Embed Size (px)
Citation preview

Rutgers CS440, Fall 2003
Neural networks
Reading: Ch. 20, Sec. 5, AIMA 2nd Ed

Rutgers CS440, Fall 2003
Outline
• Human learning, brain, neurons• Artificial neural networks• Perceptron• Learning in NNs• Multi-layer NNs• Hopfield networks

Rutgers CS440, Fall 2003
Brains & neurons
• Brain is composed of over a billion nerve cells that communicate with each other through specialized contacts called synapses. ~1000 synapses / neuron => extensive and elaborate neural circuits
• Some synapses excite neurons and cause them to generate signals called action potentials, large transient voltage changes that propagates down their axons. Other synapses are inhibitory and prevent the neuron from generating action potentials. The action potential propagates down the axon to the sites where the axon has made synapses with the dendrites of other nerve cells.
http://www.medicine.mcgill.ca/physio/cooperlab/cooper.htm

Rutgers CS440, Fall 2003
Artificial neurons
• Computational neuroscience• McCulloch-Pitts model
inj
gj
xj
wj0wj1
wji
wjN
x0=-1
x1
xi
xNInputfunction
Activationfunction
Output
Offset / bias
Weights
Input links Output links
)(
'2
1
1
10010
xWgx
gxwgwxwgxwgx
Nx
x
x
jNwjwjwjjjj
N
iijij
N
iijijj

Rutgers CS440, Fall 2003
Activation function
• Threshold activation function (hard threshold, step function)• Sigmoid activation function (soft threshold)• Bias / offset shifts activation function left/right
gj
inj
gj
inj
0,1
0,0)(
in
ining
ineing
1
1)(

Rutgers CS440, Fall 2003
X
Y
-1
X V Y
wx
wy
w0
OR
X
Y
-1
X V Y
wx=1
wy=1
w0=0.5
OR
Implementing functions
• Artificial neurons can implement different (boolean) function
X
Y
-1
X ^ Y
wx
wy
w0
AND
X
-1
Xwx
w0
NOT
X
Y
-1
X ^ Y
wx=1
wy=1
w0=1.5
AND
X
-1
Xwx=1
w0=0.5
NOT

Rutgers CS440, Fall 2003
Networks of neurons
• Feed-forward networks:– single-layer networks
– multi-layer networks
– Feed-forward networks implement functions, have no internal state
• Recurrent networks:– Hopfield networks have
symmetric weights (Wij = Wji)
– Boltzmann machines use stochastic activation functions,
– Recurrent neural nets have directed cycles with delays
Rutgers CS440, Fall 2003
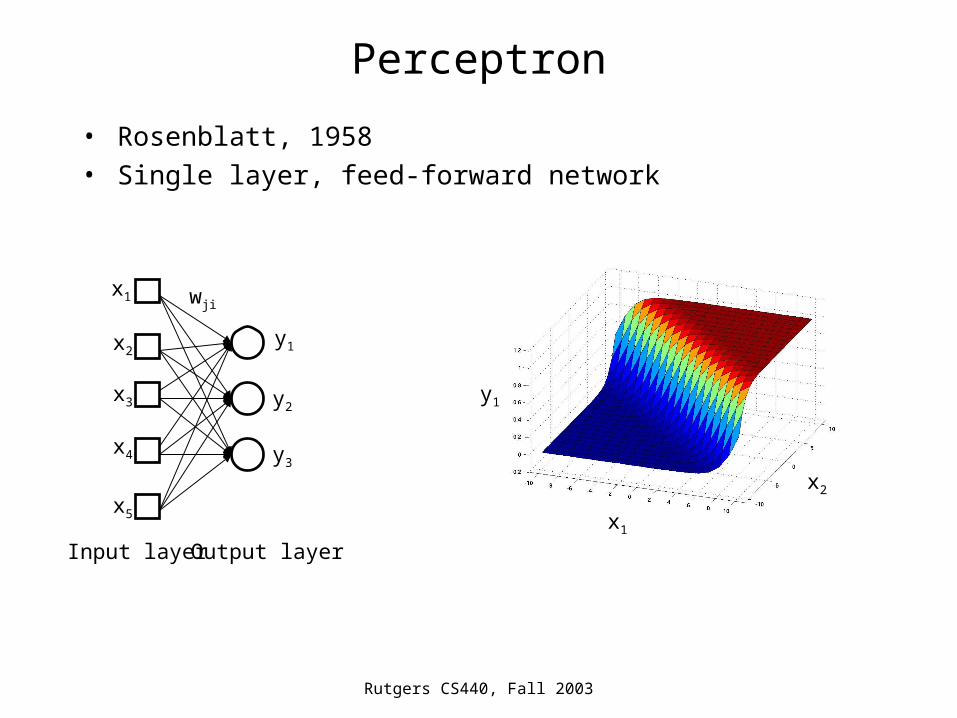
Perceptron
• Rosenblatt, 1958• Single layer, feed-forward network
x1
x2
x3
x4
x5
y1
y2
y3
Input layer Output layer
wji
x1
x2
y1

