Embed Size (px)
Citation preview

Statistinių sprendimų teorijaVytautas Kazakevičius
2018 m. balandžio 18 d.
Turinys1 Skirstiniai 3
1.1 Praktinė teorija . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Uždaviniai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.3 Sprendimai . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.4 Tikroji teorija . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2 Statistiniai uždaviniai 262.1 Praktinė teorija . . . . . . . . . . . . . . . . . . . . . . . . . . 262.2 Uždaviniai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322.3 Sprendimai . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3 Pakankamos statistikos 453.1 Praktinė teorija . . . . . . . . . . . . . . . . . . . . . . . . . . 453.2 Uždaviniai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503.3 Sprendimai . . . . . . . . . . . . . . . . . . . . . . . . . . . . 533.4 Tikroji teorija . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4 Statistinių hipotezių tikrinimas 674.1 Praktinė teorija . . . . . . . . . . . . . . . . . . . . . . . . . . 674.2 Uždaviniai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 714.3 Sprendimai . . . . . . . . . . . . . . . . . . . . . . . . . . . . 724.4 Tikroji teorija . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5 Nepaslinktieji mažiausios dispersijos įvertiniai 955.1 Teorija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 955.2 Uždaviniai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1025.3 Sprendimai . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
1

6 Efektyvūs nepaslinktieji įvertiniai 1136.1 Teorija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1136.2 Uždaviniai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1206.3 Sprendimai . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
7 Asimptotinė statistika 1217.1 Teorija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1217.2 Uždaviniai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1307.3 Sprendimai . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
8 Didžiausio tikėtinumo įvertiniai 1518.1 Teorija . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1518.2 Uždaviniai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1538.3 Sprendimai . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
2

1 Skirstiniai
1.1 Praktinė teorijaTikimybės, vidurkiai, dispersijos ir kovariacijos. Atsitiktinio dydžioX vidurkį žymiu EX. Aišku, jei X yra atsitiktinis dydis ir f — bet kokiafunkcija, tai f(X) — taip pat atsitiktinis dydis, taigi galima šnekėti ir apie jovidurkį Ef(X). Atskiru atveju, vietoje f galima imti vadinamąjį indikatorių1A, apibrėžiamą lygybe
1A(x) =
1, kai x ∈ A,0, kai x 6∈ A;
čia A — kokia nors aibė. Vietoje 1A(X) aš paprastai rašau 1X∈A. Indika-toriaus vidurkis yra tikimybė:
E1X∈A = P(X ∈ A).
Pavyzdžiui,
P(X > 0) = E1X>0, P(X2 = 1) = E1X2=1
ir pan.Jei X ir Y yra du atsitiktiniai dydžiai, skaičius
cov(X, Y ) = E(X − EX)(Y − EY ) = EXY − EXEY
vadinamas jų kovariacija. Kovariacija tarp X ir X vadinama X dydžio dis-persija ir žymima DX. Taigi
DX = cov(X,X) = E(X − EX)2 = EX2 − (EX)2.
Skaičiuojant vidurkius, naudinga žinoti tokias jų savybes:
• visadaE(cX) = cEX, E(X + Y ) = EX + EY ;
• jei X ir Y nepriklausomi, tai
EXY = EXEY, cov(X, Y ) = 0, D(X + Y ) = DX + DY.
3

Vidurkių skaičiavimas su R. Norint apytiksliai suskaičiuoti kokį norsvidurkį EX su R, reikia sugeneruoti daug X dydžio kopijų ir suskaičiuoti tųskaičių aritmetinį vidurkį, panaudojus mean funkciją. Štai tipinė programa:
N<-1000x<-rnorm(N)mean(x^4)
Iš pradžių sugeneruojama 1000 atsitiktinio dydžio X, pasiskirsčiusio pagalstandartinį normalųjį dėsnį, kopijų ir jos sudedamos į x vektorių. x^4 yranaujas vektorius, kurio kiekvienas elementas yra atitinkamo x vektoriauselemento ketvirtas laipsnis. Tada mean(x^4) bus apytikslė EX4 vidurkioreikšmė.
R funkcija ifelse gali būti panaudota indikatoriams skaičiuoti. Ji turitris argumentus: pirmasis yra sąlyga (tam tikras loginis reiškinys), antrasis —funkcijos reikšmė, kai ta sąlyga teisinga (kai to loginio reiškinio reikšmė yraTRUE), trečiasis — funkcijos reikšmė, kai sąlyga neteisinga. Taigi, pavyzdžiui,programa
N<-1000x<-rnorm(N)mean(ifelse(x>2,1,0))
apytiksliai skaičiuoja tikimybę P(X > 2); čia X yra tas pats standartiškainormaliai pasiskirstęs atsitiktinis dydis. Vietoje mean(ifelse(x>2,1,0))galima rašyti ir tiesiog mean(x>2): jei mean funkcijos argumentas loginis,skaičiuojant vidurkį reikšmė TRUE automatiškai pakeičiama į 1, o reikšmėFALSE — į 0.
Norint suskaičiuoti X dydžio dispersiją, galima skaičiuoti
mean(x^2)-mean(x)^2
arba tiesiog var(x). Rezultatai nebus identiški, bet jei x vektorius pakan-kamai ilgas, skirtumas bus nedidelis. Dalykas tas, kad jei N yra x vektoriausilgis, var(x) skaičiuojamas kaip
sum((x-mean(x))^2)/(N-1)
(dalinama iš N-1, o ne N). Panašiai cov(x,y) skaičiuoja x ir y vektorių ko-variaciją. Rezultatas šiek tiek skiriasi nuo
mean(x*y)-mean(x)*mean(y)
bet jei vektoriai pakankamai ilgi, skirtumas nedidelis.
4

Atsitiktinių dydžių skirstiniai. Norint suskaičiuoti kokį nors vidurkįEf(X) arba tikimybę P(X ∈ A), reikia žinoti X dydžio skirstinį. Kito skyre-lio uždaviniuose tas skirstinys yra vieno iš dviejų tipų: diskretusis arba toly-dusis. Diskretusis skirstinys aprašomas lentele, kurioje surašomos galimos Xreikšmės xi ir tų reikšmių tikimybės p(xi). Tolydusis skirstinys aprašomas,nurodant X dydžio reikšmių intervalą (a; b) ir tų reikšmių pasiskirstymo tan-kį p(x) (tam tikrą funkciją, apibrėžtą (a; b) intervale). Žemiau surašiau, kaipkiekvienu atveju skaičiuojami vidurkiai ir tikimybės.
Diskretusis skirstinys
X x1 · · · xkp(x1) · · · p(xk)
(p(xi) > 0, ∑i p(xi) = 1).
Ef(X) =∑i
f(xi)p(xi),
P(X ∈ A) =∑xi∈A
p(xi).
Tolydusis skirstinys
p(x) = · · · , kai a < x < b
(p(x) > 0,∫ ba p(x)dx = 1).
Ef(X) =∫ b
af(x)p(x)dx,
P(X ∈ A) =∫a<x<bx∈A
p(x)dx.
1.1 pavyzdys. TeguX yra atsitiktinis dydis, kurio skirstinys aprašomas len-tele
X −1 0 1 20.4 0.2 0.1 0.3
Tada
P(X2 > 1) = 0.4 + 0.1 + 0.3 = 0.8,E|X| = 0.4 + 0 + 0.1 + 0.6 = 1.1.
1.2 pavyzdys. Tegu X yra atsitiktinis dydis, kurio skirstinys turi tankį
p(x) = 2(x+ 1)9 su −1 < x < 2.
Tada
P(X2 > 1) =∫−1<x<2x2>1
2(x+ 1)9 dx = 2
9
∫ 2
1(x+ 1)dx = (x+ 1)2
9
∣∣∣∣21
= 59
E|X| =∫ 2
−1|x|2(x+ 1)
9 dx = −29
∫ 0
−1(x2 + x)dx+ 2
9
∫ 2
0(x2 + x)dx
= −29
[x3
3 + x2
2
]0
−1+ 2
9
[x3
3 + x2
2
]2
0= 1
27 + 2827 = 29
27 .
5

u
1
0.4
0.6
0.7 1
x=−
1
x=
0x
=1
x=
2
1 pav. Diskretaus atsitiktinio dydžio generavimas
Atsitiktinių dydžių generavimas. Kai kuriems atsitiktiniams dydžiamsgeneruoti R turi specialias funkcijas; pavyzdžiui, rnorm funkcija generuojanormaliai pasiskirsčiusius atsitiktinius dydžius. Plačiau apie tas funkcijaspakalbėsiu šiek tiek vėliau, o dabar paaiškinsiu, kaip generuojami nestandar-tiškai pasiskirstę atsitiktiniai dydžiai.
Kiekvienas atsitiktinis dydis X pasiskirstęs taip pat, kaip tam tikras f(U)pavidalo dydis; čia U yra atsitiktinis dydis, pasiskirstęs tolygiai (0; 1) inter-vale. Taigi pakanka generuoti tolygiai pasiskirsčiusius atsitiktinius dydžius(tam skirta R funkcija runif) ir juos transformuoti, pritaikius tinkamą funk-ciją f . Paprasčiausia tą atlikti, kai X skirstinys diskretus. Pavyzdžiui, jeiX yra atsitiktinis dydis, aprašytas 1.1 pavyzdyje, jo kopijas generuoja tokiaprograma:
N<-1000u<-runif(N)x<-ifelse(u<0.4,-1,ifelse(u<0.6,0,ifelse(u<0.7,1,2)))
Paaiškinimas paprastas (žr. 1 pav.). Tolygiai pasiskirsčiusio dydžio tankispastovus; jei dydis pasiskirstęs tolygiai (0; 1) intervale, tankio reikšmė visameintervale lygi 1. Tikimybė, kad toks U pateks į kokį nors intervalą, lygiplotui po tankio grafiku tame intervale, t.y. intervalo ilgiui. Taigi programojeapibrėžtas dydis X įgyja reikšmes −1, 0, 1 ir 2 su reikiamomis tikimybėmis:0.4, 0.2, 0.1 ir 0.3.
Jei X dydis tolydus, tai X = f(U) su funkcija f , kuri yra atvirkštinėvadinamajai pasiskirstymo funkcijai F , apibrėžiamai lygybe
F (x) = P(X 6 x) =∫ x
ap(t)dt su x ∈ (a; b);
čia (a; b) yra X dydžio reikšmių intervalas, o p — jo tankis. Norint rasti f ,reikia iš pradžių suskaičiuoti F , o po to išspręsti lygtį F (x) = u kintamojo xatžvilgiu.
6

Tegu, pavyzdžiui, X yra atsitiktinis dydis iš 1.2 pavyzdžio. Tada
F (x) =∫ x
−1
2(t+ 1)9 dt = (t+ 1)2
9
∣∣∣∣x−1
= (x+ 1)2
9 .
Sprendžiu lygtį F (x) = u:
(x+ 1)2
9 = u,
(x+ 1)2 = 9u,x+ 1 = 3
√u,
x = 3√u− 1.
Taigi X dydžio kopijas generuoja tokia programa:
N<-1000u<-runif(N)x<-3*sqrt(u)-1
Diskrečiuosius atsitiktinius dydžius galima generuoti ir panaudojus funk-ciją sample su replace=TRUE parinktimi. Jos pirmas argumentas apibrėžiaX dydžio galimų reikšmių aibę, po prob= nurodomos tų reikšmių tikimybės,o po size= — kiek tų reikšmių reikia (koks turi būti imties dydis):
> x<-sample(c(1,3), prob=c(0.4,0.6), size=1000, replace=T)> table(factor(x))
1 3390 610
Jei pirmas funkcijos argumentas yra natūralusis skaičius n, mašina supranta,kad galimos dydžio reikšmės yra 1, 2, . . . , n:
> x<-sample(3, prob=c(0.2,0.2,0.6), size=1000, replace=T)> table(factor(x))
1 2 3195 202 603
Dabar, kaip ir žadėjau, aprašysiu kelias mano mėgiamas skirstinių klases,kartu paminėdamas ir kaip generuojami atitinkami atsitiktiniai dydžiai su R.
7

Bernulio skirstinys. Tai diskretusis skirstinys aprašomas lentele
X 0 11− p p
Čia p ∈ (0; 1) — skirstinio parametras. Bernulio skirstinys yra atskirasbinominio skirstinio Bin(n, p) atvejis, atitinkantis n = 1. Jei X pasiskirstęspagal binominį Bin(n, p) dėsnį, tai
P(X = x) =(n
x
)(1− p)n−xpx su x = 0, . . . , n,
EX = np, DX = np(1− p).
Binominio dydžio realizacijos generuojamos naudojant R funkciją
rbinom(n,size,prob)
Čia n yra norimas realizacijų skaičius, size yra n parametro, o prob — pparametro reikšmė. Taigi, pavyzdžiui, komanda
rbinom(10,size=1,prob=0.3)
sugeneruoja 10 atsitiktinio dydžio, pasiskirsčiusio pagal Bernulio dėsnį suparametru p = 0.3, realizacijų.
Geometrinis skirstinys. Tai diskretusis skirstinys, aprašomas lygybėmis
P(X = x) = (1− p)px su x = 0, 1, 2, . . . ;
čia p ∈ (0; 1) — skirstinio parametras. Reikia turėti omenyje, kad šios ly-gybės atitinka mano mėgstamą parametrizaciją; R parametru laiko ne p, o1− p. Jei X pasiskirstęs pagal aukščiau aprašytą dėsnį, tai
EX = p
1− p ir DX = p
(1− p)2 .
Geometrinio dydžio realizacijos generuojamos naudojant R funkciją
rgeom(n,prob)
Čia n yra norimas realizacijų skaičius, o prob — parametro 1 − p reikšmė.prob reikšmė gali būti ir 1 (t.y. p gali būti ir 0); tada generuojamas išsigimusioatsitiktinio dydžio X = 0 realizacijos:
> rgeom(5,prob=1)[1] 0 0 0 0 0
8

Puasono skirstinys. Tai diskretusis skirstinys, aprašomas lygybėmis
P(X = x) = e−λλx
x! su x = 0, 1, 2, . . . ;
čia λ > 0 — skirstinio parametras. Jei X pasiskirstęs pagal tokį Puasonodėsnį, tai
EX = λ ir DX = λ.
Taigi skirstinys vienareikšmiškai aprašomas, pasakius, pavyzdžiui, kad Xpasiskirstęs pagal Puasono dėsnį su vidurkiu λ.
Puasono dydžio realizacijos generuojamos naudojant R funkciją
rpois(n,lambda)
Čia n yra norimas realizacijų skaičius, o lambda — parametro λ reikšmė.lambda reikšmė gali būti ir 0; tada generuojamas išsigimusio atsitiktinio dy-džio X = 0 realizacijos.
Tolygusis skirstinys. Simboliu U(a, b) žymiu tolygų (a; b) intervale skirs-tinį. Tai tolydusis skirstinys su tankiu
p(x) = 1b− a
, kai a < x < b;
čia a ir b — skirstinio parametrai, −∞ < a < b < ∞. Jei X pasiskirstęstolygiai (a; b) intervale, tai
EX = a+ b
2 ir DX = (b− a)2
12 .
Tolygiai pasiskirsčiusio dydžio realizacijos generuojamos naudojant R fun-kciją
runif(n,min,max)
Čia n yra norimas realizacijų skaičius, o min ir max — atitinkamai, a ir bparametrų reikšmės. Numatytosios parametrų reikšmės yra 0 ir 1. Taigikomanda
runif(5)
generuoja 5 atsitiktinio dydžio, pasiskirsčiusio tolygiai (0; 1) intervale, reali-zacijas.
9

Eksponentinis skirstinys. Tai tolydusis skirstinys su tankiup(x) = λe−λx, kai x > 0;
čia λ > 0 — skirstinio parametras. Jei X pasiskirstęs pagal tokį eksponentinįdėsnį, tai
EX = 1λ
ir DX = 1λ2 .
Eksponentiškai pasiskirsčiusio dydžio realizacijos generuojamos naudo-jant R funkciją
rexp(n,rate)
Čia n yra norimas realizacijų skaičius, o rate — λ parametro reikšmė. Nu-matytoji rate parametro reikšmė yra 1.
Gama skirstinys. Tai tolydusis skirstinys su tankiu
p(x) = λa
Γ(a)xa−1e−λx, kai x > 0;
čia a > 0 ir λ > 0 — skirstinio parametrai. Jei X pasiskirstęs pagal tokįdėsnį, tai
EX = a
λir DX = a
λ2 .
Pagal gama dėsnį pasiskirsčiusio dydžio realizacijos generuojamos naudo-jant R funkciją
rgamma(n,shape,rate)
Čia n yra norimas realizacijų skaičius, o shape ir rate — atitinkamai a ir λparametrų reikšmės. Numatytoji rate parametro reikšmė yra 1.
Normalusis skirstinys. Simboliu N(µ, σ2) aš žymiu normalųjį skirstinį sutankiu
p(x) = 1√2πσ
e−(x−µ)2/(2σ2), kai x ∈ R.
Jei X pasiskirstęs pagal tokį dėsnį, taiEX = µ ir DX = σ2.
Taigi N(µ, σ2) yra normalusis skirstinys su vidurkiu µ ir dispersija σ2.Normaliojo dydžio realizacijos generuojamos naudojant R funkciją
rnorm(n,mean,sd)
Čia n yra norimas realizacijų skaičius, o mean ir sd — atitinkamai µ ir σ(būtent σ, o ne σ2) parametrų reikšmės. Numatytosios mean ir sd parametrųreikšmės yra 0 ir 1.
10

Atsitiktinių vektorių skirstiniai. Jei reikia suskaičiuoti Ef(X, Y ) pavi-dalo vidurkį arba P((X, Y ) ∈ A) tikimybę, reikia žinoti vadinamąjį bendrąjįX ir Y dydžių skirstinį, arba tiesiog (X, Y ) vektoriaus skirstinį. Vektoriųskirstiniai irgi yra diskretieji arba tolydieji. Diskretusis skirstinys aprašo-mas lentele, kurioje surašomos galimos (X, Y ) vektoriaus reikšmės (xi, yj)ir tų reikšmių tikimybės p(xi, yj). Tolydusis skirstinys aprašomas, nurodant(X, Y ) vektoriaus reikšmių sritį D ⊂ R2 ir tų reikšmių pasiskirstymo tan-kį p(x, y) (tam tikrą funkciją, apibrėžtą D aibėje). Žemiau surašiau, kaipkiekvienu atveju skaičiuojami vidurkiai ir tikimybės.
Diskretusis skirstinys
X Y y1 · · · ylx1 p(x1, y1) . . . p(x1, yl)... ... . . . ...xk p(xk, y1) . . . p(xk, yl)
(p(xi, yj) > 0, ∑i,j p(xi, yj) = 1).
Ef(X, Y ) =∑i,j
f(xi, yj)p(xi, yj),
P((X, Y ) ∈ A) =∑
(xi,yj)∈Ap(xi, yj).
Tolydusis skirstinys
p(x, y) = · · · , kai (x, y) ∈ D
(p(x, y) > 0,∫D p(x, y)dxdy = 1).
Ef(X, Y ) =∫Df(x, y)p(x, y)dxdy,
P((X, Y ) ∈ A) =∫
(x,y)∈D(x,y)∈A
p(x, y)dxdy.
Atsitiktinių vektorių generavimas. Diskretieji atsitiktinai vektoriai ge-neruojami taip pat, kaip ir diskretieji atsitiktiniai dydžiai:
• (0; 1) intervalas suskaidomas į kl intervaliukų Iij su ilgiais p(xi, yj);
• po to generuojamas pagalbinis atsitiktinis dydis U , pasiskirstęs tolygiai(0; 1) intervale;
• jei generuota U reikšmė patenka į Iij intervaliuką, X dydžiui priskiria-ma reikšmė xi, o Y dydžiui — reikšmė yj.
1.3 pavyzdys. Tarkime, reikia generuoti atsitiktinį vektorių (X, Y ), kurioskirstinys aprašomas lentele
X Y 1 21 0.4 0.32 0.3 0
Iš pradžių suskaidau (0; 1) intervalą į tris dalis, kaip parodyta 2 pav. Poto, žiūrėdamas į tą piešinį, parašau tokią programą:
11

u
1
0.4 0.7 1
x=
1y
=1
x=
1y
=2
x=
2y
=1
2 pav. Diskretaus atsitiktinio vektoriaus generavimas
N<-1000u<-runif(N)x<-ifelse(u<0.7,1,2)y<-ifelse(0.4<u & u<0.7,2,1)
Diskrečiuosius atsitiktinius vektorius galima generuoti ir naudojant funk-ciją sample. Iš pradžių generuojame jungtinį dydį (kažką panašaus į jungtinįfaktorių, gaunamą iš dviejų faktorių), o po to apibrėžiame abu reikiamus at-sitiktinius dydžius.
1.4 pavyzdys. Tarkime, reikia generuoti atsitiktinį vektorių (X, Y ), kurioskirstinys aprašomas tokia lentele:
X Y 1 2 31 0.2 0.3 0.12 0 0.15 0.25
Žadu generuoti „jungtinį“ atsitiktinį dydį Z, kurio skirstinys aprašomas len-tele:
Z 1 2 3 4 5 60.2 0.3 0.1 0 0.15 0.25
Turėdamas Z, dydžius X ir Y galėsiu paimti tokius:
X =
1, kai Z 6 3,2, kai Z > 3;
Y =
1, kai Z ∈ 1, 4,2, kai Z ∈ 2, 5,3, kai Z ∈ 3, 6.
Štai kaip atrodo programa:
12

p<-c(0.2,0.3,0.1,0,0.15,0.25)z<-sample(6, prob=p, size=1000, replace=T)x<-ifelse(z<=3,1,2)y<-ifelse(z %in% c(1,4), 1, ifelse(z %in% c(2,5), 2,3))
Jei X dydis įgyja r reikšmių, o Y dydis — s reikšmių, jungtinis dydisZ įgyja rs reikšmių. Jei r ir s skaičiai dideli, formulės, išreiškiančios X irY per Z, pasidaro labai jau nemalonios. Tačiau jas galėtume užrašyti labaipaprastai, jei visi dydžiai įgyja reikšmes 0, . . . , k − 1; čia k yra r, s arba rs.Tegu, pavyzdžiui, r = 2 ir s = 3; tada Z, kaip (X, Y ) funkcija užrašomatokia lentele:
X Y 0 1 20 0 1 21 3 4 5
Iš jos matyti, kad X yra santykio Z/3 sveikoji dalis (atitinkama R funkcijayra z%/%3), o Y yra liekana, gaunama dalijant Z iš 3 (t.y. z%%3). Jei visgiX ir Y reikšmės prasideda nuo 1, prie rezultato galime pridėti 1.
Štai kaip galima modifikuoti programą iš 1.4 pavyzdžio:
p<-c(0.2,0.3,0.1,0,0.15,0.25)z<-sample((0:5), prob=p, size=1000, replace=TRUE)x<-z%/%3+1y<-z%%3+1
Tolydžiųjų atsitiktinių vektorių generavimas bendruoju atveju sudėtin-gesnis, bet sudėtingų uždavinių aš ir neduodu.
Vektoriai su nepriklausomomis komponentėmis. Kito skyrelio užda-viniuose bendrasis skirstinys dažniausiai aprašomas netiesiogiai: aprašomiatskirieji X ir Y dydžių skirstiniai (t.y. duodamos reikšmių tikimybės p(xi)ir q(yj) diskrečiuoju atveju arba tankiai p(x) ir q(y) tolydžiuoju atveju) irpasakoma, kad tie dydžiai nepriklausomi. Tada bendrasis skirstinys apskai-čiuojamas pagal formules
p(xi, yj) = p(xi)q(yj) arba p(x, y) = p(x)q(y).
Kartais aprašomas tik X dydžio skirstinys ir pasakoma, kad Y dydis nepri-klauso nuo X ir pasiskirstęs taip pat kaip X. Tokiu atveju taikomos tokiospat formulės tik su (y1, . . . , yl) = (x1, . . . , xk) ir q(yj) = p(yj) diskrečiuojuatveju arba q(y) = p(y) tolydžiuoju atveju.
13

Generuojant nepriklausomų dydžių kopijas pagal X = f(U) ir Y = g(U)formules, reikia naudoti skirtingas (t.y. nepriklausomas) U dydžio realizaci-jas. Pavyzdžiui, jei X yra atsitiktinis dydis iš 1.2 pavyzdžio, o Y — taip patpasiskirstęs, bet nepriklausomas nuo X, tai jų realizacijas generuoja tokiaprograma:
N<-1000u<-runif(N)x<-3*sqrt(u)-1u<-runif(N)y<-3*sqrt(u)-1
Jei programoje yra dvi sample funkcijos, jos taip pat generuoja nepri-klausomus atsitiktinius dydžius (nepriklausomas imtis).
1.2 Uždaviniai1. X dydžio skirstinys aprašomas lentele
X −2 −1 0 1 20.3 0.2 0.1 0.2 0.2
Apskaičiuokite P(X2 < 3), E|X| ir D(X2). Patikrinkite gautus rezultatus sukompiuteriu.
2. X ir Y yra nepriklausomi vienodai pasiskirstę atsitiktiniai vektoriai, ku-rių skirstinys aprašomas lentele
X, Y −1 0 10.3 0.2 0.5
Apskaičiuokite P(X < Y ), E|X − Y | ir cov(X,XY ). Patikrinkite gautusrezultatus su kompiuteriu.
3. X yra tolydusis atsitiktinis dydis su tankiu
p(x) = 3x4 , kai x > 1.
Apskaičiuokite P(X > 2), EX ir D(1X<2X).
4. X ir Y yra nepriklausomi vienodai pasiskirstę tolydieji atsitiktiniai dy-džiai su tankiu
p(x) = 2x, kai 0 < x < 1.Apskaičiuokite P(X + Y > 1), EY ir cov(X + Y,X − Y ).
14

5. X yra tolydusis atsitiktinis dydis su tankiu
p(x) = c(1− |x|), kai −1 < x < 1;
čia c ∈ R. Raskite c ir apskaičiuokite P(X > 12), E1X>0X ir D|X|.
6. X ir Y yra nepriklausomi atsitiktiniai dydžiai, X pasiskirtęs tolygiai(−1; 1) intervale, o Y — tolygiai (0; 1) intervale. Apskaičiuokite P(Y > X),E|X + Y | ir cov(1X+Y >0, 1X>0).
7. X ir Y yra nepriklausomi atsitiktiniai dydžiai, X pasiskirstęs pagal Pu-asono dėsnį su vidurkiu 3, o Y — pagal geometrinį dėsnį:
P(Y = k) = 2−k−1, k = 0, 1, 2, . . . .
Simuliuodami kompiuteriu raskite apytiksliai P(X = 3Y ) ir cov(1X=Y , Y ).
8. X yra tolydusis atsitiktinis dydis, pasiskirstęs pagal Koši dėsnį su tankiu
p(x) = 1π(1 + x2) , kai x ∈ R.
Simuliuodami kompiuteriu raskite apytiksliai P(X > 2) ir E(1|X|<2X).
9. X ir Y yra nepriklausomi vienodai pasiskirstę atsitiktiniai dydžiai, pa-siskirstę pagal normalųjį dėsnį su vidurkiu 1 ir dispersija 2. Simuliuodamikompiuteriu raskite apytiksliai P(XY > 0) ir E|X − Y |.
10. X yra tolydusis atsitiktinis dydis su tankiu
p(x) = 3x4 , kai x > 1.
Apskaičiuokite EX ir D(1X<2X). Patikrinkite gautus rezultatus su kom-piuteriu.
11. X yra atsitiktinis dydis, kurio skirstinys aprašomas lentele
X −2 −1 0 1 20.1 0.15 0.5 0.15 0.1
Apskaičiuokite P(X > 0), DX ir cov(1X<0, 1X>0). Gautus rezultatuspatikrinkite su kompiuteriu.
15

12. X yra atsitiktinis dydis su tankiu
p(x) = c
(x+ 1)3 , kai x > 0;
čia c — tam tikra konstanta. Raskite tą c ir apskaičiuokite X dydžio pa-siskirstymo funkciją bei EX1X>2. Patikrinkite su kompiuteriu, ar gautavidurkio reikšmė teisinga.
13. X yra atsitiktinis dydis, kurio pasiskirstymo funkcija
F (x) =
0, kai x < 0,x2
2 , kai 0 6 x < 1,2x−1
2x , kai x > 1.
Apskaičiuokite EX1X<2. Patikrinkite gautą rezultatą su kompiuteriu.
14. X yra atsitiktinis dydis iš 1 užduoties, o Y — kitas atsitiktinis dydis,pasiskirstęs taip pat, kaip X, bet nuo jo nepriklausomas. ApskaičiuokiteP(X + Y > 0) ir cov(X − Y,X + 2Y ). Patikrinkite gautus rezultatus sukompiuteriu.
15. (X, Y ) yra atsitiktinis vektorius, kurio skirstinys aprašomas lenteleX Y 1 2 3 4−1 1/4 1/12 0 1/12
1 1/4 0 1/6 1/6
Apskaičiuokite cov(Y 1X=−1, Y 1X=1) ir gautą rezultatą patikrinkite sukompiuteriu.
1.3 Sprendimai1. Aišku, kad
P(X2 < 3) = 0.2 + 0.1 + 0.2 = 0.5ir
E|X| = 0.6 + 0.2 + 0.2 + 0.4 = 1.4.Be to,
EX2 = 1.2 + 0.2 + 0.2 + 0.8 = 2.4 ir EX4 = 4.8 + 0.2 + 0.2 + 3.2 = 8.4;
todėlD(X2) = 8.4− 2.42 = 8.4− 5.76 = 2.64.
Tikrinu naudodamas tokią programą:
16

N=10000
u<-runif(N)x<-ifelse(u<0.3,-2,
ifelse(u<0.5,-1,ifelse(u<0.6,0,ifelse(u<0.8,1,2))))
cat("Ieškoma tikimybė yra", mean(x*x<3),"\n")cat("Ieškomas vidurkis yra", mean(abs(x)),"\n")cat("Ieškoma dispersija yra", var(x*x),"\n")
Atsakymas:
Ieškoma tikimybė yra 0.4958Ieškomas vidurkis yra 1.397Ieškoma dispersija yra 2.670118
2. (X, Y ) vektoriaus skirstinys aprašomas lentele
X Y −1 0 1−1 0.09 0.06 0.15 0.30 0.06 0.04 0.1 0.21 0.15 0.1 0.25 0.5
0.3 0.2 0.5
Taigi
P(X < Y ) = 0.06 + 0.15 + 0.1 = 0.31,E|X − Y | = 0.06 + 0.3 + 0.06 + 0.1 + 0.3 + 0.1 = 0.92.
Be to,
cov(X,XY ) = EX2Y − EXEXY = EX2EY − (EX)2EY= 0.8 · 0.2− (0.2)3 = 0.16− 0.008 = 0.152,
nesEX = EY = 0.2 ir EX2 = 0.8.
Tikrinu naudodamas tokią programą:
N<-10000u<-runif(N)
17

x<-ifelse(u<0.3,-1,ifelse(u<0.5,0,1))v<-runif(N)y<-ifelse(v<0.3,-1,ifelse(v<0.5,0,1))cat("Ieškoma tikimybė yra", mean(x<y),"\n")cat("Ieškomas vidurkis yra", mean(abs(x-y)),"\n")cat("Ieškoma kovariacija yra", cov(x,x*y),"\n")
Atsakymas:
Ieškoma tikimybė yra 0.3064Ieškomas vidurkis yra 0.9171Ieškoma kovariacija yra 0.1467696
3. Aišku, kad
P(X > 2) =∫ ∞
2
3x4 dx = −x−3
∣∣∣∣∞2
= 18
irEX =
∫ ∞1
3x4x dx = −3
2x−2∣∣∣∣∞1
= 32 .
Be to,
E1X<2X =∫ 2
1
3x4x dx = −3
2x−2∣∣∣∣21
= −32
(14 − 1
)= 9
8 ,
E(1X<2X)2 =∫ 2
1
3x4x
2 dx = −3x−1∣∣∣∣21
= −3(1
2 − 1)
= 32;
todėlD(1X<2X) = 3
2 −8164 = 15
64 .
4. Aišku, kad
P(X + Y > 1) =∫
0<x<10<y<1x+y>1
2x · 2y dxdy =∫
0<x<1dx∫
1−x<y<12x · 2y dy
=∫ 1
0dx∫ 1
1−x4xy dy =
∫ 1
02xy2
∣∣∣∣1y=1−x
dx =∫ 1
02x(1− (1− x)2)dx
=∫ 1
0(4x2 − 2x3)dx =
(43x
3 − x4
2
)∣∣∣∣10
= 43 −
12 = 5
6
irEY =
∫ 1
02y2dy = 2y3
3
∣∣∣∣10
= 23 .
18

Be to,
cov(X + Y,X − Y ) = E(X + Y )(X − Y )− E(X + Y )E(X − Y )= E(X2 − Y 2)− (EX + EY )(EX − EY )
= EX2 − EY 2 − (EX)2 + (EY )2 = 0,
nes EX = EY = 2/3 ir EX2 = EY 2 <∞.
5. Kadangi ∫ 1
−1(1− |x|)dx = 2
∫ 1
0(1− x)dx = 2
(1− 1
2
)= 1,
c = 1. Tada
P(X > 1/2) =∫ 1
1/2(1− x)dx =
(x− x2
2
)∣∣∣∣11/2
= 12 −
38 = 1
8
irE1X>0X =
∫ 1
0(1− x)x dx =
(x2
2 −x3
3
)∣∣∣∣10
= 16 .
Be to,D|X| = EX2 − (E|X|)2 = 1
6 −19 = 1
18 ,nes
E|X| =∫ 1
−1(1− |x|)|x| dx = 2
∫ 1
0(1− x)x dx = 1
3ir
EX2 =∫ 1
−1(1− |x|)x2 dx = 2
∫ 1
0(1− x)x2 dx = 2
(x3
3 −x4
4
)∣∣∣∣10
= 16 .
6. Aišku, kad
P(Y > X) =∫−1<x<10<y<1x<y
12dxdy
= 12
∫ 0
−1dx∫ 1
0dy + 1
2
∫ 1
0dx∫ 1
xdy
= 12 + 1
2
∫ 1
0(1− x)dx
= 12 + 1
4= 3
4
19

ir
E|X + Y |
=∫−1<x<10<y<1
12 |x+ y|dxdy
= 12
∫−1<x<10<y<1x+y>0
(x+ y)dxdy − 12
∫−1<x<10<y<1x+y<0
(x+ y)dxdy
= 12
∫ 0
−1dx∫ 1
−x(x+ y)dy + 1
2
∫ 1
0dx∫ 1
0(x+ y)dy − 1
2
∫ 0
−1dx∫ −x
0(x+ y)dy
= 12
∫ 0
−1
(xy + y2
2
)∣∣∣∣1y=−x
dx+ 12
∫ 1
0
(xy + y2
2
)∣∣∣∣1y=0
dx
− 12
∫ 0
−1
(xy + y2
2
)∣∣∣∣−xy=0
dx
= 12
∫ 0
−1
(x+ 1
2 + x2
2
)dx+ 1
2
∫ 1
0
(x+ 1
2
)dx+ 1
2
∫ 0
−1
x2
2 dx
= 12
(x2 + x
2 + x3
3
)∣∣∣∣0−1
+ 12x2 + x
2
∣∣∣∣10
= 16 + 1
2 = 23 .
Be to,
cov(1X+Y >0, 1X>0) = E1X+Y >01X>0−E1X+Y >0E1X>0 = 12−
38 = 1
8 ,
nesE1X+Y >01X>0 = P(X > 0, X + Y > 0) = P(X > 0) = 1
2ir
E1X+Y >0 =∫−1<x<10<y<1x+y>0
12dxdy = 1
2
∫ 0
−1dx∫ 1
−xdy + 1
2
∫ 1
0dx∫ 1
0dy
= 12
∫ 0
−1(1 + x)dx+ 1
2
∫ 1
0dx = 1
2
(x+ x2
2
)∣∣∣∣0−1
+ 12 = 3
4 .
7. Ieškomus dydžius randa tokia programa:
N<-10000x<-rpois(N,lambda=3)y<-rgeom(N,prob=0.5)cat("Ieškoma tikimybė apytiksliai lygi",
20

format(mean(x==3*y),digits=3),"\n")cat("Ieškoma kovariacija apytiksliai lygi",
format(cov(x==y,y),digits=3),"\n")
Atsakymas:
Ieškoma tikimybė apytiksliai lygi 0.0863Ieškoma kovariacija apytiksliai lygi 0.059
8. Ieškomus dydžius randa tokia programa:
N<-10000x<-rcauchy(N)cat("Ieškoma tikimybė apytiksliai lygi",
format(mean(x>2),digits=3),"\n")cat("Ieškomas vidurkis apytiksliai lygus",
format(mean((abs(x)<2)*x),digits=3),"\n")
Atsakymas:
Ieškoma tikimybė apytiksliai lygi 0.153Ieškomas vidurkis apytiksliai lygus 0.00934
9. Ieškomus dydžius randa tokia programa:
N<-10000x<-rnorm(N,mean=1,sd=sqrt(2))y<-rnorm(N,mean=1,sd=sqrt(2))cat("Ieškoma tikimybė apytiksliai lygi",
format(mean(x*y>0),digits=3),"\n")cat("Ieškomas vidurkis apytiksliai lygus",
format(mean(abs(x-y)),digits=3),"\n")
Atsakymas:
Ieškoma tikimybė apytiksliai lygi 0.631Ieškomas vidurkis apytiksliai lygus 1.61
10. Formulė X dydžio realizacijoms generuoti randama taip. PažymiuF (x) = P(X 6 x); tada su x > 1
F (x) =∫ x
1
3t4
dt = 3t−3
−3
∣∣∣∣x1
= 1− 1x3 .
21

