Embed Size (px)
Citation preview

Reliable measures of syntactic and lexicalcomplexity: The case of Iris Murdoch
Stefan Evert1, Sebastian Wankerl1, Elmar Nöth2
1Corpus Linguistics Group, 2Pattern Recognition LabUniversity of Erlangen-Nuremberg25 July 2017

Introduction (1)
Different types of quantitative measures of complexity like• vocabulary richness (e.g. type-token ratio (TTR))• readability (e.g. age-of-acquisition)• syntactic complexity (e.g. Yngve (1960) depth, sentence length)
play an important role in a wide range of applications, e.g.• investigating stylometric differences and authorship (Stamatatos 2009)• studying diachronic changes in grammar (Bentz et al. 2014)• assessing readability and difficulty level of a text (Graesser et al. 2004)• exploring the characteristics of translated texts (Volansky, Ordan, and
Wintner 2015)• identifying determinants of style in scientific writing (Bergsma, Post, and
Yarowsky 2012)• multivariate analysis of linguistic variation (Diwersy, Evert, and Neumann
2014)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 1

Introduction (2)
Some researchers have used complexity measures to detect early symptoms ofAlzheimer’s disease (AD).
However, as in most other research on complexity measures• sampling variation is not taken into account• significance tests are rarely applied• or inappropriate tests are used
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 2

Our Case Study
Previous work on detecting Alzheimer’s disease• based on the works of British novelist Iris Murdoch (diagnosed with AD)• using different measures of readability, lexical and syntactic complexity
• obtained conflicting results• decline of complexity in Murdoch’s last novel, for various measures
(Garrard et al. 2005; Pakhomov et al. 2011)• no clear effects, in particular for syntactic complexity (Le et al. 2011)
• which can be explained by lack of significance testing• no confidence intervals for complexity scores of each novel• only Le et al. (2011) applied significance tests, but for linear trends over time
(not reasonable considering the progress of the disease)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 3

Our Case Study
Previous work on detecting Alzheimer’s disease• based on the works of British novelist Iris Murdoch (diagnosed with AD)• using different measures of readability, lexical and syntactic complexity• obtained conflicting results
• decline of complexity in Murdoch’s last novel, for various measures(Garrard et al. 2005; Pakhomov et al. 2011)
• no clear effects, in particular for syntactic complexity (Le et al. 2011)
• which can be explained by lack of significance testing• no confidence intervals for complexity scores of each novel• only Le et al. (2011) applied significance tests, but for linear trends over time
(not reasonable considering the progress of the disease)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 3

Our Case Study
Previous work on detecting Alzheimer’s disease• based on the works of British novelist Iris Murdoch (diagnosed with AD)• using different measures of readability, lexical and syntactic complexity• obtained conflicting results
• decline of complexity in Murdoch’s last novel, for various measures(Garrard et al. 2005; Pakhomov et al. 2011)
• no clear effects, in particular for syntactic complexity (Le et al. 2011)• which can be explained by lack of significance testing
• no confidence intervals for complexity scores of each novel• only Le et al. (2011) applied significance tests, but for linear trends over time
(not reasonable considering the progress of the disease)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 3

Research Questions
1. How can appropriate significance tests be implemented?
2. Does AD manifest in a significant decline of complexity?
To achieve this goal, we
develop new methodology for computation of• reliable confidence intervals• significance tests
by combining ideas from• bootstrapping (Efron 1979)• cross-validation
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 4

Research Questions
1. How can appropriate significance tests be implemented?
2. Does AD manifest in a significant decline of complexity?
To achieve this goal, we
develop new methodology for computation of• reliable confidence intervals• significance tests
by combining ideas from• bootstrapping (Efron 1979)• cross-validation
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 4

The writings of Iris Murdoch
• renowned British author of the post-war era• published a total of 26 novels• mostly well received by literary critics• last novel received “without enthusiasm” (Garrard et al. 2005),
Murdoch experienced unexpected difficulties while composing it• diagnosis of AD shortly after publication
Hence
early symptoms of AD shouldbe found in this last novel
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 5

