Embed Size (px)
Citation preview

Recombining Building Blocks (again)in simple building block functions
and in natural genomesor
How two scales of optimisation can be better than one
or Another real royal road
Richard A. Watson
Natural Systems group
ECS, Southampton University, UK

blocks - 2Richard Watson
Overview
• Work in progress, no clever analysis, just some concepts
• Relationship between sex, problem decomposition, coev.
• Discussion of concatenated BB functions• Mutation vs crossover in fully-deceptive blocks• When is a block not a block? (when its an atom with a big alphabet)
• Two scales of optimisation in partially deceptive subfunctions
• What does that mean for a biological model?• Generalisations
• Natural properties of genomes

blocks - 3Richard Watson
Objectives (wish list)
• Understand sufficient conditions (if any) for evolving population to be required to use building block combination
• A ‘Royal Road’, based on building blocks, allowing use of linkage information – and, that isn’t too contrived
• Specifically, is there a kind of problem space where• GA >> hill climber (same assumptions of epistasis and linkage),
• that uses population for combination of building blocks/search combinations of blocks/move in block-sequence space (not just preserving ‘common good’)
• And, keep it simple/intuitive! biologically plausible • e.g. not HIFF (Sudholt), not gap function, not intersecting ridges

blocks - 4Richard Watson
Some thoughts about contrivance
• In general• Some (diverse) points in genotype space are easy to reach
• Recombination of genotypes from these areas results in a jump to a new genotype that is high in fitness, this peak is otherwise unreachable
• Why is the peak just where it is?
• The building block intuition is that• A-good, B-good→A+B-better
• A-easy, B-easy→A+B-easy??

blocks - 5Richard Watson
Intersecting ridges
klogk
block 1
block 2
-----------
block 1 block 2
-----------
block 1 block 2
-----------
block 1 block 2
T klogk

blocks - 6Richard Watson
An old favourite: Concatenated trap functions
• i.e.• Separable sub-functions
• With sub-optimal peak in each sub-function
• In much prior work with these it is supposed that:• Selection on bits not sufficient and not necessary
• Selection on blocks is necessary and sufficient
• precluding all utility of selection on bits, as in fully-deceptive trap functions, maximises the advantage of selecting on blocks (?) e.g.
unitation0 1 2 … k
fitness
k-1

blocks - 7Richard Watson
However
• If the selective gradient within a block is not useful, then all means to find a good block are going to be exponential in k. Hence popsize needs to be exp. in k.
• Hence assumption that blocks size, k, must be small (constant, not fraction of L)
• Afterall, if algorithmic advantage is gained by dividing a problem into pieces, then the smaller the pieces the better, right?
• And if it gets too small, so that mutation on bits is sufficient, we can always mislead it → hence, fully-deceptive traps
• Exp in k is not a problem if k is small, and • At least its not exponential in L, right?
• Well, yes – but this scenario doesn’t require recombination of good blocks… the smaller the blocks, the easier it is to do without BB recombination

blocks - 8Richard Watson
Crossover vs mutation without linkage info
• Uniform xover = ‘common good’ + macromutation• 111111111111111111000000111111 parent A• 111111000000111111111111111111 parent B• 111111??????111111??????111111 offspring
• This utilises information from the population to ‘identify’ which parts to randomise – giving expected time exponential in k (not L), regardless of linkage.
• A mutation hill-climber couldn’t do this without linkage information.
• But it doesn’t transfer good blocks from one individual to another – there’s no building-block story required
• Overall time still exp in k (at best) → requires small blocks.

blocks - 9Richard Watson
Crossover vs ‘macromutation’ with linkage info
• E.g. two-point xover = ‘common good’ + recombination of segments that disagree
• 111111111111111111000000111111 parent A• 111111000000111111111111111111 parent B• 111111AAAAA111111BBBBB111111 offspring
• Utilises common good, AND if linkage is tight, expected time to find appropriate crossover points is better than L2.
• Does transfer good blocks from one individual to another!
• However, if popsize exponential in k, then overall time is still exponential in k (at best) → requires small blocks.
• And, if use of linkage information is allowable, macromutation hill-climber is also order L22k
• i.e. pick two crossover points, randomise all bits in between.

blocks - 10Richard Watson
Reconsider assumptions
• Fully-deceptive trap function assumes optimisation at only the block scale is ideal. i.e.• Selection on blocks is necessary and sufficient
• Selection on bits not sufficient and not necessary
• After all, to the extent that selection on bits is useful, selection on blocks seems redundant…? That is, if …• selection on bits can find good blocks,
• and selection on blocks finds good genotypes then
• shouldn’t it be the case that selection only on bits is sufficient to find fit genotypes?

blocks - 11Richard Watson
…
• In order to show that selection on blocks is required• Selection on bits must be insufficient.
• But maybe• Selection on blocks may not be sufficient on its own either, and
• Selection on bits might be required too.
• Finding utility in selecting on blocks need not preclude some utility in selecting on bits. Can we utilise selection on bits to find good blocks, without precluding utility of selecting on blocks?

blocks - 12Richard Watson
Consider, partially-deceptive sub-function
• Hill-climbing (i.e. selection on bits) will reach one or the other optimum in time O(klogk) • likewise, mutation and selection, even in a small population
• Prob. 0.5 of reaching high optimum, in each block.
• As before, two point recombination can bring good blocks together in time at worst L2. (to find req. crossover points)
• There’s no need for any process that’s exponential in k, so we can use large k, without impeding the GA.• k can be a constant fraction of L, and its all still polynomial• (So long as good blocks are maintained in the population)
• Whereas hill-climber will take time exponential in L
unitation0 1 2 … k
fitness
k-1

blocks - 13Richard Watson
Likelihood of hill-climber succeeding
• If HC doesn’t arrive at AB it will be doomed
• But if some indivs arrive at Ab and some arrive at aB, then they can be crossed to find AB• But if you had enough diversity to find both Ab and aB you would
have enough diversity to find AB!
• But this isnt true for many blocks
• the probability of finding B blocks all correct in one individual is exp. small in B
• whereas there’s a reasonable probability of having each block correct in at least one individual, even with small popsize
• Consider 2 blocks: There are 4 possible results of a local hill climber: ab, Ab, aB, AB.

blocks - 14Richard Watson
Given large k (constant fraction of L)
• Uniform xover fails, and macromutation (even with the use of linkage information) also fails,
• And more to the point, both of these become far removed from performance of two-point crossover with tight linkage, O(L2)
• Large k is required to properly separate performance of algs that do not recombine building-blocks from performance of algs that do
• In concatenated trap functions with large k• Selection on bits not sufficient but is necessary
• Selection on blocks is necessary but not sufficient
• Local optimisation at both scales is required

blocks - 15Richard Watson
So what?• Partially deceptive trap functions with large k are (in principle) better
at distinguishing ability of sexual population from asexual population and hill-climbers
• The contribution is more conceptual than technical –
• I suggest that thinking of a GA as a mechanism for manipulating blocks, has blinded to importance of also utilising selection on bits
• The root of the problem is that a block is not really a block (wrt selection) if there’s no selection ‘inside’ it –its just ‘atom’ with a big alphabet. And then there’s no point to it – fully-deceptive blocks ‘block-wise one-max’ where each step is exp in k.
• But utilising two-scales of optimisation, local optimisation at bit scale (via mutational variation), and local optimisation at block scale (via recombination) can do something interesting• mutation doesn’t merely provide variation for recombination to act on, it
provides ability to follow selective gradients in nucleotide sequence space /= selective gradients in allele frequency space

