Embed Size (px)
Citation preview

Runahead ExecutionA Power-Efficient Alternative to Large Instruction
Windows for Tolerating Long Main Memory Latencies
Onur MutluEE 382N Guest Lecture

2
Outline
Motivation Runahead Execution Evaluation Limitations of the Baseline Runahead Mechanism Overcoming the Limitations
Efficient Runahead Execution Address-Value Delta (AVD) Prediction
Summary

3
Motivation
Memory latency is very long in today’s processors (hundreds of processor clock cycles) CDC 6600: 10 cycles [Thornton, 1970] Alpha 21264: 120+ cycles [Wilkes, 2001] Intel Pentium 4: 300+ cycles [Sprangle & Carmean, 2002]
And, it continues to increase (in terms of processor cycles) DRAM latency is not reducing as fast as processor cycle
time
Existing techniques to tolerate the memory latency do not work well enough.

4
Existing Latency Tolerance Techniques Caching [Wilkes, 1965]
Widely used, simple, effective, but not enough, inefficient, passive Not all applications/phases exhibit temporal or spatial locality Cache miss penalty is very high
Prefetching [IBM 360/91, 1967] Works well for regular memory access patterns Prefetching irregular access patterns is difficult, inaccurate, and
hardware-intensive
Multithreading [CDC 6600, 1964] Does not improve the performance of a single thread
Out-of-order execution [Tomasulo, 1967] Tolerates cache misses that cannot be prefetched Requires extensive hardware resources for tolerating long latencies

5
Out-of-order Execution Instructions are executed out of sequential program
order to tolerate latency. Execution of an older long-latency instruction is overlapped
with the execution of younger independent instructions.
Instructions are retired in program order to support precise exceptions/interrupts.
Not-yet-retired instructions and their results are buffered in hardware structures, called the instruction window:
Scheduling window (reservation stations) Register files Load and store buffers Reorder buffer

6
Small Windows: Full-window Stalls When a long-latency instruction is not complete,
it blocks retirement.
Incoming instructions fill the instruction window if the window is not large enough.
Processor cannot place new instructions into the window if the window is already full. This is called a full-window stall.
A full-window stall prevents the processor from making progress in the execution of the program.

7
Small Windows: Full-window Stalls
Oldest LOAD R1 mem[A]
BEQ R1, R0, target
L2 Miss! Takes 100s of cycles.
8-entry instruction window:
Independent of the L2 miss,executed out of program order, but cannot be retired.
Younger instructions cannot be executed because there is no space in the instruction window.
The processor stalls until the L2 Miss is serviced.
L2 cache misses are responsible for most full-window stalls.

8
Impact of L2 Cache Misses
05
101520253035404550556065707580859095
100
128-entry window,512KB L2
128-entry window,perfect L2
2048-entry window,512KB L2
No
rma
lize
d E
xe
cu
tio
n T
ime
Non-stall (compute) time
Full-window stall time
500-cycle DRAM latency, 4.25 GB/s DRAM bandwidth, aggressive stream-based prefetcherData averaged over 147 memory-intensive benchmarks on a high-end x86 processor model

9
The Problem
Out-of-order execution requires large instruction windows to tolerate today’s main memory latencies. Even in the presence of caches and prefetchers
As main memory latency (in terms of processor cycles) increases, instruction window size should also increase to fully tolerate the memory latency.
Building a large instruction window is not an easy task if we would like to achieve Low power/energy consumption Short cycle time Low design and verification complexity

10
Outline
Motivation Runahead Execution Evaluation Limitations of the Baseline Runahead Mechanism Overcoming the Limitations
Efficient Runahead Execution Address-Value Delta (AVD) Prediction
Summary

11
Overview of Runahead Execution [HPCA’03] A technique to obtain the memory-level parallelism benefits
of a large instruction window (without having to build it!)
When the oldest instruction is an L2 miss: Checkpoint architectural state and enter runahead mode
In runahead mode: Instructions are speculatively pre-executed The purpose of pre-execution is to discover other L2 misses L2-miss dependent instructions are marked INV and dropped
Runahead mode ends when the original L2 miss returns Checkpoint is restored and normal execution resumes

