Embed Size (px)
Citation preview

SchedulingThreadsfor Low SpaceRequirementandGoodLocality
Girija J.NarlikarMay 1999
CMU-CS-99-121
Schoolof ComputerScienceCarnegie Mellon University
Pittsburgh,PA 15213
This technicalreportis anextendedversionof a paperthatappearsin theproceedingsof theEleventhACM SymposiumonParallelAlgorithmsandArchitectures(SPAA), June1999.
This researchis supportedby ARPA ContractNo. DABT63-96-C-0071.TheU.S.Governmentis authorizedto reproduceanddistribute reprintsfor Governmentpurposes,notwithstandingany copyrightnotationthereon.Views andconclusionscontainedinthisdocumentarethoseof theauthorandshouldnotbeinterpretedasrepresentingtheofficial policies,eitherexpressedor implied,of ARPA or theU.S.Government.


Abstract
Therunningtimeandmemoryrequirementof aparallelprogramwith dynamic,lightweightthreadsdependsheavily ontheunderlyingthreadscheduler. In thispaper, wepresentasimple,asynchronous,space-efficientschedulingalgorithmfor sharedmemorymachinesthatcombinesthe low schedulingoverheadsandgoodlocality of work stealingwith the low spacerequirementsof depth-firstschedulers.For a nested-parallelprogramwith depth
�andserialspacerequirement��� , we show that the expectedspacerequirementis��������� ����� ��� on � processors.Here, is auser-adjustableruntimeparameter, whichprovidesa trade-
off betweenrunningtime andspacerequirement.Ouralgorithmachievesgoodlocality andlow schedulingoverheadsby automaticallyincreasingthegranularityof thework scheduledoneachprocessor.
Wehaveimplementedthenew schedulingalgorithmin thecontext of anative,user-level implementationof Posixstandardthreadsor Pthreads,andevaluatedits performanceusinga setof C-basedbenchmarksthathave dynamicor irregularparallelism.We comparetheperformanceof our schedulerwith thatof twoprevious schedulers:the threadlibrary’s original scheduler(which usesa FIFO queue),and a provablyspace-efficient depth-firstscheduler. At a fine threadgranularity, our scheduleroutperformsboth thesepreviousschedulers,but requiresmarginally morememorythanthedepth-firstscheduler.
Wealsopresentsimulationresultsonsyntheticbenchmarkstocompareourschedulerwith space-efficientversionsof bothawork-stealingscheduleranda depth-firstscheduler. Theresultsindicatethatunlike thesepreviousapproaches,thenew algorithmcoversa rangeof schedulinggranularitiesandspacerequirements,andallowstheuserto tradethespacerequirementof a programwith theschedulinggranularity.

Keywords: Multithreading,spaceefficiency, work stealing,dynamicscheduling,nestedparallelism,dynamicdags.

1 Intr oduction
Many parallel programminglanguagesallow the expressionof dynamic, lightweight threads. Theseinclude dataparal-lel languageslike HPF [22] or Nesl [5] (wherethe sequenceof instructionsexecutedover individual dataelementsarethe“threads”), dataflow languageslike ID [16], control-parallellanguageswith fork-join constructslike Cilk [20], CC++[13],andProteus[29], languageswith futureslike Multilisp [39],andvarioususer-level threadlibraries[3, 17, 30, 43]. In thelightweight threadsmodel,theprogrammersimply expressesall theparallelismin theprogram,while the languageimple-mentationperformsthetaskof schedulingthethreadsontotheprocessorsat runtime. Thus the advantagesof lightweight,user-level threadsincludetheeaseof programming,automaticload balancing,architecture-independentcodethat canadaptto a varying numberof processors,andthe flexibility to usekernel-independentthreadschedulers.
Programswith irregular and dynamicparallelismbenefitmostfrom theuseof lightweightthreads.Compile-timeanal-ysisof suchcomputationstopartitionandmapthethreadsontoprocessorsis generallynot possible.Therefore,theprogramsdependheavily on the implementationof the runtimesystemfor goodperformance.In particular,
1. To allow the expressionof a large numberof threads,theruntimesystemmustprovidefastthreadoperationssuchascreation,deletionandsynchronization.
2. The threadschedulermust incur low overheadswhile dy-namicallybalancingtheloadacrossall theprocessors.
3. Theschedulingalgorithmmustbespaceefficient, thatis, itmustnotcreatetoo many simultaneouslyactive threads,orschedulethemin an orderthat resultsin high memoryal-location.A smallermemoryfootprint resultsin fewer pageandTLB misses.This is particularlyimportantfor parallelprograms,sincethey aretypically usedto solve largeprob-lems,andareoftenlimited by theamountof memoryavail-able on a parallel machine. Existing commercialthreadsystems,however, canleadto poorspaceandtime perfor-mancefor multithreadedparallelprograms,if thescheduleris notdesignedto bespaceefficient [35].
4. Today’shardware-coherentsharedmemorymultiprocessors(SMPs)typically have a large off-chip datacachefor eachprocessor,with a latency significantlylowerthatthelatencyto main memory. Therefore,the threadschedulermustalsoschedulethreadsfor good cachelocality. The mostcommonheuristicto obtaingoodlocality for fine grainedthreadson multiprocessorsis to schedulethreadscloseinthecomputationgraph(e.g., a parentthreadalongwith itschild threads)on the sameprocessor, sincethey typicallysharecommondata[1, 9, 25, 27, 31, 39].
Work stealingis aruntimeschedulingmechanismthatcanprovide a fair combinationof the above requirements.Eachprocessormaintainsits own queueof readythreads;a pro-cessorstealsa threadfrom anotherprocessor’s readyqueueonly whenit runsoutof readythreadsin its own queue.Sincethreadcreationandschedulingaretypically local operations,they incur low overheadandcontention.Further, threadsclosetogetherin thecomputationgraphareoftenscheduledon thesameprocessor, resultingin good locality. Several systemshaveusedwork stealingto provide highperformance[11, 17,18, 20, 26, 39, 42, 44]. Wheneachprocessortreatsits own
readyqueueasa LIFO stack(that is, addsor removesthreadsfromthetopof thestack)andstealsfromthebottomof anotherprocessor’s stack,theschedulersuccessfullythrottlesthe ex-cessparallelism[8, 39,41,44]. For fully strict computations,sucha mechanismwas proved to require ������� spaceon �processors,where � � is the serial, depth-firstspacerequire-ment[9]. A computationwith � work (total numberof oper-ations)and � depth(lengthof thecritical path)wasshown torequire�������! #"$�!% timeon � processors[9]. Wewill hence-forth referto suchschedulersaswork-stealingschedulers.
Recentwork [6, 34] hasresultedin depth-first schedul-ing algorithmsthat require ���&�' #"(�)�*�+% spacefor nested-parallelcomputationswith depth � . For programsthat havea low depth(a high degreeof parallelism),suchas all pro-gramsin the class ,)- [14], the spaceboundof ���&�. #"(�)��!% is asymptoticallylower than the work stealingboundof�)�/��� . Further, the depth-firstapproachallows a moregen-eralmemoryallocationmodelcomparedto thestack-basedal-locationsassumedin space-efficient work stealing[6]. Thedepth-firstapproachhasbeenextendedto handlecomputa-tionswith futures[39] or I-structures[16], resultingin similarspacebounds[4]. Experimentsshowedthatanasynchronous,depth-firstscheduleroftenresultsin lower spacerequirementin practice,comparedto awork-stealingscheduler[34]. How-ever, sincedepth-firstschedulersuseagloballyorderedqueue,they do not provide someof thepracticaladvantagesenjoyedby work-stealingschedulers.Whenthe threadsexpressedbythe userarefine grained,the performancemay suffer duetopoor locality andhigh schedulingcontention(i.e., contentionover shareddatastructureswhile scheduling)[35]. Therefore,even if basicthreadoperationsarecheap,the threadshave tobecoarsenedfor depth-firstschedulersto providegoodperfor-mancein practice.
In this paper, we presenta new schedulingalgorithmforimplementingmultithreadedlanguagesonsharedmemoryma-chines.Thealgorithm,calledDFDeques 1, providesacompro-mise betweenprevious work-stealingand depth-firstsched-ulers. Readythreadsin DFDequesareorganizedin multiplereadyqueues,thataregloballyorderedasin depth-firstsched-ulers. ThereadyqueuesaretreatedasLIFO stackssimilar toprevious work-stealingschedulers.A processorstealsfroma readyqueuechosenrandomlyfrom a set of high-priorityqueues.For nested-parallel(or fully strict) computations,ouralgorithmguaranteesanexpectedspaceboundof �0�1�2 #"$34� �5��!% . Here, 3 is auser-adjustableruntimeparametercalledthememorythreshold,whichspecifiesthenetamountof memoryaprocessormayallocatebetweenconsecutivesteals.Since3is typically fixed to be a small, constantamountof memory,thespaceboundreducesto � � �6 #"$���$�7% , aswith depth-firstschedulers.For a simplisticcostmodel,we show that theex-pectedrunningtime is #"$�����!�6�!% on � processors2.
We refer to the total numberof instructionsexecutedin athreadasthe thread’s granularity. We also (informally) de-fine schedulinggranularity to be the averagenumberof in-structionsexecutedconsecutively on a singleprocessor, fromthreadsclosetogetherin thecomputationgraph.Thus,a largerschedulinggranularity typically implies better locality and
1DFDequesstandsfor “depth-firstdeques”.2Whentheschedulerin DFDequesis parallelized,thecostsof all scheduling
operationscanbeaccountedfor with a morerealisticmodel[33]. Then,in theexpectedcase,theparallelcomputationcanbeexecutedusing 8:9�;!<>=@?�ACBDAE F1G BIH spaceand <&=CJLKMBN;D?OA E F1G BIH time(includingschedulingoverheads).However, for brevity, we omit a descriptionandanalysisof sucha parallelizedscheduler.
1

lowerschedulingcontention.In theDFDequesscheduler,whenaprocessorfindsits readyqueueempty, it stealsathreadfromthe bottomof anotherreadyqueue. This threadis typicallythecoarsestthreadin thequeue,resultingin a largerschedul-ing granularitycomparedto depthfirst schedulers.Althoughwe do not analytically prove this claim, we presentexperi-mentalandsimulationresultsto verify it. Adjustingthemem-ory threshold3 in theDFDequesalgorithmprovidesa user-controllable trade-off between scheduling granularity andspacerequirement.
Posix threadsor Pthreadshave recentlybecomea popu-lar standardfor sharedmemoryparallel programming. WethereforeaddedtheDFDequesschedulingalgorithmto a na-tive, user-level Pthreadslibrary [43]. Despitebeing one ofthefastestuser-level implementationsof Pthreadstoday, theli-brary’sschedulerdoesnotefficiently supportfine-grained,dy-namicthreads.In previouswork [35], weshowedhow its per-formancecanbe improved usinga space-efficient depth-firstscheduler. In this paper, we comparethespaceandtime per-formanceof the new DFDequesschedulerwith the library’soriginalscheduler(whichusesaFIFOschedulingqueue),andwith our previous implementationof a depth-firstscheduler.To performthe experimentalcomparison,we used P parallelbenchmarkswritten with a large numberof dynamicallycre-atedPthreads. As shown in Figure 1, the new DFDequesschedulerresultsin betterlocality andhigherspeedupscom-paredto boththedepth-firstschedulerandtheFIFOscheduler.
Ideally, wewouldalsolike to compareourPthreads-basedimplementationof DFDequeswith aspace-efficientwork-steal-ing scheduler(e.g., theschedulerusedin Cilk [8]). However,supportingthe generalPthreadsfunctionality with an exist-ing space-efficient work-stealingscheduler[8] would requiresignificantmodificationsto boththeschedulingalgorithmandthePthreadsimplementation3. Therefore,to compareournewschedulerto this work-stealingscheduler, we insteadbuilt asimplesimulatorthatimplementssynthetic,fully-strict bench-marks. Our simulationresultsindicatethat by adjustingthememory threshold,our new schedulercovers a wide rangeof spacerequirementsand schedulinggranularities. At oneextreme it performssimilar to a depth-firstscheduler, withlow spacerequirementandsmall schedulinggranularity. Atthe other extreme, it behaves exactly like the work-stealingscheduler, with higherspacerequirementandlarger schedul-ing granularity.
2 Backgr ound and Previous Work
A parallelcomputationcanberepresentedbyadirectedacyclicgraph;we will refer to sucha computationgraphasa dag inthe remainderof this paper. Eachnodein thedagrepresentsa singleaction in a thread;anactionis a unit of work that re-quiresa singletimestepto beexecuted.Eachedgein thedagrepresentsadependencebetweentwo actions.Figure2 showssuchan exampledagfor a simpleparallelcomputation.Thedashed,right-to-left fork edgesin thefigurerepresenttheforkof achild thread.Thedashed,left-to-rightsynchedgesrepre-senta join betweenaparentandchild thread,while eachsolidverticalcontinueedgerepresentsasequentialdependencebe-tweenapairof consecutiveactionswithin asinglethread.For
3Even fully strict Pthreadsbenchmarkscannotbe executedusing suchawork-stealingschedulerin the existing SolarisPthreadsimplementation,be-causethe Pthreadsimplementationitself makesextensive useof blockingsyn-chronizationprimitivessuchasPthreadmutexesandconditionvariables.
t0
t2
t4
t1
t5
root thread
t3
Figure 2: An exampledag for a parallel computation;thethreadsareshown shaded.Eachright-to-left edgerepresentsa fork, andeachleft-to-right edgerepresentsa synchroniza-tion of a child threadwith its parent.Verticaledgesrepresentsequentialdependencieswithin threads.QSR is theinitial (root)thread,whichforkschild threadsQ�� , QST , QVU , and QVW in thatorder.Child threadsmayfork threadsthemselves;e.g., Q T forks QSX .computationswith dynamicparallelism,the dag is revealedandscheduledontotheprocessorsat runtime.
2.1 Scheduling for locality
Detectionof data accessesor data sharingpatternsamongthreadsin a dynamicand irregular computationis often be-yond the scopeof the compiler. Further, today’s hardware-coherentSMPsdonotallow explicit, software-controlledplace-mentof datain processorcaches;therefore,owner-computeoptimizationsfor locality thatarepopularondistributedmem-ory machinestypically do not apply to SMPs. However, inmany parallelprogramswith fine-grainedthreads,thethreadsclosetogetherin thecomputation’s dagoftenaccessthesamedata.For example,in adivide-and-conquercomputation(suchas quicksort)wherea new threadis forked for eachrecur-sive call, a threadsharesdatawith all its descendentthreads.Therefore, many parallel implementationsof lightweightthreads use per-processordata structures to store readythreads[17, 20, 24, 25, 39, 42, 44]. Threadscreatedon a pro-cessorarestoredlocally andmovedonly whenrequiredto bal-ancetheload.This techniqueeffectively increasesschedulinggranularity, andthereforeprovidesgoodlocality [7] andlowschedulingcontention.
Anotherapproachfor obtaininggood locality is to allowtheuserto supplyhintsto theschedulerregardingthedataac-cesspatternsof the threads[12, 28, 37, 45]. However, suchhints canbe cumbersomefor the userto provide in complexprograms,and areoften specificto a certainlanguageor li-brary interface. Therefore,our DFDequesalgorithminsteadusestheheuristicof schedulingthreadsclosein thedagonthesameprocessorto obtaingoodlocality.
2.2 Scheduling for space-efficiency
Thethreadschedulerplaysasignificantrole in controllingtheamountof active parallelismin a fine-grainedcomputation.For example,considerasingle-processorexecutionof thedagin Figure2. If theschedulerusesa LIFO stackto storereadythreads,anda child threadpreemptsits parentassoonas itis forked,thenodesareexecutedin a (left-to-right)depth-firstorder, resultingin at most5 simultaneouslyactive threads.In
2

