Embed Size (px)
Citation preview

Copyright © 2001 Intel Corporation. ®
Pipeline Depth Tradeoffsand the Intel® Pentium® 4 Processor
Doug CarmeanDoug Carmean
Principal ArchitectPrincipal Architect
Intel Architecture GroupIntel Architecture Group
August 21, 2001August 21, 2001

Copyright © 2001 Intel Corporation. ®
AgendaAgenda
ReviewReview
Pipeline DepthPipeline Depth
Execution Trace CacheExecution Trace Cache
L1 Data CacheL1 Data Cache
SummarySummary

Copyright © 2001 Intel Corporation. ®
Information in this document is provided in connection with Intel® products. No license,
express or implied, by estoppel or otherwise, to any intellectual property rights is
granted by this document. Except as provided in Intel’s Terms and Conditions of
Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims
any express or implied warranty, relating to sale and/or use of Intel® products
including liability or warranties relating to fitness for a particular purpose,
merchantability, or infringement of any patent, copyright or other intellectual
property right. Intel products are not intended for use in medical, life saving, or life
sustaining applications.
Intel may make changes to specifications and product descriptions at any time,
without notice.
This document contains information on products in the design phase of development.
Do not finalize a design with this information. Revised information will be published
when the product is available. Verify with your local sales office that you have the
latest datasheet before finalizing a design.
Intel processors may contain design defects or errors known as errata, which may
cause the product to deviate from published specifications. Current characterized
errata are available on request.
Intel, Pentium, and the Intel logo are trademarks or registered trademarks of Intel
