Embed Size (px)
Citation preview

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 1
Sound, Mixtures, and Learning:LabROSA overview
Sound Content Analysis
Recognizing sounds
Organizing mixtures
Accessing large datasets
Music Information Retrieval
Dan Ellis <[email protected]>
Laboratory for Recognition and Organization of Speech and Audio(Lab
ROSA
)Columbia University, New Yorkhttp://labrosa.ee.columbia.edu/
1
2
3
4
5

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 2
Sound Content Analysis
• Sound understanding: the key challenge
- what listeners do- understanding = abstraction
• Applications
- indexing/retrieval- robots- prostheses
1
0 2 4 6 8 10 12 time/s
frq/Hz
0
2000
1000
3000
4000
Voice (evil)
Stab
Rumble Strings
Choir
Voice (pleasant)
Analysis
level / dB-60
-40
-20
0

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 3
The problem with recognizing mixtures
“Imagine two narrow channels dug up from the edge of a lake, with handkerchiefs stretched across each one. Looking only at the motion of the handkerchiefs, you are to answer questions such as: How many boats are there on the lake and where are they?”
(after Bregman’90)
• Auditory Scene Analysis: describing a complex sound in terms of high-level sources/events
- ... like listeners do
• Hearing is ecologically grounded
- reflects natural scene properties = constraints- subjective, not absolute

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 4
Auditory Scene Analysis
(Bregman 1990)
• How do people analyze sound mixtures?
- break mixture into small
elements
(in time-freq)- elements are
grouped
in to sources using
cues
- sources have aggregate
attributes
• Grouping ‘rules’ (Darwin, Carlyon, ...):
- cues: common onset/offset/modulation, harmonicity, spatial location, ...
Frequencyanalysis
Groupingmechanism
Onsetmap
Harmonicitymap
Positionmap
Sourceproperties
(after Darwin, 1996)
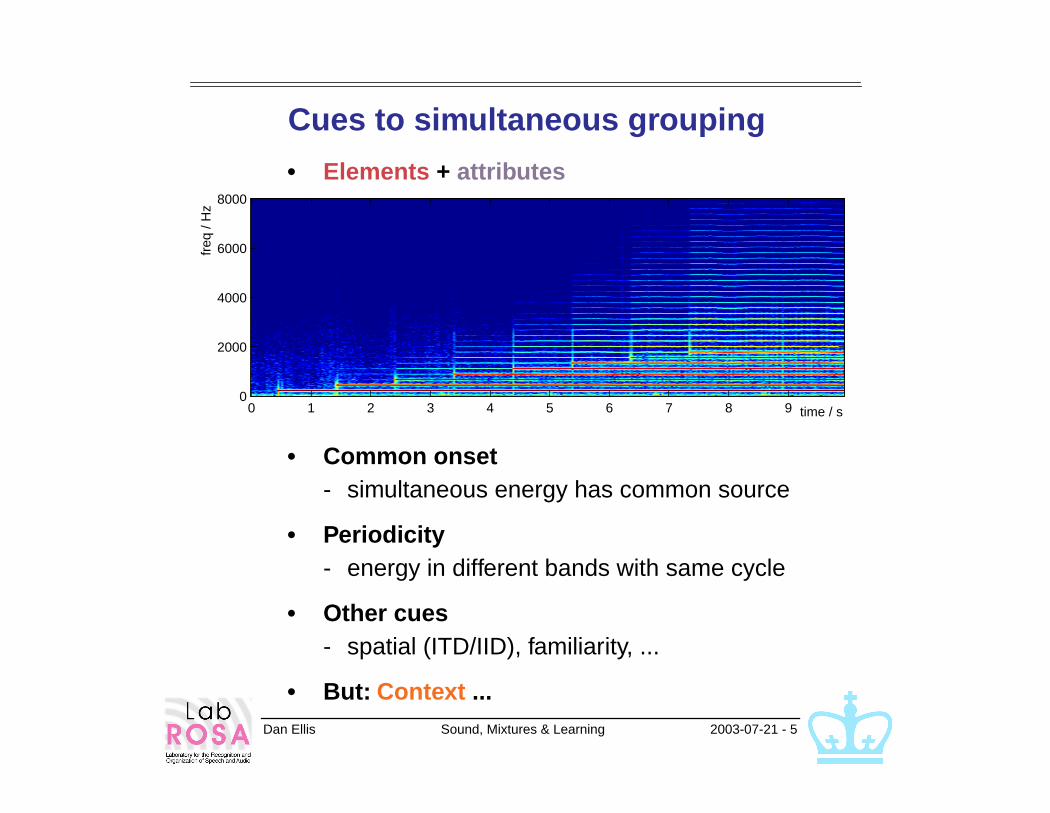
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 5
Cues to simultaneous grouping
• Elements + attributes
• Common onset
- simultaneous energy has common source
• Periodicity
- energy in different bands with same cycle
• Other cues
- spatial (ITD/IID), familiarity, ...
• But: Context ...
time / s
freq
/ H
z
0 1 2 3 4 5 6 7 8 90
2000
4000
6000
8000

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 6
Outline
Sound Content Analysis
Recognizing sounds
- Clean speech- Speech-in-noise- Nonspeech
Organizing mixtures
Accessing large datasets
Music Information Retrieval
1
2
3
4
5