The writings of Iris Murdoch
• renowned British author of the post-war era• published a total of 26 novels• mostly well received by literary critics• last novel received “without enthusiasm” (Garrard et al. 2005),
Murdoch experienced unexpected difficulties while composing it• diagnosis of AD shortly after publication
Hence
early symptoms of AD shouldbe found in this last novel
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 5

Our Corpus
• 19 of Murdoch’s 26 novels• including the nine last novels, spanning a period of almost 20 years• acquired as e-books (no errors due to OCR)
Further preprocessing• Stanford CoreNLP (Manning et al. 2014) for tokenization, sentence splitting,
POS tagging, and syntactic parsing• exclude dialogue, like Pakhomov et al. (2011) and Garrard et al. (2005),
which can be done reliably since e-books use typographic quotation marks
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 6

Complexity Measures (1)
Vocabulary richness:• vocabulary size V and type-token ratio V/N (TTR)• Yule’s κ (probability of sampling the same word twice in a row)• Honoré H (∼ proportion V1/V of hapax legomena = Zipf slope 1/a)
Readability & morphology:• proportions of different word classes, noun-verb ratio• proportion of words learnt after the age of 9 years, based on Kuperman,
Stadthagen-Gonzalez, and Brysbaert (2012)
Syntactic domain:• average number of words or clauses per sentence• Yngve and Frazier depth of parse tree, which put a higher weight on
left-branching sentences
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 7

Complexity Measures (1)
Vocabulary richness:• vocabulary size V and type-token ratio V/N (TTR)• Yule’s κ (probability of sampling the same word twice in a row)• Honoré H (∼ proportion V1/V of hapax legomena = Zipf slope 1/a)
Readability & morphology:• proportions of different word classes, noun-verb ratio• proportion of words learnt after the age of 9 years, based on Kuperman,
Stadthagen-Gonzalez, and Brysbaert (2012)
Syntactic domain:• average number of words or clauses per sentence• Yngve and Frazier depth of parse tree, which put a higher weight on
left-branching sentences
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 7

Complexity Measures (1)
Vocabulary richness:• vocabulary size V and type-token ratio V/N (TTR)• Yule’s κ (probability of sampling the same word twice in a row)• Honoré H (∼ proportion V1/V of hapax legomena = Zipf slope 1/a)
Readability & morphology:• proportions of different word classes, noun-verb ratio• proportion of words learnt after the age of 9 years, based on Kuperman,
Stadthagen-Gonzalez, and Brysbaert (2012)
Syntactic domain:• average number of words or clauses per sentence• Yngve and Frazier depth of parse tree, which put a higher weight on
left-branching sentences
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 7

Complexity Measures (2)
N-gram models (Wankerl, Nöth, and Evert 2016)• statistical language models based on n-gram probabilities• perplexity of language model determines how well part of text can be
predicted from other parts• hence gives good indication of lexical and syntactic diversity
Advantages
• language-independent• no expensive linguistic preprocessing
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 8

Results (1)
• marked decline at the end for noun-verb ratio
and Honoré H
• but also fluctuations among the earlier novels→ decline significant?• Yule’s κ and many other measures don’t show expected trend
19541956
19581962
19631966
19691971
19741976
19781980
19831985
19871989
19931995
0.725
0.750
0.775
0.800
0.825
0.850
0.875
0.900
Noun
/Ver
b Re
latio
n
19541956
19581962
19631966
19691971
19741976
19781980
19831985
19871989
19931995
70
80
90
100
110
120
Yule
's K
noun-verb ratio Yule’s κ
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 9

Results (1)
• marked decline at the end for noun-verb ratio and Honoré H• but also fluctuations among the earlier novels→ decline significant?• Yule’s κ and many other measures don’t show expected trend
19541956
19581962
19631966
19691971
19741976
19781980
19831985
19871989
19931995
0.725
0.750
0.775
0.800
0.825
0.850
0.875
0.900
Noun
/Ver
b Re
latio
n
19541956
19581962
19631966
19691971
19741976
19781980
19831985
19871989
19931995
2200
2300
2400
2500
2600
2700
Hono
re H
noun-verb ratio Honoré H
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 9