Spręsdamas lygtį F (x) = u, gaunu
1− 1x3 = u,
1x3 = 1− u,
x3 = (1− u)−1,
x = (1− u)−1/3.
Taigi ieškomus dydžius randa tokia programa:
N<-10000u<-runif(N)x<-(1-u)^(-1/3)cat("Ieškomas vidurkis apytiksliai lygus",
format(mean(x),digits=3),"\n")cat("Ieškoma dispersija apytiksliai lygi",
format(var((x<2)*x),digits=3),"\n")
Atsakymas:
Ieškomas vidurkis apytiksliai lygus 1.52Ieškoma dispersija apytiksliai lygi 0.239
1.4 Tikroji teorijaMačios erdvės. Tegu E yra kokia nors aibė. Jos poaibių aibė A vadinamaσ-algebra, jei teisingi tokie trys teiginiai: (1) ∅ ∈ A, (2) Ac ∈ A su visomisA ∈ A ir (3) ⋃nAn ∈ A su bet kokia seka (An) ⊂ A. Aibė su fiksuotapoaibių σ-algebra vadinama mačia erdve.
Jei E yra mati erdvė, tai aibės iš fiksuotosios σ-algebros vadinamos ma-čiomis (ir tada fiksuotąją σ-algebrą galima vadinti visų mačių poaibių σ-algebra). Taigi pagal apibrėžimą tuščioji aibė mati, mačios aibės papildinysyra mati aibė ir mačių aibių sekos junginys yra mati aibė. Pasirėmus aibiųteorijos lygybėmis nesunku įrodyti, kad mačios ir kitos aibės: visa E, mačiųaibių skirtumas ir mačių aibių sekos sankirta. Kitaip tariant, atlikus betkokius įprastus veiksmus su mačiomis aibėmis vėl gauname mačias aibes.
Jei E yra metrinė erdvė, joje paprastai fiksuojama Borelio σ-algebra —mažiausia σ-algebra, kuriai priklauso visi atviri E poaibiai.
22

Mačios funkcijos. Jei E ir F yra mačios erdvės, funkcija f : E → Fvadinama mačia, jei mačios visos f ∈ B = x | f(x) ∈ B pavidalo aibės;čia B — matus F erdvės poaibis.
Jei tiek E, tiek F yra metrinės erdvės (su fiksuotomis Borelio σ-algeb-romis), mačios funkcijos dar vadinamos Borelio funkcijomis. Visos tolydžiosfunkcijos yra Borelio funkcijos.
Tikimybių teorijoje paprastai fiksuojama viena mati erdvė Ω ir nagrinė-jamos mačios funkcijos iš Ω į E. Jos žymimos didžiosiomis raidėmis, pavyz-džiui, X, ir vadinamomis atsitiktiniais E erdvės elementais (arba atsitikti-niais dydžiais su reikšmėmis iš E). Taigi X yra atsitiktinis dydis, jei mačiosvisos X ∈ A = ω | X(ω) ∈ A pavidalo aibės; čia A yra matus E erdvėspoaibis.
Dviejų mačių funkcijų kompozicija yra mati funkcija. Taigi jei X yraatsitiktinis E elementas ir f — mati funkcija iš E į F , tai f(X) (t.y. funkcijaω 7→ f(X(ω))) yra atsitiktinis F erdvės elementas.
Atsitiktiniai vektoriai. Jei E1 ir E2 yra dvi mačios erdvės, E1×E2 erdvėjepaprastai fiksuojama σ-algebra, generuota visų A1×A2 pavidalo stačiakam-pių; čia A1 yra matus E1 erdvės, o A2 — matus E2 erdvės poaibis. Tada,pavyzdžiui, jei X1 yra atsitiktinis E1 erdvės elementas, o X2 — atsitiktinis E2erdvės elementas, tai į porą (X1, X2) galima žiūrėti kaip į atsitiktinį E1×E2erdvės elementą (ir jei f yra mati dviejų kintamųjų funkcija iš E1 × E2 į F ,tai f(X1, X2) bus atsitiktinis F elementas).
Šiek tiek nemaloni situacija gaunasi, kai E1 ir E2 yra metrinės erdvės.Tada E1×E2 erdvę taip pat galima būtų natūraliai metrizuoti; deja, ne visadajos Borelio σ-algebra bus generuota mačių stačiakampių. Šios problemosnelieka, kai abi E1 ir E2 erdvės separabilios. Todėl tikimybių teorijoje tiktokia situacija paprastai ir nagrinėjama. Taigi „separabiliu atveju“ jei X1 irX2 yra atsitiktiniai dydžiai, tai f(X1, X2) bus atsitiktinis dydis su bet kokiadviejų kintamųjų Borelio funkcija f .
Matai ir integralai. Matu mačioje erdvėje E vadinama bet kokia funk-cija A 7→ µ(A) iš visų mačių poaibių σ-algebros į [0;∞], tenkinati tokiasdvi sąlygas: (1) µ(∅) = 0 ir (2) µ(A) = ∑
i µ(Ai) su bet kokiu skaičiu Aaibės skaidiniu (Ai) (į mačias aibes). Įrodoma, kad kiekvienas matas turi irdaugiau gerų savybių: pavyzdžiui, kuo didesnė aibė tuo didesnis ir jos matas.
Matas µ vadinamas tikimybiniu matu, arba tiesiog tikimybe, jei µ(E) = 1;tada µ(A) 6 1 su visomis A.
Jei µ yra matas E erdvėje, tai su bet kokia neneigiama mačia funkcija ftoje erdvėje apibrėžiamas jos integralas µ mato atžvilgiu. Jis yra tam tikras
23

skaičius iš [0;∞] (gali būti lygus ∞, net jei f funkcija baigtinė), žymimas∫f(x)µ(dx), arba
∫fdµ. Su bet kokia mačia aibe A simboliu 1A žymiu jos
indikatorių — funkciją, kuri lygi 1, kai argumentas priklauso A aibei, ir lygi0 kitais atvejais. Integralas apibrėžiamas taip, kad visada
∫1Adµ = µ(A).
Jei funkcija f įgyja ir neigiamas reikšmes, ji iš pradžių užrašoma f =f+ − f− pavidalu, ir tada jos integralas apibrėžiamas
∫f dµ =
∫f+dµ −∫
f−dµ lygybe — jei tik reiškinys dešinėje pusėje apibrėžtas, t.y. jei bentvienas dėmuo yra baigtinis. Jei baigtiniai abu dėmenys, integralas ne tikapibrėžtas, bet ir baigtinis; tokiu atveju funkcija vadinama integruojama.Funkcija integruojama tada ir tik tada, kai
∫|f | dµ <∞.
Taip apibrėžtas integralas turi įprastas Rymano integralo savybes: kons-tanta išsikelia iš integralo, sumos integralas lygus integralų sumai, padidinusfunkciją integralas padidėja.
Galima apibrėžti ir f funkcijos integralą kokioje nors mačioje aibėje A:jis žymimas
∫A f(x)µ(dx), arba
∫A fdµ ir apibrėžiamas kaip
∫1Af dµ (tais
atvejais, kai tas reiškinys apibrėžtas). Pavyzdžiui,∫A dµ = µ(A).
Atsitiktinių dydžių skirstiniai. Mati erdvė su fiksuota tikimybe vadi-nama tikimybine erdve. Tikimybių teorijoje paprastai fiksuojama viena tiki-mybinė erdvė (Ω,P) ir nagrinėjami įvairūs joje apibrėžti atsitiktiniai dydžiai— su reikšmėmis kokioje nors metrinėje erdvėje E. Jei E = R, X yra rea-lioji funkcija Ω erdvėje ir galima kalbėti apie jos integralą P atžvilgiu. Jisvadinamas X dydžio vidurkiu ir paprastai žymimas EX:
EX =∫XdP =
∫X(ω)P(dω).
Bendruoju atveju (jei E yra bet kokia metrinė erdvė), X funkcijos integruotinegalime, tačiau galime nagrinėti įvairias jos skaitines charakteristikas f(X)(imdami įvairias Borelio funkcijas f : E → R) ir skaičiuoti jų vidurkiusEf(X).
Jei X yra bet koks atsitiktinis dydis, lygybe
µ(A) = P(X ∈ A)
apibrėžiamas tikimybinis matas E erdvėje; jis vadinamasX dydžio skirstiniu.Įrodoma, kad tada
Ef(X) =∫f(x)µ(dx).
Ar dirbti su vidurkiais Ef(X), ar su integralais∫f dµ — skonio reikalas.
24

Skaičiuojantieji ir Lebego matai. Bet kokioje erdvėje E lygybe λ(A) =∑x∈A 1 apibrėžiamas matas; jis vadinamas skaičiuojančiuoju matu. Integralai
skaičiuojančiojo mato atžvilgiu yra sumos:∫f dλ =
∑x∈E
f(x).
Lebego matai apibrėžiami tik E = Rk erdvėse. Integralai Lebego matųatžvilgiu yra įprasti Rymano integralai: pavyzdžiui, jei λ yra Lebego matas,atitinkamai, R, R2 arba R3 erdvėje, tai
∫A fdλ integralas atitinkamai lygus∫
Af(x)dx,
∫Af(x, y)dxdy arba
∫Af(x, y, z)dxdydz.
Tankiai. Jei jau turime vieną matą λ, galime daug lengviau apibrėžti visąšeimą su tuo λ susijusių matų: tereikia paimti bet kokią neneigiamą mačiąfunkciją p ir apibrėžti
µ(A) =∫Ap(x)λ(dx).
Nesunku įrodyti, kad toks µ tikrai yra matas; sakoma, kad jis absoliučiaitolydus λ atžvilgiu, o p funkcija vadinama jo tankiu (λ mato atžvilgiu). Darsakoma, kad λ dominuoja µ matą. Integralai µ mato atžvilgiu skaičiuojamipagal formulę ∫
Afdµ =
∫f(x)p(x)λ(dx).
Jei∫p(x)λ(dx) = 1, µ yra tikimybė. Jei X yra atsitiktinis dydis su
skirstiniu µ, sakoma, kad pats X turi tankį p (λ mato atžvilgiu).Statistikoje λ dažniausiai būna arba skaičiuojantysis matas, arba Lebego
matas. Pirmuoju atveju X dydis (ir jo skirstinys µ) vadinamas diskrečiu irpagrindinės jo charakteristikos skaičiuojamos taip:
P(X ∈ A) =∑x∈A
p(x), Ef(X) =∑x
f(x)p(x);
be to, p(x) = P(X = x) su visais x. Antruoju atveju dydis vadinamastolydžiu (nors griežtai kalbant reiktų vadinti bent jau absoliučiai tolydžiu) irjo charakteristikos skaičiuojamos taip:
P(X ∈ A) =∫Ap(x) dx, Ef(X) =
∫f(x)p(x)dx.
Jei dominuojantis matas nenurodytas, jis, matyt, yra Lebego matas. Taigijei pasakyta, kad X dydis tiesiog turi tankį, reiktų suprasti, kad jis turi tankįLebego mato atžvilgiu.
25

2 Statistiniai uždaviniai
2.1 Praktinė teorijaDuomenys. Statistiniai duomenys visada būna surašyti į vadinamąją duo-menų lentelę; jos stulpelius atitinka stebimi kintamieji, o eilutes — tų kinta-mųjų stebiniai. Tokia lentelė dar vadinama imtimi. Lentelės eilučių skaičiųvisada žymėsiu n raide ir vadinsiu imties dydžiu.
Šiuose konspektuose dažniausiai bus nagrinėjama situacija, kai tėra (ar-ba kai mus domina) tik vienas stulpelis; tada atitinkamo kintamojo reikš-mę i-ojoje eilutėje žymėsiu xi. Tokiu atveju formaliai imtis yra rinkinys(x1, . . . , xn). Jei netyčia sugalvočiau uždavinį su dviem stebimais kintamai-siais, antro kintamojo reikšmę i-ojoje eilutėje žymėsiu yi; tada turėčiau vek-torinę imtį (
(x1, y1), . . . , (xn, yn)).
Modelis. Matematinė statistika prasideda tada, kai padaromos tam tikrosprielaidos apie stebinius xi. Dažniausiai būna tokios trys:
• xi yra atsitiktinio dydžio Xi realizacija (rinkinį (X1, . . . , Xn) aš vadinuatsitiktine imtimi);
• X1, . . . , Xn yra nepriklausomi atsitiktiniai dydžiai, pasiskirstę taip pat,kaip tam tikras dydis X (tą patį galima pasakyti ir kitaip: X1, . . . , Xn
yra nepriklausomos X dydžio kopijos, arba (X1, . . . , Xn) yra paprastojiimtis iš X dydžio skirstinio);
• X dydžio skirstinys nežinomas, bet žinoma, kad jis priklauso tam tikraižinomai skirstinių aibei.
Ta žinoma skirstinių aibė dažnai parametrizuojama; teorijoje parametraspaprastai žymimas θ raide, o Θ žymi visų galimų parametro reikšmių aibę.Jei kokios nors X dydžio, arba jo kopijų, charakteristikos (vidurkiai arbatikimybės) skaičiuojamos laikant, kad parametro reikšmė yra θ, vietoje E, P,D ir cov atitinkamai rašoma Eθ, Pθ, Dθ ir covθ.
Skirstinys, atitinkantis parametro reikšmę θ, paprastai turi tankį (skai-čiuojančiojo arba Lebego mato atžvilgiu), kurį aš žymėsiu pθ simboliu. Taigijei X diskretus, tai pθ(x) = Pθ(X = x) ir
Eθf(X1, . . . , Xn) =∑
x1∈D,...,xn∈Df(x1, . . . , xn)pθ(x1) · · · pθ(xn),
26

o jei X tolydus, tai pθ yra įprastas jo tankis ir
Eθf(X1, . . . , Xn) =∫x1∈D,...,xn∈D
f(x1, . . . , xn)pθ(x1) · · · pθ(xn)dx1 . . . dxn;
čia D — galimų X dydžio reikšmių aibė.Gali atsitikti, kad ir pati reikšmių aibė priklauso nuo θ ir tada reiktų
rašyti Dθ vietoje D. Bet tokiu atveju D raide galima pažymėti visų Dθ
aibių junginį, o į pθ apibrėžimą įtraukti indikatorius. Pavyzdžiui, jei X yrapasiskirstęs tolygiai (0; θ) intervale (ir θ > 0 yra nežinomas parametras),galima laikyti, kad D = (0;∞), o tankiai apibrėžiami lygybėmis
pθ(x) = 1θ
1(0;θ)(x) su x > 0.
Statistikos. Imties (x1, . . . , xn) funkcija paprastai vadinama statistika (tai-gi terminas statistika turi keletą reikšmių). Užrašant konkrečias statistikas,iškyla pora metodologinių problemų, kurias dabar aprašysiu.
1. Modernioje matematikoje priimta funkcijas žymėti viena raide. Pa-vyzdžiui, f yra funkcija, o f(x) — tos funkcijos reikšmė x taške. Taip galimabūtų elgtis ir statistikoje: jei t yra kokia nors statistika, tai t(x1, . . . , xn) ga-lėtų būti jos reikšmė, atitinkanti konkrečią imtį (x1, . . . , xn). Deja, istoriškaisusiklostė kitokia praktika. Tarkime, labai svarbios statistikos — vadinamiejiempiriniai vidurkiai — žymimi taip:
g(x) = g(x1) + · · ·+ g(xn)n
.
Pavyzdžiui,x = x1 + · · ·+ xn
n, x2 = x2
1 + · · ·+ x2n
n
ir pan. Empirinio vidurkio reikšmė, atitinkanti konkrečią imtį, žymima taippat, kaip ir pats empirinis vidurkis: jei (x1, . . . , xn) = (1, 1, 2, 1, 2), rašomax = 1.4.
Kita vertus, daugelis statistikų žymima viena raide, tik su stogeliu viršuje;pavyzdžiui, γ. Tačiau ir šiuo atveju statistikos reikšmė, atitinkanti konkrečiąimtį rašoma taip pat: pavyzdžiui, rašoma γ = 2.7, o ne γ(1, 1, 2, 1, 2) = 2.7.
2. Jei t(x1, . . . , xn) yra kokia nors statistika, tai t(X1, . . . , Xn) yra at-sitiktinis dydis, kuris irgi vadinamas statistika. Taigi galima kalbėti apiestatistikos tikimybines charakteristikas: vidurkį, dispersiją ir pan.
Jei t(x1, . . . , xn) = g(x), tai t(X1, . . . , Xn) žymima g(X); pavyzdžiui,
X = X1 + · · ·+Xn
n, X2 = X2
1 + · · ·+X2n
n
27

ir pan. Jei statistika t(x1, . . . , xn) pažymėta raide su stogeliu, pavyzdžiui,γ, atitinkama statistika t(X1, . . . , Xn) žymima tuo pačiu simboliu γ. Iš kon-teksto visada būna aišku, ką vienoje ar kitoje vietoje tas γ žymi.
Viena filosofinė problema. Kalbėdami apie statistikas, visada turimeomenyje, kad jos priklauso tik nuo imties, t.y. nepriklauso nuo nežinomosparametro reikšmės. Bet ką tas tik konkrečiai reiškia?
Įsivaizduokime, kad parametras yra realusis skaičius ir mums reikia pa-žiūrėjus į imtį atspėti nežinomą jo reikšmę, kuri buvo panaudota tai imčiaigeneruoti. Kitaip tariant, reikia sugalvoti statistiką, kurios reikšmės būtųkuo artimesnės nežinomai „tikrajai“ parametro reikšmei. Ta tikroji para-metro reikšmė yra tam tikras skaičius, tarkime, θ0. Tada lygybe
t(x1, . . . , xn) = θ0 su visomis (x1, . . . , xn) (2.1)
korektiškai apibrėžiama tam tikra imties funkcija, t.y. statistika. Aišku, kad
Pθ0(t(X1, . . . , Xn) = θ0) = 1, (2.2)
taigi egzistuoja statistika, kuri garantuotai atspėja nežinomą parametro reik-šmę. Lyg ir norėtųsi sakyti, kad (2.1) nėra tikra statistika, nes jos apibrėžimepanaudota nežinoma reikšmė θ0. Bet kas formaliai blogai tame apibrėžime:juk kairėje lygybės pusėje nėra jokio θ, taigi t tikrai yra tik imties funkcija?
Pabandykime į šią problemą pažiūrėti iš kito taško. Panagrinėkime visąklasę statistikų, apibrėžiamų lygybėmis
t(x1, . . . , xn) = c su visomis (x1, . . . , xn); (2.3)
čia c yra koks nors skaičius. Viena iš tų statistikų (atitinkanti c = θ0, t.y.(2.1) statistika) yra labai gera. Bet kadangi tikroji parametro reikšmė θ0mums nežinoma, mes nežinome, kuri statistika yra ta geroji. Taigi praktinėsvertės mūsų atradimas neturi. Bet kaip tą praktinės vertės nebuvimą pagrįstiteoriškai?
Norint išspręsti šią problemą, reikia tiesiog pamąstyti, kas gi yra ta „tik-roji“ parametro reikšmė. Žiūrint formaliai — tai ta reikšmė, kuri atsiran-da kaip indeksas E arba P simbolio apačioje. Jei t statistika apibrėžiama(2.1) lygybe, tai teisinga (2.2) lygybė, bet
Pθ(t(X1, . . . , Xn) = θ) = 0,
kai θ 6= θ0. Kitaip tariant, (2.1) statistika labai gera, jei θ0 tikrai yra „tikroji“parametro reikšmė, ir galbūt labai bloga, jei „tikroji“ parametro reikšmė yrakitokia.
28

Dabar aišku, kad (2.1) lygybe apibrėžiama funkcija tikrai yra statistika,bet ji niekuo nesiskiria nuo bet kokios (2.3) statistikos: visos jos yra idealios,jei c yra tikroji parametro reikšmė, bet galbūt labai prastos priešingu atveju.Ir galbūt kokia nors statistika, kuri nėra tokia gera tuo vieninteliu atveju,bet ir nėra tokia bloga likusiais atvejais, mums gali pasirodyti priimtinesnė.
Reziumuoju: nagrinėjant vieną ar kitą statistiką, jos kokybę reikia ver-tinti pagal tikimybines jos charakteristikas, apskaičiuotas visų galimų θ pa-rametro reikšmių atžvilgiu.
Statistiniai uždaviniai. Žinodamas turimų duomenų struktūrą statisti-kas jau gali suplanuoti vienokią ar kitokią seriją statistinių uždavinių. Po totirdamas konkrečius duomenis jis tuos uždavinius išsprendžia. Yra trys pag-rindiniai statistinių uždavinių tipai: patikrinti kokią nors hipotezę, įvertintikokį nors išvestinį parametrą arba sukonstruoti pasikliovimo intervalą tamišvestiniam parametrui. Toliau šiame skyrelyje kiekvieną uždavinį aprašysiusmulkiau, o dabar pasakysiu, ką visi trys uždaviniai turi bendro.
Jei imtis (x1, . . . , xn) fiksuota, kiekvienas uždavinys turi sprendinį, kurispriklauso nuo uždavinio tipo. Sprendinys yra tam tikra išvada apie modelioparametrus, kuri padaroma analizuojant turimus duomenis (pavyzdžiui, sta-tistinė hipotezė priimama arba atmetama). Ta išvada gali būti vienokia arbakitokia ir nežinodami tikrosios parametro reikšmės niekada negalime pasaky-ti, ar ji teisinga, ar klaidinga, ir jei klaidinga, tai kiek. Tačiau galima vertintimetodą, pagal kurį ta išvada buvo padaryta. Statistinių sprendimų teorijojeišvados paprastai žymimos d raide (dėl decision — angliškai sprendinys), oįvairūs metodai — δ raidėmis. Formaliai δ yra imties funkcija (t.y. statis-tika), kurios reikšmės — įvairūs galimi sprendiniai. Taigi d = δ(x1, . . . , xn)reiškia, kad pagal δ metodą turint imtį (x1, . . . , xn) reikia padaryti išvadą d.
Koks bebūtų uždavinys, jį spręsti galime naudodami įvairius metodus.Du metodai, tarkime, δ1 ir δ2, lyginami, palyginant tam tikras jų tikimybinescharakteristikas; kiekviena charakteristika yra tam tikras
Eθf(θ, δ(X1, . . . , Xn))
pavidalo vidurkis. Kai kurie tokie vidurkiai turėtų būti kuo mažesni, kiti— kuo didesni. Tačiau esminis dalykas yra tas, kad tie vidurkiai priklausonuo nežinomos parametro reikšmės θ. Dažniausiai su vienomis parametroreikšmėmis vieno metodo charakteristika būna geresnė, o su kitomis reikš-mėmis — kito metodo. Tada tenka konstatuoti, kad nagrinėjami metodainepalyginami.
Toliau, kaip ir žadėjau, pakalbėsiu apie kiekvieną iš trijų statistinių užda-vinių atskirai. Kiekvienu atveju pasakysiu, kaip uždavinys formuluojamas,
29

kokie galimi uždavinio sprendiniai, kaip vadinami naudojami metodai ir pa-gal kokias charakteristikas jie paprastai lyginami.
Hipotezių tikrinimas.
• Uždavinys formuluojamas taip: turint imtį reikia patikrinti hipotezęH : θ ∈M . ČiaM yra tam tikras konkretus parametrų aibės Θ poaibis.JeiM aibė susideda iš vieno taško, hipotezė vadinama paprastąja, kitaisatvejais — sudėtingąja. Bet kokia parametro reikšmė, nepriklausantiM aibei, vadinama alternatyva.
• Yra du galimi tokio uždavinio sprendiniai: hipotezė arba priimama(toks sprendinys paprastai koduojamas skaičiumi 0), arba atmetama(koduojama skaičiumi 1).
• Uždavinio sprendimo metodas vadinamas kriterijumi. Taigi kriteri-jus δ yra imties funkcija (statistika), įgyjanti reikšmes 0 ir 1. Ly-gybė δ(x1, . . . , xn) = 0 reiškia, kad pagal δ kriterijų turint duomenis(x1, . . . , xn) hipotezę reiktų priimti, lygybė δ(x1, . . . , xn) = 1 — kadatmesti. Aprašydami konkretų kriterijų, δ raidės nerašome — tiesiogpasakome, su kokiomis imtimis hipotezė atmetama. Suprantame tada,kad su likusiomis imtimis ją reiktų priimti.
• Pagrindinė δ kriterijaus charakteristika — vadinamoji galios funkcija
β(θ) = Pθ(δ(X1, . . . , Xn) = 1).
Kitaip tariant, β(θ) yra tikimybė atmesti hipotezę, naudojant nagrinė-jamą kriterijų (arba tikimybė, kad kriterijus atmeta hipotezę).Jei θ ∈ M , hipotezė yra teisinga, taigi ją atmesdami darome klaidą.Ji vadinama pirmos rūšies klaida. Taigi šiuo atveju β(θ) yra pirmosrūšies klaidos tikimybė.Jei θ 6∈ M , hipotezė nėra teisinga, taigi klaidą darome ją priimdami.Tokia klaida vadinama antros rūšies ir jos tikimybė yra 1− β(θ). Šiuoatveju tikimybė β(θ) vadinama kriterijaus galia (todėl β ir vadinamagalios funkcija).
• Lygindami du kriterijus, žiūrime, kad β(θ) reikšmė būtų kuo mažesnė,kai θ ∈ M , ir kuo didesnė, kai θ 6∈ M . Kitaip tariant, kriterijauspirmos rūšies klaidos tikimybė turėtų būti kuo mažesnė, o galia — kuodidesnė.
30

Parametrų vertinimas.
• Uždavinys formuluojamas taip: turint imtį reikia įvertinti tam tikrąišvestinį parametrą γθ. Čia γθ yra tam tikra skaliarinė θ argumentofunkcija. Pavyzdžiui, γθ = 1/θ, jei θ > 0 yra nežinomas modelio pa-rametras. Jei pats θ yra skaliarinis dydis, dažnai reikia būtent jį irįvertinti; tada γθ = θ. Bet θ gali būti ir vektorinis parametras, pavyz-džiui, θ = (µ, σ2), o įvertinti reikia kurią nors jo komponentę, tarkime,µ; tada γθ = γµ,σ2 = µ.
• Uždavinio sprendinys yra tam tikras realusis skaičius γ. Taip koduoja-ma išvada, kad nagrinėjamu atveju parametro reikšmė yra γ.
• Uždavinio sprendimo metodas vadinamas įvertiniu ir paprastai žymimaγ. Taigi γ yra skaliarinė imties funkcija (statistika). Jos reikšmė,atitinkanti konkrečią imtį (x1, . . . , xn) vadinama išvestinio parametroγθ įverčiu. Kaip minėjau anksčiau šiame skyrelyje, ir įvertinys, ir įvertispaprastai žymimas taip pat: γ, t.y. argumentas (x1, . . . , xn) nerašomas.
• Viena iš charakteristikų, pagal kurias sprendžiama apie įvertinio koky-bę, yra vadinamoji vidutinė kvadratinė paklaida
Eθ(γ − γθ)2.
Aišku, kad ji turėtų būti kuo mažesnė.Paymėkime mθ = Eθγ. Tada iš vidurkio savybių išplaukia, kad
Eθ(γ − γθ)2 = Eθ(γ −mθ +mθ − γθ)2
= Eθ(γ −mθ)2 − 2Eθ(γ −mθ)(mθ − γθ) + (mθ − γθ)2
= Dθγ + (mθ − γθ)2.
Taigi vidutinė kvadratinė paklaida bus maža, jei bus maža tiek įvertiniodispersija, tiek vadinamasis poslinkis mθ − γθ = Eθγ − γθ. (Tiksliau,mažas turėtų būti ne poslinkis, o jo absoliutinis dydis).
Pasikliovimo intervalų konstravimas.
• Uždavinys formuluojamas taip: turint imtį reikia sukonstruoti pasik-liovimo intervalą išvestiniam parametrui γθ.
• Uždavinio sprendinys yra intervalas (a; b) (kuris ir vadinamas pasiklio-vimo intervalu), arba, jei labiau patinka, du skaičiai, a ir b, galbūt,begaliniai, iš kurių pirmas yra ne didesnis už kitą. Taip koduojama
31

statistinė išvada, kad γθ ∈ (a; b). Paprastai abu intervalo galai yrabaigtiniai. Jei vienas iš jų yra begalinis, pasikliovimo intervalas vadi-namas vienpusiu.
• Sprendimo metodas šiuo atveju yra statistikų pora (a, b), tenkinanti są-lygą a 6 b. Intervalas (a; b) tada irgi vadinamas pasikliovimo intervalu.Aišku, jei uždavinys yra sukonstruoti vienpusį pasikliovimo intervalą,užtenka sukonstruoti vieną iš statistikų a ir b.
• Pagrindinės pasikliovimo intervalo charakteristikos yra dvi: patikimu-mas Pθ(a < γ(θ) < b) ir vidutinis intervalo ilgis Eθ(b−a). Patikimumasturėtų būti kuo didesnis, o vidutinis intervalo ilgis — kuo mažesnis.
2.2 Uždaviniai1. Tegu (X1, X2) yra imtis iš skirstinio
X 0 11− θ θ
(čia θ ∈ (0; 1) — nežinomas parametras) ir tikrinama hipotezė H : θ 6 12 .
Palyginkite tokius tris kriterijus:(1) hipotezė atmetama, kai X1 = X2 = 0;(2) hipotezė atmetama, kai X1 = X2 = 1;(3) hipotezė atmetama, kai X1 = 1.
2. Tegu (X1, X2) yra imtis iš skirstinio
X 0 11− θ θ
(čia θ ∈ (0; 1) — nežinomas parametras) ir vertinamas parametras θ. Paly-ginkite tokių trijų įvertinių poslinkius ir dispersijas:
θ1 = X1, θ2 = X1 +X2
2 , θ3 = max(X1, X2).
3. Tegu (X1, X2) yra imtis iš skirstinio
X 0 11− θ θ
32

(čia θ ∈ (0; 1) — nežinomas parametras) ir ieškomas pasikliovimo intervalasparametrui θ. Palyginkite tokių trijų intervalų patikimumą ir vidutinį ilgį:
(a1; b1) =(min(X1, X2); max(X1, X2)
),
(a2; b2) = (X6 ; X3 ), X = X1 +X2
2 ,
(a3; b3) = (13 ; 2
3).
4. Tegu (X1, X2) yra imtis iš U(0; θ) skirstinio (čia θ > 0 — nežinomasparametras) ir tikrinama hipotezė H : θ 6 1. Palyginkite tokius tris krite-rijus:
(1) hipotezė atmetama, kai bent vienas Xi didesnis už 1;(2) hipotezė atmetama, kai abu Xi didesni už 1;(3) hipotezė atmetama visada.
5. Tegu (X1, X2) yra imtis iš U(0; θ) skirstinio (čia θ > 0 — nežinomasparametras) ir vertinamas θ parametras. Palyginkite tokius tris įvertinius(pagal poslinkį ir dispersiją):
θ1 = X1 +X2, θ2 = max(X1, X2), θ3 = 2.
6. Tegu (X1, X2) yra imtis iš U(0; θ) skirstinio (čia θ > 0 — nežinomasparametras) ir ieškomas pasikliovimo intervalas θ parametrui. Palyginkitetokius du intervalus (pagal patikimumą ir vidutinį ilgį):
(a1; b1) = (X1;X1 + 1), (a2; b2) = (X1;X1 +X2).
7. Tegu (X1, . . . , Xn) yra imtis iš skirstinio
X 0 11− θ θ
(čia θ ∈ (0; 1) — nežinomas parametras) ir tikrinama hipotezė H : θ 6 12 .
Palyginkite tokius du kriterijus:(a) hipotezė atmetama, kai visi Xi yra vienetai;(b) hipotezė atmetama, kai didesnė pusė Xi skaičių yra vienetai.Imkite n = 10 ir abiem atvejais sukaičiuokite funkcijos β(θ) reikšmes
su pakankamai dideliu skaičiumi θ parametro reikšmių. Nubrėžkite vienamepiešinyje abiejų funkcijų grafikus ir parašykite trumpą komentarą apie gautusrezultatus.
33

8. Tegu (X1, . . . , Xn) yra imtis iš U(0; θ) skirstinio (čia θ > 0 — nežinomasparametras) ir vertinamas θ parametras. Palyginkite tokius du įvertinius(pagal poslinkį ir dispersiją):
θ1 = X1 + · · ·+Xn, θ2 = max(X1, . . . , Xn).
Imdami n = 5, 10, . . . , 20 nubrėžkite abiejų charakteristikų grafikus ir vėlpakomentuokite.
9. Tegu (X1, . . . , Xn) yra imtis iš normalaus skirstinio su vidurkiu µ irdispersija σ2 (čia µ ∈ R ir σ > 0 — nežinomi parametrai). Palyginkitetokius µ parametro pasikliovimo intervalus (pagal patikimumą ir vidutinįilgį):
(a1; b1) = (X − 1;X + 1) ir (a2; b2) = (X − s;X + s);
čia
X = X1 + · · ·+Xn
n, s =
√(X1 −X)2 + · · ·+ (Xn −X)2
n− 1 .
Imkite n = 10 ir visada µ = 0, bet su įvairiomis σ reikšmėmis (pavyzdžiui,iš intervalo (0.1; 10)). Tyrimų rezultatus pavaizduokite grafiškai ir pakomen-tuokite.
10. (X1, . . . , Xn) yra imtis iš skirstinio, aprašomo lentele
X 1 2 3θ θ 1− 2θ
čia θ ∈ (0; 12) — nežinomas parametras. Tegu N yra trejetukų skaičius
imtyje. Panagrinėkite tokį kriterijų hipotezei H : θ 6 14 tikrinti: hipotezė
atmetama, kai N > n/2.(a) (Užduotis su kompiuteriu) Nubrėžkite viename piešinyje kriterijaus
galios funkcijų grafikus, atitinkančius n = 10, 20, . . . , 100.(b) (Užduotis ant popieriaus) Imdami n = 2, apskaičiuokite kriterijaus
galios funkciją ir nubrėžkite jos grafiką. Palyginkite kriterijų su alternatyviukriterijumi, kuris atmeta hipotezę, kai N 6 n/2.
11. (X1, . . . , Xn) yra imtis iš U(0; θ) skirstinio; čia θ > 0 — nežinomas pa-rametras. Panagrinėkite tokius du išvestinio parametro γθ = ln θ įvertinius:
γ1 = lnXn ir γ2 = max(lnX1, . . . , lnXn).
34

