Embed Size (px)
Citation preview

Scalable QoS-based ResourceAllocation
A Dissertation
Submitted to the Graduate Education Committee
At The Department of Electrical and Computer Engieneering
Carnegie Mellon University in Partial Fulfillment of the Requirements
for the degree of
Doctor of Philosophy In Electrical and Computer Engineering by
Sourav Ghosh
COMMITTEE MEMBERS:Advisor: Prof. Ragunathan (Raj) Rajkumar
Dr. Jeffery Hansen
Prof. John Lehoczky
Prof. Dan Sieworek
Pittsburgh, PennsylvaniaAugust, 2004
Copyright c©2004 Sourav Ghosh
This research was supported by the DoD Multidisciplinary University Research Initiative (MURI) program
administered by the Office of Naval Research (ONR) under Grant N00014-01-1-0576 and in part by Defense
Advanced Research Project Agency(DARPA). The views and conclusions contained in this document are
those of the author and should not be interpreted as representing the official policies ore endorsements,
either expressed or implied, of DoD, ONR or DARPA.


Dedicated to my loving parents.


Abstract
A distributed real-time or embedded system consists of a large number of applications
that interact with the physical environment and must satisfy end-to-end timing constraints.
Applications in such system may offer different quality levels (such as higher or lower frame
rates for a video conferencing application) across multiple factors or dimensions (such as
frame rate, resolution). The end-user derives different degrees of satisfaction (known as
utility) from these quality levels.
In this dissertation, we design and implement a resource allocation methodology that
determines the quality settings of the applications in a given system with the goal of max-
imizing the global utility of the system. We build on the QoS-based Resource Allocation
Model (Q-RAM) as a QoS optimizer [51]. This acts as a resource manager between the
applications and the operating system scheduler. Q-RAM was able to reduce the NP-hard
complexity of the optimal algorithm to a polynomial one while yielding a near-optimal so-
lution. Nevertheless, Q-RAM becomes practically intractable as the system becomes large
and dynamic. Hence, we develop scalable hierarchical optimization algorithms that yields
near-optimal results within 5% of Q-RAM while obtaining several orders magnitude of gain
in execution times. Collectively, we name the above techniques as Hierarchical Q-RAM
(H-Q-RAM). H-Q-RAM can be practically implemented in large-scale distributed systems
at design time and/or at run-time. We apply our scheme to: large multiprocessor systems,
hierarchical networked systems, phased-array radar systems and distributed automotive
systems. We also exemplify the interaction of this optimizer with the lower level resource
i

ii Abstract
scheduler.

Acknowledgements
Five years ago, I first talked about my prospect in pursuing a PhD to my advisor Professor
Rajkumar after the completion of my Masters. While I was still unsure if this would be
the best move for my career, Raj urged me to continue working for it. At the end of this
long journey, I not only enjoyed my work as a researcher, but also realized how important
this PhD was for my life. I do believe my life would have been unfulfilled without this
accomplishment, which has opened up a window of new opportunities for me. For that
matter, I am indebted to Raj. While his critical approach has been greatly instrumental
in refining my thought process, his encouragement to think independently left no stone
unturned in making me a successful researcher. Raj, I thank you for bestowing your trust
on me during the hard times.
I would like to offer my sincere gratitude to my thesis committee, Dr. Jeffery Hansen,
Professor John Lehoczky and Professor Dan Sieworek. Thank you all for spending your
valuable time to help me. Jeff, I have been very fortunate to have been able to work closely
with you. Your contribution to my work has been significant. A big thank to you for
working with me during the late hours. I hope to continue working with you in the future.
John, thanks for many detailed discussions we had and your deep insights into problems.
Dan, I appreciate your probing questions and comments during my proposal as well as my
thesis defense.
I would like to thank all my colleagues at the Real-Time and Multimedia Systems Lab
(RTML): Dionisio de Niz, Saowanee (Apple) Saowang, Akihiko Miyoshi, Haifeng Zhu, Rahul
iii

iv Acknowledgements
Mangharam, Anand Eswaran, Anthony Rowe and Gaurav Bhatia. It would not have been
such a wonderful experience for me without you guys. Dio, yes I agree with you that our two
minute walk to coffee at Porter Hall was intellectually very refreshing. It was an excellent
time for creating, discussing and or destroying new ideas. I appreciate your wisdom and
experience. You have been very helpful to me. Apple, I always appreciated your fastidi-
ousness, and I offer my best wishes for your career in academia. Aki, your knowledge in
systems was immensely helpful to me. I did enjoy those insightful non-technical discussions,
which turned out to be very refreshing during the course of my graduate study. Haifeng, I
enjoyed our discussions. I hope to collaborate more with you in the future. In addition, I
must thank you for your friendliness and help during tough times. Rahul, you have been
very instrumental in instilling entrepreneurial ideas in me, which helped me in shaping my
thesis in the right direction towards potential employers. Anand, you have the potential to
be a great researcher. Keep up the good spirit. Anthony, you have brought a fresh new wave
of ideas in our group. Gaurav, your technical expertise in several areas was very useful to me.
In the process of writing this dissertation, I cannot gainsay the enormous amount of
contribution a person has made by proof-reading my document. Her name is Rachel Lange.
I sincerely appreciate the help Rachel has provided to me during my busiest hours.
Lastly but not the least, I thank my dearest parents. Their hard work and sacrifices had
given me educational advantages that brought me to Carnegie Mellon. They had continued
their faith in my capability during difficult times, while patiently waiting for my day to
graduate. Without their inspiration and blessing, I would not have made this far.

Table of Contents
1 Introduction 1
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.1 QoS-Optimization Techniques and Middleware . . . . . . . . . . . . 61.3.2 QoS and Networking . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3.3 QoS and Radar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.3.4 QoS and Embedded Systems . . . . . . . . . . . . . . . . . . . . . . 10
1.4 Organization of this Dissertation . . . . . . . . . . . . . . . . . . . . . . . . 11
2 System Model 13
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.1.1 Definitions: Task and Resources . . . . . . . . . . . . . . . . . . . . 132.1.2 Time-shared resources . . . . . . . . . . . . . . . . . . . . . . . . . . 142.1.3 Spatial resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2 QoS and Resource Allocation . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2.1 Operational Dimensions . . . . . . . . . . . . . . . . . . . . . . . . . 172.2.2 Environmental Dimensions . . . . . . . . . . . . . . . . . . . . . . . 182.2.3 QoS Dimensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2.4 Set-point Generation . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.2.5 Example Application . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.2.6 Reliability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.3 Existing Optimization Algorithm . . . . . . . . . . . . . . . . . . . . . . . . 252.3.1 Approximate Multi-Resource Multi-Dimensional Algorithm (AMRMD) 262.3.2 Drawbacks of the AMRMD1 Algorithm . . . . . . . . . . . . . . . . 28
2.4 Enhanced Optimization Algorithms . . . . . . . . . . . . . . . . . . . . . . . 322.4.1 Dynamic Penalty Vector (AMRMD DP) . . . . . . . . . . . . . . . . . . 32
v

vi TABLE OF CONTENTS
2.4.2 Co-mapping of Quality Points (AMRMD CM) . . . . . . . . . . . . . . . 342.5 Large-scale Optimization Issues . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.5.1 Set-Point Generation Complexity . . . . . . . . . . . . . . . . . . . . 382.5.2 Core Algorithm Complexity . . . . . . . . . . . . . . . . . . . . . . . 392.5.3 QoS Optimization and Resource Scheduling . . . . . . . . . . . . . . 40
2.6 Chapter Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3 Resource Allocation in Multiprocessor Systems 43
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.2 Q-RAM in Multiprocessor Systems . . . . . . . . . . . . . . . . . . . . . . . 44
3.2.1 Comparison with Optimal Algorithm . . . . . . . . . . . . . . . . . . 463.2.2 Results for Larger Systems . . . . . . . . . . . . . . . . . . . . . . . 473.2.3 Results on Fault-tolerance . . . . . . . . . . . . . . . . . . . . . . . 50
3.3 Hierarchical Q-RAM in Multiprocessor System . . . . . . . . . . . . . . . . 523.3.1 Hierarchical Q-RAM Algorithm . . . . . . . . . . . . . . . . . . . . . 55
3.4 Performance Evaluation: H-Q-RAM . . . . . . . . . . . . . . . . . . . . . . 593.4.1 Multi-processor Resource Allocation . . . . . . . . . . . . . . . . . . 593.4.2 Fault-tolerance and Hierarchical Q-RAM . . . . . . . . . . . . . . . 60
3.5 Chapter Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4 Resource Allocation in Networks 67
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 674.1.1 Our Contribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.2 Modeling of Networked System . . . . . . . . . . . . . . . . . . . . . . . . . 684.2.1 Network Model and QoS . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.3 Hierarchical Network Architecture . . . . . . . . . . . . . . . . . . . . . . . 744.3.1 Graph-Theoretical Representation . . . . . . . . . . . . . . . . . . . 744.3.2 Hierarchical Route Discovery . . . . . . . . . . . . . . . . . . . . . . 80
4.4 Selective Routing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.4.1 Broadcast Routing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 814.4.2 Smart Route Discovery . . . . . . . . . . . . . . . . . . . . . . . . . 814.4.3 Route Caching . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 834.4.4 QoS Optimization in Large Networks . . . . . . . . . . . . . . . . . . 84
4.5 Hierarchical QoS Optimization (H-Q-RAM) . . . . . . . . . . . . . . . . . . 854.5.1 Hierarchical Concave Majorant Operation . . . . . . . . . . . . . . . 854.5.2 Transaction-based Resource Allocation . . . . . . . . . . . . . . . . . 874.5.3 Complexity of Network QoS Optimization . . . . . . . . . . . . . . . 92

TABLE OF CONTENTS vii
4.6 Experimental Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
4.6.1 Experimental Configuration . . . . . . . . . . . . . . . . . . . . . . . 93
4.6.2 Performance Evaluation of Selective Routing . . . . . . . . . . . . . 94
4.6.3 Performance Evaluation of Hierarchical Optimization . . . . . . . . . 100
4.7 Chapter Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
5 Resource Allocation in Phased Array Radar 107
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
5.2 Radar Task Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
5.3 Radar Resource Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
5.3.1 Radar Bandwidth . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
5.3.2 Radar Power Constraints . . . . . . . . . . . . . . . . . . . . . . . . 113
5.3.3 Radar QoS Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
5.4 Resource Management in Phased Array Radar . . . . . . . . . . . . . . . . 124
5.5 Resource Allocation with Q-RAM . . . . . . . . . . . . . . . . . . . . . . . 126
5.5.1 Slope-based Traversal (ST) . . . . . . . . . . . . . . . . . . . . . . . 127
5.5.2 Fast Set-point Traversals . . . . . . . . . . . . . . . . . . . . . . . . 128
5.5.3 Higher-Order Fast Traversal Methods . . . . . . . . . . . . . . . . . 130
5.5.4 Non-Monotonic Dimensions . . . . . . . . . . . . . . . . . . . . . . . 131
5.5.5 Complexity of Traversal . . . . . . . . . . . . . . . . . . . . . . . . . 132
5.5.6 Discrete Profile Generation . . . . . . . . . . . . . . . . . . . . . . . 132
5.6 Scheduling Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
5.6.1 Proper Nesting of Dwells . . . . . . . . . . . . . . . . . . . . . . . . 133
5.6.2 Improper Nesting of Dwells . . . . . . . . . . . . . . . . . . . . . . . 135
5.6.3 Dwell Scheduler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
5.7 Experimental Configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
5.8 Results with QoS Optimization . . . . . . . . . . . . . . . . . . . . . . . . . 139
5.8.1 Experiments with Traversal Techniques . . . . . . . . . . . . . . . . 140
5.8.2 Generation of Discrete Profiles . . . . . . . . . . . . . . . . . . . . . 145
5.8.3 Utility Variation with Discrete Profiles . . . . . . . . . . . . . . . . . 148
5.9 Results with Scheduling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
5.9.1 The Effect of Harmonic Periods . . . . . . . . . . . . . . . . . . . . . 151
5.9.2 Comparisons of Scheduling Algorithms . . . . . . . . . . . . . . . . . 154
5.9.3 Interleaving Execution Times . . . . . . . . . . . . . . . . . . . . . . 157
5.10 Chapter Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158

viii TABLE OF CONTENTS
6 Resource Allocation in Distributed Embedded Systems 1616.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1616.2 QoS and Resource Management Challenges . . . . . . . . . . . . . . . . . . 1626.3 Task Classification and Cluster Analysis . . . . . . . . . . . . . . . . . . . . 164
6.3.1 Measure of Similarity . . . . . . . . . . . . . . . . . . . . . . . . . . 1656.3.2 Utility Loss Analysis in Slope-based Classification . . . . . . . . . . 167
6.4 H-Q-RAM Algorithm Design . . . . . . . . . . . . . . . . . . . . . . . . . . 1716.4.1 Task Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1726.4.2 Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1736.4.3 QoS Optimization . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
6.5 Experimental Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1776.6 Chapter Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
7 Conclusion and Future Work 1837.1 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
7.1.1 Modeling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1847.1.2 Scalable QoS Optimization . . . . . . . . . . . . . . . . . . . . . . . 1857.1.3 Integration of QoS Optimization and Scheduling . . . . . . . . . . . 186
7.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1877.2.1 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1877.2.2 Stochastic QoS and Resource Requirements . . . . . . . . . . . . . . 1877.2.3 Profit Maximization Model for Resource Allocation . . . . . . . . . . 188

List of Figures
2.1 Dimensions and Their Relations . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2 Reliability and Utility . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.3 Equally Sized Processors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.4 Unequally Sized Processors . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.5 AMRMD DP Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.6 AMRMD CM Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.7 Q-RAM & Scheduler Admission Control . . . . . . . . . . . . . . . . . . . . 39
2.8 Dynamic Q-RAM Optimization . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.1 Typical Multiprocessor System . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.2 Utility Variation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.3 Run-time Variation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.4 Number of Admitted Tasks (20 processors) . . . . . . . . . . . . . . . . . . 48
3.5 Percentage Standard-deviation (= 100 × (Standard deviation)/mean ) ofnumber of admitted tasks on 20 processors . . . . . . . . . . . . . . . . . . 49
3.6 Utility Variation of Three Algorithms in a System of 20 Processors . . . . . 50
3.7 Run-time Variation (log-scale) of Three Algorithms in a System of 20 Pro-cessors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.8 Utility Variation under Fault-Tolerance . . . . . . . . . . . . . . . . . . . . 52
3.9 Number of Admitted Tasks (20 processors) under Fault-Tolerance . . . . . . 53
3.10 Run-time Variation (log-scale) . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.11 A typical Continuous Utility Function . . . . . . . . . . . . . . . . . . . . . 54
3.12 Initial Slope of a Task . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.13 Hierarchical QoS Optimization with Clustering . . . . . . . . . . . . . . . . 57
3.14 Number of Tasks (32 processors) . . . . . . . . . . . . . . . . . . . . . . . . 60
3.15 Run-time (276 tasks) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.16 Utility Variation (max 256 tasks) . . . . . . . . . . . . . . . . . . . . . . . . 62
ix

x LIST OF FIGURES
3.17 Run-time plot with grouping for 32 processors (max 256 tasks) . . . . . . . 633.18 Number of Tasks under Fault-Tolerance . . . . . . . . . . . . . . . . . . . . 633.19 Run-time (log-scale) under Fault-Tolerance . . . . . . . . . . . . . . . . . . 643.20 Run-time plot in log-scale with grouping for 32 processors under fault-tolerance(max
76 tasks) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 643.21 Utility Plot under Fault-Tolerance (max 76 tasks) . . . . . . . . . . . . . . 65
4.1 Hierarchical Graph Model of Network . . . . . . . . . . . . . . . . . . . . . 754.2 Network sub-domain and Supervertex Graph Example for |PG′(v′x, v′y)| = 1 774.3 Compound Resource Composition . . . . . . . . . . . . . . . . . . . . . . . 854.4 Distributed QoS Optimization . . . . . . . . . . . . . . . . . . . . . . . . . . 874.5 Distributed Resource Allocator . . . . . . . . . . . . . . . . . . . . . . . . . 914.6 Comparison of Smart Route Discovery and Random Route Discovery . . . . 954.7 Utility Variation with Number of Routes . . . . . . . . . . . . . . . . . . . . 954.8 Run-Time Variation with Number of Routes . . . . . . . . . . . . . . . . . . 974.9 Percentage Utility Drop with Routing Task Count Threshold . . . . . . . . 974.10 Percentage Run-Time Variation with Routing Task Count Threshold . . . . 984.11 Average Execution Time for Route-discovery Simulation Per Task . . . . . 994.12 Ratio of Q-RAM Optimization Time To Route-Discovery Per Task . . . . . 994.13 Absolute Utility Variation in Q-RAM and H-Q-RAM . . . . . . . . . . . . . 1004.14 Absolute Execution Time Variation in Q-RAM and H-Q-RAM . . . . . . . 1014.15 Variation of Percentage Utility Loss for 6400 Tasks with the Number of Sub-
domains . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1024.16 Variation of Percentage Run-Time Reduction for 6400 Tasks with the Num-
ber of Sub-domains . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1034.17 Number of Transactions for 6400 Tasks with the Number of Sub-domains . 1044.18 Variation of ( H-Q-RAM Execution Time/ Number of Sub-domains) for 6400
Tasks with the Number of Sub-domains . . . . . . . . . . . . . . . . . . . . 105
5.1 Radar System Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1105.2 Radar Dwell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1115.3 Average Power Exponential Window . . . . . . . . . . . . . . . . . . . . . . 1155.4 Cool-Down Time . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1155.5 Non-Optimal Initial Average Power . . . . . . . . . . . . . . . . . . . . . . . 1155.6 Resource Management Model of Radar Tracking System . . . . . . . . . . . 1245.7 Slope-Based Traversal of Concave Majorant . . . . . . . . . . . . . . . . . . 1285.8 Incremental Traversal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129

LIST OF FIGURES xi
5.9 Interleaving of Radar Dwells . . . . . . . . . . . . . . . . . . . . . . . . . . . 1335.10 Average Number of Set-points . . . . . . . . . . . . . . . . . . . . . . . . . . 1405.11 Q-RAM Execution Time . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1415.12 Q-RAM Utility Variation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1425.13 Profile Generation Time (%) . . . . . . . . . . . . . . . . . . . . . . . . . . 1435.14 Utility loss (%) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1435.15 Optimization Time (%) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1445.16 Fractional Profile Time (%) . . . . . . . . . . . . . . . . . . . . . . . . . . . 1445.17 Utility Variation with Distance . . . . . . . . . . . . . . . . . . . . . . . . . 1455.18 Utility Variation with Speed . . . . . . . . . . . . . . . . . . . . . . . . . . . 1465.19 Utility Variation with Acceleration . . . . . . . . . . . . . . . . . . . . . . . 1465.20 Utility Loss with Quantized Acceleration . . . . . . . . . . . . . . . . . . . . 1475.21 Utility Loss with Quantized Distance . . . . . . . . . . . . . . . . . . . . . . 1475.22 Utility Loss with Quantized Speed . . . . . . . . . . . . . . . . . . . . . . . 1485.23 Utility Loss with Quantized Distance . . . . . . . . . . . . . . . . . . . . . . 1495.24 Utility Variation with Energy and Tx-factor(X) . . . . . . . . . . . . . . . 1525.25 Utility Variation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1535.26 Optimization+Scheduling Run-time Variation . . . . . . . . . . . . . . . . . 1545.27 Avg Cool-Down Utilization . . . . . . . . . . . . . . . . . . . . . . . . . . . 1555.28 Avg Radar Utilization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
6.1 Typical Automotive System . . . . . . . . . . . . . . . . . . . . . . . . . . . 1636.2 Utility Curve Ranges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1666.3 Utility Functions of Two Types . . . . . . . . . . . . . . . . . . . . . . . . . 1686.4 Slope-based Task Clustering Procedure . . . . . . . . . . . . . . . . . . . . . 1746.5 Virtual Task Creation Procedure . . . . . . . . . . . . . . . . . . . . . . . . 1766.6 Utility Variation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1796.7 Percentage Utility Reduction . . . . . . . . . . . . . . . . . . . . . . . . . . 1806.8 Execution Time Variation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180


List of Tables
2.1 QoS and Operational Dimensions Example . . . . . . . . . . . . . . . . . . 232.2 Example Task Profile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.3 Example Resource Allocation . . . . . . . . . . . . . . . . . . . . . . . . . . 312.4 AMRMD1 Resource Allocation . . . . . . . . . . . . . . . . . . . . . . . . . 312.5 AMRMD1 Resource Allocation for Unequal Processor . . . . . . . . . . . . 32
3.1 Experimental Settings with Optimal Algorithm . . . . . . . . . . . . . . . . 453.2 Settings for Second Experiment . . . . . . . . . . . . . . . . . . . . . . . . . 503.3 Settings for Experiment on Fault-Tolerance . . . . . . . . . . . . . . . . . . 523.4 Experimental Specifications (H-Q-RAM) . . . . . . . . . . . . . . . . . . . . 59
4.1 Settings of Tasks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 944.2 Settings of Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 944.3 Specifications of the Networks . . . . . . . . . . . . . . . . . . . . . . . . . . 100
5.1 Filter Constants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1215.2 Utility Distribution of Search Tasks . . . . . . . . . . . . . . . . . . . . . . 1235.3 Environmental Dimensions . . . . . . . . . . . . . . . . . . . . . . . . . . . 1385.4 Period, Power and Transmission Time Distribution . . . . . . . . . . . . . . 138
6.1 Assumed Parameters for each Task Types . . . . . . . . . . . . . . . . . . . 1686.2 Experimental Settings with Optimal Algorithm . . . . . . . . . . . . . . . . 177
xiii


List of Algorithms
1 Basic “AMRMD1” algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . 282 Basic “AMRMD DP” algorithm . . . . . . . . . . . . . . . . . . . . . . . . 323 Basic “AMRMD CM” algorithm . . . . . . . . . . . . . . . . . . . . . . . . 374 Hierarchical Q-RAM Optimization for Multiprocessor System . . . . . . . . 585 Basic Route Discovery Algorithm . . . . . . . . . . . . . . . . . . . . . . . . 726 Basic Global QoS Optimization For Networks . . . . . . . . . . . . . . . . . 737 Hierarchical Broadcast Route Discovery . . . . . . . . . . . . . . . . . . . . 818 Smart Route Discovery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 829 Hierarchical Distributed QoS Optimization . . . . . . . . . . . . . . . . . . 8810 Utilization Bound Adjustment . . . . . . . . . . . . . . . . . . . . . . . . . 12511 Proper Nesting Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13412 Improper Nesting Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . 13613 Clustering Algorithm for Communicating Heterogeneous Tasks . . . . . . . 178
xv


Chapter 1
Introduction
1.1 Motivation
The built-in notion of time differentiates a real-time computing system from non-real-time
systems. A task, executing on a real-time system generates output to the external inter-
face(s) that must not only be logically correct but must also be temporally correct. The
end-user derives satisfaction depending on the degree of logical and temporal correctness
of the outputs. An output may lose its value if it is not delivered before its deadline. In
addition, the amount of the content may be adjusted or reduced in order to deliver the data
in predictable manner.
As an example, a multimedia application such as an Internet video conferencing must
provide video and audio data to the user in a timely manner. The content of an individual
video frame depends on the resolution, color of the picture it contains and that of an audio
frame depends on the size of its sample and type (stereo or mono). The user derives a
certain amount of satisfaction based on the values along these factors. Hence video frame
rate, audio sampling rate, resolution, color, audio sampling size etc. are the quality factors
that provide satisfaction to the user of a video conferencing application. Higher values
of these quality factors increase its resource usage. In addition, the satisfaction of the
1

2 Chapter 1. Introduction
user tends to increase with the increase in quality factors such as the frame rate and the
resolution. The Quality of Service (QoS) of a task expresses a state of a task in terms of
particular values of its quality factors. It increases with increase in the values of the factors.
In general, the higher QoS of a task the higher the resource demand. For example, the video
conferencing task consumes resources such as computational cycles and network bandwidth
based on the values of its quality factors. Since the capacities of the resources are finite, we
need to apportion them as efficiently as possible among multiple applications.
Many real-time systems interact directly with the physical environment and can be very
dynamic in nature. In these systems, task resource allocations must be adjusted based on
changes in the environment. An example is a radar system where the tracking precision
of a target changes based on its distance from the radar and the presence of noise in the
atmosphere. When the environmental noise increases, the radar must increase its signal
power in order to achieve the same level of tracking precision. Moreover, in a dynamic
environment, tasks may arrive or depart asynchronously at any time. This necessitates
run-time adjustments to the resource allocation of tasks in the system.
In this dissertation, we describe the design of a resource management framework for
distributed and dynamic real-time systems, which:
• performs near-optimal allocation of resources to tasks that maximizes the benefits for
the users,
• interacts with the resource scheduler to ensure that the timing requirements of the
tasks are guaranteed to be met,
• is scalable to large distributed real-time systems, and
• is adaptive to dynamic changes in the environment.

1.2. Approach 3
1.2 Approach
Our approach to distributed resource management is based on QoS-based Resource Alloca-
tion Model (Q-RAM) [49]. In Q-RAM, the quality factors of an application that indepen-
dently alter the end-user’s satisfaction are called QoS dimensions. Q-RAM expresses the
satisfaction earned by the QoS dimensions by a single scalar factor called the utility. The
utility of a task a function of utilities of its QoS dimensions, and is generally expressed as a
weighted sum of utilities of its QoS dimensions. The global utility of the system is usually
expressed as a function of the task utilities.
Definition 1.2.1 (Utility). Utility is a real number representing a user’s satisfaction with
offered services in which a higher value corresponds to higher satisfaction.
Q-RAM allocates resources to tasks in a distributed system so as to maximize the global
utility of the system. Since computing the optimal solution is NP-hard, Q-RAM determines
a near-optimal solution, the algorithm for which has a polynomial complexity relative to the
number of resources in the system and the number of QoS settings of a task. Even with this
relatively benign complexity, the execution time can become intractable when the number
of resources and tasks in the system becomes large, thereby rendering it impractical for very
large dynamic systems. Among the goals of this research is to create a QoS-Optimization
methodology that yields a near-optimal global utility close to that of Q-RAM, while scaling
with the size and the dynamics of the system.
Our contribution in this dissertation can be divided into five categories. First, we
define a generic model of QoS specifications for distributed systems and generate basic
resource allocation algorithms. The algorithms are advanced forms of the resource allocation
algorithm (AMRMD1 ) for Q-RAM [51].
Second, we investigate the scalable resource allocation problems in large systems. We
assume that tasks need only computational resources, that they multiple QoS levels, and
that they can use replication to meet its reliability requirements. Reliability of tasks is

4 Chapter 1. Introduction
modeled as a QoS dimension where a task’s degree of replication is translated into its
resource requirements. For large multiprocessor systems, we divide the entire multiproces-
sor system into multiple subsystems and solve the resource allocations on each subsystem
independently.
Third, we analyze resource allocations for tasks in networks, where tasks are charac-
terized by their network bandwidth and delay requirements. We present a scalable QoS
optimization and resource management scheme in a hierarchically structured distributed
networked environment. Each task in such a system can be represented by a flow in the
network that imposes two main requirements to the resource manager: (1) choosing the best
path between the source node and the destination node, and (2) choosing an appropriate
amount of bandwidth along the path. A hierarchical decomposition of the network allows it
to be divided into multiple subnets or sub-domains connected via backbone links. Therefore,
a route of a flow can be divided into multiple segments lying in separate sub-domains. This
translates the QoS optimization process into multiple resource allocation sub-problems spe-
cific to individual domains. Each sub-problem can be solved by a separate thread. Flows
local to sub-domains are allocated independently by their corresponding threads. For a
flow that spans across multiple sub-domains, the threads coordinate the resource alloca-
tion through a distributed transaction process. This approach exploits the hierarchy of the
network, and makes the optimization problem scalable without sacrificing the optimality
of the solution. We also are selective in choosing links within each sub-domain in order to
further improve scalability.
Fourth, we investigate scalability issues in the context of QoS and resource management
of a very dynamic real-time system that interacts directly with the physical environment.
We chose Phased Array Radar as an example of such systems. Dynamic real-time sys-
tems such as phased-array radars must manage multiple resources, satisfy physical(energy,
for example) constraints and make frequent on-line scheduling decisions. These systems
are hard to manage because task and system requirements change rapidly (e.g. in radar

1.3. Related Work 5
systems, the targets/tasks in the sky move continuously) and must satisfy a multitude of
constraints. The highly dynamic nature and stringent time constraints lead to complex
cross-layer interactions. To be able to handle these tasks, we design a QoS manager that
is adaptive, reacts to dynamic changes in the environment, adjusts the level of service and
reallocates resources efficiently. It uses efficient QoS optimization to allocate resources to
tasks and maximizes the overall utility, and then ensures schedulability of tasks in real-time.
We develop an integrated framework that incorporates an adaptive Q-RAM based resource
allocation method with the scheduler admission control in a Radar System.
Finally, we investigate QoS optimization in distributed computing systems for embedded
applications such as automotive and flight control systems. We assume a multiprocessor
system in which tasks have both computational as well as communication requirements.
Tasks are also assumed to have multiple QoS dimensions. This problem is formulated
as an extension to the hierarchical decomposition technique described for multiprocessor
QoS optimization. We develop a more general hierarchical technique that decomposes the
system into subsystems, and clusters the tasks to be deployed onto those subsystems while
satisfying the computational as well as the network bandwidth constraints.
1.3 Related Work
Much work has been done in the area of QoS-based resource management. It can be broadly
classified into three main categories: (1) high level modeling, specifications and changes in
applications, (2) development of QoS-aware middleware that translates the QoS specifi-
cations of applications to resource requirements and determines their resource allocation
based on certain policies, and (3) changes in the resource management and scheduling in
the Operating System and its cross-layer cooperation with the middleware that provides
guaranteed resource access to applications. In this dissertation, we discuss the related work
in the context of the development of middleware and resource allocation mechanisms based

6 Chapter 1. Introduction
on high level requirements of applications. In addition, we investigate the related work
that has been performed in certain specific areas of large-scale systems; namely, distributed
multiprocessor systems, large-scale networked environment and dynamic real-time systems
such as radar systems.
1.3.1 QoS-Optimization Techniques and Middleware
The Quasar Project at the Oregon Graduate Institute proposes a Quality of Service (QoS)
model for multimedia and database applications that specifies tolerance for inaccuracy in
output such as timing and information loss as QoS dimensions. Similar to Q-RAM, they use
application-level QoS specifications to drive system activities [78, 77]. For example, QoS
dimensions of a video player program include (1) getting a video frame at the right time and
(2) getting the right frame. Using these specifications, they employ heuristics to generate
resource allocations for tasks that satisfy the QoS requirements of all the tasks within a
range and guarantee near-minimal resource consumption. They integrate the infrastructure
for QoS specification and translation with adaptive resource management components and
perform dynamic system specialization for performance, predictability and survivability.
The MONET research group at the University of Illinois at Urbana-Champaign studied
system software issues to provide services and protocols for end-to-end Quality of Service
guarantees for distributed multimedia applications. They present a QoS-aware service man-
agement model called QualMan as a loadable middleware module [61]. In their model,
QoS is spread over multiple layers of the software architecture (users, applications, system
and network layers) as perceptual QoS, application QoS, system QoS and network QoS.
This classification allows each layer to specify its own quality parameters. Every applica-
tion specifies its ranges of QoS parameters. The resource admission control determines the
settings based on the availability of the resources while minimizing the resource usage.
Venkatasubramanian et al at University of California at Irvine adopts a similar approach
in developing QoS-aware middleware in their distributed resource management framework

1.3. Related Work 7
named AutoSeC (Automatic Service Composition) [82].
Jha et al, at Honeywell Inc., developed Adaptive Resource Allocation (ARA) mecha-
nisms for mission-critical and other applications that provide QoS guarantees, and adapt
resource allocation based on dynamic changes in the applications’ resource needs [67]. They
also define three dimensions to characterize an application, namely (1) timing, (2) QoS, and
(3) criticality [41]. In other words, they differentiate QoS from timing and criticality con-
straints. Using the criticality metric, the scheme tries to schedule the most critical tasks,
followed by the less critical ones. Next, it sorts the sessions in increasing order of QoS, puts
them in a circular list and expands their QoS in a round-robin order.
1.3.2 QoS and Networking
There have been several contributions in the field of QoS in networks, especially in the
context of the Internet and ATM [35, 25, 80]. These contributions to network QoS are
coarsely divided into three categories: (1) the selection of a route between the source and
the destination, (2) the bandwidth reservation across the route and (3) the scheduling of
network packets at each router across the route. We will discuss some of these contributions
in detail in the following section.
Route Selection
Ma and Steenkiste investigated several route selection schemes for flows with a fixed band-
width requirement [54]. The selection of the route is dependent on the length of the route
in terms of the number of hops and the availability of the maximum reservable network
bandwidth. The goal of their QoS routing is to select a feasible route if one exists, and
the route leading to the best resource efficiency is chosen if multiple routes are available.
The schemes are compared based on the availability of the routes for QoS-aware flows with
specified bandwidth, inaccuracy in generating routes, and the performance of best-effort
flows in terms of delays.

8 Chapter 1. Introduction
Nahrstedt et al make three contributions in the field of QoS-aware routing. First, they
use topology aggregation of hierarchically structured networks in order to provide routing
for tasks involving QoS requirements related to bandwidth and delay guarantees [13, 53]. In
hierarchical routing, nodes are clustered into groups, which are further clustered into higher-
level groups, creating a multi-level hierarchy [44]. Second, they also present distributed
ticket-based routing, which is designed to work with imprecise state information [12]. The
source node sends tickets that probe across the network in order to determine a suitable
route towards the destination. It allows the dynamic trade-off between routing performance
and overhead.
Signaling for Reservation
Resource ReserVation Protocol (RSVP) is a typical example of a signaling protocol for
network reservation [85]. It is intended to provide IP networks with the capability to sup-
port the divergent performance requirements of differing application types. Three classes
of applications are considered: best effort, rate-sensitive and delay-sensitive. Examples of
these three types are file transfer, Mpeg video transmission, and video conferencing respec-
tively. RSVP is a scalable destination-oriented simplex signaling protocol that provides a
mechanism to establish a reservation over a route between the destination and the source.
However, it does not determine the route by itself, nor does it ensure the proper scheduling
of the packets at the routers. It is designed to work in conjunction with existing routing
and scheduling protocols.
Packet Scheduling
Packet scheduling deals with scheduling policies of packets in routers for guaranteed delivery
to their destinations. Many queueing disciplines are extensions of the Generalized Processor
Sharing algorithm, assuming the fluid-flow model of the network packets [63]. Prominent
examples include: Weighted Fair Queueing (WFQ) [20], Worst-case Fair weighted Fair

1.3. Related Work 9
queueing (WF 2Q) [7] etc. Stoica et al presented core-stateless fair-queuing (CSFQ) that
makes the fair-queueing principle scalable to large networks, where per-flow management
becomes intractable [79]. It differentiates between core and edge routers. Edge routers
perform per-flow management while core routers do not perform per-flow management by
using aggregates instead. There are also other contributions that do not follow the fluid-flow
model, such as fair-Shortest Remaining Time (fair-SRPT) [55], Quantized EDF scheduling
[39] and deadline-monotonic packet-scheduling [28].
Utility-based QoS
Shenker first suggested the use of utility functions for modeling QoS in networks [72].
Bhargvan et al adopt a similar utility-function based QoS optimization method in the
wireless environment [26]. They consider throughput, fairness, delay and loss as their
system-wide QoS parameters. Similar to Q-RAM, they associate concave and continuous
utility functions with QoS parameters. They maximize the global utility of the system
by allocating channel bandwidths to applications subject to a channel capacity constraint.
They build their adaptive algorithm by choosing specific utility functions such as U(r) =
log(r). Unlike Q-RAM, their algorithm relies on the choice of a specific utility function1.
1.3.3 QoS and Radar
As mentioned earlier, there are many real-time systems where physical environment plays a
key role in determining the QoS of applications. Because of the dynamic nature of the envi-
ronment, QoS-based resource management has to be adaptive to changes of environmental
factors such as temperature, noise etc. Consequently, a whole range of resource constraints
such as power, energy etc., come into play. A radar system is a classic example of such a
system.
Many recent studies have focused on phased-array radar systems. The focus has pri-
1More details related to network QoS will be described in Chapter 4.

