactii una-în-alta deschise. Blocuri deschise care executǎ (committing) tranzactia inclusǎ child înainte de parent. Utile pentru implementarea limbajului dar si disponibile pentru aplicatii.Handlere pentru violǎri. Manipuleazǎ violǎrile asteptate fǎrǎ revenire (rolling back) în toate cazurile. Nu sunt pǎrti ale limbajului, sunt utilizate numai în implementarea limbajului.
Beneficiile memoriei tranzactionale
Mai usor a obtine rezultate scalabile.Locks:Locks-urile grosier granulate sunt simplu de utilizat. Totusi cu limitare de scalabilitate.Locks-urile fin granulate pot spori scalabilitatea. Totusi dificil de a obtine dreptul de utilizare.Tranzactii:La fel de usor de utilizat ca si locks-urile grosier granulate, scaleazǎ la fel de bine ca si locks-urile fin granulate.
Performanta HashMap
101

Tranzactiile scaleazǎ la fel de bine ca si locks-urile fin granulate.
SPECjbb2000 cu tranzactii cu includere
Accelerare de 5,4 ori cu un CMP cu opt procesoare.Timpul cu violǎrile s-a redus si s-a îmbunǎtǎtit comportarea cache-ului.Detalii în [ISCA’06].
Modelul de executie TCC
102

Coerentǎ/consistentǎ tranzactionalǎ cu garantii de non-blocare.Pentru detalii a se vedea [ISCA’04].
TCC scalant
Eliminǎ commit broadcast din TCC original.Eliminǎ proiectarea cache-ului write-through7.Suportǎ commits paralele.Prima implementare TM scalabilǎ a unui sistem cu memorie distribuitǎ în indiviziune (partajatǎ), bazatǎ pe director lipsitǎ de blocaje de tip livelock.
Performante pentru TCC scalabil
DSM cu 64 de procesoare
Commit-ul write-through nu mai lucreazǎ. Commit în douǎ faze ⇒ commit paralel. Commit-ul nu mai este o strangulare.Scalabilitate excelentǎ.
7 Cache write-back – o metodǎ de caching în care modificǎrile aduse datelor din cache nu sunt copiate în sursa cache atât timp cât nu este absolut necesar. Caching-ul write-back este disponibil în multe microprocesoare, inclusiv în procesoarele Intel de dupǎ 80486. Cu aceste microprocesoare, modificǎrile de date (operatiunile write de pildǎ) pe datele stocate în cache-ul de prim nivel nu sunt copiate în memoria principalǎ decât atunci când este absolut necesar. În contrast, cache-ul write-through executǎ toate operatiile de scriere în paralel – datele sunt scrise în memoria principalǎ si în cache-ul de nuvelul 1 simultan.Caching-ul write-back produce performante întrucâtva mai bune decât caching-ul write-through deoarece reduce numǎrul de operatii de scriere în memoria principalǎ. Cu aceastǎ crestere de performantǎ vine totodatǎ un usor risc ca datele sǎ fie pierdute dacǎ sistemul clacheazǎ.Un cache write-back este denumit uneori si cache copy-back.
103

Concluzii
Sun Niagara: CMP optimizat pentru performanta/watt pe aplicatii de server comerciale. Proiectarea: concesiile la latentǎ pentru productivitate ⇒ putere mai micǎ. Pipelines simple, CMP si multithreading, ierarhia memoriei la bandǎ de trecere largǎ. Cresteri de performante/watt de la 2 la 4 ori în comparatie cu microprocesoarele conventionale pe aplicatii comerciale.Stanford TCC: un model paralel cu memorie în indiviziune (partajatǎ) cu tranzactii. Tranzactii definite prin software ca singurele abstractii pentru paralelism, comunicare, atomicitate la eşec si optimizare. Calea simplǎ spre codul corect: prin paralelism speculativ si atomicitate/ordonare bazatǎ pe hardware. Ajustare a performantei intuitivǎ, condusǎ de feedback (feedback driven). Prin urmǎrirea si înregistrarea (data tracking and logging) continuǎ a datelor. Rezultate initiale încurajatoare. 90% din performante la 10% effort de programare.
104

Programarea pentru performante
Simularea curentilor oceanici
(a) Sectiune transversalǎ (b) Discretizarea spatialǎ a unei sectiuni transversale
Se modeleazǎ prin grile bidimensionale. Se discretizeazǎ în spatiu si în timp. Cu cât este mai finǎ rezolutia spatialǎ si temporalǎ cu atât mai ridicatǎ este precizia rezultatelor obtinute.Calcule multe si diferite pentru fiecare pas de timp; scrierea de ecuatii si rezolvarea lor. Concurentǎ de calcul în grilǎ si între grile. Staticǎ si obisnuitǎ.
(a) (b)
105

Simularea evolutiei galactice
Se simuleazǎ interactiunea între foarte multe stele cu evolutie în timp.Calculul fortelor este costisitor. Tratarea fortelor la modul brut: O(n2). Metodele ierarhice fac uz de legea fortelor: G = m1m2/r2.
Star on which for cesare being computed
Star too close toapproximate
Small group far enough away toapproximate to center of mass
Large gr oup farenough away toapproximate
Multi pasi de timp, concurentǎ bogatǎ între stele în fiecare pas.
Explorarea de scene prin urmǎrirea dispersǎrii razelor
Se trimit raze în scenǎ prin spatiul restrâns al unor pixeli de imagine planǎ.Se urmǎresc parcursurile lor. Ele ajung si lovesc obiecte din scenǎ. Sunt generate raze noi, secundare: un arbore de raze pentru fiecare razǎ incidentǎ.Rezultǎ o culoare si o opacitate pentru acel pixel.Paralelismul este aici între raze.Câtǎ concurenţǎ este în aceste exemple?
106

Patru pasi în crearea unui program paralel
P0
Tasks Processes Processors
P1
P2 P3
p0 p1
p2 p3
p0 p1
p2 p3
Partitioning
Sequentialcomputation
Parallelprogram
Assignment
Decomposition
Mapping
Orchestration
Descompunerea calculelor în taskuri.Asignarea taskurilor la procese.Orchestrarea accesului la date, comunicarea, sincronizarea.Asocierea (mapping) proceselor pe procesoare.
Ţinta performanţelor implicǎ accelerarea (speedup)
Ţinta arhitectului: observarea modului în care programul utilizeazǎ masina si proiectarea pentru a ameliora perfomanţele.
107

Ţinta programatorului: observarea modului în care programul utilizeazǎ masina si îmbunǎtǎtirea implementǎrii pentru a ameliora performanţa.Ce se observǎ? Cine la ce lucreazǎ?
Cadrul analizei
Accelerarea (speedup) este inferioarǎ raportului dintre timpul de lucru secvential si maximul sumei lucru + timpi de asteptare pentru sincronizare + timpul de comunicare + lucru suplimentar.Solutia comunicǎrii si echilibrarea încǎrcǎrii este în cazul general NP-dificilǎ (Nondeterministic Polynomial – NP-hard8). Dar solutiile simple euristice lucreazǎ destul de bine în practicǎ.Existǎ o tensiune fundamentalǎ între patru factori: încǎrcare echilibratǎ, sincronizare minimalǎ, comunicare minimalǎ si lucru suplimentar minimal.Masinile bine proiectate o atenueazǎ prin compromisuri (trade-offs) judicioase.
Descompunerea
Se identificǎ concurenta si se decide nivelul la care ea trebuie exploatatǎ.Se sparg calculele în taskuri care sunt împǎrtite între procese. Taskurile pot deveni accesibile dinamic. Numǎrul de taskuri disponibile poate varia în timp.Scopul: taskuri suficiente pentru a tine procesele ocupate, dar nu prea multe. Numǎrul de taskuri disponibile la un moment dat este limita superioarǎ a accelerǎrii (speedup) obtenabile.
Concurentǎ limitatǎ: legea lui Amdahl
Limitarea cea mai importantǎ a accelerǎrii prin paralelism.Dacǎ fractia s din secventa de executie este inerent serialǎ, atunci speedup ≤ 1/s.Exemplu: un calcul în douǎ faze: parcurgerea unei grile de nxn pentru a executa un anumit calcul independent, reluarea parcurgerii si adunarea fiecǎrei valori obtinute într-o sumǎ globalǎ.Timpul consumat pentru prima fazǎ este n2/p (p numǎrul de procesoare).Pentru faza a doua serializatǎ pe o variabilǎ globalǎ, se consumǎ timpul n2.Accelerarea este
8 NP-hard, în teoria complexitǎtii calculelor este o clasǎ de probleme care sunt “cel putin la fel de dificile ca si problemele cele mai dificile NP”. O problemǎ H este NP-hard dacǎ si numai dacǎ existǎ o problemǎ NP-completǎ L care este reductibilǎ Turing în timp polinomial la H, adicǎ L ≤T H. Cu alte cuvinte L poate fi rezolvatǎ în timp polinomial de o masinǎ oracol cu un oracol pentru H. Informal se poate imagina un algoritm care poate apela o asemenea masinǎ oracol ca o subrutinǎ de rezolvare a lui H si rezolvǎ pe L în timp polinomial dacǎ apelul subrutinei necesitǎ numai un pas pentru a desǎvârsi caculul. Problemele NP-hard pot fi de tipuri variate: decizionale, de cǎutare, de optimizare.
108

+ 2
2
22
np
nn
limitatǎ superior de valoarea 2.Truc: divizarea fazei a doua în douǎ
( )22
2
22
pnn+
cu acumulare în sume private pe parcursul primar urmatǎ de adunarea sumelor partiale (pe proces) private în suma globalǎ.Timpul paralel este
pp
np
n ++22
si se obtine cea mai bunǎ accelerare.
Întelesul legii lui Amdahl
1
p
1
p
1
n2/p
n2
p
Lucru
executat
concurential
n2
n2
Timpn2/p n2/p
(c)
(b)
(a)
109

Profile concurentiale
Aria de sub curbǎ este lucrul total executat sau timpul pe un procesor.Intervalul pe orizontalǎ este limita de jos a timpului (infinit procesoare)Accelerarea este
∑
∑∞
=
∞
=
1
1
kk
kk
pkf
kf
cu cazul de bazǎ
pss −+ 1
1
Con
curr
ency
150
219
247
286
313
343
380
415
444
483
504
526
564
589
633
662
702
733
0
200
400
600
800
1,000
1,200
1,400
Clock cycle number
Legea lui Amdahl se aplicǎ la orice overhead, nu este limitatǎ numai la concurentǎ.
Programarea ca rafinare succesivǎ
Spatiu bogat în tehnici si probleme. Compromisuri în interactiunea unora cu celelalte.Pot apǎrea probleme de naturǎ software sau hardware. Tehnici algoritmice si/sau de programare. Tehnici arhitecturale.Nu toate problemele de programare pentru performantǎ se ocupǎ de partea vizibilǎ. Partitionarea este adesea independentǎ de arhitecturǎ si se face înainte de toate. Apoi se iau în considerare interactiunile cu arhitectura: comunicatia suplimentarǎ datoratǎ interactiunilor arhitecturale, costul comunicatiei depinde de modul cum este ea structuratǎ, poate inspira schimbǎri în partitionare.
110

Partitionare pentru performantǎ
Echilibrarea sarcinii si reducerea timpilor de asteptare la punctele de sincronizare.Reducerea comunicǎrii inerente.Reducerea lucrului suplimentar.Compromisuri chiar si cu aceste probleme algoritmice: minimizarea comunicatiei ⇒ rulare pe un procesor ⇒ debalansare drasticǎ a încǎrcǎrii; maximizarea echilibrǎrii sarcinii ⇒ asignarea aleatoare de taskuri mici ⇒ lipsa de control asupra comunicǎrii; o partitionare bunǎ poate implica lucru suplimentar pentru a o calcula si pentru a o administra.Scopul este de a realiza compromisuri potrivite; din fericire, adesea nu foarte dificile de atins practic.
Echilibrarea sarcinii si sincronizarea
Speedupproblema(p) ≤ lucrul secvential/max[lucru pe oricare dintre procesoare]
Debalansǎrile de sarcinǎ instantanee se manifestǎ prin timpi de asteptare: la finalizare, la bariere, la primiri (receive), la flags, chiar la mutex (mutual exclusion).
Speedupproblema(p) ≤ lucrul secvential/max[lucru + timpul de asteptare cu sincronizarea]
P0
P1
P2
P3
P0
P1
P2
P3
111

Echilibrarea si timpul de asteptare cu sincronizarea
Limitare pentru accelerare:Speedupproblema(p) ≤ lucrul secvential/max[lucru pe oricare dintre procesoare]
Lucru include accesul la date si alte costuri. Nu tocmai egal de lucru, dar gradul de ocupare simultanǎ mare.Patru pǎrti pentru echilibrarea sarcinii si reducerea timpului de asteptare pentru sincronizare:1. Se identificǎ suficientǎ concurenţǎ.2. Se decide cum se administreazǎ concurenţa.3. Se determinǎ granularitatea la care trebuie exploatatǎ concurenţa.4. Se reduce serializarea si costul de sincronizare.
Reducerea comunicǎrii inerente
Comunicarea este costisitoare!O mǎsurǎ: raportul comunicare/calcul.Aici, focalizare pe comunicarea inerentǎ. Determinatǎ prin asignarea de taskuri pe procese. Mai departe se va vedea cum comunicarea realǎ poate fi mai mare.Asignarea de taskuri care acceseazǎ aceleasi date aceluiasi proces.În cazul general, rezolvarea comunicǎrii si echilibrului de încǎrcare este NP dificilǎ.Dar solutiile euristice simple lucreazǎ destul de bine în practicǎ. Aplicatiile au o structurǎ proprie!
Descompunerea de domeniu
Lucreazǎ bine pentru aplicatii stiintifice, ingineresti, de graficǎ, …Exploateazǎ natura local-particularǎ a problemelor fizice. Cererile de informatie sunt adesea de razǎ redusǎ. Sau de razǎ îndepǎrtatǎ dar scǎzǎtoare rapid cu distanta.Exemplu simplu: calculele pe grile pe baza vecinilor celor mai apropiati.
P0 P1 P2 P3
P4
P8
P12
P5 P6 P7
P9 P11
P13 P14
P10
n
n np
np
P15
112

Raportul comunicare/calcul circa egal cu raportul perimetru/arie (arie/volum pentru cazul tridimensional). Raportul depinde de n si p: scade cu n, creste cu p.Cea mai bunǎ descompunere de domeniu depinde de cererile de informatie.Exemplul cu vecinii cei mai apropiati: descompunere în blocuri fatǎ de descompunerea în fâsii.
P0 P1 P2 P3
P4
P8
P12
P5 P6 P7
P9 P11
P13 P14 P15
P10
n
n
n
p------
n
p------
Rapotul comunicare/calcul este: 4*√p/n pentru descompunerea în blocuri, 2*p/n pentru benzi/fâsii.Raportul depinde de aplicatie: fâsiile pot fi mai bune în alte cazuri, de pildǎ pentru curgerea de particule într-un tunel.
Stabilirea unei descompuneri a domeniului
Staticǎ, prin inspectie. Trebuie sǎ fie predicitibilǎ: exemplul grilei de mai sus.Staticǎ, dar nu prin inspectie. Dependentǎ de intrare, cere analiza structurii intrǎrilor. Exemplu: calculele cu matrici rare.Semistatic (re-partitionare periodicǎ). Caracteristicile se schimbǎ dar lent: exemplu problema celor N corpuri.Static sau semistatic cu “furtul” dinamic de taskuri. Se face descompunerea initialǎ a domeniului, dar apoi devine foarte nepredictibilǎ: exemplu urmǎrirea razelor (ray tracing).
Problema celor N corpuri: simularea evolutiei galactice
Se simuleazǎ interactiunea multor stele cu evolutie în timp. Calculul fortelor este costisitor. Tratarea brutǎ a fortelor consumǎ timp O(n2). Metodele ierarhice iau în considerare legea fortelor
G = m1m2/r2
113
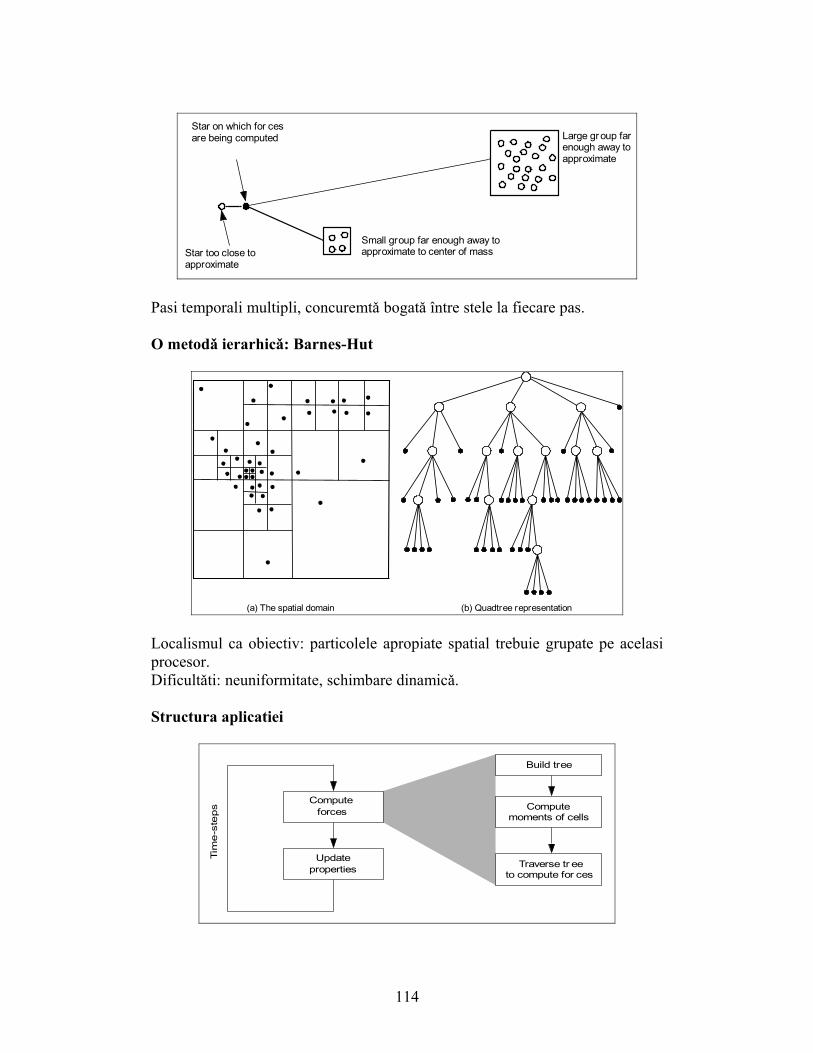
Star on which for cesare being computed
Star too close toapproximate
Small group far enough away toapproximate to center of mass
Large group farenough away toapproximate
Pasi temporali multipli, concuremtǎ bogatǎ între stele la fiecare pas.
O metodǎ ierarhicǎ: Barnes-Hut
(a) The spatial domain (b) Quadtree representation
Localismul ca obiectiv: particolele apropiate spatial trebuie grupate pe acelasi procesor.Dificultǎti: neuniformitate, schimbare dinamicǎ.
Structura aplicatiei
Computeforces
Updateproperties
Tim
e-s
teps
Build tree
Computemoments of cells
Traverse tr eeto compute for ces
114

Structura principalǎ a datelor: masiv de corpuri, de celule si de pointeri cǎtre ele. Fiecare corp/celulǎ are mai multe câmpuri: masa, pozitia, pointeri cǎtre altele. Pointerii sunt asignati proceselor.
Partitionarea
Descompunerea: corpuri în majoritatea fazelor (uneori celule).Provocǎri pentru asignare:Distributia neuniformǎ a corpurilor produce lucru si comunicare neuniforme. Nu se poate face asignarea prin inspectie.Distributia se schimbǎ dnamic de la un pas de timp la altul. Nu se poate face asignarea static.Necesitǎtile de informatie scad considerabil cu distanta de la corp. Partiţiile trebuie sǎ fie contigue spatial pentru localism.Faze diferite au distribuţii de lucru diferite între corpuri. Nu existǎ o asignare idealǎ unicǎ pentru toate corpurile. Focalizare pe faza calculului fortelor.Necesitǎtile de comunicare granulate fin în mod natural si neregulate.
Echilibrarea încǎrcǎrii
Numǎr egal de particule nu înseamnǎ lucru egal. Solutia: atribuirea de costuri pe particule pe baza lucrului pe care îl fac, îl genereazǎ.Lucrul necunoscut si schimbǎri la fiecare pas de timp. Sistemul evolueazǎ lent. Solutia: se contorizeazǎ lucrul pe particulǎ si se utilizeazǎ rezultatul ca valoare de cost în pasul urmǎtor.Tehnicǎ puternicǎ pentru sisteme fizice evolutive.
O tratare a problemei partitionǎrii: ORB – Orthogonal Recursive Bisection
Se face recursiv bisectia spatiului în subspatii de lucru egal. Lucrul este asociat cu corpurile ca mai sus.Se continuǎ pânǎ se obtine câte o parte din partitie pe fiecare procesor.
115

Overhead masiv pentru numǎr mare de procesoare.
O altǎ tratare: zone de cost
Arborele contine deja o codare pentru localismul spatial.
(a) ORB (b) Costzones
P1 P2 P3 P4 P5 P6 P7 P8
Zonele de cost au overhead mai scǎzut si sunt foarte usor de programat.
Curbe care umplu spatiul
Ordinea Morton Ordinea Peano-Hilbert
Analiza scenelor prin urmǎrirea razelor
Se trimit raze în scenǎ prin pixelii unei imagini plane.
116

