Embed Size (px)
Citation preview

Running Financial Risk Management
Applications on FPGA in the Amazon Cloud
Javier Alejandro Varela, Norbert WehnMicroelectronic Systems Design Research Group,
University of Kaiserslautern,67663 Kaiserslautern, Germany{varela,wehn}@eit.uni-kl.de
Whitepaper
Abstract
Nowadays, risk analysis and management is a core part of the dailyoperations in the financial industry, and strictly enforced by regulatoryagencies. At the same time, large financial corporations have startedmigrating their operations into cloud services. Since the latter use apay-per-use business model, there is a real need for implementationswith high performance and energy efficiency, in order to reduce theoverall cost of operation. And this is exactly where field programmablegate arrays (FPGAs) have a great advantage as accelerators, whichenables the designer to efficiently offload the compute-intensive partsof the workload from the host central processing unit (CPU). Theadvantages associated to FPGAs have recently conferred them a placein cloud services, such as the Amazon Elastic Compute Cloud (EC2).
In this work, we concentrate on widely-employed portfolio riskmeasures, namely value-at-risk and expected shortfall, by means ofcompute-intensive nested Monte Carlo-based simulations. As a proof-of-concept, we have implemented and assessed the performance ofthese simulations on a representative complex portfolio, where theworkload is efficiently distributed between CPU and FPGA on anAmazon EC2 F1 instance. Due to a lack of direct power measurementcapabilities in the cloud, energy efficiency cannot be properly assessedat the moment. Nevertheless, our FPGA implementation achieves a10x speedup on the compute intensive part of the code, comparedto an optimized parallel implementation on multicore CPU, and itdelivers a 3.5x speedup at application level for the given setup.
1

Whitepaper J.A.Varela, N. Wehn
1 Introduction
A field programmable gate array (FPGA) is a programmable device thatoffers a large set of hardware components (such as flip-flops (FFs), lookuptables (LUTs), digital signal processors (DSPs) and Block RAMs (BRAMs))that can be configured and interconnected to perform any given task (seee.g. [1, 2]). This provides FPGAs with four main advantages:
1. the possibility of creating fully pipelined architectures,
2. (almost) infinite bit-level parallelism,
3. custom precision data-types,
4. custom memory hierarchies.
. This greatly differs from the fixed hardware architecture of multicore CPUs(see e.g. [3, 4]), which are general-purpose platforms with good performanceper core/thread [5] (e.g. Intel’s Xeon processors). Whereas CPUs executea software code, FPGAs offer a flexible architecture that can be efficientlyadapted to the target application. Moreover, the power consumption of FP-GAs is in general significantly low, which makes them an ideal acceleratorwhen high performance-per-watt is required. These advantages have recentlyconfered FPGAs a place in high-performance datacenters and cloud comput-ing, such as in the Amazon Elastic Compute Cloud (EC2) (see e.g. [6, 7]).
Nowadays we experience an increasing adoption of cloud computing, whichis a pay-per-use service that gives the users on-demand access to a sharedpool of resources [8, 9]. As large financial institutions are now graduallymoving their operations into the cloud (see e.g. [10,11]), we see there a greatpotential for FPGA-based solutions for the financial industry.
This is not a new concept: for example, Maxeler Technologies is a long-standing worlwide provider of FPGA-based systems for compute-intensivefinancial applications, including recent cloud-based solutions [12–14]. As amatter of fact, the vision on the use of FPGAs in high-performance comput-ing systems and datacenters has been around for many years. This visionhas been consequently followed by our Microelectronic Systems Design Groupover the last decade, where our research has been focus on the applicationof FPGAs to different fields, including finance, in order to provide massiveacceleration and high energy efficiency. In the case of financial applications,our research timeline is summarized in Fig. 1, which is the outcome of a
Page 2

Whitepaper J.A.Varela, N. Wehn
successful interdisciplinary research cooperation between computer engineer-ing and financial mathematics, in the scope of the Research Training Group(RTG) 1932, funded by the German Research Foundation (DFG).
FPGAsas AcceleratorsIn Datacenters
Operator Precision Tuning(Heston model calibration)
Energy Efficient Acceleration of Asset simulation
Mixed-Precision Multilevel MC
Decoupled OpenCLwork-items for
parallel algorithms withdata-dependent branches
Xilinx Open HardwareCompetition: 1st place
(2015 – HLS-Track)
Hardware EfficientInversion-based RNG with Arbitrary Precision(ICDF function)
Energy Efficient FPGA Accelerator for MC Option Pricing with the Heston Model
201620152014 2017201220112010 2013
MultiLevel MC FPGA Acceleratorfor Option Pricing in the Heston Model
Vision:Cloud-based FPGA
Portfolio RiskManagement
(proof-of-concept)
MC-based multidimensional American option pricing on FPGAs,algorithmic optimizations:• Reverse Longstaff-Schwartz (LS) • Brownian Bridge LS
Amazon AWSElastic Compute Cloud (EC2)
Baidu FPGA Cloud Server
AlibabaCloud
2018
Nested MC-basedPortfolio Risk
Simulation
HyPERArchitecture(FPGA-SoC)
Altera(acquired by Intel)
Figure 1: Research timeline of the Microelectronic Systems Design ResearchGroup, on the use of FPGAs as accelerators in datacenters, with focus hereon financial risk management [15–32]. FPGAs are also available now e.g. inthe Amazon AWS [33], Baidu [34], and Alibaba cloud services [35].
In the case of the financial industry, stricter regulations have been set inplace after the 2007-2008 financial crisis. And in this regard, widely usedrisk measures, such as value-at-risk (VaR) and expected shortfall (ES) (alsocalled conditional value-at-risk (cVaR)), need to be monitored and reportedregularly, as part of the Basel III regulatory framework [36,37].
As the financial operations are moved into the cloud, we see two com-plementary needs: from the user point of view, there is a need for high-performance implementations that can minimize the overall runtime and,therefore, the total cost of execution; whereas the service provider requiresan energy efficient infrastructure that can minimize the total cost of opera-tion. As a proof-of-concept, we have implemented and assessed the MonteCarlo (MC)-based simulation of VaR and ES risk measures for a representa-tive portfolio running on an FPGA-based F1 instance in the Amazon cloud(EC2). Since at the moment power measurements are not available in thecloud, we focus on the runtime performance (from the user point of view).To this end we employ state-of-the-art algoritmic optimizations (see [38]),
Page 3