Methodology (1)
Traditional approaches to significance testingA assume that each text is a random sample of tokens
• binomial test with Gaussian approximation for measures based on counts• LNRE models (Baayen 2001) for measures of vocabulary richness
B or treat each text as a single item• Student’s t-test for independent samples + confidence intervals• linear regression on time of publication (Le et al. 2011)• non-parametric tests if normality assumption is questionable
Not valid here because
A severly underestimates sampling variation→ inflated significance
B cannot be used to test significance of a single text (n1 = 1 vs. n2 = 18)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 10

Methodology (1)
Traditional approaches to significance testingA assume that each text is a random sample of tokens
• binomial test with Gaussian approximation for measures based on counts• LNRE models (Baayen 2001) for measures of vocabulary richness
B or treat each text as a single item• Student’s t-test for independent samples + confidence intervals• linear regression on time of publication (Le et al. 2011)• non-parametric tests if normality assumption is questionable
Not valid here because
A severly underestimates sampling variation→ inflated significance
B cannot be used to test significance of a single text (n1 = 1 vs. n2 = 18)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 10

Methodology (2)
Our goal is to estimate sampling variation from a single text.
Key idea: bootstrap resampling• cut text into equally-sized slices (folds)• resample with replacement from folds• estimate sampling variation of desired measure from bootstrap samples• problem: works for counts and averages, but type-token measures are biased
(bootstrapping underestimates vocabulary size V ,V1, . . .)
Key idea: cross-validation• compute measure for each fold, then macro-average over all folds• estimate sampling variation of average from variability between folds• accounts for non-randomness within text, but not e.g. stylistic differences
+ still much more realistic than random sample of tokens
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 11

Methodology (2)
Our goal is to estimate sampling variation from a single text.
Key idea: bootstrap resampling• cut text into equally-sized slices (folds)• resample with replacement from folds• estimate sampling variation of desired measure from bootstrap samples• problem: works for counts and averages, but type-token measures are biased
(bootstrapping underestimates vocabulary size V ,V1, . . .)
Key idea: cross-validation• compute measure for each fold, then macro-average over all folds• estimate sampling variation of average from variability between folds• accounts for non-randomness within text, but not e.g. stylistic differences
+ still much more realistic than random sample of tokens
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 11

Methodology (2)
Our goal is to estimate sampling variation from a single text.
Key idea: bootstrap resampling• cut text into equally-sized slices (folds)• resample with replacement from folds• estimate sampling variation of desired measure from bootstrap samples• problem: works for counts and averages, but type-token measures are biased
(bootstrapping underestimates vocabulary size V ,V1, . . .)
Key idea: cross-validation• compute measure for each fold, then macro-average over all folds• estimate sampling variation of average from variability between folds• accounts for non-randomness within text, but not e.g. stylistic differences
+ still much more realistic than random sample of tokens
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 11

Methodology (3)
As a first step• partition each novel into folds of 10,000 consecutive tokens• discard leftover tokens• results in k ≥ 6 folds for each novel
Then• evaluate complexity measure of interest on each fold
y1, . . . ,yk
• compute macro-average as overall measure for the entire text
y =y1 + · · ·+ yk
k
• instead of value x obtained by evaluating measure on full text
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 12

Methodology (3)
As a first step• partition each novel into folds of 10,000 consecutive tokens• discard leftover tokens• results in k ≥ 6 folds for each novel
Then• evaluate complexity measure of interest on each fold
y1, . . . ,yk
• compute macro-average as overall measure for the entire text
y =y1 + · · ·+ yk
k
• instead of value x obtained by evaluating measure on full text
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 12

Methodology (4)
Significance testing procedure:• standard deviation σ of individual folds estimated from data
σ2 ≈ s2 =
1
k−1
k
∑i=1
(yi − y)2
• standard deviation of macro average can be computed as
σy =σ√
k≈ s√
k
• asymptotic 95% confidence intervals are then given by
y±1.96 ·σy
• comparison of samples with Student’s t-test, based on pooledcross-validation folds (feasible even for n1 = 1)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 13

Methodology (4)
Significance testing procedure:• standard deviation σ of individual folds estimated from data
σ2 ≈ s2 =
1
k−1
k
∑i=1
(yi − y)2
• standard deviation of macro average can be computed as
σy =σ√
k≈ s√
k
• asymptotic 95% confidence intervals are then given by
y±1.96 ·σy
• comparison of samples with Student’s t-test, based on pooledcross-validation folds (feasible even for n1 = 1)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 13