Se urmǎreste parcursul lor. La incidenta pe obiecte razele se împrǎstie în jur. Se genereazǎ raze noi, un arbore de raze pentru fiecare razǎ incidentǎ.Rezultatul este culoarea si opacitatea acelui pixel.Paralelismul este între raze.Toate cazurile au o concurentǎ abundentǎ.
Partitionarea
Tratarea orientatǎ pe scenǎ. Se partitioneazǎ celulele scenei, se proceseazǎ razele care sunt într-o celulǎ datǎ.Tratarea orientatǎ pe razǎ. Se partitioneazǎ razele primare (pixeli), se abordeazǎ datele scenei dupǎ necesitǎti. Este mai simplǎ si este utilizatǎ si aici.Este necesarǎ asignarea dinamicǎ; se utilizeazǎ blocuri contigue pentru a exploata coerenţa spaţialǎ a razelor învecinate, plus acoperiri (tiles) pentru “hoţia” de taskuri.
Se poate utiliza si asignarea intercalatǎ bidimensionalǎ (împrǎştiatǎ) de acoperiri (tiles).
Alte tehnici
Descompunerea împrǎstiatǎ (scatter), de pildǎ partitia initialǎ în Raytrace.
1
3 4 3 4 3 4 3 4
3 4 3 4 3 4 3 4
3 4 3 4 3 4 3 4
3 4 3 4 3 4 3 4
1
43
Domain decomposition Scatter decomposition
2 1 2 1 2 1 2
1 2 1 2 1 2 1 2
1 2 1 2 1 2 1 2
1 2 1 2 1 2 1 2
2
117
A block,the unit ofassignment
A tile,the unit of decompositionand stealing

Pǎstreazǎ localismul în “furtul” de taskuri. Se “furǎ” taskuri mari pentru localism, se “furǎ” din aceleasi fire de asteptare (queues), …
Determinarea granularitǎtii taskului
Granularitatea taskului: cantitatea de lucru cu un task.Regulǎ generalǎ: granularitate grosierǎ înseamnǎ adesea debalansare de încǎrcare, granularitate finǎ înseamnǎ overhead mai mare, adesea mai multǎ comunicare, conflicte.Comunicarea, conflictele sunt afectate de fapt de asignare, nu de dimensiuni. Existǎ un overhead si datorat dimensiunii, în particular în legǎturǎ cu cozile de taskuri.
Lucrul dinamic cu cozile de taskuri
Cozi centralizate sau distribuite?“Furtul” de taskuri cu cozi distribuite. Poate compromite comunicarea si localismul si creste necesitatea de sincronizare. De unde trebuie furat, cât de multe taskuri sǎ fie furate. Detectarea epuizǎrii taskurilor. Debalansarea maximǎ legatǎ de dimensiunea taskului.
QQ 0 Q2Q1 Q3
All remove tasks
P0 inserts P1 inserts P2 inserts P3 inserts
P0 removes P1 removes P2 removes P3 removes
(b) Distributed task queues (one per pr ocess)
Others maysteal
All processesinsert tasks
(a) Centralized task queue
Pǎstreazǎ localismul în furtul de taskuri. Se furǎ taskuri mari pentru localism, se furǎ din aceleasi cozi, …
Sumar asupra asignǎrii
Se sepcificǎ mecanismul prin care se divide lucrul între procese. Care proces calculeazǎ forţele pentru anumite stele, sau pentru care raze. Se echilibreazǎ sarcina, se reduce comunicarea si costul administrǎrii/managementului.
118

Tratǎrile structurate lucreazǎ uzual bine. Inspectarea codului (bucle paralele) sau întelegerea aplicatiei. Euristici binecumoscute. Asignare staticǎ sau dinamicǎ.Ca programator, prima grijǎ este cea a partiţionǎrii. Uzual este independentǎ de arhitecturǎ sau de modelul de programare. Dar costul si complexitatea utilizǎrii primitivelor poate afecta deciziile.
Paralelizarea calculelor/paralelizarea datelor
Calculul este descompus si asignat (partitionat).Partitionarea datelor iese adesea firesc în vedere. Calculele urmeazǎ datele: proprietarul calculeazǎ. Exemplul grilei; data mining.Distinctia între calcul si date este mai puternicǎ în multe alte aplicatii. Barnes-Hut. Raytrace.
Reducerea lucrului suplimentar
Surse obisnuite de lucru suplimentar:Calculul unei partitii bune, de pildǎ partitionarea Barnes-Hut sau a matricilor rare.Utilizarea de calcule redundante pentru a evita comunicarea.Overheadul managementului taskurilor, datelor si proceselor. Aplicatii, limbaje, sisteme de executie, sisteme de operare.Impunerea unei structuri asupra comunicǎrii. Coalescenta de mesaje, acceptarea de (de)numiri eficiente (allowing effective naming).Implicatii arhitecturale:Se reduc necesitǎtile prin eficientizarea comunicǎrii si orchestrǎrii.Speedup ≤ lucrul secvential/Max(lucru + timpul de asteptare la sincronizare +
costul comunicǎrii + lucrul suplimentar)
119

Nu este responsabilǎ numai partitionarea
Comunicarea inerentǎ din algoritmii paralel nu reprezintǎ totul. Comunicarea prin artefacte produse de implementarea programului si de interactiunea arhitecturalǎ poate fi încǎ dominantǎ. Astfel, cantitatea de comunicatie este tratatǎ inadecvat.Costul comunicǎrii nu este determinat numai de cantitate. Depinde si de modul cum este structuratǎ comunicarea si de costul comunicǎrii în sistem. Ambele sunt dependente de arhitecturǎ si se trateazǎ în etapa de orchestrare.
Structurarea comunicǎrii
Fiind datǎ o cantitate de comunicare (inerentǎ sau artefactualǎ), obiectivul este reducerea costului.Costul comunicǎrii asa cum este vǎzut de proces:
C = f *(o + l + nc/m + tc – overlap)– f = frecventa mesajelor– o = overhead-ul pe mesaj (la ambele capete)– l = întârzierea în retea a mesajului– nc = date totale trimise– m = numǎrul de mesaje– B = banda de trecere (bandwidth) pe calea de comunicare (determinat de
retea, de interfete (NI), de asistentul de comunicare)– tc = costul indus de conflicte pe mesaj– overlap = cantitatea din latenţǎ ascunsǎ prin suprapunerea calculului cu
comunicarea.Continutul parantezei este costul unui mesaj asa cum este vǎzut de procesor. Acelasi continut, dar cu ignorarea termenului overlap este latenţa mesajului. Obiectiv: reducerea termenilor din latenţǎ si cresterea suprapunerilor (overlap).
Reducerea de overhead
Se poate reduce numǎrul mesajelor m sau overheadul pe mesaj o.Overheadul o este determinat uzual de hardware sau de software-ul de sistem. Programul trebuie sǎ încerce sǎ reducǎ m prin coalescenţa de mesaje. Control mai mult când comunicarea este explicitǎ.Coalescenţa datelor în mesaje mai mari:Facilǎ pentru comunicarea obisnuitǎ, granulatǎ grosier.Poate fi dificilǎ pentru comunicarea mai putin obisnuitǎ, granulatǎ fin prin natura ei. Poate reclama schimbǎri de algoritm si poate implica lucru suplimetar.Coalescenţǎ a datelor si determinarea a ce si cui trebuie trimis.
120

Reducerea întârzierilor pe reţea
Componenta de întârziere pe retea este f*h*th cu– h = numǎrul de sǎrituri (hops) traversate în reţea– th = latenţa per hop, legǎturǎ plus comutare
Reducerea lui f: comunicare mai putinǎ sau mesje mai mariReducerea lui h:Asocierea (mapping) patternurilor de comunicare cu topologia retelei; vecinii cei mai apropiati pe retele mesh sau ring; all-to-all.Cât de important este acest aspect? Era odatǎ un un obiectiv major legat de algoritmii paralel. Depinde de numǎrul procesoarelor, de modul cum th se comparǎ cu celelalte componente. Este mai putin important în masinile moderne: mai importante sunt overhead-urile, numǎrul de procesoare, multiprogramarea.
Reducerea conflictelor
Toate resursele sunt ocupate (nonzero occupancy). Si memoria, si controllerul de comunicare, si legǎtura la retea, si toate cele. Numai sǎ poatǎ manipula atât de multe tranzactii în unitatea de timp.Efectul de conflict/concurentǎ: creste costul de la un cap la altul al mesajelor; reduce banda de trecere disponibilǎ pentru alte mesaje; produce debalansǎri între procesoare.Probleme de performantǎ în particular insidioase. Usor de ignorat în faza de programare. Încetineste mesaje care nici mǎcar nu au nevoie de acele resurse, prin actiunea de congestionare a altor resurse dependente. Efectul poate fi devastator: nu inundati o resursǎ! (Don’t flood a resource!)
Tipuri de conflicte
Conflicte în retea si conflicte la capǎtul de sosire (hot-spots).Hot-spots Location si Module.Location: de pildǎ la acumularea într-o variabilǎ localǎ, la o barierǎ. Solutia: comunicare structuratǎ în manierǎ arborescentǎ.
Flat Tree structured
Contention Little contention
121

Module: comunicare all-to-all personalizatǎ în transpunerea unei matrici. Solutia: acces esalonat temporal de cǎtre procesoare diferite la acelasi nod.În general, se reduce nota intempestivǎ, explozivǎ, ceea ce pate fi în conflict cu a face mesaje mai mari.
Comunicare suprapusǎ
Nu ne putem permite asteptǎri pentru latente înalte, chiar si pe sisteme uniprocesor!Suprapunere cu calculul sau cu comunicarea pentru a ascunde latenta.Se cere o extraconcurentǎ (slackness), bandǎ de trecere mai mare.Tehnici:
PrelocalizareaTransfer de date în blocuriProceduri peste comunicareMultifire
Scalarea comunicǎrii (NPB2)
Mesaje normalizate pe procesor Dimensiunea medie a mesajului
1.00E+02
1.00E+03
1.00E+04
1.00E+05
1.00E+06
1.00E+07
0 10 20 30 40
FTISLUMGSPBT
0
1
2
3
4
5
6
7
8
0 10 20 30 40
FTISLUMGSPBT
122
0
1
2
3
4
5
6
7
8
0 10 20 30 40
FTISLUMGSPBT
1.00E+02
1.00E+03
1.00E+04
1.00E+05
1.00E+06
1.00E+07
0 10 20 30 40
FTISLUMGSPBT

Scalarea comunicǎrii: volum
Asocierea (mapping)
Douǎ aspecte:Care proces ruleazǎ pe care procesor? Asocierea cu o topologie de retea.Vor rula procese multiple pe acelasi procesor?Partajare spatialǎ (Space-sharing)Masina divizatǎ în subseturi, pe un subset numai o aplicatie la fiecare moment.Procesele pot fi legate (pinned) de procesoare sau lǎsate în gestiunea sistemului de operare.Alocarea sistemului.În realitate: partial, unele aspecte sunt formulate dupǎ dorinta utilizatorului, altele sunt lǎsate pe seama sistemului.Uzual se adoptǎ schema simplǎ: proces ⇔ procesor.
Recapitulare: compromisuri (trade-offs) vizând performantele
Performanta asa cum e vǎzutǎ de programator:Speedup ≤ lucrul secvential/Max(lucru + timpul de asteptare la sincronizare +
costul comunicǎrii + lucrul suplimentar)Scopuri diferite au adesea cerinte conflictuale.Echilibrarea încǎrcǎrii – taskuri cu granulatia finǎ, asignare aleatoare sau dinamicǎ.Comunicare – taskuri granulate grosier, descompunere pentru a obtine localism.Lucru suplimentar – taskuri granulate grosier, asignare simplǎ.Costul comunicǎrii – transferuri mari pentru amortizarea overheadului si latentei; transferuri mici pentru a reduce ciocnirile.Punctul de vedere arhiectural:Nu se poate rezolva debalansarea de încǎrcare si nici nu se poate elimina comunicarea inerentǎ.Dar poate:
Bytes per Processor
0
0.2
0.4
0.6
0.8
1
1.2
0 10 20 30 40
FTISLUMGSPBT
Total Bytes
0.00E+00
1.00E+09
2.00E+09
3.00E+09
4.00E+09
5.00E+09
6.00E+09
7.00E+09
8.00E+09
9.00E+09
0 10 20 30 40
FTISLUMGSPBT
123

Reduce stimularea creǎrii de programe care se comportǎ rǎu – naming eficient, comunicare si sincronizare.Reduce artefactele de comunicare.Furnizeazǎ naming eficient pentru asignare flexibilǎ.Permite suprapunere eficientǎ a comunicǎrii.
Punctul de vedere uniprocesor
Performanta depinde mult de ierarhia memoriei. Administare prin hardware.Timpul consumat de program
Timeprog(1) = Busy(1) + Data Access(1)Se împarte la cicluri pentru a obtine ecuatia CPI.Timpul de acces la date poate fi redus prin:Optimizarea masinii – cache-uri mai mari, latentǎ mai scǎzutǎ…Optimizarea programului – localism spatial si temporal.
P
Time (
s)
100
75
50
25
Busy-useful
Data-local
124
% ti
mp

Aceeasi perspectivǎ centratǎ pe procesor
Ce este un multiprocesor?
Este o colectie de procesoare care comunicǎ între ele.Scopuri: echilibru de încǎrcare, reducerea comunicatiei inerente si reducerea lucrului suplimentar.
Un sistem multi-cache, multi-memorie. Rolul acestor componente este esential indiferent de modelul de programare. Modelul de programare si abstractiile comunicationale afecteazǎ compromisurile specifice de performantǎ.
P 0 P 1 P 2 P 3
Busy-overhead Busy-useful
Data-localSynchronization
Data-remote
Time (s)
100
75
50
25
100
75
50
25
% ti
mp
P P P...
P P P...
125
% ti
mp

Relatia între perspectivele (enumerate)
Synch wait
Data-remote
Data-localOrchestration
Busy-overheadExtra work
Performance issueParallelization step(s) Processor time component
Decomposition/assignment/orchestration
Decomposition/assignment
Decomposition/assignment
Orchestration/mapping
Load imbalance and synchronization
Inherent communication volume
Artifactual communication and data locality
Communication structure
Speedup ≤ [ocupat(1) + data(1)]/[ocupateutil(p) + datelocale(p) + sincronizare(p) + datela distantǎ(p) + ocupateoverhead(p)]
Comunicarea artefactualǎ
Accesul nu este deplin satisfǎcut în portiunea localǎ a ierarhiei de memorie, ceea ce impune comunicare.Comunicarea inerentǎ implicitǎ sau explicitǎ produce transferuri determinate prin program.Comunicarea artefactualǎ este determinatǎ de implementarea programului si de interactiunile arhitecturale; alocarea proastǎ a datelor în memoria distribuitǎ; date nenecesare într-un transfer; transferuri nenecesare datorate granularitǎtii sistemului; comunicarea de date redundantǎ; capacitate de replicare finitǎ (în cache sau în memoria principalǎ).Comunicatia inerentǎ este cea ce se produce cu capacitate nelimitatǎ, transferuri mici si cunoasterea perfectǎ a ceea ce este necesar.
Exemplu de localism spatial
Parcurgerea repetatǎ a unei grile 2D, de fiecare datǎ adunând 1 la elementele vizitate.
126

P6 P7P4
P8
P0 P1 P2 P3
P5
Încǎlecǎri de pagini în delimitarea partitiei: dificil de distribuit
memory well
Încǎlecǎri de blocuri de cache la
partitionare
(a) Un masiv bidimensional
Contiguitate în asezareaîn memorie
P6 P7P4
P8
P0 P1 P2 P3
P5
Pagina traverseazǎ granitele partitiei: dificil de distribuit
bine memoria.
Bloc de cache care traverseazǎ
partiţia
(a) Un masiv bidimensional
P0 P3
P5 P6 P7P4
P8
P2P1
Pagina nu traverseazǎ
partitia.
Blocul de cache este în partitie
(b) Un masiv cu patru dimensioni
Contiguitate în asezarea în memorie
127

De la situatia ilustratǎ în 2D se poate imagina o situatie în mai multe dimensiuni.
Compromisuri (trade-offs) în comunicarea inerentǎ
Rezultatul depinde de n si de p.
Exemplu de impact asupra performantei
Equation solver pe SGI Origin2000.
Spe
edup
Number of processors
Spe
edup
Number of processors
●●
●
●
●
●
▲▲
▲
▲
▲
▲
■■
■
■
■
■
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 310
5
10
15
20
25
30
● ●●
●
●
●
●
■ ■■
■
■
■
■
▲▲
▲
▲
▲
▲
▲
◆ ◆◆
◆
◆
◆
◆
✖✖
✖
✖
✖
✖
✖
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 310
5
10
15
20
25
30
35
40
45
504D4D-rr
■ 2D-rr▲ 2D◆ Rows-rr
✖ Rows● 2D■ 4D▲ Rows
(a) Problemǎ de dimensiune micǎ (b) Problemǎ de dimensiune mare
Localism spatial bunla accesul non-local la
partionarea pe linii
Localism spatial slabla accesul non-local lapartionarea pe coloane
128

1 4 1 6 6 4 2 5 6 1 0 2 4 4 0 9 60
2
4
6
8
1 0
1 2
1 4
D i m e n s i u n e a c a c h e - u l u i l a f i e c a r e p r o c e s o r ( k B )
S C H I M B A R E A C U P A M U L T I M I L O R D E L U C R U
4
81 6
3 2
B e n e f i c i u l as c a l a r e
N i c i u nb e n e f i c i ul a s c a l a r e
L U
Reducere de 8 ori a ratei de ratǎri de la 4 la 8 procesoare
Implicatii pentru modelele de programare
Spatiu de adresare în indiviziune (partajat) coerent si transfer de mesaje explicit.În toate cazurile se presupune cǎ memoria este distribuitǎ.Se reaminteste cǎ orice model poate avea ca suport orice arhitecturǎ. Se admite cǎ ambele sunt suportate eficient. Se admite cǎ în SAS comunicarea este numai prin încǎrcǎri si depozitǎri. Se admite cǎ în SAS (Shared Address Space) comunicarea este la granularitatea blocului de cache.
Probleme de luat în consideratie
Probleme functionale:Naming: cum sunt partajate logic datele si/sau procesele la care se face referire?Operatii: ce operatii sunt furnizate pe aceste date?Ordonarea: cum sunt ordonate si coordonate accesǎrile la date?Probleme de performantǎ:Granularitatea si overheadul la punctul final al comunicǎrii (latenta si banda de trecere depind de retea si sunt considerate similare)Replicarea: cum sunt datele replicate pentru a reduce comunicarea?
129

Usurinta de a modela performanta.Probleme de cost: Costul hardware si complexitatea proiectului.
Modelul de programare secvential
Contract:Naming: poate numi orice variabilǎ (în spatiul de adresare virtual). Hardware-ul (si probabil compilatoarele) face translatia la adrese fizice.Operatii: încǎrcare, depozitare, aritmetice, de control.Ordonare: ordine programatǎ secvential.Optimizǎri de performante:Compilatoarele si hardware-ul violeazǎ ordinea programului fǎrǎ a fi prinse (caught). Compilatorul: reordonare si alocare de registre. Hardware-ul: în afara ordinei, bypass-are pipeline, buffere de scriere.Retine ordinea dependentei pe fiecare “locatie”.Replicare transparentǎ în cache-uri.Usurinta în modelarea performantei: complicatǎ prin operatiile cu cache-ul.
Modelul de programare SAS
Naming: orice proces poate apela pe numele ei orice variabilǎ din spatiul în indiviziune (partajat).Operatii: încǎrcare si depozitare plus cele necesare pentru ordonare.Cel mai simplu sistem de ordonare:În cadrul unui proces/fir: oridinea programatǎ secvential.Între fire: o arecare intercalare (ca la eşalonarea în timp din cazul uniprocesoarelor).Ordonare suplimentarǎ prin sincronizare explicitǎ.Pot compilatoarele/hardware-ul sǎ slǎbeascǎ ordinea fǎrǎ a fi (sur)prinse? Sunt posibile de asememea modele de ordonare diferite, mai subtile (vor fi discutate mai departe).
Sincronizarea
Excluderea mutualǎ (mutex, locks): Asigurǎ ca anumite operatii pe anumite date sǎ poatǎ fi executate la un moment dat de numai un proces.Un spatiu în care nu poate intra decât câte o persoanǎ (toaletǎ?...).Nu sunt garantii pentru vreo ordonare.Sincronizarea evenimentelor: Ordonarea evenimetelor pentru a pǎstra dependentele: de pildǎ producǎtor apoi consumator de date.Trei tipuri principale: punct-la-punct, global, pe grupe.
130

Modelul de programare al transmiterii de mesaje
Naming: procesele nu pot numi/apela direct date private. Nu existǎ un spatiu de adresare partajat.Operatii: comunicare explicitǎ prin send si receive.Send transferǎ date de la spatiul de adresare privat la un alt proces.Receive copiazǎ date de la un proces în spatiul de adresare privat.Trebuie sǎ fie capabil a numi/apela procese.Ordonare: Ordine prin program în cadrul unui proces.Send si receive pot asigura sincronizare punct-la-punct între procese. Complicatǎ la transferul de mesaje asincron.Excluderea mutualǎ inerentǎ, optimizǎrile conventionale legale.Se poate construi un spatiu de adresare global: Numǎrul procesului plus adresa internǎ din spatiul de adresare al procesului. Dar nu operatii directe pe aceste nume.
Naming
La uniprocesoare: se poate numi orice variabilǎ (în spatiul de adresare virtual). Hardware-ul (si probabil compilatorul) face translatia la adrese fizice.SAS: similar cu uniprocesorul, sistemul face totul.MP: fiecare proces poate numi direct datele din spatiul de adresare propriu.Trebuie sǎ se specifice de unde se obtin sau unde se transferǎ date nonlocale.Facil pentru aplicatii obisnuite (de pildǎ aplicatia referitoare la ocean).Dificil pentru aplicatii cu necesar de date neregulat, variabil în timp. Barnes-Hut: unde sunt pǎrtile de arbore care sunt necesare (se schimbǎ în timp)? Raytrace: unde sunt pǎrtile de scenǎ care sunt necesare (impredicitibil)?Existǎ metode-solutie:Barnes-Hut: o fazǎ suplimentarǎ stabileste necesarul si transferurile înainte de faza calculului.Raytrace: tratarea orientatǎ pe scenǎ mai curând decât orientatǎ pe razǎ.Ambele: prin hashing, se emuleazǎ un spatiu de adresare în indiviziune (partajat) specific aplicatiei.
Operatii
La secvential: de încǎrcare, de depozitare, aritmetice, de control.SAS: de încǎrcare si de depozitare la care se adaugǎ cele necesare ordonǎrii.MP: comunicare explicitǎ prin send si receive.Send transferǎ date de la spatiul de adresare privat cǎtre un alt proces.Receive copiazǎ date de la un proces în spatiul de adresare privat.Trebuie sǎ existe posibilitatea de a numi procesele.
131

