Embed Size (px)
Citation preview

POLITECHNIKA POZNAŃSKA
WYDZIAŁ ELEKTRONIKI I TELEKOMUNIKACJI
KATEDRA TELEKOMUNIKACJI MULTIMEDIALNEJ
I MIKROELEKTRONIKI
Semantyczne kodowanie mowy przy bardzo
małych prędkościach transmisji.
Damian Modrzyk
Promotor: dr inż. Maciej Bartkowiak
Poznań 2008


Pracę dedykuję:
Rodzicom, w podziękowaniu za wieloletni trud włożony w
wychowanie oraz za wsparcie w ciągłym dążeniu do
zdobywania wiedzy.
Kochanej Annie, za cierpliwość i obecność przy mnie przez
ostatni rok.
Bardzo dziękuję Panu dr inż. Maciejowi Bartkowiakowi, za
fachową pomoc, jaką okazał mi w trakcie pisania pracy.

Spis treści
- 4 -
Spis treści
Spis oznaczeń………………………………………………………………………………6
1. Wstęp. Cel i zakres pracy…...………………………………………………………...8
2. Struktura sygnału mowy…………………………………………………………….11
2.1 Cechy związane z pobudzeniem…………………………………………………11
2.2 Cechy zależne od traktu głosowego……………………………………………..12
2.3 Fonemy……………………………………………………………………………14
2.3.1 Samogłoski………………………………………………………………..15
2.3.2 Spółgłoski szczelinowe…………………………………………………...17
2.3.3 Spółgłoski zwarte………………………………………………………...19
2.3.4 Spółgłoski nosowe………………………………………………………..20
2.3.5 Spółgłoski zwarto-szczelinowe...………………………………………...21
2.3.6 Spółgłoski półotwarte……………………………………………………23
2.4 Model wytwarzania mowy………….…………………………………………....25
3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji…...28
3.1 Wokoder segmentowy……………………………………………………….…...28
3.2 Wokoder sylabowy………………………………………………………….…....31
3.3 Wokoder fonetyczny……………………………………………………………..34
4. Koncepcja semantycznego kodeka mowy…………………………………………..40
4.1 Struktura systemu………….…………………………………………………….41
4.2 Model kodera……………………………………………………………………..44
4.2.1 Ekstrakcja częstotliwości podstawowej…………………………………44
4.2.2 Analiza i reprezentacja widma w postaci współczynników MFCC…...50
4.2.3 Modelowanie fonemów przy pomocy ukrytych modeli Markowa….…56
4.2.4 Rozpoznawanie fonemów………………………………………….……..65
4.2.5 Kodowanie binarne strumienia………………………………………….70
4.3 Model dekodera…………………………………………………………………..72
4.3.1 Wytwarzanie sygnału pobudzenia……...………...……………………..73
4.3.2 Rekonstrukcja cech widmowych sygnału...………………...…………..79
4.3.3 Synteza sygnału mowy………………………………………………..….83
5. Wyniki symulacji modelu kodeka…………………………………………………...91
5.1 Otrzymany strumień…………………………………………...………………..91

Spis treści
- 5 -
5.2 Ocena zrozumiałości otrzymanej mowy……………….………………………..92
5.3 Subiektywna ocena jakości sygnału zrekonstruowanego…………………...…95
6. Zakończenie…………………………………………………………………………..98
Bibliografia………………………………………………………………………………100
Dodatek. Prototyp modelu HMM……………………………………………………...102

Spis oznaczeń
- 6 -
Spis oznaczeń
ADPCM (ang. Adaptive Differential Pulse Code Modulation) – adaptacyjna różnicowa
modulacja kodowo-impulsowa
CD-HMM (ang. Continous Density Hidden Markov Model) – ukryty model Markowa z
ciągłym rozkładem prawdopodobieństw wyjściowych
CELP (ang. Code Excited Linear Prediction) – predykcja liniowa z wymuszeniem
kodowym
DC (ang. Direct Current) – prąd stały, składowa stała sygnału
DCT (ang. Discrete Cosine Transform) – dyskretna transformacja kosinusowa
DD-HMM (ang. Discrete Density Hidden Markov Model) – ukryty model Markowa z
dyskretnym rozkładem prawdopodobieństw wyjściowych
DFT (ang. Discrete Fourier Transform) – dyskretna transformacja Fouriera
DMOS (ang. Degradation Mean Opinion Score) – test średniej oceny degradacji mowy
zdekodowanej
DRT (ang. Diagnostic Rhyme Test) – diagnostyczny test rymowy, używany do oceny
zrozumiałości mowy
EM (ang. Expectation Maximization) – algorytm maksymalizacji wartości oczekiwanej
FFT (ang. Fast Fourier Transform) – szybka transformacja Fouriera
FSM (ang. Finite State Machine) – maszyna stanów o skończonej sekwencji stanów
HMM (ang. Hidden Markov Model) – ukryty (niejawny) model Markowa
HTK (ang. Hidden Markov Models Toolkit) – biblioteka w języku C używana do
rozpoznawania mowy, wykorzystująca ukryte modele Markowa
IFFT (ang. Inverse Fast Fourier Transform) – odwrotna szybka transformacja Fouriera
LPC (ang. Linear Predictive Coding) – kodowanie oparte na predykcji liniowej
MAP (ang. Maximum A’Posteriori Probability) – zasada maksymalnego
prawdopodbieństwa po zdarzeniu
MELP (ang. Mixed Excitation Linear Prediction) – liniowe kodowanie predykcyjne z
mieszanym pobudzeniem
MFCC (ang. Mel-Frequency Cepstral Coefficients) – współczynniki cepstralne w melowej
skali częstotliwości
ML (ang. Maximum Likelihood) – reguła największej wiarogodności

Spis oznaczeń
- 7 -
MLSA (ang. Mel Log Spectrum Aproximation) – filtr aproksymujący logarytm widma
amplitudowego w skali melowej
MOS (ang. Mean Opinion Score) – test średniej oceny jakości mowy zdekodowanej
PSOLA (ang. Pitch Synchronous Overlap Adding) – technika syntezy sygnału mowy
polegająca na zakładkowym składaniu segmentów w sposób synchroniczny, z okresem
podstawowym
SPTK (ang. Speech Signal Processing Toolkit) – biblioteka w języku C++ używana do
przetwarzania sygnału mowy
SRSB (ang. Speech Recognition Synthesis Based) – technika kodowania mowy oparta na
rozpoznawaniu i syntezie mowy
STFT (ang. Short Time Fourier Transform) – krótkookresowa transformacja Fouriera
TTS (ang. Text-To-Speech) – konwersja tekstu na mowę
WGN (ang. White Gaussian Noise) – szum biały gaussowski

1. Wstęp. Cel i zakres pracy
- 8 -
1. Wstęp. Cel i zakres pracy
Ze względu na powszechność komunikacji międzyludzkiej przy pomocy głosu, analiza,
modelowanie oraz kodowanie mowy odgrywają bardzo ważną rolę w dziedzinie
cyfrowego przetwarzania sygnałów. Kompresję mowy definiujemy jako metodę zmiany
reprezentacji sygnału cyfrowego, która skutkuje relatywnie mniejszą potrzebną prędkością
transmisji sygnału, w odniesieniu do reprezentacji bez kodowania. Techniki kodowania
mowy znajdują powszechne zastosowanie w przesyłaniu sygnału na dalekie odległości –
telekomunikacji konwencjonalnej, radiokomunikacji. Innymi obszarami wykorzystania
kompresji są efektywne przechowywanie sygnału oraz szyfrowanie danych.
Współczesne techniki przetwarzania sygnałów akustycznych – dźwięków muzyki
i mowy charakteryzują się silną zależnością doboru metody od spodziewanego
zastosowania. Projektant podejmując próbę realizacji systemu kodowania sygnału musi
wziąć pod uwagę szereg czynników, które decydują o wyborze danego algorytmu.
Jednymi z najważniejszych są dostępna prędkość transmisji oraz wymagany poziom
jakości sygnału.
Ze względu na obszar zastosowań kompresji sygnału, obecnie wykorzystywane techniki
możemy podzielić na trzy kategorie:
• kodowanie sygnału wysokiej jakości, gdzie mowa zrekonstruowana praktycznie nie
różni się od mowy oryginalnej;
• kodowanie sygnału w telefonii, wymagany jest tutaj odpowiednio niski strumień
binarny, aby zapewnić ekonomiczną transmisję mowy, jednak przy zachowaniu
odpowiedniego poziomu naturalności sygnału;
• silna kompresja mowy, gdzie zasadniczym celem jest bardzo duża redukcja danych,
a degradacja naturalności jest tolerowana.
W literaturze często spotykany jest też podział koderów mowy ze względu
na otrzymywaną prędkość transmisji. Wyróżniamy:
• kodery o dużej przepływności – powyżej 2,4 kbit/s, gdzie nacisk w procesie
kodowania położony jest na otrzymanie sygnału o zadowalającej jakości;
• kodery o małej przepływności – poniżej 2,4 kbit/s, gdzie nacisk kładzie się
na stopień kompresji sygnału. W przypadku strumienia poniżej 1000 kbit/s
mówimy już o koderze bardzo małej prędkości transmisji;

1. Wstęp. Cel i zakres pracy
- 9 -
W tej pracy skupiamy się nad implementacją modelu kodeka mowy cechującego się
ekstremalnie niskim strumieniem.
Umowną granicą podziału koderów ze względu na przepływność jest wielkość
strumienia równa 2,4 kbit/s, którą otrzymujemy przez zastosowanie technik z rodziny
liniowego kodowania predykcyjnego – LPC (ang. Linear Predicitive Coding). Polegają one
na podziale cyfrowego sygnału mowy na krótkie segmenty, które są parametryzowane.
Kompresja polega na reprezentacji i transmisji sygnału oryginalnego w postaci
współczynników filtru analizy. Rekonstrukcja sygnału wykonywana jest przy pomocy
filtru syntezy mowy o charakterystyce odwrotnej do filtru analizy. W literaturze algorytm
LPC często określa się mianem parametrycznej reprezentacji mowy, gdzie filtr modeluje
właściwości narządu mowy, który jest pobudzany prostym sygnałem syntetycznym.
Rozpoznawanie charakterystycznych cech mowy, realizowane w koderze oraz
rekonstrukcja sygnału na podstawie przesłanych parametrów, dokonywana w dekoderze
wyznaczają pewien paradygmat kodowania, który powszechnie przyjął się w klasie tzw.
wokoderów pozwalających otrzymać bardzo małe prędkości transmisji.
Określenie kodowania sygnału terminem „semantyczne” sugeruje ścisłą zależność
algorytmu od znaczenia strumienia danych – zawartości informacyjnej sygnału.
W związku z tym główną ideą kodowania jest analiza i rozróżnianie znaczących jednostek
mowy (akustycznych lub fonetycznych) w postaci słów, sylab czy fonemów. Projektując
model kodeka mowy należy uwzględnić fakt, że transmisja akustycznych jednostek
informacji jest granicą kompresji sygnału mowy. Przesyłanie z kodera do dekodera
jakichkolwiek informacji prozodycznych mowy automatycznie zmniejsza efektywność
kodowania w sensie otrzymywanego strumienia binarnego.
Implementowany algorytm polega na dekompozycji sygnału, na zestaw jednostek
fonetycznych o długości kilkudziesięciu milisekund, których cechy charakterystyczne są
reprezentowane przy pomocy parametrów statystycznych ukrytych modeli Markowa –
HMM (ang. Hidden Markov Model). W tym przypadku, zamiast współczynników filtru
analizy dla danego segmentu mowy transmitowane są indeksy rozpoznanych modeli tzw.
fonemów sygnału wejściowego, co skutkuje silniejszą kompresją sygnału, w odniesieniu
do kodera LPC. Podczas rekonstrukcji sygnału z rozpoznanych jednostek fonetycznych
tracona jest informacja o fazie sygnału oryginalnego, co jest cechą charakterystyczną
wokoderów o bardzo małej prędkości transmisji. Jednak przy tak silnej kompresji
otrzymanie sygnału o zadowalającym poziomie naturalności jest bardzo trudne i większy

1. Wstęp. Cel i zakres pracy
- 10 -
nacisk kładzie się tutaj na zapewnienie pożądanego poziomu zrozumiałości mowy
zrekonstruowanej.
Celem tej pracy dyplomowej jest analiza, porównanie obecnych metod kodowania
mowy przy bardzo małych prędkościach transmisji oraz opracowanie modelu kodeka,
który pozwoli zweryfikować wyniki przeprowadzonych badań. Parametrem krytycznym,
podczas implementacji algorytmu, ma być przede wszystkim wielkość strumienia
binarnego, generowanego przez koder. W dalszej części dysertacji, modele kodera
i dekodera mają umożliwić przeprowadzenie serii badań symulacyjnych, pozwalających
oszacować efektywność zaimplementowanego algorytmu, a więc wielkości otrzymanego
strumienia, poziomu zrozumiałości oraz jakości mowy zrekonstruowanej.
W rozdziale drugim pracy magisterskiej zawarty jest opis podstawowych cech sygnału
mowy, w kontekście jego analizy i syntezy. Bardzo istotna jest charakterystyka jednostek
akustycznych – fonemów. Kolejny rozdział prezentuje obecnie najpopularniejsze
algorytmy kodowania mowy przy bardzo małej prędkości transmisji. Ogólny algorytm
kodowania fonetycznego mowy został tutaj przedstawiony najobszerniej gdyż
na podstawie tej techniki, po uwzględnieniu wad i zalet został opracowany model kodeka
dla bardzo małych prędkości transmisji, który prezentowany jest w tej pracy dyplomowej.
W rozdziale czwartym znajduje się szczegółowy opis zastosowanego algorytmu analizy,
transmisji oraz syntezy sygnału mowy. Dokładniej, omówiono tutaj metody ekstrakcji
częstotliwości podstawowej, rozpoznawania fonemów, wyjaśniono cechy zastosowanego
kodera binarnego oraz zaprezentowano sposób wytwarzania sygnału pobudzenia
w dekoderze, a następnie jego kształtowania filtrem syntezy.
Rozdział piąty prezentuje otrzymane wyniki symulacji zaimplementowanego kodeka
mowy, na które składają się wielkości strumieni dla poszczególnych sygnałów testowych
oraz subiektywna ocena jakości i zrozumiałości mowy zrekonstruowanej.
W rozdziale szóstym zawarte jest podsumowanie zrealizowanych zadań szczegółowych
pracy dyplomowej oraz otrzymanych wyników symulacji.

2. Struktura sygnału mowy
- 11 -
2. Struktura sygnału mowy
W rozdziale tym zawarta jest charakterystyka elementów sygnału mowy. Ze względu
na naturę jego wytwarzania, wprowadzono podział na cechy związane z pobudzeniem oraz
cechy zależne od traktu głosowego.
Dźwięki mowy powstają w wyniku zmian ciśnienia powietrza w płucach, które powodują
powstanie fali akustycznej wydostającej się ustami oraz otworem nosowym człowieka.
Ta łączna ścieżka, jaką pokonuje drgający słup powietrza przez ludzkie organy nazywana
jest traktem głosowym. Podczas propagacji fali mogą być pobudzane struny głosowe, które
wchodzą w stan rezonansu dla częstotliwości zależnych od ich stanu naprężenia.
Zachowanie drgającego strumienia powietrza opisuje się równaniem falowym, którego
charakterystycznymi parametrami są prędkość oraz ciśnienie powietrza [1].
2.1 Cechy związane z pobudzeniem
Pierwotny sygnał pobudzający trakt głosowy to sygnał o zróżnicowanym rozkładzie
energii w dziedzinie częstotliwości rezonansowych traktu. Pobudzenie może mieć
charakter dźwięczny lub bezdźwięczny, zależnie od mechanizmu jego wytworzenia
[2, rozdz.2]:
• składniki dźwięczne (tony krtaniowe) – otrzymywane są w wyniku nagłych zmian
ciśnienia, równomiernie przepływającego powietrza z płuc, spowodowanych przez
periodyczne drgania strun głosowych; energia sygnału mowy jest tutaj przesyłana
w postaci impulsów;
• składniki bezdźwięczne (szumy) – produkowane są przez turbulencje podczas
przepływu powietrza z płuc, występujące w różnych miejscach traktu głosowego
ze względu na zwężenie gardłowo – przełykowe.
Większość samogłosek i niektóre spółgłoski zarówno w języku angielskim jak i polskim
należą do klasy składników dźwięcznych mowy np., „a”, „b”, „d”, „o”, podczas gdy
składniki bezdźwięczne to spółgłoski typu „f”, „s”, „t”, „h”.
Ze względu na różne mechanizmy i miejsca produkcji dźwięcznych i bezdźwięcznych
elementów mowy w trakcie głosowym, można także wyróżnić tzw. składniki mieszane
mowy. Cechują się one jednocześnie występującymi quasi-periodycznymi drganiami oraz
szumowymi turbulencjami strumienia powietrza. Przykładem takiej jednostki akustycznej

2. Struktura sygnału mowy
- 12 -
jest spółgłoska „z”. W sensie fonetycznym jest ona sygnałem dźwięcznym, gdyż
charakteryzuje się periodycznym pobudzeniem, lecz w kontekście budowy kodera mowy,
jej uzyskanie możliwe jest tylko przy uwzględnieniu składnika szumowego.
Częstotliwość periodycznych lub quasi-periodycznych drgań składających się
na fragmenty dźwięczne sygnału mowy określa się mianem częstotliwości podstawowej
(ang. pitch frequency). Ściślej, jest ona definiowana jako odwrotność odstępów w czasie,
pomiędzy kolejnymi momentami otwarcia strun głosowych (ang. pitch period).
W przypadku mowy ludzkiej częstotliwość podstawowa F0, przyjmuje wartości z zakresu
50 – 300 Hz, co odpowiada okresowi podstawowemu z przedziału 3 – 20 ms [2].
Dla męskiego aparatu mowy typowe są wartości z dolnej części tego zakresu, podczas gdy
kobiety i dzieci zazwyczaj mają częstotliwość podstawową mowy bliską górnej wartości
granicznej – 300 Hz. Różnica ta wynika z odmiennych fizycznych właściwości strun
głosowych oraz aparatu mowy obu płci. Wahania częstotliwości F0 w trakcie wypowiedzi
reprezentują bardzo istotną informację prozodyczną mowy, jaką jest intonacja.
Ludzkie ucho jest bardzo czułe na zmiany okresu podstawowego, w porównaniu z innymi
parametrami sygnału mowy. Z tego względu, podczas procesu kodowania mowy, kontur
częstotliwości F0 powinien być wiernie odtworzony w sygnale zrekonstruowanym.
2.2 Cechy zależne od traktu głosowego
Decydujący wpływ na brzmienie sygnału mowy ma struktura traktu głosowego oraz
charakter jego zmian w czasie. Trakt głosowy bardzo często modeluje się w postaci
szeregu tub o różnej średnicy, przez które przepływa strumień powietrza, generowany
w płucach. Tuby reprezentują organy człowieka: krtań, przestrzeń gardłową, język, jamę
ustną oraz otwór nosowy, które znajdują się na drodze propagacji (rys.1). Długość traktu
głosowego wynosi u dorosłego mężczyzny ok. 17 cm na odcinku głośnia – jama ustna,
oraz ok.13 cm na odcinku miękkie podniebienie – otwór nosowy. Przewężenia w różnych
miejscach toru powodują powstawanie rezonansów, których skutkiem są lokalne maksima
obwiedni widma amplitudowego nazywane formantami. Odpowiadające im częstotliwości
określamy mianem formantowych.
Wyróżniamy trzy główne częstotliwości formantowe, które położone są w okolicach 400
Hz (F1), 900 Hz (F2) i 2600 Hz (F3) [2]. Lokalizacja rezonansów ściśle zależy od
mówcy i jest ona nierównomierna, gdyż przekrój traktu głosowego nie jest jednakowy na
całej jego długości.

2. Struktura sygnału mowy
- 13 -
SIŁA MIĘŚNI
PŁUCA
STRUNY GŁOSOWE
GARDŁO JAMA USTNA
JĘZYK
OTWÓR NOSOWY
MOWA
MIĘKKIE PODNIEBIENIE
Rys.1. Schemat blokowy ludzkiego aparatu mowy wg [3].
Rys.2. Logarytm krótkookresowego widma amplitudowego sygnału mowy oraz
jego obwiednia ujawniająca częstotliwości formantowe.

2. Struktura sygnału mowy
- 14 -
Największe odchylenia wartości częstotliwości występują dla formantu F2 – nawet do
1500 Hz. Przykładowy rozkład rezonansów formantowych pokazany jest na rys.2.
Przedstawiony wykres pozwala wyodrębnić pasma rezonansowe danego sygnału mowy dla
wartości częstotliwości równych w przybliżeniu F1 = 300 Hz, F2 = 1400 Hz oraz F3 = 2700
Hz. Wyraźnie widoczne jest także tzw. czwarte pasmo formantowe – F4 = 3400 Hz.
Dodatkowo można zauważyć, że regularne prążki harmonicznych oddalone są od siebie
o wartość częstotliwości podstawowej – około 100 Hz.
Sposób przepływu strumienia powietrza przez trakt głosowy, oraz liczba i miejsce
ograniczeń występujących na jego drodze mają wpływ na artykulację. Aby wyprodukować
różne rodzaje dźwięku ludzki aparat mowy przyjmuje wiele konfiguracji, które modyfikują
generowany sygnał pobudzenia. Technika artykulacji poszczególnych fonemów jest
jednym z kryteriów ich klasyfikacji. Często wprowadza się ogólny podział fonemów
na głoski otwarte, w których możliwy jest swobodny przepływ powietrza przez trakt
głosowy, oraz głoski zamknięte (zwarte), gdzie w ścieżce propagacji sygnału pobudzenia
znajdują się zapory powietrza. Sposoby artykulacji poszczególnych głosek są ściśle
związane z położeniem narządów mowy podczas produkcji dźwięku oraz typem sygnału
pobudzenia. Szerzej jest to opisane w rozdziale 2.3.
2.3 Fonemy
Fonem definiujemy jako podstawową jednostkę akustyczną mowy. Do klasyfikacji
fonemów mowy wykorzystuje się cechy odpowiadającego im sygnału pobudzenia oraz
sposób i miejsce artykulacji. Bogata charakterystyka sygnału mowy, wynika właśnie
z różnorodności składników fonetycznych. Możliwe kombinacje fonemów, w różnych
kontekstach i dla różnych mówców, nazywa się alofonami.
Fonemy zazwyczaj oznaczane są przy pomocy standardowych znaków alfabetu danego
języka, gdyż reprezentują brzmienie poszczególnych głosek w mowie. Dla uwypuklenia
fonetycznego charakteru tych symboli w literaturze tematu stosuje się notację /*/
w odniesieniu do poszczególnych głosek, np. /a/, /p/, /iy/.
Poniżej zawarty jest podział fonemów na klasy, który został sporządzony przy
uwzględnieniu kryterium akustycznego oraz kryterium artykulacyjnego klasyfikacji.
Przedstawione w tym rozdziale cechy fonemów, zarówno z punktu widzenia akustycznego
jak i artykulacyjnego są niezwykle istotne w kontekście implementacji kodeka mowy dla

2. Struktura sygnału mowy
- 15 -
bardzo małej prędkości transmisji, którego działanie ma się opierać na rozpoznawaniu i
syntezie mowy.
2.3.1 Samogłoski
Samogłoski (ang. vowels) to dźwięczne składniki mowy (tony krtaniowe), które
produkowane są przez periodyczne lub quasi-periodyczne drgania strun głosowych.
Podczas generacji samogłoski w trakcie głosowym podniebienie miękkie jest uniesione
do góry blokując przepływ drgającego strumienia powietrza przez odcinek nosowy.
Samogłoski mogą podlegać dalszym podziałom ze względu na następujące kryteria:
• położenie języka podczas artykulacji:
o samogłoski przednie, np. /e/, /i/, /y/;
o samogłoski środkowe, np. /a/, /u/;
o samogłoski tylne, np. /o/;
• siła oporu powietrza podczas artykulacji:
o samogłoski wysokie, np. /i/, /u/;
o samogłoski średnie, np. /e/, /o/;
o samogłoski niskie, np. /a/;
Wykresy na rys.3 i rys.4 zawierają przebiegi czasowe oraz logarytm widma
amplitudowego odpowiednio dla samogłoski /a/ oraz samogłoski /i/. W obydwu
przypadkach częstotliwość próbkowania wynosi 16 kHz.
Cechą wspólną fonemów tej klasy, jest wyraźnie widoczny dźwięczny charakter sygnału.
Drgania są periodyczne (samogłoska /a/) lub quasi-periodyczne (samogłoska /i/).
Na wykresach logarytmu widma, wyraźnie zarysowane są pasma formantowe
analizowanych fragmentów mowy. Ze względu na impulsowy charakter pobudzenia,
widmo amplitudowe posiada wiele składowych wysokoczęstotliwościowych o znaczących
wartościach amplitudy. Zazwyczaj samogłoski cechują się stosunkowo długim czasem
trwania. Przykładowo dla samogłoski środkowej ten czas wynosi ok. 140 ms, natomiast dla
samogłoski przedniej równy jest ok. 75 ms. Różnica pomiędzy samogłoską /a/ oraz /i/
polega na tym, że dla tej pierwszej charakter pobudzenia jest wyraźnie rezonansowy.
Obserwujemy to w postaci bardziej regularnego przebiegu czasowego, co ma także
odzwierciedlenie w większej amplitudzie składowych wysokoczęstotliwościowych widma
amplitudowego.

