Embed Size (px)
Citation preview

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Supercomputing solution of large electromagnetic problems with parallel MLFMA-FFT
J.M. Taboada, M. G. Araújo, L. Landesa and F. Obelleiro
University of Extremadura, Cáceres, SpainUniversity of Vigo, Vigo, Spain
2011 International Workshop on Electromagnetic Theory, Modeling, and Simulation. UESTC Chengdu (China)
2012 ACES Conference – Columbus (OH)

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
HEMCUVE Research team
Univ. of Extremadura
José M. TaboadaLuis LandesaJavier Rivero
Univ. of Vigo
Fernando ObelleiroJosé L. RodríguezMarta G. AraújoDiego M. Solís

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Outline
Parallel FMM and MLFMAParallel FMM-FFTParallel MLFMA-FFTNumerical resultsImplementation keypoints

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Method of Moments
Method of Moments.RCS of an Airbus A-380 at 1.2 GHz
Memory > 25 PBCPU time
Setup: several decadesSolution with factorization: several thousands of yearsSolution with iterative solver: several decades
Setup and solution in a few hours using 128 parallel processors.
Fast Multipole Methods and parallel computers

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Fast Multipole Method (FMM)
O(N1.5)O(N2)
O(N1.5)
Computational cost
O(N1.5)

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Multilevel Fast Multipole Algorithm(MLFMA)
Computational cost
O(N log N)
J. M. Song, C. C. Lu, and W. C. Chew, “Multilevel fast multipole algorithm for electromagnetic scattering by large complex objects,” IEEE Transactions on Antennas and Propagation 45, pp. 1488-1493 (1997).

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Parallelization of codes for mixed-memory HPC supercomputers
Finis Terrae (CESGA)142 cc-NUMA Integrity rx7640 nodes16 processor cores and 128 GB each.INFINIBAND at 20Gbps
LUSITANIA (CénitS)2 Superdome Integrity nodes128 processor cores and 1,024GB each.

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Importance of scalability
Scalability is the ability of a code to take benefit from the use of large parallel computers and supercomputers.
Important issues to get a high-scalability code
Workload balancing among parallel processors Data localityMemory footprintInter-node communication
Besides a proper parallelization strategy, the natural scaling properties of the selected algorithm are of great importance.

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Pros and cons of parallel FMM and MLFMA
FMM
High scalability (parallelization in k-space)High computational cost O(N1.5)

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Pros and cons of parallel FMM and MLFMA
MLFMA
Lowest achievable computational cost O(N logN)Difficult to obtain high scalability
MLFMA
Lowest achievable computational cost O(N logN)Difficult to obtain high scalability

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
FMM-FFT
', ', ' ', ', '', ', '
ˆ ˆ( ) ( )i i j j k k i j ki j k
T k k− − −∑ F
Computational cost
O(N4/3 log N)2
2ˆ ˆ ˆ ˆ( ) ( ) ( )m n m
ij j ij j im mn nSj n B j G n B
Z I Z I k T k k d k∈ ∈ ∉
= +∑ ∑ ∑ ∑∫ R F
0,0,0 1,0,0 2,0,0 3,0,0
0,0,1 1,0,1 2,0,1 3,0,1
0,0,2 1,0,2 2,0,2 3,0,2
0,0,3 1,0,3 2,0,3 3,0,3
FMM-FFT
The translation stage in the FMM can be seen as a 3D circular convolution. The acceleration is obtained in terms of the FFT, preserving the natural parallel scaling propensity of the FMM
R. Wagner, J. Song, and W. C. Chew, “Montecarlo simulation of electromagnetic scattering from two-dimensional random rough surfaces,” IEEE Trans. Antennas Propag., 45, no. 2, pp. 235-245, Feb. 1997.
C. Waltz, K. Sertel, M. A. Carr, B.C. Usner, and J.L.Volakis, “Massively parallel fast multipole method solutions of large electromagnetic scattering problems,” IEEE Trans. Antennas Propag., vol. 55, no. 6, pp. 1810-1816, Jun. 2007.

