Embed Size (px)
DESCRIPTION
Redes Neurais. DSC/CEEI/UFCG Professor: Herman M Gomes. Bibliografia. Haykin S. Neural Networks: A Compreensive Foundation. Macmillan College Publishing, 1994. Kovacs Z.L. Redes Neurais: Fundamentos e Aplicações. Edição Acadëmica, 1996. - PowerPoint PPT Presentation
Citation preview

Bibliografia
Haykin S. Neural Networks: A Compreensive Foundation. Macmillan College Publishing, 1994.
Kovacs Z.L. Redes Neurais: Fundamentos e Aplicações. Edição Acadëmica, 1996.
McClelland J.L., Rumelhart D.E. Explorations in Parallel Distributed Processing. The MIT Press. 1988.
R. Beale, T. Jackson. Neural Computing: An Introduction. IOP Publishing, 1990. R. Hetch-Nielsen. “Neurocomputing”. Addison-Wesley Publishing
Company,1990. P. K. Simpson. “Artificial Neural Systems”. Pergamon Press, 1990. P. D. Wasserman. “Neural Computing: Theory and Pratice”. Van Nostrand
Reinhold, 1989. C. Bishop. Neural Networks for Pattern Recognition.

Introdução
O que é computação?

Funções computáveis e não computáveis
Funções lineares e não lineares

A estrutura do cérebro aproximadamente 1010
neurônios
cada um conectado com cerca de 104 outros
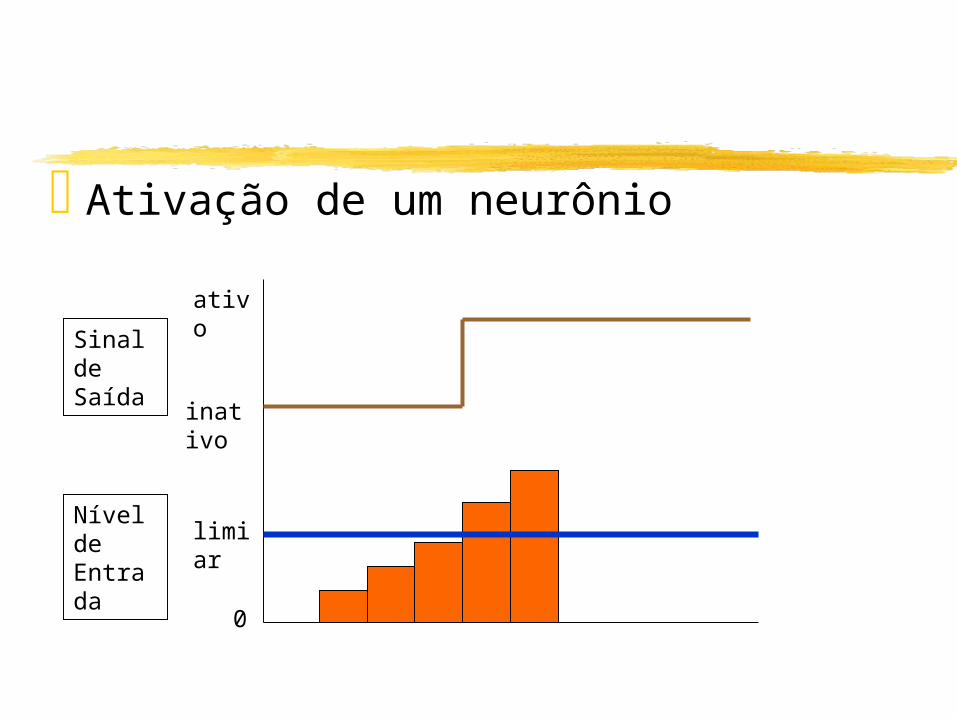
Ativação de um neurônio
Sinal de Saída
Nível de Entrada limiar
0
ativo
inativo

Aprendizagem em sistemas biológicos
0

Vetores de características e espaços de estados
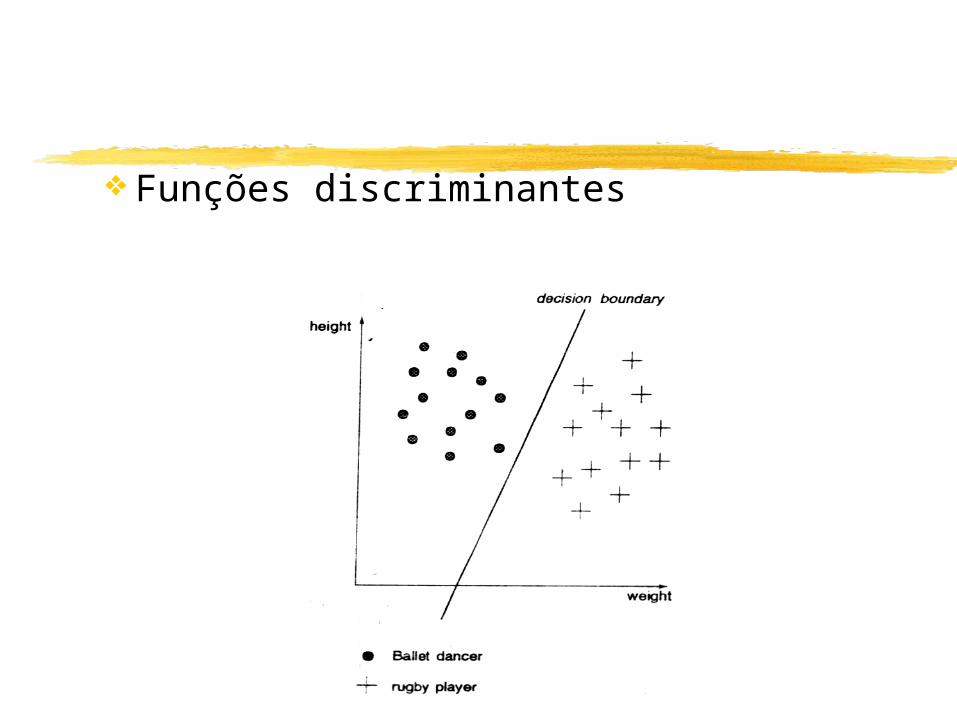
Funções discriminantes

