Embed Size (px)
Citation preview

Portability for FPGA Applications—Warp Processing and SystemC Bytecode
Contributing Ph.D. StudentsRoman Lysecky (Ph.D. 2005, now Asst. Prof. at
Univ. of ArizonaGreg Stitt (Ph.D. 2007, now Asst. Prof. at Univ. of
Florida, GainesvilleScotty Sirowy (current)David Sheldon (current)Chen Huang (current)
This research was supported in part by the National Science Foundation, the Semiconductor Research
Corporation, Intel, Freescale, IBM, and Xilinx
Frank VahidDept. of CS&E
University of California, Riverside
Associate Director, Center for Embedded Computer Systems, UC Irvine
2/64Frank Vahid, UC Riverside
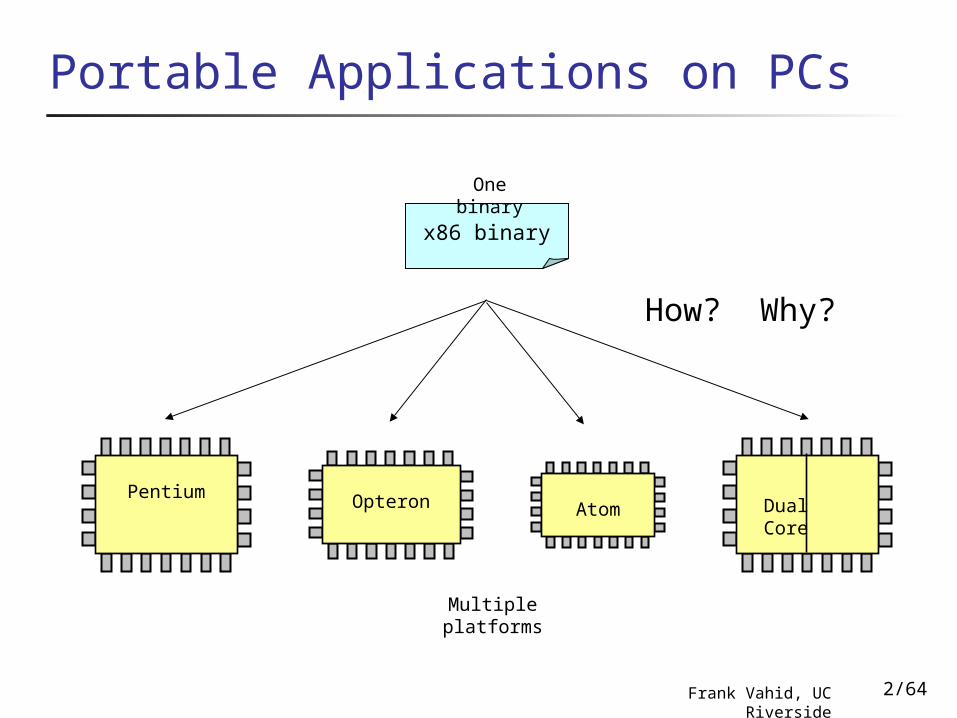
Portable Applications on PCs
x86 binary
PentiumAtomOpteron Dual
Core
How? Why?
One binary
Multiple platforms

3/64Frank Vahid, UC Riverside
Portable Applications on PCs
Standard software binary
Dynamic software binary translation
Applications
Tools Architectures
“Ecosystem”
SW binary translation
VLIWx86 µP
VLIWBinary
x86Binary

4/64Frank Vahid, UC Riverside
Meanwhile, Circuits on FPGAs Show Large Speedups
Int. Symp. on FPGAs, FCCM, FPL, CODES/ISSS, ICS, MICRO, CASES, DAC, DATE, ICCAD, RAW, …
0
10
20
30
40
50
60
Sp
ee
du
p
79.2200500
0
5
10
15
20
25
30
Sp
ee
du
p

5/64Frank Vahid, UC Riverside
FPGAs Entering Computing Mainstream
Xilinx Virtex II Pro. Source: XilinxSGI Altix supercomputer (UCR: 64 Itaniums plus 2 FPGA RASCs)
AMD Opteron Intel QuickAssist Cray, SGI Mitrionics IBM Cell (research) Xilinx, Altera

6/64Frank Vahid, UC Riverside
Circuits on FPGAs are Software Binaries
Processor Processor
001010010……
001010010……
0010…
Bits loaded into program memory
Microprocessor Binaries (Instructions)
001010010……
01110100...
Bits loaded into LUTs and SMs
FPGA “Binaries” (Circuits)
Processor FPGA0111
…
aka "bitstream"
"Software"
"Hardware"
Sep 2007 IEEE Computer
not hardware

7/64Frank Vahid, UC Riverside
“Portable Applications” + “FPGAs” Standard software
binary Dynamic translation
Applications
Tools Architectures
“Ecosystem”
SW binary translation
VLIWx86 µP
VLIWBinary
x86Binary
x86 VLIW DSP FPGA
Speedup
SW binary translation
FPGAx86 µP
FPGA binary
“Warp Processing”

8/64Frank Vahid, UC Riverside
µP
FPGAOn-chip CAD
Warp Processing
Profiler
Initially, software binary loaded into instruction memory
11
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software Binary

9/64Frank Vahid, UC Riverside
µP
FPGAOn-chip CAD
Warp Processing
ProfilerI Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryMicroprocessor executes
instructions in software binary
22
Time EnergyµP
10/64Frank Vahid, UC Riverside
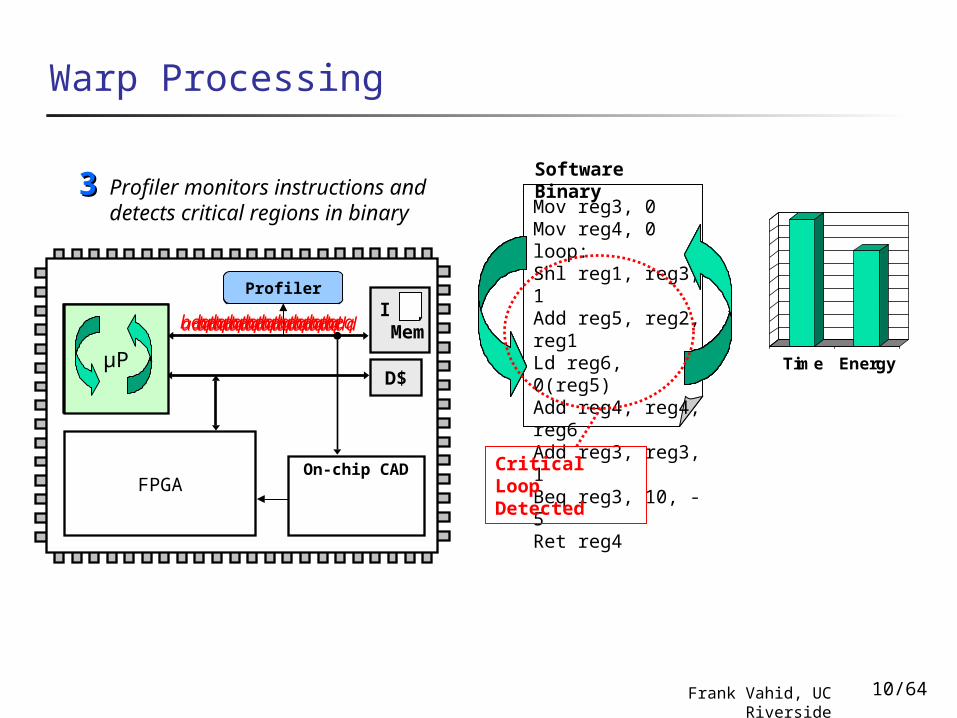
µP
FPGAOn-chip CAD
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryProfiler monitors instructions
and detects critical regions in binary
33
Time Energy
Profiler
add
add
add
add
add
add
add
add
add
add
beq
beq
beq
beq
beq
beq
beq
beq
beq
beq
Critical Loop Detected

11/64Frank Vahid, UC Riverside
µP
FPGAOn-chip CAD
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryOn-chip CAD reads in critical
region44
Time Energy
Profiler
On-chip CAD
12/64Frank Vahid, UC Riverside
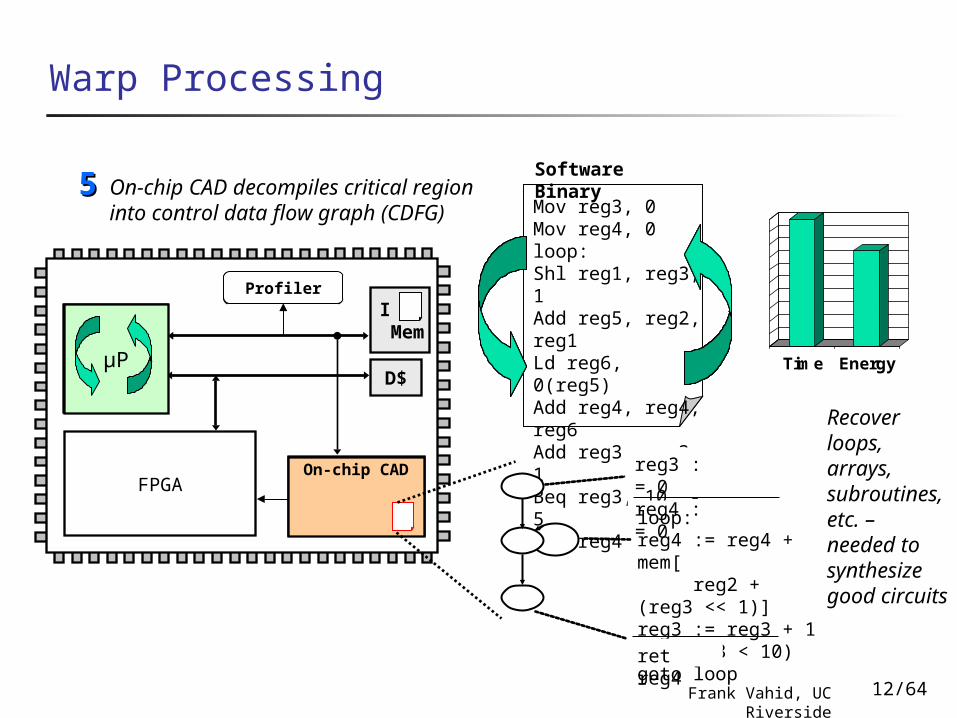
µP
FPGADynamic Part. Module (DPM)
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryOn-chip CAD decompiles critical
region into control data flow graph (CDFG)
55
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
Recover loops, arrays, subroutines, etc. – needed to synthesize good circuits