Whitepaper J.A.Varela, N. Wehn
and we efficiently split the workload between the host CPU and the FPGA.For the implementation on FPGA we employ the Xilinx SDAccel de-
velopment environment, which enables the use of Open Compute Language(OpenCL) code on Xilinx FPGAs. Implementation details are given in thefollowing sections, along with a performance comparison against an optimizedcode running on multicore CPU using Open Multi-Processing (OpenMP).
2 Background
Cloud computing is a relatively new computing paradigm, where users areprovided with on-demand access to a shared pool of computing resources(such as computing nodes, applications, and storage) which can be configuredas required by the application, with minimum management effort from theuser standpoint [8]. This is a shift from the traditional approach, wherelarge companies (e.g. in the financial industry) were forced to developedand maintain proprietary technology and large in-house hardware/softwareinfrastructures [11]. With cloud computing, the resources are (at least inprinciple) available on-demand. However, the pay-per-use business modelbehind it makes it necessary to develop high-performance implementationsthat can mainly reduce the overall runtime and, therefore, the overall costs.
In this work, our goal is to present a proof-of-concept implementation ofa financial risk management application running on an F1 instance (CPU+FPGA) in the Amazon Cloud (EC2). To this end, we employ OpenCL (tar-geting an heterogeneous hardware configuration), the Xilinx SDAccel devel-opment framework for FPGAs, and the OpenMP application programminginterface (API) for multicore CPU (used as a comparison).
The following sections cover the necessary background on OpenCL, XilinxSDAccel, OpenMP, as well as financial risk management and option pricing.
2.1 OpenCL
The Open Compute Language (OpenCL) is an open, royalty-free standardmanaged by the nonprofit technology consortium Khronos Group, and it iswidely used nowadays for general-purpose parallel programming. OpenCLsupports both data- and task-based parallel programming models [39], andit was designed to make to code portable across all platforms that supports
Page 4

Whitepaper J.A.Varela, N. Wehn
it. In order to achieve the maximum performance in each case, optimizationsare usually required based on the underlying architecture.
This framework assumes the presence of a host CPU and an accelerator(called device) connected via Peripheral Component Interconnect Express(PCIe), as show in Fig. 2 together with the basic memory hierarchy. Thehost CPU handles the main application and the corresponding OpenCL setupsteps (see e.g. [40]), whereas the code that runs on the device (the kernel)contains the code to be executed by each work-item (thread). A devicecontains compute units, which are subdivided into processing elements.
OpenCL Device
Private Memory
Local Memory
Global Memory
Processing Elements…Compute
Unit
ComputeUnit
ComputeUnitPCIe
CPU (Host)
Cores
Memory(Host)
Memory(Device)
Figure 2: OpenCL architecture and memory hierarchy.
The kernels are enqueued by the host as an N-Dimensional Range (ND-Range), with a number of work-items grouped into work-groups, or as a Task,which is basically a single-threaded kernel. On the device global memory(refer to Fig. 2), the buffers are allocated by the host CPU, which are thenused for all data transfers between host and device, as well as by the kernels.
OpenCL is also available for FPGAs, as detailed in the following section.
2.2 OpenCL on FPGAs: Xilinx SDAccel
In the case of FPGAs, the OpenCL code has to be compiled and then trans-lated into a configuration file (bitstream), required for the hardware con-figuration. SDAccel is a vendor-specific development environment targetingXilinx FPGAs, and it supports kernels expressed in OpenCL C, C/C++ andRTL (SystemVerilog, Verilog or VHDL) [41].
A Xilinx PCIe-based hardware device consists of a static region (withhandles the PCIe connection) and a programmable region (where the kernels
Page 5

Whitepaper J.A.Varela, N. Wehn
will be implemented) [41]. Since the static region needs to run continuously(to keep the PCIe connection working), the programmable region is configuredusing the partial reconfiguration technique (for more details, see e.g. [41]).
2.3 OpenMP
Open Multi-Processing (OpenMP) is an application programming interface(API) managed by the nonprofit technology consortium OpenMP Architec-ture Review Board, and it has been developed for shared-memory parallelprograms targeting multiprocessor systems. OpenMP makes use of light-weighted threads, and it supports the fork-join programming model [42].These threads are basically runtime entities able to independently execute astream of instructions, by sharing resources of the parent process (see [42]).
OpenMP provides features to be added to a sequential program (e.g.Fortran or C/C++), which describe the work allocation among the differentthreads, as well as the accesses to shared data. The section of code to run inparallel is basically marked with a compiler directive (pragma), and an id isautomatically assigned to each thread. The main advantage of OpenMP isits ease of use and applicability to parallelize existing sequential code [42].
2.4 Financial Risk Management
Whenever a financial investment is made, it is usually diversified into a port-folio of different financial products, such as securities (e.g. stocks and bonds),foreign currency, cash (to provide a certain level of liquidity), and derivatives(which are products that derive their price from an underlying asset).
At a given horizon time, any given portfolio will be subject to a profit ora loss (P&L), exposing the original investment to some risk (see e.g. [43]). Inpractice, this risk exposure is typicall measured by means of the value-at-risk(VaR) and expected shortfall (ES) [44], and they are enforced by regulatoryagencies [36, 37]. VaR states with probability α that the portfolio is notexpected to suffer a loss of more than VaR $ in the next N days, where αis usually as high as 95% or 99%, whereas ES provides an estimate of theexpected loss (it is basicall an average of the worst cases).
Three methods are available to compute VaR and ES (see e.g. [45]): 1) thevariance-covariance method, which employs an approximation of the portfo-lio loss function and assumes a multivariate normal distribution of the risk
Page 6