(a) (Užduotis su kompiuteriu) Imdami n = 20, nubrėžkite abiejų kriterijųposlinkio ir dispersijos grafikus ir palyginkite tuos kriterijus.
(b) (Užduotis ant popieriaus) Apskaičiuokite pirmojo kriterijaus poslinkį,kai n = 2.
12. (X1, . . . , Xn) yra imtis iš eksponentinio skirstinio su tankiu
pθ(x) = θe−θx, kai x > 0;
čia θ > 0 — nežinomas parametras. Panagrinėkite tokius du pasikliovimointervalus išvestiniam parametrui γθ = 1/θ:
(X − 1n;X + 1
n) ir (X;∞).
(a) (Užduotis su kompiuteriu) Imdami n = 15, nubrėžkite viename pieši-nyje abiejų intervalų patikimumo grafikus. Palyginkite tuos intervalus.
(b) (Užduotis ant popieriaus) Koks yra pirmojo pasikliovimo intervalovidutinis ilgis ir patikimumas, kai n = 1?
2.3 Sprendimai1. Rasiu visų trijų kriterijų galios funkcijas βi. (X1, X2) vektoriaus skirsti-nys aprašomas lentele
X1 X2 0 10 (1− θ)2 (1− θ)θ 1− θ1 (1− θ)θ θ2 θ
1− θ θ
Todėl
β1(θ) = P(X1 = X2 = 0) = (1− θ)2,
β2(θ) = P(X1 = X2 = 1) = θ2,
β3(θ) = P(X1 = 1) = θ.
Pirmas kriterijus prastesnis už antrą: β1(θ) > β2(θ), jei θ 6 12 , ir β1(θ) <
β2(θ), jei θ > 12 .
Antras ir trečias kriterijai nepalyginami: nors β3(θ) < β1(θ) su θ 6 12
(taigi lyg ir geresnis trečias), bet ta nelygybė teisinga ir su θ > 12 (ir tuo
požiūriu geresnis pirmas kriterijus).Pirmas ir trečias kriterijai taip pat nepalyginami: viena vertus,
β1(14) = 9
16 >14 = β3(1
4)
35

(taigi lyg ir geresnis trečias), bet
β1(12) = 1
4 <12 = β3(1
2)
(geresnis pirmas).
2. Kadangi
Eθθ1 = EθX1 = θ ir Eθθ2 = 12(EθX1 + EθX2) = EθX1 = θ,
pirmi du įvertiniai nepaslinkti (jų poslinkis lygus 0 su visomis θ reikšmėmis).Trečio įvertinio poslinkis
Eθθ3 − θ = Eθ max(X1, X2)− θ = 2θ(1− θ) + θ2 − θ = θ − θ2
visada teigiamas. Taigi šiuo požiūriu trečias įvertinys prasčiausias, o kiti duvienodi.
Kadangi
Dθθ2 = DθX1 +X2
2 = 14(DθX1 + DθX2) = 1
2DθX1 = 12Dθθ1,
antras įvertinys neabejotinai geresnis už pirmąjį (abu jie nepaslinkti, o ant-rojo dispersija mažesnė). Parodysiu, kad pirmi du įvertiniai nepalyginami sutrečiuoju. Tam tereikia įsitikinti, kad su tam tikromis θ reikšmėmis Dθθ3 <Dθθ2. Iš
DθX1 = EθX21 − (EθX1)2 = θ − θ2
išplaukia, kadDθ2 = θ − θ2
2 .
Kita vertus, θ3 įgyja tik 0 ir 1 reikšmes, todėl θ23 = θ3 ir
Dθθ3 = Eθθ3 − (Eθθ3)2 = 2θ(1− θ) + θ2 − (2θ(1− θ) + θ2)2
= 2θ − 5θ2 + 4θ3 − θ4.
Reikia rasti θ reikšmę, su kuria
2θ − 5θ2 + 4θ3 − θ4 <θ − θ2
2 ,
t.y.
3θ − 9θ2 + 8θ3 − 2θ4 < 0,
36

θ(1− θ)(3− 6θ + 2θ2) < 0,
arba3− 6θ + 2θ2 < 0.
Tokia θ reikšmė tikrai egzistuoja: kadangi 3 − 6 + 2 = −1 < 0, kvadrati-nis trinaris bus neigiamas ir su pakankamai arti 1 esančiomis θ reikšmėmis;pavyzdžiui, su θ = 2/3.
3. Iš pradžių rasiu visų trijų pasikliovimo intervalų patikimumus ci(θ). Ka-dangi a1 ir b1 įgyja tik 0 ir 1 reikšmes,
c1(θ) = Pθ(a1 < θ < b1) = Pθ(a1 = 0, b1 = 1)= Pθ(X1 = 0, X2 = 1) + Pθ(X2 = 0, X1 = 1) = 2θ(1− θ).
(a2; b2) intervalas yra arba tuščioji aibė (kai X1 = X2 = 0), arba (13 ; 2
3)intervalas (kai X1 = X2 = 1), arba (1
6 ; 13) intervalas (likusiais dviem atvejais).
Todėl
c2(θ) =
θ2, kai 1
6 < θ < 13 ;
2θ(1− θ), kai 13 < θ < 2
3 ;0 su kitais θ.
Na ir akivaizdu, kad
c3(θ) =
1, kai 13 < θ < 2
3 ;0 su kitais θ.
Jei lygintume vien tik pagal patikimumą, rezultatai būtų tokie:• antras intervalas geresnis už pirmą (nes θ2 < 2θ(1− θ) su θ < 1
3);
• trečias intervalas nepalyginamas nei su pirmu, nei su antru (kai θ ∈(1
3 ; 23), jis geresnis už abu pirmus; kai θ ∈ (1
6 ; 13) — prastesnis).
Dabar suskaičiuoju vidutinius intervalų ilgius:
Eθ(b1 − a1) = 2θ(1− θ);
Eθ(b2 − a2) = 16EθX = θ
6 ,
Eθ(b3 − a3) = 13 .
Jei lygintume vien tik pagal vidutinį ilgį, visi trys intervalai būtų nepalygi-nami. Pavyzdžiui, jei θ < 11
12 , pirmas intervalas vidutiniškai ilgesnis už antrą,o jei θ > 11
12 — atvirkščiai.Taigi apskritai visi trys pasikliovimo intervalai nepalyginami.
37

4. Rasiu visų trijų kriterijų galios funkcijas βi. Aišku, kad
β1(θ) = Pθ(X1 > 1 arba X2 > 1)= 1− Pθ(X1 6 1, X2 6 1) = 1− [Pθ(X 6 1)]2.
Bet su θ > 1Pθ(X 6 1) = 1
θ,
o su θ 6 1 ta tikimybė lygi 1. Taigi
β1(θ) =
0, kai θ 6 1;1− 1
θ2 , kai θ > 1.
Analogiškai
β2(θ) = Pθ(X1 > 1, X2 > 1) = [Pθ(X > 1)]2 =
0, kai θ 6 1;(1− 1
θ)2, kai θ > 1.
Be to, su visais θβ3(θ) = 1.
Dabar akivaizdu, kad trečias kriterijus nepalyginamas nei su pirmu, neisu antru: nors jo galia didžiausia, bet jo pirmos rūšies klaidos tikimybė irgiyra 1, o pirmų dviejų kriterijų ta tikimybė yra 0. Pirmas kriterijus geresnisuž antrą: abiejų kriterijų pirmos rūšies klaidos tikimybės identiškos (lygios 0su visais θ 6 1), bet pirmas galingesnis, nes su visais θ > 1
θ2 > θ,
2θ>
2θ2 ,
1− 1θ2 > 1− 2
θ+ 1θ2 =
(1− 1
θ
)2
ir, reiškia, β1(θ) > β2(θ).
5. Pirmo įvertinio poslinkis
Eθθ1 − θ = 2EθX − θ = 2∫ θ
0
x
θdx− θ = θ − θ = 0.
Kadangi
Eθθ2 = 1θ2
∫0<x1<θ0<x2<θ
max(x1, x2)dx1dx2
38

= 1θ2
∫0<x1<x2<θ
x2 dx1dx2 + 1θ2
∫0<x2<x1<θ
x1 dx1dx2
= 2θ2
∫ θ
0x2 dx2
∫ x2
0dx1
= 2θ2
∫ θ
0x2
2 dx2
= 2θ3 ,
antro įvertinio poslinkisEθθ2 − θ = −θ3 .
Ir, aišku,Eθθ3 − θ = 2− θ.
Jeigu lygintume tik pagal poslinkį, pirmas įvertinys būtų geresnis už kitusdu, o pastarieji nepalyginami: jei 3
2 < θ < 3,
|2− θ| < θ
3(ir, reiškia, geresnis trečias įvertinys), o su likusiais θ teisinga atvirkščia ne-lygybė.
KadangiEθX2 = 1
θ
∫ θ
0x2dx = θ2
3 ,
pirmo įvertinio dispersija
Dθθ1 = Dθ(X1 +X2) = 2DθX = 2(θ2
3 −θ2
4
)= θ2
6 .
Panašiai iš
Eθ[max(X1, X2)]2 = 2θ2
∫0<x1<x2<θ
x22 dx1dx2 = 2
θ2
∫ θ
0x2
2dx2
∫ x2
0dx1
= 2θ2
∫ θ
0x3
2dx2 = θ2
2išplaukia
Dθθ2 = θ2
2 −4θ2
9 = θ2
18 .
Ir aišku,Dθθ3 = 0.
Jei lygintume vien pagal dispersiją, trečias įvertinys būtų geriausias, opirmas — pats blogiausias. Lyginant pagal abu kriterijus išvada tokia: betkurie du kriterijai vienas su kitu nepalyginami.
39

6. Pirmo pasikliovimo intervalo patikimumas
c1(θ) = Pθ(X1 < θ < X1 + 1) = Pθ(θ − 1 < X1 < θ) =
1, kai θ 6 1;1θ, kai θ > 1.
Antro pasikliovimo intervalo patikimumas
c2(θ) = Pθ(X1 < θ < X1 +X2) = Pθ(X1 +X2 > θ) = 1θ2
∫0<x1<θ0<x2<θx1+x2>θ
dx1dx2
= 1θ2
∫ θ
0dx1
∫ θ
θ−x1dx2 = 1
θ2
∫ θ
0x1dx1 = 1
2 .
Taigi abu intervalai nepalyginami lyginant net ir vien pagal patikimumą: jeiθ < 2, geresnis pirmas, o jei θ > 2 — antras intervalas.
Dabar skaičiuoju vidutinius intervalų ilgius:
Eθ(b1 − a1) = Eθ1 = 1
irEθ(b2 − a2) = EθX2 = 1
θ
∫ θ
0x2dx2 = θ
2 .
Todėl lyginant pagal vidutinį ilgį situacija atvirkščia: jei θ < 2, geresnisantras, o jei θ > 2 — pirmas intervalas.
7. Programa:
n<-10N<-10000T<-100teta<-seq(from=0.01, to=1, by=0.01)atmete1<-numeric(N)atmete2<-numeric(N)beta1<-numeric(T)beta2<-numeric(T)for (t in 1:T)
for (i in 1:N)
u<-runif(n)x<-(u<teta[t])atmete1[i]<-(min(x)==1)atmete2[i]<-(mean(x)>0.5)
40

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
teta
beta
3 pav. Žr. 7 uždavinį
beta1[t]<-mean(atmete1)beta2[t]<-mean(atmete2)
plot(teta,beta1,type="l",ylab="beta", col="blue")lines(teta,beta2,type="l",col="red")
Rezultatai tokie (žr. 3 pav.). Antro kriterijaus (raudona linija) galiadidesnė už pirmojo su visais θ > 1/2, tačiau didesnė ir pirmos rūšies klaidostikimybė; taigi kriterijai nepalyginami.
8. Programa:
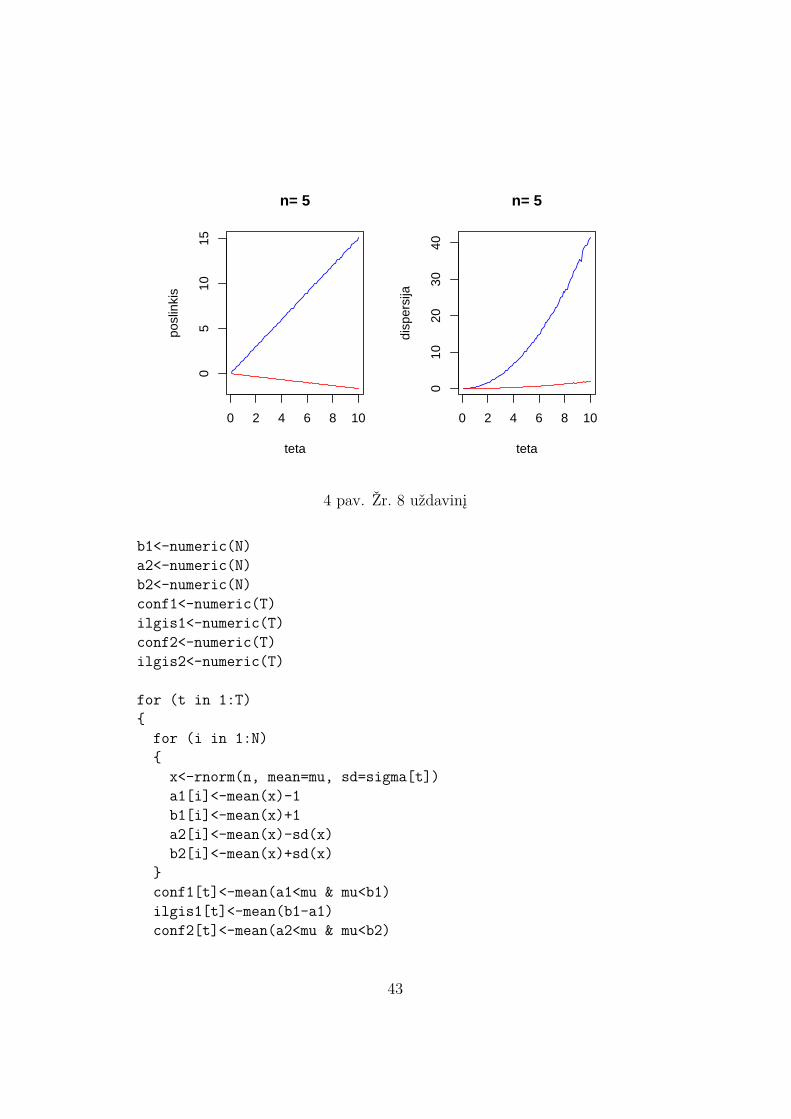
N<-10000T<-100teta<-seq(from=0.1, to=10, by=0.1)est1<-numeric(N)est2<-numeric(N)poslinkis1<-numeric(T)poslinkis2<-numeric(T)dispersija1<-numeric(T)dispersija2<-numeric(T)
41

old.par<-par(mfrow=c(1,2))for (n in c(5,10,15,20))
for (t in 1:T)
for (i in 1:N)
x<-runif(n, max = teta[t])est1[i]<-sum(x)est2[i]<-max(x)
poslinkis1[t]<-mean(est1)-teta[t]dispersija1[t]<-var(est1)poslinkis2[t]<-mean(est2)-teta[t]dispersija2[t]<-var(est2)
ymin<-min(min(poslinkis1),min(poslinkis2))ymax<-max(max(poslinkis1),max(poslinkis2))
plot(teta,poslinkis1,type="l",main=paste("n=",n),ylab="poslinkis", ylim=c(ymin,ymax), col="blue")
lines(teta,poslinkis2,type="l",col="red")plot(teta,dispersija1,type="l",main=paste("n=",n),
ylab="dispersija", col="blue")lines(teta,dispersija2,type="l",col="red")
par(old.par)
Rezultatai tokie (žr. 4 pav.). Kai n = 5, antras įvertinys (raudona linija)geresnis už pirmą (su visomis θ reikšmėmis tiek jo poslinkis, tiek dispersijamažesni). Tą patį galima pasakyti ir kai n didesnis.
9. Programa:
n<-10N<-10000T<-100mu<-0sigma<-seq(from=0.1, to=10, by=0.1)a1<-numeric(N)
42
0 2 4 6 8 10
05
1015
n= 5
teta
posl
inki
s
0 2 4 6 8 100
1020
3040
n= 5
teta
disp
ersi
ja
4 pav. Žr. 8 uždavinį
b1<-numeric(N)a2<-numeric(N)b2<-numeric(N)conf1<-numeric(T)ilgis1<-numeric(T)conf2<-numeric(T)ilgis2<-numeric(T)
for (t in 1:T)
for (i in 1:N)
x<-rnorm(n, mean=mu, sd=sigma[t])a1[i]<-mean(x)-1b1[i]<-mean(x)+1a2[i]<-mean(x)-sd(x)b2[i]<-mean(x)+sd(x)
conf1[t]<-mean(a1<mu & mu<b1)ilgis1[t]<-mean(b1-a1)conf2[t]<-mean(a2<mu & mu<b2)
43

0 2 4 6 8 10
0.4
0.6
0.8
1.0
sigma
patik
imum
as
0 2 4 6 8 100
510
1520
sigma
ilgis
5 pav. Žr. 9 uždavinį
ilgis2[t]<-mean(b2-a2)
old.par<-par(mfrow=c(1,2))conflim=c(min(min(conf1),min(conf2)),
max(max(conf1),max(conf2)))plot(sigma,conf1,type="l", ylab="patikimumas", ylim=conflim)lines(sigma,conf2,type="l",col="red")ilgislim=c(min(min(ilgis1),min(ilgis2)),
max(max(ilgis1),max(ilgis2)))plot(sigma,ilgis1,type="l", ylab="ilgis", ylim=ilgislim)lines(sigma,ilgis2,type="l",col="red")par(old.par)
Rezultatai tokie (žr. 5 pav.). Antro pasikliovimo intervalo (raudona li-nija) patikimumas nuo σ nepriklauso ir praktiškai lygus 1. Pirmo intervalopatikimumas panašus, kol σ mažas (neviršija maždaug 1), bet toliau didėjantσ jis drastiškai mažėja. Kita vertus, pirmo intervalo vidutinis ilgis pastovus(lygus 2), o antro pasikliovimo intervalo vidutinis ilgis didėja augant σ.
44

3 Pakankamos statistikos
3.1 Praktinė teorijaSąlyginiai skirstiniai. Grįžkime prie uždavinių spręstų 1 skyriuje: kaipskaičiuoti atsitiktinio vektoriaus (X, Y ) charakteristikas Ef(X, Y ). Žinome,kaip tą padaryti, kai bendras skirstinys aprašytas tiesiogiai (pavydžiui, duo-tas vektoriaus tankis p(x, y)), arba kai vektoriaus koordinatės nepriklauso-mos. Bet labai dažnai tas skirstinys aprašomas ir taip: pasakoma, koks yraX skirstinys ir aprašomi sąlyginiai Y skirstiniai X atžvilgiu.
Formaliai žiūrint, sąlyginiai skirstiniai yra įprasti skirstiniai, diskretūsarba tolydūs, tik priklausantys nuo parametro x — X dydžio reikšmės. Įsi-vaizduoti reikia taip: iš pradžių generuojamas X, gaunama jo reikšmė x irtada generuojamas Y , pasiskirstęs pagal dėsnį, atitinkantį tą reikšmę.
Kai (X, Y ) skirstinys aprašytas taip, vidurkį Ef(X, Y ) skaičiuojame taip.• Su kiekviena galima X dydžio reikšme x skaičiuojame dydžio f(x, Y )
vidurkį, laikydami, kad Y pasiskirstęs pagal x-ąjį duotąjį sąlyginį skirs-tinį. Gaunama kažkoks nuo x priklausantis skaičius, kurį pažymėsiuf(x).
• Skaičiuojamas vidurkis Ef(X), kuris ir yra ieškomasis Ef(X, Y ).Dydis f(X) vadinamas f(X, Y ) dydžio sąlyginiu vidurkiu X atžvilgiu;
aš jį žymiu EXf(X, Y ). Kiti žmonės sąlyginį vidurkį žymi E(f(X, Y ) | X),bet man tai nepatinka — per daug skliaustų. Skaičių f(x) aš vadinu sąly-ginio vidurkio reikšme, kai X = x; pavyzdžiui, rašau taip: jei X = x, taiEXf(X, Y ) = f(x). Kiti tą reikšmę žymi E(f(X, Y ) | X = x), bet tokianotacija man dar labiau nepatinka.
3.1 pavyzdys. Tarkime, (X, Y ) yra atsitiktinis vektorius, kurio skirstinysaprašomas taip: X pasiskirstęs tolygiai (0; 1) intervale ir jei X = x, tai Yskirstinys aprašomas lentele
Y 0 1x 1− x
Reikia suskaičiuoti E 1X+Y .
Sprendimas toks. Jei X = x, tai
EX 1X + Y
= E1
x+Y = 1x· x+ 1
x+ 1 · (1− x) = 1 = 1− x1 + x
= 21 + x
.
Reiškia,
E 1X + Y
= EEX 1X + Y
= E 21 +X
=∫ 1
0
2dx1 + x
= 2 ln(1 + x)∣∣∣∣10
= 2 ln 2.
45

Jei sąlyginiai Y skirstiniai tolydūs, su kiekviena x reikšme paprastai duo-damas tankis, priklausantis nuo parametro x. Jis vadinamas sąlyginiu tankiuir paprastai žymimas p(y | x). Aišku, galimas ir sudėtingesnis variantas: suvienomis x reikšmėmis sąlyginis skirstinys diskretus, su kitomis — tolydus.
3.2 pavyzdys. Tegu (X, Y ) yra atsitiktinis vektorius, kurio skirstinys ap-rašomas taip: X pasiskirstęs tolygiai (0; 1) intervale ir jei X = x, tai Ypasiskirstęs pagal eksponentinį dėsnį su tankiu
p(y | x) = x−1e−y/x, kai y > 0.
Reikia suskaičiuoti cov(X, Y ).Aišku, kad
cov(X, Y ) = EXY − EXEY
irEX =
∫ 1
0xdx = x2
2
∣∣∣∣10
= 12 .
Kiti du reikalingi vidurkiai skaičiuojami taip. Jei X = x, tai
EXY =∫ ∞
0yx−1e−y/xdy = x
∫ ∞0
ze−zdz = xΓ(2) = x
irEXXY = EXxY = xEXy = x2.
TadaEY = EEXY = EX = 1
2ir
EXY = EEXXY = EX2 =∫ 1
0x2dx = x3
3
∣∣∣∣10
= 13 .
Reiškia,cov(X, Y ) = 1
3 −14 = 1
12 .
Atsitiktinių vektorių generavimas. Tarkime, (X, Y ) skirstinys aprašy-tas taip kaip aukščiau ir norime patikrinti savo skaičiavimų rezultatus su R.Darome taip: iš pradžių generuojame daug X vektoriaus realizacijų ir sude-dame jas į vektorių x; tada generuojame atitinkamas Y vektoriaus realizacijasir sudedame jas į vektorių y. „Atitinkamas“ reiškia, kad y[i] generuojamaspagal dėsnį priklausantį nuo parametro reikšmės x[i].
Štai kaip galėtų atrodyti programa, tikrinanti 3.1 pratimo rezultatus.
46

N<-1000x<-runif(N)y<-numeric(N)
for(i in 1:N)y[i]<-sample(c(0,1), prob=c(x[i],1-x[i]), size=1, replace=T)
mean(1/(x+y))
Aš gavau rezultatą 1.331, kuris nedaug skiriasi nuo tikslaus atsakymo 2 ln 2 ≈1.386.
Nesu didelis R specialistas, tačiau esu skaitęs, kad programos veikia žy-miai efektyviau, jei operuojama su vektoriais, o ne su atskiromis tų vektoriųkoordinatėmis, kaip pavyzdyje aukščiau. Ir apskritai atrodo kvaila 1000 kar-tų kviesti funkciją sample, kiekvieną kartą generuojant tik vieną atsitiktiniodydžio reikšmę. Todėl aukščiau parašytą programą reiktų patobulinti. Rei-kia prisiminti alternatyvų diskrečių dydžių generavimo metodą: iš pradžiųgeneruojamas pagalbinis atsitiktinis dydis U , pasiskirstęs tolygiai (0; 1) in-tervale, o po to skaičiuojama tam tikra to dydžio funkcija Y = G(U). Mūsųatveju ta funkcija priklausys dar nuo papildomo parametro x.
Patobulinta programa atrodo taip:
N<-1000x<-runif(N)u<-runif(N)y<-ifelse(u<x,0,1)
mean(1/(x+y))
Jei Y sąlyginiai skirstiniai tolydūs, galimi du atvejai: arba tie skirstiniaistandartiniai, arba ne. Antruoju atveju reikia suskaičiuoti sąlyginę pasi-skirstymo funkciją F (y) ir rasti jos atvirkštinę, t.y. išspręsti lygtį F (y) = ukintamojo y atžvilgiu: y = G(u). Tada Y bus pasiskirstęs taip pat, kaipG(U); čia U yra atsitiktinis dydis, pasiskirstęs tolygiai (0; 1) intervale. Ka-dangi sąlyginiai skirstiniai priklauso nuo parametro x, tiek F , tiek G taippat priklausys nuo x.
Jei sąlyginis skirstinys standartinis, pasiskirstymo funkcijos atvirkštinėsG skaičiuoti nebereikia: jos reikšmes skaičiuoja tam tikra R funkcija. Kiekvie-ną standartinį skirstinį atitinka keturios R funkcijos: viena skaičiuoja tankį,kita — pasiskirstymo funkciją, trečia — atvirkštinę pasiskirstymo funkciją(vadinamąją kvantilių funkciją), ketvirta generuoja to skirstinio realizacijas.
47

Tarkime, eksponentinį skirstinį atitinkančios funkcijos yra dexp, pexp, qexpir rexp.
Parašysiu dvi programas, tikrinančias 3.2 pratimo rezultatus. Sąlyginiaiskirstiniai šiuo atveju eksponentiniai, todėl pasiskirstymo funkcijos atvirkš-tinės skaičiuoti nebūtina. Tačiau rašydamas pirmą programą apsimesiu, kadto nepastebėjau. Taigi sąlyginė Y dydžio pasiskirstymo funkcija
F (y | x) =∫ y
0p(t | x)dt =
∫ y
0x−1e−t/xdt =
∫ y/x
0e−zdz
= −e−z∣∣∣∣y/x0
= 1− e−y/x.
Skaičiuoju atvirkštinę funkciją:
1− e−y/x = u,
e−y/x = 1− u,
−yx
= ln(1− u),
y = −x ln(1− u).
Jei U pasiskirstęs tolygiai (0; 1) intervale, tai 1−U skirstinys yra lygiai tokspat, todėl rašant programą vietoje 1− u galima rašyti u. Pirmoji programaatrodo taip:
N<-1000x<-runif(N)u<-runif(N)y<--x*log(u)
cov(x,y)
Jei pastebime, kad sąlyginis Y skirstinys standartinis, darbo mažiau.Antroji programa atrodo taip:
N<-1000x<-runif(N)u<-runif(N)y<-qexp(u, rate = 1/x)
cov(x,y)
48

Randomizuoti sprendimai. Tarkime, turima (X1, . . . , Xn) imtis iš X dy-džio skirstinio, priklausančio nuo nežinomo parametro θ, ir reikia priimtisprendimą iš tam tikros aibės D. Ankstesniame skyriuje minėjau, kad betkokia funkcija δ(x1, . . . , xn) iš En į D vadinama sprendimų funkcija. Pagrin-dinis reikalavimas — ji negali priklausyti nuo nežinomo parametro θ. Tačiauteorijoje kartais tenka nagrinėti ir kitokias — vadinamąsias randomizuotassprendimų funkcijas. Tokios funkcijos žymimos irgi δ raidėmis, bet su kiek-vienu rinkiniu (x1, . . . , xn) ∈ En jos reikšmė δ(x1, . . . , xn) yra ne D aibėselementas, o atsitiktinis dydis su reikšmėmis iš D, t.y. atsitiktinis D elemen-tas. Kaip įprasta statistikoje, svarbus tik to elemento skirstinys, tiksliau,δ(X1, . . . , Xn) dydžio sąlyginis skirstinys (X1, . . . , Xn) atžvilgiu. Sąlyginisskirstinys priklauso nuo imties, bet nepriklauso nuo nežinomo parametro θ.
Randomizuotos sprendimų funkcijos charakteristikos skaičiuojamos tai-kant pilnos tikimybės formulę:
Eθf(θ, δ(X1, . . . , Xn)) = EθEX1,...,Xnf(θ, δ(X1, . . . , Xn)).
Norėdamas pabrėžti, kad sąlyginis δ(X1, . . . , Xn) skirstinys nepriklauso nuoθ, aš specialiai praleidau θ indeksą po sąlyginio vidurkio ženklu.
Pakankamos statistikos. Tegu vėl (X1, . . . , Xn) yra imtis iš X dydžioskirstinio, priklausančio nuo nežinomo parametro θ. Statistika vadinama betkokia mati funkcija En aibėje. Statistikos paprastai žymimos t raidėmis;tada t(x1, . . . , xn) yra statistikos reikšmė, atitinkanti imtį (x1, . . . , xn). Tareikšmė paprastai yra arba skaičius iš R (tokiu atveju statistika vadinamavienmate), arba vektorius iš Rk (k-matė statistika). Tačiau galima nagrinėtiir statistikas su reikšmėmis iš bet kokios mačios erdvės F .
Statistika t vadinama pakankama, jei imties (X1, . . . , Xn) sąlyginis skirs-tinys Y = t(X1, . . . , Xn) dydžio atžvilgiu nepriklauso nuo nežinomo para-metro θ. Terminas „pakankama“ reiškia, kad priimant sprendimus nebūtinažinoti visos imties (x1, . . . , xn) — užtenka žinoti tik statistikos t reikšmęt(x1, . . . , xn). Paaiškinsiu ši teiginį smulkiau.
Tarkime, mums reikia priimti sprendimą iš tam tikros aibės D ir δ yrakokia nors sprendimų funkcija. Tegu t yra pakankama statistika ir Y =t(X1, . . . , Xn). Tada sąlyginis δ(X1, . . . , Xn) skirstinys Y atžvilgiu nepri-klauso nuo θ ir, reiškia, yra tam tikros randomizuotos sprendimo funkcijos δiš F į D sąlyginis skirstinys. Tada su bet kokia tinkama funkcija f
Eθf(θ, δ(X1, . . . , Xn)) = EθEY f(θ, δ(X1, . . . , Xn))= EθEY f(θ, δ(Y )) = Eθf(θ, δ(Y )).
49

Taigi su bet kokia sprendimų funkcija δ : En → D egzistuoja sprendimųfunkcija δ : F → D su identiškomis tikimybinėmis charakteristikomis. Vie-nintelis nemalonus dalykas — sprendimų funkcija δ yra randomizuota, norsδ buvo paprasta.
Jei reiktų δ modeliuoti su kompiuteriu, galima būtų daryti taip: turint Ystatistikos reikšmę y, reiktų generuoti vektorių (X1, . . . , Xn), kurio skirstinyssutampa su sąlyginiu imties (X1, . . . , Xn) skirstiniu, kai Y = y, ir priim-ti sprendimą δ(y) = δ(X1, . . . , Xn). Bet tai kvailas uždavinys: jei δ nėrafunkcija nuo pakankamos statistikos, ji yra bloga sprendimų funkcija ir nėraprasmės ieškoti lygiai tokios pat blogos randomizuotos sprendimų funkcijos;priešingu atveju δ gali būti nerandomizuota ir sutapti su δ.
3.2 Uždaviniai1. Tegu (X, Y ) yra atsitiktinis vektorius, kurio skirstinys aprašomas tokio-mis lentelėmis:
X −1 0 113
13
13
ir, jei X = x, Y |x| 114
34
Apskaičiuokite P(Y = 1) ir cov(X, Y ).
2. Tegu X yra atsitiktinis dydis, įgyjantis reikšmes 1 ir 2 su vienodomistikimybėmis, ir, jei X = x, Y pasiskirstęs tolygiai (0;x2) intervale. Apskai-čiuokite P(Y < X) ir E(XY ).
3. Tegu X yra atsitiktinis dydis su tankiu
p(x) = 1x2 , kai x > 1,
o sąlyginis Y skirstinys, kai X = x, aprašomas lentele
Y 0 11x
1− 1x
Apskaičiuokite P(Y = 0) ir E(XY 1X<2).
4. Tegu X pasiskirstęs tolygiai (−1; 1) intervale, o atsitiktinio dydžio Ysąlyginis tankis, kai X = x,
p(y | x) = cx e−y su y > |x|;
čia cx ∈ R. Apskaičiuokite P(Y < 2X) ir DY .
50

5. Tegu (X, Y ) yra atsitiktinis vektorius, kurio skirstinys aprašomas tokio-mis lentelėmis:
X 1 2 312
14
14
ir, jei X = x, Y x− 1 x+ 112
12
Apskaičiuokite P(Y = X) ir EY .
6. Tegu (X1, X2) yra imtis iš Puasono skirstinio su nežinomu vidurkiuθ > 0. Tikrinama hipotezė H : θ 6 1, naudojant tokį kriterijų: hipotezėatmetama, kai X2 > X1. Yra žinoma, kad tokiu atveju Y = X1 + X2 yrapakankama statistika ir jei Y = y, tai
X1 ∼ Bin(y, 12), o X2 = y −X1.
Panagrinėkite ekvivalentų randomizuotą kriterijų, kuris remiasi tik stebėtaY statistikos reikšme, ir simuliuodami kompiuteriu patikrinkite, kad abiejųkriterijų galios funkcijos tikrai identiškos.
7. TeguPθ(X = x) = (1− θ)θx su x = 0, 1, 2, . . . ,
(X1, X2) yra imtis iš X skirstinio ir vertinamas nežinomas parametras θ ∈(0; 1). Yra žinoma, kad nagrinėjamu atveju Y = X1 + X2 yra pakankamastatistika ir jei Y = y, tai X1 įgyja reikšmes 0, . . . , y su vienodomis tiki-mybėmis, o X2 = y −X1. Panagrinėkite randomizuotą įvertinį, ekvivalentųįvertiniui
θ = X
X + 1ir besiremiantį tik stebėta pakankamos statistikos reikšme, ir simuliuodamikompiuteriu įsitikinkite, kad abiejų įvertinių poslinkiai ir dispersijos vienodi.
8. Tegu (X1, X2) yra imtis iš eksponentinio skirstinio su tankiu
pθ(x) = θe−θx, kai x > 0,
ir ieškomas pasikliovimo intervalas θ parametrui. Yra žinoma, kad tokiuatveju Y = X1 +X2 yra pakankama statistika ir jei Y = y, tai
X1 ∼ U(0; y), o X2 = y −X1.
Panagrinėkite randomizuotą pasikliovimo intervalą, konstruojamą remiantistik stebėta pakankamos statistikos reikšme ir ekvivalentų pasikliovimo inter-valui
(a; b) = (0; 2/X2).
51

Simuliuodami kompiuteriu įsitikinkite, kad abiejų pasikliovimo intervalų pa-tikimumai ir vidutiniai ilgiai sutampa.
9. (X, Y ) yra atsitiktinis vektorius, kurio skirstinys aprašomas taip: Xįgyja reikšmes 1, 2 ir 3 su vienodomis tikimybėmis; jei X = x, tai Y skirstinysaprašomas lentele
Y x x+ 112
12
Sudarykite bendro (X, Y ) pasiskirstymo lentelę ir apskaičiuokite P(X = Y ).Patikrinkite gautus rezultatus su kompiuteriu.
10. (X, Y ) yra atsitiktinis vektorius, kurio skirstinys aprašomas taip: Xpasiskirstęs pagal eksponentinį dėsnį su tankiu
p(x) = e−x, kai x > 0;
jei X = x, tai Y skirstinys aprašomas lentele
Y 0 11− e−x e−x
Apskaičiuokite cov(X, Y ). Gautą rezultatą patikrinkite su kompiuteriu.
11. (X, Y ) yra atsitiktinis vektorius, kurio skirstinys aprašomas taip: Xįgyja reikšmes 1 ir 2 su vienodomis tikimybėmis; jei X = x, tai Y turi tankį
p(y | x) = cxx+ y
, kai 0 < y < 2;
čia cx — tam tikra konstanta. Apskaičiuokite P(X < Y ). Gautą rezultatąpatikrinkite su kompiuteriu.
12. (X, Y ) yra atsitiktinis vektorius, kurio skirstinys aprašomas taip: Xpasiskirstęs tolygiai (0; 3) intervale; jei X = x, tai Y turi tankį
p(y | x) = cxy, kai 0 < y < x;
čia cx — tam tikra konstanta. Apskaičiuokite EY 2. Gautą rezultatą patik-rinkite su kompiuteriu.
52