2. Struktura sygnału mowy
- 16 -
Rys.3. Przebieg czasowy oraz logarytm widma amplitudowego fonemu /a/.
Rys.4. Przebieg czasowy oraz logarytm widma amplitudowego fonemu /i/.

2. Struktura sygnału mowy
- 17 -
Samogłoska wysoka /i/ cechuje się nieregularnymi drganiami, dla których można dostrzec
powolny spadek amplitudy o charakterze wykładniczym – stan ustalony.
W wielu językach spotykane są fonemy składające się z dwóch samogłosek, tzw.
dyftongi (ang. diphthongs). Ich właściwości czasowe oraz częstotliwościowe są bardzo
podobne do fonemów jednogłoskowych z tej grupy. Przykładem dyftongów są dźwięki
/ai/, /ou/, /ei/ często spotykane w amerykańskiej odmianie języka angielskiego. Powstają
one, gdy podczas artykulacji struktura traktu głosowego zmienia się z konfiguracji
odpowiadającej pierwszej samogłosce, do konfiguracji powodującej powstanie drugiej
samogłoski, wchodzącej w skład dyftongu.
Fonemy z tej grupy często definiuje się również jako pojedyncze samogłoski, o długim
czasie trwania i zmiennym przebiegu artykulacji, co powoduje, że są one słyszane przez
ludzkie ucho w postaci dwóch dźwięków.
2.3.2 Spółgłoski szczelinowe
Spółgłoski szczelinowe, nazywane także frykatywnymi (ang. fricatives) powstają
w wyniku turbulencji, tarć oraz szumów strumienia powietrza, przepływającego przez
wąskie szczeliny między częściami narządu mowy. Brzmienie tych spółgłosek jest
zdeterminowane przez położenie ust oraz języka. W ramach tej klasy występują zarówno
głoski dźwięczne jak i bezdźwięczne. Przykładem fonemów należących do tej grupy są
głoski /f/ oraz /v/.
W klasie spółgłosek szczelinowych często dokonuje się dalszych podziałów ze względu
na rodzaj narządu mowy, który bierze bezpośredni udział w produkcji dźwięku. Wyróżnia
się m.in. spółgłoski szczelinowe wargowo – zębowe, języczkowe, gardłowe, dwuwargowe
itd. Na rys.5 i rys.6 przedstawione są przebiegi czasowe oraz widma amplitudowe
odpowiednio dla fonemu /f/ oraz /v/ (częstotliwość próbkowania równa 16 kHz).
Spółgłoska /f/ cechuje się typowymi właściwościami szumowymi. Jej przebieg czasowy
jest aperiodyczny i posiada małą amplitudę wahań. Widmo amplitudowe również
charakteryzuje się bezdźwięczną naturą. Nie zawiera żadnych regularnie oddalonych od
siebie prążków rezonansowych.
Fonem /v/ jest dźwięcznym odpowiednikiem spółgłoski /f/. Położenie narządów artykulacji
w trakcie jej generacji jest identyczne, zmienia się natomiast charakter pobudzenia.
Przebieg czasowy jest krótki, periodyczny oraz wyraźnie widoczny jest na nim stan
ustalony. Amplituda drgań maleje wg krzywej wykładniczej.

2. Struktura sygnału mowy
- 18 -
Rys.5. Przebieg czasowy oraz logarytm widma amplitudowego fonemu /f/.
Rys.6. Przebieg czasowy oraz logarytm widma amplitudowego fonemu /v/.

2. Struktura sygnału mowy
- 19 -
Widmo amplitudowe ma charakterystykę bardzo zbliżoną do filtru dolnoprzepustowego.
Zawartość wyższych składowych harmonicznych w spółgłoskach szczelinowych
dźwięcznych jest bardzo mała, gdyż są one silnie tłumione przez trakt głosowy.
2.3.3 Spółgłoski zwarte
Spółgłoski zwarte (ang. stop consonants, plosives), zwane także zwarto-wybuchowymi
powstają, gdy podczas artykulacji następuje całkowita blokada przepływu powietrza przez
trakt głosowy, a dokładniej jamę ustną i nosową, po której następuje nagłe zwolnienie
zgromadzonego strumienia powietrza. Pierwszy etap artykulacji nazywany jest fazą
zwarcia – implozji, po której następuje faza eksplozji. Dźwięki mowy w ten sposób
produkowane są krótkie i mają charakter transientów. Fonemy z tej klasy mogą być
zarówno dźwięczne jak i bezdźwięczne, zależnie od charakteru pobudzenia. Dodatkowo
wyróżnia się kilka podtypów spółgłosek zwartych, które różnią się miejscem realizacji
fazy zwarcia. Przykładem spółgłoski zwarto-wybuchowej jest fonem /t/, którego przebieg
czasowy oraz widmo amplitudowe przedstawione są na rys.7.
Rys.7. Przebieg czasowy oraz logarytm widma amplitudowego fonemu /t/.
Częstotliwość próbkowania Fs = 16 kHz.

2. Struktura sygnału mowy
- 20 -
Jak widać na zamieszczonych wykresach, fonemy tej klasy występują w sygnale mowy
w postaci pojedynczych impulsów o ujemnej wartości amplitudy, co odpowiada fazie
implozji, po których pojawia się pojedynczy dodatni impuls reprezentujący fazę eksplozji.
Ze względu na transientowy charakter tych spółgłosek, są one ściśle uzależnione
od fragmentów mowy występujących, na krótko przed i po spółgłoskach zwarto-
wybuchowych. Ich kontekst fonetyczny może spowodować jeszcze większą redukcję czasu
trwania tych głosek oraz ich energii.
Widmo amplitudowe fonemów zwartych cechuje się typowymi właściwościami sygnału
o składnikach mieszanych (dźwięczno-szumowych). Wyraźny prążek widma dla niskich
częstotliwości reprezentuje generowany impuls, natomiast losowy rozkład energii
dla wysokich częstotliwości jest związany z szumowym charakterem sygnału, jaki
otrzymywany jest w wyniku nagłego zwolnienia powietrza w fazie eksplozji.
2.3.4 Spółgłoski nosowe
Spółgłoski nosowe (ang. nasals) są to fonemy dźwięczne produkowane podczas
przepływu strumienia powietrza przez trakt głosowy, w którym odcinek ustny jest zwarty
w wyniku opuszczenia podniebienia miękkiego i fala akustyczna propaguje się przez
odcinek nosowy. Ze względu na specyficzne właściwości aparatu mowy, spółgłoski
nosowe charakteryzują się najmniejszą energią spośród wszystkich spółgłosek
dźwięcznych. Odmienny sposób propagacji fali wzdłuż traktu głosowego jest także
widoczny w postaci nietypowego kształtu widma generowanego dźwięku. Specyficzna
konfiguracja traktu głosowego w przypadku spółgłosek nosowych powoduje powstawanie
tzw. zer w charakterystyce częstotliwościowej. Ta cecha jest powszechnie
wykorzystywana w modelowaniu i kodowaniu dźwięków tej klasy. Przykładem fonemu
nosowego jest spółgłoska /m/, której przebieg czasowy i widmo amplitudowe znajdują się
na rys.8.
Przedstawione wykresy ilustrują dźwięczny charakter spółgłosek nosowych. Ich przebieg
czasowy jest krótki i składa się z regularnych drgań, które zawierają jedynie harmoniczne
niskiego rzędu. Na wykresie logarytmu widma amplitudowego jest to widoczne w postaci
prążków, występujących dla małych wartości częstotliwości. Specyficzne dla fonemów
nosowych minimum lokalne w charakterystyce częstotliwościowej sygnału występuje w
okolicach 2500 Hz.

2. Struktura sygnału mowy
- 21 -
Rys.8. Przebieg czasowy oraz logarytm widma amplitudowego fonemu /m/.
Częstotliwość próbkowania Fs = 16 kHz.
2.3.5 Spółgłoski zwarto-szczelinowe
Spółgłoski zwarto-szczelinowe (ang. affricates) powstają w wyniku połączenia
fonemów zwarto-wybuchowych i szczelinowych. Podczas artykulacji we wstępnej fazie
dochodzi do całkowitej blokady przepływu fali akustycznej w trakcie głosowym, po czym
narządy mowy tworzą dostatecznie wąską szczelinę, by podczas propagacji zwolnionego
strumienia powietrza wytworzył się szum i tarcie. Element szczelinowy zastępuje tutaj fazę
eksplozji. Przykładem fonemu z omawianej grupy jest spółgłoska /ch/ - kombinacja
spółgłosek /t/, /sh/. Jej przebieg czasowy oraz charakterystyka częstotliwościowa
przedstawione są na rys.9.
Na obydwu zamieszczonych wykresach wyraźnie widoczne są faza implozji (zwarcia)
strumienia powietrza oraz faza szumu (tarcia) podczas przejścia fali akustycznej przez
szczelinę. Pierwszy etap charakteryzuje się pobudzeniem impulsowym o dużych
wahaniach amplitudy, podczas gdy w dalszej części sygnał jest bezdźwięczny o małej
amplitudzie.

2. Struktura sygnału mowy
- 22 -
Rys.9. Przebieg czasowy oraz logarytm widma amplitudowego fonemu /ch/.
Częstotliwość próbkowania Fs = 16 kHz.
Widmo amplitudowe również reprezentuje mieszany charakter sygnału. Dla częstotliwości
w dolnym zakresie skali (poniżej 500 Hz) można wyróżnić równo oddalone prążki, które
odzwierciedlają rezonansowy składnik fonemu. W dalszej części widma wyraźnie
widoczny jest szumowy charakter sygnału w postaci losowych wahań amplitudy, łatwo
obserwowalnych w wąskich przedziałach częstotliwości.

2. Struktura sygnału mowy
- 23 -
2.3.6 Spółgłoski półotwarte
Spółgłoski półotwarte, nazywane często półsamogłoskami (ang. semivowels) są
wytwarzane, gdy jednocześnie w pewnym miejscu traktu głosowego powstaje zwarcie,
natomiast w innym miejscu możliwy jest swobodny przepływ powietrza.
Z artykulacyjnego punktu widzenia fonemy te leżą na granicy spółgłosek i samogłosek.
Reprezentatywnymi fonemami z tej grupy są /r/, /l/, /w/, /y/ czy /j/. Dynamika tych
dźwięków oraz ich brzmienie są bardzo zróżnicowane. Co więcej, ściśle zależy to od ich
kontekstu fonetycznego w sygnale mowy. Przykładowo fonemy /r/ i /l/ są produkowane
w wyniku stabilnych drgań słupa powietrza, podczas gdy fonemy /w/, /y/ są bardzo
dynamicznymi dźwiękami, powstającymi przez zmianę konfiguracji traktu głosowego
w trakcie ich trwania.
Ze względu na powyższe cechy przedstawianej grupy fonemów, najlepszą informację o ich
widmie amplitudowym daje reprezentacja czasowo-częstotliwościowa, otrzymana przez
obliczenie krótkookresowej transformacji Fouriera – STFT (ang. Short Time Fourier
Transform) w krótkich blokach przesuwanych wzdłuż sygnału. Przykładowe rezultaty
takiego przekształcenia dla sekwencji fonemów /iy/-/r/-/ae/ oraz /ae/-/r/-/iy/ są widoczne
w postaci spektrogramów, odpowiednio na rys.10 i rys.11.
Na podstawie przedstawionych spektrogramów możliwe jest wyróżnienie częstotliwości
podstawowej wypowiadanego fragmentu mowy, który widoczny jest w postaci
pierwszego, poziomego prążka na wykresie. Jednak najbardziej istotną cechą w kontekście
rozpoznawania spółgłosek półotwartych, jest rozkład pasm rezonansowych. Formanty są
reprezentowane na spektrogramie w formie grup składowych harmonicznych
o największej energii (ciemne smugi).
Trajektoria formantu F1 jest najbardziej stabilna – widoczna jako pozioma smuga o dużej
energii dla częstotliwości ok. 500 Hz. Największym wahaniom wartości ulega natomiast
formant F2 – grupa składowych z zakresu 1000 – 2000 Hz o dużej energii, której kontur
znacznie różni się w obydwu spektrogramach. Szczególnie jest to zauważalne dla chwil
czasowych poniżej 100 ms. Można to uzasadnić występowaniem w tym fragmencie mowy
innych fonemów kontekstowych dla spółgłoski /r/.
Śledzenie trajektorii rezonansów formantowych oraz ekstrakcja innych cech sygnału
mowy ze spektrogramów bardzo ułatwia analizę widmową oraz rozpoznawanie
poszczególnych jednostek fonetycznych.

2. Struktura sygnału mowy
- 24 -
Rys.10. Spektrogram krótkookresowy sekwencji fonemów /iy/-/r/-/ae/.
Rys.11. Spektrogram krótkookresowy sekwencji fonemów /ae/-/r/-/iy/.

2. Struktura sygnału mowy
- 25 -
2.4 Model wytwarzania mowy
Zakładając chwilową stacjonarność sygnału w ramkach analizy wytwarzanie mowy
można zamodelować jako proces pobudzania filtru syntezy okresowym ciągiem impulsów
lub szumem [1]. Schemat blokowy modelu wytwarzania mowy przedstawiony jest
na rys.12.
FILTR SYNTEZY
UKŁAD DECYZYJNY
WZMOCNIENIE
WSPÓŁCZYNNIKI FILTRU
POBUDZENIE BEZDŹWIĘCZNE
POBUDZENIE DŹWIĘCZNE
F0
MOWA
Rys. 12. Model wytwarzania sygnału mowy.
Filtr syntezy jest układem liniowym, o parametrach zmiennych w czasie, który modeluje
łączną wypadkową charakterystykę głośni, traktu głosowego oraz charakterystykę
emisyjną. Źródłem energii dla filtru jest generator pobudzenia, który modeluje zarówno
tony krtaniowe jak i składniki szumowe wytwarzane w naturalnym procesie produkcji
mowy. Fragmenty dźwięczne modelowane są przez okresowy lub quasi-okresowy ciąg
impulsów, natomiast fragmenty bezdźwięczne reprezentuje się zazwyczaj przez
aperiodyczny sygnał losowy. Informacja o charakterze dźwięcznym, bezdźwięcznym lub
mieszanym pobudzenia wyznaczana jest na podstawie częstotliwości podstawowej (F0)
oraz poziomu głośności poszczególnych bloków kodowanego sygnału mowy. Na tej
podstawie następuje przełączenia typu pobudzenia generowanego w źródle.
Prostym przykładem zastosowania tego modelu wytwarzania mowy jest technika
kodowania liniowo-predykcyjnego – LPC, należąca do rodziny technik wokoderowych.
Filtr syntezujący jest tutaj układem liniowym, o transmitancji odwrotnej do charakterystyki
częstotliwościowej filtru analizy (1):

2. Struktura sygnału mowy
- 26 -
)(1
1
1)(
1
zAza
GzH P
k
kk
−=
−=
∑=
−
(1)
gdzie:
G – wzmocnienie syntetycznego pobudzenia
ka – współczynniki filtru analizy
P – rząd predykatora
Transmitancja układu syntezy posiada jedynie bieguny w dziedzinie zmiennej Ζ , podczas
gdy dla układu analizy określone są tylko zera transmitancji. Stąd łatwo można otrzymać
charakterystykę filtru dekodera przez odwrotność charakterystyki filtru analizy.
Zadaniem kodera jest odpowiednia adaptacja filtru analizującego do zmieniających się
właściwości traktu głosowego, aby po podaniu na jego wejście sygnału mowy otrzymać
błąd predykcji o najmniejszej energii (2):
∑=
⟩−−⟨=⟩⟨P
kk knsansne
1
22 )]()([)( (2)
gdzie:
)(ns – bieżąca próbka mowy
)( kns − – próbka mowy występująca k chwil wcześniej
Do rekonstrukcji sygnału w dekoderze konieczne jest przesłanie informacji o okresie drgań
ciągu impulsów pobudzenia, wartości wzmocnienia sygnału oraz współczynników filtru
ka . W zależności od wartości przyjętych parametrów analizy LPC, jak długość okna, czy
rząd predykatora, technika ta umożliwia otrzymanie wielkości strumienia wyjściowego,
w zakresie od kilku do kilkunastu kbit/s.
W wielu odmianach wokoderów blok syntezy sygnału wzorowany jest na modelu
wytwarzania mowy zaczerpniętym z algorytmu LPC. Podobne podejście zastosowano
również podczas budowy systemu kodowania, który jest tematem tej pracy.
W opracowanym modelu kodeka układ generacji sygnału pobudzenia oraz filtr syntezy są
kluczowymi elementami dekodera mowy. Metoda analizy sygnału, transmisja parametrów
między koderem, a dekoderem oraz typ parametrów odbiegają natomiast dość znacznie od
idei kodowania predykcyjnego LPC. Jest to związane z ograniczoną prędkością transmisji.

