Embed Size (px)
Citation preview

X
Y
La NATURA e la FORZA della relazione tra variabili si studiano con la REGRESSIONE e la CORRELAZIONE
REGRESSIONE lineare e CORRELAZIONE
• FORMA della relazione
• OBIETTIVO: predire o stimareil valore di una variabile in corrispondenza di un dato valoredell’altra variabile
• Misura la FORZA dellarelazione
Con variabili quantitative che si possono esprimere in un ampio ampio intervallo di valori
X
Y
X
Y
X
Y
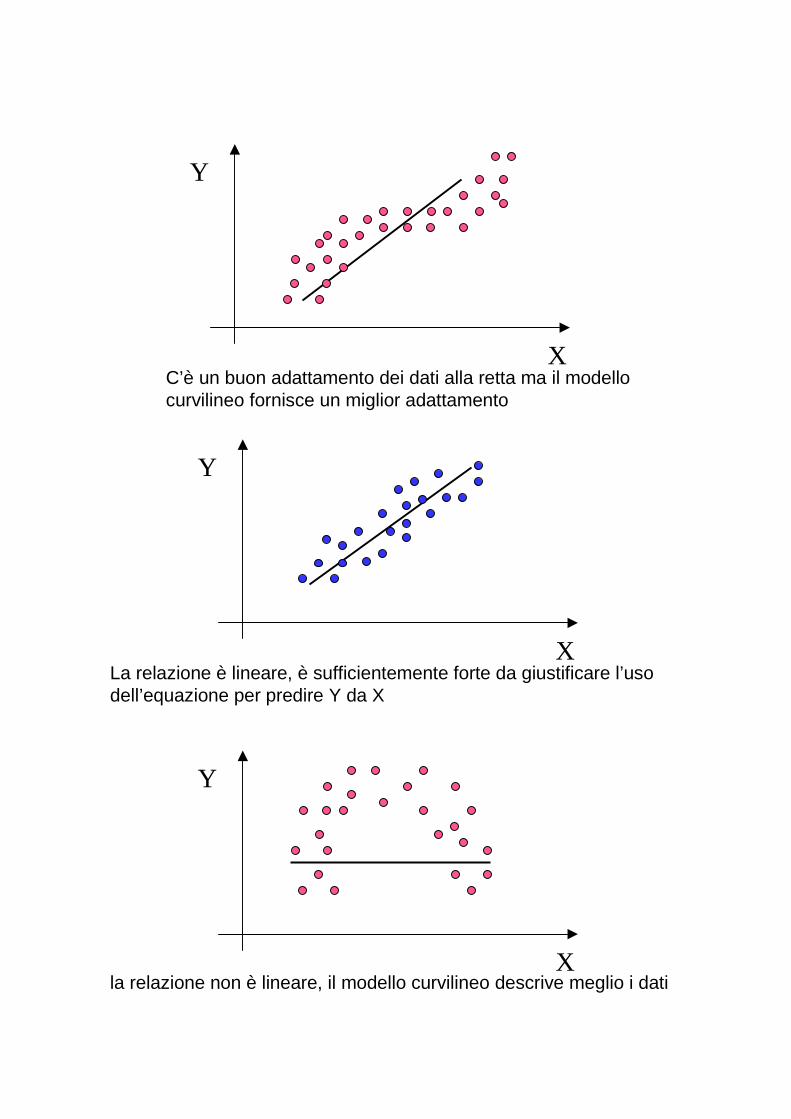
La relazione è lineare, è sufficientemente forte da giustificare l’uso dell’equazione per predire Y da X
C’è un buon adattamento dei dati alla retta ma il modello curvilineo fornisce un miglior adattamento
la relazione non è lineare, il modello curvilineo descrive meglio i dati

X
Y
La relazione sussiste è lineare ma non è sufficientemente forte da far sì che X serva a predire Y
Non sussiste relazione tra le variabili, ovvero al variare di X non corrisponde una variazione analoga di Y
La relazione è lineare, è sufficientemente forte da giustificare l’uso dell’equazione per predire Y da X, ma si evidenziano due punti outliers