3.3 Sprendimai1. Jei X = ±1, abi galimos Y reikšmės yra 1 ir todėl
EX1Y=1 = 1, EXY = 1 ir EXXY = ±EXY = ±1;
jei X = 0, tai
EX1Y=1 = 34 , EXY = 3
4 ir EXXY = EX0 = 0.
Taigi
P(Y = 1) = E1Y=1 = EEX1Y=1 = 23 · 1 + 1
3 ·34 = 11
12 ,
EY = EEXY = 23 · 1 + 1
3 ·34 = 11
12ir
EXY = EEXXY = 13 · 1 + 1
3 · (−1) = 0.
Kadangi irEX = 1
3 · 1 + 13 · (−1) = 0,
gaunucov(X, Y ) = EXY − EXEY = 0.
2. Tiek 1 6 12, tiek 2 6 22; todėl jei X = x, tai
EX1Y <X = EX1Y <x = 1x2
∫0<y<x2y<x
dy = 1x2
∫0<y<x
dy = 1x2
∫ x
0dy = 1
x.
Iš čia
P(Y < X) = E1Y <X = EEX1Y <X = E 1X
= 12 · 1 + 1
2 ·12 = 3
4 .
Analogiškai gaunu, kad jei X = x, tai
EXXY = xEXY = x1x2
∫ x2
0ydy = 1
x· y
2
2
∣∣∣∣x2
0= x3
2 ;
todėlEXY = EEXXY = EX
3
2 = 12 ·
12 + 1
2 · 4 = 94 .
53

3. Jei X = x, taiEX1Y=0 = 1
x;
todėl
P(Y = 0) = E1Y=0 = EEX1Y=0 = E 1X
=∫ ∞
1
1x2
1x
dx = x−2
−2
∣∣∣∣∞1
= 12 .
Vidurkis skaičiuojamas taip. Jei X = x < 2, tai
EX(XY 1X<2) = xEXY = x(
1− 1x
)= x− 1;
jeigu gi X = x > 2, tai
EX(XY 1X<2) = EX0 = 0.
Kitaip tariant, EXY = f(X); čia
f(x) =
x− 1 kai x < 2;0, kai x > 2.
Todėl
E(XY 1X<2) = Ef(X) =∫ ∞
1
1x2f(x)dx =
∫ 2
1
x− 1x2 dx
=(
ln x+ 1x
)∣∣∣∣21
= ln 2− 12 .
4. Iš ∫ ∞|x|
e−ydy = −e−y∣∣∣∣∞|x|
= e−|x|
išplaukia, kad cx = e|x|. Taigi jei X = x 6 0, tai
EX1Y <2X = EX1Y <2x = 0,
o jei X = x > 0, tai
EX1Y <2X = EX1Y <2x = ex∫ 2x
xe−ydy = −ex−y
∣∣∣∣2xx
= 1− e−x.
Iš čia
P(Y < 2X) = E1Y <2X = EEX1Y <2X = E(1− e−X)1X>0
54

= 12
∫ 1
0(1− e−x)dx = 1
2(x+ e−x)∣∣∣∣10
= 12e .
Dabar suskaičiuosiu dispersiją. Jei X = x, tai
EXY =∫ ∞|x|
e|x|−yydy =∫ ∞
0e−z(z + |x|)dz = Γ(2) + |x|Γ(1) = 1 + |x|
ir
EXY 2 =∫ ∞|x|
e|x|−yy2dy =∫ ∞
0e−z(z + |x|)2dz
= Γ(3) + 2|x|Γ(2) + x2Γ(1) = 2 + 2|x|+ x2.
Iš čia
EY = EEXY = E(1 + |X|) = 1 + E|X| = 1 + 12
∫ 1
−1|x|dx
= 1 +∫ 1
0x dx = 1 + x2
2
∣∣∣∣10
= 32
ir
EY 2 = EEXY 2 = E(2 + 2|X|+X2) = 12
∫ 1
−1(2 + |x|+ x2)dx
=∫ 1
0(2 + x+ x2)dx =
(2x+ x2
2 + x3
3
)∣∣∣∣10
= 176 .
TaigiDY = 17
6 −94 = 7
12 .
5. Jei X = x, tai Y = x± 1 6= x; todėl
EX1Y=X = EX1Y=x = 0.
Iš čia irP(Y = X) = E1Y=X = EEX1Y=X = E0 = 0.
Analogiškai gaunu, kad jei X = x, tai
EXY = 12(x− 1) + 1
2(x+ 1) = x;
todėlEY = EEXY = EX = 1
2 + 12 + 3
4 = 74 .
55

6. Programa:
T<-100N<-10000teta<-seq(from=0.1, to=10, by=0.1)
x2<-numeric(2)atmete<-numeric(N)atmete2<-numeric(N)beta<-numeric(T)beta2<-numeric(T)
for (t in 1:T)
for (i in 1:N)
x<-rpois(2,lambda = teta[t])atmete[i]<-(x[2]>x[1])y<-sum(x)x2[1]<-rbinom(1,size = y, prob=0.5)x2[2]<-y-x2[1]atmete2[i]<-(x2[2]>x2[1])
beta[t]<-mean(atmete)beta2[t]<-mean(atmete2)
plot(teta, beta, type = "l")lines(teta, beta2, type = "l", col = "red")
7. Programa:
T<-100N<-10000teta<-seq(from=0, to=0.99, by=0.01)
x2<-numeric(2)est<-numeric(N)est2<-numeric(N)poslinkis<-numeric(T)poslinkis2<-numeric(T)dispersija<-numeric(T)
56

dispersija2<-numeric(T)
for (t in 1:T)
for (i in 1:N)
x<-rgeom(2,prob = 1-teta[t])est[i]<-x[1]/(x[1]+1)y<-sum(x)x2[1]<-floor(runif(1, max = y+1))x2[2]<-y-x2[1]est2[i]<-x2[1]/(x2[1]+1)
poslinkis[t]<-mean(est)-teta[t]dispersija[t]<-var(est)poslinkis2[t]<-mean(est2)-teta[t]dispersija2[t]<-var(est2)
plot(teta, poslinkis, type = "l")lines(teta, poslinkis2, type = "l", col = "red")plot(teta, dispersija, type = "l")lines(teta, dispersija2, type = "l", col = "red")
Komentarai:
• Funkcijos rgeom argumentas prob negali būti 0, todėl θ negalėjo būti1. Aš ėmiau θ = 0, 0.01, . . . , 0.99.
• Norint generuoti atsitiktinį dydį, įgyjantį reikšmes 0, . . . , y su vieno-domis tikimybėmis, reiktų generuoti atsitiktinį dydį U ∼ U(0; 1) irapibrėžti
X =
0, kai 0 6 U < 1y+1 ;
1, kai 1y+1 6 U < 2
y+1 ;. . . . . . . . . . . . . . . . . . . . .
y, kai yy+1 6 U < 1.
Nesunku matyti, kad tada X = b(y + 1)Uc; čia bzc žymi z skaičiaussveikąją dalį (atitinkama R funkcija yra floor). Tačiau jei U ∼ U(0; 1),tai (y + 1)U ∼ U(0; y + 1); todėl galima generuoti atsitiktinį dydį,pasiskirsčiusį tolygiai (0; y + 1) intervale, ir paimti jo sveikąją dalį. Aštaip ir padariau.
57

8. Programa:
T<-100N<-10000teta<-seq(from=0.1, to=10, by=0.1)
x2<-numeric(2)b<-numeric(N)b2<-numeric(N)conf<-numeric(T)conf2<-numeric(T)ilgis<-numeric(T)ilgis2<-numeric(T)
for (t in 1:T)
for (i in 1:N)
x<-rexp(2,rate = teta[t])b[i]<-2/x[2]y<-sum(x)x2[1]<-runif(1, max = y)x2[2]<-y-x2[1]b2[i]<-2/x2[2]
conf[t]<-mean(teta[t]<b)ilgis[t]<-mean(b)conf2[t]<-mean(teta[t]<b2)ilgis2[t]<-mean(b2)
plot(teta, conf, type = "l")lines(teta, conf2, type = "l", col = "red")plot(teta, ilgis, type = "l")lines(teta, ilgis2, type = "l", col = "red")
3.4 Tikroji teorijaSąlyginiai skirstiniai. Tegu X ir Y yra du atsitiktiniai dydžiai su reikš-mėmis, atitinkamai, E ir F erdvėse ir µ yra X dydžio skirstinys. SimboliuEXg(Y ) žymimas toks atsitiktinis dydis Z = g(X) (čia g — mati funkcija E
58

aibėje), kad su visomis funkcijomis f
Ef(X)g(Y ) = Ef(X)g(X). (3.1)
Dydis EXg(Y ) vadinamas g(Y ) dydžio sąlyginiu vidurkiu X atžvilgiu. Skai-čius g(x) dar kartais vadinamas g(Y ) dydžio sąlyginiu vidurkiu, kai X = x.Toks terminas nėra visiškai korektiškas, nes (3.1) lygybės apibrėžia g funkcijąnevienareikšmiškai: jei g yra kita funkcija E aibėje ir g(x) = g(x) su µ-beveikvisais x, tai g(X) taip pat yra sąlyginis g(Y ) dydžio vidurkis X atžvilgiu,bet reikšmės g(x) ir g(x) nebūtinai vienodos.
Y dydžio sąlyginiu skirstiniu X atžvilgiu vadinama tokia skirstinių šeima(νx | x ∈ E), kad su kiekviena mačia B ⊂ F funkcija x 7→ νx(B) mati irνX(B) yra sąlyginis 1B(Y ) dydžio vidurkis X atžvilgiu. νx dar vadinamassąlyginiu Y skirstiniu, kai X = x. Jei (νx) yra sąlyginis Y skirstinys, tai subet kokia funkcija g
EXg(Y ) =∫g(y)νx(dy).
Atsitiktinio vektoriaus (X, Y ) skirstinys gali būti aprašytas, pasakant,koks yra X dydžio skirstinys µ, ir aprašant sąlyginius Y skirstinius νx. Tadabet kokio dydžio h(X, Y ) vidurkis randamas dviem žingsniais:
1) iš pradžių suskaičiuojami integralai
h(x) =∫h(x, y)νx(dy)
(h(x) yra dydžio h(X, Y ) dydžio sąlyginis vidurkis, kai X = x);2) suskaičiuojamas gauto sąlyginio vidurkio vidurkis:
Eh(X, Y ) = EEXh(X, Y ) = Eh(X) =∫h(x)µ(dx).
Pirma lygybė šioje grandinėje vadinama pilnos tikimybės formule.
Pakankamos statistikos. Tegu (X1, . . . , Xn) yra imtis iš skirstinio µθ,priklausančio nuo nežinomo parametro θ. Statistika Y = t(X1, . . . , Xn) va-dinama pakankama, jei sąlyginis imties (X1, . . . , Xn) skirstinys Y atžvilgiunepriklauso nuo θ.
Statistikos pakankamumas paprastai nustatomas, naudojant tokį krite-rijų: jei pθ yra µθ skirstinio tankis tam tikro σ-baigtinio mato atžvilgiu irimties tankis užrašomas pavidalu
pθ(x1) · · · pθ(xn) = aθ(t(x1, . . . , xn))b(x1, . . . , xn)
su tam tikromis funkcijomis aθ ir b, tai t yra pakankama statistika. Taivadinamasis Fisherio ir Neymano faktorizacijos kriterijus. Jį būtų galima
59

įrodyti, bet to nedarysiu, nes jei statistika jau žinoma, jos pakankamumągalima nustatyti, tiesiog suskaičiavus imties sąlyginį skirstinį jos atžvilgiu irįsitikinus, kad skirstinys nepriklauso nuo nežinomo parametro.
Sąlyginiai skirstiniai randami remiantis tokiu teiginiu: jei (νθ) ir (πy) yratokios skirstinių šeimos, kad su bet kokiomis funkcijomis f ir g
Eθf(X1, . . . , Xn)g(Y ) =∫g(y)νθ(dy)
∫f(x1, . . . , xn)πy(d(x1, . . . , xn)),
tai νθ yra Y statistikos skirstinys, o πy — sąlyginis (X1, . . . , Xn) skirstinys,kai Y = y.
3.3 pavyzdys. Tegu (X1, . . . , Xn) yra imtis iš skirstinio, aprašomo lentele
X 0 11− θ θ
Rasiu vienmatę pakankamą statistiką šiame modelyje, tos statistikos skirstinįir sąlyginį imties skirstinį tos statistikos atžvilgiu.
X dydžio tankis skaičiuojančiojo mato atžvilgiu
pθ(x) = Pθ(X = x) =
1− θ, kai x = 0,θ, kai x = 1.
Reiškia,pθ(x1) · · · pθ(xn) = (1− θ)n−yθy;
čia y = t(x1, . . . , xn) yra vienetukų skaičius imtyje. Iš Fišerio-Neymano kri-terijaus išplaukia, kad t yra pakankama statistika. Įsitikinsiu tuo, rasdamassąlyginį imties skirstinį tos statistikos atžvilgiu. Kad būtų paprasčiau, laiky-siu n = 2.
Taigi (X1, X2) yra mano imtis ir Y — vienetukų skaičius toje imtyje. Subet kokiomis tinkamomis funkcijomis f ir g
Eθf(X1, X2)g(Y ) = f(0, 0)g(0)(1− θ)2 + f(0, 1)g(1)(1− θ)θ+ f(1, 0)g(1)θ(1− θ) + f(1, 1)g(2)θ2
= g(0)(1− θ)2f(0, 0)+ g(1)(1− θ)θ
(f(0, 1) + f(1, 0)
)+ g(2)θ2f(1, 1).
Atskiru atveju, kai f(x1, x2) = 1 su visais (x1, x2),
Eg(Y ) = g(0)(1− θ)2 + g(1) · 2(1− θ)θ + g(2)θ2.
Pastaroji lygybė reiškia, kad Y skirstinys aprašomas lentele
60

Y 0 1 2(1− θ)2 2(1− θ)θ θ2
Kitaip tariant, Y pasiskirstęs pagal binominį Bin(2, θ) dėsnį.Aukščiau gautą lygybę dabar perrašau taip:
Eθf(X1, X2)g(Y ) = g(0)(1− θ)2f(0, 0)
+ g(1)2(1− θ)θ(1
2f(0, 1) + 12f(1, 0)
)+ g(2)θ2f(1, 1).
Iš jos išplaukia, kad
• jei Y = 0, taiEY f(X1, X2) = f(0, 0);
• jei Y = 1, tai
EY f(X1, X2) = 12f(0, 1) + 1
2f(1, 0);
• jei Y = 2, taiEY f(X1, X2) = f(1, 1).
Kitaip tariant,
• jei Y = 0, tai (X1, X2) = (0, 0);
• jei Y = 1, tai (X1, X2) su vienodomis tikimybėmis įgyja reikšmes (0, 1)ir (1, 0);
• jei Y = 2, tai (X1, X2) = (1, 1).
Toliau šiame skyrelyje išnagrinėsiu dar 6 modelius. Kiekviename mode-lyje rasiu vienmatę pakankamą statistiką ir, paėmęs n = 2, — tos statistikosskirstinį bei sąlyginius imties skirstinius tos statistikos atžvilgiu.
Puasono modelis. Tegu X pasiskirstęs pagal Puasono dėsnį su nežinomuvidurkiu θ > 0. Šiuo atveju E = 0, 1, 2, . . . ir X dydžio tankis skaičiuo-jančiojo mato atžvilgiu
pθ(x) = e−θ θx
x! .
Tada imties tankis
pθ(x1) · · · pθ(xn) = e−nθ θx1+···+xn
x1! · · ·xn! ;
61

todėl t(x1, . . . , xn) = x1 + · · ·+ xn yra pakankama statistika.Tegu n = 2 ir Y = X1 +X2; rasiu Y skirstinį ir imties (X1, X2) sąlyginius
skirstinius Y atžvilgiu. Su bet kokiomis tinkamomis funkcijomis f ir g
Eθf(X1, X2)g(Y ) = Eθf(X1, X2)g(X1 +X2)
=∑
x1,x2>0e−2θ θ
x1+x2
x1!x2! f(x1, x2)g(x1 + x2)
=∑y>0
y∑z=0
e−2θ θy
z!(y − z)!f(z, y − z)g(y)
=∑y>0
e−2θθyg(y)y∑z=0
1z!(y − z)!f(z, y − z).
Atskiru atveju, kai f(x1, x2) = 1 su visais (x1, x2),
Eθg(Y ) =∑y>0
g(y)e−2θ θy
y!
y∑z=0
(y
z
)=∑y>0
g(y)e−2θ (2θ)yy! .
Kitaip tariant,
Pθ(Y = y) = e−2θ (2θ)yy! su y = 0, 1, 2, . . . ,
t.y. Y pasiskirstęs pagal Puasono dėsnį su vidurkiu 2θ. Be to, jei Y = y, tai
EY f(X1, X2) = y!2y
y∑z=0
1z!(y − z)!f(z, y − z) = 1
2yy∑z=0
(y
z
)f(z, y − z).
Atskiru atveju
EY h(X1) = 12y
y∑z=0
(y
z
)h(z),
o tai reiškia, kad sąlyginis X1 skirstinys yra binominis su parametrais y ir 12 .
Taigi jei Y = y, tai
X1 ∼ Bin(y, 12), o X2 = y −X1.
Geometrinis modelis. Tegu X pasiskirstęs pagal geometrinį dėsnį su ne-žinomu parametru θ ∈ (0; 1):
Pθ(X = x) = (1− θ)θx su x = 0, 1, 2, . . . .
Šiuo atveju E = 0, 1, 2, . . . ir X dydžio tankis skaičiuojančiojo mato at-žvilgiu
pθ(x) = (1− θ)θx.
62

Tada imties tankis
pθ(x1) · · · pθ(xn) = (1− θ)nθx1+···+xn ;
todėl t(x1, . . . , xn) = x1 + · · ·+ xn yra pakankama statistika.Tegu n = 2 ir Y = X1 +X2; rasiu Y skirstinį ir imties (X1, X2) sąlyginius
skirstinius Y atžvilgiu. Su bet kokiomis tinkamomis funkcijomis f ir g
Eθf(X1, X2)g(Y ) = Eθf(X1, X2)g(X1 +X2)=
∑x1,x2>0
(1− θ)2θx1+x2f(x1, x2)g(x1 + x2)
=∑y>0
y∑z=0
(1− θ)2θyf(z, y − z)g(y)
=∑y>0
(1− θ)2θyg(y)y∑z=0
f(z, y − z).
Atskiru atveju, kai f(x1, x2) = 1 su visais (x1, x2),
Eθg(Y ) =∑y>0
(1− θ)2θyg(y)y∑z=0
=∑y>0
g(y)(y + 1)(1− θ)2θy.
Taigi Y skirstinys aprašomas lygybėmis
P(Y = y) = (y + 1)(1− θ)2θy su y = 0, 1, 2, . . . .
Be to, jei Y = y, tai
EY f(X1, X2) = 1y + 1
y∑z=0
f(z, y − z).
Atskiru atveju
EY h(X1) = 1y + 1
y∑z=0
f(z),
o tai reiškia, kad jei Y = y, tai X1 su vienodomis tikimybėmis įgyja reikšmes0, . . . , y, o X2 = y −X1.
Eksponentinis modelis. Tegu X pasiskirstęs pagal eksponentinį dėsnį sutankiu
pθ(x) = θe−θx su x > 0;čia θ > 0 — nežinomas parametras. Šiuo atveju E = (0;∞) ir imties tankis
pθ(x1) · · · pθ(xn) = θne−θ(x1+···+xn);
63

todėl t(x1, . . . , xn) = x1 + · · ·+ xn yra pakankama statistika.Tegu n = 2 ir Y = X1 +X2; rasiu Y skirstinį ir imties (X1, X2) sąlyginius
skirstinius Y atžvilgiu. Su bet kokiomis tinkamomis funkcijomis f ir g
Eθf(X1, X2)g(Y ) = Eθf(X1, X2)g(X1 +X2)
=∫x1>0x2>0
θ2e−θ(x1+x2)f(x1, x2)g(x1 + x2)dx1dx2
=∫
0<z<yθ2e−θyf(z, y − z)g(y)dydz
=∫ ∞
0θ2e−θyg(y)dy
∫ y
0f(z, y − z)dz.
Atskiru atveju, kai f(x1, x2) = 1 su visais (x1, x2),
Eθg(Y ) =∫ ∞
0θ2e−θyg(y)dy
∫ y
0dz =
∫ ∞0
g(y)θ2ye−θydy,
o tai reiškia, kad Y pasiskirstęs pagal gama dėsnį su tankiu
qθ(y) = θ2ye−θy, kai y > 0.
Be to, jei Y = y, tai
EY f(X1, X2) = 1y
∫ y
0f(z, y − z)dz.
Atskiru atvejuEY h(X1) = 1
y
∫ y
0h(z)dz,
o tai reiškia, kad jei Y = y, tai X1 pasiskirstęs tolygiai (0; y) intervale. Taigijei Y = y, tai
X1 ∼ U(0; y), o X2 = y −X1.
Tolygusis modelis. Tegu X pasiskirstęs tolygiai (0; θ) intervale; čia θ > 0— nežinomas parametras. Šiuo atveju E = (0;∞) ir imties tankis
pθ(x1) · · · pθ(xn) =
θ−n, kai x1 < θ, . . . , xn < θ;0 su kitais x1, . . . , xn;
=
θ−n, kai max(x1, . . . , xn) < θ;0 kai max(x1, . . . , xn) > θ;
todėl t(x1, . . . , xn) = max(x1, . . . , xn) yra pakankama statistika.
64

Tegu n = 2 ir Y = max(X1, X2); rasiu Y skirstinį ir imties (X1, X2)sąlyginius skirstinius Y atžvilgiu. Su bet kokiomis tinkamomis funkcijomisf ir g
Eθf(X1, X2)g(Y )= Eθf(X1, X2)g(max(X1, X2))
=∫
0<x1<θ0<x2<θ
θ−2f(x1, x2)g(max(x1, x2))dx1dx2
=∫
0<x1<x2<θθ−2f(x1, x2)g(x2)dx1dx2 +
∫0<x2<x1<θ
θ−2f(x1, x2)g(x1)dx1dx2
=∫
0<z<y<θθ−2f(z, y)g(y)dydz +
∫0<z<y<θ
θ−2f(y, z)g(y)dydz
=∫
0<y<θθ−2g(y)dy
∫ y
0(f(z, y) + f(y, z))dz.
Atskiru atveju, kai f(x1, x2) = 1 su visais (x1, x2),
Eθg(Y ) =∫ θ
0θ−2g(y)dy
∫ y
02dz =
∫ θ
0g(y)2θ−2ydy,
o tai reiškia, kad Y turi tankį
qθ(y) = 2yθ2 , kai 0 < y < θ.
Be to, jei Y = y, tai
EY f(X1, X2) = 12y
∫ y
0(f(z, y) + f(y, z))dz.
Tai galima pasakyti ir taip: jei Y = y, tai (X1, X2) pasiskirstęs tolygiailaužtėje
Ey = (x1, x2) | x1 > 0, x2 > 0, max(x1, x2) = y.
Normalusis modelis su žinoma dispersija. Tegu X pasiskirstęs pagalnormalųjį dėsnį su vidurkiu θ ir dispersija 1; čia θ ∈ R — nežinomas para-metras. Šiuo atveju E = R ir imties tankis
pθ(x1) · · · pθ(xn) = 1√2π
e−(x1−θ)2/2 · · · 1√2π
e−(xn−θ)2/2
= (2π)−n/2e−(x21+···+x2
n)/2eθ(x1+···+xn)e−nθ2/2;
todėl t(x1, . . . , xn) = x1 + · · ·+ xn yra pakankama statistika.
65

Tegu n = 2 ir Y = X1 +X2; rasiu Y skirstinį ir imties (X1, X2) sąlyginiusskirstinius Y atžvilgiu. Su bet kokiomis tinkamomis funkcijomis f ir g
Eθf(X1, X2)g(Y ) = Eθf(X1, X2)g(X1 +X2)
= e−θ2
2π
∫e−(x2
1+x22)/2eθ(x1+x2)f(x1, x2)g(x1 + x2)dx1dx2
= e−θ2
2π
∫eθye−z2/2−(y−z)2/2f(z, y − z)g(y)dydz
= e−θ2
2π
∫eθy−y2/2g(y)dy
∫e−z2+yzf(z, y − z)dz.
Atskiru atveju, kai f(x1, x2) = 1 su visais (x1, x2),∫e−z2+yzdz = ey2/4
∫e−(z−y/2)2dz = ey2/4√π;
todėl
Eθg(Y ) = e−θ2
2√π
∫g(y)eθy−y2/2ey2/4dy = 1
2√π
∫g(y)e−(y−2θ)2/4dy.
Kitaip tariant, Y pasiskirstęs pagal normalųjį N(2θ, 2) dėsnį. Be to, jei Y = y,tai
EY f(X1, X2) = e−y2/4√π
∫e−z2+yzf(z, y − z)dz
= 1√π
∫e−(z−y/2)2
f(z, y − z)dz.
Atskiru atvejuEY h(X1) = 1√
π
∫e−(z−y/2)2
h(z)dz,
o tai reiškia, kad jei Y = y, tai X1 pasiskirstęs normaliai su vidurkiu y/2 irdispersija 1/2. Taigi jei Y = y, tai
X1 ∼ N(y/2, 1/2), o X2 = y −X1.
Normalusis modelis su žinomu vidurkiu. Tegu X pasiskirstęs pagalnormalųjį dėsnį su vidurkiu 0 ir dispersija θ; čia θ > 0 — nežinomas para-metras. Šiuo atveju E = R ir imties tankis
pθ(x1) · · · pθ(xn) = 1√2πθ
e−x21/(2θ) · · · 1√
2πθe−x2
n/(2θ)
66

= (2πθ)−n/2e−(x21+···+x2
n)/(2θ);
todėl t(x1, . . . , xn) = x21 + · · ·+ x2
n yra pakankama statistika.Tegu n = 2 ir Y = X2
1 +X22 ; rasiu Y skirstinį ir imties (X1, X2) sąlyginius
skirstinius Y atžvilgiu. Su bet kokiomis tinkamomis funkcijomis f ir g
Eθf(X1, X2)g(Y ) = Eθf(X1, X2)g(X21 +X2
2 )
= 12πθ
∫e−(x2
1+x22)/(2θ)f(x1, x2)g(x2
1 + x22)dx1dx2
= 12πθ
∫r>0
0<ϕ<2πe−r2/(2θ)f(r cosϕ, r sinϕ)g(r2)rdrdϕ
= 12πθ
∫ ∞0
e−r2/(2θ)g(r2)rdr∫ 2π
0f(r cosϕ, r sinϕ)dϕ
= 14πθ
∫ ∞0
e−y/(2θ)g(y)dy∫ 2π
0f(√y cosϕ,√y sinϕ)dϕ.
Atskiru atveju, kai f(x1, x2) = 1 su visais (x1, x2),
Eθg(Y ) = 14πθ
∫ ∞0
e−y/(2θ)g(y)dy∫ 2π
0dϕ = 1
2θ
∫ ∞0
e−y/(2θ)g(y)dy,
taigi Y pasiskirstęs pagal eksponentinį dėsnį su tankiu
qθ(y) = 12θe−y/(2θ), kai y > 0.
Be to, jei Y = y, tai
EY f(X1, X2) = 12π
∫ 2π
0f(√y cosϕ,√y sinϕ)dϕ,
o tai reiškia, kad jei Y = y, tai (X1, X2) pasiskirstęs tolygiai apskritime(x1, x2) | x2
1 + x22 = y. Tiksliau, jei Y = y, tai (X1, X2) pasiskirstęs taip
pat kaip (√y cosU,√y sinU); čia U ∼ U(0; 2π).
4 Statistinių hipotezių tikrinimas
4.1 Praktinė teorijaTerminologija. Tegu (X1, . . . , Xn) yra imtis iš X skirstinio, priklausančionuo nežinomo parametro θ ∈ Θ, ir tikrinama hipotezėH : θ ∈M ; čiaM ⊂ Θ.Priminsiu jau žinomus terminus.
Sprendimo funkcija šiuo atveju vadinama kriterijumi ir yra bet kokiamati funkcija δ : En → 0, 1; sprendimas 0 interpretuojamas, kad hipotezė
67

priimama, o sprendimas 1 — kad atmetama. Aprašant kriterijų δ, pakankapasakyti, su kokiomis imties reikšmėmis hipotezė atmetama, t.y. aprašytiaibę
W = (x1, . . . , xn) | δ(x1, . . . , xn) = 1;tada
δ(x1, . . . , xn) =
1, kai (x1, . . . , xn) ∈ W ;0, kai (x1, . . . , xn) 6∈ W .
W vadinama kriterijaus kritine aibe.Pagrindinė kriterijaus charakteristika yra funkcija
β(θ) = Pθ(δ(X1, . . . , Xn) = 1) = Pθ((X1, . . . , Xn) ∈ W );
aš ją vadinu galios funkcija. Jei θ ∈ M , reikšmė β(θ) vadinama pirmosrūšies klaidos tikimybe; ji turėtų būti kuo mažesnė. Jei θ 6∈M , reikšmė β(θ)vadinama kriterijaus galia ir turėtų būti kuo didesnė. Tiek pirmos rūšiesklaidos tikimybė, tiek galia priklauso nuo θ.
Apskritai pirmos rūšies klaida laikomas hipotezės atmetimas, kai ji teisin-ga. Hipotezės priėmimas, kai ji neteisinga, vadinamas antros rūšies klaida;jos tikimybė (kai tikroji parametro reikšmė θ 6∈M) yra
Pθ(δ(X1, . . . , Xn) = 0) = 1− β(θ).
Suprantama, ji turi būti kuo mažesnė, bet taip ir bus, jei galia bus kuodidesnė.
Reikšmingumo lygmuo. Jau matėme, kad dauguma kriterijų yra nepaly-ginami: dažniausiai visada atsiras θ reikšmė, su kuria vieno kriterijaus galiosfunkcijos reikšmė bus geresnė, nei kito. Tegu, pavyzdžiui, (X1, X2) yra imtisiš skirstinio
X 0 11− θ θ
(čia θ ∈ (0; 1) — nežinomas parametras) ir tikrinama hipotezė H : θ 6 0.1.Kadangi θ yra reikšmės 1 tikimybė, galima samprotauti taip: jei hipote-zė teisinga (t.y. θ mažas), mažai tikėtina, kad imtyje bus daug vienetukų,todėl jei X1 = X2 = 1 hipotezę reiktų atmesti. Jei kitais atvejais hipotezępriimtume, gautume kriterijų su kritine sritimi
W1 = (x1, x2) | x1 = x2 = 1 = (1, 1).
Niekas nepasakys, kad tai neprotingas kriterijus.
68

Kita vertus, kriterijus su kritine sritimi
W2 = (x1, x2) | x1 < x2 = (0, 1)
atrodo visiškai beprotiškas. Bet kiterijų galios funkcijos yra
β1(θ) = θ2 ir β2(θ) = (1− θ)θ,
irβ1(θ) < β2(θ) ⇐⇒ θ <
12 .
Taigi jei β = 13 , beprotiškas kriterijus dukart galingesnis už protingąjį:
β2(13) = 2
9 >19 = β1(1
3).
Teorijos užduotis — kažkaip „atsijoti“ neprotingus kriterijus. Pirmasžingsnis ta kryptimi yra toks. Pasirenkamas tam tikras skaičius α, vadi-namas reikšmingumo lygmeniu, ir nagrinėjami tik kriterijai (pavadinsiu juosleistinais), kurių visos pirmos rūšies klaidos tikimybės neviršija α. Du leistinikriterijai lyginami toliau tik pagal jų galią, t.y. jei vieno kriterijaus galia subet kokia θ 6∈M yra didesnė (ar bent jau ne mažesnė) už kito kriterijaus ga-lią, jis laikomas geresniu kriterijumi, net jei jo pirmos rūšies klaidos tikimybėsu kokia nors θ ∈M yra didesnė.
Grįžtu prie nagrinėto pavyzdžio. Tarkime, reikšmingumo lygmuo α =0.05 (t.y. 5% — dažniausiai naudojamas reikšmingumo lygmuo). Su visaisθ 6 0.1
β1(θ) = θ2 6 0.01 < 0.05;
todėl pirmas kriterijus leistinas. Kita vertus,
β2(0.1) = 0.9 · 0.1 = 0.09 > 0.05;
todėl antrasis (beprotiškas kriterijus) nėra leistinas ir todėl nenagrinėtinas.Dar vienas leistinas kriterijus (ir vienintelis, jei nenagrinėtume rando-
mizuotų kriterijų) yra toks, kuris visada priima hipotezę, t.y. kriterijus sukritine sritimi W3 = ∅. Tokio kriterijaus galios funkcija
β3(θ) = 0
su visomis θ. Taigi pirmasis kriterijus geresnis (sakoma galingesnis) už tre-čiąjį, nežiūrint į tai, kad jo pirmos rūšies klaidos tikimybė su visomis θ 6 0.1didesnė:
β1(θ) = θ2 > 0 = β3(θ).
69

„Protingi“ kriterijai. Praktinis protingų kriterijų konstravimo metodasyra toks: iš pradžių protingai įvertinamas parametras θ ir po to hipotezėatmetama, jei įvertinys θ nepriklauso aibei M ; čia M yra aibė, „panaši“ į M ,bet parenkama taip, kad kriterijaus pirmos rūšies klaidos tikimybės neviršytųpasirinkto reikšmingumo lygmens.
Panagrinėkime tą patį pavyzdį kaip aukščiau, tik tegu dabar imties dydisn nebūtinai yra 2. Taigi iš pradžių reikia protingai įvertinti θ. Kadangi θ yrareikšmės 1 tikimybė, o tikimybė apytiksliai lygi tos reikšmės pasikartojimųimtyje dažniui, galime imti
θ = 1n
n∑i=1
1Xi=1 = 1n
n∑i=1
Xi = X.
Jei hipotezė yra θ 6 0.1 (t.y. kad θ mažas), tai ir priimti ją reiktų, kai θmažas, t.y. kai θ 6 c, tik c turėtų būti parenkamas nebūtinai 0.1, o taip, kadkriterijaus pirmos rūšies klaidos tikimybė neviršytų pasirinkto reikšmingumolygmens (pavyzdžiui, 0.05). Taigi protingas kriterijus būtų apibrėžiamastaip: hipotezė atmetama, kai X > c; čia c — tokia konstanta, kad su visaisθ 6 0.1
Pθ(X > c) 6 0.05. (4.1)c skaičius vadinamas kritine konstanta. Kuo jis mažesnis, tuo tokio ti-
po kriterijaus galia didesnė. Taigi reiktų pasirinkti mažiausią c, tenkinantį(4.1) sąlygą. Tikėtina, kad tikimybė kairėje tuo didesnė, kuo didesnis θ; todėlpakaktų parinkti c, su kuriuo
P0.1(X > c) ≈ 0.05.Kitaip tariant c būtų X dydžio skirstinio 95% kvantilis. Jį galima rastisimuliuojant daug X dydžio realizacijų kompiuteriu.
Momentų metodas parametrui vertinti. Kaip „protingai“ įvertinti θbendruoju atveju? Vienas iš būdų — vadinamasis vidurkių, arba apibend-rintųjų momentų, metodas. Pasirenkama kokia nors funkcija f : E → R irsuskaičiuojamas vidurkis Eθf(X) (jis ir vadinamas apibendrintuoju X dydžiomomentu). Jei turime pakankamai didelę imtį (X1, . . . , Xn), tas vidurkis busapytiksliai lygus vadinamajam empiriniam vidurkiui
f(X) = 1n
n∑i=1
f(Xi).
Protingas įvertinys θ gaunamas išsprendus θ atžvilgiu lygtįEθf(X) = f(X).
Kitame skyrelyje tos lygties sprendinį vadinsiu f -vidurkiniu įvertiniu.
70