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 7
Recognizing Sounds: Speech
• Standard speech recognition structure:
• How to handle additive noise?
- just train on noisy data: ‘multicondition training’
2
Featurecalculation
sound
Acousticclassifier
feature vectorsAcoustic model
parameters
HMMdecoder
Understanding/application...
phone probabilities
phone / word sequence
Word models
Language modelp("sat"|"the","cat")p("saw"|"the","cat")
s ah t
D A
T A

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 8
How ASR Represents Speech
• Markov model structure: states + transitions
• A generative model
- but not a good speech generator!
- only meant for inference of
p
(
X
|
M
)
K
A
S
0.80.18
0.9
0.1
0.02
0.9
0.1T E
0.8
0.2
M'1
O
K
A
S
0.80.05
0.9
0.1
0.15
0.9
0.1T E
0.8
0.2
O
Model M'2
0
1
2
3
4
freq
/ kH
z
10 20 30 40 50
10
20
30
40
50
State models (means) State Transition Probabilities
0 1 2 3 4 50
1
2
3
4
freq
/ kH
z
time / sec

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 9
General Audio Recognition
(with Manuel Reyes)
• Searching audio databases
- speech .. use ASR- text annotations .. search them- sound effects library?
• e.g. Muscle Fish “SoundFisher” browser
- define multiple ‘perceptual’ feature dimensions- search by proximity in (weighted) feature space
- features are global for each soundfile,no attempt to separate mixtures
Segmentfeatureanalysis
Sound segmentdatabase
Segmentfeatureanalysis
Seach/comparison
Results
Query example
Feature vectors

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 10
Audio Recognition: Results
• Musclefish corpus
- most commonly reported set
• Features
- MFCC, brightness, bandwidth, pitch ...- no temporal structure
• Results:
- 208 examples, 16 classes
Global features
: 41% corr
HMM models
: 81% corr.
Mu Sp Env An Mec Mu Sp Env An Mec
Musical
59/
4624 2 19
136/
62 1 5
Speech
11/
6 4 5 1
14/
2 5 3 1
Eviron.
7/
2 1
7/
1
Animals
2
1/
2
4/
1
Mechan
1 4 1
8/
4 3 3
12/

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 11
What are the HMM states?
• No sub-units defined for nonspeech sounds
• Final states depend structure, initialization
- number of states- initial clusters / labels / transition matrix- EM update objective
• Have ideas of what we’d like to get
- investigate features/initialization to get there
s4s7s3s4s3s4s2s3s2s5s3s2s7s3s2s4s2s3s7
1.15 1.20 1.25 1.30 1.35 1.40 1.45 1.50 1.55 1.60 1.65 1.70 1.75 1.80 1.85 1.90 1.95 2.00 2.05 2.10 2.15 2.20 2.25 2
s4s7s3s4s3s4s2s3s2s5s3s2s7s3s2s4s2s3s7
12345678
1.15 1.20 1.30 1.40 1.50 1.60 1.70 1.80 1.90 2.00 2.10 2.20 2time
freq
/ kH
z
dogBarks2

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 12
Alarm sound detection
(Ellis 2001)
• Alarm sounds have particular structure
- people ‘know them when they hear them’- clear even at low SNRs
• Why investigate alarm sounds?
- they’re supposed to be easy- potential applications...
• Contrast two systems:
- standard, global features,
P
(
X
|
M
)
- sinusoidal model, fragments,
P(M,S|Y)
time / s
hrn01 bfr02 buz01
level / dB
freq
/ kH
z
0 5 10 15 20 250
1
2
3
4
-40
-20
0
20s0n6a8+20

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 13
Alarms: Results
• Both systems commit many insertions at 0dB SNR, but in different circumstances:
20 25 30 35 40 45 50
0
6 7 8 9
time/sec0
freq
/ kH
z
1
2
3
4
0
freq
/ kH
z
1
2
3
4Restaurant+ alarms (snr 0 ns 6 al 8)
MLP classifier output
Sound object classifier output
NoiseNeural net system Sinusoid model system
Del Ins Tot Del Ins Tot
1 (amb) 7 / 25 2 36% 14 / 25 1 60%
2 (bab) 5 / 25 63 272% 15 / 25 2 68%
3 (spe) 2 / 25 68 280% 12 / 25 9 84%
4 (mus) 8 / 25 37 180% 9 / 25 135 576%
Overall 22 / 100 170 192% 50 / 100 147 197%

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 14
Outline
Sound Content Analysis
Recognizing sounds
Organizing mixtures- Auditory Scene Analysis- Parallel model inference
Accessing large datasets
Music Information Retrieval
1
2
3
4
5

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 15
Organizing mixtures:Approaches to handling overlapped sound
• Separate signals, then recognize- e.g. CASA, ICA- nice, if you can do it
• Recognize combined signal- ‘multicondition training’- combinatorics..
• Recognize with parallel models- full joint-state space?- or: divide signal into fragments,
then use missing-data recognition
3

