Embed Size (px)
Citation preview

Probabilistic Topic Models
ChengXiang Zhai
Department of Computer ScienceGraduate School of Library & Information Science
Institute for Genomic BiologyDepartment of Statistics
University of Illinois, Urbana-Champaign
http://www.cs.illinois.edu/homes/czhai [email protected]

2
Outline
1. General Idea of Topic Models
2. Basic Topic Models
- Probabilistic Latent Semantic Analysis (PLSA)
- Latent Dirichlet Allocation (LDA)
- Applications of Basic Topic Models to Text Mining
3. Advanced Topic Models - Capturing Topic Structures
- Contextualized Topic Models
- Supervised Topic Models
4. Summary
We are here

Document as a Sample of Mixed Topics
• How can we discover these topic word distributions?
• Many applications would be enabled by discovering such topics– Summarize themes/aspects
– Facilitate navigation/browsing
– Retrieve documents
– Segment documents
– Many other text mining tasks
Topic 1
Topic k
Topic 2
…
Background k
government 0.3 response 0.2
...
donate 0.1relief 0.05help 0.02
...
city 0.2new 0.1
orleans 0.05 ...
is 0.05the 0.04a 0.03
...
[ Criticism of government response to the hurricane primarily consisted of criticism of its response to the
approach of the storm and its aftermath, specifically in the delayed response ] to the [ flooding of New Orleans. …
80% of the 1.3 million residents of the greater New Orleans metropolitan area evacuated ] …[ Over seventy countries
pledged monetary donations or other assistance]. …
3
4
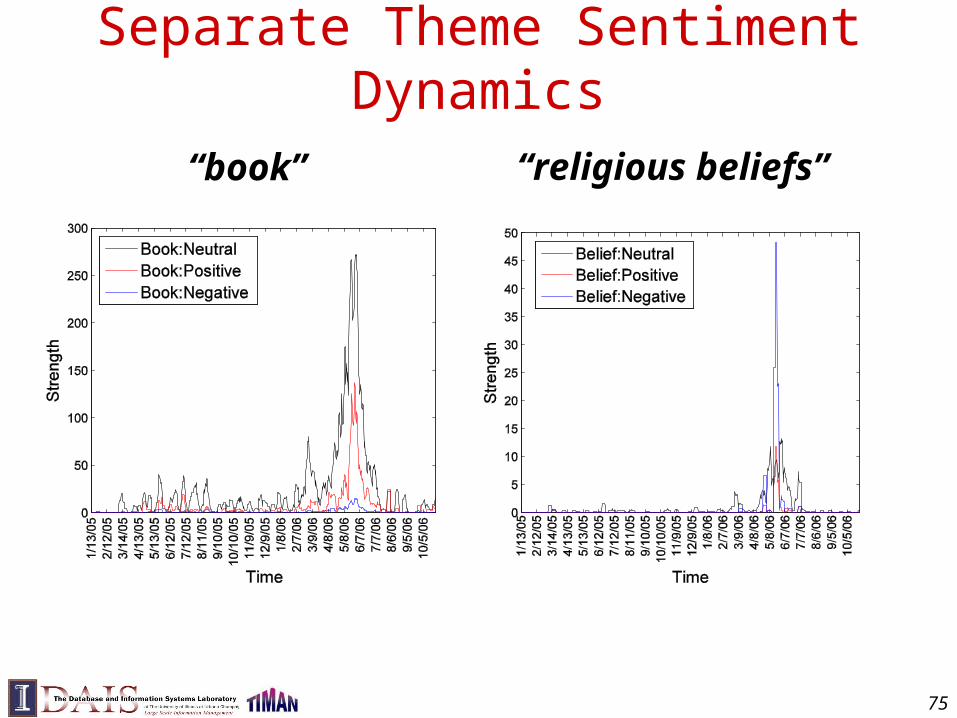
Simplest Case: 1 topic + 1 “background”
the 0.031a 0.018…text 0.04mining 0.035association 0.03clustering 0.005computer 0.0009…food 0.000001…
General BackgroundEnglish Text
Text miningpaper
the 0.03a 0.02is 0.015we 0.01...food 0.003computer 0.00001…text 0.000006…
B
Background LM: p(w|B) Document LM: p(w|d)
d
How can we “get rid of” the common words from the topic
to make it more discriminative?
d
Assume words in d are from two distributions:
1 topic + 1 background(rather than just one)
B

The Simplest Case: One Topic + One Background Model
w
w
Document d
)|(logmaxargˆ
dpMaximum Likelihood
P(w| )
P(w|B)
1-
P(Topic)
Background words
Topic words
Assume p(w|B) and are known = assumed percentage of background words in d
Topicchoice
)]|()1()|([log),()|(log
)|()1()|()(
wpwpdwcdp
wpwpwp
BVw
B
5

Understanding a Mixture Model the 0.2a 0.1we 0.01to 0.02…text 0.0001mining 0.00005
…
KnownBackground
p(w|B)
…text =? mining =? association =?word =?
…
Unknownquery topic
p(w|)=?
“Text mining”
Suppose each model would be selected with equal probability =0.5
The probability of observing word “text”: p(“text”|B) + (1- )p(“text”| )=0.5*0.0001 + 0.5* p(“text”| )
The probability of observing word “the”: p(“the”|B) + (1- )p(“the”| )=0.5*0.2 + 0.5* p(“the”| )
The probability of observing “the” & “text”(likelihood) [0.5*0.0001 + 0.5* p(“text”| )] [0.5*0.2 + 0.5* p(“the”| )]
How to set p(“the”|) and p(“text”|) so as to maximize this likelihood?assume p(“the”| )+p(“text”| )=constant
give p(“text”|) a higher probability than p(“the”|) (why?)
B and are competing for explaining words in document d!
6

Simplest Case Continued: How to Estimate ?
the 0.2a 0.1we 0.01to 0.02…text 0.0001mining 0.00005…
KnownBackground
p(w|B)
…text =? mining =? association =?word =? …
Unknownquery topic
p(w|)=?
“Text mining”
=0.7
=0.3
Observedwords
Suppose we know the identity/label of each word ...
MLEstimator
7

Can We Guess the Identity?
Identity (“hidden”) variable: zi {1 (background), 0(topic)}
thepaperpresentsatextminingalgorithmthepaper...
zi
111100010...
Suppose the parameters are all known, what’s a reasonable guess of zi? - depends on (why?) - depends on p(w|B) and p(w|) (how?)
Initially, set p(w| ) to some random values, then iterate …
E-step
M-step
Vw i
iiii
new
currentB
B
iiii
iiii
wzpdwc
wzpdwcwp
wpwp
wp
zwpzpzwpzp
zwpzpwzp
'))'|1(1)(,'(
))|1(1)(,()|(
)|()1()|(
)|(
)0|()0()1|()1(
)1|()1()|1(
8

An Example of EM Computation
Word # P(w||B) Iteration 1 Iteration 2 Iteration 3 P(w|) P(z=1) P(w|) P(z=1) P(w|) P(z=1)
The 4 0.5 0.25 0.67 0.20 0.71 0.18 0.74 Paper 2 0.3 0.25 0.55 0.14 0.68 0.10 0.75 Text 4 0.1 0.25 0.29 0.44 0.19 0.50 0.17 Mining 2 0.1 0.25 0.29 0.22 0.31 0.22 0.31
Log-Likelihood -16.96 -16.13 -16.02
Assume =0.5
Expectation-Step:Augmenting data by guessing hidden variables
Maximization-Step With the “augmented data”, estimate parameters
using maximum likelihood
vocabularywjj
nj
iin
ii
n
in
Bi
Biii
n
j
wzpdwc
wzpdwcwp
wpwp
wpwzp
))|1(1)(,(
))|1(1)(,()|(
)|()1()|(
)|()|1(
)(
)()1(
)()(
9

10
Outline
1. General Idea of Topic Models
2. Basic Topic Models
- Probabilistic Latent Semantic Analysis (PLSA)
- Latent Dirichlet Allocation (LDA)
- Applications of Basic Topic Models to Text Mining
3. Advanced Topic Models - Capturing Topic Structures
- Contextualized Topic Models
- Supervised Topic Models
4. Summary
We are here

Discover Multiple Topics in a Collection
Topic 1
Topic k
Topic 2
…
Topic coverage in document d
Background B
warning 0.3 system 0.2..
aid 0.1donation 0.05support 0.02 ..
statistics 0.2loss 0.1dead 0.05 ..
is 0.05the 0.04a 0.03 ..
k
1
2
B
W
d,1
d, k
1 - Bd,2
“Generating” word w in doc d in the collection
Cd
k
jjjdBBB
Vw
k
jjjdBBB
Vw
k
jjjdBBBd
wpwpdwcCp
wpwpdwcdp
wpwpwp
])|()1()|([log),()|(log
])|()1()|([log),()(log
)|()1()|()(
1,
1,
1,
??
??
?
???
??
?
B
Parameters: =(B, {d,j}, { j})
Can be estimated using ML Estimator
Percentage of background words
Coverage of topic j in doc d
Prob. of word w in topic j
11

