Embed Size (px)
Citation preview

Slide 1
Archive Computing: Scalable Computing Environments
on Very Large Archives
Andreas J. Wicenec13-June-2002

Slide 2
Processing? Yes, but where?
Knowledge Grid
Information Grid
Data Grid
Knowledge Grid ?Knowledge Discovery
Information Grid ?Information Discovery
Data Grid ?Data Reduction

Slide 3
VO Ready Archives
Are our archives VO ready??Resource and service descriptions are TBD and data quality standards/descriptions are not yet defined.
There is no standard for the description of instrument modes and capabilities, nor for filters, grisms and other relevant optical elements.
Once VO data standards have been established, the metadata has to be extracted from the archives or determined.
This potentially means reducing all the data to a certain degree and to manually add a lot of observatory information.

Slide 4
Scalable Archive Computing:Why?
Process ScalingArchive QC Increase of data sourcesOn-the-fly Increase of accessAdd-on parameters(regular)
Increase of data sources
Maintenance Increase of hardwareAdd-on parameters(new)
Volume
Data health check VolumeLarge scale processing VolumeData migration VolumeCross-correlation Volume

Slide 5
Scalable Archive Computing: Actors
Two major customer groups:
A)Archive internalhealth checking, archive QC, data migration, metadata extraction, preview and master calibration production.
B)External users or systemsOn-the-fly reduction, cross-correlation, archive retrieval and visualization, VO

Slide 6
Scalable Archive Computing:How?
Just 'add' a couple of the following buzzwords to NGAS:
GRID, WebServices, UDDI, SOAP, dynamic process distribution
MPI, GDFS, Gigabit Ethernet, Myrinet
What is NGAS: Next Generation Archive System:
Archiving system, which scales like the controlled data volume, i.e. archiving and retrieval time is independent from total data volume.

Slide 7
Data (pull)
Client
NGASUnit
Client
Data
AR
CH
IVE
req
ues
t
RE
TR
IVE
req
ues
t
●NGAS messages are delivered through HTTP using XML●All NGAS commands are implemented as standard URLs
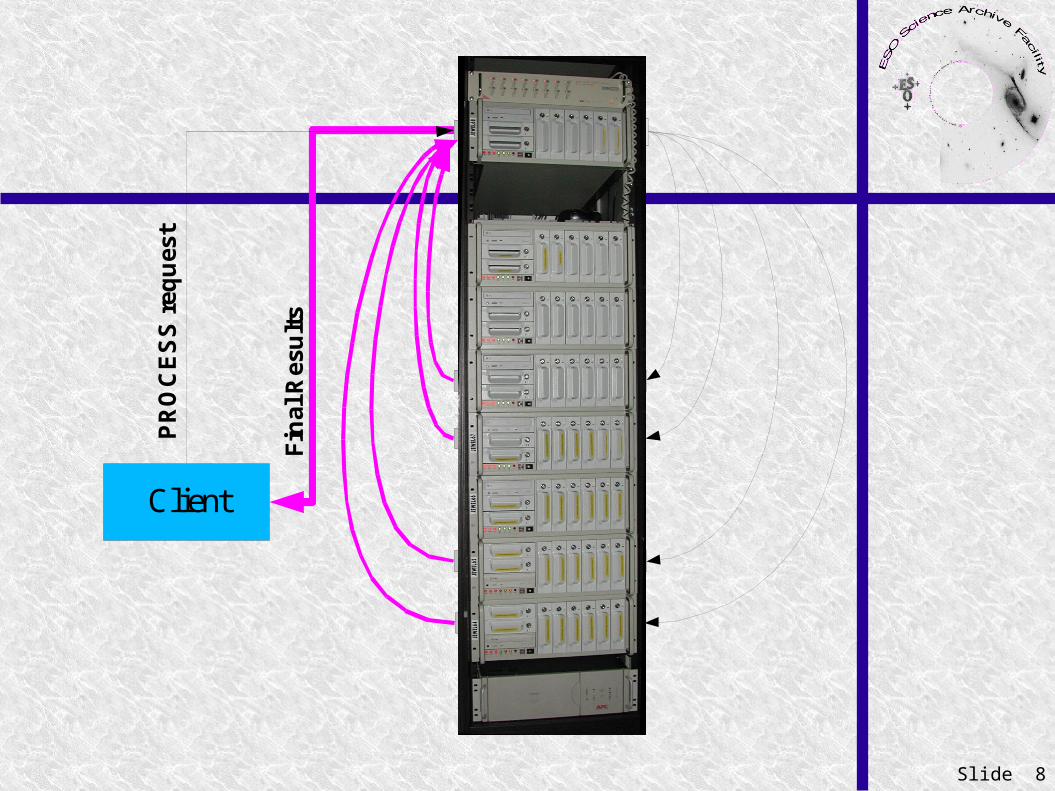
Slide 8
Client
PR
OC
ES
S r
equ
est
Fin
al R
esu
lts

Slide 9
NGAS Processing
PROCESS (http PUT) request passing XML in the body.
PROCESS commands have to be registered in the NGAS config, but else they are just executed in threads as shell commands.
NGAS master forwards PROCESS command to the node which holds the data.
Tested with small pipeline producing preview frames.
Future: Implement processing recipe for optimization of resource usage.
Far Future: Implement possible usage of MPI.

Slide 10
Scaling
Primitive example: The NGAS units are calculating checksums on all the files every second day. This process took about 10 hours when we had the first complete unit (~ 10000 frames). It takes now 10 hours as well (86000 frames)!
With careful hardware, software and process configuration this kind of scaling is possible even for complicated processing requests.
With smart data distribution and process data flow control it can be improved.

Slide 11
Connection to VO
Initially NGAS provides the lowest level of VO data processing exactly where the bulk of the data is.
Idle cycles can be offered to higher level processing.
NGAS will publish registered commands as web services through an auth/auth interface (GRID).
Data can be reduced and the results directly archived. Results are immediately available in the VO context, i.e. fully asynchronous, very large scale reduction is possible.

Slide 12
Access --- Data
Archive access is modulated through low level description of the data using known types and units:Example: Access to a specific pixel of an image is usually done through sky coordinates, not in the native pixel space. Metadata provides conversion between the coordinate systems.Problem: Metadata might be incomplete, i.e. conversion inaccurate.
VO access is modulated through high level description of services and resources using TBD types and units. Problem: Another layer of metadata, might be even more incomplete, i.e. conversion impossible or simply wrong!
Metadata

Slide 13
VO ComputingMetadata
Archive Computing
Metadata for processing description??!!
Feasible: Single reduction steps.
What's about complete pipelines with parts running on machines around the world?? Sounds like a metadata and configuration nightmare!

Slide 14
Conclusion
NGAS can provide a scalable archive and processing environment.
Using this we have to clean our house first → make ESO/ECF archives VO compliant, i.e. process most of the data.
NGAS does not impose any constraint on the kind of data it handles and the data is still in normal files and on a standard file system.
Offering 'VO processing' capabilities seems to be very challenging.





