Corporation or its subsidiaries in the United States and foreign countries.
Copyright © (2001) Intel Corporation.
Copyright © 2001 Intel Corporation. ®
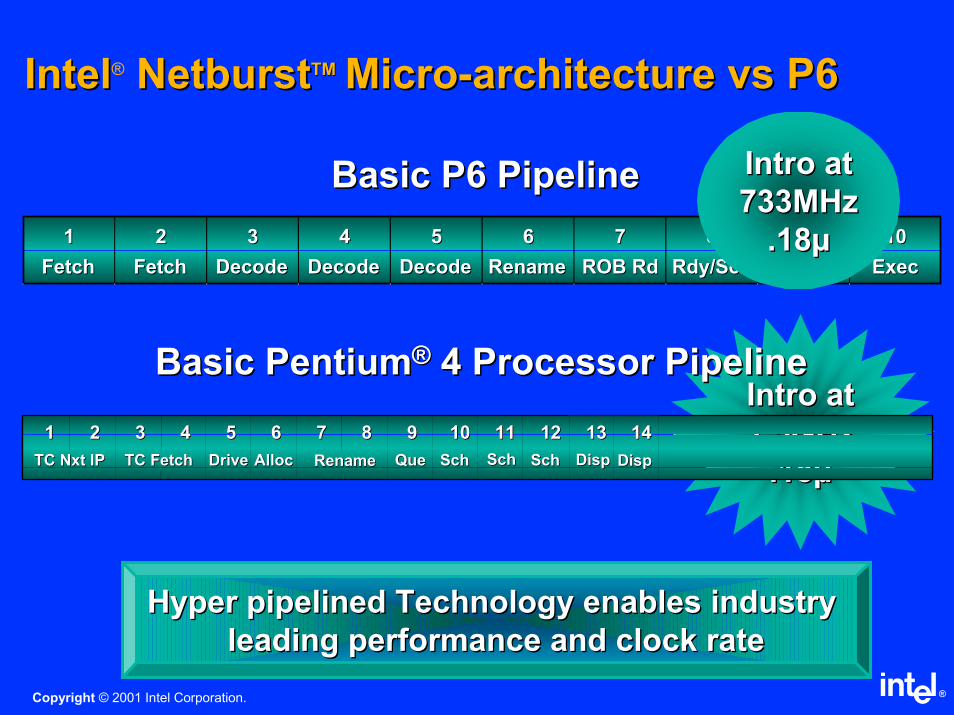
IntelIntel® NetburstNetburstTMTM MicroMicro--architecture vs P6architecture vs P6
11 22 33 44 55 66 77 88 99 1010
FetchFetch FetchFetch DecodeDecode DecodeDecode DecodeDecode RenameRename ROB RdROB Rd RdyRdy/Sch/Sch DispatchDispatch ExecExec
Basic P6 PipelineBasic P6 Pipeline Intro at Intro at
733MHz733MHz
.18µ.18µ
1515 1616 1717 1818 1919 2020
RFRF ExEx FlgsFlgs Br CkBr Ck DriveDriveRF RF
Intro at Intro at
1.5GHz1.5GHz
.18µ.18µ
Basic PentiumBasic Pentium®® 4 Processor Pipeline4 Processor Pipeline
11 22 33 44 55 66 77 88 99 1010 1111 1212
TC TC Nxt Nxt IPIP TC FetchTC Fetch DriveDrive AllocAlloc RenameRename QueQue SchSch SchSch SchSch
1313 1414
DispDisp DispDisp
Hyper pipelined Technology enables industry Hyper pipelined Technology enables industry
leading performance and clock rateleading performance and clock rate
Copyright © 2001 Intel Corporation. ®
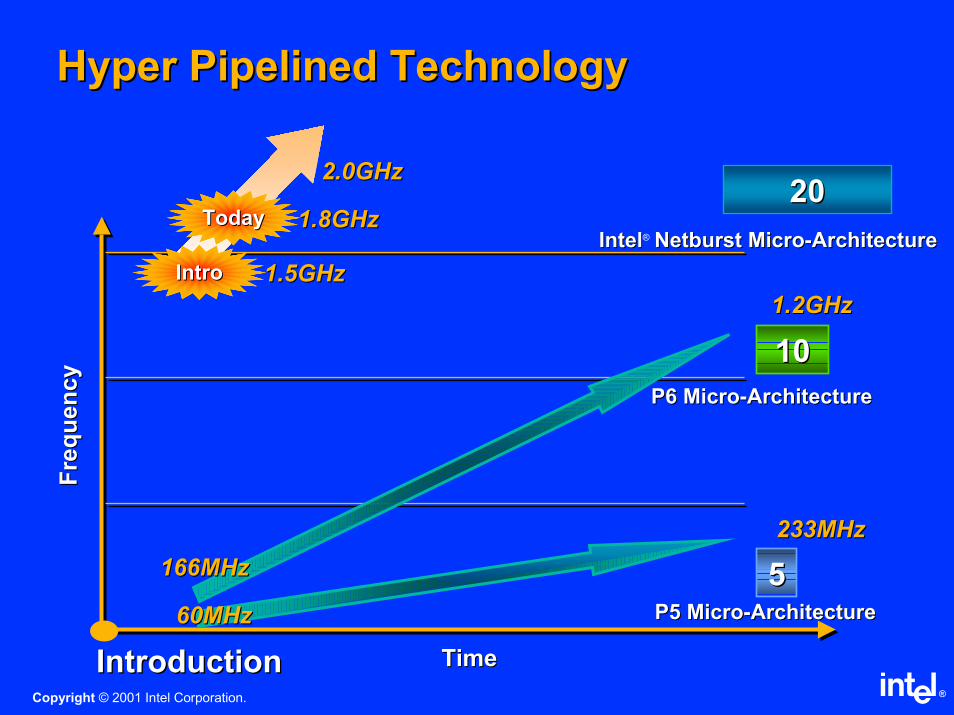
Hyper Pipelined TechnologyHyper Pipelined TechnologyF
req
uen
cy
Fre
qu
en
cy
TimeTimeIntroductionIntroduction
233MHz233MHz
60MHz60MHz P5 MicroP5 Micro--ArchitectureArchitecture
55
1.2GHz1.2GHz
166MHz166MHz
P6 MicroP6 Micro--ArchitectureArchitecture
1010
2020
IntelIntel® Netburst MicroNetburst Micro--ArchitectureArchitecture
IntroIntro 1.5GHz1.5GHz
TodayToday 1.8GHz1.8GHz
2.0GHz2.0GHz
Copyright © 2001 Intel Corporation. ®
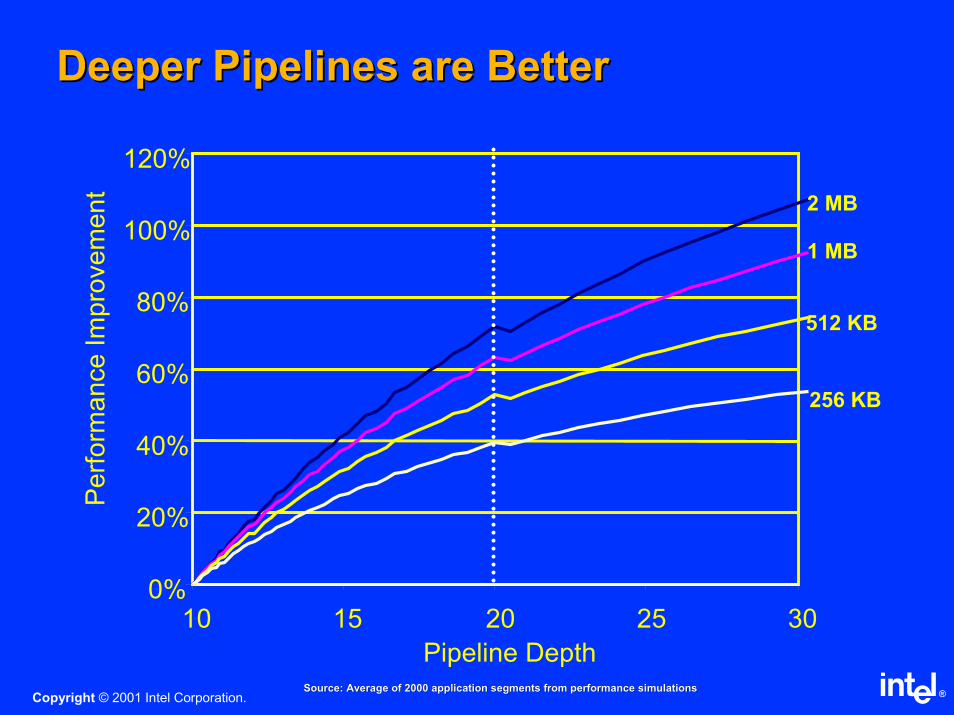
Deeper Pipelines are BetterDeeper Pipelines are Better
0%
20%
40%
60%
80%
100%
120%
10 15 20 25 30
Pipeline Depth
Perf
orm
ance Im
pro
vem
ent
2 MB
1 MB
512 KB
256 KB
Source: Average of 2000 application segments from performance siSource: Average of 2000 application segments from performance simulationsmulations

