Embed Size (px)
Citation preview

Full Terms & Conditions of access and use can be found athttps://www.tandfonline.com/action/journalInformation?journalCode=gits20
Journal of Intelligent Transportation SystemsTechnology, Planning, and Operations
ISSN: 1547-2450 (Print) 1547-2442 (Online) Journal homepage: https://www.tandfonline.com/loi/gits20
Predicting duration of traffic accidents based oncost-sensitive Bayesian network and weighted K-nearest neighbor
Li Kuang, Han Yan, Yujia Zhu, Shenmei Tu & Xiaoliang Fan
To cite this article: Li Kuang, Han Yan, Yujia Zhu, Shenmei Tu & Xiaoliang Fan (2019)Predicting duration of traffic accidents based on cost-sensitive Bayesian network and weightedK-nearest neighbor, Journal of Intelligent Transportation Systems, 23:2, 161-174, DOI:10.1080/15472450.2018.1536978
To link to this article: https://doi.org/10.1080/15472450.2018.1536978
Published online: 20 Feb 2019.
Submit your article to this journal
Article views: 33
View Crossmark data
Citing articles: 1 View citing articles

Predicting duration of traffic accidents based on cost-sensitive Bayesiannetwork and weighted K-nearest neighbor
Li Kuanga, Han Yana, Yujia Zhua, Shenmei Tua, and Xiaoliang Fanb,c
aSchool of Software, Central South University, Changsha, China; bFujian Key Laboratory of Sensing and Computing for Smart Cities,Xiamen University, Xiamen, China; cDigital Fujian Institute of Urban Traffic Big Data Research, Xiamen University, Xiamen, China
ABSTRACTWith the development of urbanization, road congestion has become increasingly serious, andan important cause is the traffic accidents. In this article, we aim to predict the duration of traf-fic accidents given a set of historical records and the feature of the new accident, which canbe collected from the vehicle sensors, in order to help guide the congestion and restore theroad. Existing work on predicting the duration of accidents seldom consider the imbalance ofsamples, the interaction of attributes, and the cost-sensitive problem sufficiently. Therefore, inthis article, we propose a two-level model, which consists of a cost-sensitive Bayesian networkand a weighted K-nearest neighbor model, to predict the duration of accidents. After data pre-processing and variance analysis on the traffic accident data of Xiamen City in 2015, the modeluses some important discrete attributes for classification, and then utilizes the remainingattributes for K-nearest neighbor regression prediction. The experiment results show that ourproposed approach to predicting the duration of accidents achieves higher accuracy com-pared with classical models.
ARTICLE HISTORYReceived 30 November 2017Revised 28 September 2018Accepted 3 October 2018
KEYWORDSAccident durationprediction; Bayesiannetwork; cost-sensitive;KNN regression
Introduction
In recent years, intelligent transportation provides all-round support for transportation planning, manage-ment, transportation and public travel, by effectivelyintegrating sensor technology, network communica-tion technology, data processing technology and busi-ness application (Fan, Khattak, & Shay, 2007; Ran, Jin,Boyce, Qiu, & Cheng, 2012). It not only promotes theprecision and intelligence of traffic management, butalso improves the operational efficiency and servicelevels of transportation systems. The governance ofurban traffic congestion is an important research topicin the field of intelligent transportation. Among them,traffic accidents are an important cause of roadcongestion and they often happen occasionally, sohow to predict the duration of traffic accidents fromoccurrence to release quickly and accurately, so as toguide the congestion and restore the road, has becomea significant and challenging research problem.
The rich historical data collected by various kinds ofvehicle sensors provide the possibility of predicting theduration of traffic accidents. Ring coil can detect roadtraffic conditions, such as traffic flow, speed, occupancy,
and vehicle length. The ultrasonic sensor utilizes theinfluence of the shape of vehicles on the ultrasonic wavefront to detect whether the vehicle is approaching ormoving away. Video vehicle detectors can be highly effi-cient wide-area video surveillance and real-time collec-tion of various traffic parameters. Piezoelectric sensorsare useful for dynamic weighing, vehicle classificationstatistics, speed detection, and parking area monitoring.We can extract the start time, the end time, the locationof the accident, the number of vehicles involved in theaccident and the description of the accident from the ori-ginal data obtained by sensors, and construct the predic-tion model with these characteristic data to predict theduration of traffic accidents.
In the related work on predicting the duration oftraffic accidents, scholars initially use single modelssuch as decision tree, neural network, and multiplelinear regression models. In order to improve theprediction accuracy, some scholars consider theadvantages of combining multiple models, in whichtraffic accidents are classified from the perspective ofclustering first, and then regression algorithms foreach type of accidents are used to predict the exact
CONTACT Xiaoliang Fan [email protected] Fujian Key Laboratory of Sensing and Computing for Smart Cities, Xiamen University, Xiamen361000, China.Color versions of one or more of the figures in the article can be found online at www.tandfonline.com/gits.� 2019 Taylor & Francis Group, LLC
JOURNAL OF INTELLIGENT TRANSPORTATION SYSTEMS2019, VOL. 23, NO. 2, 161–174https://doi.org/10.1080/15472450.2018.1536978