MODELLO DI REGRESSIONE lineare semplice
X Variabile INDIPENDENTE, controllata dalricercatore. Vale a dire, il ricercatore sceglieun valore di X ed ottiene uno o più valori di Y
Y Variabile DIPENDENTE (regressione di Y su X)
130
Y = αααα + ββββx + e
Assunzioni : L-I-N-E
L = Linearità della relazioneI = Indipendenza dei campioniN = Normalità delle distribuzioniE = Eguaglianza delle varianze di Y
I valori della variabile Y dipendente sono determinati dai valori della variabile X indipendente in relazione ad un coefficiente angolare ββββ, ad un valore αααα di intercetta ed un valore e di errore residuo casuale
Inoltre:
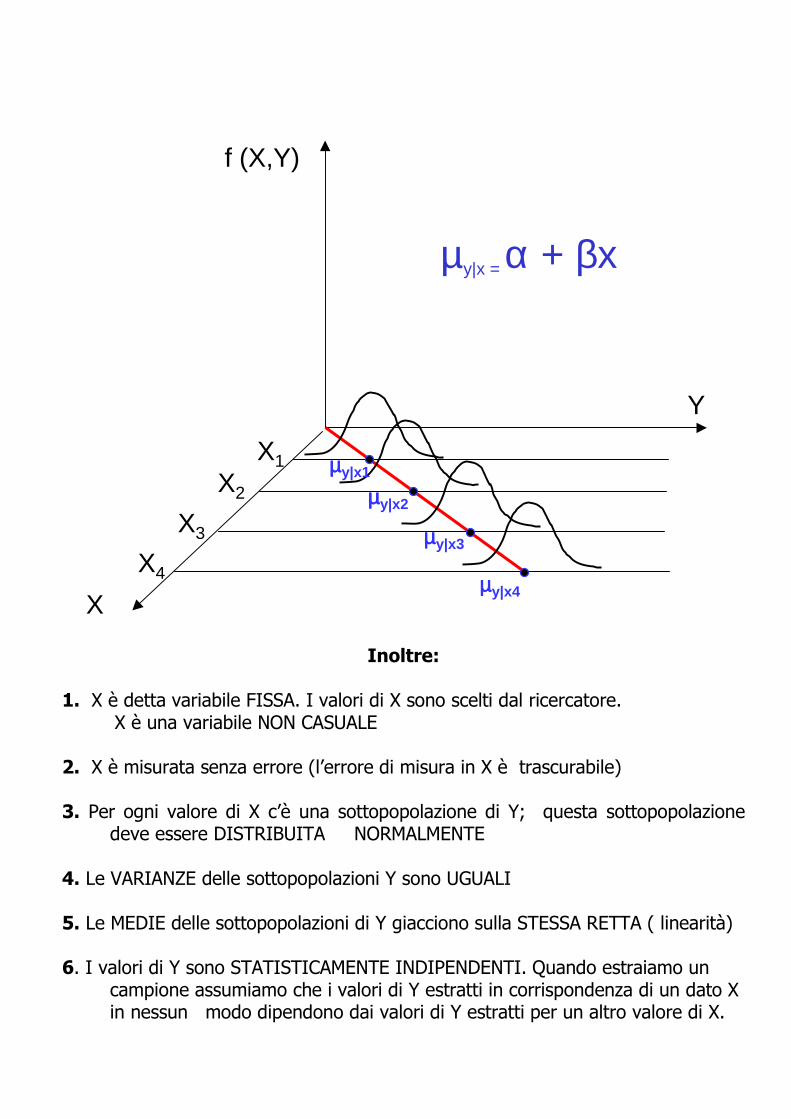
1. X è detta variabile FISSA. I valori di X sono scelti dal ricercatore.X è una variabile NON CASUALE
2. X è misurata senza errore (l’errore di misura in X è trascurabile)
3. Per ogni valore di X c’è una sottopopolazione di Y; questa sottopopolazione deve essere DISTRIBUITA NORMALMENTE
4. Le VARIANZE delle sottopopolazioni Y sono UGUALI
5. Le MEDIE delle sottopopolazioni di Y giacciono sulla STESSA RETTA ( linearità)
6. I valori di Y sono STATISTICAMENTE INDIPENDENTI. Quando estraiamo un campione assumiamo che i valori di Y estratti in corrispondenza di un dato X in nessun modo dipendono dai valori di Y estratti per un altro valore di X.
X1
X2
X3
X4
X
Y
f (X,Y)
µy|x = α + βx
µµµµy|x1
µµµµy|x2
µµµµy|x3
µµµµy|x4