Probabilistic Latent Semantic Analysis/Indexing (PLSA/PLSI) [Hofmann 99a, 99b]
• Mix k multinomial distributions to generate a document
• Each document has a potentially different set of mixing weights which captures the topic coverage
• When generating words in a document, each word may be generated using a DIFFERENT multinomial distribution (this is in contrast with the document clustering model where, once a multinomial distribution is chosen, all the words in a document would be generated using the same multinomial distribution)
• By fitting the model to text data, we can estimate (1) the topic coverage in each document, and (2) word distribution for each topic, thus achieving “topic mining”
12
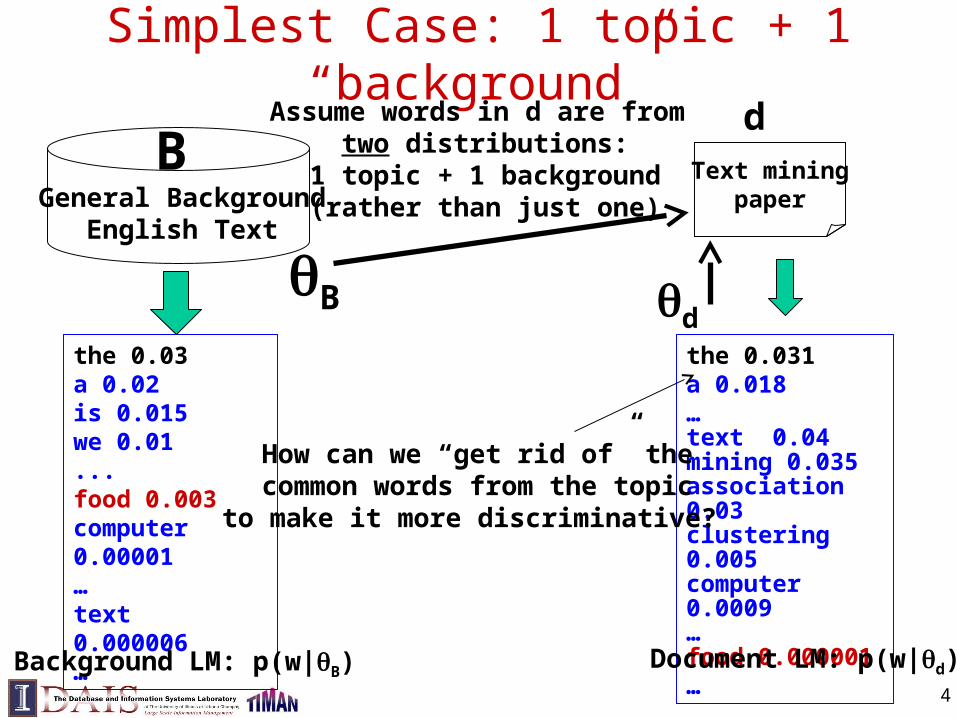
How to Estimate Multiple Topics?(Expectation Maximization)
the 0.2a 0.1we 0.01to 0.02…
KnownBackground
p(w | B)
…text =? mining =? association =?word =? …
Unknowntopic model
p(w|1)=?
“Text mining”
Observed Words
M-Step: Max. Likelihood
Estimatorbased on
“fractionalcounts”…
…information =? retrieval =? query =?document =? …
Unknowntopic model
p(w|2)=?
“informationretrieval”
E-Step:Predict topic labels using Bayes Rule
13

Vw Cd wdwd
Cd wdwdj
n
j Vw wdwd
Vw wdwdnjd
k
j jnn
jdBBB
BBwd
k
j jnn
jd
jnn
jdwd
jzpBzpdwc
jzpBzpdwcwp
jzpBzpdwc
jzpBzpdwc
wpwp
wpBzp
wp
wpjzp
' ',',
,,)1(
' ,,
,,)1(,
1
)()(,
,
1' ')()(
',
)()(,
,
)())(1)(,'(
)())(1)(,()|(
)'())(1)(,(
)())(1)(,(
)|()1()|(
)|()(
)|(
)|()(
Parameter EstimationE-Step: Word w in doc d is generated- from cluster j- from background
Application of Bayes rule
M-Step:Re-estimate - mixing weights- topic LM
Fractional counts contributing to- using cluster j in generating d- generating w from cluster j
Sum over all docsin the collection
14

How the Algorithm Works
aidprice
oil
πd1,1 ( P(θ1|d1) )
πd1,2 ( P(θ2|d1) )
πd2,1 ( P(θ1|d2) )
πd2,2 ( P(θ2|d2) )
aidprice
oil
Topic 1 Topic 2
aid
price
oil
P(w| θ)
Initial value
Initial value
Initial value
Initializing πd, j and P(w| θj) with random values
Iteration 1: E Step: split word counts with different topics (by computing z’ s)
Iteration 1: M Step: re-estimate πd, j and P(w| θj) by adding and normalizing
the splitted word counts
Iteration 2: E Step: split word counts with different topics (by computing z’ s)
Iteration 2: M Step: re-estimate πd, j and P(w| θj) by adding and normalizing
the splitted word counts
Iteration 3, 4, 5, …Until converging
756
875
d1
d2
c(w, d)c(w,d)p(zd,w = B)
c(w,d)(1 - p(zd,w = B))p(zd,w=j)Topic coverage
15

PLSA with Prior Knowledge
• Users have some domain knowledge in mind, e.g.,
– We expect to see “retrieval models” as a topic in IR literature
– We want to see aspects such as “battery” and “memory” for opinions about a laptop
– One topic should be fixed to model background words (infinitely strong prior!)
• We can easily incorporate such knowledge as priors of PLSA model
16

Adding Prior :Maximum a Posteriori (MAP) Estimation
Topic 1
Topic k
Topic 2
…
Background B
warning 0.3 system 0.2..
aid 0.1donation 0.05support 0.02 ..
statistics 0.2loss 0.1dead 0.05 ..
is 0.05the 0.04a 0.03 ..
k
1
2
B
B
W
d,1
d, k
1 - Bd,2
“Generating” word w in doc d in the collection
Parameters: B=noise-level (manually set)’s and ’s are estimated with Maximum A Posteriori (MAP)
)|()(maxarg*
DatappMost likely
Topic coverage in document d
Prior can be placed on as well(more about this later)
17
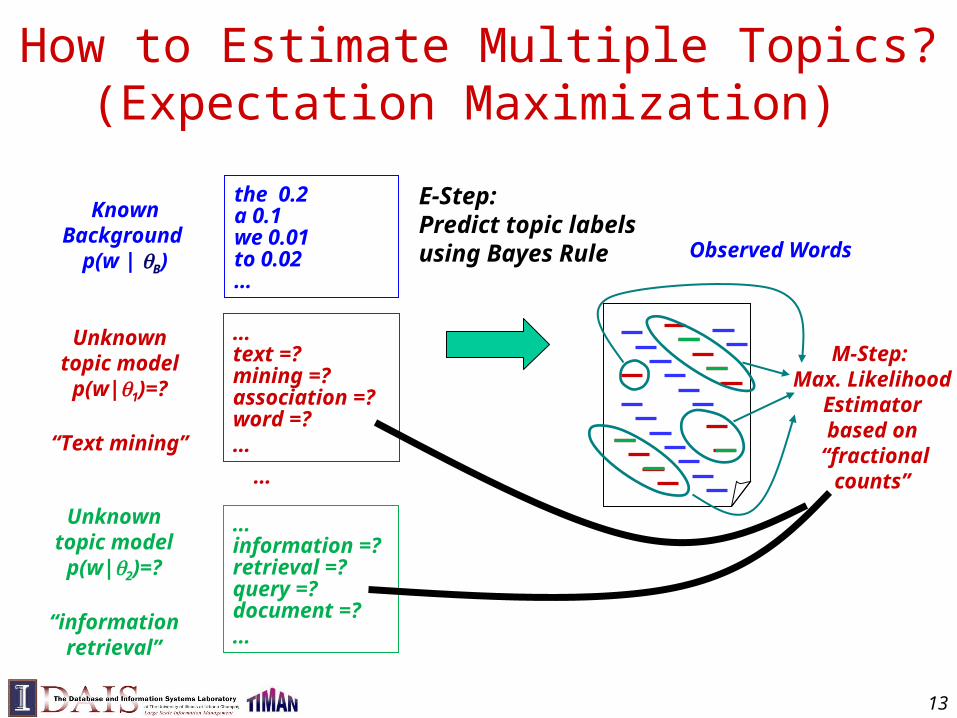
Adding Prior as Pseudo Counts
the 0.2a 0.1we 0.01to 0.02…
KnownBackground
p(w | B)
…text =? mining =? association =?word =? …
Unknowntopic model
p(w|1)=?
“Text mining”
…information =? retrieval =? query =?document =? …
…
Unknowntopic model
p(w|2)=?
“informationretrieval”
Suppose, we knowthe identity of each word ...
Observed Doc(s)
MAPEstimator
Pseudo Doc
Size = μtext
mining
18

Maximum A Posterior (MAP) Estimation
+p(w|’j)+
Pseudo counts of w from prior ’
Sum of all pseudo counts
What if =0? What if =+?
Vw Cd wdwd
Cd wdwdj
n
j Vw wdwd
Vw wdwdnjd
k
j jnn
jdBBB
BBwd
k
j jnn
jd
jnn
jdwd
jzpBzpdwc
jzpBzpdwcwp
jzpBzpdwc
jzpBzpdwc
wpwp
wpBzp
wp
wpjzp
' ',',
,,)1(
' ,,
,,)1(,
1
)()(,
,
1' ')()(
',
)()(,
,
)())(1)(,'(
)())(1)(,()|(
)'())(1)(,(
)())(1)(,(
)|()1()|(
)|()(
)|(
)|()(
A consequence of using conjugate prior is that the prior can be converted into “pseudo data” which can then be “merged” with the actual data for parameter estimation
19

A General Introduction to EM
Data: X (observed) + H(hidden) Parameter:
“Incomplete” likelihood: L( )= log p(X| )“Complete” likelihood: Lc( )= log p(X,H| )
EM tries to iteratively maximize the incomplete likelihood:
Starting with an initial guess (0),
1. E-step: compute the expectation of the complete likelihood
2. M-step: compute (n) by maximizing the Q-function
( 1)
( 1) ( 1)( ; ) [ ( ) | ] ( | , ) log ( , )n
i
n nc i i
h
Q E L X p H h X P X h
( ) ( 1) ( 1)arg max ( ; ) arg max ( | , ) log ( , )i
n n ni i
h
Q p H h X P X h
20

Convergence Guarantee
Goal: maximizing “Incomplete” likelihood: L( )= log p(X| ) I.e., choosing (n), so that L((n))-L((n-1))0
Note that, since p(X,H| ) =p(H|X, ) P(X| ) , L() =Lc() -log p(H|X, ) L((n))-L((n-1)) = Lc((n))-Lc( (n-1))+log [p(H|X, (n-1) )/p(H|X, (n))]
Taking expectation w.r.t. p(H|X, (n-1)), L((n))-L((n-1)) = Q((n); (n-1))-Q( (n-1); (n-1)) + D(p(H|X, (n-1))||p(H|X, (n)))
KL-divergence, always non-negativeEM chooses (n) to maximize Q
Therefore, L((n)) L((n-1))!
Doesn’t contain H
21

