Embed Size (px)
DESCRIPTION
Statistik Lektion 2. Sandsynlighedsregning Analyse af kontingenstabeller. Sandsynlighedsregning. Definition : Hændelse , resultat af et ”eksperiment” Fx hændelsen at det regner i morgen. - PowerPoint PPT Presentation
Citation preview

StatistikLektion 2
Sandsynlighedsregning
Analyse af kontingenstabeller

SandsynlighedsregningDefinition: Hændelse, resultat af et ”eksperiment”
Fx hændelsen at det regner i morgen
Definition: Sandsynlighed, andelen af gange hændelsen indtræffer når vi udfører eksperimentet maaaaange gange.
Fx. Kast med en mønt. Sandsynligheden for plat er 50%, da andelen af plat er 50% i det lange løb.
Notation: Lad A være en hændelse.P(A) betegner sandsynligheden for
hændelsen A.

Regneregler for sandsynlighederLad A være en hændelse
P(ikke A) = 1- P(A)
Hvis A og B er hændelser, der ikke kan indtræffe samtidigt:P(A eller B) = P(A) + P(B)
Fx. sandsynligheden for at yngste persons navn begynder med A eller B
To hændelser er (statistisk) uafhængige hvis og kun hvisP(A og B) = P(A)P(B)
Fx sandsynligheden for to 6’ere i et terningkast…

Sandsynlighedsfordeling: Diskret variabelDefinition: Diskret variabelEn variabel er diskret, hvis den kan tage højst tælleligt mange værdier. Fx. Antal børn i en familie. Antal terning kast inden 6’er.
Definition: SandsynlighedsfunktionSandsynligheds fordelingen for en diskret variabel er beskrevet ved en sandsynligheds funktion P(y), så
0 ≤ P(y) ≤ 1 og Salle y P(y) = 1
hvor y er et enkelt udfald af vores eksperiment.
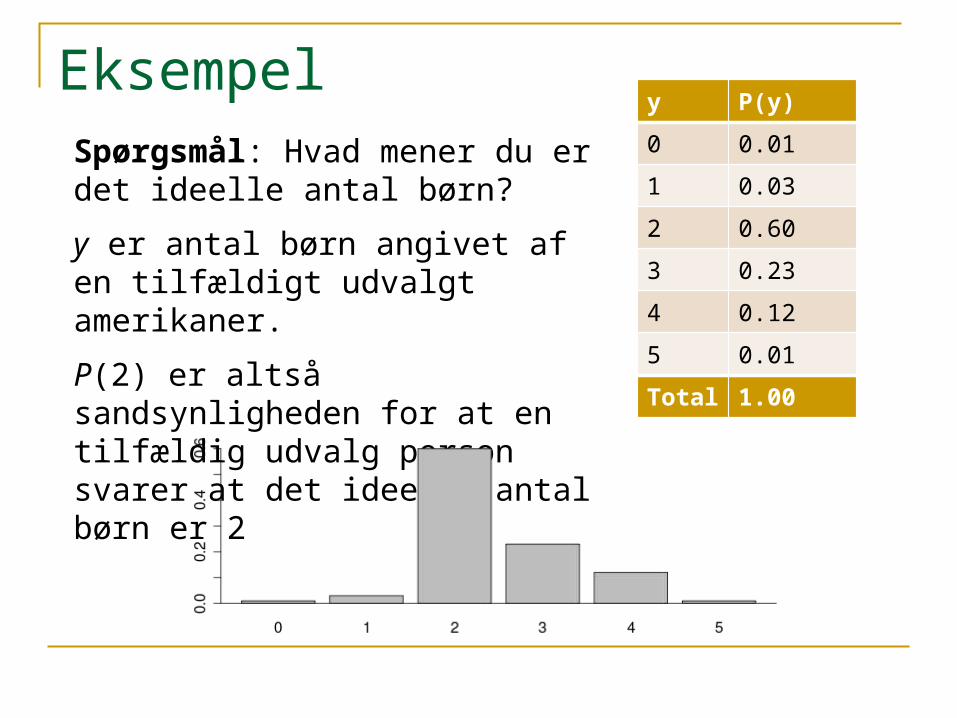
Eksempely P(y)
0 0.01
1 0.03
2 0.60
3 0.23
4 0.12
5 0.01
Total 1.00
Spørgsmål: Hvad mener du er det ideelle antal børn?
y er antal børn angivet af en tilfældigt udvalgt amerikaner.
P(2) er altså sandsynligheden for at en tilfældig udvalg person svarer at det ideelle antal børn er 2