values. In addition, there are some studies aimingat solving the heterogeneity of traffic accidents, theconfidence interval of predicted values, and theprobability of occurrence of the second accident.
However, there are still some shortcomings in exist-ing work: (1) the number of traffic accident durationsamples has been proved to be unbalanced, but fewstudies have solved the problem. (2) In the process ofmodeling with the characteristic attributes, the inter-action effects between the attributes are not fully consid-ered, which may affect the prediction accuracy ofduration values. (3) The prediction of traffic accidentduration is a cost-sensitive problem in practice. Forexample, if a long-lasting accident is estimated incor-rectly, vehicles will be misled to select a wrong route,thereby increasing the congestion and road pressure,while if a short-lasting accident is estimated incorrectly,vehicles will plan other routes, only slightly increasingthe car energy consumption. However, there is littlework on the introduction of cost-sensitive issues intothe prediction of traffic accident duration.
Aiming at addressing the shortcomings of existingwork, in this article, we propose a method of predictingthe traffic accident duration based on the combination ofcost-sensitive Bayesian network and weighted K-nearestneighbor (KNN). First, we make a two-factor varianceanalysis of discrete features by collecting the externalparameters of accidents, and constructing a network top-ology diagram among features based on MMPC(Max-Min Parents and Children) and K2(a heuristic searchalgorithm). Then, a Bayesian network model is con-structed by introducing a cost-sensitive function, whichdivides the duration of the accident into two classes, thatis, more than 30min and less than 30min. Finally, afterdetermining the class label, KNN regression based pre-diction is performed using the continuous characteristicparameters to obtain the predicted duration value.
KNN regression model is a nonparametric lazylearning algorithm and works well in practice. It firstfind similar K neighbors by defining the similaritydistance of input features, and then predict the targetvalue based on the records of K neighbors. In theapplication of predicting accidents duration, we findthat under similar context including time and loca-tion, the duration of accidents are similar. Therefore,it is natural to employ KNN regression to capture thesimilarity of durations under similar context.
The remainder of the article is organized as follows:Related work section discusses the related work.Predicting the accident duration section defines theproblem to be solved and illustrates the detailed solu-tion to predicting the duration of traffic accidents.
Experiment section presents the experimental verifica-tion design and result analysis. Finally, Conclusionsection gives conclusions and future work.
Related work
In recent year, the problem of predicting the durationof traffic accidents has attracted wide attention ofscholars. Related work on the research issue focus onthe following aspects: (1) investigating the statisticalcharacteristics of traffic accident data; (2) exploringthe influence factors which affect the length of acci-dent; (3) constructing a proper prediction model.
Usually it is a first step to investigate the statisticalcharacteristics of the accident data before building theprediction model, such as the distribution of accidentduration. Such statistical characteristic of data isimportant to the choice of prediction model, as wellas the choice of data discretion. Some researcherswork on the distributions of accident duration andfind different distributions in different dataset, suchas logarithmic normal distribution (Garib, Radwan, &Al-Deek, 1997; Giuliano, 1989; Golob, Recker, &Leonard,1987), log-logical distribution (Jones, Janssen,& Mannering, 1991), Weibull distribution(Hojati,Ferreira, Washington, & Charles, 2013; Nam &Mannering, 2000;), Gamma distribution(Li & Guo,2015), generalized distribution, etc. For example,Golob et al. (1987) proposed to use Markov to testthe duration of a truck traffic accident and find thedurations follow the logarithmic normal distribution,and the significant levels are from 0.31 to 0.99.Subsequently, Giuliano (1989) and Garib et al. (1997)also proved that the durations of various kinds oftraffic accidents subject to logarithmic normal distri-bution. Jones et al. (1991) conducted appropriatestatistical analysis through the frequency and durationof accidents on the Seattle expressway, and found thatthe accident data follow log-logical distribution. Namand Mannering (2000) divided the duration of theaccident into four stages, due to the mutual influencebetween every two stages, different models are usedfor each stage, and each stage corresponds to log-nor-mal distribution, double logarithmic distribution, andWeibull distribution, respectively.
Feature recognition and construction is alsoimportant to model building. Many researches workon exploring the features that affects the accidentduration. The main features that they have foundinclude: accident type (rear-end collision, turn over,vehicle breakdown, etc.) (Nam & Mannering, 2000)and accident severity; geographical location
162 L. KUANG ET AL.

characteristics (longitude and latitude, cross roadinformation) (Li & Guo, 2015); the number and typeof vehicles involved(trucks, buses, cars, etc.) (Chung,2010); road surface condition (dry, wet, snowy, andicy conditions) (Chung, 2010), reporter type (inde-pendent drivers, Freeway Service Patro, TrafficInformation Service Provider, and FreewayInformation Center) (Chung, 2010); the lane type (left,middle, right, emergency lane) (Kang & Fang, 2011);weather (sunshine, cloudy, rain, snow, fog) (Alkaabi,Dissanayake, & Bird, 2011); time characteristics (non-peak days, peak days, nights, weekdays, weekends)(Hojati et al., 2013); incident characteristic (severity,type, injury, medical requirements, etc.) and infrastruc-ture characteristics (roadway shoulder availability)(Hojati, Ferreira, Washington, Charles, & Shobeirinejad,2014). For example, Chung (2010) studied the durationof traffic accidents on freeway in Korea, and they com-bined time, location, accident type, involved vehicletype, accident severity, road surface condition, andreporter type to build prediction model. Wang, Cong,and Qiao (2013) used the combination of weather, timewhen policeman arrived, accident type, and lanes type tomodel the accident dataset of freeway in Zhejiang prov-ince. Being different from the freeway, there are somedifferences in factors that affect the accident duration inurban roads. And it is not definite to employ more fea-tures to get better results. In the study of Alkaabi et al.(2011), they presents the results of investigating theeffects of features on the accident clearance time withemphasize of accelerated failure time (AFT) metric, andbefore modeling, they carry out correlation analysis, soonly useful features are kept.
The main challenge of predicting accident durationfocusses on constructing a proper prediction model.Researchers first tried to apply various kinds of singlemodels in the field, and the models can be roughlydivided into four kinds: regression model (Khattak,Schofer, & Wang, 1995; Valenti, Lelli, & Cucina, 2010;Wang, Cong, et al., 2013; Wu, Chen, Zheng, et al.,2011), tree classification model (Boyles, Fajardo, &Waller, 2007; Kim, Chang, Rochon, et al., 2008; Pan,Wang, Zhan, & Deng, 2018; Zhan, Gan, & Hadi,2011), artificial neural network (Park, Haghani, &Zhang, 2016; Valenti et al., 2010; Vlahogianni &Karlaftis, 2013; Wei & Lee, 2007), and statisticalmodeling (Giuliano, 1989; Golob et al., 1987; Hojatiet al., 2013; Jones et al., 1991).
1. Regression model: Khattak et al. (1995) proposedto use truncated regression models to verifya series of hypotheses on influence factors first,
and then develop a time sequential methodologyto predict the incident durations. Valenti et al.(2010) proposed to apply several models to inci-dent duration prediction and compare their per-formance, include multiple linear regression,support/relevance vector machine and K-near-est neighbor.
2. Tree classification model: By comparing differentmodels including simple linear regression modeland two nonparametric regression models,Koppelman, Sethi, and Ivan (1994) established theaccident duration model based on decision treemethod. Based on the Classification andRegression Tree (CART) and the findings frompreliminary analysis of data set, Kim et al. (2008)has redesigned a classification tree named Rule-Based Tree Model (RBTM) to identify variablesinfluencing the incident duration and estimateincident duration. Zhan et al. (2011) proposed toutilize M5P tree algorithm for predicting the inci-dent duration.
3. Artificial neural network: Wei and Lee (2007) cre-ates an adaptive procedure for sequential forecast-ing of incident duration, which includes twoadaptive artificial neural network-based models aswell as the data fusion techniques. Vlahogianniand Karlaftis (2013) think that incident durationdata is incomplete and inaccurate, and theyaddress the problem of incident duration predic-tion from the survival analysis perspective usingadvanced artificial intelligent techniques.
4. Statistical models: Researchers also try to employprobability distribution model (Giuliano, 1989;Golob et al., 1987), and discrete selection model(Jones et al., 1991) to predict accident duration.For example, Hojati et al. (2013) proposed ahazard-based duration modeling approach tomodel incident duration as a function of a varietyof factors that influence traffic incident duration.
In order to address the limited ability of singlemodel and further improve the prediction accuracy,some scholars considered combining the advantagesof multiple models. Li and Guo (2015) proposeda mixture model which uses the multinomial logisticmodel and parametric hazard-based model to assessthe influence of covariates on the probability of clear-ance methods and on the duration of the incident.Ghosh, Asif, and Dauwels (2016) propose BayesianSupport Vector Regression (BSVR), which gives errorbars as the measurement of uncertainty along with thepredicted duration of incidents. They also evaluatesensitivity and specificity for different error tolerance
JOURNAL OF INTELLIGENT TRANSPORTATION SYSTEMS 163