EM as Hill-Climbing:converging to a local maximum
Likelihood p(X| )
current guess
Lower bound(Q function)
next guess
E-step = computing the lower boundM-step = maximizing the lower bound
L()= L((n-1)) + Q(; (n-1)) -Q( (n-1); (n-1) ) + D(p(H|X, (n-1) )||p(H|X, ))
L((n-1)) + Q(; (n-1)) -Q( (n-1); (n-1) )
22

Deficiency of PLSA
• Not a generative model
– Can’t compute probability of a new document
– Heuristic workaround is possible, though
• Many parameters high complexity of models
– Many local maxima
– Prone to overfitting
• Not necessary a problem for text mining (only interested in fitting the “training” documents)
23

Latent Dirichlet Allocation (LDA) [Blei et al. 02]
• Make PLSA a generative model by imposing a Dirichlet prior on the model parameters – LDA = Bayesian version of PLSA
– Parameters are regularized
• Can achieve the same goal as PLSA for text mining purposes
– Topic coverage and topic word distributions can be inferred using Bayesian inference
24

25
LDA = Imposing Prior on PLSA
Topic coverage in document d
k
1
2 W
d,1
d, k
d,2
“Generating” word w in doc d in the collection
PLSA: Topic coverage d,j is specific to the “training documents”, thus can’t be used to generate a new document
)()(
Dirichletp i
In addition, the topic word distributions {j } are also drawn from another Dirichlet prior
)()( Dirichletp d
LDA: Topic coverage distribution {d,j } for any document is sampled from a Dirichlet distribution, allowing for generating a new doc
{d,j } are regularized
{d,j } are free for tuning
Magnitudes of and determine the variances of the prior,
thus also the strength of prior(larger and stronger prior)

Equations for PLSA vs. LDA
26
kj
k
jCdj
dd
k
jjjd
Vwj
k
jjjdjdjd
ddpdpCp
dpwpdwcdp
wpwp
...)|(}){,|(log),|(log
)|(])|([log),(}){,|(log
)|(}){},{|(
11
1,
1,,
Cdjdjjdj
k
jjjd
Vwjdj
k
jjjdjdjd
dpCp
wpdwcdp
wpwp
}){},{|(log}){},{|(log
])|([log),(}){},{|(log
)|(}){},{|(
,,
1,,
1,,
PLSA
LDA
Core assumption in all topic models
PLSA component
Added by LDA

Parameter Estimation & Inferences in LDA
27
kj
k
jCdj
dd
k
jjjd
Vwj
k
jjjdjdjd
ddpdpCp
dpwpdwcdp
wpwp
...)|(}){,|(log),|(log
)|(])|([log),(}){,|(log
)|(}){},{|(
11
1,
1,,
Parameter estimation can be done in the same say as in PLSA:Maximum Likelihood Estimator:
),|(logmaxarg)ˆ,ˆ(,
Cp
However, must now be computed using posterior inference: }{},{ , jdj
),|(
)|(),,|(
),|(
),|(),,|(),,|(
),|(
)|}({)},{|(
),|(
),|}({),},{|(),,|}({
Cp
pCp
Cp
pCpCp
Cp
pCp
Cp
pCpCp
ddddd
jjjjj
Computationally intractable, must resort to approximate inference!

LDA as a graph model [Blei et al. 03a]
Nd D
zi
wi
(d)
(j)
(d) Dirichlet()
zi Discrete( (d) )
(j) Dirichlet()
wi Discrete( (zi) )
T
distribution over topicsfor each document
(same as d on the previous slides)
topic assignment for each word
distribution over words for each topic
(same as j on the previous slides)
word generated from assigned topic
Dirichlet priors
Most approximate inference algorithms aim to infer from which other interesting variables can be easily computed
),,|(
wzp i
28

Approximate Inferences for LDA
• Many different ways; each has its pros & cons
• Deterministic approximation– variational EM [Blei et al. 03a]
– expectation propagation [Minka & Lafferty 02]
• Markov chain Monte Carlo– full Gibbs sampler [Pritchard et al. 00]
– collapsed Gibbs sampler [Griffiths & Steyvers 04]
29
Most efficient, and quite popular, but can only work with conjugate prior

The collapsed Gibbs sampler [Griffiths & Steyvers 04]
• Using conjugacy of Dirichlet and multinomial distributions, integrate out continuous parameters
• Defines a distribution on discrete ensembles z
dpPPTW
)(),|()|( zwzw
dpPPDT
)()|()( zz
z
zzw
zzwwz
)()|(
)()|()|(
PP
PPP
T
jw
jw
Ww
jw
n
Wn
1)(
)(
)(
)(
)(
)(
D
dj
dj
T
j
dj
n
Tn
1)(
)(
)(
)(
)(
)(
30

The collapsed Gibbs sampler [Griffiths & Steyvers 04]
• Sample each zi conditioned on z-i
• This is nicer than your average Gibbs sampler:
– memory: counts can be cached in two sparse matrices
– optimization: no special functions, simple arithmetic
– the distributions on and are analytic given z and w, and can later be found for each sample
Tn
n
Wn
nzP
i
i
i
i
i
d
dj
z
zw
ii
)(
)(
)(
)(
),|( zw
31

Gibbs sampling in LDA
i wi di zi123456789
101112...
50
MATHEMATICSKNOWLEDGE
RESEARCHWORK
MATHEMATICSRESEARCH
WORKSCIENTIFIC
MATHEMATICSWORK
SCIENTIFICKNOWLEDGE
.
.
.JOY
111111111122...5
221212212111...2
iteration1
32

Gibbs sampling in LDA
i wi di zi zi123456789
101112...
50
MATHEMATICSKNOWLEDGE
RESEARCHWORK
MATHEMATICSRESEARCH
WORKSCIENTIFIC
MATHEMATICSWORK
SCIENTIFICKNOWLEDGE
.
.
.JOY
111111111122...5
221212212111...2
?
iteration1 2
33

Gibbs sampling in LDA
i wi di zi zi123456789
101112...
50
MATHEMATICSKNOWLEDGE
RESEARCHWORK
MATHEMATICSRESEARCH
WORKSCIENTIFIC
MATHEMATICSWORK
SCIENTIFICKNOWLEDGE
.
.
.JOY
111111111122...5
221212212111...2
?
iteration1 2
Count of instances where wi isassigned with topic j
Count of all wordsassigned with topic j
words in di assigned with topic j
words in di assigned with any topic
34

i wi di zi zi123456789
101112...
50
MATHEMATICSKNOWLEDGE
RESEARCHWORK
MATHEMATICSRESEARCH
WORKSCIENTIFIC
MATHEMATICSWORK
SCIENTIFICKNOWLEDGE
.
.
.JOY
111111111122...5
221212212111...2
?
iteration1 2
Gibbs sampling in LDA
How likely would di choose topic j?
What’s the most likely topic for wi in di?
How likely would topic j generate word wi ?
35

Gibbs sampling in LDA
i wi di zi zi123456789
101112...
50
MATHEMATICSKNOWLEDGE
RESEARCHWORK
MATHEMATICSRESEARCH
WORKSCIENTIFIC
MATHEMATICSWORK
SCIENTIFICKNOWLEDGE
.
.
.JOY
111111111122...5
221212212111...2
2?
iteration1 2
36

Gibbs sampling in LDA
i wi di zi zi123456789
101112...
50
MATHEMATICSKNOWLEDGE
RESEARCHWORK
MATHEMATICSRESEARCH
WORKSCIENTIFIC
MATHEMATICSWORK
SCIENTIFICKNOWLEDGE
.
.
.JOY
111111111122...5
221212212111...2
21?
iteration1 2
37

Gibbs sampling in LDA
i wi di zi zi123456789
101112...
50
MATHEMATICSKNOWLEDGE
RESEARCHWORK
MATHEMATICSRESEARCH
WORKSCIENTIFIC
MATHEMATICSWORK
SCIENTIFICKNOWLEDGE
.
.
.JOY
111111111122...5
221212212111...2
211?
iteration1 2
38

Gibbs sampling in LDA
i wi di zi zi123456789
101112...
50
MATHEMATICSKNOWLEDGE
RESEARCHWORK
MATHEMATICSRESEARCH
WORKSCIENTIFIC
MATHEMATICSWORK
SCIENTIFICKNOWLEDGE
.
.
.JOY
111111111122...5
221212212111...2
2112?
iteration1 2
39

Gibbs sampling in LDA
i wi di zi zi zi123456789
101112...
50
MATHEMATICSKNOWLEDGE
RESEARCHWORK
MATHEMATICSRESEARCH
WORKSCIENTIFIC
MATHEMATICSWORK
SCIENTIFICKNOWLEDGE
.
.
.JOY
111111111122...5
221212212111...2
211222212212...1
…
222122212222...1
iteration1 2 … 1000
40

Applications of Topic Models for Text Mining:Illustration with 2 Topics
Likelihood:
Application Scenarios:
-p(w|1) & p(w|2) are known; estimate
-p(w|1) & are known; estimate p(w|2)
-p(w|1) is known; estimate & p(w|2)
is known; estimate p(w|1)& p(w|2)
-Estimate , p(w|1), p(w|2)
The doc is about text mining and food nutrition, how much percent is about text mining?
30% of the doc is about text mining, what’s therest about?
The doc is about text mining, is it also about someother topic, and if so to what extent?
30% of the doc is about one topic and 70% is aboutanother, what are these two topics?
The doc is about two subtopics, find out what these two subtopics are and to what extent the doc covers each.
)]|()1()|(log[),()|(log
)]|()1()|([)|(
2121
),(2121
wpwpdwcdp
wpwpdp
Vw
dwc
Vw
41