Replicarea
Cine o administreazǎ (adicǎ cine face cópii locale ale datelor)? În SAS – sistemul, în MP – programul.Unde în ierarhia memoriei locale se face mai întâi replicarea? În SAS – cache (sau si în memorie), în MP – memoria principalǎ.La ce granularitate sunt alocate datele în spatiul-depozit de replicare? În SAS – blocul de cache, în MP – determinatǎ prin program.Cum sunt mentinute coerente datele replicate? În SAS – sistemul, în MP – programul.Cum este administratǎ înlocuirea datelor replicate? În SAS – dinamic la granulatie finǎ spatialǎ si temporalǎ (la fiecare acces), în MP – la limitele fazei sau prin emularea software de cache în memoria principalǎ.Desigur, SAS îsi permite chiar mult mai multe optiuni (se va reveni)
Overheadul si granularitatea de comunicare
Overheadul este direct legat de suportul hardware asigurat. Este mai mic în SAS (un ordin de mǎrime sau mai mult).Taskuri majore:Translatia de adrese si protectia. SAS utilizeazǎ MMU (Memory Management Unit), MP necesitǎ protectie software cu implicarea uzualǎ a sistemului de operare.Administrarea bufferelor. În SAS mesajele mici de dimensiune fixǎ sunt usor de lucrat în hardware. În MP mesajele de dimensiuni flexibile necesitǎ implicarea software-ului.Verificare si potrivirea de tipuri. MP o face în software: multe tipuri de mesaje posibile datoritǎ flexibilitǎtii.Se consumǎ eforturi de cercetare apreciabile pentru reducerea costurilor din MP, dar este încǎ mult de lucrat.Naming, replicarea si overheadul sunt în favoarea SAS. Multe aplicatii MP neobisnuite emuleazǎ acum prin software SAS/cache.
Transferul blocurilor de date
Comunicarea la granulatie finǎ nu este cea mai eficientǎ pentru mesaje lungi. Latenta si overheadul la fel ca si traficul (headers pentru fiecare linie de cache)SAS: poate utiliza transferul de blocuri de date. În sistemele presupuse aici, explicit, dar poate fi în general automatizat la nivel de paginǎ sau obiect (se va relua). Important în special pentru amortizarea overheadului când este mare; latenta poate fi ascunsǎ si prin alte tehnici.Transferul de mesaje: overheadul este mai mare asa încât transferul de blocuri este mai important; dar este foarte natural a fi utilizat deoarece mesajele sunt explicite si flexibile, inerent în model.
132

Sincronizarea
SAS: separatǎ de comunicare (de transferul de date). Programatorul trebuie sǎ facǎ orchestrarea separat.MP: excluderea mutualǎ prin fiat; sincronizarea evenimentelor este deja fǎcutǎ în împerecherea send-receive în cazul sincron; în cazul asincron este necesarǎ o orchestrare separatǎ (prin utilizarea de probes sau flags).
Costul hardware si complexitatea proiectului
Cost mare în SAS, în special pentru SAS cache-coerent.Dar ambele sunt probleme mai complexe.Costul: trebuie comparat cu cel al replicǎrii în memorie; depinde de factori de piatǎ, de volumul de vânzǎri si de alti factori nontehnici.Complexitatea: trebuie comparatǎ cu complexitatea scrierii de programe de înaltǎ performantǎ; se reduce prin cresterea experientei.
Modelul performantei
Trei componente:Modelarea costului evenimentelor primitive din sistem de tipuri diferite.Modelarea aparitiei acestor evenimente la încǎrcare.Integrarea celor douǎ într-un model pentru prezicerea performantei.Componenta a doua si a treia sunt cele mai provocatoare.A doua corespunde cazului SAS cache-coerent care este mai dificil. Replicarea si comunicarea sunt implicite, asa încât evenimentele de interes sunt si ele implicite; similarǎ problemelor aduse de caching în monoprocesoare.MP are o linie directoare bunǎ: mesajele sunt costisitoare, trimiteri cât mai rare.Dificultǎti pentru aplicatiile neobisnuite în ambele cazuri (dar mai mult în SAS).Transferul în blocuri, sincronizarea, costul/complexitate si modelarea performantei sunt avantaje pentru MP.
Sumar pentru modelele de programare
Date fiind compromisurile (trade-offs), arhitectul trebuie sǎ se refere la:Suportul hardware pentru SAS (naming transparent) este de valoare?Suportul hardware pentru replicare si coerentǎ este de valoare?În SAS, trebuie asigurat si suport pentru comunicare explicitǎ?Trendul curent:Suport de multiprocesoare strâns cuplate pentru SAS cache-coerent în hardware.Alte platforme majore sunt clustere de statii de lucru sau multiprocesoare. În prezent nu suportǎ SAS în hardware, cele mai multe utilizeazǎ transferul de mesaje.
133

Ca obiectiv cel mai înalt, clustere de multiprocesoare SAS cache-coerente.
Sumar
Crucial în a întelege caracterisiticile programelor paralel. Implicatii pentru o multime de probleme de arhitecturǎ la toate nivelurile.Convergenta arhitecturalǎ a condus la:Mai mare portabilitate a modelelor de programare si a software-ului. Multe probleme de performantǎ similare pentru multe modele de programare.O articulare mai clarǎ a problemelor de performantǎ. Utilizate pentru modelul PRAM pentru proiectarea de algoritmi. Acum modele care încorporeazǎ costul comunicǎrii (BSP, logP, …). Accentul în modelare deplasat la punctele finale (end-points), unde costul este cel mai mare. Dar sunt necesare tehnici de a modela comportarea aplicatiei, nu numai a masinii.Problemele de performantǎ, compromisuri între ele; rafinarea iterativǎ.Gata pentru a întelege utilizarea de încǎrcǎri (workloads) pentru a evalua problemele sistemului.
134

Multiprocesoare scalabile
Subiecte
Problema scalabilitǎtiiSuport pentru modele de programareInterfata de reteaReteaua de interconectareConsideratii în proiectul Bluegene/L
Scalarea limitatǎ a unui bus
Caracteristicile unui busLungimea fizicǎ: ~ 1 ftNumǎrul de conexiuni: fixatBanda de trecere maximǎ: fixatǎInterfata cu mediul de comunicare: memoriaOrdinea globalǎ: arbitrarǎProtectia: virtualǎ ⇒ fizicǎÎncredere: totalǎSistem de operare: unicAbstractii de comunicare: HW
Limitǎ la scalareCuplare strânsǎ între componente.
135

Comparatie cu o retea LAN
Characteristica: Bus LANLungimea fizicǎ: ~1 ft kmNumǎr de conexiuni: fixat multeBanda de trecere maximǎ: fixatǎ ???Interfata cu mediul de comunicare: memoria perifericeOrdinea globalǎ: arbitrarǎ ???Protectia: virtualǎ ⇒ fizicǎ OSÎncredere: totalǎ micǎSistem de operare: unic independentAbstractii de comunicare: HW SW
În cazul LAN nu existǎ o limitǎ clarǎ pentru scalarea fizicǎ, încrederea este redusǎ, ordinea globalǎ este inexistentǎ, este greu de atins consensul.Defectǎrile si repornirile sunt independente.
Calculatoare scalabile
Care sunt compromisurile (trade-offs) si între care aspecte la proiectarea spectrului impresionant de masini?Noduri specializate sau obisnuite (din categoria commodity, comune, ieftine)?Capabilitatea interfetelor nod-retea.Cât suport pentru modelele de programare?Ce înseamnǎ scalabilitate?Evitarea limitelor inerente ale proiectului asupra resurselor.Largimea de bandǎ creste odatǎ cu n.Latenţa nu creste cu n.Costul creste lent cu n.
Scalabilitatea benzii de trecere
136

Comutatoare (switches)
Ce limiteazǎ fundamental banda de trecere?Un set unic de fire.Trebuie sǎ aibe multe fire independente.Se conecteazǎ modulele prin comutatoare (switches).
Modele de programare realizate prin protocoale
Primitive pentru tranzactii pe retea
Transfer de informatie unidirectional de la un buffer de iesire (sursǎ) la un buffer de intrare (destinatie).
137

Produce o anumitǎ actiune la destinatie.Aparitia (occurrence) nu este vizibilǎ direct la sursǎ.Se depun datele, schimbare de stare, rǎspuns.
Abstractii pentru spatiul de adresare în indiviziune (partajat)
Fundamental un protocol bilateral cerere/rǎspuns (request/response). Scrierile (writes) au o confirmare (acknowledgement).Probleme:Transferuri de lungime fixǎ sau variabilǎ (bulk)?Adrese virtuale la distantǎ sau fizice, unde este executatǎ actiunea?Evitarea blocajelor (deadlock) si umplerea bufferului de intrare.
Problema localizǎrii blocajului
Chiar dacǎ un nod nu poate emite o cerere, el trebuie sǎ observe tranzactiile de pe retea.Tranzactiile care sosesc pot fi o cerere care va genera un rǎspuns.Sisteme închise (buferizare finitǎ).
Proprietǎti cheie ale abstractiilor SAS9
Adresele datelor la sursǎ si la destinatie sunt specificate de sursa solicitǎrii. Un grad mare de cuplare logicǎ si de încredere. Nu existǎ logic memorare “în afara spatiului/spatiilor de adresare ale aplicatiei”.
9 SAS (se pronuntǎ ca litere separate) – Prescurtare pentru Serial Attached SCSI, o evolutie a SCSI (Small Computer System Interface) paralele într-o interfatǎ perifericǎ punct-la-punct în care controllerele sunt legate direct la discuri. SAS prezintǎ o ameliorare de performantǎ fatǎ de traditionalele SCSI deoarece SAS abiliteazǎ dispozitive multiple (pânǎ la 128) de dimensiuni si tipuri diferite conectate simultan cu cabluri mai subtiri si mai lungi; transmiterea de semnale full-duplex duce pânǎ la 3,0 Gb/s. În plus, drive-urile SAS pot fi hot-plugged (introduse din mers, cu recunoastere imediatǎ de cǎtre sistemul de operarea).
138

Dar poate angaja temporar buffere pentru transport. Operatiile sunt în esentǎ solicitare/rǎspuns. Operatiile la distantǎ pot fi efectuate pe memoria la distantǎ. Nu necesitǎ logic interventia procesorului situat la distantǎ.
Transferul de mesaje
Transfer bulk.Semantica sincronizǎrii complexǎ.Protocoale mai complexe.Actiuni mai complexe.Sincron:Un send se încheie dupǎ ce îsi gǎseste perechea recv si datele de la sursǎ sunt expediate.Un recv se încheie dupǎ ce se încheie transferul de la send-ul pereche.Asincron:Un send se încheie când bufferul de expediere poate fi reutilizat.
Transferul de mesaje sincron
Modelul de programare este restrictionat. Determinist! Ce se întâmplǎ când sunt adǎugate fire? Conflictele de destinatie foarte limitate.
139

Transferul de mesaje asincron: varianta optimistǎ
Un model de programare mai puternic. Primirea (recv) cu wildcard îl face non-determinist. Se cere memorie în stratul mesajelor?
Transferul de mesaje asincron: varianta conservatoare
Unde este bufferizarea?Controlul conflictelor? Protocol initiat de recv?Optimizarea mesajelor scurte.
140

Particularitǎtile cheie ale abstractiilor transferului de mesaje
Sursa cunoaste adresa datelor trimise, destinatia cunoaste adresa datelor primite. Dupǎ schimbul de saluturi (handshake) ambele sunt în cunostintǎ de cauzǎ. Memorie arbitrarǎ “în afara spatiului de adresare local”. Se pot posta multe send-uri înainte oricǎror recv-uri. Trimiterile asincrone fǎrǎ blocare reduc cerintele la un numǎr arbitrar de descriptori. Scrieri speciale spun cǎ si acestia sunt limitati.Fundamental, o tranzactie în 3 faze care include o cerere/un rǎspuns. Poate uza de o schemǎ optimistǎ cu o singurǎ fazǎ în cazuri limitate numite “sigure”.
Interfata cu reteaua
Transfer între memoria localǎ si bufferele NIC (Network Interface Card).Software-ul traduce VA (Virtual Address) la PA (Program Addres) si invers.Software-ul initiazǎ DMA (Direct Memory Access).Software-ul face managementul bufferelor.NIC initiazǎ întreruperile la primire (recv). Furnizeazǎ protectie. Transfer între bufferele NIC si retea. Generarea de pachete. Controlul fluxului cu reteaua.
Metrici ale performatei retelelor
141

Comunicare protejatǎ la nivelul utilizatorului
NIC-urile traditionale (de pildǎ Ethernet) cer ca sistemului de operare prin kernelul sǎu sǎ initieze accesul direct la memorie (DMA) si sǎ administreze bufferele.Prevenirea situatiilor în care o aplicatie ar putea face disfunct sistemul de operare sau alte aplicatii.Overheadul este mare (cât de mare?).NIC-uri pentru multicomputere sau multiprocesoare.Aplicatiile initiazǎ DMA-uri utilizând adrese VA sau handlere de descriptori.NIC utilizeazǎ buffere mapped PA pentru a executa DMA-uri.Exemple.Cercetǎri: mesaje active, UDMA (Ultra Direct Memory Access).Industria: VIA (Virtual Interface Architecture [Intel]) si RDMA (Remote Direct Memory Access)
Porturi de retea la nivelul utilizatorului
Un port de retea apare utilizatorului ca un sir logic de mesaje în asteptare plus un indicator de stare.Ce se întâmplǎ dacǎ nu se iveste nici un utilizator?
Abstractii la nivelul utilizatorului
142

Orice proces utilizator poate posta o tranzactie cu oricare altul în domeniul protejat. Stratul de comunicare mutǎ OQsrc la IQdest. Poate implica o redirectionare VASsrc la VASdest (OQ – Output Quest; IQ – Input Quest; src, dest – sursǎ, destinatie; VAS – Virtual Address Space).
Arhitecturǎ genericǎ pentru multiprocesoare
Caracteristici ale retelei
Banda de trecere a retelei: reteaua de interconectare on-chip si off-chip.Cerintele de bandǎ: fire/procese independente care comunicǎ.Latenta: localǎ si la distantǎ.
Retele de interconectare scalabile
Retelele de interconectare fac parte din miezul arhitecturilor paralel. Cerinte si compromisuri la multe niveluri. Structuri matematice elegante. Relatii adânci cu structura algoritmilor. Administrarea multor fluxuri de transfer. Proprietǎti ale legǎturilor electrice si optice. Consens putin. Interactiuni între niveluri.Metrici ale performantei, metrici ale costului. Sarcina de calcul. Toate acestea cer o întelegere cuprinzǎtoare (holistic).
143

Cerinte superioare
Raportul comunicare/calcul, banda de trecere care trebuie sustinutǎ pentru o vitezǎ de calcul datǎ.Traficul este localizat sau dispers? Inegal (uneori exploziv) sau uniform în timp?Modelul de programare. Protocol. Granularitate a transferului. Gradul de suprapunere (slackness). Misiunea unei retele de interconectare a unei masini paralel este de a transfera informatia de la nodul sursǎ la nodul destinatie ca suport al tranzactiilor pe retea care realizeazǎ modelul de programare.
Caracteristici ale unei retele
Topologie (cum?).Structura de interconectare fizicǎ în graful model al retelei.Directǎ: nodurile conectate la fiecare comutator (switch).Indirectǎ: nodurile conectate la un subset particular de comutatoare.Algoritmul de rutare (care?).Restrictioneazǎ multimea de cǎi pe care mesajele le pot parcurge.Algoritmi de rutare multipli cu proprietǎti variate.Strategia de comutare (cum?).Cum face sǎ traverseze o rutǎ datele dintr-un mesaj.Memoreazǎ-si-trimite fatǎ de cut-through.Mecanismul controlului fluxurilor (când?)Când un mesaj sau o portiune din el traverseazǎ o rutǎ.Ce se întâmplǎ când este întâlnit trafic bogat (excesiv)?
Definitii de bazǎ
Interfata de retea. Comunicare între un nod si o retea.Legǎturi. Mǎnunchiuri de fire sau fibre care transportǎ semnalele.Comutatoare (switches). Conecteazǎ un numǎr fix de canale de intrare cu un numǎr fix de canale de iesire.
Bazele retelelor
Legǎtura este fǎcutǎ de un mediu fizic, fir, fibrǎ, aer.
144

Existǎ un transmitǎtor (tx) la un capǎt care converteste simbolurile digitale în analogice si le împinge pe legǎturǎ.Mai existǎ si un receptor (rx) la celǎlalt capǎt care capteazǎ semnalul analogic si-l converteste din nou la digital.O combinatie tx + rx este denumit adesea transceiver.
Medii de retea traditionale
Perechea de fire rǎsucite.
Din cupru, de 1 mm, rǎsucite pentru a evita efecte inductive. “Cat 5” este constituit din patru perechi rǎsucite într-un învelis.Cablul coaxial.
utilizat de companiile de cablu (TV). Bandǎ largǎ, o imunitate la zgomote bunǎ.Fibrǎ opticǎ
Contine trei pǎrti: cablul, sursa de luminǎ si detectorul de luminǎ. Fibra este unidirectionalǎ. Pentru duplex complet sunt necesare douǎ cabluri optice.
145

Medii emergente
Proiectul Proximity (Sun Microsystems). Capabil potential de a livra TB/s între cipuri. Plǎcute metalice microscopice acoperite cu izolatie de microni pentru a proteja cipurile de electicitate staticǎ. Douǎ câte douǎ cipuri sunt în contact.
Retele în masinile paralele
În unele masini ma vechi
În masinile noi:Cray XT3 si XT4, toruri tridimensionale, fiecare legǎturǎ capabilǎ de 7 GB/s.IBM Bluegene/L, toruri tridimensionale, fiecare legǎturǎ capabilǎ de 1.4 GB/s.
Masive liniare si structuri circulare (rings)
Masive liniare, toruri si toruri structurate pentru ca firele sǎ fie scurte.
146

Masiv liniar: diametru, distanta medie, banda de trecere la bisectie? Ruta de la A la B este datǎ prin adresa relativǎ R = B – AToruri?Exemple: FDDI, SCI, FiberChannel Arbitrated Loop, KSR1
Structuri liniare si toruri multidimensioanle
Masive d-dimensionale.Numǎrul de noduri N = kd–1x…xk0. Descrise prin coordonate de d vectori cu d componente (id–1, …, i0)Site de ordinul k (mesh) d-dimensionale: N = kd ( d Nk = ). Descrise de d vectori cu radical din k coordonate.Toruri de ordinul k de dimensiune d (sau d-cuburi k-are)?
Proprietǎti
Rutare – distanta relativǎ: R = (bd–1 – ad–1, …, b0 – a0); traverseazǎ ri = bi – ai
salturi (hops) în fiecare dimensiune; rutarea de ordinul dimensiunii.Distanta medie Lungimea firelor?
Pentru meshes dx2k/3Pentru cuburi dk/2
Gradul?Banda de trecere la bisectie? Partitionare?
kd–1 legǎturi bidimensionaleAsezarea fizicǎ?
2d în spatiu de O(N) Fire scurteDimensiuni superioare?
147

Scufundǎri (embeddings) în douǎ dimensiuni
Se scufundǎ/încorporeazǎ dimensiuni logice multiple în una singurǎ prin folosirea de fire lungi.
Hipercuburi
Asa-numitele cuburi binare de ordinul n. Numǎrul de noduri este o putere a lui 2: N = 2n.Salturi (hops) de ordinul O(logN).Bandǎ de trecere la bisectie bunǎ.Complexitate: gradul iesirilor este n = logN, dimensiuni corecte în ordine, cu comunicare aleatoare douǎ porturi pe fiecare procesor.
148

Retele în trepte multiple
Rutare de la stânga la dreapta. Tipic, n = log(p)
Arbori
Diametrul si distanta medie variazǎ logaritmic. Un arbore k-ar are înǎltimea d = logkN. Adresele sunt specificate de un d-vector cu radical indice k coordonate care descriu drumul pânǎ la rǎdǎcinǎ.Grad fix.Rutele sunt pânǎ la ascendentul comun si apoi înapoi în jos. R = B xor A. Fie i pozitia celei mai semnificative pozitii unitare în R, se ruteazǎ în sus i + 1 niveluri. Apoi în jos în directia datǎ de cei mai de jos i + 1 biti din B.Spatiul unui arbore H este O(N) cu fire în lungime de O( N ).Banda de trecere la bisectie?
149

Arbori îngrosati (fat trees)
Legǎturi îngrosate (multe dintre ele) pe mǎsurǎ ce legǎtura este mai sus, astfel cǎ banda de trecere la bisectie scaleazǎ cu N.
Sumar de topologie
Toate au anumite “permutǎri rele”. Multe permutǎri populare sunt foarte rele pentru site (meshes) (transpusa). Aleatorizarea în legarea prin fire sau în rutare fac dificilǎ gǎsirea unei permutǎri rele!
Câte dimensiuni?
n = 2 sau n = 3. Fire scurte, usor de confectionat. Multe salturi (hops), banda de trecere la bisectie redusǎ. Se cere localism de trafic.n ≥ 4. Dificil de confectionat, mai multe fire, lungimea medie mai mare. Mai putine salturi, o bandǎ de trecere la bisectie mai bunǎ. Poate manevra bine traficul non-local.Cuburile d k-are asigurǎ un cadru consistent pentru comparatii. n = kd. Scaleazǎ pe dimensiunea (d) sau nodurile pe dimensiunea (k). Presupune cut-through.
150

