Embed Size (px)
DESCRIPTION
ppt on analysis
Citation preview

MEASURING SEMANTIC SIMILARITY BETWEEN TWO WORDS USING EMPIRICAL ANALYSIS
TEAM GUIDE:Ms.L.PRIYADHARSHINI
TEAM MEMBERSS.BHARATHIKANNAMMA(09P117)
M.BHUVANESHWARI(09P118)
G.DEEPA(09P121)
G.GAYATHRI(09P129)

ABSTRACT
Measuring the semantic similarity between words plays a vital role in many real time application.Though semantic similarity is useful in many applications such as web mining, information retrieval, and natural language processing, accurately measuring semantic similarity between two words remains a challenging task. The project proposes an empirical method to estimate semantic similarity using page counts and text snippets for two words.It defines various word co-occurrence measures using page counts and integrates that result with lexical patterns extracted from text snippets.The project proposes a novel pattern extraction algorithm and a pattern clustering algorithm to identify the numerous semantic relations that exist between given words.The proposed method outperforms various baselines and web-based semantic similarity measures.The proposed method significantly improves the accuracy in a community mining task.

EXISTING SYSTEM
• Accurately measuring the semantic similarity between words is an important problem in web mining, information retrieval, and natural language processing
• Manually maintaining ontologies to capture these new words and senses is costly, if not, impossible
• Efficient estimation of semantic similarity between words is critical for various natural language processing tasks
• Using page counts alone as a measure of co-occurrence of two words presents several drawbacks

PROPOSED SYSTEM
• In our proposed system, we propose an empirical method to estimate the semantic similarity between words or entities using web search engines
• Because of the numerous documents and the high growth rate of the web, it is time consuming to analyse each document separately
• The new system presents an automatically extracted lexical syntactic patterns-based approach to compute the semantic similarity between words or entities, using text snippets retrieved from a web search engine

NEED FOR PROPOSED SYSTEM
• The new system integrates different web-based similarity measures using a machine learning approach
• The new system extracts synonymous word pairs from WordNet, as positive training instances and automatically generate negative training instances
• Identifies the different patterns that describe the same semantic relation
• Lexical pattern extraction algorithm considers word subsequences in text snippets

MODULES
1.SEMANTIC SIMILARITY• In this module, we describe an approach to combine both page
counts based co-occurrene measures and snippets-based lexical pattern clusters to construct a robust semantic similarity measure
• This module enables us to find the presence of two input words as individual and also together in the web document easily with less manual work.
2.CO-OCCURANCE MEASURE• In this module,we find the co-occurance measure between words
using four method,web jaccard,web dice,web overlap,web PMI.

MODULES
3.LEXICAL PATTERN EXTRACTION• The words in pages are extracted . It uses counts-based co-
occurrence measures• The snippets returned for the conjunctive query of two words
provide useful clues related to the semantic relations that exists between the two words
4.LEXICAL PATTERN CLUSTERING• The semantics relation can be expressed using more than one pattern• Identifying different patterns that expresses the same semantic
relation enables us to find the similarity between the two words
SCREEN SHOTS

SCREEN SHOTSMAIN FORM

SCREEN SHOTSMODULE 1
SCREEN SHOTS

SCREEN SHOTSMODULE 2

SCREEN SHOTSMODULE 2

SCREEN SHOTSMODULE 2

SCREEN SHOTSMODULE 2

SCREEN SHOTSMODULE 3

SCREEN SHOTSMODULE 4
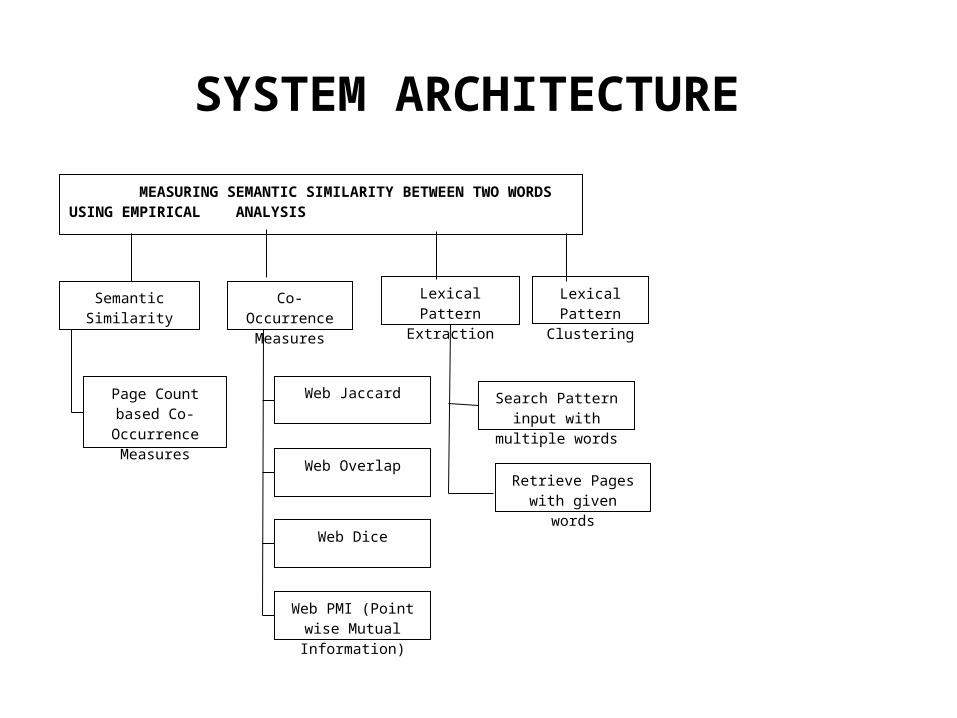
SYSTEM ARCHITECTURE
MEASURING SEMANTIC SIMILARITY BETWEEN TWO WORDS USING EMPIRICAL ANALYSIS
Semantic Similarity
Web Jaccard
Co-Occurrence Measures
Page Count based Co-Occurrence
Measures
Lexical Pattern Extraction
Web Overlap
Lexical Pattern Clustering
Web Dice
Web PMI (Point wise Mutual Information)
Search Pattern input with multiple words
Retrieve Pages with given words

