Embed Size (px)
Citation preview

Protein analysis and proteomics
September 27, 2006
Introduction to BioinformaticsJ. Pevsner

Many of the images in this powerpoint presentationare from Bioinformatics and Functional Genomicsby J Pevsner (ISBN 0-471-21004-8). Copyright © 2003 by Wiley.
These images and materials may not be usedwithout permission from the publisher.
Visit http://www.bioinfbook.org
Copyright notice

Outline for the course
Today (Sept. 27): protein analysis and proteomics, part IFriday, Sept. 29: lab 4 (proteomics)Monday, October 2: no classWednesday October 4: protein structure, part I
October 9: protein structure, part II (Ingo Ruczinski)October 11: multiple sequence alignment (Sarah Wheelan)October 16, 18: phylogeny
Wednesday, October 25: final exam; find-a-gene due

Outline for today
Protein analysis and proteomics
Individual proteinsProtein familiesPhysical propertiesLocalization Function
Large-scale protein analysis2D protein gelsYeast two-hybridRosetta Stone approachPathways

protein
Page 224
RNADNA
protein
[1] Protein families
Page 224

protein
[1] Protein families
[2] Physical properties
Page 224

protein
[1] Protein families
[2] Physical properties
[3] Protein localization
Page 224
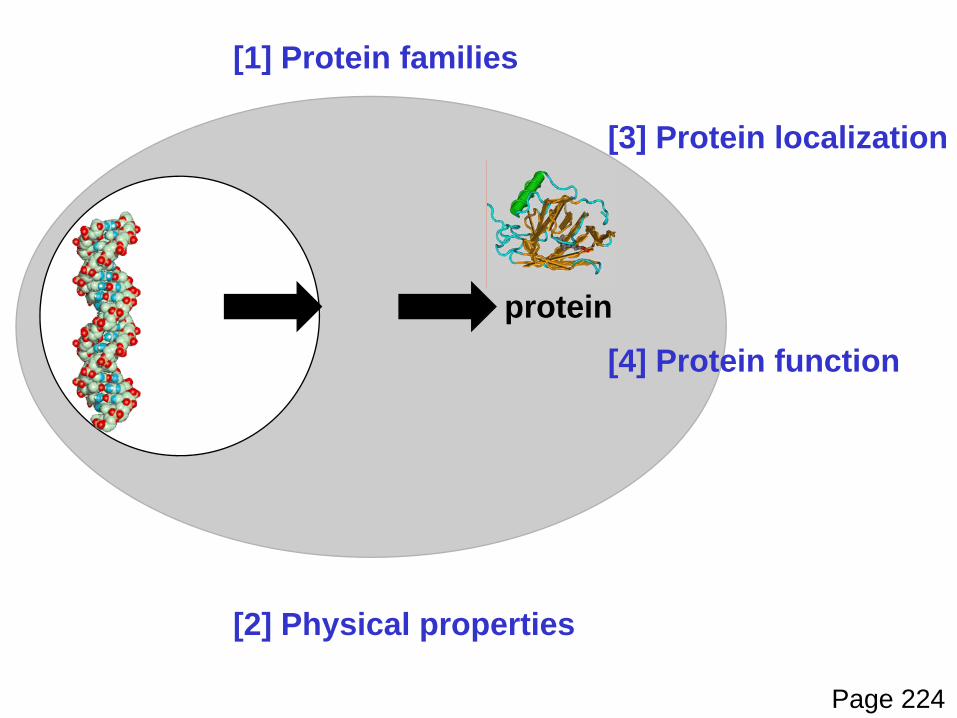
protein
[1] Protein families
[4] Protein function
[2] Physical properties
[3] Protein localization
Page 224

protein
[1] Protein families
[4] Protein function
[2] Physical properties
[3] Protein localization
Gene ontology (GO):--cellular component--biological process--molecular function
Page 224

Perspective 1: Protein domains and motifs
Page 225

Definitions
Signature:• a protein category such as a domain or motif
Page 225

Definitions
Signature:• a protein category such as a domain or motif
Domain:• a region of a protein that can adopt a 3D structure• a fold• a family is a group of proteins that share a domain• examples: zinc finger domain
immunoglobulin domain
Motif (or fingerprint):• a short, conserved region of a protein• typically 10 to 20 contiguous amino acid residues
Page 225