Técnicas de classificação: vizinho mais próximo

Medidas de distância entre vetores• Distância de Hamming =
• Distância Euclidiana = |)(| yx ii
n
i
yx ii1
2
)(

Classificadores lineares•

Técnicas estatísticas: classificação Bayesiana
• Importante técnica analítica que facilita o entendimento da natureza estatística dos dados
• Baseia-se na teoria estatística de probabilidades e probabilidades condicionais
• Em reconhecimento de padrões, medições são feitas sobre os padrões (componentes do vetor de características) a fim de se obter uma estimativa da probabilidade de um padrão pertencer a uma classe particular.
• Mais formalmente, seja Gi (i=1,2,...,n) a lista de possíveis grupos ou classes, define-se a probabilidade de um padrão pertencer a uma classe como sendo P(Gi), onde 0 P(Gi) 1

• O uso de probabilidades condicionais permite a inclusão de conhecimento prévio sobre o problema de forma a melhorar a estimativa de um padrão pertencer a uma dada classe
• Dados dois eventos X e Y, a probabilidade condicional é definida como sendo a probabilidade do evento Y dada a ocorrência do evento X: P(Y |X)
• Em reconhecimento de padrões, o conhecimento prévio que é combinado com a função de probabilidade da classe são as medições de dados obtidas para o padrão, ou seja, o vetor de características X = (x1, x2 , ..., xn )
• Assim, o problema de classificação de padrões pode ser enunciado como: Considerando um conjunto de medições, X, qual é a probabilidade dele pertencer à classe Gi , ou seja P(Gi |X) ?

Regra de Bayes
• Decida por x pertencer à classe i se:P(Gi |X) > P(Gj |X) para i=1,2,...,n i j
• Como estimar as probabilidades condicionais? Fazendo suposições sobre os dados de padrões
Descrevendo distribuições desconhecidas através de modelos
Dado que se sabe que o padrão deva pertencer a um dos n grupos, então define-se a probabilidade de se se obter aquele padrão em cada um dos grupos P(X | Gi)
P(Gi |X) = P(X | Gi ) . P(Gi) / ( j P(X | Gj) . P(Gj) )

Outras técnicas estatísticas
• EM algorithm: Expectation-Maximisation
• Support Vector Machines

Modelando um único neurônio
Perceptrons
n
iixwify
0
w0
w1
w2
w3
wn
...
y
x0
x1
x2
x3
x4

Funções de ativação

Funções de ativação

Funções de ativação
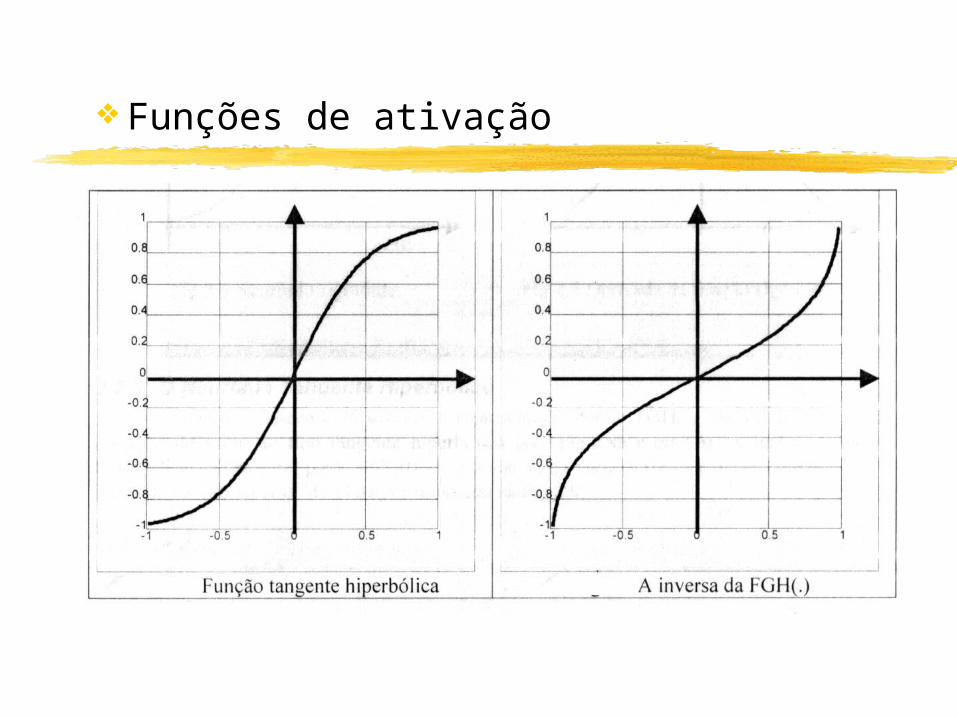
Funções de ativação

Aprendizagem do perceptron
1. Inicializar pesos e limiarDefinir wi(t), (0 i n) como o peso da entrada i no tempo t e w0 como sendo -, o limiar, e x0=1Ajustar wi(0) com pequenos valores randômicos
2. Apresentar entradas x0, x1, ..., xn e saída desejada d(t)3. Calcular a saída do neurônio4. Adaptar os pesos
se correto wi(t+1) = wi(t)se saída=0, mas devia ser 1 wi(t+1) = wi(t)+xi(t)se saída=1, mas devia ser 0 wi(t+1) = wi(t)-xi(t)
n
iixwify
0

Modificações da adaptação dos pesos
4. Adaptar os pesosse correto wi(t+1) = wi(t)se saída=0, mas devia ser 1 wi(t+1) =wi(t)+xi(t)se saída=1, mas devia ser 0 wi(t+1) =wi(t)-xi(t)onde 0 1 controla a taxa de adaptação do peso
4. Adaptar os pesos - regra delta de Widrow-Hoff = d(t) - y(t)wi(t+1) = wi(t) + xi(t)Neurônios com este algoritmo de aprendizagem: ADALINEUso de entradas bipolares acelera o treinamento, por que?

