Embed Size (px)
Citation preview

“KonspPreamb” 2013/10/3 page 1 #1
POLITECHNIKA WARSZAWSKA
Wydział Elektroniki i TechnikInformacyjnych
ROZPRAWA DOKTORSKA
mgr inż. Grzegorz Nieradka
Dopasowanie obrazów pary stereoskopowejz wykorzystaniem logiki rozmytej
Promotor
prof. dr hab. inż. Bohdan Butkiewicz
Warszawa, 2013

“KonspPreamb” 2013/10/3 page 2 #2
Streszczenie
Metody umożliwiające akwizycję i prezentację obrazów przestrzennych nabra-
ły bardzo dużego znaczenia w dziedzinie przetwarzania obrazów. Poszukiwane są
zarówno nowe rozwiązania, jak i udoskonalane są znane metody. Jedną z metod
umożliwiających akwizycję obrazów trójwymiarowych jest widzenie stereoskopo-
we.
Rozprawa poświęcona jest jednemu z głównych problemów widzenia stereo-
skopowego, jakim jest zagadnienie dopasowania pary obrazów stereoskopowych.
Problem ten jest jednym z najważniejszych problemów przetwarzania obrazów
przestrzennych, którego efektywne rozwiązanie umożliwia zastosowanie technik
widzenia stereoskopowego w praktyce. Pomimo jego bardzo dobrego rozpoznania
i zaproponowania bardzo wielu rozwiązań, pozostaje ciągle problemem nierozwią-
zanym w zadowalającym stopniu.
W pracy opracowane zostały metody służące do dopasowania obrazów pary ste-
reoskopowej z wykorzystaniem elementów teorii zbiorów rozmytych. Wykorzysta-
nie zbiorów rozmytych wpisuje się w trend badawczy polegający na poszukiwaniu
nowych dróg rozwiązania.
Przedstawione metody oraz wyniki badań eksperymentalnych pozwalają stwier-
dzić, że zastosowanie teorii zbiorów rozmytych pozwala na uzyskanie nie gorszych,
a w niektórych przypadkach lepszych wyników, niż uzyskiwane z wykorzystaniem
metod i algorytmów znanych z literatury.
2

“KonspPreamb” 2013/10/3 page 3 #3
Abstract
Methods making possible an acquisition and presentation of spatial images have
become of very high importance in the field of image processing. There are many
scientific workers doing an extensive research for finding new solutions, as well as
improving known methods. One method enabling acquisition of three–dimensional
images is so called stereoscopic vision.
This doctoral thesis pertains to one of stereoscopic vision’s major problems,
which is matching the pair of stereoscopic images. The matching problem is one
of the most important questions because its effective solution enables the use of
stereoscopic vision techniques in practice. Despite the fact that it is a well known
problem, and there are many different propositions on how it could be solved, the
issue still remains unsolved to a satisfactory level for use in the real applications.
In this thesis, novel methods using some elements from the fuzzy set theory
for the matching the pair of stereoscopic images have been developed. Using the
fuzzy set theory is a part of a research trend which consists in finding new ways of
solution.
The presented methods and experimental results should conclude that in some
cases the application of fuzzy set theory allows to accomplish better results than
obtained with the use of methods and algorithms known from the specialist litera-
ture.
3

“KonspPreamb” 2013/10/3 page 1 #4
Spis treści
Wykaz oznaczeń . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Wykaz akronimów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1. Wprowadzenie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.1. Uwagi o terminologii przyjętej w pracy . . . . . . . . . . . . . . . . . . 18
1.1.1. Uwagi o nazewnictwie dotyczącym przetwarzania obrazów . . . 18
1.1.2. Uwagi o nazewnictwie dotyczącym teorii zbiorów rozmytych . . 21
1.2. Teza i cel pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.3. Główne rezultaty pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.4. Układ pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2. Zagadnienie widzenia stereoskopowego . . . . . . . . . . . . . . . . . . . . 26
2.1. Maszynowe widzenie stereoskopowe . . . . . . . . . . . . . . . . . . . . 26
2.2. Podstawy geometrii układu stereoskopowego . . . . . . . . . . . . . . . 29
2.2.1. Model kamery perspektywicznej . . . . . . . . . . . . . . . . . 30
2.3. Geometria układu dwóch kamer . . . . . . . . . . . . . . . . . . . . . . 34
2.4. Dysparycja w obrazach pary stereoskopowej . . . . . . . . . . . . . . . 37
2.4.1. Rektyfikacja obrazów pary stereoskopowej . . . . . . . . . . . . 39
2.5. Problemy występujące przy projektowaniu algorytmów dopasowania
pary stereoskopowej . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2.6. Założenia procesu dopasowania par stereoskopowych . . . . . . . . . . . 46
3. Przegląd metod dopasowania obrazów pary stereoskopowej . . . . . . . . . 49
3.1. Próba klasyfikacji metod dopasowania obrazów pary stereoskopowej . . . 49
3.2. Metody globalne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.2.1. Metoda minimalnego rozcięcia grafu . . . . . . . . . . . . . . . 53
3.2.2. Zastosowanie metody minimalnego rozcięcia grafu
w zagadnieniu dopasowania pary stereoskopowej . . . . . . . . . 55
3.2.3. Dopasownie obrazów pary stereoskopowej za pomocą
programowania dynamicznego . . . . . . . . . . . . . . . . . . 58
3.3. Metody dopasowania obszarami . . . . . . . . . . . . . . . . . . . . . . 61
3.3.1. Algorytm metody dopasowania obszarami . . . . . . . . . . . . 62
3.3.2. Miary wykorzystywane w algorytmach dopasowania obszarami . 63
3.3.3. Dopasowanie w dziedzinie transformat . . . . . . . . . . . . . . 70
3.3.4. Transformata rankingowa . . . . . . . . . . . . . . . . . . . . . 75
1

“KonspPreamb” 2013/10/3 page 2 #5
Spis treści
3.3.5. Transformata CENSUS . . . . . . . . . . . . . . . . . . . . . . 76
3.4. Metody dopasowania cech obrazów . . . . . . . . . . . . . . . . . . . . 77
3.4.1. Algorytm Marra-Poggio-Grimsona . . . . . . . . . . . . . . . . 79
3.5. Wykorzystanie obrazów kolorowych w dopasowaniu obrazów . . . . . . 83
3.6. Inne metody dopasowania pary stereoskopowej . . . . . . . . . . . . . . 85
4. Elementy teorii zbiorów rozmytych . . . . . . . . . . . . . . . . . . . . . . . 88
4.1. Podstawy teorii zbiorów rozmytych . . . . . . . . . . . . . . . . . . . . 88
4.1.1. Pojęcie zbioru . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
4.1.2. Zbiór rozmyty i funkcja przynależności . . . . . . . . . . . . . . 90
4.1.3. Przykłady funkcji przynależności . . . . . . . . . . . . . . . . . 91
4.2. Miary rozmytości . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
4.2.1. Całkowita entropia rozmyta . . . . . . . . . . . . . . . . . . . . 97
4.2.2. Indeks rozmytości . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.3. Odległość zbiorów rozmytych . . . . . . . . . . . . . . . . . . . . . . . 100
4.4. Korelacja zbiorów rozmytych . . . . . . . . . . . . . . . . . . . . . . . 102
4.5. Relacje rozmyte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
4.5.1. Rozmyta relacja podobieństwa . . . . . . . . . . . . . . . . . . 103
4.6. Teoria intuicjonistycznych zbiorów rozmytych . . . . . . . . . . . . . . . 105
4.7. Miary podobieństwa intuicjonistycznych zbiorów rozmytych . . . . . . . 107
4.7.1. Odległość intuicjonistycznych zbiorów rozmytych . . . . . . . . 107
4.7.2. Korelacja intuicjonistycznych zbiorów rozmytych . . . . . . . . 108
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania pary
stereoskopowej obrazów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
5.1. Wykorzystanie zbiorów rozmytych w zagadnieniach przetwarzania obrazów111
5.2. Przetwarzanie obrazów z wykorzystaniem fuzzyfikacji obrazu . . . . . . 112
5.2.1. Metody fuzzyfikacji wykorzystywane w przetwarzaniu obrazów . 113
5.3. Zastosowanie zbiorów rozmytych w problemie dopasowania pary
stereoskopowej . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
5.3.1. Zastosowanie zbiorów rozmytych w algorytmach dopasowania
obszarami . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
5.3.2. Teoria zbiorów rozmytych w algorytmach dopasowania cechami 120
5.4. Proponowany algorytm znajdowania funkcji przynależności . . . . . . . 121
5.4.1. Wybór kształtu funkcji przynależności . . . . . . . . . . . . . . 122
5.4.2. Indeks rozmytości określony dla obrazu . . . . . . . . . . . . . 124
5.4.3. Zagadnienie optymalizacyjne . . . . . . . . . . . . . . . . . . . 125
5.4.4. Przykłady wyznaczonych funkcji przynależności . . . . . . . . . 128
2

“KonspPreamb” 2013/10/3 page 3 #6
Spis treści
5.5. Dopasowanie obrazów pary stereoskopowej w dziedzinie zbiorów
rozmytych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
5.6. Przetwarzanie obrazów opisanych w dziedzinie intuicjonistycznych
zbiorów rozmytych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
5.6.1. Określanie indeksu zaufania . . . . . . . . . . . . . . . . . . . . 132
5.6.2. Znajdowanie wartości funkcji nieprzynależności . . . . . . . . . 135
5.6.3. Przykłady wyznaczonych funkcji umożliwiających opis obrazu
w dziedzinie intuicjonistycznych zbiorów rozmytych . . . . . . . 136
5.6.4. Dopasowanie obrazów pary stereoskopowej w dziedzinie
intuicjonistycznych zbiorów rozmytych . . . . . . . . . . . . . . 137
5.7. Detekcja krawędzi w obrazie w oparciu o teorię zbiorów rozmytych . . . 139
5.8. Detekcja krawędzi w oparciu o rozmytą relację podobieństwa . . . . . . 141
5.8.1. Przykłady obrazów krawędziowych otrzymanych w efekcie
działania rozmytego detektora krawędzi . . . . . . . . . . . . . 144
5.8.2. Wykrywanie pikseli charakterystycznych w obrazach
krawędziowych . . . . . . . . . . . . . . . . . . . . . . . . . . 146
5.8.3. Algorytm dopasowania pikseli charakterystycznych w obrazach
krawędziowych . . . . . . . . . . . . . . . . . . . . . . . . . . 148
5.9. Dopasowanie obrazów pary steroskopowej w oparciu o rozmytą
transformatę rankingową . . . . . . . . . . . . . . . . . . . . . . . . . . 150
6. Kryteria i metody oceny działania algorytmów . . . . . . . . . . . . . . . . 155
6.1. Metody oceny i porównania algorytmów . . . . . . . . . . . . . . . . . 155
6.2. Algorytmy dopasowania w obecności zakłóceń obecnych w obrazach . . 162
6.3. Wzorcowe pary stereoskopowe . . . . . . . . . . . . . . . . . . . . . . . 163
6.3.1. Para stereoskopowa „Tsukuba” . . . . . . . . . . . . . . . . . . 164
6.3.2. Para stereoskopowa „Venus” . . . . . . . . . . . . . . . . . . . . 166
6.3.3. Para stereoskopowa „Cones” . . . . . . . . . . . . . . . . . . . 167
6.3.4. Para stereoskopowa „Teddy” . . . . . . . . . . . . . . . . . . . 168
6.4. Charakterystyka zakłóceń szumowych . . . . . . . . . . . . . . . . . . . 170
6.4.1. Podstawowe modele szumu . . . . . . . . . . . . . . . . . . . . 170
6.4.2. Miary szumu zawartego w obrazie . . . . . . . . . . . . . . . . 172
6.4.3. Szum addytywny o rozkładzie normalnym . . . . . . . . . . . . 173
6.4.4. Szum addytywny o rozkładzie jednostajnym . . . . . . . . . . . 175
6.4.5. Szum multiplikatywny . . . . . . . . . . . . . . . . . . . . . . . 176
6.4.6. Szum impulsowy typu „sól i pieprz” . . . . . . . . . . . . . . . 178
6.5. Miary oceny jakości rozwiązań . . . . . . . . . . . . . . . . . . . . . . 180
6.5.1. Ocena efektywności algorytmów dopasowania cechami . . . . . 181
6.5.2. Ocena efektywności algorytmów dopasowania obszarami . . . . 182
3

“KonspPreamb” 2013/10/3 page 4 #7
Spis treści
7. Wyniki badań eksperymentalnych . . . . . . . . . . . . . . . . . . . . . . . 185
7.1. Założenia oceny efektywności działania algorytmów dopasowania pary
stereoskopowej . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
7.2. Podstawowe parametry działania algorytmów dopasowania cechami . . . 187
7.3. Rozmiar okien w algorytmach dopasowania obszarami . . . . . . . . . . 190
7.4. Wyniki działania algorytmów w przypadku obrazów zakłóconych
szumem gaussowskim . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
7.4.1. Wyniki działania algorytmów dopasowania cechami . . . . . . . 202
7.4.2. Wyniki działania algorytmów dopasowania obszarami . . . . . . 204
7.5. Wyniki działania algorytmów w przypadku obrazów zakłóconych
szumem addytywnym o rozkładzie jednostajnym lub szumem
multiplikatywnym . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207
7.5.1. Wyniki działania algorytmów dopasowania cechami . . . . . . . 207
7.5.2. Wyniki działania algorytmów dopasowania obszarami . . . . . . 209
7.6. Wyniki działania algorytmów w przypadku obrazów zakłóconych
szumem impulsowym typu „sól i pieprz” . . . . . . . . . . . . . . . . . 211
7.6.1. Wyniki działania algorytmów dopasowania cechami . . . . . . . 212
7.6.2. Wyniki działania algorytmów dopasowania obszarami . . . . . . 213
7.7. Wnioski . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
8. Zakończenie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220
8.1. Komentarz uzyskanych rezultatów . . . . . . . . . . . . . . . . . . . . . 221
8.2. Perspektywy dalszego rozwoju . . . . . . . . . . . . . . . . . . . . . . . 222
Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224
4

“KonspPreamb” 2013/10/3 page 5 #8
Wykaz oznaczeń
d – mapa dysparycji
dopt – optymalna mapa dysparycji
F – macierz fundamentalna
g – histogram obrazu
g – unormowany histogram obrazu
gF – rozmyty histogram obrazu
gF – unormowany histogram rozmyty
H1,H2 – macierz określająca homograficzne przekształcenia obrazu w al-
gorytmie rektyfikacji
Pc – wektor wyznaczający położenie punktu P w układzie współ-
rzędnych kamery
Pw – wektor wyznaczający położenie punktu P w zewnętrznym ukła-
dzie współrzędnych
R – macierz rotacji
t – wektor translacji
α – nośnik liczby rozmytej
βR – parametr rozmytej transformaty rankingowej
χZ – funkcja charakterystyczna
∆Ip – znormalizowany zakres dynamiczny jasności w obrazie
ǫ – przekształcenie określające miarę rozmytości
η – metryka odległości zbiorów rozmytych
ηFH
– odległość Hamminga zbiorów rozmytych
ηFH
– unormowana odległość Hamminga zbiorów rozmytych
ηIFSH
– odległość Hamminga zbiorów IFS
ηIFSH
– unormowana odległość Hamminga zbiorów IFS
ηFE
– odległość euklidesowa zbiorów rozmytych
ηFE – unormowana odległość euklidesowa zbiorów rozmytych
ηIFSE
– odległość euklidesowa zbiorów IFS
ηIFSH
– unormowana odległość euklidesowa zbiorów IFS
5

“KonspPreamb” 2013/10/3 page 6 #9
Wykaz oznaczeń
ζG – odpowiedź rozmytego detektora krawędzi wykorzystującego gaus-
sowską relację rozmytą
ζT – odpowiedź rozmytego detektora krawędzi wykorzystującego trój-
kątną relację rozmytą
γ – indeks rozmytości
γK – kwadratowy indeks rozmytości
γL – liniowy indeks rozmytości
λ – stała o ustalonej wartości
µAF – funkcja przynależności zbioru rozmytego
µAF – funkcja przynależności dopełnienia zbioru rozmytego
µAF – średnia wartość funkcji przynależności zbioru rozmytegoAF
µAIFS – funkcja przynależności intuicjonistycznego zbioru rozmytego
µAIFS – średnia wartość funkcji przynależności zbioru IFS
µΩ – funkcja przynależności relacji rozmytej
µΩG– funkcja przynależności gaussowskiej relacji rozmytej
µΩT– funkcja przynależności trójkątnej relacji podobieństwa
µ – funkcja przynależności trójkątnej liczby rozmytej
νAIFS – funkcja nieprzynależności intuicjonistycznego zbioru rozmyte-
go
νAIFS – średnia wartość funkcji nieprzynależności zbioru IFS
Ω – rozmyta relacja dwuargumentowa
Ωp – rozmyta relacja podobieństwa
Ψ,Ψ1,Ψ2 – płaszczyzna tworzenia obrazu
φre f , φsz – widmo fazowe Fouriera
πAIFS – indeks zaufania IFS
ψ (x) – funkcja macierzysta transformaty falkowej
ψp, ψm – płaszczyna epipolarna
ρAF,BF – współczynnik korelacji zbiorów rozmytych
ρIFS – współczynnik korelacji zbiorów IFS
ρIFSµAIFS ,µBIFS
– współczynnik korelacji funkcji przynależności zbiorów IFS
ρIFSνAIFS ,νBIFS
– współczynnik korelacji funkcji nieprzynależności zbiorów IFS
σAF – wariancja wartości funkcji przynależności zbioru rozmytegoAF
σG – parametr gaussowskiej relacji podobieństwa
σT – parametr trójkątnej rozmytej relacji podobieństwa
6

“KonspPreamb” 2013/10/3 page 7 #10
Wykaz oznaczeń
τ – parametr przesunięcia transformaty falkowej
ξ – funkcja porównania w transformacie CENSUS
AF – zbiór rozmyty
AFC – najbliższy zbiór zwykły do zbioru rozmytego
AIFS – intuicjonistyczny zbiór rozmyty
C (S,T ) – rozcięcie grafu
E – zbiór krawędzi grafu GG – graf skierowany
L – zbiór etykiet
N – zbiór n-krawędzi grafu
P – zbiór niewyróżnionych wierzchołków grafu
P2 – rzutnia – dwuwymiarowa płaszczyzna rzutu
P3 – trójwymiarowa przestrzeń rzutowa
P (X) – zbiór potęgowy przestrzeni X
R – relacja incydencji grafu GS,T – podzbiory wierzchołków grafu
V – zbiór wierzchołków grafu GW – właściwość spełniana przez elementy zbioru
Z – zbiór
A, B – zmienna losowa
aS, bS, cS – parametry S-funkcji
b – linia bazowa w stereoskopowym układzie kamer
d (·, ·) – miara odległości
d – dysparycja
dmax – maksymalna wartość poszukiwanej dysparycji
dmin – minimalna wartość poszukiwanej dysparycji
dp – dysparycja piksela p
dq – miara Minkowskiego
dxy – dysparycja odległościowa
dy – dysparycja wertykalna
E (d) – funkcja kosztu globalnej metody dopasowania
Ed (d) – składowa funkcji kary globalnej metody dopasowania
Es (d) – składowa funkcji kosztu metodach w globalnych
7

“KonspPreamb” 2013/10/3 page 8 #11
Wykaz oznaczeń
e1, e2 – punkt epipolarny
f – ogniskowa kamery
H – miara entropii Shannona
h – połowa długości linii bazowej kamer
H (A) – entropia własna zmiennej losowej A
H (A, B) – entropia łączna zmiennych losowych A i B
H (B) – entropia własna zmiennej losowej B
Hc – całkowita miara entropijna
Ii j – jasność piksela położonego na pozycji (i, j)
Imin – minimalny poziom jasności (szarości) w obrazie
Ip – poziom jasności (szarości) piksela p
Imax – maksymalny poziom jasności (szarości) piksela p
K – składowa funkcji kosztu w metodach globalnych
L (X) – rodzina podzbiorów rozmytych
m1,m2 – rzut punktu M na płaszczyznę obrazową
N (p) – sąsiedztwo piksela p
na – addytywna składowa szumowa
Nh – horyzontalny rozmiar okna
nm – multiplikatywna składowa szumowa
Np – liczba pikseli zawartych w oknie
Nv – wertykalny rozmiar okna
Nw – rozmiar kwadratowego okna
o – punkt główny kamery
O1,O2 – punkt ogniskowy kamery
Oi – początek układu współrzędnych pikselowych obrazu
O1P, O1M – promień optyczny
O2P, O2M – promień optyczny
Oc – punkt ogniskowy (centralny) przekształcenia rzutowego
Ow – punkt początkowy zewnętrznego układu współrzędnych
ox, oy – współrzędne punktu głównego kamery
p – obraz punktu przestrzeni
p – piksel obrazu
P,M – punkt w przestrzeni trójwymiarowej
lp1 , lp2 , lm1 , lm2 – linia epipolarna
8

“KonspPreamb” 2013/10/3 page 9 #12
Wykaz oznaczeń
p1, p2 – rzut punktu P na płaszczyznę obrazową
pi – prawdopodobieństwa zajścia zdarzenia
pi, j – piksel położony na pozycji (i, j)
rs – rozmiar sąsiedztwa
RF – rozmyta transformata rankingowa określona w dziedzinie zbio-
rów rozmytych
RFI
– rozmyta transformata rankingowa określona w dziedzinie jasno-
ści
R – wartość transformaty rankingowej
s – parametr skali transformaty falkowej
s – źródło grafu
S(
µiAF
)
– niepewność określenia przynależności zdarzenia do zbioru roz-
mytego
S – wartość średnia określenia przynależności zdarzeń do zbioru
rozmytego
sx, sy – fizyczne rozmiary piksela
T – zbiór zdarzeń losowych
t – ujście grafu
Tc – wynik działania transformaty CENSUS
TSAD – ustalona wartość progowa
u1, v1 – współrzędne obrazu punktu
u2, v2 – współrzędne obrazu punktu
u, v,w – współrzędne punktu w obrazie wyrażone w układzie współrzęd-
nych kamery
Vp,q – składowa funkcji kosztu w metodach globalnych
W – okno; wyróżniony zbiór pikseli w obrazie
wLoG – rozmiar maski filtru LoG
Wre f – okno referencyjne
Wsz – okno przeszukiwania
xw, yw, zw – współrzędne punktu w przestrzeni wyrażone w zewnętrznym
układzie współrzędnych
xi, yi – oś układu współrzędnych pikselowych
Xre f , Xsz – wynik transformaty Fouriera
|Xre f |, |Xsz | – widmo amplitudowe Fouriera
9

“KonspPreamb” 2013/10/3 page 10 #13
Wykaz oznaczeń
z1, z2, . . ., zn – elementy należące do zbioruZ
R – zbiór liczb rzeczywistych
||C|| – moc zbioru C
Z – zbiór liczb całkowitych
I – obraz
Ire f – obraz referencyjny pary stereoskopowej
Isz – obraz przeszukiwania pary stereoskopowej
ICH – obraz krawędziowych pikseli charakterystycznych
IK – obraz krawędziowy
∇ – operator Laplasjanu
⊙ – operacja algebraiczna np. dodawanie
⊗ – konkatenacja
∝ – proporcjonalność
– liczba rozmyta
X – przestrzeń; ogół rozważanych przedmiotów
10

“KonspPreamb” 2013/10/3 page 11 #14
Wykaz akronimów
AC1C2 – model Meyera przestrzeni kolorów
CC (ang. Cross Correlation) – korelacja wzajemna
CCD (ang. Charge Coupled Device) – monolityczny przetwornik obrazowy ze
sprzężeniem ładunkowym
CIE LAB – model przestrzeni kolorów przyjęty przez Międzynarodową Komisję
Oświetleniową (CIE)
CIE LUV – model przestrzeni kolorów przyjęty przez Międzynarodową Komisję
Oświetleniową CIE
CIE XYZ – model przestrzeni kolorów przyjęty przez Międzynarodową Komisję
Oświetleniową (CIE)
CWT (ang. Continuous Wavelet Transform) – ciągła transformata falkowa
DWT (ang. Discrete Wavelet Transform) – dyskretna transformata falkowa
EEG – elektroencefalografia
EKG – elektrokardiografia
FCM (ang. Fuzzy c-Means) – rozmyty algorym analizy skupień c-średnich
FFT (ang. Fast Fourier Transform) – algorytm obliczania szybkiej transforma-
ty Fouriera
FPGA (ang. Field Programmable Gate Array) – bezpośrednio programowalna
macierz bramek logicznych
H1H2H3 – model Braquelaire’a przestrzeni kolorów
HSL (ang. Hue Saturation Lightness) – model opisu przestrzeni barw, opisy-
wanej przez podanie trzech parametrów: H – częstotliwości fali światła, S –
nasycenia barwy, L – poziomu światła białego
HSV (ang. Hue Saturation Value) – model opisu przestrzeni barw, opisywanej
przez podanie trzech parametrów: H – częstotliwości fali światła, S – nasycenia
barwy, V – moc światła białego
I1I2I3 – model Ohty przestrzeni kolorów
11

“KonspPreamb” 2013/10/3 page 12 #15
Wykaz akronimów
IDWT (ang. Inverse Discrete Wavelet Transform) – odwrotna dyskretna trans-
format falkowa
IFS (ang. Intuitionistic Fuzzy Set) – intuicjonistyczny zbiór rozmyty
LoG (ang. Laplacian of Gaussian) – rodzaj filtru stosowanego w przetwarza-
niu obrazów
LSAD (ang. Locally Scaled Sum of Absolute Differences) – lokalnie skalowana
suma wartości bezwzględnych różnic
LSSD (ang. Locally Scaled Sum of Squared Differences) – lokalnie skalowana
suma kwadratów różnic
MCC (ang. Moravec Cross Correlation) – korelacja wzajemna Moraveca
MI (ang. Mutual Information) – informacja wzajemna
MPG (ang. Marr–Poggio–Grimson) – nazwa algorytmu umożliwiającego ob-
liczenie rzadkiej mapy dysparycji
MRA (ang. Multi resolution Analysis) – analiza wielorozdzielcza
MSE (ang. Mean Squared Error) – błąd średniokwadratowy
NCC (ang. Normalized Cross Correlation) – znormalizowana korelacja wzajem-
na
NMI (ang. Normalized Mutual Information) – znormalizowana informacja wza-
jemna
PSO (ang. Particle Swarm Optimization) – algorytm optymalizacji rojem czą-
stek
RGB (ang. Red Green Blue) – model przestrzeni barw, opisywany przez poda-
nie zawartości trzech kolorów podstawowych: R – czerwonego, G – zielonego,
B – niebieskiego
RMSE (ang. Root Mean Squared Error) – błąd średniokwadratowy
ROC (ang. Receiver Operating Characteristic) – krzywa charakterystyki opera-
cyjnej odbiornika
SAD (ang. Sum of Absolute Differences) – suma wartości bezwzględnych róż-
nic
SAR (ang.Synthetic Aperture Radar) – radar z syntetyczną aperturą
SNR (ang. Signal to Noise Ratio) – stosunek sygnału do szumu
12

“KonspPreamb” 2013/10/3 page 13 #16
Wykaz akronimów
SSD (ang. Sum of Squared Differences) – suma kwadratów różnic
SUSAN (ang. Smallest Univalue Segment Assimilating Nucleus) – najmniejszy
segment w obrazie wykazujący się jednorodnością wartości
TSAD (ang. Truncated Sum of Absolute Differences) – ucięta suma wartości bez-
względnych różnic
USG – ultrasonografia
YC1C2 – model przestrzeni kolorów przyjęty przez firmę Kodak
ZNCC (ang. Zero mean Normalized Cross–Correlation) – centralnie znormali-
zowana korelacja wzajemna
ZSAD (ang. Zero mean Sum of Absolute Differences) – centralnie znormalizo-
wana suma wartości bezwzględnych różnic
ZSSD (ang. Zero mean Sum of Squared Differences) – centralnie znormalizowa-
na suma kwadratów różnic
13

“KonspPreamb” 2013/10/3 page 14 #17
Rozdział 1
Wprowadzenie
System wzrokowy człowieka dostarcza mu ciągły potok informacji o otaczają-
cym go świecie. Widzenie i późniejsze przetwarzanie informacji obrazowej odbywa
się praktycznie w każdej chwili, podczas pracy, odpoczynku, a również nieświa-
domie w czasie snu. Procesy pozyskiwania, przetwarzania i interpretacji obrazów
przez człowieka odbywają się bez wkładania w nie świadomego wysiłku.
Postrzegane obrazy niosą ze sobą bardzo wiele różnorodnych informacji. Pierw-
szą warstwą informacji dostarczanej przez obrazy jest ich ogólne znacznie. Obrazy
mogą być wykorzystywane w celach:
dokumentacyjnych, np. zdjęcia z wakacji lub przyjęć rodzinnych,
medycznych, np. zdjęcia tomografii komputerowej lub przebiegi EKG, EEG,
naukowych, np. zdjęcia z teleskopów astronomicznych lub sond kosmicznych,
strategiczno-obronnych, np. zdjęcia z satelitarne lub radarowe,
estetycznych, np. malarstwo i grafika,
biznesowych, np. wykresy zmian walut lub wykresy giełdowej analizy techni-
cznej.
W każdym widzianym obrazie, oprócz głównej treści znaczeniowej, znajdu-
je się wiele elementów, które człowiek rozpoznaje i klasyfikuje w automatyczny,
zazwyczaj zupełnie nieświadomy sposób. Wśród elementów składających się na
widziany obraz, które człowiek dostrzega i rozpoznaje, można wymienić:
jasność: jasny, ciemny, kontur: linia, kąt,
barwa: biały, czarny, kształt: koło, kwadrat,
obiekt: człowiek, samochód, materiał: metal, drewno,
ruch: spada, wznosi się, ilość: dużo, mało,
treść napisów informacyjnych: apteka, bank, odległość: daleko, blisko,
wrażenie estetyczne: ładne, brzydkie, symbol znaczeniowy:
znak drogowy. lokalizacja w przestrzeni: pod, nad, obok, za,
Ze względu na ilość dostarczanej i pozyskiwanej informacji w procesie widze-
nia przez człowieka sposoby symulacji tego procesu stały się bardzo ważną i sze-
14

“KonspPreamb” 2013/10/3 page 15 #18
1. Wprowadzenie
roką dziedziną badań naukowych. Wraz z rozwojem techniki obliczeniowej oraz
technik akwizycji obrazów następuje coraz szybszy rozwój algorytmów umożli-
wiających komputerową analizę obrazu w celu pozyskania i wykorzystania zawartej
w nich informacji.
Analiza i synteza informacji obrazowej stanowi w chwili obecnej rozległą dzie-
dzinę nauki. Można w niej wyróżnić kilka, zazwyczaj zazębiających się, odrębnych
gałęzi. Wszystkie z nich są silnie związane z szeroko rozumianym przetwarzaniem
obrazów. Do najważniejszych należą:
Widzenie maszynowe lub widzenie komputerowe którego celem jest wykre-
owanie modelu świata rzeczywistego z obrazów. System widzenia maszynowego
jest system odtwarzającym użyteczną informację o scenie z jej dwuwymiarowych
projekcji. Zazwyczaj głównym celem tej gałęzi badań są możliwości uzyskania in-
formacji przestrzennej;
Przetwarzanie obrazów jest zbiorem technik umożliwiających przekształcenie
jednego obrazu w inny zmieniony obraz. Z reguły technik tych nie stosuje się do
wydobycia informacji obrazowej, pozostawiając to jako osobne zadanie dla użyt-
kownika. W obszarze tym można wymienić zagadnienia poprawy jakości obrazu,
np. poprzez jego filtrację, detekcję miejsc charakterystycznych, jak krawędzie czy
narożniki, metody kompresji obrazu pozwalające na efektywne magazynowanie
i przesyłanie obrazów, czy też korekcję zniekształceń;
Rozpoznawanie wzorców stanowią metody zajmujące się klasyfikacją danych
numerycznych i symbolicznych. W przypadku przetwarzania danych obrazowych
najczęściej spotykanym zagadnieniem jest automatyczne rozpoznawanie obiektów
na obrazie. Zagadnienie to często występuje w praktyce w systemach przemysło-
wych, gdzie obiekt należy rozpoznać i zaklasyfikować jako wadliwy lub prawidło-
wy. Z technik umożliwiających rozpoznawanie wzorców korzystają również roz-
wiązania umożliwiające detekcję i śledzenie określonych obiektów;
Grafika komputerowa obejmuje techniki służące do generowania obrazów z pod-
stawowych elementów, takich jak linie, koła lub powierzchnie. Grafika komputero-
wa odgrywa bardzo znaczącą rolę w wizualizacji i kreowaniu rzeczywistości roz-
szerzonej i wirtualnej. W ostatnich latach często zazębia się z technikami widzenia
maszynowego;
Rozumienie obrazów jest zbiorem technik opartych na symbolicznym trak-
15

“KonspPreamb” 2013/10/3 page 16 #19
1. Wprowadzenie
towaniu informacji obrazowej, wykorzystujących zazwyczaj informację uzyskaną
w procesie przetwarzania obrazów.
Jedną z cech budowy ludzkiego systemu wzrokowego jest umiejętność postrze-
gania świata w sposób trójwymiarowy. W obecnej chwili możliwość symulacji tej
umiejętności przez sztuczne systemy wizyjne jest jednym z bardzo intensywnie ba-
danych zagadnień leżących w obszarze szeroko rozumianego cyfrowego przetwa-
rzaniu obrazów. Jedną z metod pozwalających na uzyskanie efektu widzenia trój-
wymiarowego wzorującą się na ludzkim systemie wzrokowym jest widzenie stereo-
skopowe. Technika ta wykorzystuje znajomość budowy ludzkiego układu wzroko-
wego. Gałki oczne zastępowane są kamerami, natomiast rolę mózgu ma spełniać
program komputerowy. Idea ta została zilustrowana na rys. 1.1. W ludzkim układzie
Rys. 1.1. Ludzkie postrzeganie stereoskopowe oraz jego maszynowa imitacja.
wzrokowym następuje fuzja dwóch niezależnie uzyskiwanych obrazów w jeden ob-
raz z zawartą w nim informacją przestrzenną. Nie jest to jedyna cecha ludzkiego
mózgu związana z procesem widzenia, która stała się przedmiotem badań. Wśród
innych cech, które próbuje się imitować w maszynowych systemach wizyjnych,
można wymienić np. interpretację widzianego obrazu oraz wykorzystanie rezulta-
tów tej intepretacji do określonego celu.
16

“KonspPreamb” 2013/10/3 page 17 #20
1. Wprowadzenie
Przedmiotem badań stały się również możliwości ludzkiego mózgu w sferze
podejmowania decyzji, umiejętności posługiwania się informacją oraz wyciągania
wniosków. Powstała gałąź nauki, nazywana sztuczną inteligencją, której celem jest
opracowanie metod umożliwiających symulację podobnych zdolności przez sys-
temy komputerowe. Narzędziami sztucznej inteligencji są algorytmy ewolucyjne,
sieci neuronowe wzorujące się wprost na działaniu ludzkiego mózgu, teoria zbio-
rów przybliżonych (ang. rough sets), teoria zbiorów rozmytych (ang. fuzzy sets)
oraz ogólnie pojęte metody inspirowane przyrodą, jak np. algorytmy mrówkowe
lub algorytmy oparte o inteligencję roju. Popularność zyskują również rowiązania
hybrydowe łączące te narzędzia, jak np. rozmyte sieci neuronowe lub rozmyte algo-
rytmy ewolucyjne. Algorytmy te są stosowane do trudnych zadań obliczeniowych,
jak np. do przetwarzania mowy i wizji, budowy systemów ekspertowych i syste-
mów sterowania, wyszukiwania i przetwarzania informacji w coraz to bardziej bo-
gatych bazach danych oraz uczenia się maszyn.
Do metod sztucznej inteligencji należy wspominana wyżej teoria zbiorów roz-
mytych ze stowarzyszoną z nią logiką rozmytą. Teoria zbiorów rozmytych znalazła
swoją stabilną pozycję w algorytmach analizy danych przy założeniu ich niepełne-
go lub nieprecyzyjnego opisu. Logika rozmyta natomiast miała w zamyśle umożli-
wić budowę maszyn wnioskujących naśladujących proces ludzkiego myślenia. Jed-
nym z obszarów zastosowań logiki rozmytej stała się też dziedzina przetwarzania
obrazów. Metody oparte na teorii zbiorów rozmytych umożliwiły w licznych przy-
padkach opracowanie algorytmów pozwalających na uzyskiwanie lepszych rezul-
tatów w stosunku do rozwiązań klasycznych.
Problematyka prezentowanej pracy łączy elementy dwóch teorii: teorii widze-
nia maszynowego i teorii zbiorów rozmytych. Praca stanowi próbę zastosowania
niektórych elementów teorii zbiorów rozmytych w zagadnieniu maszynowego wi-
dzenia steroskopowego, a ściślej mówiąc, jest poświęcona kluczowemu proble-
mowi maszynowego widzenia stereoskopowego, jakim jest problem dopasowania
obrazów pary stereoskopowej będący odpowiednikiem fuzji obrazów wykonywa-
nych przez mózg ludzki. Problem ten, mimo wielu propozycji, nie doczekał się
jeszcze ostatecznego i w pełni zadowalającego rozwiązania. Z tego względu próba
zastosowania teorii zbiorów rozmytych do jego rozwiązania wydaje się interesują-
ca i w pełni uzasadniona tym bardziej, że zastosowanie teorii zbiorów rozmytych
w innych zagadnieniach przetwarzania obrazów przyniosło pozytywne efekty.
17

“KonspPreamb” 2013/10/3 page 18 #21
1. Wprowadzenie
1.1. Uwagi o terminologii przyjętej w pracy
Napisanie pracy technicznej związanej z tematyką przetwarzania obrazów
i sztucznej inteligencji, w którą wpisuje się teoria zbiorów rozmytych, jest zada-
niem trudnym od strony językowej. W związku z szybkim rozwojem obu dziedzin
do określania pewnych pojęć stosowane są terminy nie występujące w języku for-
malnym, zarówno angielskim jak i polskim. Często w języku polskim funkcjonu-
ją proste spolszczenia angielskich terminów, co również utrudnia redakcję tekstu,
bez uniknięcia nieformalnych terminów obiegowych. Z tego względu terminologia
przyjęta w pracy wymaga krótkiego komentarza.
1.1.1. Uwagi o nazewnictwie dotyczącym przetwarzania obrazów
Rozważając systemy wzrokowe przywołuje się stwierdzenie, że większość zwie-
rząt wyposażona jest w dwie gałki oczne. Wykorzystanie dwóch oczu w procesie
widzenia określa się w języku angielskim terminem binocular vision [1]. W języ-
ku polskim wykorzystanie dwóch oczu w procesie widzenia nazywa się widzeniem
obuocznym [2]. Wszystkie zwierzęta posiadające dwoje oczu posługują się widze-
niem obuocznym. Nawet te, których oczy położone są po różnych stronach gło-
wy (ryby, gady) wykazują pewne zdolności do integracji informacji pochodzących
z obu oczu [3]. Większość zwierząt ma jednak tak zbudowany układ wzrokowy,
że obraz jest widziany równocześnie przez oboje oczu, co wykorzystywane jest do
percepcji głębi.
Analogiczną budowę ma układ wzrokowy człowieka, w którym prawie cały
obraz widziany jest niezależnie przez każde z dwóch oczu. Widzenie obuoczne,
oprócz zdolności postrzegania głębi, pozwala także na uzyskanie lepszych rezulta-
tów w koordynacji ruchowej, a także dostrzeganie i rozróżnianie obiektów. Zdol-
ność percepcji głębi określa się w języku angielskim jako stereoscopic vision [1].
Polskim odpowiednikiem tego terminu jest określenie widzenie stereoskopowe [4].
Określenia te dotyczą widzenia polegającego na postrzeganiu trójwymiarowości
przedmiotów i ich przestrzennego rozmieszczenia. Najczęściej widzenie przestrzen-
ne jest związane z widzeniem obuocznym, choć może wystąpić również przy wi-
dzeniu jednoocznym. Wśród przyczyn umożliwiających dostrzeganie głębi przy
widzeniu jednoocznym można wymienić: perspektywę, cienie, wzajemne zasłania-
nie się obiektów, paralaksę ruchu oraz różnice w ostrości widzenia [3]. W układzie
18

“KonspPreamb” 2013/10/3 page 19 #22
1. Wprowadzenie
wzrokowym widzenia obuocznego wykorzystuje się do postrzegania głębi dwie
cechy. Pierwszą z nich jest fiksacja, czyli ustalenie takiej osi widzenia, która łączy
wybrany punkt przestrzeni z miejscem najlepszej ostrości wzroku na siatkówce.
Drugą bardzo ważną cechą umożliwiającą widzenie przestrzenne jest różnica w po-
łożeniu obiektów tworzonych w niezależnych obrazach obu oczu.
Zjawisko zdolności dostrzegania głębi na podstwawie różnic w położeniu
i kształtach określane jest w języku angielskim wyrażeniem stereopsis lub binocu-
lar stereopsis [3]. Różnice te są efektem rozmieszenia oczu, które w konsekwencji
daje różne kąty promieni optycznych, pod którymi widziana jest scena. W języku
polskim istnieje analogiczne określenie stereopsja [5]. Pojęcie to definiuje widze-
nie przestrzenne, czyli postrzeganie głębi, które wynika z fuzji dwóch obrazów
powstających w nieznacznie różnych punktach siatkówek. Pojęcie stereopsji uży-
wane jest głównie w medycynie, jako jeden z trzech warunków, obok widzenia
obuocznego i fuzji (czyli nakładania się i zlewania w ośrodku korowym mózgu
dwu jednakowych obrazów w jeden), które umożliwiają percepcję głębi.
Niestety żaden z powyższych terminów nie jest używany w literaturze tech-
nicznej. Prawdopodobnie przez analogię do terminów computer vision, machine
vision w literaturze anglojęzycznej stosowany jest termin stereo vision [6]. Ter-
min ten jest dość często stosowany na określenie możliwości uzyskania w układzie
stereoskopowym informacji przestrzennej o widzianej scenie przy wykorzystaniu
dwóch przetworników obrazowych. Termin ten nie występuje w słowniku języka
angielskiego [1].
Analogicznie do angielskiego określenia stereo vision, w języku polskim w od-
niesieniu do sytemu zbudowanego z dwóch przetworników obrazowych umożli-
wiających określenie przestrzenne widzianej sceny zaczęło funkcjonować określe-
nie stereowizja [7, 8]. Słowo to nie jest definiowane ani przez encyklopedię [4],
ani przez słowniki języka polskiego [2], i w chwili obecnej można go uznać za
funkcjonujące nieformalnie.
Ważnym pojęciem w dziedzinie widzenia stereoskopowego jest przesunięcie,
które powstaje w dwóch obrazach tej samej sceny, ale otrzymanych z różnych punk-
tów w przestrzeni. W języku angielskim przyjęte zostało określenie binocular di-
sparity lub po prostu disparity [3], używane w sensie różnicy współrzędnych tych
samych punktów na dwóch obrazach [1]. Najbliższymi znaczeniowo tłumaczeniami
terminu disparity są: rozbieżność lub przesunięcie. Niestety nie udało się jak dotąd
19

“KonspPreamb” 2013/10/3 page 20 #23
1. Wprowadzenie
znaleźć trafnego polskiego odpowiednika i w języku polskim funkcjonuje termin
dysparycja, będący spolszczeniem terminu angielskiego [9, 8].
Na określenie dwóch obrazów przedstawiających tę samą scenę widzianą z róż-
nych kątów widzenia funkcjonuje w języku angielskim termin stereo pair [6]. W ję-
zyku polskim do opisania takich obrazów używany jest termin para stereoskopo-
wa, chociaż w nowym wydaniu encyklopedii PWN zamieszona jest również rów-
nież definicja terminu stereopara [4]. W algorytmach umożliwiających rozwiąza-
nie problemu dopasowania pary stereoskopowej jeden z obrazów tej pary jest przyj-
mowany jako obraz referencyjny, nazywany również obrazem odniesienia (ang. re-
ference image), drugi zaś jako obraz przeszukiwania (ang. matching image; target
image) [10, 11, 12]. Jest przy tym rzeczą arbitralną, który z obrazów tworzących
parę stereoskopową wybierany jest jako obraz referencyjny, a który jako obraz prze-
szukiwania.
Usytuowanie dwóch przetworników obrazowych w sposób analogiczny do ludz-
kiego systemu widzenia doczekało się własnego opisu geometrycznego. Opis ten
funkcjonuje w literaturze angielskiej pod nazwą epipolar geometry. Z geometrią tą
związane jest pojęcie punktów środkowych kamer w przestrzeni, które określane są
w języku angielskim jako epipole, oraz pojęcie linii wyznaczanych przez promienie
optyczne przekształcenie rzutowego, określane jako epipolar line. W języku pol-
skiem najbliższe znaczeniowo byłyby tłumaczenia związane z angielskim słowem
pole, czyli biegun. Niektórzy autorzy próbują stosować taką terminologię, nazy-
wając punkty chrakterystyczne przekształcenia biegunami oraz wspomniane linie
liniami biegunowymi [13]. Geometria układu jest nazywana zazwczaj polskim spo-
lszczeniem geomeria epipolarna. Stosowane są również często spolszczenia: punkt
epipolarny oraz linia epipolarna [9, 8].
W pracy autor zdecydował się używać terminu maszynowe widzenie stereo-
skopowe lub jego formę skróconą widzenie stereoskopowe. Chociaż wydaje się, że
określnie stereowizja będzie wkrótce pełnoprawną nazwą, na razie zostało uznane
jako termin nieformalny. Podobnie, na określenie pary obrazów umożliwiających
określenie głębi w pracy używany jest termin para stereoskopowa, chociaż termin
stereopara jest już zwrotem uznanym za poprawny. Ze względu na popularność
określenia dysparycja, jak również problemy w oddaniu znaczenia tego pojęcia
innym terminem, autor zdecydował się używać w pracy tego właśnie określenia,
mając nadzieję, że z określenia obiegowego stanie się ono wkrótce terminem uzna-
20

“KonspPreamb” 2013/10/3 page 21 #24
1. Wprowadzenie
nym przez językoznawców. Podobnie w przypadku opisu geometrii układu dwóch
kamer będą używane polskie spolszczenia terminów angielskich. Są one już tak
utartymi zwrotami, że wprowadzanie jakichkolwiek innych polskich odpowiedni-
ków wprowadziłoby dodatkową niespójność w stosowanym nazewnictwie.
1.1.2. Uwagi o nazewnictwie dotyczącym teorii zbiorów rozmytych
W obszarze zastosowań teorii zbiorów rozmytych również istnieją rozbieżności
związane z nazewnictwem pojęć i operacji występujących w tej teorii. Podstawową
operacją, jaką wykorzystuje się w aplikacjach zbiorów rozmytych jest zmiana dzie-
dziny opisu umożliwiająca opis zmiennych za pomocą elementów teorii zbiorów
rozmytych. Termin określający tę operację brzmi po angielsku fuzzification, często
również spotykany w formie fuzzyfication. Najbliższym znaczeniowo polskim tłu-
maczeniem jest rozmywanie. Termin ten bywa czasami stosowany [14], ale częściej
przyjmuje się spolszczenie angielskiego terminu, a mianowicie fuzyfikacja [14] lub
fuzzyfikacja [15].
Drugą fundamentalną operacją jest zamiana wielkości rozmytej na wielkość
nierozmytą. Terminem angielskim określającym tę operację jest defuzzification,
często również występujący w literaturze w formie defuzzyfication. Polskim odpo-
wiednikiem jest ostrzenie lub wyostrzanie [16], ale zazwyczaj używane jest polskie
spolszczenie defuzyfikacja [14] lub defuzzyfikacja [15].
Trzecim terminem, który jest kluczowy w teorii zbiorów rozmytych, jest okre-
ślanie wartości poprzez zastosowanie elementów logiki na zbiorach roztmytych.
Angielskim terminem określającym to działanie jest inference. Istnieje również
polskie spolszczenie tego słowa brzmiące inferencja [14], choć autor pracy skła-
niałby się tutaj do używania polskiego tłumaczenia wnioskowanie [17].
W pracy przyjęty został termin fuzzyfikacja, jako już zwyczajowo używany
w większości polskojęzycznych publikacji. W prezentowanych algorytmach nie
będzie wykorzystywany mechanizm wnioskowania, dlatego uniknięto konieczno-
ści stosowania terminów defuzzyfikacja oraz wnioskowanie, które również wydają
się już standardowymi zwrotami w polskiej literaturze dotyczącej zbiorów rozmy-
tych. W miejscach, gdzie mogłyby się pojawić wątpliwości dotyczące stosowanego
nazewnictwa, podane zostały ich angielskie odpowiedniki. Również wtedy, kiedy
stosowane będą akronimy angielskich terminów, pozostawione zostały ich orygi-
21

“KonspPreamb” 2013/10/3 page 22 #25
1. Wprowadzenie
nalne nazwy, z podanym pełnym rozwinięciem. Intencją autora było tu ułatwienie
redakcji tekstu, bez zbędnego definiowania nazw własnych.
1.2. Teza i cel pracy
Zasadniczą tezę pracy można sformułować następująco: W celu efektywnego
rozwiązania problemu dopasowania pary stereoskopowej możliwe jest opracowa-
nie metod i algorytmów przetwarzania obrazów par stereoskopowych opartych
na teorii zbiorów rozmytych. Ich zastosowanie umożliwia uzyskanie nie gorszej,
a w niektórych przypadkach lepszej jakości dopasowania, ocenianej na podsta-
wie odpowiednich miar jakości, w porównaniu z jakością dopasowania osiąganą
za pomocą odpowiadających im metod i algorytmów znanych z literatury i nie
wykorzystujących teorii zbiorów rozmytych.
Powinnością rozprawy doktorskiej jest oczywiście przeprowadzanie dowodu
postawionej tezy. Aby udowodnić tezę rozprawy autor opracował własną koncepcję
i metodykę wykorzystania elementów teorii zbiorów rozmytych, której celem było
efektywne rozwiązanie problemu dopasowania pary stereoskopowej. Składa się na
nią zarówno dobór i sformułowanie metod umożliwiających rozwiązanie problemu
dopasowania z wykorzystaniem zbiorów rozmytych, jak i przeprowadzenie analizy
i oceny uzyskanych rezultatów. Ważnym aspektem pracy jest również przeprowa-
dzenie analizy porównawczej efektywności działania opracowanych algorytmów
z algorytmami znanymi z literatury.
1.3. Główne rezultaty pracy
Do głównych osiągnięć autorskich pracy, stanowiących zarazem element do-
wodu postawionej tezy, należy:
algorytm znajdowania krawędzi w obrazie w oparciu o relację rozmytą [18]
(p. 5.7, str. 139),
algorytm dopasowania cech w oparciu o rozmyty detektor krawędzi [19] (p. 5.8.3,
str. 148),
algorytm znajdowania funkcji przynależności dla pikseli obrazu umożliwiający
jego opis w dziedzinie zbiorów rozmytych [20] (p. 5.4, str. 121),
22

“KonspPreamb” 2013/10/3 page 23 #26
1. Wprowadzenie
algorytm wykorzystujący metodę fuzzyfikacji do dziedziny zbiorów intuicjo-
nistycznych oraz jego zastosowanie w problemie dopasowania pary stereosko-
powej [21] (p. 5.6, str. 131 oraz p. 5.6.4, str. 137),
zastosowanie opracowanej metody fuzyfikacji obrazu do rozwiązanie dopaso-
wania pary obrazów stereoskopowych (p. 5.5, str. 129),
sformułowanie metody umożliwiającej obliczanie rozmytej transformaty ran-
kingowej oraz jej zastosowanie w problemie dopasowania pary stereoskopowej
(p. 5.9, str. 150).
Należy podkreślić, że opracowane metody i algorytmy: wykrywania krawędzi,
wyznaczania funkcji przynależności oraz metoda opisu obrazu w dziedzinie intu-
icjonistycznych zbiorów rozmytych są na tyle ogólne, że mogą być wykorzystane
w praktycznie dowolnym zagadnieniu widzenia maszynowego, nie ograniczając za-
kresu ich zastosowania do problemu rozwiązywanego w pracy. Warto także wspo-
mnieć, że autor podjął również badania mające na celu wykorzystanie teorii zbio-
rów rozmytych w zagadnieniu trójwymiarowej rekonstrukcji obserwowanej sceny,
uzyskując dobre jakościowo rezultaty [22]. Opracowany algorytm rekonstrukcji nie
jest jednak ściśle związany z tezą pracy i z tego względu nie będzie prezentowany.
1.4. Układ pracy
Praca składa się z ośmiu rozdziałów.
Rozdział 1, kończący się w tym miejscu, stanowi ogólne wprowadzenie do
zagadnień rozważanych w dalszych częściach pracy. Przedstawiono w nim uwagi
dotyczące terminów pojawiających się w dalszych częściach pracy, sformułowano
cele i tezę pracy oraz przedstawiono osiągnięcia autora dotyczące tematu pracy.
Rozdział 2 charakteryzuje w ogólny sposób zagadnienie widzenia stereosko-
powego, a w szczególności problem dopasowania pary stereoskopowej. Przedsta-
wiono w nim podstawowe zagadnienia geometryczne związane z akwizycją obra-
zów pary stereoskopowej. Wprowadzono modele geometryczne akwizycji jednego
obrazu, jak również model geometryczny umożliwiający akwizycję i późniejszą
analizę prawidłowej pary stereoskopowej, tj. takiej pary obrazów, która obrazu-
je tę samą scenę z różnych punktów widzenia. W ramach omówienia zagadnień
geometrycznych przedstawiono algorytm rektyfikacji obrazu, jako algorytm wy-
23

“KonspPreamb” 2013/10/3 page 24 #27
1. Wprowadzenie
konywany zwykle we wstępnej fazie analizy pary stereoskopowej i poprzedzają-
cy etap optymalizacji dopasowania. W dalszym ciągu przedyskutowano założenia
i ograniczenia przyjmowane przy konstruowaniu algorytmów dopasowania pary
stereoskopowej. Część z tych założeń i ograniczeń wynika z przyjętego modelu
geometrycznego, inne są uwarunkowane zawartością obrazowanej sceny.
Rodział 3 stanowi przegląd znanych z literatury metod i algorytmów wykorzy-
stywanych do rozwiązania problemu dopasowania pary stereoskopowej. Algorytmy
te podzielono na dwa podstawowe typy, a mianowicie algorytmy globalne, w któ-
rych dopasowywany jest pełny obraz, oraz algorytmy dopasowania cech, w któ-
rych dopasowywane są wyróżnione elementy bądź też cechy obrazu. W literaturze
znanych jest bardzo wiele propozycji konstrukcji zarówno algorytmów dopasowa-
nia globalnego, jak i algorytmów dopasowania cech, różniących się odmiennym
podejściem do rozwiązania problemu dopasowania, różnymi kryteriami optymal-
ności dopasowania i różnymi technikami optymalizacji. Z uwagi na ograniczone
ramy pracy bardziej szczegółowo omówiono jedynie najbardziej reprezentatyw-
ne, a wśród nich algorytm Marra-Poggio-Grimsona, który wybrano jako algorytm
odniesienia w celu porównania efektywności własnych algorytmów zaproponowa-
nych przez autora w pracy i opartych na teorii zbiorów rozmytych. Inne algorytmy
scharakteryzowano jedynie w sposób ogólny.
Rozdział 4 stanowi wprowadzenie do teorii zbiorów rozmytych. Przedstawiono
w nim podstawowe pojęcia i definicje, jak również formalizm matematyczny teorii
zbiorów rozmytych. Ograniczono się jedynie do tych elementów tej teorii, które
są dalej wykorzystywane w pracy. Omówiono również podstawowe pojęcia oraz
niektóre elementy teorii intuicjonistycznych zbiorów rozmytych, także w ujęciu
dostosowanym do potrzeb pracy w zakresie niezbędnym do przedstawienia autor-
skich propozycji algorytmów wykorzystujących ten właśnie formalizm.
Rozdział 5 zawiera głównie opis autorskich algorytmów wykorzystujących
w swoim działaniu elementy teorii zbiorów rozmytych i intuicjonistycznych zbio-
rów rozmytych służące do rozwiązania problemu dopasowania obrazów pary ste-
reoskopowej.
Rodział 6 poświęcono metodom badania efektywności rozwiązań algorytmicz-
nych. Omówiono w nim metody i miary zastosowane do obiektywnej oceny jakości
algorytmów. Przedstawiono przykłady par stereoskopowych obrazów, dla których
24

“KonspPreamb” 2013/10/3 page 25 #28
1. Wprowadzenie
dokonano weryfikacji doświadczalnej jakości algorytmów. Wprowadzono cztery
typowe modele zakłóceń szumowych, dla których przeprowadzone zostały badania
doświadczalne zarówno opracowanych przez autora algorytmów, jak i algorytmów
referencyjnych znanych z literatury.
Rozdział 7 zawiera głównie numeryczną analizę efektywności zaproponowa-
nych przez autora rozwiązań algorytmicznych. Przedstawiono wyniki badań eks-
perymentalnych przeprowadzonych dla par testowych w przypadku zastosowania
algorytmów referenycjnych jak i algorytmów opracowanych przez autora. Zawarto
w nim również porównanie otrzymywanych rozwiązań. Ważnym aspektem przed-
stawionym w tym rozdziale było przebadanie odporności zaproponowanych algo-
rytmów na różnego typu zakłócenia.
Rodział 8 kończy pracę. W rodziale tym podsumowano otrzymane wyniki ba-
dań eksperymentalnych, sformułowano wnioski wynikające z przeprowadzonych
badań, przedstawiono w formie syntetycznej główne rezultaty pracy oraz wskazano
na kierunki możliwych dalszych badań nad zastosowaniem teorii zbiorów rozmy-
tych w problematyce dopasowania pary stereoskopowej obrazów.
25

“KonspPreamb” 2013/10/3 page 26 #29
Rozdział 2
Zagadnienie widzenia stereoskopowego
W rozdziale wprowadzono podstawowe pojęcia i definicje dotyczące zagadnie-
nia maszynowego widzenia stereoskopowego. Przedstawiono także krótkie wpro-
wadzenie do zagadnień związanych z geometrią układu stereoskopowego. Omó-
wiono główne problemy i założenia przyjmowane podczas projektowania systemu
maszynowego widzenia stereoskopowego.
2.1. Maszynowe widzenie stereoskopowe
Widzenie stereoskopowe jest pasywną techniką umożliwiającą akwizycję obra-
zów trójwymiarowych. W technice tej informacja o trzecim wymiarze (odległości)
określana jest na podstawie przesunięcia występującego między dwoma obrazami
przedstawiającymi tę samą scenę, lecz widzianą z różnych punktów przestrzeni.
Ludzki układ widzenia postrzega głębię widzianej sceny w sposób naturalny, bez
dodatkowego świadomego wysiłku wkładanego w ten proces.
W zagadnieniach widzenia maszynowego algorytmy próbujące naśladować dzia-
łanie ludzkiego układu wzrokowego w zakresie postrzegania głębi stały się ważną
i intensywnie rozwijaną gałęzią badań. Analogicznie do dwóch obrazów tworzo-
nych na gałkach ocznych ludzkiego układu wzrokowego, w maszynowym widze-
niu stereoskopowym następuje akwizycja dwóch obrazów, które następnie muszą
zostać przetworzone i zinterpretowane. Na rys. 2.1 przedstawione zostały typowe
etapy przetwarzania, jakie można wyróżnić w komputerowym systemie widzenia
stereoskopowego. Pierwszym krokiem w pełni kompletnego procesu przetwarza-
nia obrazów stereoskopowych jest ich akwizycja. Etap ten związany jest z wyborem
przetworników obrazowych pod kątem ich właściwości optycznych i elektrycznych.
W zależności od zastosowań, dobierane są w nim rozdzielczości przetworników ob-
razowych, ich pasmo działania (widzialne, na podczerwień), czułości oraz wszyst-
kie pozostałe parametry techniczne. Na tym etapie rozważane są również zależno-
ści i uwarunkowania mechaniczne budowanego układu, jak również określana jest
26

“KonspPreamb” 2013/10/3 page 27 #30
2. Zagadnienie widzenia stereoskopowego
Akwizycja obrazówpary stereoskopowej
Rektyfikacja obrazówpary stereoskopowej
Wstępne przetwarzanieobrazów pary
stereoskopowej
Dopasowanieobrazów pary
stereoskopowej
Rekonstrukcjagłębi sceny
Wykorzystanie wyniku
Obrazy parystereoskopowej
Zrektyfikowanapara obrazów
Wyszukane cechy obrazówTransformaty obrazów
Obrazy po filtracji
Mapa dysparycji
Mapa głębi
Parametry kamer orazgeometria i orientacja układu
akwizycji
Rys. 2.1. Główne etapy ogólnego systemu komputerowego realizującego widzeniestereoskopowe
geometria układu (np. odległość przetworników obrazowych, kąt skręcenia umoż-
liwiający widzenie tego samego obszaru).
Drugim krokiem, zaliczanym już do procesów przetwarzania otrzymanych ob-
razów, jest ich rektyfikacja. Etap ten pozwala na zmniejszenie zagadnienia poszu-
kiwania dopasowania z dwóch wymiarów (przesunięcie pionowe i poziome) do
27

“KonspPreamb” 2013/10/3 page 28 #31
2. Zagadnienie widzenia stereoskopowego
jednego, tj. poszukiwania wartości różnicy położenia pomiędzy tymi samymi punk-
tami tylko w kierunku poziomym (por. p. 2.4.1).
Jako etap przetwarzania wstępnego obrazów można rozumieć ogólne algoryt-
my poprawy ich jakości. Może to być: zastosowanie filtracji, korekcja zniekształceń
geometrycznych wnoszonych przez układy optyczne, ekstrakcja cech lub zmiana
przestrzeni barw. W zależności od konkretnej realizacji systemu widzenia, techniki
te mogą umożliwić uzyskiwanie lepszych wyników w czasie działania algorytmu
dopasowywania.
Najbardziej złożonym krokiem całego systemu, któremu poświęcona jest pre-
zentowana praca, jest etap dopasowania obrazów otrzymanej pary. Ze względu na
różnicę w położeniu przestrzennym przetworników obrazowych w obrazach wy-
stępuje przesunięcie we współrzędnych określających położenie poszczególnych
elementów sceny. Celem tego kroku jest znalezienie jak największej liczby praw-
dziwych wartości przesunięć występujących w obrazach. Wartość różnicy poło-
żenia elementu (piksela) p w obrazach jest nazywana dysparycją i oznaczana dp,
natomiast wartości określone dla wszystkich pikseli obrazów są nazywane mapą
dysparycji i oznaczane d. Uzyskanie tej mapy jest efektem przeprowadzenia proce-
su dopasowania obrazów pary stereoskopowej. Otrzymana mapa dysparycji może
zostać dodatkowo poddana pewnemu procesowi przetwarzania końcowego, którym
może być jej filtracja lub interpolacja. Krok ten nie został wyróżniony na rys. 2.1
jako jeden z głównych etapów procesu maszynowego widzenia stereoskopowego,
ale czasami jest wykonywany jako krok pośredni umożliwiający poprawę uzyski-
wanych wyników.
Dysponując mapą dysparycji d oraz znając geometrię układu, dla którego zo-
stała ona wyznaczona, możliwe jest obliczenie metrycznych wartości odległości
w przestrzeni trójwymiarowej widzianej sceny. Wynik wyrażony w jednostkach
metrycznych nazywany jest mapą głębi i określa odległość obrazowanego elemen-
tu sceny od przetwornika obrazowego. Zagadnienie to jest nazywane rekonstrukcją
i jest jednym z podstawowych zadań, jakie stawiane jest przed systemami maszy-
nowego widzenia stereoskopowego.
Końcowym etapem jest wykorzystanie otrzymanych wyników. Jako obszary
zastosowań widzenia stereoskopowego można przytoczyć przykłady: wizualizacji
sceny trójwymiarowej (np. w przemyśle filmowym, grach komputerowych, w ce-
lach digitalizacji zbiorów muzealnych), algorytmów tworzenia rzeczywistości roz-
28

“KonspPreamb” 2013/10/3 page 29 #32
2. Zagadnienie widzenia stereoskopowego
szerzonej (np. wirtualne tablice w e-nauczaniu), aplikacji w medycynie (a szcze-
gólnie telemedycynie) oraz zastosowań w algorymach nawigacji (np. w robotach
mobilnych).
Poniżej przedstawione zostaną podstawowe zagadnienia związane z geometrią
układu stereoskopowego. Umożliwia to bardziej szczegółowe zdefiniowanie pro-
blemu dopasowania obrazów pary stereoskopowej oraz dokonanie przeglądu algo-
rytmów rozwiązujących zagadnienie dopasowania.
2.2. Podstawy geometrii układu stereoskopowego
Rozważanie zagadnień widzenia stereoskopowego, a szczególnie niektórych je-
go elementów, jak metryczna lokalizacja widzianych obiektów w przestrzeni lub
rekonstrukcja obserwowanej sceny, wymaga zastosowania złożonego aparatu geo-
metrii rzutowej. W pracy przedstawione zostaną tylko podstawowe elementy po-
zwalające na wyjaśnienie ograniczeń i założeń, jakie zostały przyjęte na etapie do-
świadczeń eksperymentalnych.
W prezentowanych dalej zagadnieniach autor zdecydował się nie wprowadzać
aparatu współrzędnych jednorodnych pozwalającego na zapisywanie praktycznie
wszystkich zależności w postaci rachunku macierzowego. Zapis w postaci macie-
rzowej umożliwia łatwiejszą implementację w programach komputerowych, ale nie
wnosi nic nowego do ogólnych zasad geometrycznych układu stereoskopowego.
Poszczególne zagadnienia omówiono z wykorzystaniem rachunku geometrii eu-
klidesowej, który jest wystarczający do podstawowego opisu zależności procesu
powstawania i akwizycji obrazów stereoskopowych.
Geometria rzutowa wraz z zapisem macierzowym przy zastosowaniu współ-
rzędnych jednorodnych stała się samodzielną gałęzią badań nad maszynowymi sys-
temami widzenia. Problematyka systemów widzenia stereoskopowego została omó-
wiona w kilku monografiach, które stały się praktycznie pozycjami klasycznymi
tej dziedziny, skupiającymi się jedynie na opisie zagadnień geometrycznych takich
systemów. Obszerne opisy geometrii stosowanej w analizie obrazów stereoskopo-
wych można znaleźć w dedykowanych tym zagadnieniom pozycjach, np. [23, 24]
oraz w rozdziałach książek poświęconych zagadnieniom przetwarzania obrazów
[25, 26, 27] lub w artykułach, gdzie oprócz podstaw geometrii układów widzenia
29

“KonspPreamb” 2013/10/3 page 30 #33
2. Zagadnienie widzenia stereoskopowego
stereoskopowego prezentowane są szczegółowe zagadnienia przekształceń rzuto-
wych [28, 29, 30].
2.2.1. Model kamery perspektywicznej
Elektroniczne urządzenia służące do akwizycji obrazów, podobnie jak ludzkie
oko, wykonują przekształcenie trójwymiarowej przestrzeni rzutowej P3 na dwu-
wymiarową płaszczyznę – rzutnię P2 . Na płaszczyźnie rzutni tworzony jest płaski
dwuwymiarowy obraz widzianej przestrzeni trójwymiarowej.
Modelowanie takiego przekształcenia jest istotnym zagadnieniem przetwarza-
nia obrazów. Jednym z najczęściej stosowanych modeli procesu akwizycji obrazu
jest model kamery perspektywicznej (ang. pin-hole camera) [31, 32], przedstawio-
ny na rys. 2.2. W przypadku, gdy prosty model przekształcenia perspektywicznego
nie jest wystarczający, uzupełniany jest on o parametry opisujące zniekształcenia
geometryczne wnoszone przez układ optyczny kamery [33, 34, 35] lub stosowany
jest model uwzględniający nieliniowości przekształcenia rzutowego [36, 37].
Dla zagadnień prezentowanych w pracy model kamery perspektywicznej jest
wystarczający, dlatego zostanie przedstawiony bardziej szczegółowo.
W modelu liniowej kamery perspektywicznej przedstawionym na rys. 2.2 obraz
każdego punktu trójwymiarowej przestrzeni tworzony jest na płaszczyźnie obrazu
Ψ będącej częścią rzutni P2. Kamera reprezentowana jest przez przez punkt ogni-
skowy Oc (czasami nazywany również środkiem optycznym lub punktem central-
nym projekcji) [38, 39, 40]. Punkt ogniskowy kamery Oc rzutowany prostopadle na
płaszczyznę obrazową Ψ wyznacza na niej punkt główny o (0, 0, f ) . Prosta łącząca
punkt ogniskowy kamery Oc i przechodząca przez punkt główny o wyznaczony na
płaszczyźnie obrazowania Ψ nazywana jest osią optyczną. Natomiast proste łączą-
ce dowolny punkt P przestrzeni z punktem ogniskowym Oc kamery nazywane są
promieniami optycznymi. Obraz tworzony jest na płaszczyźnie Ψ odległej o pewną
wartość f nazywaną ogniskową kamery, która jest jej parametrem.
Z przekształceniem rzutowym przedstawionym na rys. 2.2 związany jest ze-
wnętrzny układ współrzędnych Ow niezależny od położenia i właściwości kamery
oraz układ współrzędnych z nią związany, o początku umieszczonym w punkcie
ogniskowym kamery Oc. Położenie dowolnego punktu przestrzeni P określone jest
przez wektor Pw =[
xw, yw, zw]
w zewnętrznym układzie współrzędnych oraz wek-
tor Pc = [u,w, v] w układzie współrzędnych kamery. Pomiędzy układami współ-
30

“KonspPreamb” 2013/10/3 page 31 #34
2. Zagadnienie widzenia stereoskopowego
R t
Pc
Pw
Układ współrzędnychkamery
Zewnętrzny układwspółrzędnych
Układ współrzędnychobrazu
Punkt sceny
Rzut punktu P
P (x, y, z)
p (u,w, v)
Oś optyc
zna
Promień
optyc
zny
PłaszczyznaobrazowaniaΨ
Punkt główny
f
o (0, 0, f )
Oc
yc
xc
zc
Oi
xi
yi
Owxw
ywzw
Rys. 2.2. Liniowy model kamery perspektywicznej powstawania dwuwymiarowe-go obrazu p punktu P z przestrzeni trójwymiarowej.
rzędnych zewnętrzym Ow oraz kamery Oc istnieje jednoznaczne przekształcenie,
pozwalające na zamianę współrzędnych wyrażonych w obu układach współrzęd-
nych. Wzajemna zależność pomiędzy układami współrzędnymi układu zewnętrz-
nego i kamery jest złożeniem przesunięcia wyrażonego za pomocą wektora trans-
lacji t i macierzy rotacji R . Wektor translacji jest trzyelementowym wektorem
zawierającym przesunięcie układu współrzędnych kamery Oc wzdłuż każdej z osi
zewnętrznego układu współrzędnych Ow , natomiast macierz rotacji R jest macie-
rzą o wymiarach 3 × 3 zawierającą kąty obrotu układu współrzędnych kamery Oc
względem każdej osi zewnętrznego układu współrzędnych Ow.
Korzystając z prostych zależności geometrycznych (podobieństwa trójkątów),
współrzędne obrazu p pewnego wyróżnionego punktu przestrzeni P, wyrażone
w układzie współrzędnych kamery Oc, mogą być opisane wyrażeniem [38, 23]:
u = fxw
z, w = f
yw
z, v = f (2.1)
gdzie xw, yw, zw są współrzędnymi punktu P wyrażonymi w zewnętrznym ukła-
31

“KonspPreamb” 2013/10/3 page 32 #35
2. Zagadnienie widzenia stereoskopowego
dzie współrzędnych Ow, natomiast u,w, v są współrzędnymi obrazu punktu p wy-
rażonymi w układzie współrzędnych kamery Oc. Współrzędne położenia punktu
w układzie kamery mogą zostać wyznaczone również na podstawie znajomości
współrzędnych punktu w zewnętrznym układzie współrzędnych oraz parametrów
geometrycznych układu stereoskopowego. W przypadku, gdy określony został wek-
tor translacji t oraz macierz rotacji R, przejście pomiędzy zewnętrznym układem
współrzędnych Ow i układem współrzędnych kamery Oc odbywa się według zależ-
ności:
Pc = R (Pw − t) (2.2)
gdzie Pc to wektor współrzędnych punktu określający jego położenie w układzie
współrzędnych związanym z kamerą, natomiast Pw to wektor współrzędnych punk-
tu wyrażonych w zewnętrznym układzie współrzędnych Ow. Macierz rotacji R oraz
wektor translacji t nazywane są parametrami zewnętrznymi kamery, natomiast wy-
znaczanie ich wartości związane jest z zagadnieniem kalibracji kamery [41, 42].
Ostatnim etapem powstawania obrazu cyfrowego jest przekształcenie dowolnej
ciągłej funkcji dwóch zmiennych przestrzennych reprezentujących umowną inten-
sywność nośnika obrazu do jej reprezentacji w formie cyfrowej. Umownym no-
śnikiem obrazu może być wybrany zakres promieniowania elektromagnetyczne-
go, wiązka korpuskuł w polu elektrycznym lub magnetycznym albo powierzchnio-
wy rozkład temperatury. W przedstawianej pracy rozważane są obrazy otrzymane
w efekcie przekształcenia widzialnego zakresu widma elektromagnetycznego pa-
dającego na płaszczyznę obrazowania Ψ (rys. 2.3a). Natomiast jako obraz cyfrowy
rozumiana jest reprezentacja dyskretna tej ciągłej funkcji promieniowania elektro-
magnetycznego z zakresu widzialnego padającej na płaszczyznę obrazowania Ψ.
Wartości liczbowe odpowiadające intensywności promieniowania reprezetują ja-
sność powstającego obrazu.
Wynikowy obraz cyfrowy charakteryzowany jest również za pomocą dwóch pa-
rametrów: rozdzielczości przestrzennej obrazu, która określana jest przez wymiar
macierzy wynikowego obrazu cyfrowego (rys. 2.3d) oraz rozdzielczość poziomów
szarości (często nazywanych równoważnie jako poziomy jasności) określoną przez
ich liczbę w wynikowym obrazie cyfrowym (rys. 2.3c). Najmiejszy element ob-
razu cyfrowego otrzymany w wyniku dyskretyzacji nazywany jest pikselem. Licz-
ba pikseli i poziomów jasności może być w ogólnym przypadku dowolna, jednak
względy technologiczne i sposób reprezentacji danych w technice komputerowej
32

