Embed Size (px)
Citation preview

Statisticke i numericke metode
Materijali za seminare iz kolegija:
Statisticke i numericke metode,
Numericke i statisticke metode,
Osnove statistike okolisa i numericke metode.
Erna Begovic Kovac
Miroslav Jerkovic
Zavod za matematiku
Fakultet kemijskog inzenjerstva i tehnologije
Sveuciliste u Zagrebu

Sadrzaj
1 Deskriptivna statistika 11.1 Tablica frekvencija i histogram . . . . . . . . . . . . . . . . . . 3
2 Slucajne varijable 52.1 Diskretna slucajna varijabla . . . . . . . . . . . . . . . . . . . 5
2.1.1 Binomna razdioba . . . . . . . . . . . . . . . . . . . . 72.1.2 Poissonova razdioba . . . . . . . . . . . . . . . . . . . 8
2.2 Kontinuirana slucajna varijabla . . . . . . . . . . . . . . . . . 92.2.1 Normalna razdioba . . . . . . . . . . . . . . . . . . . . 102.2.2 Eksponencijalna razdioba . . . . . . . . . . . . . . . . 11
3 Testovi hipoteza 143.1 Interval pouzdanosti za ocekivanje . . . . . . . . . . . . . . . . 143.2 Testovi hipoteza . . . . . . . . . . . . . . . . . . . . . . . . . . 143.3 Naredba IF u Excelu . . . . . . . . . . . . . . . . . . . . . . . 17
4 Metoda najmanjih kvadrata 19
5 Interpolacija i ekstrapolacija 225.1 Interpolacijski polinom . . . . . . . . . . . . . . . . . . . . . . 22
6 Jednadzbe i sustavi 246.1 Metoda bisekcije . . . . . . . . . . . . . . . . . . . . . . . . . 256.2 Metoda sekante . . . . . . . . . . . . . . . . . . . . . . . . . . 266.3 Metoda tangente . . . . . . . . . . . . . . . . . . . . . . . . . 266.4 Solver . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276.5 Sustavi jednadzbi . . . . . . . . . . . . . . . . . . . . . . . . . 28
7 Obicne diferencijalne jednadzbe 307.1 Eulerova metoda . . . . . . . . . . . . . . . . . . . . . . . . . 307.2 Runge-Kutta 4 metoda . . . . . . . . . . . . . . . . . . . . . . 31
i

Poglavlje 1
Deskriptivna statistika
Primjeri u Excelu vezani za ovu cjelinu nalaze se u dokumentu Deskriptiv-nastatistika.xlsx .
Deskriptivna statistika je dio matematicke statistike koji se koristi zaopisivanje i bolje razumijevanje izmjerenog (ili zadanog) skupa podataka.Upoznat cemo se s osnovnim pojmovima deskriptivne statistike.
• Duljina uzorka je broj podataka.
• Najmanji podatak
• Najveci podatak
• Raspon je razlika najveceg i najmanjeg podatka.
• Aritmeticka sredina (prosjek)
• Medijan je srednji podatak. Pola podataka nalazi se iznad, a polaispod medijana.
• Prvi kvartil (donji kvartil) je broj od kojeg je manje ili jednako 25%podataka.
• Drugi kvartil je broj od kojeg je manje ili jednako 50% podataka.Drugi kvartil je isto sto i medijan.
• Treci kvartil (gornji kvartil) je broj od kojeg je manje ili jednako 75%podataka.
• Mod uzorka je podatak koji se u uzorku pojavljuje najvise puta.
1

POGLAVLJE 1. DESKRIPTIVNA STATISTIKA 2
Napomenimo da je nulti kvartil zapravo najmanji podatak, a cetvrti kvartilje najveci podatak. Kvartili dijele skup podataka na cetiri dijela. Analognobi mogli podijeliti podatke i na neki drugi broj dijelova. Podjela na 100dijelova je podjela na percentile. Onda je primjerice sedmi percentil broj odkojeg je manje ili jednako 7% podataka.
U donjoj tablici navedene su Excel formule koje se koriste za racunanjenavedenih pojmova. Umjesto rijeci “uzorak” u desnom stupcu upisuje seraspon polja u kojima se nalaze podatci, npr. MIN(A1:A50).
POJAM NAREDBAduljina uzorka COUNT(uzorak)
najmanji podatak MIN(uzorak)najveci podatak MAX(uzorak)
raspon MAX(uzorak) - MIN(uzorak)aritmeticka sredina AVERAGE(uzorak)
medijan MEDIAN(uzorak)1. kvartil QUARTILE(uzorak; 1)3. kvartil QUARTILE(uzorak; 3)
mod MODE(uzorak)7. percentil PERCENTILE(uzorak; 0.07)
Za bolju interpretaciju podataka bitno je znati koliko su podatci rasprseni,odnosno koliko odstupaju od prosjeka. Pretpostavimo da skup podataka imaduljinu n i oznacimo njegovu aritmeticku sredinu s x. Suma apsolutnihodstupanja podataka od aritmeticke sredine (SAO) definira se kao
SAO =n∑i=1
|xi − x| = |x1 − x|+ |x2 − x|+ · · ·+ |xn − x|.
Prosjecno apsolutno odstupanje od aritmeticke sredine (PAO) dobije setako sto se suma apsolutnih odstupanja podijeli s brojem podataka,
PAO =SAO
n.
Umjesto da gledamo apsolutno odstupanje od prosjeka, mozemo gledati kva-dratno odstupanje. Prosjecno kvadratno odstupanje od aritmeticke sredinenaziva se varijanca uzorka ((s′)2) i definirana je sa
(s′)2 =1
n
n∑i=1
(xi − x)2 =(x1 − x)2 + (x2 − x)2 + · · ·+ (xn − x)2
n.