Limitações dos perceptrons de 1 camada
• Foi provado (Rosemblatt) que se for possível classificar linearmente um conjunto de entradas, então uma rede de perceptrons pode aprender a solução
• Um perceptron tenta encontrar uma reta que separa as classes de padrões
• Porém há situações em que a separação entre as classes precisa ser muito mais complexa do que uma simples reta, por exemplo, o problema do XOR: linearmente inseparável
X Y Z0 0 0
0 1 1
1 0 1
1 1 00 1
10
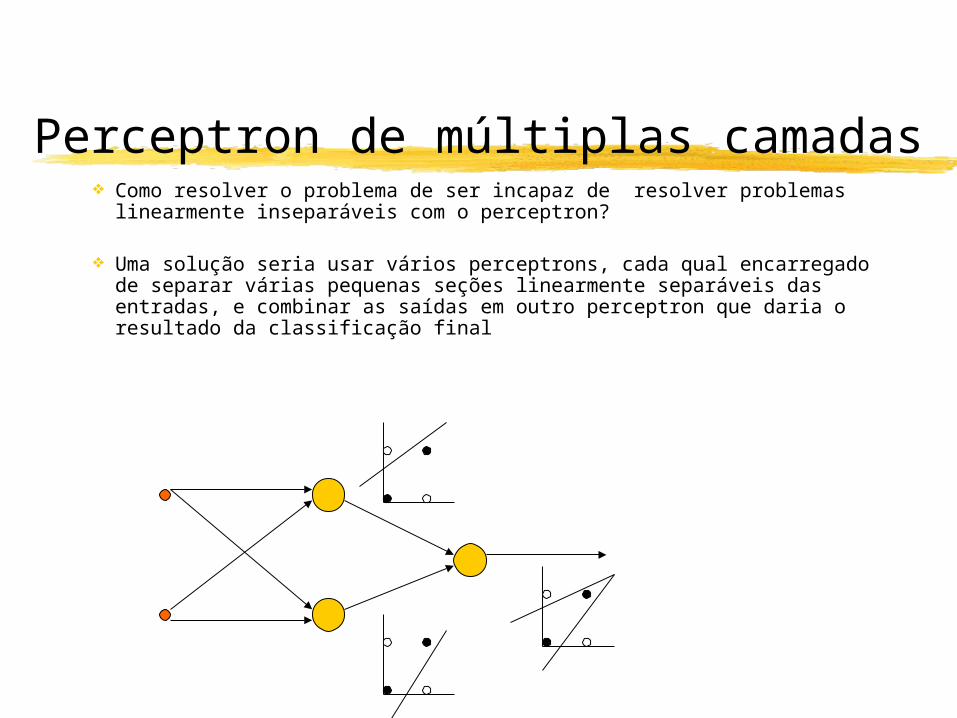
Como resolver o problema de ser incapaz de resolver problemas linearmente inseparáveis com o perceptron?
Uma solução seria usar vários perceptrons, cada qual encarregado de separar várias pequenas seções linearmente separáveis das entradas, e combinar as saídas em outro perceptron que daria o resultado da classificação final
Perceptron de múltiplas camadas

O problema com este arranjo em camadas é que os neurônios não podem aprender usando a aprendizagem do perceptron
Os neurônios da primeira camada recebem as entradas diretamente, mas os da segunda camada não conhecem o estado das entradas reais, apenas o resultado do processamento pela 1a camada
Como o aprendizado de perceptrons corresponde ao reforço de conexões entre entradas ativas e neurônios ativos, seria impossível reforçar as partes corretas da rede, uma vez que as entradas são mascaradas pelas camadas intermediárias
Perceptron de múltiplas camadas
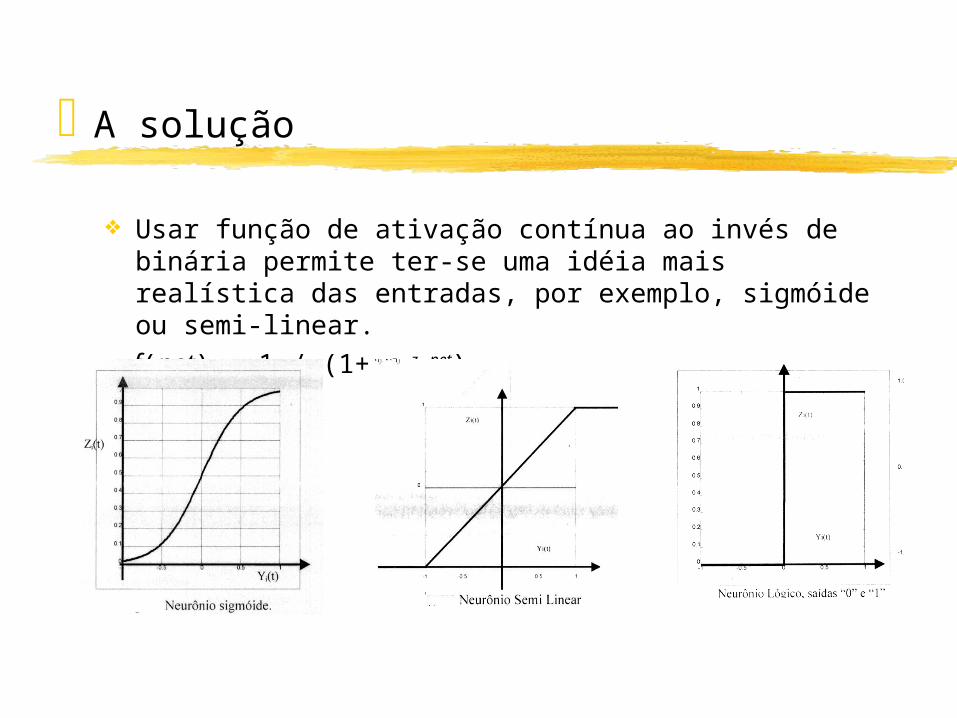
A solução
Usar função de ativação contínua ao invés de binária permite ter-se uma idéia mais realística das entradas, por exemplo, sigmóide ou semi-linear.
f(net) = 1 / (1+ e -z . net)