Copyright © 2001 Intel Corporation. ®
Why not deeper pipelines?Why not deeper pipelines?
Increases complexityIncreases complexity
––Harder to balanceHarder to balance
––More challenges to architect aroundMore challenges to architect around
––More algorithmsMore algorithms
––Greater validation effortGreater validation effort
––Need to pipeline the wiresNeed to pipeline the wires
Overall Engineering Effort Increases Quickly Overall Engineering Effort Increases Quickly
as Pipeline depth increasesas Pipeline depth increases

Copyright © 2001 Intel Corporation. ®
PerformancePerformance
High bandwidth front endHigh bandwidth front end
Low latency coreLow latency core
Lower memory latencyLower memory latencyHigh Bandwidth Front EndHigh Bandwidth Front EndHigh Bandwidth Front End

Copyright © 2001 Intel Corporation. ®
Higher Frequency increases Higher Frequency increases requirements of front endrequirements of front end
Branch prediction is more importantBranch prediction is more important
––So we improved itSo we improved it
Need greater uop bandwidthNeed greater uop bandwidth
––Branches constantly change the flowBranches constantly change the flow
––Need to decode more instructions in Need to decode more instructions in
parallelparallel
Copyright © 2001 Intel Corporation. ®
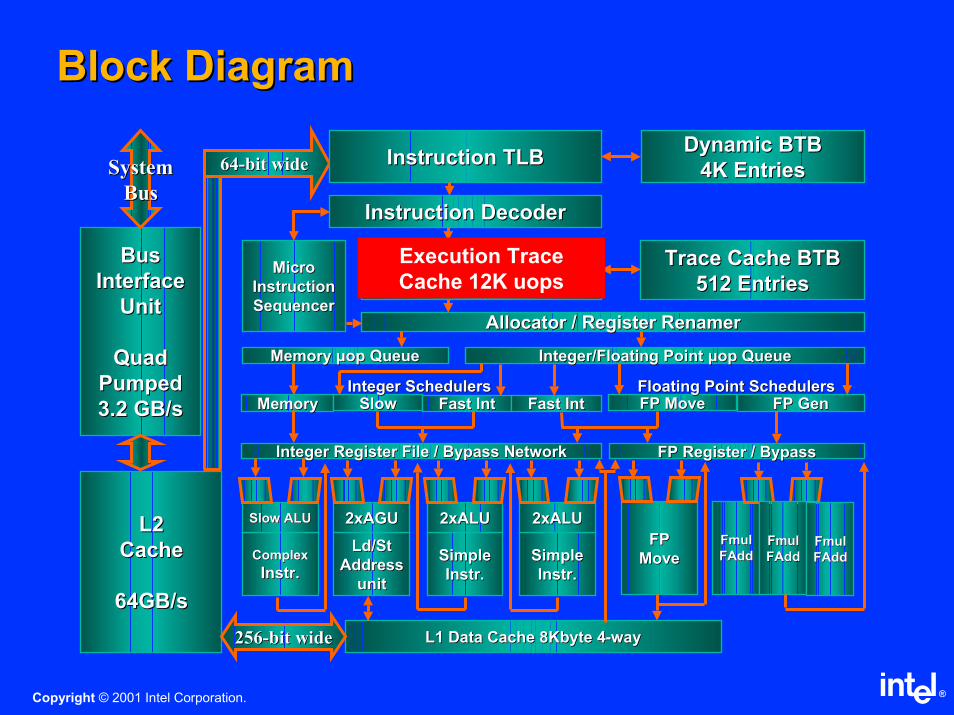
Block DiagramBlock Diagram
BusBus
InterfaceInterface
UnitUnit
Quad Quad
PumpedPumped
3.2 GB/s3.2 GB/s
L2L2
CacheCache
64GB/s64GB/s
SystemSystem
BusBus
6464--bit widebit wide Instruction TLBInstruction TLBDynamic BTBDynamic BTB
4K Entries4K Entries
Instruction DecoderInstruction Decoder
Execution Trace Execution Trace
Cache 12K Cache 12K µµopsopsTrace Cache BTBTrace Cache BTB
512 Entries512 EntriesMicroMicro
InstructionInstruction
SequencerSequencerAllocatorAllocator / Register / Register RenamerRenamer
Memory Memory µµop op QueueQueue Integer/Floating Point Integer/Floating Point µµop op QueueQueue
MemoryMemory SlowSlow Fast Fast IntInt Fast Fast IntInt FP MoveFP Move FP GenFP Gen
Ld/St Ld/St
Address Address
unitunit
Integer Register File / Bypass NetworkInteger Register File / Bypass Network FP Register / BypassFP Register / Bypass
2xAGU2xAGU
Complex Complex
InstrInstr..
Slow ALUSlow ALU
Simple Simple
InstrInstr..
2xALU2xALU
Simple Simple
InstrInstr..
2xALU2xALU
L1 Data Cache 8Kbyte 4L1 Data Cache 8Kbyte 4--wayway
FP FP
MoveMove
FmulFmul
FAddFAddFmulFmul
FAddFAddFmulFmul
FAddFAdd
256256--bit widebit wide
Integer SchedulersInteger Schedulers Floating Point SchedulersFloating Point Schedulers
Execution Trace
Cache 12K uops

Copyright © 2001 Intel Corporation. ®
Execution Trace CacheExecution Trace Cache
1 1 cmpcmp2 br 2 br --> T1 > T1
....
... (unused code)... (unused code)
T1:T1: 3 sub3 sub4 br 4 br --> T2> T2....... (unused code)... (unused code)
T2:T2: 5 5 movmov6 sub6 sub7 br 7 br --> T3> T3
....
... (unused code)... (unused code)
T3:T3: 8 add8 add9 sub9 sub
10 10 mulmul11 11 cmpcmp12 br 12 br --> T4> T4
Trace Cache DeliveryTrace Cache Delivery
10 mul 11 cmp 12 br T4
7 br T3 8 T3:add 9 sub
4 br T2 5 mov 6 sub
1 cmp 2 br T1 3 T1: sub

