Embed Size (px)
Citation preview

Roundup on Speed
Dennis Wall, PhDParul KudtarkarKris St. GabrielTodd DeLuca

Introduction
• Roundup is a one of the largest repositories of orthologs covering ~250 genomes
• Built using the Reciprocal Smallest Distance Algorithm

Estimating relative evolutionary rates from sequence comparisons:
1. Identification of probable orthologs
A B C D E
S. cerevisiae C. elegans
species treegene tree
Admissible comparisons:
A or B vs. DC vs. E
Inadmissible comparisons:
A or B vs. EC vs. D

Estimating relative evolutionary rates from orthologs:
1. orthologs found using the Reciprocal smallest distance algorithm
2. Build alignment between two orthologs
A B C D E
S. cerevisiae C. elegansspecies treegene tree
Phe Ala Pro Leu ThrPhe Ala µπPro µπ µπ µπLeu µπ µπ µπ µπThr µπ µπ µπ µπ
3. Estimate distance given a substitution matrix
>Sequence CMSGRTILASTIAKPFQEEVTKAVKQLNFT-----PKLVGLLSNEDPAAKMYANWTGKTCESLGFKYEL-…
>Sequence EMSGRTILASKVAETFNTEIINNVEEYKKTHNGQGPLLVGFLANNDPAAKMYATWTQKTSESMGFRYDL…

Reciprocal blast is incomplete when searching for orthologs
• The highest blast hit is often not the nearest phylogenetic neighbor (Koski and Golding, 2001)
• Reciprocal blast is more likely to fail in either forward or reverse direction, forcing a rejection of the pair.
• 1824 BBH orthologs, 2777 rsd orthologs

mgapmtnpargactt...
>orf6.7505.protMVLTIYPDELVQIVSDKIASNKGKITLNQLWDISGKYFDLSDKKKQFVLSCVILKKDIEVYCDGAITTKNVTDIIGDANHSYSVGITEDSLWTLLTGYTKKESTIGNSAFELLLEVAKSGEKGINTMDLAQVTGQDPRSVTGRIKKINHLLTSSQLIYKGHVVKQLKLKKFSHDGVDSNGRIKKINHL
1 2 3>ORFP:YKR080WMSGRTILASKVAETFNTEIINNVEEYKKTHNGQGPLLVGFLANNDPAAKMYATWTQKTSESMGFRYDL…>orf6.7505.protMSGRTILASTIAKPFQEEVTKAVKQLNFT-----PKLVGLLSNEDPAAKMYANWTGKTCESLGFKYEL-…
0.25 0.5 0.75 1 1.25 1.5
20
40
60
80distance obtained by maximum likelihood
Phe Ala Pro Leu ThrPhe Ala µπPro µπ µπ µπLeu µπ µπ µπ µπThr µπ µπ µπ µπ
Reciprocal smallest distance algorithm(forward)
Jones model of amino acid substitution (Jones et al. 1992)
continuous gamma with alpha = 1.530 used.
ORFP:YKR080W orf6.1984.prot
0.7786ORFP:YKR080W orf6.2111.prot
2.7786
Smallest distanceorf6.1984.prot
0.7786
HSPs

mgapmtnpargactt...
> ORFP:YKR080WMVLTIYPDELVQIVSDKIASNKGKITLNQLWDISGKYFDLSDKKKQFVLSCVILKKDIEVYCDGAITTKNVTDIIGDANHSYSVGITEDSLWTLLTGYTKKESTIGNSAFELLLEVAKSGEKGINTMDLAQVTGQDPRSVTGRIKKINHLLTSSQLIYKGHVVKQLKLKKFSHDGVDSNGRIKKINHL
1 2 3>orf6.7505.protMSGRTILASTIAKPFQEEVTKAVKQLNFT-----PKLVGLLSNEDPAAKMYANWTGKTCESLGFKYEL-…>ORFP:YKR080WMSGRTILASKVAETFNTEIINNVEEYKKTHNGQGPLLVGFLANNDPAAKMYATWTQKTSESMGFRYDL…
0.25 0.5 0.75 1 1.25 1.5
20
40
60
80distance obtained by maximum likelihood
Phe Ala Pro Leu ThrPhe Ala µπPro µπ µπ µπLeu µπ µπ µπ µπThr µπ µπ µπ µπ
Jones model of amino acid substitution (Jones et al. 1992)
continuous gamma with alpha = 1.530 used.
orf6.1984.prot ORFP:YKR080W
1.26orf6.2111.prot ORFP:YKR080W
2.7786
Smallest distanceORFP:YKR080W
1.26
Found RSD
Compare with original query sequence
Reciprocal smallest distance algorithm(reverse)
HSPs

ab
bb
cb
c
c
c
a
b
c
vs.
vs.
vs.
vs.
vs.
vs.
Align sequences &Calculate distances
D=0.2
D=0.3
D=0.1
D=1.2
D=0.1
D=0.9
Orthologs:ib - jc D = 0.1
HL Align sequences &Calculate distances
JcIb
Genome I Genome J
RSD algorithm summary