Methodology (4)
Significance testing procedure:• standard deviation σ of individual folds estimated from data
σ2 ≈ s2 =
1
k−1
k
∑i=1
(yi − y)2
• standard deviation of macro average can be computed as
σy =σ√
k≈ s√
k
• asymptotic 95% confidence intervals are then given by
y±1.96 ·σy
• comparison of samples with Student’s t-test, based on pooledcross-validation folds (feasible even for n1 = 1)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 13

Methodology (4)
Significance testing procedure:• standard deviation σ of individual folds estimated from data
σ2 ≈ s2 =
1
k−1
k
∑i=1
(yi − y)2
• standard deviation of macro average can be computed as
σy =σ√
k≈ s√
k
• asymptotic 95% confidence intervals are then given by
y±1.96 ·σy
• comparison of samples with Student’s t-test, based on pooledcross-validation folds (feasible even for n1 = 1)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 13

Methodology (4)
But is y a valid substitute for the full-text measure x?
• for all measures based on frequency counts (proportions of word categories)or averages (sentence length)
y ≈ x
(except for marco- vs. micro-averaging)• n-gram perplexity is computed by cross-validation anyway• type-token statistics might show a substantial difference
y < x or y > x
but only if x systematically depends on text size• y then allows for meaningful comparison of different text lengths• e.g. cross-validated type-token ratio = standardised TTR
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 14

Methodology (4)
But is y a valid substitute for the full-text measure x?• for all measures based on frequency counts (proportions of word categories)
or averages (sentence length)y ≈ x
(except for marco- vs. micro-averaging)
• n-gram perplexity is computed by cross-validation anyway• type-token statistics might show a substantial difference
y < x or y > x
but only if x systematically depends on text size• y then allows for meaningful comparison of different text lengths• e.g. cross-validated type-token ratio = standardised TTR
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 14

Methodology (4)
But is y a valid substitute for the full-text measure x?• for all measures based on frequency counts (proportions of word categories)
or averages (sentence length)y ≈ x
(except for marco- vs. micro-averaging)• n-gram perplexity is computed by cross-validation anyway
• type-token statistics might show a substantial difference
y < x or y > x
but only if x systematically depends on text size• y then allows for meaningful comparison of different text lengths• e.g. cross-validated type-token ratio = standardised TTR
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 14

Methodology (4)
But is y a valid substitute for the full-text measure x?• for all measures based on frequency counts (proportions of word categories)
or averages (sentence length)y ≈ x
(except for marco- vs. micro-averaging)• n-gram perplexity is computed by cross-validation anyway• type-token statistics might show a substantial difference
y < x or y > x
but only if x systematically depends on text size• y then allows for meaningful comparison of different text lengths• e.g. cross-validated type-token ratio = standardised TTR
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 14

Theoretical Validation
We can draw random samples from the Zipf-Mandelbrot law
πi =C
(i + b)a
to explore the appropriateness of y as a measure of vocabulary richness in theidealised situation underlying traditional binomial tests.
• Is y consistent with intuitive expectations for different fold sizes?• assumption: vocabulary richness determined by Zipf slope (larger values
a > 1 result in smaller vocabulary and proportion of hapax legomena)
• How do cross-validated confidence intervals for y compare to binomialfull-text confidence intervals for x?
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 15

Measures of vocabulary richness depend on fold size
1 2 3 4 5 6 7
a = 3.0a = 2.0a = 1.5
Frequency spectrum at 100k tokens
m
E[V
m]
020
0060
0010
000
0 10000 20000 30000 40000 50000
0.0
0.1
0.2
0.3
0.4
0.5
0.6
type−token ratio (TTR)
fold size
E[y
]=E
[yi]
a = 3.0a = 2.0a = 1.5
0 10000 20000 30000 40000 50000
020
4060
8010
0 Yule's K
fold size
E[y
]=E
[yi]
a = 3.0a = 2.0a = 1.5
0 10000 20000 30000 40000 50000
010
0020
0030
0040
00
Honoré H
fold size
E[y
]=E
[yi]
a = 3.0a = 2.0a = 1.5
AEvert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 16