Arquitetura
Entrada Saída
Escondida

A solução
Algoritmo de aprendizagem:1. Iniciar pesos e limiar para pequenos valores
randômicos2. Apresentar entrada e saída desejada
Xp=x0,x1,...,xn-1, Tp=t0,t1,...,tm-13. Calcular as saídas da rede, cada camada produz:
e passa os resultados como entradas para a próxima camada. As saídas da última camada são opj
4. Adaptar os pesos
1
0
n
iipjxwy if

Algoritmo de aprendizagem (backpropagation):
4. Adaptar os pesos, começar na camada de saída e prosseguir de trás para frente
wij(t+1) = wij(t) + pj opj
Para neurônios de saída:
pj = z opj (1 - opj) (tpj - opj)
Para neurônios de camadas escondidas
pj = z opj (1 - opj) k pk wjk

Algoritmo backpropagation (prova):
• Vamos definir a função de erro como sendo proporcional ao quadrado das diferenças entre as saídas reais e desejadas para todos os padres a serem aprendidos:
• O objetivo final será minimizar esta função
• A ativação de cada unidade j para um padrão p pode ser escrita como:
)1(2
1 )(2
j
p otE pjpj
)2(ownet pii
ijpj

Algoritmo backpropagation (prova):
• A saída do neurônio j é definida como:
• Pela regra da cadeia, pode-se escrever a derivada da energia associada ao padrão p com respeito ao peso wij:
• Substituindo (2) em (4):
)3()(netfo pjjpj
)4(wnet
netE
wE
ij
pj
pj
p
ij
p

Algoritmo backpropagation (prova):
• Substituindo (2) em (4):
• uma vez que:
• exceto quando k=i, quando a expressão acima é igual a 1.
)5(
o
oww
owwwnet
pi
kpk
ij
kj
kpkkj
ijij
pj
0ww
ij
kj

Algoritmo backpropagation (prova):
• A mudança em erro pode ser definida como uma função da mudança nas entradas da rede para um certo neurônio:
• Substituindo em (4):
• Decrementar o valor da Energia, significa portanto tornar as mudanças de pesos proporcional a
)6( pjpj
p
netE
)7(owE
pipjij
p
)8(ow pipjijp opipj
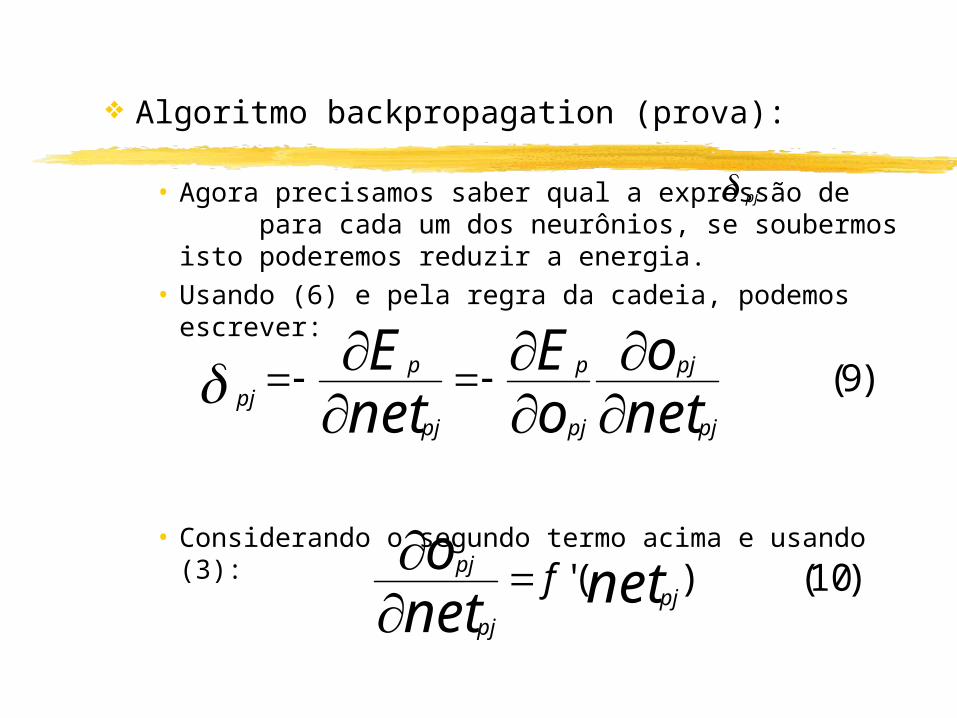
Algoritmo backpropagation (prova):
• Agora precisamos saber qual a expressão de para cada um dos neurônios, se soubermos isto poderemos reduzir a energia.
• Usando (6) e pela regra da cadeia, podemos escrever:
• Considerando o segundo termo acima e usando (3):
pj
)9(neto
oE
netE
pj
pj
pj
p
pj
p
pj
)10()(' netneto
pjpj
pj f

Algoritmo backpropagation (prova):
• Considerando agora o primeiro termo de (9) e usando (1), podemos derivar Ep com relação a opj :
• Portanto:
o que é bastante útil para neurônios de saída, mas não para neurônios em camadas intermediárias, uma vez que suas saídas desejadas não são conhecidas
)11()( otoE
pjpjpj
p
)12())((' otnet pjpjpjpjf