Mecanismul de rutare
Este necesar a selecta portul de iesire pentru fiecare pachet de intrare. În cicluri de ceas putine.Aritmeticǎ simplǎ în topologiile regulate. Exemplu: rutarea Dx, Dy într-o grilǎ:• west (–x) Dx < 0• east (+x) Dx > 0• south (–y) Dx = 0, Dy < 0• north (+y) Dx = 0, Dy > 0• processor Dx = 0, Dy = 0Reduce adresa relativǎ a fiecǎrei dimensiuni în ordine. Rutarea dimensiune-ordine în cuburile d de ordinul k. Rutarea e-cub în n-cub.
Bazat pe sursǎ. Headerul mesajului transportǎ seria de selectii de port. Utilizat si stripat din mers. CRC? Formatul pachetului?Determinat de tabel (table-driven). Headerul mesajului transportǎ indicele pentru portul urmǎtor la switch-ul urmǎtor o = R[i]. Tabelul dǎ si indexul pentru hop-ul care urmeazǎ o, l’ = R[i]. ATM, HHPI.
Proprietǎti ale algoritmilor de rutare
Deterministi: ruta determinatǎ de sursǎ si de destinatie nu de etape intermediare.Adaptivi: ruta este influentatǎ de traficul de-a lungul drumului.Minimali: selecteazǎ numai între drumurile cele mai scurte.Fǎrǎ blocaje (deadlock): nici un pattern de trafic nu poate duce la o situatie în care nici un pachet nu avanseazǎ.
Rutarea mesajelor
Medii în indiviziune (partajate). Difuzare (broadcast) cǎtre toti.Optiuni:Rutare cu baza la plecare, la sursǎ: mesajul specificǎ calea spre destinatie (schimbǎrile de directie);Rutare cu baza la destinatie: mesajul specificǎ destinatia, comutatoarele trebuie sǎ aleagǎ calea.Rutarea poate fi:Deterministǎ: totdeauna urmeazǎ aceeasi cale.Adaptivǎ: alege cǎi diferite pentru a evita congestionǎrile, esecul transmiterii.Aleatoare: alege între mai multe cǎi bune pentru a echilibra încǎrcarea retelei.
151

Lipsa blocajelor (deadlock)
Cum pot apǎrea? Conditii necesare: resurse în indiviziune (partajate), alocate incremental, non-preemtible. A se imagina un canal ca o resursǎ în indiviziune care este obtinutǎ incremental: buffer la sursǎ apoi buffer la destinatie, canal de rutare.Cum pot fi evitate blocajele de tip deadlock? Prin restrictionarea modului în care sunt alocate resursele canalului.Cum se poate verifica dacǎ un algoritm de rutare este sau nu liber de blocaje (deadlock)?
Exemple de rutare deterministǎ
Sitǎ (mesh): rutarea în ordinea dimensiunilor. De transmis de la (x1, y1) la (x2, y2). Mai întâi x = x2 – x1, apoi y = y2 – y1.Hipercub: rutare pe muchiile cubului. De la X = x0x1x2…xn la Y = y0y1y2…yn (în binar). Ruta este R = X xor Y. Se traverseazǎ dimensiunile diferentelor între adrese în ordine.Arbori: ascendentul comun.Fǎrǎ blocaje?
152

Memoreazǎ si înainteazǎ sau cut-through (Store and Forward vs. Cut-Through)
Store-and-forward. Înainte de a-l expedia la un switch urmǎtor, fiecare switch asteaptǎ ca pachetul sǎ soseascǎ integral. Aplicatii: LAN sau WAN.Rutarea cut-through. Comutatorul (switch) examineazǎ headerul, decide unde sǎ trimitǎ mesajul. Porneste expedierea imediat.
Rutarea store&forward fatǎ-n fatǎ cu rutarea cut-through
h(n/b + D) fatǎ-n fatǎ cu n/b + hD.Ce se întâmplǎ dacǎ mesajul este fragmentat?
Rutarea cut-through vs. rutarea wormhole
În rutarea wormhole, când capul mesajului este blocat, mesajul stǎ suspendat în retea, blocând potential alte mesaje (necesitǎ numai bufferizarea bucǎtii din pachet care este trimisǎ între comutatoare).Rutarea cut-through lasǎ coada sǎ continue deplasarea când capul este blocat, acordeonând (fǎcând armonicǎ) întregul mesaj într-un singur switch (necesitǎ spatiu suficient pentru a cuprinde cel mai mare pachet).Referiri bibliografice:P. Kermani si L. Kleinrock, “Virtual cut-through: A new computer communication switching technique”, Computer Networks, vol. 3,pp. 267-286, 1979.W.J. Dally si C.L. Seitz, “Deadlock-Free Message Routing in Multiprocessor Interconnection Networks,” IEEE Trans.Computers, Vol. C-36, No. 5, May 1987, pp. 547-553
153

Conflicte
Douǎ pachete care încearcǎ sǎ utilizeze aceeasi legǎturǎ în acelasi timp. Buferizare temporarǎ sau renuntare?Retelele celor mai multe masini paralel blocheazǎ pachetele în locul lor de plecare. Se executǎ un control al fluxului la nivelul legǎturilor. Saturatia pe arbore.Sisteme închise – încǎrcarea oferitǎ depinde de cea livratǎ.
Controlul fluxului
Ce-i de fǎcut când presiunea devine deja îmbulzealǎ?Ethernet: detectarea coliziunilor si reluarea încercǎrii dupǎ un timp de asteptare/întârziere.FDDI (Fiber Distributed Data Interface), token ring: arbitraj.TCP/WAN: bufferizare, renuntare, ajustare de vitezǎ.Orice solutie trebuie sǎ se plieze pe viteza de iesire.
Controlul fluxului la nivelul legǎturii.
Netezirea fluxului
154

Câtǎ rezervǎ este necesarǎ pentru a maximiza banda de trecere?
Canale virtuale
W.J.Dally, “Virtual-Channel Flow Control”, Proceedings of the 17th annual international symposium on Computer Architecture, p.60-68, May 28-31, 1990
Banda de trecere
Ce afecteazǎ banda de trecere localǎ?Densitatea pachetelor bxn/(n + ne).Întârzierea de rutare bxn/(n + ne +wD).Conflictele la capete si în retea.
Banda de trecere agregatǎ:Banda de trecere la bisectie, suma benzilor de trecere ale celui mai mic set de legǎturi care partitioneazǎ reteaua.
Banda de trecere totalǎ a tuturor canalelor: Cb.Se presupne cǎ N hosts genereazǎ un pachet la fiecare M cicluri cu destinatie la distantǎ medie. Fiecare mesaj ocupǎ h canale pentru l = n/w cicluri fiecare. C/N canale disponibile pe fiecare nod. Utilizarea legǎturilor r = MC/Nhl < 1.
Câteva exemple
Cray T3D: scurt, larg, sincron (300 MB/s)24 biti: 16 de date, 4 de control, 4 pentru controlul fluxului în directie inversǎ.Unic ceas de 150 MHz (inclusiv procesorul).
155

flit10 = phit11 = 16 biti.Doi biti de control identificǎ tipul flit (idle si framinf). No-info, routing tag, packet, end-of-packet.Cray T3E: lung, larg, asincron (500 MB/s).14 biti, 375 MHz.flit = 5, phits = 70 biti: 64 de biti de date si 6 de control.Comutatoarele opereazǎ la 75 de MHz.Încadrate (framed) în pachete solicitare read/write de 1 si 8 cuvinte.Costul este functie de lungime si lǎtime: Cost = f(length, width)?
Comutatoare (switches)
Cu canale virtuale, un buffer se transformǎ în mai multe buffere.Cine selecteazǎ un canal virtual?
Componente de switch
Porturile de iesire: transmitǎtor (tipic dirijeazǎ ceasul si datele).Porturile de intrare: sincronizator care aliniazǎ semnalul de date cu domeniul ceasului local; în esentǎ un buffer FIFO (First-In-First-Out).Crossbar: conecteazǎ fiecare intrare cu oricare dintre iesiri; gradul este limitat de suprafata disponibilǎ sau de numǎrul de pini.Controlul logic: complexitatea depinde de logica rutǎrii si algoritmul de planificare/esalonare; determinǎ portul de iesire pentru fiecare pachet care soseste; arbitreazǎ între intrǎrile directionate cǎtre aceeasi iesire.
10 În rutarea wormhole un mesaj este divizat într-un numǎr de pachete-messaj mai mici denumite flits11 O legǎturǎ prin care se comunicǎ contine tipic douǎ canale unidirectionale. Fiecare canal din legǎturǎ contine preferabil date, Physical Unit (Phit) Type (tipul unitǎtii fizice) etc.
156

Bluegene/L: un proiect la putere micǎ
20.1 kW 20.3 kW
Comparatie între sisteme
Performate de vârf ale supercalculatoarelor
157

BlueGene/L calculeazǎ ASIC (Application-Specific Integrated Circuit)
IBM CU-11, 0,13 microniDimensiunea plǎcutei suport 11x11 mmCBGA (Ceramic Ball Grid Array) de 25x32 mm474 de pini, 328 de semnale, 1,5/2,5 volti.
158

BlueGene/L – reteaua de interconectare
Tor tridimensional. Interconecteazǎ toate nodurile de calcul (65536). Rutare hardware cut-through virtualǎ. Legǎturi de 1,4 Gb/s pe toate cele 12 legǎturi de noduri (2,1 GB/s pe nod). Latentǎ de 1 µs între noduri vecine, 5 µs la cele de mai departe. Latentǎ de 4 µs pentru un salt (hop) cu MPI (Multi-Processor Interconnect), 10 µs la cel mai depǎrtat. Comunicare backbone pentru calcule. Banda de trecere la bisectie 0,7/1,4 TB/s, banda de trecere totalǎ 68 TB/s.
159

Arbore global. Functionalitate difuzivǎ (broadcast) one-to-all. Functionalitate pentru operatii de reducere. Banda de trecere pe legǎturǎ 2,8 Gb/s. Latenta la traversarea arborelui într-un singur sens 2,5 µs. Banda de trecere totalǎ pe arborele binar (masina de 64k) ~ 23 TB/s. Interconectazǎ toate nodurile de calcul si dispozitivele I/O (1024).Bariere si întreruperi globale de latentǎ redusǎ. Latenta la dus-întors 1,3 µs.Ethernet. Încorporat în fiecare nod ASIC. Activ în nodurile I/O (1:64). Toatǎ comunicarea externǎ (fisiere de intrare/iesire, control, interactiunea cu utilizatorul etc.)
BlueGene/L cu 512 cǎi
BlueGene/L: 16384 noduri (IBM Rocehster)
160

Sumar
Multicalculatoarele scalabile trebuie sǎ ia în considerare problema scalǎrii în banda de trecere, latentǎ, putere si cost.Proiectarea interfetelor cu reteaua. Reduce substantial overheadul cu send si receive.Retelele trebuie sǎ suporte bine modelele de programare si aplicatiile.S-au studiat multe topologii de retea, cele mai obisnuite sunt sitele (meshes), torurile, arborii si multietajatele.Ruterele de retea curente utilizeazǎ cut-through virtual, rutarea wormhole cu canale virtuale.Calculatoarele scalabile din noua generatie trebuie sǎ ia în consideratie si scalarea de putere (watt).Controlul fluxului în canale virtuale
William J. Dally (Stanford University)
Prezentare de John M.Calandrino (University of North Carolina at Chapel Hill)
Motivatie
În retelele de interconectare sunt implicate douǎ tipuri de resurse: buffere care retin/detin flits si canale care transportǎ flits.Obisnit, aceste resurse sunt împerecheate: un buffer cu un canal.Dacǎ bufferul este alocat pachetului A, nici un alt pachet în afarǎ de A nu poate utiliza canalul asociat.Pachetul A poate bloca alte pachete care necesitǎ acelasi canal.
Canale virtuale
Canalele virtuale constau dintr-un buffer flit + altǎ stare.Canale virtuale multiple pe fiecare canal fizic, sau buffere multiple pe fiecare canal.Se decupleazǎ alocarea de buffere si de canale.O metaforǎ împrumutatǎ din domeniul infrastructurii de autostrǎzi: canalele virtuale sunt piste, benzi; canalele virtuale multiple permit pachetelor blocate sǎ treacǎ.Foarte compatibile cu rutarea wormhole.
Exemplu
O pistǎ:
161

Douǎ piste:
Beneficii
Capacitate de trecere (throughput) sporitǎ. Utilizare mai intensǎ a capacitǎtii retelei.Mai multǎ libertate în alocarea resurselor. O dimensiune în plus: cu canalele virtuale se poate face un gen de service.Schimbǎri hardware minimale. Bufferele FIFO sunt înlocuite de buffere cu mai multe benzi/piste. Complexitate hardware suplimentarǎ minimalǎ.
Privire asupra aspectelor operationale
Canalele virtuale sunt alocate pe pachete. Pot fi reasignate când pleacǎ ultimul flit dintr-un pachet. Dacǎ nici un canal virtual nu este disponibil, pachetul se blocheazǎ.Flit-urile cǎlǎtoresc prin canalul fizic. Canalul fizic este utilizat în comun de mai multe pachete din canale virtuale diferite. Canalul fizic este alocat potrivit unei anumite politici de planificare (FIFO, round-robin, prioritatea pachetului, vechimea pachetului etc.)
162

Modelul analitic
Latenta Volumul trecerilor (throughput) (n-cubul binar)
Revendicare: “pentru cele mai multe retele, 4 la 8 piste/benzi pe un canal fizic sunt potrivite.” De ce 60%+ din capacitate reprezintǎ o situatie adecvatǎ?
Volumul de trecere (throughput) (la memorie constantǎ)
163

Planificare aleatoare sau prin termene limitǎ (deadline)
Trafic prioritar
Probleme
Se poate utiliza modelul analitic pentru a da garantii asupra timpului necesar unui pachet pentru a ajunge la destinatie? Probabil nu în cazul general –
164

premisele modelului ar putea fi prea simpliste. Dar dacǎ pachetele care necesitǎ asemenea garantii primesc cea mai înaltǎ prioritate?Existǎ aplicatii pentru care beneficiile canalelor virtuale nu sunt obtenabile? Ce se întâmplǎ dacǎ pachete multiple de pe aceeasi cale se pot bloca frecvent?
165

Coerenta cache în masinile scalabile
Sisteme cache-coerente scalabile
Scalabile, memorie distribuitǎ plus replicare coerentǎ.Masini scalabile cu memorie distribuitǎ. Noduri P-C-M conectate printr-o retea. Asistentul de comunicare interpreteazǎ tranzactiile pe retea, formeazǎ interfata.Punctul final era spatiul de adresare fizic în indiviziune (partajat). Cache miss satisfǎcut transparent din memoria localǎ sau de la distantǎ.Tendinta naturalǎ a cache-ului este a se replica. Dar coerenta? Nu existǎ un mediu de difuzare (broadcast) pe care sǎ-l tii sub observatie (snoop).Nu numai latenta/banda de trecere a hardware-ului, ci si protocolul trebuie sǎ fie scalabil.
Ce trebuie sǎ facǎ un sistem coerent?
Sǎ furnizeze o multime de stǎri, o diagramǎ de tranzitie a stǎrilor si actiuni.Sǎ administreze protocolul de coerentǎ.(0) Determinǎ când se invocǎ protocolul de coerentǎ.(1) Gǎseste sursa de informatie despre starea liniei în alte cache-uri. Dacǎ
trebuie sǎ comunice cu cópiile din alte cache-uri.(2) Aflǎ unde sunt celelalte cópii.(3) Comunicǎ cu acele cópii (invalidare, actualizare).Pasul (0) este executat la fel în toate sistemele. Starea liniei este mentinutǎ/retinutǎ în cache. Protocolul este invocat dacǎ apare un acces nereusit la linie.Tratǎri diferite se constatǎ la punctele (1) si (3).
Coerenta bazatǎ pe bus
Toate etapele (1), (2) si (3) se executǎ prin difuzare (broadcast) pe bus. Procesorul în eroare trimite un “search”, celelalte rǎspund la sondajul de cǎutare si executǎ actiunea necesarǎ.Se poate face si în retelele scalabile. Difuzare cǎtre toate procesoarele si asteptarea rǎspunsurilor.Simplǎ conceptual, dar difuzarea nu se scaleazǎ cu p. Pe bus, banda de trecere prin bus nu se scaleazǎ; pe retelele scalabile, fiecare defect (fault) conduce la cel putin p tranzactii pe retea.
166

Coerenta scalabilǎ: poate avea aceleasi stǎri de cache si aceeasi diagramǎ de tranzitie a stǎrilor. Mecanisme diferite de a administra protocolul.
Tratarea #1: supravegherea (snooping) ierarhicǎ
Tratare prin supraveghere extinsǎ: ierarhie a mediului de difuzare. Arbori de bus-uri sau ring-uri (KSR-1). Procesoarele sunt în multiprocesoare bazate pe bus sau pe ring ca frunze. Nodurile pǎrinti si nodurile descendenti sunt conectate prin interfete cu supraveghere bidirectionale; supravegheazǎ ambele bus-uri si propagǎ tranzactiile relevante. Memoria principalǎ poate fi centralizatǎ la rǎdǎcinǎ sau distribuitǎ între frunze.Etapele (1) – (3) sunt manipulate similar pe bus, dar nu prin difuzare totalǎ. Procesoarele în eroare trimit tranzactii de bus “search” pe propriul bus. Se propagǎ în sus si în jos pe ierarhie pe baza rezultatelor supravegherii (snoops).Probleme: latenţǎ mare: niveluri multiple si supraveghere/examinare (snoop/lookup) la fiecare nivel. Strangulare de bandǎ de trecere la rǎdǎcinǎ.Nu este o solutie popularǎ în zilele noastre.
Tratarea #2: scalabilǎ pe bazǎ de director
Fiecare bloc de memorie are informatie de director asociatǎ. Tine evidenta cópiilor blocurilor cache-ate si a stǎrii lor. La un miss, gǎseste intrarea din director, o examineazǎ si comunicǎ numai cu nodurile care au cópii dacǎ este necesar. În retelele scalabile, comunicarea cu directorul si cópiile este prin tranzactii de retea.
P
A M/D
C
P
A M/D
C
P
A M/D
C
Read requestto directory
Reply withowner identity
Read req.to owner
DataReply
Revision messageto directory
1.
2.
3.
4a.
4b.
P
A M/D
CP
A M/D
C
P
A M/D
C
RdEx requestto directory
Reply withsharers identity
Inval. req.to sharer
1.
2.
P
A M/D
C
Inval. req.to sharer
Inval. ack
Inval. ack
3a. 3b.
4a. 4b.
R e que stor
Node withdir ty copy
D ire c tor y nodefor block
R e que stor
D ire c tor y node
Shar e r Shar e r
(a) Read miss to a block in dirty state (b) Write miss to a block with two sharers
(a) read miss pe un bloc în starea dirty (b) write miss pe un bloc cu doi utilizatori în indiviziune
Multe alternative de organizare a informatiei de director.
167

Un teren de mijloc popular
O ierarhie pe douǎ niveluri.Nodurile individuale sunt microprocesoare conectate non-ierarhic, cum a fi mesh-urile de SMP-uri.Coerenta între noduri este bazatǎ pe director. Directorul tine evidenta nodurilor nu a procesoarelor individuale.Coerenta în noduri este prin supraveghere (snooping) sau prin director. Ortogonalǎ dar necesitǎ o interfatǎ bunǎ ca functionalitate.Exemple de la începuturi:Convex Exemplar: directory-directory; Sequent, Data General, HAL: directory-snoopy.
Exemplu de ierarhii pe douǎ niveluri
P
C
Snooping
B1
B2
P
C
P
CB1
P
C
MainMem
MainMem
AdapterSnoopingAdapter
P
CB1
Bus (or Ring)
P
C
P
CB1
P
C
MainMem
MainMem
Network
Assist Assist
Network2
P
C
AM/D
Network1
P
C
AM/D
Directory adapter
P
C
AM/D
Network1
P
C
AM/D
Directory adapter
P
C
AM/D
Network1
P
C
AM/D
Dir/Snoopy adapter
P
C
AM/D
Network1
P
C
AM/D
Dir/Snoopy adapter
(a) Snooping-snooping (b) Snooping-directory
Dir. Dir.
(c) Directory-directory (d) Directory-snooping
Avantajele nodurilor multiprocesor
Potential potrivite unor avantaje de cost si de performante.• Amortizarea costurilor fixe ale nodurilor fatǎ de procesoarele multiple; se
aplicǎ chiar dacǎ procesoarele sunt puse laolaltǎ simplu chiar dacǎ nu sunt coerente.
• Pot uza de SMP-uri din categoria commodity.• Mai putine noduri pentru care directorul sǎ tinǎ evidenta.• Mai multǎ comunicare poate fi continutǎ în cadrul nodului, ceea ce este mai
ieftin.• Nodurile prelocalizeazǎ si prerecupereazǎ date (prefetch) unul pentru altul
(putine “misses” la solicitǎrile la distantǎ).• Combinarea solicitǎrilor (ca acelea ierarhice, numai pe douǎ niveluri).
168

• Pot chiar sǎ foloseascǎ în indiviziune (partajat) cache-urile (suprapuneri de seturi de lucru).
• Beneficiile depind de schema de partajare (si de asocieri – mapping); bunǎ pentru cele pe larg utilizate pentru partajare la citire, de pildǎ pentru date arborescente în metoda Barnes-Hut; pentru vecinii cei mai apropiati, dacǎ asocierea (mapping) este potrivitǎ; nu tocmai bunǎ pentru comunicarea toti-cu-toti.
Dezavantaje ale nodurilor MP coerente
Banda de trecere partajatǎ între noduri. Exemplul all-to-all. Se aplicǎ la sistem coerent sau nu.Bus-ul creste latenta spre memoria localǎ.Cu coerentǎ, asteptarea tipicǎ pentru supravegherea (snoop) localǎ rezultǎ înainte de trimiterea cererii la distantǎ.Busul cu supraveghere (snoopy) la nodul la distantǎ creste întârzierea si acolo, crescând latenta si reducând banda de trecere.În general, poate afecta performanta dacǎ patternurile de partajare nu se imbinǎ potrivit.
Outline
Privire generalǎ asupra solutiei bazate pe director.Protocoalele directorului: corectitudine care include si serializare si consistentǎ; implementare; studiu prin cazuri: SGI Origin2000, Sequent NUMA-Q; discutarea unor tratǎri alternative în proces.Sincronizarea.Implicatii pentru saoftware-ul paralel.Modele de consistentǎ a memoriei relaxate.Tratǎri alternative pentru spatiu de adresare partajat coerent.
Operatii de bazǎ ale directorului
Procesoare în numǎr de k.
• ••
P P
Cache Cache
Memory Directory
presence bits dirty bit
Interconnection Network
169