Compute
Compute
Compute
Load 1 Miss
Miss 1
Stall Compute
Load 2 Miss
Miss 2
Stall
Load 1 Hit Load 2 Hit
Compute
Load 1 Miss
Runahead
Load 2 Miss Load 2 Hit
Miss 1
Miss 2
Compute
Load 1 Hit
Saved Cycles
Perfect Caches:
Small Window:
Runahead:
Runahead Example

13
Benefits of Runahead Execution
Instead of stalling during an L2 cache miss:
Pre-executed loads and stores independent of L2-miss instructions generate very accurate data prefetches: From main memory to L2 From L2 to L1 For both regular and irregular access patterns
Instructions on the predicted program path are prefetched into the instruction/trace cache and L2.
Hardware prefetcher and branch predictor tables are trained using future access information.

14
Runahead Execution Mechanism Entry into runahead mode
Instruction processing in runahead mode INV bits and pseudo-retirement Handling of store/load instructions (runahead cache) Handling of branch instructions
Exit from runahead mode
Modifications to pipeline

15
When an L2-miss load instruction is the oldest in the instruction window:
Processor checkpoints architectural register state (correctness) branch history register (performance) return address stack (performance)
Processor records the address of the L2-miss load. Processor enters runahead mode. L2-miss load marks its destination register as INV
(invalid) and it is removed from the instruction window.
Entry into Runahead Mode
Compute
Load 1 Miss
Miss 1

16
Processing in Runahead Mode
Compute
Load 1 Miss
Runahead
Miss 1
Runahead mode processing is the same as normal instruction processing, EXCEPT:
It is purely speculative (No architectural state updates)
L2-miss dependent instructions are identified and treated specially.
They are quickly removed from the instruction window. Their values are not trusted.

17
Processing in Runahead Mode
Compute
Load 1 Miss
Runahead
Miss 1
Two types of results are produced: INV (invalid), VALID INV = Dependent on an L2 miss
First INV result is produced by the L2-miss load that caused entry into runahead mode.
An instruction produces an INV result If it sources an INV result If it misses in the L2 cache (A prefetch request is generated)
INV results are marked using INV bits in the register file, store buffer, and runahead cache.
INV bits prevent introduction of bogus data into the pipeline. Bogus values are not used for prefetching/branch resolution.

18
Pseudo-retirement in Runahead ModeCompute
Load 1 Miss
Runahead
Miss 1
An instruction is examined for pseudo-retirement when it becomes the oldest in the instruction window.
An INV instruction is removed from window immediately. A VALID instruction is removed when it completes execution and updates only the microarchitectural state.
Architectural (software-visible) register/memory state is NOT updated in runahead mode.
Pseudo-retired instructions free their allocated resources.
This allows the processing of later instructions. Pseudo-retired stores communicate their data and INV
status to dependent loads.

19
Store/Load Handling in Runahead ModeCompute
Load 1 Miss
Runahead
Miss 1
A pseudo-retired store writes its data and INV status to a dedicated scratchpad memory, called runahead cache.
Purpose: Data communication through memory in runahead mode.
A runahead load accesses store buffer, runahead cache, and L1 data cache in parallel.
If a runahead load is dependent on a pseudo-retired runahead store, it reads its data and INV status from the runahead cache.
Does not need to be always correct Size of runahead cache is very small (512 bytes).

20
Branch Handling in Runahead ModeCompute
Load 1 Miss
Runahead
Miss 1
Branch instructions are predicted in runahead mode (as in normal mode execution).
Runahead branches use the same predictor as normal branches.
VALID branches are resolved and initiate recovery if mispredicted.
VALID branches update the branch predictor tables. Early training of the predictor. Reduces mispredictions in normal mode.
INV branches cannot be resolved. A mispredicted INV branch causes the processor to stay on the wrong program path until the end of runahead execution.

