Embed Size (px)
Citation preview

Specifying resources and services inmetacomputing environments
Matthias Brune, J�orn Gehring, Axel Keller, Burkhard Monien,Friedhelm Ramme, Alexander Reinefeld *
Paderborn Center for Parallel Computing, Universit�at-GH Paderborn, F�urstenallee 11, 33102 Paderborn,
Germany
Received 12 November 1997; received in revised formzz 6 February 1998
Abstract
With a steadily increasing number of services, metacomputing is now gaining importance in
science and industry. Virtual organizations, autonomous agents, mobile computing services,
and high-performance client±server applications are among the many examples of meta-
computing services. For all of them, resource description plays a major role in organizing
access, use, and administration of the computing components and software services. We
present a generic Resource and Service Description (RSD) for specifying the hardware and
software components of (meta-) computing environments. Its graphical interface allows
metacomputer users to specify their resource requests. Its textual counterpart gives service
providers the necessary ¯exibility to specify topology and properties of the available system
and software resources. Finally, its internal object-oriented representation is used to link
di�erent resource management systems and service tools. With these three representations, our
generic RSD approach is a key component for building metacomputer environments. Ó 1998
Elsevier Science B.V. All rights reserved.
Keywords: Resource management; Metacomputing; Heterogeneous system integration; Internet services
1. Introduction
The idea of metacomputing [43] emerged from the wish to utilize geographicallydistributed high-performance systems for solving large problems that require
Parallel Computing 24 (1998) 1751±1776
* Corresponding author. E-mail: [email protected]
0167-8191/98/$ ± see front matter Ó 1998 Elsevier Science B.V. All rights reserved.
PII: S 0 1 6 7 - 8 1 9 1 ( 9 8 ) 0 0 0 7 6 - 3

computing capabilities not available in a single computer. From a user's perspective,a metacomputer can be seen as a powerful, cost-e�ective high-performance com-puting system based on existing WAN- or MAN-connected systems. In principle,networked supercomputers can both increase the total amount of computing powerand enable an assembly of unique special purpose resources that otherwise could notbe accessed.
However, metacomputing is more than just distributed computing. While theterm `distributed computing' emphasizes the user's egocentric view on the e�ectiveuse of the computing environment for some given application, the concept of`metacomputing' addresses the organizational, administrational and managementalaspects of a virtual, geographical dispersed machine room.
Metacomputing comes in many ¯avors. A wide spectrum of network-basedmetacomputing services is currently o�ered, ranging from the traditional client±server applications over distributed Intranet- or Internet-services, virtual organiza-tions, tele-working, conferencing to autonomous Internet agents (e.g. search engines).All these services ± and many more ± are to be managed by a `meta-computingmiddleware', which, by itself, is often also geographically distributed. Clearly, themiddleware must be generic and versatile enough to cover newly emerging tech-nologies as well.
In a much broader sense, a general tendency towards an open, distributed com-putation paradigm can be spotted.· User interfaces have been improved from the early command line interfaces to-
wards system-speci®c graphical user interfaces and further on to web-based jobsubmission sheets that are run in standard browsers.
· Resource management systems have mutated from the single-system view paradigm(e.g. MACS, local NQS) via site oriented views (e.g. CCS) towards fully distribut-ed metacomputing environments (e.g. Globus).
· Programming models and execution environments have emerged from the initialproprietary libraries (e.g. MPL, NX, PARIX) to standard programming models(e.g. PVM, MPI), which may be linked by communication libraries such asPVMPI, PACX, or PLUS.In all three domains, the representation of resources plays a core role. System
services and resource requests can be represented by structured, attributed resourcedescriptions. Just like the bids and o�ers at a public market place, metacomputingalso deals with two sides: resource requests and resource o�ers. Assuming a set ofcompatible resource descriptions, the task is then to determine a suitable mappingbetween the two representations subject to constraints such as node performance,connectivity, required software packages etc.
In this paper, we focus on resource and service descriptions for metacomputingenvironments. In Sections 2 and 3 we brie¯y review metacomputing projects anddiscuss current trends in user interfaces. In Section 4 we present our center-orientedresource management CCS with extensions towards metacomputing. The link toparallel programming models is discussed in Section 5, and in Section 6 we presentour Resource and Services Description (RSD). Section 7 gives a brief summary andoutlook.
1752 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

2. Trends in metacomputing
In the past few years, several prototype metacomputing environments have beendesigned and implemented at various sites throughout the world. On a broaderperspective, the e�orts can be categorized into the three domains: user interface,resource management, and program environments.
2.1. A review of current projects
While there exist also some top±down designs, most metacomputing projectsfollow a bottom±up approach by ®rst focusing on some selected aspects, which aresubsequently extended towards a full metacomputing environment. In the following,we review some projects belonging to this category.
Parallel programming models were a popular starting point. Many projects targetat extending existing programming models towards a full metacomputing environ-ment. One such example is the Local Area Multicomputer (LAM) developed at theOhio Supercomputer Center [11]. The LAM project team used the message passinginterface (MPI) to build a system development and execution environment for het-erogeneous networked computers. The use of MPI has the advantage that all LAMapplications are source code portable to any other MPI system. The Italian Wide-Area Metacomputer Manager (WAMM) [4] is a similar project, but it builds onPVM instead. WAMM provides a PVM programming environment with extensionsfor parallel task control, remote compilation and a graphical user interface. With thePLUS communication library (cf. Section 5 and Ref. [9]) taken from our Meta-computer Online toolbox [41,35], WAMM now also supports MPI applications.
Object-oriented languages have been proposed as a means to alleviate the di�-culties of developing architecture independent applications that are to be run ondi�erent metacomputers. Charm [27], Mentat [24] and Legion for example, supportthe development of portable applications by object-oriented parallel programmingenvironments. In a similar approach, the Dome project [2] at CMU uses a C++object library to facilitate parallel programming in a heterogeneous multi-user en-vironment. The disadvantage of these systems is their limitation to the use of aspeci®c programming language. This restriction is especially hard in an industrialsetting, where very large codes must be supported that cannot be ported to otherlanguages. As a remedy, existing code modules can be wrapped into a language thatis supported by the target system.
Projects originating in the management of workstation clusters usually emphasizetopics such as resource management, task mapping, checkpointing and migration.Existing workstation cluster management systems like Condor, Codine, or LSF havebeen adapted for managing large, geographically distributed `¯ocks' of clusters. Thisapproach is taken by the Iowa State University project Batrun [46], the Yale Uni-versity Piranha project [12], and the Dutch Polder initiative [37], all focusing on theutilization of idle workstations for large-scale computing and high-throughputcomputing. Complex simulation codes, such as air pollution or laser atom simula-tions have been run in the Nimrod project [1] that supports multiple executions of the
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1753