Cu fiecare bloc de cache în memorie: k biti de prezentǎ, un bit murdar (dirty).Cu fiecare bloc de cache în cache: un bit de validitate si un bit murdar (de proprietar).Citire din memoria principalǎ de cǎtre procesorul i:
Dacǎ bitul murdar este OFF atunci {citeste din memoria principalǎ; schimbǎ p[i] – bitul de prezentǎ – în ON;}Dacǎ bitul murdar este ON atunci {recheamǎ linia din procesorul murdar (starea cache-ului la “comun”); actualizeazǎ memoria; schimbǎ bitul murdar la OFF; schimbǎ p[i] la ON; furnizeazǎ datele rechemate cǎtre i;}.
Scriere în memoria principalǎ de cǎtre procesorul i:Dacǎ bitul murdar este OFF atunci {furnizeazǎ date lui i; trimite invalidǎri cǎtre toate cache-urile care au blocul: schimbǎ bitul murdar la ON; schimbǎ p[i] la ON; …} …
Scalarea cu numǎrul de procesoare
Este asiguratǎ scalarea benzii de trecere a memoriei si a directorului.Directorul centralizat este strangulant în ceea ce priveste banda de trecere, ca si memoria centralizatǎ.Cum se mentine/întretine informatia de director în modul distribuit?Scalarea caracteristicilor de performantǎ. Traficul: numǎrul de tranzactii pe retea de fiecare datǎ când protocolul este invocat. Latenta = numǎrul de tranzactii pe retea pe drumul critic de fiecare datǎ.Scalarea cerintelor de memorie pentru director. Numǎrul bitilor de prezentǎ necesari creste odatǎ cu numǎrul de procesoare.Modul cum este organizat directorul afecteazǎ toate acestea, performata la o scarǎ tintǎ, la fel ca si problemele de management al coerentei.
Privire asupra directoarelor
Caracteristici inerente ale programului:Se determinǎ dacǎ directoarele furnizeazǎ avantaje mari fatǎ de difuzare (broadcast). Se asigurǎ o privire în modul de organizare si modul de depozitare a informatiei de director.Caracteristici care conteazǎ:Frecventa ratǎrilor la scriere (write misses); câte procesoare uzeazǎ în indiviziune de zonǎ la o ratare la scriere; cum se scaleazǎ acestea.
Patternuri de invalidare de cache
Patternuri de invalidare LU (Lower-Upper).Patternuri de invalidare la problema modelǎrii oceanului.Patternuri de invalidare la metoda Barnes-Hut.Patternuri de invalidare în problema explorǎrii cu raze (Raytrace).
170

LU Invalidation Patterns
8.75
91.22
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.220
10
2030
40
5060
7080
90
100
0 1 2 3 4 5 6 7
8 to
11
12 to
15
16 to
19
20 to
23
24 to
27
28 to
31
32 to
35
36 to
39
40 to
43
44 to
47
48 to
51
52 to
55
56 to
59
60 to
63
# of inv alidations
% o
f sha
red
writ
es
Ocean Invalidation Patterns
0
80.98
15.06
3.04 0.49 0.34 0.03 0 0.03 0 0 0 0 0 0 0 0 0 0 0 0 0.020
10
20
30
40
50
60
70
80
90
0 1 2 3 4 5 6 7
8 to
11
12 to
15
16 to
19
20 to
23
24 to
27
28 to
31
32 to
35
36 to
39
40 to
43
44 to
47
48 to
51
52 to
55
56 to
59
60 to
63
# of inv alidations
% o
f sha
red
writ
es
Barnes-Hut Invalidation Patterns
1.27
48.35
22.87
10.56
5.332.87 1.88 1.4 2.5 1.06 0.61 0.24 0.28 0.2 0.06 0.1 0.07 0 0 0 0 0.33
05
10
1520
253035
4045
50
0 1 2 3 4 5 6 7
8 to
11
12 to
15
16 to
19
20 to
23
24 to
27
28 to
31
32 to
35
36 to
39
40 to
43
44 to
47
48 to
51
52 to
55
56 to
59
60 to
63
# of inv alidations
% o
f sha
red
write
s
171

Radiosity Invalidation Patterns
6.68
58.35
12.04
4.16 2.24 1.59 1.16 0.97 3.28 2.2 1.74 1.46 0.92 0.45 0.37 0.31 0.28 0.26 0.24 0.19 0.19 0.910
10
20
30
40
50
60
0 1 2 3 4 5 6 7
8 to
11
12 to
15
16 to
19
20 to
23
24 to
27
28 to
31
32 to
35
36 to
39
40 to
43
44 to
47
48 to
51
52 to
55
56 to
59
60 to
63
# of inv alidations
% o
f sha
red
write
s
Sumar pentru patternuri de partajare
În genral, numai câteva procese partajante la o scriere, se scaleazǎ (lent) cu numǎrul de procesoare, P.
Codul si obiectele read-only (de pildǎ datele scenei în Raytrace); nu sunt probleme deoarece scrierile sunt rare.Obiecte migratoare (de pildǎ celule de masiv de costuri în LocusRate); chiar dacǎ numǎrul de PE scaleazǎ, numai 1-2 invalidǎri.Obiecte majoritar citite (de pildǎ rǎdǎcina de arbore în metoda Barnes); invalidǎrile sunt mari dar rare în timp, de aici impact redus asupra performantei.Obiecte cu scrieri/citiri frecvente (de pildǎ cozile de taskuri); invalidǎrile rǎmân uzual mici desi frecvente.Obiectele de sincronizare; lacǎtele (locks) de redusǎ confruntare (contention) produc invalidǎri de mici proportii; lacǎtele (locks) de înaltǎ confruntare necesitǎ suport special (arbori software, lacǎte (locks) de coadǎ de asteptare).
Implicǎ directoare foarte utile în continerea traficului.Dacǎ se organizeazǎ potrivit, traficul si latenta n-ar trebui sǎ scaleze tocmai rǎu.
Se sugereazǎ tehnici de a reduce overheadul memorǎrii.
Organizarea directoarelor
De vǎzut cum lucreazǎ ele si caracteristicile lor de scalare cu P.
Cum se regǎseste informatia din director
Pentru memoria si directorul centralizat, usor: se merge acolo, dar nu scaleazǎ.Pentru memorie si director distribuite:
172

Scheme plate. Director distribuit cu memoria: acasǎ; bazat local pe adrese (hashing): actiune pe retea trimisǎ direct acasǎ (to home).Scheme ierarhice. Director organizat ca o structurǎ ierarhicǎ de date; frunzele sunt noduri procesoare, nodurile interioare au numai starea directorului; intrǎrile în directorul nodului pentru un bloc spun dacǎ fiecare subarbore cache-azǎ blocul; pentru a regǎsi informatia de director, se trite mesajul de cǎutare “search” pânǎ la pǎrinte: se ruteazǎ singur prin examinarea directorului; la snooping ierarhic, dar mesaje punct-la-punct între copii si pǎrinti.
Cum lucreazǎ directoarele ierarhice
Se ia urma, se localizeazǎ care dintre descendentii nivelului 1 de directoare au o copie a blocului de memorie. Se localizeazǎ care blocuri de memorie localǎ sunt cache-ate în afara acestui subarbore. Incluziunea este mentinutǎ între directoarele de nivel 1 si directorul din nivelul 2.Directoarele sunt structuri de date ierarhice. Frunzele sunt noduri procesoare, nodurile interioare sunt numai directoare. Ierarhia logicǎ, nu este în mod necesar fizicǎ (poate fi scufundatǎ în reteaua generalǎ).
Centralized Distributed
HierarchicalFlat
Memory-based Cache-based
Directory Schemes
How to find source ofdirectory information
How to locate copies
• • • • • •
● ● ●
Noduri procesoare
Directoare nivelul 1
Director nivelul 2
173

Proprietǎti care scaleazǎ
P0 P1 P2 P3 P4 P5 P6 P7 P8 P9 P10 P11 P12P13 P14P15
Banda de trecere: rǎdǎcina poate deveni strangulantǎ. Se pot utiliza directoare cu mai multe rǎdǎcini în interconectarea generalǎ.Traficul (numǎrul de mesaje): Depinde de localismul din ierarhie. Poate fi rea la capǎtul de jos – 4*logP cu numai o copie. Poate avea capacitatea de a exploata combinarea de mesaje.Latenta: depinde si ea de localismul din ierarhie. Poate fi mai bunǎ în masinile mari când nu sunt de parcurs distante mari (home la distantǎ). Dar poate avea tranzactii multiple pe retea asezate pe ierarhie si cǎutǎri în directoare de-a lungul parcursului.Overheadul memoriei.
Cum sunt retinute locatiile cópiilor?
Scheme ierarhice: prin ierarhie, fiecare director are biti de prezentǎ pentru descendentii sǎi (subarbori) si bit murdar.Scheme plate: variazǎ mult. Caracteristici de performantǎ si overheaduri cu memoria diferite. Schemele bazate pe memorie: informatii despre cópii depuse toate acasǎ (at the home) cu blocul de memorie; Dash, Alewife, SGI Origin, Flash.Schemele bazate pe cache: informatiile despre cópiile distribuite printre cópii ele însesi, fiecare cópie pointeazǎ cǎtre urmǎtoarea. Interfatǎ coerentǎ scalabilǎ (Scalable Coherent Interface – SCI: standardul IEEE).
174

Scheme plate bazate pe memorie
Toate informatiile despre cópii co-locate cu însusi blocul acasǎ (at the home). Lucreazǎ ca si schemele centralizate, cu deosebirea cǎ sunt distribuite.Scalarea caracterisiticilor de performantǎ. Traficul pe un write: proportional cu numǎrul de partajanti; latenta unui write: poate genera invalidǎri pentru partajantii în paralel.Scalarea overhead-ului de memorie. Reprezentarea cea mai simplǎ: full bit vector, adicǎ un bit de prezentǎ pe nod. Overhead-ul de memorie nu scaleazǎ bine cu P; linia de 64 de bytes implicǎ 64 de noduri: 12,7% overhead, 256 de noduri: 50% overhead, 1024 de noduri: 200% overhead. Pentru M blocuri de memorie în memorie, overhead-ul de depozitare este proportional cu P*M.
Reducerea overhead-ului de memorare
Optimizǎri pentru schemele cu vector full bit. Cresterea dimensiunii blocului de cache (reduce overhead-ul de stocare proportional). Utilizarea nodurilor multiprocesor (bit pe nod multiprocesor, nu pe procesor). Scaleazǎ încǎ la fel ca P*M, dar nu este o problemǎ pentru toate, doar masinile foarte mari: 256 de procesoare, 4 pe fiecare cluster, 128 B pe linie: 6,25% overhead.Reducerea “latimii12”: relativ la factorul P. observatie: cele mai multe blocuri sunt cache-ate de numai câteva noduri, putine. Nu au un bit pe nod, dar intrarea contine câtiva pointeri la nodurile partajante. P = 1024 implicǎ pointeri de 10 biti, se pot utiliza 100 de pointeri si încǎ se economiseste spatiu. Patternurile de partajare indicǎ faptul cǎ sunt suficienti putini pointeri (cinci sau asa ceva). Necesitǎ o strategie pentru depǎsire (overflow) când existǎ mai multi partajanti (se va vedea mai departe).
12 Termenii lǎtime si înǎltime se referǎ la figura anterioarǎ: pe “lǎtime” sunt plasate (multi)procesoarele, pe “înǎltime” sunt plasate modulele de memorie.
P
M
175

Reducerea “înǎltimii”: relativ la factorul M. Observatie: numǎrul de blocuri de memorie este mult mai mare decât blocurile de cache. În orice moment, cea mai mare parte a intrǎrilor directorului este inutilǎ. Organizeazǎ directorul ca un cache, mai curând decât a pune câte o intrare pentru fiecare bloc de memorie.
Schemele plate, bazate pe cache
Cum lucreazǎ:Numai Home detine pointeri la restul informatiei directorului.Listǎ linkatǎ distribuitǎ de cópii, circulǎ (weaves) între cache-uri. Tag-ul de cache are pointer, pointeazǎ la cache-ul urmǎtor detinǎtor al unei cópii.La read, se adaugǎ pe sine în capul listei (necesar pentru comunicare).La write, se propagǎ lantul de invalidate în josul listei.
P
Cache
P
Cache
P
Cache
Main Memory(Home)
Node 0 Node 1 Node 2
Standardul IEEE Scalable Coherent Interface (SCI): listǎ dublu linkatǎ
Scalarea proprietǎtilor (cache-based)
Traficul la write: proportional cu numǎrul de partajanti.Latenta la write: proportionalǎ cu numǎrul de partajanti! Nu stie identitatea partajantului urmǎtor pânǎ când nu este atins partajantul curent. Asistǎ totodatǎ procesarea la fiecare nod de-a lungul cǎii (chiar read-urile implicǎ mai mult decât un alt asistent: home si primul partajant din listǎ).Overhead-ul de stocare: scalare destul de bunǎ de-a lungul ambelor axe. Numai un pointer principal pe fiecare bloc de memorie; restul este total în proprietatea dimensiunii cache.Alte proprietǎti (discutate mai departe):Bune: mature, standardul IEEE, usurintǎ.Rele: complexitate.
176

Sumar despre organizǎrile directorului
Schemele plate:Problema (a): aflarea sursei datelor directorului; la home, pe bazǎ de adresǎ.Problema (b): aflarea locurilor unde sunt cópiile; la cele bazate pe memorie: toate informatiile sunt în directorul at home; la cele bazate pe cache: home are pointer la primul element al listei linkate distribuite.Problema (c): comunicarea cu acele cópii; memory-based: mesaje punct-la-punct (probabil mai grosiere la depǎsire (overflow)) – pot fi multicast sau suprapuse (overlapped); cache-based: parte a traversǎrii listei linkate punct-la-punct pentru a le localiza – serializate.Schemele ierarhice:Toate cele trei probleme prin trimiterea de mesaje în sus si în jos pe arbore; nu existǎ o listǎ unicǎ explicitǎ a partajantilor; comunicarea directǎ este numai între ascendenti si descendenti.
Sumar despre solutiile cu director
Directoarele oferǎ coerentǎ scalabilǎ pe retele generale; nu sunt necesare mijloace de difuzare (broadcast).Multe posibilitǎti de organizare a directorului si multe protocoale de administrare.Directoarele ierarhice nu sunt foarte utilizate; latentǎ mare, tranzactii pe retea multiple si strangularea benzii de trecere la nivelul rǎdǎcinii.Schemele plate atât mamory-based cât si cache-based sunt vii; pentru cele memory-based, full bit vector este suficient la scarǎ moderatǎ – mǎsurat în nodurile vizibile protocolului de director, nu procesoarelor; se vor examina studii de caz pentru fiecare.
Probleme pentru protocoalele de director
Corectitudine.Performantǎ.Complexitatea tratǎrii erorilor.Se discutǎ imediat problemele majore privind corectitudinea is performanta cu care se confruntǎ un protocol.Apoi se va adânci studiul problemelor cu protocoalele memory- si cache-based, compromisurile în modul de rezolvare (studii de caz). Prin acestea complexitatea va apǎrea la vedere.
Corectitudinea
Asigurǎ bazele coerentei la nivelul tranzitiei stǎrilor. Liniile sunt updatate/invalidate/recuperate, se produc actiuni si tranzitii de la o stare la alta corecte.
177

Asigurǎ ordonarea si sunt satisfǎcute restrictiile la serializare. Pentru coerentǎ (o singurǎ locatie). Pentru consistentǎ (locatii multiple): presupune încǎ o consistentǎ secventialǎ.Evitǎ blocajele (deadlock, livelock), înfometarea (starvation).Probleme: Cópii multiple şi cǎi multiple prin retea (cǎi de acces distribuite). Spre deosebire de sistemele pe bus cache non-coerente (fiecare are numai una). Latenta mare face optimizǎrile atractive – cresterea concurentei complicǎ problema corectitudinii.
Coerenta: serializarea la o locatie
Pe un bus, cópii multiple dar ordine impusǎ de serializarea prin bus.Pe scalabilele fǎrǎ coerentǎ, modulele memoriei principale determinǎ ordinea.Se pot utiliza si aici modulele din memorie principalǎ, dar cu cópii multiple. Copia validǎ a datelor ar putea sǎ nu fie în memoria principalǎ. Atingerea memoriei principale într-o ordine nu înseamnǎ cǎ exemplarul valid va fi atins în acea ordine. Serializarea într-un loc nu înseamnǎ serializare în raport cu toate cópiile (se va discuta).
Consistenta secventialǎ
Bus-based:Executarea completǎ de scrieri: asteptare pânǎ ce se acceseazǎ bus-ul.Atomicitatea unui write: furnizatǎ de ordonarea datǎ de bus si de buffer.În cazul scalabil non-coerent:Executarea completǎ de scrieri: asteptare pentru înstiintarea explicitǎ de la memorie.Atomicitatea unui write: usor de realizat la cópii singulare.Acum, cu cópii multiple si cǎi de acces în retea multiple:Executarea completǎ a unui write: necesitǎ înstiintǎri explicite de la cópiile însesi.Scrierile nu sunt fǎcute atomice cu usurintǎ.Altele în plus fatǎ de problemele de la bus-based si non-coerent.
Problema atomicitǎtii scrierii
Interconnection Network
Cache
Mem
P1
Cache
Mem
P2
Cache
Mem
P3
A=1; while (A==0) ;B=1; while (B==0) ;
print A;
A=1
A=1
B=1delay
A:0->1 A:0B:0->1
178

Blocaje (deadlock, livelock), înfometare (starvation)
Protocol cerere-rǎspuns (request-reply).Probleme similare celor discutate mai devreme. Un nod poate primi prea multe mesaje. Controlul fluxului poate produce blocaje (deadlock). Retele separate pentru cerere-rǎspuns cu protocol cerere-rǎspuns (request-reply). Sau NACK-uri (Negative Acknowledgement) dar cu riscurile blocajelor (livelock) si ale problemelor cu traficul.Problemǎ nouǎ: protocoalele adesea nu sunt strict cerere-rǎspuns. De pildǎ, rd-excl (read exclusive) genereazǎ cereri invalide (care genereazǎ rǎspunsuri de înstiintare (ack). Alte cazuri de reducere a latentei si de a permite concurentǎ.Referiri asemǎnǎtoare trebuie fǎcute la blocajele livelock si la înfometare (starvation).Vom vedea cum protocoalele se ocupǎ de aceste probleme de corectitudine.
Performanta
Latenta. Optimizǎri de protocol pentru a reduce actiunile suplimetare în retea pe drumul critic. Suprapunerea de actiuni/activitǎti sau accelerarea lor.Capacitatea de prelucrare (throughput). Reducerea numǎrului de operatii de protocol la fiecare invocare.Grijǎ relativ la modul în care acestea scaleazǎ cu numǎrul de noduri.
Eficientizarea protocolului sub aspectul latentei
Înaintarea de mesaje: protocoale bazate pe memorie.
L H R1: req
2:reply
3:intervention
4a:revise
4b:response
L H R
1: req 2:intervention
3:response4:reply
L H R
1: req 2:intervention
3b:response
3a:revise
(a) Strict request-reply (a) Intervention forwarding
(a) Reply forwarding
Înaintarea de mesaje: protocoale bazate pe cache.
179

S3
5:inval
6:ack
H S1 S2
1: inval
2:ack
3:inval
4:ack
H S1 S2
1: inval 2a :inval
3b:ack2b:ack
H S1 S2
2:inval
4:ack
(c)
S3
3a:inval
4b:ack
S3
3:inval1:inval
(b)(a)
Alte optimizǎri relativ la latentǎ
Se utilizeazǎ/aruncǎ hardware-ul la drumul critic. SRAM pentru director (sparse sau cache), bit pe bloc în SRAM pentru a spune dacǎ protocolul ar trebui invocat.Se suprapun activitǎtile pe drumul critic. Invalidǎri multiple concomitent în varianta memory-based, invalidǎri suprapuse si înstiintǎri în varianta cache-based, examinǎri (lookups) de director si de memorie sau examinǎri cu tranzactii – operatii de protocol speculative.
Cresterea capacitǎtii de prelucrare (throughput)
Reducerea numǎrului de tranzactii pe operatie. Invalidǎri si înstiintǎri, indicatii (hints) de înlocuire, toate implicǎ banda de trecere si gradul de ocupare a asistentului de comunicare.Reducerea gradului de ocupare a asistentului sau a overheadului legat de protocolul de procesare. Tranzactii scurte si frecvente, astfel încât gradul de ocupare devine foarte important.Pipeline pentru assist(entul de comiunicare) (procesarea protocolului).Multe modalitǎti de a reduce latenta si totodatǎ de a creste capacitatea de prelucrare (throughput). De pildǎ, înaintarea (forward) cǎtre un nod murdar, aruncarea hardware pe drumul critic…
Complexitatea
Protocoalele de coerentǎ a cache-urilor sunt complexe.Alegerea tratǎrii/solutiei. Conceptual si proiectarea protocolului fatǎ-n fatǎ cu implementarea.Compromisuri într-o tratare (approach). Ameliorǎrile de performantǎ adaugǎ adesea complexitate, complicǎ corectitudinea – mai multǎ concurentǎ, posibile conditii de cursǎ (race), nu cerere-rǎspuns stricte.Multe cazuri subtile, dar, cresterea întelegerii/adoptǎrii face actiunea mult mai usoarǎ; verificarea automatǎ este importantǎ dar dificilǎ.Sǎ examinǎm mai atent versiunile memory- si cache-based.
180

