Embed Size (px)
Citation preview

pOSKI: A Library to Parallelize OSKI
Ankit Jain
Berkeley Benchmarking and OPtimization (BeBOP) Projectbebop.cs.berkeley.eduEECS Department, University of California, Berkeley
April 28, 2008
Outline
• pOSKI Goals• OSKI Overview
– (Slides adopted from Rich Vuduc’s SIAM CSE 2005 Talk)
• pOSKI Design• Parallel Benchmark• MPI-SpMV

pOSKI Goals
• Provide a simple serial interface to exploit the parallelism in sparse kernels (focus on SpMV for now)
• Target Multicore Architectures• Hide the complex process of parallel tuning
while exposing its cost• Use heuristics, where possible, to limit search
space• Design it to be extensible so it can be used in
conjunction with other parallel libraries (e.g. ParMETIS)
Take Sam’s Work and present it in a distributable, easy-to-use format.
Outline
• pOSKI Goals• OSKI Overview
– (Slides adopted from Rich Vuduc’s SIAM CSE 2005 Talk)
• pOSKI Design• Parallel Benchmark• MPI-SpMV
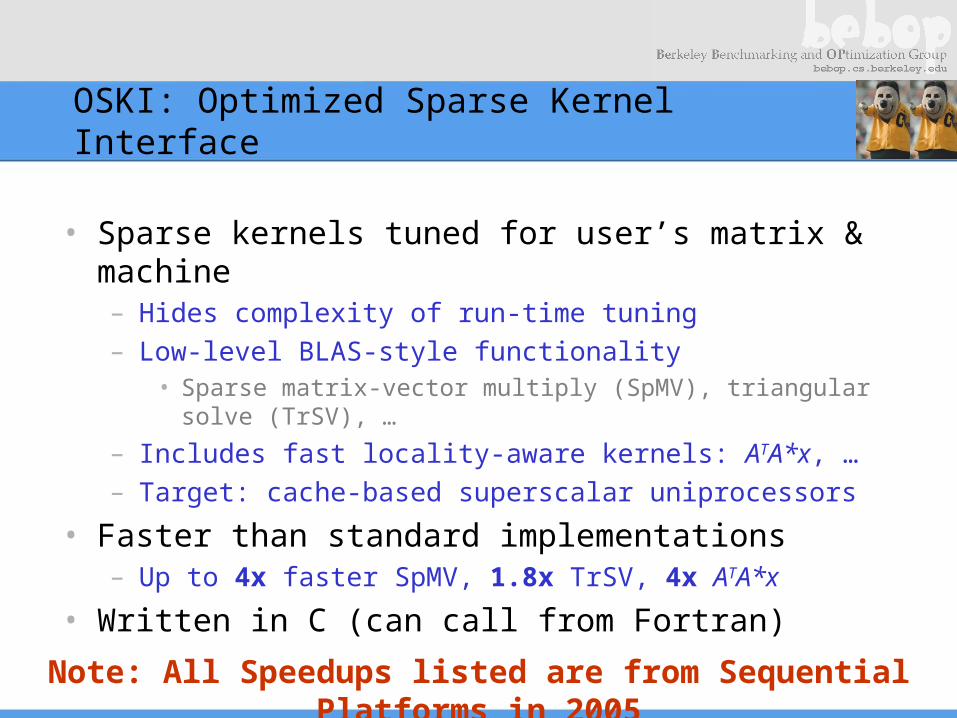
OSKI: Optimized Sparse Kernel Interface
• Sparse kernels tuned for user’s matrix & machine– Hides complexity of run-time tuning – Low-level BLAS-style functionality
• Sparse matrix-vector multiply (SpMV), triangular solve (TrSV), …
– Includes fast locality-aware kernels: ATA*x, …– Target: cache-based superscalar uniprocessors
• Faster than standard implementations– Up to 4x faster SpMV, 1.8x TrSV, 4x ATA*x
• Written in C (can call from Fortran)
Note: All Speedups listed are from Sequential Platforms in 2005