POGLAVLJE 1. DESKRIPTIVNA STATISTIKA 3
Standardna devijacija (s′) je korijen iz varijance. Korigirana varijancauzorka (s2) je velicina
s2 =1
n− 1
n∑i=1
(xi − x)2 =(x1 − x)2 + (x2 − x)2 + · · ·+ (xn − x)2
n− 1,
a korigirana standardna devijacija (s) je korijen iz korigirane varijance.Za ove cemo pojmove takoder navesti odgovarajuce Excel formule.
POJAM NAREDBAprosjecno apsolutno odstupanje AVEDEV(uzorak)
suma apsolutnih odstupanja AVEDEV(uzorak)·COUNT(uzorak)varijanca VARP(uzorak)
standardna devijacija STDEVP(uzorak)korigirana varijanca VAR(uzorak)
korigirana standardna devijacija STDEV(uzorak)
1.1 Tablica frekvencija i histogram
Zbog bolje interpretacije podataka, cesto je korisno podijeliti veliki skuppodataka na podskupove koji se nazivaju razredi. Podjelu na n razredaradimo tako da interval od najmanjeg do najveceg podatka podijelimo na ndijelova. Duljina svakog od tih n podintervala naziva se sirina razreda, adobije se kao kvocijent raspona i broja razreda n. (Svi su razredi jednakesirine.)
Bitno je dobiti granice svakog razreda, a potom je lako rasporediti po-datke po razredima. Pocetna vrijednost prvog razreda je najmanji poda-tak, a zavrsna vrijednost jednaka je zbroju pocetne vrijednosti i sirine raz-reda. Zavrsna vrijednost prvog razreda ujedno je i pocetna vrijednost drugograzreda. Opcenito, osim za prvi razred, pocetna vrijednost nekog razredajednaka je zavrsnoj vrijednosti prethodnog razreda. Zavrsna vrijednost ne-kog razreda jednaka je zbroju njegove pocetne vrijednosti i sirine razreda.Zavrsna vrijednost zadnjeg razreda uvijek je jednaka najvecem podatku.
Na primjer, neka je zadan skup podataka medu kojima je najmanji jednak4, a najveci 14. Zadatak je podijeliti taj skup na 10 razreda. Tada je sirinarazreda jednaka 14−4
10= 1. Prvi se razred proteze od 4 (sto je najmanji
podatak) do 5 (4 + 1 = 5), drugi razred od 5 do 6 (5 + 1 = 6), itd. Konacno,zadnji razred obuhvaca podatke od 13 do 14.
Frekvencija razreda je broj podataka u pojedinom razredu. U Exceluse ona dobije koristenjem naredbe

POGLAVLJE 1. DESKRIPTIVNA STATISTIKA 4
0
2
4
6
8
10
12
14
16
18
20
5,84 6,83 7,82 8,81 9,80 10,79 11,78 12,77 13,76 14,75
F
r
e
k
v
e
n
c
i
j
a
Završna vrijednost razreda
Histogram frekvencija
0,00
0,02
0,04
0,06
0,08
0,10
0,12
0,14
0,16
0,18
0,20
5,84 6,83 7,82 8,81 9,80 10,79 11,78 12,77 13,76 14,75
R
e
l
a
t
i
v
n
a
f
r
e
k
v
e
n
c
i
j
a
Završna vrijednost razreda
Distribucija frekvencija
Slika 1.1: Graf frekvencija i graf relativnih frekvencija
FREQUENCY(uzorak; skup zavrsnih vrijednosti razreda).
Relativna frekvencija razreda dobije se tako da se frekvencija razreda podijelis ukupnim brojem podataka. Zbroj svih frekvencija razreda jednak je ukup-nom broju podataka jer je svaki podatak ubrojen tocno jednom i pripadasamo jednom razredu. Zbroj svih relativnih frekvencija je 1.
RAZRED ZAVRSNA VRIJEDNOST FREKVENCIJA REL. FREKVENCIJA1 5.84 3 0.032 6.83 5 0.053 7.82 8 0.084 8.81 16 0.165 9.80 16 0.166 10.79 15 0.157 11.78 19 0.198 12.77 8 0.089 13.76 4 0.0410 14.75 6 0.06
Graf koji predocava frekvencije razreda naziva se histogram frekven-cija. Crta se kao stupcasti graf gdje su na x-osi zavrsne vrijednosti razreda, ana y-osi frekvencije. S druge strane, graf koji predocava relativne frekvencijenaziva se distribucija frekvencija. To je takoder stupcasti graf, na x-osisu zavrsne vrijednosti razreda, a na y-osi relativne frekvencije.

Poglavlje 2
Slucajne varijable
Primjeri u Excelu vezani za ovu cjelinu nalaze se u dokumentu Slucajnevari-jable.xlsx .
Slucajna varijabla je funkcija koja svakom mogucem ishodu nekog po-kusa pridruzuje realni broj. Jednostavnijim rijecima, vrijednost slucajnevarijable mozemo promatrati kao numericki ishod slucajnog eksperimenta.Glavna podjela slucajnih varijabli je na diskretne i kontinuirane. Diskretnaslucajna varijabla je ona kojoj je skup vrijednosti konacan ili prebrojiv, akontinuirana je ona kojoj je skup vrijednosti neprebrojiv. Za pocetak sebavimo diskretnim slucajnim varijablama.
2.1 Diskretna slucajna varijabla
Primjer 2.1Bacamo tri novcica. (S jedne strane svakog novcica je pismo, s druge glava.)Slucajna varijabla X biljezi broj dobivenih pisama. Pogledajmo koje se svemogucnosti mogu dogoditi.
Ishod Broj pisamaGGG 0GGP 1GPG 1PGG 1GPP 2PGP 2PPG 2PPP 3
5

POGLAVLJE 2. SLUCAJNE VARIJABLE 6
Na svakom novcicu imamo dvije mogucnosti, a imamo tri novcica. Stogaje broj svih mogucih ishoda jednak 2 · 2 · 2 = 8. Skup vrijednosti slucajnevarijable X je {0, 1, 2, 3}. Uocimo da se u tablici neke vrijednosti pojavljujuvise puta, tj. nekim je ishodima pridruzena ista numericka vrijednost. Svakojvrijednosti slucajne varijable, xi, pridruzena je njena vjerojatnost, P (X=xi).Ta je vjerojatnost jednaka
P (X=xi) =broj ishoda koji daju vrijednost xi
broj svih mogucih ishoda.
Nula pisama mozemo dobiti na samo jedan nacin (GGG) pa je P (X =0) = 1
8. Jedno pismo mozemo dobiti na tri nacina (GGP, GPG, PGG) pa je
P (X = 1) = 38. Na isti se nacin dobiju vjerojatnosti za preostale vrijednosti
slucajne varijable.
X P (X=xi)0 1
8
1 38
2 38
3 18
Vjerojatnosti P (X=xi) su brojevi izmedu 0 i 1. Mozemo ih interpretiratii kao postotke. Ako ce se nesto sigurno dogoditi, to ima vjerojatnost 1(100%), a ako se sigurno nece dogoditi, ima vjerojatnost 0 (0%). Zbrojvjerojatnosti svih vrijednosti slucajne varijable je 1.
Ocekivanje diskretne slucajne varijable X s vrijednostima x1, x2, . . . , xndefinira se kao
E(X) =n∑i=1
xiP (xi) = x1P (x1) + x2P (x2) + · · ·+ xnP (xn),
a njena varijanca (disperzija) iznosi
V (X) =n∑i=1
(xi−E(X))2P (xi) = (x1−E(X))2P (x1)+· · ·+(xn−E(X))2P (xn).
U prethodnom primjeru ocekivanje iznosi
E(X) = 0 · 1
8+ 1 · 3
8+ 2 · 3
8+ 3 · 1
8= 1.5,
a varijanca
V (X) = (0− 1.5)2 · 18
+ (1− 1.5)2 · 38
+ (2− 1.5)2 · 38
+ (3− 1.5)2 · 18
= 0.75.

