Embed Size (px)
Citation preview

IOAN DZIłAC GRIGOR MOLDOVAN
SISTEME DISTRIBUITE
MODELE INFORMATICE
Editura UniversităŃii Agora, Oradea
2006

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 2
Referent: Prof. univ. dr. Răzvan Andonie, Central Washington University, SUA Editor: Prof. univ. dr. ing. Mişu-Jan Manolescu, Universitatea Agora Coperta şi asistent editorial: Emma M. Văleanu, Universitatea Agora, student doctorand la Academia Română
Descrierea CIP a Bibliotecii NaŃionale a României
DZIłAC, IOAN Sisteme distribuite - Modele informatice / Ioan DziŃac, Grigor Moldovan. - Oradea : Editura UniversităŃii Agora, 2006 Bibliogr. ISBN (10) 973-87960-9-1 ; ISBN (13) 978-973-87960-9-6 I. Moldovan, Grigor 004
Copyright © 2006 by CCC Publications, Agora University Publishing House.
Title: DISTRIBUTED SYSTEMS: INFORMATION SYSTEM MODELS Abstract: This work presents various definitions and models for the distributed informatics systems starting from the parallel and distributed computation general models, usual models from Internet and Intranet (client/server, cluster, grid etc.), and also the communication models in these kind of systems. The book is addressed especially by the students and by the professorate that wants to study/teach the applied informatics (economical informatics, medical informatics) but can also be used by all the other that are interested in using the distributed informatics systems.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
3
CONTENTS CHAPTER 1 DISTRIBUTED INFORMATICS SYSTEMS 1.1. A short description of the distributed informatics systems
1.1.1. Distributed informatics system. Homogeneous/heterogeneous systems. Tightly /loosely coupled systems 1.1.2. Specific characteristics and advantages of the distributed systems 1.1.3. Middleware
1.2. The requirements of a distributed informatics system
1.2.1. Heterogeneously
1.2.2. Scalability
1.2.3. Security
1.2.4. Errors treatment
1.2.5. Openess
1.2.6. Concurrency 1.2.7. Transparency
1.3. Remarkable examples of distributed informatics systems 1.3.1. Internet networks: SIPRNET, FidoNet, Internet 1.3.2. Intranet and extranet 1.3.3. Nomadic computing and ubiquitous computing 1.3.4. Internet2 1.3.5. PlanetLab 1.3.6. Cluster 1.3.7. Grid
CHAPTER 2 PARALLEL AND DISTRIBUTED COMPUTATION SYSTEMS: TAXONOMY AND MODELS 2.1. Binary classification of the parallel and distributed computing systems (SCPD) architectures
2.1.1. SCPD classification after the number of the central units connected to the memory 2.1.2. SCPD classification after the control mechanism type 2.1.3. SCPD classification after the number of the processing instruction sets 2.1.4. SCPD classification after the processing management strategy type 2.1.5. SCPD classification after the number of the processing data stream 2.1.6. SC class partition after the number of the processing data stream

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 4
2.1.7. SIMD class partition after the processing data type 2.1.8. SF class partition after the processing data type 2.1.9. MIMD class partition after the organization way of the address- space of memory (Bell) 2.1.10. Multiprocessors partition after the used memory type (Bell) 2.1.11. Multicomputer partition after the used memory type (Bell)
2.2.The parallelism in various computing systems 2.2.1. The parallelism in the SISD modern scalar computers 2.2.2. The parallelism in the MISD multiscalar computers 2.2.3 The parallelism in the MIMD systems
2.3. Flynn’s classification 2.3.1. SISD class (Single Instruction stream - Single Data stream) 2.3.2. SIMD class (Single Instruction stream - Multiple Data stream) 2.3.3. MISD class(Multiple Instruction stream - Single Data stream) 2.3.4. MIMD class(Multiple Instruction stream - Multiple Data stream)
2.4. A synthesis of various taxonomy of SCPD 2.4.1. The inclusion of Flynn’s classes 2.4.2. The inclusion of Bell’s classes (SASA multiprocessors, MPA multicomputer)
2.4.3. The inclusion of Hwang’s classes (UMA, NUMA, ccNUMA, COMA models) 2.4.4. The models Cluster and Grid 2.4.5. A synthesis taxonomical schema
2.5. The software needed for the configuration and the management of the distributed informatics systems
2.5.1. Multiuser operating systems 2.5.2. Parallel Virtual Machine (PVM) 2.5.3. Message Passing Interface (MPI) 2.5.4. Globus Toolkit
CHAPTER 3 THE INTERCONNECTION IN THE PARALLEL AND DISTRIBUTED COMPUTATION SYSTEMS 3.1. PRAM, an idealist parallel computer 3.2. Interconnection methods in the parallel and distributed computation systems architecture. Computer networks
3.2.1. “Crossbar” networks 3.2.2. “Switchboard” interconnection 3.2.3. Network interconnection with limited direct links
3.2.3.1. Bus network 3.2.3.2. Linear and cyclic network 3.2.3.3. Perfect mixing network

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
5
3.2.3.4. Tree network 3.2.3.5. Lattice network 3.2.3.6. Hypercube network
CHAPTER 4 THE INTERNET: A SCALABLE OPEN DISTRIBUTED SYSTEM 4.1. The architectural schema of the Internet 4.2. The functional schema of the Internet (router, gateway, host) 4.3. The client/server model. The TCP/IP protocol
4.3.1. IP (Internet Protocol). 4.3.2. TCP (Transmission Control Protocol) 4.3.3. UDP (User Datagram Protocol) 4.3.4. DNS (Domain Name System) 4.3.5. POP3 or the Post Office protocol– Version 3 4.3.6. IMAP (Internet Message Access Protocol) 4.3.7. SMTP (Simple Mail Transfer Protocol) 4.3.8. HTTP (HyperText Transfer Protocol) 4.3.9. HTTPS 4.3.10. SSL (Secure Sockets Layer) 4.3.11. FTP (File Transfer Protocol) 4.3.12. LDAP
4.4. World Wide Web: a distributed application over the Internet 4.4.1. Generalities about the Web. Hypertext and hypermedia 4.4.2. The hypertext marking (SGML, XML, HTML, WML, XHTML) 4.4.3. URI (Uniform Resource Identifier): URL and URN 4.4.4. HTTP (HyperText Transfer Protocol)
APPENDIX A minidictionary for parallel and distributed computing REFERENCES WEB REFERENCES

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 6
Conf. univ. dr. Ioan DziŃac
Domenii de interes:
Calcul paralel şi distribuit, Matematică şi informatică economică
Ioan DZIłAC (n. 14.02.1953, Poieni de sub Munte - Repedea, Maramureş), este doctor în informatică, conferenŃiar universitar şi şeful catedrei de informatică economică la Universitatea AGORA din Oradea. A obŃinut doctoratul în informatică în 2002 sub conducerea ştiinŃifică a prof. Grigor MOLDOVAN. A fost directorul Departamentului de Matematică şi Informatică al UniversităŃii din Oradea, iar în prezent este directorul centrului de cercetare „Tehnologii informatice avansate în management şi inginerie” la Universitatea AGORA. A publicat 11 cărŃi şi a editat 4 volume ale unor conferinŃe internaŃionale şi peste 40 de articole. Este fondator şi editor executiv la International Journal of Computers, Communications and
Control.
Prof. univ. dr. Grigor Moldovan
Domenii de interes:
Sisteme distribuite, Limbaje formale
Grigor MOLDOVAN (n. 29.12.1939, Vadu Izei, Maramureş), este doctor în matematică, profesor universitar şi conducător de doctorate în informatică la Universitatea „Babeş-Bolyai” din Cluj - Napoca, Facultatea de Matematică şi Informatică. A obŃinut doctoratul în matematică în 1972 sub conducerea ştiinŃifică a acad. Tiberiu POPOVICIU şi prof. Dimitrie STANCU. Este unul din pionieri în informatica românească, predând cursuri de informatică începând încă din anul 1971, scriind articole şi cărŃi de informatică şi fiind directorul Centrului de Calcul al UniversităŃii, de la înfiinŃarea sa în 1975, până în anul 1990. A fost mulŃi ani şi directorul Departamentului de Informatică. A publicat 18 cărŃi şi peste 65 de articole ştiinŃifice.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
7
CUPRINS CAPITOLUL 1 SISTEME INFORMATICE DISTRIBUITE 11 1.1. Scurtă descriere a sistemelor informatice distribuite 12 1.1.1. Sistem informatic distribuit. Sisteme
omogene/eterogene. Sisteme puternic/slab cuplate 12
1.1.2. Caracteristici şi avantaje specifice ale sistemelor distribuite
14
1.1.3. Midlleware 16 1.2. CerinŃele unui sistem informatic distribuit 17 1.2.1. Eterogenitatea 17 1.2.2. Scalabilitatea 18 1.2.3. Securitatea 20
1.2.4. Tratarea erorilor 23 1.2.5. Deschiderea 24 1.2.6. ConcurenŃa 24 1.2.7. TransparenŃa 24 1.3. Exemple remarcabile de sisteme informatice distribuite 26 1.3.1. ReŃele de tip internet: SIPRNET, FidoNet, Internet 26 1.3.2. Intranet şi extranet 27 1.3.3. Nomadic computing şi ubiquitous computing 28 1.3.4. Internet2 28 1.3.5. PlanetLab 29 1.3.6. Cluster 38 1.3.7. Grid 43 CAPITOLUL 2 SISTEME DE CALCUL PARALEL ŞI DISTRIBUIT: TAXONOMIE ŞI MODELE
47
2.1. Clasificări binare ale arhitecturilor sistemelor de calcul paralel şi distribuit (SCPD)
48
2.1.1. Clasificarea SCPD după numărul de unităŃi centrale conectate la memorie
49
2.1.2. Clasificarea SCPD după tipul mecanismului de control 50 2.1.3. Clasificarea SCPD după numărul de seturi de
instrucŃiuni prelucrabile 50

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 8
2.1.4. Clasificarea SCPD după tipul strategiei de management al procesării
50
2.1.5. Clasificarea SCPD după numărul de seturi de date prelucrabile
51
2.1.6. Divizarea clasei SC după numărul de seturi de date prelucrabile
51
2.1.7. Divizarea clasei SIMD după tipul de date prelucrabile 51 2.1.8. Divizarea clasei SF după tipul de date prelucrabile 52 2.1.9. Divizarea clasei MIMD după modul de organizare a
adresării spaŃiului de memorie (Bell) 52
2.1.10. Divizarea multiprocesoarelor după tipul de memorie utilizat (Bell)
52
2.1.11. Divizarea multicalculatoarelor după tipul de memorie utilizat (Bell)
52
2.2. Paralelismul în diverse sisteme de calcul 53 2.2.1. Paralelismul în calculatoarele scalare moderne de tip
SISD 53
2.2.2. Paralelismul în calculatoarele multiscalare de tip MISD 55 2.2.3. Paralelismul în sistemele MIMD 60 2.3. Clasificarea lui Flynn 62 2.3.1. Clasa SISD (Single Instruction stream - Single Data
stream) 62
2.3.2. Clasa SIMD (Single Instruction stream - Multiple Data stream)
62
2.3.3. Clasa MISD (Multiple Instruction stream - Single Data stream)
62
2.3.4. Clasa MIMD (Multiple Instruction stream - Multiple Data stream)
62
2.4. O sinteză a diverselor taxonomii ale SCPD 64 2.4.1. Includerea claselor lui Flynn 64 2.4.2. Includerea claselor lui Bell (multiprocesor de tip
SASA, multicalculator de tip MPA) 65
2.4.3. Includerea claselor lui Hwang (modelele UMA, NUMA, ccNUMA, COMA)
65
2.4.4. Modelele Cluster şi Grid 67 2.4.5. O schemă taxonomică de sinteză 69 2.5. Software pentru configurarea şi managementul sistemele
informatice distribuite 70
2.5.1. Sisteme de operare multiuser 70 2.5.2. Parallel Virtual Machine (PVM) 71 2.5.3. Message Passing Interface (MPI) 84 2.5.4. Globus Toolkit 89

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
9
CAPITOLUL 3 INTERCONECTAREA ÎN SISTEMELE DE CALCUL PARALEL ŞI DISTRIBUIT
95
3.1. PRAM, un calculator paralel idealizat 95 3.2. Procedee de interconectare în arhitecturile sistemelor de calcul
paralel şi distribuit. ReŃele de calculatoare 97
3.2.1. ReŃea de tip “crossbar” 98 3.2.2. Interconectarea de tip “switchboard” 98 3.2.3. ReŃea de interconectare cu legături directe limitate 99 3.2.3.1. Magistrala comună (bus) 99 3.2.3.2. ReŃeaua liniară şi ciclică 99 3.2.3.3. ReŃeaua de tip amestecare perfectă 100 3.2.3.4. ReŃeaua arborescentă 101 3.2.3.5. ReŃeaua de tip latice 102 3.2.3.6. ReŃeaua de tip hipercub 103 CAPITOLUL 4 INTERNETUL: UN SISTEM DISTRIBUIT DESCHIS ŞI SCALABIL
105
4.1. Schema arhitecturală a Internetului 106 4.2. Schema funcŃională a Internetului (router, gateway, host) 108 4.3. Modelul client/server. Protocolul TCP/IP 109 4.3.1. IP (Internet Protocol) 110 4.3.2. TCP (Transmission Control Protocol) 110 4.3.3. UDP (User Datagram Protocol) 110 4.3.4. DNS (Domain Name System) 111 4.3.5. POP3 sau Protocolul Post Office – Versiunea 3 122 4.3.6. IMAP (Internet Message Access Protocol) 122 4.3.7. SMTP (Simple Mail Transfer Protocol) 122 4.3.8. HTTP (HyperText Transfer Protocol) 122 4.3.9. HTTPS 123 4.3.10. SSL (Secure Sockets Layer) 123 4.3.11. FTP (File Transfer Protocol) 123 4.3.12. LDAP 123 4.4. World Wide Web: o aplicaŃie distribuită în Internet 124 4.4.1. GeneralităŃi despre Web. Hipertext şi hipermedia 124 4.4.2. Marcarea hipertextului (SGML, XML, HTML, WML,
XHTML) 126
4.4.3. URI (Uniform Resource Identifier): URL şi URN 126 4.4.4. HTTP (HyperText Transfer Protocol) 127

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 10
ANEXĂ MinidicŃionar de calcul paralel şi distribuit 128 BIBLIOGRAFIE 143 WEBGRAFIE 146

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
11
CAPITOLUL 1 SISTEME INFORMATICE DISTRIBUITE 1.1. Scurtă descriere a sistemelor informatice distribuite
1.1.1. Sistem informatic distribuit. Sisteme omogene/eterogene. Sisteme puternic/slab cuplate 1.1.2. Caracteristici şi avantaje specifice ale sistemelor distribuite 1.1.3. Midlleware
1.2. CerinŃele unui sistem informatic distribuit
1.2.1. Eterogenitatea 1.2.2. Scalabilitatea 1.2.3. Securitatea 1.2.4. Tratarea erorilor 1.2.5. Deschiderea 1.2.6. ConcurenŃa 1.2.7. TransparenŃa
1.3. Exemple remarcabile de sisteme informatice distribuite
1.3.1. ReŃele de tip internet: SIPRNET, FidoNet, Internet 1.3.2. Intranet şi extranet 1.3.3. Nomadic computing şi ubiquitous computing 1.3.4. Internet2 1.3.5. PlanetLab 1.3.6. Cluster 1.3.7. Grid

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 12
1.1. Scurtă descriere a sistemelor informatice distribuite
1.1.1. Sistem informatic distribuit. Sisteme omogene/eterogene. Sisteme puternic/slab cuplate 1.1.2. Caracteristici şi avantaje specifice ale sistemelor distribuite 1.1.3. Midlleware
1.1.1. Sistem informatic distribuit. Sisteme omogene/eterogene. Sisteme puternic/slab cuplate
Vom admite că prin sistem distribuit de calcul sau sistem informatic distribuit se înŃelege o mulŃime de programe peste o reŃea de noduri (calculatoare, multiprocesoare, procesoare paralele masive, staŃii de lucru, clustere, grid ..) care au acces fiecare la o memorie proprie (dar pot avea acces şi la anumite memorii comune partajate), fiind conectate între ele prin nişte linii de comunicaŃie (fir, fibră optică, unde radio, sateliŃi), având diverse topologii de conexiune (magistrală comună, stea, ...), sistemul fiind conceput cu scopul partajării unor resurse sau/şi pentru rezolvarea concurentă a unor aplicaŃii paralele sau paralelizabile.
MotivaŃia pentru construirea şi utilizarea sistemelor capabile de calcul paralel vine din nevoia de a reduce timpul de calcul prin diviziunea unei probleme mari în sub-probleme ce se pot rezolva simultan pe structuri de calcul adecvate, iar sistemele informatice distribuite răspund cerinŃelor de simultaneitate a calcului paralel şi au în plus facilităŃi de a putea partaja unele resurse scumpe: hardware (imprimante, discuri, scanere, faxuri) şi software (pagini web, baze de date, fişiere).
Din punct de vedere al investiŃiei în echipamente, costurile se pot reduce
considerabil, dacă se utilizează un sistem distribuit care partajează unele resurse
hardware scumpe (imprimante, servere cu baze de date, plăci pentru achiziŃie de
date, discuri, scanere, faxuri etc.), dar şi a unor produse software cu licenŃe
scumpe (medii de programare, limbaje de programare, programe utilitare,
programe pentru achiziŃii de date etc.). Acest lucru se face de obicei în
organizaŃii (instituŃii, întreprinderi) prin organizarea sistemului de calcul într-o
reŃea Intranet în care este reglementat accesul distribuit la resurse.
Utilizatorii propriu-zişi a sistemelor distribuite de tip Internet sau
intranet sunt în multe cazuri mai puŃin preocupaŃi de costurile resurselor

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
13
folosite, fiind interesaŃi mai mult de funcŃionalitatea modalităŃii de partajare a
resurselor de care trebuie să se folosească în aplicaŃiile lor.
Partajarea resurselor se face începând de la indivizi foarte apropiaŃi (de
exemplu, membri unei familii sau colegi de serviciu care folosesc aceeaşi
imprimantă sau cooperează în mod direct prin partajarea unor fişiere comune
dintr-un intranet local) şi până la indivizi care nu se cunosc între ei şi nici nu
intră vreodată în contact (de exemplu, utilizatorii unor motoare de căutare pe
Internet).
În cadrul partajării resurselor într-un sistem distribuit denumirea de
serviciu este considerată ca o parte distinctă a unui sistem care face
managementul unei colecŃii de resurse asemănătoare şi face publică
funcŃionalitatea lor utilizatorilor şi aplicaŃiilor care apelează la ele. Dacă, de
exemplu invocăm un fişier partajat cu ajutorul unui serviciu pentru fişiere,
accesul se face de fapt printr-o serie de operaŃii: read, write, delete.
Termenul de server se referă la un program care rulează (proces) pe un
computer dintr-o reŃea şi care acceptă cereri de la computere din reŃea, iar cei
care trimit cereri poartă numele de clienŃi, funcŃionalitatea fiind asigurată prin
protocolul client/ server.
Într-un sistem distribuit care este modelat prin folosirea programării
orientate obiect, resursele pot fi încapsulate ca obiecte şi pot fi accesate de aşa
numiŃii client object prin cererea unei metode de la server object. Din punct de vedere al structurii hardware şi a tipului de conexiune, sistemele care cuprind mai multe procesoare pot fi:
• puternic cuplate (conectate la nivel de memorie, de exemplu multiprocesoare, clustere);
• slab cuplate (conectate la nivel de reŃea de calculatoare, de exemplu, multicalculatoare, griduri).
Sistemele puternic cuplate sunt sisteme în care mai multe procesoare partajează aceeaşi memorie internă şi folosesc acelaşi ceas intern. De exemplu, sistemele din clasa MIMD sunt sisteme puternic cuplate (multiprocesoarele şi calculatoarele paralele masive).
Sistemele slab cuplate sunt sisteme în care fiecare procesor are propria memorie şi propriul ceas intern (grid).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 14
Sistemele informatice distribuite se împart în două clase: • sisteme informatice distribuite omogene (bazate pe multiplicarea unor
resurse identice, de exemplu unele multiprocesoare, MPP sau unele clustere);
• sisteme informatice distribuite eterogene (neomogene), de exemplu reŃeaua Internet, unele clustere, un sistem grid etc. În practică se întâlnesc cel mai frecvent sistemele distribuite eterogene
(neomogene) formate în general din componente eterogene: • hardware local neomogen: echipamentele electrice şi electronice fizice
diferite, • software local neomogen: programele de reŃea şi procese care
formează sistemul distribuit sunt făcute în diverse limbaje de programare, sistemele de operare din nodurile reŃelei pot fi diferite etc.;
• componente conceptuale neomogene: topologia reŃelelor care intră în alcătuirea sistemului distribuit, modul de comunicare, sincronizare şi coordonare între procese etc.
1.1.2. Caracteristici şi avantaje specifice ale sistemelor distribuite
Din modul de definire a sistemelor distribuite rezultă câteva
caracteristici de bază ale lor: • concurenŃa: se poate lucra simultan pe diferite computere din reŃea,
eventual partajându-se aceleaşi resurse (pagini web, fişiere, etc.); • lipsa unui ceas global: există limite în ceea ce priveşte capacitatea
computerelor din reŃea de a-şi sincroniza ceasurile interne; • rezistenŃa la erori: un defect în reŃea poate duce la izolarea unor
computere, însă reŃeaua va funcŃiona în continuare şi de obicei programele care vor rula pe nodul deconectat nu vor detecta că a fost întreruptă conexiunea sau că aceasta a devenit neobişnuit de înceată, ba mai mult, nici celelalte noduri din sistem nu vor sesiza imediat că unul din noduri a căzut.
Proiectarea şi utilizarea sistemelor informatice distribuite este argumentată
de câteva avantaje specifice sistemelor distribuite: • Facilitatea schimbului de informaŃii: creşterea exponenŃială a
cantităŃii de informaŃie şi necesitatea de a schimba rapid informaŃii între diferitele puncte aflate în locuri geografice depărtate fac necesară conectarea între calculatoare autonome. Sistemele distribuite oferă facilităŃi de comunicare la distanŃă: un sistem distribuit reprezintă un mijloc eficient şi comod de comunicare a unor informaŃii la distanŃă, de

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
15
exemplu aplicaŃia Internet, prin intermediul căreia se poate realiza comunicarea şi corespondenŃa electronică între indivizi aflaŃi în locuri diferite (email, chat, forum), cu condiŃia ca expeditorul şi destinatarul să se găsească într-o reŃea conectată la Internet.
• Partajarea resurselor scumpe: o organizaŃie preferă să cumpere mai multe calculatoare mai ieftine şi de puteri rezonabile în loc să cumpere unul performant şi scump. Prin interconectarea acestor calculatoare mai mici între ele, eventual cu un număr redus de calculatoare mai puternice ale căror resurse (memorie, putere a procesorului, periferice de capacităŃi mari) să fie partajate între acestea; costul măririi capacităŃii unei astfel de reŃele este mult mai mic decât în cazul resurselor conectate la un singur calculator, fie el cât de performant;
• Fiabilitate mărită în funcŃionare: dacă un sistem de calcul este format dintr-un singur calculator, defectarea acestuia face imposibilă utilizarea întregului sistem. La proiectarea unui sistem distribuit trebuie să Ńinem seama de siguranŃa în funcŃionare a acestuia, astfel încât căderea unui nod să nu perturbe funcŃionarea sistemului în ansamblu, ci alte noduri vor prelua sarcinile nodului căzut. Într-un sistem distribuit avem această posibilitate datorită faptului că aplicaŃiile care se rulează într-un sistem distribuit sunt astfel concepute încât ele să nu sufere din cauza nefuncŃionării corecte sau deloc a unor componente, respectiv procese.
• Creşterea performanŃei prin paralelizarea calculului: existenŃa mai multor procesoare într-un sistem distribuit face posibilă reducerea timpului de realizare a unui calcul laborios prin împărŃirea sarcinilor între diferite procesoare, colectarea ulterioară a rezultatelor parŃiale şi determinarea rezultatului final (acest procedeu este cunoscut sub numele de paralelizare a calculului). Deci, se obŃine timp de execuŃie redus pentru aplicaŃii paralele sau susceptibile de paralelizare;
• Specializarea nodurilor: proiectarea unui sistem de calcul autonom cu funcŃionalităŃi multiple este destul de dificilă. Din motive practice; la proiectare sistemul se împarte în module, fiecare modul implementând o parte din funcŃionalităŃi şi comunicând cu alte module;
• Scalabilitatea sau extensibilitatea: un sistem distribuit poate fi modificat relativ uşor prin adăugarea sau îndepărtarea unor noduri; Dintre principale dezavantaje putem aminti:
• exploatarea permanentă a unor vulnerabilităŃi privind securitatea de către persoane răuvoitoare care lansează atacuri, programe maliŃioase, troieni, viruşi etc.;
• dependenŃa utilizatorilor de furnizorii de servicii.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 16
Dificultatea construirii unor astfel de sisteme apare în momentul elaborării algoritmilor de prelucrare ce sunt folosiŃi în sistemele distribuite. Algoritmii utilizaŃi în sistemele distribuite, pe lângă faptul trebuie să fie corecŃi, flexibili şi eficienŃi, trebuie să Ńină cont de resursele care pot fi puse să lucreze în paralel şi de modul de comunicare între acestea. Dezvoltarea unui algoritm distribuit diferă esenŃial faŃă de dezvoltarea unui algoritm centralizat, mai ales datorită particularităŃii sistemelor distribuite, cum ar fi lipsa informaŃiilor despre starea globală, lipsa unui timp global, nedeterminismul etc.
1.1.3. Midlleware
Majoritatea sistemelor informatice actuale sunt sisteme deschise neomogene (eterogene), ale căror date si aplicaŃii coexistă pe platforme hardware şi software neomogene. Cu toate precauŃiile producătorilor de hardware şi software de a respecta anumite cerinŃe generale pentru a facilita comunicarea între aceste platforme, este evident că sunt necesare o serie de programe de translatare de la o platformă hardware sau software la alta. Acest lucru se face cu ajutorul unor programe intermediare sau midlleware (middle - de mijloc, intermediar, în limba engleză).
Conceptul midlleware joacă un rol esenŃial în sistemele informatice distribuite eterogene. Aceste programe de traducere/ translatare trebuie să îndeplinească o condiŃie esenŃială: transparenŃa pentru utilizator.
Se poate utiliza middlware orientat pe obiecte, care permite programatorului să creeze un model orientat pe obiecte al unei întreprinderi şi apoi să scrie aplicaŃiile care cer informaŃii din obiecte şi nu din anumite surse de date. Cererea este coordonată de un Object Request Broker (ORB), adică un intermediar de cereri orientat pe obiecte, care reprezintă un middleware.
Middleware-ul de aplicaŃie execută operaŃiile de detaliu privind conexiunea dintre diferitele platforme hardware şi software care trebuie să comunice între ele pentru a satisface cererile utilizatorului.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
17
1.2. CerinŃe în proiectarea unui sistem informatic distribuit
1.2.1. Eterogenitatea
1.2.2. Scalabilitatea
1.2.3. Securitatea
1.2.4. Tratarea erorilor
1.2.5. Deschiderea
1.2.6. ConcurenŃa
1.2.7. TransparenŃa
1.2.1. Eterogenitatea
Această caracteristică a sistemelor informatice distribuite se manifestă
la diverse nivele. Un sistem distribuit de tip intranet poate fi format din
calculatoare eterogene. La rândul său, Internetul este compus din conectarea
unor intraneturi şi calculatoare eterogene, dar diferenŃele dintre ele sunt ascunse
de faptul că se utilizează pentru comunicare aceleaşi protocoale. La nivel de
hardware, tipurile de date, cum ar fi întregii, de exemplu, au o reprezentare
diferită în funcŃie de tipul de procesor folosit. De asemenea, la sistemele de
operare, modul cum se face de pildă schimbul de mesaje în UNIX este diferit de
modul cum se face schimbul de mesaje în Windows. Eterogenitatea apare şi la
utilizarea limbajelor de programare şi aplicaŃiilor diferite utilizate de diverşi
utilizatori.
Pentru mascarea eterogenităŃii la nivelurile amintite mai sus se
utilizează conceptul de arhitectură distribuită middleware, cele mai
reprezentative fiind:
• CORBA (Common Object Request Broker Architecture);
• DCE (Distributed Computing Environment);
• DCOM (Distributed Component Object);
• Java RMI (Remote Method Invocation).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 18
CORBA este un cadru standard de dezvoltare a aplicaŃiilor distribuite în medii eterogene, la elaborarea căruia au participat toate marile companii de soft, cu excepŃia Microsoft care şi-a făcut produsul propriu DCOM, în care un sistem distribuit este alcătuit din "clienŃi" ce utilizează diferite obiecte distribuite. Datorită diverselor modalităŃi de comportare a obiectelor în sisteme de operare diferite, CORBA lucrează cu noŃiunea de "server" (fiecare obiect este asociat unui server). Rolul acestuia este de a include implementarea obiectelor asociate, modelul impunând doar invocarea de către clienŃi a obiectelor de pe server şi nu a serverului însuşi.
DCOM (Distributed Component Object) este soluŃia oferită de Microsoft, similară cu CORBA, pentru platforme Windows. Acesta permite un sistem de transmitere a mesajelor. Un model de comunicare între obiecte COM (Component Object Model), un model de document compus OLE (Object Linking and Embedding), cu servicii de comunicare între documente şi gestiunea lor, ActiveX- pentru aplicaŃii Web.
DCE (Distributed Computing Environment) este promovat de către OSF (Open Software Foundation). FacilitaŃi oferite: thread-uri, apeluri de procedură la distanŃă, servicii de directoare. Există un standard gateway între DCE şi CORBA prin care CORBA poate lucra peste DCE (protocolul DCE CIOP). DiferenŃa dintre DCE si CORBA constă în stilurile de programare adoptate: CORBA foloseşte un model obiectual, DCE are la bază un model procedural în care se folosesc apeluri la distanŃă (RPC - Remote Procedure Call).
Java RMI (Remote Method Invocation) a fost dezvoltată de Sun Microsystem. InterfaŃa de programare Java RMI se calează perfect pe modelul orientat obiect oferit de Java, unde se pot crea obiecte ale căror metode pot fi invocate din alte maşini virtuale. Aici intervine conceptul de cod mobil, ce desemnează codul care poate fi trimis de pe o maşina pe alta şi rulează la destinaŃie (de exemplu apleturile Java). Pentru a putea rula este nevoie de existenŃa unei maşini virtuale.
RelaŃia între Java RMI şi CORBA este mai mult una de complementaritate decât de concurenŃă, însă se poate vorbi de o adevărată rivalitate între Java/CORBA pe de o parte şi DCOM, pe de altă parte.
1.2.2. Scalabilitatea
Scalabilitatea a fost introdusă la început pentru compararea sistemelor
paralele. În această accepŃiune scalabilitatea înseamnă modificarea liniară a
performanŃelor unui sistem, adică nu se produce o modificare semnificativă a

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
19
performanŃelor odată cu modificarea numărului sau calităŃii resurselor instalate
(număr de procesoare sau procesoare mai rapide, capacitatea memoriei etc.). Un
calculator paralel de tip multiprocesor cu memorie comună asigură
scalabilitatea numai până la aproximativ 30 de procesoare. În plus, costurile
sistemelor paralele sunt prea mari raportate la ciclul de viaŃă, motiv pentru
interesul s-a deplasat spre sisteme distribuite eterogene, formate din colecŃii de
PC-uri, staŃii de lucru, supercalculatoare, multiprocesoare, MPP (Masssively
Parallel Processors) şi reŃele de calculatoare.
Vom considera că un sistem distribuit eterogen este scalabil, dacă
funcŃionarea sa nu este afectată atunci când se modifică semnificativ numărul şi
tipul de resurse, precum şi numărul de utilizatori.
Deşi numărul de utilizatori de Internet creşte drastic în fiecare an, totuşi
sistemul distribuit şi eterogen Internet rămâne scalabil.
Din punctul de vedere al programării, marele avantaj al scalabilităŃii este
următorul: creşterea în timp a complexităŃii unei aplicaŃii sau mărirea
dimensiunii sale nu prezintă nici o problemă pentru programator, dacă sistemul
pe care se execută este scalabil. Pentru ca un sistem distribuit să fie scalabil, la proiectarea sa trebuie
găsite soluŃii la probleme ca: • controlul costului resurselor fizice: pentru ca un sistem cu n utilizatori
să fie scalabil, cantitatea de resurse fizice trebuie să fie în jur de O(n); • controlul pierderii performanŃelor: creşterea dimensiunii duce în
general la scăderea performanŃelor, deci trebuie găsite soluŃii pentru ca această scădere să fie semnificativă ;
• prevenirea căderii resurselor software; • evitarea strangulărilor: un exemplu de strangulare se întâlnea la
predecesorul DNS-ului actual când tabelul era Ńinut într-un singur fişier master care putea fi downloadat de oricine avea nevoie, dar situaŃia s-a complicat când numărul de computere din reŃea a început să crească.
Rezolvarea problemei scalabilităŃii este una foarte importantă şi dificilă
în domeniul sistemelor distribuite. În mod ideal un sistem nu ar trebui modificat
atunci când numărul de utilizatori sau de resurse cresc, dar acest lucru este greu
de realizat. Ca soluŃii de ameliorare a scalabilităŃii s-au propus: replicarea
datelor, tehnici de cashing, crearea de taskuri similare care sa funcŃioneze

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 20
concurent, crearea de servere care să conlucreze pentru rezolvarea anumitor
taskuri etc.
1.2.3. Securitatea Există trei concepte fundamentale de securitate a informaŃiei: 1. Atac de securitate: orice acŃiune care poate compromite securitatea
informaŃiilor dintr-un sistem; 2. Mecanism de securitate: mijloc pentru detectarea şi prevenirea
atacurilor de securitate; 3. Serviciu de securitate: monitorizează atacurile şi declanşează
mecanismele de securitate adecvate.
Principalele atacuri de securitate, pasive sau active, asupra unui sistem informatic distribuit (în special în reŃelele de calculatoare) sunt:
1. Întreruperea: un element al sistemului este scos din uz (distrugerea unei piese hardware sau compromiterea unei linii de comunicaŃie); 2. IntercepŃia: o entitate neautorizată (o persoană sau un program) are acces în sistem, putând captura date sau copia fişiere şi programe; 3. Modificarea: o entitate neautorizată poate modifica conŃinutul mesajelor transmise sau poate schimba date în fişiere; 4. Falsificarea: o entitate neautorizată poate să însereze mesaje false în reŃea sau să adauge înregistrări false în fişierele de date. Atacurile pasive dintr-o reŃea de calculatoare doar spionează (studiază şi monitorizează) activitatea din sistem, fără a face modificări asupra fişierelor sau a mesajelor transmise şi din acest motiv sunt foarte greu de depistat.
Se cunosc două tipuri de atacuri pasive: • atacuri care interceptează conŃinutul mesajelor transmise în reŃea, • atacuri care analizează traficul în reŃea, putând determina locaŃiile sursei
şi destinatarului, frecvenŃa şi lungimea mesajelor etc. Atacurile active pot fi de grupate în patru categorii: • Mascarada: o entitate se prezintă ca fiind o altă entitate, de exemplu o
entitate cu drepturi mai puŃine în sistem poate să pretindă că este o alta cu mai multe privilegii;
• Retransmiterea: după capturarea pasivă a datelor, acestea sunt retransmise pentru a produce un efect neautorizat;
• Modificarea mesajelor: porŃiunea unui mesaj poate fi modificată astfel încât să producă efecte de modificare a autorizării iniŃiale, de exemplu, mesajul „se permite lui Dorin Ifrim să citească fişierul

