Embed Size (px)
Citation preview

R-TREES: A Dynamic Index Structure for R-TREES: A Dynamic Index Structure for Spatial SearchingSpatial Searching
by by A. Guttman, SIGMOD 1984.A. Guttman, SIGMOD 1984.
Shahram GhandeharizadehShahram GhandeharizadehComputer Science DepartmentComputer Science DepartmentUniversity of Southern CaliforniaUniversity of Southern California

Motivating ExampleMotivating Example
Type in your street address in GoogleType in your street address in Google
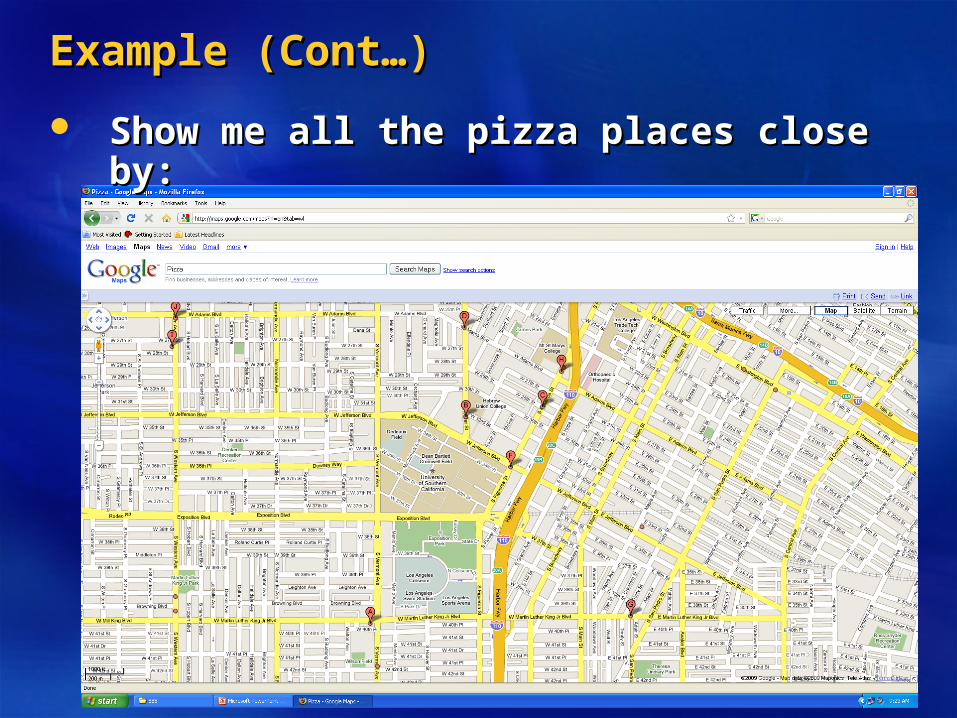
Example (Cont…)Example (Cont…)
Show me all the pizza places close by:Show me all the pizza places close by:

TerminologyTerminology
Example query is termed a Example query is termed a spatialspatial query. query. R-tree is a R-tree is a spatialspatial index structure. index structure.
K-D-B trees are useful for point data only.K-D-B trees are useful for point data only. Exact-point lookup!Exact-point lookup!
Show me the USC Salvatory Computer Science building.Show me the USC Salvatory Computer Science building.
R-tree represents data objects in intervals in R-tree represents data objects in intervals in several dimensions.several dimensions. Exact-point and range lookups!Exact-point and range lookups!
Show me all Pizza places in a 2 mile radius of USC Show me all Pizza places in a 2 mile radius of USC Salvatory Computer Science building.Salvatory Computer Science building.
R-tree is:R-tree is: A height-balanced tree similar to B-tree with A height-balanced tree similar to B-tree with
index records in its leaf nodes containing index records in its leaf nodes containing pointers to data objects.pointers to data objects.
A node is a disk page.A node is a disk page. Assumes each tuple has a unique identifier, RID.Assumes each tuple has a unique identifier, RID.