Algoritmo backpropagation (prova):
• Assim, se um neurônio não está na camada de saída, pode-se escrever novamente pela regra da cadeia:
também usando (2) e (6) e notando que a soma é cancelada uma vez que a derivada parcial não é zero para apenas um valor, como em (5).
)14(
)13(
kjkpk
k ipiik
pjpk
p
k pj
pk
pj
p
w
owonetE
onet
net
EoE
pk
p

Algoritmo backpropagation (prova):
• Substituindo (14) em (9), finalmente chaga-se à função que representa a mudança no erro, com respeito aos pesos da rede:
• A função acima é proporcional aos erros em neurônios subsequentes, assim o erro deve ser calculado nos neurônios de saída primeiro.
)15()(' wnet jkk
pkpjpjf

Algoritmo backpropagation (prova):
• Usando a função sigmóide como função de ativação, tem-se:
)16()1(
1)( .
eo netzpj
netf
)17()1(.
))(1)((..
)(')1(
2
.
ooeze
pjpj
netz
k
netfnetfknetz
netf

Redes RAM-based e Goal Seeking Neurons (GSN)Neurônio RAM
Dificuldades para implementar neurônios de McCulloch-Pitts
Primeiro proposto por Aleksander (1967), quando era denominado de SLAM (Stored Logic Adaptive Microcircuit)
As entradas, saídas e pesos são discretos (binários)
Adaptação através da mudança de conteúdos endereçáveis, ao invés dos pesos da conexão
Da mesma forma que em memórias RAM, existem terminais de endereçamento e terminais de dados
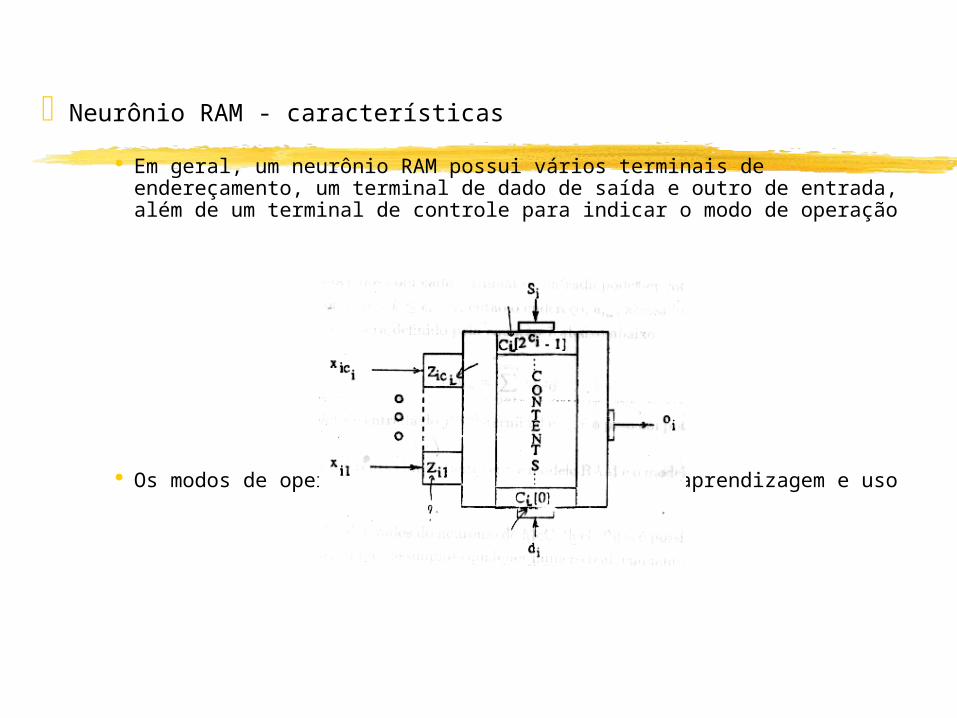
Neurônio RAM - características
Em geral, um neurônio RAM possui vários terminais de endereçamento, um terminal de dado de saída e outro de entrada, além de um terminal de controle para indicar o modo de operação
Os modos de operação de um neurônio RAM são: aprendizagem e uso

Neurônio RAM - características
Pode-se imaginar que os pesos das conexões entre neurônios do tipo RAM, seriam as potências de 2, associadas a cada terminal de entrada, para cálculo do endereço acessado
Por outro lado, alguns autores constumam denominar este tipo de neurônio como neurônio sem peso, uma vez que os pesos são fixos, não sendo utilizados durante o processo de adaptação da rede

Neurônio RAM - endereçamento e ativação
Sendo Xi=xi1, xi2,..., xic os terminais de entrada, zi1, zi2,..., zic os pesos escritos na forma de potências de 2 associados a cada entrada, a fórmula para calcular o endereço acessado pela entrada Xi será:
A função de ativação para o neurônio RAM é definida pela equação:
zxa ij
j
jijim
ci
1
][acO imii

Neurônio PLN
Baseado no neurônio RAM, adicionando a possibilidade de um tratamento probabilístico (PLN=Probabilistic Logic Neuron)
A extensão feita ao neurônio RAM é incluir um terceiro valor lógico (indefinido), além de 0 e 1
Quando o valor lógico indefinido é endereçado, a saída produzida tem uma certa probabilidade de produzir 1 e uma outra probabilidade (complementar) de produzir 0.
A interpretação deste novo valor lógico pode ser dada como uma condição de desconhecimento, sendo representado pelo símbolo u

Neurônio PLN - ativação
A função de saída do neurônio PLN é a seguinte:
O neurônio PLN requer o dobro da memória requerida pelo neurônio RAM, em função da inclusão do terceiro valor lógico
O papel do valor indefinido no neurônio PLN é fazer com que ele generalize
usssRan
sss
sss
aCaCaC
Oimi
imi
imi
i
][)1,0(
1][1
0][0