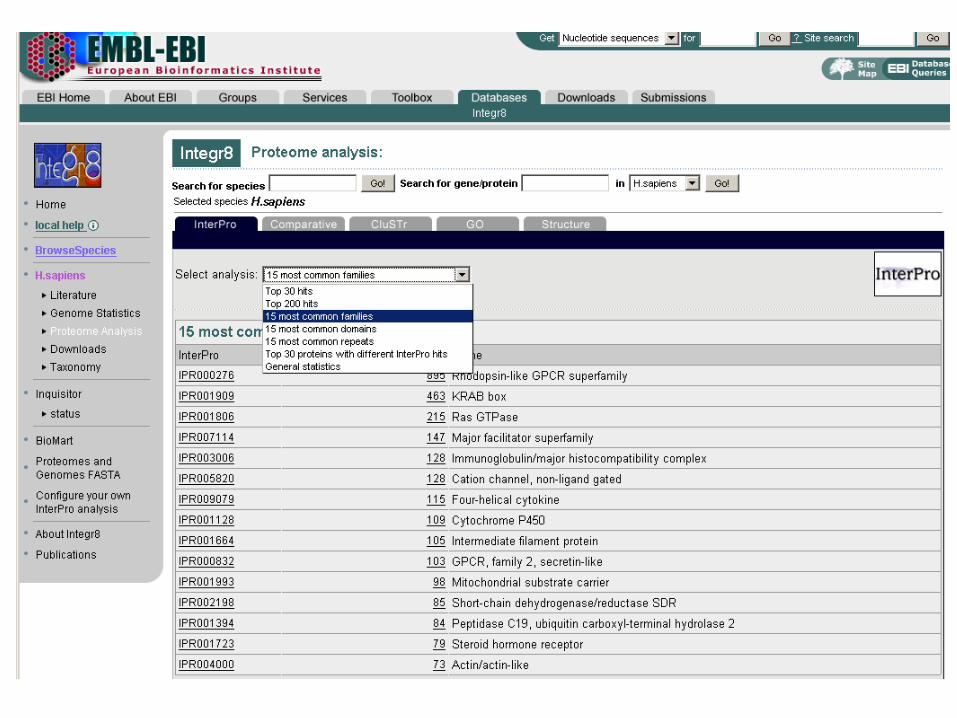
15 most common domains (human)
Zn finger, C2H2 type 1093 proteinsImmunoglobulin 1032EGF-like 471Zn-finger, RING 458Homeobox 417Pleckstrin-like 405RNA-binding region RNP-1 400SH3 394Calcium-binding EF-hand 392Fibronectin, type III 300PDZ/DHR/GLGF 280Small GTP-binding protein 261BTB/POZ 236bHLH 226Cadherin 226 Page 227

15 most common domains (various species)
The European Bioinformatics Institute (EBI) offers many key proteomics resources at the Integr8 site:
http://www.ebi.ac.uk/proteome/
Page 227

Definition of a domain
According to InterPro at EBI (http://www.ebi.ac.uk/interpro/):
A domain is an independent structural unit, found aloneor in conjunction with other domains or repeats.Domains are evolutionarily related.
According to SMART (http://smart.embl-heidelberg.de):
A domain is a conserved structural entity with distinctivesecondary structure content and a hydrophobic core.Homologous domains with common functions usuallyshow sequence similarities.
Page 226

Varieties of protein domains
Page 228
Extending along the length of a protein
Occupying a subset of a protein sequence
Occurring one or more times

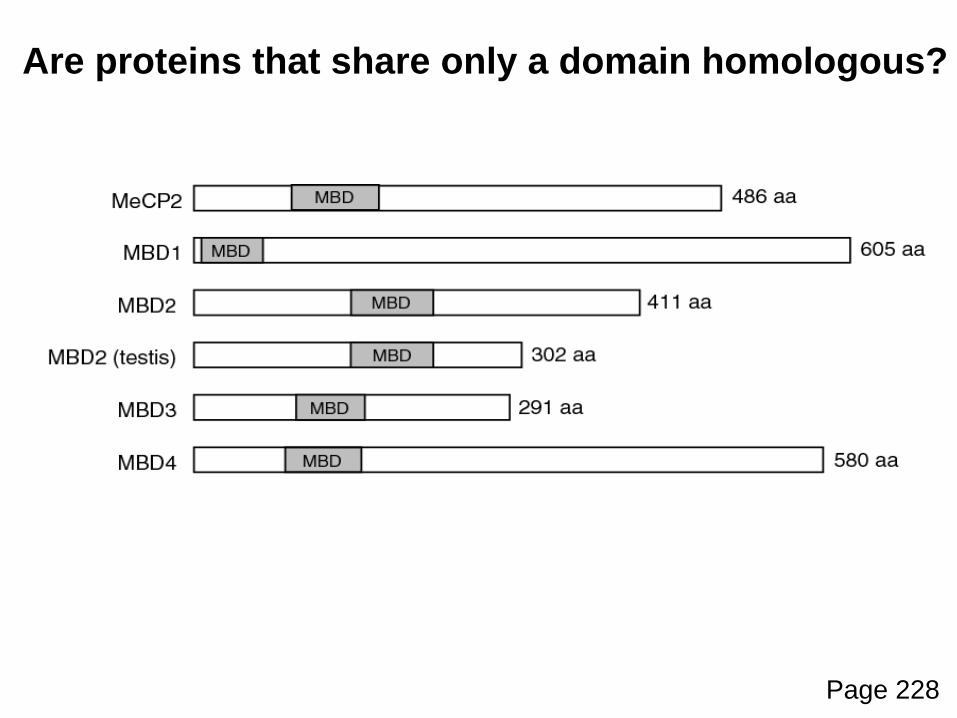
Example of a protein with domains: Methyl CpG binding protein 2 (MeCP2)
MBD
Page 227
TRD
The protein includes a methylated DNA binding domain(MBD) and a transcriptional repression domain (TRD).MeCP2 is a transcriptional repressor.
Mutations in the gene encoding MeCP2 cause RettSyndrome, a neurological disorder affecting girlsprimarily.

Page 228
Result of an MeCP2 blastp search:A methyl-binding domain shared by several proteins
Page 228
Are proteins that share only a domain homologous?

