Embed Size (px)
DESCRIPTION
Subspace Clustering/Biclustering. CS 685: Special Topics in Data Mining Spring 2008 Jinze Liu. Data Mining: Clustering. K-means clustering minimizes. Where. Clustering by Pattern Similarity ( p- Clustering). - PowerPoint PPT Presentation
Citation preview

CS685 : Special Topics in Data Mining, UKY
The UNIVERSITY of KENTUCKY
Subspace Clustering/Biclustering
CS 685: Special Topics in Data MiningSpring 2008
Jinze Liu

CS685 : Special Topics in Data Mining, UKY
2
Data Mining: Clustering
k
t citi
t
cxdist1
2),(
m
jtjijti cxcxdist
1
2)(),(Where
K-means clustering minimizes
CS685 : Special Topics in Data Mining, UKY
3
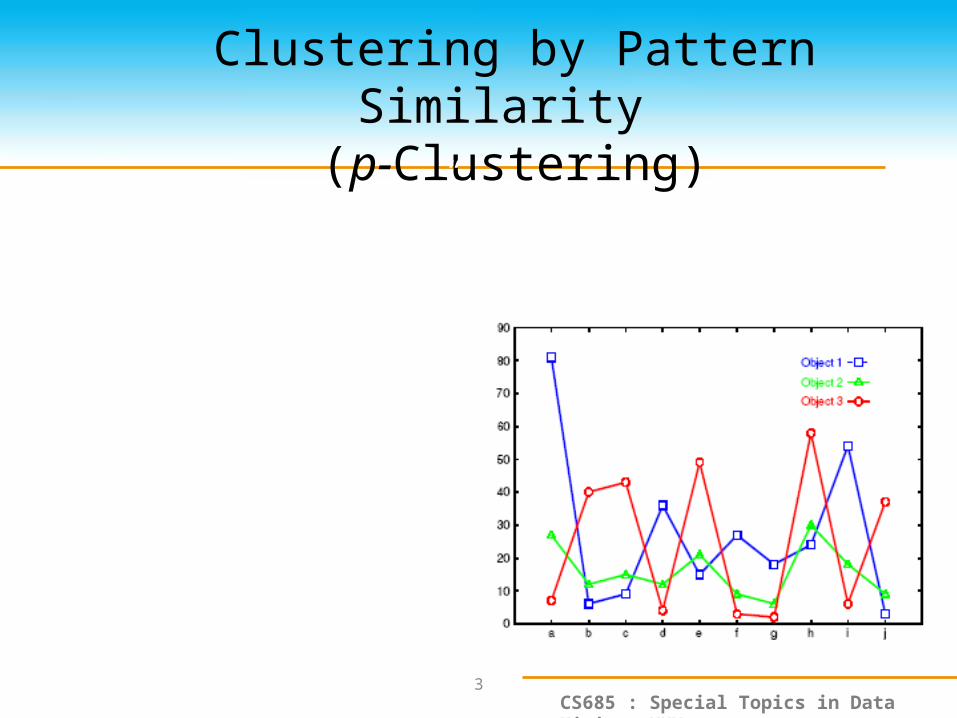
Clustering by Pattern Similarity (p-Clustering)
• The micro-array “raw” data shows 3 genes and their values in a multi-dimensional space– Parallel Coordinates Plots
– Difficult to find their patterns
• “non-traditional” clustering

CS685 : Special Topics in Data Mining, UKY
4
Clusters Are Clear After Projection

CS685 : Special Topics in Data Mining, UKY
5
Motivation
• E-Commerce: collaborative filtering
Movie 1
Movie 2
Movie 3
Movie 4
Movie 5
Movie 6
Movie 7
Viewer 1 1 2 4 3 5
Viewer 2 4 6 7 1
Viewer 3 2 3 4 6 3
Viewer 4 3 4 5 7
Viewer 5 5 5 3 4

CS685 : Special Topics in Data Mining, UKY
6
Motivation
012345678
rating
viewer 1
viewer 2
viewer 3
viewer 4
viewer 5