“KonspPreamb” 2013/10/3 page 33 #36
2. Zagadnienie widzenia stereoskopowego
powoduje, że wartości te są zazwyczaj wielokrotnościami liczby 2, np. 512 × 512
pikseli i 256 poziomów jasności [35]. W przedstawianej pracy rozważane są obrazy
przedstawiane w skali szarości o 8 bitowej reprezentacji poziomów jasności (a więc
ich liczba jest równa 256) oraz o rozmiarze zależnym od określonej testowej pary
stereoskopowej (por. p. 6.3).
[
ox, oy
] x
y
Obrazowanypunkt sceny
Płaszczyznaobrazowania
Ψ
(a) Ciągła funkcja nośnika obrazu określonana płaszczyźnie obrazowania Ψ
pikselp (i, j)
Obrazowanypunkt sceny
(x,y)
kolumna j
wiersz i
[0,0] j
i
N kolumn
M wierszy
(b) Przestrzenna dyskretyzacja ciągłej funkcji no-śnika obrazu zachodząca w przetworniku ob-
razowym
2k poziomów kwantowania
k-t
ypo
ziom
jasn
o-ci
i-tywiersz
M wierszy
N kolumn
j-takolumna
(c) Dyskretyzja i kwantyzacja amplitudy cią-głej funkcji promieniowania w celu otrzy-
mania wartości liczbowych
i-tywiersz
M wierszy
N kolumnj-ta kolumna
[0, 0]
(d) Płaska reprezentacja otrzymanego obra-zu cyfrowego w formie macierzy liczb(nazywanej macierzą wartości jasności).Różnym wartościom liczbowym odpo-
wiadają różne odcienie szarości.
Rys. 2.3. Zobrazowanie tworzenia cyfrowej reprezentacji obrazu przez dyskretyza-cję i kwantyzację ciągłej funkcji nośnika obrazu
Z obrazem cyfrowym zazwyczaj związany jest układ współrzędnych pikselo-
wych, którego początek znajduje się „w lewym górnym rogu”, natomiast wartości
zmieniają się w „dół” i w „prawo”. Położenie danego piksela określa się przez po-
danie numeru wiersza i kolumny, w której się on znajduje. Początek tego układu
współrzędnych jest oznaczony na rys.2.2 przez Oi , a osie przez xi i yi.
33

“KonspPreamb” 2013/10/3 page 34 #37
2. Zagadnienie widzenia stereoskopowego
Przeliczenie współrzędnych położenia punktu należącego od obrazu z układu
współrzędnych związanym z kamerą Oc na układ współrzędnych pikselowych Oi
przy założeniu, że osie obu układów współrzędnych mają zgodne zwroty, odbywa
się zgodnie z zależnościami:
xi = u/sx + ox i u = (xi − ox) sx
yi = v/sy + oy i v = (yi − oY ) sy
(2.3)
gdzie u, v to współrzędne punktu wyrażone w układzie współrzędnych związanych
z kamerą Oc, xi, yi są współrzędnymi punktu wyrażonymi w układzie współrzęd-
nych pikselowych Oi, ox i oy są współrzędnymi punktu głównego o przekształcenia
(wyrażone w numerach pikseli przyjmują wartości ox = N /2 i oy = M/2, jeżeli
punkt główny znajduje się w środku obrazu wynikowego o rozmiarze M × N),
zaś parametry sx oraz sy opisują fizyczne rozmiary uzyskanego piksela wyrażo-
ny w jednostkach metrycznych, zazwyczaj milimetrach. W przypadku stosowania
przetworników CCD (ang. Charge Coupled Device) wartości te określają rozmiary
pojedynczego elementu światłoczułego rejestrującego padające na niego światło.
Dwa rozmiary wynikają z faktu, że w rzeczywistych przetwornikach CCD elemen-
ty światłoczułe mogą przyjmować kształt kwadratu (wtedy sx = sy) lub prostokąta
(wtedy sx , sy) [43].
W ogólnym przypadku wartości współrzędnych otrzymywane przez zastosowa-
nie wzorów (2.3) są wartościami ułamkowymi. Jednak w praktycznych realizacjach
stosuje się zaokrąglanie otrzymanych wartości do liczb całkowitych.
Czasami wprowadzane są dodatkowe parametry, jak np. skośność, która może
wystąpić, gdy w czasie produkcji kamery przetwornik optyczny nie został umiesz-
czony dokładnie prostopadle do płaszczyzny tworzenia obrazu lub sam przetwornik
nie jest dokładnie prostokątny [44]. Wszystkie parametry opisujące zmianę układu
współrzędnych z układu kamery do współrzędnych pikselowych zbierane są w for-
mie macierzy i nazywane parametrami wewnętrznymi kamery [42].
2.3. Geometria układu dwóch kamer
Akwizycja pary stereoskopowej wymaga zastosowania dwóch kamer oraz zna-
jomości ich relatywnego położenia względem siebie. Model układu złożonego
z dwóch kamer perspektywicznych, wraz ze związanymi z nim zależnościami geo-
34

“KonspPreamb” 2013/10/3 page 35 #38
2. Zagadnienie widzenia stereoskopowego
metrycznymi, definiuje tzw. geometrię epipolarną, której model został przedsta-
wiony na rys. 2.4. Model ten jest bardzo dobrze znany i praktycznie zawsze stoso-
wany podczas analizy obrazów pary stereoskopowej [45, 46, 23, 38, 39].
PM
m1
m2
p1p2
e1 e2
O1 O2
lp2Ψ1
Ψ2
ψpψm
lp1
lm1
lm2
Rys. 2.4. Geometria epipolarna układu dwóch kamer perspektywicznych
W układzie dwóch kamer ważnym elementem jest linia łącząca punkty ogni-
skowe kamer O1 i O2, która nazywana jest linią bazową (ang. baseline) układu.
Linia ta przecina płaszczyzny tworzenia się obrazów Ψ1 i Ψ2 w punktach e1 i e2,
nazywanych punktami epipolarnymi (ang. epipoles). Dowolny punkt sceny widzia-
ny przez obydwie kamery (P i M na rys. 2.4), wraz z odpowiadającymi im pro-
mieniami optycznymi prowadzącymi do kamer, definiują płaszczyzny epipolarne
(ang. epipolar planes), ψp i ψm. Płaszczyzny te przecinają płaszczyzny obrazowa-
nia, wyznaczając linie epipolarne (ang. epipolar lines), odpowiednio lp1 i lp2 dla
punktu P oraz lm1 i lm2 dla punktu M. Linie epipolarne wyznaczane są również
przez projekcję promienia optycznego związanego z jedną kamerą na płaszczyznę
obrazową związaną z drugą kamerą. Wszystkie linie epipolarne związane z jedną
kamerą przecinają się w odpowiadającym im punkcie epipolarnym.
Niech p1 i m1 będą rzutami pewnych punktów przestrzeni P i M na płaszczyznę
obrazową jednej z kamer, zaś p2 i m2 odpowiadającymi im rzutami na płaszczyznę
drugiej kamery. Promienie optyczne O1P i O1M, które definiują położenie obra-
zów punktów na płaszczyźnie obrazowej Ψ1, widziane są jako linie epipolarne lp2
35

“KonspPreamb” 2013/10/3 page 36 #39
2. Zagadnienie widzenia stereoskopowego
i lm2 na drugiej płaszczyźnie obrazowej Ψ2. Tak więc, punkt p2 odpowiadający
punktowi p1, musi leżeć na linii epipolarnej lp2 określonej przez promień optycz-
ny O1P rzutowany na płaszczyznę obrazową Ψ2. Analogiczna zależność zachodzi
dla obrazów punktu M, dlatego punkt m2 odpowiadający punktowi m1 musi leżeć
na linii epipolarnej lm2 wyznaczonej przez promień optyczny O1M rzutowany na
płaszczyznę obrazową Ψ2.
Sytuacja ta jest oczywiście symetryczna i jeżeli pod uwagę zostanie wzięta dru-
ga płaszczyzna obrazowa Ψ1, to punkty p1 i m1 muszą leżeć na odpowiednich li-
niach epipolarnych lp1 i lm1 wyznaczanych przez rzuty rzuty promieni optycznych
O2P i O2M przechodzących przez punkty p2 i m2 na płaszczyźnie obrazowej Ψ2.
Tak więc, miejsce rzutu dowolnego punktu na jedną płaszczyznę nie jest dowolne,
lecz określone przez odpowiadające im linie epipolarne. Właściwość ta jest znana
pod nazwą ograniczenia epiplarnego (ang. epipolar constraint) i jest jedną z fun-
damentalnych właściwości maszynowego widzenia stereoskopowego [23, 47, 26,
48].
Zgodnie z założeniami ograniczenia epipolarnego, punkt p1 na jednym obrazie
posiada odpowiadającą mu linię epipolarną lp2 na drugim obrazie. Natomiast punkt
m1 jednego obrazu posiada odpowiadającą mu linię lm2 na drugim obrazie (por.
rys. 2.4). Punkt p2 drugiego obrazu będący odpowiednikiem punktu p1, musi leżeć
na odpowiadającej mu linii epipolarnej lp2 i taka zależność zachodzi również dla
obrazów punktu M, tzn. punkt m2 będący odpowiednikiem punktu m1 musi leżeć
na odpowiadającej mu linii epipolarnej lm2 . Linia epipolarna jest rzutem w dru-
gim obrazie odpowiedniego promienia optycznego przechodzącego przez punkt
p1 lub m1 i punkt środkowy kamery O1. Stąd istnieje przekształcenie p1 → lp2 ,
m1 → lm2 , przekształcające punkt jednego obrazu w odpowiadającą mu linię epi-
polarną w drugim obrazie. Jest to przekształcenie rzutowe z punktu w linię, które
określane jest przez tzw. macierz fundamentalną F (ang. fundamental matrix) [24].
Macierz fundamentalna zależy tylko od konfiguracji kamer (parametrów wewnętrz-
nych, położenia i orientacji w przestrzeni) i jest niezależna od położenia punktów
obserwowanej sceny. Definiuje ona ograniczenie epipolarne opisujące odpowied-
niość punktów widzianych na dwóch obrazach.
W układzie skalibrowanym, tzn. takim, dla którego wyznaczone zostały macie-
rze przekształcenia rzutowego kamer, ograniczenie epipolarne zapisywane jest za
pomocą tzw. macierzy zasadniczej (ang. essential matrix) [49, 24]. Wyznaczanie
36

“KonspPreamb” 2013/10/3 page 37 #40
2. Zagadnienie widzenia stereoskopowego
wartości numerycznych macierzy zasadniczej i fundamentalnej stanowi złożone
zagadnienie numeryczne i nazywane jest kalibracją układu widzenia [50, 51, 52,
24].
2.4. Dysparycja w obrazach pary stereoskopowej
Pojęcie dysparycji najwygodniej jest przedstawić w stereoskopowym układzie
kanonicznym przedstawionym na rys. 2.5. Układem kanonicznym kamer nazywa-
ne jest takie ich ustawienie, w którym osie optyczne obydwu kamer są równoległe,
płaszczyzny obrazów pokrywają się ze sobą, a linie obrazów tworzonych w obu
kamerach są współliniowe. Układ taki nazywany jest również układem standardo-
wym, układem podstawowym lub układem zrektyfikowanym [38, 39].
P (x, y, z)
p1 (u1, v1) p2 (u2, v2)
O1 O2
u1 u2
X
Z
linia bazowa b
hh
f
Rys. 2.5. Geometria kamer w stereoskopowym układzie kanonicznym
W kanonicznym układzie kamer osie optyczne obu kamer są równoległe i od-
dalone od siebie o odległość b = 2h. W obu kamerach tworzony jest obraz punktu P
o współrzędnych (x, y, z). Punkt ten rzutowany jest jako obraz p1 o współrzędnych
(u1, v1) w jednym z przetworników oraz obraz p2 = (u2, v2) w drugim z prze-
37

“KonspPreamb” 2013/10/3 page 38 #41
2. Zagadnienie widzenia stereoskopowego
tworników obrazowych. Układ współrzędnych pokazany na rys. 2.5 tworzy oś Z
reprezentująca odległość od kamery (z = 0 odpowiada płaszczyźnie tworzenia ob-
razu) oraz oś X reprezentująca odległość horyzontalną (oś Y prostopadła do płasz-
czyzny rysunku nie została zaznaczona). Wartość x = 0 ustalona została w poło-
wie odległości między kamerami. Każda z kamer posiada skojarzony z nią lokalny
układ współrzędnych z początkiem położonym w środku każdego obrazu. Warto-
ści u1, v1, u2, v2 określają położenie rzutów punktu w lokalnych układach współ-
rzędnych obu kamer mierzone na takiej samej wysokości obrazów (dla obrazów
w postaci cyfrowej odpowiada to temu samemu numerowi wiersza w macierzach
wartości obrazów), stąd v1 = v2 = v.
Z uwagi na różne położenia kamer względem obserwowanego punktu, między
wartościami współrzędnych u1 i u2 występuje różnica wartości d = u2−u1. Różnicę
tę nazywamy dysparycją. Z podobieństwa trójkątów [39, 24] pomiędzy poszcze-
gólnymi punktami wynikają następujące zależności:
−u1
f=
h + x
z,
u2
f=
h − x
z(2.4)
Eliminując x z równań (2.4), otrzymujemy wyrażenie określające odległość punktu
P od płaszczyzny tworzenia się jego rzutu:
z =2h f
u2 − u1=
b f
u2 − u1=
b f
d(2.5)
Tak więc znajomość dysparycji d pomiędzy rzutami punktu na dwóch obrazach
pozwala na obliczenie jego odległości od płaszczyzny tworzenia się rzutu, tożsa-
mej z płaszczyzną tworzenia obrazu. Jeżeli d = (u2 − u1) → 0, wtedy z → ∞.
Zerowa dysparycja oznacza, że punkt jest położony w nieskończonej odległości od
obserwujących go kamer, natomiast odległość ta maleje wraz ze wzrostem war-
tości dysparycji d. Pozostałe dwie współrzędne punktu P mogą być wyznaczone
z zależności [38, 39]:
x =b (u2 − u1)
2d, y =
bv
d(2.6)
Powyższy przypadek definiuje dysparycję horyzontalną. W ogólnym przypad-
ku przesunięcie w obrazie może występować również w kierunku pionowym i wte-
dy definiuje się również dysparycję wertykalną. Jest ona określona jako różnica
38

“KonspPreamb” 2013/10/3 page 39 #42
2. Zagadnienie widzenia stereoskopowego
położenia tych samych punktów, względem współrzędnych wertykalnych:
dy = v2 − v1 (2.7)
Najbardziej ogólnym, lecz bardzo rzadko wykorzystywanym w praktyce, jest
pojęcie dysparycji zdefiniowanej jako odległość euklidesowa rzutów punktów wy-
stępujących w dwóch obrazach [53]:
dxy =
√
(u2 − u1)2 + (v2 − v1)2 (2.8)
Ponieważ praktycznie każdy przypadek obliczania wartości dysparycji moż-
na sprowadzić do poszukiwania dysparycji horyzontalnej, w niniejszej pracy pod
pojęciem dysparycji rozumiana jest tylko dysparycja horyzontalna. Rozumiana jest
ona jako różnica współrzędnych horyzontalnych w cyfrowych obrazach pary stereo-
skopowej reprezentowanych przez macierze wartości jasności tych obrazów (por.
rys. 2.3d). Przy takiej reprezentacji obrazów dysparycja horyzontalna jest różni-
cą pomiędzy numerami kolumn macierzy obrazów, w których znajduje się piksel
będący obrazem tego samego punktu sceny.1
2.4.1. Rektyfikacja obrazów pary stereoskopowej
Rektyfikacja pary stereoskopowej, schematycznie przedstawiona na rys. 2.6,
polega na wyznaczeniu takich przekształceń homograficznych, które po zastoso-
waniu do każdego z dwóch obrazów powodują, że odpowiadające sobie linie epi-
polarne stają się współliniowe i równoległe do poziomych krawędzi obrazu. Proces
rektyfikacji odgrywa ważną rolę, ponieważ pozwala na zmniejszenie przestrzeni
poszukiwań dysparycji tylko do jednowymiarowego przeszukiwania na odpowia-
dających sobie liniach obrazów. Ze względu na to, że rektyfikacja umożliwia zna-
czące zmniejszenie kosztu obliczeniowego w czasie dopasowania pary stereosko-
1 W pracy wartość dysparycji wyznaczana jest dla obrazów cyfrowych, więc rozumiana jestjako różnica pomiędzy numerami kolumn, które określają położenie tego samego piksela w dwóchobrazach pary stereoskopowej. Z tego względu, jeżeli wartość tej różnicy wynosi n używane jestskrótowe określenie, że dysparycja wynosi n pikseli.
39

“KonspPreamb” 2013/10/3 page 40 #43
2. Zagadnienie widzenia stereoskopowego
powej, stała się standardowym krokiem przetwarzania wstępnego w algorytmach
dopasowania [54, 55].
Rektyfikacja obrazów pary stereoskopowej jest możliwa praktycznie dla każ-
dego systemu stereoskopowego widzenia maszynowego [56]. Można ją wykonać
zarówno przy założeniu znajomości parametrów geometrycznych systemu, jak i dla
systemu nieskalibrowanego, tzn. dla obrazów par stereoskopowych o nieznanych
parametrach geometrycznych układu akwizycji. Warunkiem wystarczającym do
przeprowadzenia procesu rektyfikacji obrazów jest jedynie spełnienie założenia,
że dwa obrazy tworzą parę stereoskopową.
P
l1
l1
p1
p1
O1 e1
l2
l2
p2
p2
O2e2
Rys. 2.6. Proces rektyfikacji obrazów pary stereoskopowej prowadzący do zrów-noleglenia linii epipolarnych
Proces rektyfikacji pary stereoskopowej składa się zazwyczaj z następujących
kroków [23, 57]:
1. W kroku pierwszym wyznaczany jest zbiór odpowiadających sobie pikseli na
obrazach pary stereoskopowej. Zbiór ten musi zawierać co najmniej trzy odpo-
wiadające sobie piksele, przy czym zwiększenie liczebności zbioru odpowiada-
jących sobie pikseli poprawia dokładność uzyskanych macierzy przekształceń,
jak również ułatwia ich znalezienie.
2. Następnie wyznaczane jest jednoznaczne przekształcenie zbioru pikseli z jed-
nego obrazu do zbioru pikseli pochodzących z drugiego obrazu. Ponieważ od-
powiadające sobie piksele pochodzą z obrazów tworzących parę stereoskopo-
40

“KonspPreamb” 2013/10/3 page 41 #44
2. Zagadnienie widzenia stereoskopowego
wą, przekształcenie umożliwiające przejście z jednego zbioru w drugi musi
spełniać warunki geometrii epipolarnej. Przekształcenie takie opisane jest przez
macierz fundamentalną F zawierającą opis geometrii epipolarnej układu widze-
nia w zewnętrznym układzie współrzędnych [23].
3. Z kolei wyznaczane jest pewne przekształcenie rzutowe H1, które zastosowane
do jednego z obrazów pary powoduje przesunięcie odpowiadającego mu punktu
epipolarnego do nieskończoności.
4. Podobnie wyznaczane jest przekształcenie rzutowe H2, które zastosowane do
drugiego obrazu przesuwa jego punkt epipolarny do nieskończoności. Warun-
kiem koniecznym przy tym jest, aby przekształcenie to wraz z przekształceniem
H1 spełniało ograniczenia określone w punkcie 2, czyli aby było spójne z geo-
metrią epipolarną układu widzenia.
5. W ostatnim kroku macierze przekształceń H1 i H2 są wykorzystane do prze-
kształcenia odpowiadających im obrazów.
Przykład działania powyżej przedstawionego algorytmu rektyfikacji [57], za-
stosowanego do rzeczywistej pary stereoskopowej, dla której nie była znana geo-
metria układu, został przedstawiony na rys. 2.7.
Zastosowanie macierzy przekształceń H1 i H2 jest równoznaczne z resamplin-
giem (ang. resampling) obrazu, zazwyczaj powodującym jego rotację oraz zmianę
kształtu. Efekt zastosowania resamplingu widoczny jest na rys. 2.7 w postaci czar-
nych obszarów na brzegach obrazów. Jest to praktycznie jedyna cecha niekorzystna
zastosowania takiego kroku przetwarzania wstępnego, gdyż przy źle dobranej geo-
metrii może znacząco zmniejszyć liczbę pikseli widocznych równocześnie na obu
obrazach. Sytuacja taka może zachodzić, gdy macierze przekształceń H1 i H2 defi-
niują dużą rotację obrazów, w efekcie czego w obrazach po resamplingu pozostaje
niewielka część wspólna.
2.5. Problemy występujące przy projektowaniu algorytmów
dopasowania pary stereoskopowej
Pomimo prostoty sformułowania, zagadnienie znalezienia jak największej licz-
by odpowiadających sobie pikseli na obrazach pary stereoskopowej jest trudnym
zagadnieniem algorytmicznym. O jego złożoności decyduje wiele czynników po-
chodzących z różnych źródeł. Poniżej przedstawione zostały typowe, najczęściej
41

“KonspPreamb” 2013/10/3 page 42 #45
2. Zagadnienie widzenia stereoskopowego
Rys. 2.7. Przykład pary stereoskopowej przed i po procesie rektyfikacji. Na ob-razach zaznaczony został zbiór odpowiadających sobie punktów „⋆”. Liniąprzerywaną zaznaczono linie epipolarne przed rektyfikacją, natomiast liniami
ciągłymi linie epipolarne po zastosowaniu algorytmu rektyfikacji
spotykane problemy maszynowego widzenia stereoskopowego, jakie można napo-
tkać w czasie projektowania algorytmu dopasowania. Przy każdym z wymienio-
nych problemów podany został krótki komentarz metody za pomocą której próbuje
się go rozwiązać.
Przesłonięcia
Schematyczną ilustrację powstawania przesłonięć pokazano na rys.2.8. Efek-
tem przesłonięcia nazywana jest sytuacja, gdy pewien fragment obrazu widziany
jest tylko przez jedną z kamer, natomiast nie jest widoczny w drugim obrazie pa-
ry. W takiej sytuacji brak jest odpowiadających sobie pikseli pewnego fragmentu
jednego obrazu w drugim obrazie. Uniemożliwia to znalezienie prawidłowego do-
pasowania w tych obszarach [58, 59].
Metody stosowane w celu rozwiązania zagadnienia obszarów przesłoniętych
42

“KonspPreamb” 2013/10/3 page 43 #46
2. Zagadnienie widzenia stereoskopowego
Powierzchnia obiektuP
M
N
p1 m1 n1 p2 n2 m2?
O1 O2
Rys. 2.8. Występowanie zjawiska przesłonięć w zagadnieniu widzenia stereosko-powego. Punkt M widziany jest przez jedną kamerę jako obraz m1, natomiast
brak jest jego rzutu tworzącego obraz punktu m2 w drugiej kamerze
są oparte głównie na nałożeniu ograniczenia na ciągłość mapy dysparycji, tzn.
uwzględnieniu że wartości dysparycji nie mogą zmieniać się gwałtownie [60].
W przypadku poszukiwania wartości dysparycji w obszarach przesłoniętych algo-
rytm osiąga maksymalną wartość dysparycji, co może świadczyć o niemożliwości
znalezienia prawidłowego dopasowania. U podstaw tej metody stoi przypuszczenie,
że w realnej scenie obiekty nie znajdują się bardzo daleko od siebie.
Innym podejściem jest zamiana miejscami obrazu referencyjnego i obrazu prze-
szukiwania, po czym ponownie przeprowadzany jest algorytm dopasowania. War-
tości dysparycji dla zamienionych obrazów powinny róznić się tylko znakiem, a nie
wartością. W przypadku występowania znaczącej różnicy wartości, przyjmuje się,
że są to obszary przesłonięte. Technika ta jest znana jako badanie spójności lewo-
prawo (ang. Left-Right Consistency Checking) [61].
Powtarzający się wzór tekstury
Problem ten występuje w sytuacji, gdy jednemu pikselowi na jednym obrazie
może odpowiadać kilka pikselów z innego obrazu. Występowanie tego typu zakłó-
cenia jest związane z zawartością widzianej sceny i w przeciwieństwie do obszarów
przesłoniętych nie występuje w każdej parze obrazów.
43

“KonspPreamb” 2013/10/3 page 44 #47
2. Zagadnienie widzenia stereoskopowego
Propozycją rozwiązania tego problemu jest zastosowanie transformaty Fouriera
w celu wykrywania w obrazie regionów o powtarzającym się wzorze tekstury [62].
Powtarzający się wzór tekstury powinien dać znaczący wzrost wartości transforma-
ty Fouriera obrazu, co można poddawać detekcji na etapie przetwarzania wstępne-
go, a następnie uwzględnić w kroku dopasowywania.
Region o stałej wartości jasności
Są to obszary, w których występuje zupełny brak tekstury. W efekcie tego war-
tości jasności nie zmieniają się na tyle znacząco, aby dostarczyć wystarczającej
ilości informacji umożliwiającej dopasowanie [59].
Wśród propozycji rozwiązania tego problemu występuje grupa algorytmów
opartych na wstępnej segmentacji obrazu i szukaniu dopasowania między wyzna-
czonymi segmentami [63]. Umożliwia to określenie położenia takich obszarów
i dopasowywanie ich jako cały fragment w sposób analogiczny do pojedynczych
pikseli [64, 65].
Zniekształcenia perspektywiczne
Zniekształcenia te są związane z zawartością obserwowanej sceny. Występują
w przypadku, gdy w scenie znajdują się obiekty zmieniające swój kształt podczas
ich obserwacji z różnych położeń. Problem ten praktycznie nie jest podejmowany
w literaturze. Autorowi nie udało się znaleźć żadnej wzmianki na temat zapobie-
gania zniekształceniom perspektywicznym.
Zniekształcenia radiometryczne
Te z kolei zniekształcenia są związane z parametrami elektrycznymi kamer.
Zależą one od jakości wykonania przetworników obrazowych i stanowią ich cechy
charakterystyczne. Składają się na nie takie parametry wykonania przetwornika ob-
razowego, jak: wzmocnienie, prąd ciemny, obciążenie składową stałą, czułość pro-
gowa układu, czy zakres dynamiczny działania przetwornika. Parametry te mogą
być różne dla dwóch kamer wykorzystanych do budowy systemu widzenia, w efek-
cie czego dwa obrazy cyfrowe tej samej sceny mogą posiadać różne wartości ja-
sności pikseli. Jedynym sposobem uniknięcia tych zniekształceń jest wybór kamer
o dokładnie takich samych parametrach, co często jest niemożliwe ze względu na
sposób produkcji przetworników obrazowych. Innym rozwiązaniem jest kalibracja
44

“KonspPreamb” 2013/10/3 page 45 #48
2. Zagadnienie widzenia stereoskopowego
kamer układu stereoskopowego, i korekcja otrzymanych obrazów względem wy-
znaczonych poprawek.
Zniekształcenia optyczne
Zniekształcenie te wynikają z charakterystyki budowy układu optycznego ka-
mer użytych do akwizycji obrazów. Zalicza się do nich wszystkie zniekształce-
nia wnoszone przez układ optyczny kamery, wśród których najczęściej spotykany-
mi są: zniekształcenia poduszkowe (ang. pincushion distortions), zniekształcenia
baryłkowe (ang. barrel distortions) oraz aberracje chromatyczna (ang. chromatic
aberration) i sferyczna (ang. spherical aberration) [66, 67]. W przypadku znie-
kształceń optycznych również możliwa jest kalibracja układu i uwzględnienie po-
prawek w czasie przetwarzania obrazów pary stereoskopowej.
Obecność powierzchni nielambertowskich
Problem ten związany jest z obserwowanymi obiektami. Powierzchnie nielam-
bertowskie, to powierzchnie nie odbijające światła równomiernie we wszystkich
kierunkach [68, 69]. Powierzchnie takie najczęściej posiadają przedmioty szklane
lub przezroczyste. Równie często występującymi powierzchniami nielambertow-
skimi są lustra lub przedmioty silnie błyszczące. Efekt ten jest często zauważalny
na fotografiach przedstawiających powierzechnie błyszczące. Próbą rozwiązywania
tego problemu jest uwzględnienie w algorytmie założenia o ciągłości mapy dyspa-
rycji [70] i estymacja wartości dysparycji w obszarach, gdzie wartości te znacząco
się różnią.
Zakłócenia szumowe
Zakłócenia szumowe powstają w urządzeniach elektronicznych podczas akwi-
zycji i przetwarzania obrazów do postaci cyfrowej. Ten rodzaj zakłóceń występuje
zawsze w przypadku przetwarzania dowolnych obrazów rzeczywistych i nie jest
możliwy do uniknięcia. W celu zmniejszenia wpływu zakłóceń szumowych stoso-
wane są algorytmy przetwarzania wstępnego. Zazwyczaj stosowane są algorytmy
filtracji umożliwiające usunięcie przynajmniej części zakłóceń szumowych.
Należy podkreślić, że przedstawiona lista na pewno nie wyczerpuje wszystkich
przeszkód, jakie można napotkać w czasie budowy stereoskopowego systemu wi-
zyjnego. Lista ta obejmuje jedynie najbardziej znane problemy. Zapewne można
45

“KonspPreamb” 2013/10/3 page 46 #49
2. Zagadnienie widzenia stereoskopowego
by było wymienić i inne, lecz są one zazwyczaj związane ze specyfiką konkretnej
sceny, czy też konkretnego zastosowania systemu wizyjnego. Z tego względu nie
zostały tutaj wymienione.
2.6. Założenia procesu dopasowania par stereoskopowych
W czasie analizy obrazów pary steroskopowej przyjmowanych jest wiele zało-
żeń dotyczących procesu dopasowania. Założenia te pomagają zmniejszyć złożo-
ność zagadnienia, a czasami stanowią bardzo ważny element algorytmu decydują-
cy o jego działaniu. Do najczęściej przyjmowanych i stosowanych założeń procesu
dopasowania pary stereoskopowej należą:
Ograniczenie epipolarne (ang. epipolar constraint)
Ograniczenie to wynika wprost z geometrii układu widzenia stereoskopowego.
Jest to najczęściej wykorzystywane założenie przyjmowane w czasie realizacji al-
gorytmów dopasowania pary stereoskopwej. Oznacza ono, że odpowiadające sobie
piksele obrazów leżą na odpowiadających sobie liniach epipolarnych. Dodatkowo,
przyjmowane jest z reguły założenie, że obrazy pary stereoskopowej zostały pod-
dane rektyfikacji, czyli wiersze obrazów odpowiadają liniom epipolarnym.
Jednoznaczność odpowiedników (ang. uniqueness constraint)
Przyjęcie tego założenia oznacza, że każdy punkt widziany przez jedną kamerę
ma dokładnie jeden odpowiednik w drugim obrazie. Założenie to nie jest spełnione,
gdy dwa punkty leżą na jednym promieniu optycznym obrazu jednej kamery i rów-
nocześnie obydwa są widoczne przez drugą kamerą. Sytuacja taka może zaistnieć,
gdy w obserwowanej scenie znajdują się np. obiekty przezroczyste.
Założenie jednoznaczności odpowiedników jest fundamentalnym założeniem,
na którym opiera się metoda sprawdzania spójności lewo-prawo. Metoda ta umoż-
liwia wykrycie błędnie dopasowanych pikseli poprzez zamianę miejscami obrazu
przeszukiwań i obrazu referencyjnego i powtórne wykonanie algorytmu dopaso-
wania. Jeżeli nie zostały znalezione wszystkie wartości dysparycji, które zostały
znalezione w pierwszym przebiegu algorytmu, na tej podstawie decyduje się, że
piskele te należą do grupy pikseli przesłoniętych [59].
46

“KonspPreamb” 2013/10/3 page 47 #50
2. Zagadnienie widzenia stereoskopowego
Ograniczenie zmienności wartości dysparycji (ang. smoothness
constraint)
W tym przypadku zakłada się, że w rzeczywistych obrazach dysparycja nie
może zmieniać się gwałtownie o dużą wartość. Jeżeli taka sytuacja występuje, to
prawdopodobnie nie można znaleźć właściwego dopasowania ze względu na obec-
ność zakłóceń lub występowanie przesłonięcia w obrazie.
Ograniczenie to wykorzystywane jest w algorytmach dopasowania obrazów po-
przez wbudowanie pewnych funkcji kary opartych o wartość gradientu zmienno-
ści jasności samego obrazu lub wyznaczonych wcześniej wartości dysparycji. Jeśli
w obrazie niewielkiej zmianie jasności odpowiada duża zmiana wartości dyspary-
cji lub jeśli sama wartość dysparycji zmienia się o większą wartość, niż pewien
założony próg, wówczas wartość ta zostaje odrzucona jako nieprawidłowa [71].
Ograniczenie gradientu wartości dysparycji (ang. limit of disparity
gradient)
Jest to założenie analogiczne do poprzedniego, ale dotyczące ograniczenia prze-
biegu zmienności dysparycji, przy czym zmienność dysparycji jest określona przez
jej pochodną. Wartość dysparycji zostaje uznana za nieprawidłową, jeżeli wartość
pochodnej dysparycji przekracza pewien ustalony próg [72].
Ograniczenie zakresu poszukiwanej dysparycji (ang. disparity limit)
Ograniczenie to oznacza założenie, że poszukiwane wartości dysparycji znaj-
dują się w pewnym przedziale wartości [dmin, dmax] ustalanym przed wykonaniem
algorytmu dopasowania. Ograniczenie to stosowane jest praktycznie zawsze w rze-
czywistych realizacjach algorytmów dopasowania. Problemem pozostaje ustalenie
przedziału zmienności dysparycji, szczególnie w przypadku nieznajomości zawar-
tości analizowanej sceny.
Zachowanie kolejności punktów w obrazach (ang. ordering constraint)
Przykład sceny, dla której założenie to nie jest spełnione, przedstawiono na
rys. 2.9. Zachowanie kolejności punktów w obrazach jest często przyjmowanym
założeniem, zgodnie z którym piksele obrazu widziane przez jedną kamerę są rów-
nież widziane przez drugą kamerę w takiej samej kolejności [73]. Kolejność wi-
47

“KonspPreamb” 2013/10/3 page 48 #51
2. Zagadnienie widzenia stereoskopowego
dzianych punktów obrazów może nie być zachowana, jeżeli w obserwowanej scenie
występują wąskie obiekty, co odpowiada sytuacji przedstawionej na rys. 2.9.
Powierzchnia obiektuP N
M
p1 n1 m1 p2 m2 n2
O1 O2
Rys. 2.9. Zobrazowanie złamania warunku zachowania kolejności punktów na ob-razach. Obrazy tworzone przez punkty przestrzeni N i M w jednej z kamer n1
i m1, tworzone są w odwrotnej kolejności w drugiej kamerze n2 i m2
48

“KonspPreamb” 2013/10/3 page 49 #52
Rozdział 3
Przegląd metod dopasowania obrazów pary
stereoskopowej
W rozdziale dokonano przeglądu literatury dotyczącej najczęściej spotykanych
metod rozwiązywania zagadnienia dopasowania obrazów pary stereoskopowej.
Rozdział rozpoczyna się próbą klasyfikacji znanych rozwiązań. W dalszej części
rozdziału bardziej szczegółowo przedstawiono metody ściśle związane z prezen-
towaną pracą. Szczególną uwagę zwrócono na metody dopasowania obrazów pa-
ry stereoskopowej obszarami oraz metodę Marra-Poggio-Grimsona dopasowania
obrazów pary stereoskopowej cechami, która jest metodą odniesienia do propono-
wanego rozwiązania dopasowania cechami wykorzystującego w swoim działaniu
teorię zbiorów rozmytych. Rozdział zakończono krótkim przeglądem metod umoż-
liwiających rozwiązanie zagadnienia dopasowania obrazów pary stereoskopowej
z wykorzystaniem obrazów kolorowych oraz przedstawieniem innych metod roz-
wiązywania zagadnienia dopasowania pary stereoskopowej rzadziej spotykanych
w literaturze.
3.1. Próba klasyfikacji metod dopasowania obrazów pary
stereoskopowej
Bardzo duża popularność i znaczenie praktyczne zagadnienia dopasowania ob-
razów pary stereoskopowej spowodowały powstanie bardzo dużej liczby algoryt-
mów, za pomocą których próbuje się je rozwiązać. Szeroka gama i różnorodność
znanych metod w znaczący sposób utrudnia ich klasyfikację i spójną prezentację.
Na rys. 3.1 przedstawiono schemat klasyfikacyjny dostępnych metod, z podzia-
łem na grupy. Pierwsza grupa metod, jaka może zostać wyróżniona, to metody
umożliwiające znalezienie dopasowania dla wszystkich pikseli obrazu, realizowa-
ne zazwyczaj przez dopasowywanie wartości jasności pikseli. Odrębną grupą są
metody umożliwiające znalezienie dopasowania tylko dla wyróżnionych fragmen-
tów obrazów, nazywanych cechami obrazu. Metody te wyróżnione są poprzez fakt,
49

“KonspPreamb” 2013/10/3 page 50 #53
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Metody dopasowaniapary stereoskopowej
Dopasowania pikseli Dopasowania cech obrazów
Dopasowanie obszarów(lokalne)
Dopasowanie obrazów(globalne)
Kooperacyjne
Dopasowanie oknami*
*W metodzie tej wykorzystywanesą wszystkie rodzaje miar:odległościowe, korelacyjne,statystyczne, funkcyjne oraz
miary w dziedzinie transformat
Programowanie dynamiczne
Rozcięcie grafów
Relaksacja
Algorytmy genetyczne
Dyfuzja nieliniowa
Krawędzie
Narożniki
Tensory
„Edgels”*
*edgel – „edge” ele-ment opisany przez
krawędź i jej orientację
Rys. 3.1. Ogólna klasyfikacja istniejących metod rozwiązywania problemu dopa-sowania pary stereoskopowej
że przed właściwym procesem dopasowania w obrazach wyszukiwane zostają ich
cechy charakterystyczne. Mogą nimi być krawędzie, narożniki lub obszary o sta-
łej jasności identyfikowane za pomocą algorytmów segmentacji obrazów. Czasami
wykorzystywana jest symboliczna reprezentacja wyszukanych cech.
Wśród metod dopasowywania wartości jasności pikseli można rozróżnić me-
tody lokalne i globalne. Metody globalne polegają na dopasowaniu całego obrazu
równocześnie. Charakteryzują się one wykorzystaniem pewnej funkcji kosztu, któ-
ra podlega optymalizacji. Funkcja kosztu jest określona względem poszukiwanej
mapy dysparycji. Główne różnice między poszczególnymi metodami globalnymi
50

“KonspPreamb” 2013/10/3 page 51 #54
3. Przegląd metod dopasowania obrazów pary stereoskopowej
sprowadzają się sposobu formułowania postaci funkcji kosztu oraz sposobu poszu-
kiwania rozwiązania optymalnego.
Wśród metod lokalnych najczęściej wykorzystywaną grupę metod stanowią me-
tody dopasowania obszarami. Charakteryzuje je wykorzystanie numerycznych war-
tości pikseli określających ich jasność lub zawartość składowych barwnych, w celu
wyznaczania poszukiwanej wartości dysparycji. Ponieważ porównywanie wartości
pojedynczych pikseli nie daje dobrych rozwiązań, zazwyczaj do znalezienia prawi-
dłowego dopasowania używa się okien, które obejmują piksel wraz z pewnym jego
sąsiedztwem.
Inną grupą, nie sklasyfikowaną na rys. 3.1, są algorytmy oparte na przekształ-
ceniu obrazu do innej dziedziny za pomocą zastosowania różnego rodzaju transfor-
mat. W dziedzinie transformat stosowana jest zazwyczaj metoda dopasowania ob-
szarami. Wśród popularnych transformat wykorzystywanych do zmiany dziedziny
reprezentacji obrazu można wymienić transformaty: Fouriera, falkową, rankingową
i transformatę CENSUS (por. p. 3.3.3).
W kolejnych punktach pracy przedstawione zostaną bardziej szczegółowo re-
prezentatywne i najczęściej spotykane metody dopasowania obrazów pary stereo-
skopowej.
3.2. Metody globalne
Podstawą globalnych metod dopasowania pary stereoskopowej jest ich formu-
łowanie w postaci zagadnienia optymalizacji pewnej funkcji kosztu. Przy takim
postawieniu zadania możliwe jest użycie ogólnych metod optymalizacyjnych. Ar-
gumentem funkcji kosztu jest poszukiwana mapa dysparycji d, tzn. zbiór warto-
ści dysparycji wszystkich pikseli należących do obrazu referencyjnego określonych
względem odpowiadających im pikselom w obrazie przeszukiwania.
Ogólna postać funkcji kosztu poddawanej optymalizacji (w zależności od przy-
jętej jawnej postaci – maksymalizacji lub minimalizacji) przyjmuje zazwyczaj for-
mę sumy [74, 75, 76]:
E (d) = Ed (d) + Es (d) (3.1)
W wyrażeniu (3.1) poszukiwana mapa dysparycji d stanowi parametr, względem
którego przeprowadzana jest procedura optymalizacji, natomiast E (d) określa mia-
51

“KonspPreamb” 2013/10/3 page 52 #55
3. Przegląd metod dopasowania obrazów pary stereoskopowej
rę kosztu, która ma podlegać optymalizacji. W wyniku procedury optymalizacyjnej
otrzymywana jest mapa dysparycji dopt będąca poszukiwanym rozwiązaniem.
Składnik Ed (d) wyrażenia (3.1) jest miarą dopasowania znajdowanych warto-
ści d dysparycji w odniesieniu do analizowanych pikseli p pochodzących z obrazu
referencyjnego, określoną wyrażeniem:
Ed (d) =∑
p∈Ire f
K(
p, dp
)
(3.2)
gdzie p to piksel należący do obrazu referencyjnego Ire f analizowanej pary ste-
reoskopowej, dp to jego poszukiwana wartość dysparycji, natomiast K(p, dp) jest
miarą kosztu dopasowania między wyróżnionym pikselem p pochodzącym z ob-
razu referencyjnego oraz odpowiadającym mu pikselem z obrazu przeszukiwania
o położeniu określonym przez wartość dysparycji dp. Miara ta jest zazwyczaj okre-
ślana na podstawie różnicy w wartościach jasności odpowiadających sobie pikseli
w obu obrazach.
Składnik Es (d) sumy określonej wyrażeniem (3.1) jest związany zazwyczaj
z ograniczeniem narzuconym na gładkość dysparycji w modelu sceny. Jest to pe-
wien rodzaj funkcji kary o wartościach tym większych, w przypadku minimalizacji
funkcji kosztu, im większe są różnice w wartościach dysparycji określonych dla
sąsiadujących ze sobą w obrazie pikseli:
Es (d) =∑
p,q∈N(p)
Vp,q
(
dp, dq
)
(3.3)
gdzie p, q są pikselami obrazu referencyjnego pochodzącymi z ustalonego zbio-
ru N (p) sąsiadujących ze sobą pikseli, dp i dq są wartościami przypisanych im
dysparycji, natomiast Vp,q
(
dp, dq
)
jest wartością kary umożliwiającą zapewnienie
gładkości poszukiwanej mapy dysparycji.
Funkcja kary może być na przykład zdefiniowana wyrażeniem:
Vp,q
(
λ|dp − dq|)
(3.4)
gdzie λ jest arbitralnie ustaloną stałą, decydującą o wartości funkcji kary w przy-
padku zwiększania się wartości bezwzględnej różnicy wartości dysparycji dp i dq
przypisanych do pikseli p i q.
52

“KonspPreamb” 2013/10/3 page 53 #56
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Na etapie projektowania globalnego algorytmu dopasowania dobierane są jaw-
ne postacie miary dopasowania K(p, dp) pikseli p pochodzących z obrazów ana-
lizowanej pary stereoskopowej względem wartości dysparycji dp oraz progi dla
których przyjmowany jest warunek naruszenia gładkości mapy dysparycji.
Po zdefiniowaniu jawnej postaci funkcji kosztu należy dobrać metodę jej opty-
malizacji. Dwoma najbardziej znanymi metodami globalnego rozwiązywania pro-
blemu dopasowania są: metoda polegająca na wyznaczeniu minimalnego rozcięcia
odpowiednio skonstruowanego grafu oraz metoda programowania dynamicznego.
Metody te zostaną poniżej krótko scharakteryzowane.
3.2.1. Metoda minimalnego rozcięcia grafu
Przed przedstawieniem zastosowania metody poszukiwania minimalnego roz-
cięcia grafu, umożliwiającej rozwiązanie zagadnienia dopasowania pary stereosko-
powej, omówione zostaną podstawowe pojęcia dotyczące teorii grafów.
Jako etykietowany, skierowany graf G rozumiana jest szóstka uporządkowana
G = (V,E,R, s, t,w), gdzie: V jest zbiorem wierzchołków, E zbiorem krawędzi,
R relacją incydencji określoną na zbiorzeV ×V, s, t ∈ V dwoma wyróżnionymi
wierzchołkami, zwanymi źródłem s i odpowiednio ujściem t, oraz w : E → R
funkcją etykietowania przyporządkowującą każdej krawędzi (p, q) ∈ R pewną wa-
gę w (p, q) ze zbioru liczb rzeczywistych. Zbiór niewyróżnionych wierzchołków
grafu oznaczamy przez P, zatemV = s, t ∪ P.
Funkcja wagi w (p, q) jest pewną miarą kosztu przypisaną krawędzi (p, q) ∈ R,
przy czym koszt krawędzi skierowanej (p, q) może być różny od kosztu krawędzi
(q, p) skierowanej w odwrotnym kierunku. Krawędź nazywana jest m-krawędzią,
jeśli łączy dowolny niewyróżniony wierzchołek p ∈ P z wierzchołkiem wyróżnio-
nym, a więc źródłem s lub ujściem t oraz n-krawędzią, jeśli łączy dwa niewyróż-
nione wierzchołki. Zbiór wszystkich n-krawędzi będzie oznaczany przez N .
Przyjmowane jest założenie, że zbiór krawędzi grafuG zawiera wszystkie n-kra-
wędzie (p, q) ∈ N oraz wszystkie m-krawędzie typu (s, p) (p, t) , p ∈ P. Na rys. 3.2a
przedstawiono, w postaci wielowymiarowej siatki, strukturę grafu stosowanego
z reguły w aplikacjach przetwarzania obrazów i grafice komputerowej.
Każdy podział zbioru V wierzchołków grafu G na dwa rozłączne podzbiory
S oraz T , takie że źródło s znajduje się w zbiorze S, natomiast ujście t w zbiorze
T nazywane jest rozcięciem typu s/t (krótko rozcięciem lub przekrojem) grafu G.
53

“KonspPreamb” 2013/10/3 page 54 #57
3. Przegląd metod dopasowania obrazów pary stereoskopowej
sźródło
p q
tujście
(a) Graf G
sźródło
p q
tujście
rozcięcie
(b) Rozcięcie grafu G
Rys. 3.2. Postać grafu wykorzystywana w zagadnieniach przetwarzania obrazu.Grubość krawędzi odzwierciedla ich wagę.
Rozcięcie grafu oznaczane jest symbolem C (S,T ). Przykład rozcięcia pokazano
na rys. 3.2b. Kosztem rozcięcia C = (S,T ) jest suma kosztów (wag) krawędzi
brzegowych (p, q), takich że p ∈ S i q ∈ T . Zagadnienie wyznaczenia minimalnego
rozcięcia grafu G polega na znalezieniu takiego rozcięcia, które ma najmniejszy
koszt spośród wszystkich możliwych rozcięć C = (S,T ) tego grafu [77].
Problem znalezienia minimalnego rozcięcia grafu G może być rozpatrywany
także w kategoriach wyznaczenia maksymalnego przepływu tego grafu ze źródła
s do ujścia t, rozumianego jako największa suma wag krawędzi umożliwiających
podział grafu na dwa rozłączne zbiory S i T . Dowodzi się mianowicie, że maksy-
malny przepływ uzyskuje się jako największą sumę wag tych krawędzi dzielących
graf na dwa rozłączne podzbiory, które odpowiadają krawędziom definiującym mi-
nimalne rozcięcie [78]. Tak więc problemy wyznaczenia minimalnego rozcięcia
i maksymalnego przepływu grafu są równoważne, a suma wartości wag krawędzi
definiujących maksymalny przepływ jest równa kosztowi minimalnego rozcięcia.
Twierdzenie powyższe jest jednym z fundamentalnych rezultatów optymalizacji
kombinatorycznej.
54

“KonspPreamb” 2013/10/3 page 55 #58
3. Przegląd metod dopasowania obrazów pary stereoskopowej
3.2.2. Zastosowanie metody minimalnego rozcięcia grafu
w zagadnieniu dopasowania pary stereoskopowej
Zagadnienie dopasowania pary obrazów stereoskopowych należy do klasy pro-
blemów przetwarzania obrazów, które mogą być rozwiązane za pomocą wykorzy-
stania teorii grafów, a w szczególności rozwiązania problemu znalezienia mini-
malnego rozcięcia grafu. W aspekcie wykorzystania teorii grafów, problem dopa-
sowania obrazów pary stereoskopowej przedstawiany jest zazwyczaj w kategoriach
problemu etykietowania wierzchołków grafu. Etykietowanie grafu polega na przy-
pisaniu do wierzchołków grafu, wartości etykiet pochodzących z pewnego okre-
ślonego zbioru etykiet L.
Aby znaleźć rozwiązanie dopasowania obrazów pary stereoskopowej tworzo-
ny jest graf, którego wyróżnionymi wierzchołkami są piksele obrazów tworzących
parę stereoskopową a etykietowane są piksele obrazu referencyjnego. Celem ta-
kiego etykietowania jest przypisanie do każdego piksela obrazu referencyjnego
p (i, j) ∈ Ire f etykiety z pewnego określonego zbioru etykiet L. W problemie do-
pasowania pary stereoskopowej zbiorem dopuszczalnych etykietL, jakie mogą być
przypisane do pikseli obrazu Ire f , jest zbiór poszukiwanych wartości dysparycji
pochodzących z przedziału wartości dopuszczalnych [dmin, dmax].
Problem etykietowania może być z kolei sformułowany z wykorzystaniem za-
gadnienia minimalizacji pewnej funkcji kosztu, której argumentem jest poszukiwa-
ny zbiór etykiet. Celem minimalizacji funkcji kosztu jest znalezienie takiego zbioru
etykiet d =
dp : p ∈ Ire f
, który minimalizuje wyrażenie:
E (d) =∑
p∈Ire f
K(
dp
)
+∑
p,q∈N(p)
V(
dp, dq
)
(3.5)
gdzie K(dp) jest kosztem przypisania etykiety dp do piksela p, N(p) jest zbiorem
pikseli sąsiadujących z pikselem p w ustalonym w danym algorytmie sąsiedztwie
tego piksela, natomiast V (dp, dq) jest kosztem przypisania etykiet dp i dq do pikseli
p i q należących do sąsiedztwa N(p).
Widoczne jest oczywiście podobieństwo pomiędzy wzorem (3.5) i wzorem
(3.1), dlatego metoda ta zaliczana jest do globalnych metod dopasowania pary ste-
reoskopowej. Ponieważ, zgodnie z przyjętym wyżej założeniem, zbiorem etykietL
55

“KonspPreamb” 2013/10/3 page 56 #59
3. Przegląd metod dopasowania obrazów pary stereoskopowej
są dopuszczalne wartości dysparycji, znalezienie optymalnego etykietowania grafu
jest równoznaczne z wyznaczeniem poszukiwanej mapy dysparycji d.
Wykorzystanie metody poszukiwania minimalnego rozcięcia grafu w celu obli-
czenia mapy dysparycji zostało zaproponowane w artykułach [79, 80]. Aby rozwią-
zać problem optymalizacji funkcji kosztu konstruowany jest graf którego źródłem s
są piksele obrazu referencyjnego Ire f . Piksele obrazu przeszukiwania Isz stanowią
natomiast ujście t budowanego grafu. Piksele obrazu referencyjnego (źródło s gra-
fu) oraz piksele obrazu przeszukiwania (ujście t grafu) wyznaczające wyróżnione
wierzchołki grafu, łączone są krawędziami z wagami równymi kosztowi przypi-
sanemu do określonych wartości dysparycji. Dodatkowo wierzchołki grafu wyzna-
czane przez wartości dysparycji łączone są dodatkowymi krawędziami, których wa-
gi mogą być modelem dodatkowej funkcji kary obliczanej w czasie optymalizacji
funkcji kosztu.
Obrazowe przedstawienie przestrzenne tak utworzonego grafu pokazane zo-
stało na rys. 3.3b. Graf przestrzenny może być również utworzony przez złożenie
i połączenie krawędziami grafów płaskich utworzonych dla każdego wiersza ob-
razu cyfrowego. Graf płaski jaki powstałby dla jednego wiersza obrazu cyfrowego
wraz z przykładowym rozcięciem przedstawia rys. 3.3a.
t
s
dmax
dmin
di
(a) Rozcięcie jednej z płasz-czyzn grafu trójwymia-
rowego
t
s
(b) Reprezentacja gra-fu trówymiarowe-
go
d
(i, j)
(c) Ilustracja rozcię-cia grafu
Rys. 3.3. Rozcięcie grafu odpowiadające podziałowi przestrzeni w której graf tenjest umieszczony. Graf trójwymiarowy (b) może być zobrazowany jako prze-
strzenne ułożenie grafów dwuwymiarowych (a)
Rozwiązaniem problemu dopasowania (wyznaczenia wartości mapy dyspary-
cji) jest hiperpowierzchnia d = f (i, j) pokazana na rys. 3.3c. Powierzchnia ta de-
finiowana jest przez optymalny zbiór etykietowania f określony względem pikseli
56

“KonspPreamb” 2013/10/3 page 57 #60
3. Przegląd metod dopasowania obrazów pary stereoskopowej
obrazu referencyjnego (źródła s grafu). Hiperpowierzchnia wyznaczana przez war-
tości dysparycji (zbiór etykiet określony przez funkcję etykietowania f ) d = f (i, j)
rozdziela źródło s (piksele obrazu referencyjnego Ire f ) i ujście t (piksele obrazu
przeszukiwania Isz), definiując jego rozcięcie oraz wyznaczony zbiór etykiet (zbiór
wyznaczonych wartości dysparycji). Przykład zobrazowania otrzymanej hiperpo-
wierzchni przedstawiony został na rys. 3.3c.
Spotykane w literaturze różnice między rozwiązaniami wykorzystującymi mi-
nimalne rozcięcie grafu w celu rozwiązania problemu dopasowania obrazów pary
stereoskopowej sprowadzają się głównie do wykorzystania różnych metod umożli-
wiających wyznaczenie minimalnego rozcięcia grafu. W proponowanych rozwią-
zaniach przyjmowane są także różne modyfikacje postaci funkcji kosztu.
Jedna z propozycji rozwiązania problemu dopasowania pary stereoskopowej
przedstawiona została przez Ishikawę i Geigera [81]. W proponowanym rozwiąza-
niu wykorzystany został graf o postaci trójwymiarowej, jak na rys. 3.3b. Funkcja
kosztu oparta została o różnice wartości jasności pikseli obrazów referencyjnego
i przeszukiwania. Dodatkowy człon funkcji kosztu zwiększa koszt przy próbie przy-
pisania znacząco różnych wartości dysparycji dla sąsiednich pikseli. Do rozwiąza-
nia znalezienie minimalnego rozcięcia grafu zastosowany został algorytm Gold-
berga – Tarjana znany pod nazwą ang. push relabel.
W propozycji przedstawionej w [82, 83] autor skupił się głównie na badaniach
algorytmu umożliwiającego znalezienie optymalnego rozcięcia grafu względem
poszukiwanego zbioru etykiet. Zaproponowany został ogólny algorytm umożliwia-
jący znalezienie minimalnego rozcięcia grafu, w przypadku gdy etykiety pochodzą
z dowolnie dużego skończonego zbioru. Algorytmy te są algorytmami iteracyjnymi
znanymi w literaturze pod nazwami ang. α-expansion i ang. α-β swap.1 W propo-
nowanym rozwiązaniu funkcja kosztu była oparta na różnicy wartości jasności pik-
seli i zawierała składnik zwiększający koszt w przypadku próby przypisania sąsied-
nim pikselom znacząco różnych wartości dysparycji. Inną cechą przedstawionego
rozwiązania było uwzględnienie w funkcji kosztu dodatkowego składnika, zwięk-
szającego wartość kary, jeżeli w czasie wykonywania algorytmu podejmowana była
próba przypisania wartości dysparycji do piksela przesłoniętego.
W pracach [84, 85, 77] przedstawiona została szczegółowa matematyczna ana-
1 Autorowi nie udało się znaleźć nawet przybliżonych tłumaczeń nazw tych algorytmów na ję-zyk polski.
57

“KonspPreamb” 2013/10/3 page 58 #61
3. Przegląd metod dopasowania obrazów pary stereoskopowej
liza postaci funkcji kosztu, jakie mogą być wykorzystane w algorytmach poszuki-
wania minimalnego rozcięcia grafu. Przedstawione rozważania zostały zastosowa-
ne do rozwiązania problemu dopasowania obrazów pary stereoskopowej. W roz-
wiązaniu tego problemu autorzy wprowadzili do funkcji kosztu dodatkowy skład-
nik, zwiększający jej wartość przy próbie przypisania wartości dysparycji do pikseli
przesłoniętych. Funkcja kosztu podlegała minimalizacji, a jako algorytm umożli-
wiający wyznaczenie minimalnego rozcięcia grafu zastosowany został algorytm
α-expansion.
3.2.3. Dopasownie obrazów pary stereoskopowej za pomocą
programowania dynamicznego
Terminem programowanie dynamiczne określa się ogólną metodę projektowa-
nia algorytmów umożliwiających rozwiązanie problemu poprzez jego rozłożenie
na mniejsze podproblemy. W algorytmach opartych o programowanie dynamicz-
ne każdy podproblem rozwiązuje się jednokrotnie, zapamiętując jego wynik do
późniejszego wykorzystania. Pozwala to na uniknięcie wielokrotnych obliczeń te-
go samego prodproblemu, co występuje np. przy zastosowaniu algorytmów typu
„dziel i zwyciężaj”.
Programowanie dynamiczne stosowane jest zazwyczaj do problemów optyma-
lizacyjnych, w których możliwych jest wiele rozwiązań. Z każdym rozwiązaniem
jest związany pewien koszt, a rozwiązanie optymalne to takie, które generuje opty-
malną (minimalną lub maksymalną) wartość kosztu [86].
W przypadku zastosowania programowania dynamicznego w zagadnieniu do-
pasowania obrazów pary stereoskopowej rozwiązanie szukane jest oddzielnie dla
każdego wiersza obrazu. Zakładając, że obraz ma rozmiary M × N pikseli i ozna-
czając prze pi j piksel leżący na przecięciu i-tego wiersza i j-tej kolumny, funkcję
kosztu dla poszczególnych wierszy i = 0, . . . ,M − 1 definiuje się jako:
E (di) =N−1∑
j=0
K(
di j
)
(3.6)
gdzie di jest wektorem dysparycji di j , j = 0, . . . ,N − 1, przypisanych kolejnym
pikselom pi j należącym do i-tego wiersza, zaś K(di j) jest kosztem przypisania
pikselowi pi j wartości dysparycji di j .
58

“KonspPreamb” 2013/10/3 page 59 #62
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Dla każdego wiersza o numerze i = 0, . . . ,M − 1 w obrazie referencyjnym
i odpowiadającego mu wiersza w obrazie przeszukiwania tworzona jest macierz
kosztu. Wyznaczenie optymalnej wartości dysparycji dla danego wiersza polega
na znalezieniu ścieżki w tak utworzonej macierzy, która, w zależności od jawnej
postaci miary kosztu E(di) minimalizuje lub maksymalizuje tę miarę. Optymal-
na ścieżka odpowiada poszukiwanemu wektorowi dysparycji di dla i-tego wiersza
obrazu [87].
Na rys.3.4 przedstawiona została wizualna reprezentacja konstruowania macie-
rzy kosztu, określona dla jednego wiersza obrazów pary stereoskopowej.
Ire f
Isz
Macierz kosztu dladla wyróżnionego wiersza
(a) Konstrukcja macierzy kosztu dla wyróżnio-nego wiersza obrazów pary stereoskopowejwykorzystywana w algorytmie dopasowa-
nia obrazów pary stereoskopowej
(b) Przykładowa macierzkosztu dla wyróżnionego
wiersza
Rys. 3.4. Graficzne przedstawienie macierzy kosztów używanych w algorytmie do-pasowania z wykorzystaniem programowania dynamicznego
Całościowe rozwiązanie w postaci mapy dysparycji określonej dla całych obra-
zów otrzymywane jest zazwyczaj przez iteracyjne rozwiązywanie problemu dopa-
sowania dla wierszy macierzy liczb reprezentujących cyfrowe obrazy pary stereo-
skopowej. Szczegółowe sposoby postępowania zarówno w przypadku poszukiwa-
nia rozwiązania dla jednego wiersza obrazu jak i całego obrazu uzależnione są od
implementacji algorytmu.
Jako koszt dopasowania stosowane są miary miary SAD (ang. Sum of Absolute
Differences), SSD (ang. Sum of Squared Differences) lub ZNCC (ang. Zero mean
Normalized Cross–Correlation) [88] (por. p. 3.3.2). W funkcję kosztu wbudowy-
59

“KonspPreamb” 2013/10/3 page 60 #63
3. Przegląd metod dopasowania obrazów pary stereoskopowej
wane są dodatkowe ograniczenia, jak np. zakres wartości poszukiwanej dysparycji.
Ograniczenie zakresu wartości poszukiwanej dysparycji zilustrowane zostało na
rys. 3.4b, jako białe kwadraty w przekroju macierzy kosztu. Poszukiwanie opty-
malnej ścieżki w macierzy kosztu odbywa się wzdłuż przekątnej macierzy kosztu,
jednak zakres przeszukiwania ograniczony jest przez maksymalną wartość dopusz-
czalnej dysparycji dmax. W przypadku macierzy kosztu przedstawionej na rys. 3.4b
optymalna ścieżka zawiera się na pomiędzy wartościami umieszczonymi na prze-
kątnej i wartościami położonymi o dmax w prawo komórek od przekątnej macierzy.
Funkcja kosztu zawiera również często składnik odpowiadający za nałożenie
dodatkowych wartości kary w przypadku próby przypisania wartości dysparycji do
pikseli przesłoniętych. Funkcja kary wyrażana jest za pomocą różnicy dysparycji
określonych dla sąsiednich dopasowywanych pikseli lub wariancji wartości obli-
czanej dysparycji [87].
W [88] przedstawiony został algorytm oparty na programowaniu dynamicz-
nym, w którym struktura danych miała formę odpowiednio skonstruowanego drze-
wa. Innym aspektem prezentowanego tam algorytmu jest implementacja równocze-
snej optymalizacji funkcji kosztu zarówno dla wierszy jaki i dla kolumn określonej
macierzy kosztu. Efekt ten został osiągnięty przez zastosowanie technik programo-
wania równoległego.
W [89] zaprezentowany został algorytm dopasowania pary stereoskopowej z wy-
korzystaniem dwukierunkowego programowania dynamicznego (ang. bidirectio-
nal dynamic programming). Na podstawie obliczonej macierzy kosztu opartej o mia-
rę SSD wartość najlepszego dopasowania obliczana jest w dwóch krokach. Po wy-
konaniu pierwszego kroku, jakim jest obliczenie mapy dysparycji za pomocą pro-
gramowania dynamicznego, następuje poszukiwanie najlepszego rozwiązania
w drugim kierunku przeszukiwania. Jest to rozwiązanie analogiczne do zamiany
miejscami obrazu odniesienia i przeszukiwania, co według autorów pozwoliło na
zwiększenie odporności algorytmu w regionach gdzie występują piksele przesło-
nięte.
W [72] programowanie dynamiczne wykorzystane zostało w dopasowaniu ob-
razów w przestrzeni RGB (ang. Red Green Blue), z zastosowaniem miary kosztu
MSE (ang. Mean Squared Error) jako średniej ważonej dla każdego z kanałów.
Autorzy doszli do stwierdzenia, że wykorzystanie obrazów kolorowych pozwala
na uzyskanie lepszych wyników, niż zastosowanie obrazów w skali szarości.
60

“KonspPreamb” 2013/10/3 page 61 #64
3. Przegląd metod dopasowania obrazów pary stereoskopowej
3.3. Metody dopasowania obszarami
Metody dopasowania obszarami stanowią najbardziej liczną grupę metod w al-
gorytmach dopasowania obrazów. Nazwa wzięła swoje pochodzenie ze specyfi-
ki działania tych metod, których działanie opiera się na znajdowaniu dopasowa-
nia między fragmentami obrazów. Schematyczne przedstawienie działania meto-
dy dopasowania obrazów pary stereoskopowej obszarami przedstawione zostało
na rys. 3.5.
Region przeszukiwania
j
i
D
S
j∗j′ − dmax j
′ − dmin
Rys. 3.5. Zobrazowanie działania algorytmu dopasowania obszarami. Poszukiwa-nie rozwiązania odbywa się wzdłuż wierszy obrazu, a więc przy założeniu rek-
tyfikacji pary stereoskopowej
W typowym algorytmie w obrazie referencyjnym (lewy obraz na rys. 3.5) usta-
lane jest położenie okna na pozycji o współrzędnych środka okna (i, j). W obra-
zie przeszukiwania (prawy obraz na rys. 3.5) znajduje się okno przeszukiwania
o zmiennym położeniu w ustalonym zakresie dopuszczalnych wartości przesunię-
cia, czyli dysparycji z przedziału [dmin, dmax].
Rysunek 3.5 przedstawia tę sytuację w przypadku obrazów zrektyfikowanych
(tzn. linie epipolarne odpowiadają wierszom obrazów), stąd poszukiwanie odpo-
wiednika odbywa się tylko wzdłuż wiersza określonego przez współrzędną i na
lewym (referencyjnym) obrazie pary stereoskopowej, a poszukiwania jest wartość
współrzędnej j położenia okna w obrazie przeszukiwania. Dla każdego położenia
okna przeszukiwania określana jest pewna miara podobieństwa S (ang. similari-
61

“KonspPreamb” 2013/10/3 page 62 #65
3. Przegląd metod dopasowania obrazów pary stereoskopowej
ty) lub rozbieżności D (ang. dissimilarity). W zależności od budowy algorytmu, za
znalezioną wartość dysparycji uważa się współrzędną j∗ położenia okna przeszuki-
wania, dla której wartość przyjętej miary osiągnęła wartość optymalną (minimalną
lub maksymalną).
3.3.1. Algorytm metody dopasowania obszarami
Metoda poszukiwania dopasowań obszarami zapisana w formie algorytmicznej
przyjmuje postać określoną przez algorytm 3.1.
Algorytm 3.1 Ogólny algorytm dopasowania obrazów pary stereoskopowej przydopasowaniu obszarami.
Dane wejściowe: Obrazy tworzące parę stereoskopową Ire f i Isz o rozmiarach M×N pikseli
Dane wejściowe: Przedział dopuszczalnych wartości dysparycji [dmin, dmax]Dane wejściowe: Rozmiary okien referencyjnego i przeszukiwania Nv i Nh
for Dla każdego piksela obrazu referencyjnego do
Ustaw okno przeszukiwania w obrazie referencyjnym Ire f , na pozycji (i, j)for Dla każdej wartości dysparycji z zakresu [dmin, dmax] do
Ustaw okno przeszukiwania w drugim obrazie przeszukiwania Isz na pozy-cji (i, j + d)Oblicz wartość miary dopasowania pomiędzy oknamiif Obliczenia wykonywane są dla pierwszej wartości dysparycji d = dmin
then
Zapamiętaj wartość dysparycji d (i, j), oraz wartość obliczonej miaryS (i, j) lub D (i, j)
else
Porównaj bieżącą wartość miary z wartością otrzymaną dla poprzednie-go położenia okna przeszukiwania
end if
if Jeżeli wartość miary jest lepsza, tzn. większa lub mniejsza then
Zapamiętaj bieżącą wartość dysparycji d (i, j), oraz wartość miary S (i, j)lub D (i, j)
end if
end for
end for
Obliczona mapa wartości d jest wyznaczoną mapą dysparycji
W przypadku działania algorytmu 3.1 pozostaje do ustalenia miara, jaką można
posłużyć się do porównywania podobieństwa między pikselami zawartymi w oknie
62

“KonspPreamb” 2013/10/3 page 63 #66
3. Przegląd metod dopasowania obrazów pary stereoskopowej
referencyjnym i oknie przeszukiwania. W następnym punkcie przedstawiony zosta-
nie wybrany zbiór miar używany w procesie dopasowania.
3.3.2. Miary wykorzystywane w algorytmach dopasowania
obszarami
Aby przedstawić najczęściej stosowane miary w algorytmach dopasowania ob-
szarami, przyjęte zostaną oznaczenia podane w tabl. 3.1.
Tabl. 3.1. Oznaczenia stosowane przy opisie miar dopasowania używanych w al-gorytmach dopasowania obszarami
Symbol oznaczenia Wyjaśnienie znaczenia
Nv, Nh, Nw Rozmiary okien przeszukiwania i referencyjnego. W przy-
padku okna prostokątnego Nv określa rozmiar wertykalny,
a Nh rozmiar horyzontalny. W przypadku stosowania okna
kwadratowego rozmiary Nv = Nh są równe i rozmiar okna
kwadratowego jest oznaczany symbolem Nw.
W = W (i, j) Zbiór pikseli obrazu określonych przez okno o środku
umieszczonym na pozycji o współrzędnych (i, j).
Np Liczba pikseli zawartych w oknie. Dla okna prostokątnego
Np = Nv × Nh, dla okna o kształcie kwadratowym Np =
Nw × Nw.
Ire f (i, j) Wartość jasności piksela obrazu referencyjnego Ire f , le-
żącego na pozycji określonej przez współrzędne (i, j).
Isz (i, j) Wartość jasności piksela obrazu przeszukiwania Isz, leżą-
cego na pozycji określonej przez współrzędne (i, j).
Kontynuacja na następnej stronie …
63

“KonspPreamb” 2013/10/3 page 64 #67
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Tabl. 3.1 – Kontynuacja z poprzedniej strony
Symbol oznaczenia Wyjaśnienie znaczenia
Ire f (i, j) =
1Np
∑
m,n∈Wre f
Ire f
(
i + m,j + n
)
Średnia wartość jasności pikseli obrazu referencyjnego
Ire f w obszarze określonym przez okno referencyjne Wre f
umieszczone na pozycji o współrzędnych (i, j). Zakłada
się, że wszystkie piksele obrazu zawarte w oknie referen-
cyjnym Wre f umieszczonym na pozycji o współrzędnych
(i, j) należą do obrazu. W innym przypadku wartość ta
powinna być zdefiniowana w inny sposób.
Isz (i, j) =
1Np
∑
m,n∈Wsz
Isz
(
i + m,j + n
)
Średnia wartość jasności pikseli obrazu przeszukiwania
Isz w obszarze określonym przez okno przeszukiwania
Wsz umieszczone na pozycji o współrzędnych (i, j). Zakła-
da się, że wszystkie piksele obrazu zawarte w oknie prze-
szukiwania należą do obrazu. W innym przypadku war-
tość ta powinna być zdefiniowana w inny sposób.
d (i, j) , di j Wartość dysparycji horyzontalnej, czyli przesunięcia od-
powiadających sobie pikseli w obrazach pary stereosko-
powej w kierunku poziomym. Dla takiej wartości prze-
sunięcia okna przeszukiwania, względem położenia okna
referencyjnego przedstawione zostały miary dopasowania.
Miara korelacji wzajemnej
Korelacja wzajemna CC (ang. Cross Correlation) jest ogólną miarą statystycz-
ną podobieństwa dwóch zmiennych. W przypadku określania miary podobieństwa
między grupami pikseli należących do dwóch obrazów korelacja wzajemna jest
zdefiniowana wyrażeniem:
CC =∑
m,n∈WIre f (i + m, j + n) · Isz
(
i + m, j + n + di j
)
(3.7)
Wartości korelacji wzajemnej zawierają się w przedziale [0;+∞].
64

“KonspPreamb” 2013/10/3 page 65 #68
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Znormalizowana korelacja wzajemna
W zagadnieniach widzenia stereoskopowego, a w szczególności w algorytmach
dopasowania pary stereoskopowej [58, 90, 91, 92], często stosowana jest znormali-
zowana korelacja wzajemna NCC (ang. Normalized Cross Correlation), określona
wyrażeniem:
NCC =
∑
m,n∈WIre f (i + m, j + n) · Isz
(
i + m, j + n + di j
)
√
∑
m,n∈WI2re f
(i + m, j + n) · ∑
m,n∈WI2sz
(
i + m, j + n + di j
)
(3.8)
Wartości znormalizowanej korelacji wzajemnej zawierają się w przedziale [0; 1].
Centralnie znormalizowana korelacja wzajemna
Kolejną miarą należącą do grupy miar korelacyjnych jest znormalizowana ko-
relacja wzajemna o zerowej wartości średniej ZNCC [93, 94], określona wzorem:
ZNCC =
∑
m,n∈W
[
Ire f (i + m, j + n) − Ire f (i, j)]
·√
∑
m,n∈W
[
Ire f (i + m, j + n) − Ire f (i, j)]2 ·
·[
Isz
(
i + m, j + n + di j
)
− Isz
(
i, j + di j
)
]
·√
[
Isz
(
i + m, j + n + di j
)
− Isz
(
i, j + di j
)
]2(3.9)
Wartości tej miary zawierają się w przedziale [−1; 1].
65