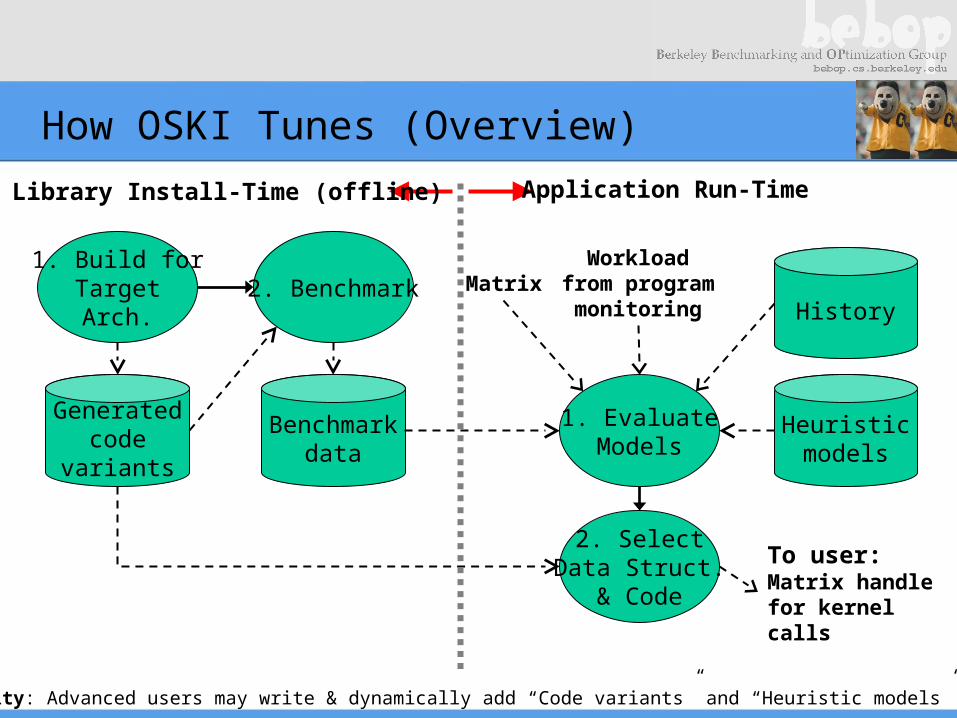
How OSKI Tunes (Overview)
Benchmarkdata
1. Build forTargetArch.
2. Benchmark
Heuristicmodels
1. EvaluateModels
Generatedcode
variants
2. SelectData Struct.
& Code
Library Install-Time (offline) Application Run-Time
To user:Matrix handlefor kernelcalls
Workloadfrom program
monitoring
Extensibility: Advanced users may write & dynamically add “Code variants” and “Heuristic models” to system.
HistoryMatrix
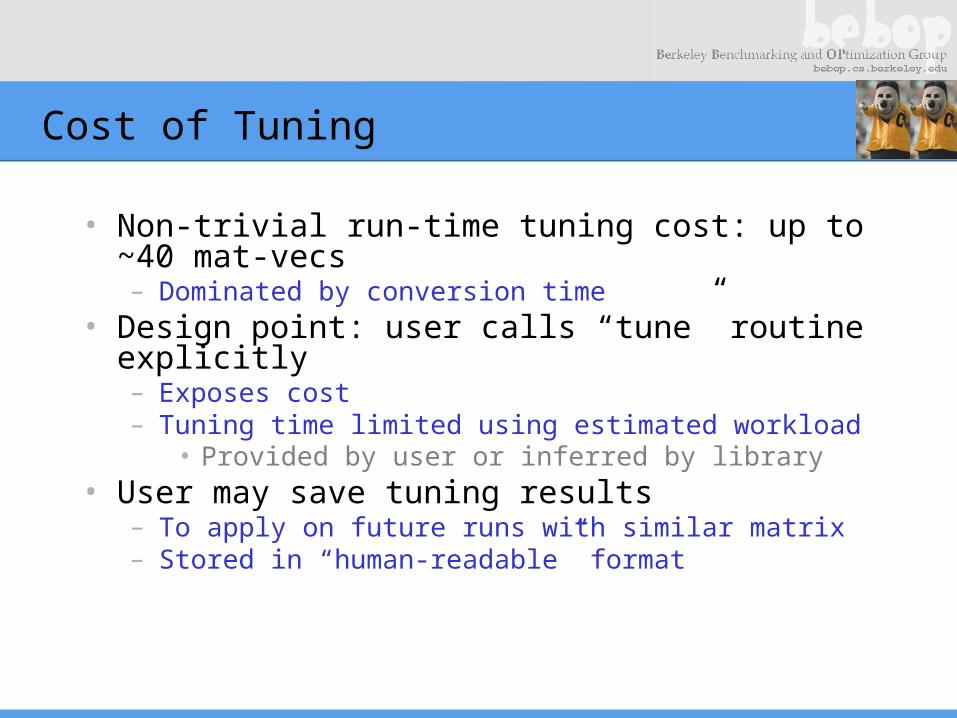
Cost of Tuning
• Non-trivial run-time tuning cost: up to ~40 mat-vecs– Dominated by conversion time
• Design point: user calls “tune” routine explicitly– Exposes cost– Tuning time limited using estimated workload
• Provided by user or inferred by library• User may save tuning results
– To apply on future runs with similar matrix– Stored in “human-readable” format
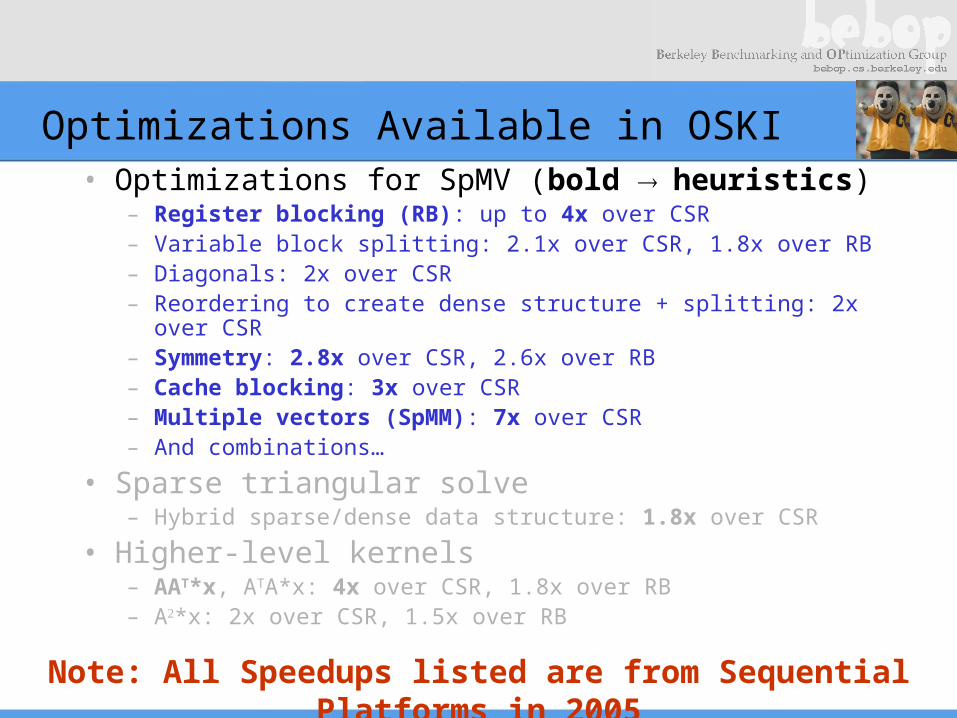
Optimizations Available in OSKI• Optimizations for SpMV (bold heuristics)
– Register blocking (RB): up to 4x over CSR– Variable block splitting: 2.1x over CSR, 1.8x over RB– Diagonals: 2x over CSR– Reordering to create dense structure + splitting: 2x over
CSR– Symmetry: 2.8x over CSR, 2.6x over RB– Cache blocking: 3x over CSR– Multiple vectors (SpMM): 7x over CSR– And combinations…
• Sparse triangular solve– Hybrid sparse/dense data structure: 1.8x over CSR
• Higher-level kernels– AAT*x, ATA*x: 4x over CSR, 1.8x over RB– A*x: 2x over CSR, 1.5x over RB
Note: All Speedups listed are from Sequential Platforms in 2005