Copyright © 2001 Intel Corporation. ®
Execution Trace CacheExecution Trace Cache
1 cmp 2 br T1
3 T1: sub 4 br T2
5 mov 6 sub 7 br T3
8 T3:add 9 sub 10 mul
11 cmp 12 br T4
P6 MicroarchitectureP6 Microarchitecture Trace Cache DeliveryTrace Cache Delivery
10 mul 11 cmp 12 br T4
7 br T3 8 T3:add 9 sub
4 br T2 5 mov 6 sub
1 cmp 2 br T1 3 T1: sub
BW = 1.5 uops/nsBW = 1.5 uops/ns BW = 6 uops/nsBW = 6 uops/ns
Copyright © 2001 Intel Corporation. ®
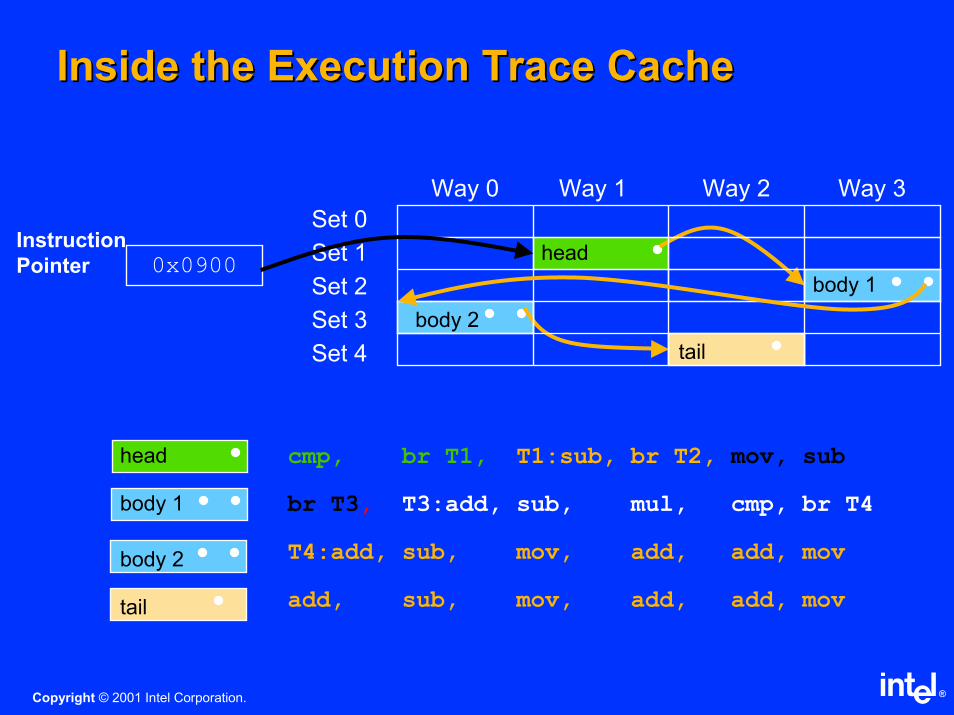
Inside the Execution Trace CacheInside the Execution Trace Cache
0x0900
Instruction
Pointerhead
body 1
body 2
tail
Way 0 Way 1 Way 2 Way 3
Set 0
Set 1
Set 2
Set 3
Set 4
head cmp, br T1, T1:sub, br T2, mov, sub
body 1 br T3, T3:add, sub, mul, cmp, br T4
body 2 T4:add, sub, mov, add, add, mov
tail add, sub, mov, add, add, mov

Copyright © 2001 Intel Corporation. ®
Self Modifying CodeSelf Modifying Code
Programs that modify the instruction Programs that modify the instruction
stream that is being executedstream that is being executed
Very common in Java* code from JITsVery common in Java* code from JITs
Requires hardware mechanisms to Requires hardware mechanisms to
maintain consistencymaintain consistency
*Other names and brands may be claimed as the property of others.

