Embed Size (px)
Citation preview

Sharpe-optimal SPDR portfoliosor
How to beat the marketand sleep well at night
by
Vic NortonBowling Green State University
Bowling Green, Ohio 43402-2223USA
mailto:[email protected]://vic.norton.name

Abstract
The Sharpe Ratio of an investment portfolio is, loosely speak-ing, the ratio of its reward to its risk. We seek portfolios ofmaximum Sharpe Ratio from a fixed universe of ExchangeTraded Funds (Select Sector SPDRs).
It is convenient to look at this problem in a geometric set-ting. Then a portfolio is identified with its risk vector in ahigh-dimensional Euclidean space, and the Sharpe Ratio ofthe portfolio is proportional to the cosine of the angle be-tween the risk vector and an expected-reward axis. Now weseek to maximize this cosine (and thus the Sharpe Ratio)over a convex polytope of portfolios. The maximization isaccomplished by a simplex-type algorithm using updatedQR-factorizations.

Sharpe Ratio
The Sharpe Ratio of an investment is the ratio of its ex-pected reward to its risk. The higher the Sharpe ratio thebetter. William F. Sharpe introduced the Sharpe Ratio (byanother name) in 1966.
http://www.stanford.edu/~wfsharpe/art/sr/sr.htm
In 1990 Sharpe won the Nobel Prize for Economics for hisCapital Asset Pricing Model, sharing the prize with HarryMarkowitz and Merton Miller. Together, their work revolu-tionized the financial/business industries.
– 2006 New York Times Almanac

Select Sector SPDRs
The Select Sector SPDRs (pronounced “spiders”) are ETFs(Exchange Traded Funds) that partition the S&P 500 (U.S.large-cap stocks) into 9 categories:
XLY – Consumer DiscretionaryXLP – Consumer StaplesXLE – EnergyXLF – FinancialXLV – Health CareXLI – IndustrialXLB – MaterialsXLK – TechnologyXLU – Utilities
http://www.sectorspdr.com

Investment Strategy
How to beat the market and sleep well at night.
One investment strategy:Invest your money in the current ex post Sharpe-optimal-long SPDR portfolio, SOLNG. Check your investment portfo-lio at the end of each week. When its Sharpe Ratio divergesfrom the Sharpe Ratio of the ex post SOLNG portfolio bymore than 30%, reinvest in the ex post SOLNG portfolio.
Other strategies might include deleveraging with the basefund or reinvesting in the Sharpe-optimal-long-short port-folio SOLS0, especially when the prospects for pure longinvestment are suspect.
Sharpe-Optimal SPDR Portfolios Website:http://vic.norton.name/finance-math/sospdr

Investment Portfolio SOLNG

Investment Portfolio SOLNGB

Investment Portfolio SOMIX

Overwrought Portfolio SOLNGW
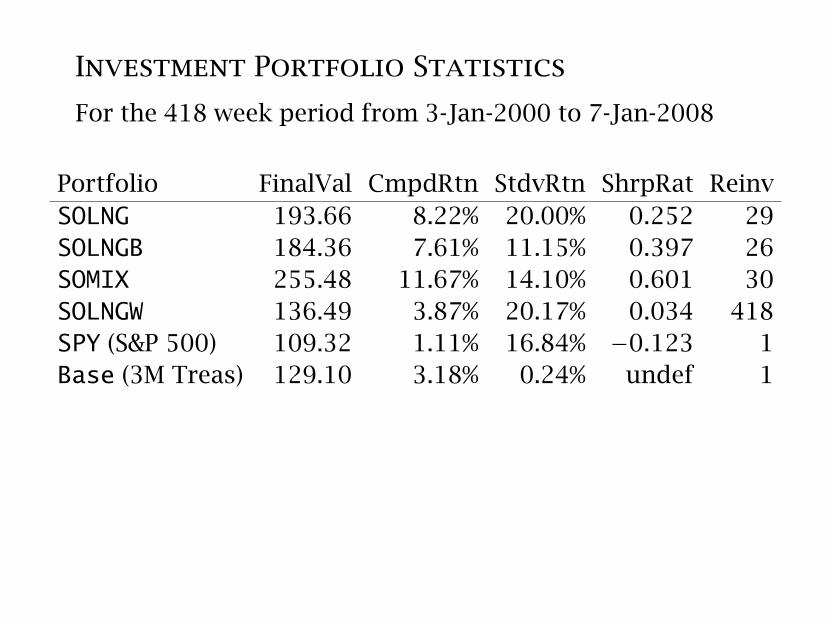
Investment Portfolio Statistics
For the 418 week period from 3-Jan-2000 to 7-Jan-2008
Portfolio FinalVal CmpdRtn StdvRtn ShrpRat ReinvSOLNG 193.66 8.22% 20.00% 0.252 29SOLNGB 184.36 7.61% 11.15% 0.397 26SOMIX 255.48 11.67% 14.10% 0.601 30SOLNGW 136.49 3.87% 20.17% 0.034 418SPY (S&P 500) 109.32 1.11% 16.84% −0.123 1Base (3M Treas) 129.10 3.18% 0.24% undef 1