“KonspPreamb” 2013/10/3 page 66 #69
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Korelacja Moravca
Czasami stosowana bywa także miara korelacyjna MCC (ang. Moravec Cross
Correlation) zaproponowana przez Moravca, o postaci:
MCC =
2 · ∑
m,n∈W
[
Ire f (i + m, j + n − Ire f
(
i, j + di j
)
]
·
∑
m,n∈W
[
Ire f (i + m, j + n) − Ire f
(
i, j + di j
)
]
+
·[
Isz
(
i + m, j + n + di j
)
− Isz
(
i, j + di j
)
]
+∑
m,n∈W
[
Isz
(
i + m, j + n + di j
)
− Isz
(
i, y + di j
)
] (3.10)
Wartości korelacji MCC zawierają się w przedziale [−1; 1]. Zaletą tej miary jest jej
inwariatność na obciążenie składową stałą.
Drugą grupą miar, bardzo często wykorzystywaną w algorytmach dopasowania
obszarami, są miary charakteryzujące „odległość” między odpowiadającymi sobie
obszarami w dwóch obrazach. Są to miary, których zakres zmienności zawiera się
w przedziale[
0; NpImax
]
lub[
0; NpI2max
]
, gdzie Imax to maksymalna wartość jasno-
ści piksela, natomiast Np oznacza liczbę pikseli sąsiedztwa.
Suma wartości bezwzględnych różnic
Najprostszą, a równocześnie bardzo często stosowaną miarą odległości, jest su-
ma wartości bezwzględnych różnic SAD (ang. Sum of Absolute Differences), okre-
ślona wzorem (3.11), która jest normą w przestrzeni L1:
SAD =∑
m,n∈W
∣
∣
∣
∣
Ire f (i + m, j + n) − Isz
(
i + m, j + n + di j
)
∣
∣
∣
∣
(3.11)
Ze względu na swoją intuicyjna prostotę, jak również łatwość implementacji
w rzeczywistych algorytmach, miara ta jest często stosowaną miarą w algorytmach
dopasowania obrazów [95, 96, 97, 73]. Miara SAD przyjmuje wartości[
0; NpImax
]
,
gdzie Imax to maksymalna wartość jasności piksela, natomiast Np liczba pikseli
sąsiedztwa.
66

“KonspPreamb” 2013/10/3 page 67 #70
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Centralnie znormalizowna suma wartości bezwględnych różnic
Znormalizowana suma wartości bezwzględnych różnic ZSAD (ang. Zero mean
Sum of Absolute Differences) jest zmodyfikowaną miarą SAD (3.11). Normaliza-
cja pozwala na uzyskanie lepszych wyników w przypadku, gdy wartości jasności
jednego z obrazów obciążone są składową stałą.
ZSAD =∑
m,n∈W
∣
∣
∣
∣
[
Ire f (i + m, j + n) − Ire f (i, j)]
−
−[
Isz
(
i + m, j + n + di j
)
− Isz
(
i, j + di j
)
]
∣
∣
∣
∣
∣
(3.12)
Zakresem zmienności miary ZSAD jest[
0; NpImax
]
.
Suma kwadratów różnic
Suma kwadratów różnic SSD (ang. Sum of Squared Differences) jest częstą
miarą przyjmowaną w algorytmach dopasowania obrazów pary stereoskopowej [6].
Jest to norma euklidesowa w przestrzeni wektorów jasności obrazów.
SSD =∑
m,n∈W
[
Ire f (i + m, j + n) − Isz
(
i + m, j + n + di j
)]2(3.13)
Miara SSD jest miarą podobieństwa wartości pikseli o zakresie zmienności[
0,NpI2max
]
.
Centralnie znormalizowna suma kwadratów różnic
Jako jedna z miar dopasowania bywa również stosowana znormalizowana cen-
tralnie suma kwadratów różnic [98] ZSSD (ang. Zero mean Sum of Squared Dif-
ferences). Jest ona wyrażona wzorem:
ZSSD =
∑
m,n∈W
[
Ire f (i + m, j + n) − Isz
(
i + m, j + n + di j
)]2
√
∑
m,n∈WI2re f
(i + m, j + n) · ∑
m,n∈WI2sz
(
i + m, j + n + di j
)
(3.14)
Miara ta przyjmuje wartości z przedziału[
0; NpImax
]
.
67

“KonspPreamb” 2013/10/3 page 68 #71
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Inne miary dopasowania
Przedstawione powyżej miary nie wyczerpują wszystkich miar jakie mogą zo-
stać zastosowane w algorytmie dopasowania. Są to miary najbardziej popularne,
natomiast jako przykłady innych, rzadziej stosowanych miar, można wymienić:
Lokalnie skalowana suma wartości bezwzględnych różnic
Lokalnie skalowana suma wartości bezwzględnych różnic LSAD (ang. Locally
Scaled Sum of Absolute Differences) jest zdefiniowana wzorem [99]:
LSAD =∑
m,n∈W
∣
∣
∣
∣
∣
∣
∣
∣
∣
Ire f (i + m, j + n) −Ire f (i, j)
Isz
(
i, j + di j
)
· Isz
(
i + m, j + n + di j
)
∣
∣
∣
∣
∣
∣
∣
∣
∣
(3.15)
Lokalnie skalowana suma kwadratów różnic
Lokalnie skalowana suma kwadratów różnic LSSD (ang. Locally Scaled Sum
of Squared Differences) określona jest wyrażeniem [99]:
LSSD =∑
m,n∈W
Ire f (i + m, j + n) −Ire f (i, j)
Isz
(
i, j + di j
)
· Isz
(
i + m, j + n + di j
)
2
(3.16)
Ucięta suma wartości bezwzględnych różnic
Ucięta suma różnic TSAD (ang. Truncated Sum of Absolute Differences) jest
miarą określoną wyrażniem [100]:
TSAD =∑
m,n∈Wmin
[∣
∣
∣
∣
Ire f (i + m, j + n) − Isz
(
i + m, j + n + di j
)
∣
∣
∣
∣
, TSAD
]
(3.17)
gdzie TSAD jest pewną stałą wartością progową.
Informacja wzajemna
Informacja wzajemna MI (ang. Mutual Information) jest teoretyczną miarą po-
dobieństwa informacji niesionej przez dwie zmienne losowe, która również znala-
zła zastosowanie jako miara podobieństwa między grupami pikseli w algorytmach
dopasowania obrazów pary stereoskopowej. Miara informacji wzajemnej jest okre-
68

“KonspPreamb” 2013/10/3 page 69 #72
3. Przegląd metod dopasowania obrazów pary stereoskopowej
ślona przez odpowiednie prawdopodobieństwa związane z porównywanymi zmien-
nymi losowymi.
Informacja wzajemna MI między dwoma zmiennymi losowymi A i B jest zde-
finiowana wyrażeniem [101, 102, 103]:
MI (A, B) = H (A) + H (B) − H (A, B) (3.18)
gdzie H (A) i H (B) są entropiami własnymi tych zmiennych losowych wyrażonymi
wzorami:
H (A) = −∑
a
p (a) log2 p (a) ; H (B) = −∑
b
p (b) log2 p (b) (3.19)
p (a) i p (b) są ich rozkładami, natomiast H (A, B) jest entropią łączną określoną
przez łączny rozkład prawdopodobieństwa p (a, b):
H (A, B) = −∑
a
∑
b
p (a, b) log2 p (a, b) (3.20)
Miara informacji wzajemnej MI jest miarą podobieństwa przyjmującą wartości
z zakresu 0 6 MI (A, B) 6 min [H (A) , H (B)]. Wartość minimalna równa zeru
występuje w przypadku, gdy zmienne losowe A i B są niezależne statystycznie, na-
tomiast wartość maksymalna jest przyjmowana w przypadku, gdy A i B są zmien-
nymi losowymi zależnymi funkcyjnie.
Zaproponowana została również wersja znormalizowana miary informacji wza-
jemnej NMI (ang. Normalized Mutual Information) [104]:
NMI (A, B) =H (A) + H (B)
H (A, B)(3.21)
W przypadku zastosowania miary informacji wzajemnej w algorytmie dopaso-
wania obrazów pary stereoskopowej wartości jasności pikseli traktowane są jako
wartości pewnych zmiennych losowych, natomiast ich rozkłady prawdopodobień-
stwa wyznaczane są za pomocą histogramów. W celu określenia łącznego rozkładu
prawdopodobieństwa stosowany jest histogram dwuwymiarowy lub estymator Pa-
rzena [105, 106].
69

“KonspPreamb” 2013/10/3 page 70 #73
3. Przegląd metod dopasowania obrazów pary stereoskopowej
3.3.3. Dopasowanie w dziedzinie transformat
Zastosowanie transformat w algorytmach dopasowania obrazów polega na za-
mianie dziedziny opisu obrazu z przestrzeni jasności pikseli na opis określony przez
zastosowaną transformatę, a następnie wykonanie algorytmu dopasowania w dzie-
dzinie transformat.
Praktycznie każda transformata, która może być zastosowana do obrazu cyfro-
wego może zostać wykorzystana w algorytmach dopasowania. Oprócz najbardziej
znanych transformat, takich jak transformata Fouriera, czy transformata falkowa,
stosowane bywają również mniej znane transformaty, takie jak cepstrum [107] lub
curvelet [108]. W następnych punktach przedstawione zostaną algorytmy dopaso-
wania, w których wykorzystano najbardziej znane transformaty.
Dopasowanie z zastosowaniem przekształcenia Fouriera
Ze względu na specyfikę obrazów, które są sygnałami dyskretnymi, w algoryt-
mach przetwarzania obrazów wykorzystujących przekształcenie Fouriera zastoso-
wanie znalazła dyskretna transformata Fouriera. Transformatę tę oblicza się z wy-
korzystaniem algorytmu FFT (ang. Fast Fourier Transform) [109].
Z uwagi na uwarunkowania implementacyjne, podczas obliczania transforma-
ty Fouriera obrazu posługujemy się z reguły oknem kwadratowym o nieparzystym
rozmiarze Nw. Zazwyczaj jest również przyjmowane typowe założenie o rektyfi-
kacji obrazów pary stereoskopowej. W takim przypadku poszukiwana jest wartość
dysparycji horyzontalnej co pozwala na zmniejszenie rozmiaru obliczanej trans-
formaty Fouriera. Wymiar okien przyjmowany jest wówczas jako 1 × Nw. Przy
wyborze takiego okna wartości jasności zawierających się nim pikseli określone są
jako: I (i, j − (Nw − 1) /2 + n) gdzie: n = 0, . . . ,Nw − 1.
W algorytmach wykorzystujących transformatę Fouriera w zagadnieniu dopa-
sowania pary stereoskopowej wartości transformaty wyznaczane są dla fragmen-
tów wierszy obrazów określonych przez położenia okien w obrazie referencyjnym
Ire f i przeszukiwania Isz. W przypadku ustalenia położenia okna referencyjnego
w obrazie referencyjnym Ire f transformata Fouriera fragmentu wiersza obrazu wy-
znaczonego przez to okno wyraża się zależnością:
Xre f (k) =Nw−1∑
n=0
Ire f (i, j − (Nw − 1) /2 + n) e− j2πkn/Nw =∣
∣
∣Xre f
∣
∣
∣ e− jφre f (k) (3.22)
70

“KonspPreamb” 2013/10/3 page 71 #74
3. Przegląd metod dopasowania obrazów pary stereoskopowej
dla k = 0, . . . ,Nw−1. Analogiczne wyrażenie jest słuszne dla transformaty Fouriera
Xsz (k) fragmentu obrazu wyznaczonego przez okno przeszukiwania.
Jeżeli w obrazie przeszukiwania istnieje piksel o takiej samej wartości, ale prze-
sunięty o wartość d w stosunku do położenia w obrazie referencyjnym, pomiędzy
transformatami powinna zachodzić zależność:
∣
∣
∣Xre f (k)∣
∣
∣ e− jφre f (k)= |Xsz (k)| e− jφsz(k)e− jφd (k) (3.23)
Jeżeli wartości jasności pikseli w obrazie referencyjnym i obrazie przeszukiwania
są takie same, wtedy ich widma amplitudowe∣
∣
∣Xre f (k)∣
∣
∣ oraz |Xsz (k)| są identyczne.
Natomiast wartość dysparycji d (k) może być obliczona poprzez różnicę wystę-
pującą w widmie fazowym:
d (k) = φd (k)Nw
2πk(3.24)
dla k = 0, . . . ,Nw − 1, gdzie φd (k) = φre f (k) − φsz (k). Ze względu na okresowość
fazy widma, wartości te należą do przedziału [−2π, 2π]. Dlatego w celu znalezie-
nia wartości dysparycji na podstawie wyznaczonego przesunięcia stosowane jest
liniowe przedłużenie przebiegu fazy, np. za pomocą algorytmu regresji liniowej
[109].
W algorytmach dopasowania z wykorzystaniem transformaty Fouriera główny-
mi różnicami są aspekty algorytmiczne. W [110] zaproponowany został algorytm
umożliwiający obliczanie wartość przesunięcia fazowego bezpośrednio z wartości
próbek transformaty. Umożliwia to uniknięcie bezpośredniego obliczania wartości
dwóch faz oraz problemu uciąglania fazy. Inną propozycją przedstawioną w [111]
jest estymacja częstotliwości i fazy z wykorzystaniem banku filtrów Gabora. Po-
zwoliło to na zrównoleglenie obliczeń oraz implementację algorytmu w układzie
FPGA (ang. Field Programmable Gate Array).
Transformata falkowa
Metody zastosowania transformaty falkowej w zagadnieniu dopasowania ob-
razów pary stereoskopowej są analogiczne do przypadku transformaty Fouriera.
Obydwa obrazy pary stereoskopowej przekształcane są do dziedziny transformaty
falkowej, po czym szukane jest rozwiązanie problemu dopasowania obrazów pary
71

“KonspPreamb” 2013/10/3 page 72 #75
3. Przegląd metod dopasowania obrazów pary stereoskopowej
stereoskopowej z wykorzystaniem otrzymanych współczynników opisu obrazów
wyrażonych za pomocą transformaty falkowej.
Ogólna definicja ciągłej transformaty falkowej CWT (ang. Continuous Wavelet
Transform) dla jednowymiarowego ciągłego sygnału f (x) ∈ L2 (R), gdzie L2 (R)
jest przestrzenią funkcji całkowalnych z kwadratem określonych na zbiorze liczb
rzeczywistych R, dana jest wzorem [112, 113]:
CWT (s, τ) =∫
f (x)ψ∗s,τ (x) dx (3.25)
gdzie ψ∗s,τ (x) jest pewną ustaloną funkcją określoną przez dwa parametry: parametr
skali s i parametr przesunięcia τ, natomiast ∗ oznacza operator sprzężenia zespolo-
nego.
Transformata odwrotna, umożliwiająca rekonstrukcję sygnału na podstawie otrzy-
manej transformaty według wyrażenia (3.25) określona jest wzorem [112, 113]:
f (x) ="
CWT (s, τ)ψs,τ (x) dτds (3.26)
Transformata falkowa pozwala na reprezentację sygnału za pomocą ustalonej
rodziny funkcji stanowiącej ortogonalną bazę przekształcenia. Baza ta ustalana jest
za pomocą operacji przesuwania i skalowania podstawowej funkcji matki ψ (x),
zwanej również funkcją macierzystą lub prototypową (ang. mother wavelet) [114,
115]. W wyniku tych operacji otrzymywany jest zbiór funkcji:
ψs,τ (x) =1√
sψ
(
x − τs
)
(3.27)
umożliwiający jednoznaczną reprezentację sygnału w dziedzinie transformaty [112,
113] gdzie parametr√
s normalizuje energię falki.
Należy zwrócić uwagę, że w wyrażeniach (3.25), (3.26) i (3.27) nie jest okre-
ślona jawna postać funkcji falkowej. Stanowi to zasadniczą różnicę między trans-
formatą Fouriera, w której określona jest konkretna baza rozkładu. W przypadku
transformaty falkowej funkcję podstawową ψ (x) można dobierać praktycznie do-
wolnie, zakładając że spełnia ona określony zbiór warunków. Przykładem jednej
z często stosowanych funkcji macierzystych, będącej podstawą zbudowania bazy
rozkładu w transformacie falkowej, jest dobrze znana falka Haara [112, 116, 117].
72

“KonspPreamb” 2013/10/3 page 73 #76
3. Przegląd metod dopasowania obrazów pary stereoskopowej
W przypadku obliczania dyskretnej transformaty falkowej DWT (ang. Discrete
Wavelet Transform), która jest użyteczna w zastosowaniu do analizy obrazów cy-
frowych, najczęściej próbkowana jest płaszczyzna czas–częstotliwość. W tym przy-
padku transformata falkowa obliczana jest jedynie dla dyskretnych wartości para-
metrów skali s i przesunięcia τ.
W celu wyznaczenia dyskretnej reprezentacji funkcji falkowych modyfikowany
jest wzór (3.27). Popularnym sposobem dyskretyzacji zbioru funkcji falkowych jest
przyjęcie, że są one wyznaczane dla dyskretnych wartości parametrów s i τ:
sm = sm0 , τn = nτ0sm
0 (3.28)
gdzie m i n są wartościami całokowitoliczbowymi, zaś s0 jest liczbą rzeczywistą
większą od 1, ustaloną w celu dyskretyzacji wartości parametru skali s z całkowi-
tym parametrem skali m, natomiast τ0 jest niezerową liczbą rzeczywistą, wykorzy-
staną do dyskretyzacji przesunięcia τ z całkowitym parametrem n. Tak więc dys-
kretna transformata falkowa określona jest dla dyskretnych wartości parametrów
skali s ∈
sm0 ; m ∈ Z
i przesunięć τ ∈
nτ0sm0 ; m, n ∈ Z
.
W efekcie dyskretyzacji wzór (3.27) przybiera postać:
ψm,n (x) = s−m/20 ψ
(
s−m0 x − nτ0
)
(3.29)
Przy dyskretyzacji zbioru funkcji falkowych istnieje dowolność w wyborze war-
tości parametrów s0 i τ0. Jednak najczęściej wybieranymi wartościami w przypad-
ku zastosowań dyskretnej transformaty falkowej są: s0 = 2 i τ0 = 1. Wówczas
zachodzi zależność sm = 2m i τn = n2m. Pozwala to na otrzymanie diadycznego
próbkowania ciągłych wartości parametrów s i τ, co powoduje że parametry prób-
kowania zmieniają się z mnożnikiem równym 2. Pozwala to z kolei na otrzymanie
diadycznej dekompozycji sygnału w dziedzinie transformaty falkowej.
Na podstawie dyskretnego zbioru funkcji falkowych wyznaczane są współczyn-
niki określające dyskretną transformatę falkową DWT funkcji f (x) [112, 116]:
DWT (sm, τn) = s−m/20
∫
f (x)ψ(
s−m0 t − nτ0
)
dx (3.30)
73

“KonspPreamb” 2013/10/3 page 74 #77
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Jeżeli parametry funkcji macierzystej s i τ były poddane diadycznej dyskrety-
zacji, współczynnki dyskretnej transformaty falkowej obliczane są według wzoru:
DWT (sm, τn) = 2−m/2∫
f (x)ψ(
2−mx − n)
dx (3.31)
Odwrotna dyskretna transformata falkowa pozwala na rekonstrukcję sygnału
oryginalnego f (x) na podstawie znajomości współczynników jego rozkładu w dzie-
dzinie transformaty. Odwrotna dyskretna transformata falkowa IDWT (ang. Inverse
Discrete Wavelet Transform) określona jest wzorem:
IDWT (x) =∞∑
m=−∞
∞∑
n=−∞DWT (sm, τn)ψm,n (x) (3.32)
W celu dalszego wprowadzenia do zagadnień zastosowania transformaty falko-
wej w algorytmach przetwarzania obrazów należy wprowadzić elementy analizy
wielorozdzielczej MRA (ang. Multi resolution Analysis) oraz przedstawić meto-
dy obliczania transformaty falkowej w przypadku sygnału dwuwymiarowego ja-
kim jest obraz cyfrowy. Zagadnienia te nie będą tutaj omawiane, a szczegółowe
omówienia można znaleźć w obszernej literaturze dotyczącej transformaty falko-
wej, np. [118, 119]. Wystarczy zaznaczyć, że korzystając z technik MRA i definicji
dwuwymiarowej transformaty falkowej możliwe jest uzyskanie reprezentacji obra-
zu cyfrowego w dziedzinie transformaty falkowej za pomocą jej współczynników,
analogicznie do wyznaczenia współczynników transformaty falkowej sygnału jed-
nowymiarowego obliczanych wg. wzoru (3.30). Możliwość ta została wykorzystana
do przedstawienia propozycji algorytmów wykorzystujących transformatę falkową
do rozwiązania problemu dopasowania obrazów pary stereoskopowej.
Wykorzystanie transformaty falkowej w zagadnieniu dopasowania obrazów pa-
ry stereoskopowej sprowadza się zazwyczaj do znalezienia reprezentacji obrazów
w dziedzinie transformaty falkowej oraz znalezienia dopasowań współczynników
otrzymanych transformat. Główne różnice w stosowanych algorytmach sprowadza-
ją się do wykorzystania różnych funkcji falki podstawowej stanowiącej podstawę
obliczenia reprezentacji obrazów w dziedzinie transformaty.
Xiong [120] zaprezentował algorytm umożliwiający dopasowanie w dziedzinie
transformaty falkowej z wykorzystaniem sieci neuronowych ze wsteczną propa-
gacją błędu. Przedstawiony przykład działania algorytmu pokazuje bardzo dobre
74

“KonspPreamb” 2013/10/3 page 75 #78
3. Przegląd metod dopasowania obrazów pary stereoskopowej
działanie tej metody. Brak jest jednak analizy porównawczej uzyskiwanych wyni-
ków z wynikami osiąganymi przez zastosowanie innych metod dopasowania obra-
zów pary stereoskopowej.
Innym algorytmem opartym na analizie falkowej obrazu jest metoda zapropo-
nowana w [121]. W artykule tym zaproponowano rozkład obrazu za pomocą falki
Cai-Wanga. Wykorzystując reprezentację obrazów w dziedzinie transformat obli-
czana jest wartość dysparycji na podstawie współczynników transformaty falkowej.
Dysparycja obliczana jest za pomocą miary SSD obliczanej dla współczynników
transformaty falkowej. Autorzy przedstawili działanie proponowanego algorytmu
dla dwóch par stereoskopowych, wyciągając wniosek, że prezentowany algorytm
pozwala na uzyskanie bardzo dobrych rezultatów dopasowania obrazów.
Oprócz podstawowego zastosowania transformaty falkowej, w literaturze moż-
na znaleźć rozwiązania oparte na transformacie wielofalkowej (ang. multiwave-
lets transform). Takie rozwiązanie zostało zaproponowane w [122]. Jako miarę
dopasowania współczynników transformaty falkowej zastosowana została miara
SSD. Przedstawione zostały wyniki dla dwóch przykładowych par stereoskopo-
wych, a w konkluzjach autorzy sformułowali tezę, że transformata wielofalkowa
pozwala na uzyskanie lepszych rezultatów niż transformaty jednofalkowe.
3.3.4. Transformata rankingowa
Jedną z transformat zaproponowaną przez Zabiha i Woodfilla jest transformata
rankingowa (ang. rank transform) [123]. Transformata rankingowa określa liczbę
pikseli w pewnym sąsiedztwie wyróżnionego piksela, dla którego obliczana jest
wartość transformaty, o tej właściwości, że ich wartości jasności są mniejsze od
wartości jasności tego piksela.
Wartość transformaty rankingowej R (p) dla ustalonego piksela p w obrazie jest
definiowana wyrażeniem:
R (p) =∥
∥
∥
∥
p′ ∈ N (p) : Ip′ < Ip
∥
∥
∥
∥
(3.33)
gdzie Ip jest wartością jasności piksela p, natomiast N (p) jest pewnym, zazwyczaj
kwadratowym sąsiedztwem tego piksela o rozmiarze Nw. Symbol ||C|| oznacza moc
zbioru C. Transformata rankingowa R (p) przybiera wartości całkowite z zakresu
75

“KonspPreamb” 2013/10/3 page 76 #79
3. Przegląd metod dopasowania obrazów pary stereoskopowej
[
0,N2p − 1
]
, gdzie Np określa liczbę pikseli należących do sąsiedztwa piksela p,
zawierających się w oknie o rozmiarze Nw.
W celu znalezienia dopasowania, w obrazach poddanych transformacie wyko-
nywany jest algorytm dopasowania obszarami z zastosowaniem miary SAD [123,
124]. Zastosowanie transformaty rankingowej zmniejsza wrażliwość algorytmu do-
pasowania na lokalne zmiany wartości jasności występujące w obrazach [124, 125].
3.3.5. Transformata CENSUS
W przypadku transformaty CENSUS zaproponowanej w [123], podobnie jak
w transformacie rankingowej, porównywane są jasności wyróżnionego piksela z war-
tościami jasności jego sąsiadów. Zasadniczą różnicą jest jednak wynik tego porów-
nania, którym w przypadku transformaty CENSUS jest ciąg wartości binarnych.
Jest on konstruowany w oparciu o funkcję porównania ξ.
Jeżeli p jest określonym pikselem w obrazie, Ip jest wartością jego jasności,
natomiast Ip′ jest wartością jasności piksela z pewnego, określonego sąsiedztwa
N (p), to funkcja ξ jest zdefiniowana wzorem:
ξ[
Ip, Ip′]
=
1 jeżeli Ip > Ip′
0 jeżeli Ip 6 Ip′(3.34)
Wyniki porównania są następnie poddawane konkatenacji ⊗ . Kontaktencja
(ang. concatenation), oznaczona symbolem ⊗, jest operacją polegającą na połą-
czeniu kilku różnych elementów w jeden. Ponieważ wyniki uzyskiwane w wyniku
zastosowania funkcji ξ mogą przyjmować jedynie wartości 1 lub 0 dla każdego pik-
sela, ich ustawienie w ciąg i połączenie daje w efekcie ciąg kolejnych zer i jedynek,
który może być interpretowany jako zapis binarny pewnej liczby.
Końcowy wynik transformaty CENSUS jest zdefiniowany wzorem:
TC (p) = ⊗N(p)
ξ[
Ip, Ip′]
(3.35)
Po obliczeniu transformaty CENSUS dalszy etap dopasowania odbywa się przez
zastosowanie algorytmu dopasowania obszarami. Miara dopasowania musi być do-
stosowana do porównywania ciągów wartości binarnych. Najczęściej wykorzysty-
waną w tym celu miarą jest miara odległości Hamminga [123, 125].
76

“KonspPreamb” 2013/10/3 page 77 #80
3. Przegląd metod dopasowania obrazów pary stereoskopowej
Jedną z proponowanych modyfikacji transformaty CENSUS jest porównywanie
wartości jasności wyróżnionego piksela z wartością średnią jasności w sąsiedztwie
[126]. Wydłuża to długość wynikowego ciągu binarnego transformaty o jeden, ale
pozwala na zwiększenie rozróżnialności elementów obrazu. Dodatkową modyfika-
cją transformaty CENSUS jest wydłużenie wynikowego ciągu binarnego o warto-
ści gradientów, jakie znajdują się w otoczeniu piksela poddawanemu transformacji
[126]. W wynikowym ciągu binarnym zapisywane są wartości o horyzontalnych
i wertykalnych wartościach gradientów, jakie występują w otoczeniu piksela, co
również pozwala na zwiększenie ilości informacji zawartej w wynikowym ciągu
binarnym.
3.4. Metody dopasowania cech obrazów
Metody dopasowania cech obrazów, nazywane także metodami dopasowania
cechami, polegają na wyznaczaniu tzw. rzadkiej mapy dysparycji (ang. sparse di-
sparity map). Oznacza to, że wartości dysparycji określane są tylko dla pewnego
wyróżnionego podzbioru pikseli w obrazie, a nie dla wszystkich pikseli. Ze wzglę-
du na ograniczony zbiór wartości dysparycji, a z drugiej strony wzrost mocy ob-
liczeniowej urządzeń sprzętowych, jak również gwałtowny rozwój metod umożli-
wiających uzyskanie pełnej mapy dysparycji, metody dopasowania cech obrazów
obecnie tracą obecnie na znaczeniu i popularności. Wykorzystywane są jednak na-
dal w niektórych zastosowaniach praktycznych, jak również w rozwiązaniach wy-
korzystujących niezależnie dwa lub więcej różnych algorytmów. Rezultaty otrzy-
mane przez niezależne wykonanie różnych algorytmów poddawane są fuzji w celu
otrzymania końcowego wyniku, którym jest gęsta mapa dysparycji. Rozwiązania
takie znane są w literaturze pod nazwą algorytmów mieszanych lub hybrydowych
(ang. hybrid algorithm).
Jednym z przykładów metody mieszanej służącej do wyznaczenia gęstej mapy
dysparycji, w którym zastosowano dwa niezależnie działające algorytmy, może być
propozycja przedstawiona w [127]. W metodzie tej wykorzystany został algorytm
detekcji krawędzi oraz algorytm segmentacji. Detekcja krawędzi pozwoliła na zna-
lezienie regionów, gdzie wartość dysparycji zmienia się gwałtownie. Dopasowanie
krawędzi pozwoliło na uzyskanie rzadkiej mapy dysparycji. Natomiast segmentacja
pozwoliła na znalezienie regionów o stałej wartości jasności pikseli, które zostały
77

“KonspPreamb” 2013/10/3 page 78 #81
3. Przegląd metod dopasowania obrazów pary stereoskopowej
dopasowane przez niezależny algorytm. W wyniku fuzji wyników otrzymanych
jako rezultat algorytmu dopasowania krawędzi oraz algorytmu dopasowania regio-
nów o stałej jasności otrzymana została gęsta mapa dysparycji
W [128] zaproponowany został algorytm oparty na detekcji odcinków krawę-
dzi. Przyjęte zostało założenie, że zamknięte odcinki krawędzi ograniczają obiekty
o stałej wartości dysparycji. Po dopasowaniu określonych odcinków linii można
poddać dopasowaniu ograniczone nimi obszary, uzyskując gęstą mapę dysparycji.
Wśród algorytmów dopasowania cech charakterystycznych obrazów odrębną
grupę stanowią algorytmy umożliwiające detekcję miejsc szczególnych w obrazie.
Najczęściej wykorzystywane miejsca charakterystyczne, które mogą być łatwo wy-
kryte, to narożniki i krawędzie.
Właściwości detektorów narożników obrazów w kontekście użyteczności w al-
gorytmach dopasowania pary stereoskopowej zostały przedstawione obszernie
w [129]. Badaniom poddane zostały popularne detektory Harrisa i SUSAN (ang.
Smallest Univalue Segment Assimilating Nucleus). Jako miary podobieństwa przy
wyznaczaniu dopasowania zastosowane zostały miary SAD i NCC. Na podstawie
uzyskanych wyników sformułowany został wniosek, że dobre wyniki dopasowania
daje detektor Harrisa wraz z miarą NCC. Należy podkreślić, że w przypadku zasto-
sowania algorytmów detekcji narożników uzyskiwana jest stosunkowo niewielka
liczba wartości dopasowań, ale są to algorytmy użyteczne w czasie automatyzacji
zadania znajdowania grupy dopasowanych pikseli w czasie rektyfikacji obrazów
pary stereoskopowej [130, 131].
Jeśli dopasowaniu podlegają obrazy krawędziowe, również w pierwszym etapie
następuje ich detekcja za pomocą ogólnego algorytmu. W przypadku zastosowania
detektora krawędzi w otrzymanym obrazie krawędziowym znajduje się zwykle za
mało informacji, aby można było przeprowadzić pełny proces dopasowania. Z tego
względu częstym krokiem jest wprowadzenie dodatkowego opisu obrazu wyniko-
wego, na podstawie którego można uzyskać prawidłowe wartości dopasowań.
W [132] zastosowany został algorytm detekcji krawędzi Canny’ego. Następnie
na wyznaczonym obrazie krawędziowym wyszukiwane były odcinki krawędzi, do
których przypisywany był wektor cech zawierający: punkt środkowy segmentu, dłu-
gość segmentu, średnia wartość jasności pikseli w otoczeniu punktu środkowego
oraz kierunek segmentu określony jako kąt nachylenia segmentu względem kierun-
ku horyzontalnego w obrazie. Tak określone wektory cech służyły do dopasowania
78

“KonspPreamb” 2013/10/3 page 79 #82
3. Przegląd metod dopasowania obrazów pary stereoskopowej
obrazów. W artykule przestawiona została również możliwość wykorzystania uzy-
skanej mapy dysparycji do rekonstrukcji widzianej sceny.
W [133] przedstawiony został algorytm dopasowania odcinków krawędzi. W ob-
razach krawędziowych otrzymanych w wyniku działania detektora krawędzi De-
riche’a wyszukiwane były odcinki linii prostych, które następnie zostały opisane
przez wektor ośmiu cech charakterystycznych, na który składały się: współrzędne
położenia w pionie i poziomie, orientacja linii, kontrast lewej i prawej połowy seg-
mentu, średnia wartość jasności pikseli w lewej i prawej połowie segmentu oraz
wariancja wartości jasności.
W [134] zaproponowany został algorytm, w którym detekcja krawędzi odbywa
się przy zastosowaniu maski filtru gaussowskiego. W drugim kroku wyszukane
krawędzie są cieniowane oraz przypisywane są im znaki krawędzi dodatniej lub
ujemnej w zależności od kierunku gradientu otrzymanego po zastosowaniu maski
filtru gaussowskiego. Aby dodatkowo zwiększyć odporność algortymu na zakłóce-
nia, dopasowanie krawędzi odbywa się w dziedzinie transformaty falkowej.
Klasycznym już algorytmem umożliwiającym dopasowanie krawędzi w obra-
zie, jest algorytm Marra-Poggio-Grimsona. Algorytm ten został przyjęty jako al-
gorytm referencyjny w eksperymentalnej części pracy, którego efektywność będzie
porównywana z efektywnością algorytmów opracowanych przez autora, i z tego
względu zostanie przedstawiony poniżej w sposób szczegółowy.
3.4.1. Algorytm Marra-Poggio-Grimsona
Algorytm Marra-Poggio-Grimsona określany akronimem MPG (ang. Marr–
Poggio–Grimson) uchodzi za klasyczny algorytm umożliwiający rozwiązanie za-
dania dopasowania cech charakterystycznych obrazów. Algorytm MPG wykorzy-
stuje w swoim działaniu detektor krawędzi oparty o filtr LoG (ang. Laplacian of
Gaussian). Krawędzie otrzymane w wyniku działania detektora podlegają proceso-
wi dopasowania i w efekcie końcowym otrzymywana jest rzadka mapa dysparycji,
której wartości są określone dla tych miejsc obrazu które zawierały krawędzie.
Na algorytm MPG składa się sześć następujących kroków:
1. Filtracja LoG
W pierwszym kroku wykonywany jest dwuwymiarowy splot obrazów z maską
filtru typu LoG, który służy jako operator detektora krawędzi. Rozmiar maski filtru
79

“KonspPreamb” 2013/10/3 page 80 #83
3. Przegląd metod dopasowania obrazów pary stereoskopowej
wLoG określa poziom szczegółowości, czyli liczbę pikseli uznawanych za należące
do krawędzi w uzyskanym obrazie wynikowym. Wraz ze zwiększaniem się rozmia-
ru maski filtru zwiększa się liczba pikseli uznawanych za należące do krawędzi,
co oznacza mniejszy poziom szczegółowości otrzymanego obrazu krawędziowe-
go. Filtracja LoG polega na wykonaniu splotu dyskretnego obrazu z maską filtru
otrzymanego na podstawie zależności:
LoG= ∇Gσ (x, y) =
∂2
∂x2Gσ (x, y)+
∂2
∂y2Gσ (x, y) =
x2 + y2 − 2σ2
σ4e− x2+y2
2σ2 (3.36)
gdzie ∇ jest operatorem Laplasjanu ∇ = ∂2
∂x2 +∂2
∂y2 , natomiast Gσ (x, y) jest obrazem
otrzymanym w wyniku splotu obrazu oryginalnego z maską filtru określoną przez
funkcję Gaussa:
Gσ (x, y) =1
√2πσ2
e− x2+y2
2σ2 (3.37)
Funkcja ta w splocie z obrazem wykazuje własności filtru dolnoprzepustowego, po-
zwalającego na usunięcie zakłóceń szumowych. W praktycznych implementacjach
przeprowadza się wstępne obliczenie wartości maski filtru o zadanym rozmiarze
wLoG, po czym obliczany jest splot dyskretny maski z obrazem. W przypadku stoso-
wania maski filtru typu LoG przyjmowana jest zależność pomiędzy szerokością ka-
nału działania filtru wLoG i parametrem σ funkcji Gaussa w postaci: wLoG =√
2σ.
2. Ekstracja przecięcia zer
Na obrazach krawędziowych uzyskanych w wyniku zastosowania filtracji LoG
wykonywane jest przeszukiwanie obrazów wzdłuż wierszy w celu znalezienia ta-
kich miejsc, gdzie dwie sąsiadujące horyzontalnie ze sobą wartości macierzy re-
prezentującej obraz wynikowy po zastosowaniu filtru LoG mają różne znaki. Po-
szukiwane są też miejsca, w których trzy wartości macierzy reprezentującej obraz
wynikowy otrzymany po zastosowaniu filtru LoG położone horyzontalnie obok sie-
bie ułożone są w taki sposób, że środkowa ma wartość zerową, a dwie horyzontalnie
z nią sąsiadujące mają przeciwne znaki. Miejsca takie określane są jako przejście
przez zero (ang. zero crossing).
W przypadku znalezienia takich miejsc zapamiętywane są ich współrzędne oraz
znaki przejść przez zero. Jako znak przejścia przez zero rozumie się horyzontalny
kierunek zmiany znaku wartości komórek macierzy uzyskanej w wyniku zastoso-
wania filtru LoG uzyskanych w obrazie po filtracji, tzn. jeżeli dwie horyzontalnie
80

“KonspPreamb” 2013/10/3 page 81 #84
3. Przegląd metod dopasowania obrazów pary stereoskopowej
sąsiadujące wartości macierzy lub trzy wartości macierzy, wśród których środko-
wa jest zerowa, zmieniają się od ujemnych do dodatnich, to znak uznawany jest
za dodatni. Podobnie jest określany znak ujemny przecięcia zera. Jeżeli w macie-
rzy wynikowej otrzymanej w wyniku zastosowania filtru LoG znajdują się dwie
horyzontalnie sąsiadujące wartości lub trzy wartości, wśród których środkowa jest
zerowa, zmieniające się od dodatnich do ujemnych to temu przejściu przez zero
przypisywany jest znak ujemny.
3. Szukanie dopasowań
Dla każdego wiersza w jednym z obrazów ustalonym jako obraz referencyjny
i dla każdego wcześniej znalezionego przejścia przez zero, w obrazie referencyj-
nym ustawiane jest okno referencyjne na pozycji wyznaczonej przez współrzędne
wybranego przejścia przez zero. W drugim obrazie krawędziowym przeszukiwania
umieszczane jest okno przeszukiwania na pozycji określonej przez współrzędne
przejścia przez zero ustalonego w obrazie referencyjnym. Okno przeszukiwania
przesuwane jest horyzontalnie w ustalonym zakresie poszukiwanych wartości dys-
parycji [dmin, dmax]. Dla każdego położenia okna przeszukiwania wykonywane jest
sprawdzenie, czy w oknie tym zawiera się przecięcie zera o takim samym znaku,
jakie znajduje się w oknie referencyjnym.
W przypadku znalezienia dopasowania zapamiętywana jest wartość przesunię-
cia (dysparycji) oraz dodatkowa informacja dotycząca znalezionego dopasowania.
Jeżeli w zakresie poszukiwanej dysparycji znalezione zostało tylko jedno przejście
przez zero o takim samym znaku, jakie ma przejście przez zero w oknie referen-
cyjnym, zapamiętywana jest informacja o dopasowaniu jednoznacznym. W przy-
padku, gdy w zakresie przeszukiwania znalezione zostały dwa lub więcej przejść
przez zero o takim samym znaku jak w oknie referencyjnym, zapamiętywana jest
informacja o wystąpieniu dopasowania wielokrotnego. W przypadku, gdy nie udało
się znaleźć odpowiadającego przejścia przez zero o takim samym znaku, zapamię-
tywana jest informacja o braku dopasowania.
4. Usuwanie niejednoznaczności
W tym kroku otrzymana mapa dysparycji jest sprawdzana pod kątem uzyska-
nych dopasowań wielokrotnych. Dopasowania takie usuwane są poprzez porówna-
nie mapy dysparycji otrzymanej na bieżącym poziomie szczegółowości, określo-
nym przez rozmiar maski filtru LoG równy wLoG, z wartościami dysparycji otrzy-
81

“KonspPreamb” 2013/10/3 page 82 #85
3. Przegląd metod dopasowania obrazów pary stereoskopowej
manymi w czasie wykonywania dopasowania na mniejszym poziomie szczegóło-
wości, czyli obrazów krawędziowych, gdzie zastosowana była maska filtru o więk-
szym rozmiarze. Dla każdego znalezionego dopasowania sprawdzane jest, czy ist-
nieje odpowiadające mu dopasowanie uzyskane w poprzednim przebiegu algoryt-
mu oraz dodatkowa informacja o tym, czy było to dopasowanie jednokrotne czy
wielokrotne.
Jeżeli dla określonego przejścia przez zero z informacją o dopasowaniu jedno-
znacznym istnieje jednoznaczne dopasowanie uzyskane dla mniejszego poziomu
szczegółowości, to ta wartość dysparycji uznawana jest za prawidłową. W przypad-
ku, gdy w bieżącym przebiegu znalezione zostało dopasowanie, którego brak jest
w poprzednim przebiegu algorytmu, wartość ta zostaje uznana za nieprawidłową.
W przypadku znalezienia dopasowań wielokrotnych znaleziona wartość dyspary-
cji odrzucana jest jako wartość nieprawidłowa lub w niektórych implementacjach
przyjmowana jest wartość średnia dysparycji wynikająca z wystąpienia dopasowa-
nia wielokrotnego. Krok ten możliwy jest do wykonania jedynie w przypadku, gdy
istnieje mapa dysparycji obliczona na mniejszym poziomie szczegółowości. Nie
jest on więc wykonywany w czasie pierwszego przebiegu algorytmu.
5. Pętla
Po wyznaczeniu mapy dysparycji dla określonego poziomu szczegółowości
algorytm wraca do kroku filtracji obrazów ze zmienionym (mniejszym) rozmia-
rem maski filtru wLoG. Następnie wykonywane jest obliczenie mapy dysparycji dla
określonego poziomu szczegółowości.
6. Końcowe określenie spójności
Ostatnim krokiem, jaki jest wykonywany w algorytmie MPG, jest końcowe
sprawdzenie spójności mapy dysparycji. Krok ten jest wykonywany, gdy wyzna-
czone zostały mapy dla każdego założonego na wstępie poziomu szczegółowości
określonego przez rozmiar maski filtru wLoG. Zaczynając od mapy dysparycji uzy-
skanej dla obrazu poddanego filtracji o najmniejszej masce, sprawdzana jest zgod-
ność otrzymanych wartości dysparycji z uzyskanymi w przypadku zastosowania
filtru o większej masce. Jeżeli w obu mapach występują niezgodności w otrzy-
manych wartościach dysparycji, są one usuwane jako wartości nieprawidłowe. Po
wykonaniu sprawdzenia dla wszystkich poziomów szczegółowości otrzymywany
jest wynik działania algorytmu w postaci końcowej mapy dysparycji.
82

“KonspPreamb” 2013/10/3 page 83 #86
3. Przegląd metod dopasowania obrazów pary stereoskopowej
3.5. Wykorzystanie obrazów kolorowych w dopasowaniu
obrazów
Jednym z kierunków badań nad dopasowaniem obrazów stereoskopowych jest
wykorzystanie w tym celu obrazów kolorowych. Najczęściej spotykanym rozwią-
zaniem wykorzystania obrazów kolorowych jest wykonanie algorytmu dopasowa-
nia obszarami oddzielnie w każdym z kanałów obrazu, np. kanałów przestrzeni
RGB, a następnie przeprowadzenie fuzji otrzymanych wyników.
W algorytmie zaproponowanym przez Belliego i innych [135] wykorzystana
została miara korelacyjna niezależnie w każdym z kanałów RGB obrazów, a koń-
cowa wartość dysparycji obliczana jest za pomocą operatora fuzji wykorzystują-
cego w swoim działaniu elementy logiki rozmytej. Wykorzystanie logiki rozmytej
pozwoliło na bardziej elastyczne wyznaczenie wartości dysparycji. Ciekawym spo-
strzeżeniem autorów był fakt, że wartości korelacji obliczane w kanale niebieskim
nie dawały łatwych do wykrycia pików korelacyjnych. Spowodowane to było du-
żą zawartością zakłóceń szumowych zawartych w obrazach kanału niebieskiego,
co z kolei było efektem postaci transmitancji, jaką ma filtr niebieski przetwornika
obrazowego. Ponieważ autorzy artykułu nie chcieli tracić żadnej informacji, która
pozwoliłaby na poprawę uzyskiwanych rezultatów, wartości dysparycji obliczone
na podstawie kanału niebieskiego były również poddawane fuzji. Jednak operator
fuzji preferował wartości dysparycji, dla których wystąpił wyraźny pik korelacyj-
ny niezależnie od kanału, w którym pik ten wystąpił. Autorzy przedstawili wyniki
działania algorytmu dla jednej pary testowej, uzyskując poprawę na poziomie 1%
wzrostu prawidłowych dopasowań w stosunku do obrazów w skali reprezentowa-
nych w skali szarości.
Bardzo wyczerpujące studium wykorzystania obrazów kolorowych w proble-
mie dopasowania pary stereoskopowej zostało przedstawione w [136]. Autorzy wy-
konali badania jakości otrzymywanych rozwiązań przy zastosowanie różnych mo-
deli opisu obrazów kolorowych. Algorytmy dopasowania były wykonywane nieza-
leżnie przy wykorzystaniu ośmiu modeli przestrzeni kolorów: dwóch modeli pod-
stawowych: RGB i CIE XYZ, czterech modeli opartych o reprezentację typu lu-
minancja-chrominancja CIE LUV, CIE LAB, AC1C2 i YC1C2 oraz dwóch modeli
o niezależnych statystycznie składowych I1I2I3 i H1H2H2. Dodatkowym modelem
koloru, dla którego zostały przeprowadzone badania, była skala szarości. Badaniom
83

“KonspPreamb” 2013/10/3 page 84 #87
3. Przegląd metod dopasowania obrazów pary stereoskopowej
zostały poddane algorytmy oparte o miarę znormalizowanej korelacji wzajemnej
ZNCC, transformatę CENSUS oraz miarę informacji wzajemnej MI. Testy zostały
przeprowadzone na ogólnie dostępnych obrazach testowych pakietu opracowane-
go przez grupę Middlebury Stereo Vision. Obrazy tworzące pary stereoskopowe
dostępne w tym pakiecie wykorzystane zostały również w tej pracy jako mate-
riał badawczy służący do przeprowadzania części eksperymentalnej pracy. Z tego
względu sam pakiet, jak i dostępne obrazy par stereoskopowych, zostaną bliżej
przedstawione w części przedstawiającej metody opracowania wyników ekspery-
mentalnych otrzymanych w ramach pracy (por. p.6.3).
Interesującym wnioskiem, wyciągniętym przez autorów artykułu [136], jest
stwierdzenie, że w przypadku algorytmów wykorzystujących miarę ZNCC oraz
transformatę CENSUS otrzymane wyniki nie były lepsze w porównaniu do uzy-
skiwanych w przypadku obrazów w skali szarości. Co więcej, część z nich okazała
się gorsza. Stosując algorytm oparty o miarę informacji wzajemnej, również nie
uzyskano znaczącej poprawy wyników w stosunku do obrazów w skali szarości.
Jedyną pozytywną cechą zastosowania obrazów kolorowych, jaką stwierdzili auto-
rzy, jest większa odporność algorytmów na zakłócenia w regionach obrazów, gdzie
występują zniekształcenia radiometryczne, np. ze względu na różnicę oświetlenia.
W [137] autorzy wykonali badania jakości rozwiązań uzyskiwanych w przypad-
ku wykorzystania obrazów kolorowych za pomocą algorytmów globalnych opar-
tych na poszukiwaniu minimalnego rozcięcia grafu i programowaniu dynamicz-
nym. Autorzy wykorzystali dziewięć różnych przestrzeni kolorów, dla których ja-
ko miarę dopasowania zastosowano sumę wartości bezwzględnych różnic jasności
poszczególnych pikseli składowych oraz odległość euklidesowską dla każdej prze-
strzeni kolorów. Na podstawie badań sformułowano wniosek, że zastosowanie obra-
zów kolorowych w tych algorytmach pozwala na uzyskiwanie lepszych wyników,
niż przy obrazach reprezentowanych w skali szarości. Konkluzję badań stanowi-
ło również stwierdzenie, że uzyskiwane rozwiązania zależą do zastosowanej prze-
strzeni kolorów. Najlepsze wyniki zostały osiągnięte przy zastosowaniu przestrzeni
opartej o luminację-chrominancję CIE LUV, AC1C2 oraz YC1C2. Natomiast naj-
częściej spotykana i wykorzystywana przestrzeń kolorów jaką jest RGB dawała
mało znaczącą poprawę jakości wyników w stosunku do algorytmów działających
na obrazach w skali szarości.
W [138] przedstawione zostały wyniki badań jakości uzyskiwanych rozwiązań
84

“KonspPreamb” 2013/10/3 page 85 #88
3. Przegląd metod dopasowania obrazów pary stereoskopowej
uzyskiwanych przez zastosowanie algorytmu dopasowania obszarami pod wzglę-
dem zastosowanej miary dopasowania. Badaniu poddanych zostało 15 różnych miar
dopasowania. Głównym celem założonym w artykule [138] było sprawdzenie wraż-
liwości algorytmów na radiometryczne zniekształcenia obrazów, w tym zniekształ-
cenia liniowe i nieliniowe. Duża część artykułu poświęcona została porównaniu
wyników uzyskiwanych przy wykorzystaniu obrazów w skali szarości oraz obra-
zów kolorowych. Uzyskane wyniki były zaskakujące również dla autorów, którzy
stwierdzili, że wykorzystanie obrazów kolorowych nie poprawia znacząco lub po-
prawia bardzo mało rezultaty uzyskiwane przez algorytmy dopasowania z zastoso-
waniem skali szarości. Końcowy wniosek sformułowany przez autorów dotyczący
zastosowania obrazów kolorowych brzmi, że nie dały one praktycznie znaczącej
poprawy uzyskiwanych wyników. Dodatkowo autorzy postawili tezę, że obrazy
kolorowe są bardziej wrażliwe na zakłócenia w stosunku do obrazów reprezen-
towanych w skali szarości. Wnioski te zostały sformułowane przy zastrzeżeniu, że
dotyczą one prezentowanych w artykule wyników i obrazów, natomiast potrzeb-
ne są bardziej szczegółowe badania dotyczące wykorzystania obrazów kolorowych
w algorytmach dopasowania pary stereoskopowej.
W [139] wykorzystane zostały obrazy kolorowe reprezentowane w przestrzeni
HSL (ang. Hue Saturation Lightness). Jako algorytm dopasowania zastosowany
został algorytm optymalizacji globalnej funkcji kosztu. Optymalizacja odbywała
się za pomocą algorytmu symulowanego wyrzażania. Autorzy prezentując wyniki
stwierdzili, że zastosowanie obrazów kolorowych dało znaczącą poprawę uzyski-
wanych wyników. Niestety, nie przedstawiono badań numerycznych potwierdzają-
cych postawioną tezę.
3.6. Inne metody dopasowania pary stereoskopowej
Omówione dotychczas metody dotyczące problemu dopasowania obrazów pary
stereoskopowej oraz algorytmy umożliwiające jego rozwiązanie nie stanowią wy-
czerpującego przeglądu tej problematyki. W literaturze można znaleźć liczne po-
zycje poświęcone zarówno innym aspektom problemu dopasowania, jak i szeroką
gamę innych algorytmów pozwalających na rozwiązanie problemu dopasowania.
Jednym z nie omówionych wyżej zagadnień dotyczącym poszukiwania mapy
dysparycji jest określanie ciągłych wartości dysparycji. Do tego celu stosowane
85

“KonspPreamb” 2013/10/3 page 86 #89
3. Przegląd metod dopasowania obrazów pary stereoskopowej
są metody interpolacyjne pozwalające wyznaczyć wartości dysparycji z wykorzy-
staniem dopasowania funkcji w obszarach pomiędzy wyznaczonymi wartościami.
W tym celu zazwyczaj stosowane są standardowe algorytmy interpolacji różniące
się tylko rodzajem i stopniem wykorzystanych wielomianów [140, 141, 142].
W kontekście rozwiązania problemu dopasowania spotykane są inne algorytmy
umożliwiające jego uzyskanie. Wśród nich istnieją propozycje algorytmów opar-
tych na propagacji przekonań (ang. belief propagation). Należą one do grupy al-
gorytmów, w których wykorzystywany jest schemat wnioskowania Bayesa. Algo-
rytmy te zazwyczaj bywają łączone z programowaniem dynamicznym do opisania
funkcji optymalizacji [143, 144, 145].
Wśród metod optymalizacyjnych stosowane są również metody optymalizacji
oparte o algorytmy genetyczne [146, 147, 148, 149]. Algorytmy genetyczne są na-
rzędziami, które pozwalają na znalezienie wartości optymalnej definiowanej wcze-
śniej funkcji kosztu. W celu optymalizacji funkcji kosztu zaproponowano również
wykorzystanie algorytmu mrówkowego [150].
Proponowane są także inne rozwiązania umożliwiające znalezienie dopaso-
wania w punktach charakterystycznych. W [151] przedstawiony został algorytm,
którego cechą charakterystyczną jest zastosowanie detektora łączeń krawędzi typu
„T”. Łączniki tego typu wyszukane na obrazie traktowane są jako punkty charak-
terystyczne, służące następnie do obliczenia dysparycji. Jako miary dopasowania
wykorzystane zostały miary SAD oraz znormalizowana korelacja wzajemna NCC.
Wśród algorytmów wykorzystujących narzędzia sztucznej inteligencji znajdują się
również algorytmy wykorzystujące sztuczne sieci neuronowe [152].
Na zakończenie przeglądu metod dopasowania pary stereoskopowej należy wy-
mienić próby wykorzystania w tym celu teorii zbiorów rozmytych. W doniesieniach
literaturowych można znaleźć rozwiązania dotyczące zastosowania teorii zbiorów
rozmytych i logiki rozmytej zarówno w zagadnieniu dopasowania obszarami, jak
i zagadnieniu dopasowania cech. Są one jednak fragmentaryczne i często nieza-
dowalające, np. dotyczą obszarów o bardzo małej liczbie pikseli, bądź też są bar-
dzo nieefektywne obliczeniowo. Metody wykorzystujące w swoim działaniu zbiory
rozmyte lub logikę rozmytą znane z literatury zostaną przedstawione (por. p. 5.3)
po wprowadzeniu do teorii zbiorów rozmytych.
Brak jest także unifikacji tych metod i całościowego spojrzenia na problem do-
pasowania pary stereoskopowej z wykorzystaniem teorii zbiorów rozmytych. Te
86

“KonspPreamb” 2013/10/3 page 87 #90
3. Przegląd metod dopasowania obrazów pary stereoskopowej
właśnie czynniki stanowiły dla autora motywację do podjęcia systematycznych ba-
dań w tym kierunku, przeprowadzenia gruntownej analizy znanych z literatury me-
tod i algorytmów i zaproponowania na tym tle własnych rozwiązań. Rezultaty prze-
prowadzonych badań będą prezentowane w kolejnych rozdziałach niniejszej pracy.
87

“KonspPreamb” 2013/10/3 page 88 #91
Rozdział 4
Elementy teorii zbiorów rozmytych
W rozdziale zaprezentowane zostały niektóre z podstawowych pojęć i definicji
dotyczących teorii zbiorów rozmytych. Przedstawione zostały także pojęcia i defi-
nicje dotyczące innego rodzaju zbiorów rozmytych, a mianowicie intuicjonistycz-
nych zbiorów rozmytych. W obu przypadkach ograniczono się jedynie do zakresu
pojęć wykorzystywanych w pracy. Zostały przedstawione jedynie elementy, które
zostały wykorzystane w czasie projektowania algorytmów umożliwiających roz-
wiązanie zagadnienia dopasowania obrazów pary stereokopowej z zastosowaniem
teorii zbiorów rozmytych i intuicjonistycznych zbiorów rozmytych.
4.1. Podstawy teorii zbiorów rozmytych
Teorię zbiorów rozmytych oraz zbudowaną na jej podstawie teorię logiki roz-
mytej można uznać za jedną z gałęzi metod sztucznej inteligencji, a mówiąc do-
kładniej metod inteligencji obliczeniowej. Za twórcę teorii zbiorów rozmytych i po-
wstałej na jej kanwie teorii logiki rozmytej uznawany jest Lotfi Zadeh, który w
1965 roku opublikował artykuł pod znamiennym tytułem „Fuzzy Sets” (pol. zbiory
rozmyte) [153].
Po pełnym entuzjazmu przyjęciu teorii logiki rozmytej przez świat akademicki
została ona uznana za metodę, która umożliwi rozwiązanie wielu nierozwiązanych
do tej pory problemów. Okres największego rozkwitu teorii i w efekcie tego po-
jawienia się licznych propozycji zastosowań zbiorów rozmytych i logiki rozmytej
przypada na przełom lat 80–90 ubiegłego wieku. W późniejszych latach zaintereso-
wanie problematyką logiki rozmytej malało, aczkolwiek nadal była ona intensyw-
nie rozwijana. W chwili obecnej teoria logiki rozmytej stanowi dojrzałą i dopra-
cowaną koncepcyjnie teorię dostarczającą narzędzi umożliwiających rozwiązanie
niektórych problemów w szybszy i bardziej intuicyjny sposób, niż za pomocą in-
nych metod.
Teoria zbiorów rozmytych i logiki rozmytej znalazła zastosowanie w bardzo
różnorodnych dziedzinach nauki. Jako przykłady można tu przytoczyć: teorię ste-
88

“KonspPreamb” 2013/10/3 page 89 #92
4. Elementy teorii zbiorów rozmytych
rowania [154], eksplorację i przetwarzanie danych [155], systemy ekspertowe [156]
oraz przetwarzanie obrazów [157, 158]. W przedstawianej pracy niektóre elementy
teorii zbiorów rozmytych wykorzystane zostały w celu konstrukcji algorytmów do-
pasowania obrazów pary stereoskopowej. W dalszej części rozdziału przedstawione
zostaną podstawowe pojęcia tej teorii. Należy jednak podkreślić, że przestawione
pojęcia i definicje stanowią zaledwie niewielki ułamek całej teorii. Opisane zostały
jedynie te elementy, które mają ścisły związek z tematyką poruszaną w pracy i są
niezbędne do przedstawienia opracowanych algorytmów dopasowania pary stereo-
skopowej.
4.1.1. Pojęcie zbioru
Pojęcie zbioru jest pojęciem pierwotnym (niedefiniowanym), należącym do fun-
damentalnych pojęć matematyki. W klasycznej matematyce spotykane są trzy me-
tody określania zbioru zawierającego się zwykle w pewnym ustalonym zbiorze na-
zywanym przestrzenią X. Przestrzeń X bywa czasami nazywana również ogółem
rozważanych przedmiotów (ang. universe of discourse) lub zbiorem uniwersalnym
(ang. universal set) [159, 160].
1. Dowolny zbiórZmoże zostać określony przez podanie i wyliczenie wszystkich
jego elementów (metoda listy). Definicja ta jednak ogranicza się jedynie do
zbiorów skończonych.
Formalnie skończony zbiórZ zawierający elementy z1, z2, . . . , zn może zostać
zdefiniowany przez podanie wszystkich jego elementów, co zapisywane jest
wyrażeniem:
Z = z1, z2, . . . , zn
2. Dowolny zbiór Z może być określony przez opisanie właściwości spełnianej
przez elementy w nim zawarte (metoda reguły). Zazwyczaj zbiór określony
z wykorzystaniem metody reguły zapisywany jest w postaci:
Z = z | W (z)
gdzie symbol | oznacza wyrażenie „taki że” orazW (z) oznacza stwierdzenie
w formie „element z spełnia właściwośćW”.
89

“KonspPreamb” 2013/10/3 page 90 #93
4. Elementy teorii zbiorów rozmytych
Tak więc w zbiorze Z zawierają się tylko takie elementy z dla których stwier-
dzenieW jest prawdziwe. W klasycznej teorii zbiorów wymagane jest aby wa-
runekW był prawdziwy lub nie dla wszystkich elementów z ∈ X.
3. Zbiór Z może być określony przez funkcję nazywaną zazwyczaj funkcją cha-
rakterystyczną. Funkcja ta określa, które elementy z przestrzeni X są zaliczane
jako elementy tego zbioru, a które nie.
Zbiór Z jest definiowany przez funkcję charakterystyczną χZ w następujący
sposób:
χZ =
1 dla każdego z ∈ Z0 dla każdego z < Z
Funkcja charakterystyczna jest funkcją przyporządkowującą elementom z prze-
strzeni X, elementy zbioru dwuelementowego 0, 1:
χZ : X→ 0, 1
Dla każdego elementu z ∈ X, jeżeli χZ (z) = 1, oznacza to że element z należy
do zbioru Z, natomiast gdy χZ = 0 oznacza to, że element z nie należy do
zbioruZ.
4.1.2. Zbiór rozmyty i funkcja przynależności
Podstawą teorii zbiorów rozmytych jest dopuszczenie możliwości niepełnej przy-
należności elementu do zbioru. W klasycznym zbiorze element należy do zbioru
lub znajduje się poza nim. Teoria zbiorów rozmytych pozwala na przyjęcie częścio-
wej przynależności elementu do zbioru. Element równocześnie może częściowo
należeć i nie należeć do zbioru.
Do opisu zbioru rozmytego wykorzystana zostanie funkcja charakterystyczna,
która w przypadku zbioru klasycznego przyjmuje wartości 1 lub 0 dla argumen-
tów będących elementami rozważanego zbioru. Wartości funkcji charakterystycz-
nej pozwalają na rozróżnienie między elementami należącymi do zbioru i do niego
nie należącymi
W teorii zbiorów rozmytych pojęcie przynależności elementu do zbioru rozmy-
tego zostało rozszerzone o wartości pośrednie. Jeżeli jest ustalona pewna przestrzeń
X, to elementy tej przestrzeni mogą należeć do zbioru rozmytego jedynie częścio-
wo. Większe wartości funkcji charakterystycznej oznaczają większy stopień przy-
90

“KonspPreamb” 2013/10/3 page 91 #94
4. Elementy teorii zbiorów rozmytych
należności do zbioru rozmytego i z tego względu funkcja ta w kontekście teorii
zbiorów rozmytych jest nazywana funkcją przynależności, natomiast zbiór przez
nią określany jest nazywany zbiorem rozmytym.
W ogólnym przypadku wartości funkcji przynależności mogą przyjmować do-
wolne wartości rzeczywiste. Zazwyczaj jednak zakres jej wartości ograniczany jest
do intuicyjnie rozumianego przedziału jednostkowego [0, 1]. W takim przypadku
funkcja przynależności przypisuje każdemu elementowi z przestrzeni X liczbę rze-
czywistą z zakresu [0, 1], określającą stopień przynależności elementu do danego
zbioru. Wartość 0 oznacza, że element nie należy do zbioru, natomiast wartość
równa 1 określa pełną przynależność elementu do zbioru.
Aby określić zbiór rozmyty, należy zatem dla każdego elementu x ∈ X podać
wartość jego funkcji przynależności do zbioru rozmytego. Formalnie zbiór rozmyty
AF określa następująca definicja [161, 17].
Definicja 4.1. Zbiorem rozmytymAF w pewnej przestrzeniX nazywamy uporząd-
kowany zbiór par:
AF =[
x, µAF (x)]
; x ∈ X
(4.1)
przy czym:
µAF : X→ [0, 1]
Funkcja µAF jest nazywana funkcją przynależności zbioru rozmytegoAF, przypi-
sującą każdemu elementowi x pochodzącemu z przestrzeni X stopień jego przyna-
leżności do zbioru rozmytegoAF.
Zwyczajowo w teorii zbiorów rozmytych zakłada się, że funkcja przynależno-
ści przybiera wartości ze zbioru domkniętego [0, 1]. W niektórych zastosowaniach
przyjmuje się jednak czasami, że przeciwdziedziną funkcji przynależności jest do-
wolny zbiór domknięty[
µmin, µmax]
, który można traktować jako przeskalowanie
odcinka [0, 1], dokonane np. z uwagi na wygodę obliczeń numerycznych.
4.1.3. Przykłady funkcji przynależności
Funkcja przynależności jest jednym z najważniejszych pojęć teorii zbiorów roz-
mytych. Definiuje ona jednoznacznie skojarzony z nią zbiór rozmyty, określając za-
równo element zbioru, jak i jego stopień przynależności do pewnego określonego
91

“KonspPreamb” 2013/10/3 page 92 #95
4. Elementy teorii zbiorów rozmytych
zbioru. Funkcje przynależności mogą przyjmować bardzo różne postacie i mogą
być wyrażone w różny sposób, np. diagramu, tabeli, wektora lub najczęściej wzoru
matematycznego. Funkcja przynależności może być praktycznie dowolnego kształ-
tu, ale istnieją standardowe funkcje często wykorzystywane w różnych zastosowa-
niach zbiorów rozmytych [162, 163].
Poniżej przedstawione zostaną niektóre ze stosowanych funkcji przynależności.
Funkcje te określone zostały dla najczęściej wykorzystywanej w zastosowaniach
obliczeniowych przestrzeni liczb rzeczywistych R.
1. Funkcja singleton rozmyty (rys.4.1a):
µAF (x) =
µ ∈ [0, 1] , jeżeli x = a
0, jeżeli x , a(4.2)
Funkcja singleton rozmyty jest funkcją charakteryzującą jednoelementowy zbiór
rozmyty. Przybiera ona pewną wartość µ ∈ [0, 1] tylko dla jednego elemen-
tu x = a pochodzącego z przestrzeni liczb rzeczywistych R, który należy do
zbioru rozmytego ze stopniem przynależności µ. Dla każdego innego elementu
pochodzącego z R przyjmuje ona wartość równą 0, co oznacza że żaden inny
element nie należy do zbioru rozmytegoAF. Funkcja singleton jest często sto-
sowana do wykonania operacji fuzzyfikacji w rozmytych systemach sterowania,
jak również w technikach przetwarzania obrazów.
x
µAF (x)
µ
a0
14
12
34
1
(a)
x
µAF (x)
a0
14
12
34
1
(b)
Rys. 4.1. Przykładowe funkcje przynależności: singleton (a) oraz gaussowska (b)
92

“KonspPreamb” 2013/10/3 page 93 #96
4. Elementy teorii zbiorów rozmytych
2. Funkcja gaussowska (rys. 4.1b):
µAF (x) = exp
−(
x − a
b
)2
(4.3)
Parametr a określa położenie funkcji na osi zmiennych x, natomiast b okre-
śla szerokość krzywej gaussowskiej. Jest to jedna z bardzo często spotykanych
funkcji przynależności.
3. Funkcja klasy t (rys. 4.2a), nazywana również trójkątną funkcją przynależno-
ści:
µAF (x) =
0 dla x 6 ax−ab−a
dla a < x 6 bc−xc−b
dla b < x 6 c
0 dla x > c
(4.4)
Parametry a, b i c pozwalają na łatwy dobór kształtu funkcji. Ze względu na pro-
sty zapis i możliwość pełnego określenia kształtu funkcji przez podanie trzech
parametrów, bywa ona często wykorzystywana w systemach sterowania.
4. Funkcja klasy s (rys. 4.2b):
µAF (x) =
0 dla x 6 a
2(
x−ac−a
)2dla a < x 6 b
1 − 2(
x−cc−a
)2dla b < x 6 c
1 dla x > c
(4.5)
W celu zachowania ciągłości funkcji klasy s przyjmuje się, że b = (a + c) /2
lub b = (a + b) /2. W efekcie tej zależności wartość funkcji przynależności
w punkcie x = b jest równa 0.5, a punkt ten jest punktem przegięcia funkcji.
Nazwa funkcji prawdopodobnie pochodzi od kształtu wykresu, który graficz-
nie przypomina literę „s”. Kształt funkcji może być zmieniany poprzez dobór
wartości parametrów a, b i c.
93

“KonspPreamb” 2013/10/3 page 94 #97
4. Elementy teorii zbiorów rozmytych
x
µAF (x)
a b c0
14
12
34
1
(a)
x
µAF (x)
a b c0
14
12
34
1
(b)
Rys. 4.2. Przykładowe funkcje przynależności typu t (a) oraz typu s (b)
5. Funkcja klasy π (rys. 4.3a):
µAF (x) =
0 dla x 6 c − b
2(
x−c+bb
)2dla c − b < x 6 c − b/2
1 − 2(
x−cb
)2dla c − b/2 < x 6 c + b/2
2(
x−c−bb
)2dla c + b/2 < x < c + b
0 dla x > c + b
(4.6)
Kształtem funkcja przynależności klasy π przypomina funkcję gaussowską.
Trzeba jednak zauważyć, że funkcja klasy π pozwala na większą swobodę w do-
borze swojego kształtu ze względu na swoje trzy parametry a, b i c. Dodat-
kowo funkcja klasy π ma skończony nośnik, tzn. przyjmuje wartości zerowe
dla x > c + b oraz x 6 c − b, podczas gdy funkcja gaussowska określona
wzorem (4.3) ma nośnik nieskończony, tzn. ma niezerową wartość dla każdego
x ∈ R.
6. Funkcje klasy u (rys. 4.3b):
µAF (x) =
1 dla x 6 c − b
1 − 2(
x−c+bb
)2dla c − b < x 6 c − b/2
2(
x−cb
)2dla c − b/2 < x 6 c + b/2
1 − 2(
x−c−bb
)2dla c + b/2 < x < c + b
1 dla x > c + b
(4.7)
94

“KonspPreamb” 2013/10/3 page 95 #98
4. Elementy teorii zbiorów rozmytych
Funkcja klasy u jest funkcją dualną względem funkcji klasy π.
x
µAF (x)
b
c − b c − b2
c c + b2
c + b0
14
12
34
1
(a)
x
µAF (x)
b
c − b c − b2
c c + b2
c + b0
14
12
34
1
(b)
Rys. 4.3. Przykładowe funkcje przynależności typu π (a) oraz typu u (b)
Przedstawione przykłady funkcji przynależności nie wyczerpują oczywiście całego
wachlarza znanych i wykorzystywanych funkcji przynależności. Nawet w odniesie-
niu do przedstawionych tutaj funkcji można w łatwy sposób tworzyć funkcje zmo-
dyfikowane lub pochodne, będące nowymi funkcjami przynależności. Na przykład,
z funkcji klasy t można otrzymać szereg funkcji trapezowych, a przez ograniczenie
nośnika funkcji gaussowskiej otrzymywana jest funkcja dzwonowa. Nietrudno tak-
że utworzyć funkcję przyjmującą kształt odwrotny do funkcji klasy s, otrzymując
w efekcie funkcję klasy z.
Przedstawione tutaj funkcje stanowią jedynie przykłady typowych funkcji przy-
należności. Wiele innych funkcji przynależności można znaleźć w literaturze po-
dejmującej tematykę zbiorów rozmytych [14, 16, 164].
4.2. Miary rozmytości
Miary rozmytości, adekwatnie do swojej nazwy, charakteryzują stopień rozmy-
cia określonego zbioru. Odgrywają one istotną rolę przy próbach wykorzystania
teorii zbiorów rozmytych do budowy modeli systemów. Podczas dobierania zbio-
rów rozmytych opisujących model ważna staje się odpowiedź na pytanie, który
z dwóch różnych zbiorów rozmytych jest bardziej rozmyty oraz jak można ilościo-
wo określić różnicę pomiędzy zbiorem rozmytym, a zbiorem zwykłym.
95

“KonspPreamb” 2013/10/3 page 96 #99
4. Elementy teorii zbiorów rozmytych
Ogólnie miarę rozmytości określa się jako pewne przekształcenie ǫ , które każ-
demu zbiorowi będącemu podzbiorem przestrzeni X (inaczej każdemu elementowi
zbioru potęgowego przestrzeni X) przypisuje wartość z przedziału [0,∞) i które
spełnia następujące warunki [165]:
1. ǫ(
AF)
= 0 wtedy i tylko wtedy, gdyAF jest zwykłym podzbiorem przestrze-
ni X, tzn. ∀x ∈ X, µAF (x) = 0 ∨ µAF (x) = 1 (4.8a)
2. ǫ(
AF)
osiąga wartość maksymalną dla najbardziej rozmytego zbioru,
tzn. takiego, którego funkcja przynależności spełnia zależność:
µFA (x) =
12∀x ∈ X (4.8b)
3. ǫ(
AF∗) 6 ǫ(
AF)
, gdzieAF∗ jest mniej rozmytym zbiorem niżAF, tzn.
µAF∗ (x) 6 µAF (x) jeżeli µAF (x) 612∧ µAF∗ (x) > µAF (x) jeżeli
µAF (x) >12
(4.8c)
4. ǫ(
AF)
= ǫ(
AF)
, tzn. dopełnienie AF zbioru AF definiowane jako:
∀x ∈ X, µAF (x) = 1 − µAF (x) jest tak samo rozmyte jak zbiór AF.
(4.8d)
W literaturze dotyczącej teorii zbiorów rozmytych można znaleźć wiele różnych
miar rozmytości wykorzystujących różne własności zbiorów. Istnieją miary okre-
ślające stopień rozmytości zbioru biorąc za podstawę niepewność probabilistycz-
ną i niepewność rozmytą [166], energię informacyjną (ang. information energy)
[167], czy też odległość między zbiorem i jego dopełnieniem [168, 169]. Wśród
miar rozmytości zbiorów istnieje także duża grupa miar opartych na pojęciu entropi
[170] oraz jedna z bardzo popularnych miar oparta na odległości między zbiorami
nazywana indeksem rozmytości.
W pracy wykorzystane zostały dwie spośród znanych miar, mianowicie jedna
z miar entropijnych nazywana całkowitą entropią rozmytą oraz tzw. indeks rozmy-
tości, które z tego względu zostaną przedstawione bardziej szczegółowo. Ponieważ
w rozważanym w tej pracy zagadnieniu dopasowania pary stereoskopowej mamy
do czynienia ze zbiorami skończonymi, definicje miar zostały przytoczone jedynie
w odniesieniu do skończonych zbiorów rozmytych.
96