Copyright © 2001 Intel Corporation. ®
Self Modifying CodeSelf Modifying Code
The hardware needs to handle two The hardware needs to handle two
basic cases:basic cases:
––Stores that write to instructions in the Stores that write to instructions in the
Trace CacheTrace Cache
–– Instruction fetches that hit pending storesInstruction fetches that hit pending stores
–– SpeculativeSpeculative
–– CommittedCommitted
Copyright © 2001 Intel Corporation. ®
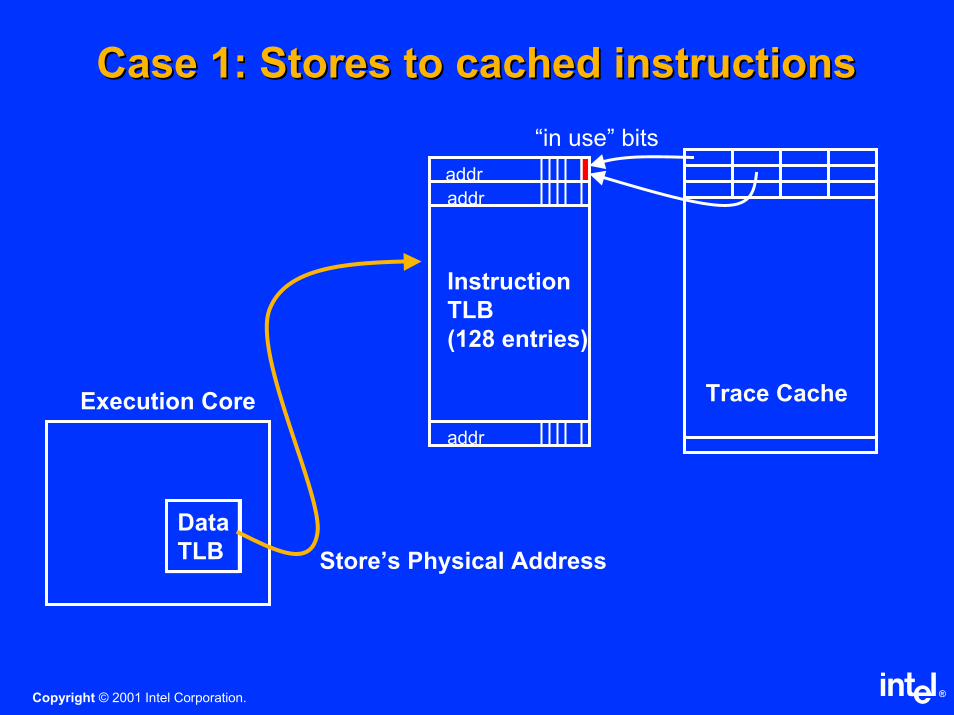
Case 1: Stores to cached instructionsCase 1: Stores to cached instructions
Execution Core
Data
TLB Store’s Physical Address
Trace Cache
addr
addr
Instruction
TLB
(128 entries)
addr
“in use” bits
Copyright © 2001 Intel Corporation. ®
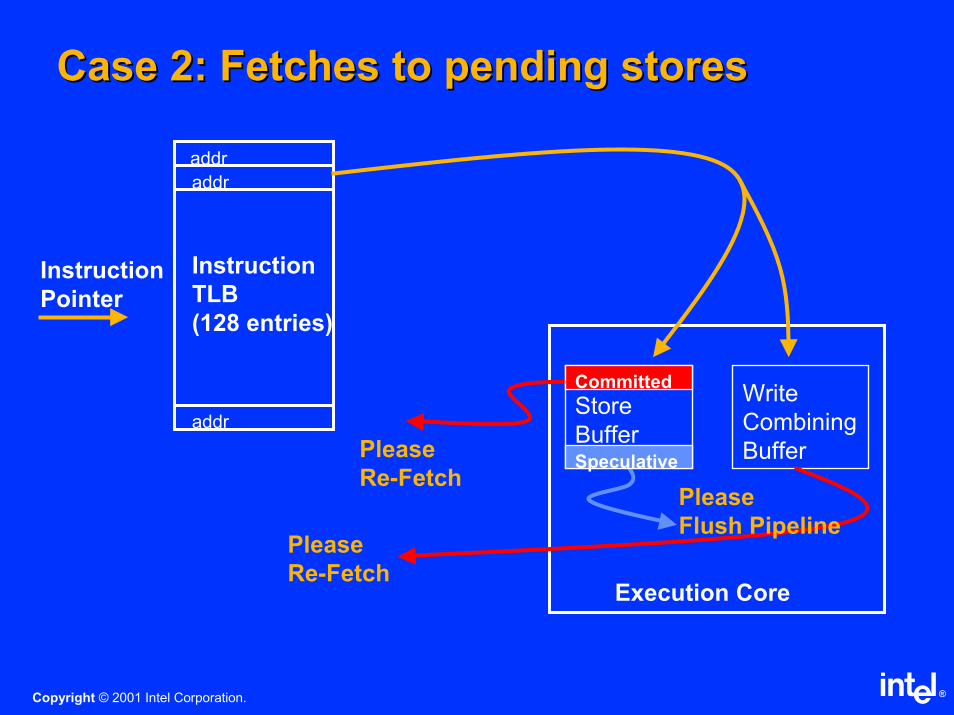
Case 2: Fetches to pending storesCase 2: Fetches to pending stores
Instruction
TLB
(128 entries)
addr
addr
addr
Instruction
Pointer
Store
Buffer
Write
Combining
Buffer
Execution Core
Please
Re-Fetch
Please
Flush Pipeline
Please
Re-FetchSpeculative
Committed

Copyright © 2001 Intel Corporation. ®
Execution Trace CacheExecution Trace Cache
Provides higher bandwidth for higher Provides higher bandwidth for higher
frequency corefrequency core
Reduces fetch latencyReduces fetch latency
Requires new fundamentally new Requires new fundamentally new
algorithmsalgorithms