0
20
40
60
80
100
120
0 20 40 60 80 100 120
DEVIAZIONE
RETTA AI MINIMI QUADRATI
L’equazione della retta è Y= a + bX
Determinazione della retta di regressione, ovvero dei coefficienti beta ed alfa, b ed a.
In funzione della retta dei minimi quadratiovvero quella che rende minori, rispetto a qualsiasi altra retta, le distanze dei punti dalla linea determinata dalla funzione y= bX+a

( )( )( )22∑∑
∑∑∑−
−=
xxn
yxxynb
n
xbya ∑ ∑−
=
Nel corso non vengono effettuati calcoliManuali ed i coefficienti sono determinatimediante Excel, R o Stata
Esempio di regressione lineare file dati regressioneLm1.xls
•Grafico tipo dispersione XY, •inserisci linea di tendenza•Visualizza equazione e R2 ( attenzione a R2 = coefficiente di determinazione non r Pearson di correlazione r Pearson = radq di R2 )
Calcolo manuale dei coefficienti a e b

statura/peso statura=X peso =Yregressione del peso sulla statura
y = 86.038x - 41.065R2 = 0.2114
6070
8090
100110
120130
140
1.45 1.5 1.55 1.6 1.65 1.7 1.75 1.8
statura m
peso K
g peso
Lineare (peso)
età/statura età=X statura=Yregressione della statura sull'età y = -0.0029x + 1.7718
R2 = 0.0972
1.45
1.5
1.55
1.6
1.65
1.7
1.75
1.8
30 40 50 60 70 80
età anni
sta
tura
m statura
Lineare (statura)

> fit= lm(peso~ statura)
>coefficients(fit)
(Intercept) statura -41.06470 86.03811
alfa beta
Y= 86.03811X – 41.0647
Regressione lineare semplice in R
Dopo aver aperto il file dati e comandi base
Statura=X peso= Y
Età=X Statura= Y
fit= lm(statura~eta)
> coefficients(fit)
(Intercept) eta
1.7718 -0.0029alfa beta
Y= -0.0029X + 1.7718

E’ necessario
• valutare la significatività dei coefficientidella regressione mediante test di ipotesi specifici
• valutare la forza della relazionecon i coefficiente di correlazione re di determinazione R2
• valutare la bontà del modello di regressionemediante l’analisi dei residui
SIGNIFICATIVITA ’ DEI COEFFICIENTIE FORZA DELLA RELAZIONE
Prima di giungere a qualsiasi conclusionerispetto alla analisi di regressione

Significatività dei coefficienti
I pacchetti statistici forniscono analisi relativealla significatività dei coefficienti mediante:
1) La determinazione dell’errore standard dei coefficienti alfa e beta e quindi con il calcolo di un valore di t di Student e relativa probabilità sotto l’ipotesi H0 che i coefficienti alfa e beta hanno valore 0 e Ha valore diverso da 0
2) Viene fornito l’intervallo di confidenza degli stessi coefficienti per cui a seconda che se esso contenga o meno 0 è possibile decidere in merito alla loro significatività
3) Viene effettuato un test F relativo al rapporto varianza dovuta alla regressione (scarto quadratico medio dei valori calcolati dalla retta sulla media generale) / varianza dei residui(scarto quadratico medio dei valori effettivi da quelli della retta) Nella ipotesi H0 che il rapporto sia 1 ( ovvero che la retta di regressione sia poco esplicativa della dispersione dei dati) Rispetto alla Ha rapporto > di 1 ( ovvero che la retta di regressione sia ben esplicativa della dispersione dei dati)
Vedi anche schema grafico coefficiente determinazione