10 Chapter 1. Introduction
marily been on performing schedulability analysis of radar tasks for their given execution
times. For example, Kuo et al proposed a reservation-based approach for real-time radar
scheduling [48]. This approach allows the system to guarantee the performance requirement
when the schedulability condition holds. However, they do not consider energy constraints.
Shih et al use a template-based scheduling algorithm in which a set of templates is con-
structed offline, and tasks are fit into the templates at run-time [74, 73]. The templates
consider both the timing and power constraints. They also consider interleaving of dwells
that allow beam transmissions (or receptions) on one target to be interleaved with beam
transmissions and receptions on another. The space requirements of templates limit the
number of templates that can be used, and “service classes” designed offline determine how
QoS operating points are assigned to discrete sets of task configurations across an expected
operating range. Goddard et al addressed real-time back-end scheduling of radar tracking
algorithms using a data flow model [33]. Our work in radar QoS optimization is most sim-
ilar to the work of Jha et al[67]. They use their adaptive QoS middleware framework (as
mentioned in Section 1.3.1) for QoS-based resource allocation and schedulability analysis
in Radar Systems.
1.3.4 QoS and Embedded Systems
There has been comparatively less amount of work about QoS in distributed embedded
systems, which are mostly binary control systems. Abdelzaher et al first introduced the
notion of QoS in such systems [1]. They developed a negotiation model that adjusts the
QoS levels of the applications in real-time while maximizing application-perceived system
utility or reward. They incorporated the proposed QoS mechanism into a middleware service
called “RTPOOL”. It uses a QoS optimization heuristic that starts with the maximum
QoS of all tasks, and then reduces the QoS of a task whose drop in reward is minimum
for a lower QoS level. Next, they introduce a distributed QoS-optimization protocol, where
the hosts negotiate with each other and share the load based on the reward of accepting a

1.4. Organization of this Dissertation 11
task of a certain reward level. Based on that work, Sanfridson introduces the concept of
integrating QoS with a feedback control mechanism for automotive systems [70].
1.4 Organization of this Dissertation
We organize this dissertation as follows.
In Chapter 2, we describe our generic model of QoS and distributed systems. In Chap-
ter 3, we describe our resource allocation algorithms for large multiprocessor systems. In
Chapter 4, we describe our distributed resource allocation in scheme for large hierarchical
networks with large numbers of resources and tasks where each task requires many re-
sources. In Chapter 5, we describe an integrated resource allocation and scheduling model
for a Phased Array Radar System as a dynamic scalable real-time system with many dif-
ferent constraints. In Chapter 6, we describe QoS-based resource allocation in distributed
embedded systems. Finally, in Chapter 7, we summarize our research contributions and
discuss future work.


Chapter 2
System Model
2.1 Introduction
In this chapter, we describe a generic model of distributed systems that we use throughout
this dissertation. A distributed system consists of multiple tasks and multiple resources. A
task executes on the system by using the resources. An end-user derives a benefit or utility
from the system due to the execution of these tasks.
This chapter is divided into three parts. First, we define the terms task and resource
and discuss their interactions. Secondly, we elaborate on our mathematical model of a dis-
tributed system. Finally, we describe our basic optimization algorithms [31] that maximize
the accrued utility of the end-user while allocating resources to tasks.
2.1.1 Definitions: Task and Resources
In computer systems, a task is a basic unit of programming that an operating system
controls. Depending on how the operating system defines a task in its design, this unit
of programming may be an entire program or each successive invocation of a program.
A task is considered to be a container that holds a set of instantiating objects known as
threads, as in the case of Mach, Mach-type operating systems and Linux. In BSD Unix-like
13

14 Chapter 2. System Model
environments, however, the word process is used instead of task. When multiple processes
work in the same “context” (address space) of a task, we refer to them as threads.
In this dissertation, we refer to a task as an application that provides a service to the
end-user. It can be a video conferencing task, or a tracking task that tracks a target using a
phased array radar. In its implementation, it consists of one or more processes or threads.
A resource, on the other hand, is defined as a source of aid or supply that can be drawn
upon when needed. Tasks need resources to be executed. Furthermore, a resource is a
measurable entity that has a finite supply. The major computer system resource categories
are processor cycles, network bandwidth, memory, and disk space. Embedded systems may
have other resources. For example, in a radar system, resources include antenna bandwidth
and antenna power.
Resources can be classified into 2 main categories. They are: (1) Time-shared resources,
and (2) Spatial resources. Each is discussed in the following subsections.
2.1.2 Time-shared resources
A resource is time-shared when at a given instant, only one task receives the entire supply
of a resource, while other tasks that require it receive none of it. Processor (CPU) cycles,
and network bandwidth are time-shared resources. We can either express a time-shared
resource as a system-wide supply of an amount ∆R available in every small time unit ∆T ,
such that the rate of the supply can be expressed as:
r(t) =∆R
∆T. (2.1)
A task τi can specify its requirement as a total share Ci over a time spent Di. In this case,
we can express the task’s average usage rate as CiDi
.
If a task is periodic, its requirements can be expressed as Ci units of resource in every
period of Ti time units1. The resource requirement of a periodic task can be expressed as1Periodic and aperiodic tasks are described in [59] in more detail.

2.1. Introduction 15
a rate by:
si(t) =Ci
Ti. (2.2)
For n periodic tasks, Liu and Layland in [16] introduced a fixed priority scheduling
scheme in which the scheduling priority of a task is inversely proportional to its period and
a higher priority task can instantly preempt a lower priority task with no context-switching
overhead. This is known as rate-monotonic scheduling (RMS) algorithm. They proved that
each task τi obtains its share of Ci units in every period Ti if
1r(t)
n∑i=1
si(t) ≤ n(21/n − 1). (2.3)
The number (n(21/n − 1)) provides the least upper bound on the utilization of a time-
shared resource under RMS. In other words, this is only a sufficient condition, not a nec-
essary one. An average case behavior provides a much higher utilization in RMS than the
one presented in Equation (2.3).
As n → ∞, it reaches ln 2 = 0.69. In addition, if a task has non-preemptive regions
during its resource usage, then it causes blocking times of tasks of higher priority. This is
known as priority inversion [71, 65]. Priority inversion happens when a low-priority task
holds a resource that a high-priority task is waiting for. Considering Bi as the blocking
time, Equation 2.3 is transformed to:
1r(t)
n∑i=1
Ci + Bi
Ti≤ n(21/n − 1). (2.4)
Thus, the effective least upper bound∑n
i=1CiTi
r(t) is reduced below the least upper bound of
0.693. However, as mentioned before, this is a pathological case.
If the periods of the tasks are harmonic, then the utilization bound for the Rate-
Monotonic scheduling algorithm is 1.0. Hence, in a special case, if we assume that all
tasks have the same constant small period T and the context-switching cost is zero, we

16 Chapter 2. System Model
can transform Equation 2.4 to a General Processor Share (GPS) [63] model, which is a
special case of rate-monotonic model with harmonic periods. In this case, the task-set is
schedulable when:1
r(t)
n∑i=1
Ci
T= 1. (2.5)
2.1.3 Spatial resources
A spatial resource can be shared by multiple tasks simultaneously. Disk space is a good
example of a spatial resource. Each task requires a certain amount of disk-space to store
its data and instructions. A memory buffer is also a spatial resource. If R is the total size
of a spatial resource at any time t and Si is the demand made by task i for that resource,
then,n∑
i=1
Si ≤ R, (2.6)
is the constraint on the resource demands.
In addition, there are other resources such as memory that can be divided spatially into
multiple time-shared resources. We will discuss this as future work in Chapter 7 of this
dissertation. In the next section, we will discuss our resource allocation model.
2.2 QoS and Resource Allocation
In our QoS optimization model, each task is assumed to have multiple QoS settings, each
of which provides a different quality level to the user. Each setting is associated with
certain resource levels. We employ a modified version of the existing QoS-Based Resource
Allocation Model (Q-RAM) [49, 51, 50, 66] as the basic building block of the optimization
process. Our model determines the near optimal quality levels of each task and apportions
the available resources to them. We assume a simple model of resources where each resource
can be divided among the tasks, either in a time-shared or in a spatial manner. In the case
of a time-shared resource, we limit the total allocable amount by its exact schedulability

2.2. QoS and Resource Allocation 17
bound or an approximate utilization bound.
As a generic model, let us consider a distributed system with m shared resources
r1, . . . , rm. Resources can be of any type including CPU, memory, link bandwidth, or
even radar bandwidth in the case of a radar tracking application. We use the term Re-
source Vector to describe a set of resource units (e.g., a processor of certain frequency,
a network link of certain bandwidth) in a multi-resource environment. For example, the
resource vector ~Rmax = (rmax1 , . . . , rmax
m ) denotes the capacity of the individual resources.
The resources are shared by a set of n independent tasks τ1, . . . , τn. Each task is as-
sumed to have a set of parameters that can be changed to configure its quality levels and
resource demands. We commonly refer to these parameters as dimensions. They are mainly
classified into two main categories: operational dimensions and environmental dimensions.
However, from the perspective of the user, we have only one type of dimension known as
QoS dimensions. We discuss all these dimensions in detail next.
2.2.1 Operational Dimensions
Operational dimensions are the control knobs that are directly controlled by the user or
the system administrator. Values of these dimensions determine the resource allocation of
the application and hence directly or indirectly influence its quality. The choice of a coding
scheme for video conferencing, and the choice of a route for a networked application between
its source and destination are examples of operational dimensions.
Operational Space: This is defined as the set of operational points, as shown for task
τi in Equation 2.7, where Φ is the jth operational dimension and NΦi is the number of
operational dimensions.
Φi = Φi1 × · · · × ΦiNΦi
(2.7)

18 Chapter 2. System Model
Operational Indices: An index in 1, 2, ..|Φij | enumerating the possible values of op-
erational dimension j is called an operational index. Operational dimensions can be of two
types: monotonic and non-monotonic.
Monotonic Operational Dimensions: The value of this type of dimension is directly
or inversely related to the utility of the task. In other words, increasing values along this
dimension either increases or decreases utility. For example, increasing the frequency of a
tracking task in radar increases the quality of tracking.
Non-Monotonic Operational Dimensions: The value of this dimension is not directly
or inversely related to the utility of a task. An example is the selection of a video coding
algorithm for a video task. There may be multiple types of video coding algorithms, but it
may not be possible to sort them in the increasing or decreasing order of utility.
Next, we will introduce another type of dimension that affects the QoS of tasks and
hence the utility, but is not in the direct control of the user or the system administrator.
2.2.2 Environmental Dimensions
The quality obtained by a task may even depend on factors in the environment in addition
to the operational settings. For example, the quality of a video conferencing task in a
wireless medium can depend not only on the strength of the wireless signal received at the
receiver, but also on factors such as the environmental noise. Therefore, the noise is an
example of an environmental dimension.
Environmental Space: This is defined as the set of environmental points, as shown for
task τi in Equation 2.8, where Θ is the jth environmental dimension and NΘi is the number
of environmental dimensions.
Θi = Θi1 × · · · ×ΘiNΘi
(2.8)

2.2. QoS and Resource Allocation 19
Environmental Indices: An index in 1, 2, ..|Θij | enumerating the possible values of
environmental dimension j is called an environmental index.
With different values in the operational and environmental dimensions, a task gets a
different value of the QoS setting. Next, we discuss the dimensions that are of direct
relevance to the end-user and that provide QoS to the end-user.
2.2.3 QoS Dimensions
The dimensions that are of direct relevance to the user are known as QoS dimensions. For
example, the frame rate of a video-conferencing task and the tracking precision of a radar
tracking task are QoS dimensions. A higher value along a QoS dimension generally requires
higher resource levels.
QoS dimensions are derived from operational and environmental dimensions. A QoS
dimension can also be same as a monotonic operational dimension. For example, frame
rate of a videoconferencing task is an operational dimension (controllable knob) that is also
a QoS dimension.
Users derive satisfaction or utilities through various values of QoS dimensions. The
higher the value of a QoS dimensions, the higher the utility to the user. For example, a
higher frame-rate in a video-conferencing application provides a higher utility to the user.
The value of the utility along different QoS dimensions depends on the task, and perhaps
the user.
In the context of QoS dimensions, we use the following terms from [49].
Quality Space: This is defined as a set of quality points, as given by:
Qi = Qi1 × · · · ×QiNQ
i, (2.9)
for task τi, where Qij is the jth QoS dimension and NQi is the number of QoS dimensions.

20 Chapter 2. System Model
QoS Dimensions
EnvironmentalDimensionsDimensions
Operational
System−centric dimensions
Resource requirements
User−centric dimensions
Utility
Figure 2.1: Dimensions and Their Relations
Quality Indices: An index in 1, 2, . . . , |Qij |, enumerating the quality levels for dimen-
sion j arranged in increasing value of the quality level is called a quality index.
Dimension-wise Utility: This is the utility associated with a particular quality level of
a QoS dimension. In other words, it is defined as the mapping uij : Qij → < representing
the utility achieved by assigning quality level qij to dimension Qij .
Application Utility: It is normally expressed as the weighted sum of dimension-wise
utilities across all QoS dimensions as a mapping ui : Qi → <.
For example, if an application has 2 QoS dimensions, its particular QoS setting is denoted
by (qj1, qk2), where j and k are the indices of its respective QoS dimensions. The utility of
the application at this QoS setting is expressed as (w1uj1 + w2uk2), where w1 and w2 are
the respective weights of the two dimensions.
Based on operational and environmental dimensions, we generate the different operating

2.2. QoS and Resource Allocation 21
points of a task. We refer to them as set-points.
Definition 2.2.1 (Set-point). It is an operating point of the task. It consists of a partic-
ular of each of its operational and environmental dimensions and a utility value.
2.2.4 Set-point Generation
Set-points are generated by creating a QoS Profile and a Resource Profile [49].
QoS Profile Generation
The QoS Profile consists of different QoS levels of the task and the values of the corre-
sponding utilities. For some tasks, the operational dimensions and QoS dimensions may
be equivalent and there may be no environmental dimensions, but in general we say that
there is a Quality Function fqi : Φi ×Θi → Qi mapping each point in the cross product of
the operational space and environment space to a point in the quality space. The relation
between operational, environmental and QoS dimensions is illustrated in Figure 2.1.
Resource Profile Generation
In order for a task to operate at a particular set-point φi, it requires resources. We define
a function gi : Φi → ~Ri specifying the amount of resources required for the task to oper-
ate at each set-point, where ~Ri = ri1 , . . . , rim is defined as the Resource Vector describing
the resource requirements of the task at that set-point. Apart from the resource require-
ment of the task, it also has a deployment constraint which is given by an non-monotonic
operational dimension. For example, in a networked system, if a task requires bandwidth
between a source and a destination, the multiple choices of paths belong to a non-monotonic
operational dimension[31].
For each task, all QoS dimensions Qij must satisfy the conditions as
∀k∈1,...,m∂rk
∂qij≥ 0, (2.10)

22 Chapter 2. System Model
where rk denotes the kth resource. That is, an increase in any quality index value never
results in the decrease in any resource requirement value. Set-points that do not satisfy
these conditions can be dropped from consideration. This is because there are other set-
points that can yield higher QoS with reduced resources. The same condition is applicable
for monotonic operational dimensions.
However, for non-monotonic operational dimensions, the conditions are given by:
∃k∈1,...,m∂rk
∂φij< 0, (2.11)
∃k′∈1,...,m,k′ 6=k∂rk′
∂φij> 0. (2.12)
These equations indicate that the switching from one value of “resource configuration” to
another results in subtraction of resource from one or more resource element and addition
to one or more different resource elements.
2.2.5 Example Application
As an example, consider a video conference application with QoS and operational dimensions
as shown in Table 2.1. There are two monotonic operational dimensions that have one-to-
one correspondence with QoS dimensions: frame rate and resolution. They are assumed
to have weights 0.4 and 0.6 respectively. The weights represent the relative importance of
the QoS dimensions from the user’s perspective. For frame rate, there are three possible
levels of service at 10 frames/sec, 20 frames/sec and 30 frames/sec. A quality index is
associated with each of these service levels with 1 for the lowest level of service, and 3 for
the highest level of service. The user of the application has assigned utility values to each
of these levels of service indicating the relative desirability of these service levels. Similar
quality index and utility values are assigned for various resolutions.
In addition to the monotonic operational dimensions, there are also two non-monotonic
operational dimensions. The first operational dimension is the format, or codec, to use for

2.2. QoS and Resource Allocation 23
QoS/Monotonic Operational Levels Quality/Monotonic UtilityDimensions (weight) Operational Index
Frame rate (0.4) 10 fps 1 0.220 fps 2 0.630 fps 3 1.0
Resolution (0.6) 176x144 1 0.1352x288 2 0.8704x576 3 1.0
Non-monotonic Levels Non-monotonicOperational Dimensions Levels Operational Index
Codec NV 1CELLB 2h.261 3
Path B-C-D 1B-E-F 2
Table 2.1: QoS and Operational Dimensions Example
the actual video data. In this example, we assume that NV , CELLB and h.261 are the
video formats. Since each of these formats does differing amounts of compression, some
of them will consume substantial CPU while reducing the network bandwidth required,
while others will minimize the use of CPU at the expense of network bandwidth. Each of
these is assigned an operational index, but ordering does not matter. Furthermore, since
the selected video format does not directly impact the user, there are no QoS dimensions
associated with this dimension.
The other non-monotonic operational dimension is the actual path through the network
used to connect the two endpoints. In its first setting, links B, C and D are used, while in
the second setting links B, E and F are used. Again, while the actual network path selected
does not directly affect the user, it may have an impact on available system resources.
Using the concatenation of operational indices (qi, φi) with the above values listed in
Table 2.1, each possible set-point of the application can be assigned a unique vector. For
example, the set-point (3, 2, 3, 1) would represent the video conference application running
at 30 frames/sec, 352×288 resolution, using the h.261 video codec, and routing the packets

24 Chapter 2. System Model
0
0.2
0.4
0.6
0.8
1
0 90% 99% 99.9% 99.99%
Uti
lity
Reliability (%)
Figure 2.2: Reliability and Utility
for the video flow along links B, C and D. The resources required for this set-point would be
determined by applying the resource mapping function gi. This function may be provided
by the application developer or a QoS engineer. The utility for a set-point is normally
determined as the weighted sum of the dimension utilities. In this case, the utility for the
set-point (3, 2, 3, 1) would be (0.4× 1.0) + (0.6× 0.8) or 0.88.
2.2.6 Reliability
Reliability or Fault-tolerance of the task is desirable in many systems. Higher reliability
provides higher utility and vice versa. The idea of fault-tolerance in the form of active
or passive replication has been studied in great detail [4]. Many fault-models have been
presented for determining the necessity of having a certain number of replicas of tasks[15],
but not in conjunction with a QoS optimization framework. In our QoS framework, we treat
fault-tolerance or reliability as an additional aspect of QoS. If we can quantify reliability
under a particular fault-model, we can assume a graph of utility versus reliability as shown
in Figure 2.2.

2.3. Existing Optimization Algorithm 25
Higher reliability of a task can be accomplished through replication. Replicas will run
on different resources relative to the original. Replication enables the application to provide
reliable output even when one (or more) copies of the same application fail(s). The number
of replicas that need to be executed in order to achieve a certain amount of reliability
depends on the fault model of the system.
Reliability can be mapped as a QoS dimension and each discrete level of reliability can
be mapped to a QoS index. For example, consider a task τi that has the following resource
vector allocation choices (options): ~Ri1, ~Ri2 and ~Ri3. At the same level of quality, any
of these resource choices can be allocated to the task. In order for the task to be fault-
tolerant, more than one resource vector needs to be allocated. Thus, we can generate the
QoS set-points in the following way:
Reliability Quality Indices Number of Replicas Resources
1 0 ~Ri1, ~Ri2, ~Ri3
2 1 ( ~Ri1 + ~Ri2),( ~Ri1 + ~Ri3),( ~Ri2 + ~Ri3)
3 2 ( ~Ri1 + ~Ri2 + ~Ri3)
For a task with N resource vector options, the reliability QoS index of M can be at-
tained in
N
M
combinations of resource vectors. This automatically limits the maximum
number of replicas to the number of independent resource options.
2.3 Existing Optimization Algorithm
We can now define the core problem of QoS-based resource allocation as follows. For each
task τi in the set τ1, . . . , τn, we assign a set-point such that the system utility is maximized
and no resource utilization exceeds its capacity. The system utility is defined as a function
of utilities of all the tasks. Normally, it is defined as the weighted sum of the task utilities.

26 Chapter 2. System Model
But in case of “fair” sharing, it can also be defined as the minimum of the utilities among
tasks.
Formally, we write this as:
maximize: u(φ1, ..., φn) =∑n
i=1 wiφiui(φi) ⇐ System Utility
subject to: ∀1≤k≤m∑n
i=1 rik ≤ rmaxk
∀1≤k≤m,1≤i≤n rik = gik(φi)
In [51, 49], it was demonstrated that the QoS optimization problem involving multiple
resources (MR) and multiple QoS dimensions (MD) is NP-hard. An exact optimal solution
to the problem based on dynamic programming and an approximation scheme based on the
local search technique was presented.
In the next section, we discuss the limitations of the approximation scheme when applied
to problems with non-monotonic operational dimensions, typically in handling resource
trade-offs. We then present our algorithms that address these limitations.
2.3.1 Approximate Multi-Resource Multi-Dimensional Algorithm (AM-
RMD)
In this section, we briefly describe the optimization technique presented in [51, 49]. We
denote the number of tasks by n and the number of resources by m. Let Ci represent the
set of utility-resource pairs for task τi, as shown:
Ci = 〈
ui1
~Ri1
, ....,
uiki
~Riki
〉. (2.13)
Next, we would like to determine and compare the costs of the resource vectors in order
to choose one which gives higher utility at a lower cost. When there is a single resource in
the system, the cost of a set-point is simply equal to its resource amount. When there are

2.3. Existing Optimization Algorithm 27
multiple resources, a scalar metric known as compound resource is computed.
To compute the compound resource, we first compute a penalty vector for the resources
(assuming we have m resources) ~P = (p1, ..., pm) to assign a “price” on each resource.
The value of an element in the vector is directly related to the overall demand of the
corresponding resource, and is defined to be:
pk =rsumk
rmax k+ 1, (2.14)
where rsumkis computed as the sum of the kth resource elements of all the set-points of all
the tasks as given by:
rsumi =∑
All tasks
∑All set−points
rji . (2.15)
The compound resource h is a scalar metric, which is defined for each set-point is defined
by:
h =√
(r1.p1)2 + . . . + (rm.pm)2. (2.16)
The metric h is used to compare the relative cost of each of the resource combinations. We
now augment Ci by adding h to get:
Cic = 〈
ui1
ri1
hi1
, ....,
uiki
riki
hiki
〉. (2.17)
Cic is called a compound resource vector. We use the parameters in Cic to determine the
near-optimal resource allocation for tasks that maximizes the global utility value. The
algorithm is called Approximate Multiple Resource Multiple Dimension or AMRMD1 [51]. It
is briefly presented in Algorithm 1.
This algorithm computes the compound resource vector of a resource. The procedure
concave majorant() chooses to retain the points in Cic falling along the line of highest

28 Chapter 2. System Model
input : profiles of tasksoutput: resource allocation of tasks by maximizing utilityCalculate initial penalty vector;for iter = 0 to max iter do
//max iter is usually set to 3for All tasks i do
Generate compound resource Cic for each task τi;Perform concave majorant optimization [51] on Cic;
endCreate slope list by merging set-points of all Cics based on their slopes;Go through the entire slope list and enter/update the resource allocation of thetasks;Update penalty vector from the usage of the individual resources;if the utility in the previous iteration differs from this utility by a small fractionε then
Break from the loop;end
endFinalize resource allocations of the tasks;
Algorithm 1: Basic “AMRMD1” algorithm
slope. The slope of the utility function at a set-point j is defined by:
slope(j) =u(j)− u(j − 1)h(j)− h(j − 1)
, (2.18)
where h(j) and u(j) are the compound resource and the utility at the set-point j respectively.
This is also known as the marginal utility.
2.3.2 Drawbacks of the AMRMD1 Algorithm
There are 2 problems in applying the above algorithm in a multi-resource environment. We
describe them in the order of importance.

2.3. Existing Optimization Algorithm 29
Static Penalty Vector Computation
The AMRMD1 algorithm statically computes the “penalty” vector. It is determined based on
the aggregate potential demand placed on a resource, and penalizes the choices of resources
that are perceived to be heavily loaded in favor of the less loaded resources. The aggregate
is determined by summing the resource requirements of all set-points of all the tasks. In
a true sense, the computation of the penalty vector should reflect the real usage of the
resources at any given point in time during resource allocation. In other words, the penalty
vector should be computed dynamically each time a set-point gets admitted, based on the
quality points that have already been admitted into the system so far. This is particularly
true for a large distributed system where a task can have multiple values of its operational
dimensions in terms of its resource trade-offs. Adding all possible resource trade-off values
will unnecessarily create heavy penalties for small resources. If the dynamic computation
is to be avoided for complexity reasons2, we need to obtain a smarter way of evaluating the
penalty vector that does not unnecessarily penalize resources of small size.
Neglecting Co-located Points
Even after using the static penalty vector computation, there can still be many set-points
that have the same values of utility and compound resource but different resource vectors
(or resource combinations). These set-points are known as co-located set-points.
There can be multiple co-located set-points, and keeping only one of them can be poten-
tially sub-optimal. However, while determining the concave majorant, the AMRMD1 algorithm
will choose only one out of those co-located points whichever appears first in the list and
eliminate others completely from consideration. This decision may not be the best one
simply because during the course of the resource allocation process, one point may be in-
feasible while another co-located point with the same utility may be feasible. This depends
on the status of the current allocation of resources. As a result, AMRMD1 may stop allocating
2We discuss the complexity of dynamic penalty vector computation in Section 2.4.1

30 Chapter 2. System Model
10 10
Figure 2.3: Equally Sized Processors
Quality Requirements Resources Utility1 3 (3,0),(0,3) 0.32 5 (5,0),(0,5) 0.53 7 (7,0),(0,7) 0.7
Table 2.2: Example Task Profile
resources even though additional feasible allocations exist.
Example 1
Consider a system consisting of 2 processors each of size 10 units, as shown in Figure 2.3.
There are two tasks, each with the QoS profile detailed in Table 2.2. The QoS specification
indicates the resource requirements for a task on each processor. According to the above
specification, each task has two options on resource requirements at each QoS level. The
utility values are chosen as shown.
As can be easily seen, the resource demands on both the nodes are completely balanced
and hence the elements in the penalty vectors are identical. This produces a pair of co-
located points at every QoS level. The optimal solution is the one presented in Table 2.3,
where each task is allocated to its own processor and is assigned the maximum QoS. The
total utility achieved is 0.7 + 0.7 = 1.4.
In contrast, the AMRMD1 algorithm neither keeps co-located set-points nor does it compute
the penalty vector dynamically. Therefore, it may end up producing the following allocation

2.3. Existing Optimization Algorithm 31
Task QoS level Resource Vector Utility0 3 (7,0) 0.71 3 (0,7) 0.7
Table 2.3: Example Resource Allocation
Task QoS level Resource Vector Utility0 3 (5,0) 0.51 3 (5,0) 0.5
Table 2.4: AMRMD1 Resource Allocation
presented in Table 2.4. This yields a total utility of 0.5 + 0.5 = 1.0, which is sub-optimal.
Example 2
Consider the situation where the sizes of the processors are unequal and they are 12 units
and 9 units respectively. Assuming the same task profiles as in the previous example, the
resource demand on two nodes are balanced and the optimal solution is same as before,
The total utility obtained is again 1.4.
However, due to the smaller size of Processor 2, it has the higher penalty and hence the
set-points corresponds to the deployment to Processor 2 are always eliminated. Hence, the
result of the AMRMD1 algorithm will always be the same as in Table 2.5, and will yield a total
utility of 1.0, nearly 30% less than the optimal solution.
12 9
Figure 2.4: Unequally Sized Processors

32 Chapter 2. System Model
Task QoS level Resource Vector Utility0 3 (0,5) 0.51 3 (0,5) 0.5
Table 2.5: AMRMD1 Resource Allocation for Unequal Processor
In short, the original AMRMD1 algorithm can clearly lead to sub-optimal solutions. In
the next two sections, we will discuss two new algorithms that attempt to overcome these
limitations of AMRMD1.
2.4 Enhanced Optimization Algorithms
We now describe two new algorithms that address the limitations of the AMRMD1 algorithm
described earlier.
2.4.1 Dynamic Penalty Vector (AMRMD DP)
In this algorithm, we compute the penalty vector dynamically as we assign set-points for
the tasks. It works as follows.
input : profiles of tasksoutput: resource allocation of tasks by maximizing utility using Dynamic Penalty
VectorsCalculate initial penalty vector;while Number of set-points of all tasks more than 1 and Resources are available do
Create sorted slope list by merging all set-points of the tasks based on theirslopes;Allocate set-point of highest slope/marginal utility;Eliminate the set-points of the task with same or lower utilities;Recompute penalty vector based on the available resources;Update compound resources of the remaining set-points of the tasks;
endFinalize resource allocations of the tasks;
Algorithm 2: Basic “AMRMD DP” algorithm
First, it creates the Ci lists. Without performing the concave majorant operation, it

2.4. Enhanced Optimization Algorithms 33
Compound Resource
Util
ity UpdateinPenalty Vector
Another update in penalty vectorFewer points left
Util
ity
Util
ity
Compound Resource
Compound Resource
Figure 2.5: AMRMD DP Algorithm
computes the marginal utility as the slope of the compound resource/utility curve. Next,
it selects the point of the highest marginal utility to be allocated. If the allocation is
successful, it updates the penalty vector. This step requires an update in the compound
resource parameters of all tasks containing the remaining set-points. Thus, the set-points
migrate from one location to another in compound resource-utility space during the progress
of the algorithm. Then, it repeats the procedure until all the set-points of all the tasks or
the resources are exhausted.
Complexity of AMRMD DP
The asymptotic computational complexity of AMRMD DP is as follows. The initial computa-
tion of the penalty vector takes O(nL) operations, where n is the number of tasks and L

34 Chapter 2. System Model
is the maximum number of set-points per task. Within the loop, the procedure for updat-
ing the compound resource takes O(nL) operations, the procedure for selecting a set-point
takes O(nL) operations and the procedure for adjusting the penalty takes O(nL) opera-
tions. Now this loop can repeat nL times in the worst case. This yields a total complexity
of: O(nL) + nL(O(nL) + O(nL) + O(nL)) + O(nL) = O(n2L2).
Therefore, this algorithm has a higher degree of complexity than AMRMD1, whose com-
plexity is O(nL log(nL)); however, unlike AMRMD1, AMRMD DP yields the optimal solutions for
both the examples discussed in Section 2.3.2.
2.4.2 Co-mapping of Quality Points (AMRMD CM)
Util
ity
Compound Resource
Co−located points
Generate K_listandperform convex_hull
Convex_hull_map operationBring back essential co−locatedpoints
Eliminated pointsafter convex_hull
Co−located points
Util
ity
Util
ity
Compound Resource
Compound Resource
Figure 2.6: AMRMD CM Algorithm
The AMRMD CM algorithm explicitly keeps track of co-located quality points, and performs
both a penalty vector and a concave majorant computations in ways different from AMRMD1.

2.4. Enhanced Optimization Algorithms 35
Penalty Vector Computation
Similar to AMRMD1, AMRMD CM algorithm also evaluates the penalty vector statically. However,
its computation is different from that of AMRMD1. In AMRMD1, all the resource deployment
options are added together to determine the potential resource demand. However, we know
that only one out of multiple of resource options need to be selected for a task and each
resource option may not be equally likely to be selected. Therefore, we would like to
include the likelihood of selection of a resource option while computing the penalty vector
of resources.
Let us consider the likelihood of a particular resource trade-off to be chosen. At a par-
ticular utility value, let us denote the resource vector of jth trade-off by ~Rj = (rj1 , . . . , rjm),
where rjk, rmax
k and m denote the demand of the kth resource, the capacity of the kth re-
source and the number of resources in the resource vector respectively. In this context, we
define the following two terms.
Definition 2.4.1 (Bottleneck Resource). At a given utility level, the kth resource is
said to be the bottleneck resource of the resource vector corresponding to the jth trade-off, if
rjk/rmax
k ≥ (rjl/rmax
l ), ∀1 ≤ l ≤ m. (2.19)
Definition 2.4.2 (Bottleneck Factor). At a given utility level, for jth trade-off, if kth
resource is the bottleneck resource, then the factor βj = rmax/rjkis defined as the Bottleneck
Factor of the jth trade-off.
Definition 2.4.3 (Selection Factor). The selection factor of jth trade-off at a fixed utility
level is given by:
ρj =(βj)∑NTi=1 (βi)
, (2.20)
where NT denotes the number of elements for the trade-off dimension.
Using Definition 2.4.3, at a given utility level, multiple resource allocations are weighed

36 Chapter 2. System Model
based on the values of their Selection Factors in order to evaluate their demands. For
example, if a task is allocable to 2 processors of unequal capacities, the selection factor of
the larger processor is higher. However, if the task is allocable to only one processor, the
selection factor of that processor is 1 while that of the other one is 0. We evaluate the
demand of resources by modifying Equation 2.15 as given by:
rsumi =∑
All tasks:n
∑All set−points:L
ρjri. (2.21)
Next, we compute the penalty vector using Equation (2.14) and consequently derive
compound resource for the set-points using Equation (2.16).
Concave Majorant Computation
Similar to AMRMD1, the AMRMD CM algorithm computes the concave majorant procedure to
retain only the necessary set-points. However, unlike AMRMD1, it retains all the co-located
set-points which yield the same utility values with the same compound resource values but
with different resource vectors.
From Cic lists, we create another compound resource list Ki by including the elements
from Cic that only have distinct values of compound resources (h). In other words, if two or
more elements in Cic have the same value3 for h but different vector values for r, then they
are mapped to a single element in the Ki list. This is called “co-mapping” of set-points.
Each element in Ki also stores the indices of the corresponding elements in Cic.
AMRMD CM then performs the concave majorant operation on the Ki list instead of the
Cic list, and maintains the set of co-located points of the same utility if they lie on the
concave majorant. It attempts to allocate one of the co-located points of a task if a point
is infeasible due to resource constraints, and allocation lasts until all the points of all the
3In order to account for the floating point precision issue, we consider two points co-located when thefractional difference between their compound resource values is less than a small fraction ε, which is typicallyset to 0.1.