4.2 Uždaviniai1–8 uždaviniuose (X1, . . . , Xn) yra imtis iš X dydžio skirstinio, priklausan-čio nuo nežinomo parametro θ, ir tikrinama tam tikra hipotezė H apie tąparametrą. Reikia rasti parametro vidurkinį įvertinį, atitinkantį nurodytąfunkciją f , aprašyti juo paremtą kriterijų ir nubrėžti to kriterijaus galiosfunkcijos grafiką. Kritinė konstanta (atitinkanti duotą reikšmingumo lygme-nį α) ir galios funkcijos reikšmės skaičiuojamos simuliuojant daug tinkamųimčių kompiuteriu; galios funkcijos grafikas brėžiamas irgi naudojant kom-piuterį.
Prieš sprendžiant 9–10 uždavinius reikia paskaityti „tikrąją“ teoriją pas-kutiniame šio skyriaus skyrelyje.
1. X pasiskirstęs pagal Puasono dėsnį su nežinomu vidurkiu θ > 0, tikri-nama hipotezė H : θ > 1, n = 20, α = 0.05 ir f(x) = x.
2. X pasiskirstęs pagal geometrinį dėsnį:
P(X = x) = (1− θ)θx su x = 0, 1, 2, . . . ;
čia θ ∈ (0; 1) — nežinomas parametras. Tikrinama hipotezė H : θ 6 0.5,n = 15, α = 0.1 ir f(x) = 10(x).
3. X pasiskirstęs pagal eksponentinį dėsnį su tankiu
pθ(x) = θe−θx, kai x > 0;
čia θ > 0 — nežinomas parametras. Tikrinama hipotezė H : θ > 2, n = 25,α = 0.05 ir f(x) = x.
4. X pasiskirstęs pagal normalųjį dėsnį su nežinomu vidurkiu θ ir dispersija1. Tikrinama hipotezė H : |θ| 6 1, n = 10, α = 0.01 ir f(x) = x.
5. X pasiskirstęs pagal normalųjį dėsnį su vidurkiu 0 ir nežinoma dispersijaθ > 0. Tikrinama hipotezė H : θ 6 1, n = 10, α = 0.05 ir f(x) = x2.
6. X pasiskirstęs pagal neigiamą binominį dėsnį:
Pθ(X = x) = (1− θ)2(x+ 1)θx su x = 0, 1, 2, . . . ;
čia θ ∈ (0; 1) — nežinomas parametras. Tikrinama hipotezė H : θ > 1,n = 10, α = 0.1 ir f(x) = x.
71

7. X pasiskirstęs pagal eksponentinį dėsnį su tankiu
pθ(x) = θe−θx, kai x > 0;
čia θ > 0 — nežinomas parametras. Tikrinama hipotezė H : θ 6 2, n = 15,α = 0.05 ir f(x) = 1(0;2)(x).
8. X pasiskirstęs tolygiai (−θ; θ) intervale; čia θ > 0 — nežinomas para-metras. Tikrinama hipotezė H : θ 6 3, n = 20, α = 0.05 ir f(x) = |x|.
9. Tegu (X1, X2) yra imtis iš skirstinio, aprašomo lentele
X 0 11− θ θ
(čia θ ∈ (0; 1) — nežinomas parametras) ir tikrinama hipotezė H : θ 6 0.5su reikšmingumo lygmeniu α = 0.1. Raskite (analiziškai) konstantas c ir q,apibrėžiančias tolygiai galingiausią kriterijų, ir nubrėžkite (jau panaudodamikompiuterį) to kriterijaus galios funkcijos grafiką.
10. Tegu (X1, . . . , Xn) yra imtis iš eksponentinio skirstinio su tankiu
pθ(x) = θe−θx, kai x > 0.
Čia θ > 0 yra nežinomas parametras ir tikrinama hipotezė H : θ > 1 sureikšmingumo lygmeniu α = 0.1. Raskite (naudodami kompiuterį, bet ne-simuliuodami imčių) tolygiai galingiausio kriterijaus kritines konstantas cn,atitinkančias imties dydžius n = 1, 2, . . . , 50, ir nubrėžkite jas iliustruojantįgrafiką. Konstantą c1 suskaičiuokite analiziškai ir palyginkite su kompiuterioduota reikšme.
4.3 Sprendimai1. Kadangi EθX = θ, imsiu
θ = X.
Tada protingas bus tokio pavidalo kriterijus: hipotezė atmetama, kai X < c.Kritinę konstantą randu ir galios funkcijos grafiką nubrėžiu, atlikęs tokią
programą:
n<-20alfa<-0.05N<-10000
72

teta0<-1est<-numeric(N)
for (i in 1:N)
x<-rpois(n,lambda=teta0)est[i]<-mean(x)
c<-quantile(est,probs=alfa)cat("Kritinė konstanta c=",c,"\n")
T<-200teta<-seq(from=0.01, to=2, by=0.01)atmete<-numeric(N)beta<-numeric(T)
for (t in 1:T)
for (i in 1:N)
x<-rpois(n,lambda=teta[t])atmete[i]<-(mean(x)<c)
beta[t]<-mean(atmete)
plot(teta,beta,type="l")abline(a=0.05, b=0, col="red")
Rezultatai: kritinė konstanta c = 0.65, o galios funkcijos grafikas paro-dytas 6 pav.
2. KadangiEθ1X=0 = Pθ(X = 0) = 1− θ,
laikysiu, kad
1− θ = 1X=0,
θ = 1− 1X=0.
Ieškomas kriterijus hipotezę atmeta, kai
1− 1X=0 > c,
73

0.0 0.5 1.0 1.5 2.0
0.0
0.2
0.4
0.6
0.8
1.0
teta
beta
6 pav. Žr. 1 uždavinį
1X=0 < 1− c.
Kadangi c kol kas nežinau, rašysiu c vietoje 1 − c ir kriterijų formuluosiutaip: hipotezę reikia atmesti, kai
1X=0 < c.
Kritinę konstantą rasiu ir galios funkcijos grafiką nubrėšiu, atlikęs tokią prog-ramą:
n<-15alfa<-0.1N<-10000teta0<-0.5est<-numeric(N)
for (i in 1:N)
x<-rgeom(n,prob=1-teta0)est[i]<-mean(x==0)
c<-quantile(est,probs=alfa)cat("Kritinė konstanta c=",c,"\n")
74

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
teta
beta
7 pav. Žr. 2 uždavinį
T<-100teta<-seq(from=0, to=0.99, by=0.01)atmete<-numeric(N)beta<-numeric(T)
for (t in 1:T)
for (i in 1:N)
x<-rgeom(n,prob=1-teta[t])atmete[i]<-(mean(x==0)<c)
beta[t]<-mean(atmete)
plot(teta,beta,type="l")abline(a=alfa, b=0, col="red")
Rezultatai: kritinė konstanta c = 0.33, o galios funkcijos grafikas paro-dytas 7 pav.
75

3. Kadangi
EθX = θ∫ ∞
0xe−θxdx = θ−1
∫ ∞0
ye−ydy = θ−1Γ(2) = θ−1,
vidurkinis įvertinys randamas taip:
θ−1 = X,
θ = (X)−1.
Hipotezę reiktų atmesti, kai
(X)−1 < c,
X > 1/c.
Kadangi c kol kas nežinau, rašysiu c vietoje 1/c ir kriterijų formuluosiu taip:hipotezę reikia atmesti, kai
X > c.
Kritinę konstantą rasiu ir galios funkcijos grafiką nubrėšiu, atlikęs tokią prog-ramą:
n<-25alfa<-0.05N<-10000teta0<-2est<-numeric(N)
for (i in 1:N)
x<-rexp(n,rate=teta0)est[i]<-mean(x)
c<-quantile(est,probs=1-alfa)cat("Kritinė konstanta c=",c,"\n")
T<-300teta<-seq(from=0.01, to=3, by=0.01)atmete<-numeric(N)beta<-numeric(T)
for (t in 1:T)
76

0.0 0.5 1.0 1.5 2.0 2.5 3.0
0.0
0.2
0.4
0.6
0.8
1.0
teta
beta
8 pav. Žr. 3 uždavinį
for (i in 1:N)
x<-rexp(n,rate=teta[t])atmete[i]<-(mean(x)>c)
beta[t]<-mean(atmete)
plot(teta,beta,type="l")abline(a=alfa, b=0, col="red")
Rezultatai: kritinė konstanta c = 0.68, o galios funkcijos grafikas paro-dytas 8 pav.
4. Kadangi EθX = θ, vidurkinis įvertinys yra θ = X ir protingas kriterijusgalėtų skambėti taip: hipotezę reikia atmesti, kai |X| > c. Kritinę konstantąrasiu ir galios funkcijos grafiką nubrėšiu, atlikęs tokią programą:
n<-10alfa<-0.01N<-10000teta1<-1
77

teta2<--1est<-numeric(N)
for (i in 1:N)
x<-rnorm(n,mean=teta1)est[i]<-mean(x)
c1<-quantile(abs(est),probs=1-alfa)for (i in 1:N)
x<-rnorm(n,mean=teta2)est[i]<-mean(x)
c2<-quantile(abs(est),probs=1-alfa)c=max(c1,c2)cat("Kritinė konstanta c=",c,"\n")
T<-100teta<-seq(from=-5, to=4.9, by=0.1)atmete<-numeric(N)beta<-numeric(T)
for (t in 1:T)
for (i in 1:N)
x<-rnorm(n,mean=teta[t])atmete[i]<-(abs(mean(x))>c)
beta[t]<-mean(atmete)
plot(teta,beta,type="l")abline(a=alfa, b=0, col="red")
Rezultatai: kritinė konstanta c = 1.73, o galios funkcijos grafikas paro-dytas 9 pav.
5. KadangiEθX2 = DθX + (EθX)2 = θ,
78

−4 −2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
teta
beta
9 pav. Žr. 4 uždavinį
vidurkinis įvertinys yra θ = X2 ir protingas kriterijus galėtų skambėti taip:hipotezę reikia atmesti, kaiX2 > c. Kritinę konstantą rasiu ir galios funkcijosgrafiką nubrėšiu, atlikęs tokią programą:
n<-10alfa<-0.05N<-10000teta0<-1est<-numeric(N)
for (i in 1:N)
x<-rnorm(n,sd=sqrt(teta0))est[i]<-mean(x*x)
c<-quantile(est,probs=1-alfa)cat("Kritinė konstanta c=",c,"\n")
T<-100teta<-seq(from=0.1, to=10, by=0.1)atmete<-numeric(N)beta<-numeric(T)
79

0 2 4 6 8 10
0.0
0.2
0.4
0.6
0.8
1.0
teta
beta
10 pav. Žr. 5 uždavinį
for (t in 1:T)
for (i in 1:N)
x<-rnorm(n,sd=sqrt(teta[t]))atmete[i]<-(mean(x*x)>c)
beta[t]<-mean(atmete)
plot(teta,beta,type="l")abline(a=alfa, b=0, col="red")
Rezultatai: kritinė konstanta c = 1.73, o galios funkcijos grafikas paro-dytas 10 pav.
6. Tolygiai galingiausias kriterijus aprašomas taip:jei X1 +X2 > c, hipotezė atmetama;jeiX1+X2 = c, hipotezė atmetama su tikimybe q ir priimama su tikimybe
1− q;jei X1 +X2 < c, hipotezė priimama.
80

Konstantos randamos iš sąlygos
P0.5(X1 +X2 > c) + qP0.5(X1 +X2 = c) = 0.1.
Iš pradžių rasiu c — tai mažiausias iš 0, 1, 2 skaičių, su kuriuo
P0.5(X1 +X2 > c) 6 0.1.
Kai parametro reikšmė yra 0.5, bendras (X1, X2) skirstinys aprašomas lenteleX1 X2 0 10 1
414
1 14
14
Todėl
P0.5(X1 +X2 > 0) = 34 > 0.1, P0.5(X1 +X2 > 1) = 1
4 > 0.1,
oP0.5(X1 +X2 > 2) = 0.
Taigi c = 2, o
q = 0.1− P0.5(X1 +X2 > 2)P0.5(X1 +X2 = 2) = 0.1− 0
14
= 0.4.
Rasto kriterijaus galios funkcijos grafiką nubrėžiu, atlikęs tokią programą:n<-2teta<-seq(from=0.01, to= 1, by=0.01)T<-length(teta)beta<-numeric(T)N<-10000
for (j in 1:T)
atmete<-numeric(N)for (i in 1:N)
x<-rbinom(n, size=1, prob=teta[j])if (sum(x)==2) atmete[i]<-rbinom(1, size=1, prob=0.4)
beta[j]<-mean(atmete)
plot(teta, beta, type="l")abline(a=0.1, b=0, col="red")
81

7. Tolygiai galingiausias kriterijus hipotezę atmeta, kai Tn > cn; čia Tn =X1 + · · ·+Xn. Todėl kritinė konstanta randama iš lygties
P1(Tn > cn) = 0.1,
t.y. ji yra Tn skirstinio 90% lygmens kvantilis. Yra žinoma, kad jei tikrojiparametro reikšmė yra θ, tai Tn pasiskirstęs pagal gama dėsnį su tankiu
q(t) = θn
Γ(n)tn−1e−θn, t > 0.
Taigi kritines konstantas randu, atlikęs tokią programą:
teta0<-1c<-numeric(50)
for (n in 1:50) c[n]<-qgamma(0.9, shape=n, rate=teta0)
plot (1:50, c, type="l", xlab="n")
Kompiuterio suskaičiuota c1 konstantos reikšmė yra 2.302585. Rasiu jąanaliziškai:
P1(X1 > c) = 0.1,∫ ∞c
e−xdx = 0.1,
e−c = 0.1
ir c = − ln 0.1 ≈ 2.302585.
4.4 Tikroji teorijaNeimano-Pirsono lema. Kai kada leistinų kriterijų aibėje galima rastigalingiausią kriterijų. Visais tokiais atvejais remiamasi Neimano-Pirsono le-ma, kurią šiame paragrafe suformuluosiu ir įrodysiu. Bet iš pradžių įsivesiukeletą naujų žymenų.
Neimano-Pirsono lema taikoma situacijoje, kai visų parametrų aibė Θdvitaškė, o „hipotetinė“ aibė M vientaškė. Laikysiu, kad Θ = 0, 1, o M =0. Taigi aiškinsiuos, kaip reikia tikrinti „paprastąją“ hipotezę H : θ = 0 su„paprasta alternatyva“ θ = 1.
Laikysiu taip pat, kad abu galimi X dydžio skirstiniai turi tankius topaties mato λ atžvilgiu: tankį, atitinkantį parametro reikšmę 0, žymėsiu p0,o kitą tankį — p1. Pažymiu
L0(x1, . . . , xn) = p0(x1) · · · p0(xn), L1(x1, . . . , xn) = p1(x1) · · · p1(xn);
82

tada L0 ir L1 yra imties (X1, . . . , Xn) tankiai tam tikro mato λn atžvilgiu.Kad būtų paprasčiau, užrašydamas integralus λn mato atžvilgiu pačio matoλn išvis neminėsiu. Taigi simbolis
∫f žymės integralą∫
f dλn =∫f(x1, . . . , xn)λn(d(x1, . . . , xn)).
Tada su bet kokia tinkama funkcija f ir su θ = 0, 1
Eθf(X1, . . . , Xn) =∫fLθ.
Kalbėdamas apie kriterijus, laikysiu, kad jie gali būti ir randomizuoti.Kaip matysim, ypatingai svarbūs yra tokio pavidalo kriterijai:
δ(x1, . . . , xn) =
1, kai L1(x1, . . . , xn) > cL0(x1, . . . , xn);Zq, kai L1(x1, . . . , xn) = cL0(x1, . . . , xn);0, kai L1(x1, . . . , xn) < cL0(x1, . . . , xn);
(4.2)
čia c > 0 ir q ∈ [0; 1] yra du parametrai, o Zq yra atsitiktinis dydis, kurioskirstinys aprašomas lentele
Zq 0 11− q q
Aš juos vadinsiu tikėtinumų santykio kriterijais.
4.1 teorema. Koks bebūtų reikšmingumo lygmuo α ∈ (0; 1), egzistuoja vie-nintelis tikėtinumų santykio kriterijus, kurio pirmos rūšies klaidos tikimybėyra α. Jis yra ne mažiau galingas, nei bet koks kitas leistinas kriterijus.
Įrodymas. 1 žingsnis: tegu δ kriterijus apibrėžiamas (4.2) lygybe; įrody-siu, kad su tam tikrais c ir q tokio kriterijaus pirmos rūšies klaidos tikimybėyra lygi α.
Tegu β yra to kriterijaus galios funkcija; tada pirmos rūšies klaidos tiki-mybė
β(0) = P0(δ(X1, . . . , Xn) = 1) = E01δ(X1,...,Xn)=1
= E0f(X1, . . . , Xn) =∫L0f ;
čia f(x1, . . . , xn) yra sąlyginio vidurkio EX1,...,Xn1δ(X1,...,Xn)=1 reikšmė, kai(X1, . . . , Xn) = (x1, . . . , xn). Mūsų atveju
f(x1, . . . , xn) =
1, kai L1(x1, . . . , xn) > cL0(x1, . . . , xn);q, kai L1(x1, . . . , xn) = cL0(x1, . . . , xn);0, kai L1(x1, . . . , xn) < cL0(x1, . . . , xn);
83

todėlβ(0) =
∫L1>cL0
L0 + q∫L1=cL0
L0.
Ieškau tokių c > 0 ir q ∈ [0; 1], kad suma dešinėje pusėje būtų lygi α.Su c > 0 pažymiu
g(c) =∫L1>cL0
L0.
Jei c < c′, tai L1 > c′L0 ⊂ L1 > cL0; todėl
g(c) =∫L1>cL0
L0 >∫L1>c′L0
L0 = g(c′).
Taigi g funkcija nedidėjanti. Didžiausia g funkcijos reikšmė yra
g(0) =∫L1>0
L0.
Jei cn ↓ c ∈ [0;∞), tai
L1 > cnL0 ↑⋃n
L1 > cnL0
= ∃n L1 > cnL0= L0 = 0 < L1 ∪ L0 > 0, ∃n L1/L0 > cn= L0 = 0 < L1 ∪ L0 > 0, L1/L0 > c= L0 = 0 < L1 ∪ L0 > 0, L1 > cL0;
todėlg(cn) ↑
∫L0=0<L1
L0 +∫L0>0L1>cL0
L0 =∫L1>cL0
L0 = g(c).
Taigi g tolydi iš dešinės.Jei cn ↑ c ∈ (0;∞], tai
L1 > cnL0 ↓⋂n
L1 > cnL0
= ∀n L1 > cnL0= L0 = 0 < L1 ∪ L0 > 0, ∀n L1/L0 > cn= L0 = 0 < L1 ∪ L0 > 0, L1/L0 > c= L0 = 0 < L1 ∪ L0 > 0, L1 > cL0.
Kadangi L0 funkcija integruojama, iš čia išplaukia
g(cn) ↓∫L0=0<L1
L0 +∫L0>0L1>cL0
p0 =∫L0>0L1>cL0
L0.
84

Jei c =∞, integralas dešinėje lygus 0; jei c <∞, jis lygus∫L1>cL0
L0 = g(c) +∫L1=cL0
L0.
Taigi g(c)→ 0, kai c→∞, bet g funkcija apskritai nėra tolydi iš kairės: jeikokiame nors c taške yra trūkis,
g(c−)− g(c) =∫L1=cL0
L0.
Dabar jau galiu paaiškinti, kaip renkami c ir q. Galimi trys atvejai.1. α = g(c) su tam tikru c > 0; tada paimu q = 0 ir gaunu reikiamą
lygybę:α = g(c) =
∫L1>cL0
L0 =∫L1>cL0
L0 + q∫L1=cL0
L0.
2. g(c) < α 6 g(c−) su tam tikru c > 0; tada pažymiu
q = α− g(c)g(c−)− g(c) .
Akivaizdu, kad 0 < q 6 1; be to,
α = g(c) + q(g(c−)− g(c)) =∫L1>cL0
L0 + q∫L1=cL0
L0,
t.y. reikiama lygybė ir vėl teisinga.3. g(0) < α < 1; tada pažymiu c = 0 ir
q = α− g(0)1− g(0) .
Akivaizdu, kad 0 < q < 1; be to,
α = g(0) + q(1− g(0)) =∫L1>0
L0 + q(
1−∫L1>0
L0
)=∫L1>0
L0 + q∫L1=0
L0.
Akivaizdu, kad reikiama lygybė teisinga ir šiuo atveju.2 žingsnis: įrodysiu, kad sukonstruoto kriterijaus galia ne mažesnė nei
bet kokio kito kriterijaus galia.1 žingsniu sukonstruoto kriterijaus galia yra
β(1) = E1f(X1, . . . , Xn) =∫L1f =
∫L1>cL0
L1 + q∫L1=cL0
L1.
Iš čia ir iš lygybės β(0) = α išplaukia
85

β(1)− cα = β(1)− cβ(0)
=∫L1>cL0
L1 + q∫L1=cL0
L1 − c∫L1>cL0
L0 − cq∫L1=cL0
L0
=∫L1>cL0
(L1 − cL0) + q∫L1=cL0
(L1 − cL0) =∫L1>cL0
(L1 − cL0).
Tegu δ′ yra bet koks kitas leistinas randomizuotas kriterijus, β′ — jogalios funkcija ir f ′(x1, . . . , xn) — sąlyginio vidurkio EX1,...,Xn1δ′(X1,...,Xn)=1reikšmė, kai (X1, . . . , Xn) = (x1, . . . , xn). Tada
β′(0) =∫L0f
′ ir β′(1) =∫L1f
′.
Kadangi δ′ leistinas, o 0 6 f ′ 6 1,
β′(1)− cα 6 β′(1)− cβ′(0) =∫L1f
′ − c∫L0f
′ =∫
(L1 − cL0)f ′
=∫L1>cL0
(L1−cL0)f ′+∫L1<cL0
(L1−cL0)f ′ 6∫L1>cL0
(L1−cL0) = β(1)−cα.
Taigi β′(1) 6 β(1).
Tolygiai galingiausi kriterijai. Aprašysiu situaciją, kurioje galima rastileistiną kriterijų, ne mažiau galingą už bet kokį kitą leistiną kriterijų, kokiabebūtų alternatyva θ. Tokie kriterijai vadinami tolygiai galingiausiais.
Tegu (X1, . . . , Xn) yra imtis iš X dydžio skirstinio, priklausančio nuo ne-žinomo realiojo parametro θ, kurio galimų reikšmių aibė yra koks nors inter-valas Θ = (a; b). Tegu θ∗ ∈ (a; b) ir su reikšmingumo lygmeniu α tikrinamaarba hipotezė H1 : θ 6 θ∗, arba hipotezė H2 : θ > θ∗.
Tarkime, galimi X skirstiniai turi tankius pθ kokio nors mato atžvilgiu.Pažymiu
Lθ(x1, . . . , xn) = pθ(x1) . . . pθ(xn).Šiaip jau Lθ yra imties (X1, . . . , Xn) tankis, atitinkantis parametro reikšmęθ. Bet jei imties reikšmę (x1, . . . , xn) fiksuojame ir į Lθ(x1, . . . , xn) žiūri-me kaip į θ argumento funkciją, ji vadinama tikėtinumo funkcija. Tiksliau,Lθ(x1, . . . , xn) vadinamas θ reikšmės tikėtinumu, atitinkančiu (x1, . . . , xn) im-tį.
Kriterijus δ vadinamas tikėtinumų santykio kriterijumi, atitinkančiu porą(θ0, θ1), jei su tam tikromis konstantomis c > 0 ir q ∈ [0; 1]
δ(x1, . . . , xn) =
1, kai Lθ1(x1, . . . , xn) > cLθ0(x1, . . . , xn);Zq, kai Lθ1(x1, . . . , xn) = cLθ0(x1, . . . , xn);0, kai Lθ1(x1, . . . , xn) < cLθ0(x1, . . . , xn);
86

čia Zq yra toks pat atsitiktinis dydis kaip aukščiau.Jei δ yra koks nors tikėtinumų santykio kriterijus, atitinkantis porą (θ0, θ1),
δ′ — bet koks kitas kriterijus ir β, β′ yra tų kriterijų galios funkcijos, tai išNeimano-Pirsono lemos išplaukia tokia implikacija:
β′(θ0) 6 β(θ0)⇒ β(θ1) > β′(θ1). (4.3)
Dabar suformuluosiu teiginį, kuriuo remiamės, konstruodami tolygiai ga-lingiausius kriterijus H1 ir H2 hipotezėms tikrinti.
4.2 teorema. Tegu δ yra kriterijus su galios funkcija β ir tokiomis dviemsavybėmis:
1) β(θ∗) = α;2) kokie bebūtų θ0 < θ1 (atitinkamai, θ0 > θ1) iš (a; b), δ yra tikėtinumų
santykio kriterijus, atitinkantis porą (θ0, θ1).Tada δ yra tolygiai galingiausias kriterijus hipotezei H1 (atitinkamai, H2)tikrinti.
Įrodymas. Laikysiu, kad tikrinama H1 hipotezė; H2 hipotezės atvejusamprotavimai analogiški.
1 žingsnis: įrodysiu, kad δ kriterijus leistinas, t.y. kad β(θ) 6 α su visaisθ < θ∗.
Tariu priešingai, β(θ) > α su tam tikru θ0 < θ∗. Pažymiu α0 = β(θ0) irtegu δ′ yra randomizuotas kriterijus, kuris atmeta hipotezę su tikimybe α0nepriklausomai nuo imties reikšmės (x1, . . . , xn). Tada β′(θ) = α0 su visaisθ. Kadangi δ yra tikėtinumų santykio kriterijus, atitinkantis porą (θ0, θ
∗), iš(4.3) išplaukia
α0 6 β(θ0)⇒ β(θ∗) > α0.
Implikacijos prielaida teisinga, o išvada klaidinga; taigi gavau prieštarą.2 žingsnis: įrodysiu, kad su bet kokiu θ1 > θ∗ kriterijaus δ galia β(θ1)
nemažesnė už bet kokio kito leistino kriterijaus galią tame taške.Tegu δ′ yra bet koks leistinas kriterijus, β′ — jo galios funkcija ir θ1 > θ∗.
Kadangi δ yra tikėtinumų santykio kriterijus, atitinkantis porą (θ∗, θ1), iš(4.3) išplaukia
β′(θ∗) 6 β(θ∗)⇒ β(θ1) > β′(θ1).
Implikacijos prielaida teisinga, nes β′(θ∗) 6 α = β(θ∗); reiškia, teisinga irišvada: β(θ1) > β′(θ1).
Toliau išnagrinėsiu keletą pavyzdžių.
87

Bernulio modelis. Tegu (X1, . . . , Xn) yra imtis iš skirstinio, aprašomolentele
X 0 11− θ θ
(čia θ ∈ (0; 1) — nežinomas parametras); sukonstruosiu tolygiai galingiausiąkriterijų hipotezei H : θ 6 θ∗ tikrinti su reikšmingumo lygmeniu α.
Nagrinėjamu atveju tikėtinumo funkcija
Lθ(x1, . . . , xn) = (1− θ)n−tθt;
čia t = t(x1, . . . , xn) yra vienetukų skaičius imtyje (kadangi kiekvienas xi yraarba 0, arba 1, vienetukų skaičius t = x1 + · · · + xn). Jei θ0 < θ1 yra duskaičiai iš (0; 1), tai tikėtinumų santykio kriterijus, atitinkantis porą (θ0, θ1),hipotezę atmeta, kai
(1− θ1)n−tθt1 > c(1− θ0)n−tθt0, (4.4)
ir priima, kai teisinga analogiška nelygybė, tik su < ženklu vietoje >. (4.4)nelygybė ekvivalenti tokioms:
(1− θ1)n−tθt1 > c(1− θ0)n−tθt0,
(1− θ1)n(
θ1
1− θ1
)t> c(1− θ0)n
(θ0
1− θ0
)t,(
θ1
1− θ1
)t> c′
(θ0
1− θ0
)t(pažymėjau c′ = c(1− θ0)n/(1− θ1)n),
t ln θ1
1− θ1> ln c′ + t ln θ0
1− θ0,
t(
ln θ1
1− θ1− ln θ0
1− θ0
)> ln c′.
Su x ∈ (0; 1) pažymiu f(x) = x1−x ; tada su visais x
f ′(x) = 1− x+ x
(1− x)2 = 1(1− x)2 > 0
ir todėl f funkcija yra didėjanti (0; 1) intervale. Tada
θ1
1− θ1>
θ0
1− θ0,
88

ln θ1
1− θ1> ln θ0
1− θ0
ir, reiškia, (4.4) nelygybė ekvivalenti nelygybei t > c′′ su
c′′ = ln c′
ln θ11−θ1− ln θ0
1−θ0
.
Taigi bet koks tikėtinumų santykio kriterijus, atitinkantis bet kokius θ0 <θ1, atmeta hipotezę, kai t > c, ir priima ją, kai t < c; čia c — tam tikra kons-tanta. Akivaizdu, kad teisingas ir atvirkščias teiginys: bet koks tokio pavi-dalo kriterijus yra tikėtinumų santykio kriterijus, atitinkantis porą (θ0, θ1),kokie bebūtų θ0 < θ1. Iš 4.2 teoremos tada išplaukia, kad ieškomas tolygiaigalingiausias kriterijus, aprašomas, pavyzdžiui, taip.
Tegu t = t(x1, . . . , xn) yra vienetukų skaičius imtyje, T = t(X1, . . . , Xn)ir skaičiai c ir q ∈ [0; 1] tenkina sąlygą
Pθ∗(T > c) + qPθ∗(T = c) = α.
Tada:jei t > c, hipotezę reikia atmesti;jei t = c, hipotezę reikia atmesti su tikimybe q ir priimti su tikimybe
1− q;jei t < c, hipotezę reikia priimti.Ieškant konstantų c ir q, galima remtis tuo, kad T statistikos skirstinys,
atitinkantis parametro reikšmę θ, yra binominis Bin(n, θ) skirstinys. Ieško-jimo algoritmas galėtų būti toks: iš pradžių randame mažiausią c > 0, sukuriuo
Pθ∗(T > c) 6 α
(kadangi T įgyja tik 0, . . . , n reikšmes, pakanka ir tikrinti tik c = 0, . . . , n),o tada paimame
q = α− Pθ∗(T > c)Pθ∗(T = c) .
Praktikoje randomizuoti kriterijai nelabai mėgstami, todėl paprastai su-randamas tik c, o q imamas lygus 0 (t.y. hipotezė priimama, kai T 6 c).Toks kriterijus irgi yra tolygiai galingiausias, tik su šiek tiek mažesniu reikš-mingumo lygmeniu
α′ = Pθ∗(T > c) 6 α.
89

Geometrinis modelis. Tegu (X1, . . . , Xn) yra imtis iš geometrinio skirs-tinio, aprašomo lygybėmis:
Pθ(X = k) = (1− θ)θk su k = 0, 1, 2, . . . ;
čia θ ∈ (0; 1) — nežinomas parametras. Sukonstruosiu tolygiai galingiausiąkriterijų hipotezei H : θ > θ∗ tikrinti su reikšmingumo lygmeniu α.
Nagrinėjamu atveju tikėtinumo funkcija
Lθ(x1, . . . , xn) = (1− θ)θx1 · · · (1− θ)θxn = (1− θ)nθx1+···+xn .
Kad būtų trumpiau, pažymiu tn = x1 + · · ·+ xn.Jei θ0 > θ1, tikėtinumų santykio kriterijus, atitinkantis porą (θ0, θ1), hi-
potezę atmeta, kai
(1− θ1)nθtn1 > c(1− θ0)nθtn0 ,θtn1 > c′θtn0 ,
tn ln θ1 > ln c′ + tn ln θ0,
tn(ln θ1 − ln θ0) > ln c′,tn < c′′.
Todėl ieškomas tolygiai galingiausias kriterijus, gali būti aprašytas taip.Tegu Tn = X1 + · · ·+Xn ir skaičiai c ir q ∈ [0; 1] tenkina sąlygą
Pθ∗(Tn < c) + qPθ∗(Tn = c) = α.
Tada:jei x1 + · · ·+ xn < c, hipotezę reikia atmesti;jei x1 + · · · + xn = c, hipotezę reikia atmesti su tikimybe q ir priimti su
tikimybe 1− q;jei x1 + · · ·+ xn > c, hipotezę reikia priimti.Konstantos c ir q gali būti rastos taikant tokį algoritmą: iš pradžių ran-
dame didžiausią sveikąjį c, su kuriuo Pθ∗(Tn < c) 6 α (pakanka perrinkinėtitik sveikąsias neneigiamas reikšmes: c = 0, 1, 2, . . . ), o tada imame
q = α− Pθ∗(Tn < c)Pθ∗(Tn = c) .
Dėl visa ko rasiu ir Tn statistikos skirstinį, atitinkantį parametro reikšmęθ. Taikysiu vadinamąjį generuojančių funkcijų metodą. Su k = 0, 1, 2, . . .pažymiu pk = Pθ(Tn = k); tada su |z| < 1∑
k>0pkz
k = EθzTn = EθzX1+···+Xn = EθzX1 · · · zXn = (EθzX)n.
90