2. Struktura sygnału mowy
- 27 -
Chcąc otrzymać strumień mniejszy niż 2,4 kbit/s (standard LPC-10), nie możemy
przesyłać parametrów analizy mowy w standardowej postaci, tak jak odbywa się to w
kodowaniu liniowo-predykcyjnym. Rozwiązanie tego problemu jest tematem pracy
magisterskiej, natomiast cechy kodera LPC i jego efektywność stanowią bardzo ważny
kontekst dla oceny zaimplementowanego systemu.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 28 -
3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
Za zakres strumieni koderów dla bardzo małych prędkości transmisji przyjmuje się
wartości poniżej 1000 bit/s. W literaturze spotyka się trzy główne techniki kodowania
sygnału mowy, które pozwalają na otrzymanie takiej przepływności. Rozdział ten zawiera
charakterystykę tych metod, z uwzględnieniem wad i zalet danego rozwiązania.
Wysoka kompresja sygnału wymusza stosowanie innych technik kodowania niż
te powszechnie spotykane w kodekach MELP (ang. Mixed Excitation Linear Prediction),
CELP (ang. Code Excited Linear Prediction) czy ADCPM (ang. Adaptive Differential
Pulse Code Modulation). Jest to spowodowane faktem, że użycie klasycznych algorytmów
przy mocno ograniczonej prędkości transmisji, wymusza ekstremalnie silną kwantyzację,
co nie pozwala na prawidłowe przesłanie wszystkich parametrów sygnału niezbędnych do
jego rekonstrukcji. Obecnie stosowane techniki kodowania mowy przy bardzo małych
prędkościach transmisji oparte są na analizie i syntezie sygnału – SRSB (ang. Speech
Recognition Synthesis Based). Takie podejście pozwala na uzyskanie bardzo małych
strumieni przy zachowaniu zadowalającego poziomu zrozumiałości oraz naturalności.
3.1 Wokoder segmentowy
Główną ideą kodowania segmentowego mowy jest podział sygnału na spójne
fragmenty o zmiennej długości, które uprzednio kwantowane, przechowywane są
w specjalnej bazie danych. Dla nieznanej wypowiedzi dokonuje się wyszukiwania
i rozpoznawania fragmentów sygnału, które najlepiej pasują do wzorców
przechowywanych w bazie segmentów. Zawartość takiej bazy może być różna
w zależności od zastosowanego podejścia, tzn. za jednostkę segmentacji przyjmuje się całe
ramki sygnału lub segmenty odpowiadające poszczególnym fonemom, czy sylabom.
Im dłuższy segment stanowi jednostkę, tym wyjściowy strumień jest mniejszy, ale
jednocześnie rośnie złożoność obliczeniowa związana z jego rozpoznaniem. Kryterium
dopasowania może być np. energia segmentu, jego częstotliwość podstawowa, bądź inna
cecha. Koder segmentowy dokonuje rozpoznania jednostek mowy, które wchodzą w skład
oryginalnego sygnału i przesyła tę informację do dekodera.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 29 -
Synteza mowy polega na pobraniu z bazy danych rozpoznanych fragmentów sygnału oraz
ich połączeniu. Niezbędna jest do tego tekstowa transkrypcja zakodowanego sygnału, gdyż
umożliwia ona wybór odpowiednich jednostek z bazy oraz odtworzenie struktury czasowej
sygnału.
Jeden z najbardziej popularnych algorytmów kodowania segmentowego mowy został
zaproponowany przez Ki-Seung Lee i Richarda Cox’a w [4]. Według nich koder
segmentowy powinien być wykorzystywany w aplikacjach gdzie parametrem krytycznym
nie jest złożoność obliczeniowa, oraz ilość pamięci potrzebna na przechowywanie bardzo
dużej bazy fragmentów mowy. Efektywność kodowania algorytmu przedstawionego przez
Lee i Cox’a kryje się właśnie w liczbie zgromadzonych fragmentów wypowiedzi, które
używa się do syntezy sygnału.
Prezentowany w cytowanej pracy kodek segmentowy pozwala na uzyskanie strumienia ok.
800 bit/s. Jego zasada działania opiera się na rozpoznawaniu mowy i konwersji tekstu
do mowy – TTS (ang. Text-To-Speech). Technika ta polega na łączeniu rozpoznanych
segmentów sygnału, reprezentowanych w postaci jednostek (indeksów, znaków itp.),
branych z obszernych baz danych. W wyniku takiego złożenia jednostek otrzymujemy
przebieg, który dodatkowo wzbogacany jest informacją o prozodii sygnału, a więc
uwzględniane są:
• długości trwania segmentów mowy;
• głośność segmentów;
• okres drgań głośni (ang. pitch period);
• częstotliwości formantowe.
Koder segmentowy można łatwo przedstawić w postaci systemu zawierającego bardzo
bogatą książkę kodową (bazę wypowiedzi), oraz mechanizmy wyznaczające dodatkowe
parametry prozodyczne sygnału, które służą do zminimalizowania residuum pomiędzy
sygnałem oryginalnym a odtworzonym. Schemat takiego kodeka, na podstawie pracy [4],
pokazany jest na rys.13.
W ramach ekstrakcji cech wykonywana jest estymacja częstotliwości podstawowej traktu
głosowego, estymacja amplitudy oraz reprezentacja cech widma w postaci
współczynników cepstrum, w melowej skali częstotliwości – MFCC (ang. Mel-Frequency
Cepstral Coefficients).
Reprezentacja cech sygnału w postaci współczynników MFCC jest powszechnie spotykaną
techniką stosowaną w kodowaniu mowy dla bardzo małych prędkości transmisji.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 30 -
Częstotliwość podstawową sygnału wyznacza się przy wykorzystaniu jednego
z algorytmów prezentowanych w rozdziale 4.2.1. Wokoder segmentowy zawiera dwie
bazy danych. Pierwsza służy do rozpoznawania segmentów (jednostek) współczynników
MFCC, w odniesieniu do wzorców przechowywanych w systemie. Te wzorce parametrów
mel-cepstrum muszą być wyznaczane z sygnałów przechowywanych w bazie, z
zachowaniem tych samych parametrów, które są wykorzystywane do analizy sygnału
wejściowego.
SYGNAŁ WEJŚCIOWY
BAZA CECH SYGNAŁU
EKSTRAKCJA CECH SYGNAŁU
CZĘSTOTLIWOŚĆ F0AMPLITUDA
SELEKCJA JEDNOSTEK
KODER
DOBÓR SEGMENTÓW
BAZA FRAGMENTÓW
SYGNAŁU
MODYFIKACJA CZĘSTOTLIWOŚCI I
AMPLITUDY
KONKATENACJA
SYGNAŁ WYJŚCIOWY
DEKODER
Rys. 13. Schemat kodeka segmentowego.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 31 -
Dekoder segmentowy mowy posiada drugą bazę danych, w której pod odpowiednimi
indeksami umieszczone są oryginalne fragmenty mowy, wzięte z dużej liczby wypowiedzi
konkretnego mówcy. Ten fakt wskazuje na ścisłą zależność cech sygnału wyjściowego
od mówcy, który generuje wypowiedzi składające się na bazę segmentów.
Jak widać na rys.13, kodowana jest jedynie informacja o rozpoznanych jednostkach
parametrów oraz informacja o częstotliwości i obwiedni sygnału. Te właściwości
przetwarzania decydują o bardzo małym strumieniu binarnym.
Cechą charakterystyczną wokoderów segmentowych jest rekonstrukcja sygnału bez
wykorzystania filtrów syntezy. Sygnał jest odtwarzany przez proste zestawienie
segmentów mowy, wziętych z bazy, które zostały uprzednio zmodyfikowane przez
zdekodowaną informację o częstotliwości F0 dla danego segmentu, oraz jego
wzmocnienie.
Sygnał zrekonstruowany otrzymywany z wokodera segmentowego ma jakość
porównywalną z konwencjonalnymi koderami mowy dla małych przepływności, np.
MELP 2,4 kbit/s, przy czym otrzymywany strumień waha się w zakresie 400 – 1000 bit/s.
Poziom naturalności i zrozumiałości jest zadowalający, co jest okupione dużą złożonością
obliczeniową algorytmu, oraz rozmiarami baz danych kodera i dekodera.
3.2 Wokoder sylabowy
Kodowanie sylabowe polega na analizie wejściowego strumienia i rozpoznawaniu
jednostek sygnału mowy, którymi są w tym przypadku sylaby. Rozróżnianie jednostek
na poziomie fonetycznym jest jedną z podstawowych cech, które odróżniają koder
sylabowy od przedstawionego w rozdziale 3.1 kodera segmentowego. Zastosowanie sylab
jako jednostek mowy, które poddaje się analizie i rozpoznawaniu wynika z faktu, iż bardzo
często, dla konkretnego języka, występują one niezależnie od siebie w wypowiedziach.
Kechu Yi i pozostali w [5] wskazują, że ta niezależność ma wpływ na pogorszenie
poziomu zrozumiałości i naturalności zrekonstruowanej mowy. W swojej pracy sugerują
konieczność kodowania informacji o podziale słowa na sylaby jako bardzo istotnego
składnika prozodycznego sygnału. Nie jest to jedyna informacja dodatkowa, jaką przesyła
się do dekodera. W celu odtworzenia sygnału o zadowalającej jakości należy, podobnie jak
dla wokodera segmentowego, kodować kontur częstotliwości podstawowej, amplitudę
segmentów odpowiadających danej sylabie, a także czas trwania składowych dźwięcznych,
czy kontekst sylab.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 32 -
Kodowanie sylabowe, co można także wnioskować z [5], jest silnie zależne od składni
języka. Schemat blokowy kodera i dekodera segmentowego znajduje się odpowiednio
na rys.14 i rys.15.
BAZA MODELI HMM DLA
SYLAB
TABLICA INDEKSÓW
SYLAB
ROZPOZNAWANIE SYLAB
KODER PARAMETRYCZNY
ANALIZA PROZODYCZNA
STRUMIEŃ WYJŚCIOWY
SYGNAŁ WEJŚCIOWY
Rys. 14. Struktura kodera sylabowego.
BAZA FRAGMENTÓW
MOWY
TABLICA INDEKSÓW
SYLAB
DEKODER PARAMETRYCZNY SYNTEZA MOWY
MODYFIKACJA PROZODII SYGNAŁU
SYGNAŁ WYJŚCIOWYSTRUMIEŃ
WEJŚCIOWY
Rys. 15. Struktura dekodera sylabowego.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 33 -
Jak przedstawiono to na schematach, w koderze następuje rozpoznawanie sylab
zależne od mówcy. W tym procesie korzysta się ze wzorców sylab reprezentowanych
w postaci ukrytych modeli Markowa – HMM (ang. Hidden Markov Model). Na tych
strukturach opiera się większość algorytmów rozpoznawania mowy. Ze względu
na podejście analizy przez resyntezę znalazły one również szerokie zastosowanie
w kodowaniu mowy dla bardzo niskich prędkości transmisji.
Łańcuchy Markowa przedstawiane w postaci sekwencji stanów, prawdopodobieństw
przejść między tymi stanami oraz prawdopodobieństw wyjść z poszczególnych stanów
bardzo dobrze sprawdzają się w modelowaniu charakterystycznych cech sygnału mowy -
sylab, fonemów. Dokładna analiza tego zastosowania modelu Markowa zawarta jest
w rozdziale 4.2.3.
Kechu Yi i pozostali [5] stosują w swoim modelu kodeka wzorce sylab składające się
z dwóch dwustanowych modeli HMM dla każdej półsylaby oraz korzystają z algorytmu
Viterbiego do wyznaczania prawdopodobieństw wyjściowych rozkładów Gaussa
dla poszczególnych stanów modeli. Dodatkowo w koderze z fragmentów sygnału
odpowiadającym poszczególnym sylabom ekstrahowane są informacje prozodyczne, jak
kontur częstotliwości podstawowej, czas trwania składowej dźwięcznej sylaby, czy
znaczniki połączeń między sylabami (stanowią istotną informację o podziale słowa).
Rozpoznane sylaby reprezentowane są w postaci indeksów tablicy skojarzonej z bazą
modeli. Ta informacja wraz z cechami prozodycznymi sygnału wejściowego kodowana
jest parametrycznie, tzn. poszczególne składniki strumienia mają przydzieloną inną
długość słowa kodowego.
Dekoder sylabowy dokonuje rekonstrukcji sygnału poprzez zestawienie rozpoznanych
sylab, których przebiegi czasowe przechowywane są w bazie danych. Do syntezy sygnału
stosuje się tutaj dobrze znany w przetwarzaniu mowy algorytm PSOLA (ang. Pitch
Synchronous Overlap Adding) [6]. Jest to technika, która polega na odtwarzaniu sygnału
ciągłego poprzez łączenie nakładających się fragmentów sygnału, których długość zależy
od zmieniającego się okresu podstawowego sygnału. Częstotliwość generowania takich
fragmentów czasowych sygnału, oraz poziom ich wzajemnego nakładania się (wielkość
przesunięcia okresu podstawowego) jest regulowana przez odtworzoną w dekoderze
częstotliwość podstawową. Rekonstrukcja częstotliwości F0 oraz pozostałych cech sygnału
składa się na modyfikację prozodii syntezowanego sygnału.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 34 -
Wokoder sylabowy umożliwia otrzymanie mniejszego strumienia niż koder
segmentowy. Typowe wartości wahają się w zakresie 100 – 200 bit/s. Kodowanie to daje
jednak gorszy poziom zrozumiałości i naturalności sygnału zrekonstruowanego, co stanowi
jego podstawową wadę. Kolejnym problemem jest tutaj konieczność przechowywania
dużej liczby fragmentów sygnału o różnej intonacji, najlepiej branych z dużej grupy
mówców. Ten fakt, oraz bardzo ścisła zależność metody od składni języka powoduje, że
wokodery sylabowe nie cieszą się taką popularnością jak wokodery segmentowe, czy
fonetyczne.
3.3 Wokoder fonetyczny
Główną ideą kodowania fonetycznego jest rozpoznawanie mowy wykonywane
na poziomie fonemów. To rozpoznawanie polega na porównywaniu cech widma sygnału
ze wzorcami przechowywanymi w postaci wektorów cech skojarzonych ze stanami
ukrytych modeli Markowa (HMM). Zastosowanie modelowania występowania fonemów
oraz odpowiadającego im charakteru sygnału przy pomocy HMM oferuje bardzo duży
wzrost efektywność kodowania. Bardzo istotną cechą wokodera fonetycznego jest fakt, że
umożliwia on realizację kodowania mowy zarówno zależnego jak i niezależnego od
mówcy. Jest to możliwe dzięki efektywnym technikom adaptacji modeli fonemów
przechowywanych w bazie danych do konkretnego mówcy.
W literaturze związanej z tematem spotyka się często określenie, że kodowanie
fonetyczne mowy jest odporne na błędy rekonstrukcji sygnału. Wynika to z faktu, że dla
przeciętnego odbiorcy błędy w rozpoznaniu fonemów należących do jednej klasy nie są
zauważalne. Znaczące są jedynie błędy, które są spowodowane przynależnością fonemu
oryginalnego i zrekonstruowanego do innych grup. Pod synonimem klasy (grupy)
fonemów kryje się tutaj typ głoski, np. dźwięczna – bezdźwięczna.
Joseph Picone i George R. Doddington w jednej z pierwszych prac [7] na temat kodowania
fonetycznego mowy wskazują, że przedstawione tutaj cechy wokodera decydują o małych
rozmiarach zbiorów fonemów, koniecznych do prawidłowej syntezy sygnału. Pilone
i Doddington dowodzą także, że otrzymywany strumień zależy od typu zastosowanych
modeli HMM fonemów. W ogólności kodowanie fonetyczne zakłada rozpoznawanie
mowy z wykorzystaniem ukrytych modeli Markowa, których przykładowe grafy przejść
przedstawione są na rys.16 i rys.17.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 35 -
W schematach tych współczynniki a reprezentują prawdopodobieństwa przejść między
stanami, natomiast współczynniki b to prawdopodobieństwa wektorów obserwacji,
przechowywanych w modelu HMM. Wektory cech łącznie stanowią wzorzec konkretnej
głoski w sygnale mowy.
2 3 41 5
22a 33a 44a
23a34a
1π
)(2 ob )(3 ob )(4 ob
45a
Rys. 16. Graf przejść progresywnego modelu HMM.
2 3 41 5
22a
13a24a
23a 34a1π
)(2 ob )(3 ob )(4 ob
33a 44a
45a
35a
Rys. 17. Graf przejść modelu HMM uwzględniający skoki pomiędzy stanami.
Modele uwzględniające przeskoki pomiędzy stanami pozwalają na bardziej wierne
odwzorowanie parametrów widma poszczególnych fonemów, gdyż zakładają większą
zmienność wektorów cech, ale implikują jednocześnie nieco większy strumień niż proste
modele progresywne (ang. left-to-right).
Bazy modeli fonemów zawierają inny charakter sygnału w porównaniu do poprzednio
omawianych technik kodowania mowy przy bardzo małych prędkościach transmisji.
Różnica polega na tym, że baza nie zawiera wielu segmentów (fragmentów) sygnału
odpowiadających poszczególnym sylabom, wziętych z dużej liczby wypowiedzi.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 36 -
W przypadku wokodera fonetycznego ta baza zawiera ściśle określoną i niezmienną liczbę
wytrenowanych zestawów współczynników widmowych odpowiadających poszczególnym
głoskom w mowie. Ekstrakcja cech sygnału wykonywana jest najczęściej poprzez analizę
LPC mowy, czy analizę cepstralną (mel-cepstralną). Trening modeli polega na uśrednianiu
współczynników widmowych, po największej dostępnej liczbie wystąpień danego fonemu,
dla różnych mówców i zmiennej intonacji. Z procesem treningu wiąże się jeden z
elementów ograniczających efektywność tej techniki kodowania. Częstotliwość
występowania poszczególnych fonemów w mowie jest bardzo zmienna. Nawet posiadanie
bardzo dużej liczby próbek treningowych nie powoduje, że wszystkie modele fonemów
estymowane są na takim samym poziomie. Jest to jedna z niewielu wad koderów
fonetycznych.
Przykładowy histogram występowania pewnej grupy fonemów dla języka angielskiego
przedstawiony jest na rys.18. Baza danych treningowych składa się z 452 wypowiedzi.
Na podstawie takiego histogramu można na przykład stwierdzić, że fonemy /ax/, /ih/ będą
bardzo dobrze reprezentowały cechy sygnału mowy, w odróżnieniu do fonemów /oy/ czy
/uh/. Składnik mowy oznaczony symbolem /sil/ odzwierciedla fragmenty ciszy w sygnale.
Jego liczba wystąpień w sygnałach treningowych jest duża, gdyż pojawia się on zawsze
na początku i końcu nagrania.
Rys. 18. Histogram występowania pewnej grupy fonemów w bazie treningowej.
0
200
400
600
800
1000
1200
1400
/ax / /ay / /eh / /er / /ey / /hh / /ih / /iy / /jh / /ng / /ow / /oy / /sh / /th / /uh / /sil/
Indeks fonemu
Licz
ba w
ystą
pień

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 37 -
Problem odpowiedniego pokrycia bazy fonemów przez sygnały treningowe rośnie
znacznie, gdy w rozpoznawaniu mowy biorą udział nie pojedyncze modele, lecz np. pary
modeli lub zestawy trójfonemowe. Stosowanie takich modeli kontekstowych znacznie
polepsza efektywność algorytmów rozpoznawania, lecz częstość występowania
poszczególnych par czy trójek fonemów w wypowiedziach treningowych, jest o wiele
mniejsza niż w przypadku pojedynczych fonemów. Pilone i Doddington w swojej pracy
[7] prezentują przykładowe statystyki dla bazy treningowej TIMIT – jest to najczęściej
używany zbiór wypowiedzi oraz ich transkrypcji, wykorzystywany w rozpoznawaniu
fonetycznym mowy. Wskazują oni, że w bazie tej składającej się z 2792 wypowiedzi,
występuje 75% możliwych par fonemów oraz jedynie 9,25% możliwych trójek fonemów.
Na podstawie tych wartości można wysunąć wniosek, że wzrost efektywności kodera
niesie ze sobą konieczność zastosowania modeli złożonych, dzięki którym otrzymuje się
mniejszy strumień oraz większy poziom zrozumiałości sygnału zrekonstruowanego, jednak
kosztem znacznie większej bazy danych treningowych i czasochłonności jej
przygotowania.
Do rozwoju technik kodowania fonetycznego mowy, bardzo przyczyniły się badania
i prace Keiichi Tokudy. Jego model kodera i dekodera przedstawiony w [8] ilustruje ideę
kodowania mowy dla bardzo małej prędkości transmisji, opartą na rozpoznawaniu
fonemów i resyntezie sygnału. Ten kodek korzysta z bazy wytrenowanych modeli HMM
fonemów, która tutaj używana jest zarówno do rozpoznawania mowy w koderze, jak i do
syntezy sygnału w dekoderze. Strumień binarny przesyłany do dekodera oprócz indeksów
rozpoznanych modeli niesie informację o czasie trwania poszczególnych stanów
rozpoznanych modeli oraz ekstrahowany kontur częstotliwości podstawowej sygnału
wejściowego. Schemat blokowy wokodera fonetycznego przedstawionego w [8] znajduje
się na rys.19.
Modele HMM przechowują w każdym stanie wzorce widma sygnału, odpowiadające
poszczególnym fonemom, reprezentowane w postaci współczynników cepstrum,
w melowej skali częstotliwości – MFCC. Przyporządkowanie rozpoznanych jednostek
mowy do tych wzorców dokonywane jest przy wykorzystaniu algorytmu Viterbiego.
Natomiast generacja parametrów w dekoderze odbywa się wg reguły największej
wiarogodności – ML (ang. Maximum Likelihood) stosowanej do sekwencji parametrów
otrzymanych w wyniku zestawienia modeli, odpowiadających zdekodowanym indeksom
fonemów. Sekwencja wystąpień poszczególnych stanów odtwarzana jest na podstawie
przesłanej informacji o czasie trwania modeli.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 38 -
Tak otrzymane współczynniki widma sygnału są następnie przeliczane na współczynniki
filtru aproksymującego logarytm widma amplitudowego – MLSA (ang. Mel Log Spectrum
Aproximation filter).
SYGNAŁ WEJŚCIOWY
ANALIZA MEL-CEPSTRALNAEKSTRAKCJA CZĘSTOTLIWOŚCI F0
BAZA MODELI HMM FONEMÓW
ROZPOZNAWANIE FONEMÓW
KODER
GENERACJA WSPÓŁCZYNNIKÓW
CEPSTRUM
CZASY TRWANIA STANÓW
INDEKSY MODELI
FILTR MLSA
SYGNAŁ WYJŚCIOWY
DEKODER
Rys. 19. Koder i dekoder dla bardzo niskich prędkości transmisji wg
K. Tokudy.

3. Przegląd technik kodowania mowy dla bardzo małych prędkości transmisji
- 39 -
Aby dokonać syntezy sygnału, filtr ten musi być pobudzony ciągiem impulsów
dla fonemów dźwięcznych lub szumem białym dla fonemów bezdźwięcznych. Odstęp
pomiędzy impulsami wyznaczany jest na podstawie konturu częstotliwości podstawowej
przesłanego do dekodera Wadą kodera fonetycznego prezentowanego w [8] jest
konieczność zdefiniowania gramatyki wypowiedzi w celu prawidłowego rozpoznania
fonemów. Ten problem jest szczegółowo opisany w dokumentacji systemu HTK (ang.
Hidden Markov Models Toolkit) [9], który stanowi bardzo rozbudowane środowisko do
tworzenia modeli HMM, ich trenowania oraz rozpoznawania mowy.
W skrócie, gramatykę wypowiedzi stanowią wszystkie możliwe kombinacje sekwencji
fonemów, wchodzących w skład wejściowego sygnału mowy. Ta informacja musi być
znana a’priori. Na jej podstawie buduje się grafy, których ścieżki przejść odpowiadają
wystąpieniom możliwych sekwencji fonemów. Taka informacja znacznie usprawnia
algorytm Viterbiego, wyznaczający najbardziej prawdopodobną ścieżkę w grafie.
Opisany tutaj wokoder fonetyczny pozwala uzyskać strumień na poziomie ok. 150
bit/s. Otrzymujemy podobny stopień kompresji jak przy zastosowaniu kodowania
sylabowego, jednak poziom zrozumiałości sygnału zdekodowanego jest w tym
rozwiązaniu wyższy. Wokodery fonetyczne uważa się za najbardziej sprawne narzędzia
stosowane do silnej kompresji sygnału mowy, przy zachowaniu zadowalającej stopy
zrozumiałości sygnału zrekonstruowanego. Wspieranie kodowania nieznanego sygnału
mowy, jego gramatyką, która wcześniej musi być znana, stanowi jednak bardzo znaczące
ograniczenie tej techniki.

4. Koncepcja semantycznego kodeka mowy
- 40 -
4. Koncepcja semantycznego kodeka mowy
Implementacja modelu kodera i dekodera mowy dla bardzo małych prędkości
poprzedzona była analizą wielu współczesnych technik. Najważniejsze i najczęściej
spotykane algorytmy kodowania umożliwiające otrzymanie niskich przepływności zostały
omówione w poprzednim rozdziale. Głównymi założeniami tej pracy dyplomowej było
opracowanie modelu kodeka wg jednej z poznanych metod, weryfikacja otrzymanego
strumienia oraz subiektywna ocena jakości i zrozumiałości sygnału zrekonstruowanego.
Ustalono następujące wymagania stawiane przed projektowanym modelem kodeka:
1. otrzymany strumień powinien być mniejszy niż 500 bit/s;
2. sygnał odtworzony ma być zrozumiały dla przeciętnego słuchacza;
3. model kodera i dekodera powinien być jak najprostszy.
Kierując się tymi trzema założeniami, po uprzednich studiach literaturowych, wybrano
implementację kodeka z klasy wokoderów fonetycznych. Opracowana koncepcja
semantycznego kodeka mowy dla małych przepływności prezentowana jest w tym
rozdziale. Należy zaznaczyć, iż ostateczna wersja proponowanego rozwiązania bardzo
długo ewoluowała, zanim przyjęła ostateczną formę. Projektując kodek, który jest tematem
tej pracy, przeprowadzono wiele pobocznych badań związanych z technikami
przetwarzania mowy.
Opracowany koder i dekoder mowy składają się z kilku bloków realizujących etapy
przetwarzania mowy. W rozdziale 4.1 zawarty jest opis ogólnej struktury
zaimplementowanego kodeka mowy, z uwzględnieniem wymiany danych pomiędzy
blokami analizy i syntezy mowy. Szczegółowa charakterystyka modułu kodera zawarta
jest w rozdziale 4.2, natomiast opis projektu dekodera mowy znajduje się w rozdziale 4.3.

4. Koncepcja semantycznego kodeka mowy
- 41 -
4.1 Struktura systemu
Schemat blokowy zaprojektowanego modelu semantycznego kodeka mowy z klasy
wokoderów fonetycznych przedstawiony jest na rys.20. Struktura systemu bardzo
przypomina schemat blokowy wokodera fonetycznego. Podobnie jak na rys.19, mamy tutaj
blok odpowiedzialny ze ekstrakcję częstotliwości podstawowej oraz wyznaczanie
reprezentacji widma sygnału w postaci współczynników cepstrum w melowej skali
częstotliwości – MFCC. Zaprojektowany model kodera i dekodera różni się od wokodera
zaproponowanego przez Tokudę [8] tym, że zawiera dwie bazy modeli HMM fonemów.
Pierwsza baza modeli znajduje się w koderze i zawiera wzorce współczynników MFCC,
które służą do rozpoznawania fonemów. Baza modeli dekodera składa się
ze współczynników mel-cepstrum, które uwzględniają energię sygnału i stosowana jest
do syntezy mowy.
Na schemacie kodera widoczne jest, że analiza mel-cepstralna oraz rozpoznawanie
fonemów, realizowane przez algorytm Viterbiego, są wykonywane po przetwarzaniu
wstępnym sygnału wejściowego. W wyniku tego przetwarzania zostaje usunięta składowa
stała wejściowego sygnału mowy oraz dokonuje się jego korekty, przy pomocy filtru
preemfazy. Sygnał wejściowy musi być wstępnie przetworzony, aby parametry analizy
sygnału wejściowego, oraz sygnałów treningowych były identyczne. Parametry modeli
HMM wyznaczane są przy pomocy systemu HTK v.3.4 [9], natomiast cały proces
kodowania wejściowego sygnału mowy wykonywany jest w środowisku Matlab 6.5.
Ekstrakcja częstotliwości podstawowej to bardzo ważny blok systemu kodera mowy
dla bardzo małej prędkości transmisji. Ta informacja prozodyczna musi być bardzo wiernie
odtworzona aby zachować naturalną intonację mówcy. Z tego powodu częstotliwość F0
ekstrahuje się bezpośrednio z sygnału wejściowego. Przy wyborze metody wyznaczania
częstotliwości podstawowej kierowano się przede wszystkim jej dokładnością. Spośród
szerokiej gamy technik ekstrakcji częstotliwości F0 [10] wybrano metodę wykorzystującą
cepstrum sygnału.
Wyznaczone współczynniki MFCC, oraz wzorce pobrane z bazy danych modeli HMM
dla kodera umożliwiają rozpoczęcie procesu rozpoznawania fonemów, który w głównej
mierze opiera się na algorytmie Viterbiego. Poszukiwanie najbardziej prawdopodobnej
ścieżki w grafie modelu HMM wykonuje się równolegle dla wszystkich modeli fonemów
i jest to poprzedzone wyznaczaniem prawdopodobieństw wyjściowych z modeli, wg
rozkładu Gaussa.