R-Tree: Leaf NodesR-Tree: Leaf Nodes
Leaf nodes contain index records:Leaf nodes contain index records: (I, tuple-identifier) (I, tuple-identifier)
tuple-identifier is RID,tuple-identifier is RID, I is an n-dimensional rectangle that bounds I is an n-dimensional rectangle that bounds
the indexed spatial objectthe indexed spatial object I = (II = (I00, I, I11, …, I, …, In-1n-1) where n is the number of ) where n is the number of
dimensions.dimensions. IIii is a closed bounded interval [a,b] is a closed bounded interval [a,b]
describing the extent of the object along describing the extent of the object along dimension i.dimension i.
Values for a and b might be infinity, Values for a and b might be infinity, indicating an unbounded object along indicating an unbounded object along dimension i.dimension i.

R-Tree: Non-leaf nodesR-Tree: Non-leaf nodes
Non-leaf nodes contain entries of the form:Non-leaf nodes contain entries of the form: (I, child-pointer)(I, child-pointer) Child-pointer is the address of a lower node Child-pointer is the address of a lower node
in the R-Tree.in the R-Tree. I covers all rectangles in the lower node’s I covers all rectangles in the lower node’s
entries.entries.

R-Tree: A 2-D (n=2) ExampleR-Tree: A 2-D (n=2) Example

R-Tree: Non-leaf nodesR-Tree: Non-leaf nodes
Non-leaf nodes contain entries of the form:Non-leaf nodes contain entries of the form: (I, child-pointer)(I, child-pointer) Child-pointer is the address of a lower node Child-pointer is the address of a lower node
in the R-Tree.in the R-Tree. I covers all rectangles in the lower node’s I covers all rectangles in the lower node’s
entries.entries.
Questions?Questions?

R-Tree: Non-leaf nodesR-Tree: Non-leaf nodes
Non-leaf nodes contain entries of the form:Non-leaf nodes contain entries of the form: (I, child-pointer)(I, child-pointer) Child-pointer is the Child-pointer is the addressaddress of a lower node of a lower node
in the R-Tree.in the R-Tree. I covers all rectangles in the lower node’s I covers all rectangles in the lower node’s
entries.entries.
Questions?Questions?
What is this?What is this?

R-Tree: Non-leaf nodesR-Tree: Non-leaf nodes
Non-leaf nodes contain entries of the form:Non-leaf nodes contain entries of the form: (I, child-pointer)(I, child-pointer) Child-pointer is the Child-pointer is the addressaddress of a lower node of a lower node
in the R-Tree.in the R-Tree. I covers all rectangles in the lower node’s I covers all rectangles in the lower node’s
entries.entries.
Questions?Questions?
Disk Page address!Disk Page address!

R-Tree: Non-leaf nodesR-Tree: Non-leaf nodes
Non-leaf nodes contain entries of the form:Non-leaf nodes contain entries of the form: (I, child-pointer)(I, child-pointer) Child-pointer is the address of a lower node Child-pointer is the address of a lower node
in the R-Tree.in the R-Tree. II covers all rectangles in the lower node’s covers all rectangles in the lower node’s
entries.entries.
Questions?Questions?
How about this? What is it?How about this? What is it?

R-Tree: Non-leaf nodesR-Tree: Non-leaf nodes
Non-leaf nodes contain entries of the form:Non-leaf nodes contain entries of the form: (I, child-pointer)(I, child-pointer) Child-pointer is the address of a lower node Child-pointer is the address of a lower node
in the R-Tree.in the R-Tree. II covers all rectangles in the lower node’s covers all rectangles in the lower node’s
entries.entries.
Questions?Questions?
An n dimensional rectangle:An n dimensional rectangle:I = (II = (I00, I, I11, …, I, …, In-1n-1))