POGLAVLJE 2. SLUCAJNE VARIJABLE 7
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
0,18
0,2
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
P(x)
x
Razdioba vjerojatnosti
Slika 2.1: Graf razdiobe vjerojatnosti binomne slucajne varijable s parame-trima n = 30, p = 0.2.
2.1.1 Binomna razdioba
Binomna slucajna varijabla je diskretna slucajna varijabla koja se gene-rira tako sto se n puta ponavlja isti pokus. Slucajna varijabla registrira kolikoje puta pokus uspio, odnosno, koliko se puta dogodio neki fiksirani dogadaj Akoji ima vjerojatnost p. Parametri n i p odreduju binomnu slucajnu varijabluX i pisemo
X ∼ B(n, p).
Kako ova slucajna varijaba registrira koliko se puta, od n pokusaja, dogodioA, lako je vidjeti da su njene vrijednosti cijeli brojevi izmedu 0 i n. Unajgorem se slucaju dogadaj A pojavio 0 puta, a u najboljem slucaju svih nputa.
Vjerojatnost svakog pojedinog ishoda i iznosi
P (X= i) =
(n
i
)p(1− p)n−i, i = 0, . . . , n.
U Excelu za racunanje vjerojatnosti P (X= i) koristimo naredbu
=BINOMDIST(i; n; p; FALSE).
Pomocu iste naredbe mozemo racunati i vjerojatnost da je slucajna varijablamanja ili jednaka od neke vrijednosti i, P (X ≤ i),
=BINOMDIST(i; n; p; TRUE).

POGLAVLJE 2. SLUCAJNE VARIJABLE 8
Ocekivanje binomne slucajne varijable X dano je formulom
E(X) = np,
a varijancaV (X) = np(1− p).
Primjer 2.2Bacamo kocku 20 puta. (Brojevi na kocki su od 1 do 6.) Slucajna vari-jabla X biljezi broj dobivenih jedinica. Ovo je binomna slucajna varijabla.Odredimo njene parametre. S obzirom da se pokus ponavlja 20 puta, n = 20.Vjerojatnost da dobijemo jedinicu u jednom bacanju je 1
6jer je jedinica jedna
od ukupno 6 mogucnosti. Stoga je p = 16, tj. X ∼ B(20, 1
6).
Primjer 2.3Bacamo kockicu 5 puta. Slucajna varijabla Y biljezi broj dobivenih parnihbrojeva. Ovo je takoder binomna slucajna varijabla. Parametri su joj n = 5i p = 3
6= 1
2, jer su tri od sest brojeva na kocki parni.
2.1.2 Poissonova razdioba
Poissonova slucajna varijabla je diskretna slucajna varijabla koja brojikoliko se puta pojavio fiksni dogadaj A. Medutim, za razliku od binomne,Poissonova slucajna varijabla ima prebrojiv (beskonacan) skup vrijednosti
{0, 1, 2, 3, . . .}.
Poissonova slucajna varijabla odredena je parametrom a,
X ∼ P (a),
za koji vrijedi
P (X= i) = e−aai
i!, i = 0, 1, 2, 3, . . .
Racunanje u Excelu je slicno kao za binomnu slucajnu varijablu. Dadobijemo vrijednost P (X= i) u Excelu koristimo naredbu
=POISSON(i; a; FALSE),
a za racunanje P (X ≤ i),
=POISSON(i; a; TRUE).

POGLAVLJE 2. SLUCAJNE VARIJABLE 9
0
0,05
0,1
0,15
0,2
0,25
0 1 2 3 4 5 >=6
P(X)
X
Poissonova razdioba
Slika 2.2: Graf razdiobe vjerojatnosti Poissonove slucajne varijable s para-metrom a = 4.
Za ocekivnje i varijancu Poissonove slucajne varijable X vrijedi
E(X) = a, V (X) = a.
Primjer 2.4Pretpostavimo da Marija prosjecno dobije 4 poruke na sat. Slucajna varijablakoja biljezi broj poruka koje je Marija dobila unutar jednog sata je Poissonovas parametrom 4, tj. X ∼ P (4).
2.2 Kontinuirana slucajna varijabla
Skup vrijednosti kontinuirane slucajne varijable je neprebrojiv. Ovakva slucajnavarijabla poprima sve vrijednosti u nekom intervalu [a, b]. Razdioba vjero-jatnosti na tom intervalu zadana je funkcijom f za koju vrijedi
(i) f(x) ≥ 0, x ∈ [a, b],
(ii)∫ baf(x) dx = 1.
Vjerojatnost da slucajna varijabla poprimi vrijednost iz intervala [a0, b0] jed-naka je
P (a0 < X < b0) =
∫ b0
a0
f(x) dx.
Funkciju f nazivamo funkcija gustoce vjerojatnosti.

POGLAVLJE 2. SLUCAJNE VARIJABLE 10
Uz funkciju gustoce definira se i funkcija distribucije vjerojatnosti nor-malne slucajne varijable X u x. To je vjerojatnost da je X < x. Funkcijadistribucije je primitivna funkcija funkcije gustoce vjerojatnosti. Tocnije,vrijedi F ′(x) = f(x) osim za zanemarivo mnogo vrijednosti x. Racuna se poformuli
F (x) =
∫ x
−∞f(t) dt,
Ocekivanje kontinuirane slucajne varijable X je integral
E(X) =
∫ ∞−∞
f(x) dx,
a njena varijanca je
V (X) =
∫ ∞−∞
(x− E(X))2f(x) dx.
2.2.1 Normalna razdioba
Normalna (Gaussova) slucajna varijabla je kontinuirana slucajna vari-jabla. Normalna slucajna varijablaX odredena je s dva parametra, ocekivanjemµ i standardnom devijacijom σ (odnosno varijancom σ2), te pisemo
X ∼ N(µ, σ2).
Funkcija gustoce vjerojatnosti normalne slucajne varijable dana je izra-zom
f(x) =1
σ√
2πe−
(x−µ)2
2σ2 ,
a u Excelu se racuna naredbom
=NORMDIST(x; µ; σ; FALSE).
Funkcija distribucije dobije se naredbom
=NORMDIST(x; µ; σ; TRUE).
Interval tri sigme je interval oko ocekivanja µ, od 3σ lijevo od ocekivanjado 3σ desno od ocekivanja, tj.
[µ− 3σ, µ+ 3σ].
Unutar tog intervala nalaze se gotovo sve vrijednosti normalno distribuiraneslucajne varijable X, njih 99.7%. Intervali jedna sigma i dvije sigme dobijuse analogno kao [µ− σ, µ+ σ], odnosno [µ− 2σ, µ+ 2σ].
Uobicajeni primjeri normalne slucajne varijable su varijable koje registri-raju rezultate nekog mjerenja ili gresku mjerenja.

