Embed Size (px)
Citation preview

Predictive models for utility from positive and negative syndrome scale clinical questionnaires for schizophrenia in the United Kingdom, France and Germany – findings of the European schizophrenia cohort (EuroSC) - Carole Siani (Université Lyon 1, Laboratoire ERIC, ISPB) - Christian De Peretti (Université Lyon 1, Laboratoire SAF) - Aurélie Millier (Creativ-Ceutical) - Laurent Boyer (Université Aix-Marseille) - Mondher Toumi (Université Lyon 1, Département d’Odontologie, Chair of Market Access) 2013.10
Laboratoire SAF – 50 Avenue Tony Garnier - 69366 Lyon cedex 07 http://www.isfa.fr/la_recherche

Predictive models for utility from positive andnegative syndrome scale clinical questionnaires forschizophrenia in the United Kingdom, France andGermany – Findings of the European Schizophrenia
Cohort (EuroSC)
Carole Siani a ∗, Christian de Peretti b,Aurelie Millier c, Laurent Boyer d, Mondher Toumi e
February 12, 2013
a Research Laboratory in Knowledge Engineering (ERIC, EA3083), Institute of Phar-maceutical and Biological Sciences (ISPB), University Claude Bernard Lyon 1, Uni-versity of Lyon.Address: batiment d’odontologie, 11 Rue Guillaume Paradin, 69372 Lyon cedex 08,
France.
b Laboratory of Actuarial and Financial Sciences (SAF, EA2429), Institute of Fi-nancial and Insurance Sciences (ISFA School), University Claude Bernard Lyon 1,University of Lyon.Address: 50 avenue Tony Garnier, 69366 Lyon cedex 7, France.
c Creativ-CeuticalAddress: 215, rue du Faubourg St-Honore, 75008 Paris, France.
d Aix-Marseille University, EA 3279, 13005 Marseille, France.
e Chair of Market Access, Department of Odontology, University Claude BernardLyon 1, University of Lyon.Address: 11, rue Guillaume Paradin, 69372 LYON CEDEX 08, France.
Abstract
Objective: The purpose of this article is to provide a mapping function inthe context of schizophrenic patients to predict the unobserved utility values fromclinical information. The clinical symptoms of schizophrenia are associated withserious functioning, social, and quality of life alterations. Among the characteristicsof schizophrenic patients, we focus on determining the variables (i.e., positive and
∗Corresponding author: Carole Siani. Email: [email protected]. Tel: +33 (0)4.78.77.10.23.Fax: +33 (0)4.72.43.10.55.
1

negative syndrome scale - PANSS) and the covariates (i.e., age, sex, country, an-tipsychotic type, depression, Functioning, and extra-pyramidal symptoms), whichare predictors of the utility values.
Study Design: The analysis was performed using data from a 2-year, multi-centre, cohort study conducted in France (N = 288), Germany (N = 618), andthe United-Kingdom (N = 302) (EuroSC), including 1208 patients. Utility wascomputed based on the EQ-5D questionnaire.
Principal Findings: The relationships between the utility values and thepatients socio-demographic and clinical characteristics are modelled using a randomindividual effects panel linear model and a random individual effects panel logitmodel. From a clinical perspective, age, gender, psychopathology, and depressionwere the most important predictors associated with the EQ-5D.
Conclusions: The analysis provides evidence of the utility predictors in schizo-phrenic patients.
Keywords: Schizophrenia, quality of life, positive and negative syndrome scale, map-ping.
JEL codes: I1, C23, C25.
2

1 Introduction
Economic evaluations are designed to compare several alternative therapies in terms ofcosts and outcomes. The evaluations allow decision makers to consider the value of alter-native uses of available resources. Cost-utility analyses are a common type of economicevaluation. The primary outcomes of cost-utility analyses are the incremental cost-utilityratio (ICUR) and the incremental cost per quality-adjusted life years (QALYs). TheICUR is calculated as the ratio of the difference between the expected costs of two alter-native therapies and the difference between the expected QALYs produced by the twotherapies. To estimate the QALYs, the appropriate utility values are required.
Schizophrenia affects approximately 1% of the general population, and onset usuallyoccurs before the age of 25 years. A high heterogeneity in the manifestation of symptomsexists. The positive symptoms appear to reflect an excess or distortion of normal func-tions, including hallucinations, delusions, and racing thoughts. The negative symptomsreflect a decrease in or loss of normal functions, such as apathy, lack of emotion, andpoor or missing social functioning. Finally, the disorganised symptoms include disorgan-ised thoughts, difficulty concentrating and/or following instructions, difficulty completingtasks, and memory problems.
When utility is considered to be a multidimensional concept that measures the dif-ferent aspects of life in a variety of ways, it corresponds to the desire or preference thatindividuals exhibit for a certain health state. Utility can be viewed as an alternativemethod of appraising the quality of life (QOL) of individuals affected by a chronic illness,such as schizophrenia.
Because clinical schizophrenia symptoms are associated with serious functioning, so-cial, and QOL alterations, assessing its utility is a significant challenge. However, incost-utility analyses, utility measurements are rarely available and are generally pre-dicted using a mapping extrapolation from a clinical questionnaire and other covariates(see Beresniak et al. [2007]). Consequently, developing a predictive equation to estimateutility measure based on clinical, functioning and QOL variable would address the unmetneeds for a health economics assessment. QOL has emerged as a key concept in assessingthe impact of an illness on peoples day-to-day lives, and it is one of the key outcomevariables in the treatment of schizophrenia (Matsui et al. [2008]).
Several studies have investigated the independent predictors of QOL in people withschizophrenia. These studies have reported that clinical factors, such as positive andnegative symptoms, depression, and extra-pyramidal symptoms, are associated with lowQOL (FB et al. [1998], TE et al. [1999], RMG et al. [2000], P et al. [2005], SA et al.[2005]; Bozikas et al., 2006; A et al. [2006], H et al. [2008], K et al. [2008]). In 2010,Mavranezouli [2010] reported that 7 cost-utility analyses were performed. Out of theseanalyses, no study used utility values for schizophrenia generated using the EQ-5D, whichis widely used in cost-utility analyses and preferred by the National Institute for Healthand Clinical Excellence NICE [2008].
The objective of this article is to determine the variables and covariates that arepredictors of utility measured by the EQ-5D in schizophrenic patients. The connectionbetween the utility measures and sub-scores of the positive and negative syndrome scale(PANSS) for schizophrenia is investigated. Other covariates are used, including age,sex, country, depression, Global Assessment of Functioning (GAF), Antipsychotic Type(APT) and extra-pyramidal symptoms. Two predictive models are developed for moreflexibility according to the clinical variables available to the practitioners. The predictive
3