Use PLSA/LDA for Text Mining • Both PLSA and LDA would be able to generate
– Topic coverage in each document: p(d = j)
– Word distribution for each topic: p(w|j)
– Topic assignment at the word level for each document
– The number of topics must be given in advance
• These probabilities can be used in many different ways
j naturally serves as a word cluster
d,j can be used for document clustering
– Contextual text mining: Make these parameters conditioned on context, e.g.,
• p(j |time), from which we can compute/plot p(time| j )
• p(j |location), from which we can compute/plot p(loc| j )
jjdj ,maxarg*
42
44
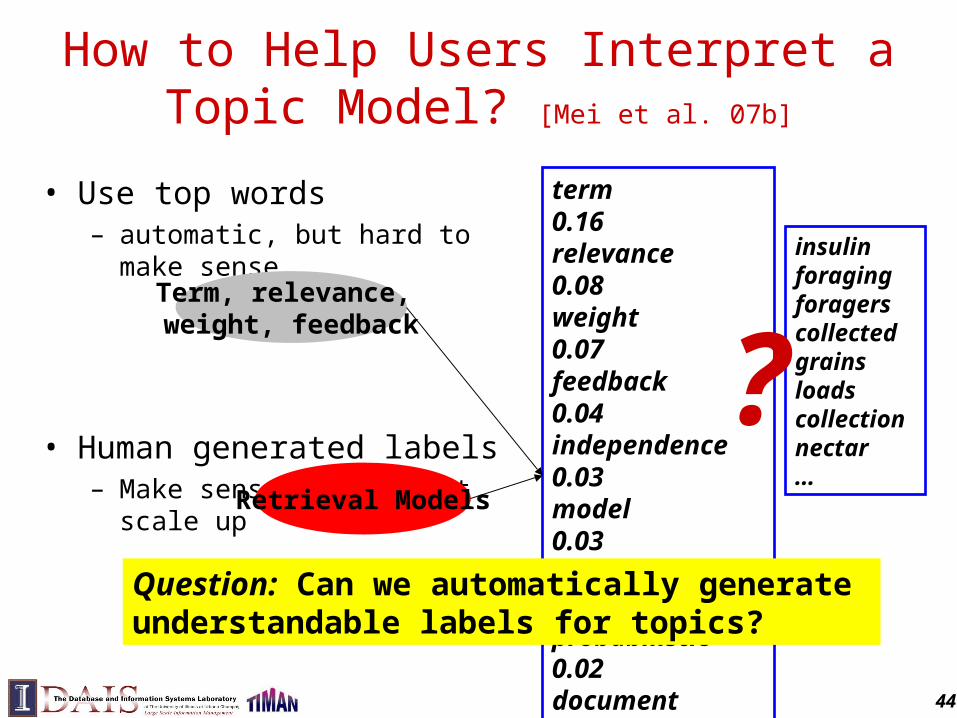
How to Help Users Interpret a Topic Model? [Mei et al. 07b]
• Use top words– automatic, but hard to make sense
• Human generated labels– Make sense, but cannot scale up
term 0.16relevance 0.08weight 0.07 feedback 0.04independence 0.03model 0.03frequent 0.02probabilistic 0.02document 0.02…
Retrieval Models
Question: Can we automatically generate understandable labels for topics?
Term, relevance, weight, feedback
insulin foragingforagerscollectedgrainsloadscollectionnectar…
?

45
Automatic Labeling of Topics [Mei et al. 07b]
Statistical topic models
NLP ChunkerNgram stat.
term 0.1599relevance 0.0752weight 0.0660 feedback 0.0372independence 0.0311model 0.0310frequent 0.0233probabilistic 0.0188document 0.0173…
term 0.1599relevance 0.0752weight 0.0660 feedback 0.0372independence 0.0311model 0.0310frequent 0.0233probabilistic 0.0188document 0.0173…
term 0.1599relevance 0.0752weight 0.0660 feedback 0.0372independence 0.0311model 0.0310frequent 0.0233probabilistic 0.0188document 0.0173…
Multinomial topic models
database system, clustering algorithm, r tree, functional dependency, iceberg cube, concurrency control, index structure …
Candidate label pool
Collection (Context)
Ranked Listof Labels
clustering algorithm;distance measure;…
Relevance Score Re-ranking
Coverage; Discrimination
1 2

46
Relevance: the Zero-Order Score
• Intuition: prefer phrases well covering top words
Clustering
dimensional
algorithm
birch
shape
Latent Topic
…
Good Label (l1): “clustering algorithm”
body
Bad Label (l2): “body shape”
…
p(w|)
p(“clustering”|) = 0.4
p(“dimensional”|) = 0.3
p(“body”|) = 0.001
p(“shape”|) = 0.01
√>)lg(
)|lg(
orithmaclusteringp
orithmaclusteringp
)(
)|(
shapebodyp
shapebodyp

47
Clustering
hash
dimension
key
algorithm
…Bad Label (l2):
“hash join”
p(w | hash join)
Relevance: the First-Order Score
• Intuition: prefer phrases with similar context (distribution)
Clustering
dimension
partition
algorithm
hash
Topic
…P(w|)
D( | clustering algorithm) < D( | hash join)
SIGMOD Proceedings
Clustering
hash
dimension
algorithm
partition
…
p(w | clustering algorithm )
Good Label (l1):
“clustering algorithm”
w
ClwPMIwp )|,()|( Score (l, )

48
Results: Sample Topic Labelssampling 0.06estimation 0.04approximate 0.04histograms 0.03selectivity 0.03histogram 0.02answers 0.02accurate 0.02 tree 0.09
trees 0.08spatial 0.08b 0.05r 0.04disk 0.02array 0.01cache 0.01
north 0.02case 0.01trial 0.01iran 0.01documents 0.01walsh 0.009reagan 0.009charges 0.007
the, of, a, and,to, data, > 0.02…clustering 0.02time 0.01clusters 0.01databases 0.01large 0.01performance 0.01quality 0.005
clustering algorithmclustering structure
…
large data, data quality, high data,
data application, …
selectivityestimation …
iran contra…
r treeb tree …
indexing methods

49
Results: Contextual-Sensitive Labeling
samplingestimationapproximationhistogramselectivityhistograms…
selectivity estimation;random sampling;
approximate answers;
multivalue dependencyfunctional dependency
Iceberg cube
distributed retrieval;parameter estimation;
mixture models;
term dependency;independence assumption;
Context: Database(SIGMOD Proceedings)
Context: IR(SIGIR Proceedings)
dependenciesfunctionalcubemultivaluedicebergbuc…
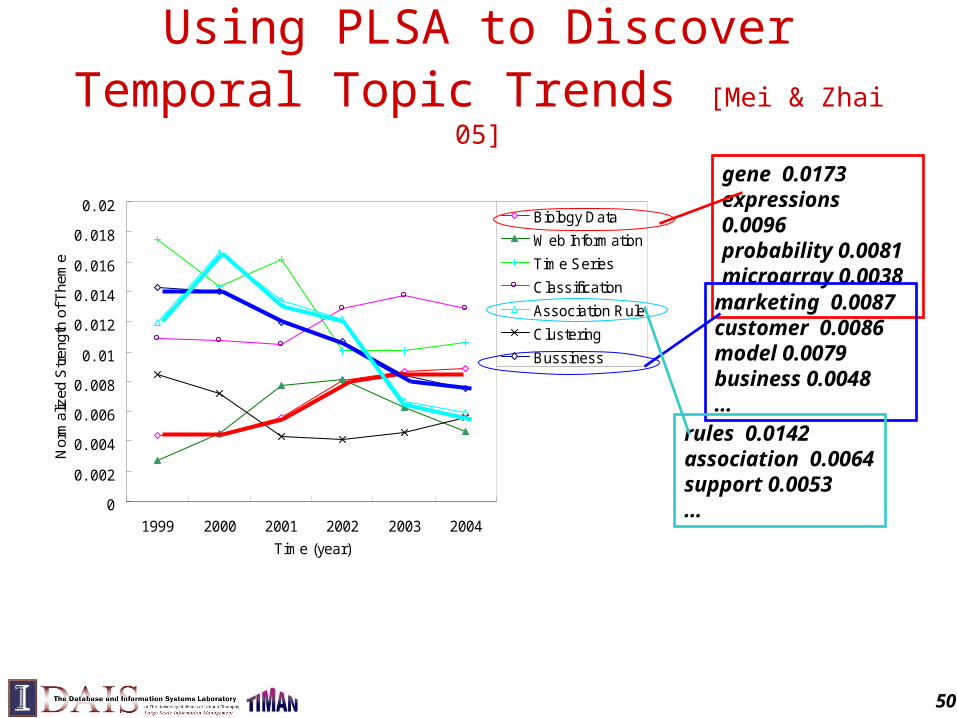
Using PLSA to Discover Temporal Topic Trends [Mei & Zhai 05]
0
0. 002
0. 004
0. 006
0. 008
0. 01
0. 012
0. 014
0. 016
0. 018
0. 02
1999 2000 2001 2002 2003 2004Time (year)
Nor
mal
ized
Str
engt
h of
The
me
Biology Data
Web Information
Time Series
Classification
Association Rule
Clustering
Bussiness
gene 0.0173expressions 0.0096probability 0.0081microarray 0.0038…
marketing 0.0087customer 0.0086model 0.0079business 0.0048…
rules 0.0142association 0.0064support 0.0053…
50
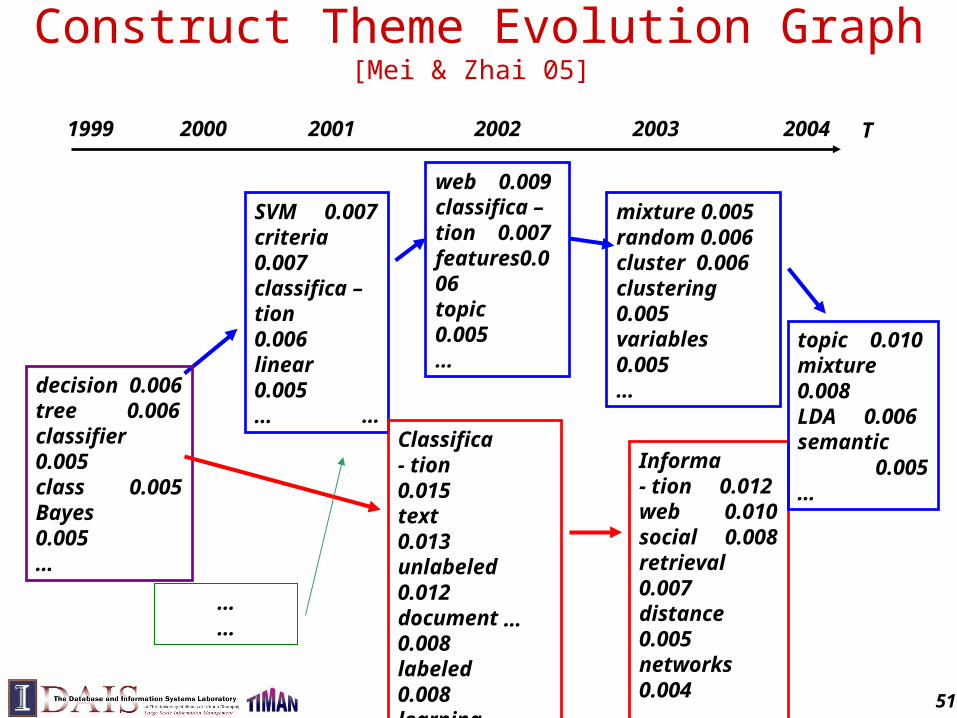
Construct Theme Evolution Graph [Mei & Zhai 05]
T
SVM 0.007criteria 0.007classifica – tion 0.006linear 0.005…
decision 0.006tree 0.006classifier 0.005class 0.005Bayes 0.005…
Classifica - tion 0.015text 0.013unlabeled 0.012document 0.008labeled 0.008learning 0.007…
Informa - tion 0.012web 0.010social 0.008retrieval 0.007distance 0.005networks 0.004…
……
1999
…
web 0.009classifica –tion 0.007features0.006topic 0.005…
mixture 0.005random 0.006cluster 0.006clustering 0.005variables 0.005… topic 0.010
mixture 0.008LDA 0.006 semantic 0.005…
…
2000 2001 2002 2003 2004
51