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
21
confidenŃial accounts”, se poate modifica în „se permite lui Dan Ivan să citească fişierul confidenŃial accounts”;
• Refuzul de servicii (denial of service): o entitate neautorizată poate suspenda drepturile de acces a unei alte entităŃi autorizate sau poate supraîncărca reŃeaua cu mesaje de bruiaj, scăzându-i astfel performanŃele.
Serviciile de securitate a unei resurse (computer, bază de date, fişier,
imprimantă etc.) aflate într-un sistem distribuit vizează următoarele aspecte: • ConfidenŃialitatea: protecŃia datelor împotriva atacurilor pasive (de la
protecŃia fizică la algoritmi matematici); • Controlul accesului: dreptul de acces la resursă doar pentru utilizatorii
autorizaŃi pe bază de username şi parolă şi protecŃie împotriva accesului neautorizat;
• Integritatea: protecŃie împotriva manipulării de date (alterării sau coruperii) resursei prin programe maliŃioase lansate de o entitate neautorizată;
• Disponibilitatea: protecŃie împotriva interferenŃelor atunci când se doreşte accesarea unei resurse la care avem drept de utilizare şi asigurarea că datele, aplicaŃiile sau programele sunt întotdeauna disponibile pentru entităŃile autorizate;
• Autenticitatea: două entităŃi se pot identifica una pe alta prin asigurarea la iniŃierea comunicaŃiei că cele două entităŃi sunt autentice şi protecŃia împotriva interferării unei a treia entităŃi neautorizate pe parcursul comunicaŃiei, care ar putea pretinde că este una din cele două entităŃi autorizate;
• Nerepudierea: previne ca nici o entitate să nu refuze recunoaşterea faptului că a beneficiat de un serviciu executat, de exemplu, când un mesaj este trimis, se poate demonstra de către destinatar că mesajul primit este cel trimis de emiŃător, respectiv emiŃătorul poate demonstra că destinatarul a primit mesajul trimis de emiŃător.
InformaŃii suplimentare despre securitatea datelor şi siguranŃa
comunicaŃiilor. ŞtiinŃa care se ocupă de studiul siguranŃei comunicaŃiilor se numeşte criptologie. Criptologia are două ramuri: • Criptografia: studiază algoritmii de criptare şi decriptare pentru
asigurarea secretizării şi autenticităŃii mesajelor (poate fi simetrică - cu cheie secretă sau asimetrică – cu chei publice);
• Criptanaliza: studiază spargerea cifrurilor pentru refacerea informaŃiilor.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 22
Mecanismele de securitate stabilite de OSI (Open System Interchange) sunt:
• Criptarea: se utilizează pentru asigurarea confidenŃialităŃii şi are rolul de a transforma datele, astfel încât să devină inteligibile numai de către entitatea autorizată;
• Mecanismul de semnătură digitală: are scopul de a confirma că datele au fost produse chiar de semnatar (cuprinde mecanismul pentru producerea semnăturii şi mecanismul pentru verificarea semnăturii);
• Mecanismul de integritate a datelor: este menit să asigure integritatea datelor în timpul transmisiei, adică asigurarea faptului că în timpul transmisiei datele nu pot fi şterse sau amestecate (la expediere, expeditorul adaugă o informaŃie adiŃională ce depinde numai de datele transmise, iar la recepŃie, receptorul generează aceeaşi informaŃie adiŃională şi o compară cu cea primită);
• Mecanismul de control al accesului: controlul accesului la resurse a entităŃilor prin mecanisme bazate pe una sau multe din următoarele instrumente: lista drepturilor de acces, parole, etichete de securitate, durata accesului, timpul de încercare a accesului, calea de încercare a
accesului;
• Mecanismul de autentificare a schimbului: constă în parole sau tehnici criptografice menite să dovedească identitatea entităŃilor (la expediere, expeditorul adaugă o informaŃie adiŃională ce depinde numai de datele transmise, iar la recepŃie, receptorul generează aceeaşi informaŃie adiŃională şi o compară cu cea primită);
• Mecanismul de control al rutării: informaŃiile sunt dirijate pe baza unui protocol prestabilit sau pe baza unuia dinamic pe rutele considerate mai sigure;
• Mecanismul de umplere artificială a traficului: ajută la protecŃia împotriva analizei traficului şi constă în una din următoarele procedee: generarea unui trafic fals, umplerea pachetelor de date transmise cu date redundante; transmiterea de pachete şi spre alte destinaŃii în afara celei vizate;
• Mecanismul de notariat: implică existenŃa unui mecanism de arbitraj, numit notar, în care au încredere toate entităŃile, cu scopul obŃinerii de garanŃii în privinŃa autenticităŃii şi integrităŃii.
Principalele soluŃii de securitate relativ la informaŃiile din Internet sunt:
• la nivel de reŃea: s-a dezvoltat o arhitectură de securitate la nivel de IP şi la nivel de protocolul TCP/IP (Transmision Control Protocol/ Internet Protocol);

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
23
• la nivel de sesiune: se foloseşte deseori protocolul SSL (Secure Sockets Layer), care oferă servicii de securitate chiar deasupra nivelului TCP, folosind criptosisteme cu chei publice şi secrete, astfel încât să asigure confidenŃialitatea, integritatea şi autenticitatea clientului sau serverului din sistem.
1.2.4. Tratarea erorilor
Un procesor/computer din reŃea poate eşua în mod independent de
celelalte. De aceea fiecare componentă din sistem trebuie să Ńină cont de faptul
că o altă componentă de care depinde poate eşua şi să fie capabilă să găsească o
soluŃie în caz de avarie. Iată câteva tehnici folosite pentru tratarea erorilor: 1. Detectarea erorilor (care pot fi detectate). De exemplu, utilizarea
sumei de control poate fi folosită pentru a verifica dacă nişte date au fost corupte. Sunt şi erori care sunt greu de detectat, de exemplu căderea la distanŃă a unui server, marea provocare fiind de a găsi soluŃii în cazul de erori care nu pot fi detectate cu precizie, ci doar suspectate.
2. Mascarea erorilor (unele erori care pot fi detectate pot fi ascunse sau găsite soluŃii de ameliorare a lor). Exemplu de situaŃii de ascundere a erorilor : un mesaj poate fi retransmis atunci când transmisia sa a eşuat; unui fişier i se poate păstra o copie pe un alt suport şi dacă o variantă a fost coruptă se poate folosi varianta buna pusă la păstrare.
3. ToleranŃa la erori. De exemplu, un browser Web performant care nu poate intra în contact cu un server, informează utilizatorul asupra problemei şi nu îl face să aştepte indefinit.
4. Recuperarea datelor. Sistemul trebuie astfel proiectat încât datele să poată fi recuperate după ce serverul a căzut.
5. RedundanŃa. Serviciile dintr-un sistem distribuit trebuie să fie tolerante la erori prin folosirea unor tehnici de redundanŃă (multiplicare a datelor şi căilor de comunicare). De exemplu, între două rutere din Internet întotdeauna trebuie să existe minim două căi de acces diferite. În Domain Name Service (DNS), fiecare tabel se găseşte pe cel puŃin două servere diferite, o bază de date poate fi replicată pe mai multe servere (atunci când un server cade utilizatorul este redirectat către serverul care funcŃionează).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 24
1.2.5. Deschiderea
Termenul de deschidere (openness) este caracteristica unui sistem care
indică, dacă el poate fi extins şi implementat în moduri diferite. Deschiderea
pentru un sistem distribuit se referă în primul rând la disponibilitatea de
adăugare şi publicarea de noi servicii de partajare a resurselor (interfeŃele cărora
devin publice). Sistemele distribuite deschise sunt bazate pe asigurarea unui
mecanism uniform de comunicare şi publicare a interfeŃelor pentru accesul la
resursele partajate în mod transparent. Sistemele distribuite pot fi constituite din
entităŃi eterogene, dar trebuie să se asigure buna funcŃionare a acestora în cadrul
SD. Marea provocare a deschiderii constă în integrarea componentelor scrise de
utilizatori diferiŃi.
1.2.6 ConcurenŃa Într-un sistem distribuit există posibilitatea ca o aceeaşi resursă partajată
să poată fi accesată de mai mulŃi utilizatori simultan. O soluŃie limitativă şi greu
acceptabilă ar fi ca mecanismul care face managementul resursei să servească
numai câte un client odată. În general însă aplicaŃiile în sistemele distribuite
sunt construite pentru a putea deservi mai mulŃi clienŃi simultan
(multiprocessing, multitasking etc.). Pentru ca un obiect să fie sigur într-un
mediu concurent, operaŃiile asupra lui trebuie să poată fi sincronizate astfel
încât să avem date consistente pentru fiecare utilizator. Acest lucru se poate
obŃine prin tehnici standard de sincronizare, cum ar fi semafoarele.
1.2.7. TransparenŃa
Un sistem este transparent atunci când este perceput ca un întreg şi nu
ca o simplă colecŃie de componente independente şi eterogene.
Există mai multe tipuri de transparenŃă: 1. Acces transparent: permite ca resursele remote şi cele locale să poată
fi accesate prin aceleaşi operaŃii; 2. TransparenŃa localizării: face posibilă accesarea resurselor fără să se
ştie unde sunt localizate; 3. TransparenŃa concurenŃei: permite ca mai multe procese să opereze
concurent folosind resursele partajate fără să interfereze între ele;

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
25
4. TransparenŃa replicării: oferă posibilitatea ca mai multe instanŃe a unei resurse să poată fi folosite, mărindu-se astfel performanŃa şi robusteŃea;
5. TransparenŃa erorilor: facilitează ascunderea erorilor, permiŃând utilizatorilor să-şi rezolve task-ul chiar dacă apar erori software sau hardware;
6. Mobilitate transparentă: face posibilă mobilitatea resurselor şi a clienŃilor în SD fără să fie afectată operaŃionalitatea;
7. PerformanŃa transparentă: permite SD să poată fi reconfigurat pentru a-i se îmbunătăŃi performanŃele;
8. Scalabilitate transparentă: permite extinderea SD fără să fie nevoie de schimbarea structurii sistemului sau a algoritmilor folosiŃi.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 26
1.3. Exemple remarcabile de sisteme informatice distribuite
1.3.1. ReŃele de tip internet: SIPRNET, FidoNet, Internet 1.3.2. Intranet şi extranet 1.3.3. Nomadic computing şi ubiquitous computing 1.3.4. Internet2 1.3.5. PlanetLab
1.3.1. ReŃele de tip internet: SIPRNET, FidoNet, Internet
Cuvântul „internet” provine din concatenarea prescurtărilor a două cuvinte englezeşti, interconnected (interconectat) şi network (reŃea) şi desemnează o reŃea de mari dimensiuni formată prin interconectarea mai multor reŃele autonome eterogene.
Astfel, substantivul comun „internet” (cu minusculă) desemnează în general o reuniune de reŃele, văzută ca o reŃea unitară, împreună cu informaŃia şi serviciile care sunt oferite utilizatorilor prin intermediul acestei reŃele (Web, E-Mail, FTP etc.).
Exemple de reŃele mari de tip internet sunt • Secret Internet Protocol Router Network (SIPRNET), vezi http://www.fas.org/irp/program/disseminate/siprnet.htm; • FidoNet, vezi http://www.fidonet.org/ ; • Internet, vezi http://www.internet.com/ .
Cea mai mare, mai notorie şi uzuală dintre reŃele de tip internet la ora actuală (în 2006, dar lucrurile evoluează incredibil de rapid) este numită Internet (nume propriu, scris cu majusculă), adică super-reŃeaua mondială unică de computere, interconectate prin protocolul IP/TCP. Precursorul Internetului datează din 1965, când Defence Advanced Research Projects Agency (DARPA) din SUA a creat prima reŃea de computere interconectate sub numele Arpanet. Super-reŃeaua Internet de azi a rezultat din extinderea reŃelei Arpanet.
Atât Internetul sau The NET (ReŃeaua), cum i se mai spune în lume,
cât şi alte reŃele mai mici de tip internet sunt exemple de sisteme informatice distribuite.
Astfel, prin Internet multe resursele dint-o anumită locaŃie geografică pot fi partajate (exploatate în comun) de către utilizatori din cele mai diverse locuri geografice. De exemplu, varianta online a publicaŃiei International

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
27
Journal of Computers, Communications and Control (IJCCC), a cărui bază de date se află pe serverul UniversităŃii AGORA, la adresa www.journal.univagora.ro, este citită simultan de către cititori din România, SUA, India, China, Canada etc. De asemenea, oricine dispune de un nume de user şi o parolă pentru administrarea bazei de date a IJCCC, poate face modificări în aceasta bază de date de la orice computer din lume care este conectat la Internet.
Utilizând în Internet aplicaŃia distribuită WWW, putem deschide diverse pagini web, de exemplu pagina web a UniversităŃii „Babeş-Bolyai” din Cluj Napoca se află la adresa http://www.ubbcluj.ro/, iar a UniversităŃii Agora Oradea – la adresa http://www.univagora.ro.
1.3.2. Intranet şi extranet
Un alt exemplu de sistem distribuit (SD) este intranetul, care este o reŃea particulară cu aceleaşi principii de funcŃionare ca şi Internetul, dar cu acces restrâns, de exemplu intranetul sau intraneturile unei firme particulare.
Un intranet este o reŃea închisă sau o sub-reŃea dintr-un internet sau chiar din Internet care este administrată autonom şi pentru care exista un sistem de securitate local. Un intranet poate fi format din mai multe reŃele de tip Local Area Network (LAN), legate între ele prin anumite sisteme de comutare. Un intranet poate fi conectat la Internet printr-un router , care permite utilizatorilor din intranet să utilizeze servicii ca Web, FTP sau EMAIL. De asemenea permite utilizatorilor din exterior (din Internet) să acceseze servicii pe care le pune eventual la dispoziŃie intranetul. Pentru a se proteja de diferite atacuri maliŃioase, sunt utilizate soft-uri de tip firewall, care previn utilizatorul că anumite mesaje neautorizate încearcă să intre sau să plece. Un firewall este implementat să filtreze anumite mesaje conform unor criterii, de exemplu el permite trecerea doar a mesajelor legate de poşta electronică.
Tot mai multe organizaŃii investesc în intranet şi în diverse sisteme informatice/informaŃionale integrate, de tip ERP (Enterprise Planning Resource) sau sisteme expert pentru asistarea deciziei. Într-o bază de date comună şi unică se găsesc toate informaŃiile necesare angajaŃilor şi managerilor, unele fiind disponibile şi partenerilor sau chiar publice. Există organizaŃii care din motive de securitate, pentru a preveni spionajul prin mijloace informatice, nu doresc conectarea intraneturilor lor la Internet (anumite organizaŃii militare, unele centre de cercetare, etc).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 28
Extranetul este un intranet particular al unei firme, la care însă au acces limitat şi anumite persoane sau grupuri din exterior, din alte firme, ca de exemplu de la firme-furnizor sau firme-client.
1.3.3. Nomadic computing şi ubiquitous computing
În lumea sistemelor informatice distribuite un rol deosebit îl au în
prezent dispozitivele miniaturizate şi reŃelele wireless. De exemplu, cu ajutorul unui laptop sau chiar a telefonului mobil, printr-o conexiune de tip wireless ne putem conecta aproape de pretutindeni la intranetul „home” şi putem utiliza resursele de acolo (de pe calculatorul de acasă sau de la serviciu). Putem vorbi astfel de un calcul mobil (nomadic computing).
Ubiquitous computing promovează ideea aparent opusă, „computere omniprezente”, adică să existe computere conectate la internet în locuri în care există indivizi obligaŃi să stea un timp mai lung sau mai scurt (imobilizaŃi acasă sau în spitale, în staŃiuni turistice, în gări şi aeroporturi etc.), pe care indivizii le pot accesa pentru a comunica sau pentru a accesa anumite informaŃii din exterior. De exemplu, de la calculatorul de acasă conectat la Internet, putem accesa diverse informaŃii de la serviciu sau putem citi presa din Bucureşti sau Londra, sau putem coresponda prin email sau online cu orice persoană din lume care dispune de aceleaşi facilităŃi. În afară de laptopuri şi de telefoanele mobile performante, amintim imprimantele inteligente, ceasurile inteligente, PDA (Personal Digital Assistant), camere video digitale, iPOD-uri, care contribuie la dezvoltarea tot mai expansivă a calculului nomadic.
1.3.4. Internet2
Sursa: http://www.internet2.edu/
Internet2 este cel mai avansat consorŃiu de networking din SUA organizat pe principiul non-profit. ÎnfiinŃat de comunitatea de cercetare şi educaŃie începând cu anul 1996, Internet2 are în vedere dezvoltarea de aplicaŃii şi tehnologii de reŃea avansate, cu scopul de a accelera modernizarea Internetului şi utilizarea tehnologiilor sale revoluŃionare.
În afară de implicarea a peste 200 de universităŃi din SUA, Internet2 promovează colaborarea cu peste 70 mari corporaŃii (Microsoft, IBM, CISCO, SUN, ...) şi organizaŃii, precum şi 45 organizaŃii guvernamentale americane (laboratoare de cercetare, departamente guvernamentale etc.). De asemenea, la acest proiect colaborează peste 50 de parteneri din afara graniŃelor SUA.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
29
Din punct de vedere practic, Internet2 nu este o reŃea fizică separată şi această reŃea nu-şi propune să înlocuiască omniprezentul Internet. Ideea pe care se merge este că pe platforma Internet existentă deja, prin colaborarea universităŃilor, institutelor de cercetare şi companiilor să se accelereze procesul de dezvoltare de noi tehnologii şi aplicaŃii. Pare incredibil, dar prin Internet2 se ating viteze de transfer de 20.000 de ori mai mari decât printr-o conexiune tradiŃională dial-up! Experimentele efectuate au demonstrat că, de exemplu, o copie a DVD-ului cu filmul „The Matrix” poate fi downloadată în aproximativ 30 de secunde utilizând Internet2, proces care pe Internet la o conexiune de viteză medie ar putea dura circa 15-20 de ore.
În ce măsura vor fi avantajaŃi utilizatorii casnici de facilităŃile pe care le oferă sau le va oferi Internet2? La începuturile sale, Internetul avea doar câteva mii de utilizatori, fiind axat pe interconectare între super-calculatoare, acces de la distanŃă şi transfer de fişiere. Azi există sute de milioane de utilizatori, iar serviciile principale utilizate sunt e-mailul, chatul, transmisii video şi tehnologii P2P sau VoIP. În viitor se aşteaptă creşterea drastică a numărului de utilizatori şi a dispozitivelor dedicate, convergenŃa aplicaŃiilor multimedia: chat, telefonie, video-conferinŃe sau HDTV (High-Definition TeleVision).
Cine se conectează la Internet2? Evident că deocamdată universităŃile, organizaŃiile şi cei care au acces la aceasta reŃea ca parteneri în consorŃiu. Dacă dorim să aflăm, dacă computerul nostru este conectat la Internet2, se poate afla acest lucru fără dificultate folosind un applet Java de la adresa http://detective.internet2.edu/applet/index.html.
1.3.5. PlanetLab
Sursa: http://www.planet-lab.org/
PlanetLab era la sfârşitul anului 2006 format dintr-o reŃea de 723 maşini distribuite pe tot globul, fiind găzduit de 353 situri, de pe cuprinsul a peste 25 de Ńări. Majoritatea maşinilor este găzduită de institute de cercetare, deşi unele din ele sunt găzduite în co-locaŃie şi cu diverse centre de rutare (cum ar fi Internet2 Abilene backbone). Toate maşinile sunt conectate la Internet, Ńinta PlanetLab fiind de a creşte la peste 1000 numărul nodurilor în majoritatea dintre importantele zone regionale ale backbonurilor de Internet.
PlanetLab are mai multe aspecte, despre care se pot afla mai multe informaŃii citind următoarele două articole, care se pot descărca de pe pagina oficială a PlanetLab: http://www.planet-lab.org/:

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 30
• [PAC+02] : Larry Peterson, Tom Anderson, David Culler, and Timothy Roscoe, A Blueprint for Introducing Disruptive Technology into the Internet, Proceedings of the First ACM Workshop on Hot Topics in
Networking (HotNets), October 2002.
• [BBC+04]: Andy Bavier, Mic Bowman, Brent Chun, David Culler, Scott Karlin, Steve Muir, Larry Peterson, Timothy Roscoe, Tammo Spalink, and Mike Wawrzoniak, Operating System Support for Planetary-Scale Services, Proceedings of the First Symposium on Network Systems Design and Implementation (NSDI), March 2004.
Primul din aceste articole prezintă viziunea iniŃială despre PlanetLab, iar al doilea descrie principiile de organizare şi arhitectura sa. Mai multe informaŃii se pot afla citind PlanetLab Design Notes (PDNs), care se pot descărca de la pagina http://www.planet-lab.org/PDN/.
PlanetLab este o reŃea de servicii de calcul şi o bază de testare deschisă şi globală pentru dezvoltarea noilor tehnologii Internet. După cum vom prezenta mai jos, cele mai importante centre de cercetare şi universităŃi din lume sunt deja membre ale PlanetLab, inclusiv: AT&T Labs, Cambridge University, France Telecom, HP, NEC Labs, Princeton University, UC Berkeley, alături de centre educaŃionale din Brazilia, Canada, China şi organizaŃia Internet2.
În 2004, Intel Corporation a descris schimbările semnificative care ar trebui implementate pentru ca infrastructura Internetului să devină mai sigură, mai fiabilă, mai eficientă şi mai accesibilă. Vicepreşedintele senior al Intel, Pat Gelsinger, a afirmat că prin adăugarea la Internet a unei reŃele de servicii care conŃine resurse de calcul şi stocare, industria poate adăuga un plus de inteligenŃă în şi de-a lungul reŃelei nucleu. Acest lucru ar transforma Internetul într-o vastă platforma care găzduieşte servicii disponibile celor peste şase miliarde de locuitori ai Terrei.
Gelsinger s-a referit la posibilitatea de a oferi servicii pe scară mondiala a Internetului, care să detecteze şi să alarmeze în legătură cu atacurile viruşilor, să redirecŃioneze traficul reŃelei pentru a se evita nodurile lente, pentru a uşura accesul utilizatorilor din regiunile în care furnizarea electricităŃii lipseşte sau nu este de calitate. Gelsinger a apelat la industria si potenŃialii utilizatori ai serviciului pe scară planetară să ajute la crearea unui Internet mai „deştept” prin alăturarea la PlanetLab Consortium.
În sublinierea provocărilor de a îmbunătăŃi serviciile Internetului, lui Pat Gelsinger i s-a alăturat şi „părintele Internetului” Vint Cerf, vicepreşedinte senior al strategiei tehnologice MCI. Pentru a oferi serviciile Internetului miliardelor de noi utilizatori, cercetătorii industriali propun o nouă generaŃie de dispozitive operate de baterii la preŃuri reduse care pot fi folosite în regiuni

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
31
defavorizate, unde nu se pot folosi calculatoarele tradiŃionale datorită lipsei de electricitate. S-a descris modul în care serviciile la scară globală ar putea ajuta aceşti utilizatori prin suportul a noi tipuri de conexiuni şi stocare „in-network”, care pot opri întreruperile şi întârzierile în tranzacŃii. Un alt serviciu inteligent propus ar fi trans-codarea, adică capacitatea reŃelei de a converti de a lungul reŃelei conŃinutul într-o forma potrivită diverselor dispozitive.
Următoarele instituŃii găzduiau la sfârşitul anului 2006 sau îşi propuneau să găzduiască în viitor noduri aparŃinând PlanetLab, cf. http://www.planet-lab.org/php/institutions.php :
1. Academia Sinica – Taiwan 2. ADETTI/ISCTE 3. American University of Beirut 4. Architecture Technology 5. AT&T Labs—Research 6. Bar-Ilan University 7. BeiHang University 8. Beijing Institute of Technology,
Intelligent Information Network Lab
9. Ben-Gurion University of the Negev
10. Birkbeck University of London 11. Boston University 12. Brigham Young University 13. California Institute of Technology 14. CANARIE 15. Canarie – Calgary 16. Canarie – Halifax 17. Canarie – Montreal 18. Canarie – Ottawa 19. Canarie – Toronto 20. Canarie – Winnipeg 21. Carnegie Mellon University 22. Case Western Reserve University 23. Centre for Development of
Advanced Computing 24. CERNET - Fudan University 25. Centro Nacional de Calculo
Cientifico Universidad de Los Andes
26. CERNET - Harbin Institude of Technology
27. CERNET - Huazhong University of Science & Technology
28. CERNET - Jilin University 29. CERNET 30. CERNET - Beihang University 31. CERNET - Beijing Jiao Tong
University 32. CERNET - Beijing University of
Posts and Telecommunications 33. CERNET - Central South
University 34. CERNET - Chongqing University 35. CERNET - Dalian University of
Technology 36. CERNET - Lanzhou University 37. CERNET-MSR Joint Lab,
Tsinghua University 38. CERNET - Northeast University 39. CERNET - Peiking University 40. CERNET - Shandong University 41. CERNET - Shanghai Jiao Tong
University 42. CERNET - South China
University of Technology 43. CERNET - Southeast University 44. CERNET - Tianjin University 45. CERNET - Tongji University 46. CERNET - Tsinghua University 47. CERNET - University of
Electronic Science & Technology of China

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 32
48. CERNET - University of Science & Technology of China
49. CERNET - Xiamen University 50. CERNET - XiAn Jiao Tong
University 51. CERNET - Zhejiang University 52. CERNET - Zhengzhou Univeristy 53. CESNET - Czech Education and
Research Network 54. Chinese Academy of Sciences,
Computer Network Information Center
55. Chinese University of Hong Kong 56. Chungnam National University 57. City College of the City
University of New York 58. Collegium Budapest 59. Colorado State University 60. Columbia University 61. Cornell University 62. CSLab - Institute of
Communication and Computer Systems of National Technical University of Athens
63. Darmstadt University of Technology
64. Dartmouth College, Computer Science
65. Datalogisk Institut Copenhagen 66. Delft University of Technology 67. Department of Electrical
Engineering, National Taiwan University
68. DePaul University 69. Dept. of Computer Science,
National Chengchi University 70. Dipartimento di Informatica di
Torino 71. Duke University 72. Ecole Nationale Superieure des
Telecommunications 73. ERNET India 74. ETH Zuerich
75. Eurecom Institute 76. Forschungsgemeinschaft
elektronische Medien e.V. (FeM)
77. France Telecom R&D 78. France Telecom R&D Lannion 79. Fraunhofer-Institute for
Telecommunications - Heinrich-Hertz-Institut
80. Fraunhofer Institut fur Techno- und Wirtschaftsmathematik
81. Friedrich-Alexander University Erlangen-Nuremberg
82. Fu Jen Catholic University 83. George Mason University 84. Georgetown University 85. Georgia Institute of Technology 86. GIST 87. Google 88. Haifa University 89. Harvard University 90. Helsinki Institute for
Information Technology 91. Helsinki Institute of Physics 92. Howard University 93. HP Brazil - RandD 94. HP Labs 95. HP Labs, Bristol 96. HP Labs, Cambridge 97. HP Labs, Internet 2 98. IBBT - Ghent University 99. IIS, UniBw Munich 100. Illinois Institute of
Technology 101. Imperial College London -
ISN 102. Indiana University
(Bloomington) 103. Indian Institute of Information
Technology, Bangalore 104. Indian Institute Of
Technology Bombay

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
33
105. Indian Institute of Technology Delhi
106. Indian Institute of Technology Roorkee
107. Information and Communications University
108. INRIA Sophia Antipolis 109. Institute for Applied
Supercomputing, California State University San Bernardino
110. Instituto de Pesquisa Tecnologicas de São Paulo
111. Instituto Superior Tecnico 112. Inst. of Computer Science,
Foundation for Research and Technology - Hellas
113. Intel IT - Folsom 114. Intel Labs - Oregon 115. Intel – Leixlip 116. Intel - Nizhny Novgorod 117. Intel Research at Seattle 118. Intel Research Berkeley 119. Intel Research Pittsburgh 120. International University Bremen 121. Internet2 122. Internet2 - Atlanta 123. Internet2 - Chicago 124. Internet2 - Denver 125. Internet2 – Houston 126. Internet2 - Indianapolis 127. Internet2 - Kansas City 128. Internet2 - Los Angeles 129. Internet2 - New York 130. Internet2 - Seattle 131. Internet2 - Sunnyvale 132. Internet2 - Washington 133. Interxion – Frankfurt 134. Iowa State University Electrical
and Computer Engineering
135. ITEC, Klagenfurt University
136. Japan Advanced Institute of Science and Technology (JAIST)
137. Japan Gigabit Network II 138. Johns Hopkins CNDS 139. Johns Hopkins Information
Security Institute 140. KAIST 141. Kansas State University 142. Keio University 143. KREONET at KISTI-
DAEJON 144. Laboratoire d'Informatique
de Paris 6 145. Lancaster University 146. LARC - University of Sao
Paulo 147. Lawrence Berkeley
National Laboratory 148. Learning Lab Lower
Saxony (L3S) University of Hannover
149. Massachusetts Institute of Technology
150. Max Planck Institute for
Software Systems 151. McGill University 152. MCI GRID Lab 153. Michigan State University 154. Monash University - DSSE 155. Moscow Institute of
Physics and Technology 156. Moscow State University 157. Moscow State University,
Chemistry

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 34
158. Munich University of Technology
159. Nara Institute of Science and Technology, Graduate School of Information Science
160. National Institute of Information and Communications Technology
161. National Taiwan University, Department of Information Management
162. National Tsing Hua University 163. National University of
Singapore 164. NEC Laboratories 165. New York University 166. Nizhny Novgorod State
University 167. North Carolina AT State
University 168. North Carolina State
University 169. Northeastern University CCIS 170. Northwestern University at
Illinois 171. Ohio State University 172. Oklahoma State University
(Tulsa) 173. Orbit 174. Oregon State University
School of Electrical Engineering and Computer Science
175. Packet Clearing House - San Francisco
176. Penn State University 177. PlanetLab Central 178. PlanetLab Colo - AMST 179. PlanetLab Colo - McLean, VA 180. PlanetLab Colo - NICT JGN2
Fukuoka
181. PlanetLab Colo - NICT JGN2 Hiroshima
182. PlanetLab Colo - NICT JGN2 Kochi
183. PlanetLab Colo - NICT JGN2 Nagoya
184. PlanetLab Colo - NICT JGN2 Okayama
185. PlanetLab Colo - NICT JGN2 Osaka
186. PlanetLab Colo - NICT JGN2 Sendai
187. PlanetLab Colo - Santa Clara
188. PlanetLab Colo - SJCE 189. PlanetLab Colo - Sterling,
VA 190. PlanetLab Colo - TP
Gdansk 191. PlanetLab Colo - TP
Piotrkow Trybunalski 192. PlanetLab Colo - TP Poznan 193. PlanetLab Colo - TP
Warsaw 194. Politecnico di Milano - Dip.
di Elettronica e Informazione 195. Politecnico di Torino 196. Polytechnic University 197. Princeton 198. Princeton - DSL 199. Public Broadcasting Service 200. Purdue 201. Queen Mary, University of
London 202. Rensselaer Polytechnic
Institute 203. Reykjavik University -
Network Laboratory 204. Rice University

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
35
205. RNP 206. RNP – Ceara 207. RNP - Rio de Janeiro 208. RNP - Rio Grande do Sul 209. Royal Institute of Technology
(KTH), Sweden 210. Rutgers University 211. RWTH Aachen 212. San Jose State University 213. Seoul National University 214. Simon Fraser University 215. Simula Research Laboratory 216. Singapore Advanced Research
and Education Network 217. Stanford University 218. Stevens Institute of Technology 219. Stony Brook University 220. Swedish Institute of Computer
Science 221. Swiss Federal Institute of
Technology Lausanne (EPFL) 222. SwRI/UT San Antonio 223. Technical University Ilmenau 224. Technical University of Madrid 225. Technion - Israel Institute of
Technology 226. Technische Universitaet
Dresden 227. Technische Universitat Berlin 228. Tel-Aviv University 229. Telecom Italia Learning
Services 230. Telecommunications Research
Laboratory 231. Telekomunikacja Polska R&D
at Krakow
232. Telekomunikacja Polska R&D at Olsztyn
233. Telekomunikacja Polska R&D at Piotrkow Trybunalski
234. Telekomunikacja Polska R&D at Swidnik
235. Telekomunikacja Polska R&D at Warsaw
236. Texas AM University 237. The Hebrew University of
Jerusalem 238. The Hong Kong University of
Science and Technology 239. The University of Hong Kong 240. Trinity College Dublin 241. UC Berkeley - DSL 242. UCLA - EE 243. UC Santa Cruz 244. Universidad Complutense de
Madrid 245. Universidade Federal de
Campina Grande - Laboratório de Sistemas Distribuídos
246. Universidade Federal de Minas Gerais
247. Università degli Studi di Napoli 248. Universita' di Roma 249. Universitat Politenica de
Catalunya 250. Universitat Rovira i Virgili 251. Universite catholique de
Louvain 252. Universite de Montreal 253. University College Dublin 254. University College London

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 36
255. University of Arizona 256. University of Basel, Switzerland 257. University of Bern, IAM 258. University of Bologna 259. University of British Columbia 260. University of Calgary 261. University of California at
Berkeley 262. University of California at Los
Angeles 263. University of California at San
Diego 264. University of California at Santa
Barbara 265. University of California, Davis 266. University of California, Irvine 267. University of California,
Riverside 268. University of Cambridge 269. University of Canterbury, New
Zealand 270. University of Central Florida -
EECS 271. University of Chicago 272. University of Cincinnati 273. University of Colorado at
Boulder 274. University of Connecticut 275. University of Cyprus 276. University of Delaware 277. University of Duisburg-Essen 278. University of Florida - ACIS
Lab 279. University of Georgia 280. University of Goettingen
281. University of Illinois at Urbana-Champaign
282. University of Ioannina 283. University of Kaiserslautern,
Germany 284. University of Kansas 285. University of Karlsruhe 286. University of Kent Computer
Science Dept, UK 287. University of Kentucky 288. University of Lisbon 289. University of Manchester, UK 290. University of Maryland 291. University of Massachusetts at
Amherst 292. University of Melbourne -
CSSE 293. University of Michigan 294. University of Minnesota 295. University of Missouri Kansas
City 296. University of Nebraska at
Kearney 297. University of Nebraska -
Lincoln 298. University of Neuchatel 299. University of New Brunswick 300. University of Newcastle 301. University of New Mexico 302. University of North Carolina at
Chapel Hill 303. University of North Carolina at
Charlotte 304. University of Notre Dame 305. University of Oregon 306. University of Osaka