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 16
Computational Auditory Scene Analysis:The Representational Approach
(Cooke & Brown 1993)
• Direct implementation of psych. theory
- ‘bottom-up’ processing- uses common onset & periodicity cues
• Able to extract voiced speech:
inputmixture
signalfeatures
(maps)
discreteobjects
Front end Objectformation
Groupingrules
Sourcegroups
onset
period
frq.mod
time
freq
0.2 0.4 0.6 0.8 1.0 time/s
100
150200
300400
600
1000
15002000
3000
frq/Hzbrn1h.aif
0.2 0.4 0.6 0.8 1.0 time/s
100
150200
300400
600
1000
15002000
3000
frq/Hzbrn1h.fi.aif
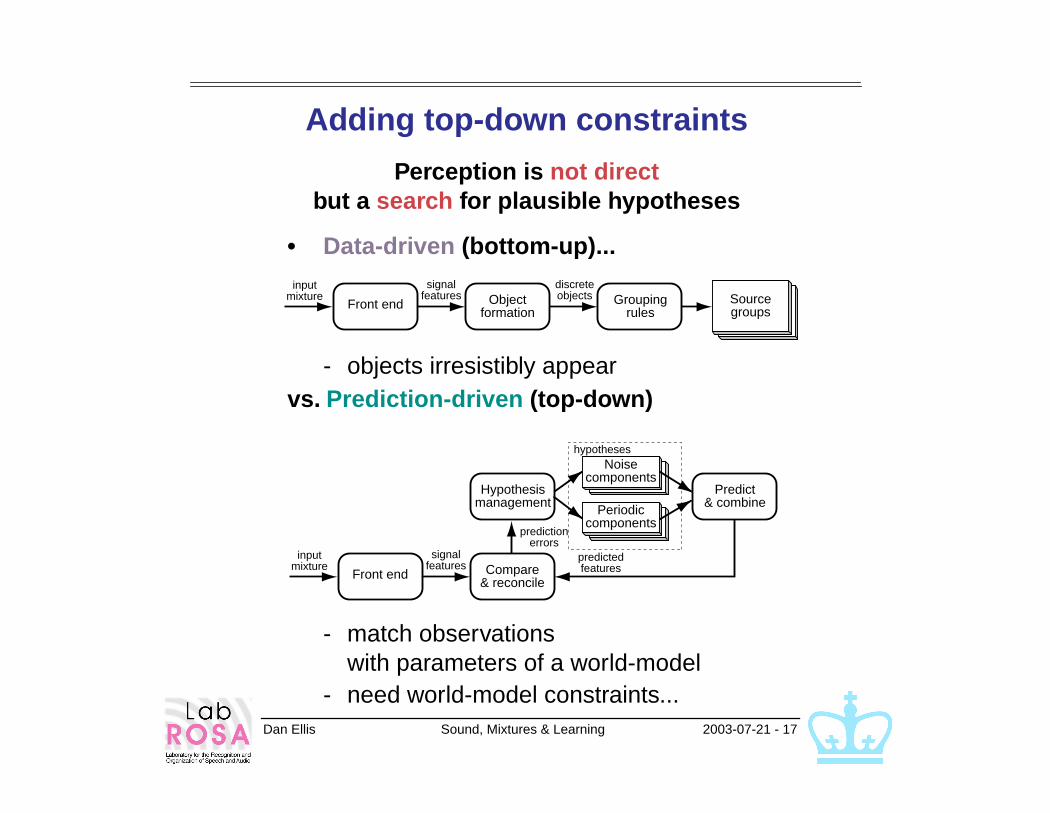
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 17
Adding top-down constraints
Perception is not directbut a search for plausible hypotheses
• Data-driven (bottom-up)...
- objects irresistibly appearvs. Prediction-driven (top-down)
- match observations with parameters of a world-model
- need world-model constraints...
inputmixture
signalfeatures
discreteobjects
Front end Objectformation
Groupingrules
Sourcegroups
inputmixture
signalfeatures
predictionerrors
hypotheses
predictedfeaturesFront end Compare
& reconcile
Hypothesismanagement
Predict& combinePeriodic
components
Noisecomponents

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 18
Prediction-Driven CASA
−70
−60
−50
−40
dB
200400
100020004000
f/Hz Noise1
200400
100020004000
f/Hz Noise2,Click1
200400
100020004000
f/Hz City
0 1 2 3 4 5 6 7 8 9
50100200400
1000
Horn1 (10/10)
Crash (10/10)
Horn2 (5/10)
Truck (7/10)
Horn3 (5/10)
Squeal (6/10)
Horn4 (8/10)Horn5 (10/10)
0 1 2 3 4 5 6 7 8 9time/s
200400
100020004000
f/Hz Wefts1−4
50100200400
1000
Weft5 Wefts6,7 Weft8 Wefts9−12

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 19
Segregation vs. Inference
• Source separation requires attribute separation- sources are characterized by attributes
(pitch, loudness, timbre + finer details)- need to identify & gather different attributes for
different sources ...
• Need representation that segregates attributes- spectral decomposition- periodicity decomposition
• Sometimes values can’t be separated- e.g. unvoiced speech- maybe infer factors from probabilistic model?
- or: just skip those values, infer from higher-level context
- do both: missing-data recognition
p O x y, ,( ) p x y, O( )→

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 20
Missing Data Recognition
• Speech models p(x|m) are multidimensional...- i.e. means, variances for every freq. channel- need values for all dimensions to get p(•)
• But: can evaluate over a subset of dimensions xk
• Hence, missing data recognition:
- hard part is finding the mask (segregation)
xk
xu
y
p(xk,xu)
p(xk|xu<y ) p(xk )
p xk m( ) p xk xu, m( ) xud∫=
P(x1 | q)
P(x | q) =
· P(x2 | q) · P(x3 | q) · P(x4 | q) · P(x5 | q) · P(x6 | q)
Present data mask
time →
dim
ensi
on →