CS685 : Special Topics in Data Mining, UKY
7
Motivation
Movie 1
Movie 2
Movie 3
Movie 4
Movie 5
Movie 6
Movie 7
Viewer 1 1 2 4 3 5
Viewer 2 4 6 7 1
Viewer 3 2 3 4 6 3
Viewer 4 3 4 5 7
Viewer 5 5 5 3 4

CS685 : Special Topics in Data Mining, UKY
8
Motivation
0
2
4
6
8
movie 1 movie 2 movie 4 movie 6
rating
viewer 1
viewer 3
viewer 4

CS685 : Special Topics in Data Mining, UKY
Gene Expression Data

CS685 : Special Topics in Data Mining, UKY
Biclustering of Gene Expression Data
• Genes not regulated under all conditions• Genes regulated by multiple
factors/processes concurrently• Key to determine function of genes• Key to determine classification of conditions

CS685 : Special Topics in Data Mining, UKY
11
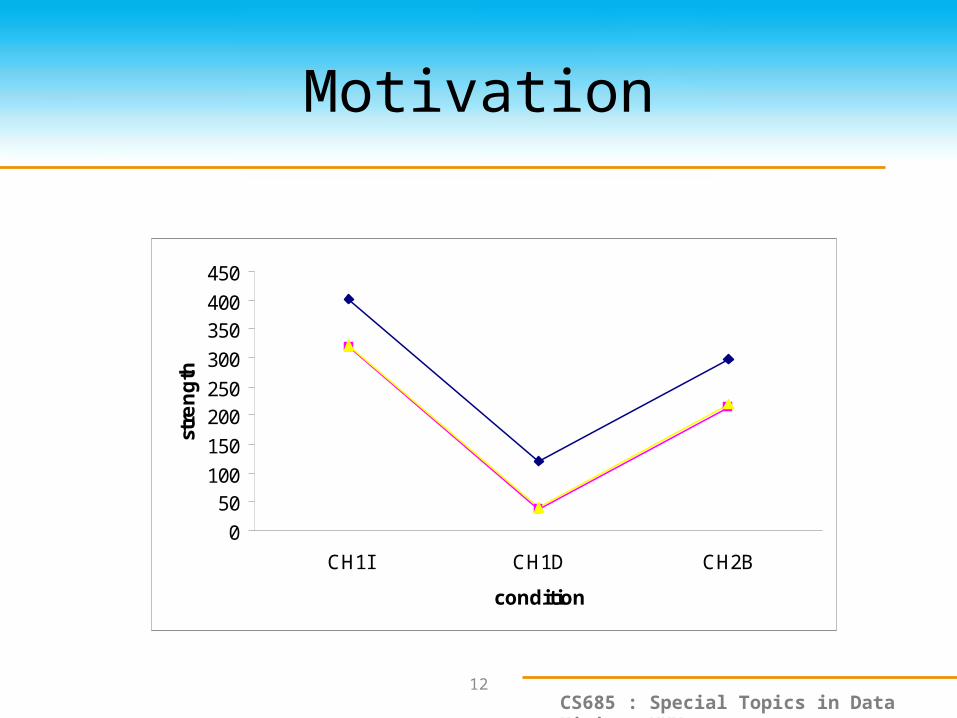
Motivation
• DNA microarray analysisCH1I CH1B CH1D CH2I CH2B
CTFC3 4392 284 4108 280 228
VPS8 401 281 120 275 298
EFB1 318 280 37 277 215
SSA1 401 292 109 580 238
FUN14 2857 285 2576 271 226
SP07 228 290 48 285 224
MDM10 538 272 266 277 236
CYS3 322 288 41 278 219
DEP1 312 272 40 273 232
NTG1 329 296 33 274 228
CS685 : Special Topics in Data Mining, UKY
12
Motivation
0
50100
150
200250
300
350400
450
CH1I CH1D CH2B
condition
strength

CS685 : Special Topics in Data Mining, UKY
13
Motivation
• Strong coherence exhibits by the selected objects on the selected attributes.– They are not necessarily close to each other but
rather bear a constant shift.– Object/attribute bias
• bi-cluster