Bet
EθzX =∑k>0
Pθ(X = k)zk =∑k>0
(1− θ)θkzk = (1− θ)∑k>0
(θz)k = 1− θ1− θz .
Todėl∑k>0
pkzk =
( 1− θ1− θz
)n= (1− θ)n(1− θz)−n = (1− θ)n
∑k>0
(−nk
)(−θz)k
ir, reiškia,
pk = (1−θ)n(−nk
)(−θ)k = (1−θ)nθk(−1)k (−n)(−n− 1) · · · (−n− k + 1)
k!
= (1− θ)nθkn(n+ 1) · · · (n+ k − 1)k! = (1− θ)nθk
(n+ k − 1
k
).
Taigi
Pθ(Tn = k) =(n+ k − 1
k
)(1− θ)nθk su k = 0, 1, 2, . . . .
Toks skirstinys vadinamas neigiamu binominiu. R aplinkoje n parametrasvadinamas size, o 1− θ yra prob.
Puasono modelis. Tegu (X1, . . . , Xn) yra imtis iš Puasono skirstinio sunežinomu vidurkiu θ > 0:
Pθ(X = k) = e−θ θk
k! su k = 0, 1, 2, . . . .
Sukonstruosiu tolygiai galingiausią kriterijų hipotezei H : θ 6 θ∗ tikrinti sureikšmingumo lygmeniu α.
Nagrinėjamu atveju tikėtinumo funkcija
Lθ(x1, . . . , xn) = e−θ θx1
x1! · · · e−θ θ
xn
xn! = e−nθ θx1+···+xn
x1! · · ·xn! .
Kad būtų trumpiau, pažymiu tn = x1 + · · ·+ xn.Jei θ0 < θ1, tikėtinumų santykio kriterijus, atitinkantis porą (θ0, θ1), hi-
potezę atmeta, kai
e−nθ1θtn1
x1! · · ·xn! > ce−nθ0θtn0
x1! · · ·xn! ,
91

e−nθ1θtn1 > ce−nθ0θtn0 ,
θtn1 > c′θtn0 ,
tn ln θ1 > ln c′ + tn ln θ0,
tn(ln θ1 − ln θ0) > ln c′,tn > c′′.
Todėl ieškomas tolygiai galingiausias kriterijus, gali būti aprašytas taip.Tegu Tn = X1 + · · ·+Xn ir skaičiai c ir q ∈ [0; 1] tenkina sąlygą
Pθ∗(Tn > c) + qPθ∗(Tn = c) = α.
Tada:jei x1 + · · ·+ xn > c, hipotezę reikia atmesti;jei x1 + · · · + xn = c, hipotezę reikia atmesti su tikimybe q ir priimti su
tikimybe 1− q;jei x1 + · · ·+ xn < c, hipotezę reikia priimti.Konstantos c ir q gali būti rastos taikant tokį algoritmą: iš pradžių ran-
dame mažiausią sveikąjį c, su kuriuo Pθ∗(Tn > c) 6 α, o tada imame
q = α− Pθ∗(Tn > c)Pθ∗(Tn = c) .
Gerai žinoma, kad Tn skirstinys, atitinkantis parametrą θ yra Puasonoskirstinys su vidurkiu nθ.
Eksponentinis modelis. Tegu (X1, . . . , Xn) yra imtis iš eksponentinioskirstinio su tankiu
pθ(x) = θe−θx, kai x > 0;čia θ > 0 — nežinomas parametras. Sukonstruosiu tolygiai galingiausiąkriterijų hipotezei H : θ > θ∗ tikrinti su reikšmingumo lygmeniu α.
Nagrinėjamu atveju tikėtinumo funkcija
Lθ(x1, . . . , xn) = θe−θx1 · · · θe−θxn = θne−θ(x1+···+xn).
Kad būtų trumpiau, pažymiu tn = x1 + · · ·+ xn.Jei θ0 > θ1, tikėtinumų santykio kriterijus, atitinkantis porą (θ0, θ1), hi-
potezę atmeta, kai
θn1 e−θ1tn > cθn0 e−θ0tn ,
e−θ1tn > c′e−θ0tn ,
−θ1tn > ln c′ − θ0tn,
92

tn(θ0 − θ1) > ln c′,tn > c′′.
Todėl ieškomas tolygiai galingiausias kriterijus, gali būti aprašytas taip.Tegu Tn = X1 + · · ·+Xn ir skaičius c > 0 toks, kad
Pθ∗(Tn > c) = α. (4.5)
Tada:jei x1 + · · ·+ xn > c, hipotezę reikia atmesti;jei x1 + · · ·+ xn 6 c, hipotezę reikia priimti.Gerai žinoma, kad Tn skirstinys, atitinkantis parametrą θ yra gama skirs-
tinys su tankiuq(t) = θn
Γ(n)tn−1e−θt, kai t > 0.
Kadangi jis tolydus, visada atsiras c, tenkinantis (4.5) sąlygą, ir todėl tolygiaigalingiausias kriterijus yra nerandomizuotas.
Normalusis modelis su žinoma dispersija. Tegu (X1, . . . , Xn) yra imtisiš normaliojo N(θ, σ2) skirstinio su nežinomu vidurkiu θ ∈ R ir žinoma dis-persija σ2. Sukonstruosiu tolygiai galingiausią kriterijų hipotezei H : θ 6 θ∗
tikrinti su reikšmingumo lygmeniu α.Nagrinėjamu atveju tikėtinumo funkcija
Lθ(x1, . . . , xn) = 1√2πσ
e−(x1−θ)2/(2σ2) · · · 1√2πσ
e−(xn−θ)2/(2σ2)
= 1(√
2πσ)ne−1/(2σ2)
∑n
i=1(xi−θ)2.
Jei θ0 < θ1, tikėtinumų santykio kriterijus, atitinkantis porą (θ0, θ1), hi-potezę atmeta, kai
1(√
2πσ)ne−1/(2σ2)
∑n
i=1(xi−θ1)2> c
1(√
2πσ)ne−1/(2σ2)
∑n
i=1(xi−θ0)2,
e−1/(2σ2)∑n
i=1(xi−θ1)2> ce−1/(2σ2)
∑n
i=1(xi−θ0)2,
− 12σ2
n∑i=1
(xi − θ1)2 > ln c− 12σ2
n∑i=1
(xi − θ0)2,
12σ2
( n∑i=1
(xi − θ0)2 −n∑i=1
(xi − θ1)2)> ln c,
n∑i=1
((xi − θ0)2 − (xi − θ1)2
)> c′,
93

n∑i=1
(x2i − 2xiθ0 + θ2
0 − x2i + 2xiθ1 − θ2
1) > c′,
2(θ1 − θ0)n∑i=1
xi + n(θ20 − θ2
1) > c′,
2(θ1 − θ0)n∑i=1
xi > c′ − n(θ20 − θ2
1)
n∑i=1
xi > c′′.
Todėl ieškomas tolygiai galingiausias kriterijus, gali būti aprašytas taip.Tegu Tn = X1 + · · ·+Xn ir skaičius c > 0 toks, kad
Pθ∗(Tn > c) = α.
Tada:jei x1 + · · ·+ xn > c, hipotezę reikia atmesti;jei x1 + · · ·+ xn 6 c, hipotezę reikia priimti.Gerai žinoma, kad Tn skirstinys, atitinkantis parametrą θ yra normalusis
N(nθ, nσ2) skirstinys.
Normalusis modelis su žinomu vidurkiu. Tegu (X1, . . . , Xn) yra imtisiš normaliojo N(a, θ) skirstinio su žinomu vidurkiu a ir nežinoma dispersijaθ > 0. Sukonstruosiu tolygiai galingiausią kriterijų hipotezei H : θ > θ∗
tikrinti su reikšmingumo lygmeniu α.Nagrinėjamu atveju tikėtinumo funkcija
Lθ(x1, . . . , xn) = 1√2πθ
e−(x1−a)2/(2θ) · · · 1√2πθ
e−(xn−a)2/(2θ)
= 1(√
2πθ)ne−1/(2θ)
∑n
i=1(xi−a)2.
Kad būtų trumpiau, pažymiu tn = ∑ni=1(xi − a)2.
Jei θ0 > θ1, tikėtinumų santykio kriterijus, atitinkantis porą (θ0, θ1), hi-potezę atmeta, kai
1(√
2πθ1)ne−tn/(2θ1) > c
1(√
2πθ0)ne−tn/(2θ0),
e−tn/(2θ1) > c′e−tn/(2θ0),
− tn2θ1
> ln c′ − tn2θ0
,
94

tn
( 12θ0− 1
2θ1
)> ln c′,
tn < c′′.
Todėl ieškomas tolygiai galingiausias kriterijus, gali būti aprašytas taip.Tegu Tn = ∑n
i=1(Xi − a)2 ir skaičius c > 0 toks, kad
Pθ∗(Tn < c) = α.
Tada:jei ∑n
i=1(xi − a)2 < c, hipotezę reikia atmesti;jei ∑n
i=1(xi − a)2 > c, hipotezę reikia priimti.Gerai žinoma, kad jei imtis yra iš N(a, θ) skirstinio, tai θ−1/2Tn pasiskirstęs
pagal χ2 dėsnį su n laisvės laipsnių.
5 Nepaslinktieji mažiausios dispersijos įver-tiniai
5.1 TeorijaNepaslinktieji įvertiniai. Tegu (X1, . . . , Xn) yra imtis iš X dydžio skirs-tinio, priklausančio nuo nežinomo parametro θ ir vertinamas išvestinis pa-rametras γ = γ(θ) ∈ R. Įvertinys γ vadinamas nepaslinktu, jei su visaisθ
Eθγ = γ(θ).Tegu, pavyzdžiui, X skirstinys aprašomas lentele
X 0 11− θ θ
(čia θ ∈ (0; 1)), n = 2 ir γ(θ) = θ2. Įvertinys γ1 = X1 +X2 paslinktas, nes
Eθγ1 = 2EθX = 2θ 6= γ(θ),
o įvertinys γ2 = 1X1=X2=1 — nepaslinktasis, nes su visais θ
Eθγ2 = Pθ(X1 = X2 = 1) = θ2 = γ(θ).
Nagrinėtas modelis geras dar ir dėl to, kad nesunku aprašyti visus išves-tinius parametrus, kuriuos galima įvertinti be poslinkio. Tikrai, tegu γ yrakokio nors išvestinio parametro γ nepaslinktasis įvertinys. Pažymiu
γ(0, 0) = c00, γ(0, 1) = c01, γ(1, 0) = c10 ir γ(1, 1) = c11. (5.1)
95

Tada
γ(θ) = c00(1− θ)2 + (c01 + c10)θ(1− θ) + c11θ2 = a+ bθ + cθ2
su a = c00, b = −2c00 + c01 + c10 ir c = −c01 − c10 + c11. Atvirkščiai, jeiγ(θ) = a+bθ+cθ2 su kokiais nors a, b, c ∈ R, tai paėmęs c00 = a, c01 = b+2a,c10 = 0, c11 = c + b + 2a ir apibrėžęs γ (5.1) lygybėmis, gausiu Eθγ = γ(θ).Taigi nagrinėjamame modelyje nepaslinktasis įvertinys egzistuoja tada ir tiktada, kai išvestinis parametras yra ne didesnės už 2 eilės daugianaris.
Nepaslinktasis vidurkio įvertinys. Jei (X1, . . . , Xn) yra imtis išX skirs-tinio ir f — kokia nors funkcija, žymiu
f(X) = f(X1) + · · ·+ f(Xn)n
.
Pavyzdžiui,
X = X1 + · · ·+Xn
n, X2 = X2
1 + · · ·+X2n
n,
1X>1 = 1X1>1 + · · ·+ 1Xn>1
n
ir t.t. Atkreipiu dėmesį, kad X2 6= X2.
f(X) reiškinį aš vadinu empiriniu f(X) dydžio vidurkiu. Kitaip nei „teo-rinis“ vidurkis Eθf(X), kuris yra tiesiog skaičius, empirinis vidurkis yra at-sitiktinis dydis; tiksliau, (X1, . . . , Xn) imties funkcija, t.y. statistika. Tačiaujo savybės panašios į teorinio vidurkio savybes:
c = c, cf(X) = cf(X), f(X) + g(X) = f(X) + g(X).
Pirmos dvi savybės gali būti apibendrintos: c gali būti ne tik bet kokia kons-tanta, bet ir kitas empirinis vidurkis, ar tokio vidurkio funkcija. Pavyzdžiui,reiškinys X2
X2 suprantamas kaip
X2X2
1 + · · ·+X2X2n
n= X
2X21 + · · ·+X2
n
n
ir yra lygus X2X2.
Štai suformuluotų savybių taikymo pavyzdys:
(X −X)2 = X2 − 2XX +X2 = X2 − 2XX +X
2 = X2 −X2.
96

Su bet kokiu θ
Eθf(X1) + · · ·+ f(Xn)
n= 1n
(Eθf(X1) + · · ·+ Eθf(Xn))
= 1nnEθf(X) = Eθf(X),
t.y.Eθf(X) = Eθf(X).
Kitaip tariant, empirinis vidurkis f(X) yra nepaslinktasis teorinio vidurkioγ(θ) = Eθf(X) įvertinys.
Nepaslinktasis dispersijos įvertinys. Išsiaiškinsiu, kaip atrodo nepas-linktasis dispersijos γ(θ) = Dθf(X) įvertinys. Tam iš pradžių suskaičiuosiuEθf(X)2. Kad būtų trumpiau, rašysiu U vietoje f(X) ir Ui vietoje f(Xi).Taigi
EθU2 = Eθ
(U1 + · · ·+ Un
n
)2= 1n2 Eθ
∑i,j
UiUj = 1n2
∑i,j
EθUiUj
= 1n2
∑i
EθU2i + 1
n2
∑i 6=j
EθUiUj = 1n2
∑i
EθU2i + 1
n2
∑i 6=j
EθUiEθUj
= 1n2nEθU2 + 1
n2 (n2 − n)(EθU)2 = (EθU)2 + 1n
(EθU2 − (EθU)2
)= (EθU)2 + 1
nDθU.
Pažymiu T = (U − U)2 = U2 − U2; tada
EθT = EθU2 − EθU2 = EθU2 − (EθU)2 − 1
nDθU
= DθU −1n
DθU =(
1− 1n
)DθU = n− 1
nDθU.
Iš čiaEθ
n
n− 1T = DθU,
t.y. nepaslinktasis dispersijos DθU = Dθf(X) įvertinys yra
n
n− 1T = n
n− 1(U − U)2 = n
n− 1(U1 − U)2 + · · ·+ (Un − U)2
n
= (f(X1)− f(X))2 + · · ·+ (f(Xn)− f(X))2
n− 1 .
97

Pilnos statistikos. Statistika T = t(X1, . . . , Xn) vadinama pilna, jei subet kokia funkcija f iš to, kad Eθf(T ) = 0 su visais θ, išplaukia, kadPθ(f(T ) = 0) = 1 su visais θ.
Vėl panagrinėsiu tą patį modelį kaip ankstesniame paragrafe. Tegu
T1 = X1, T2 = X1 +X2 ir T3 = X1 −X2.
Išsiaiškinsiu, kurios iš tų statistikų pilnos, o kurios — ne. Naudosiu tokįgerai žinomą faktą: jei q yra daugianaris ir q(θ) = 0 su visais θ ∈ (0; 1), taivisi to daugianario koeficientai lygūs 0.
Tegu su visais θEθf(T1) = 0,
t.y.
(1− θ)f(0) + θf(1) = 0,f(0) +
(f(1)− f(0)
)θ = 0.
Tadaf(0) = 0 ir f(1)− f(0) = 0,
t.y. f(0) = f(1) = 0. Iš čia beveik tikrai f(T1) = 0, nes 0 ir 1 yra visosgalimos T1 statistikos reikšmės. Taigi T1 statistika pilna.
Tegu su visais θEθf(T2) = 0,
t.y.
(1− θ)2f(0) + 2θ(1− θ)f(1) + θ2f(2) = 0,f(0) +
(−2f(0) + 2f(1)
)θ +
(f(0)− 2f(1) + f(2)
)θ2 = 0.
Tada
f(0) = 0, −2f(0) + 2f(1) = 0 ir f(0)− 2f(1) + f(2) = 0,
t.y. f(0) = f(1) = f(2) = 0. Iš čia beveik tikrai f(T2) = 0, nes 0, 1 ir 2 yravisos galimos T2 statistikos reikšmės. Taigi T2 statistika pilna.
Tegu su visais θEθf(T3) = 0,
t.y.
(1− θ)2f(0) + θ(1− θ)f(−1) + θ(1− θ)f(1) + θ2f(0) = 0,f(0) +
(−2f(0) + f(−1) + f(1)
)θ +
(2f(0)− f(−1)− f(1)
)θ2 = 0.
98

Tada
f(0) = 0, −2f(0) + f(−1) + f(1) = 0 ir 2f(0)− f(−1)− f(1) = 0,
t.y. f(0) = 0 ir f(−1) + f(1) = 0. Tačiau f(1) ir f(−1) nebūtinai yra 0;pavyzdžiui, gali būti f(−1) = −1 ir f(1). Tokiu atveju f(T3) 6= 0 su teigiamatikimybe. Taigi T3 statistika nėra pilna.
Statistika nebūtinai turi būti vienmatė. Tegu, pavyzdžiui,
T4 = (X1, X2);
išsiaiškinsiu, ar T4 pilna. Tegu visais θ
Eθf(T4) = 0,
t.y.
(1− θ)2f(0, 0) + θ(1− θ)f(0, 1) + θ(1− θ)f(1, 0) + θ2f(1, 1) = 0
ir
f(0, 0) +(−2f(0, 0) + f(0, 1) + f(1, 0)
)θ+(
f(0, 0)− f(0, 1)− f(1, 0) + f(1, 1))θ2 = 0.
Panašiai kaip aukščiau gaunu, kad tada
f(0, 0) = 0, f(0, 1) + f(1, 0) = 0 ir f(1, 1) = 0,
bet f(0, 1) ir f(1, 0) nebūtinai yra 0; pavyzdžiui, gali būti f(0, 1) = 1, of(1, 0) = −1. Taigi T4 statistika nėra pilna.
Pilnos pakankamos statistikos. Pilnos statistikos sąvoka pasidaro pra-smingesnė, jei nagrinėjam ne bet kokias, o tik pilnas statistikas. Aukš-čiau išnagrinėtame pavyzdyje pilnos buvo tik statistikos T2 = X1 + X2 irT4 = (X1, X2). Iš jų T2 statistika pilna, o T4 nepilna. Kaip išsiaiškinom 3skyriuje, T2 yra minimali statistika, o T4 — ne. Čia nieko nuostabaus, neskiek žinau pilnos statistikos visada minimalios. Atvirkščias teiginys apskritaineteisingas: galima sugalvoti modelį, kuriame minimali statistika nėra pilna.
Taigi sąvoka „pilna statistika“ nėra labai vykusi: jei pilną statistiką pa-pildysiu, ji nustos būti pilna.
Panagrinėsiu tris bendresnius pavydžius. Visuose naudosiuosi tokiu faktuiš analizės: jei ∑k>0 akθ
k = 0 su visais θ ∈ (0; 1), tai ak = 0 su visais k > 0.1. Tegu (X1, . . . , Xn) yra imtis iš skirstinio, aprašomo lentele
99

X 0 11− θ θ
ir T yra vienetukų skaičius imtyje. Tada, kaip jau išsiaiškinom anksčiau Tyra pakankama statistika ir
Pθ(T = k) =(n
k
)(1− θ)n−kθk su k = 0, . . . , n.
Įrodysiu, kad T pilna.Tegu su visais θ ∈ (0; 1)
Eθf(T ) = 0,n∑k=0
(n
k
)(1− θ)n−kθkf(k) = 0,
(1− θ)nn∑k=0
(n
k
)(1− θ)−kθkf(k) = 0,
n∑k=0
(n
k
)(1− θ)−kθkf(k) = 0.
Kai θ auga nuo 0 iki 1, dydis u = θ/(1−θ) auga nuo 0 iki∞. Todėl su visaisu > 0
n∑k=0
(n
k
)f(k)uk = 0.
Iš čia su k = 0, . . . , n (n
k
)f(k) = 0,
t.y. f(k) = 0. Tada ir f(T ) = 0 (nes 0, . . . , n yra visos galimos T reikšmės).2. Tegu (X1, . . . , Xn) yra imtis iš geometrinio skirstinio, aprašomo lygy-
bėmisPθ(X = k) = (1− θ)θk, k = 0, 1, 2, . . . ;
čia θ ∈ (0; 1). Tada, kaip jau išsiaiškinom anksčiau, T = X1 + · · · + Xn yrapakankama statistika ir
Pθ(T = k) =(−nk
)(1− θ)n(−θ)k su k = 0, 1, 2, . . . .
Įrodysiu, kad T pilna.Tegu su visais θ ∈ (0; 1)
Eθf(T ) = 0,
100

∞∑k=0
(−nk
)(1− θ)n(−θ)kf(k) = 0,
(1− θ)n∞∑k=0
(−nk
)(−1)kf(k)θk = 0,
∞∑k=0
(−nk
)(−1)kf(k)θk = 0.
Iš čia su k = 0, 1, 2, . . . (−nk
)(−1)kf(k) = 0,
t.y. f(k) = 0. Tada ir f(T ) = 0.3. Tegu (X1, . . . , Xn) yra imtis iš Puasono skirstinio su vidurkiu θ > 0.
Tada, kaip jau išsiaiškinom anksčiau, T = X1 + · · · + Xn yra pakankamastatistika, pasiskirsčiusi pagal Puasono dėsnį su vidurkiu nθ. Įrodysiu, kadT pilna.
Tegu su visais θ > 0
Eθf(T ) = 0,∞∑k=0
e−nθ θk
k! f(k) = 0,
e−nθ∞∑k=0
θk
k! f(k) = 0,
∞∑k=0
f(k)k! θk = 0.
Iš čia su k = 0, 1, 2, . . .f(k)k! = 0,
t.y. f(k) = 0. Tada ir f(T ) = 0.
Nepaslinktieji mažiausios dispersijos įvertiniai.
5.1 teorema. Jei egzistuoja (1) bent vienas nepaslinktasis įvertinys ir (2)pilna pakankama statistika T , tai egzistuoja ir γ = f(T ) pavidalo nepas-linktasis įvertinys; be to, jo dispersija Dθ(γ) ne didesnė už bet kokio kitonepaslinktojo įvertinio dispersiją, kokia bebūtų parametro reikšmė θ.
Įrodymas. Tegu γ0 yra koks nors nepaslinktasis įvertinys. Pažymiuγ = ET γ0. Kadangi T statistika pakankama, γ nepriklauso nuo nežinomo
101

parametro θ ir todėl tikrai yra įvertinys. Be to, jis yra f(T ) pavidalo irnepaslinktasis, nes su visais θ
Eθγ = EθET γ0 = Eθγ0 = γ(θ).
Tegu γ1 yra bet koks kitas nepaslinktasis įvertinys. Pažymiu γ = ET γ1.Panašiai kaip aukščiau įrodau, kad γ = g(T ) su tam tikra funkcija g ir kadγ yra nepaslinktasis įvertinys. Tada su visais θ
Eθ(f(T )− g(T )
)= Eθγ − Eθγ = γ − γ = 0;
todėl su visais θ beveik tikrai Pθ atžvilgiu f(T ) = g(T ) (nes T statistikapilna). Taigi γ ir γ skirstiniai neatskiriami ir galima laikyti, kad jie stutampa,t.y. γ = ET γ1. Tada
Dθγ1 = Eθ(γ1 − γ)2 = Eθ(γ1 − γ)2 + 2Eθ(γ1 − γ)(γ − γ) + Eθ(γ − γ)2.
Iš sąlyginio vidurkio savybių išplaukia, kad
Eθ(γ1 − γ)(γ − γ) = EθET (γ1 − γ)(γ − γ) = EθET (γ1 − γ)(f(T )− γ)= Eθ(f(T )− γ)ET (γ1 − f(T )) = Eθ(f(T )− γ)(ET γ1 − f(T ))
= Eθ(f(T )− γ)(γ − γ) = 0.
TodėlDθγ1 = Eθ(γ1 − γ)2 + Eθ(γ − γ)2 > Eθ(γ − γ)2 = Dθγ.
5.2 UždaviniaiVisuose uždaviniuose reikia (ant popieriaus):
a) įsitikinti, kad duotas įvertinys γ1 paslinktas;b) sugalvoti kokį nors γ2 = U pavidalo nepaslinktąjį įvertinį;c) n = 2 atveju rasti nepaslinktąjį mažiausios dispersijos įvertinį γ3.
Po to — n = 2 atveju patikrinti gautus rezultatus, simuliuojant atitinkamasimtis kompiuteriu: įsitikinti, kad pirmasis įvertinys paslinktas, o kiti du —ne ir kad trečiojo įvertinio dispersija tikrai visada mažesnė nei antrojo.
1. (X1, X2) yra imtis iš skirstinio, aprašomo lenteleX 0 1
1− θ θ
(čia θ ∈ (0; 1) — nežinomas parametras). Vertinamas išvestinis parametrasγ = 1− θ + θ2; γ1 = 1X1=X2=0.
102

2. (X1, . . . , Xn) yra imtis iš skirstinio, aprašomo lygybėmis
Pθ(X = k) = (1− θ)θk, k = 0, 1, 2, . . . ;
čia θ ∈ (0; 1) — nežinomas parametras. Vertinamas išvestinis parametrasγ = θ; γ1 = X.
3. (X1, . . . , Xn) yra imtis iš Puasono skirstinio su nežinomu vidurkiu θ > 0.Vertinamas išvestinis parametras γ = θ2; γ1 = X2.
4. (X1, . . . , Xn) yra imtis iš eksponentinio skirstinio su tankiu
pθ(x) = θe−θx, kai x > 0;
čia θ > 0 — nežinomas parametras. Vertinamas išvestinis parametras γ =e−θ; γ1 = X
2.
5.3 Sprendimai1. Bendras imties skirstinys aprašomas lentele
X1 X2 0 10 (1− θ)2 θ(1− θ)1 θ(1− θ) θ2
TodėlEθγ1 = Eθ1X1=X2=0 = (1− θ)2 6= γ.
Taigi γ1 įvertinys tikrai paslinktas.Kadangi
γ = 1− θ + θ2 = 1− 2θ + θ2 + θ = (1− θ)2 + θ
= Pθ(X1 = X2 = 0) + Pθ(X1 = 1) = Eθ1X1=X2=0 + Eθ1X1=1,
vienas iš nepaslinktųjų įvertinių bus
γ2 = 1X1=X2=0 + 1X1=1 = 1X16X2.
Nepaslinktasis mažiausios dispersijos įvertinys yra nepaslinktasis γ3 =f(T ) pavidalo įvertinys; čia T — pilna pakankama statistika. Nagrinėja-mu atveju T yra vienetukų skaičius imtyje; be to, T skirstinys, atitinkantisparametro reikšmę θ, aprašomas lentele
103

T 0 1 2(1− θ)2 2θ(1− θ) θ2
Tegu f(i) = ci su i = 0, 1, 2; tada
Eθγ3 = c0(1− θ)2 + 2c1θ(1− θ) + c2θ2 = c0 + (−2c0 + 2c1)θ+ (c0−2c1 + c2)θ2.
Reiškinys dešinėje sutaps su γ, kaic0 = 1,−2c0 + 2c1 = −1,c0 − 2c1 + c2 = 1,
t.y. kai c0 = 1, c1 = 1/2 ir c2 = 1. Taigi
γ3 =
1/2, jei T = 1,1 kitais atvejais;
čia T yra vienetukų skaičius imtyje.Gautus rezultatus patikrinu, atlikęs tokią programą:
n<-2N<-10000gama1<-numeric(N)gama2<-numeric(N)gama3<-numeric(N)teta<-seq(from=0.01, to=0.99, by=0.01)gama<-1-teta+teta*tetaT<-length(teta)vid1<-numeric(T)vid2<-numeric(T)vid3<-numeric(T)var2<-numeric(T)var3<-numeric(T)
for (j in 1:T) for (i in 1:N)
x<-rbinom(n, size = 1, prob = teta[j])gama1[i]<-(sum(x)==0)gama2[i]<-(x[1]<=x[2])gama3[i]<-ifelse(sum(x)==1,0.5,1)
104

vid1[j]<-mean(gama1)vid2[j]<-mean(gama2)vid3[j]<-mean(gama3)var2[j]<-var(gama2)var3[j]<-var(gama3)
old.par<-par(mfrow=c(1,2))
ymin<-min(vid1)plot(teta, gama, type="l", ylim=c(ymin,1))lines(teta, vid1, type="l", col="green")lines(teta, vid2, type="l", col="blue")lines(teta, vid3, type="l", col="red")
plot(teta, var2, type="l", col="blue", ylab="dispersija")lines(teta, var3, type="l", col="red")
par(old.par)
Rezultatai parodyti 11 pav.: pirmo, antro ir trečio įvertinio charakteris-tikos nubrėžtos, atitinkamai, žaliai, mėlynai ir raudonai; pirmame brėžinyjejuoda linija (kurios beveik nesimato) yra γ funkcijos grafikas.
2. Kadangi
Eθγ1 = EθX = EθX =∑k>0
(1−θ)θkk = (1−θ)θ∑k>0
kθk−1 = (1−θ)θ(∑k>0
θk)′
= (1− θ)θ( 1
1− θ
)′= (1− θ)θ 1
(1− θ)2 = θ
1− θ 6= γ
γ1 įvertinys tikrai paslinktas.Kadangi
γ = θ = 1− (1− θ) = 1− Pθ(X = 0) = Pθ(X > 0) = Eθ1X>0,
vienas iš nepaslinktųjų įvertinių yra
γ2 = 1X>0.
105

0.0 0.4 0.8
0.0
0.2
0.4
0.6
0.8
1.0
teta
gam
a
0.0 0.4 0.80.
050.
100.
15teta
disp
ersi
ja
11 pav.
Toliau laikysiu n = 2 ir rasiu nepaslinktąjį mažiausios dispersijos įvertinį.Žinau, kad T = X1 +X2 yra pilna pakankama statistika ir kad jos skirstinys,atitinkantis parametro reikšmę θ, aprašomas lygybėmis
Pθ(T = k) =(k + 1k
)(1− θ)2θk = (k + 1)(1− θ)2θk, k = 0, 1, 2, . . . .
Tegu γ3 = f(T ) yra nepaslinktasis įvertinys ir f(k) = ck su k = 0, 1, 2, . . . .Tada
θ = γ = Eθγ3 =∑k>0
ck(k + 1)(1− θ)2θk.
Iš čia
∑k>0
ck(k + 1)θk = θ(1− θ)−2 = θ∑k>0
(−2k
)(−θ)k =
∑l>1
(−2l − 1
)(−1)l−1θl.
Reiškia, c0 = 0 ir su k > 1
ck(k + 1) =(−2k − 1
)(−1)k−1
= (−2) · (−3) · (−2− k + 2)(k − 1)! (−1)k−1 = k!
(k − 1)! = k,
106

t.y.ck = k
k + 1su visais k > 0. Taigi γ3 = k/(k + 1), kai T = k, koks bebūtų k. Kitaiptariant,
γ3 = T
T + 1;
čia T = X1 +X2.Gautus rezultatus patikrinu, atlikęs tokią programą:
n<-2N<-10000gama1<-numeric(N)gama2<-numeric(N)gama3<-numeric(N)teta<-seq(from=0.01, to=0.99, by=0.01)gama<-tetaT<-length(teta)vid1<-numeric(T)vid2<-numeric(T)vid3<-numeric(T)var2<-numeric(T)var3<-numeric(T)
for (j in 1:T) for (i in 1:N)
x<-rgeom(n, prob = 1-teta[j])gama1[i]<-mean(x)gama2[i]<-mean(x>0)t<-sum(x)gama3[i]<-t/(t+1)
vid1[j]<-mean(gama1)vid2[j]<-mean(gama2)vid3[j]<-mean(gama3)var2[j]<-var(gama2)var3[j]<-var(gama3)
107

0.0 0.4 0.8
020
4060
8010
0
teta
gam
a
0.0 0.4 0.80.
020.
060.
10teta
disp
ersi
ja
12 pav.
old.par<-par(mfrow=c(1,2))
ymin<-min(0,min(vid1),min(vid2),min(vid3))ymax<-max(1,max(vid1),max(vid2),max(vid3))plot(teta, gama, type="l", ylim=c(ymin,ymax))lines(teta, vid1, type="l", col="green")lines(teta, vid2, type="l", col="blue")lines(teta, vid3, type="l", col="red")
plot(teta, var2, type="l", col="blue", ylab="dispersija")lines(teta, var3, type="l", col="red")
par(old.par)
Rezultatai parodyti 12 pav.
3. Kadangi
Eθγ1 = EθX2 = EθX2 = DθX + (EθX)2 = θ + θ2 6= γ,
γ1 įvertinys tikrai paslinktas. Tačiau jį nesunku modifikuoti taip, kad jistaptų nepaslinktuoju: kadangi
γ = θ2 = (θ + θ2)− θ = EθX2 − EθX,
108

vienas iš nepaslinktųjų įvertinių yra
γ2 = X2 −X = X2 −X.
Rasiu nepaslinktąjį mažiausios dispersijos įvertinį. Žinau, kad T = X1 +· · ·+Xn yra pilna pakankama statistika; be to, ji pasiskirsčiusi pagal Puasonodėsnį su vidurkiu nθ. Taigi
θ2 = 1n2 (nθ)2 = 1
n2 Eθ(T 2 − T )
ir, reiškia, nepaslinktasis mažiausios dispersijos įvertinys yra
γ3 = T 2 − Tn2 ;
čia T = X1 + · · ·+Xn.Gautus rezultatus patikrinu, atlikęs tokią programą:
n<-2N<-10000gama1<-numeric(N)gama2<-numeric(N)gama3<-numeric(N)teta<-seq(from=0.1, to=10, by=0.1)gama<-teta*tetaT<-length(teta)vid1<-numeric(T)vid2<-numeric(T)vid3<-numeric(T)var2<-numeric(T)var3<-numeric(T)
for (j in 1:T) for (i in 1:N)
x<-rpois(n, lambda = teta[j])gama1[i]<-mean(x*x)gama2[i]<-mean(x*x-x)t<-sum(x)gama3[i]<-(t*t-t)/(n*n)
vid1[j]<-mean(gama1)
109

0 2 4 6 8 10
020
4060
80
teta
gam
a
0 2 4 6 8 100
500
1000
2000
teta
disp
ersi
ja
13 pav.
vid2[j]<-mean(gama2)vid3[j]<-mean(gama3)var2[j]<-var(gama2)var3[j]<-var(gama3)
old.par<-par(mfrow=c(1,2))
ymin<-min(0,min(vid1),min(vid2),min(vid3))ymax<-max(1,max(vid1),max(vid2),max(vid3))plot(teta, gama, type="l", ylim=c(ymin,ymax))lines(teta, vid1, type="l", col="green")lines(teta, vid2, type="l", col="blue")lines(teta, vid3, type="l", col="red")
plot(teta, var2, type="l", col="blue", ylab="dispersija")lines(teta, var3, type="l", col="red")
par(old.par)
Ir štai kas gavosi (žr. 13 pav.)
110

4. Eksponentinio skirstinio momentus nesunku suskaičiuoti:
EθXk =∫ ∞
0θe−θxxkdx = θ−k
∫ ∞0
yke−ydy = θ−kΓ(k + 1) = k!θk.
Pavyzdžiui,
EθX = 1θ, EθX2 = 2
θ2 ir DθX = 2θ2 −
1θ2 = 1
θ2 .
Kadangi
Eθγ1 = EθX2 = (EθX)2 + 1
nDθX = 1
θ2 + 1n
1θ2 6= γ,
γ1 įvertinys paslinktas.Su bet kokiu y > 0
Pθ(X > y) =∫ ∞y
θe−θxdx = −e−θx∣∣∣∣∞y
= e−θy.
Taigie−θ = Pθ(X > 1) = Eθ1X>1
ir, reiškia,γ2 = 1X>1
yra nepaslinktasis įvertinys.Žinau, kad T = X1 + · · ·+Xn yra pilna pakankama statistika, pasiskirs-
čiusi pagal gama dėsnį su tankiu
q(t) = θntn−1
(n− 1)!e−θt, kai t > 0.
Taigi jei n = 2 ir γ3 = f(T ) yra nepaslinktasis įvertinys, tai su visais θ > 0
e−θ = γ = Eθγ3 =∫ ∞
0f(t)θ2te−θtdt. (5.2)
Reikia šią funkcinę lygtį išspręsti f atžvilgiu. Tai padarysiu, aukščiau gautąlygybę
e−θy =∫ ∞y
θe−θxdx
suintegruodamas intervale (1;∞). Kairės pusės integralas yra∫ ∞1
e−θydy = −θ−1e−θy∣∣∣∣∞1
= θ−1e−θ,
111

o suintegravęs dešinę pusę gaunu∫ ∞1
dy∫ ∞y
θe−θxdx =∫ ∞
1θe−θxdx
∫ x
1dy =
∫ ∞1
(x− 1)θe−θxdx.
Taigie−θ = θ
∫ ∞1
(x− 1)θe−θxdx =∫ ∞
1(x− 1)θ2e−θxdx,
o tai reiškia, kad (5.2) lygties sprendinys yra
f(t) =
0, kai t 6 1,(t− 1)/t, kai t > 1.
Taigi nagrinėjamu n = 2 atveju nepaslinktasis mažiausios dispersijos įverti-nys atrodo taip:
γ3 = T − 1T
1T>1;
čia T = X1 +X2.Savo skaičiavimus patikrinu atlikęs tokią programą:
n<-2N<-10000gama1<-numeric(N)gama2<-numeric(N)gama3<-numeric(N)teta<-seq(from=0.1, to=5, by=0.1)gama<-exp(-teta)T<-length(teta)vid1<-numeric(T)vid2<-numeric(T)vid3<-numeric(T)var2<-numeric(T)var3<-numeric(T)
for (j in 1:T) for (i in 1:N)
x<-rexp(n, rate = teta[j])m<-mean(x)gama1[i]<-m*mgama2[i]<-mean(x>1)t<-sum(x)gama3[i]<-ifelse(t>1,(t-1)/t,0)
112

vid1[j]<-mean(gama1)vid2[j]<-mean(gama2)vid3[j]<-mean(gama3)var2[j]<-var(gama2)var3[j]<-var(gama3)
old.par<-par(mfrow=c(1,2))
ymin<-min(0,min(vid1),min(vid2),min(vid3))ymax<-max(1,max(vid1),max(vid2),max(vid3))plot(teta, gama, type="l", ylim=c(ymin,ymax))lines(teta, vid1, type="l", col="green")lines(teta, vid2, type="l", col="blue")lines(teta, vid3, type="l", col="red")
plot(teta, var2, type="l", col="blue", ylab="dispersija")lines(teta, var3, type="l", col="red")
par(old.par)
Gavosi štai kas (žr. 14 pav.)
6 Efektyvūs nepaslinktieji įvertiniai
6.1 TeorijaInformacijos kiekis. Tegu (X1, . . . , Xn) yra imtis iš skirstinio su tankiu pθ(kokio nors mato atžvilgiu), priklausančio nuo nežinomo parametro θ. Kaipir anksčiau, raide Lθ žymėsiu tikėtinumo funkciją:
Lθ(x1, . . . , xn) = pθ(x1) · · · pθ(xn).
Tada su bet kokia statistika t
Eθt(X1, . . . , Xn) =∫t(x1, . . . , xn)Lθ(x1, . . . , xn).
Kaip ir kažkuriame skyrelyje anksčiau, užrašydamas integralą aš praleidžiunuorodą į dominuojantį matą. Šiame skyrelyje žadu dar labiau supapras-tinti žymenis ir vietoje
∫t(x1, . . . , xn)Lθ(x1, . . . , xn) rašyti tiesiog
∫tLθ, t.y.
113