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 21
Comparing different segregations
• Standard classification chooses between models M to match source features X
• Mixtures → observed features Y, segregation S, all related by
- spectral features allow clean relationship
• Joint classification of model and segregation:
- probabilistic relation of models & segregation
M∗ P M X( )M
argmax P X M( )P M( )P X( )--------------⋅
Margmax = =
P X Y S,( )
freq
ObservationY(f )
Segregation S
SourceX(f )
P M S Y,( ) P M( ) P X M( )P X Y S,( )
P X( )-------------------------⋅ Xd∫ P S Y( )⋅=

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 22
Multi-source decoding
• Search for more than one source
• Mutually-dependent data masks
• Use e.g. CASA features to propose masks- locally coherent regions
• Lots of issues in models, representations, matching, inference...
Y(t)
S1(t)q1(t)
S2(t)q2(t)

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 23
Outline
Sound Content Analysis
Recognizing sounds
Organizing mixtures
Accessing large datasets- Spoken documents- The Listening Machine- Music preference modeling
Music Information Retrieval
1
2
3
4
5

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 24
Accessing large datasets:The Meeting Recorder Project
(with ICSI, UW, IDIAP, SRI, Sheffield)
• Microphones in conventional meetings- for summarization / retrieval / behavior analysis- informal, overlapped speech
• Data collection (ICSI, UW, IDIAP, NIST):
- ~100 hours collected & transcribed
• NSF ‘Mapping Meetings’ project
4

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 25
Meeting IR tool
• IR on (ASR) transcripts from meetings
- ASR errors have limited impact on retrieval
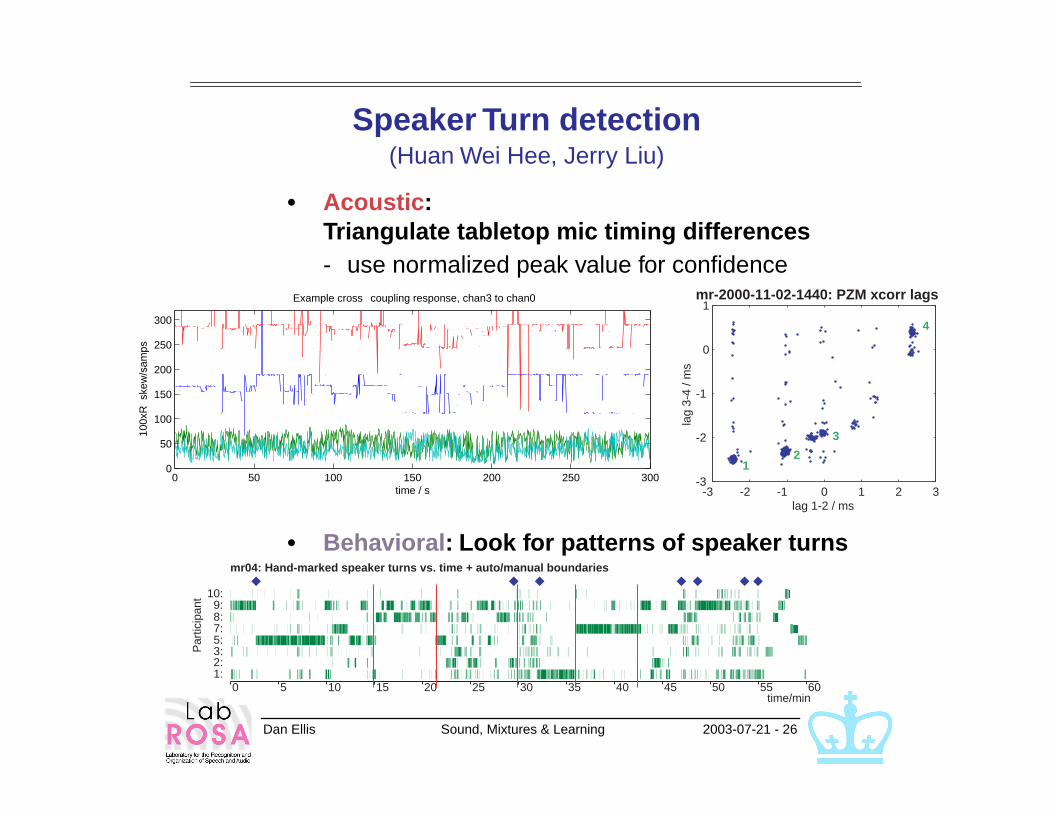
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 26
Speaker Turn detection(Huan Wei Hee, Jerry Liu)
• Acoustic: Triangulate tabletop mic timing differences- use normalized peak value for confidence
• Behavioral: Look for patterns of speaker turns
-3 -2 -1 0 1 2 3-3
-2
-1
0
1
lag 1-2 / ms
lag
3-4
/ ms
mr-2000-11-02-1440: PZM xcorr lags
4
12
3
0 50 100 150 200 250 3000
50
100
150
200
250
300
time / s
100x
R s
kew
/sam
ps
Example cross coupling response, chan3 to chan0
3:
8:
10:9:
7:5:
2:1:
0 5 10 15 20 25 30 35 40 45 50 55 60
mr04: Hand-marked speaker turns vs. time + auto/manual boundaries
Pa
rtic
ipa
nt
time/min