blocks - 16Richard Watson
Generalising required properties of intra-block epistasis
• Doesn’t have to be as contrived as a ‘trap’ function in the sense of complementary optima
• Single-peaked wont do – selection on blocks is not required
• Random intra-gene landscapes won’t do – selection on bits is not useful for finding good blocks
• NKs won’t do either – direct trade-off between • Utility of local adaptation vs
• Non-utility/insufficiency of local adaptation
• Necessary and sufficient: multiple peaks, with smooth-ish slopes, with significant separation between them

blocks - 17Richard Watson
Does that help with the evolutionary biology perspective of sex?
• Genes as blocks
• Usually think of blocks meaning groups of ‘genes’
• But the blocks should contain many mutational units (not many genes)
• In natural genomes, mutational scale is very different from recombinational units

blocks - 18Richard Watson
Assumptions for an epistasis model of a natural genome
• Genes contain many nucleotides
• Nucleotides within a gene are strongly epistatic
• Epistasis between genes is relatively weak
• Thus, large disjoint sets of nucleotides are grouped both functionally and physically
• Intra-gene epistasis creates multiple local optima (in nucleotide-sequence-space)• That are significantly distant from one another in nucleotide
sequence space
• That have significantly different fitnesses
• Following selective gradients in nucleotide sequence space from a given ancestral sequence will not always result in discovery of the same local optimum

blocks - 19Richard Watson
Inter-gene interactions
• Assume that the fitness of a genotype, G, will be given by the fitness of each of the genes, g1, g2,…,gB, with no epistasis between genes (i.e. multiplicative fitness):
• where f(gi) is the fitness contribution of the ith gene.
B
iigfGF
1
)ˆ()ˆ(

blocks - 20Richard Watson
e.g. Intra-gene landscape (i.e. one sub-function)
• The fitness contribution of each gene, g, will be an epistatic function of some nucleotides that it contains defined using P randomly positioned peaks:
• Where bp is a locally optimal sequence, ωp is the height of peak bp, and h(x) defines the shape of the peak
P
ppp bghgf
1
)ˆˆ(1)ˆ(
xe
xh1
11)(

blocks - 21Richard Watson
Intra-gene landscape, 2D illustration• Using 10 randomly positioned peaks with heights
j=1/(1+j) to create a range of heights.
00.5
11.5
22.5
33.5
44.5
55.5
66.5
f(g)

blocks - 22Richard Watson
Intra-gene landscape; A couple of 1D illustrations
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
• Not as contrived as the trap sub-function – its just a multi-peaked sub-function
• Hill climbing from a random start position might not always reach the same peak.

blocks - 23Richard Watson
Overall landscape
• Represented using the product of two 1-D intra-gene landscapes
1
3
5
7
9
11
13
15
17
19
21
23
25S1 S
3 S5 S
7 S9 S11 S
13 S15 S
17 S19 S
21 S23 S
250
5
10
15
20
F(g)
f(g 1 )
f(g 2 )

blocks - 24Richard Watson
Simulation parameters
• 25 genes of 25 bits each.
• 10 randomly positioned peaks in each gene.
• “if competing block solutions are maintained long enough”… i.e. first good-ish block doesn’t fix before others have chance to find a better one.
• population subdivision• 30 demes of 10 individuals each. Rank selection
• Migration rate = 1 individual per deme per 10 generations is a migrant.
• (Converged initialisation)
• 30 runs per point; ave of ave, and ave of best

blocks - 25Richard Watson
Asexuals, to low-rate crossover, to uniform
• A low per-locus crossover rate, that can keep nucleotides of a gene together but assort genes, is preferred over asexuals (1000 fold) and over free recombination of nucleotides (10000 fold).
xoverperlocus rate (migration 0.0005, mut 0.0125)
1.E+00
1.E+01
1.E+02
1.E+03
1.E+04
1.E+05
1.E+06
1.E+07
1.E+08
1.E+09
1.E+10
1.E+11
1.E+12
1.E+13
1.E+14
1.E+15
1.E+16
xover 0.0000 xover 0.0062 xover 0.0125 xover 0.0250 xover 0.0500 xover 0.1000 xover 0.5000
ave of ave
ave of best
Fitn
ess
afte
r 10
00 g
ener
atio
ns
Crossover rate

blocks - 26Richard Watson
Block-wise crossover, and shuffled control
crossover blocksize (migration 0.0005, mut 0.05)
1.E+00
1.E+01
1.E+02
1.E+03
1.E+04
1.E+05
1.E+06
1.E+07
1.E+08
1.E+09
1.E+10
1.E+11
1.E+12
1.E+13
block5 block25 block50 shuf f led
ave of ave
ave of best
Fitn
ess
afte
r 10
00 g
ener
atio
ns
Linkage model

blocks - 27Richard Watson
Subdivision not essential
migration rates (blockwise 25, mut 0.05)
1.E+00
1.E+01
1.E+02
1.E+03
1.E+04
1.E+05
1.E+06
1.E+07
1.E+08
1.E+09
1.E+10
1.E+11
1.E+12
1.E+13
mig0 mig0.00025 mig0.0005 mig0.001 mig1
ave of ave
ave of best

blocks - 28Richard Watson
Mutation sensitivity (block-wise crossover)
mutation rate (migration 0.0005, blockwise 25)
1.E+001.E+011.E+021.E+031.E+041.E+051.E+061.E+071.E+081.E+091.E+101.E+111.E+121.E+131.E+141.E+151.E+16
ave of ave
ave of best

blocks - 29Richard Watson
observations
• Crossover enables large specific changes in genotype space• Not small ones
• Not random ones
• Low mutation wont do
• High mutation wont do
• Both is OK• in two phases
• Still needs linkage info (nearest basin boundary is k/2 bits away, if mutations affect many blocks, it’ll trade improvements for steps backward)
• Q what can a GA do that MMHC with two scales of mutation cannot?• Do the things that are put together _need_ to be found in parallel? need
• Gap function!

blocks - 30Richard Watson
Conclusions
• Simple concat BB functions DO show adv of recombining blocks if blocks are large, not fully deceptive, and tightly linked
• Has ‘natural’ interpretation
• If you don’t need/cant use selection any selective gradients on parts within a block, then finding a block takes time exp in blocksize, → blocks must be small
• Although dividing a problem into small subproblems seems like a good idea, the other way to look at it is that the smaller the block the better able is mutation to find the block by chance (and the less essential is the combination of blocks)

blocks - 31Richard Watson
Conclusions 2
• The benefit of sexual recombination in natural genomes may derive simply from their most basic genetic architecture: the fact that genomes contain thousands of functionally and physically particulate genes, each composed of thousands of strongly epistatic nucleotides.

blocks - 32Richard Watson

blocks - 33Richard Watson

blocks - 34Richard Watson

blocks - 35Richard Watson

blocks - 36Richard Watson
Motives from Evolutionary Biology
• In population genetics, sex defines the units of selection. and forces selection to act on these ‘particulate’ units… specifically, genes (not organisms, not genotypes, hence ‘selfish gene’)• Thus, evolution = movement in allele freq space
• In Evolutionary Biology view (both Wright and Fisher)• Alleles of different genes are essentially unlinked (freely
recombining=uniform xover)
• If they’re tightly linked then they behave as if a single allele
• There is never any utility in discussing selection on combinations of alleles – either a pair of alleles recombine or they’re one allele
• Is that view correct?

