Embed Size (px)
Citation preview

©2015, Amazon Web Services, Inc. or its affiliates. All rights reserved
Real-World Predictive Applications
with Amazon Machine Learning
Guy Ernest, Solutions Architecture

Agenda
Why ML?
We will build an end-to-end social media listening application powered by machine learning technology
Services we will use: Amazon Machine Learning, Amazon Kinesis, AWS Lambda, Amazon Mechanical Turk, Amazon SNS
Full source code and additional documentation are on GitHubhttps://github.com/awslabs/machine-learning-samples/blob/master/social-media/

Motivation for ML Modeling
E*BI
RTML

Motivation For Listening To Social Media
Customer is reporting a possible service issue

Motivation For Listening To Social Media
Customer is making a feature request
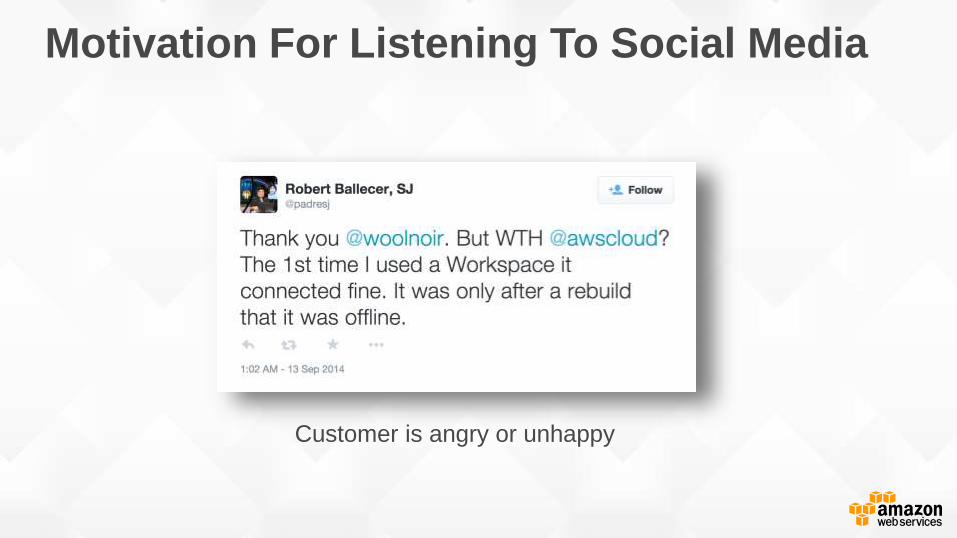
Motivation For Listening To Social Media
Customer is angry or unhappy

Motivation For Social Media Listening
Customer is asking a question

Why Do We Need Machine Learning For This?
The social media stream is high-volume, and most of the
messages are not CS-actionable

Why Do We Need Machine Learning For This?
The social media stream is high-volume, and most of the
messages are not CS-actionable

Formulating The Problem
We would like to…
Find new tweets mentioning @awscloud, ingest and
analyze each one to predict whether an AWS customer
service agent should take a look at it, and if so, send that
tweet to the customer service queue

Formulating The Problem
We would like to…
Find new tweets mentioning @awscloud, ingest and
analyze each one to predict whether an AWS customer
service agent should take a look at it, and if so, send that
tweet to the customer service queue
Twitter API

Formulating The Problem
We would like to…
Find new tweets mentioning @awscloud, ingest and
analyze each one to predict whether an AWS customer
service agent should take a look at it, and if so, send that
tweet to the customer service queue
Twitter API Amazon
Kinesis

Formulating The Problem
We would like to…
Find new tweets mentioning @awscloud, ingest and
analyze each one to predict whether an AWS customer
service agent should take a look at it, and if so, send that
tweet to the customer service queue
Twitter API Amazon
Kinesis
AWS
Lambda

Formulating The Problem
We would like to…
Find new tweets mentioning @awscloud, ingest and
analyze each one to predict whether an AWS customer
service agent should take a look at it, and if so, send
that tweet to the customer service queue
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning

Formulating The Problem
We would like to…
Find new tweets mentioning @awscloud, ingest and
analyze each one to predict whether an AWS customer
service agent should take a look at it, and if so, send that
tweet to the customer service queue
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS

Our Game Plan
Frame the
ML Task
1
Collect
Data
2 3
Create
ML model
4
Build
end-to-end
application
5
Try it out!