equations for the utility score will be presented according to the various covariates. Apredictive model for the utility sub-scores is also proposed. To ensure the strength of theanalyses, the results are compared to those using SF-6D rather than the EQ-5D.
2 Data and methods
2.1 Design and sample
The EUROSC (European Schizophrenia Cohort) cohort is a European cohort conductedin France, Germany and the United Kingdom with a prospective follow-up from 1998 to2001. A total of 1208 participants were interviewed at 6-month intervals for a total of 2years in France (N=288), Germany (N=618), and the United Kingdom (N=302). Thisstudy was sponsored by Lundbeck.
The first objective of the study was to identify and describe the types of treatmentand methods of care for patients with schizophrenia and to correlate these treatmentswith clinical outcomes, states of health, and QOL. In each country, catchment areas werechosen based on socio-demographic factors and on the styles of service delivery. 9 Euro-pean centres were considered: 2 in Britain, 4 in Germany and 3 in France. The specificlocations were chosen because they are socio-demographically distinct and exhibit differ-ent styles of service delivery. The participants were selected to provide a representativesample of the patients treated in secondary psychiatric services in each catchment area.Random sampling from these patients was used to generate a representative sample. Thisproject was conducted in accordance with the Declaration of Helsinki and French GoodClinical Practices (et Senat [2004], of Helsinki [2008]). A description of the rationalesand methods of the study is presented by Bebbington et al. [2005].
2.2 Data collection and instruments
The collected data included socio-demographic characteristics (i.e., age and sex), utilitymeasures, and clinical and medication information.
2.2.1 EuroQol EQ-5D
The utility measure is computed from the multi-attribute EuroQol EQ-5D questionnaire,using the British scoring formula (see Brazier et al. [1993]). The EQ-5D measure consistsof five dimensions with three categories of severity: mobility, self-care, usual activities,pain/discomfort, and anxiety/depression.
2.2.2 Positive and negative syndrome scale (PANSS)
PANSS is a comprehensive tool that includes 30 items and requires a long interviewwith each patient (30–40 minutes) (see Kay et al. [1989]). The items are assessed basedon the patient perceptions related to their experiences in the previous week. The in-terview includes the following items: a positive sub-score (PANSS POS) based on delu-sions, conceptual disorganisation, hallucinations, hyperactivity, grandiosity, suspicious-ness/persecution and hostility; a negative sub-score (PANSS NEG) based on blunted af-fect, emotional withdrawal, poor rapport, passive/apathetic social withdrawal, difficultyin abstract thinking, lack of spontaneity, flow of conversation and stereotyped think-ing; and a general psychopathology sub-score (PANSS PSY) based on somatic concern,
4

anxiety, feelings of guilt, tension, mannerisms, posturing, depression, motor retarda-tion, uncooperativeness, unusual thoughts, content, disorientation, poor attention, lackof judgment and insight, disturbance of volition, poor impulse control, preoccupation,and active social avoidance. The PANSS POS and PANSS NEG contain 7 items rangingfrom 1 (no problem) to 7 (problem). The PANSS POS and PANSS NEG scores rangefrom 7 (no problem) to 49 (problem). The PANSS PSY contains 16 items ranging from1 (no problem) to 7 (problem). The PANSS PSY score ranges from 16 (no problem) to112 (problem).
2.2.3 Socio-demographic variables
Other covariates are also available, including the following: country of origin (COUN-TRY) including the UK, France and Germany, the age of the patient at the date of thevisit (AGE), gender (SEX), antipsychotic type (ATYP) including typical, atypical ormixed (containing at least one typical antipsychotic and one atypical antipsychotic), de-pression measured by the Calgary Depression Scale for Schizophrenia (CDSS) 1, GlobalAssessment of Functioning (GAF) 2, extra-pyramidal symptoms measured by BarnesAkathisia Scale (BAS) 3.
2.2.4 SF-6D
For comparison purposes, the SF-6D is also evaluated to verify the strength of the EQ-5D. 4 The SF-36 is the most widely used measure of general health in clinical studies.The SF-36 generates eight dimension scores and two summary scores for physical andmental health. The scores provide an acceptable method for judging the effectiveness ofhealth care interventions; however, they have limited application in economic evaluationbecause they are not based on preferences.
The SF-6D provides a method for using the SF-36 in economic evaluations by estimat-ing a preference-based single index measure for health from data using general populationvalues. The SF-6D is composed of six multi-level dimensions. Any patient who completesthe SF-36 or the SF-12 can be uniquely classified according to the SF-6D. The SF-6Ddescribes a total of 18 000 health states.
2.3 Predictive models
Two predictive models are developed for more flexibility according to the available clinicalvariables for practitioners. Both the developed predictive models can be summarized byEquation 1 and Equation 2. In addition, a predictive model for the utility sub-scores isproposed in Equation 3.
19 items, from 0 (no problem) to 3 (very serious). Total score from 0 (no depression) to 27 (seriousdepression).
2VAS from 0 (bad) to 100 (good).34 questions.4The algorithm for deriving the SF-6D utility from the SF36 sub-scores is provided on the following
web page: http://www.openhealthmeasures.org/repository/index.html.
5

2.3.1 Predictive model 1: Using only the PANSS scores
EQ− 5Dit = α + β1 ∗ PANSS POSit + β2 ∗ PANSS NEGit + β3 ∗ PANSS PSYit
+ β4,1 ∗ AGEit + β4,2 ∗ AGE2it + β5 ∗ SEXi + β6 ∗ FRi + β7 ∗GEi
+ ui + eit, (1)
where FRi and GEi are dummy variables for France and Germany.
2.3.2 Predictive model 2: Using additional covariates
EQ− 5Dit = α + β1 ∗ PANSS POSit + β2 ∗ PANSS NEGit + β3 ∗ PANSS PSYit
+ β4,1 ∗ AGEit + β4,2 ∗ AGE2it + beta5 ∗ SEXi + β6 ∗ FRi + β7 ∗GEi
+ β8 ∗ AP1it + β9 ∗ AP2it + β10 ∗ CDSSit + β11 ∗GAFit + β12 ∗BASit
+ ui + eit, (2)
where AP1 =1 if AP is “Mixed”, 0 otherwise; AP2 =1 if AP is “Only Atypical”, 0 other-wise; the complement is when AP is “Only Typical”.
2.3.3 Predictive model 3: Predicting sub-scores using only the PANSS scores
Prob(EQ− 5D(d)it = j) =exp(xit,jβj)∑3k=1 exp(xit,kβk)
, for j = 1, 2, 3, (3)
where EQ − 5D(d) is the domain number d = 1, . . . , 5 of the EQ-5D, j is the domainlevel, and xit,j is the set of variables PANSS POSit, PANSS NEGit, PANSS PSYit,AGEit, AGE
2it, SEXi, FRi, GEi or a subset of these variables depending on j. This
model is equivalent to a universal multinomial logit model.
2.3.4 Predictive models for the SF-6D
For comparison, to verify the strength of the EQ-5D analyses, the EQ-5D utility measureis replaced by the SF-6D utility measure in Equation 1 and in Equation 2.
2.4 Statistical analyses
2.4.1 Modelling
To estimate predictive Models 1 and 2, a panel model with random individual effects isused:
Uit = α +Xit ∗ β + ui + eit, (4)
ui ∼ i.i.d.N(0, σ2u), (5)
eit ∼ i.i.d.N(0, σ2e), (6)
where i = 1, . . . , N is the individual dimension and t = 1, . . . , 5 is the time dimension.The indice i corresponds to the patients and t represents the visit number (1 to 5). Uit
is the utility measure, Xit is a row vector of explanatory variables, eit is an error termspecific to individual i at visit t, and ui is an error term specific to individual i. Here,corr(ui, X) = 0.
6