blocks - 37Richard Watson
Contrast with EC
• Some kinds of EC propose sex as a means to manipulate ‘building-blocks’. – to select on ‘composite’ things.
• In a building-block function, we suppose that• Selection on bits not sufficient
• Selection on blocks is necessary
• Ideally(?), precluding the utility of selection on bits, as in fully-deceptive trap functions, should secure the requirement and maximise advantage of selecting on blocks
• But that just means that the blocks are really macro ‘atoms’ – like an allele with 2K alleles

blocks - 38Richard Watson
No use for block concept?
• If selection acts only on blocks – then they’re not really blocks (wrt selection)
• If selection acts on bits, then it cant act on blocks as well
• Maybe there’s no use for block concept?
• Is there ever any circumstance where two-scales of selection are required to understand what’s going on? – forcing us to treat one of these scales as a combination of units from the lower scale, rather than an macro unit.

blocks - 39Richard Watson
Interaction of recombination and mutation
• Everybody knows that (even if you believe that recombination does something clever and important with blocks) mutation is required to provide the variation for recombination to act on. Is that all it does?
• Note that recombination and point mutation in biological systems operate on units at very different scales:• Spontaneous point mutation facilitates movements in nucleotide sequence
space
• Recombination manipulates alleles, each containing thousands of nucleotides; hence facilitates movement in allele sequence space
• What if• mutation doesn’t merely provide variation for recombination to act on, it
provides ability to follow selective gradients in nucleotide sequence space /= selective gradients in allele frequency space
• Interaction of mutation and recombination → two scales of optimisation

blocks - 40Richard Watson
Simple analysis: with recombination
k
block 1
block 2
-----------
block 1 block 2
-----------
block 1 block 2
-----------
block 1 block 2
T k

blocks - 41Richard Watson
For pop gen
• Pop gen of sex view depends on alleles being mutational neighbours – here neighbours in crossover variation are a subset of mutational neighbours• No neighbours in allele seq space that are not neighbours in
nucleotide seq space
• But natural alleles differ at many nucleotide sites

blocks - 42Richard Watson
notes
• It means we can use a simplified linkage model: inter-block crossover points only (no partial linkage nec.)

blocks - 43Richard Watson

blocks - 44Richard Watson

blocks - 45Richard Watson

blocks - 46Richard Watson
• So, can selection operate on both bits and blocks?

blocks - 47Richard Watson
• Either genes are tightly linked and behave as if a single allele, or they’re unlinked
• Blocks are only meaningful to selection if they’re heritable – and bits are only meaningful to selection if they’re heritable (individually).
• If sex defines the unit of selection, does that mean the internals of building-blocks are irrelevant?• In order for a composite to be a meaningful composite, its parts
have to be significant.
• However, recombination and spontaneous point mutation operate at quite different scales. • Is variation at these two different scales (together) the key to
unifying EC BB view of sex with EB view that sex defines the units of selection?

blocks - 48Richard Watson
• Are natural genes ‘atomic’ or ‘composite’ things?
• Are ‘genes’ in a GA ‘genes’ or ‘nucleotides’?
• If sex defines the unit of selection, are the internals of the gene irrelevant?
• Are building-blocks in a GA ‘genes’ or ‘groups of genes’?
• For a block to be group, it must have meaningful component parts.

blocks - 49Richard Watson
Overview
• (Supposed) Preconditions for utility of selecting on blocks• Selection on bits not sufficient and not necessary
• Selection on blocks is sufficient and necessary
• An old favourite (that does not require BB combination!)• Concatenated trap functions (fully-deceptive, with small k)
• Preserving common alleles + macro-mutation (exp in k)
• Uniform vs two-point
• Concatenated trap functions with large k• Selection on bits not sufficient but is necessary
• Selection on blocks is not sufficient but is necessary
• Local optimisation at both scales is required
• A slightly less contrived (more believable) example

blocks - 50Richard Watson

blocks - 51Richard Watson

blocks - 52Richard Watson

blocks - 53Richard Watson

blocks - 54Richard Watson

blocks - 55Richard Watson
Overview2
• (Supposed) Preconditions for utility of selecting on blocks• Selection on bits is insufficient (and not required)
• Selection on blocks is sufficient
• An old favourite (that does not require BB combination!)• Concatenated trap functions (fully-deceptive, with small k)
• Preserving common alleles + macro-mutation (exp in k)
• Uniform vs two-point
• Concatenated trap functions with large k• Selection on bits is required (but insufficient)
• Selection on blocks is insufficient (but required)
• Local optimisation at two-scales
• A slightly less contrived (more believable) example

blocks - 56Richard Watson
Overview
• What do population genetics models for the benefit of sexual recombination look like• Linkage disequilibrium• Fisher/Muller• Muller’s Ratchet• Deterministic mutation hypothesis
• Contrast with computational ideas for benefit of sex• Why are they so different?• Selection on individual alleles vs combinations of alleles
• Wright vs Fisher
• A simple model where selection on more than one level of unit is required
• What this means for Wright vs Fisher and benefit of sex

blocks - 57Richard Watson
Recombination of EC and EB
Evolutionary Computation (EC)
Genetic AlgorithmsEvolutionary Algorithms
Evolutionary Biology (EB)Population Genetics
Evolutionary Genetics
Recombination(Crossover)
Evolutionary Computation
Evolutionary Biology

blocks - 58Richard Watson
Population genetics
• The study of genetic variation within a population
• The mathematical, formal kind of evolutionary biology• Origins in The Modern Synthesis, Fisher, Haldane, Wright 1930s
• Between Darwinian theory of evolution and Mendelian genetics
• Solved the problem of loss of variation under blending inheritance
• Research questions such as• How does the frequency of a beneficial allele in a population
change over time?
• What is the probability that it goes to ‘fixation’ or is ‘lost’ from the population?
• What would you expect the variation in a population to look like if it was all neutral?

blocks - 59Richard Watson
Sexual reproduction
diploid parent cells
meiosis
parent one parent two
haploid gametes
syngamy
diploid offspring cell

blocks - 60Richard Watson
Sexual recombination
parent one parent two
Chromosomal reassortment

blocks - 61Richard Watson
Sexual recombination crossover
parent one parent two

blocks - 62Richard Watson
What’s the difference really?
• Both chromosomal reassortment and crossover result in sexual recombination – new combinations of genes in the haplotypes
• If genes are on different chromosomes they recombine with probability 0.5
• If genes are on the same chromosome they recombine with probability between 0 and 0.5 depending on their ‘genetic distance’

blocks - 63Richard Watson
‘Crossover’ in genetic algorithms
parent one parent two
parent one parent twoOne-point crossover
Uniform crossover

blocks - 64Richard Watson
What is recombination good for?
• Well what does recombination do?
• It reduces the probability that two alleles in a parent both appear in the offspring…
• Or it creates the possibility that two alleles that did not both appear in either parent may appear together in the offspring…
• One is just the flip-side of the other…

blocks - 65Richard Watson
Genetic linkage, linkage (dis)equilibrium
• Linkage equilibrium: joint frequencies of alleles are product of marginal frequencies• i.e. f(AB)=f(A)*f(B)• i.e. no particular combinations of alleles are over or under
represented
• Linkage disequilibrium (genetic linkage)• Any deviation from the above
• Physical linkage• The tendency of alleles to travel together during recombination
due to physical proximity on the chromosome
• Under uniform crossover (free recombination) there is no physical linkage
• Returns alleles to linkage equilibrium • The more recombination – the less linkage disequilibrium

blocks - 66Richard Watson
Population Genetics and sex
• Bear in mind that reversion to asexual reproduction (parthenogenesis) is readily available in most species (except mammals)
• Pop. Gen. models for the benefit of sex have many flavors• e.g. Single locus models, rapid adaptation to changing or
oscillating environment (esp. parasites), DNA repair.• I’m going to focus only on 3 that involve adaptive benefit of
recombination
• If sex reduces linkage disequilibrium:• then for a benefit we need
• a) a reason for LD. • b) a benefit to reducing it.