same sequential task with di�erent parameter sets. While these schemes emphasizemostly on the application support on homogeneous systems with comparable per-formance characteristics, the San Diego AppLeS project [8] provides application-level scheduling agents on heterogeneous systems, taking into account their actualresource performance. This has been shown to be especially advantageous in dis-tributed systems running contending applications under the control of multiplesystem schedulers, i.e., typical conditions found in practice.
Networking is also an important issue, giving impetus to still another class ofresearch projects. I-WAY [13], for example, is a large-scale wide area computingtestbed connecting US supercomputing sites with several hundreds or thousands ofusers. Aspects of security, usability and network protocol were among the primaryresearch issues of I-WAY, whereas distributed resource brokerage has been the focusof the sister project I-Soft.
On a much broader scale, the Globus [17] project now builds on the results of I-Way, I-Soft, Legion, AppLeS, Nexus, and others. A National Computational Sci-ence Alliance [45] has been founded to implement a framework of an `adaptive widearea resource environment'. This `AWARE' framework shall provide a set of toolsthat enable applications to adapt to heterogeneous and dynamically changingmetacomputing environments. Besides Globus, the workstation cluster managementsystems Condor and Symbio play another important role in establishing the dis-tributed computing infrastructure. The new Symbio project is expected to provide inthe near future a similar software environment for managing Windows-NT clustersjust as Condor does today for UNIX clusters.
Some ideas in our Computing Center Software (CCS) [28] are similar to theconcepts used in Globus. As an example, our CCS Center Information Server (CIS)provides similar resource informations as the Globus Metacomputing DirectoryService (MDS) [16], and the Center Resource Manager (CRM) [28] locates and al-locates resources in local sites like the Globus Resource Manager (GRM) [23].
2.2. Metacomputing in industry
Not only the scienti®c community but also industrial enterprises became aware ofthe high-performance computing power available in the Internet. Here, the idea is too�er computing services to small and medium enterprises which otherwise would nothave access or could not a�ord to operate dedicated HPC systems for their com-putational tasks. The increasing industrial interest may be seen as a nucleus of afuture commercial market on metacomputing services. Following the just risingdemand, researchers have devised generic architectures for electronic commercesystems [38]. In the following, we present some concrete implementations that arealready in practical use.
Funded by the European Commission, several ESPRIT projects in the ®eld ofapplication centered metacomputing have been conducted. The MICA project [21],for example, provides a virtual computation ¯uid dynamics (CFD) server that runsdistributedly on several HPC systems throughout Europe. Users may submit theirCFD problem data (e.g. layout of industrial furnaces, oil platforms, urban pollution
1754 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

scenes) to a virtual access point of the MICA±Net server which takes over control forautomatic load balancing and proper job execution at the participating computeservers. The current work-load, network performance, problem size, and the re-quired response time are all taken into account when determining a suitable set ofcompute servers.
In a similar approach, a distributed pharmaceutical application server (PHASE)has been implemented, that allows pharmaceutical companies and molecular biologyresearch institutes to access HPC systems for truly interactive drug target design.Here, codes for the prediction of potential protein functions, for sensitive proteinsequence searches, for 3D-modelling and for structural comparisons are o�ered viaInternet, allowing interactive drug modelling or even large-scale screening. For themost sensitive drug design projects, that are to be kept in-house for security reasons,the same server software can be installed on the pharmaceutical company's Intranets[21].
We believe that the key to practical metacomputing lies (at least initially) in therestriction to pre-registered applications that are run on speci®c HPC systems on theInternet. This has the advantage, that the program implementation, compilation,debugging and testing must be done only once. Only when the application code is ina stable condition, it will be ported to the target platforms. At runtime, the end-userexecutes the `registered' application with a problem dependent set of data. The jobrequirements, such as expected response time, data requirements, maximum ac-ceptable cost, are speci®ed on web sheets displayed at the user's local PC or work-station. The input is then sent to a virtual access point which distributes the parallelprocesses to the best suited hardware platform.
3. User interface level
3.1. Command line interfaces
While some activities have been initiated to standardize the resource descriptionsand command line interfaces of batch queuing systems (e.g. POSIX standard1003.2d), the special requirements of parallel and distributed computing systems,modern graphical interface technologies (e.g. Java), and the facilities provided bymodern HPC management software are not su�ciently recognized. Further diver-gence is added by vendor-speci®c interfaces.
Command line interfaces are often somewhat cryptographic. For example, on anIBM SP2, the LoadLeveler [44] command
qsubÿ l nodes � 2:hippi� mem � mem:disk� 12allocates two processors with HIPPI connections, one processor with additionalmemory, one with additional memory and disk-space, and 12 normal processors. Analternative to command line input would be the use of batch script ®les, as illustratedin Fig. 1.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1755

For specifying properties of compute nodes and software access paths, systemoperators often use text con®guration ®les, which are typically extended by dozens ofenvironment variables expressing the relationship between the system software andthe corresponding hardware con®guration. Often, the interconnection structurewithin a HPC system, e.g. the linkage between a system and its network, is assumedto be known and therefore is not explicitly speci®ed.
Neither the command line speci®cations nor the combination of con®guration®les and environment variables are adequate tools for specifying resources in ametacomputer context. Hence, we devised a graphical representation for specifyinginterconnected, attributed resources (see Section 6).
3.2. Web interfaces
Driven by the growing popularity of the Internet, modern user interfaces oftenbuild on web sheets, CGI scripts or Java applets. WebSubmit [30], for example,provides a web page interface to supercomputing applications. It is run on whateverweb browser the user has at hand, and it allows interaction with user's data ®les anddirectories on the target supercomputer as if the user was logged on that machine.The current implementation of WebSubmit interfaces to an IBM SP2 running theLoadLeveler job scheduler.
In a broader context, the German UNICORE consortium [47] aims at imple-menting a uniform interface for computer resources based on the use of web browsers.Initially, common batch functionality, formulated as an object framework, will beprovided for HPC systems from Fujitsu, IBM, NEC, SGI/Cray, and Siemens-Nix-dorf.
4. Resource management level
4.1. Previous approaches
Software environments for resource management emerged from the need for abetter utilization of expensive HPC systems. One of the ®rst resource management
Fig. 1. A sample resource request on the SP2.
1756 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