Outline
• pOSKI Goals• OSKI Overview
– (Slides adopted from Rich Vuduc’s SIAM CSE 2005 Talk)
• pOSKI Design• Parallel Benchmark• MPI-SpMV
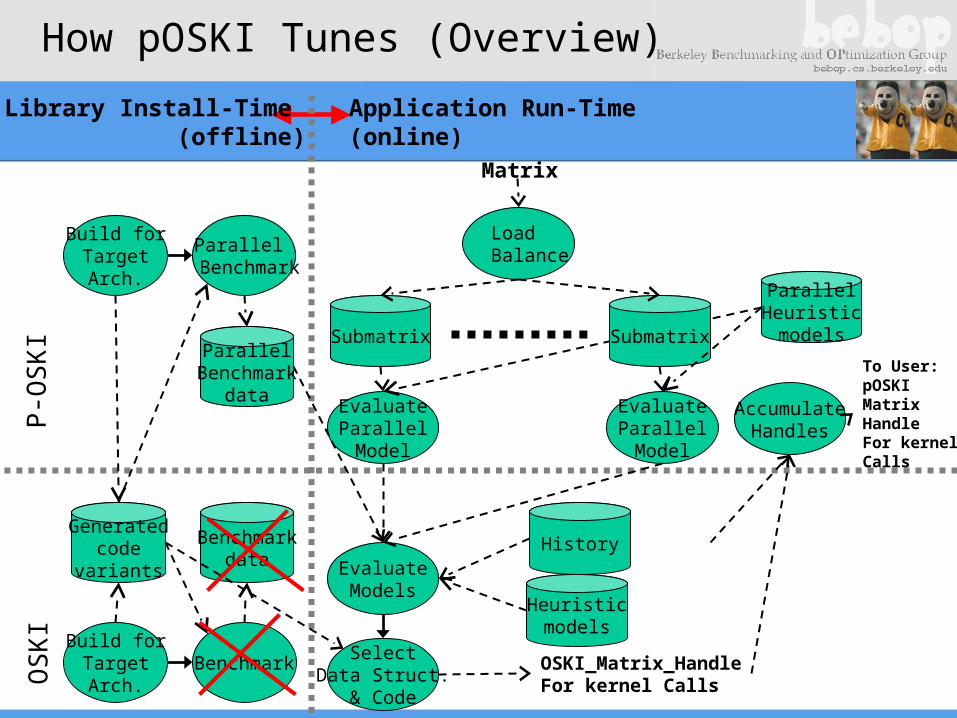
Library Install-Time (offline)
Application Run-Time(online)
Matrix
P-O
SK
IO
SK
I
Benchmarkdata
Build forTargetArch.
Benchmark
Generatedcode
variants
ParallelBenchmark
data
Build forTargetArch.
Parallel Benchmark
Heuristicmodels
EvaluateModels
SelectData Struct.
& Code
OSKI_Matrix_HandleFor kernel Calls
History
ParallelHeuristicmodels
EvaluateParallelModel
Submatrix
Load Balance
EvaluateParallelModel
Submatrix
AccumulateHandles
To User:pOSKIMatrixHandleFor kernel Calls
How pOSKI Tunes (Overview)