CS685 : Special Topics in Data Mining, UKY
14
Challenges
• The set of objects and the set of attributes are usually unknown.
• Different objects/attributes may possess different biases and such biases– may be local to the set of selected
objects/attributes– are usually unknown in advance
• May have many unspecified entries

CS685 : Special Topics in Data Mining, UKY
What’s Biclustering?
• Given an n x m matrix, A, find a set of submatrices, Bk, such that the contents of each Bk follow a desired pattern
• Row/Column order need not be consistent between different Bks

CS685 : Special Topics in Data Mining, UKY
Bipartite Graphs
• Matrix can be thought of as a Graph Rows are one set of vertices L, Columns are another set R
• Edges are weighted by the corresponding entries in the matrix If all weights are binary, biclustering becomes biclique finding

CS685 : Special Topics in Data Mining, UKY
Bicluster Structures

CS685 : Special Topics in Data Mining, UKY
18
Previous Work
• Subspace clustering– Identifying a set of objects and a set of
attributes such that the set of objects are physically close to each other on the subspace formed by the set of attributes.
• Collaborative filtering: Pearson R– Only considers global offset of each
object/attribute.
2
222
11
2211
)()(
))((
oooo
oooo

CS685 : Special Topics in Data Mining, UKY
19
bi-cluster
• Consists of a (sub)set of objects and a (sub)set of attributes– Corresponds to a submatrix– Occupancy threshold
• Each object/attribute has to be filled by a certain percentage.
– Volume: number of specified entries in the submatrix
– Base: average value of each object/attribute (in the bi-cluster)

CS685 : Special Topics in Data Mining, UKY
20
bi-cluster
CH1I CH1B CH1D CH2I CH2B Obj base
CTFC3
VPS8 401 120 298 273
EFB1 318 37 215 190
SSA1
FUN14
SP07
MDM10
CYS3 322 41 219 194
DEP1
NTG1
Attr base 347 66 244 219

CS685 : Special Topics in Data Mining, UKY
Bicluster Structures

CS685 : Special Topics in Data Mining, UKY
22
Cheng and Church
• Example:
• Correlation between any two columns = correlation between any two rows = 1.
• aij = aiJ + aIj – aIJ, where aiJ = mean of row i, aIj = mean of column j, aIJ = mean of A.
• Biological meaning: the genes have the same (amount of) response to the conditions.
Back.: 5 Col 0: 1 Col 1: 3 Col 2: 2
Row 0: 2 8 10 9
Row 1: 4 10 12 11
Row 2: 1 7 9 8
CS685 : Special Topics in Data Mining, UKY
23
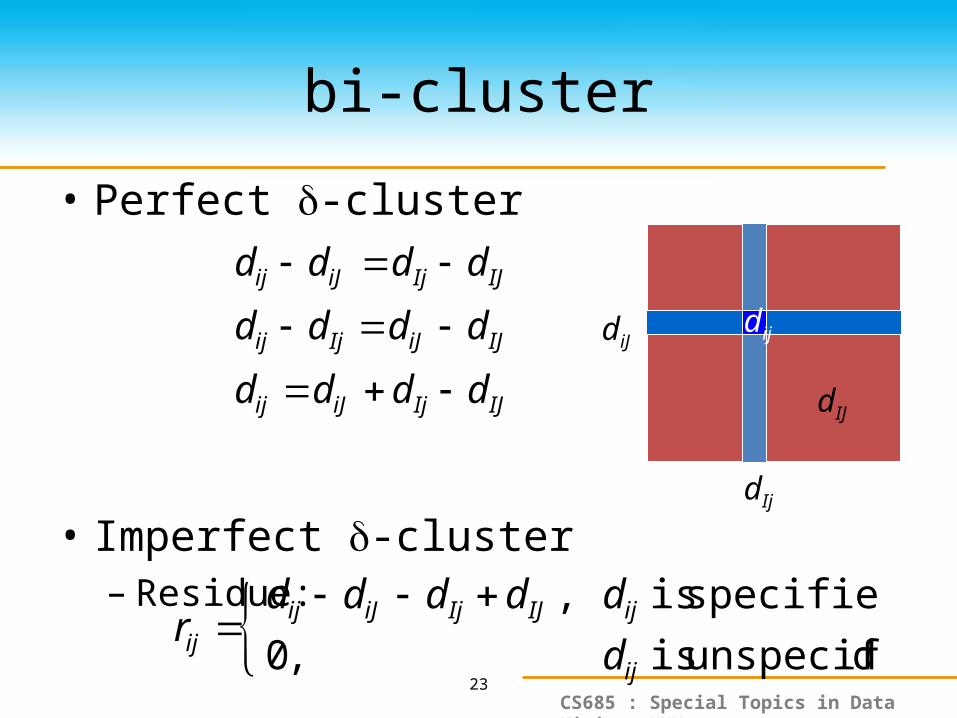
bi-cluster
• Perfect -cluster
• Imperfect -cluster– Residue:
IJIjiJij
IJiJIjij
IJIjiJij
dddd
dddd
dddd
îíì
dunspecifie is ,0
specified is ,
ij
ijIJIjiJijij d
dddddr
dIJ
dIj
diJdij