Measures of vocabulary richness depend on fold size
1 2 3 4 5 6 7
a = 3.0a = 2.0a = 1.5
Frequency spectrum at 100k tokens
m
E[V
m]
020
0060
0010
000
0 10000 20000 30000 40000 50000
0.0
0.1
0.2
0.3
0.4
0.5
0.6
type−token ratio (TTR)
fold size
E[y
]=E
[yi]
a = 3.0a = 2.0a = 1.5
0 10000 20000 30000 40000 50000
020
4060
8010
0 Yule's K
fold size
E[y
]=E
[yi]
a = 3.0a = 2.0a = 1.5
0 10000 20000 30000 40000 50000
010
0020
0030
0040
00
Honoré H
fold size
E[y
]=E
[yi]
a = 3.0a = 2.0a = 1.5
BEvert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 16
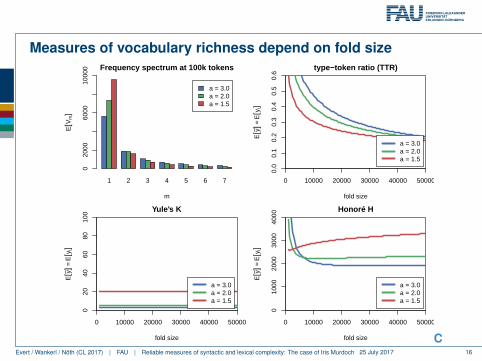
Measures of vocabulary richness depend on fold size
1 2 3 4 5 6 7
a = 3.0a = 2.0a = 1.5
Frequency spectrum at 100k tokens
m
E[V
m]
020
0060
0010
000
0 10000 20000 30000 40000 50000
0.0
0.1
0.2
0.3
0.4
0.5
0.6
type−token ratio (TTR)
fold size
E[y
]=E
[yi]
a = 3.0a = 2.0a = 1.5
0 10000 20000 30000 40000 50000
020
4060
8010
0 Yule's K
fold size
E[y
]=E
[yi]
a = 3.0a = 2.0a = 1.5
0 10000 20000 30000 40000 50000
010
0020
0030
0040
00
Honoré H
fold size
E[y
]=E
[yi]
a = 3.0a = 2.0a = 1.5
CEvert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 16

Cross-validated vs. full-text measures
• two Zipf-Mandelbrot populations from group A• fixed fold size of N0 = 1000 tokens (confidence intervals too small for 10k)• length of full text differs (k folds→ k ·N0 tokens)
0 2 4 6 8 10 12 14
050
010
0015
0020
0025
0030
0035
00
95% confidence intervals in random samples
# folds of 1000 tokens
Hon
oré
H
a = 1.5a = 2.0
full binomial samplecross−validated measure
0 2 4 6 8 10 12 14
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
95% confidence intervals in random samples
# folds of 1000 tokens
TT
R
a = 1.5a = 2.0
full binomial samplecross−validated measure
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 17

Cross-validated vs. full-text measures
• two Zipf-Mandelbrot populations from group A• fixed fold size of N0 = 1000 tokens (confidence intervals too small for 10k)• length of full text differs (k folds→ k ·N0 tokens)
0 2 4 6 8 10 12 14
050
010
0015
0020
0025
0030
0035
00
95% confidence intervals in random samples
# folds of 1000 tokens
Hon
oré
H
a = 1.5a = 2.0
full binomial samplecross−validated measure
0 2 4 6 8 10 12 14
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
95% confidence intervals in random samples
# folds of 1000 tokens
TT
R
a = 1.5a = 2.0
full binomial samplecross−validated measure
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 17

Results (2)
• confidence intervals show that most fluctuations among earlier novels can beexplained by sampling variation
• Jackon’s Dilemma shows significantly lower complexity according to HonoréH, but confidence intervals for noun-verb ratio overlap
19541956
19581962
19631966
19691971
19741976
19781980
19831985
19871989
19931995
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
Noun/V
erb
Rela
tion
19541956
19581962
19631966
19691971
19741976
19781980
19831985
19871989
19931995
2100
2200
2300
2400
2500
2600
2700
2800
2900
Honore
H
noun-verb ratio Honoré H
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 18