“KonspPreamb” 2013/10/3 page 97 #100
4. Elementy teorii zbiorów rozmytych
4.2.1. Całkowita entropia rozmyta
Klasyczna miara entropii Shannona jest miarą informacji. Podobnie, rozmyte
miary entropijne są nazywane rozmytymi miarami informacji. Odpowiednikiem
klasycznej miary Shannona w dziedzinie zbiorów rozmytych jest entropia rozmyta
[170]. W pracy wykorzystana została rozmyta miara entropijna nazywana entropią
całkowitą [171]. Miara ta uwzględnia dwa rodzaje informacji. Pierwsza jest zwią-
zana z losową naturą eksperymentu, druga zaś z niepewnością wprowadzaną przez
opisanie tego eksperymentu za pomocą zbioru rozmytego.
W celu zdefiniowania miary entropii całkowitej przyjmiemy założenie, że ist-
nieje ustalony zbiór T pewnych zdarzeń losowych x1, x2, . . . , xn w pewnym eks-
perymencie. Każdemu ze zdarzeń ze zbioru T może być przypisana wartość praw-
dopodobieństwa pi zajścia tego zdarzenia oraz wartość funkcji przynależności µiAF
do pewnego zbioru rozmytegoAF.
Jak wspomniano wyżej, opisanie tego zbioru zdarzeń T za pomocą zbioru roz-
mytegoAF wprowadza dwa rodzaje niepewności: jeden związany z losową naturą
eksperymentu oraz drugi związany z określeniem przynależności tych zdarzeń do
pewnego zbioru rozmytegoAF. Aby uwzględnić obydwa rodzaje niepewności oraz
wykorzystać zawarte w nich informacje, przyjmuje się, że entropia całkowita zbio-
ru rozmytego AF, który jest określony na podstawie zbioru zdarzeń T , jest sumą
dwóch składników.
Pierwszy składnik entropii całkowitej jest miarą wykorzystującą wiedzę o loso-
wej naturze eksperymentu. Wartość oczekiwana tej miary niepewności określana
jest przez entropię Shannona:
H (p1, p2, . . . , pn) = −n
∑
i=1
pi log (pi) (4.9)
Drugi składnik entropii całkowitej jest miarą niepewności związaną sciśle z roz-
mytością zbioru AF w odniesieniu do zbioru zdarzeń T . Wartość tej miary okre-
ślona dla zdarzenia xi o przypisanej do niego wartości funkcji przynależności µiAF ,
wyrażana jest przez zależność:
S(
µiAF
)
= −µiAF log
(
µiAF
)
−(
1 − µiAF
)
log(
1 − µiAF
)
(4.10)
97

“KonspPreamb” 2013/10/3 page 98 #101
4. Elementy teorii zbiorów rozmytych
Wartość średnia S niepewności, określona dla całego zbioru zdarzeń, jest zdefinio-
wana wzorem:
S(
µAF , p1, p2, . . . , pn)
=
n∑
i=1
piS(
µiAF
)
(4.11)
Natomiast entropia całkowita zbioru AF określona jest przez sumę niepewności
związanej z losową naturą eksperymentu oraz niepewności związanej z opisaniem
tego zbioru zdarzeń za pomocą zbioru rozmytego:
Hc = H (p1, p2, . . . , pn) + S(
µAF , p1, p2, . . . , pn)
(4.12)
Miara entropijna określona wyrażeniem (4.12) może być interpretowana jako
całkowita średnia informacja o przewidywanym pojawieniu się pewnego zbioru
zdarzeń pochodzących ze zbioru zdarzeń T , które mogą wystąpić w wyniku do-
świadczenia losowego, i podjęciu decyzji o ich stopniu przynależności do rozpa-
trywanego zbioru rozmytegoAF.
Jeżeli H (p1, p2, . . . , pn) = 0, oznacza to że w doświadczeniu nie ma losowości,
a jedyne pewne zdarzenie xi pochodzące ze zbioru T zdarzy się z prawdopodo-
bieństwem równym pi = 1. Pozostaje wówczas tylko niepewność określenia jego
przynależności do zbioru rozmytego:
Hc = S(
µiAF (x)
)
(4.13)
Natomiast jeżeli S(
µAF , p1, p2 . . . , pn)
= 0, to całkowita miara entropijna Hc redu-
kuje się do klasycznej miary entropii Shannona, tzn.:
Hc = H (p1, p2, . . . , pn) (4.14)
4.2.2. Indeks rozmytości
Indeks rozmytości jest jedną z miar, która została skonstruowana w celu zna-
lezienia odpowiedzi na pytanie o stopień rozmytości określonego zbioru rozmy-
tego [165, 172]. Miara ta została wykorzystana w niniejszej pracy dla przypadku
zbiorów o skończonej liczbie elementów i dla takich zbiorów zostanie niżej zdefi-
niowana. Aby miarę tę przedstawić bardziej szczegółowo, rozważmy pewną prze-
strzeń elementów X oraz zbiór potęgowy P (X) tej przestrzeni. Indeks rozmytości
98

“KonspPreamb” 2013/10/3 page 99 #102
4. Elementy teorii zbiorów rozmytych
Kaufmanna γ zbioru rozmytegoAF ⊆ P (X) jest zdefiniowany wyrażeniem [173]:
γ(
AF)
=2
Nkd(
AF,AFC
)
(4.15)
gdzie d (·, ·) jest pewną miarą odległości określoną w zbiorze P (X), k jest liczbą
dodatnią zależną co do wartości od wybranej miary odległości, N jest liczbą ele-
mentów zbioru rozmytego AF, natomiast AFC jest zbiorem zwykłym, najbliższym
w sensie przynależności elementów przestrzeni do zbioru rozmytegoAF. Funkcja
przynależności zbioruAFC określona jest następująco:
µAFC
(x) =
1 µAF 6 0.5
0 µAF > 0.5(4.16)
Często jako miara odległości d (·, ·) przyjmowana jest odległość Minkowskiego wy-
rażona wzorem:
dq(
AF,AFC
)
=
N∑
i=1
∣
∣
∣
∣
µAF (xi) − µAFC
(xi)∣
∣
∣
∣
q
1q
(4.17)
gdzie q jest rzędem metryki Minkowskiego. Miara Minkowskiego wyrażona wzo-
rem (4.17) jest określona dla wszystkich wartości q > 0, jednak najczęściej wyko-
rzystywane są miary o wartościach q = 1, q = 2 i q = ∞.
Po podstawieniu wzoru (4.17) do (4.15) otrzymujemy ogólne wyrażenie opisu-
jące indeks rozmytości Kaufmanna:
γ(
AF)
=2
N1q
N∑
i=1
|µFA (xi) − µAF
C(xi)|
1q
(4.18)
Przyjmując we wzorze (4.18) wartość q = 1, otrzymujemy miarę Hamminga od-
ległości zbiorów. Indeks rozmytości Kaufmanna nazywany jest wówczas liniowym
indeksem rozmytości. Indeks ten wyrażony jest wzorem:
γL
(
AF)
=2N
N∑
i=1
∣
∣
∣
∣
µAF (xi) − µAFC
(xi)∣
∣
∣
∣
(4.19)
Czasami stosowany jest także kwadratowy indeks rozmytości przy podstawieniu q =
2 we wzorze (4.18). Miara odległości jest w takim przypadku miarą euklidesową,
99

“KonspPreamb” 2013/10/3 page 100 #103
4. Elementy teorii zbiorów rozmytych
a wyrażenie opisujące kwadratowy indeks rozmytości Kaufmanna ma postać:
γK
(
AF)
=2√
N
√
√
√
N∑
i=1
[
µAF (xi) − µAFC
(xi)]2
(4.20)
4.3. Odległość zbiorów rozmytych
Określanie podobieństwa między różnego rodzaju elementami ze względu na
ich określone wyróżnione cechy odgrywa bardzo dużą rolę zarówno w zagadnie-
niach o charakterze praktycznym, jak i teoretycznym. Istotna rola określenia po-
dobieństwa elementów występuje np. w algorytmach klasteryzacji i klasyfikacji
danych, procesie wnioskowania na podstawie bazy wiedzy lub odkrywania wiedzy
zawartej w danych.
W przypadku próby wykorzystania zbiorów rozmytych w konkretnym zagad-
nieniu również istnieje potrzeba określenia miary podobieństwa między dwoma
zbiorami rozmytymi. Problem ten doczekał się propozycji wielu rozwiązań wy-
korzystujących zależności geometryczne zachodzące pomiędzy graficznymi repre-
zentacjami zbiorów [174], zależności funkcyjne zachodzące pomiędzy funkcjami
przynależności [175], czy też rozwiązań opartych na pewnych operacjach wyko-
nywanych na zbiorach [176]. Jednym z podejść do problemu określenia miary po-
dobieństwa między zbiorami rozmytymi jest określanie odległości między nimi,
analogicznie do znanych klasycznych miar odległości.
Definicja miary odległości między zbiorami rozmytymi powinna spełniać ogól-
ne warunki metryki, tzn. jeżeliAF,BF,CF są pewnymi zbiorami rozmytymi okre-
ślonymi w przestrzeni X, to odległość powinna być funkcją η : L (X) × L (X) →R+∪0, gdzie L (X) jest rodziną wszystkich podzbiorów rozmytych przestrzeni X.
Ogólne warunki metryki, które powinna spełniać definicja miary odległości między
zbiorami rozmytymi wyrażone są przez zależności [177]:
1. η(
AF,BF)
> 0 (4.21a)
2. jeżeli AF = BF, to η(
AF,BF)
= 0 (4.21b)
3. η(
AF,BF)
= η(
BF,AF)
(4.21c)
100

“KonspPreamb” 2013/10/3 page 101 #104
4. Elementy teorii zbiorów rozmytych
4. η(
AF,CF)
6 η(
AF,BF)
⊙ η(
BF,CF)
(4.21d)
gdzie ⊙ jest pewną operacją algebraiczną, np. dodawaniem. Ostatnia nierówność
(4.21d) jest nazywana nierównością trójkąta.
Najczęściej stosowane są następujące miary odległości między dwoma skoń-
czonymi zbiorami rozmytymi AF,BF ⊆ X = x1, x2, . . . , xn o określonych funk-
cjach przynależności µAF i µBF [177, 178, 179]:
Odległość Hamminga (liniowa), oznaczona przez ηFH
(
AF,BF)
:
ηFH
(
AF,BF)
=
N∑
i=1
∣
∣
∣µAF (xi) − µBF (xi)∣
∣
∣ (4.22)
Względna odległość Hamminga (liniowa unormowana), oznaczana ηFH
(
AF,BF)
:
ηFH
(
AF,BF)
=1N
N∑
i=1
|µAF (xi) − µBF (xi)| (4.23)
Odległość euklidesowa (kwadratowa), oznaczana ηFE
(
AF,BF)
:
ηFE
(
AF,BF)
=
√
√
√
N∑
i=1
[
µAF (xi) − µBF (xi)]2 (4.24)
Względna odległość euklidesowa (unormowana kwadratowa), oznaczana symbo-
lem ηFE
(
AF,BF)
:
ηFH
(
AF,BF)
=
√
√
√
1N
N∑
i=1
[
µAF (xi) − µBF (xi)]2 (4.25)
101

“KonspPreamb” 2013/10/3 page 102 #105
4. Elementy teorii zbiorów rozmytych
4.4. Korelacja zbiorów rozmytych
Ogólnie korelacja jest pewnym wskaźnikiem statystycznym służącym do okre-
ślania zależności między dwoma zmiennymi losowymi. Większa wartość korelacji
oznacza większą zależność elementów, dla których została ona określona. Cechę tę
próbuje się wykorzystać również w dziedzinie zbiorów rozmytych w celu określe-
nia podobieństwa zbiorów na podstawie ich korelacji. Obliczenie wartości współ-
czynnika korelacji między dwoma zbiorami rozmytymi pozwala na uzyskanie in-
formacji o ich podobieństwie analogicznie do miary korelacji stosowanej w innych
dziedzinach [180].
Współczynnik korelacji ρAF,BF między dwoma zbiorami rozmytymi AF i BF
wyrażony jest następującym wzorem [181]:
ρAF,BF =1
N − 1
∑Ni=1
[
µAF (xi) − µAF] [
µBF (xi) − µBF]
σAF · σBF(4.26)
gdzie µAF oraz µBF oznaczają wartości średnie funkcji przynależności:
µAF =1N
N∑
i=1
µAF (xi) ; µBF =1N
N∑
i=1
µBF (xi) (4.27)
natomiast σAF i σBF są wariancjami funkcji przynależności:
σAF =
√
√
√
1N − 1
N∑
i=1
[
µAF (xi) − µAF]2 ; σBF =
√
√
√
1N − 1
N∑
i=1
[
µBF (xi) − µBF]2
(4.28)
4.5. Relacje rozmyte
Ogólnie pod pojęciem relacji rozumie się zachodzenie określonego związku
między wyróżnionymi elementami pewnych zbiorów. W kategoriach teorii mno-
gości jako relację rozumie się podzbiór iloczynu kartezjańskiego dwóch zbiorów.
Niech dane będą dwa niepuste zbiory X i Y oraz zbiór Z będący iloczynem
kartezjańskim zbiorówX iY, tzn.:Z = X×Y. Elementami zbioruZ są wszystkie
pary uporządkowane elementów (x, y), takie że x ∈ X i y ∈ Y. Jeżeli w przypadku
102

“KonspPreamb” 2013/10/3 page 103 #106
4. Elementy teorii zbiorów rozmytych
elementów tworzących parę zostanie ustalona pewna właściwość to jej zachodze-
nie między elementami pary (x, y) będzie wyznaczało zbiór Ω, będący podzbio-
rem iloczynu kartezjańskiego zbiorówX×Y. Właściwość ta nazywana jest relacją
dwuczłonową lub krócej relacją. Wyznacza ona jednoznacznie zbiór Ω składający
się z takich par elementów (x, y), które ją spełniają. O elementach tych mówi się,
że pozostają ze sobą w relacji [182]. Problem powstaje jednak wtedy, gdy chcemy
wyrazić częściową lub niezbyt ściśle wyrażoną współzależność zachodzącą między
elementami zbiorówX iY. W takim przypadku można zastosować relację rozmytą,
która w sposób analogiczny do pojęcia zbioru rozmytego dopuszcza częściowe za-
chodzenie określonej właściwości, tzn. uwzględnia, że elementy mogą pozostawać
ze sobą w częściowej relacji.
W takim sensie relacja rozmyta jest uogólnieniem relacji nierozmytej. Pewne
elementy mogą nie tylko być lub nie być ze sobą w pewnym związku, ale pozo-
stawać ze sobą związane tylko w pewnym stopniu. W pracy wykorzystana została
jedynie rozmyta relacja dwuargumentowa, którą definiuje się w następujący spo-
sób [177, 171]:
Definicja 4.2. Relacja rozmyta dwuargumentowa Ω między dwoma zbiorami (nie-
rozymytymi) X = x i Y = y definiowana jest jako zbiór rozmyty Ω ⊆ X × Y =(x, y) : x ∈ X, y ∈ Y, taki że:
Ω = (x, y) , µΩ (x, y) , ∀x ∈ X, ∀y ∈ Y, (4.29)
gdzie µΩ : X×Y → [0, 1] jest funkcją przynależności relacji rozmytej Ω przypisu-
jąca każdej parze (x, y) , x ∈ X, y ∈ Y jej stopień przynależności µΩ (x, y) ∈ [0, 1]
będący miarą „siły” relacji rozmytej Ω między elementami x i y.
4.5.1. Rozmyta relacja podobieństwa
Relacja dwuargumentowa Ω może być oczywiście określona między elemen-
tami tego samego zbioru X, tzn. Ω ⊂ X × X. Pozwala ona wtedy na opisanie
bardzo istotnej właściwości, która może zachodzić między elementami tego sa-
mego zbioru, jaką jest ich podobieństwo pod pewnym względem. Dlatego wśród
relacji rozmytych wyodrębniona została również klasa relacji nazywana relacjami
103

“KonspPreamb” 2013/10/3 page 104 #107
4. Elementy teorii zbiorów rozmytych
podobieństwa, które oprócz tego że muszą być relacjami w sensie definicji (4.2),
to dodatkowo muszą spełniać także inne warunki [177].
Definicja 4.3. Rozmytą relacją podobieństwa ΩP ⊆ X × X określoną w zbiorze
X o skończonej liczbie elementów nazywana jest relacja rozmyta w sensie definicji
(4.2), która jest dodatkowo:
zwrotna: µΩP(x, x) = 1, ∀x ∈ X
symetryczna: µΩP(x, y) = µΩP
(y, x), ∀x, y ∈ Xprzechodnia: µΩP
(x, z) > maxy∈X
min[
µΩp(x, y) , µΩP
(y, z)]
, ∀x, y, z ∈ X
Wśród relacji podobieństwa istnieją relacje, które określają zachodzenie właści-
wości „x jest podobne do y” dla elementów będących liczbami. Relacje takie można
interpretować zgodnie ze znaczeniem „x jest w przybliżeniu równe y”. Rozmyta re-
lacją podobieństwa między dwoma liczbami x i y może być na przykład określona
przez funkcję przynależności:
µΩG(x, y) = exp
−(
x − y
σG
)2
(4.31)
Ze względu na zbieżność z wyrażeniem opisującym rozkład normalny oraz kształt
krzywych funkcji przynależności, relacja ta jest nazywana gaussowską relacją po-
dobieństwa. Przykłady funkcji przynależności relacji tego typu przedstawiono na
rys. 4.4. ParametrσG decyduje o „sile” relacji, umożliwiając pewną swobodę w do-
borze intensywności relacji między elementami. Jeżeli σG przyjmuje większe war-
tości oznacza to, że dopuszczane są coraz większe różnice między wartościami
elementów x i y, aby uznać je za podobne.
Druga z rozmytych relacji podobieństwa wykorzystana w pracy jest określona
jako funkcja przynależności:
µΩT(x, y) =
1 − |x−y|σT
jeżeli |x − y| < σT
0 w innym przypadku(4.32)
gdzieσT jest arbitralnie ustalonym parametrem ustalającym „siłę” relacji. Ze wzglę-
du na kształt krzywych funkcji przynależności, których przykłady przedstawiono
na rys. 4.5, relacja ta jest nazywana trójkątną relacją podobieństwa.
104

“KonspPreamb” 2013/10/3 page 105 #108
4. Elementy teorii zbiorów rozmytych
0 50100150
200255
050100150
2002550
0.250.5
0.751
xy
µΩ
G( x
,y)
0.2 0.4 0.6 0.8 1
(a)
0 50100150
200255
050100150
2002550
0.250.5
0.751
xy
µΩ
G( x
,y)
0 0.2 0.4 0.6 0.8 1
Rys. 4.4. Gaussowska relacja podobieństwa o parametrze σG = 127 (a) orazσG = 63 (b)
0 50100150
200255
050100150
2002550
0.250.5
0.751
xy
µΩ
T( x
,y)
0 0.2 0.4 0.6 0.8 1
(a)
0 50100150
200255
050100150
2002550
0.250.5
0.751
xy
µΩ
T( x
,y)
0 0.2 0.4 0.6 0.8 1
Rys. 4.5. Trójkątna relacja podobieństwa dla σT = 127 (a) oraz dla σT = 63 (b)
4.6. Teoria intuicjonistycznych zbiorów rozmytych
Teoria intuicjonistycznych zbiorów rozmytych została zaproponowana przez Ata-
nassova w 1986 roku [183, 184]. Teoria ta zyskała akceptację głównie wśród ba-
daczy zajmujących się teorią zbiorów rozmytych, którzy podjęli intensywne ba-
dania nad właściwościami intuicjonistycznych zbiorów rozmytych [185, 186] oraz
nad ich zastosowaniami praktycznymi. W efekcie tych badań teoria intuicjonistycz-
105

“KonspPreamb” 2013/10/3 page 106 #109
4. Elementy teorii zbiorów rozmytych
nych zbiorów rozmytych znalazła zastosowanie w wielu różnych dziedzinach nauki
i techniki, wśród których jako przykłady można wymienić: algorytmy wykorzy-
stywane do wspomagania diagnostyki medycznej [187] i algorytmy wspomagania
podejmowania decyzji [188]. Teoria ta znalazła również zastosowanie w dziedzinie
przetwarzania obrazów [189, 190].
Definicja intuicjonistycznego zbioru rozmytego, który w dalszej części pracy
będzie oznaczany akronimem IFS (ang. Intuitionistic Fuzzy Set), podana zostanie
poniżej za Atanssovem [183, 184].
Definicja 4.4. Intuicjonistyczny zbiór rozmytyAIFS w przestrzeniX określony jest
jako trójka uporządkowana:
AIFS =⟨
x, µAIFS (x) , νAIFS (x)⟩ |x ∈ X
(4.33)
gdzie:
µAIFS : X→ [0, 1] ∧ νAIFS : X→ [0, 1] (4.34)
przy spełnieniu dodatkowego warunku:
0 6 µAIFS (x) + νAIFS (x) 6 1 (4.35)
dla każdego x ∈ X.
Symbole µAIFS (x) i νAIFS (x) oznaczają odpowiednio funkcję przynależności oraz
funkcję nieprzynależności elementu x do zbioruAIFS.
Dla dowolnego IFSAIFS określonego w przestrzeniX definiowany jest również
indeks zaufania (ang. hesitancy index) πAIFS , nazywany również indeksem intu-
icjonistycznym (ang. intuitionistic index) lub indeksem wahania elementu x ∈ X
należącego do zbioruAIFS.
Definicja 4.5. Dla danego IFSAIFS jego indeksem zaufania nazywamy funkcję:
πAIFS (x) = 1 − µAIFS (x) − νAIFS (x) , x ∈ X (4.36)
Indeks zaufania πAIFS (x) wprowadza się w celu modelowania stopnia zaufania, że
element x należy do zbioru AIFS [183, 184]. Z warunku (4.35) wynika, że indeks
zaufania spełnia nierówność 0 6 πAIFS (x) 6 1 dla każdego x ∈ X
106

“KonspPreamb” 2013/10/3 page 107 #110
4. Elementy teorii zbiorów rozmytych
Zgodnie z definicjami 4.4 i 4.5, aby określić jednoznacznie dowolny zbiór IFS
muszą być podane dwie z trzech funkcji: funkcja przynależności i funkcja nieprzy-
należności lub też jedna z tych funkcji oraz indeks zaufania.
W pracy teoria rozmytych zbiorów intuicjonistycznych wykorzystana została
w celu rozwiązania zadania dopasowania pary stereoskopowej. Aby umożliwić wy-
korzystanie zbiorów IFS do rozwiązania tego zdania, zaproponowany został algo-
rytm umożliwiający opis obrazu w dziedzinie IFS, zawierający procedurę wyzna-
czenia funkcji przynależności zbioru IFS oraz indeksu zaufania na podstawie da-
nych obrazowych. Zgodnie z wyrażeniem (4.36) wyznaczenie części określającej
funkcję nieprzynależności staje się zadaniem trywialnym, a tym samym obraz może
być łatwo opisany w dziedzinie zbiorów IFS.
4.7. Miary podobieństwa intuicjonistycznych zbiorów
rozmytych
Podobnie jak w przypadku zbiorów rozmytych, podobieństwo dwóch zbiorów
IFS może być określane z wykorzystaniem różnych miar. W literaturze zapropo-
nowane zostały sposoby określenia podobieństwa zbiorów IFS na podstawie miar
odległości [191, 192], miar opartych o korelację [193] lub miar opartych o entropię
[194]. Poniżej przedstawione zostały typowe miary podobieństwa, które wykorzy-
stane będą do rozwiązania zagadnienia dopasowania obrazów pary stereoskopowej
w dziedzinie IFS. Tak jak w przypadku zwykłych zbiorów rozmytych, miary te
zostaną zdefiniowane dla przypadku zbiorów skończonych.
4.7.1. Odległość intuicjonistycznych zbiorów rozmytych
Jeżeli określone są dwa skończone zbiory IFS AIFS i BIFS o znanych funk-
cjach przynależności µAIFS i µBIFS oraz znane są ich funkcje nieprzynależności νAIFS
i νBIFS , to odległości między tymi zbiorami definiuje się następująco [186, 195,
196]:
Odległość Hamminga (liniowa):
ηIFSH
(
AIFS,BIFS)
=
N∑
i=1
[∣
∣
∣µAIFS (xi) − µBIFS (xi)∣
∣
∣ +∣
∣
∣νAIFS (xi) − νBIFS (xi)∣
∣
∣
]
(4.37)
107

“KonspPreamb” 2013/10/3 page 108 #111
4. Elementy teorii zbiorów rozmytych
Względna odległość Hamminga (unormowana liniowa):
ηIFSH
(
AIFS,BIFS)
=1
2N
N∑
i=1
[∣
∣
∣µAIFS (xi) − µBIFS (xi)∣
∣
∣ +∣
∣
∣νAIFS (xi) − νBIFS (xi)∣
∣
∣
]
(4.38)
Odległość euklidesowa (kwadratowa):
ηIFSE
(
AIFS,BIFS)
=
√
√
√
N∑
i=1
[
µAIFS (xi) − µBIFS (xi)]2+
[
νAIFS (xi) − νBIFS (xi)]2
(4.39)
Względna odległość euklidesowa (unormowana kwadratowa):
ηIFSH
(
AIFS,BIFS)
=
√
√
√
12N
N∑
i=1
[
µAIFS (xi) − µBIFS (xi)]2+
[
νAIFS (xi) − νBIFS (xi)]2
(4.40)
4.7.2. Korelacja intuicjonistycznych zbiorów rozmytych
Problem określania podobieństwa między zbiorami IFS na podstawie zależno-
ści korelacyjnych był intensywnie rozważany zarówno w kontekście teoretycznym
jak i zastosowań praktycznych. W związku z tym w literaturze można znaleźć wiele
różnych metod obliczania korelacji zbiorów IFS wraz z szeroką analizą ich właści-
wości [197, 198, 199, 200, 201].
W pracy przyjęto następującą definicję współczynnika korelacji między dwoma
zbiorami IFSAIFS i BIFS [202]:
ρIFS(
AIFS,BIFS)
=12
(
ρIFSµAIFS ,µBIFS
+ ρIFSνAIFS ,νBIFS
)
(4.41)
gdzie ρIFSµAIFS ,µBIFS
i ρIFSνAIFS ,νBIFS
są odpowiednio współczynnikami korelacji funkcji
przynależności i nieprzynależności zbiorów IFSAIFS iBIFS określonymi wzorami:
108

“KonspPreamb” 2013/10/3 page 109 #112
4. Elementy teorii zbiorów rozmytych
ρµAIFS ,µBIFS =
N∑
i=1
[
µAIFS (xi) − µAIFS] [
µBIFS (xi) − µBIFS]
√
N∑
i=1
[
µAIFS (xi) − µAIFS]2[µBIFS (xi) − µBIFS
]2
(4.42)
i odpowiednio:
ρIFSνAIFS ,νBIFS
=
N∑
i=1
[
νAIFS (xi) − νAIFS] [
νBIFS (xi) − νBIFS]
√
N∑
i=1
[
νAIFS (xi) − νAIFS]2 [
νBIFS (xi) − νBIFS]2
(4.43)
oraz µAIFS , µBIFS , νAIFS i νBIFS są wartościami średnimi funkcji przynależności i nie-
przynależności zbiorów IFSAIFS i BIFS:
µAIFS = 1N
N∑
i=1µAIFS (xi) ; µBIFS = 1
N
N∑
i=1µBIFS (xi)
νAIFS = 1N
N∑
i=1µAIFS (xi) ; νBIFS = 1
N
N∑
i=1µBIFS (xi)
(4.44)
Wprowadzone wyżej pojęcia i ich definicje stanowią zaledwie niewielką część
warstwy pojęciowej, jaką operuje teoria zbiorów rozmytych i teoria intuicjonistycz-
nych zbiorów rozmytych. Tworzą jednak kompletny zbiór pojęć niezbędny do pre-
zentacji opracowanych algorytmów umożliwiających rozwiązanie problemu dopa-
sowania pary stereoskopowej z wykorzystaniem tych teorii, jak również do przed-
stawienia dalszych wyników pracy.
109

“KonspPreamb” 2013/10/3 page 110 #113
Rozdział 5
Zastosowanie teorii zbiorów rozmytych
w zagadnieniu dopasowania pary
stereoskopowej obrazów
W rozdziale przedstawiono metody i algorytmy dopasowania pary stereoskopo-
wej obrazów z wykorzystaniem formalizmu zbiorów rozmytych, w tym propozycje
rozwiązań własnych autora stanowiące zasadniczą część rozdziału. Rozdział rozpo-
czyna omówienie koncepcji wykorzystania zbiorów rozmytych w ogólnej proble-
matyce przetwarzania obrazów. Przedstawiono m.in. zasady opisu obrazów w dzie-
dzinie zbiorów rozmytych oraz dokonano krótkiego przeglądu źródeł literaturo-
wych omawiających najczęściej stosowane metody fuzzyfikacji obrazów.
Kolejne punkty rozdziału dotyczą zasadniczego problemu rozważanego w pra-
cy i są poświęcone rozwiązaniu problemu dopasowania pary stereoskopowej z wy-
korzystaniem teorii zbiorów rozmytych i intuicjonistycznych zbiorów rozmytych.
Prezentację opracowań własnych autora poprzedzono omówieniem dostępnych po-
zycji literatury dotyczącej tego problemu, z podziałem na zagadnienie dopasowania
pary stereoskopowej obszarami oraz dopasowania cechami. Wśród opracowań au-
torskich przedstawiono m.in. metodykę konstrukcji funkcji przynależności stoso-
wanej w zaproponowanych algorytmach i zaprezentowano opracowane na jej pod-
stawie algorytmy dopasowania obrazów pary stereoskopowej, zarówno w dziedzi-
nie zbiorów rozmytych, jak i intuicjonistycznych zbiorów rozmytych. Zapropono-
wano ponadto nowy detektor krawędzi opary na relacji rozmytej oraz metodę dopa-
sowania obrazów pary stereoskopowej wykorzystującą tenże detektor. W ostatnim
punkcie rozdziału przedstawiono propozycję obliczania rozmytej transformaty ran-
kingowej oraz sposób jej wykorzystania do rozwiązania zagadnienia dopasowania
pary stereoskopowej obrazów.
110

“KonspPreamb” 2013/10/3 page 111 #114
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
5.1. Wykorzystanie zbiorów rozmytych w zagadnieniach
przetwarzania obrazów
Zastosowanie teorii zbiorów rozmytych i elementów logiki rozmytej w zagad-
nieniach związanych z komputerowym przetwarzaniem obrazów określane jest cza-
sami jako rozmyte przetwarzanie obrazów [203]. Proponowane w literaturze po-
dejścia, które umożliwiają wykorzystanie zbiorów rozmytych w komputerowym
przetwarzaniu obrazów, nie stanową jednolitej teorii, lecz są zbiorem różnorodnych
metod wykorzystujących wybrane elementy teorii zbiorów rozmytych. Można spo-
tkać propozycje wykorzystania teorii zbiorów rozmytych w takich zagadnieniach
jak usuwanie szumów zawartych w obrazach lub zmiana właściwości obrazu, jaką
jest np. poprawa kontrastu lub normalizacja kolorów. Zbiory rozmyte zostały także
wykorzystane do zdefiniowania operatorów morfologii rozmytej, w algorytmach
segmentacji obrazów, w zagadnieniach związanych z rozpoznawaniem obiektów
przedstawianych na obrazach, czy wreszcie zagadnieniach rozumienia sceny przed-
stawianej na obrazie.
Pomimo braku jednolitego podejścia, można spróbować zdefiniować pojęcie
rozmytego przetwarzania obrazów w sposób następujący [203]:
Rozmyte przetwarzanie obrazów obejmuje wszystkie możliwe podejścia do roz-
wiązywania zagadnień związanych z komputerowym przetwarzaniem obrazów, w któ-
rych wykonywane są operacje na obrazach, ich elementach lub częściach, z wyko-
rzystaniem zbiorów rozmytych. Reprezentacja oraz metoda przetwarzania zależą
od wyboru konkretnej, znanej z teorii zbiorów rozmytych techniki przetwarzania
oraz problemu, do rozwiązania którego jest ona wykorzystana. Jako przykład takiej
techniki można wymienić przetwarzanie za pomocą fuzzyfikacji obrazów i prze-
prowadzanie działań na ich reprezentacjach w dziedzinie zbiorów rozmytych lub
wykorzystanie jedynie wybranych elementów teorii zbiorów rozmytych, takich jak
relacja rozmyta, czy miara rozmyta.
Można oczywiście zadać pytanie, dlaczego zbiory rozmyte używane są w tak
dobrze rozwiniętej dziedzinie, jak przetwarzanie obrazów. W odpowiedzi na to py-
tanie można wymienić następujące powody:
- zbiory rozmyte są efektywnym i sprawdzonym narzędziem, które może być wy-
korzystane do reprezentacji i przetwarzania wiedzy na temat obiektu, którego
dotyczy problem,
111

“KonspPreamb” 2013/10/3 page 112 #115
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
- techniki wykorzystujące w swoim działaniu zbiory rozmyte są adekwatne do re-
prezentacji i modelowania niepewności, niejednoznaczności, niejasności, jakie
mogą występować w przetwarzanych danych,
- teoria zbiorów rozmytych oraz teoria logiki rozmytej są doskonałymi narzę-
dziami do reprezentacji rozumowania człowieka na podstawie wiedzy w formie
reguł, w wyniku czego w niektórych dziedzinach przetwarzania obrazów, jak
np. rozpoznawanie obiektów, czy analiza sceny, zbiory rozmyte mogą być użyte
w celu wykorzystania wiedzy eksperta na temat rozwiązywanego zagadnienia.
5.2. Przetwarzanie obrazów z wykorzystaniem fuzzyfikacji
obrazu
Jeden z często stosowanych sposobów wykorzystania teorii zbiorów w przetwa-
rzaniu obrazów polega na zmianie dziedziny przetwarzanych obrazów do dziedziny
zbiorów rozmytych i wykonywaniu działań na reprezentacjach obrazów w dziedzi-
nie zbiorów rozmytych. W tym celu należy zdefiniować funkcję przynależności
zmiennych będących przedmiotem rozważań. W przypadku obrazów są to zazwy-
czaj pewne cechy pikseli, jak wartość ich jasności dla obrazów wyrażonych w skali
szarości lub ich kolor dla obrazów kolorowych. Znajomość funkcji przynależności
pozwala na ich opis w kategoriach zbiorów rozmytych. Operacja ta jest nazywana
fuzzyfikacją.
Jednym z najbardziej ogólnych problemów występujących w teorii zbiorów
rozmytych, jest dobór kształtu i parametrów funkcji przynależności. Problem ten
jest rozważany w wielu aspektach zastosowań zbiorów rozmytych i w literaturze
można znaleźć wiele propozycji różnych metod, których zadaniem jest określenie
postaci funkcji przynależności na podstawie przesłanek dotyczących rozważanych
danych [204, 205, 206, 207].
Problem wyboru kształtu funkcji przynależności był również rozważany w kon-
tekście możliwości zastosowania zbiorów rozmytych w algorytmach przetwarzania
obrazów [208]. W przypadku próby zastosowania teorii zbiorów rozmytych w prze-
twarzaniu obrazów zazwyczaj definiowana jest funkcja przynależności pikseli do
pewnego określonego zbioru rozmytego, zdefiniowanego na podstawie pewnej ce-
chy pikseli lub całego obrazu. Znajomość funkcji przynależności pikseli obrazu
pozwala na przeprowadzenie ich fuzzyfikacji oraz wykonywanie działań na ich
112

“KonspPreamb” 2013/10/3 page 113 #116
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
reprezentacji w dziedzinie zbiorów rozmytych oraz wykorzystanie teorii zbiorów
rozmytych na etapie przetwarzania obrazów.
Ogólny schemat przetwarzania obrazów wykorzystujący fuzzyfikację i teorię
zbiorów rozmytych został przedstawiony na rys. 5.1
Pt ♣ Pt ③ r②t② Pt ♣
② ③ r②t②
♣t ♣ ②
③ r②t② r②t
❲ ♣t
Rys. 5.1. Ogólny schemat przetwarzania obrazów wykorzystujący fuzzyfikacjęi teorię zbiorów rozmytych
5.2.1. Metody fuzzyfikacji wykorzystywane w przetwarzaniu obrazów
Jedną z najczęściej stosowanych metod fuzzyfikacji obrazu jest jego opis w ka-
tegoriach zbiorów rozmytych z wykorzystaniem funkcji przynależności typu sin-
gleton rozmyty (por. p. 4.1.3). W metodzie tej zakłada się, że obraz I składający
się z M × N pikseli pi j , i = 0, . . . ,M − 1, j = 0, . . . ,N − 1, z których każdy może
przybierać L poziomów szarości ponumerowanych od 0 do L − 1, jest traktowany
jako macierz singletonów rozmytych o postaci(
Ii j , µA(
Ii j
))
, gdzie Ii j jest pozio-
mem szarości piksela pi j , zaś µA(
Ii j
)
jest wartością funkcji przynależności po-
ziomu szarości Ii j tego piksela, określającą stopień jego przynależności do zbioru
rozmytego określonego na podstawie pewnej cechy obrazu, np. „jasność piksela”,
113

“KonspPreamb” 2013/10/3 page 114 #117
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
„przynależność piksela do krawędzi”, „przynależność piksela do pewnego obiektu
w obrazie”, itp. Reprezentacja macierzy singletonów rozmytych ma postać:
µI =
µA (I00) · · · µA (I0N−1)...
. . ....
µA (IM−10) · · · µA (IM−1N−1)
(5.1)
Można zatem powiedzieć, że w metodzie fuzzyfikacji za pomocą funkcji sin-
gleton rozmyty każdy piksel pi j jest fuzzyfikowany oddzielnie, przy czym spo-
śród przestrzeni poziomów szarości tylko poziomowi szarości Ii j tego piksela jest
przypisywana niezerowa wartość funkcji przynależności, podczas gdy wartość tej
funkcji dla pozostałych poziomów szarości są zerowe. Najprostsza tego typu fuz-
zyfikacja obrazu jest dokonywana na podstawie cechy jasności pikseli, tzn. zbiór
rozmyty będzie określany jako „zbiór pikseli białych”.
Z reguły wartości funkcji przynależności są, zgodnie z podstawową definicją
4.1, normowane do przedziału [0, 1]. W przypadku fuzzyfikacji obrazów wygodnie
jest niekiedy przeskalować ten przedział na przedział numerów poziomów jasności
[0, L − 1] i stopień przynależności danego piksela (np. do zbioru rozmytego „pik-
sele białe”) wyrażać bezpośrednio jako numer poziomu jego jasności [209, 210,
211].
W [212] zaproponowana została metoda znajdowania funkcji przynależności
z wykorzystaniem histogramu obrazu. W proponowanym algorytmie wartości ja-
sności pikseli przypisywane są do pewnej liczby abstrakcyjnie określonych klas.
Przynależność piksela do danej klasy określana jest przez wartość funkcji przyna-
leżności o kształcie trapezowym, będącym prostym rozszerzeniem funkcji klasy t
(por. p. 4.1.3). W początkowym kroku algorytmu znajdowania funkcji przynależ-
ności cały przedział wartości jasności pikseli, dla których wyznaczony został histo-
gram obrazu, dzielony jest na przedziały, na których definiowane są funkcje przy-
należności o początkowym, standardowym, symetrycznym na danym przedziale
kształcie trapezowym. Końcowy kształt funkcji przynależności określający przyna-
leżność piksela do pewnej klasy na podstawie jego wartości jasności określany jest
przez dobór parametrów opisujących trapezową funkcję przynależności. Parametry
te są dobierane w efekcie przeprowadzenia algorytmu minimalizacji odległości eu-
klidesowej między wartościami funkcji przynależności dla danej klasy określonej
114

“KonspPreamb” 2013/10/3 page 115 #118
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
na danym przedziale jasności i jej odległością od wartości histogramu przyjmo-
wanego przez wartości jasności pikseli obrazu na tym przedziale. Po otrzymaniu
ostatecznych kształtów funkcji przynależności dla klas, pikselom o określonych
wartościach jasności przypisywane są wartości funkcji przynależności do klasy
przez nią określonej. Wadą proponowanego rozwiązania jest wstępne określenie
liczby klas, do których zaliczamy piksele obrazu, jak również wykorzystanie al-
gorytmu optymalizacji w celu znalezienia minimalnej odległości poszukiwanych
funkcji przynależności od histogramu obrazu.
Inną metodą stosowaną do określenia funkcji przynależności jasności pikseli
obrazu jest wykorzystanie rozmytych algorytmów grupowania [213]. Jedna z pro-
pozycji wykorzystania rozmytego algorytmu grupowania c-średnich FCM (ang.
Fuzzy c-Means) została przedstawiona w [214]. Autorzy w celu wyznaczenia war-
tości funkcji przynależności pikseli do pewnych klas wykorzystali obraz kolorowy
reprezentowany w przestrzeni HSV (ang. Hue Saturation Value). Wykonanie algo-
rytmu rozmytego algorytmu grupowania na pikselach obrazu pozwoliło na uzyska-
nie wartości ich przynależności do pewnych abstrakcyjnych grup. W wyniku dzia-
łania algorytmu FCM otrzymywane są funkcje przynależności zbliżone kształtem
do funkcji gaussowskich (por. p. 4.1.3), które mogą posłużyć do przypisania pikseli
o określonych wartościach koloru przedstawionego w przestrzeni HSV do pewnych
klas. Wadą algorytmu jest konieczność określenia liczby klas, na które dzielone są
piksele oraz znaczna złożoność algorytmu rozmytego grupowania c-średnich.
W literaturze można także znaleźć rozwiązania opierające się na przekształ-
ceniu rozkładów prawdopodobieństwa do rozkładu możliwości, który następnie
wykorzystywany jest w celu określenia przynależności pikseli o określonych war-
tościach jasności do pewnej klasy [215]. Inne propozycje rozwiązań znajdowania
funkcji przynależności polegają na optymalizacji zadanej funkcji celu [216, 217].
5.3. Zastosowanie zbiorów rozmytych w problemie
dopasowania pary stereoskopowej
Pomimo bardzo dużego zainteresowania problemem dopasowania pary stereo-
skopowej wśród badaczy zajmujących się komputerowym przetwarzaniem obra-
zów, w literaturze nie ma zbyt wielu propozycji rozwiązań wykorzystujących do
tego celu teorię zbiorów rozmytych lub teorię logiki rozmytej. W tym punkcie do-
115

“KonspPreamb” 2013/10/3 page 116 #119
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
konany zostanie krótki przegląd dostępnych publikacji, do jakich udało się autorowi
dotrzeć podczas studiów literaturowych. Propozycje własne autora przedstawione
zostaną w kolejnych punktach tego rozdziału.
5.3.1. Zastosowanie zbiorów rozmytych w algorytmach dopasowania
obszarami
W przypadku zastosowania teorii zbiorów rozmytych w algorytmach dopaso-
wania obszarami istnieją dwa główne podejścia do rozwiązania tego zagadnienia.
Pierwszym z nich jest fuzzyfikacja obrazu. Na obrazach poddanych algorytmowi
fuzzyfikacji można wykonywać operacje z wykorzystaniem elementów teorii zbio-
rów rozmytych lub logiki rozmytej. Drugim z podejść jest wykorzystanie elemen-
tów teorii zbiorów rozmytych w celu opracowania odpowiednich miar dopasowa-
nia.
Przykładem algorytmu wykorzystującego przejście z opisem obrazów do dzie-
dziny zbiorów rozmytych i obliczanie podobieństwa w dziedzinie zbiorów rozmy-
tych jest algorytm podany w [218]. Obliczanie funkcji przynależności pikseli ob-
razów wykonywane jest lokalnie w danym oknie za pomocą funkcji gaussowskiej
(por. p.4.1.3) z lokalnie wyznaczanymi parametrami ją opisującymi, którymi są:
wartość średnia i wariancja wartości jasności pikseli w oknie referencyjnym.
Algorytm ten działa zgodnie z ogólną zasadą algorytmu dopasowania obsza-
rami (por. p. 3.1). Dla każdego położenia okna referencyjnego Wi j
re fi każdego
położenia okna przeszukiwania Wi jsz (zakładamy okna kwadratowe o rozmiarach
Nw × Nw), umieszczonych na pozycji (i, j), i = 0, . . . ,M − 1, j = 0, . . . ,N − 1,
gdzie M i N są rozmiarami obrazów, dokonywana jest fuzzyfikacja jasności pikseli
zawartych w tych oknach. Fuzzyfikacja jest przeprowadzona na podstawie gaussow-
skich funkcji przynależności µi j
re fi µi j
sz o wartościach oczekiwanych i wartościach
wariancji obliczonych indywidualnie dla obu okien jako wartość średnia i wariancja
wszystkich pikseli zawierających się w danym oknie położonym na pozycji (i, j).
W efekcie fuzzyfikacji otrzymuje się dwie macierze µre f i µsz, których elementami
są funkcje przynależności µi j
re fi µi j
sz otrzymane na podstawie fuzzyfikacji jasności
pikseli zawartych w oknach Wi j
re fi odpowiednio W
i jsz .
Z kolei na podstawie macierzy µre f i µsz dla każdej pary indeksów i, j, i =
0, . . . ,M − 1 , j = 0, . . . ,N − 1, obliczane są macierze Ri j o rozmiarach Nw × Nw
116

“KonspPreamb” 2013/10/3 page 117 #120
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
i o elementach:
Ri j
kl=
min
µi j
re f(k, l) , µi j
sz (k, l)
max
µi j
re f(k, l) , µi j
sz (k, l) , (5.2)
gdzie µi j
re f(k, l) i µi j
sz (k, l) są wartościami rozmytymi przypisanymi poszczególnym
pikselom zawartymi odpowiednio w oknie referencyjnym i oknie przeszukiwania,
k, l = 1, . . . ,Nw. Operacje min oraz max w wzorze (5.2) oznaczają, że spośród
dwóch elementów zbioru ·, · wybierany jest element o mniejszej i odpowiednio
większej wartości. We wprowadzonych wielkościach nie występuje w formie jaw-
nej zależność aktualnych wartości dysparcyji piskeli od położenia okna przeszuki-
wania. Zależność ta jednak oczywiście istnieje i jest uwzględniana zgodnie z ogól-
ną zasadą działania algorytmów dopasowania obszarami (por. p. 3.1).
Wartości macierzy Ri j , i = 0, . . . ,M − 1, j = 0, . . . ,N − 1, służą następ-
nie do wyznaczania podobieństwa między wartościami jasności pikseli zawartych
w oknach referencyjnym Wi j
re fi przeszukiwania W
i jsz położonymi na pozycji (i, j),
wyrażonymi w dziedzinie zbiorów rozmytych, tzn. określonymi przez wyznaczone
wcześniej lokalne gaussowskie funkcje przynależności µi j
re fi µi j
sz. Za miarę podo-
bieństwa wartości jasności pikseli w oknach referencyjnym i przeszukiwania na
pozycji (i, j) przyjęto unormowaną sumę:
Si j =1
N2w
Nw∑
k=1
Nw∑
l=1
ri j
kl(5.3)
Jako wynikową wartość dysparycji wybierana jest ta wartość, dla której miara miara
Si j określona wzorem (5.3) przyjmuje wartość maksymalną.
W [218] zaproponowana została również dodatkowa wersja algorytmu z lokal-
ną fuzzyfikacją jasności pikseli za pomocą gaussowskiej funkcji przynależności,
ale z odmienną niż (5.3) miarą podobieństwa. W tej wersji algorytmu w macie-
rzy (5.2) znajdowane są elementy o wartościach większych od pewnych arbitral-
nie ustalonych progów αm, gdzie m jest numerem progu. Dla ustalonej wartości
progu αm wybierane są te wartości jasności pikseli należących do okna referencyj-
nego Wi j
re fi okna przeszukiwania W
i jsz , dla których rozmyte wartości elementów
macierzy Ri j przekraczają ten próg. Dla tych wartości jasności pikseli obliczana
jest znormalizowana korelacja wzajemna ZNCC. Wartość tej miary dla progu αm
oznaczana jest jako ρi jαm
. W zależności od przyjętej implementacji algorytmu miara
117

“KonspPreamb” 2013/10/3 page 118 #121
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
ta jest obliczana dla kilku lub kilkunastu wartości progów. Końcowa miara po-
dobieństwa między wartościami jasności pikseli zawartymi oknach referencyjnym
i przeszukiwania określona jest wyrażeniem:
S′ i j =
∑
mαmρ
i jαm
∑
mαm
(5.4)
Jako wartość dysparycji wybierana jest wartość, dla której miara (5.4) jest maksy-
malna.
Proponowane algorytmy algorytmy zawierają również dodatkowy krok spraw-
dzenia poprawności otrzymanej mapy dysparycji, wykonywany przez porównanie
wartości map dysparycji otrzymanych po zamianie rolami obrazu referencyjnego
i przeszukiwania. Autorzy [218] porównali dwa proponowane algorytmy z algoryt-
mem dopasowania obszarami wykorzystującym miarę NCC dla trzech par obrazów
testowych. Niestety porównanie to obejmowało tylko 20 wybranych pikseli z każ-
dego obrazu. Przedstawione wyniki pozwoliły autorom na sformułowanie wniosku,
że zaproponowane przez nich algorytmy pozwalają na osiągnięcie lepszych wyni-
ków, niż algorytm dopasowania obszarami wykorzystujący miarę NCC zastosowa-
ny bezpośrednio w dziedzinie jasności pikseli.
W algorytmie dopasowania obrazów pary stereoskopowej opisanym w [219]
autorzy przedstawili metodę wykorzystania całki rozmytej w algorytmie dopaso-
wania pary stereoskopowej. Zaproponowane zostało rozwiązanie problemu dopa-
sowania z wykorzystaniem obrazów kolorowych reprezentowanych w przestrzeni
barw RGB. W tym algorytmie dla każdego kanału koloru obrazów wykonywa-
ny jest niezależnie algorytm dopasowania obszarami. Jako miary dopasowania al-
gorytmu wykonywanego w każdym z kanałów opisu obrazu wykorzystane zosta-
ły: miara SSD, miara oparta o model rozkładu możliwości jasności pikseli oraz
miara oparta o wzajemne zawieranie się jasności piskeli w oknach referencyjnym
i przeszukiwania. Istotnym krokiem algorytmu jest agregacja wyników otrzyma-
nych w każdym z kanałów i podjęcie decyzji o istnieniu dopasowania. W jednym
przypadku jako całkowita miara dopasowania wykorzystana została suma wartości
miary dopasowania uzyskana w każdym z kanałów niezależnie. Autorzy porównali
sumę algebraiczną zastosowaną jako metodę agregracji wyników otrzymywanych
z poszczególnych kanałów z proponowaną metodą wykorzystującą całkę rozmytą.
118

“KonspPreamb” 2013/10/3 page 119 #122
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
W wyniku wykonanych eksperymentów przedstawiony został wniosek, że wyko-
rzystanie całki rozmytej jako metody agregacji wyników dopasowania z każdego
kanału pozwala na uzyskanie większej ilości poprawnie dopasownych pikseli, niż
w przypadku zastosowania sumy algebraicznej otrzymywanych wartości miary po-
dobieństwa jako metody agregacji wyników dopasowania z każdego kanału. Do-
datkowym wnioskiem, przedstawionym jako rezultat badań było stwierdzenie, że
wyniki uzyskiwane przez wykorzystanie całki rozmytej w celu agregacji wyników
otrzymanych z każdego kanału koloru niezależnie, silnie zależą od dobranych war-
tości parametrów całki rozmytej zastosowanej do agregacji wyników otrzymywa-
nych z poszczególnych kanałów.
Shamir [220] zaproponował algorytm rozwiązujący zagadnienie dopasowania
obrazów pary stereoskopowej oparty w pełni na schemacie wnioskowania rozmyte-
go. Zaproponowany algorytm działa w przestrzeni kolorów HSV, przeprowadzając
proces wnioskowania o podobieństwie pikseli obrazów na podstawie różnicy war-
tości między poszczególnymi elementami składowych HSV. Etap wnioskowania
przeprowadzany jest na podstawie 64 reguł według schematu: jeżeli – to. Przykła-
dowa reguła wnioskowania wykorzystana w algorytmie brzmi: jeżeli różnica mię-
dzy składową koloru H jest bardzo mała i różnica między składową koloru S jest
bardzo mała i różnica między składową koloru V jest bardzo mała, wtedy piksele są
takie same. Do wartości różnic przypisane zostały cztery zbiory rozmyte związa-
ne z wykorzystanymi na etapie wnioskowania określeniami lingwistycznymi: bar-
dzo mała, mała, średnia i duża. Dla każdego z tych zbiorów zdefiniowana została
funkcja przynależności kształtu trójkątnego umożliwiająca określenie przynależ-
ności różnic składowych HSV obliczanych w czasie wnioskowania do każdego ze
zdefiniowanych zbiorów rozmytych. Wniosek o podobieństwie pikseli i istnieniu
jednoznacznego dopasowania otrzymywany był za pomocą defuzzyfikacji wartości
zbioru rozmytego otrzymanego w wyniku przeprowadzonego wnioskowania.
Proponowany algorytm został przez autora przetestowany dla rzeczywistej pary
obrazów i przedstawione rezultaty przekonują do jego użyteczności. Jedyną nie-
korzystną cechą jest czas wykonania algorytmu, który dla obrazów o rozmiarze
320 × 240 pikseli oszacowany został na 42 godziny.
W [221] zaprezentowany został algorytm dopasowania obszarami, w którym
miara podobieństwa oparta została o rozmytą relację podobieństwa. W celu popra-
wienia uzyskiwanych wyników zastosowane zostały obrazy kolorowe. Dodatkowo,
119

“KonspPreamb” 2013/10/3 page 120 #123
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
aby uzyskać lepsze wyniki, autorzy zdecydowali się na obliczanie wartości dyspa-
rycji za pomocą piramidalnej dekompozycji obrazu.
Inna propozycja wykorzystania zbiorów rozmytych została przedstawiona przez
Hugesa [222]. W artykule zastosowane zostały filtry rozmyte umożliwiające popra-
wę otrzymanej mapy dysparycji. Pierwotny algorytm dopasowania wykorzystywał
miarę SSD do otrzymania mapy dysparycji, natomiast filtry wykorzystujące ele-
menty teorii zbiorów rozmytych zostały użyte do poprawienia jej jakości.
5.3.2. Teoria zbiorów rozmytych w algorytmach dopasowania
cechami
W przypadku zastosowań teorii zbiorów rozmytych w algorytmach dopasowa-
nia miejsc charakterystycznych logika rozmyta stosowana jest w celu poprawienia
jakości detektorów oraz konstruowania miary dopasowania.
Autorzy artykułu [223] wykorzystali zbiory rozmyte na etapie detekcji linii pro-
stych, konstruując w tym celu wieloetapowy algorytm. W pierwszym kroku na ob-
razach wykrywane są krawędzie za pomocą detektora Sobela. W efekcie działania
detektora Sobela otrzymywane są obrazy krawędziowe zawierające piksele, których
wartości określają przynależność piksela obrazu oryginalnego do krawędzi w ob-
razie. Wynikowe obrazy krawędziowe zostają poddane algorytmowi tłumienia nie
maksymalnych wartości pikseli określających położenie krawędzi w obrazie orygi-
nalnym, a pozostałe piksele określające położenie krawędzi zostają pogrupowane
w odcinki liniowe. Tłumienie wartości nie maksymalnych (ang. non maximum sup-
pression) jest algorytmem wykorzystywanym w celu znalezienia lokalnych maksi-
mów leżących w pewnym określonym regionie obrazu [224]. Grupowanie pikseli
otrzymanych w wyniku działania algorytmu tłumienia wartości nie maksymalnych
odbywa się za pomocą regułowego systemu rozmytego. W podobny sposób prze-
biega etap dopasowania. Na etapie tym działa system wnioskowania rozmytego,
w którym za pomocą pięciu reguł porównywane jest podobieństwo wyszukanych
odcinków. Niestety autorzy przedstawili wyniki tylko jednego eksperymentu, na
podstawie którego trudno jest wnioskować o cechach algorytmu.
Inna propozycja wykorzystania zbiorów rozmytych w celu dopasowania krawę-
dzi zawartych w obrazie została przedstawiona w [225]. W opisanym tam algoryt-
mie wykorzystany został detektor krawędzi Canny’ego. W otrzymanych obrazach
krawędziowych usuwane są krawędzie poziome, natomiast pozostałe łączone są
120

“KonspPreamb” 2013/10/3 page 121 #124
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
w odcinki. Do każdego z wyznaczonych odcinków przypisywanych jest pięć atry-
butów: orientacja i wartość gradientu odcinka, średnia wartość jasności pikseli kra-
wędziowych na prawej i lewej części odcinka oraz podobieństwo dwóch sąsiednich
krawędzi. Wartości tych atrybutów zostają przekształcone za pomocą funkcji przy-
należności do dziedziny zbiorów rozmytych, w której wykonywane jest obliczenie
miary podobieństwa.
Dodatkowym krokiem algorytmu jest możliwość wykorzystania algorytmu ge-
netycznego, w celu interpolacji pozostałych wartości dysparycji. Przedstawione
rezultaty pokazały użyteczność proponowanego rozwiązania. Głównym aspektem
prezentowanych wyników była możliwość interpolacji wartości dysparycji.
Główną cechą propozycji, które udało się autorowi wyszukać w literaturze, jest
wykorzystanie jedynie niektórych elementów zbiorów rozmytych do rozwiązania
problemu dopasowania. Metody opracowane w niniejszej pracy pozwalają na pełne
rozwiązanie problemu dopasowania w dziedzinie zbiorów rozmytych i w dziedzi-
nie zbiorów IFS. W dalszych punktach pracy przedstawione zostaną metody umoż-
liwiające opis obrazu zarówno w dziedzinie zbiorów rozmytych jak i w dziedzinie
zbiorów IFS. Przedstawione zostaną również algorytmy umożliwiające rozwiąza-
nie problemu dopasowania pary stereoskopowej w obu dziedzinach zbiorów.
Innym aspektem, który zostanie przedstawiony w dalszych punktach pracy, bar-
dziej zgodnym z przedstawionymi propozycjami jest algorytm dopasowania cecha-
mi. W tym algorytmie, podobnie jak w większości przedstawionych algorytmów,
wykorzystany został tylko jeden z elementów pochodzący z teorii zbiorów roz-
mytych, umożliwiający poprawę otrzymywanych wyników algorytmu dopasowania
cechami pary stereoskopowej.
5.4. Proponowany algorytm znajdowania funkcji
przynależności
Autor pracy zaproponował metodę określania funkcji przynależności pikseli
obrazów opisanych w skali szarości, która może być wykorzystana w ogólnych al-
gorytmach przetwarzania obrazów. W pracy metoda ta została wykorzystana do
rozwiązania zadania dopasowania obrazów pary stereoskopowej w dziedzinie zbio-
rów rozmytych. Polega ona na poszukiwaniu optimum funkcji celu konstruowanej
121

“KonspPreamb” 2013/10/3 page 122 #125
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
z wykorzystaniem przedstawionych wcześniej miar: entropii całkowitej i indeksu
rozmytości [18]. 1
Miary te umożliwiają konstrukcję funkcji celu, która następnie zostaje wyko-
rzystana do znalezienia funkcja przynależności umożliwiającej fuzzyfikację pikse-
li obrazu. Po określeniu funkcji celu problem znalezienia funkcji przynależności
zostaje sformułowany jako problem optymalizacyjny poszukiwania jej optymal-
nej wartości. Celem postawionego zadania optymalizacyjnego jest znalezienie ta-
kiej postaci funkcji przynależności, która zawierałaby maksymalną ilość informacji
o obrazie. Kryterium optymalizacyjne jest w tym przypadku formułowane na pod-
stawie miary entropii całkowitej. Biorąc pod uwagę że entropia jest miarą informa-
cji, można powiedzieć że funkcja przynależności charakteryzująca się maksymalną
entropią jest najlepszą funkcją z informacyjnego punktu widzenia.
Z drugiej jednak strony poszukiwana funkcja przynależności powinna w dużym
stopniu wykorzystywać zalety teorii zbiorów rozmytych umożliwiających uwzględ-
nienie niepewności co do wartości jasności pikseli zawartych w obrazie. Powinna
ona zatem przypisywać wartości jasności pikseli w możliwie arbitralny sposób.
W tym celu zaproponowane zostało wykorzystanie indeksu rozmytości jako mia-
ry, która mówi o rozmytości otrzymanej funkcji przynależności. Aby znaleziona
funkcja przynależności umożliwiała fuzzyfikację danych w stopniu umożliwiają-
cym uwzględnienie niepewności przynależności jasności piksela do określonego
zbioru, należy znaleźć taką jej postać, dla której indeks rozmytości osiąga wartość
maksymalną.
Stąd problem stawiany jest jako problem znalezienia funkcji, która optymal-
nie opisuje zbiór ze względu na miarę entropii oraz indeks rozmytości. Względem
zastosowanych miar będzie to najlepsza funkcja umożliwiająca wykonanie fuzzy-
fikacji obrazu.
5.4.1. Wybór kształtu funkcji przynależności
W celu określenia funkcji przynależności należy ustalić zbiór, do którego przy-
należność będzie ona opisywała. W proponowanym algorytmie przyjęte zostało za-
łożenie, że poszukiwana funkcja przynależności będzie opisywała przynależność
1 Autor wykorzystał również proponowaną metodę znajdowania funkcji przynależności i ele-menty teorii zbiorów rozmytych do modelowania rozkazów dotyczących przetwarzania obrazów wy-rażonych w języku naturalnym [18]. Temat ten jednak, jako nie mający związku z tezą przedstawianejpracy, nie jest w niej poruszany.
122

“KonspPreamb” 2013/10/3 page 123 #126
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
pikseli obrazu do zbioru „białych pikseli”. Do opisania przynależności do takiego
zbioru wybrana została funkcja przynależności reprezentowana przez S-funkcję,
oryginalnie wprowadzona przez Zadeha [226].
W literaturze istnieje kilka odmian S-funkcji (jedna z nich była np. już przedsta-
wiona w p. 4.1.3), spośród których w pracy wykorzystana została S-funkcja o po-
staci [217]:
S (x; aS, bS, cS) =
0, x 6 aS
(x − aS)2
(bS − aS) (cS − aS) , aS < x 6 bS
1 − (x − cS)2
(cS − bS) (cS − aS) , bS < x 6 cS
1, x > cS
(5.5)
gdzie x jest zmienną, natomiast parametry aS, bS oraz cS determinują dokładny
przebieg S-funkcji. W odróżnieniu do funkcji opisanej wyrażeniem (4.5), w de-
finicji tej parametr bS może być dowolnym punktem między aS i cS, co znacznie
ułatwia zadanie dopasowania jej przebiegu według proponowanej funkcji celu.
W pracy rozważane są obrazy wyrażone w skali szarości, a więc takie, któ-
rych wartości jasności pikseli są liczbami całkowitymi z przedziału [0, 255]. Kształ
S-funkcji modeluje w naturalny sposób przynależność pikseli wyrażonych w skali
szarości do zbioru białych pikseli. Jeżeli wartość piksela wyrażona w skali szaro-
ści będzie równa 255 (biały piksel), to funkcja przynależności będzie przyjmowała
wartość 1. W przypadku wartości jasności piksela równej 0 (czarny piksel) war-
tość funkcji przynależności jest równa 0. Oznacza to, że piksel o wartości jasności
równej 0 (czarny piksel) nie należy do zbioru białych pikseli.
Cały pozostały zakres wartości jakie przybierają jasności pikseli zostanie przy-
pisany do zbioru białych pikseli w sposób tylko częściowy. Dobór parametrów aS,
bS i cS pozwala na swobodne kształtowanie przebiegu krzywej określającej funkcję
przynależności, a tym samym stopień przynależności piksela o określonej wartości
jasności do zbioru białych pikseli. Wartości parametrów aS, bS i cS mogą przybierać
dowolne wartości z przedziału [0, 255] na skali szarości.
Przykładowe kształty S-funkcji dla różnych wartości parametrów ją opisują-
cych przedstawione zostały na rys. 5.2.
Po przyjęciu założenia, że funkcja przynależności jest S-funkcją opisaną przez
wyrażenie (5.5), poszukiwanym rozwiązaniem jest zbiór optymalnych parametrów
123

“KonspPreamb” 2013/10/3 page 124 #127
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
x
µAF (x)
0 32 64 96 128 160 192 224 2560
14
12
34
1
aS = 0bS = 63.5cS = 127.5
x
µAF (x)
0 32 64 96 128 160 192 224 2560
14
12
34
1
aS = 0bS = 127.5cS = 255
x
µAF (x)
0 32 64 96 128 160 192 224 2560
14
12
34
1
aS = 63.5bS = 191cS = 255
x
µAF (x)
0 32 64 96 128 160 192 224 2560
14
12
34
1
aS = 127.5bS = 191cS = 255
Rys. 5.2. Kształty S-funkcji dla różnych zestawów parametrów aS, bS i cS
aS, bS i cS, dla którego poszukiwana S-funkcja będzie osiągała warunki maksymal-
nej entropii oraz maksymalnej wartości indeksu rozmytości.
5.4.2. Indeks rozmytości określony dla obrazu
W celu wykorzystania indeksu rozmytości do wyznaczenia optymalnych para-
metrów aS, bS, cS założonej funkcji przynależności typu S należy jego ogólną defi-
nicję (4.15) zmodyfikować w sposób umożliwiający zastosowanie go do rozpatry-
wanego zagadnienia dopasowania pary stereoskopowej obrazów. W pracy przyjęto
liniową wersję indeksu rozmytości (4.19), która zostanie zmodyfikowana następu-
jąco.
Niech I będzie obrazem o rozmiarze M ×N pikseli. Założymy, że poszczegól-
ne piksele p należące do obrazu przybierają poziomy szarości Ip reprezentowane
liczbami całkowitymi na całkowitoliczbowej skali szarości od 0 do Imax. Dla ob-
razu I wyznaczamy jego histogram przez zliczenie wszystkich pikseli o kolejnych
poziomach szarości Ip ∈ [0, Imax]. Wartości tego histogramu oznaczymy g(Ip). Za-
łożymy dalej, że dla obrazu I jest określona jego funkcja przynależności µA(Ip)
określająca na podstawie jego poziomu szarości Ip stopień przynależności pikse-
la p do zbioru rozmytego pikseli białych. Liniowy indeks rozmytości tego zbioru
124

“KonspPreamb” 2013/10/3 page 125 #128
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
definiujemy wówczas wzorem:
γL
(
AF)
=2
MN
Imax∑
0
g(
Ip
)
·min[
µA(
Ip
)
, µA(
Ip
)]
(5.6)
gdzie µA(Ip) = 1− µA(Ip) jest funkcją przynależności piksela p o poziomie szaro-
ści Ip do dopełnienia zbioru rozmytego AF. Sumowanie w tym wzorze przebiega
po wszystkich poziomach szarości Ip z przedziału [0, Imax]. Jak już wspomniano
wcześniej, w pracy przyjęto, że przedział ten jest równy [0, 255].
5.4.3. Zagadnienie optymalizacyjne
Zagadnienie poszukiwania optymalnych parametrów aS, bS, cS funkcji przy-
należności typu S zostało rozwiązane przez autora jako zagadnienie optymalizacji
dwukryterialnej. Najpierw wyznaczane są optymalne wartości aHSopt, bH
Sopt, cHSopt ze
względu na kryterium maksymalnej entropii całkowitej Hc zdefiniowanej wzorem
(4.12):
Hc max
(
aHSopt, b
HSopt, c
HSopt
)
= maxaS ,bS ,cS
Hc (as, bS, cS) : 0 6 aS, bS, cS 6 Imax (5.7)
Następnie wyznaczane są optymalne wartości aγ
Sopt, bγ
Sopt, cγ
Sopt ze względu na kry-
terium maksimum indeksu rozmytości (5.6):
γL max
(
aγ
Sopt, bγ
Sopt, cγ
Sopt
)
= maxaS ,bS ,cS
γL (aS, bS, cS) : 0 6 aS, bS, cS 6 Imax (5.8)
W proponowanym algorytmie oba zadania optymalizacyjne rozwiązywane są
niezależnie. W wyniku otrzymywane są dwa zbiory rozwiązań opisujące dwie róż-
ne S-funkcje. Jako rozwiązanie końcowe wybierane jest rozwiązanie kompromi-
sowe między informacyjnością funkcji, a jej rozmytością. Kompromis ten jest za-
pewniony przez wybranie optymalnych wartości parametrów aS, bS, cS jako śred-
nich arytmetycznych wartości otrzymanych w wyniku rozwiązania każdego z zadań
optymalizacyjnych:
aSopt =aH
Sopt+aγ
Sopt
2 ,
bSopt =bH
Sopt+bγ
Sopt
2 ,
cSopt =cH
Sopt+cγ
Sopt
2 .
(5.9)
125

“KonspPreamb” 2013/10/3 page 126 #129
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
Można uznać, że S-funkcja określona przez ten zbiór parametrów zapewni wła-
ściwy wybór pomiędzy informacyjnością zbioru rozmytego „białe piksele”, a jego
rozmytością. Przyjęcie tego rozwiązania ma oczywiści charakter arbitralny i możli-
we jest rozważanie innego operatora służącego do złożenia otrzymanych rozwiązań
cząstkowych, np. sumy ważonej lub średniej geometrycznej.
Pełne rozwiązanie problemu znalezienia optymalnego zbioru parametrów funk-
cji przynależności uzyskuje się w wyniku rozwiązania problemu optymalizacyjne-
go z równoczesnym uwzględnieniem obydwu kryteriów. Zwiększa to jednak zde-
cydowanie trudność rozwiązania problemu optymalizacji i z tego względu zagad-
nienie to nie zostało podjęte na tym etapie badań.
W pracy jako algorytm optymalizacji służący do znalezienia rozwiązania opty-
malizacyjnego zastosowany został algorytm optymalizacji rojem cząstek znany ja-
ko algorytm PSO (ang. Particle Swarm Optimization) [227]. Algorytm ten oparty
jest o stochastyczny ruch cząstek w przestrzeni poszukiwania rozwiązania, w efek-
cie czego nie gwarantuje uzyskania w pełni optymalnego rozwiązania. Dokładność
uzyskiwanego rozwiązania zależna jest od zastosowanego kryterium zatrzymania
algorytmu. Jego zaletą jest jednak szybkość przeszukiwania przestrzeni rozwiązań
i przy zastosowaniu dobrze dobranego kryterium zatrzymania algorytmu pozwala
on na uzyskiwanie dokładnych rozwiązań.
Przedstawiony schemat wyznaczania funkcji przynależności pikseli obrazu do
zbioru „białych pikseli” został wykorzystany w celu fuzzyfikacji obrazów, tj. znale-
zienia reprezentacji obrazów pary stereoskopowej w dziedzinie zbiorów rozmytych
i rozwiązania problemu dopasowania w tej dziedzinie. Algorytm ten ma postać:
126

“KonspPreamb” 2013/10/3 page 127 #130
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
Algorytm 5.1 Fuzzyfikacja obrazu
Dane wejściowe: Obraz I o rozmiarze M × N pikseli, których wartości jasnościIp są reprezentowane w przyjętej całkowitoliczbowej skali szarości [0, Imax].
Dane wejściowe: Początkowe wartości parametrów S-funkcji aS = 0, bS = 0,cS = 0
1: Oblicz histogram g(
Ip
)
obrazu I
2: Na podstawie histogramu g(
Ip
)
oblicz względne częstości ν(
Ip
)
=
g(
Ip
)
/ (M · N) występowania w obrazie pikseli o kolejnych wartościach jasno-ści Ip.
3: Oblicz początkową wartość entropii całkowitej wg. wzoru (4.12)4: Oblicz początkową wartość liniowego indeksu rozmytości wg. wzoru (5.6)5: Znajdź zbiór parametrów opisujących S-funkcję optymalny ze względu na kry-
terium (5.7)6: Znajdź zbiór parametrów opisujących S-funkcję optymalny ze względu na kry-
terium (5.8)7: Wyznacz końcowe, optymalne wartości parametrów S-funkcji, zgodnie ze
wzorem (5.9)8: for i = 1 to M do
9: for j = 1 to N do
10: Dla każdego piksela p położonego na pozycji o współrzędnych (i, j),o wartości jasności Ip (i, j), znajdź wartość µA
[
Ip (i, j)]
jego funkcjiprzynależności do zbioru rozmytego białych pikseli na podstawie wy-znaczonej optymalnej S-funkcji: µA
(
Ip
)
= S(
Ip; aSopt, bSopt, cSopt
)
. Wy-
nik umieść na pozycji (i, j) macierzy IF =[
IF (i, j)]
zfuzzyfikowa-
nego obrazu IF , której elementy IF (i, j) są parami liczb: IF (i, j) =
(
Ip (i, j) ; µA[
Ip (i, j)])
, i = 1, . . . ,M, j = 1, . . . ,N .11: end for
12: end for
13: Zwróć: Macierz IF zfuzzyfikowanego obrazu IF .
127