2.4. Enhanced Optimization Algorithms 37
input : profiles of tasksoutput: resource allocation of tasks by maximizing utilityCalculate initial penalty vector;for iter = 0 to max iter do
//max iter is usually set to 3for All tasks i do
Generate compound resource Cic for each task τi;Generate new list Ki where multiple co-located points in Cic are mapped toa single point in Ki;Perform concave majorant optimization [51] on Ki;Retain the corresponding set-points of Cic that map to the remainingset-points in Ki in terms of compound resources and utilities and discardthe rest;
endCreate slope list by merging set-points of all Cics of all tasks based on theirslopes;Go through the entire slope list and enter/update the resource allocation of thetasks;After the procedure is finished update penalty vector from the usage of theindividual resources;if the utility in the previous iteration differs from this utility by a small fractionε then
Break from the loop;end
endFinalize resource allocations of the tasks;
Algorithm 3: Basic “AMRMD CM” algorithm
tasks are exhausted.
The process of forming a Ki list and the corresponding retrieval of the relevant co-
located points are illustrated in Figure 2.6. In Step (1), co-located points are gathered. In
Step (2), the concave majorant is determined. In Step (3), only points (and their co-located
points) along the concave majorant are used for making resource allocation decisions. The
procedure is briefly described in Algorithm 3.

38 Chapter 2. System Model
Complexity of AMRMD CM
The asymptotic computational complexity of AMRMD CM can be obtained as follows. Let
L = maxni=1|Qi| and L′ = maxn
i=1|Ci|. In other words, L is assumed to the maximum
number of QoS levels and L′ is assumed to be the maximum number of set-points that may
have multiple set-points at a particular QoS level. The procedures for creating Klist and co-
mapping set-points require O(nL′) operations each. The concave majorant operation takes
O(nL log(L)) [51]. The merging operation takes O(nL′ log(n)). Therefore, the complexity
of the algorithm is: O(nL′(1 + log(n))) + O(nL log(L)) = O(nL log(L)) + O(nL′ log(n)).
This is somewhat higher than that of AMRMD1 since L′ ≥ L, but much smaller than that of
AMRMD DP. In addition, AMRMD CM yields the optimal results for both the examples discussed
in Section 2.3.2, similar to AMRMD DP.
2.5 Large-scale Optimization Issues
Based on the above discussion, we shall use AMRMD CM as the algorithm for optimization in
the rest of the dissertation. It exhibits a benign computational complexity (O(nL log(nL)))
compared to the optimal algorithm which is NP-hard. However, we have other problems in
using this algorithm directly in a large-scale distributed system.
2.5.1 Set-Point Generation Complexity
The computational complexity of O(nL(log(nL))) ignores the processing of the generation
of set-points from the various dimensions. In many applications, the generation of different
values of the operational dimensions can itself be of much higher complexity than the core
optimization process. For example, in a networked system, determining all the possible
paths between a source and a destination can be much more complex than finding a right
path with an appropriate bandwidth by Q-RAM. This will be discussed in more detail in
Chapter 4.

2.5. Large-scale Optimization Issues 39
NetworkDisk CPU
Q−RAM Resource Allocator
Resource Admission Control of Scheduler
Tasks
Resources
QoS and resource specifications from Tasks
Resource reservation request to OSRequest success/failure
QoS and resource assignments for Tasks
Figure 2.7: Q-RAM & Scheduler Admission Control
If the task is highly configurable i.e., it has a large number of possible values per di-
mension, we should generate only a few values of each dimensions before we perform the
concave majorant instead of exhaustively generating all possible values. This will have the
effect of reducing the complexity of the concave majorant step O(nL log(L)) by reducing L.
2.5.2 Core Algorithm Complexity
After reducing L, we would like to reduce the second part of the complexity that comes
from merging all set-points of all n tasks, which is O(nL log(n)). This is solved by dividing
the problem into smaller subproblems and solving these subproblems as independently as
possible. This includes the clustering of the tasks into a small number of groups and the
division of the entire distributed system into a number of small partitions. This reduces
both the complexity of the concave majorant and the merging operations. The technique
to perform this division varies depending on the type of the system.

40 Chapter 2. System Model
Sche
dule
r Adm
issi
onC
ontr
olQ−RAMResourceAllocator
Requested Task Queue
Q−RAM Reconfiguaration Clock
Output Task Setting
Rec
onfi
gura
ble
Tas
k Q
ueue
Figure 2.8: Dynamic Q-RAM Optimization
2.5.3 QoS Optimization and Resource Scheduling
In our QoS optimization model, we assume a simple model of resources where each resource
can be perfectly divisible among the tasks, either in time-shared or in spatial manner.
However, in the case of time-shared resources, in order to obtain real-time guarantees, we
need to perform scheduler admission tests for tasks once the resources are allocated to them
by Q-RAM. Moreover, the admission tests of multiple resources must be integrated with
each other [29, 69]. The interaction between a resource scheduler and Q-RAM optimization
are shown in Figure 2.7. Q-RAM can allocate resources more optimistically or conservatively
depending on the assigned utilization bounds on the resources. We know that the bound
must be set less than or equal to 1.
In addition, Q-RAM optimization needs to be performed either reactively or at regular
intervals (known as the reconfiguration rate) as a background process in a dynamic scenario
where the task set is not fixed and tasks are continuously arriving and departing the system.
In this case, the arriving tasks form a queuing system with Q-RAM as the “server” [38]. Q-
RAM accepts multiple newly arrived tasks, performs optimizations along with the existing

2.6. Chapter Summary 41
schedulable tasks, and finally produces the resource allocations of those tasks. In this
process, only a few out of all existing tasks need to be selected for optimization along with
the newly arrived tasks. The process is illustrated in Figure 2.8. The details of this dynamic
process are described in [38] along with experimental results.
Based on the above model, it must be noted that the scalability of the Q-RAM opti-
mization depends on how many tasks it can handle for optimization for a particular recon-
figuration rate. During the rest of this dissertation, we will investigate the improvement of
the scalability of Q-RAM.
2.6 Chapter Summary
In this chapter, we developed a generic model of a distributed system consisting of multiple
resources and applications. We also presented our QoS model, which is based on Q-RAM.
In the context of Q-RAM, we have presented new QoS optimization algorithms that handle
resource trade-offs more efficiently in a multi-resource environment. Finally, we highlighted
the challenges involved in performing QoS-based resource allocation in large systems. In the
next chapter, we will discuss QoS-based resource allocation in large multiprocessor systems.


Chapter 3
Resource Allocation in
Multiprocessor Systems
3.1 Introduction
In this chapter, we present our approach to QoS-based resource allocation in a multipro-
cessor environment. The tasks are assumed to be independent of each other i.e., there is
no communication among the tasks and they are indivisible. We also consider the fault-
tolerance requirements for the tasks along with the standard QoS requirements such as
timeliness.
A typical multiprocessor system consists of multiple processors connected via a bus, as
shown in Figure 3.1. Typical examples of multiprocessor systems are present in distributed
embedded environments such as automotive systems, back-end processors in phased-array
radar and distributed server systems.
There are existing algorithms such as bin-packing [11, 18, 19, 17, 3, 8, 43, 42] and load-
balancing [75] for deploying tasks with fixed resource requirements to a fixed set of resources.
There are QoS-based resource allocation schemes such as Q-RAM that determines the QoS
setting and associated resource allocation for tasks in any generic distributed system. How-
43

44 Chapter 3. Resource Allocation in Multiprocessor Systems
ever, these algorithms are not effective of performing resource allocation in multiprocessor
systems that integrate the QoS requirements with the fault-tolerance requirements of appli-
cations. In this chapter, we address this problem with new algorithms for combining QoS
optimization and fault-tolerance with resource selection.
P P P
P
1 23
4
I/O
Figure 3.1: Typical Multiprocessor System
One other problem with existing QoS optimization algorithms is that they are not scal-
able to very large numbers of resources and tasks. We present a new hierarchical decom-
position technique for solving very large optimization problems. The hierarchical technique
divides the problem into smaller sub-problems, and then solves these sub-problems individ-
ually. As we shall see, this leads to two or more orders of magnitude reduction in execution
time.
3.2 Q-RAM in Multiprocessor Systems
In this chapter, we make the following 4 assumptions in our model of a multiprocessor
system.
• A task has no specific bias or preference for any processor. In other words, a task can
be deployed to any processor as long as there is a space for it to be allocated.
• The number of QoS dimensions and the number of elements along any dimension are
both small. We have limited our analysis to 2 or 3 QoS dimensions each with only 2
or 3 discrete levels.

3.2. Q-RAM in Multiprocessor Systems 45
Number of QoS dimensions q 2Length of each dimension 3Utilities for QoS dimension (u(q)) (0.5,0.7,0.8)Weight for each QoS dimension random (0.00,1.00)Minimum resource for each task random (1,3) unitsResource increment for higher QoS random (1,2) unitsNumber of processors 5Resource amount per processor 10 units
Table 3.1: Experimental Settings with Optimal Algorithm
• Tasks do not communicate with one another. In other words, there are no communi-
cation bandwidth requirements among the tasks.
• A task is deployed to only one (or in the case of fault-tolerance, several) resource
(processor) from a pool of resources.
As we know, Q-RAM has an algorithm called AMRMD1 that performs the resource alloca-
tion for tasks in a multi-resource environment. In Chapter 2, we presented two algorithms
AMRMD CM and AMRMD DP as modified versions of AMRMD1 that were perceived to handle the
resource deployment trade-offs more efficiently. In this section, we evaluate the perfor-
mances of these algorithms in multiprocessor systems. For a given number of task profiles
and resources, our experiments focus on measuring the following performance metrics:
• the maximum number of tasks that can be admitted while satisfying the minimum
QoS requirements of all the admitted tasks,
• the utility obtained with the maximum number of admitted tasks when their minimum
QoS is 0, and
• the execution time of the algorithms.

46 Chapter 3. Resource Allocation in Multiprocessor Systems
0
2
4
6
8
10
12
14
16
18
0 5 10 15 20 25 30 35 40 45 50 55
Util
ity a
crue
d ->
Number of Tasks ->
Optimal Algorithm Comparison
mrmd-optimalamrmd1
amrmd_cmamrmd_dp
Figure 3.2: Utility Variation
3.2.1 Comparison with Optimal Algorithm
The first experiment compares all three AMRMD algorithms that are presented in Chapter 2,
along with the optimal exhaustive search algorithm called MRMD. The optimal algorithm is
presented in [49].
A small multi-processor system consisting of 5 processors is assumed for the sake of
convenience to be running the exponentially complex optimal algorithm. The assumed
configurations of the tasks and that of the system are presented in Table 3.1.
Figure 3.2 shows the variation in the utility as the number tasks is varied from 2 to
52. The result is averaged over 50 runs. It shows that AMRMD CM performed closest to the
optimal MRMD scheme in terms of utility, AMRMD1 being the farthest.
Figure 3.3 shows the variation of the execution time of the algorithms. The results
are plotted on log-scale as the optimal solution runs approximately 30, 000 times slower
than AMRMD1. The execution time of AMRMD CM is approximately 1.5 times greater than that

3.2. Q-RAM in Multiprocessor Systems 47
100
1000
10000
100000
1e+06
1e+07
1e+08
1e+09
0 5 10 15 20 25 30 35 40 45 50 55
Run
tim
es (u
sec)
in lo
g sc
ale
->
Number of Tasks ->
Optimal Algorithm Comparison
mrmd-optimalamrmd1
amrmd_cmamrmd_dp
Figure 3.3: Run-time Variation
of AMRMD1 as expected. The algorithm AMRMD DP has quadratic complexity and thus runs
slower by an order of magnitude compared to the other two AMRMD algorithms.
These results show that AMRMD CM yields utility values closest to those of the optimal
algorithm with somewhat higher execution times than those of AMRMD1.
3.2.2 Results for Larger Systems
In this experiment, we consider a system with 20 processors. The full experimental set-up
is given in Table 3.2. In the first case, we do not allocate the tasks with their minimum QoS
before performing the optimization. Instead, we compare the three algorithms in terms of
the maximum number of tasks they can admit into the system where each task has non-zero
QoS requirements that must be satisfied for admission into the system.
The results for the maximum number of tasks that can be admitted under each algo-
rithm, averaged over 100 randomly generated task configurations, are shown in Figure 3.4.

48 Chapter 3. Resource Allocation in Multiprocessor Systems
amrmd1 amrmd_dp amrmd_cm0
20
40
60
80
100
120
140Results on Number of Admitted Tasks
Algorithms
Num
ber o
f Adm
itted
Tas
ks
Figure 3.4: Number of Admitted Tasks (20 processors)
As can be seen, AMRMD CM is able to admit 6 times more tasks than AMRMD1 and twice as
many than AMRMD DP.
Figure 3.5 shows the standard deviation of the results for 3 algorithms. We observed
a very high relative standard deviation of the results of AMRMD1, the least being that of
AMRMD CM. The reason for this behavior is the following. AMRMD1 algorithm randomly selects
one of any co-mapped resource deployment points for a QoS setting and discards the rest
based on its own concave majorant operation. This random selection makes a significant
difference in the performance and contributes to the large standard deviation results for
AMRMD1. AMRMD DP, on the other hand, uses a better technique by evaluating the penalty
vector dynamically at each resource allocation. However, it follows the same technique as
AMRMD1 in discarding deployment options (trade-offs), resulting in a high standard deviation
similar to that of AMRMD1. This shows that AMRMD CM is the most consistent and predictable
in its result that does not depend on the randomness in the sequence of the input data.
In the next experiment, we vary the number of tasks and determine the utility accrued
under each algorithm. In this case, we assume all tasks have the zero minimum QoS

3.2. Q-RAM in Multiprocessor Systems 49
amrmd1 amrmd_dp amrmd_cm0
5
10
15
20
25
30
35
40
45Results Standard Deviation on Number of Admitted Tasks
Algorithms
Per
cent
age
Sta
ndar
d D
evia
tion
Figure 3.5: Percentage Standard-deviation (= 100× (Standard deviation)/mean ) of num-ber of admitted tasks on 20 processors
requirements and thus all can be “admitted”. This assumption equalizes all the algorithms
in terms of their admission control characteristics and allows us to compare utility accrual.
We plot the results that are averaged over 100 randomly generated problems in Figures 3.6
and 3.7. As AMRMD CM accommodates more resource options for each task, the results show
higher utility for AMRMD CM than for AMRMD1. Although it also shows that AMRMD1 algorithm
performed better in terms of yielding utility closer to that of AMRMD CM, this is again due
to the randomized ordering of trade-off values and the distribution of utilities among tasks.
This also can be made worse by choosing a different utility distribution for tasks. In other
words, in the case of AMRMD1, a few tasks obtained very high utility values at the expense
of many tasks remaining at the 0 utility level. In terms of execution times, AMRMD CM shows
slightly higher execution time than AMRMD1 while AMRMD DP needs close to two orders of
magnitudes (or higher) execution times compared to the other two.

50 Chapter 3. Resource Allocation in Multiprocessor Systems
0
10
20
30
40
50
60
70
80
0 20 40 60 80 100 120 140 160
Util
ity ->
Number of tasks ->
amrmdamrmd_cmamrmd_dp
Figure 3.6: Utility Variation of Three Algorithms in a System of 20 Processors
3.2.3 Results on Fault-tolerance
The notion of incorporating fault-tolerance in the QoS-based Resource Allocation Model
(Q-RAM) was explained in Section 2.2.6 of Chapter 2. We assume that fault-tolerance is
supported using replication on multiple processors. The higher the degree of replication, the
higher the utility obtained along the fault-tolerance dimension. In this experiment, tasks
are assumed to have fault-tolerance as the only QoS dimension for ease of comparison. Table
Number of QoS dimensions (q) 2Length of each dimension 3Utilities for each quality dimension (u(q)) (0.5,0.7,0.8)Computational resource on each processor 100Minimum resource for each task random (1,25)Resource increment for higher QoS random (1,10)Number of processors 20
Table 3.2: Settings for Second Experiment

3.2. Q-RAM in Multiprocessor Systems 51
1000
10000
100000
1e+06
1e+07
1e+08
0 20 40 60 80 100 120 140 160
Run
tim
es (u
sec)
in lo
g-sc
ale
->
Number of tasks ->
amrmdamrmd_cmamrmd_dp
Figure 3.7: Run-time Variation (log-scale) of Three Algorithms in a System of 20 Processors
3.3 lists the experimental specifications.
The results shown in Figures 3.8 and 3.9 demonstrate that AMRMD CM outperforms the
other two algorithms with respect to the number of tasks it admits and the utility it achieves
for a fixed number of tasks. The number of tasks it typically admits varies between 2 to 6
times that of AMRMD1. Essentially, if tasks are assumed be admitted with zero QoS (i.e., they
are “rejected”), AMRMD1 can maximize utility fairly well depending on utility values of tasks.
However, if all incoming tasks must be admitted at a nonzero QoS level, AMRMD1 performs
poorly compared to AMRMD CM. In other words, AMRMD1 admits fewer number of tasks and
thus it provides higher average utility value per task. On the other hand, AMRMD CM admits
more number of tasks and thus it provides lower average utility value per task. For certain
utility values of tasks where a minimum QoS gives a very large marginal utility, the utility
of the result of AMRMD1 can be made arbitrarily worse than that of AMRMD CM.
The results show an abundance of co-located set-points in the case of fault-tolerant

52 Chapter 3. Resource Allocation in Multiprocessor Systems
multi-processor scheduling.
Number of QoS dimensions 1Number of copies 1-2Number of quality indices 2Utilities (0.5, 0.7,0.8)
Table 3.3: Settings for Experiment on Fault-Tolerance
0
10
20
30
40
50
60
70
80
90
100
0 20 40 60 80 100 120 140 160
Util
ity ->
Number of tasks ->
Utility variation for fault-tolerant case
amrmd1amrmd_cmamrmd_dp
Figure 3.8: Utility Variation under Fault-Tolerance
3.3 Hierarchical Q-RAM in Multiprocessor System
None of the algorithms we have presented so far scale well when there is a large number of
resources. For example, in multi-dimensional radar systems, 64 or more processing nodes
are common. Under these conditions, all three algorithms can consume large amount of
computation time and memory, making them usable only offline. This scalability bottleneck

3.3. Hierarchical Q-RAM in Multiprocessor System 53
amrmd1 amrmd_cm amrmd_dp0
20
40
60
80
100
120
140
160
180
200Two copies: 20 Processors
Algorithms
Num
ber o
f Adm
itted
Tas
ks
Figure 3.9: Number of Admitted Tasks (20 processors) under Fault-Tolerance
10000
100000
1e+06
1e+07
1e+08
0 20 40 60 80 100 120 140 160
Exe
cutio
n tim
e (u
sec)
in lo
g-sc
ale
->
Number of tasks ->
Execution time variation for fault-tolerant case
amrmd1amrmd_cmamrmd_dp
Figure 3.10: Run-time Variation (log-scale)

54 Chapter 3. Resource Allocation in Multiprocessor Systems
arises because the factor L1 increases proportionately with the number of resources in the
system. This happens because we enumerate all possible allocations of each task in all
resource unit (processor), where a task is allocated to only one resource unit (processor)
out of many, unless fault-tolerance is required. Even under fault-tolerance, the number
of resource units assigned is equal to the number of replicas needed for a task. Thus we
propose a hierarchical Q-RAM approach in which we partition the problem into smaller
sub-problems each dealing with a smaller number of resources.
Before we discuss the details of our approach, we provide the following definitions and
then state a theorem based on theorems of constrained extrema in linear programming [83].
Definition 3.3.1 (Task Profile). The profile or type of a task is defined by its set-points
containing different values of its operational and environmental dimensions and the associ-
ated utility values.
Definition 3.3.2 (Identical Tasks). Two tasks are said to be identical if they are of the
same type, i.e., they have identical task profiles.
Definition 3.3.3 (Utility function). It is defined as the function that describes the vari-
ation of utility of a task relative to its allocated resource(s).
Util
ity f
(r) −
>
Resource (r) −>
Figure 3.11: A typical Continuous Utility Function
1L denotes the maximum number of set-points per task, as mentioned in complexity analysis in Section 2.4of Chapter 2.

3.3. Hierarchical Q-RAM in Multiprocessor System 55
Theorem 3.3.4 (Resource Distribution of Identical Tasks). If a resource has to be
distributed among identical tasks with continuous monotonically increasing concave utility
function, the total utility is maximized when each task is allocated equal amount of resource.
Proof. The proof of this theorem follows directly from the theorems of constrained extrema
in Linear Programming [83] as a special case of Karush Kunn Tucker’s theorem [64].
Corollary 3.3.5. If a resource has to be allocated among various tasks with a fixed number
of types with continuous utility functions, the maximum utility is obtained when the same
resource amount is allocated to the tasks of the same type.
Proof. This corollary can also be derived from Karush Kuhn Tucker’s theorem.
Corollary 3.3.5 guides us in designing an efficient QoS allocation scheme when tasks
can be classified into a finite set of categories. In our case, tasks do not have continuous
utility functions. Instead, each of them has a few discrete set-points that corresponds to
a set of discrete utility-resource pairs. Lee et al [49] derived the bound in the obtained
global utility relative to the optimal utility when we apply Karush-Kuhn-Tucker’s theorem
on such occasions.
3.3.1 Hierarchical Q-RAM Algorithm
In order to reduce the complexity of Q-RAM optimization, we employ a “divide-n-conquer”
technique. In other words, we would like to divide the problem into identical subproblems
and solve these subproblems independently. Each subproblem is considered a cluster and
each cluster contains an equal number of resources. Hence the total number of resources in
the system must be an integral multiple of the number of clusters created.

56 Chapter 3. Resource Allocation in Multiprocessor Systems
XY
Y
X
_
Initial slope = Util
ity
Resource
Figure 3.12: Initial Slope of a Task
Next, we assume that there are only a small number of types of tasks. We would like to
allocate the computing resource equally to all tasks of the same type. Hence, we distribute
tasks to clusters where each cluster contains identical numbers of tasks of the same type.
If the number of tasks of a particular type is not an integral multiple of the number of
clusters, we will have a few residual tasks of that type which cannot be distributed equally
among the clusters. We keep those tasks temporarily un-allocated.
We then sort the un-allocated tasks in the increasing order of their initial slopes of
utility functions. As shown in Figure 3.12, the initial slope of a task is the ratio of the
utility and the resource requirement at its minimum non-zero QoS level. In other words,
we prioritize these tasks by their initial marginal utility values. We sequentially choose a
task from the list and allocate it to a group that is least populated. Finally, we perform
resource allocation within each cluster by executing AMRMD CM algorithm for each of them
individually.
For example, let us consider a multiprocessor system of R = l× p number of processors.
If we divide the system into P clusters p1, ..., pP , each cluster will contain RP = l number of
resources. Let us assume that we have 2 types of tasks a and b and the number of tasks of
types are na and nb respectively Hence, each cluster also obtains bna/P c number of tasks
of type a and bnb/P c number of tasks of type b. The number of un-allocated tasks are

3.3. Hierarchical Q-RAM in Multiprocessor System 57
Type a
Type b
p
p p
0
Figure 3.13: Hierarchical QoS Optimization with Clustering
(na/P − bna/P c) and (nb/P − bnb/P c) for types a and b respectively.
Based on task profiles, let us assume that the initial slope of a task of type a is higher
than that of type b. Therefore, we allocate the remaining tasks of type a among the clusters
first in a load-balancing manner followed by the remaining tasks of type b. In this way, we
approximately divide the system into P near-identical subsystems. Figure 3.13 illustrates
the process where each cluster contains a single processor i.e., l = 1. Algorithm 4 details
the whole procedure.
Complexity Analysis of H-Q-RAM
First, let us estimate the complexity of AMRMD CM in a multiprocessor system. If |Qm| denotes
the maximum number of QoS setting of a task and R denotes the number of processors. If

58 Chapter 3. Resource Allocation in Multiprocessor Systems
input : Tasks of fixed number of types and a multiprocessor systemoutput: QoS assignment and resource allocation of tasksCluster the resources/processors into p groups;Divide the tasks of each type into p identical groups. If the number of tasks of atype is not an integral multiple of p, keep the remaining tasks un-allocated;Each of the p identical groups of tasks is assigned to a distinct resource cluster, ofwhich there are p clusters;Form p identical groups of tasks and allocate them to p resource clusters;for all remaining tasks do
Perform Concave Majorant;Order with their initial slope of the utility-resource curve;
endfor all sorted remaining tasks do
Choose a task based on the highest initial slope, and allocate it to a group leastpopulated with the same type;
endfor all processor groups do
Run AMRMD algorithm for QoS optimization;Run the selected algorithm only once for multiple identical groups of tasks.Apply the result obtained directly on those subsequent groups;
end
Algorithm 4: Hierarchical Q-RAM Optimization for Multiprocessor System
tasks do not have any fault-tolerance requirements, the maximum number of set-points of
a task is given by L = |Qm|R. Using the expression of complexity obtained for the basic
AMRMD CM in Chapter 2, the complexity of the Q-RAM optimization in a multiprocessor
system is O(nL log(nL)) = O(n|Qm|R log(n|Qm|R)), where n is the total number of tasks.
For H-Q-RAM, if we divide the system into P clusters, the maximum number of set-
points of a task within a cluster is given by L = |Qm|RP . Each cluster contains d nP e tasks.
Hence the complexity of the optimization for each cluster is O(d nP e|Qm|RP log(d n
P e|Qm|RP )).
If we run the operation in a single processor the total complexity is (d nP e|Qm|R log(d n
P e|Qm|RP )),
but since the optimization per cluster can be performed in parallel the total complexity is
reduced to the complexity of a single cluster.
As can be seen from the expressions, the complexity of H-Q-RAM reduces by a factor
P 2 log(P ) compared to that of Q-RAM, where P is the number of clusters.

3.4. Performance Evaluation: H-Q-RAM 59
Number of task Types 8 (0,1,2,3,4,5,6,7)Type of a task random(0,7)Utilities on QoS dimension [0.5,0.7,0.8]/[0.4,0.6,0.65]Minimum resource 24− 2TypeResource increment random(16− 2Type, 20− 2Type)Distribution of task types: 12.5% each on averageNumber of processors 32Number groups formed 1, 2, 4, 8 and 16
Table 3.4: Experimental Specifications (H-Q-RAM)
3.4 Performance Evaluation: H-Q-RAM
In this section, we evaluate the scalability of H-Q-RAM. In this process, we primarily
measure the variation of execution time of H-Q-RAM with respect to the number of clusters
and the corresponding performance in terms of the accrued utility2.
We assume the presence of 8 types of tasks in the system. Each task is independently,
randomly assigned a task type out of these 8 different types. The specifications of the tasks
are detailed in Table 3.4. We assume a multiprocessor system consisting 32 processors.
Hence, we can create 1, 2, 4, 8 and 16 possible clusters under 5 different configurations and
each cluster has 32, 16, 8, 4 and 2 processors in those 5 configurations respectively. Having
a single cluster of all 32 processors is equivalent to the basic Q-RAM algorithm.
3.4.1 Multi-processor Resource Allocation
This experiment deals with the tasks that have no Fault-tolerant QoS specification. We
measure the maximum number of tasks admitted under each of the 5 configurations and
plot them in Figure 3.14. The result is the average over 100 randomly generated task-sets.
The results in Figure 3.14 show that the Hierarchical AMRMD (H-AMRMD) under each
grouping was able to admit nearly the same number of tasks as the non-hierarchical AMRMD.
The maximum drop in the number of admitted tasks was only 5%, from 291 in non-
2H-Q-RAM is transformed to the basic Q-RAM when there is only one cluster.

60 Chapter 3. Resource Allocation in Multiprocessor Systems
1 2 4 8 160
50
100
150
200
250
300Variation of number of admitted tasks (32 processors)
Number of groups formed
Max
imum
num
ber o
f tas
ks a
dmitt
ed
Figure 3.14: Number of Tasks (32 processors)
hierarchical version to 276 in the hierarchical version with 16 groups.
Next, we keep the number of tasks constant at 276, the maximum that can be admitted
by groups of 16 processors and measure the execution time under each case. The results
averaged over 100 iterations are presented in 3.15. It shows a very sharp drop in execution
time as the number of groups is increased. For example, the execution time for non-
hierarchical AMRMD is 73 times that of hierarchical AMRMD with groups of 16.
Next, we vary the number of input tasks from 16 to 256 and plot the utility and execution
time of the algorithms against the number of tasks in Figures 3.16 and 3.17. The results
show a negligible difference in utilities for a fixed number of tasks. It also shows a huge
drop in execution time (73 times for 276 tasks) as the number of groups is increased from
1 to 16.
3.4.2 Fault-tolerance and Hierarchical Q-RAM
In this experiment, we consider tasks having fault-tolerance as the only QoS dimension.
The specifications for the fault-tolerance are the same as presented in Table 3.3 of the non-

3.5. Chapter Summary 61
1 2 4 8 160
1
2
3
4
5
6
7
8
9x 105 Time variation with hierarchical Q−RAM (276 tasks)
Number of groups formed
Tim
e (u
sec)
take
n to
run
Figure 3.15: Run-time (276 tasks)
hierarchical case. Other configuration parameters are maintained to be the same as those
of the previous experiments.
As observed from Figures 3.18 and 3.19, a relatively smaller number of tasks (112 to 82)
are admitted with 16 groups. This is because each group of 16 has only 2 processors, and the
maximum number of replicas for the fault-tolerance is 2, thereby significantly reducing the
number of possible trade-off options. On the other hand, we observe 37, 000 times reduction
in the execution time as the grouping is increased from 1 to 16 (Figure 3.19). In addition,
all of the groupings produce a near-identical utility curve when we vary the number of tasks
from 16 to 76, as shown in Figure 3.21.
In summary, H-Q-RAM obtains a near-optimal system utility while reducing execution
time by two orders of magnitude or more.
3.5 Chapter Summary
In this chapter, we investigated extensions to Q-RAM to apply it to multi-processor systems.
We showed that AMRMD CM was able to admit more tasks and achieve larger global utility

62 Chapter 3. Resource Allocation in Multiprocessor Systems
0
1000
2000
3000
4000
5000
6000
7000
0 50 100 150 200 250 300
Util
ity a
crue
d ->
Number of Tasks ->
No grouping (1 group)2 groups4 groups8 groups
16 groups
Figure 3.16: Utility Variation (max 256 tasks)
values compared to the basic algorithm AMRMD1 with only a small increase in the execution
time. A similar pattern was observed when we used reliability as a QoS dimension.
Unfortunately, algorithms AMRMD1, AMRMD CM and AMRMD DP take too long to run when
allocating resources on large multi-processor systems. For example, a radar tracking system
may consist of a bank of 64 or more processors for signal processing tasks. It would take
around 5s to perform the resource allocation under AMRMD CM, which may be unacceptably
long.
We then presented a hierarchical decomposition approach for applying our QoS opti-
mization algorithms to such systems. In this approach, we divided the system into multiple
smaller identical subsystems and uniformly distributed tasks into those subsystems. Then,
we performed QoS optimization on each of these subsystems independently. We showed that
this hierarchical approach significantly reduced the execution time for all of the algorithms.
In particular, the resource allocation problem involving fault tolerance as a QoS dimension

3.5. Chapter Summary 63
0
5e+06
1e+07
1.5e+07
2e+07
2.5e+07
3e+07
3.5e+07
4e+07
4.5e+07
5e+07
0 50 100 150 200 250 300
Run
-tim
e (in
use
c) ->
Number of Tasks ->
No grouping (1 group)2 groups4 groups8 groups
16 groups
Figure 3.17: Run-time plot with grouping for 32 processors (max 256 tasks)
1 2 4 8 160
20
40
60
80
100
120Variation of the number of task admitted with F−T
Number of groups formed
Max
num
ber o
f tas
ks a
dmitt
ed
Figure 3.18: Number of Tasks under Fault-Tolerance

64 Chapter 3. Resource Allocation in Multiprocessor Systems
1 2 4 8 16102
103
104
105
106
107
108
Number of groups formed
Tim
e (u
sec)
take
n to
run
[Log
sca
le]
Time variation with groups FT (76 tasks)
Figure 3.19: Run-time (log-scale) under Fault-Tolerance
100
1000
10000
100000
1e+06
1e+07
1e+08
10 20 30 40 50 60 70 80
Exe
cutio
n tim
e (u
sec)
in lo
g-sc
ale
Number of tasks ->
No grouping (1 group)2 groups4 groups8 groups
16 groups
Figure 3.20: Run-time plot in log-scale with grouping for 32 processors under fault-tolerance(max 76 tasks)

3.5. Chapter Summary 65
10
15
20
25
30
35
40
45
50
55
10 20 30 40 50 60 70 80
Util
ity ->
Number of tasks ->
No grouping (1 group)2 groups4 groups8 groups
16 groups
Figure 3.21: Utility Plot under Fault-Tolerance (max 76 tasks)
becomes feasible as a result of our hierarchical approach since it reduces the execution time
by 5 orders of magnitude for a system of 32 processors. This difference increases with the
increase in the size of the system.
In the next chapter, we consider the extension of the first assumption where a task has
constraints in selecting resource trade-offs. For example, if a task needs a route between a
source and destination in a network, the selection of the links (as resources) is not arbitrary
and is dependent on the topology of the network.