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
FMM-FFT
3
3 3
3 3 3
3 3
3
( 1; ;k++)ˆ( ) inflate[ ( ,:)]ˆ ˆ( ) FFT[ ( )]ˆ ˆ ˆ( ) ( ) ( )ˆ ˆ( ) IFFT[ ( )]
ˆ( ,:) deflate[ ( )]
D k
D k D k
D k D k D k
D k D k
D k
k k K
k k
k k
k k T k
k k
k k
for
F F
F F
G F
G G
G Gend
K k-
spac
efie
ld s
ampl
es
M non-empty groups
FFTIFFT
F
( ,:)kF
3ˆ( )
D kkF 3
ˆ( )D k
T k
( ,:)kGG
inflate
deflate
K k-
spac
efie
ld s
ampl
es
M non-empty groups
Q groupsQ groups3D-FFT convolution
Embarrassingly parallel
Computational cost
O(N4/3 log N)

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Parallel FMM-FFT. High scalability behavior
Currents on a PEC sphere with 10,024,752 unknowns.Solved using from 1 to 1,024 parallel processes (Finis Terraesupercomputer).High scalability behavior.
J. M. Taboada, L. Landesa, F. Obelleiro, J. L. Rodriguez, J. M. Bertolo, M. G. Araujo, J. C. Mouriño, and A. Gomez, “High scalability FMM-FFT electromagnetic solver for supercomputer systems”, IEEE Antennas and Propagation Magazine, vol. 51, no. 6, pp. 20-28, Dec. 2009
Internaional Awards

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
150 million unknowns

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
High memory consumption…
Trade-off for the size of octree groups in very large problems
Small groups imply large 3D FFT matricesLarge groups imply large near-coupling matricesMemory consumption about four times higher than with MLFMA
2
2ˆ ˆ ˆ ˆ( ) ( ) ( )m n m
ij j ij j im mn nSj n B j G n B
Z I Z I k T k k d k∈ ∈ ∉
= +∑ ∑ ∑ ∑∫ R F

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
MLFMA-FFT
Parallel MLFMA-FFT for mixed-memory HPC computers
Multilevel octree decomposition of the geometryFar interactions: distributed FMM-FFT at the coarsest levelNear interactions: local shared-memory MLFMA at finer levels
J. M. Taboada, M. Araújo, J. M. Bértolo, L. Landesa, F. Obelleiro, J. L. Rodríguez, “MLFMA-FFT parallel algorithm for the solution of large-scale problems in electromagnetics (Invited Paper)”, Progr. in Electromagnetics Research (PIER), 105, pp. 15-30, 2010
J. M. Taboada, M. G. Araújo, F. Obelleiro, J. L. Rodríguez, L. Landesa, “MLFMA-FFT parallel algorithm for the solution of extremely large problems in electromagnetics”, to appear in Proceedings of the IEEE, 2012.
Computational costTending to O(N log N) for mixed-memory
Local shared-memory MLFMA
Distributed FMM-FFT

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
MPI/OpenMP parallel programming
MLFMA-FFT is optimum for mixed-memory configurations
The high scalability of the FMM-FFT for distributed computations is combined with the high efficiency of MLFMA for shared-memory computations
OpenMP OpenMP OpenMP
MPI
Group-drivendistribution
Field-drivendistribution

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
MPI/OpenMP parallel programming
MLFMA-FFT is optimum for mixed-memory configurations
The high scalability of the FMM-FFT for distributed computations is combined with the high efficiency of MLFMA for shared-memory computations
OpenMP OpenMP OpenMP
Group-drivendistribution
Field-drivendistribution
We need communications
inside MVP
MPI

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
MLFMA-FFT communications
MVP
MLFMA: aggregation, interp., near-field transl.Forward communicationFMM-FFT: 3D-FFT far-field translationBackward communicationMLFMA: anterpolation, disaggregation
The concentration of communications greatly reduces the degradation due to the network latency idle times.
Communication of noncontiguous data layout, because of the distributed transposition.
Nonuniform communication volumes, because the size of the actual transferred data to each node differs.

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Pros & Cons
MLFMA-FFT communications
We have addressed these communications by means of the asymmetric collective communication operation MPI::Alltoallw.By properly defining the arrays with the separate send and receive MPI derived datatypes for every node, the complete all-to-all, noncontiguous, nonuniform communications can be completed at once using a single call.
Pros: the complete management of the communications is left to the MPI library.Cons: the performance of this communication becomes very dependent on the MPI implementation, which may affect the portability.We are using HP-MPI version 2.3.1