blocks - 67Richard Watson
Fisher/Muller hypothesis (1930)
A
B
A
B
A+B
• Linkage disequilibrium created by new mutations in finite populations.
• Decrease in L.D. beneficial because removes competition between simultaneously segregating beneficial alleles i.e. sex is advantageous because it allows alleles to be selected for independently
• See also: ‘traffic problem’, clonal interference, Hill and Robertson effect.
time
Proportion of population

blocks - 68Richard Watson
Muller’s Ratchet
• In finite populations with mutation• If every copy of a good genotype has acquired one or more deleterious
mutations then an asexual population cannot recover the superior wild type. One click of the ratchet.
• But a sexual population can cross two half-unmutated individuals to recover an unmutated individual.
• Assumes no elitism, no back mutations, (no beneficial mutations).• Complement of Fisher/Muller: combination of good non-mutants vs
combination of good mutants (start in high frequency vs start in low frequency)
• Pro• Deleterious mutations more common than beneficial mutations
(co-occurrence more likely)• Cons
• Both models only apply to finite pops• Charlesworth: time for a click VERY long on large pops.

blocks - 69Richard Watson
Deterministic mutation hypothesis (Kondrashov 1989)
• Assume negative epistasis: two mutants worse than twice as bad as one
• L.D. created because selection removes double mutants faster, giving over-representation of single-mutants
• Reducing L.D. is good because: this L.D. decreases variance in mutation number, reducing effectiveness of subsequent selection (if you had double-mutants you could get rid of mutations quicker)
• Recombination decreases L.D., (recreating double mutants) increasing efficacy of selection
• Pros.• Deleterious mutations more common than beneficial mutations (co-
occurrence more likely)• Applies in infinite pop size (no drift) hence ‘deterministic’• Empirical investigations underway to measure epistasis of single and
double mutants

blocks - 70Richard Watson
From an EC point of view
• There’s no problem here from EC point of view. • There are no local optima – hill-climber or population with elitism
makes all issues disappear
• In EC • we look for scenarios showing principled difference in time to find
fittest genotypes (e.g. polynomial versus exponential)
• Something that a simpler algorithm e.g hill-climber couldn’t do

blocks - 71Richard Watson
A slightly more general view?
• Pop gen models view sex as reducing linkage disequilibrium
• Enabling selection to act on individual alleles
• Alternatively, we can see sex as defining the unit of selection – a la Dawkins, Williams
• In pop gen this is taken to define what an individual allele is, but in evolutionary computation we do not think of it as ‘atomic’
• The building-block hypothesis says that GA works well when it does because it searches combinations of ‘schema’
• Tightly physicially linked alleles… but not individual alleles

blocks - 72Richard Watson
What’s an allele anyway?
• Pop. Gen. models for benefit of recombination follow assumption of free recombination (uniform crossover)
• Obviously, there isn’t free recombination of nucleotides – physical linkage permits selection on sets of nucleotides
• In pop. gen. an allele is defined as the particulate unit of inheritance
• If loci are not physically linked then selection acts on individual loci
• If loci are physically linked then treat as one locus• Either way, selection acts on of individual ‘alleles’

blocks - 73Richard Watson
The benefit of recombination in EC
• It’s been difficult to show any simple case where an EA with crossover outperforms and EA without crossover in a principled manner• Holland, Goldberg, Mitchell and Forrest, Jones, Vose…
• I’ve done some work on this (Watson 1998-2002)

blocks - 74Richard Watson
Prior work
• For a sexual population • Different individuals discover different modules• Crossover exchanges whole modules between
individuals
• shows fundamental distinction in EC: • poly vs exp in size of system → large systems
unevolvable to asexual popn.
• Example of general class of ‘compositional mechanisms’: sex, lateral gene transfer, symbiogenesis
• But these models are too complex/weird for Pop. Gen. audience
• Fitness landscape too esoteric• Details of algorithm (crowding method) non-
biological
P1: 1111111100000000P2: 0000000011111111C1: 1111111111111111

blocks - 75Richard Watson
What’s an allele anyway?
• In EC we have the idea of finding solutions to building blocks and then putting them together – an essentially two-level process
• But pop gen definition suggests that recombination rate defines the unit of selection – there cannot be two levels
• Why might we need two-levels?• What are the bits in a genetic algorithm?
• Nucleotides? Alleles of genes? Does it matter?
• Consider mutation on nucleotide sites and recombination of genes…• Suppose mutation on nucleotide sites finds good alleles for a gene and
recombination of genes finds good genotypes.• Is a two-level description of selection ever necessary?• If selection on individual sites finds good alleles then more of that finds
good genotypes, no?

blocks - 76Richard Watson
Two module system
gene 1 gene 2
i j
Nucleotide sites within a gene are grouped both functionally and physically by virtue of shared transcription and translation. →A simple form of biologically-real modularity.
Assume mutations in the same gene have stronger synergy than mutations in different genes
i.e. more beneficial mutations there are within a gene, the more effect additional mutations have. Equivalently, the closer to proper/complete functioning the gene is, the more important mutations are.
e.g. each deleterious mutation halves binding affinity - exponential decay with distance from ideal sequence