POGLAVLJE 2. SLUCAJNE VARIJABLE 11
0
0,02
0,04
0,06
0,08
0,1
0,12
-12 -10 -8 -6 -4 -2 0 2 4 6 8 10 12
f(x)
x
Funkcija gustoće vjerojatnosti
Slika 2.3: Graf funkcije gustoce vjerojatnosti normalne slucajne varijable sparametrima µ = 0, σ = 4.
2.2.2 Eksponencijalna razdioba
Eksponencijalna slucajna varijabla je kontinuirana slucajna varijablaodredena parameterom λ,
X ∼ E(λ).
Ona poprima sve vrijednosti u iz skupa 〈0,∞〉. Funkcija gustoce vjerojatnostieksponencijalne slucajne varijable dana je izrazom
f(x) =
{λe−λx, x > 0,
0, x ≤ 0.
Iz toga se izracuna da je funkcija distribucije vjerojatnosti
F (x) =
{1− e−λx, x > 0,
0, x ≤ 0.
U Excelu se vrijednosti ovih funkcija racunaju naredbom
=EXPONDIST(x; λ; FALSE),
odnosno
=EXPONDIST(x; λ; TRUE).
Za ocekivnje i varijancu Poissonove slucajne varijable X vrijedi
E(X) =1
λ, V (X) =
1
λ2.
Primjer eksponencijalne slucajne varijale je varijabla koja biljezi vrijemeproteklo do pojave nekog dogadaja.
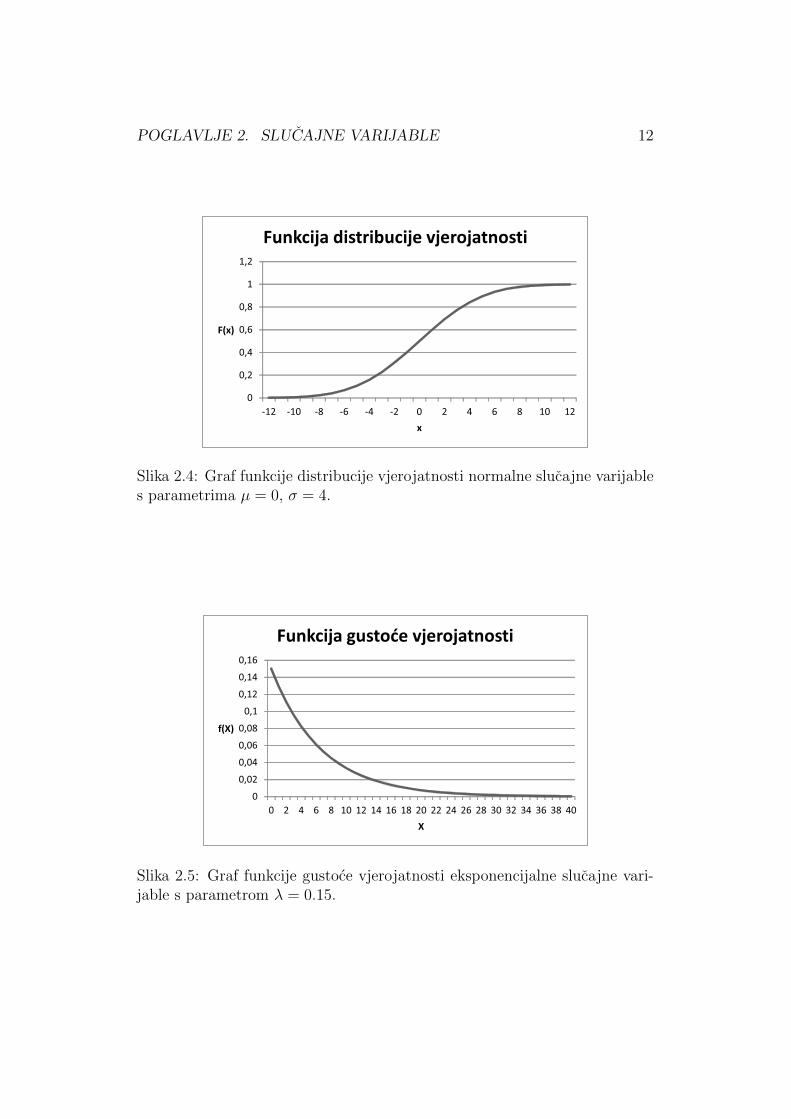
POGLAVLJE 2. SLUCAJNE VARIJABLE 12
0
0,2
0,4
0,6
0,8
1
1,2
-12 -10 -8 -6 -4 -2 0 2 4 6 8 10 12
F(x)
x
Funkcija distribucije vjerojatnosti
Slika 2.4: Graf funkcije distribucije vjerojatnosti normalne slucajne varijables parametrima µ = 0, σ = 4.
0
0,02
0,04
0,06
0,08
0,1
0,12
0,14
0,16
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40
f(X)
X
Funkcija gustoće vjerojatnosti
Slika 2.5: Graf funkcije gustoce vjerojatnosti eksponencijalne slucajne vari-jable s parametrom λ = 0.15.

POGLAVLJE 2. SLUCAJNE VARIJABLE 13
0
0,2
0,4
0,6
0,8
1
1,2
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40
F(X)
X
Funkcija distribucije vjerojatnosti
Slika 2.6: Graf funkcije distribucije vjerojatnosti eksponencijalne slucajnevarijable s parametrom λ = 0.15.

Poglavlje 3
Testovi hipoteza
Primjeri u Excelu vezani za ovu cjelinu nalaze se u dokumentu Testovihipo-teza.xlsx .
3.1 Interval pouzdanosti za ocekivanje
Ocekivanje neke slucajne varijable procjenjujemo aritmetickom sredinom do-bivenih podataka x1, x2, . . . , xn. Trazimo interval oko aritmeticke sredine xunutar kojeg se, uz odredenu vjerojatnost, nalazi ocekivanje µ. Takav inter-val nazivamo interval pouzdanosti za ocekivanje slucajne varijable.
Da bismo iz poznatih vrijednosti x1, x2, . . . , xn normalno distribuiraneslucajne varijable odredili njen interval pouzdanosti uz pouzdanost 1 − 2ppotrebno je znati broj podataka n, njihovu aritmeticku sredinu x te korigi-ranu standardnu devijaciju s. Tada interval pouzdanosti zapisujemo kao
〈a, b〉 = 〈x− tp(n− 1)s√n, x+ tp(n− 1)
s√n〉,
pri cemu je broj tp(n− 1) vrijednost t-razdiobe s n− 1 stupnjeva slobode.U Excelu tp(n− 1) racunamo na sljedeci nacin
=TINV(1− p; n− 1).
Sto je veca pouzdanost koju zahtijevamo, siri je interval pouzdanosti.
3.2 Testovi hipoteza
Kod statistickih testova razlikujemo dva slucaja. Prva mogucnost je da testi-ramo rezultate dobivene mjerenjem u odnosu na neki kontrolni uzorak. Tada
14