Rutgers CS440, Fall 2003
Expressiveness of perceptron
• With threshold function, can represent AND, OR, NOT, majority• Linear separator (linear discriminant classifier)
0:
0:
0
0
N
iiji
N
iiji
xwX
xwX
0:
0:
WXX
WXX
Line: WX = 0
Rutgers CS440, Fall 2003
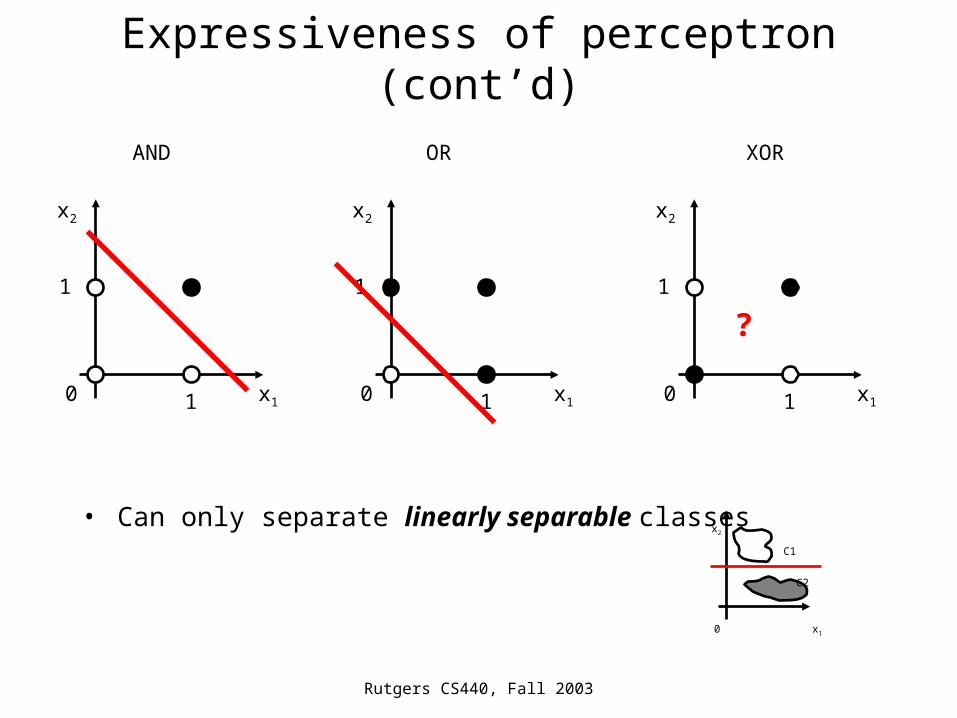
Expressiveness of perceptron (cont’d)