R-tree: PropertiesR-tree: Properties
Assume: Assume: 1.1. M = Maximum number of entries in a node.M = Maximum number of entries in a node.2.2. m <= M/2m <= M/23.3. N = Number of recordsN = Number of records
R-tree has the following properties: R-tree has the following properties: Every leaf node contains between m and M index records. Every leaf node contains between m and M index records.
Root node is the exception.Root node is the exception. For each index record (I, tuple-identifier) in a leaf node, I is For each index record (I, tuple-identifier) in a leaf node, I is
the smallest rectangle that spatially contains the n the smallest rectangle that spatially contains the n dimensional data object represented in the indicated tuple. dimensional data object represented in the indicated tuple.
Every non-leaf node has between m and M children. Root Every non-leaf node has between m and M children. Root node is the exception.node is the exception.
For each entry (I, child-pointer) in a non-leaf node, I is the For each entry (I, child-pointer) in a non-leaf node, I is the smallest rectangle that spatially contains the rectangles in smallest rectangle that spatially contains the rectangles in the child node.the child node.
The root node has at least two children unless it is a leaf.The root node has at least two children unless it is a leaf. All leaves appear on the same level.All leaves appear on the same level. Height of a tree = Ceiling(logHeight of a tree = Ceiling(logmmN)-1.N)-1. Worst case utilization for all nodes except the root is m/M. Worst case utilization for all nodes except the root is m/M.

SearchingSearching Descend from root to leaf Descend from root to leaf
in a B+-tree manner.in a B+-tree manner. If multiple sub-trees If multiple sub-trees
contain the point of interest contain the point of interest then follow all.then follow all.
Assume:Assume: EI denotes the rectangle EI denotes the rectangle
part of an index entry E,part of an index entry E, Ep denotes the tuple-Ep denotes the tuple-
identifier or child-pointer.identifier or child-pointer. Search (T: Root of the R-Search (T: Root of the R-
tree, S: Search Rectangle)tree, S: Search Rectangle) If T is not a leaf, check If T is not a leaf, check
each entry E to determine each entry E to determine whether EI overlaps S. whether EI overlaps S. For all overlapping For all overlapping entries, invoke Search(Ep, entries, invoke Search(Ep, S).S).
If T is a leaf, check all If T is a leaf, check all entries E to determine entries E to determine whether EI overlaps S. If whether EI overlaps S. If so, E is a qualifying so, E is a qualifying record.record.