Benchmark Max threads L2 Cachemissrate 8 processorspeedupFIFO ADF DFD FIFO ADF DFD FIFO ADF DFD
Vol. Rend. 436 36 37 4.2 3.0 1.8 5.39 5.99 6.96
DenseMM 3752 55 77 24.0 13 8.7 0.22 3.78 5.82SparseMVM 173 51 49 13.8 13.7 13.7 3.59 5.04 6.29
FFTW 510 30 33 14.6 16.4 14.4 6.02 5.96 6.38FMM 2030 50 54 14.0 2.1 1.0 1.64 7.03 7.47
BarnesHut 3570 42 120 19.0 3.9 2.9 0.64 6.26 6.97DecisionTr. 194 138 149 5.8 4.9 4.6 4.83 4.85 5.39
Figure1: Summaryof experimentalresultswith theSolarisPthreadslibrary. For eachschedulingtechnique,weshow themaximumnumberof simultaneouslyactive threads(eachof which requiresmin. 8kB stackspace),theL2 cachemissesrates(%), andthespeedupsonan8-processorEnterprise5000SMP. “FIFO” is theoriginalPthreadsscheduler, “ADF” is anasynchronous,depth-firstscheduler[35], and“DFD” is ournew DFDequesscheduler.
contrast,if the schedulerusesa FIFO queue,the threadsareexecutedin abreadth-firstorder, resultingin all 16threadsbe-ing simultaneouslyactive. Systemsthatsupportfine-grained,dynamicparallelismcansuffer from sucha creationof excessparallelism.
Initial attemptsto controltheactiveparallelismwerebasedon heuristics[3, 16, 31, 40, 39], which includedwork stealingtechniques[31, 39]. Heuristicattemptswork well for someprograms,but do not guaranteean upperboundon thespacerequirementsof aprogram.More recently, two differenttech-niqueshavebeenshown to beprovablyspace-efficient: work-stealingschedulers,anddepth-firstschedulers.
In additionto beingspaceefficient [8, 41], work stealingcanoftenresultin large schedulinggranularities,by allowingidle processorsto stealthreadshigherup in thedag(e.g., seeFigure3(a)). Severalsystemsusesuchanapproachto obtaingoodparallelperformance[8, 17,26,39,44].
Depth-firstschedulersguaranteean upperboundon thespacerequirementof a parallel computationby prioritizingits threadsaccordingto their serial,depth-firstexecutionor-der [6, 34]. In a recentpaper[35], we showed that the per-formanceof a commercialPthreadsimplementationcouldbeimprovedfor predominantlynested-parallelbenchmarksusingadepth-firstscheduler. However, depth-firstschedulerscanre-sult in high schedulingcontentionandpoor locality whenthethreadsin theprogramareveryfine grained[34, 35] (seeFig-ure3).
Thenext sectiondescribesanew schedulingalgorithmthatcombinesideasfromtheabovetwospace-efficientapproaches.
3 The DFDeques Scheduling Algorithm
Wefirstdescribetheprogrammingmodelfor themultithreadedcomputationsthat areexecutedby the DFDequesschedulingalgorithm. We thenlist thedatastructuresusedby thesched-uler, followed by a descriptionof the DFDequesschedulingalgorithm.
3.1 Programming model
As with depth-firstschedulers,our schedulingalgorithmap-pliestopure,nested-parallelcomputations,whichcanbemod-eledby series-paralleldags[6]. Nested-parallelcomputationsareequivalentto the subsetof fully strict computationssup-ported by Cilk’s space-efficient work-stealingscheduler[8,
(a)
P3 P2 P1 P0
(b)
P1P2 P0P3
Figure3: Possiblemappingsof threadsof thedagin Figure2onto processorsY R[Z]\]\]\1Z Y�U by (a) work-stealingschedulers,and(b) depth-firstschedulers.If, say, the ^V_a` thread(goingfrom left to right) accessesthe ^ _a` block or elementof anar-ray, thenschedulingconsecutivethreadsonthesameprocessorprovidesbettercachelocality andlowerschedulingoverheads.
20]. Nestedparallelismcanbeusedto expressa largevarietyof parallelprograms,includingrecursive,divide-and-conquerprogramsandprogramswith nested-parallelloops.Ourmodelassumesbinary forks andjoins; the exampledagin Figure2representssuchanested-parallelcomputation.
Althoughwedescribeandanalyzeouralgorithmfor nested-parallelcomputations,in practiceit canbe extendedto exe-cuteprogramswith otherstylesof parallelism.For example,the Pthreadsschedulerdescribedin Section5 supportscom-putationswith arbitrarysynchronizations,suchasmutexesandconditionvariables.However, ouranalyticalspacebounddoesnotapplyto suchgeneralcomputations.
A threadis active if it hasbeencreatedbut hasnotyet ter-
3

85
11
79
10
1
3
26
4
Figure4: The serial,depth-firstexecutionorderfor a nested-parallelcomputation.The ^ _a` nodeexecutedis labelled ^ inthisdag;thelowerthelabelof athread’scurrentnode(action),thehigheris its priority in DFDeques.
minated.A parentthreadwaiting to synchronizewith a childthreadis said to be suspended. We say an active threadisready to be scheduledif it is not suspended, and is not cur-rently beingexecutedby a processor. Eachactionin a threadmayallocateanarbitraryamountof spaceon thethreadstack,or on thesharedheap.
Everynested-parallelcomputationhasanaturalserialexe-cutionorder, whichwecall its depth-firstorder. Whenachildthreadis forked, it is executedbeforeits parentin a depth-first execution(e.g., seeFigure 4). Thus, the depth-firstor-der is identical to the uniqueserial executionorder for anystack-basedlanguage(suchasC), whenthe threadforks arereplacedby simplefunctioncalls. Algorithm DFDequespri-oritizesreadythreadsaccordingto their serial,depth-firstex-ecutionorder;an earlierserialexecutionordertranslatesto ahigherpriority.
3.2 Scheduling data structures
Althoughthedagfor a computationis revealedastheexecu-tion proceeds,dynamicallymaintainingtherelative threadpri-orities for nested-parallelcomputationsis straightforward[6]and inexpensive in practice[34]. In algorithm DFDeques,the readythreadsare storedin doubly-endedqueuesor de-ques[15]. Eachof thesedequessupportspoppingfrom andpushingontoits top,aswell aspoppingfromthebottomof thedeque.At any timeduringtheexecution,a processorownsatmostonedeque,andexecutesthreadsfrom it. A singledequehasatmostoneowneratany time. However, unliketraditionalwork stealing,thenumberof dequesmayexceedthenumberof processors.All thedequesarearrangedin agloballist b ofdeques.Thelist supportsaddingof a new dequeto theimme-diateright of anotherdeque,deletionof a deque,andfindingthe c _C` dequeuefrom theleft endof b .
3.3 The DFDeques scheduling algorithm
The processorsexecutethe code in Figure 5 for algorithmDFDeques( 3 ); here3 is thememorythreshold,auser-definedruntime parameter. Eachprocessortreatsits own dequeasa regular LIFO stack,andis assigneda memoryquotaof 3bytesfrom which to allocateheapandstackdata.This mem-ory threshold3 is equivalentto theper-threadmemoryquotain depth-firstschedulers[34]; however, in algorithmDFDe-ques, thememoryquotaof 3 bytescanbeusedby a proces-sorto executemultiple threadsfrom onedeque.A threadexe-cuteswithout preemptionon a processoruntil it forks a childthread,suspendswaiting for a child to terminate,terminates,or theprocessorrunsoutof its memoryquota.If a terminatingthreadwakesupits previouslysuspendedparent,theprocessor
while ( d threads)if (currS= NULL) currS:= steal();if (currT = NULL) currT := pop from top(currS);executecurrTuntil it forks,suspends,terminates,
or memoryquotaexhausted:case (fork):
pushto top(currT, currS);currT := newly forkedchild thread;
case (suspend):currT := NULL;
case (memoryquotaexhausted):pushto top(currT, currS);currT := NULL;currS:= NULL; / e giveupstack e /
case (terminate):if currTwakesup suspendedparentT f
currT := T f ;else currT := NULL;
if ((is empty(currS)) and (currT= NULL))currS:= NULL; / e giveupanddeletestack e /
endwhile
procedure steal():setmemoryquotato K;while (TRUE )c := randomnumberin [ g \]\]\ � ];
S := ch_a` dequein b ;T := pop from bot(S);if (T ij NULL)
createnew dequeS f containingTandbecomeits owner;
placeS f to immediateright of S in b ;return S f ;
Figure5: Pseudocodefor theDFDeques( 3 ) schedulingalgo-rithm executedby eachof the � processors;3 is thememorythreshold. currS is the processor’s currentdeque. currT isthecurrentthreadbeingexecuted;changingits valuedenotesa context switch. Memory managementof the dequesis notshown herefor brevity.
startsexecutingtheparentnext; for nestedparallelcomputa-tions,wecanshow thattheprocessor’sdequemustbeemptyatthis stage[33]. Whenanidle processorfindsits dequeempty,it deletesthe deque. Whena processordeletesits deque,orwhenit givesup ownershipof its dequedueto exhaustionofits memoryquota,it usesthesteal() procedureto obtaina new deque. Every invocationof steal() resetsthe pro-cessor’smemoryquotato 3 bytes.Wecall aniterationof theloop in thesteal() procedureastealattempt.
A processorexecutesa stealattemptby picking a randomnumberc between1 and� , where� is thenumberof proces-sors. It then tries to steal the bottom threadfrom the c _a`deque(starting from the left end) in b . A stealattemptmayfail (that is, pop from bot() returnsNULL) if two ormoreprocessorstarget the samedeque(seeSection4.1), orif the dequeis emptyor non-existent. If the stealattemptissuccessful(pop from bot() returnsa thread),thestealingprocessorcreatesanew dequefor itself, placesit to theimme-diateright of the targetdeque,andstartsexecutingthestolenthread.Otherwise,it repeatsthestealattempt.Whenaproces-sorstealsthelastthreadfrom adequenotcurrentlyassociated
4

