Embed Size (px)
Citation preview

Stanford University
NVIDIA GeForce GTX 690
NVIDIA Tesla M2090
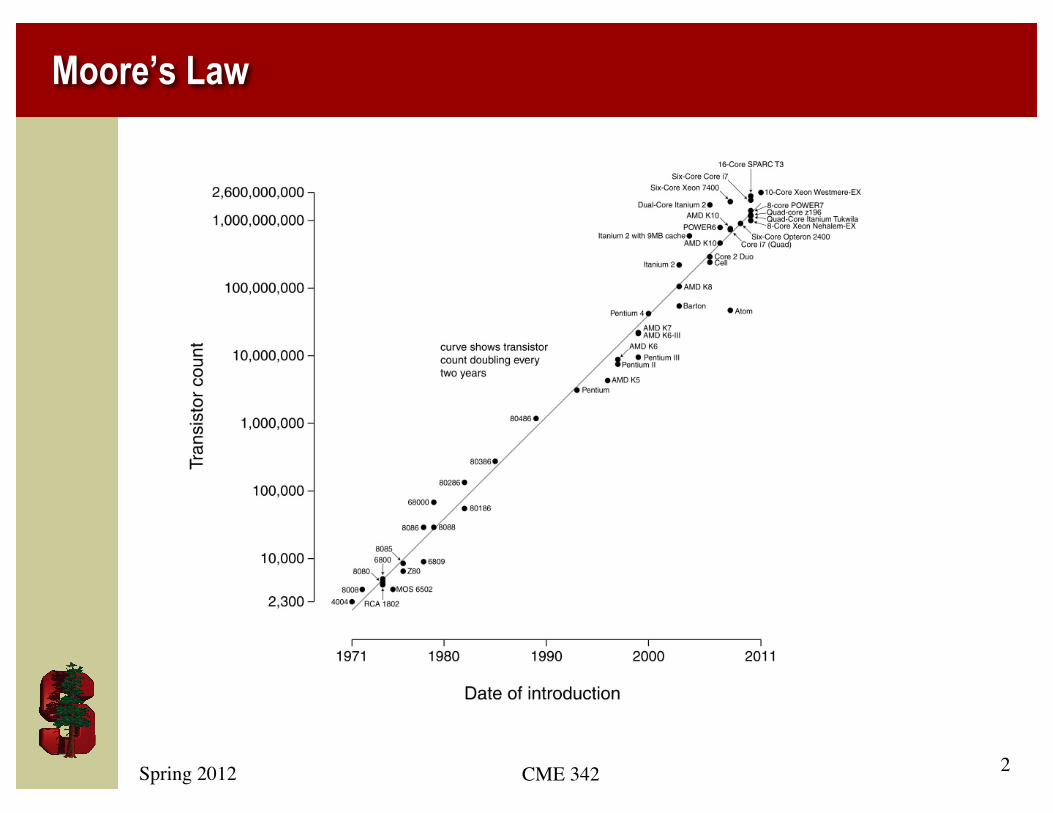
Spring 2012 CME 342 2
Moore’s Law

Spring 2012 CME 342 3
Clock Speed
Sandy Bridge
Nehalem
Core 2
Pentium 4 Prescott
Pentium 4 Williamette
Pentium II
Pentium
80486
80386
80286
8086
Pentium III
8080
1
10
100
1000
10000
1974 1978 1982 1985 1989 1993 1997 1999 2000 2004 2006 2008 2011
Date of Introduction
Clo
ck S
peed
(M
Hz)

Spring 2012 CME 342 4
• Additional functionality – Floating point units – SSE vector units
• Caches – Data – Instructions – Translation Lookaside Buffer (virtual memory) – Hardware prefetcher
• Instruction Level Parallelism – Instruction pipelining – Superscalar execution – Out of order execution – Speculative execution – Branch prediction
How did they use all those additional transistors?