13/64Frank Vahid, UC Riverside
µP
FPGADynamic Part. Module (DPM)
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryOn-chip CAD synthesizes
decompiled CDFG to a custom (parallel) circuit
66
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .

14/64Frank Vahid, UC Riverside
µP
FPGADynamic Part. Module (DPM)
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryOn-chip CAD maps circuit onto
FPGA77
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
CLB
CLB
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
++
FPGA

15/64Frank Vahid, UC Riverside
µP
FPGADynamic Part. Module (DPM)
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software Binary88
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
CLB
CLB
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
++
FPGA
On-chip CAD replaces instructions in binary to use hardware, causing performance and energy to “warp” by an order of magnitude or more
Mov reg3, 0Mov reg4, 0loop:// instructions that interact with FPGA
Ret reg4
FPGA
Time Energy
Software-only“Warped”
>10x speedups for some apps
Warp speed, Scotty

16/64Frank Vahid, UC Riverside
Warp Processing Challenges
Can we decompile binaries sufficiently for synthesis?
Can we just-in-time (JIT) compile to FPGAs?
µPI$
D$
FPGA
Profiler
On-chip CAD
BinaryBinary
Decompilation
BinaryFPGA binary
Profiling & partitioning
Binary Updater
BinaryMicrop Binary
CDFG
JIT FPGA compilation

17/64Frank Vahid, UC Riverside
Decompilation
Recover high-level information from binary: branches, loops, arrays, subroutines, …
Adapted previous methods for processor-processor translation (UQBT) Developed new synthesis-oriented methods (e.g., “reroll” loops,
strength “promotion”)
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
long f( short a[10] ) { long accum; for (int i=0; i < 10; i++) { accum += a[i]; } return accum;}
loop:reg1 := reg3 << 1reg5 := reg2 + reg1reg6 := mem[reg5 + 0]reg4 := reg4 + reg6reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
Control/Data Flow Graph CreationOriginal C Code
Corresponding Assembly
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
Data Flow Analysis
long f( long reg2 ) { int reg3 = 0; int reg4 = 0; loop: reg4 = reg4 + mem[reg2 + reg3 << 1)]; reg3 = reg3 + 1; if (reg3 < 10) goto loop; return reg4;}
Function Recovery
long f( long reg2 ) { long reg4 = 0; for (long reg3 = 0; reg3 < 10; reg3++) { reg4 += mem[reg2 + (reg3 << 1)]; } return reg4;}
Control Structure Recovery
long f( short array[10] ) { long reg4 = 0; for (long reg3 = 0; reg3 < 10; reg3++) { reg4 += array[reg3]; } return reg4; }
Array Recovery
Almost Identical Representations
18/64Frank Vahid, UC Riverside
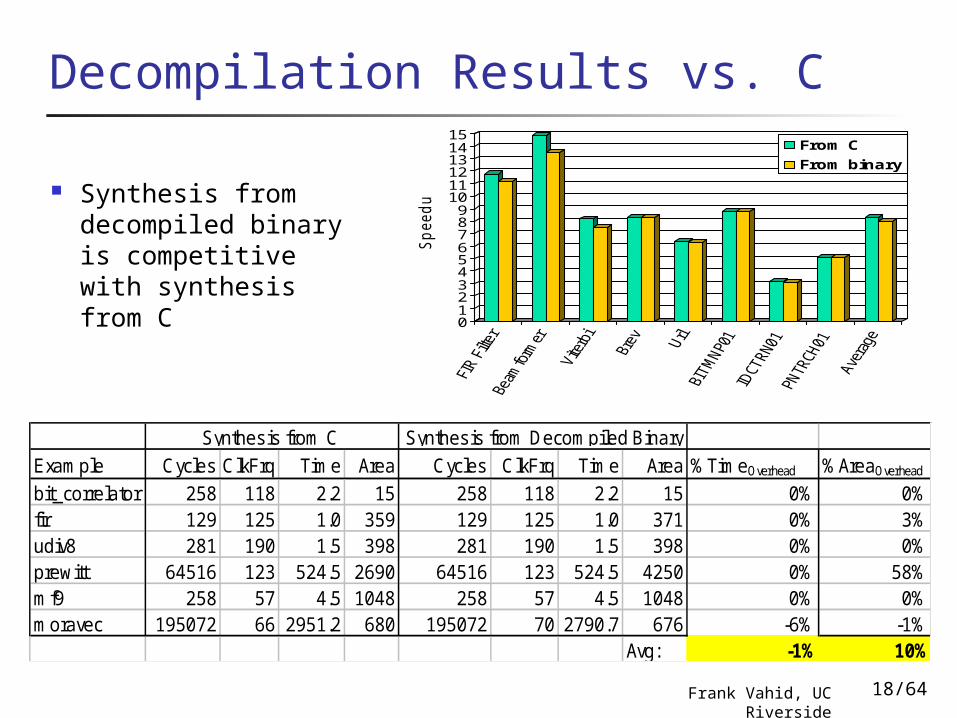
Decompilation Results vs. C
Synthesis from decompiled binary is competitive with synthesis from C
Example Cycles ClkFrq Time Area Cycles ClkFrq Time Area %TimeOverhead %AreaOverhead
bit_correlator 258 118 2.2 15 258 118 2.2 15 0% 0%fir 129 125 1.0 359 129 125 1.0 371 0% 3%udiv8 281 190 1.5 398 281 190 1.5 398 0% 0%prewitt 64516 123 524.5 2690 64516 123 524.5 4250 0% 58%mf9 258 57 4.5 1048 258 57 4.5 1048 0% 0%moravec 195072 66 2951.2 680 195072 70 2790.7 676 -6% -1%
Avg: -1% 10%
Synthesis from C Synthesis from Decompiled Binary
0123456789
101112131415
Speedup
From C
From binary
19/64Frank Vahid, UC Riverside
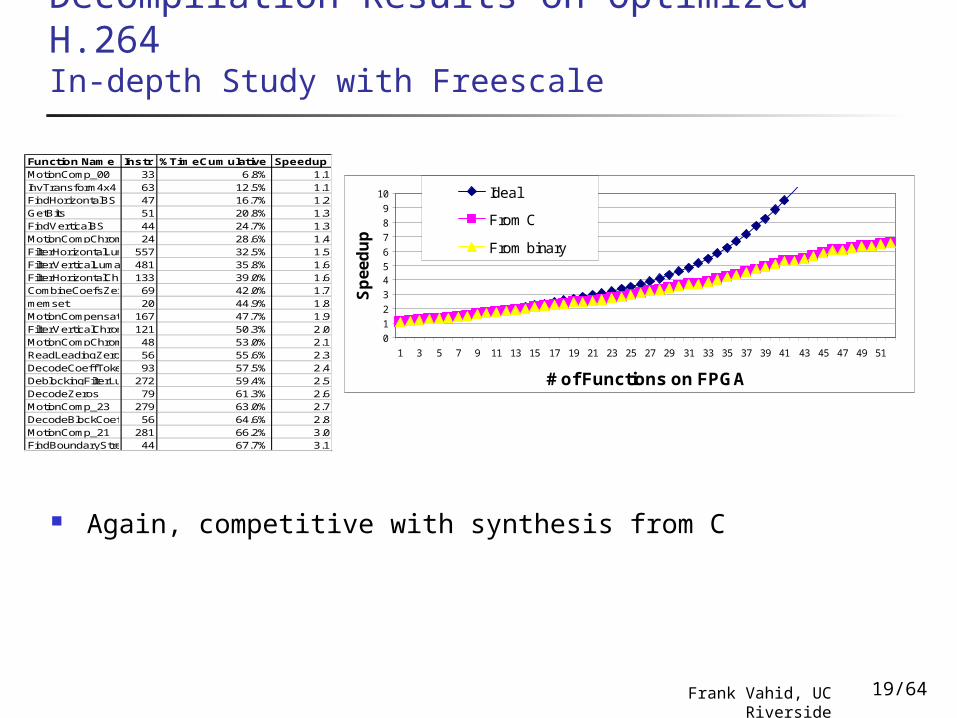
Decompilation Results on Optimized H.264In-depth Study with Freescale
Again, competitive with synthesis from C
Function Name Instr %TimeCumulative SpeedupMotionComp_00 33 6.8% 1.1InvTransform4x4 63 12.5% 1.1FindHorizontalBS 47 16.7% 1.2GetBits 51 20.8% 1.3FindVerticalBS 44 24.7% 1.3MotionCompChromaFullXFullY24 28.6% 1.4FilterHorizontalLuma 557 32.5% 1.5FilterVerticalLuma 481 35.8% 1.6FilterHorizontalChroma133 39.0% 1.6CombineCoefsZerosInvQuantScan69 42.0% 1.7memset 20 44.9% 1.8MotionCompensate 167 47.7% 1.9FilterVerticalChroma 121 50.3% 2.0MotionCompChromaFracXFracY48 53.0% 2.1ReadLeadingZerosAndOne56 55.6% 2.3DecodeCoeffTokenNormal93 57.5% 2.4DeblockingFilterLumaRow272 59.4% 2.5DecodeZeros 79 61.3% 2.6MotionComp_23 279 63.0% 2.7DecodeBlockCoefLevels56 64.6% 2.8MotionComp_21 281 66.2% 3.0FindBoundaryStrengthPMB44 67.7% 3.1
0
1
2
3
45
6
7
8
9
10
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51
# of Functions on FPGAS
pee
du
p
Ideal
From C
From binary
20/64Frank Vahid, UC Riverside
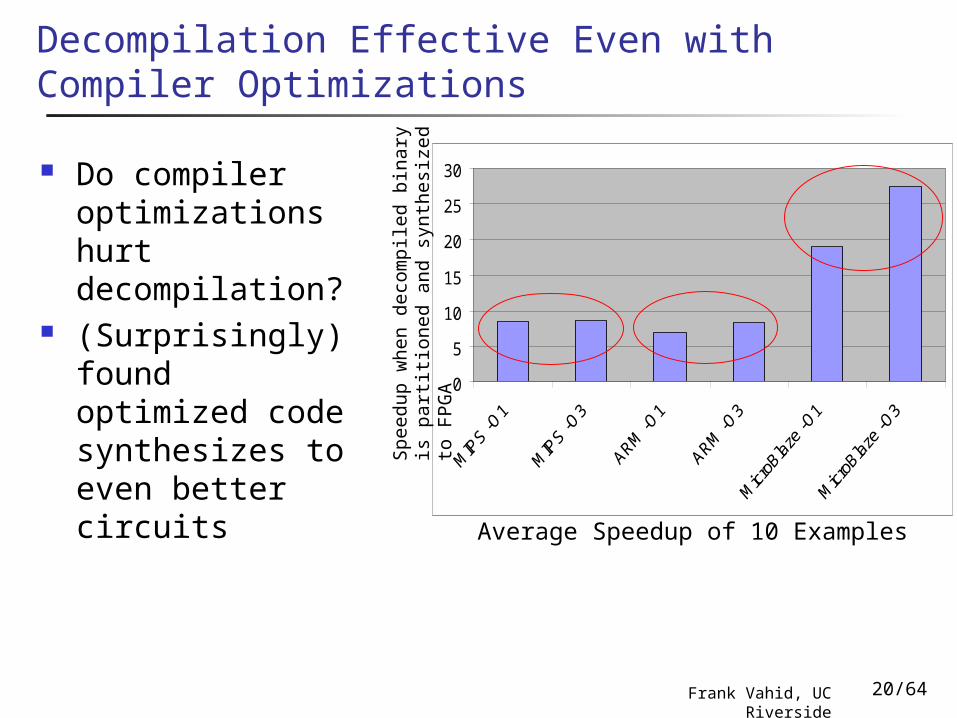
Decompilation Effective Even with Compiler Optimizations
Average Speedup of 10 Examples
0
5
10
15
20
25
30 Do compiler optimizations hurt decompilation?
(Surprisingly) found optimized code synthesizes to even better circuits
Sp
eedu
p w
hen d
eco
mp
iled b
inary
is
part
itio
ned a
nd s
ynth
esi
zed
to F
PG
A

