Embed Size (px)
Citation preview

#TDPARTNERS16 GEORGIA WORLD CONGRESS CENTER
Reducing System Downtime Through The Use of Multiple
Hash Maps
Rich Charucki
Engineering Fellow, Teradata Labs

2
Multiple Hash Maps
• Description – Provide the ability to have multiple hash maps defined and used within a single
Teradata system.
• Benefits – The goals of the MAPS are as follows: 1. Improve system throughput by allowing for the definition of small tables to reside
on a subset of AMPs and not all the AMPs in a system. 2. Leveraging the multiple hash maps to dramatically reduce planned downtime
caused by in-place system expansions. 3. Eliminate the current all-or-nothing reconfiguration process.
• Considerations – Feature introduces a new database, TD_USERS, that will be used to house the
database tables and stored procedures that will support the table map migration process.

3
Teradata Hash Maps - Basics
• A Teradata Hash Map – A hash map tells Teradata where data
belongs in a parallel system.
• Primary Index data values are hashed – Hashing algorithm +
– Divide by 1M hash buckets
• Hash Buckets own AMPs – The "Hash Map" maps each of the 1M
buckets to whatever number of AMPs exist within the system.
– Rows are assigned to the AMPs via the hash bucket
• Spreads data evenly – For performance
– Reduce skew
– Enables co-located table rows
Primary Index Data Values
Hash Bucket

4
Teradata Hash Maps - Basics
• Teradata Hash Maps – Key to the distribution of a table
in an MPP System
– The “PI” Fields are concatenated and run through a mathematical function that returns a “bucket”, a number between 1 and 1,048,576 (20 bits)
– The “Hash Map” maps each of the buckets to whatever number of AMP’s exist within the system
0 1 … 8 9
1,
11, 21, …,
1048567
2,
12, 22 ,…,
1048568
9,
19, 29, …,
1048575
10,
20, 30,
…,1048576
PI_col_1 … PI_col_n
17 “Aloha”
29
function
Bucket#
Lookup

5
Teradata Hash Maps - Basics
• Historical Use Of Hash Maps – The primary means of table data distribution in an MPP system.
– The hash map has purview over all the AMPs in a given system.
– In general, a table loaded to a system will be distributed via the hash map over all the AMPs in the system.
– "Fallback" is an existing mechanism that uses an alternate hash map to store a second copy of the data.
– Fallback has the special property built in, in that the second copy is guaranteed to be different hardware.
6
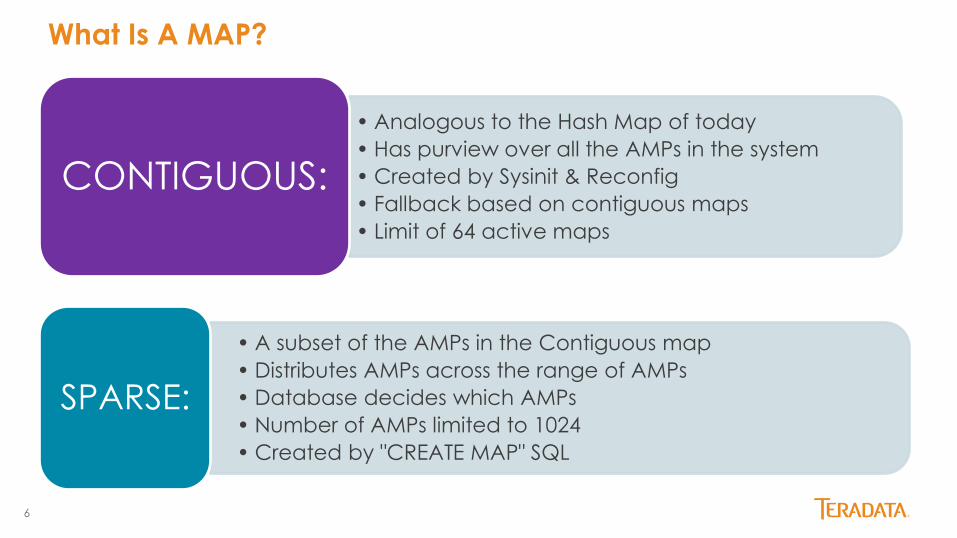
What Is A MAP?
• Analogous to the Hash Map of today
• Has purview over all the AMPs in the system
• Created by Sysinit & Reconfig
• Fallback based on contiguous maps
• Limit of 64 active maps
CONTIGUOUS:
• A subset of the AMPs in the Contiguous map
• Distributes AMPs across the range of AMPs
• Database decides which AMPs
• Number of AMPs limited to 1024
• Created by "CREATE MAP" SQL
SPARSE:

7
Contiguous Maps vs. Sparse Maps
• Contiguous Map – "All AMPs" Map
– Created by Sysinit & Reconfig
– Limit of 64 Active Maps
A table on an "All Amps"
Contiguous Map.
• Sparse Map – "Few Amps" Map
– Created by "CREATE MAP" SQL
– Limit of 1024 AMPs per Sparse map
A table on a "Few Amps"
Sparse Map.
8
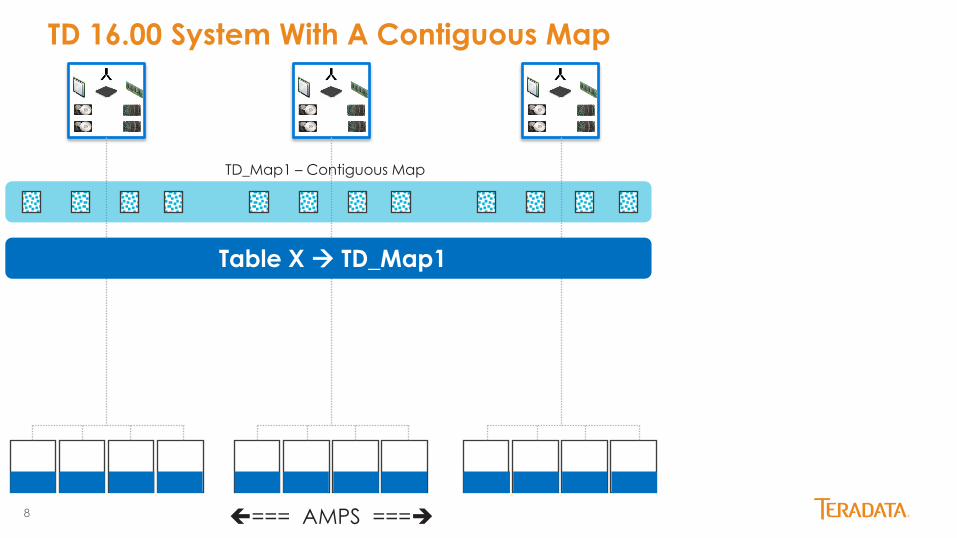
TD 16.00 System With A Contiguous Map
TD_Map1 – Contiguous Map
Table X TD_Map1
=== AMPS ===

9
TD 16.00 System With A Contiguous Map + Sparse Map
TD_Map1 – Contiguous Map
Table X TD_Map1
=== AMPS ===
My_5AMP_Map – Sparse Map
Table Y My_5AMP_Map

10
TD 16.00 System Post Expansion
TD_Map1 – Contiguous Map
Table X TD_Map1
=== AMPS ===
TD_Map2 – Contiguous Map
Table Z TD_Map2

11
Create Map
CREATE MAP <map_name>
FROM <contiguous_map_name>
SPARSE
AMPCOUNT=<n>;
Create Map
Statement
• Create Map Specifics: – Limit 64 Contiguous Maps
– Contiguous maps are only created by Sysinit or Reconfig
– SPARSE Maps are created by users
– Limit of 2 billion Sparse Maps
– SPARSE Maps are limited to 1024 AMPs

12
Create Table
CREATE TABLE <table_name>
[,[NO] [FALLBACK]]
[,MAP = <map_name>]
(column definitions);
CREATE TABLE Sales,
MAP = TD_Map1
(column definitions)
PRIMARY INDEX (Store_Id, Product_Id, Sales_Date);
CREATE TABLE Store_Codes,
MAP = OneAmpMap
(column definitions)
PRIMARY INDEX (Store_Code, Store_Name);
Create Table
Definition
Create Table
Using A
Contiguous Map
Create Table
Using A
Sparse Map