• Can only separate linearly separable classes
x1
x2
0 1
1
x1
x2
0 1
1
x1
x2
0 1
1
AND OR XOR
?
x1
x2
0
C1
C2
Rutgers CS440, Fall 2003
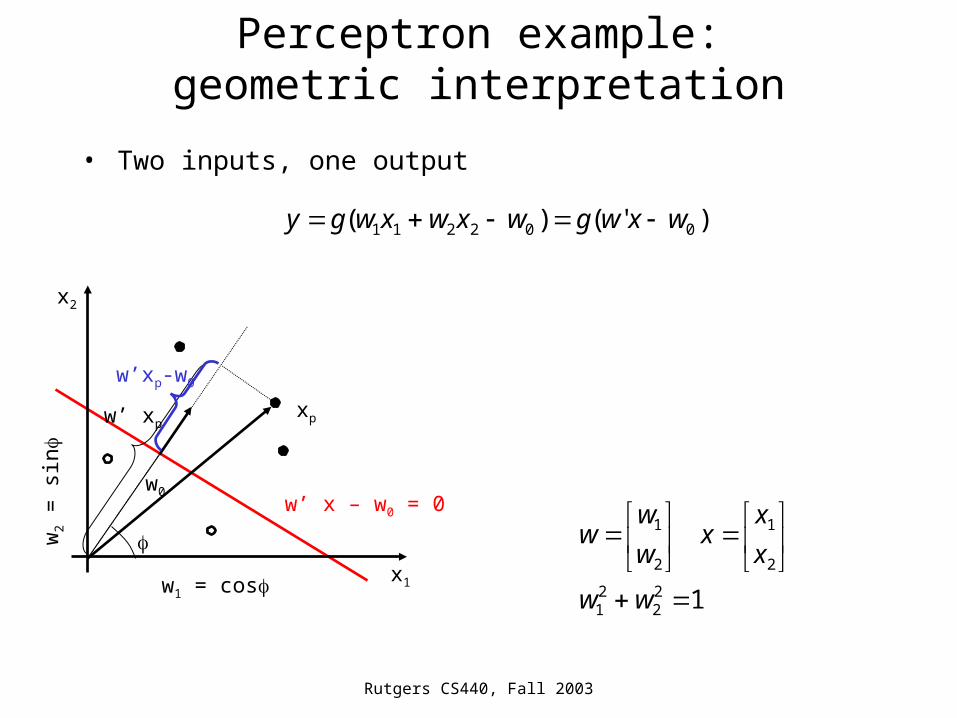
Perceptron example:geometric interpretation
• Two inputs, one output
w’ x – w0 = 0
122
21
2
1
2
1
ww
x
xx
w
ww
w0
w1 = cos
w2
= s
in
)'()( 002211 wxwgwxwxwgy
xpw’ xp
x1
x2
w’xp-w0