Where the Optimizations Occur
Optimization OSKI P-OSKI
Load Balancing/
NUMA
Register Blocking
Cache Blocking
TLB Blocking (future) (currently)

Current Implementation
• The Serial Interface– Represents SP composition of ParLab Proposal.
The parallelism is hidden under the covers– Each serial-looking function call triggers a set of
parallel events– Manages its own thread pool
• Supports up to the number of threads supported by underlying hardware
– Manages thread and data affinity

Additional Future Interface
• The Parallel Interface– Represents PP composition of ParLab Proposal– Meant for expert programmers– Can be used to share threads with other parallel
libraries– No guarantees of thread of data affinity management– Example Use: y ATAx codes
• Alternate between SpMV and preconditioning step. • Share threads between P-OSKI (for SpMV) and some
parallel preconditioning library
– Example Use: UPC Code• Explicitly Parallel Execution Model• User partitions matrix based on some information P-
OSKI would not be able to infer

Thread and Data Affinity (1/3)
• Cache Coherent Non Uniform Memory Access (ccNUMA) times on Modern MultiSocket, MultiCore architectures
• Modern OS’ ‘first touch’ policy in allocating memory
• Thread Migration between Locality Domains is expensive– In ccNUMA, a locality domain is a set of processor cores
together with locally connected memory which can be accessed without resorting to a network of any kind.
• For now, we have to deal with these OS policies ourselves. The ParLab OS Group is trying to solve these problems in order to hide such issues from the programmer.