4. Koncepcja semantycznego kodeka mowy
- 42 -
EKSTRAKCJA CZĘSTOTLIWOŚCI F0
PRZETWARZANIE WSTĘPNE
ROZPOZNAWANIE FONEMÓW
(ALGORYTM VITERBIEGO)
ANALIZA MEL-CEPSTRALNA BAZA MODELI HMM
KODERA
KODER BINARNY
SYGNAŁ WEJŚCIOWY
2 3 41 5
„a”
2 3 41 5
„dh”
F0CZASY
TRWANIA MODELI
INDEKSY MODELI
KODER
DEKODER BINARNY
F0 CZASY TRWANIA MODELI
INDEKSY MODELI
GENERATOR SYGNAŁU
POBUDZENIA
ODTWARZANIE WIDMA SYGNAŁU
SYNTEZA MOWY
BAZA MODELI HMMDEKODERA
2 3 41 5
„a”
2 3 41 5
„dh”
SYGNAŁ WYJŚCIOWY
ZAKODOWANY STRUMIEŃ
DEKODER
Rys.20. Struktura opracowanego semantycznego kodeka mowy.

4. Koncepcja semantycznego kodeka mowy
- 43 -
Dla danego fragmentu sygnału poszukuje się modelu fonemu, który pierwszy osiągnie stan
końcowy wg reguły MAP (ang. Maximum A’Posteriori Probability), tj. za rozpoznany
fonem przyjmuje się ten, którego prawdopodobieństwo przejścia przez graf modelu jest
największe.
W wyniku zastosowania algorytmu Viterbiego do rozpoznawania fonemów otrzymujemy
nie tylko indeksy rozpoznanych modeli HMM, ale również informację o ich czasie
trwania. W tej implementacji kodera mowy, struktura czasowa sygnału syntezowanego nie
jest odtwarzana wprost jak to jest zazwyczaj robione w wokoderach fonetycznych.
Zaprojektowany kodek zakłada bezpośrednią transmisję informacji o czasie trwania modeli
z kodera do dekodera i jest ona wyrażona w postaci liczby występujących kolejno po sobie
modeli HMM danego fonemu. Szerzej jest to opisane w rozdziale 4.2.4.
Trzy strumienie danych konieczne do syntezy mowy są kodowane binarnie przy
zastosowaniu kodu Huffmana. Taka metoda skutkuje efektywnie zakodowanym
strumieniem bitów, który przesyłany jest do dekodera. W układzie rekonstrukcji mowy,
na podstawie odtworzonej informacji o częstotliwości podstawowej F0 generowany jest
sygnał pobudzenia. Idea konstrukcji tego sygnału zaczerpnięta jest z kodera MELP, gdzie
fragmenty dźwięczne mowy reprezentuje się w postaci ciągu impulsów (ang. impulse
train), natomiast fragmenty bezdźwięczne są generowane przy pomocy szumu białego
gaussowskiego – WGN (ang. White Gaussian Noise).
Oprócz sygnału pobudzenia, w dekoderze odtwarza się także charakterystykę
częstotliwościową toru przetwarzania sygnału mowy. Ten proces realizowany jest
na podstawie otrzymanych z dekodera binarnego indeksów rozpoznanych modeli fonemów
oraz czasów ich trwania. W efekcie otrzymujemy aproksymację widma amplitudowego
traktu głosowego, która służy do odpowiedniej filtracji sygnału pobudzenia. Filtracja ta
jest realizowana w dziedzinie częstotliwości za pomocą przekształcenia FFT. Szczegółowe
opisy poszczególnych modułów proponowanego semantycznego kodeka mowy zawarte są
w kolejnych podrozdziałach.

4. Koncepcja semantycznego kodeka mowy
- 44 -
4.2 Model kodera
Prezentowany tutaj projekt został utworzony w środowisku Matlab 6.5, przy
wykorzystaniu systemu HTK v3.4 do treningu modeli fonemów. Takie rozwiązanie
umożliwiło znaczne przyspieszenie prac nad koderem, oraz wyeliminowało konieczność
implementacji skomplikowanych funkcji do estymacji parametrów modeli HMM,
co wykraczałoby poza ramy tej pracy magisterskiej.
Opracowany koder realizuje algorytm rozpoznawania fonemów w wejściowym sygnale
mowy oraz dokonuje ekstrakcji częstotliwości podstawowej sygnału w poszczególnych
segmentach analizy. Oprócz tych parametrów wyznaczane są także czasy trwania
poszczególnych fonemów. Te trzy rodzaje informacji, po uprzednim kodowaniu
entropijnym, przesyłane są do dekodera.
4.2.1. Ekstrakcja częstotliwości podstawowej
Efektywne obliczeniowo i dokładne techniki estymacji częstotliwości podstawowej
są tematem poszukiwań od wielu lat. Problem z efektywnością ekstrakcji częstotliwości
podstawowej pojawia się szczególnie w przypadku sygnałów zaszumionych,
lub składających się z kilku szeregów harmonicznych o różnych F0.
W literaturze [10], [11] często wprowadza się podział metod wyznaczania częstotliwości
podstawowej na trzy główne klasy:
1. algorytmy w dziedzinie czasu – o niskiej złożoności obliczeniowej, oparte na
obserwacjach przebiegów czasowych ilustrujących zmiany pewnych cech sygnału
jak np. liczba przejść przez zero, liczba wystąpień wartości szczytowych; zaletą
tych technik jest duża dokładność dla małych częstotliwości, gdyż wtedy dłuższe
okresy wyznaczane są z dużą precyzją;
2. algorytmy w dziedzinie częstotliwości – o większej złożoności obliczeniowej,
częstotliwość F0 wyznacza się na podstawie poszczególnych składowych
harmonicznych sygnału; zaletą tych technik jest duża dokładność dla dźwięków o
wysokiej częstotliwości podstawowej, ponieważ wtedy odległości pomiędzy
prążkami harmonicznymi mogą być wyznaczone z dużą precyzją;
3. algorytmy statystyczne – polegają na klasyfikowaniu poszczególnych ramek
sygnału do pewnych grup, dla których utworzone są estymatory częstotliwości F0.

4. Koncepcja semantycznego kodeka mowy
- 45 -
W zaimplementowanym modelu kodera zastosowano ekstrakcję częstotliwości
podstawowej opartą na analizie cepstralnej. Jest to metoda z klasy algorytmów
w dziedzinie częstotliwości. Dla sygnału mowy oferuje ona zadowalające wyniki i jest
prosta w implementacji.
Widmo krótkookresowe sygnału periodycznego charakteryzującego się częstotliwością F0
wykazuje zafalowania, ze względu na harmoniczną strukturę tego sygnału. Według teorii
Nolla [11] są one najbardziej widoczne dla logarytmu widma mocy sygnału, gdyż
przyjmują wtedy kształt kosinusoidy. W dziedzinie pseudoczęstotliwości sygnału jest to
widoczne w postaci prążka o dużej amplitudzie, który pojawia się na skali w momencie
odpowiadającym okresowi podstawowemu 1/F0.
Cepstrum rzeczywiste sygnału definiujemy w postaci odwrotnej dyskretnej transformaty
Fouriera z logarytmu amplitudy dyskretnej transformaty Fouriera sygnału. Można
to wyrazić w postaci wzoru (3):
|)))((|(log)( nxdftidftdCx = (3)
gdzie:
)(nx – n-ta próbka sygnału wejściowego
W wyniku takiego przekształcenia otrzymujemy próbki cepstrum w dziedzinie
pseudoczasu – indeks „d”.
Częstotliwość podstawową (okres podstawowy) efektywnie wyznacza się zakładając
chwilową stacjonarność sygnału w ramkach analizy, których długość waha się między 40 –
80 ms. Dłuższe okno skutkuje większą korelacją próbek w czasie, co z kolei wpływa
na bardziej wierne odwzorowanie intonacji. Zastosowanie krótszych okien analizy, np.
20 ms powoduje gorsze efekty działania algorytmu.
Widmo sygnału oryginalnego )(nx posiada drobną strukturę pobudzenia splecioną
z rezonansową odpowiedzią traktu głosowego. Wykonując przekształcenie DFT (ang.
Discrete Fourier Transform) ujawniamy poszczególne harmoniczne sygnału
zmodyfikowane o charakterystykę filtru – toru przetwarzania.
Jest to pokazane na rys.21, który przedstawia widmo amplitudowe dla pojedynczej
dźwięcznej ramki sygnału trwającej 60 ms. Składowe harmoniczne są widoczne
na wykresie w postaci prążków widma pojawiających się dla określonych wartości na skali
częstotliwości. Na zróżnicowanie amplitudy zafalowań wpływa charakterystyka toru
przetwarzania – traktu głosowego w przypadku sygnału mowy.

4. Koncepcja semantycznego kodeka mowy
- 46 -
Rys.21. DFT wyznaczone dla pojedynczej, dźwięcznej ramki sygnału mowy,
częstotliwość próbkowania w 16 kHz, długość okna – 960 próbek.
Rys.22. Wygładzone widmo DFT dla dźwięcznej ramki sygnału, częstotliwość
próbkowania w 16 kHz, długość okna – 960 próbek.

4. Koncepcja semantycznego kodeka mowy
- 47 -
Zastosowanie logarytmu na tak otrzymanym przebiegu skutkuje wygładzeniem widma,
co jest widoczne na rys.22, w postaci wyraźnego trendu zmian amplitudy prążków. Na tym
wykresie wolnozmienny przebieg reprezentuje podbicia rezonansowe, natomiast
szybkozmienne składowe są odwzorowaniem prążków pobudzenia.
Ostatecznie cepstrum sygnału oryginalnego wyznacza się przez zastosowanie odwrotnej
transformacji DFT z logarytmu widma, co powoduje rozdzielenie składowej
wolnozmiennej od składowej szybkozmiennej. Na rys.23 podbicia rezonansowe widoczne
są w postaci prążków dla małej wartości pseudoczasu (w okolicach zera), natomiast
pobudzenie reprezentowane jest w postaci pojedynczego maksimum, położonego dalej
na osi pseudoczasu. Odległość tego maksimum cepstrum od początku skali definiuje okres
podstawowy sygnału. Wyróżnienie prążka cepstrum związanego z pobudzeniem
w przypadku składników bezdźwięcznych mowy nie udaje się (rys.24).
W zaimplementowanym algorytmie poszukiwania częstotliwości F0 najpierw
wyszukuje się prążka cepstrum o maksymalnej amplitudzie, a następnie podejmowana jest
decyzja o jego dźwięcznym lub bezdźwięcznym charakterze, przez porównanie z wartością
progową. Ten próg dobiera się doświadczalnie. Jeśli jest on zbyt mały wtedy pewne
fragmenty sygnału zostają błędnie zakwalifikowane jako dźwięczne. Natomiast, gdy jego
wartość jest duża, wtedy niektóre fragmenty dźwięczne mogą być rozpoznane jako
składniki szumowe sygnału. Przykład ekstrakcji częstotliwości podstawowej z sygnału
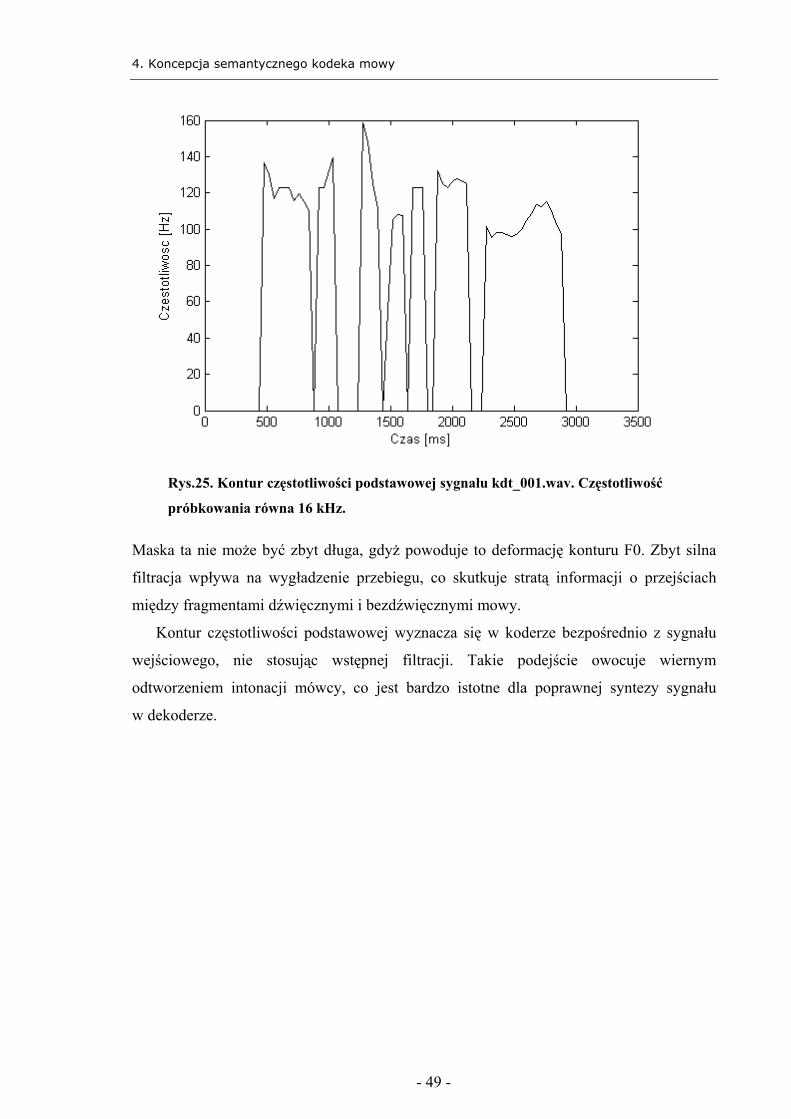
mowy „kdt_001.wav”, wziętego z bazy treningowej kdt US English TIMIT [12]
przedstawiony jest na rys.25.
Innym parametrem, który podlega regulacji przy estymacji częstotliwości
podstawowej, jest zakres, w którym poszukiwana jest wartość F0. W tej implementacji za
przedział możliwych wartości częstotliwości przyjęto 70 – 300 Hz. Gdy maksymalny
prążek cepstrum znajduje się poza tym zakresem jako wartość częstotliwości podstawowej
przyjmuje się zero. W wyniku wielu eksperymentów, w których dokonywano zmian tego
zakresu, otrzymano lepsze lub gorsze wyniki estymacji konturu częstotliwości F0,
w zależności od charakteru sygnału. Jednak w większości przypadków przyjęty zakres 70
– 300 Hz skutkował dobrymi wyniki działania algorytmu.
Częstotliwość podstawowa jako naturalna cecha mowy, która jest rozpoznawalna
w postaci intonacji, charakteryzuje się płynnymi zmianami w trakcie wypowiadania
kolejnych fragmentów sygnału. Ten efekt ciągłości uzyskuje się w zaimplementowanym
algorytmie przez filtrację medianową otrzymanego konturu F0. Stosujemy filtr
jednowymiarowy o długości maski równej 3.

4. Koncepcja semantycznego kodeka mowy
- 48 -
Rys.23. Cepstrum dźwięcznej ramki sygnału.
Rys.24. Cepstrum bezdźwięcznej ramki sygnału.
4. Koncepcja semantycznego kodeka mowy
- 49 -
Rys.25. Kontur częstotliwości podstawowej sygnału kdt_001.wav. Częstotliwość
próbkowania równa 16 kHz.
Maska ta nie może być zbyt długa, gdyż powoduje to deformację konturu F0. Zbyt silna
filtracja wpływa na wygładzenie przebiegu, co skutkuje stratą informacji o przejściach
między fragmentami dźwięcznymi i bezdźwięcznymi mowy.
Kontur częstotliwości podstawowej wyznacza się w koderze bezpośrednio z sygnału
wejściowego, nie stosując wstępnej filtracji. Takie podejście owocuje wiernym
odtworzeniem intonacji mówcy, co jest bardzo istotne dla poprawnej syntezy sygnału
w dekoderze.

4. Koncepcja semantycznego kodeka mowy
- 50 -
4.2.2 Analiza i reprezentacja widma w postaci współczynników
MFCC
Jedną z najczęściej spotykanych technik ekstrakcji cech widmowych sygnału mowy
jest analiza cepstralna w melowej skali częstotliwości. Współczynniki otrzymane
w wyniku takiego przekształcenia sygnału określa się skrótem MFCC (ang. Mel Frequency
Cepstral Coefficients). W porównaniu do innych metod analizy widmowej sygnału jak np.
LPC, ta technika pozwala na lepsze odwzorowanie ludzkiego systemu słyszenia, który
opisany jest nieliniową krzywą. Rozdzielczość ludzkiego ucha spada ze wzrostem
częstotliwości, dla tego samego poziomu natężenia sygnału. Wyniki wielu badań
empirycznych potwierdzają fakt, że zastosowanie percepcyjnej skali częstotliwości do
analizy widma sygnału znacznie polepsza proces rozpoznawania charakterystycznych
składników mowy. Transformacja częstotliwości ze skali liniowej do skali melowej
wyrażona jest w postaci wzoru (4):
)
7001(log2595 10
Hzmel
ff += (4)
To nieliniowe odwzorowanie pokazane jest na rys.26.
Rys.26. Transformacja liniowej skali częstotliwości do skali melowej.

4. Koncepcja semantycznego kodeka mowy
- 51 -
W celu polepszenia warunków analizy wejściowego sygnału mowy, dokonuje się jego
wstępnego przetwarzania przy pomocy filtru preemfazy o transmitancji dyskretnej (5):
11)( −⋅α−= zzH (5)
gdzie:
α – współczynnik nieliniowości charakterystyki transmitancji (zazwyczaj równy 0.97)
W wyniku takiej filtracji otrzymujemy spłaszczenie widma sygnału tzn., eksponowane są
składniki wysokoczęstotliwościowe, kosztem zmniejszenia amplitudy składników widma
odpowiadających niskim częstotliwościom. W dziedzinie czasu efektem ubocznym jest
obniżenie dynamiki sygnału.
Po zastosowaniu preemfazy do wejściowego sygnału mowy wykonywana jest analiza
cepstralna w skali melowej (6). Na wstępie oblicza się dyskretną transformację Fouriera z
sygnału wejściowego, stosują algorytm FFT. Bardzo ważnym parametrem stosowanego
przekształcenia FFT jest odpowiedni dobór okna analizy. Najczęściej stosuje się okna
Hamminga o długości 20 – 30 ms, z zakładką [8], [13]. Długości zakładki wynosi
zazwyczaj pół długości okna analizy.
Kolejnym etapem analizy jest filtracja widma przy pomocy zespołu filtrów pasmowo-
przepustowych, których częstotliwości środkowe są rozmieszczone w równych odstępach
na melowej skali częstotliwości. Filtry najczęściej mają trójkątną charakterystykę, ale
spotyka się też charakterystyki prostokątne, lub o kształcie krzywej Gaussa. Liczba filtrów
wchodzących w skład zespołu decyduje o rzędzie analizy MFCC. Zwiększanie liczby
współczynników powyżej kilkunastu nie wnosi znaczącego zysku w proces ekstrakcji cech
sygnału.
∑=
−⋅
⋅⋅=N
jji j
Nim
Nc
0))12(
2cos(2 π (6)
gdzie:
ic – otrzymany współczynnik MFCC
N – rząd przekształcenia
jm – logarytm łącznej mocy sygnału, otrzymanej dla j-tego filtru z zespołu filtrów
Przed transformacją do melowej skali częstotliwości szerokość pasma przepustowego
każdego z filtrów określa się korzystając z równania (7):

4. Koncepcja semantycznego kodeka mowy
- 52 -
N
fff w
minmax −= (7)
gdzie:
wf – otrzymana szerokość pasma przepustowego filtru
maxf – częstotliwość maksymalna – zazwyczaj połowa częstotliwości próbkowania
minf – częstotliwość minimalna – zazwyczaj 0 Hz
N – liczba filtrów wchodzących w skład zespołu
Przykładowe rozmieszczenie zespołu filtrów analizy na skali częstotliwości pokazane jest
na rys.27.
Rys.27. Przykład zestawu filtrów dla analizy MFCC. Liczba filtrów wynosi 12,
częstotliwość próbkowanie 16kHz.
Powyżej częstotliwości 1 kHz szerokość pasma filtrów wzrasta w miarę zwiększania
częstotliwości. Natomiast ze względu na logarytmiczną transformację skali,
dla częstotliwości poniżej 1 kHz filtry są oddalone od siebie w równych odległościach.
Największa selektywność widoczna jest dla składowych o małych częstotliwościach, gdyż
tutaj rozdzielczość ludzkiego systemu słyszenia jest bardzo dobra. Współczynniki
wysokoczęstotliwościowe, aby niosły znaczącą informację muszą być wyznaczone dla
większego zakresu częstotliwości (rys.27).

4. Koncepcja semantycznego kodeka mowy
- 53 -
Składniki widma mocy sygnału, zawarte w pasmach przepustowych poszczególnych
filtrów są sumowane, a następnie z tych sum wyznaczane są logarytmy. Ostatecznie
wykonując dyskretną transformację kosinusową – DCT (ang. Discrete Cosine Transform)
otrzymujemy wartości MFCC.
Współczynniki o indeksach zerowych – oc niosą informację o logarytmie energii sygnału
w danej ramce analizy. Zazwyczaj nie biorą one udziału w procesie rozpoznawania mowy,
gdyż energia sygnału jest cechą ściśle zależną od mówcy, w odróżnieniu od reprezentacji
widmowej poszczególnych jednostek mowy – fonemów. Współczynniki energii są jednak
w tym projekcie wykorzystywane jako informacja prozodyczna do odtworzenia obwiedni
natężenia sygnału syntezowanego.
Aby zwiększyć efektywność algorytmu rozpoznawania mowy opartego na analizie
mel-cepstralnej często oprócz współczynników statycznych wyznacza się także ich
pochodne czasowe. Współczynniki dynamiczne, zwane współczynnikami delta otrzymuje
się stosując następujący wzór (8):
∑
∑
=
=−+
⋅
−⋅=∆ N
n
N
nnini
i
n
ccnc
1
2
1
2
)( (8)
gdzie:
ic∆ – otrzymany współczynnik dynamiczny MFCC w ramce czasowej i
N – tzw. szerokość okna delta
Formuła (8) jest także używana do wyznaczania wyższych pochodnych MFCC, jak np.
współczynniki akceleracji tzw. delta-delta, które reprezentują drugą pochodną po czasie
współczynników statycznych MFCC. W opracowanym modelu kodeka cechy dynamiczne
widma sygnału nie są uwzględniane podczas rozpoznawania fonemów, gdyż znacznie
upraszcza to algorytm syntezy sygnału. Eliminujemy w ten sposób konieczność
implementacji skomplikowanych, numerycznych metod estymacji współczynników
wypadkowych MFCC.
Wartości mel-cepstrum, używane w procesie rozpoznawania mowy bardzo często poddaje
się procesowi wygładzania widma, zwanego liftracją, którego celem jest wyeliminowanie
wpływu pobudzenia na wartości współczynników. Przekształcenie to jest opisane wzorem
(9):

4. Koncepcja semantycznego kodeka mowy
- 54 -
ii cL
iLl ⋅⋅
⋅+= ))sin(2
1( π (9)
gdzie:
il – otrzymany w wyniku liftracji i-ty współczynnik mel-cepstrum
ic – wartość i-tego współczynnika mel-cepstrum przed liftracją
L – rząd przekształcenia
Na rys.28 i rys.29 przedstawione są otrzymane wartości współczynników analizy mel-
cepstralnej dla wybranego fragmentu mowy z bazy treningowej. Już na podstawie takich
obrazów można rozróżnić charakterystyczne cechy sygnału, np. synchroniczne zmiany
pasm formantowych. Różnica pomiędzy tymi dwoma wykresami polega na tym, że
na pierwszym z nich widoczna jest analizę wykonano bez przeprowadzania liftracji
współczynników, natomiast podczas drugiej zastosowano przekształcenie rzędu 22.
Na prezentowanych rysunkach kolor reprezentuje amplitudę współczynników MFCC.
Wykonanie liftracji powoduje, że wykres staje się bardziej czytelny. Ekstrakcja cech jest
łatwiejsza, gdyż wartości współczynników odpowiadające poszczególnym jednostkom
mowy – fonemom, są zróżnicowane. Co więcej przedstawione tutaj obrazy potwierdzają,
że największa informacja o cechach fragmentów mowy zawarta jest w kilku pierwszych
współczynnikach MFCC. Analiza spektrogramów pozwala też łatwo wyodrębnić
fragmenty dźwięczne i bezdźwięczne sygnału. Przykładowo cechą charakterystyczną
fonemów szumowych są bardzo zbliżone wartości współczynników MFCC o indeksach 2
– 12.