Example of a multidomain protein: HIV-1 pol
• 1003 amino acids long
• cleaved into three proteins with distinct activities:-- aspartyl protease-- reverse transcriptase-- integrase
We will explore HIV-1 pol and other proteins at theExpert Protein Analysis System (ExPASy) server.
Visit www.expasy.org/
Page 229

Page 230


Page 230
SwissProt entry for HIV-1 pol links to many databases
Page 231
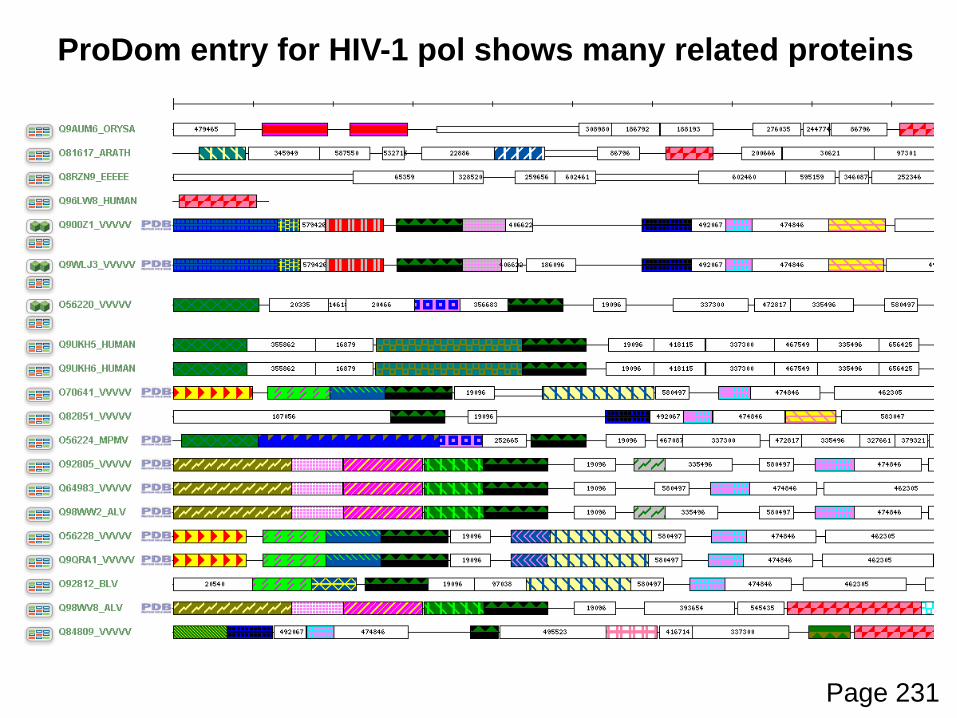
ProDom entry for HIV-1 pol shows many related proteins

Page 231
Proteins can have both domains and patterns (motifs)
Domain(aspartylprotease)
Domain(reversetranscriptase)
Pattern(severalresidues)
Pattern(severalresidues)

Page 232

Definition of a motif
A motif (or fingerprint) is a short, conserved region of a protein. Its size is often 10 to 20 amino acids.
Simple motifs include transmembrane domains andphosphorylation sites. These do not imply homologywhen found in a group of proteins.
PROSITE (www.expasy.org/prosite) is a dictionary of motifs (there are currently 1600 entries). In PROSITE,a pattern is a qualitative motif description (a proteineither matches a pattern, or not). In contrast, a profileis a quantitative motif description. We will encounterprofiles in Pfam, ProDom, SMART, and other databases.
Page 231-233

Perspective 2: Physical properties of proteins
Page 233

Page 234

Physical properties of proteins
Many websites are available for the analysis ofindividual proteins. ExPASy and ISREC are twoexcellent resources.
The accuracy of these programs is variable. Predictions based on primary amino acid sequence (such as molecular weight prediction) are likely to be more trustworthy. For many other properties (such asposttranslational modification of proteins by specific sugars), experimental evidence may be required rather than prediction algorithms.
Page 236

Page 235

Page 235

Page 235

Page 236
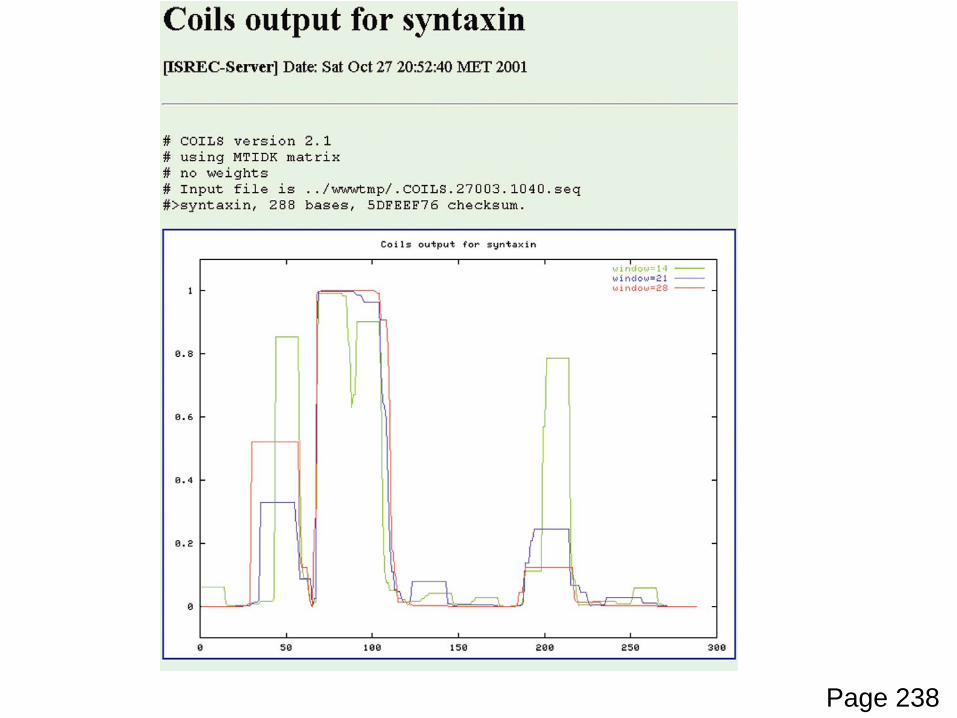
Page 238

Page 238

Page 238

Syntaxin, SNAP-25 and VAMP are three proteins that interact via coiled-coil domains