RSD vs BBH

RSD results
• Stored in MySQL • Ad hoc exploratory queries possible
1) Transitive closure2) Any orthos between genome A
and [b,c,d…]3) All orthologs among genomes
[a,b,c,d…]
A v C
A v Bgi gj 0.3gi gj 0.3gi gj 0.3
A v D
A. B. C.
(1) (2) (3)
(g1) 0000011000000000000011111110000(g2) 0000011000000000000011111110000(g3) 0000011000000000000011111110001(g4) 0000011000000000000011111110001

Roundup usages
• discovery of functional linkages and uncharacterized cellular pathways
• deciphering network organization of the cell
• propensity for gene loss

Use of Logic Relationships to Decipher Protein Network Organization
Peter M. Bowers, Shawn J. Cokus, David Eisenberg, and Todd O. Yeates Science 306 2246.

Use of Logic Relationships to Decipher Protein Network Organization
Peter M. Bowers, Shawn J. Cokus, David Eisenberg, and Todd O. Yeates Science 306 2246.

0000011000000000000011111110000000001100000000000001111111000000000110000000000000111111100010000011000000000000011111110001
Subgraph 1 (S1)
Kin = [0,0,1,1,0,0]
Subgraph 2
Subgraph 3
.
.
.Subgraph N(=885)
000111100…000111100…000111000…
111001100…111001100…111001100…
000001100…000001100…000001100…
Kout = [1,2,3,4,0,0,3,4,5,1,1,4]
Kout = [1,2,3,4,0,0,3,4,5,1,1,4]
Kout = [1,2,3,4,0,0,3,4,5,1,1,4]
P=0.05
P=0.01
P=0.2
S1 S2 S3 S4. . . SNS1 * .05 .03S2 *S3 *S4 *...SN
T test(kin, kout)
MATRIX of P Values (885X885)
EVERY S has 885-1 p values.

0
100
200
300
400
500
600
700
800
900
1000
1 33 65 97 129 161 193 225 257 289 321 353 385 417 449 481 513 545 577 609 641 673 705 737 769 801 833 865
all
Cint
Ame
Cel
Aga
Spu
Sce
Ath
Dme
Spa
Cgl
Cal
Spo
Sba
Sca
Gga
Dre
Tni
Fru
Sku
Mmu
Xtr
Skl
Ptr
Mdo
Smi
Cfa
Rno
Bta
Ecu
Nu
mb
er o
f S
ign
ific
ant
p v
alu
es (
Acc
ura
cy)
Functional Modules
Phylogenetic profiles predict function

Z1 Z2 Z3 Z4
Acc
urac
y
Functional modules
Pro
file
size

Propensity for gene lossE
ncep
halit
ozoo
n cu
nicu
li
Cae
norh
abdi
tis e
lega
ns
Api
s m
ellif
era
Ano
phel
es g
ambi
ae
Dro
soph
ila m
elan
ogas
ter
Str
ongy
loce
ntro
tus
purp
urat
us
Cio
na in
test
inal
is
Gal
lus
gallu
s
Mon
odel
phis
dom
estic
a
Bos
taur
us
Can
is f
amili
aris
Pan
trog
lody
tes
Hom
o sa
pien
s
Mac
aca
mul
atta
Mus
mus
culu
s
Rat
tus
norv
egic
us
Dan
io r
erio
Fug
u ru
brip
es
Tet
raod
on n
igro
virid
is
Sch
izos
acch
arom
yces
pom
be
Can
dida
alb
ican
s
Sac
char
omyc
es k
luyv
eri
Can
dida
gla
brat
a
Sac
char
omyc
es c
aste
llii
Sac
char
omyc
es b
ayan
us
Sac
char
omyc
es k
udria
vzev
ii
Sac
char
omyc
es m
ikat
ae
Sac
char
omyc
es c
erev
isia
e
Sac
char
omyc
es p
arad
oxus
Ara
bido
psis
thal
iana
1 1 1 1 1 0 0 1 0 1 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 0 11 1 1 1 1 0 0 1 1 1 1 0 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 11 1 1 1 0 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 0 1 0 0 1 1 1 1 1 11 1 1 1 0 1 0 1 1 1 1 1 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 1 0 1 1
D-PGL Dist4 0.939 1 1.103 6 2.7785 0.977
•Phylogenetic profiles drawn from Roundup (Deluca et al. 2006)
•Phylogeny built using maximum parsimony•Profiles mapped via Dollo parsimony