13
Show Map
Show Map
Statement
CREATE MAP OneAmpMap
FROM TD_Map1
SPARSE
AMPCOUNT=1;
Sparse Map
Definition
SHOW MAP <map_name>;
Contiguous Map
Definition
CREATE MAP TD_Map1
CONTIGUOUS
AMP BETWEEN 0 AND 400;

14
Drop Map
DROP MAP <map_name>;
Create Map
Statement
• Drop Map Specifics: – Used to drop unwanted maps
– Can be used to drop Contiguous Maps
– All tables must be removed from a Map,
before the Map itself can be dropped

15
Grant Map
• Grant Map Specifics:
– Map creation/management is a privilege.
– Users may be granted the ability to create/drop Sparse maps via the following new commands:
GRANT CREATE MAP to <user>, GRANT DROP MAP to <user>
– Like other privileges, the aforementioned privileges may be combined into one statement via the following privilege:
GRANT MAP to <user>
– Once sparse maps have been created, they must be granted to a user before they may be used:
GRANT MAP OneAmpMap to <user>
– Grantees (users or roles) will then be allowed to specify granted maps in any CREATE TABLE statement, or assign them to other users and profiles.
– Secure Zone restrictions apply:
- Maps created within a secure zone can only be granted to users and roles within that zone.
GRANT MAP <recipient_list>;
Grant Map
Statement

16
The Colocation Label
• Sparse Tables and the Colocation Label – Tables in sparse maps reside on a subset of AMPs in the parent contiguous map.
– Feature introduces the new Colocation Label parameter, the purpose of which is twofold:
1) It is the mechanism used to determine which AMPs a table utilizing a sparse map will reside on.
2) Can be used to insure that two tables with the same sparse map are colocated on the same AMPs.
– The Colocation Label parameter is specified as part of a CREATE TABLE statement and can have a specified value or a default value.
– The Colocation Label can only be specified for tables that utilize sparse maps.

17
The Colocation Label Specification
CREATE TABLE RJC.MyTable
[,[NO] [FALLBACK]]
[,MAP = TwoAmpMap COLOCATE USING RJC_MyTable
(column definitions)
PRIMARY INDEX (My_PI_Cols);
Colocation Label
Default
Specification
CREATE TABLE RJC.MyTable
[,[NO] [FALLBACK]]
[,MAP = TwoAmpMap COLOCATE USING ApplGroup
(column definitions)
PRIMARY INDEX (My_PI_Cols);
Colocation Label
Value
Specification

18
Tables in Sparse Maps without Colocation
• Sparse Maps & the Colocation Label – In this case, the Default Colocation Label is hashed to pick the starting AMP from the
parent contiguous map.
– In the above example, the two effectively identical tables will not hash to the same AMPs.
CREATE TABLE RJC.Jan_Accounts
[,[NO] [FALLBACK]]
[,MAP = TwoAmpMap COLOCATE USING RJC_Jan_Accounts
(column definitions)
PRIMARY INDEX (Account_Id);
CREATE TABLE RJC.Feb_Accounts
[,[NO] [FALLBACK]]
[,MAP = TwoAmpMap COLOCATE USING RJC_Feb_Accounts
(column definitions)
PRIMARY INDEX (Account_Id);

19
Tables in Sparse Maps with Colocation
• Sparse Maps & the Colocation Label
– The Specified Colocation Label is hashed to pick the starting AMP from the parent contiguous map.
– Sparse table colocation is achieved if:
- The tables are using the same sparse map
- The Primary Index columns are the same
- The tables are using the same Colocation label value
CREATE TABLE RJC.Jan_Accounts
[,[NO] [FALLBACK]]
[,MAP = TwoAmpMap COLOCATE USING Active_Accounts
(column definitions)
PRIMARY INDEX (Account_Id);
CREATE TABLE RJC.Feb_Accounts
[,[NO] [FALLBACK]]
[,MAP = TwoAmpMap COLOCATE USING Active_Accounts
(column definitions)
PRIMARY INDEX (Account_Id);