21/64Frank Vahid, UC Riverside
Decompilation
Summary: Decompilation is surprisingly effective at recovering high-level program structures for synthesisStitt et al ICCAD’02, DAC’03, CODES/ISSS’05, ICCAD’05, FPGA’05, TODAES’06, TODAES’07
Ph.D. work of Greg Stitt (Ph.D. UCR 2007, now Asst. Prof. at UF Gainesville)

22/64Frank Vahid, UC Riverside
Warp Processing Challenges
Can we decompile binaries sufficiently for synthesis?
Can we just-in-time (JIT) compile to FPGAs?
µPI$
D$
FPGA
Profiler
On-chip CAD
BinaryBinary
Decompilation
BinaryFPGA binary
Profiling & partitioning
Binary Updater
BinaryMicrop Binary
CDFG
JIT FPGA compilation

23/64Frank Vahid, UC Riverside
Expand
Reduce
Irredundant
dc-seton-set off-set Developed ultra-lean CAD heuristics for synthesis,
placement, routing, and technology mapping, e.g., Logic synthesis: run single expand phase Technology mapping: bottom-up graph clustering
heuristic Placement: place critical path first, then adjacent items Routing: use resource graph that matches switch
matrix / channel structure
Challenge: JIT Compile to FPGA 60 MB
Logic synthesis Tech. map. Placement Routing
9.1 s
Commercial tool
3.6MB0.2 s
Ultra-lean Riverside JIT FPGA tools (drawn to scale)
1.4s
Ultra-lean Riverside JIT FPGA tools on a 75MHz ARM7
3.6MB
Penalty: 1.3-2x in performance & size(even more might be acceptable)

24/64Frank Vahid, UC Riverside
JIT Compile to FPGA
Summary: Ultra-lean JIT FPGA compiler 40x speedup, 20x less memory, 1.3x-2x circuit penaltyLysecky et al, DAC’03, ISSS/CODES’03, DATE’04, DAC’04, DATE’05, FCCM’05, TODAES’06
Ph.D. work of Roman Lysecky (Ph.D. UCR 2005, now Asst. Prof. at Univ. of Arizona)

25/64Frank Vahid, UC Riverside
191 130
0
10
20
30
40
50
60
70
80
Spee
dup
Warp Proc.
Warp Processing ResultsPerformance Speedup (Most Frequent Kernel Only)
Average kernel speedup of 41
1 = ARM-only execution
Overall application speedup average is 7.4
vs. 200 MHz ARM
µPI$
D$
FPGA
Profiler
On-chip CAD
26/64Frank Vahid, UC Riverside
µP
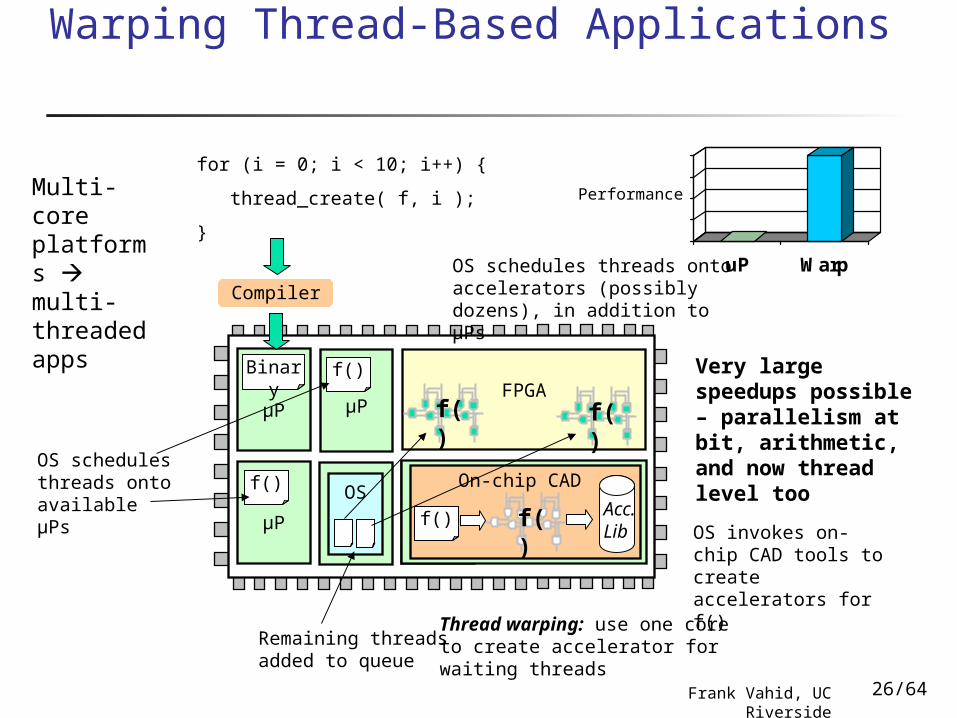
Warping Thread-Based Applications
FPGAµPµP
µP
OS
µP
f()
f()f()
Compiler
Binary
for (i = 0; i < 10; i++) {
thread_create( f, i );
}
f()
µP
On-chip CAD
Acc. Lib
f() f()
OS schedules threads onto available µPs
Remaining threads added to queue
OS invokes on-chip CAD tools to create accelerators for f()
OS schedules threads onto accelerators (possibly dozens), in addition to µPs
Thread warping: use one core to create accelerator for waiting threads
Very large speedups possible – parallelism at bit, arithmetic, and now thread level too
uP Warp
PerformanceMulti-core platforms multi-threaded apps
27/64Frank Vahid, UC Riverside
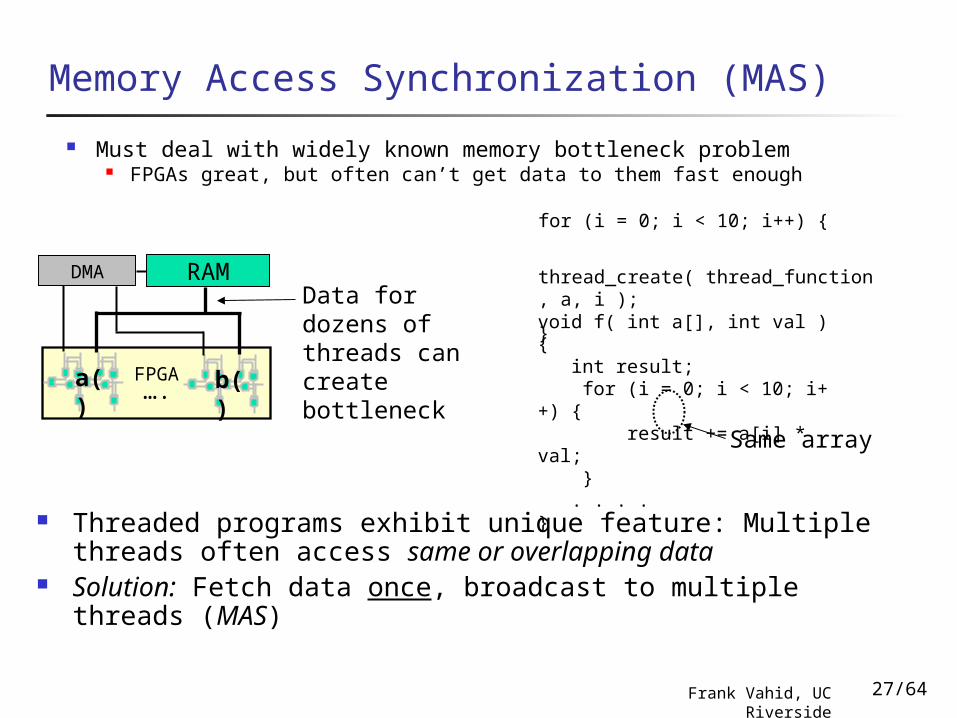
Must deal with widely known memory bottleneck problem FPGAs great, but often can’t get data to them fast enough
void f( int a[], int val ){ int result; for (i = 0; i < 10; i++) { result += a[i] * val; } . . . . }
Memory Access Synchronization (MAS)
Same array
FPGA b()a()
RAMData for dozens of threads can create bottleneck
for (i = 0; i < 10; i++) {
thread_create( thread_function, a, i );
}DMA
Threaded programs exhibit unique feature: Multiple threads often access same or overlapping data
Solution: Fetch data once, broadcast to multiple threads (MAS)
….