To verify the strength of the estimates, the model is also estimated with the errorterms following an autoregressive process of order 1 (AR(1)).
To estimate predictive Model 3, the principle of the universal multinomial logit model(McFadden, 1975) is extended to the panel framework by combining two classical panellogit models (Bertschek and Lechner [1998]). A panel logit model with random individualeffects is first applied for estimating the probability that EQ − 5D(d)it = 1 against theprobability that EQ − 5D(d)it = 2 or 3 (which is a classical panel dichotomous model).When EQ − 5D(d)it 6= 1, another panel logit model with random individual effects isapplied to estimate the probability thatEQ − 5D(d)it = 2 against the probability thatEQ−5D(d)it = 3. The combination of the two dichotomous models leads to a polytomousmodel with flexible explanatory variables (as in the conditional logit model, see Chapter3 in Maddala [1983]) and parameters depending on EQ-5D(d) level j (as in the universalmultinomial logit model).
2.4.2 Variable selection
Because the correlation between some variables is large (see subsection 3.1), estimationbiases may appear because of variables too close to collinearity. Consequently, the relevantvariables cannot be selected with respect to their statistical significance and an alternativemethod must be used for the variable selection. For this purpose, in the cases of linearModels 1 and 2, the following procedure is proposed. The first variable is selected withrespect to its largest contribution to the variance (or equivalently to the R2) of the utilitymeasure. The effect of this first variable is removed from the utility measure (the vector ofthe utility measure observations is projected on the sub-space generated by the constantterm and the first variable). The second variable is then selected with respect to itscontribution to the R2 of the utility measure removed from the effect of the first variable.We continue this procedure by removing the effect of the variables and selecting the nextvariable with respect to the largest contribution to the R2 until the contribution becomesnegligible. This is similar to the Principal Components Analysis (PCA), but no variablecombination is used to keep the interpretation of the model.
In the case of nonlinear Model 3, the same problem that occurred for the linear regres-sion arises: a correlation that is too large between the PANSS NEG and the PANSS PSYvariables leads to unrealistic results. Nevertheless, the previous procedure of variable se-lection cannot be applied to nonlinear models such as logit models. We then propose thefollowing similar procedure. The variables are selected with respect to their contributionto the pseudo R2 of McFadden (rather than the classical R2 which is not defined fornonlinear models):
R2McFadden = 1− ln L
ln Lc
, (7)
where L is the unconstrained maximum likelihood and Lc is the constrained maximumlikelihood. In the case of a linear model, for assessing the remaining effect of the nextvariable Xitl, the effect of the previous variable Xitk is removed from the explanatoryvariable Uit: Uit− βkXitk, which is equivalent to estimate Uit = βkXitk +βlXitl +εit underthe constraint that βk = βk. Consequently, for assessing the remaining effect of the nextvariable Xitl in the case of a nonlinear model, the logit model is estimated under theconstraint that βk = βk.
7

2.4.3 Measuring the predictive ability of regression models
The classical goodness-to-fit measure for regression models is the R2 statistic, whichmeasures the explanatory power of the variables of the model in terms of the proportionof the explained variance Gujarati [2004]. However, in mapping studies, the primaryconcern is the ability to predict the dependent variable from the model rather thanthe explanatory power of the regression models Consequently, we use two measures ofpredictive error (Greene [2002]):
1. The average of the absolute difference between the observed and the predicted value,named the Mean Absolute Error (MAE).
2. The square root of the average of the difference between the observed and predictedvalue squared, named the Root Mean Squared Error (RMSE).
2.4.4 Cross validation
The data are partitioned into complementary subsets, the training set and the validationset (or testing set). The models are estimated on the training set and the prediction erroris computed on the validation set. To measure the prediction error, the MAE and theRMSE can also be used.
The sample is split randomly, and each observation has a probability p to be selectedto be in the training set, where p is chosen arbitrarily. Here, we chose p = 10, 0.25, andp =0.5. However, the prediction error will depend on the random partition. Consequently,to reduce variability, multiple rounds of cross-validation are performed using differentpartitions, and the validation results are averaged among the rounds.
3 Results
The three countries are pooled. STATA R© software is used to estimate the models.
3.1 Descriptive statistics
The descriptive statistics are presented in Table 1, and the correlation structure of theexplanatory variables is examined in Table 2.
A strong correlation is observed between the PANSS POS and PANSS PSY scores(0.71), the PANSS NEG and PANSS PSY scores (0.69), and also the PANSS NEG andGAF scores (-0.5). The Hausman test shows that these correlations lead to a collinearityproblem for the estimates, which justifies our variable selection procedure.
3.2 Missing values and selection bias
To assess the selection bias, two subsamples are considered, the subsample with no missingdata and the subsample with missing values in at least one of the following variables: EQ-5D, PANSS POS, PANSS NEG, PANSS PSY, age, sex, ATYP, CDSS, GAF, or BAS. Nomissing data for the COUNTRY variable exist. The sample mean for all the variables iscompared between both subsamples to determine whether there is a statistical differencebetween the subsamples, and the consequent selection bias when a missing value occurs.The results are presented in Table 3 and show that both subsamples are very close interms of the structures. Thus, it can be concluded that there is no selection bias.
8