Copyright © 2001 Intel Corporation. ®
PerformancePerformance
High bandwidth front endHigh bandwidth front end
Low latency coreLow latency core
Lower memory latencyLower memory latency
Low Latency CoreLow Latency CoreLow Latency Core
Copyright © 2001 Intel Corporation. ®
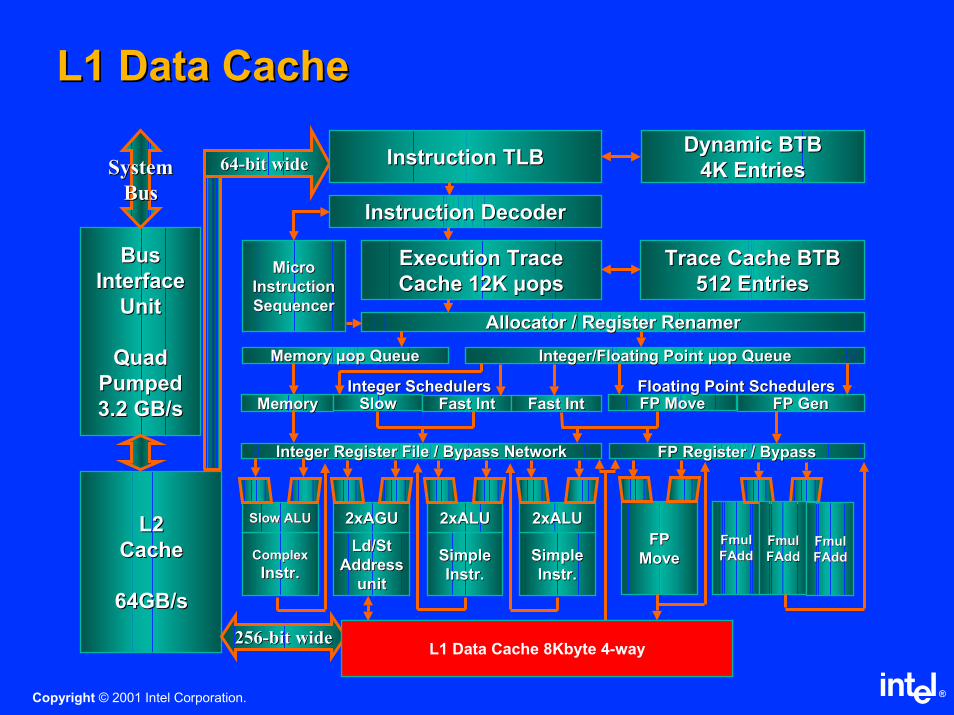
L1 Data CacheL1 Data Cache
BusBus
InterfaceInterface
UnitUnit
Quad Quad
PumpedPumped
3.2 GB/s3.2 GB/s
L2L2
CacheCache
64GB/s64GB/s
SystemSystem
BusBus
6464--bit widebit wide Instruction TLBInstruction TLBDynamic BTBDynamic BTB
4K Entries4K Entries
Instruction DecoderInstruction Decoder
Execution Trace Execution Trace
Cache 12K Cache 12K µµopsopsTrace Cache BTBTrace Cache BTB
512 Entries512 EntriesMicroMicro
InstructionInstruction
SequencerSequencerAllocatorAllocator / Register / Register RenamerRenamer
Memory Memory µµop op QueueQueue Integer/Floating Point Integer/Floating Point µµop op QueueQueue
MemoryMemory SlowSlow Fast Fast IntInt Fast Fast IntInt FP MoveFP Move FP GenFP Gen
Ld/St Ld/St
Address Address
unitunit
Integer Register File / Bypass NetworkInteger Register File / Bypass Network FP Register / BypassFP Register / Bypass
2xAGU2xAGU
Complex Complex
InstrInstr..
Slow ALUSlow ALU