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
37
307. University of Oslo 308. University of Passau 309. University of Pennsylvania 310. University of Pittsburgh 311. University of Puerto Rico at
Mayaguez 312. University of Puerto Rico, Rio
Piedras Campus 313. University of Rochester 314. University of Saskatchewan 315. University of Sevilla 316. University of Southern
California, ISI 317. University of South Florida
(CSE) 318. University of St. Andrews 319. University of Stirling 320. University of Sussex 321. University of Technology at
Sydney 322. University of Tennessee at
Knoxville 323. University of Texas at Arlington 324. University of Texas at El Paso 325. University of Texas at San
Antonio 326. University of Texas, Austin 327. University of Tokyo 328. University of Toronto 329. University of Toronto at
Mississauga 330. University of Tromso 331. University of Tuebingen 332. University of Utah
333. University of Utah - Emulab 334. University of Victoria 335. University of Virginia 336. University of Washington 337. University of Washington -
Accretive DSL 338. University of Waterloo 339. University of Wisconsin 340. University of Wuerzburg 341. University of Zurich, Institut fur
Informatik 342. Uppsala University at Sweden 343. Vanderbilt University 344. Vrije Universiteit 345. Warsaw University of
Technology 346. Washington State University 347. Washington University in St
Louis 348. Waterford Institute of
Technology 349. Wayne State University 350. WIDE Project 351. Wroclaw University of
Technology 352. Yonsei University

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 38
1.3.6. Cluster Clusterul este un tip de sistem distribuit ce permite calculul paralel,
format fizic dintr-o reŃea de cel puŃin două procesoare, numite staŃii de lucru (care pot fi calculatoare complete, PC-uri, supercalculatoare, calculatoarele vectoriale, multiprocesoare, MPP), care pot fi folosite şi de sine stătător, interconectate într-o reŃea, fiind utilizat ca o resursă de calcul integrată şi singulară. În practică se utilizează două tipuri de clustere: clustere dedicate (formate din procesoare omogene) şi clustere de întreprindere (formate din procesoare neomogene).
Un cluster are, în mod iluzoriu, pentru utilizator o imagine de sistem unic -SSI (Single System Image). Aceasta este impresia utilizatorului, că are acces la un sistem unic cu resurse multiplicate, cu control unic asigurat prin intermediul unei singure interfeŃe. Sistemul este simetric, în sensul că un serviciu poate fi solicitat de pe orice nod, iar accesul la resurse este transparent. Astfel, clusterul pare la fel de uşor de folosit ca un PC.
Elementele clusterului sunt văzute din afară ca fiind anonime şi interschimbabile.
Rolul principal într-un cluster îl joacă staŃiile de lucru, iar sistemele paralele din reŃea pot fi folosite ca nuclee de calcul foarte puternice în aplicaŃii de mare complexitate (fizica atomului, studiul genomului uman, meteorologie etc.).
Conceptul software corespunzător conceptului de cluster este domeniul de execuŃie, care reprezintă o maşină virtuală foarte puternică, are o evoluŃie dinamică în funcŃie de necesităŃi: se pot scoate sau introduce în orice moment staŃii de lucru, servere de baze de date, procesoare specializate etc.
Domeniul de execuŃie al unei aplicaŃii distribuite poate cuprinde unul sau mai multe clustere, iar pentru definirea sa se folosesc mai multe criterii:
• disponibilitatea resurselor şi estimarea încărcării; • caracteristicile aplicaŃiei (timp de execuŃie, raport
calcule/comunicaŃii, necesarul de resurse), • maparea grafului posibilităŃilor de execuŃie al aplicaŃiei pe graful
de comunicaŃii al domeniului de execuŃie; • condiŃii de performanŃă impuse (execuŃie în timp real - dacă este
cazul, toleranŃă la defecte, gradul de precizie etc.).
Elementele specifice ce diferenŃiază clusterul în cadrul soluŃiilor multi-calculator sunt: • fiecare nod este un calculator de sine stătător, cu un sistem de
operare propriu în general de tip Unix şi elemente software necesare managementului clusterului: comunicare, alocare de resurse,

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
39
echilibrarea încărcării, dar nu îi sunt neapărat necesare unele dispozitive periferice cum ar fi monitor, mouse, tastatură;
• nodurile pot comunica printr-o reŃea obişnuită, de exemplu ethernet, dar există şi clustere comerciale care folosesc reŃele de mare viteză;
• interfaŃa de reŃea este ataşată magistralei I/O şi nu celei de memorie; • clusterul este administrat ca o resursă de calcul unică printr-un
ansamblu de tehnici denumite single-system image (SSI); • are disponibilitate ridicată, adică sistemul poate utilizat un procent
mai mare de timp; • datorită multiplicării resurselor clusterul oferă o performanŃă foarte
bună, fie ca timp de execuŃie mai scurt fie ca servire simultană a mai multor utilizatori.
Clusterele pot fi clasificate în baza următoarelor atribute: • asamblare (compact sau distribuit); • control (local sau centralizat); • omogenitate (eterogen sau omogen); • securitate (închis sau deschis).
În practică se folosesc îndeosebi două tipuri de clustere: • Cluster dedicat: este instalat cu toate nodurile într-un rack compact,
este omogen (toate nodurile folosesc acelaşi tip de procesor şi acelaşi sistem de operare), este controlat centralizat şi este accesat via un sistem front-end (închis pentru exterior);
• Cluster de întreprindere: este distribuit geografic cu noduri în rack-uri diferite din aceeaşi cameră sau în camere diferite, este eterogen (nodurile pot avea procesoare şi sisteme de operare diferite), cu un control limitat, iar joburile locale au prioritate faŃă de cele ale întreprinderii.
Pentru ca un sistem să fie robust şi eficient este necesar să fie:
• fiabil (timpul mediu până la defectare să fie cât mai mare); • disponibil (procentul de timp cât este disponibil utilizatorului să fie cât
mai mare); • uşor de întreŃinut (service facil şi rapid).
Pentru asigurarea disponibilităŃii unui cluster se folosesc următoarele
tehnici: • RedundanŃa izolată: se folosesc componente redundante pentru ca, în
cazul că una cade, funcŃia sa să fie preluată de altă componentă,

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 40
componentele trebuie să fie izolate, în sensul să nu poată fi afectate de aceeaşi sursă de cădere (două componente se pot testa reciproc şi în timp ce una funcŃionează, cealaltă poate fi reparată sau înlocuită, după caz). O strategie judicioasă de realizare a unui cluster fiabil este cea care elimină punctele unice susceptibile de cădere, de exemplu la arhitectura client/server vor fi dublate liniile de comunicaŃie, serverul şi adaptorul său, discul, magistrala SCSI (Small Computer System Interface);
• Preluarea (failover): când o componentă cade, restul sistemului preia serviciile oferite de componenta respectivă. Un mecanism de diagnoză, numit heartbeat („bătaia/pulsul inimii”,
v. http://www.linux-ha.org/HeartbeatProgram), asigură diagnoza notificarea şi refacerea. Nodurile îşi trimit mesaje heartbeat, iar dacă sistemul nu primeşte mesaje de la un nod, însemnă că nodul sau/ şi conexiunea la reŃea a căzut. De regulă se folosesc două căi de conexiune între noduri şi fiecare nod are un demon heartbeat care trimite la un anumit interval de timp prestabilit un mesaj pe ambele conexiuni către master (unul din noduri este desemnat master). Dacă masterul primeşte două mesaje, totul este în regulă. Dacă primeşte un singur mesaj, însemnă că una din conexiuni a căzut, iar dacă nu primeşte nici-un mesaj însemnă că ori au căzut ambele conexiuni, ori a căzut nodul în cauză. Odată diagnosticată o cădere, sistemul notifică acest eveniment şi se iau măsuri pentru refacere şi remedierea defecŃiunii; • Scheme de refacere (recovery schemes). Se utilizează două scheme de
refacere: prima constă în salvarea periodică a stării proceselor ce se execută (backward recovery – checkpoint), iar a doua este forward recovery. În primul caz, după o cădere, sistemul este reconfigurat astfel încât să izoleze componenta căzută şi se continuă funcŃionarea normală din punctul de salvare (tehnica rollback). Această tehnică se poate implementa şi portabil, independent de aplicaŃie. A doua soluŃie se bazează pe reluarea execuŃiei pe baza diagnosticului dintr-o stare validă anterioară şi se foloseşte de obicei când timpul de execuŃie este critic. Schema este dependentă de aplicaŃie şi poate necesita un hardware suplimentar.
Imaginea unică de sistem -SSI (Single System Image) se referă la faptul
că utilizatorul are iluzia că accesează un sistem unic, care are resurse multiplicate, are control unic asigurat printr-o singură interfaŃă, este simetric (un serviciu poate fi solicitat de pe orice nod), iar accesul la resurse este transparent.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
41
Fig. 1.3.1. Arhitectura principială a unui cluster
Fig. 1.3.2. RelaŃii între componente software/hardware într-un nod de cluster

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 42
Iluzia imaginii unice a sistemului - SSI (Single System Image) poate fi obŃinută:
• la nivelul aplicaŃiei: utilizatorul are impresia că foloseşte o simplă staŃie de lucru şi nu un cluster;
• la nivelul hardware sau kernel: într-un cluster omogen se poate realiza iluzia de sistem unic chiar la nivel de sistem de operare sau hardware (într-un cluster eterogen acest lucru este mai greu de realizat);
• la nivelul situat deasupra kernelului: este cel mai potrivit nivel pentru construcŃia iluziei SSI, deoarece este independent de platformă şi nu modifică aplicaŃia.
SSI realizează următoarele:
• Punct de intrare unic: un utilizator se poate conecta la un cluster ca la un singur calculator (gazdă). Trebuiesc rezolvate probleme precum crearea directorului home (unde să fie plasat: se poate păstra o copie pe fiecare calculator gazdă sau se pot memora toate directoarele home într-un spaŃiu de stocare sigur al clusterului), autentificare, gestiunea conexiunilor multiple, căderea gazdei etc.
• Ierarhie unică de fişiere: producerea unei imagini care include discurile locale, globalwe sau late dispozitive (NFS sau AFS);
• SpaŃiu de memorie unic (iluzoriu): produce iluzia unei memorii principale mari, care în realitate este o sumă de memorii locale;
• SpaŃiu I/O unic; • Un punct de control; • ReŃea unică; • Un singur sistem de gestiune a joburilor; • SpaŃiu unic pentru procesare.
Sistemul de gestiune a unui cluster trebuie să conŃină:
• un server pentru utilizator: acesta permite utilizatorilor lansarea în execuŃie a joburilor şi cererea de resurse;
• un planificator de aplicaŃii/ joburi: face planificarea în funcŃie de tipul jobului, de resursele necesare, de politicile de planificare;
• un gestionar de resurse: alocă şi monitorizează resursele şi verifică politicile de planificare.
NOW. În 1998 a fost terminat proiectul NOW (Network of Workstations) al UniversităŃii Berkely, care şi-a propus să realizeze un software pentru gestiunea unui cluster. S-a proiectat un strat software de tip cluster middleware, numit GLUnix, care se aşează deasupra sistemelor de operare existente şi permite executarea joburilor interactive cu viteza unei staŃii de lucru, dar şi a unor joburi care ar fi prea mari pentru o singură staŃie de lucru.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
43
1.3.7. Grid
Diverse definiŃii descriptive.
1. Grid-ul este o colecŃie de resurse informatice eterogene (PC-uri, supercomputere, MPP, clustere, ....), fără o localizare determinată, fără control centralizat, fără o imagine de sistem unic, accesibilă unor organizaŃii virtuale prin intermediul unui software suport pentru configurare (uzual, Globus Toolkit, http://www.globus.org/ ).
2. Grid-ul este un tip de sistem paralel şi distribuit care permite partajarea, selectarea şi agregarea serviciilor unor resurse distribuite eterogene peste domenii cu administrare multiplă, bazate pe disponibilitate, capabilitate, performanŃă, cost şi cerinŃe calitative ale utilizatorilor. (Rajkumar BUYYA, http://www.gridcomputing.com/ )
3. Grid-ul reprezintă modalitatea flexibilă şi securizată de a coordona punerea în comun a resurselor diverselor colective dinamice de indivizi, instituŃii sau organizaŃii (organizaŃii virtuale). [FKT01];
4. Grid-ul reprezintă un efort ambiŃios şi incitant de a dezvolta un mediu în care fiecare utilizator să poată accesa calculatoare, baze de date şi facilităŃi experimentale într-un mod simplu şi transparent, fără să Ńină seama unde sunt localizate aceste facilităŃi [RealityGrid, Engineering & Physical Sciences Research Council, UK 2001] http://www.realitygrid.org/information.html ;
5. Grid computing este un model care permite unor companii să folosească un număr larg de resurse de calcul la cerere, indiferent unde s-ar afla acestea. www.informatica.com/solutions/resource_center/glossary/default.htm ;
6. Un grid este o infrastructură informatică de tip reŃea, constituită virtual dintr-o mulŃime de resurse informatice distribuite, eterogene, cu potenŃial de partajare, fără o administrare centralizată, fără imagine de sistem unic, care permite unor utilizatori de tip organizaŃional să-şi rezolve unele probleme de dimensiuni mari utilizând resurse de pretutindeni (din afara organizaŃiei).
Deci, resursele unui Grid sunt caracterizate prin
1. Partajare: sunt puse la dispoziŃia utilizatorilor care au nevoie de ele pentru rezolvarea unor aplicaŃii;
2. Distribuire: sunt amplasate în locaŃii geografice oriunde pe glob;

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 44
3. Eterogenitate: nu sunt toate de aceeaşi natură, pot diferi prin sisteme de gestiune a fişierelor, prin sisteme de operare, prin tipul de procesoare utilizate etc.;
4. Coordonare: resursele sunt organizate virtual , conectate şi exploatate în funcŃie de nevoi (obiective) şi mijloace disponibile pe baza unui software de configurare şi gestiune a gridului;
5. Externalizare: resursele sunt accesibile la cerere de către furnizori externi;
6. Autonomie (descentralizare): în contrast cu clusterul, lipseşte imaginea de sistem unic şi controlul centralizat.
Domeniile de aplicabilitate pentru Grid Computing:
1. Modelare predictivă şi simulare: prognoze meteo prin simulări numerice; oceanografie, simulări de semiconductoare; astrofizică; prognozarea albiilor râurilor şi fluviilor; studiul genomului uman; proiecte socio-economice şi guvernamentale.
2. Proiecte inginereşti şi automatizări: modelări prin metoda elementului finit, aerodinamică, inteligenŃă artificială (procesarea imaginilor, recunoaşterea formelor, vizualizare computerizată).
3. Explorarea resurselor energetice: siguranŃa reactoarelor nucleare, explorări seismice, puterea de fuziune a plasmei; modelarea rezervelor energetice.
4. Cercetări fundamentale în medicină şi probleme militare: imagini şi vizualizări în explorări medicale, probleme de mecanică cuantică, chimia polimerilor, proiecte de atac nuclear.
5. Vizualizare: vizualizări grafice, video, animaŃie, film cu ajutorul calculatorului.
Sistemele GRID pot fi clasificate în trei mari categorii:
1. Grid computaŃional: supercalcul distribuit şi transfer de mare viteză, vezi http://www.nwicgrid.org/
2. Data Grid: exploatarea unor baze de date de mari dimensiuni, v. http://eu-datagrid.web.cern.ch/eu-datagrid/ http://www.eu-egee.org/ 3. Service Grid: servicii grid la cerere, colaborativ, multimedia, v.
http://www.globus.org/ogsa/

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
45
Notă. Uneori se mai fac confuzii între cele două concepte: cluster computing şi grid computing. Este necesar de la bun început să facem o distincŃie categorică între cele două concepte, comparând următoarele definiŃii ale celor două concepte: • Cluster computing: este o colecŃie de staŃii de lucru (PC-uri, supercomputere, MPP,...) omogene sau neomogene, puternic cuplate într-o reŃea bine localizată (într-o încăpere sau în câteva locaŃii ale unei întreprinderi), cu control centralizat, accesibilă utilizatorilor de la terminalele staŃiilor de lucru prin intermediul unui software de administrare (uzual, GLUnix realizat în cadrul proiectului NOW sau CODINE, vezi şi http://www.linux-ha.org/ClusterResourceManager ), prin intermediul căruia văd clusterul ca o unică resursă de calcul la fel de uşor de utilizat ca un PC. Pentru programare în clustere se utilizează de obicei MPI (Message Pasing Interface) http://www-unix.mcs.anl.gov/mpi/ sau PVM (Parallel Virtual Machine) http://www.csm.ornl.gov/pvm/ ; • Grid computing: este o colecŃie de resurse informatice eterogene (PC-uri, supercomputere, MPP, clustere, ....), fără o localizare determinată, fără control centralizat, fără o imagine de sistem unic, accesibilă unor organizaŃii virtuale prin intermediul unui software suport (uzual, Globus Toolkit, http://www.globus.org/ ).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 46

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
47
CAPITOLUL 2 SISTEME DE CALCUL PARALEL ŞI DISTRIBUIT. TAXONOMIE ŞI MODELE
2.1. Clasificări binare ale arhitecturilor sistemelor de calcul paralel şi distribuit (SCPD)
2.1.1. Clasificarea SCPD după numărul de unităŃi centrale conectate la memorie 2.1.2. Clasificarea SCPD după tipul mecanismului de control 2.1.3. Clasificarea SCPD după numărul de seturi de instrucŃiuni prelucrabile 2.1.4. Clasificarea SCPD după tipul strategiei de management al procesării 2.1.5. Clasificarea SCPD după numărul de seturi de date prelucrabile 2.1.6. Divizarea clasei SC după numărul de seturi de date prelucrabile 2.1.7. Divizarea clasei SIMD după tipul de date prelucrabile 2.1.8. Divizarea clasei SF după tipul de date prelucrabile 2.1.9. Divizarea clasei MIMD după modul de organizare a adresării spaŃiului de memorie (Bell) 2.1.10. Divizarea multiprocesoarelor după tipul de memorie utilizat (Bell) 2.1.11. Divizarea multicalculatoarelor după tipul de memorie utilizat (Bell)
2.2.Paralelismul în diverse sisteme de calcul
2.2.1. Paralelismul în calculatoarele scalare moderne de tip SISD 2.2.2.Paralelismul în calculatoarele multiscalare de tip MISD 2.2.3 Paralelismul în sistemele MIMD
2.3. Clasificarea lui Flynn
2.3.1. Clasa SISD (Single Instruction stream - Single Data stream) 2.3.2. Clasa SIMD (Single Instruction stream - Multiple Data stream) 2.3.3. Clasa MISD (Multiple Instruction stream - Single Data stream) 2.3.4. Clasa MIMD (Multiple Instruction stream - Multiple Data stream)
2.4. O sinteză a diverselor taxonomii ale SCPD
2.4.1. Includerea claselor lui Flynn 2.4.2. Includerea claselor lui Bell (multiprocesor de tip SASA, multicalculator de tip MPA)
2.4.3. Includerea claselor lui Hwang (modelele UMA, NUMA, ccNUMA, COMA) 2.4.4. Modelele Cluster şi Grid 2.4.5. O schemă taxonomică de sinteză
2.5. Software pentru configurarea şi managementul sistemele informatice distribuite
2.5.1. Sisteme de operare multiuser 2.5.2. Parallel Virtual Machine (PVM) 2.5.3. Message Passing Interface (MPI) 2.5.4. Globus Toolkit

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 48
2.1. Clasificări binare ale arhitecturilor sistemelor de calcul paralel şi distribuit (SCPD)
2.1.1. Clasificarea SCPD după numărul de unităŃi centrale conectate la memorie 2.1.2. Clasificarea SCPD după tipul mecanismului de control 2.1.3. Clasificarea SCPD după numărul de seturi de instrucŃiuni prelucrabile 2.1.4. Clasificarea SCPD după tipul strategiei de management al procesării 2.1.5. Clasificarea SCPD după numărul de seturi de date prelucrabile 2.1.6. Divizarea clasei SC după numărul de seturi de date prelucrabile 2.1.7. Divizarea clasei SIMD după tipul de date prelucrabile 2.1.8. Divizarea clasei SF după tipul de date prelucrabile 2.1.9. Divizarea clasei MIMD după modul de organizare a adresării spaŃiului de memorie (Bell) 2.1.10. Divizarea multiprocesoarelor după tipul de memorie utilizat (Bell) 2.1.11. Divizarea multicalculatoarelor după tipul de memorie utilizat (Bell)
Dintre cei care s-au ocupat de taxonomia arhitecturilor paralele îi putem
aminti pe: Flynn (1966), Shore (1973), Händler (1977), Kuck (1978), Schwartz (1980), Gajski (1985), Trealeven (1985), Hockney (1988), Williams (1990), Bell (1992), Lewis (1993). În [Dzi01c], [Dzi02] şi [Dzi06] se face o sinteză a acestor clasificări, din care vom reproduce parŃial câteva informaŃii în acest capitol.
Prin acronimul SCPD vom desemna sistemele de calcul paralel şi
distribuit. Vom numi clasificare binară, clasificarea care împarte o anumită
clasă exact în două subclase, pe baza unui criteriu unic sau a unei mulŃimi de
criterii.
Elementele hardware de bază ale unui calculator sunt: • Unitatea centrală (CPU) este creierul unui calculator. Ea este formată
din circuite necesare pentru stocare, prelucrare şi control. În unităŃile centrale cu microprocesor, ALU şi CU sunt incluse în microprocesor, iar memoriile ROM şi RAM sunt plasate separat pe placa de bază sau pe o placă conectată la magistrala de extensie.
• Memoria este formată din circuite necesare pentru stocarea datelor şi instrucŃiunilor, precum şi a datelor intermediare şi dispune de mecanisme de acces la acestea. Există mai multe tipuri de memorie.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
49
• Microprocesorul este un circuit integrat care conŃine: unitatea
aritmetico-logică (ALU), unitatea de comandă (CU) şi uneori unitatea de calcul în virgulă mobilă. Microprocesorul este conectat la diverse unităŃi de memorie şi este înglobat în unitatea centrală (CPU).
NotaŃii utilizate în acest capitol:
• AU = [Arithmetic Unit] := Unitate aritmetică; • LU = [Logic Unit] := Unitate logică • ALU = [Arithmetic- Logic Unit] := Unitate logico-aritmetică • PL = [Pipe-Line] := Conveier • CU = [Control Unit] = Unitate de control • CPU =[Central Processing Unit] : = unitate de control stăpân • MCU =[Master Control Unit] : = unitate de control stăpân • µP = Microprocessor := Microprocesor; • ROM [Read Only Memory] := Memorie nevolatilă; • RAM [Random-Access Memory] := Memorie volatilă; • IM [Interleaved Memory] := Memorie întreŃesută • DiM =[Distributed Memory] := Memorie distribuită; • ShM =[Shared Memory] := Memorie partajată; • SASA =[Shared Address Space Arhitecture] := Arhitectură bazată pe
adresarea partajată, la sistemele cu memorie comună; • MPA =[Message Passing Arhitecture] := Arhitectură bazată pe
transmitere de mesaje (în memoriile distribuite); • CaM [Cache Memory] :=Memorie cache; • CMD [CaM for Data] := CaM pentru date; • CMI [CaM for Instruction] := CaM pentru instrucŃiuni.
2.1.1. Clasificarea SCPD după numărul de unităŃi centrale conectate la memorie
1. Clasa SCPU [Single CPU]: SCPD are o arhitectură cu o singură unitate centrală (CPU, Central Processor Unit) legată la memorie. Astfel de arhitecturi mai sunt numite şi arhitecturi de tip von Neumann (v. [Kum+94], [PW95]);
2. Clasa MCPU [Multiple CPU]: Mai multe unităŃi centrale sunt legate la memorie. Mai sunt numite şi arhitecturi de tip non von Neumann.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 50
2.1.2. Clasificarea SCPD după tipul mecanismului de control
1. Clasa GCU [Global Control Unit]: O arhitectură cu mecanism de control global, în sensul unui centralism fizic (exercitat de un singur CPU), sau centralism conceptual (un MCU = Master Control Unit, adică un CPU stăpân exercită controlul asupra întregului sistem);
2. Clasa LCU [Local Control Unit]: Arhitectură cu mecanism de control local, în sensul că mai multe procesoare locale, care pot avea fiecare câte un CPU sau posedă numai unităŃi de control CU, controlează execuŃia proceselor locale.
2.1.3. Clasificarea SCPD după numărul de seturi de instrucŃiuni prelucrabile
1. Clasa SI [Single Instruction stream]: Sistemul este capabil să execute doar un singur set de instrucŃiuni;
2. Clasa MI [Multiple Instruction stream]: Sistemul este capabil să execute mai multe seturi de instrucŃiuni simultan.
2.1.4. Clasificarea SCPD după tipul strategiei de management al procesării
1. Clasa SC [Sistem Centralizat]: Am ales această denumire pentru a desemna un sistem de calcul care este în acelaşi timp din clasele SCPU, GCU şi SI;
2. Clasa SF [Sistem Federalizat]: Am ales această denumire pentru a desemna un sistem de calcul care este în acelaşi timp MCPU, LCU şi MI.
Prin strategie de management al procesării vom înŃelege modul de gestionare a mecanismului de comandă şi control în timpul procesării (execuŃiei instrucŃiunilor). Acesta va fi de două tipuri: centralizat (sistem cu o singură unitate centrală şi mecanism de control global, ce permite execuŃia numai a unui singur set de instrucŃiuni) sau federalizat (sistem cu mai multe unităŃi centrale şi mecanism de control local, ce permite execuŃia numai a mai multor seturi de instrucŃiuni simultan).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
51
Termenul federalizat a fost introdus în [Dzi02]: prin analogie cu tipologia sistemelor de guvernare statală. Un stat federal modern (SCPD), cuprinde mai multe state (MCPU), fiecare stat având o anumită autonomie locală, cu o conducere locală proprie (LCU). Astfel, un proiect federal cu mai multe module (program paralel cu mai multe seturi de instrucŃiuni - MI), poate fi distribuit spre execuŃie la mai multe state simultan, fiecare stat răspunzând de execuŃia modulului său şi, eventual, colaborând (comunicând) în timpul execuŃiei cu alte state (procesoare/calculatoare).
2.1.5. Clasificarea SCPD după numărul de seturi de date prelucrabile
1. Clasa SD [Single Data stream]: Sistemul este capabil să execute unul sau mai multe seturi de instrucŃiuni asupra doar a unui singur set de date deodată;
2. Clasa MD [Multiple Data stream]: Sistemul este capabil să execute unul sau mai multe seturi de instrucŃiuni asupra a mai multor seturi de date simultan.
2.1.6. Divizarea clasei SC după numărul de seturi de date prelucrabile
1. Clasa SISD = Single Instruction stream - Single Data stream (clasă Flynn): Un sistem centralizat, capabil să execute doar un singur set de instrucŃiuni numai pe un singur set de date (SI, SD). Calculatoarele din această clasă se mai numesc şi calculatoare scalare. Este o clasă din clasificarea lui Flynn. 2. Clasa SIMD = Single Instruction stream - Multiple Data stream (clasă Flynn): Un sistem centralizat, capabil să prelucreze mai multe seturi de date simultan, pe acelaşi set de instrucŃiuni (SI, DM).
2.1.7. Divizarea clasei SIMD după tipul de date prelucrabile
1. Clasa SIVD = Single Instruction stream - Vector Data (procesoare vectoriale):
2. Clasa SIAD = Single Instruction stream - Array Data (procesoare matriceale).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 52
2.1.8. Divizarea clasei SF după tipul de date prelucrabile
1. Clasa MISD = Multiple Instruction stream - Single Data stream (clasă Flynn): Sistemul este capabil să execute mai multe seturi de instrucŃiuni asupra doar a unui singur set de date;
2. Clasa MIMD = Multiple Instruction stream - Multiple Data stream (clasă Flynn): Sistemul este capabil să execute mai multe seturi de instrucŃiuni asupra a mai multor seturi de date simultan.
2.1.9. Divizarea clasei MIMD după modul de organizare a adresării spaŃiului de memorie (Bell)
1. Clasa SASA = Shared-Address-Space Architecture: Sunt arhitecturi de
tip MIMD care utilizează un spaŃiu unic de adrese, localizat în memoria comună. Ele se mai numesc şi multiprocesoare;
2. Clasa MPA = Message-Passing Architecture: Sunt arhitecturi de tip MIMD care utilizează mai multe spaŃii de adrese, comunicarea între procesoare realizându-se prin transmitere de mesaje. Ele se mai numesc şi multicalculatoare.
2.1.10. Divizarea multiprocesoarelor după tipul de memorie utilizat (Bell)
1. Multiprocesor scalabil: Un multiprocesor cu memorie distribuită local. Scalabilitatea se referă la posibilitatea creşterii accelerării odată cu creşterea numărului de procesoare.
2. Multiprocesor nescalabil: Un multiprocesor cu memorie comună partajată de toate procesoarele.
2.1.11. Divizarea multicalculatoarelor după tipul de memorie utilizat (Bell)
1. Multicalculator scalabil: Multicalculator cu memorie distribuită local. 2. Multicalculator cu memorie comună: Multicalculator cu memorie
comună partajată de toate procesoarele.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
53
2.2. Paralelismul în diverse arhitecturi de calcul
2.2.1. Paralelismul în calculatoarele scalare moderne de tip SISD 2.2.2.Paralelismul în calculatoarele multiscalare de tip MISD 2.2.3. Paralelismul în sistemele MIMD
2.2.1. Paralelismul în calculatoarele scalare moderne
Despre calculatoarele seriale moderne (calculatoarele scalare, Fig. 2.2.1,
Fig. 2.2.2), putem spune că au o arhitectură pseudoparalelă, deoarece, deşi ele execută numai programe seriale, totuşi înglobează foarte multe concepte de paralelism real sau aparent, mai ales în procesare. Ele sunt sisteme centralizate de tip SISD.
Viteza de calcul într-o astfel de maşină este influenŃată atât de viteza de execuŃie a instrucŃiunilor cât şi de viteza de schimb a informaŃiilor între unitatea centrală şi memorie.
John von Neumann a constatat că un program pierde mai mult timp cu regăsirea datelor în memorie decât cu prelucrarea propriu-zisă. Acest aspect este cunoscut sub numele de limitare de tip von Neumann [von Neumann bottleneck].
Fig. 2.2.1. Structura principială a unui calculator secvenŃial (SISD)

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 54
Fig. 2.2.2. Tipuri de SISD: a) tradiŃional; b) cu IM (memorie întreŃesută); c) cu CaM
(memorie cache); d) cu CaM şi microprocesor; e) cu PL (conveier pipeline); f)
PENTIUM
SoluŃiile la limitarea de tip von Neumann sunt multiple:
� Utilizarea memoriei întreŃesute (v. Fig. 2.2.2. b). Prin acest procedeu mai multe date pot fi accesate simultan din memorie de către CPU.
� Utilizarea memoriei cache (v. Fig. 2.2.2. c).Prin acest procedeu se stochează în CaM datele care au probabilitatea mai mare de a fi utilizate în procesul de calcul. CaM fiind mai apropiată de CPU şi având un canal de acces separat, permite creşterea vitezei de accesare a datelor;
� Utilizarea a două memorii cache, separate, una pentru datele şi una pentru instrucŃiuni (v. Fig. 2.2.2. f):
� Pentru creşterea vitezei de execuŃie a instrucŃiunilor, prin care se realizează o procesare paralelă în timp a instrucŃiunilor (v. Fig. 2.2.2. e), se utilizează tehnica pipelining.
� Pentru eludarea procesării strict secvenŃiale s-a implementat conceptul de program stocat [stored program concept], conform căruia un program se stochează în memorie împreună cu datele, astfel în timpul

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
55
execuŃiei programului se poate sări de la o instrucŃiune la alta, în loc de a se executa secvenŃial. În cazul programului stocat se execută instrucŃiunea pentru care se dispune la momentul respectiv de toate datele necesare execuŃiei ei. Acest procedeu poate fi extins prin stocarea în memorie a mai multor programe, prin tehnica multiprelucrării [multiprocessing] cu partajarea timpului [time sharing]. Astfel, se execută aparent simultan, mai multe programe în acelaşi interval de timp. Acesta este un concept de natură hardware.
� Multiprogramarea [multiprogramming] este un concept de natură software care constă tot în execuŃia aparent simultană a mai multor programe în acelaşi interval de timp, dar printr-o planificare [sheduling] adecvată a joburilor sau prin întrepătrunderea lor. Dacă, de exemplu la un moment dat un program necesită o comunicare de mai lungă durată cu periferia, execuŃia sa poate fi trecută sub controlul unui procesor de intrare/ieşire şi în acest timp unitatea centrală se poate ocupa cu execuŃia altui program.
� Se mai utilizează conceptul de natură software: paralelism simulat prin randomizare sau de natură hardware: multiprelucrare distribuită.
2.2.2. Paralelismul în calculatoarele multiscalare
Spre deosebire de o arhitectură de tip SISD (Fig. 2.2.1 şi 2.2.2), care prelucrează un singur set de instrucŃiuni pe un singur set de date, realizând procesări paralele cu programe seriale, în arhitecturile multiscalare de tip SIMD (Fig. 2.2.3, Fig. 2.2.4, Fig. 2.2.5, Fig. 2.2.6, Fig. 2.2.7, Fig. 2.2.8), nivelul de paralelism creşte, permiŃând execuŃia unui set de instrucŃiuni pe mai multe seturi de date, paralelismul datorându-se atât structurii fizice cât şi programării.
În modelul SIMD, mai multe procesoare identice, P1, P2, …, Pn sunt puse să execute simultan, pe baza unui program paralel–sincron, o aceeaşi instrucŃiune, fiecare pe date distincte ale multidatei (dată cu o structură de tip vector sau matrice). Procesoarele comunică între ele prin intermediul memoriei comune, care este o memorie partajată, dar în unele cazuri pot avea şi memorie locală. În acest model o resursă scumpă (memoria) este exploatată în comun de mai multe resurse ieftine (procesoare simple). Aceste procesoare lucrează sub comanda şi controlul unităŃii centrale CPU, care procedează astfel: dacă data este simplă o execută, iar dacă este multiplă o distribuie (câte una sau mai multe componente) spre prelucrare procesoarelor-sclavi, astfel ca efortul de calcul să fie similar pentru fiecare procesor. Deci mecanismul de control este de tip global.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 56
Fig. 2.2.3. SIMD cu memorie partajată (ShM- Shared Memory)
Limitările în astfel de arhitecturi paralele sunt încă serioase :
� raportul cost / eficienŃă este justificat doar în rezolvarea unor probleme specifice (care admit o descompunere regulată în sub-probleme ce presupun un efort de calcul similar, în care se schimbă doar datele);
� dacă dimensiunea datei multiple este cu mult mai mare decât numărul de procesoare pot apărea limitări datorate distribuŃiei inegale şi a necesităŃii de sincronizare;
� dacă dimensiunea datei multiple este cu mult mai mică decât numărul de procesoare sistemul nu-şi justifică oportunitatea (nu este exploatat la întreaga capacitate);
� eficienŃa este afectată negativ dacă problema conŃine multe operaŃii condiŃionale, care nu pot fi efectuate decât de unitatea centrală, apărând astfel timpi morŃi în funcŃionarea procesoarelor sclavi.
Exemple tipice de arhitecturi multiscalare sunt:
� procesoarele vectoriale (Fig. 2.2.4, Fig. 2.2.5, Fig. 2.2.6); � procesoarele matriciale (arii de procesoare, Fig. 1.3.7, 1.3.8).
Exemple de procesoare vectoriale sunt: STAR-100, TI-ASC, CRAY-1, CYBER-200, FUJITSU VP-200 şi CRAY X-MP, etc.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
57
Fig. 2.2.4. Structura tipică a unui procesor vectorial
Fig.2.2.5. Procesor vectorial tip coloană
Procesoarele matriceale sunt structuri regulate alcătuite din mai multe elemente de procesare, cu sau fără memorie locală, cu posibilităŃi de transfer a