systems is the Network Queuing System (NQS) [29], which was originally developedby NASA Ames for managing the computational resources of the Cray2 and CrayY-MP. NQS is commonly regarded as the grandfather of several other queuingsystems, such as Cray's Network Queuing Environment (NQE) [36] and the PortableBatch System (PBS) [6].
Following another path in the line of ancestors, the IBM LoadLeveler and Codine[22] are both descendants of the Condor system [31], which supports high-throughput computing on UNIX workstation clusters. Here, the goal is to run alarge number of (mostly sequential) batch jobs on workstation clusters without af-fecting concurrent interactive use. The Load Sharing Facility (LSF) [32] is a similarscheme to utilize LAN-connected workstations for (mainly) batch processing.
With the steadily increasing number of parallel codes, these systems have beenextended towards supporting the coordinated execution of parallel applications [14],many of them based on the PVM model. However, in the view of metacomputing,these cluster management systems are still in their infancy, because they do notsupport the notion of locality, and the network-load is not taken into account whenmapping processes onto the underlying hardware. For more detailed information oncluster management software, the reader is referred to Refs. [3,26].
In the following section, we present the resource management software CCS. Itprovides easy access and administration of a set of heterogeneous parallel high-performance computers in a computing center context. In contrast to the abovementioned systems, CCS supports multi-site applications and has an extensible in-terface to metacomputing management services.
4.2. Managing networked high-performance computers: CCS
The Computing Center Software [39,40,28] has been designed to serve two pur-poses: For HPC users it provides a homogeneous access interface to a pool of dif-ferent HPC systems, while for system administrators it provides a means fordescribing, organizing and managing HPC systems that are operated in a computingcenter. Hence the name ``Computing Center Software'', (CCS).
The project has been started in 1992 with a hierarchical concept for managingexclusively partitionable transputer systems. It mainly aimed at:· hardware independent scheduling of interactive and batch jobs,· e�ective partitioning of exclusive and non-exclusive resources,· high degree of reliability,· fault tolerance for external access via unreliable WANs.
The ®rst releases of CCS were capable of managing all machines in a computingcenter with one middleware. However, this caused performance bottlenecks andsingle points of failure, especially in large computing environments. With thefourth release [28], each system is now managed by a dedicated CCS, resulting inset of self-su�cient islands which can be operated stand-alone. Fig. 2 depicts thisapproach.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1757
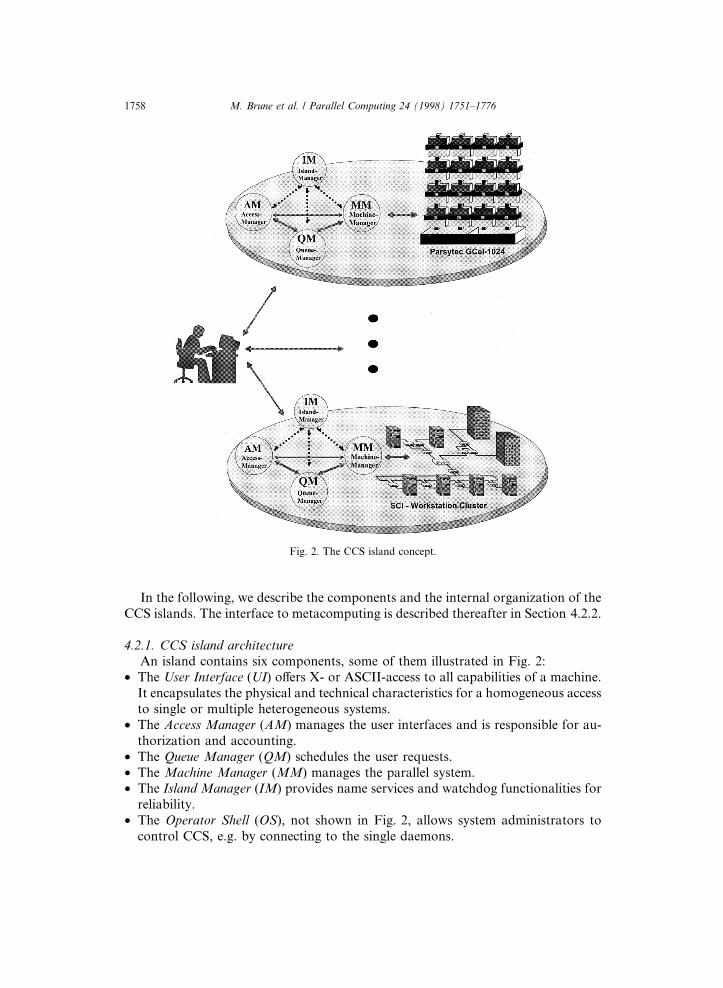
In the following, we describe the components and the internal organization of theCCS islands. The interface to metacomputing is described thereafter in Section 4.2.2.
4.2.1. CCS island architectureAn island contains six components, some of them illustrated in Fig. 2:
· The User Interface (UI) o�ers X- or ASCII-access to all capabilities of a machine.It encapsulates the physical and technical characteristics for a homogeneous accessto single or multiple heterogeneous systems.
· The Access Manager (AM) manages the user interfaces and is responsible for au-thorization and accounting.
· The Queue Manager (QM) schedules the user requests.· The Machine Manager (MM) manages the parallel system.· The Island Manager (IM) provides name services and watchdog functionalities for
reliability.· The Operator Shell (OS), not shown in Fig. 2, allows system administrators to
control CCS, e.g. by connecting to the single daemons.
Fig. 2. The CCS island concept.
1758 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

The UI runs in a standard UNIX shell environment like tcsh, bsh, or ssh.Common UNIX mechanisms like IO-redirection, piping, and shell scripts can beused and all job control signals are supported. An additional X±Windows interface isgiven for standard resource requests.
The AM is responsible for authentication, authorization, and accounting.Authorization is always project speci®c. Privileges can be granted to a whole projector to selected members.
Incoming user requests are analyzed by the AM and then sent to the QM. Itschedules the requests according to the current scheduling policy. The QM maintainsa single queue for both batch and interactive requests.
CCS computes a fair and deterministic schedule, which enables the reservation ofsystem resources for a given time in the future. Let us assume a user wants to run acode on 64 processors of the Parsytec GCel from 9 to 11 a.m. at 13.2.1999. This isdone with the command: ccsalloc ) m gcel ) p 64 ) s 9.00:13.02.1999
) t 2h.The system administrator has the choice between several scheduling modules
(FCFS, FFIH, FFDH, IVS) [19,40] which can be exchanged at runtime. We delib-erately designed the QM to be independent of the underlying hardware architecture.As a result, the scheduler daemon has no information on hardware mapping con-straints, such as the minimum cluster size, or the available user entries and theirphysical location.
These constraints are checked by the MM. It wraps all machine dependentproperties and corresponding tasks. With its system-speci®c information, the MMveri®es whether a schedule given by the QM can be mapped onto the hardware at thespeci®ed time, now also considering concurrent system use by other applications.
This separation between the hardware-independent QM and the system-speci®cMM allows to use optimal mapping strategies with system-dependent heuristics. Forexample, special user demands, like the usage of IO-nodes, the shape of a partition,memory constraints, etc. are taken into account in the scheduling process. Moreover,with all machine-speci®c information encapsulated in the MM daemon, a CCS islandcan be easily adapted to other architectures.
At con®guration time, the user request is sent from the QM to the MM. The MMis now responsible for allocating the PEs, for loading and starting the applicationcode, and for releasing the resources thereafter.
The IM supervises the other daemons. The IM is a small module with fewdependencies on other CCS daemons. At startup and shutdown time all daemonsnotify the IM which has a consistent view on all running CCS daemons. The IM isauthorized to stop erroneous daemons or to restart crashed ones.
In summary, the CCS island concept has the following advantages:· It provides a high degree of scalability, reliability and easy recovery by separating
the management of di�erent machines into di�erent islands.· Each machine may run its own local scheduling policy or it may run in a di�erent
mode (e.g. only batch or shared access).· Speci®c user interfaces can be used to better re¯ect the features of the speci®c
machines.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1759