Introduction to Perspectives 3 and 4: Gene Ontology (GO) Consortium
Page 237

The Gene Ontology Consortium
An ontology is a description of concepts. The GOConsortium compiles a dynamic, controlled vocabularyof terms related to gene products.
There are three organizing principles: Molecular functionBiological processCellular compartment
You can visit GO at http://www.geneontology.org.There is no centralized GO database. Instead, curatorsof organism-specific databases assign GO termsto gene products for each organism.
Page 237

Page 241
GO terms are assigned to Entrez Gene entries
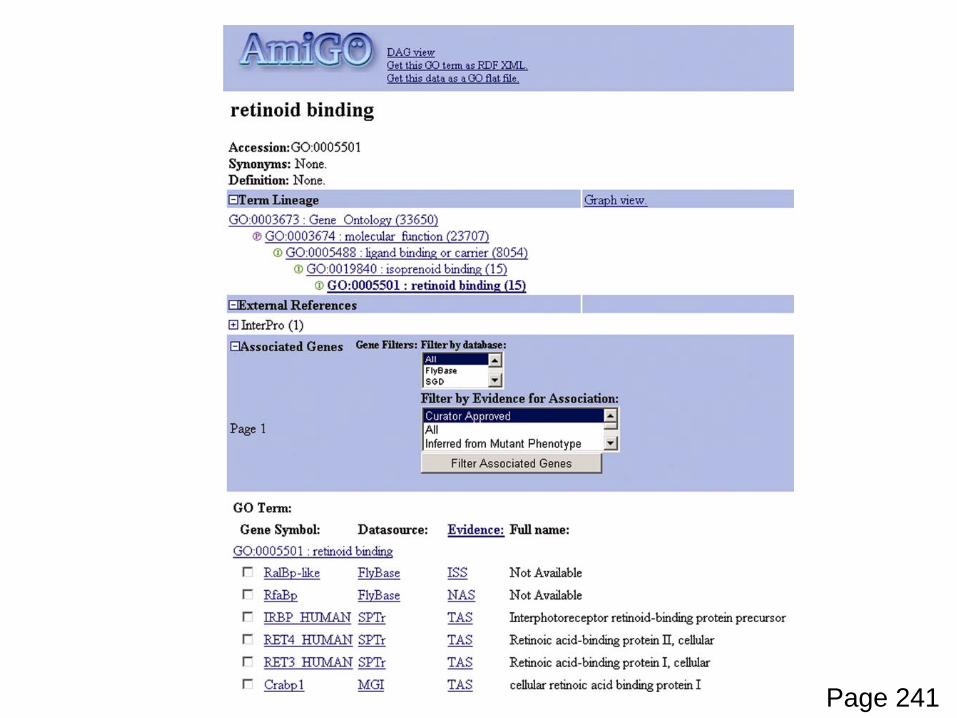
Page 241

Page 241
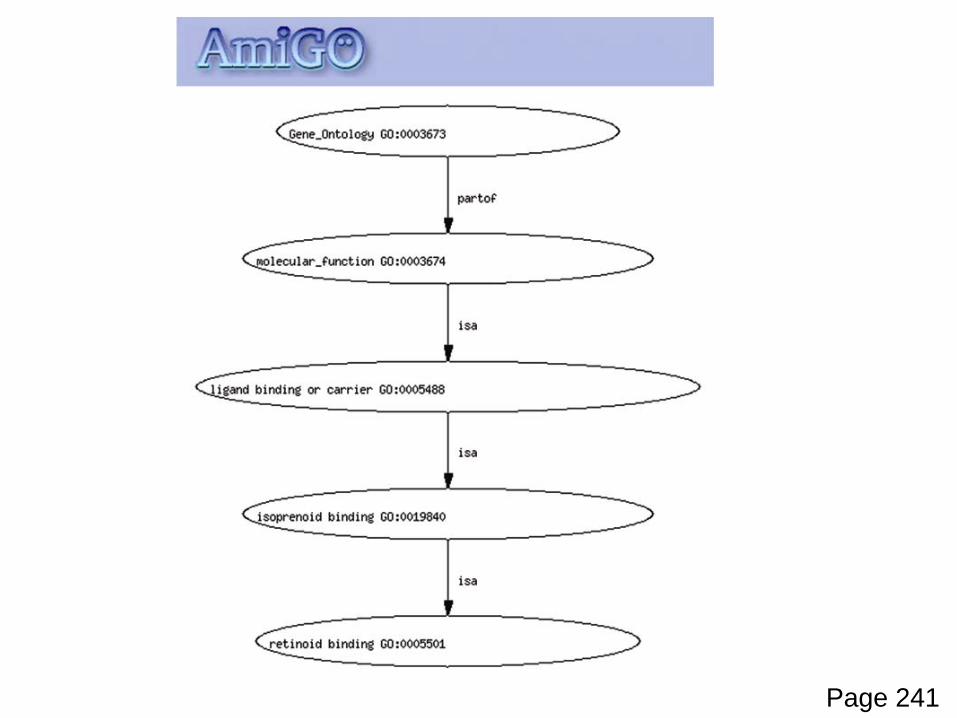
Page 241

The Gene Ontology Consortium: Evidence Codes
IC Inferred by curatorIDA Inferred from direct assayIEA Inferred from electronic annotationIEP Inferred from expression patternIGI Inferred from genetic interactionIMP Inferred from mutant phenotypeIPI Inferred from physical interactionISS Inferred from sequence or structural similarityNAS Non-traceable author statementND No biological dataTAS Traceable author statement
Page 240