52
Use PLSA to Integrate Opinions [Lu & Zhai 08]
cute… tiny… ..thicker..last many hrs
die out soon
could afford it
still expensive
DesignBatteryPrice..
DesignBatteryPrice..
Topic: iPod
Expert review with aspects
Text collection of ordinary
opinions, e.g. Weblogs
Integrated Summary
DesignBattery
Price
DesignBattery
Price
iTunes … easy to use…warranty …better to extend..
Revi
ew
Aspe
cts
Extr
a As
pect
s
Similar opinions
Supplementaryopinions
InputOutput

Methods
• Semi-Supervised Probabilistic Latent Semantic Analysis (PLSA) – The aspects extracted from expert reviews
serve as clues to define a conjugate prior on topics
– Maximum a Posteriori (MAP) estimation– Repeated applications of PLSA to integrate
and align opinions in blog articles to expert review
53
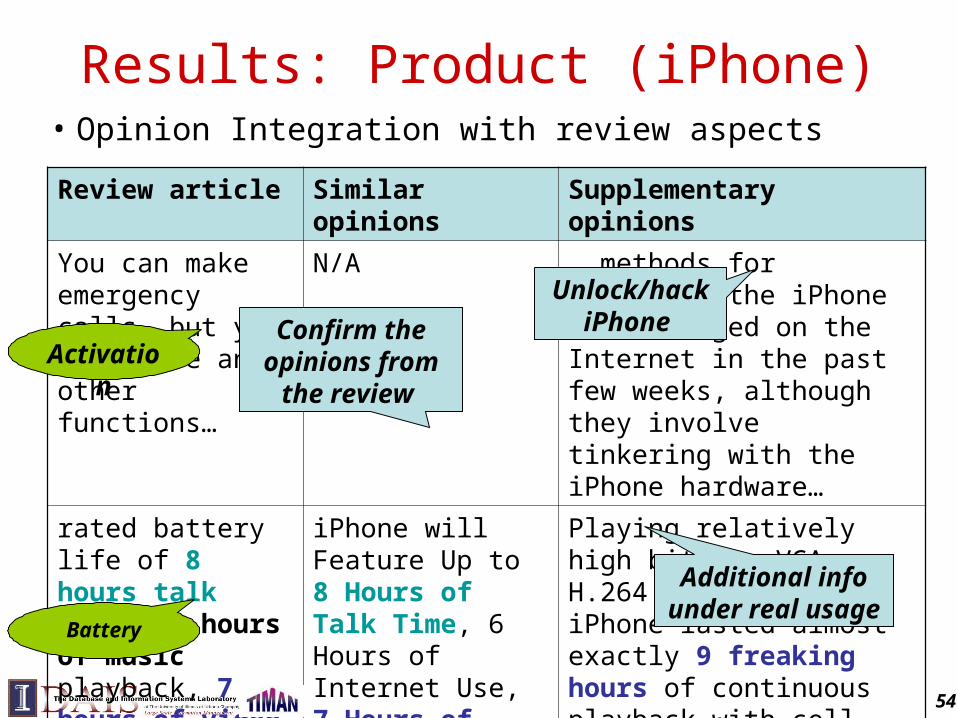
Results: Product (iPhone)• Opinion Integration with review aspectsReview article Similar opinions Supplementary opinions
You can make emergency calls, but you can't use any other functions…
N/A … methods for unlocking the iPhone have emerged on the Internet in the past few weeks, although they involve tinkering with the iPhone hardware…
rated battery life of 8 hours talk time, 24 hours of music playback, 7 hours of video playback, and 6 hours on Internet use.
iPhone will Feature Up to 8 Hours of Talk Time, 6 Hours of Internet Use, 7 Hours of Video Playback or 24 Hours of Audio Playback
Playing relatively high bitrate VGA H.264 videos, our iPhone lasted almost exactly 9 freaking hours of continuous playback with cell and WiFi on (but Bluetooth off).
Unlock/hack iPhone
Activation
Battery
Confirm the opinions from the
review
Additional info under real usage
54

Results: Product (iPhone)
• Opinions on extra aspects
support Supplementary opinions on extra aspects
15 You may have heard of iASign … an iPhone Dev Wiki tool that allows you to activate your phone without going through the iTunes rigamarole.
13 Cisco has owned the trademark on the name "iPhone" since 2000, when it acquired InfoGear Technology Corp., which originally registered the name.
13 With the imminent availability of Apple's uber cool iPhone, a look at 10 things current smartphones like the Nokia N95 have been able to do for a while and that the iPhone can't currently match...
Another way to activate iPhone
iPhone trademark originally owned by
Cisco
A better choice for smart phones?
55
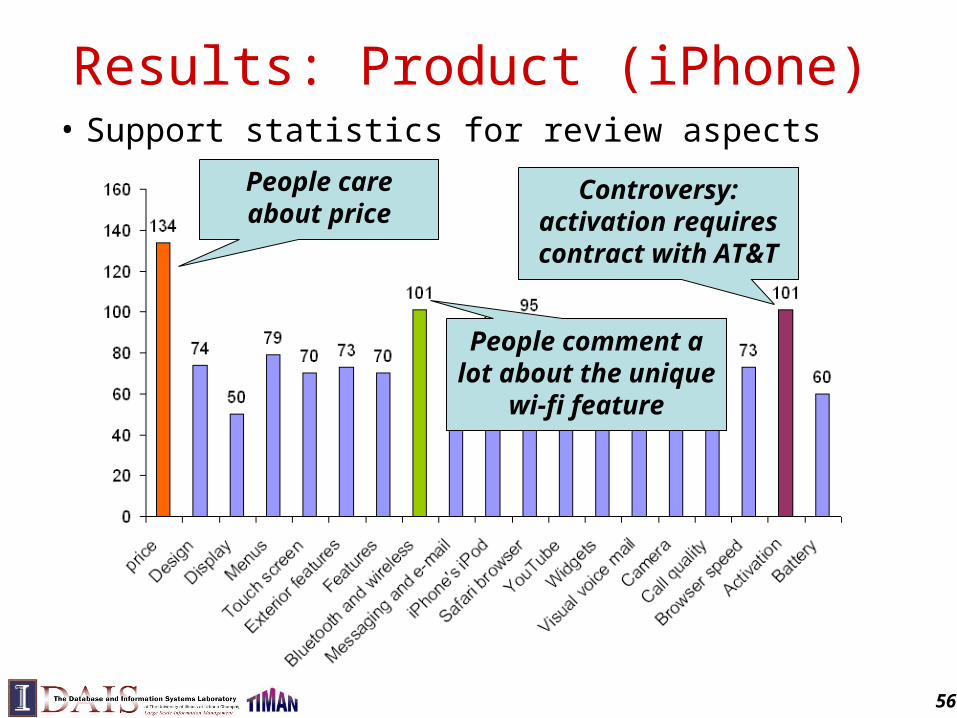
Results: Product (iPhone)• Support statistics for review aspects
People care about price
People comment a lot about the unique wi-fi
feature
Controversy: activation requires contract with
AT&T
56

Comparison of Task Performance of PLSA and LDA [Lu et al. 11]
• Three text mining tasks considered– Topic model for text clustering– Topic model for text categorization (topic model is used to obtain low-
dimensional representation) – Topic model for smoothing language model for retrieval
• Conclusions– PLSA and LDA generally have similar task performance for clustering
and retrieval – LDA works better than PLSA when used to generate low-dimensional
representation (PLSA suffers from overfitting) – Task performance of LDA is very sensitive to setting of
hyperparameters– Multiple local maxima problem of PLSA didn’t seem to affect task
performance much
57

58
Outline
1. General Idea of Topic Models
2. Basic Topic Models
- Probabilistic Latent Semantic Analysis (PLSA)
- Latent Dirichlet Allocation (LDA)
- Applications of Basic Topic Models to Text Mining
3. Advanced Topic Models - Capturing Topic Structures
- Contextualized Topic Models
- Supervised Topic Models
4. Summary
We are here