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 58
informaŃiei între ele, toate lucrând în paralel, sub comanda unei unităŃi centrale unice.
Un procesor matricial poate executa operaŃii scalare şi vectoriale pe seturi masive de date. Toate elementele de procesare execută aceleaşi operaŃi, sub comanda CPU, dar asupra unor operanzi diferiŃi obŃinuŃi din memoriile locale (în cazul memoriei distribuite local, Fig. 2.2.7) sau din memoria comună organizată pe module (Fig. 2.2.6).
Un exemplu tipic de procesor matricial de primul tip este Illiac IV, iar din cel de-al doilea este BSP [Buroughs Scientific Processor].
Un rol deosebit de important în eficienŃa unor astfel de sisteme îl joacă modul de interconectare a procesoarelor (reŃele statice, reŃele dinamice, etc.).
Fig. 2.2.6. Procesor vectorial cu memorie modulară partajată

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
59
Fig. 2.2.7. Procesor vectorial cu memorie distribuită local

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 60
2.2.3. Paralelismul în sistemele MIMD
În Fig. 2.2.8 este schematizată o structură de tip MIMD, cu memorie partajată, iar în Fig. 2.2.9 avem o structură MIMD cu memorie distribuită.
Fig. 2.2.8. MIMD cu memorie partajată
DiferenŃa principială dintre MIMD cu memorie distribuită şi MIMD cu memorie partajată constă în modul de comunicare între procesoare. În primul model comunicarea se realizează prin transmitere de mesaje, iar în al doilea prin intermediul memoriei comune, care este partajată de cele n procesoare simple.
Un sistem de tip MIMD cu memorie distribuită foloseşte de regulă drept procesoare, transputere (v.[Gri00]). Un transputer este un cip microprocesor cu memorie adiŃională, ALU şi facilităŃi de comunicare.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
61
Fig. 2.2.9. MIMD cu memorie distribuită
Fig. 2.2.10. Arhitectură sistolică de tip MISD

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 62
2.3. Clasificarea lui Flynn
2.3.1. Clasa SISD (Single Instruction stream - Single Data stream) 2.3.2. Clasa SIMD (Single Instruction stream - Multiple Data stream) 2.3.3. Clasa MISD (Multiple Instruction stream - Single Data stream) 2.3.4. Clasa MIMD (Multiple Instruction stream - Multiple Data stream)
Clasificarea lui Flynn are cel mai mare impact în literatura de specialitate.
Ea constă într-o combinaŃie a claselor SI, MI cu clasele SD, MD (v. Fig. 2.3.1.
şi Fig. 2.3.2).
Seturi de INSTRUCłIUNI/ DATE Singulare Multiple
Singulare SISD MISD
Multiple SIMD MIMD
Fig. 2.3.1. Categoriile (clasele) lui Flynn
2.3.1. Clasa SISD (Single Instruction stream - Single Data stream)
În această clasă intră calculatoarele obişnuite, calculatoarele seriale scalare.
2.3.2. Clasa SIMD (Single Instruction stream - Multiple Data stream)
În această clasă se încadrează supercalculatoarele: calculatoarele vectoriale şi matriciale.
2.3.3. Clasa MISD (Multiple Instruction stream - Single Data stream)
Flynn nu a dat exemple din această clasa, dar aici s-ar încadra
arhitecturile de tip sistolic. 2.3.4. Clasa MIMD (Multiple Instruction stream - Multiple Data stream)
În această clasă intră calculatoarele paralele masive (compacte), care pot
fi multiprocesoare sau multicalculatoare. Calculatoarele din clasa MIMD sunt blocuri unitare de procesoare înzestrate cu unităŃi de control, ce comunică între ele prin schimb de mesaje sau prin intermediul memoriei comune şi colaborează la rezolvarea unei unice probleme complexe.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
63
a) SISD b)SIMD
c)MISD
d) MIMD
Global CU[CPU]
Procesor Data stream
P+CU
(SI) (SD)
(SISD)
(SIMD) Global CU[MCU]
l
P2
(SI) (MD) P1
Pn
I
I
I
(MISD) Local CU[MCU]
P2
(MI) (SD) P1
Pn
I2
I1
In Date
(MIMLocal CU[MCU
}
P2+CU
(MI) (MD) P1+
CU
Pn+CU
I2
I1
In
ReŃea de interconectare
Fig. 2.3.2 Schemele funcŃionale ale categoriilor Flynn

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 64
2.4. O sinteză a diverselor taxonomii ale SCPD
2.4.1. Includerea claselor lui Flynn 2.4.2. Includerea claselor lui Bell (multiprocesor de tip SASA, multicalculator de tip MPA)
2.4.3. Includerea claselor lui Hwang (modelele UMA, NUMA, ccNUMA, COMA) 2.4.4. Modelele Cluster şi Grid 2.4.5. O schemă taxonomică de sinteză
2.4.1 Includerea claselor lui Flynn
În figura 2.4.1 prezentăm o sinteză a celor mai importante clasificări [Dzi02]. Înainte de a face o clasificare de sinteză, vom aminti şi de clasa
MSISD [Multiple SISD]. Aceasta este de fapt o reŃea de calculatoare SISD,
care poate lucra ca şi un sistem MIMD. Între ele există totuşi diferenŃe, în
primul rând de ordin constructiv, dar şi de ordin principial. Calculatoarele din
clasa MIMD sunt blocuri unitare de procesoare înzestrate cu unităŃi de control,
ce comunică între ele prin schimb de mesaje sau prin intermediul memoriei
comune şi colaborează la rezolvarea unei unice probleme complexe. În schimb,
calculatoarele din clasa MSISD sunt nişte calculatoare paralele virtuale care
pot produce aceleaşi efecte ca şi cele din clasa MIMD, dar în timpul execuŃiei
unui program paralel unităŃile de control şi cele de execuŃie, din SISD-uri
diferite, nu comunică între ele.
Clasificarea arborescentă se va baza pe clasele binare prezentate anterior, la
care vom adăuga clasa MSISD şi modelele lui Hwang.
La primul nivel al arborelui din figura 2.4.1 avem o discriminare triplă,
după: numărul de CPU care sunt conectate la memorie (1/n); mecanism de
control (centralizat / local); tipul de seturi de instrucŃiuni pe care le poate
prelucra (simple / multiple). Se obŃin următoarele noduri:
� sistem centralizat, cu următoarele caracteristici: arhitectură de tip von Neumann (cu o singură CPU); mecanism de control centralizat (nu neapărat fizic); capabil să prelucreze seturi singulare de instrucŃiuni ;

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
65
� sistem federalizat, cu următoarele caracteristici: arhitectură de tip non von Neumann (are mai multe CPU); mecanism de control local; seturi multiple de instrucŃiuni prelucrabile.
Din aceste noduri începe discriminarea după capacitatea de prelucrare a seturilor de date (SD- singulare / MD- multiple).
La următorul nivel obŃinem clasele:
• calculator scalar, care este un calculator centralizat ce poate prelucra numai un set simplu de date (de tip SISD);
• calculator multiscalar, care este un calculator centralizat ce poate prelucra seturi multiple de date (de tip SIMD, calculatoarele vectoriale şi matriciale);
• calculator paralel virtual, care este un calculator federalizat ce poate prelucra seturi multiple de date (MSIMD, reŃele de calculatoare);
• calculator paralel compact (masiv), care este un calculator federalizat ce poate prelucra seturi multiple de date (MIMD: multiprocesoare şi multicalculatoare).
2.4.2. Includerea claselor lui Bell (multiprocesor SASA, multicalculator MPA)
Din ultimul nod începe clasificarea lui Bell a sistemelor MIMD, după modul de adresare a spaŃiului de memorie, prezentată în [Gri00], pag. 28.
ObŃinem astfel clasele:
• multiprocesor: calculator paralel de tip SASA: [Shared Address Space Arhitecture] := arhitectură bazată pe adresarea partajată într-un spaŃiu unic de memorie (memoria comună);
• multicalculator: calculator paralel cu MPA: [Message Passing Arhitecture] := arhitectură bazată pe transmitere de mesaje (memorie distribuită).
La nivelul următor avem mai întâi împărŃirea multiprocesoarelor în funcŃie de tipul memoriei utilizate (distribuită- DiM / partajată- ShM), iar apoi nodurile cu discriminarea multicalculatoarelor.
2.4.3. Includerea claselor lui Hwang (UMA, NUMA, ccNUMA, COMA)
Clasificarea lui Hwang (v. [Kum+94], [Gri00]):
� UMA = Uniform-Memory-Access; � NUMA = Non- Uniform-Memory-Access; � ccNUMA = cache coherent NUMA; � COMA = Cache –Only-Memory-Access.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 66
Uniform Memory Access (UMA) este un tip arhitectural de memorie utilizat la calculatoarele paralele, care utilizează procesoare multiple şi posibil şi cipuri de memorie. Toate procesoarele partajează memoria fizică uniform şi de asemenea şi perifericele. Memoria cache poate fi privată pentru fiecare procesor, iar timpul de acces la memoria comună este independent pentru fiecare procesor. Acest tip de memorie este utilizat în multiprocesoarele simetrice, bazate pe Symmetric Multiprocessing, (SMP). Mai multe procesoare identice sunt conectate la o singură memorie principală (v. fig. 2.4.1.). Unele modele folosesc o combinaŃie snoopy bus (în care memoriile cache „ascultă” magistrala) cu un switch (comutator) de tip reŃea cu acces încrucişat, ca de exemplu SUN Ultra Enterprise 10000, care are un switch pentru 4 magistrale.
Fig. 2.4.1. Schema arhitecturală a unui multiprocesor simetric (SMP cu UMA)
Non-Uniform Memory Access sau Non-Uniform Memory Architecture (NUMA) este utilizat în multiprocesoare în care timpul de acces la memorie este neuniform, adică depinde de locaŃia topologică a procesorului faŃă de memorie. Procesoarele unui sistem cu memorie de tip NUMA au acces la întreg spaŃiul de memorie şi asigură posibilitatea scalabilităŃii sistemului, motiv pentru care păstrarea coerenŃei informaŃiei este o cerinŃă fundamentală, ceea ce a dus la apariŃia tipului de arhitectură numită ccNUMA (cache coherent NUMA).
Un sistem ccNUMA este o colecŃie de mai multe multiprocesoare simetrice un toate memoriile centrale formează un spaŃiu comun de adresare alocat în ordine crescătoare. Magistralele sunt interconectate între ele prin intermediul unor directoare care păstrează evidenŃa alocării domeniilor de adrese pe

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
67
multiprocesoare. Un protocol ingenios pentru păstrarea coerenŃei este interconectarea coerentă scalabilă (Scalable Coherent Interconnect), în care magistrala snoopy este înlocuită de un inel.
Cache only Memory Architecture (COMA) este un caz special de memorie NUMA, în care memoria comună este convertită în cache. 2.4.4. Modelele Cluster şi Grid
Pentru creşterea eficienŃei calculatorului serial (mărirea puterii de calcul şi a timpului de răspuns) se pot avea în vedere trei soluŃii:
• creşterea vitezei de operare a componentelor (care se loveşte de nişte limite fizice),
• paralelizarea procesului de calcul (prin algoritmi paraleli sau/şi prin utilizarea unor structuri de calcul paralel),
• specializarea calculatoarelor pentru rezolvarea unei anumite clase de probleme.
Calculatoarele paralele au o viteză şi o capacitate de stocare superioare
calculatorului serial. Dar un sistem paralel de tip MPP sau SMP performant are o durată de viaŃă relativ scurtă (aproximativ o jumătate din durata de viaŃă şi-o consumă cu o singură aplicaŃie paralelă complexă) şi un cost prea ridicat (doar instituŃiile militare de tip Pentagon sau instituŃii de cercetare de tip NASA îşi permit să achiziŃioneze astfel de sisteme). În acelaşi timp performanŃele PC-urilor şi a staŃiilor de lucru cresc, iar gradul lor de utilizare rămâne sub 10%, dacă nu sunt utilizate şi în reŃea.
Se caută soluŃii pentru rularea mai rapidă a programelor paralele prin distribuirea sarcinilor de lucru pe mai multe calculatoare dintr-o reŃea. Se ajunge astfel la conceptele de cluster (ciorchine, în traducere liberă) şi grid (grilă).
Deseori se fac confuzii între cele două concepte: cluster computing şi grid computing. Este necesar să facem o distincŃie categorică între cele două concepte: • Cluster computing: este o colecŃie de staŃii de lucru (PC-uri, supercomputere, MPP,...) omogene sau neomogene, puternic cuplate într-o reŃea bine localizată (într-o încăpere sau în câteva locaŃii ale unei întreprinderi), cu control centralizat, accesibilă utilizatorilor de la terminalele staŃiilor de lucru prin intermediul unui software de administrare (uzual, GLUnix realizat în cadrul proiectului NOW sau CODINE, vezi şi http://www.linux-ha.org/ClusterResourceManager ), prin intermediul căruia văd clusterul ca o unică resursă de calcul la fel de uşor de utilizat ca un PC.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 68
Pentru programare în clustere se utilizează de obicei MPI (Message Pasing Interface) http://www-unix.mcs.anl.gov/mpi/ sau PVM (Parallel Virtual Machine) http://www.csm.ornl.gov/pvm/ ; • Grid computing: este o colecŃie de resurse informatice eterogene (PC-uri, supercomputere, MPP, clustere, ....), fără o localizare determinată, fără control centralizat, fără o imagine de sistem unic, accesibilă unor organizaŃii virtuale prin intermediul unui software suport (uzual, Globus Toolkit, http://www.globus.org/ ).
Deosebirile esenŃiale dintre cele două concepte sunt date în tabelul 2.4.1. şi vor fi explicate mai pe larg în acest paragraf.
Caracteristicile unui cluster/
Cluster computing characteristics Carcteristicile unui grid/
Grid computing characteristics
Sistem puternic cuplat/ Tightly coupled computers
Sistem slab cuplat/ Loosely coupled system
Management centralizat al joburilor şi planificării/
Centralized job management and
scheduling system
Management distribuit al joburilor şi planificării/
Distributed job management &
scheduling Imagine iluzorie de sistem unic/
Single system image (SSI)
Nu are imagine de sistem unic / No SSI
Tabel 2.4.1. Cluster Computing vs. Grid Computing

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
69
2.4.5. O schemă de sinteză
Fig. 2.4.2. O sinteză a clasificărilor sistemelor de calcul [Dzi02]

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 70
2.5. Software pentru sistemele de calcul paralel şi distribuit
2.5.1. Sisteme de operare multiuser din familia UNIX 2.5.2. Sistemul de operare Linux 2.5.3. Sistemul de operare PARIX 2.5.4. Parallel Virtual Machine (PVM) 2.5.5. Message Passing Interface (MPI) 2.5.6. Globus Toolkit
În gestiunea şi managementul sistemelor distribuite se utilizează software specializat, în funcŃie de arhitectura sistemului:
• DOS (Distributed Operating Systems): sisteme de operare pentru sistemele distribuite puternic cuplate: multiprocesoare şi multicalculatoare omogene (este ascuns şi gestionează resursele hardware);
• NOS (Network Operating Systems): sisteme de operare pentru sistemele distribuite slab cuplate: multicalculatoare eterogene (oferă service pentru clienŃi de pretutindeni din reŃea);
• Middleware: nivel adiŃional al NOS, care intermediază/traduce între entităŃile eterogene şi asigură transparenŃa.
2.5.1. Sisteme de operare multiuser din familia UNIX
Surse: [DL03], [Dzi01] http://www.linux.org
http://info.tech.pub.ro/~fionescu/CP/CP.html
Sistemele de operare multiutilizator [multiuser operating system] sunt înzestrate cu mecanisme adecvate procesării paralele. Când se implementează o problemă pe un calculator paralel, prima sarcină este aceea de a o descompune, astfel încât procesoarele să lucreze simultan la obŃinerea soluŃiei. Comunicarea între procesoare poate însă să genereze anumite conflicte, care se pot evita, dacă se are în vedere sincronizarea proceselor şi minimizarea numărului de comunicaŃii.
UNIX este cel mai uzual sistem multiuser. Acesta se bazează pe tehnica pipelining, pentru conectarea programelor sau întrepătrunderea execuŃiei

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
71
coproceselor concurente prin mecanismele fork şi join. Mecanismul fork împarte procesul părinte în două coprocese distribuite, iar join recombină două coprocese într-unul singur, cu posibilitatea aşteptării (delay), dacă unul din ele nu este terminat.
UNIX este o marcă înregistrată a AT&T Bell Laboratories. Orice sistem care cuprinde cuvântul UNIX în numele său este considerat ca autentic.
Restul sistemelor sunt clasificate în: � Sisteme derivate din UNIX (UNIX based); � Sisteme similare cu UNIX (UNIX like).
UNIX based sunt sisteme personalizate de către un constructor pe propria maşină, a unui UNIX obŃinut prin licenŃă de la AT&T. Numele cu sufixul NIX, IX, sau X se aplică versiunilor comerciale ale unor astfel de sisteme, de exemplu:
� XENIX care rulează pe toată gama de calculatoare personale, � HP-UX (familia Hewlett-Packard 9000), � A/UX (Apple MacIntosh), � AIX/ESA (IBM), � SINIX (Siemens), � PARIX, pentru sistemele bazate pe transputere, � DYNIX, pentru sistemul Sequent Symmetry ş.a.
Un rol deosebit îl ocupă sistemele de operare SunOS şi Solaris ale firmei Sun Microsystems, care fac parte tot din familia UNIX. UNIX este un sistem de operare multitasking şi multiuser, utilizabil atât pe un singur PC cât şi pentru reŃele de PC-uri, care suportă concepte ca:
� multiproces (poate planifica concurent spre execuŃie mai multe procese), � multiutilizator (poate suporta simultan sesiuni de lucru pentru mai mulŃi
utilizatori), � multiecran (pe ecranul calculatorului pot fi afişate rând pe rând mai
multe ecrane virtuale), � multi-interactiv (mai multe procese se pot executa simultan- grad înalt
de multiprogramare).
2.5.2. Sistemul de operare Linux
Linux este o versiune de UNIX, distribuită gratuit, dezvoltată în principal de Linus Torvalds la Universitatea din Helsinki, Finlanda. Mai mulŃi programatori dedicaŃi (hack-eri de sistem) şi-au unit forŃele prin intermediul Internetului, dând astfel oricărui amator posibilitatea să participe la dezvoltarea şi modificarea sistemului. Nucleul Linux-ului nu utilizează deloc cod care să fie

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 72
în vreun fel proprietatea cuiva, mare parte din programele disponibile pentru Linux fiind dezvoltate în cadrul proiectului GNU al FundaŃiei pentru Software Liber (Free Software Foundation) din Cambridge, Massachusetts. În plus, programatorii din întreaga lume au contribuit la software-ul pentru Linux. Astăzi, Linux este o variantă de UNIX completă, capabilă să execute Xwindows, TCP/IP, Emacs, poştă electronică şi ştiri. Aproape toate pachetele de programe distribuite liber au fost transportate şi pe Linux, tot mai multe aplicaŃii comerciale devenind disponibile şi pentru acest sistem de operare.
Linux este compatibil în mare măsură cu un număr de standarde UNIX, incluzând caracteristicile IEEE POSIX. 1, System V şi BSD, la nivel de sursă. Scopul principal în timpul dezvoltării acestui sistem de operare a fost acela de a asigura un nivel de compatibilitate cât mai mare cu restul sistemelor şi aplicaŃiilor UNIX. Un număr mare de programe UNIX, accesibile liber, disponibile prin Internet sau altfel, pot fi compilate imediat pe Linux. În plus, tot codul sursă al Linux-ului, incluzând nucleul, driverele pentru periferice, bibliotecile, programele utilizator şi utilitarele de dezvoltare sunt distribuite liber. Caracteristicile Linux-ului sunt:
� controlul execuŃiei job-urilor tip POSIX, � pseudoterminalele, suportul pentru versiuni naŃionale sau particularizate
de tastatură folosind driverele de tastatură încărcate dinamic şi console virtuale.
� nucleul poate emula instrucŃiuni în virgulă mobilă astfel încât toate programele pot fi executate şi pe procesoare fără coprocesor integrat,
� pot fi memorate date în varii sisteme de gestiune a fişierelor: cel nativ, ext2fs, dar şi Minix-1, Xenix, DOS şi ISO9660 pentru discuri,
� posedă o implementare completă a suitei de protocoale de comunicaŃie TCP/IP. Sunt incluse drivere pentru cele mai răspândite plăci de reŃea Ethernet, implementări pentru SLIP, PLIP şi PPP, sistem de fişiere în reŃea (NFS). De asemenea este inclusă gama completă de servicii client şi server TCP/IP, cum sunt ftp, telnet, smtp, nntp,
� poate lansa execuŃia programelor cu ajutorul tehnicii de paginare la cerere. adică numai acele porŃiuni de program necesare pentru execuŃie într-un anumit moment sunt citite de pe disc în memoria principală,
� utilizează partajarea de memorie între programe cu copiere la scriere, adică are loc o reducere a necesarului de memorie şi deci o mai bună utilizare globală a acesteia,
� pentru creşterea memoriei disponibile pentru execuŃia programelor, Linux implementează paginarea pe disc, permiŃând alocarea a până la 256 MB a spaŃiului de swap; nucleul gestionează întreaga memorie internă atât pentru execuŃia programelor cât şi pentru accesul mai rapid

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
73
la fişiere, de tip cache. în acest fel, toată memoria disponibilă este utilizată pentru cache de fişiere; dacă se rulează programe mai mari, zona de cache este diminuată corespunzător,
� programele executabile pot folosi legarea dinamică la bibliotecile partajate: codul bibliotecii, utilizat în comun, se găseşte într-un unic fişier pe disc, adică programele executabile pot ocupa mai puŃin spaŃiu,
� există şi posibilitatea legării statice, când codul este introdus în întregime în fişierul executabil, pentru cei care doresc depanarea sau întreŃinerea unor executabile complete,
� pentru a uşura depanarea programelor, nucleul face posibil vidajul de memorie şi analiza lui în cazul terminării anormale, pentru a putea determina cauzele execuŃiei defectuoase.
În UNIX/ Linux mai mulŃi utilizatori pot folosi calculatorul în acelaşi
timp executând independent aplicaŃii diferite. Un utilizator este oricine care poate interacŃiona cu sistemul prin deschiderea unei sesiuni de lucru, fie de la un terminal, fie din alt sistem în cadrul reŃelei.
Sistemele permit deschiderea simultană a mai multor sesiuni de lucru de către acelaşi utilizator. Consolele virtuale pot fi comutate apăsând simultan <Alt> împreună cu una din tastele funcŃionale F1,F2,F3,F4.
Contul unui utilizator este caracterizat de câteva atribute simple, scrise în
fişierul /etc/passwd, unde sunt separate prin caracterul ':': � :numele - desemnează utilizatorul într-un mod unic şi este format din
litere, cifre, '.' sau '_'; � :UID - ID-ul utilizatorului, un număr asociat numelui; � :GID - ID-ul grupului de utilizatori implicit; � parola - parola este un şir de caractere pe care îl cunoaşte numai
utilizatorul; � numele real - alte informaŃii despre utilizator, în mod obişnuit
numele întreg; � directorul de bază - este directorul implicit iniŃial; fiecare
utilizator trebuie să aibă un director de bază, de obicei în /home, al cărui proprietar trebuie să fie;
� shell pentru login - programul pornit de sistem pentru utilizator după ce acesta este admis în sistem; de cele mai multe ori este un interpretor de comenzi (shell); Crearea unui nou utilizator poate fi făcută numai de către superuser
folosind comenzi care pot diferi de la un sistem UNIX la altul. Aceste comenzi pot fi date fie direct prin intermediul interpretorului de comenzi, fie prin

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 74
intermediul programului sysadmsh care oferă facilităŃi de administrare a sistemului.
Comenzi pentru gestiunea utilizatorilor:
� #adduser stabileşte în dialogul cu administratorul sistemului toate elementele care caracterizează noul utilizator: nume, număr, apartenenŃa la un grup, parola, shell-ul utilizat, etc.
� #rmuser folosită de superuser este pentru a şterge un utilizator din sistem,
� $ cat/etc/passwd - afişează conŃinutul fişierului care conŃine informaŃii despre utilizator;
� $ logname - afişează numele utilizatorului curent, adică al utilizatorului care are o sesiune deschisă pe terminalul sau ecranul de la care este dată comanda;
� $ whoami - afişează numărul şi numele de utilizator şi de grup al utilizatorului curent;
� $ who - afişează numele tuturor utilizatorilor activi la un moment dat pe un sistem UNIX, informaŃii despre terminalul la care se află şi momentul deschiderii sesiunii curente.
Structura sistemului de fişiere UNIX/Linux Una din contribuŃiile importante ale UNIX-ului este încercarea de
standardizare a sistemelor de operare. Pe lângă standardizarea serviciilor sistem şi a comenzilor utilizator, un efort particular a fost depus şi în domeniul sistemului de fişiere. În cazul Linux-ului, acest efort s-a concretizat într-un document numit Linux Filesystem Standard (Standardul sistemului de Fişiere Linux), prescurtat FSSTND, ajuns la versiunea 1.2.
Cea mai importantă caracteristică a sistemului de fişiere Linux este structura sa arborescentă, cu o rădăcină unică. PartiŃia rămâne baza pentru gestiunea spaŃiului pe discul magnetic, aşa cum o cunoaştem din DOS sau alte sisteme de operare. Prin formatare o partiŃie poate fi organizată ca sistem de fişiere, adică poate memora directoare şi fişiere. Structura fişierelor într-o partiŃie este de asemenea arborescentă, posedând. Sub Linux, o partiŃie devine disponibilă utilizatorilor numai prin integrarea în arborele ierarhic de fişiere al unui calculator. Acest lucru se realizează prin montare. Montarea asociază rădăcina unei partiŃii cu o cale din sistemul de fişiere existent, cale care se numeşte punct de montare.
De exemplu, montarea unităŃii de disc se poate realiza cu comanda: # mount [-t iso9660] /dev/cdrom /mnt/cdrom

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
75
La pornire, sistemul de operare montează o partiŃie în punctul de
montare /, rădăcina absolută a ierarhiei de fişiere a calculatorului. Această partiŃie găzduieşte sistemul de fişiere rădăcină. Sistemul de fişiere rădăcină trebuie să conŃină anumite directoare, programe şi fişiere de configurare necesare pornirii corecte a sistemului. Astfel, Linux permite o configurare extrem de flexibilă: nucleul Linux şi sistemul de fişiere rădăcină se pot găsi oriunde: pe o dischetă, pe o partiŃie DOS sau în reŃea, fără condiŃionări reciproce; singura problemă este ca nucleul să ştie unde este această partiŃie. Structura subdirectoarelor din directorul rădăcină este următoarea: / - directorul rădăcină -bin - programele pentru comenzile esenŃiale
-boot - fişierele statice ale încărcătorului
-dev - fişierele speciale pentru acces la periferice
-etc - fişierele de configurare locale
-home - directoarele de bază ale utilizatorilor
-lib - bibliotecile partajate
-mnt - punct de montare temporară a altor partiŃii diverse
-proc - pseudo-sistem de fişiere cu informaŃii ale sistemului de operare
-root - directorul de bază pentru utilizatorul root
-sbin - comenzile esenŃiale de sistem
-tmp - director pentru fişiere temporare
-usr - alte utilitare şi biblioteci
-var - date variabile.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 76
Interpretorul de comenzi/ interfaŃa SHELL. Accesul primar la calculator se face printr-un program care citeşte comenzile de la tastatură, le interpretează şi le execută. Dincolo de această aparenŃă simplă se ascund posibilităŃi sofisticate de combinare a programelor, fişiere de comenzi, monitorizarea şi controlul execuŃiei.
Shell-ul este interfaŃa primară a utilizatorului cu sistemul de operare. Un shell UNIX este în primul rând un interpretor de comenzi, permiŃând execuŃia bogatului set de utilitare UNIX. În al doilea rând, shell-ul este un limbaj de programare care dă posibilitatea combinării acestor comenzi în activităŃi complexe. El oferă utilizatorului un control complet asupra programelor: execuŃia lor poate fi sincronă sau asincronă, intrările şi ieşirile pot fi redirecŃionate, mediul de execuŃie poate fi ajustat după dorinŃă. În mod neinteractiv shell-ul citeşte comenzi dintr-un fişier. Astfel, utilizatorul poate folosi facilităŃile de programare ale shell-ului: variabile, structuri de control (if, while, for), subprograme.
Unul din shell-urile tradiŃionale UNIX este BASH (acronim pentru Bourne-Again Shell), scris de Stephen Bourne. Toate comenzile interne ale shell-ului sunt disponibile şi în bash. FacilităŃile de macroprelucrare sunt în conformitate cu POSIX 1003.2.
Exemplu. Să se sorteze în ordine inversă lista fişierelor din directorul: $ ls cuprins bibliografie capitolul 2 capitolul 1 introducere
SoluŃie: $ ls > lista_fişiere $ sort -r lista_fişiere
Rezultat afişat: introducere capitolul 1 capitolul 2 bibliografie cuprins

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
77
Metoda de mai sus necesită folosirea explicită a unui fişier intermediar temporar precum şi execuŃia succesivă a unor comenzi. O soluŃie mai bună este oferită de shell şi se numeşte prelucrare în conductă (pipelining). Prelucrarea în conductă permite să se conecteze un şir de comenzi în care ieşirea standard a fiecăreia dintre ele este conectată direct la intrarea standard a celei care urmează. Această conectare între o ieşire şi o intrare este simbolizată de caracterul "|".
Astfel lista sortată este obŃinută prin conectarea în conductă a comenzii ls şi a programului sort.
$ ls | sort -r
Pentru examinarea conŃinutului unui director mai mare, se foloseşte
programul less (pentru vizualizare): $ ls /usr/bin | less
Comenzi generale: $ date - afişează data curentă; $ exit - închide sesiunea de lucru; $ man - această comandă realizează o căutare a subiectului indicat în
sistemul de fişiere cu documentaŃie de care dispune eventual sistemul; $ man man - pentru a afla informaŃii despre sistemul de manuale on-
line; ObservaŃie. Pe unele sisteme cu resurse reduse (memorie internă, spaŃiu
pe disc) sistemul de manuale este înlocuit cu un help mai puŃin consumator de resurse, dar cu mai puŃine informaŃii:
$ help who - se obŃin informaŃii despre opŃiunile comenzii who; Comenzi SHELL referitoare la fişiere:
$ mkdir nume_catalog - creează un nou catalog (director) cu numele: nume_catalog, în directorul curent;
$ rmdir nume_catalog - şterge directorul nume_catalog; acesta trebuie să nu conŃină nici un fişier;
$ pwd - afişează catalogul curent de lucru al utilizatorului; $ cd [nume_catalog] - schimbă catalogul curent, noul catalog de
lucru fiind cel specificat în nume_catalog; $ ln nume_fişier nume_legatură - creează o noua legătură
cu numele la fişierul nume_fişier; $ rm nume_fişier - şterge fişierul nume_fişier; $ mv nume_vechi nume_nou - redenumeşte/ mută un fişier;

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 78
$ cp fişier_sursă fişier_destinaŃie - copiază fişiere $ find catalog_start -name fişier –print - afişează
numele cataloagelor (din structura arborescentă a cărei rădăcini este specificată ca prim parametru al comenzii), care conŃin fişierul cu numele fişier.
Dezvoltarea de programe sub UNIX Pentru editarea fişierelor sursă se poate folosi unul dintre următoarele
editoare: vi, joe, jed. De exemplu, cel mai simplu şi mai folosit mod de a apela vi este: $ vi nume_fisier unde nume_fişier este numele fişierului de editat. După
introducerea acestei linii de comandă, pe ecran vor fi afişate liniile de început ale fişierului. Pe ultima linie a ecranului apare un mesaj care constă din numele fişierului şi dimensiunea sa în cazul în care fişierul există pe disc sau numele fişierului şi mesajul ”No such file or directory” sau ”New file” în funcŃie de versiunea de vi.
Dialogul utilizator/ vi se desfăşoară fie în modul comandă, fie în modul introducere text. La terminarea introducerii textului se apasă <ESC> pentru trecerea în modul comandă.
Exemple de comenzi vi: • :wq – salvarea pe disc şi ieşirea din vi;
• :w – scriere în fişierul specificat în linia de apel a editorului fără închiderea editorului;
• :w nume_fisier2 – scrierea în fişierul nume_fisier2 (alt fişier decât cel specificat iniŃial în linia de apel);
• :q - ieşirea din editor fără salvare dacă nu s-au făcut modificări;
• :q! - ieşirea din editor fără salvarea modificărilor.
O altă variantă este lansarea shell-ului Midnight Commander prin
comanda: $ mc şi editarea fişierului sursă ca şi în Norton Commander sau Dos
Navigator.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
79
Linux oferă un mediu complet UNIX pentru dezvoltarea de programe şi aplicaŃii, incluzând bibliotecile standard, compilatoarele, depanatoarele şi întregul set de utilitare software necesar. În mod obişnuit, dezvoltarea de programe pentru UNIX se face în limbajele C/C++. Compilatorul standard pentru aceste limbaje este compilatorul GNU, gcc pentru C şi g++ pentru C++.
În afară de C şi C++, multe alte limbaje compilate sau interpretate sunt disponibile sub Linux, cum ar fi Smalltalk, FORTRAN, Pascal, Lisp, Scheme, JAVA şi Ada. În plus, sunt disponibile asambloare pentru scrierea de cod în mod protejat pentru i80386. Interpretoare sofisticate, răspândite în lumea UNIX, cum este Perl sau Tcl/Tk pentru dezvoltarea de aplicaŃii sub Xwindow sunt disponibile şi sub Linux. Depanatorul standard este gdb, care permite execuŃia controlată a unui program sau analiza unui vidaj de memorie. Cu ajutorul utilitarului Gprof se realizează culegerea de statistici referitoare la execuŃia unui program în scopul ameliorării performanŃelor sale. Alte utilitare includ make pentru compilarea aplicaŃiilor mari şi RCS, un sistem pentru întreŃinerea versiunilor unui program. Legarea bibliotecilor se poate face dinamic, permiŃând fişiere executabile mici sau înlocuirea de rutine din bibliotecă cu rutine utilizator. Linux este astfel un mediu ideal pentru dezvoltarea de programe: modern, standard şi bine echipat.
Portabilitatea pe alte sisteme de tip UNIX este facilă. Exemplu. SecvenŃa de comenzi: $ gcc p1.c $ mv a.out p1
care este similară cu: $ gcc p1.c -o p1 $ p1 are ca efect compilarea programului p1.c în programul p1. Dacă nu se specifică parametrul [-o nume] compilatorul produce ca
ieşire executabilul a.out.
Alte opŃiuni ale compilatorului gcc se pot găsi prin comanda: $ man gcc
Exemplu de opŃiuni: • O realizează optimizarea codului executabil, este bine să se folosească în
special, dacă se urmăreşte viteza de execuŃie şi nu lungimea codului;