blocks - 78Richard Watson
Synergistic epistasis within genes
0 0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9 1
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in gene 1 (i )
(e i+e j)
blocks - 79Richard Watson
0
0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9
0
0.25
0.5
0.75
1
F(G)
beneficial mutations in gene 2 ( j)
beneficial mutations in gene 1 (i )
Ri,j
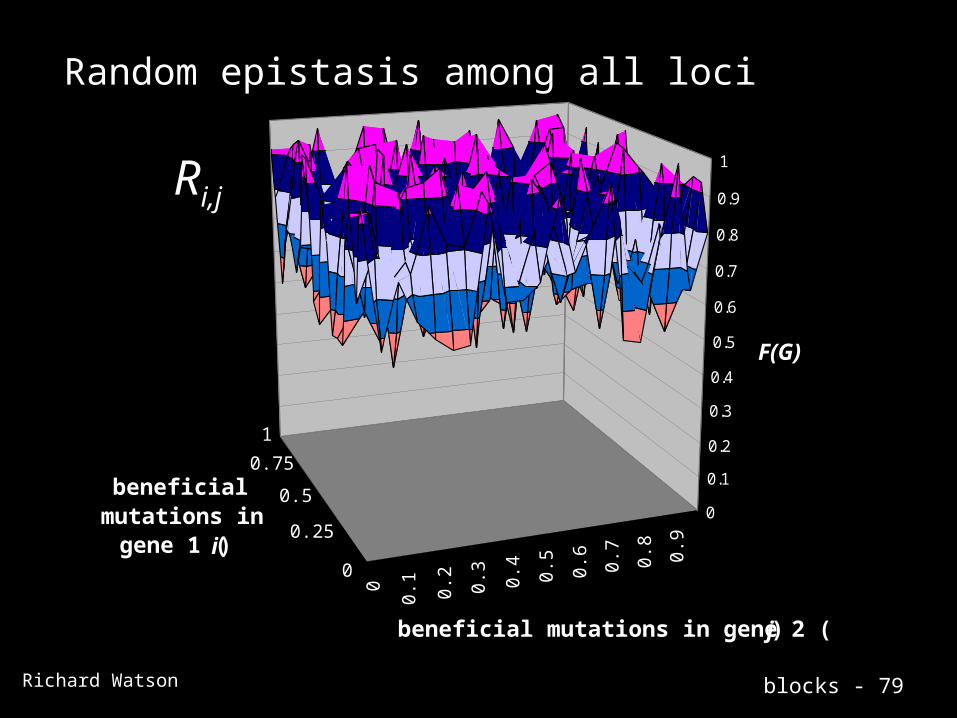
Random epistasis among all loci
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1

blocks - 80Richard Watson
Synergistic epistasis within genes and random epistasis
0 0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9 1
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in gene 1 (i )
(e i+e j)Ri,j

blocks - 81Richard Watson
2k
Simple analysis: without recombination
k
kgene 1
gene 2
Finding peak of one gene is easy.Finding the peak of the second
gene without disrupting the first is difficult.
T 2k

blocks - 82Richard Watson
Simple analysis: with recombination
k
gene 1
gene 2
-----------
gene 1 gene 2
-----------
gene 1 gene 2
-----------
gene 1 gene 2
T k

blocks - 83Richard Watson
Simulation study
• Sufficient diversity required.
• Multi deme model • 50 demes of 200 individuals each
• Island migration (0.005)
• Mutation (0.03 per site)
• Recombination: crossover 0.0, 0.013 (1/L), 0.5
• Two genes, 40 sites each
• 1% Elitism: retain fittest 2 individuals in each deme
• Simulation example…

blocks - 84Richard Watson
Simulation results
0
200000
400000
600000
800000
1000000
1200000
1400000
1600000
1800000
2000000
0 10 20 30 40 50 60 70 80 90
k
tim
e t
o p
ea
k
no recombination
with recombination

blocks - 87Richard Watson
In this two-module model
• We cannot abstract combinations of sites into alleles of genes • Although they’re particulate under recombination,
• Because these alleles not particulate under mutation (mutation on sites is required to find fit alleles for genes, but not sufficient (by itself) to find fit genotypes)
• i.e. To see this effect we need both• Selection on individual site mutations to find good alleles• And selection on combinations of sites (alleles of genes) to find
good genotypes
• i.e. find solutions to blocks and them put them together
• Selection on either one level is insufficient, cannot abstract combinations of sites into alleles

blocks - 88Richard Watson
Wright vs Fisher: on epistasis, sex, the unit of selection
• Wright:• Epistasis creates local fitness peaks, central problem of evolution is
escaping local optima• Fisher:
• A) epistasis doesn’t create peaks in multi-dimensional landscapes • B) even if it did, evolution has no way to select on combinations of alleles
(because of sex) so selected change will always be a reaction to average excess of individual alleles (in the current population) and nothing more
• So: Epistasis is only variation in average excess of an allele, Evolution is change in freq of alleles in a population
• Wright:• A) ? (Kauffman shows that expected number of peaks in random
landscape is 2^L/L!)• B) Shifting balance theory (SBT): in a subdivided population, different
subpopulations (demes) may select for different combinations of alleles• Big problems with SBT
• Fisher:• I win! :) - average excess of individual alleles governs evolution

blocks - 89Richard Watson
Unit of selection (in population genetics)
• Both Fisher and Wright, (and Williams and Dawkins) follow the assumption that because sexual recombination breaks up combinations of alleles (and combinations of alleles are therefore not heritable) selection cannot act on combinations of alleles (in a panmictic population).
• Selection must act on individual alleles (genes not genotypes/individuals) →
• Mass selection: Evolution is change in freq of individual alleles, macro evolution is just this many times, at many loci.
• What about epistasis?: For sure changes in genetic background change fitness effects of an allele and thus alter its subsequent changes in freq, but what can you say about that? Evolution is cannot anticipate it, and thus neither will I.
• Not: there is no epistasis. But: epistatic interaction systems can’t be selected for so I’m going to treat epistasis as noise (not Wright).

blocks - 90Richard Watson
A personal view of the big picture
• Why are EC and Pop. Gen. so different?
• Darwinian assumption of gradual change, • A theory of evolution by natural selection needed an optimisation
algorithm that could be implemented in natural mechanisms
• Darwins model was a hill-climbing model
• Hill-climbing is the simplest algorithm
• Fisher reinforced/formalised a gradual change framework
• Although epistasis may be present, only need to model additive
effects → models with small number of loci with simple epistasis (or none)

blocks - 91Richard Watson
…
• In EC we know that accumulation of small changes can only find good solutions if epistasis is simple – (to the extent that evolution behaves like a hill-climber its not interesting to EC)
• But that’s OK for biology – natural evolution isn’t expected to find best solutions – only to show some propensity for adaptation
• But – there are other algorithmic possibilities…

blocks - 92Richard Watson

blocks - 93Richard Watson

blocks - 94Richard Watson
Shifting balance theory (Wright 1939, 1971)
• Wright suggested that evolution in a subdivided (multi-deme) population would differ from that of a panmictic (freely mixing) population.
• Three phases assume population is stuck on a peak…I) Each deme drifts around a bit - because drift (random variation
in allele frequencies from sampling error) is greater in small populations
II) Some deme finds fitter combination of alleles (another peak) and increases in abundance
III) Increased migration from fitter/bigger deme recruits less fit demes
…thus population as a whole escapes local peak and arrives at fitter peak.

blocks - 95Richard Watson
…Shifting Balance Theory
• Two important aspects to the theory:• Each subpopulation will be subject to greater genetic drift
• Selection may act on the combination of alleles in a subpopulation (which Wright called ‘interaction systems’)
• There’s free recombination within each deme but not among demes
• So different demes have different genetic make-up, and the growth/decline of different demes thus enables selection on allele combinations
• Problems:• Balance of selection pressures and population sizes – population
must be small enough to drift off first peak but big enough to select for better peak.