Spring 2012 CME 342 5
Multicore CPUs
16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
2003 2004 2005 2006 2007 2008 2009 2010 2011
Max
imum
# c
ores
Date of Introduction for AMD Opteron CPUs
Six core AMD Opteron (image from AMD)

Spring 2012 CME 342 6
• Leverages demand and volume from video game players
• Consumer versions widely available at any electronics store at a variety of price points
• Programmable via free software options
(images from NVIDIA)
Graphics Processing Unit (GPU)

Spring 2012 CME 342 7
Compute and Bandwidth Performance
FLOPS Bandwidth
Source: NVIDIA CUDA C Programming Guide Version 4.2

Spring 2012 CME 342 8
• 3 or 4 generations of NVIDIA CUDA architectures released from 2007 - 2012
• Key characteristics are: – Architectural differences
• Double precision floating point on newer generations • Memory system
– Newer generations are much more flexible – L1 and L2 caches have been added in later generations
– Number of cores and the rate at which they’re clocked – Bandwidth
• Depends on memory clock and width of the memory interface – Amount of on-board memory (256 MB to 6 GB) – Power consumption
• Higher end GPUs need auxiliary 6- and/or 8-pin PCIe power connectors
Hardware Characteristics

Spring 2012 CME 342 9
NVIDIA Fermi Architecture

Spring 2012 CME 342 10
Fermi Streaming Multiprocessor

Spring 2012 CME 342 11
• Multicore CPU needs one or two threads per core to run efficiently
• GPUs need thousands to tens of thousands of threads to run efficiently – Each time a GPU computes a frame (which it does tens of
times a second) it uses a thread per pixel, of which there are millions
– In the context of computation, this means fine grain parallelism
– This is possible because GPU threads are different than CPU threads
GPU Parallelism

Spring 2012 CME 342 12
• Lightweight compared to CPU threads • Creation, scheduling, destruction are done in
hardware • Fast switching between threads • Many times more threads than cores
– Typically about 100x more threads than cores – Why so many threads?
GPU Threads

Spring 2012 CME 342 13
• GPU doesn’t rely solely on cache to hide memory latency – Many more transistors available for computational units
• Can do without cache because it’s specialized to handle parallel computations
• When a thread stalls due to memory access latency, a core switches to executing another thread and when that thread eventually stalls, the core switches to another thread, etc. – Registers are partitioned to allow fast switching (one clock cycle) – More threads means more opportunity for latency hiding
• A GPU can run a single-threaded function but the performance will be horrible
GPU Memory System

Spring 2012 CME 342 14
• NVIDIA CUDA C and Fortran • OpenCL • Microsoft DirectCompute • OpenACC
GPU Programming Today

Spring 2012 CME 342 15
• Hardware – Requires compatible hardware (emulator no longer available) – Any reasonably new NVIDIA GPU supports CUDA – Check NVIDIA website for more information:
http://www.nvidia.com/object/cuda_learn_products.html • CUDA C
– Freely available from NVIDIA website: http://www.nvidia.com/getcuda – CUDA driver (part of display driver), toolkit (compiler and libraries), and SDK
code examples – Windows, Linux, and Mac OS X supported
• Use the “Quick Start Guides” for installation and verification
Getting Started with CUDA

Spring 2012 CME 342 16
• CPU code – API for interacting with the GPU(s) – Extension for easily invoking computational kernels that run on the GPU
• GPU code – Subset of C
• Kernels must return void • Recursion, malloc / free or new / delete, printf, assert, etc. only supported on
Fermi GPUs and beyond – Extensions
• Parallel programming model • Libraries
– Callable from the CPU, run on the GPU – BLAS, FFT, CURAND, CUSPARSE, NPP, Thrust, etc.
CUDA C

Spring 2012 CME 342 17
__global__ void addVectors(float *a, float *b, float *c)
{
int idx = blockIdx.x*blockDim.x + threadIdx.x
c[idx] = a[idx] + b[idx];
}
// CPU code calls GPU code
… addVectors<<<nValues/256, 256>>>(a_d, b_d, c_d);
…
Keyword that indicates GPU code
Each thread computes a unique index to access the data it will access and produce
CPU specifies how many GPU threads to start, in this case one thread per element in the vectors
Simple CUDA C Program

Spring 2012 CME 342 18
• CPU and GPU each have their own physical memory • Data transferred over PCI Express (PCIe)
– 8 GB/s theoretical peak for Gen 2 x16, up to ~5.5 GB/s observed
PCI Express
CPU and GPU Memory