4.2.2. CCS metacomputing interfaceWith the autonomous island concept we have an important building block for
managing a metacomputing environment. The CCS interface to such an environ-ment comprises a passive and an active part.
The passive part is realized by the CIS. It maintains a consistent view on allsystems and on the network topology of the whole center. The CIS database includesinformation on the network characteristics, the system software (programmingmodels, libraries, etc.) and the time constraints (for speci®c connections, etc.). Thisinformation must be up-to-date, since the characteristics of shared resources likenetwork performance may vary over time.
For external users or mobile agents, the CIS plays the role of a `docking station'.Hence, the data managed by the CIS can be converted in formats used by otherresource management systems.
The CRM plays the active part of the CCS metacomputing interface. It isresponsible for the set-up and execution of multi-site applications. For resourcelocation, the CRM maps the user requests against the information (from CIS) onthe available system resources. In this mapping process, data on the actual loadof computing nodes and the interconnection network should be taken into ac-count [20].
When the target resources have been located, they must be allocated. This can bedone in analogy to the two-phase-commit protocol in distributed database man-agement systems: the CRM requests the allocation of all required resources at allinvolved islands. If not all resources were available, it either re-schedules the job or itdenies the user request. Otherwise the job can now be started in a synchronized way.Here, machine-speci®c preprocessing tasks or inter-machine speci®c initializations(e.g. starting of special daemons) must be initialized.
Like the MM on the island level, the CRM is able to migrate user resourcesbetween machines to achieve a better utilization. Accounting and authorization atthe metacomputing level can also be negotiated at this layer. Fig. 3 shows allcomponents of a site managed by CCS.
In the ESPRIT project PHASE, we have developed a job distribution schemewhich works on top of the CRM layer. This scheme allows users from various placesin the Internet to submit jobs to a CCS island. It is even possible to run multi-siteapplications, i.e. programs that are executed on multiple computing centers simul-taneously. The algorithm used in this project is a modi®ed brokerage strategy basedon the reservation features in CCS: whenever a broker is requested to allocate re-sources for a multi-site application, it selects a subset of servers based upon avail-ability and current network speed. Each of the servers o�ers a subset of its resourcesto the broker. The broker collects the o�ers and determines which resources of whichcenters to use. The application is then distributed accordingly and the responsibilityfor allocating the sub-partitions is transfered to the CCS islands [18].
4.2.3. Resource description in CCSAlready the ®rst release of CCS included a Resource Description Language (RDL)
[5] that was used:
1760 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

· at the administrator's level for describing type and topology of the available re-sources, and
· at the user's level for specifying the required system con®guration for a given ap-plication.Due to this uniform approach the resource location is reduced to a mapping
problem (user description onto resource description) ± a task that is well understoodin Computer Science.
However, as some of our users found it too inconvenient to write RDL ®les forspecifying resource requests, we developed a more comfortable interface that gen-erates RDL ®les from command line options. This scheme works quite well when theuser takes the decision on which machine to run his code. But entering the world ofmetacomputing, other rules apply. Here, only the resource management system candecide which components to use. Its decision is based on:· the communication characteristics of the user's application,· the network characteristics between the computing nodes,· the required software packages,· the dynamic behavior of the environment to which it should adapt.
In metacomputing environments, users need to describe resource classes insteadof speci®c machines, thereby allowing the system to decide which subset of theavailable hard-/software resources to use. User requests can best be represented by
Fig. 3. A site managed by CCS.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1761

dependency graphs, where the nodes denote computing elements and the edgesrepresent communication links (with corresponding latency and bandwidth). In themapping and migration process, the application's communication pattern and dataon the previous runtime behavior [20] can be taken into consideration.
5. Program environment level
Aside from resource management, another obstacle in executing metacomputingapplications lies in the incompatibility of the vendor-speci®c message passing li-braries such as MPL, NX, PARIX, and others. On the one hand, the vendors usuallyprovide the most e�cient communication software for their machines, but on theother hand, these communication libraries are not compatible to each other. Whilethe standard message passing models PVM [25] and MPI [33] have improved thecode portability, it is currently not possible to communicate between di�erent pro-gramming models.
Three recent approaches somewhat alleviate the problem by providing a linkagebetween standard programming models.· PVMPI [15] is an extension of PVM that provides a communication link to tasks
running under MPI. However, PVMPI lacks openness towards other models.· PACX [7] is a similar approach, but it aims at linking two or more homogeneous
systems. It was used in a trans-atlantical experiment to link two Cray T3Es forrunning a large simulation code under MPI.
· The PLUS [9] library, described below, is an autonomous library that providesplug-ins for linking arbitrary programming models.PLUS was designed for industrial multi-site applications. Due to their mere size,
large industrial codes [34] cannot be easily ported from one programming model toanother, and there is a clear need for an e�ective communication interface linking theisolated programming models.
5.1. PLUS: A linkage between programming models
PLUS [9,42] (programming environment linkage by universal software interfaces)provides an extensible communication interface between message passing methods,including both vendor-speci®c and standard models. PLUS consists of daemons anda library that is linked to the application code. Only four commands are needed tointegrate PLUS into existing codes:· plus init� � for signing on at the nearest PLUS daemon· plus exit� � for logging o�· plus system� � for spawning a task on another (remote) system· plus info� � for obtaining information on the accessible (remote) tasks
From the view of the application, the PLUS communication [42] is hidden behindthe native communication routines used in the application. By means of macro-substitution PLUS provides linkage to external systems without the need to modifythe source code. Thereby, an MPL application, for example, could make implicit use
1762 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