Machine Learning Task Framing
Tweet Metadata:
Text, Username, Time Zone, Location, User description, # of followers, etc
Tweet categories:
Customer request, question, problem report, angry customer, other/non-actionable
Problem statement:
Want to predict whether a tweet should be routed to CS representative
Framing Approach:
We will collect the categorical data, but approach this problem as a binary classification task

Our Game Plan
Frame the
ML Task
1
Collect
Data
2 3
Create
ML model
4
Build
end-to-end
application
5
Try it out!

Collect Data
Twitter API can be used to search for tweets containing our
company’s handle (e.g. @awscloud)
import twitter
twitter_api = twitter.Api(**twitter_credentials)
twitter_handle = ‘awscloud’
search_query = '@' + twitter_handle + ' -from:' + twitter_handle
results = twitter_api.GetSearch(term=search_query, count=100, result_type='recent')
# Go further back in time by issuing additional requests with max_id parameter
Good news: data is well-structured and clean *
Bad news: data does not have labels (categories)
* No dataset is 100% clean. But it is good enough for our purposes.

Label Data
What is this?
Labeling is the process of obtaining “ground truth” for the question that we want our ML model to answer.
How does labeling work?
For our application, a person looks at each example tweet and decide whether it is customer service actionable or not
How many examples need to be labeled?
The number depends on data richness and task difficulty. A few thousands to start with for text classification.
Can I pay someone to do this?
Yes! Amazon Mechanical Turk is a marketplace for tasks that require human intelligence.

Labeling With Amazon Mechanical Turk

Join Labels With Tweets
A few sample lines from the training data file
(most metadata fields removed for clarity)

Our Game Plan
Frame the
ML Task
1
Collect
Data
2 3
Create
ML model
4
Build
end-to-end
application
5
Try it out!

Working With Machine Learning Technology
Most real-world ML projects have two stages:
• Interactive modeling: create model, evaluate, adjust, rinse, repeat.
• Automation: take new data, apply known-good settings, create and deploy new model
With Amazon ML, you can use the service console for interactive modeling, and service APIs/SDKs for automation
In this tutorial, I will use a combination of the python SDK and service console

Training High-Quality Machine Learning Models
1. Create datasource(s)A datasource is an Amazon ML containing metadata and summary statistics obtained from your training dataset.
2. Create ML modelTo create an ML model we will need to provide a datasource ID, model type and (optional) data transformations + model parameters.
3. Evaluate ML modelUse a fair data subset to compute model quality metrics. Decide if the results are good enough to go to production.
4. Adjust ML modelAlign ML model outputs with business goals

Defining Data Schema
Data schema is a JSON string that may contain:
• Names and types for each of your input data fields
• Names of special fields – label, ID, excluded attributes
• File format name and other metadata
Schema can be provided to the API as a parameter, or you may pass the
URI to a schema file in S3 (good reuse pattern)
Amazon Machine Learning console can guess the schema from input
data, and you can adjust the guesses as needed.

Building Datasource and ML model with the console

Defining Data Schema{
"dataFileContainsHeader": true,
"dataFormat": "CSV",
"excludedAttributeNames": [],
"rowId": "sid",
"targetAttributeName": "trainingLabel",
"version": "1.0”,
"attributes": [
{
"attributeName": "created_at_in_seconds",
"attributeType": "NUMERIC"
},
{
"attributeName": "description",
"attributeType": "TEXT"
},
<additional attributes here>
{
"attributeName": "trainingLabel",
"attributeType": "BINARY"
}
]
}

Splitting to Training/Evalution

Creating The Training Datasource
import boto
ml = boto.connect_machinelearning()
data_rearrangement = “””
{
"splitting”: {
"percentBegin": 0,
"percentEnd”: 70
}
}
“”” # Use the first 70% of the datasource for training. Don’t forget to shuffle your data!
data_spec['DataLocationS3'] = s3_uri # E.g.: s3://my-bucket/dir/data.csv
data_spec['DataSchema'] = data_schema # Schema string (alternately, use ‘DataSchemaLocationS3’)
data_spec['DataRearrangement'] = data_rearrangement
ml.create_data_source_from_s3( ds_id = “ds-tweets-train”,
data_spec,
data_source_name = “Tweet training data (70%)”,
compute_statistics = True)

Creating The Evaluation Datasource
import boto
ml = boto.connect_machinelearning()
data_rearrangement = “””
{
"splitting”: {
"percentBegin": 70,
"percentEnd”: 100
}
}
“”” # Use the last 30% of the datasource for evaluation.
data_spec['DataLocationS3'] = s3_uri # E.g.: s3://my-bucket/dir/data.csv
data_spec['DataSchema'] = data_schema # Schema string (alternately, use DataSchemaLocationS3)
data_spec['DataRearrangement'] = data_rearrangement
ml.create_data_source_from_s3( ds_id = “ds-tweets-eval”,
data_spec,
data_source_name = “Tweet evaluation data (30%)”,
compute_statistics = True)