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 27
Speech/nonspeech detection(Williams & Ellis 1999)
• ASR run over entire soundtracks?- for nonspeech, result is nonsense
• Watch behavior of speech acoustic model:- average per-frame entropy- ‘dynamism’ - mean-squared 1st-order difference
• 1.3% error on 2.5 second speech-music testset
0 0.05 0.1 0.15 0.2 0.25 0.3Dynamism
Dynamism vs. Entropy for 2.5 second segments of speecn/music
0
0.5
1
1.5
2
2.5
3
3.5
Ent
ropy
Speech Music Speech+Music
0
2000
4000
frq/Hz
0 2 4 6 8 10 12 time/s0
20
40
Spectrogram
Posteriors
speech music speech+music

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 28
The Listening Machine
• Smart PDA records everything
• Only useful if we have index, summaries- monitor for particular sounds- real-time description
• Scenarios
- personal listener → summary of your day- future prosthetic hearing device- autonomous robots
• Meeting data, ambulatory audio

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 29
Personal Audio
• LifeLog / MyLifeBits / Remembrance Agent:Easy to record everything you hear
• Then what?- prohibitively time consuming to
search- but .. applications if access easier
• Automatic content analysis / indexing...
50 100 150 200 2500
2
4
14:30 15:00 15:30 16:00 16:30 17:00 17:30 18:00 18:30
5
10
15
freq
/ H
zfr
eq /
Bar
k
time / min
clock time

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 30
Outline
Sound Content Analysis
Recognizing sounds
Organizing mixtures
Accessing large datasets
Music Information Retrieval- Anchor space- Playola browser
1
2
3
4
5

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 31
Music Information Retrieval
• Transfer search concepts to music?- “musical Google”- finding something specific / vague / browsing- is anything more useful than human annotation?
• Most interesting area: finding new music- is there anything on mp3.com that I would like?- audio is only information source for new bands
• Basic idea:Project music into a space where neighbors are “similar”
• Also need models of personal preference- where in the space is the stuff I like- relative sensitivity to different dimensions
• Evaluation problems- requires large, shareable music corpus!
5
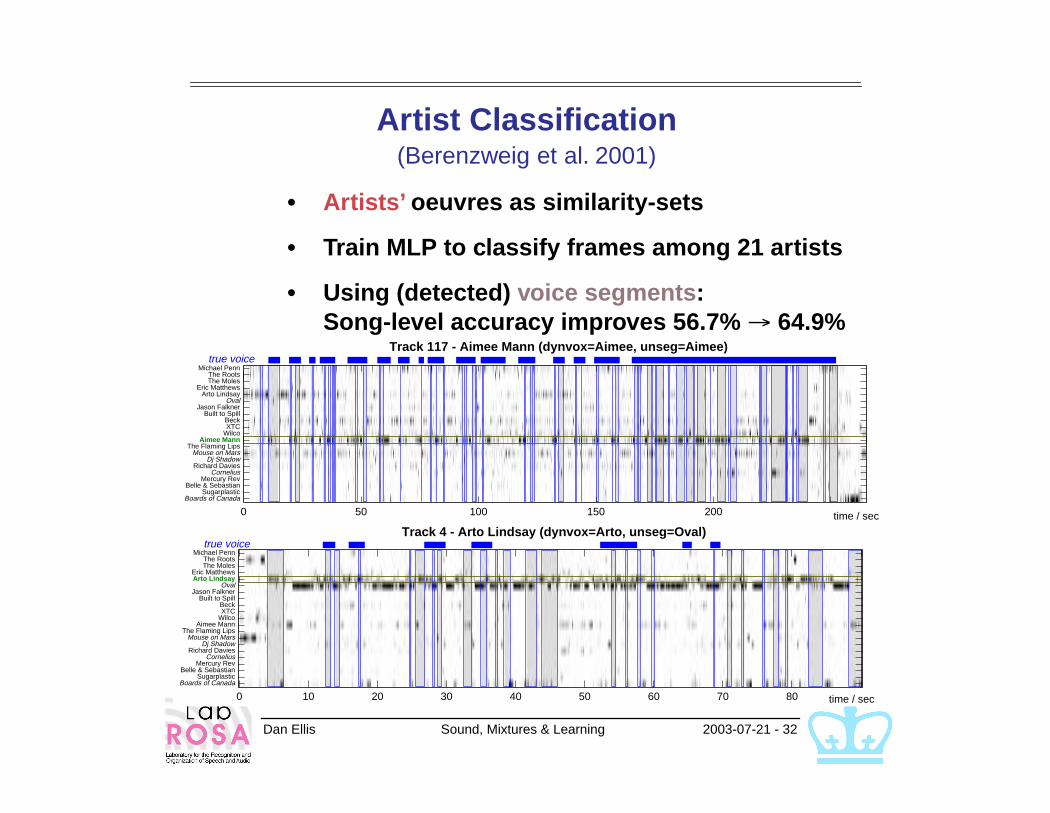
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 32
Artist Classification(Berenzweig et al. 2001)
• Artists’ oeuvres as similarity-sets
• Train MLP to classify frames among 21 artists
• Using (detected) voice segments:Song-level accuracy improves 56.7% → 64.9%
0 10 20 30 40 50 60 70 80
Boards of CanadaSugarplastic
Belle & SebastianMercury Rev
CorneliusRichard Davies
Dj ShadowMouse on Mars
The Flaming LipsAimee Mann
WilcoXTCBeck
Built to SpillJason Falkner
OvalArto LindsayEric Matthews
The MolesThe Roots
Michael Penntrue voice
time / sec
Track 4 - Arto Lindsay (dynvox=Arto, unseg=Oval)
0 50 100 150 200
Boards of CanadaSugarplastic
Belle & SebastianMercury Rev
CorneliusRichard Davies
Dj ShadowMouse on Mars
The Flaming LipsAimee Mann
WilcoXTCBeck
Built to SpillJason Falkner
OvalArto Lindsay
Eric MatthewsThe MolesThe Roots
Michael Penntrue voice
time / sec
Track 117 - Aimee Mann (dynvox=Aimee, unseg=Aimee)