limit to assess the performance of BSVR. In theresearch study of He, Kamarianakis, Jintanakul, andWynter (2013), they proposed a hybrid tree-basedquantile regression method and quantification of theeffects of various incident and traffic characteristicsthat determine duration. They show that hybrid tree-based quantile regression incorporates the merits ofboth quantile regression modeling and tree-structuredmodeling: robustness to outliers, simple interpretation,flexibility in combining categorical covariates, andcapturing nonlinear associations. Lin, Wang, andSadek (2016) proposes a novel approach for accidentduration prediction, which improves on the originalM5P tree algorithm through the construction ofa M5P-Hazard-Based Duration Model (HBDM)model, in which the leaves of the M5P tree model areHBDMs instead of linear regression models. And theproposed M5P-HBDM managed to identify moresignificant and meaningful variables than either M5Por HBDMs. The multimodels indeed improve theaccuracy of duration prediction, but the effects ofinteraction between attributes are not fully takeninto consideration in the multimodels. As well, thereis little work on introducing cost-sensitive issues intothe prediction of accident duration.
Cost-sensitive learning is a kind of problems inwhich the cost of missing a target is much higherthan that of a false-positive, and classifiers withrespect to losses are designed to weigh certain types oferrors more heavily than others. Cost-sensitive learn-ing has been imported into the problem of frauddetection, medical diagnosis, or object detection incomputer vision (Deng & Chen, 2015; Kuang et al.,2018; Liao et al., 2017; Yang, Wang, Mi, Lin, & Cai,2009; Zeng et al., 2018). In the research of Liu, Zhang,Zhang, and Wang (2011), cost-sensitivity is alsointroduced to analyze uncertain data in traffic flowprediction. However, cost-sensitive issue has not beenfully addressed in existing solutions to accidentduration prediction.
Compared with the existing related work, our maininnovations include: (1) most of the existing work justuse a single model to predict the duration of acci-dents, either classification model or regression model,however, in this article, based on a thorough analysis
on data, we explore to classify the accident durationinto two categories first, that is, less or larger than30min, and then predict the detailed value with aregression model. (2) Most of the existing work donot fully consider the interaction effect of influencefactors, assuming that the factors are independentwith each other. However, they are not independent,for example, a bad weather may lead to a serious acci-dent. Therefore, in this article, we explore the inter-action between influence factors and employ Bayesiannetwork to model their interaction relation. (3) Weimport cost-sensitive problem into the prediction ofaccident duration. If an accident with long duration ispredicted to be a short one, more vehicles will beguided to choose the road, and it will lead to a moreserious traffic congestion. Therefore, in this article, wepropose a cost-sensitive Bayesian network for durationclassification, so as to guarantee that a wrong classifi-cation on accident with long duration to a short onewould get a heavy penalty.
Predicting the accident duration
Problem definition
Given the data set R ¼ r1; r2; ::: � � � ; rnf g, where ridenotes the ith traffic accident history, ri canbe represented as a 6-tuple, ri ¼ X; Y; carnumber;hdescription; starttime; endtimei, where X and Y are thelongitude and latitude of the accident location;carnumber is the number of vehicles involved in theaccident; description is the description of the accident,mainly including the safety and responsibility of thepersons involved, and the damage of vehicles; thestarttime is the occurrence time of accident; the endtime
is the time when the road is clear; The duration ofthe accident is the end time minus the start time.Some samples are shown in Table 1.
Given the data set R, and a new accidente ¼ X; Y; carnumber; description; starttimeh i, that is,the latitude and longitude of the new accident, thenumber of vehicles involved, the accident descriptionand the start time, based on the historical records,we aim to predict the duration of the new accident.
Table 1. Samples of traffic accident dataset.X Y Car number Accident description Start time End time
118.110169 24.48329 2 A has a safety problem and B has no fault behavior,the accident results in a right side damage of carA, a left side damage of car B.
2015/01/01 00:09 2015/01/01 00:42
118.101324 24.50446 2 A and B have a safety problem, the accident resultsin a left side damage of car A, a right side dam-age of car B.
2015/01/01 00:10 2015/01/01 00:31
164 L. KUANG ET AL.