blocks - 96Richard Watson
Population Genetics in contrast with EC
Population genetics Evolutionary Comp.
Focus on small models and simple epistasis
Large systems and complex epistasis
Single locus two-allele models, or infinite alleles
(single locus) models
Poly locus two-allele
Freq of existing alleles new mutations, discovery of genotypes
Microscopic allele-centric/ Selection on alleles
macroscopic genotype-centric / Selection on genotypes
Time scale of population size generations
Long timescales

blocks - 97Richard Watson
Why might EC and Pop. Gen. be so different?
Pop. Gen. EC
Different motives nature as it is problem solving
Tools Lack of numerical methods/ necessity of
analytic results
intrinsically computational methods
Styles of science vs engineering
rigorous (uptight) Creative (sloppy)
Historical contingency: types of questions that were pertinent take field in different directions
• All of the above, and something deeper?• Selection on individual alleles vs selection on genotypes
(combinations of alleles)…

blocks - 98Richard Watson
Compare with EC
• Background assumption that we’re doing combinatorial optimisation and looking for fit genotypes (not so strong in ALife)
• Mutation hill-climbing as first approximation for evolution
• We know that an EA with crossover potentially changes this: Holland suggests selection on schemata• Given free recombination (uniform crossover) → schemata are
‘order 1’ ≡ Pop. Gen. framework. (see PBIL - Baluja 1994)
• But one-point or two-point crossover → schemata are many alleles
• We assume that sex is allowing selection on combinations of alleles (building blocks), not preventing it!
• In fact, low rates of recombination in an EA prevent selection on whole genotypes but enable selection on small groups of alleles
• But the ‘alleles’ that Pop. Gen. is talking about are defined as particulate heritable units – schemata scale.

blocks - 99Richard Watson
Conclusions to part 3
• Pop. Gen. focuses on change in frequency of individual alleles
• This is because natural selection cannot act on combinations of alleles that are broken-up by recombination
• SBT was the only serious attempt to find an exception – but it is generally not accepted
• In EC we focus more on search for fit genotypes (not changes in freq of alleles)
• We know that crossover potentially changes the unit of selection but we have a very different view of its impact
• …

blocks - 100Richard Watson
… Conclusions to part 3
• So there are very different emphases• Many reasons for this including: a desire to answer the burning question
of blending inheritance and the maintenance of variation in a population (on very short timescales) vs combinatorial optimisation (more akin to evolution writ large)
• Accept our differences• still valuable exchanges – e.g testing for neutrality of evolutionary change
in ALife systems
• an understanding of the differences is a first step to building bridges
• But there are also actual disagreements here about how evolution works and what it can do • Next section: look deeper into one of the critical issues at the heart of the
different views… Sex and the unit of selection
• I think there’s a chance here to use EC thinking to challenge Pop. Gen. thinking and make valuable contribution from EC to Pop. Gen.

blocks - 101Richard Watson

blocks - 102Richard Watson

blocks - 103Richard Watson

blocks - 104Richard Watson

blocks - 105Richard Watson
EB in contrast with EC
Large systems with complex frustration of variables
Small models with simple epistasis
ECEB
Time (prob.) of finding fittest genotype
Time (prob.) to fix an allele (given that it arises/is present)
Evolution as an optimisation method:
How to find good (best) candidate solutions from the space of all possible candidate
solutions
Evolution as a dynamic process altering frequencies of alleles in a
population:How genetic make-up of population
changes over time
Genetic Algorithm, GA:(Holland 1975) following Wright/Fisher
model
Population genetics: Fisher/Haldane/Wright 1930s

blocks - 106Richard Watson
Why such different emphases?
• Engineering motives vs Science: solve hard problems vs natural evolution is just what it is ?
• P.G. pre-computers → analytic statistics, difficult to apply to large systems vs. E.C. applications easy to apply to large systems ?
• E.B.: Darwin assumption of gradual change, Fisher formalised selection for average excess of an allele → evolution ≈ hill-climbing
• E.C.: hard problems cant be solved by hill-climbers, if evolution is hill-climbing what’s the point?
• Recombination → hill-climbing (E.B.)
→ not hill-climbing! (E.C.)

blocks - 107Richard Watson
Recombination in E.C.
• What can a Genetic Algorithm, G.A., do that a hill-climber cannot do?• Population → population of hill-climbers, random re-start HC?
• Recombination → exchange of co-adapted subsets of variables
• Holland: Schema Theorem (1975)• Increase in frequency of schemata of above average fitness
• Goldberg: Building Block Hypothesis (1989)• Emphasis on combining fit low-order schemata into higher-order
schemata of higher fitness
• Mitchell and Forrest, Jones (1991-1995) – Royal Roads and Headless Chicken test• → general failure to demonstrate anything a GA can do that a non-
population-based mutation/selection algorithm cannot do.

blocks - 108Richard Watson
Recombination in E.C.
• Hierarchical-IFF: Watson (2000)• Hierarchical modular building-block problem• Hill-climber O(eN/2)• GA with tight linkage can solve in O(N2log2N)• Recursive divide and conquer problem
decomposition
P1: 1111111100000000P2: 0000000011111111C1: 1111111111111111
P1: 0001111111100000P2: 1110000000011111C1: 1111111111111111
.• Jansen (2001)
• ‘Gap’ function (non-recursive)
• Limitations• Both example landscapes very complex/contrived
for the purpose of illustrating the distinction
• Both use modified GAs : diversity maintenance
• Neither has direct biological correlate

blocks - 109Richard Watson
Recombination in E.B.: classical model• Fisher/Muller (1930)
• Formalised by Hill and Robertson 1969
A
B
A
B
A+B
Requires: interval between ben mutations to be small wrt time to fix a beneficial mutation
- small selection coeficients- large populations
For EC: a HC is best (beneficial mutations can be accumulated sequentially
time
Proportion of population

blocks - 110Richard Watson
Recombination in EB: deterministic mutation hypothesis
• ‘deterministic mutation hypothesis’ (Kondrashov 1989)• (‘deterministic’ - Infinite population, all alleles present at all times)• Focussing on purging of deleterious alleles• ‘Synergistic Epistasis’– two deleterious mutations worse than twice as bad as one
deleterious mutation• Creates linkage disequilibrium: single-del-mutants over-represented• Recombination reduces linkage disequilibrium: double-del-mutant frequency
increased• Selection against double-del-mutants more than double the selection against single-
del-mutants• Therefore deleterious alleles are purged from the population more rapidly in sexual
population
• Pros• Deleterious mutations more common than ben. mutations (co-occur. more likely)• Empirical investigations underway to measure epistasis of single and double
mutants
• EC: fittest genotype already present in population (and if not HC can accumulate beneficial mutations sequentially)

blocks - 111Richard Watson
Summary of prior work
• EB• Two-locus two-allele exemplars
• Even with more loci: All examples are single-peaked so HC can solve in time linearly proportional to number of mutations required
• No example where recombination allows evolution of something that’s unevolvable with asexual population. Only:
• W/F: faster (prop. to size of pop.) to reach double mutant
• DMH: Increase freq. of beneficial alleles at equilibrium
• EC• Has shown exponential vs polynomial (in size of problem)
• Contrived/complex
• No direct biological correlates

blocks - 112Richard Watson
Unidimensional and multidimensional epistasis
• All EB models so far
• (Mutations are unambiguously del. or ben.)
• Unidimensional epistasis models• Counting number of mutations in the genotype
• Multidimensional epistasis (m.d.e.) models• Cant be modelled by counting mutations