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 33
Artist Similarity
• Recognizing work from each artist is all very well...
• But: what is similarity between artists?
- pattern recognition systems give a number...
• Need subjective ground truth:Collected via web site
www.musicseer.com
• Results:- 1,000 users, 22,300 judgments collected over 6 months
backstreet_boys
whitney_
new_ron_carter
a
all_saints
annie_lennox
aqua
belinda_carlislers
celine_dionchristina_aguilera
eiffel_65
erasure
miroquai
janet_jacksonjessica_simpson lara_fabian
lauryn_hill
madonna
mariah_carey
nelly_furtado
pet_shop_boys
pr
roxette
sade
wain
sof
spice_girls
toni_braxtone
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 34
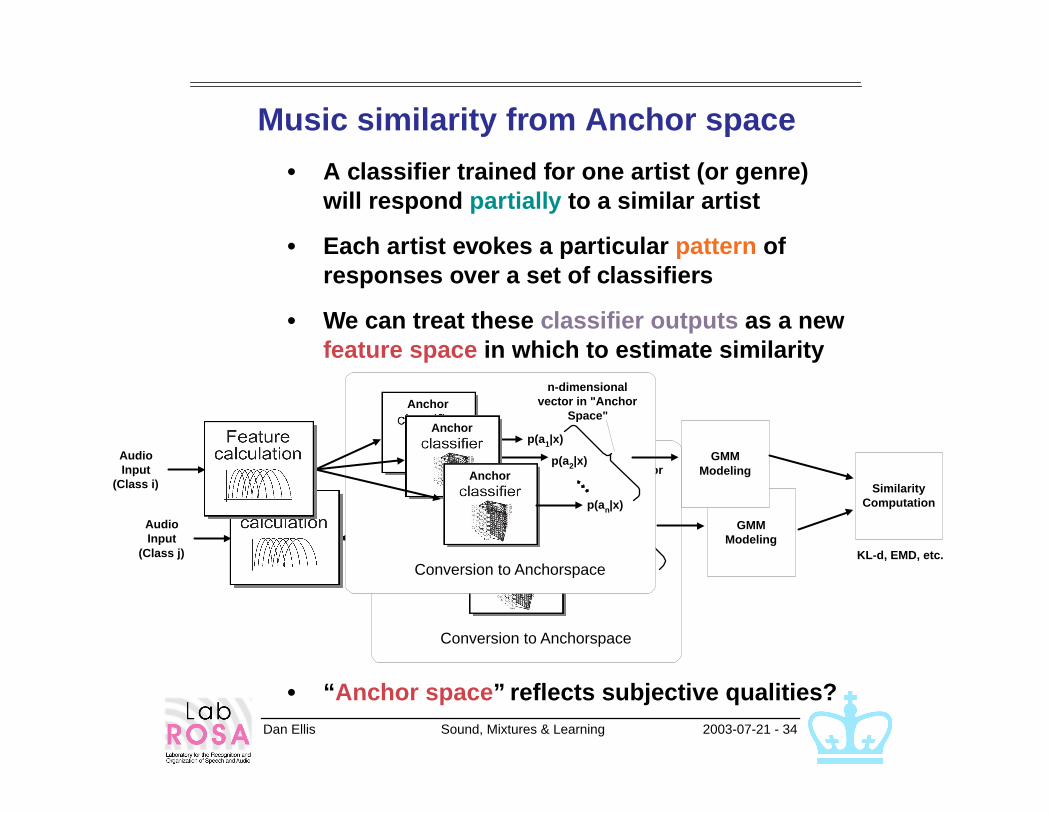
Music similarity from Anchor space
• A classifier trained for one artist (or genre) will respond partially to a similar artist
• Each artist evokes a particular pattern of responses over a set of classifiers
• We can treat these classifier outputs as a new feature space in which to estimate similarity
• “Anchor space” reflects subjective qualities?
n-dimensionalvector in "Anchor
Space"Anchor
Anchor
Anchor
AudioInput
(Class j)
p(a1|x)
p(a2|x)
p(an|x)
GMMModeling
Conversion to Anchorspace
n-dimensionalvector in "Anchor
Space"Anchor
Anchor
Anchor
AudioInput
(Class i)
p(a1|x)
p(a2|x)
p(an|x)
GMMModeling
Conversion to Anchorspace