list of dequesktop
bottom
executing threads
owners P0 P3 P2 P1
ta
tb
deques
-- --
Figure6: Thelist b of dequesmaintainedin thesystemby al-gorithmDFDeques. Eachdequemayhaveone(or no) ownerprocessor. Thedottedline tracesthedecreasingorderof prior-ities of thethreadsin thesystem;thus Q$l in this figurehasthehighestpriority, while QMm hasthelowestpriority.
with (ownedby) any processor, it deletesthedeque.If a threadcontainsan actionthatperformsa memoryal-
locationof c unitssuchthat conp3 (where 3 is themem-ory threshold),then qVcr�s3ut dummythreadsmustbe forkedin a binary treeof depth v#"aw@x[yzch�[3O% beforetheallocation4.We do not show this extensionin Figure5 for brevity. Eachdummythreadexecutesa no-op. However, processorsmustgive up their dequesandperforma stealevery time they exe-cutea dummythread.Onceall thedummythreadshave beenexecuted,a processormay proceedwith the memoryalloca-tion. This transformationtakesplaceat runtime.Theadditionof dummythreadseffectivelydelayslargeallocationsof space,so that higherpriority threadsmay be scheduledinstead. Inpractice,3 is typically setto a few thousandbytes,sothattheruntimeoverheaddueto thedummythreadsis negligible (e.g.,seeSection5).
We now prove a lemmaregardingtheorderof threadsinb maintainedby algorithmDFDeques; this order is shownpictorially in Figure6.
Lemma 3.1 Algorithm DFDequesmaintains the followingorderingof threadsin thesystem.
1. Threadsin each dequearein decreasingorderof prioritiesfromtop to bottom.
2. A threadcurrentlyexecutingona processorhashigherpri-ority thanall otherthreadson theprocessor’sdeque.
3. Thethreadsin anygivendequehavehigherpriorities thanthreadsin all thedequesto its right in b .
Proof: By inductionon the timesteps.The basecaseis thestartof theexecution,whenthe root threadis theonly threadin the system.Let the threepropertiesbe true at the startofany subsequent timestep. Any of the following eventsmaytakeplaceoneachprocessorduringthetimestep;wewill showthatthepropertiescontinueto holdat theendof thetimestep.
Whena threadforks a child thread,theparentis addedtothetopof theprocessor’sdeque,andthechild startsexecution.Sincetheparenthasa higherpriority thatall otherthreadsintheprocessor’sdeque(by induction),andsincethechild threadhasa higherpriority (earlierdepth-firstexecutionorder)thanits parent,properties(1) and (2) continueto hold. Further,
4This transformationdiffers slightly from depth-firstschedulers[6, 34],whichallow dummythreadsto beforkedin amulti-wayfork of constantdepth.
sincethe child now hasthepriority immediatelyhigherthanits parent,property(3) holds.
When a thread { terminates,the processorchecksif {hasreactivateda suspendedparentthread {/| . In this case,it startsexecuting {:| . Sincethecomputationis nestedparal-lel, theprocessor’sdequemustnow beempty(sincetheparent{:| musthave beenstolenat someearlierpoint andthensus-pended).Therefore,all 3 conditionscontinueto hold. If { didnotwakeupits parent,theprocessorpicksthenext threadfromthe top its deque.If the dequeis empty, it deletesthe dequeandperformsa steal. Thereforeall threepropertiescontinueto hold in thesecasestoo.
Whenathreadsuspendsor is preempteddueto exhaustionof theprocessor’smemoryquota,it isputbackonthetopof itsdeque,andthedequeretainsits positionin b . Thusall threepropertiescontinueto hold.
Whena processorstealsthe bottomthreadfrom anotherdeque,it addsthenew dequeto theright of the targetdeque.Sincethe stolenthreadhad the lowest priority in the targetdeque,thepropertiescontinueto hold. Similarly, removal of athreadfrom thetargetdequedoesnotaffect thevalidity of thethreepropertiesfor the targetdeque.A threadmaybe stolenfrom a processor’s dequewhile oneof theabove eventstakesplaceon the processoritself; this doesnot affect the validityof ourargument.
Finally, deletionof oneor moredequesfrom b doesnotaffect thethreeproperties.
Work stealing as a special case of algorithm DFDeques .Considerthe casewhen we set the memorythreshold3 j} . Then, for nested-parallelcomputations,algorithmDFD-eques( } ) producesa scheduleidenticalto theoneproducedby the provably-efficient work-stealingscheduler“WS” [9].Theprocessorsin DFDeques} never give up a dequeduetoexhaustionof their memoryquota,andtherefore,aswith thework stealer, therearenever morethan � dequesin the sys-tem. Further, in both algorithms,when a processor’s dequebecomesempty, it picks anotherprocessoruniformly at ran-dom,andstealsthe bottommostthreadfrom that processor’sdeque.Similarly, for nestedparallelcomputations,theruleforwakingup asuspendedparentin DFDeques( } ) is equivalentto thecorrespondingrule in WS5. Of course,theschedulesareidenticalassumingthe samecostmodel for both algorithms;themodelcouldbeeithertheatomic-accessmodelusedto an-alyzeWS[9], or ourcostmodelfrom Section4.1.
4 Anal ysis of Time and Space Bounds Us-ing Algorithm DFDeques
We now prove the spaceandtime boundsfor nested-parallelcomputations.
4.1 Cost model
We definethe total numberof unit actionsin a parallelcom-putation(or the numberof nodesin its dag)as its work � .Further, let � be the depth of the computation,that is, thelengthof the longestpathin its dag. For example,the com-putationrepresentedin Figure4 haswork � j g[g anddepth
5In WS, the reawakenedparentis placedaddedto the currentprocessor’sdeque(which is empty);for nestedparallelcomputations,thechild musttermi-nateat thispoint,andtherefore,thenextthreadexecutedby theprocessoris theparentthread.
5

� j�~ . We assumethatanallocationof c bytesof memory(for any c�n6� ) hasadepthof v#"aw@xsyzcr% units6.
For this analysis,we assumethattimesteps(clock cycles)aresynchronizedacrossall theprocessors.If multipleproces-sorstargetanon-emptydequein asingletimestep,weassumethatoneof themsucceedsin thesteal,while all theothersfailin thattimestep.If thedequetargetedby oneor morestealsisempty, all of thosestealsfail in asingletimestep.Whenastealfails, theprocessorattemptsanotherstealin thenext timestep.Whena stealsucceeds, the processorinsertsthe newly cre-ateddequeinto b andexecutesthefirst actionfrom thestolenthreadin the sametimestep. At the end of a timestep,if aprocessor’scurrentthreadterminatesor suspends,andit findsits dequeto beempty, it immediatelydeletesits dequein thattimestep. Similarly, when a processorstealsthe last threadfrom a dequenot currentlyassociatedwith any processor, itdeletesthe dequein that timestep. Thus, at the start of atimestep,if adequeis empty, it mustbeownedby aprocessorthatis busyexecutinga thread.
Our costmodelis somewhatsimplistic,becauseit ignoresthecostof maintainingtheorderedsetof dequesb . If wepar-allelize theschedulingtasksof insertinganddeletingdequesin b (by performingthemlazily), we canaccountfor all theiroverheadsin the time bound. We canthenshow that in theexpectedcase,thecomputationcanbeexecutedin #"$�����!�����w@x[y���% timeand � � �� #"(�+�]w@xsy��!�s�!% spaceon � proces-sors,includingtheschedulingoverheads[33]. In practice,theinsertionsanddeletionsof dequesfrom b canbeeitherserial-izedandprotectedby a lock (for small � ), or performedlazilyin parallel(for large � ).
4.2 Space bound
We now analyzethe spaceboundfor a parallelcomputationexecutedby algorithmDFDeques. The analysisusesseveralideasfrom previouswork [2, 6, 34].
Let � bethedagthat representstheparallelcomputationbeingexecuted.Dependingon theresultingparallelschedule,weclassifyits nodes(actions)into oneof two types:heavy andlight. Every time a processorperformsa steal,the first nodeit executesfrom thestolenthreadis calledaheavyaction.Allremainingnodesin � arelabelledaslight.
Wefirst assumethateverynodeallocatesatmost 3 space;wewill relaxthis assumptionin theend.Recallthataproces-sormayallocateatmost 3 spacebetweenconsecutivesteals;thus,it mayallocateat most 3 spacefor every heavy nodeitexecutes.Therefore,wecanattributeall thememoryallocatedby light nodesto thelastheavy nodethatprecedesthem.Thisresultsin aconservativeview of thetotal spaceallocation.
Let � | j�� � Z]\1\]\]Z ��� be the parallelscheduleof the daggeneratedby algorithmDFDeques( 3 ). Here ��� is the setofnodesthat are executedat timestep ^ . Let �[� be the serial,depth-firstscheduleor the 1DF-schedulefor the samedag;e.g., the nodesin Figure 4 are numberedaccordingto theirorderof executionin a1DF-schedule.
Wenow view anintermediatesnapshotof theparallelsched-ule ��| . At any timestep g)�p�O��� during the executionof� | , all thenodesexecutedsofar form aprefix of � | . Thispre-fix of � | is definedas � | j��+��@� � ��� . Let � � be the longestprefix of �[� containingonly nodesin ��| , that is, ���O����| .
6This is a reasonableassumptionin systemswith binaryforks thatzerooutthe memoryas soonas it is allocated. The zeroingthenrequiresa minimumdepthof ��= E F]G7� H ; it canbeperformedin parallelby forking a treeof height��= E F]G7� H .
Thentheprefix � � is calledthecorresponding serialprefix of��| . Thenodesin theset ��|��6��� arecalledprematurenodes,sincethey havebeenexecutedout of orderwith respectto the1DF-schedule �[� . All othernodesin ��| , thatis, theset ��� , arecallednon-premature. For example,Figure7 showsasimpledagwith aparallelprefix � | for anarbitrary� -schedule� | , itscorrespondingserialprefix ��� , andapossibleclassificationofnodesasheavy or light.
A readythreadbeingpresentin a dequeis equivalenttoits first unexecutednode(action)beingin thedeque,andwewill usethetwo phrasesinterchangeably. Givena � -schedule��| of adag � generatedby algorithmDFDeques, wecanfinda uniquelast parent for every nodein � (exceptfor the rootnode)asfollows. The lastparentof a node � in � is definedas the last of � ’s parentnodesto be executedin the sched-ule � | . If two or moreparentnodesof � werethe last to beexecuted,theprocessorexecutingoneof themcontinuesexe-cutionof � ’s thread.We labeltheuniqueparentof � executedby this processorasits last parent. This processormayhaveto preempt� ’s threadwithout executing � if it runsout of itsmemoryquota;in this case,it puts � ’s threadon to its dequeandthengivesup thedeque.
Considertheprefix ��| of theparallelschedule��| afterthefirst � timesteps,for any g)�p�O��� . Let � be the last non-prematurenode(i.e., the last nodefrom ��� ) to be executedduringthefirst � timestepsof � | . If morethanonesuchnodeexist, let � beany oneof them.Let Y beasetof nodesin thedagconstructedasfollows: Y is initialized to �s�I ; for everynode � in Y , the last parentof � is addedto Y . Sincetheroot is theonly nodeat depth1, it mustbe in Y , andthus, Ycontainsexactlyall thenodesalongaparticularpathfrom theroot to � . Further, since � is non-premature,all thenodesin Yarenon-premature.
Let � � be the nodein Y at depth ^ ; then �7� is the root,and ��¡ is thenode � , where ¢ is thedepthof � . Let Q � bethetimestepin which � � is executed;then Q � j g sincethe rootis executedin thefirst timestep.For ^ j¤£ Z1\]\]\]Z ¢ let ¥ � betheinterval �[Q �a¦ � ��g Z]\]\]\1Z Q � , andlet ¥ � j ��g§ . Let ¥ ¡�¨�� j�[Q ¡ �©g Zª\]\1\]Z �* . Since � | consistsof all the nodesexecutedin the first � timesteps,the intervals ¥«� Z]\]\]\]Z ¥]¡�¨�� cover thedurationof executionof all nodesin � | .
Wefirst prove thefollowing lemmaregardingthenodesinadequebelow any of thenodes� � in Y .
Lemma 4.1 For any g)��^¬�¢ , let � � be the nodein Y atdepth . Then,
1. If duringtheexecution� � isonsomedeque,theneverynodebelowit in its dequeis theright child of somenodein Y .
2. When� � is executedona processor,everynodeon thepro-cessor’sdequemustbetheright child of somenodein Y .
Proof: We can prove this lemmato be true for any � � byinductionon ^ . The basecaseis the root node. Initially it istheonly nodein its deque,andgetsexecutedbeforeany newnodesarecreated.Thus, the lemmais trivially true. Let usassumethelemmais truefor all � � , for �r�.�h�'^ . We mustprove thatit is truefor � � ¨0� .
Since � � is the last parentof � � ¨�� , � � ¨�� becomesreadyimmediatelyafter � � is executedonsomeprocessor. Therearetwo possibilities:
1. � � ¨�� is executedimmediatelyfollowing � � on thatproces-sor. Property(1) hold trivially since � � ¨�� is never puton a
6