Simple Simple
InstrInstr..
2xALU2xALU
Simple Simple
InstrInstr..
2xALU2xALU
L1 Data Cache 8Kbyte 4L1 Data Cache 8Kbyte 4--wayway
FP FP
MoveMove
FmulFmul
FAddFAddFmulFmul
FAddFAddFmulFmul
FAddFAdd
256256--bit widebit wide
Integer SchedulersInteger Schedulers Floating Point SchedulersFloating Point Schedulers
L1 Data Cache 8Kbyte 4-way

Copyright © 2001 Intel Corporation. ®
L1 Cache is 3x FasterL1 Cache is 3x Faster
PentiumPentium® 4 Processor :4 Processor :
––2 clocks @ 2GHz2 clocks @ 2GHz
3ns3ns
1ns1ns
P6:P6:––3 clocks @ 1GHz3 clocks @ 1GHz
Lower Latency is Higher PerformanceLower Latency is Higher PerformanceLower Latency is Higher Performance
Copyright © 2001 Intel Corporation. ®
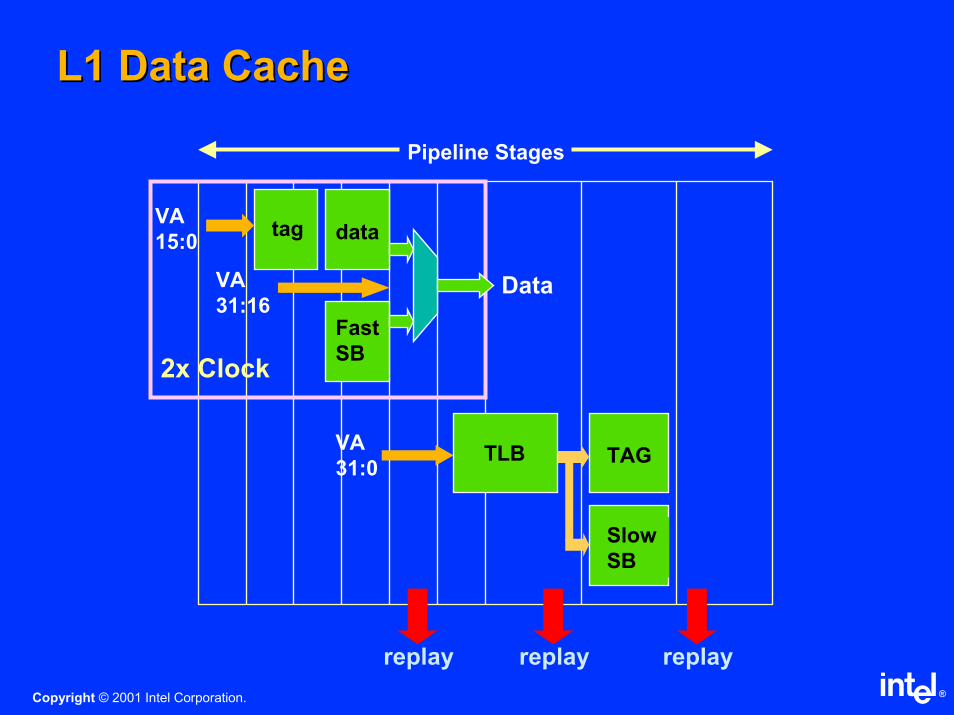
L1 Data CacheL1 Data Cache
Pipeline Stages
2x Clock
VA
15:0
VA
31:16Fast
SB
replay replay replay
VA
31:0TAG
Slow
SB
TLB
data
Data
tag
Copyright © 2001 Intel Corporation. ®
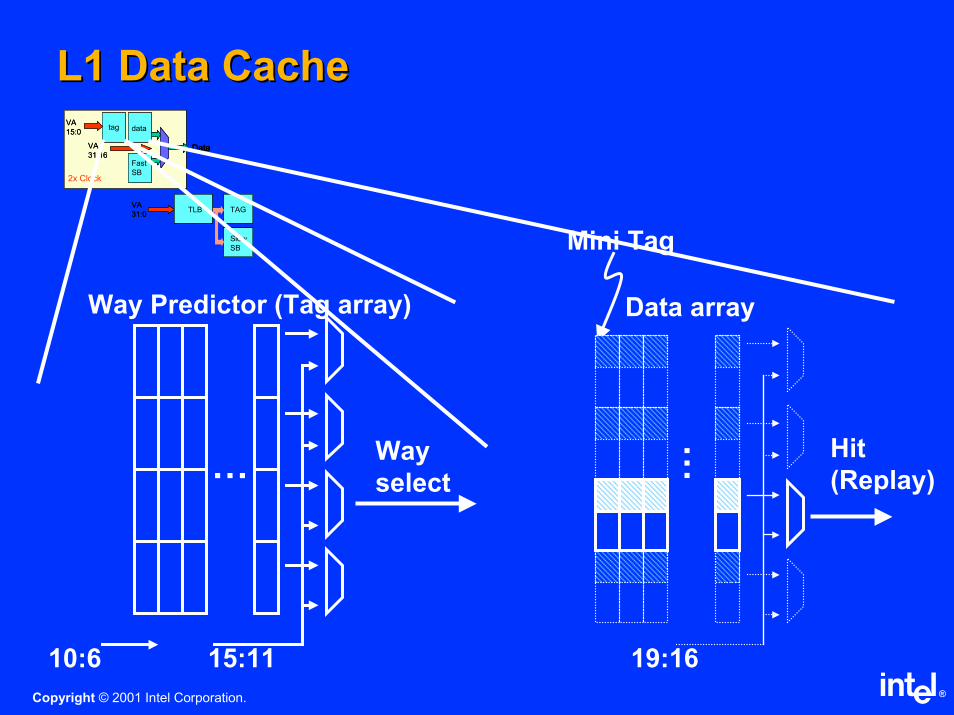
L1 Data CacheL1 Data Cache
2x Clock2x Clock
tagtag
TAGTAG
Slow
SB
Slow
SB
VA
15:0
VA
15:0
VA
31:16
VA
31:16
datadata
Fast
SB
Fast
SB
VA
31:0
VA
31:0
DataDataData
TLBTLB
Mini Tag
10:6 15:11
Way Predictor (Tag array)
Way
select…
Data array
19:16
Hit
(Replay)…