of PLUS when using MPL communication routines. Conversion between di�erentdata representations on the participating hardware platforms (little/big endian) istransparently handled by PLUS, similarly as in XDR.
The design of the PLUS software package is modular to allow for easy extensionsto other programming environments. Much emphasis has been put on providingmaximum communication speed. The communication within a single programmingenvironment is not a�ected by PLUS. External communication is based on fastcommunication protocols, which was shown to outperform raw stream-socket TCP/IP communication on wide area networks.
5.1.1. PLUS in practiceFig. 4 illustrates a process communication between a C/MPI code and a C/PVM
code. At the beginning, both applications register at the PLUS master daemon. Theplus init� � command takes the daemon location and a logical name of theprogramming environment as parameters. When the initialization was successful, thedaemons start exchanging process tables and control information. The remoteprocesses are now able to communicate with each other via PLUS. From the MPIapplication, the communication is done by calling MPI Send� � with a partneridenti®er that is bigger than the last (maximum) process identi®er managed by MPIin the communicator group MPI COMM WORLD: For further information see Ref.[9,42].
5.1.2. Network con®guration in PLUSBefore starting the distributed application, a PLUS master daemon must be
brought up with the UNIX command startplushtarget machinei. Thereafter,the master daemon autonomously starts additional daemons that are logically in-terconnected in a clique topology. Clearly, the daemons' locations in the network areessential for the overall communication performance. PLUS daemons should be runon network routers (e.g. machine `gate' in Fig. 5), or on powerful workstations (e.g.
Fig. 4. Process communication via PLUS between di�erent programming environments.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1763

`jupiter'). In addition, it is useful to have a daemon running on the frontends of aparallel system (e.g. machines `frontend1' and `frontend2' in Fig. 5).
In practice, each sub-network contains at least one PLUS daemon. Depending onthe actual communication load in the sub-network, more daemons may be started bythe master daemon. Any daemon that has a work load (number of supported usertasks) larger than a given threshold may ask the master to bring up further daemons.
In summary, PLUS also needs information on the physical network topology(WAN, MAN, LAN) ± just like the resource management systems discussed inSection 4. An information base must be maintained, holding data on the topology,the current network speed, and the current load of the principal compute servers.Based on this information, PLUS can decide where to start daemons and where toroute the messages between concurrently executing program modules. Clearly, aversatile, abstract resource description is needed.
In the following section, we present the general RSD, which supports all three levels:the user interface, the resource management, and the programming model level.
6. Resource and service description ± The link between the levels
6.1. Requirements and concept
Any scheme for describing resources should meet the following requirements.
Fig. 5. Network positions of PLUS daemons.
1764 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

· Simple resource requirements should be easy to generate: Users do not want to typein long and complex descriptions just for launching a small program. Therefore, auser-friendly graphical editor is needed.
· Powerful tools for generating complex descriptions: System administrators need ad-equate tools for describing complex systems made up of heterogeneous computingnodes and various kinds of interconnection networks. Although the system con®g-uration is likely to remain constant over a long time, it might be quite di�cult tospecify all components, especially for large HPC centers. A simple graphical inter-face is insu�cient. Rather, a mixture between a text based description and a GUIis needed.
· Application programming interface (API): For the automatic evaluation and map-ping of resource descriptions an API is needed that allows to access the data byfunction calls and/or method invocations. Furthermore, the API encapsulatesthe internal structure of the resource description and allows future extensionswithout the need to update other software.
· Portable representation: Resource descriptions are sent across the network andthey are exchanged between a vast variety of di�erent hardware architecturesand operating systems. The representation should be designed to be easily under-stood by each participating system.
· Recursive structure: Computer resources are usually organized in a hierarchicalway: A metacomputer might comprise several HPC centers, which might includeseveral supercomputers that in turn consist of a number of processing elements.The resource description facility should re¯ect this general approach by recursiveconstructs.
· Graph structured: HPC hard- and software and dynamic (time dependent) data¯ow are often described by graphs. Thus, the resource description facility shouldallow to de®ne graph based structures.
· Attributed components: For describing properties of nodes, network connections,jobs, and communication requirements, it should be possible to assign valued at-tributes to arbitrary nodes and edges of the resource description.Fig. 6 depicts the general concept of the RSD framework [10]. It was designed to
®t the needs of both, the user as well as the system administrator. This is achieved byproviding three di�erent representations: a graphical interface, a textual interface,and an application programming interface.
While the GUI editor will usually su�ce for the end-user, system administratorsmay need to describe the more complex components by an additional text basedinterface. The editor combines the textual parts with the graphical input and createsan internal data representation (see Section 6.4). The resulting data structure isbundled with the API access methods and sent as an attributed object to the targetsystems in order to be matched against other hard- or software descriptions.
The internal data description can only be accessed through the API. For latermodi®cations it is re-translated into its original form of graphic primitives andtextual components. This is possible, because the internal data representation alsocontains a description of the component's graphical layout. In the following, wedescribe the core components of RSD in more detail.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1765

6.2. Graphical interface
In this section we present the general layout of a graphical RSD editor [10]. Itcontains a tool-box of modules that can be edited and linked together to build acomplex dependency graph or a system resource description.
At the administrator level, the graphical interface is used to describe the com-puting and networking components in a center. Fig. 7 illustrates a typical admin-istrator session. The components in a center are speci®ed in a top±down manner withthe interconnection topology as a starting point. With drag and drop techniques, theadministrator speci®es the available machines and their interconnections.
In the next step, the machines are speci®ed in more detail. This is done byclicking on a node, whereby the editor opens a window showing detailed infor-mation on the machine (if available). The GUI o�ers a set of standard machinelayouts like Cray T3E, IBM SP2 or Parsytec and some generic topologies like
Fig. 6. General concept of the RSD approach.
1766 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

grid or torus. The administrator de®nes the size of the machine and its generalattributes. Attributes are speci®ed in a textual manner, as described in Sec-tion 6.3. When the whole machine has been speci®ed, a window with a graphicalrepresentation of the machine opens, in which single nodes can be selected forspecifying detailed attributes like network interface cards, disk size, I/Othroughput, the automatic start of daemons.
At the user level, request speci®cations can be given either by (remote) login or viaa graphical web interface. Analogously to the WAMM metacomputer manager [4],the user may click on a center and the target machines. Interconnection topologies,node availability and the current job schedule may be inspected. Partitions can beselected via drag and drop or in a textual manner. For multi-site applications, theuser may either specify the target machines or constraints in order to let the RMSchoose a suitable set of systems.
Fig. 7. Graphical RSD editor.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1767