= non-premature= premature
σp
= heavy nodes
P1
P2
P3
P4
(a) (b)
Figure7: (a) An examplesnapshotof a parallelschedulefor a simpledag. Theshadednodes(thesetof nodesin � | ) have beenexecuted,while theblank(white) nodeshave not. Of thenodesin � | , theblacknodesform thecorrespondingparallelprefix � � ,while theremaininggrey nodesarepremature.(b) A possiblepartitioningof nodesin �I| into heavy andlight nodes.Eachshadedregiondenotesthesetof nodesexecutedconsecutively in depth-firstorderonasingleprocessor( Y � Z Y T Z Y U or Y W ) betweensteals.Theheavy nodein eachregion is shown shadedblack.
deque.If thedequeremainsunchangedbefore� � ¨�� is exe-cuted,property(2) holdstrivially for � � ¨�� . Otherwise,theonly changethatmaybemadeto thedequeis theadditionof the right child of � � before � � ¨�� is executed,if � � wasa fork with � � ¨�� asits left child. In this casetoo, property(2) holds,sincethenew nodein thedequeis right child ofsomenodein Y .
2. � � ¨�� is addedto theprocessor’sdequeafter � � is executed.This mayhappenbecause� � wasa fork and � � ¨�� wasitsrightchild (seeFigure8),orbecausetheprocessorexhausteditsmemoryquota.In theformercase,since� � ¨�� is therightchild of � � , nothingcanbeaddedto thedequebefore� � ¨�� .In thelattercase(thatis, thememoryquotais exhaustedbe-fore � � ¨�� is executed),theonly nodethatmaybeaddedtothedequebefore� � ¨�� is theright child of � � , if � � is a fork.Thisdoesnotviolatethelemma.Once� � ¨0� is addedto thedeque,it mayeithergetexecutedonaprocessorwhenit be-comesthetopmostnodein thedeque,or it maygetstolen.If it getsexecutedwithout beingstolen,properties(1) and(2) hold, sinceno new nodescanbe addedbelow � � ¨�� inthedeque.If it is stolen,the processorthat stealsandex-ecutesit hasan emptydeque,andthereforeproperties(1)and(2) aretrue,andcontinueto hold until � � ¨0� hasbeenexecuted.
Recallthatheavy nodesareapropertyof theparallelschedule,while prematurenodesaredefinedrelative to agivenprefixoftheparallelschedule.Toprovethespacebound,wefirst boundthenumberof heavyprematurenodesin anarbitraryprefix ��|of � | .Lemma 4.2 Let � | beanyparallel prefixof a � -schedulepro-ducedby algorithm DFDeques( 3 ) for a computationwithdepth � , in which every action allocatesat most 3 space.Thentheexpectednumberof heavyprematurenodesin �I| is #"(�)�*�+% . Further, for any ®Lnp� , thenumberof heavypre-maturenodesis #"(�¬�]"$�6�rw(¯�"�g§�«®1%�%�% with probabilityat leastgz�O® .Proof: Considerthe start of any interval ¥ � of ��| , for ^ jg Z1\]\]\]Z ¢ (wewill look at thelastinterval ¥]¡�¨�� separately).By
Lemma3.1, all nodesin thedequesto the left of � � ’s deque,andall nodesabove � � in its dequearenon-premature.Let ° �bethenumberof nodesbelow � � in its deque.Becausestealstarget thefirst � dequesin b , heavy prematurenodescanbepickedin any timestepfrom at most � deques.Further, everytime a heavy prematurenodeis picked,thedequecontaining� � mustalsobea candidatedequeto bepickedasa target forasteal;that is, � � mustbeamongtheleftmost� deques.Con-sideronly the timestepsin which � � is amongthe leftmost �deques;wewill referto suchtimestepsascandidatetimesteps.Becausenew dequesmay be createdto the left of � � at anytime,thecandidatetimestepsneednotbecontiguous.
Wenow boundthetotal numberof stealattemptsthattakeplaceduringthecandidatetimesteps.Eachsuchstealattemptmayresultin theexecutionof a heavy prematurenode;stealsin all othertimestepsresultin theexecutionof heavy, but non-prematurenodes.Eachtimestepcanhave at most � stealat-tempts. Therefore,we canpartition the candidatetimestepsinto phases, suchthat eachphasehasbetween� and £ �)�'gstealattempts.We call a phasein interval ¥ � successfulif atleastoneof its v#"(�7% stealattemptstargetsthedequecontain-ing � � . Let ± � � be the randomvariablewith value1 if the� _a` phasein interval ¥ � is successful,and0 otherwise. Be-causetargetsfor stealattemptsarechosenat randomfrom theleftmost� dequeswith uniform probability, andbecauseeachphasehasat leastY stealattempts,²5³5´ ± � � j g�µ·¶ gz� ¸ gz� g�&¹ |¶ gz� gº¶ g£Thus,eachphasesucceedswith probabilitygreaterthan gª� £ .Because� � mustget executedbeforeor by the time ° � �pgsuccessfulstealstarget � � ’s deque,therecanbeatmost ° � ��gsuccessfulphasesin interval ¥ � . The node � � may get exe-cutedbefore° � ��g stealattemptstargetits deque,if its ownerprocessorexecutes� � off the top of the deque. Let therebesome» � �'"V° � �4g§% successfulphasesin theinterval ¥ � . From
7

ui+1
ui
ui-1
ui-2
ui-3
ui-4
b
c
da
a
bc
ui+1
d top
bottom
deque
: nodes along pathP
(a) (b)
Figure8: (a)A portionof thedynamicallyunfoldingdagduringtheexecution.Node � � ¨�� alongthepath Y is ready, andiscurrentlypresentin somedeque.Thedequeis shown in (b); all nodesbelow � � ¨�� on thedequemustberight childrenof somenodeson Yabove � � ¨�� . In this example,node � � ¨�� wastheright child of � � , andwasaddedto thedequewhenthefork at � � wasexecuted.Subsequently, descendentsof theleft child of � � (e.g., node¼ ), maybeaddedto thedequeabove � � ¨�� .Lemma4.1,the ° � nodesbelow � � areright childrenof nodesin Y . Thereare "V¢&��gª%&½.� nodesalong Y not including ��¡ ,andeachof themmayhave at mostoneright child. Further,eachsuccessfulphasein any of thefirst ¢ intervalsresultsin atleastoneof theseright children(or thecurrentreadynodeonY ) beingexecuted.Therefore,the total numberof successfulphasesin thefirst ¢ intervalsis ¾ ¡�¿� � » � ½ £ � .
Finally, considerthefinal phase¥1¡�¨0� . Let À bethe readynodeatthestartof theinterval with thehighestpriority. Then,ÀÁi �I| , becauseotherwiseÀ (or someothernode),andnot � ,would have beenthe lastnon-prematurenodeto be executedin �I| . Hence,if À is about to be executedon a processor,theninterval ¥ ¡�¨�� is empty. Otherwise,À mustbe at the topof the leftmostdequeat the startof interval ¥ ¡�¨0� . Using anargumentsimilar to thatof Lemma4.1,we canshow that thenodesbelow À in the dequemustbe right childrenof nodesalongapathfrom theroot to À . Thus, À canhaveatmost "$�Ã�£ % nodesbelow it. BecauseÀ mustbe amongthe leftmost �dequesthroughouttheinterval ¥]¡�¨�� , thephasesin this intervalareformedfrom all its timesteps.We call a phasesuccessfulin interval ¥ ¡�¨�� if at leastoneof the v#"(��% stealattemptsin thephasetargetsthedequecontainingÀ . Thenthis interval musthavelessthan � successfulphases.As before,theprobabilityof aphasebeingsuccessfulis at least g§� £ .
We have shown that thefirst ���Ä� timestepsof the par-allel execution(i.e., thetime within which nodesfrom � | areexecuted)must have ½ÆÅI� successfulphases.Eachphasemay result in #"(�7% heavy prematurenodesbeingstolenandexecuted. Further, for ^ j g Z]\]\]\1Z ¢ , in eachinterval ¥ � , an-other ���'g heavy prematurenodesmay be executedin thesametimestepthat � � is executed.Therefore,if � | hasa totalof , phases,the numberof heavy prematurenodesin ��| isat most "$,Ç���!%���� . Becausetheentireexecutionmusthavelessthan Å*� successfulphases,andeachphasesucceedswithprobability n.gª� £ , theexpectednumberof total phasesbeforewe see Å*� successfulphasesis at most ~ � . Therefore,theexpectednumberof heavy prematurenodesin ��| is at most" ~ �'���!%��M� j #"(�!�ª�!% .
Thehighprobabilityboundcanbeprovedasfollows. Sup-posetheexecutiontakesatleastg £ �)�#È�w(¯5"�g§�«®1% phases.Then
theexpectednumberof successfulphasesisat leastÉ j.~ �O�Ê w(¯5"�g§�«®1% . Using the Chernoff bound[32, Theorem4.2] onthe numberof successfulphasesX, and setting Ë jÌ~ ���È�w(¯5"�g§�«®1% , weget7²Í³N´ ±Ì½�Ér�OË/� £ µ ½ Î]Ï[Ð4Ñ ��"VË/� £ % T£ É ÒTherefore,²5³�´ "V±Ì½�ÅI�!%Sµ·½ Î]Ï[Ð4Ñ �zË T � Êg £ �¤��ÈÍw(¯0"�gª�«®1%§Òj Î]Ï[Ð Ñ �zË TÊ �[" £ Ë#�OÈÍw(¯0"�gª�«®1%�%«Ò� º ¦ l]Ó]ÔMÕ�lj º ¦ l«Ô$Õj º ¦�Ö(×]Ø ¨�Õ�Ù Ú Ö ��ÔÜÛaÝaÝMÔ$Õ½ º ¦ Õ[Ù Ú Ö ��Ô�ÛaÝMÔ$Õj ®Becausetherecan be at most ÅI� successfulphases,algo-rithm DFDequesrequires g £ �Þ�©È�w(¯5"�gª�ª®]% or more phaseswith probabilityat most ® . Recallthateachphaseconsistsofv#"(�7% stealattempts.Therefore,� | has #"(�r�["$�ß��w(¯0"�gª�«®1%�%�%heavy prematurenodeswith probabilityat least gz��® .We cannow statea lemmarelatingthenumberof heavy pre-maturenodesin ��| with thememoryrequirementof ��| .Lemma 4.3 Let � beadagwithdepth� , in whicheverynodeallocatesat most 3 space,and for which the serial depth-first executionrequires � � space. Let � | bethe � -scheduleoflength { generatedfor � by algorithmDFDeques( 3 ). If forany ^ such that gr�Ä^à�p{ , theprefix ��| of �1| representingthe computationafter the first ^ timestepscontainsat most á
7The probability of successfor a phaseis not necessarilyindependentofpreviousphases;however, becauseeachphasesucceedswith probabilityat leastâ K]ã , independentof otherphases,wecanapplytheChernoff bound.
8