Overview of Advanced Topic Models
• There are MANY variants and extensions of the basic PLSA/LDA topic models!
• Selected major lines to cover in this tutorial
– Capturing Topic Structures
– Contextualized Topic Models
– Supervised Topic Models
59
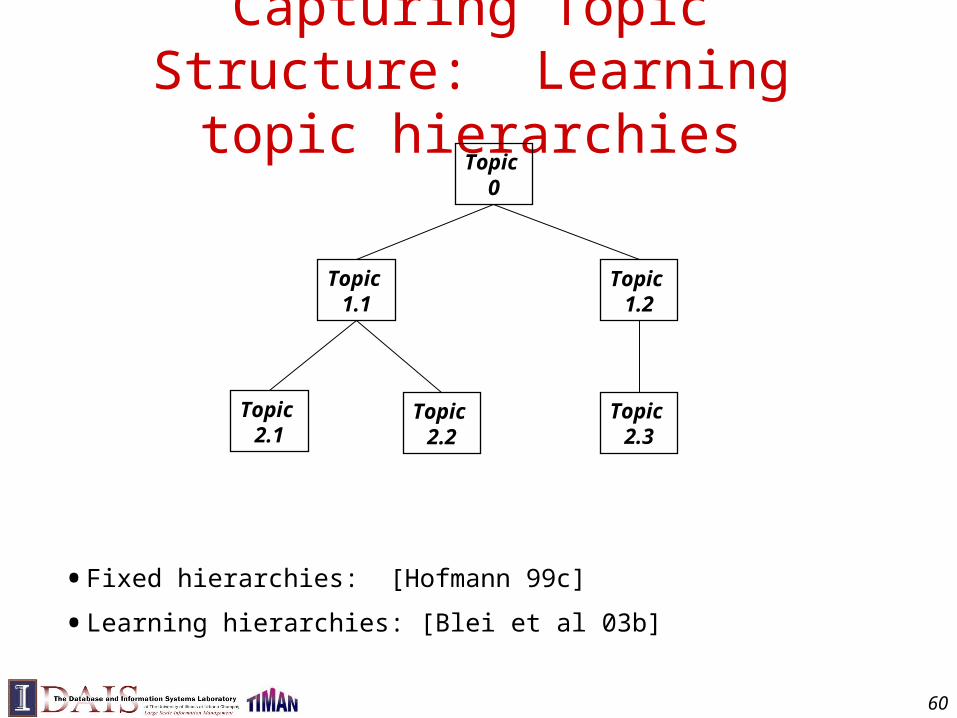
Capturing Topic Structure: Learning topic hierarchies
• Fixed hierarchies: [Hofmann 99c]
• Learning hierarchies: [Blei et al 03b]
Topic 0
Topic 1.1
Topic 1.2
Topic 2.1
Topic 2.2
Topic 2.3
60

Learning topic hierarchies
Topic 0
Topic 1.1
Topic 1.2
Topic 2.1
Topic 2.2
Topic 2.3
The topics in each document form a path
from root to leaf
• Fixed hierarchies: [Hofmann 99c]
• Learning hierarchies:[Blei et al. 03b]61

Capturing Topic Structures:Correlated Topic Model (CTM) [Blei & Lafferty 05]
63

65
Outline
1. Background - Text Mining (TM)
- Statistical Language Models
2. Basic Topic Models
- Probabilistic Latent Semantic Analysis (PLSA)
- Latent Dirichlet Allocation (LDA)
- Applications of Basic Topic Models to Text Mining
3. Advanced Topic Models - Capturing Topic Structures
- Contextualized Topic Models
- Supervised Topic Models
4. Summary
We are here

Contextual Topic Mining
• Documents are often associated with context (meta-data)
– Direct context: time, location, source, authors,…
– Indirect context: events, policies, …
• Many applications require “contextual text analysis”:
– Discovering topics from text in a context-sensitive way
– Analyzing variations of topics over different contexts
– Revealing interesting patterns (e.g., topic evolution, topic variations, topic communities)
66

Example: Comparing News Articles
Common Themes “Vietnam” specific “Afghan” specific “Iraq” specific
United nations … … …Death of people … … …… … … …
Vietnam War Afghan War Iraq War
CNN Fox Blog
Before 9/11During Iraq war Current
US blog European blog Others
What’s in common? What’s unique?
67

More Contextual Analysis Questions
• What positive/negative aspects did people say about X (e.g., a person, an event)? Trends?
• How does an opinion/topic evolve over time?
• What are emerging research topics in computer science? What topics are fading away?
• How can we mine topics from literature to characterize the expertise of a researcher?
• How can we characterize the content exchanges on a social network?
• …
68

Documentcontext:
Time = July 2005Location = Texas
Author = xxxOccup. = Sociologist
Age Group = 45+…
Contextual Probabilistic Latent Semantics Analysis [Mei & Zhai 06b]
View1 View2 View3Themes
government
donation
New Orleans
government 0.3 response 0.2..
donate 0.1relief 0.05help 0.02 ..
city 0.2new 0.1
orleans 0.05 ..
Texas July 2005
sociologist
Theme coverages
:
Texas July 2005 document
……
Choose a view
Choose a Coverage
government
donate
new
Draw a word from i
response
aid help
Orleans
Criticism of government response to the
hurricane primarily consisted of criticism of its response to … The
total shut-in oil production from the Gulf
of Mexico … approximately 24% of the
annual production and the shut-in gas
production … Over seventy countries pledged monetary donations or other
assistance. …
Choose a theme
69

Comparing News Articles [Zhai et al. 04]
Iraq War (30 articles) vs. Afghan War (26 articles)
Cluster 1 Cluster 2 Cluster 3
Common
Theme
united 0.042nations 0.04…
killed 0.035month 0.032deaths 0.023…
…
Iraq
Theme
n 0.03Weapons 0.024Inspections 0.023…
troops 0.016hoon 0.015sanches 0.012…
…
Afghan
Theme
Northern 0.04alliance 0.04kabul 0.03taleban 0.025aid 0.02…
taleban 0.026rumsfeld 0.02hotel 0.012front 0.011…
…
The common theme indicates that “United Nations” is involved in both wars
Collection-specific themes indicate different roles of “United Nations” in the two wars
70

71
Spatiotemporal Patterns in Blog Articles[Mei et al. 06a]
• Query= “Hurricane Katrina”
• Topics in the results:
• Spatiotemporal patterns
Government Response New Orleans Oil Price Praying and Blessing Aid and Donation Personal bush 0.071 city 0.063 price 0.077 god 0.141 donate 0.120 i 0.405president 0.061 orleans 0.054 oil 0.064 pray 0.047 relief 0.076 my 0.116federal 0.051 new 0.034 gas 0.045 prayer 0.041 red 0.070 me 0.060government 0.047 louisiana 0.023 increase 0.020 love 0.030 cross 0.065 am 0.029fema 0.047 flood 0.022 product 0.020 life 0.025 help 0.050 think 0.015administrate 0.023 evacuate 0.021 fuel 0.018 bless 0.025 victim 0.036 feel 0.012response 0.020 storm 0.017 company 0.018 lord 0.017 organize 0.022 know 0.011brown 0.019 resident 0.016 energy 0.017 jesus 0.016 effort 0.020 something 0.007blame 0.017 center 0.016 market 0.016 will 0.013 fund 0.019 guess 0.007governor 0.014 rescue 0.012 gasoline 0.012 faith 0.012 volunteer 0.019 myself 0.006

Theme Life Cycles (“Hurricane Katrina”)
city 0.0634orleans 0.0541
new 0.0342louisiana 0.0235
flood 0.0227evacuate 0.0211
storm 0.0177…
price 0.0772oil 0.0643
gas 0.0454 increase 0.0210product 0.0203
fuel 0.0188company 0.0182
…
Oil Price
New Orleans
72

Theme Snapshots (“Hurricane Katrina”)
Week4: The theme is again strong along the east coast and the Gulf of Mexico
Week3: The theme distributes more uniformly over the states
Week2: The discussion moves towards the north and west
Week5: The theme fades out in most states
Week1: The theme is the strongest along the Gulf of Mexico
73
74
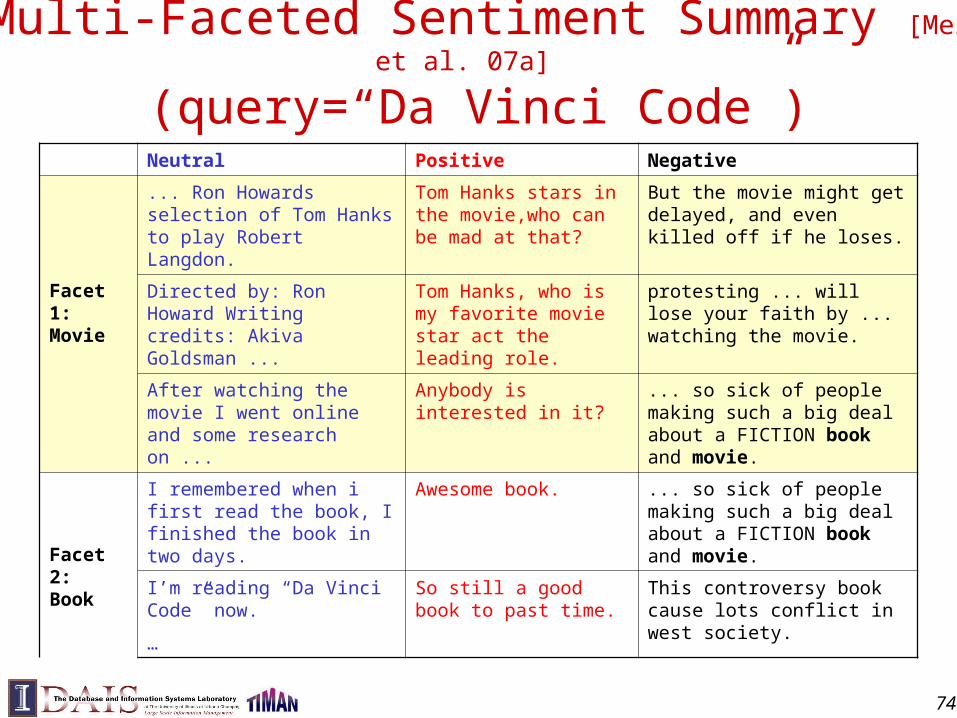
Multi-Faceted Sentiment Summary [Mei et al. 07a]
(query=“Da Vinci Code”)Neutral Positive Negative
Facet 1:Movie
... Ron Howards selection of Tom Hanks to play Robert Langdon.
Tom Hanks stars in the movie,who can be mad at that?
But the movie might get delayed, and even killed off if he loses.
Directed by: Ron Howard Writing credits: Akiva Goldsman ...
Tom Hanks, who is my favorite movie star act the leading role.
protesting ... will lose your faith by ... watching the movie.
After watching the movie I went online and some research on ...
Anybody is interested in it?
... so sick of people making such a big deal about a FICTION book and movie.
Facet 2:Book
I remembered when i first read the book, I finished the book in two days.
Awesome book. ... so sick of people making such a big deal about a FICTION book and movie.
I’m reading “Da Vinci Code” now.
…
So still a good book to past time.
This controversy book cause lots conflict in west society.