3.3 Predictive model 1: Using only the PANSS scores
3.3.1 Variable selection
The results are presented in Table 4.When the EQ-5D is used as a dependent variable in Equation 1, the first relevant
variable is PANSS PSY with a contribution to R2 of 8.75%. When the PANSS PSYeffect is removed from the EQ-5D, none of the variables demonstrate a large contributionto R2 (less or equal to 1%). In the final model, the SEX and AGE variables are retained,because they are normally available in all the studies. The PANSS NEG has a negligiblecontribution to R2 (0.68%) and is too highly correlated with the PANSS PSY (69%), itis therefore not used in the analyses.
3.3.2 Model estimation
The estimates are presented in Table 5. The PANSS PSY and AGE variables havenegative effects on the EQ-5D, whereas the male gender has a positive effect.
3.3.3 Specification tests
The model for the EQ-5D is also estimated with error terms following an AR(1) process.Small autocorrelation is observed (the estimated autocorrelation coefficient is 0.1786),but the estimated coefficients of the model with AR(1) error terms do not change withrespect to the original model without AR(1) error terms. The Hausman test is appliedand does not reveal any correlation between ui and X (the P value is 0.1866). Conse-quently, the GLS estimator of the panel model is consistent. The normality hypothesis isrejected (the P values for skewness=0, for kurtosis=3, and for the Jarque-Bera test are0.0000). However, the skewness and the kurtosis are not large (respectively -1.1125 and5.8921) and the probability density function is roughly unimodal, as can be seen fromthe kernel density estimate of the residuals in Figure 1(a). (Kernel density estimationis a non-parametric method for estimating the probability density function of a randomvariable.) Finally, the test of Ramsey-reset for linearity of the model is applied and thenull hypothesis of linearity is rejected (the P value is 0.0130).
3.4 Predictive model 2: using additional covariates
3.4.1 Variable selection
The results are presented in Table 6. When the EQ-5D is used as dependent variablein Equation 1, three variables are relevant: the CDSS (contribution to R2=16.27%),PANSS PSY (3.10%) and AGE (1.30%). In the final model, we also include the SEX(0.45%) variable.
3.4.2 Model estimation
The estimates using the EQ-5D as an explanatory variable are presented in Table 7. TheHausman test P value is 0.0000. Consequently, there is a correlation between ui and X,and the GLS estimator of the panel model is inconsistent. We then compare the fixedindividual effect model estimates with the random individual effect model estimates (seeTable 8). The problem arises from the CDSS variable, which may be correlated with the
9

random individual effect ui (the fixed effect estimate minus the random effect estimate =0.00679, with standard error of 0.0007483). The fixed effect model is consistent under thishypothesis, and lead to a coefficient estimate for the CDSS of -0.0124, with a confidenceinterval of [-0.0151;-0.0097].
3.4.3 Specification tests
The model for the EQ-5D is also estimated with error terms following an AR(1) process.Small autocorrelation is observed (the estimated autocorrelation coefficient is 0.1706),but the estimated coefficients of the model do not change. The normality hypothesis isstill rejected (the P values for skewness=0, for kurtosis=3 and for the Jarque-Bera testare 0.0000). However, the skewness and kurtosis are not highly substantial (-1.1350 and5.8888 respectively) and the probability density function is roughly unimodal (see thekernel density estimate of the residuals in Figure 1(c)). Finally, the Ramsey-reset test forlinearity is applied and the null hypothesis of linearity is retained (the P value is 0.1645).
3.5 Predictive model 3: sub-scores
The coefficient estimates are summarised in Table 9. The complete results are availableby request to the corresponding author.
For the EQ5D1 domain (mobility), the PANSS PSY and AGE negatively affect theprobability of State 1 to occur (the best one), whereas male gender affects it positively. Noconclusion can be reached regarding the variables that affect the probability of States 2and 3 to occur because there are only three observations in State 3, which is not enoughto estimate the parameters. For the EQ5D2 domain (self-care), the PANSS PSY andAGE negatively affects the probability that State 1 occurs. However, the PANSS NEGdetermines if the health state is 3 (the worst state). There is some specificity with respectto the countries. The results are similar for the EQ5D3 domain (usual activities). Forthe EQ5D4 domain (pain/discomfort) and the EQ5D5 domain (anxiety/depression), thePANSS PSY has a negative effect on all the health states. A larger PANSS PSY iscorrelated with a worse health state (close to 3). For the EQ5D4 domain, the AGE hasalso a negative effect.
3.6 Predictive models for the SF-6D
3.6.1 Variable selection
The same methodology used for the EQ-5D is used for the SF-6D. Detailed results areavailable by request to the corresponding author.
3.6.2 Model 1 estimation
The estimates when the SF-6D is used as a dependent variable in Equation 1 are presentedin Table 10. The results are similar with those for the EQ-5D. The PANSS PSY negativelyaffects the utility measure, whereas male gender affects it positively.
3.6.3 Specification tests
The same specification tests as for the EQ-5D are applied when SF-6D is used as depen-dent variable. Small autocorrelation is observed (the estimated autocorrelation coefficient
10

is 0.1685), however, the estimated coefficients of the model do not change. No correlationbetween ui and X is found (the Hausman P value is 0.1068). To reiterate, the normalityhypothesis is rejected (the P value for skewness=0 is 0.004, the P value for kurtosis=3 is0.0000, and the P value for the Jarque-Bera test is 0.0000). However, the skewness andthe kurtosis are close to 0 and 3 respectively (-0.1079 and 3.3619 respectively). In addi-tion, the probability density function is unimodal and close to the Gaussian probabilitydensity function (see the kernel density estimate of the residuals in Figure 1(b)). Thenull hypothesis of linearity is rejected (Ramsey-reset P value=0.0000).
3.6.4 Model 2 estimation
The estimates when SF-6D is used as dependent variable in Equation 2 are presented inTable 11. A better estimate for CDSS is provided by the fixed effect model: -0.0067173with a confidence interval of [-0.0080064,-0.0054282].
3.6.5 Specification tests
Small autocorrelation is observed again (the estimated autocorrelation coefficient is 0.1743),but the estimated coefficients of the model do not change. The normality hypothesis isstill rejected (the P value for skewness=0 is 0.004, the P values for kurtosis=3 and forthe Jarque-Bera test are 0.0000). However, the skewness and the kurtosis are close to 0and 3, respectively (-0.1588 and 3.3702 respectively). In addition, the probability densityfunction is unimodal and resembles the Gaussian probability density function (see thekernel density estimate of the residuals in Figure 1(d)). The null hypothesis of linearityis rejected (the Ramsey-reset P value is 0.0000).
3.7 Measuring predictive ability and cross validation
The predictive errors for the various models are presented in Table 12. The results forthe cross validation are reported in the same table for facilitating comparison. Variousproportions p of the observations used to construct the training set are chosen to verifythe strength of the models, where: p = 0.5, 0.25, and 0.1. For distinguishing predictiveerrors of the models and predictive errors in the context of cross validation, the crossvalidation is indicated using star(s) in the table.
The results of the cross-validation demonstrate that estimating the models on a train-ing set and using them to predict utility on a validation set does not increase the RMSEand the MAE . It can be concluded that the models are reliable, and can be used topredict the utility measure for other datasets.
11

(a) EQ-5D on only the PANSSscores
(b) SF-6D on only the PANSSscores
(c) EQ-5D on additional vari-ables
(d) SF-6D on additional variables
Figure 1: Residuals of the regressions
12