Chapter 4
Resource Allocation in Networks
4.1 Introduction
In this chapter, we discuss QoS optimization in distributed networked environments. Apart
from the Internet, examples of distributed networked systems include sensor networks, au-
tonomous systems and overlay networks. In order to provide QoS to tasks executing on these
systems, we need to guarantee the allocation and scheduling of resources. The resources
include computational cycles, storage and network bandwidth across a route between the
source and the destination. For example, a typical video transmission application requires
a certain amount of network bandwidth and CPU cycles from various network links and
routers respectively. Higher quality in terms of its frame rates and resolutions requires a
greater quantity of these resources.
For a large number of tasks to be deployed on a system consisting of a large number
of resources, we designed a hierarchical scheme in Chapter 3 that provides near-optimal
resource allocation in a scalable manner. The hierarchical technique divides the problem
into smaller independent sub-problems. Specifically, it divides the system into identical
subsystems, assigns tasks to these subsystems in an equitable fashion so that each subsystem
obtains a (nearly) identical number of tasks of the same type, and then makes resource
67

68 Chapter 4. Resource Allocation in Networks
allocation decisions within each subsystem independently. Implementing this scheme on a
networked system, however, presents two major difficulties. First, it is difficult to divide a
networked system into a number of identical subsystems if the architecture is heterogeneous
(even if it is hierarchical). Secondly and most importantly, it is not possible to isolate the
subsystems in the network. This is because the route of a task can potentially span a very
large number of links and routers over the entire network. If we consider each network sub-
domain as a subsystem, many tasks can have routes across multiple sub-domains and thus
the resource allocation in one subsystem may be dependent on that obtained in another
and vice versa. Hence, multiple subsystems need to negotiate with each other in order to
determine near-optimal resource allocations.
4.1.1 Our Contribution
In the context of network QoS, we make our contribution in network bandwidth allocation
and route selection. However, our model differs in two fundamental ways. First, instead of
specifying a single QoS requirement, our Q-RAM-based QoS model allows a task/flow to
specify multiple levels of bandwidth and delay requirements for different levels of service.
Second, our resource allocation scheme determines the allocation of a near-optimal route
and a near-optimal network bandwidth along the route for each flow. The scheme relies on a
signaling protocol such as RSVP and packet scheduling policies across the network in order
to satisfy the network bandwidth reservations. In addition, as we will discuss later in this
chapter, it can also exploit the existing routing protocols to perform efficient optimization.
4.2 Modeling of Networked System
In this section, we describe our model of a distributed networked system. We first briefly
describe our generic resource allocation model based on Q-RAM. Next, we introduce a
graph-theoretical model of the network and demonstrate how to formulate and solve the

4.2. Modeling of Networked System 69
network QoS optimization problem in Q-RAM.
4.2.1 Network Model and QoS
We assume that the network is a distributed system consisting of multiple resources where
each resource corresponds to the link capacity in terms of the available bandwidth of the
link1. We consider a set of tasks that involve the transfer of data from one node in the
network to another. Each task has a set of QoS set-points in terms of bandwidth and
delay requirements. In addition, there is a utility associated with each of its set-points. In
general, a higher bandwidth provides higher quality and hence higher utility for a task. If
a network is modeled as an undirected graph, these tasks can be modeled as flows across
the graph with variable capacity requirements.
Q-RAM optimization in a network works as follows. Using the edges of the graph as
network links with a certain amount of bandwidth R, we construct a resource capacity
vector ~R = R1, . . . , Rm where m is the total number of weighted edges of the graph and Ri
is the bandwidth of the ith edge. We enumerate the operational dimensions of each task as
follows.
Set of bandwidth settings
The number of choices of bandwidth settings of a task τi is given by:
Bi = bi1, · · · , biNBi, (4.1)
where, NBi = number of possible bandwidth settings for task τi. The bandwidth maps
directly to the resource requirement on the network link.
1It is relatively straightforward to extend our formulation to include processing resources but we do notdo so for simplicity of presentation.

70 Chapter 4. Resource Allocation in Networks
Set of delay settings
The number of choices of delay settings of τi is given by:
Di = di1, · · · , diNDi
, (4.2)
where NDi = number of delay levels for τi.
The network delay encountered by a flow is dependent on the value of total bandwidth
(or speed) of the network link(s) used. It is expressed as the sum of three components:
(1) circuit delay (propagation delay of 1 bit), (2) transmission delay, and (3) switching
delay [68]. In our model, for simplicity, we assume that the circuit delay is much smaller
compared to the other two factors and much smaller than the minimum delay requirements
of the applications. The transmission delay is the manifestation of bandwidth capacities
of the links along a route. In other words, it is expressed as the sum of the transmission
delays of a single packet across each link. Finally, the switching delay is the sum of the
queueing delay and the processing delay at each node of the route. Assuming the node has
enough computing power, the queuing delay is a more dominant factor than the processing
delay. This, in turn, depends on the scheduling policy of the packet scheduler on the node.
Since our QoS model deals with resource allocation that separates it from the scheduling
concern at the lower level, we only need to consider the bandwidth of the links for our
model. We assume that once the bandwidth has been allocated, the router will have enough
processing cycles to process the packets between its incoming and outgoing links, and its
lower level packet scheduler can schedule the packets appropriately so that each flow meets
their deadlines 2.
In conclusion, assuming that the routers can provide scheduling guarantees to meet the
deadlines of the packets, the delay encountered by a flow is simply expressed as the sum
of the transmission times along all links in the route. In this case, we can also add an
2A lot of work in packet scheduling has been done in the past with varying degree of schedulable utilizationbounds on the routers [79, 39, 28].

4.2. Modeling of Networked System 71
estimated queueing delay time along each hop in the route. Having this constraint will
prevent the QoS optimizer Q-RAM from choosing a too long route. However, the delay
must be managed by a proper packet scheduling scheme once the bandwidth is allocated to
each flow or task.
Set of routes :
The number of choices of routes of a task τi is given by:
Pi = pi1 × · · · × piNPi
(4.3)
For a connected graph, we always have |Pi| ≥ 1.
The procedure for determining all the routes for a fixed source-destination (S-D) pair is
described in Algorithm 5. This is similar to the basic broadcast route discovery except that
all possible routes are discovered in this case. First, the source node broadcasts its route
request to the destination to its neighboring nodes. Each neighboring node, upon receiving
the request, constructs a temporary route, and forwards that route along with the original
request to all of its neighbors other than the sender of the request (in this case, it was the
source node). Each intermediate node copies that route, creates a new route adding itself
and sends that its other neighbors. An intermediate node makes sure to prevent cycles by
not forwarding the request to a neighbor that has already been included in the temporary
route that is copied. This process continues recursively until a neighbor does not have any
node to forward the request or the destination node is discovered.
Basic Q-RAM Algorithm
By combining Equations (4.1), (4.2) and (4.3), we obtain the set-points of the tasks Si :
Bi×Di×Pi. The utility of a set-point is obtained from the QoS dimensions as Bi → u,
while the corresponding resource requirements are obtained as Bi ×Di × Pi → R. Thus

72 Chapter 4. Resource Allocation in Networks
input : Source vertex S, Destination vertex D, Intermediate node I
//I = S for when the algorithm is called for the first time
output: Set of routes connecting S and D
// p = pending/incomplete route under consideration
//Vp = set of vertices for p
for All edges ei leaving I dor ← 0 ;//accept the link by default;if Next vertex N of the edge already belongs to the pending route then
r ← 1;endif r 6= 1 then
if N = D thenA route is constructed;Insert the route into the list of routes;Update the routing table entries of the vertices falling on this route;
endelse
I ← N ;Call this algorithm with (S, D, N) as inputs;//recursion;
endend
end
Algorithm 5: Basic Route Discovery Algorithm

4.2. Modeling of Networked System 73
a set-point is represented by qj , uj , (rj1 , . . . , rjm), hj where
qj = Quality level,
uj = Utility level,
(rj1 , . . . , rjm) = resource vector representing resource requirement at each edge of the
system, and
hj = compound resource describing a cost of allocating the resource.
The procedure is detailed in Algorithm 6.
input : profiles of tasks with bandwidth and network routesoutput: route and bandwidth allocation of tasks by maximizing utilityfor Each task i = 0 to n do
Determine QoS points as bandwidths Bi;Determine Pi as the set of resource options using Algorithm 5;Generate set-points Si = Bi ×Di × Pi for τi and map to resource requirementsSi → R in terms of link bandwidths;Determine “compound resource” as a scalar cost metric for each set-point;Determine concave majorant of the set-points based on their (compoundresource, utility) values and the corresponding gradient;
endMerge set-points of n tasks with decreasing values of their gradients and perform aglobal resource allocation starting with the point of highest gradient;
Algorithm 6: Basic Global QoS Optimization For Networks
Algorithm 6 is the most direct way of solving the problem of network bandwidth allo-
cation in Q-RAM. However, there are two main drawbacks to this approach.
First, it requires each task to enumerate all of its set-points, which, in turn, requires
them to determine all possible routes Pi between the source and destination. As the size
of the network increases, |Pi| increases exponentially, and the complexity of the whole
route discovery process supersedes the complexity of the optimization, making the process
intractable for large networks. Therefore, we must use an efficient route discovery technique
that can exploit the architecture of the network, namely hierarchical route discovery [34][53].
Second, suppose that each task has a small set(≤ 10 for example) of QoS levels for the
sake of simplicity. Even in this case, since Pi is the enumerated list of all routes between

74 Chapter 4. Resource Allocation in Networks
two nodes in the network, it can potentially be very large. Therefore, we must select a few
routes to make the problem tractable. The challenge is to pick these few routes such that
the resulting utility is close to what would be achieved if the exhaustive lists of routes were
considered.
4.3 Hierarchical Network Architecture
In this section, we first formulate the hierarchical network problem using Graph-theoretical
techniques. Next, we describe how this formulation can be used in decomposing our opti-
mization process.
4.3.1 Graph-Theoretical Representation
We follow the description of the hierarchical network model as presented for the Internet
[10, 34, 81]. The ATM forum also adopts a hierarchical architecture for their network [14].
The entire network is represented as a connected undirected graph G = (V,E) as shown
in Figure 4.1, where V denotes the set of vertices and E denotes the number of edges.
The nodes or vertices of a graph represent switches, and the edges represent links. The
bandwidth across each link ej is expressed as the capacity cj of an edge in the graph. If the
network is hierarchically organized, Gp represents the network architecture at a particular
layer p.
The nodes get clustered to form the graph of the next layer. The nodes of the same layer
that are clustered into the same higher layer are said to belong to the same peer group [14].
At a particular layer, a set of edges partition the graph into multiple induced subgraphs,
whose vertices form peer groups. This set of edges defines the edges of the graph at the
next higher layer. We call these edges backbone-edges. If two subgraphs are connected by a
single edge, their connecting backbone-edge becomes a cut-edge of the graph.
If we collapse all the vertices and edges of a subgraph Gi of G into a single vertex, it is

4.3. Hierarchical Network Architecture 75
Layer 3
Layer 2
Layer 1
Layer 1 backbone-edge
Layer 2 backbone-edge
(a) Layer 1 Architecture
Layer 2 vertices /Layer 1 Supervectices
(b) Layer 2 Architecture
Layer 3 vertices /Layer 2 Supervectices
(c) Layer 3
Figure 4.1: Hierarchical Graph Model of Network

76 Chapter 4. Resource Allocation in Networks
called a supervertex. Thus the graph at a higher layer is the supervertex graph of that of
the next lower layer. This layered architecture is illustrated in Figure 4.1. Expanding each
supervertex at any layer reveals the entire network of nodes in that subgraph at the lower
layer.
Let us consider a task that sends data from a source node x to a destination node y. We
define PG(x, y) to be the set of all possible routes from x to y. For a connected graph, we
have |PG(x, y)| ≥ 1. Let us also define pG(x, y) ∈ PG(x, y) as a particular route from x to
y. This is formed by concatenating a set of edges that connect x and y. This includes the
edges inside multiple sub-graphs and the backbone edges connecting them. Let us assume
that Vx and Vy are sets of vertices of two subgraphs of G such that x ∈ Vx,y ∈ Vy and
Vx ∩ Vy = ∅. Let the supervertices v′x and v′y of the supervertex graph G′ represent the sets
of vertices Vx and Vy in the original graph G. By definition, PG′(v′x, v′y) denotes the set of
routes between the supervertices v′x and v′y. Therefore, for every pG′(v′x, v′y) ∈ PG′(v′x, v′y),
there is at least one corresponding pG(x, y) ∈ PG(x, y).
Definition 4.3.1 (Border vertices). The vertices in two different induced sub-graphs that
are connected by one or more backbone-edges are known as border vertices.
Definition 4.3.2 (Sub-Route). The set of edges of a particular route connecting two
border vertices of an induced sub-graph between two backbone-edges is called a “sub-route”
or a “child-route”.
Definition 4.3.3 (Parent Route). The route in the supervertex graph that connects the
source and the destination supervertices is called the “parent route” of the “sub-routes”
internal to each supervertex of the (supervertex) graph.
According to the above definitions, each parent route has sub-routes within each super-
vertex it connects. Using the same notation, PG′(v′x, v′y) denotes the set of parent routes, and
each element in PG(x, y) consists of a concatenation of the edges from a route in PG′(v′x, v′y)
and its sub-routes one from each of the supervertices it traverses. As an example, in the

4.3. Hierarchical Network Architecture 77
Subdomain 1 Subdomain 2 Subdomain 3
dstsrc
Supervextex graph
S D
Backbone 1 Backbone 2
Route in the Supervertex Graph
Figure 4.2: Network sub-domain and Supervertex Graph Example for |PG′(v′x, v′y)| = 1
case of the Internet, border vertices denote the edge routers that connect two sub-domains,
a parent route represents a route corresponding to “Inter-domain routing” and a sub-route
represents that corresponding to “Intra-domain routing”.
Next, we state theorems dealing with route selection for a given flow with a fixed capacity
(or bandwidth) constraint.
Lemma 4.3.4 (Backbone edge and Route selection). If all routes in PG(x, y) share
the same set of backbone edges, in Graph G, then |PG′(v′x, v′y)| = 1.
Proof. If all routes in PG share the same set of backbone edges, they go through the same
set of subgraphs. In the supervertex graph G′, these subgraphs are replaced by vertices.
Thus all routes in PG(x, y) collapse to having the same set of supervertices and hence are
connected by the same set of edges in G′. Therefore they collapse to a single route. In other
words, |PG′(v′x, v′y)| = 1.
Let us consider the network of 3 sub-domains illustrated in Figure 4.2. The source node
is present in Sub-domain 1 while the destination node is present in Sub-domain 3. As can
be seen from the figure, every route connecting the source “src” and the destination “dst”
has to go through the same sub-domains 1, 2, 3 and the backbone edges 1 and 2 connecting
those sub-domains. Hence, in the supervertex graph, all routes collapse to a single route
that traverses across 3 supervertices.

78 Chapter 4. Resource Allocation in Networks
Next, we would like to determine the routes internal to each sub-domain. Using the same
example in Figure 4.2, we build a complete route between the source and the destination
by selecting a sub-route within each sub-domain that connects the backbone edges. We can
have multiple possible choices of sub-routes inside each sub-domain. If the selection of the
sub-route in one sub-domain does not affect the same at another, we say that the sub-routes
can be chosen independently of each other. Based on that, we state Lemma 4.3.5 under the
situation where we would like to determine a route of a particular bandwidth for a flow.
Lemma 4.3.5 (Independent Sub-Route Selection). For a fixed route pG′(v′x, v′y) ∈
PG′(v′x, v′y) in the supervertex graph with a fixed capacity (bandwidth) requirement, the sub-
routes inside each sub-graph can be chosen independently of each other.
Proof. Let us consider a hierarchical Graph G consisting of multiple induced subgraphs and
backbone edges joining them. The source node and the destination node of a particular task
are denoted by x and y respectively. Any route pG(x, y) ∈ PG(x, y) traverses a fixed set of
subgraphs g1, .., gl and a fixed set of backbone edges L1, .., Ll−1. If pg1 , .., pglare the sub-
routes in the respective subgraphs g1, .., gl of the route pG(x, y), then we express pG(x, y) as
pG(x, y) = pg1 ·L1 ·pg2 · . . . ·Ll−1 ·pgland the corresponding pG′ as pG′(v′x, v′y) = L1 · . . . ·Ll−1.
The maximum capacity of the route pG(x, y) is given by
c(pG(x, y)) = min(c(pg1), c(L1), c(pg2), c(L2), ..., c(Ll−1), c(pgl)), (4.4)
and that of pG′(v′x, v′y) is given by
c(pG′(v′x, v′y)) = min(c(L1), c(L2), ..., c(Ll−1)). (4.5)

4.3. Hierarchical Network Architecture 79
Combining Equations (4.4) and (4.5), we obtain:
c(pG(x, y)) = min(c(pG′(v′x, v′y)), c(pg1), c(pg2), ..., c(pgl), (4.6)
⇒ c(pG(x, y)) = min(c(pg1), c(pg2), ..., c(pgl), (4.7)
⇒ c(pG(x, y)) ≤ c(pgi), ∀1 ≤ i ≤ l. (4.8)
This shows that selecting edges inside each subgraph can be performed independently
under a fixed capacity constraint.
Delay and Hierarchical Routing Lemma 4.3.5 holds true when delay is not considered.
The approximated delay is the main drawback of hierarchical routing [53]. In order to satisfy
the delay constraint in terms of the number hops as mentioned in Section 4.2.1, we divide
the delay requirements equally in each subgraph falling in the route, similar to what is done
in [39].
Based on Lemma 4.3.4 and Lemma 4.3.5, we state a theorem on the complexity of route
selections.
Lemma 4.3.6 (Complexity of Route Selections). Suppose all routes in PG(x, y) share
the same set of backbone edges L1, . . . , Ll−1, and hence the same set of subgraphs g1, . . . , gl
in Graph G. Furthermore, suppose that the set of edges for the route within a subgraph
gi can be chosen in si different ways under a bandwidth constraint. Then the number of
possible routes is∏l
i=1 si and the number of computational steps required to choose a route
is∑l
i=1 si.
Proof. Using the notation from (4.4), the set of links pg1 satisfying the bandwidth constraint
from the sub-graph g1 can be chosen in s1 different ways. From Lemma 4.3.5, for each choice
in g1, we can choose the set of links in g2 by s2 different ways and so on. Therefore, the
maximum number of possible ways a route can be selected is s1 × . . .× sl =∏l
i=1 si.

80 Chapter 4. Resource Allocation in Networks
Next, the number of steps required to choose the near-optimal set of edges inside a
subgraph gi (sub-route) is si. Since all routes map to a single route in the supervertex
domain, Lemma 4.3.5 proved that the selection of edges in each subgraph can be done
independent of each other under a fixed capacity requirement. Therefore, the maximum
number of steps required to choose a suitable route is s1 + . . . + sl =∑l
i=1 si.
Based on Theorem 4.3.6, we describe our hierarchical route discovery method next.
Later, we will also discuss how it also assists in hierarchical QoS optimization.
4.3.2 Hierarchical Route Discovery
The process of route discovery assumes a top-down approach. In other words, we obtain
the set of routes for a task at its highest level of network hierarchy. Next, for each of the
(super)vertices in each route, we obtain the sub-routes inside the subgraphs represented by
those vertices. The process starts with the highest level of the task and continues to the
lowest level of the hierarchy. This recursive procedure is described in Algorithm 7. From
Theorem 4.3.6, if we would like to determine ηth number of sub-routes for each sub-domain,
the complexity of hierarchical route discovery is O(pηth), where p is the number of sub-
domains. On the other hand, a flat route discovery will have the complexity of O(ηpth) for
the same set of routes.
For each subgraph at every level, Algorithm 7 determines the set of routes between the
two edge routers using Algorithm 5 or the more efficient Algorithm 8.
4.4 Selective Routing
As proved in Theorem 4.3.6, the hierarchical scheme is able to reduce the complexity of
the route discovery process. However, it does not reduce the overall number of routes per
task. In order to reduce the complexity of the Q-RAM optimization, we must also limit the

4.4. Selective Routing 81
input : Level of the hierarchy of the graph, source and destination nodesoutput: Hierarchical routes between source and destination nodesDetermine routes between source and destination node within their domain (AS);//Use Algorithm 5 or 8 or something similar;
if Level of the routes is not the lowest thenfor Each node in the route do
Obtain the corresponding subgraph represented by the node;Determine the entry router node and the exit router node of the subgraph;Call this Procedure between the above two nodes within the domain of thesubgraph recursively;
endend
Algorithm 7: Hierarchical Broadcast Route Discovery
number of routes per task.
The route discovery process employed in our scheme is developed in three phases, start-
ing from generating the exhaustive lists of routes for each task to a smart discovery of
a fewer routes, with the aim of improving on the execution time without incurring any
significant loss in overall utility.
4.4.1 Broadcast Routing
Broadcast routing is the basic approach that uses flooding from the source across the net-
work to determine all possible routes to the destination. It assumes that each node only
knows its neighbors. This process can potentially yield an exponentially large number of
routes, and can therefore become intractable as the size of the network increases.
4.4.2 Smart Route Discovery
Instead of choosing all possible routes between a source and a destination, we would like to
select only a few best or least-cost routes. We use a metric called Route Count Threshold.
Definition 4.4.1 (Route Count Threshold). The route count threshold is defined as
the maximum number of choices of routes for a particular source-destination pair.

82 Chapter 4. Resource Allocation in Networks
input : Source vertex S, Destination vertex D
output: Set of routes connecting S and D
// p = pending/incomplete route under consideration
//Vp = set of vertices for p
if T > Tth thenSort all edges ei connected to I within the Graph in terms its minimum cost ofrouting to D ;//T = Task ID, Tth = Task Count Threshold
endfor All edges ei do
r ← 0 ;//accept the link by default
if The cost of a potential route added by the load of the edge exceeds themaximum cost of the routes already included and the number of routes ηi = ηth
thenr ← 1 ;// reject this link from route discovery
endelse if Next vertex N of the edge already belongs to the pending route then
r ← 1;
if r 6= 1 thenif N = D then
A route is constructed;Insert the route into the list of routes;Update the routing table entries of the vertices falling on this route;
endelse
I ← N ;Call this algorithm recursively;
endend
end
Algorithm 8: Smart Route Discovery

4.4. Selective Routing 83
We denote this limit by ηth. We assume that the number of hops is the measure of the
cost of a route. Using this principle, for ηth = 1, we know that Dijkstra’s shortest route
algorithm can provide the best route between a source and a destination [22]. However,
Dijkstra’s algorithm for each source-destination has O(|V |2) complexity, where |V | is the
number of nodes. This can be quite expensive for large networks.
Another alternative is the Bellman-Ford algorithm. This algorithm finds the shortest
routes from a single source vertex to all other vertices in a weighted, directed graph [6, 24].
The algorithm initializes the distance to the source vertex to 0 and all other vertices to
∞. It then does |V | − 1 passes over all edges relaxing, or updating, the distance to the
destination of each edge. The time complexity is O(|V ||E|), where |E| is the number of
edges. A variant of this algorithm is used for distance-vector routing in the Internet, such
as RIP, BGP, ISO IDRP, NOVELL IPX etc.
In our routing scheme that we call “Smart Route Discovery”, we use a modified version
of the Bellman-Ford algorithm within each sub-domain of a network, where we determine
ηth shortest routes for each source-destination pair.
4.4.3 Route Caching
In a distance vector routing algorithm a router learns routes from neighboring routers’
perspectives and then advertises the routes from its own perspective. We implement a
reactive distance vector routing protocol in our simulation.
According to this protocol, each node (router) is initialized with the routes of its next
hop neighbors. The algorithm discovers routes of a task starting from its source. Once a
route is established, each node across the route adds the entry to its routing table. The
existing routing table, in turn, is exploited in route discovery. During this process, at any
intermediate node, we sort the neighboring vertices in increasing order of the minimum cost
of routing to the destination based on their routing tables, and reject the neighbors with
more expensive routing in their tables once the number of routes reaches the limit ηth. This

84 Chapter 4. Resource Allocation in Networks
algorithm can provide a potentially sub-optimal route compared to the exhaustive discovery
of the best routes. Therefore, we would like to use this routing information to assist in this
step only after we finish discovering routes for a sufficient number of tasks. We define a
parameter called Task Count Threshold Tth.
Definition 4.4.2 (Task Count Threshold). The task count threshold is defined as the
number of tasks whose routes are determined by exhaustive search using only the next-hop
routing information for each node.
The exploitation of cached routes is simply used to reduce the complexity of route
discovery process. The process becomes intractable for a large dynamic system if we perform
the exhaustive search for every incoming request. Instead, we eliminate this complexity
using cached routing information present in the node. However, we need to make sure that
the network is sufficiently discovered by nodes. Otherwise, the cached route information
at the intermediate nodes may provide sub-optimal routes. Therefore, we would like to
have Tth to be sufficiently large so that the cached routing information can be used without
significantly sacrificing optimality. Route caching is very important in a dynamic networked
system, where flows dynamically enter and leave the system.
Algorithm 8 describes the procedure for Smart Route Discovery that includes the usage
of parameters ηth and Tth.
4.4.4 QoS Optimization in Large Networks
So far, we have discussed a single centralized optimization scheme that distributes band-
width among tasks. In a large network, a centralized scheme is likely to be infeasible. In
addition, it may not scale well with a very large number of tasks. In the next section, we
will describe a hierarchical QoS optimization technique that exploits the inherent hierarchy
of the network. It can also be distributed across the entire system, thus making the QoS
optimization feasible and scalable for a large network using a large number of tasks or flows.

4.5. Hierarchical QoS Optimization (H-Q-RAM) 85
4.5 Hierarchical QoS Optimization (H-Q-RAM)
In this section, we present H-Q-RAM for networks that utilizes the hierarchical architecture
of networks [81]. In this dissertation, we confine our discussion to only 2 levels of hierarchy
for ease of presentation. The process is divided into two major steps. They are: (1) hierar-
chical concave majorant operation, and (2) distributed resource allocation. The process is
outlined in Algorithm 9 which will be described in detail in the following sections.
g2
S
G1G2
G
1
23
4 5
11D6
7
89
10
S :u,q,<R> ,h
S :u,q,<R> ,h
g1 g
2
S:u,q,<<R> ,<R> >,h + h
Subgraph set−pointSubgraph set−point
Composite set−point
g1 g2
1g
g1
2g
1g g
2
Figure 4.3: Compound Resource Composition
4.5.1 Hierarchical Concave Majorant Operation
This process is divided into 2 steps. First, we generate separate profiles for each task in
each of the sub-domains containing its sub-routes. Second, we combine information from
each sub-domain and update the set-points.
Creation of Multiple Profiles
At the lowest level for each sub-graph, we obtain the set of tasks whose routes include the
sub-graph. Next, we generate local set-points Si = Bi × Dig × Pig for these tasks, where

86 Chapter 4. Resource Allocation in Networks
Pig is the set of sub-routes inside the subgraph g and Dig is the delay assigned for the
route inside subgraph g. As mentioned before, a set-point consists of a utility value, a
corresponding QoS level and a resource vector specifying the route inside the subgraph and
the bandwidth requirement of the links of that route. Thus each task has distinct profiles
within each subgraph.
Next, we evaluate the compound resources for set-points. Using compound resource
values, we prune the list of set-points and discard the ones that are “inefficient”. A set-
point is called inefficient if it has a larger compound resource value than another point at
the same utility level. In other words, if we have multiple set-points for a particular value
of utility, we keep the one that has the smallest compound resource value and discard the
rest. If there is more than one set-point with the same minimum compound resource value
at a utility level, we keep all of those points as co-located set-points (see Chapter 2).
Creation of Composite Profiles
We next merge the profiles of multiple subgraphs or sub-domains into a single profile for
each task. First, we choose a single set-point for each utility value from each subgraph for
each parent route, and then combine the compound resource values of all subgraphs. Since
all the resources in this case are considered to be of identical type (as network links), the
compound resource of the global set-point of a task spanning two subgraphs g1 and g2 is
given by:
hcomp = hg1 + hg2 , (4.9)
where hg1 and hg2 are the compound resource values of the task(or flow) at its particular
quality setting in the two sub-domains g1 and g2. The generation of a composite set-point
is illustrated in Figure 4.3, where the local set-points of the subgraphs are assumed to be
(Sg1 : u, q, < R >g1 , hg1) and (Sg2 : u, q, < R >g2 , hg2) for a particular value of utility u and
quality level q.

4.5. Hierarchical QoS Optimization (H-Q-RAM) 87
G1
G
Optimization thread 1
Optimization thread 2
Global Information Transaction
G2
Figure 4.4: Distributed QoS Optimization
Second, we determine the concave majorant of these global set-points.
Third, we replace the compound resource values of the local set-points in each sub-
domain by the corresponding composite compound resource values. For example, as shown
in Figure 4.3, the set-points for a task in subgraphs g1 and g2 are changed from (Sg1 : u, q, <
R >g1 , hg1) and (Sg2 : u, q, < R >g2 , hg2) to (Sg1 : u, q, < R >g1 , hg1 + hg2) and (Sg2 : u, q, <
R >g2 , hg1 +hg2) respectively. In addition, since the concave majorant operation eliminates
set-points, a few global set-points may be discarded. In that case, we also discard the
corresponding local set-points in the subgraphs.
Finally, we merge all the local set-points of tasks in each sub-domain to create lists of
set-points called slope lists (see Section 2.3), which are going to be traversed for resource
allocation purposes. As mentioned in Chapter 2, the set-points in the slope list are ordered
by increasing slope or marginal utility values. We will discuss the resource allocation in the
next section.
4.5.2 Transaction-based Resource Allocation
We perform concurrent resource allocation within each sub-domain. Thus, the entire global
resource allocation problem is partitioned into multiple sub-problems within each subgraph,

88 Chapter 4. Resource Allocation in Networks
for Each sub-domain in the network dofor Each task in the sub-domain do
Determine set-points Qi = Bi ×Di × Pg(i) ;//Pg(i) = number of sub-routes for task τi in the domain;
endendfor Each task in the entire network do
Generate global set-points by combining compound resource at each utilitylevel;Perform concave majorant on global set-points;
endfor Each sub-domain in the network do
for Each task in the sub-domain doDiscard the set-points whose global counter-part has been eliminated byconcave majorant operation;
endMerge the remaining set-points of all tasks in the sub-domain in a single list;
endfor Each sub-domain in the network do
Execute transaction-based resource allocation as described in Figure 4.5;end
Algorithm 9: Hierarchical Distributed QoS Optimization

4.5. Hierarchical QoS Optimization (H-Q-RAM) 89
similar to the situation in Chapter 3. However, the sub-problems are not completely in-
dependent of each other in this case, since some tasks may be present in more than one
sub-problem. Such tasks must be assigned the resources to achieve the same utility value
(or quality setting) in all the sub-problems that they are present in. This requires coordi-
nation between these sub-problems, since a resource allocation in one sub-domain may be
infeasible in another sub-domain. In this context, we define three parameters.
Definition 4.5.1 (Local Task). A task is called a local task if its source and destination
nodes are in the same sub-domain.
Definition 4.5.2 (Global Task). A task is called a global task if its source and destination
nodes are in different sub-domains.
Definition 4.5.3 (Locality of Tasks). The locality is the fraction of tasks that are local,
Distributed Negotiation
The resource allocator in each sub-domain sequentially goes through its slope list. If it finds
the set-point in the list belonging to a local task, it determines its feasibility of allocation
locally, and accepts or rejects it based on the availability of local resources. Hence it works
independently for local tasks assuming that the best route for a local task is available within
the sub-domain it belongs to3.
When the allocator comes across a set-point of a global task that needs to have a route
spanning multiple subgraphs, it does the following. First, it checks if the corresponding
global set-point has already been rejected. It happens when another sub-domain that is
included in the parent route of the task fails to allocate the corresponding local set-point.
In that case, the current allocator also discards the set-point and moves on. Otherwise,
it marks the set-point as allocable and waits until every other sub-domain along the route
decides the allocations of their corresponding set-points. During this time, it goes to sleep3A network sub-domain is designed in such a way that the best route for a local task falls within the
sub-domain unless its links are extremely crowded.

90 Chapter 4. Resource Allocation in Networks
and and wakes up only when all other sub-domains make their decisions. Upon waking
up, it checks if the allocation has been successful. The allocation becomes successful when
all sub-domains are able to allocate their corresponding local set-points that complete the
route with a specific utility value. The allocation is unsuccessful if one of the sub-domains
fails. Upon a successful allocation, it finalizes the local allocation. Otherwise, it rejects the
initial tentative allocation. Next, it proceeds further to complete the operation of QoS-based
resource allocation.
Deadlock Avoidance in Negotiation
Since allocators negotiate the allocation for set-points belonging to global tasks, it is im-
portant to ensure that a deadlock never happens. Since an allocator follows the slope list
that is ordered in the increasing marginal utility4 values, it is feasible to have the same
marginal utility values for multiple set-points belonging to different tasks or flows or for
different routes of the same task. In that case, we must implement an ordering mechanism
of set-points to avoid any deadlock.
We implement two levels of ordering to avoid the deadlock. First, we assign a global
number to each flow or task in the entire network. This global number can obtained as a
combination of IP addresses of the source and the destination nodes, and the corresponding
port numbers.
Second, we also assign a global number to each “Parent Route” within a flow. Using
these numbers, we resolve the contention in the slope list when multiple set-points have the
same marginal utility value. First, we order them in the increasing order of their global
flow IDs. Next, for multiple co-located set-points of the same flow, we order them in the
increasing order of their Parent Route IDs. For the co-located points of the same Parent
Route of the same task, we do not require any ordering since their selections are independent
in sub-domains, as proved in Lemma 4.3.5. The allocation process is illustrated in Figure 4.44The marginal utility of a task is defined as the ratio of the difference between the utility values and the
compound resource values between two successive set-points of different utility values.