Event Impact Analysis: IR Research [Mei & Zhai 06b]
vector 0.0514concept 0.0298extend 0.0297 model 0.0291space 0.0236boolean 0.0151function 0.0123feedback 0.0077
…
xml 0.0678email 0.0197 model 0.0191collect 0.0187judgment 0.0102rank 0.0097subtopic 0.0079
…
probabilist 0.0778model 0.0432logic 0.0404 ir 0.0338boolean 0.0281algebra 0.0200estimate 0.0119weight 0.0111
…
model 0.1687language 0.0753estimate 0.0520 parameter 0.0281
distribution 0.0268probable 0.0205smooth 0.0198markov 0.0137likelihood 0.0059
…
1998
Publication of the paper “A language modeling approach to information
retrieval”
Starting of the TREC conferences
year1992
term 0.1599relevance 0.0752weight 0.0660 feedback 0.0372independence 0.0311model 0.0310frequent 0.0233probabilistic 0.0188document 0.0173
…
Theme: retrieval models
SIGIR papersSIGIR papers
76

The Author-Topic model[Rosen-Zvi et al. 04]
Nd D
zi
wi
(a)
(j)
(a) Dirichlet()
zi Discrete( (xi) )
(j) Dirichlet()
wi Discrete( (zi) )
T
xi
A
xi Uniform(A (d) )
each author has a distribution over topics
the author of each word is chosen uniformly at random
77

Four example topics from NIPS
WORD PROB. WORD PROB. WORD PROB. WORD PROB.
LIKELIHOOD 0.0539 RECOGNITION 0.0400 REINFORCEMENT 0.0411 KERNEL 0.0683
MIXTURE 0.0509 CHARACTER 0.0336 POLICY 0.0371 SUPPORT 0.0377
EM 0.0470 CHARACTERS 0.0250 ACTION 0.0332 VECTOR 0.0257
DENSITY 0.0398 TANGENT 0.0241 OPTIMAL 0.0208 KERNELS 0.0217
GAUSSIAN 0.0349 HANDWRITTEN 0.0169 ACTIONS 0.0208 SET 0.0205
ESTIMATION 0.0314 DIGITS 0.0159 FUNCTION 0.0178 SVM 0.0204
LOG 0.0263 IMAGE 0.0157 REWARD 0.0165 SPACE 0.0188
MAXIMUM 0.0254 DISTANCE 0.0153 SUTTON 0.0164 MACHINES 0.0168
PARAMETERS 0.0209 DIGIT 0.0149 AGENT 0.0136 REGRESSION 0.0155
ESTIMATE 0.0204 HAND 0.0126 DECISION 0.0118 MARGIN 0.0151
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB.
Tresp_V 0.0333 Simard_P 0.0694 Singh_S 0.1412 Smola_A 0.1033
Singer_Y 0.0281 Martin_G 0.0394 Barto_A 0.0471 Scholkopf_B 0.0730
Jebara_T 0.0207 LeCun_Y 0.0359 Sutton_R 0.0430 Burges_C 0.0489
Ghahramani_Z 0.0196 Denker_J 0.0278 Dayan_P 0.0324 Vapnik_V 0.0431
Ueda_N 0.0170 Henderson_D 0.0256 Parr_R 0.0314 Chapelle_O 0.0210
Jordan_M 0.0150 Revow_M 0.0229 Dietterich_T 0.0231 Cristianini_N 0.0185
Roweis_S 0.0123 Platt_J 0.0226 Tsitsiklis_J 0.0194 Ratsch_G 0.0172
Schuster_M 0.0104 Keeler_J 0.0192 Randlov_J 0.0167 Laskov_P 0.0169
Xu_L 0.0098 Rashid_M 0.0182 Bradtke_S 0.0161 Tipping_M 0.0153
Saul_L 0.0094 Sackinger_E 0.0132 Schwartz_A 0.0142 Sollich_P 0.0141
TOPIC 19 TOPIC 24 TOPIC 29 TOPIC 87
78

Dirichlet-multinomial Regression (DMR) [Mimno & McCallum 08]
79
Allows arbitrary features to be used to influence choice of topics

Latent Aspect Rating Analysis [Wang et al. 11]
• Given a set of review articles about a topic with overall ratings (ratings as “supervision signals”)
• Output– Major aspects commented on in the reviews
– Ratings on each aspect
– Relative weights placed on different aspects by reviewers
• Many applications– Opinion-based entity ranking
– Aspect-level opinion summarization
– Reviewer preference analysis
– Personalized recommendation of products
– …
82

How to infer aspect ratings?
Value Location Service …..
How to infer aspect weights?
Value Location Service …..
83
An Example of LARA

Excellent location in walking distance to Tiananmen Square and shopping streets. That’s the best part of this hotel!The rooms are getting really old. Bathroom was nasty. The fixtures were falling off, lots of cracks and everything looked dirty. I don’t think it worth the price.Service was the most disappointing part, especially the door men. this is not how you treat guests, this is not hospitality.
A Unified Generative Model for LARA
84
Aspects
locationamazingwalkanywhere
terriblefront-desksmileunhelpful
roomdirtyappointedsmelly
Location
Room
Service
Aspect Rating Aspect Weight
0.86
0.04
0.10
Entity
Review
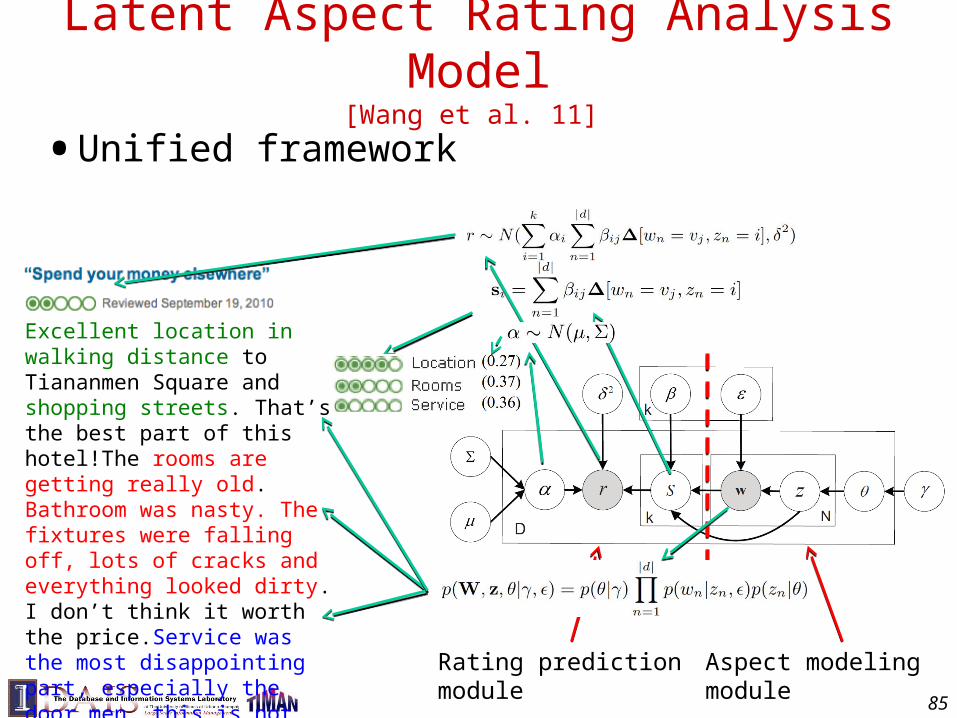
Latent Aspect Rating Analysis Model[Wang et al. 11]
• Unified framework
85
Excellent location in walking distance to Tiananmen Square and shopping streets. That’s the best part of this hotel!The rooms are getting really old. Bathroom was nasty. The fixtures were falling off, lots of cracks and everything looked dirty. I don’t think it worth the price.Service was the most disappointing part, especially the door men. this is not how you treat guests, this is not hospitality.
Rating prediction module Aspect modeling module

Aspect Identification
• Amazon reviews: no guidance
86
battery life accessory service file format volume video

Network Supervised Topic Modeling [Mei et al. 08]
• Probabilistic topic modeling as an optimization problem (e.g., PLSA/LDA: Maximum Likelihood):
• Regularized objective function with network constrains
– Topic distribution are smoothed over adjacent vertices
• Flexibility in selecting topic models and regularizers
87
))|(log()|( ModelCollectionPModelCollectionO
)|,( ModelNetworkCollectionO
),(e))|(log( NetworkModelgularizerRModelCollectionP
)|][,(maxarg ModelNetworkCollectionOsModelParamparams

Evu
k
jjj
jd w
k
jj
vpupvuw
wpdpdwcGCO
, 1
2
1
)))|()|((),(2
1(
))|()|(log),(()1(),(
Instantiation: NetPLSA
• Basic Assumption: Neighbors have similar topic distribution
PLSA
Graph Harmonic Regularizer,
Generalization of [Zhu ’03],
Evu
k
jjj
jd w
k
jj
vpupvuw
wpdpdwcGCO
, 1
2
1
)))|()|((),(2
1(
))|()|(log),(()1(),(
importance (weight) of
an edge
tradeoff
topic distribution of a document
)|( , 2
1,
...1
upfwhereff jujkj
jTj
difference of topic
distribution
88