Perspective 3: Protein localization
Page 242

protein
Protein localization
Page 242

Protein localization
Proteins may be localized to intracellular compartments,cytosol, the plasma membrane, or they may be secreted. Many proteins shuttle between multiple compartments.
A variety of algorithms predict localization, but thisis essentially a cell biological question.
Page 240

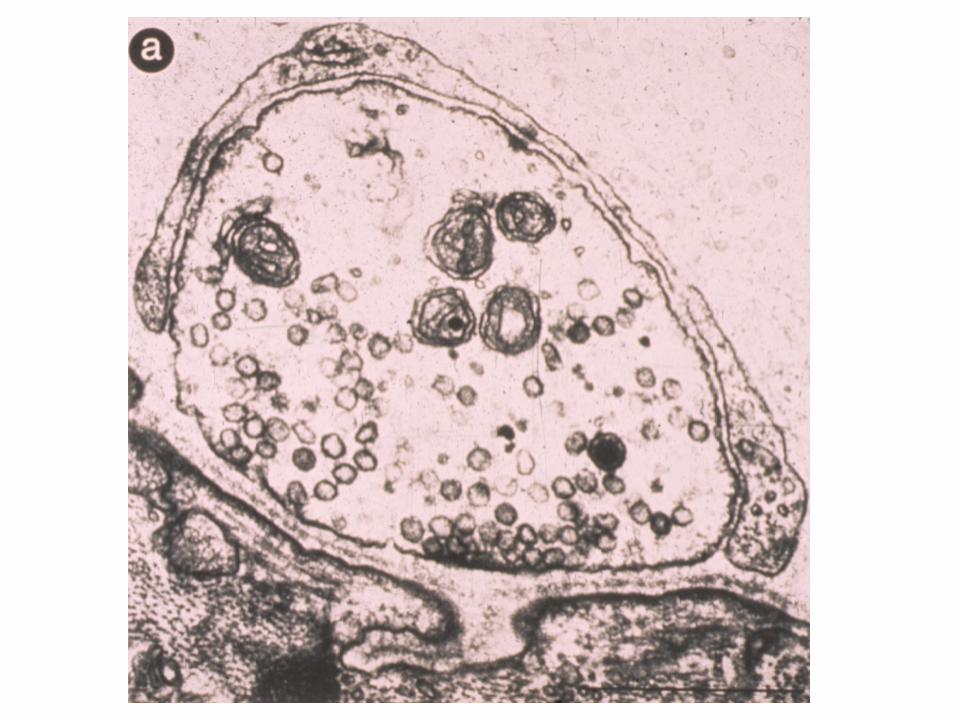

Page 242
Page 244

Page 244

Localization of 2,900 yeast proteins
Michael Snyder and colleagues incorporated epitopetags into thousands of S. cerevisiae cDNAs,and systematically localized proteins (Kumar et al., 2002).
See http://ygac.med.yale.edu for the TRIPLES database including 2,900 fluorescence micrographs.
Page 243

Perspective 4: Protein function
Page 243

Protein function
Function refers to the role of a protein in the cell.We can consider protein function from a varietyof perspectives.
Page 243

1. Biochemical function(molecular function)
RBP binds retinol,could be a carrier
Page 245
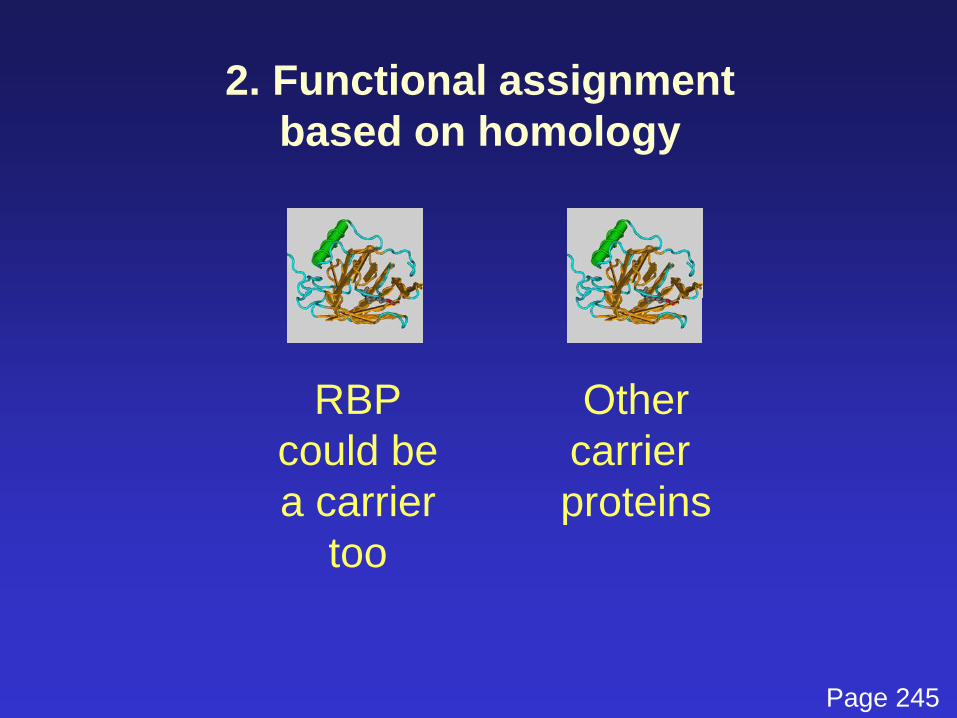
2. Functional assignmentbased on homology
RBPcould bea carrier
too
Othercarrier proteins
Page 245