4. Koncepcja semantycznego kodeka mowy
- 55 -
Rys.28. Wynik analizy mel-cepstralnej dla sygnału kdt_003.wav, wykonanej bez
zastosowania liftracji. Liczba współczynników MFCC – 12, okno analizy 20 ms
(320 próbek).
Rys.29. Wynik analizy mel-cepstralnej dla sygnału kdt_003.wav, przy
zastosowanej liftracji 22-go rzędu. Liczba współczynników MFCC – 12, okno
analizy 20 ms (320 próbek).

4. Koncepcja semantycznego kodeka mowy
- 56 -
4.2.3 Modelowanie fonemów przy pomocy ukrytych modeli
Markowa
Ukryty (niejawny) model Markowa – HMM to standardowe narzędzie analizy
statystycznej, używane do modelowania parametrów procesów losowych. Struktury te są
powszechnie wykorzystywane w kodekach mowy dla bardzo małych prędkości transmisji,
a dokładnie w algorytmach rozpoznawania i syntezy mowy. W tej klasie wokoderów, przy
ich pomocy tworzy się wzorce jednostek akustycznych, jakimi są fonemy.
Niejawny model Markowa definiuje się jako skończoną maszynę stanów – FSM (ang.
Finite State Machine), która generuje sekwencję obserwacji dyskretnych w czasie. W danej
jednostce czasu, np. ramce sygnału, maszyna zmienia stan zgodnie
z prawdopodobieństwem przejść między stanami, a następnie generuje wektor obserwacji
wg rozkładu prawdopodobieństwa wyjściowego w danym stanie. Dla każdego modelu
HMM, o liczbie stanów równej N możemy określić następującą przestrzeń
probabilistyczną (10):
),,{ ΠBA=λ (10)
gdzie: N
jijia 1,, }{ ==A – rozkład prawdopodobieństwa przejść między stanami modelu HMM
Njjb 1)}({ == oB – rozkład prawdopodobieństwa wektorów obserwacji
Nii 1}{ =π=Π – rozkład prawdopodobieństwa wejść do poszczególnych stanów modelu
Łączna notacja prezentowana we wzorze (10) jest stosowana do opisu parametrów modeli
HMM. Ze względu na charakter przejść między stanami definiuje się różne typy modeli.
Dla celów rozpoznawania i syntezy mowy istotny jest tzw. model progresywny, którego
graf przedstawiony jest na rys.30.
Ukryte modele Markowa często w literaturze [14], [15] określa się mianem procesów
podwójnie stochastycznych (11):
Tttt BA 1),( = (11)
gdzie dziedziną procesów losowych tA i tB jest zbiór chwil Tt ∈ , natomiast
przeciwdziedziną zbiór stanów modelu. Te dwa procesy losowe opisane są wtedy przez
rozkłady prawdopodobieństwa (10).

4. Koncepcja semantycznego kodeka mowy
- 57 -
2 3 41 5
22a 33a 44a
23a34a
1π
)(2 ob )(3 ob )(4 ob
45a
Rys.30. Pięciostanowy progresywny (ang. left-to-right) model HMM.
Niejawność modeli HMM polega na tym, że obserwujemy jedynie realizacje procesu
stochastycznego tB , podczas gdy realizacje procesu tA wpływające na realizacje tB
pozostają niewidoczne.
Wyjściowy rozkład prawdopodobieństwa )(ojb może być dyskretny lub ciągły,
w zależności od charakteru obserwacji. Ze względu na typ rozkładu prawdopodobieństwa
wyjściowego rozróżniamy klasę modeli HMM o rozkładach ciągłych – CD-HMM (ang.
Continous Density Hidden Markov Model) lub dyskretnych – DD-HMM (ang. Discrete
Density Hidden Markov Model).
Najczęściej w implementacjach algorytmów rozpoznawania mowy stosuje się modele
z rozkładem ciągłym, gdzie prawdopodobieństwa wyjściowe modelu HMM są mieszaniną
wielowymiarowych rozkładów Gaussa wg wzoru (12):
∑=
=M
mjmjmjmj Nwb
1),|()( Uµoo (12)
gdzie:
M – liczba rozkładów Gaussa wchodzących w skład mieszaniny
jmw – waga składnika m w stanie j
jmµ – wektor (o długości d ) wartości średniej składnika m w stanie j
jmU – macierz (o rozmiarze dxd ) kowariancji składnika m w stanie j

4. Koncepcja semantycznego kodeka mowy
- 58 -
W opracowanym projekcie kodeka zastosowany jest uproszczony model HMM, w którym
prawdopodobieństwa wektorów obserwacji w poszczególnych stanach modelu wyrażone
są w postaci pojedynczego, wielowymiarowego rozkładu Gaussa, a więc (13):
),|()( jjj Nb Uµoo = (13)
gdzie:
jµ – wektor wartości średnich obserwacji w stanie j (o długości d )
jmU – macierz kowariancji wektora obserwacji w stanie j (o rozmiarze dxd )
We wzorach (12) i (13) gaussowski, wielowymiarowy rozkład prawdopodobieństwa
określa się jako (14):
))()(21exp(
||)2(
1),|( 1jj
TjdjjN µoUµo
UUµo −−−
π= − (14)
gdzie:
d – wymiar wektora obserwacji o
Podstawowym zagadnieniem w teorii HMM jest estymacja parametrów modeli w postaci
prawdopodobieństw przejść między stanami oraz prawdopodobieństw wyjść
z poszczególnych stanów, które dają maksymalne prawdopodobieństwo otrzymania
pewnej sekwencji obserwacji na wyjściu. To całkowite prawdopodobieństwo
wygenerowania sekwencji wyjściowej ],...,,[ 21 ToooO = , z modelu HMM o parametrach
],,[ ΠBA=λ jest wyrażone w postaci wzoru (15):
∑∏=
−=λ
Q
T
ttqqq ttt
baP1
)()|(1
oO (15)
gdzie:
)( tqtb o – prawdopodobieństwo otrzymania wektora obserwacji o w chwili t , przebywając
w stanie q modelu HMM
tt qqa1−
– prawdopodobieństwo przejścia ze stanu poprzedniego w chwili 1−t , do stanu
aktualnego w chwili t
Sumowanie iloczynu prawdopodobieństw tt qqa
1− i )( tqt
b o odbywa się po wszystkich
możliwych sekwencjach stanów q .

4. Koncepcja semantycznego kodeka mowy
- 59 -
Estymacja parametrów modeli HMM jest zagadnieniem trudnym. Nie istnieją analityczne
metody ich wyznaczania, bazujące na kryterium największej wiarogodności – ML (ang.
Maximum Likelihood). Rozwiązaniem są metody iteracyjne, które pozwalają otrzymać
zestaw parametrów λ , lokalnie maksymalizując prawdopodobieństwo całkowite P(O| λ).
Przykładem jest metoda EM (ang. Expectation Maximization), nazywana często
algorytmem Bauma-Welcha, w której wykorzystuje się także algorytm prefiksowo-
sufiksowy do modyfikacji wartości parametrów rozkładów [14].
W przypadku ciągłego sygnału mowy, sekwencje parametrów poszczególnych
jednostek mowy mogą się różnić, w zależności od kontekstu zarówno lingwistycznego, jak
i fonetycznego. Aby uwzględnić to zjawisko, często wykorzystuje się wzorce zależne
od kontekstu nazywane modelami trójfonemowymi HMM. Polepszają one efektywność
procesu rozpoznawania mowy, jednak bardzo poważnym problemem w takim rozwiązaniu
jest przygotowanie odpowiednio dużej bazy danych treningowych, aby zapewnić pokrycie
wszystkich możliwych permutacji trójek fonemów. Poza tym, wadą jest także duży rozrzut
częstotliwości występowania poszczególnych jednostek kontekstowych w sygnałach
treningowych, co skutkuje bardzo zróżnicowanym stopniem wytrenowania tych modeli.
Aby zmniejszyć skalę tego problemu stosuje się techniki gromadzenia stanów modeli
HMM w grupy, w których następuje wymiana parametrów modeli między stanami.
Przykładem takiej metody jest grupowanie wykorzystujące drzewa decyzyjne (ang.
decision tree-based context clustering) [15].
Ze względu na stosunkowo niewielkie rozmiary wykorzystywanej w projekcie bazy
danych treningowych oraz opisane powyżej wady stosowania modeli trójfonemowych,
w opracowanej koncepcji kodera wybrano modele pojedynczych fonemów, tworząc tzw.
monofony HMM. W projekcie wykorzystywana jest biblioteka HTK v.3.4 [9], przy
pomocy której dokonuje się inicjalizacji i reestymacji parametrów modeli. Baza danych
treningowych składa się z 452 wypowiedzi, pochodzących od jednego mówcy, zebranych
w tzw. korpusie CMU/CSTR kdt US English TIMIT database [12]. Ten zbiór zawiera nie
tylko fragmenty mowy w formacie WAV, ale również pliki z etykietami fonemów, a także
transkrypcje tekstowe wypowiedzi. Dla sygnałów z tej bazy wykonuje się analizę mel-
cepstralną otrzymując współczynniki MFCC, które są później wykorzystywane
w estymacji parametrów modeli fonemów. Sygnały treningowe wchodzące w skład bazy
zawierają łącznie 41 typów fonemów, uwzględniając jednostkę ciszy – /sil/ (tab.1).

4. Koncepcja semantycznego kodeka mowy
- 60 -
Tab.1. Typy fonemów dostępne w bazie CMU/CSTR kdt US English TIMIT.
Fonemy dźwięczne Fonemy bezdźwięczne
/aa/, /ae/, /ah/, /ao/, /aw/, /ax/, /ay/, /b/,
/d/, /dh/, /eh/, /er/, /ey/, /g/, /ih/, /iy/,
/jh/, /l/, /m/, /n/, /ng/, /ow/, /oy/, /r/,
/uh/, /uw/, /v/, /w/, /y/, /z/, /zh/
/ch/, /f/, /hh/, /k/, /p/, /s/ , /sh/, /sil/, /t/, /th/
Aby zdefiniować topologię modeli HMM używanych w projekcie, system HTK określa
sposób tworzenia w plikach tekstowych specjalnych struktur, które m.in. definiują liczbę
stanów modelu, możliwe przejścia między nimi oraz rodzaj parametrów generowanych
w postaci wektorów obserwacji. Definicje modeli są następnie uaktualniane podczas
reestymacji parametrów.
Po zakończeniu procesu treningu HMM zmodyfikowane rozkłady poszczególnych
modeli są wczytywane do środowiska Matlab 6.5, gdzie odbywa się główne kodowanie
sygnału mowy. Przykładowy prototyp modelu HMM używany w projekcie umieszczony
jest w dodatku pracy.
Definicja modelu zawsze rozpoczyna się nagłówkiem ~o, który zawiera informację
o ogólnych parametrach modelu:
• <VECSIZE> – ten symbol definiuje długość wektora wartości średnich parametrów
przechowywanych w modelu;
• <NULLD> – informacja, że czasy trwania stanów nie są reprezentowane
w modelu;
• <MFCC_0> – typ parametrów, które są przechowywane w modelu, w tym
przypadku są to współczynniki MFCC. System HTK [9] pozwala definiować
modele HMM także dla innych typów parametrów reprezentujących cechy sygnału
mowy jak np. współczynniki LPC;
• <FullC> – ten symbol wskazuje, że w strukturze modeli HMM macierze
kowariancji dla wielowymiarowych rozkładów wyjściowych są przechowywane
w postaci górnej półmacierzy. Inną opcją jest reprezentacja tej macierzy w postaci
głównej przekątnej – <DiagC>.
Po tych informacjach w prototypie modelu występuje nagłówek ~h, który definiuje nazwę
modelu HMM. Dalej umieszczamy znaczniki początku modelu <BeginHMM>, za którym
występuje znacznik liczby stanów <NumStates>. Kolejnymi elementami struktury modelu

4. Koncepcja semantycznego kodeka mowy
- 61 -
są wektory wartości średnich obserwacji <MEAN>, oraz odwrotne macierze kowariancji
<InvCovar> dla stanów emitujących modelu. W projekcie kodera korzystamy właśnie
z odwrotnej macierzy kowariancji gdyż upraszcza to obliczenia wyjściowych
prawdopodobieństw modeli wg rozkładu Gaussa (wzór 13).
Współczynniki wektora wartości średnich i odwrotnej macierzy kowariancji są inicjowane
zerami, ale nie ma to większego znaczenia, gdyż sensowne wartości są tam wpisywane
dopiero podczas reestymacji modeli.
Na końcu definicji modelu HMM, za znacznikiem <TRANSP> znajduje się kwadratowa
macierz zawierająca prawdopodobieństwa przejść między stanami, której wymiar równy
jest liczbie stanów modelu. Z macierzy tej zawsze można wywnioskować typ modelu,
który w tym przypadku jest prostym modelem progresywnym, z prawdopodobieństwem
przejścia ze stanu 1 do stanu 2 równym 1.0. Definicję struktury modelu kończy znacznik
<EndHMM>.
Po utworzeniu prototypów modeli dla wszystkich fonemów zawartych w tab.1
wykonywane są następujące kroki przetwarzania:
1. Inicjalizacja modeli przy pomocy narzędzia HCompV.
Algorytm ten nie wymaga przechowywania w bazie plików etykiet dla
poszczególnych fonemów. Każdy sygnał treningowy poddawany jest segmentacji na
jednostki mowy o tej samej długości, a parametry prototypów tych jednostek – wektor
wartości średnich obserwacji i macierz kowariancji obserwacji, przyjmują wartości
globalne wyznaczone dla całego fragmentu mowy. Ten proces inicjalizacji nazywany
jest często płaskim startem (ang. flat-start). Przykładowa komenda wywołująca
realizująca opisane tutaj przetwarzanie jest przedstawiona poniżej:
HCompV -f 0.01 -m -S trainlist -M hmm0 proto
2. Pierwsza reestymacja modeli przy pomocy narzędzia HERest.
Mając zainicjowane modele dla wszystkich fonemów można przystąpić
do reestymacji ich parametrów. W systemie HTK ten proces może zostać wykonany
przez dwa narzędzia: HRest i HERest. W przypadku HRest najpierw wyznacza się
prawdopodobieństwo przebywania w danym stanie modelu, w aktualnej ramce
sygnału, korzystając z algorytmu wprzód-wstecz (ang. forward-backward),
a następnie metodą Bauma-Welcha dokonuje reestymacji parametrów modelu. Takie
uaktualnianie parametrów modeli HMM określa się mianem estymacji izolowanej

4. Koncepcja semantycznego kodeka mowy
- 62 -
jednostki (ang. isolated unit reestimation). Użycie tego narzędzia musi być
poprzedzone wywołaniem funkcji HInit do inicjalizacji modeli HMM.
Alternatywą dla reestymacji izolowanych modeli jest wykorzystanie narzędzia HERest,
które realizuje algorytm tzw. reestymacji wbudowanej (ang. embedded training). Tutaj
modyfikacja parametrów dokonywana jest jednocześnie dla wszystkich modeli
fonemów, jakie występują w danej wypowiedzi treningowej. Dla każdego takiego
fragmentu mowy z bazy danych, przy wykorzystaniu dostępnych plików etykiet
fonemów tworzy się transkrypcję modeli występujących w sygnale treningowym.
Na tej podstawie buduje się złożone struktury HMM, łącząc pojedyncze modele
fonemów, które występują w utworzonej transkrypcji dla aktualnie przetwarzanego
fragmentu mowy. Następnie, na tak przygotowanym modelu złożonym HMM realizuje
się algorytm prefiksowo-sufiksowy, a otrzymane w ten sposób wagi modyfikują
wartości parametrów modelu. Algorytm treningu wbudowanego przedstawiony jest
w postaci schematu blokowego na rys.31, natomiast przykładowa komenda realizująca
opisane tutaj przetwarzanie ma formę:
HERest -L labs -S trainlist -H hmm_models\hmacs.mmf -M
hmm_out monophone_list
Aby wykonać proces reestymacji należy najpierw utworzyć plik zawierający prototypy
wszystkich modeli HMM występujących w bazie. W systemie HTK v3.4 taki plik
nazywany jest MMF (ang. Master Macro File). Parametrem wejściowym dla narzędzia
HERest jest także lista modeli fonemów, lista sygnałów treningowych przy użyciu,
który wykonana zostanie reestymacja parametrów, oraz zbiór plików etykiet
dla wszystkich sygnałów treningowych. Gdy te dane zostaną załadowane, funkcja
HERest przetwarza, każdy plik z danymi treningowymi – współczynnikmai MFCC,
uaktualniając w ten sposób parametry statystyczne złożonego modelu HMM.

4. Koncepcja semantycznego kodeka mowy
- 63 -
TWORZENIE ZŁOŻONYCH MODELI
HMM
kdt_001.labkdt_002.lab
kdt_003.labPROTOTYPY MODELI HMM FONEMÓW . . .
kdt_452.lab
ALGORYTM PREFIKSOWO -
SUFIKSOWY
MODYFIKACJA PARAMETRÓW MODELI
kdt_001.mfcckdt_002.mfcc
kdt_003.mfcc
kdt_004.mfcc. . .
UAKTUALNIONY ZESTAW MODELI HMM
ETYKIETY FONEMÓW
DANE TRENINGOWE
Rys.31. Algorytm reestymacji wbudowanej dla modeli HMM.
3. Kolejne iteracje reestymacji wbudowanej modeli.
Aby dobrze wytrenować modele HMM fonemów należy powtórzyć proces
reestymacji wbudowanej kilkakrotnie, podając za każdym razem na wejście
uaktualnione w ostatnim kroku parametry modeli. Na podstawie przeprowadzonych
symulacji można powiedzieć, że najlepiej wytrenowane parametry otrzymuje się
po dwukrotnej lub trzykrotnej reestymacji modeli. Gdy liczba iteracji algorytmu jest
większa, wtedy występuje zjawisko przetrenowania modeli HMM. W takim przypadku
wartości parametrów są zbyt bliskie danym treningowym, a proces rozpoznawania
fonemów staje się mniej efektywny dla sygnałów testowych spoza bazy treningowej.
Po wykonaniu treningu modeli HMM dla wszystkich fonemów znajdujących się w bazie,
plik zawierający uaktualnione parametry zostaje wczytany do programu w środowisku

4. Koncepcja semantycznego kodeka mowy
- 64 -
Matlab, gdzie następuje integracja innych algorytmów przetwarzania w ramach
zaimplementowanego kodeka mowy.
Wart uwagi jest fakt, że biblioteka HTK jest bardzo użytecznym systemem do treningu
modeli HMM i rozpoznawania mowy. Przedstawione tutaj przykłady definicji modeli
i estymacji parametrów to jedne z najbardziej podstawowych funkcjonalności tego
systemu. Można powiedzieć, że ostateczna forma tej pracy powstała dzięki wnioskom
i doświadczeniom zdobytym podczas pracy z systemem HTK. Dzięki wielu narzędziom
do edycji i rozbudowy modeli HMM, oraz rozpoznawania mowy z tej biblioteki zostały
przeprowadzone doświadczenia dotyczące tematu tej pracy. Na podstawie badań
wysunięto m.in. wniosek, że nie opłaca się budować modeli trójfonemowych – zależnych
od kontekstu, dla baz danych treningowych składających się z małej liczby wypowiedzi.
Okazało się także, że dla takich baz nieefektywne jest realizowanie grupowania stanów
fonemów (ang. tying). Znaczącej poprawy w proces rozpoznawania nie wnosi także
tworzenie modeli dla krótkich fragmentów ciszy – pauz między poszczególnymi
fonemami.
Podczas pracy z narzędziem HVite badano skuteczność algorytmu rozpoznawania mowy
dla różnych sygnałów testowych. Bardzo znaczącą wadą systemu HTK jest fakt, że
zastosowany tutaj algorytm rozpoznawania mowy wymaga tworzenia tzw. sieci słów, które
budowane są na podstawie gramatyki wejściowej wypowiedzi. Te grafy możliwych
sekwencji słów, są następnie zamieniane na możliwe kombinacje stanów modeli HMM,
których prawdopodobieństwa są wyznaczane podczas procesu rozpoznawania.
Przykład sieci słów dla wypowiedzi z pliku kdt_005.wav, pochodzącego z bazy kdt US
English TIMIT przedstawiony jest na rys.32. W sieci tej zawsze na początku i końcu
wypowiedzi znajduje się fragment ciszy, natomiast pozostałe ciągi słów mogą być
tworzone dowolnie na podstawie dostępnej gramatyki.
Stosowanie tego typu grafów znacznie zawęża obszar poszukiwania fonemów
w przetwarzanym fragmencie mowy, co wpływa na większą efektywność rozpoznawania.
Algorytmy, które wymuszają posiadanie pewnych informacji a’priori o sygnale
wejściowym znajdują zastosowanie w systemach biometrycznych, gdzie rozpoznawaniu
podlega mowa oparta na z góry określonym słowniku. W przypadku tradycyjnych technik
kodowania mowy zdefiniowanie gramatyki nieznanego sygnału wejściowego przed
procesem przetwarzania jest w większości przypadków niemożliwe.

4. Koncepcja semantycznego kodeka mowy
- 65 -
([SIL] < SHE | IS | TINNER | THAN | I | AM > [SIL])
SIL SIL
IS
TINNER
THAN
I
AM
SHE
Rys.32. Przykład gramatyki i sieci słów utworzonej dla fragmentu mowy
kdt_005.wav z bazy danych treningowych kdt US English TIMIT.
4.2.4 Rozpoznawanie fonemów
Podczas budowy modelu kodera w środowisku Matlab zaistniała konieczność
implementacji nieco innego algorytmu rozpoznawania fonemów niż ten, który
zastosowany jest w systemie HTK v.3.4. Celem prac nad nowym algorytmem było m.in.
wyeliminowanie konieczności tworzenia sieci słów na podstawie gramatyki sygnału
wejściowego. Opracowana technika bazuje na algorytmie Viterbiego, który jest
wykonywany równolegle dla wszystkich modeli HMM fonemów z bazy treningowej.
Pierwszym etapem prezentowanej metody jest wyznaczenie wyjściowych
prawdopodobieństw – a’posteriori rozkładu Gaussa wg wzoru (14). Wektory obserwacji w
tym przypadku to wartości współczynników MFCC otrzymane w wyniku analizy mel-
cepstralnej sygnału wejściowego, gdzie d określa rząd analizy. Prawdopodobieństwa
wyjściowe wyznaczane są jedynie dla stanów emitujących (o indeksach 2, 3, 4) modelu.