0 1 2 3 4 5
050
100
150
teta
gam
a
0 1 2 3 4 50.
000.
040.
080.
12teta
disp
ersi
ja
14 pav.
integralo ženklas visada reikš, kad integruojama (x1, . . . , xn) atžvilgiu. Vie-toje Eθt(X1, . . . , Xn) irgi rašysiu tik Eθt suprasdamas, kad statistika t yraatsitiktinis dydis t(X1, . . . , Xn). Taigi su bet kokia statistika t ir visais θ
Eθt =∫tLθ.
Pavyzdžiui, su visais θ ∫Lθ = 1.
Pastarąją lygybę žadu dukart diferencijuoti θ atžvilgiu. Išvestinę θ at-žvilgiu žymėsiu tašku virš funkcijos ženklo ir laikysiu, kad visais atvejaisintegralo išvestinė yra išvestinės integralas. Tada su visais θ∫
Lθ = 0 ir∫Lθ = 0. (6.1)
Pažymiu `θ = lnLθ; tada Lθ = e`θ ir
Lθ = e`θ ˙θ = Lθ ˙
θ,
Lθ = Lθ ˙θ + Lθ ¨
θ = Lθ( ˙θ)2 + Lθ ¨
θ.
Įstatęs šias išraiškas į (6.1) gaunu
0 =∫Lθ lθ = Eθ ˙
θ
114

ir0 =
∫Lθ( ˙
θ)2 +∫Lθ ¨
θ = Eθ( ˙θ)2 + Eθ ¨
θ.
Iš pastarosios lygybės išplaukia, kad Eθ( ˙θ)2 = −Eθ ¨
θ. Šis dydis vadinamasnagrinėjamo modelio Fišerio informacijos kiekiu ir žymimas Iθ. Taigi
Eθ ˙θ = 0 ir Eθ( ˙
θ)2 = −Eθ ¨θ = Iθ. (6.2)
Rao-Kramero nelygybė. Tarkime, vertinamas realusis išvestinis para-metras γ = γ(θ) ir γ yra jo nepaslinktasis įvertinys. Šiame skyrelyje mannorisi rašyti γθ vietoje γ(θ). Taigi su visais θ
γθ = Eθγ =∫γLθ
ir išdiferencijavęs gaunu
γθ =∫γLθ =
∫γLθ ˙
θ = Eθγ ˙θ.
Iš čia ir (6.2) išplaukia
Eθ(γ − γθ −
γθ ˙θ
Iθ
)2= Eθ(γ − γθ)2 − 2Eθ(γ − γθ)
γθ ˙θ
Iθ+ Eθ
γ2θ
˙2θ
I2θ
= Dθγ − 2 γθIθ
(Eθγ ˙θ − γθEθ ˙
θ) + γ2θ
I2θ
Eθ ˙2θ
= Dθγ − 2 γθIθ
(γθ − 0) + γ2θ
I2θ
Iθ
= Dθγ −γ2θ
Iθ. (6.3)
Kadangi neneigiamo dydžio vidurkis neneigiamas, iš čia gaunu vadinamąjąRao-Kramero nelygybę:
Dθγ >γ2θ
Iθ.
Efektyvūs nepaslinktieji įvertiniai. Nepaslinktasis įvertinys γ vadina-mas efektyviu, jei su juo Rao-Kramero nelygybė virsta lygybe, t.y.
Dθγ = γ2θ
Iθ.
Apskritai santykiseθ = γ2
θ
IθDθγ
115

vadinamas nepaslinktojo įvertinio γ efektyvumu. Tas skaičius visada yra tarp0 ir 1; jei eθ = 1 su visais θ, įvertinys yra efektyvus.
Terminas „efektyvus“ nelabai vykęs, nes efektyvumas yra ne tik įvertinioγ, bet ir pačios funkcijos γθ savybė. Gali atsitikti taip, kad netgi nepaslinkta-sis mažiausios dispersijos įvertinys nėra efektyvus — tada efektyvių įvertiniųapskritai nėra.
Tais retais atvejais, kai efektyvūs įvertiniai egzistuoja, efektyvumas nu-statomas pasirėmus tokiu teiginiu.
6.1 teorema. Tarkime,˙θ = aθ(t− bθ); (6.4)
čia aθ ir bθ nepriklauso nuo imties, o t — nuo θ (t.y. t yra statistika). Tadaγ = t yra efektyvus nepaslinktasis parametro γθ = bθ įvertinys.
Įrodymas. Nepaslinktumas įrodomas taip: iš (6.4) išplaukia, kad
γ = t =˙θ
aθ+ bθ =
˙θ
aθ+ γθ,
todėl iš (6.2)Eθγ = 1
aθEθ ˙
θ + γθ = γθ.
Dabar įrodysiu efektyvumą. Išdiferencijavęs (6.4) gaunu¨θ = aθ(t− bθ)− aθbθ,
todėlEθ ¨
θ = aθ(Eθt− bθ)− aθbθ = aθ(Eθγ − γθ)− aθγθ = −aθγθ.Taigi
aθ = −Eθ ¨θ
γθ= Iθγθ
irγ =
˙θγθIθ
+ γθ.
Tada iš (6.3) išplaukia
Dθγ −γ2θ
Iθ= 0,
o tai ir reiškia, kad γ yra efektyvus γθ parametro įvertinys. Toliau šiame skyrelyje panagrinėsiu 6 modelius ir kiekvienu atveju išsi-
aiškinsiu, kokie išvestiniai parametrai γθ gali būti efektyviai įvertinti ir kokieyra efektyvūs nepasinktieji tų parametrų įvertiniai; be to, suskaičiuosiu ir tąmodelį atitinkantį informacijos kiekį.
116

Bernulio modelis. Tegu (X1, . . . , Xn) yra imtis iš skirstinio, aprašomolentele
X 0 11− θ θ
Šiuo atvejuLθ = (1− θ)n−T θT ;
čia T yra vienetukų skaičius imtyje. Kadangi visi imties nariai yra 0 arba 1,T = X1 + · · ·+Xn = nX. Taigi
`θ = (n− nX) ln(1− θ) + nX ln θ
ir
˙θ = −n− nX1− θ + nX
θ= − n
1− θ + nX( 1
1− θ + 1θ
)= − n
1− θ + nX
θ(1− θ) = n
θ(1− θ)(X − θ).
Taigi X yra efektyvus nepaslinktasis θ parametro įvertinys.Kadangi
¨θ = −n− nX(1− θ)2 −
nX
θ2 ,
informacijos kiekis Bernulio modelyje yra
Iθ = n− nEθX(1− θ)2 + nEθX
θ2 = n− nθ(1− θ)2 + nθ
θ2 = n
1− θ + n
θ= n
(1− θ)θ .
Geometrinis modelis. Tegu (X1, . . . , Xn) yra imtis iš geometrinio skirs-tinio, aprašomo lygybėmis:
Pθ(X = k) = (1− θ)θk su k = 0, 1, 2, . . . ;
čia θ ∈ (0; 1) — nežinomas parametras. Šiuo atveju
Lθ = (1− θ)θX1 · · · (1− θ)θXn = (1− θ)nθX1+···+Xn = (1− θ)nθnX ,`θ = n ln(1− θ) + nX ln θ
ir˙θ = − n
1− θ + nX
θ= n
θ
(X − θ
1− θ
).
117

Taigi X yra efektyvus nepaslinktasis parametro γθ = θ1−θ įvertinys.
Be to,¨θ = − n
(1− θ)2 −nX
θ2 ,
todėl informacijos kiekis geometriniame modelyje lygus
Iθ = n
(1− θ)2 + nEθXθ2 = n
(1− θ)2 +n θ
1−θθ2 = n
(1− θ)2 + n
θ(1− θ) = n
θ(1− θ)2 .
Puasono modelis. Tegu (X1, . . . , Xn) yra imtis iš Puasono skirstinio sunežinomu vidurkiu θ > 0. Tada
Lθ = e−θ θX1
X1! · · · e−θ θ
Xn
Xn! = e−nθ θnX
X1! · · ·Xn! ,
`θ = −nθ + nX ln θ − ln(X1! · · ·Xn!)
ir˙θ = −n+ nX
θ= n
θ(X − θ).
Taigi X yra efektyvus nepaslinktasis θ parametro įvertinys.Be to,
¨θ = −nX
θ2 ,
todėl informacijos kiekis Puasono modelyje lygus
Iθ = nEθXθ2 = nθ
θ2 = n
θ.
Eksponentinis modelis. Tegu (X1, . . . , Xn) yra imtis iš eksponentinioskirstinio su tankiu
pθ(x) = θe−θx, kai x > 0.
Šiuo atveju
Lθ = θe−θX1 · · · θe−θXn = θne−nθX ,`θ = n ln θ − nθX
ir˙θ = n
θ− nX = −n
(X − 1
θ
).
Taigi X yra efektyvus nepaslinktasis parametro γθ = 1/θ įvertinys.
118

Be to,¨θ = − n
θ2 ,
todėl informacijos kiekis eksponentiniame modelyje lygus
Iθ = n
θ2 .
Normalusis modelis su žinoma dispersija. Tegu (X1, . . . , Xn) yra imtisiš N(θ, 1) skirstinio. Šiuo atveju
Lθ = 1√2π
e−(X1−θ)2/2 · · · 1√2π
e−(Xn−θ)2/2 = 1(√
2π)ne−n(X−θ)2/2,
`θ = −n ln√
2π − n(X − θ)2
2 = −n ln√
2π − n
2 (X2 − 2θX + θ2)
ir˙θ = −n2 (−2X + 2θ) = n(X − θ).
Taigi X yra efektyvus nepaslinktasis parametro θ įvertinys.Be to,
¨θ = −n,
todėl informacijos kiekis šiame modelyje Iθ = n.
Normalusis modelis su žinomu vidurkiu. Tegu (X1, . . . , Xn) yra imtisiš N(0, θ) skirstinio. Šiuo atveju
Lθ = 1√2πθ
e−X21/(2θ) · · · 1√
2πθe−X2
n/(2θ) = 1(√
2πθ)ne−nX2/(2θ),
`θ = −n2 (ln 2π + ln θ)− nX2
2θir
˙θ = − n
2θ + nX2
2θ2 = n
2θ2 (X2 − θ).
Taigi X2 yra efektyvus nepaslinktasis nežinomos dispersijos θ įvertinys.Be to,
¨θ = n
2θ2 −nX2
θ3 ,
todėl informacijos kiekis šiame modelyje
Iθ = − n
2θ2 + nEθX2
θ3 = − n
2θ2 + nθ
θ3 = n
2θ2 .
119

6.2 Uždaviniai1. Tegu (X1, . . . , Xn) yra imtis iš geometrinio skirstinio, aprašomo lygybė-mis
Pθ(X = k) = (1− θ)θk, k = 0, 1, 2, . . . ,
irγ = 1X lyginis.
Kokio išvestinio parametro γθ nepaslinktasis įvertinys yra γ ir koks jo efekty-vumas? Įvertinio dispersiją suskaičiuokite ir efektyvumo grafiką nubrėžkitenaudodami kompiuterį (imkite n = 10).
6.3 Sprendimai1. Aišku, kad
γθ = Eθγ = Eθ1X lyginis = Eθ1X lyginis = Pθ(X lyginis)
=∑k>0
(1− θ)θ2k = 1− θ1− θ2 = 1
1 + θ.
Tadaγθ = − 1
(1 + θ)2 ;
be to, informacijos kiekis geometriniame modelyje
Iθ = n
θ(1− θ)2 .
Todėl įvertinio efektyvumas
eθ = θ(1− θ)2
n(1 + θ)4Dθγ.
Įvertinio dispersiją suskaičiuosiu ir efektyvumo funkcijos grafiką nubrėšiu,atlikęs tokią programą:
n<-10N<-10000est<-numeric(N)teta<-seq(from=0.01, to=0.99, by=0.01)T<-length(teta)disp<-numeric(T)
120

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
teta
e
15 pav.
for (j in 1:T) for (i in 1:N)
x<-rgeom(n, prob = 1-teta[j])est[i]<-mean(x%%2==0)
disp[j]<-var(est)
e<-teta*(1-teta)^2/(n*(1+teta)^4*disp)
plot(teta,e, type="l")
Kompiuterio nubrėžtas grafikas parodytas 15 pav.
7 Asimptotinė statistika
7.1 TeorijaOptimalumo paieškos statistikoje. Ankstesniuose skyriuose išsiaiški-nau, kad tik retais atvejais pavyksta rasti optimalias statistinių sprendimųfunkcijas:
• tolygiai galingiausi kriterijai egzistuoja faktiškai tik vienmačiuose eks-ponentiniuose modeliuose ir tik jei hipotezė yra θ 6 θ∗ arba θ > θ∗
121

pavidalo;
• nepaslinktieji mažiausios dispersijos įvertiniai egzistuoja tik jei statisti-niame modelyje yra pilna pakankama statistika (o taip yra irgi beveiktik eksponentiniuose modeliuose); be to, vertinama funkcija turi būtine bet kokia — kitaip nepaslinktųjų įvertinių gali apskritai nebūti;
• nepaslinktųjų įvertinių efektyvumo sąvoka atrodo kvaila, nes netgi ne-paslinktieji mažiausios dispersijos įvertiniai gali būti neefektyvūs;
• optimalių pasikliovimo intervalų teorijos išvis nėra.
Visų šių nemalonių dalykų nėra vadinamojoje asimptotinėje statistikoje, ku-rioje ieškoma ne optimalių, o tik asimptotiškai optimalių sprendimo funkcijų.
Konvergavimas pagal pasiskirstymą. Primenu, kad analizėje funkcijosf(x) asimptotiniu skleidiniu (pavyzdžiui, kai x→ 0) vadinamas
f(x) = g1(x) + g2(x) + · · ·+ gk(x) + o(gk(x))
pavidalo reiškinys; čia
g2(x) = o(g1(x)), g3(x) = o(g2(x)), . . . , gk(x) = o(gk−1),
kai x→ 0. Dažniausiai pasitaikantis atvejis —
f(x) = c0 + c1x+ · · ·+ ckxk + o(xk)
pavidalo skleidinys; jei teisinga ši formulė, tai
f(x)→ c0, x−1(f(x)− c0)→ c1, x−2(f(x)− c0 − c1x)→ c2
(kai x→ 0) ir t.t.Kažkas panašaus yra ir statistikoje: vietoje funkcijos f(x) nagrinėjamos
atsitiktinių dydžių sekos Tn (taigi x vaidmenų atlieka imties dydis n), orodyklė → žymi konvergavimą pagal pasiskirstymą, kuris apibrėžiamas taip:Tn → T , kai
P(Tn 6 t)→ P(T 6 t) (7.1)su visais t, tenkinančiais sąlygą P(T = t) = 0. Yra ir kitokių atsitiktiniųdydžių konvergavimo sąvokų (pavyzdžiui, konvergavimas beveik tikrai, pagaltikimybę, L2 prasme ir pan.) Kad nesipainiotų, tada konvergavimas pagalpasiskirstymą žymimas d−→, →d ar net . Man tų kitų sąvokų neprireiks,todėl aš naudosiu → žymenį.
122

Konvergavimas pagal pasiskirstymą gali būti apibrėžtas ir atsitiktiniamsvektoriams ir netgi atsitiktiniams dydžiams su reikšmėmis iš bet kokios met-rinės erdvės E — tada (7.1) sąlyga pakeičiama tokia:
Ef(Tn)→ Ef(T )
su bet kokia aprėžta tolydžiąja funkcija f : E → R.Taip jau atsitinka statistikoje, kad dažniausiai įmanoma gauti tik
Tn = C0 + op(1) arba Tn = c0 + C1√n
+ op(n−1/2) (7.2)
pavidalo skleidinius; čia C0, C1 yra neišsigimę atsitiktiniai dydžiai, c0 — skai-čius (t.y. išsigimęs atsitiktinis dydis), o op yra „stochastinis o“: op(1) žymibet kokią atsitiktinių dydžių seką, kuri pagal pasiskirstymą artėja į 0, oop(n−1/2) = n−1/2op(1).
Kai aš prašau surasti asimptotinį Tn sekos skirstinį, turiu omeny, kadreikia įrodyti vieną iš dviejų (7.2) formulių. Pirmoji formulė tiesiog reiškia,kad
Tn → C0.
Jei C0 dydis neišsigimęs, asimptotinio skirstinio ieškojimo uždavinys baigtas.Jei C0 dydis išsigimęs (beveik tikrai įgyja vienintelę reikšmę c0), tada reikiaieškoti antrojo asimptotikos nario — tokio neišsigimusio dydžio C1, kad
√n(Tn − c0)→ C1.
Žemiau surašysiu, ką reikia žinoti, norint rasti tą nelemtą asimptotinįskirstinį.
Skaliarinis atvejis. Visuose mano duodamuose uždaviniuose Tn yra vienoar kelių empirinių vidurkių funkcija. Iš pradžių aprašysiu „skaliarinį“ atvejį— kai Tn = f(U); čia f — kokia nors vieno realaus kintamojo funkcija, oU = g(X) su tam tikra skaliarine funkcija g. Pavyzdžiui,
Tn = 1X2
;
tada U = X2, o f(u) = 1/u.Ieškodami asimptotinio skirstinio tokiu atveju, remiamės tokiais teigi-
niais:1) (didžiųjų skaičių dėsnis ir centrinė ribinė teorema) jei EU = a ir DU =
b2, taiU → a ir
√n(U − a)→ Z ∼ N(0, b2);
123

2) (tolydaus atvaizdžio principas) jei Tn → T ir f — tolydžioji funkcija,tai f(Tn)→ f(T );
3) (delta metodas) jei√n(Tn − a)→ Z ir f — glodi funkcija, tai
√n(f(Tn)− f(a))→ f ′(a)Z.
Taikant delta metodą, Z dažniausiai būna atsitiktinis dydis su normaliuo-ju N(0, b2) skirstiniu; tada f ′(a)Z turi taip pat normalųjį N(0, σ2) skirstinį su
σ2 =(f ′(a)
)2b2.
Vektorinis atvejis. Dabar aprašysiu atvejį, kai ieškomas statistikos Tn =f(U1, . . . , Uk) asimptotinis skirstinys; čia f yra k realių kintamųjų funkcija,o Uj = gj(X) su tam tikromis skaliarinėmis funkcijomis gj. Pavyzdžiui,
Tn = X2 −X2;
tada f(u1, u2) = u1 − u22, U1 = X2 ir U2 = X.
Remiamės tokiais teiginiais:1) (didžiųjų skaičių dėsnis ir centrinė ribinė teorema) jei EUi = ai ir
Σ = (σij) su σij = cov(Ui, Uj), taiU1...Uk
→a1...ak
ir√n
U1...Uk
−a1...ak
→
Z1...Zk
∼ N(0,Σ);
2) (tolydaus atvaizdžio principas) jei (Tn1, . . . , Tnk)→ (T1, . . . , Tk) ir f —tolydžioji funkcija, tai
f(Tn1, . . . , Tnk)→ f(T1, . . . , Tk);
3) (delta metodas) jei
√n(Tn − a) =
√n
Tn1...Tnk
−a1...ak
→ Z =
Z1...Zk
,ir f — glodi k kintamųjų funkcija, tai
√n(f(Tn)− f(a))→ f ′(a)Z =
(∂1f(a) · · · ∂kf(a)
)Z1...Zk
.124

Taikant delta metodą, Z dažniausiai būna atsitiktinis vektorius su norma-liuoju N(0,Σ) skirstiniu; tada f ′(a)Z turi taip pat normalųjį N(0, σ2) skirstinįsu
σ2 = f ′(a)Σf ′(a)> =(∂1f(a) · · · ∂kf(a)
)σ11 · · · σ1k... . . . ...σk1 · · · σkk
∂1f(a)
...∂kf(a)
.
Asimptotinis įvertinių normalumas. Dabar atėjo laikas prisiminti, kadstatistikoje dirbame ne su vienu skirstiniu, o su skirstinių šeima, priklausančianuo nežinomo parametro θ. Norėdamas pabrėžti, kad koks nors konverga-vimas pagal pasiskirstymą atitinka būtent parametro reikšmę θ, vietoje →rašysiu −→
θ.
Tarkime, vertinamas išvestinis parametras γθ ir γ yra koks nors jo įver-tinys. Gali atsitikti, kad teisingas vienas (o gal ir abu) iš tokių teiginių: suvisais θ
γ −→θγθ, (7.3)
√n(γ − γθ) −→
θN(0, σ2
θ). (7.4)
Jei su visais θ teisinga (7.3) formulė, γ įvertinys vadinamas pagrįstu. Jei suvisais θ teisinga (7.4) formulė, įvertinys vadinamas asimptotiškai normaliu,o σ2
θ skaičius — jo asimptotine dispersija.Paprastai iš (7.4) išplaukia, kad
√n(Eθγ − γθ)→ EθZ = 0 ir nEθ(γ − γθ)2 → EθZ2 = σ2
θ ;
čia Z žymi atsitiktinį dydį su N(0, σ2θ) skirstiniu. Kadangi
Eθ(γ − γθ)2 = Eθ(γ − Eθγ + Eθγ − γθ)2
= Eθ(γ − Eθγ)2 + 2Eθ(γ − Eθγ)(Eθγ − γθ) + (Eθγ − γθ)2
= Dθγ + (Eθγ − γθ)2,
tadanDθγ → σ2
θ .
Šis sąryšis paaiškina, kodėl σ2θ vadinama asimptotine dispersija. Tačiau reikia
turėti omeny, kad γ įvertinio dispersija apytiksliai lygi ne σ2θ , o σ2
θ/n.
125

Asimptotinis efektyvumas. Ankstesniame skyrelyje buvo apibrėžtas ne-paslinktojo įvertinio γ efektyvumas — taip buvo vadinamas dydis
γ2θ
IθDθγ;
čia
Iθ = −Eθ ¨θ(X1, . . . , Xn), `θ(x1, . . . , xn) = ln pθ(x1) + · · ·+ ln pθ(xn),
o pθ yra X dydžio tankis tam tikro mato atžvilgiu. Informacijos kiekis Iθ irtikėtinumo funkcijos logaritmas `θ priklauso nuo imties dydžio n, todėl dabartuos dydžius žymėsiu Iθ,n ir `θ,n. Kadangi visi Xi vienodai pasiskirstę,
Iθ,n = −n∑i=1
Eθ∂2 ln pθ(Xi)
∂θ2 = −nEθ∂2 ln pθ(X1)
∂θ2 = −nEθ ¨θ,1(X1) = nIθ,1.
Taigi efektyvumas lygus
γ2θ
Iθ,1nDθγ≈ γ2
θ
Iθ,1σ2θ
.
Dydis dešinėje ir vadinamas γ įvertinio asimptotiniu efektyvumu.Rao-Kramero nelygybė buvo įrodyta tik nepaslinktiesiems įvertiniams.
Asimptotinėje statistikoje analogiška nelygybė įrodoma asimptotiškai nor-maliems įvertiniams (tai nėra labai stebuklingas faktas, nes tokie įvertiniaiasimptotiškai nepaslinkti):
σ2θ >
γ2θ
Iθ,1.
Taigi asimptotinis efektyvumas visada neviršija 1.
Asimptotiniai pasikliovimo intervalai. Aprašysiu, kaip asimptotinėjestatistikoje konstruojami pasikliovimo intervalai išvestiniam parametrui γθ.Kad nebūtų taip nuobodu, rašysiu pirmu asmeniu ir esamuoju laiku. Taigimano veiksmai tokie:
• randu kokį nors asimptotiškai normalų γθ parametro įvertinį γ ir su-skaičiuoju jo asimptotinę dispersiją σ2
θ ;
• randu pagrįstą σθ parametro įvertinį σ;
• sakau garsiai tokius žodžius: su visais θ√n(γ − γθ)
σ−→θZ ∼ N(0, 1),
126

√n|γ − γθ|σ
−→θ|Z|
ir todėl su tam tikru c
Pθ(√
n|γ − γθ|σ
6 c)→ P(|Z| 6 c) = 1− α;
taigi jei n didelis, tai su apytiksliai 1− α tikimybe√n|γ − γθ|σ
6 c,
|γ − γθ| 6cσ√n
irγ − cσ√
n6 γθ 6 γ + cσ√
n. (7.5)
(7.5) nelygybės ir apibrėžia ieškomą pasikliovimą intervalą. Aš jį vadinusimetriniu 1 − α patikimumo asimptotiniu pasikliovimo intervalu su centruγ. Konstantą c randu iš sąlygos P(|Z| 6 c) = 1− α, arba
α = 1− P(|Z| 6 c) = P(|Z| > c) = 2P(Z > c),
t.y.P(Z > c) = α/2.
Ji vadinama standartinio normalaus skirstinio (α/2) lygmens kritine reikšmeir žymima zα/2.
Transformuoti pasikliovimo intervalai. Jei g yra kokia nors didėjantifunkcija, (7.5) nelygybės ekvivalenčios nelygybėms
g(γ − cσ√
n
)6 g(γθ) 6 g
(γ + cσ√
n
). (7.6)
Taigi jos apibrėžia pasikliovimo intervalą naujam parametrui g(γθ), kuriopatikimumas lygiai toks pat, kaip ir (7.5) intervalo: jei (7.5) buvo 1−α pati-kimumo asimptotinis pasikliovimo intervalas parametrui γθ, tai (7.6) irgi bus1−α patikimumo asimptotinis pasikliovimo intervalas, tik kitam parametrui,g(γθ). Procedūrą, kurią atlikus iš (7.5) intervalo gaunamas (7.6) intervalas,aš vadinu (7.5) intervalo transformavimu.
Aišku, transformuoti galima bet kokius pasikliovimo intervalus, nebūtinaisimetrinius su centru γ.
(7.5) intervalą galima transformuoti ir naudojant mažėjančią funkciją g:(7.5) nelygybės tada ekvivalenčios nelygybėms
g(γ + cσ√
n
)6 g(γθ) 6 g
(γ − cσ√
n
).
127

Asimptotiškai leistini kriterijai. Aprašysiu procedūrą, kuri asimptoti-nėje statistikoje naudojama kriterijams konstruoti. Kad pasakojimas būtųgyvesnis, rašysiu pirmu asmeniu ir esamuoju laiku. Taigi tarkime, kad θyra vienmatis parametras ir man reikia patikrinti hipotezę H : θ = θ∗ sureikšmingumo lygmeniu α. Aš elgiuosi taip:
• randu kokį nors asimptotiškai normalų θ parametro įvertinį θ, suskai-čiuoju jo asimptotinę dispersiją σ2
θ ir pažymiu σ∗ = σθ∗ ;
• sakau tokį užkeikimą: su visais θ√n(θ − θ)σθ
−→θZ ∼ N(0, 1),
todėl ir√n(θ − θ∗)σ∗
−→θ∗
Z,
√n|θ − θ∗|σ∗
−→θ∗|Z|;
tada su tam tikru c (tiksliau, su c = zα/2)
Pθ∗(√
n|θ − θ∗|σ∗
> c)→ P(|Z| > c) = α;
• formuluoju kriterijų: hipotezę atmesiu, jei√n|θ − θ∗|σ∗
> c;
tada užkeikimas iš praeito žingsnio reiškia, kad jei hipotezė teisinga(t.y. θ = θ∗) ir n didelis, tai tikimybė hipotezę atmesti apytiksliai lygiα.
Tokį kriterijų aš vadinu asimptotiškai leistinu kriterijumi, grindžiamu sta-tistika θ. Žodžiai „asimptotiškai leistinas“ reiškia, kad kriterijaus pirmosrūšies klaidos tikimybė gal ir nėra 6 α (taigi jis gal ir nėra leistinas), betnedaug skiriasi nuo α, jei n didelis.
Sudėtinių hipotezių tikrinimas. Tikrindamas hipotezę H : θ > θ∗ elg-čiausi lygiai taip pat, tik kriterijų formuluočiau taip: hipotezę reikia atmesti,kai √
n(θ − θ∗)σ∗
< −c.
128

Kritinę konstantą c reiktų tada parinkti taip, kad būtų teisinga lygybė
P(Z < −c) = α.
Aišku, kad −c yra standartinio normalaus skirstinio α-kvantilis, bet manmalonesnis kitas to skaičiaus aprašymas: kadangi P(Z < −c) = P(Z > c), cyra α lygmens kritinė reikšmė, t.y. c = zα.
Jei β yra tokio kriterijaus galios funkcija, tai, kaip matyti iš konstrukcijos,β(θ∗) ≈ α, kai n didelis. Gali kilti klausimas, ar nelygybė β(θ) 6 α busteisinga su θ > θ∗. Pasirodo, tikrai taip, ir štai kodėl: kadangi θ įvertinyspagrįstas, su visais θ > θ∗
θ − θ∗
σ∗−→θ
θ − θ∗
σ∗> 0,
√n(θ − θ∗)σ∗
−→θ∞
ir, reiškia,
β(θ) = Pθ(√
n(θ − θ∗)σ∗
< −c)→ 0.
Aišku, tikrinant hipotezę H : θ 6 θ∗ naudojamas toks kriterijus: hipo-tezė atmetama, kai √
n(θ − θ∗)σ∗
> c;
čia c randama iš sąlygos P(Z > c) = α, t.y. ir vėl c = zα.
Atvejis, kai parametras daugiamatis. Šis tas įdomesnio gaunasi, jeiθ parametras daugiamatis, o tikrinama hipotezė H : γθ = γ∗; čia γθ yrakoks nors vienmatis išvestinis parametras (pavyzdžiui, pirma θ parametrokoordinatė). Iš pirmo žvilgsnio atrodo, kad čia nieko nauja:
• randame kokį nors asimptotiškai normalų γθ parametro įvertinį γ irapskaičiuojame jo asimptotinę dispersiją σ2
θ ;
• tada su visais θ √n(γ − γθ)σθ
−→θZ ∼ N(0, 1).
Būtent šitoje vietoje iškyla problema: jei tarčiau, kad hipotezė teisinga, vie-toje γθ aš galėčiau įstatyti γ∗, bet ką rašyti vietoje σθ? Todėl šiuo atvejuprocedūra šiek tiek kitokia:
129

• randame kokį nors asimptotiškai normalų γθ parametro įvertinį γ irapskaičiuojame jo asimptotinę dispersiją σ2
θ ;
• randame kokį nors pagrįstą σθ parametro įvertinį σ;
• tada su visais θ √n(γ − γθ)
σ−→θZ ∼ N(0, 1);
• todėl jei hipotezė teisinga,√n(γ − γ∗)
σ−→θZ,
√n|γ − γ∗|σ
−→θ|Z|
ir su c = zα/2
Pθ(√
n|γ − γ∗|σ
> zα/2
)→ α.
Taigi galima naudoti tokį kriterijų: hipotezę atmesti, kai√n|γ − γ∗|σ
> c; (7.7)
čia c = zα/2. Akivaizdu, kad taip apibrėžiamas kriterijus yra asimptotiškaileistinas. Įdomu, kad (7.7) nelygybė ekvivalenti teiginiui
γ∗ 6∈ [γ − cσ√n; γ + cσ√
n].
Kitaip tariant, kriterijus atmeta hipotezę, kai reikšmė γ∗ nepatenka į 1− αpatikimumo asimptotinį pasikliovimo intervalą γθ parametrui.
7.2 Uždaviniai1. Tegu (X1, . . . , Xn) yra imtis iš skirstinio, aprašomo lentele
X 1 2 3 40.4 0.3 0.2 0.1
Raskite statistikosTn = n+N√
n2 +N2
asimptotinį skirstinį; čia N yra didesnių už 1 narių skaičius imtyje.
130

2. Tegu (X1, . . . , Xn) yra imtis iš tolygaus (0; 2) intervale skirstinio. Raskitestatistikos
Tn = 1X2
asimptotinį skirstinį.
3. Tegu (X1, . . . , Xn) yra imtis iš skirstinio su tankiu
p(x) =
1/2, kai 0 < x < 1;1/4, kai 1 6 x < 3.
Raskite statistikosTn = n
n+N
asimptotinį skirstinį; čia N yra mažesnių už 2 narių skaičius imtyje.
4. Tegu (X1, . . . , Xn) yra imtis iš skirstinio, aprašomo lentele
X 1 2 30.4 0.2 0.4
Raskite statistikosTn = N1 +N2
N3
asimptotinį skirstinį; čia Nj yra j reikšmės pasikartojimų skaičius imtyje.
5. Tegu (X1, . . . , Xn) yra imtis iš skirstinio su tankiu
p(x) = 2x, kai 0 < x < 1.
Raskite statistikosTn = 1
1 +X2
asimptotinį skirstinį.
6. Tegu (X1, . . . , Xn) yra imtis iš skirstinio, aprašomo lentele
X 1 2 30.2 0.3 0.5
Raskite statistikosTn = N1
n+N2
asimptotinį skirstinį; čia Nj yra j reikšmės pasikartojimų skaičius imtyje.
131

7. Tegu (X1, . . . , Xn) yra imtis iš tolygaus (0; 2) intervale skirstinio. Raskitestatistikos
Tn = N
nX
asimptotinį skirstinį; čia N yra mažesnių už 1 narių skaičius imtyje.
8. Tegu X ir Y yra nepriklausomi atsitiktiniai dydžiai, pasiskirstę toly-giai (0; 1) intervale, o ((X1, Y1), . . . , (Xn, Yn)) yra imtis iš (X, Y ) skirstinio.Raskite statistikos
Tn = 1XY
asimptotinį skirstinį.
9. (X1, . . . , Xn) yra imtis iš skirstinio, aprašomo lentele
X 1 2 3p1 p2 p3
Čia θ = (p1, p2, p3) — nežinomas vektorinis parametras, kurio galimų reikš-mių sritis aprašoma nelygybėmis p1 > 0, p2 > 0, p3 > 0, p1 + p2 + p3 = 1.Tegu Nj žymi j reikšmės pasikartojimų skaičių imtyje ir
γ = N1
N2.
(a) Kokio išvestinio parametro pagrįstas įvertinys yra γ ir kokia jo asimp-totinė dispersija?
(b) Patikrinkite gautus rezultatus, simuliuodami reikiamas imtis kompiu-teriu.
10. (X1, . . . , Xn) yra imtis iš eksponentinio skirstinio su tankiu
pθ(x) = θe−θx, kai x > 0;
čia θ > 0 — nežinomas parametras. Vertinamas išvestinis parametras γθ =θ2.
(a) Sukonstruokite γ = f(X) pavidalo pagrįstą įvertinį ir apskaičiuokitejo asimptotinę dispersiją.
(b) Nubrėžkite sukonstruoto įvertinio kvadratinės rizikos grafikus, atitin-kančius nedidelius n; pavyzdžiui, n = 5, 10, 15, 20.
132