blocks - 113Richard Watson
Recombination in E.B. – multidimensional epistasis
• Multidimensional epistasis and the disadvantage of sex (Kondrashov and Kondrashov 2001): count mutations in two disjoint subsets of sites
The fitness ridge used in K&K 2001
0
4
8
12
16
0 4 8 12 16
Number of 1-alleles at loci from the 1st set
Num
ber o
f 1-a
llele
s at
loci
from
the
2nd
set
Time to reach point (18,18) is twice as long for sexual population and asexual population
1-allele in second set may arise in beneficial background (i.e. exactly 6 1-alleles in first set) and this genotype may rise in freq in asexual popn. But this allele may be deleterious in background of other individuals in pop. and not rise in freq in sexual populations until popn. fixed for exactly 6 1-alleles.
F(G)=1.1n0.7D
1st set 2nd set
i j

blocks - 114Richard Watson
• Varying crossover rate
100
1000
10000
100000
0.000 0.016 0.031 0.063 0.125 0.250 0.500
crossover rate (log scale)
gene
ratio
ns (
log
scal
e)
Kondrashov m.d.e. – sensitivity
• Varying mutation rate & population size
10
100
1000
10000
1 2 3 4
gene
ratio
ns (l
og s
cale
)
asexualsexual
N =106, µ =310-5
N =105, µ =310-4
N =104, µ =310-3
N =103, µ =310-2
population size, mutation rate

blocks - 115Richard Watson
100
1000
10000
100000
0.000 0.016 0.031 0.063 0.125 0.250 0.500
crossover rate (log scale)ge
nera
tions
(lo
g sc
ale)
K&K model
Multidimensional epistasis – variations of K&K model
• Sensitivity to placement of gaps
With fork
With gaps
The fitness ridge used in K&K 2001
0
4
8
12
16
0 4 8 12 16
Number of 1-alleles at loci from the 1st set
Num
ber o
f 1-a
llele
s at
loci
from
the
2nd
set
• Fork and large gap
Fitness ridge with a ‘fork’
0
4
8
12
16
0 4 8 12 16
Number of 1-alleles at loci from the 1st set
Num
ber o
f 1-a
llele
s at
loci
from
the
2nd
set
0 4
P1: 000000000000000000 010000110000110010P2: 100110000100101000 000000000000000000C1: ?00??0000?00?0?000 0?0000??0000??00?0

blocks - 116Richard Watson
A simpler multidimensional epistasis modelFor EB and EC

blocks - 117Richard Watson
No modularity – all sites behave the same
0 0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9 1
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in gene 1 (i )
jieGF )(

blocks - 118Richard Watson
dependencies in gene 1 only
0 0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9 1
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in gene 1 (i )
ieGF )(

blocks - 119Richard Watson
dependencies in gene 2 only
0 0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9 1
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in gene 1 (i )
jeGF )(

blocks - 120Richard Watson
Resultant modularity
0 0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9 1
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in gene 1 (i )
ji eeGF )(

blocks - 121Richard Watson
Modular with random noise
0 0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9 1
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in gene 1 (i )
(e i+e j)Ii,j

blocks - 122Richard Watson
2k
Simple analysis: without recombination
k
kgene 1
gene 2
Finding peak of one gene is easy.Finding the peak of the second
gene without disrupting the first is difficult.
T 2k

blocks - 123Richard Watson
Simple analysis: with recombination
k
gene 1
gene 2
-----------
gene 1 gene 2
-----------
gene 1 gene 2
-----------
gene 1 gene 2
T k

blocks - 124Richard Watson
Simulation study
• Sufficient diversity required.
• Multi deme model • 50 demes of 200 individuals each
• Island migration (0.005)
• Mutation (0.03 per site)
• Recombination: crossover 0.0, 0.013 (1/L), 0.5
• Two genes, 40 sites each
• 1% Elitism: retain fittest 2 individuals in each deme
• Simulation example…

blocks - 125Richard Watson
Simulation results
0
200000
400000
600000
800000
1000000
1200000
1400000
1600000
1800000
2000000
0 10 20 30 40 50 60 70 80 90
k
tim
e t
o p
ea
k
no recombination
with recombination

blocks - 126Richard Watson
Simulation results
1000
10000
100000
1000000
10000000
0 10 20 30 40 50 60 70 80 90
k
tim
e t
o p
ea
k
no recombination
with recombination

blocks - 127Richard Watson
Simulation results - controls
0
200000
400000
600000
800000
1000000
1200000
1400000
1600000
1800000
2000000
0 10 20 30 40 50 60 70 80 90
k
tim
e to
pea
k
no recombination
with recombination
free recombination
randomized linkage map

blocks - 128Richard Watson
Biological plausibility
epistasis
sites
Assumptions. Sites divide into subsets (genes) such that:- Epistasis is stronger intra-gene than inter-gene.- Physical linkage stronger intra-gene than inter-gene.
gene 1 gene 2
i j
• Possible to show effect on landscape w/o noise• With converged initialisation• Without elitism

blocks - 129Richard Watson
Why ignore genetic map at molecular scale?
• Molecular genetics history
• Assumption that• If loci are not physically linked then selection acts on loci
• If loci are linked then treat as one locus
• Either way, selection acts on (average excess) of individual ‘alleles’
• However, although alleles of genes are particulate under recombination they are not under mutation• Combination of mutation on sites and recombination of genes
together cannot be accommodated in single level model
• Certain kinds of epistasis make fit genotypes unevolvable for asexual populations and yet easily evolvable for sexual pops.

blocks - 130Richard Watson
Fisher vs Wright
• Both Fisher and Wright believed that fitness landscapes contained epistasis
• But, Fisher argued that • local optima were rare in high-dimensional spaces (which is wrong)• that even if there were local optima, selection cannot act on combinations
of alleles (because recombination disrupts them)
• Wright had to show a mechanism where selection on combinations of alleles was possible• Shifting Balance Theory: selection in subdivided populations not the same
as selection in panmictic population• But, relies on particular selection coefficients and population sizes
• Here, • No need for genetic drift (works with deterministic selection within
demes)• Selection on parts and wholes via variation from mut. and rec. (not via
selection within demes and among demes)• Particular to correspondence of genetic map and epistasis

blocks - 131Richard Watson
Message for EC
• Recombinative population ≠ hill climber(s)• Divide and conquer problem decomposition
• Find two parts and then combine• Exp. vs poly. time
• Simple demonstration of building block recombination• Not hard to imagine this form of modularity in engineering problems
• Two different subsystems are easy to find individually but having found one, variation that improves the other without disrupting the first is rare
• Note that a problem can be modular and still have important dependencies between modules: the dependencies between modules prevent good modules from accumulating sequentially (otherwise HC is superior)
• Potential to exploit modularity in problem domains
• However• Result dependent on ‘tight-linkage’• Previous work on HIFF has shown that discovery of linkage map is
possible• Not yet attempted in this problem class

blocks - 132Richard Watson
Conclusion: Recombination in EC and EB
• Why is it the mechanism of recombination that provides a good domain to exchange results between EC and EB?
• In EC: looking for ways that GA ≠ hill-climber• Recombination: divide-and-conquer problem decomposition
• In EB: deeply rooted assumption that evolution is a hill-climbing process• Recombination ensures that selection acts on individual alleles
→ over-simplified models of epistasis
• What was needed was a simple demonstration of how evolution ≠ hill-climbing• Variation (and selection) at more than one scale

blocks - 133Richard Watson

blocks - 134Richard Watson

blocks - 135Richard Watson

blocks - 136Richard Watson

blocks - 137Richard Watson

blocks - 138Richard Watson
Synthesis of EC and EB
• Variation at more than one scale missed by early PG
• Not just that neighbourhood space is different, or varies with popn – but that it is a dimensional reduction of the search space• In HIFF its from bits to blocks with two solns each
• Here its from a large set of alleles to a smaller set of alleles
• Why should good alleles be selected for but yet we are unable, without recombination, to discover good genotypes?• Because you need to search combinations of them
• Or because there is intereference between them – diminishing accessibility

blocks - 139Richard Watson
Preferred results
• Time to peak for various C• Using max eval limit
• Even if its only 3 runs each or something
• I should do c=0.016 first to set eval limit low.
• Using proper island model w. low migration
• Using with and without noise
• ?time to fix peak?
• For k=30 only
• Kondrashov code doesn’t have subdivision
• My code outputs 30 runs for one C, does use (an almost standard form of) subdivision – fine.