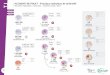
The architecture of our solution
Figure 1 shows the architecture of our proposedsolution to accident duration prediction. It containsthree main steps: (1) data preprocessing and analysis.Data preprocessing includes data cleaning andtransformation. We deal with missing value, formatcleaning, and unreasonable value removal. And thenwe convert the attribute data into the format whichcan be used by subsequent algorithms. After complet-ing data preprocessing, we analyze the distribution ofthe traffic accident durations and the relationshipsbetween the feature attributes and the duration. (2)Duration classification based on cost-sensitive Bayesiannetwork. According to the data analysis results, someattributes are selected to build the Bayesian networkmodel, the attributes are enough to qualitatively deter-mine whether the duration time is more or less than30min. (3) Duration value prediction based on KNNregression. After getting the class label of the accident,KNN regression model is used to get the duration valuein each class. In this case, the nearest neighbor selectionis performed with the remaining characteristic attributes,and the average value of the accident duration of Kneighbors is output as the predicted value.
Data preprocessingData quality is related to the performance of themodel and the final result closely, so it is necessaryfor us to clean the data. We deal with the data fromthree perspectives: first, determine the range ofmissing values and calculate the ratio of missing val-ues for each field; second, clean the contents whichdo not match the format; third, remove the outliers,
that is, the values which are not accordant with thecommon sense.
In order to prepare the original data as the inputof subsequent algorithms, we need to convertthe three attributes “start_time,” “car_number,”“description” according to the following rules:
1. “start_time” is the time when the accident occurs,and it is consist of year, month, day, hour, andminute. We extract three kinds of informationfrom the “start_time”: first, minutes that countfrom 0 o’clock in that day, which is named as“time”; second, “weekend,” that is, whether theday is on weekend or not, where 1 representsweekend and 0 represents workday; third, theweather of the day, since we can supplement theweather information from online weather serviceaccording to the date.
2. “car_number” is the number of cars that areinvolved in the accident. According to the statis-tics, there are 3125 accidents of single-car colli-sion and 22,806 accidents of two cars, the numberof multicars collision accident is relatively small,especially speaking, the number of accidents thatinvolve three, four and five cars are 1626, 176,and 35, respectively. In order to prevent thelearning model from overfitting, we classifythe multicars crash into one class. Since most ofthe algorithm count from 0, the original semanticof the accident is preserved. The attribute‘car number’ is mapped as follows: 0 stands forsingle-car accident, 1 stands for double-cars acci-dent, 2 stands for multicars accident (the numberof cars that involved in one accident >2).
= , , _ , , _ , _
= , ,……,
Data preprocessing
Data cleaning
Data transformation
Data analysis
Analysis of duration
distribution
Analysis of variance
Visualization of the
relationship between
attributes and goal
Duration classification based on
Bayesian Network
Input the values
, ,
Cost-sensitive Bayesian network
Less than
30 minutes
More than
30 minutes
Predicting the duration
based on KNN
Input the values, ,
Weight KNN model
Accident
duration value
Figure 1. Architecture of the proposed solution to accident duration prediction.
JOURNAL OF INTELLIGENT TRANSPORTATION SYSTEMS 165

3. “description” describes the information of accident.We extract the keywords which have obviousimpact on the increase of duration of an accident,and they are: “rear-end,” “rollover,” “rescue,” “tiredamage,” “injured.” We then derive “severity” fromthe description as an ordinal property. According tothe analysis of statistical data, the average durationof the “rear-end” accident is lower than that of allaccidents, and this kind of accidents is marked as“0.” The average duration of the accidents that areconcerned with the keywords “rollover,” “rescue,”“tire damage,” and “injury” is higher than that ofall accidents, and these kinds of accidents aremarked as “2.” The average duration of the acci-dents that do not contain the five keywords is thesame as that of all accidents, and this kind of acci-dents is marked as “1."
Table 2 shows the variable name, data type, con-verting rule, and the statistics of each attribute:
Analysis of dataDistribution of duration. We first make a statisticalanalysis on the duration of accidents. We count howmany times when the duration is x minutes while xranges between [7,120]. The result is shown asFigure 2, where the horizontal ordinate represents theduration minutes of the accident and the verticalordinate represents the number of accidents. We cansee that the distribution of durations is imbalanced.The number of accidents increases rapidly when theduration is between 0 and 20min; it reaches the high-est point when the duration is about 20min; and thenit declines to zero gradually when the duration islarger than 20min. The number of accidents when theduration is between 15 and 30min accounts for about40% of the total accidents. Therefore, in order toclassify the duration of accidents effectively, thereare two ways to determine the intervals: (1) makea further segmentation for the time interval [15min,30min], so that a balance on amounts for eachinterval can be kept. (2) Enlarge the time interval
[15min, 30min], until the number of accidents in theenlarged interval is relatively balanced with that ofother intervals. However, an uneven division of thetime interval may lead to decrease on classificationaccuracy since there are more categories and lesssamples in each category. Therefore, we tend toemploy the second solution.
Analysis of attributes. We then analyze the four dis-crete attributes, that is, “weekend,” “severity,”“car_number,” and “weather,” by one-factor varianceanalysis, in order to find how the change of values oneach attribute affects the target “duration:” The resultof one-factor variance analysis is shown in Table 3.
We set the significance level to 0.1, and accordingto Table 3, the values of “Prob > F” on “weekend; ”“severity; ” and “carnumber” are less than 0.1, that is,the significance level, therefore, we have more than90% confidence that the three features have significanteffects on the target duration and the feature“weather” has little significant effect on the target.
In order to further find the relationship betweenthe features, we adopt two-factor analysis of varianceto analyze whether the interaction between featureswill affect the target duration remarkably or not. Theresult of the two-factor analysis of variance is shownin Table 4.
We set the significance level to 0.1, and according toTable 4, the values of “Prob> F” on “severity�carnumber” and “severity�weekend” are less than 0.1,
Figure 2. The distribution of accident duration.
Table 3. The results of the one-factor variance analysis.Source Sum sq. df Mean sq. F Prob > F
weekend 1140 1 1140 3.58 0.0585severity 48,364.6 2 24,182.3 75.94 0.0carnumber 13,838.5 2 6919.3 21.73 0.0weather 576 1 576 1.81 0.1787
Table 2. Attributes in traffic accidents.Variables Type Coding Statistics
weekend Binary 0: No; 1: yes 21,035; 6677carnumber Ordinal 0: One; 1: two;
2: >two3125; 22,806; 1781
severity Ordinal 0: Slight; 1: medium;2: serious
7783; 19,057; 872
weather Nominal 1: Sunny; 2: rainy;3: terrible
24,896; 11,707; 1472
X (longitude) ContinuousY (latitude) Continuoustime Continuous
166 L. KUANG ET AL.