“KonspPreamb” 2013/10/3 page 128 #131
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
5.4.4. Przykłady wyznaczonych funkcji przynależności
Działanie zaproponowanego sposobu wyznaczania funkcji przynależności zo-
stało sprawdzone w praktyce dla różnych obrazów testowych. Rys. 5.3 przedstawia
obrazy wraz z wyznaczonymi dla nich optymalnymi funkcjami przynależności.
Ze względu na niezależne rozwiązywanie zadania optymalizacji względem mia-
ry entropii i indeksu rozmytości, dla każdego z obrazów przedstawione zostały
trzy S-funkcje: o maksymalnej entropii, maksymalnym indeksie rozmytości oraz
o optymalnych wartościach parametrów uzyskanych jako średnie arytmetyczne pa-
rametrów maksymalizujących entropię całkowitą i indeks rozmytości.
(a)
Ip
0 32 64 96 128 160 192 224 2560
14
12
34
1
g(
Ip
)
µA(
Ip
)
µHA
(
Ip
)
µγ
A(
Ip
)
(b)
(c)
Ip
0 32 64 96 128 160 192 224 2560
14
12
34
1
g(
Ip
)
µA(
Ip
)
µHA
(
Ip
)
µγ
A(
Ip
)
(d)
Rys. 5.3. Przykłady wyznaczonych optymalnych funkcji przynależności dla róż-nych obrazów testowych
128

“KonspPreamb” 2013/10/3 page 129 #132
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
(e)
Ip
0 32 64 96 128 160 192 224 2560
14
12
34
1
g(
Ip
)
µA(
Ip
)
µHA
(
Ip
)
µγ
A(
Ip
)
(f)
Rys. 5.3. Kontynuacja. Przykłady wyznaczonych optymalnych funkcji przynależ-ności dla różnych obrazów testowych
Na rys. 5.3 widoczny jest duży wpływ miar entropii całkowitej i liniowego in-
deksu rozmytości na otrzymywany kształt S-funkcji. Kształty funkcji otrzymywa-
nych przez parametry obliczone w wyniku optymalizacji każdej z miar są znacząco
różne. Dobór wartości parametrów jako średnich arytmetycznych wartości otrzy-
manych w wyniku dwóch niezależnych przebiegów algorytmu optymalizacji po-
woduje, że S-funkcja opisana przez ten zbiór parametrów znajduje się w położeniu
pośrednim.
5.5. Dopasowanie obrazów pary stereoskopowej w dziedzinie
zbiorów rozmytych
W celu wykorzystania elementów teorii zbiorów rozmytych w problemie dopa-
sowania pary stereoskopowej obydwa obrazy pary zostają przekształcone do dzie-
dziny zbiorów rozmytych zgodnie z algorytmem 5.1. Po zamianie dziedziny opisu
obrazów można zastosować algorytm analogiczny do algorytmu 3.1 dopasowania
obszarami. Zasada działania algorytmu 3.1 pozostaje taka sama jak w przypadku
algorytmu działającego w dziedzinie jasności pikseli. Główna zmiana dotyczy kro-
ku obliczania podobieństwa, który w przypadku wykorzystania obrazów opisanych
w dziedzinie zbiorów rozmytych jest ustalany nie na podstawie wartości jasności
pikseli, tylko na podstawie ich reprezentacji w dziedzinie zbiorów rozmytych.
129

“KonspPreamb” 2013/10/3 page 130 #133
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
W celu wyznaczenia mapy dysparycji w dziedzinie zbiorów rozmytych zapro-
ponowany został algorytm. 5.2.
Algorytm 5.2 Dopasowanie obrazów w dziedzinie zbiorów rozmytych
Dane wejściowe: Obrazy pary stereoskopowej Ire f i Isz o rozmiarach M×N pikse-li, których wartości jasności są reprezentowane w przyjętej całkowitoliczbowejskali szarości [0, Imax].
Dane wejściowe: Założony przedział wartości dysparycji [dmin, dmax].1: Przeprowadź fuzzyfikację obrazów Ire f i Isz, znajdując ich reprezentacje
IFre f
i IFsz w dziedzinie zbiorów rozmytych zgodnie z algorytmem 5.1.
2: for i = 0 do M − 1 do
3: for j = 0 do N − 1 do
4: Ustaw okno referencyjne Wre f na pozycji (i, j) w zfuzzyfikowanym obra-zie referencyjnym I
Fre f
.5: for od d = dmin do dmax z krokiem ∆d do
6: Ustaw okno przeszukiwania Wsz na pozycji (i, j + d) w zfuzzzyfikowa-nym obrazie przeszukiwania IF
sz.7: Oblicz miarę podobieństwa η między wartościami funkcji przynależ-
ności pikseli w oknie referencyjnym Wre f i oknie przeszukiwania Wsz
i zapamiętaj wartość tej miary.8: if bieżąca wartość miary η jest większa niż poprzednio (lub mniejsza
– w zależności od przyjętej miary podobieństwa) then
9: Zapamiętaj wartość miary η oraz wyznaczoną wartość dysparycji dlapiksela położonego na pozycji (i, j).
10: Zapisz znalezioną wartość dysparycji na pozycji (i, j) w wynikowejmacierzy dysparycji d.
11: else
12: Zwiększ bieżącą wartość d o krok ∆d i oblicz wartość miary η dlapołożenia (i, j + d + ∆d) okna przeszukiwania Wsz.
13: end if
14: end for
15: end for
16: end for
17: Zwróć: Otrzymaną macierz dysparycji d jako znalezioną mapę dysparycji.
Jako miary podobieństwa wykorzystane do obliczania podobieństwa między
reprezentacjami piskeli w dziedzinie zbiorów rozmytych przyjęte zostały: unor-
mowana odległość Hamminga zbiorów rozmytych (4.23), unormowana odległość
euklidesowa (4.25) oraz korelacja zbiorów rozmytych (4.26).
Efektywność proponowanego algorytmu 5.2 została zweryfikowana dla testo-
130

“KonspPreamb” 2013/10/3 page 131 #134
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
wego zbioru par stereoskopowych w wyniku przeprowadzenia szeregu ekspery-
mentów. Otrzymane wyniki wraz z ich analizą oraz porównaniem z wynikami osią-
ganymi przez najbliższe ideowo algorytmy działające bezpośrednio w dziedzinie
jasności pikseli przedstawione zostaną w rodziale 7 pracy.
5.6. Przetwarzanie obrazów opisanych w dziedzinie
intuicjonistycznych zbiorów rozmytych
Metody przetwarzania obrazów, w których wykorzystuje się elementy teorii
zbiorów IFS wymagają reprezentacji obrazów w dziedzinie IFS. Dysponując obra-
zami reprezentowanymi w dziedzinie zbiorów IFS, można do ich przetwarzania za-
stosować elementy teorii IFS. Działania wykonywane są nie w przestrzeni pikseli,
ale na ich odpowiednich reprezentacjach w dziedzinie IFS. W dalszej części przed-
stawiona zostanie proponowana metoda umożliwiająca zmianę opisu obrazów re-
prezentowanych w dziedzinie jasności pikseli na ich opis w dziedzinie zbiorów
IFS. Metoda ta zostanie dalej wykorzystana do rozwiązania zadania dopasowania
obrazów pary stereoskopowej w dziedzinie zbiorów IFS.
Aby można było opisać obraz w dziedzinie zbiorów IFS, należy znać postać
funkcji przynależności oraz nieprzynależności piksela do pewnego zbioru IFS. W ce-
lu wyznaczania funkcji przynależności do zbioru „białych pikseli” można wyko-
rzystać zaproponowany przez autora algorytm znajdowania funkcji przynależności
przez optymalny dobór kształtu S-funkcji (algorytm 5.1).
Do pełnego opisu obrazu w dziedzinie zbiorów IFS potrzebna jest jednak zna-
jomość dwóch funkcji: funkcji przynależności i funkcji nieprzynależności. Można
jednak bardzo łatwo znaleźć opis obrazu w dziedzinie zbiorów IFS, jeżeli znana jest
jedna z tych funkcji i określony dla niej indeks zaufania πAIFS (por. definicję 4.5).
Proponowana metoda postępowania pozwala na znalezienie kształtu optymalnej
S-funkcji i wartości indeksu zaufania πAIFS jako drugiego elementu umożliwiają-
cego opis obrazu w dziedzinie IFS. Dysponując znajomością funkcji przynależno-
ści oraz indeksem zaufania, można uzupełnić opis o funkcję nieprzynależności na
podstawie wzoru (4.36).
131

“KonspPreamb” 2013/10/3 page 132 #135
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
5.6.1. Określanie indeksu zaufania
Algorytm wyznaczania funkcji przynależności o optymalnie dobranych para-
metrach S-funkcji wykorzystuje w swoim działaniu histogram wartości jasności
wszystkich pikseli obrazu. Jednakże, głównie z powodu kwantyzacji przeprowa-
dzanej w czasie akwizycji obrazu cyfrowego, wartości jasności mogą być obarczo-
ne błędami powstającymi w czasie tego procesu. Na przykład, piksel odpowiadają-
cy poziomowi szarości Ip w wynikowym obrazie mógł mieć w istocie inną wartość,
która została zaburzona w czasie procesu kwantowania wartości jasności. W celu
eliminacji tego rodzaju niepewności zawartej w obrazach została zaproponowa-
na koncepcja histogramu rozmytego [228]. W takim przypadku wartości jasności
pikseli obrazu reprezentowanego w skali szarości traktowane są jako liczby rozmy-
te. Pozwala to na uwzględnienie niepewności powstających w wyniku kwantyzacji
wartości jasności pikseli oraz obliczenie histogramu w dziedzinie zbiorów rozmy-
tych.
W celu obliczenia histogramu rozmytego obrazu, wykorzystywana jest repre-
zentacja jasności pikseli obrazu za pomocą liczb rozmytych. Liczbą rozmytą :
R → [0, 1] nazywany jest zbiór rozmyty określony na dziedzinie liczb rzeczywi-
stych, który jest zbiorem normalnym i wypukłym. Normalny zbiór rozmyty to taki,
którego funkcja przynależności przyjmuje wartość równą 1 co najmniej dla jednej
wartości argumentu.
W pracy w celu obliczenia histogramu rozmytego wykorzystane zostały rozmy-
te symetryczne liczby trójkątne, pozwalające na liczbową reprezentację koncepcji,
według której określony poziom jasności piksela jest „w przybliżeniu równy Ip”.
Trójkątne liczby rozmyte opisywane są funkcją przynależności zdefiniowaną wzo-
rem:
µ∆ (x) = max
(
0, 1 −|x − Ip|α
)
(5.10)
gdzie parametr α będący wartością stałą, ustala nośnik liczby rozmytej, czyli za-
kres wartości zmiennej x, dla którego wartości funkcji przynależności µ (x) są
różne od zera. W przypadku zwiększania wartości parametru α wartości funkcji
przynależności µ są różne od zera w szerszym zakresie zmian jasności pikseli Ip
znajdujących się w rozważanym obrazie I.
Do każdej wartości jasności piksela Ip rozważanego obrazu I o rozmiarze M na
N pikseli może być przypisana liczba rozmyta kształtu trójkątnego. Wykorzystu-
132

“KonspPreamb” 2013/10/3 page 133 #136
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
jąc te liczby, można zdefiniować rozmyty histogram obrazu gF(
Ip
)
określony dla
kolejnych poziomów jasności pikseli w obrazie Ip ∈ 0, . . . , Imax wzorem [228]:
gF(
Ip
)
=
∥
∥
∥
∥
(i, j) | µ(
Ip (i, j))
; i = 1, . . . ,M, j = 1, . . . ,N
∥
∥
∥
∥
(5.11)
gdzie ‖ · ‖ jest mocą zbioru rozmytego∥
∥
∥AF∥
∥
∥ =∑
i, j µ(
Ip (i, j))
.
Wartości histogramu rozmytego gF(
Ip
)
określone dla konkretnych wartości ja-
sności pikseli Ip w obrazie reprezentują częstości występowania w obrazie pikseli
o wartości jasności „w przybliżeniu równych Ip”.
Błędy powstające w czasie kwantyzacji wartości jasności pikseli mogą być okre-
ślone dla całego rozważanego obrazu I przez porównanie i obliczenie różnicy mię-
dzy histogramem g(
Ip
)
obliczonym na podstawie wartości jasności pikseli nie za-
wierających modelu tego błędu oraz histogramem rozmytym gF(
Ip
)
obliczonym
z wykorzystaniem liczb rozmytych, w którym błąd ten został uwzględniony.
W dziedzinie zbiorów IFS modelem zaufania do wartości funkcji przynależ-
ności, przypisującej danemu elementowi stopień przynależności do pewnego zbio-
ru, jest dodatkowy składnik opisu tych zbiorów nazywany indeksem zaufania (por.
wzór (4.36)). W pracy [229] zaproponowano aby indeks zaufania, określany w cza-
sie fuzzyfikacji obrazów umożliwiającej ich opis w dziedzinie zbiorów IFS, był
proporcjonalny do znormalizowanej różnicy między wartościami znormalizowa-
nego histogramu obliczonego na podstawie wartości jasności pikseli a wartościa-
mi znormalizowanego histogramu rozmytego obliczonego z wykorzystaniem liczb
rozmytych:
πAIFS
(
Ip
)
∝
∣
∣
∣
∣
g(
Ip
)
− gF(
Ip
)
∣
∣
∣
∣
maxIp
∣
∣
∣
∣
g(
Ip
)
− gF(
Ip
)
∣
∣
∣
∣
(5.12)
gdzie g(
Ip
)
i gF(
Ip
)
są odpowiednio znormalizowanymi histogramami klasycznym
i rozmytym, natomiast ∝ jest symbolem proporcjonalności.
Normalizacja histogramów przebiega w taki sposób, aby mogły być one inter-
pretowane jako aproksymacje funkcji gęstości prawdopodobieństwa wystąpienia
jasności pikseli Ip w rozważanym obrazie I:
g(
Ip
)
=g(
Ip
)
∑ImaxI0
g(
Ip
) gF(
Ip
)
=gF
(
Ip
)
∑ImaxI0
gF(
Ip
) (5.13)
133

“KonspPreamb” 2013/10/3 page 134 #137
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
Wartość maksymalna indeksu zaufania πmaxAIFS
(
Ip
)
dla określonego poziomu Ip
szarości jest określana przez przyjęcie wartości νAIFS
(
Ip
)
= 0 we wzorze (4.35).
Z tego względu zachodzi zależność:
πmaxAIFS
(
Ip
)
= 1 − µAIFS
(
Ip
)
(5.14)
Oznacza to, że poddając fuzzyfikacji określoną wartość jasności piksela Ip najwięk-
sza niepewność istnieje w przypadku, gdy znana jest tylko wartość funkcji przy-
należności do zbioru rozmytego µAIFS
(
Ip
)
. W przypadku, gdy do fuzzyfikowanej
wartości jasności piksela Ip można przypisać również wartość funkcji nieprzyna-
leżności νAIFS
(
Ip
)
, na mocy wyrażenia (4.35) indeks zaufania przyjmuje mniejszą
wartość. W przedstawianym tutaj przypadku wyraża on niepewność przypisania do
danej wartości jasności piksela Ip stopnia przynależności do pewnego zbioru roz-
mytego wyznaczonego przez funkcję przynależności µAIFS
(
Ip
)
. Z wyrażenia (5.14)
wynika, że gdy wartość jasności określająca poziom szarości w obrazie maleje,
wartość indeksu zaufania wzrasta. Wyrażenie (5.12) przyjmuje wartości z zakresu
[0, 1]. Biorąc te dwa spostrzeżenia pod uwagę można przyjąć założenie, że:
πAIFS
(
Ip
)
∝(
1 − µAIFS
(
Ip
))
(5.15)
co zapewnia, że ograniczenie narzucane przez (5.14) jest spełnione.
Wzór ten wyraża stopień pewności o możliwości przypisania jasności piksela Ip
do pewnego zbioru rozmytego określonego przez funkcję przynależności µAIFS
(
Ip
)
.
Im wartość funkcji przynależności jest większa, a więc istnieje większe przeko-
nanie o prawidłowo sformułowanym warunku przynależności jasności piksela do
zbioru rozmytego, tym indeks zaufania jest mniejszy. Podobnie jak w przypadku
wyrażenia określającego wartość maksymalną indeksu zaufania, opisuje on tutaj
niepewność o stopniu przynależności jasności piksela do zbioru określonego przez
funkcję przynależności µAIFS
(
Ip
)
.
W przypadku gdy Imin , 0 indeks zaufania skojarzony z wartością jasności
określanej w skali szarości powinien być również malejącą funkcją znormalizowa-
nego zakresu dynamicznego wartości jasności zawartych w obrazie zdefiniowane-
go jako [229]:
∆Ip =Imax − Imin
Imax(5.16)
134

“KonspPreamb” 2013/10/3 page 135 #138
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
gdzie Imin i Imax są odpowiednio wartością minimalną i maksymalną wartości ja-
sności pikseli w obrazie. Jeżeli zakres dynamiczny wartości jasności w obrazie się
zmniejsza, to również powinna zmniejszać się pewność o rzeczywistej wartości
jasności danego piksela.
Po uwzględnieniu przedstawionych rozważań, model indeksu zaufania odpo-
wiadający poziomowi szarości Ip w obrazie jest wyrażony wzorem:
πAIFS
(
Ip
)
=(
1 − µAIFS
(
Ip
))
∣
∣
∣
∣
g(
Ip
)
− gF(
Ip
)
∣
∣
∣
∣
maxIp
∣
∣
∣
∣
g(
Ip
)
− gF(
Ip
)
∣
∣
∣
∣
(
1 − k∆Ip
)
(5.17)
gdzie parametr k ∈ (0, 1) określa siłę wpływu zakresu dynamicznego wartości
w obrazie na wartość indeksu zaufania przypisanego do poziomu szarości Ip.
Na wartość tego indeksu składają się trzy czynniki. Pierwszy z nich jest mo-
delem niepewności przypisania wartości jasności piksela Ip do zbioru rozmyte-
go wyznaczonego przez funkcję przynależności µAIFS
(
Ip
)
, drugi jest miarą błę-
du kwantyzacji otrzymaną w wyniku porównania znormalizowanych histogramów
klasycznego i rozmytego, a trzeci uwzględnia zależność od zakresu dynamicznego
jasności pikseli zawartych w obrazie. Ważnym aspektem jest to, że aby wyznaczyć
indeks zaufania w przedstawiony sposób, musi być znana funkcja przynależności
µAIFS
(
Ip
)
jasności pikseli do intuicjonistycznego zbioru rozmytego. W pracy wy-
korzystany został w tym celu zaproponowany wcześniej algorytm 5.1 znajdowania
funkcji przynależności, a następnie opis obrazu był rozszerzany do dziedziny zbio-
rów IFS przy wykorzystaniu przedstawionego wyżej schematu.
5.6.2. Znajdowanie wartości funkcji nieprzynależności
Funkcja nieprzynależności może zostać znaleziona na podstawie zależności
definicyjnych zbiorów IFS. Dla obrazu, dla którego wyznaczona została funkcja
przynależności oraz indeks zaufania, funkcja nieprzynależności wyznaczana jest
według wzoru:
νAIFS
(
Ip
)
= 1 − µAIFS
(
Ip
)
− πAIFS
(
Ip
)
(5.18)
135

“KonspPreamb” 2013/10/3 page 136 #139
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
5.6.3. Przykłady wyznaczonych funkcji umożliwiających opis obrazu
w dziedzinie intuicjonistycznych zbiorów rozmytych
Przedstawiony powyżej schemat wyznaczania indeksu zaufania wraz z algo-
rytmem wyznaczania funkcji przynależności został zastosowany w celu znalezie-
nia opisu obrazów w dziedzinie zbiorów IFS. Na rys. 5.4 przedstawione zostały
rezultaty działania algorytmu dla kilku obrazów testowych.
(a)
Ip
0 32 64 96 128 160 192 224 2560
14
12
34
1
g(
Ip
)
µIFSA
(
Ip
)
νIFSA
(
Ip
)
πIFSA
(
Ip
)
(b)
(c)
Ip
0 32 64 96 128 160 192 224 2560
14
12
34
1
g(
Ip
)
µIFSA
(
Ip
)
νIFSA
(
Ip
)
πIFSA
(
Ip
)
(d)
Rys. 5.4. Przykłady wyznaczonych funkcji przynależności, nieprzynależności i in-deksu zaufania, umożliwiających opis obrazu w dziedzinie intuicjonistycznych
zbiorów rozmytych
136

“KonspPreamb” 2013/10/3 page 137 #140
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
(e)
Ip
0 32 64 96 128 160 192 224 2560
14
12
34
1
g(
Ip
)
µIFSA
(
Ip
)
νIFSA
(
Ip
)
πIFSA
(
Ip
)
(f)
Rys. 5.4. Kontynuacja. Przykłady wyznaczonych funkcji przynależności, nieprzy-należności i indeksu zaufania, umożliwiających opis obrazu w dziedzinie intu-
icjonistycznych zbiorów rozmytych
5.6.4. Dopasowanie obrazów pary stereoskopowej w dziedzinie
intuicjonistycznych zbiorów rozmytych
Proponowany algorytm dopasowania obrazów pary stereoskopowej w dziedzi-
nie zbiorów IFS jest bardzo podobny do algorytmu dopasowania z wykorzysta-
niem zwykłych zbiorów rozmytych. Po przeprowadzaniu fuzzyfikacji obu obrazów
i zmianie ich reprezentacji do dziedziny zbiorów IFS, można zastosować analo-
giczny schemat do algorytmu dopasowania obszarami. Takie rozwiązanie zostało
zaproponowane w pracy i zostało przedstawione w postaci algorytmu 5.3.
Jako miary dopasowania w dziedzinie zbiorów intuicjonistycznych wykorzy-
stane zostały: unormowana odległość Hamminga dla zbiorów IFS (4.38), unormo-
wana odległość euklidesowa zbiorów IFS (4.40) oraz korelacja intuicjonistycznych
zbiorów rozmytych (4.41).
137

“KonspPreamb” 2013/10/3 page 138 #141
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
Algorytm 5.3 Dopasowanie obrazów w dziedzinie intuicjonistycznych zbiorówrozmytych
Dane wejściowe: Obrazy pary stereoskopowej Ire f i Isz o rozmiarach M×N pikse-li, których wartości jasności są reprezentowane w przyjętej całkowitoliczbowejskali szarości [0, Imax].
Dane wejściowe: Założony przedział wartości dysparycji [dmin, dmax].1: Przeprowadź fuzzyfikację obrazów Ire f i Isz, znajdując ich reprezentacje IIFS
re f
i IIFSsz w dziedzinie intuicjonistycznych zbiorów rozmytych.
2: for i = 0 do M − 1 do
3: for j = 0 do N − 1 do
4: Ustaw okno referencyjne Wre f na pozycji (i, j) w zfuzzyfikowanym obra-zie referencyjnym I
IFSre f
.5: for d = dmin do dmax z krokiem ∆d do
6: Ustaw okno przeszukiwania Wsz na pozycji (i, j + d) w zfuzzyfikowa-nym obrazie przeszukiwania IIFS
sz .7: Oblicz miarę podobieństwa η między reprezentacjami pikseli wyrażo-
nymi w dziedzinie zbiorów IFS w oknie referencyjnym Wre f i oknieprzeszukiwania Wsz i zapamiętaj wartość tej miary.
8: if bieżąca wartość η jest większa niż poprzednia (lub mniejsza – w za-leżności od przyjętej miary podobieństwa then
9: Zapamiętaj wartość η oraz wyznaczoną wartość dysparycji dla pik-sela położonego na pozycji (i, j).
10: Zapisz wyznaczoną wartość dysparycji na pozycji (i, j) wynikowejmacierzy dysparycji d.
11: else
12: Zwiększ bieżącą wartość d o krok ∆d i oblicz wartość miary η dlapołożenia (i, j + d + ∆d) okna przeszukiwania Wsz.
13: end if
14: end for
15: end for
16: end for
17: Zwróć: Otrzymaną mapę dysparycji d jako znalezioną mapę dysparycji.
138

“KonspPreamb” 2013/10/3 page 139 #142
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
5.7. Detekcja krawędzi w obrazie w oparciu o teorię zbiorów
rozmytych
Detekcja krawędzi obecnych w obrazie jest bardzo istotnym i często wykorzy-
stywanym zagadnieniem komputerowego przetwarzania obrazów. Znalezienie kra-
wędzi stanowi często pierwszy krok w bardziej skomplikowanych zagadnieniach
komputerowego widzenia maszynowego, spośród których jako przykłady można
wymienić: rozumienie obrazów [230, 231], rozpoznawanie wzorców [232, 233]
i przedstawiane w tej pracy zagadnienie dopasowania obrazów pary stereoskopo-
wej [234, 235]. W niektórych zastosowaniach znalezione krawędzie używane są
również bezpośrednio np. w przemysłowych systemach wizyjnych [236, 237].
W literaturze można znaleźć bardzo wiele różnorodnych podejść rozwiązują-
cych zagadnienie wyszukiwania krawędzi w obrazie. Prawdopodobnie najbardziej
znanym i popularnym jest algorytm nazywany od nazwiska jego twórcy detektorem
Canny’ego [238, 239], działający w oparciu o detekcję zmian jasności w obrazie.
Na podobnej zasadzie działają również popularne operatory służące do wykrywa-
nia krawędzi oparte o detekcję gradientu zmian jasności nazywane od nazwisk swo-
ich twórców: operatorem Sobela [40, 240] lub operatorem krzyżowym Robertsa
[241, 240].
Zupełnie inne podejście umożliwiające detekcję krawędzi w obrazie zostało
zaproponowane w [242]. Proponowany operator służący do wykrywania krawędzi
oparty jest na znajdowaniu różnic między wartościami jasności pikseli zawartymi
w pewnym wyróżnionym regionie. Znany jest on jako detektor krawędzi i narożni-
ków pod nazwą SUSAN. Podobna idea wyszukiwania pikseli o różnych poziomach
jasności w pewnym określonym otoczeniu została użyta również do opracowania
algorytmów detekcji narożników [243, 244].
Problem wykrywania krawędzi zawartych w obrazie był także rozważany w kon-
tekście zastosowania do tego celu elementów teorii zbiorów rozmytych [245, 246,
32]. W pracy zaproponowany został autorski algorytm umożliwiający znalezienie
krawędzi obecnych w obrazie, wykorzystujący w swoim działaniu elementy teorii
zbiorów rozmytych. Algorytm ten jest ideowo najbardziej zbliżony do algorytmu
SUSAN [242]. Podobnie jak algorytm SUSAN opiera się na przypuszczeniu, że w
pewnym regionie obrazu, gdzie istnieje krawędź w obrazie, pewna liczba pikseli
musi mieć znacząco różną jasność od innych. W algorytmie SUSAN badana jest
139

“KonspPreamb” 2013/10/3 page 140 #143
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
różnica w wartościach jasności między wyróżnionym pikselem a jasnościami pik-
seli leżącymi w jego sąsiedztwie. Oryginalnie w algorytmie SUSAN wykorzystane
zostało sąsiedztwo w kształcie koła zawierającego 37 pikseli. Jeżeli suma wartości
różnic między jasnością wyróżnionego piksela i jasnościami pikseli z sąsiedztwa
przekracza wartość ustalonego progu, wtedy piksel ten jest klasyfikowany jako na-
leżący do krawędzi. Zależnie od dobrania wartości progu schemat ten może być
wykorzystany do wykrywania krawędzi lub narożników w obrazie.
W proponowanym rozwiązaniu wykorzystany został podobny schemat opar-
ty o badanie różnic między jasnością wyróżnionego piksela i jasnościami pikseli
położonymi w jego pewnym, określonym sąsiedztwie. Zasadniczą różnicą w po-
równaniu do algorytmu SUSAN, jest wykorzystanie rozmytej relacji podobieństwa
w celu określenia podobieństwa między wartością jasności piksela wyróżnione-
go i jasności pikseli położonych w jego sąsiedztwie. Odpowiedź detektora określa
równocześnie przynależność badanego piksela do pikseli krawędziowych w obra-
zie. W przypadku, gdy porównywane są jasności dwóch pikseli za pomocą rozmy-
tej relacji podobieństwa, podobieństwo między nimi wyrażane jest liczbą z zakresu
[0, 1] będącą miarą liczbową rozmytej relacji podobieństwa. Jako końcowa odpo-
wiedź proponowanego detektora przyjmowana jest suma tych liczb, po wszystkich
pikselach należących do badanego sąsiedztwa. W przypadku, gdy detektor działa
w jednorodnym regionie obrazu, liczby wyznaczane przez rozmytą relacją podo-
bieństwa przyjmują wartość równą 1, co oznacza że badane piksele mają takie same
jasności. Ich suma, stanowiąca odpowiedź detektora, przyjmuje wartość maksy-
malną. Oznacza to, że w badanym regionie nie ma piksela należącego do krawędzi.
W przypadku, gdy w badanym regionie znajduje się piksel krawędziowy, liczby
otrzymane w wyniku zastosowania rozmytej relacji podobieństwa przyjmują war-
tości mniejsze od 1, a odpowiedź detektora będąca sumą tych liczb jest mniejsza od
maksymalnej będącej sumą jedynek. Oznacza to, że w badanym regionie znajduje
się piksel należący do krawędzi. Im wartość odpowiedzi detektora jest mniejsza
od maksymalnej, tym bardziej różnorodny region obrazu był poddawany badaniu
i tym większa możliwość, że badany piksel jest pikselem należącym do krawędzi
w obrazie.
140

“KonspPreamb” 2013/10/3 page 141 #144
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
5.8. Detekcja krawędzi w oparciu o rozmytą relację
podobieństwa
Idea badania podobieństwa pikseli będących w pewnym sąsiedztwie została
wykorzystana do opracowania algorytmu umożliwiającego detekcję krawędzi.
W tym celu na obrazie wybierany jest piksel i badane jest jego podobieństwo do
sąsiadów. Podobieństwo między wyróżnionym pikselem i jego sąsiadami określane
jest z wykorzystaniem rozmytej relacji podobieństwa. Podczas opracowania algo-
rytmu testowane było sąsiedztwo o kwadratowym kształcie i dwóch rozmiarach
określonych przez promień sąsiedztwa rs = 1 i rs = 2 (rys. 5.5).
Ip
(
i − 1,j − 1
)
Ip
(
i − 1,j
)
Ip
(
i − 1,j + 1
)
Ip
(
i,j − 1
)
Ip
(
i,j
)
Ip
(
i,j + 1
)
Ip
(
i + 1,j − 1
)
Ip
(
i + 1,j
)
Ip
(
i + 1,j + 1
)
(a)
Ip
(
i − 2,j − 2
)
Ip
(
i − 2,j − 1
)
Ip
(
i − 2,j
)
Ip
(
i − 2,j + 1
)
Ip
(
i − 2,j + 2
)
Ip
(
i − 1,j − 2
)
Ip
(
i − 1,j − 1
)
Ip
(
i − 1,j
)
Ip
(
i − 1,j + 1
)
Ip
(
i − 1,j + 2
)
Ip
(
i,j − 2
)
Ip
(
i,j − 1
)
Ip
(
i,j
)
Ip
(
i,j + 1
)
Ip
(
i,j + 2
)
Ip
(
i + 1,j − 2
)
Ip
(
i + 1,j − 1
)
Ip
(
i + 1,j
)
Ip
(
i + 1,j + 1
)
Ip
(
i + 1,j + 2
)
Ip
(
i + 2,j − 2
)
Ip
(
i + 2,j − 1
)
Ip
(
i + 2,j
)
Ip
(
i + 2,j + 1
)
Ip
(
i + 2,j + 2
)
(b)
Rys. 5.5. Ilustracja sąsiedztwa o promieniu rs = 1 (rys. 5.5a) oraz o promieniurs = 2 (rys. 5.5b) wykorzystywanych w detektorze krawędzi
W sąsiedztwie przedstawionym na rys. 5.5 dla wyróżnionego piksela w obra-
zie obliczana jest wartość relacji podobieństwa między jego jasnością a jasnościa-
mi wszystkich pikseli z jego sąsiedztwa. W pracy wykorzystana została zarówno
gaussowska, jak i trójkątna relacja podobieństwa. Relacja gaussowska opisana jest
wyrażeniem (por. p. 4.5.1):
µΩG
(
Ip (i, j) , Ip(
i′, j′)
)
= exp
−
∣
∣
∣Ip (i, j) − Ip (i′, j′)∣
∣
∣
σG
2
(5.19)
141

“KonspPreamb” 2013/10/3 page 142 #145
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
gdzieσG jest arbitralnie wybranym parametrem ustalającym zakres i stopień zacho-
dzenia rozmytej gaussowskiej relacji podobieństwa, natomiast IP (i, j) oraz Ip (i′, j′)
są wartościami jasności pikseli położonych na pozycjach o współrzędnych (i, j)
i odpowiednio (i′, j′).
Druga postać relacji rozmytej wykorzystywanej w pracy oparta jest na trójkąt-
nej funkcji przynależności (por. p. 4.5.1):
µΩT
(
Ip (i, j) , Ip(
i′, j′)
)
=
1 − |Ip(i, j)−Ip(i′, j′)|σT
jeżeli∣
∣
∣Ip (i, j) − Ip (i′, j′)∣
∣
∣ < σT
0 przeciwnie(5.20)
gdzie σT jest arbitralnie ustalonym parametrem ustalającym zakres i stopień za-
chodzenia rozmytej trójkątnej relacji podobieństwa.
Za pomocą parametrówσG we wzorze (5.19) lubσT we wzorze (5.20) dobiera-
ny jest zakres zachodzenia relacji rozmytej i zarazem miara liczbowa podobieństwa
między jasnością analizowanego piksela a jasnością pikseli należących do jego są-
siedztwa. W wyniku obliczenia tych miar podobieństwa otrzymywane są zbiory
liczb:
µΩG
[
Ip (i, j) , Ip (i + k, j + l)]
: −rs 6 k, l 6 rs; k, l , 0
, (5.21)
w przypadku relacji gaussowskiej, lub:
µΩT
[
Ip (i, j) , Ip (i + k, j + l)]
: −rs 6 k, l 6 rs; k, l , 0
, (5.22)
w przypadku relacji trójkątnej. Zbiory te zawierają w sobie informację o jednorod-
ności badanego regionu. Na ich podstawie definiowana jest odpowiedź detektora.
W opracowanym algorytmie jako odpowiedź detektora określona dla piksela (i, j)
przyjęta została suma wszystkich elementów należących do tych zbiorów, czyli
suma stopni podobieństwa pikseli należących do określonego sąsiedztwa piksela
(i, j):
ζG (i, j) =k,l=rs∑
k,l=−rsk,l,0
µΩG
[
Ip (i, j) , Ip (i + k, j + l)]
(5.23)
142

“KonspPreamb” 2013/10/3 page 143 #146
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
lub
ζT (i, j) =k,l=rs∑
k,l=−rsk,l,0
µΩT
[
Ip (i, j) , Ip (i + k, j + l)]
. (5.24)
W przypadku sąsiedztwa o promieniu rs = 1 sumy powyższe obejmują 8 elemen-
tów, zaś w przypadku sąsiedztwa o promieniu rs = 2 aż 24 elementy. Biorąc pod
uwagę definicje rozmytych relacji podobieństwa, można łatwo zauważyć, że zarów-
no w przypadku gaussowskiej funkcji przynależności (5.19), jak i trójkątnej funkcji
przynależności (5.20), największa wartość odpowiedzi detektora ζ (i, j), wynosi
ζmax = 8, jeśli promień sąsiedztwa jest równy rs = 1, oraz wynosi ζmax = 24, jeśli
promień sąsiedztwa jest równy rs = 2. Najmniejsza wartość odpowiedzi detektora
ζmin jest zależna od wyboru parametru σG w gaussowskiej funkcji przynależności
(5.19) lub parametru σT w trójkątnej funkcji przynależności (5.20).
Maksymalne wartości odpowiedzi detektora otrzymuje się dla tych pikseli (i, j),
dla których wszystkie sąsiadujące z nim piksele (i′, j′) mają identyczne wartości
jasności Ip (i′, j′) jak wartość jasności Ip (i, j) piksela (i, j). Oznacza to, że piksel
(i, j) należy wówczas do obszaru całkowicie jednorodnego, a więc nie zawierają-
cego krawędzi. Im wartość odpowiedzi detektora jest mniejsza, tym stopień przy-
należności danego piksela do pikseli krawędziowych jest większy.
Wyniki działania detektora krawędzi mogą być zapisane w postaci macierzy
o wymiarach M × N : Z =[
ζ (i, j)]
, i = 1, . . . ,M, j = 1, . . . ,N , której elementy
przybierają ciągłe wartości należące do przedziału[
ζmin, ζmax]
. Na podstawie tej
macierzy jest tworzony obraz IK , który nazywać będziemy obrazem krawędzio-
wym. W celu skontrastowania oznaczenia obrazu krawędziowego od obrazu pier-
wotnego został użyty we frakcji górnej indeks K . Na obrazie krawędziowym piksele
należące w analizowanym oryginalnym obrazie do obszarów jednorodnych, o du-
żych wartościach ζ (i, j) odpowiedzi detektora powinny być odzwierciedlone jako
piksele białe, natomiast piksele o małych wartościach ζ (i, j) jako piksele ciemniej-
sze, tym bardziej czarne im wartość ta jest mniejsza. Z tego względu w opracowa-
nym detektorze krawędzi i metodzie tworzenia obrazu krawędziowego przeprowa-
dzono przeskalowanie przedziału wartości możliwych odpowiedzi detektora kra-
wędzi[
ζmin, ζmax]
w przedział [Imin, Imax] skwantowanych wartości jasności pikseli
IK (i, j), gdzie wartości ζmin odpowiada wartość Imin, zaś wartości ζmax – wartość
Imax. Jak podkreślano już wyżej, w pracy w implementacji wszystkich algorytmów
143

“KonspPreamb” 2013/10/3 page 144 #147
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
założone całkowitoliczbową skalę jasności pikseli, przy czym przyjęto konwencję,
że Imin = 0 (całkowita czerń) oraz Imax = 255 (całkowita biel).
5.8.1. Przykłady obrazów krawędziowych otrzymanych w efekcie
działania rozmytego detektora krawędzi
W wyniku przeprowadzonego przeskalowania i dyskretyzacji przedziału war-
tości odpowiedzi detektora krawędzi macierz Z =[
ζ (i, j)]
zostaje przekodowa-
na w macierz IK =[
Ik (i, j)]
wartości jasności pikseli definiującą wynikowy ob-
raz krawędziowy IK . Na rys. 5.6 i 5.7 przedstawione zostały przykładowe obrazy
krawędziowe uzyskane jako rezultaty działania proponowanego algorytmu detek-
cji krawędzi. Algorytm zastosowany został dla dwóch obrazów testowych, dwóch
kształtów rozmytych relacji podobieństwa i dwóch rozmiarów sąsiedztw.
(a) (b) (c)
(d) (e) (f)
Rys. 5.6. Obrazy oryginalne i obrazy krawędziowe otrzymane w wyniku działaniadetektora krawędzi wykorzystującego rozmytą relację podobieństwa kształtu
gasussowskiego z parametrem σG = 127.
Na rys. 5.6 przedstawione zostały obrazy uzyskane w wyniku działania algoryt-
mu wykorzystującego rozmytą relację podobieństwa kształtu gaussowskiego. Ob-
razy oryginalne przedstawione zostały na rys. 5.6a i 5.6d. Obrazy krawędziowe
144

“KonspPreamb” 2013/10/3 page 145 #148
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
otrzymane w wyniku zastosowania sąsiedztwa o promieniu rs = 1 przedstawio-
ne zostały na rys. 5.6b i 5.6e, natomiast obrazy uzyskane w wyniku zastosowania
sąsiedztwa o promieniu rs = 2 na rys. 5.6c i 5.6f.
Na rys. 5.7 przedstawione zostały obrazy krawędziowe otrzymane w wyniku
zastosowania detektora wykorzystującego rozmytą relację podobieństwa kształtu
trójkątnego. Obrazy oryginalne są pokazane na rys. 5.7a i 5.7d. Obrazy krawędzio-
we w przypadku sąsiedztw o promieniu rs = 1 i o promieniu rs = 2 przedstawione
zostały na rys. 5.7b i 5.7e i odpowiednio rys. 5.7c i 5.7f.
(a) (b) (c)
(d) (e) (f)
Rys. 5.7. Obrazy oryginalne i obrazy krawędziowe otrzymane w efekcie działaniadetektora krawędzi wykorzystującego rozmytą relację podobieństwa kształtu
trójkątnego o parametrze σT = 127.
Ogólnie można powiedzieć, że w przypadku zastosowanie rozmytej trójkątnej
relacji podobieństwa pikselom są przypisywane mniejsze wartości jasności IK (i, j)
w obrazach krawędziowych w porównaniu z gaussowską relacją podobieństwa, tzn.
stopień przynależności pikseli do zbioru pikseli krawędziowych jest w tym przy-
padku większy. Z tego względu obrazy krawędziowe uzyskane z wykorzystaniem
trójkątnej relacji podobieństwa mają nieco silniej zarysowane krawędzie, a otrzy-
mane krawędzie są nieco grubsze i ciemniejsze. Podobnie można zauważyć, że
145

“KonspPreamb” 2013/10/3 page 146 #149
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
zwiększenie rozmiaru promienia sąsiedztwa prowadzi do uzyskania bardziej wy-
razistego obrazu krawędziowego.
5.8.2. Wykrywanie pikseli charakterystycznych w obrazach
krawędziowych
Przedstawiony algorytm wykrywania krawędzi w obrazie i tworzenia obrazów
krawędziowych wykorzystany został jako krok wstępny w zaproponowanym przez
autora algorytmie dopasowania punktów charakterystycznych w obrazach pary ste-
reoskopowej. Ze względu na specyfikę działania opracowanego rozmytego detek-
tora, otrzymywane w efekcie jego działania krawędzie są zbyt „grube”, aby łatwo
można dokonać identyfikacji pikseli charakterystycznych. Z tego względu w pierw-
szym kroku algorytmu wykorzystywana jest przedstawiona poniżej metoda wykry-
wania pikseli charakterystycznych w obrazach krawędziowych otrzymanych w wy-
niku działania rozmytego detektora. Stanowi ona podstawę do znajdowania odpo-
wiedników w pełnym algorytmie dopasowania pikseli charakterystycznych.
Przed prezentacją tej metody wprowadzone zostanie pojęcie krawędziowości
pikseli. Jako miarę krawędziowości piksela (i, j) w obrazie krawędziowym IK wy-
godnie jest przyjąć wielkość:
IK
(i, j) = Imax − IK (i, j) , (5.25)
a więc wyrazić krawędziowość pikseli w odwrotnej skali jasności pikseli. W ten
sposób pikselom ciemniejszym, o mniejszych wartościach jasności, przypisany jest
większy stopień krawędziowości. Inaczej mówiąc, im piksel w obrazie krawędzio-
wym jest ciemniejszy, tym większy stopień krawędziowości. W krańcowym przy-
padku pikselom białym, dla których IK (i, j) = Imax = 255, przyporządkowana jest
zerowa krawędziowość IK
(i, j) = Imin = 0.
Na zaproponowaną metodę wykrywania i dopasowania punktów (pikseli) cha-
rakterystycznych w obrazach krawędziowych składają się następujące kroki.
1. Progowanie globalne.
W kroku tym eliminowane są z obrazów krawędziowych piksele, którym przy-
pisana jest zbyt mała wartość krawędziowości. Polega on na przeprowadzeniu
progowania wartości krawędziowości pikseli. W obrazie krawędziowym pozo-
146

“KonspPreamb” 2013/10/3 page 147 #150
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
stawiane są jedynie takie piksele, których krawędziowość spełnia warunek:
IK
(i, j) > λ · IK
sr , (5.26)
gdzie IK
sr jest średnią wartością krawędziowości pikseli obrazu krawędziowego
zdefiniowaną wzorem:
IK
sr =1
MN
M∑
i=0
N∑
j=0
IK
(i, j) (5.27)
natomiast λ jest arbitralnie ustalonym parametrem progowania. W pracy przy-
jęta została wartość λ = 1.25.
2. Eliminacja pikseli o nie maksymalnych poziomych wartościach krawę-
dziowości
W kolejnym kroku spośród pikseli, które pozostały w obrazie krawędziowym
po przeprowadzeniu progowania globalnego, usuwane są piksele nie mające
maksymalnych wartości krawędziowości w porównaniu z sąsiadującymi z ni-
mi pikselami położonymi w kierunku poziomym obrazu. Eliminacja odbywa
się według zasady:
IK
(i, j) =
IK
(i, j) , jeżeli IK
(i, j) > IK
(i − 1, j)∧I
K(i, j) > I
K(i + 1, j) ,
0, przeciwnie
(5.28)
3. Eliminacja pikseli o nie maksymalnych pionowych wartościach krawę-
dziowości
Krok ten przebiega identycznie jak krok 2, przy czym porównywana jest w tym
przypadku krawędziowość pikseli pionowych. W jego wyniku następuje dalsza
eliminacja pikseli nie mających maksymalnych wartości krawędziowości w po-
równaniu z sąsiadującymi z nimi pikselami położonymi w kierunku pionowym
obrazu:
IK
(i, j) =
IK
(i, j) , jeżeli IK
(i, j) > IK
(i, j − 1)∧I
K(i, j) > I
K(i, j + 1) ,
0, przeciwnie
(5.29)
147

“KonspPreamb” 2013/10/3 page 148 #151
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
W rezultacie progowania globalnego i eliminacji pikseli o nie maksymalnych
wartościach krawędziowości, w obrazie krawędziowym uwypuklane są piksele cha-
rakterystyczne, którym detektor krawędzi przypisał dostatecznie duże wartości kra-
wędziowości. W efekcie otrzymuje się obraz krawędziowy, który oznaczany będzie
dalej ICH, o bardzo cienkich krawędziach. W przeprowadzonych przez autora eks-
perymentach jeden przebieg przedstawionej metody pozwalał na uzyskanie obra-
zów ICH, na których otrzymane krawędzie były szerokości jednego piksela. Tak
cienkie krawędzie mogą być w łatwy sposób wykorzystane do detekcji położenia
punktów krawędziowych o bardzo dużej krawędziowości, które w dalszej kolejno-
ści będą poddane algorytmowi poszukiwania odpowiedników na dwóch obrazach
pary stereoskopowej i wyznaczenia poszukiwanej wartości dysparycji.
5.8.3. Algorytm dopasowania pikseli charakterystycznych
w obrazach krawędziowych
Omówiony wyżej detektor krawędzi i metoda wykrywania pikseli charaktery-
stycznych zostały wykorzystane przez autora w pełnym algorytmie dopasowania
punktów charakterystycznych w obrazach krawędziowych pary stereoskopowej. Po
przeprowadzeniu dopasowania pikseli odpowiadającym tym punktom można, jako
wynik końcowy, wyznaczyć poszukiwaną mapę dysparycji.
Jak podkreślano wcześniej, odpowiedzi detektora krawędzi (wzory (5.23)
i (5.24)) mogą być traktowane jako miary stopni przynależności pikseli w obrazach
oryginalnych do zbioru pikseli krawędziowych. Cecha ta mogłaby być podstawą do
wykorzystania w algorytmie dopasowania pikseli charakterystycznych elementów
zbiorów rozmytych. Jednak biorąc pod uwagę prostotę obliczeniową, autor zrezy-
gnował z obliczeń w dziedzinie zbiorów rozmytych i przeprowadził je w zwykłej
dziedzinie jasności pikseli. Jako miara dopasowania, umożliwiające znalezienie od-
powiadających sobie pikseli w obrazach krawędziowych wykorzystana została mia-
ra korelacji wzajemnej CC określona wzorem (3.7). Poniżej podano pełny algorytm
dopasowania pikseli charakterystycznych w obrazach krawędziowych i wyznacze-
nia mapy dysparycji.
148

“KonspPreamb” 2013/10/3 page 149 #152
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
Algorytm 5.4 Dopasowanie punktów charakterystycznych w obrazach krawędzio-wych
Dane wejściowe: Obrazy pary stereoskopowej Ire f i Isz o rozmiarach M×N pikse-li, których wartości jasności są reprezentowane w przyjętej całkowitoliczbowejskali szarości [0, Imax].
Dane wejściowe: Założony przedział dopuszczalnych wartości dysparycji[dmin, dmax].
1: Korzystając z algorytmu opisanego w p. 5.8 utwórz obrazy krawędziowe IKre f
i IKsz.
2: W referencyjnym obrazie krawędziowym IKre f
znajdź punkty charakterystycz-ne, wykorzystując metodę opisaną w p. 5.8.2. Wynik zapamiętaj jako obrazI
CH.3: for i = 1 do M do
4: for j = 1 do N do
5: if (i, j) jest pikselem charakterystycznym then
6: Ustaw okno referencyjne Wre f w referencyjnym obrazie ICHre f
na pozycji(i, j).
7: for d = dmin do dmax z krokiem ∆d do
8: Oblicz wartość korelacji CC określonej wzorem (3.7) między oknemreferencyjnym Wre f a oknem przeszukiwania Wsz ustawionym w po-zycji (i, j + d) w krawędziowym obrazie przeszukiwania ICH
sz .9: if bieżąca wartość korelacji CC jest większa niż poprzednia then
10: Zapamiętaj bieżącą wartość korelacji CC oraz bieżącą wartość d
jako znalezioną wartość dysparycji d (i, j) dla piksela (i, j).11: else
12: Zwiększ bieżącą wartość d o ∆d i oblicz wartość korelacji CC dlanastępnego położenia okna przeszukiwania Wsz.
13: end if
14: end for
15: else
16: Zwiększaj wartości i oraz j aż do znalezienia następnego punktu cha-rakterystycznego w obrazie krawędziowym.
17: end if
18: end for
19: end for
20: Zwróć: Otrzymaną mapę dysparycji d jako znalezione rozwiązanie problemudopasowania pikseli charakterystycznych.
149

“KonspPreamb” 2013/10/3 page 150 #153
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
5.9. Dopasowanie obrazów pary steroskopowej w oparciu
o rozmytą transformatę rankingową
W niniejszym punkcie przedstawiona została propozycja obliczania rozmytej
transformaty rankingowej. Transformata ta została wykorzystana jako wstępny krok
przetwarzania obrazów zastosowany w algorytmie dopasowania pary stereosko-
powej. Pełen algorytm dopasowania polega na zamianie dziedziny opisu obrazów
z dziedziny jasności pikseli do dziedziny transformaty, a następnie zastosowaniu
algorytmu dopasowania obszarami działającego w dziedzinie transformaty.
W punkcie 3.3.4 opisana została transformata rankingowa, polegająca na ba-
daniu różnicy między wartościami jasności wyróżnionego piksela i wartościami
jasności pikseli znajdujących się w jego określonym sąsiedztwie. W przedstawionej
transformacie rankingowej brana jest jednak pod uwagę jedynie ostro ograniczo-
na właściwość większości lub mniejszości jasności piksela od jasności sąsiednich
pikseli, decydująca o wartości transformaty określanej dla wyróżnionego piksela.
Ideą zaproponowaną przez autora jest zwiększenie rozróżnialności pomiędzy
wartościami jasności pikseli przez wzięcie pod uwagę wielkości różnicy pomię-
dzy wartościami jasności badanych pikseli. Polega ona na określeniu, czy wartość
jasności wyróżnionego piksela poddawanego transformacie jest „dużo większa”,
„trochę większa”, „prawie równa” a może tylko „trochę mniejsza” lub o „wiele
mniejsza” od wartości jasności otaczających go pikseli położonych w określonym
sąsiedztwie.
Koncepcję porównywania wartości jasności pikseli reprezentowanych w dzie-
dzinie zbiorów rozmytych można wyrazić za pomocą funkcji, której argumentami
są wartości funkcji przynależności jasności pikseli do określonego zbioru rozmy-
tego poddawane transformacie, natomiast wartość tej funkcji odpowiada lingwi-
stycznemu modelowi różnicy. Idea funkcyjnego wyrażenia lingwistycznych warto-
ści „większy”, „mniejszy” oraz porównywania reprezentacji pikseli obrazów opisa-
nych w dziedzinie zbiorów rozmytych, zaczerpnięta została z teorii zbiorów rozmy-
tych, stąd proponowana nazwa tej transformaty: rozmyta transformata rankingowa.
W celu wprowadzenia matematycznego modelu wyrażenia zależności lingwi-
stycznych „większy”, „mniejszy” umożliwiającego przeprowadzenie obliczeń, za-
proponowane zostało wykorzystanie funkcji wykładniczej, a następnie przy jej po-
150

“KonspPreamb” 2013/10/3 page 151 #154
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
mocy zdefiniowana została tranformata rozmyta według zależności:
RFµ (p) =
∑
p∈N(p)
1
1 + exp[
βR
(
µ(
Ip′)
− µ(
Ip
))] (5.30)
gdzie RFµ (p) jest wartością transformaty określonej dla wyróżnionego piksela p,
dla którego obliczana jest transformata, natomiast p′ to piksele położone w określo-
nym sąsiedztwie N (p) wyróżnionego piksela p, µ(
Ip
)
i µ(
Ip′)
to wartości funkcji
przynależności pikseli do pewnego zbioru rozmytego określone na podstawie ich
jasności Ip i Ip′ zaś βR jest dowolnie ustalonym parametrem.
Formalnie we wzorze (5.30) wykorzystane zostały funkcje przynależności ja-
sności pikseli µ(
Ip
)
i µ(
Ip′)
do pewnego zbioru rozmytego. W celu otrzymania
reprezentacji wartości jasności w dziedzinie zbiorów rozmytych może być zasto-
sowana dowolna metoda fuzzyfikacji obrazów, również metoda zaproponowana
w tej pracy. Inną intuicyjną i łatwą do implementacji metodą fuzzyfikacji obrazu
jest metoda wykorzystujacą funkcję przynależności typu singleton rozmyty (por.
p. 4.1.3). W przypadku zastosowania fuzzyfikacji obrazu z wykorzystaniem funk-
cji przynależności typu singleton rozmyty, każdej wartości jasności piksela obrazu
Ip przypisywana jest wartość przynależności do zbioru białych piskeli µ(
Ip
)
równa
co do wartości jasności tego piksela Ip.
Możliwe jest jednak zastosowanie rozmytej transformaty rankingowej działają-
cej bezpośrednio na wartościach jasności pikseli Ip. W tym przypadku wykorzysty-
wany jest model zależności „większy”, „mniejszy”, natomiast uproszczony zostaje
algorytm obliczania wartości transformaty. Przy wykorzystaniu tak zdefiniowanej
rozmytej transformaty rankingowej nie wykonywany jest krok fuzzyfikacji obra-
zów. Formalnie wartości transformaty wyrażone są wówczas wzorem:
RFI (p) =
∑
p∈N(p)
1
1 + exp[
βR
(
Ip′ − Ip
)] (5.31)
gdzie: RFI
(p) to wartość transformaty określonej dla wyróżnionego piksela p, p′ to
piksele z pewnego sąsiedztwa N (p) natomiast Ip i Ip′ to wartości jasności pikse-
li, a βR jest dowolnie ustalanym parametrem. Parametr βR decyduje o przebiegu
krzywej definiującej transformatę, a tym samym o wartości transformaty w przy-
padku reprezentacji pikseli w dziedzinie zbiorów rozmytych (wzór 5.30) lub ich
151
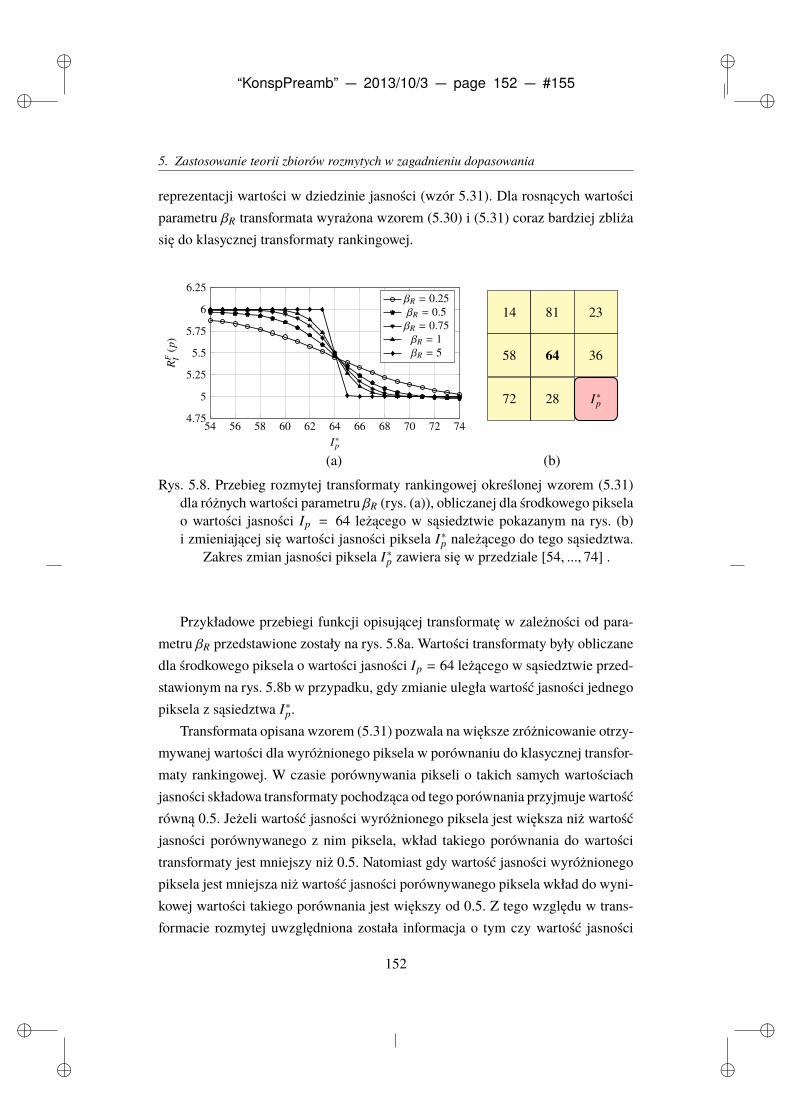
“KonspPreamb” 2013/10/3 page 152 #155
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
reprezentacji wartości w dziedzinie jasności (wzór 5.31). Dla rosnących wartości
parametru βR transformata wyrażona wzorem (5.30) i (5.31) coraz bardziej zbliża
się do klasycznej transformaty rankingowej.
54 56 58 60 62 64 66 68 70 72 744.75
5
5.25
5.5
5.75
6
6.25
I∗p
RF I
( p)
βR = 0.25βR = 0.5βR = 0.75βR = 1βR = 5
14 81 23
58 64 36
72 28 I∗p
(a) (b)
Rys. 5.8. Przebieg rozmytej transformaty rankingowej określonej wzorem (5.31)dla różnych wartości parametru βR (rys. (a)), obliczanej dla środkowego pikselao wartości jasności Ip = 64 leżącego w sąsiedztwie pokazanym na rys. (b)i zmieniającej się wartości jasności piksela I∗p należącego do tego sąsiedztwa.
Zakres zmian jasności piksela I∗p zawiera się w przedziale [54, ..., 74] .
Przykładowe przebiegi funkcji opisującej transformatę w zależności od para-
metru βR przedstawione zostały na rys. 5.8a. Wartości transformaty były obliczane
dla środkowego piksela o wartości jasności Ip = 64 leżącego w sąsiedztwie przed-
stawionym na rys. 5.8b w przypadku, gdy zmianie uległa wartość jasności jednego
piksela z sąsiedztwa I∗p.
Transformata opisana wzorem (5.31) pozwala na większe zróżnicowanie otrzy-
mywanej wartości dla wyróżnionego piksela w porównaniu do klasycznej transfor-
maty rankingowej. W czasie porównywania pikseli o takich samych wartościach
jasności składowa transformaty pochodząca od tego porównania przyjmuje wartość
równą 0.5. Jeżeli wartość jasności wyróżnionego piksela jest większa niż wartość
jasności porównywanego z nim piksela, wkład takiego porównania do wartości
transformaty jest mniejszy niż 0.5. Natomiast gdy wartość jasności wyróżnionego
piksela jest mniejsza niż wartość jasności porównywanego piksela wkład do wyni-
kowej wartości takiego porównania jest większy od 0.5. Z tego względu w trans-
formacie rozmytej uwzględniona została informacja o tym czy wartość jasności
152

“KonspPreamb” 2013/10/3 page 153 #156
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
sąsiedniego piksela jest mniejsza, czy większa od wartości jasności wyróżnionego
piksela poddawanego transformacie rozmytej.
Praktycznie dla parametru βR > 5 wartości uzyskiwane w wyniku zastosowania
proponowanej transformaty rozmytej przy założeniu, że wartości jasności są zapi-
sane jako liczby całkowite, są takie same jak dla transformaty rankingowej opartej
o badanie większości lub mniejszości wartości jasności piksela względem jego są-
siedztwa. Z tego względu proponowana postać rozmytej transformaty rankingowej
może być traktowana jako uogólnienie rozmytej transformaty rankingowej. Jako
uogólnienie rozumiany jest fakt, że po wybraniu odpowiednio dużej wartości pa-
rametru βR transformata rozmyta pozwala na uzyskanie takich samych wyników,
jakie otrzymane byłby w czasie zastosowania klasycznej transformaty rankingo-
wej. Możliwe jest więc emulowanie działania klasycznej transformaty rankingo-
wej, z wykorzystaniem rozmytej transformaty rankingowej, za pomocą właściwego
doboru wartości parametru βR, definiującego przebieg wartości rozmytej transfor-
maty rankingowej.
Na rys. 5.9 przedstawione zostały reprezentacje przykładowego obrazu w dzie-
dzinie transformaty rankingowej uzyskane przez zastosowanie transformaty kla-
sycznej i proponowanej transformaty rozmytej. W celu przedstawienia ich jako ob-
razów w skali szarości wartości otrzymane w wyniku zastosowania transformaty
zostały unormowane do przedziału wartości [0, 255]. Rys. 5.9a przedstawia repre-
zentację obrazu uzyskaną w wyniku zastosowania transformaty rankingowej opar-
tej o badanie ostrej nierówności między wartościami jasności pikseli w pewnym
sąsiedztwie (por. p. 3.3.4). Natomiast rys. 5.9b przedstawia reprezentację rozmytej
transformaty rankingowej obliczonej z wykorzystaniem wzoru (5.31) o wartości
parametru βR = 0.55. Obydwie transformaty zostały obliczone dla sąsiedztwa pik-
sela o promieniu równym 2.
153

“KonspPreamb” 2013/10/3 page 154 #157
5. Zastosowanie teorii zbiorów rozmytych w zagadnieniu dopasowania
(a) (b)
Rys. 5.9. Reprezentacje obrazów w dziedzinie transformat rankingowych przedsta-wione jako obrazy w skali szarości
W pracy wykorzystana została rozmyta transformata rankingowa działająca na
wartościach jasności pikseli opisana wzorem (5.31). Wykorzystanie tej postaci trans-
formaty pozwoliło na zmniejszenie złożoności obliczeniowej algorytmu. Następnie
dla obrazów reprezentowanych w dziedzinie transformaty może być zastosowany
algorytm dopasowania obszarami z dowolną miarą podobieństwa operującą na re-
prezentacjach pikseli w dziedzinie transformaty. W pracy przedstawione zostaną
rezultaty przy wykorzystaniu algorytmu dopasowania obszarami wykorzystujące-
go miarę dopasowania SAD (wzór (3.11)), dopasowaną do działania na wartościach
reprezentacji pikseli w dziedzinie rozmytej transformaty rankingowej.
154

“KonspPreamb” 2013/10/3 page 155 #158
Rozdział 6
Kryteria i metody oceny działania
algorytmów
W rozdziale omówiono metodykę badań przeprowadzonych w celu porówna-
nia efektywności działania różnych algorytmów stosowanych do rozwiązania pro-
blemu dopasowania obrazów pary stereoskopowej. Przedstawiono testowy zbiór
par stereoskopowych, który posłużył jako materiał badawczy do oceny rezultatów
otrzymywanych za pomocą zaproponowanych algorytmów. Omówiono charaktery-
styki najczęściej występujących zakłóceń szumowych obrazów, w obecności któ-
rych przeprowadzone zostały badania tych algorytmów. Scharakteryzowano ponad-
to miary stosowane do oceny numerycznej rozwiązań otrzymywanych przez różne
algorytmy.
6.1. Metody oceny i porównania algorytmów
Porównywanie wyników uzyskiwanych w efekcie działania różnych algoryt-
mów zastosowanych do rozwiązania tego samego zadania, a często również oce-
na przydatności określonego sposobu rozwiązywania zagadnienia do zastosowań
praktycznych, stanowi zazwyczaj trudne i złożone zagadnienie w większości ob-
szarów nauki i techniki. Problem wyboru metod umożliwiających łatwe porówna-
nie rezultatów lub mogących dostarczyć wskazówek co do jakości algorytmu pod-
czas procesu dobierania algorytmu do rozwiązywanego zadania występuje również
w obszarze zagadnień komputerowego przetwarzania obrazów.
Opracowanie metod umożliwiających obiektywne porównywanie wyników, jak
również sposobów oceny ich przydatności do zastosowań praktycznych w obszarze
komputerowego przetwarzania obrazów, stało się przedmiotem dyskusji zapocząt-
kowanej w latach 80 ubiegłego wieku [247, 248] i trwającej nieprzerwanie do dnia
dzisiejszego. Dyskusja ta prowadzona jest zarówno w formie publikacji książko-
wych [249], artykułów [250, 251], jak i cyklicznych dedykowanych spotkań ro-
boczych, np. NIST’s Performance Metrics for Intelligent Systems [252]. Problem
155

“KonspPreamb” 2013/10/3 page 156 #159
6. Kryteria i metody oceny działania algorytmów
obiektywnej metody porównywania otrzymywanych rozwiązań jest przedmiotem
dyskusji również w obszarze zagadnień widzenia stereoskopowego.
Metody widzenia stereoskopowego w ogólności, a szczególnie problem dopa-
sowania obrazów pary stereoskopowej, stanowią bardzo intensywnie badaną dzie-
dzinę i w efekcie tych badań zaproponowanych zostało bardzo wiele różnorodnych
metod umożliwiających uzyskanie rozwiązania. W raporcie z roku 1993 Koschan
[253] oszacował liczbę istniejących rozwiązań na około 200. Kolejne lata przyno-
siły idee nowych rozwiązań [47] i ciągle są proponowane nowe rozwiązania [254,
255, 256, 257, 258, 259, 260] przy równoczesnym braku uznanych metod umoż-
liwiających ocenę ich przydatności do zastosowań praktycznych lub przynajmniej
możliwości ich porównywania pod względem otrzymywanych wyników.
Jednym z powodów takiego stanu rzeczy był na pewno brak odpowiedniego
materiału badawczego mogącego umożliwić przynajmniej próbę obiektywizacji
oceny otrzymywanych rozwiązań. Dostępnych było co prawda kilka standardowych
obrazów, często wykorzystywanych do prezentacji wyników, jednak otrzymywane
wyniki były prezentowane głównie w formie wizualnej jako obrazy w skali sza-
rości, gdzie wartości jasności piksela były uzyskiwane przez przeliczanie wartości
dysparycji [261, 262]. Natomiast ocena rozwiązania odbywała się poprzez ocenę
wizualną tak przedstawianej mapy dysparycji, sprowadzając się do stwierdzenia, że
mapa dysparycji prezentowana jako obraz w skali szarości „na oko wygląda lepiej
lub gorzej” [263].
Dużym krokiem naprzód było zaprezentowanie wyników dla obrazów pary ste-
reoskopowej, dla której znane było idealne rozwiązanie w postaci mapy dysparycji
z ręcznie wyznaczonymi prawdziwymi wartościami [264, 265]. Obrazy te zosta-
ły bardzo szybko zaakceptowane przez społeczność zajmującą się badaniami nad
widzeniem stereoskopowym, która dostrzegła możliwość testowania własnych roz-
wiązań względem istniejącego idealnego rozwiązania znanego pod nazwą „wzor-
cowej mapy dysparycji” (ang. true disparity map). Para stereoskopowa przedsta-
wiona w punkcie 6.3.1 jest dzisiaj jednym z najbardziej znanych i najczęściej wy-
korzystywanych obrazów testowych. Znana jest pod nazwą „Tsukuba” pochodzącą
prawdopodobnie od nazwy macierzystego uniwersytetu jej twórców, tj. „University
of Tsukuba”.
W ostatnich latach pojawiają się nowe projekty, których celem jest wypraco-
wanie jednolitego sposobu postępowania przy ocenie wyników otrzymywanych za
156

“KonspPreamb” 2013/10/3 page 157 #160
6. Kryteria i metody oceny działania algorytmów
pomocą różnych algorytmów. Jednym z pierwszych, który uzyskał równocześnie
najszersze uznanie jest projekt Middlebury Stereo Vision [266] wraz z poświęco-
ną mu stroną internetową [267]. Autorzy tego projektu użyli aktywnej techniki
uzyskiwania obrazów trójwymiarowych opartej o skanowanie laserowe z wyko-
rzystaniem światła strukturalnego [268]. Eksperyment ten został przeprowadzony
w warunkach laboratoryjnych, a w jego efekcie otrzymane zostały pary stereosko-
powe ze znanymi, wzorcowymi mapami dysparycji. Pozwoliło to na zwiększenie
różnorodności materiału badawczego w stosunku do jedynej do tej pory istniejącej
pary stereoskopowej „Tsukuba”. Projekt ten jest ciągle kontynuowany i rozwijany
poprzez akwizycję kolejnych obrazów w formie par stereoskopowych, dla których
wyznaczone i znane są wartości wzorcowej mapy dysparycji.
Drugą istotną cechą projektu Middlebury Stereo Vision jest próba opracowania
uniwersalnej metody porównań algorytmów dopasowania obrazów pary stereosko-
powej. Autorzy tego projektu wykorzystali do tego celu pary stereoskopowe o zna-
nej mapie dysparycji i zaproponowali, aby porównywać algorytmy pod względem
najprostszej, a zarazem najbardziej intuicyjnej miary, jaką jest liczba prawidłowo
dopasowanych pikseli obrazu (tzn. takich, dla których wyznaczona wartość dyspa-
rycji różni się mniej niż o pewien założony błąd od wartości wzorcowej).
Dalszym krokiem mającym na celu polepszenie analizy własności algorytmów
dopasowania jest podział analizowanej sceny przedstawionej na obrazach pary ste-
reoskopowej na trzy rozłączne części i wyznaczanie liczby prawidłowo dopaso-
wanych pikseli odrębnie dla każdej z tych części. Na podział proponowany przez
autorów Middlebury Stereo Vision składają się trzy obszary, którymi są:
— obszar pełnego dopasowania, tzn. taki w którym istnieje jednoznaczna odpwied-
niość pikseli w obu obrazach umożliwiająca ich bezbłędne dopasowanie,
— obszar przesłonięty, tzn. taki w którym piksele nie mogą zostać dopasowane ze
względu na ich obecność tylko w jednym obrazie pary i brak ich odpowiedni-
ków w drugim z obrazów pary,
— obszar nieciągłości dysparycji, tzn. taki w którym zmiana wartości dysparycji
następuje skokowo, co dzieje się głównie na brzegach obiektów widzianych na
obrazach sceny.
Autorzy stworzyli własny zestaw algorytmów wykorzystywanych do rozwiąza-
nia zagadnienia dopasowania obrazów pary stereoskopowej oraz testowania i oceny
osiąganych przez nich rezultatów. Udostępnili ponadto interfejs internetowy, który
157

“KonspPreamb” 2013/10/3 page 158 #161
6. Kryteria i metody oceny działania algorytmów
umożliwia dodanie wyników działania kolejnych algorytmów samodzielnie przez
ich twórców, którzy dodatkowo są do tego zachęcani w celu zwiększenia różno-
rodności dostępnych rozwiązań i wyników. Zbiór testowy wykorzystywany przez
autorów projektu Middlebury Stereo Vision do celów analizy wyników działania
algorytmów składa się z czterech par stereoskopowych. Zawiera parę „Tsukuba”
oraz trzy dodatkowe pary stereoskopowe uzyskane przez autorów w wyniku zasto-
sowania metody skanowania aktywnego.
Pomimo wielu niewątpliwych zalet projektu, wśród których można wymienić
przede wszystkim udostępnienie bez żadnych ograniczeń prawnych par stereosko-
powych ze znanymi (wzorcowymi) mapami dysparycji oraz próbę skolekcjonowa-
nia i usystematyzowania algorytmów stosowanych do rozwiązania problemu do-
pasowania par stereoskopowych, ma on również pewne wady. Jedną z tych wad,
zdaniem autora niniejszej pracy, jest sposób porównywania algorytmów z wyko-
rzystaniem zasady „czarnej skrzynki” (ang. black box). Na stronie internetowej
Middlebury Stereo Vision można co prawda sprawdzić liczbę dopasowywanych
pikseli przez algorytm w regionach określonych przez autorów, ale przy zupełnym
braku jakichkolwiek informacji o innych cechach algorytmu, jak również wielko-
ści błędu jakie były otrzymane w wyniku wykonania algorytmu. Błędy określane
w projekcie Middlebury Stereo Vision wyznaczane są na zasadzie klasyfikacji, bez
żadnego odniesienia się do ich miary liczbowej.
Dodatkowo niewiele wiadomo o parametrach, jakie zastosowali autorzy prezen-
towanych algorytmów w celu uzyskania rozwiązania. Można wysnuć uzasadnione
przypuszczenie, iż autorzy, ze względu na to że strona Middlebury jest prowadzona
na zasadzie rankingu, starali się uzyskać jak najlepsze rezultaty, aby zająć jak naj-
wyższą pozycję w tym rankingu. Prawdopodobnie odbywało się to poprzez celowy
dobór parametrów algorytmów umożliwiających uzyskanie jak najlepszych roz-
wiązań branych pod uwagę w czasie ustalania pozycji algorytmu w rankingu. Brak
jest również jawnej informacji o zastosowanych krokach przetwarzania wstępne-
go i końcowego w zastosowanych algorytmach zarówno w odniesieniu do samych
obrazów wejściowych, jak i otrzymanej mapy dysparycji. Z tego względu wyższa
pozycja w rankingu nie musi świadczyć o obiektywnej poprawie uzyskiwanych
wyników, jak również przewadze prezentowanego algorytmu nad innymi.
Inna warta wspomnienia próba usystematyzowania wyników otrzymywanych
za pomocą różnych algorytmów dopasowania pary stereoskopowej jest związana
158