Esempio di regressione lineare file dati
regressioneLm1.xls
Regressione statura (x) peso (y)
Statistica della regressioneR multiplo 0.460R al quadrato 0.211R al quadrato corretto 0.188Errore standard 13.355Osservazioni 35.000
ANALISI VARIANZAgdl SQ MQ F Significatività F
Regressione 1.000 1578.352 1578.352 8.849 0.005Residuo 33.000 5886.172 178.369Totale 34.000 7464.524
Coefficienti Errore standard Stat t Valore di significatività Inferiore 95% Superiore 95%Intercetta -41.065 46.555 -0.882 0.384 -135.782 53.653statura 86.038 28.923 2.975 0.005 27.193 144.883
Il coefficiente beta =86.038 è diverso da 0 in maniera significativa. Il suo IC al 95% non contiene 0. La pendenza è quindi significativamente diversa da 0.
Il coefficiente alfa intercetta non è diverso da 0, il suo IC 95% contiene 0, l’intercetta alfa non è diversa da 0
La regressione è significativa ovvero il rapporto tra varianza dovuta alla regressione / varianza dovuta ai residui è > di 1, ovvero la retta spiega la variazione e la relazione

Residuals:Min 1Q Median 3Q Max
-16.532 -11.228 -4.174 8.504 32.743
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -41.06 46.56 -0.882 0.38412 statura 86.04 28.92 2.975 0.00545 **---Signif. codes: 0 ‘*** ’ 0.001 ‘** ’ 0.01 ‘* ’ 0.05 ‘ . ’ 0.1 ‘ ’ 1
Residual standard error: 13.36 on 33 degrees of fre edom
Multiple R-squared: 0.2114, Adjusted R-squared: 0.1876
F-statistic: 8.849 on 1 and 33 DF, p-value: 0.0054 5
Comandi in R statura (x) peso (y)
> fit= lm(peso~ statura)
> summary(fit)
Il coefficiente beta =86.04 è diverso da 0 in maniera significativa.La pendenza è quindi significativamente diversa da 0.
Il coefficiente alfa intercetta non è diverso da 0,
La regressione è significativa ovvero il rapporto tra varianza dovuta alla regressione / varianza dovuta ai residui è > di 1, ovvero la retta spiega la variazione e la relazione
Viene fornito anche il coefficiente R2 di determinazione

Esempio di regressione lineare file dati
regressioneLm1.xls
Regressione eta (x) statura (y)OUTPUT RIEPILOGO
Statistica della regressioneR multiplo 0.312R al quadrato 0.097R al quadrato corretto 0.070Errore standard 0.076Osservazioni 35.000
ANALISI VARIANZAgdl SQ MQ F Significatività F
Regressione 1.000 0.021 0.021 3.551 0.068Residuo 33.000 0.193 0.006Totale 34.000 0.213
Coefficienti Errore standard Stat t Valore di significatività Inferiore 95% Superiore 95%Intercetta 1.772 0.088 20.124 0.000 1.593 1.951eta -0.003 0.002 -1.884 0.068 -0.006 0.00023
Il coefficiente beta =-0.003 non è diverso da 0 in maniera significativa. Il suo IC al 95% contiene 0. La pendenza è quindi non significativamente diversa da 0.
Il coefficiente alfa intercetta è diverso da 0, il suo IC 95% non contiene 0, l’intercetta alfa è diversa da 0
La regressione è non significativa per alfa= 0.05 (ma lo è per alfa=0.1) ovvero il rapporto tra varianza dovuta alla regressione / varianza dovuta ai residui non è > di 1, ovvero la retta non spiega la variazione e la relazione.

Comandi in R eta (x) statura (y)
> fit= lm (statura~ eta)
> summary(fit)
Residuals:Min 1Q Median 3Q Max
-0.165732 -0.065900 -0.000264 0.039418 0.139418
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.771835 0.088045 20.124 <2e-16 * **eta -0.002903 0.001540 -1.884 0.0683 .---Signif. codes: 0 ‘*** ’ 0.001 ‘** ’ 0.01 ‘* ’ 0.05 ‘ . ’ 0.1 ‘ ’ 1
Residual standard error: 0.07638 on 33 degrees of f reedom
Multiple R-squared: 0.09715 , Adjusted R-squared: 0.06979
F-statistic: 3.551 on 1 and 33 DF, p-value: 0.06834
Il coefficiente beta =-0.0029 non è diverso da 0 in maniera significativa .La pendenza è quindi non significativamente diversa da 0.
Il coefficiente alfa intercetta è diverso da 0.
Viene fornito anche il coefficiente R2 di determinazione
La regressione è non significativa per alfa= 0.05 (ma lo è per alfa=0.1) ovvero il rapporto tra varianza dovuta alla regressione / varianza dovuta ai residui non è > di 1, ovvero la retta non spiega la variazione e la relazione.