3. Functionbased on structure
RBP forms a calyx
Page 245

4. Function based onligand binding specificity
RBP binds vitamin A
Page 245
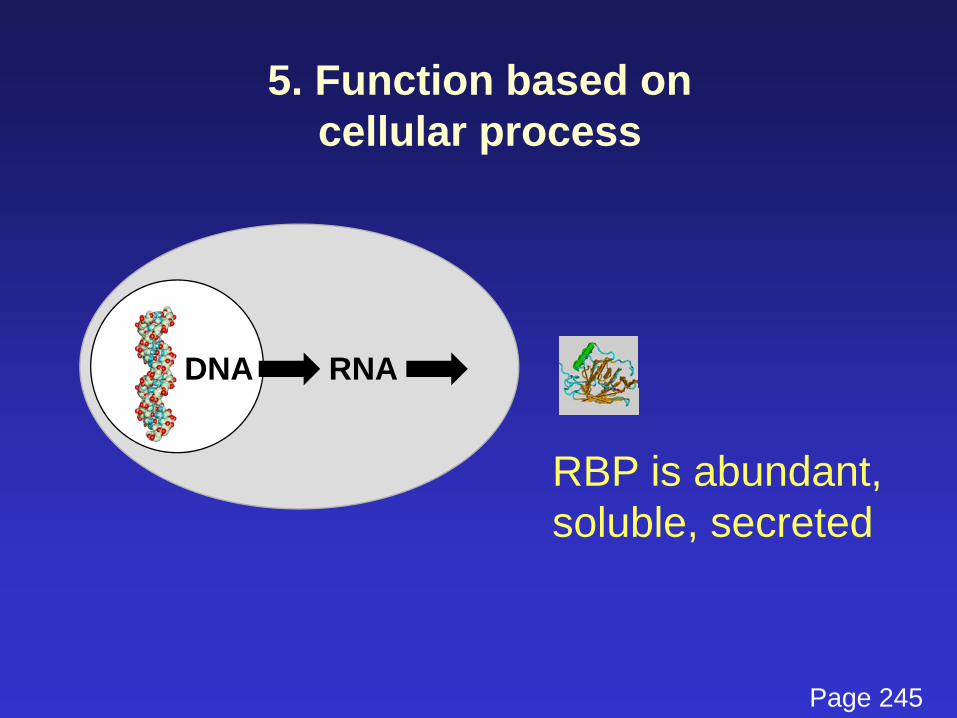
5. Function based oncellular process
DNA RNA
RBP is abundant,soluble, secreted
Page 245

6. Function basedon biological process
RBP is essential for vision
Page 245

7. Function based on “proteomics”or high throughput “functional genomics”
High throughput analyses show...
RBP levels elevated in renal failureRBP levels decreased in liver disease
Page 245

Functional assignment of enzymes:the EC (Enzyme Commission) system
Oxidoreductases 1,003Transferases 1,076Hydrolases 1,125Lyases 356Isomerases 156Ligases 126
Page 246

Functional assignment of proteins:Clusters of Orthologous Groups (COGs)
Information storage and processing
Cellular processes
Metabolism
Poorly characterized
Page 247

Functional assignment of proteins:Clusters of Orthologous Groups (COGs)
Information storage and processing
Cellular processes
Metabolism
Poorly characterized
(Most useful for prokaryotes; we will describe COGs in the Genomics course)
Page 247

Proteomics: High throughput protein analysis
Proteomics is the study of the entire collection of proteins encoded by a genome
“Proteomics” refers to all the proteins in a celland/or all the proteins in an organism
Large-scale protein analysis2D protein gelsYeast two-hybridRosetta Stone approachPathways
Page 247

Classical biochemical approach
Identify an activityDevelop a bioassayPerform a biochemical purification
Strategies: size, charge, hydrophobicityPurify protein to homogeneityClone cDNA, express recombinant protein
Grow crystals, solve structure (next Wednesday)Page 247

Two-dimensional protein gels
First dimension: isoelectric focusing
Second dimension: SDS-PAGE
Page 248

Page 249

Two-dimensional protein gels
First dimension: isoelectric focusing
Electrophorese ampholytes to establisha pH gradient
Can use a pre-made strip
Proteins migrate to their isoelectric point(pI) then stop (net charge is zero)
Range of pI typically 4-9 (5-8 most common)
Page 248

Two-dimensional protein gels
Second dimension: SDS-PAGE
Electrophorese proteins through an acrylamidematrix
Proteins are charged and migrate through an electric field v = Eq / d6πrη
Conditions are denaturing
Can resolve hundreds to thousands of proteins
Page 248