that is, the significance level, therefore, we have morethan 90% confidence that the two combinationshave significant effects on the target duration and othercombinations have little significant effect on the target.
We then analyze the feature “time” and the target“duration” visually, and the result is shown inFigure 3, in which the x-axis represents the time ofthe day, y-axis represents the duration. It can be seenfrom Figure 3 that there is no linear correlationbetween the time and the duration, but there is nosignificant changes within a certain time interval,since the traffic flow as well as the traffic managementare similar within a certain time, therefore, we canutilize the data with similarity on time for prediction.
Accident duration classification based onBayesian networkBy analyzing the distribution of duration values, wecan divide the continuous values into several intervalsas the target categories reasonably. By analyzing thecorrelation between the features and the target dur-ation, we can select the useful features, which havesignificant impact on the prediction of duration.Therefore, in our solution to predicting the durationof new accidents, we classify the duration of accidentsinto two categories, i.e. more or less than 30minutes,according to its severity, involved car number and
the condition whether it happened in workdays orweekends first.
The reason why we choose 30minutes as the div-ision point and divide the duration of accidents intotwo categories is, according to Figure 2 and the analysisin Distribution of duration section, we can see that thedistribution of duration is extremely imbalanced, andthere are about 40% of samples whose duration isbetween 15 and 30min. We have analyzed the draw-back if we divide the time interval unevenly. But if wedivide the duration evenly with a smaller interval, theproblem of imbalanced samples in each category willbecome especially obvious, the classifier cannot learnthe features of the category with little sample suffi-ciently and the possibility that a test data is classifiedto the category with little samples is also little.Therefore, we divide the duration of accidents into twocategories, that is, less and larger than 30min, so as tokeep the balance of samples in both categories, as wellas guarantee that there are enough samples in bothcategories. In addition, we compare the two ways ofinterval division in the experiment part, and verify thatwe model the accidents duration classification as binaryclassification performs better than multiclassification.
According to the result of two-factor analysisof variance, the interaction between attributes hasa significant effect on prediction target. Therefore, weemploy the Bayesian network for classification in thefirst step. The Bayesian network structure is a directedacyclic graph in which nodes represent domain varia-bles and arcs between nodes represent probabilisticdependencies (Koppelman et al., 1994). We will trainthe Bayesian network by MMPC and K2 algorithmsfirst and then improve the model by adding a cost-sensitive function.
Training of Bayesian network. In order to train theBayesian network, we need to determine the hierarch-ical order between the nodes in the topology. MMPCis a local discovery and learning algorithm whichreturns the set of parent nodes of the target variableT, given the target variable T and the dataset D.The MMPC algorithm mainly calls two functions,Ind(X; T|Z) and Assoc(X; T|Z). Ind(X; T|Z) tests theconditional independence of two nodes X and T.Assoc(X; T|Z) evaluates the correlation strength ofnode X and T when the evidence Z is given(Koppelman et al., 1994).
After determining the order of nodes by MMPC,we then construct the topology of the Bayesian net-work by K2 algorithm. The main idea of K2 isdescribed as follows: for each node i in the given
Table 4. The result of the two-factor variance analysis.Source Sum sq. df Mean sq. F Prob > F
severity�carnumber 72,376.9 4 18,094.2 56.82 0.0severity�weekend 10,973.5 2 5486.8 17.23 0.0severity�weather 1023.8 2 511.9 1.49 0.22carnumber
�weekend 669.2 2 334.6 0.98 0.38carnumber
�weather 1203.9 2 602.0 1.76 0.17weekend�weather 193.2 1 193.2 0.56 0.45
Figure 3. The relationship between the duration of accidentsand the time when it occurred in a day.
JOURNAL OF INTELLIGENT TRANSPORTATION SYSTEMS 167

order, the i – 1 nodes that are in front of node i willbe the candidate parent node of i, and the Bayesianscore of the network structure will be calculated aftereach candidate parent node is added. The Bayesianscore is defined as formula (1), where paðxiÞ denotesthe candidate parent node ofxi, qi denotes the numberof states of the parent of xi, ri denotes the number ofstates of xi, Nij denotes the number of samples whenthe parent of xi is in state j, Nijk denotes the numberof samples when the state of xi is k and the state ofits parent is j. If the Bayesian score become higherafter adding a candidate parent, the node will beadded to the parent set of i, and a directed edge fromthe parent to node i will be added. The loop will con-tinue until the score no longer increases or the max-imum number of parents have reached.
g xi; pa xið Þð Þ ¼Yqij¼1
ri�1ð Þ!Nij þ ri � 1ð Þ!
Yrik¼1
Nijk! (1)
The T_type represents the type of the duration,which is discretized into several time intervals. In oursolution, we just divide the values of duration into twotypes C0 and C1, where C0 represents the values thatare less than 30min, and C1 represents the values thatare more than 30min. The topology of the constructedBayesian network is shown in Figure 4. We can see theinteraction relations between the four properties fromFigure 4. The property “car_number” has a direct effecton “severity” and “T_type,” and “T_type” are affectedby both “severity” and “weekend.”
Cost-sensitive Bayesian network. There is a cost-sensitive problem in the prediction of traffic accidentsduration in practical application. For example, if along-lasting accident is estimated incorrectly, vehicleswill be misled to select a wrong route, thereby
increasing the congestion and road pressure; While if ashort-lasting accident is estimated incorrectly, vehicleswill plan other routes, only slightly increasing the carenergy consumption. So we would like to introduce acost-sensitive function into the Bayesian networkmodel.
Table 5 shows the cost matrix, in which C0 and C1
have been introduced above; the values of F(C0, C0)and F(C1, C1) are 0; F(C0, C1) represents the cost ofmisjudging C0 as C1, F(C1, C0) represents the cost ofmisjudging C1 as C0. The value of F(C0, C1) and F(C1,C0) are calculated as formula (2) shows:
F ci; cjji 6¼ j� � ¼
xixj
� �b; xi>xj;
xjxi
� �a; xi<xj;
1; xi ¼ xj
8>>><>>>:
(2)
, in which xi denotes the ratio of samples in cat-egory Ci and xj denotes the ratio of samples in cat-egory Cj. According to our analysis, we will adjust thevalue of a and b in the cost-sensitive function tomake sure that the punishment of F(C1, C0) is greaterthan that of F(C0, C1).
Then the cost-sensitive Bayesian network can beachieved by replacing the comparison of P(C0|weekend,severity, car_number) and P(C1|weekend, severity, car_number) by that of R(C0|weekend, severity, car_number) and R(C1|weekend, severity, car_number),where they can be calculated as follow:
R C0 jweekend; severity; carnumber� �
¼ P C0jweekend; severity; carnumber� � � F C0; C0ð Þþ
P C1jweekend; severity; carnumber� � � F C1; C0ð Þ
¼ P C1jweekend; severity; carnumber� � � F C1; C0ð Þ
(3)
R C1jweekend; severity; carnumber� �
¼ P C0jweekend; severity; carnumber� � � F C0; C1ð Þþ
P C1jweekend; severity; carnumber� � � F C1; C1ð Þ
¼ P C0jweekend; severity; carnumber� � � F C0; C1ð Þ
(4)
Predicting the value of accident duration basedon KNNAfter the duration of a new accident is classified intoa determined range, we then predict the detailed valueFigure 4. Bayesian network topology of involved features.
Table 5. The cost matrix.Type C0 C1C0 F(C0, C0) F(C0, C1)C1 F(C1, C0) F(C1, C1)
168 L. KUANG ET AL.