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 80
• c realizează numai compilarea, care în combinaŃie cu -o generează mai multe fişiere obiect care apoi vor fi link-edit-ate într-un singur executabil;
• l[biblioteca] introduce la link-edit-are biblioteca cerută, în desfăşurarea lucrărilor de laborator se va utiliza biblioteca matematică (lm) şi pthread (lpthread);
• L/path dă indicaŃii asupra localizării bibliotecilor suplimentare, nu cele implicite ale compilatorului;
• I/path dă indicaŃii asupra localizării header-elor suplimentare.
Exemplu. SecvenŃa: $gcc -c p1.c -o p1.o -I/home/user/include $gcc -c p2.c -o p2.o -I/usr/local/include $gcc p1.o p2.o main.c -L/usr/local/lib -
L/home/user/lib -lmylib -luser -o program
• compilează p1.c cu header-ele suplimentare în /home/user/include şi generează p1.o;
• compilează p2.c cu header-ele suplimentare în /usr/local/include şi generează p2.o;
• compilează main.c şi generează executabilul program, el va fi link-edit-at cu obiectele p1.o şi p2.o împreună cu bibliotecile libmylib.a şi libuser.a care se găsesc în /usr/local/lib şi /home/user/lib.
Căutarea în biblioteci se face în ordinea specificării opŃiunilor -l în linia
de comandă. Bibliotecile sunt fişiere cu extensia .a (archive file pentru biblioteci statice) sau .so (pentru biblioteci dinamice).
Cele mai folosite biblioteci se află în cataloagele /lib, /usr/lib şi /usr/local/lib, dar pot exista şi în /opt/lib în alte sisteme (dependent de distribuŃie).
Pentru a verifica dacă o rutină este inclusă într-o anumită bibliotecă se poate utiliza bibliotecarul UNIX ar şi comanda:
$ ar -t nume_biblioteca
care va determina listarea la terminal a tuturor numelor rutinelor din biblioteca cu numele specificat. Numele bibliotecii trebuie să înceapă cu lib şi să aibă extensia a

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
81
După ce o bibliotecă a fost creată ea trebuie iniŃializată (se comunică
sistemului existenŃa unei noi biblioteci) cu comanda: $ ranlib libxxx.a
Acum biblioteca poate fi semnalată compilatorului cu opŃiunea –lxxx;
se observă că nu se specifică numele întreg , ci numai secvenŃa din nume cuprinsă între lib şi extensie.
Biblioteca folosită implicit în editarea de legături este /usr/lib/libc.a.
Utilitarul make a fost creat pentru întreŃinerea programelor mari, compuse dîntr-o mulŃime de fişiere sursă, a căror compilare poate deveni problematică. Pe baza unui fişier de descriere, make determină care componentă trebuie recompilată şi execută comenzile corespunzătoare pentru recompilare.
Fişierul de descriere al lui make se recomandă a fi numit makefile sau Makefile dar poate avea orice nume dorit dacă se lansează:
$ make -f nume_makefile
Un fişier makefile este în principal compus din reguli. O regulă are schema următoare: łINTA (sau SCOPUL): DEPENDENłE COMANDA1 COMANDA2 łINTA sau SCOPUL este de obicei numele unui fişier generat sau
actualizat de program. O dependenŃă este un fişier utilizat în crearea Ńintei. O Ńintă poate avea mai multe dependenŃe care apar pe aceeaşi linie.
Exemplu. Se consideră fişierul makefile: prog: principal.o sub1.o sub2.o cc -o prog principal.o sub1.o sub2.o principal.o: principal.c def.h sub1.o: sub1.c def.h sub2.o: sub2.c def.h clean: rm -rf prog *.o

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 82
Acest fişier descrie dependenŃele programului executabil prog. Acesta este compus din modulele obiect principal.o, sub1.o, sub2.o. Este regula pe care make o aplică implicit. Dacă unul din modulele obiect este mai recent decât executabilul, atunci se va da comanda de link-edit-are asociată.
Înainte de link-edit-are make va examina regulile următoare care determină generarea fiecărei dependenŃe ale primei reguli. Aceste trei reguli descriu dependenŃele modulelor obiect de sursele corespunzătoare şi de fişierul antet def.h. Ele nu au comenzi: make ştie că fişierele *.o se obŃin din fişierele *.c prin compilare. Din cauză că fişierul executabil depinde de aceste obiecte, ori de câte ori se modifică o sursă sau antetul, obiectul corespunzător va fi regenerat ceea ce va conduce la re-link-edit-area din prima regulă. Ultima regulă are Ńinta clean şi nu are dependenŃe, deci nu va fi executată decât la comanda explicită a utilizatorului make clean. Ştergerea fişierului executabil şi a celor obiect forŃează ulterior regenerarea completă a programului prog.
În practică, fişierele makefile sunt sensibil mai complicate: includ alte fişiere makefile, conŃin definiri de variabile precum şi prelucrări condiŃionate.
Comenzi SHELL referitoare la gestiunea proceselor Pentru a obŃine o imagine a stării la un moment dat a proceselor sistem se poate utiliza comanda:
$ ps [optiuni]
Dacă nu se specifică alte opŃiuni se afişează numai lista de procese asociate terminalului curent. Câteva din opŃiunile posibile: • -a - afişarea de informaŃii despre toate procesele din sistem cu excepŃia
proceselor de tip process group leaders şi a proceselor neasociate cu un terminal;
• -e - afişarea de informaŃii despre absolut toate procesele din sistem; • -f - listing complet; se caută atât în memorie cât şi în zona de evacuare
(swapping) pentru a afla comanda completă cu care s-a creat procesul; dacă nu se reuşeşte, se afişează numai numele prescurtat al comenzii între [].
• -l - format lung de afişare (informaŃie completă).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
83
Tot pentru vizualizarea proceselor din sistem se poate folosi programul top (Linux) prin comanda: $ top [opŃiuni] [fişier]
Programul permite monitorizarea în timp real a proceselor din sistem şi a altor parametrii cum ar fi încărcarea sau utilizarea memoriei.
Lista opŃiunilor:
• k - distruge un proces; • i - afişează doar procesele active; • n sau # - modifică numărul proceselor afişate; • r – modifică prioritatea (vezi nice) a unui proces; • S - schimbă modul cumulativ; totalizează sau nu şi timpul proceselor; • s - schimba intervalul de actualizare a datelor pe ecran; • f sau F - adaugă sau scade câmpuri afişate; • o sau O - modifică ordinea de afişare a informaŃiilor; Utilizatorul are posibilitatea să determine terminarea forŃată a unor procese care lucrează, durează mult, nu evoluează conform aşteptărilor, sunt blocate în aşteptarea unor condiŃii care nu se vor îndeplini niciodată. Pentru aceasta el are la dispoziŃie comanda: $ kill [număr_semnal] identificator_proces
Comanda kill poate controla într-un mod mai complex execuŃia proceselor, mod dependent chiar de procesele controlate. Procesele pot primi din exterior semnale şi pot reacŃiona la acestea în modul în care programatorul crede de cuviinŃă.
Semnalul SIGKILL (cu numărul 9) nu poate fi tratat de procese şi efectul va fi ca procesul dispare. OpŃiunea -l tipăreşte o listă a semnalelor disponibile în sistem pentru comunicarea cu procesele. Utilizarea cea mai frecventă este de forma: $ kill -SIGTERM 678

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 84
care transmite procesului cu identificatorul 678 semnalul SIGTERM în speranŃa că acesta se va termina.
În administrarea sistemului se folosesc frecvent semnalele SIGHUP sau SIGINT pentru a comunica unor procese server faptul că s-au efectuat modificări în sistem şi acestea vor trebui, de exemplu, să-şi recitească fişierele de configuraŃie. Utilizarea semnalelor în acest scop depinde de fiecare caz în parte şi este descrisă în documentaŃia fiecărui proces în parte. Modificarea priorităŃii de execuŃie a unui proces se realizează prin comanda: $ nice [-increment] comanda [argumente]
Astfel comanda se va executa la o prioritate, de regulă, mai mică. Prioritatea de planificare este un întreg între -20 (cea mai mare prioritate) şi 19 (cea mai mică). Valoarea increment se adaugă priorităŃii moştenite. Dacă nu se specifică, prioritatea este implicit egală cu 10. Crearea a noi procese de către utilizator va reprezenta subiectul lucrării următoare. 2.5.3. Sistemul de operare PARIX
PARIX este un sistem de operare destinat transputerelor. Limbajele de programare care permit, în momentul actual, utilizarea facilităŃilor acestui sistem sunt: C, ANSI C, PASCAL, MODULA, , C++, FORTRAN 77, FORTRAN 90.
Fiecare procesor aparŃine partiŃiei de lucru destinată utilizatorului şi deŃine o copie a programului.
Comportarea diferită a procesoarelor se datorează:
• execuŃiei codului care depinde de poziŃia procesorului în reŃea; • execuŃiei unor instrucŃiuni identice asupra unor date diferite.
Topologia reŃelei fizice a unui sistem de transputere sub PARIX este bazat pe o grilă tridimensională. Sistemul permite şi emularea pe o grilă bidimensională. Identificarea poziŃiei unui procesor este esenŃială pentru execuŃia unui program. Ea este realizată printr-un set de date globale păstrate în fiecare nod-element de procesoare.
Principalele date sunt:
• dimensiunile spaŃiale ale reŃelei de procesoare;

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
85
• numărul de procesoare din reŃea; • poziŃia în spaŃiu a procesorului; • identificatorul procesorului.
Identificatorul este utilizat pentru a atribui date sau cod unui anumit pro-cesor. Mecanismul de accesare a datelor de identificare diferă de la un limbaj la altul.
Partea statică a unui program sub sistem PARIX include un mecanism iniŃial de încărcare care distribuie un program “principal” identic tuturor procesoarelor. Datele globale ale unui nod conŃin setul ce permite identificarea poziŃiei procesorului în reŃea (în “structura rădăcină”). Depinzând de poziŃia proprie, fiecare procesor execută diferite secŃiuni ale programului.
FacilităŃile de comunicare sub PARIX sunt reprezentate de legăturile virtuale. O legătură virtuală este o linie de comunicare între două procesoare, bidirecŃională, sincronizată, ce nu utilizează buffere. Definirea corectă a unui set de legături virtuale permite construirea unei topologii virtuale, ca de exemplu arborele binar sau hipercubul.
Există patru tipuri de comunicare posibile în sistemul PARIX:
• comunicarea sincronă printr-o legătură virtuală. Procesele conectate printr-o legătură virtuală sunt sincronizate în timpul comunicării. Procesul care atinge primul un punct de comunicare aşteaptă intrarea în aceeaşi fază a celuilalt, astfel încât transferul de date are loc numai când ambele procese sunt pregătite pentru comunicare. Un proces poate aştepta simultan comunicaŃiile prin mai multe legături. FuncŃiile C de bibliotecă utilizate pentru comunicarea sincronă printr-o legătură virtuală sunt: Send( ), Recv( ), SendLink( ), RecvLink( ), Select( );
• comunicarea sincronă aleatoare nu necesită definirea unor legături virtuale. FuncŃiile C de bibliotecă sunt: SendNode( ), ReceiveNode( );
• comunicarea asincronă printr-o legătură virtuală. Se efectuează simultan cu calculul. Emiterea şi recepŃionarea informaŃiilor este realizată în timp ce procesul continuă execuŃia. Mesajele sunt stocate în buffere intermediare atât la emiŃător cât şi la receptor. FuncŃiile C corespunzătoare sunt: AInit( ), ASend( ), ARecv( ), ASync( );
• comunicarea asincronă aleatoare este bazată pe principiul „cutiilor poştale”. Nu este necesară o legătură virtuală între cele două procese care comunică. Transferul de date are loc pe baza utilizării reŃelei fizice. Procesul receptor are posibilitatea de a gestiona „cutia poştală” şi poate

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 86
aştepta sosirea unui anumit mesaj. FuncŃiile specifice sunt: PutMessage(), GetMessage( ), ExchangeMessage( ).
Decizia de utilizare unui anumit tip de comunicare este la îndemâna utilizatorului. PerformanŃele cele mai ridicate se obŃin în cazul primelor trei tipuri.
Pentru realizarea asincronă a unor operaŃii distincte se utilizează tehnica thread (sarcină, obligaŃie), care permite rularea concurentă în acelaşi context şi partajarea tuturor variabilelor globale definite în program. Sincronizarea se realizează prin operarea asupra unor semafoare. Tehnica thread permite rularea concurentă a mai multor procese pe un singur procesor.
Într-un sistem de calcul conceptul de proces este fundamental. Acesta este creat în memoria calculatorului de către sistemul de operare atunci când utilizatorul comandă calculatorului execuŃia unui program şi este format din instrucŃiuni, date şi o parte administrativă. În memoria calculatorului informaŃia unui proces se organizează în trei regiuni repartizate în două zone: partea administrativă a procesului (tabelul paginilor de memorie alocate, fişiere deschise, valoarea registrului numărător de program la pierderea controlului CPU etc.) este în zona alocată sistemului de operare, iar instrucŃiunile şi datele sunt repartizate în zona utilizator. Un proces poate fi activ (atâta timp cât sistemul execută instrucŃiuni ale sale) sau inactiv (când nu este în execuŃie şi se află într-una din stările: gata de execuŃie, în aşteptare pe disc etc.). Sistemul de operare acŃionează ca un comutator, repartizând diferitele procese diverselor procesoare (planificarea proceselor -scheduling) şi protejând zonele de memorie ale fiecărui proces faŃă de celelalte (gestiune a memoriei –memory management).
Procesele concurente pot fi create în mod static (dacă sunt specificate înaintea execuŃiei, în acest caz numărul de procese este fix) sau dinamic (dacă se generează şi se distrug în timpul execuŃiei, în acest caz numărul de procese este variabil). În ambele cazuri programele sunt compilate şi transformate în coduri executabile înaintea execuŃiei propriu-zise.
Pentru execuŃia unui program paralel, procesele concurente pot fi grupate şi asignate unor procesoare virtuale (unităŃi de planificare). Paralelismul este introdus atât de ansamblul proceselor definite în cadrul programului cât şi de ansamblul procesoarelor. Se definesc patru tipuri de paralelism: paralelismul pur (când fiecare proces este încapsulat de un procesor virtual constituit dintr-un singur procesor); paralelism la nivel de utilizator (când un procesor virtual format dintr-un singur procesor are atribuite mai multe procese); paralelism la nivel de sistem (când un procesor virtual încapsulează un singur proces, iar pe un procesor sunt definite mai multe

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
87
procesoare virtuale); paralelism dublu imbricat (când un procesor virtual încapsulează mai multe procese şi pe un singur procesor se definesc mai multe procesoare virtuale). Sistemele de operare sunt şi ele programe paralele, chiar dacă sunt formate din supervizoare separate pentru fiecare procesor (o copie a sistemului de operare), o structură stăpân-sclav (un procesor - master lucrează în mod supervizor, iar celelalte -slave, lucrează în mod utilizator), sau o structură simetrică (sistemul de operare se execută de către toate procesoarele).
În cazul în care limbajul de programare paralelă nu permite exprimarea explicită a paralelismului, pentru crearea şi distrugerea proceselor paralele se pot folosi construcŃii de tipul process_fork (care are ca efect copierea zonei de memorie ocupată de procesul părinte de un număr de ori dat de numărul proceselor nou create, cu excepŃia regiunii partajate cu alte procese) şi process_join (care are ca efect asocierea proceselor).
Conceptul de thread sau proces uşor (lightweight), permite realizarea unei operaŃii echivalente cu process_fork, dar mult mai rapid. Când se încarcă programul în memorie, se creează un număr de copii ale procesului părinte, egal cu numărul de procesoare, iar după încărcare se trece controlul procesului părinte, singurul care se execută. Când acesta apelează process_fork, thread-urile vor începe execuŃia din punctual indicat în apel, iar la întâlnirea unui apel process_join, tread-ul este suspendat şi nu distrus, ceea ce va permite reutilizarea sa, întâlnirea unui nou process_fork. Pentru această operaŃie se extinde modelul de proces prin crearea unei biblioteci pentru thread-uri sau prin modificări ale sistemului UNIX (utilizarea sistemului MACH, SYMUNIX, TROLLIUS sau IDRIS, vezi [Gri00]).
O facilitate dinamică este posibilitatea de încărcare a unui cod adiŃional la orice moment pentru unul sau mai multe procesoare. FuncŃia C de bibliotecă care permite apelul unor coduri adiŃionale este Execute( ).
Fiecărei legături virtuale i se asociază un bloc de control a legăturii, LinkCB. ComunicaŃiile prin legăturile virtuale se realizează pe baza accesării blocului LinkCB corespunzător. Într-o topologie virtuală, comunicarea datelor se efectuează pe baza aceluiaşi mecanism, dar blocul de control este înlocuit cu anumite adrese topologice, identificate prin ID şi poziŃii relative.
Topologiile virtuale au fost construite pentru a uşura munca utilizatorului. Legăturile care constituie structura unei grile tridimensionale pot fi gestionate separat de legăturile care formează, de exemplu, un hipercub. O legătură dintr-un asemenea context poate fi specificată prin numărul de legătură relativ la topologia virtuală.
Astfel, se pot conferi nume simbolice legăturilor unei grile bidimensionale, *sud*, de exemplu, sau legăturii *părinte* într-un arbore. FuncŃiile Send( ),

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 88
Recv( ), ASend( ), ARecv( ) operează asupra topologiilor virtuale prin specificarea orientării relative în topologie, iar funcŃiile SendLink( ), RecvLink( ) se referă direct la blocul de control LinkCB. Biblioteca topologiilor virtuale ajută programatorul în construirea reŃelelor de comunicare pentru anumite probleme standard. În plus, prin utilizarea topologiilor din bibliotecă, la execuŃie se realizează implicit o optimizare a legăturilor virtuale pe structura fizică de comunicare.
Astfel, la nivelul:
- legăturilor virtuale, transpunerea pe reŃea se realizează implicit;
- topologiilor definite de utilizator, transpunerea se face de asemenea implicit;
- topologiilor din bibliotecă, se realizează optimizarea proiecŃiei pe reŃeaua fizică.
Este permisă adăugarea unor legături suplimentare într-o topologie virtuală. În acest scop au fost construite o serie de funcŃii care extrag blocul de control al unei legături dintr-o topologie dată.
Multiplicarea mesajelor se explică prin faptul că la execuŃie programul este multiplicat la numărul de procesoare specificat în comanda run.
Comportarea fiecărui procesor este determinată de poziŃia procesorului în reŃea. Structura definitorie pentru poziŃia procesorului în configuraŃie este: GET_ROOT()->ProcRoot (din fişierul root.h) care conŃine o serie de informaŃii:
typedef struct { int MyProcID; /*identificatorul procesorului*/ int MyX; /*coordonata pe axa x*/ int MyY; /*coordonata pe axa y*/ int MyZ; /*coordonata pe axa z*/ int nProcs; /*numarul de procesoare*/ int DimX; /*dimens. max. a grilei pe axa x*/ int DimY; /*dimens. max. a grilei pe axa y*/ int DimZ; /*dimens. max. a grilei pe axa z*/ }
RootProc_t;

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
89
2.5.4. Parallel Virtual Machine (PVM) Surse: [DL03], Pagina oficială a PVM: http://www.epm.ornl.gov/pvm/pvm_home.html
PVM (Parallel Virtual Machine) este un pachet de programe dezvoltat de Oak Ridge National Laboratory, Universitatea statului Tennessee şi Universitatea Emory, care permite ca o mulŃime eterogenă de maşini UNIX (PC, staŃii de lucru, calculatoare paralele, calculatoare vectoriale), legate în reŃea, să funcŃioneze ca un singur calculator paralel. Astfel, prin utilizarea puterii de calcul a mai multor calculatoare, pot fi rezolvate probleme care necesitau utilizarea unor calculatoare paralele foarte puternice, prohibitive din punct de vedere al costului (circa 10 mil. $). Mai mult decât atât, dacă se vor conecta în această reŃea si câteva calculatoare masiv paralele sau supercalculatoare, se poate obŃine o putere de calcul foarte greu de realizat în alt mod. Proiectul PVM a fost demarat în vara anului 1989 la Oak Ridge National Laboratory. Sistemul prototip PVM 1.0 a fost conceput de Vaidy Sunderam si Al Geist, această versiune fiind utilizată numai în cadrul laboratorului. Versiunea 2 a PVM a fost scrisă la Universitatea Tennessee si distribuită în martie 1991. Deja în anul următor, PVM era utilizat pentru rezolvarea multor probleme ştiinŃifice. Versiunile PVM 2.1 până 2.4 au fost dezvoltate pe baza sugestiilor primite de la utilizatori, astfel corectându-se unele greşeli si operându-se mici modificări. În februarie 1993, PVM a fost complet rescris si a fost distribuit ca PVM 3. Cu versiunea PVM 3.3.0 din iunie 1994 a fost adăugată si o interfaŃă grafică X-window, numită XPVM. Pagina oficială a PVM-ului este la http://www.epm.ornl.gov/pvm/pvm_home.html. Software-ul şi documentaŃia pot fi obŃinute prin ftp anonim de la netlib.att.com şi netlib2.cs.utk.edu/pvm3 sau http://www.netlib.org/pvm3. PVM asigură un mediu de lucru unitar în care programele paralele pot fi dezvoltate într-o manieră eficientă, utilizând mediul hardware deja existent. Se asigură o transparenŃă în rutarea mesajelor prin reŃea, în conversia datelor si în planificarea taskurilor pe calculatoarele din reŃea (care sunt diferite). Modelul de calcul utilizat de PVM este simplu: utilizatorul va scrie aplicaŃiile ca o colecŃie de taskuri care cooperează. Aceste taskuri vor accesa resursele PVM cu ajutorul unor biblioteci de rutine de interfaŃă. Rutinele din cadrul bibliotecilor asigură iniŃierea si terminarea taskurilor, comunicarea si sincronizarea între taskuri. În orice punct al execuŃiei unei aplicaŃii concurente, orice task în

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 90
execuŃie poate iniŃia sau termina alte taskuri, poate adăuga sau elimina calculatoare din maşina virtuală. Sunt incluse facilitatea de asigurare a toleranŃei la defecte. Astfel, dacă unul sau mai multe calculatoare "cad", se asigură funcŃionarea în continuare a maşinii virtuale. Utilizatorii pot scrie aplicaŃii paralele în Fortran sau C utilizând Rutinele din bibliotecile PVM. Modelul de programare utilizat este cel cu transfer de mesaje (message-passing), adică prin trimiterea si recepŃionarea mesajelor, taskurile aplicaŃiei pot coopera pentru a rezolva o problemă în paralel . PVM este utilizat în peste o mie de locuri din lume ca o alternativă, eficientă din punct de vedere al raportului cost/performanŃe, pentru calculatoarele paralele puternice. În Statele Unite cei mai importanŃi utilizatori sunt NASA şi Departamentul Energiei, fără să mai luăm în considerare numeroasele universităŃi unde este utilizat atât pentru cercetare cât si pentru realizarea orelor de aplicaŃii. Şi la noi în Ńară PVM este utilizat în unele universităŃi, dintre acestea se pot aminti Universitatea Transilvania Braşov (unde se desfăşoară un seminar PVM), Universitatea Tehnică "Gh. Asachi" Iaşi (în cadrul orelor de aplicaŃii la disciplinele de calcul paralel ;i distribuit), Universitatea "Politehnica" Bucureşti, Universitatea Tehnică Timişoara şi Universitatea din Oradea. Mai există câteva sisteme software cu o funcŃionalitate asemănătoare, dintre acestea se pot aminti: P4 (Argonne National Laboratory), Express (ParaSoft Corporation), Linda (Scientific Computing), MPI-Message Passing Interface. Obiectivul general al sistemului PVM este să permită unei mulŃimi de calculatoare să fie utilizată pentru calculul paralel sau concurent.
Prezentăm pe scurt principiile pe care se bazează PVM: • "Host-pool" configurat de utilizatori: taskurile aplicaŃiei sunt
executate pe un set de maşini (hosts) care sunt selectate de utilizatori pentru o rulare dată a PVM. Din acest host-pool pot face parte atât maşini uniprocesor, cât si maşini multiprocesor (incluzând calculatoare cu memorie partajată si cu memorie distribuită). În timpul rulării acest host-pool poate fi modificat prin adăugarea sau eliminarea unor maşini, aceasta fiind o trăsătură importantă pentru asigurarea toleranŃei la defecte.
• Acces transparent la hardware: programele de aplicaŃie pot vedea mediul hardware ca o colecŃie de procesoare virtuale asemenea sau pot alege ca părŃi ale problemei să fie rulate pe o anume gazdă, adică pe cea mai potrivită pentru subproblema respectivă.
• Calcul bazat pe procese: unitatea de calcul în cadrul PVM este taskul (adeseori, dar nu totdeauna un proces UNIX). Nu este implicată o mapare proces - procesor, în particular mai multe taskuri pot fi executate într-un singur procesor.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
91
• Model message-passing explicit: taskurile unei aplicaŃii cooperează prin trimitere si recepŃionare de mesaje. Mărimea mesajelor este limitată doar de mărimea memoriei disponibile.
• Suport pentru eterogenitate: sistemul PVM suportă eterogenitatea în termenii maşinii, ai reŃelei şi ai aplicaŃiilor. În ceea ce priveşte schimbul de mesaje, PVM permite ca mesajele să conŃină mai mult de un singur tip de date şi să fie schimbate între maşini cu reprezentări diferite ale datelor.
• Suport pentru multiprocesoare: PVM utilizează facilităŃile hardware native de transfer a mesajelor din cadrul sistemelor multiprocesor.
Sistemul PVM este alcătuit din două componente: • Prima parte este reprezentată de un demon, numit pvmd3 sau pvmd, care
trebuie lansat pe fiecare procesor fizic participant la maşina virtuală. Denumirea demon vine de la faptul că respectivul program este lansat în background (în fundal) şi rămâne în aşteptarea unei solicitări la care să răspundă. Acest demon a fost proiectat, astfel încât orice utilizator să-l poată instala pe orice maşină, dacă dispune de un login valid. Când un utilizator doreşte să ruleze o aplicaŃie PVM, va trebui să-şi creeze maşina virtuală si apoi să pornească maşina. O aplicaŃie PVM poate fi pornită de la orice gazdă. Mai mulŃi utilizatori pot configura maşini virtuale care se pot suprapune, iar fiecare utilizator poate executa câteva aplicaŃii PVM simultan.
• A doua componentă este reprezentată de o bibliotecă de rutine PVM. Aceasta conŃine un set complet de primitive care sunt necesare pentru cooperarea între taskuri . ConŃine setul de funcŃii prin intermediul cărora o aplicaŃie PVM poate folosi mecanismele de schimb de mesaje, sincronizare între procese, de creare de noi procese sau de modificare a maşinii virtuale oferite de PVM. Deoarece PVM suportă programe scrise în limbajele C si FORTRAN, vor exista de fapt două biblioteci, una pentru C (libpvm3.a) si alta pentru FORTRAN (libfpvm3.a).
Modelul de calcul utilizat se bazează pe faptul că o aplicaŃie este alcătuită din mai multe taskuri. Fiecare task este responsabil pentru calculul unei părŃi a problemei.
O aplicaŃie poate accesa resursele de calcul în trei moduri diferite: • modul transparent - în care taskurile sunt plasate automat de sistem pe
maşina cea mai potrivită, fără intervenŃia utilizatorului.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 92
• modul dependent de arhitectură - în care utilizatorul poate indica o arhitectură specifică pe care un task să fie executat.
• modul „lowe-level”, cu specificare a maşinii - în care utilizatorul poate specifica o maşină anume pe care să se execute un anumit task.
Această flexibilitate permite diferitelor taskuri ale unei aplicaŃii să exploateze eficient puterea de calcul din cadrul maşinii virtuale. Dacă o aplicaŃie este paralelizată din punct de vedere al funcŃiilor pe care le realizează, adică fiecare task execută o funcŃie diferită (de exemplu intrare, soluŃionare, ieşire, afişare), acest proces se numeşte paralelism funcŃional. O altă metodă de paralelizare este exploatarea paralelismului datelor. În cadrul acestei metode toate taskurile sunt identice, dar fiecare din ele deŃine şi utilizează pentru rezolvare numai o parte din date. Acest model mai este denumit SPMD (Single Program Multiple Data). Ambele modele, sau o combinaŃie a lor, pot fi utilizate pentru a dezvolta o aplicaŃie PVM. Toate taskurile PVM sunt identificate cu un întreg numit task identifier (TID). Aceste TID-uri trebuie să fie unice în cadrul maşinii virtuale si sunt asigurate de demonul pvmd local (deci nu sunt alese de utilizator). PVM conŃine rutine care returnează valoarea TID, astfel încât aplicaŃiile pot identifica taskurile din sistem. Pentru a programa o aplicaŃie, un utilizator va scrie unul sau mai multe programe secvenŃiale în C, C++, Fortran 77, cu apeluri la rutinele din bibliotecile PVM. Fiecare program va fi de fapt un task, toate aceste taskuri formând aplicaŃia, a cărui execuŃie poate fi paralelizată prin intermediul unor primitive de comunicaŃie prin mesaje, tipice oricărei maşini MIMD cu memorie distribuită. În acest fel, prin schimb de mesaje, mai multe task-uri pot coopera pentru rezolvarea paralelă a unei probleme. Fiecare task va fi compilat pentru fiecare arhitectură existentă în host-pool şi fişierele se vor plasa la locaŃii accesibile maşinilor din host-pool. Pentru a executa o aplicaŃie, un utilizator iniŃiază o copie a unui task (numit task master) de la o maşină din host-pool, iar acesta va iniŃia taskuri PVM care pot fi rulate pe alte maşini sau pe aceeaşi maşină cu taskul master. Acesta este scenariul tipic, dar pot exista situaŃii în care mai multe taskuri sunt iniŃiate de utilizator, iar ele pot iniŃia la rândul lor alte taskuri. Consola PVM Consola PVM este un task PVM de sine stătător care permite utilizatorului să pornească, să interogheze şi să modifice maşina virtuală. Consola poate fi pornită si oprită de mai multe ori pe orice gazde din PVM fără a afecta rularea PVM sau a altor aplicaŃii. La pornire consola PVM determină dacă nu cumva aceasta rulează, dacă nu, pvm execută pvmd pe acea gazdă şi apoi execută pvmd, dar de această dată cu opŃiunea slave, pe celelalte gazde din configuraŃie. La pornire se afişează un prompter:

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
93
pvm> şi se aşteaptă introducerea unei comenzi.
Pentru mai multe detalii despre PVM se poate consulta [DL03] precum
pagina oficială a PVM: http://www.epm.ornl.gov/pvm/pvm_home.html.
2.5.5. Message Passing Interface (MPI)
Sursa web: http://www-unix.mcs.anl.gov/mpi/
MPI este un mediu de programare bazat pe transmitere de mesaje, open source, pentru programarea sistemelor paralele masive şi a staŃiilor de lucru din clustere. La pagina indicată mai sus se pot găsi detalii despre MPI şi chiar şi articole care fac comparaŃii între MPI Ńi PVM. De asemenea se poate descărca gratuit şi se poate instala o versiune a MPI. Tot aici se găsesc şi diverse articole şi manuale pentru învăŃarea MPI. S-a ajuns la MPI Standard 2.0 şi este disponibilă gratuit implementarea portabilă MPICH, standardul pentru bibliotecile bazate transmitere de mesaje, disponibilă la adresa de mai sus.
2.5.6. Globus Toolkit
Sursa web: Pagina oficială a comunităŃii Globus: http://www.globus.org/
Globus® Toolkit este standardul “de facto” al arhitecturii Grid, este un software open source utilizat în configurarea şi proiectarea grid-urilor. Versiunea Globus 1.0 a apărut în 1998 A început să fie dezvoltat de Globus Alliance şi de mulŃi alŃi participanŃi din întreaga lume. Un număr tot mai mare de proiecte şi companii folosesc Globus Toolkit pentru a exploata potenŃialul gridurilor. Comunitatea open source Globus Alliance produce o vastă varietate de componente software pentru Grid.
Problemele cheie în configurarea şi utilizarea sistemelor Grid în aplicaŃii de mare complexitate sunt:
• punerea în comun a resurselor (calculatoare, spaŃiu de stocare, senzori, reŃele), condiŃionată de problema încrederii, politici, negocieri, plată;
• rezolvare coordonată de probleme (integrarea resurselor distribuite, calcul colaborativ, organizaŃii virtuale dinamice şi multi-instituŃionale);
• reorganizarea dinamică comunităŃii (numeroasă sau restrânsă, statică sau dinamică).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 94
Principalele cerinŃe pentru buna funcŃionare a unui Grid sunt: autentificarea, autorizarea şi politici, descoperirea de resurse, caracterizarea resurselor, proiectarea de algoritmi distribuiŃi, accesul la date de la distanŃă şi transfer de mare viteză a datelor.
În rezolvarea problemelor de programare, utilizând Gridul, trebuie avute în vedere următoarele aspecte: facilitarea dezvoltării de aplicaŃii complexe, facilitarea utilizării codului în comun, existenŃa mediilor de programare (API, SDK)
În rezolvarea problemelor de sistem trebuie să luăm în considerare: folosirea coordonată de resurse, accesul la infrastructură (autorităŃi de certificare, servicii informaŃionale), existenŃa sistemelor (protocoale, servicii). Serverul GASS (Global Access to Secondary Storage) utilizat la sistemele
Grid permite următoarele facilităŃi: • simplifică rularea aplicaŃiilor care folosesc fişierele de I/O către mediul
Globus; • librăriile şi utilitarele sale permit eliminarea nevoii de a efectua manual
logarea la site-uri şi fişiere ftp. Pe serverul GASS se instalează un sistem distribuit de fişiere utilitare, cum
ar fi: • globus-gass-server, care permite utilizatorului pornirea unui server
GASS de sine stătător în care se pot încărca/descărca fişierele din sistemul local de fişiere;
• globus-gass-server-shutdown, care permite oprirea serverului GASS anterior pornit aflat la distanŃă;
• globus-gass-put, care permite încărcarea unui fişier în serverului GASS de la distanŃă;
• globus-gass-get, face posibilă descărcarea unui fişier în serverului GASS de la distanŃă;
• globus-gass-cache, care dă permisiunea unui utilizator să manipuleze conŃinutul unui server local sau la distanŃă şi diverse funcŃii ca: add, cleanup_tag, cleanup_file, list, delete.
Alte concepte importante utilizate de Globus Toolkit sunt:
• GRAM (Globus Resource Allocation Manager); • MDS (Monitoring and Discovery Service); • (GRIS) Grid Resource Information Service; • (GIIS) Grid Index Information Service.
Cei interesaŃi de utilizarea soluŃiilor oferite Globus Toolkit în aplicaŃii Grid vor găsi documentaŃia şi pachetele necesare instalării softului la pagina web: http://www.globus.org/toolkit/.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
95
CAPITOLUL 3 INTERCONECTAREA ÎN SISTEMELE DE CALCUL PARALEL ŞI DISTRIBUIT 3.1. PRAM, un calculator paralel idealizat 3.2. Procedee de interconectare în arhitecturile sistemelor de calcul paralel şi distribuit. ReŃele de calculatoare
3.2.1. ReŃea de tip “crossbar” 3.2.2. Interconectarea de tip “switchboard” 3.2.3. ReŃea de interconectare cu legături directe limitate
3.2.3.1. Magistrala comună (bus) 3.2.3.2. ReŃeaua liniară şi ciclică 3.2.3.3. ReŃeaua de tip amestecare perfectă 3.2.3.4. ReŃeaua arborescentă 3.2.3.5. ReŃeaua de tip latice 3.2.3.6. ReŃeaua de tip hipercub
3.1. PRAM: un calculator paralel idealizat
PRAM (Parallel Random Access Machine), este un model teoretic de calculator paralel cu memorie partajată.
Formal, un PRAM constă în p procesoare şi o memorie globală nelimitată, accesibilă uniform tuturor procesoarelor. Astfel, toate procesoarele accesează acelaşi spaŃiu de adrese. Procesoarele partajează un ceas comun, astfel încât pot executa instrucŃiuni diferite în acelaşi ciclu. Ca urmare, modelul PRAM are o memorie partajată sincron, în maniera calculatoarelor MIMD. Un model PRAM idealizează modelul secvenŃial de calcul, în sensul că este o extensie naturală a acestuia şi furnizează o metodă nelimitată de interacŃiune între calculatoare. Într-un astfel de model idealizat, orice procesor are posibilitatea de a scrie şi a citi simultan în aceeaşi locaŃie de memorie.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 96
Modelul PRAM poate fi împărŃit în patru subclase, în funcŃie de modul de accesare simultană a memoriei:
1.) PRAM-EREW (Exclusive-Read, Exclusive-Write) În acest model este exclusă scrierea sau citirea concurentă într-o locaŃie de memorie.
2.) PRAM-CREW (Conccurent-Read, Exclusive-Write)
În acest tip este permisă scrierea concurentă, iar citirea este serializată.
3.) PRAM-ERCW (Conccurent-Read, Conccurent Write)
Este modelul opus lui PRAM-CREW.
4.) PRAM-CRCW (Conccurent-Read, Conccurent-Write)
Este modelul cel mai puternic, în care sunt permise atât scrierea cât şi citirea concurentă.
Protocoalele de rezolvare a conflictelor în modelele descrise, pot fi:
� protocol comun: toate procesoarele care execută o operaŃie de scriere într-o locaŃie de memorie trebuie să scrie aceeaşi valoare comună;
� protocol prioritar: fiecărui procesor i se asociază un index, prioritate de scriere va avea procesul cu indexul mai mic;
� protocol arbitrar: procesorul care scrie mai puŃin are prioritate de acces la o locaŃie de memorie faŃă de restul.
În realitate, în calculatoarele paralele, procesoarele sunt legate între ele prin diverse reŃele de interconectare concrete şi au posibilităŃi limitate de comunicare.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
97
3.2. Procedee de interconectare în arhitecturile sistemelor de
calcul paralel şi distribuit. ReŃele de calculatoare
3.2.1. ReŃea de tip “crossbar” 3.2.2. Interconectarea de tip “switchboard” 3.2.3. ReŃea de interconectare cu legături directe limitate
3.2.3.1. Magistrala comună (bus) 3.2.3.2. ReŃeaua liniară şi ciclică 3.2.3.3. ReŃeaua de tip amestecare perfectă 3.2.3.4. ReŃeaua arborescentă 3.2.3.5. ReŃeaua de tip latice 3.2.3.6. ReŃeaua de tip hipercub
Într-un sistem de calcul paralel ideal de tip PRAM, fiecare procesor este
conectat cu oricare altul. În practică, însă, acest tip de interconectare este
posibil numai pentru un număr redus de procesoare. În construirea
calculatoarelor paralele, un rol important îl joacă tipul de problemă care se
rezolvă pe maşina respectivă, ceea ce influenŃează numărul de conexiuni între
procesoare. Reconfigurarea logică este posibilă, dar are un efect negativ asupra
timpului de execuŃie: dacă cerinŃele de conectare pentru un algoritm dat nu
corespund configuraŃiei reŃelei, atunci comunicarea între procesoare va reduce
viteza de execuŃie. PerformanŃele unei arhitecturi paralele depind mult de
numărul de procesoare dar şi de modul în care acestea sunt interconectate
(v.[Pet94], [Gri00], ş. a.).
Se utilizează o mare varietate de tipuri de interconectări, obŃinându-se o
multitudine de topologii arhitecturale, cum ar fi: structuri liniare, structuri
ciclice, “amestecare perfectă”, arbore binar, latice, hipercub ş.a.
În descrierea unei reŃele de interconectare trebuie să avem în vedere: topologia reŃelei (dinamică sau statică), modul de operare (sincron sau asincron), tehnica de comutare a circuitelor sau pachetelor şi tipul
mecanismului de control (global sau local).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 98
Vom descrie succint principalele tipuri de reŃele de interconectare.
3.2.1. ReŃea de tip “crossbar”
Este o topologie a unei arhitecturi paralele sub formă de reŃea ideală, în care fiecare procesor este conectat direct cu oricare altul. În fig. 3.2.1. avem o reŃea cu 4 procesoare. CerinŃele constructive şi preŃul mare nu permit însă realizări acceptabile pentru structuri cu mai mult de 16 procesoare.
Fig. 3.2.1. ReŃea de tip crossbar cu 4 procesoare
3.2.2. Interconectarea de tip “switchboard”
Este o topologie în care interconectarea procesoarelor se face indirect, prin intermediul unei punŃi de legătură numită “switchboard”, astfel încât într-un număr mic de paşi pot fi conectate oricare două procesoare. Se pot face şi conexiuni directe între procesoarele învecinate.
Fig. 3.2.2. O reŃea de tip switchboard cu 6 procesoare

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
99
3.2.3. ReŃea de interconectare cu legături directe limitate
3.2.3.1. Magistrala comună (bus) 3.2.3.2. ReŃeaua liniară şi ciclică 3.2.3.3. ReŃeaua de tip amestecare perfectă 3.2.3.4. ReŃeaua arborescentă 3.2.3.5. ReŃeaua de tip latice 3.2.3.6. ReŃeaua de tip hipercub
În acest tip de arhitectură paralelă, fiecare procesor este conectat direct cu un anumit număr de alte procesoare, topologia reŃelei depinzând de problema de rezolvat. Vom descrie în continuare cele mai importante modele de acest tip.
3.2.3.1. Magistrala comună (bus)
Este cea mai simplă soluŃie din punct de vedere logic şi constructiv al modului de interconectare a procesoarelor într-un sistem de calcul paralel, în care procesoarele comunică între ele doar prin intermediul memoriei comune. Această soluŃie este puŃin performantă, datorită limitărilor de comunicare.
3.2.3.2. ReŃeaua liniară şi ciclică
Într-o reŃea liniară, un procesor Pi este conectat cu vecinii săi Pi-1 şi Pi+1.
ReŃeaua ciclică aduce un plus de flexibilitate prin stabilirea unei comunicări şi
între primul şi ultimul procesor (v. Fig. 3.2.3).
Fig.3.2.3 Conexiunea liniară şi ciclică de ordinul n

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 100
3.2.3.3. ReŃeaua de tip amestecare perfectă
Atât numele acestei reŃele, cât şi modul de conexiune al procesoarelor
care o caracterizează provin dintr-o problemă de zi cu zi (din viaŃa unui amator
de jocuri de noroc!): amestecarea perfectă a cărŃilor de joc dintr-un pachet.
Astfel, să presupunem că un pachet cu n=2m cărŃi de joc numerotate de sus în
jos C0,…,Cn–1, este tăiat în două părŃi egale, formate din primele n/2 cărŃi şi din
ultimele n/2 cărŃi, părŃi care apoi se intercalează la fel ca în figura 3.2.4. (unde
am luat n=8).
Fig.3.2.4. Amestecare perfectă pentru n=8
Acest proces este cunoscut sub numele de amestecare perfectă (iar
realizarea lui depinde de experienŃa jucătorului de cărŃi!).
Se poate observa, că amestecarea perfectă se bazează de fapt pe o
permutare, pe care o notăm cu π. Ceea ce ne interesează este rezultatul acestei
permutări, π(i), unde am notat cu π(i) indicele cărŃii care ocupă poziŃia i în urma
amestecării (i = 0, …, n–1):
−−+
−−
112
1...21
2
11
2
10
12...43210:
nnnn
nnπ
Prin urmare, 0 este conectat cu el însuşi, 1 este conectat cu 4 care este conectat cu 2 care, la rândul său este conectat cu 1, ş.a.m.d. Se observă uşor că π–1(x)=2x (modulo n–1) pentru x=0,…,n–2, şi π–1(n–1) =n–1. În cazul execuŃiei paralele, procesoarele P0, …, Pn–1 sunt conectate după cum urmează:
Pi∏Pπ–1
(i) (i = 0,…, n–1) P0√P1,…, Pn–2 √Pn–1.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
101
ReŃeaua de tip amestecare perfectă este utilizată în algoritmi de sortare.
3.2.3.4. ReŃeaua arborescentă
Numeroşi algoritmi de rezolvare a problemelor de sortare, căutare,
evaluare a expresiilor algebrice, clasificare şi luarea de decizii în teoria jocurilor
pot fi implementaŃi convenabil pe calculatoare paralele ale căror procesoare
sunt conectate în structură de arbore binar. din acest motiv, vom studia în con-
tinuare caracteristicile şi aplicabilitatea unui asemenea tip de reŃea. Figura 3.2.5
prezintă arborele binar Bn de ordinul n, cu 1+2+22+…+2n–1=2n–1 vârfuri şi 2n–2
muchii.
Într-un asemenea sistem, fiecare procesor de al nivelul k este conectat
direct cu exact zero sau două procesoare de la nivelul k+1; invers, fiecare
procesor de la nivelul k+1 este conectat direct cu un singur procesor de la
nivelul k, cu excepŃia procesorului de la nivelul 0, care corespunde nodului
rădăcină.
În general, în cazul unui sistem SIMD cu această conectivitate, calculele
de la nivelul k sunt executate simultan de către toate procesoarele, acestea
acŃionând sub controlul unităŃii centrale de procesoare.
În exemplul următor se presupune ca fiind egal costul trecerii datelor de-
a lungul unei legături, lucru care în practică poate să nu fie adevărat. Să
presupunem, deci, că dorim să determinăm suma a s=2n-1 numere.
Fig.3.2.5 Arborele binar Bn de ordinul n

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 102
Metoda de rezolvare: Presupunem s=8 şi n=4 (cazul general se poate
deduce imediat) şi memorăm numerele, fie ele x8,…,x15, în P8, …, P15.
Pasul 1: � adunăm x8 şi x9 în P4 şi memorăm rezultatul ca x4 (v. Fig.3.2..3.); � adunăm x10 şi x11 în P5 şi memorăm rezultatul ca x5, etc.;
Pasul 2: adunăm x4 şi x5 în P2 şi memorăm rezultatul ca x2, etc.; Pasul 3:adunăm x2 şi x3 în P1 şi memorăm rezultatul ca x1.
La fiecare nivel calculele se execută simultan; evident în exact
n-1=log2s paşi paraleli, iar suma va apare în P1.
3.2.3.5. ReŃeaua de tip latice
În cazul unei structuri de conectare de tip latice (sau grilă pătrată),
arhitectura constă din n2 procesoare, fiecare conectat cu cei patru vecini ai săi,
după cum se vede în figura 3.2.6, în cazul n=4.
Dacă procesoarele sunt numerotate P(i,j), i,j∈{1,…,n}, atunci P(i,j) este
conectat cu P(i,j-1),P(i,j+1),P(i-1,j), P(i+1,j). În mod normal, procesoarele de la
margini sunt conectate ciclic: P(1,1) cu P(1,n) şi P(n,1); P(1,2) cu P(n,2)
ş.a.m.d., ceea ce înseamnă că valorile ce numerotează procesoarele sunt
considerate modulo n. Prin urmare, este mai firesc să înŃelegem desfăşurarea
laticei pe un thor şi nu pe un plan. Un sistem de tip SIMD cu această reŃea
poate avea, pe lângă conectivitatea directă, un bus global de comunicaŃie.
Fig.3.2.6 ReŃeaua latice cu n = 4

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
103
3.2.3.6. ReŃeaua de tip hipercub
Pentru a introduce acest tip de reŃea, convenim să numim hipercub Hn un
cub n-dimensional format cu 2n vârfuri şi n 2n-1⋅ muchii; dacă vârfurile sunt
reprezentate prin numerele binare ε1,…,εn∈{0,1}, atunci se consideră că două
vârfuri sunt unite prin muchie dacă şi numai dacă reprezentarea lor binară diferă
exact într-o singură poziŃie. Cazul n=1, n=2 (pătratul) şi n=3 (cubul) sunt
prezentate în figura 3.2.5, iar cazul n=4 (hipercubul) în figura 3.2.7
Fig. 3.2.7. Hipercuburile H1, H2( pătratul), H3 (cubul)
Fig. 3.2.8. Hipercubul H4
Din modul de definire a hipercubului Hn este evidentă modalitatea de definire a hipercubului de ordin superior Hn+1, prin unirea nodurilor corespunzătoare a două copii ale lui Hn. Ca exemplu, considerăm cazul n=4 din figura 3.2.8.
01 11
00
H2 H3
001 101
100 000
010
011 111
110
0 1
H1

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 104
În tabelul 3.2.1 sunt prezentate accelararea S (n, p) şi eficienŃa E (n, p), în cazul sumarii a n numere (n = 64, 512), pe un hipercub format din p procesoare (pentru p = 4, 8, 19).
n
Numărul
term.
sumei
p
Numărul
de proc.
din
hipercub
S=S(n,p)
Speedup
(acc.)
Θ(n/log n)
E(n,p)= S/p
EficienŃa
Θ(1/log n)
n p n*p/(n+2*p*log p) n/(n+2*p*log p)
64 4 3,72 0,93
64 8 6,48 0,81
64 16 9,92 0,62
64 32 12,48 0,39
512 4 3,96 0,99
512 8 7,76 0,97
512 16 14,88 0,93
512 32 26,88 0,84
Tabelul 3.2.1: Accelerarea şi eficienŃa sumării a n numere pe un hipercub Hp

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
105
CAPITOLUL 4 INTERNETUL: UN SISTEM DISTRIBUIT DESCHIS ŞI SCALABIL 4.1. Schema arhitecturală a Internetului 4.2. Schema funcŃională a Internetului (router, gateway, host) 4.3. Modelul client/server. Protocolul TCP/IP
4.3.1. IP (Internet Protocol). 4.3.2. TCP (Transmission Control Protocol) 4.3.3. UDP (User Datagram Protocol) 4.3.4. DNS (Domain Name System) 4.3.5. POP3 sau Protocolul Post Office – Versiunea 3 4.3.6. IMAP (Internet Message Access Protocol) 4.3.7. SMTP (Simple Mail Transfer Protocol) 4.3.8. HTTP (Hypertext Transfer Protocol) 4.3.9. HTTPS 4.3.10. SSL (Secure Sockets Layer) 4.3.11. FTP (File Transfer Protocol) 4.3.12. LDAP
4.4. World Wide Web: o aplicaŃie distribuită în Internet 4.4.1. GeneralităŃi despre Web. Hipertext şi hipermedia 4.4.2. Marcarea hipertextului (SGML, XML, HTML, WML, XHTML) 4.4.3. URL (Uniform Resource Locator) 4.4.4. HTTP (HyperText Transfer Protocol)
Sistemul Internet, din punct de vedere fizic, este un ansamblu de componente hardware (calculatoare, procesoare, dispozitive de memorare si procesare, echipamente intrare/ieşire, echipamente de conectare, echipamente de transmisie) pentru memorarea, procesarea, conversia, reprezentarea şi comunicarea informaŃiilor la nivel local, regional sau mondial, iar din punct de vedere logic, este un ansamblu de componente software (sisteme de operare-Unix, Linux, programe de control şi transmisie, programe de protecŃie, aplicaŃii pentru căutare, procesare şi reprezentare) pentru a oferi utilizatorilor conectaŃi la reŃea servicii diversificate în orice moment şi la orice distanŃă de resursele accesate, pe baza modelului client/server.
Mediul Internet cuprinde un set de protocoale de reŃea care specifică detaliile comunicaŃiilor între nodurile (calculatoarele) interconectate, împreună cu convenŃiile de interconectare a reŃelelor şi de dirijare a informaŃiilor în reŃea.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 106
4.1. Schema arhitecturală a Internetului
Din punct de vedere arhitectural, reŃeaua Internet este eterogenă, adică
este formată dintr-o mare varietate de sisteme de calcul: PC-uri, mainframe-uri (ex. IBM), supercalculatoare (ex. RISC 6000), reŃele de calculatoare (ex. LAN: Local Area Network, MAN: Metropolitan Area Network, WAN:Wide area Network), interconectate între ele în cele mai variate topologii (v. fig. 1.5.2).
FuncŃionarea reŃelei Internet se realizează cu ajutorul unor noduri (calculatoare de tip server respectiv terminal) ce funcŃionează pe baza protocoalelor de exploatare eficientă a resurselor mediului Internet. Aceste noduri ce se numesc furnizori de servicii.
Accesul unui utilizator (client) la serviciile Internet poate avea loc dacă utilizatorul are acces la un terminal (calculator - staŃie de lucru) conectat la reŃeaua Internet, şi anume la un nod din reŃea. Terminalul se poate afla acasă la utilizator sau locul de muncă, la şcoală, la universitate, la bibliotecă, la un café-Internet, etc.
Fig. 4.1.1. SecvenŃă arhitecturală a reŃelei Internet
Din punct de vedere arhitectural, în sistemul Internet există următoarele
clase de noduri: • clasa A: noduri de nivel înalt - noduri la nivel mondial la care sunt
conectate nodurile continentale de la nivelul Ńărilor (ex. nodul EARN: European Academic and Research Network);

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
107
• clasa B: noduri continentale - noduri la nivelul unei Ńări de care sunt conectate noduri locale ale unor reŃele (în România există, de ex. nodul de la Universitatea Politehnica Bucureşti, nodul de la Institutul NaŃional de Cercetare - Dezvoltare în Informatică ş.a..);
• clasa C: noduri locale - noduri la nivel local(regional) ce trebuie să fie recunoscute de un nod continental (în România există noduri locale în Bucureşti: Universitatea Bucureşti, IMAR, ASE, Guvern, Parlament, şi în marile oraşe: Cluj, Iaşi, ConstanŃa, Craiova, Piteşti, etc.);
• clasa D: noduri terminale- noduri la nivel de utilizator PC care are un IP în Internet. Un utilizator poate avea acces la serviciile Internet numai dacă lucrează
la un terminal (calculator) conectat la un nod din reŃeaua Internet.
Conectarea la un astfel de nod (server) se realizează fizic prin intermediul unei firme specializate prin diverse tipuri de conexiuni:
• conexiune de tip “dial-up”: prin modem ce utilizează comutarea pe linia telefonică. Dezavantaje: viteza lentă de transmisie a datelor, scoaterea din uz a serviciului telefonic în timpul conectării la Internet;
• conexiune prin cablu TV: conectare prin cablu TV cu următoarele servicii simultane: telefonie, televiziune, acces la Internet. Avantaje: o viteză mai mare de 50 de ori decât cea de pe dial-up, conexiune permanentă, cost accesibil;
• conexiune prin fibră optică: este soluŃia pentru accesul de mare viteză la serviciile Internet. Acest tip de conexiune este recomandat firmelor cu un număr mare de calculatoare cuplate la reŃea şi cu un transfer susŃinut pe tot timpul unei zile de lucru;
• VPN: Virtual Private Network, o reŃea privată de transmisiuni de date în comunicaŃiile metropolitane şi regionale ale unei corporaŃii, în care transferul de informaŃii se face criptat. VPN-ul poate asigura de exemplu legătura dintre bazele de date prezente la sediul firmei şi celelalte locaŃii ale firmei, schimbul de documente şi informaŃii cu caracter confidenŃial. LocaŃiile unei firme din două sau mai multe puncte geografice, din oraş sau din regiune, pot fi interconectate între ele cu ajutorul tehnologiei VPN;
• conexiune prin modem radio (wireless): principalul avantaj al acestui tip de conexiune este aria de acoperire. Acest tip de conexiune suplineşte cu succes lipsa fibrei optice sau a cablului TV dintr-o anumita zonă.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 108
4.2. Schema funcŃională a Internetului (router, gateway, host)
Fig. 4.2.1. SecvenŃă din schema funcŃională a Internetului Din punct de vedere funcŃional în Internet sunt operaŃionale trei tipuri de
calculatoare (servere): 1. calculator router (de dirijare): calculator ce furnizează servicii de
dirijare a informaŃiilor între două noduri (calculatoare din reŃea), care se adresează prin emisie-recepŃie;
2. calculator gateway (de legătură): calculator de legătură între nivelele reŃelei Internet şi care realizează conectarea între două reŃele distincte;
3. calculator host (gazdă): calculator conectat la reŃeaua Internet pe unul din cele patru nivele (utilizator, local, Ńara şi mondial) de la care se pot cere servicii Internet.
LAN ReŃea locală
Router
Gateway
Gateway
Intranet: reŃeaua unei firme
Host
Mediul Internet Furnizori locali şi regionali
Router Router
Router Router
Router
PC Host

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
109
4.3. Modelul client/server. Protocolul TCP/IP
4.3.1. IP (Internet Protocol). 4.3.2. TCP (Transmission Control Protocol) 4.3.3. UDP (User Datagram Protocol) 4.3.4. DNS (Domain Name System) 4.3.5. POP3 sau Protocolul Post Office – Versiunea 3 4.3.6. IMAP (Internet Message Access Protocol) 4.3.7. SMTP (Simple Mail Transfer Protocol) 4.3.8. HTTP (HyperText Transfer Protocol) 4.3.9. HTTPS 4.3.10. SSL (Secure Sockets Layer) 4.3.11. FTP (File Transfer Protocol) 4.3.12. LDAP
Modelul client/server reglementează relaŃia între două programe de
computer, unde programul-client cere un serviciu programului-server, care răspunde acestei cereri.
De altfel, conceptul client/server poate fi utilizat şi într-un singur calculator, dar el devine foarte important, de fapt un concept de bază, în reŃelele de calculatoare. Într-o reŃea, modelul client/server este un mijloc convenabil şi eficient de interconectare a programelor aflate în locaŃii geografice diferite. De exemplu, un cetăŃean care doreşte să-şi acceseze un cont dintr-o bancă, utilizează un program-client, care trimite cererea către un program-server din bancă, care la rândul său poate înainte cererea unui alt computer din bancă să caute în baza de date situaŃia contului cetăŃeanului respectiv.
Fig. 4.3.1. Un model client/server în mediul Internet

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 110
În modelul uzual client/server există un server, numit daemon – ce funcŃionează non-stop, care este activat să aştepte cererile clienŃilor şi să le înainteze altor programe/procese/servere, care sunt capabile să răspundă la aceste cereri. De exemplu, în Internet, un browser Web este de fapt un program-client care cere un serviciu (trimiterea unei pagini Web sau a unui fişier) de la server Web (care tehnic se realizează prin http, adică Hypertext Transport Protocol) la un alt computer din reŃeaua Internet (de unde s-a iniŃiat cererea prin browser). Similar se petrec lucrurile, dacă un client cu protocolul TCP/IP instalat cere/trimite fişiere prin FTP (File Transfer Protocol).
Protocoalele din nivelul de bază asigură comunicarea şi interoperabilitatea între orice două calculatoare din Internet. Le vom prezenta în continuare.
4.3.1. IP (Internet Protocol)
IP este protocolul prin care datele sunt trimise de la un calculator la altul prin intermediu Internetului. Fiecare calculator (cunoscut ca HOST), pe Internet are cel puŃin o adresă IP unică, care îl identifică între toate computerele de pe Internet. Când se trimite sau se recepŃionează date (e-mail, pagini web), mesajul se divide în părŃi mai mici numite pachete. Fiecare pachet cuprinde adresa expeditorului, datele, precum şi adresa destinatararului. Fiecare pachet este trimis, prima dată la un "Gateway Computer" care înŃelege o mică parte din Internet. Computerul "Gateway" citeşte destinaŃia pachetelor şi trimite pachetele la un alt "Gateway" şi tot aşa până ce pachetul ajunge la "Gateway"-ul vecin cu computerul destinatar. Adică, fiecare computer cuplat la Internet este identificat printr-o adresă unică, cunoscută prin aşa-numita IP Address, aceasta fiind utilizată la nivelul programelor de prelucrare în reŃea. În schimb, la nivelul utilizatorilor cu acces la Internet, identificarea calculatoarelor se face printr-un nume de calculator HOST, gestionat de sistemul DNS (după cum vom vedea mai jos).
4.3.2. TCP (Transmission Control Protocol)
TCP este folosit de obicei de aplicaŃii care au nevoie de confirmare de primire a datelor. Efectuează o conectare virtulă full duplex între două puncte terminale, fiecare punct fiind definit de către o adresă IP şi de către un port TCP.
4.3.3. UDP (User Datagram Protocol)
UDP reprezintă un protocol ce aparŃine layerului 4 al modelului OSI(despre care vom vorbi mai târziu), împreună cu protocolul IP, acesta face

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
111
posibilă livrarea mesajelor într-o reŃea. Spre deosebire de TCP, UDP este un protocol ce nu oferă siguranŃa sosirii datelor la destinaŃie.
4.3.4. DNS (Domain Name System)
DNS este un sistem distribuit de păstrare şi interogare a unor date arbitrare într-o structură ierarhică, folosită pentru gestionarea domeniilor în Internet.
Cităm din sursa: http://gac.icann.org/web/about/gac-outreach_Romanian.htm
SISTEMUL DE NUME DE DOMENII INTERNET ŞI COMITETUL GUVERNAMENTAL CONSULTATIV (GAC) AL CORPORAłIEI
INTERNET PENTRU ALOCAREA DE NUME ŞI NUMERE (ICANN)
CE ESTE SISTEMUL DE NUME DE DOMENII INTERNET?
Sistemul de Nume de Domenii (DNS) îi ajută pe utilizatori să trimită cu uşurinŃă mesaje de poştă electronică (e-mail) şi să navigheze pe Internet. Asemănător cu numerele de telefon, fiecare calculator are o adresă unică pe Internet, numită număr pentru Protocol Internet sau număr IP. Deoarece este dificil să se memoreze aceste numere, a fost creat DNS-ul care permite folosirea numelor de domenii în locul cifrelor, fiind astfel mai uşor de memorat. De exemplu, cu ajutorul DNS-ului, utilizatorii Internet pot găsi o adresă pe Internet doar tastând un nume, cum ar fi "www.internic.net", în loc să tasteze numărul 207.151.159.3.
DNS-ul permite înregistrarea numelor de domenii în cadrul unor registre, cunoscute ca "domenii de nivel superior", sau TLD-uri. La rândul său, fiecare TLD (Top Level Domain), poate să aibă câteva sub-domenii. Astăzi, TLD-urile se pot încadra în două categorii mari: 1) domenii generice de nivel superior (gTLDs) cum ar fi .com, .net, .org şi .info, care sunt deschise pentru înregistrare pentru toŃi utilizatorii de Internet din lume şi 2) domenii de nivel superior pe coduri de Ńară (ccTLDs), cum ar fi .uk pentru Marea Britanie, sau .ng pentru Nigeria, corespunzător unei Ńări, unui teritoriu, sau altei locaŃii geografice. În timp ce ambele categorii de domenii de nivel superior funcŃionează asemănător din punct de vedere tehnic, regulile şi politicile de înregistrare a numelor de domeniu în gTLD şi în ccTLD pot avea deosebiri semnificative. Pentru

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 112
informaŃii suplimentare în legătură cu structura DNS accesaŃi http://www.internic.net/faqs/domain-names.html.
Cine administrează sistemul de NUME DE DOMENII INTERNET?
Timp de mulŃi ani, operarea şi administrarea DNS s-a făcut mai mult pe bază informală, ad-hoc. În general, aceste funcŃii au fost îndeplinite de o reŃea globală de cercetători, organizaŃii tehnice, ingineri specialişti în Internet, voluntari şi contractori independenŃi cu guvernul SUA. Dezvoltarea Internetului în anii '90, ca un instrument important pentru comerŃ, comunicare, şi educaŃie, a evidenŃiat necesitatea dezvoltării unui sistem mai robust, formal şi reprezentativ, pentru a administra aceste funcŃii.
Pe baza informaŃiilor adunate la scară globală, Guvernul SUA a început procesul de privatizare şi "internaŃionalizare" al administrării DNS-ului şi a funcŃiilor de coordonare legate de activitatea pe Internet. În 1998, Guvernul SUA a început să transfere responsabilitatea pentru administrarea DNS către CorporaŃia Internet pentru Alocarea de Nume şi Numere (ICANN). Aceasta este o organizaŃie formată de comunitatea globală a deŃinătorilor de spaŃiu pe Internet. ICANN este o corporaŃie a sectorului privat, independentă, non-profit, cu sediul în California. Sarcina sa este să administreze funcŃiile tehnice de coordonare pentru Internet. Dacă se poate vorbi despre o singură organizaŃie care răspunde în totalitate de funcŃiile tehnice ale Internetului, aceasta este ICANN.
ICANN are un comitet internaŃional de conducere format din 19 directori care este ajutat în lucru de personal specializat. Acest organism încearcă să dezvolte o abordare consensuală a problemelor şi a politicii DNS, prin dezbateri Ńinute în cele trei organizaŃii de suport tehnic. Aceste "organizaŃii de suport tehnic" reprezintă o gamă largă de grupuri de interese, care includ, printre alŃii, oameni de afaceri, consumatori şi furnizori de servicii Internet (ISP).
De la înfiinŃarea sa, ICANN a desfăşurat mai multe activităŃi, şi a avut mai multe iniŃiative, printre care:
• Introducerea competiŃiei globale în înregistrarea numelor de domenii, acreditând peste 100 de înregistratori independenŃi de nume de domenii, în toată lumea;
• Dezvoltarea şi adoptarea unei Politici Uniforme de Rezolvare a Litigiilor survenite la înregistrarea numelor de domenii (UDRP) pentru a rezolva problemele legate de “pirateria informatică” -- înregistrarea cu rea-intenŃie a numelor de domeniu, cu nerespectarea drepturilor decurgând din marca înregistrată ( trademarks) -- conform

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
113
recomandărilor făcute de OrganizaŃia Mondială a ProprietăŃii Intelectuale (WIPO);
• Desfăşurarea unui proces de selectare a şapte noi domenii de nivel superior (TLDs), .biz, .info, .pro, .name, .museum, .aero, şi .coop – constituind prima lărgire a gTLD-urilor de când a început dezvoltarea sistemului de nume de domenii;
• Stabilirea unor grupuri de lucru pentru a face studii privind diverse probleme, cum ar fi introducerea numelor multilingve de domenii, coordonarea înregistrării numelor de domeniu, baza de date "WHOIS", ca şi probleme legate de acordarea de numere pentru IP.
Mai multe informaŃii despre ICANN, organizaŃiile sale adiacente şi comitetele consultative puteŃi găsi la adresa: www.ICANN.org.
RelaŃii cu guverne naŃionale, economii distincte, şi alte organizaŃii
ICANN este unic din anumite puncte de vedere. Multe dintre funcŃiile tehnice de coordonare pe care le desfăşoară au implicaŃii în politici de interes public. În alte domenii, funcŃiile tehnice de coordonare care au implicaŃii în politici de interes public sunt desfăşurate de organizaŃii create ca urmare a existenŃei unor tratate inter-guvernamentale, cum ar fi Uniunea InternaŃională a TelecomunicaŃiilor (ITU) pentru telecomunicaŃii, sau de OrganizaŃia InternaŃională a AviaŃiei Civile, în cazul călătoriilor aeriene. S-a considerat că o astfel de abordare pe bază de tratate nu era adecvată pentru administrarea Internetului. S-a considerat că e mai bine ca Internetul să se administreze printr-o abordare conformă cu punctul de vedere al sectorului privat.
Aceasta nu înseamnă că guvernele nu joacă nici un rol. ICANN primeşte date de la guverne prin intermediul Comitetului Consultativ Guvernamental (GAC). Rolul principal al acestui comitet consultativ este să ofere consultanŃă pentru ICANN în probleme legate de politici de interes public. GAC Ńine cont în special de activităŃile şi politicile desfăşurate de ICANN referitoare la preocupările guvernelor privind problemele unde pot exista neconcordanŃe între politicile ICANN şi legile naŃionale sau acordurile internaŃionale. Întâlnirile GAC au loc de obicei de trei sau de patru ori pe an, corelate cu întâlnirile ICANN. În prezent, mai mult de 30 de guverne naŃionale iau parte la întâlnirile GAC. Acestora li se alătură reprezentanŃi separaŃi din economie şi organizaŃii guvernamentale multinaŃionale cum ar fi ITU sau OrganizaŃia Mondială a ProprietăŃii Intelectuale (WIPO).
Toate guvernele naŃionale, reprezentanŃi ai lumii de afaceri organizaŃi în forumuri internaŃionale, organizaŃii guvernamentale multinaŃionale şi