Protocoale memory-based plate
Se utilizeazǎ studiul de caz SGI Origin2000. Protocol similar celui pentru Stanford DASH, dar cu compromisuri (tradeoffs) diferite. Tot asa sunt si Alewife, FLASH, HAL.Teme principale:Privire generalǎ asupra sistemului.Stǎrile de coerentǎ, reprezentare si protocol.Compromisuri la corectitudine si performantǎ.Probleme de implemetare.Caracteristici de implementare cantitative.
Privire generalǎ asupra sistemului Origin2000
L2 cache
P
(1-4 MB)L2 cache
P
(1-4 MB)
Hub
Main Memory(1-4 GB)
Direc-tory
L2 cache
P
(1-4 MB)L2 cache
P
(1-4 MB)
Hub
Main Memory(1-4 GB)
Direc-tory
Interconnection Network
SysAD busSysAD bus
PCB (Printed Circuit Board) unicǎ, dimensiuni 16x11 inches.Director în aceleasi DRAM sau în DRAM separate, accesate în paralel.Pânǎ la 512 noduri (1024 procesoare).Cu procesor 10 k registre, 195 MHz, cu un vârf de 390 Mflops sau 780 MIPS pe procesor.Banda de trecere la vârf pentru bus-ul SysAD (System Administrator/ Administration) este 780 MB/s, la fel pentru hub-memorie.Banda pentru hub la router si la Xbow este 1,56 GB/s (ambele sunt în afara plǎcii de bazǎ).
181

Placa de nod Origin
R10K
SC SC
SC SC
Tag
R10K
SC SC
SC SC
Tag
ExtendedMain Memory
Main Memory
BC BC BC BC BCBCHub
Pwr/gnd Pwr/gnd Pwr/gndNetwork I/O
Connections to Backplane
and 16-bit Directory
and 16-bit Directory
Directory
Hub-ul este cu 500 k-porti în 0,5 µ CMOS.Are buffere majore pentru tranzactii pe fiecare procesor (4 de fiecare).Are douǎ motoare de transfer în blocuri (de copiat si de completat memoria).Interfete si conexiuni la procesor, memorie, retea si I/O.Furnizeazǎ suport pentru primitive de sincronizare si pentru migrare de pagini (se discutǎ mai departe).Douǎ procesoare în fiecare nod nu snoopy-coherent (din motive de cost).
Reteaua Origin
N
N
N
N
N
N
N
N
N
N
N
N
(b) 4-node (c) 8-node (d) 16-node
(e) 64-node
(d) 32-node
meta-router
Fiecare ruter are sase perechi de legǎturi unidirectionale de 1,56 MB/s, douǎ la noduri, patru la alte routere; latenta în ruter 41 ns pin-la-pin.Cabluri flexibile lungi de pânǎ la 3 ft.
182

Patru “canale virtuale”: cerere, rǎspuns, celelalte douǎ pentru prioritǎti sau I/O.
I/O pentru Origin
Bridge IOC3 SIO
SCSI SCSI
Bridge
LINC CTRL
To Bridge
To Bridge
16
Graphics
Graphics
16
161616
16
16
16
Hub1
Hub2Xbow
Xbow este un crossbar cu 8 porturi, conecteazǎ douǎ hub-uri (noduri) la sase cards.Similar ruterelor dar mai simple astfel cǎ pot sustine 8 porturi.Cu exceptia celor grafice, multe alte dispozitie se conecteazǎ prin bridge si bus; poate rezerva bandǎ de trecere pentru lucruri ca video sau timp-real.Spatiu I/O global: orice procesor poate accesa dispozitivele I/O; prin memorie fǎrǎ cache (non-cached) operatori la spatiul I/O sau DMA coerentǎ; orice dispozitiv I/O poate scrie în sau citi din orice memorie (comunicare prin rutere).
Structura directorului Origin
Plat, bazat pe memorie: toatǎ informatia directorului at the home.Trei formate de director:(1) Dacǎ este exclusiv într-un cache, intrarea este pointer la acel procesor
specific (nu nod).(2) Dacǎ este partajat, bit vector: fiecare bit pointeazǎ la un nod (Hub), nu la un
procesor. Invalidarea trimisǎ la un Hub este difuzatǎ (broadcast) cǎtre ambele procesoare din nod. Douǎ dimensiuni, în functie de scarǎ: formatul pe 16 biti (32 de procesoare) este detinut de mamoria DRAM principalǎ; formatul pe 64 de biti (128 de procesoare), extrabiti detinuti de extensia de memorie.
(3) Pentru masini mai mari, coarse vector: fiecare bit corespunde la p/64 noduri. Invalidarea este trimisǎ tuturor Hub-urilor din acel grup, cu fiecare mesaj de invalidare difuzat (broadcast) la cele douǎ procesoare pe care le posedǎ hub-ul. Masina poate alege între bit vector si coarse vector în mod dinamic. Este aplicatia consacratǎ, asociatǎ unei pǎrti a masinii de cel mult 64 de noduri?
Pentru simplitate, în discutie se ignorǎ alternativa coarse vector.
183

Stǎrile cache si directory pentru Origin
Stǎrile cache-ului: MESI (Modified Exclusive Shared Invalid (states of cache memory)).Sapte stǎri de director:• Fǎrǎ posesor (unowned): nici un cache nu are o copie, copia din memorie
este validǎ.• În indiviziune (partajatǎ) (shared): unul sau mai multe cache-uri are/au o
copie partajatǎ, memoria este validǎ.• Exclusivǎ (exclusive): un cache (la care se pointeazǎ) are blocul în starea
modificatǎ sau exclusivǎ.• Trei stǎri dependente (pending) sau ocupate (busy), una pentru fiecare din
cele de mai sus.o Indicǎ faptul cǎ directorul a primit o cerere precedentǎ pentru
bloc.o Nu o poate satisface ea însǎsi, se trimite la un alt nod si este în
asteptare.o Nu poate încǎ sǎ preia o altǎ cerere pentru bloc.
• Starea otrǎvitǎ (poisoned), utilizatǎ pentru migrarea de paginǎ eficientǎ (se va detalia mai departe).
Sǎ vedem cum sunt manipulate cererile de citire si de scriere. Nu se presupune vreo ordine punct-la-punct în retea.
Manipularea unei ratǎri la citire (read miss)
Hub-ul priveste la adresǎ:Dacǎ este la distantǎ, trimite cererea (request) la Home.Dacǎ este localǎ, exploreazǎ el însusi intrǎrile directorului si memoria.Directorul poate indica una din mai multe stǎri.Shared sau Unowned:Dacǎ este partajatǎ, directorul seteazǎ bitul de prezentǎ.Dacǎ este fǎrǎ proprietar, merge la starea exclusivǎ si utilizeazǎ formatul de pointer.Rǎspunde cu blocul celui care a formulat cererea. Cerere-rǎspuns strict (nu are loc vreo tranzactie în retea dacǎ Home este local).În realitate, se exploreazǎ si memoria la modul speculativ pentru a obtine datele, în paralel cu directorul. Explorarea directorului revine un ciclu mai devreme. Dacǎ directorul este partajat sau fǎrǎ proprietar, este un câstig: datele sunt deja detinute de Hub. Dacǎ nu avem nici una din aceste situatii, accesul speculativ la memorie este o risipǎ.Starea busy: nu este pregǎtit pentru manipulare. NACK (Negative Acknowledgement), asta pentru a nu tine ocupat spatiul de buffer prea mult timp.
184

Read Miss pentru un bloc în starea exclusivǎ
Este cel mai interesant caz. Dacǎ detinǎtorul nu este Home, este necesar a lua datele la Home si cel care a formulat cererea de la proprietar. Se utilizeazǎ rǎspunsul care se înainteazǎ pentru cea mai redusǎ latentǎ si cel mai redus trafic – nu cerere-rǎspuns la modul strict.
L H R
1: req 2:intervention
3b:response
3a:revise
Probleme cu optiunea “intervention forwarding”. Rǎspunsul vine la Home (care rǎspunde apoi celui care a formulat cererea). Un nod poate fi în situatia de a tine evidenta a P*k cereri deosebite (outstanding) ca Home – la înaintarea rǎspunsului numai ultimele k rǎspunsuri merg la petent. Mai complex si cu performante mai reduse.
Actiuni la Home si la Proprietar
La Home:Se seteazǎ directorul la starea busy si NACK (Negative Acknowledgement) pentru cererile urmǎtoare. Filozofia generalǎ a protocolului; nu se poate seta la shared sau la exclusive; alternativa este a bufferiza la Home pânǎ la final, dar este o problemǎ cu buffer de intrare. Setarea si desetarea potrivitǎ a bitilor de prezentǎ. Se presupune cǎ blocul este curat-exclusiv si se trimite rǎspuns speculativ.La Prorpietar:Dacǎ blocul este dirty, se trimite rǎspunsul cu datele la cel care le-a cerut si se face “sharing writeback” cu datele la Home. Dacǎ blocul este clean-exclusive, similar, dar nu se trimit datele (mesajul la Home este denumit “downgrade”).Home schimbǎ starea la shared dacǎ primeste un mesaj de revizuire.
Influenta procesorului asupra protocolului
De ce rǎspunsuri speculative?Solicitantul (requestor) trebuie sǎ astepte pentru rǎspuns de la proprietar în orice modalitate de a afla. Nu se economiseste latentǎ. Ar putea obtine imediat datele de la proprietar totdeauna.Procesorul este proiectat a nu rǎspunde cu date dacǎ este clean-exclusive. Astfel, este necesar a obtine datele de la Home; n-ar avea nevoie de rǎspunsuri speculative cu înaintare (forwarding) de interventie.
185

Abiliteazǎ si altǎ optimizare (a se vedea mai departe). Nu trebuie sǎ retrimitǎ datele la Home când este înlocuit un bloc clean-exclusive.
Manipularea unui Write Miss
Cererea la Home poate fi de upgrade sau read-exclusive.Starea este busy: NACK.Starea este unowned: dacǎ RdEx, se seteazǎ bitul, se schimbǎ starea la dirty, se rǎspunde cu date. Dacǎ este un upgrade, înseamnǎ cǎ blocul a fost înlocuit din cache si directorul deja notificat, astfel cǎ upgrade-ul este o cerere inadecvatǎ – NACK-ed – (va fi reîncercat ca RdEx).Starea este shared sau exclusive:Trebuie trimise invalidǎri. Se utilizezǎ înaintarea (forwarding) rǎspunsului, adicǎ înstiintǎrile (acks) de invalidare se trimit la solicitant, nu la Home.
Scrierea într-un bloc în starea shared
La Home:Se seteazǎ starea directorului la exclusive si se seteazǎ bitul de prezentǎ pentru solicitant – se asigurǎ cǎ solicitǎrile urmǎtoare vor fi înaintate la solicitnat. Dacǎ RdEx, se trimite “rǎspuns exclusiv cu invalidǎrile asociate” la solicitant (contine date) – de la câti partajanţi trebuie sǎ se astepte invalidǎri. Dacǎ upgrade, rǎspuns similar “înstiintare (ack) de upgrade cu invalidǎrile asociate”, fǎrǎ date. Se expediazǎ invalidǎri cǎtre partajanţi, care vor înstiinţa (ack) solicitantul.La soliciant, înainte de “închiderea” operatiei se asteaptǎ sǎ revinǎ toate confirmǎrile (acks). Solicitarea urmǎtoare pentru bloc la Home este înaintatǎ ca interventie la solicitant. Pentru o serializare adecvatǎ, solicitantul nu o manipuleazǎ pânǎ nu primeste toate confirmǎrile pentru solicitarea sa majorǎ (outstanding).
Scrierea într-un bloc în starea exclusive
Dacǎ upgrade, nu este validǎ asa cǎ se aplicǎ NACK-ed. Un alt write l-a “bǎtut” pe acesta la Home asa cǎ datele solicitantului nu sunt valide.Dacǎ RdEx, ca la read, se seteazǎ starea busy, se seteazǎ bitul de pezenţǎ, se trimite rǎspuns speculativ. Se trimite invalidare la proprietar cu identitatea solicitantului.La proprietar: dacǎ blocul este dirty în cache, se trimite la Home un mesaj de revizuire “ownership xfer” (fǎrǎ date), se trimite rǎspuns cu date la solicitant (mai tare fatǎ de rǎspunsul speculativ); dacǎ blocul este în starea clean exclusive, se trimite la Home un mesaj de revizuire “ownership xfer” (fǎrǎ date), se trimite confirmare (ack) la solicitant (fǎrǎ date; se obtin din rǎspuns speculativ).
186

Manipularea solicitǎrilor writeback
Starea directorului nu poste fi partajatǎ sau fǎrǎ proprietar. Solicitantul are blocul dirty, dacǎ o altǎ solicitare ar veni pentru a seta starea la shared, ar fi înaintatǎ la proprietar si starea ar fi busy.Starea este exclusivǎ. Starea directorului se seteazǎ la unowned si se returneazǎ confirmare (ack).Starea este busy: race condition interesantǎ. Busy din cauza interventiei datorate solicitǎrii de la un alt nod (Y) care a fost înaintatǎ nodului X care face writeback-ul – interventia si writeback-ul s-au intersectat reciproc. Operatia lui Y este deja în derulare si si-a produs efectul asupra directorului. Nu se poate renunta la writeback (numai copie validǎ). Nu se poate NACK writeback-ul si sǎ se reia încercarea dupǎ ce referirea lui Y se încheie – cache-ul lui Y va avea o copie validǎ în timp ce o copie dirty diferitǎ este written back.
Solutia pentru writeback race
Se combinǎ cele douǎ operatii.Când writeback-ul ajunge la director, el schimbǎ starea: la shared dacǎ este busy-shared (adicǎ Y a solicitat o copie cititǎ); la exclusive dacǎ este busy-exclusive.Home înainteazǎ datele writeback-ului solicitantului Y. Trimite confirmare de writeback la X.Când X primeste interventia, o ignorǎ. Stie sǎ facǎ asta deoarece el are un writeback major (outstanding) pentru linie.Operatia lui Y se isprǎveste când obtine rǎspunsul.Writeback-ul lui X se încheie când obtine confirmarea de writeback.
Înlocuirea unui bloc partajat
S-ar putea trimite o indicatie (hint) de înlocuire la director, pentru a elimina nodul din lista de partajare.Poate elimina o invalidare data urmǎtoare când blocul este scris.Dar nu reduce traficul. Trebuie sǎ trimitǎ indicatia de înlocuire, produce trafic la un moment diferit.Protocolul Origin nu foloseste indicatii de înlocuire.Tipuri de tranzactii totale:• Memorie coerentǎ: 9 tipuri de tranzactii la solicitare, 6 de
invalidare/interventie, 39 de rǎspuns.• Necoerentǎ (I/O, sincronizare, operatii speciale): 19 solicitare, 14 rǎspuns
(nu invalidare/interventie).
187

Pǎstrarea consistentei secventiale
R100000 este planificat dinamic. Permite operatiilor cu memoria a fi lansate (issue) si excutate în afara ordinei din program. Dar asigurǎ cǎ ele devin vizibile si se încheie în ordine. Nu satiface conditii suficiente dar asigurǎ consistenta secventialǎ (SC).O problemǎ interesantǎ în ceea ce priveste pǎstrarea SC.La o scriere într-un bloc în indiviziune, solicitantul primeste douǎ tipuri de rǎspunsuri: rǎspuns exclusiv de la Home care indicǎ scriere serializatǎ în memorie; confirmǎri de invalidare care indicǎ faptul cǎ scrierea a fost încheiatǎ din punctul de vedere al procesoarelor.Dar microprocesorul asteaptǎ numai un rǎspuns (ca într-un sistem uniprocesor). Asa cǎ rǎspunsurile sunt tratate de Hub-ul solicitantului (interfata procesorului).Pentru a asigura SC, Hub-ul trebuie sǎ astepte pânǎ când sunt primite confirmǎrile de invalidare, înainte de a rǎspunde procesorului; nu poate rǎspunde de îndatǎ ce s-a primit rǎspunsul exclusiv. Va lǎsa ca accesǎrile de la procesor mai târzii sǎ se încheie (scrierile devin vizibile) înainte de acest write.
Tratarea problemelor de corectitudine
Serializarea operatiilor.Blocaje de tipul deadlock.Blocaje de tipul livelock.Starvation (înfometarea).
Serializarea operatiilor
Necesitǎ un agent de serializare. Memoria Home este un candidat de considerat deoarece toate ratǎrile (misses) merg mai întâi acolo.Mecanism posibil: bufferizarea solicitǎrilor pe principiul FIFO la Home. Pânǎ când la solicitarea anterioar înaintatǎ s-a returnat rǎspunsul de la Home. Dar problema bufferului de intrare devine acutǎ la Home.Solutii posibile:Se lasǎ bufferul de intrare sǎ deverseze în memoria principalǎ (MIT Alewife).Nu se bufferizeazǎ la Home, ci se înainteazǎ la nodul proprietar (Stanford DASH). Serializarea este determinatǎ de Home când este clean, de proprietar când este exclusive; dacǎ nu poate fi satisfǎcutǎ la proprietar, de pildǎ written back sau reunutarea la proprietate, NACK-ed înapoi la solicitant fǎrǎ a fi serializatǎ. Se serializeazǎ când se reia încercarea.Nu se bufferizeazǎ la Home, se utilizeazǎ starea busy pentru NACK (Origin). Ordinea de serializare este aceea în care solicitǎrile sunt acceptate (not NACK-ed).Se mentine bufferul FIFO în manierǎ distribuitǎ (SCI, explicat mai târziu).
188

Serializare la o locatie (continuare)
A avea o singurǎ entitate care sǎ determine ordinea nu este suficient. Ea ar putea sǎ nu stie când toate x-actiunile pentru acea operatie s-au executat pretutindeni.1. P1 emite o solicitare read la nodul Home pentru A.2. P2 emite o solicitarea read-exclusive la nodul Home care corespunde unui
write al lui A. Dar n-o proceseazǎ pânǎ nu s-a terminat cu read-ul.3. Home primeste 1 si în replicǎ trimite rǎspuns la P1 (si seteazǎ în director
bitul de prezentǎ). Home crede acum cǎ read este încheiat. Din nefericire, rǎspunsul nu merge la P1 imediat
4. În replicǎ la 2, Home trimite invalidare la P1; ea ajunge la P1 înaintea tranzactiei 3 (nu existǎ o ordine punct-la-punct între solicitǎri si rǎspunsuri).
5. P1 primeste si aplicǎ invalidarea, trimite la Home confirmarea (ack).6. Home trimite rǎspunsul cu date la P2 corespunzǎtor solicitǎrii 2.În final, tranzactia 3 (rǎspunsul la read) ajunge la P1.
Home se ocupǎ cu accesul pentru write înainte ca cel dinainte sǎ fi fost încheiat.P1 n-ar trebui sǎ permitǎ un nou acces la linie pânǎ când vechiul acces nu este desǎvârsit.
Blocaje de tipul deadlock
Douǎ retele nu sunt suficiente când protocolul nu este request-reply. Retele aditionale sunt costisitoare si subutilizate.Se utilizeazǎ douǎ dar care detecteazǎ potentialele blocaje deadlock si le dejoacǎ. De pildǎ. Când bufferele cu solicitarea de intrare si cu solicitarea de iesire se umplu dincolo de un anumit prag si solicitarea din capul cozii de intrare este una care generazǎ mai multe solicitǎri sau când bufferul solicitǎrilor de iesire este plin si nu a avut vreo relaxare pentru T cicluri.Douǎ tehnici majore:Se iau solicitǎrile din coadǎ si se NACK pânǎ când una din cap nu va genera alte solicitǎri sau coada solicitǎrilor de iesire s-a relaxat (DASH).Se revine (fall back) la request-reply strict (Origin) – în loc de NACK se trimite un rǎspuns care spune sǎ se facǎ solicitarea direct la proprietar; mai bine
Home
5 1 3 4
6 2
P1
P2
189

deoarece NACK-urile pot conduce la multe încercǎri repetate si chiar la un blocaj de tipul livelock.Filozofia Origin:Fǎrǎ memorie (memory-less): nodul reactioneazǎ la evenimentele sosite utilizând numai starea localǎ.O operatie nu mentine resurse în indiviziune (partajate) în timp ce solicitǎ altele.
Blocaje de tipul livelock
Problema clasicǎ a douǎ procesoare care încearcǎ sǎ scrie un bloc. Origin rezolvǎ aceastǎ situatie cu starea busy si NACK-uri – primul care ajunge acolo progreseazǎ, celelalte sunt NACK-ed.Problemǎ cu NACK-urile. Utile pentru a rezolva conditiile de race (race conditions) ca mai sus. Nu la fel de bune când sunt utilizate pentru a usura competitia (contention) în situatiile înclinate spre deadlock – pot provoca livelock; de pildǎ NAK-urile de la DASH pot provoca situatii în care toate solicitǎrile sunt reluate imediat, regenerând problema în mod continuu; implementarea DASH evitǎ cazul prin utilizarea unui buffer de intrare suficient de mare.Nu existǎ livelock când de face back-off de request-reply strict.
Starvation (înfometare)
Nici o problemǎ la bufferizarea FIFO, dar sunt probleme mai timpurii, anterioare.Lista FIFO distribuitǎ (a se vedea mai departe SCI).NACK-urile pot produce înfometare (starvation).Solutii posibile:A nu face nimic; starvation n-ar trebui sǎ se întâmple prea des (DASH).Întârzieri aleatoare între reformularea solicitǎrilor.Prioritǎti (Origin).
Protocoale bazate pe cache, plate
Se utilizezǎ studiul de caz Sequent NUMA-Q. Protocolul este SCI (Scalable Coherent Interface) pe noduri, snooping în nod. De asemenea Convex Exemplar, Data General.Outline:Vedere generalǎ asupra sistemului.Coerenta stǎrilor SCI, reprezentare si protocol.Probleme de implementare.Caracteristici de performantǎ cantitative.
190