Neurônio GSN (Goal Seeking Neuron)
O neurônio GSN desenvolvido por Carvalho Filho em 1990
Assim como o neurônio PLN, o neurônio GSN baseia-se no neurônio RAM
As diferenças entre o neurônio GSN e o neurônio PLN estão nos valores que eles podem propagar, e nos modos de operação
Um neurônio GSN pode armazenar {0,1,u}, e todos estes três valores podem também ser enviados a outros neurônios e recebidos
Dependendo do estado das entradas, pode-se acessar uma única célula ou um conjunto de células

Neurônio GSN - modos de operação
O neurônio busca por objetivos diferentes quando em modos ou estados diferentes.
Há três estados ou modos de operação:
Validação: o neurônio valida a possibilidade de aprender uma saída desejada sem destruir informações aprendidas anteriormente
Aprendizagem: o neurônio seleciona um endereço e armazena a saída desejada
Uso: o neurônio produz a melhor saída com base na aprendizagem

Neurônio GSN - estrutura
Além das estruturas básicas do neurônio RAM, o neurônio GSN possui terminais de entradas desejadas: di1, di2,..., dic, os quais informam qual entrada satisfaz o objetivo procurado
Quando há valores indefinidos presentes nos terminais de entrada, tem-se acesso a um conjunto de endereços possíveis (conjunto endereçável) ao invés de um único endereço

Neurônio GSN - endereçamento
O neurônio GSN exemina o conjunto endereçável para escolher o melhor conteúdo para o objetivo procurado
O endereço fixo para as entradas com valores definidos (0,1) é dado por:
O conjunto endereçável é dado por:
uc
xi
ij
j
jijij
f
i zxa
1
1210 ,...,,, um izbaaAm
ij
m
j
f
iimi

Neurônio GSN - estado de validação
No estado de validação o neurônio procura produzir uma saída indefinida, representando a possibilidade de aprender qualquer saída saída desejada
Caso não seja possível encontrar um valor indefinido, então o neurônio pode produzir e aprender apenas um valor binário

Neurônio GSN - estado de validação
A saída oi de um neurônio é dada pela fórmula:
][][,
][,
1][,1
0][,0
aCaCaaaCAa
aCAaaCAa
o
ijiimiijim
imiiim
imiiim
imiiim
i uu

Neurônio GSN - estado de aprendizagem
O neurônio procura por um endereço que já armazene a saída desejada Se isto não for possível, então um endereço
que contém um valor indefinido é utilizado A fórmula para o endereço procurado é:
0/)/(
0/)/(
dAdAdaii
iiiim uARan
ARan

Neurônio GSN - estado de aprendizagem
Depois de calculado o endereço e armazenada a saída desejada, são geradas as entradas desejadas que acessam o seu conteúdo:
Estas entradas desejadas (sinais de saída)
se conectam às saídas desejadas (sinais de entrada) dos neurônios na camada anterior
azxxd imijj jjijci 1

Neurônio GSN - estado de uso
O objetivo neste estado é produzir o valor binário de maior ocorrência no conjunto endereçável:
0/1/
0/1/1
1/0/0
AAAAAA
oii
ii
ii
i
sssu
sss
sss

Redes GSN
Arquitetura piramidal feedforward com aprendizagem supervisionada com duas fases de processamento: aprendizagem e uso
ENTRADAS
11100100
11100100
11100100
11100100
11100100
11100100
11100100

Redes GSN - fase de aprendizagem
• Subfase de Validação
Os neurônios estão no estado de validação, ou seja cada neurônio informará sua capacidade de aprender alguma coisa
A rede passa informações para frente, e o objetivo é produzir um valor indefinido no último neurônio

Redes GSN - fase de aprendizagem
• Subfase de Aprendizagem
Os neurônios estão no estado de aprendizagem, a operação da rede é feedbackward, da última camada em direção à primeira camada
Os neurônios são inicializados com valores indefinidos em seus conteúdos
Quando a rede produz uma saída indefinida, é sinal que houve rejeição de resposta para o padrão de entrada

Redes GSN - fase de uso
Os neurônios estão no estado de uso e a rede procura a saída que melhor representa a aprendizagem realizada, pois cada neurônio procura pela saída binária de maior probabilidade no conjunto endereçável

• Idealizadas por Carpenter e Grossberg, 1987
• Resultado da pesquisa sobre o problema da estabilidade/plasticidade: os algoritmos mantém a plasticidade requerida para aprender mais padrões, enquanto previnem a modificação contínua dos padrões que foram previamente aprendidos.
• Os dois subparadigmas ART mais comuns são: ART1, que aceita entradas binárias apenas, e ART2, que aceita entradas tanto binárias como contínuas.
• A rede ART recebe um vetor de entrada e o classifica em uma dentre um conjunto de categorias, dependendo dos padrões armazenados com os quais ele mais se parece.
Redes ART (Adaptive Resonance Theory)
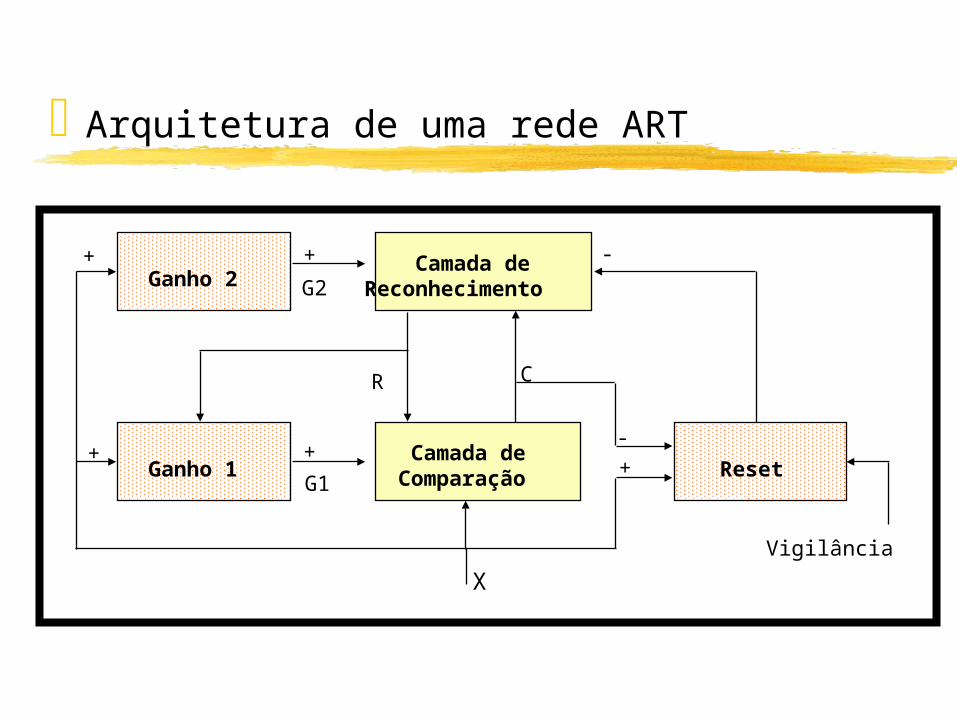
Arquitetura de uma rede ART
Ganho 2 Camada deReconhecimento
Ganho 1 Camada deComparação Reset
G2
+
G1
+
R
+
+
C
-
-
+
Vigilância
X