28/64Frank Vahid, UC Riverside
Memory Access Synchronization (MAS)
Detect overlapping memory regions – “windows”
void f( int a[], int i ){ int result; result += a[i]+a[i+1]+a[i+2]+a[i+3]; . . . . }
for (i = 0; i < 100; i++) { thread_create( thread_function, a, i );}
a[0] a[1] a[2] a[3] a[4] a[5] ………
f() f() ……………… f()
DMA RAMA[0-103]
A[0-3] A[1-4] A[6-9]
Data streamed to “smart buffer”
Smart Buffer
Buffer delivers window to each thread
W/O smart buffer: 400 memory accessesWith smart buffer: 104 memory accesses
Synthesis creates active “smart buffer” [Guo/Najjar FPGA04] Actively fetches data, stores the reused data, delivers windows to threads Active rather than passive component; designed for specific threads
Each thread accesses different addresses – but addresses may overlap
enable

29/64Frank Vahid, UC Riverside
Speedups from Thread Warping
Chose benchmarks with extensive parallelism Four core (ARM11 400 MHz) base system Virtex IV FPGA at circuit-specific clock frequency (~100-300 MHz) Average 130x speedup
38
01020304050
Fir Prewitt Linear Moravec Wavelet Maxfilter 3DTrans N-body Avg. Geo.Mean
4-uP
TW
8-uP
16-uP
32-uP
64-uP
Still 20x faster than 32-core system (and 11x faster than 64-core) Simulation pessimistic, actual results likely better FPGA more flexible
But, FPGA uses additional area. Our FPGA size = ~36 ARM11s
30/64Frank Vahid, UC Riverside
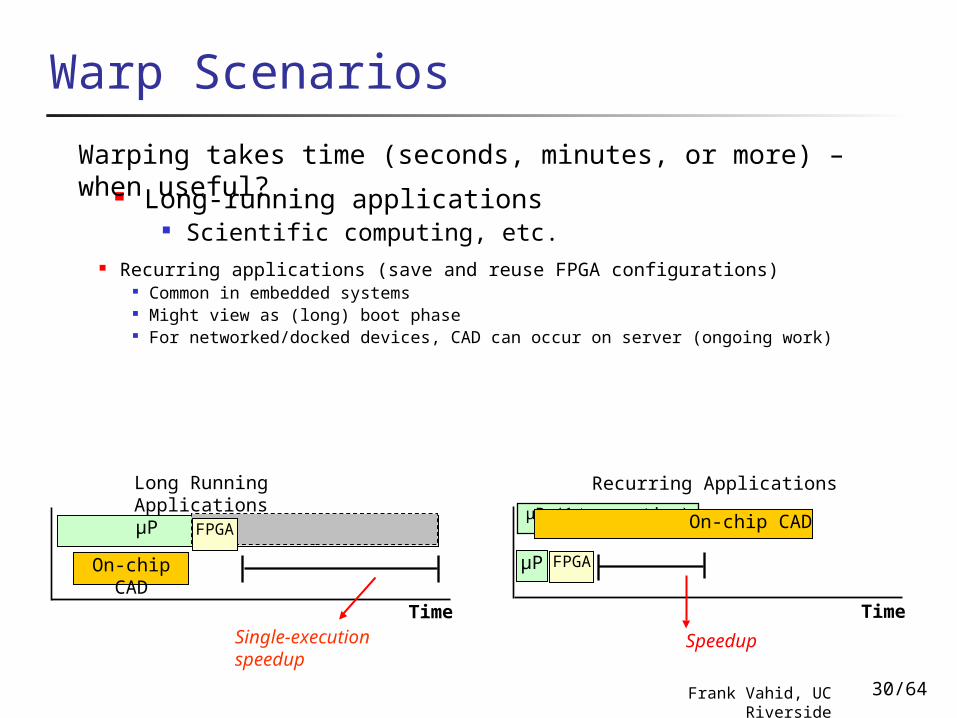
Warp Scenarios
µP
Time
µP (1st execution)
Time
On-chip CAD
µP FPGA
Speedup
Long Running Applications Recurring Applications
Long-running applications Scientific computing, etc.
Recurring applications (save and reuse FPGA configurations) Common in embedded systems Might view as (long) boot phase For networked/docked devices, CAD can occur on server (ongoing work)
On-chip CAD
Single-execution speedup
FPGA
Warping takes time (seconds, minutes, or more) – when useful?
31/64Frank Vahid, UC Riverside
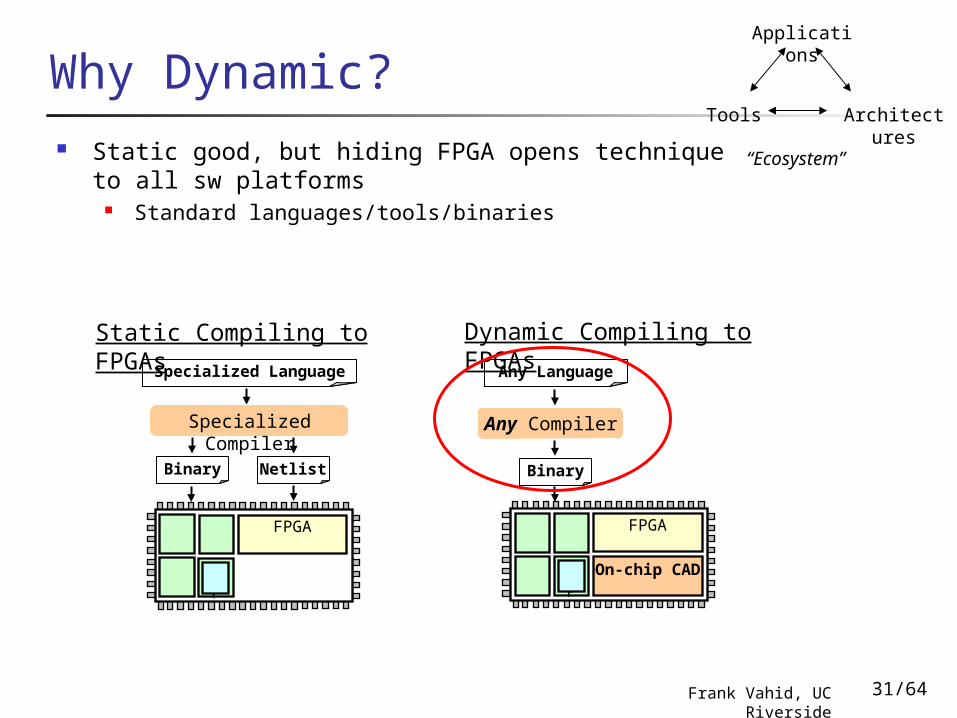
Why Dynamic? Static good, but hiding FPGA opens technique to all
sw platforms Standard languages/tools/binaries
On-chip CAD
FPGA
µP
Any Compiler
FPGA
µP
Specialized Compiler
Binary Netlist Binary
Specialized Language Any Language
Static Compiling to FPGAs Dynamic Compiling to FPGAs
Applications
Tools Architectures
“Ecosystem”