4. Koncepcja semantycznego kodeka mowy
- 66 -
Obliczenia konieczne do otrzymania wyniku są proste, gdyż większość potrzebnych
danych jest pobierana bezpośrednio z wytrenowanych modeli HMM fonemów.
Do obliczeń wykorzystujemy wektory wartości średnich współczynników MFCC dla
konkretnych stanów modelu fonemu, odwrotne macierze kowariancji wielowymiarowego
rozkładu Gaussa, a także wartości stałe, w postaci wyznacznika macierzy kowariancji.
Wyjściowe prawdopodobieństwa wyznaczane są dla trzech stanów emitujących
jednocześnie. Przetwarzane są zawsze trzy kolejne wektory obserwacji w postaci
współczynników MFCC wejściowego sygnału mowy. Otrzymane prawdopodobieństwa
zapisywane są w macierzy o wymiarach NxTxQ )2( − , gdzie Q oznacza liczbę
stanów w prototypie modelu HMM, T określa liczbę ramek czasowych wejściowej mowy,
natomiast N to liczba modeli fonemów znajdujących się w bazie. Należy tutaj zaznaczyć,
że prawdopodobieństwa stanów nieemitujących mają na stałe przypisaną wartość 1
dla każdej chwili czasowej.
Po obliczeniu prawdopodobieństw wyjściowych wg wielowymiarowego rozkładu
Gaussa, równolegle dla wszystkich modeli HMM realizowany jest algorytm Viterbiego.
Dla każdego fonemu szukamy najbardziej prawdopodobnej sekwencji stanów wg
następującej rekurencji (16):
)(})1({max)( tjijiij batt o−φ=φ (16)
gdzie:
)(tjφ – wypadkowe prawdopodobieństwo najbardziej prawdopodobnej sekwencji stanów,
kończącej się w stanie j. Inaczej, jest to maksymalne prawdopodobieństwo otrzymania
wektorów obserwacji tooo ..., 21 , przebywając w stanie j, w chwili t;
ija – prawdopodobieństwo przejścia ze stanu poprzedzającego i do stanu aktualnego j;
)( tjb o – prawdopodobieństwo wyjściowe wektora obserwacji o , podczas przebywania w
stanie j, w chwili t.
Powyższy wzór wykorzystuje regułę MAP. Inicjalizacja algorytmu opisana jest wzorem
(17):
)()1( 11 ojjj ba=φ (17)

4. Koncepcja semantycznego kodeka mowy
- 67 -
Algorytm Viterbiego umożliwia znalezienie najbardziej prawdopodobnej ścieżki
w kracie, która na osi odciętych zawiera kolejne ramki sygnału mowy, natomiast na osi
rzędnych występują stany modelu HMM fonemu. Przykład takiej kraty stanów znajduje się
na rys.33. W danej chwili t wyznaczane są częściowe prawdopodobieństwa ścieżek
w grafie prowadzących do wszystkich stanów modelu wg wzoru (16).
Prawdopodobieństwa te wyrażone są w skali logarytmicznej, aby uniknąć zaokrąglania
do zera bardzo małych wartości. Graf przejść przez kratę rozrasta się od lewej do prawej
strony osi odciętych. W oryginalnym algorytmie Viterbiego zakończenie obliczeń
równoznaczne jest z osiągnięciem końca sekwencji zdarzeń w chwili T , podczas gdy
w tym rozwiązaniu obliczenia przerywane są w momencie osiągnięcia stanu końcowego
(o numerze 5) modelu HMM.
54
32
1
STAN
RAMKACZASOWA
1 2 3 4 5 6
a22
a23
a34
a45
b2(o6)
b3(o6)
b4(o6)
Rys.33. Krata stanów wykorzystywana podczas poszukiwania najbardziej
prawdopodobnej ścieżki w modelu HMM wg algorytmu Viterbiego.
Jak wspomniano wcześniej, poszukiwanie najbardziej prawdopodobnej ścieżki w
grafie rozpoczyna się równocześnie dla wszystkich modeli fonemów. W pierwszym kroku
do obliczeń brana jest cała macierz wyznaczonych wcześniej prawdopodobieństw
wyjściowych rozkładu Gaussa. Po osiągnięciu stanów końcowych przez kolejne modele

4. Koncepcja semantycznego kodeka mowy
- 68 -
fonemów, spośród otrzymanych końcowych wartości prawdopodobieństw przejść
wybierane jest maksimum. Model, dla którego realizacja algorytmu Viterbiego dała
największe prawdopodobieństwo końcowe uważa się za rozpoznany fonem w aktualnie
rozważanym zakresie czasu. Wraz z najbardziej prawdopodobną ścieżką przejść przez
stany modelu HMM otrzymujemy także, końcową wartość czasu, w postaci liczby ramek,
jaka potrzebna była na osiągnięcie stanu końcowego. O tę liczbę kolumn pomniejszana jest
macierz prawdopodobieństw wyjściowych rozkładu Gaussa, przed kolejną iteracją
algorytmu. W ten sposób rozpoznawane są fonemy w kolejnych fragmentach
analizowanego sygnału wejściowego. Indeksy rozpoznanych fonemów zapisywane są
w wyjściowej tablicy. Informacja o czasie trwania poszczególnych jednostek akustycznych
jest tutaj wyznaczana bardzo zgrubnie w postaci liczby modeli HMM występujących
kolejno po sobie. Przykładowo gdy danemu indeksowi odpowiada długość trwania równa
4, oznacza to, że podczas analizy sygnału, rozpoznano czterokrotne, kolejne występowanie
fonemu o danym indeksie. Jest to równoznaczne z trwaniem tego fonemu przez 20 ramek
czasowych sygnału. Wywołania omówionego tutaj algorytmu powtarzane są do momentu
osiągnięcia ostatniej ramki kodowanego sygnału mowy.
Opracowaną technikę rozpoznawania fonemów testowano dla wielu sygnałów z bazy
kdt US English TIMIT [12]. Na podstawie przeprowadzonych symulacji można
powiedzieć, że często spotykane są błędy leksykalne w ramach konkretnej grupy
fonemów, których informacja akustyczna jest bardzo podobna. Jest to dobrze widoczne na
poniższych transkrypcjach fonemów, otrzymanych w wyniku kodowania przykładowych
sygnałów mowy z bazy:
Sygnał kdt_003.wav – „This was easy for me”.
Transkrypcja oryginalna:
sil dh ih s w aa z iy z iy f ao r m iy sil
Transkrypcja otrzymana przy zastosowaniu opracowanego algorytmu:
sil th ih z s z w l z iy z iy jh f r ng m y ng hh ao sil
Sygnał kdt_431.wav – „The fifth jar contains big juicy peaches”.
Transkrypcja oryginalna:
sil dh ax f ih f th jh aa r sil k ax n t ey n z b ih g jh uw s iy p iy ch ax z sil

4. Koncepcja semantycznego kodeka mowy
- 69 -
Transkrypcja otrzymana przy zastosowaniu opracowanego algorytmu:
sil dh ih sil f ih ey th s sil ch sh ey eh aa ey k n p hh ey n d z b ey iy g b p ch zh iy y z s
iy p jh y iy y t sh zh jh z s sil
Typowe błędy w otrzymanych transkrypcjach to rozpoznanie fonemu /th/ zamiast /dh/ lub
fonemu /y/ zamiast /iy/. Zdarzają się także przypadki, w których poszczególne fonemy
składające się na sygnał oryginalny, są rozpoznawane w postaci zbioru innych fonemów,
o łącznej podobnej informacji akustycznej, np. /ch/ – /t/, /sh/. Błędy tego typu są
uzasadnione słabo wytrenowanymi modelami HMM fonemów, na co ma wpływ wielkość
stosowanej bazy danych sygnałów treningowych.
Ścisłą zależność efektywności rozpoznawania fonemów od stopnia wytrenowania modeli
HMM potwierdza przypadek jednostki ciszy – /sil/, która występuje w każdym sygnale
treningowym z bazy, przez co jej parametry statystyczne są bardzo dokładnie estymowane
i jest ona bezbłędnie rozpoznawana.
Typy otrzymywanych błędów podczas procesu rozpoznawania sugerują, że algorytm
dobrze radzi sobie z rozróżnianiem fonemów należących do różnych klas, np. dźwięczny-
bezdźwięczny, a zawodzi przy analizie fonemów bardzo zbliżonych akustycznie, np.
samogłosek i dyftongów. Jednak w kontekście późniejszej syntezy sygnału mowy, takie
przekłamania jednostek leksykalnych o bardzo podobnej informacji akustycznej są
nieistotne i niemal niezauważalne. Na pogorszenie subiektywnej jakości sygnału
odtworzonego mają wpływ jedynie te błędy, które skutkują syntezą głoski dźwięcznej
w miejsce szumowej, lub odwrotnie.
Największą zaletą opracowanego algorytmu jest fakt, iż do jego realizacji nie wykorzystuje
się sieci słów, w odróżnieniu do techniki z systemu HTK. Główną wadą przedstawionego
rozwiązania są liczne błędy podczas procesu rozpoznawania, które jednak nie powodują
zakłócenia istotnej informacji akustycznej kodowanej mowy. W rezultacie efektywność
opracowanego algorytmu można uznać za zadowalającą.

4. Koncepcja semantycznego kodeka mowy
- 70 -
4.2.5 Kodowanie binarne strumienia
Ostatnim etapem przetwarzania sygnału mowy w modelu kodera dla bardzo małej
prędkości transmisji, przedstawionym na rys.20, jest kodowanie binarne – entropijne
wyjściowego strumienia danych. Kodowaniu poddaje się wszystkie informacje przesyłane
do układu dekodera, a więc:
• otrzymane wartości częstotliwości podstawowej (F0) dla kolejnych ramek
analizy sygnału;
• czasy trwania rozpoznanych fonemów w postaci liczby kolejnych wystąpień
odpowiadających modeli HMM;
• indeksy rozpoznanych modeli HMM fonemów.
W projekcie stosowany jest koder Huffmana, na wyjściu którego otrzymujemy kody
o zmiennej długości słowa, dla danych wejściowych w postaci liczb całkowitych,
nieujemnych. Elementem kluczowym wpływającym na sprawność kodowania jest tutaj
zakładana maksymalna długość słowa kodowego.
W przeprowadzonych symulacjach zastosowano 8-bitowe słowo, co daje dozwolone
wartości parametrów wyjściowych kodera w zakresie od 0 do 255. Indeksy fonemów
różnią się w zakresie od 1 do 41, natomiast czasy trwania modeli HMM to zazwyczaj
wartości mniejsze od 15. Zatem współczynniki przesyłane w tych dwóch strumieniach z
powodzeniem mogą być kodowane z wykorzystaniem 8-bitowej reprezentacji. Jedyną
możliwość przekroczenia zakresu wartości otrzymujemy w przypadku kodowania
częstotliwości podstawowej sygnału. Zakres zmian F0 jest ściśle zależny od płci mówcy.
Na podstawie przeprowadzonych symulacji można jednak powiedzieć, że najczęściej ta
wartość częstotliwości zawiera się pomiędzy 100, a 200 Hz, co pozwala stosować
zakładaną długość słowa kodowego dla kodera Huffmana.
Wejściowe strumienie danych, które podlegają kodowaniu binarnemu na tym etapie
przetwarzania charakteryzują się różną entropią źródła, a co za tym idzie efektywność
kompresji jest inna dla każdego z trzech strumieni danych. Poglądowa informacja
o sprawności kodowania strumieni danych otrzymywanych w zaimplementowanym
koderze przedstawiona jest na rys.34, w postaci krzywych kompresji. Przebiegi
sporządzono na podstawie dziesięciu sygnałów testowych z bazy kdt US English TIMIT.
Otrzymane wyniki pokazują, że największy rozrzut wartości uzyskiwany jest
dla strumienia indeksów modeli HMM fonemów.

4. Koncepcja semantycznego kodeka mowy
- 71 -
Rys.34. Krzywe kompresji dla strumieni wyjściowych kodera.
Mimo pewnych odchyleń, np. w przypadku jednostki ciszy, której częstość występowania
w strumieniu jest największa, można powiedzieć, że prawdopodobieństwa otrzymania
poszczególnych indeksów są dość zrównoważone. Źródło, które generuje
równoprawdopodobne symbole charakteryzuje się największą entropią, co w konsekwencji
wpływa na najniższy stopień kompresji strumienia binarnego indeksów fonemów.
Wektor częstotliwości podstawowych sygnału zawiera stosunkowo dużo wartości
zerowych, które sygnalizują bezdźwięczne fragmenty sygnału. Wpływa to na zmniejszenie
entropii źródła. Pozostałe przesyłane wartości F0 odpowiadające fragmentom dźwięcznym
mowy są do siebie zbliżone, co również powoduje zmniejszenie entropii. W efekcie
stopień kompresji otrzymany dla strumienia częstotliwości podstawowych jest większy niż
dla strumienia indeksów.
Najlepszy stopień kompresji otrzymujemy kodując czasy trwania rozpoznanych fonemów.
Tutaj rozrzut wartości jest bardzo mały. Typowy czas trwania modelu, wyrażony w liczbie
jego kolejnych wystąpień wynosi zazwyczaj 1 – 2. Powoduje to najmniejszą entropię
źródła spośród trzech generowanych strumieni i co za tym idzie najlepszą efektywność
kodowania strumienia binarnego.
0
0,5
1
1,5
2
2,5
3
3,5
1 2 3 4 5 6 7 8 9 10Numer wejściowego sygnału testowego
Stop
ień
kom
pres
ji
Indeksy modeliCzasy trwania modeliCzęstotliwość podstawowa

4. Koncepcja semantycznego kodeka mowy
- 72 -
Średnie wartości stopnia kompresji uzyskane dla kodowanych strumieni zależą
również od długości wektorów danych poddawanych kodowaniu. Najwyższą efektywność
kodowania otrzymujemy dla długich sygnałów testowych, gdzie statystyka wystąpień
poszczególnych symboli (indeksów, wartości częstotliwości, wartości czasów trwania)
charakterzuje się mniejszym rozrzutem, niż w przypadku przetwarzania krótkich sygnałów
testowych.
4.3 Model dekodera
W ramach niniejszej pracy magisterskiej, oprócz przedstawionego w rozdziale 4.2
układu kodera mowy, zaimplementowano także model dekodera w celu weryfikacji
poprawności działania systemu oraz oceny jego efektywności. Moduł ten realizuje
popularną technikę rekonstrukcji sygnału, która wzorowana jest na syntezie LPC. Tor
przetwarzania (trakt głosowy) reprezentowany jest w postaci filtru o skończonej
odpowiedzi impulsowej i współczynnikach zmiennych w czasie. Wartości parametrów
filtru są odtwarzane dla kolejnych ramek sygnału, przy pomocy współczynników mel-
cepstralnych przechowywanych w modelach HMM fonemów. Wybór odpowiednich
modeli z bazy znajdującej się w dekoderze, dokonywany jest na podstawie indeksów
fonemów przesyłanych w strumieniu binarnym z kodera. Wykorzystany algorytm
odtwarzania widma sygnału przedstawiony jest w rozdziale 4.3.2.
Źródłem energii dla filtru syntezy jest generowany w dekoderze sygnał pobudzenia, który
modeluje składniki dźwięczne i bezdźwięczne mowy. W tej implementacji dźwięczny
charakter pobudzenia odtwarzany jest przez ciąg impulsów o zmiennym okresie
podstawowym, natomiast fragmenty bezdźwięczne sygnału pobudzane są szumem.
Dokładny opis użytej tutaj metody znajduje się w rozdziale 4.3.1.
Pierwszym blokiem przetwarzania w opracowanym modelu jest dekoder binarny.
W wyniku jego działania otrzymujemy wektor częstotliwości podstawowych
zakodowanego sygnału mowy, wektor indeksów rozpoznanych fonemów oraz wektor
zawierający liczbę wystąpień poszczególnych fonemów. Zdekodowane parametry są
danymi wejściowymi dla kolejnych modułów wchodzących w skład dekodera, których
opis jest tematem tego rozdziału.

4. Koncepcja semantycznego kodeka mowy
- 73 -
4.3.1 Wytwarzanie sygnału pobudzenia
W modelu wytwarzania mowy przedstawionym na rys.12 istotne jest zapewnienie
prawidłowego pobudzenia, które pozwoli dobrze reprezentować fragmenty dźwięczne oraz
bezdźwięczne mowy. Przeprowadzone eksperymenty pokazały, że wytwarzanie
pobudzenia jest kluczowym etapem fonetycznego dekodowania mowy, mającym ogromny
wpływ na subiektywną ocenę jakości sygnału zrekonstruowanego.
W literaturze spotyka się wiele rozwiązań wytwarzania sygnału pobudzenia dla filtru
syntezy. Ich cechą wspólną jest fakt, że tony krtaniowe, o dużej energii modelowane są
w postaci okresowego ciągu impulsów, natomiast składniki szumowe o znacznie mniejszej
energii i aperiodycznym przebiegu odtwarza się w postaci sygnału losowego, jakim jest
szum biały gaussowski. Oprócz algorytmów twardo-decyzyjnych, które produkują jedynie
fonemy dźwięczne i bezdźwięczne, spotykane są także bardziej wyrafinowane i efektywne
metody, które umożliwiają wytwarzanie dźwięków o charakterze pośrednim – tonalno-
szumowym.
Za najbardziej efektywną technikę generacji sygnału pobudzenia dla filtru syntezy mowy
uważa się algorytm mieszanego pobudzenia, zastosowany w standardzie kodowania MELP
[2, rozdz.11]. Model pobudzenia wg tego standardu jest mieszaniną składników
dźwięcznych i bezdźwięcznych, których zawartość procentowa w generowanym
fragmencie sygnału zależy od energii harmonicznych w określonych pasmach widma.
Takie podejście, w którym regulowany jest poziom głośności sygnału szczególnie dobrze
sprawdza się w przypadku modelowania dźwięcznych fonemów szczelinowych np. /z/. Technikę mieszanego pobudzenia (ang. mixed excitation) stworzono w celu eliminacji
najczęstszego artefaktu w syntezowanej mowie, jakim jest nienaturalne brzmienie
fragmentów dźwięcznych, charakterystyczne dla technik LPC. Jest ono spowodowane zbyt
zgrubnym modelowaniem drgań fali akustycznej w postaci ciągu impulsów. Mieszane
pobudzenie w koderze MELP uzyskiwane jest przy zastosowaniu następujących
rozwiązań:
• filtr kształtujący impuls, składający się z zestawu filtrów pasmowo-przepustowych,
liczba pasm zazwyczaj wynosi 4 – 10 i jest stała dla każdej ramki kodowanego
sygnału;
• filtr kształtujący szum, o charakterystyce odwrotnej do filtru kształtującego impuls;

4. Koncepcja semantycznego kodeka mowy
- 74 -
• wzmocnienie w każdym paśmie dobierane na podstawie kryterium głośności
sygnału; wykorzystywana jest tutaj metoda autokorelacji obwiedni filtrowanego
sygnału mowy w każdym z pasm;
• płaskie widmo pobudzenia ze względu na sumę odpowiedzi obu filtrów;
• nieokresowy ciąg impulsów; odległości między impulsami podlegają fluktuacjom;
• filtr dyspersji impulsu – powoduje rozmycie impulsów występujących w odstępach
równych okresowi podstawowemu; powoduje to lepsze dopasowanie sygnału
syntezowanego do oryginalnego w pasmach pomiędzy formantami.
Naturalność oraz wysoka jakość mowy zrekonstruowanej techniką MELP okupiona jest
stosunkowo dużą złożonością bloku generacji pobudzenia oraz wielkością strumienia – 2,4
kbit/s. Głównie ze względu na ten fakt, nie da się wprost zastosować algorytmu
mieszanego pobudzenia w koderze dla bardzo małej prędkości transmisji.
Aby ominąć ten problem w wokoderach fonetycznych wykorzystujących modele HMM
często stosuje się inne podejście. Oprócz wektorów cech, które służą do odtwarzania
charakterystyki traktu głosowego, stany modeli fonemów przechowują także informacje
o właściwościach pobudzenia w analizowanej ramce sygnału, dla której wyznaczono
wektor cech. Takimi informacjami mogą być np. poziomy głośności dla filtrów pasmo-
przepustowych kształtujących impulsy [16], czy modele transmitancji filtrów
dla składowej dźwięcznej i bezdźwięcznej w analizowanej ramce [17]. Metody te na ogół
umożliwiają wyeliminowanie dokuczliwych artefaktów w sygnale zrekonstruowanym,
kosztem budowy bardzo złożonych modeli HMM fonemów.
Na podstawie przeprowadzonych symulacji dostępnych rozwiązań opracowano
uproszczoną technikę generacji pobudzenia, której model pokazany jest na rys.35. Idea
budowy tego modelu pobudzenia zaczerpnięta jest z algorytmu kodera MELP, jednak
wykorzystane algorytmy przetwarzania są bardzo proste ze względu na ograniczoną
prędkość transmisji.
Zaimplementowany model wytwarzania sygnału nieco różni się od tego przedstawionego
na rys.12. Jedyną informacją potrzebną do rekonstrukcji sygnału pobudzenia dla potrzeb
syntezy, jest częstotliwość podstawowa wyznaczona dla poszczególnych ramek czasowych
przetwarzanego sygnału. Ponieważ wartość tej częstotliwości jest niezerowa
dla fragmentów dźwięcznych oraz jest nieokreślona w przypadku składników szumowych,
na jej podstawie podejmowana jest decyzja o charakterze generowanego pobudzenia.

4. Koncepcja semantycznego kodeka mowy
- 75 -
UKŁAD DECYZYJNY
POBUDZENIE BEZDŹWIĘCZNE
POBUDZENIE DŹWIĘCZNE
F0
F0 > 0
F0 = 0
SYGNAŁ WYJŚCIOWY
Rys.35. Blok produkcji sygnału pobudzenia w układzie dekodera mowy dla
bardzo małej prędkości transmisji.
Nie wykorzystuje się tutaj żadnej informacji o poziomie głośności poszczególnych ramek
sygnału. Tony krtaniowe odtwarza się w postaci quasi-okresowego ciągu impulsów,
którego okres w danej ramce sygnału jest równy odwrotności częstotliwości podstawowej,
estymowanej w koderze. Wahania częstotliwości podstawowej podczas wypowiedzi są
tutaj reprezentowane w postaci zmian odstępu między generowanymi impulsami ciągu.
Naturalne pobudzenie produkowane przez płuca oprócz quasi-okresowego przebiegu,
charakteryzuje się także zmienną amplitudą impulsów. Aby zamodelować to zjawisko, do
amplitudy prążków można wprowadzić pewną losową nieregularność.
Składnik bezdźwięczny jest uzyskiwany z układu generatora pseudolosowego
wytwarzającego szum biały. Wariancja szumu powinna być odpowiednio dobrana w
stosunku do amplitudy impulsów. W zaimplementowanym rozwiązaniu dobre efekty
otrzymano dla stosunku tych wartości równego 1:10.
Podczas rekonstrukcji pobudzenia dekodowane są wartości częstotliwości podstawowej,
wyznaczone dla kolejnych okien analizy. Odwrotność F0, czyli okres podstawowy sygnału
mowy, wyznacza odstępy impulsów w danej ramce czasowej. Dla analizowanego okna
otrzymujemy fragment sygnału pobudzenia, który jest sumą impulsów poprzesuwanych
o wielokrotność okresu podstawowego (rys.36).

4. Koncepcja semantycznego kodeka mowy
- 76 -
Rys.36. Fragment sygnału pobudzenia otrzymany na podstawie analizy sygnału
kdt_001.wav z bazy TIMIT.
W naturalnym sygnale mowy zmiany konturu F0 przebiegają w sposób ciągły, w efekcie
odstępy między impulsami pobudzenia również powinny zmieniać się płynnie. Ze względu
na kwantyzację wartości F0 możliwa jest jedynie pewna aproksymacja naturalnych zmian
częstotliwości podstawowej w czasie. W algorytmie zastosowano technikę wyznaczania
odstępów impulsów we fragmentach dźwięcznych pobudzenia, na podstawie zmian fazy.
Wyznaczamy ją z wektora częstotliwości podstawowej, przesłanego z kodera do dekodera,
korzystając z zależności definicyjnej (18):
00
)()( ϕ+ττ=ϕ ∫t
dft (18)
gdzie:
)(τf – zakumulowana wartość częstotliwości sygnału w chwili τ
Ponieważ wartość częstotliwości F0 wyznaczana jest w koderze raz na okno analizy N,
konieczna jest interpolacja jej zmian pomiędzy oknami. Kontur F0 w takiej formie może
posłużyć do obliczenia fazy sygnału wg (18). Otrzymany przebieg ma charakter
monotonicznie rosnący ze względu na akumulację fazy dla kolejnych próbek sygnału.
W rezultacie operacji modulo 1 otrzymujemy skokowe zmiany wartości w przebiegu fazy.