COEFFICIENTE DI DETERMINAZIONE
Per valutare la forza dell’equazione di regressione possiamo confrontare la dispersione dei punti intorno alla retta e la dispersione dei punti intorno alla media Y ( )Y
X
Y
media
La dispersione intorno alla retta è molto MINORE di quella intorno alla media!
non possiamo giudicare ad occhio
MA
dobbiamo trovare una MISURA OGGETTIVA
COEFFICIENTE DI DETERMINAZIONE

0
20
40
60
80
100
120
0 20 40 60 80 100 120
Yi
deviazionetotale
deviazionespiegata
deviazionenon spiegata
Consideriamo un punto Yi
�Distanza verticale dalla retta Y
�Distanza verticale tra la retta di
regressione Y e la retta Y
Mostra quanto della deviazione totale può essere ridotto quando si fitta una retta di regressione ai dati
�Distanza verticale tra il punto osservato
Yi e la retta di regressione Y
Cioè quella deviazione che rimane dopo aver fittato la retta di regressione
^
^
DEVIAZIONE TOTALE
DEVIAZIONE SPIEGATA
DEVIAZIONE NON SPIEGATA
yyi −
yy −ˆ
yyi ˆ−
Y
iY

( ) ( ) ( )iiii yyyyyy ˆˆ −+−=−
( ) ( ) ( )∑∑∑ −+−=− 222 ˆˆ iiii yyyyyy
DEV. TOTALE DEV. SPIEGATADEV. NON SPIEGATA
Se noi misuriamo queste deviazioni al quadrato e le sommiamosu tutti i punti:
SOMMA QUADRATITOTALE
SOMMA QUADRATI SPIEGATI
SOMMA QUADRATI
NON SPIEGATI
SST SSR SSE
SST = SSR + SSE
SST, SSR, SSE sono misure di dispersione
SST: dispersione dei valori di y intorno alla media
SSR: dispersione dei valori di y spiegata dalla relazione lineare tra Y ed X
SSE: dispersione dei valori di y intorno alla retta di regressione

La retta descrive bene la relazione tra Y ed X se i valori determinati dalla retta sono vicini a tutti quelli reali
ovvero se la deviazione dei valori SPIEGATA dalla retta (distanze dalla retta dalla media generale)
costituisce una ampia porzione della deviazione TOTALE(distanze dei valori reali dalla media generale ).
Per determinare la grandezza di questa porzioneÈ necessario calcolare il rapporto SSR/SST ovvero
la somma dei quadrati spiegati dalla regressione /somma dei quadrati totale
Questo rapporto identifica il coefficiente di determinazione
SST
SSRr =2 Coefficiente di
determinazione
Tanto più grande è r 2 tanto meglio la RETTA fitta i dati
149

r2 = 0.986 r2 = 0.40
r2 = 1 r2 = 0
r2 grande,adeguamento ottimo
r2 piccolo,adeguamento povero
r2 = 1 r2 = 0
a b
c d
150

Residuals:Min 1Q Median 3Q Max
-16.532 -11.228 -4.174 8.504 32.743
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -41.06 46.56 -0.882 0.38412 statura 86.04 28.92 2.975 0.00545 **---Signif. codes: 0 ‘*** ’ 0.001 ‘** ’ 0.01 ‘* ’ 0.05 ‘ . ’ 0.1 ‘ ’ 1
Residual standard error: 13.36 on 33 degrees of fre edom
Multiple R-squared: 0.2114, Adjusted R-squared: 0.1876
F-statistic: 8.849 on 1 and 33 DF, p-value: 0.0054 5
Comandi in R
> fit= lm(peso~ statura)
> summary(fit)
Il coefficiente beta =86.04 è diverso da 0
La regressione è significativa
coefficiente R2 di determinazione indica che la regressionestatura/peso spiega solo il 21,14% della variabilitàdel peso che quindi è influenzato anche da altri fattorioltre la statura ( es. robustezza, massa grassa, obesità)
Nell’esempio di analisi prima effettuato