CS685 : Special Topics in Data Mining, UKY
24
Cheng and Church
• Model:o A bicluster is represented the submatrix A of the whole
expression matrix (the involved rows and columns need not be contiguous in the original matrix).
o Each entry Aij in the bicluster is the superposition (summation) of:o The background levelo The row (gene) effecto The column (condition) effect
o A dataset contains a number of biclusters, which are not necessarily disjoint.

CS685 : Special Topics in Data Mining, UKY
25
Cheng and Church
• Finding the largest -bicluster:– The problem of finding the largest square -
bicluster (|I| = |J|) is NP-hard.– Objective function for heuristic methods (to
minimize):
=> sum of the components from each row and column, which suggests simple greedy algorithms to evaluate each row and column independently.
JjIi
IJIjiJij aaaaJI
JIH,
2)(1
),(

CS685 : Special Topics in Data Mining, UKY
26
Cheng and Church• Greedy methods:
– Algorithm 0: Brute-force deletion (skipped)– Algorithm 1: Single node deletion
• Parameter(s): (maximum squared residue).• Initialization: the bicluster contains all rows and
columns.• Iteration:
1. Compute all aIj, aiJ, aIJ and H(I, J) for reuse.2. Remove a row or column that gives the maximum decrease
of H.• Termination: when no action will decrease H or H <=
.• Time complexity: O(MN)

CS685 : Special Topics in Data Mining, UKY
27
Cheng and Church
• Greedy methods:– Algorithm 2: Multiple node deletion (take one more
parameter . In iteration step 2, delete all rows and columns with row/column residue > H(I, J)).
– Algorithm 3: Node addition (allow both additions and deletions of rows/columns).

CS685 : Special Topics in Data Mining, UKY
28
Cheng and Church
• Handling missing values and masking discovered biclusters: replace by random numbers so that no recognizable structures will be introduced.
• Data preprocessing:– Yeast: x 100log(105x)– Lymphoma: x 100x (original data is already log-
transformed)