“KonspPreamb” 2013/10/3 page 159 #162
6. Kryteria i metody oceny działania algorytmów
z propozycją wykorzystania krzywych ROC (ang. Receiver Operating Characteris-
tic) [269] jako obiektywnej miary jakości otrzymywanych rozwiązań. Podobnie jak
w projekcie Middlebury Stereo Vision, również z tą propozycją związana jest strona
internetowa CMP Stereo Algorithm Evaluation [270] prowadzona przez Center for
Machine Perception czeskiego Uniwersytetu Technicznego w Pradze.
Krzywe ROC są ogólnymi narzędziami matematycznymi, które znalazły zasto-
sowanie w różnych dziedzinach. Na przykład, w przetwarzaniu sygnałów, a mówiąc
ściślej w zagadnieniu detekcji sygnałów są one często wykorzystywane do oce-
ny jakości detektorów [271]. Innym przykładem stosowania krzywych ROC jest
ocena dyskryminacyjnych klasyfikatorów, np. danych biomedycznych [272, 273].
Jedną z cech charakterystycznych metod oceny opartych o krzywe ROC jest wy-
maganie zdefiniowania błędów określających układ współrzędnych, w którym są
one wykreślane. W przypadku zastosowaniu krzywych ROC do oceny problemu
decyzyjnego określa się zazwyczaj liczbę przypadków prawdziwie i fałszywie po-
zytywnych oraz prawdziwie i fałszywie negatywnych. Następnie na ich podstawie
wyznaczona zostaje czułość (ang. sensitivity) oraz specyficzność (ang. specifity)
danej metody klasyfikacyjnej [274]. Czułość metody klasyfikacyjnej określa się
jako stosunek liczby przypadków prawdziwie pozytywnych do sumy przypadków
prawdziwie pozytywnych i fałszywie negatywnych. Natomiast specyficzność me-
tody określana jest jako stosunek liczby przypadków prawdziwie negatywnych do
sumy przypadków fałszywie pozytywnych i prawdziwie negatywnych.
Podobne podejście, związane z przedstawieniem problemu dopasowania obra-
zów pary stereoskopowej w ramach problemu decyzyjnego i przeprowadzanie jego
oceny jako metody klasyfikacyjnej, zostało przedstawione przez autorów projektu
CMP Stereo Evalutaion [275]. Autorzy tego projektu zaproponowali wykorzysta-
nie w celu wyznaczania przebiegów krzywych ROC dwa błędy: jednym z nich jest
stopa błędu (ang. error rate) natomiast drugim jest stopa wypełnienia (ang. spar-
sity rate). Stopa błędu wyznaczana jest jako iloraz sumy liczby wszystkich błędnie
znalezionych dopasowań oraz dopasowań znalezionych w obszarach przesłoniętych
do liczby wszystkich pikseli w obrazie. Natomiast stopa wypełnienia określana jest
jako iloraz liczby niedopasowanych pikseli, dla których istnieje prawidłowe dopa-
sowanie (np. w przypadku blokowych braków w wartościach dysparycji, powsta-
jących często przy dopasowywaniu obszarów o braku tekstury) do liczby wszyst-
kich pikseli, jakie można dopasować w obrazie. Błędy te wyznaczają układ współ-
159

“KonspPreamb” 2013/10/3 page 160 #163
6. Kryteria i metody oceny działania algorytmów
rzędnych do wykreślania krzywych ROC oraz są wykorzystywane do definicji dal-
szych możliwych miar, takich jak efektywność metody klasyfikacyjnej określona
jako wartość całki obliczanej dla określonej krzywej ROC lub poprawa klasyfika-
cji określona jako różnica między wartościami całek dwóch krzywych ROC [275,
269].
Inicjatywa ta nie zyskała jednak szerokiej popularności w środowisku osób
zajmujących się przetwarzaniem obrazów. Na stronie projektu CMP Stereo Evalu-
ation przedstawione są jedynie autorskie rozwiązania twórców projektu. Wynika to
prawdopodobnie z trudności jakie wiążą się z uzyskaniem wyników w formie krzy-
wych ROC proponowanych przez autorów. Co prawda umieszczają oni na swojej
stronie internetowej program umożliwiający otrzymywanie krzywych ROC według
zaproponowanej przez nich metody, jednak oprogramowanie to działa w licencjo-
nowanym środowisku obliczeniowym MATLAB® oraz wymaga dużego wkładu
własnego w celu jego uruchomienia oraz uzyskania wyników.
Dodatkowo przy wykorzystaniu krzywych ROC istnieje praktycznie dowolność
w definiowaniu błędów określających układ współrzędnych. W efekcie tego przyj-
mowane są różne definicje błędów określających układ współrzędnych krzywych
ROC. Czasami mimo podobnie brzmiących nazw definicje błędów są różne. Na
przykład w pracach [276, 277] do oceny rozwiązań również zostały zastosowane
krzywe ROC wykreślone w układzie współrzędnych opisanym przez gęstość oraz
stopę błędu. Jednak gęstość określona została jako iloraz liczby prawidłowo dopa-
sowanych pikseli do wszystkich pikseli zawartych w obrazie, natomiast stopa błędu
zdefiniowana została jako iloraz liczby błędnie dopasowanych pikseli do wszystkich
pikseli w obrazie. Dowolność w definiowaniu błędów prowadzi do polemiki co
do zalet i wad poszczególnych definicji wykorzystywanych przez różnych autorów
[278] i praktycznie uniemożliwia porównywanie wyników osiąganych za pomocą
różnych algorytmów przy pozornie tej samej metodzie oceny.
Jako obrazy testowe autorzy projektu CMP Stereo Evaluation wykorzystali pary
stereoskopowe udostępnione w projekcie Middlebury Stereo Vision. Stosując po-
dobną metodę skanowania aktywnego dokonali także akwizycji i udostępnili dodat-
kowe obrazy par stereoskopowych wraz ze wzorcowymi mapami dysparycji [268,
269].
Oprócz ogólnych rozważań dotyczących możliwości porównywania wyników
osiąganych przez różne algorytmy dopasowania pary stereoskopowej coraz czę-
160

“KonspPreamb” 2013/10/3 page 161 #164
6. Kryteria i metody oceny działania algorytmów
ściej pojawiają się prace poświęcone konkretnemu zagadnieniu związanemu z pro-
blemem dopasowania. Jako przykład przytoczyć można pracę Tombariego [279],
w której autor porównał 26 różnych algorytmów dopasowania obszarami wykorzy-
stujących w swoim działaniu zmienny rozmiar okien. Jako zbiór testowy obrazów
wykorzystany został zbiór par stereoskopowych pochodzący z projektu Middlebu-
ry Stereo Vision, a jako rezultaty przedstawione zostały dane liczbowe dotyczące
prawidłowo dopasowanych pikseli w dwóch regionach. Pierwszy z nich to region,
gdzie istnieje pełna jednoznaczność pikseli i możliwe jest prawidłowe dopasowa-
nie, podczas gdy drugi region został określony jako obszar nieciągłości dysparycji
zgodnie z metodyką określoną przez autorów projektu Middlebury Stereo Vision.
Na podstawie powyższych rozważań można wysnuć wniosek, że pomimo pro-
pozycji metodyk mogących ujednolicić sposoby porównywania algorytmów dopa-
sowania par stereoskopowych ciągle brak jest sposobu ogólnie akceptowanego. Ze
względu na obecność i łatwą dostępność wzorcowych map dysparycji standardem
stał się zbiór par stereoskopowych udostępnionych w projekcie Middlebury Stereo
Vision. Także zastosowanie bardzo prostej i intuicyjnie zrozumiałej miary jaką jest
liczba prawidłowo dopasowanych pikseli zyskało szeroką aprobatę.
W celu przeprowadzenia badań eksperymentalnych autor wykorzystał zbiór te-
stowych par stereoskopowych pochodzący z projektu Middlebury Stereo Vision. Po-
szczególne pary stereoskopowe z tego zbioru zostaną przedstawione w sposób bar-
dziej szczegółowy w punkcie 6.3. Dostępność wzorcowych map dysparycji pozwo-
liła na zdefiniowanie intuicyjnie zrozumiałych błędów dopasowania, które omó-
wione będą w punkcie 6.5. Do oceny algorytmów nie wykorzystano metodyki
zaproponowanej w projekcie Middlebury Stereo Vision, ani też opartej o krzy-
we ROC, gdyż implementacja proponowanych w pracy algorytmów nie zawierała
żadnych dodatkowych etapów przetwarzania obrazów. Natomiast w opisanych pro-
jektach ocenie podlegają pełne algorytmy, które często zawierają dodatkowe etapy
przetwarzania, a to uniemożliwiłoby zachowanie obiektywności przy porównywa-
niu rezultatów z algorytmami zaproponowanymi przez autora.
161

“KonspPreamb” 2013/10/3 page 162 #165
6. Kryteria i metody oceny działania algorytmów
6.2. Algorytmy dopasowania w obecności zakłóceń obecnych
w obrazach
Obecność zakłóceń w obrazach jest jednym z ogólnych problemów dotyczących
zagadnień ich przetwarzania. Problem ten występuje również w zagadnieniu dopa-
sowania pary stereoskopowej i stanowi jedno z zagadnień, które zostały poddane
badaniom eksperymentalnym prowadzonym w ramach niniejszej pracy. Pomimo
istotnego znaczenia tego problemu w literaturze można znaleźć jedynie nielicz-
ne prace poświęcone zagadnieniu wpływu zakłóceń na rezultaty otrzymywane za
pomocą różnych algorytmów dopasowania pary stereoskopowej.
Analizie wpływu różnego typu zakłóceń obecnych w obrazach na wyniki do-
pasowania obrazów pary stereoskopowej jest poświęcona praca [138]. Jej autorzy
przedstawili wyniki uzyskane za pomocą 15 różnych algorytmów dopasowania
obrazów pary stereoskopowej działających na obrazach z różnymi zakłóceniami.
W czasie eksperymentu symulowane było zakłócenie liniowe (zmiana wzmocnie-
nia) oraz zakłócenie nieliniowe uzyskiwane przez zastosowanie nieliniowej (wy-
kładniczej) operacji zniekształcenia jasności pikseli obrazów (ang. gamma correc-
tion). Innym zakłóceniem poddanym badaniom przez autorów była symulacja efek-
tu winietowania (ang. vignetting effect), polegającego na niedoświetleniu brzegów
obrazu spowodowanego przez niedoskonałości układu optycznego urządzenia, nie-
odpowiednie oświetlenie lub zakłócenie brzegów toru optycznego urządzenia przez
inne elementy otoczenia. Dodatkowo przeprowadzony został również eksperyment
przy zakłóceniu obrazów szumem gaussowskim. Jako obrazy testowe użyty został
zbiór obrazów z projektu Middlebury Stereo Vision, a jako rezultaty podane zostały
liczby nieprawidłowo dopasowanych pikseli w regionach, gdzie istnieje możliwość
ich jednoznacznego dopasowania.
Zagadnienie wpływu zakłóceń na działanie poszczególnych algorytmów dopa-
sowania pary stereoskopowej obrazów zostało podjęte także przez autora niniej-
szej pracy i stanowi jej istotny element. Ponieważ zarówno rezultaty przytoczone
w [138], jak i podane w innych pozycjach literaturowych, nie mogły – zdaniem
autora – służyć jako miarodajny punkt odniesienia do przeprowadzenia analizy po-
równawczej w pracy przeprowadzono pełne własne analizy wszystkich rozpatry-
wanych dopasowania pary stereoskopowej pod kątem ich wrażliwości na różnego
rodzaju zakłócenia obrazów. Różne typy zakłóceń zostaną dokładnie omówione
162

“KonspPreamb” 2013/10/3 page 163 #166
6. Kryteria i metody oceny działania algorytmów
w p. 6.4, natomiast wyniki przeprowadzonych analiz będą przedstawione w odpo-
wiednich punktach rodziału 7.
6.3. Wzorcowe pary stereoskopowe
W projekcie Middlebury Stereo Vision [267] udostępnionych jest 38 par stereo-
skopowych. Dodatkowe pary ze znanymi mapami dysparycji udostępniane są przez
autorów projektu CMP Stereo Algorithm Evaluation [270]. Jednak najczęściej jako
zbiór obrazów testowych wykorzystywany jest zbiór składający się z czterech par
stereoskopowych. Zbiór ten został użyty również w tej pracy i posłużył autorowi
do przeprowadzenia własnych testów badanych algorytmów dopasowania pary ste-
reoskopowej.
Wymieniony zbiór składa się z pary stereoskopowej „Tsukuba”, przedstawionej
na rys. 6.1, i jak wspomniano wcześniej udostępnionej przez naukowców z Uni-
wersytetu w Tsukubie, oraz trzech dodatkowych par uzyskanych w czasie trwania
projektu Middlebury Stereo Vision znanych pod zwyczajowymi nazwami „Venus”
(rys. 6.2), „Cones” (rys. 6.3) i „Teddy” (rys. 6.4).
Jako najważniejsze cechy obrazów tego zbioru, które decydują o tym, że jest on
dobrym zbiorem testowym par stereoskopowych wykorzystanym do oceny jakości
algorytmów dopasowania, można wymienić:
- Zestaw tych par wyczerpuje praktycznie wszystkie elementy sceny, które można
spotkać w rzeczywistych obrazach. Zawierają one między innymi dużo drob-
nych elementów, duże powierzchnie prostopadłe do płaszczyzny obrazowania
oraz powierzchnie do niej skośne, a także powierzchnie stożkowe, obszary o bra-
ku tekstury i obszary o powtarzającym się wzorze tekstury.
- Ponieważ znane są ich wzorcowe mapy dysparycji, znane są również przedziały
wartości dysparycji w jakich może znajdować się poszukiwana wartość dyspa-
rycji. Ustalenie wartości dopuszczalnego przedziału dysparycji przeszukiwa-
nia, szczególnie w obrazach rzeczywistych, jest dosyć złożonym zagadnieniem
podejmowanym jako jeden z problemów badawczych występujących przy pró-
bach stosowaniu algorytmów widzenia stereoskopowego [280].
- Obrazy tworzące parę stereoskopową są zrektyfikowane, tzn. że wiersze ma-
cierzy składających się na obrazy są równoważne z geometrycznymi liniami
epipolarnymi. W przypadku obrazów zrektyfikowanych poszukiwanie dyspa-
163

“KonspPreamb” 2013/10/3 page 164 #167
6. Kryteria i metody oceny działania algorytmów
rycji odbywa się tylko w kierunku poziomym, co znacząco zmniejsza koszt
wykonywania algorytmu natomiast nie zmniejsza jego ogólności rozwiązania.
W wyniku zastosowania przekształceń geometrycznych w fazie przetwarzania
wstępnego obrazów problem poszukiwania dysparycji w obrazie zawsze mo-
że zostać sprowadzony do poszukiwania dysparycji horyzontalnej [57, 6] (por.
również. p. 2.4.1).
- W obrazach obecne są tylko, poza kilkoma wyjątkami lśniących powierzch-
ni w parze stereoskopowej „Tsukuba”, elementy o powierzchniach lambertow-
skich, tzn. równomiernie rozpraszających światło. Obecność elementów o po-
wierzchniach nielambertowskich, jak np. szyby, lustra, powodują znaczne utrud-
nienia w znajdowaniu prawidłowych dopasowań i stanowią odrębną gałąź badań
nad algorytmami dopasowania pary stereoskopowej [281, 282].
- Wszystkie obrazy zostały uzyskane w warunkach laboratoryjnych, zawierają
więc minimalną liczbę składowych niepożądanych powodowanych przez nie-
jednorodność oświetlenia, zniekształcenia geometryczne, czy szumy [268, 264].
6.3.1. Para stereoskopowa „Tsukuba”
Para stereoskopowa „Tsukuba”, przedstawiona na rys. 6.1a i rys. 6.1b, jest histo-
rycznie jedną z pierwszych par, dla których znana była wzorcowa mapa dysparycji.
Mapa ta została otrzymana w manualny sposób przez przypisanie wartości dyspa-
rycji dla każdego piksela obrazu i przedstawiona została na rys. 6.1c. Para ta cza-
sami bywa nazywana Head and Lamp, prawdopodobnie ze względu na widoczne
na obrazach elementy sceny.
Na parę tę składają się dwa obrazy o rozmiarach 384 × 288 pikseli. Wartości
dysparycji widocznej sceny zmieniają się w zakresie [0, 16] pikseli. W oryginalnej
wzorcowej mapie dysparycji brak jest wyznaczonych wartości na brzegach obra-
zu w pasie o szerokości 16 pikseli. Obrazy tej pary mają najmniejsze rozmiary
z całego zbioru 4 par testowych oraz najmniejszy zakres wartości dysparycji. Dla
prezentacji wizualnej jako obrazu w skali szarości wartości dysparycji mnożone
są przez stałą liczbę równą 16. Cechami charakterystycznymi pary stereoskopowej
„Tsukuba” jest obecność w obrazach obszarów lśniących (powierzchni nielamber-
towskich), które odbijają światło w sposób nierównomierny. Elementami tymi są
półka w lewej górnej części obrazu, powierzchnia lampy i przednia część statuetki.
164

“KonspPreamb” 2013/10/3 page 165 #168
6. Kryteria i metody oceny działania algorytmów
(a) Lewy obraz pary stereoskopowej „Tsukuba” (b) Prawy obraz pary stereoskopowej „Tskuba”
(c) Wzorcowa mapa dysparycji (d) Regiony mapy dysparycji określone wg.Middlebury Stereo Vision.
Rys. 6.1. Testowa para stereoskopowa „Tsukuba” (a) i (b) wraz ze wzorcową mapądysparycji (c) oraz regionami wyznaczonymi w projekcie Middlebury Stereo
Vision (d). Kolor biały – region umożliwiający jednoznaczne dopasowanie, ko-lor czarny – piksele przesłonięte, kolor szary – obszary nieciągłości wartości
dysparycji.
Ze względu na obecność różnych elementów w obrazowanej scenie wartości
dysparycji zmieniają się w sposób ciągły (sferyczna powierzchnia statuetki lub
walcowa lampy), jak również skokowo (np. między kamerą, a ścianą z półkami).
W scenie brakuje natomiast skośnych do płaszczyzny obrazowania płaszczyzn oraz
powtarzających się elementów, a wszystkie proste płaszczyzny są prostopadłe do
płaszczyzny obrazowania. W obrazach znajdują się ponadto regiony o pełnym bra-
ku tekstury (ściana w prawym górnym rogu lub obszar w cieniu poniżej stołu).
165

“KonspPreamb” 2013/10/3 page 166 #169
6. Kryteria i metody oceny działania algorytmów
6.3.2. Para stereoskopowa „Venus”
Para stereoskopowa „Venus” składa się z obrazów przedstawionych na rys. 6.2a
i rys. 6.2b. Obrazy te pochodzą ze zbiorów uzyskanych i udostępnionych w ramach
projektu Middlebury Stereo Vision [267]. Nazwa pary pochodzi prawdopodobnie
od widocznego w prawym dolnym rogu obrazu napisu „Venus”.
(a) Lewy obraz pary stereoskopowej „Venus” (b) Prawy obraz pary stereoskopowej „Venus”
(c) Wzorcowa mapa dysparycji pary „Venus” (d) Regiony mapy dysparycji określone wg.Middlebury Stereo Vision
Rys. 6.2. Testowa para stereoskopowa „Venus” (a) i (b) ze wzorcową mapą dys-parycji (c) oraz regionami dysparycji określonymi według Middlebury Stereo
Vision (d). Kolor biały – obszar o możliwym jednoznacznym dopasowaniu, ko-lor czarny – regiony przesłonięte, kolor szary – regiony nieciągłości dysparycji
Na parę tę składają się dwa obrazy o rozmiarach 434 × 383 pikseli. Wartości
dysparycji zawierają się w przedziale [0, 32] pikseli. Wartości wzorcowej mapy
166

“KonspPreamb” 2013/10/3 page 167 #170
6. Kryteria i metody oceny działania algorytmów
dysparycji wyznaczone zostały za pomocą aktywnej techniki obrazowania trójwy-
miarowego i są określone dla każdego piksela obrazu. W celu prezentacji mapy
dysparycji jako obrazu w skali szarości wartości te mnożone są przez stałą liczbę
równą 8.
Cechą charakterystyczną pary stereoskopowej „Venus” jest konstrukcja obra-
zowanej sceny. Składają się na nią trzy duże powierzchnie skośne do płaszczyzny
obrazowania. Wartości dysparycji określone dla tych powierzchni zmieniają się
w sposób ciągły. Para ta miała być prawdopodobnie w zamierzeniu jej autorów uzu-
pełnieniem pary „Tsukuba” o elementy sceny zawierające duże płaszczyzny sko-
śne do płaszczyzny obrazowania. W obrazach pary obecne są obszary o skokowej
zmianie wartości dysparycji znajdujące się na krawędziach płaszczyzn, a także du-
że obszary o jednolitych wartościach jasności pikseli, klasyfikowane jako obszary
bez tekstury.
6.3.3. Para stereoskopowa „Cones”
Para stereoskopowa „Cones”, której nazwa pochodzi prawdopodobnie od stoż-
ków widocznych na obrazach, pokazana jest na rys. 6.3a i 6.3b. Para ta pochodzi
z projektu Middlebury Stereo Vision i składa się z dwóch obrazów o rozmiarach
540 × 375 pikseli. Parę tę cechuje również dużo większy zakres zmienności dys-
parycji w zawierający się w przedziale [0, 64] pikseli.
Aby przedstawić mapę dysparycji pary „Cones” w postaci obrazu w skali sza-
rości pokazanego na rys.6.3c, wartości dysparycji mnożone są przez liczbę 4. Pa-
ra „Cones” obrazuje bardzo złożoną scenę. Jej cechą charakterystyczną jest bar-
dzo duża liczba powierzchni stożkowych, dla których zmiana dysparycji następuje
w ciągły sposób. W obrazach pary występuje powtarzający się wzór tekstury two-
rzony przez drabinkę umiejscowioną w prawym górnym rogu sceny. W parze ist-
nieje bardzo dużo miejsc o skokowej zmianie dysparycji umieszczonych głównie na
brzegach obrazowanych stożków. Obecne są również obszary o bardzo małym stop-
niu pokrycia teksturą lub jej zupełnym braku (powierzchnia drabinki, powierzchnie
stożków).
167

“KonspPreamb” 2013/10/3 page 168 #171
6. Kryteria i metody oceny działania algorytmów
(a) Lewy obraz pary stereoskopowej „Cones” (b) Prawy obraz pary stereoskopowej „Cones”
(c) Wzorcowa mapa dysparycji (d) Regiony mapy dysparycji określone wg.Middlebury Stereo Vision
Rys. 6.3. Testowa para stereoskopowa „Cones” (a) i (b) wraz z wzorcową mapą dys-parycji (c) oraz regionami dysparycji określonymi według projektu Middlebury
Stereo Vision (d). Kolor biały – obszar umożliwiający znalezienie jednoznacz-nego dopasowania, kolor czarny – region przesłoniętych pikseli, kolor szary –
regiony nieciągłości dysparycji.
6.3.4. Para stereoskopowa „Teddy”
Para stereoskopowa „Teddy” jest przedstawiona na rys. 6.4a i 6.4b. Jej nazwa
pochodzi prawdopodobnie od pluszowych zabawek widocznych w obrazach two-
rzących tę parę. Para ta pochodzi ze zbioru par udostępnionego w projekcie Mid-
dlebury Stereo Vision. Obrazy tworzące parę mają rozmiar 450× 375 pikseli. Dys-
parycja zmienia się w szerokim przedziale wartości wynoszącym [0, 64] pikseli.
168

“KonspPreamb” 2013/10/3 page 169 #172
6. Kryteria i metody oceny działania algorytmów
(a) Lewy obraz pary stereoskopowej „Teddy” (b) Prawy obraz pary stereoskopowej „Teddy”
(c) Wzorcowa mapa dysparycji (d) Regiony mapy dysparycji określone wg.Middlebury Stereo Vision
Rys. 6.4. Testowa para stereoskopowa „Teddy” (a) i (b) wraz ze wzorcową mapądysparycji (c) oraz regionami dysparycji określonymi przez Middlebury Stereo
Vision (d). Kolor biały – region w którym możliwe jest jednoznaczne dopaso-wanie pikseli, kolor czarny – region pikseli przesłoniętych, kolor szary – region
gwałtownych zmian wartości dysparcji.
W celu przedstawienia mapy dysparycji jako obrazu w skali szarości, wartości
dysparycji mnożone są przez 4. Para stereoskopowa „Teddy” jest złożoną sceną za-
równo ze względu na przedmioty tworzące scenę jak i duży zakres dopuszczalnych
wartości dysparycji. W obrazach znajdują się zarówno duże skośne płaszczyzny
o liniowej zmianie wartości dysparycji (dach domku), jak również nieregularna
płaszczyzna tworzona przez materiał umieszczony po lewej stronie obrazu. Obec-
ne są również płaszczyzny walcowe tworzone przez zabawki. Obrazowana scena
zawiera dużą liczbę detali tworzonych przez liście kwiatu w prawym dolnym rogu
169

“KonspPreamb” 2013/10/3 page 170 #173
6. Kryteria i metody oceny działania algorytmów
obrazów i wzór ściany w najdalszej płaszczyźnie obrazu. W obrazach widoczne
są obszary o zupełnym braku tekstury, jak również obszary o dobrym pokryciu
teksturą.
Przedstawiony zbiór obrazów par stereoskopowych wykorzystany został jako
zbiór testowy umożliwiający przeprowadzenie badań eksperymentalnych algoryt-
mów dopasowania pary stereoskopowej. W czasie prowadzenia badań dla obrazów
zakłóconych obrazy testowe były sztucznie zakłócane szumem o zadanej charak-
terystyce. W dalszej części rozdziału omówione zostaną zakłócenia szumowe, dla
których przeprowadzone zostały badania eksperymentalne.
6.4. Charakterystyka zakłóceń szumowych
Pod pojęciem szumu rozumie się zazwyczaj obecność dodatkowych elementów
w obrazie, zazwyczaj niepożądanych i przeszkadzających w prawidłowym rozpo-
znawaniu, przetwarzaniu i interpretacji danych użytecznych składających się na ob-
raz. Zakłócenia szumowe występują praktycznie zawsze w czasie akwizycji i prze-
twarzania obrazów. Ich źródłem są zarówno czynniki zewnętrzne, np. zmienność
oświetlenia w czasie akwizycji obrazów sceny, jak i czynniki wynikające z za-
sad działania urządzeń elektronicznych służących do akwizycji obrazów, np. szum
kwantowania.
Właściwości zakłóceń szumowych obecnych w obrazach charakteryzowane są
zazwyczaj poprzez ich cechy statystyczne. W niniejszej pracy przeanalizowany zo-
stał wpływ czterech rodzajów zakłóceń szumowych na wyniki otrzymywane za
pomocą różnych algorytmów dopasowania pary stereoskopowej. Poniżej zostaną
omówione modele tych zakłóceń.
6.4.1. Podstawowe modele szumu
Jednym z ogólnych modeli szumu jest szum addytywny [38], który może być
modelowany jako niezależna addytywna składowa obrazu. W ogólnym modelu szu-
mu addytywnego przyjmuje się, że wartości szumu opisane są przez pewną zmien-
ną losową o wartościach niezależnych od wartości jasności pikseli obrazu. W przy-
padku, gdy składowa szumowa opisana jest statystycznym rozkładem normalnym,
model ten jest popularnym modelem szumu cieplnego urządzeń elektronicznych
występującego praktycznie w każdym urządzeniu elektronicznym [283].
170

“KonspPreamb” 2013/10/3 page 171 #174
6. Kryteria i metody oceny działania algorytmów
Ogólny model szumu addytywnego wyraża się zależnością:
Ina= I (i, j) + na (i, j) (6.1)
gdzie Ina(i, j) jest jasnością piksela obrazu I położonego na pozycji o współrzęd-
nych (i, j) zakłóconą addytywną składową szumową na (i, j), natomiast I (i, j) jest
jasnością piksela obrazu bez składowej szumowej. Wartości jasności pikseli obrazu
bez zawartości szumu I (i, j) oraz sygnał szumu na (i, j) są zmiennymi niezależny-
mi.
Ponieważ szum addytywny nie jest wystarczający do opisu wszystkich zakłó-
ceń występujących w obrazach, bardzo często stosowany jest drugi ogólny model
szumu nazywany szumem multiplikatywnym [284]. Model szumu multiplikatywne-
go znajduje zastosowanie m.in. w obrazach radarowych uzyskiwanych za pomocą
techniki SAR (ang. Synthetic Aperture Radar) [285] oraz w obrazowaniu medycz-
nym, a szczególnie w obrazowaniu ultrasonograficznym [286, 287].
Najbardziej charakterystyczną cechą szumu multiplikatywnego jest brak nieza-
leżności składowej szumowej od wartości jasności pikseli tworzących obraz. Skła-
dowa szumowa nm (i, j) może być również modelowana różnymi rozkładami pro-
babilistycznymi, ale wartość szumu zawsze zależy od wartości jasności pikseli two-
rzących obraz użyteczny. Ogólny model szumu multiplikatywnego wyraża się wzo-
rem:
Inm= I (i, j) · nm (i, j) (6.2)
gdzie Inm(i, j) jest wartością jasności piksela położnego na pozycji określonej przez
współrzędne (i, j) obrazu zniekształconego przez szumową składową multiplika-
tywną nm (i, j), natomiast I (i, j) jest jasnością piksela obrazu nie zawierającego
zakłóceń szumowych.
Często do zakłóceń obecnych w obrazie nie można dopasować wyłącznie jed-
nego z powyższych modeli szumu, tzn. zakłócenia te nie mogą być modelowane
dokładnie ani szumem addytywnym ani multiplikatywnym. Stąd najbardziej ogól-
ny model szumu zawiera obydwie składowe. Poprzez dobór odpowiednich modeli
statystycznych składowych szumu model ten można dopasować do bardziej złożo-
nych zakłóceń.
171

“KonspPreamb” 2013/10/3 page 172 #175
6. Kryteria i metody oceny działania algorytmów
Model zakłóceń szumowych uwzględniających zarówno składową addytywną
jak i multiplikatywną określony jest wyrażeniem:
In (i, j) = I (i, j) · nm (i, j) + na (i, j) (6.3)
gdzie: nm (i, j) jest zależną statystycznie od zawartości obrazu multiplikatywną
składową szumu, natomiast na (i, j) jest niezależną adddytywną składową szumu.
Podobnie jak poprzednio I (i, j) określa wartość jasności piksela obrazu nie zakłó-
conego, podczas gdy In (i, j) jest jasnością piksela obrazu obarczoną obydwoma
zakłóceniami szumowymi.
Powyższe proste modele zawierają jedynie zakłócenia liniowe. Przykładem szu-
mu, który nie może być opisany tymi modelami jest szum impulsowy [288], którego
szczególny przypadek został omówiony w punkcie 6.4.6.
6.4.2. Miary szumu zawartego w obrazie
Miary zawartości szumu oraz innych niepożądanych składowych w obrazie są
jednym z przedmiotów dyskusji w obszarze cyfrowego przetwarzania obrazów.
Dyskusja ta jest wynikiem chęci znalezienia takiej miary, która odpowiadałaby su-
biektywnym odczuciom człowieka dotyczącym zniekształcenia obrazu [289, 290,
291]. Z drugiej strony w literaturze podawanych jest wiele miar umożliwiających
numeryczne określenie wartości zniekształcenia obrazu [292]. Jedną z najbardziej
znanych, powszechnie akceptowaną i wykorzystywaną miarą, która została wyko-
rzystana również w tej pracy, jest miara określona przez stosunek sygnału do szumu
SNR (ang. Signal to Noise Ratio) [293, 294]. Miarę tę definiuje się w następujący
sposób: jeżeli I (i, j) jest wartością jasności piksela rozważanego obrazu cyfrowe-
go, natomiast In (i, j) jest jasnością tego piksela zakłóconą w wyniku wystąpienia
w obrazie pewnego szumu lub zakłóconego w wyniku przeprowadzenia pewnej
operacji przetwarzania obrazu, np. filtracji to stosunek sygnału do szumu SNR wy-
rażony w dB określony jest wyrażeniem:
SNR = 10 log10
M∑
i=1
N∑
j=1
[
I (i, j)]2
M∑
i=1
N∑
j=1
[
I (i, j) − In (i, j)]2
(6.4)
172

“KonspPreamb” 2013/10/3 page 173 #176
6. Kryteria i metody oceny działania algorytmów
gdzie M i N określają rozmiary obrazu wyrażone w pikselach, natomiast (i, j) okre-
śla położenie piksela w obrazie.
W niniejszej pracy miara SNR (6.4) została użyta do określenia zawartości szu-
mów, dla których wykonane zostały badania algorytmów dopasowania pary stereo-
skopowej, oprócz szumu impulsowego typu „sól i pieprz”. W przypadku zakłóce-
nia obrazu tego typu szumem miara SNR wydaje się być bardzo mało intuicyjna
i dodatkowo, ze względu na skalę logarytmiczną, wykazuje zbyt małą czułość.
Dla określenia zawartości zakłócenia obrazu szumem typu „sól i pieprz” uży-
ta została prosta miara procentowa zdefiniowana jako liczba zakłóconych pikseli
zawartych w obrazie w stosunku do liczby wszystkich pikseli w obrazie. Zgodnie
ze specyfiką tego szumu jasność piksela może być zmieniona tylko do wartości
minimalnej lub maksymalnej (por. p. 6.4.6) i z tego względu prostszym i wygod-
niejszym rozwiązaniem jest podanie procentowej liczby pikseli, które uległy zakłó-
ceniu.
W przypadku szumu „sól i pieprz” miara zawartości szumu w obrazie będzie
oznaczana SP i obliczana ze wzoru:
SP =Ls
N · M · 100% (6.5)
gdzie Ls jest liczbą zakłóconych pikseli.
6.4.3. Szum addytywny o rozkładzie normalnym
Szum o normalnym (gaussowskim) rozkładzie prawdopodobieństwa jest bar-
dzo często stosowanym modelem zakłóceń szumowych. W dziedzinie przetwarza-
nia obrazów znajduje zastosowanie jako model niemożliwych do uniknięcia addy-
tywnych szumów cieplnych urządzeń elektronicznych, model statystycznej niesta-
bilności zliczania fotonów w przetwornikach obrazowych, a także model probabi-
listyczny szumu ziarnistego (ang. grain noise) [283].
W przypadku modelowania addytywnego szumu o rozkładzie normalnym przyj-
muje się, że sygnał użyteczny zostaje zakłócony pewną losową wielkością, której
funkcja gęstości prawdopodobieństwa w przypadku jednowymiarowym ma postać:
p (x) =1
σ√
2πexp
− (x − µ)2
2σ2 (6.6)
173
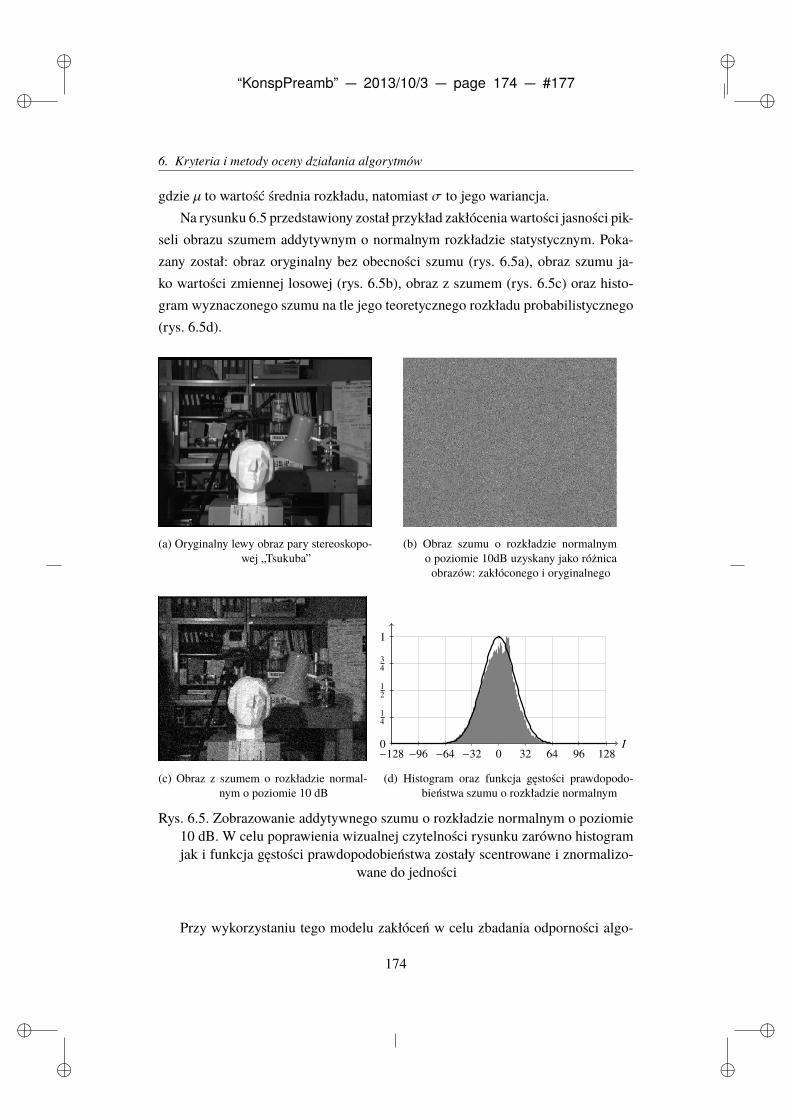
“KonspPreamb” 2013/10/3 page 174 #177
6. Kryteria i metody oceny działania algorytmów
gdzie µ to wartość średnia rozkładu, natomiast σ to jego wariancja.
Na rysunku 6.5 przedstawiony został przykład zakłócenia wartości jasności pik-
seli obrazu szumem addytywnym o normalnym rozkładzie statystycznym. Poka-
zany został: obraz oryginalny bez obecności szumu (rys. 6.5a), obraz szumu ja-
ko wartości zmiennej losowej (rys. 6.5b), obraz z szumem (rys. 6.5c) oraz histo-
gram wyznaczonego szumu na tle jego teoretycznego rozkładu probabilistycznego
(rys. 6.5d).
(a) Oryginalny lewy obraz pary stereoskopo-wej „Tsukuba”
(b) Obraz szumu o rozkładzie normalnymo poziomie 10dB uzyskany jako różnicaobrazów: zakłóconego i oryginalnego
(c) Obraz z szumem o rozkładzie normal-nym o poziomie 10 dB
I−128 −96 −64 −32 0 32 64 96 1280
14
12
34
1
(d) Histogram oraz funkcja gęstości prawdopodo-bieństwa szumu o rozkładzie normalnym
Rys. 6.5. Zobrazowanie addytywnego szumu o rozkładzie normalnym o poziomie10 dB. W celu poprawienia wizualnej czytelności rysunku zarówno histogramjak i funkcja gęstości prawdopodobieństwa zostały scentrowane i znormalizo-
wane do jedności
Przy wykorzystaniu tego modelu zakłóceń w celu zbadania odporności algo-
174

“KonspPreamb” 2013/10/3 page 175 #178
6. Kryteria i metody oceny działania algorytmów
rytmów dopasowania obrazów pary stereoskopowej na ich obecność w obrazach,
do każdej wartości jasności piksela I pochodzącej z rozważanego obrazu doda-
wana była losowa wartość o rozkładzie (6.6) oraz zadanych wartościach µ i σ.
W przypadku, gdy wartość jasności piksela po zakłóceniu szumem addytywnym
przekraczała granice przedziału jasności obrazów reprezentowanych w skali sza-
rości [0, 255], była ona zaokrąglana do wartości granicznych 0 lub 255. Poziom
szumu równy 10 dB (por. rys. 6.5b i 6.5c) oznacza, że miara (6.4) zawartości tego
szumu w obrazie oryginalnym ma wartość 10 dB.
6.4.4. Szum addytywny o rozkładzie jednostajnym
Szum addytywny o rozkładzie jednostajnym jest bardzo często przyjmowany
jako model zakłóceń powstających w procesie kwantowania ciągłej zmiennej do
formy cyfrowej [283]. W dziedzinie przetwarzania obrazów zjawisko to zachodzi
najczęściej na etapie akwizycji obrazów, gdy ciągła funkcja jasności zapisywana
jest przez dyskretne wartości jasności pikseli tworzące obraz cyfrowy.
Rozkład prawdopodobieństwa szumu jednostajnego [295] opisany jest funkcją
gęstości prawdopodobieństwa:
p (x) =
0 dla x < a1
b − adla a 6 x 6 b
0 dla x > b
(6.7)
gdzie wartości parametrów a i b ustalają przedział przyjmowanych wartości na skali
szarości.
Przykład zakłócenia obrazu szumem o rozkładzie jednostajnym został przed-
stawiony na rys. 6.6. Rysunek 6.6a przedstawia oryginalny obraz. Na rys. 6.6b
przedstawiony został szum jako obraz w skali szarości, rys. 6.6c przedstawia obraz
z zawartym w nim szumem, natomiast rys. 6.6d prezentuje histogram szumu na tle
jego teoretycznego rozkładu probabilistycznego.
175

“KonspPreamb” 2013/10/3 page 176 #179
6. Kryteria i metody oceny działania algorytmów
(a) Oryginalny lewy obraz pary stereoskopo-wej „Tsukuba”
(b) Obraz szumu o rozkładzie jednostajnymo poziomie 10 dB otrzymany jako różni-ca obrazów: zakłóconego i oryginalnego
(c) Obraz „Tsukuba” zakłócony szumemo rozkładzie jednostajnym o poziomie
10 dB
I−128 −96 −64 −32 0 32 64 96 1280
14
12
34
1
(d) Histogram oraz funkcja gęstości prawdopodo-bieństwa szumu jednostajnego
Rys. 6.6. Zobrazowanie addytywnego szumu o rozkładzie jednostajnym o poziomie10dB. W celu poprawienia czytelności obrazu, zarówno histogram jak i funkcjagęstości prawdopodobieństwa zostały scentrowane i unormowane do wartości 1
6.4.5. Szum multiplikatywny
Szum multiplikatywny, nazywany szumem plamkowym (ang. speckle noise)
[296], jest najczęstszą wadą obrazów uzyskiwanych za pomocą systemów obrazo-
wania używających koherentnej demodulacji odbitej fali elektromagnetycznej lub
fal dźwiękowych. Dobrze znanymi przykładami tak uzyskiwanych obrazów są ob-
razy radarowe i sonarowe oraz medyczne obrazy ultradźwiękowe USG.
Do modelowania rozkładu szumu multiplikatywnego używane są rozkłady praw-
dopodobieństwa: Rayleigha, Gamma lub wykładniczy [297, 298, 283]. Czasami
176

“KonspPreamb” 2013/10/3 page 177 #180
6. Kryteria i metody oceny działania algorytmów
stosowanym rozkładem szumu multiplikatywnego jest szum o rozkładzie jedno-
stajnym określony wzorem (6.7). Taki model przyjmowany jest np. przy analizie
obrazów satelitarnych [299] i ze względu na prosty opis statystyczny został również
wykorzystany w tej pracy jako reprezentant multiplikatywnego typu zakłócenia ob-
razu opisanego wzorem (6.2).
(a) Oryginalny lewy obraz pary stereoskopo-wej „Tsukuba”
(b) Obraz szumu multiplikatywnego o pozio-mie 10 dB otrzymany jako różnica obra-
zów: zakłóconego i oryginalnego
(c) Obraz „Tsukuba” zakłócony szumemmultiplikatywnym o poziomie 10 dB
I−128 −96 −64 −32 0 32 64 96 1280
14
12
34
1
(d) Histogram oraz funkcja gęstości prawdopodo-bieństwa szumu multiplikatywnego
Rys. 6.7. Przykład zakłócenia obrazu szumem multiplikatywnym o poziomie 10dB. Histogram oraz funkcja gęstości prawdopodobieństwa zostały scentrowanei unormowane do wartości 1 w celu lepszej czytelności rysunku. Widocznajest zmiana kształtu histogramu ze względu na mnożenie wartości szumu przezjasność piksela, natomiast teoretyczny rozkład prawdopodobieństwa pozostajetaki sam, jak w przypadku zakłócenia adddytywnym szumem jednostajnym
Na rys. 6.7 przedstawiony został przykład zakłócenia obrazu szumem multi-
177

“KonspPreamb” 2013/10/3 page 178 #181
6. Kryteria i metody oceny działania algorytmów
plikatywnym. Rys. 6.7c przedstawia obraz z zawartym w nim szumem otrzyma-
ny w wyniku zastosowania wzoru (6.2). Na rys. 6.7b przedstawiony został obraz
szumu uzyskany jako różnica arytmetyczna między obrazem zakłóconym szumem
(rys. 6.7c), a obrazem oryginalnym (rys. 6.7a). Wyraźnie widać zależność wartości
szumu od wartości jasności pikseli obrazu. Rys. 6.7d przedstawia rozkład prawdo-
podobieństwa szumu na tle uzyskanego histogramu. Wyraźnie widać rozbieżność
pomiędzy teoretycznym rozkładem prawdopodobieństwa a wartościami histogra-
mu szumu, które uzależnione są od wartości jasności pikseli.
6.4.6. Szum impulsowy typu „sól i pieprz”
Szum impulsowy jest modelem szumu, który może powstawać w efekcie błę-
dów podczas transmisji obrazów, błędów przetworników A/C, a także w wyniku
uszkodzeń matryc urządzeń do akwizycji obrazów lub uszkodzeń komórek pamięci
urządzeń, w których obraz jest przechowywany [300, 301]. Wizualnie szum im-
pulsowy objawia się na obrazie w postaci ciemnych i jasnych pikseli widocznych
w obrazie. W przypadku granicznym, gdy wartości zakłóceń są równe zakresowi
dynamicznemu wartości jasności pikseli uwidacznia się on w postaci białych lub
czarnych pikseli.
Szum impulsowy należy do zakłóceń nieliniowych [288], tzn. takich, których
nie da się opisać za pomocą parametrów składowych na oraz nm w wyrażeniu (6.3).
Rozkład prawdopodobieństwa szumu impulsowego jest rozkładem dwupunktowym
[295]:
p (x) =
Pa dla x = a
Pb = 1 − Pa dla x = b
0 w przeciwnym przypadku
(6.8)
Jeżeli b > a, to poziom jasności b będzie widoczny w obrazie jako jasny piksel.
I odwrotnie, poziom jasności a będzie widoczny w obrazie o skali szarości jako
ciemny piksel. W przypadku, gdy jedno z prawdopodobieństw Pa lub Pb będzie
równe zero, w obrazie widoczne będą zakłócenia w postaci pikseli jednego rodzaju,
a rozkład prawdopodobieństwa (6.8) redukuje się do rozkładu jednopunktowego.
Najbardziej znanym typem szumu impulsowego jest szum znany pod nazwą
„sól i pieprz”. Szum tego rodzaju powstaje wtedy, gdy żadne z prawdopodobieństw
178

“KonspPreamb” 2013/10/3 page 179 #182
6. Kryteria i metody oceny działania algorytmów
rozkładu szumu impulsowego nie jest równe zero i ponadto mają one w przybli-
żeniu równe wartości. W przypadku, gdy wartości impulsów szumu przybierają
wartości graniczne, które w przypadku 8-bitowego obrazu wynoszą a = 0 (kolor
czarny) i b = 255 (kolor biały), obraz zostaje zakłócony czarnymi (pieprz) oraz
białymi (sól) pikselami.
(a) Oryginalny lewy obraz pary stereoskopo-wej „Tsukuba”
(b) Obraz szumu „sól i pieprz” o zawartości10%
(c) Lewy obraz pary stereoskopowej „Tsu-kuba” zakłócony szumem typu „sól
i pieprz” o zawartości 10%
I−32 0 32 64 96 128 160 192 224 2550
14
12
34
1
(d) Histogram oraz funkcja gęstości prawdopodo-bieństwa szumu typu „sól i pieprz”
Rys. 6.8. Zobrazowanie zakłócenia obrazu szumem typu „sól i pieprz” o zawartości10%. Podobnie jak w przypadku poprzednich zakłóceń zarówno histogram jak
i funkcja gęstości prawdopodobieństwa zostały unormowane do wartości 1.
Zakłócenie szumem typu „sól i pieprz” zilustrowane zostało na rys. 6.8, gdzie
rys.6.8b przedstawia obraz szumu w postaci białych (sól) i czarnych (pieprz) kro-
179

“KonspPreamb” 2013/10/3 page 180 #183
6. Kryteria i metody oceny działania algorytmów
pek. Rysunek 6.8c przedstawia obraz z zawartym w nim zakłóceniem, natomiast na
rys. 6.8d przedstawiony został histogram szumu na tle jego rozkładu teoretycznego.
6.5. Miary oceny jakości rozwiązań
Na podstawie przedstawionej wcześniej dyskusji można stwierdzić, że mimo
prób wprowadzenia jednolitej metodyki oceny rozwiązań algorytmów dopasowa-
nia pary stereoskopowej ciągle brak jest kryteriów oceny, które wyznaczałyby sze-
roko przyjęty standard.
W pracy skupiono się na możliwościach zastosowania elementów teorii zbio-
rów rozmytych w celu rozwiązania zadania dopasowania pary stereoskopowej.
W opracowanych algorytmach nie wykorzystano żadnych dodatkowych kroków
przetwarzania wstępnego obrazów, ani przetwarzania końcowego otrzymanych map
dysparycji w celu uzyskania poprawy otrzymywanych wyników. Celem przeprowa-
dzonych badań było uzyskanie odpowiedzi na pytanie, czy zastosowanie elementów
teorii zbiorów rozmytych w algorytmie dopasowania pary stereoskopowej pozwala
na uzyskanie innych wyników, niż wyniki otrzymywane za pomocą algorytmów,
w których nie wykorzystuje się tej teorii. Przeprowadzone badania umożliwiły po-
równanie opracowanych algorytmów z najbliższymi co do idei działania algoryt-
mami dopasowania wykorzystującymi obrazy w skali szarości. Aby jak najbardziej
zobiektywizować otrzymywane rezultaty przyjęte zostały takie miary, które w zało-
żeniu mają umożliwić obiektywne porównanie i ocenę otrzymywanych rozwiązań.
Starano się również zachować jak największą obiektywność uzyskiwanych wyni-
ków. Została ona osiągnięta poprzez zachowanie w implementacjach prezentowa-
nych algorytmów dokładnie takich samych warunków i stałości parametrów algo-
rytmów, jak również nie stosowanie dodatkowych kroków przetwarzania obrazów
wejściowych, ani też kroku końcowego przetwarzania mapy dysparycji.
Istotną częścią pracy jest również badanie jakości uzyskiwanych rozwiązań
w obecności zakłóceń szumowych. Aby uzyskać jakościowe i ilościowe wyniki,
poddano badaniom wszystkie algorytmy przy takich samych poziomach zakłóceń
obecnych w obrazach.
180

“KonspPreamb” 2013/10/3 page 181 #184
6. Kryteria i metody oceny działania algorytmów
6.5.1. Ocena efektywności algorytmów dopasowania cechami
W przypadku algorytmów dopasowania cechami najpierw badana była liczba
pikseli zaklasyfikowanych przez algorytm jako piksele charakterystyczne obrazu
i określana była procentowa liczba wykrytych pikseli charakterystycznych w sto-
sunku do wszystkich pikseli składających się na obraz. Jeżeli Pch jest liczbą wy-
krytych pikseli charakterystycznych, to ich procentowa zawartość w obrazie była
obliczana ze wzoru:
Lch =Pch
M · N · 100% (6.9)
gdzie M i N są rozmiarami obrazu wyrażonymi w liczbach pikseli.
W drugim kroku badana była zdolność algorytmu do prawidłowego dopasowa-
nia pikseli zaklasyfikowanych jako piksele charakterystyczne. W tym celu, po wy-
znaczeniu zbioru pikseli charakterystycznych, dla każdego elementu tego zbioru
dokonywane było sprawdzenie, czy jest on prawidłowo dopasowany. Aby spraw-
dzić prawidłowość dopasowania obliczany był błąd bezwzględny między wyzna-
czoną wartością dysparycji dch(i, j) piksela charakterystycznego położonego na po-
zycji obrazu o współrzędnych (i, j) a wzorcową wartością tej dysparycji dre f
ch(i, j)
określoną na podstawie wzorcowej mapy dysparycji. Inaczej mówiąc, dla każdego
piksela zaklasyfikowanego przez algorytm jako piksel charakterystyczny obliczane
były wartości błędów bezwzględnych:
Err (i, j) = |dch (i, j) − dre f
ch(i, j)| (6.10)
Przyjęto założenie, że piksel o współrzędnych (i, j) jest prawidłowo dopasowa-
ny, jeśli wartość dch(i, j) dysparycji obliczanej różni się od wartości dre f
ch(i, j) dys-
parycji wzorcowej co najwyżej o 1, tzn. jeśli błąd bezwzględny Err(i, j) 6 1. Jest to
założenie powszechnie przyjmowane w literaturze [302, 303, 304, 305, 306] i wy-
nika z faktu, że dysparycja jest w praktyce obliczana z dokładnością do jednego pik-
sela z uwagi na cyfrową reprezentację obrazów w formie liczb stałoprzecinkowych,
mimo że w istocie rzeczy wartości dysparycji mogą zmieniać się w sposób ciągły,
szczególnie w przypadku obecności skośnych powierzchni w obrazowanej scenie.
Inny sposób dyskretyzacji obrazów lub na przykład zastosowanie przetworników
A/C o innej rozdzielczości może spowodować, że wyznaczone wartości dysparycji
są ułamkowe. W przyjętym sposobie reprezentacji obrazu wartości te są następnie
odpowiednio zaokrąglane.
181

“KonspPreamb” 2013/10/3 page 182 #185
6. Kryteria i metody oceny działania algorytmów
Oznaczając przez Dch = (i, j) : Err(i, j) 6 1 zbiór prawidłowo dopasowanych
pikseli spośród pikseli zaklasyfikowanych przez algorytm jako piksele charaktery-
styczne, definiujemy ich procentowy udział w obrazie jako:
Lch =Dch
M · N · 100% (6.11)
gdzie Dch jest licznością zbioru Dch. Procentowy udział wykrytych i prawidłowo
dopasowanych przez algorytm pikseli charakterystycznych w całym obrazie, okre-
ślony wzorem (6.11), przyjęto w pracy za miarę efektywności algorytmu dopaso-
wania cechami.
6.5.2. Ocena efektywności algorytmów dopasowania obszarami
Analogiczne kryterium oceny efektywności algorytmu przyjęto w przypadku
algorytmów dopasowania obszarami. Także w tym przypadku wykorzystywana jest
wzorcowa mapa dysparycji, na podstawie której dla każdego piksela (i, j) obrazu
wyznaczany jest lokalny błąd bezwzględny dopasowania piksela:
Err (i, j) = |d (i, j) − dre f (i, j)| (6.12)
gdzie d(i, j) jest wartością dysparycji piksela (i, j) obliczona przez algorytm, zaś
dre f (i, j) jest wartością dysparycji tego piksela określoną na podstawie dostępnej
wzorcowej mapy dysparycji.
Błąd globalny algorytmu dopasowania
Jako prostą, naturalną miarę globalną jakości rozwiązań otrzymywanych za po-
mocą algorytmów dopasowania obszarami przyjęto liczbę prawidłowo dopasowa-
nych pikseli wyrażoną procentowo w stosunku do wszystkich pikseli składających
się na obraz. Jeżeli przez D = (i, j) : Err(i, j) 6 1 oznaczymy zbiór prawidłowo
dopasowanych pikseli, to miara ta jest określona wzorem:
Ld =D
M · N · 100% (6.13)
182

“KonspPreamb” 2013/10/3 page 183 #186
6. Kryteria i metody oceny działania algorytmów
Przyjęte tu zostało założenie, analogiczne jak w przypadku algorytmów dopaso-
wania cechami, że wartość dysparycji różniąca o się co najwyżej o 1 od wartości
wzorcowej jest wartością prawidłową.
Oszacowanie spójności mapy dysparycji
Ważną cechą otrzymywanych map dysparycji jest ich wypełnienie rozumia-
ne jako liczba prawidłowych dopasowań. Zazwyczaj jednak w mapie dysparycji
otrzymanej w wyniku działania algorytmu pozostają błędne wartości dysparycji.
Sytuacja taka ma na przykład miejsce przy próbie znalezienia wartości dysparycji
dla regionów obrazu o zupełnym braku tekstury. Miara opisana w tym punkcie
ma za zadanie dostarczyć numerycznego oszacowania liczby błędnych dopasowań.
Przy czym przyjęto założenie, że miara ta będzie pozwalała na oszacowanie liczby
błędnych dopasowań pozostających w swoim bliskim sąsiedztwie, tworzących gru-
py błędnie obliczonych wartości dysparycji. Grupy błędnych dopasowań określane
będą jako błędne izolowane dopasowania.
Miarę tę można określić przez liczbę wartości dysparycji w relatywnie „ma-
łych” regionach, w których wartości dysparycji różnią się od sąsiednich regionów
w sposób „znaczący”. Grupa wartości dysparycji znacznie odbiegająca wartością
od wartości pozostających w jej sąsiedztwie ma prawdopodobnie błędnie obliczone
wartości.
W celu oszacowania liczby pikseli o błędnie znalezionych wartościach dyspa-
rycji, które dodatkowo pozostają w grupie, wykorzystany został prosty algorytm
kolorowania plam (ang. blob coloring) [307].
Jeżeli przez Dizol = (i, j)izol oznaczymy zbiór pikseli o dysparycjach okre-
ślonych przez algorytm 6.1 jako błędne izolowane dopasowania, to procentowa
zawartość błędnych izolowanych dopasowań w całej mapie dysparycji określona
jest wzorem:
Lizol =Dizol
M · N · 100% (6.14)
Oszacowanie dokładności mapy dysparycji
W pracy badano również dokładność rozwiązań otrzymanych za pomocą róż-
nych algorytmów dopasowania obrazów pary stereoskopowej. Jako miarę dokład-
ności przyjęto unormowany empiryczny błąd średniokwadratowy RMSE (ang. Root
183

“KonspPreamb” 2013/10/3 page 184 #187
6. Kryteria i metody oceny działania algorytmów
Algorytm 6.1 Kolorowanie plam
Dane wejściowe: Obliczona mapa dysparycji d o rozmiarach M na N
Dane wejściowe: Okno sąsiedztwa o rozmiarach x_okna, y_okna orazzadany_prog
x_brzeg = f loor(x_okna/2)y_brzeg = f loor(y_okna/2)obszar = x_okna ∗ y_okna
for i = x_brzeg+ 1 to M − x_brzeg do
for j = y_brzeg+ 1 to N − y_brzeg do
dla danego położenia (i, j) okna sumuj wartości dysparycji znajdującychsię w oknie, wynik zapisz jako suma
oblicz średnią wartość dysparycji w oknie srednia = suma/obszar
oblicz różnicę R (i, j) = abs (d (i, j) − srednia)if R(i, j) > zadany_prog then
oznacz bieżącą wartość dysparycji d(i, j) jako izolowaną dizol (i, j)end if
end for
end for
Zwróć: Mapę dysparycji z błędnie wyznaczonymi izolowanymi dopasowaniamidizol
Mean Square Error), który obliczany był ze wzoru:
RMSE =
√
√
√
1M · N
M−1∑
i=0
N−1∑
j=0
[
d (i, j) − dre f (i, j)]2 (6.15)
gdzie d(i, j) jest obliczoną wartością dysparycji piksela położonego na pozycji
(i, j), dre f (i, j) jest wartością wzorcową dysparycji tego piksela, zaś M i N są roz-
miarami mapy dysparycji.
184

“KonspPreamb” 2013/10/3 page 185 #188
Rozdział 7
Wyniki badań eksperymentalnych
W rozdziale przedstawiono wyniki weryfikacji eksperymentalnej opracowa-
nych algorytmów dopasowania pary stereoskopowej. Materiałem testowym był
zbiór czterech wzorcowych par stereoskopowych opisanych w poprzednim roz-
dziale. Zbadano między innymi efektywność zaproponowanego algorytmu dopa-
sowania cechami wykorzystującego w swoim działaniu opracowany przez auto-
ra detektor krawędzi oparty na rozmytej relacji podobieństwa. Otrzymane wyniki
porównano z wynikami uzyskanymi za pomocą algorytmu dopasowania cechami
Marra-Poggio-Grimsona (MPG). Przedstawiono również wyniki testów zapropo-
nowanych algorytmów dopasowania pary stereoskopowej obszarami, działających
na reprezentacjach obrazów w dziedzinie zbiorów rozmytych i w dziedzinie in-
tuicjonistycznych zbiorów rozmytych. Uzyskane wyniki porównano z wynikami
otrzymanymi za pomocą algorytmów dopasowania obszarami działającymi w dzie-
dzinie jasności pikseli. W drugiej części rozdziału omówiono wyniki testowania
opracowanych algorytmów w przypadku występowania w obrazach pary stereo-
skopowej różnego rodzaju zakłóceń szumowych.
Wyniki badań przedstawiono w formie umożliwiającej łatwe i poglądowe po-
równanie zaproponowanych algorytmów z algorytmami literaturowymi. Wszyst-
kie otrzymane rezultaty opatrzone zostały komentarzami i nasuwającymi się na ich
podstawie wnioskami. Rozdział kończy krótkie podsumowanie przeprowadzonych
eksperymentów.
7.1. Założenia oceny efektywności działania algorytmów
dopasowania pary stereoskopowej
Prezentowane w tym rodziale rezultaty weryfikacji eksperymentalnej działania
zaproponowanych algorytmów dopasowania pary stereoskopowej zostały otrzyma-
ne w wyniku zastosowania każdego z tych algorytmów w odniesieniu do czterech
wytypowanych wcześniej wzorcowych par stereoskopowych. We wszystkich algo-
rytmach przedziały poszukiwania wartości dysparycji dla danej pary stereoskopo-
185

“KonspPreamb” 2013/10/3 page 186 #189
7. Wyniki badań eksperymentalnych
wej zostały ograniczone do wartości określonych indywidualnie dla danej wzorco-
wej pary stereoskopowej w punkcie 6.3.
Podczas obliczania wyników numerycznych nie były uwzględniane wartości
dysparycji dla pikseli znajdujących się w przesłoniętych regionach obrazów pary
stereoskopowej. Regiony przesłonięte były określone zgodnie z maskami je wy-
znaczającymi przedstawionymi w punkcie 6.3. W regionach tych prawidłowe do-
pasowania i tym samym prawidłowe wartości dysparycji nie mogą zostać znale-
zione bez zastosowania dodatkowych kroków wykonywanych w czasie działania
algorytmu lub implementacji metod wykrywania takich regionów. Gdyby regiony
przesłonięte nie były wykluczone a priori, wówczas w wyniku badania algorytmów
nie zawierających takich kroków, a tylko takie algorytmy były badane w niniejszej
pracy, otrzymywane wyniki zostałby obciążone dodatkowymi błędnymi wartościa-
mi utrudniającymi wykonanie analizy rozwiązań i ich obiektywne porównanie.
Regiony obrazów, w których występują duże zmiany wartości dysparycji, okre-
ślone dla badanych par stereoskopowych przez maski opisane w punkcie 6.3, trakto-
wane były podczas obliczeń tak samo jak obszary, w których istnieje jednoznaczne
dopasowanie pikseli. Ponieważ dla pikseli położonych w tych regionach wartości
dysparycji mogą zostać znalezione, w czasie prowadzonych eksperymentów nie
zostały one wyróżnione jako obszary specjalne obrazów, ani też nie podlegały spe-
cjalnemu traktowaniu.
W wynikach nie uwzględniano wartości dysparycji określonych dla pikseli znaj-
dujących się na brzegach obrazów w pasach o szerokości równej rozmiarowi po-
łowy okna przeszukiwania. Wiąże się to z ogólnym problemem implementacji al-
gorytmów przetwarzania obrazów wynikającym z faktu, że ich przetwarzanie na
brzegach jest bardzo trudne i wymaga zastosowania specjalnych metod. W prezen-
towanej pracy postanowiono pominąć te piksele, a wyniki przedstawiać tylko dla
obszarów w pełni obejmowanych przez okna. W konsekwencji, podczas oblicza-
nia wielkości wyrażonych jako miary procentowe pikseli w obrazie uwzględniano
zmniejszenie rozmiarów obrazów o pasy o szerokości równej połowie rozmiaru
okna przeszukiwania.
Ważnym założeniem, jakie przyjęto przy ocenie efektywności działania algo-
rytmów, jest także to, że otrzymane wyniki obliczeń są prezentowane jako średnie
arytmetyczne rezultatów uzyskanych dla każdej pary stereoskopowej oddzielenie.
Prezentacja wyników w tej formie pozwoliła na uniezależnienie się od zawarto-
186

“KonspPreamb” 2013/10/3 page 187 #190
7. Wyniki badań eksperymentalnych
ści jednej sceny przedstawionej na poszczególnych obrazach pary stereoskopowej,
jak również od cech charakterystycznych danej pary stereoskopowej. Umożliwiło
to równocześnie uogólnienie analizy i bardziej ogólną ocenę wyników osiąganych
przez różne algorytmy dopasowania dla różnych obrazów par stereoskopowych.
7.2. Podstawowe parametry działania algorytmów
dopasowania cechami
W algorytmie MPG podstawowymi parametrami, które muszą zostać dobra-
ne w początkowej fazie implementacji algorytmu są: liczba filtrów LoG oraz roz-
miary masek zastosowanych filtrów (por. p. 3.4.1). W pracy założono, że liczba
filtrów LoG jest ustalona i równa 4. Liczba ta, przy braku innych przesłanek, zosta-
ła wybrana jako najczęściej przyjmowana w literaturze (por. rys. 7.1). Natomiast
rozmiary masek zastosowanych filtrów zostały dobrane w sposób doświadczalny.
Wybrane zostały takie rozmiary masek filtrów LoG, które dla badanej grupy par
stereoskopowych pozwoliły na uzyskiwanie najlepszych rozwiązań pod względem
zastosowanych miar ich oceny.
Podobna sytuacja ma miejsce w przypadku algorytmu dopasowania cechami
opartego o rozmyty detektor krawędzi, w którym należy dobrać rodzaj stosowa-
nej rozmytej relacji podobieństwa w algorytmie detekcji krawędzi oraz rozmiar
sąsiedztwa badanego piksela, które jest używane podczas detekcji krawędzi (por.
p. 5.8.3). Zdecydowano, że przy braku przesłanek teoretycznych umożliwiających
dobór tych parametrów algorytmu zostaną one dobrane na podstawie przeprowa-
dzonych doświadczeń z zastosowaniem różnych rozmytych relacji podobieństwa
i rozmiarów sąsiedztw. Do dalszych analiz wybrane zostały parametry pozwalają-
ce na uzyskiwanie najlepszych rozwiązań pod względem miar zastosowanych do
oceny jakości algorytmu.
Na rys. 7.1 przedstawione zostały wyniki badań algorytmu MPG o różnych roz-
miarach masek filtrów LoG. W załączonej tabeli poszczególne warianty algorytmu
różniące się rozmiarami masek oznaczono literami od A do J. Podano także numer
pozycji literatury, w której dany wariant algorytmu został opisany. Przedmiotem
obliczeń były średnie procentowe wartości liczby znalezionych charakterystycz-
nych, tj. krawędziowych pikseli obrazu oraz średnie procentowe wartości liczby
prawidłowo dopasowanych pikseli odniesione do wszystkich pikseli w obrazie.
187

“KonspPreamb” 2013/10/3 page 188 #191
7. Wyniki badań eksperymentalnych
Pierwszym wnioskiem, który może być wysnuty na podstawie otrzymanych re-
zultatów jest stwierdzenie, że zastosowanie dużych masek filtrów LoG daje gorsze
wyniki. Duże maski filtrów LoG zastosowane zostały w wariantach algorytmu C,
E i H, dla których otrzymano najmniejszą liczbę pikseli klasyfikowanych jako nale-
żące do krawędzi zawartych w obrazie. Zwiększenie rozmiarów masek filtrów LoG
prowadzi zatem do zmniejszenia liczby pikseli klasyfikowanych jako należące do
krawędzi w obrazie, co pociąga za sobą spadek liczby prawidłowo dopasowanych
pikseli. W efekcie zastosowania algorytmu J oraz A otrzymywane są najlepsze re-
zultaty zarówno pod względem liczby pikseli klasyfikowanych jako należące do
krawędzi, jak i pod względem liczby prawidłowo dopasowanych pikseli. Jako al-
gorytm do przeprowadzenia dalszych badań, a zarazem algorytm odniesienia do
zaproponowanego przez autora algorytmu dopasowania wykorzystującego rozmy-
tą relację podobieństwa w celu detekcji krawędzi zawartych w obrazie, wybrany
został wariant J algorytmu, pozwalający na uzyskanie najlepszych rezultatów na
testowanym zbiorze par stereoskopowych.
A B C D E F G H I J0
1
2
3
4
5
6
7
Algorytm
%pi
ksel
iobr
azu
Liczba pikseli krawędziowychLiczba pikseli dopasowanych
Alg. Rozmiar LoG Bib.A 17, 13, 9, 5 [310]B 33, 17, 9, 5 [310]C 72, 36, 18, 9 [311]D 35, 17, 9, 4 [312]E 105, 51, 27, 13 [313]F 63, 35, 17, 9 [314]G 35, 21, 17, 9 [315]H 81, 41, 21, 11 [316]I 35, 27, 21, 13 *J 13, 9, 5, 3 *
Rys. 7.1. Średnie procentowe wartości znalezionych charakterystycznych (krawę-dziowych) i prawidłowo dopasowanych pikseli dla poszczególnych wariantówalgorytmu MPG oraz oznaczenie algorytmów o określonych maskach filtrów
LoG wraz z numerem pozycji literaturowej, gdzie algorytm został opisany
W przypadku autorskiego algorytmu wykorzystującego detektor krawędzi opar-
ty o rozmytą relację podobieństwa, zastosowano dwa typy rozmytej relacji podo-
bieństwa: trójkątną i gaussowską (por. p. 4.5.1). Średnie procentowe liczby pikseli
obrazów określonych jako należące do krawędzi oraz średnie procentowe liczby
prawidłowo dopasowanych pikseli w przypadku trójkątnej relacji podobieństwa
188

“KonspPreamb” 2013/10/3 page 189 #192
7. Wyniki badań eksperymentalnych
przedstawione zostały na rys. 7.2a, zaś w przypadku gaussowskiej relacji podo-
bieństwa na rys. 7.2b. Dla każdego typu relacji podobieństwa przeprowadzone zo-
stały obliczenia z zastosowaniem dwóch rozmiarów sąsiedztw zawierających 8 i 24
pikseli.
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
0123456789
101112
Rozmiar okna korelacji [piks.]
%pi
ksel
iobr
azu
znalezionych; (8 piks. sąsiedz.)dopasowanych; (8 piks. sąsiedz.)znalezionych; (24 piks. sąsiedz.)dopasowanych; (24 piks. sąsiedz.)
(a) Trójkątna relacja podobieństwa
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
0123456789
101112
Rozmiar okna korelacji [piks.]
%pi
ksel
iobr
azu
znalezionych; (8 piks. sąsiedz.)dopasowanych; (8 piks. sąsiedz.)znalezionych; (24 piks. sąsiedz.)dopasowanych; (24 piks. sąsiedz.)
(b) Gaussowska relacja podobieństwa
Rys. 7.2. Średnie procentowe wartości znalezionych i prawidłowo dopasowanychkrawędziowych pikseli obrazu przy zastosowaniu trójkątnej (a) i gaussowskiej(b) rozmytej relacji podobieństwa w algorytmie wykrywania krawędzi oraz róż-nych rozmiarów sąsiedztwa względem rozmiarów okien referenycjnego i prze-
szukiwania
Z porównania otrzymanych wyników można zauważyć, że przy zastosowaniu
gaussowskiej relacji podobieństwa zarówno liczba pikseli określonych jako nale-
żące do krawędzi, jak i liczba prawidłowo dopasowanych pikseli jest około 1%
mniejsza, niż przy zastosowaniu trójkątnej relacji podobieństwa. Ze względu na
swój kształt rozmyta relacja podobieństwa typu gaussowskiego mniej różnicuje
wartości jasności pikseli w sąsiedztwie piksela, co zmniejsza zdolność algorytmu
do detekcji pikseli krawędziowych. Przekłada się to na mniejsza liczbę prawidłowo
dopasowanych pikseli w stosunku do trójkątnej relacji podobieństwa, w przypadku
której zdolność różnicowania wartości jasności pikseli jest zdecydowanie większa.
Wpływ rozmiaru sąsiedztwa zarówno na liczbę pikseli określanych jako nale-
żące do krawędzi w obrazach, jak i na liczbę prawidłowo dopasowanych pikseli jest
niewielki. Można jednak zauważyć, że ze zwiększeniem ilości informacji o poło-
189

“KonspPreamb” 2013/10/3 page 190 #193
7. Wyniki badań eksperymentalnych
żeniu danego piksela względem sąsiadów przez zwiększenie rozmiaru sąsiedztwa
badanego piksela osiągane są wyższe procentowe wartości zarówno wykrytych pik-
seli krawędziowych jak i ilości pikseli prawidłowo dopasowanych.
Ze względu na otrzymane wyniki do dalszych badań wybrany został algorytm
dopasowania wykorzystujący w kroku znajdowania pikseli charakterystycznych roz-
mytą relację podobieństwa kształtu trójkątnego przy ustalonym rozmiarze sąsiedz-
twa badanego piksela równym 24 piksele.
Rezultaty przeprowadzonych eksperymentów prowadzą do wniosku, że autor-
ski algorytm dopasowania punktów charakterystycznych opierający swoje działa-
nie o rozmyty detektor krawędzi pozwala na uzyskanie procentowo dwukrotnie
większej liczby zarówno pikseli klasyfikowanych jako charakterystyczne, jak i pik-
seli prawidłowo dopasowanych w porównaniu z algorytmem MPG.
W celu porównania efektywności wykrywania pikseli krawędziowych przez al-
gorytm oparty na rozmytym detektorze krawędzi oraz algorytm MPG oparty na
działaniu filtrów LoG, na tym samym materiale testowym przeprowadzono podob-
ne eksperymenty z zastosowaniem innych znanych i często wykorzystywanych de-
tektorów krawędzi. W wyniku zastosowania detektora Canny’ego, otrzymano śred-
nią procentową liczbę pikseli zaklasyfikowanych jako krawędziowe równą 9.94%.
Zastosowanie algorytmu detekcji krawędzi opartego o maskę Sobela dało wynik
4.24%, opartego o maskę Prewitta – 4.20%, natomiast opartego o krzyż Robertsa
– zaledwie 3.52%. Wytypowany wariant algorytmu detekcji krawędzi wykorzystu-
jący rozmytą relację podobieństwa ma zatem zdolność wykrywania pikseli krawę-
dziowych porównywalną z algorytmem Canny’ego, natomiast za pomocą pozosta-
łych typów detektorów uzyskuje się wyniki porównywalne z detektorem opartym
na filtrach LoG. Można więc powiedzieć, że w zastosowaniach, gdzie ważna jest
efektywność wykrywania pikseli należących do krawędzi, a takim jest przypadek
zagadnienia dopasowania pary stereoskopowej, lepszym wyborem jest zastosowa-
nie detektora krawędzi opartego o rozmytą relację podobieństwa.
7.3. Rozmiar okien w algorytmach dopasowania obszarami
W przypadku problemu dopasowania obrazów pary stereoskopowej obszara-
mi parametrami, które muszą zostać dobrane na samym początku implementacji
algorytmów dopasowania są rozmiar i kształt okien referencyjnego i przeszukiwa-
190