21
Exit from Runahead Mode
Compute
Load 1 Miss
Runahead
Miss 1
Compute
Load 1 Re-fetched and Re-executed
When the runahead-causing L2 miss is serviced: All instructions in the machine are flushed. INV bits are reset. Runahead cache is flushed. Processor restores the architectural state as it was before
the runahead-causing instruction was fetched. Architecturally, NOTHING happened. But, hopefully useful prefetch requests were generated (caches warmed up).
Processor starts fetch beginning with the runahead-causing instruction. Mode is switched to normal mode.
Instructions executed in runahead mode are re-executed in normal mode.

22
Modifications to Pipeline< 0.05% area overhead
Uop Queue
StoreBuffer
INV
INV
INV
InstructionDecoder
L2 Access Queue
Front Side BusAccess Queue
From memory
To memory
Frontend
RAT
Backend
FP Queue
Int Queue
Mem QueueADDR
FP FP
RAT
Prefetcher
Sel
ecti
on L
ogic
TraceCacheFetchUnit
L2 Cache
Renamer
Reorder
Buffer
MEM
Sched
INT
Sched
FP
Sched Regfile
Regfile
INT
Units
Units
INT
UnitsGEN
L1Data
Cache
CHECKPOINTED
RUNAHEADCACHE
STATE

23
Outline
Motivation Runahead Execution Evaluation Limitations of the Baseline Runahead Mechanism Overcoming the Limitations
Efficient Runahead Execution Address-Value Delta (AVD) Prediction
Summary

24
Baseline Processor
3-wide fetch, 29-stage pipeline x86 processor 128-entry instruction window
48-entry load buffer, 32-entry store buffer
512 KB, 8-way, 16-cycle unified L2 cache Approximately 500-cycle L2 miss latency
Bandwidth, contention, conflicts modeled in detail
Aggressive streaming data prefetcher (16 streams) Next-two-lines instruction prefetcher

25
Evaluated Benchmarks
147 Intel x86 benchmarks simulated for 30 million instructions
Benchmark Suites SPEC CPU 95 (S95): 10 benchmarks, mostly FP SPEC FP 2000 (FP00): 11 benchmarks SPEC INT 2000 (INT00): 6 benchmarks Internet (WEB): 18 benchmarks: SpecJbb, Webmark2001 Multimedia (MM): 9 benchmarks: mpeg, speech rec., quake Productivity (PROD): 17 benchmarks: Sysmark2k, winstone Server (SERV): 2 benchmarks: TPC-C, timesten Workstation (WS): 7 benchmarks: CAD, nastran, verilog

26
12%
35%
13%
15%
22% 12%
16% 52%
22%
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
S95 FP00 INT00 WEB MM PROD SERV WS AVG
Mic
ro-o
per
atio
ns
Per
Cyc
le
No prefetcher, no runaheadPrefetcher, no runahead (baseline)Runahead, no prefetcherRunahead and prefetcher
Performance of Runahead Execution
27
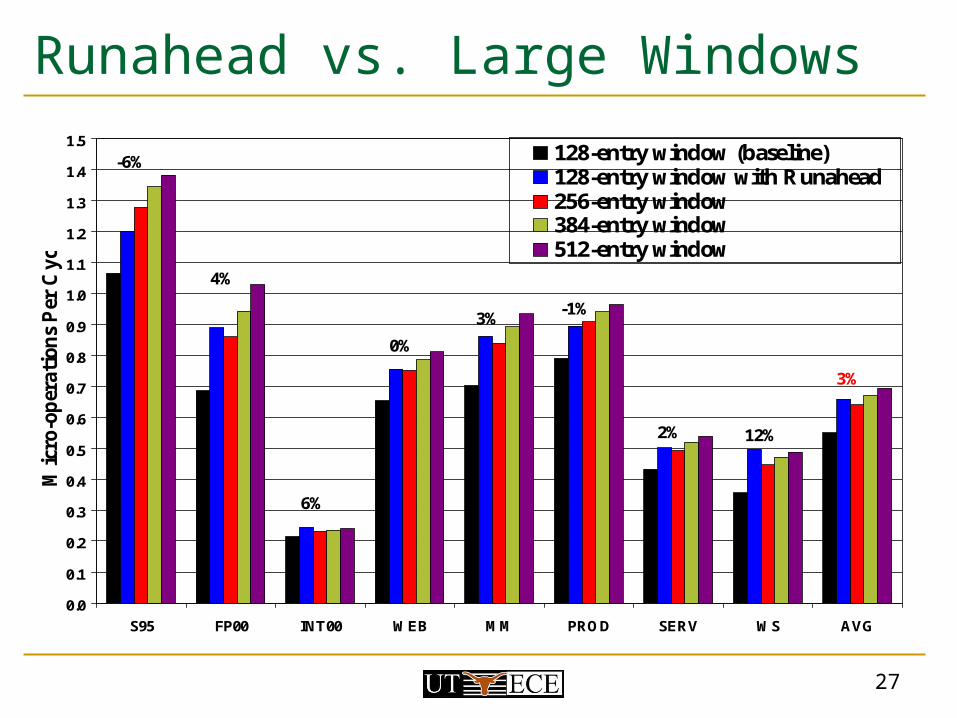
Runahead vs. Large Windows
-6%
4%
6%
0%
3%-1%
2% 12%
3%
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
1.4
1.5
S95 FP00 INT00 WEB MM PROD SERV WS AVG
Mic
ro-o
per
ati
on
s P
er C
ycl
e
128-entry window (baseline)128-entry window with Runahead256-entry window384-entry window512-entry window