blocks - 140Richard Watson
Differences for Bham vs Oxford
• For oxford• Skip EC background, go straight into m.d.e
• Interpretation as speciation/hybridisation
• New m.d.e results without noise
• Why is evolution constrained on single peak?
• Why has it been missed before: linkage map, nonuniform epistasis
• For Bham• Background on R in EB and EC: HIFF and Gap func
• Mde results with noise
• Emphasise impact for EC
• Show Time vs k
• Limitations: linkage map

blocks - 141Richard Watson
Classical Fisher/Muller story
AA+B
A
B
A+B
Second beneficial mutation appears (in parallel) in different background and is brought together by recombination.
Second beneficial mutation appears (serially) in context of first.
The former is likely only if simultaneously segregating beneficial alleles are likely – i.e. Mutations fix slowly wrt time for mutations to arise. (Fix slowly → Small selection coefs., large popn.).
Classically, combinations that could appear by recombination, could appear by mutation alone.

blocks - 142Richard Watson
Classical Fisher/Muller story
A
B
A
B
A+B
A
B
A+B

blocks - 143Richard Watson
With noise (gene 1)
0 0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9 1
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in gene 1 (i )

blocks - 144Richard Watson

blocks - 145Richard Watson

blocks - 146Richard Watson

blocks - 147Richard Watson
Simulation results
1000
10000
100000
1000000
10000000
0 10 20 30 40 50 60 70 80 90
k
tim
e t
o p
ea
k
no recombination
with recombination

blocks - 148Richard Watson
• Varying crossover rate
100
1000
10000
100000
0.000 0.016 0.031 0.063 0.125 0.250 0.500
crossover rate (log scale)
gene
ratio
ns (
log
scal
e)
K&K model
Kondrashov m.d.e. – sensitivity
• Varying mutation rate & population size
10
100
1000
10000
1 2 3 4
gene
ratio
ns (l
og s
cale
)
asexualsexual
N =106, µ =310-5
N =105, µ =310-4
N =104, µ =310-3
N =103, µ =310-2
population size, mutation rate
• Placement of gaps
With gaps

blocks - 149Richard Watson
Recombination in population genetics
• Fisher/Muller

blocks - 150Richard Watson
Conclusions
• Two-locus two-allele models cannot account for effects coming from large scale structure in the fitness landscape.
• Simple modular structure can be supposed from simple observations of genomics.
• Such modularity can have a profound effect on the benefit of recombination.
• This effect of recombination is not explained by existing two-locus models.
• The magnitude of the effect shown here grows exponentially with number of sites involved.

Acknowledgements
Dan Weinreich - Harvard Alex Platt - Harvard
Jordan Pollack - Brandeis

blocks - 152Richard Watson
Some inter-gene dependencies (gene 1)
0 0.1 0.2 0.3 0.4 0.5
0.6 0.7
0.8 0.9 1
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in gene 1 (i )
iji
i eIeGF ,)(

blocks - 153Richard Watson
Some inter-gene dependencies (gene 2)
0
0.15 0.
3
0.45 0.
6
0.75 0.
9
0
0.25
0.5
0.75
1
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
F(G)
beneficial mutations in gene 2 (j )
beneficial mutations in
gene 1 (i )
jji
j eIeGF ,)(

blocks - 154Richard Watson
Simple analysis: with recombination
k
gene 1
gene 2
-----------
gene 1 gene 2
-----------
gene 1 gene 2
-----------
gene 1 gene 2
-----------
T k

blocks - 155Richard Watson
Classical Fisher/Muller story
AA+B
A
B
A+B
Second beneficial mutation appears (in parallel) in different background and is brought together by recombination.
Second beneficial mutation appears (serially) in context of first.
The former is likely only if simultaneously segregating beneficial alleles are likely – i.e. Mutations fix slowly wrt time for mutations to arise. (Fix slowly → Small selection coefs., large popn.).
Classically, combinations that could appear by recombination, could appear by mutation alone.

blocks - 156Richard Watson
Consider 4 loci
• Four genes with two alleles each:• a/A, b/B, c/C, d/D – in that order on the
chromosome
• ancestral genotype = abcd• f(ABCD) >• f(ABcd) = f(abCD) >• f(Abcd) = f(aBcd) = f(abCd) = f(abcD) >• f(abcd) >• f([..others..]).
• Two ‘modules’ – AB and CD.• AB and CD can be reached by one-point
mutation• But ABCD is mutationally isolated.• But, ABcd can be crossed with abCD to reach
ABCD without passing through a lower fitness state.
cd Cd/cD CD
ab 1 1+s 1+2s
Ab/aB 1+s 1-s 1-s
AB 1+2s 1-s 1+3s

blocks - 157Richard Watson
Fitness = K ℮1 ℮2 = C1 C2
= f1(g1) f2(g2)
Fitness = K ℮1 ℮2 = C1 C2
= f1(g1) f2(g2)
= f1(n1,…,n10) f2(n11,…,n20)
Interpretation
M1 M2 M7M6…
g1
P1
C1
g2
P2
C2
I21
I12
I21 I12
℮1 ℮2
K ℮1 ℮2
n1 n10n11 n20
Fitness = K ℮1 ℮2 = C1 C2 I12 I21
= f1(g1) f2(g2) f3(g1,g2) f4(g1,g2)
= f1(n1,…,n10) f2(n11,…,n20) f3(n1,…,n20) f4(n1,…,n20)

blocks - 158Richard Watson
Random: f3 only
1 23 4
56
78
910
S1
S3
S5
S7
S9
00.10.20.30.40.50.60.70.80.91

blocks - 159Richard Watson
Separable: f1 and f2 only
12 3
45
67
89
10S1
S3
S5
S7
S9
00.10.20.30.40.50.60.70.80.9
f1
f2

blocks - 160Richard Watson
Modular: f1, f2 and f3
12 3
45
67
89
10S1
S3
S5
S7
S9
00.10.20.30.40.50.60.70.80.9
f1
f2

blocks - 161Richard Watson
Claims for discussion
1. The conception of modularity as nearly-independent sub-systems is often interpreted as though inter-module connections are unimportant: This is grossly misleading, and precludes multi-level hierarchical organisation.
2. Although modularity and hierarchical organisation are ubiquitous in the natural world/ biological systems, strong interdependencies between modules are also ubiquitous
3. Therefore, their evolution is not explained by accretive evolution
4. However, compositional evolution is fundamentally different, and can explain the evolution of systems that cannot be evolved accretively. Specifically hierarchically modular systems with significant inter-module dependencies can be evolved only by compositional evolution.





