20
Alter Table for Maps
• Alter Table Specifics: – ALTER TABLE can be used to change the map of a table from one map to another map.
– Can also be used to change the map of a table from a sparse map to a co-located sparse map.
– The ALTER TABLE process, makes a complete copy of the source table in the new map and then deletes the source table in the old map.
– A Read lock is imposed on the table during the table copy process from one map to another.
– Once the copy operation is complete the READ lock is upgraded to an EXCLUSIVE lock, then:
- The original source table is dropped
- The copy of the table in the new map is made available for use.
ALTER TABLE Customer_Contacts,
MAP = TwoAmpMap;
ALTER TABLE Feb_Fraud_Accounts,
MAP = FourAmpMap COLOCATE USING Fraud_Appl;

21
System Expansion & Table Migration
Process
Queue Table
View
Point
Yes
System
Online
No
Move
dictionary
?
Redistribute
Dictionary
Tables to
move?
No
Yes
Yes
No
Run
List?
Generate
tables list
Offline
Reconfigure
Install
Hardware
Queue
Table
Alter
Table

22
Moving Tables to other Maps using ALTER TABLE
• New "Analyze" Store Procedure – Create a Workflow
– Populate workflow with a set of tables
– Select a particular map
– Run the Analyze stored procedure
• End User Selection – View the Analyze Results
• Schedule, run via Viewpoint – Run the recommended moves
– At a time of your choosing
• New Stored Procedure – Consume queue table
– Submit ALTER TABLE requests
– Read lock on the source table
– Upgraded to Exclusive lock at transaction end.
Viewpoint
Queue table
Acct_type_tbl
Countrys_tbl
Tax_codes_tbl

23
Migration Of Large Partitioned Tables
CREATE TABLE Sales,
MAP = TD_Map1
(column definitions)
PRIMARY INDEX (Product_Id, Sales_Date)
PARTITION BY RANGE_N Sales_Date BETWEEN
DATE '2010-01-01' AND '2015-12-31';
CREATE VIEW Sales_View AS,
SELECT * FROM SALES;
RENAME TABLE Sales AS Sales_History_Partitions;
CREATE TABLE Sales,
MAP = TD_Map2
(column definitions)
PRIMARY INDEX (Product_Id, Sales_Date)
PARTITION BY RANGE_N Sales_Date BETWEEN
DATE '2010-01-01' AND '2015-12-31';
REPLACE VIEW Sales AS,
SELECT * FROM Sales_History_Partitions
WHERE Sales_Date < '2014-09-01'
UNION ALL
SELECT * FROM Sales
WHERE Sales_Date >= '2014-09-01';

24
Viewpoint: Workflow Portlet
This will be the initial screen displayed when a customer first pulls up the portlet

25
Viewpoint: Workflow List Portlet
This will be the initial
screen of the portlet once
the customer has created
various workflows to run
the analysis/move
actions

26
Viewpoint: CWF Details During Move Portlet
This is a drill down from
#2, and shows a single
workflow when a move
action is in progress

27
Viewpoint: Analysis Schedule Portlet
The screen that will
allow the user to
schedule when an
analysis will run.

28
The TD 16.10 MAPS Project
• Multiple MAPS Infrastructure
• Provide the ability to have multiple hash maps defined and used within a single Teradata system.
• Improve system throughput by defining small tables to reside on a subset of AMPs.
• Leveraging the multiple hash maps to dramatically reduce planned downtime caused by system expansions.
• Ability to move a table to a new map via the ALTER TABLE mechanism.
• Ability to automate the ALTER TABLE process via a Queue Table mechanism.
• UNION All Enhancements
• Fully Optimizer aware

Thank You
Questions/Comments
Email:
Rate This Session #
with the PARTNERS Mobile App
Remember To Share Your Virtual Passes
181
29

















![Hash Functions and Hash Tablestcs/ds/lecture6.pdf · Hash Functions and Hash Tables A hash function h maps keys of a given type to integers in a fixed interval [0;:::;N -1]. We call](https://img.dokumen.tips/doc/110x75/5ade96e97f8b9a595f8e5db8/hash-functions-and-hash-tables-tcsds-functions-and-hash-tables-a-hash-function.jpg)