CS685 : Special Topics in Data Mining, UKY
29
Cheng and Church
• Some results on yeast cell cycle data (288417):
CS685 : Special Topics in Data Mining, UKY
30
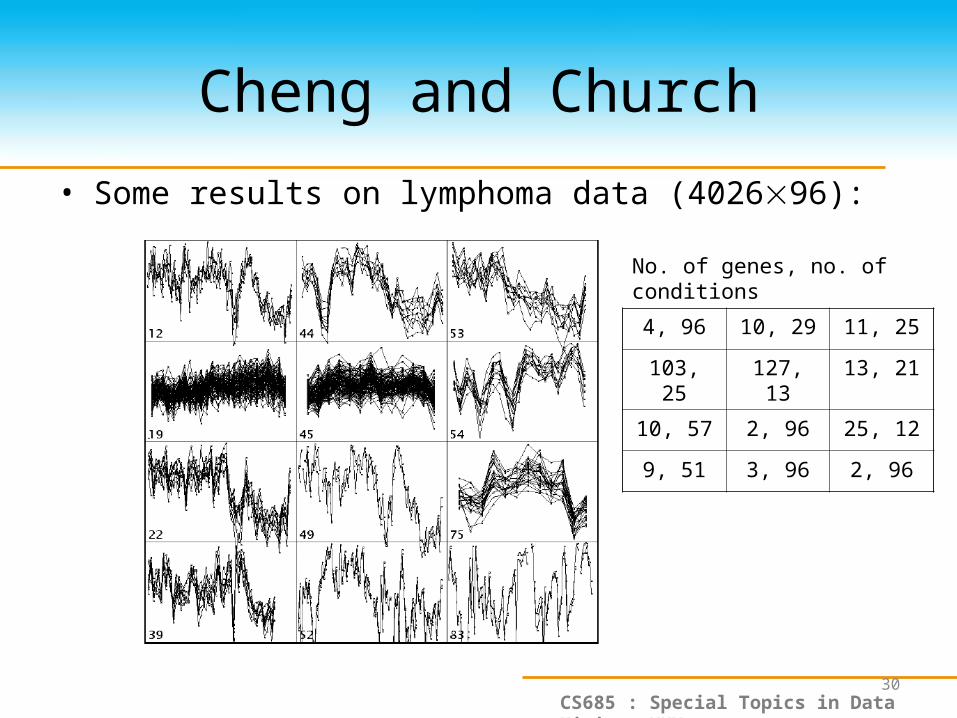
Cheng and Church
• Some results on lymphoma data (402696):
No. of genes, no. of conditions
4, 96 10, 29 11, 25
103, 25 127, 13 13, 21
10, 57 2, 96 25, 12
9, 51 3, 96 2, 96

CS685 : Special Topics in Data Mining, UKY
31
Cheng and Church
• Discussion:– Biological validation: comparing with the clusters
in previously published results.– No evaluation of the statistical significance of the
clusters.– Both the model and the algorithm are not tailored
for discovering multiple non-disjoint clusters.– Normalization is of utmost importance for the
model, but this issue is not well-discussed.

CS685 : Special Topics in Data Mining, UKY
The FLOC algorithm
Generating initial clusters
Determine the best action for each row and each column
Perform the best action of each row and column sequentially
Improved?Y
N

CS685 : Special Topics in Data Mining, UKY
33
The FLOC algorithm
• Action: the change of membership of a row(or column) with respect to a cluster
3 4
4
1 3
2 2
3
2
2
0 4
column
row 1
3
2
1
2 3 4
M+N actions arePerformed ateach iteration
N=3
M=4