4.5. Hierarchical QoS Optimization (H-Q-RAM) 91
and is detailed by a flow-chart in Figure 4.5.
Start
Any pending global
allocation?
Check the next set-point in the list that
increses the current utility of the task
1. Feed the list with sorted set-points
of all tasks2. Utitlities of tasks
intialized to '0.0'
Local Task?
Y
Resource allocation feasible?
Y
Allocate
N
Resource allocation
locally and globally feasible?
Y
Mark it allocable
Task allocated/rejected by other allocator(s)?
Sleep and wait for
the completion of the total allocation
N
N
YAllocated?
AllocateLocally
Y
De-allocateLocally
N
Y
Next set-point is co-located of this one (of same parent path)?
N
N
Y
Mark it rejected
Wake up
pointleft?
Finished!
N
Y
Figure 4.5: Distributed Resource Allocator

92 Chapter 4. Resource Allocation in Networks
4.5.3 Complexity of Network QoS Optimization
In this section, we compare the complexities of the Q-RAM and the H-Q-RAM optimization.
Q-RAM Complexity
Suppose there are n tasks in the entire network. Using the same notation as before, let
us assume that |Qm| denotes the maximum number of QoS settings, ηth = maxni=1|PG(i)|.
This definition yields the the maximum number of set-points L = |Qm||etath|. Hence, the
complexity of the concave majorant operation is O(n|Qm| log |Qm|), and the complexity of
the merging operation is O(n|Qm||etath| log(n)).
Since the complexity of the Q-RAM optimization is the sum of the complexities of the
concave majorant and the merging operation, we have the total complexity as O(n|Qm|(log |Qm|+
|etath| log(n)))
H-Q-RAM Complexity
For H-Q-RAM, initial local set-point pruning has O(lnl|Qm|ηth) complexity per sub-domain,
where l equals the number of sub-domains and nl equals the maximum number of tasks per
sub-domain. Unlike the Q-RAM optimization, ηth denotes the upper limit on the number
of routes inside each sub-domain for a task.
Next, we have the concave majorant operation that has the global complexity of O(n|Qm| log(|Qm|)).
The second pruning operation after the concave majorant also has the same complexity
O(lnl|Qm|ηth).
The merging operation requires O(lnl|Qm|ηth log(nl)) steps, and the distributed trans-
action requires a maximum of O(nlηth|Qm|) steps per sub-domain.
We can now express the generic complexity expression for H-Q-RAM, namely: O(lnl|Qm|ηth)+
O(n|Qm| log(|Qm|))+O(lnl|Qm|ηth)+O(lnl|Qm|ηth log(nl))+O(nlηth|Qm|) = O(n|Qm| log(|Qm|)+
O(n|Qm|(log |Qm|+ lnln ηth log(nl))).

4.6. Experimental Evaluation 93
From the expression, in the worst case, when every task has a profile in every sub-
domain, we have nl = n. Then, the complexity of H-Q-RAM is higher than that of Q-RAM.
In the best case, which corresponds to the case when every flow is a local task that does
not span sub-domains, we have nl = n/l, which is better than that of Q-RAM. However,
in a very large network (the size of the Internet), it is very unlikely that a task traverses
across all sub-domains. Therefore, H-Q-RAM performs better than Q-RAM for practical
cases. Since H-Q-RAM computations can be distributed (one node per sub-domain), we
can further reduce the complexity to O(nl |Qm|(log |Qm|+ nl
n ηth log(nl))). Thus, H-Q-RAM
can scale well with large networks.
4.6 Experimental Evaluation
Our experimental evaluation is intended to quantify the performance of H-Q-RAM and Q-
RAM in terms of the trade-off between optimality and scalability. We focus on measuring
two main parameters:
• the global utility obtained by the optimization, and
• the total execution time of the algorithm.
First, we investigate the efficiency of our enhancements in route discovery. We deter-
mine how a selective set of routes obtained through our smart route discovery process can
eliminate the necessity of selecting a large number of routes for the optimization purposes.
We also investigate the performance of the optimization when we vary the parameter Tth.
Second, we compare the performance of H-Q-RAM optimization with respect to Q-RAM
optimization.
4.6.1 Experimental Configuration
In order to validate our technique, we generate network topologies using BRITE [56, 57] a
topology generation tool. The bandwidth distribution of the network links is presented in

94 Chapter 4. Resource Allocation in Networks
Table 4.1: Settings of Tasks
Number of QoS dimensions (Bandwidth, Delay) 2Length of bandwidth dimension random(1, 4)Length of delay dimension 1Minimum Bandwidth(Bmin) min((Rayleigh Distr. : µ = 152 Kbps),
8000.0 Kbps)Bandwidth Increment 0.3Bmin
Maximum Delay random(16, 20) hops
Utilities for QoS dimension (u(q)) (0.5,0.7,0.8)
Table 4.2: Settings of NetworksNetwork topology generator BRITE [56]Intra-domain link bandwidth 10.0 Mbps
Inter-domain link bandwidth 10000.0 Mbps
Table 4.2.
The specifications of the tasks are presented in Table 4.1. As seen from the table,
the minimum bandwidth is randomly chosen following a Rayleigh distribution with µ =
152 Kbps. This distribution ensures a positive value for the minimum bandwidth of any
task. For simplicity, we choose a single value of delay, which is expressed by a certain
maximum number of hops for a route. The source and the destination nodes of a task are
chosen randomly across the entire network. The experiments are performed on a 2.0 GHz
Pentium IV processor with 768 MB of memory.
4.6.2 Performance Evaluation of Selective Routing
In this section, we evaluate the performance of the selective routing algorithms.
Results on Smart Route Selection
In this experiment, we demonstrate the effectiveness of smart route selection as described
in Section 4.4.2.

4.6. Experimental Evaluation 95
0
50
100
150
200
250
300
350
400
0 50 100 150 200 250 300 350
Uti
lity
Number of Tasks
Random Path DiscoverySmart Path Discovery
Figure 4.6: Comparison of Smart Route Discovery and Random Route Discovery
0
50
100
150
200
250
300
350
400
0 100 200 300 400 500 600 700
Uti
lity
Number of Tasks
ηth = 1ηth = 2ηth = 5
ηth = 80ηth =∞ in bar-graph
Figure 4.7: Utility Variation with Number of Routes

96 Chapter 4. Resource Allocation in Networks
First, we compare the smart route discovery algorithm with the random route discovery
algorithm, where we randomly select ηth routes out of all possible routes. We vary the num-
ber the number of tasks in the system in geometric progression as N = 10, 20, 40, . . . , 640.
We plot the accrued utility against the number of tasks for ηth = 5 under both schemes
in Figure 4.6. The results show that a random route selection scheme yields a much lower
utility (29.5% for N = 320) compared to the smart route selection.
Next, we compare smart route selection for different values of ηth. In this case, we use
5 values of ηth as [1, 2, 5, 80,∞]. The value ∞ signifies that all possible routes are chosen
for each source-destination pair. The plots of utility against the number of tasks are shown
in Figure 4.7. The “ηth =∞” case is shown by the bar graph instead of a line.
From the bar graph, we observe that we do not have any data beyond N = 40 for
ηth = ∞. This is because for N ≥ 80, the route discovery and the optimization processes
become intractable. This is further confirmed by its steep rise in execution time as shown
in Figure 4.8.
On average, the utility increases as ηth increases since it provides more alternative
routes for each task. However, the difference between utilities at ηth = 5 and ηth = ∞
is statistically insignificant(< 0.09%), whereas the reduction in execution time for ηth = 5
is 93.6% (or, 15.6 times). Overall, we observe a 99.997% (or, 38239.4 times) reduction in
execution time for ηth = 5 relative to ηth = ∞ when the number of tasks is 40. Even for
ηth = 2, the reduction in utility is only 3.57% relative to ηth = 80 for 640 tasks, with a
run-time reduction of 96.9%.
Results on Route Caching
This experiment demonstrates how caching route information helps in reducing the execu-
tion time of the optimization. In this case, we fix the number of tasks N to 640 and vary
the parameter Task Count Threshold Tth. Figure 4.9 shows the percentage drop in utility
for different values of Tth compared to the same under no Route Caching, or Tth =∞. The

4.6. Experimental Evaluation 97
0.0001
0.001
0.01
0.1
1.0
10.0
100.0
1000.0
0 100 200 300 400 500 600 700
Opt
imiz
atio
nR
un-T
ime
(s)
Number of Tasks
ηth =∞ (All Paths)ηth = 80ηth = 5ηth = 2ηth = 1
Figure 4.8: Run-Time Variation with Number of Routes
-10
-8
-6
-4
-2
0
0 10 20 30 40 50 60 70
Per
cent
age
Uti
lity
Dro
p
Task Count Threshold (Tth)
Figure 4.9: Percentage Utility Drop with Routing Task Count Threshold

98 Chapter 4. Resource Allocation in Networks
-80
-70
-60
-50
-40
-30
-20
-10
0
0 10 20 30 40 50 60 70
Per
cent
age
Exe
cuti
onT
ime
Cha
nge
Task Count Threshold (Tth)
Figure 4.10: Percentage Run-Time Variation with Routing Task Count Threshold
value of ηth is kept constant at 5.
We observe that even for Tth = 1, for example, we start exploiting route discovery
information right after the first task’s routes have been determined. The percentage loss of
utility is less than 3%. On the other hand, we also observe a huge drop in execution time
(> 60%) as shown in Figure 4.10.
Using the route caching technique, the route discovery time per task will reduce with
time as nodes keep adding more entries to their routing tables. Figure 4.11 shows the plot
of route discovery time per task against the number of tasks considered for optimization.
It clearly shows that the route discovery time decreases exponentially with the number of
tasks. Hence it decreases with time in a dynamic system where tasks regularly arrive in and
depart from the system. In other words, we can claim that in a dynamic scenario, in steady
state, the optimization time dominates the route discovery time. This is also corroborated
in Figure 4.12, which shows the ratio of route discovery time and optimization time per
task.

4.6. Experimental Evaluation 99
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
11000
0 2000 4000 6000 8000 10000 12000 14000
Rou
ting
Dis
cove
ryT
ime
per
Tas
k
Number of Tasks
Figure 4.11: Average Execution Time for Route-discovery Simulation Per Task
0
0.05
0.1
0.15
0.2
0.25
0.3
0 2000 4000 6000 8000 10000 12000 14000Q-R
AM
/Rou
teD
isco
very
Rat
ioPer
Tas
k
Number of Tasks
’Ratio in run-time’
Figure 4.12: Ratio of Q-RAM Optimization Time To Route-Discovery Per Task

100 Chapter 4. Resource Allocation in Networks
Table 4.3: Specifications of the NetworksNetwork ID Number of Sub-domains Number of nodes Number of links1 5 100 2072 8 160 3343 15 450 9304 20 600 1240
4.6.3 Performance Evaluation of Hierarchical Optimization
In this section, we evaluate the performance of Hierarchical QoS optimization. We use 2
levels of hierarchy for our experimental evaluation. We use the same specifications of tasks
as mentioned in Table 4.1. In order to validate the usefulness of H-Q-RAM, we use larger
networks, consisting of 5, 8, 15 and 20 sub-domains respectively. Their specifications are
presented in Table 4.3, and their bandwidth distributions as specified in Table 4.2. For these
large networks, we use ηth = 2, and Tth = 1, since these settings have provided reasonably
good utility values(< 5%) with great reductions execution time for smaller networks.
0
500
1000
1500
2000
2500
3000
3500
0 2000 4000 6000 8000 10000 12000
Uti
lity
Number of Tasks
Q-RAMH-Q-RAM
Figure 4.13: Absolute Utility Variation in Q-RAM and H-Q-RAM
In the first experiment, we use Network 3 from Table 4.3. In this case, we vary the
number of tasks for optimization between 100 and 10240 in a geometric progression with

4.6. Experimental Evaluation 101
0
1000.0
2000.0
3000.0
4000.0
5000.0
6000.0
7000.0
0 2000 4000 6000 8000 10000 12000
Exe
cuti
onT
ime
(sec
)
Number of Tasks
Q-RAMH-Q-RAM
Figure 4.14: Absolute Execution Time Variation in Q-RAM and H-Q-RAM
a power of 2. Figure 4.13 shows the variation of utility between Q-RAM and H-Q-RAM
against the number of tasks. Figure 4.14 shows the variation of execution time against the
number of tasks.
We observe that H-Q-RAM reduces the optimization time for 10, 240 tasks by 64%
while incurring a utility reduction of less than 2% utility than Q-RAM. From Figure 4.14,
we also observe that the difference between Q-RAM and H-Q-RAM increases further with
the increase in the number of tasks.
Implementation Considerations: As can be seen from Figure 4.14, the execution time
of the optimization increases exponentially for a large number of tasks to be deployed
in larger networks. This is because the simulation becomes memory-intensive under this
situation and hence many page faults and swapping operations cause the non-linear (expo-
nential) increase in the execution times. Consequently, it becomes difficult to simulate the
hierarchical optimization of a very large network in a single host, as the memory require-
ment for the optimization process also increase. This effectively suggests the necessity of

102 Chapter 4. Resource Allocation in Networks
0
2
4
6
8
10
10 20 30 40 50 60 70 80 90
Per
cent
age
Los
sin
Glo
balU
tilit
y
Locality of Tasks(%)
Number of SubNets=5Number of SubNets=15Number of Subnets=20
Figure 4.15: Variation of Percentage Utility Loss for 6400 Tasks with the Number of Sub-domains
studying the performance improvement of distributed transaction-based optimization using
H-Q-RAM. The execution time for H-Q-RAM will be reduced further if the optimization
is distributed over multiple hosts. This will be the only option available, since running the
Q-RAM optimization for all the tasks in a single host becomes intractable.
Next, we measure the performance of H-Q-RAM relative to the locality of tasks in
different sub-domains. From our complexity analysis, we know that H-Q-RAM performs
best when the source and the destination of a task are confined within a single domain, which
in turn also eliminates transactions between sub-domains during the optimization step. In
this experiment, we keep the number of tasks constant at 6400 and vary the locality of tasks
between 0% and 96% and measure the performance of Q-RAM and H-Q-RAM. The results
are taken for Networks 1, 3 and 4 from Table 4.3.
Figure 4.15 plots the percentage loss in utility under H-Q-RAM, which does not exceed
4.5%. In addition, the loss drops with the increase in the locality of the task and with the
increase in the size of the network.

4.6. Experimental Evaluation 103
-40
-20
0
20
40
60
80
100
10 20 30 40 50 60 70 80 90Per
cent
age
Red
ucti
onin
Exe
cuti
onT
ime
Locality of Tasks(%)
Number of SubNets=5Number of SubNets=15Number of Subnets=20
y=0 Line
Figure 4.16: Variation of Percentage Run-Time Reduction for 6400 Tasks with the Numberof Sub-domains
Figure 4.16 plots the percentage gain in execution time under H-Q-RAM. As seen from
the figure, H-Q-RAM actually has 20% higher execution time under 0% task locality for
the smallest network (Network 1 with 5 sub-domains). However, it increases with the size
of the network as well as with the locality of the tasks. Moreover, the rate of increase in
percentage gain decreases with the increase in the size of the network. In other words, for a
very large network, H-Q-RAM performs better than Q-RAM and the significance of locality
on this performance decreases.
The above experiment shows that H-Q-RAM provides a significant gain in performance
when (a) the size of the network is large, and (b) the locality of the tasks is high. These
results are in agreement the complexity analysis of H-Q-RAM.
In Figure 4.17, we also plot the number of transactions against the locality of the
tasks. As expected, the number of transactions decreases with the increase in task locality.
However, we observe a larger number of transactions with the increase in the size of the
network. This affects the absolute execution time of H-Q-RAM in our simulation due to

104 Chapter 4. Resource Allocation in Networks
a large number of switching among optimization threads and the consequent page faults.
Figure 4.18 plots the H-Q-RAM execution time against the number of sub-domains under
0
5000
10000
15000
20000
25000
0 20 40 60 80 100
Num
ber
ofTra
nsac
tion
s
Locality of Tasks (%)
Number of Sub-domains = 5Number of Sub-domains = 8
Number of Sub-domains = 15Number of Sub-domains=20
Figure 4.17: Number of Transactions for 6400 Tasks with the Number of Sub-domains
different values of the task localities for 6400 tasks. At a very high task locality (96%), the
number of transactions becomes negligible, and the execution time becomes independent of
the number of sub-domains. On the other hand, the execution time monotonically increases
with the number of sub-domains for lower task locality values.
Based on the above results, we conclude that H-Q-RAM performs well for large networks
compared to Q-RAM, which makes it feasible to employ QoS-based optimization in large
networked environments. However, we also observe that the number of transactions also
increases with the increase in the size of the network. Therefore, we would like to reduce
the number of transactions for future implementations.

4.7. Chapter Summary 105
0.1
1
10
100
4 6 8 10 12 14 16 18 20
Tim
ein
seco
nds
(log
sale
)
Number of Sub-domains
Locality of Tasks = 0.96Locality of Tasks = 0.72Locality of Tasks = 0.48Locality of Tasks = 0.24Locality of Tasks = 0.0
Figure 4.18: Variation of ( H-Q-RAM Execution Time/ Number of Sub-domains) for 6400Tasks with the Number of Sub-domains
4.7 Chapter Summary
In this chapter, we have discussed a resource allocation scheme for a networked system based
on Q-RAM. First, we proposed several pruning algorithms for smart route selections that
makes the basic optimization more scalable without any significant loss in the optimality
of the solution. Our main goal was to analyze the trade-off between optimality and the
execution time of our QoS optimization. Although the specific values may vary depending
on the topology, restricting the maximum number of routes only to 2 reduces the optimality
only by 5%. In addition, exploiting the cached route information across the network becomes
more useful as the size of the network increases.
Next, we presented a transaction-based hierarchical scheme (H-Q-RAM) that can make
the problem more scalable by exploiting the presence of hierarchy in networks. The perfor-
mance of H-Q-RAM improves with the increase in the size of the network and the locality
of the tasks. We also observed that the simulation is memory intensive, and it becomes in-
creasingly expensive in a single host with the increase in the size of the network. Therefore,

106 Chapter 4. Resource Allocation in Networks
a centralized scheme becomes infeasible for a network with the size of the Internet. Since H-
Q-RAM can be executed concurrently on multiple machines using distributed transactions,
it can be run in parallel to address large networks. In addition, we would also like to reduce
the number of transactions which increases with the size of the network. This can be done
if we can aggregate multiple tasks into a few “super-tasks” and perform transactions for
“super-tasks”. Hence our future work will investigate efficient methods of task aggregation.

Chapter 5
Resource Allocation in Phased
Array Radar
5.1 Introduction
There are certain systems where a task has a large number of operational dimensions and/or
a large number of elements across these dimensions1. For example, an application that has
10 operational dimensions with 10 levels along each dimension, will have 1010 set-points or
more. These tasks are called highly configurable tasks.
In addition, there are also certain tasks for which environmental factors play a key role
in deciding the QoS levels. In a dynamically changing environment, the mapping between
resources and utility may change with time. That necessitates frequent QoS optimizations
in order to allocate the resources among the tasks in a near-optimal manner.
Certain distributed embedded systems operate in conditions where both the above situ-
ations hold. An example of such a system is a phased array radar tracking system. A radar
system is an example for which environmental factors outside the direct control of the sys-
tem affect the relationship between the level of service and the resource requirements of the
1The operational and the environmental dimensions are defined in Chapter 2.
107

108 Chapter 5. Resource Allocation in Phased Array Radar
tasks, which in turn affect the perceived utility. In these systems, a finite amount of radar
bandwidth and computing resources must be apportioned among multiple tasks tracking
and searching targets in the sky. In addition, environmental factors such as noise, heating
constraints of the radar and the speed, distance and maneuverability of the tracked targets
dynamically affect the mapping between the level of service and resource requirements as
well as the mapping between the level of service and the user-perceived utility. Their highly
dynamic nature and stringent time constraints lead to complex cross-layer interactions in
these systems. Therefore, the design of such systems has long been a handcrafted mixture
of pre-computed schedules, pessimistic resource allocations, and cautious energy usage, and
operator intuition.
In this chapter, we consider an integrated framework for QoS optimization and schedul-
ing for a phased-array radar system. The antenna in a phased-array radar system can
electronically steer the energy beam in a desired direction. This allows it to track targets at
differing frequencies depending upon its distance, acceleration, and its characteristics such
as speed, acceleration etc. Some characteristics of a radar system are as follows.
• The longer the distance between the target and the radar, the higher the energy
requirement.
• Once a beam transmission starts, it cannot be preempted.
The goal of the radar system is to utilize its finite energy and time resources to maximize
the quality of tracking. In addition to the tracking tasks, the system also includes search
tasks and target confirmation task. A search task searches for new targets in the sky and
a target confirmation task confirms the target after it is detected by the search task.
A radar system must make two sets of decisions. First, it must decide what fraction
of resources (energy and time) to spend on each target. It must then schedule the radar
antenna(s) to transmit the beams and receive the return echoes in a non-preemptive fashion.
Since targets in the sky are continually moving, resource allocation and scheduling decisions
must be made on a frequent basis. Due to the multi-dimensional nature of radar resource

5.1. Introduction 109
allocation, the problem of maximizing the benefits gained is NP-hard.
In our scheme, we develop an integrated framework that performs a near-optimal re-
source allocation and scheduling of the tracking tasks in real-time. We show that such
decisions can be made near-optimally, while maintaining schedulability and satisfying the
resource constraints of the system. We concentrate primarily on the radar antenna resources
as these are generally scarce compared to the computing resources. Unlike traditional radar
systems, we use two layered components. A QoS optimization component is concerned
with determining how much of the resources should be given to each task, and a scheduling
component is concerned with determining when radar tracking tasks should be scheduled.
In short, our radar resource management scheme deals with two primary concerns: the
selections of operating points and ensuring schedulability.
Selection of Operating Points: This is performed by using Q-RAM. In this chapter,
we describe a scalable Q-RAM technique for allocating resources to radar tasks. This is
also presented in [27, 32, 36].
Ensuring Schedulability: As we know, only straightforward resource constraints (such
as total usage of any resource must be less than some utilization bound) is used by Q-
RAM in general. In the radar system, a given allocation generated by Q-RAM may or
may not be schedulable, and furthermore, jitter constraints can be violated even if all the
resource utilizations are less than 100%. In other words, the QoS allocator (Q-RAM) and
the scheduler need to be tightly integrated. Therefore, we present a scheme that integrates
the Q-RAM framework with the radar schedulability test. This is also described in [30].
Although radar scheduling incorporates a pipelined scheduling of a back-end and a front-
end, the front-end antenna remains the bottleneck resource. Therefore, we concentrate our
schedulability analysis on the front-end only. In order to provide stringent periodic jitter
constraints, we use harmonic periods for tasks [52].
The rest of this chapter is organized as follows. Section 5.2 presents our model of the

110 Chapter 5. Resource Allocation in Phased Array Radar
R1 only
R2 only
R3 only
R4 only
R1&R2
R2&R3 R3&R4
R1&R4
Figure 5.1: Radar System Model
radar system, its associated resources and constraints. Section 5.6 describes our radar dwell
interleaving scheme. Section 5.4 presents our integrated resource management model. In
Section 5.9, we present an evaluation of our experimental results. Finally, in Section 5.10,
we summarize our concluding remarks and provide a brief description of our future work.
5.2 Radar Task Model
We assume the same radar model as used in [30, 32]. It consists of a single ship with 4 radar
antennas oriented at 90 to each other as shown in Figure 5.1. We also assume that each
antenna is capable of tracking targets over a 120 arc. This means that there are regions
of the sky that are capable of being tracked by only one radar antenna, as well as regions
that can be tracked by two antennas. The antennas are assumed to share a large pool of
processors used for tracking and signal-processing algorithms, and a common power source
to supply energy to the antennas. The main tasks of an antenna are search and tracking.
• Search: There are multiple search tasks that cover the entire angular range of the
radar.

5.2. Radar Task Model 111
• Tracking: There is one tracking task corresponding to each target being tracked.
A single instance of tracking a particular target consists of sending a radar signal con-
sisting of a series of high frequency pulses and receiving the echo of those pulses. This
instance is known as a dwell, as shown in Figure 5.2. It is characterized in terms of a trans-
mit power Ai, a transmission time txi, a wait time twi and a receive time tri. Note that in
an actual radar, the transmission time actually consists of a series of rapid pulses over a
time period txi as opposed to a continuous transmission. Generally, txi = tri, and the wait
time is based on the round-trip time of the radar signal (e.g., about 1 ms for a target 100
miles away). Also, while the radar may dissipate some power while receiving, this power is
much smaller than the transmit power. For simplicity, we assume that the receive power
is negligible compared to the transmit power. The time between two successive dwells is
called the dwell period (Ti).
t
txi twi triTi
Ai
Figure 5.2: Radar Dwell
In order to appropriately track a target, the dwell needs to have a sufficient number of
pulses (target illumination time or txi) with a sufficient amount of power (Ai) on the pulses
to traverse through the air, illuminate the target and return back after reflection. Larger
txi (more pulses) and Ai provide better tracking information. The value of Ai required to
adequately track a target is proportional to the 4th power of distance between the target
and the radar [46]. Apart from the power output capability of the energy source, it is also
limited by the heat dissipation constraint of the radar. The tracking information is also

112 Chapter 5. Resource Allocation in Phased Array Radar
dependent on many environmental factors beyond the radar system’s control such as the
speed, the acceleration, the distance and the type of the target, the presence of noise in the
atmosphere and the use of electronic counter-measures by the target.
Based on the received pulses, an appropriate signal-processing algorithm must be used
in order to properly estimate the target range, velocity, acceleration, type, etc. There are
many tracking algorithms used in radar systems. They provide trade-offs between the noise
tolerance and dealing with target maneuverability. They also have different computational
requirements. Thus, each radar task consists of a front-end sub-task at the antenna and a
back-end signal-processing sub-task at the processors.
Since a target can maneuver to avoid being tracked, the estimates are valid only for the
duration of illumination time. Based on these data, the time-instant of the next dwell for the
task must be determined. Therefore, the tracking task needs to be repeated periodically with
a smaller period providing better estimates. In the absence of any jitter, the tracking period
is equal to the temporal distance between two consecutive dwells. For a large temporal
distance, the estimated error can be so large that the dwell will miss the target. On the
other hand, a small temporal distance will require higher resource utilization. The radar
needs to track the targets with higher importance using greater tracking precision than the
ones with lower importance [30].
A radar task is periodic with a strict jitter constraint. For example, for a task with
period Ti, the start of each dwell must be exactly2 Ti milliseconds from the start of the
previous dwell. We make the seemingly conservative choice of using only harmonic periods
for radar tasks since by using harmonics we can automatically satisfy the stringent periodic
jitter constraints (a pin-wheel scheduling problem [52]).
2In practice, if two successive dwells are not separated exactly by Ti, lower tracking quality will result.If the jitter is higher than a (small) threshold, an entire track may be lost.

5.3. Radar Resource Model 113
5.3 Radar Resource Model
The radar resources-space consists of the following resource dimensions: radar bandwidth,
radar power, and computing resources.
5.3.1 Radar Bandwidth
As we mentioned earlier, a radar can track only a limited number of targets at a specific
time. Since the radar is unused during the waiting period of a dwell, this time can often be
used by other dwells through interleaving. This gives us a radar utilization value of:
Ur =N∑
i=1
txi + tri
Ti. (5.1)
If we assume the receiving time to be equal to the transmission time, we obtain:
Ur = 2N∑
i=1
txi
Ti. (5.2)
5.3.2 Radar Power Constraints
In addition to timing constraints, radars also have power constraints. Violating a power
constraint can lead to overheating and even permanent damage to the radar. The radar can
have both long-term and short-term constraints. For example, there may be a long-term
constraint of operating below an average power of 1 kW , and a (less stringent) short-term
constraint of operating below an average power of 1.25 kW in a 200 ms window. The
short-term constraint is generally specified using an exponential waiting within a sliding
window.

114 Chapter 5. Resource Allocation in Phased Array Radar
Long-Term Power Utilization Bound
If Pmax is the maximum sustained long-term power dissipation for the radar, then we define
the long-term power utilization for a set of N tasks as:
UP =1
Pmax
N∑i=1
Aitxi
Ti. (5.3)
That is, the long-term power is given by the fraction of time each task is transmitting,
multiplied by the transmit power for that task. Dividing by Pmax gives a utilization value
that cannot exceed 1. To handle long-term constraints in Q-RAM, we simply treat power
as a resource, and denote the amount of that resource consumed by task i as 1Pmax
AitxiTi
.
Short-Term Power Utilization Bound
We will now derive a short-term power utilization bound. Short-term power needs are
defined in terms of a sliding window [5] with time constant τ . With an exponential sliding
window, pulses transmitted more recently have a larger impact on the average power value
than less recently transmitted pulses. Also, the rate that the average power decreases is
proportional to the average power value meaning that immediately after transmitting a
pulse, we have a relatively high but steadily decreasing cooling rate. The use of a sliding
exponential window has two benefits: it is memory-less, and it closely models thermal
cooling, which is the primary motivation for the constraint.
In order to define the short-term average power, we first define instantaneous power
dissipation as p(t). This function is 0 when the radar is not transmitting and Ai while pulse
i is being transmitted. We then define the average power at time t for a time constant τ as:
P τ (t) =1τ
∫ t
−∞p(x)e(x−t)/τdx. (5.4)

5.3. Radar Resource Model 115
t
t=t0
Pτ(t)
e(t-t0)/τ
p(t)
Figure 5.3: Average Power Exponential Window
Ps
Pin
Pout
tcd
ttx
A
P(t)
Pmax
t
Figure 5.4: Cool-Down Time
Ps
Pin
Pout
tcd
ttx
A
P(t)
Pmax
t
Figure 5.5: Non-Optimal Initial Average Power

116 Chapter 5. Resource Allocation in Phased Array Radar
Figure 5.3 shows an example of the average power value for a set of pulses along with the
exponential sliding window at time t0. The shaded bars represent the transmitted radar
energy, and the dotted line represents the sliding window at time t0. The short-term average
power constraint is considered satisfied if (5.4) never exceeds some bound P τ max. This
bound is called the power threshold over a look-back period τ . Alternatively, the expression
Eth = P τ maxτ is defined as the Energy threshold of the system.
Now, we would like to translate the short-term energy constraint of the radar antenna
to a timing constraint. In this context, we define a timing parameter called the cool-down
time tci that precedes a dwell of each task i.
Definition 5.3.1 (Cool-down Time). The cool-down time for a task is the time required
for P τ (t) to fall from P τ max to a value just low enough that at the end of the transmit phase
of a dwell P τ (t) will be restored to P τ max.
The effect of cool-down time is shown in Figure 5.4. It is a function of the transmit time
txi and the average power Ai of a dwell, the time constant τ and the short-term average
power constraint P τ max. This factor allows the power constraints to be converted into
simple timing constraints.
We will now derive the cool-down time tci for a task i. We will assume that for this
task Ai ≥ P τ max. For a task with Ai ≤ P τ max, there is no necessity of having a cool-down
time since the radar cools down even when it continues transmissions, that is tc = 0. Let
P s be the average power at the beginning of the cool-down period, P in be the average
power at the end of the cool-down period, and Pout be the average power at the end of the
transmission. We want P s = Pout = Pmax. We can express P in in terms of P s as:
P in = P se−tci/τ , (5.5)

5.3. Radar Resource Model 117
and Pout in terms of P in as:
Pout = P ine−tx/τ + Ai(1− e−txi/τ ). (5.6)
Substituting P τ max for Pout in (5.6) and solving for P in, we get:
P in =Pmax −Ai(1− e−txi/τ )
e−txi/τ. (5.7)
We can now substitute P τ max for P s in (5.5) and set the forward and backward definitions
(5.5) and (5.7) for P in to be equal and solve for tci to yield the expression for the cool-down
time:
tci = −τ lnP τ max −Ai(1− e−txi/τ )
P τ maxe−txi/τ. (5.8)
We now present the following theorem:
Theorem 5.3.2. For any set of N periodic radar tasks which do not violate the short-term
average power constraint (where Ai ≥ P τ max for all tasks), the total short-term average
power utilization given by
Uτ =N∑
i=1
tci + txi
Ti. (5.9)
must be no greater than 1.
Proof. Assume that we have a set of tasks for which Uτ = 1. From (5.8), it can be shown
that any decrease in P τ max will cause the tci to increase and thus cause Uτ to exceed 1. If
we can show that when Uτ = 1 the optimal schedule must include a point where the average
power Pτ (t) equals P τ max, then this implies that the theorem must hold. Now, assume that
we have a schedule S where tasks are scheduled such that each dwell transmission period
txi is preceded by an idle time of tci with the cool-down time for each dwell beginning
exactly at the end of the previous dwell’s transmission. Now let P s be the average power
at the beginning of the cool-down period preceding a dwell transmission. It can be shown

118 Chapter 5. Resource Allocation in Phased Array Radar
from (5.5) and (5.6) that if P s < P τ max, then the Pout for that dwell must satisfy P s <
Pout < Pmax as shown in Figure 5.5 due to the fact that the cooling rate is proportional
to the current average power. This implies that at the end of each transmit period for each
successive dwell, the average power will increase until it converges to P τ max. This means
that in the steady state, the average power will be P τ max at the end of the transmission
period for every dwell. The schedule S must be optimal since moving a dwell any sooner
would result in an increase in P in for that dwell and thus increase Pout as well (exceeding
P τ max). Moving a dwell any later would trade-off the efficient cooling immediately after the
transmission when average power is at P τ max for less efficient cooling before the transmission
resulting in a violation after the next dwell. This shows that the schedule S must be optimal
and that it must have a point where average power is equal to P τ max.
Based on (5.9), we model the short-term average power constraint in the Q-RAM opti-
mization framework by treating power as a pseudo-resource with a maximum value of 1 and
treating each radar task as if it consumes tci+txiTi
units of that resource, with tci computed
using (5.8). Hence, the expression in (5.9) is also referred to as the cool-down utilization Uc
of the system.
It is interesting to note that if we take the limτ→∞ in Equation (5.8), it can be shown
that
tci = (Ai
P τ max
− 1)txi. (5.10)
If we then substitute the above into (5.9), we obtain:
Uτ=∞ =1
P τ max
N∑i=1
Aitxi
Ti. (5.11)
We see that this equation has the exact same form as the long-term power utilization given
in Equation (5.3).

5.3. Radar Resource Model 119
Computational Resource
In addition to the radar resource, each track requires computing resources to process the
radar data, and to predict the next location of the target. The computing resources required
depend on the tracking algorithm Πi used, and the period Ti. We assume that the required
CPU is of the form CΠi/Ti where CΠi is the coefficient representing the computational cost
of algorithm Πi in each time period Ti. If we treat the back-end multiprocessor system as
a single resource, then we have the CPU constraint:
∑i
CΠi/Ti ≤ Cmax, (5.12)
where Cmax represents the total processing power of the bank of processors. This abstraction
is reasonable as long as the amount of processing required by each of the individual tasks
is small compared with the amount available on each of the processors.
5.3.3 Radar QoS Model
In [32], we developed a Q-RAM model for the radar tracking problem. There are two
principal QoS dimensions in the quality space of the radar tracking problem: tracking error
and search quality.
Tracking Error
This is the difference between the actual position and the tracked position of the target.
Although one cannot know the true tracking error, many tracking algorithms yield a pre-
cision of a particular tracking result. As mentioned in Section 5.3, this tracking precision
is dependent on the availability of the physical resources in addition to the computing re-
sources. A smaller tracking error leads to better tracking precision and hence better quality
of tracking. Therefore, we assume that the tracking quality qtrack is inversely dependent on

120 Chapter 5. Resource Allocation in Phased Array Radar
tracking error ε, as given by:
qtrack =1ε. (5.13)
Search Quality
We also define a QoS parameter for the search task. A search task must span the entire
angle in order to find the targets. It consists of multiple dwells (radar beams) to search
a particular angular space. Hence, the searching QoS increases with the increase in the
number of beams within a fixed angular space.
Reliability
This is the probability that there is no hardware/software failure in a specified time interval.
Higher reliability of a task is obtained by replicating resources, such as using two radars
to track a single target. Since we handle the use of replicas in Chapter 3, we will consider
tracking and searching errors as the only QoS dimensions.
Next, we list the operational and environmental dimensions of the system.
Operational Dimensions
In our tracking model, the operational dimensions are the dwell period (Ti), the dwell time
(txi), the dwell power (Ai), and the choice of the tracking algorithm Πi.
The above parameters can be controlled by the system designer or the optimizer in order
to achieve the desired quality of tracking of a target.
Environmental dimensions
The environmental dimensions we consider are the type of target ξi (e.g., airplane, helicopter,
missile etc.), the distance of the target from the radar ri, the velocity vector of the target ~vi,
the acceleration vector of the target ~ai, the active noise or the presence of electro-magnetic
interference as counter-measures ni, and the angular location of the target in the sky.