of the duration based on KNN. In the selection of Knearest neighbors, we defined the distance betweentwo accident samples A and B as formula (5) shows:
distance A; Bð Þ ¼ 1�kð Þ � timeDist A; Bð Þþk � spaceDist A; Bð Þ; (5)
where timeDist(A, B) and spaceDist(A, B) are defined asformula (6) and (7) shows:
timeDist A; Bð Þ ¼ jTA�TBj; (6)
in which TA and TB are the starting time of accident Aand B respectively. where R denotes the radius of the
earth, (lonA; latA) and (lonB; latB) are the coordi-nates of A and B, respectively.
After K neighbors are selected according to formula(5), the average value of K neighbors are generated asthe predicted value.
Experiment
After data cleaning and processing, there are 37,712traffic accident samples of Xiamen City in 2015. Weuse 27,712 samples as the training set, and theremaining 10,000 samples as the test set. In eachexperiment, we use the whole training set to train themodel, and we randomly select 1000 samples from thetest set as six subdatasets and record the performance.The metric that we use for evaluating the performanceof the classification models is Accuracy rate, for thepredicting model is MAPE, and their definitions aregiven as formula (8) and (9).
Accuracy rate ¼ nN; (8)
where:N denotes the number of samples in test dataset;nrepresents the number of samples that are classifiedcorrectly in test dataset;
MAPE ¼PNi¼1
���� observedi�predictediobservedi
����N
; (9)
where:N denotes the number of samples in test dataset;observedi denotes the real value of the accident
duration;predictedi denotes the predicted value of the acci-dent duration.
In the following, we will first determine the param-eters involved in our approach, and then compare ourmodels with other relative ones.
Determining the parameters
First, we aim to discretize the duration valuesinto several time intervals reasonably to avoid theimbalance of samples. According to the analysis on
distribution of duration values, we have two solutions:(1) divide the range of duration every 15min, there-fore, we can map the duration values into five catego-ries, that is, [0,15], [15,30], [30,45], [45,60], and[60,þ1]; (2) divide the range of duration into twocategories, that is [0,30] and [30,þ1].
In order to decide which solution would be better,we introduce a base classifier, and compare it with ourclassification model, that is, cost-sensitive Bayesiannetwork. The base classifier predicts the category that atest data belongs to according to the highest proportionof categories in the training dataset.
Figure 5(a) shows comparison of two classificationmodels with interval of 15min, while Figure 5(b)shows that with interval of 30min, in both of whichx-axis denotes the six randomly generated subdatasetsin the test set, the y-axis denotes the accuracy rateof classification. According to the experimental results,we can see that the performance of two classificationmodels are almost the same for each test set inFigure 5(a) while the cost-sensitive Bayesian networkoutperforms much than base classifier in Figure 5(b),therefore, it is reasonable to classify the durationvalues into two categories, that is, [0,30] and [30,þ1], since it can deal with the imbalance of samplesin each categories effectively.
Next, we aim to decide the parameters a and bin the cost-sensitive function. According to formula(2), when a¼ b, FðC1;C0Þ¼ FðC0 ;C1Þ. But in ourscenario, in order to make the model biased towardsthe accidents with duration value more than 30min,the value of F ðC0 ; C1Þ should be less thanthat of F ðC1; C0Þ, so we need to adjust the D
spaceDist A;Bð Þ ¼ R � cos�1 sin latAð Þ � sin latBð Þ � cos lonA�lonBð Þ þ cos latAð Þ � cos latBð Þð Þ � p180
; (7)
JOURNAL OF INTELLIGENT TRANSPORTATION SYSTEMS 169

value between a and b as much as possible. In theexperiments, we reduce the value of a from 1.0, andincrease the value of b from 1.0, and we observethe changes on the accuracy rate of classificationon both types of accidents, as well as the misclassi-fication rate on the second type of accidents.
Figure 6 shows the experimental result of determin-ing a and b. We can see that, the total accuracy rateincreases slowly first, reaches the highest point whena¼ 0.5 and b¼ 1.5, and then it gradually decreases.When the total accuracy rate is the highest, the mis-classification rate of the accidents with long durationis 12.65%. And when a¼ 0.5, b¼ 2.2, though the totalaccuracy rate is 74.6%, the misclassification rate of theaccidents with long duration is only 1.19%, thus weset a and b values to 0.5 and 2.2, respectively.
Next, we will determine the parameter k in formula(5). We use MAPE to evaluate the performance ofduration value prediction based on KNN. Figure 7shows the result, in which x-axis is the value of k, y-axis is the MAPE result, the lines in different colorsrepresent the performance under different values of k.We can see from Figure 7 that, when k is in [0, 0.1],the change of MAPE presents a downward trend;when k is in [0.1,0.3], the values of MAPE arerelatively stable with some small fluctuations; when kis in [0.3,0.5], MAPE tends to increase. Therefore,when k is in [0.1, 0.3], the prediction model presentsa better performance, and finally we set k to 0.3.
Finally, we aim to determine the value of k inthe KNN model. Figure 8 shows the MAPE underdifferent values of k, while the lines in different colors
Figure 5. Accuracy rate with different discretions of duration values.
Figure 6. Accuracy rate with the change of a and b.
170 L. KUANG ET AL.