Vedere generalǎ asupra sistemului NUMA-Q
IQ-Link
PCII/O
PCII/O Memory
P6 P6 P6 P6
QuadQuad
QuadQuad
QuadQuad
I/O device
I/O device
I/O device
Mgm t. and Diag-nostic Controller
Utilizarea de SMP-uri de mare volum (high-volume) ca blocuri constructive.Bus-ul de Quad13 este de 532 MB/s split-translation in-order responses. Facilitǎti limitate pentru rǎspunsuri în afara ordinei pentru accesǎrile off-node.Interconectarea pe multimea nodurilor este un circuit unidirectional de 1 GB/s.Sistemele SCI mai mari sunt construite din mai multe circuite (rings) conectate prin punti.
NUMA-Q IQ-Link Board
13 Quad – un tip de tehnologie multi-core care include douǎ suporturi fizice (dies) dual-core separate. Dual-core înseamnǎ un CPU care include douǎ cores de executie complete pe fiecare procesor fizic instalate împreunǎ într-un pachet CPU. În aceastǎ constructie, cores 1 si 2 partajeazǎ un cache, cum se întâmplǎ si cu cores 3 si 4. Dacǎ cores 1 si 2 trebuie sǎ comunice cu 3 si 4, existǎ o comuicare externǎ, uzual prin frontside bus.
DirectoryController
NetworkInterface
(DataPump)
Orion BusInterface
(SCLIC)
(OBIC)
SCI ring in
SCI ring out
Quad Bus
RemoteCache Tag
RemoteCache Tag
RemoteCache Data
LocalDirectory
LocalDirectory
Network Size Tagsand Directory
Bus Size Tagsand Directory
Interftata la bus-ul quad.Administreazǎ datele decache la distantǎ si bus-ullogic. Controllerul de pseudo-memorie si pseudo-procesor.
Pompa interfatǎ-date,OBIC, controllerul deîntreruperi si etichetele(tags) de director.Administreazǎ protocolulSCI uzând de motoareprogramabile.
191

Joacǎ rolul de Hub Chip în SGI Origin.Poate genera întreruperi între quads.Cache la distantǎ (vizibil pentru SCI) cu dimensiunea blocului de 64 de bytes (32 MB, 4 cǎi). Cache-urile de procesor nu sunt vizibile (coerente snoopy si cu cache-ul la distantǎ – remote).Data Pump (GaAs) implementazǎ transportul SCI, împinge înafarǎ pachetele relevante.
NUMA-Q Interconnect
Un singur ring pentru oferta initialǎ de 8 noduri. Sistemele mai mari sunt ringuri multiple conectate prin LAN-uri.Ring SCI larg de 18 biti condus de Data Pump la 1 GB/s.Protocol de transport strict request-reply. Se mentine o copie a pachetului în bufferul de plecare pânǎ când vine ecoul (ack). Când se preia un pachet din ring, se înlocuieste cu un “ecou pozitiv”. Dacǎ se detecteazǎ un pachet relevant dar nu poate fi preluat, se trimite un “ecou negativ” (NACK). Pompa de date a expeditorului vǎzând returul NACK va relua încercarea automat.
NUMA-Q I/O
FibreChannel
PCI
Quad Bus
FibreChannel
PCI
Quad Bus
SCIRing
FC link
FC Switch
FC/SCSIBridge
FC/SCSIBridge
Masina este intentionatǎ pentru încǎrcǎri comerciale; transferul I/O este foarte important.Dispozitivele I/O adresabile global, ca la Origin. Foarte convenabil pentru misiuni/sarcini comerciale.Fiecare bus PCI este ca lǎrgime pe jumǎtate fatǎ de bus-ul memoriei si are o vitezǎ a ceasului pe jumǎtate.Dispozitivele I/O de pe alte noduri pot fi accesate prin SCI sau prin canal pe fibrǎ. I/O prin read-uri si write-uri pe dispozitive PCI, nu DMA. Canalul pe fibrǎ poate fi si el utilizat pentru a conecta NUMA-Q multiple sau la discul în indiviziune (partajat).
192

Dacǎ I/O prin FC-ul local esueazǎ, OS îl poate ruta prin SCI la alt nod si FC.
Structura directorului SCI
Plat, bazat în cache: lista cu partajarea este distribuitǎ în cache-uri. Noduri head, tail si middle, pointeri downstream (fwd) si upstream (bkwd). Intrǎrile în director si pointerii se depun în S-DRAM în IQ-Link board.Coerentǎ de nivelul 2 în NUMA-Q. Cache la distantǎ si SCLIC de patru procesoare aratǎ ca un nod pentru SCI. Protocolul SCI nu are în vedere câte procesoare si cache-uri sunt în nod. Mentinerea acestora coerente cu cache-urile la distantǎ se face prin OBIC14 si SCLIC15.
Ordine fǎrǎ deadlock?
SCI: serializeazǎ la Home, utilizeazǎ o listǎ de dependente distribuitǎ pe linie. La fel ca lista de partajare: solicitantul se adaugǎ pe sine la coada listei. Buffer nelimitat, prin urmare nu au loc blocaje deadlock. Nodul cu solicitarea satisfǎcutǎ o trece mai departe nodului urmǎtor din listǎ. Overhead spatial scǎzut si corect (fair). Dar latenta este mare – la read, alminteri ar putea rǎspunde tuturor solicitantilor deodatǎ.Schemele cu baza în memorie: utilizeazǎ cozi dedicate în nod pentru a evita solicitǎri blocante care depind una de alta. DASH: înaintare la nod dirty, îl lasǎ sǎ determine el ordinea – el rǎspunde solicitantului direct, trimite un writeback la Home; dar dacǎ linia rescrisǎ (written back) în timpul solicitǎrii înaintate este pe drum?
Scheme cu baza în cache
Protocol mai complex. De pildǎ, eliminarea unei linii din listǎ la înlocuire – trebuie coordonate si trebuie sǎ se obtinǎ excluderea mutualǎ pe pointerii nodurilor adiacente; ele pot fi în starea de a înlocui aceeasi linie a lor la acelasi moment.Latentǎ si overhead mai mari. Fiecare actiune de protocol impune ca mai multe controllere sǎ facǎ ceva. În sistemul bazat pe memorie, citirile (reads) sunt manipulate numai de Home. Trimiterea de invalidǎri serializatǎ de traversarea listei – creste latenta.Dar Standardul IEEE a adoptat schema. Convex Exemplar.
Verificarea
Protocoalele de coerentǎ sunt complicat de proiectat si de implementat. Încǎ mai complicat de verificat.
14 OBIC – Orion Bus Interface Controller15 SCLIC – SCI Line Interface Controller
193

Verificare formalǎ.Generarea de vectori de testare: aleator, specializati pentru cazurile comune si unghiulare, utilizând tehnici de verificare formalǎ.
Scheme de depǎsire (overflow) pentru pointeri limitati (limited pointers)
P0 P1 P2 P3
P4 P5 P6 P7
P8 P9 P10 P11
P12 P13 P14 P15
0
Over½ow bit 2 Pointers
(a) No over½ow
P0 P1 P2 P3
P4 P5 P6 P7
P8 P9 P10 P11
P12 P13 P14 P15
1
Over½ow bit 8-bit coarse vector
(a) Over½ow
Broadcast (DiriB)• Bitul de broadcast pus pe on la overflow.• Solutie rea pentru datele larg partajate citite frecvent.No-broadcast (DiriNB)• La overflow, un nou sharer înlocuieste unul din cele vechi (invalidate).• Solutie rea pentru date mult/larg citite.Coarse vector (DiriCV)• Se schimbǎ reprezentarea la un coarse vector, 1 bit la k noduri.• La un write, se invalideazǎ toate nodurile cǎrora le corespunde un bit.Software (DiriSW)• O trapǎ pentru software, se utilizeazǎ orice numǎr de pointeri (nu se pierde
din precizie). La MIT Alewife, 5 pointeri plus un bit pentru nodul local.• Dar apare un extra cost al procesǎrii intreruperilor prin software. Ovrhead
de procesor si ocupare. Latentǎ: 40 la 425 de cicluri pentru un read la distantǎ la Alewife, 84 de cicluri pentru 5 invalidǎri, 707 pantru 6.
Dynamic pointers (DiriDP)• Se utilizeazǎ pointeri dintr-o listǎ de hardware liber din portiunea de
memorie.• Manipularea este fǎcutǎ prin asistare hardware, nu software.• Exemplu: Stanford FLASH.
194

Câteva date
0
100
200
300
400
500
600
700
800
Loc us R oute C holes k y Barnes -H ut
No
rmali
zed
Inva
lidati
on
s
BN BC V
64 de procesoare, 4 pointeri, normalizati la full-bit-vector. Coarse vector destul de robust.Concluzii generale:Vectorul full bit este simplu si bun pentru scarǎ moderatǎ.Pentru scarǎ mare, mai multe scheme ar fi reusite dar nu existǎ încǎ un câstigǎtor detasat.
Reducerea înǎltimii: directoare rare (sparse)
Reducerea factorului M în produsul P*M.Observatie: numǎrul total de intrǎri ale cache-ului este mult mai mic decât cantitatea de memorie. Cele mai multe din intrǎrile memoriei sunt în repaos (idle) cea mai mare parte a timpului. Cache-ul IMB si 64 de MB pe nod implicǎ 98,5% din intrǎri sunt în repaos.Se organizeazǎ directorul ca un cache. Dar nu este necesar a dubla (backup) depozitul – se trimit invalidǎri tuturor partajantilor când o intrare este înlocuitǎ. O intrare pentru fiecare “linie”; fǎrǎ localism spatial. Patternuri de acces diferite (de la multe procesoare dar filtrate). Se permite utilizarea SRAM, poate fi pe drumul critic, necesitǎ asociativitate înaltǎ si trebuie sǎ fie suficient de largǎ.Se poate face un compromis între lǎrgime si înǎltime.
Coerentǎ cache snoopy ierarhic
Cel mai simplu mod: ierarhie de bus-uri; coerentǎ snoopy la fiecare nivel. Sau ringuri.Considerând bus-urile. Douǎ posibilitǎti:(a) Toatǎ memoria principalǎ pe bus-ul global (B2).
195

(b) Memoria principalǎ distribuitǎ între clustere.
P P
L1 L1
L2B1
P P
L1 L1
L2B1
B2
Main Memory (Mp)
(a)
P P
L2
L1 L1
B1
Memory
P P
L1 L1
B1
L2Memory
B2
(b)
Ierarhii de bus cu memoria centralizatǎ
P P
L1 L1
L2B1
P P
L1 L1
L2B1
B2
Main Memory (Mp)
Bus-urile B1 urmeazǎ protocolul snoopy standard.Necesitǎ un monitor pe bus-ul B1. Decide ce tranzactii sǎ circule înainte si înapoi între bus-uri. Actioneazǎ ca filtru pentru a reduce necesitǎtile de bandǎ de trecere.Se utilizeazǎ cache-ul de nivelul 2. Mai mare decât cache-urile de de nivel 1 (set associative). Trebuie sǎ mentinǎ incluziunea. Are bit dirty-but-stale pe
196

fiecare linie. Cache-ul de nivel 2 poate fi bazat pe DRAM deoarece la el merg putine referiri.
Exemple de referiri
P
L1
L2
Main Memory
B1
B2
P
L1
P
L1
L2
B1
P
L1
ld AA: dirty
A: dirty -stale
A: not-present
A: not-present
st B
B: shared
B:sharedB:shared
B:shared B:shared1 2 3 4
Cum sunt manipulate problemele (a), (b) si (c) între clustere.(a) Informatie suficientǎ despre stare în alte clustere în bitul dirty-but-stale.(b) Pentru a gǎsi alte cópii, broadcast pe bus (ierarhic); ele fac snooping.(c) Comunicare cu cópii executate ca parte a gǎsirii/localizǎrii lor. Problemele
de ordonare si de consistentǎ mai înselǎtoare (trickier) decât cele pe un singur bus.
Avantaje si dezavantaje
Avantaje:Extensie simplǎ a schemei cu baza pe bus.Ratǎrile (misses) pe memoria principalǎ cer o singurǎ traversare la rǎdǎcina ierarhiei.Plasarea datelor în indiviziune (partajate) nu reprezintǎ o problemǎ.Dezavantaje:Ratǎrile pe date locale (de pildǎ pe stivǎ) traverseazǎ tot asa ierarhia – trafic mai intens si latentǎ mai mare.Memoria la bus-ul global trebuie sǎ fie înalt intercalatǎ pentru câstig de bandǎ de trecere.
Ierarhii de bus-uri cu memorie distribuitǎ
P P
L2
L1 L1
B1
Mem ory
P P
L1 L1
B1
L2Mem ory
B2
197

Memoria principalǎ distribuitǎ între clustere.Clusterul este o masinǎ complet echipatǎ bazatǎ pe bus, memorie si celelalte.Scalare automatǎ a memoriei (fiecare cluster aduce ceva memorie cu sine).Plasamentul bun poate reduce traficul global pe bus si latenta – dar latenta la memoria depǎrtatǎ poate fi mai mare decât la rǎdǎcinǎ.
Întretinerea coerentei
Cache-ul de nivelul 2 lucreazǎ bine ca si înainte pentru datele alocate la distantǎ.Ce se poate spune despre datele alocate local care sunt cache-ate la distantǎ – nu intrǎ în cache-ul de nivelul 2.Este necesar un mecanism de monitorizare a tranzactiilor pentru aceste date – pe bus-urile B1 si B2.Urmeazǎ examinarea unui studiu de caz.
Studiu de caz: Gigamax
P
C
P
C
UCC UIC
UIC
Fiber-optic link
UIC
P
C
P
C
UCC UIC
Global Nano Bus
LocalNano Bus
Motorola 88K processors8-way interleavedm em ory
(64-bit data, 32-bit address,split-transaction, 80ns cy cles)
Tag RAM onlyfor rem ote datacached locally
Tag RAM onlyfor local datacached rem otely
Tag and Data RAMSfor rem ote datacached locally
(Bit seria l,4 by tes every 80ns)
(Two 16MB banks4-way associative)
(64-bit data, 32-bit address,split-transaction, 80ns cy cles)
Coerenta de cache la Gigamax
Un write pe bus-ul local este trecut la bus-ul global dacǎ: datele sunt alocate în Mp la distantǎ sau dacǎ sunt alocate local dar sunt prezente si în vreun alt cache la distantǎ.Un read pe bus-ul local este trecut pe bus-ul global dacǎ: este alocat în Mp la distantǎ si nu în cache-ul de cluster sau este alocat local dar este dirty în vreun cache la distantǎ.Un write de pe bus-ul global este trecut pe bus local dacǎ: este cu alocare în Mp localǎ sau este cu alocare la distantǎ dar este dirty în cache-ul local.Multe conditii race posibile (write-back pe plecare în timp ce solicitarea (request) pe sosire).
198

Ierarhii de ring-uri (exemplu KSR)
O retea de ringuri nu de bus-uri.Snoop pe solicitǎrile care circulǎ pe ring.Structura punct-la-punct de ring implicǎ: o bandǎ de trecere potential mai mare decât la bus-uri, o latentǎ mai mare.KSR este o arhitecturǎ cu memoria numai de cache (discutatǎ mai departe).
Ierarhii, un sumar
Avantaje:Simple de construit conceptual (se aplicǎ snooping recursiv).Se pot alǎtura si combina dupǎ solicitǎri în hardware.Dezavantaje:Banda de trecere la bisectie scǎzutǎ: strangulǎri cǎtre rǎdǎcinǎ – solutii patch: mai multe bus-uri/ring-uri la nivelele superioare.Latentele sunt adesea mai mari decât în retelele directe.
199

Toleranţa în latenţǎ
Tematica
Reducerea costului comunicaţieiProcesoare cu multifirFire multiple simultane
Reducerea costului cu comunicarea
Reducerea latenţei efective.Evitarea latenţei.Tolerarea latenţei.Latenţa comunicǎrii, latenţa sincronizǎrii, latenţa instrucţiunii.Comunicarea cu iniţierea expeditorului si cu iniţierea destinatarului.
Exemple
Pipeline pe comunicare
200

P1 trimite, NI bufferizeazǎ, NI trimite, etapǎ de comutare SW, …, etapǎ de comutare SW, NI receptioneazǎ, P2 primeste.Overhead-ul pentru send si timpul între comutatoare (SW) si overhead-ul pentru receive.
Tratarea toleranţei pentru latenţǎ
Transferul de date în blocuri. Combinǎ transferul multiplu în unul singur. La ce ajutǎ aceasta? Precomunicarea. Genereazǎ comunicarea înainte de a fi realmente necesarǎ (pregǎtire asincronǎ).Derulare ulterioarǎ unui eveniment comunicaţional deosebit. Se continuǎ cu lucrul independent în acelasi fir pe durata acelui eveniment deosebit (mai asincron).Multifir – gǎsirea de lucru independent. Comutarea procesorului la alt fir.
Un alt exemplu
Metode:Combinǎ mai multe expedieri în una singurǎ.Trimitere asincronǎ.Primire asincronǎ (furnizarea de buffer timpurie).
Cerinţe fundamentale
Extraparalelism.Lǎrgime de bandǎ.Memorie.Protocoale rafinate, sau instrumente automate, sau suport arhitectural.
201

De ce fire multiple?
Zidul de putere. Tranzistorii sunt gratuiti, dar puterea nu. Mai multe cores mai simple cu rata ceasului mai scǎzutǎ produc performante mai bune pe watt.Zidul ILP. Retur diminuat pe superscalare. Aplicatiile multifir fac performante mai bune pe fiecare cip.Zidul memoriei. Prǎpastia dintre timpul de acces la CPU si la memorie creste exponential. Firele multiple pot ascunde latenţa memoriei mai eficient decât un singur fir OOO.Toate “zidurile” conduc la fire multiple si la multicore.
Dincolo de proiectarea multicore simplǎ
Reducerea latenţei este importantǎ în proiectarea procesoarelor. Latenţele sunt variabile si dependenţele sunt complexe. Au loc conflicte de resurse. L1: 2-4 cicluri; L2: ~10 cicluri; DRAM: ~200 de cicluri ale ceasului.Latenţele în sistemele multiprocesor cu memorie în indiviziune (partajatǎ). Accesul la memorie de la distanţǎ costǎ mult mai mult decât cel local. Tranzacţiile de la distanţǎ în protocolul de coerenţǎ: de 10-100 de ori.Mai mulţi tranzistori disponibili. Core-urile simple pot avea probleme multiple.
Clasificarea multifirelor
Un fir sau intercalare sau granulatie grosierǎ?
202

Un fir: dependenţele limiteazǎ utilizarea hardware-ului.Fluxurile de instrucţiuni intercalate cresc utilizarea harware-ului.
Probleme multiple: un fir, sau IMT (Interleaved MultiThreading), sau BMT (Block MultiThreading)
Procesoare periferice CDC 6600 (Cray, 1965) [CDC 6600 Peripheral Processors (Cray, 1965)]
Prima structurǎ hardware multifir.10 procesoare I/O “virtuale”.Intercalare fixǎ pe pipeline simplu. Pipeline-ul are un ciclu temporal de 100 ns. Fiecare procesor executǎ o instructiune la 10 cicluri. Set de instructiuni bazate pe acumulator pentru a reduce starea procesorului.
203

Pipeline multifir simplu
Selectarea firului face ca pipeline-ul sǎ asigure bitii de stare corecti.Dacǎ nu existǎ fir gata pentru selectie, se insereazǎ unul fals (bubble).(I$ – Instruction cache; D$ – Data cache; IR – Index Register)
Costurile multifirelor
Apar software-ului (inclusiv sistemului de operare) ca procesoare multiple mai lente.Fiecare fir cere starea sa de utilizator proprie. GPR-urile (General Purpose Register), PC-urile (Program Counter).Necesitǎ, de asemenea, propria stare de control prin OS. Registru de bazǎ tabelar pentru paginile de memorie virtualǎ. Registre pentru manipularea exceptiilor.
HEP (Heterogeneous Element Processor)
Burdon Smith (proiectant) la Denelcor (1982).Masinǎ paralel. 16 procesoare. 128 de fire pe fiecare procesor. Registre în indiviziune (partajate).Pipeline de procesor. 8 etape. Fiecare fir pe o etapǎ. Comutare la alt fir, diferit, la fiecare ciclu al ceasului. Dacǎ coada de fire este vidǎ, se planificǎ o
204

instructiune independentǎ din ultimul fir. Nu este necesarǎ vreo precautie asupra dependentei între etape.
Arhitectura HEP în mai multe detalii
Componente de bazǎ:PEM (Processing Element Module) – modul de elemente de procesare.DMM (Data Memory Module) – modul de memorie pentru date.Retea de interconectare multietapǎ.Functionarea:Fiecare PEM are 2k registre. Fiecare PEM are un DMM. Orice PEM poate accesa orice memorie (toate fizice). Orice PEM poate accesa orice registru.Bit indicator plin/gol (F/E). Fiecare cuvânt are un bit F/E. Gol (E) înseamnǎ absenta datelor. Plin (F) înseamnǎ date valide. Citirea unui bit care indicǎ cuvânt de memorie gol produce o functionare rea sau o exceptie. De ce este utilǎ aceasta?
Ascunderea latentei instructiunilor
În fiecare ciclu este lansatǎ în pipeline o instructiune care apartine unui fir diferit.În cel ma rǎu caz, accesul la DRAM, poate dura mai multe cicluri (mai multe fire).Cum se pot echilibra CPU si memoria?
205

Horizon (proiect pe hâtie din 1988)
Componente principale:Pânǎ la 256 de procesoare.Pânǎ la 512 module de memorie.Retea internǎ 16x16x6.
Procesor:Pânǎ la 128 de fire active pe procesor.128 seturi de registre.Comutare contextualǎ pe fiecare ciclu de ceas.Permite accesǎri multiple deosebite ale memoriei pe fir.
Tera/Cray MTA (dupǎ 1990)
Arhitectura sistemului MTX (evoluat din MTA )
206