5.3. Radar Resource Model 121
Filter Computation K1 K2 K3 KC
Time(ms)Kalman 0.022 0.60 0.4 1000.0 [1, 16]
Least-squares .00059 0.60 0.4 30.71 [1, 16]αβγ 0.0004 0.80 0.2 0.0 [1, 16]
Table 5.1: Filter Constants
Tracking Error Computation
Considering all the operational and environmental dimensions, assuming that we can model
the tracking error in terms of these dimensions, we can define a function:
εi = E( ξi, ri, ~vi,~ai, ni︸ ︷︷ ︸environmental
, Ti, txi, Ai,Πi︸ ︷︷ ︸operational
) (5.14)
that estimates the tracking error εi as a function of the position of the target along the
environmental and operational dimensions. Here, we make the following assumptions:
• The error increases with an increase in speed (vi), distance (ri) or acceleration (ai).
• An increase in the signal-to-noise ratio at the receiver reduces error. In addition, the
received signal power is directly proportional to the transmitted signal power and is
inversely proportional to the 4th power of the distance.
• A longer dwell time (duration of transmission) reduces error.
• The error increases with an increase in the dwell period. The error due to acceleration
also increases with an increase in the dwell period.
• The Kalman tracking algorithm provides best precision under noisy environment. The
Least Squares offers less precision but more than αβγ. Targets with high maneuver-
ability can be best tracked by the αβγ filter, followed by the Least Squares and the
Kalman.

122 Chapter 5. Resource Allocation in Phased Array Radar
We assume the transmission time txi consisting of ηi pulses of width w. Since the
tracking error is expressed as the ratio of the deviation in displacement of the target to the
estimated displacement of the target in a tracking period Ti, with the help of [46],[84] and
[60], we formulate a general expression of the tracking error given by:
εi =K1σr + K2(σvTi + K3ai ∗ T 2
i )(ri − d)
, (5.15)
σr =c
2Bw
√Ai(txi/KC)/(2Ti)
ni
, (5.16)
σv =λ
2(txi/KC)√
Ai(txi/KC)/(2Ti)ni
, (5.17)
Bw =M
w, (5.18)
d = viT +12aiT
2, (5.19)
where
σr = standard deviation in distance measurement,
σv = standard deviation in speed measurement,
λ = wavelength of the radar signal,
Bw = bandwidth of the radar signal,
M = bandwidth amplification factor by modulation,
d = estimated displacement of the target in time T ,
K1 = position tracking constant,
K2 = period tracking constant,
K3 = acceleration tracking constant, and
KC = transmission time tracking constant (Tx-factor).
The values we chose for the constants are presented in Table 5.1.

5.3. Radar Resource Model 123
Type Number of beams Utility15 20× 0.3
Hi-Priority 30 20× 0.745 20× 0.8560 20× 0.9510 2× 0.3
Lo-Priority 20 2× 0.730 2× 0.9
Table 5.2: Utility Distribution of Search Tasks
Tracking Utility
Higher tracking quality yields higher utility. Hence we assume that the utility of tracking
a target for a certain quality qtrack is given by the following concave exponential function:
U(qtrack) = Wtrack(1− e−βqtrack), (5.20)
where β is a parameter specific to the ranges of the speeds of three different types of
targets (airplane, missile or helicopter). Equation 5.20 assumes the utility increases with
increase in tracking precision, which ultimately saturates at a very high precision [49]. The
parameter Wtrack is a weight factor that determines the importance of the target and it is
also dependent on the type of the target. Moreover, it is also assumed to be proportional
to the speed and is inversely proportional to the distance of the target. We assume a weight
factor Wtrack of the form:
Wtrack = Kt(vi
ri + Kr), . (5.21)
providing an estimate of the importance of a particular target. The Kt and Kr terms
represent the importance based on the target type, and the right-most term represents the
time-to-intercept (i.e., the time that would be required for a target to reach the ship if flying
directly toward it).
The objective of our optimization is to allocate resources to each tracking process such
that the total utility is maximized. From our stated assumptions on tracking precision,

124 Chapter 5. Resource Allocation in Phased Array Radar
Return?End SchedulerAdmissionControl
QoS Optimizer(Q-RAM)
Start Tracking & Searching Tasks
Tasks with assigned QoS and Resource
Resource Allocation
Radar Utilization Bound
Adjustment Detection
1
0
Perform Utilization Bound Adjustment
Task Profiler
Figure 5.6: Resource Management Model of Radar Tracking System
quality and utility, we obtain an expression for utility as a function of the tracking error,
U(ε) = Wtrack(1− e−γ/ε), (5.22)
where γ is a function of β and the relation between quality and tracking error. The required
values of operational dimensions needed to obtain a particular value of tracking error from
(5.14) can be translated into the resource usages.
5.4 Resource Management in Phased Array Radar
Since radar systems are very dynamic with a constantly changing environment, it is neces-
sary for the radar to continuously redistribute its resources among the tasks. The resource
allocation process needs to be repeated at regular intervals. Hence, its efficient execution
is of critical importance to be of practical use. Our proposed radar resource management
approach consists of 3 main steps: (1) QoS-based resource allocation, (2) resource scheduler
admission test, and (3) utilization bound adjustment. These steps may need to be repeated
more than once in order to obtain a near-optimal solution. We next describe these three
steps.
1. QoS-based Resource Allocation: Basic Q-RAM optimization maximizes the
global utility of the system by allocating the resources to the tasks. We use the

5.4. Resource Management in Phased Array Radar 125
input : schedulability fails or Ub needs adjustment/* Ub = present utilization bound, Up = previous utilization bound,
Umax= upper level of bound, Umin = lower level of bound */if schedulability fails then
Umax ← Ub ;Un ← (Umax + Umin)/2 ;// Un = next utilization bound
if previous schedule was successful and (Un − Up)/Un < .1% thenSwitch to previous schedule;Ub ← Up;return 1;//Previous schedule is selected
endelse
Ub ← Un;//Utilization bound is reduced
Up ← Ub;Return 0;//Return to Q-RAM
endendelse
Umin ← Ub ;//Successful schedule
Un ← (Umax + Umin)/2;if (Un − Ub)/Un < .1% then
Return 1 ;//Current schedule is selected
endelse
Ub ← Un;//Utilization bound is increased
Up ← Ub;Return 0;//Return to Q-RAM
endend
Algorithm 10: Utilization Bound Adjustment

126 Chapter 5. Resource Allocation in Phased Array Radar
current snapshot of the sky at a particular instant during which the environmental
dimensions of the objects are constant. Next, we generate profiles for each target
with the values of its environmental parameters and picking the ranges of values of
the operational parameters. Profiles are used in the optimization process to provide
resource allocations for the tasks. The resulting resource allocation does not always
guarantee schedulability. This is due to the non-preemptive nature of the radar front-
end tasks, which require us to perform a sophisticated scheduler admission test to
determine the schedulability.
2. Scheduler Admission Test: The resource scheduler takes the results of the Q-RAM
resource allocations, interleaves the tasks and then runs the schedulability test. If the
task set is not schedulable, we reduce the utilization bound of the radar and return
to Step 1 in order produce a schedulable task-set.
3. Utilization Bound Adjustment: This function reduces the utilization bound if the
interleaved tasks are not schedulable, or increases the utilization bound if they are
schedulable. Thus, it searches for the maximum utilization bound for a schedulable
task-set using a binary search technique. This is described in Algorithm 10.
The entire resource allocation process iteratively searches for the best possible utilization
bound. It stops when it reaches a schedulable task-set, and the utility values from two
successive iterations differ by only a small value (such as 0.1%), called the “utiliity precision
factor”. This is detailed in Figure 5.6 as a flow-chart.
5.5 Resource Allocation with Q-RAM
As we recall, the Q-RAM optimization involves the following steps:
• Generate set-points for each task.
• Construct the concave majorant of its set-points.

5.5. Resource Allocation with Q-RAM 127
• Merge all the set-points of all tasks based on their marginal utility values.
• Traverse the sorted list of set-points to generate resource allocations to the tasks.
The basic Q-RAM optimization requires that each task explicitly provide the list of all
possible set-points. The concave majorant is determined on these input set-points next. We
know that the best-known algorithm for computing the exact concave majorant of L set-
points is O(L log L). Even though it is a relatively benign complexity, it has two drawbacks.
• We need to generate all possible set-points of a task and use them in determining the
penalty vector of the resources before we determine their concave majorant.
• The computational complexity of the concave majorant operation can be prohibitively
expensive when the number of set-points is large even when the number of output set-
points it generates is much smaller.
Since an application with d operational dimensions and p index values per dimension
has a total of l = pd set-points, the number of set-points can quickly become unmanageable
when there are a large number of operational dimensions. In the following sections, we
describe algorithms that traverse the set-point space generating the subsets of set-points
that are likely to lie on the concave majorant and thus eliminate the requirement of enu-
merating all possible set-points. For simplicity, we will first assume all tasks have only
monotonic operational dimensions. Later we discuss the general case in which some tasks
have operational dimensions that are non-monotonic.
5.5.1 Slope-based Traversal (ST)
This is the simplest approach to the traversal process. Let the minimum set-point for a
task τi for which all operational dimensions are monotonic be defined as ~Φmini = 1, . . . , 1,
and let the maximum set-point be defined as ~Φmaxi = φmax
i1 , . . . , φmaxiNΦ
i. Clearly, all of
the set-points in the utility/compound resource space that lie below a “terminating” line
from (u( ~Φmini ), h( ~Φmin
i )) to (u( ~Φmaxi ), h(Φmax
i )) as shown in Figure 5.7 cannot be on the

128 Chapter 5. Resource Allocation in Phased Array Radar
Compound Resource0.0 0.2 0.4 0.6 0.8 1.0
Util
ity
0.0
0.2
0.4
0.6
0.8
1.0
Figure 5.7: Slope-Based Traversal of Concave Majorant
concave majorant. These points can be eliminated immediately without being passed on
to the concave majorant step. We call this heuristic “slope-based traversal” (ST). While
this heuristic can reduce the time to compute the concave majorant by a constant factor, it
must still scan all of the set-points to determine if they are above or below the terminating
line.
5.5.2 Fast Set-point Traversals
We now consider a set of fast traversal heuristics that do not require computations on all
of the set-points. We (temporarily) assume that all operational dimensions are monotonic.
A key observation we make is that when the actual concave majorant is generated using
all of the set-points for typical tasks, the concave majorant tends to consist of sequences
of set-points that vary in only one dimension at a time with occasional jumps between
sequences of points. This insight suggests that we can use local search techniques to follow
the set-points up the concave majorant. We also know that ~Φmini will always be the first
point on the concave majorant, and ~Φmaxi will always be the last. The methods presented

5.5. Resource Allocation with Q-RAM 129
<1,1,*>
<1,*,5>
<*,7,5>
Composite Cost
Util
ity
Outer Envelope
Figure 5.8: Incremental Traversal
here differ primarily in the method used to perform the local search.
As an example, consider a task with three operational dimensions. If we consider the
subset of the set-points < 1, 1, ∗ > consisting of all the set-points for which dimensions 1
and 2 have index value 1, these points will tend to form a line as shown in Figure 5.8. The
concave majorant will tend to follow such a line until it switches to some other line, in this
case < 1, ∗, 5 > followed by < ∗, 7, 5 >.
While the fast traversal heuristics presented in this section are not guaranteed to find
the exact concave majorant, in Section 5.8 we will show that these heuristics produce very
good approximations to the concave majorant in our radar QoS optimization and more
importantly that the drop in system utility from using the approximations is negligible.

130 Chapter 5. Resource Allocation in Phased Array Radar
First-Order Fast Traversal (FOFT)
In first-order fast traversal (FOFT), we keep a current point ~Φi for each task τi which we
initialize to ~Φmini . We then compute the marginal utility for all the set-points adjacent to
~Φi. A set-point is adjacent if all of its index values except for one are identical, and the one
that differs varies by only one (i.e., they have a Manhattan distance of one). We, in fact,
need only consider positive index value changes. We then choose the point that has the
highest marginal utility, add it to the concave majorant and make that point the current
point. Formally, if ~Φi is the current point we choose the next current point ~Φ′i = ~Φi + ~Ξj
where j maximizes the marginal utility:
u( ~Φi + ~Ξj)− u( ~Φi)
h( ~Φi + ~Ξj)− h( ~Φi), (5.23)
and where ~Ξj is a vector that is zero everywhere except in dimension j where it is equal
to 1. We repeat this step until we reach ~Φmaxi . After we have generated this set of points,
the resulting curve may not be a concave majorant. Hence, we perform a final concave
majorant operation (albeit on a much smaller number of points than before).
The number of set-points generated before the final concave majorant step will be the
Manhattan distance between ~Φmini and ~Φmax
i which is:∑NΦ
ij=1(φ
maxij −φmin
ij ). Ignoring bound-
ary conditions, at each point we only consider NΦi possible next set-points. This means that
when we have d dimensions and k index levels per dimensions then the complexity of this
algorithm is O(kd2). If we include the complexity of the concave majorant determination,
we have the total complexity of O(kd2 + kd log kd)
5.5.3 Higher-Order Fast Traversal Methods
We can generalize the FOFT algorithm to an m-step p-order Fast Traversal algorithm as
follows. Just as in the FOFT heuristic, initialize the current point ~Φi to ~Φmini . Then choose
the next point ~Φ′i = ~Φi + ~Z where ~Z ∈ Gpm such that the marginal utility is maximized and

5.5. Resource Allocation with Q-RAM 131
Gpm is defined as:
G1m =
⋃1≤j≤NΦ,1≤k≤m
kΞj, (5.24)
Gpm = ~X + ~Y : ~X ∈ G1
m, ~Y ∈ Gp−1m , ~X • ~Y ≡ 0 ∪Gp−1
m . (5.25)
That is, we look all of the next set-points that can be reached from the current set-point by
increasing up to p dimensions and up to m steps. The FOFT algorithm described above then
corresponds to G11. As with FOFT, we need to perform a final concave majorant operation
on the points generated by this heuristic. As we observe, if we let m take as large a value
as possible, the procedure becomes a standard concave majorant operation.
5.5.4 Non-Monotonic Dimensions
The fast traversal algorithms described above assume that all of the operational dimensions
are monotonic. Unlike monotonic dimensions, non-monotonic operational dimensions gen-
erally do not have a structure that can be easily exploited. For example, the choice of a
coding scheme for a video, the choice of a route in a networked system, or the choice of a
tracking algorithm in a radar system can be considered to be non-monotonic.
Suppose that some of the operational dimensions are non-monotonic. Then, for every
combination of the index values of the non-monotonic dimensions, we simply apply the fast
traversal algorithms to the subset that is monotonic. We then form the union of all these
results and apply a concave majorant. In the worst-case that a task has only non-monotonic
dimensions, this simply reduces to a full concave majorant operation. For example, in a
radar tracking system, we can apply fast-traversal methods for each of the three tracking
algorithms separately, and then merge all three results and perform a concave majorant
operation.
If there is a large number of non-monotonic operational dimensions, we apply smart
heuristics to guess the best possible values of those dimensions to perform the same traversal.
How this is done depends on the characteristic of a particular system and the influence of

132 Chapter 5. Resource Allocation in Phased Array Radar
the dimensions on the resource requirements of the task.
5.5.5 Complexity of Traversal
Since, we linearly traverse the points and do not examine a point more than once, the worst
case complexity of these scheme is O(L) instead of O(L log L). However, it is likely to be
much smaller on average since we go through only a small number of points. We discuss
the experiments related to these techniques in detail in Section 5.8.
5.5.6 Discrete Profile Generation
Under certain situations, we can find that even efficient profile generation at run-time
takes too long. An alternative is to generate the profiles off-line, but the profile space
has multiple dimensions with wide ranges. Therefore, off-line computation and storage of
profiles requires exponentially large space and becomes unwieldy. The approach we adopt
is to quantize each continuous environmental dimension into a collection of discrete regions.
We then only need to generate a number of discrete task profiles offline for a variety of
environmental conditions. At run-time, we simply map each task into one of the discrete
profiles. Any quantization carried out must be such that (1) the storage needs of the discrete
profiles are practical, and (2) there is no significant drop in the quality of the tracks (as
measured by the total system utility). The quantization along any dimension can employ
an arithmetic, a geometric or some other progression.
5.6 Scheduling Considerations
Our model of each radar dwell task, as discussed in Section 5.2, consists of 4 phases: cool-
down time(tc), transmission time (tx), waiting time (tw), and receiving time (tr), as shown
in Figure 5.9(a). The durations tx and tr are non-preemptive, since a radar can only perform
a single transmission or a single reception at a time. However, the tc of one task can be

5.6. Scheduling Considerations 133
tx tw trtc
(a) Dwell with cool-down time
Offset
W1
W2
tC1 tC2
(b) Proper Nesting Ex-ample
Offset
W1
W2
tC1 tC2
(c) Improper NestingExample
Figure 5.9: Interleaving of Radar Dwells
overlapped with tr or tw of another task, since the radar can cool down during the waiting
and the receiving period.
Considering the entire duration of a dwell (from transmission start to reception end) as
a non-preemptive job wastes resources and decreases the schedulability of the system [74].
Task dwells can be interleaved to improve schedulability. Dwells can be interleaved in two
ways: (1) properly nested interleaving and (2) improperly nested interleaving. An optimal
construction of interleaved schedules using a branch-and-bound method has been described
in [74] and [73].
In this thesis, we focus on fast and inexpensive construction of dwell interleavings in the
presence of dynamically changing task-sets. The interleavings that we construct may not
necessarily be optimal in the sense of [74], but they will be schedulable.
5.6.1 Proper Nesting of Dwells
Two dwells are said to be properly nested if one dwell fits inside the waiting time (tw) of
another. Figure 5.9(b) demonstrates this situation in which dwell W1 fits in the waiting
time of dwell W2. The necessary condition for this interleaving is given by
tww1 ≥ (tcw2 + txw2 + tww2 + trw2). (5.26)

134 Chapter 5. Resource Allocation in Phased Array Radar
input : n > 1nv ← n;// n = Number of inputted tasks, nv = number of virtual tasks
Create a sorted list of the tasks in increasing order of (tc + tx + tw + tr);Create a sorted list of the tasks in increasing order of tw;while 1 do
if nv > 1 thenChoose the task τa with smallest tc + tx + tw + tr;Find the task τw with smallest possible tw that can properly nest τa in itstw;if no task τw is found then
Break from the loop;endelse
Fit τa inside τw by proper nesting (Figure 3) to form a single virtualtask;Remove the original two tasks from the sorted lists and insert the newvirtual task into them;nv ← nv − 1;
endendelse
Break from the loop;end
end
Algorithm 11: Proper Nesting Algorithm
We define a phase offset for a proper interleaving as given by:
op = tww1 − (tcw2 + txw2 + tww2 + trw2). (5.27)
For instance, we can schedule the cool-down time of the dwell W2 right after the transmission
time of W1. Thus, the value of the phase offset determines how tightly two nested tasks fit
together. Our aim is to minimize this offset.
The proper nesting procedure is detailed in Algorithm 11. The core of the scheme deals
with fitting a dwell of the smallest size into a dwell with the smallest feasible waiting time.

5.6. Scheduling Considerations 135
5.6.2 Improper Nesting of Dwells
Two dwells are said to be improperly nested when one dwell only partially overlaps with
another (e.g. as illustrated in Figure 5.9(c)). Suppose that task W1 is improperly inter-
leaved with task W2, where W1 starts first. Task W1 is called the leading task and task W2
is called the trailing task. Based on the phasing illustrated in Figure 5.9(c), the necessary
conditions for the interleaving to occur are given by
tww1 ≥ tcw2 + txw2, (5.28)
tcw2 + txw2 + tww2 ≥ tww1 + trw1. (5.29)
We define a phase offset for this case by
oi = tcw2 + txw2 + tww2 − (tww1 + trw1). (5.30)
Our improper nesting scheme is given in Algorithm 12. It starts with the task with
the largest waiting time (tw), and attempts to interleave it with the task with the largest
possible tw that is smaller than that of the original task and satisfies the conditions stated
in Equations (5.28) and (5.29). The algorithm repeats the process until it reaches the task
with the smallest tw that can no longer be interleaved, or all tasks are interleaved to form
a single virtual task.
5.6.3 Dwell Scheduler
The responsibilities of the radar dwell scheduler are as follows:
• Obtain the period and the dwell-time information (tc, tx, tw, tr) from Q-RAM for each
task.
• Interleave tasks with the same period using proper and/or improper nesting to create
a smaller number of virtual tasks.

136 Chapter 5. Resource Allocation in Phased Array Radar
input : Set of tasks with n > 1output: Modified set of virtual (improperly interleaved) tasks with nv ≥ 1nv ← n ;//n = Number of inputted tasks, nv = number of virtual tasks
Sort the list of tasks in increasing order of tw;while nv > 1 do
Start with a task τw with biggest twwhile A task is found do
Find a task τwn with biggest possible tw smaller than that of τw that can bethe leading task in improper nesting with τw;if τwn is found then
Compute the nesting offset as on;endFind a task τwi with biggest possible tw smaller than that of τw that can bethe trailing task in improper nesting with τw;if τwi is found then
Compute the nesting offset as oi;endif Both τwn and τwi are found then
if on < oi thenMerge τw and τwn by improper nesting with τwn as the leading task;
endelse
Merge τw and τwi by improper nesting with τwi as the trailing task;endnv ← nv − 1 ;Remove the merged two tasks from the sorted list and insert the newvirtual task into it;
endelse if Only τwn is found then
Merge τw and τwn by improper nesting with τwn as the leading task ;nv ← nv − 1 ;Remove the merged two tasks from the sorted list and insert the newvirtual task into it;
else if Only τwi is found thenMerge τw and τwi by improper nesting with τwi as the trailing task;nv ← nv − 1 ;Remove the merged two tasks from the sorted list and insert the newvirtual task into it;
elseGo to the task with next lower tw;
endend
end
Algorithm 12: Improper Nesting Algorithm

5.6. Scheduling Considerations 137
• Perform a non-preemptive schedulability test for the virtual tasks.
Next, we describe our schedulability test.
Schedulability Test
As mentioned earlier, in order to satisfy the jitter requirements, only relatively harmonic
periods are used for the dwells3. We define the following terms:
• Ni = Number of tasks with a period Ti
• Cij = Total run-time of the jth task among the tasks within the period Ti
• NT = Total number of periods
• Ti > Tj ,∀i < j
The response time tRi of the tasks for a given period Ti is given by
tRi =i−1∑j=1
dTi
Tje
Nj∑k=1
Cjk︸ ︷︷ ︸run-time of higher priority tasks
+Ni∑
k=1
Cik︸ ︷︷ ︸run-time of tasks with period Ti
+ Bi︸︷︷︸Blocking term
.
(5.31)
The blocking term Bi is defined as the maximum run-time Cmj among tasks with lower
priority, as defined by:
Bi = max(Cmn),∀i < m ≤ NT , 1 ≤ n ≤ Nm︸ ︷︷ ︸Maximum task size among all tasks of lower priority
. (5.32)
As already mentioned, each radar task (virtual or otherwise) is considered to be non-
preemptive under the schedulability test.
For a task-set to be schedulable, it must satisfy:
tRi ≤ Ti,∀i ∈ NT . (5.33)3As we show in the next section, our model of radar system does not show significant degradation in the
accrued utility due to the restricting use of harmonic periods

138 Chapter 5. Resource Allocation in Phased Array Radar
It must be remembered that using nesting we combine multiple tasks into a few virtual dwell
tasks within each period. The run time of a task is given by Cjk= tcjk
+ txjk+ twjk
+ trjk,
where the parameters tcjketc. may be virtual parameters if the dwells are nested.
5.7 Experimental Configuration
Parameter Type RangeDistance All [30, 400] kmAcceleration All [0.001g, 6g]Noise All [kTBw,103kTBw] a
1 (helicopter) [60,160] km/hrspeed 2 (fighter-jet) [160,960] km/hr
3 (missile) [800, 3200] km/hrAngle All [0, 360]
Table 5.3: Environmental DimensionsaBw = Bandwidth of the radar signal, k = Boltzmann constant, T = Temperature in Kelvin
We assume a radar model as described in Figure 5.1. Radar tasks are classified into
tracking tasks, high priority search tasks, and low-priority search tasks. The ranges that
we use for periods, dwell time, dwell power and the number of dwells among them are given
in Table 5.4.
As mentioned earlier, tracking error is assumed to be the only QoS dimension for each
tracking task, and the number of beams is the QoS dimension for the search tasks. The
Tasks Number of Period (ms) Dwell Transmissionbeams(dwells) power (kw) Time (ms)
Hi-Priority [15, 60] 800 5.0 0.5Search
Tracking 1 [100, 110, 120, [0.001, 0.002, 0.004, [0.02, 0.04, 0.06,, .., 1600] , .., 16.0] , .., 50.0]
Arithmetic series Geometric series Arithmetic seriesLo-Priority [10, 30] 1600 3.0 0.25
Search
Table 5.4: Period, Power and Transmission Time Distribution

5.8. Results with QoS Optimization 139
tracking error in turn is assumed to be a function of environmental dimensions (target dis-
tance ri, target speed vi, target acceleration ai, target noise ni) and operational dimensions
(dwell period Ti, number of pulses ηi in dwell transmission time Ci, pulse width w, dwell
transmission pulse power Ai, tracking filter algorithm) [32]. For a search task, each beam
corresponds to a single dwell parameterized by values of Ti,ηi and Ai.
The assumed ranges of the environmental dimensions for targets are shown in Table 5.7.
The ranges of various operational dimensions for all types of tasks are shown in Table 5.4.
As mentioned in Table 5.1, we assume three types of tracking filters, namely Kalman, αβγ
and least-squares, to account for computational resources. Their estimated run-times have
been extrapolated to equivalent run-times of a 300MHz processor as shown in Table 5.1 in
Section 5.3.3. This is because the radar computing system is assumed to be a distributed
system consisting of a large (128) number of 300MHz processors. We also assume that the
overhead for a search task is assumed to be the same as that of the Kalman filter.
We use a 2.0GHz Pentium IV with 256MB of memory for all of our experiments.
5.8 Results with QoS Optimization
In this set of experiments, we deal with tracking tasks only. Using the settings presented in
Tables 5.4 and 5.7, we perform the processes of task profile generation and QoS optimization.
We vary the number of targets, compute the utility accrued and determine the execution
time of the two processes. This is averaged over 50 iterations involving independent sets of
targets.
From the settings of the operational dimensions presented in Table 5.4, we observe that
each tracking task can have a very large number of configurable set-points. In fact, a single
task can have as many as 16500 set-points.

140 Chapter 5. Resource Allocation in Phased Array Radar
1 2 3 4 5 6101
102
103
104
105
Traversal Algorithms
Num
ber o
f Set
−poi
nts/
Task
(log
scal
e) 1.Basic Q−RAM2. Concave−Majorant3. ST4. FOFT5. 2−FOFT6. SOFT
Figure 5.10: Average Number of Set-points
5.8.1 Experiments with Traversal Techniques
We perform a series of experiments on each of the optimization methods with the number
of tasks varying geometrically from 8 to 512. In the basic Q-RAM case, we were not able
to continue beyond 128 due to memory exhaustion of our machine. This is due to the fact
that approximately 2 millions set-points are generated for 128 tasks. Each set-point requires
approximately 100 bytes of space. This means that we need more around 200MB just for
set-point storage.
The bar-graph in Figure 5.10 shows the average number of set-points per task after the
task profile generation step using different techniques. We observe a drop of 99%, from
16500 to 91 when we apply the concave majorant operation. We also observe that 2-FOFT
reduces the number of points to 47, which is a 48% drop compared to the full concave
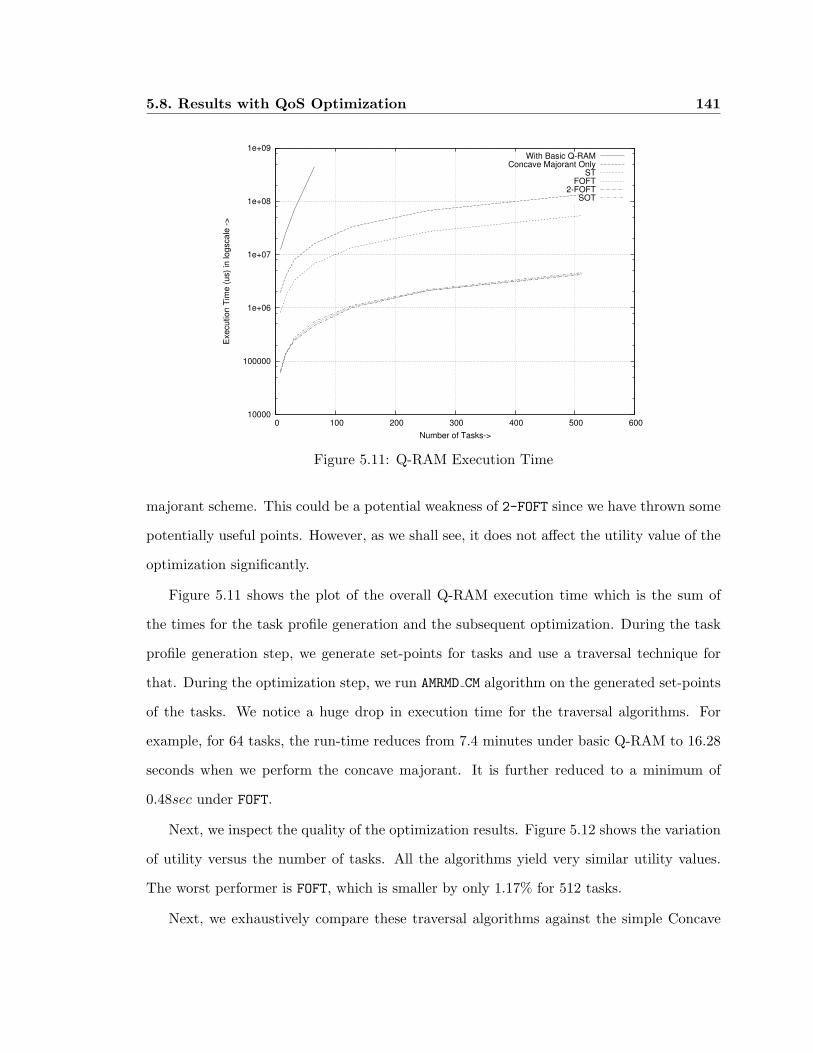
5.8. Results with QoS Optimization 141
10000
100000
1e+06
1e+07
1e+08
1e+09
0 100 200 300 400 500 600
Exe
cutio
n Ti
me
(us)
in lo
gsca
le ->
Number of Tasks->
With Basic Q-RAMConcave Majorant Only
STFOFT
2-FOFTSOT
Figure 5.11: Q-RAM Execution Time
majorant scheme. This could be a potential weakness of 2-FOFT since we have thrown some
potentially useful points. However, as we shall see, it does not affect the utility value of the
optimization significantly.
Figure 5.11 shows the plot of the overall Q-RAM execution time which is the sum of
the times for the task profile generation and the subsequent optimization. During the task
profile generation step, we generate set-points for tasks and use a traversal technique for
that. During the optimization step, we run AMRMD CM algorithm on the generated set-points
of the tasks. We notice a huge drop in execution time for the traversal algorithms. For
example, for 64 tasks, the run-time reduces from 7.4 minutes under basic Q-RAM to 16.28
seconds when we perform the concave majorant. It is further reduced to a minimum of
0.48sec under FOFT.
Next, we inspect the quality of the optimization results. Figure 5.12 shows the variation
of utility versus the number of tasks. All the algorithms yield very similar utility values.
The worst performer is FOFT, which is smaller by only 1.17% for 512 tasks.
Next, we exhaustively compare these traversal algorithms against the simple Concave

142 Chapter 5. Resource Allocation in Phased Array Radar
0
100
200
300
400
500
600
700
800
900
1000
0 100 200 300 400 500 600
Util
ity ->
Number of Tasks->
With Basic Q-RAMConcave Majorant Only
STFOFT
2-FOFTSOFT
Figure 5.12: Q-RAM Utility Variation
Majorant scheme for 1024 tasks. The results are averaged over 100 independent sets of
tasks. As shown in Figure 5.14, we obtained the maximum utility loss under FOFT, which
is still only 2.7% less than the simple concave majorant scheme. However, all incremental
traversal algorithms provided large (97%) reductions in the profile generation time as shown
in Figure 5.13, as well as considerable reductions in the optimization time (close to 50%) as
shown in Figure 5.15.
The total run-time of the algorithm is the sum of the profile generation and optimization
times. The percentage contribution of the profile generation time to the execution time of
the whole process under all traversal techniques is plotted in Figure 5.16. The task profile
generation always contributes more than 87% of the overall time which is quite expensive.
Unfortunately, even the fastest scheme takes more than 7sec for 1024 tasks. This is still
unlikely to be acceptable for online use. In the next section, we show how we can reduce
the optimization time even further.