4 Discussion
This study aimed to build a model to map the demographic and clinical measures ofschizophrenic patients to the EQ-5D index and sub-scores. Although the EQ-5D is cur-rently recommended by NICE [2008] for use in economic evaluation, it remains largelyunderutilised in clinical trials for schizophrenia. As suggested by the NICE [2008], map-ping can be used when the EQ-5D is not included in the trial. The proposed mappingfunctions can constitute the first step in promoting the assessment of the utility valuesrequired in cost-utility analyses in schizophrenia. Our findings suggest that the mappingrelationship between the socio-demographic and clinical characteristics and the EQ-5Dis reliable and robust.
From a clinical perspective, age, gender, PANSS psychopathology score, and CDSSscore are the most important predictors associated with the EQ-5D. These findings areconsistent with those of studies focusing on non-preference-based health status measures.Age negatively affects the utility measure. According to Kemmler et al. [1997], socialproblems, isolation and stigmatisation of schizophrenic patients tend to increase withage. Male gender positively affects the utility measure in our study. This finding appearsto be consistent with the general literature, in which the quality of life of women isoften reported to be lower than that of men, especially with regard to psychological andmental health domains (Reine et al. [2005], Hofer et al. [2005]). Regarding the influenceof the PANSS scores, we find that the PANSS psychopathology factor negatively affectsthe utility measure (the P value is < 0.001) whereas the PANSS Positive and negativefactors do not affect the utility measure. Similarly to the PANSS psychopathology factor,the CDSS score negatively affects the utility measure (the P value is < 0.001). Thesefindings concur with those of several studies and meta-analyses that reveal that symptomshave only a modest relationship with quality of life, and that general psychopathologysymptoms (e.g. anxiety and depression) were the most important predictors (Heslegraveet al. [1997], Bechdolf et al. [2003], Eack and Newhill [2007]). Finally, extra-pyramidalsymptoms (BAS) are associated with lower utility measures. This result appears to belogical because the burden of the side-effects has been extensively explored as a predictorof poor medication adherence, relapse, and poor QoL (Fenton et al. [1997], Aksaray et al.[2002], Hofer et al. [2005]).
From a methodological aspect, there was a serious problem of collinearity among theexplanatory variables, which was solved by using a variable selection procedure based onthe principle of PCA and led to reasonable results. There is also a problem of correlationbetween some explanatory variables and the errors terms of the regression, which led toinconsistent parameter estimates. These parameters were re-estimated using the fixedeffects panel model, which provides consistent estimates. Additionally, many other spec-ification tests were performed that provided evidence that the mappings we provide arewell specified and reliable. Finally, the strength of our model was also tested with SF-6D,which confirmed the reliability of our model with the EQ-5D. In their paper, McCroneet al. [2009] showed that, from an analytical perspective, the SF-6D has advantages overthe EQ-5D due to its normal distribution and the lack of a ceiling effect. However, bothmeasures produced similar mean utility scores and further comparisons of the EQ-5Dand SF-6D were required. Moreover, from a statistical aspect, Model 1 only explainsapproximately 10% of the R2 of the regression, but Model 2 explains approximately 20%of the R2 which is a usual proportion in the literature. Additionally, the prediction errorsare small. For the EQ-5D the RMSE is around 0.25 and the MAE is approximately 0.18
13

(whereas the EQ-5D goes from -0.42 up to 1) and for the SF-6D the RMSE is approxi-mately 0.12 and the MAE is approximately 0.10 (whereas the SF-6D goes from 0.30 up to1). The cross validation confirms the stability of the models. Consequently, the modelsare usable to predict utility measures.
Regarding the analysis limitations, the representativeness of our sample should firstbe discussed. Although the sampling procedure for the EuroSC aimed to provide arepresentative sample of the patients treated, this cohort of patients demonstrated mostlyparanoid schizophrenia and is characterized by long-term illness. Moreover, excludedpatients presented with a higher clinical severity than included patients. Replication istherefore required, using larger and more diverse groups of patients. However, this studyexamined 1,208 patients with schizophrenia, controlled for important socio-demographic,clinical, and medication factors, and attempted to overcome the limitations of past studiesby using a larger sample size and longer a follow-up Lenert et al. [2005]. The questionof whether a selection bias exists in regard to remaining sample after cancelling missingdata can arise. We have shown in subsection 3.2 that the data do not differ between thesubsample with no missing data, and the subsample with missing data, with respect togender, age, and all the other variables including the PANSS scores and the EQ-5D.
5 Conclusion
Because treatments for schizophrenia have significant effects on the quality of life ofpatients, economic evaluations require reliable methods to account for effects of treatmentand to assess the utility values that are required in cost-utility analyses to calculate theQALY. This paper proposes reliable and accurate mapping models for the EQ-5D indexand sub-scores using demographic and clinical measures in schizophrenia. These modelsare easy to apply to clinical trials. An advantage of these mapping functions is that theyuse data generally available in clinical trials of schizophrenia, such as the PANSS, whichexpands the applicability.
References
Hofer A, Rettenbacher MA, Widschwendter CG, Kemmler G, Hummer M, and Fleis-chhacker WW. Correlates of subjective and functional outcomes in outpatient clinicattendees with schizophrenia and schizoaffective disorder. Eur Arch Psychiatry ClinNeurosci, 256:246–55, 2006. 1
G. Aksaray, S. Oflu, C. Kaptanoglu, and C. Bal. Neurocognitive deficits and quality oflife in outpatientswith schizophrenia. Prog Neuropsychopharmacol Biol Psychiatry, 26:1217–9, 2002. 4
P.E. Bebbington, M. Angermeyer, J.M. Azorin, T. Brugha, R. Kilian, S. Johnson,M. Toumi, and A. Kornfeld. The european schizophrenia cohort (eurosc): a naturalis-tic prognostic and economic study. EuroSC Research Group. Soc Psychiatry PsychiatrEpidemiol, 40(9):707–17, Sep 2005. 2.1
A. Bechdolf, J. Klosterkotter, M. Hambrecht, B. Knost, C. Kuntermann, S. Schiller, andet al. Determinantsof subjective quality of life in post acute patients with schizophrenia.Eur Arch Psychiatry Clin Neurosci, 253:228–235, 2003. 4
14