Spring 2012 CME 342 19
• GPU memory explicitly allocated and freed – cudaMalloc, cudaFree
• Pointers to memory allocated on the GPU are not valid on the CPU and vice versa
• GPU uses a virtual memory system, but: – On Windows Vista systems (and their derivatives, e.g. Windows HPC
Server 2008) and up, allocating beyond physical memory will automatically result in paging to CPU memory
– On all other operating systems allocations will fail • Done for performance reasons
• Allocation has the life of the host CPU process/thread – Automatically cleaned up by driver if application doesn’t
Allocating GPU Memory

Spring 2012 CME 342 20
• No type distinction between CPU and GPU pointers – Recommend adopting a standard convention, e.g. _d suffix
• Be sure to implement some sort of error checking consistent with your application
cudaError_t cudaMalloc(void **devPtr, size_t size)
float *a_d;
status = cudaMalloc((void **) &a_d, 1024*sizeof(float));
assert(status == cudaSuccess);
cudaMalloc

Spring 2012 CME 342 21
cudaError_t cudaFree(void *devPtr)
status = cudaFree(a_d);
assert(status == cudaSuccess);
cudaFree

Spring 2012 CME 342 22
cudaError_t cudaMemcpy(void *dst, const void *src,
size_t count,
enum cudaMemcpyKind kind)
• Copy from memory area pointed to by src to memory area pointed to by dst • kind specifies the direction of the copy:
– cudaMemcpyHostToHost – cudaMemcpyHostToDevice – cudaMemcpyDeviceToHost – cudaMemcpyDeviceToDevice
• Calls with dst and src pointers inconsistent with the copy direction will result in undefined behavior (typically garbage in the destination, or perhaps even an application crash)
• cudaMemcpy will block until the memory copy has completed – Options for asynchronous copies also available
cudaMemcpy

Spring 2012 CME 342 23
size_t bytes = 1024*sizeof(float);
a = (float *) malloc(bytes);
b = (float *) malloc(bytes);
cudaMalloc((void **) &a_d, bytes);
cudaMalloc((void **) &b_d, bytes);
cudaMemcpy(a_d, a, bytes, cudaMemcpyHostToDevice);
cudaMemcpy(b_d, a_d, bytes, cudaMemcpyDeviceToDevice);
cudaMemcpy(b, b_d, bytes, cudaMemcpyDeviceToHost);
for(int n = 0; n < 1024; n++) assert(a[n] == b[n]);
cudaMemcpy Example

Spring 2012 CME 342 24
• Parallel portions of the code are initiated from the CPU and run on the GPU
• Parallelism is based on many threads running in parallel • Developer writes one thread program
– Each instance of the thread will use a unique index to determine which portion of the computation to perform
• Sometimes referred to as SIMD, SPMD, or SIMT – Single Instruction Multiple Data – Single Program Multiple Data – Single Instruction Multiple Threads
Parallel Programming Model

Spring 2012 CME 342 25
. . .
idx 0 1 2 3 nThreads - 1
x = input[idx];
y = func(x);
output[idx] = y;
Parallel Threads

Spring 2012 CME 342 26
• Useful to have threads cooperate with one another – Share intermediate results – Reduce memory accesses (stencil operations, etc.)
• Cooperation is difficult to scale – Synchronization is expensive – Potential for deadlock
• Kernels launched as grid of thread blocks
Thread Cooperation

Spring 2012 CME 342 27
• Threads in the same block can cooperate – More on this later when we discuss shared memory
• Threads in different blocks cannot cooperate
. . .
Block 0 1 2 nBlocks - 1
Grid
Grid of Thread Blocks

Spring 2012 CME 342 28
. . .
Thread
Thread Block
Grid
Thread Processor
Multiprocessor
Device
Software Hardware
Hardware Execution

Spring 2012 CME 342 29
• Blocks scheduled across one or more multiprocessors – Correctly written program will work for any number of multiprocessors and
ordering of blocks • Blocks which won’t fit are queued and started when other blocks finish
Time
Device A Device B
Scalability Across GPUs

Spring 2012 CME 342 30
• Kernel is a C function with restrictions: – Must return void – Cannot access host memory – No variable number of arguments – No recursion on older generations of GPUs – No static variables
• Function arguments automatically copied from host to device – But not memory that backs pointers
GPU Code