Rutgers CS440, Fall 2003
Perceptron learning
• Given a set of (linearly separable) points, X+ and X- ( or a set of points with labels, D = { (x,y)k }, y { 0, 1 } ), find a perceptron that separates (classifies) the two
• Algorithm: – Minimize error of classification. How?– Start with some random weights and adjust them (iteratively) so that the error is
minimal
K
k
K
kk
N
ikiik errxwgyE
1 1
221
2
0,2
1
)(minarg* wEww
i
li
li
kik
K
kk
i
w
Eww
xingerrw
E
)1()(
,1
)('
in
g’(in)

Rutgers CS440, Fall 2003
Analysis of the perceptron learning algorithm
• Consider 1D case: 1 input, 1 output
0
)1(0
)(0
10
0
)1)(('
)(
w
Eww
ingerrw
E
wxgy
ll
k
K
kk
x0
w0(l-1)
0 0 -1 0 0err
)('00)(')1(00)1)((' 3310
xgxgingerrw
Ek
K
kk
)('))('( 3)1(
03)1(
00
)1(0
)(0 xgwxgw
w
Eww llll
w0(l)
)(' 3xg
x3
Rutgers CS440, Fall 2003
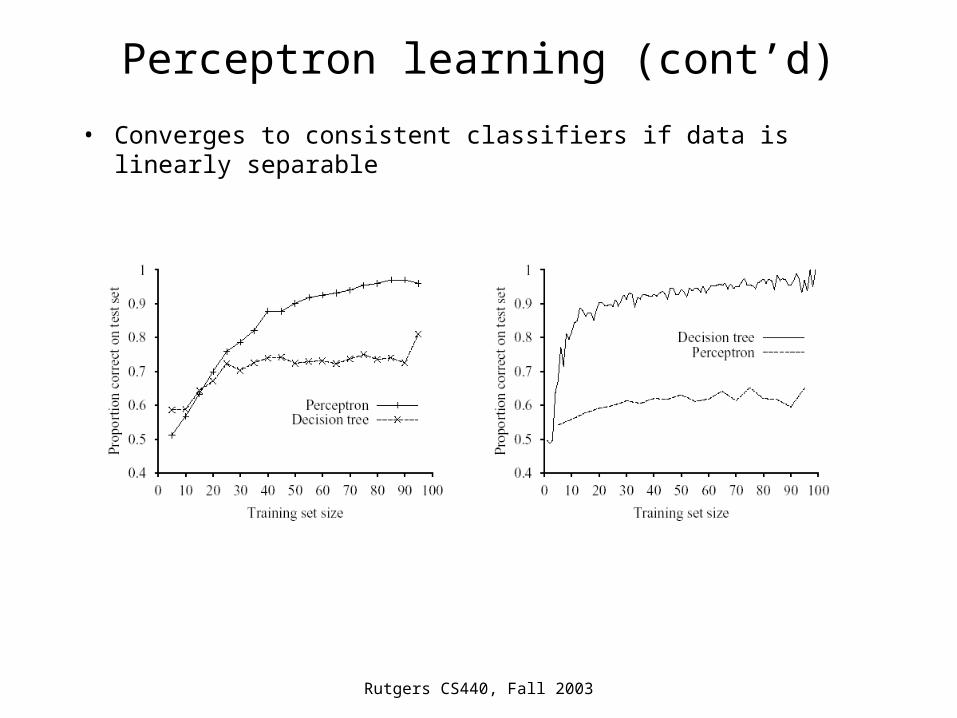
Perceptron learning (cont’d)
• Converges to consistent classifiers if data is linearly separable

Rutgers CS440, Fall 2003
Multilayer perceptrons
• Number of hidden layers• Usually fully connected• 2-layers can represent all
continuous functions• 3-layers can represent all
functions• Learning:
backpropagation algorithm, extension of the perceptron learning– Backpropagate the error from
the output layer into hidden layer(s)
x1
x2
x3
x4
x5
y1
y2
Input layer Output layer
w(1)ji
Hidden layer
w(2)ji

Rutgers CS440, Fall 2003
Application: handwritten digit recognition

Rutgers CS440, Fall 2003
Probabilistic interpretation
• Two classes, X+ and X-, elements of which are distributed randomly according to some densities p+(x) and p-(x)
• Classes have prior probabilities p+ and p-
• Given an element x decide which class it belongs to.
X+
X-
0 )(
)(log
)|(
)|(log
?
pxp
pxp
xp
xp
)|(
)|(logg ) Class(
xp
xp
)|()|()|(
)|(
)|(
)|(1
1e1
1 ) is Class(
)|(
)|(log
xpxpxp
xp
xp
xp
xp
xp
• Output of NN is the posterior probability of a data class

Rutgers CS440, Fall 2003
Hopfield NN
• “Associative memory” – associate unknown input with entities encoded in the network
)( )1()( tt Wxgx
Activation potential at “time” t-1(state of network at t-1)
Activation potential at “time” t(state of network at t)
• Learning:Use a set of examples X = { x1, …, xK} and set W to
1...0
1
0...1
1
' KxxWK
kkk
• Association:To associate an unknown input xu with one of K memorized elements, set x(0) = xu and let the network converge

Rutgers CS440, Fall 2003
Hopfield NN example
Training set
Test example
t=0 t=1 t=2 t=3