6.3. Language interface
From a system administrator's point of view, graphical user interfaces do notseem to be powerful enough to describe a metacomputing environment comprising alarge number of services and resources. Administrators need an additional tool forspecifying irregularly interconnected, attributed structures.
6.3.1. Language de®nitionIn RSD [10], services and resources consist of nodes interconnected by an arbi-
trary topology (dependency graph). Active nodes are indicated by the keywordNODE. Communication interfaces (i.e. sockets) are declared by the keyword PORT.Depending on whether RSD is used to describe hardware or software topologies, thekeyword NODE is interpreted as a ``processor'' or a ``process''. A PORT may be aphysical socket, a passive hardware entity, e.g. a crossbar or a process that behavespassively within the parallel program.A NODE de®nition consists of three parts.
1. In the optional DEFINITION section, identi®ers and attributes are introduced byIdentifier �� �value; . . .��.
2. The DECLARATION section declares all nodes with corresponding attributes. Thenotion of a `node' in a dependency graph is recursive. They are described by NODENodeName fDECLARATION:attribute 1; . . .g.
3. The CONNECTION section is again optional. It is used to de®ne attributed edgesbetween the ports of the nodes declared above: EDGE NameOfEdgefNODE w PORT x <�> NODE y PORT z; attribute 1; . . .g.
In addition, the notion of a `virtual edge' is used to provide a link between di�erentlevels of the hierarchy in the dependency graph. This allows to establish a link fromthe described module to the `outside world' by `exporting' a physical port to the nexthigher level. These edges are de®ned by: ASSIGN NameOfVirtualEdgefNODE w PORT x <�> PORT a g. NODE w and PORT a are the only entities knownto the outside world.
This hierarchical concept allows di�erent dependency graphs to be grouped forbuilding more complex nodes, that is hypernodes. These are also introduced byNODE ComplexNodeName f. . .g.
6.3.2. ExampleThe example in Fig. 8 illustrates a metacomputer �My Metacomputer� made up
of a heterogeneous SCI workstation cluster and a parallel system. These two com-ponents are interconnected by a bidirectional ATM link.
The de®nition of My Metacomputer is straight forward, see Fig. 9. Fig. 10shows the speci®cation of the SCI cluster component, consisting of 8 nodes, two ofthem with quad-processor systems. For each node, the following attributes arespeci®ed: CPU type, memory, operating system, and the port of the SCI link. Allnodes are interconnected by a uni-directional SCI ring with 1.0 Gbps.
1768 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

The ®rst node acts as a gateway to the workstation cluster. It presents its ATMport to the next higher node level (see the ASSIGN statement in Fig. 10) to allow forremote connections.
6.4. Internal data representation
In this section, we describe the abstract data type that establishes the link betweengraphical and text based representations. This RSD data format is also used to storedescriptions on disk and to exchange them across networks.
6.4.1. Abstract data typesAs stated in Sections 6.1±6.3 the internal data representation must be capable of
describing:· arbitrary graph structures,· hierarchical systems or organizations,· nodes and edges with arbitrary sets of valued attributes.
Furthermore it should be possible to reconstruct the original representation, ei-ther graphical or text based. This facilitates the maintenance of large descriptions(e.g. a complex HPC center) and allows visualization at remote sites.
Fig. 9. RSD Speci®cation of My Metacomputer.
Fig. 8. My Metacomputer, cf. Figs. 9 and 10.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1769

Following these considerations we de®ne the data structure RSDGraph as thefundamental concept of the internal data representation:
RSDGraph :� �V ;E� withV being a set of RSDNode and
E � �V � V � RSDAttribute�:
(�1�
and
RSDNode :� RSDAttributej�RSDGraph;RSDAttribute� �2�Thus, an RSDGraph is a graph which may have assigned attributes to its nodes and
edges. Since a node may also represent a complete substructure it is possible torepresent hierarchies of any depth.
For maximum ¯exibility, we de®ne RSDAttribute to be either a (possibly empty) listof names and values or a single name for a more complex structure of attributes:
RSDAttribute :� ;j�Name; Value�; . . . j�Name;RSDAttribute� �3�
Fig. 10. RSD speci®cation of the SCI cluster component of My Metacomputer.
1770 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

The name of an attribute follows the common naming conventions of programminglanguages while the value may have one of the following types: boolean, integer, real,string, bytearray, and bit®eld. All these types can represent either static values, whichare `hard-coded' into the description, or dynamic parameters, which are calculatedby an external function each time the attribute is evaluated.
Fig. 11 depicts a small example of this concept. There are two RSDNode structuresrepresenting compute centers interconnected by a 34 MBit/s ATM link. The sub-structure contained in Center A indicates that there are three machines within thiscenter, one of them is a HPC system called ``GCel-1024''.
6.4.2. Access methodsHaving described the data structure, we now introduce the basic methods for
dealing with the RSD abstract data type. Only those methods are provided that areabsolutely necessary. All higher level functions build upon them.· Nodes (RSDGraph) ± Returns a list of nodes in the highest level of the graph. Re-
ferring to Fig. 11 these would be Center A and Center B.· Neighbors (RSDNode) ± Gives a list of all nodes connected to RSDNode in the same
level. In Fig. 11, Center B is a neighbor of Center A but not of Machine A.· Sub-Nodes (RSDNode) ± These are all nodes contained in RSDNode. As an example
the sub-nodes of Center A comprise Machine A, Machine B, and Machine C, butnone of their processors.
· Attributes (RSDNode | (RSDNode, RSDNode)) ± Returns a list of all top level attri-butes of the speci®ed node or edge.
Fig. 11. Example con®guration for RSD.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1771