Whitepaper J.A.Varela, N. Wehn
factors; 2) the historical simulation, which relies on past data on the indi-vidial returns (therefore limited to past events only), and the (nested) MCsimulation of the portfolio loss function, which is considered to be the mostgeneral and versatile approach.
In mathematical terms, the MC estimator for VaR is given by
V aRα(L̃t+τ ) , inf`∈<{F̃t+τ (`) ≥ α}, (1)
where F̃t+τ (`) is the empirical distribution of the simulated loss distributionL̃t+τ at time t+ τ . In the case of ES, the MC estimator is given by
ESα(L̃t+τ ) ,1
1− α
∫ 1
α
V aRγ(L̃t+τ )dγ. (2)
The drawback of the MC approach is its usually long runtime, especiallyif combined with the revaluation of the full portfolio [46]. As an example, areport presented by McKinsey & Company in 2012 showed that only 15% ofthe surveyed financial institutions would use this approach, with a downwardtendency, whereas easier but less accurate approaches [47], such as historicalsimulation or first order approximations [46,47], would be preferred.
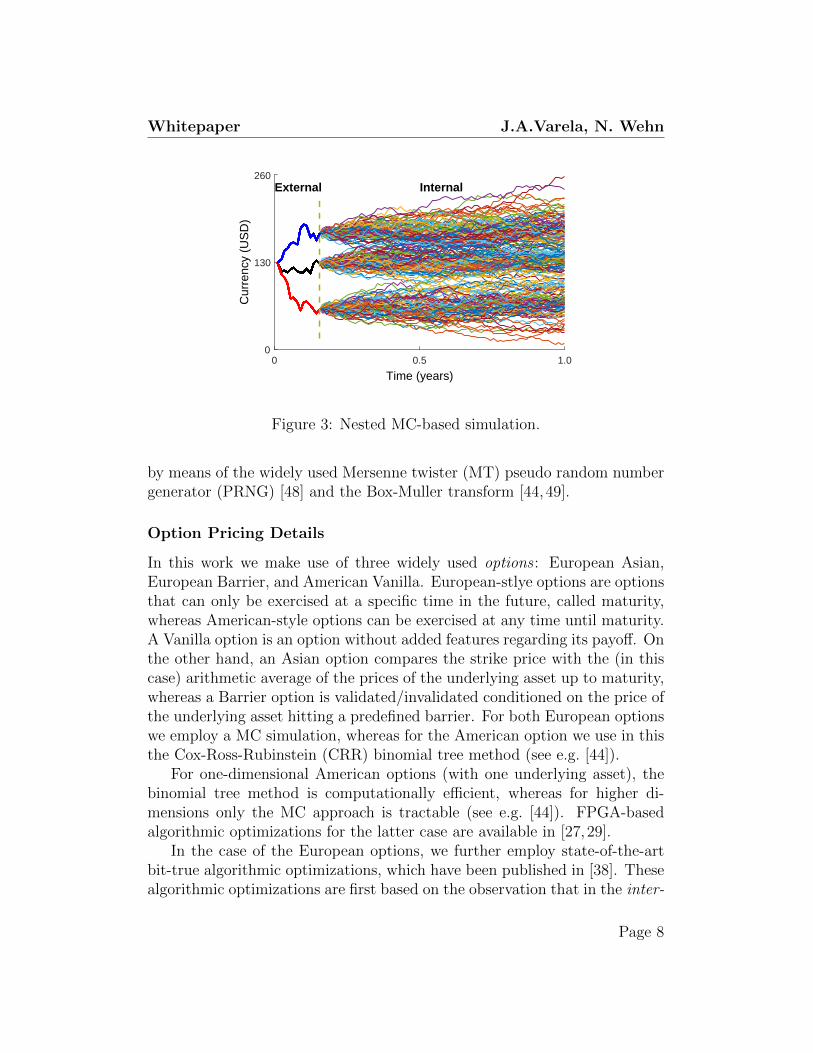
The runtime of the MC simulation is dependent on the complexity ofthe princing algorithms used for the corresponding products in the portfolio.Nowadays, typical portfolios include options (a derivative contract) in orderkeep the risk exposure of the given portfolio under control. An option isbasically a contract that gives the holder the right, but not the obligation,to buy or sell an underlying asset at a specified price and time [44]. Exceptfor very simple options, complex types usually require their own simulation,creating the nested MC simulation exemplified in Fig. 3: an external partfor the underlying asset, and an internal part for the option pricing.
To generate the paths in the MC simulations, we employ the Black-Scholes(BS) model. This model has one input parameter, and it is relatively simplebut very robust and widely used in practice (see e.g. [44]). Its discretizedversion under the Euler-Maruyama scheme is represented by:
St+1 = St exp
((r − 1
2σ2
)dt+ σ
√dtZ
), (3)
where r is the risk-free interest rate (and assuming zero dividend yield), dtis the time step, and Z is a random number (RN) with standard normal dis-tribution. This model relies on normally distributed RNs, which we generate
Page 7
Whitepaper J.A.Varela, N. Wehn
0 0.5 1.0
Time (years)
0
130
260
Cur
renc
y (U
SD
)
External Internal
Figure 3: Nested MC-based simulation.
by means of the widely used Mersenne twister (MT) pseudo random numbergenerator (PRNG) [48] and the Box-Muller transform [44,49].
Option Pricing Details
In this work we make use of three widely used options : European Asian,European Barrier, and American Vanilla. European-stlye options are optionsthat can only be exercised at a specific time in the future, called maturity,whereas American-style options can be exercised at any time until maturity.A Vanilla option is an option without added features regarding its payoff. Onthe other hand, an Asian option compares the strike price with the (in thiscase) arithmetic average of the prices of the underlying asset up to maturity,whereas a Barrier option is validated/invalidated conditioned on the price ofthe underlying asset hitting a predefined barrier. For both European optionswe employ a MC simulation, whereas for the American option we use in thisthe Cox-Ross-Rubinstein (CRR) binomial tree method (see e.g. [44]).
For one-dimensional American options (with one underlying asset), thebinomial tree method is computationally efficient, whereas for higher di-mensions only the MC approach is tractable (see e.g. [44]). FPGA-basedalgorithmic optimizations for the latter case are available in [27,29].
In the case of the European options, we further employ state-of-the-artbit-true algorithmic optimizations, which have been published in [38]. Thesealgorithmic optimizations are first based on the observation that in the inter-
Page 8