Sandsynlighedsfordeling: Kont. variabelDefinition: Kontinuert variabelEn variabel er kontinuert, hvis den kan tage alle værdier i et interval. Fx. Højden eller indkomst for en BEM studerende.
Definition: TæthedsfunktionSandsynlighedsfordelingen for en kontinuert variabel er beskrevet ved en tæthedsfunktion f(y), så
0 ≤ f(y) og .
hvor y er et enkelt udfald af vores eksperiment.
1)( dyyf

EksempelVentetid på at komme igennem til help-line:
Lad T være den (tilfældige) ventetid.
Sandsynligheden for at vente mere en 15 minutter:
06.0)()15(15
dttfTP
6%
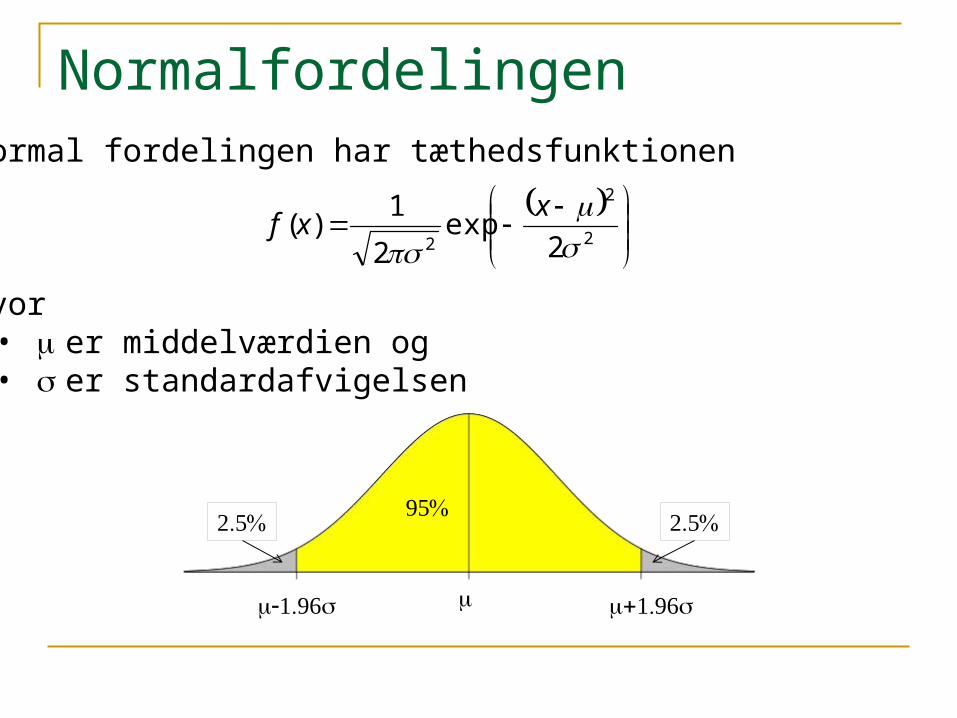
NormalfordelingenNormal fordelingen har tæthedsfunktionen
hvor • m er middelværdien og • s er standardafvigelsen
2
2
2 2exp
2
1)(
x
xf
m +1.96m s-1.96m s
95%2.5%2.5%

Stikprøvefordeling: Motivation Påstand: Andelen af vælgere der ville stemme på
Schwarzenegger er 50%. Stikprøve: Vi spørger 508 tilfældigt udvalgte
stemmeberettigede. 284 siger svarer ja.
Spørgsmål 1: Hvis påstanden er korrekt, hvor mange Schwarzenegger stemmer ville vi have forventet?
Spørgsmål 2: Hvad er umiddelbart det bedste bud på, hvad den sande andel af Schwarzenegger stemmer er?
Spørgsmål 3: Er denne afvigelse, så stor at vi kan afvise vores påstand?