represents the six test datasets. We can see fromFigure 8, generally speaking, for all the test sets, whenk is increased from 1 to 10, the value of MAPE
reduces quickly, and when k is greater than 10, thevalue of MAPE increases gradually. So we set k to10to get a better performance.
Verifying the models
Traditional Bayesian network vs. cost-sensitiveBayesian networkFirst, we aim to compare the traditional Bayesiannetwork with our improved cost-sensitive Bayesiannetwork, from the perspective of total accuracy rateand the misclassification rate of the accidents withlong duration. The results are shown in Table 6, wecan see that the accuracy rate increases 3.8%, whilethe misclassification rate of accidents with longduration decreases 13.83% if we use cost-sensitiveBayesian network.
In order to find the influence of cost-sensitivefunction on the final prediction, we measure theMAPE without and with cost-sensitive function, inwhich the time range is divided further into 0–15,15–30, 30–45, 45–60, and 60–þ1. The experimentsrun on six test datasets. The result is shown inTable 7. It shows that we have a little loss on predic-tion accuracy if we use cost-sensitive function, sinceit tends to have a larger prediction value for shortduration of accidents, but it can greatly decrease thepossibility of misclassifying a large duration to the firstcategory, that is, [0–30]. But generally speaking, theloss can be acceptable, according to Table 7, MAPEonly increases 0.0265 on average for accidents with lessthan 30min duration, while decreases 0.076 on averagefor accidents with more than 30min duration.
Comparison of classification modelsSince we find the interaction effects between the inputfeatures, we choose Bayesian network as the classifica-tion model. In this section, we aim to compare ourcost-sensitive Bayesian network with three other classifi-cation models, which are Naive Bayesian, decision treeand random forest. Experiments run on six test datasets,and accuracy rate is used for evaluating the performanceof models, and the result is shown in Figure 9.
Figure 7. MAPE under different values of k and K.
Figure 8. MAPE under different values of K in sixtest datasets.
Table 6. Comparison between Bayesian network and cost-sensitive Bayesian network.
Accuracyrate
Misclassificationrate of accident
with long duration
Bayesian network 71.7% 26.48%Cost-sensitive Bayesian network 75.5% 12.65%
Table 7. MAPE of the Bayesian network without and with cost-sensitive function.
Test data
MAPE without cost-sensitive MAPE with cost-sensitive
0–15 15–30 30–45 45–60 >60 0–15 15–30 30–45 45–60 >60
DataSet1 0.518 0.314 0.182 0.355 0.572 0.540 0.340 0.167 0.244 0.514DataSet2 0.520 0.315 0.177 0.343 0.573 0.558 0.349 0.145 0.240 0.493DataSet3 0.540 0.336 0.230 0.386 0.582 0.551 0.340 0.217 0.241 0.496DataSet4 0.510 0.330 0.212 0.341 0.557 0.558 0.348 0.161 0.232 0.500DataSet5 0.581 0.332 0.209 0.327 0.571 0.600 0.342 0.136 0.224 0.493DataSet6 0.587 0.326 0.215 0.339 0.564 0.603 0.339 0.141 0.223 0.495Average 0.532 0.326 0.204 0.349 0.570 0.568 0.343 0.161 0.234 0.499
JOURNAL OF INTELLIGENT TRANSPORTATION SYSTEMS 171

We can see that, cost-sensitive Bayesian networkperforms the best in all the test datasets, and in thefirst three test datasets, naive Bayes performs thesecond, while in the latter three test datasets, randomforest performs the second. Therefore, we can makea conclusion that it is reasonable to choose cost-sensi-tive Bayesian network for the classification ofduration values.
Comparison of regression modelsIn this part, we aim to compare our KNN model withlinear model for predicting duration value.Experiments run on six test datasets and MAPE isused for evaluation. The result is shown in Figure 10.The MAPE of KNN model is 0.391 in the third data-set, which is the lowest in the six test datasets, andthe MAPE of linear model is 0.577 under the same
condition. The MAPE of KNN model is 0.471 in thefirst dataset, which is the highest in all datasets, whilethe MAPE of linear model is 0.670 under the sameconditions. We can see that KNN always performsbetter than linear model, therefore it is reasonable tochoose KNN model as the regression model to predictthe duration of traffic accidents.
Conclusions
In this article, we propose a Bayesian network-weighted KNN model to predict the duration of acci-dents, using the traffic accident data of Xiamen,China, from January to December 2015, and experi-mental results show that the algorithm can improvethe prediction accuracy in cost-sensitive way. In thefuture, we aim to explore visualization techniques
Figure 9. Comparison on accuracy rate between cost-sensitive Bayesian network and other three classical classification models.
Figure 10. Comparison on MAPE between weighted KNN and linear regression model.
172 L. KUANG ET AL.