A. Beresniak, A. S. Russell, B. Haraoui, L. Bessette, C. Bombardier, and G. Duru.Advantages and limitations of utility assessment methods in rheumatoid arthritis. TheJournal of Rheumatology, 34(11):2193–2200, 2007. 1
I. Bertschek and M. Lechner. Convenient estimators for the panel probit model. Journalof Econometrics, 87(2):329–372, 1998. 2.4.1
J. Brazier, N. Jones, and P. Kind. Testing the validity of the euroqol and comparing itwith the sf-36 health survey questionnaire. Quality of Life Research, 2:169–80, 1993.2.2.1
S. M. Eack and C. E. Newhill. Psychiatric symptoms and quality of life in schizophrenia:a meta-analysis. Schizophr Bull, 33:1225–1237, 2007. 4
Assemblee Nationale et Senat. Data files and individual liberties (amended by the act of6 august 2004 relating to the protection of individuals with regard to the processing ofpersonal data). Journal officiel de la Republique Francaise, Act No 78-17 of 6 January1978 on Data Processing, 2004. France. 2.1
Dickerson FB, Ringel NB, and Parente F. Subjective quality of life in out-patients withschizophrenia: clinical and utilization correlates. Acta Psychiatr Scand, 98:124–7, 1998.1
W. S. Fenton, C. R. Blyler, and R. K. Heinssen. Determinants of medication compliancein schizophrenia: empirical and clinical findings. Schizophr Bull, 23:637–51, 1997. 4
W. H. Greene. Econometric Analysis. Upper Saddle River, NJ: Prentice Hall, 4th edition,2002. 2.4.3
D. Gujarati. Basic Econometrics. Boston: McGraw-Hill, 4th edition, 2004. 2.4.3
Aki H, Tomotake M, Kaneda Y, Iga J, Kinouchi S, Shibuya-Tayoshi S, and et al. Sub-jective and objective quality of life, levels of life skills, and their clinical determinantsin outpatients with schizophrenia. Psychiatry Res, 158:19–25, 2008. 1
R. J. Heslegrave, A. G. Awad, and L. N. Voruganti. The influence of neurocognitivedeficits and symptomson quality of life in schizophrenia. J Psychiatry Neurosci, 22:235–243, 1997. 4
A. Hofer, S. Baumgartner, M. Edlinger, M. Hummer, G. Kemmler, M. A. Rettenbacher,and et al. Patient outcomes in schizophrenia i: correlates with sociodemographicvariables, psychopathology, and side effects. Eur Psychiatry, 20:386–394, 2005. 4
Yamauchi K, Aki H, Tomotake M, Iga J, Numata S, Motoki I, and et al. Predictors ofsubjective and objective quality of life in outpatient with schizophrnia. Psychiatry ClinNeurosci, 62:404–11, 2008. 1
S. R. Kay, L. A. Opler, and J. P. Lindenmayer. The positive and negative syndrome scale(panss): rationale and standardisation. Br J Psychiatry, Suppl.(7):59–67, Nov 1989.2.2.2
15

G. Kemmler, B. Holzner, C. Neudorfer, U. Meise, and H. Hinterhuber. General lifesatisfaction and domain-specific quality of life in chronic schizophrenic patients. QualLife Res, 6(3):265–273, 1997. 4
L. A. Lenert, M. F. Rupnow, and C. Elnitsky. Application of a disease-specific mappingfunction to estimate utility gains with effective treatment of schizophrenia. Health QualLife Outcomes, 11:3–57, Sep 2005. 4
G. S. Maddala. Limited-Dependent and Qualitative Variables in Economics. New York:Cambridge University Press, 1983. A book with an explicit publisher. 2.4.1
M. Matsui, T. Sumiyoshi, H. Arai, Y. Higuchi, and M. Kurachi. Cognitive functioningrelated to quality of life in schizophrenia. Prog Neuropsychopharmacol Biol Psychiatry,32:280–7, 2008. 1
I. Mavranezouli. 21. Pharmacoeconomics, 28(12):1109–21, 2010. 1
P. McCrone, A. Patel, M. Knapp, A. Schene, M. Koeter, M. Amaddeo, F. Ruggeri,A. Giessler, B. Puschner, and G. Thornicroft. A comparison of sf-6d and eq-5d utilityscores in a study of patients with schizophrenia. J Ment Health Policy Econ., 12(1):27–31, 2009. 4
NICE. Guide to the methods of technology appraisal. Technical report, National Instituteof Health and Clinical Excellence (NICE), London, 2008. 1, 4
Declaration of Helsinki. Ethical principles for medical research involving human subjects.In General Assembly. World Medical Association, October 2008. Seoul. 2.1
Rocca P, Bellino S, Calvarese P, Marchiaro L, Patria L, Rasetti R, and et al. Depressiveand negative symptoms in schizophrenia: different effects on clinical features. ComprPsychiatry, 46:304–10, 2005. 1
G. Reine, M. C. Simeoni, P. Auquier, A. Loundou, V. Aghababian, and C. Lancon. Assess-ing health-related quality of life in patients suffering from schizophrenia: a comparisonof instruments. Eur Psychiatry, 20(7):510–519–, 2005. 4
Norman RMG, Malla AK, Mclean T, Voruganti LPN, Cortese L, McIntosh E, and et al.The relationship of symptoms and level of functioning in schizophrenia to generalwellbeing and quality of life scale. Acta Psychiatr Scand, 102:303–9, 2000. 1
Strejilevich SA, Palatnik A, Avila R, Bustin J, Cassone J, Figueroa S, and et al. Lack ofextrapyramidal side effects predicts quality of life in outpatients treated with clozapineor with typical antipsychotics. Psychiatry Res, 133:277–80, 2005. 1
Smith TE, Hull JW, Goodman M, Hedayat-Harris A, Willson DF, Israel LM, and et al.The relative inuences of symptoms, insight, and neurocognition on social adjustmentin schizophrenia and schizoaffective disorder. J Nerv Ment Dis, 187:102–8, 1999. 1
16

Table 1: Descriptive statistics
Variable Mean Std. Dev. Min Max
EQ-5D 0.76 0.26 -0.43 1.00PANSS POS 11.71 5.13 7 35PANSS NEG 15.39 7.16 7 43PANSS PSY 27.87 9.65 16 71AGE 41.80 10.88 0.08 66.62SEX (proportion of male) 0.63 0.48 0 1FR (proportion from France) 0.22 0.41 0 1GE (proportion from Germany) 0.51 0.50 0 1AP1 (Proportion of “Mix”) 0.18 0.39 0 1AP2 (Proportion of “Only Atypiq”) 0.29 0.46 0 1Proportion of “Only Typiq” 0.50 0.53 0 1CDSS 2.49 3.41 0 21GAF 52.04 15.66 0 99BAS 1.02 2.12 0 36
17