Copyright © 2001 Intel Corporation. ®
PerformancePerformance
High bandwidth front endHigh bandwidth front end
Low latency coreLow latency core
Lower memory latencyLower memory latency
Lower Memory LatencyLower Memory LatencyLower Memory Latency

Copyright © 2001 Intel Corporation. ®
Reducing LatencyReducing Latency
As frequency increases, it is important As frequency increases, it is important
to improve the performance of the to improve the performance of the
memory subsystemmemory subsystem
Data Prefetch LogicData Prefetch Logic
––Watches processor memory trafficWatches processor memory traffic
––Looks for patternsLooks for patterns
–– Initiates accessesInitiates accesses
Copyright © 2001 Intel Corporation. ®
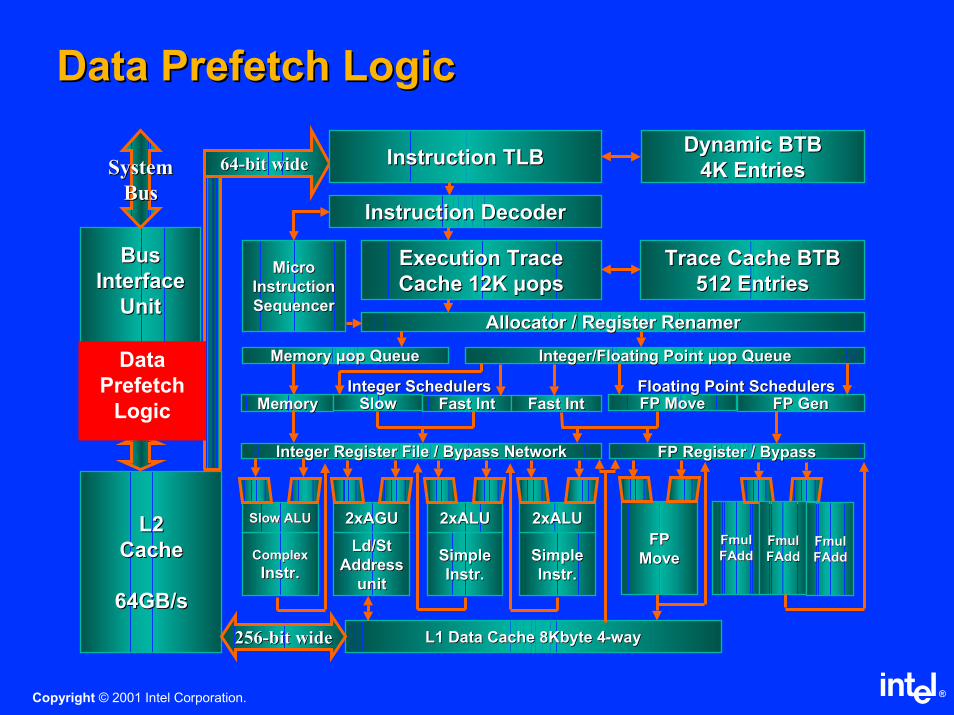
Data Prefetch LogicData Prefetch Logic
BusBus
InterfaceInterface
UnitUnit
Quad Quad
PumpedPumped
3.2 GB/s3.2 GB/s
L2L2
CacheCache
64GB/s64GB/s
SystemSystem
BusBus
6464--bit widebit wide Instruction TLBInstruction TLBDynamic BTBDynamic BTB
4K Entries4K Entries
Instruction DecoderInstruction Decoder
Execution Trace Execution Trace
Cache 12K Cache 12K µµopsopsTrace Cache BTBTrace Cache BTB
512 Entries512 EntriesMicroMicro
InstructionInstruction
SequencerSequencerAllocatorAllocator / Register / Register RenamerRenamer
Memory Memory µµop op QueueQueue Integer/Floating Point Integer/Floating Point µµop op QueueQueue
MemoryMemory SlowSlow Fast Fast IntInt Fast Fast IntInt FP MoveFP Move FP GenFP Gen
Ld/St Ld/St
Address Address
unitunit
Integer Register File / Bypass NetworkInteger Register File / Bypass Network FP Register / BypassFP Register / Bypass
2xAGU2xAGU
Complex Complex
InstrInstr..
Slow ALUSlow ALU
Simple Simple
InstrInstr..
2xALU2xALU
Simple Simple
InstrInstr..
2xALU2xALU
L1 Data Cache 8Kbyte 4L1 Data Cache 8Kbyte 4--wayway
FP FP
MoveMove
FmulFmul
FAddFAddFmulFmul
FAddFAddFmulFmul
FAddFAdd
256256--bit widebit wide
Integer SchedulersInteger Schedulers Floating Point SchedulersFloating Point Schedulers
Data
Prefetch
Logic
Copyright © 2001 Intel Corporation. ®
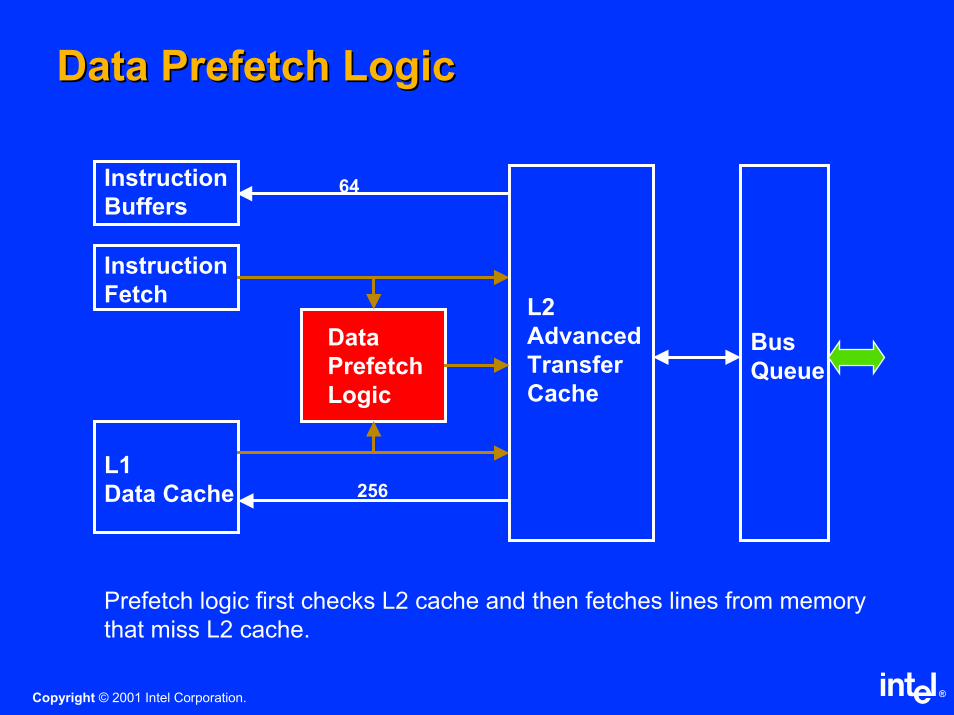
Data Prefetch LogicData Prefetch Logic
L1
Data Cache
Instruction
Fetch
Instruction
Buffers64
256
L2
Advanced
Transfer
Cache
Data
Prefetch
Logic
Bus
Queue
Prefetch logic first checks L2 cache and then fetches lines from memory
that miss L2 cache.

Copyright © 2001 Intel Corporation. ®
Data Prefetch LogicData Prefetch Logic
Watches for streaming memory access Watches for streaming memory access
patternspatterns
–– Can track 8 multiple independent streamsCan track 8 multiple independent streams
–– Loads, Stores or InstructionLoads, Stores or Instruction
–– Forward or BackwardForward or Backward
Analysis on 32 byte cache line granularityAnalysis on 32 byte cache line granularity
Looks for “mostly” complete streams:Looks for “mostly” complete streams:
–– Access to cache lines 1,2,3,4,5,6 will prefetchAccess to cache lines 1,2,3,4,5,6 will prefetch
–– Access to cache lines 1,2, 4,5,6 will prefetchAccess to cache lines 1,2, 4,5,6 will prefetch
–– 1, ,3, , ,6, , ,9 will not prefetch1, ,3, , ,6, , ,9 will not prefetch

Copyright © 2001 Intel Corporation. ®
PerformancePerformance
High bandwidth front endHigh bandwidth front end
Low latency coreLow latency core
Lower memory latencyLower memory latency

Copyright © 2001 Intel Corporation. ®
SummarySummary
The PentiumThe Pentium®® 4 Processor’s deep pipelines 4 Processor’s deep pipelines
provide high performance by enabling high provide high performance by enabling high
frequency frequency
Deep pipelines are more difficult to engineerDeep pipelines are more difficult to engineer
Larger caches further improve benefits of Larger caches further improve benefits of
PentiumPentium®® 4 Processor’s deep pipeline4 Processor’s deep pipeline
Compilers further increase benefits of deep Compilers further increase benefits of deep
pipelines by removing hazardspipelines by removing hazards

Copyright © 2001 Intel Corporation. ®





