Procesorul MTA/MTX (de la Cray)
Sistemul MTA/MTX (de la Cray)
Procesorul MTA/MTX
Fiecare procesor suportǎ 128 de fire active.Registre cuvânt de stare 1x128.Registre ramurǎ-tintǎ 8x128.Registre GP 32x128.
Fiecare instructiune de 64 de biti face trei operatii.Cu memoria (M), aritmetice (A), aritmetice sau ramificare (C).3 câmpuri de explorare (lookahead) care indicǎ numǎrul de instructiuni independente urmǎtoare.
21 de etape pipeline.Fiecare etapǎ face comutare contextualǎ.
8 solicitǎri deosebite la memorie pe fiecare fir.
207

Pipeline în MTA
În fiecare ciclu, este generatǎ (issued) o instructiune a unui fir activ.Operatia cu memoria implicǎ cca. 150 de cicluri.Admitând cǎ un fir genereazǎ 1 instructiune la 21 de cicluri, si ceasul are o frecventǎ de 220 MHz;Care este performanta?
Comparatii MTA-2/MTX (Cray)
Câte fire poate suporta cel mai mare MTX?
208

Red Storm Compute Board (from Cray)
MTX Compute Board (Cray)
CANAL
Analiza compilatorului.Instrument static.
209
Aratǎ cum este compilat codul si de ce.
Traceview
210

Dashboard
Multiplicarea matrice rarǎ – vector
C = A*B (dimensiuni nx1, nxm, mx1).Se memoreazǎ A în forma pachete-de-linii.A[nz], cu nz numǎrul de valori nenule, cols[nz] memoreazǎ indicele coloanei cu o valoare nenulǎ, rows[n] memoreazǎ indicele de început al fiecǎrei linii din A.
#pragma mta use 100 streams#pragma mta assert no dependencefor (i = 0; i < n; i++) {int j;double sum = 0.0;for (j = rows[i]; j < rows[i+1]; j++)sum += A[j] * B[cols[j]];C[i] = sum;}
Raportul canalului
| #pragma mta use 100 streams| #pragma mta assert no dependence| for (i = 0; i < n; i++) {| int j;3 P | double sum = 0.0;
211

4 P- | for (j = rows[i]; j < rows[i+1]; j++)| sum += A[j] * B[cols[j]];3 P | C[i] = sum;| }Parallel region 2 in SpMVMMultiple processor implementationRequesting at least 100 streamsLoop 3 in SpMVM at line 33 in region 2In parallel phase 1Dynamically scheduledLoop 4 in SpMVM at line 34 in loop 3Loop summary: 3 memory operations, 2 floating point operations3 instructions, needs 30 streams for full utilization,pipelined
Performante
N = M = 1.000.000.Valori nenule pânǎ la 1000 pe linie, distributie uniformǎ; nz = 499.902.410
timpul = (3 cicluri * 499902410 iteratii)/220000000 cicluri/s = 6,82 s.utilizare 96%
MTX Sweet Spot (dupǎ cum pretinde Cray)
Orice aplicatie paralel nepotrivitǎ cache-ului.Orice aplicatie a cǎrei performantǎ depinde de:
Tabele cu acces aleator (GUPS, tabele hash);Structuri de date relationale (arbori binari, grafuri relationale);Metode pentru masive rare (sparse), înalt destructurate;Sortare.
Câteva domenii de aplicare candidate:Site (meshes) adaptive;Probleme legate de grafuri (inteligentǎ, plierea de proteine, bioinformaticǎ);Probleme de optimizare (branch-and-bound, programare liniarǎ);
212

Geometrie pe calculator (graficǎ, recunoasterea de scene si urmǎrirea de scene).
Alewife Prototype (MIT, 1994)
Procesorul Sparcle (granulare grosierǎ)
Pârghii Sparc.Foloseste fiecare fereastrǎ registru ca ramǎ (frame).Firele încǎrcate sunt limitate de frames.Fiecare cuvânt de memorie are un bit plin/gol. J-structure: ridicǎ exceptie; L-structure: blocare/nonblocare.Comutare numai la latentǎ îndelungatǎ. Coerentǎ, acceseazǎ date vide.
213

Realizarea simultanǎ de multifire
Ideea principalǎ: partajarea flexibilǎ si dinamicǎ a unitǎtilor functionale de cǎtre fire.Observatia principalǎ: cresterea utilizǎrii implicǎ cresterea capacitǎtii de prelucrare (throughput).Schimbǎ pipeline-ul OOO. Multiple motoare de context si de regǎsire (fetch). Resursele pot satisface fire multiple sau superscalare.
Superscalar OOO sau SMT pipeline
Procesoare SMT (Simultaneous Multi-Threading)
Alpha EV8 (anulat). Superscalar de lǎrgime 8 cu suport SMT de 4 cǎi. Modulul SMT este ca 4 CPU cu cache-uri partajate si TLB-uri. PC-uri si registre replicate. Cozi de instructiuni partajate, cache-uri, TLB (Thread Local Buffer), predictori de ramificatie.Pentium4 HT (douǎ fire). CPU-urile logice partajeazǎ cache-urile, FU-uri (Functional Unit), predictori. Context separat, registre etc. Nici un suport de sincronizare (cum este bitul full/empty). Accesarea aceleiasi linii de cache declanseazǎ un eveniment costisitor.IBM Power5.Sun Niagara I si Niagara II (lectia lui Kunle)
214

SMT fatǎ-n fatǎ cu CMP multi-issue (Chip Multi-Processor)
Provocǎri la utilizarea mai bunǎ a SMT
Resurse partajate. Unitǎti de executie partajate (Niagara II are douǎ). Cache partajat.Coordonarea firelor. Resurse de consum rotitoare (spinning consume resources).Falsa partajare a liniilor de cache. Pot declansa evenimente costisitoare. Pentium4 HT o numeste eveniment Memory Order Machine Clear sau MOMC.
Suport arhitectural SMT
Care fir este de planificat? Firul cu minimum “ICOUNT” care contorizeazǎ numǎrul de instructiuni în pipeline-ul unui fir.Ce se întâmplǎ dacǎ un fir se rǎsuceste (is spinning)? Se utilizeazǎ o instructiune care “pasivizeazǎ (“quiescing”)” pantru a permite unui fir sǎ “doarmǎ” pânǎ când memoria îsi schimbǎ starea.
Loop:ARM r1, 0(r2) //load and watch 0(r2)BEQ r1, got_itQUIESCE //not schedule until 0(r2)changesBR loopgot_it:
Programarea SMT-Aware
Se divide intrarea si se foloseste un fir separat pentru procesarea fiecǎrei pǎrti. Exemplu, un fir pentru tuplele pare, unul pentru tuplele impare. Pas de partitionare explicit nenecesar.
215

Evitarea falsei partajǎri. Se partitioneazǎ iesirea si se utilizeazǎ locuri separate. Se pune laolaltǎ rezultatul final.Se utilizeazǎ mai bine cache-ul partajat. Se planificǎ firele pentru localismul de cache.Se utilizeazǎ un fir helper. Se preîncarcǎ datele în cache. Nu poate fi prea rapid sau lent (în special pe Pentium4 HT).
Performanta operatorului paralel (din Zhou, Cieslewicz, Ross, Shah, 2005)
Performanta operatorului paralel (din Zhou, Cieslewicz, Ross, Shah, 2005)
Sumar
216

Reducerea costului cu comunicarea. Reducerea overhead-ului. Suprapunerea calculului cu comunicarea.Lucrul multifir. Cresterea utilizǎrii hardware cu fire multiple. Cheia este a crea multe fire (exemplu: MTX suportǎ 1M fire).Fire multiple simultane (SMT – Simultaneous Multiple Threading). Se combinǎ multifirele cu superscalarele. Se combinǎ cu cores multiple. Mai trebuie lucrat pentru a utiliza bine SMT-urile.
217

Excluderea mutualǎ: ceva istorie, unele probleme si o urmǎ de sperantǎ
Andrew Birell si Michael Isard, Microsoft Research, Silicon Valley
Outline
Scopul: a crea programe concurente care sunt corecte, au performante bune, rǎmân la asemenea calitǎti cel putin câtiva ani.Discutia prezentǎ: ce este concurenta? Cum se ajunge la asa ceva? Ce-i rǎu în asta? Ce se poate face în loc?
Nu sunt incluse: crearea de concurentǎ, demonstratii, concurentǎ fǎrǎ memorie partajatǎ (de pildǎ, limbaje functionale, unele proiecte hardware).
Ce este concurenta?
Program care face mai multe lucruri deodatǎ.Douǎ cazuri:(A) Unul fals: asteptarea pentru a citi un fisier, se poate face între timp altceva.(B) Unul real: procesoare multiple care folosesc în indiviziune (partajeazǎ) resurse.Notǎ: un disc DMA este efectiv un procesor.Cazul (A) este mult mai usor: fǎrǎ intercalǎri arbitrare. Evenimente secventiale, sau fire non-preemptive. Discutia de fatǎ este, asadar, în cea mai mare parte dedicatǎ cazului (B), dar nu în întregime.
Dijkstra (versiunea din anii ‘60)
Abstractie: memorie partajatǎ de procesoare multiple. Se considerǎ aici numai cazul (B).Utilizarea instructiunilor read/write atomice (CACM 1965).Utilizarea ParBegin/Semaphore/P/V (CACM 1968).Foarte potine rezultate demonstrabile dar nici o abstractie de nivel mai înalt.Solicitǎ un doctorat de la o universitate bunǎ.
218

Hansen si Hoare (versiunea 1974)
Abstractie: procese secventiale si monitoare – (“variabile de conditie” pentru blocare în proces).Monitorul leagǎ excluderea mutualǎ de date. Grupe de programatori partajeazǎ datele în monitoare. Sistemul garanteazǎ excluderea mutualǎ pe fiecare monitor.Programatorul trebuie sǎ spunǎ ce trebuie protejat.Programatorul trebuie sǎ mentinǎ invarianti de monitor.Programatorul trebuie sǎ aseze programul în manierǎ ierarhicǎ.Se solicitǎ un doctorat (dar nu unul asa de bun).
Hoare (versiunea 1978)
Abstractie: transfer de mesaje pe masini de stare secventiale (procese de comunicare secventialǎ).Digresiune: dualitate (Lauer si Needham, 1979). Asociere (mapping) între programe de tip CSP (Communicating Sequential Processes) si de tipul Monitor.Lucreazǎ bine cu masini secventiale (dacǎ DAG – Data Analysis Group sau Data Authentication Group).Nu ajutǎ când se utilizeazǎ memorie partajatǎ.
Modula-2+ (1984)
Fire si lacǎte (mutex): nu monitoare.Abandonarea legǎturii între mutex si datele ei. Nici un fel de excludere mutualǎ fortatǎ.Retinerea problemei monitoarelor lui Hoare.SRC a scris un milion de linii de program concurent. A lucrat în mare parte. Noi aproape toti aveam doctorate.
Rememorare din anii 19xx
Solutia SRC (DEC Systems Research Center) era larg adoptatǎ.- OSF DCE (open software foundation distributed computing environment).- Posix.- Windows (într-o oarecare mǎsurǎ).- Java.- C.Este usor: a fi descris; a fi utilizat; a gresi.“Introduction to Programming with Threads”Cu precǎdere pe uniprocesoare; programele în majoritate lucreazǎ.
219

Reluare: clasicul fir/mutex/CV
VAR t = Fork(method, args)“method(args)” se executǎ într-un fir nou asincron.LOCK m {……}– TRY Acquire(m); …… FINALLY Release(m);UNTIL b DO Wait(m, cv);– UNTIL b DOTRY Atomically {Release(m); P(cv);}FINALLY Acquire(m);
Variantǎ: programe bazate pe evenimente
Sistemul invocǎ o metodǎ pentru “evenimentele” care sosesc.Evenimentele se executǎ pânǎ la finalul lor.“wait” este înlocuit de crearea evenimentului. De pildǎ: se initiazǎ o citire de fisier, apoi are loc iesirea din eveniment; mai târziu, evenimentul de fisier isprǎvit este manipulat (handled).În timpul asteptǎrii, masina de stare event-handler înlocuieste starea detinutǎ în stivele de fir.Dacǎ este concurent, este încǎ necesarǎ excluderea mutualǎ. Problemele sunt identice pentru clasicul fir/mutex/CV (Cross Validation).
Variantǎ: NT’s “Completion Port” (1996)
Sistemul mentine un pool de fire pregǎtite.Când un eveniment soseste, îl dirijeazǎ cǎtre un fir – supus conditiei de a nu depǎsi nivelul de concurentǎ dorit.Dacǎ firul se blocheazǎ, se distribuie un alt eveniment – se memtine nivelul de concurentǎ în timp real.Implementare de nivel jos, legat de planificator (scheduler).Mecanismul primar pentru programarea bazatǎ pe evenimente în Windows.Lasǎ problemele excluderii mutuale neatinse.
Si ce este rǎu?
Selectia manualǎ a excluderii mutuale. Default-ul este prea putin (si de aici races); easy fix este prea mult (stǎri deadlock sau blank).Proiectele nu creazǎ abstractii ierarhice. Nu poate decide si/sau mentine oridini de încuiere (locking) aciclice.“Compunerea” cere abstractii complet noi.Optimizǎrile “clever” nu sunt de mentinut si sunt adesea rele.“Stack-ripping” în programele bazate pe evenimente.
220

Problemele cu ordinea încuierii (locking)
Clasa “A”:FUNCTION f1() {LOCK a { … b.f4(); }FUNCTION f2() {LOCK a { … }; }
Clasa “B”FUNCTION f3() {LOCK b { … a.f2(); }FUNCTION f4() {LOCK b { … }; }
Abstractii si graful apelurilor.
Produse de dependentele ciclice.Abstractiile trebuie sǎ formeze un DAG (Directed Acyclic Graph). În general dificil. Dificil si de întretinut.
Probleme de compunere cu monitoare
Se considerǎ o clasǎ de tabel hash cu operatiile:h.insert(k,v);v = h.read(k);h.delete(k);
Se considerǎ un client care stratificǎ o operatie “move”:h.move(k, g) = {VAR v = h.read(k); g.insert(k,v); h.delete(k); }
Cum face clientul acest “move” atomic?
O solutie inteligentǎ: Double-Check Locking
Paradigma “initializeazǎ-la-prima-utilizare”VAR v = NULL;FUNCTION ensureInitialized() {IF (v == NULL) THEN {LOCK m {IF (v == NULL) THEN v = NEW Obj();};};}
221

Stack-Ripping
În versiunea 1.0 a bibliotecii:“h.read(k)” acceseazǎ structura de date in-memory. Codul eveniment non-blocking poate apela “h.read(k)” în sigurantǎ.În versiunea 2.0 a bibliotecii:“h” a devenit mare, utilizezǎ acum un arbore binar (B-Tree) pe disc. Patternul de apelare este acum “h.startRead(k)”, urmat mai târziu de un eveniment de finalizare (completion event) care livreazǎ valoarea. Se propagǎ la toti apelantii, si la apelantii lor, …În cel mai bun caz disruptiv; adesea o defectiune (bug) de performantǎ.
Tranzactii pentru Rescue?
Se marcheazǎ regiuni ale programului ca “atomice”.Sistemul promite:Tranzactii concurente executate ca si când ar fi secventiale. Tranzactiile sunt realmente executate în paralel dacǎ este posibil.Se aplicǎ la fel de bine si la memorie ca si la o bazǎ de date.Implementǎri software azi, hardware mâine (or so).Simplitate ademenitoare.Experientǎ extrem de limitatǎ cu aceastǎ utilizare.
Excluderea mutualǎ cu blocuri atomice
Firul A: ATOMIC {total = total – debit}Firul B: ATOMIC {total = total + debit}Se eliminǎ problemele legate de ordinea încuierii (locking) în sens larg.Compunerea/extinderea sunt facile.Programatorul decide încǎ relativ la a proteja anumite lucruri; codul cel mai simplu aduce încǎ protectia cea mai redusǎ.Iscusinta nu este încǎ explicitǎ si de aceea de nementinut (not maintainable).Nu ajutǎ stack-ripping în codurile bazate pe evenimente.
Distractie (fun): amestecul de cod ATOMIC cu cod neatomic
• Global: VAR x = 0; VAR shared = TRUE;• Thread A:
ATOMIC { x = 0; shared = FALSE };VAR temp = x;
• Thread B:ATOMIC { if (shared) { … ; x = 17; …… } }
222

În loc: programare în cea mai mare parte secventialǎ
Default pentru programele sincronizate corect, sistemul asigurǎ excluderea mutualǎ.Lasǎ sistemul sǎ facǎ optimizarea (în cea mai mare parte).Face optimizǎrile programatorului explicite si, se sperǎ, prin aceasta mentenabile.Câteva exemple: executarea interogǎrilor SQL, JavaScript parte din AJAX, Map/Reduce sau DRYad, AME (Automatic Mutual Exclusion).
Client-side JavaScript (în AJAX)
Programe pure bazate pe evenimente.Acces la latura de server prin XMLHttp: se initiazǎ solicitarea asincron, rǎspunsul soseste cândva mai târziu ca un eveniment.Interactiunile utilizatorului prin evenimente “onclick” (etc.).Ecranul obtine updatǎri numai între evenimente, adicǎ update-urile UI aratǎ atomic.Facil, lucreazǎ bine, dar are aplicabilitate foarte limitatǎ.
Dryad
Programatorul furnizeazǎ: programe de vârf (vertex) secventiale (de pildǎ în C++), graful fluxului de date care le instantiazǎ si le conecteazǎ.Sistemul furnizeazǎ: repartizarea vârfurilor pe procesoare (localǎ sau distribuitǎ), comunicare si sincronizare, tolerantǎ la defecte.Lucreazǎ frumos, pentru categoria de programe care se potriveste acestui pattern.Scaleazǎ extrem de bine.
AME (Automatic Mutual Exclusion)
Totul este în tranzactii (aproape totul).Executia = un set de “apeluri la metode asincrone”. “main” este apelul la metoda asincronǎ initialǎ. Programul creazǎ mai multe prin sintagma “ASYNC x.m(args)”. Apelurile ramificate se executǎ dacǎ si numai dacǎ tranzactia se angajeazǎ efectiv.Sistemul garanteazǎ cǎ executia este o serializare a apelurilor asincrone, apelurile asincrone se executǎ în paralel dacǎ este posibil.
223

AME: BlockUntil
Într-o metodǎ asincronǎ se poate spune “BlockUntil(b)”.O tranzactie se angajeazǎ numai dacǎ toate apelurile ei “BlockUntil” executate au argumentul TRUE.Altminteri, tranzactia este avortatǎ si se reia mai târziu.Sistemul este rǎspunzǎtor de planificarea înteleaptǎ a tranzactiei (expresia “b” este o bunǎ indicatie).
Exemplu în AME: citirea concurentǎ a unui fisier
• void OpenRead(FileName name) {• File f = AsyncOpenFile(name);• async StartRead(f);• }••void StartRead(File f) {• BlockUntil(f.Opened);• g_nextOffset = 0;• g_nextOffsetToEnqueue = 0;• for (int i = 0; i < 4; ++i) {• ReadBlock block = new ReadBlock;• block.offset = g_nextOffset;• block.file = f;• g_nextOffset += block.size;• f.StartAsyncRead(block);• async WaitForBlock(block);• }• }
224

• void WaitForBlock(ReadBlock block) {• BlockUntil(block.ready &&• g_nextOffsetToEnqueue ==• block.offset);• if (block.EOF) {• g_endOfFile = true;• } else {• g_queuedBlocks.PushBack(block);• block.offset = g_nextOffset;• g_nextOffset += block.size;• block.file.StartAsyncRead(block);• async WaitForBlock(block);• }• g_nextOffsetToEnqueue +=• block.size;• }
AME: Yield
Un mecanism prin care se permit angajǎri (commits) intermediate: într-o metodǎ asincronǎ se poate spune “Yield()”, angajeazǎ aceastǎ tranzactie si initiazǎ una nouǎ.Programul este acum un set de “fragmente atomice” si ele sunt cele care se serializeazǎ.Un mecanism general de a permite ca alte tranzactii sǎ progreseze. “Yield(); BlockUntil(b)” este ca “Wait(…)” în varianta cu monito(riz)are, dar totodatǎ rezolvǎ problema stack-ripping.
Douǎ exemple (separate) care folosesc “Yield”
• void RunZombie() yields {• Zombie z;• z.Initialize();• do {• Yield();• Time now = GetTimeNow();• BlockUntil(now - z.lastUpdate >• z.updateInterval);• z.lastUpdate = now;• MoveAround(z);• if (Distance(z, g_player) <• DeathRadius) {• KillPlayer();• }• } while (Distance(z, g_player) >=• DeathRadius);• }
225

• void DoQueue(Queue inQ,• Queue outQ) yields {• do {• Yield();• BlockUntil(inQ.Length() > 0 ||• g_finished);• while (inQ.Length() > 0) {• Item i = inQ.PopFront();• async DoItem(i, outQ);• }• } while (!g_finished);• }••void DoItem(Item i,• Queue outQ) yields {• DoSlowProcessing(i);• Yield();• outQ.PushBack(i);• }
AME: Unprotected
O metodǎ asincronǎ poate spune “UNRPOTECTED{…}”. Angajeazǎ tranzactia curentǎ, apoi executǎ codul non-tranzactional, apoi initiazǎ o nouǎ tranzactie.Utilizare pentru cod cu efecte laterale (de pildǎ I/O) sau pentru apelarea codului mostenire (legacy).Starea tranzactionatǎ trebuie sǎ fie triatǎ in/out.Defaultul mai bun: codul periculos este etichetat/marcat.
Sumar
Mecanismele de excludere mutualǎ existente sunt prea greu de utilizat.Tranzactiile sunt probabil de ajutor.Blocurile atomice nu ajutǎ suficient.AME: poate produce efecte corecte cu ceva asistentǎ din partea programatorului; este la un nivel destul de înalt pentru a permite multǎ optimizare.
Bibliografie
Articole istorice: http://birrell.org/andrew/concurrency/Dryad: http://research.microsoft.com/research/sv/dryad/Automatic Mutual Exclusion: http://research.microsoft.com/research/sv/ame/
226


