4. Koncepcja semantycznego kodeka mowy
- 77 -
Zadaniem algorytmu produkcji pobudzenia jest lokalizacja tych skoków oraz wstawienie
w tych miejscach impulsów, modelujących składowe dźwięczne. Takie podejście skutkuje
otrzymaniem sygnału zsyntezowanego, który pozbawiony jest charakterystycznych
„schodków” związanych ze skokową zmianą częstotliwości chwilowej. Naturalne zmiany
intonacji są również dobrze odwzorowane.
Istotnym elementem konstrukcji sygnału pobudzenia jest także odpowiedni dobór
kształtu impulsów w generowanym ciągu. W wielu prostych implementacjach wokoderów
stosowany jest ciąg impulsów prostokątnych. Otrzymany w ten sposób sygnał widoczny
jest na rys.36. Bardzo poważnym problemem takiej postaci pobudzenia jest możliwość
wystąpienia aliasingu w zrekonstruowanej mowie. Wynika on z faktu, że widmo
amplitudowe impulsu prostokątnego jest nieograniczone. Podczas splotu okresowego
sygnału pobudzenia z odpowiedzią impulsową modelu traktu głosowego otrzymujemy
sygnał wyjściowy, którego widmo jest dyskretne i posiada składowe aliasowe, które
bardzo negatywnie wpływają na subiektywną ocenę jakości zrekonstruowanej mowy.
Sytuacja ta wystąpi zawsze gdy filtr syntezy będzie pobudzany syntetycznym ciągiem
impulsów prostokątnych bez zaokrąglania ich położenia z dokładnością do pojedynczej
próbki.
W celu eliminacji aliasingu zastosowano technikę składania sekwencji pobudzającej
z impulsów o kształcie krzywej sinc, których widmo amplitudowe jest ściśle ograniczone
i wyraża się wzorem (19):
)2
(2)}({0
0 ffftSaF −Π⋅π=π⋅ (19)
gdzie:
0f – szerokość pasma impulsu
Dodatkową zaletą takiego rozwiązania jest fakt, że ograniczony pasmowo sygnał, w formie
ciągu impulsów sinc, nie pobudza fragmentu charakterystyki filtru modelującego, który
jest zniekształcony podczas procesu rekonstrukcji widma ze współczynników MFCC.
Analiza mel-cepstralna jest mniej dokładna dla składowych wysokoczęstotliwościowych,
dlatego też ich stratna kompresja, a następnie rekonstrukcja skutkuje słyszalnymi
artefaktami w zdekodowanej mowie. Stosując impulsy sinc można ten efekt
wyeliminować.

4. Koncepcja semantycznego kodeka mowy
- 78 -
Rys.37. Przykład dźwięcznej ramki sygnału pobudzenia o długości 60 ms, szerokość
impulsu 0,33 ms, częstotliwość F0 równa 80 Hz.
Rys.38. Widmo amplitudowe fragmentu sygnału pobudzenia. Szerokość pasma
impulsu sinc równa 3 kHz, częstotliwość F0 równa 200 Hz, częstotliwość próbkowania
16 kHz. Do analizy zastosowano okno Hamminga.

4. Koncepcja semantycznego kodeka mowy
- 79 -
Podczas produkcji sygnału pobudzenia ważny jest dobór odpowiedniej szerokości impulsu.
Należy wziąć pod uwagę fakt, że w paśmie sygnału powinny znaleźć się częstotliwości,
których występują w widmie typowej mowy.
Przebieg czasowy sygnału pobudzenia, otrzymany przy zastosowaniu impulsów sinc,
widoczny jest na rys.37, natomiast rys.38 ilustruje przykładowe widmo amplitudowe
takiego sygnału. Ze względu na quasi-okresową naturę pobudzenia jego widmo jest
dyskretne.
Powyżej 3 kHz obserwujemy zanik prążków widma wynikający z szerokości impulsów
Spadek ten nie jest jednak gwałtowny, ze względu na niedokładną aproksymację wysokich
częstotliwości sygnału. Efekt ten należy uwzględnić przy wyborze szerokości impulsu, aby
wyeliminować występowanie aliasingu w zrekonstruowanej mowie.
4.3.2 Rekonstrukcja cech widmowych sygnału
Aby wykonać proces syntezy sygnału niezbędne jest odtworzenie charakterystyki
częstotliwościowej traktu głosowego. W opracowanym systemie widmo mocy
reprezentowane jest w postaci współczynników MFCC, które są przechowywane
w dekoderze jako wektory cech, stowarzyszone ze stanami modeli HMM fonemów.
W literaturze najczęściej spotykanym algorytmem rekonstrukcji widma z modeli HMM
jest metoda przedstawiona w pracy Junichi Yamagishi [15]. Demonstruje on rozwiązanie
problemu produkcji optymalnej sekwencji wektorów parametrów ],...,,[ 21 toooO = , która
maksymalizuje prawdopodobieństwo jej otrzymania ),|( TP λO względem rozkładu λ
modelu HMM i długości sekwencji parametrów T (20):
),|(maxarg TP λ= OOO
opt (20)
Yamagishi wskazuje, że nie istnieje proste rozwiązanie analityczne tego równania. Z tego
względu często stosuje się aproksymację w formie sekwencji wektorów obserwacji dla
najbardziej prawdopodobnej sekwencji stanów q (21):
),|,(maxmaxarg TP λ≅ qOOqO
opt (21)
Używając wzoru Bayes’a łączne prawdopodobieństwo O i q można przedstawić jako
(22):

4. Koncepcja semantycznego kodeka mowy
- 80 -
),|(),,|(maxmaxarg TPTP λ⋅λ≅ qqOOqO
opt (22)
Zatem problem znalezienia optymalnej sekwencji wektorów obserwacji może być
rozłożony na dwa podrzędne problemy [15]:
1. Znalezienie optymalnej sekwencji stanów optq modelu HMM (23):
),|(maxarg TP λ= qqq
opt (23)
2. Znalezienie optymalnej sekwencji parametrów Oopt, dla określonej sekwencji
stanów modelu HMM (24):
),,|(maxarg TP λ= optO
opt qOO (24)
Pierwszy krok realizowany jest w postaci rozpoznawania fonemów, w koderze. Tam, przy
pomocy algorytmu przedstawionego w rozdziale 4.2.4, wyznaczana jest najbardziej
prawdopodobna kombinacja stanów modeli fonemów, która jest przesyłana do dekodera
w formie transkrypcji indeksów tych modeli.
Rozwiązanie drugiego etapu procesu optymalizacji jest skomplikowane w przypadku, gdy
wektory cech oprócz współczynników statycznych MFCC, zawierają także współczynniki
dynamiczne (delta, delta-delta). Składowe dynamiczne, wyznaczone podczas analizy
umożliwiają odtworzenie ciągłości w generowanej mowie, gdyż podczas ich estymacji
uwzględniane są informacje o ramkach poprzedzających i ramkach następujących mowy.
Zastosowanie współczynników dynamicznych wymaga użycia metod numerycznych do
znalezienia optymalnego rozwiązania równania ze wzoru (24), jak np. dekompozycja
Cholesky’ego, czy dekompozycja QR dla równań macierzowych. Ponieważ zadaniem
szczegółowym pracy magisterskiej było opracowanie uproszczonego modelu kodeka
mowy, nie zdecydowano się na implementację wymienionych metod i zastosowano
jedynie współczynniki statyczne MFCC do modelowania cech widmowych fonemów.
W takim przypadku, rozwiązaniem równania (24) jest sekwencja wektorów wartości
średnich współczynników, odczytanych z kolejnych stanów modeli HMM, dla optymalnej
sekwencji optq . Uniknięcie skomplikowanych obliczeń numerycznych dla macierzy
parametrów okupione jest tutaj gorszą jakością odtworzonej mowy, wynikającą
z braku płynności w zmianach krótko-okresowej charakterystyki częstotliwościowej.
Baza modeli HMM fonemów używana w dekoderze mowy różni się nieco od tej
zawartej w koderze. Tutaj dodatkowo wektory cech zawierają współczynnik zerowy

4. Koncepcja semantycznego kodeka mowy
- 81 -
MFCC. Jest on niezbędny do rekonstrukcji obwiedni widma sygnału, gdyż zawiera
informację o jego energii. Ten parametr nie odzwierciedla cech intonacji mówcy sygnału
oryginalnego, lecz reprezentuje uśrednioną energię mówcy treningowego, estymowaną na
podstawie wypowiedzi z bazy danych. Jest to znacząca wada tego rozwiązania, jednak
współczynniki energii, odczytane z modeli, umożliwiają zgrubne odtworzenie rozkładu
energii dla poszczególnych harmonicznych sygnału. Rekonstrukcja sygnału bez informacji
o jego obwiedni skutkuje otrzymaniem mowy o bardzo złej jakości.
Inną możliwością w takim przypadku mogłoby być przesyłanie informacji o obwiedni
sygnału z kodera, w postaci dodatkowych parametrów strumienia. Pozostaje to
w perspektywie dalszej rozbudowy systemu.
W typowych implementacjach koderów fonetycznych odtwarzanie cech widmowych
sygnału ze współczynników MFCC, zawartych w stanach modelu HMM jest wykonane
przy uwzględnieniu informacji o rozkładzie prawdopodobieństwa czasu trwania
poszczególnych stanów. Funkcja gęstości rozkładu prawdopodobieństwa jest wtedy
estymowana jako kolejny parametr modelu HMM.
W prezentowanym rozwiązaniu nie tworzy się rozkładów czasu trwania stanów. Przyjęto
założenie, że największa informacja o cechach danej głoski skupiona jest w środkowym
stanie emitującym modelu – 3. Stany 2 i 4 reprezentują informację o cechach danej głoski
odpowiednio na początku i na końcu czasu jej trwania.
Odtwarzanie współczynników MFCC w module rekonstrukcji mowy przebiega wg
następującego schematu:
1. Odbiór zdekodowanego indeksu modelu HMM fonemu oraz czasu jego trwania,
w postaci liczby kolejnych wystąpień fonemu – N.
2. Wczytanie parametrów statystycznych modelu z bazy, na podstawie odebranego
indeksu.
3. Powiększenie macierzy współczynników MFCC o kolumnę, zawierającą wektor
wartości średnich współczynników MFCC wyczytany ze stanu 2 modelu HMM.
4. Powiększenie macierzy współczynników MFCC o N – 2 kolumn, zawierających
wektor wartości średnich współczynników MFCC wyczytany ze stanu 3 modelu
HMM.
5. Powiększenie macierzy współczynników MFCC o kolumnę, zawierającą wektor
wartości średnich współczynników MFCC wyczytany ze stanu 4 modelu HMM.
6. Powtórzenie kroków 3 – 5 tyle razy, ile wynosi wartość zdekodowanego czasu
trwania fonemu – N.

4. Koncepcja semantycznego kodeka mowy
- 82 -
Opracowany schemat jest prosty, ale aproksymacja widma traktu głosowego otrzymana
w ten sposób jest zadowalająca, czego efektem są wyniki oceny jakości mowy
zrekonstruowanej przedstawione w rozdziale 5.
Po odczytaniu wszystkich indeksów przesłanych z kodera, otrzymujemy macierz
współczynników mel-cepstrum, o wymiarach M x T, gdzie M to liczba współczynników
(uwzględniająca logarytm energii), a T oznacza otrzymaną liczbę ramek czasowych
sygnału – okno analizy jest dwukrotnie większe, ze względu na zakładkę.
Przykładowy rezultat generacji współczynników MFCC z modeli HMM, w odniesieniu
do oryginalnych wartości analizy mel-cepstralnej pokazany jest na rys.43. Różnice
zauważalne są dla współczynników niskiego rzędu, gdyż zawierają one najwięcej
informacji o cechach sygnału. Współczynniki wysokiego rzędu mają zazwyczaj mniejsze
wartości, co przekłada się również na mniejszą wartość różnicy.
Rys.39. Przykładowy obraz różnicowy pomiędzy oryginalnymi współczynnikami
MFCC, a wartościami otrzymanymi z modeli HMM.
Prezentowany obraz dobrze ilustruje błędnie rozpoznane wektory cech. Objawia się to
większymi wartościami różnic między współczynnikami, dla ramki odpowiadającej
danemu wektorowi cech. Błędy wynikają ze zbyt słabego wytrenowania modeli fonemów.
Wyjątkiem jest jednostka ciszy – /sil/, dla której obserwujemy najmniejszy poziom błędu –
ramki sygnału 0 – 45 i 270 – 290.

4. Koncepcja semantycznego kodeka mowy
- 83 -
Wektory cech jego modelu HMM są najdokładniej estymowane, gdyż pojawia się on
w prawie każdej wypowiedzi treningowej. W przypadku pozostałych fonemów ta
estymacja nie jest już tak dokładna, co jest widoczne na przedstawionym rysunku dla
ramek sygnału 45 – 270.
4.3.3 Synteza sygnału mowy
Ostatnim etapem przetwarzania danych w dekoderze jest synteza mowy.
Wykorzystujemy do tego wygenerowany wcześniej sygnał pobudzenia oraz aproksymację
charakterystyki częstotliwościowej traktu głosowego, otrzymaną przy pomocy
współczynników MFCC.
Jedną z możliwych technik rekonstrukcji mowy w dekoderze jest rozwiązanie
prezentowane przez Chazana i pozostałych w pracy [18]. Ich algorytm opiera się
na modelu sinusoidalnym, gdzie krótko-okresowy sygnał jest reprezentowany w postaci
sumy sinusoid. Wartości amplitudy oraz fazy przebiegu, odtwarzane są z wektorów cech
sygnału – współczynników MFCC, a następnie rekonstruowane jest widmo
krótkookresowe – STFT.
Najpopularniejszym rozwiązaniem spotykanym w literaturze [8], [15], jest synteza
sygnału przy pomocy filtru aproksymującego logarytm widma amplitudowego – MLSA.
Jest to typowa metoda rekonstrukcji sygnału dla klasy wokoderów fonetycznych, którą
zaimplementowano w pierwszej kolejności, korzystając z biblioteki SPTK (ang. Speech
Signal Processing Toolkit) [19].
Dyskretna funkcja transmitancji filtru MLSA ma charakter wykładniczy, a jej bardzo
dokładna aproksymacja, wykorzystywana podczas implementacji wyraża się wzorem (25):
∑=
Φ=M
mm zmbzH
0)()(exp)( (25)
gdzie:
M – rząd analizy mel-cepstralnej
)(mb – m-ty współczynnik filtru MLSA, otrzymywany przy pomocy formuły (26):
⎩⎨⎧
<≤+α−=
=α
α
MmmbmcMmmc
mb0),1()(
),()( (26)

4. Koncepcja semantycznego kodeka mowy
- 84 -
Współczynniki )(mcα w tym wzorze to wartości cepstrum sygnału w melowej skali
częstotliwości.
)(zmφ – funkcja zmiennej Z, zależna od współczynnika kompresji skali częstotliwości α
(27):
⎪⎩
⎪⎨⎧
≥α−
α−⋅
α−α−
==Φ
−−
−−
−
−
0,11
)1(0,1
)()1(
)1(
1
12
mz
zz
zm
zm
mm (27)
Charakterystyka fazowa powyższej transmitancji jest uzależniona od zmiennej α , której
wartość reprezentuje odpowiednią transformację skali częstotliwości np., przyjęcie
współczynnika α równego 0,41 dla częstotliwości próbkowania 16 kHz umożliwia
przybliżenie charakterystyki ludzkiego systemu słyszenia w postaci skali melowej.
Transmitancję filtru MLSA zapisuje się często w formie iloczynu (28):
)()( zDKzH ⋅= (28)
gdzie:
)0(expbK = - informacja o obwiedni funkcji transmitancji
∑=
Φ=M
mm zmbzD
1)()(exp)( - transmitancja filtru syntezy
Podczas prób włączenia filtru do modelu dekodera mowy wykryto poważną wadę
wykorzystywanej metody. Okazało się, że współczynniki MFCC używane
do rozpoznawania fonemów w koderze, nie nadają się do rekonstrukcji widma sygnału.
W efekcie, generowane przy ich pomocy współczynniki filtru MLSA są nieprawidłowe.
Problem polega na tym, że wartości b(m) we wzorze (26), wyznaczane są na podstawie
cepstrum sygnału, które uprzednio transformowane jest do melowej skali częstotliwości.
Cepstrum to obliczane jest wg wzoru (3), co odbiega od definicji współczynników MFCC
(6). Podczas estymacji wektorów cech, dla celów rozpoznawania mowy, znacząca ilość
informacji o widmie sygnału jest zatem bezpowrotnie tracona. Na przykład w trakcie
analizy odrzucane są współczynniki MFCC wyższego rzędu, reprezentujące składowe
wysokoczęstotliwościowe widma.

4. Koncepcja semantycznego kodeka mowy
- 85 -
ODWROTNA LIFTRACJA
REKONSTRUKCJA SUMY AMPLITUD W PASMACH ANALIZY
REKONSTRUKCJA ZESPOŁU FILTRÓW
ANALIZY
MACIERZ WSPÓŁCZYNNIKÓW MFCC
MACIERZ SUM AMPLITUD WIDMA W
PASMACH
MACIERZ ODWROTNOŚCI WAG
AMPLITUD FFT
REKONSTRUKCJA WIDMA MOCY
TRAKTU GŁOSOWEGO
WIDMO MOCY TORU SYGNAŁU
FFT
SYGNAŁ POBUDZENIA
IFFT
WIDMO SYGNAŁU MOWY
ZSYNTEZOWANA MOWA
Rys.40. Schemat blokowy algorytmu syntezy mowy w dekoderze.

4. Koncepcja semantycznego kodeka mowy
- 86 -
W trakcie pracy nad projektem kodeka podjęto szereg prób konwersji współczynników
MFCC do postaci dogodnej do wyznaczenia gabarytów filtru MLSA, jednak nie uzyskano
zadowalającego efektu. Nieodpowiednie wartości współczynników wykorzystywane
do budowy filtru powodowały jego niestabilność. W wyniku napotkanych trudności
podjęto decyzję o zastosowania innej metody syntezy sygnału mowy.
Rozwiązaniem okazał się algorytm rekonstrukcji widma amplitudowego sygnału
ze współczynników MFCC zaproponowany przez Dana Ellisa i pozostałych z grupy
LabROSA, Uniwersytetu Columbii [20].
Wykorzystana technika składa się z etapów rekonstrukcji mowy, zaprezentowanych
w formie schematu blokowego na rys.40.
Pierwszym krokiem jest odwrotna liftracja, którą wykonujemy na wektorze
współczynników MFCC. Podczas tej operacji otrzymujemy zmodyfikowane
współczynniki mel-cepstrum (9). Zastosowanie tego typu przekształcenia pozwala
skompensować efekt wygładzania widma, wykonany dla celów efektywnego
rozpoznawania cech mowy.
Kolejnym etapem przetwarzania jest rekonstrukcja sum składników widma mocy,
otrzymanych w wyniku wymnożenia energii kolejnych próbek w pasmach przepustowych
filtrów analizy, przez ich trójkątne charakterystyki. W celu wyznaczenia wartości sum
przeprowadza się odwrotną transformację kosinusową – IDCT. Ogólnie proces
otrzymywania sum składników widma w poszczególnych segmentach można przedstawić
w postaci następującego równania macierzowego (29):
)exp( MFCCIDCTS_SUM ⋅= (29)
gdzie:
SUMS _ – otrzymana macierz sum składników widma mocy w poszczególnych pasmach
widma, wymiar TFB × , gdzie FB oznacza liczbę filtrów analizy składających się na
zespół filtrów analizy, natomiast T reprezentuje liczbę ramek czasowych sygnału
zrekonstruowanego.
IDCT – odwrotna macierz transformacji DCT.
MFCC – macierz współczynników MFCC.
Funkcja wykładnicza kompensuje tutaj operację logarytmowania wartości sum,
wykonywaną w trakcie analizy mel-cepstralnej.

4. Koncepcja semantycznego kodeka mowy
- 87 -
W kolejnej fazie syntezy sygnału mowy następuje rekonstrukcja zespołu filtrów
analizy, przy pomocy którego wyznaczono współczynniki MFCC. Proces ten polega
na wyznaczeniu częstotliwości środkowych pasm przepustowych, które są położone
w równych odległościach, w melowej skali częstotliwości. Wiąże się to z uprzednią
konwersją skali. Oprócz odpowiedniego rozmieszczenia zespołu filtrów, przywracane są
także wagi amplitud, które składają się na trójkątne charakterystyki tłumienia
w poszczególnych pasmach. Wymienione tutaj operacje, w ramach rekonstrukcji zespołu
filtrów wykonywane są dla każdego ramki sygnału, której długość zdefiniowana jest
w module dekodera mowy. Ostatecznie otrzymywana jest macierz o rozmiarze
FB × N/2+1, gdzie N określa długość okna analizy FFT, zawierająca wartości wag
amplitudy widma w danym paśmie zespołu filtrów. Następnie wyznaczana jest macierz
odwrotności tych wag o rozmiarze N/2+1 × FB, którą wymnaża się z macierzą wartości
sum składników widma mocy, wg wzoru (30):
S_SUMIWTSS_POW ⋅= (30)
gdzie:
S_POW – otrzymane widmo mocy traktu głosowego, o rozmiarze TN×+1
2.
IWTS – macierz odwrotnych wag, składających się na trójkątne charakterystyki tłumienia
zespołu filtrów, rozmiar FBN×+1
2.
S_SUM – macierz sum składników widma mocy w poszczególnych pasmach zespołu
filtrów, rozmiar TFB × .
W efekcie przeprowadzonych transformacji i przekształceń dysponujemy aproksymacją
widma mocy traktu głosowego, z której wyznaczamy widmo amplitudowe. Przykładowa
charakterystyka częstotliwościowa tak otrzymanego filtru syntezy dla pojedynczej,
dźwięcznej ramki sygnału przedstawiona jest na rys.1. Na wykresie dobrze wyraźnie
widoczne są pasma formantowe, w których sygnał pobudzenia jest wzmacniany w
największym stopniu. Charakterystyczne zafalowania transmitancji wpływają na
kształtowanie impulsu pobudzenia. Rozkład pasm formantowych zmienia się z ramki na
ramkę w czasie trwania sygnału.