28
Runahead vs. Large Windows (Alpha)
0.00
0.25
0.50
0.75
1.00
1.25
1.50
1.75
2.00
2.25
2.50
2.75
3.00
64 128 256 384 512 1024 2048 4096 8192
Instruction Window Size (mem latency = 500 cycles)
Ins
tru
ctio
ns
Per
Cyc
le P
erfo
rman
ce
Baseline
Runahead0.00
0.25
0.50
0.75
1.00
1.25
1.50
1.75
2.00
2.25
2.50
2.75
3.00
64 128 256 384 512 1024 2048 4096 8192
Instruction Window Size (mem latency = 1000 cycles)
Ins
tru
cti
on
s P
er
Cy
cle
Pe
rfo
rma
nc
e
Baseline
Runahead

29
Outline
Motivation Runahead Execution Evaluation Limitations of the Baseline Runahead Mechanism Overcoming the Limitations
Efficient Runahead Execution Address-Value Delta (AVD) Prediction
Summary

30
Limitations of the Baseline Runahead Mechanism Energy Inefficiency
Many instructions are speculatively executed, sometimes without providing any performance benefit
On average 27% extra instructions for 22% IPC improvement Efficient Runahead Execution [ISCA’05, IEEE Micro Top
Picks’06]
Ineffectiveness for pointer-intensive applications Runahead cannot parallelize dependent L2 cache misses Address-Value Delta (AVD) Prediction [MICRO’05]
Irresolvable branch mispredictions in runahead mode Cannot recover from a mispredicted L2-miss dependent
branch Wrong Path Events [MICRO’04]

31
Outline
Motivation Runahead Execution Evaluation Limitations of the Baseline Runahead Mechanism Overcoming the Limitations
Efficient Runahead Execution Address-Value Delta (AVD) Prediction
Summary

32
Causes of Energy Inefficiency
Short runahead periods Periods that last for 10s of cycles instead of 100s
Overlapping runahead periods Two periods that execute the same dynamic
instructions (e.g. due to dependent L2 cache misses)
Useless runahead periods Periods that do not result in the discovery of L2 cache
misses

33
Efficient Runahead Execution
Key idea: Predict if a runahead period is going to be short, overlapping, or useless. If so, do not enter runahead mode.
Simple hardware and software (compile-time profiling) techniques are effective predictors. Details in our papers.
Extra executed instructions decrease from 27% to 6%
Performance improvement remains the same (22%)

34
Outline
Motivation Runahead Execution Evaluation Limitations of the Baseline Runahead Mechanism Overcoming the Limitations
Efficient Runahead Execution Address-Value Delta (AVD) Prediction
Summary

35
Runahead execution cannot parallelize dependent misses
This limitation results in wasted opportunity to improve performance wasted energy (useless pre-execution)
Runahead performance would improve by 25% if this limitation were ideally overcome
The Problem: Dependent Cache Misses
Compute
Load 1 Miss
Miss 1
Load 2 Miss
Miss 2
Load 2 Load 1 Hit
Runahead: Load 2 is dependent on Load 1
Runahead
Cannot Compute Its Address!
INV