SimilarityComputation
KL-d, EMD, etc.
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 35
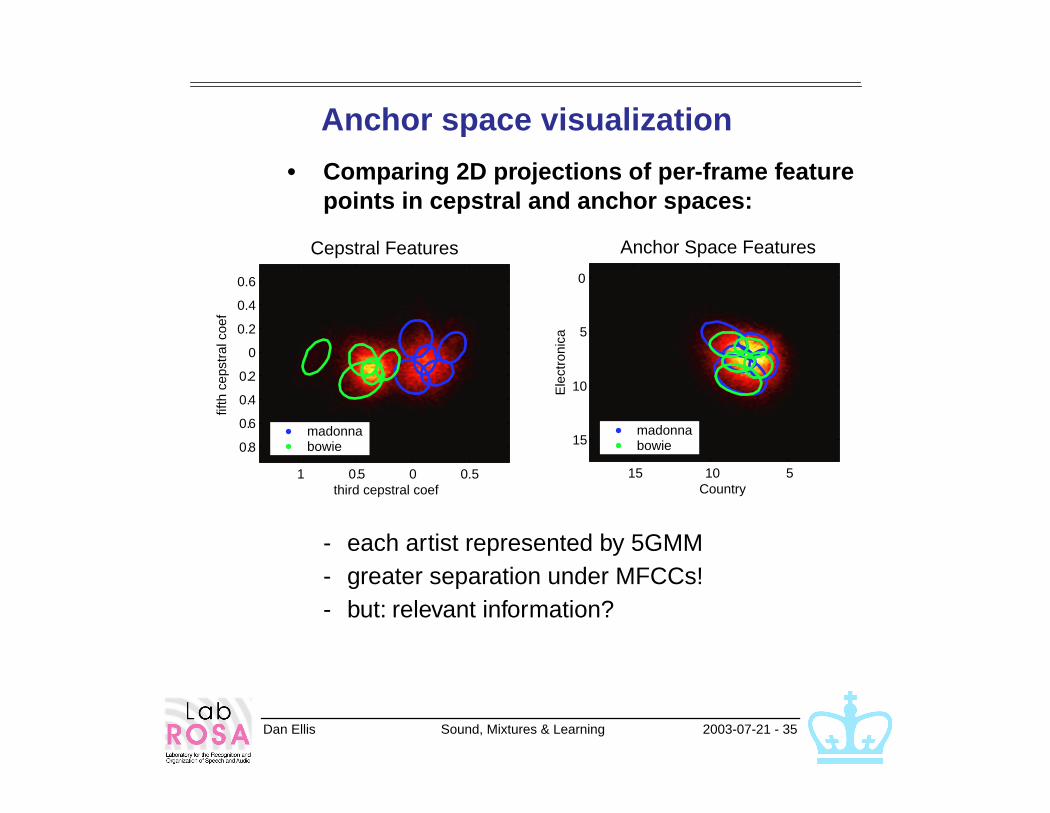
Anchor space visualization
• Comparing 2D projections of per-frame feature points in cepstral and anchor spaces:
- each artist represented by 5GMM- greater separation under MFCCs!- but: relevant information?
third cepstral coef
fifth
cep
stra
l coe
f
madonnabowie
Cepstral Features
1 0.5 0 0.5
0.8
0.6
0.4
0.2
0
0.2
0.4
0.6
Country
Ele
ctro
nica
madonnabowie
10
5
Anchor Space Features
15 10 5
15
0
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 36
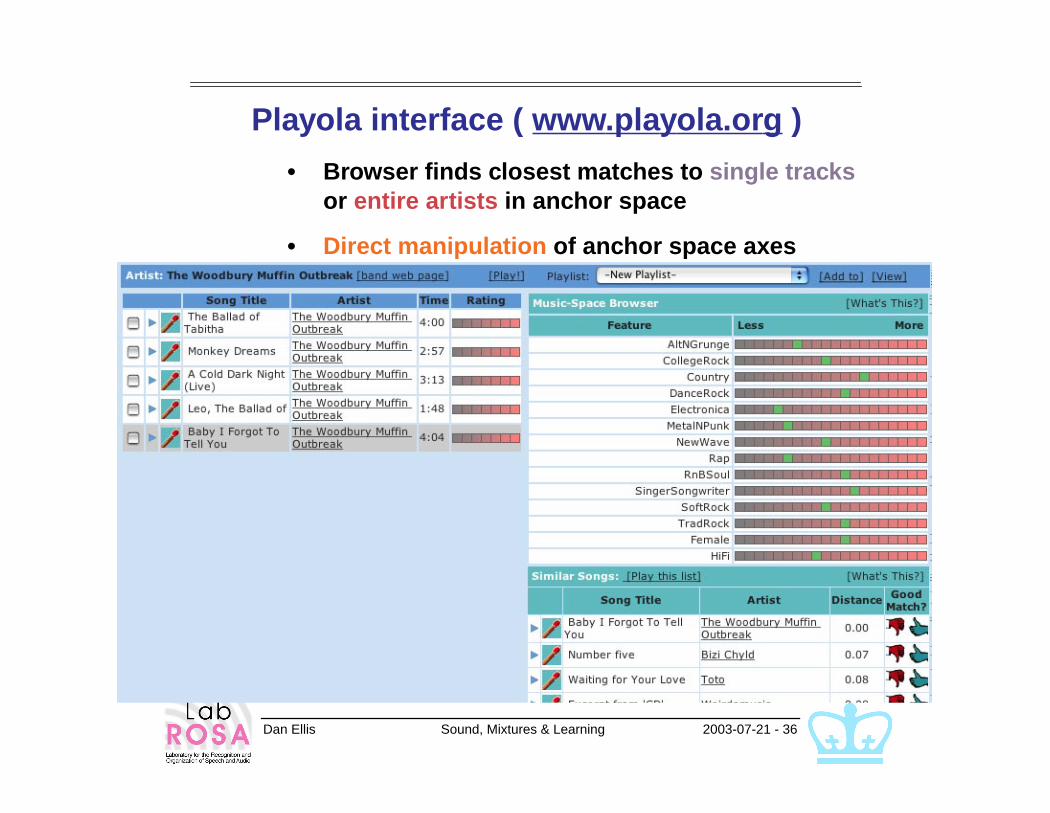
Playola interface ( www.playola.org )
• Browser finds closest matches to single tracks or entire artists in anchor space
• Direct manipulation of anchor space axes
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 37
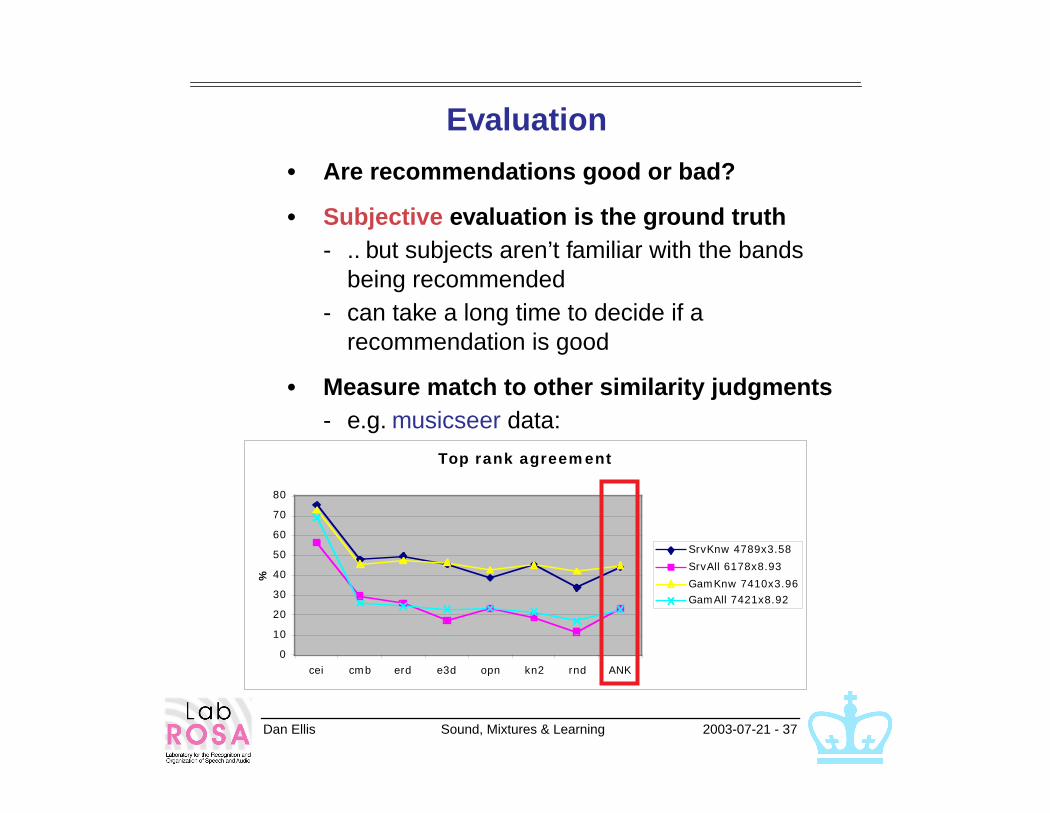
Evaluation
• Are recommendations good or bad?
• Subjective evaluation is the ground truth- .. but subjects aren’t familiar with the bands
being recommended- can take a long time to decide if a
recommendation is good
• Measure match to other similarity judgments- e.g. musicseer data:
Top rank agreement
0
10
20
30
40
50
60
70
80
cei cmb erd e3d opn kn2 rnd ANK
%
SrvKnw 4789x3.58
SrvAll 6178x8.93
GamKnw 7410x3.96GamAll 7421x8.92

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 38
Summary
• Sound- .. contains much, valuable information at many
levels- intelligent systems need to use this information
• Mixtures- .. are an unavoidable complication when using
sound- looking in the right time-frequency place to find
points of dominance
• Learning- need to acquire constraints from the
environment- recognition/classification as the real task

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 39
LabROSA Summary
DO
MA
INS
AP
PLI
CA
TIO
NS
ROSA
• Broadcast• Movies• Lectures
• Meetings• Personal recordings• Location monitoring
• Speech recognition• Speech characterization• Nonspeech recognition
• Object-based structure discovery & learning
• Scene analysis• Audio-visual integration• Music analysis
• Structuring• Search• Summarization• Awareness• Understanding

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 40
Extra Slides

Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 41
Independent Component Analysis (ICA)(Bell & Sejnowski 1995 et seq.)
• Drive a parameterized separation algorithm to maximize independence of outputs
• Advantages:- mathematically rigorous, minimal assumptions- does not rely on prior information from models
• Disadvantages:- may converge to local optima...- separation, not recognition- does not exploit prior information from models
m1m2
s1s2
a11a21
a12a22
x
−δ MutInfoδa





