Simuleret svar på spørgsmål 3… Spørgsmål: Hvis påstand om 50% opbakning er korrekt,
hvor ekstrem er vores rundspørge? Ide: Få en computer til at simulere 1000 ”kunstige”
rundspørger, hvor påstanden er korrekt. Konkret: Computeren kaster en fair mønt 508 gange og
udregner andelen af plat. Gentages 1000 gange. Resultat:
Andel ”mere ekstreme” simulationer: 18,6%

Formaliseret svar Setup: Sande andel betegnes p Hypoteser:
Arbejds-hypotese (H0): p = 0.5
Alternativ-hypotese (H1): p 0.5 Observerede andel:
Sandsynlighed for ekstrem andel: 18,3% (p-værdi)
53.0508/269ˆ
Normal-approksimation til stikprøvefordelingen

Konfidensinterval
Eksempel: Antag er den estimerede andel baseret på n svar. Da er et 95% konfidensinterval givet ved
I Schwarzenegger eksempel
Dvs. vi 95% sikre på at den sande andel af ja’er blandt vælgerne er mellem 0.53 og 0.59.
Definition: KonfidensintervalEt 95% konfidensinterval indeholder den sande parameterværdi med 95% sikkerhed.
n ˆ1ˆ96.1ˆ
03.056.050856.0156.096.156.0

Kontingenstabel I en kontingenstabel indeholder hver celle det antal observationer,
der falder inden for den givne kombination af kategorier.
Spørgsmål: Er der sammenhæng mellem farvevalg og køn?
Farve på foretrukne M&M
Rød Grøn Blå
Køn Mand 2135.0%
1321.7%
2643.3%
60100.0%
Kvinde 3453.2%
710.9%
2335.9%
64100.0%
Total 5544.4%
2016.1%
4939.5%
124100.0%
Celle: Antal personer, der er kvinde og som foretrækker rød

Spørgsmålet på hovedet
Spørgsmål: Er der sammenhæng mellem farvevalg og køn? Vi vender spørgsmålet på hovedet: Spørgsmål: Kan vi afvise at der ingen sammenhæng er mellem
køn og farvevalg?
Antag at der ingen sammenhæng er mellem køn og farvevalg. Hvilket antal observationer ville vi så forvente i hver celle i vores
kontingenstabel?
Vi antager at de marginale antal ligger fast, dvs. det totale antal mænd, kvinder, røde, grønne og blå.

Forventede antal Hvis der ingen sammenhæng er mellem køn og farvevalg, så bør
procentfordelingen være den samme blandt mænd og kvinder.
Andel røde: 55/124 = 44.4% Forventede røde blandt mænd: 44.4% af 64 = 64*55/124 = 28.4
Farve på foretrukne M&M
Rød Grøn Blå
Køn Mand 60100.0%
Kvinde 64100.0%
Total 5544.4%
2016.1%
4939.5%
124100.0%

Generel formel for det forventede antal I hver celle har vi
Xij : observerede antal i celle (i,j)
Eij : forventede antal i celle (i,j)
Desuden har vi N: Totale antal observationer Ci
: Antal observationer i ’te kolonne Rj: Antal observationer er j’te række
Forventede antal for celle ( i,j ) er Eij
= Ci Rj / N

Ombytning uden betydning
Vi kan bytte rundt på farve og køn uden at det gør en forskel: Andelen af mænd: 60/124 = 48.4% Forventede antal mænd blandt røde: 48.4% af 55 = 55*60/124 =
28.4

Så langt så godt
Vi har… Vi har arbejdshypotesen at der ikke er sammenhæng mellem køn
og farvevalg Vi har fundet de forventede antal, hvis arbejdshypotesen er sand.
Vi mangler… Vi mangler et mål for hvor meget de forventede antal afviger fra
de forventede. Vi mangler en måde at afgøre, hvornår afvigelsen er så stor, at vi
ikke længere kan acceptere arbejdshypotesen.

Mål for afvigelsen
Vi bruger følgende mål
Vi kalder c2 (”ki-i-anden”) en teststørrelse. c2 bruges til at teste arbejdshypotesen.
Bemærk: c2 ≥ 0 c2 = 0 perfekt match Jo større c2 , jo mindre tror vi på arbejdshypotesen
i j ij
ijij
E
EX 2
2

c2 teststørrelse for eksemplet I en kontingenstabel indeholder hver celle det antal observationer,
der falder inden for den givne kombination af kategorier.
Spørgsmål: 4.9 er ikke nul! Men er det så langt fra nul, at vi ikke kan acceptere arbejdshypotesen om ingen sammenhæng?
Farve på foretrukne M&M
Rød Grøn Blå
Køn Mand 2126.6
139.7
2623.7
60
Kvinde 3428.4
710.3
2325.3
64
Total 55 20 49 124
9.4
3.25
3.2523
7.23
7.2326
7.9
7.913
6.26
6.2621 22222

Lidt mere teoretisk tilgang Vi har en teoretisk fordeling:
En såkaldt c2-fordeling med 2 frihedsgrader. Det røde areal svarer til sandsynligheden for at observere en mere
ekstrem c2-værdi. Her er arealet 8.49%. Denne værdi kaldes også p-værdien.
I en generel tabel med r rækker og c kolonner, vil histogrammet svare til en c2-fordeling med (r-1)(c-1).