Console Interlude: Inspect Training Data

Creating The ML Model
import boto
ml = boto.connect_machinelearning()
ml.create_ml_model( ml_model_id = “ml-tweets”,
ml_model_type = “BINARY”,
ds_id = “ds-tweets-train”)
All the metadata about our dataset is retrieved from Datasource ID
Since no data transformation instructions (“recipe”) or model parameters have
been provided, Amazon ML will use the suggested data recipe and default
parameters

Evaluating The ML Model
import boto
ml = boto.connect_machinelearning()
ml.create_evaluation( ml_model_id = “ml-tweets”,
evaluation_id = “ev-tweet”,
ds_id = “ds-tweets-eval”)
We are using our evaluation datasource here to ensure a fair result.
Amazon ML automatically selects and computes an industry-standard
evaluation metric based on your ML model type.

Console Interlude: Inspect Evaluation & Adjust

Console Interlude: Deploy Model To
Production

Our Game Plan
Frame the
ML Task
1
Collect
Data
2 3
Create
ML model
4
Build
end-to-end
application
5
Try it out!

Reminder: Our Intended Data Pipeline
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS

Create an Amazon ML Endpoint for Retrieving Real-
Time Predictions
import boto
ml = boto.connect_machinelearning()
ml.create_realtime_endpoint(“ml-tweets”)
# Endpoint information can be retrieved at any time with the get_ml_model() method. Sample: #"EndpointInfo": {
# "CreatedAt": 1424378682.266,
# "EndpointStatus": "READY",
# "EndpointUrl": ”<HTTPS endpoint URL here>",
# "PeakRequestsPerSecond": 200}
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS

Create an Amazon SNS Topic For Distributing
Notifications
import boto
sns = boto.connect_sns()
sns_topic = sns.create_topic(‘RespondToTweet’)
# Customer service-actionable tweets will be published to this SNS topic
# You can add one or many subscribers to this topic, using the protocol of choice
# Supported protocols: {json | http | https | sqs | sms | application}
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS

Create an Amazon Kinesis Stream For Receiving
Tweets
import boto
kinesis = boto.connect_kinesis()
kinesis.create_stream(‘tweetStream’, 1)
# Poll stream status until it flips over to “ACTIVE”
while kinesis.describe_stream(‘tweetStream’)['StreamDescription']['StreamStatus'] != 'ACTIVE':
print('Kinesis Stream is not active yet.')
sleep(5)
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS

Set up AWS Lambda To Coordinate
Tweet/Prediction/Notification Flow
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS
A few moving pieces to connect:
• Create and upload the Lambda functions that will process and route tweets
• Configure the Lambda function invocation policy (who is allowed to call it?)
• Configure the Lambda function execution policy (what is it allowed to do?)
• Add the Kinesis stream as a source for the Lambda function

Set up AWS Lambda To Coordinate
Tweet/Prediction/Notification Flow
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS
// These are function signatures and globals only. See GitHub repository for full source.
var ml = new AWS.MachineLearning();
var endpointUrl = '';
var mlModelId = ’ml-tweets';
var snsTopicArn = 'arn:aws:sns:{region}:{awsAccountId}:{snsTopic}';
var snsMessageSubject = 'Respond to tweet';
var snsMessagePrefix = 'ML model '+mlModelId+': Respond to this tweet: https://twitter.com/0/status/';
var processRecords = function(){…} // Base64 decode the Kinesis payload and parse JSON
var callPredict = function(tweetData){…} // Call Amazon ML real-time prediction API
var updateSns = function(tweetData) {…} // Publish CS-actionable tweets to SNS topic
var updateRealtimeEndpoint = function(err, data){…} // Retrieve/update Amazon ML endpoint URI
Create Lambda function

Set up AWS Lambda To Coordinate
Tweet/Prediction/Notification Flow
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS
{
"Statement": [
{
"Action": [
"kinesis:ReadStream",
"kinesis:GetRecords",
"kinesis:GetShardIterator",
"kinesis:DescribeStream",
"kinesis:ListStreams"
],
"Effect": "Allow",
"Resource": "arn:aws:kinesis:{region}:{awsAccountId}:stream/{kinesisStream}” },
{
"Action": [
"lambda:InvokeFunction"
],
"Effect": "Allow",
"Resource": "arn:aws:lambda:{region}:{awsAccountId}:function:{lambdaFunctionName}” } ]
}
Configure Lambda invocation policy