Spring 2012 CME 342 31
• Function qualifiers used to specify where a function will be called from and where it will execute
__global__
__device__
__host__
• Called from the host and executes on the device
• Called from the device and executes on the device
• Called from the host and executes on the host
• Combine with __device__ for overloading
Function Qualifiers

Spring 2012 CME 342 32
• Special syntax for invoking kernels:
• <<< , >>> referred to as the execution configuration – dimGrid is the number of blocks in the grid
• One or two dimensional: dimGrid.x, dimGrid.y – dimBlock is the number of threads in a block
• One, two, or three dimensional: dimBlock.x, dimBlock.y, dimBlock.z
• Multidimensional grids and blocks are for programming convenience • Unspecified dim3 fields default to 1
myKernel<<<dim3 dimGrid, dim3 dimBlock>>>( );
Kernel Launch

Spring 2012 CME 342 33
dim3 grid, block;
grid.x = 2; grid.y = 4;
block.x = 16; block.y = 16;
myKernel<<<grid, block>>>( );
dim3 grid(2, 4), block(16, 16);
myKernel<<<grid, block>>>( );
myKernel<<<8, 256>>>( );
Execution Configuration Examples

Spring 2012 CME 342 34
• __global__ and __device__ functions have access to several automatically defined variables
dim3 gridDim
dim3 blockDim
dim3 blockIdx
dim3 threadIdx
• Dimension of the grid in blocks
• Dimension of the block in threads
• Block index within the grid
• Thread index within the block
Built in Variables

Spring 2012 CME 342 35
. . .
0 1 2 nBlocks - 1
0 1 2 3 0 1 2 3 0 1 2 3 0 1 2 3
blockIdx.x
threadIdx.x
idx 0 1 2 3 4 5 6 7 8 9 10 11
idx = blockIdx.x*blockDim.x + threadIdx.x;
Globally Unique Thread Indices
Grid

Spring 2012 CME 342 36
__global__ void addVectors(float *a, float *b, float *c,
int N)
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
if (idx < N)
c[idx] = a[idx] + b[idx];
}
...
blocksize = 256;
dim3 dimGrid(ceil(nValues/(float)blocksize));
addVectors<<<dimGrid, blocksize>>>(a_d, b_d, c_d, nValues);
Vector Addition Example

Spring 2012 CME 342 37
• Combine the elements of an array using an associative, commutative operator – Typical examples include: sum, min, max, product, etc.
• Note that CUDPP and Thrust implement very efficient reductions as library calls: – http://gpgpu.org/developer/cudpp – http://code.google.com/p/thrust/
sum = 0.;
for (n = 0; n < nValues; n++)
sum += a[n];
Reduction

Spring 2012 CME 342 38
• Implemented using recursive pairwise reduction
7 3 8 -5 19 27 0 9
10 3 46 9
13 55
68
Generic Parallel Reduction

Spring 2012 CME 342 39
7 3 8 -5 19 27 0 9
26 30 8 4 19 27 0 9
34 34 8 4 19 27 0 9
68 34 8 4 19 27 0 9
Kernel 1
Kernel 2
Kernel 3
Simple Parallel Reduction

Spring 2012 CME 342 40
__global__ void sumReductionKernel(float *a, int nThreads){
int idx = blockDim.x*blockIdx.x + threadIdx.x;
if (idx < nThreads)
a[idx] += a[idx + nThreads];
}
...
nThreads = nValues/2;
while (nThreads > 0){
gridDim.x = ceil((float)nThreads/blocksize);
sumReductionKernel<<<nValues/256,blocksize>>>(a_d, nThreads);
nThreads /= 2;
}
cudaMemcpy(a, a_d, sizeof(float), cudaMemcpyDeviceToHost);
printf(“sum of a = %f\n”, a[0]);
Simple Parallel Reduction

Spring 2012 CME 342 41
• So far we’ve seen per thread variables (like idx) which are stored in registers and memory in the off-chip DRAM (device/global memory)
. . .
Registers: Accessible by one thread Life of the thread
Device: Accessible by all threads Life of the application
Memory Model