Table 2: Correlation structure
18
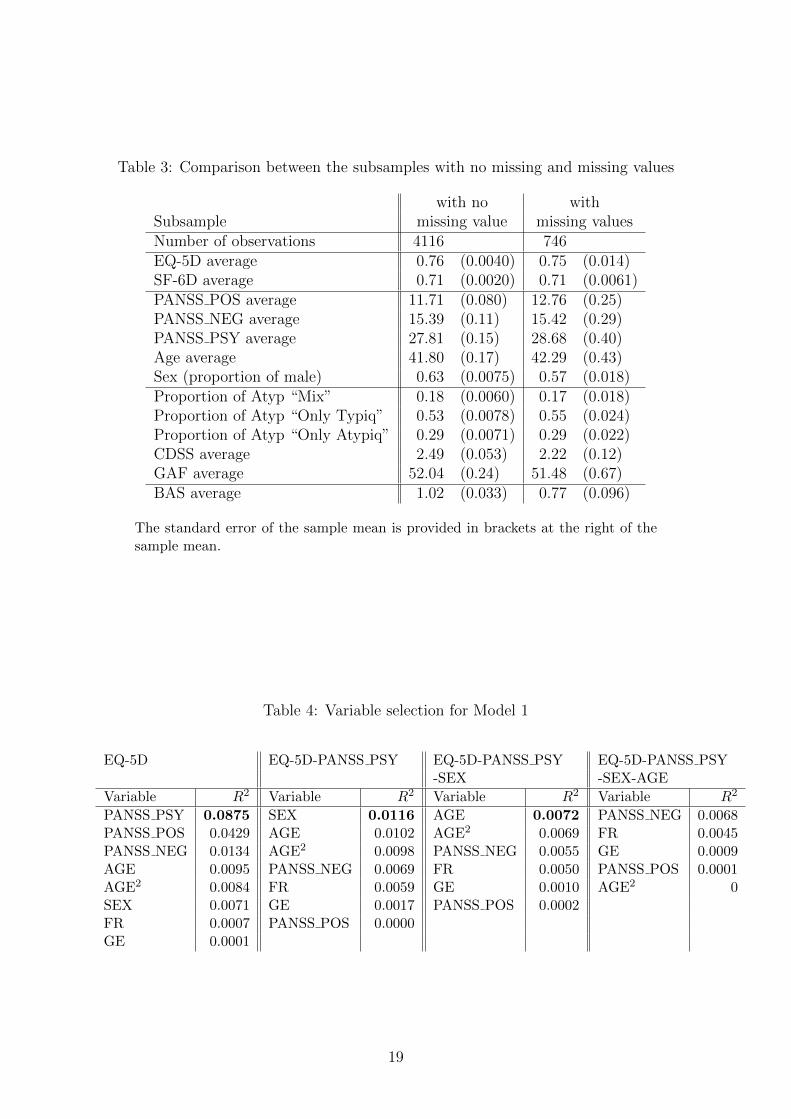
Table 3: Comparison between the subsamples with no missing and missing values
with no withSubsample missing value missing valuesNumber of observations 4116 746EQ-5D average 0.76 (0.0040) 0.75 (0.014)SF-6D average 0.71 (0.0020) 0.71 (0.0061)PANSS POS average 11.71 (0.080) 12.76 (0.25)PANSS NEG average 15.39 (0.11) 15.42 (0.29)PANSS PSY average 27.81 (0.15) 28.68 (0.40)Age average 41.80 (0.17) 42.29 (0.43)Sex (proportion of male) 0.63 (0.0075) 0.57 (0.018)Proportion of Atyp “Mix” 0.18 (0.0060) 0.17 (0.018)Proportion of Atyp “Only Typiq” 0.53 (0.0078) 0.55 (0.024)Proportion of Atyp “Only Atypiq” 0.29 (0.0071) 0.29 (0.022)CDSS average 2.49 (0.053) 2.22 (0.12)GAF average 52.04 (0.24) 51.48 (0.67)BAS average 1.02 (0.033) 0.77 (0.096)
The standard error of the sample mean is provided in brackets at the right of thesample mean.
Table 4: Variable selection for Model 1
EQ-5D EQ-5D-PANSS PSY EQ-5D-PANSS PSY EQ-5D-PANSS PSY-SEX -SEX-AGE
Variable R2 Variable R2 Variable R2 Variable R2
PANSS PSY 0.0875 SEX 0.0116 AGE 0.0072 PANSS NEG 0.0068PANSS POS 0.0429 AGE 0.0102 AGE2 0.0069 FR 0.0045PANSS NEG 0.0134 AGE2 0.0098 PANSS NEG 0.0055 GE 0.0009AGE 0.0095 PANSS NEG 0.0069 FR 0.0050 PANSS POS 0.0001AGE2 0.0084 FR 0.0059 GE 0.0010 AGE2 0SEX 0.0071 GE 0.0017 PANSS POS 0.0002FR 0.0007 PANSS POS 0.0000GE 0.0001
19

Table 5: Predictive model 1: explaining EQ-5D using only the PANSS scores
EQ-5D Coef. Std. Err. z P > |z| [95% Conf. Interval]Constant term 1.026055 0.0277925 36.92 0.000 0.971583 1.080527PANSS PSY -0.0076876 0.0004386 -17.53 0.000 -0.0085473 -0.006828SEX 0.0457537 0.0120427 3.80 0.000 0.0221504 0.0693569AGE -0.0020646 0.0005313 -3.89 0.000 -0.0031059 -0.0010233
Number of observations = 4471, number of groups = 1181.R2: within = 0.0394, between = 0.1500, overall = 0.1035.Wald test for significance (∼ χ2(3)) = 334.57 (P value = 0.0000).σu = .1697, σe = .1842, ρ = .4589 (fraction of variance due to ui).Breusch and Pagan Lagrangian multiplier test for random effects (∼ χ2(1))= 1324.56 (P value = 0.0000).
Table 6: Variable selection for Model 2
EQ-5D EQ-5D-CDSS EQ-5D-CDSS EQ-5D-CDSS-PANSS PSY -PANSS PSY-AGE
Variable R2 Variable R2 Variable R2 Variable R2
CDSS 0.1627 PANSS PSY 0.0310 AGE 0.0130 GAF 0.0056PANSS PSY 0.0875 GAF 0.0276 AGE2 0.0130 PANSS NEG 0.0048GAF 0.0522 PANSS POS 0.0240 GAF 0.0092 SEX 0.0045PANSS POS 0.0429 AGE 0.0134 SEX 0.0079 BAS 0.0035BAS 0.0164 AGE2 0.0128 BAS 0.0040 FR 0.0024PANSS NEG 0.0134 BAS 0.0070 ATYP2 0.0038 ATYP2 0.0012AGE 0.0095 ATYP2 0.0051 PANSS NEG 0.0038 ATYP1 0.0011AGE2 0.0084 SEX 0.0050 FR 0.0031 PANSS POS 0.0010SEX 0.0071 PANSS NEG 0.0031 PANSS POS 0.0012 GE 0.0005ATYP2 0.0053 ATYP1 0.0019 GE 0.0008 AGE2 0.0000ATYP1 0.0050 FR 0.0001 ATYP1 0.0007FR 0.0007 GE 0.0001GE 0.0001
20