Roundup Computational Demand
• Number of rsd processes scales quadratically with the number of genomes.
• Could take ~2700 years to complete on a single machine
N
2= (N)(N-1)/2 * 12 parameters combos
1000 genomes = 5,994,000 processes = 23,976,000 hours

Hadoop may help
• Apache Hadoop Core is a software platform that lets one easily write and run applications that process vast amounts of data.
• Hadoop implements MapReduce, using the Hadoop Distributed File System (HDFS). MapReduce divides applications into many small blocks of work. HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster. MapReduce can then process the data where it is located.
• Hadoop has been demonstrated on clusters with 2000 nodes. The current design target is 10,000 node clusters.

MapReduce: High Level
JobTrackerMapReduce job
submitted by client computer
Master node
TaskTracker
Slave node
Task instance
TaskTracker
Slave node
Task instance
TaskTracker
Slave node
Task instance
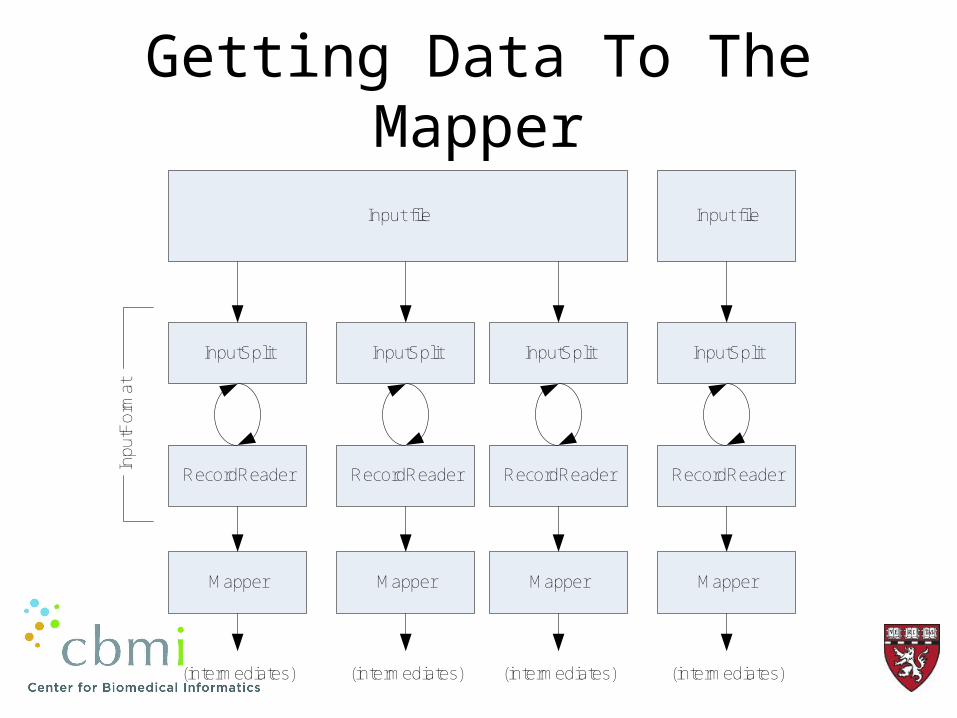
Getting Data To The Mapper
Input file
InputSplit InputSplit InputSplit InputSplit
Input file
RecordReader RecordReader RecordReader RecordReader
Mapper
(intermediates)
Mapper
(intermediates)
Mapper
(intermediates)
Mapper
(intermediates)
Inpu
tFor
mat

Partition And Shuffle
Mapper
(intermediates)
Mapper
(intermediates)
Mapper
(intermediates)
Mapper
(intermediates)
Reducer Reducer Reducer
(intermediates) (intermediates) (intermediates)
Partitioner Partitioner Partitioner Partitioner
shu
fflin
g

Writing The Output
Reducer Reducer Reducer
RecordWriter RecordWriter RecordWriter
output file output file output file
Out
putF
orm
at

HDFS -- Limitations
• No file update options (record append, etc); all files must be written only once.
• Does not implement demand replication
• Designed for streaming – Random seeks devastate performance

Vanilla Hadoop
Assumptions– Data are the data to
be processed– Data can be arbitrarily
subdivided across the cluster
– Mapper and reducer are Java
Roundup cannot accommodate any of these assumptions without serious pain

Hadoop Streaming is an answer
• Hadoop streaming is a utility that comes with the Hadoop distribution. The utility allows you to create and run map/reduce jobs with any executable or script as the mapper and/or the reducer. For example:
• $HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar -input myInputDirs -output myOutputDir -mapper /bin/cat - reducer /bin/wc
• Mapper and the Reducer are executables that read the input from stdin (line by line) and emit the output to stdout. The utility will create a map/reduce job, submit the job to an appropriate cluster, and monitor the progress of the job until it completes.