Spring 2012 CME 342 42
• Exchanging data through device memory is expensive due to bandwidth and latency and it also requires multiple kernel launches – Global synchronization between kernel launches
• Instead use high performance on-chip memory – ~100 times lower latency than device memory – ~10 times more bandwidth
• 16 KB to 48 KB SRAM per multiprocessor – 16 KB on compute capability 1.x – 16 KB to 48 KB on compute capability 2.x+
• Allocated per thread block and can be read and written by any thread in the block
• Has the lifetime of the thread block
Shared Memory

Spring 2012 CME 342 43
. . .
Registers: Accessible by one thread Life of the thread
Device: Accessible by all threads Life of the application
Shared Memory: Accessible by all threads in a block Life of the thread block
Expanded Memory Model

Spring 2012 CME 342 44
__device__ – Located in off-chip DRAM memory – Allocated with cudaMalloc (__device__ qualifier implied) – Life of the application – Accessible from threads and host
__shared__ – Located in on-chip shared memory – Life of the thread block – Only accessible from threads within the block
__constant__ – See the documentation
• Unqualified variables in device code normally reside in registers
Variable Qualifiers

Spring 2012 CME 342 45
#define BLOCKSIZE 256
__global__ void myKernel(float *a, int nValues)
{ /* Per thread block shared memory. */
__shared__ float a_s[BLOCKSIZE];
/* Local (per thread) variables. */
int idx; ...
}
Example of Shared Memory Declaration

Spring 2012 CME 342 46
__global__ void myKernel(float *a, int nValues) { /* Per thread block shared memory. */ extern __shared__ float a_s[];
/* Local variables. */ int idx; ... } ... bytes = 256*sizeof(float); myKernel<<<dimGrid, dimBlock, bytes>>>(a_d, nValues);
Size of a_s specified at kernel launch
More on Shared Memory Declaration

Spring 2012 CME 342 47
• Threads can cooperate by writing and reading to shared memory but there is potential for race conditions – Thread reads from shared memory before another thread has
written the data, etc. • __syncthreads() synchronizes all threads in a
block – Acts as a barrier – No thread in the block can continue until all threads reach it – Allowed in conditional code only if the conditional is uniform
across the entire thread block!
Thread Synchronization

Spring 2012 CME 342 48
a[0] … a[255] a[256] … a[511] a[512] … a[767] …
Block 0 Block 1 Block 2
a[0] a[1] a[2] …
Block 0
a[0] …
• Reductions within each thread block significantly reduce the number of kernel invocations and the amount of data written back to memory from each kernel
Kernel 1
Kernel 2
Better Parallel Reduction

Spring 2012 CME 342 49
#define BLOCKSIZE 256
__global__ void sumReductionKernel(float *a, int nValues
{
int n = BLOCKSIZE/2;
int idx = blockIdx.x*blockDim.x + threadIdx.x;
/* Shared memory common to all threads within a block. */
__shared__ float a_s[BLOCKSIZE];
/* Load data from global memory into shared memory. */
if (idx < nValues) a_s[threadIdx.x] = a[idx];
else a_s[threadIdx.x] = 0.f;
__syncthreads();
...
Better Parallel Reduction: GPU Code (1)

Spring 2012 CME 342 50
...
/* Reduction within this thread block. */
while (n > 0)
{
if (threadIdx.x < n)
a_s[threadIdx.x] += a_s[threadIdx.x + n];
n /= 2;
__syncthreads();
}
/* Thread 0 writes the one value from this block back to
global memory. */
if (threadIdx.x == 0)
a[blockIdx.x] = a_s[0];
}
Better Parallel Reduction: GPU Code (2)

Spring 2012 CME 342 51
...
nThreads = nValues;
while (nThreads > 0)
{
gridDim.x = ceil((float)nThreads/BLOCKSIZE);
sumReductionKernel<<<gridDim, BLOCKSIZE>>>(a_d, nThreads);
nThreads /= BLOCKSIZE;
}
...
Better Parallel Reduction: CPU Code

Spring 2012 CME 342 52
From: Computer Architecture: A Quantitative Approach by Hennessy and Patterson
Processor-Memory Gap