Results (3)
Hypothesis test for equal complexity• sample 1: Jackson’s Dilemma (k1 = 6 folds)• sample 2: first 17 novels (k2 = 151 folds in total)
• penultimate novel (The Green Knight) excluded because of unclear status
• Honoré H: t =−6.100, df=5.52, p = .0012**• 95% confidence interval: decline in complexity by at least 155 points (6.1%)• ANOVA finds marginally significant fluctuations in sample 2 (p = .0231)
• noun-verb ratio: t =−2.414, df=5.33, p = .0574 n.s.• fluctuations in sample 1 consistent with sampling variation
Mixed results for other measures• syntactic measures not significant, in accordance with Le et al. (2011)• proportion of words acquired beyond the age of 9 shows a significant decline• perplexity declines towards the end, but not significant
Evidence for significant decline in The Green Knight (e.g. Honoré H: p = .0053)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 19

Results (3)
Hypothesis test for equal complexity• sample 1: Jackson’s Dilemma (k1 = 6 folds)• sample 2: first 17 novels (k2 = 151 folds in total)
• penultimate novel (The Green Knight) excluded because of unclear status• Honoré H: t =−6.100, df=5.52, p = .0012**
• 95% confidence interval: decline in complexity by at least 155 points (6.1%)• ANOVA finds marginally significant fluctuations in sample 2 (p = .0231)
• noun-verb ratio: t =−2.414, df=5.33, p = .0574 n.s.• fluctuations in sample 1 consistent with sampling variation
Mixed results for other measures• syntactic measures not significant, in accordance with Le et al. (2011)• proportion of words acquired beyond the age of 9 shows a significant decline• perplexity declines towards the end, but not significant
Evidence for significant decline in The Green Knight (e.g. Honoré H: p = .0053)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 19

Results (3)
Hypothesis test for equal complexity• sample 1: Jackson’s Dilemma (k1 = 6 folds)• sample 2: first 17 novels (k2 = 151 folds in total)
• penultimate novel (The Green Knight) excluded because of unclear status• Honoré H: t =−6.100, df=5.52, p = .0012**
• 95% confidence interval: decline in complexity by at least 155 points (6.1%)• ANOVA finds marginally significant fluctuations in sample 2 (p = .0231)
• noun-verb ratio: t =−2.414, df=5.33, p = .0574 n.s.• fluctuations in sample 1 consistent with sampling variation
Mixed results for other measures• syntactic measures not significant, in accordance with Le et al. (2011)• proportion of words acquired beyond the age of 9 shows a significant decline• perplexity declines towards the end, but not significant
Evidence for significant decline in The Green Knight (e.g. Honoré H: p = .0053)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 19

Results (3)
Hypothesis test for equal complexity• sample 1: Jackson’s Dilemma (k1 = 6 folds)• sample 2: first 17 novels (k2 = 151 folds in total)
• penultimate novel (The Green Knight) excluded because of unclear status• Honoré H: t =−6.100, df=5.52, p = .0012**
• 95% confidence interval: decline in complexity by at least 155 points (6.1%)• ANOVA finds marginally significant fluctuations in sample 2 (p = .0231)
• noun-verb ratio: t =−2.414, df=5.33, p = .0574 n.s.• fluctuations in sample 1 consistent with sampling variation
Mixed results for other measures• syntactic measures not significant, in accordance with Le et al. (2011)• proportion of words acquired beyond the age of 9 shows a significant decline• perplexity declines towards the end, but not significant
Evidence for significant decline in The Green Knight (e.g. Honoré H: p = .0053)
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 19

Results (3)
Hypothesis test for equal complexity• sample 1: Jackson’s Dilemma (k1 = 6 folds)• sample 2: first 17 novels (k2 = 151 folds in total)
• penultimate novel (The Green Knight) excluded because of unclear status• Honoré H: t =−6.100, df=5.52, p = .0012**
• 95% confidence interval: decline in complexity by at least 155 points (6.1%)• ANOVA finds marginally significant fluctuations in sample 2 (p = .0231)
• noun-verb ratio: t =−2.414, df=5.33, p = .0574 n.s.• fluctuations in sample 1 consistent with sampling variation
Mixed results for other measures• syntactic measures not significant, in accordance with Le et al. (2011)• proportion of words acquired beyond the age of 9 shows a significant decline• perplexity declines towards the end, but not significant
Evidence for significant decline in The Green Knight (e.g. Honoré H: p = .0053)Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 19