Pa
Pbwv
u
thread t
Figure9: An examplescenariowhena processormaynot ex-ecuteacontiguoussubsequenceof nodesbetweensteals.Theshadedregionsindicatethesubsetof nodesexecutedon eachof the two processors,Y l and Y5m . Here,processorY l stealsthe threadQ andexecutesnode � . It thenforks a child thread(containingnode � ), putsthreadQ on its deque,andstartsexe-cutingthechild. In themeantime,processorY5m stealsthreadQ from thedequebelongingto Y5l , andexecutesit until it sus-pends.Subsequently, Y l finishedexecutingthe child thread,andwakesup the suspendedparent Q andresumesexecutionof Q . Thecombinedsetsof nodesexecutedon bothprocessorsformsacontiguoussubsequenceof 1DF-schedule.
heavyprematurenodes,thentheparallel spacerequirement of� | is at most � � ��áD�]ä2å(¯5"$3 Z � � % . Further, thereareat most�'��áD�1ä#å(¯5"$3 Z ���1% activethreadsduring theexecution.
Proof: We can partition � | into the set of non-prematurenodesand the setof prematurenodes. Since,by definition,all non-prematurenodes form some serial prefix of the1DF-schedule, their netmemoryallocationcannotexceed��� .We now boundthe net memoryallocatedby the prematurenodes.Considerastealthatresultsin theexecutionof aheavyprematurenodeon aprocessorY5l . Thenodesexecutedby Y5luntil its next steal,cannotallocatemorethan 3 space.Be-causethereareatmost á heavy prematurenodesexecuted,thetotalspaceallocatedacrossall processorsafter ^ timestepscan-notexceed� � �6áD�§3 .
We cannow obtaina tigherboundwhen 3ænÇ�0� . Con-siderthecasewhenprocessorY5l stealsa threadandexecutesa heavy prematurenode. The nodesexecutedby Y5l beforethe next stealareall premature,andform a seriesof oneormore subsequences of the 1DF-schedule. The intermediatenodesbetweenthesesubsequences(in depth-firstorder) areexecutedon otherprocessors(e.g., seeFigure9). Thesein-termediatenodesoccur when other processorssteal threadsfrom the dequebelongingto Y5l , and finish excecutingthestolenthreadsbefore Y l finishesexecutingall the remainingthreadsin its deque.Subsequently, when Y5l ’s dequebecomesempty, the threadexecutingon Y5l may wakeup its parent,so that Y5l startsexecutingtheparentwithout performingan-othersteal.Therefore,thesetof nodesexecutedby Y5l beforethenext steal,possiblyalongwith prematurenodesexecutedon otherprocessors,form a continguoussubsequence of the1DF-schedule.
Assumingthatthenetspaceallocatedduringthe1DF-schedulecannever benegative, this subsequencecannotallocatemorethan � � unitsof netmemory. Therefore,thenetmemoryallo-
cationof all theprematurenodescannotexceedá[� ä#å(¯0"$3 Z � � % ,andthetotalspaceallocatedacrossall processorsafter ^ timestepscannotexceed�����)áÍ�$ä#å(¯5"$3 Z ���1% . Becausethisboundholdsfor everyprefixof ��| , it holdsfor theentireparallelexecution.
Themaximumnumberof activethreadsisatmostthenum-berof threadswith prematurenodes,plusthemaximumnum-ber of active threadsduring a serial execution,which is � .Assumingthat eachthreadneedsto allocateat leasta unitof spacewhenit is forked(e.g., to storeits registerstate),atmost ä#å(¯5"$3 Z ���1% threadswith prematurenodescanbeforkedfor eachheavy prematurenodeexecuted.Therefore,the totalnumberof active threadsis at most �©�6áD�1ä#å(¯5"$3 Z ���1% .
Note that eachactive threadrequiresat most a constantamountof spaceto be storedby thescheduler(not includingstackspace).Wenow extendtheanalysisto handlelargeallo-cations.
Handling large allocations of space. We hadassumedear-lier in this sectionthat every nodeallocatesat most 3 unitsof memory. Individual nodesthatallocatemorethan 3 spacearehandledasdescribedin Section3. Thekey ideais to delaythebig allocations,sothatif threadswith higherprioritiesbe-comeready, they will beexecutedinstead.Thesolutionis toinsertbeforeevery allocationof c bytes( cçn�3 ), a binaryfork treeof depth w@x[y7"$cr�s3�% , so that ch�[3 dummythreadsarecreatedat its leaves. Eachof the dummythreadssimplyperformsa no-op that takesonetimestep,but the threadsatthe leavesof the fork treearetreatedas if it wereallocating3 space;a processorgivesup its dequeandperformsa stealafter executingeachof thesedummythreads.Therefore,bythe time the ch�[3 dummythreadsareexecuted,a processormayproceedwith theallocationof c byteswithoutexceedingour spacebound.Recallthat in our costmodel,anallocationof c bytesrequiresadepthof #"aw@x[y>cr% ; therefore,this trans-formationof thedagincreasesits depthby at mostaconstantfactor. This transformationtakesplaceat runtime,andtheon-line DFDequesalgorithmgeneratesa schedulefor this trans-formeddag. Therefore,thefinal boundon thespacerequire-mentof thegeneratedschedule,usingLemmas4.2and4.3, isstatedbelow.
Theorem 4.4 (Upper bound on space requirement)Considera nested-parallel computationwith depth� andse-rial, depth-firstspacerequirement ��� . Then,for any 3èn'� ,the expectedvalueof the spacerequiredto executethe com-putationon � processors usingalgorithm DFDeques( 3 ), in-cluding the spacerequired to store active threads,is ����� #"Vä#å(¯5"$3 Z ���1%&���)�*�!% . Further, for any ®rnÇ� , the proba-bility that thecomputationrequires � � �6 #"Vä#å(¯�"$3 Z � � %5���+�"$�'��w(¯0"�gª�«®1%�%�% spaceis at least gD��® .
We now show that theabove spaceboundis tight (withinconstantfactors)in the expectedcase,for algorithmDFDe-ques.
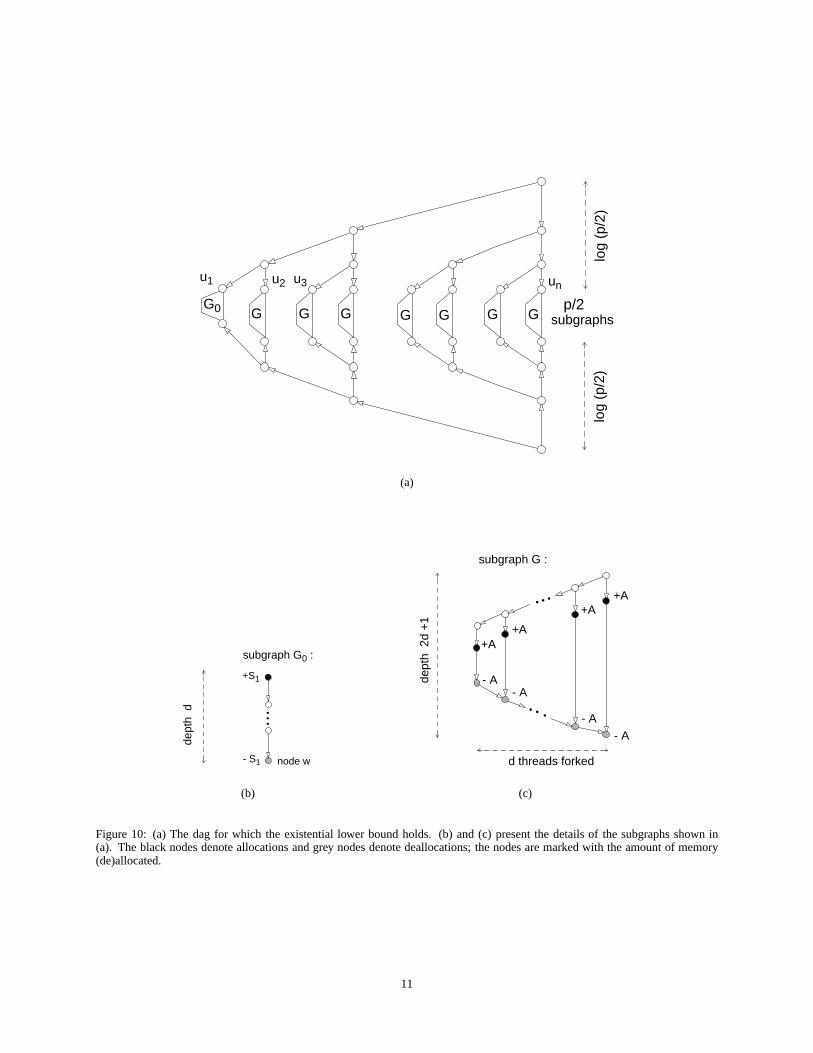
Theorem 4.5 (Lower bound on space requirement)For any �0�)nÇ� , �'n�� , 3énÇ� , and �ê¶ £ Ê w@xsy�� , thereexistsa nestedparallel dag with a serial spacerequirementof ��� and depth � , such that the expectedspacerequiredby algorithm DFDeques( 3 ) to executeit on � processors isë "$���5��ä#å(¯5"$3 Z ���1%����L�s�!% .Proof: Considerthedagshown in Figure10. Theblacknodesdenoteallocations,while thegrey nodesdenotedeallocations.
9

The dagessentiallyhasthe a fork treeof depth w@xsy�"(�7� £ % , attheleavesof whichexist subgraphs8. Theroot nodesof thesesubgraphsarelabelled � � Z � T Z]\]\]\]Z ��ì , where » j ��� £ . Theleftmostof thesesubgraphs,� R , shown in Figure10 (b), con-sistsof aserialchainof ¼ nodes.Theremainingsubgraphsareidentical,have adepthof £ ¼¬�.g , andareshown in Figure10(c). Theamountof spaceallocatedby eachof theblacknodesin thesesubgraphsis definedas í j ä#å(¯0"$3 Z � � % . Sinceweareconstructinga dagof depth � , thevalueof ¼ is setsuchthat £ ¼2�©g�� £ w@xsy�"(��� £ % j � . Thespacerequirementof a1DF-schedulefor thisdagis ��� .
Wenow examinehow algorithmDFDeques( 3 ) wouldex-ecutesuchadag.Oneprocessorstartsexecutingtherootnode,andexecutestheleft childof thecurrentnodeateachtimestep.Thus, within w@x[y7"(�7� £ % j w@xsyz» timesteps,it will have exe-cutednode � � . Now considernode ��ì ; it is guaranteedto beexecutedonce w@x[yz» successfulstealstarget the root thread.(Recallthat theright child of a forking node,that is, thenextnodein the parentthread,mustbe executedeitherbeforeorwhenthe parentthreadis next stolen.) Becausethereareal-ways » j ��� £ processorsin thisexamplethatareidle andat-temptstealstargetting � dequesat thestartof every timestep,theprobability Y�î@ïVðMñMÙ thatastealwill targetaparticulardequeis givenby
Y�î¿ïòðMñMÙ·¶ gz� ¸ g&� g� ¹ |[Ô$T¶ gz� º ¦ ��ÔMTn gÅWe call a timestep successfulif somenodealongthe pathfrom the root to ��ì getsexecuted;this happenswhena stealtargetsthedequecontainingthatnode.Thus,after w@x[yz» suc-cessfultimesteps,node � ì mustget executed;after that, wecanconsiderevery subsequent timestepto besuccessful.Let� be the numberof successfultimestepsin the first g £ w@x[yz»timesteps.Then,theexpectedvalueis givenbyór´ ��µ·¶ g £ w@xsyz»+�§Y�î¿ïVðMñMÙ¶ Ê w@x[y>»UsingtheChernoff bound[32,Theorem4.2] onthenumberofsuccessfultimesteps,wehave²5³ª´ ��½Þô[gz� ÅÊ5õ � ó)´ ��µ/µ·� Î1Ï[Ð Ñ �¤ô ÅÊNõ T � ór´ ��µ£ ÒTherefore,²5³ª´ ��½Ãw@xsyz»:µ·� Î]Ï[Ð�öM�!÷È w@x[yz»�øj Î]Ï[Ð�öM�!÷È � w(¯ù»w(¯ £ ø½ º ¦ ��ú × T]û Ù Ú ìj » ¦ R ú × T � g»½ £Å � g» ü x ³ �)¶ Ê
8All logarithmsdenotedasE F]G
areto thebase2.
Recallthat » j �7� £ . (Thecaseof ��½ Ê canbe easilyhan-dled separately.) Let ý � be the event that node � � is not ex-ecutedwithin the first g £ w@xsyz» timesteps.We have showedthat
²5³ª´ ý ì µr½ £ �«År�7g§�[» . Similarly, we can show that foreach ^ j g Z]\]\]\]Z »Ã�pg , ²5³ª´ ý � µO½ £ �«Å)��g§�[» . Therefore,²5³ª´ � ì � ý � µ¬½ £ �ªÅ . Thus,for ^ j g Z]\]\]\1Z » , all the � � nodesgetexecutedwithin thefirst g £ w@x[yz» timestepswith probabil-ity greaterthan gª�ªÅ .
Eachsubgraph� has ¼ nodesat differentdepthsthat al-locatememory; the first of thesenodescannotbe executedbefore timestepw@xsyz» . Let Q be the first timestepat whichall the � � nodeshave beenexecuted.Then,at this timestep,thereareat least "V¼&�uw@xsyz»#�ÁQM% nodesremainingin eachsub-graph � thatallocateí byteseach,but have not yet beenex-ecuted.Similarly, node þ in sugraph� R will not beexecutedbeforetimestep "V¼h�©w@x[yz»7% , that is, another "V¼h�©w@x[yz»��QM% timestepsafter timestep Q . Therefore,for the next "V¼h�w@x[y>»��'QM% timestepstherearealways »��¤g j "(��� £ %ù�ßgnon-emptydeques(out of a total of � deques)during theex-ecution. Eachtime a threadis stolenfrom oneof thesede-ques,a black node(seeFigure 10 (c)) is executed,and thethreadthen suspends.Because�7� £ processorsbecomeidleandattempta stealat thestartof eachtimestep,we canshowthat in the expectedcase,at leasta constantfraction of the�7� £ stealsaresuccessfulin every timestep. Eachsuccessfulstealresultsin í j ä#å(¯5"$� � Z 3�% units of memorybeingal-located. Considerthe casewhen Q j g £ w@xsyz» , Then,usinglinearityof expectations,over the ¼��6g[g7w@x[yz» timestepsaftertimestepQ , the expectedvalueof the total spaceallocatedis���7� ë "Ví��a�¬�]"V¼z��gsg�w@x[yz»7%�% j �0��� ë "Ví��a�¬�1"$�ÿ�!w@x[y���%�% .( ��¶ £ Ê w@x[y�� ensuresthat "V¼2�Ãgsg�w@xsyz»7%>n6� .)
Weshowedthatwith constantprobability( n©g§�«Å ), all the� � nodeswill be executedwithin thefirst g £ w@xsyz» timesteps.Therefore,in the expectedcase,thespaceallocated(at somepoint during the executionafter all � � nodeshave beenexe-cuted)is
ë "$� � ��ä#å(¯0"$� � Z 3O%��["$�¤�������1�7%Í����% .Corollary 4.6 (Lower bound using work stealing)For any � � n�� , �pnÞ� , and �æ¶ £ Ê w@x[y�� , there existsanestedparallel dagwith a serial spacerequirementof ��� anddepth � , such that the expectedspacerequiredto executeitusingthespace-efficientworkstealerfrom[9] on � processorsisë "$�����M�!�ª�!% .
ThecorollaryfollowsfromTheorem4.5andthefactthatalgo-rithmDFDequesbehaveslike thespace-efficientwork-stealingschedulerfor 3 j } . BlumofeandLeiserson[9] presentedan upperboundon spaceof ����� � using randomizedworkstealing.Their resultis not inconsistentwith theabovecorol-lary, becausetheir analysisallows only “stack-like” memoryallocation9, which is morerestrictedthanourmodel.For suchrestricteddags,theirspaceboundof �z�$��� alsoappliesdirectlyto DFDeques( } ). Ourlowerboundis alsoconsistentwith theupperboundof �!�ª� by SimpsonandBurton[41], where � isthe maximumspacerequirementover all possibledepth-firstschedules;in this example,� j � � �§� .
9Their modeldoesnot allow allocationof spaceon a global heap. An in-structionin a threadmayallocatestackspaceonly if thethreadcannotpossiblyhave a living child whenthe instructionis executed.Thestackspaceallocatedby thethreadmustbefreedwhenthethreadterminates.
10
GGGGGG p/2
GG0
u1 u2 unu3
log
(p/2
)lo
g (p
/2)
subgraphs
(a)
subgraph G0 :
dept
hd
+S1
- S1
...
node w
...
...+A
+A
+A+A
d threads forked
subgraph G :
dept
h 2
d+
1
- A
- A
- A- A
(b) (c)
Figure10: (a) The dagfor which the existential lower boundholds. (b) and(c) presentthe detailsof the subgraphsshown in(a). The blacknodesdenoteallocationsandgrey nodesdenotedeallocations;thenodesaremarkedwith theamountof memory(de)allocated.
11