Spring 2012 CME 342 53
• Thread blocks are made up of groups of threads called warps – Warp size on all current hardware is 32, but could change on future hardware
(can query through device properties) • A warp is executed in lock step SIMD on a multiprocessor
– Hardware automatically handles divergence due to branching – Note that you are free to specify an arbitrary number of threads per block, but
the hardware can only work in increments of warps – Number of threads is internally rounded up to a multiple of the warp size and
extras are “masked out” in terms of memory accesses
• Trivia: – Warps is a term which comes from weaving. They are threads woven in
parallel.
Thread Warps

Spring 2012 CME 342 54
… … = … … …
Thread block Warp 0 Warp 1 Warp 2 Warp n
…
…
Warp n
= …
Half warp
…
Half warp
Warps and Half Warps

Spring 2012 CME 342 55
• Compute capability is a versioning scheme for keeping track of multiprocessor capabilities / features
– Compute capability 1.0 • “Tesla” architecture, first CUDA capable multiprocessor
– Compute capability 1.1 • Adds atomic operations for global memory, etc.
– Compute capability 1.2 • “Tesla 2” architecture • Doubles the number of registers from 1.0 and 1.1 • Adds atomic operations for shared memory, etc.
– Compute capability 1.3 • Adds double precision floating point, etc.
– Compute capability 2.x • “Fermi” architecture
– Compute capability 3.x • “Kepler” architecture
• Compute capability of a GPU can be queried at runtime
Compute Capability

Spring 2012 CME 342 56
• Coalescing is the process of combining global memory access (load or store) across threads within a warp or half warp into one or more transactions
• How coalescing is performed depends on the compute capability – 1.0 and 1.1 have the same coalescing characteristics – 1.2 and 1.3 have the same coalescing characteristics
• 1.0 and 1.1 are subsets of 1.2 and 1.3 – 2.0 and 3.0 adds L1 and L2 caches
• Global memory divided into segments of size 32, 64, 128, and 256 bytes – Pointers from cudaMalloc are always at least 256 byte aligned
Memory Coalescing

Spring 2012 CME 342 57
Global Memory Segments

Spring 2012 CME 342 58
• Global memory accesses by a half warp are combined to minimize the total number of transactions – Eliminates the dependence on the order in which threads access data in
compute capability 1.0 and 1.1 • In addition, transaction sizes are automatically reduced to avoid
wasted bandwidth – Recursively reduces the transaction size if only the upper or lower half of the
segment is needed – See the programming guide for more details of the algorithm – Minimum transaction size of 32 bytes and per thread word sizes of 32, 64,
and 128 bits • Note that the coalescing for Compute Capability 1.2 and 1.3 is a
superset of the requirements for Compute Capability 1.0 and 1.1 – Code that is efficient on 1.0 and 1.1 will continue to be efficient on 1.2 and
1.3 but not necessarily vice versa
Coalescing on Compute Capability 1.2 and 1.3

Spring 2012 CME 342 59
Examples of Memory Transactions

Spring 2012 CME 342 60
Examples of Memory Transactions

Spring 2012 CME 342 61
• Each multiprocessor has 64 KB of SRAM for shared memory and L1 cache – Can choose split between shared memory and L1 on a per kernel basis
• GPU as a whole has an L2 cache • Memory accesses are coalesced across the full warp of 32
threads • The cache line size is 128 bytes, so any misses in L1 will result in
one or more 128 bytes transactions from L2 to L1 • If the L1 cache is bypassed, either through a compilation flag or
an inline assembly instruction, the requests are served from L2 using 32 byte transactions
• There is no way to bypass L2 cache
Coalescing and Caching on Compute Capability 2.x+

Spring 2012 CME 342 62
• On a CPU, you want spatial locality of data down a thread • On a GPU, you want spatial locality of data across threads
– True for both NVIDIA and AMD GPUs
…
CPU GPU
time
Big Picture on Global Memory Access










![Designingenergyefficient’ microprocessor:Howtofight ... Memory ... [MHz] 8086 80286 386DX 486DX 486DX4 Pentium Pentium Pro Pentium II Pentium MMX Pentium III ... Delay buffers are](https://img.dokumen.tips/doc/110x75/5ac1a5637f8b9ac6688d9ef1/designingenergyecient-microprocessorhowtoght-memory-mhz-8086.jpg)


