Hadoop Streaming
• We cannot think of stanard Roundup input (i.e. genomes) as input to Hadoop
• But we can “trick” hadoop into receiving and processing Roundup job commands as inputs
• Undocumented, uncharted use of Hadoop streaming

MapReduce RSD Code and Hadoop Streaming
• Mapper Script:Input: command lines (runstuff)forgenomes to be comparedFunction: runs RSD algorithmOutput: gene pairs and their evolutionary distances
• Reducer Script: Bypassed (set 0 in the configuration)
• Streaming :Hadoop programs are typically written in JavaRoundup Code base is in pythonOptions:1.Translate python code using Jython into jar files2.Use Hadoop streaming to pass data to the mapper function via STDIN and
STDOUT

HADOOP JOB DISTRIBUTIONAWSMedium High CPUInstance Specs:
1. 2.5 EC2 compute unit per core*
2. 2virtual Core
3. 1.7 GB memory
4. 32- bit platform
5. 1690 GB instance storage
6. $0.20 per hour
Cost estimate:Cost per hour × Number of instances× Number of hours to run the jobFor this particular test:$0.20 × 6 medium instances × ~11 mins =$1.2[Used 10 nodes for 15 comparisons across 6 genomes]
*One EC2 Compute Unit = 1.0-1.2 GHz 2007 Opteron or 2007 Xeon processor

AWS access keys and other parameters excluded from config. file as they are private and specific to group
HADOOP Configuration Setup to run RSD jobs on AWS

Mapper
import sysFor cmd in sys.stdin:
os.system(cmd)
Streaming Input file (on HDFS) “rsdrunner”Line 1:python /user/local/hadoop/RSD.py –thresh=0.8 –div=0.2
-s /user/local/hadoop/genome/genome1.aa -q /user/local/hadoop/genome/genome1.aa-output /user/local/hadoop/wank
…
Limitations of HDFS and Streaming forced us to printRSD output to stdout… but it worked…

Hadoop cluster launch on AWS• To start the cluster
• Initializing the cluster

Roundup job run on AWS
• Copy input file to HDFS
• Run RSD jobs powered by HadoopStreming utility$bin/hadoop jar contrib/streaming/hadoop-0.18.3-streaming.jar
-mapper /usr/local/hadoop-0.18.3/newmapper.py
-reducer NONE
-input rsdrunner
-output RsdResult
-jobconfmapred.map.tasks=10

Roundup job run on AWS• Output of previous command in console

Monitoring Roundup Jobs• JobTracker and cluster monitoring

Monitoring Roundup Jobs• TaskTracker Monitoring

Monitoring Roundup Jobs
• MapReduce job summary

Monitoring Roundup Jobs• Running Task = No. of Map task

Monitoring Roundup JobsTime Split for job completion

Montioring Roundup Jobs• Summary Post Job Completion

Shutting down the Hadoop cluster on AWS
• Terminate the cluster after job completion and copying data locally
• Terminating the cluster

Future Considerations
• Careful design of Roundup AWS jobs to minimize time and maximize instance resources.
• Could be prohibitively expensive – Medium HPC instance $0.20/hour– Medium HPC = 5 EC2 compute units (5 jobs per
instance) – Assume 1 RSD run = 4 hours = $0.16– All of Roundup would cost ~$1M, but would only take
~100 days to complete if using 10000 compute units

HADOOP Usage Examples• IBM Blue cloud computing cluster at IBM uses Hadoop parallel work load scheduling
• Yahoo! 100,000 CPU’s running Hadoop: 2000 nodes currently used by Ad systems and Web
Search(webgrep)
• The New York Times Converted ~11 million articles (scanned images) into PDF format using EC2 for
computation and S3 for datastorage
• Apache Mahout Uses Hadoop to built scalable machine learning algorithms like canopy clustering and
k-means
• Facebook Use Hadoop to store internal logs and dimension data sources which is used for
reporting analytics and machine
• Able GrapeWorlds smallest hadoop cluster: 2 node@ 8 CPUs/node, vertical search engine for
wine knowledge base
http://wiki.apache.org/hadoop/PoweredBy

Acknowledgements
• Parul Kudtarkar• Kris St. Gabriel• Todd DeLuca• Rimma Pivovarov• Vince Fusaro• Prasad Patil • Peter Kos
• Peter Tonellato• Mike Banos• All palaver
participants





