Portfolio Calculator (Saturday, 29-Dec-2007)
XLE: 700 @ $80.37, XLI: 300 @ $39.34, XLB: 600 @ $41.95
http://vic.norton.name/finance-math/sospdr/pcalc

Portfolio Calculator
(Saturday, 29-Dec-2007)
http://vic.norton.name/finance-math/sospdr/pcalc

Mathematics Begins (more or less)
>Agewmètrhtoc mhdeÈc eÊsÐtw
Let no one ignorant of geometry enter here
– inscription above the gateway to Plato’s Academy

Returns
risky fund return vector: r ∈ Rmbase fund return vector: r0 ∈ Rm
Examples
ri =pipi+13
− 1
13-week simple return.Here pi is the adjusted closingprice of the risky fund at the endof week i (with week indices in-creasing toward the past).
r0,i = 152
∑12k=0y
3Mi+k
13-week average return.Here y3M
i is the average annual-ized yield on a 3-month Treasurybill (secondary market, discountbasis) over week i.

Data
Historical Adjusted Closing Priceshttp://finance.yahoo.com/
Historical Interest Rateshttp://federalreserve.gov/Releases/h15/data.htm

Reward and the Sharpe Ratio
weights: µi (i = 1, . . . ,m), µi > 0,∑µi = 1 (fixed)
reward vector: w = r− r0 ∈ Rmexpected reward: w =
∑µiwi
variance of reward: v =∑µi(wi −w)2
standard deviation of reward: σ = √v (risk)
Sharpe Ratio: s = wσ
(expected reward
risk
)

Weights
µi (i = 1, . . . ,m), µi > 0,∑µi = 1
m = 39
1/39
0.01
0.02
0.03
0.04
00 13 26 39

Root-Weighted Reward
root-weights: βi=√µi (i = 1, . . . ,m)
root-weight vector: β = [β1, . . . , βm]T ∈ Rm, ‖β‖ = 1root-weight matrix: B = diagβ ∈ Rm×m
root-weighted reward vector: z = Bwexpected reward: w = βTzrisk vector: f = z−βwvariance of reward: v = ‖f‖2
standard deviation of reward: σ = ‖f‖ (risk)
Sharpe Ratio: s = wσ
(expected reward
risk
)

(Root-Weighted) Reward Space
1
w = βTz
σ = ‖f‖
β
z=B
w
f = z−βwRisk
Hyperplane
Expected
Reward
0
Sharpe Ratio: s = wσ
(expected reward
risk
)

Risk Space and Expected Reward
Risky fund universe: F1, . . . , Fn (9 Select Sector SPDRs)Fund risk vectors: f1, . . . , fn ∈ Rm (linearly independent)Risk matrix: F = [f1, . . . , fn] ∈ Rm×n (rank n)
Risk space: F = span(f1, . . . , fn) = range(F) (dimension n)
Fund expected rewards: w1, . . . ,wn
Expected reward vector: e = F(FTF)−1
w1...wn
∈ Fsatisfies
eT[f1, . . . , fn] = [w1, . . . ,wn]
Thus expected reward is a linear function of risk:
w = eT f ( f = F p )

Portfolios of Risky Funds
Portfolio: p = [p1, . . . , pn]T ,∑nj=1 |pj| = 1
pj is the signed proportion of fund Fj in the portfolio:
pj > 0: shares of fund Fj bought longpj < 0: shares of fund Fj sold shortpj = 0: no investment in fund Fj
Example
Fund Shares Price Value PortfolioF1 500 $20.10 $10,050.00 21.3%F2 −300 $37.40 −$11,220.00 −23.7%F3 0.0%F4 800 $32.50 $26,000.00 55.0%
Nominal Value $47,270.00 100.0%

Simple Necessity
Portfolio: p = [p1, . . . , pn]T ,∑nj=1 |pj| = 1
Simple rates work well with portfolios:
1+ r 4t =∑nj=1 |pj|[1+ sign(pj)rj4t]
where
r =∑nj=1pjrj
Compound rates do not:
exp(r 4t) =∑nj=1 |pj| exp[sign(pj)rj4t]
where
r = 14t log
{∑nj=1 |pj| exp[sign(pj)rj4t]
}Here r is the rate of return on the portfolio (simpleor compound) resulting from the individual fund ratesr1, . . . , rn.