32/64Frank Vahid, UC Riverside
Synthesis-Friendly Applications
Coding style impacts synthesis results
0
1
2
3
4
5
6
7
8
9
10
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51
Number of Functions in Hardware
Sp
ee
du
p
Ideal Speedup (Zero-time Hw Execution)
Speedup After Rewrite (C Partitioning)
Speedup from C Partititioning

33/64Frank Vahid, UC Riverside
Synthesis-Friendly Application Coding Guidelines
Conversion to Constants (CC)
Conversion to Fixed Point (CF)
Conversion to Explicit Data Flow (CEDF)
Conversion to Explicit Memory Accesses (CEMA)
Function Specialization (FS)
Constant Input Enumeration (CIE)
Loop Rerolling (LR)
Conversion to Explicit Control Flow (CECF)
Algorithmic Specialization (AS)
Pass-By-Value Return (PVR)
Coding Guidelines

34/64Frank Vahid, UC Riverside
Conversion to Explicit Control Flow (CECF)
Problem: Function pointers may prevent static control flow analysis
Guideline: Don’t use function pointers. Replace with if-else, static calls
Makes possible targets explicit
void f( int (*fp) (int) ) { . . . . . for (i=0; i < 10; i++) { a[i] = fp(i); }}
enum Target { FUNC1, FUNC2, FUNC3 };void f( enum Target fp ) { . . . . . for (i=0; i < 10; i++) { if (fp == FUNC1) a[i] = f1(i); else if (fp == FUNC2) a[i] = f2(i); else a[i] = f3(i); }}
Synthesis unlikely to determine possible targets of function pointer
?a[i]
Synthesized Hardware
a[i]
Synthesized Circuit
f1(i) f2(i) f3(i)
3x1fp
35/64Frank Vahid, UC Riverside
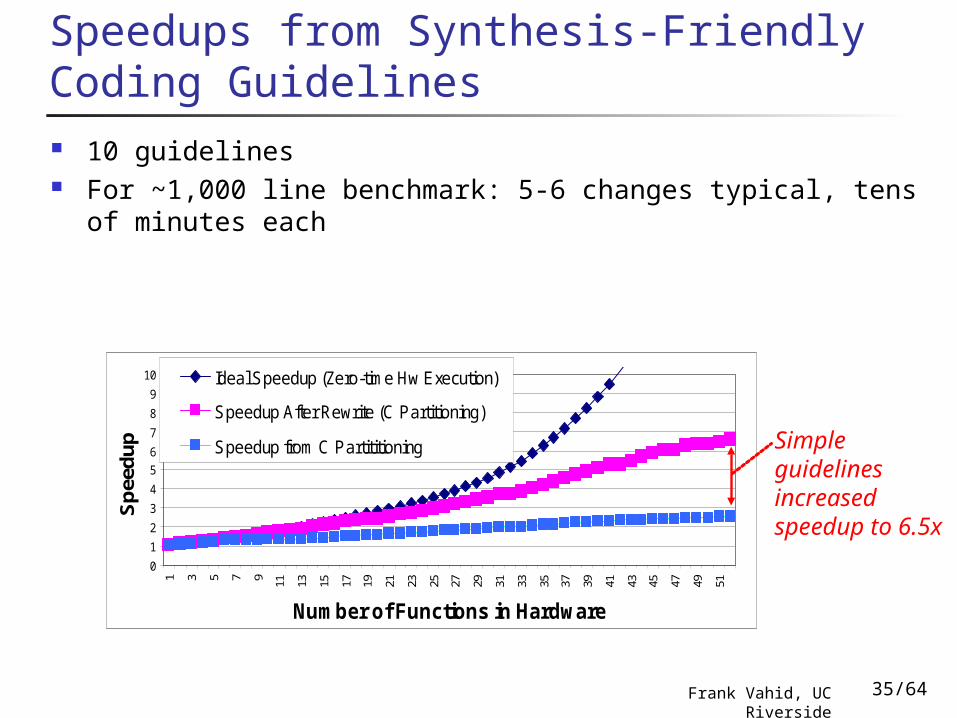
Speedups from Synthesis-Friendly Coding Guidelines 10 guidelines For ~1,000 line benchmark: 5-6 changes typical, tens of
minutes each
0
1
2
3
4
5
6
7
8
9
10
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51
Number of Functions in Hardware
Sp
eed
up
Ideal Speedup (Zero-time Hw Execution)
Speedup After Rewrite (C Partitioning)
Speedup from C Partititioning Simple guidelines increased speedup to 6.5x
36/64Frank Vahid, UC Riverside
Speedups from Synthesis-Friendly Coding Guidelines
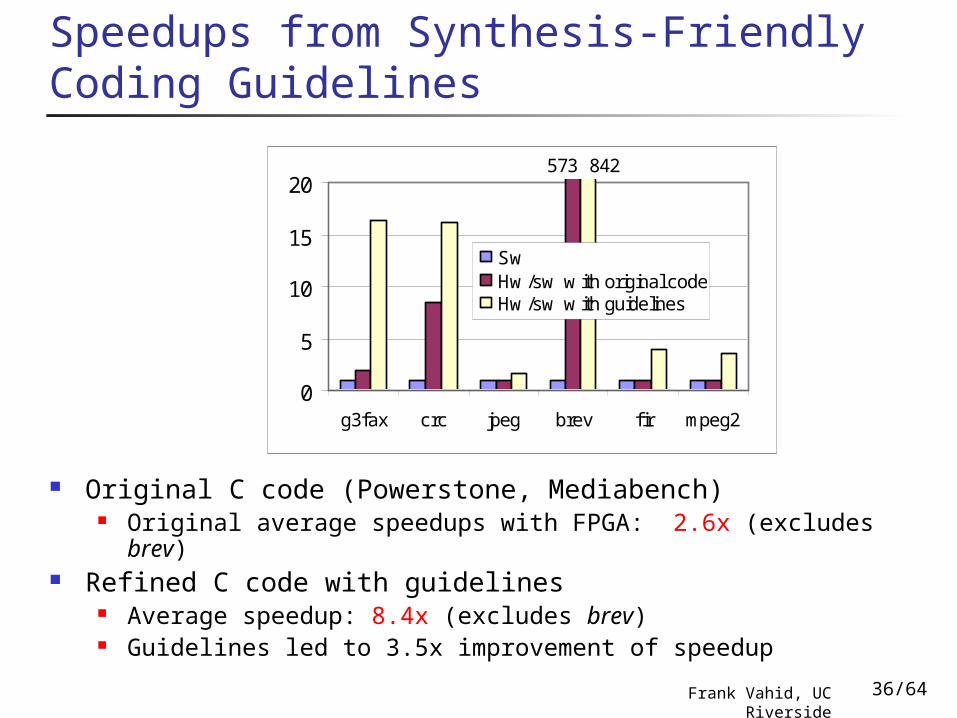
573 842
0
5
10
15
20
g3fax crc jpeg brev fir mpeg2
SwHw /sw w ith original codeHw /sw w ith guidelines
Original C code (Powerstone, Mediabench) Original average speedups with FPGA: 2.6x (excludes brev)
Refined C code with guidelines Average speedup: 8.4x (excludes brev) Guidelines led to 3.5x improvement of speedup
37/64Frank Vahid, UC Riverside
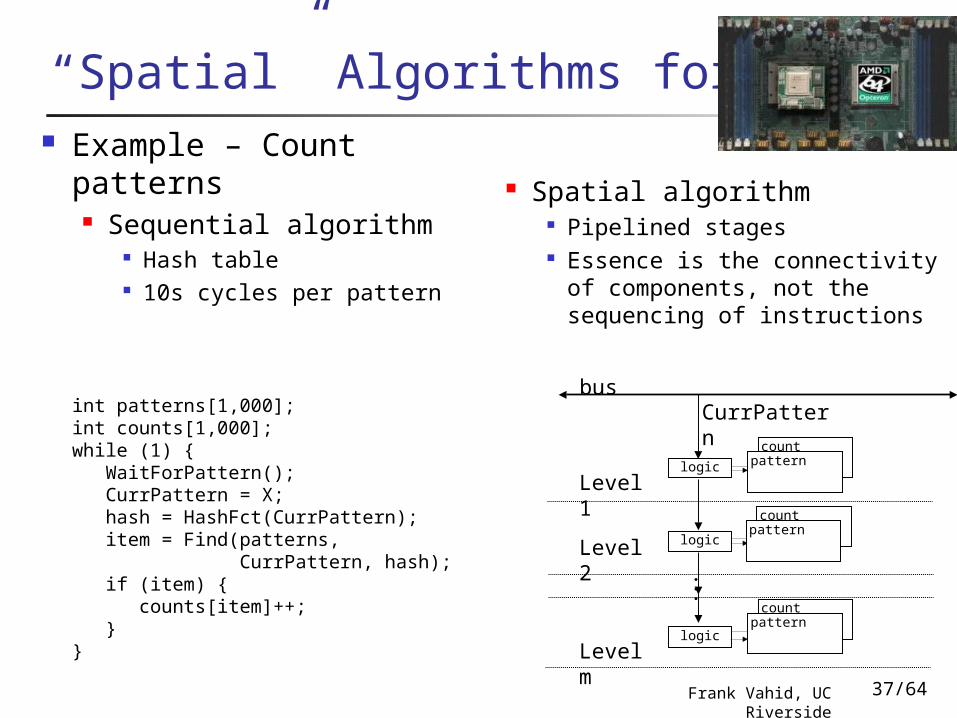
“Spatial” Algorithms for FPGAs Example – Count patterns
Sequential algorithm Hash table 10s cycles per pattern
int patterns[1,000]; int counts[1,000];while (1) { WaitForPattern(); CurrPattern = X; hash = HashFct(CurrPattern); item = Find(patterns, CurrPattern, hash); if (item) { counts[item]++; } }
count
Level 1logic pattern
logicLevel 2
Level mlogic
CurrPattern
countpattern
countpattern
.
.
.
bus
Spatial algorithm Pipelined stages Essence is the connectivity
of components, not the sequencing of instructions
38/64Frank Vahid, UC Riverside
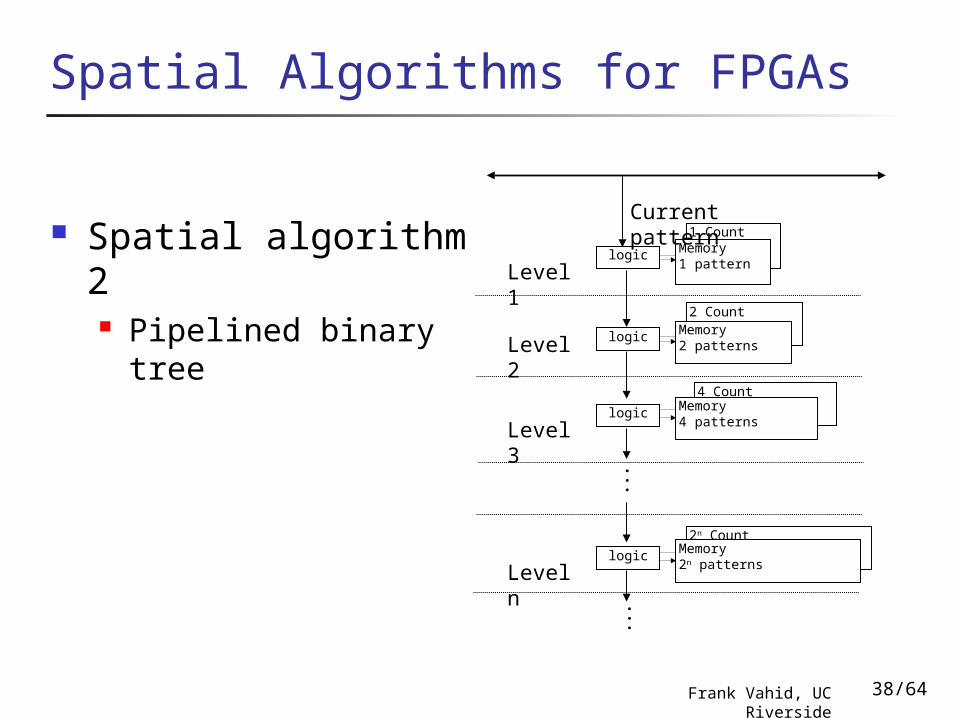
2n Count2n patterns
4 Count4 patterns
2 Count2 patterns
1 Count
Spatial Algorithms for FPGAs
Spatial algorithm 2 Pipelined binary tree Level 1
logic Memory1 pattern
logic Memory2 patterns
logic Memory4 patterns
Level 2
Level 3
Level nlogic Memory
2n patterns
.
.
.
Current pattern
.
.
.