Thread and Data Affinity (2/3)
• The Problem with malloc() and free()– malloc() first looks for free pages on heap and then
requests OS to allocate new pages.– If available free pages reside on a different locality
domain, malloc() still allocates them– Autotuning codes are malloc() and free() intensive so
this is a huge problem

Thread and Data Affinity (3/3)
• The solution: Managing our own memory– One large chunk (heap) allocated at the beginning of
tuning per locality domain– Size of this heap controlled by user input through
environment variable [P_OSKI_HEAP_IN_GB=2]– Rare case: allocated space is not big enough
• Stop all threads• Free all allocated memory • Grow the amount of space significantly across all
threads and locality domains• Print a strong warning to the user
Outline
• pOSKI Goals• OSKI Overview
– (Slides adopted from Rich Vuduc’s SIAM CSE 2005 Talk)
• pOSKI Design• Parallel Benchmark• MPI-SpMV
Justification
• OSKI’s Benchmarking– Single Threaded– All the memory bandwidth is given to this one thread
• pOSKI’s Benchmarking– Benchmark’s 1, 2, 4, …, threads (based on hardware
limit) in parallel– Each thread uses up memory bandwidth which
resembles run-time more accurately– When each instance of OSKI choose appropriate data
structures and algorithms, it uses the data from this parallel benchmark
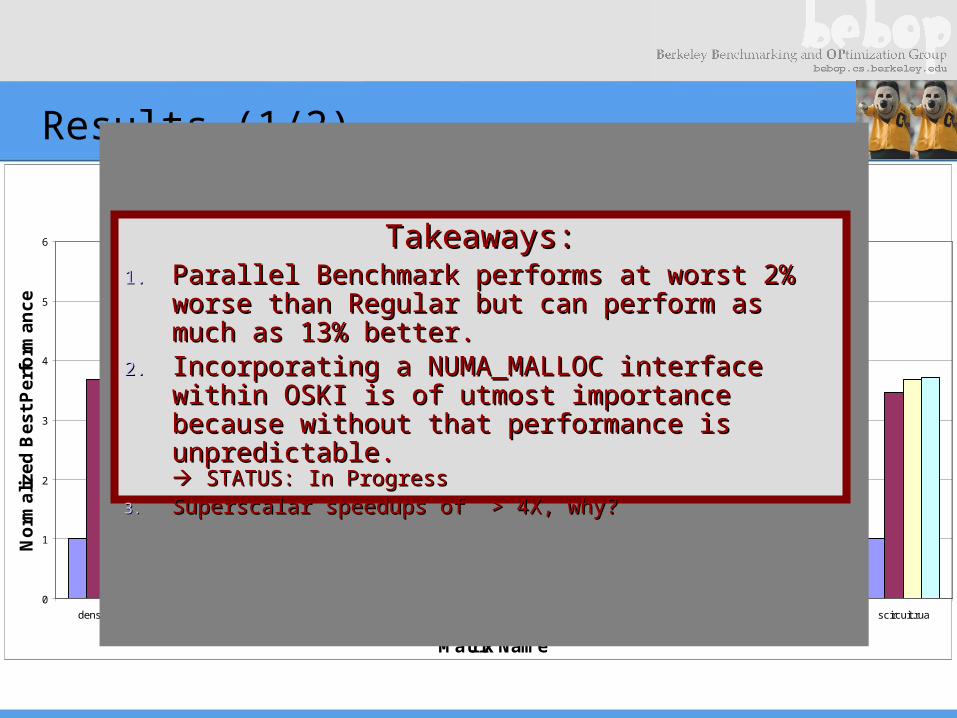
Results (1/2)
SpMV Performance of Optimizations for Matrix Suite
0
1
2
3
4
5
6
dense2.pua w ebbase-1M.rua rail4824s.pua raefsky4.rua bibd_22_8.pua marca_tcomm.rua mc2depi.rua ex11.rua scircuit.rua
Matrix Name
No
rma
lize
d B
es
t P
erf
orm
an
ce
OSKI pOSKI pOSKI + tuning pOSKI + tuning + pBenchTakeaways:Takeaways:
1.1. Parallel Benchmark performs at worst 2% worse than Regular Parallel Benchmark performs at worst 2% worse than Regular but can perform as much as 13% better.but can perform as much as 13% better.
2.2. Incorporating a NUMA_MALLOC interface within OSKI is Incorporating a NUMA_MALLOC interface within OSKI is of utmost importance because without that performance is of utmost importance because without that performance is unpredictable.unpredictable. STATUS: In Progress STATUS: In Progress
3.3. Superscalar speedups of > 4X, why?Superscalar speedups of > 4X, why?