POGLAVLJE 3. TESTOVI HIPOTEZA 15
testiramo hipotezu o jednakosti varijance i jednakosti ocekivanja
H0 : σ2 = σ20, µ = µ0, (3.1)
gdje su σ0 i µ0 poznate (deklarirane) vrijednosti vezane uz kontrolni uzorak,a σ i µ su nepoznate vrijednosti. Druga mogucnost je testiranje rezultata do-bivenih u dva odvojena skupa mjerenja. Tu testiramo hipotezu o jednakostivarijance i ocekivanja dobivenih u ta dva skupa mjerenja,
H0 : σ21 = σ2
2, µ1 = µ2. (3.2)
Statisticka testiranja ne daju 100% sigurnost u dobiveni rezultat. Prili-kom testiranja unaprijed zadajemo dozvoljenu pogresku, tzv. nivo signifi-kantnosti. Uobicajeno se uzima signifikantnost α = 0.05, sto znaci da jevjerojatnost odbacivanja istinite hipoteze 5%. Naravno, moze se uzeti i nekidrugi nivo signifikantnosti.
(a) Neka je dan kontrolni uzorak s ocekivanjem µ i standardnom devijaci-jom σ, te neka je u n mjerenja dobiven prosjecni rezultat x uz korigiranustandardnu devijaciju s.
(i) Testiramo hipotezuH0 : σ2 = σ2
0,
uz alternativnu hipotezu
Ha : σ2 > σ20.
Za testiranje ove hipoteze koristimo hi-kvadrat test s n−1 stup-njeva slobode, χ2(n − 1). Test se zasniva na cinjenici iz teorijevjerojatnosti da je
(n− 1)s2
σ20
∼ χ2(n− 1).
Racunamo χ2(n− 1), u Excelu za to koristimo naredbu
=CHIINV(signifikantnost; n− 1),
i velicinu
χ2exp = (n− 1)
s2
σ20
.
Hipotezu H0 prihvacamo ako je
χ2exp < χ2
α(n− 1). (3.3)

POGLAVLJE 3. TESTOVI HIPOTEZA 16
(ii) Testiramo hipotezuH0 : µ = µ0,
uz alternativnu hipotezu
Ha : µ 6= µ0.
Ovdje koristimo t-test s n − 1 stupnjeva slobode, t(n − 1), atestiranje se zasniva na cinjenici iz teorije vjerojatnosti da je
x− µ0s√n
∼ t(n− 1).
Za racunanje vrijednosti t(n− 1) koristimo naredbu
=TINV(signifikantnost; n− 1),
te racunamo
texp =x− µ0
s√n
.
Hipotezu H0 prihvacamo ako je
|texp| < tα2(n− 1). (3.4)
(b) Neka je u n1 mjerenja jedne normalno distribuirane slucajne varijabledobiven prosjecni rezultat x1 uz korigiranu standardnu devijaciju s1, au n2 mjerenja druge normalno distribuirane slucajne varijable dobivenprosjecni rezultat x2 uz korigiranu standardnu devijaciju s2. Indeksecemo odabrati tako da je s21 > s22.
(i) Testiranje hipoteze
H0 : σ21 = σ2
2,
Ha : σ21 > σ2
2.
Koristimo F test s (n1 − 1, n2 − 1) stupnjeva slobode. Test sezasniva na cinjenici iz teorije vjerojatnosti da je
s21s22∼ F (n1 − 1, n2 − 1).
Stoga racunamo F (n1 − 1, n2 − 1) koristeci naredbu
=FINV(signifikantnost; n1 − 1; n2 − 1),

POGLAVLJE 3. TESTOVI HIPOTEZA 17
i velicinu
Fexp =s21s22.
Slicno kao do sad, hipotezu H0 prihvacamo ako je
Fexp < Fα(n1 − 1, n2 − 1). (3.5)
(ii) Testiranje hipoteze
H0 : µ1 = µ2,
Ha : µ1 6= µ2.
Za testiranje hipoteze o jednakosti ocekivanja opet koristimo t-test, ali sada s n1+n2−2 stupnjeva slobode. Testiranje se zasnivana cinjenici iz teorije vjerojatnosti da je
x1 − x2√(n1−1)s21+(n2−1)s22
n1+n2−2
√n1+n2
n1n2
∼ t(n1 + n2 − 2).
Izracunamo
texp =x1 − x2√
(n1−1)s21+(n2−1)s22n1+n2−2
√n1+n2
n1n2
,
a hipotezu prihvacamo ako je
|texp| < tα2(n1 + n2 − 2). (3.6)
3.3 Naredba IF u Excelu
Kada u Excelu testiramo vrijedi li neka od relacija (3.3)– (3.6), to radimo nasljedeci nacin. Recimo da u polju B1 imamo vrijednost χ2(n− 1), a u poljuB2 vrijednost χ2
exp. Tada u polje u kojem testiramo relaciju (3.3) upisujemo
=B2 < B1.
Rezultat ce biti TRUE ili FALSE, ovisno o tome je li vrijednost u polju B2manja od one u polju B1 ili nije. S ovakvim se poljima moze dalje racunatijer TRUE ima numericku vrijednost 1, a FALSE 0.
Da bi konacni rezultat testiranja (3.1) bio pozitivan, moraju vrijeditirelacije (3.3) i (3.4). Dakle, kao rezultate tih pojedinacnih testiranja mo-ramo dobiti TRUE i TRUE. U bilo kojem drugom slucaju, rezultat ukupnogtestiranja je negativan. Isto vrijedi i kod testiranja hipoteze (3.2) gdje pro-vjeravamo vrijede li relacije (3.5) i (3.6).
Za ukupni test mozemo korisiti naredbu IF,

POGLAVLJE 3. TESTOVI HIPOTEZA 18
=IF(uvjet; ako uvjet vrijedi; ako uvjet ne vrijedi).
Ako u slucaju da uvjet koji provjeravamo vrijedi zelimo u polju ispisati da,a u slucaju da ne vrijedi ne, onda pisemo
=IF(uvjet; “da”; “ne”).

Poglavlje 4
Metoda najmanjih kvadrata
Primjeri u Excelu vezani za ovu cjelinu nalaze se u dokumentu MNK.xlsx .
Pretpostavimo da su zadana dva skupa podataka,
x = {x1, x2, . . . , xn} i y = {y1, y2, . . . , yn}.
Zanima nas jesu li ta dva skupa podataka medusobno povezana (korelirana)i ako da, na koji nacin. U slucaju da su velicine x i y korelirane, onda akoznamo jednu od njih, xi, mozemo procijeniti drugu, yi. Najjednostavnijaveza medu podatcima je linearna. To znaci da su vrijednosti x i y povezanelinearnom funkcijom,
y := f(x) = ax+ b.
Podatke prikazujemo kao tocke u koordinatnom sustavu pri cemu je
T1 = (x1, y1), T2 = (x2, y2), . . . , Tn = (xn, yn).
Imajuci u vidu da je graf linearne funkcije pravac, vezu medu podatcimagraficki prikazujemo kao pravac. Taj se pravac naziva regresijski pravac ilipravac linearne regresije.
U opcem slucaju nije moguce povuci jedan pravac koji ce prolaziti krozsve tocke. Stoga, trazimo pravac koji prolazi “dovoljno blizu” svim tockama.Biramo ga tako da promatramo udaljenosti di, (slika 4.1)
di = yi − (axi + b),
gdje su a i b nepoznati parametri. Potrebno je da suma kvadrata ovih uda-ljenosti bude sto manja,
n∑i=1
d2i = d21 + d22 + . . .+ d2n → min .
19