Table 7: Predictive model 2: explaining EQ-5D using additional covariates
EQ-5D Coef. Std. Err. z P > |z| [95% Conf. Interval]Constant term 1.011187 0.025353 39.88 0.000 0.9614961 1.060878CDSS -0.0192384 0.0011701 -16.44 0.000 -0.0215317 -0.016945PANSS PSY -0.0047262 0.0004566 -10.35 0.000 -0.005621 -0.0038314AGE -0.0023449 0.0004802 -4.88 0.000 -0.003286 -0.0014038SEX 0.0322763 0.0108972 2.96 0.003 0.0109182 0.0536345
Number of observations = 4470, number of groups = 1181.R2: within = 0.0615, between = 0.2958, overall = 0.1922.Wald test for significance (∼ χ2(3)) = 649.19 (P value = 0.0000).σu = .1458, σe = .1821, ρ = .3906 (fraction of variance due to ui).Breusch and Pagan Lagrangian multiplier test for random effects (∼ χ2(1))= 979.44 (P value = 0.0000).
Table 8: Hausman test: Difference between fixed and random effect model estimates
Model Fixed Random Fixed - Randomeffect effect effects
Variable Coefficient estimates s.e.CDSS -0.0124484 -0.0192384 0.00679 0.0007483PANSS PSY -0.0048544 -0.0047262 -0.0001282 0.0004532AGE 0.0019578 -0.0023449 0.0043027 0.0040731
Fixed effect: consistent under Ho and Ha.Random effect: inconsistent under Ha, efficient under Ho.
21

Table 9: Predictive model 3: explaining sub-scores of the EQ-5D using only the PANSSscores
This table presents the parameter estimates βj of the model described in Equation 3.Column “1” corresponds to the dichotomous logit model explaining P (Domainit =1) against P (Domainit 6= 1), where 1 is the best level of the domain. When thelevel is not 1, Column 2|−1 corresponds to the dichotomous logit model explainingP (Domainit = 2|Domainit 6= 1) against P (Domainit = 3|Domainit 6= 1), where 3 isthe worst level of the domain.
Domain EQ5D1 EQ5D2 EQ5D3 EQ5D4 EQ5D5mobility self-care usual activities pain/discomfort anxiety/depression
Level 2| − 1 1 2| − 1 1 2| − 1 1 2| − 1 1 2| − 1 1
Constant term 5.2828 6.0761 5.9866 4.9867 3.2671 6.9469 3.4402 4.9348 2.3770PANSS POSPANSS NEG -0.1108 -0.0952PANSS PSY -0.0432 -0.0790 -0.0767 -0.0550 -0.0397 -0758 -0.0792AGE -0.0473 -0.0232 0.0096 -0.0397 -0.0409SEX 0.5643FR 1.3462 1.3888GE 1.0144 -0.8791 0.8440
Sample size 836 4524 891 4545 1577 4536 1814 4543 2158 4591
Table 10: Predictive model 1: explaining SF-6D using only the PANSS scores
SF-6D Coef. Std. Err. z P > |z| [95% Conf. Interval]Constant term 0.7958439 .0073481 108.31 0.000 .781442 .8102459PANSS PSY -0.0037952 .0002124 -17.86 0.000 -.0042115 -.0033788SEX .0243601 .0058699 4.15 0.000 .0128554 .0358648
Number of observations = 4338, number of groups = 1169.R2: within = 0.0460, between = 0.1306, overall = 0.1036.Wald test for significance (∼ χ2(3)) = 327.86 (P value = 0.0000).σu = 0.0840, σe = 0.0856, ρ = 0.4904 (fraction of variance due to ui).Breusch and Pagan Lagrangian multiplier test for random effects (∼ χ2(1))= 1653.046 (P value = 0.0000.
22

Table 11: Predictive model 2: explaining SF-6D using additional covariates
SF-6D Coef. Std. Err. z P > |z| [95% Conf. Interval]Constant term 0.8198619 0.0124882 65.65 0.000 .7953856 .8443382CDSS -0.009496 0.0005595 -16.97 0.000 -0.0105926 -0.0083993PANSS PSY -0.0021323 0.0002253 -9.46 0.000 -0.002574 -0.0016907BAS -0.0040303 .000773 -5.21 0.000 -0.0055454 -0.0025152AGE -0.0008743 0.0002373 -3.68 0.000 -0.0013394 -0.0004092SEX 0.0139095 0.0053836 2.58 0.010 0.0033579 0.0244612
Number of observations = 4258, number of groups = 1166.R2: within = 0.0812, between = 0.2908, overall = 0.2166.Wald test for significance (∼ χ2(3)) = 704.73 (P value = 0.0000).σu = .0687, σe = .0874, ρ = .3819 (fraction of variance due to ui).Breusch and Pagan Lagrangian multiplier test for random effects (∼ χ2(1))= 1212.22 (P value = 0.0000.
Table 12: Predictive error results: Predicted versus observed
Dependent Independent Mean Min Max Corr RMSE MAEvariable variables
EQ-5D Observed 0.758 -0.429 1 1 0 0EQ-5D Only PANSS 0.752 0.369 0.907 0.321 0.246 0.182EQ-5D Only PANSS * 0.753 0.362 0.905 0.328 0.250 0.184EQ-5D Only PANSS ** 0.755 0.367 0.924 0.316 0.248 0.182EQ-5D Only PANSS *** 0.735 0.219 0.930 0.317 0.246 0.186EQ-5D Additional 0.753 0.251 0.920 0.438 0.234 0.173EQ-5D Additional * 0.754 0.314 0.917 0.442 0.234 0.173EQ-5D Additional ** 0.753 0.230 0.919 0.439 0.235 0.174EQ-5D Additional *** 0.750 0.114 0.910 0.433 0.234 0.173
SF-6D Observed 0.707 0.301 1 1 0 0SF-6D Only PANSS 0.704 0.514 0.775 0.328 0.119 0.098SF-6D Only PANSS * 0.706 0.552 0.774 0.342 0.119 0.098SF-6D Only PANSS ** 0.702 0.552 0.773 0.342 0.119 0.097SF-6D Only PANSS *** 0.703 0.512 0.765 0.325 0.120 0.098SF-6D Additional 0.704 0.466 0.782 0.465 0.112 0.091SF-6D Additional * 0.708 0.441 0.788 0.454 0.112 0.092SF-6D Additional ** 0.703 0.422 0.785 0.457 0.112 0.091SF-6D Additional *** 0.706 0.399 0.786 0.466 0.112 0.092
Cross validation:* training set: 50% of the original sample (drawn randomly), validation set: 50%.** training set: 25% of the original sample (drawn randomly), validation set: 75%.*** training set: 10% of the original sample (drawn randomly), validation set: 90%.
23