Results (2/2)
rail4824s.pua
750
800
850
900
950
1000
RThreads = 1,CThreads = 4
RThreads = 2,CThreads = 2
RThreads = 4,CThreads = 1
Matrix Layout
MF
lop
s/se
c
marca_tcomm.rua
0200400600800
1000120014001600
RThreads = 1,CThreads = 4
RThreads = 2,CThreads = 2
RThreads = 4,CThreads = 1
Matrix Layout Across Cores
MF
lop
s/se
c
• Justifies Need for Search• Need Heuristics to reduce this since the
multicore search space is expanding exponentially

Outline
• pOSKI Goals• OSKI Overview
– (Slides adopted from Rich Vuduc’s SIAM CSE 2005 Talk)
• pOSKI Design• Parallel Benchmark• MPI-SpMV

Goals
• Target: MultiNode, MultiCore architectures• Design: Build an MPI-layer on top of pOSKI
– MPI is a starting point
• Tuning Parameters:– Balance of Pthreads and MPI tasks
• Rajesh has found for collectives, the balance is not always clear
• Identifying if there are potential performance gains by assigning some of the threads (or cores) to only handle sending/receiving of messages
• Status:– Just started, should have initial version in next few weeks
• Future Work:– Explore UPC for communication– Distributed Load Balancing, Workload Generation

Questions?
pOSKI GoalsOSKI Overview pOSKI Design
Parallel BenchmarkMPI-SpMV

Extra Slides
Motivation for Tuning
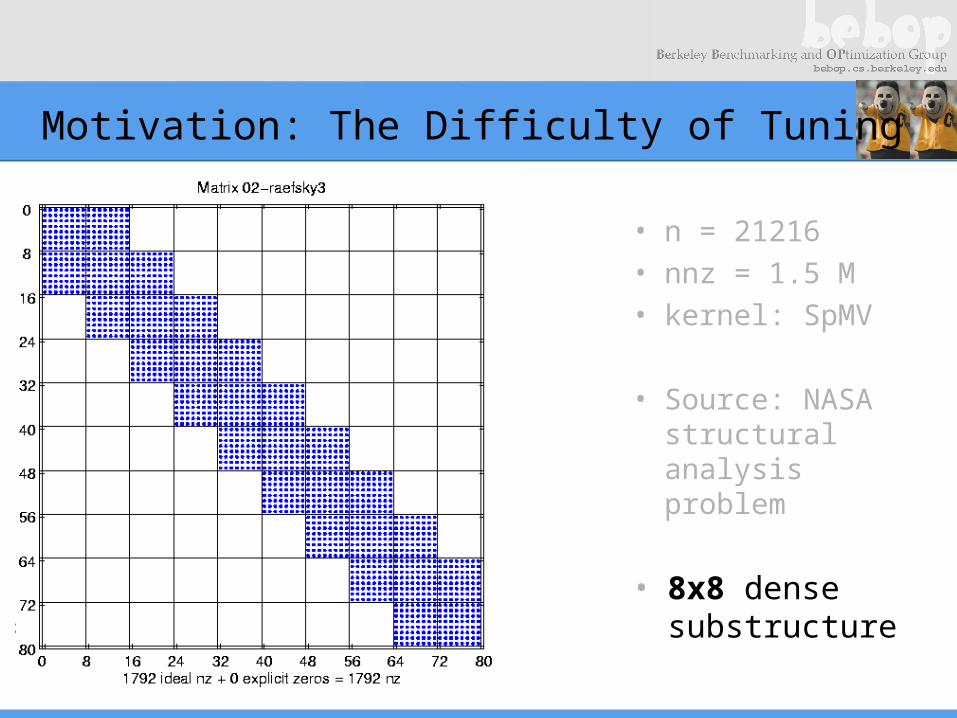
Motivation: The Difficulty of Tuning
• n = 21216• nnz = 1.5 M• kernel: SpMV
• Source: NASA structural analysis problem
• 8x8 dense substructure