Whitepaper J.A.Varela, N. Wehn
nal part of the nested MC simulation, the sequence of RNs must be reusedamong the different simulations for the same (derivative) product. This op-timization, which we called RNs-reuse approach, is detailed in [31]. Sincethe sequence of RNs is now reused, the paths can be then generated ina normalized way, and denormalized based on the final price of the corre-sponding external simulation. This approach is called Paths-reuse, and it isexplained in detail in [38]. Besides, European-style options base their priceon the stochastic information obtained from the simulation. In turn, thisinformation can be obtained from a normalized internal simulation using thePaths-reuse approach, and denomalized based on the external simulation.This Info-reuse approach is detailed in [38], and it is employed in this work.
3 Cloud-based CPU+FPGA Implementation
The target hardware configuration is an F1 instance in the Amazon AWS EC2cloud, which consists of an Intel Xeon processor (CPU) and a Xilinx VirtexUltrascale+ FPGA connected via PCIe (details are given in Section 4.1). Ourtarget application is the portfolio risk measurement under compute intensivenested MC-based simulations, which requires the following steps:
1. load the simulation parameters,
2. generate the required RN sequences,
3. compute the price of each product in the portfolio today (we assumethat they are not readily available in the market),
4. run the nested MC-based simulation, either the external or the internalpart based on the corresponding product in the portfolio: the outcomeis a vector of simulated profit/loss (P&L) scenarios for each product,
5. aggregate the simulated scenarios (taking into account the correspond-ing weights in the portfolio) and substract the current value of the wholeportfolio, in order to obtain the simulated profit/loss (P&L) scenariosof the whole portfolio at the selected horizon time,
6. sort the vector of simulated scenarios in ascending order: VaR is ba-sically the value of an element in that vector (where the VaR-index isdetermined by the α-quantile), and ES corresponds to the average ofall the elements in that vector up to the mentioned index.
Page 9

Whitepaper J.A.Varela, N. Wehn
The steps 1-3 and 5-6 above can be efficiently run on the host CPU. In thecase of nested MC-based simulations (step 4), the external part can be exe-cuted on multicore CPU (at least in our setup, see Section 4.2), whereas theinternal part (which is the most compute-intensive part, and corresponds tothe option pricing algorithms) can be efficiently parallelized and implementedon FPGA, as shown in Fig. 4. For comparison purposes, we also implementthe products in the internal simulation using OpenMP for multicore CPU.
FPGA
PCIe
Xilinx SDAccelOpenMP
CPU (Host)
Cores
Memory(Host)
Memory(Device)
American Vanilla 1D (CRR Binomial Tree)
European Asian +European Barrier(Monte Carlo)
Figure 4: Design overview using Xilinx SDAccel (OpenCL) for an heteroge-neous CPU+FPGA configuration, and OpenMP on multicore CPU.
Here we employ the OpenCL API targetting an heterogeneous CPU+FPGA configuration, and to this end the Xilinx SDAccel development en-vironment for FPGAs. The kernel code is written in C/C++ and launchedas a task (refer to Sections 2.1 and 2.2), in order to have enough low-levelcontrol over the hardware architecture, and to reuse part of our legacy codewritten in Xilinx Vivado high-level synthesis (HLS). Nevertheless, the kernelcode could also be converted to OpenCL C and launched as an NDRange.
In our setup we have three options to price in the internal part of thesimulation: European Asian and European Barrier using a MC approachand Eq. (3), and American Vanilla using a CRR binomial tree method. Sinceboth European options differ mainly on the payoff, it is possible to efficientlycombine (from a simulation point-of-view) both pricing algorithms into oneminimizing resources/computation: when both options use the same set ofparameters, the merged kernel will yield both prices together.
Page 10

Whitepaper J.A.Varela, N. Wehn
In the proof-of-concept presented here, the kernels are implemented fol-lowing the main parallelization and implementation guidelines in [38], butadapted for FPGAs. The innermost loops of the kernels are fully pipelinedwith an initiation interval of one clock cycle (II=1), and unrolled by a factorof 32. As shown in Fig. 4, there is one instance of the EuropeanAsianBarrierkernel, and in the case of the AmericanVanilla kernel the workload is equallydistributed among 4 instances. Both kernels (and there respective instances)are carefully combined into a main function under a dataflow pragma, whichenables them to run concurrently. Nevertheless, a similar effect can alsobe achieved using two independent kernels (on the device side) and (fromthe host side) either two separate command queues or a single out-of-ordercommand queue. In this regard, a good set of examples are available under/home/centos/aws-fpga/SDAccel/examples/xilinx/ in the FPGA DeveloperAMI that can be obtained from the Amazon AWS Marketplace.
The kernels could also be run independently, one after the other, byreconfiguring the FPGA in each case accordingly (this was actually our firstapproach). However, the OpenCL cl::Program step, which is responsibleof compiling at runtime from the binary file and configuring the FPGA, iscurrently taking ≈ 6.8 seconds, far larger than the runtime of any the kernelsin our setup (this is detailed in in Section 5). This is the reason why thekernels are combined and run concurrently on the FPGA in our case.
Finally, it is necessary to mention that all vectors (buffers) include thealigned allocator<> struct for proper allignment in memory, in order toavoid unnecessary memcpy operations at runtime (for more details, refer tofile /home/centos/aws-fpga/SDAccel/examples/xilinx/libs/xcl2/xcl2.hpp, in-cluded in the FPGA Developer AMI indicated previously).
4 Setup
This section provides details on the hardware and simulation setup, theVaR/ES numerical results validation under the given set of parameters, andthe place-and-route (P&R) resources utilization on FPGA.
4.1 Hardware Setup
Amazon AWS EC2 Instance: f1.2xlarge [7]. CPU : Intel(R) Xeon(R) CPUE5-2686 v4 @ 2.30GHz, 8 cores, 122GB DDR4, technology node: 14nm [7,
Page 11