36
The Goal of AVD Prediction
Enable the parallelization of dependent L2 cache misses in runahead mode with a low-cost mechanism
How: Predict the values of L2-miss address (pointer)
loads Address load: loads an address into its destination
register, which is later used to calculate the address of another load
as opposed to data load

37
Parallelizing Dependent Cache Misses
Compute
Load 1 Miss
Miss 1
Load 2 Hit
Miss 2
Load 2 Load 1 Hit
Value Predicted
RunaheadSaved Cycles
Can Compute Its Address
Compute
Load 1 Miss
Miss 1
Load 2 Miss
Miss 2
Load 2 INV Load 1 Hit
Runahead
Cannot Compute Its Address!
Saved Speculative Instructions
Miss

38
AVD Prediction
Address-value delta (AVD) of a load instruction defined as:
AVD = Effective Address of Load – Data Value of Load
For some address loads, AVD is stable An AVD predictor keeps track of the AVDs of address
loads When a load is an L2 miss in runahead mode, AVD
predictor is consulted
If the predictor returns a stable (confident) AVD for that load, the value of the load is predicted
Predicted Value = Effective Address – Predicted AVD

39
Identifying Address Loads in Hardware If the AVD is too large, the value being loaded is
likely NOT an address
Only predict loads that have satisfied: -MaxAVD < AVD < +MaxAVD
This identification mechanism eliminates almost all data loads from consideration Enables the AVD predictor to be small

40
An Implementable AVD Predictor Set-associative prediction table Prediction table entry consists of
Tag (PC of the load) Last AVD seen for the load Confidence counter for the recorded AVD
Updated when an address load is retired in normal mode
Accessed when a load misses in L2 cache in runahead mode
Recovery-free: No need to recover the state of the processor or the predictor on misprediction Runahead mode is purely speculative

41
Why Do Stable AVDs Occur?
Regularity in the way data structures are allocated in memory AND traversed
Two types of loads can have stable AVDs Traversal address loads
Produce addresses consumed by address loads Leaf address loads
Produce addresses consumed by data loads

42
Traversal Address LoadsRegularly-allocated linked list:
A
A+k
A+2k
A+3k
A+4k
A+5k...
A traversal address load loads the pointer to next node:
node = nodenext
Effective Addr Data Value AVD
A A+k -k
A+k A+2k -k
A+2k A+3k -k
A+3k A+4k -k
A+4k A+5k -k
Stable AVDStriding data value
AVD = Effective Addr – Data Value

43
Stable AVDs can be captured with a stride value predictor
Stable AVDs disappear with the re-organization of the data structure (e.g., sorting)
Stability of AVDs is dependent on the behavior of the memory allocator Allocation of contiguous, fixed-size chunks is useful
Properties of Traversal-based AVDs
A
A+k
A+2k
A+3k
A+3k
A+k
A
A+2k
Sorting
Distance betweennodes NOT constant!

44
Leaf Address LoadsSorted dictionary in parser: Nodes point to strings (words) String and node allocated consecutively
A+k
A C+k
C
B+k
B
D+k E+k F+k G+k
D E F G
Dictionary looked up for an input word.
A leaf address load loads the pointer to the string of each node:
Effective Addr Data Value AVD
A+k A k
C+k C k
F+k F k
lookup (node, input) { // ... ptr_str = nodestring;
m = check_match(ptr_str, input); if (m>=0) lookup(node->right, input);
if (m<0) lookup(node->left, input); }
Stable AVDNo stride!
AVD = Effective Addr – Data Valuestring
node

45
Properties of Leaf-based AVDs
Stable AVDs cannot be captured with a stride value predictor
Stable AVDs do not disappear with the re-organization of the data structure (e.g., sorting)
Stability of AVDs is dependent on the behavior of the memory allocator
A+k
AB+k
B C
C+kSorting
Distance betweennode and stringstill constant!
C+k
CA+k
A B
B+k