11. (X1, . . . , Xn) yra imtis iš geometrinio skirstinio:
Pθ(X = k) = (1− θ)θk su k = 0, 1, 2, . . . .
Ieškomas pasikliovimo intervalas nežinomam parametrui θ > 0.(a) Raskite asimptotinio 95% patikimumo pasikliovimo intervalą su f(X)
pavidalo centru.(b) Patikrinkite gautą rezultatą, simuliuodami reikiamas imtis kompiu-
teriu. Koks tikrasis sukonstruoto intervalo patikimumas, kai n nedidelis;pavyzdžiui, n = 15?
12. (X1, . . . , Xn) yra imtis iš normaliojo N(0, θ) skirstinio su nežinoma dis-persija θ > 0 ir ieškomas pasikliovimo intervalas standartiniam nuokrypiui√θ.(a) Sukonstruokite du 90% asimptotinio patikimumo intervalus: vienas
turi būti simetrinis su f(X2) pavidalo centru, kitas — gautas transformuojantanalogišką pasikliovimo intervalą dispersijai θ.
(b) Simuliuodami reikiamas imtis kompiuteriu, palyginkite abiejų inter-valų vidutinius ilgius, kai n = 10.
13. (X1, . . . , Xn) yra imtis iš Puasono skirstinio su nežinomu vidurkiu θ > 0ir tikrinama hipotezė H : θ > 1 su reikšmingumo lygmeniu α = 0.05.
(a) Sukonstruokite asimptotiškai leistiną kriterijų, grindžiamą f(N) pa-vidalo statistika; čia N yra nulių skaičius imtyje.
(b) Koks tikrasis to kriterijaus reikšmingumo lygmuo, kai n nedidelis;pavyzdžiui, n = 5, 10, 15, 20?
14. (X1, . . . , Xn) yra imtis iš normaliojo N(a, b2) skirstinio; čia a ∈ R ir b >0 — nežinomi parametrai. Tikrinama hipotezė H : a = 0 su reikšmingumolygmeniu α = 0.05.
(a) Sukonstruokite asimptotiškai leistiną kriterijų, grindžiamą statistikaX.
(b) Sukonstruoto kriterijaus galios funkcija β yra vektorinio argumento(a, b) funkcija. Nubrėžkite viename piešinyje trijų dalinių pirmo argumentofunkcijų β(·, b) grafikus, atitinkančius b = 0.5, 1, 2.
7.3 Sprendimai1. Aišku, kad
Tn = 1 +N/n√1 +N2/n2
= 1 + 1X>1√1 + 1X>1
2= f(U);
133

čia U = 1X>1 ir
f(u) = 1 + u√1 + u2
, f ′(u) = 1√1 + u2
− (1 + u)u(1 + u2)3/2 .
KadangiEU = EU2 = 0.6 ir DU = 0.6− 0.36 = 0.24,
iš centrinės ribinės teoremos išplaukia√n(U − 0.6)→ N(0, 0.24).
Kadangi
f(0.6) = 1.6√1.36
≈ 1.372, f ′(0.6) = 1√1.36
− 1.6 · 0.61.363/2 ≈ 0.252,
panaudojęs delta metodą gaunu√n(Tn − 1.372)→ N(0, 0.2522 · 0.24) = N(0, 0.015).
2. Aišku, kad Tn = f(U) su U = X2 ir f(u) = 1/u. Kadangi
EU = EX2 = 12
∫ 2
0x2dx = x3
6
∣∣∣∣20
= 43 ,
EU2 = EX4 = 12
∫ 2
0x4dx = x5
10
∣∣∣∣20
= 165 ,
gaunuDU = 16
5 −169 = 64
45ir iš centrinės ribinės teoremos
√n(U − 4
3)→ N(0, 6445).
Kadangif(4
3) = 34 ir f ′(4
3) = − 1169
= − 916 ,
pritaikęs delta metodą gaunu√n(Tn − 3
4)→ N(0, 81256 ·
6445) = N(0, 9
20).
134

3. Šiuo atveju
Tn = 11 +N/n
= 11 + 1X<2
= f(U)
su U = 1X<2 ir
f(u) = 11 + u
, f ′(u) = − 1(1 + u)2 .
Kadangi
EU = EU2 =∫ 2
0p(x)dx = 1
2
∫ 1
0dx+ 1
4
∫ 2
1dx = 1
2 + 14 = 3
4 ,
DU = 34 −
916 = 3
16 ,
iš centrinės ribinės teoremos išplaukia√n(U − 3
4)→ N(0, 316).
Kadangif(3
4) = 47 ir f ′(3
4) = −1649 ,
pritaikęs delta metodą gaunu√n(Tn − 4
7)→ N(0, 162
492 · 316) = N(0, 48
2401).
4. Šiuo atveju
Tn = n−N3
N3= 1−N3/n
N3/n= 1
1X=3− 1 = f(U)
su U = 1X=3 irf(u) = 1
u− 1, f ′(u) = − 1
u2 .
KadangiEU = EU2 = 0.4, DU = 0.4− 0.16 = 0.24,
iš centrinės ribinės teoremos išplaukia√n(U − 0.4)→ N(0, 0.24).
Kadangif(0.4) = 3
2 ir f ′(0.4) = −254 ,
pritaikęs delta metodą gaunu√n(Tn − 1.5)→ N(0, 625
16 ·625) = N(0, 75
8 ).
135

5. Aišku, kad Tn = f(U) su U = X ir
f(u) = 11 + u2 , f ′(u) = − 2u
(1 + u2)2 .
Kadangi
EU = EX =∫ 1
02x2dx = 2x3
3
∣∣∣∣10
= 23 ,
EU2 = EX2 =∫ 1
02x3dx = x4
2
∣∣∣∣10
= 12
irDU = 1
2 −49 = 1
18 ,
iš centrinės ribinės teoremos išplaukia√n(U − 2
3)→ N(0, 118).
Kadangi
f(23) = 9
13 ir f ′(23) = −
43
16981
= −108169 ,
pritaikęs delta metodą gaunu√n(Tn − 9
13)→ N(0, 1082
1692 · 118) = N(0, 648
28561).
6. Šiuo atveju
Tn = N1
n+N2= N1/n
1 +N2/n= 1X=1
1 + 1X=2= f(U1, U2)
su U1 = 1X=1, U2 = 1X=2 ir
f(u1, u2) = u1
1 + u2, f ′(u1, u2) =
(1
1+u2− u1
(1+u2)2
).
KadangiEU1 = EU2
1 = 0.2, EU2 = EU22 = 0.3
ir
cov(U1, U1) = EU21 − (EU1)2 = 0.2− 0.04 = 0.16,
cov(U2, U2) = EU22 − (EU2)2 = 0.3− 0.09 = 0.21,
cov(U1, U2) = EU1U2 − EU1EU2 = 0− 0.06 = −0.06,
136

iš centrinės ribinės teoremos išplaukia
√n
[(U1U2
)−(
0.20.3
)]→ N(0,Σ)
suΣ =
(0.16 −0.06−0.06 0.21
).
Kadangi
f(0.2, 0.3) = 0.21.3 = 2
13 ir f ′(0.2, 0.3) =(
1013 −
20169
),
pritaikęs delta metodą gaunu√n(Tn − 2
13)→ N(0, σ2)
su
σ2 =(
1013 −
20169
)( 0.16 −0.06−0.06 0.21
)(1013− 20
169
)=(
22169 −
12169
)( 1013− 20
169
)= 460
2197 .
7. Aišku, kad
Tn = 1X<1
X= f(U1, U2)
su U1 = 1X<1, U2 = X ir
f(u1, u2) = u1
u2, f ′(u1, u2) =
( 1u2−u1u2
2
).
Kadangi
EU1 = EU21 = 1
2
∫ 1
0dx = 1
2 ,
EU2 = 12
∫ 2
0xdx = x2
4
∣∣∣∣20
= 1,
EU22 = 1
2
∫ 2
0x2dx = x3
6
∣∣∣∣20
= 43 ,
EU1U2 = 12
∫ 1
0xdx = x2
4
∣∣∣∣10
= 14 ,
gaunu
cov(U1, U1) = 12 −
14 = 1
4 ,
137

cov(U2, U2) = 43 − 1 = 1
3 ,
cov(U1, U2) = 14 −
12 = −1
4ir iš centrinės ribinės teoremos
√n
[(U1U2
)−(
121
)]→ N(0,Σ)
suΣ =
(14 −1
4−1
413
).
Kadangif(1
2 , 1) = 12 ir f ′(1
2 , 1) =(1 −1
2
),
pritaikęs delta metodą gaunu√n(Tn − 0.5)→ N(0, σ2)
suσ2 =
(1 −1
2
)( 14 −1
4−1
413
)(1−1
2
)=(
58 −
512
)( 1−1
2
)= 5
6 .
8. Aišku, kad Tn = f(U) su U = XY ir
f(u) = 1u, f ′(u) = − 1
u2 .
Kadangi
EX =∫ 1
0xdx = x2
2
∣∣∣∣10
= 12 ,
EX2 =∫ 1
0x2dx = x3
3
∣∣∣∣10
= 13 ,
EU = EXY = EXEY = (EX)2 = 14 ,
EU2 = EX2Y 2 = EX2EY 2 = (EX2)2 = 19
irDU = 1
9 −116 = 7
144 ,
iš centrinės ribinės teoremos išplaukia√n(U − 1
4)→ N(0, 7144).
138

Kadangif(1
2) = 2 ir f ′(12) = −4,
pritaikęs delta metodą gaunu√n(Tn − 2)→ N(0, 16 · 7
144) = N(0, 79).
9. Aišku, kad
γ = N1/n
N2/n= 1X=1
1X=2= f(U1, U2);
čia U1 = 1X=1, U2 = 1X=2,
f(u1, u2) = u1
u2ir f ′(u1, u2) =
( 1u2−u1u2
2
).
KadangiEθU1 = p1 ir EθU2 = p2,
iš didžiųjų skaičių dėsnioγ → p1
p2.
Taigi γ yra parametro γθ = p1/p2 pagrįstas įvertinys.Kadangi
covθ(U1, U1) = EθU21 − (EθU1)2 = p1 − p2
1,
covθ(U2, U2) = EθU22 − (EθU2)2 = p2 − p2
2,
covθ(U1, U2) = EθU1U2 − EθU1EθU2 = −p1p2,
iš centrinės ribinės teoremos išplaukia√n
[(U1U2
)−(p1p2
)]−→θ
N(0,Σ) su Σ =(p1 − p2
1 −p1p2−p1p2 p2 − p2
2
).
Tada pritaikęs delta metodą gaunu, kad√n(γ − γθ) −→
θN(0, σ2
θ) su
σ2θ =
( 1p2−p1p2
2
)(p1 − p21 −p1p2
−p1p2 p2 − p22
)( 1p2
−p1p2
2
)
= 1p4
2
(p2 −p1
)(p1 − p21 −p1p2
−p1p2 p2 − p22
)(p2−p1
)
= 1p4
2
(p2p1 −p1p2
)( p2−p1
)
= p1
p32(p1 + p2).
Gautus rezultatus patikrinau, atlikęs tokią programą:
139

T<-45p<-matrix(nrow=T,ncol=2)k<-0for (i in 1:9)
for (j in 1:(10-i))k<-k+1p[k,1]=i/10p[k,2]=j/10
sigma<-p[,1]*(p[,1]+p[,2])/p[,2]^3disp<-numeric(T)
N<-10000est<-numeric(N)n<-100for (j in 1:T)
for (i in 1:N)u<-runif(n)x<-ifelse(u<p[j,1], 1, ifelse(u<p[j,1]+p[j,2], 2, 3))est[i]<-sum(x==1)/max(sum(x==2),1)
disp[j]<-var(est)*n
plot(sigma, disp, log="xy", main="Asimptotinė dispersija",xlab="tikra", ylab="simuliuota")
Simuliavau n = 100 dydžio imtis, formulę γ įvertiniui skaičiuoti šiek tiekmodifikavau, kad jis būtų apibrėžtas ir kai N2 = 0. Kompiuterio nupieš-tas grafikas rodo, kad klaidos, ko gero, nepadariau (žr. 16 pav., kad būtųvaizdžiau, tiek tikrąją, tiek simuliuotą asimptotinės dispersijos reikšmę pa-vaizdavau logaritminėje skalėje).
10. Kadangi
EθX =∫ ∞
0xθe−θxdx = θ−1
∫ ∞0
ye−ydy = θ−1Γ(2) = θ−1,
EθX2 =∫ ∞
0x2θe−θxdx = θ−2
∫ ∞0
y2e−ydy = θ−2Γ(3) = 2θ−2
irDθX = 2
θ2 −1θ2 = 1
θ2 ,
140

1e−01 1e+00 1e+01 1e+02 1e+03
1e−
011e
+01
1e+
03Asimptotinė dispersija
tikra
sim
uliu
ota
16 pav.
iš centrinės ribinės teoremos išplaukia√n(X − θ−1) −→
θN(0, θ−2).
Aišku, kad θ2 = f(θ−1) su
f(u) = 1u2 ir f ′(u) = − 2
u3 .
Taigi pagrįstas γθ parametro įvertinys yra
γ = f(X) = 1X
2 .
Be to, pritaikęs delta metodą gaunu, kad√n(γ − γθ) −→
θN(0, σ2
θ) su
σ2θ = 4
θ−6 θ−2 = 4θ4.
γ įvertinio kvadratinės rizikos grafikus nubrėžiu, atlikęs tokią programą(rezultatus žr. 17 pav.):
n<-c(5,10,15,20)teta<-seq(from=0.1, to=10, by=0.1)
141

T<-length(teta)N<-10000est<-numeric(N)rizika<-matrix(0, nrow=4, ncol=T)
for (k in 1:4)for (j in 1:T)
for (i in 1:N)x<-rexp(n[k], rate=teta[j])est[i]<-1/mean(x)^2
rizika[k,j]<-mean((est-teta[j])^2)
old.par<-par(mar=c(5.1,4.1,4.1,8), xpd=TRUE)ymin<-min(rizika)ymax<-max(rizika)cl<-c("darkblue","darkgreen","yellow","darkred")plot(teta, rizika[1,], type="l", ylab="rizika",
col=cl[1], ylim=c(ymin,ymax))for (k in 2:4)
lines(teta, rizika[k,], type="l", col=cl[k])leg.txt<-c("n=5","n=10","n=15","n=20")legend(x="topright", inset=c(-0.3,0), legend=leg.txt,
lwd=1, col=cl)par(old.par)
Rezultatas — 17 pav.
11. Su visais z ∈ (0; 1)
EθzX =∞∑k=0
(1− θ)θkzk = 1− θ1− θz .
Diferencijuodamas z atžvilgiu šią lygybę panariui gaunu
EθXzX−1 = (1− θ)θ(1− θz)2 ,
EθX(X − 1)zX−2 = 2(1− θ)θ2
(1− θz)3 .
142

0 2 4 6 8 10
010
0000
2500
00
teta
rizik
a
n=5n=10n=15n=20
17 pav.
Iš čiaEθX = θ
1− θ , EθX(X − 1) = 2θ2
(1− θ)2 ,
todėl
EθX2 = 2θ2
(1− θ)2 + EθX = 2θ2
(1− θ)2 + θ
1− θ = θ2 + θ
(1− θ)2 ,
DθX = θ2 + θ
(1− θ)2 −θ2
(1− θ)2 = θ
(1− θ)2
ir iš centrinės ribinės teoremos√n(X − θ
1−θ ) −→θ N(0, θ(1−θ)2 ).
Transformacija f turi būti tokia, kad f( θ1−θ ) = θ, t.y. f(u) = θ, kai
u = θ1−θ . Išsprendžiu pastarąją lygtį θ atžvilgiu:
u(1− θ) = θ
u = θ + uθ = θ(1 + u),
θ = u
1 + u.
143

Taigif(u) = u
1 + u, f ′(u) = 1
(1 + u)2
irθ = f(X) = X
1 +X.
Pritaikęs delta metodą gaunu√n(θ − θ) −→
θN(0, σ2
θ) su
σ2θ = [f ′( θ
1−θ )]2 θ
(1− θ)2 = 1(1 + θ
1−θ )4θ
(1− θ)2 = θ(1− θ)2.
Kadangi θ −→θθ, pagristas σθ parametro įvertinys yra σ =
√θ(1 − θ).
Taigi ieškomas pasikliovimas intervalas apibrėžiamas nelygybėmis
θ − cσ√n6 θ 6 θ + cσ√
n;
čiaθ = X
1 +X, σ =
√θ(1− θ) ir c = z0.025.
Gautą rezultatą patikrinau, atlikęs tokią programą:
n<-c(15,100)teta<-seq(from=0.01, to=0.99, by=0.01)T<-length(teta)conf<-matrix(0, nrow=2, ncol=T)N<-10000pateko<-numeric(N)c<-qnorm(0.975)
for (k in 1:2)for (j in 1:T)
for (i in 1:N)x<-rgeom(n[k], prob=1-teta[j])vid<-mean(x)est.teta<-vid/(1+vid)est.sigma<-sqrt(est.teta)*(1-est.teta)pateko[i]=(abs(est.teta-teta[j])<c*est.sigma/sqrt(n[k]))
conf[k,j]<-mean(pateko)
144

0.0 0.2 0.4 0.6 0.8 1.0
0.2
0.4
0.6
0.8
teta
patik
imum
as
n=15n=100
18 pav.
ymin<-min(conf)ymax<-max(conf)cl<-c("darkblue","darkgreen")plot(teta, conf[1,], type="l", ylab="patikimumas",
col=cl[1], ylim=c(ymin,ymax))lines(teta, conf[2,], type="l", col=cl[2])leg.txt<-c("n=15","n=100")legend(x="bottomright", legend=leg.txt, lwd=1, col=cl)abline(h=0.95,col="red")
Rezultatai — 18 pav.
12. Jei Z yra standartiškai normaliai pasiskirstęs atsitiktinis dydis, tai subet kokiu k > 1
EZ2k = 1√2π
∫ ∞−∞
x2ke−x2/2dx = 2√2π
∫ ∞0
x2ke−x2/2dx
= 2√2π
∫ ∞0
2kyke−y√
22√ydy = 2k√
πΓ(k + 1
2)
145

= 2k√π
(k − 12)(k − 3
2) · · · 12Γ(1
2) = (2k − 1)!!.
Pavyzdžiui,EZ2 = 1 ir EZ4 = 3.
Jei X pasiskirstęs pagal N(0, θ) dėsnį, tai X =√θZ su standartiškai
normaliai pasiskirsčiusiu Z, todėl
EθX2 = θ, EθX4 = 3θ2 ir DθX2 = 3θ2 − θ2 = 2θ2.
Tada iš centrinės ribinės teoremos√n(X2 − θ) −→
θN(0, 2θ2).
Statistika√
2X2 yra pagrįstas standartinio nuokrypio įvertinys, todėl nely-gybės
X2 − c√
2X2√n6 θ 6 X2 + c
√2X2√n
(7.8)
apibrėžia pasikliovimo intervalą θ parametrui. Transformavęs jį gaunu pasi-kliovimo intervalą
√θ parametrui:√√√√(X2 − c
√2X2√n
)+6√θ 6
√√√√X2 + c√
2X2√n
(7.9)
(kairysis (7.8) intervalo galas gali būti ir neigiamas, todėl šaknį traukiu iš joteigiamosios dalies).
Kitą pasikliovimo intervalą√θ parametrui konstruoju taip. Pritaikęs
delta metodą gaunu√n(√X2 −
√θ) −→
θN(0, σ2
θ) su
σ2θ =
( 12√θ
)22θ2 = θ
2 .
Kaip ir anksčiau,√X2/2 yra pagrįstas standartinio nuokrypio įvertinys, todėl
pasikliovimo intervalas aprašomas nelygybėmis√X2 − c
√X2√
2n6√θ 6
√X2 + c
√X2√
2n. (7.10)
Tiek (7.9), tiek (7.10) nelygybėse c = z0.05.Abiejų pasikliovimo intervalų vidutinius ilgius palyginu, atlikęs tokią pro-
gramą:
146

n<-10teta<-seq(from=0.1, to=10, by=0.1)T<-length(teta)vid.ilgis<-matrix(0, nrow=2, ncol=T)N<-10000ilgis<-matrix(0, nrow=2, ncol=N)c<-qnorm(0.95)
for (j in 1:T)for (i in 1:N)
x<-rnorm(n, sd=sqrt(teta[j]))vid<-mean(x*x)ilgis[1,i]<-sqrt(vid+c*vid/sqrt(n/2))
-sqrt(max(0,vid-c*vid/sqrt(n/2)))ilgis[2,i]<-c*sqrt(2*vid/n)
vid.ilgis[1,j]<-mean(ilgis[1,])vid.ilgis[2,j]<-mean(ilgis[2,])
ymin<-min(vid.ilgis)ymax<-max(vid.ilgis)cl<-c("darkblue","darkred")plot(teta, vid.ilgis[1,], type="l", col=cl[1],
ylim=c(ymin,ymax), ylab="vidutinis ilgis")lines(teta, vid.ilgis[2,], type="l", col=cl[2])leg.txt<-c("transformuotas","simetrinis")legend(x="bottomright", legend=leg.txt, lwd=1, col=cl)
Simetrinis pasikliovimo intervalas pasirodė besąs vidutiniškai siauresnis(žr. 19 pav.)
13. Bet kokia f(N) pavidalo statistika yra kartu ir f(N/n) = f(1X=0)pavidalo (su šiek tiek kitokia funkcija f). Kadangi
Eθ1X=0 = Eθ12X=0 = e−θ ir Dθ1X=0 = e−θ − e−2θ,
iš centrinės ribinės teoremos išplaukia√n(1X=0 − e−θ) −→
θN(0, e−θ − e−2θ).
147

0 2 4 6 8 10
0.5
1.0
1.5
2.0
2.5
teta
vidu
tinis
ilgi
s
transformuotassimetrinis
19 pav.
Transformacija f turi būti tokia, kad f(e−θ) = θ. Išsprendęs lygtį u = e−θ,gaunu θ = − ln u. Taigi
f(u) = − ln u, f ′(u) = −1u
ir θ = − ln 1X=0.
Pritaikęs delta metodą gaunu√n(θ − θ) −→
θN(0, σ2
θ) su
σ2θ = 1
e−2θ (e−θ − e−2θ) = e2θ(e−θ − e−2θ) = eθ − 1.
Atskiru atveju, kai θ = 1,√n(θ − 1) −→
1N(0, e− 1).
Taigi turėtų tikti kriterijus, atmetantis hipotezę, kai√n(θ − 1)√
e− 1< −z0.95.
Tikrąjį reikšmingumo lygmenį su nedidelėmis n reikšmėmis randu, atlikęstokią programą:
n<-c(5,10,15,20)
148

N<-10000atmete<-numeric(N)c<-qnorm(0.05)
for (k in 1:4)for (i in 1:N)
x<-rpois(n[k], lambda=1)est<--log(max(sum(x==0),1)/n[k])atmete[i]<-(sqrt(n[k])*(est-1)/sqrt(exp(1)-1)<c)
beta<-mean(atmete)cat("n=",n[k],", beta(1)=",beta,"\n")
Pasirodo, kriterijus labai jau konservatyvus:
n= 5 , beta(1)= 0.0072n= 10 , beta(1)= 0.0079n= 15 , beta(1)= 0.0212n= 20 , beta(1)= 0.0311
14. Pažymiu θ = (a, b). Kadangi
EθX = a ir DθX = b2,
iš centrinės ribinės teoremos√n(X − a) −→
θN(0, b2).
(Šiuo konkrečiu atveju√n(X − a) skirstinys yra net ne asimptotiškai, o
tiksliai N(0, b2).) Kadangi EθX2 = b2 +a2, iš didžiųjų skaičių dėsnio išplaukia
X −→θa ir X2 −→
θa2 + b2.
Reiškia,X2 −X2 −→
θb2
ir √n(X − a)√X2 −X2
−→θ
N(0, 1)
Atskiru atveju, jei hipotezė teisinga (t.y. jei a = 0),√n(X)√
X2 −X2−→θ
N(0, 1).
149

Taigi turėtų būti neblogas kriterijus, atmetantis hipotezę, kai√n|X|√
X2 −X2> z0.025.
Kriterijaus galios funkcijos grafikus nubrėžiu, atlikęs tokią programą (ka-dangi sąlygoje imties dydis nenurodytas, imsiu n = 100):
n<-100b<-c(0.5,1,2)a<-seq(from=-5, to=5, by=0.1)A<-length(a)beta<-matrix(0, nrow=3, ncol=A)N<-10000atmete<-numeric(N)c<-qnorm(0.975)
for (jb in 1:3)for (ja in 1:A)
for (i in 1:N)x<-rnorm(n, mean=a[ja], sd=b[jb])vid1<-mean(x)vid2<-mean(x*x)atmete[i]<-(abs(vid1)/sqrt(vid2-vid1*vid1)>c)
beta[jb,ja]<-mean(atmete)
old.par<-par(mar=c(5.1,4.1,4.1,8), xpd=TRUE)ymin<-min(beta)ymax<-max(beta)cl<-c("darkblue","darkgreen","yellow")plot(a, beta[1,], type="l", ylab="galia", col=cl[1],
ylim=c(ymin,ymax))for (jb in 2:3)
lines(a, beta[jb,], type="l", col=cl[jb])leg.txt<-c("b=0.5","b=1","b=2")legend(x="topright", inset=c(-0.3,0), legend=leg.txt,
lwd=1, col=cl)par(old.par)
150

−4 −2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
a
galia
b=0.5b=1b=2
20 pav.
Rezultatas — 20 pav.
8 Didžiausio tikėtinumo įvertiniai
8.1 TeorijaDidžiausio tikėtinumo įvertiniai. Tegu (X1, . . . , Xn) yra imtis iš skirs-tinio su tankiu pθ (čia θ — nežinomas parametras) ir vertinamas išvestinisparametras γθ. Tegu, kaip ir anksčiau, Lθ žymi modelio tikėtinumo funkciją
Lθ = pθ(X1) · · · pθ(Xn).
γθ parametro didžiausio tikėtinumo (sutrumpintai DT) įvertiniu vadinamasįvertinys
γ = γθ;
čia θ yra parametro reikšmė, su kuria
Lθ = supθLθ. (8.1)
Aišku, kad jei teisinga (8.1) lygybė, tai θ yra θ parametro DT įvertinys.Kitaip tariant, ieškant išvestinio parametro DT įvertinio reikia iš pradžių
151

rasti θ parametro DT įvertinį θ ir tada γ = γθ lygybėje uždėti „stogelius“ant γ ir θ. Pavyzdžiui, jei γ = θ2, tai γ = θ2.
Kadangi logaritmas yra griežtai didėjanti funkcija, (8.1) lygybė ekviva-lenti lygybei
`θ = supθ`θ;
čia `θ = lnLθ. Paprastai θ parametro kitimo sritis yra atviras kokios norsRk erdvės poaibis, o `θ funkcija glodi toje srityje. Tada θ yra lygties
˙θ = 0
sprendinys. Ta lygtis vadinama didžiausio tikėtinumo lygtimi.Kaip ir ankstesniame skyrelyje, žymėsiu `θ,1(x) = ln pθ(x). Tada `θ =
n`θ,1(X) ir DT lygtis gali būti užrašyta taip:
˙θ,1(X) = 0. (8.2)
Asimptotinis efektyvumas. Paaiškinsiu, kodėl DT įvertiniai tokie svar-būs. Kad būtų paprasčiau, laikysiu, kad θ parametras vienmatis. Tegu θ yratikroji parametro reikšmė, o θn → θ; tada
˙θn,1(X)− ˙
θ,1(X) = ¨θ,1(X)(θn − θ)(1 + op(1))
(op(1) žymi tam tikrą atsitiktinių dydžių seką, artėjančią pagal pasiskirstymąį 0). Galima tikėtis, kad DT įvertinys pagrįstas, t.y. θ −→
θθ ir kad tada taip
pat˙θ,1(X)− ˙
θ,1(X) = ¨θ,1(X)(θ − θ)(1 + op(1)).
Kadangi θ yra (8.2) lygties sprendinys, iš čia išplaukia
− ˙θ,1(X) = ¨
θ,1(X)(θ − θ)(1 + op(1)),
θ − θ = −˙θ,1(X)
¨θ,1(X)
(1 + op(1))
ir√n(θ − θ) =
√n ˙
θ,1(X)−¨
θ,1(X)(1 + op(1)).
Kadangi
Eθ ˙θ,1(X) = 0, Dθ
˙θ,1(X) = Eθ ˙2
θ,1(X) = Iθ,1,
152

iš centrinės ribinės teoremos išplaukia, kad√n ˙
θ,1(X) −→θ
N(0, Iθ,1).
Kita vertus, iš didžiųjų skaičių dėsnio
−¨θ,1(X) −→
θ−Eθ ¨
θ,1(X) = Iθ,1.
Taigi√n(θ − θ) −→
θ
N(0, Iθ,1)Iθ,1
= N(0, I−1θ,1 ).
Jei γ yra išvestinio parametro DT įvertinys, pritaikęs delta metodą gaunu√n(γ − γθ) −→
θN(0, σ2
θ)
su asimptotine dispersijaσ2θ = γ2
θ
Iθ,1.
Taigi DT įvertiniai turėtų būti asimptotiškai efektyvūs.
Pagrįstumas. Visi ankstesnio paragrafo samprotavimai gali būti griežtaipagrįsti: reikia padaryti tam tikras prielaidas apie pθ, bet tos prielaidos atro-do labai simpatiškai. Pagrindinė problema — kaip įrodyti, kad DT įvertinyspagrįstas. Čia irgi yra kelios teoremos, kurias galima taikyti, bet jų prielaidosjau nėra tokios simpatiškos. Kada nors reiktų ta problema užsiimti ir man.
8.2 UždaviniaiVisuose uždaviniuose duodamas tam tikras statistinis modelis ir reikia rastinurodyto išvestinio parametro DT įvertinį.
1. (X1, . . . , Xn) yra imtis iš skirstinio aprašomo lentele
X 0 11− θ θ
Vertinamas parametras θ ∈ (0; 1).
2. (X1, . . . , Xn) yra imtis iš geometrinio skirstinio:
Pθ(X = k) = (1− θ)θk su k = 0, 1, 2, . . . .
Vertinamas parametras θ > 0.
153

3. (X1, . . . , Xn) yra imtis iš Puasono skirstinio su nežinomu vidurkiu θ > 0.Vertinamas išvestinis parametras γθ = ln θ.
4. (X1, . . . , Xn) yra imtis iš eksponentinio skirstinio su tankiu
pθ(x) = θe−θx, kai x > 0.
Vertinamas parametras θ > 0.
5. (X1, . . . , Xn) yra imtis iš normaliojo N(θ, 1) skirstinio. Vertinamas neži-nomas vidurkis θ ∈ R.
6. (X1, . . . , Xn) yra imtis iš normaliojo N(0, θ) skirstinio su nežinoma dis-persija θ > 0. Vertinamas standartinis nuokrypis γθ =
√θ.
7. (X1, . . . , Xn) yra imtis iš normaliojo N(a, b2) skirstinio; čia nežinomas tiekvidurkis a ∈ R, tiek standartinis nuokrypis b > 0. Vertinamas parametrasθ = (a, b).
8. (X1, . . . , Xn) yra imtis iš skirstinio aprašomo lentele
X 1 2 3p1 p2 1− p1 − p2
Vertinamas parametras θ = (p1, p2), kintantis srityje
p1 > 0, p2 > 0, p1 + p2 < 1.
8.3 Sprendimai1. Šiuo atveju
pθ(X) =
1− θ, kai X = 0,θ, kai X = 1,
`θ,1(X) =
ln(1− θ), kai X = 0,ln θ, kai X = 1,
= 1X=0 ln(1− θ) + 1X=1 ln θ,
˙θ,1(X) = −1X=0
11− θ + 1X=1
1θ
ir reikia išspręsti lygtį
−1X=01
1− θ + 1X=11θ
= 0.
154

Kad būtų mažiau rašymo pažymiu a = 1X=1. Aišku, kad
1X=0 + 1X=1 = 1X=0 + 1X=1 = 1,
todėl 1X=0 = 1− a ir lygties sprendimas užrašomas taip:
−1− a1− θ + a
θ= 0,
1− a1− θ = a
θ,
(1− a)θ = a(1− θ),(1− a)θ + aθ = a,
θ = a.
Taigiθ = 1X=1.
2. Šiuo atveju
pθ(X) = (1− θ)θX , `θ,1(X) = ln(1− θ) +X ln θ,
˙θ,1(X) = − 1
1− θ + X
θ
ir DT lygtis atrodo taip:
− 11− θ + X
θ= 0.
Spręsdamas ją gaunu
X
θ= 1
1− θ ,
(1− θ)X = θ,
X = θ + θX
ir, reiškia,
θ = X
1 +X.
3. Šiuo atveju
pθ(X) = e−θ θX
X! ,
`θ,1(X) = −θ +X ln θ − lnX!,
155

˙θ,1(X) = −1 + X
θir DT lygtis atrodo taip:
−1 + X
θ= 0.
Spręsdamas ją gaunuX
θ= 1,
X = θ.
Reiškia,θ = X ir γ = lnX.
4. Šiuo atvejupθ(X) = θe−θX ,
`θ,1(X) = ln θ − θX,˙θ,1(X) = 1
θ−X
ir DT lygtis atrodo taip:1θ−X = 0.
Spręsdamas ją gaunu1θ
= X,
θX = 1ir, reiškia,
θ = 1X.
5. Šiuo atveju
pθ(X) = 1√2π
e−(X−θ)2/2,
`θ,1(X) = − ln√
2π − (X − θ)2
2 ,
˙θ,1(X) = X − θ
ir DT lygtis atrodo taip:X − θ = 0.
Iš jos iškart gaunuθ = X.
156

6. Šiuo atveju
pθ(X) = 1√2πθ
e−X2/(2θ),
`θ,1(X) = − ln√
2π − 12 ln θ − X2
2θ ,
˙θ,1(X) = − 1
2θ + X2
2θ2
ir DT lygtis atrodo taip:
− 12θ + X2
2θ2 = 0.
Spręsdamas ją gaunu
X2
2θ2 = 12θ ,
X2 = θ.
Reiškia,θ = X2 ir γ =
√X2.
7. Šiuo atveju
pθ(X) = 1√2πb
e−(X−a)2/(2b2),
`θ,1(X) = − ln√
2π − ln b− (X − a)2
2b2 ,
˙θ,1(X) =
(X−ab2 −1
b+ (X−a)2
b3
)ir DT lygtis iš tikrųjų yra dviejų lygčių sistema:
X − ab2 = 0, −1
b+ (X − a)2
b3 = 0.
Iš pirmos lygties iškart gaunu a = X, o tada iš antrosios
(X − a)2
b3 = 1b,
(X − a)2 = b2,
b =√
(X − a)2 =√
(X −X)2.
Taigia = X ir b =
√(X −X)2.
157

8. Šiuo atveju
`θ(X) = 1X=1 ln p1 + 1X=2 ln p2 + 1X=3(1− p1 − p2),˙θ(X) =
(1X=1
1p1− 1X=3
11−p1−p2
1X=21p2− 1X=3
11−p1−p2
)ir DT lygčių sistema atrodo taip:
1X=11p1− 1X=3
11− p1 − p2
= 0,
1X=21p2− 1X=3
11− p1 − p2
= 0.
Kad būtų trumpiau, pažymiu a1 = 1X=1 ir a2 = 1X=2; tada 1X=3 =1− a1 − a− 2. Taigi reikia išspręsti sistemą
a1
p1= 1− a1 − a2
1− p1 − p2= a2
p2
Kairysis grandinės narys lygus dešiniajam, todėl
p2 = a2p1
a1.
Įstatęs šią išraišką į pirmą lygtį, gaunu
a1
p1= 1− a1 − a2
1− p1 − a2p1a1
,
a1
(1− p1 −
a2p1
a1
)= (1− a1 − a2)p1,
a1 − a1p1 − a2p1 = (1− a1 − a2)p1
ir p1 = a1. Tada p2 = a2. Taigi
p1 = 1X=1 ir p2 = 1X=2.
158