InsertionInsertion
Similar to B-trees, new index records are Similar to B-trees, new index records are added to the leaves, nodes that overflow are added to the leaves, nodes that overflow are split, and splits propagate up the tree.split, and splits propagate up the tree.
Insert (T: Root of the R-tree, E: new index Insert (T: Root of the R-tree, E: new index entry)entry)1.1. Find position for new record: Invoke Find position for new record: Invoke
ChooseLeaf to select a leaf node L in which to ChooseLeaf to select a leaf node L in which to place E.place E.
2.2. Add record to leaf node: If L has room for E then Add record to leaf node: If L has room for E then insert E and return. Otherwise, invoke SplitNode insert E and return. Otherwise, invoke SplitNode to obtain L and LL containing E and all the old to obtain L and LL containing E and all the old entries of L.entries of L.
3.3. Propagate changes upwards: Invoke AdjustTree Propagate changes upwards: Invoke AdjustTree on L, also passing LL if a split was performed.on L, also passing LL if a split was performed.
4.4. Grow tree taller: If node split propagation Grow tree taller: If node split propagation caused the root to split, create a new root whose caused the root to split, create a new root whose children are the two resulting nodes.children are the two resulting nodes.
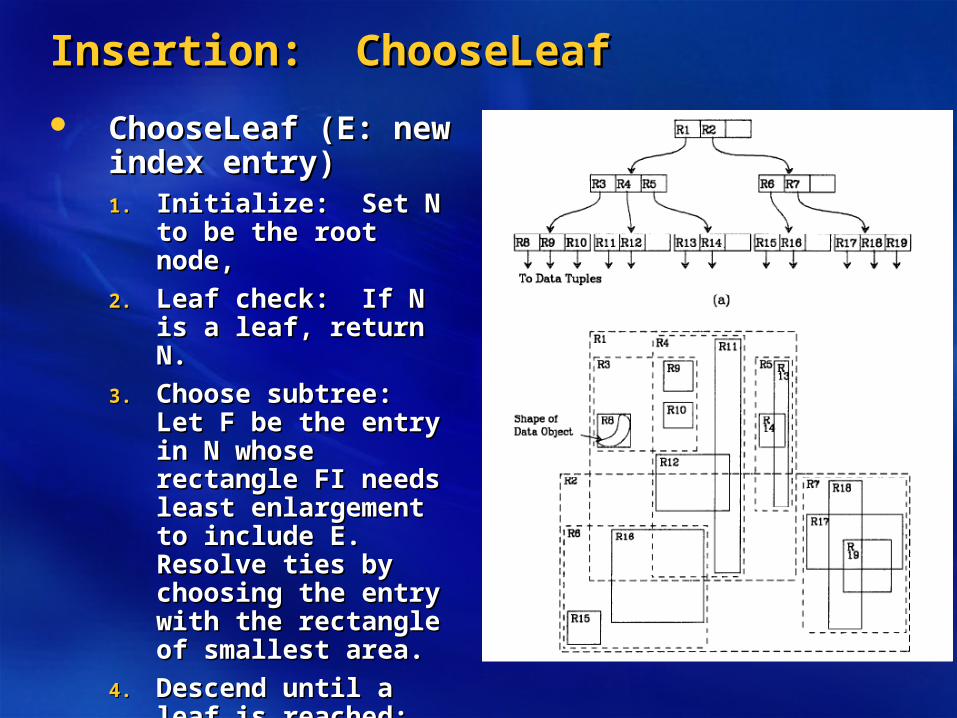
Insertion: ChooseLeafInsertion: ChooseLeaf
ChooseLeaf (E: new ChooseLeaf (E: new index entry)index entry)1.1. Initialize: Set N to be Initialize: Set N to be
the root node,the root node,
2.2. Leaf check: If N is a Leaf check: If N is a leaf, return N.leaf, return N.
3.3. Choose subtree: Let F Choose subtree: Let F be the entry in N whose be the entry in N whose rectangle FI needs least rectangle FI needs least enlargement to include enlargement to include E. Resolve ties by E. Resolve ties by choosing the entry with choosing the entry with the rectangle of the rectangle of smallest area.smallest area.
4.4. Descend until a leaf is Descend until a leaf is reached: Set N to be reached: Set N to be the child node pointed the child node pointed to by Fp and repeat to by Fp and repeat from step 2.from step 2.

SplitNode: Node SplittingSplitNode: Node Splitting
A full node contains M A full node contains M entries. Divide the entries. Divide the collection of M+1 collection of M+1 entries between 2 entries between 2 nodes.nodes.
Objective: Make it as Objective: Make it as unlikely as possible unlikely as possible for the resulting two for the resulting two new nodes to be new nodes to be examined on examined on subsequent searches.subsequent searches.
Heuristic: The total Heuristic: The total area of two covering area of two covering rectangles after a split rectangles after a split should be minimized.should be minimized.
Total area is larger!Total area is larger!

SplitNode: Node SplittingSplitNode: Node Splitting
A full node contains M A full node contains M entries. Divide the entries. Divide the collection of M+1 collection of M+1 entries between 2 entries between 2 nodes.nodes.
Objective: Make it as Objective: Make it as unlikely as possible unlikely as possible for the resulting two for the resulting two new nodes to be new nodes to be examined on examined on subsequent searches.subsequent searches.
Heuristic: The total Heuristic: The total area of two covering area of two covering rectangles after a split rectangles after a split should be minimized.should be minimized.
Total area is larger!Total area is larger!