Page 249

Proteins identified on 2D gels (IEF/SDS-PAGE)
Direct protein microsequencing byEdman degradations
-- done at Hopkins, other cores-- typically need 5 picomoles-- often get 10 to 20 amino acids sequenced
Protein mass analysis by MALDI-TOF
-- done at core facilities-- often detect posttranslational
modifications-- matrix assisted laser desorption/ionization
time-of-flight spectroscopy
Page 250-1

Page 252

Page 253

Page 253

Page 254

Evaluation of 2D gels (IEF/SDS-PAGE)
Advantages:Visualize hundreds to thousands of proteinsImproved identification of protein spots
Disadvantages:Limited number of samples can be processedMostly abundant proteins visualizedTechnically difficult
Page 251

Affinity chromatography/mass spec
Bait proteinGST
Page 252

Affinity chromatography/mass spec
Bait proteinGST
Add yeast extractProtein complexes bindMost proteins do not bind
Page 252
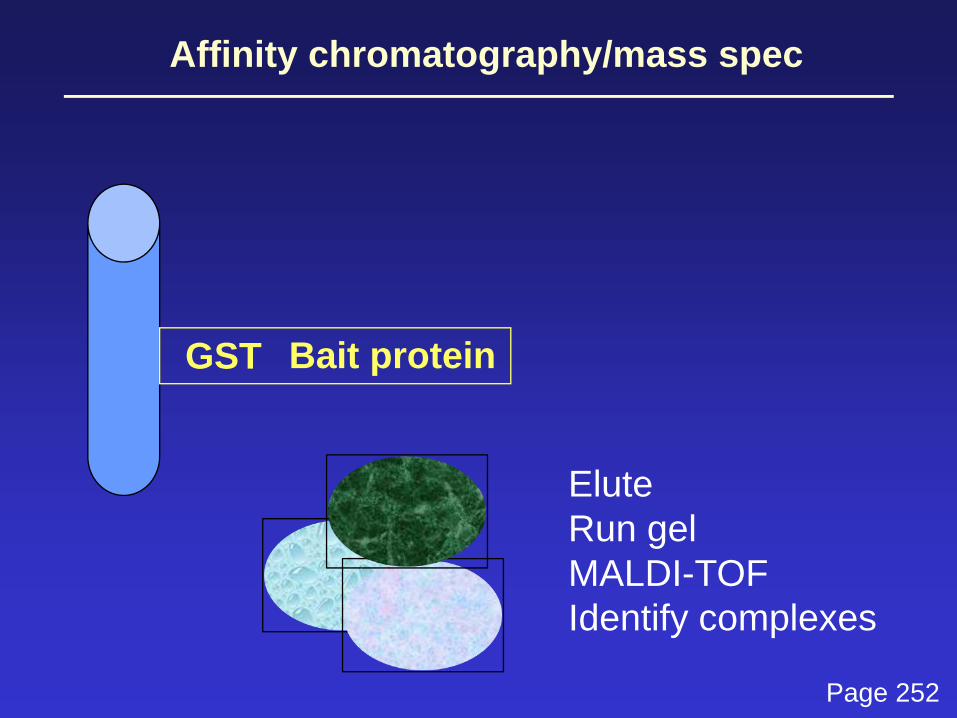
Affinity chromatography/mass spec
Bait proteinGST
EluteRun gelMALDI-TOFIdentify complexes
Page 252

Affinity chromatography/mass spec
Data on complexes deposited in databases
http://yeast.cellzome.comhttp://www.bind.ca
Page 252

Page 252

Page 252

Evaluation of affinity chromatography/mass spec
Advantages:Thousands of protein complexes identifiedFunctions can be assigned to proteins
Disadvantages:False negative resultsFalse positive results
Page 253-254

Affinity chromatography/mass spec
False negatives:• Bait must be properly localized and
in its native condition• Affinity tag may interfere with function• Transient protein interactions may be missed• Highly specific physiological conditionsmay be required
• Bias against hydrophobic, and small proteins
Bait proteinGST
Page 253

Affinity chromatography/mass spec
False positives:• sticky proteins
Bait proteinGST
Page 253