Conclusion
• measures of lexical and syntactic complexity important for many applications,but often lack of significance testing (or inappropriate tests)
• our claim: can estimate sampling variation by bootstrapping/cross-validation• confidence intervals and significance tests based on normal approximation• our data show now evidence against normality
• assumption: texts are random samples of folds (from a single population)• accounts for most of the variability between earlier novels
• Honoré H shows significant decline, even in the penultimate novel
Thank you!
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 20

References

Baayen, R. Harald (2001). Word Frequency Distributions. Dordrecht: KluwerAcademic Publishers.
Bentz, Christian et al. (2014). “Zipf’s law and the grammar of languages: Aquantitative study of Old and Modern English parallel texts”. In: CorpusLinguistics and Linguistic Theory 10.2, pp. 175–211.
Bergsma, Shane, Matt Post, and David Yarowsky (2012). “Stylometric Analysis ofScientific Articles”. In: Proceedings of the 2012 Conference of the NorthAmerican Chapter of the Association for Computational Linguistics: HumanLanguage Technologies (NAACL-HLT 2012). Montréal, Canada, pp. 327–337.
Diwersy, Sascha, Stefan Evert, and Stella Neumann (2014). “A weakly supervisedmultivariate approach to the study of language variation”. In: AggregatingDialectology, Typology, and Register Analysis. Linguistic Variation in Text andSpeech. Ed. by Benedikt Szmrecsanyi and Bernhard Wälchli. Linguae etLitterae: Publications of the School of Language and Literature, FreiburgInstitute for Advanced Studies. Berlin, Boston: De Gruyter, pp. 174–204.
Efron, Bradley (1979). “Bootstrap Methods: Another Look at the Jackknife”. In: TheAnnals of Statistics 7.1, pp. 1–26.
Garrard, Peter et al. (2005). “The effects of very early Alzheimer’s disease on thecharacteristics of writing by a renowned author”. In: Brain 128.2, pp. 250–260.
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 20

Graesser, Arthur C. et al. (2004). “Coh-Metrix: Analysis of text on cohesion andlanguage”. In: Behavior Research Methods, Instruments, & Computers 36.2,pp. 193–202.
Kuperman, Victor, Hans Stadthagen-Gonzalez, and Marc Brysbaert (2012).“Age-of-acquisition ratings for 30,000 English words”. In: Behavior ResearchMethods 44.4, pp. 978–990.
Le, Xuan et al. (2011). “Longitudinal detection of dementia through lexical andsyntactic changes in writing: a case study of three British novelists”. In: Literaryand Linguistic Computing 26.4, pp. 435–461.
Manning, Christopher D. et al. (2014). “The Stanford CoreNLP Natural LanguageProcessing Toolkit”. In: Association for Computational Linguistics (ACL) SystemDemonstrations, pp. 55–60.
Pakhomov, Serguei et al. (2011). “Computerized assessment of syntacticcomplexity in Alzheimer’s disease: a case study of Iris Murdoch’s writing”. In:Behavior Research Methods 43.1, pp. 136–144.
Stamatatos, Efstathios (2009). “A Survey of Modern Authorship AttributionMethods”. In: Journal of the American Society For Information Science andTechnology 60.3, pp. 538–556.
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 20

Volansky, Vered, Noam Ordan, and Shuly Wintner (2015). “On the features oftranslationese”. In: Literary and Linguistic Computing 30.1, pp. 98–118.
Wankerl, Sebastian, Elmar Nöth, and Stefan Evert (2016). “An Analysis ofPerplexity to Reveal the Effects of Alzheimer’s Disease on Language”. In:ITG-Fachbericht 267: Speech Communication. Paderborn, Germany,pp. 254–259.
Yngve, Victor H. (1960). “A Model and an Hypothesis for Language Structure”. In:Proceedings of the American Philosophical Society 104.5, pp. 444–466.
Evert / Wankerl / Nöth (CL 2017) | FAU | Reliable measures of syntactic and lexical complexity: The case of Iris Murdoch 25 July 2017 20





