5.8. Results with QoS Optimization 143
Conc−Majorant ST FOFT 2−FOFT SOFT0
10
20
30
40
50
60
70
80
90
100
Traversal Algorithms
Per
cent
age
Exe
cutio
n Ti
me
Figure 5.13: Profile Generation Time (%)
ST FOFT 2−FOFT SOFT
0
1
2
3
4
5
6
7
8
9
10
Traversal Algorithms
Per
cent
age
Loss
in U
tility
Figure 5.14: Utility loss (%)

144 Chapter 5. Resource Allocation in Phased Array Radar
Conc−Majorant ST FOFT 2−FOFT SOT0
10
20
30
40
50
60
70
80
90
100
Traversal Algorithms
Per
cent
age
Exe
cutio
n Ti
me
Figure 5.15: Optimization Time (%)
Conv−Majorant ST FOFT 2−FOFT SOFT0
10
20
30
40
50
60
70
80
90
100
Traversal Algorithms
Per
cent
age
Pro
file
Run
−Tim
e
Figure 5.16: Fractional Profile Time (%)

5.8. Results with QoS Optimization 145
0
1
2
3
4
5
6
7
8
9
10
11
0 1 2 3 4 5 6 7 8 9 10
Util
ty ->
Distance ->
Distance Variation
Figure 5.17: Utility Variation with Distance
5.8.2 Generation of Discrete Profiles
The idea of discrete profile generation has been described in Section 5.5.6. In this section,
we perform experiments on discrete profiles. We vary one environmental dimension at a
time while keeping the others constant and plot the utility values. Figures 5.17, 5.18 and
5.19 show the variation of utility under the variations of acceleration, speed and distance
respectively.
As observed from the figures, the utility variation can be reasonably approximated by
a linear regression with respect to speed and acceleration as independent variables. The
plot for speed has approximately three linear steps due to the use of three different types of
targets. This means the arithmetic progression is appropriate for discrete values of speed
and acceleration. On the other hand, the utility variation is hyperbolic relative to the
distance of the target. Therefore, a geometric progression represents the best scheme for
quantizing distance.
For each combination of the quantized environmental dimensions, a profile is generated

146 Chapter 5. Resource Allocation in Phased Array Radar
0
2
4
6
8
10
12
0 500 1000 1500 2000 2500 3000 3500
Util
ty ->
Speed ->
Speed Variation
Figure 5.18: Utility Variation with Speed
1.38
1.4
1.42
1.44
1.46
1.48
1.5
1.52
1.54
1.56
0 20 40 60 80 100 120 140 160
Util
ity->
Acceleration->
Acceleration Variation
Figure 5.19: Utility Variation with Acceleration

5.8. Results with QoS Optimization 147
-25
-20
-15
-10
-5
0
0 200 400 600 800 1000 1200
Per
cent
age
Loss
in U
tility
->
Resolution in Acceleration (8,16,32,...) ->
Acceleration Resolution Variation
Figure 5.20: Utility Loss with Quantized Acceleration
-1
-0.9
-0.8
-0.7
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0
0 50 100 150 200 250 300 350 400 450 500 550
Per
cent
age
Loss
in U
tility
->
Resolution in Distance (16,32,...,512) ->
Distance Resolution Variation
Figure 5.21: Utility Loss with Quantized Distance

148 Chapter 5. Resource Allocation in Phased Array Radar
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0 20 40 60 80 100 120 140
Per
cent
age
Loss
in U
tility
->
Resolution in Speed (2,4,8,...)->
Speed Resolution Variation
Figure 5.22: Utility Loss with Quantized Speed
offline. Then, during the optimization process, each task is mapped to one of the discrete
profiles based on target characteristics. We always round up to conservative estimates on
the environmental parameters in order to determine the suitable quantization level for each
task. In addition, the weight factor of the profile obtained offline is adjusted based on the
real values of the speed and the distance of the target.
5.8.3 Utility Variation with Discrete Profiles
The aim of these experiments is to determine the loss in the utility relative to the resolutions
of the environmental dimensions. Higher resolutions result in utility values closer to the
optimal, but require more storage for offline profiling. Also, one dimension may be more
dominant in influencing the utility value than others, hence we need higher resolution for
this dimension. This gives us a trade-off between the loss in utility and the storage space.
Figure 5.20 shows the percentage loss in utility from using discrete profiles for different
resolutions of acceleration. Each result was taken for 1024 independent tasks over 100
iterations. The resolution of acceleration is varied from 16 to 1024 m/sec2 by powers of 2

5.8. Results with QoS Optimization 149
-25
-20
-15
-10
-5
0
0 200 400 600 800 1000 1200
Per
cent
age
Util
ity L
oss
->
Space Requirements (Number of Offline Profiles) ->
Distance VariationSpeed Variation
Acceleration Variation
Figure 5.23: Utility Loss with Quantized Distance
keeping speed and distance continuous. The plot is a concave curve saturating close to the
continuous optimization at higher resolution. Next, we vary the resolution of the distance
from 16 to 256 points keeping acceleration and speed continuous. Figure 5.21 shows the
comparative utility variations. The same experiment is repeated by varying the resolution
of speed keeping the other two dimensions continuous. Figure 5.22 shows the result. All
the results show concave curves approaching a zero utility loss relative to that obtained
under all continuous environmental dimensions. But the variation across the acceleration
dimension is much more significant than the other two, and can be up to 25%.
Next, we plot the same results from the above three experiments as the loss in utility at
1024 tasks against the amount of space required for discrete off-line profiling. For each curve,
we keep two dimensions continuous (or at their maximum possible resolution) and keep
increasing the resolution of one dimension. The amount of storage space required for off-line
profiling is proportional to the resolution of a particular dimension. For the speed dimension,
it is also proportional to the number of types of targets (3 in our case) since the speed of each
type of target is quantized independently. From this, we can obtain the storage requirements

150 Chapter 5. Resource Allocation in Phased Array Radar
and the corresponding utility loss for each setting of the environmental parameters. For
example, for a resolution of 16 for distance, the loss is 2.47%, the other factors being
continuous. Similarly it is 2.89% for speed at a resolution of 2 and 2.59% for acceleration at
a resolution 256. Therefore, for a setting of (16, 2, 256) for distance, speed and acceleration
respectively, we would incur an approximate utility loss of 1−(100−2.47100 )(100−2.89
100 )(100−2.59100 ) =
7.74%, assuming the losses under these three parameters are mutually independent for the
sake of simplicity4. If each set-point requires 100 bytes, the total space requirement is
100 bytes× 16× (2× 3)× 256 ' 2.34MB, which is certainly very acceptable with today’s
memory technology.
As seen in Figure 5.23, we observe that the acceleration dimension is dominant in de-
ciding the quality of optimization. This is because the other two dimensions saturate very
quickly for the tracking error model we have chosen. The primary cause is the weight factor,
which is always computed based on the exact values of the speed and the distance of the
individual targets independent of their quantization. This can be done without incurring
additional complexity, and it dramatically minimizes the effect of quantization on speed
and distance. With the quantization in place, the on-line profile generation time reduces to
the order of microseconds, and only requires the reading of discrete profiles. Overall, the
run-time of the algorithm is mainly contributed by the Q-RAM optimization step. With
profile generation now becoming essentially negligible, the total run-time with discrete pro-
files can be determined from the data presented in Figure 5.11 and the fraction of time not
spent in profile generation presented in Figure 5.16. For example, Figure 5.11 indicates that
with 512 tasks, the total execution time with on-line profile generation is about 5 seconds.
Of these 5 seconds, Figure 5.16 indicates that 87% of the time is spent on on-line profile
generation. With offline profile generation taking only microseconds, the optimization time
for 512 tasks now takes just 13% of 5 seconds, i.e. 650 ms. Even in the unlikely event
that the number of tasks increases to 1024, the total run-time reduces from 7sec for on-line
4This is not exactly true. However, we found the real loss very close the one estimated in this way.

5.9. Results with Scheduling 151
profile generation to only 1sec for off-line discrete profile generation with a negligible loss in
utility. This brings the utility maximization performance to a level where it is practical for
real-time control. In the following section, we will investigate the results when we include
schedulability analysis with the QoS optimization. These two together will determine how
frequent we can invoke QoS optimization in a dynamic environment.
5.9 Results with Scheduling
This section is divided into 3 parts. First, we present a set of experiments to study the
impact of using only harmonic periods in QoS optimization. Next, we compare two different
harmonic period distributions against a wide choice of periods. Finally, we run the entire
resource allocation process as described in Figure 5.6 using various interleaving schemes for
radar scheduling and compare their performances.
5.9.1 The Effect of Harmonic Periods
Our first experiment studies the effect of using only harmonic periods on the total utility
obtained by QoS optimization. For simplicity, we consider only tracking tasks. We study
the impact of harmonic periods across a wide range of system configurations. Specifically,
we vary the amount of the two primary resources in the system, namely energy limits and
available time. We achieve this by varying two factors:
• Energy threshold (Eth): Lowering Eth increases the cool-down time for each quality
set-point of a radar task, and therefore the increases the cool-down utilization requirement.
Eth is defined at the end of Section 5.3.2.
•Transmission-time tracking constant (Tx-factor): This factor directly influences
the requirement of transmission time. A higher Tx-factorincreases the transmission time
for a particular quality set-point. This in turn increases both the radar utilization as well
as the cool-down utilization requirements for a given quality of any task. Tx-factor is

152 Chapter 5. Resource Allocation in Phased Array Radar
present in Equations (5.16) and (5.17) as a dividing factor of tx.
We use the settings from Tables 5.7, 5.4 and 5.1 to randomly generate 512 tasks (tracks)
and develop their profiles. We also vary Tx-factor from 1 to 16 in a geometric fashion,
and Eth from 20J to 670J keeping the look-back period τ constant at 200ms[48]. We then
perform the QoS optimization under three distributions of available periods between the
range [100, 1600]ms:
• A: Arithmetic distribution in steps of 10ms (to approximate a continuous range of
available periods to choose from),
• G2: Geometric distribution with a common ratio of 2 (100, 200, 400, · · · ),
• G4: Geometric distribution with a common ratio of 4 (100, 400, 1600).
0
20
40
60
80
100
120
140
160
0 100 200 300 400 500 600 700
Uti
lity
Energy Threhold
Tx-f=1, ATx-f=1, G2Tx-f=1, G4Tx-f=2, A
Tx-f=2, G2Tx-f=2, G4Tx-f=4, A
Tx-f=4, G2
Tx-f=4, G4Tx-f=8, A
Tx-f=8, G2Tx-f=8, G4Tx-f=16, A
Tx-f=16, G2Tx-f=16, G4
Figure 5.24: Utility Variation with Energy and Tx-factor(X)
Figure 5.24 shows the plot of utility against Eth at various values of Tx-factor aver-
aged over several randomly generated tasks. As expected, when Eth increases, cool-down
times decrease and higher utility is accrued since higher energy levels are available. As

5.9. Results with Scheduling 153
Tx-factor increases, higher transmission times are required for achieving the same track-
ing error, and the accrued utility is lowered since the system runs out of time.
In fact, at a Tx-factor of 16 and Eth of around 100, not all tasks are admitted into
the optimizer under G2 or G4. That is, some tasks do not even get their minimum QoS
operating points. These conditions represent an over-constrained system, and occur for
Tx-factor values above 16 and Eth ≤ 100. Likewise, the system becomes under-constrained
for Eth ≥ 500.
60
80
100
120
140
160
180
0 50 100 150 200 250 300
Uti
lity
Number of Tracking Tasks
Utility variation with tx-factor 4
No SchedulingImproper Nesting
Proper NestingImproper-proper NestingProper-Improper Nesting
Figure 5.25: Utility Variation
Let us only consider the general case when all tasks are admitted and can get at least
a minimum (non-zero) amount of tracking. Under these conditions, the maximum utility
drop for G2 relative to a wide choice of periods (represented by A) is 12.35% at an Eth value
of 170J and a Tx-factor value of 16. Similarly, the maximum drop for G4 is 24.5% at
an Eth value of 270J and a Tx-factor value of of 16. The average utility drops for G2
and G4 are 2.22% and 6.82% respectively and the corresponding standard deviations are 9.4
and 38.83 respectively across the entire range of Tx-factor and Eth. We limit periods to
harmonics only to satisfy jitter constraints, and these experiments show that the choice of

154 Chapter 5. Resource Allocation in Phased Array Radar
0
500000
1e+06
1.5e+06
2e+06
2.5e+06
3e+06
0 50 100 150 200 250 300
Run
-tim
e(us
)
Number of Tracking Tasks
Run-time variation with tx-factor 4
Improper NestingProper Nesting
Improper-proper NestingProper-Improper Nesting
Figure 5.26: Optimization+Scheduling Run-time Variation
G2 satisfies jitter constraints with only a small reduction in utility.
From the above experiment, we observe that a harmonic set of period G2 yields a utility
value very close to that of a fine-grained arithmetic set. Therefore, we can safely use only
harmonic periods for our radar model. This has the following additional effects: (1) it
improves the execution time of the optimization as it generates a smaller number of set-
points per task, (2) it automatically satisfies the jitter constraints, and (3) it does not affect
the optimality of the solution with respect to the fine-grained arithmetic period-set and (4)
makes the schedulability test easier.
Next, we perform the iterative (binary search) process of resource allocation for tasks
and analyze the performances of different dwell interleaving schemes.
5.9.2 Comparisons of Scheduling Algorithms
In this set of experiments, we maintain an Eth value of 250J [48] and a Tx-factor value of
4 with the aim of keeping the system to be neither under-constrained nor over-constrained.
Under these conditions, smart schemes will be better able to exploit available resources to

5.9. Results with Scheduling 155
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0 50 100 150 200 250 300
Uti
lizat
ion
Number of Tracking Tasks
Cooldown-Utilization variation with tx-factor 4
Improper NestingProper Nesting
Improper-proper NestingProper-Improper Nesting
Figure 5.27: Avg Cool-Down Utilization
maximize overall utility. We vary the number of tasks from 16 to 256 and perform the
whole iterative resource allocation process as shown in Figure 5.6. The period distribution
is limited to G2 (namely 100, 200, 400, 800 and 1600) based on our earlier experiments.
The process of QoS optimization and generation of schedule repeats until we arrive at a
schedulable task-set where the radar utilization precision factor is 0.1%.
Our next experiment deals with comparing performances of various interleaving schemes,
under the condition that the schedulability test must be satisfied. We use the following 4
different interleaving schemes:
• Proper scheme: Perform Proper nesting of tasks alone.
• Improper scheme: Perform Improper nesting of tasks alone.
• Improper-proper scheme: Perform Improper nesting followed by Proper nesting.
• Proper-improper scheme: Perform Proper nesting followed by Improper nesting.
For each task configuration and each interleaving scheme, we determine the overall
accrued utility, the execution time and the radar utilization. We finally average the results
across 50 runs.

156 Chapter 5. Resource Allocation in Phased Array Radar
0.340.360.380.4
0.420.440.460.480.5
0.520.54
0 50 100 150 200 250 300
Uti
lizat
ion
Number of Tracking Tasks
Utilization variation with tx-factor 4
Improper NestingProper Nesting
Improper-proper NestingProper-Improper Nesting
Figure 5.28: Avg Radar Utilization
Figure 5.25 shows the variation of utility accrued as the number of tracking tasks in-
creases under our interleaving schemes. From the figure, the Improper-proper scheme pro-
vides the highest utility followed in descending sequence by Proper-Improper, Improper
and Proper. The difference in utility between Improper-proper and Proper is 18.11% at
256 tasks. The drop in utility from Q-RAM with no scheduling constraints to Improper-proper
is 11.17% at the same number of tasks. In other words, the need to schedule the raw out-
puts of Q-RAM (operating with only 100% utilization requirements and no scheduling
constraints) leads to a drop of 11.17%.
Next, we plot the variation of radar cool-down utilization (Equation (5.9)) under these
schemes in Figure 5.27. We again observe that the Improper-proper scheme provides the
best utilization (close to 73.11%), and the Proper scheme performs the worst (on average
48.64%). We also observe that the radar utilization actually drops for large task sets (e.g.
from 128 tasks to 256 tasks). This is because we admit all tasks in the systems at their
minimum QoS level before performing any optimization or allocation. This reduces the
radar utilization of the system as the tasks are non-preemptive, and we admit tasks whose

5.9. Results with Scheduling 157
minimum QoS itself is expensive. Our conclusion that the Improper-proper performs the
best among the four schemes is also further substantiated in the plot of radar utilization
(Equation (5.1)) in Figure 5.28. Figure 5.28 also shows that the cool-down utilization plays
a bigger role in determining the utilization of the system than the radar utilization in our
model.
Our experiments show that task-sets are best interleaved by improper nesting followed
by proper nesting. They also show that simple improper nesting performs better than
proper nesting. Therefore, the task-sets generated by the optimization steps are easier to
improperly nest.
5.9.3 Interleaving Execution Times
We measured the execution time of our resource allocation methods as the number of tasks
is varied. The results are shown in Figure 5.26. The execution time includes the Q-RAM
optimization followed by the schedulability analysis on the 4 radar system. We note that
the execution times of the scheduling results do not include the task profile generation time
(which occurs only once). This is because the task profile generation does not depend on
the interleaving scheme, and the task-set can choose their profiles very quickly (in the order
of µs) by using discrete profiles generated offline as described in Section 5.5.6.
The plot shows that all the interleaving schemes have comparable run-times, with
Improper being the fastest and Proper-Improper being the slowest. As can be seen, with
about 256 tasks, dynamic interleaving can be performed in about 2.5 sec -with very little
optimization carried out in our code. This shows that the reconfiguration rate of the op-
timizer can be once in 2.5 seconds for 256 tasks. In other words, the radar system can
re-evaluate the entire system and re-optimize every 2.5 seconds. In practice, the number of
tasks is unlikely to exceed 100 tasks. In that case, the reconfiguration rate can be increased
to roughly once in 0.7 seconds. In addition, our experimental results show that this can
be drastically dropped to the order of 100 ms if we increase the radar utilization precision

158 Chapter 5. Resource Allocation in Phased Array Radar
factor of the binary search technique to 1% or more.
5.10 Chapter Summary
We developed a QoS optimization scheme for a radar system. It incorporated the physical
and environmental factors that influence the QoS of the various tracking and search tasks .
In order to perform QoS optimization dynamically in real-time, the profiles of the tasks must
be dynamically generated, but this can lead to unacceptable execution times. We proposed
two approaches to solve this problem. First, we showed how only the “relevant” set-points
of the tasks are generated using traversal techniques that significantly reduce the complexity
of the optimization. A Two-step First-order Fast Traversal scheme (2-FOFT) proves to be
the best in reducing computational time significantly with negligible loss in system utility.
Next, we showed that the profiles can be generated offline based on quantization of the
environmental dimensions, with acceptable storage requirements. Only a limited number of
profiles need to be generated with quantized values of the environmental dimensions. With
such offline discrete profile generation, the total optimization time takes only 650 ms for
512 tasks with minimal loss in utility. This makes the Q-RAM optimization feasible for
real-time use.
Next, we developed an integrated QoS resource management and scheduling framework
for radar that can rapidly adapt to dynamic changes in the environment. This framework
relaxes the need for maximizing (or minimizing) an objective function using only strict
inequalities as resource constraints. We accomplish this by introducing an efficient schedu-
lability test on system resources, and repeating the optimization a small number of times
using a binary search technique. The scheduling of tasks on radar antenna deals with three
primary constraints. First, tasks must satisfy the energy constraint of the antenna. Sec-
ond, tasks must satisfy zero-jitter requirements. Third, tasks cannot be preempted during
transmission or reception.

5.10. Chapter Summary 159
We transformed the energy constraint into a timing constraint by defining a concept
called cool-down time. We then restricted ourselves to choosing only harmonic periods in
order to satisfy the jitter requirements, and we showed that such a restriction leads only to
small drops in the overall utility of the system. Finally, we interleave the phases of different
radar tasks so as to minimize the time utilization. We found that “improper nesting” of
tasks followed by “proper nesting” yields the best results. In the next chapter, we will
describe the resource allocation problem in distributed embedded systems.


Chapter 6
Resource Allocation in Distributed
Embedded Systems
6.1 Introduction
Distributed embedded control systems are used in cars, airplanes, houses, information and
communication devices such as digital TV and mobile phones, and autonomous systems
such as service or entertainment robots. Due to the steady improvement of production
processes, each of these applications is now realized as a system-on-a-chip. Furthermore, on
the hardware side, low-cost broadband communication media are essential in the realization
of distributed systems. In order to ease the difficulties of having a communication system,
middleware solutions for embedded systems are emerging. In distributed embedded systems,
typically, multiple threads work together to process real-time tasks. These threads can be
distributed across multiple processors.
Let us consider the case of automotive systems. The latest generation of road vehicles has
seen a tremendous growth in on-board electronic systems, which control increasingly large
parts of a vehicle’s functionality. The development of new automotive functions based on the
use of modern electronic, computer, and communication technologies has been accelerated
161

162 Chapter 6. Resource Allocation in Distributed Embedded Systems
in recent years. Several products such as ABS (anti-lock Brake Systems), Cruise Control,
and Engine Management Systems have been developed. These systems are controlled by
Electronic Control Units (ECUs). A typical diagram of a distributed automotive system is
shown in Figure 6.1.
The early ECUs were quite autonomous, and thus had very little exchange of information
among them. However, as the functionality increases, more advanced functions are required
for cooperation among the ECUs [2]. Currently, vehicles contain up to 20 ECUs that are
as close as possible to the device they control, and are connected via a few distribution
networks. The networks usually run protocols such as Controller Area Network (CAN) [9],
Time-Triggered Architecture [47], Local Interconnect Network (LIN) among many others.
The inclusion of electronics in the automotive industry will continue to increase, and at
the same time, cost pressure will limit the functionality to be added to the system. In the
future, it is expected that the number of ECUs will not grow dramatically because of cost,
space and weight constraints. This will lead to greater integration of software and hardware
modules to meet the demand for increased functionality.
6.2 QoS and Resource Management Challenges
The QoS of a distributed embedded system is generally characterized by the accuracy and
the precision of various measurements (e.g., speed), along with reliability, security and
other multimedia-specific requirements. Measurements on precision in embedded systems
like avionics and automotive systems are dependent on the feedback control mechanisms
used. In other words, the resource requirements for a given level of precision may change
dynamically due to changes in the environment.
As the functionality increases, we must provide an efficient layered software architecture
so that components of the software can be reused [21]. These components may have multiple
QoS levels that include dimensions in real-time, fault-tolerance and security. In addition to

6.2. QoS and Resource Management Challenges 163
Gateway
Gateway
Input/Output
FPGARAM
CACHE
CPUABS Cruise Control
Engine ControlThrottle Control
Safety critical Network
Non−safety criticial high−speed network
Network Interface.
Non−safety critical low−speed Network
Figure 6.1: Typical Automotive System
using computational resources, they also communicate with each other. Hence, an efficient
resource management scheme must determine the QoS settings and resource requirements
of these components, while scheduling them in the distributed system. In addition, the
scheme must also be dynamic enough to satisfy varying resource requirements of these
components under various environmental conditions. This may lead to a change in the QoS
of a task based on the demand of the situation. For example, the engine throttle control task
increases its frequency based on the RPM (Revolution Per Minute) of the engine crankshaft.
This essentially requires more resources for the same QoS level, thereby forcing the system
to adjust the QoS levels assigned to tasks.
We can assume that an embedded system consists of a series of ECUs as multiproces-
sors connected by a bus running a large number of small tasks (or software components).
Many of these components communicate with each other. In Chapter 3, we discussed QoS
optimization in a large multiprocessor system where we assumed that there was a finite
number of types of tasks and negligible communication requirements among them. In this

164 Chapter 6. Resource Allocation in Distributed Embedded Systems
case, we summarize the main distinguishing features of a distributed automotive system as
follows.
• A large number of tasks (> 1000) is allocated to a small (< 20) number of processors.
• Tasks (or software components) communicate with one another. This means that the
communication bandwidth must be allocated appropriately in addition to processor
bandwidth in order to satisfy timeliness.
• The possible number of types of tasks may not be limited.
• This system can be very dynamic as in the case of radar tracking, based on the
environmental factors.
In order to tackle the above issues, we summarize our approach as follows. First, we use
cluster analysis to classify and prioritize tasks. Second, we hierarchically group the tasks
based on their obtained priorities and allocate resources among groups. Third, we execute
QoS Optimization independently on each group to perform resource allocation among tasks
within a group.
In the next section, we briefly describe our cluster analysis principles [23].
6.3 Task Classification and Cluster Analysis
Clustering has been used as a method of scalable optimization for many applications [76].
It is normally used to group objects based on their similarities or differences, which is com-
monly termed the distance between objects. The first step typically begins with measuring
each of a set of n objects on each of k attributes. Next, a measure of similarity or, alterna-
tively, the distance or difference between each pair of objects is obtained based on those k
variables, using Euclidean distance, Manhattan distance, Mahalanobis distance etc. Then
an algorithm, or a set of rules, must be employed to cluster the objects into sub-groups

6.3. Task Classification and Cluster Analysis 165
based on inter-object similarities. The ultimate goal is to arrive at clusters of objects which
display small intra-cluster variations, but large inter-cluster variations.
The overall cluster analysis procedure involves two key problems: (1) obtaining a mea-
sure of inter-object similarity and (2) specifying a procedure for forming clusters based on
the similarity measures.
6.3.1 Measure of Similarity
An essential step for cluster analysis is to obtain a measure of the similarity or proximity
between each pair of objects under study (or, alternatively the difference). There are
various ways to measure this metric under different circumstances such as : (1) Correlation
coefficients, (2) Euclidean distances, (3) Matching-type measures of similarity and (4) Direct
scaling of similarity. In our case, we will discuss the similarities between the tasks based on
their Profiles.
Recall that a task in our model consists of multiple set-points. Each set-point contains
values of several operational dimensions, resource requirements and utility. In the case
of multiple resources, we obtain a scalar parameter called the compound resource that
expresses the price of a particular resource combination.
We want to compare the utility functions of tasks with reference utility functions. There-
fore, we would like to generate reference curves for individual classes offline. Each task will
be allocated to one of the classes depending on which reference curve it is closest to. The
proximity is based on the above four quantities.
Similarity in Utility functions
Using the notion of an Lp−metric [58], the pth order difference between two functions f(x)
and g(x) in the range Ω = [a, b] can be expressed as:
||f − g||p = (
∫ ba |f(x)− g(x)|pdx
b− a)
1p . (6.1)

166 Chapter 6. Resource Allocation in Distributed Embedded Systems
Figure 6.2: Utility Curve Ranges
Considering only the first order difference, the output of the above equation is pro-
portional to the area between the curves f(x) and g(x). Considering the second order
difference yields a root-mean-square (RMS) measure. The infinite order difference yields
the maximum distance between the functions.
For functions with discrete domain Ω = [x1, .., xn], this can be alternatively expressed
as:
||f − g||p = (n∑
i=1
(f(xi)− g(xi))p)1p . (6.2)
Let us now apply this concept to finding tasks with similar utility functions. From Figure
6.2, comparing functions with Ω = [0, b], we observe that any utility function starting from
0 at x = 0 and ending in the range [g(b), f(b)] at x = b lies within the trapezoidal region
covered by the lines [l(x) = (g(b)xb )], [m(x) = f(b)], the y-axis and [x = b]. The area covered
is equal to b2f(b) + (f(b) − g(b)). Hence, if two functions h(x) and g(x) have the same
end-points at y = l(b), then they maximally differ from each other by the triangular area

6.3. Task Classification and Cluster Analysis 167
between the y-axis, [l(x)] and [n(x) = l(b)]. The area is equal to bl(b)2 . These two functions
have the same end-point and hence the same average slope.
Therefore, if two functions h(x) and g(x) have the same end-points at y = l(b), then
they maximally differ from each other by the triangular area between the y-axis, [l(x)] and
[n(x) = l(b)]. The area is equal to bl(b)2 .
Next, we investigate the relation between functions g(x) and h(x) relative to their deriva-
tives. If we impose two more conditions, g′(0) = h′(0) and g′(b) = h′(b), from Figure 6.2,
we can observe that the range of f(x) and g(x) are confined within the triangular area
between the intersecting lines [i(x) = (g′(0))x], [j(x) = (g′(b))x + (g(b)− bg′(b))] and [l(x)].
This area is smaller than the area of the previously defined triangle between l(x), n(x) and
the y-axis.
From the above discussion, we can define task similarity using the following four quan-
tities:
• f(x) at x = 0 and x = b (b = last estimated point on the curve)
• f ′(x) at x = 0 and x = b.
As seen from the last section, we can make the maximum error between two functions
arbitrarily smaller by using higher order derivatives. The above conditions can be used as
guidelines to classify tasks.
6.3.2 Utility Loss Analysis in Slope-based Classification
In this section, we evaluate the potential loss in utility that would occur when tasks are
classified based their values at two end-points. Let us suppose that each task has a contin-
uous utility function and its value increases linearly with resource up to a certain amount
of resource beyond which it saturates to a maximum value. We also assume that their
utility functions have the same end-points. This is illustrated in Figure 6.3. The assumed
parameters are listed in Table 6.1.

168 Chapter 6. Resource Allocation in Distributed Embedded Systems
Util
ity
r2r1
u
Resource
Figure 6.3: Utility Functions of Two Types
Number of types of tasks 2 (T1 and T2)Number of tasks of each type n1 for T1, n2 for T2
Maximum achievable utility for a task uMinimum resource to accrue utility u r1 for T1, r2 for T2
Total resource amount R
Table 6.1: Assumed Parameters for each Task Types
If we employ our approximated classification, all tasks are considered identical since all
have the same end-points. We will inquire how much utility loss we incur if we employ this
approximation. We define 3 cases based on different ranges of the value of R.
Case 1: R ≤ n2r2: This case represents the situation when there are insufficient resources
to allocate all of the T2 tasks at their highest QoS level and thus in the optimal allocation,
no resources will be given to T1 tasks. The optimal algorithm will distribute the entire
resource of amount R equally among tasks of the type T2. The total optimal utility is given

6.3. Task Classification and Cluster Analysis 169
by:
Uopt = uR
r2. (6.3)
If all tasks are classified to be of the same type based on their identical end-points, the
resource is distributed equally among (n1 + n2) tasks. The accrued utility is given by:
Us = uRn1r1
+ n2r2
n1 + n2. (6.4)
The fractional loss in utility from the optimal value is given by:
ε =Uopt − Us
Uopt=
1− r2r1
1 + n2n1
. (6.5)
Since R ≤ n2r2, the bound of the value of ε is expressed by:
ε ≤1− R
n2r1
1 + n2n1
, (6.6)
⇒ ε ≤ 1− R
n2r1, (6.7)
where n1 >> n2 in the extreme case. If we assume r1 = r2 + ∆r, where ∆r ≥ 0 since
r1 ≥ r2, we obtain:
ε ≤ 1− (1 +n2∆r
R)−1. (6.8)
From Equation (6.8), we observe that the utility loss increases with the increase in ∆r.
The utility loss can be potentially very high if the maximum resource requirement of a task
is much larger than the capacity of the resource i.e., ∆r >> R and the number of tasks
of the type T1 is much larger than the number of tasks of the type T2, namely n1 >> n2.
However, the obtained utility will be small when n2 and r2 both are small since Uopt ≤ un2
as R ≤ n2r2.

170 Chapter 6. Resource Allocation in Distributed Embedded Systems
Case 2: (n1r1 + n2r2) ≥ R > (n1 + n2)r2: This case represents the situation where
there are sufficient resources available to allocate all of the T2 tasks at their highest QoS
level but the remaining resources are not enough to maximize the QoS of tasks of the type
T1. The optimal algorithm will maximize the utility values of tasks of type T2 while allo-
cating the remaining resource equally among tasks of type T1. The optimal utility value is
given by:
Uopt = n2u +u(R− n2r2)
r1. (6.9)
The utility value obtained by using our approximated classification is given by:
Us = uRn2r1 + n1r2
(n1 + n2)r1r2. (6.10)
The value of the utility loss ε is expressed by:
ε =(r1 − r2)n2[(n1 + n2)r2 −R](R + n2(r1 − r2))r2(n1 + n2)
, (6.11)
which can be simplified as:
ε ≤ 1(1 + n2
n1)[ R
n2∆r + 1]. (6.12)
If in the limiting case, when ∆rR →∞, we obtain:
ε ≤ 11 + n2
n1
. (6.13)
This shows that although the error is always < 100%, it can be made arbitrarily close
to 1 when ∆r >> R.
Case 3: (n1 + n2)r1 ≥ R > (n1r1 + n2r2) :
This case represents the situation where sufficient resources are available to maximize

6.4. H-Q-RAM Algorithm Design 171
the QoS levels of all tasks of both types. The optimal utility is given by:
Uopt = (n1 + n2)u. (6.14)
Using the approximated classification, the obtained utility is given by:
Us = n2u +Rn1
(n1 + n2)r1u. (6.15)
The fractional utility loss is given by:
ε =n1[(n1 + n2)r1 −R]
(n1 + n2)2. (6.16)
Considering the lowest value of R in this range, we obtain:
ε ≤1− r2
r1n1n2
+ n2n1
+ 2. (6.17)
The worst case happens when r2 = 0 and n2 = n1. In this case, the value of error is 25%.
Based on the above results, we conclude that the approximated classification is applicable
where ∆r, the difference between maximum resource requirements of two tasks of two types,
is less than the capacity of the entire resource R, which is usually the case for most systems.
In addition, the worst case happens when the optimal utility value is infinitesimally small.
In the next section, we will discuss the design of our H-Q-RAM algorithm in detail that
classifies tasks based on their average slope values i.e., the slope of the line joining their
end-points.
6.4 H-Q-RAM Algorithm Design
This algorithm is a more generalized version of Algorithm 4 described in Chapter 3. The
whole process is divided into 4 main parts: (1) Task classification, (2) Clustering, (3)

172 Chapter 6. Resource Allocation in Distributed Embedded Systems
Virtual task formation, and (4) Hierarchical resource allocation.
First, we classify tasks by ordering them in decreasing values of their average slopes.
Next, we create two groups and allocate tasks in each group alternatively. This way, the
average slopes of tasks in each group are similar. Once two groups are formed, we com-
pute the resource demand of each group and allocate processors and communication (bus)
bandwidth to them proportional to their demands. We then recursively divide each group
hierarchically until we allocate at most 2 processors per group.
6.4.1 Task Classification
Tasks are classified to based on average slopes of their utility functions. We make the
following assumptions.
• A task always needs some amount of processing resource.
• If two tasks communicate with each other, we can eliminate their communication
bandwidth requirements by placing them in the same processor. Thus, unlike the
CPU bandwidth, the communication bandwidth may not always be needed for tasks.
We assume a weight of 0.5 for network bandwidth (sending) while assuming that of
1.0 for CPU bandwidth.
Based on the above observations, we express the resource requirement of task i in terms
of a 2-element resource vector consisting of communication (bus) bandwidth and processing
bandwidth at each QoS level1.
If rcj= the processing resource requirement at a QoS level j, rnj= the corresponding
total communication (bus) bandwidth requirement with other tasks, we define a composite
resource metric at level j by:
Hj =√
r2cj
+ (0.5rnj )2. (6.18)
1We are yet to obtain resource dimensions for tasks since clustering is not done. Hence these settings arenot set-points in the pure sense.