Whitepaper J.A.Varela, N. Wehn
50]. FPGA: Virtex UltraScale+ VU9P (xilinx:aws-vu9p-f1:4ddr-xpr-2pr:4.0),64GB DDR4, technology node: 16nm [7,51].
4.2 Simulation Setup
The porfolio is composed of: one stock, and three options on that stock:European Asian, European Barrier, American Vanilla 1D. Simulation model:BS under Euler-Maruyama discretization scheme (MC simulation) (see e.g.[52]) to price the stock and the European-style options, and the Cox-Ross-Rubinstein (CRR) binomial tree (BT) method (see e.g. [44]) to price theAmerican Vanilla 1D. For the nested MC-based simulation, the followingparameters are necessary: pathsMCext=32k, stepsMCext=10, pathsMCint=32k, stepsMCint=252, stepsTree=252.
All time measurements are carried out on the host side, by employingthe clock gettime() function from the time.h library, and applying the corre-sponding synchronization when measuring OpenCL runtime.
4.3 VaR/ES Numerical Results Validation
Value of the portfolio today = 1, 367, 463.63 USD, with the following initialcomposition: Stock-A (66.5%), European Asian option (9.8%), EuropeanBarrier option (10.5%), American Vanilla 1D (13.2%). For an α=99%, the10-day risk measures (VaR, ES) = (9.8%, 10.2%), with an average P&L of1.3% and an average profit of 7.0% (excluding losses).
Simulation parameters: Stock-A: S0=130.00 USD, σ=0.20, r=0.025, q=0.0,amount=7000; European Asian: underlying=Stock-A, call option, T=1.0years, K=130.00 USD, σ=0.20, r=0.025, q=0.00, amount=200 ∗ 100; Euro-pean Barrier: underlying=Stock-A, call-up-in option, T=1.0 years, K=130.00USD, Sb=162.50 USD, σ=0.20, r=0.025, q=0.00, amount=160 ∗ 100; Amer-ican Vanilla 1D: underlying=Stock-A, put option, T=1.0 years, K=130.00USD, σ=0.20, r=0.025, q=0.00, amount=200 ∗ 100.
4.4 Resources Utilization
The place-and-route (P&R) resources utilization on FPGA is detailed inTable 1. The average resources distribution among the concurrent kernels is:AmericanBT1D≈ 70%, EuropeanAsianBarrier≈ 30% (refer to Fig. 4).
Page 12

Whitepaper J.A.Varela, N. Wehn
Table 1: P&R Resources utilization.
ResourcesDescription
LUT LUTMem REG BRAM1 DSP
User budget 879913 551690 1966125 1615 6828Kernel 191169 2779 294724 737 3271
21.73 % 0.50 % 14.99 % 45.63 % 47.91 %
1 Corresponds to BRAM 36Kb; UltraRAM (URAM): available 960, utilized 0%.
4.5 OpenMP Scaling
We have three kernels in the nested MC-based simulation: external part:Stock ; internal part: EuropeanAsianBarrier (two options are priced in onekernel) and AmericanVanilla. To determine the optimal number of OpenMPthreads under the given setup, we measure the runtime while scaling thenumber of threads. Fig. 5 shows the normalized speedup with respect to 1thread (this makes it feasible to plot the three kernels together).
From Fig. 5 we obtain an optimal number of threads equal to 8. As areference, the individual runtimes for (1-thread, 8-threads) are: Stock (7.9ms,1.8ms); EuropeanAsianBarrier (30.4s, 6.4s); AmericanVanilla (9.7s, 2.3s).
0.0
1.0
2.0
3.0
4.0
5.0
1 2 4 8 16
No
rmal
ized
Sp
eed
up
(x)
Number of OpenMP Threads
OpenMP scaling - normalized speedup
Stock
EuroAsianBarrier
AmericanVanilla
Figure 5: Speedup on multicore CPU while scaling the number of OpenMPthreads (normalized to 1 thread), of the kernels in the nested MC-based simu-lation: Stock (external), EuroAsianBarrier and AmericanVanilla (internal).
Page 13

Whitepaper J.A.Varela, N. Wehn
5 Results
The full rumtime breakdown is detailed in Table 2, and it is graphically sum-marized in Fig. 6. The main comparison is made between the implementationon CPU+FPGA and the multicore CPU implementation using OpenMP (re-fer also to Fig. 4). The performance of the single-threaded CPU code is givenhere as a reference for the OpenMP version.
Table 2: Full runtime breakdown in (s).
CPU CPU + FPGA
single- full skippedDescriptionthreaded
openmpprog1 prog1
Global Time 42.334 10.983 9.485 3.075– RNG 0.726 0.726 0.726 0.726– Today prices 1.501 1.501 1.501 1.501– Host (kernels) 40.086 8.733 0 0– – EuroAsianBarrier 30.360 6.419 0 0– – AmericanVanilla 9.726 2.315 0 0– OpenCL 0 0 7.230 0.823– – cl::Program 0 0 6.814 0.409– – kernel: Concurrent 0 0 0.207 0.207– – misc. (OpenCL) 0 0 0.209 0.207– Risk Measures 0.013 0.014 0.013 0.013– misc. (global) 0.007 0.008 0.015 0.012
1 The OpenCL cl::Programm prog(...); step automatically recognizes if the local
image has been previously uploaded, and if so it skips part of the procedure
and outputs the message: Successfully skipped reloading of local image.
The kernel that simulates the stock (see Section 4.2), which correspondsto the external part of the nested MC simulation, requires 7.9ms in a single-threaded code, and 1.8ms using OpenMP with 8 threads. As expected, thisruntime is small compared to the one required by the internal simulations.
The Concurrent kernel mentioned in Table 2 is the one that simulates thethree options concurrently on FPGA (see details in Section 3). The OpenCLruntime in Table 2, which is also graphically shown in Fig. 7, includes notonly the runtime of the Concurrent kernel, but also the required initializa-
Page 14