POGLAVLJE 4. METODA NAJMANJIH KVADRATA 20
d1
d4
d3
d2
Slika 4.1: Metoda najmanjih kvadrata
Iz gornjeg zahtjeva dobiju se parametri a i b koji se potom uvrste u jed-nadzbu y = ax + b. Ovdje necemo raditi izvod tih parametara, nego cemoza dobivanje jednadzbe regresijskog pravca korisiti mogucnosti Excela.
Odgovor na pitanje koliko dobro regresijski pravac aproksimira zadanepodatke daje koeficijent linearne korelacije R. Njegova vrijednost jeizmedu −1 i 1. Koeficijent R je pozitivan ako je regresijska funkcija rastuca,a negativan ako je padajuca. Sto je R po apsolutnoj vrijednosti blize 1, toje aproksimacija bolja. Ako bi imali situaciju u kojoj sve zadane tocke lezena regresijskom pravcu, vrijednost koeficijenta R bila bi 1 ili −1. Sto cemouzeti za dovoljno dobru aproksimaciju ovisi o problemu. Uglavnom mozemosmatrati da su podatci jako linearno korelirani ako je
|R| ≥ 0.9.
U Excelu se koeficijent R racuna naredbom
CORREL(vrijednosti x; vrijednosti y).
Kada znamo vezu podataka x i y, za dodatne vrijednosti xk pripadnevrijednosti yk racunamo jednostavnim uvrstavanjem u jednadzbu regresijskogpravca. Ovdje treba imati na umu da su dobivene vrijednosti priblizne, tevise vjerodostojne sto je bolji koeficijent R.
Takoder, potrebno je znati da koreliranost podataka ne uvjetuje nuznoi njihovu uzrocnost. Odnosno, moguce je da su dva skupa podataka dobrokorelirana, ali su u stvarnosti neovisni. Stoga uvijek treba biti pazljiv priinterpretaciji rezultata.

POGLAVLJE 4. METODA NAJMANJIH KVADRATA 21
0,0
100,0
200,0
300,0
400,0
500,0
600,0
700,0
800,0
900,0
0 1 2 3 4 5 6
y
x
Regresijski pravac
Slika 4.2: Primjer regresijskog pravca

Poglavlje 5
Interpolacija i ekstrapolacija
Primjeri u Excelu vezani za ovu cjelinu nalaze se u dokumentu Interpola-cija.xlsx .
Problem interpolacije i ekstrapolacije javlja se u praksi kada imamo za-dane vrijednosti neke funkcije samo na diskretnom skupu podataka. Tada jepomocu poznatih podataka potrebno aproksimirati (priblizno izracunati) ne-poznate vrijednosti. Racunanje vrijednosti funkcije unutar nekog poznatogintervala naziva se interpolacija, a izvan tog intervala ekstrapolacija.
5.1 Interpolacijski polinom
Slicno kao kod metode najmanjih kvadrata trazimo vezu izmedu dva skupapodataka
x = {x1, x2, . . . , xn} i y = {y1, y2, . . . , yn}.
Ovdje ta veza nece biti linearna funkcija nego polinom. Vec smo rekli da uopcem slucaju pravac (graf polinoma 1. stupnja) nije moguce izabrati takoda prolazi kroz n tocaka (gdje je n ≥ 3). Da bi graf sigurno prolazio kroz svihn tocaka, to mora biti graf polinoma stupnja barem n− 1. Takav se polinomnaziva interpolacijski polinom. Interpolacijski polinom je jednstven uzuvjet da je stupnja najvise n − 1. Stoga, radimo s polinomima stupnjatocno n − 1. Za dobivanje jednadzbe interpolacijskog polinoma koristimomogucnosti Excela pa necemo ulaziti u izvod koeficijenata.
Napomenimo da bi polinom stupnja viseg od n − 1 takoder mogli iza-brati tako da prolazi kroz svih n tocaka, no ne zelimo dobiti kompliciranijufunkciju nego sto je to nuzno. Takoder, u praksi je preporucljivo koristiti in-terpolacijski polinom najvise treceg stupnja jer se kod polinoma viseg stupnja
22

POGLAVLJE 5. INTERPOLACIJA I EKSTRAPOLACIJA 23
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
5
0 1 2 3 4 5
y
x
Interpolacijski polinom
Slika 5.1: Primjer interpolacijskog polinoma stupnja 3
pri racunanju na racunalu mogu javiti velike greske nastale zbog greske za-okruzivanja koju radi racunalo. U takvim se situacijama uglavnom prelazina tzv. interpolaciju splajnovima.

Poglavlje 6
Numericko rjesavanje jednadzbii sustava
Primjeri u Excelu vezani za ovu cjelinu nalaze se u dokumentu Jednadzbe.xlsx .
Cesto se nelinearne jednadzbe ne mogu rijesiti egzaktno. U tom slucajutrazimo priblizno rjesenje jednadzbe.
Svaku jednadzbu s jednom nepoznanicom mozemo zapisati u obliku
f(x) = 0.
Npr. ako je zadana jednadzba ex − x = 2, vrijedi ex − x − 2 = 0 pa jef(x) = ex − x − 2. Za svako rjesenje jednadzbe x∗ vrijedi f(x∗) = 0. Stogase trazenje rjesenja dane jednadzbe svodi na trazenje nultocki funkcije f .
Za daljnju analizu pretpostavljamo da je funkcija f neprekidna i da su jojnultocke izolirane. Odredivanje nultocki funkcije f provodi se u dva koraka.
(1) Odredimo interval na kojem se nalazi nultocka.
(2) Koristimo neku iterativnu metodu za nalazenje nultocke.
Prvi se korak radi analizom toka funkcije. Iz grafa mozemo vidjeti kolikonultocki ima i gdje se one (priblizno) nalaze. U drugom koraku mozemokoristiti razlicite iterativne metode. Te metode generiraju niz aproksimacijax0, x1, x2, . . . Zaustavljamo se kod neke aproksimacije xN koja je “dovoljnoblizu” egzaktnog rjesenja x∗.
S obzirom da ne mozemo mjeriti koliko je xN daleko od x∗ jer ne znamox∗, odstupanje od egzaktnog rjesenja mjerimo odstupanjem f(xN) od 0 jerza egzaktno rjesenje x∗ vrijedi f(x∗) = 0. Vrijednost f(xN) nazivamo greskaaproksimacije. Bitna svojstva svake metode su da li konvergira (vodi premarjesenju) te brzina konvergencije.
24