6.4. H-Q-RAM Algorithm Design 173
Thus, we construct set-points of a task by computing the composite resource value at each
QoS level. Next, we compute the average slope of the utility function.
Definition 6.4.1 (Average Slope of a Task). The average slope of a task i is given by
the following expression:
si =Umax − Umin
Hmax −Hmin, (6.19)
where Hmin = composite resource at the lowest QoS level, Hmax = composite resource at
the highest QoS level, Umin = utility at the lowest QoS level, and Umax = utility at the
highest QoS level.
Tasks are sorted based on their average slopes. We can either sort the tasks in decreasing
order of their slopes, or perform a radix sorting [45], in which we can divide the slope range
into N discrete slots and fit the tasks into one of the slots.
6.4.2 Clustering
First, we create two clusters and allocate tasks to them. The allocation is performed in
such a way that the tasks with the same class (i.e., similar average slopes) are distributed
in equal numbers between the clusters. Each cluster can again be divided into two more
clusters and thus, the clustering process continues recursively. It lasts until we have a certain
maximum threshold number of tasks or a certain maximum threshold number of resources
per cluster. The scalability and the accuracy of the solution depends on these thresholds.
In this chapter, for simplicity, we assume that the threshold for resources is 2 processors
per cluster. We do not assume any threshold number for tasks.
In order to distribute tasks and resources to the clusters, we require the following defi-
nitions.
Definition 6.4.2 (Mean Slope of a Cluster). The mean slope of a cluster is given by
the arithmetic mean of the average slopes of tasks present in the cluster.

174 Chapter 6. Resource Allocation in Distributed Embedded Systems
Division of Tasks among Groups/Cluster
Allocation of Processors to Groups
Figure 6.4: Slope-based Task Clustering Procedure
Definition 6.4.3 (Average Demand of a task). The average demand of a particular
type of resource (processing bandwidth or communication bandwidth) of a task is given by:
ravgc =
∑Nj=1 rcj
N, (6.20)
where N= the number of QoS levels of a task, and rcj= the resource vector consisting of
two components: CPU and network bandwidth at the jth level.
Definition 6.4.4 (Resource Demand of a Cluster). The resource demand of a cluster
is given by the sum of the average demands of its tasks.
Task Clustering
At a particular stage of the clustering algorithm, we start with the task with the highest
slope, and allocate tasks to each cluster so that the mean slopes of the two clusters are
nearly equal.

6.4. H-Q-RAM Algorithm Design 175
In order to minimize the network resource requirements, we would like to allocate tasks
that communicate with each other in the same cluster. This may conflict with our goal of
balancing mean slopes on clusters. As mentioned before, we divide the slope range into a
number of discrete slots and fit each task into one of the slots. Within each slot, we sort the
tasks by their communication (sending) bandwidth requirements in increasing order. Next,
we select a cluster for each task. If both clusters have the same mean slope, we allocate
the task to the cluster that contains its communicating tasks with largest value of total
communication bandwidth. If the mean slopes are not equal, the allocation is done to the
appropriate cluster so as to equalize the mean slope.
In this way, we ensure two aspects. First, the mean slopes of the clusters are equalized.
Second, the tasks that communicate with one another with larger communication bandwidth
requirements fall in the same cluster and may eventually be allocated to the same processor.
If two tasks are allocated to the same processor, their mutual communication bandwidth is
eliminated.
Resource Clustering
Once two clusters are formed, we apportion the processing and communication resources
based on the resource demands of the clusters. For example, if Rd1 and Rd2 are the total
processing resource demands of two clusters, P is the total number of processors each of
capacity C, the resource allocations Ra1 and Ra2 are given by:
Ra1 =PCRd1
Rd1 + Rd2
, (6.21)
Ra2 =PCRd2
Rd1 + Rd2
, (6.22)
This resource allocation may lead to a fractional allocation of processors, which must
be managed while performing the scheduler admission test on each processor. In the same
way, we distribute the bus bandwidth between the clusters. The process of hierarchical

176 Chapter 6. Resource Allocation in Distributed Embedded Systems
Virtual Task Formation
Figure 6.5: Virtual Task Creation Procedure
clustering for one iteration is illustrated in Algorithm 13.
6.4.3 QoS Optimization
So far, we have been able to divide the system into multiple independent subsystems called
clusters. In this step, we perform QoS optimization independently on each cluster. We will
compare this with basic Q-RAM optimization in which we directly model the entire system
without performing clustering. The optimization process is divided into two steps: Virtual
Task Formation and Resource Allocation.
Virtual Task Formation
As mentioned earlier, when a group of tasks communicate only with each other, their
network bandwidth requirements disappear when they are allocated to the same processor.
Therefore, the resource allocation of these tasks are mutually dependent. We form virtual
tasks by combining these tasks, as shown in Figure 6.5. Consequently, we generate profiles
of virtual tasks by enumerating their resource allocation in the cluster (or in the entire
system for basic Q-RAM).

6.5. Experimental Results 177
Number of QoS dimensions q 1Number of elements of each dimension 3Utility range for QoS dimension (u(q)) random [0.1-1.0]Weight range for each QoS dimension random [0.01,1.00]CPU requirement for a task random [2 MHz - 200 MHz]Network bandwidth requirement between two tasks random [20 Kbps - 200 Kbps]Number of communicating tasks for each task random [1,8]Number of processors 16Resource capacity per processor 2 GHzNetwork bandwidth capacity of the bus 100 Mbps
Table 6.2: Experimental Settings with Optimal Algorithm
Resource Allocation
The resource allocation within each cluster follows the basic AMRMD CM algorithm, as men-
tioned in Chapter 2. We perform allocation in each cluster independently.
6.5 Experimental Results
In this section, we compare the performances of H-Q-RAM and Q-RAM optimizations. As
in previous chapters, our experiment focuses on measuring two parameters: (1) the global
utility obtained by the optimization, and (2) the total execution time of the algorithm.
We consider a distributed system consisting of 16 processors, each with a frequency of
2GHz, connected by a bus of bandwidth 100Mbps. The assumed configuration of the tasks
and that of the system are presented in Table 6.2.
In the case of Q-RAM optimization, we enumerate all possible choices of deployment of
tasks in the system in order to obtain the optimal result. In H-Q-RAM optimization, we
implement Algorithm 13 to divide the system into multiple subsystems or clusters, repeat
the clustering process until we have fewer than 3 processors per cluster, enumerate possible
choices of deployment of tasks within each cluster, and determine the near-optimal resource
allocation within each cluster independently.

178 Chapter 6. Resource Allocation in Distributed Embedded Systems
Create 2 clusters;Create a 3rd cluster;//This stores odd-numbered task from each region
Linearly divide slope ranges (0,∞) in nth number of discrete regions;// nth = number of discrete regions, 100, for example
Fit the tasks into the regions based on average slope values of their utilityfunctions;Classify a task to be of a type based on its presence in a region;for Each slope region do
Within a region, sort the tasks based on decreasing order of their Averagetransmission bandwidth requirements;if number of tasks is odd then
Put the last task in the 3rd cluster;//This takes the last odd-numbered task from the next loop
endfor Each task in the region do
Determine the proportion of communication bandwidth requirements fortasks already allocated in 2 clusters;if Each cluster has equal number of tasks of this type then
Allocate the task to the cluster whose tasks have greater communicationbandwidth with this task;
endelse
Allocate the task to the cluster that has a less number of tasks of thistype;
endend
end/*We would like take tasks out of the 3rd cluster and put them intothe first two of them */
if There are non-zero number of tasks in 3rd cluster thenif Slopes of the first 2 clusters are equal then
Determine the proportion of communication bandwidth requirements fortasks already allocated in 2 clusters;Allocate the task to the cluster that has more tasks that are communicatingwith this task;
endelse
Allocate task to the cluster that balances the mean slopes of the 2 clusterend
end
Algorithm 13: Clustering Algorithm for Communicating Heterogeneous Tasks

6.5. Experimental Results 179
Figure 6.6: Utility Variation
We vary the number of tasks as N = 50, 100, . . . , 300, measure the accrued utility and
execution time for Q-RAM and H-Q-RAM. Each configuration is averaged over 50 iterations.
Figure 6.6 shows the bar-graph containing the variation of the obtained utility against
the number of tasks. From the figure, we notice that H-Q-RAM yields a utility very close
to that of Q-RAM. In fact, the maximum reduction in utility is less than 4%. In addition,
this drop decreases with an increase in the number of tasks, as shown in Figure 6.7.
We plot execution times for Q-RAM and H-Q-RAM in Figure 6.8. As expected, H-Q-
RAM shows a big improvement on execution time. For example, the reduction in execution
time for H-Q-RAM is 85% for 300 tasks. Moreover, the difference in execution times between
the algorithms increases with the number of tasks in the system. This proves the usefulness
of H-Q-RAM for large distributed embedded systems.

180 Chapter 6. Resource Allocation in Distributed Embedded Systems
Figure 6.7: Percentage Utility Reduction
Figure 6.8: Execution Time Variation

6.6. Chapter Summary 181
6.6 Chapter Summary
In this chapter, we investigated the QoS-based resource allocation problem in distributed
embedded systems. This is an extension of the resource allocation we discussed for mul-
tiprocessor systems in Chapter 3. However, we relaxed a few assumptions that we had
made in Chapter 3. First, tasks can communicate with each other. Therefore, we need to
consider allocating the network bandwidth (which is assumed to be bus bandwidth) along
with the processor cycles. Second, we did not assume any fixed set of types of tasks. In
other words, a task can have any possible profile within certain ranges of processor cycles
and network bandwidth requirements. In this case, in order to implement a similar hierar-
chical decomposition technique, we discretized profiles based on their average slopes. We
also minimized the usage of network bandwidth by clustering heavily communicating tasks
together as much as possible. This ensures that highly communicating tasks are likely to
be allocated to the same processor thereby eliminating the network bandwidth requirement
among themselves. The results also demonstrated that our H-Q-RAM is scalable enough
to be used as an adaptive run-time QoS optimizer for distributed embedded systems.
As future work, we would like to implement this as adaptive QoS-aware middleware
in specific types of embedded systems such as automotive systems. We would also like to
integrate this approach with a design-time code-generation tool, such as Time Weaver[21].


Chapter 7
Conclusion and Future Work
The fundamental motivation for this dissertation is the growing need for the development
of scalable resource management infrastructure for large, dynamic and distributed real-
time systems. Instead of maximizing the throughput of one or more resources, the goal
of our scheme is to maximize the satisfaction of the end-users. We consider traditional
distributed systems as well as embedded distributed systems that interact directly with the
physical environment, and hence operate under physical constraints. In all such systems,
the satisfaction of the end-users is the primary parameter that must be maximized.
Our goal was to address the complexity of resource management schemes that allocate
resources to a large number of tasks, perform their deployment in the system and ensure
their timing guarantees by interacting with the admission control of the scheduler. Since the
algorithm for optimally solving this problem is NP-hard, we investigated scalable heuristic
solutions that scale well with the size of the systems.
7.1 Contributions
The contribution of this dissertation can be divided into three major areas. First, we
designed a generic model of a distributed system consisting of resources and other physical
183

184 Chapter 7. Conclusion and Future Work
constraints. Secondly, we developed a set of algorithms that perform the QoS optimization
in a large system in a scalable manner while obtaining a global utility close that of the
optimal algorithm. Finally, we designed and implemented a scheme that integrates our
QoS optimization model with the admission control mechanisms of resources for guaranteed
schedulability.
7.1.1 Modeling
We borrowed the existing model of resources and tasks from the QoS-based Resource Al-
location Model (Q-RAM) [49]. In Q-RAM, a resource vector, whose number of elements
denotes the number of resources, represents a system and the value of an element denotes
the capacity of the corresponding resource. A task is represented by a set of QoS dimen-
sions as user-level dimensions. Each QoS dimension is associated with a utility function.
A particular QoS level of a task contains a fixed value for each of the QoS dimensions.
Hence, each QoS level is associated with a utility that is a sum of the utilities obtained
from the individual QoS dimensions. We also defined a set of system-level dimensions that
influence the allocation of resources of a task. These include operational dimensions and
environmental dimensions.
Operational Dimensions: The operational dimensions are the parameters that are
within the control of the system administrator that influence the resource demands of an
application. Some of the operational dimensions may be of direct relevance to the user
in terms of the quality. Hence, some operational dimensions can be QoS dimensions. Ex-
amples of operational dimensions include resource deployment options, coding schemes for
video applications etc.
Environmental Dimensions: The environmental dimensions are the parameters that
are not in control of the system administrator or the user. An example is the noise in a

7.1. Contributions 185
wireless environment. Changes in the environmental conditions require us to re-optimize
the QoS of the system.
The system dimensions determine the resource requirements, the values of the QoS di-
mensions and the corresponding utility values. Combining all these dimensions, we generate
set-points of tasks, where each set-point consists of a utility value and a particular setting
of operational and environmental dimensions, which includes a QoS level and a resource
configuration.
7.1.2 Scalable QoS Optimization
Our QoS optimization algorithm chooses a set-point for each task and allocates resources
to tasks according to the requirements of their assigned set-points. We define the global
utility of the system as the sum of the utilities of the assigned set-points of tasks. The
optimization process maximizes the global utility.
We developed a basic algorithm of polynomial complexity called AMRMD CM as a modified
version of AMRMD1 algorithm for Q-RAM [51]. AMRMD CM extends the functionality of the
basic algorithm by handling trade-offs more efficiently for tasks with multiple resource
deployment options. The complexity of the basic algorithm is O(nL log(nL)), where n
equals the number of tasks and L equals the maximum number of set-points per task.
Although this is a seemingly benign complexity, it increases monotonically with the increase
in either n or L, which can be problematic when either n or L is very large. To manage this
complexity, we have developed a hierarchical decomposition technique, collectively called
Hierarchical Q-RAM or H-Q-RAM for large distributed systems.
In multiprocessor systems, where a task can be allocated to any of the processors, we
divide the problem into multiple sub-problems, and solve these subproblems independently.
This is done by distributing the processors into near identical processor-groups, distributing
the tasks into near-identical task-clusters, assigning each task-cluster to each processor-
group to form near-identical subsystems, and finally performing the QoS optimization in

186 Chapter 7. Conclusion and Future Work
each of the subsystems concurrently.
A hierarchical networked architecture similar to the Internet consists of loosely connected
sub-domains. Each sub-domain can be considered to be a separate subsystem. However,
if a task has a fixed source and a destination in different sub-domains, then it has fixed
sub-domains for source and destination and the routes between its source and destination
can span across multiple sub-domains. In such cases, we cannot perform sub-domain QoS
optimization independently since the routes of tasks may pass through multiple sub-domains.
The resource allocation is very likely to be made locally within a sub-domain if the source
node and the destination node of a task both fall inside the same sub-domain. This type
of task is called a local task. A task whose source and destination nodes belong to different
sub-domains is called a global task. Sub-domains negotiate with each other using transaction
techniques to allocate resources (route and bandwidth) to a global task.
For certain systems, the complexity arises from the size of L, i.e., the number of the
set-points per tasks. In a certain system, a task may have a very large number of possible
configurations. A typical example is a Radar System. In this case, we have developed
efficient algorithms that select only a few important set-points per task efficiently without
enumerating all possible set-points. We studied the performance of these algorithms in
terms of the global utility and the execution time.
7.1.3 Integration of QoS Optimization and Scheduling
In this dissertation, we have presented an integrated approach that simultaneously maxi-
mizes overall system utility, performs task scheduling analysis and satisfies multi-resource
constraints in dynamic real-time systems such as a radar system. In our implementation
of a resource manager for a phased array radar system, we show that our approach is not
only efficient enough to be used on-line in real-time, but also performs within 10% of the
optimal solution. In this process, we develop efficient scheduling schemes for radar tracking
tasks that can generate high resource utilization of the radar by interleaving tasks with each

7.2. Future Work 187
other.
7.2 Future Work
This dissertation analyzes the complexities associated with QoS-based resource management
in distributed systems, and outlines a scalable framework for it. This has opened up multiple
directions for future research, from modest, incremental improvements to more broad and
fundamental ones. We present these different areas of future work here.
7.2.1 Implementation
We have a prototype implementation of a middleware that performs the QoS optimization
in a distributed networked system consisting of 12 nodes. A global server known as “Session
Coordinator” or SesCo, runs on a single node and performs QoS-based resource allocation for
the entire system [40]. It enforces resource reservations by interacting with “Local Resource
Managers (LRMD)” running on individual hosts. LRMD, in turn, relies on the reservation
mechanisms of the real-time operating system Linux/RK running on individual hosts [62].
Following the principles of H-Q-RAM, we would like to extend this prototype by incor-
porating the distributed implementation of SesCo. In addition, the emulation of large-scale
networks can also been performed in this test-bed for future research problems.
7.2.2 Stochastic QoS and Resource Requirements
In this dissertation, we have subtly assumed deterministic resource requirements of tasks.
Even if this could either be worst-case or the average-case, the variation of the resource
usages of tasks was not considered. If the resource requirement of a task changes, the
current configuration will rerun the optimization to generate a new resource allocation.
However, this may not be sufficient if the resource requirements of a task vary rapidly. In
this case, our system may not meet the deadlines of all the tasks if it uses average-case

188 Chapter 7. Conclusion and Future Work
utilization, or it will be heavily underutilized if it uses worst-case resource utilization.
In Q-RAM, we currently have two types of Probabilistic Level of Service (PLoS) metrics
in the context of network bandwidth [40]: (a) QoS availability (fraction of time there
is no degradation) and (b) fraction of packets delivered (not dropped). The “Resource
Priority Multiplexing” (RPM) policy module and its kernel-level mechanisms implement
the probabilistic guarantees for network bandwidth [37].
Apart from the two PLoS metrics as probabilistic QoS dimensions, there are other prob-
abilistic QoS dimensions such as the number of packets (or jobs) that meet their deadlines.
In this context, Zhu et al designed a Quantized EDF (Q-EDF) [86] scheduling mechanism
that minimizes the number of deadline misses of tasks. Hence, if we want to consider the
deadline miss rate as a QoS dimension (or, a PLoS metric), we would have to integrate
Q-EDF with the QoS optimization scheme. In our QoS optimization model, the criticality
can be considered a QoS dimension that determines the utility loss relative to the number
of deadline misses of a task. Based on the statistics of resource usage of the task, we would
like to determine the resource requirements of a task in order to obtain a specific deadline
miss rate. However, determining the resource requirement for a specific deadline miss rate
can be a difficult problem.
7.2.3 Profit Maximization Model for Resource Allocation
Our QoS-based resource allocation model maximizes the global utility of the system, by
apportioning resources of fixed quantities to a set of tasks. In this case, we maximize the
utilization of resources as well, since more resource usage generally provides more utility
to the end-users. Hence, we optimize our system toward maximizing benefits of the end-
users under the constraint of limited resource capacities. This is a typical consumer-centric
model where the consumer would like to maximize his/her satisfaction or utility by buying
a particular bundle of goods under his/her budget constraint.
The producer, on the other hand, sets the prices of goods based on the utility they

7.2. Future Work 189
provide to the customers. Hence the revenue earned by the producer is proportional to
the sum of the utilities of his/her consumers. However, the producer strives to maximize
his/her profit, which is defined as the difference between the revenue and cost. It is possible
that maximizing the revenue may not maximize the profit, since the cost generally increases
with the size of the system, and therefore, it may be too large at a very large revenue.
In computer systems, the cost to the producer includes the purchasing cost and the
maintenance cost of hardware and software components. Therefore, the profit maximization
principle leads to producer-driven hardware-software co-design issues. As future work, we
would like to develop analytical tools that determine the hardware composition and the
software deployment for embedded systems driven by profit maximization principles.


Bibliography
Bibliography
[1] Abdelzaher, T., Atkins, E., and Shin, K. G. (1997). QoS negotiation in real-time systems
and its application to automated flight control. In IEEE Real Time Systems Symposium
(RTAS), pages 228–238.
[2] Axelsson, J. (2000). Efficient integration of distributed automotive real-time systems.
In EDA-meeting.
[3] Baker, B. S. (1985). A new proof fro the first-fit decreasing bin-packing algorithm.
Journal of Algorithms, 6:49–70.
[4] Banerjee, P. and Abraham, J. (1984). Fault-secure algorithms for multiprocessor sys-
tems. In 11th International Symp. on Computer Architecture.
[5] Baugh, R. (1973). Computer Control of Modern Radars. RCA M&SR-Moorestown
Library.
[6] Bellman, R. (1958). On a routing problem. Quart. Appl. Math., 16:87–90.
[7] Bennett, J. and Zhang, H. (1996). Wf2q: Worst-case fair weighted fair queueing. In
Conference on Computer Communications (INFOCOM).
[8] Bentley, J. L., Johnson, D. S., Leighton, F. T., McGeoch, C. C., and McGeoch, L. A.
191

192 Bibliography
(1984). Some unexpected expected behavior results for bin packing. In 16th annual ACM
symposium on Theory of computing, pages 279–288.
[9] Bosch (1991). Can specification, version 2.0.
[10] Calvert, K. L., Doar, M. B., and Zegura, E. W. (1997). Modeling internet topology.
IEEE Communications Magazine, 35(6):160–163.
[11] Chan, L. M. A., Simchi-Levi, D., and Bramel, L. (1998). Worst-case analyses, linear
programming and the bin-packing problem. Mathematical Programming, 83:213–227.
[12] Chen, S. and Nahrstedt, K. (1998a). Distributed quality-of-service routing in high-
speed networks based on selective probing. In IEEE Annual Conference on Local Area
Networks (LCN), pages 80–89.
[13] Chen, S. and Nahrstedt, K. (1998b). An overview of quality-of-service routing for the
next generation high-speed networks: Problems and solutions. IEEE Network Magazine,
Special Issue on Transmission and Distribution of Digital Video, 12(6):64–79.
[14] Cherukuri, R., Dykeman(eds.), D., and Gouguen(chair), M. (1995). Pnni draft speci-
fication.
[15] Chevochot, P. and Puaut, I. (1999). Scheduling fault-tolerant distributed hard real-
time tasks independently of the replication strategies. In 6th International Conference
on Real-Time Computing Systems and Applications.
[16] C.L. Liu, J. L. (1973). Scheduling algorithms for multiprogramming in a hard real-time
environment. Journal on ACM, 2(1):46–61.
[17] Coffman, E., Garey, J. M., and Johnson, D. (1987). Bin packing with divisible item
size. Journal of Complexity, 3:406–428.

BIBLIOGRAPHY 193
[18] Coffman, E., Jr., Garey, M., and Johnson, D. (1996). Approximation Algorithms for Bin
Packing: A Survey. Approximation Algorithms for NP-Hard Problems. PWS Publishing,
Boston.
[19] David and Simchi-Levi (1994). New worst-case results for the bin-packing problem.
Naval Research Logistics, 41:579–585.
[20] Demers, A., Keshav, S., and Shenker, S. (1989). Analysis and simulation of a fair queue-
ing algorithm. In ACM Special Interest Group on Data Communication (SIGCOMM).
[21] Deniz, D. (2004). Modeling Functional and Para-Functional Concerns In Embedded
Real-Time Systems. PhD thesis, Department of Electrical and Computer Engineering,
Carnegie Mellon University.
[22] Dijkstra, E. (1959). A note on two problems in connection with graphs. Num. Math.,
1:269–271.
[23] Everitt, B. S., Landau, S., and Leese, M. (2001). Cluster Analysis. Edward Arnold.
[24] Ford, L. and Fulkerson, D. (1963). Flows in Networks. Princeton Univ. Press.
[25] Forum/95-0013R8, A. (1995). Atm forum traffic management specification version 4.0.
[26] Gao, X., Nandagopal, T., and Bharghavan, V. (2001). Achieving application level
fairness through utility-based wireless fair scheduling. In IEEE Global telecommunications
Conference (GLOBECOM).
[27] Ghosh, S., Hansen, J., Rajkumar, R., and Lehoczky, J. (2004a). Adaptive QoS op-
timizations with applications to radar tracking. In 10th International Conference on
Real-Time and Embedded Computing Systems and Applications (RTCSA).
[28] Ghosh, S. and Rajkumar, R. (1999). Practical management of end-to-end network
bandwidth reservation. In Proc. of Conference on Software in Telecommunications and
Computer Networks (SOFTCOM).

194 Bibliography
[29] Ghosh, S. and Rajkumar, R. (2002). Resource management of the os network subsys-
tem. In IEEE International Symposium on Object-oriented Real-time distributed Com-
puting.
[30] Ghosh, S., Rajkumar, R., Hansen, J., and Lehoczky, J. (2004b). Integrated resource
management and scheduling with multi-resource constraints. Technical Report 18-2-04,
Institute for Complex Engineering Systems, Carnegie Mellon University.
[31] Ghosh, S., Rajkumar, R. R., Hansen, J., and Lehoczky, J. (2003). Scalable resource
allocation for multi-processor QoS optimization. In 23rd IEEE International Conference
on Distributed Computing Systems (ICDCS 2003).
[32] Ghosh, S., Rajkumar, R. R., Hansen, J., and Lehoczky, J. (2004c). Adaptive QoS
optimizations with applications to radar tracking. Technical Report 18-3-04, Institute
for Complex Engineering Systems, Carnegie Mellon University.
[33] Goddard, S. and Jeffay, K. (1997). Analyzing the real-time properties of a dataflow
execution paradigm using a synthetic aperture radar application. In Proceedings of the
IEEE Real-Time and Embedded Technology and Applications Symposium.
[34] Guerin, R. and Orda, A. (1999). QoS-based routing in networks with inaccurate infor-
mation: Theory and algorithms. IEEE Transactions on Networking, 1(3).
[35] Guerin, R., Orda, A., and Williams, D. (1996). QoS routing mechanisms and ospf
extensions.
[36] Hansen, J., Ghosh, S., Rajkumar, R., and Lehoczky, J. (2004). Resource management
and highly configurable tasks. In 12th International Workshop on Parallel and Distributed
Real-Time Systems.
[37] Hansen, J., Zhu, H., and Rajkumar, R. (2001a). Probabilistic bandwidth reservation

BIBLIOGRAPHY 195
by resource priority multiplexing. In Real-Time Technology and Applications Symposium
(RTAS), pages 171–178.
[38] Hansen, J. P., Lehoczky, J., and Rajkumar, R. (2001b). Optimization of quality of
service in dynamic systems. In Proceedings of the 9th International Workshop on Parallel
and Distributed Real-Time Systems (WPDRTS).
[39] Hansen, J. P., Zhu, H., Lehoczky, J., and Rajkumar, R. (2002). Quantized edf schedul-
ing in a stochastic environment. In Proc. of 10th International Workshop on Parallel and
Distributed Real-Time Systems (WPDRTS).
[40] Hoover, C., Hansen, J., Koopman, P., and Tamboli, S. (1999). The amaranth frame-
work: Probabilistic, utility-based quality of service management for high-assurance com-
puting. In 4th IEEE International Symposium on High-Assurance Systems Engineering
(HASE), pages 207–216.
[41] Huang, J., Wan, P. J., and Du, D. Z. (1998). Criticality- and QoS-based multiresource
negotiation and adaptation for continuous multimedia. Journal of Real-Time Systems,
15(1):249–273.
[42] Johnson, D. (1973). Near-Optimal Bin Packing Algorithms. PhD thesis, MIT, Cam-
bridge, MA.
[43] Johnson, D., Demers, A., Ullman, J., Garey, M., and Graham, L. (1974). Worst-case
performance bounds for simple one-dimensional packing algorithms. SIAM J. Compt.,
3(4).
[44] Kleinrock, L. and Kamoun, F. (1977). Hierarchical routing for large networks-
performance evaluation and optimizations. Computer Networks, 1:155–174.
[45] Knuth, D. (1973). The art of Computer Programming, volume 3/Sorting and Searching.
Addison-Wesley.

196 Bibliography
[46] Kolawole, M. O. (2002). Radar Systems, Peak Detection and Tracking. Newnes Press.
[47] Kopetz, H. (1998). The time-triggered architecture. ISORC ’98, April 1998, in Kyoto,
Japan.
[48] Kuo, T. W., Chao, Y. S., Kuo, C. F., Chang, C., and Su., Y. (2002). Real-time dwell
scheduling of component-oriented phased array radars. In IEEE 2002 Radar Conferences.
[49] Lee, C. (1999). On Quality of Service Management. PhD thesis, Department of Elec-
trical and Computer Engineering, Carnegie Mellon University.
[50] Lee, C., Lehoczky, J., Rajkumar, R., and Siewiorek, D. (1998). On quality of service
optimization with discrete QoS options. In Proceedings of the IEEE Real-Time Technology
and Applications Symposium. IEEE.
[51] Lee, C., Lehoczky, J., Siewiorek, D., Rajkumar, R., and Hansen, J. (1999). A scalable
solution to the multi-resource QoS problem. In Proceedings of the IEEE Real-Time
Systems Symposium.
[52] Lin, K. (1995). Distributed pinwheel scheduling with end-to-end timing constraints.
In IEEE Real-Time Systems Symposium.
[53] Lui, K.-S., Nahrstedt, K., and Chen, S. (2000). Hierarchical QoS routing in delay-
bandwidth sensitive networks. In IEEE Local Computer Networks (LCN 2000), pages
579–588.
[54] Ma, Q. and Steenkiste, P. (1997). On path selection for traffic with bandwidth guar-
antees. In IEEE International Conference on Network Protocols.
[55] Mangharam, R., Demirhan, M., Rajkumar, R., and Raychaudhuri, D. (2004). Size
matters: Size-based scheduling for mpeg-4 over wireless channels. In SPIE Conference
on Multimedia Computing and Networking (MMCN), pages 110–122.

BIBLIOGRAPHY 197
[56] Medina, A., Lakhina, A., Matta, I., and Byers, J. (2001a). Brite: An approach to
universal topology generation. In International Workshop on Modeling, Analysis and
Simulation of Computer and Telecommunications Systems (MASCOTS 2001).
[57] Medina, A., Lakhina, A., Matta, I., and Byers, J. (2001b). Brite: Universal topology
generation from a user’s perspective. Technical Report 2001-003, Boston University.
[58] Megginson, R., Axler, S., and Gehring, F. (2001). An Introduction Banach Space
Theory (Graduate Texts in Mathematics, 183). John Wiley and Sons Inc.
[59] Mercer, C. (1997). Operating System Resource Reservation for Real-Time and Multi-
media Applications. PhD thesis, School of Computer Science, Carnegie Mellon University.
[60] Munu, M., Harrison, I., Wilkin, D., and Woolfson, M. (1992). Target tracking al-
gorithms for phased array radar. Radar and Signal Processing, IEE Proceedings-F,
139(5):336–342.
[61] Nahrstedt, K., hua Chu, H., and Narayan, S. (1999). QoS-aware resource management
for distributed multimedia applications. Journal of High Speed Networking, 7(3-4):229–
257.
[62] Oikawa, S. and Rajkumar, R. (1999). Portable RK: A portable resource kernel for guar-
anteed and enforced timing behavior. In IEEE Real-Time Technology and Applications
Symposium (RTAS).
[63] Parekh, A. and Gallager, R. G. (1993). A generalized processor sharing approach to flow
control in integrated services networks: the single node case. IEEE/ACM Transactions
on Networking, pages 344–357.
[64] Peressini, A., Sullivan, F., and Jr, J. U. (1988). The Mathematics of Nonlinear Pro-
gramming. Springer Verlag.

198 Bibliography
[65] Rajkumar, R. (1991). Synchronization in Real-Time Systems: A Priority Inheritence
Approach. Kluwer Academic Publishers.
[66] Rajkumar, R., Lee, C., Lehoczky, J., and Siewiorek, D. (1997). A resource allocation
model for QoS management. In IEEE Real-Time Systems Symposium.
[67] Rosu, D. I., Schwan, K., Yalamanchili, S., and Jha, R. (1997). On adaptive resource
allocation for complex real-time applications. In 18th IEEE Real-Time Systems Sympo-
sium.
[68] Rutgers, C. L. H. (2002). Cisco white paper: An introduction to igrp.
[69] Saewong, S. and Rajkumar, R. (1999). Cooperative scheduling of multiple resources.
In IEEE Real-time Systems Symposium.
[70] Sanfridson, M. (2000). Problem formulations for QoS management in automatic con-
trol. Technical report, Mechatronics Lab, Department of Machine Design Royal Institute
of Technology.
[71] Sha, L., Rajkumar, R., and Lehoczky, J. (1990). Priority inheritance protocols: An
approach to real-time synchronization. IEEE Transactions on Computers, pages 1175–
1185.
[72] Shenker, S. (1995). Fundamental design issues for the future internet. IEEE Journal
of Selected Areas in Communication, 13(7):1176–1188.
[73] Shih, C., Gopalakrishnan, S., Ganti, P., Caccamo, M., and Sha, L. (2003a). Scheduling
real-time dwells using tasks with synthetic periods. In Proceedings of the IEEE Real-Time
Systems Symposium.
[74] Shih, C., Gopalakrishnan, S., Ganti, P., Caccamo, M., and Sha, L. (2003b). Template-
based real-time dwell scheduling with energy constraint. In Proceedings of the IEEE
Real-Time and Embedded Technology and Applications Symposium.

BIBLIOGRAPHY 199
[75] Shirazi, B., Hurson, A., and Kavi, K. (1995). Scheduling and Load Balancing in Parallel
and Distributed Systems. Wiley.
[76] Smith, C. A. and Kroll, M. J. (1989). Utility theory and rent optimization: Utilizing
cluster analysis to segment rental markets. Journal of Real Estate Research, 4(1):61–71.
[77] Staehli, R. (1996). Quality of Service Specification for Resource Management in Multi-
media Systems. PhD thesis, Department of Computer Science and Engineering, Oregon
Graduate Institute.
[78] Staehli, R., Walpole, J., and Maier, D. (1995). Quality of service specification for
multimedia presentations. Multimedia Systems, 3(5).
[79] Stoica, I., Shenker, S., and Zhang, H. (1998). Core-stateless fair queueing: Achiev-
ing approximately fair bandwidth allocations in high speed networks. In Proceedings of
SIGCOMM’98.
[80] Stoica, I. and Zhang, H. (1999). Providing guaranteed services without per flow man-
agement. In ACM Special Interest Group on Data Communication (SIGCOMM).
[81] Tauro, L., Palmer, C., Siganos, G., and Faloutsos, M. (2001). A simple conceptual
model for the internet topology. In 6th IEEE Global Internet Symposium.
[82] Venkatasubramanian, N., Talcott, C., and Agha, G. A. (2004). A formal model for
reasoning about adaptive QoS-enabled middleware. ACM Transactions on Software En-
gineering and Methodology, 13(1):86–147.
[83] Walker, R. (1999). Introduction to Mathematical Programming. Prentice Hall.
[84] Wilkin, D., Harrison, I., and Wooflson, M. (1991). Target tracking algorithms for
phased array radar. Radar and Signal Processing, IEE Proceedings-F, 138(3):255–262.
[85] Zhang, L., Deering, S., and Estrin, D. (1993). RSVP: A new resource ReSerVation
protocol. IEEE network, 7(5):8–18.

200 Bibliography
[86] Zhu, H., Lehoczky, J., Hansen, J., and Rajkumar, R. (2004). Design tradeoffs in
networks with soft end-to-end timing constraints. In IEEE Real Time Systems Symposium
(RTAS).





