Arquitetura de uma rede ART
A decisão de classificação é indicada na Camada de Reconhecimento.
Quando um padrão armazenado que casa com o vetor de entrada for encontrado, conforme um limiar de vigilância, o padrão é modificado para tornar-se mais parecido com o vetor de entrada.
Quando o vetor de entrada não casa com nenhum padrão armazenado, então uma nova categoria de classificação é criada através do armazenamento de um novo padrão que é o próprio padrão de entrada.
O problema da estabilidade/plasticidade é resolvido pois nenhum padrão armazenado é modificado se ele não casa com a entrada corrente, e novos padrões podem criar novas categorias de classificação.
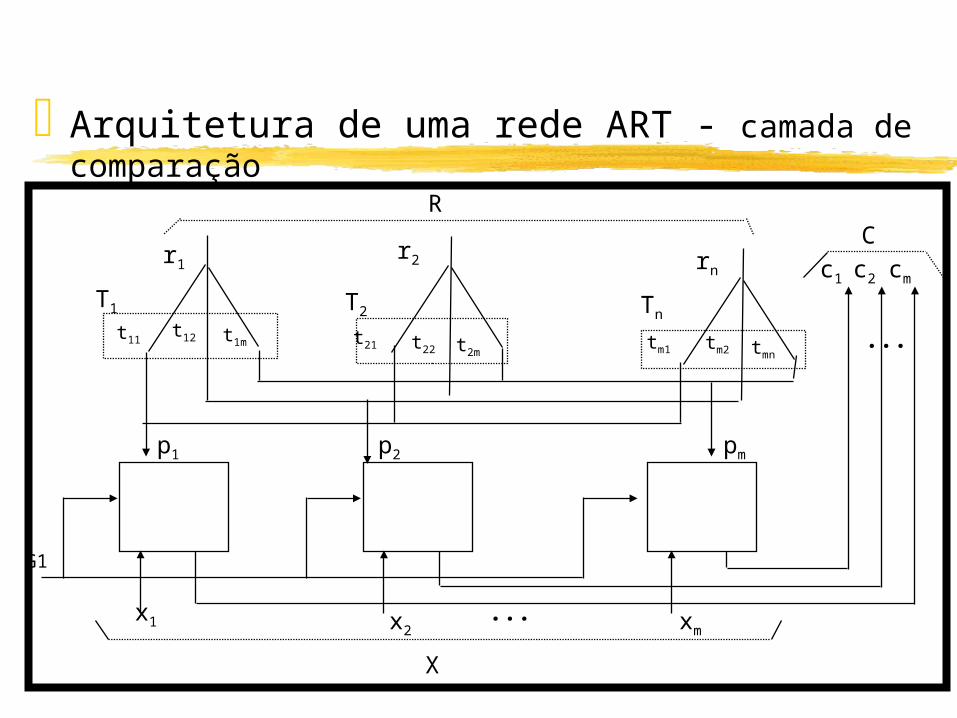
Arquitetura de uma rede ART - camada de comparação
G1
x1 x2 xm
X
...
...
c1 c2 cm
C
t11t12 t1m t21 t22 t2m
tm1 tm2 tmn
T1 T2 Tn
r1r2 rn
R
p1 p2 pm