Comandi in R eta (x) statura (y)
> fit= lm (statura~ eta)
> summary(fit)
Residuals:Min 1Q Median 3Q Max
-0.165732 -0.065900 -0.000264 0.039418 0.139418
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.771835 0.088045 20.124 <2e-16 * **eta -0.002903 0.001540 -1.884 0.0683 .---Signif. codes: 0 ‘*** ’ 0.001 ‘** ’ 0.01 ‘* ’ 0.05 ‘ . ’ 0.1 ‘ ’ 1
Residual standard error: 0.07638 on 33 degrees of f reedom
Multiple R-squared: 0.09715 , Adjusted R-squared: 0.06979
F-statistic: 3.551 on 1 and 33 DF, p-value: 0.06834
Il coefficiente beta =-0.0029 non è diverso da 0 in maniera significativa .
La regressione è non significativa
coefficiente R2 di determinazione indica che la regressioneeta/statura spiega solo il 9,71% della variabilitàdell’età che quindi appare poco legata alla statura

ANALISI DEI RESIDUI
Per la verifica della bontà del modello della regressione si effettua una analisi dei residui, ovvero della distribuzione delle differenza (scarti-residui) tra i valori effettivi dei punti XY e quelli determinati dalla retta di regressione.
I valori dei residui vengono standardizzati-normalizzati in maniera tale da variare attorno al valore 0 ed assumere valori corrispondenti a probabilità di Z normale standardizzata, per cui valori di residui pari o superiori a + - 2 e quindi corrispondenti a probabilitàmolto basse (inferiori al 0.05, 5%)devono essere presenti in numero molto limitato .
In un buon modello di regressione i valori dei residui si collocano in una fascia ristretta attorno ai valori determinati dalla retta di regressione, i residui si distribuiscono inoltre con una distribuzione normale gaussianasimmetrica attorno ai valori della retta di regressione.
In un modello non buono i valori dei residui standardizzati spaziano in una fascia molto amplia con molti casi che eccedono i valori +-2.
In un modello non buono di regressione i valori dei residui standardizzati risentono di una tendenza ad aumentare, diminuire o variare in funzione dei valori della Y prevista dalla regressione ( e quindi anche della avariabile X).

modello non buono: residui in una fascia troppo ampia e con netta tendenza
modello buono: residui in una fascia ristretta ed uniforme
modello non buono: residui con netta tendenza

Esempio di analisi residui con dati
regressioneLm1.xls peso/statura
OUTPUT RESIDUI
statura peso Previsto peso Residui Residui standard1.730 93.200 107.781 -14.581 -1.1081.620 86.000 98.317 -12.317 -0.9361.580 80.200 94.876 -14.676 -1.1151.710 99.200 106.060 -6.860 -0.5211.690 92.400 104.340 -11.940 -0.9071.620 87.800 98.317 -10.517 -0.7991.630 91.000 99.177 -8.177 -0.6211.490 70.600 87.132 -16.532 -1.2561.570 86.100 94.015 -7.915 -0.6021.660 92.200 101.759 -9.559 -0.7261.510 74.800 88.853 -14.053 -1.0681.650 85.200 100.898 -15.698 -1.1931.590 88.400 95.736 -7.336 -0.5581.550 80.000 92.294 -12.294 -0.9341.540 77.000 91.434 -14.434 -1.0971.710 101.600 106.060 -4.460 -0.3391.560 96.800 93.155 3.645 0.2771.730 115.800 107.781 8.019 0.6091.610 97.400 97.457 -0.057 -0.0041.740 107.400 108.642 -1.242 -0.0941.580 90.000 94.876 -4.876 -0.3711.570 96.000 94.015 1.985 0.1511.530 86.400 90.574 -4.174 -0.3171.660 110.000 101.759 8.241 0.6261.620 101.800 98.317 3.483 0.2651.680 113.000 103.479 9.521 0.7241.540 100.200 91.434 8.766 0.6661.630 111.200 99.177 12.023 0.9141.490 103.400 87.132 16.268 1.2361.610 130.200 97.457 32.743 2.4891.490 108.200 87.132 21.068 1.6011.560 107.600 93.155 14.445 1.0981.780 140.800 112.083 28.717 2.1831.530 97.200 90.574 6.626 0.5041.510 105.000 88.853 16.147 1.227