39/64Frank Vahid, UC Riverside
Example
Stage 1
Stage 2
Stage 3
Stage 4
73
48 Level 1logic Memory
1 pattern
logicMemory2 patterns
logicMemory4 patterns
Level 2
Level 3
Level nlogic
Memory2n patterns
.
.
.
Current pattern
.
.
.
Possible patterns pre-stored in binary search tree circuit

40/64Frank Vahid, UC Riverside
Example
Stage 1
Stage 2
Stage 3
Stage 4
48
23 Level 1logic Memory
1 pattern
logicMemory2 patterns
logicMemory4 patterns
Level 2
Level 3
Level nlogic
Memory2n patterns
.
.
.
Current pattern
.
.
.
73

41/64Frank Vahid, UC Riverside
Example
Stage 1
Stage 2
Stage 3
Stage 4
23
75 Level 1logic Memory
1 pattern
logicMemory2 patterns
logicMemory4 patterns
Level 2
Level 3
Level nlogic
Memory2n patterns
.
.
.
Current pattern
.
.
.
48
73

42/64Frank Vahid, UC Riverside
Example
Stage 1
Stage 2
Stage 3
Stage 4
75
11 Level 1logic Memory
1 pattern
logicMemory2 patterns
logicMemory4 patterns
Level 2
Level 3
Level nlogic
Memory2n patterns
.
.
.
Current pattern
.
.
.
23
73
48
1

43/64Frank Vahid, UC Riverside
Example
Stage 1
Stage 2
Stage 3
Stage 4
11
Level 1logic Memory
1 pattern
logicMemory2 patterns
logicMemory4 patterns
Level 2
Level 3
Level nlogic
Memory2n patterns
.
.
.
Current pattern
.
.
.
48
23
1
75
1
1

44/64Frank Vahid, UC Riverside
Study of Spatial Algorithms in FCCM Year ApplicationType2001 3D Vec. Normalization Spatial2001 Efficient CAM --2001 Automated Sensor Temporal2001 Regular Expression Spatial2002 Hyperspectral Image Spatial2002 Machine VisionSpatial2002 RC4 Temporal2002 Set Covering Spatial2002 Template Matching Spatial2002 Triangle Mesh Spatial2003 Congruential Sieves Temporal2003 Content Scanning Temporal2003 F.P and Square Root Spatial2003 Gaussian NoiseSpatial2003 TRNG --2004 3D FDTD Method Spatial2004 Deep Packet Filter --2004 Online Floating Point --2004 Molecular Dynamics Spatial2004 Pattern Matching Spatial2004 Seismic Migration Spatial2004 Software Deceleration --2004 V.M Window --2005 Data Mining Spatial2005 Cell Automata Temporal2005 Particle Graphics Spatial2005 Radiosity Temporal2005 Transient Waves Spatial2005 Road Traffic Temporal2006 All Pairs Shortest Path Spatial2006 Apriori Data Mining Spatial2006 Molecular Dynamics Spatial2006 Gaussian Elimination Spatial2006 Radiation DoseTemporal2006 Random Variates Spatial
FCCM 2001-2006 70 papers describing fast
application on FPGA Examined 35 in depth (every
other one) 6 used device-specific features 9 represented expected
synthesized circuit from the obvious sequential algorithm
20 were spatially-oriented applications
e.g., earlier pipelined binary tree

45/64Frank Vahid, UC Riverside
Portable Spatial Applications? Current portable microprocessor binaries – sequential
Extensions for threads, processes, ... How support spatial constructs
Ports, connections, timing model .....
www.systemc.org
Adds libraries and macros, still standard C++
Sequential and spatial constructs Compiling links in the simulation kernel
Self-executing simulation Intended for SoC simulation

46/64Frank Vahid, UC Riverside
Bytecode Modern portability approach
Java, C#
PentiumAtomOpteron
bytecode
Compiler
VM VM VM
Virtual Machine (VM): Program that executes bytecode
May JIT compile to native architecture

47/64Frank Vahid, UC Riverside
SystemC Bytecode?
PentiumFPGA
SystemC bytecode
Compiler
VM VM
SystemC
Opteron+
FPGA
VM

48/64Frank Vahid, UC Riverside
UCR SystemC Bytecode and Compiler
class EDGE_DETECTOR : public sc_module {//signal declarations…EDGE_DETECTOR() { SC_method(mainComp); sensitive << dataReady;
SC_method(getPixel); sensitive << clock.pos();
void getPixel(){ … dataReady.write(1);}
void mainComp(){ int i, j; for(i = 0; i < 3; i++){ for(j = 0; j < 3; j++){ sumX = sumX + mem.read()*GX[i][j] } } … edge.write(sumX + sumY)}
SystemC
--headersignal clock : 1signal reset : 1signal memory_in : 32signal fb_data : 32signal leds : 4
process(clock)READ $1 memory_inADD $2 $0 3ADD $3 $2 $1WRITE $3 s1ADDI $1 $0 1WRITE $1 dataReadyEND
process(dataReady)READ $5 val6 SW $5 24($0) READ $5 val7 …ADDI $10 $0 0 ADDI $7 $0 0ADDI $13 $0 8 …END
UCR’s SystemC bytecode
UCR’s SystemC-to-
bytecode compiler
MIPS-like sequential instructions
Spatial Constructs