Node Splitting: How?Node Splitting: How?
How to find the minimum area node split?How to find the minimum area node split?1.1. Exhaustive algorithm,Exhaustive algorithm,
2.2. Quadratic-cost algorithm,Quadratic-cost algorithm,
3.3. Linear cost algorithm.Linear cost algorithm.

Exhaustive AlgorithmExhaustive Algorithm
Generate all possible groups and choose the Generate all possible groups and choose the best with minimum area.best with minimum area.
Number of possibilities ~ 2 to power of M-1Number of possibilities ~ 2 to power of M-1 M ~ 50 M ~ 50 Number of possibilities ~ 600 Trillion Number of possibilities ~ 600 Trillion

Exhaustive AlgorithmExhaustive Algorithm
Generate all possible groups and choose the Generate all possible groups and choose the best with minimum area.best with minimum area.
Number of possibilities ~ 2 to power of M-1Number of possibilities ~ 2 to power of M-1 M ~ 50 M ~ 50 Number of possibilities ~ 600 Trillion Number of possibilities ~ 600 Trillion
US deficit pales!US deficit pales!

Quadratic-Cost algorithmQuadratic-Cost algorithm
A heuristic to find a A heuristic to find a small-area split.small-area split.
Cost is quadratic in M Cost is quadratic in M and linear in the and linear in the number of dimensions.number of dimensions.
Pick two of the M+1 Pick two of the M+1 entries to be the first entries to be the first elements of the two elements of the two new groups.new groups. Choose these in a Choose these in a
manner to waste the manner to waste the most area if both were most area if both were put in the same group.put in the same group.
Assign remaining Assign remaining entries to groups one entries to groups one at a time.at a time.

Quadratic-Cost algorithmQuadratic-Cost algorithm
A heuristic to find a A heuristic to find a small-area split.small-area split.
Cost is quadratic in M Cost is quadratic in M and linear in the and linear in the number of dimensions.number of dimensions.
Pick two of the M+1 Pick two of the M+1 entries to be the first entries to be the first elements of the two elements of the two new groups.new groups. Choose these in a Choose these in a
manner to waste the manner to waste the most area if both were most area if both were put in the same group.put in the same group.
Assign remaining Assign remaining entries to groups one entries to groups one at a time.at a time.

Quadratic-Cost algorithmQuadratic-Cost algorithm
A heuristic to find a A heuristic to find a small-area split.small-area split.
Cost is quadratic in M Cost is quadratic in M and linear in the and linear in the number of dimensions.number of dimensions.
Pick two of the M+1 Pick two of the M+1 entries to be the first entries to be the first elements of the two elements of the two new groups.new groups. Choose these in a Choose these in a
manner to waste the manner to waste the most area if both were most area if both were put in the same group.put in the same group.
Assign remaining Assign remaining entries to groups one entries to groups one at a time.at a time.

Linear Cost AlgorithmLinear Cost Algorithm
Identical to Quadratic Identical to Quadratic with the following with the following differences:differences: Uses a different version Uses a different version
of PickSeeds.of PickSeeds. PickNext simply PickNext simply
chooses any of the chooses any of the remaining entries.remaining entries.
Linear: Choose two objects that are furthest apart.Linear: Choose two objects that are furthest apart.Quadratic: Choose two objects that create as much empty Quadratic: Choose two objects that create as much empty space as possible.space as possible.

ComparisonComparison
Linear node-split is simple, fast, and as good Linear node-split is simple, fast, and as good as quadratic!as quadratic! Quality of the splits is slightly worse!Quality of the splits is slightly worse!