Residui standard eta/statura
-2.600
-1.600
-0.600
0.400
1.400
2.400
80.000 85.000 90.000 95.000 100.000 105.000 110.000 115.000
valori della retta di regressione, previsti
diffe
ren
ze s
tan
d. d
alla
Y p
revi
sta
Si evidenzia una distribuzione dei residui attorno ai valori dellaretta di regressione non molto amplia ma con 2 casi che arrivanoed eccedono il valore 2 + come outliers, entrambi positivinon si osserva particolare tendenza -autocorrelazione
peso/statura
Analisi in R

OUTPUT RESIDUI
eta statura Previsto statura Residui Residui standard50 1.73 1.627 0.103 1.37354 1.62 1.615 0.005 0.06567 1.58 1.577 0.003 0.03556 1.71 1.609 0.101 1.33855 1.69 1.612 0.078 1.03449 1.62 1.630 -0.010 -0.12851 1.63 1.624 0.006 0.08240 1.49 1.656 -0.166 -2.20355 1.57 1.612 -0.042 -0.56152 1.66 1.621 0.039 0.52059 1.51 1.601 -0.091 -1.20455 1.65 1.612 0.038 0.50255 1.59 1.612 -0.022 -0.29554 1.55 1.615 -0.065 -0.86551 1.54 1.624 -0.084 -1.11455 1.71 1.612 0.098 1.30050 1.56 1.627 -0.067 -0.88743 1.73 1.647 0.083 1.10351 1.61 1.624 -0.014 -0.18359 1.74 1.601 0.139 1.85366 1.58 1.580 0.000 -0.00472 1.57 1.563 0.007 0.09559 1.53 1.601 -0.071 -0.93851 1.66 1.624 0.036 0.48166 1.62 1.580 0.040 0.52874 1.68 1.557 0.123 1.63476 1.54 1.551 -0.011 -0.14955 1.63 1.612 0.018 0.23767 1.49 1.577 -0.087 -1.16153 1.61 1.618 -0.008 -0.10663 1.49 1.589 -0.099 -1.31551 1.56 1.624 -0.064 -0.84842 1.78 1.650 0.130 1.72960 1.53 1.598 -0.068 -0.89963 1.51 1.589 -0.079 -1.050
Esempio di analisi residui con dati
regressioneLm1.xls statura / eta

Residui standard eta/statura
-2.500
-2.000
-1.500
-1.000
-0.500
0.000
0.500
1.000
1.500
2.000
2.500
1.540 1.560 1.580 1.600 1.620 1.640 1.660 1.680
valori della retta di regressione, previsti
diff
eren
ze s
tan
d. d
alla
Y p
revi
sta
Si evidenzia una distribuzione dei residui attorno ai valori dellaretta di regressione amplia con casi che arrivano ai valori + e – 2ma non si osserva particolare tendenza -autocorrelazione
Analisi in R
eta/statura

MODELLO DI CORRELAZIONE
La misura della forza specifica della relazione tra due variabili viene valutata mediante il calcolo del coefficiente di correlazione che ha logica analoga del coefficiente di determinazione individuato nella regressione ma può assumere valori negativi o positivi a seconda del tipo di relazione tra le variabili:
Il coefficiente di correlazione varia tra –1 e 0per variabili tra le quali vi è un rapporto inversamente proporzionale( all’aumentare di X diminuisce Y)
Il coefficiente di correlazione varia tra 0 e +1per variabili tra le quali vi è un rapporto direttamente proporzionale( all’aumentare di X diminuisce Y)
Per valori del coefficiente di correlazione pari a 0 la relazione tra le variabili èinesistente,
per valori pari a +-1 la relazione è perfetta