The yeast two-hybrid system
Reporter gene
Bait proteinDNA Binding
Page 255

The yeast two-hybrid system
Reporter gene
Prey proteinDNA activation
Prey proteinDNA activation
Prey proteinDNA activation Prey protein
DNA activation
Page 255
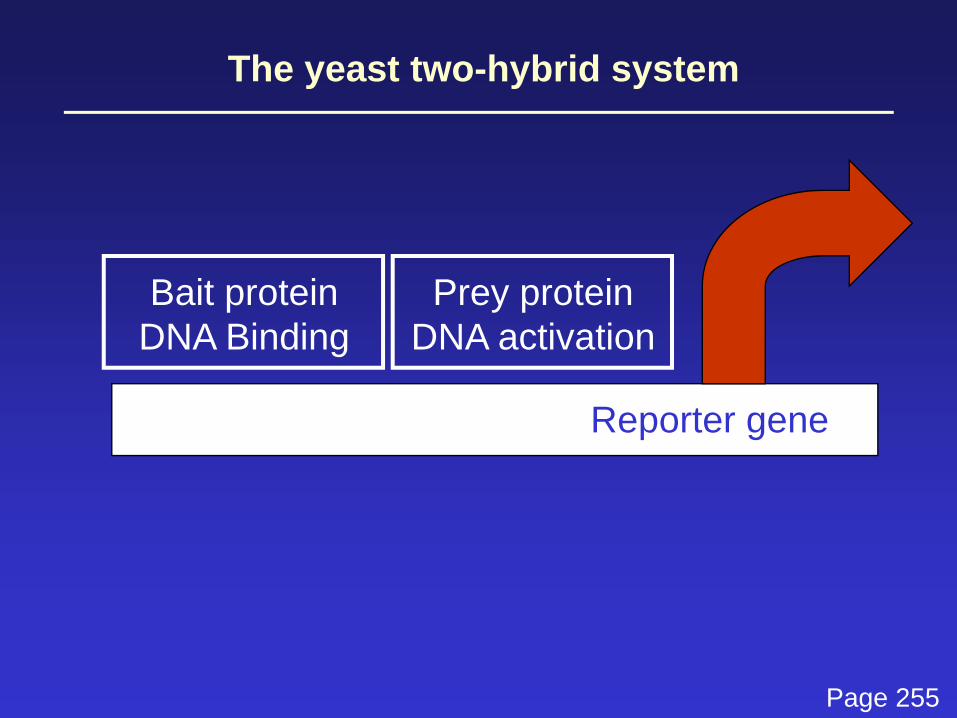
The yeast two-hybrid system
Reporter gene
Bait proteinDNA Binding
Prey proteinDNA activation
Page 255

The yeast two-hybrid system
Reporter gene
Bait proteinDNA Binding
Prey proteinDNA activation
Isolate and sequence the cDNAof the binding partner you have found
Page 255

red = cellular role & subcellular localization of interacting proteins are identical; blue = localiations are identical; green = cellular roles are identical

Evaluation of the yeast two-hybrid system
Advantages:Thousands of protein complexes identifiedFunctions can be assigned to proteins
Disadvantages:Detects only pairwise protein interactionsFalse-negative results (as for affinity chromatography)
-- bait may be mislocalized-- transient interactions may be missed-- some complexes require special conditions-- bias against hydrophobic proteins
False-positive results-- some proteins may be sticky-- bait protein may auto-activate a reporter
Page 256

The Rosetta Stone approach
Page 258
Marcotte et al. (1999) and other groups hypothesized that some pairs of interacting proteins are encoded by two genes in many genomes, but occasionally theyare fused into a single gene.
By scanning many genomes for examples of “fusedgenes,” several thousand protein-protein predictionshave been made.
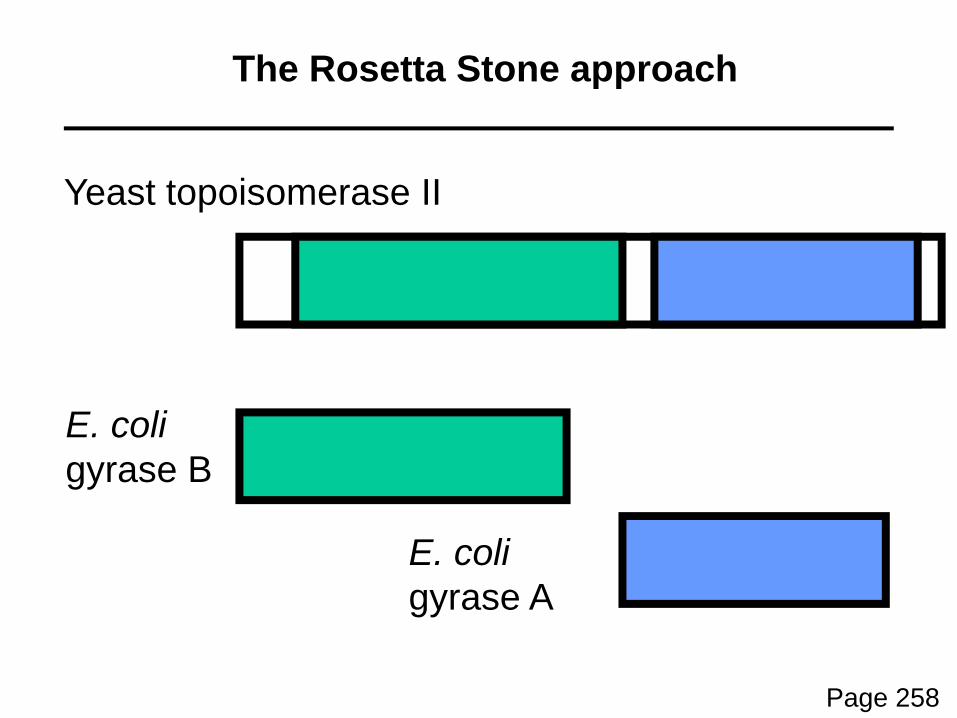
Yeast topoisomerase II
E. coligyrase B
E. coligyrase A
The Rosetta Stone approach
Page 258


6,217 yeast proteins
Experimental data (500 links)Related metabolic function (2,000 links)Related phylogenetic profiles (20,000 links)Rosetta Stone method (45,000 links)Correlated mRNA expression (26,000 links)
Marcotte et al. (1999) Nature 402:83

Pathway maps
A pathway is a linked set of biochemical reactions
ExPASyProNetEcoCyc: E. coli pathwaysMetaCyc: 450 pathways, 158 organismsKEGG: Kyoto Encyclopedia of Genes & Genomes
Issues:Is the extrapolation between species valid?Have orthologs been identified accurately?False positive, false negative findings
Page 258

Page 257

Page 257

Page 260

Page 262

Page 262





