InsertionInsertion
Similar to B-trees, new index records are Similar to B-trees, new index records are added to the leaves, nodes that overflow are added to the leaves, nodes that overflow are split, and splits propagate up the tree.split, and splits propagate up the tree.
Insert (T: Root of the R-tree, E: new index Insert (T: Root of the R-tree, E: new index entry)entry)1.1. Find position for new record: Invoke Find position for new record: Invoke
ChooseLeaf to select a leaf node L in which to ChooseLeaf to select a leaf node L in which to place E.place E.
2.2. Add record to leaf node: If L has room for E then Add record to leaf node: If L has room for E then insert E and return. Otherwise, invoke SplitNode insert E and return. Otherwise, invoke SplitNode to obtain L and LL containing E and all the old to obtain L and LL containing E and all the old entries of L.entries of L.
3.3. Propagate changes upwards: Invoke Propagate changes upwards: Invoke AdjustTreeAdjustTree on L, also passing LL if a split was performed.on L, also passing LL if a split was performed.
4.4. Grow tree taller: If node split propagation Grow tree taller: If node split propagation caused the root to split, create a new root whose caused the root to split, create a new root whose children are the two resulting nodes.children are the two resulting nodes.

AdjustTreeAdjustTree
Ascend from a leaf node L to the root, Ascend from a leaf node L to the root, adjusting covering rectangles and adjusting covering rectangles and propagating node splits.propagating node splits.

DeletesDeletes
Straightforward. The only complication is Straightforward. The only complication is under-flows:under-flows:
An under-full node can be merged with An under-full node can be merged with whichever sibling will have its area whichever sibling will have its area increased least.increased least. Orphaned entries are inserted back into the R-Orphaned entries are inserted back into the R-
Tree.Tree.

R-TreeR-Tree

R-tree VariationsR-tree Variations
R+-tree enhances retrieval performance by avoiding visiting R+-tree enhances retrieval performance by avoiding visiting multiple paths when searching for point queries.multiple paths when searching for point queries. No overlap for minimum bounding rectangels at the same level.No overlap for minimum bounding rectangels at the same level. Specific object’s entry might be duplicated.Specific object’s entry might be duplicated. Insertions might lead to a series of update operations in a chain-Insertions might lead to a series of update operations in a chain-
reaction.reaction. Under certain circumstances, the structure may lead to a Under certain circumstances, the structure may lead to a
deadlock, e.g., every rectangle encloses a smaller one.deadlock, e.g., every rectangle encloses a smaller one.

R*-tree [1990]R*-tree [1990]
Node split is more sophisticated.Node split is more sophisticated. Does not obey the limitation of the number of Does not obey the limitation of the number of
pairs per node.pairs per node. When a node overflows, p entries are extracted When a node overflows, p entries are extracted
and reinserted in the tree (p might be 25%).and reinserted in the tree (p might be 25%). Considers minimization of:Considers minimization of:
the overlapping between minimum bounding rectangles the overlapping between minimum bounding rectangles at the same level.at the same level.
the perimeter of the produced minimum bounding the perimeter of the produced minimum bounding rectangles.rectangles.
Insertion is more expensive while retrievals Insertion is more expensive while retrievals are faster.are faster.

Static R-treesStatic R-trees
Assumes the dataset is known in advance.Assumes the dataset is known in advance. Static R-trees are more efficient than Static R-trees are more efficient than
dynamic ones:dynamic ones: Tree structure is more compact,Tree structure is more compact, Contains fewer news,Contains fewer news, Overlap between minimum bounding rectangles Overlap between minimum bounding rectangles
is reduced.is reduced.

SummarySummary
R-tree is a spatial index structure that R-tree is a spatial index structure that provides competitive average performance.provides competitive average performance.
Many different variations in the literature:Many different variations in the literature: Spatio-temporal access methods, 3-d R-tree.Spatio-temporal access methods, 3-d R-tree. Historical R-trees and Time-Parameterized R-tree Historical R-trees and Time-Parameterized R-tree
fo spatiotemporal applications.fo spatiotemporal applications.
Have been used to speed-up operations in Have been used to speed-up operations in OLAP applications, data warehouses and OLAP applications, data warehouses and data mining.data mining.





