49/64Frank Vahid, UC Riverside
SystemC Bytecode for FPGAs
Demo
50/64Frank Vahid, UC Riverside
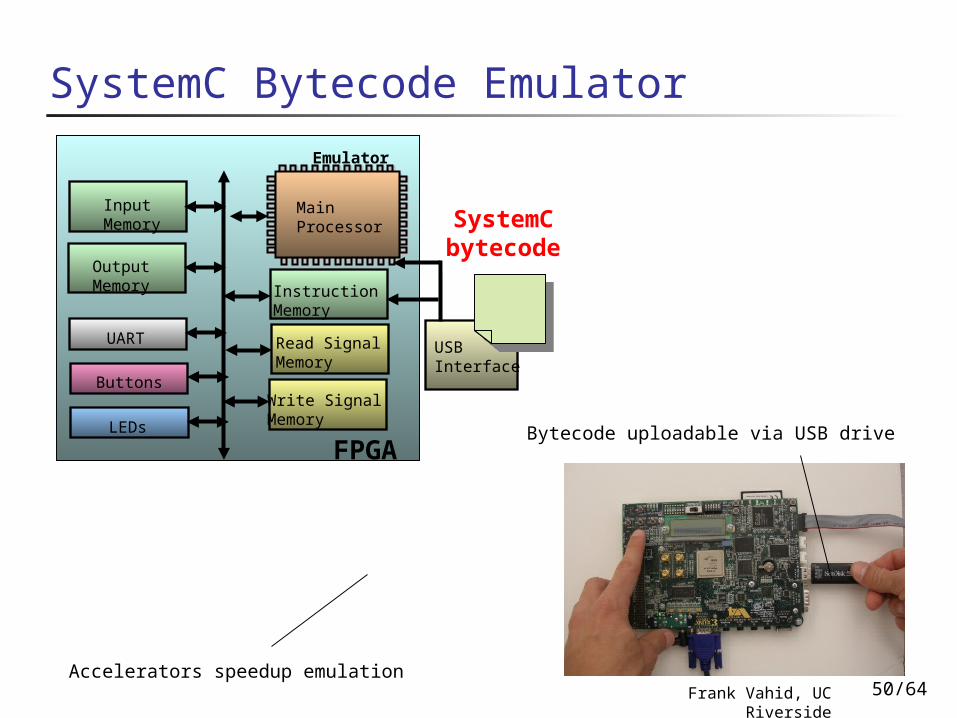
SystemC Bytecode Emulator
Emulator
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Main Processor
Instruction Memory
USB Interface
FPGABytecode uploadable via USB drive
Accelerators speedup emulation
SystemC bytecode
51/64Frank Vahid, UC Riverside
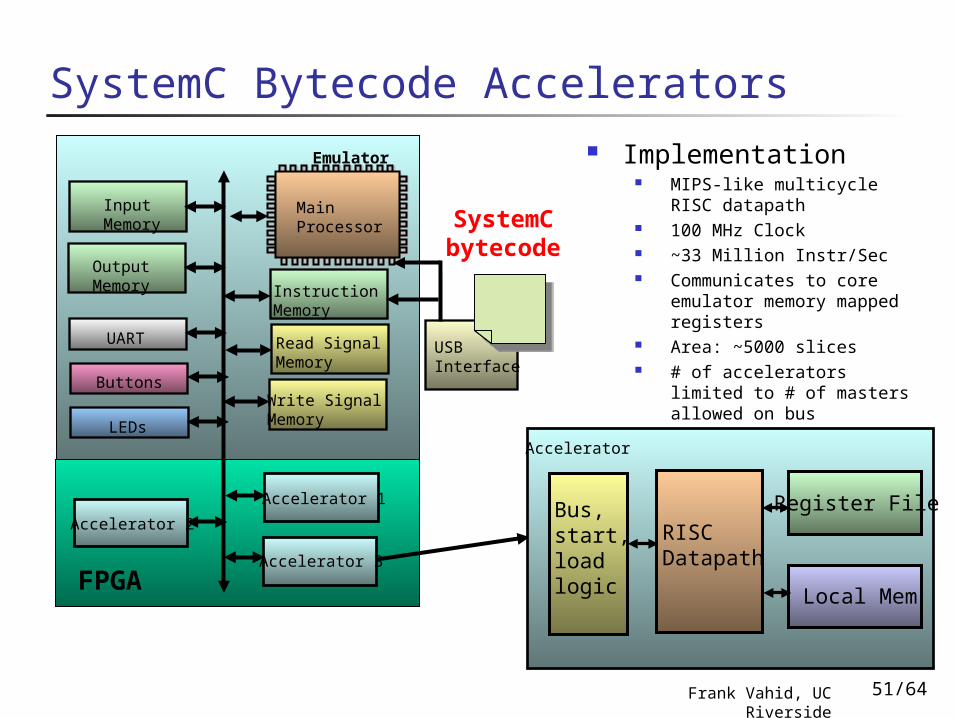
SystemC Bytecode Accelerators
Emulator
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Main Processor
Instruction Memory
USB Interface
Accelerator 1
Accelerator 2
Accelerator 3FPGA
SystemC bytecode
Implementation MIPS-like multicycle RISC
datapath 100 MHz Clock ~33 Million Instr/Sec Communicates to core
emulator memory mapped registers
Area: ~5000 slices # of accelerators limited to #
of masters allowed on bus ~1200 lines of VHDL
Accelerator
RISC Datapath
Register File
Local Mem
Bus, start,load logic
52/64Frank Vahid, UC Riverside
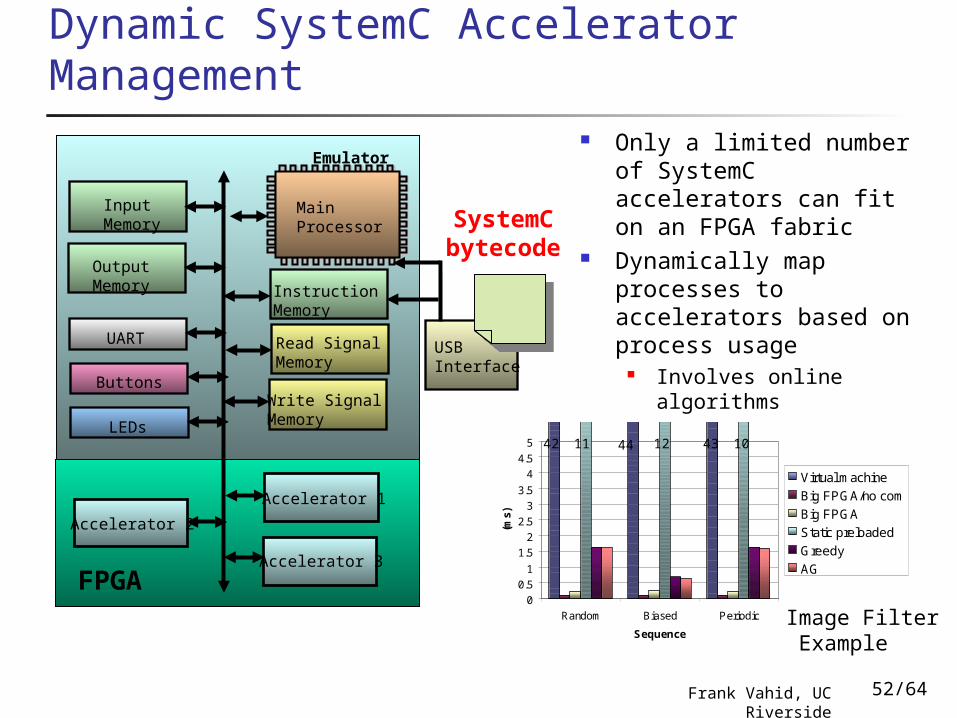
Dynamic SystemC Accelerator Management
Emulator
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Main Processor
Instruction Memory
USB Interface
Accelerator 1
Accelerator 2
Accelerator 3FPGA
SystemC bytecode
Only a limited number of SystemC accelerators can fit on an FPGA fabric
Dynamically map processes to accelerators based on process usage
Involves online algorithms
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Random Biased Periodic
Sequence
(ms
)
Virtual machine
Big FPGA/no com
Big FPGA
Static preloaded
Greedy
AG
42 44 4311 12 10
Image Filter Example
53/64Frank Vahid, UC Riverside
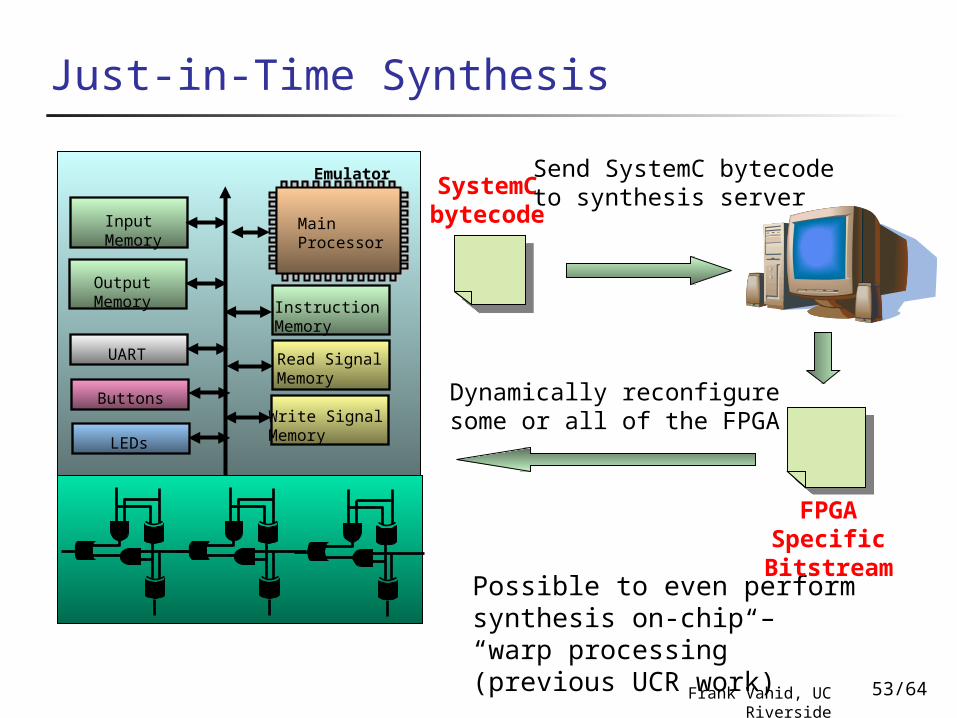
Just-in-Time Synthesis
Emulator
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Main Processor
Instruction Memory
Accelerator 1
Accelerator 2
Accelerator 3FPGA
SystemC bytecode
Possible to even perform synthesis on-chip – “warp processing” (previous UCR work)
Send SystemC bytecode to synthesis server
FPGA Specific Bitstream
Dynamically reconfiguresome or all of the FPGA