Topical Communities with PLSA
Topic 1 Topic 2 Topic 3 Topic 4
term 0.02 peer 0.02 visual 0.02 interface 0.02
question 0.02 patterns 0.01 analog 0.02 towards 0.02
protein 0.01 mining 0.01 neurons 0.02 browsing 0.02
training 0.01 clusters 0.01 vlsi 0.01 xml 0.01
weighting 0.01
stream 0.01 motion 0.01 generation 0.01
multiple 0.01 frequent 0.01 chip 0.01 design 0.01
recognition 0.01 e 0.01 natural 0.01 engine 0.01
relations 0.01 page 0.01 cortex 0.01 service 0.01
library 0.01 gene 0.01 spike 0.01 social 0.01
?? ? ?
Noisy community assignment
89

Topical Communities with NetPLSA
Topic 1 Topic 2 Topic 3 Topic 4
retrieval 0.13 mining 0.11 neural 0.06 web 0.05
information 0.05 data 0.06 learning 0.02 services 0.03
document 0.03 discovery 0.03 networks 0.02 semantic 0.03
query 0.03 databases 0.02 recognition 0.02 services 0.03
text 0.03 rules 0.02 analog 0.01 peer 0.02
search 0.03 association 0.02 vlsi 0.01 ontologies 0.02
evaluation 0.02 patterns 0.02 neurons 0.01 rdf 0.02
user 0.02 frequent 0.01 gaussian 0.01 management 0.01
relevance 0.02 streams 0.01 network 0.01 ontology 0.01
Information Retrieval
Data mining Machine learning
Web
Coherent community assignment
90

91
Outline
1. General Idea of Topic Models
2. Basic Topic Models
- Probabilistic Latent Semantic Analysis (PLSA)
- Latent Dirichlet Allocation (LDA)
- Applications of Basic Topic Models to Text Mining
3. Advanced Topic Models - Capturing Topic Structures
- Contextualized Topic Models
- Supervised Topic Models
4. Summary We are here

Summary
• Statistical Topic Models (STMs) are a new family of language models, especially useful for
– Discovering latent topics in text
– Analyzing latent structures and patterns of topics
– Extensible for joint modeling and analysis of text and associated non-textual data
• PLSA & LDA are two basic topic models that tend to function similarly, with LDA better as a generative model
• Many different models have been proposed with probably many more to come
• Many demonstrated applications in multiple domains and many more to come
92

Summary (cont.)
• However, all topic models suffer from the problem of multiple local maxima
– Make it hard/impossible to reproduce research results
– Make it hard/impossible to interpret results in real applications
• Complex models can’t scale up to handle large amounts of text data
– Collapsed Gibbs sampling is efficient, but only working for conjugate priors
– Variational EM needs to be derived in a model-specific way
– Parallel algorithms are promising
• Many challenges remain….
93

94
Challenges and Future Directions
• Challenge 1: How can we quantitatively evaluate the benefit of topic models for text mining? – Currently, most quantitative evaluation is based on
perplexity which doesn’t reflect the actual utility of a topic model for text mining
– Need to separately evaluate the quality of both topic word distributions and topic coverage
– Need to consider multiple aspects of a topic (e.g., coherent?, meaningful?) and define appropriate measures
– Need to compare topic models with alternative approaches to solving the same text mining problem (e.g., traditional IR methods, non-negative matrix factorization)
– Need to create standard test collections

• Challenge 2: How can we help users interpret a topic?
– Most of the time, a topic is manually labeled in a research paper; this is insufficient for real applications
– Automatic labeling can help, but the utility still needs to evaluated
– Need to generate a summary for a topic to enable a user to navigate into text documents to better understand a topic
– Need to facilitate post-processing of discovered topics (e.g., ranking, comparison)
95

96
Challenges and Future Directions (cont.)
• Challenge 3: How can we address the problem of multiple local maxima? – All topic models have the problem of multiple local maxima,
causing problems with reproducing results
– Need to compute the variance of a discovered topic
– Need to define and report the confidence interval for a topic
• Challenge 4: How can we develop efficient estimation/inference algorithms for sophisticated models? – How can we leverage a user’s knowledge to speed up
inferences for topic models?
– Need to develop parallel estimation/inference algorithms

97
Challenges and Future Directions (cont.)
• Challenge 5: How can we incorporate linguistic knowledge into topic models?
– Most current topic models are purely statistical
– Some progress has been made to incorporate linguistic knowledge (e.g., [Griffiths et al. 04, Wallach 08])
– More needs to be done
• Challenge 6: How can we incorporate domain knowledge and preferences from an analyst into a topic model to support complex text mining tasks?
– Current models are mostly pre-specified with little flexibility for an analyst to “steer” the analysis process
– Need to develop a general analysis framework to enable an analyst to use multiple topic models together to perform complex text mining tasks

98
References[Blei et al. 02] D. Blei, A. Ng, and M. Jordan. Latent dirichlet allocation. In T G Dietterich, S. Becker, and Z. Ghahramani,
editors, Advances in Neural Information Processing Systems 14, Cambridge, MA, 2002. MIT Press.
[Blei et al. 03a] David M. Blei, Andrew Y. Ng, Michael I. Jordan: Latent Dirichlet Allocation. Journal of Machine Learning Research 3: 993-1022 (2003)
[Griffiths et al. 04] Thomas L. Griffiths, Mark Steyvers, David M. Blei, Joshua B. Tenenbaum: Integrating Topics and Syntax. NIPS 2004
[Blei et al. 03b] David M. Blei, Thomas L. Griffiths, Michael I. Jordan, Joshua B. Tenenbaum: Hierarchical Topic Models and the Nested Chinese Restaurant Process. NIPS 2003
[Teh et al. 04] Yee Whye Teh, Michael I. Jordan, Matthew J. Beal, David M. Blei: Sharing Clusters among Related Groups: Hierarchical Dirichlet Processes. NIPS 2004
[Blei & Lafferty 05] David M. Blei, John D. Lafferty: Correlated Topic Models. NIPS 2005
[Blei & McAuliffe 07] David M. Blei, Jon D. McAuliffe: Supervised Topic Models. NIPS 2007
[Hofmann 99a] T. Hofmann. Probabilistic latent semantic indexing. In Proceedings on the 22nd annual international ACM-SIGIR 1999, pages 50-57.
[Hofmann 99b] Thomas Hofmann: Probabilistic Latent Semantic Analysis. UAI 1999: 289-296
[Hofmann 99c] Thomas Hofmann: The Cluster-Abstraction Model: Unsupervised Learning of Topic Hierarchies from Text Data. IJCAI 1999: 682-687
[Jelinek 98] F. Jelinek, Statistical Methods for Speech Recognition, Cambirdge: MIT Press, 1998.
[Lu & Zhai 08] Yue Lu, Chengxiang Zhai: Opinion integration through semi-supervised topic modeling. WWW 2008: 121-130
[Lu et al. 11] Yue Lu, Qiaozhu Mei, ChengXiang Zhai: Investigating task performance of probabilistic topic models: an empirical study of PLSA and LDA. Inf. Retr. 14(2): 178-203 (2011)
[Mei et al. 05] Qiaozhu Mei, ChengXiang Zhai: Discovering evolutionary theme patterns from text: an exploration of temporal text mining. KDD 2005: 198-207
[Mei et al. 06a] Qiaozhu Mei, Chao Liu, Hang Su, ChengXiang Zhai: A probabilistic approach to spatiotemporal theme pattern mining on weblogs. WWW 2006: 533-542

99
References ]Mei & Zhai 06b] Qiaozhu Mei, ChengXiang Zhai: A mixture model for contextual text mining. KDD 2006: 649-655
[Met et al. 07a] Qiaozhu Mei, Xu Ling, Matthew Wondra, Hang Su, ChengXiang Zhai: Topic sentiment mixture: modeling facets and opinions in weblogs. WWW 2007: 171-180
[Mei et al. 07b] Qiaozhu Mei, Xuehua Shen, ChengXiang Zhai: Automatic labeling of multinomial topic models. KDD 2007: 490-499
[Mei et al. 08] Qiaozhu Mei, Deng Cai, Duo Zhang, ChengXiang Zhai: Topic modeling with network regularization. WWW 2008: 101-110
[Mimno & McCallum 08[ David M. Mimno, Andrew McCallum: Topic Models Conditioned on Arbitrary Features with Dirichlet-multinomial Regression. UAI 2008: 411-418
[Minka & Lafferty 03] T. Minka and J. Lafferty, Expectation-propagation for the generative aspect model, In Proceedings of the UAI 2002, pages 352--359.
[Pritchard et al. 00] J. K. Pritchard, M. Stephens, P. Donnelly, Inference of population structure using multilocus genotype data,Genetics. 2000 Jun;155(2):945-59.
[Rosen-Zvi et al. 04] Michal Rosen-Zvi, Thomas L. Griffiths, Mark Steyvers, Padhraic Smyth: The Author-Topic Model for Authors and Documents. UAI 2004: 487-494
[Wnag et al. 10] Hongning Wang, Yue Lu, Chengxiang Zhai: Latent aspect rating analysis on review text data: a rating regression approach. KDD 2010: 783-792
[Wang et al. 11] Hongning Wang, Yue Lu, ChengXiang Zhai: Latent aspect rating analysis without aspect keyword supervision. KDD 2011: 618-626
[Zhai et al. 04] ChengXiang Zhai, Atulya Velivelli, Bei Yu: A cross-collection mixture model for comparative text mining. KDD 2004: 743-748










![Text Retrieval and Mining Lecture 12 [Borrows slides from Viktor Lavrenko and Chengxiang Zhai]](https://img.dokumen.tips/doc/110x75/56649f3f5503460f94c6042b/text-retrieval-and-mining-lecture-12-borrows-slides-from-viktor-lavrenko-and.jpg)