POGLAVLJE 6. JEDNADZBE I SUSTAVI 25
X0 X1 X0 X1
f f
Slika 6.1: Izbor pocetnih tocaka kod metode bisekcije
6.1 Metoda bisekcije
Najjednostavnija metoda za trazenje nultocke funkcije f je metoda bisek-cije (raspolavljanja). Polazimo od nekog intervala I = [x0, x1] koji sadrzinultocku. U svakom koraku taj interval raspolavljamo i time suzavamo po-drucje oko nultocke. Pretpostavka koja mora biti zadovoljena da bismo moglikorisiti ovu metodu je
f(a)f(b) < 0, (6.1)
gdje je a = x0, b = x1. Drugim rijecima, mora vrijediti
f(x0) > 0, f(x1) < 0 ili f(x0) < 0, f(x1) > 0.
Cinjenica da je funkcija na jednom rubu intervala pozivitvna, a na drugomnegativna osigurava postojanje nultocke unutar intervala, slika 6.1. (Zbogpotpunosti, napomenimo da ovo vrijedi jer smo jos na pocetku pretpostavilida je f neprekidna. Osim toga, metoda bisekcije koristi se samo za nultockeneparnog reda jer kod nultocki parnog reda relacija (6.1) ne moze vrijediti.)
Nakon sto pravilno izaberemo pocetne tocke x0 i x1, za sljedecu tocku,x2, uzimamo aritmeticku sredinu tocaka x0 i x1,
x2 =x0 + x1
2.
Tako smo prepolovili pocetni interval [x0, x1] i dalje nastavljamo ili s inter-valom [x0, x2] ili [x2, x1]. Uzimamo onaj od ta dva koji sadrzi nultocku. Tose provjeri iz uvjeta (6.1). Dakle, uzet cemo onaj podinterval za kojeg jefunkcija pozitivna na jednom rubu, a negativna na drugom, slika 6.2.
Opisani postupak raspolavljanja pocetnog intervala ponavlja se dalje naisti nacin. U svakom koraku podrucje oko nultocke postaje sve uze te je timenultocka sve preciznije odredena. Postupak zavrsavamo kada je interval okonultocke dovoljno mali ili kada je ispunjen zadani broj koraka.
Uz pretpostavku da pocetni interval sadrzi tocno jednu nultocku, metodabisekcije je konvergentna, uvijek ce nakon dovoljnog broja koraka dovesti dorjesenja, ali je spora.

POGLAVLJE 6. JEDNADZBE I SUSTAVI 26
X0 X3 X2 X1
f
Slika 6.2: Graficki prikaz metode bisekcije
6.2 Metoda sekante
Metoda sekante temelji se na aproksimaciji grafa funkcije njegovom sekan-tom. Kao kod metode bisekcije, uzimamo dvije pocetne tocke, x0 i x1, samosto sada interval [x0, x1] ne mora sadrzavati nultocku.
Sekanta (pravac) se povlaci kroz tocke (x0, f(x0)) i (x1, f(x1)). Sljedecatocka, x2, nalazi se na presjeku dobivene sekante i x-osi, slika 6.4. Opcenito,tocka xn+1 dobije se kao sjeciste sekante kroz (xn−1, f(xn−1)) i (xn, f(xn))i x-osi. Njena formula izvodi se iz formule za jednadzbu pravca kroz dvijetocke i glasi
xn+1 = xn − f(xn)xn − xn−1
f(xn)− f(xn−1).
Metodu zaustavljamo kada je vrijednost funkcije f u trenutnoj aproksi-maciji xN , f(xN), dovoljno mala ili kada je ispunjen zadani broj koraka. Me-toda sekante nije nuzno konvergentna. Konvergencija ovisi o izboru pocetnihtocaka sto predstavlja problem. S druge strane, ako konvergira, onda je brzaod metode bisekcije.
6.3 Metoda tangente
Metoda tangente (Newtonova metoda) ima dosta slicnosti s metodom se-kante. Razlika je u tome sto ovdje imamo jednu pocetnu tocku, x0. Kroztocku (x0, f(x0)) povlaci se tangenta na graf funkcije f , a sljedece tocka, x1,nalazi se na presijeku te tangente i x-osi. Opcenito, tocka xn+1 nalazi se napresijeku tangente na f kroz tocku (xn, f(xn)) i x-osi. Formula za tocku xn+1
glasi
xn+1 = xn −f(xn)
f ′(xn).
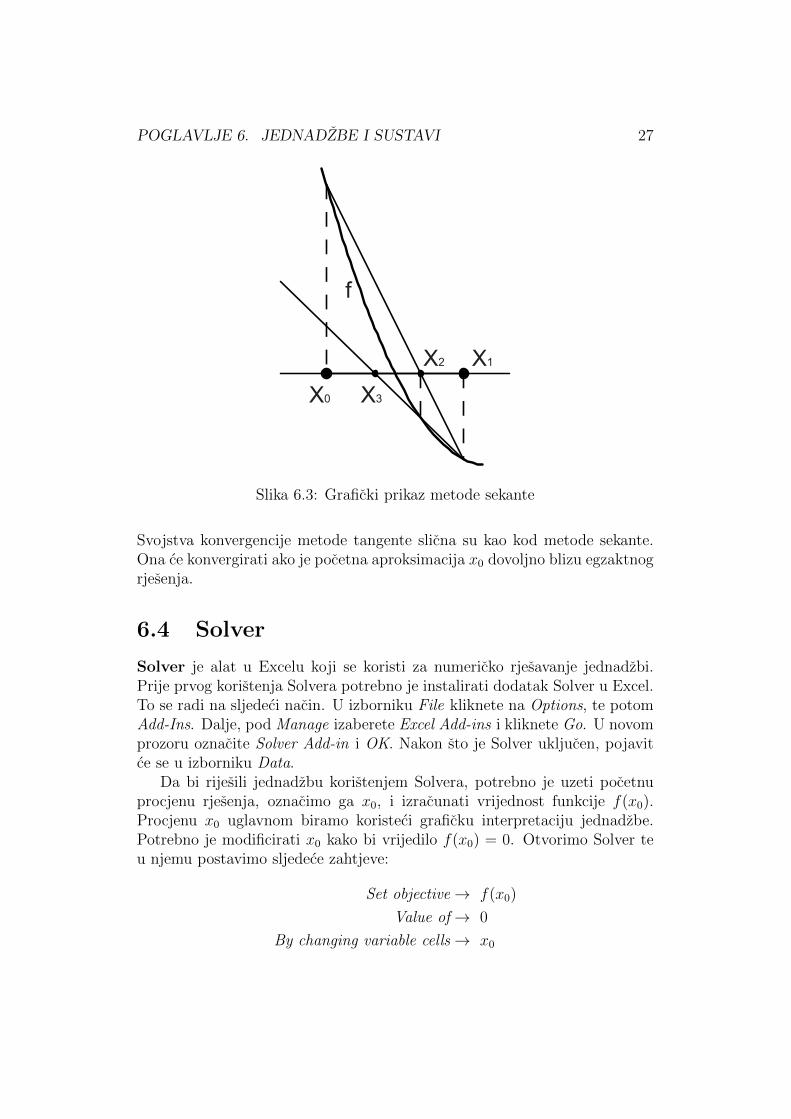
POGLAVLJE 6. JEDNADZBE I SUSTAVI 27
X0 X3
X2 X1
f
Slika 6.3: Graficki prikaz metode sekante
Svojstva konvergencije metode tangente slicna su kao kod metode sekante.Ona ce konvergirati ako je pocetna aproksimacija x0 dovoljno blizu egzaktnogrjesenja.
6.4 Solver
Solver je alat u Excelu koji se koristi za numericko rjesavanje jednadzbi.Prije prvog koristenja Solvera potrebno je instalirati dodatak Solver u Excel.To se radi na sljedeci nacin. U izborniku File kliknete na Options, te potomAdd-Ins. Dalje, pod Manage izaberete Excel Add-ins i kliknete Go. U novomprozoru oznacite Solver Add-in i OK. Nakon sto je Solver ukljucen, pojavitce se u izborniku Data.
Da bi rijesili jednadzbu koristenjem Solvera, potrebno je uzeti pocetnuprocjenu rjesenja, oznacimo ga x0, i izracunati vrijednost funkcije f(x0).Procjenu x0 uglavnom biramo koristeci graficku interpretaciju jednadzbe.Potrebno je modificirati x0 kako bi vrijedilo f(x0) = 0. Otvorimo Solver teu njemu postavimo sljedece zahtjeve:
Set objective→ f(x0)
Value of→ 0
By changing variable cells→ x0