Il coefficiente di correlazione più usato è quello r prodotto momento di Pearson, che necessita diverse condizioni di verifica delle assunzioni.
L’alternativa non parametrica più usata è quella del coefficiente rho di Spearman che necessita di condizioni di verifica delle assunzioni meno stringentie procede con l’assegnazione dei ranghi.
Nei pacchetti statistici ed in particolare in R è possibile effettuare una valutazione relativa alla significativitàstatistica dei coefficienti di correlazione ovvero valutare se il valore determinato è significativamente diverso da 0.Viene quindi esposto il p-value di significatività
(Per rho di Spearman questo è possibile per n>30 altrimenti si ricorre ad apposite tavole)
Viene impostato un test di ipotesi sullastatistica test
• Ipotesi nulla: ρ = 0 (ρ è il coefficiente di correlazione della popolazione, r del campione).
• significatività alfa per t con GDL = n-2
21
2
r
nrt
−−=

Correlazione parametrica r prodotto momento di Pearson
Assunzioni: LINE
• entrambe le variabili devono essere quantitative continue a livello di misurazione
• entrambe le variabili devono seguire una distribuzione normale
• la relazione tra le variabili è lineare
• Le sottopopolazioni di X ed Y hanno la stessa varianza
( )( )( ) ( )∑ ∑∑ ∑
∑ ∑∑
−−
−=
2222iiii
iiii
yynxxn
yxyxnr
ionedeterminaz
di tecoefficien=r
La correlazione tra due variabili aleatorie X e Y èil rapporto tra la loro
covarianza * e il prodotto delle loro deviazioni standard:
* Date due variabili aleatorie X e Y , chiamiamo covarianza di X e Y la media dei prodotti dei loro scostamenti dalla media:

21
2
r
nrt
−−=
Esempio di analisi correlazione con dati
regressioneLm1.xls
Correlazione età/ staturasolo comandi in R con significatività
>cor.test(eta, statura)-------------------------------------------------------Pearson' s product-moment correlation
data: eta and statura t = -1.8844, df = 33, p-value = 0.06834alternative hypothesis: true correlation is not equ al to 0 95 percent confidence interval:
-0.58425284 0.02405182sample estimates:
cor -0.311693
in questo caso r= -0.311 e il suo p-value=0.068 ovvero non significativo per alfa= 0.05
cor.test(eta, statura, method="spearman")-------------------------------------------------------Spearman's rank correlation rho
data: eta and statura S = 9264.358, p-value = 0.08259alternative hypothesis: true rho is not equal to 0 sample estimates:
rho -0.2975291
in questo caso rho= -0.297 ed il suo p value= 0.082ovvero non significativo per alfa= 0.05

Correlazione peso/ staturasolo comandi in R con significatività
Esempio di analisi correlazione con dati
regressioneLm1.xls
>cor.test(peso, statura)
Pearson's product-moment correlation
data: peso and statura
t = 2.9747, df = 33, p-value = 0.00545
alternative hypothesis: true correlation is not equa l to 0 95 percent confidence interval: 0.1494956 0.6876987
sample estimates:
cor 0.4598338
in questo caso r= 0.46 e il suo p-value=0.0054 ovvero significativo per alfa= 0.05
>cor.test(peso, statura, method="spearman")
Spearman's rank correlation rho
data: peso and statura
S = 4604.624, p-value = 0.03633
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho 0.3550946in questo caso rho= 0.355 ed il suo p value= 0.0363
ovvero significativo per alfa= 0.05

età/statura età=X statura=Yregressione della statura sull'età y = -0.0029x + 1.7718
R2 = 0.0972
1.45
1.5
1.55
1.6
1.65
1.7
1.75
1.8
30 40 50 60 70 80
età anni
sta
tura
m statura
Lineare (statura)
Spearmanrho = -0.2975291 p-value = 0.08259
Pearson r = -0.311693 p-value = 0.06834
Non significativi
F-statistic: 3.551 on 1 and 33 DF, p-value: 0.06834
Evidenziando rispetto allo scatterplot

statura/peso statura=X peso =Yregressione del peso sulla statura
y = 86.038x - 41.065R2 = 0.2114
6070
8090
100110
120130
140
1.45 1.5 1.55 1.6 1.65 1.7 1.75 1.8
statura m
peso
Kg peso
Lineare (peso)
Pearson r= 0.46 e il suo p-value= 0.0054
Spearmanrho= 0.355 ed il suo p value= 0.0363
F-statistic: 8.849 on 1 and 33 DF, p-value: 0.0054 5
significativi
Evidenziando rispetto allo scatterplot





