Beslutningen! Jo mere ekstrem c2 -værdi, jo mindre tror vi på arbejdshypotesen. Jo mere ekstrem c2 -værdi, jo mindre p-værdi.
Hvis p-værdien er mindre end 5% så afviser vi arbejdshypotesen. Vi siger at testen (af arbejdshypotesen) er signifikant.
Grænsen på de 5% kaldes signifikans-niveauet, og betegnes a. Signifikans-niveauet kan vælges frit, mer er typisk 10%, 5% eller
1%. Signifikans-niveauet vælges før teststørrelsen udregnes!
I eksemplet kan vi ikke afvise arbejdshypotesen. Vi kan altså ikke afvise af der ingen sammenhæng er mellem køn og farvevalg.

Signifikanstest generelt1) Opstil statistisk model / statistiske antagelser
1) Fx. at stikprøven er tilfældigt udvalgt.
2) Opstil arbejds-hypotese
1) Betegnes H0 , nul-hypotesen
2) Fx. uafhængighed mellem køn og farvevalg
3) Opstil alternativ-hypotese
1) Den ”modsatte” hypotese af H0
2) Betegnes H1
Bemærk: Arbejdshypotesen er ikke nødvendigvis den hypotese vi tror på eller gerne vil ”bevise”.
Arbejdshypotesen er generelt valgt, så den er mere ”præcis” end alternativ-hypotesen. Uafhængighed (ingen sammenhæng) er præcist, mens alternativet, afhængighed, kan være mange ting.

Signifikanstest generelt forts.1) Vælg signifikansniveau a
1) Typisk 5%.
2) Konstruer en test-størrelse
1) Hvilke værdier er ekstreme for H0?
2) Beregn teststørrelsen3) Beregning af test-størrelse ordnes af SPSS
3) Beregn p-værdien
1) p-værdien er sandsynligheden for at observere en mere ekstrem test-størrelse ”næste gang”, under antagelse af at H0 er sand, og at modellen og dens antagelser er korrekte.
4) Hvis p-værdien < a, så kan vi ikke afvise H0.
5) Hvis p-værdien > a, så afviser vi H0 og accepterer H1 hypotesen.
6) Fortolk resultatet.

Man begår fejl
Når vi udfører en signifikanstest kan vi begå en af to fejl
Type 1 fejl: Vi afviser H0 selvom den er sand Type 2 fejl: Vi accepterer H0 selvom den er falsk
Antag modellen er korrekt, H0 er sand og at vi har valg et signifikans-niveau a.
Hvad er da sandsynligheden for at begå en Type 1 fejl?

Lidt gode råd
p-værdien er ikke sandsynligheden for at H0 er sand. p-værdien er ikke er udtryk for styrken af sammenhængen mellem
to variable.
p-værdien kan fortolkes som et udtryk for hvor meget vi tror på H0 hypotesen.
HVER GANG i ser en p-værdi i SPSS (”sig.”), så gør jer hver gang klart, hvilken H0 hypotese den passer sammen med!!!
Det er nemt nu, men det bliver mere indviklet senere…

Eksempel i SPSS Analyze → Descriptive Statistics →
Crosstabs

SPSS output
c2-teststørrelse p-værdi
Da p-værdien < 0.05 afviser vi at arbejdsløshed og vold/trusler er uafhængige.
Opstiller hypoteser: H0 : Uafhængighed mellem
arbejdsløs og vold/trusler H0 : Afhængighed Sig. niv. a = 5%

Mere end to variable
Indtil nu: Afgøre om der er en (statistisk signifikant) sammenhæng mellem to kategoriske variable.
Det næste: Kan andre kategoriske kontrolvariable hjælpe med at forstå en sammenhæng?
Ideen er at inddele det indsamlede data efter hvert svar i kontrolvariablen. Og derefter gentage tabelanalysen for hver delmængde af data. Vi siger vi stratificerer efter kontrolvariablen.
Lad os se på nogle eksempler…