Whitepaper J.A.Varela, N. Wehn
0
5
10
15
20
25
30
35
40
45
singlethreaded
openmp fullcl::Program
skipped localimage
CPU CPU + FPGA
Ru
nti
me
(s) -- miscellaneous
-- elapsedRiskMeasuresTime
-- elapsedOpenCLTime
-- elapsedHostKernelsTime
-- elapsedTodayTime
-- elapsedRNGTime
Figure 6: Runtime breakdown. The OpenCL runtime also includes the ini-tialization overhead and the data transfers between host and device (FPGA).
tion steps and all data transfers between host and device: only cl::Programis indicated separatelly, the remaining overhead is included as miscellaneous(misc.). In the case of the cl::Program step (refer to Section 3), it automat-ically recognizes if the same local image has been uploaded in the previouscall to this step, and if so it skips part of the procedure (the console willoutput the message: Successfully skipped reloading of local image). The fullruntime of this step is ≈ 6.8s, which is far larger than the 207ms required bythe Concurrent kernel. Therefore, in our case we assume that this local im-age has been already uploaded, and that the simulation is run several timesunder different sets of parameters.
The kernel implementation on FPGA using Xilinx SDAccel (OpenCL)achieves approximately 10x speedup compared to the multicore CPU versionusing OpenMP with 8 threads (823ms vs 8.733s respectively). At applicationlevel (global runtime), this translates into a speedup of 3.5x (3.075s vs 10.983srepectively), under the assumptions given previously.
6 Conclusions
By efficiently offloading the compute-intensive part of the nested MC-basedsimulation from the host CPU to an FPGA, we have achieved a substantialspeedup, both at kernel level (10x) and at application level (3.5x), compared
Page 15

Whitepaper J.A.Varela, N. Wehn
elapsedProgramTime 94%
kernelConcurrent 3%
miscellaneous3%
reprog
(a) With full OpenCL program step:cl::Program prog1(ctx1, dev1, bin1);
elapsedProgramTime 50%
kernelConcurrent 25%
miscellaneous25%
noReprog
(b) “Successfully skipped reloading of lo-cal image” (2nd run of the application)
Figure 7: OpenCL runtime on FPGA: main breakdown.
to a multicore CPU implementation. This speedup could be further increasedby carefully replicating the number of kernel instances on the FPGA, whichcurrently occupy 45%∼48% of the available BRAM and DSP resources.
To correctly evaluate the system-level energy consumption (which is theone that affects the total cost of operation), we would require power mea-surements in the cloud, which are currently not available at user-level. Thenecessary runtime measurements are already detailed in Table 2 and Fig. 6.
Although so far we have not been able to run this application on graphicsprocessor unit (GPU) in the cloud, which is left as future work, we know thatGPUs are strong competitors versus FPGAs when targetting algorithms withmassive regular parallelism (like in our setup). Nevertheless, the goal of thisproof-of-concept implementation was to provide a representative test case ofa portfolio risk management application (here by means of value-at-risk andexpected shortfall risk measures) executed on FPGA in the Amazon Cloud.In fact, one of the shortcomings preventing an earlier widespread adoption ofFPGA in the cloud was the lack of proper hardware/software infrastructure,and we have shown here that this infrastructure is now available.
Acknowledgments:
We gratefully acknowledge funding from the Deutsche Forschungsgemein-schaft (DFG) within the research training group 1932 ”Stochastic Modelsfor Innovations in the Engineering Sciences”, and the Center of Mathemat-ical and Computational Modeling CM2 of the University of Kaiserslautern.The authors alone are responsble for the content of this whitepaper.
Page 16

Whitepaper J.A.Varela, N. Wehn
References
[1] Xilinx. SDAccel Environment Optimization Guide (UG1207), v2017.2 edition,Aug. 2017. Online: https://www.xilinx.com/support/documentation/
sw_manuals/xilinx2017_2/ug1207-sdaccel-optimization-guide.pdf
Last access: 16 Dec. 2017.[2] S. M. Trimberger. Three Ages of FPGAs: A Retrospective on the First Thirty
Years of FPGA Technology. Proceedings of the IEEE, 103(3):318–331, March2015.
[3] J. L. Hennessy and D. A. Patterson. Computer Architecture: A QuantitativeApproach. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 5thedition, 2012.
[4] D. A. Patterson and J. Hennessy. Computer Organization and Design. Mor-gan Kaufmann, 4 edition, 2009.
[5] J. Reinders. An Overview of Programming for Intel Xeon processors and IntelXeon Phi coprocessors, 2012. last access: 31 Aug 2017.
[6] N. Tarafdar, N. Eskandari, T. Lin, and P. Chow. Designing for FPGAs inthe Cloud. IEEE Design Test, PP(99):1–1, 2017.
[7] Amazon Web Services (AWS). Amazon EC2 Instance Types. Online: https://aws.amazon.com/ec2/instance-types/, 2017. last access: 15 Dec. 2017.
[8] NIST Cloud Computing Standards Roadmap Working Group. NIST CloudComputing Standards Roadmap. Technical Report Special Publication (NISTSP) - 500-291, Version 2, National Institute of Standards and Technology, July2013. http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.
SP.500-291r2.pdf , Last accessed: 12 Dec. 2017.[9] Amazon Web Services (AWS). AWS Pricing: How does AWS pricing work?
Online: https://aws.amazon.com/pricing/, 2018. Last access: 04 Jan.2018.
[10] JPMorgan Chase & Co. 2016 Annual Report, 2017. https://www.
jpmorganchase.com/corporate/investor-relations/document/2016-
annualreport.pdf. Last access: 05 Nov 2017.[11] Accenture. Accelerating the Journey to Cloud: Top 10 Chal-
lenges for Investment Banks, 2017. https://www.accenture.com/
t20170111T213812__w__/us-en/_acnmedia/Accenture/Designlogic/16-
3360/documents/Accenture-2017-Top-10-Challenges-07-Cloud.pdf.Last access: 05 Nov 2017.
[12] S. Weston, J.-T. Marin, J. Spooner, O. Pell, and O. Mencer. Accelerating theComputation of Portfolios of Tranched Credit Derivatives. In High Perfor-mance Computational Finance (WHPCF), 2010 IEEE Workshop on, pages1–8, Nov. 2010.
Page 17