“KonspPreamb” 2013/10/3 page 191 #194
7. Wyniki badań eksperymentalnych
nia. W pracy w celu przeprowadzenia eksperymentów przyjęty został kwadratowy
kształt obu okien. Wybór ten był motywowany głównie popularnością kwadrato-
wego kształtu okien, jak również prostszą implementacją programową algorytmów
wykorzystujących taki kształt okien. Autor nie znalazł przesłanek przemawiają-
cych za doborem innego kształtu okien, choć intuicyjnie wydaje się, że zagadnie-
niem wartym przeprowadzenia badań jest wykorzystanie w algorytmie dopasowa-
nia również okien o kształcie prostokątnym.
Drugą istotną decyzją w przypadku próby implementacji algorytmów dopaso-
wania obszarami jest określenie rozmiarów okien. Optymalny rozmiar okien nie
powinien być zbyt mały, gdyż w takich oknach nie będzie wystarczającej informa-
cji potrzebnej do znalezienia odpowiadających sobie pikseli. Zbyt duży rozmiar
okien powoduje natomiast niepotrzebny wzrost kosztu obliczeniowego algorytmu,
a ponadto zmniejszenie rozróżnialności pikseli i spadek liczby prawidłowo wy-
znaczonych dopasowań ze względu na zbyt duże zróżnicowanie wartości jasności
pikseli obejmowanych przez okno.
W celu uzyskania przesłanek dotyczących doboru rozmiaru okien, przepro-
wadzone zostały obliczenia liczby prawidłowo dopasowanych pikseli dla różnych
rozmiarów okien i dla różnych klas algorytmów. Wyniki obliczeń przedstawione
zostały na rys. 7.3.
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
7273747576777879808182
Rozmiar okien [piks.]
%pi
ksel
iobr
azu
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące miary oparte o róż-nicę
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
7475767778798081
Rozmiar okien [piks.]
%pi
keli
obra
zu
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące miary oparteo kwadrat różnicy
Rys. 7.3. Średnie procentowe liczby prawidłowo dopasowanych pikseli w zależno-ści od rozmiarów okien referencyjnego i przeszukiwania, przy założeniu ich
jednakowych rozmiarów
Analizując wyniki przedstawione na rys.7.3a, można stwierdzić, że algorytmy
191

“KonspPreamb” 2013/10/3 page 192 #195
7. Wyniki badań eksperymentalnych
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
76
77
78
79
80
81
82
Rozmiar okien [piks.]
%pi
ksel
liob
razu
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące miary korelacyjne
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
78
79
80
81
82
83
Rozmiar okien [piks.]
%pi
ksel
iobr
azu
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące transformaty obra-zów
Rys. 7.3. Średnie procentowe liczby prawidłowo dopasowanych pikseli w zależno-ści od rozmiarów okien referencyjnego i przeszukiwania, przy założeniu ich
jednakowych rozmiarów (kontynuacja)
dopasowania obszarami wykorzystujące fuzzyfikację obrazów oraz miary oparte
o różnicę wartości jasności pikseli reprezentowanych w dziedzinie zbiorów rozmy-
tych i zbiorów IFS pozwalają na uzyskanie większej o kilka procent liczby prawi-
dłowo dopasowanych pikseli w całym zakresie rozmiarów badanych okien w po-
równaniu do algorytmu dopasowania obszarami działającego bezpośrednio w dzie-
dzinie jasności pikseli i wykorzystującego miarę SAD (por. p. 3.3.2). Lepszy wy-
nik, w sensie większej liczby prawidłowo dopasowanych pikseli, w zakresie małych
rozmiarów okien (do 13 × 13 pikseli), uzyskiwany jest jedynie w metodzie wyko-
rzystującej miarę z normalizacją wartości jasności pikseli ZSAD (por. p. 3.3.2).
Propozycją, która nasuwa się w tym momencie, jest przeprowadzenia podobnego
zabiegu normalizacyjnego w dziedzinie zbiorów rozmytych, co prawdopodobnie
pozwoliłoby na polepszenie wyników uzyskiwanych przez algorytmy działające
w dziedzinie zbiorów rozmytych.
W przypadku zastosowania miar opartych o kwadrat różnicy (rys. 7.3b) oraz
algorytmów wykorzystujących miary korelacyjne (rys. 7.3c) również zauważalna
jest kilkuprocentowa poprawa rezultatów osiąganych przez algorytmy działające
w dziedzinie zbiorów rozmytych w stosunku do ich odpowiedników działających
w dziedzinie jasności obrazów. Normalizacja pozwala na uzyskanie lepszych wy-
ników dla małych rozmiarów okien w przypadku zastosowania miary ZSSD (por.
p. 3.3.2). W przypadku algorytmów wykorzystujących miary korelacyjne osiągane
192

“KonspPreamb” 2013/10/3 page 193 #196
7. Wyniki badań eksperymentalnych
rezultaty są prawie takie same jak dla algorytmów wykorzystujących fuzzyfikację
obrazów i działających na ich reprezentacjach w dziedzinie zbiorów rozmytych. Na
wykresach prezentujących wyniki dla miar opartych o kwadrat różnic (rys. 7.3b),
jak również korelację (rys.7.3c), dostrzegalne jest pewne maksimum osiąganych
wyników względem rozmiarów zastosowanych w algorytmie okien.
Opierając się na wynikach przedstawionych na rys. 7.3, do dalszych obliczeń
zdecydowano się stosować algorytm o rozmiarach okien referencyjnego i przeszu-
kiwania równych 11 × 11 pikseli. Rozmiary te wydają się optymalnym wyborem
pod względem jakości uzyskiwanych rozwiązań rozumianej jako liczba prawidłowo
dopasowanych pikseli. Dla większych rozmiarów okien poprawa uzyskiwanych wy-
ników jest nieznaczna, albo wręcz następuje ich pogorszenie. Efekt osiągania pew-
nego optimum rozmiaru okien szczególnie dobrze widoczne jest na rys. 7.3c dla
przypadku algorytmów dopasowania wykorzystujących w swoim działaniu miary
korelacyjne.
W przypadku algorytmów wykorzystujących transformaty rankingowe oraz trans-
formatę CENSUS obrazów (por. p. 3.3.4 i p. 3.3.5) (rys. 7.3d) można zauważyć, że
największe liczby prawidłowo dopasowanych pikseli otrzymywane są dla algoryt-
mów z oknami o rozmiarach 5 × 5 oraz 7 × 7 pikseli. Widoczna jest również prze-
waga zastosowania rankingowej transformaty rozmytej, dla której osiągana jest naj-
większa liczba prawidłowo dopasowanych pikseli dla wszystkich rozmiarów okien
większych niż 9×9 pikseli. W dalszych analizach algorytmów dopasowania wyko-
rzystujących transformaty obrazów zdecydowano się jednak na stosowanie okien
o rozmiarach 11× 11 pikseli. Wybór ten był motywowany chęcią zachowania spój-
ności prezentowanych wyników w odniesieniu do pozostałych algorytmów dopa-
sowania, dla których również przyjęto rozmiary okien równe 11 × 11 pikseli.
W celu jakościowego porównania i zobrazowania osiąganych wyników, na
rys. 7.4 zaprezentowane zostały mapy dysparycji dla pary stereoskopowej „Tsuku-
ba” otrzymane w wyniku wykonania algorytmów działających z rozmiarami okien
równymi 11 × 11 pikseli. Wizualne porównanie map dysparycji przedstawionych
jako obrazy w skali szarości nie pozwala na obiektywne porównywanie osiąganych
wyników. Z tego względu mapy dysparycji dla pozostałych par stereoskopowych
nie będą prezentowane, ponieważ różnice wizualne, podobnie jak dla pary stereo-
skopowej „Tsukuba”, są na obrazach map dysparycji trudno zauważalne. Jako efekt
wszystkich pozostałych przeprowadzonych eksperymentów przedstawione zostaną
193

“KonspP
ream
b”
2013/1
0/3
page
194
#197
7.
Wyn
ikibadań
eksperym
enta
lnych
Wzorcowa SAD SSD NCC
RANK+SAD ZSAD ZSSD ZNCC
FuzzyRANK+SAD FUZZ+HAMM FUZZ+EUCL FUZZ+CORR
CENSUS IFS+HAMM IFS+EUCL IFS+CORR
Rys. 7.4. Wizualne porównanie map dysparycji otrzymanych jako efekt wykonania różnych algorytmów dopasowania dla parystereoskopowej „Tsukuba”
194

“KonspPreamb” 2013/10/3 page 195 #198
7. Wyniki badań eksperymentalnych
w związku z tym tylko wyniki numeryczne, bez wizualnej prezentacji otrzymywa-
nych map dysparycji.
Drugą miarą liczbową, która posłużyła do oceny jakości otrzymywanych roz-
wiązań jest zaproponowana w punkcie 6.5.2 liczba nieprawidłowych dopasowań,
które pozostają w swoim sąsiedztwie. Miara ta miała na celu numeryczne odzwier-
ciedlenie cechy spójności otrzymywanych map dysparycji. Wartości tej miary okre-
ślano przez zliczanie nieprawidłowych dopasowań występujących w wyznaczanych
mapach dysparycji, otrzymanych w wyniku wykonania algorytmu 6.1 opisanego
w punkcie 6.5.2. Na rys. 7.5 przedstawione zostały mapy dysparycji wyznaczo-
ne przez różne algorytmy dopasowania dla pary stereoskopowej „Venus”. Na ma-
pach tych zaznaczone zostały w postaci białych plam izolowane grupy błędnych
wartości dysparycji otrzymanych w wyniku zastosowania algorytmu 6.1. Również
w przypadku tej miary wizualne porównywanie osiąganych wyników nie pozwala
na sformułowanie jednoznacznych wniosków dotyczących jakości otrzymywanych
rozwiązań, aczkolwiek w tym przypadku mapy dysparycji są bardziej zróżnicowa-
ne. Z tego względu dalej będą prezentowane jedynie wyniki numeryczne dotyczące
tej miary.
195

“KonspP
ream
b”
2013/1
0/3
page
196
#199
7.
Wyn
ikibadań
eksperym
enta
lnych
Wzorcowa SAD SSD NCC
RANK+SAD ZSAD ZSSD ZNCC
FuzzyRANK+SAD FUZZ+HAMM FUZZ+EUCL FUZZ+CORR
CENSUS IFS+HAMM IFS+EUCL IFS+CORR
Rys. 7.5. Zobrazowanie grup błędnie dopasowanych pikseli, widocznych w postaci białych plam na przedstawionych mapachdysparycji, otrzymanych w efekcie wykonania różnych algorytmów dopasowania dla pary stereoskopowej „Venus”
196

“KonspPreamb” 2013/10/3 page 197 #200
7. Wyniki badań eksperymentalnych
Wyniki numeryczne obliczeń średnich procentowych liczb błędnych izolowa-
nych dopasowań zostały przedstawione na rys. 7.6. Dla trzech grup algorytmów wy-
korzystujących miary oparte o różnicę (rys.7.6a), kwadrat różnicy (rys.7.6b) oraz
korelację (rys.7.6c) otrzymywane wyniki są bardzo podobne.
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
48
12162024283236
Rozmiar okien [piks.]
%pi
ksel
iobr
azu
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące miary oparte o róż-nicę
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
48
12162024283236
Rozmiar okien [piks.]
%pi
ksel
iobr
azu
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące miary oparteo kwadrat różnicy
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
48
121620242832364044
Rozmiar okien [piks.]
%pi
ksel
iobr
azu
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące miary korelacyjne
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
56789
101112131415
Rozmiar okien [piks.]
%pi
ksel
iobr
azu
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące transformaty obra-zów
Rys. 7.6. Średnie procentowe liczby błędnych izolowanych dopasowań w zależno-ści od rozmiarów okien referenycjnego i przeszukiwania, przy założeniu ich
jednakowych rozmiarów
Niewielkie różnice są zauważalne dla małych rozmiarów okien, gdzie algoryt-
my dopasowania wykorzystujące miary znormalizowane ZSAD oraz ZSSD wy-
kazały znacząco większą tendencję do znajdowania błędnych dopasowań pozosta-
jących w swoim sąsiedztwie. Większe zróżnicowanie otrzymywanych rezultatów
widoczne jest w przypadku algorytmów wykorzystujących transformaty obrazów
(rys. 7.6d). Wyraźnie widać, że najbardziej spójna mapa dysparycji, o najmniejszej
197

“KonspPreamb” 2013/10/3 page 198 #201
7. Wyniki badań eksperymentalnych
liczbie błędnych izolowanych dopasowań, otrzymana została w efekcie zastosowa-
nia algorytmu wykorzystującego rozmytą transformatę rankingową.
Na podstawie wyników przedstawionych na rys. 7.6 można stwierdzić, że dla
wszystkich algorytmów średnia procentowa liczba błędnych izolowanych dopaso-
wań zmienia się nieznacznie dla okien o rozmiarach większych niż 11×11 pikseli.
Potwierdza to decyzję wyboru rozmiaru okien równego 11 × 11 pikseli jako roz-
miaru optymalnego dla algorytmów dopasowania obszarami w eksperymentach
przeprowadzonych dla badanego zbioru par stereoskopowych.
Ostatnią badaną miarą będącą wyznacznikiem jakości otrzymywanych rozwią-
zań jest empiryczny błąd średniokwadratowy RMSE zdefiniowany wzorem (6.15).
Średnie wartości błędu RMSE w zależności od rozmiarów okien zastosowanych
w algorytmie dopasowania przedstawione zostały na rys. 7.7.
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
2832364044485256
Rozmiar okien [piks.]
RM
SE
[pik
s.]
SADZSADFUZZ+HAMMIFS+HAMM
(a) Średnia wartość błędu RMSE dla algorytmówwykorzystujących miary oparte o różnicę
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
2832364044485256
Rozmiar okien [piks.]
RM
SE
[pik
s.]
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Średnia wartość błędu RMSE dla algoryt-mów wykorzystujących miary oparte o kwa-
drat różnicy
Rys. 7.7. Średnie wartości błędu RMSE w zależności od rozmiarów okien referen-cyjnego i przeszukiwania, przy założeniu ich jednakowych rozmiarów
Dla wszystkich badanych algorytmów widoczna jest tendencja do zmniejsza-
nia się tego błędu wraz ze wzrostem rozmiarów okien. Otrzymane wartości błędu
RMSE są bardzo zbliżone do siebie dla wszystkich badanych algorytmów dopaso-
wania. Jednakże w przypadku algorytmu wykorzystującego transformatę CENSUS
obrazów widoczny jest wyraźny spadek wartości błędu RMSE przy zwiększaniu
rozmiarów okien.
Większy rozmiar okna pozwala na uzyskanie wartości dysparycji bliższych
do wzorcowych wartości dysparycji określonych dla poszczególnych pikseli. Ze
198

“KonspPreamb” 2013/10/3 page 199 #202
7. Wyniki badań eksperymentalnych
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
303438424650545862
Rozmiar okien [piks.]
RM
SE
[pik
s.]
NCCZNCCFUZZ+CORRIFS+CORR
(c) Średnia wartość błędu RMSE dla algorytmówwykorzystujących miary korelacyjne
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
2426283032343638404244
Rozmiar okien [piks.]
RM
SE
[pik
s.]
RANK+SADFuzzyRANK+SADCENSUS
(d) Średnia wartość błędu RMSE dla algorytmówwykorzystujących transformaty obrazów
Rys. 7.7. Średnie wartości błędu RMSE w zależności od rozmiarów okien referen-cyjnego i przeszukiwania, przy założeniu ich jednakowych rozmiarów (konty-
nuacja)
względu na wartości błędu RMSE najkorzystniejszym wydaje się wybór okien
o dużych rozmiarach. Okna takie zwiększają jednak niepotrzebnie koszt oblicze-
niowy algorytmu, nie poprawiając jakości otrzymywanych map dysparycji zarówno
w sensie liczby prawidłowych dopasowań, jaki i spójności otrzymanej mapy dys-
parycji.
Ostatnim zagadnieniem, które zostanie przeanalizowane w tym punkcie, jest
złożoność obliczeniowa badanych algorytmów. Zagadnienie to jest bardzo istotne
w aspekcie praktycznych zastosowań algorytmów. W pracy złożoność algorytmów
oszacowana została poprzez zmierzenie czasu wykonania każdego algorytmu, któ-
ry jest często przyjmowanym wyznacznikiem złożoności obliczeniowej algorytmu
[138, 317, 318]. Średnie czasy wykonania algorytmów dla badanego zbioru par
stereoskopowych przedstawione zostały na rys. 7.8.
Na przedstawionych wykresach widoczny jest wzrost czasu wykonania algoryt-
mu wraz ze zwiększaniem rozmiarów okien zastosowanych w algorytmie. W przy-
padku algorytmów wykorzystujących fuzzyfikację obrazów i działanie w dziedzi-
nie zbiorów rozmytych, na wykresach nie uwzględniono czasu fuzzyfikacji obra-
zów, który jest stały i wynosi średnio 31 ms. Z tego względu czasy wykonania tych
algorytmów, jak ich i odpowiedników działających w dziedzinie jasności pikseli
są równe. Sytuacja ta zachodzi np. dla algorytmu wykorzystującego miarę SAD
w dziedzinie jasności pikseli i miarę Hamminga w dziedzinie zbiorów rozmytych
199

“KonspPreamb” 2013/10/3 page 200 #203
7. Wyniki badań eksperymentalnych
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
05
101520253035404550556065
Rozmiar okien [piks.]
Śre
dnic
zas
wyk
onan
ia[s
]
SADZSADFUZZ+HAMMIFS+HAMM
(a) Średni czas wykonania algorytmów wykorzy-stujących miary oparte o różnicę
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
05
1015202530354045
Rozmiar okien [piks.]
Śre
dnic
zas
wyk
onan
ia[s
]
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Średni czas wykonania algorytmów wykorzy-stujących miary oparte o kwadrat różnicy
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
05
10152025303540455055
Rozmiar okien [piks.]
Śre
dnic
zas
wyk
onan
ia[s
]
NCCZNCCFUZZ+CORRIFS+CORR
(c) Średni czas wykonania algorytmow wykorzy-stujących miary oparte o korelację
3×3
5×5
7×7
9×9
11×11
13×13
15×15
17×17
19×19
21×21
23×23
0
5
10
15
20
25
Rozmiar okien [piks.]
Śre
dnic
zas
wyk
onan
ia[s
]RANK+SADFuzzyRANK+SADCENSUS
Czas wykonania : 10
(d) Średni czas wykonania algorytmów wykorzy-stujących transformaty obrazów
Rys. 7.8. Średnie czasy wykonania algorytmów w zależności od rozmiarów okienzastosowanych w algorytmie dopasowania
(rys. 7.8a). Podobnie, jednakowe czasy wykonania mają algorytm wykorzystują-
cy miarę SSD i algorytm wykorzystujący miarę euklidesową w dziedzinie zbio-
rów rozmytych FUZZ+EUCL (rys. 7.8b), jak również algorytm wykorzystujący
miarę korelacji jasności pikseli NCC i algorytm wykorzystujący miarę korelacji
w dziedzinie zbiorów rozmytych FUZZ+CORR (rys. 7.8c). Wynika to z faktu, że po
obliczeniu wartości funkcji przynależności dla pikseli wyznaczanie odpowiednich
miar dopasowania przebiega identycznie zarówno w dziedzinie jasności pikseli, jak
i w dziedzinie zbiorów rozmytych.
Na rys. 7.8 nie uwzględniono również czasu fuzzyfikacji obrazów do dziedziny
intuicjonistycznych zbiorów rozmytych. Średni czas fuzzyfikacji obrazu do dzie-
dziny zbiorów IFS wynosił dla badanego zbioru par stereoskopowych 76 ms. Jak
200

“KonspPreamb” 2013/10/3 page 201 #204
7. Wyniki badań eksperymentalnych
wynika z rys. 7.8, algorytmy działające w dziedzinie zbiorów IFS cechuje dłuższy
czas wykonania ze względu na konieczność przeprowadzenia wszystkich obliczeń
na dwóch elementach liczbowych reprezentujących opis obrazu w dziedzinie zbio-
rów IFS.
Osobnego komentarza wymaga czas wykonania algorytmu opartego o trans-
formatę CENSUS, który jest bardzo długi (rys. 7.8d). Wynika to z przyjętej przez
autora implementacji algorytmu, w której nie zastosowano bitowego typu danych
w celu reprezentacji obliczanych wartości transformaty CENSUS. Wartości przyj-
mowane w wyniku zastosowania transformaty CENSUS były reprezentowane na
wbudowanym w język programowania typie całkowitym zawierającym 8 bitów, co
spowodowało znaczny wzrost czasu wykonywania algorytmu. Można przyjąć, że
obliczanie transformaty CENSUS z wykorzystaniem reprezentacji bitowej znaczą-
co przyśpieszyłoby działanie algorytmu wykorzystującego transformatę CENSUS.
Metoda ta nie została wykorzystana w przedstawionych algorytmach ze względu
na cechę programowania języka C++, w którym zrealizowano programowo przed-
stawiane algorytmy. W używanej wersji języka brak było wbudowanego bitowego
typu danych umożliwiającego łatwą reprezentację wartości transformaty CENSUS.
Ponieważ zagadnienie to potraktowane zostało jako złożony szczegół techniczny,
w celu reprezentacji wartości transformaty CENSUS zdecydowano się na wyko-
rzystanie wbudowanego w język całkowitego typu danych, co nie zmieniło cech
algorytmu dopasowania pary stereoskopowej, a znacząco ułatwiło programową re-
alizację algorytmu dopasowania pary stereoskopowej.
Czasy wykonania poszczególnych algorytmów dla przyjętych w dalszych eks-
perymentach rozmiarów okien 11×11 pikseli mogą być odczytane wprost z rys. 7.8.
Generalnie można stwierdzić, że zastosowanie fuzzyfikacji obrazów nie zwiększa
znacząco nakładów obliczeniowych poniesionych na wykonanie algorytmów do-
pasowania pary stereoskopowej działających w dziedzinie zbiorów rozmytych lub
intuicjonistycznych zbiorów rozmytych w porównaniu z algorytmami klasycznymi.
Są one zwiększone jedynie nieznacznie o stały czas fuzzyfikacji wynoszący, jak
podano powyżej 31 ms w przypadku fuzzyfikacji do dziedziny zbiorów rozmytych
i 76 ms do dziedziny IFS. Zastosowanie odpowiednich technik optymalizacji opro-
gramowania umożliwiłoby prawdopodobnie zmniejszenie niezbędnych nakładów
obliczeniowych, jednak przeprowadzenie takiej optymalizacji nie było celem auto-
201

“KonspPreamb” 2013/10/3 page 202 #205
7. Wyniki badań eksperymentalnych
ra, bowiem nie wpływa ono na ogólną interpretację uzyskanych w pracy rezultatów
i wynikające z nich podstawowe wnioski.
7.4. Wyniki działania algorytmów w przypadku obrazów
zakłóconych szumem gaussowskim
W kolejnych punktach pracy omówione zostaną wyniki badania odporności
algorytmów dopasowania obrazów pary stereoskopowej na zakłócenia obrazów
szumami o różnych charakterystykach probabilistycznych. Jako pierwszy przedys-
kutowany zostanie przypadek zakłócenia obrazów szumem gaussowskim (por. p.
6.4.3).
W celu zbadania zachowania się analizowanych algorytmów w obecności szu-
mu gaussowskiego obydwa obrazy pary zakłócano sztucznie tym szumem, a na-
stępnie przeprowadzono eksperymenty na tak zakłóconych obrazach. W literatu-
rze można spotkać opis eksperymentów [138], w których zakłócany jest tylko je-
den z obrazów pary stereoskopowej. Autor przeprowadził szereg testów, które nie
będę tu omawiane, na podstawie których można stwierdzić, że wyniki otrzymy-
wane w przypadku zakłócenia tylko jednego z obrazów nie różnią się jakościowo
od wyników otrzymywanych w przypadku zakłócania obu obrazów. W pierwszym
przypadku wyniki ilościowe są lepsze, natomiast zachowane są relacje między wy-
nikami liczbowymi otrzymywanymi w rezultacie wykonania różnych algorytmów
dopasowania.
W praktycznych zastosowaniach algorytmów dopasowania pary stereoskopo-
wej zakłócenia są obecne zazwyczaj w obu obrazach równocześnie. Dlatego w pra-
cy zdecydowano się do przedstawienia wyników eksperymentów przeprowadzo-
nych dla tego właśnie przypadku. Będą one prezentowane w funkcji wzrastającego
poziomu szumu określonego w mierze decybelowej wyrażonej wzorem (6.4).
7.4.1. Wyniki działania algorytmów dopasowania cechami
Na rys. 7.9 przedstawiono wyniki eksperymentów obliczeniowych przeprowa-
dzonych przy założeniu zakłócania obrazów pary stereoskopowej szumem gaus-
sowskim w przypadku algorytmu MPG oraz algorytmu dopasowania wykorzystu-
jącego w swoim działaniu zaproponowany rozmyty detektor krawędzi. Analizując
wyniki uzyskane za pomocą algorytmu MPG (rys. 7.9a), można stwierdzić, że za-
202

“KonspPreamb” 2013/10/3 page 203 #206
7. Wyniki badań eksperymentalnych
równo procent pikseli zakwalifikowanych przez algorytm jako krawędziowe, jak
i procent pikseli prawidłowo dopasowanych różnią się znacznie od odpowiadają-
cych im liczb procentowych otrzymanych w przypadku obrazów nie zawierających
zakłóceń szumowych. Duży poziom szumu, przy stosunku sygnał-szum SNR poni-
żej 25 dB, powoduje wzrost liczby pikseli uznanych przez algorytm jako należące
do krawędzi obrazu, co oznacza zwiększenie liczby błędnych decyzji o zakwalifiko-
waniu poszczególnych pikseli jako piksele krawędziowe. Jednocześnie zmniejsza
się liczba prawidłowo dopasowanych pikseli i określonych dla nich prawidłowych
wartości dysparycji.
5 10 15 20 25 30 35 40 45 500123456789
10
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
Liczba pikseli krawędziowychLiczba pikseli dopasowanych
(a) Wyniki działania algorytmu MPG
5 10 15 20 25 30 35 40 45 5002468
101214161820
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
Liczba pikseli krawędziowychLiczba pikseli doapasowanych
(b) Wyniki działania algorytmu wykorzystującegodetektor krawędzi oparty o rozmytą trójkątnąrelację podobieństwa i sąsiedztwo o rozmia-
rze 24 pikseli
Rys. 7.9. Średnie procentowe liczby pikseli zakwalifikowanych jako krawędzioweoraz pikseli prawidłowo dopasowanych uzyskane w wyniku zastosowania al-gorytmów dopasowania cechami w przypadku zakłócania obrazów pary stre-
oskopowej szumem gaussowskim
Podobny efekt jest zauważalny w wynikach algorytmu wykorzystującego roz-
myty detektor krawędzi (rys. 7.9b), gdzie duża zawartość szumu (dla SNR poniżej
25 dB) zaburza wyraźnie działanie detektora, a w konsekwencji zmniejsza się licz-
ba prawidłowo dopasowanych pikseli. Ogólnie można stwierdzić, że szum gaus-
sowski przy SNR powyżej 25 dB jest znacznie lepiej tolerowany przez algorytm
z rozmytym detektorem krawędzi w porównaniu do algorytmu MPG. Na przykład,
dla SNR = 25 dB względna procentowa liczba prawidłowo dopasowanych pikseli
przez zaproponowany algorytm jest prawie czterokrotnie większa. Należy podkre-
ślić, że wprawdzie na osi rzędnych na wykresach podane zostały liczby procentowe
w odniesieniu do wszystkich pikseli obrazów, to właściwa ocena uzyskanych wyni-
203

“KonspPreamb” 2013/10/3 page 204 #207
7. Wyniki badań eksperymentalnych
ków powinna być dokonana przez ich względne odniesienie do liczby tych pikseli,
które faktycznie należą do krawędzi obrazów.
7.4.2. Wyniki działania algorytmów dopasowania obszarami
Wyniki eksperymentów przeprowadzonych w celu zbadania odporności algo-
rytmów dopasowania obszarami na zakłócenia obrazów pary stereoskopowej szu-
mem gaussowskim ilustrują wykresy pokazane na rys. 7.10. Na wykresach zauwa-
żalny jest wyraźny wzrost średniej procentowej liczby prawidłowo dopasowanych
pikseli wraz ze zmniejszaniem się poziomu szumu (wzrostem SNR).
5 10 15 20 25 30 35 40 45 506264666870727476788082
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące miary oparte o róż-nice
5 10 15 20 25 30 35 40 45 506264666870727476788082
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące miary oparteo kwadrat różnic
5 10 15 20 25 30 35 40 45 506264666870727476788082
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące miary korelacyjne
5 10 15 20 25 30 35 40 45 50626466687072747678808284
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące transformaty obra-zów
Rys. 7.10. Średnie liczby procentowe prawidłowo dopasowanych pikseli uzyskanew wyniku zastosowania różnych algorytmów dopasowania obszarami w przy-
padku zakłócenia obrazów pary stereoskopowej szumem gaussowskim
W grupie algorytmów wykorzystujących miarę jakości opartą na różnicy (rys. 7.10a),
przy dużych poziomach szumu (dla SNR mniejszych od 30 dB), wszystkie algo-
rytmy osiągają bardzo podobne wyniki. Natomiast dla małych poziomów szumu
204

“KonspPreamb” 2013/10/3 page 205 #208
7. Wyniki badań eksperymentalnych
można zauważyć, że algorytm wykorzystujący miarę ZSAD oraz algorytm dzia-
łający w dziedzinie zbiorów IFS wykorzystujący miarę Hamminga IFS+HAMM
wykazują większą odporność na tego typu zakłócenie.
W przypadku algorytmów wykorzystujących miary oparte o kwadrat różnicy
(rys. 7.10b) jak również algorytmów wykorzystujących miary korelacyjne
(rys. 7.10c) uzyskano bardzo podobne wyniki, niewiele różniące się liczbowo od
wyników otrzymywanych przy zastosowaniu algorytmów z miarami opartymi o róż-
nicę. Jedynie w grupie algorytmów wykorzystujących miary korelacyjne widoczny
jest niewielki wpływ szumu na pogorszenie wyników osiąganych przez algorytm
wykorzystujący miarę NCC.
W przypadku algorytmów wykorzystujacych transformatę obrazu, dla których
wyniki przedstawione zostały na rys. 7.10d, najlepsze rezultaty osiągane są przez
zastosowanie rozmytej transformaty rankingowej. Dobrą tolerancją na szum gaus-
sowski cechuje się również algorytm wykorzystujący transformatę CENSUS.
Drugą badaną miarą jakości działania algorytmów była liczba nieprawidłowych
dopasowań tworzących grupy izolowanych pikseli. Wyniki numeryczne dotyczące
tej miary przedstawione zostały na rys. 7.11.
5 10 15 20 25 30 35 40 45 505
101520253035404550556065
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące miary oparte o róż-nicę
5 10 15 20 25 30 35 40 45 505
101520253035404550556065
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące miary oparteo kwadrat różnic
Rys. 7.11. Średnie procentowe liczby błędnych izolowanych dopasowań otrzymanedla obrazów par stereoskopowych z zawartym w nich szumem gaussowskim
Widoczny jest tu wyraźny wpływ szumu na liczbę błędnych izolowanych do-
pasowań, szczególnie dla algorytmów wykorzystujących w swoim działaniu znor-
malizowane miary ZSAD i ZSSD. Także duża liczba błędnie dopasowanych pikseli
otrzymana została w przypadku algorytmu wykorzystującego transformatę rankin-
gową RANK+SAD. W grupie algorytmów wykorzystujących miary korelacyjne
205

“KonspPreamb” 2013/10/3 page 206 #209
7. Wyniki badań eksperymentalnych
5 10 15 20 25 30 35 40 45 505
101520253035404550556065
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące miary korelacyjne
5 10 15 20 25 30 35 40 45 505
101520253035404550556065
Zawartość szumu gaussowskiego [dB]
%pi
ksel
iobr
azu
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące transformaty obra-zów
Rys. 7.11. Średnie procentowe liczby błędnych izolowanych dopasowań otrzymanedla obrazów par stereoskopowych z zawartym w nich szumem gaussowskim
(kontynuacja)
(rys. 7.11c) brak jest wyraźnych rozbieżności w wynikach otrzymywanych przez
różne algorytmy.
Ogólny wniosek, jaki może być sformułowany na podstawie otrzymanych wy-
ników, sprowadza się do stwierdzenia, iż algorytmy działające w dziedzinie jasno-
ści pikseli i wykorzystujące miary znormalizowane ZSAD i ZSSD mają większą
tendencję do znajdowania grup pikseli o błędnie przypisanych im wartościach dys-
parycji.
Ze względu na błąd RMSE, którego wyniki analizy przedstawione zostały na
rys. 7.12, największe wartości tego błędu otrzymano w przypadku algorytmów
wykorzystujących miary ZSAD oraz ZSSD. Potwierdza to wcześniejsze stwierdze-
nie, że algorytmy dopasowania wykorzystujące miary znormalizowane są najmniej
efektywne z grupy badanych algorytmów w sytuacji, gdy obrazy zawierają zakłó-
cenia szumem gaussowskim. W grupie algorytmów wykorzystujących miary kore-
lacyjne dostrzegalne jest, że dla dużego poziomu szumu, poniżej 25 dB, algorytm
wykorzystujący miarę NCC daje największe wartości błędu.
W przypadku algorytmów wykorzystujących transformaty obrazów (rys. 7.12d)
największy błąd RMSE jest osiągany przez algorytm wykorzystujący transformatę
rankingową RANK+SAD i działający w dziedzinie jasności pikseli. Najbardziej
efektywny z uwagi na miarę RMSE okazał się algorytm wykorzystujący transfor-
matę CENSUS. Nieznacznie gorsze od niego wyniki daje algorytm oparty o trans-
formatę rozmytą FuzzyRANK+SAD.
206

“KonspPreamb” 2013/10/3 page 207 #210
7. Wyniki badań eksperymentalnych
5 10 15 20 25 30 35 40 45 5034384246505458626670747882
Zawartość szumu gaussowskiego [dB]
RM
SE
[pik
s.]
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące miary oparte o róż-nice
5 10 15 20 25 30 35 40 45 5034384246505458626670747882
Zawartość szumu gaussowskiego [dB]
RM
SE
[pik
s.]
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące miary oparteo kwadrat różnic
5 10 15 20 25 30 35 40 45 503438424650545862667074788286
Zawartość szumu gaussowskiego [dB]
RM
SE
[pik
s.]
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące miary korelacyjne
5 10 15 20 25 30 35 40 45 50303438424650545862667074788286
Zawartość szumu gaussowskiego [dB]
RM
SE
[pik
s.]
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące transformaty obra-zów
Rys. 7.12. Średnie wartości błędu RMSE w przypadku zakłócenia obrazów parstereoskopowych szumem gaussowskim
7.5. Wyniki działania algorytmów w przypadku obrazów
zakłóconych szumem addytywnym o rozkładzie
jednostajnym lub szumem multiplikatywnym
Podobnie jak w przypadku szumu gaussowskiego, eksperymenty przeprowa-
dzono przy założeniu, że moce szumów zakłócających oba obrazy pary stereosko-
powej są identyczne. Charakter i struktura eksperymentów były analogiczne.
7.5.1. Wyniki działania algorytmów dopasowania cechami
W pierwszej serii eksperymentów porównano rezultaty uzyskane za pomocą
algorytmu dopasowania cechami MPG oraz zaproponowanego algorytmu wyko-
rzystującego detektor krawędzi oparty o rozmytą relację podobieństwa. Przypadek
zakłócania obrazów pary stereoskopowej szumem addytywnym o rozkładzie jedno-
207

“KonspPreamb” 2013/10/3 page 208 #211
7. Wyniki badań eksperymentalnych
stajnym ilustruje rys. 7.13, zaś szumem multiplikatywnym rys. 7.14. Zachowanie
5 10 15 20 25 30 35 40 45 500123456789
10
Zawartość szumuo rozkładzie jednostajnym [dB]
%pi
ksel
iobr
azu
Liczba pikseli krawędziowychLiczba pikseli dopasowanych
(a) Wyniki działania algorytmu MPG
5 10 15 20 25 30 35 40 45 5002468
101214161820
Zawartość szumuo rozkładzie jednostajnym [dB]
%pi
ksel
iobr
azu
Liczba pikseli krawędziowychLiczba pikseli dopasowanych
(b) Wyniki działania algorytmu opartego o rozmy-ty detektor krawędzi wykorzystujący trójkąt-ną relację podobieństwa i sąsiedztwo o roz-
miarze 24 pikseli
Rys. 7.13. Średnie procentowe liczby pikseli zakwalifikowanych jako krawędzioweoraz pikseli prawidłowo dopasowanych uzyskane w wyniku zastosowania algo-rytmów dopasowania cechami przy założeniu zakłócenia obrazów pary stereo-
skopowej szumem addytywnym o rozkładzie jednostajnym
5 10 15 20 25 30 35 40 45 500123456789
10
Zawartość szumu multiplikatywnego [dB]
%pi
ksel
iobr
azu
Liczba pikseli krawędziowychLiczba pikseli dopasowanych
(a) Wyniki działania algorytmu MPG
5 10 15 20 25 30 35 40 45 5002468
101214161820
Zawartość szumu multiplikatywnego [dB]
%pi
ksel
iobr
azu
Liczba pikseli krawędziowychLiczba pikseli dopasowanych
(b) Wyniki działania algorytmu wykorzystującegorozmyty detektor krawędzi z trójkątną relacjąpodobieństwa i sąsiedztwie równym 24 pik-
sele
Rys. 7.14. Średnie procentowe liczby pikseli zakwalifikowanych jako krawędzioweoraz pikseli prawidłowo dopasowanych uzyskane w wyniku zastosowania algo-rytmów dopasowania cechami przy zakłóceniu obrazów pary stereoskopowej
szumem multiplikatywnym o rozkładzie jednostajnym
obu algorytmów dla obu rodzajów szumów niewiele różni się od przypadku zakłó-
208

“KonspPreamb” 2013/10/3 page 209 #212
7. Wyniki badań eksperymentalnych
cania obrazów szumem gaussowskim. W przypadku algorytmu MPG zauważalna
jest jedynie większa liczba pikseli (w mierze względnej o około 20%) zaklasyfi-
kowanych przez algorytm jako krawędziowe w całym zakresie zmian SNR w po-
równaniu do przypadku szumu gaussowskiego. Dla oceny wyników uzyskanych
w pracy nie ma to większego znaczenia. Natomiast istotny jest fakt, że zapropono-
wany przez autora algorytm zarówno dla szumu addytywnego o rozkładzie jedno-
stajnym, jak i szumu multiplikatywnego, wykazuje w całym zakresie zmian SNR
niemal identyczną odporność na zakłócenia jak dla szumu gaussowskiego. Można
zatem sformułować generalny wniosek, że dla wszystkich trzech rodzajów szumu
zaproponowany w pracy algorytm dopasowania cechami dobrze toleruje zakłóce-
nia szumowe do poziomu SNR = 25 dB, natomiast poniżej tego poziomu algo-
rytm ma tendencje do błędnej klasyfikacji pikseli jako krawędziowe, co wpływa na
zmniejszanie się liczby prawidłowo dopasowanych pikseli. Tym nie mniej, podob-
nie jak dla szumu gaussowskiego, względne procentowe liczby prawidłowo dopa-
sowanych pikseli w przypadku zaproponowanego algorytmu są znacząco większe
w porównaniu z algorytmem MPG. Tak więc również dla szumu o rozkładzie jed-
nostajnym i szumu multiplikatywnego zaproponowany algorytm ma przewagę nad
algorytmem MPG.
7.5.2. Wyniki działania algorytmów dopasowania obszarami
W celu zbadania wpływu zakłóceń obrazów addytywnym szumem o rozkładzie
jednostajnym oraz szumem multiplikatywnym na zachowanie się algorytmów do-
pasowania obszarami pary stereoskopowej powtórzono cykl eksperymentów prze-
prowadzony w przypadku szumu gaussowskiego. Badaniu podlegały zatem: śred-
nie procentowe liczby prawidłowo dopasowanych pikseli, średnie procentowe licz-
by błędnych izolowanych dopasowań oraz średnie wartości błędu RMSE.
Wykresy średnich procentowych liczb prawidłowo dopasowanych pikseli
w funkcji stosunku sygnał-szum SNR są pokazane na rys. 7.15 (przypadek za-
kłócania addytywnym szumem o rozkładzie jednostajnym) oraz rys. 7.16 (przy-
padek zakłócania szumem multiplikatywnym). Z porównania tych wykresów z od-
powiadającymi im wykresami z rys. 7.10 otrzymanymi dla przypadku szumu gaus-
sowskiego wynika, że są one praktycznie identyczne. Niewielkie różnice mieszczą
się w ramach błędu wynikającego ze statystycznego charakteru eksperymentów.
Podobną zbieżność wyników otrzymano podczas badania średnich procentowych
209

“KonspPreamb” 2013/10/3 page 210 #213
7. Wyniki badań eksperymentalnych
liczb błędnie izolowanych dopasowań oraz średnich wartości błędu RMSE. Dlatego
wykresy tych miar jakości działania algorytmów nie będą tu przytoczone.
5 10 15 20 25 30 35 40 45 506264666870727476788082
Zawartość szumuo rozkładzie jednostajnym [dB]
%pi
ksel
iobr
azu
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące w swoim działaniumiary oparte o różnice
5 10 15 20 25 30 35 40 45 506264666870727476788082
Zawartość szumuo rozkładzie jednostajnym [dB]
%pi
ksel
iobr
azu
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące w swoim działaniumiary oparte o kwadrat różnicy
5 10 15 20 25 30 35 40 45 506264666870727476788082
Zawartość szumuo rozkładzie jednostajnym [dB]
%pi
ksel
iobr
azu
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące w swoim działaniumiary korelacyjne
5 10 15 20 25 30 35 40 45 50626466687072747678808284
Zawartość szumuo rozkładzie jednostajnym [dB]
%pi
ksel
iobr
azu
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące w swoim działaniutransformaty obrazów
Rys. 7.15. Średnie procentowe liczby prawidłowo dopasowanych pikseli w zależ-ności poziomu szumy wyrażonego w mierze SNR otrzymane dla algorytmówdziałających na obrazach zakłóconych szumem addytywnym o rozkładzie jed-
nostajnym
Ogólnie można stwierdzić, że zachowanie się badanych w pracy algorytmów
dopasowania pary stereoskopowej cechami, a także algorytmów dopasowania ob-
szarami jest bardzo podobne dla trzech analizowanych dotąd rodzajów szumu, tj.
szumu addytywnego gaussowskiego, szumu addytywnego o rozkładzie jednostaj-
nym oraz szumu multiplikatywnego. Wykresy przeanalizowanych wskaźników ja-
kości tych algorytmów nie wykazują istotnych różnic w całym zakresie zmian sto-
sunku sygnał-szum SNR. Wszystkie wnioski i komentarze sformułowane w od-
niesieniu do poszczególnych algorytmów, sformułowane w p. 7.4.2 dla przypadku
210

“KonspPreamb” 2013/10/3 page 211 #214
7. Wyniki badań eksperymentalnych
5 10 15 20 25 30 35 40 45 5064666870727476788082
Zawartość szumu multiplikatywnego [dB]
%pi
ksel
iobr
azu
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące miary oparte o róż-nice
5 10 15 20 25 30 35 40 45 5064666870727476788082
Zawartość szumu multiplikatywnego [dB]
Pro
cent
obra
zu[%
]
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące miary oparteo kwadrat różnicy
5 10 15 20 25 30 35 40 45 5064666870727476788082
Zawartość szumu multiplikatywnego [dB]
%pi
ksel
iobr
azu
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące miary korelacyjne
5 10 15 20 25 30 35 40 45 506466687072747678808284
Zawartość szumu multiplikatywnego [dB]
%pi
ksel
iobr
azu
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące transformaty obra-zów
Rys. 7.16. Średnie procentowe liczby prawidłowo dopasowanych pikseli w zależno-ści od poziomu szumu wyrażonego w mierze SNR otrzymane przez algorytmydziałające na obrazach par stereokopowych zakłóconych szumem multiplika-
tywnym o rozkładzie jednostajnym
zakłócania obrazów pary stereoskopowej szumem gaussowskim, są słuszne zatem
również w przypadku szumu o rozkładzie jednostajnym i szumu multiplikatywne-
go.
7.6. Wyniki działania algorytmów w przypadku obrazów
zakłóconych szumem impulsowym typu „sól i pieprz”
Inaczej sytuacja przedstawia się w przypadku zakłócania obrazów pary stereo-
skopowej szumem impulsowym typu „sól i pieprz”. Przypadek ten charakteryzuje
się odrębną specyfiką w porównaniu do poprzednich trzech typów szumów zakłó-
cających, dlatego też będzie omówiony dokładniej.
211

“KonspPreamb” 2013/10/3 page 212 #215
7. Wyniki badań eksperymentalnych
Eksperymenty przeprowadzono według tego samego schematu jak w przypad-
ku poprzednich zakłóceń, jednak zasadniczą różnicą była odmienna miara zawar-
tości szumu w obrazach. Dla szumu impulsowego typu „sól i pieprz” zawartość
szumu nie była wyrażana za pomocą miary SNR, ale jako procentowy udział pikseli
zaszumionych w stosunku do wszystkich pikseli składających się na obraz. Miara
ta w przypadku szumu impulsowego typu „sól i pieprz” jest bardziej zrozumiała
intuicyjnie (por. p. 6.4.2) i dlatego tę właśnie miarę przyjęto w przeprowadzonych
eksperymentach.
7.6.1. Wyniki działania algorytmów dopasowania cechami
Tak jak poprzednio, w ramach tej serii eksperymentów porównano odporność
na zakłócenia obrazów szumem impulsowym typu „sól i pieprz” algorytmu dopa-
sowania cechami MPG i zaproponowanego algorytmu wykorzystującego w detek-
torze krawędzi rozmytą relację podobieństwa. Otrzymane wyniki przedstawiono na
rys 7.17.
5 10 15 20 25 30 35 40 45 500123456789
1011
Zawartość szumu „sól i pieprz” [%]
%pi
ksel
iobr
azu
Liczba pikseli charakterystycznychLiczba pikseli dopasowanych
(a) Wyniki działania algorytmu MPG
5 10 15 20 25 30 35 40 45 5002468
10121416182022
Zawartość szumu „sól i pieprz” [%]
%pi
ksel
iobr
azu
Liczba pikseli charakterystycznychLiczba pikseli dopasowanych
(b) Wyniki działania algorytmu wykorzystującegodetektor krawędzi oparty o rozmytą trójkątnąrelację podobieństwa i sąsiedztwo o rozmia-
rze 24 pikseli
Rys. 7.17. Średnie procentowe liczby pikseli zakwalifikowanych jako krawędzio-we oraz pikseli prawidłowo dopasowanych uzyskane w wyniku zastosowaniaalgorytmów dopasowania cechami w przypadku zakłócania obrazów pary ste-
reoskopowej szumem impulsowym typu „sól i pieprz”
Na wykresach widoczna jest istotna różnica między liczbą pikseli sklasyfiko-
wanych przez oba algorytmy jako należące do krawędzi. W przypadku algorytmu
wykorzystującego detektor oparty na rozmytej relacji podobieństwa liczba ta jest
prawie dwukrotnie większa. Ponieważ szum impulsowy przyjmuje tylko skrajne
212

“KonspPreamb” 2013/10/3 page 213 #216
7. Wyniki badań eksperymentalnych
wartości jasności pikseli, jego wpływ na działanie detektorów krawędzi jest znacz-
nie silniejszy. W konsekwencji powoduje to zwiększenie liczby pikseli błędnie za-
kwalifikowanych przez algorytm jako krawędziowe. Ogólnie można powiedzieć,
że – w porównaniu do trzech poprzednio rozważanych typów szumu – zakłócenie
obrazów pary stereoskopowej szumem „sól i pieprz” znacznie silniej degraduje
działanie algorytmów zarówno pod względem liczby prawidłowo sklasyfikowa-
nych pikseli krawędziowych, jak i liczby prawidłowo dopasowanych pikseli. Efekt
ten pogłębia się wraz ze wzrostem procentowego udziału pikseli zaszumionych
w obrazach.
7.6.2. Wyniki działania algorytmów dopasowania obszarami
Wyniki efektywności poszczególnych klas algorytmów dopasowania pary ste-
reoskopowej pod względem ich zdolności do wyznaczania prawidłowych dopaso-
wań pikseli przy założeniu obecności w obrazach szumu impulsowego „sól i pieprz”
ilustrują wykresy pokazane na rys. 7.18. Występują tu istotne różnice w porówna-
niu z odpowiadającymi im wykresami z rysunków 7.10, 7.15 i 7.16.
5 10 15 20 25 30 35 40 45 506264666870727476
Zawartość szumu „sól i pieprz” [%]
%pi
ksel
iobr
azu
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące miary oparte o róż-nice
5 10 15 20 25 30 35 40 45 506061626364656667686970
Zawartość szumu „sól i pieprz” [%]
%pi
ksel
iobr
azu
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące miary oparteo kwadrat różnic
Rys. 7.18. Średnie procentowe liczby prawidłowo dopasowanych pikseli uzyskanew wyniku zastosowania różnych algorytmów dopasowania obszarami w przy-padku zakłócenia obrazów pary stereoskopowej szumem impulsowym „sól
i pieprz”
W przypadku zakłócenia „sól i pieprz” w grupie algorytmów wykorzystujących
miary oparte o różnice (rys. 7.18a) wyraźnie widoczna jest kilkuprocentowa prze-
waga algorytmów działających w dziedzinie zbiorów rozmytych FUZZ+HAMM
i zbiorów IFS IFS+HAMM nad algorytmami działającymi w dziedzinie jasności
213

“KonspPreamb” 2013/10/3 page 214 #217
7. Wyniki badań eksperymentalnych
5 10 15 20 25 30 35 40 45 50606162636465666768697071
Zawartość szumu „sól i pieprz” [%]
%pi
ksel
iobr
azu
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące miary korelacyjne
5 10 15 20 25 30 35 40 45 506264666870727476788082
Zawartość szumu „sól i pieprz” [%]
%pi
ksel
iobr
azu
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące transformaty obra-zów
Rys. 7.18. Średnie procentowe liczby prawidłowo dopasowanych pikseli uzyskanew wyniku zastosowania różnych algorytmów dopasowania obszarami w przy-padku zakłócenia obrazów pary stereoskopowej szumem impulsowym „sól
i pieprz” (kontynuacja)
pikseli i wykorzystującymi miary SAD i ZSAD. Najmniejszą liczbę prawidłowo
dopasowanych pikseli otrzymano w efekcie wykonania algorytmu wykorzystują-
cego miarę ZSAD.
Podobna sytuacja występuje dla grupy algorytmów wykorzystujących w swoim
działaniu miary oparte o kwadrat różnicy (rys. 7.18b). Widoczne jest, że algoryt-
my działające w dziedzinie zbiorów rozmytych i zbiorów IFS pozwalają na prawi-
dłowe dopasowanie znacząco większej liczby pikseli od algorytmów działających
w dziedzinie jasności pikseli. Tendencja ta jest zachowana i zauważalna w wy-
nikach otrzymanych dla grupy algorytmów wykorzystujących w swoim działaniu
miary korelacyjne (rys. 7.18c). Również w tej grupie algorytmów algorytmy dzia-
łające w dziedzinie zbiorów rozmytych oraz w dziedzinie zbiorów IFS pozwoliły
na uzyskanie znacząco większej liczby prawidłowych dopasowań, przy czym jest
rzeczą charakterystyczną, że otrzymane wykresy dla obu tych typów algorytmów
praktycznie się pokrywają.
W grupie algorytmów wykorzystujących transformaty obrazów (rys. 7.18d),
najgorsze wyniki otrzymano w przypadku algorytmu wykorzystującego transfor-
matę rozmytą FuzzyRANK+SAD. Algorytmy wykorzystujące transformatę ran-
kingową RANK+SAD oraz transformatę CENSUS pozwoliły na uzyskanie więk-
szej liczby prawidłowo dopasowanych pikseli. Tak więc w grupie algorytmów opar-
214

“KonspPreamb” 2013/10/3 page 215 #218
7. Wyniki badań eksperymentalnych
tych na transformatach obrazów wykorzystanie rozmytej transformaty rankingowej
prowadzi do gorszych rezultatów.
Wyniki analizy błędnych izolowanych dopasowań przy zakłócaniu obrazów
szumem „sól i pieprz” przedstawiono na rys. 7.19. W przypadku grupy algorytmów
wykorzystujących miary oparte o różnice (rys. 7.19a) oraz miary oparte o kwa-
draty różnic (rys. 7.19b) algorytmy działające w dziedzinie zbiorów rozmytych:
FUZZ+HAMM i odpowiednio FUZZ+EUCL oraz algorytmy działające w dzie-
dzinie intuicjonistycznych zbiorów rozmytych: IFS+HAMM i odpowiednio IFS+
EUCL dają znacząco mniejsze liczby błędnych izolowanych dopasowań w porów-
naniu z algorytmami bez zastosowania fuzzyfikacji obrazów. Można zatem stwier-
dzić, że w grupie algorytmów wykorzystujących dwie pierwsze miary algorytmy
z fuzzyfikacją obrazów mają wyraźną przewagę. Także i tym razem należy odno-
tować, że uzyskane wykresy dla algorytmów działających w dziedzinie zbiorów
rozmytych i w dziedzinie IFS się pokrywają.
5 10 15 20 25 30 35 40 45 5025303540455055606570
Zawartość szumu „sól i pieprz” [%]
%pi
ksel
iobr
azu
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące miary oparte o róż-nice
5 10 15 20 25 30 35 40 45 5045
50
55
60
65
70
Zawartość szumu „sól i pieprz” [%]
%pi
ksel
iobr
azu
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące miary oparteo kwadrat różnic
Rys. 7.19. Średnie procentowe liczby błędnych izolowanych dopasowań otrzyma-ne dla obrazów par stereoskopowych zakłóconych szumem impulsowym „sól
i pieprz”
Nieco odmienne wnioski wynikają z analizy wykresów otrzymanych dla gru-
py algorytmów wykorzystujących miary korelacyjne (rys. 7.19c). W tym przypad-
ku algorytmy z fuzzyfikacją obrazów mają przewagę nad algorytmami bez zasto-
sowania fuzzyfikacji jedynie dla małych poziomów zakłócenia obrazów szumem
„sól i pieprz”, poniżej 20% zaszumionych pikseli. Dla wyższych stopni zaszumie-
nia lepsze wyniki daje algorytm NCC. Natomiast najmniej odporny na szum „sól
i pieprz” prawie w całym zakresie stopnia zaszumienia jest algorytm ZNCC. Gor-
215

“KonspPreamb” 2013/10/3 page 216 #219
7. Wyniki badań eksperymentalnych
5 10 15 20 25 30 35 40 45 5045
50
55
60
65
70
Zawartość szumu „sól i pieprz”[%]
%pi
ksel
iobr
azu
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące miary korelacyjne
5 10 15 20 25 30 35 40 45 505
10152025303540455055606570
Zawartość szumu „sól i pieprz” [%]
%pi
ksel
iobr
azu
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące transformaty obra-zów
Rys. 7.19. Średnie procentowe liczby błędnych izolowanych dopasowań otrzyma-ne dla obrazów par stereoskopowych zakłóconych szumem impulsowym „sól
i pieprz” (kontynuacja)
sze zachowanie się algorytmów z fuzzyfikacją obrazów dla większych poziomów
zakłócania obrazów można wytłumaczyć dużą wrażliwością przyjętej relacji podo-
bieństwa na specyficzny rodzaj szumu, jakim jest szum typu „sól i pieprz” przyj-
mujący jedynie dwie skrajne wartości jasności pikseli.
Z kolei spośród algorytmów wykorzystujących transformaty obrazów najlep-
sze wyniki dla wszystkich poziomów zaszumienia osiągane są przez algorytm wy-
korzystujący transformatę CENSUS. Nieco gorsze wyniki daje algorytm RANK+
SAD, natomiast wyraźnie najgorsze algorytm wykorzystujący rozmytą transforma-
tę rankingową FuzzyRANK+SAD. Zastosowanie rozmytej transformaty rankingo-
wej obrazów powoduje, podobnie jak w grupie algorytmów z miarami korelacyj-
nymi, że w przypadku zakłócenia obrazów szumem „sól i pieprz” w mapach dys-
parycji występuje duża liczba błędnie dopasowanych pikseli pozostających w izo-
lowanych grupach.
Wyniki dotyczące trzeciego rozpatrywanych wskaźników jakości algorytmów,
tj. błędu RMSE, dla przypadku zakłócania obrazów pary stereoskopowej szumem
„sól i pieprz” przedstawia rys. 7.20. Dla trzech pierwszych miar jakości dopasowa-
nia (rys. 7.20a, 7.20b, 7.20c) widoczna jest wyraźna przewaga algorytmów działa-
jących w dziedzinie zbiorów rozmytych lub zbiorów IFS. Natomiast w grupie al-
gorytmów wykorzystujących transformaty obrazów algorytm FuzzyRANK+SAD
z rozmytą transformatą rankingową daje najgorsze wyniki (rys. 7.20d). Najbardziej
216

“KonspPreamb” 2013/10/3 page 217 #220
7. Wyniki badań eksperymentalnych
odpornym z algorytmów tej klasy okazał się algorytm wykorzystujący transformatę
CENSUS.
5 10 15 20 25 30 35 40 45 5046505458626670747882
Zawartość szumu „sól i pieprz” [%]
RM
SE
[pik
s.]
SADZSADFUZZ+HAMMIFS+HAMM
(a) Algorytmy wykorzystujące miary oparte o róż-nice
5 10 15 20 25 30 35 40 45 506266707478828690
Zawartość szumu „sól i pieprz” [%]R
MSE
[pik
s.]
SSDZSSDFUZZ+EUCLIDIFS+EUCLID
(b) Algorytmy wykorzystujące miary oparteo kwadrat różnic
5 10 15 20 25 30 35 40 45 506670747882869094
Zawartość szumu „sól i pieprz” [%]
RM
SE
[pik
s.]
NCCZNCCFUZZ+CORRIFS+CORR
(c) Algorytmy wykorzystujące miary korelacyjne
5 10 15 20 25 30 35 40 45 5030354045505560657075808590
Zawartość szumu „sól i pieprz” [%]
RM
SE
[pik
s.]
RANK+SADFuzzyRANK+SADCENSUS
(d) Algorytmy wykorzystujące transformaty obra-zów
Rys. 7.20. Średnie wartości błędu RMSE wprzypadku zakłócenia obrazów par ste-roskopowych szumem impulsowym typu „sól i pieprz”
Zestawienie otrzymanych w tym punkcie rezultatów dla przypadku zakłócania
obrazów szumem typu „sól i pieprz” prowadzi do wniosku, że przejście do dziedzi-
ny transformat i zastosowanie fuzzyfikacji daje wyniki niezadowalające. Bardziej
odporne na ten rodzaj zakłócenia są algorytmy działające w dziedzinie transfor-
mat bez stosowania fuzzyfikacji. W przypadku pozostałych klas rozpatrywanych
algorytmów fuzzyfikacja obrazów umożliwia uzyskanie lepszych, a dla niektórych
miar jakości znacząco lepszych wynników, zarówno w przypadku problemu dopa-
sowania pary stereoskopowej cechami, jak i dopasowania obszarami.
217

“KonspPreamb” 2013/10/3 page 218 #221
7. Wyniki badań eksperymentalnych
7.7. Wnioski
Zasadniczym celem niniejszej pracy była próba odpowiedzi na pytanie, czy za-
stosowanie zbiorów rozmytych i/lub intuicjonistycznych zbiorów rozmytych umoż-
liwia skonstruowanie algorytmów, za pomocą których rozwiązanie zagadnienia do-
pasowania pary stereoskopowej byłoby bardziej efektywne. Przeprowadzone bada-
nia, których rezultaty numeryczne zostały przedstawione powyżej, nie pozwalają,
zdaniem autora, na udzielenie prostej i jednoznacznej odpowiedzi na to pytanie.
Aczkolwiek w wielu eksperymentach algorytmy z fuzzyfikacją obrazów wykazały
przewagę nad algorytmami klasycznymi, to w innych ich efektywność była gorsza.
Ocena algorytmów działających w dziedzinie zbiorów rozmytych i zbiorów IFS
zależy od rodzaju zastosowania, od przyjętej miary jakości dopasowania obrazów
oraz od tego, czy wykorzystane są w nich transformaty obrazów, czy też działają
one w dziedzinie jasności pikseli. Efektywność algorytmów jest również zależna od
tego, czy obrazy pary stereoskopowej są niezakłócone, czy też zakłócone, a także
od statystyki szumu zakłócającego i jego poziomu.
Na podstawie przeprowadzonych obliczeń można stwierdzić, że w przypadku
algorytmów dopasowania cechami zaproponowany w pracy algorytm detekcji kra-
wędzi z rozmytą trójkątną relacją podobieństwa pozwala na uzyskanie lepszych re-
zultatów niż klasyczny i często stosowany algorytm MPG. Dla obrazów nie zawie-
rających zakłóceń algorytm ten umożliwia detekcję większej liczby pikseli krawę-
dziowych, jak również uzyskanie większej liczby prawidłowych dopasowań. Rów-
nież w przypadku obrazów zakłóconych zaproponowany algorytm, pomimo jego
wrażliwości na zakłócenia w fazie detekcji pikseli krawędziowych, jest bardziej
efektywny praktycznie dla wszystkich rodzajów szumów zakłócających i pozio-
mów zakłócania.
W przypadku grupy algorytmów dopasowania obszarami wykorzystujących mia-
ry oparte o różnice, widoczna jest pewna przewaga algorytmów zawierających fuz-
zyfikację obrazów. Szczególnie dobrze przewaga algorytmów wykorzystujących
fuzzyfikację uwidaczniana jest w przypadku obrazów par stereoskopowych zakłó-
conych szumem impulsowym typu „sól i pieprz”. Wyniki otrzymane przez te al-
gorytmy są znacznie lepsze od wyników osiąganych przez algorytmy działające
w dziedzinie jasności pikseli.
W przypadku grupy algorytmów wykorzystujących miary oparte o kwadrat róż-
218

“KonspPreamb” 2013/10/3 page 219 #222
7. Wyniki badań eksperymentalnych
nic, również widoczna jest znaczna przewaga algorytmów wykorzystujących fuz-
zyfikację obrazów w przypadku obrazów zakłóconych szumem impulsowym typu
„sól i pieprz”. W przypadku pozostałych zakłóceń nie udało się osiągnąć aż tak
znaczącej poprawy otrzymywanych rezultatów.
W grupie algorytmów wykorzystujących miary korelacyjne najlepsze wyniki
w przypadku zakłócenia typu „sól i pieprz” zawartego w obrazach par stereosko-
powych otrzymane zostały przez zastosowanie algorytmów zawierających fuzzyfi-
kację obrazów. W przypadku pozostałych zakłóceń obecnych w obrazach par ste-
reoskopowych, nie udało się osiągnąć aż tak znacznej przewagi w wynikach otrzy-
mywanych przez algorytmy wykorzystujące opis obrazów w dziedzinie zbiorów
rozmytych i zbiorów IFS.
W przypadku algorytmów wykorzystujących transformaty obrazów dla wszyst-
kich typów zakłóceń wykorzystanie rozmytej transformaty rankingowej pozwoliło
na uzyskanie lepszych rezultatów w stosunku do algorytmu wykorzystującego kla-
syczną transformatę rankingową. Jednak w przypadku zakłócenia szumem impul-
sowym „sól i pieprz”, wykorzystanie transformaty rozmytej w algorytmie dopaso-
wania spowodowało spadek ilości prawidłowych dopasowań.
Wnioskiem kończącym może być stwierdzenie, że algorytm dopasowania ce-
chami wykorzystujący detektor krawędzi oparty o trójkątną rozmytą relację po-
dobieństwa pozwala na uzyskiwanie lepszych wyników w stosunku do algorytmu
MPG. Wykorzystanie algorytmów dopasowania obszarami działających w dziedzi-
nie zbiorów rozmytych i zbiorów IFS pozwala na uzyskiwanie nie gorszych rezul-
tatów dopasowania we wszystkich badanych przypadkach, niż przez zastosowanie
odpowiadających im algorytmów działających w dziedzinie jasności pikseli. Efekt
ten szczególnie dobrze widoczny jest w czasie analizy wyników otrzymanych dla
par stereoskopowych zakłóconych szumem impulsowym typu „sól i pieprz”, gdzie
rezultaty otrzymywane przez zastosowanie algorytmów działających w dziedzinie
zbiorów rozmytych i zbiorów IFS są zdecydowanie lepsze od rezultatów uzyskiwa-
nych przez zastosowanie algorytmów działających w dziedzinie jasności pikseli.
219

“KonspPreamb” 2013/10/3 page 220 #223
Rozdział 8
Zakończenie
Problem dopasowania obrazów pary stereoskopowej i ściśle z nim związany
problem wyznaczenia mapy dysparycji jest jednym z bardzo ważnych zagadnień
w dziedzinie maszynowego widzenia. Pomimo bardzo intensywnie prowadzonych
badań nad jego rozwiązaniem, nie istnieje metoda pozwalająca na uzyskanie pra-
widłowych wyników dla dowolnej pary stereoskopowej. Powodem takiego stanu
rzeczy są problemy związane z samym zagadnieniem, jak np. występowanie regio-
nów przesłoniętych w obrazach lub prawidłowe określenie zakresu poszukiwanej
dysparycji. W przypadku próby zastosowania maszynowego widzenia stereosko-
powego liczba problemów się zwiększa. Przykładem problemów występujących
w rzeczywistych zastosowaniach maszynowego widzenia stereoskopowego mogą
być zakłócenia wnoszone przez urządzenia elektroniczne akwizycji i przetwarzania
obrazów, jak również zakłócenia związane z niejednorodnością oświetlenia obra-
zowanej sceny.
Ciągle trwają więc prace nad poszukiwaniem nowych algorytmów pozwalają-
cych na rozwiązanie problemu dopasowania, jak również nad poprawą efektywno-
ści istniejących metod. Poszukiwane są metody odporne na zakłócenia oraz takie,
które umożliwiają znalezienie dopasowania w rzeczywistych zastosowaniach.
Przedstawiona praca wpisuje w się w nurt badawczy wykorzystania nowych
metod obliczeniowych stosowanych w celu poprawy wyników uzyskiwanych przez
algorytmy dopasowania. Celem przedstawionej pracy było sprawdzenie możliwo-
ści wykorzystania teorii zbiorów rozmytych do zaprojektowania metod umożliwia-
jących rozwiązanie problemu dopasowania obrazów pary stereoskopowej. Moty-
wacją do podjęcia badań nad próbą zastosowania zbiorów rozmytych w problemie
dopasowania pary stereoskopowej był fakt, że pomimo dużej popularności proble-
mu dopasowania obrazów pary stereoskopowej, jak również dużej popularności
teorii zbiorów rozmytych w literaturze istnieje niewielka ilość publikacji poświęco-
nych zagadnieniu zastosowanie teorii zbiorów rozmytych w celu rozwiązania pro-
blemu dopasowania. Aspektem decydującym o braku proponowanych rozwiązań
jest prawdopodobnie duża złożoność tak postawionego problemu. Podjęty w pracy
220

“KonspPreamb” 2013/10/3 page 221 #224
8. Zakończenie
temat badawczy znajduje się na pograniczu dwóch bardzo rozwiniętych teorii. Pra-
ca nad takim zagadnieniem wymaga więc dobrego zrozumienia obu teorii w sposób
umożliwiający poprawne połączenie ich elementów w jedną całość.
Jednak podjęcie badań w tym kierunku wydawało się bardzo dobrą decyzją. Za-
stosowanie zbiorów rozmytych jako narzędzia umożliwiającego przeprowadzanie
obliczeń na danych niepewnych i nieprecyzyjnych może doprowadzić do polepsze-
nia uzyskiwania rezultatów algorytmów operujących na tego rodzaju danych. Ob-
razy z zawartymi w nich zakłóceniami niewątpliwie zaliczają się do tego rodzaju
danych.
Przedstawione w pracy wyniki eksperymentalne pozwoliły na potwierdzenie
tej tezy. W algorytmach, w których wykorzystane zostały elementy teorii zbiorów
rozmytych otrzymane zostały lepsze rezultaty, niż w odpowiadających im znanych
z literatury algorytmach nie zawierających w swoim działaniu elementów teorii
zbiorów rozmytych. Zgodnie z wynikami przedstawionymi w pracy można stwier-
dzić, że zależność ta jest szczególnie prawdziwa, gdy obrazy pary stereoskopowej
zawierają zakłócenia szumowe.
8.1. Komentarz uzyskanych rezultatów
W pracy przedstawione zostały wyniki dla kilku kierunków zastosowań zbio-
rów rozmytych w problemie dopasowania obrazów pary stereoskopowej. Pierw-
szym z nich jest wykorzystanie relacji rozmytej w celu konstrukcji rozmytego de-
tektora krawędzi. Algorytm dopasowania pary stereoskopowej wykorzystujący ten-
że detektor pozwala na osiągnięcie znacząco lepszych rezultatów, niż dobrze znany
z literatury algorytm odniesienia MPG. Tak więc przedstawione wyniki ekspery-
mentalne potwierdziły zasadność podjęcia tego kierunku badań, jak również zasto-
sowania teorii zbiorów rozmytych w tak postawionym zagadnieniu.
Kolejna grupa przedstawionych metod rozwiązania problemu dopasowania pa-
ry stereoskopowej wykorzystuje zmianę dziedziny opisu obrazów i pozwala na uzy-
skanie opisu obrazów w dziedzinie zbiorów rozmytych. W pracy przedstawione zo-
stały dwie metody opisu. Pierwsza z nich pozwala na opisanie obrazu za pomocą
funkcji przynależności, podczas gdy druga pozwala na opis obrazu w dziedzinie in-
tuicjonistycznych zbiorów rozmytych. Po otrzymaniu opisu obrazów w dziedzinie
zbiorów rozmytych i zbiorów IFS możliwe jest rozwiązanie problemu dopasowa-
221

“KonspPreamb” 2013/10/3 page 222 #225
8. Zakończenie
nia pary stereoskopowej w ich dziedzinach. Zgodnie z przedstawionymi wynikami
można powiedzieć, że dopasowanie w dziedzinie zbiorów rozmytych jak i zbiorów
IFS również pozwala na osiągnięcie lepszych rezultatów, niż rezultaty osiągane
przez algorytmy dopasowania działające w dziedzinie jasności pikseli. Zależność
ta zachodzi przynajmniej dla odpowiadających sobie ideowo metod działających
w różnych dziedzinach, które zostały poddane szczegółowym badaniom w przed-
stawianej pracy.
Możliwy jest do sformułowania zarzut, że poprawa wyników jest niewielka.
Jednak przy tak dużej liczbie znanych algorytmów opracowanie algorytmu umoż-
liwiającego bardzo znaczną poprawę wyników wydaje się praktycznie niemożliwe.
Należy jednak stwierdzić, że osiągana poprawa jest jednak na tyle znacząca, że
może uzasadnić celowość podjęcia badań, jak również zastosowań opracowanych
w ich efekcie algorytmów dopasowania pary stereoskopowej wykorzystujących ele-
menty teorii zbiorów rozmytych.
Inną przedstawioną w pracy ideą jest zastosowanie rozmytej transformaty ran-
kingowej. Również w tym przypadku uzyskane zostały lepsze wyniki dopasowania
obrazów pary stereoskopowej, niż przy zastosowaniu algorytmów wykorzystują-
cych klasyczną transformatę rankingową.
Dużą wartością przedstawianej pracy jest znaczna ogólność części zaprojekto-
wanych metod. Zarówno rozmyty detektor krawędzi jak i metody fuzyfikacji obra-
zów umożliwiających ich opis w dziedzinie zbiorów rozmytych jak i zbiorów IFS są
na tyle ogólne, że można je z łatwością zastosować do projektowania algorytmów
rozwiązujących inne zagadnienia przetwarzania obrazów, jak np. segmentacja lub
filtracja obrazów.
8.2. Perspektywy dalszego rozwoju
Bardzo dobrym kierunkiem dalszego rozwoju zagadnień przedstawionych w pra-
cy wydaje się zastosowanie obrazów kolorowych w algorytmach dopasowania. Na-
turalnym stwierdzeniem wydaje się, że niebieska kropka nie powinna zostać za-
klasyfikowana jako odpowiadająca kropce zielonej. Jednak to intuicyjnie stwier-
dzenie, nie zostało potwierdzone przez badaczy, którzy już podjęli ten kierunek
w przedstawionych przez nich wynikach badań. Wykorzystanie obrazów koloro-
wych w problemie dopasowania obrazów pary stereoskopowej ciągle należy do
222