Set up AWS Lambda To Coordinate
Tweet/Prediction/Notification Flow
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS
{
"Statement": [
{
"Action": [
"logs:*"
],
"Effect": "Allow",
"Resource": "arn:aws:logs:{region}:{awsAccountId}:log-group:/aws/lambda/{lambdaFunctionName}:*” },
{
"Action": [
"sns:publish"
],
"Effect": "Allow",
"Resource": "arn:aws:sns:{region}:{awsAccountId}:{snsTopic}” },
{
"Action": [
"machinelearning:GetMLModel",
"machinelearning:Predict"
],
"Effect": "Allow",
"Resource": "arn:aws:machinelearning:{region}:{awsAccountId}:mlmodel/{mlModelId}” } ] }
Configure Lambda execution policy

Set up AWS Lambda To Coordinate
Tweet/Prediction/Notification Flow
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS
import boto
aws_lambda = boto.connect_awslambda()
with open(zip_file_name) as zip_blob:
aws_lambda.upload_function(
function_name = “process_tweets”,
function_zip = zip_blob.read(),
runtime = "nodejs",
role = 'arn:aws:iam::' +aws_account_id + ':role/' + lambda_execution_policy_name
handler = "index.handler",
mode = "event",
description = “Tweet processing”,
timeout = 60,
memory_size = 128)
Upload Lambda function
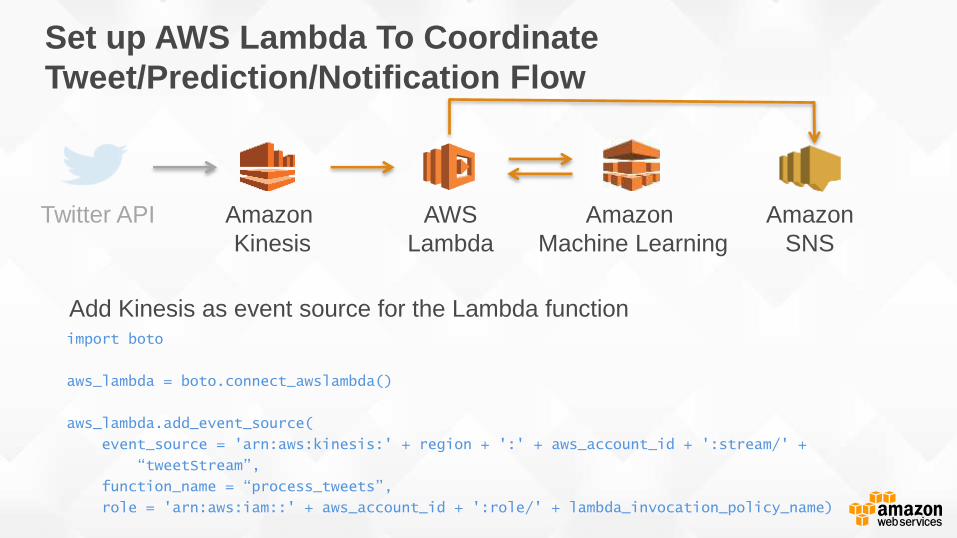
Set up AWS Lambda To Coordinate
Tweet/Prediction/Notification Flow
Twitter API Amazon
Kinesis
AWS
Lambda
Amazon
Machine Learning
Amazon
SNS
import boto
aws_lambda = boto.connect_awslambda()
aws_lambda.add_event_source(
event_source = 'arn:aws:kinesis:' + region + ':' + aws_account_id + ':stream/' +
“tweetStream”,
function_name = “process_tweets”,
role = 'arn:aws:iam::' + aws_account_id + ':role/' + lambda_invocation_policy_name)
Add Kinesis as event source for the Lambda function

SNS Subscription to Amazon WorkMail

WorkMail Inbox

Tweet that needs a response

Generalizing To Additional Feedback Channels
Twitter API Amazon
Kinesis
AWS
Lambda
Model 1 Amazon
SNS
Model 2
Model 3

BERLIN

BACKUP
















![[AWS Black Belt Online Seminar] Amazon Athena · • Amazon EMR ログ • AWS Global Accelerator ログ • Amazon GuardDuty ログ • Amazon VPC フローログ • AWS WAF ログ](https://img.dokumen.tips/doc/110x75/601d01fb736ace68ef3b87a8/aws-black-belt-online-seminar-amazon-athena-a-amazon-emr-f-a-aws-global.jpg)