4.3 Time bound
Wenow prove thetimeboundrequiredfor aparallelcomputa-tion usingalgorithmDFDeques. This timebounddoesnot in-cludetheschedulingcostsof maintainingtherelative orderofthedeques(i.e., insertinganddeletingdequesin b ), or findingthe cr_a` deque.Elsewhere[33], wedescribehow theschedulercanbeparallelized,andthenprove the time boundincludingtheseschedulingcosts. We first assumethat every actional-locatesat most 3 space,for someconstant3 , andprove thetime bound. We thenrelax this assumptionand provide themodifiedtimeboundat theendof thissubsection.
Lemma 4.7 Considera parallel computationwith work �anddepth� , in whicheveryactionallocatesat most3 space.Theexpectedtimeto executethiscomputationon � processorsusing the DFDeques( 3 ) schedulingalgorithm is #"$�����O��!% . Further, for any ®Lnp� , the time requiredto executethecomputationis #"$�����Á�¤�Ç�w(¯5"�g§�«®1%�% with probability atleast gz�O® .Proof: Considerany timestep of the � -schedule;let » � bethenumberof dequesin b attimestep . Wefirst classifyeachtimestep into oneof two types(A andB), dependingon thevalueof » � . We thenboundthetotal numberof timesteps{��and {�� of typesA andB, respectively.
Type A: » � ¶�� . At thestartof timestep , let therebe ár�� stealattemptsin this timestep. Thenthe remaining�O�.áprocessorsare busy executingnodes,that is, at least ���ßánodesareexecutedin timestep . Further, atmost�L��á of theleftmost � dequesmay be empty; the restmusthave at leastonethreadin them.
Let ± � betherandomvariablewith value1 if the �*_a` non-emptydequein b (from the left end)getsexactly onestealrequest,and0 otherwise. Then,
ó)´ ± � µ j ²Í³N´ ± � j g�µ j"$áª����%D�:"�g¬�.g§����% ¦ � . Let ± be the randomvariablerepre-sentingthetotalnumberof non-emptydequesthatgetexactlyonestealrequest.Becausethereareat least á non-emptyde-ques,theexpectedvalueof ± (assumingthat ��¶ £ ) is givenby óh´ ±rµ ¶ � � � � ó)´ ± � µj áD� á� �["�g&� g� % ¦ �¶ á T� �["�gz� g� % |¶ á T� �["�gz� g� %Í� gº¶ á T£ ��� � ºRecallthat �h��á nodesareexecutedby thebusyprocessors.Therefore,if � is therandomvariabledenotingthetotalnum-berof nodesexecutedduringthis timestep,thenó)´ �Dµæ¶ "(�+��áª%���á T � £ º �¶ �7� £ º �� Î ³ Î ü x ³ Î Z ór´ �!����µæ� �+�h�7� £ ºj ��"�gz��g§� £ º %
Thequantity "(�r���#% mustbenon-negative; therefore,usingtheMarkov’s inequality[32, Theorem3.2],weget²Í³N´ "(�!���2%>n)�N"�gD��gª� Ê º %Sµ·½ ó)´ "(�L���2%Sµ����gz� �W����� � gz� �T�� �
� gz� �W�� � �� Î ³ Î ü x ³ Î Z ²5³5´ ��½)��� Ê º µ ½ ÷g]�� ��� � å�� Z ²5³5´ ��¶)��� Ê º µ n gg]�We will call eachtimestepof typeA successfulif at least�7� Ê º nodesgetexecutedduringthetimestep.Thentheproba-
bility of thetimestepbeingsuccessfulisatleastg§��g1� . Becausethereare � nodesin the entirecomputation,therecanbe atmost
Ê º �s����� successfultimestepsof typeA. Therefore,theexpectedvaluefor { � is atmost
Ê � º �ª����� .The analysisof the high probability boundis similar to
that for Lemma4.2. Supposethe executiontakesmore thanÈ[� º �����ù� Ê �5w(¯5"�g§�«®1% timestepsof typeA. ThentheexpectednumberÉ of successfultimestepsof typeA isatleastÈ º �������Ê w(¯5"�g§�«®1% . If � is therandomvariabledenotingthetotal num-berof successfultimesteps,thenusingtheChernoff bound[32,Theorem4.2],andsettingË j Ê � º �����N� Ê ��w(¯5"�gª�ª®]% , weget10
²5³�´ �ÿ½�É!��Ë/��g1�«µ ½ Î]Ï[Ð4Ñ �O"VË/��g]�*% T£ É ÒTherefore,²Í³N´ �.½ Ê º �����/µ ½ º ¦ l Ó Ô$T R�R��j Î]Ï[Ð Ñ � Ë T£ �[�/"VË/�� à� Ê w(¯5"�gª�ª®]%�%]Ò� Î]Ï[Ð Ñ � Ë T£ �[�¬�]Ë/�! �Òj º ¦ lªÔMW Rj º ¦ �#"¬ÔV| ¦ Ù Ú Ö ��ÔÜÛaÝ� º ¦ Ù Ú Ö ��ÔÜÛaÝj ®Wehaveshown thattheexecutionwill notcompleteevenafterÈ[� º �����O� Ê �Íw(¯5"�g§�«®1% type A timestepswith probability atmost ® . Thus,for any ®¬n'� , {�� j #"$����� �4w(¯5"�g§�«®1%�% withprobabilityat least gz�O® .Type B: » � ½Ç� . We now considertimestepsin which thenumberof dequesin b is lessthan � . As with the proof ofLemma4.2, we split type B timestepsinto phasessuchthateachphasehasbetween� and £ �h�.g stealattempts.We canthenuseapotentialfunctionargumentsimilarto thededicatedmachinecaseby Aroraetal. [2]. Composingphasesfrom onlytypeB timesteps(ignoringtypeA timesteps)retainsthevalid-ity of their analysis.We briefly outlinetheproof here.Nodesareassignedexponentiallydecreasingpotentialsstartingfrom
10As with the proof of Lemma4.2, we canusetheChernoff boundherebe-causeeachtimestepsucceedswith probability at least
â K â�$ , even if the exactprobabilitiesof successesfor timestepsarenot independent.
12

theroot downwards.Thus,a nodeat a depthof ¼ is assignedapotentialof Å T ÖCØ�¦&% Ý , andin thetimestepin which it is aboutto be executedon a processor, a weightof Å T ÖaØ�¦�% Ý ¦ � . Theyshow thatin any phaseduringwhichbetween� and £ �5�2g stealattemptsoccur, thetotalpotentialof thenodesin all thedequesdropsby a constantfactorwith at leastaconstantprobability.Sincethe potentialat thestartof theexecutionis Å T Ø�¦ � , theexpectedvalueof the total numberof phasesis #"$�!% . Thedifferencewith our algorithmis thata processormayexecuteanode,andthenputupto 2 (insteadof 1) childrenof thenodeon the dequeif it runsout of memory;however, this differ-encedoesnot violatethebasisof theirarguments.Sinceeachphasehas v#"(�7% stealattempts,the expectednumberof stealattemptsduring typeB timestepsis #"(�7�!% . Further, for any®�nÞ� , we canshow that the total numberof stealattemptsduringtimestepsof typeB is #"(�¬�]"$���uw(¯5"�g§�«®1%�%�% with prob-ability at least gz�O® .
Recall that in every timestep,eachprocessoreitherexe-cutesastealattemptthatfails,orexecutesanodefrom thedag.Therefore,if ,àî¿ïòðMñMÙ is the total the numberof stealattemptsduringtypeB timesteps,then { � is at most "$� ��, î@ïVðMñMÙ %���� .Therefore,theexpectedvaluefor { � is #"$�����z�)�!% , andforany ®zn6� , thenumberof timestepsis #"$�������r���Lw(¯�"�gª�«®1%�%with probabilityat least gz��® .
The total numberof timestepsin the entire executionis{ � �©{�� . Therefore,the expectednumberof timestepsinthe executionis #"$�����h�'�!% . Further, combiningthe highprobabilityboundsfor timestepsof typeA andB, (andusingthefact that Y#"Ví('*)2%ù�ÿY#"Ví¬%7��Y#"+)2% ), we canshow thatfor any ®�nÞ� , the total numberof timestepsin the parallelexecutionis #"$����� �Ã�.��w(¯5"�g§�«®1%�% with probabilityat leastgz�O® .
To handleeachlarge allocationof c units (where c n3 ), recall that we add qVcr�s3ut dummythreads;the dummythreadsare forked in a binary tree of depth v#"aw@x[y7"$cr�s3�%�% .Becausewe assumea depthof v#"aw@xsyzcr% for every allocationof c bytes,this transformationof thedagincreasesits depthby at mosta constantfactor. If �7l is thetotal spaceallocatedin theprogram(notcountingthedeallocations),thenumberofnodesin thetransformeddagisatmost ��#�7l[�s3 . Therefore,usingLemma4.7,themodifiedtimeboundisstatedasfollows.
Theorem 4.8 (Upper bound on time requirement)Theexpectedtime to executea parallel computationwith �work, � depth,andtotal spaceallocation � l on � processorsusingalgorithm DFDeques( 3 ) is #"$�����Á�©�7lI���73Ì�'�!% .Further, for any ®2n©� , thetimerequiredto executethecom-putationis #"$�������r� l ���73.�r��� w(¯N"�gª�«®1%�% with probabilityat least gz��® .In a systemwhereevery memorylocationallocatedmustbezeroed,� l j #"$�©% . Theexpectedtime boundthereforebe-comes #"$�����h�.�!% . This time bound,althoughasymptoti-cally optimal [10], is not aslow asthetime boundof �����!� #"$�!% for work stealing[9].
Trade-off between space, time, and scheduling granular-ity. As thememorythreshold3 is increased,theschedulinggranularityincreases,sincea processorcanexecutemorein-structionsbetweensteals.In addition,thenumberof dummythreadsaddedbeforelargeallocationsdecreases.However, thespacerequirementincreaseswith 3 . Thus,adjustingthevalueof 3 providesatrade-off betweenrunningtime(or schedulinggranularity),andspacerequirement.
5 Experiments with Pthreads
We implementedthe scheduleraspart of an existing libraryfor Posix standardthreadsor Pthreads[23]. The library isthenative, user-level Pthreadslibrary on Solaris2.5 [38, 43].Pthreadson Solarisaremultiplexed at theuserlevel on top ofkernelthreads,whichact like virtual processors.Theoriginalschedulerin the Pthreadlibrary usesa FIFO queue.Our ex-perimentswereconductedon an 8 processorEnterprise5000SMPwith 2GB mainmemory. Eachprocessoris a 167MHzUltraSPARC with a512kB L2 cache.
Having to supportthe generalPthreadsfunctionalitypre-ventseven a user-level Pthreadsimplementationfrom beingextremelylightweight. For example,a threadcreationis twoordersof magnitudemoreexpensive thana null functioncallon the UltraSPARC. Therefore,the useris requiredto createPthreadsthatarecoarseenoughto amortizethecostof threadoperations.However, with a depth-firstscheduler, threadsatthisgranularityhadtobecoarsenedfurthertogetgoodparallelperformance[35]. We show that usingalgorithmDFDeques,good speedupscan be achieved using Pthreadswithout thisadditionalcoarsening.Thus,the usercannow fix the threadgranularityto amortizethreadoperationcosts,andexpect togetgoodparallelperformancein bothspaceandtime.
ThePthreadsmodelsupportsabinaryfork andjoin mech-anism.Wemodifiedmemoryallocationroutinesmalloc andfree to keeptrack of thememoryquotaof the currentpro-cessor(or kernel thread)and to fork dummy threadsbeforean allocation if required. Our schedulerimplementationisa simpleextensionof algorithmDFDequesthat supportsthefull Pthreadsfunctionality(includingblocking11 mutexesandconditionvariables)by maintainingadditionalentriesin b forthreadssuspendedon synchronizations.Our benchmarksarepredominantlynestedparallel,and makelimited useof mu-texesandconditionvariables.For example,the tree-buildingphasein Barnes-Hutusesmutexesto protectmodificationstothetree’scells.However, theSolarisPthreadsimplementationitself makesextensive useof blockingsynchronizationprimi-tivessuchasPthreadmutexesandconditionvariables.
Sinceour executionplatform is an SMP with a modestnumberof processors,accessto the readythreadsin b wasserialized. b is implementedasa linked list of dequespro-tectedby a sharedschedulerlock. We optimizedthecommoncasesof pushingandpoppingthreadsontoa processor’s cur-rent dequeby minimizing locking time. A stealrequiresthelock to beacquiredmoreoftenandfor a longerperiodof time.
In the existing Pthreadsimplementation,it is not alwayspossibletoplaceareawakenedthreadonthesamedequeasthethreadthatwakesit up; therefore,ourimplementationof DFD-equesis anapproximationof thepseudocodein Figure5. Fur-ther, sincewe serializeaccessto b , andsupportmutexesandconditionvariables,settingthememorythreshold3 to infin-ity doesnot producethesamescheduleasthespace-efficientwork-stealing scheduler intended for fully strictcomputations[9]. Therefore,we canusethis settingonly asa roughapproximationof apurework-stealingscheduler.
Wefirst list thebenchmarksusedin ourexperiments.Next,we comparethe spaceandtime performanceof the library’soriginal scheduler(labelled“FIFO”) with an asynchronous,depth-firstscheduler[35] (labelled“ADF”), andthenew DFD-equesscheduler(labelled“DFD”) for afixedvalueof themem-ory threshold3 . We alsouseDFDeques( } ) asan approx-
11We use the term “blocking” for synchronizationthat causesthe callingthreadto blockandsuspend,ratherthanspinwait.
13