CS685 : Special Topics in Data Mining, UKY
34
Performance
• Microarray data: 2884 genes, 17 conditions– 100 bi-clusters with smallest residue were
returned.– Average residue = 10.34
• The average residue of clusters found via the state of the art method in computational biology field is 12.54
– The average volume is 25% bigger– The response time is an order of magnitude faster
CS685 : Special Topics in Data Mining, UKY
35
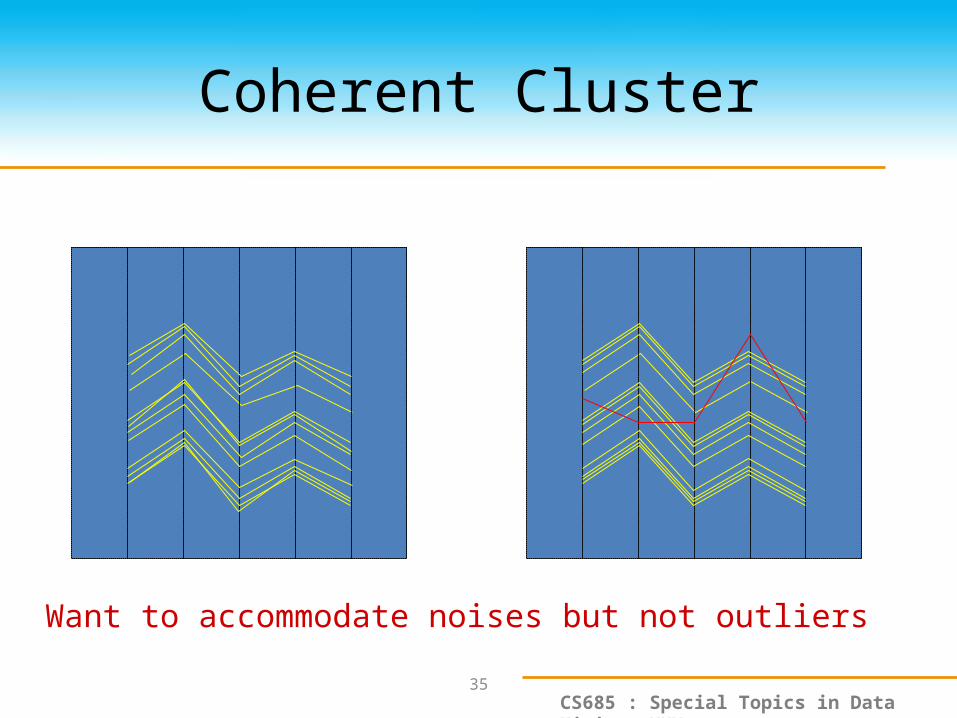
Coherent Cluster
Want to accommodate noises but not outliers

CS685 : Special Topics in Data Mining, UKY
36
Coherent Cluster• Coherent cluster
– Subspace clustering
• pair-wise disparity– For a 22 (sub)matrix consisting of objects {x,
y} and attributes {a, b}
)()( ybxbyaxa
ybya
xbxa
dddd
dd
ddD
x
y
a b
dxa
dya
dxb
dyb
x
y
a b
z
attributemutual bias
of attribute amutual bias
of attribute b

CS685 : Special Topics in Data Mining, UKY
37
Coherent Cluster
– A 22 (sub)matrix is a -coherent cluster if its D value is less than or equal to .
– An mn matrix X is a -coherent cluster if every 22 submatrix of X is -coherent cluster.
• A -coherent cluster is a maximum -coherent cluster if it is not a submatrix of any other -coherent cluster.
– Objective: given a data matrix and a threshold , find all maximum -coherent clusters.

CS685 : Special Topics in Data Mining, UKY
38
Coherent Cluster
• Challenges:– Finding subspace clustering based on distance itself
is already a difficult task due to the curse of dimensionality.
• The (sub)set of objects and the (sub)set of attributes that form a cluster are unknown in advance and may not be adjacent to each other in the data matrix.
– The actual values of the objects in a coherent cluster may be far apart from each other.
• Each object or attribute in a coherent cluster may bear some relative bias (that are unknown in advance) and such bias may be local to the coherent cluster.

CS685 : Special Topics in Data Mining, UKY
39
References
• J. Young, W. Wang, H. Wang, P. Yu, Delta-cluster: capturing subspace correlation in a large data set, Proceedings of the 18th IEEE International Conference on Data Engineering (ICDE), pp. 517-528, 2002.
• H. Wang, W. Wang, J. Young, P. Yu, Clustering by pattern similarity in large data sets, to appear in Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD), 2002.
• Y. Sungroh, C. Nardini, L. Benini, G. De Micheli, Enhanced pClustering and its applications to gene expression data Bioinformatics and Bioengineering, 2004.
• J. Liu and W. Wang, OP-Cluster: clustering by tendency in high dimensional space, ICDM’03.



























![A Provable Subspace Clustering: When LRR meets SSCyuxiangw/docs/LRSSC_tit_submitted.pdfCurvature Clustering [10], Sparse Subspace Clustering (SSC) [5], [11], Low Rank Representation](https://img.dokumen.tips/doc/110x75/6051bc4c27e4ff1b64567e70/a-provable-subspace-clustering-when-lrr-meets-ssc-yuxiangwdocslrssctit-curvature.jpg)