(Liao et al., 2018) for data analysis, and investigate onhow to use sensors to take more valuable informationon the intelligent traffic management system.
Disclosure statement
No potential conflict of interest was reported bythe authors.
Funding
The research is supported by National Natural ScienceFoundation of China (no. 61772560, 61876190, and61872306) and Scientific Research Project for Professors inCentral South University, China (no. 904010001).
References
Alkaabi, A. M. S., Dissanayake, D., & Bird, R. (2011).Analyzing clearance time of urban traffic accidents inAbu Dhabi, United Arab Emirates, with hazard-basedduration modeling method. Transportation ResearchRecord, 2229(1), 46–54.
Boyles, S., Fajardo, D., & Waller, S. T. (2007, January). Anaive Bayesian classifier for incident duration prediction.In 86th Annual Meeting of the Transportation ResearchBoard, Washington, DC.
Chung, Y. (2010). Development of an accident durationprediction model on the Korean Freeway Systems.Accident Analysis & Prevention, 42(1), 282–289.
Deng, L., & Chen, Z. (2015). An integrated framework forfunctional annotation of protein structural domains.IEEE/ACM Transactions on Computational Biology andBioinformatics (Bioinformatics), 12(4), 902–913.
Fan, Y., Khattak, A. J., & Shay, E. (2007). Intelligent transpor-tation systems: What do publications and patents tell us?Journal of Intelligent Transportation Systems, 11(2), 91–103.
Garib, A., Radwan, A. E., & Al-Deek, H. (1997). Estimatingmagnitude and duration of incident delays. Journal ofTransportation Engineering, 123(6), 459–466.
Giuliano, G. (1989). Incident characteristics, frequency, andduration on a high volume urban freeway. TransportationResearch Part A: General, 23(5), 387–396.
Ghosh, B., Asif, M. T., & Dauwels, J. (2016, November).Bayesian prediction of the duration of non-recurringroad incidents. In Region 10 Conference (TENCON), 2016IEEE (pp. 87–90). Piscataway, NJ: IEEE.
Golob, T. F., Recker, W. W., & Leonard, J. D. (1987). Ananalysis of the severity and incident duration of truck-involved freeway accidents. Accident Analysis &Prevention, 19(5), 375–395.
He, Q., Kamarianakis, Y., Jintanakul, K., & Wynter, L.(2013). Incident duration prediction with hybrid tree-based quantile regression. In Advances in dynamicnetwork modeling in complex transportation systems(pp. 287–305). New York, NY: Springer.
Hojati, A. T., Ferreira, L., Washington, S., & Charles, P.(2013). Hazard based models for freeway traffic incidentduration. Accident Analysis & Prevention, 52, 171–181.
Hojati, A. T., Ferreira, L., Washington, S., Charles, P., &Shobeirinejad, A. (2014). Modelling total duration of traf-fic incidents including incident detection and recoverytime. Accident Analysis & Prevention, 71, 296–305.
Jones, B., Janssen, L., & Mannering, F. (1991). Analysis ofthe frequency and duration of freeway accidents inSeattle. Accident Analysis & Prevention, 23(4), 239–255.
Kang, G., & Fang, S. E. (2011). Applying survival analysisapproach to traffic incident duration prediction. In ICTIS2011: Multimodal Approach to Sustained TransportationSystem Development: Information, Technology, Implementation(pp. 1523–1531). Wuhan, China: ASCE Press.
Khattak, A. J., Schofer, J. L., & Wang, M. H. (1995). A sim-ple time sequential procedure for predicting freeway inci-dent duration. Journal of Intelligent TransportationSystems, 2(2), 113–138.
Kim, W., Chang, G. L., & Rochon, S. M. (2008). Analysis of free-way incident duration for ATIS applications. In Proceedings ofthe 15th World Congress on Intelligent Transport Systems andITS America Annual Meeting (pp. 950–958). New York,United States: ERTICOITS JapanTransCore.
Koppelman, F., Sethi, V., & Ivan, J. (1994). Calibration of datafusion algorithm parameters with simulated data. In Advanceproject technical report. Evanston, IL: Northwestern University.
Kuang, L., Yu, L., Huang, L., Wang, Y., Ma, P., Li, C., & Zhu,Y. (2018). A Personalized QoS prediction approach for CPSservice recommendation based on reputation and location-aware collaborative filtering. Sensors, 18(5), 1556.
Li, R., & Guo, M. (2015). Competing risks analysis on traf-fic accident duration time. Journal of AdvancedTransportation, 49(3), 402–415.
Liao, Z., Zhao, B., Liu, S., Jin, H., He, D., Yang, L., & Wu, J.(2017). A prediction model of the project life-span inopen source software ecosystem. Mobile Networks andApplications, 2018, 1–10.
Liao, Z., He, D., Chen, Z, et al. (2018). Exploring theCharacteristics of Issue-Related Behaviors in GitHubUsing Visualization Techniques[J]. IEEE Access, 2018, 6:24003–24015.
Lin, L., Wang, Q., & Sadek, A. W. (2016). A combinedM5P tree and hazard-based duration model for predict-ing urban freeway traffic accident durations. AccidentAnalysis & Prevention, 91, 114–126.
Liu, M., Zhang, Y., Zhang, X., & Wang, Y. (2011, December).Cost-sensitive decision tree for uncertain data. InInternational Conference on Advanced Data Mining andApplications (pp. 243–255). Berlin, Heidelberg: Springer.
Nam, D., & Mannering, F. (2000). An exploratory hazard-based analysis of highway incident duration. TransportationResearch Part A: Policy and Practice, 34(2), 85–102.
Pan, Y., Wang, Z., Zhan, W., & Deng, L. (2018).Computational identification of binding energy hot spotsin protein–RNA complexes using an ensemble approach.Bioinformatics, 34(9), 1473–1480.
Park, H., Haghani, A., & Zhang, X. (2016). Interpretation ofBayesian neural networks for predicting the duration ofdetected incidents. Journal of Intelligent TransportationSystems, 20(4), 385–400.
JOURNAL OF INTELLIGENT TRANSPORTATION SYSTEMS 173

Ran, B., Jin, P. J., Boyce, D., Qiu, T. Z., & Cheng, Y. (2012).Perspectives on future transportation research: Impact ofintelligent transportation system technologies on next-generation transportation modeling. Journal of IntelligentTransportation Systems, 16(4), 226–242.
Valenti, G., Lelli, M., & Cucina, D. (2010). A comparativestudy of models for the incident duration prediction.European Transport Research Review, 2(2), 103–111.
Vlahogianni, E. I., & Karlaftis, M. G. (2013). Fuzzy-entropyneural network freeway incident duration modeling withsingle and competing uncertainties. Computer Aided Civiland Infrastructure Engineering, 28(6), 420–433.
Wang, J. H., Cong, H. Z., & Qiao, S. (2013). Estimatingfreeway incident duration using accelerated failure timemodeling. Safety Science, 54, 43–50.
Wang, X., Chen, S., & Zheng, W. (2013). Traffic incidentduration prediction based on partial least squares regression.Procedia-Social and Behavioral Sciences, 96, 425–432.
Wei, C. H., & Lee, Y. (2007). Sequential forecast of incidentduration using artificial neural network models. AccidentAnalysis & Prevention, 39(5), 944–954.
Wu, W. W., Chen, S. Y., & Zheng, C. J. (2011). Trafficincident duration prediction based on support vectorregression. In ICCTP 2011: Towards SustainableTransportation Systems (pp. 2412–2421). ASCE Press.
Yang, F., Wang, H-Z., Mi, H., Lin, C-D., & Cai, W-W.(2009). Using random forest for reliable classificationand cost-sensitive learning for medical diagnosis. BMCBioinformatics, 10(Suppl 1), S22.
Zhan, C., Gan, A., & Hadi, M. (2011). Prediction oflane clearance time of freeway incidents using the M5P treealgorithm. IEEE Transactions on Intelligent TransportationSystems, 12(4), 1549–1557.
Zeng, C., Zhan, W., & Deng, L. (2018). SDADB:A functional annotation database of protein structuraldomains. Database, 2018, 1–8.
174 L. KUANG ET AL.














![Predicting Traffic Accidents Through Heterogeneous Urban ...urbcomp.ist.psu.edu/2017/papers/Predicting.pdf · to predict the traffic accident risk level using human mo- bilitydata.Caliendoetal.[4]developedPoisson,Negative](https://img.dokumen.tips/doc/110x75/5f077c017e708231d41d361b/predicting-traffic-accidents-through-heterogeneous-urban-to-predict-the-traffic.jpg)