Portfolio in Risk Space
w = eTf
ef =F
p
Expected
Reward
ER = 00
P
θto
tal risk
non-productive
risk
productive
risk
Sharpe Ratio: s = wσ= S(p) = eT f
‖f‖ = ‖e‖ cosθ
Productivity quotient: Q(p) = cosθ = productive risktotal risk

Sharpe-Optimal Portfolios
The Sharpe-optimal long-short portfolio SOLS1:
SOLS1 = x /∑nj=1 |xj|, x = (FTF)−1
w1...wn
Moreover S(SOLS1) = ‖e‖.
The Sharpe-optimal long portfolio SOLNG:
Maximize cosθ = eT f
‖e‖‖f‖for f = F p,
∑nj=1pj = 1, pj ≥ 0 (j = 1, . . . , n).
Then SOLNG = pmax , S(SOLNG) = ‖e‖max(cosθ),
and Q(SOLNG) =max(cosθ) = S(SOLNG)/S(SOLS1).

Productivity Quotient of SOLNG

Caveat
Our definition of reward implies that short money receivedis invested in the base fund, just as base fund money isused for long investments. The corresponding Sharpe Ra-tio has been denoted by S, with Sharpe-optimal long-shortportfolio SOLS1.
This situation does not generally apply to small investors,who receive no interest on short money received. We de-note the corresponding Sharpe Ratio by S0, with Sharpe-optimal long-short portfolio SOLS0.
Then
≤ S(SOLS0) ≤ S(SOLS1)S(SOLNG) ≤ S0(SOLS1) ≤ S0(SOLS0)

How to maximize a cosine
by
Vic NortonBowling Green State University
Bowling Green, Ohio 43402-2223USA
mailto:[email protected]://vic.norton.name

Abstract
Given a unit m-vector u and a nonzero m × n matrix F ,we describe a simplex-type algorithm, using updated QRfactorizations, to maximize the cosine function
cosu(P) = (uTP)/‖P‖on the convex hull of the columns of F . The maximizingpoint Pmax is returned in the form
Pmax = FJ p ,
where J is a sequence of nJ distinct indices from {1, . . . , n},the nJ columns of FJ are linearly independent, and p is annJ-vector satisfying
∑p = 1, p > 0.

Picture of the Algorithm – Scenario 1

Picture of the Algorithm – Scenario 2

End of Talk
This is the end of my talk (except for some technical mumbojumbo that I might gloss over).
Thanks for listening!

QR-Decomposition
QR = FJ = [A,B,C]the QR-decomposition of FJ:QTQ = I, R upper-triangular,nonsingular
u+ = F+J u = R−1QTuthe FJ-coordinates of the projec-tion of u onto the range of FJ
Q = FJ (u+/∑
u+)the unique critical point of cosu
restricted to the affine subspacespanned by the columns of FJ

To Add a Vertex (e.g., at P1)
QR = FJ = [A,B]. To add vertex (column) C:
Set
r = QTC, x = C−Qr, s = ‖x‖, q = r/s .
Then replace
Q :=[Q q
], R :=
[R r0T s
], J := [J, index of C],
To get
QR = FJ = [A,B,C].

To Remove a Vertex (e.g., at P2)
QR = FJ = [A,B,C]. To remove vertex (column) A:
Let Q0 = Q and set J := [index of B, index of C].
Then
FJ = [B,C] = Q0
R0∗ ∗∗ ∗0 ∗
= Q1
R1∗ ∗0 ∗0 ∗
= Q2
R2∗ ∗0 ∗0 0
,whereQj = Qj−1GTj , Rj = GjRj−1, and GTj Gj = I (j = 1,2).
(The Gj are called “Givens rotations.”)
SetQ := Q2 with the last column removed and R := R2 withthe last row removed. Then
QR = FJ = [B,C].

Octave Code for Removal of a Vertex
## remove column i of nJi f i < nJ
R( 1 : nJ , i : nJ−1) = R( 1 : nJ , i +1:nJ ) ;J ( i : nJ−1) = J ( i +1:nJ ) ;## do Givens rotat ions to remove subdiagonal## elements of R and adjust Q accordinglyfor j = i : nJ−1
[ cs , sn ] = givens (R( j , j ) , R( j +1 , j ) ) ;G = [ cs , sn ; −sn , cs ] ; # Givens rotationR( j : j +1 , j : nJ−1) = G * R( j : j +1 , j : nJ−1);Q( : , j : j +1) = Q( : , j : j +1) * G ’ ;
endforendifnJ −= 1;

Really the End
Goodbye!!!





