SYSTEM ARCHITECTURE

SYSTEM SPECIFICATION
HARDWARE SPECIFICATION• Processor : Pentium IV 1.7 GHz• Hard Disk Capacity : 80 GB• RAM : 1 GB SD• Monitor : 15” Color• Keyboard : 102 keys• Mouse : 3 buttons
SOFTWARE SPECIFICATION• Environment : Net Beans 6.8 IDE• Front-End : Java 1.6• Back-End : MS-SQL Server 2000

SOFTWARE DESCRIPTION
JAVA
• Java has a major role in internet applications. It involves the OOPS
concepts and also provides security and portability
SQL SERVER
• SQL Server is a relational database management system (RDBMS)
from Microsoft that's designed for the enterprise environment

SCOPE OF THE PROJECT
• The project proposes an empirical method to estimate semantic similarity using page counts and text snippets retrieved from a web search engine for two words
• To identify the numerous semantic relations that exist between two given words, the project proposes a novel pattern extraction algorithm and a pattern clustering algorithm
• The proposed method outperforms various baselines and web-based semantic similarity measures. Moreover, the proposed method significantly improves the accuracy in a community mining task

CONCLUSION
• In our proposed system, we proposed a measure that uses both page counts and snippets to robustly calculate semantic similarity between two given words or named entities
• The method consists of four page-count-based similarity scores and automatically extracted lexico-syntactic patterns
• We integrated page-counts-based similarity scores with lexico syntactic patterns using support vector machines
• Results of our experiments indicate that the proposed method can robustly capture semantic similarity between named entities

FUTURE ENHANCEMENT
• The proposed method can robustly capture semantic similarity between named entities
• In future research, we intend to apply the proposed semantic similarity measure in automatic synonym extraction, query suggestion and name alias recognition
• We also intend to perfom Ranking based on the search results

REFERENCES
• [1] Measuring Semantic Similarity between Words Using Web Search Engines. Danushka Bollegala, Yutaka Matsuo, Mitsuru Ishizuka
• [2] Z. Bar-Yossef and M. Gurevich. Random sampling from a search engine's index. In Proceedings of 15th International World Wide Web Conference, 2006
• [3] R. Bekkerman and A. McCallum. Disambiguating web appearances of people in a social network. In Proceedings of the World Wide Web Conference (WWW)
• [4] N. Cristianini and J. Shawe-Taylor. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods. Cambridge University Press, 2000.

CONT…
• [5] D. Bollegala, Y. Matsuo, and M. Ishizuka, “Disambiguating Personal Names on the Web Using Automatically Extracted Key Phrases,” Proc. 17th European Conf. Artificial Intelligence, pp. 553-557, 2006.
• [6] P. Mika, ‘Bootstrapping the foaf-web: and experiment in social networking network minning’, in Proceedings of 1st Workshop on Friend of a Friend, Social Networking and the Semantic Web, (2004).
• [7] Yutaka Matsuo, Junichiro Mori, and Masahiro Hamasaki, ‘Polyphonet: An advanved social network extraction system from the web’, in Proceedings of the World Wide Web Conference, (to appear in 2006).

THANK YOU

QUERIES?











![[Ppt] an Efficient Identity-Based Batch Verification Scheme for Vehicular Sensor Networks](https://img.dokumen.tips/doc/110x75/55cf9ad9550346d033a3b659/ppt-an-efficient-identity-based-batch-verification-scheme-for-vehicular-sensor.jpg)


![[Slideshare] fardh'ain(aug-2016-batch#16)-1b-cont'nd-(introdn-b)-26-aug-2016.ppt](https://img.dokumen.tips/doc/110x75/58a4bec31a28ab2d688b6ad9/slideshare-fardhainaug-2016-batch16-1b-contnd-introdn-b-26-aug-2016ppt.jpg)