“KonspPreamb” 2013/10/3 page 223 #226
8. Zakończenie
zagadnień nie zbadanych bardzo szczegółowo i możliwe jest podjęcie dalszych ba-
dań w tym kierunku. Dopuszczalne jest także przypuszczenie, że przedstawione
w tej pracy algorytmy wykorzystujące w swoim działaniu elementy teorii zbiorów
rozmytych, działające na obrazach kolorowych pozwoliłby na uzyskanie znaczą-
co lepszych rezultatów. Odpowiedź na to pytanie, pozostaje jednak jako otwarty
kierunek badań.
Prawdopodobnym kierunkiem rozwoju algorytmów rozwiązujących problem
dopasowania pary stereoskopowej wydaje się również rozwój metod hybrydowych.
W obecnej chwili istnieją algorytmy pozwalające na uzyskanie bardzo dobrych
wyników w przypadku spełnienia szczególnych warunków dotyczących zawarto-
ści obrazowanej sceny lub rodzaju zakłóceń obecnych w obrazach pary stereosko-
powej. Rozwiązanie hybrydowe umożliwiające wykorzystanie tylko cech różnych
pozytywnych algorytmów pozwala na uzyskiwanie dobrych wyników w szerszym
obszarze zastosowań.
Takim rozwiązaniem hybrydowym bazującym na wynikach przedstawionej pra-
cy, mógłby być algorytm hybrydowy wykorzystujący zarówno wynik działania
algorytmu dopasowania krawędzi jak i algorytmu dopasowania obszarami. Teo-
ria zbiorów rozmytych mogłaby znaleźć tutaj dalsze zastosowania jako narzędzie
umożliwiające fuzje wyników otrzymywanych z dwóch różnych algorytmów. Ta-
ki algorytm prawdopodobnie pozwoliłby na uzyskanie bardzo dobrych wyników
rozwiązania problemu dopasowania obrazów pary stereoskopowej.
223

“KonspPreamb” 2013/10/3 page 224 #227
Bibliografia
[1] The Oxford Advanced Learner’s Dictionary, 7th Edition. Red. Wehmeier S.
Oxford New York: Oxford University Press, 2005. isbn: 01-94-31649-1.
[2] Słownik języka polskiego [online]. Wydawnictwo Naukowe PWN. [Dostęp:
29 sierpnia 2011]. Dostępny w Internecie: url: http://sjp.pwn.pl/.
[3] Howard I. P., Rogers B. J.: Binocular vision and stereopsis. USA: Oxford
University Press, Inc., 1995. isbn: 01-95-08476-4.
[4] Nowa encyklopedia powszechna PWN. Red. Kaczorowski B. Warszawa:
Wydawnictwo Naukowe PWN, 2004. isbn: 83-01-14179-4.
[5] Niżankowska M. H.: Podstawy okulistyki. Wyd. 2. Wrocław: Volumed, 2000.
isbn: 83-87804-14-2.
[6] Trucco E., Verri A.: Introductory techniques for 3-D computer vision. Up-
per Saddle River, New Jersey: Prentice Hall, Inc., 1998. isbn: 01-32-61108
-2.
[7] Duchinski M.: “Współpraca manipulatora z systemem wizyjnym”. Praca
magisterska. Wrocław: Politechnika Wrocławska, 2003.
[8] Rzeszotarski D., Strumiłło P., Pełczyński P., [i in.]: “System obrazowa-
nia stereoskopowego sekwencji scen trójwymiarowych”. Elektronika: pra-
ce naukowe 10, 2005, str. 165–184.
[9] Cyganek B.: Komputerowe przetwarzanie obrazów trójwymiarowych. War-
szawa: Akademicka Oficyna Wydawnicza EXIT, 2001. isbn: 83-87674-34
-6.
[10] Hong L., Chen G.: “Segment-based stereo matching using graph cuts”. Pro-
ceedings of the 2004 IEEE Computer Society Conference on Computer Vi-
sion and Pattern Recognition CVPR 2004. Tom 1. Washington, DC, USA,
2004, str. 74–81.
[11] Hannah M. J.: “Digital stereo image matching techniques”. International
Archives for Photogrammetry and Remote sensing 27(111), 1988, str. 280
–293.
224

“KonspPreamb” 2013/10/3 page 225 #228
BIBLIOGRAFIA
[12] Lazaros N., Sirakoulis G. C., Gasteratos A.: “Review of stereo vision algo-
rithms: from software to hardware”. International Journal of Optomecha-
tronics, 2(4), 2008, str. 435 –462.
[13] Tomaszewski M., Skarbek W.: “Liniowa odpowiedniość pozy kamery w bie-
gunowym dopasowaniu obrazów”. Przegląd Telekomunikacyjny i Wiado-
mości Telekomunikacyjne (KKRRiT 2009) 82(6), 2009, str. 384–387.
[14] Piegat A.: Modelowanie i sterowanie rozmyte. Warszawa: Akademicka Ofi-
cyna Wydawnicza EXIT, 1999. isbn: 83-87674-14-1.
[15] Butkiewicz B.: Metody wnioskowania przybliżonego. Właściwości i zasto-
sowanie. Warszawa: Oficyna Wydawnicza Politechniki Warszawskiej, 2001.
[16] Łachwa A.: Rozmyty świat zbiorów, liczb, relacji, faktów, reguł i decyzji.
Warszawa: Akademicka Oficyna Wydawnicza EXIT, 2001. isbn: 83-87674
-21-4.
[17] Rutkowski L.: Metody i techniki sztucznej inteligencji. Wydawnictwo Na-
ukowe PWN, 2006. isbn: 83-01-14529-3.
[18] Nieradka G.: “Method for edge detection in images using fuzzy relation”.
Proceedings of the SPIE. Tom 6937. 2008, str. 69373E–8.
[19] Nieradka G., Butkiewicz B.: “Features stereo matching based on fuzzy
logic”. Proceedings of the Joint International Fuzzy Systems Association
World Congress and European Society of Fuzzy Logic and Technology Con-
ference. Lisbon, Portugal, 2009, str. 1188–1193.
[20] Nieradka G., Butkiewicz B.: “A method for automatic membership func-
tion estimation based on fuzzy measures”. Foundations of Fuzzy Logic and
Soft Computing. Tom 4529. Lecture Notes in Computer Science. Springer
Berlin / Heidelberg, 2007, str. 451–460.
[21] Nieradka G.: Rozdz. Intuitionistic fuzzy sets applied to stereo matching pro-
blem. [w:] “Development in Fuzzy Sets, Intuitionistic Fuzzy Sets, Gene-
ralized Nets and Related Topics. Applications.” Pod. red. Atanassov A,
Chountas P, Kacprzyk J, [i in.]. Tom 2. Warszawa: Akademicka Oficyna
Wydawnicza EXIT, 2008, str. 161–171. isbn: 978-83-60434-53-6.
[22] Nieradka G.: “Disparity smoothing algorithm for three-dimensional scene
reconstruction”. Proceedings of the 14th International Conference on Me-
thods and Models in Automation and Robotics. Tom 14 (1). 2009, str. 1–6.
225

“KonspPreamb” 2013/10/3 page 226 #229
BIBLIOGRAFIA
[23] Hartley R., Zisserman A.: Multiple view geometry in computer vision. Wyd.
2. Cambridge, United Kingdom: Cambridge University Press, 2003. isbn:
05-21-54051-8.
[24] Faugeras O., Loung Q.-T., Papadopoulo T.: The geometry of multiple ima-
ges. London, England: The MIT Press, 2001. isbn: 02-62-06220-8.
[25] Wöhler C.: 3D computer vision. Efficient methods and applications. New
York: Springer-Verlag, 2009. isbn: 36-42-01731-2.
[26] Emerging topics in computer vision. Red. Medioni G., Kang S. B. Up-
per Saddle River, New Jersey: IMSC Press Multimedia Series, 2003. isbn:
01-31-01366-1.
[27] Elias R.: Rozdz. Geometric Modeling in Computer Vision: An Introduction
to Projective Geometry. [w:] “Wiley Encyclopedia of Computer Science
and Engineering”. Pod. red. Wah B. Tom 3. John Wiley & Sons, Inc., 2009,
str. 1400–1416. isbn: 0-471-38393-7.
[28] Elias R.: “Projective geometry for three-dimensional computer vision”. Pro-
ceedings of the Seventh World Multiconference on Systemics, Cybernetics
and Informatics, SCI’03. Tom 5. Orlando, Florida, USA, 2003, str. 99–104.
[29] Kuffar H., Takaya K.: “Depth measurement and 3D metric reconstruction
from two uncalibrated stereo images”. Proceedings of the Canadian Con-
ference on Electrical and Computer Engineering, (CCECE 2007). Vanco-
uver, BC, 2007, str. 1460–1463.
[30] Bocquillon B., Bartoli A., Gurdjos P., [i in.]: “On constant focal length
self-calibration from multiple views”. Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, 2007. CVPR ’07. Minneapo-
lis, MN, 2007, str. 1–8.
[31] Guerchouche R., Coldefy F.: “Camera calibration methods evaluation pro-
cedure for images rectification and 3D reconstruction”. Proceedings of the
16th International Conference in Central Europe on Computer Graphics,
Visualization and Computer Vision’2008 (WSCG’2008). Plzen, Czech Re-
public, 2008, str. 205–210.
[32] Miosso C. J., Almeida Mencari M. de, Bauchspiess A.: “Stereo vision sys-
tem applied to the reconstruction of polyhedric structures”. Proceedings
of the Fourth Industry Applications Conference (INDUSCON’2000). Porto
Alegre, Brasil, 2000, str. 576–581.
226

“KonspPreamb” 2013/10/3 page 227 #230
BIBLIOGRAFIA
[33] Ke X, Sutton M. A., Lessner S. M., [i in.]: “Robust stereo vision and calibra-
tion methodology for accurate three-dimensional digital image correlation
measurements on submerged objects”. The Journal of Strain Analysis for
Engineering Design 43(8), 2008, str. 689–704.
[34] Thormaählen T., Broszio H., Wassermann I.: “Roubst line-based calibra-
tion of lens distortion from a single view”. Proceedings of Mirage 2003
( Computer Vision / Computer Graphics Collaboration for Model-based
Imaging, Rendering, Image Analysis and Graphical Special Effects). IN-
RIA Rocquencourt, France, 2003, str. 105–112.
[35] Ricolfe-Viala C., Sánchez-Salmerón A.-J.: “Roubst metric calibration of
non-linear camera lens distortion”. Pattern Recognition 43, 2010, str. 1688–
1699.
[36] Wu J., Ding W., Yuan Z., [i in.]: “Improving registration accuracy of AR
with non-linear camera model”. Proceedings of the IEEE Conference on
Mechatronics and Automation. Luoyang, China, 2006, str. 200–204.
[37] Chen H, Che R. S., Chen G: “A technique for binocular stereo vision system
calibration by the nonlinear optimization and calibration points with accu-
rate coordinates”. Journal of Physics: Conference Series 48, 2006, str. 806–
810.
[38] Sonka M., Hlavac V., Boyle R.: Image processing, analysis, and machine vi-
sion. Wyd. 3. Toronto, Ontario: Thomson Learning, 2008. isbn: 04-95-08-
252-X.
[39] Cyganek B., Siebert J. P.: An introduction to 3D computer vision techniques
and algorithms. Great Britain, Wiltshire: John Wiley & Sons, Ltd., 2009.
isbn: 04-70-01704-X.
[40] Jähne B.: Digital Image Processing. Wyd. 6. Berlin, Germany: Springer-
Verlag, 2002. isbn: 35-40-24035-7.
[41] Hesch J. A., Mourikis A. I., Roumeliotis S. I.: “Extrinsic camera calibration
using multiple reflections”. Lecture Notes in Computer Science 6301, 2010,
str. 311–325.
[42] Sun W., Cooperstock J. R.: “An empirical evaluation of factors influen-
cing camera calibration accuracy using three publicly available techniqu-
es”. Machine Vision and Applications 17(1), 2006, str. 51–67.
227

“KonspPreamb” 2013/10/3 page 228 #231
BIBLIOGRAFIA
[43] Bradley D., Heidrich W.: “Binocular camera calibration using rectification
error”. Proceedings of the Canadian Conference on Computer and Robot
Vision (CRV). Kanada, Ottawa, 2010, str. 183 –190.
[44] Beyer H. A.: “Accurate calibration of CCD cameras”. Proceedings of the
IEEE Computer Society Conference on Computer Vision and Pattern Re-
cognition (CVPR ’92). Champaign, IL, USA, 1992, str. 96–101.
[45] Zhang Z., Deriche R., Faugeras O., [i in.]: A robust technique for matching
two uncalibrated images throughe the recovery of the unknown epipolar
geometry. Raport badawczy, 2273. Institut national de recherche en infor-
matique en automatique (INRIA), 1994.
[46] Zhang Z.: “Determining the epipolar geometry and its uncertainty: a re-
view”. International Journal of Computer Vision 27(2), 1998, str. 161–198.
[47] Brown M. Z., Burschka D., Hager G. D.: “Advances in computational ste-
reo”. IEEE Transactions on Pattern Analysis and Machine Intelligence 25(8),
2003, str. 993–1008.
[48] Gosta M., Grgic M.: “Accomplishments and challenges of computer stereo
vision”. Proceedings ot the 52 International Symposium ELMAR-2010, Za-
dar, Croatia, 2010, str. 57–64.
[49] Whitehead A., Roth G.: “Estimating intrinsic camera parameters from the
fundamental matrix using an evolutionary approach”. EURASIP Journal
on Applied Signal Processing 8, 2004, str. 1112–1124.
[50] Bert J., Dembèlè S., Lefort-Piat N.: “Performing weak calibration at the
microscale, application to micromanipulation”. Proceedings of the IEEE
International Conference on Robotics and Automation. Roma, Italy, 2007,
str. 4937 –4942.
[51] Ihrke I., Ahrenberg L., Magnor M.: “External camera calibration for syn-
chronized multi-video systems”. Journal of WSCG 12(1–3), 2004, str. 1–
12.
[52] Armangué X, Salvi J, Batlle J: “A comparative review of camera calibra-
ting methods with accuracy evaluation”. Pattern Recognition 35(7), 2002,
str. 1617–1635.
[53] Barnard S. T., Thomson W. B.: “Disparity analysis of images”. IEEE Trans-
actions on Pattern Analysis and Machine Intelligence PAMI-2(4), 1980,
str. 333–340.
228

“KonspPreamb” 2013/10/3 page 229 #232
BIBLIOGRAFIA
[54] Lin G.-Y., Chen X.: “A robust epipolar rectification method of stereo pairs”.
Proceedings of the IEEE International Conference on Measuring Techno-
logy and Mechatronics Automation. Changsha, China, 2010, str. 322–326.
[55] Jawed K., Morris J., Khan T., [i in.]: “Real time rectification for stereo cor-
respondence”. Proceedings of the International Conference on Computa-
tional Science and Engineering. 2009, str. 277–284.
[56] Liebowitz D., Zisserman A.: “Metric rectification for perspective images of
planes”. Proceedings of the IEEE Computer Society Conference on Compu-
ter Vision and Pattern Recognition. Santa Barbara, CA, USA, 1998, str. 482
–488.
[57] Fusiello A., Trucco E., Veri A.: “A compact algorithm for rectification of
stereo pairs”. Machine Vision and Applications 12(1), 2000, str. 16–22.
[58] Sàra R., Bajscy R.: “On occluding contour artifacts in stereo vision”. Proce-
edings of the IEEE Computer Society Conference on Computer Vision and
Pattern Recognition, CVPR ’97. San Juan, Puerto Rico, 1997, str. 852–857.
[59] Kim J. C., Lee K. M., Choi B. T., [i in.]: “A dense stereo matching using
two-pass dynamic programming with generalized ground control points”.
Proceedings of the IEEE Computer Society Conference on Computer Vision
and Pattern Recognition (CVPR’05). Tom 2. 2005, str. 1075–1082.
[60] Kang S. B., Szeliski R., Chi J.: “Handling occlusions in dense multi-view
stereo”. Proceedings of the IEEE Computer Society Conference on Com-
puter Vision and Pattern Recognition, (CVPR 2001). Tom 1. 2001, str. I–
103–110.
[61] Egnal G., Wildes R. P.: “Detecting binocular half-occlusions: empirical
comparisons of five approaches”. IEEE Transactions on Pattern Analysis
and Machine Intelligence 24(8), 2002, str. 1127–1133.
[62] Barrois B., Konrad M., Wöhler C., [i in.]: “Resolving stereo matching er-
rors due to repetitive structures using model information”. Pattern Reco-
gnition Letters 31(1), 2010, str. 1683–1692.
[63] Kim Y.-K., Kim S.-Y., Ho Y.-S.: “Stereo matching using global and local
segmentation”. International Technical Conference on Circuits/Systems,
Computers and Communications (ITC-CSCC). Busan, Korea, 2007, str.
1225 –1226.
229

“KonspPreamb” 2013/10/3 page 230 #233
BIBLIOGRAFIA
[64] Gerrits M., Bekaert P.: “Local stereo matching with segmentation based
outlier rejection”. Proceedings of the 3rd Canadian Conference on Com-
puter and Robot Vision. 2006, str. 66–66.
[65] Bleyer M., Gelautz M.: “Graph-cut-based stereo matching using image seg-
mentation with symmetrical treatment of occlusions”. Signal Processing:
Image Communication 22, 2007, str. 127–143.
[66] Candocia F. M.: “A scale-preserving lens distortion dodel and its applica-
tion to image registration”. Proceedings of the Florida Conference on Re-
cent Advances in Robotics, (FCRAR 2006). Miami, Florida, 2006, str. 1–6.
[67] Villiers J. P. de, Leuschner F. W., Geldenhuys R.: “Centi-pixel accura-
te real-time inverse distortion correction”. Proceedings of the Internatio-
nal Symposium on Optomechatronic Technologies. Tom 7266. ISOT2008.
2008, str. 1–8.
[68] Jin H., Soatto S., Yezzi Anthony J: “Multi-view stereo beyond Lambert”.
Proceeding of the IEEE Computer Society Conference on Computer Vision
and Pattern Recognition (CVPR 03). Tom 1. 2003, str. I–171–178.
[69] Ihrke I., Kutulakos K. N., Lensch H. P. A., [i in.]: “State of the art in transpa-
rent and specular object reconstruction”. Proceedings of the Eurographics.
Crete, Greece, 2008, str. 87–108.
[70] Tsin Y., Kang S. B., Szeliski R.: “Stereo matching with reflections and
translucency”. Proceedings of the IEEE Computer Society Conference on
Computer Vision and Pattern Recognition. Tom 1. 2003, str. I–702–709.
[71] Mayer H.: “Analysis of means to improve cooperative disparity estimation”.
International Archives of the Photogrammetry, Remote Sensing and Spatial
Information Sciences 34(3/8), 2003, str. 25–32.
[72] Sadeghi H., Moallem P., Monadjemi S. A.: “Feature based dense stereo
matching using dynamic programming and color”. International Journal
of Information and Mathematical Sciences 4(3), 2008, str. 179–186.
[73] Mark W. van der, Gavrila D.: “Real-time dense stereo for intelligent vehic-
les”. IEEE Transactions on Intelligent Transportation Systems 7(1), 2006,
str. 38–50.
[74] Szeliski R., Zabih R., Scharstein D., [i in.]: “A comparative study of energy
minimization methods for markov random fields”. IEEE Transactions on
Pattern Analysis and Machine Intelligence 30(6), 2006, str. 1068–1080.
230

“KonspPreamb” 2013/10/3 page 231 #234
BIBLIOGRAFIA
[75] Sarkis M., Diepold K.: “Towards real-time stereo using non-uniform ima-
ge sampling and sparse dynamic programming”. Proceedings of the Fourth
International Symposium on 3D Data Processing, Visualization and Trans-
mission. Atlanta, GA, USA, 2008, str. 1–8.
[76] Cassisa C.: “Local vs global energy minimization methods: application
to stereo matching”. Proceedings of the IEEE International Conference
on Progress in Informatics and Computing (PIC). Shanghai, China, 2010,
str. 678–683.
[77] Handbook of mathematical models in computer vision. Red. Paragois N.,
Chen Y., Faugeras O. New York, USA: Springer Science+Business Media,
Inc., 2006. isbn: 0-387-26371-3.
[78] West D. B.: Introduction to graph theory. Wyd. 2. Delhi, India: Pearson
Education Pte. Ltd., 2002. isbn: 81-7808-830-4.
[79] Roy S., Cox I. J.: “A maximum-flow formulation of the N-camera stereo
correspondence problem”. Proceedings of the Sixth International Confe-
rence on Computer Vision (ICCV’98). Bombay, India, 1998, str. 492–499.
[80] Roy S.: “Stereo without epipolar lines: a maximum-flow formulation”. In-
ternational Journal of Computer Vision 34(2/3), 1999, str. 147–161.
[81] Ishikawa H., Geiger D.: “Occlusions, discontinuities and epipolar lines in
stereo”. Proceedings of the Fifth European Conference on Computer Vision
(ECCV ’98). Freiburgh, Germany, 1998, str. 1–14.
[82] Bykov Y., Veksler O., Zabih R.: “Fast approximate energy minimization
via graph cuts”. Proceedings of the International Conference on Computer
Vision. Tom 1. Kerkyra, Greece, 1999, str. 377–384.
[83] Bykov Y., Veksler O., Zabih R.: “Fast Approximate energy minimization
via graph cuts”. IEEE Transactions on Pattern Analysis and Machine In-
telligence 23(11), 2001, str. 1–18.
[84] Kolmogorov V., Zabih R.: “Computing visual correspondence with occ-
lusions using graph cuts”. Proceedings of the Eighth IEEE International
Conference on Computer Vision (ICCV 2001). Tom 2. Vancouver, BC, Ca-
nada, 2001, str. 508 –515.
[85] Kolmogorov V., Zabih R.: “What energy functions can be minimized via
graph cuts?” IEEE Transactions on Pattern Analysis and Machine Intelli-
gence 26(2), 2004, str. 147–159.
231

“KonspPreamb” 2013/10/3 page 232 #235
BIBLIOGRAFIA
[86] Cormen T. H., Leiserson C. E., Rivest R. L.: Wprowadzenie do algorytmów.
Warszawa: Wydawnictwa Naukowo-Techniczne, 2001. isbn: 83-204-2665
-0.
[87] Ohta Y., Kanade T.: “Stereo by intra-and inter-scanline search using dyna-
mic programming”. IEEE Transactions on Pattern Analysis and Machine
Intelligence 7(2), 1985, str. 139–154.
[88] Leung C., Appleton B., Changming S.: “Fast stereo matching by itera-
ted dynamic programming and quadtree subregioning”. Proceedings of the
British Machine Vision Conference. Kingston University, London, 2004,
str. 97–106.
[89] Sorgi L., Neri A.: “Bidirectional dynamic programming for stereo mat-
ching”. Proceedings of the IEEE International Conference on Image Pro-
cessing. Atlanta, GA, 2006, str. 1013–1016.
[90] Ferrari V., Tuytelaars T., Van Gool L.: “Wide-baseline multiple-view cor-
respondences”. Proceedings of the IEEE Computer Society Conference on
Computer Vision and Pattern Recognition (CVPR’03). Tom 1. 2003, str. I–
718–725.
[91] Di Stefano L., Mattoccia S.: “Fast template matching using bounded partial
correlation”. Machine Vision and Applications 13(4), 2003, str. 213–221.
[92] Tsai D.-M., Lin C.-T., Chen J.-F.: “The evaluation of normalized cross cor-
relations for defect detection”. Pattern Recognition Letters 24(15), 2003,
str. 2525–2535.
[93] Sun C.: “A fast stereo matching method”. Digital Image Computing: Tech-
niques and Applications. New Zealand, 1997, str. 95–100.
[94] Di Stefano L., Mattoccia S., Tombari F.: “ZNCC-based template matching
using bounded partial correlation”. Pattern Recognition Letters 26(14), 2005,
str. 2129–2134.
[95] Arcara P, Di Stefano L, Mattoccia S, [i in.]: “Perception of depth infor-
mation by means of a wire-actuated haptic interface”. Proceedings of the
IEEE International Conference on Robotics & Automation. Tom 4. San
Francisco, CA , USA, 2000, str. 3443–3448.
[96] Di Stefano L., Marchionni M., Mattoccia S.: “A fast area-based stereo mat-
ching algorithm”. Image and Vision Computing 22(12), 2001, str. 983–
1005.
232

“KonspPreamb” 2013/10/3 page 233 #236
BIBLIOGRAFIA
[97] Hirschmüller H.: “Improvements in real-time correlation-based stereo vi-
sion”. Proceedings of the IEEE Workshop on Stereo and Multi-Baseline
Vision (SMBV’01). Kauai, HI , USA, 2001, str. 141–148.
[98] Cai J.: “Fast stereo matching: coarser to finer with selective updating”. Pro-
ceedings of the Image and Vision Computing New Zealand Conference.
Hamilton, New Zealand, 2007, str. 266–270.
[99] Roma N., Santos-Victor J., Tomé J.: Rozdz. A comparative analysis of cross
-correlation matching algorithms using a pyramidal resolution approach.
[w:] “Empirical evaluation methods in computer vision”. Pod. red. Chri-
stensen H. I., Phillips P. J. World Scientific Press, 2002, str. 117–143. isbn:
98-10-24953-5.
[100] Yoon K.-J., Kweon I. S.: “Adaptive support-weight approach for correspon-
dence search”. IEEE Transactions on Pattern Analysis and Machine Intel-
ligence 28(4), 2006, str. 650–656.
[101] Lourakis M. I. A., Argyros Antonis A., Marias K.: “A graph-based ap-
proach to corner matching using mutual information as a local similarity
measure”. Proceedings of the 17th International Conference on Pattern Re-
cognition (ICPR’04). Tom 2. Cambridge, UK, 2004, str. 827–830.
[102] Hirschmüller H.: “Accurate and efficient stereo processing by semi-global
matching and mutual information”. Proceedings of the IEEE Computer So-
ciety Conference on Computer Vision and Pattern Recognition (CVPR).
Tom 2. San Diego, CA, USA, 2005, str. 807–814.
[103] Sarkar I., Bansal M.: “A wavelet-based multiresolution approach to so-
lve the stereo correspondence problem using mutual information”. IEEE
Transactions on Systems, Man and Cybernetics Part B: Cybernetics 37(4),
2007, str. 1009–1014.
[104] Studholme C, Hill D, Hawkes D: “An overlap invariant entropy measure of
3D medical image alignment”. Pattern Recognition 32(1), 1999, str. 71–96.
[105] Egnal G.: Mutual information as a stereo correspondence measure. Raport
badawczy, MS-CIS-00-20. University of Pennsylvania, 2000.
[106] Fookes C., Maeder A., Sridharan S., [i in.]: “Multi-spectral stereo image
matching using mutual information”. Proceedings of the 2nd Internatio-
nal Symposium on 3D Data Processing, Visualization, and Transmission
(3DPVT’04). Thessaloniki, Greece, 2004, str. 961–968.
233

“KonspPreamb” 2013/10/3 page 234 #237
BIBLIOGRAFIA
[107] Ramírez J. M., Paz-Luna O., Salazar H.: “A hierachical block matching ste-
reo algorithm based on cepstrum analysis for remote sensing”. Proceedings
of the XIV Iberchip Workshop. Puebla, Mexico, 2008, str. 1–4.
[108] Mukherjee D., Wang G., Wu Q.: “Stereo matching algorithm based on cu-
rvelet decomposition and modified support weights”. Proceedings of the
IEEE International Conference on Acoustics Speech and Signal Processing
(ICASSP). Dallas, TX, 2010, str. 758–761.
[109] Ahlvers U., Zoelzer U., Rechmeier S.: “FFT-based disparity estimation for
stereo image coding”. Proceedings of the International Conference on Ima-
ge Processing. Tom 1. Barcelona, Catalonia, Spain, 2003, str. I –761–4.
[110] Solari F, Sabatini S. P., Bisio G. M.: “A fast technique for phase-based di-
sparity estimation with no explicit calculation of phase”. Electronics Letters
37(23), 2001, str. 1382–1383.
[111] Díaz J., Ros E., Sabatini S. P., [i in.]: “A phase-based stereo vision system-
on-a-chip”. BioSystems 87, 2007, str. 314–321.
[112] Goswami J. C., Chan A. K.: Fundamentals of wavelets : theory, algorithms,
and applications. Hoboken, New Jersey: John Wiledy & Sons, Inc., 2011.
isbn: 04-71-19748-3.
[113] Burrus C. S., Gopinath R. A., Guo H.: Introduction to wavelets and wavelet
transforms: a primer. Upper Saddle River, New Jersey: Prentice Hall, 1998.
isbn: 01-34-89600-9.
[114] Wawrzyniak K.: “Analiza czasowo-częstotliwościowa akustycznych obra-
zów falowych za pomocą tranformaty falkowej”. Geologia 31(3/4), 2005,
str. 309–335.
[115] Bołt W.: “Zastosowanie układów falkowych do aproksymacji rozwiązań
równań różniczkowych”. Praca magisterska. Uniwersytet Gdański, Wydział
Matematyki, Fizyki i Informatyki, 2008.
[116] Wavelets and their applications. Red. Misiti M., Misiti Y., Oppenheim G.,
[i in.]. London, UK: ISTE Ltd., 2007. isbn: 9-781-90520931-6.
[117] Calderbank A. R., Daubechies I., Sweldens W., [i in.]: “Wavelet transforms
that map integers to integers”. Applied and Computational Harmonic Ana-
lysis 5, 1998, str. 332–369.
[118] Białasiewicz J. T.: Falki i aproksymacje. Warszawa: Wydawnictwa Nauko-
wo-Techniczne, 2004. isbn: 83-204-2557-3.
234

“KonspPreamb” 2013/10/3 page 235 #238
BIBLIOGRAFIA
[119] Wojtaszczyk P.: Teoria falek. Warszawa: Wydawnictwo Naukowe PWN,
2000. isbn: 83-01-13322-8.
[120] Xiong Y., Quek F. “Stereo matching approach based on wavelet analysis for
3D reconstruction in neurovision system”. Proceedings of SPIE. Pod. red.
Nasrabadi N. M., Katsaggelos Aggelos K. Tom 5015. 2003.
[121] Wu Y.-T., Chen L.-F., Lee P.-L., [i in.]: “Discrete signal matching using
coarse-to-fine wavelet basis functions”. Pattern Recognition 36, 2003, str.
171 –192.
[122] Zadeh P. B., Serdean C. V.: “Stereo correspondence matching using mul-
tiwavelets (ICDT ’10)”. Proceedings ot the IEEE Fifth International Confe-
rence on Digital Telecommunications. Washington, DC, USA, 2010, str. 153
–157.
[123] Zabih R., Woodfill J.: “Non-parametric local transform for computing vi-
sual correspondence”. Proceedings of the third European conference on
Computer Vision ECCV ’94. Tom 2. Stockholm, Sweden, 1994, str. 151–
158.
[124] Banks J., Bennamoun M.: “Reliability analysis of the rank transform for
stereo matching”. IEEE Transactions on Systems, Man and Cybernetics –
Part B: Cybernetics 31(6), 2001, str. 870–880.
[125] Ambrosch K., Kubinger W., Humenberg M., [i in.]: “Flexible hardware–
based stereo matching”. EURASIP Journal on Embedded Systems, 2008,
str. 1–12.
[126] Fröba B., Ernst A.: “Face detection with the modified census transform”.
Proceedings of the Sixth IEEE Conference on Automatic Face and Gesture
Recognition. Santa Barbara, USA, 2004, str. 91–96.
[127] Kim H. J., Lee Y.-G., Cho K. H., [i in.]. “Disparity estimation using ed-
ge model for stereo video compresion”. Proceedings of SPIE-IS&T Elec-
tronic Imaging. Pod. red. Apostolopoulos J. G., Said A. Tom 6077. 2006,
60772A–1–9.
[128] Bay H., Ferrari V., Van Gool L.: “Wide-baseline stereo matching with line
segments”. Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition. Tom 1. San Diego, CA, USA, 2005, str. 329–336.
235

“KonspPreamb” 2013/10/3 page 236 #239
BIBLIOGRAFIA
[129] Étienne V., Laganiére R.: “Matching feature points in stereo pairs: a com-
parative study of some matching strategies”. Machine Graphics & Vision
10(3), 2001, str. 237–259.
[130] Dankers A., Barnes N., Zelinsky A.: “Active vision - rectification and depth
mapping”. Proceedings of the Australian Conference on Robotics and Au-
tomation (ACRA). Canberra, Australia, 2004, str. 1–11.
[131] Ivaturi A., Kalmar H.: Uncalibrated rectification with reduced geometric
and visual distortion. Raport badawczy, Blekinge Tekniska Högskola, 2007.
[132] Lu Y., Smith S.: “A comprehesive tool for recovering 3d models from
2d photos with wide baselines”. Proceedings of the IASTED Internatio-
nal Conference Human-Computer Interaction. Phoenix, AZ, USA, 2005,
str. 108–113.
[133] Loaïza H., Triboulet J., Lelandais S., [i in.]: “Matching segments in ste-
reoscopic vision”. IEEE Instrumentation & Measurement Magazine 4(1),
2001, str. 37–42.
[134] Moallem P., Faez K.: “Fast edge-based stereo matching and geometric para-
meters”. International Journal of Pattern Recognition and Image Analysis
(Advances in Mathematical Theory and Application) 13, 2003, str. 518 –
524.
[135] Belli T., Cord M., Philipp-Foliguet S.: “Color contribution for stereo image
matching”. Proceeding of the Internationl Conference on Colour in Gra-
phics and Image Processing, CGIP’2000. Saint-Étienne, France, 2000, str.
317 –322.
[136] Bleyer M., Chambon S.: “Does color really help in dense stereo matching?”
Proceedings of the Fifth International Symposium on 3D Data Processing,
Visualization and Transmission (3DPVT’10). Espace Saint-Martin, Paris,
France, 2010, str. 1–8.
[137] Bleyer M., Chambon S., Poppe U., [i in.]: “Evaluation of different methods
for using colour information global stereo matching approaches”. The In-
ternational Archives of the Photogrammetry, Remote Sensing and Spatial
Information Sciencies. Tom XXXVII. Beijing, China, 2008, str. 63–68.
[138] Hirschmüller H., Scharstein D.: “Evaluation of stereo matching costs on
images with radiometric differences”. IEEE Transactions on Pattern Ana-
lysis and Machine Intelligence 31(9), 2009, str. 1582–1599.
236

“KonspPreamb” 2013/10/3 page 237 #240
BIBLIOGRAFIA
[139] Compañ P., Satorre R., Rizo R., [i in.]: “Improving depth estimation using
colour information stereo vision”. Proceedings of the Fifth IASTED Inter-
national Conference on Visualization, Imaging, and Image Processing. Be-
nidorm, Spain, 2005, str. 520–525.
[140] Matthies L., Kanade T., Szeliski R.: “Kalman filter-based algorithms for es-
timating depth from image sequences”. International Journal of Computer
Vision 3(3), 1989, str. 209–238.
[141] Ivekovic S., Trucco E.: “Fitting subdivision surface models to noisy and
incomplete 3-D data”. Proceedings of the Third International Conference
Computer Vision/Computer Graphics Collaboration Techniques (MIRAGE
2007). Rocquencourt, France, 2007, str. 542–554.
[142] Moravec K., Harvey R., Bangham J. A.: “Improving stereo performance in
regions of low texture”. Proceedings of the British Machine Vision Confe-
rence (BMVC’98). Southampton, UK, 1998, str. 822–831.
[143] Sun J., Shum H.-Y., Zheng N.-N.: “Stereo matching using belief propaga-
tion”. Lecture Notes in Computer Science 2351, 2000, str. 510–524.
[144] Yang Q., Wang L., Ahuja N.: “A constant-space belief propagation algo-
rithm for stereo matching”. Proceedings of the IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR). San Francisco, CA, 2010,
str. 1458–1465.
[145] Klaus A., Sormann M., Karner K.: “Segment-based stereo matching using
belief propagation and a self-adapting dissimilarity measure”. Proceedings
of the 18th International Conference on Pattern Recognition (ICPR’06).
Hong Kong, 2006, str. 15–18.
[146] Gong M., Yang Y.-H.: “Multi-resolution stereo matching using genetic al-
gorithm”. Proceedings of the IEEE Workshop on Stereo and Multi-Baseline
Vision (SMBV’01). Kauai, Hawaii, 2001, str. 21–29.
[147] Han K.-P., Song K.-W., Chung E.-Y., [i in.]: “Stereo matching using gene-
tic algorithm with adaptive chromosomes”. Pattern Recognition 34, 2001,
str. 1729–1740.
[148] Liatsis P., Goulermas J. Y., Wang Y.: “Stereo correspondence using sym-
biotic genetic algorithms”. Proceedings of the 9th WSEAS International
Conference on Mathematics & Computers in Business and Economics
(MCBE ’08). Bucharest, Romania, 2008, str. 97–104.
237

“KonspPreamb” 2013/10/3 page 238 #241
BIBLIOGRAFIA
[149] Issa H., Ruichek Y., Postaire J.-G.: “A specific encoding scheme for ge-
netic stereo correspondence searching: application to obstacle detection”.
Journal of Systemics, Cybernetics and Informatics 1(1), 2003, str. 9–17.
[150] Wang X. N., Jiang P.: “Multiple ant colony optimizations for stereo mat-
ching”. International Journal of Image Processing 3(5), 2009, str. 203–217.
[151] Elias R.: “Sparse view stereo matching”. Pattern Recognition Letters 28,
2007, str. 1667–1678.
[152] Wang J.-H., Hsiao C.-P.: “On disparity matching in stereo vision via a neu-
ral network framework”. Proceedings of the National Science Council Re-
public of China Part A: Physical Science and Engineering 23(5), 1999,
str. 665–677.
[153] Zadeh L. A.: “Fuzzy sets”. Information and Control 8, 1965, str. 338–353.
[154] Guanrong C., Trung T. P.: Introduction to fuzzy sets, fuzzy logic, and fuz-
zy control systems. Washington, D.C., USA: CRC Press LLC, 2001. isbn:
08-49-31658-8.
[155] Wolkenhauer O.: Data engineering. Fuzzy mathematics in systems theory
and data analysis. New York, USA: John Wiley & Sons, Inc., 2001. isbn:
04-71-41656-8.
[156] Siler W., Buckley J. J.: Fuzzy expert systems and fuzzy reasoning. Hoboken,
New Jersey, USA: John Wiley & Sons, Inc., 2005. isbn: 04-71-38859-9.
[157] Fuzzy techniques in image processing. Red. Kerre E. E., Nachtegael M.
Heidelberg, Germany: Physica-Verlag, 2000. isbn: 37-90-81304-4.
[158] Chaira T., Ray A. K.: Fuzzy image processing and applications with MA-
TLAB. Washington, D.C., USA: CRC Press, 2009. isbn: 14-39-80708-6.
[159] Kuratowski K., Mostowski A.: Teoria mnogości. Warszawa: Polskie To-
warzystwo Matematyczne, 1952. isbn: Książka dostępna w internecie: http:
//matwbn.icm.edu.pl/kstresc.php?tom=27&wyd=10.
[160] Klir G. J., Yuan B.: Fuzzy sets and fuzzy logic. Theory and applications. Up-
per Saddle River, New Jersey: Prentice Hall PTR, 1995. isbn: 01-31-01171
-5.
[161] Zimmermann H.-J.: Fuzzy set theory and its applications. Wyd. 2. Nor-
well, Massachusetts, USA: Kluwer Academic Publishers, 1991. isbn: 07-
92-39075-X.
238

“KonspPreamb” 2013/10/3 page 239 #242
BIBLIOGRAFIA
[162] Sivanandam S., Sumathi S., Deepa S.: Introduction to fuzzy logic using
MATLAB. Berlin Heidelberg: Springer-Verlag, 2007. isbn: 35-40-35780-7.
[163] Cox E.: The fuzzy systems handbook: a practitioner’s guide to building,
using, and maintaining fuzzy systems. Chestnut Hill, MA,USA: AP Profes-
sional, 1994. isbn: 01-21-94270-8.
[164] Applications of fuzzy sets theory. Red. Masulli F., Mitra S., Pasi G. Berlin
Heidelberg: Springer-Verlag, 2007. isbn: 978-3-540-73399-7.
[165] Dubois D. J., Prade H.: Fuzzy sets and systems. Theory and applications.
Chestnut Hill, MA, USA: Academic Press, Inc., 1980. isbn: 01-22-22750–6.
[166] Pal N. R., Bezdek C: “Measuring fuzzy uncertainty”. IEEE Transactions
on Fuzzy Systems 2(2), 1994, str. 107–118.
[167] Wang W.-J., Chiu C.-H.: “Entropy and information energy for fuzzy sets”.
Fuzzy Sets and Systems 108, 1999, str. 333–339.
[168] Yager R.: “On the Measure of Fuzziness and Negation. Part I :Membership
in the Unit Interval”. International Journal of Intelligent Systems 5, 1979,
str. 221–229.
[169] Yager R.: “On the Measure of Fuzziness and Negation. Part II:Lattices”.
Information Control 44, 1980, str. 236–280.
[170] Al-sharhan S., Karray F., Gueaieb W., [i in.]: “Fuzzy entropy: a brief su-
rvey”. Proceedings of the IEEE International Fuzzy Systems Conference.
Tom 3. Melbourne, Vic., Australia, 2001, str. 1135–1139.
[171] Czogała E., Pedrycz W.: Elementy i metody teorii zbiorów rozmytych. War-
szawa: Państwowe Wydawnictwa Naukowe, 1985. isbn: 83-01-05726-2.
[172] Bezdek J. C., Keller J., Krisnapuram R., [i in.]: Fuzzy models and algori-
thms for pattern recognition and image processing. New York / Heidelberg:
Springer Science+Business Media, Inc., 2005. isbn: 03-87-24515-4.
[173] Fundamentals of fuzzy sets. Red. Dubois D., Prade H. Tom 7. The Handbo-
oks of Fuzzy Sets. New York: Springer-Verlag Inc., 2012. isbn: 978-1-4613
-6994-3.
[174] Zoran M., Rusov S.: “Z similarity measure among fuzzy sets”. FME Trans-
actions 34(2), 2006, str. 115–119.
[175] Zwick R., Carlstein E., Budescu D. V.: “Measures of similarity among fuz-
zy concepts: a comparative analysis”. International Journal of Approximate
Reasoning 1, 1987, str. 221–242.
239

“KonspPreamb” 2013/10/3 page 240 #243
BIBLIOGRAFIA
[176] Bloch I.: “On fuzzy distances and their use in image processing under im-
precision”. Pattern Recognition 32, 1999, str. 1873–1895.
[177] Kacprzyk J.: Zbiory rozmyte w analizie systemowej. Warszawa: Państwowe
Wydawnictwa Naukowe, 1986. isbn: 83-01-05497-2.
[178] Merigó J., Casanovas M.: “Decision making with distance measures and
linguistic aggregation operators”. International Journal of Fuzzy Systems
12(3), 2010, str. 190–198.
[179] Janis V., Montes S.: “Distance between fuzzy sets as a fuzzy quantity”. Acta
Universitatis Matthiae Belli 14, 2007, str. 41–49.
[180] Chaudhuri B. B., Bhattacharya A: “On correlation between two fuzzy sets”.
Fuzzy Sets and Systems 118, 2001, str. 447–456.
[181] Chiang D.-A., Lin N. P.: “Correlation of fuzzy sets”. Fuzzy Sets and Systems
102, 1999, str. 221–226.
[182] Matuszewska H., Matuszewski W.: Elementy logiki i teorii mnogości dla in-
formatyków. Warszawa: BEL Studio Sp. z o.o., 2003. isbn: 83-88442-56-2.
[183] Atanassov K. T.: “Intuitionistic fuzzy sets”. Fuzzy Sets and Systems 20,
1986, str. 87–96.
[184] Atanassov K. T.: “More on intuitionistic fuzzy sets”. Fuzzy Sets and Systems
33, 1989, str. 37–45.
[185] Atanassov K.: “On four intuitionistic fuzzy topological operators.” Math-
ware & Soft Computing 8, 2001, str. 65–70.
[186] Szmidt E., Kacprzyk J.: “Distances between intuitionistic fuzzy sets”. Fuz-
zy Sets and Systems 114, 2000, str. 505–518.
[187] Szmidt E., Kacprzyk J.: “Intuitionistic fuzzy sets in some medical applica-
tions”. Proceedings of the Fifth International Conference on Intuitionistic
Fuzzy Sets. Sofia, 2001, str. 22–23.
[188] Szmidt E., Kacprzyk J.: “A concept of similarity for intuitionistic fuzzy sets
and its use in group decision making.” Proceedings of the IEEE Interna-
tional Conference on Fuzzy Syststems. Budapest, Hungary, 2004, str. 1129–
1134.
[189] Kuppannan J., Rangasamy P.: “Intuitionistic fuzzy approach to enhance text
documents.” Proceedings of the 3rd International IEEE Conference on In-
telligent Systems. London, 2006, str. 733–737.
240

“KonspPreamb” 2013/10/3 page 241 #244
BIBLIOGRAFIA
[190] Vlachos I., Sergiadis G.: “Intuitionistic fuzzy information application to
pattern recognition.” Pattern Recognition Letters 28(2), 2007, str. 197–206.
[191] Szmidth E., Kacprzyk J.: “A measure of similarity for intuitionistic fuzzy
sets”. Proceedings of the Third Conference of the European Society for
Fuzzy Logic and Technology (EUSFLAT). Zittau, Germany, 2003, str. 206
–209.
[192] Hung W.-L., Yang M.-S.: “Similarity measures of intuitionistic fuzzy sets
based on Hausdorff distance”. Pattern Recognition Letters 25, 2004, str.
1603 –1611.
[193] Hong D. H.: “A note on correlation of interval-valued intuitionistic fuzzy
sets”. Fuzzy Sets and Systems 95(1), 1998, str. 113–117.
[194] Xie B., Mi J.-S., Han L.-W.: “Entropy and similarity measure of intuitioni-
stic fuzzy sets”. Proceedings of the International Conference on Machine
Learning and Cybernetics. Kunming, 2008, str. 501–506.
[195] Huang G.-S., Liu Y.-S., Wang X.-D.: “Some new distances between intu-
itionistic fuzzy sets”. Proceedings of the Fourth International Conference
on Machine Learning and Cybernetics. Guangzhou, 2005, str. 18–21.
[196] Hung W.-L., Yang M.-S.: “Similarity measures of intuitionistic fuzzy sets
based on Lp metric”. International Journal of Approximate Reasoning 46,
2007, str. 102–136.
[197] Zeng W., Li H.: “Correlation coefficient of intuitionistic fuzzy sets”. Jour-
nal of Industrial Engineering International 3(5), 2007, str. 33–40.
[198] Bustince H., Burillo P.: “Correlation of interval-valued intuitionistic fuzzy
sets”. Fuzzy Sets and Systems 75, 1995, str. 237–244.
[199] Park D. G., Kwun Y. C., Park J. H., [i in.]: “Correlation coefficient of
interval-valued intuitionistic fuzzy sets and its application to multiple attri-
bute group decision making problems”. Mathematical and Computer Mo-
delling 50, 2009, str. 1279–1293.
[200] Xu Z.: “On correlation measures of intuitionistic fuzzy sets”. Lecture Notes
on Computer Scienes 4224, 2006, str. 16–24.
[201] Mitchell H. B.: “A correlation coefficient for intuitionistic fuzzy sets”. In-
ternational Journal of Intelligent Systems 19, 2004, str. 483–490.
241

“KonspPreamb” 2013/10/3 page 242 #245
BIBLIOGRAFIA
[202] Hung W.-L.: “Using statistical viewpoint in developing correlation of intu-
itionistic fuzzy sets”. International Journal of Uncertainty, Fuzziness and
Knowledge-Based Systems 9(4), 2001, str. 509–516.
[203] Homepage of Fuzzy Image Processing [online]. Hamid R. Tizhoosh. [Do-
stęp: 29 sierpnia 2011]. Dostępny w Internecie: url: http://pami.uwaterloo.
ca/tizhoosh/readme.htm.
[204] Dombi J.: “Membership function as an evaluation”. Fuzzy Sets and Systems
35(1), 1990, str. 1–21.
[205] Makrehchi M., Basir O., Kamel M.: “Generation of fuzzy membership
function using information theory measures and genetic algorithm”. Fuzzy
Sets and Systems — IFSA 2003. Tom 2715. Lecture Notes in Computer
Science. Springer Berlin / Heidelberg, 2003, str. 603–610.
[206] Derbel I., Hachani N., Ounelli H.: “Membership functions generation ba-
sed on density function”. Proceddings of the International Conference on
Computational Intelligence and Security. Tom 1. Los Alamitos, CA, USA,
2008, str. 96–101.
[207] Nasibov E., Peker S.: “Exponentail membership function evaluation based
on frequency”. Asian Journal of Mathematics and Statistics 4(1), 20011,
str. 8–20.
[208] Medasani S., Kim J., Krishnapuram R.: “An overview of membership func-
tion generation techniques for pattern recognition”. Int. Journal of Appro-
ximate Reasoning 19(3-4), 1998, str. 391–417.
[209] Amaral T. G., Crisóstomo M. M., de Almeida A. T.: “Image thresholding
by minimisation of fuzzy compactness and linear index of fuzziness”. Pro-
ceedings of the IEEE International Conference on Fuzzy Systems. Tom 2.
IEEE. Seoul, Korea, 1999, str. 1116–1121.
[210] Vlachos I. K., Sergiadis G. D.: “Parametric indices of fuzziness for auto-
mated image enhancement”. Fuzzy Sets and Systems 157(8), 2006, 1126 –
1138.
[211] Anzueto-Rios A., Moreno-Cadenas J. A., Gómez-Castañeda: “Fuzzy tech-
nique for image enhancement using B-spline”. Proceedings of the 52nd IE-
EE International Midwest Symposium on Circuits and Systems (MWSCAS
’09). Cancun, 2009, str. 869–872.
242

“KonspPreamb” 2013/10/3 page 243 #246
BIBLIOGRAFIA
[212] Bloch I., Aurdal L., Bijno D., [i in.]: “Estimation of class membership func-
tions for grey level based image fusion”. Proceedings of the International
Conference on Image Processing. Tom 3. Santa Barbara, CA, USA, 1997,
str. 268–271.
[213] Bezdek J.: Pattern recognition with fuzzy objective function algorithms.
Norwell, MA, USA: Plenum, New York, 1981. isbn: 03-06-40671-3.
[214] Anvarifard M. K., Imandoost S., Yazdi H. S., [i in.]: “Image semantic retrie-
val using image fuzzyfication based on weighted relevance feedback”. Pro-
ceedings of the 18th Iranian Conference on Electrical Engineering
(ICEE’10). Isfahan, Iran, 2010, str. 476–482.
[215] Bharathi B., Sarma V.: “Estimation of fuzzy membership from histograms”.
Information Sciences 35(1), 1985, str. 43–59.
[216] Civanlar M., Trussel H.: “Construction membership functions using stati-
stical data”. Fuzzy Sets and Systems 18(1), 1986, str. 1–13.
[217] Cheng H., Cheng J.: “Automatically determine the membership function
based on the maximum entropy principle”. Information Sciences: an Inter-
national Journal 96(3-4), 1997, str. 163–182.
[218] Kumar S. S., Chatterji N: “Stereo matching algorithms based on fuzzy ap-
proach”. International Journal of Pattern Recognition and Artificial Intel-
ligence 16(7), 2002, str. 883–899.
[219] Knoll A., Wolfram A.: “Searching correspondences in colour stereo images
an approach using the fuzzy integral”. Proceedings of the 4th IEEE In-
ternational Conference on Fuzzy Systems and the 2nd International Fuzzy
Engineering Symposium. Tom 5. Yokohama, Japan, 1995, str. 2033–2038.
[220] Shamir L.: “A proposed stereo matching algorithm for noisy sets of color
images”. Computers & Geosciences 33, 2007, str. 1052–1063.
[221] Tolt G., Kalykov I.: “Measures based on fuzzy similarity for stereo mat-
ching of color images”. Soft Computing 10, 2006, str. 1117–1126.
[222] Hughes N. R., Roberts G. N., Wilson G. R.: “Application of fuzzy signal
processing to three dimensional vision”. Proceedings of the Fifth Interna-
tional Conference on The Technology Exploitation Process; Factory 2000.
Cambridge , UK, 1997, str. 319–324.
[223] Luo A, Tao W, Burkhardt H: “A new multilevel line-based stereo vision
algorithm based ond fuzzy techniques”. Proceedings of the 13th Interna-
243

“KonspPreamb” 2013/10/3 page 244 #247
BIBLIOGRAFIA
tional Conference on Pattern Recognition. Tom 1. Vienna, Austria, 1996,
str. 383 –387.
[224] Neubeck A., Van Gool L.: “Efficient non-maximum suppression”. Proce-
edings of the 18th International Conference on Pattern Recognition (ICPR
2006). Tom 3. Hong Kong, 2006, str. 850 –855.
[225] Goulermas J., Liatsis P.: “Hybrid symbiotic genetic optimisation for robust
edge-based stereo correspondence”. Pattern Recognition 34, 2001, str. 2477
–2496.
[226] Zadeh L.: “A fuzzy-algorithmic approach to the definition of complex or
imprecise concepts”. International Journal Man-Machines Studies 8(3),
1976, str. 249–291.
[227] Parsopoulos K. E., Vrahatis Michael N: Particle swarm optimization and
intelligence: advances and applications. Hershey, USA: Information Scien-
ce Reference (IGI Global), 2010. isbn: 16-15-20666-3.
[228] Jawahar C., Ray A.: “Fuzzy statistics of digital images”. IEEE Signal Pro-
cessing Letters 3(8), 1996, str. 225–227.
[229] Vlachos I., Sergiadis G.: “Towards intuitionistc fuzzy image processing”.
Proceedings of the International Conference on Computational Intelligen-
ce for Modelling, Control and Automation and International Conference
on Intelligent Agents, Web Technologies and Internet Commerce. Vienna,
Austria, 2005, str. 2–7.
[230] Shin M. C., Goldgof D. B., Bowyer K. W.: “Comparison of edge detector
performance through use in an object recognition task”. Computer Vision
and Image Understanding 84(1), 2001, str. 160–178.
[231] Lee M., Nepal S., Srinivasan U. “Role of edge detection in video seman-
tics”. Selected Papers from the 2002 Pan-Sydney Workshop on Visualisa-
tion. Pod. red. Jin J. S., Eades P., Feng D. D., [i in.]. Tom 161. ACM Inter-
national Conference Proceedings. 2003, str. 59–68.
[232] Wang D., Zhang X., Liu Y.: “Recognition system of leaf images based on
neuronal network”. Journal of Forestry Research 17(3), 2006, str. 243–246.
[233] Gao Y., Maylor K. H.: “Face recognition using line edge map”. IEEE Trans-
actions on Pattern Analysis and Machine Intelligence 24(6), 2002, str. 764–
779.
244

“KonspPreamb” 2013/10/3 page 245 #248
BIBLIOGRAFIA
[234] Liguori C., Paolillo A., Pietrosanto A.: “An on-line stereo-vision system
for dimensional measurements of rubber extrusions”. Measurement 35(3),
2004, str. 221–231.
[235] Wan Y. F., Cabestaing F., Burie J.-C.: “A new edge detector for obstacle
detection with a linear stereo vision system”. Proceedings of the Intelligent
Vehicles Symposium. Tom 161. Detroit, MI , USA, 1995, str. 130–135.
[236] Truchetet F., Nicolier F., Laligant O.: “Subpixel edge detection for dimen-
sional control by artificial vision”. Journal of Electronic Imaging 10(1),
2001, str. 234–239.
[237] Hou T.-H., Kuo W.-L.: “A new edge detection method for automatic visual
inspection”. The International Journal of Advanced Manufacturing Tech-
nology 13(6), 1997, str. 407–412.
[238] Canny J.: “A computational approach to edge detection”. IEEE Transac-
tions on Pattern Analysis and Machine Intelligence 8(6), 1986, str. 679–
698.
[239] Forsyth D. A., Ponce J.: Computer vision: a modern approach. Upper Sad-
dle River, USA: Prentice Hall, 2002. isbn: 01-30-85198-1.
[240] Pratt W. K.: Digital image processing. Wyd. 3. New York, USA: John Wiley
and Sons, Inc., 2001. isbn: 04-71-37407-5.
[241] Vernon D.: Machine vision, automated visual inspection and robot vision.
London, Great Britain: Prentice Hall, 1991. isbn: 01-35-43398-3.
[242] Smith S. M., Brady J. M.: “A new Approach to low level image processing”.
International Journal of Computer Vision 23(1), 1997, str. 45–78.
[243] Rosten E., Drummond T. “Machine learning for high-speed corner detec-
tion”. Proccedings of the European Conference on Computer Vision
(ECCV’06). Pod. red. Leonardis A., Bischof H., Pinz A. Tom 1. 2006,
str. 430–443.
[244] Trajković M., Hedley M.: “Fast corner detection”. Image and Vision Com-
puting 16(2), 1998, str. 75–87.
[245] Russo F.: “Edge detection in noisy images using fuzzy reasoning”. IEEE
Transactions on Instrumentation and Measurement 47(5), 1998, str. 1102–
1105.
245

“KonspPreamb” 2013/10/3 page 246 #249
BIBLIOGRAFIA
[246] Ishii H., Kimura T., Sone M., [i in.]: “An edge detection from images cor-
rupted by mixed noise using fuzzy inference”. Electronics and Communi-
cations in Japan 83(8), 2000, str. 39–50.
[247] Price K.: “Anything you can do, I can do better (no you can’t) ...” Computer
Vision, Graphics, And Image Processing 36(2/3), 1986, str. 387–391.
[248] Haralick R.: “Computer vision theory: the lack thereof”. Computer Vision,
Graphics and Image Processing 36, 1986, str. 272–286.
[249] Bowyer K. W., Phillips P. J.: Empirical evaluation techniques in compu-
ter vision. Los Alamitos, CA, USA: Wiley-IEEE Computer Society Press,
1998. isbn: 978-0-8186-8401-2.
[250] Wu A., Xu D., Xu Y., [i in.]: “Performance characterization in computer
vision: the role of visual cognition theory”. Lecture Notes in Artificial In-
telligence 3614, 2005, str. 1255–1264.
[251] Thacker N. A., Clark A. F., Barron J. L., [i in.]: “Performance characteri-
zation in computer vision: A guide to best practices”. Computer Vision and
Image Understanding 109, 2008, str. 305–334.
[252] Performance metrics for intelligent Systems (PerMIS’10) Workshop [onli-
ne]. The National Institute of Standards and Technology (NIST). [Dostęp:
28 sierpnia 2011]. Dostępny w Internecie: url: http://www.nist.gov/
el/isd/permis2010.cfm.
[253] Koschan A.: What is new in computational stereo since 1989: a survey
on current stereo papers. Raport badawczy, 93-22. Technische Universität
Berlin, 1993.
[254] Nalpantidis L., Sirakoulis G. C., Gasteratos A.: “Review of stereo matching
algorithms for 3D vision”. Proceedings of the 16th International Sympo-
sium on Measurement and Control in Robotics (ISMCR 2007). Warsaw,
Poland, 2007, str. 116–124.
[255] Ng O.-E., Ganapathy V.: “A novel modular framework for stereo vision”.
Proceedings of the IEEE/ASME International Conference on Advanced In-
telligent Mechatronics (AIM 2009). Singapore, 2009, str. 857 –862.
[256] Chowdhury M. H., Bhuiyan M. A.-A.: “A new approach for disparity map
determination”. Daffodil International University Journal of Science and
Technology 4(1), 2009, str. 9–13.
246

“KonspPreamb” 2013/10/3 page 247 #250
BIBLIOGRAFIA
[257] Nalpantidis L., Gasteratos A.: “Biologically and psychophysically inspired
adaptive support weights algorithm for stereo correspondence”. Robotics
and Autonomous Systems 58, 2010, str. 457–464.
[258] Humenberger M., Zinnera C., Webera M., [i in.]: “A fast stereo matching
algorithm suitable for embedded real-time systems”. Computer Vision and
Image Understanding 114(11), 2010, str. 1180–1202.
[259] Hu T., Huang M.: “A new stereo matching algorithm for binocular vision”.
International Journal of Hybrid Information Technology 3(1), 2010, str. 1–
8.
[260] Zigh E, Belbachir M. F.: “A neural method based on new constraints for
stereo matching of urban high-resolution satellite imagery”. Journal of Ap-
plied Sciences 10(18), 2010, str. 2010–2018.
[261] Silva C., Santos-Victor J.: “Intrinsic images for dense stereo matching with
ccclusions”. Proceedings of the 6th European Conference on Computer Vi-
sion Dublin (ECCV 2000). Dublin, Ireland, 2000, str. 100 –114.
[262] Felzenszwalb P. F., Huttenlocher D. P.: “Efficient belief propagation for
early vision”. Proceedings of the IEEE Computer Society Conference on
Computer Vision and Pattern Recognition (CVPR’04). Tom 1. Washington,
D.C., USA: IEEE Computer Society, 2004, str. 261–268.
[263] Scharstein D.: “View synthesis using stereo vision”. Praca doktorska. Cor-
nell University, 1997.
[264] Satoh K., Ohta Y.: “Occlusion detectable stereo – systematic comparison
of detection algorithms”. Proceedings of the 13th International Conference
on Pattern Recognition (ICPR’96). Vienna, Austria, 1996, str. 280–286.
[265] Nakamura Y., Matsuura T., Satoh K., [i in.]: “Occlusion detectable stereo
– occlusion patterns in camera matrix”. Proceedings of the IEEE Computer
Society Conference on Computer Vision and Pattern Recognition (CVPR’96).
San Francisco, CA , USA, 1996, str. 371–379.
[266] Scharstein D., Szeliski R.: “A taxonomy and evaluation of dense two-frame
stereo correspondence algorithms”. International Journal of Computer Vi-
sion 47(1-3), 2002, str. 7–42.
[267] Middlebury stereo vision page [online]. Middlebury College. [dostęp: 15
marca 2010]. Dostępny w Internecie: url: http://www.vision.middle-
bury.edu/stereo.
247

“KonspPreamb” 2013/10/3 page 248 #251
BIBLIOGRAFIA
[268] Scharstein D., Szeliski R.: “High-accuracy stereo depth maps using structu-
red light”. Proceedings of the IEEE Computer Society Conference on Com-
puter Vision and Pattern Recognition (CVPR ’03). Tom 1. Los Alamitos,
CA, USA, 2003, str. 195–202.
[269] Kostlivá J., Cech J., Šára R.: ROC based evaluation of stereo algorithms.
Raport badawczy, 8. Center for Machine Perception, Czech Technical Uni-
versity in Prague, 2007.
[270] CMP Stereo Algorithm Evaluation [online]. Center for Machine Perception,
Czech Technical University Prague. [dostęp: 13 kwietnia 2010]. Dostępny
w Internecie: url: http://cmp.felk.cvut.cz/~stereo/stereointro.
php.
[271] Advanced signal processing. Theory and implementation for sonar, radar
and non-invasive medical diagnostic systems. Red. Stergiopoulos S. Wyd.
2. CRC Press, Taylor & Francis Group, LLC, 2009. isbn: 14-20-06238-7.
[272] Zweig M. H., Campbell G.: “Receiver-Operating Characteristic (ROC) plots:
a fundamental evaluation tool in clinical medicine”. Clinical Chemistry
39(4), 1993, str. 561–577.
[273] Stoch P.: “Zastosowanie narzędzi statystycznych i matematycznych metod
sztucznej inteligencji do predykcji wystąpienia dysplazji oskrzelowo-płuc-
nej noworodków”. Praca doktorska. Kraków: Akademia Górniczo-Hutnicza
im. Stanisława Staszica w Krakowie, 2007.
[274] Fawcett T.: ROC graphs: notes and practical considerations for resear-
chers. Raport badawczy, HPL-2003-4. Palo Alto, CA: HP Laboratories,
2004.
[275] Kostlivá J., Sàra R.: “Feasibility boundary in dense and semi-dense ste-
reo matching”. Proceedings of the IEEE Computer Society Conference on
Computer Vision and Pattern Recognition (CVPR 2007). Minneapolis, Min-
nesota, USA, 2007, str. 1–8.
[276] Minglun G., Yang Y.-H.: “Fast unambiguous stereo matching using reliabi-
lity-based dynamic programming”. IEEE Transactions on Pattern Analysis
and Machine Intelligence 27(6), 2005, str. 998–1003.
[277] Rabin J., Delon J., Gousseau Y.: “A contrario matching of SIFT-like de-
scriptors”. Proceddings of the 19th International Conference on Pattern
Recognition (ICPR’08). Tampa, FL, 2008, str. 1–4.
248

“KonspPreamb” 2013/10/3 page 249 #252
BIBLIOGRAFIA
[278] Mordohai P.: “The self-aware matching measure for stereo”. Proceedings of
the 12th International Conference on Computer Vision (ICCV’09). Kyoto,
Japan, 2009, str. 1841–1848.
[279] Tombari F., Mattoccia S., Di Stefano L., [i in.]: “Classification and eva-
luation of cost aggregation methods for stereo correspondence”. Proce-
edings of the IEEE Conference on Computer Vision and Pattern Recogni-
tion (CVPR ’08). Anchorage, AK, 2008, str. 1–8.
[280] Kostková J., Šára R. “Automatic disparity search range estimation for ste-
reo pairs of unknown scenes”. Proceedings of the Computer Vision Winter
Workshop 2004 (CVWW’04). Pod. red. Skocaj D. University of Ljubljana,
Faculty of Computer and Information Science. Ljubljana, Slovenia: Slove-
nian Pattern Recognition Society, 2004, str. 1–10.
[281] Schluüns K.: “Photometric stereo for non-lambertian surfaces using color
information”. Lecture Notes in Computer Science 719, 1993, str. 444–451.
[282] Tsin Y., Kang S. B., Szeliski R.: “Stereo matching with linear superposition
of layers”. IEEE Tansactions on Pattern Analysis and Machine Inteliigence
28(2), 2006, str. 290–301.
[283] Boncelet C.: Rozdz. Image noise models. [w:] “Handbook of image and
video processing”. Pod. red. Bovik A. Academic Press, 2000, str. 325–335.
isbn: 0-12-119790-5.
[284] Acharya T., Ray A. K.: Image processing. Principles and applications. John
Wiley & Sons, Inc., 2005. isbn: 978-0-471-71998-4.
[285] Huang S.-Q., Liu D.-Z., Gao G.-Q., [i in.]: “A novel method for speckle
noise reduction and ship target detection in SAR images”. Pattern Reco-
gnition 42(7), 2009, str. 1533–1542.
[286] Thangavel K., Manavalan R., Aroquiaraj I. L.: “Removal of speckle noise
from ultrasound medical image based on special filters: comparative stu-
dy”. ICGST-GVIP Journal of Applied Sciences 9(3), 2009, str. 25–32.
[287] Nadernejad E., Karami M. R., Sharifzadeh S., [i in.]: “Despeckle filtering
in medical ultrasound imaging”. Contemporary Engineering Sciences 2(1),
2009, str. 17–36.
[288] Chan T. F., Shen J. J.: Image processing and analysis: variational, PDE,
wavelet and stochastic methods. Philadelphia, PA: Society for Industrial
Applied Mathematics (SIAM), 2005. isbn: 08-98-71589-X.
249

“KonspPreamb” 2013/10/3 page 250 #253
BIBLIOGRAFIA
[289] Cosman P. C., Gray R. M., Olshen R. A.: “Evaluating quality of compres-
sed medical images: snr, subjective rating, and diagnostic accuracy”. Pro-
ceedings of the IEEE 82(6), 1994, str. 919–932.
[290] Keelan B. W., Cookingham R. E., Kane P. J., [i in.]: Handbook of image
quality: characterization and prediction. New York: Marcel Dekker, Inc.,
2002. isbn: 08-24-70770-2.
[291] Shnayderman A., Gusev A., Eskicioglu A. M.: “An svd-based grayscale
image quality measure for local and global assessment”. IEEE Transactions
on Image Processing 15(2), 2006, str. 422–429.
[292] Woźnicki J.: Podstawowe techniki przetwarzania obrazu. Warszawa: Wy-
dawnictwa Komunikacji i Łączności, Warszawa, 1996. isbn: 83-206-1189
-X.
[293] Gonzalez R. C., Woods R. E.: Digital image processing. Wyd. 2. Upper
Saddle River, New Jersey: Prentice-Hall, Inc., 2002. isbn: 02-01-18075-8.
[294] Image processing and analysis – a practical approach. Red. Baldock R.,
Graham J. Oxford, USA: Oxford University Press, 2000. isbn: 01-99-6370
0-8.
[295] Plucińska A., Pluciński E.: Probalistyka. Rachunek prawdopodobieństwa.
Statystyka matematyczna. Procesy stochastyczne. Warszawa: Wydawnic-
twa Naukowo-Techniczne, 2000. isbn: 978-83-204-3617-4.
[296] Pau V., Cretu E.: “Cyfrowe przetwarzanie obrazów plamkowych w specjal-
nych urządzeniach optoelektronicznych.” Elektronika 8–9, 2004, str. 296–
298.
[297] Hawwar Y., Reza A.: “Spatially adaptive multiplicative noise image deno-
ising technique”. IEEE Transactions on Image Processing 11(12), 2002,
str. 1397–1404.
[298] Bioucas-Dias J. M., Figueiredo M. A. T.: “Multiplicative noise removal
using variable splitting and constrained optimization”. IEEE Transactions
on Image Processing 19(7), 2010, str. 1720–1730.
[299] Al-Amri S. S., Kalyankar N. V., Khamitkar S. D.: “A comparative study of
removal noise from remote sensing image”. International Journal of Com-
puter Science Issues 7(1), 2010, str. 32–36.
[300] López-Rubio E.: “Restoration of images corrupted by Gaussian and uni-
form impulsive noise”. Pattern Recognition 43(5), 2010, str. 1835–1846.
250

“KonspPreamb” 2013/10/3 page 251 #254
BIBLIOGRAFIA
[301] Alajan N., Kamel M., Jernigan E.: “Detail preserving impulsive noise re-
moval”. Signal Processing: Image Communication 19, 2004, 993–1003.
[302] Szeliski R., Scharstein D.: “Sampling the disparity space image”. IEEE
Transactions on Pattern Analysis and Machine Intelligence 25(3), 2004,
str. 419–425.
[303] Wei Y., Quan L.: “Region-based progressive stereo matching”. Proceedings
of the IEEE Computer Society Conference on Computer Vision and Pattern
Recognition (CVPR 2004). Tom 1. Washington, DC, 2004, str. I–106–113.
[304] Yang Q., Engels C., Akbarzadeh A.: “Near real-time stereo for weakly-tex-
tured scenes”. Proceedings of the British Machine Vision Conference
(BMVC). Leeds, UK, 2008, str. 80–87.
[305] Brockers R.: “Cooperative stereo matching with color-base adaptive local
support”. Proceedings of the 13th International Conference on Compu-
ter Analysis of Images and Patterns (CAIP ’09). Münster, Germany, 2009,
str. 1019–1027.
[306] Bleyer M., Rother C., Kohli P., [i in.]: “Object stereo – joint stereo mat-
ching and object segmentation”. Proceedings of the IEEE Computer Socie-
ty Conference on Computer Vision and Pattern Recognition (CVPR 2011).
Colorado Springs, USA, 2011, str. 3081–3088.
[307] Ballard D. H., Brown C. M.: Computer vision. Englewood Cliffs, New Jer-
sey: Prentice-Hall, Inc., 1982. isbn: 01-31-65316-4.
[308] Leclercq P., Morris J.: “Assessing stereo algorithm accuracy”. Proceedings
of the Image Vision Computing New Zealand Conference (IVCNZ). Auc-
kland, New Zealand, 2002, str. 110–115.
[309] Zhu Q., Wu B., Xu Z.-X.: “Seed point selection method for triangle constra-
ined image matching propagation”. IEEE Geoscience and Remote Sensing
Letters 3(2), 2006, str. 207–211.
[310] Grimson W. E. L.: A computer implementation of a theory of human stereo
vision. Raport badawczy, A.I. Memo 762. AI Lab, Massachusetts Institute
of Technology, 1984.
[311] Grimson W. E. L.: “Computational experiments with a feature based stereo
algorithm”. IEE Transactions on Pattern Analysis and Machine Intelligence
7(1), 1985, str. 17–34.
251

“KonspPreamb” 2013/10/3 page 252 #255
BIBLIOGRAFIA
[312] Hemayed E., Sandbek A., Wassal A., [i in.]: “Investigation of stereo-based
3D surface reconstruction”. Proceedings of the SPIE 3023, 1997, str. 191–
202.
[313] Cyganek B., Siebert J. P.: An introduction to 3D computer vision techniques
and algorithms. Great Britain, Wiltshire: John Wiley & Sons, Ltd, 2009.
isbn: 04-70-01704-X.
[314] Grewe L., Kak A.: Rozdz. Stereo Vision. [w:] “Handbook of Pattern Reco-
gnition and Image Processing: Computer Vision”. Pod. red. Tzay Y. Y. Or-
lando, FL, USA: Academic Press, Inc., 1994, str. 239–317. isbn: 01-27-7456
1-0.
[315] Sadayuki H., Sohehara N., Yoroizawa I.: “Edge-based binocular stereopsis
algorithm – a matching mechanism with probabilistic feedback”. Neural
Networks 9(3), 1996, str. 379–395.
[316] Harvey R. J.: “The extraction of features and disparities from images by a
model based on the neurological organisation of the visual system”. Vision
Research 48, 2008, 1297–1306.
[317] Wang Z.-F., Zheng Z.-G.: “A region based stereo matching algorithm using
cooperative optimization”. Proceedings of the IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR 2008). Anchorage, AK, 2008,
str. 1–8.
[318] Min D., Sohn K.: “Cost aggregation and occlusion handling with WLS
in stereo matching”. IEEE Transaction on Image Processing 17(8), 2008,
str. 1431–1442.
252





