4. Koncepcja semantycznego kodeka mowy
- 88 -
Syntezę sygnału mowy przeprowadzamy wg modelu źródłowo-filtrowego (rozdział
2.4). W dziedzinie czasu proces filtracji realizowany jest w postaci splotu liniowego
odpowiedzi impulsowej traktu głosowego oraz sygnału pobudzenia. Operacją dualną jest
iloczyn transformat Fouriera tych składników. Pomijając informację o fazie, która nie jest
syntezowana, realizujemy jedynie iloczyn widm amplitudowych toru oraz pobudzenia.
Konieczne jest wyznaczenie transformacji Fouriera sygnału pobudzenia, który uprzednio
dzieli się na segmenty o długości ramek analizy mel-cepstralnej.
Rys.41. Charakterystyka częstotliwościowa filtru modelującego mowę otrzymana
poprzez rekonstrukcję widma amplitudowego ze współczynników MFCC.
Następnie na końcu każdego segmentu dodawany jest wektor zerowych próbek (ang. zero
padding). Skutkuje to prawidłową realizacją splotu liniowego sygnałów dyskretnych.
Przebieg czasowy sygnału w każdym segmencie jest rekonstruowany przez odwrotną
transformację Fouriera z iloczynu widm amplitudowych. Ostatecznie mowa jest
syntezowana w wyniku składania otrzymanych segmentów czasowych, przy
uwzględnieniu długości zakładki ramki.
Końcowym etapem przetwarzania sygnału w układzie dekodera jest zastosowanie filtru
deemfazy do zrekonstruowanej mowy, którego działanie jest dokładnie odwrotne do filtru

4. Koncepcja semantycznego kodeka mowy
- 89 -
preemfazy przedstawionego w rozdziale 4.2.2. Przykładowe wyniki syntezy mowy
w dekoderze widoczne są na rys.42 w postaci przebiegu czasowego oraz na rys.43 w
postaci spektrogramu sygnału oryginalnego oraz zrekonstruowanego.
Spoglądając na wykres czasowy można zauważyć, że ogólna struktura sygnału –
fragmenty dźwięczne i bezdźwięczne – została wiernie odtworzona. Słabo
zrekonstruowane są transienty. Wynika to z faktu, że te nieharmoniczne, wybuchowe
składniki mowy nie są modelowane w koderze. Niosą one głównie informację o zmianie
fazy sygnału, podczas gdy rozpoznawanie cech w koderze fonetycznym opiera się jedynie
na właściwościach widma amplitudowego. Niedokładnie odwzorowana wartość obwiedni
sygnału nie stanowi większego problemu, natomiast wynika z licznych transformacji
wykonywanych podczas syntezy sygnału. Nieciągłości w przebiegu czasowym
spowodowane są nie uwzględnieniem właściwości dynamicznych sygnału podczas jego
kodowania oraz błędami w rozpoznawaniu fonemów.
Podobne wnioski można wysunąć analizując spektrogram sygnału zsyntezowanego.
Pokazuje on, że najlepiej odtworzone są składniki dźwięczne o dużej energii, a także
fragmenty o charakterze szumowym. Słabe efekty otrzymujemy w przypadku składników
mieszanych mowy. Częstotliwość podstawowa sygnału jest rozróżnialna,
w przeciwieństwie do słabo zarysowanych pasm formantowych. W otrzymanym spektrogramie widoczne są typowe cechy sygnałów syntetycznych –
bardzo regularny odstęp prążków widma, nagły spadek amplitudy widma powyżej granicy
widma impulsu, przy pomocy którego wygenerowano sygnał pobudzenia. Co więcej,
ograniczone pasmo impulsu w modelu generacji pobudzenia oraz ograniczony rząd analizy
mel-cepstralnej w koderze mają wpływ na niedokładne odwzorowanie składników
wysokoczęstotliwościowych widma. Przedstawione tutaj cechy sygnału zrekonstruowanego mają swoje odzwierciedlenie
w percepcyjnie postrzeganym poziomie jakości i zrozumiałości otrzymanej mowy. Wyniki
subiektywnych ocen tych miar przedstawione są w następnym rozdziale pracy.

4. Koncepcja semantycznego kodeka mowy
- 90 -
Rys.42. Przebieg czasowy sygnału oryginalnego oraz sygnału zrekonstruowanego.
Rys.43. Spektrogram sygnału oryginalnego i sygnału zrekonstruowanego.

5. Wyniki symulacji modelu kodeka
- 91 -
5. Wyniki symulacji modelu kodeka
Najważniejszym parametrem, który należy oszacować przy ocenie efektywności, jest
wielkość otrzymanego strumienia binarnego na wyjściu kodera. Ocena ta powinna być
poparta rezultatami badań w zakresie poziomu zrozumiałości i jakości sygnału
zrekonstruowanego. Aby otrzymane wyniki testów miały praktyczne odniesienie są one
przedstawione w porównaniu z popularną techniką kodowania mowy, jaką jest LPC.
5.3.1 Otrzymany strumień
Do oszacowania typowych wielkości strumienia binarnego na wyjściu kodera
wykorzystujemy grupę dziesięciu fragmentów mowy, pochodzących z bazy treningowej
kdt US English TIMIT [12]. Na poziom kompresji poszczególnych sygnałów testowych,
wpływ ma przede wszystkim poziom trudności danej wypowiedzi – w sensie leksykalnym,
zróżnicowanie fonemów wchodzących w jej skład oraz poziom wytrenowania modeli
HMM składających się na dany fragment mowy.
Szacowana prędkość transmisji wyznaczana jest przez zsumowanie przepływności
potrzebnych do zakodowania wektora częstotliwości F0, indeksów fonemów oraz czasu
ich trwania w postaci liczby kolejnych wystąpień, w kodowanej frazie. Wyniki symulacji
przedstawione są w tab.2.
Dla reprezentatywnej grupy dziesięciu sygnałów testowych otrzymano strumień 302,17 ±
23,91 bit/s. Odchylenia od tej wartości są stosunkowo niewielkie. O niskiej wartości
przepływności decyduje w głównej mierze poprawny wynik algorytmu rozpoznawania
fonemów. Zmniejsza się wtedy liczba przesyłanych indeksów modeli HMM, co powoduje
wzrost kompresji sygnału. Błędy w algorytmie rozpoznawania mowy skutkują dłuższym
wektorem tych indeksów, a także wzrostem wielkości strumienia.

5. Wyniki symulacji modelu kodeka
- 92 -
Tab.2. Otrzymane wielkości strumieni binarnych dla sygnałów testowych.
Fragment mowy Przepływność [bit/s].
kdt_001.wav 320,72
kdt_002.wav 339,29
kdt_006.wav 320,70
kdt_028.wav 322,10
kdt_081.wav 303,37
kdt_098.wav 282,24
kdt_146.wav 274,99
kdt_210.wav 308,73
kdt_280.wav 274,18
kdt_431.wav 275,35
średnia 302,17
odchylenie stand. 23,91
5.3.2 Ocena zrozumiałości otrzymanej mowy
W badaniu zrozumiałości sygnału mowy mierzymy poziom zniekształcenia jego
zawartości informacyjnej. Najpopularniejszym testem zrozumiałości dla koderów mowy
jest tzw. diagnostyczny test rymowy – DRT (ang. Diagnostic Rhyme Test) [2, rozdz.8].
Polega ona na pytaniu słuchacza o rozpoznanie par wypowiadanych słów, które różnią się
pierwszą sylabą. Wynik testu określa się jako stosunek odpowiedzi prawidłowych
do całkowitej liczby par słów.
Przeprowadzenie testu DRT wymusza posiadanie odpowiedniej grupy fragmentów mowy,
które różnią się jedną sylabą. Baza sygnałów treningowych wykorzystywana w tym
projekcie składa się z 452 wypowiedzi, przy czym są to całe zdania. Przeprowadzanie testu
DRT w takim przypadku jest niemożliwe, ze względu na brak odpowiednich danych
wejściowych. Co więcej, opracowany kodek jest systemem zależnym od mówcy
treningowego i użycie sygnałów spoza bazy powoduje spadek efektywności zarówno
analizy jak i rekonstrukcji.

5. Wyniki symulacji modelu kodeka
- 93 -
Ze względu na powyższe przyczyny zaistniała konieczność przeprowadzenia badania
zrozumiałości inną metodą. Aby zgrubnie ocenić poziom zrozumiałości zdekodowanych
sekwencji słów poproszono słuchaczy o wystawienie oceny wg następującej skali:
1 - mowa całkowicie niezrozumiała
2 - mowa częściowo zrozumiała
3 - mowa całkowicie zrozumiała
Test wykonano w grupie ośmiu słuchaczy, przy wykorzystaniu tych samych fragmentów
mowy, co w rozdziale 5.3.1. Subiektywna ocena zrozumiałości oraz jakości sygnału
zrekonstruowanego została wykonana dla opracowanego systemu kodowania oraz
referencyjnego kodeka LPC. Został on skonfigurowany do pracy przy parametrach analizy,
umożliwiających otrzymanie bardzo niskiego strumienia binarnego:
rząd predyktora = 4
okno analizy = 640 próbek
współczynniki LPC w formie PARCOR
przydział bitów:
współczynniki filtru = 2 bity/ramkę
wzmocnienie = 0 bitów/ramkę
Jak widać rząd predykatora jest bardzo niski, długości ramki analizy znacznie dłuższa niż
typowe 160 próbek, a kwantyzacja współczynników filtru bardzo silna. Informacja
o wzmocnieniu w ogóle nie jest kodowana. Tylko takie nastawy umożliwiają zmniejszenie
generowanej przepływności kodeka LPC z 2,4 kbit/s do ok. 600 bit/s.
Dodatkowo podczas syntezy sygnału wykorzystuje się algorytm generacji pobudzenia
zaczerpnięty z opracowanego systemu kodowania mowy. Otrzymana wartość
przepływności dla referencyjnego kodeka LPC uwzględnia liczbę bitów konieczną do
transmisji wektora częstotliwości F0, który jest wykorzystywany do produkcji sygnału
pobudzenia. Wyniki subiektywnej oceny zrozumiałości mowy zrekonstruowanej zawarte
są w tab.3.
Dla opracowanego modelu kodeka mowy otrzymaną średnią ocenę poziomu zrozumiałości
równą 1,7, co oznacza, że słuchacze uznali wypowiadane sekwencje za częściowo
zrozumiałe.

5. Wyniki symulacji modelu kodeka
- 94 -

5. Wyniki symulacji modelu kodeka
- 95 -
W przypadku kodeka LPC średni poziom zrozumiałości dla dziesięciu sygnałów testowych
określono na 1,15. Można zatem uznać, że fragmenty mowy zakodowane przy pomocy
wykorzystanego kodeka LPC dla 600 bit/s, są całkowicie niezrozumiałe dla słuchacza.
5.3.3 Subiektywna ocena jakości sygnału zrekonstruowanego
Celem badania jakości mowy zsyntezowanej jest ocena stopnia zniekształceń,
otrzymanych w wyniku stratnej kompresji sygnału. Podobnie jak w badaniu zrozumiałości
otrzymane wyniki są całkowicie zależne od słuchacza i dlatego mogą się znacznie różnić.
W literaturze [2, rozdz.8] można spotkać kilka metod pomiaru jakości zdekodowanej
mowy. Najczęściej wykorzystuje się tzw. test średniej oceny jakości – MOS (ang. Mean
Opinion Score), w którym słuchacz używa pięcio-punktowej skali do określenia jakości
sygnału mowy. Wadą tej techniki jest duży rozrzut otrzymanych wyników ze względu na
różną percepcję słuchaczy, ich samopoczucia itp. Bardzo subiektywny charakter
rezultatów testu MOS nie pozwala na wiarygodne ich porównanie z wynikami
otrzymanymi przy pomocy innych metod.
Lepszym badaniem w takiej sytuacji okazuje się test średniej oceny degradacji sygnału
– DMOS (ang. Degradation Mean Opinion Score). Podczas jego realizacji słuchacz
otrzymuje referencję dla analizowanego fragmentu, w postaci oryginalnej wypowiedzi.
Jego zadaniem jest ocena stopnia degradacji mowy wg następującej skali [21]:
5 – degradacja jest niesłyszalna
4 – degradacja jest słyszalna, ale niedokuczliwa
3 – degradacja jest w małym stopniu dokuczliwa
2 – degradacja jest dokuczliwa
1 – degradacja jest bardzo dokuczliwa
Dzięki porównywaniu sygnału zdekodowanego z sygnałem oryginalnym możliwe jest
otrzymanie bardziej zbliżonych wyników, pochodzących od wielu słuchaczy. Ten fakt
zadecydował o wykorzystaniu testu DMOS do zbadania jakości fragmentów mowy
otrzymanych na wyjściu zaimplementowanego kodeka. W celu porównania, zbadano także
jakość sygnału na wyjściu kodeka LPC, którego parametry dobrano jak w rozdziale 5.3.2.
Podobnie jak w ocenie zrozumiałości, reprezentatywna grupa słuchaczy składała się
z ośmiu osób, które analizowały dziesięć testowych sygnałów mowy. Otrzymane wyniki
badania przedstawione są w tab.4.

5. Wyniki symulacji modelu kodeka
- 96 -

5. Wyniki symulacji modelu kodeka
- 97 -
Średnia ocena jakości fragmentów kodowanych przy użyciu systemu, będącego tematem
pracy wyniosła 2,61. Słuchacze uznali, że degradacja sygnału występuje, ale jest ona
umiarkowanie dokuczliwa. Gorszą ocenę jakości uzyskano dla kodeka LPC (przy
strumieniu 600 bit/s). Tutaj średni stopień degradacji sygnału osiągnął wartość 1,19.
Można uznać, że mowa otrzymana na wyjściu kodeka LPC jest bardzo silnie
zdegradowana.
Podczas badań jakości oraz zrozumiałości mowy zrekonstruowanej największe błędy,
a co za tym idzie najgorsze oceny, wystawiano w przypadku fragmentów bardzo
zróżnicowanych leksykalnie oraz cechujących się dużą zawartością składników
dźwięcznych. Wynika to z błędów w rozpoznawaniu odpowiednich jednostek
akustycznych, realizowanym w koderze. Wpływa na to także mocno uproszczony model
syntezy pobudzenia w module rekonstrukcji sygnału. Percepcja fragmentów,
zawierających stosunkowo dużo składników bezdźwięcznych jest lepsza, gdyż szum
można łatwo zamodelować.
Bardzo ważnym wnioskiem płynącym z wyników badań jest znacząca przewaga
efektywności kodowania opracowanego systemu w stosunku do kodera LPC dla strumienia
600 bit/s. Słuchacze ocenili, że kodowanie mowy przy użyciu zaprojektowanego systemu
daje mowę o wiele lepszej jakości (różnica rzędu półtora punktu skali). Badanie
zrozumiałości również wypadło tutaj lepiej (ok. pół punktu skali). Należy także zaznaczyć,
że średni strumień binarny generowany przez opracowany koder waha się na poziomie 300
bit/s. Możemy zatem powiedzieć, że algorytm kodowania mowy, który jest tematem pracy,
daje dwukrotnie większy stopień kompresji sygnału, niż kodek LPC pracujący przy
podobnych parametrach analizy oraz pozwala otrzymać mowę zrekonstruowaną o wiele
lepszej jakości.

6. Zakończenie
- 98 -
6. Zakończenie
Celem niniejszej pracy magisterskiej była weryfikacja możliwości implementacji
systemu kodowania mowy przy ekstremalnie małych prędkościach transmisji. W tym
rozdziale zawarte jest podsumowanie zrealizowanych zadań szczegółowych, które
sformułowano przed rozpoczęciem prac badawczych i projektowych.
Na wstępie zweryfikowano użyteczność współczesnych technik kodowania mowy dla
bardzo małych przepływności, pod kątem wielkości otrzymywanego strumienia, poziomu
złożoności algorytmu, wielkości potrzebnych baz danych mowy itp. Spośród trzech
podstawowych technik budowy koderów mowy – wokodera segmentowego, wokodera
sylabowego oraz wokodera fonetycznego zdecydowano się na implementację tego
ostatniego.
Budowa sprawnego systemu kodowania wymusiła konieczność głębszego zrozumienia
wielu procesów, które zachodzą podczas produkcji sygnału mowy. Wytwarzanie sygnału
pobudzenia, reprezentowanie traktu głosowego w postaci układu liniowego o parametrach
zmiennych oraz charakterystyka podstawowych jednostek akustycznych mowy, jakimi są
fonemy, stanowią istotny kontekst merytoryczny dla implementacji kodeka mowy opartego
na algorytmach analizy i resyntezy sygnału.
Podczas prac nad koderem konieczne było przeprowadzenie wielu badań w zakresie
rozpoznawania mowy przy wykorzystaniu ukrytych modeli Markowa – HMM. Analizę
zagadnień budowy takich struktur oraz reprezentacji przy ich pomocy cech widmowych
fonemów wykonano przy wykorzystaniu popularnego narzędzia do treningu modeli HMM
i rozpoznawania mowy, jakim jest biblioteka HTK [9]. Przy jej pomocy opracowano
ostateczną formę modelu HMM, który wykorzystano podczas realizacji algorytmu
kodowania mowy, będącego tematem pracy. W projekcie wykorzystano także dostępne
narzędzia inicjalizacji i treningu modeli HMM zawarte w systemie HTK.
Do rozpoznawania fonemów przy pomocy HMM opracowano autorski algorytm, który
pozwolił na efektywne przeprowadzenie analizy wejściowego sygnału mowy, bez
konieczności posiadania informacji o jego gramatyce.
W dalszych etapach pracy nad koderem zaimplementowano algorytm analizy mel-
cepstralnej sygnału mowy oraz metodę ekstrakcji częstotliwości podstawowej,
wykorzystującą cepstrum sygnału.

6. Zakończenie
- 99 -
Stopień kompresji strumienia binarnego otrzymywanego na wyjściu układu, polepszono
stosując koder entropijny.
W celu zapewnienia spójnego systemu kodeka konieczne było opracowanie modułu
rekonstrukcji mowy. Kluczową sprawą okazał się wybór odpowiedniej metody filtracji
syntetycznie wygenerowanego sygnału pobudzenia. Zagadnieniu temu poświęcono wiele
badań eksperymentalnych. W rezultacie wykorzystano znany algorytm rekonstrukcji
widma amplitudowego ze współczynników MFCC, otrzymanych z modeli HMM.
Doświadczenia zdobyte podczas prac nad syntezą sygnału mowy pokazały, że znaczącym
elementem w tego typu systemie jest odpowiednio generowany sygnału pobudzenia. Jego
rekonstrukcja musi być wierna, gdyż znacząco wpływa on na ocenę subiektywną
odtwarzanej mowy. W opracowanym modelu dekodera przy pomocy techniki ciągłej
interpolacji częstotliwości F0 oraz doboru odpowiedniego – ograniczonego pasmowo
ciągu impulsów otrzymano zadowalający efekt.
Model kodera i dekodera mowy, składający się na część implementacyjna pracy,
pozwolił na przeprowadzenie symulacji opracowanego rozwiązania. Badano wielkość
otrzymanego strumienia oraz poziom jakości i zrozumiałości sygnału zrekonstruowanego.
Wyniki testów pokazały, że osiągnięto założony, główny cel projektu, w postaci bardzo
silnej kompresji sygnału na poziomie 300 bit/s. Jako odniesienie dla zaimplementowanego
systemu kodowania wybrano kodek LPC, skonfigurowany do pracy przy bardzo małej
prędkości transmisji – rzędu 600 bit/s. Przy pomocy fragmentów mowy z bazy danych
treningowych przeprowadzono także zgrubne badania poziomu zrozumiałości oraz
dokonano subiektywnej oceny jakości sygnału zrekonstruowanego. Otrzymane rezultaty
pokazały wyższość opracowanego schematu kodowania w stosunku do technik LPC przy
prędkości 600 bit/s.
Niniejsza praca magisterska zawiera opis architektury i rozwiązań szczegółowych
sprawnie działającego kodeka mowy, oferującego bardzo silną kompresję sygnału.
Efektywność jego działania zależy przede wszystkim od jakości i wielkości bazy danych
treningowych używanych do estymacji parametrów modeli HMM w koderze. Drugim
elementem krytycznym przedstawionego tutaj modelu jest algorytm produkcji pobudzenia
w układzie rekonstrukcji, który bezpośrednio wpływa na postać zrekonstruowanej mowy.
W perspektywie dalszych prac nad kodekiem zostaje reprezentacja cech dynamicznych
widma amplitudowego sygnału, analiza i transmisja informacji o jego obwiedni, czy
modyfikacja algorytmu otrzymywania współczynników MFCC z modeli fonemów.

Bibliografia
- 100 -
Bibliografia
[1] Bartkowiak M., Materiały z wykładu Przetwarzanie Dźwięku i Mowy, Politechnika
Poznańska 2006
[2] Goldberg R., Riek L., A Practical Handbook of Speech Coders, CRC Press LLC,
2000
[3] Al-Akaidi M., Fractal Speech Processing, Cambridge University Press New York,
2004
[4] Lee K., Cox R., A very low bitrate speech coder based on a recognition/synthesis
paradigm, IEEE Transactions On Speech and Audio Processing, 2001, vol.9, no. 5
[5] Yi K., Cheng J., Wang A., Zhang P., Liu F., Li W., Yang B., Du S., Gong J.,
A vocoder based on speech recognition and synthesis, Global Telecommunications
Conference, GLOBECOM’95, IEEE, 1995
[6] Bastien P., Voice Specific Signal Processing Tools, 23rd International Conference on
Signal Processing in Audio Recording and Reproduction, TC – Helicon, 2003
[7] Picone J., Doddington G., A phonetic vocoder, International Conference on
Acoustics, Speech, and Signal Processing, ICASSP-89, 1989
[8] Tokuda K., Masuko T., Hiroi J., Kobayashi T., Kitamura T., A very low bit rate
speech coder using HMM-based speech recognition/synthesis techniques,
Proceedings of the International Conference on Acoustics, Speech and Signal
Processing, IEEE, vol. 2, 1998
[9] Young S., EvermannG., Gales M., Hain T., Kershaw D., Liu X., Moore G., Odell J.,
Ollason D., Povey D., Valtchev V., Woodland P., The HTK Book (for HTK Version
3.4), Cambridge University Engineering Department, 2006
[10] Gerhard D., Pitch Extraction and Fundamental Frequency: History and Current
Techniques, Technical Report TR-CS 2003-06, University of Regina, Canada, 2003
[11] Noll A.M., Cepstrum pitch determination, The Journal of the Acoustical Society of
America, vol.44, no.6, str.1585 – 1591, 1968
[12] The CMU/CSTR kdt US English TIMIT database for speech synthesis,
http://festvox.org/dbs/dbs_kdt.html, stan na dzień 16.07.2008
[13] Niewiadomy D., Pelikant A., Digital Speech Signal Parametrization by Mel
Frequency Cepstral Ceofficients and Word Boundaries, 33 Journal of Applied
Computer Science

Bibliografia
- 101 -
[14] Zwiernik P., Wstęp do ukrytych modeli Markowa i metody Bauma-Welcha,
Uniwersytet Warszawski, 2005
[15] Yamagishi J., An Introduction to HMM-Based Speech Synthesis,
https://wiki.inf.ed.ac.uk/pub/CSTR/TrajectoryModelling/HTS-Introduction.pdf, 2006
[16] Yoshimura T., Tokuda K., Masuko T., Kobayashi T., Kitamura T., Mixed Excitation
for HMM-based Speech Synthesis, 7th European Conference on Speech
Communication and Technology, EUROSPEECH 2001
[17] Maia R., A Novel Excitation Approach for HMM-based Speech Synthesis, Report IV,
http://www.sp.nitech.ac.jp/~tokuda/tips/excitation8.pdf , 2007
[18] Chazan D., Hoory Ron., Cohen G., Zibulski M., Speech Reconstruction from Mel
Frequency Cepstral Coefficients and Pitch Frequency, Proceedings of the
International Conference on Acoustics, Speech and Signal Processing, IEEE, vol.3,
2000
[19] Tokuda K., Zen H., Sako S., Yamagishi Y., Masuko T., Nankaku Y., Reference
Manual for Speech Signal Processing Toolkit Ver. 3.0, SPTK Working Group, 2003
[20] RASTA/PLP/MFCC feature calculation and inversion,
http://labrosa.ee.columbia.edu/matlab, stan na dzień 18.08.2008.
[21] Keagy S., Integrating Voice and Data Networks, Cisco Press, 2000

Dodatek. Prototyp modelu HMM
- 102 -
Dodatek. Prototyp modelu HMM
~o
<VECSIZE> 13<NULLD><MFCC_0><FullC>
~h "proto"
<BEGINHMM>
<NUMSTATES> 5
<STATE> 2
<MEAN> 13
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<InvCovar> 13
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0
1.0 0.0 0.0
1.0 0.0
1.0
<STATE> 3
<MEAN> 13
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<InvCovar> 13
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0

Dodatek. Prototyp modelu HMM
- 103 -
1.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0
1.0 0.0 0.0
1.0 0.0
1.0
<STATE> 4
<MEAN> 13
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<InvCovar> 13
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0 0.0
1.0 0.0 0.0 0.0
1.0 0.0 0.0
1.0 0.0
1.0
<TRANSP> 5
0.0 1.0 0.0 0.0 0.0
0.0 0.6 0.4 0.0 0.0
0.0 0.0 0.6 0.4 0.0
0.0 0.0 0.0 0.7 0.3
0.0 0.0 0.0 0.0 0.0
<ENDHMM>





