imation for a work-stealingscheduler(labelled“DFD-inf ”).To studyhow theperformanceof theschedulersis affectedbythreadgranularity, wepresentresultsof theexperimentsattwodifferent threadgranularities.Finally, we measurethe trade-off betweenrunning time, schedulinggranularity, andspacefor algorithmDFDequesby varyingthevalueof thememorythreshold3 for oneof thebenchmarks.
5.1 Parallel benchmarks
The benchmarkswereeitheradaptedfrom publicly availablecoarsegrainedversions[19,36, 42, 46], orwrittenfromscratchusingthe lightweight threadsmodel[35]. The parallelisminbothdivide-and-conquerrecursionandparallelloopswasex-pressedasa binarytreeof forks, with a separatePthreadcre-atedfor eachrecursive call. Threadgranularitywasadjustedby serializingthe recursionnearthe leafs. In thecomparisonresultsin Section5.2,mediumgranularityrefersto thethreadgranularitythatprovidesgoodparallelperformanceusingthedepth-firstscheduler[35]. Even at mediumgranularity, thenumberof threadssignificantlyexceedsthenumberof proces-sors;this allowssimplecodingandautomaticloadbalancing,while resultingin performanceequivalentto hand-partitioned,coarse-grainedcodeusingthedepth-firstscheduler[35]. Finegranularityrefersto thefinestthreadgranularitythatallowsthecostof threadoperationsin asingle-processorexecutionto beup to 5% of theserialexecutiontime12. The benchmarksarevolumerendering,densematrixmultiply, sparsematrixmulti-ply, FastFourierTransform,FastMultipole Method,Barnes-Hut, and a decisiontree builder13. Figure 11 lists the totalnumberof threadsexpressedin eachbenchmarkat both thethreadgranularities.
5.2 Comparison results
In all the comparisonresults,we usea memorythresholdof3 j ª� Z �s�[� bytes for “ADF” and “DFD” 14. Eachactivethreadis allocateda minimum8kB (1 page)stack.Therefore,thespace-efficientschedulerseffectively conservestackmem-ory by creatingfewersimultaneouslyactive threadscomparedto the original FIFO scheduler(seeFigure 11). The FIFOschedulerspendssignificantportionsof timeexecutingsystemcalls relatedto memoryallocationfor the threadstacks[35];this problemis aggravatedwhen the threadsare madefinegrained.
The8-processorspeedupsfor all thebenchmarksatmediumandfine threadgranularitiesareshown in Figure12. To con-centrateon the effect of the scheduler, andto ignore the ef-fect of increasedthreadoverheads(up to 5% for all exceptdensematrix multiply) at the fine granularity, speedupsforeachthreadgranularityarewith respectto thesingle-processormultithreadedexecutionatthatgranularity. Thespeedupsshowthatboththedepth-firstschedulerandthenew DFDequessched-uler outperformthe library’s original FIFO scheduler. How-ever, at thefinethreadgranularity, thenew schedulerprovidesbetterperformancethanthedepth-firstscheduler. Thisdiffer-encecanbeexplainedby thebetterlocality andlowerschedul-ing contentionexperiencedby algorithmDFDeques.
12Theexceptionwasthedensematrix multiply, which we wrote for ,.-/,blocks,where, isapowerof two. Therefore,finegranularityinvolvedreducingtheblocksizeby a factorof 4, andincreasingthenumberof threadsby a factorof 8, resultingin 10%additionaloverhead.
13Detailson thebenchmarkscanbefoundelsewhere[33].14In thedepth-firstscheduler, thememorythreshold0 is thememoryquota
assignedto eachthreadbetweenthreadpreemptions[35].
Medium-Grain
Fine-Grain
0
2
4
6
8
FIFO ADF DFD
(a)VolumeRendering
0
2
4
6
8
FIFO ADF DFD
0
2
4
6
8
FIFO ADF DFD
(b) DenseMatrix Multiply (c) SparseMatrix Multiply
0
2
4
6
8
FIFO ADF DFD
0
2
4
6
8
FIFO ADF DFD
(d) FastFourierTransform (e)FastMultipole Method
0
2
4
6
8
FIFO ADF DFD
0
2
4
6
8
FIFO ADF DFD
(f) BarnesHut (g) DecisionTreeBuilder
Figure12: Speedupson 8 processorswith respectto single-processorexecutionsfor the three schedulers(the original“FIFO”, the depth-first “ADF”, and the new “DFD” orDFDeques) at both medium and fine thread granularities,with 1 = 50,000 bytes. Performanceof “DFD-inf ” (orDFDeques( 243 ), being very similar to that of “DFD”,is not shown here. All benchmarkswere compiled us-ing cc -fast -xarch=v8plusa -xchip=ultra-xtarget=native -xO4.
14

Benchmark Input size Mediumgrained Finegrainedtotal FIFO ADF DFD total FIFO ADF DFD
Vol. Rend. 576987: vol, ;�<769= img 1427 195 29 29 4499 436 36 37
DenseMM >�?!5A@�BC>�?�59@ doubles 4687 623 33 48 37491 3752 55 77SparseMVM 30K nodes,151K edges 1263 54 31 31 5103 173 51 49
FFTW DFE45 == 177 64 13 18 1777 510 30 33FMM DGEH>�?7I , 5 mpl terms 4500 1314 21 29 36676 2030 50 54
BarnesHut DJEH>�?�?7I , Plmrmodel 40893 1264 33 106 124767 3570 42 120DecisionTree 133,999instances 3059 82 60 77 6995 194 138 149
Figure11: Inputsizesfor eachbenchmark,totalnumberof threadsexpressedin theprogramatmediumandfine granularities,andmax. numberof simultaneouslyactive threadscreatedby eachschedulerat bothgranularities,for 1 = 50,000bytes.“DFD-inf ”createsat most twice asmany threadsas“DFD” for DenseMM, andat most15% morethreadsthan“DFD” for the remainingbenchmarks.
0
10
20
30
40
50
1 2 3 4 5 6 7 8
ME
MO
RYK
# PROCESSORS
CilkDFDADF
Input size
Figure13: Variationof thememoryrequirementwith thenum-berof processorsfor densematrixmultiply usingthreesched-ulers: depth-first (“ADF”), DFDeques(“DFD”), and Cilk(“Cilk”).
We measuredthe external(L2) cachemissratesfor eachbenchmarkusingon-chipUltraSPARC performancecounters.Figure1, which lists the resultsat thefine threadgranularity,shows that our schedulerachievesrelatively low cachemissrates(i.e., resultsin betterlocality).
Threeout of the seven benchmarksmakesignificantuseof heapmemory. For thesebenchmarks,we measuredthehigh watermark for heapmemoryallocationusingthe threeschedulers.Figure14 showsthatalgorithmDFDequesresultsin slightly higherheapmemoryrequirementcomparedto thedepth-firstscheduler, but still outperformsthe original FIFOscheduler.
TheCilk runtimesystem[20] usesaprovablyspace-efficientwork stealingalgorithmto schedulethreads15. Figure13com-paresthe spaceperformanceof Cilk with the depth-firstandDFDequesschedulersfor the densematrix multiply bench-mark(at thefine threadgranularity).ThefigureindicatesthatDFDequesrequiresmorememorythanthedepth-firstsched-uler, but lessmemorythanCilk. In particular, similar to thedepth-firstscheduler, the memoryrequirementof DFDequesincreasesslowly with thenumberof processors.
5.3 Measuring the tradeoff between space, time, andscheduling granularity
We studiedthe effect of the sizeof memorythreshold1 ontherunningtime,memoryrequirement,andschedulinggranu-
15BecauseCilk requiresgcc to compile the benchmarks(which resultsinslower codefor floating point operationscomparedto the native cc compileron UltraSPARCs), we do not show a direct comparisonof running times orspeedupsof Cilk benchmarkswith ourPthreads-basedsystemhere.
larity usingDFDeques( 1 ). Eachprocessorkeepstrackof thenumberof timesathreadfrom its owndequeis scheduled,andthenumberof timesit hasto performasteal.Theratioof thesetwo counts,averagedover all the processors,is our approx-imation of the schedulinggranularity. The trade-off is bestillustratedin thedensematrix multiply benchmark,which al-locatessignificantamountsof heapmemory. Figure15 showsthe resultingtrade-off for this benchmarkat the fine threadgranularity. As expected,bothmemoryandschedulinggran-ularity increasewith 1 , while runningtime reducesas 1 isincreased.
6 Simulating the scheduler s
To comparealgorithmDFDequeswith awork-stealingsched-uler, webuilt asimplesystemthatsimulatestheparallelexecu-tion of synthetic,nested-parallel,divide-and-conquerbench-marks16. Our implementationsimulatestheexecutionof thespace-efficientwork-stealingscheduler[9] (labeled“WS”), thespace-efficient,asynchronousdepth-firstscheduler[34] (“ADF”),andournew DFDequesscheduler(labeled“DFD”).
Due to limited space,we presentresultsfor only one ofthe syntheticbenchmarkshere17, in which both the memoryrequirementandthethreadgranularitydecreasegeometricallydown the recursiontree. A numberof divide-and-conquerprogramsexhibit suchproperties.Schedulinggranularitywasmeasuredastheaveragenumberof actionsexecutedby apro-cessorbetweentwosteals. Figure16showsthatworkstealingresultsin high schedulinggranularityandhigh spacerequire-ment,thedepthfirst schedulerresultsin low schedulinggran-ularity and low spacerequirement, while DFDequesallowsschedulinggranularityto betradedwith spacerequirementbyvaryingthememorythreshold1 .
7 Summary and Discussion
Depth-first schedulersare space-efficient, but unlike work-stealingschedulers,they requiretheuserto explicitly increasethe threadgranularitybeyond what is requiredto amortizebasic threadcosts. In contrast,algorithm DFDequesauto-matically increasesthe schedulinggranularityby executing
16Tomodelirregularapplications,thespaceandtimerequirementsof athreadateachlevelof therecursionareselecteduniformlyat randomwith thespecifiedmean.
17Resultsfor otherbenchmarksandadetaileddescriptionof thesimulatorcanbefoundelsewhere[33].
15

Medium-Grain Fine-Grain
0
40
80
120
160
200
240
FIFO ADF DFD DFD-inf
0
0.5
1
1.5
2
2.5
3
FIFO ADF DFD DFD-inf
0
10
20
30
40
50
60
FIFO ADF DFD DFD-inf
(a)DenseMatrix Multiply (b) FastMultipole Method (c) DecisionTreeBuilder
Figure14: High watermark of heapmemoryallocation(in MB) on 8 processorsfor benchmarksinvolving dynamicmemoryallocation( 1 = 50,000bytesfor “ADF” and “DFD”), at both threadgranularities. “DFD-inf ” is our approximationof workstealingusingDFDeques( 2 ).
0
1
2
3
4
5
6
1e+02 1e+04 1e+06
Tim
e (s
ec)
K (bytes)
0
20
40
60
80
1e+02 1e+04 1e+06
Mem
ory
(MB
)
L
K (bytes)
0
5
10
15
20
1e+02 1e+04 1e+06
Sch
ed. g
ranu
larit
y
L
K (bytes)
(a)Runningtime (b) MemoryAllocation (c) Schedulinggranularity
Figure 15: Trade-off betweenrunning time, memoryallocationand schedulinggranularityusing algorithm DFDequesas thememorythreshold1 is varied,for thedensematrixmultiply benchmarkatfinethreadgranularity.
0
0.02
0.04
0.06
0.08
0.1
0.12
0 40 80 120 160
Sch
edul
ing
Gra
nula
rity
Memory Threshold K (KB)
WSDFDADF
400
800
1200
1600
2000
0 40 80 120 160
Mem
ory
(KB
)
M
Memory Threshold (KB)
WSDFDADF
(a)Schedulinggranularity (b) Memory
Figure16: Simulationresultsfor adivide-and-conquerbenchmarkwith 15 levelsof recursionrunningon64 processors.Themem-ory requirementandthreadgranularitydecreasegeometrically(by a factorof 2) down therecursiontree.Schedulinggranularityisshownasapercentageof thetotalwork in thedag.“WS” is thespace-efficientwork-stealingscheduler, “ADF” is thespace-efficientdepth-firstscheduler, and“DFD” is ournew DFDequesscheduler.
16