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 114
organizaŃii ale unor tratate pot deveni membri GAC. Pentru informaŃii suplimentare despre GAC accesaŃi: www.gac.icann.org
De ce este important pentru guverne să fie reprezentate în GAC?
Internetul este un fenomen global şi oferă oportunităŃi uriaşe pentru toŃi locuitorii lumii şi pentru economiile tuturor statelor. Totuşi lumea nu este uniformă. Fiecare Ńară şi economie, luate separat, au legi diferite, atitudini şi politici diferite. GAC încearcă să includă diversitatea acestor opinii în consultanŃa acordată ICANN. Participarea la GAC permite Ńărilor şi economiilor distincte să influenŃeze politicile referitoare la administrarea DNS şi a funcŃiilor corelate acestuia, care sunt importante pentru funcŃionarea globală a Internetului. Deoarece GAC adună o gamă largă de cunoştinŃe şi experienŃă, membrii GAC au avut mult de câştigat datorită participării lor în acest Comitet.
Ce a făcut GAC recent? GAC a luat în considerare şi a asigurat consultanŃa pentru o gamă variată de domenii, printre care:
• Ce probleme şi politici de interes public trebuie să ia în considerare ICANN atunci când alege noi domenii generale de nivel superior;
• Orientare în probleme legate de dezvoltarea sistemului multilingv de nume de domenii (denumiri de domeniu în alte alfabete decât cel latin, cum ar fi cel chinez, cirilic, sau, de exemplu, cel arab) inclusiv protecŃia proprietăŃii intelectuale, protecŃia consumatorului, şi probleme culturale;
• Stabilirea de principii pentru coordonarea viitoarelor platforme de test pentru nume de domenii, în concordanŃă cu necesitatea de a sprijini inovarea şi experimentarea creativă; şi
• Principii pentru managementul şi administrarea corectă a ccTLD-urilor, inclusiv crearea documentului GAC Principii pentru delegarea şi managementul numelor de domeniu de nivel superior ce folosesc codul
de Ńară, care oferă explicaŃii privind rolul jucat de ICANN, guverne, şi registrele de operare a ccTLD-urilor.
GAC caută în mod activ să atragă noi membri pentru a creşte gradul de conştientizare globală şi participarea în problemele importante de management a Internetului. GAC caută să se asigure că activitatea de consultanŃă oferită ICANN reflectă diversitatea comunităŃii internaŃionale. În particular, GAC dă foarte mare atenŃie creşterii gradului de participare a Ńărilor şi economiilor distincte, acolo unde Internetul este încă în faza de dezvoltare.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
115
CUM PUTEłI PARTICIPA ÎN GAC
În prezent GAC are 100 de membri, dintre care aproximativ 40 sunt participanŃi activi. Acest organism este deschis pentru orice reprezentant al guvernelor naŃionale. Fiecare guvern poate numi un reprezentant şi un consultant în acest Comitet. De asemenea, asociaŃiile economice recunoscute de forumuri internaŃionale, cât şi organizaŃiile guvernamentale multinaŃionale şi organizaŃiile diverselor tratate pot deveni membri la invitaŃia preşedinŃiei GAC.
Internetul joacă un rol din ce în ce mai mare în economiile naŃiunilor. Este important pentru guverne să fie implicate în luarea de decizii privind administrarea şi operarea Internetului. Sistemul de nume de domenii este infrastructura care stă la baza modului de lucru al Internetului şi are multe implicaŃii în politicile publice.
Pentru a fi siguri că se iau în considerare toate opiniile relevante, este important să se mărească numărul participanŃilor în Comitetul consultativ guvernamental ICANN astfel încât atât ICANN cât şi Internetul să devină cu adevărat internaŃionale.
GAC încurajează toŃi membrii potenŃiali să ceară informaŃii despre participarea lor în comitet. Pentru informaŃii suplimentare privind rolul şi activităŃile desfăşurate de GAC vă rugăm să luaŃi legătura cu secretariatul GAC:
Mr Richard Delmas GAC Secretariat C/o European Commission 1049 Brussels Belgium
Tel: +32 2 295 88 73 Fax: +32 2 295 39 98 Email: [email protected]
Adrese Web pentru informaŃii suplimentare
InformaŃii în legătură cu ICANN, împreună cu materialele prezentate în şedinŃe, documente de elaborare a politicilor, detalii despre organizaŃiile de suport tehnic, informaŃii referitoare la şedinŃele viitoare, împreună cu informaŃii cu caracter general se pot afla de la http://www.ICANN.org

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 116
InformaŃii în legătură cu comitetul consultativ guvernamental (GAC), alături de comunicate anterioare şi alte documente, se pot afla accesând adresa: http://www.gac.icann.org/docs/index.htm
Am încheiat citatul de pe pagina: http://gac.icann.org/web/about/gac-outreach_Romanian.htm
Cităm acum de pe pagina: http://www.domreg.ro/domain.html
Listă de nume de domenii în Internet
.EU - Uniunea Europeană, se poate acum înregistra şi pe numele persoanelor fizice şi juridice din România.
.com - cel mai folosit domeniu in Internet. Din 75 milioane de domenii existente în Internet, peste 53 milioane sunt .com, nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .com
.net - folosit ca înlocuitor pentru .com, nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .net
.org - folosit în general pentru organizaŃii, dar poate fi folosit şi ca înlocuitor pentru .com, nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .org
.info - folosit în general pentru site-uri informaŃionale, prezentarea de produse, servicii sau organizaŃii, dar poate fi folosit şi ca înlocuitor pentru .com, nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .info
.biz - folosit ca un domeniu concurent cu .com, nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .biz. Este o alternativă de succes la domeniile .com.
.us (SUA), nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .us
.name - folosit în general pentru persoane fizice, dar poate fi folosit şi pentru activităŃi comerciale, nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .name. Domeniile .name pot fi înregistrate pe nivelul doi

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
117
sub forma nume.name. Dacă nume.name este ocupat, este bine să verificaŃi disponibilitatea domeniului de nivel trei - [email protected].
.tv - folosit în general pentru servicii de televiziune sau broadcasting, nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .tv
.eu.com (Europa) - Recomandat în special pentru firmele ce au afaceri în Europa, nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .eu.com (A nu se confunda cu .eu - Uniunea Europeana)
.ws - folosit în general pentru WebSite-uri, nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .ws
.mobi - destinat realizării de site-uri special proiectate pentru a fi afişate pe ecranul telefoanelor mobile.
.eu (Uniunea Europeana), poate fi înregistrat doar de persoane fizice/juridice din Ńările membre UE
.co.uk (Anglia), nu exista restricŃii la înregistrare, oricine poate înregistra un domeniu .co.uk
.org.uk (Anglia), nu există restricŃii la înregistrare, oricine poate înregistra un domeniu .co.uk
.de (Germania), oricine poate înregistra un domeniu .de, dar cu condiŃia ca una din persoanele deŃinător sau contact administrativ al domeniului să aibă o adresă în Germania. DeŃinătorul poate fi în orice Ńară, dar în acest caz trebuie ca persoana de contact administrativ să aibă o adresă în Germania.
.fr (FranŃa), un domeniu .fr poate fi înregistrat de o persoană juridică sau fizică din FranŃa sau de oricine posedă o marcă înregistrată la National Intellectual Property Institute, în UE sau o marcă internaŃională care include în mod expres teritoriile franceze.
.it (Italia), un domeniu .it poate fi înregistrat de o persoană juridică sau fizică dintr-o tară membră UE. Persoanele fizice sau organizaŃiile care nu au număr VAT (TVA) sau cod fiscal nu pot avea mai mult de un singur nume de domeniu .it.
.es (Spania), un domeniu .es poate fi înregistrat de orice persoană, neexistând restricŃii la înregistrare.
.at (Austria), un domeniu .at poate fi înregistrat de orice persoană, neexistând restricŃii la înregistrare.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 118
.be (Belgia), un domeniu .be poate fi înregistrat de orice persoana, neexistând restricŃii la înregistrare.
.nl (Olanda), un domeniu .nl poate fi înregistrat de orice persoană, neexistând restricŃii la înregistrare. Dacă solicitantul unui nume de domeniu nu este din Olanda va trebui să indice o adresă din Olanda unde să poată primi documente scrise sau notificări juridice.
.ro (România), un domeniu .be poate fi înregistrat de orice persoană, neexistând restricŃii la înregistrare.
Tabelul de coduri de Ńară folosite în numele de domenii Internet
.ae – United Arab Emirates
.af – Afghanistan
.al – Albania
.am – Armenia
.an – Netherlands Antilles
.ao – Angola
.aq – Antarctica
.ar – Argentina
.as – American Samoa
.at – Austria
.au – Australia
.aw – Aruba
.ax – Aland Islands
.az – Azerbaijan
.ba – Bosnia and Herzegovina
.bb – Barbados
.bd – Bangladesh
.be – Belgium
.bf – Burkina Faso
.bg – Bulgaria
.bh – Bahrain
.bi – Burundi
.bj – Benin
.bm – Bermuda
.bn – Brunei Darussalam
.bo – Bolivia
.br – Brazil
.bs – Bahamas
.bt – Bhutan
.bv – Bouvet Island
.bw – Botswana
.by – Belarus
.bz – Belize
.ca – Canada
.cc – Cocos (Keeling) Islands
.cf – Central African Republic
.cg – Congo, Republic of
.ch – Switzerland
.ci – Cote d'Ivoire
.ck – Cook Islands
.cl – Chile
.cm – Cameroon
.cn – China
.co – Colombia
.cr – Costa Rica
.cu – Cuba
.cv – Cape Verde
.cx – Christmas Island
.cy – Cyprus
.cz – Czech Republic

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
119
.de – Germany
.dj – Djibouti
.dk – Denmark
.dm – Dominica
.do – Dominican Republic
.dz – Algeria
.ec – Ecuador
.ee – Estonia
.eg – Egypt
.eh – Western Sahara
.er – Eritrea
.es – Spain
.et – Ethiopia
.eu – European Union
.fi – Finland
.fj – Fiji
.fk – Falkland Islands (Malvinas)
.fm – Micronesia, Federated States of
.fo – Faroe Islands
.fr – France
.ga – Gabon
.gb – United Kingdom
.gd – Grenada
.ge – Georgia
.gf – French Guiana
.gg – Guernsey
.gh – Ghana
.gi – Gibraltar
.gl – Greenland
.gm – Gambia
.gn – Guinea
.gp – Guadeloupe
.gq – Equatorial Guinea
.gr – Greece
.gs – South Georgia and the South Sandwich Islands .gt – Guatemala .gu – Guam .gw – Guinea-Bissau .gy – Guyana .hk – Hong Kong
.hm – Heard and McDonald Islands .hn – Honduras .hr – Croatia/Hrvatska .ht – Haiti .hu – Hungary .id – Indonesia .ie – Ireland .il – Israel .im – Isle of Man .in – India .io – British Indian Ocean Territory .iq – Iraq .ir – Iran, Islamic Republic of .is – Iceland .it – Italy .je – Jersey .jm – Jamaica .jo – Jordan .jp – Japan .ke – Kenya .kg – Kyrgyzstan .kh – Cambodia .ki – Kiribati .km – Comoros .kn – Saint Kitts and Nevis .kp – Korea, Democratic People's Republic .kr – Korea, Republic of .kw – Kuwait .ky – Cayman Islands .kz – Kazakhstan .la – Lao People's Democratic Republic .lb – Lebanon .lc – Saint Lucia .li – Liechtenstein .lk – Sri Lanka .lr – Liberia .ls – Lesotho .lt – Lithuania .lu – Luxembourg

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 120
.lv – Latvia (Lituania) .ly – Libyan Arab Jamahiriya .ma – Morocco .mc – Monaco .md – Moldova, Republic of .me – Montenegro .mg – Madagascar .mh – Marshall Islands .mk – Macedonia, The Former Yugoslav Republic of .ml – Mali .mm – Myanmar .mn – Mongolia .mo – Macao .mp – Northern Mariana Islands .mq – Martinique .mr – Mauritania .ms – Montserrat .mt – Malta .mu – Mauritius .mv – Maldives .mw – Malawi .mx – Mexico .my – Malaysia .mz – Mozambique .na – Namibia .nc – New Caledonia .ne – Niger .nf – Norfolk Island .ng – Nigeria .ni – Nicaragua .nl – Netherlands .no – Norway .np – Nepal .nr – Nauru .nu – Niue .nz – New Zealand .om – Oman
.pa – Panama
.pe – Peru
.pf – French Polynesia
.pg – Papua New Guinea
.ph – Philippines
.pk – Pakistan
.pl – Poland
.pm – Saint Pierre and Miquelon
.pn – Pitcairn Island
.pr – Puerto Rico
.ps – Palestinian Territory, Occupied
.pt – Portugal
.pw – Palau
.py – Paraguay
.qa – Qatar
.re – Reunion Island
.ro – Romania
.rs – Serbia
.ru – Russian Federation
.rw – Rwanda
.sa – Saudi Arabia
.sb – Solomon Islands
.sc – Seychelles
.sd – Sudan
.se – Sweden
.sg – Singapore
.sh – Saint Helena
.si – Slovenia
.sj – Svalbard and Jan Mayen Islands
.sk – Slovak Republic
.sl – Sierra Leone
.sm – San Marino
.sn – Senegal
.so – Somalia
.sr – Suriname
.st – Sao Tome and Principe
.su – Soviet Union (being phased out)
.sv – El Salvador
.sy – Syrian Arab Republic
.sz – Swaziland

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
121
.tc – Turks and Caicos Islands .td – Chad .tf – French Southern Territories .tg – Togo .th – Thailand .tj – Tajikistan .tk – Tokelau .tl – Timor-Leste .tm – Turkmenistan .tn – Tunisia .to – Tonga .tp – East Timor .tr – Turkey .tt – Trinidad and Tobago .tv – Tuvalu .tw – Taiwan .tz – Tanzania .ua – Ukraine .ug – Uganda .uk – United Kingdom .um – United States Minor Outlying Islands .us – United States .uy – Uruguay .uz – Uzbekistan .va – Holy See (Vatican City State) .vc – Saint Vincent and the Grenadines .ve – Venezuela .vg – Virgin Islands, British .vi – Virgin Islands, U.S. .vn – Vietnam .vu – Vanuatu .wf – Wallis and Futuna Islands .ws – Samoa .ye – Yemen .yt – Mayotte .yu – Yugoslavia
.za – South Africa
.zm – Zambia
.zw – Zimbabwe

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 122
4.3.5. POP3 sau Protocolul Post Office – Versiunea 3,
POP3 este serviciul informatic sau protocolul utilizat de un calculator gazdă (host), pentru recepŃionarea poştei electronice (e-mail).
4.3.6. IMAP (Internet Message Access Protocol)
IMAP4rev1 permite accesul la mesaje din foldere de email de pe un server. Spre deosebire de POP3, care este proiectat pentru a transfera şi şterge e-mail-urile de pe server, scopul IMAP este de a le stoca pe toate pe server şi să poată fi accesate din orice loc. Mesajele pot fi stocate pe server, transferate sau mutate între foldere.
4.3.7. SMTP (Simple Mail Transfer Protocol)
SMPT este un protocol server/client simplu, folosit pentru transmiterea mesajelor în format electronic pe Internet. SMTP foloseşte portul de aplicaŃie 25 TCP şi determină adresa unui server SMTP pe baza înregistrării MX (Mail eXchange) din configuraŃia serverului DNS. Protocolul SMTP specifică modul în care mesajele de poştă electronică sunt transferate între procese SMTP aflate pe sisteme diferite. Procesul SMTP care are de transmis un mesaj este numit client SMTP iar procesul SMTP care primeşte mesajul este serverul SMTP. Protocolul nu se referă la modul în care mesajul ce trebuie transmis este trecut de la utilizator către clientul SMTP, sau cum mesajul recepŃionat de serverul SMTP este livrat utilizatorului destinatar şi nici cum este memorat mesajul sau de câte ori clientul SMTP încearcă să transmită mesajul;
4.3.8. HTTP (HyperText Transfer Protocol)
HTTP este metoda cea mai des utilizată pentru accesarea informaŃiilor în Internet care sunt păstrate pe servere WWW. Protocolul HTTP este un protocol de tip text, fiind protocolul "implicit" al WWW. Adică, dacă un URL nu conŃine partea de protocol, aceasta se consideră ca fiind http. Acesta presupune rularea unui program corespunzător pe calculatorul destinaŃie care înŃelege protocolul respectiv. Fişierul destinaŃie poate fi un document html, un fişier grafic, de sunet, de animaŃie, un program executabil pe server-ul respectiv sau un editor de texte. După clasificarea în funcŃie de modelele de referinŃă OSI, protocolul HTTP este un protocol de nivel aplicaŃie. Dezvoltarea sa este coordonată de W3C (World Wide Web Consortium).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
123
4.3.9. HTTPS
HTTPS reprezintă HTTP încapsulat într-un flux SSL/TLS.
4.3.10. SSL (Secure Sockets Layer)
SSL este un protocol de securitate care asigură comunicaŃii confidenŃiale prin Internet. El permite aplicaŃiilor client/server să comunice, în aşa fel încât să fie evitată interceptarea, modificarea sau falsificarea mesajelor.
4.3.11. FTP (File Transfer Protocol)
FTP este metoda cea mai des utilizată pentru descărcarea fişierelor de pe Internet. care sunt păstrate pe servere speciale.
4.3.12. LDAP este un protocol standard, stabilit de Internet Engineering Task Force (IETF), care oferă utilizatorilor unei reŃele, posibilitatea de a căuta şi modifica informaŃiile dintr-un Directory Service.
În internet mai există o serie de protocoale, cum ar fi: PPP (Point-to-Point Protocol); SLIP (Serial line IP); ICMP (Internet Control Message Protocol); TLS (Transport Layer Security) ş.a.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 124
4.4. World Wide Web: o aplicaŃie distribuită în Internet
4.4.1. GeneralităŃi despre Web. Hipertext şi hipermedia 4.4.2. Marcarea hipertextului (SGML, XML, HTML, WML, XHTML) 4.4.3. URL (Uniform Resource Locator) 4.4.4. HTTP (HyperText Transfer Protocol)
4.4.1. GeneralităŃi despre Web. Hipertext şi hipermedia
World Wide Web, prescurtat WWW sau simplu Web, este un sistem de distribuŃie locală sau globală a informaŃiilor hipermedia.
Din punct de vedere tehnic, spaŃiul Web nu trebuie confundat cu Internetul sau cu o reŃea, cum se crede greşit uneori. SpaŃul Web este doar o aplicaŃie distribuită în Internet care pune la dispoziŃia utilizatorilor un sistem global şi standardizat de comunicare multimedia.
IniŃial WWW a fost conceput de cercetătorii de la Laboratorul European pentru Particule Fizice de la CERN (Centrul de Cercetări Nucleare de la Geneva), sub conducerea lui Tim Berners-Lee, care au propus un sistem hipertext (text neliniar, care permite salturi, analog trimiterilor din Biblie), care permitea partajarea eficientă a informaŃiilor între membri unui grup de cercetătători care studiau fizica energiilor înalte.
Deci, sistemul Web poate fi folosit şi pe calculatoare dintr-o reŃea care nu este conectată la Internet sau chiar pe un singur calculator izolat, dar astăzi se foloseşte mai ales în Internet pentru distribuŃia informaŃiilor hipermedia.
World Wide Web are facilităŃi multimedia şi integrative, o interfaŃă grafică pentru utilizator - GUI (Graphic User Interface) foarte atrăgătoare din punct de vedere grafic, practică şi simplu de folosit (prietenoasă).
Deci, Web-ul este un sistem distribuit deschis utilizat pentru distribuŃia locală sau globală a informaŃiilor, putând fi extins şi implementat în diferite moduri fără a-i afecta funcŃionalitatea. Se utilizează în prezent, în general, în Internet pe baza modelului client/server. ClienŃii, adică navigatoarele Web sau browserele Web (Internet Explorer, Netscape Navigator, NCSA Mosaic,
Mozilla, Opera ş.a.), au acces la informaŃiile hipermedia şi multiprotocol organizate asociativ, aflate pe un server Web (cele mai cunoscute servere Web sunt: Apache, Netscape Enterprise Server, Sun Web Server, Microsoft Internet
Information Server, Stronghold, Jigsaw).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
125
Modelul client/server pentru calculatoarele conectate în reŃea angrenează trei componente în cazul unei aplicaŃii Web:
• program client, este o aplicaŃie care de obicei rulează pe calculatorul utilizatorului final;
• program server, este o aplicaŃie care rulează de obicei pe calculatorul furnizorului de informaŃii;
• protocolul de reŃea, pe baza căruia se transportă cererea de la client la server şi răspunsul de la server la client.
Programul client este adaptat sistemului hardware pe care rulează şi
funcŃionează ca o interfaŃă între sistemul respectiv şi informaŃiile furnizate de server. Programul server analizează cererea programului client (care poate fi o actualizare sau o căutare într-o bază de date etc.) şi execută procesele corespunzătoare. Toate tranzacŃiile între client şi server se fac pe baza unor reguli şi protocoale definite de sistemul client/server.
Calculatorul pe care rulează un server Web şi care găzduieşte pagini WWW (pagini Web), se mai numeşte şi sit (site).
Pentru ca informaŃiile dintr-un text să poată fi accesate în manieră globală şi distribuită, ele se organizează într-o formă specială numită hipertext. Hipertextul este un text neliniar (termenul a fost introdus de Ted Nelson în 1965, dar după cum am spus deja, ideea trimiterilor de la un text de pe o pagină la un alt text de pe o altă pagină apare încă la versetele din Biblie.
DefiniŃiile actuale ale hipertextului menŃionează următoarele atribute şi funcŃionalităŃi ale hipertextului: o formă de document electronic; o metodă de organizare a informaŃiilor în care datele sunt memorate într-o reŃea de noduri şi legături, putând fi accesată prin intermediul navigatoarelor interactive şi manipulată de un editor structural; o tehnică pentru organizarea informaŃiei textuale printr-o metodă complexă neliniară, în vederea facilitării explorării rapide a unei cantităŃi mari de date (cunoştinŃe).
Ca model matematic, o bază de date hipertext poate fi asociată cu graf orientat, în care fiecare nod stochează un fragment de text , iar arcele grafului conectează fragmente de text cu altele înrudite, legăturile putând fi traversate utilizând o interfaŃă pentru salturi de la un text la altul (browser).
Actualmente hipertextul se confundă deja de multe ori cu hipermedia, care este o colecŃie de documente multimedia conectate prin hiperlegături. Multimedia este o aplicaŃie ce conŃine atât documente discrete (texte sau
imagini statice), dar şi documente continue (video sau audio).
Un sistem hipertext sau hipermedia este constituit din: • noduri (concepte); • legături (relaŃii între concepte).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 126
Un nod reprezintă de obicei un concept unic (text, grafică, animaŃie, audio, video, imagine, program). Unui nod i se poate asocia un tip cu informaŃie semantică (detaliu, propoziŃie, colecŃie etc.). Nodurile sunt conectate cu alte noduri prin legături, nodul sursă numindu-se referinŃă, iar cel destinaŃie - referent. Nodurile conectate prin legături se mai numesc şi ancore. La activarea legăturii se afişează conŃinutul nodului. 4.4.2. Marcarea hipertextului (SGML, XML, HTML, WML, XHTML)
Stocarea informaŃiei în noduri se face prin diverse tehnici ce utilizează
limbaje de marcare a hipertextului (metalimbajele SGML, XML), care stau la baza variantelor actuale standard ca MHEG (Multimedia and Hypermedia Information Coding Expert Group) sau HTML (HyperText Markup Language) XHTML ş.a. HTML (HyperText Markup Language) este un limbaj folosit pentru
marcarea hipertextului, specificarea conŃinutului şi a cadrului paginilor afişate de browserele Web, fiind considerat lingua franca a spaŃiului Web.
Limbajul HTML este bazat pe metalimbajul SGML (Standard Generalized Markup Language), a cărui specificaŃii oficiale au fost publicate în 1986. Este de fapt o aplicaŃie restrânsă a SGML dedicată reprezentării informaŃiilor hipermedia într-o manieră facilă şi distribuită. Trecând prin diverse variante tot mai perfecŃionate, tinde în prezent de a fi înlocuit cu XHTML, o variantă de tranziŃie la XML (Extensible Markup Language). Familia de limbaje XML, concepută ca o tehnică complementară şi universală de marcare a hipertextului într-o manieră cât mai facilă, mai cuprinde XLL (Extensible Linking Language), XSL (Extensible Stylsheet Language) şi XUA (XML User Agent) şi diverse variante ale acestora. Pentru a marca textul afişat pe dispozitivele de calcul mobile, în loc de HTML se poate utiliza WML (Wireless Markup Language) sau HDML (Handheld Device Markup Language). Pentru a îmbogăŃii mijloacele de afişare a informaŃiilor multimedia, documentelor HTML li se asociază aşa-zisele foi de stiluri în cascadă, CSS (Cascading Style Sheet). 4.4.3. URI (Uniform Resource Identifier): URL şi URN
Modalitatea de adresare pe Web folosită pentru transferul documentelor hipertext sau ceea ce este deseori denumit adresă WWW; este reprezentată de indicatori uniformi de resurse, URI (Uniform Resource Identifier), care are două submulŃimi importante:
• URL (Uniform Resource Locator) şi • URN (Uniform Resource Name).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
127
URI este reprezentat într-o formă unică şi consistentă, independent de
sistemul de stocare şi convenŃiile reŃelei. URL este un nume folosit pentru identificarea unei anumite resurse pe
Internet prin protocolul HTTP (HyperText Transfer Protocol). Sintaxa URL pentru Web este:
*http:*//* server [*:* port ] [absolut_way [*?*interogare]]
Dacă nu este dat explicit, portul este considerat a fi portul 80. Semantica unui URL este: resursa se află pe un server, identificat prin
server, care răspunde la cererea de conectare prin portul specificat sau implicit, resursa este identificată prin absolut_way, iar interogarea este trimisă pentru a obŃine un răspuns dinamic de la server în acord cu parametrizarea cererii.
Un exemplu de URL este http://www.ubbcluj.ro/structura/facultati.htm ,
care este format din 4 mari părŃi protocolul (http), numele domeniului (www.ubbcluj.ro), calea către fişierul cautat relativ la root-ul domeniului (/structura/) şi numele fişierului (facultati.htm). Alte exemple de URL-uri:
• http://www.answers.com • http://www.journal.univagora.ro
Un URN reprezintă o submulŃime a URI care rămâne permanent şi unic, chiar dacă resursa a dispărut sau a devenit inaccesibilă, de exemplu:
urn:schemas-microsoft-com:datatypes
4.4.4. HTTP (HyperText Transfer Protocol)
HTTP un protocol folosit pentru obŃinerea anumitor documente sau resurse de pe Internet. De exemplu, tastând într-un browser web: http://www.iccc.univagora.ro/icccc2006proc.pdf, se va obŃine ca rezultat Proceedings-ul în format pdf a conferinŃei ICCCC 2006.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 128
ANEXĂ MinidicŃionar de calcul paralel şi distribuit Surse: [Dzi01], [DL03] ş.a.
Pentru a satisface nevoia tot mai mare de reducere a timpului de rezolvare a
unei probleme de mari dimensiuni, a fost găsită soluŃia de a pune mai multe să lucreze simultan la rezolvarea sa, adică prelucrarea paralelă.
Calculul paralel/ distribuit/ concurent, paralelismul în general, cuprinde trei domenii interdependente:
� arhitectura sistemelor, � algoritmica, � limbaje de programare paralelă/ distribuită/ concurentă.
În lucrarea [Dzi01] sunt prezentate cele trei domenii şi interdependenŃa dintre ele, precum şi un minidicŃionar de noŃiuni şi concepte de paralelism.
În acest minidicŃionar sunt explicaŃi sumar principalii termeni şi sintagmele ce exprimă concepte utilizate în limbajul şi metalimbajul calcului paralel şi distribuit, astfel ca şi cititorul neiniŃiat să poată înŃelege manualul de faŃă fără a consulta alte materiale. Ordinea de prezentare a terminologiei nu este cea alfabetică, ci am încercat o anumită ordonare logică, aşa cum am crezut că ar trebui să parcurgă un începător minidicŃionarul nostru pentru a se familiariza cât mai rapid cu problematica extrem de complexă a calculului paralel şi distribuit.
Pentru explicaŃii suplimentare necesare aprofundării am utilizat următoarele notaŃii pentru trimiteri:
� paranteze drepte pentru indicarea sursei din bibliografie: ex. [Gri00] indică lucrarea prefixată astfel în bibliografie;
� paranteze rotunde pentru a indica numărul de ordine din tabelul minidicŃionarului: de exemplu, (1) se referă la expresia din tabel cu numărul curent 1, adică la paralelism.
Expresia în română // engleză
Descriere:
1. Paralelism //parallelism [PW95] [Mor98+] [Gri00]
“Paralelism” (P): = termen generic pentru desemnarea unui ansamblu de tehnici şi procedee de creştere a performanŃelor unui sistem informatic prin exploatarea simultană a mai multor resurse similare sau nu (în special elemente de procesare sau procesoare interconectate în diverse moduri în acelaşi sistem fizic sau computere cuplate într-o reŃea eterogenă etc.);
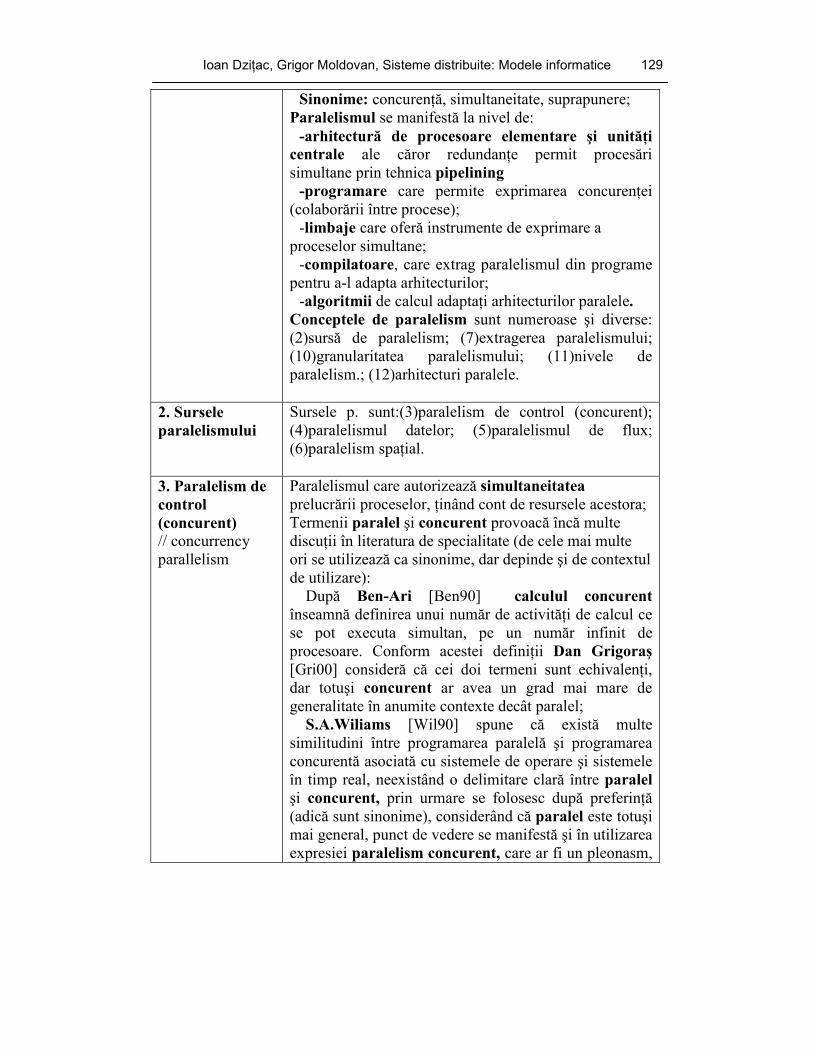
Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
129
Sinonime: concurenŃă, simultaneitate, suprapunere; Paralelismul se manifestă la nivel de: -arhitectură de procesoare elementare şi unităŃi centrale ale căror redundanŃe permit procesări simultane prin tehnica pipelining -programare care permite exprimarea concurenŃei (colaborării între procese); -limbaje care oferă instrumente de exprimare a proceselor simultane; -compilatoare, care extrag paralelismul din programe pentru a-l adapta arhitecturilor; -algoritmii de calcul adaptaŃi arhitecturilor paralele. Conceptele de paralelism sunt numeroase şi diverse: (2)sursă de paralelism; (7)extragerea paralelismului; (10)granularitatea paralelismului; (11)nivele de paralelism.; (12)arhitecturi paralele.
2. Sursele paralelismului
Sursele p. sunt:(3)paralelism de control (concurent); (4)paralelismul datelor; (5)paralelismul de flux; (6)paralelism spaŃial.
3. Paralelism de control (concurent) // concurrency parallelism
Paralelismul care autorizează simultaneitatea prelucrării proceselor, Ńinând cont de resursele acestora; Termenii paralel şi concurent provoacă încă multe discuŃii în literatura de specialitate (de cele mai multe ori se utilizează ca sinonime, dar depinde şi de contextul de utilizare): După Ben-Ari [Ben90] calculul concurent înseamnă definirea unui număr de activităŃi de calcul ce se pot executa simultan, pe un număr infinit de procesoare. Conform acestei definiŃii Dan Grigoraş [Gri00] consideră că cei doi termeni sunt echivalenŃi, dar totuşi concurent ar avea un grad mai mare de generalitate în anumite contexte decât paralel; S.A.Wiliams [Wil90] spune că există multe similitudini între programarea paralelă şi programarea concurentă asociată cu sistemele de operare şi sistemele în timp real, neexistând o delimitare clară între paralel şi concurent, prin urmare se folosesc după preferinŃă (adică sunt sinonime), considerând că paralel este totuşi mai general, punct de vedere se manifestă şi în utilizarea expresiei paralelism concurent, care ar fi un pleonasm,