Sammenhæng mellem race og dom
Test: H0: Ingen sammenhæng ml. race og dom. Teststørrelse: c2 = 3.1, df = 1, p = 0.078 ( > 0.05 ), g = -0.155 Konklusion: Vi kan ikke afvise H0. Dvs., vi kan ikke afvise, at der er
uafhængighed mellem morders race og afsagt dom. (Simpelt: Ingen sammenhæng)
Dom
Dødsdom Anden dom Total
Morder Sort 592.4%
244897.6%
2507100.0%
Hvid 723.2%
218596.8%
2257100.0%
Total 1312.7%
463397.3%
4764100.0%
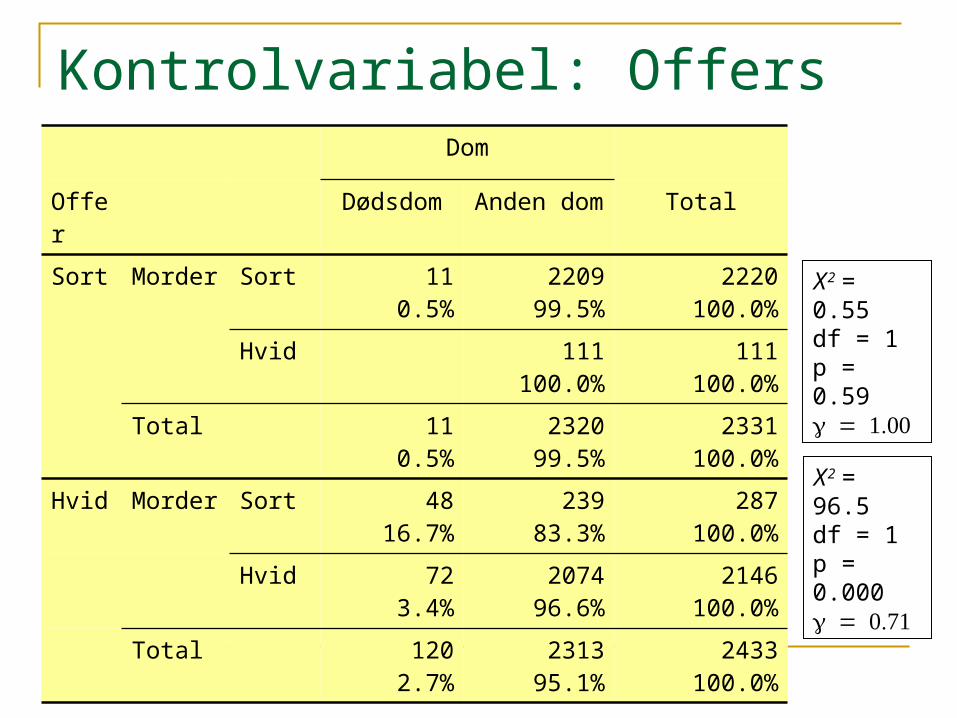
Kontrolvariabel: Offers raceDom
Offer Dødsdom Anden dom Total
Sort Morder Sort 110.5%
220999.5%
2220100.0%
Hvid 111100.0%
111100.0%
Total 110.5%
232099.5%
2331100.0%
Hvid Morder Sort 4816.7%
23983.3%
287100.0%
Hvid 723.4%
207496.6%
2146100.0%
Total 1202.7%
231395.1%
2433100.0%
Χ2 = 0.55 df = 1p = 0.59 = 1.00g
Χ2 = 96.5 df = 1p = 0.000 = 0.71g

Opsummering
Sammenhængen mellem race og dom var skjult Ikke-stratificeret analyse: Ikke-signifikant sammenhæng Stratificeret analyse: Signifikant sammenhæng
Sammenhængen er muligvis lokal Kun signifikant sammenhæng når offer er hvid
Simpsons paradoks – sammenhængen er ”vendt” Ikke-stratificeret analyse: Hvide straffes hårdest! Stratificeret analyse: Sorte straffes hårdest – uanset offers
race.

Stratificering i SPSS Stratificering efter offers race.