Arquitetura de uma rede ART - camada de comparação
• Inicialmente propaga o vetor de entrada X inalterado para a camada de reconhecimento.
• Cada neurônio recebe 3 entradas binárias: componente xi da entrada X, sinal de feedback pj (soma ponderada de rj) e G1. Regra 2-dentre-3.
• Ganho é inicializado em 1, e R em 0, assim C é inicialmente X.
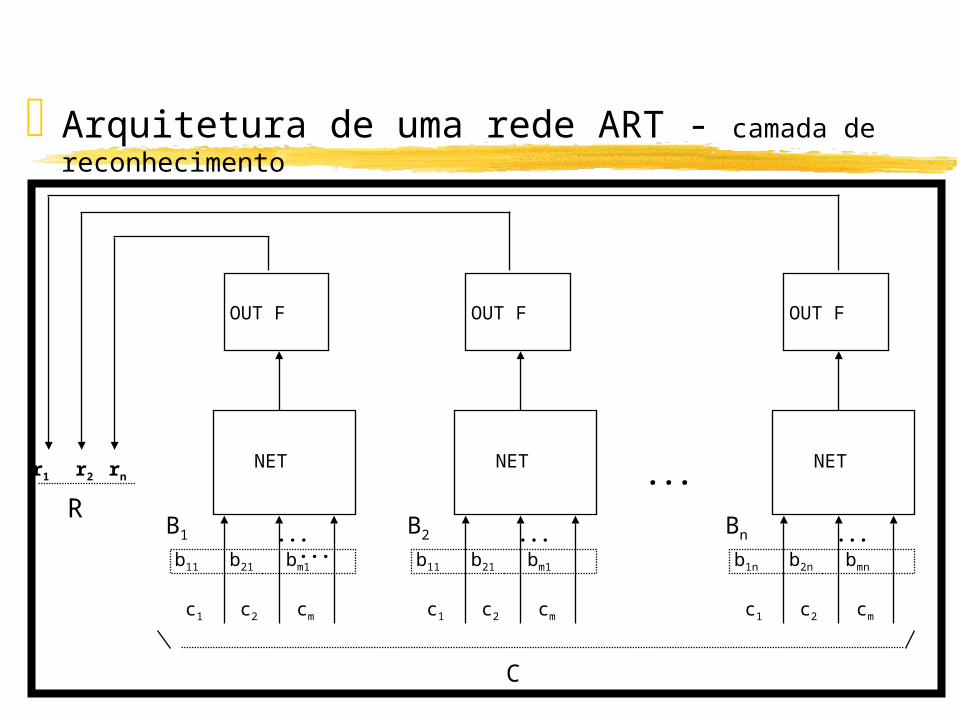
Arquitetura de uma rede ART - camada de reconhecimento
...b11 b21 bm1
B1
OUT F
c1 c2 cm
NET
......
b1n b2n bmn
Bn
OUT F
c1 c2 cm
NET
...b11 b21 bm1
B2
OUT F
c1 c2 cm
NET...
C
r1 r2 rn
R

Arquitetura de uma rede ART - camada de reconhecimento
• A função desta camada é classificar o vetor de entrada.
• Cada neurônio tem associado um vetor de pesos contínuos Bj.
• Regra de disparo do tipo “winner-takes-all”: apenas o neurônio que mais se aproxime d vetor de entrada é quem dispara.
• Os pesos Bj representam uma categoria (classe) de vetores de entrada.
• Uma versão binária do mesmo padrão é também armazenada em um conjunto de pesos Tj correspondente na camada de comparação

Arquitetura de uma rede ART - camada de reconhecimento
• Os neurônios desta camada computam o produto interno de seus pesos pelo vetor C.
• O neurônio vencedor será aquele que tiver os seus pesos mais parecidos com os componentes do vetor C.
• Existem conexões excitatórias ligando um neurônio a ele mesmo, e inibitórias ligando a saída de um neurônio às entradas dos outros neurônios.

Arquitetura de uma rede ART - G2, G1, Reset
Ganho 2– A saída G2 é o OU lógico dos componentes xi do vetor de entrada
binário X.
Ganho 1– Se todos os componentes de R são 0 então a saída Ga é o OU lógico
dos componentes xi do vetor de entrada binário X, caso contrário, G1 é 0.
Reset– A função deste módulo é medir a similaridade entre os vetores X e
C. – Se o quociente entre onúmero de 1’s em C pelo número de 1’s em X
estiver abaixo do fator de vigilância, então Reset é ativado para desabilitar o neurônio que disparou na Camada de Reconhecimento.

Rede ART - processo de classificação
A operação de uma rede ART, também referida como processo de classificação, consiste de 5 fases:
– Inicialização– Reconhecimento– Comparação– Busca– Treinamento

Rede ART - fase de inicialização
• Os pesos dos vetores Bj (bottom-up) são inicializados com os mesmos valores: bij=L/(L-1+m), i,j (m é o número de componentes do vetor de entrada, e L é normalmente 2).
• Os pesos dos vetores Tj (top-down) são todos inicializados com 1
• O fator de vigilância pode ficar na faixa de 0 a 1.

Rede ART - fase de reconhecimento
• Os pesos Bj de cada neurônio representam uma única categoria de classificação. Inicialmente o vetor C copia o vetor X.
• No passso seguinte, cada neurônio da camada de reconhecimento efetua um produto intero de seu vetor de pesos Bj pelo vetor C.
• O neurônio com pesos mais próximos do vetor de entrada irá disparar sozinho, ou seja um simples componente rj será igual a 1.

Rede ART - fase de comparação
O único neurônio que disparou na Camada de Reconhecimento propaga um 1 de volta à Camada de Comparação através de seu sinal de saída rj
• O algoritmo de treinamento e a inicialização deverão garantir que cada T seja formado por valores binários e cada Bj seja uma versão contínua de Tj

Rede ART - fase de busca
• Se o grau de similaridade entre os veores X e C não for suficiente para atender ao fator de vigilância, então outros padrões armazenados precisam ser pesquisados para se encontrar o que mais se aproxima da entrada.
• Isto é conseguido através da inibição provida pelo sinal Reset
• O processo de busca se repete até que um dos seguintes eventos aconteça:
1. Um padrão que casa com X é encontrado e o fator de vigilância é satisfeito
2. Todos os padrões armazenados são selecionados, porém nenhum deles satisfaz o fator de vigilância, e, neste instante os neurônios na Camada de Reconhecimento são inibidos. Neste caso a busca irá terminar num neurônio descomprometido com os pesos em 1.

Rede ART - fase de treinamento
• O algoritmo de aprendizagem deve ser aplicado tanto nas buscas com sucesso quanto nas buscas sem sucesso.
• No caso de uma busca com sucesso, a rede deverá entrar num ciclo que modificará tanto T quanto Bj , o objetivo é que o vetor X atualize os pesos de sua categoria de classificação: bij = (Lci)(L-1 + ck)
ci é o i-ésimo componente do vetor de saída da Camada de Comparação
j é o número do neurônio vencedor na Camada de Reconhecimentobij é o peso em B conectando o neurônio i na camada de
comparação ao neurônio j da camada de reconhecimentoL é uma constante > 1, normalmente L=2/
Tij = ci
• No caso de uma busca sem sucesso, um neurônio previamente desalocado é quem será usado.





