· Value (RSDAttribute) ± Returns the value of an RSDAttribute. This may also be a set ofattributes in the case of hierarchically structured attributes.In addition, there exists a number of auxiliary methods, e.g. for list handling, that
build on the basic methods. These are not described in this paper.Note that the internal data types are also used for reconstructing the original
graphical and/or text representation. As an example, a system administrator mayhave de®ned a Fast Fourier Transformation (FFT) network by a few lines of the RSDlanguage. The internal representation of such a node is much more complex and noteasy to translate back into its original form. However, it is possible to keep thesource code of this special node as one of its attributes. This can then be used by theeditor whenever the FFT is to be modi®ed. The same is possible with nodes that werecreated graphically and require a uniform layout of their components.
6.5. Implementation
In order to use RSD in a distributed environment a common format for ex-changing RSD data structures is needed. The traditional approach to this would beto de®ne a data stream format. However, this would involve two transformationsteps whenever RSD data is to be exchanged (internal representation into datastream and back). Since the RSD internal representation has been de®ned in anobject-oriented way, this overhead can be avoided, if the complete object is sentacross the net.
Today there exists a variety of standards for transmitting objects over the In-ternet, e.g. CORBA, JavaBeans, or COM+. Because it seems hard to decide which ofthem will survive in the future, we only de®ne the interfaces of the RSD object classbut not its private implementation. This allows others to choose an implementationthat ®ts best to their own data structures. Inter operability between di�erent im-plementations can be improved by de®ning translating constructors, i.e. constructorsthat take an RSD object as an argument and create a copy of it using another in-ternal representation.
This ¯exible concept allows to enhance the RSD de®nition and the communica-tion paradigm while still maintaining downward compatibility with previous im-plementations.
6.6. Other approaches
We are aware of only one other scheme with similar features: the Globus project[17] aims at building an adaptive wide area resource environment with a set of toolsthat enables applications to adapt to heterogeneous and dynamically changingmetacomputing environments. In this environment, applications must be able to getanswers to questions like: ``Which average bandwidth is available from 3p.m. until7p.m. between host A and host B?'' or ``Which PVM version is running on systemxy?'' This information is obtained from multiple sources, e.g. the Network Infor-
1772 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

mation Service (NIS), the Simple Network Management Protocol, or from system-speci®c ®les.
The Globus MDS [16] addresses the need for e�cient and scalable access to di-verse, dynamic, and distributed information. MDS has been built on the data rep-resentation and API de®ned by the Lightweight Directory Access Protocol (LDAP)[48], which in turn is based on the X.500 standard. This standard de®nes a directoryservice that provides access to general data about entities, such as people, institu-tions, or computers. The MDS information base is structured as a set of entries (e.g.computer, network, organization, person, etc.), where each entry may be mandatoryor optional.
All entries are organized in a hierarchical, tree structured name space called di-rectory information tree (DIT). Each MDS server is responsible for a DIT sub-tree(e.g. for a single machine or all entries of a computing center). MDS is used forobtaining information on the metacomputer by higher-level services like a resourcebroker which supports specialized searches for MDS information.
To describe resources for a job request, the Globus Resource Manager (RM)provides a Resource Speci®cation Language, given by a string of parameter speci®-cations and conditions on MDS entries. As an example, 32 nodes with a minimum of128 MB and three nodes with ATM interface are speci®ed by:
��&�count � 32��memory >� 128M���&�count � 3��network � ATM��
7. Conclusion
Caused by· their distributed nature,· their heterogeneity,· their vast number of (possibly recursively structured) components,· and their dynamical behavior,metacomputing environments are much more di�cult to access, organize andmaintain than any single high-performance computing system. Hence, a powerfulscheme for resource and service description is of prime importance.
In this paper, we presented the framework of a generic RSD for specifyinghardware and software components of a geographically distributed metacomputer.Its graphical interface allows the user to specify resource requests. Its textual in-terface gives a service provider enough ¯exibility for specifying computing nodes,network topology, system properties and software attributes. Its internal object-oriented resource representation is used to link di�erent resource management sys-tems and service tools.
The ideas and concepts presented in this paper re¯ect the experiences gained in thevarious metacomputer projects conducted in the past few years at the PaderbornCenter for Parallel Computing.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1773

Acknowledgements
This work was supported by the European Union with the projects MICA (ES-PRIT 20966), PHASE (ESPRIT 23486), DYNAMITE (ESPRIT 23499), and by theGerman Ministry of Research and Technology (BMBF) project UNICORE.
References
[1] D. Abramson, R. Sosic, J. Giddy, B. Hall, Nimrod: A tool for performing parameterized simulations
using distributed workstations, in: The Fourth IEEE Symposium on High Performance Distributed
Computing, August 1995, pp. 206±214.
[2] J. �Arabe, A. Lowekamp, E. Seligman, M. Starkey, P. Stephan, Dome: Parallel programming
environment in a heterogeneous multi-user environment, Supercomputing, 1995.
[3] M. Baker, G. Fox, H. Yau, Cluster computing review, Northeast Parallel Architectures Center,
Syracuse University, November 1995, New York, http://www.npar.syr.edu/techreports/index.html.
[4] R. Baraglia, G. Faieta, M. Formica, D. Laforenza, Experiences with a wide area network
metacomputing management tool using IBM SP-2 parallel systems, in: Concurrency: Practice and
Experience, vol. 8, Wiley, New York, 1996.
[5] B. Bauer, F. Ramme, A general purpose resource description language, in: R. Grebe, M. Baumann
(Eds.), Parallel Datenverarbeitung mit dem Transputer, Springer, Berlin, 1991, pp. 68±75.
[6] A. Bayucan, R.L. Henderson, T. Proett, D. Tweten, B. Kelly, Portable batch system: External
reference speci®cation, Release 1.1.7, NASA Ames Research Center, June 1996.
[7] T. Beisel, E. Gabriel, M. Resch, An Extension to MPI for Distributed Computing on MPPs, in: M.
Bubak, J. Dongarra, J. Wasniewski (Eds.), Recent Advances in Parallel Virtual Machine and
Message Passing Interface, Lecture Notes in Computer Science, Springer, Berlin, 1997, pp. 25±33.
[8] F. Berman, R. Wolski, S. Figueira, J. Schopf, G. Shao, Application-level scheduling on distributed
heterogeneous networks, Supercomputing, November 1996.
[9] M. Brune, J. Gehring, A. Reinefeld, Heterogeneous message passing and a link to resource
management, Journal of Supercomputing 11 (1997) 355±369.
[10] M. Brune, J. Gehring, A. Keller, A. Reinefeld, RSD ± Resource and Services Description, 12th Int.
Symp. on High-Performance Computer Systems and Applications, Edmonton, Canada, May 1998,
Kluwer.
[11] G. Burns, R. Daoud, J. Vaigl, LAM: An open cluster environment for MPI, in: Supercomputing
Symposium '94, Toronto, Canada, June 1994.
[12] N. Carriero, E. Freeman, D. Gelernter, D. Kaminsky, Adaptive parallelism and Piranha, IEEE
Computer 28 (1) (1995) 40±49.
[13] T. DeFanti, I. Foster, M. Papka, R. Stevens, T. Kuhfuss, Overview of the I-Way: Wide area visual
supercomputing, International Journal of Supercomputer Applications 10 (2) (1996) 123±130.
[14] D. Epema, M. Livny, R. van Dantzig, X. Evers, J. Pruyne, A worldwide ¯ock of Condors: Load
sharing among workstation clusters, Future Generation Computer Systems, vol. 12, Elsevier,
Amsterdam, 1996, pp. 53±66.
[15] G.E. Fagg, J. Dongarra, PVMPI: An integration of the PVM and MPI systems, Calculateurs
Paralleles 8 (1996) 151±166.
[16] S. Fitzgerald, I. Foster, C. Kesselman, G. von Laszewski, W. Smith, S. Tuecke, A directory service
for con®guring high-performance distributed computations, in: Proceedings of The Sixth IEEE
Symposium on High-Performance Distributed Computing, 1997.
[17] I. Foster, C. Kesselman. Globus: A Metacomputing Infrastructure Toolkit, Journal of Supercom-
puter Applications 11 (1997) 115±128.
[18] J. Gehring, A. Weber, Developing a job distribution scheme for multi-site applications, Technical
Report TR-001-98, Paderborn Center of Parallel Computing, 1998.
1774 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776