POGLAVLJE 6. JEDNADZBE I SUSTAVI 28
f
X0X3X2X1
Slika 6.4: Graficki prikaz metode tangente
i kliknemo Solve te Keep solver solution. U polju u kom je prije bila upisanaprocjena x0 sada dobijemo novi broj koji je priblizno rjesenje jednadzbe.
6.5 Sustavi jednadzbi
Sustav jednadzbi takoder mozemo rijesiti koristenjem Solvera. Pokazat cemoto na primjeru dvije jednadzbe s dvije nepoznanice, x i y.
Dvije zadane jednadzbe mozemo poistovijetiti s dvije funkcije dvije vari-jable, F1(x, y) i F2(x, y). Npr., ako je zadan sustav
3x2 − y2 = 3,
2x− y = 5,
imamo
F1(x, y) = 3x2 − y2 − 3,
F2(x, y) = 2x− y − 5.
Stoga su rjesenja sustava (x∗, y∗) ujedno nultocke funkcija F1 i F2.Sada su potrebne pocetne procjene za obe nepoznanice, x0 i y0. Njih
modificiramo u Solveru. Buduci da u polje Set objective u Solveru nijemoguce istovremeno upisati i F1(x0, y0) i F2(x0, y0), uvodimo pomocno polje

POGLAVLJE 6. JEDNADZBE I SUSTAVI 29
F1(x0, y0) + F2(x0, y0). Postavljamo sljedece zahtjeve:
Set objective→ F1(x0, y0) + F2(x0, y0)
Value of→ 0
By changing variable cells→ x0; y0
Subject to the constrains→ F1(x0, y0) = 0; F2(x0, y0) = 0.
Kao i u primjeru jedne jednadzbe, kliknemo Solve te Keep solver solution. Upoljima u kojima su bile upisane procjene x0 i y0 dobijemo rjesenja sustava.

Poglavlje 7
Numericko rjesavanja obicnihdiferencijalnih jednadzbi
Primjeri u Excelu vezani za ovu cjelinu nalaze se u dokumentu ODJ.xlsx .
U razlicitim primjenama susrecemo se s problemima koji ukljucuju rjesavanjediferencijalnih jednadzbi. Cesto diferencijanlu jednadzbu nije moguce rijesitiegzaktno, ili je pak postupak rjesavanja dug i tezak. Tada pribjegavamonekoj numerickoj metodi za rjesavanje.
Ovdje se bavimo rjesavanjem obicnih diferencijalnih jednadzbi (ODJ) pr-vog reda,
y′(x) = f(x, y(x)),
uz pocetni uvjet y(x0) = y0. Ovakvu vrstu problema nazivamo Cauchyjev iliinicijalni problem. Jednadzbe rjesavamo na intervalu [a, b] koji je podijeljentockama
a = x0, x1, x2, . . . , xn = b.
Udaljenost svake dvije susjedne tocke iznosi h, tj. vrijedi xi+1 = xi + h,i = 0, . . . , n− 1.
7.1 Eulerova metoda
Eulerova metoda je najjednostavnija metoda za numericko rjesavanje Ca-uchyjevog problema
y′ = f(x, y), y(x0) = y0.
Prvu derivaciju y′ mozemo, uz odredenu gresku, aproksimirati izrazom
y′ ≈ y(x+ h)− y(x)
h.
30

POGLAVLJE 7. OBICNE DIFERENCIJALNE JEDNADZBE 31
Uvrstavanjem u zadanu jednadzbu dobijemo
y(x+ h)− y(x)
h≈ f(x, y),
iz cega se lako izvede relacija
y(x+ h) ≈ y(x) + hf(x, y).
Iz gornjeg izraza slijedi rekurzivna formula za Eulerovu metodu
yi+1 = yi + hf(xi, yi), i = 0, . . . , n− 1. (7.1)
Vrijednost y0 zadana je pocetnim uvjetom. Vrijednosti yi dobivene formu-lom(7.1) su aproksimacije rjesenja diferencijalne jednadzbe u tockama xi,i = 1, . . . , n. Rjesenje je tocnije sto je manji korak h.
Formulu (7.1) ponekad zapisujemo u obliku
yi+1 = yi + k,
k = hf(xi, yi), i = 0, . . . , n− 1.
7.2 Runge-Kutta 4 metoda
Runge-Kutta metode zasnivaju se na istoj ideji kao i Eulerova metoda. Uzpoznatu vrijednost vrijednost yi u tocki xi racunamo vrijednost yi+1 u tockixi+1 = xi + h. Ove su metode gotovo uvijek tocnije od Eulerove metode, alisu slozenije za racunanje. Runge-Kutta metode razlikuju se medusobno pobroju stadija, a najpopularnija je ona s cetiri statdija, tzv. Runge-Kutta4 metoda.
Runge-Kutta 4 metoda odredena je formulom
yi+1 = yi +1
6(k1 + 2k2 + 2k3 + k4),
k1 = hf(xi, yi),
k2 = hf(xi +1
2h, yi +
1
2k1),
k3 = hf(xi +1
2h, yi +
1
2k2),
k4 = hf(xi + h, yi + k3), i = 0, . . . , n− 1.
Izvod formule ovdje preskacemo.

POGLAVLJE 7. OBICNE DIFERENCIJALNE JEDNADZBE 32
0
5
10
15
20
25
0 0,5 1 1,5 2 2,5 3 3,5
y
x
Rješenje ODJ
Euler
RK4
Slika 7.1: Usporedba rjesenja dobivenih Eulerovom i Runge-Kutta 4 meto-dom za jednadzbu y′ = y.

















![Matura 2015 - język polski [arkusz CKE]](https://img.dokumen.tips/doc/110x75/55ae3d5d1a28ab09658b456a/matura-2015-jezyk-polski-arkusz-cke.jpg)