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
620 million unknowns

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
1 billion unknowns
1,042,977,546 unknowns
NASA Almond at 3 THzICTS HPC resource petition64 nodes of FinisTerraesupercomputer (1024 parallel processors)5 TB of total memory8 iterations GMRES(80)35 hours of executionResidue: 0.023
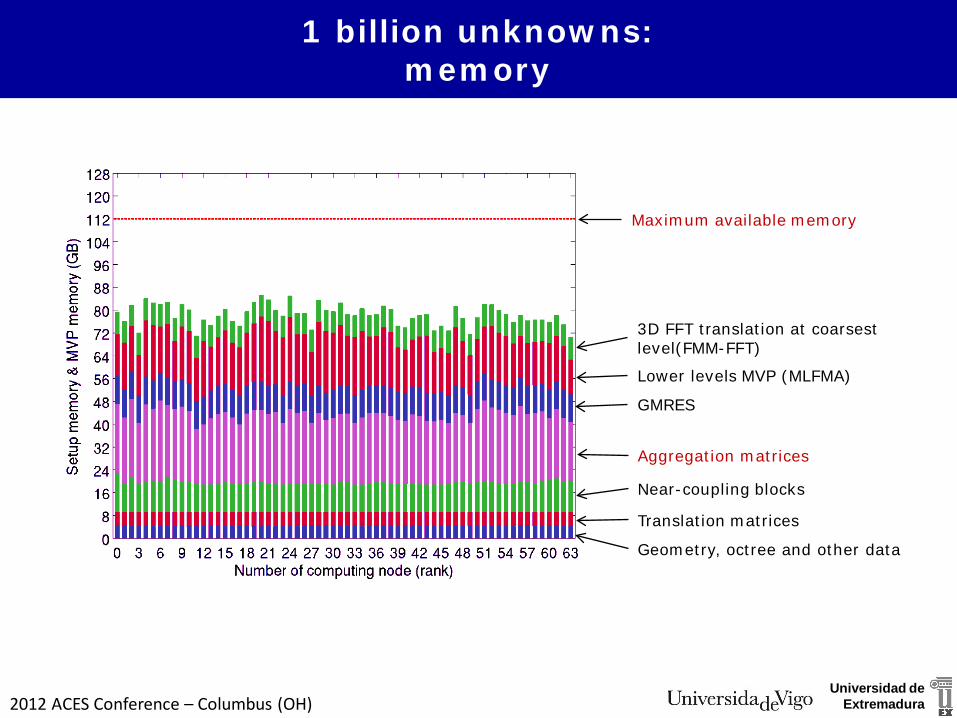
2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
1 billion unknowns: memory
Geometry, octree and other data
Translation matrices
Near-coupling blocks
Aggregation matrices
GMRES
Lower levels MVP (MLFMA)
3D FFT translation at coarsest level(FMM-FFT)
Maximum available memory

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
1 billion unknowns: wall-clock time
Translation matrices
Near-coupling blocks
Aggregation matrices
Alltoallv communication
MVP computation and inner com.
Parallel GMRES computation
Geometry input and octree generation (not included in graph): 59 min.

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
1 billion unknowns: MVP wall-clock time
(166.199 sec.)

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
1 billion unknowns: MVP wall-clock time
(166.199 sec.)

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
1 billion unknowns: MVP wall-clock time
(166.199 sec.)

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Distributed octree decomposition

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Distributed octree decomposition

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Parallelization keypoints
We do not parallelize MLFMA among distributed nodesWe do not parallelize FFTAll MPI parallel processes are equal (no master-slave strategy, except for read/write to disk)We use parallel GMRES. The SIAM Templates book implementation was adapted for complex arguments and parallelized with MPI/OpenMPExcitation vector, currents, MVP and GMRES director vectors are never stored in a single node, but distributed among nodes (except at the very end to write it to disk)
Implementation details

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
C++ Hybrid MPI/OpenMP programming
C++ programming language: combines high-level programming with low-level management of memory (Intel compiler version 11.1.056)Linear algebra (BLAS, LAPACK) and FFT routines provided by optimized Intel Math Kernel Library (MKL version 10.0.2.018). Programming strategy: hybrid MPI/OpenMP (optimal for mixed memory computers)
Distributed memory: Message Passing Interface (HP-MPI version 2.3.1)Shared memory: Parallelization by threads using OpenMP
Implementation details

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Implementation details
Thread safety
All libraries must be thread-safeSome shallow-assign techniques may not be thread-safeEven C++ new and malloc operators are NOT thread-safe depending on the implementation!
Preventing memory fragmentation, memory leaks and idle times
Use of shallow-assign techniques to avoid unnecessary memory copyingPre-allocation of memory in MVPC++ template wrappers to memory (Template Numerical Toolkit)

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
Current work
Perfect lens made of double negative (DNG) metamaterial.
Nano-optical plasmonic gold-made Yagi-Udaantenna at 817nm.
Extend fast integral-equation & supercomputing tools to new fields in nanoscience and nanotechnology
Plasmonic metals at optical frequenciesMetamaterials

2012 ACES Conference – Columbus (OH)Universidad de
Extremadura
This work was supported by Spanish Government and European Union:
Acknowledgments
Projects: TEC2008-06714-C02 TEC2011-28784-C02-01 CONSOLIDER-INGENIO2010 CSD2008-00068 ICTS-2009-40 Junta de Extremadura (GR10126).





