Whitepaper J.A.Varela, N. Wehn
[13] S. Weston, J. Spooner, J.-T. Marin, O. Pell, and O. Mencer. FPGAs Speedthe Computation of Complex Credit Derivatives. Xcell Journal, (74):18–25,Mar. 2011.
[14] Maxeler Technologies. New Amazon EC2 F1 instance bringing Maxeler Maxi-mum Performance Computing to The Cloud. https://www.maxeler.com/f1/,Dec 2016. last access 2016-12-22.
[15] C. de Schryver, D. Schmidt, N. Wehn, E. Korn, H. Marxen, and R. Korn. ANew Hardware Efficient Inversion Based Random Number Generator for Non-Uniform Distributions. In Proceedings of the 2010 International Conferenceon Reconfigurable Computing and FPGAs (ReConFig), pages 190–195, Dec.2010.
[16] C. de Schryver, D. Schmidt, N. Wehn, E. Korn, H. Marxen, A. Kostiuk, andR. Korn. A Hardware Efficient Random Number Generator for NonuniformDistributions with Arbitrary Precision. International Journal of Reconfig-urable Computing (IJRC), 2012, Mar. 2012. Article ID 675130, 11 pages.
[17] C. de Schryver, I. Shcherbakov, F. Kienle, N. Wehn, H. Marxen, A. Kostiuk,and R. Korn. An Energy Efficient FPGA Accelerator for Monte Carlo OptionPricing with the Heston Model. In Proceedings of the 2011 International Con-ference on Reconfigurable Computing and FPGAs (ReConFig), pages 468–474, Cancn, Mexico, Dec. 2011.
[18] C. de Schryver, M. Jung, N. Wehn, H. Marxen, A. Kostiuk, and R. Korn.Energy Efficient Acceleration and Evaluation of Financial Computations to-wards Real-Time Pricing. In A. Knig, A. Dengel, K. Hinkelmann, K. Kise,R. J. Howlett, and L. C. Jain, editors, Knowledge-Based and Intelligent Infor-mation and Engineering Systems, volume 6884 of Lecture Notes in ComputerScience, pages 177–186. Springer Berlin Heidelberg, Sept. 2011. Proceedingsof 15th International Conference on Knowledge-Based and Intelligent Infor-mation & Engineering Systems (KES).
[19] C. de Schryver. High-Performance Hardware Acceleration for Asset Simula-tions. Invited Talk at the HiPEAC Design and Simulation Cluster Meetingin Barcelona, Spain, Nov. 2011.
[20] C. de Schryver, H. Marxen, S. Weithoffer, and N. Wehn. High-PerformanceHardware Acceleration of Asset Simulations. In W. Vanderbauwhede andK. Benkrid, editors, High-Performance Computing Using FPGAs, pages 3–32. Springer New York, 2013.
[21] C. de Schryver, P. Torruella, and N. Wehn. A Multi-Level Monte Carlo FPGAAccelerator for Option Pricing in the Heston Model. In Proceedings of theIEEE Conference on Design, Automation and Test in Europe (DATE), pages248–253, Mar. 2013.
[22] C. Brugger, C. de Schryver, and N. Wehn. HyPER: A Runtime Reconfig-urable Architecture for Monte Carlo Option Pricing in the Heston Model. In
Page 18

Whitepaper J.A.Varela, N. Wehn
Proccedings of the 24th IEEE International Conference of Field ProgrammableLogic and Applications (FPL), pages 1–8, Sept. 2014.
[23] C. Brugger, C. D. Schryver, and N. Wehn. Bringing Flexibility to FPGABased Pricing Systems. In C. De Schryver, editor, FPGA Based Acceleratorsfor Financial Applications, pages 167–190. Springer International Publishing,1st edition, July 2015.
[24] C. Brugger and N. Wehn. Winning Project in the Category High LevelSynthesis. Xilinx OpenHardware 2015 Competition. Awarded at the 25thIEEE International Conference of Field Programmable Logic and Applica-tions (FPL), London, UK, Sept. 2015. For the Project ”Bringing Flexibilityto FPGAs with HyPER: Exotic Derivative Pricing on Zynq”.
[25] C. Brugger, C. de Schryver, N. Wehn, S. Omland, M. Hefter, K. Ritter,A. Kostiuk, and R. Korn. Mixed Precision Multilevel Monte Carlo on HybridComputing Systems. In Proceedings of the 2014 IEEE Conference on Com-putational Intelligence for Financial Engineering Economics (CIFEr), pages215–222, Mar. 2014.
[26] S. Omland, M. Hefter, K. Ritter, C. Brugger, C. D. Schryver, N. Wehn, andA. Kostiuk. Exploiting Mixed-Precision Arithmetics in a Multilevel MonteCarlo Approach on FPGAs. In C. De Schryver, editor, FPGA Based Ac-celerators for Financial Applications, pages 191–220. Springer InternationalPublishing, 1st edition, July 2015.
[27] C. Brugger, J. A. Varela, N. Wehn, S. Tang, and R. Korn. Reverse Longstaff-Schwartz American Option Pricing on hybrid CPU/FPGA Systems. In Pro-ceedings of the 2015 Design, Automation & Test in Europe Conference &Exhibition (DATE), pages 1599–1602, mar 2015.
[28] J. A. Varela, C. Brugger, S. Tang, N. Wehn, and R. Korn. PricingHigh-Dimensional American Options on Hybrid CPU/FPGA Systems. InC. De Schryver, editor, FPGA Based Accelerators for Financial Applications,pages 143–166. Springer International Publishing, 1st edition, July 2015.
[29] J. A. Varela, C. Brugger, C. De Schryver, N. Wehn, S. Tang, and S. Omland.Exploiting the Brownian Bridge Technique to improve Longstaff-SchwartzAmerican Option Pricing on FPGA Systems. In Proceedings of the 2015International Conference on Reconfigurable Computing and FPGAs (ReCon-Fig), pages 1–6, Dec. 2015.
[30] C. Brugger, G. Liu, C. De Schryver, and N. Wehn. Precision-tuning andhybrid pricer for closed-form solution-based Heston calibration. Concurrencyand Computation: Practice and Experience (JCCPE), Oct. 2015.
[31] S. Desmettre, R. Korn, J. A. Varela, and N. Wehn. Nested MC-Based RiskMeasurement of Complex Portfolios: Acceleration and Energy Efficiency.Risks, 4(4), 2016.
Page 19