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 130
dacă concurenŃa ar fi mai generală decât paralelismul; De fapt cei doi termeni fac parte din metalimbajul asociat CP şi au definiŃii imprecise, o definire matematică precisă a celor două noŃiuni ar clarifica lucrurile; evident, se poate accepta şi un punct de vedere de compromis, adică cele două sfere noŃionale au o mare parte comună, nefiind totuşi una inclusă în cealaltă.
4. Paralelismul datelor //data parallelism
P. în care aceeaşi prelucrare este aplicată unor date diferite, fie printr-un pipeline de instrucŃiuni vectoriale, fie printr-o arhitectură paralelă de tip SIMD.
5. Paralelismul de flux // data flow parallelism // flux parallelism
care efectuează o aceeaşi prelucrare asupra unui flux de date, de exemplu căutare multicriteriu într-o bază de date, printr-un operator pipeline din care fiecare secŃiune triază după unul din criterii cu viteza fluxului de date ce provine de pe disc
6. Paralelism spaŃial // spatial parallelism
P. care efectuează o descompunere a datelor reprezentative în spaŃiu, în regiuni prelucrate de procesoare diferite (calcul numeric, prelucrare de imagini)
7. Extragerea paralelismului
Paralelism implicit (8); paralelism explicit (9)
8. Paralelism implicit sau extras // implicit parallelism
P. în care compilatorul extrage posibilităŃile de paralelism ale programului şi le adaptează arhitecturii, cum ar fi paralizarea executării buclelor de programe când iteraŃiile succesive sunt independente, sau reordonarea instrucŃiunilor pentru utilizarea optimă a arhitecturilor RISC superscalare.
9. P. explicit // explicit parallelism
P. definit de către programatorul-utilizator
10. Granularitatea paralelismului, aplicaŃiei, sistemului ; // granularity // grain size
În paralelismul de concurenŃă [Mor98+] avem următoarele grade de granularitate: -inferior (la nivel de programe); -mediu (la nivel de procese); -ridicat (la nivel de threads, adică procese simple). După Schwatz [Qui88] granularitatea se mai referă şi la numărul de procesoare dintr-un sistem paralel:

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
131
- brută (zeci şi sute de procesoare); - fină (mii şi zeci de mii de procesoare).
În [Gri00] se defineşte granularitatea aplicaŃiei ca valoarea minimă a granularităŃii pentru toate activităŃile paralele componente (proces, thread)= dimensiunea minimă, exprimată în numărul de instrucŃiuni, dintr-o unitate secvenŃială. Valoarea minimă sub care performanŃa sistemului paralel scade semnificativ este numită granularitatea sistemului.
11. Nivele de paralelism
Nivel scăzut // low level parallelism:= p. la nivelul procesorului elementar (arhitectură cu instrucŃiuni pipeline, superscalară, sistolică); Nivel înalt // high level parallelism:= care pune în funcŃiune mai multe procesoare elementare
12. Arhitectura paralelismului
P. centralizat (puternic cuplat) // centralized (highly coupled) parallelism := permiŃând o vedere şi un control global prin partajarea unei resurse comune între procesoare, ca în multiprocesoarele cu memorie comună; P. distribuit // distributed parallelism:= unde procesoarele independente nu dialoghează decât prin mesaje transmise prin reŃea, ca în cazul unui hipercub; p. masiv // massive parallelism:= mai multe procesoare universale sau specifice )arhitecturi celulare şi reŃele neuronale).
13. Paralelizarea unui program/ algoritm
Adaptarea unui program / algoritm conceput pentru un calculator monoprocesor pentru a fi executat pe calculator multiprocesor, adică izolarea unor subcomponente care pot fi executate simultan.
14. Clasificarea Flynn
Flynn clasifică arhitecturile în funcŃie de modul de prelucrare a seturilor de instrucŃiuni şi a seturilor de date în: SISD (Single Instruction stream-Single Data stream); SIMD (Single Instruction stream-Multiple Data stream); MISD (Multiple Instruction stream-Single Data stream); MIMD (Multiple Instruction stream-Multiple Data stream);

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 132
15. Arhitectură masiv paralelă // large parallel architecture
Arhitectura sistemului central implicând un mare număr de procesoare (de ordinul sutelor) elementare, interconectate în diverse structuri topologice (magistrală, inel, matrice, arborescentă, plasă/grilă, hipercub etc.) care lucrează în colaborare la rezolvarea uneia sau mai multor probleme;
16. Arhitectură multiprocesor // multiprocessor architecture
Arhitectură a sistemului central / unităŃii centrale care include mai multe procesoare elementare de prelucrare;
17. Arhitectură pipeline // pipeline architecture
Arhitectură a operatorului sau procesorului care permite un paralelism înlănŃuit, de tip conductă / bandă rulantă; operatorul este împărŃit în sectoare traversate succesiv de date, după frecvenŃa ceasului, eliberând secŃiunea pentru operaŃia următoare, astfel încât o nouă operaŃie poate fi iniŃializată la fiecare perioadă de ceas; Un pipeline de instrucŃiuni permite procesoarelor RISC prelucrarea unui debit de instrucŃiuni într-o bătaie de ceas, atunci când o instrucŃiune necesită cinci operaŃii: căutarea instrucŃiunii în cache, decodarea, căutarea operanzilor, execuŃia, pregătirea rezultatului; Pipeline (canal de prelucrare paralelă):= o „linie de asamblare” care creşte substanŃial viteza de citire, executare şi scriere a instrucŃiunilor. Utilizată de mult în UNIX, structura pipeline a fost inclusă în Intel 80486 şi permite prelucrarea unei instrucŃiuni în fiecare perioadă de ceas. Microprocesorul Intel Pentium conŃine două astfel de structuri, una pentru date şi alta pentru instrucŃiuni; Pipelining := prelucrare paralelă.
18. Procesor CISC (procesor cu set complex de instrucŃiuni) // Complex Instruction Set Computer (CISC)
Arhitectură de procesor în care a existat tendinŃa de a mări setul de instrucŃiuni cablate, evoluŃia lor orientându-se spre execuŃia dinamică, care se bazează pe trei concepte: predicŃia salturilor, analiza dependenŃelor de date şi execuŃia speculativă. Ex.: microprocesoarele Intel Pentium Pro.[Gri00]
19. Procesor RISC (procesor cu set redus de
O alternativă la CISC; Cele mai populare arhitecturi de procesoare pentru CP în care obŃinerea performanŃelor este urmărită prin

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
133
instrucŃiuni) // Reduced Instruction Set Computer (RISC) [Gri00]
utilizarea unui set redus de instrucŃiuni cablate ce permite prelucrarea pipeline a instrucŃiunilor de executat; Obiectivul arhitecturilor RISC ideale este realizarea unei instrucŃiuni la fiecare bătaie de ceas, cea ce implică strădania de alimentare cu instrucŃiuni şi date a memoriilor cache, evitarea aşteptărilor în pipeline-rile de instrucŃiuni în caz de racordări, evitarea timpilor de schimbare de context în cazul apelurilor de proceduri; Premergătoarele RISC-ului au fost IBM 801, SPARC, MIPS.
20. Arhitectură superscalară // superscalar architecture [Gri00]
extensie RISC în care mai multe instrucŃiuni de tip diferit sunt decodificate simultan, apoi lansate în paralel, fiecare către operatorul corespunzător: de exemplu, o operaŃie în virgulă fixă, o operaŃie în virgulă mobilă şi o operaŃie cu memoria; Compilatorul este cel care se ocupă cu reorganizarea instrucŃiunilor pentru obŃinerea celei mai bune utilizări pipeline şi a unui maxim paralelism superscalar, garantând coerenŃa programului.
21. Hipercub // hypercub
Calculator paralel cu cuplare slabă şi memorie distribuită la un număr de procesoare ce uneori depăşeşte 65 000 (de ex, CM 1).
22. Multiprocesor // multiprocessor
Denumire dată unui calculator sau unui sistem de calcul care are mai multe procesoare de prelucrare
22. Multiprocesor simetric // symetric multiprocessor
Multiprocesor în care gestiunea sarcinilor sistem este partajată de către toate procesoarele, spre deosebire de multiprocesorul de tipul master/slave, unde master-ului (stăpânului) îi revine gestiunea sistemului de exploatare, sclavii fiind puşi doar să execute , Ex. Sequent Symmetry
23. Multiprograma-re //multiprogra-mming
Concept de natură hardware prin care mai multe programe stocate în memoria unui calculator sunt executate cu întreruperi, cu partajarea timpului:

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 134
24. Multitasking Executarea a mai multor programe în acelaşi timp pe un sistem de calcul ExecuŃia unui program presupune utilizarea mai multor resurse sistem: în afara efectuării calculelor pe procesorul sistemului, un program poate transfera date într-un fişier implicând o "comunicaŃie" cu discurile fixe, poate trimite date la imprimantă pentru a fi tipărite, sau poate aştepta reacŃia umană furnizată prin intermediul mouse-ului sau tastaturii. Toate aceste operaŃii sunt realizate la viteza la care perifericul respectiv poate funcŃiona fizic, viteza net inferioara celei la care funcŃionează procesorul. ExecuŃia programelor prin întrepătrundere (multitasking) este o tehnica ce permite utilizarea la maximum a procesorului, prin planificarea spre execuŃie a altor programe pe perioadele de inactivitate ale acestuia. Pentru a evita situaŃiile în care un program acaparează integral procesorul (prin evitarea dialogului cu periferia), tehnica "multitasking" prevede ca după o cuantă maxima de timp, un astfel de program sa fie suspendat permiŃând astfel şi execuŃia altor programe. Un alt avantaj al unui astfel de mecanism constă în robusteŃea conferită sistemului. Astfel, indiferent dacă programul utilizator ce se executa la un moment dat e corect sau nu, prin "prelevarea forŃată" a sa (suspendarea din execuŃie) controlul este redat sistemului de operare, permiŃând astfel terminarea sau "uciderea" acelui program. Un sistem de operare care funcŃionează pe principiul "multitasking"-ului (de ex. UNIX) creează iluzia execuŃiei simultane a mai multor programe - o execuŃie în acest caz este văzută ca fiind un proces distinct. Bazându-se pe această iluzie, un astfel de sistem de operare prevede mecanisme de "comunicaŃie" şi "sincronizare" între procese, şi deci dezvoltarea aplicaŃiilor "concurente". Atâta timp însa cât este utilizat un singur procesor, nu se pot aştepta creşteri spectaculoase de performanŃă. O creştere există, dar ea se datorează utilizării mai eficiente a acestui unic procesor, şi nu creşterii puterii de calcul a sistemului în ansamblu. Pe sistemele real paralele (distribuite sau nu), procesele

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
135
ce compun un program sunt executate efectiv în acelaşi timp. În plus, particularităŃile constructive ale sistemului paralel pot reduce mulŃimea mecanismelor disponibile (de exemplu absenŃa memoriei partajate în mediile distribuite), impunând o modelare a mecanismelor absente. ExistenŃa mai multor procesoare oferă o creştere categorica a performanŃelor, dar induce şi probleme complexe în controlul execuŃiilor programelor. O astfel de problemă constă în decizia plasării proceselor pe procesoarele fizice disponibile. Aceasta decizie poate aparŃine programatorului, dacă limbajul utilizat permite acest lucru, fiind vorba astfel de un paralelism explicit.
25. AplicaŃie multifir // multithreaded application
Un program care poate rula în acelaşi timp două sau trei fire (//threads), porŃiuni independente de program; Avantajul divizării în fire (threads) constă în posibilitatea oferită sistemului de operare de a decide care fir are prioritate maximă de execuŃie.
26. Multiprelucrare // multiprocessing
Concept de natură software, un mod de exploatare a unui calculator în care mai multe sarcini sunt executate simultan de către mai multe procesoare printr-o planificare, când unul aşteptă încă date de intrare de care are nevoie pentru continuarea execuŃiei, unitatea centrală se ocupă de un alt program; astfel că se creează impresia de paralelism în execuŃie, adică în acelaşi interval de timp sunt terminate mai multe programe.
27. Sincronizare // synchronization
Mecanism utilizat în execuŃii paralele ce permite introducerea de întârzieri în execuŃia unui program, necesare unor constrângeri impuse de algoritm sau de structura intimă a procesorului; Sincronizarea se petrece în primul rând la operaŃiile indivizibile la nivelul procesorului, execuŃia cărora trebuie terminată înaintea oricărei alte utilizări a procesorului (în acest caz nu se permit intercalări în execuŃie, deci e nevoie de sincronizare); Există două tehnici importante de sincronizare: mecanismul fork-join şi utilizarea mecanismelor de control: cobegin-coend, parbegin–parend;

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 136
Primul este un mecanism mai puternic (permite crearea dinamică a proceselor, pe când al doilea introduce o structură de control cu o singură intrare şi o singură ieşire);
28. Mecanismul fork-join
Mecanism utilizat în limbajele de programare paralelă (concurentă) pentru specificarea execuŃiei concurente (paralele), adecvat pentru aplicaŃii în care nici o funcŃie majoră a aplicaŃiei nu necesită rezultate de la o altă funcŃie a acesteia, adică sunt independente şi pot fi evaluate simultan; variante ale sale se utilizează în Unix pentru specificarea proceselor concurente; instrucŃiunea fork Q, apărută într-un proces P, declanşează execuŃie paralelă a procesului Q În acelaşi timp ce se execută şi procesul P în care apare fork-ul; instrucŃiunea join Q apărută într-un proces P, recombină două procese într-unul singur ca în următorul exemplu: program P begin....fork Q...join Q... program Q begin...end; end. pentru exemplul de mai sus execuŃia lui Q este începută când se ajunge la fork Q din P, moment din care P şi Q se execută simultan fie până când P execută join Q, fie până când Q se termină. Dacă Q nu este terminat şi P execută join Q, el va aştepta până când Q se va termina şi numai apoi îşi va continua execuŃia. Dacă însă Q se termină înainte ca p să execute join Q, atunci execuŃia acestei comenzi nu va avea nici un efect asupra lui P, acesta continuându-şi execuŃia cu instrucŃiunile ce urmează după join Q.
29. mecanismele de control: cobegin-coend/ parbegin-parend
Sunt mecanisme pentru specificarea execuŃiei concurente/ paralele a instrucŃiunilor din lista cuprinsă între început şi sfârşit; de exemplu în programul program P begin...cobegin Q, R coend
S...end. instrucŃiunile Q şi R vor începe să fie executate simultan când se ajunge la cobegin, iar R va fi pornită doar după ce ambele instrucŃiuni sunt terminate (dacă R se termină mai repede, se aşteptă şi după terminarea lui Q,

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
137
adică după terminarea tuturor instrucŃiunilor din listă); parbegin-parend are acelaşi efect.
30. Sistem multiuser //multiuser system
Sistem cu mai mulŃi utilizatori; sisteme de operare multiuser: UNIX, Linux etc.
31. conceptul de program stocat // stored program concept
Este un concept utilizat în programarea serială în care un program se stochează în memorie împreună cu datele, urmând ca execuŃia instrucŃiunilor din program să nu se facă neapărat în ordinea secvenŃială de scriere a programului ci să fie executată acea instrucŃiune care are disponibile datele necesare execuŃiei.
32. transputer // TRANSistor and comPUTER
Numit şi calculator într-un cip, este un microcircuit VLSI cu memorie adiŃională, microprocesor, posibilităŃi de comunicaŃie şi interconectare; Construit pe baza unei arhitecturi RISC (INMOS, 1985), este strâns legat de limbajul Occam şi constituie elementul de bază al sistemelor multiprocesor masiv paralele
33. limitare de tip von Neumann // von Neumann bottleneck
Limitarea vitezei de prelucrare constatată de însuşi John von Neumann în arhitecturile care-i poartă numele, conform căreia un calculator de acest tip pierde mai mult timp cu căutarea datelor în memorie decât cu prelucrarea propriu –zisă.
34. limbajul Occam
Descendent direct din CSP, Occam (numele filozofului englez din secolul XIV de la care a rămas principiul simplităŃii în structura entităŃilor, briciul lui Occam); un limbaj simplu, cu mecanisme puternice de implementare a algoritmilor paraleli pe sisteme bazate pe transputere şi sisteme distribuite.
35. Limbajul TIMP / TIMişoara Parallel (TIMP)
Limbaj concurent destinat calculatoarelor vectoriale, elaborat de un colectiv de la Universitatea Politehnica din Timişoara
36. Limbajul PVM / Parallel Virtual Machine
Limbaj destinat calculatoarelor paralele virtuale configurate dintr-o mulŃime de calculatoare conectate într-o reŃea distribuită. Un pachet de programe destinat programării calculatoarelor paralele virtuale.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 138
37. Sistem distribuit de prelucrare // distributed processing sistem
Un sistem de calcul proiectat pentru mai mulŃi utilizatori, în maniera client / calculator, care oferă fiecărui utilizator un calculator complet funcŃional: În domeniul PC prelucrarea distribuită are forma reŃelelor locale (LAN), în care PC-urile unui departament sunt legate prin conexiuni de mare viteză, resursele scumpe putând avea o utilizare în comun; se deosebeşte de sistemele cu mai mulŃi utilizatori.
38. Sistem centralizat de prelucrare // centralized processing sistem
Un sistem de calcul proiectat pentru mai mulŃi utilizatori, în maniera mainframe (un calculator de mare capacitate necesar unei organizaŃii departamentale, cu mai multe terminale şi cu o bază de date comună şi partajarea unor resurse scumpe în comun); deosebirea esenŃială dintre sistemele centralizate şi cele distribuite este că puterea de calcul se realizează în primele printr-un calculator de mare capacitate, iar în cele distribuie prin mai multe calculatoare de capacităŃi mai mici.
39. Scalabilitatea (sistemului paralel) / scalability (of parallel system) [Gri00], p. 68
Se referă la posibilitatea de a asigura creşterea eficienŃei prin creşterea numărului de procesoare , în ipoteza că programul prezintă un potenŃial suficient de mare de paralelism şi o granularitate suficient de mare; Dacă se obŃine o creştere liniară a accelerării, se spune că sistemul este scalabil liniar.
40. Procese asincrone // asynchronous processes
Procese concurente care nu fac schimb de date direct, după perioade prestabilite (ca la procesele sincrone), sau prin mesaje la cerere (ca la procesele sincronizabile), ci fac schimb de date prin intermediul memoriei comune în orice moment al desfăşurării proceselor
41. Sistem de calcul în timp real // real time computing system
Este un sistem de calcul online (sistem în care datele de intrare sunt introduse direct de la locul de generare în sistemul de calcul, iar datele de ieşire sunt transmise direct la locul de utilizare), ataşat unui fenomen în desfăşurare reală, astfel încât intervalul de timp scurs de la începerea preluării datelor de intrare şi până la obŃinerea rezultatelor, să fie suficient de scurt pentru ca desfăşurarea ulterioară a fenomenului să mai poată fi

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
139
influenŃată: Elementul esenŃial ce caracterizează un sistem de calcul în timp real este timpul de răspuns al aplicaŃiei, timp care de multe ori nu poate fi suficient de micşorat decât prin mijloace sau procedee de calcul paralel
42. UNIX Sistem de operare multitasking şi multiuser utilizabil atât pe un PC cât şi pentru reŃele de PC-uri; are multe variante specializate: Linux pentru configurarea unui calculator paralel virtual, care poate fi programat în limbaj PVM, Parix, pentru sistemele bazate pe transputere; Dynix, pentru sistemul Sequent Symmetry ş.a.
43. / Grand Challenge
Categorie de probleme de mari dimensiuni, cu caracter ştiinŃific sau ingineresc, de o asemenea complexitate încât nici un cercetător sau institut de cercetări nu le poate rezolva prin eforturi individuale; astfel de probleme sunt Ńinte ale calcului paralel şi distribuit.
44. Algoritmi paraleli // parallel algorithms
Există mai multe modalităŃi de obŃinere a algoritmilor paraleli: -prin multiplicare şi izolare, adică fiecare procesor execută în mod independent acelaşi program, fiind izolat de restul procesoarelor (acelaşi program, date locale diferite, fără comunicare între procesoare); -prin paralelism spaŃial, fiecare procesor executând acelaşi program dar asupra unor date locale rezultate în urma unei divizări a domeniului datelor (acelaşi program, date locale diferite, comunicare pentru datele de la frontiera domeniului); -prin paralelism algoritmic, fiecare procesor fiind responsabil de o anumită parte din program, toate datele trecând prin fiecare procesor (secvenŃe de program diferite, date globale, comunicare prin intermediul unei memorii comune); algoritmii paraleli pot fi numerici (se execută calcule cu numere), sau nenumerici (se execută operaŃii de căutare, sortare ş.a.).
45. Internet / The Net
Cuvântul „internet” provine din concatenarea prescurtărilor a două cuvinte englezeşti, interconnected (interconectat) şi network (reŃea) şi desemnează o reŃea

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 140
de mari dimensiuni formată prin interconectarea mai multor reŃele autonome eterogene. Astfel, substantivul comun „internet” (cu minusculă) desemnează în general o reuniune de reŃele, văzută ca o reŃea unitară, împreună cu informaŃia şi serviciile care sunt oferite utilizatorilor prin intermediul acestei reŃele (Web, E-Mail, FTP etc.). Cea mai mare dintre reŃele de tip internet este numită Internet (nume propriu, scris cu majusculă), adică super-reŃeaua mondială unică de computere, interconectate prin protocolul IP Atât Internetul sau The NET (ReŃeaua), cum i se mai spune în lume, cât şi alte reŃele mai mici de tip internet sunt exemple de sisteme informatice distribuite.
46. Intranet/
Un intranet este o reŃea închisă sau o sub-reŃea dintr-un internet sau chiar din Internet care este administrată autonom şi pentru care exista un sistem de securitate local. Un intranet poate format din mai multe reŃele de tip Local Area Network (LAN), legate între ele prin anumite sisteme de comutare. Un intranet poate fi conectat la Internet printr-un router , care permite utilizatorilor din intranet să utilizeze servicii ca Web, FTP sau EMAIL. De asemenea permite utilizatorilor din exterior (din Internet) să acceseze servicii pe care le pune eventual la dispoziŃie intranetul. Pentru a se proteja de diferite atacuri maliŃioase, sunt utilizate soft-uri de tip firewall, care previn utilizatorul că anumite mesaje neautorizate încearcă să intre sau să plece. Un firewall este implementat să filtreze anumite mesaje conform unor criterii, de exemplu el permite trecerea doar a mesajelor legate de poşta electronică.
47. Calcul mobil/ Nomadic
computing
În lumea sistemelor informatice distribuite un rol deosebit îl au în prezent dispozitivele miniaturizate şi reŃelele wireless. De exemplu, cu ajutorul unui laptop sau chiar a telefonului mobil, printr-o conexiune de tip wireless ne putem conecta aproape de pretutindeni la intranetul „home” şi putem utiliza resursele de acolo (de pe calculatorul de acasă sau de la serviciu). Putem vorbi astfel de un calcul mobil (nomadic computing).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
141
48. Computere-omniprezente/ Ubiquitous
computing
Ubiquitous computing promovează ideea aparent opusă, „computere omniprezente”, adică să existe computere conectate la internet în locuri în care există indivizi obligaŃi să stea un timp mai lung sau mai scurt (imobilizaŃi acasă sau în spitale, în staŃiuni turistice, în gări şi aeroporturi etc.), pe care indivizii le pot accesa pentru comunica sau pentru a accesa anumite informaŃii din exterior. De exemplu, de la calculatorul de acasă conectat la Internet, putem accesa diverse informaŃii de la serviciu sau putem citi presa din Bucureşti sau Londra, sau putem coresponda prin email sau online cu orice persoană din lume care dispune de aceleaşi facilităŃi. In afară de laptopuri şi de telefoanele mobile performante, amintim imprimantele inteligente, ceasurile inteligente, PDA (personal digital assistant), camere video digitale etc., care contribuie la dezvoltarea tot mai expansivă a calculului nomadic.
49. Sistem puternic cuplat/ Tightly coupled
system
50. Sistem slab cuplat/ Loosely coupled
system
Din punct de vedere al structurii hardware şi a tipului de conexiune, sistemele care cuprind mai multe procesoare pot fi:
• puternic cuplate (conectate la nivel de memorie, ex. multiprocesoare);
• slab cuplate (conectate la nivel de reŃea de calculatoare, ex. multicalculatoare).
Sistemele puternic cuplate sunt sisteme în care mai multe procesoare partajează aceeaşi memorie internă şi folosesc acelaşi ceas intern. De exemplu sistemele din clasa MIMD sunt sisteme puternic cuplate (multiprocesoarele şi calculatoarele paralele masive).
Sistemele slab cuplate sunt sisteme în care fiecare procesor are propria memorie şi propriul ceas intern.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 142
51. Cluster („ciorchine”) Se mai utilizează uneori denumirea Farm („fermă”) pentru desemnarea aceluiaşi concept
Clusterul este un tip de sistem distribuit ce permite calculul paralel, format fizic dintr-o reŃea de cel puŃin două procesoare, numite staŃii de lucru (care pot fi calculatoare complete, PC-uri, supercalculatoare, calculatoarele vectoriale, multiprocesoare, MPP), care pot fi folosite şi de sine stătător, interconectate într-o reŃea, fiind utilizat ca o resursă de calcul integrată şi singulară. În practică se utilizează două tipuri de clustere: clustere dedicate (formate din procesoare omogene) şi clustere de întreprindere (formate din procesoare neomogene). Un cluster are, în mod iluzoriu, pentru utilizator o imagine de sistem unic -SSI (Single System Image). Aceasta este impresia utilizatorului, că are acces la un sistem unic cu resurse multiplicate, cu control unic asigurat prin intermediul unei singure interfeŃe. Sistemul este simetric, în sensul că un serviciu poate fi solicitat de pe orice nod, iar accesul la resurse este transparent. Astfel, clusterul pare la fel de uşor de folosit ca un PC. Elementele clusterului sunt văzute din afară ca fiind anonime şi interschimbabile.
52. Bază de date distribuită //distributed database
Este o colecŃie de date distribuită în mai multe locaŃii fizice, controlată de un sistem de management al bazei de date în care dispozitivele de stocare nu sunt ataşate în totalitate de o singură unitate centrală de prelucrare obişnuită. Datele pot fi stocate în mai multe calculatoare plasate în aceeaşi locaŃie fizică sau într-o reŃea. O bază de date distribuită este distribuită în partiŃii/fragmente separate. Fiecare partiŃie/fragment a unei baze de date distribuită poate fi reprodusă (adică eşecuri redundante, cum ar fi o matrice de hard-disk-uri). În afară de replicarea şi fragmentarea bazelor de date distribuite, există multe alte modele de tehnologii ale bazelor de date distribuite. De exemplu, autonomia locală, şi tehnologii sincrone şi asincrone ale bazelor de date distrbuite. Aceste implementări ale tehnologiilor poate, şi în mod sigur, depinde de nevoile beneficiarului şi sensibilitatea/confidenŃialitatea datelor care vor fi stocate în baza de date.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
143
BIBLIOGRAFIE
[AG94] G. S. ALMASI, A. GOTTLIEB :
Highly Parallel Computing: Second Edition, Benjamin /Cummings, Redwood City, CA, 1994.
[Ben90] M. BEN-ARI: Principles of concurrent and distributed programming, Prentice Hall, 1990.
[BBC+04] A. BAVIER, M. BOWMAN, B. CHUN, D. CULLER, S. KARLIN, S. MUIR, L. PETERSON, T. ROSCOE, T. SPALINK, M. WAWRZONIAK: Operating System Support for Planetary-Scale Services, Proceedings of the First Symposium on Network Systems Design and Implementation (NSDI), March 2004.
[BTT02] S. BURAGA, V. TARHON-ONU, Ş. TANASĂ, Programare Web în Bash şi Perl, Editura Polirom, Iaşi, 2002.
[Chi95] I. CHIOREAN: Calcul paralel, Ed. Albastră, Cluj-Napoca,1995.
[DL03] I. DZIłAC, E. LASLO, Programarea paralela utilizând PVM, Ed. Univ. din Oradea, 2003
[Dzi98] I. DZIłAC: Parallel and concurrent in informatics vocabulary, An. Univ.
din Oradea, Tom VI, 1997-1988, pp. 30-34 [Dzi01b] I. DZIłAC:
A binary graph for the parallel architecture, The PAMM’s periodical Bulletins for Applied & Computer Mathematics, Budapest, BAM-1906/2001 (XCVI-C), pp.151-164.
[Dzi01c] I. DZIłAC: Calcul paralel, Ed. Univ. din Oradea, 2001
[Dzi02] I. DZIłAC: Procedee de calcul paralel si distribuit in rezolvarea unor
ecuaŃii operatoriale, PhD Thesis, Supervisor Grigor Moldovan, Univ. „Babes-Bolyai”, Cluj Napoca, 2002
[Dzi02a] I. DZIłAC: Survey of Taxonomy of the Parallel Computers, In Proc. of The 27th Annual Congress, of the American Romanian Acad. of Arts (ARA) and Univ.of Oradea, 2002, pp. 672 – 673.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 144
[Dzi06] I. DZIłAC: Parallel and Distributed Methods for Algebraic Systems
Resolution, Ed. Univ. Agora, Oradea, 2006. [FKT01] I. FOSTER, C. KESSELMAN, S. TUECKE.
The anatomy of the Grid: Enabling scalable virtual
organization. The Intl. Journal of High Performance Computing Applications, 15(3):200--222, Fall 2001.
[Gri00] D. GRIGORAŞ: Calculul paralel- De la sisteme la programarea aplicaŃiilor, Ed. Agora, 2000.
[HJ91] R.W. HOCKNEY, C.R. JESSHOPE: Calculatoare paralele, arhitectură, programare şi algoritmi, Ed. Tehnică, 1991 (traducere de Dan Grigoraş).
[Hwa93] K. HWANG: Advanced Computer Architecture: Parallelism, Scalability,
Programability, Mc Graw-Hill, NV, 1993. [Jod95a] E. JODAL:
DicŃionar de tehnică de calcul englez român, Ed.Albastră, 1995. [Jod95b] E. JODAL:
DicŃionar de tehnică de calcul român englez, Ed, Albastră. 1995. [KBM02] K. KRAUTER, R. BUYYA, M. MAHESWARAN:
A taxonomy and survey of grid resource management systems
for distributed computing, Softw. Pract. Exper. 2002; 32:135–164 (DOI: 10.1002/spe.432)
[Kum+94] V. KUMAR, A. GRAMA , A. GUPTA, G. KARYPIS: Introduction to Parallel Computing, Design and Analysis of
Algorithms, The Benjamin/ Cummings Publishing Company, Inc., 1994.
[Lew93] T. LEWIS: Foundations of parallel programming. A machine independent
approach, IEEE Computer Society Press, Los Alamitos, 1993. [Mar+99] V. MARINESCU, R. HRIN, M. TOMESCU, M. HRIN, L.
ANANIA: DicŃionar informatic trilingv, Ed. ALL, 1999.
[MD87] G. MOLDOVAN; S. DAMIAN: On some generalizations of an optimization problem for
distributed databases, Stud. Univ. Babes-Bolyai, Math. 32, No.3, pp. 67-76 (1987).
[MD88] GR. MOLDOVAN; S. DAMIAN: On an optimization problem for distributed databases, An. Univ. Bucur., Mat. 37, No.2, pp. 82-87 (1988).

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice
145
[MD89] GR. MOLDOVAN; S. DAMIAN: A local optimization problem for data base redistribution in a
computer net, Stud. Univ. Babes-Bolyai, Math. 34, No.3, pp. 3-16 (1989).
[Mol93b] GR. MOLDOVAN: The problem of redistribution of a distributed service system
following some given criteria,Babes-Bolyai Univ., Fac. Math. Comput. Sci., Res. Semin., Prepr. 1993, No.5, pp. 75-78 (1993).
[MR92] G. MOLDOVAN, I. RÂP: Files d'attente dans des systèmes distribuées des services.
(Queues in distributed service systems) Stud. Univ. Babes-Bolyai, Math.37, No.3, pp. 69-74 (1992).
[PAC+02] L. PETERSON, T. ANDERSON, D. CULLER, T. ROSCOE: A Blueprint for Introducing Disruptive Technology into the
Internet, Proceedings of the First ACM Workshop on Hot Topics in Networking (HotNets), October 2002.
[Pet94] D. PETCU: Calcul paralel, Ed. de Vest, Timişoara, 1994.
[Pet98] D. PETCU: Parallelism in solving ordinary differential equations, Univ. de Vest din Timişoara, 1998.
[PO02] C. POPESCU, H. OROS: Securitatea reŃeleor de calculatoare, Editura UniversităŃii din Oradea, 2002
[PW95] B. PFAFFENBERGER, D. WALL: Que’s Computer & Internet Dictionary, 1995 (traducere în limba română de N.D. Pora, Ed. Teora, 1999).
[Sto93] H. S. STONE: High-Performance Computer Architectures –Third Edition, Addison-Wesley, Reading, MA, 1993.
[Tan97] A. TANENBAUM: ReŃele de calculatoare, Computer Press Agora, 1997.
[Vin96] L. VINłAN: Exploatarea paralelismului în microprocesoarele avansate, Ed. Univ. Sibiu, 1996.
[Wil90] S. A. WILLIAMS: Programming Models for Parallel Systems, John Wiley & Sons, Chicester, 1990.
[Wil93] N. B. WILDING: Notes to accompany Introductory Talks on Parallel Computing, Heilderberg, apr.1993.

Ioan DziŃac, Grigor Moldovan, Sisteme distribuite: Modele informatice 146
Webgrafie:
1. http://www.networkcomputing.com/ 2. http://boinc.berkeley.edu/ 3. http://www.networkcomputing.co.uk/ 4. http://www.distributed.net/ 5. http://dsonline.computer.org/portal/site/dsonline/index.jsp 6. http://distributedcomputing.info/ 7. www.informatica.com/solutions/resource_center/glossary/default.htm 8. http://www.gridcomputing.com/ 9. http://www-1.ibm.com/grid/ 10. http://www.oracle.com/technologies/grid/index.html 11. http://www.gridcomputingplanet.com/ 12. http://gridcafe.web.cern.ch/gridcafe/ 13. http://www.realitygrid.org/information.html 14. http://www.springerlink.com/content/1573-7543/ 15. http://www.ieeetfcc.org/ 16. http://www.trygve.com/furbeowulf.html 17. http://library.thinkquest.org/C007645/english/0-welcome.htm 18. http://www.internet.com/ 19. http://www.legi-internet.ro/ 20. http://www.intranetjournal.com/ 21. http://www.ici.ro/ici//revista/ria2003_4/art3.html 22. http://www-unix.mcs.anl.gov/mpi/ 23. http://www.csm.ornl.gov/pvm/ 24. http://www.linux.org 25. http://info.tech.pub.ro/~fionescu/CP/CP.html 26. http://www.linux-ha.org/ClusterResourceManager 27. http://www.csm.ornl.gov/pvm/ 28. http://www.globus.org/ 29. http://www.globus.org/toolkit/ 30. http://detective.internet2.edu/applet/index.html 31. http://www.epm.ornl.gov/pvm/pvm_home.html 32. http://www.netlib.org/pvm3 33. http://www.ICANN.org 34. http://www.gac.icann.org/docs/index.htm 35. http://gac.icann.org/web/about/gac-outreach_Romanian.htm 36. http://www.domreg.ro/domain.html








![CURRICULUM VITAE - Agora Universityunivagora.ro/m/filer_public/2013/03/26/cv_en_dzitac.pdf · CURRICULUM VITAE Prof.dr. Ioan Dzitac ... Dan Tufis, Florin Gheorghe Filip, ... [19]](https://img.dokumen.tips/doc/110x75/5b14f1187f8b9a4e2c8cbc7c/curriculum-vitae-agora-curriculum-vitae-profdr-ioan-dzitac-dan-tus.jpg)



