57/64Frank Vahid, UC Riverside
Transmuting Coprocessors
Demo

58/64Frank Vahid, UC Riverside
FPGA is a Size-Limited Coprocessing Resource
CP library
00010010100100100101
00010010100100100101
New FPGA binary
DOOM: 23secBlowfish: 6sec
DOOM: 23secBlowfish: 6sec
User app profile info
ServerUser device
Internet
μ P
FPGA
DMABus
I/O
Memory
A software updateA coprocessor update
CP selection
CP placement
FPGA implement
s coprocesso
rs
Upload app profile
infoSelect
coproc. set, generate new FPGA bitstream
Send back new
bitstream, re-program
FPGA
Speedup with
previous apps
App executions change. Must decide which coprocessors should be FPGA-resident at a given time – transmuting
coprocessors
59/64Frank Vahid, UC Riverside
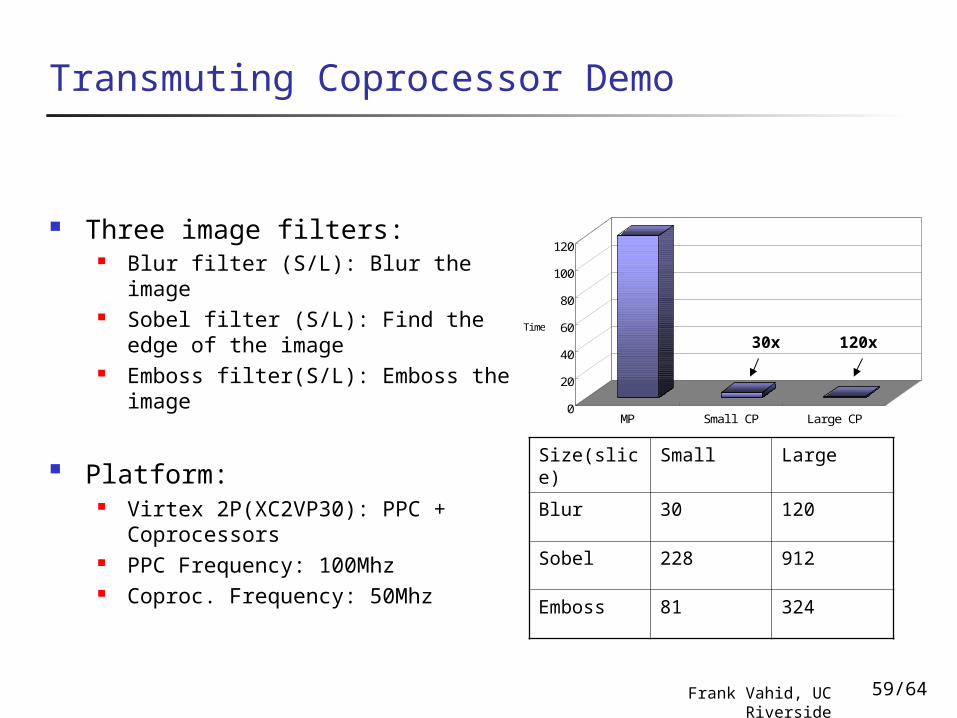
Transmuting Coprocessor Demo
Three image filters: Blur filter (S/L): Blur the image Sobel filter (S/L): Find the edge of
the image Emboss filter(S/L): Emboss the
image
Platform: Virtex 2P(XC2VP30): PPC +
Coprocessors PPC Frequency: 100Mhz Coproc. Frequency: 50Mhz
0
20
40
60
80
100
120
Ti me
MP Smal l CP Large CP
30x 120x
Size(slice) Small Large
Blur 30 120
Sobel 228 912
Emboss 81 324

60/64Frank Vahid, UC Riverside
Demo architecture
PPC Peripherals
InstructionBRAM
EDK
Interface to external
DisplayBRAM
ImageBRAM
Coproc
VGA control
VGA display
UART Push button
ISE
Image (128*128 pixels and 24bit color): 24 BRAMs
Soft version: Read (Image BRAM)Execution (PPC)Write (Display BRAM)
Coprocessor version: Read (Image BRAM)Execution(Coproc)Write (Display BRAM)
Dock: send the profile information through UART.
PLB

61/64Frank Vahid, UC Riverside
Coprocessor configurations
Microprocessor only Small blur+ small sobel Small blur + small emboss Small sobel + small emboss Large blur Large sobel Large emboss
Choose the configuration according to app profile info.
PPC Peripherals
Memory
Virtex2P
Coprocessor region
Blur (S)Sobel(S)
Blur (S)Emboss(s)
Sobel(s)Emboss(s)
Blur (L)Sobel (L)
Emboss(L)
63/64Frank Vahid, UC Riverside
µP
Cache
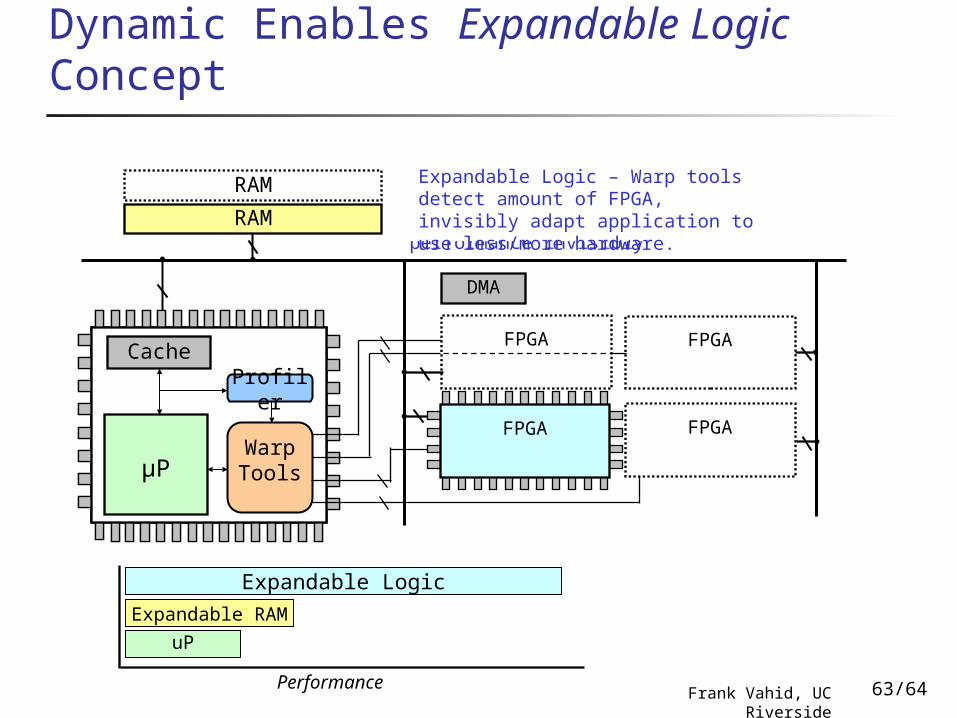
Dynamic Enables Expandable Logic Concept
RAM
Expandable RAM
uP
Performance
Profiler
µP
Cache
Warp Tools
DMA
FPGAFPGA
FPGA FPGA
RAM Expandable RAM – System detects RAM during start, improves performance invisibly
Expandable Logic – Warp tools detect amount of FPGA, invisibly adapt application to use less/more hardware.
Expandable Logic

64/64Frank Vahid, UC Riverside
Summary
FPGAs entering mainstream Portability of applications is important Dynamic binary translation to FPGAs – Warp
processing Shown feasible; Extensive future work
Trends towards FPGA ubiquity Microprocessor binaries need extensions for
spatial constructs One approach: SystemC bytecode and virtual
machine Can also be warped for circuit-speed
http://www.cs.ucr.edu/~vahid/pubs





