46
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
bisort health mst perimeter treeadd tsp voronoi mcf parser twolf vpr AVG
No
rma
lize
d E
xe
cu
tio
n T
ime
4096 entries16 entries4 entries
Performance of AVD Prediction
12.1%
47
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
bisort health mst perimeter treeadd tsp voronoi mcf parser twolf vpr AVG
No
rma
lize
d N
um
be
r o
f E
xe
cu
ted
In
str
uc
tio
ns
4096 entries
16 entries
4 entries
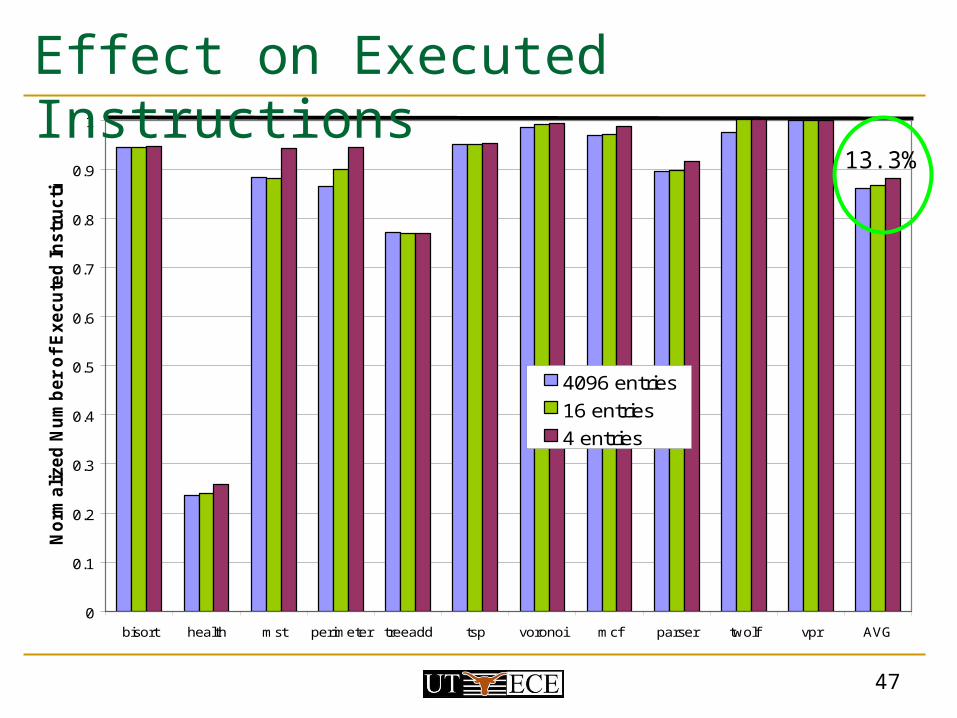
Effect on Executed Instructions
13.3%

48
AVD Prediction vs. Stride Value Prediction Performance:
Both can capture traversal address loads with stable AVDs e.g., treeadd
Stride VP cannot capture leaf address loads with stable AVDs e.g., health, mst, parser
AVD predictor cannot capture data loads with striding data values Predicting these can be useful for the correct resolution of
mispredicted L2-miss dependent branches, e.g., parser
Complexity: AVD predictor requires much fewer entries (only address
loads) AVD prediction logic is simpler (no stride maintenance)

49
AVD vs. Stride VP Performance
0.80
0.82
0.84
0.86
0.88
0.90
0.92
0.94
0.96
0.98
1.00
16 entries 4096 entries
No
rma
lize
d E
xe
cu
tio
n T
ime
AVD
stride
hybrid
12.1%
2.5%
13.4%12.6%
4.5%
16%
16 entries 4096 entries

50
Outline
Motivation Runahead Execution Evaluation Limitations of the Baseline Runahead Mechanism Overcoming the Limitations
Efficient Runahead Execution Address-Value Delta (AVD) Prediction
Summary