Whitepaper J.A.Varela, N. Wehn
[32] J. A. Varela, N. Wehn, Q. Liang, and S. Tang. Exploiting Decoupled OpenCLWork-Items with Data Dependencies on FPGAs: A Case Study. In 2017IEEE International Parallel and Distributed Processing Symposium Work-shops (IPDPSW), pages 124–131, May 2017.
[33] Xilinx. AWS Cloud: Xilinx FPGAs in Worlds Largest Cloud. On-line: https://www.xilinx.com/products/design-tools/acceleration-
zone/aws.html, 2017. Last access: 08 Jan. 2018.[34] Xilinx. Baidu Deploys Xilinx FPGAs in New Public Cloud Acceleration Ser-
vices. Online: https://www.xilinx.com/news/press/2017/baidu-
deploys-xilinx-fpgas-in-new-public-cloud-acceleration-
services.html, Jul. 2017. Last access: 08 Jan. 2018.[35] Xilinx. Xilinx Selected by Alibaba Cloud for Next-Gen FPGA Cloud
Acceleration. Online: https://www.xilinx.com/news/press/2017/
xilinx-selected-by-alibaba-cloud-for-next-gen-fpga-cloud-
acceleration.html, Oct. 2017. Last access: 08 Jan. 2018.[36] Basel Committee on Banking Supervision. Basel III: A global regulatory
framework for more resilient banks and banking systems. Technical report,Bank for International Settlements, Dec 2010. (rev June 2011).
[37] Basel Committee on Banking Supervision. Minimum capital requirements formarket risk. Technical report, Bank for International Settlements, Jan 2016.
[38] J. A. Varela and N. Wehn. Near Real-Time Risk Simulation of Complex Port-folios on Heterogeneous Computing Systems with OpenCL. In Proceedingsof the 5th International Workshop on OpenCL, number 2 in IWOCL 2017,pages 2:1–2:10, New York, NY, USA, 2017. ACM.
[39] L. Howes and A. Munshi. The OpenCL Specification. online, Jan 2015.[40] Xilinx. SDAccel Environment User Guide (UG1023), v2017.2 edition,
Aug. 2017. Online: https://www.xilinx.com/support/documentation/
sw_manuals/xilinx2017_2/ug1023-sdaccel-user-guide.pdf Last access:16 Dec. 2017.
[41] Xilinx. SDAccel Environment - Platform Development Guide (UG1164),v2017.2 edition, Aug. 2017. Online: https://www.xilinx.com/support/
documentation/sw_manuals/xilinx2017_2/ug1164-sdaccel-platform-
development.pdf Last access: 16 Dec. 2017.[42] B. Chapman, G. Jost, and R. van der Pas. Using OpenMP: Portable Shared
Memory Parallel Programming (Scientific and Engineering Computation).The MIT Press, 2007.
[43] A. Meucci. Risk and Asset Allocation. Springer Finance. Springer, BerlinHeidelberg, 2005.
[44] J. C. Hull. Options, Futures, And Other Derivatives. Pearson, 8th edition,2012.
Page 20

Whitepaper J.A.Varela, N. Wehn
[45] S. Desmettre and R. Korn. 10 Computational Challenges in Finance. InC. De Schryver, editor, FPGA Based Accelerators for Financial Applications,chapter 1, pages 1–32. Springer, Switzerland, 2015.
[46] A. J. McNeil, R. Frey, and P. Embrechts. Quantitative Risk Management:Concepts, Techniques, and Tools. Princeton University Press, Princeton andOxford, 2005.
[47] A. Mehta, M. Neukirchen, S. Pfetsch, and T. Poppensieker. Managing marketrisk: Today and tomorrow. McKinsey Working Papers on Risk 32, McKinsey& Company, may 2012.
[48] M. Matsumoto and T. Nishimura. Mersenne Twister: A 623-DimensionallyEquidistributed Uniform Pseudo-Random Number Generator. ACM Trans.Model. Comput. Simul., 8(1):3–30, Jan. 1998.
[49] G. Box and M. Muller. A note on the generation of random normal deviates.The Annals of Mathematical Statistics, 29(2):610–611, 1958.
[50] D. Mulnix. Intel Xeon Processor E5-2600 V4 Product FamilyTechnical Overview. Online: https://software.intel.com/en-
us/articles/intel-xeon-processor-e5-2600-v4-product-family-
technical-overview, Apr. 2016. Last access: 15 Dec. 2017.[51] Xilinx. UltraScale Architecture and Product Data Sheet: Overview (DS890),
v3.1 (Preliminary Product Specification) edition, Nov. 2017.[52] R. Korn, E. Korn, and G. Kroisandt. Monte Carlo Methods and Models in
Finance and Insurance. Boca Raton, FL: CRC Press., 2010.
Page 21




