[19] J. Gehring, F. Ramme, Architecture-independent request-scheduling with tight waiting-time estima-
tions, in: IPPS'96 Workshop on Scheduling Strategies for Parallel Processing, Hawaii, 1996, pp. 41±54.
[20] J. Gehring, A. Reinefeld, MARS ± A framework for minimizing the job execution time in a
metacomputing environment, in: Future Generation Computer Systems, Elsevier, Amsterdam, 1996,
pp. 87±99.
[21] J. Gehring, A. Reinefeld, A. Weber, PHASE and MICA: Application speci®c metacomputing, in:
Europar'97, Passau, Germany, 1997, pp. 1321±1326.
[22] GENIAS Software GmbH, Codine: Computing in distributed networked environments, http://
www.genias.de/products/codine/, January 1998.
[23] K. Czajkowski, I. Foster, H. Karonis, C. Hesselman, S. Martin, W. Smith and S. Tuecke, A resource
management architecture for metacomputing systems, Proc. IPPS ISPDP'98, Workshop on Job
Scheduling Strategies, Orlando, FL (March 1998) 26±30.
[24] A. Grimshaw, J.B. Weissman, E.A. West, E.C. Loyot, Metasystems: An approach combining parallel
processing and heterogeneous distributed computing systems, Journal of Parallel and Distributed
Computing 21 (1994) 257±270.
[25] A. Geist, A. Beguelin, J. Dongarra, W. Liang, B. Manchek, V. Sunderam, PVM: Parallel Virtual
machine ± A User's Guide and Tutorial for Network Parallel Computing, MIT Press, Cambridge,
MA, 1994.
[26] J. Jones, C. Brickell, Second Evaluation of Job Queueing/Scheduling Software: Phase 1 Report,
NASA Technical Report NAS-97-013, NASA Ames Research Center, June 1997.
[27] L. Kale, S. Krishnan, CHARM++: A portable concurrent object oriented system based on C++, in:
Conference on Object Oriented Programming, Languages and Applications (OOPSLA), vol. 28,
September 1993, pp. 91±108.
[28] A. Keller, A. Reinefeld, CCS resource management in networked HPC systems, in: Heterogeneous
Computing Workshop (HCW'98), IPPS, Orlando, March 1998 44-56.
[29] B. A. Kinsbury, The network queuing system, in: Cosmic Software, NASA Ames Research Center,
1986.
[30] R.R. Lipman, J.E. Devaney, WebSubmit ± Running supercomputer applications via the Web, in:
Supercomputing'96, Pittsburgh, November 1996, pp. 17±22.
[31] M.J. Litzkow, M. Livny, Condor ± A hunter of idle workstations, in: Proceedings of The Eighth
IEEE International Conference on Distributed Computing Systems, June 1988, pp. 104±111.
[32] LSF, Product Overview, http://www.platform.com/products/, January 1998.
[33] Message Passing Interface Forum, MPI: A message-passing interface standard, Journal of
Supercomputer Applications 8(3/4) (1994).
[34] H. Mierendor�, K. Stueben, C. Thole, O. Thomas, Europort-1: Porting industrial codes to parallel
architectures, in: Springer Lecture Notes in Computer Science 919, Springer, Berlin, 1995.
[35] NRW, Metacomputing ± Verteiltes H�ochstleistungsrechnen, http://www.-uni-paderborn.de/pc2/nrw-
mc/, January 1998.
[36] NQE-Administration, Cray-Soft USA, SG-2150 2.0, May 1995.
[37] Polder, http://www.wins.uva.nl/projects/polder/, October 1997.
[38] C. Powley, D. Benjamin, D. Grossman, R. Neches, P. Postel, E. Brodersohn, R. Fadia, Q. Zhu, P.
Will, DASHER: A prototype for federated E-commerce services, IEEE Internet Computing 1 (6)
(1997) 62±71.
[39] F. Ramme, T. R�omke, K. Kremer, A distributed computing center software for the e�cient use of
parallel computer systems, in: HPCN Europe, Springer Lecture Notes in Computer Science 797, vol.
2, Springer, Berlin, 1994, pp. 129±136.
[40] F. Ramme, Transparente und e�ziente Nutzung partitionierbarer Parallelrechner, Ph.D. Thesis,
ISBN 3-89722-013-X, Logos, Berlin, April 1997.
[41] A. Reinefeld, R. Baraglia, T. Decker, J. Gehring, D. Laforenza, F. Ramme, T. RÈ omke, J. Simon, The
MOL project: An open extensible metacomputer, in: Heterogeneous Computing Workshop at
IPPS'97, Geneve 1997.
[42] A. Reinefeld, J. Gehring, M. Brune, Communicating across parallel message-passing environments,
Journal of Systems Architecture Elsevier 44 (1998) 261±272.
M. Brune et al. / Parallel Computing 24 (1998) 1751±1776 1775

[43] L. Smarr, C.E. Catlett, Metacomputing, Commun. ACM 35 (6) (1992) 45±52.
[44] SP, Parallel Programming Workshop: LoadLeveler. http://www.mhpcc. edu/training/workshop/html/
loadleveler/LoadLeveler.html.
[45] R. Stevens, P. Woodward, T. DeFanti, C. Catlett, From I-WAY to the national technology grid,
Commun. ACM 11 (1997) 51±60.
[46] F. Tandiary, S.C. Kothari, A. Dixit, E.W. Anderson, Batrun: Utilizing idle workstations for large-
scale computing, IEEE Parallel and Distributed Technics, 1996, pp. 41±48.
[47] UNICORE project home page: http://www.kfa-juelich.delzam/RD/coop/unicore January 1998.
[48] W. Yeong, T. Howes, S. Kille, Lightweight Directory Access Protocol, RFC 1777, Draft Standard,
March 1995.
1776 M. Brune et al. / Parallel Computing 24 (1998) 1751±1776





