51
Summary Cache misses are a major performance limiter in current
processors. Tolerating L2 cache miss latency by traditional out-of-order
execution is too costly in terms of hardware complexity and energy consumption.
Efficient runahead execution provides the latency tolerance benefit of a large instruction window by parallelizing independent cache misses in the shadow of an L2 miss Modest increases in hardware cost or energy consumption 22% performance increase on a 128-entry window with
6% increase in executed instructions <0.05% increase in processor area
Address-Value Delta (AVD) prediction enables the parallelization of dependent cache misses by taking advantage of the regularity in the memory allocation patterns A 16-entry AVD predictor improves the performance of runahead
execution by 12% on pointer-intensive applications

52
For more information…
Onur Mutlu, Jared Stark, Chris Wilkerson, and Yale N. Patt, "Runahead Execution: An Alternative to Very Large Instruction Windows for Out-of-order Processors,“ Proceedings of the 9th International Symposium on High-Performance Computer Architecture (HPCA), pages 129-140, Anaheim, CA, February 2003. http://www.ece.utexas.edu/~onur/mutlu_hpca03.pdf
Onur Mutlu, Jared Stark, Chris Wilkerson, and Yale N. Patt, "Runahead Execution: An Effective Alternative to Large Instruction Windows,“ IEEE Micro, Special Issue: Micro's Top Picks from Microarchitecture Conferences (MICRO TOP PICKS), Vol. 23, No. 6, pages 20-25, November/December 2003. http://www.ece.utexas.edu/~onur/mutlu_ieee_micro03.pdf

53
For even more information…
Onur Mutlu, Hyesoon Kim, and Yale N. Patt, "Techniques for Efficient Processing in Runahead Execution Engines,“ Proceedings of the 32nd International Symposium on Computer Architecture (ISCA), pages 370-381, Madison, WI, June 2005. http://www.ece.utexas.edu/~onur/mutlu_isca05.pdf http://www.ece.utexas.edu/~onur/mutlu_ieee_micro06.pdf
Onur Mutlu, Hyesoon Kim, and Yale N. Patt, "Address-Value Delta (AVD) Prediction: Increasing the Effectiveness of Runahead Execution by Exploiting Regular Memory Allocation Patterns,“ Proceedings of the 38th International Symposium on Microarchitecture (MICRO), pages 233-244, Barcelona, Spain, November 2005. http://www.ece.utexas.edu/~onur/mutlu_micro05.pdf

More Questions?

55
In-order vs. Out-of-order Execution (Alpha)
0.00
0.25
0.50
0.75
1.00
1.25
1.50
1.75
2.00
2.25
2.50
2.75
3.00
100 300 500 700 900 1100 1300 1500 1700 1900
Memory Latency (in cycles)
Inst
ruct
ion
s P
er C
ycle
Per
form
ance
OOO+RA
OOO
IO+RA
IO

56
Sensitivity to L2 Cache Size
20%
48%15%
12%22%
13%
16%
23%
10%
17%
40%13%
10%19%
12%
14%
23%
7%
16%
32%
8%
8%13%
11%
30%
20%
6%
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
S95 FP00 INT00 WEB MM PROD SERV WS AVG
Mic
ro-o
per
atio
ns
Per
Cyc
le
No RA - 0.5 MB
RA - 0.5 MB
No RA - 1 MB
RA - 1 MB
No RA - 4 MB
RA - 4 MB

57
Effect of a Better Front-end
22%
52%
16%
12%
22%15%
13%
35%
12% 13%
35%
13%
21%26%
15%
27%
75%
27%
13%
36%
13%
29%34%
20%
37%
89%
31%
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
1.4
S95 FP00 INT00 WEB MM PROD SERV WS AVG
Mic
ro-o
pera
tion
s P
er C
ycle
BaseRunaheadBase w/ perf TCRunahead w/ perf TCBase w/ perf TC/BPRunahead w/ perf TC/BP





























![Precise Runahead Executionleeckhou/papers/hpca2020.pdf · a technique that remedies the aforementioned shortcomings of prior runahead proposals [45]. PRE builds upon the key obser-vation](https://img.dokumen.tips/doc/110x75/5f532e7f1d8f846c51115daf/precise-runahead-execution-leeckhoupapers-a-technique-that-remedies-the-aforementioned.jpg)