Speedups on Itanium 2: The Need for Search
Reference
Best: 4x2
Mflop/s
Mflop/s

Extra Slides
Some Current Multicore Machines

Rad Lab Opteron

Niagara 2 (Victoria Falls)
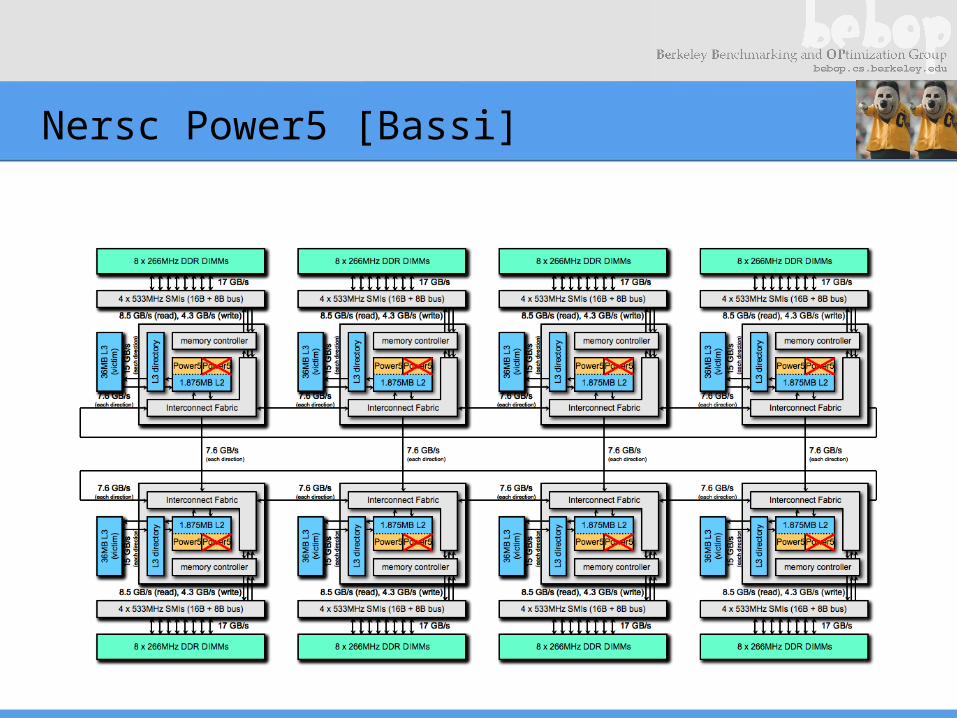
Nersc Power5 [Bassi]

Cell Processor

Extra Slides
SpBLAS and OSKI Interfaces
SpBLAS Interface
• Create a matrix handle• Assert matrix properties• Insert matrix entries• Signal the end of matrix creation• Call operations on the handle• Destroy the handle
Tune here

OSKI Interface
• The basic OSKI interface has a subset of the matrix creation interface of the Sparse BLAS, exposes the tuning step explicitly, and supports a few extra kernels (e.g., A^(T)*A*x).
• The OSKI interface was designed with the intent of implementing the Sparse BLAS using OSKI under-the-hood.

Extra Slides
Other Ideas for pOSKI

Challenges of a Parallel Automatic Tuner
• Search space increases exponentially with number of parameters
• Parallelization across Architectural Parameters– Across Multiple Threads– Across Multiple Cores– Across Multiple Sockets
• Parallelizing the data of a given problem– Across Rows, Across Columns, or Checkerboard– Based on User Input in v1– Future Versions can integrate ParMETIS or other
graph partitioners

A Memory Footprint Minimization Heuristic
The Problem: Search Space is too Large Auto-tuning takes too long
• The rate of increase in aggregate memory bandwidth over time is not as fast as the rate of increase in processing power per machine.
• Our Two Step Tuning Process:– Calculate the top 20% memory efficient
configurations on Thread 0– Each Thread finds its optimal block size for its sub-
matrix from the list in Step 1





