Medium-Grain Fine-Grain
0
2
4
6
8
FIFO ADF DFD Cilk
Figure 17: Speedupsfor the tree-building phaseof BarnesHut (for 1M particles). The phaseinvolvesextensive useoflocks on cells of the tree to ensuremutual exclusion. ThePthreads-basedschedulers(all exceptCilk) supportblockinglocks. “DFD” doesnot result in a large schedulinggranular-ity dueto frequentsuspensionof the threadson locks; there-fore, its performanceis similar to that of “ADF”. Cilk [20]usesa purework stealerandsupportsspinwaiting locks. Forthisbenchmark,thesingle-processorexecutiontimeonCilk iscomparablewith thatonthePthreads-basedsystem.
neighboring,fine-grainedthreadson the sameprocessortoyield good locality and low schedulingcontention. In the-ory, for nested-parallelprogramswith a large amountof par-allelism, algorithmDFDequeshasa lower spaceboundthanwork-stealingschedulers.We showed that in practice,it re-quiresmorememorythanadepth-firstscheduler,andlessmem-ory thanwork stealing.DFDequesalsoallowstheuserto con-trol thetrade-off betweenspacerequirementandrunningtime(or schedulinggranularity).BecausealgorithmDFDequesal-lows moredequesthanprocessors,it canbe easilyextendedto supportblocking synchronizations.For example,prelimi-naryresultson a benchmarkwhichmakesa significantuseoflocks, indicatethat DFDequeswith blocking locksresultsinbetterperformancethana work stealerthatusesspin-waitinglocks(seeFigure17).
SincePthreadsarenot very lightweight,serializingaccessto the setof readythreadsN did not significantlyaffect theperformancein our implementation.However, serial accessto N can becomea bottleneckif threadsare extremely finegrained,andrequirefrequentsuspensiondueto memoryallo-cationor synchronization.Tosupportsuchthreads,theschedul-ingoperations(suchasupdatesto N ) needtobeparallelized[33].
Eachprocessorin DFDequestreatsits dequeasa regularstack. Therefore,in a systemthat supportsvery lightweightthreads,the algorithmshouldbenefitfrom stack-basedopti-mizationssuchas lazy threadcreation[21, 31]; thesemeth-odsavoid allocatingresourcesfor a threadunlessit is stolen,therebymakingmostthreadcreationsnearlyascheapasfunc-tion calls.
Increasingschedulinggranularitytypically serves to en-hancedata locality on SMPs with limited-size, hardware-coherentcaches.However, on distributedmemorymachines(or software-coherentclusters),executingthreadswherethedatapermanentlyresidesbecomesimportant. A multi-levelschedulingstrategy may allow the threadimplementationtoscaleto clustersof SMPs. For example,the DFDequesal-gorithmcould be deployedwithin a singleSMP, while someschemebasedondataaffinity is usedacrossSMPs.
An openquestionis how to automaticallyfind theappro-priatevalueof thememorythreshold1 , whichmaydependonthe benchmark,andon the threadimplementation.Onepos-siblesolutionis for theuser(or the runtimesystem)to set 1to anappropriatevalueafterrunningtheprogramfor a range
of valuesof 1 onsmallerinputsizes.Alternatively, it maybepossiblefor thesystemto keepstatisticsto dynamicallyset 1to anappropriatevalueduringtheexecution.
Ackno wledgements
Guy Blelloch, RobertBlumofe, and Bwolen Yang providedvaluablefeedbackon previousversionsof this paper. We alsothankAdamKalai andAvrim Blum for usefuldiscussions.
References
[1] T. E. Anderson,E. D. Lazowska,andH. M. Levy. Theperformanceimplicationsof threadmanagementalterna-tives for shared-memorymultiprocessors.PerformanceEvaluationReview, 17:49–60,May 1989.
[2] N. S. Arora, R. D. Blumofe,andC. G. Plaxton. Threadschedulingfor multiprogrammedmultiprocessors. InACMsymp.Parallel AlgorithmsandArchitectures,1998.
[3] F. BellosaandM. Steckermeier. Theperformanceimpli-cationsof locality informationusagein shared-memorymultiprocessors.J. Parallel andDistributedComputing,37(1):113–121,August1996.
[4] G. Blelloch, P. Gibbons, Y. Matias, and G. Narlikar.Space-efficient schedulingof parallelismwith synchro-nizationvariables. In Proc. ACM Symp.on Parallel Al-gorithmsandArchitectures, pages12–23,1997.
[5] G. E. Blelloch, S. Chatterjee,J. C. Hardwick, J. Sipel-stein,andM. Zagha.Implementationof aportablenesteddata-parallellanguage.J. Parallel andDistributedCom-puting, 21(1):4–14,April 1994.
[6] G. E. Blelloch, P. B. Gibbons,and Y. Matias. Prov-ablyefficientschedulingfor languageswith fine-grainedparallelism. In Proc. ACM symp.Parallel Algorithmsand Architectures, pages1–12,SantaBarbara,Califor-nia,July 17–19,1995.
[7] R. D. Blumofe,M. Frigo, C. F. Joerg, C. E. Leiserson,andK. H. Randall. An analysisof dag-consistentdis-tributedshared-memoryalgorithms.In Proc.ACM Sym-posiumon Parallel AlgorithmsandArchitectures, pages297–308,June1996.
[8] R. D. Blumofe,C. F. Joerg, B. C. Kuszmaul,C. E. Leis-erson,K. H. Randall,andY. Zhou. Cilk: An efficientmultithreadedruntimesystem. J. Par. and Distr. Com-puting, 37(1):55–69,August1996.
[9] R. D. Blumofe andC. E. Leiserson.Schedulingmulti-threadedcomputationsby work stealing.In Proc.Symp.Foundationsof ComputerScience, pages356–368,1994.
[10] R. P. Brent.Theparallelevaluationof generalarithmeticexpressions.J. ACM, 21(2):201–206,April 1974.
[11] F. W. BurtonandM. R. Sleep.Executingfunctionalpro-gramsonavirtual treeof processors.In Proc.ACM Conf.on FunctionalProgrammingLanguagesand ComputerArchitecture, pages187–194,1981.
17

[12] R. Chandra,A. Gupta,andJ. L. Hennessy. Datalocal-ity and load balancingin COOL. In Proc. ACM symp.Principles & Practiceof Parallel Programming, pages239–259,1993.
[13] K. M. ChandyandC. Kesselman.Compositionalc++:compositionalparallelprogramming.In Proc. Intl. Wk-shp.on LanguagesandCompilersfor Parallel Comput-ing, pages124–144,New Haven,CT, August1992.
[14] S. A. Cook. A taxonomyof problemswith fastparallelalgorithms.InformationandControl, 64:2–22,1985.
[15] T. H. Cormen,C. E. Leiserson,and R. L. Rivest. In-troductionto algorithms. MIT PressandMcGraw-HillBookCompany, 6thedition,1992.
[16] D. E. Culler andG. Arvind. Resourcerequirementsofdataflow programs. In Proc. Intl. Symp.on ComputerArchitecture, pages141–151,1988.
[17] D. R.Engler, G. R. Andrews,andD. K. Lowenthal.Fila-ments:Efficientsupportfor fine-grainparallelism.Tech-nicalReport93-13,Universityof Arizona.Dept.of Com-puterScience,1993.
[18] R. Feldmann,P. Mysliwietz, andB. Monien. Studyingoverheadsin massively parallelmin/max-treeevaluation(extendedabstract).In ACM Symp.Parallel AlgorithmsandArchitectures, pages94–103,1994.
[19] M. Frigo andS. G. Johnson.The fastestfourier trans-form in the west. TechnicalReportMIT-LCS-TR-728,MassachusettsInstituteof Technology, September1997.
[20] M. Frigo,C.E.Leiserson,andK. H. Randall.Theimple-mentationof theCilk-5 multithreadedlanguage.In Proc.ACM Conf. on ProgrammingLanguageDesignandIm-plementation, pages212–223,1998.
[21] S. C. Goldstein,K. E. Schauser, andD. E. Culler. En-abling primitives for compiling parallel languages. InWorkshopon Languages,Compilers,andRun-TimeSys-temsfor ScalableComputers, May 1995.
[22] High PerformanceFortran Forum. High performancefortranlanguagespecificationvertion1.0,1993.
[23] IEEE. InformationTechnology–PortableOperatingSys-temInterface(POSIX)–Part1: SystemApplication:Pro-gram Interface(API) [C Language]. IEEE/ANSI Std1003.1,1996Edition.
[24] V. Karamcheti,J. Plevyak, and A. A. Chien. Runtimemechanismsfor efficientdynamicmultithreading.J. Par-allel and Distributed Computing, 37(1):21–40,August1996.
[25] R. Karp andY. Zhang. A randomizedparallelbranch-and-boundprocedure. In Proc. Symp.Theoryof Com-puting, pages290–300,1988.
[26] D. A. Kranz,R. H. Halstead,Jr., andE. Mohr. Mul-T:A High-PerformanceParallel Lisp. In Proc. Program-ming LanguageDesign and Implementation, Portland,Oregon,June21–23,1989.
[27] E. P. Markatos and T. J. LeBlanc. Locality-basedschedulingin shared-memorymultiprocessors. Tech-nical Report94, Inst for ICS-FORTH, Heraklio, Crete,Greec,1993.
[28] EvangelosMarkatosand ThomasLeBlanc. Locality-basedscheduling in shared-memorymultiprocessors.Technical Report TR93-0094, ICS-FORTH, Heraklio,Crete,Greece,1993.
[29] P. H. Mills, L. S.Nyland,J.F. Prins,J.H. Reif, andR. A.Wagner. Prototypingparalleland distributedprogramsin Proteus.TechnicalReportUNC-CHTR90-041,Com-puterScienceDepartment,Universityof NorthCarolina,1990.
[30] T. Miyazaki, C. Sakamoto,M. Kuwayama,L. Saisho,andA. Fukuda.Parallelpthreadlibrary (PPL):user-levelthreadlibrary with parallelismandportability. In Proc.Intl. ComputerSoftwareandApplicationsConf. (COMP-SAC), pages301–306,November1994.
[31] E. Mohr, D. Kranz,andR. Halstead.Lazy taskcreation:A techniquefor increasingthegranularityof parallelpro-grams.IEEETrans.onParallel andDistributedSystems,1990.
[32] R. Motwani andP. Raghavan. RandomizedAlgorithms.CambridgeUniversityPress,Cambridge,England,June1995.
[33] G. J. Narlikar. Space-Efficient Schedulingfor Parallel,MultithreadedComputations. PhDthesis,CarnegieMel-lon University, 1999.AvailableasCMU-CS-99-119.
[34] G. J.NarlikarandG. E. Blelloch. Space-efficientimple-mentationof nestedparallelism.In Proc.ACM SIGPLANSymp.PrinciplesandPracticeof Parallel Programming,pages25–36,June1997.
[35] G. J. Narlikar andG. E. Blelloch. Pthreadsfor dynamicand irregular parallelism. In Proc. of Supercomputing’98, November1998.
[36] D. O’Hallaron. Spark98: Sparsematrix kernels forsharedmemoryandmessagepassingsystems.TechnicalReportCMU-CS-97-178,Schoolof ComputerScience,CarnegieMellon University, 1997.
[37] J.Philbin,J.E.,O.J.Anshus,andC. C.Douglas.Threadschedulingfor cachelocality. In Intl. Conf. Architec-tural Supportfor ProgrammingLanguagesandOperat-ing Systems, pages60–71,1996.
[38] M. L. Powell, S. R. Kleiman, S. Barton, D. Shah,D. Stein, and M. Weeks. SunOSmulti-threadarchi-tecture. In Proc. Winter 1991USENIXTechnical Con-ferenceandExhibition, pages65–80,Dallas,TX, USA,January1991.
[39] Jr. R. H. Halstead. Multilisp: A languagefor concur-rent symbolic computation. ACM Trans.on Program-mingLanguagesandSystems, 7(4):501–538,1985.
18

[40] C. A. RuggieroandJ. Sargeant. Control of parallelismin the manchesterdataflow machine. In G. Kahn, edi-tor, FunctionalProgrammingLanguagesandComputerArchitecture, pages1–16.Springer-Verlag,Berlin, DE,1987.
[41] D. J. SimpsonandF. W. Burton. Spaceefficient execu-tion of deterministicparallelprograms. IEEE Transac-tionson SoftwareEngineering, 25(3),May/June1999.
[42] J. P. Singh,A. Gupta,andM. Levoy. Parallelvisualiza-tion algorithms:Performanceandarchitecturalimplica-tions. IEEE Computer, 27(7):45–55,July 1994.
[43] D. SteinandD. Shah.Implementinglightweightthreads.In Proc. Summer1992 USENIX Technical Conferenceand Exhibition, pages1–10, San Antonio, TX, 1992.USENIX.
[44] M. T. VandevoordeandE. S. Roberts. WorkCrews: anabstractionfor controlling parallelism. Intl. J. ParallelProgramming, 17(4):347–366,August1988.
[45] B. Weissman. Performancecountersand statesharingannotations:aunifiedapproachto threadlocality. In Intl.Conf. on Architectural Supportfor ProgrammingLan-guagesandOperatingSystems, pages262–273,October1998.
[46] S.C.Woo,M. Ohara,E.Torrie,J.P. Singh,andA. Gupta.TheSPLASH-2programs:Characteriationandmethod-ological considerations.In Proc. Intl. Symp.ComputerArchitecture, pages24–37,June1995.
19





