Elaborering: Arbejde og boligforhold
Test: H0: Ingen sammenhæng mellem arbejde og boligforhold. Teststørrelse: Χ2 = 12.9, df = 3, p = 0.005 Konklusion: Signifikant sammenhæng
Bolig
God Dårlig Total
Tilknytning til arbjeds-markedet
Fuldtid 8369.7%
3630.3%
119100.0%
Deltid 7482.2%
1617.8%
90100.0%
Pensioneret 73682.5%
15617.5%
892100.0%
Ingen 16777.0%
5023.0%
217100.0%
Total 106080.4%
25819.6%
1318100.0%

Bemærkninger
Tabellen viser sammenhængen mellem arbejde og boligforhold blandt 70-årige i 1967 og 1984.
Hvad mon forklarer denne sammenhæng? Lad os stratificere efter år, dvs. separate tabeller for
1967 og 1984.
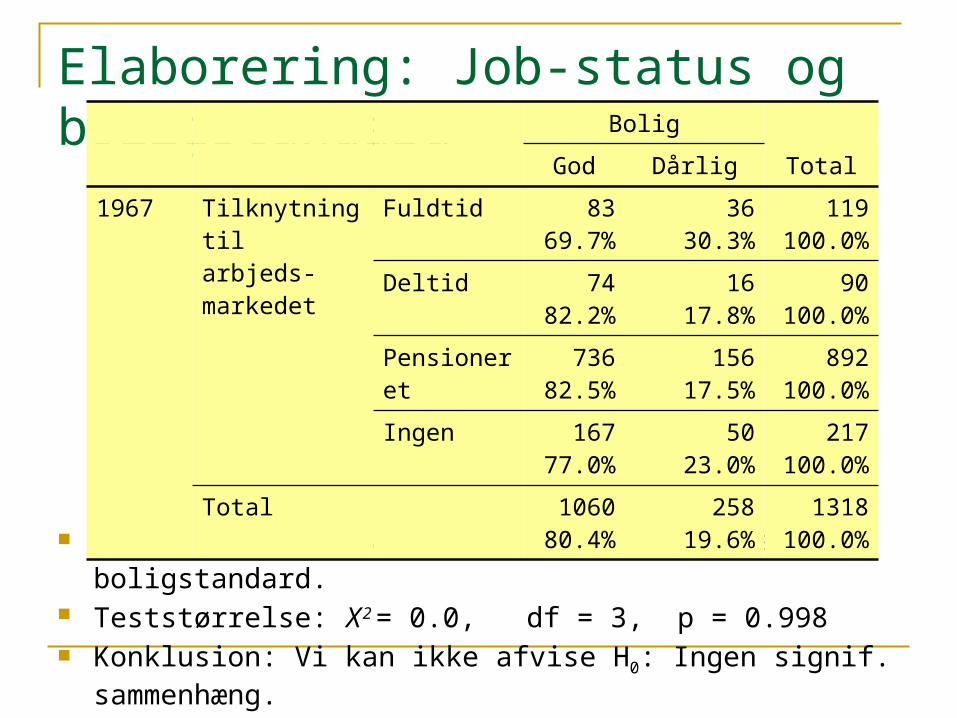
Elaborering: Job-status og boligstandard
Test: H0: Ingen sammenhæng ml. job-status og boligstandard. Teststørrelse: Χ2 = 0.0, df = 3, p = 0.998 Konklusion: Vi kan ikke afvise H0: Ingen signif. sammenhæng.
Bolig
God Dårlig Total
1967 Tilknytning til arbjeds-markedet
Fuldtid 8369.7%
3630.3%
119100.0%
Deltid 7482.2%
1617.8%
90100.0%
Pensioneret 73682.5%
15617.5%
892100.0%
Ingen 16777.0%
5023.0%
217100.0%
Total 106080.4%
25819.6%
1318100.0%

Elaborering: Job-status og boligstandard
Test: H0: Ingen sammenhæng ml. job-status og boligstandard. Teststørrelse: Χ2 = 1.3, df = 3, p = 0.725 Konklusion: Vi kan ikke afvise H0: Ingen signif. sammenhæng.
Bolig
God Dårlig Total
1984 Tilknytning til arbjeds-markedet
Fuldtid 1890.0%
210.0%
20100.0%
Deltid 4695.8%
24.2%
48100.0%
Pensioneret 52891.8%
47 8.2%
575100.0%
Ingen 85 93.4%
66.6%
91 100.0%
Total 677 92.2%
577.8%
1318100.0%

Konklusioner
Sammenhængen mellem arbejde og boligforhold forsvinder når vi stratificerer efter kohordeår.
Vi siger at kohordeåret forklarer sammenhængen mellem arbejde og boligforhold.
Statistiker: Betinget uafhængighed.





























