Embed Size (px)
Citation preview

Pig vs HiveBig Data 2014

Pig Configuration
In the bash_profile export all needed environment variables

Pig Configuration
Download a release of apache pig:
pig-0.11.1.tar.gz

Pig ConfigurationGo to the conf directory in the pig-home directory
rename the file pig.properties.template in pig.properties

Pig RunningRunning Pig:
$:~pig-*/bin/pig <parameters>
Try the following command, to get a list of Pig commands:
Run modes:
$:~pig-*/bin/pig -help
$:~pig-*/bin/pig -x locallocal
!
mapreduce$:~pig-*/bin/pig
or
$:~pig-*/bin/pig -x mapreduce

Pig in LocalRunning Pig in Local:
$:~pig-*/bin/pig -x local
Grunt Shell:
grunt> A = LOAD 'passwd' using PigStorage(':');
grunt> B = FOREACH A GENERATE $0 as id;
grunt> dump B;
grunt> store B;
Script file:
$:~pig-*/bin/pig -x local myscript.pig

Pig in Local: Examples
Word Count using Pig
Basic idea:
Load this file using a loader
Foreach record generate word token
Group by each word
Count number of words in a group
Store to file
words.txtprogram program
pig pig
program pig
hadoop pig
latin latin
Count words in a text file separated by lines and spaces

Pig in Local: Examples
Word Count using Pig
$:~pig-*/bin/pig -x local
!grunt> myinput = LOAD ‘<myhome>/words.txt’ USING TextLoader() as (myword:chararray);
grunt> words = FOREACH myinput GENERATE FLATTEN(TOKENIZE(*));
grunt> grouped = GROUP words BY $0;
grunt> counts = FOREACH grouped GENERATE group, COUNT(words);
grunt> store counts into '<myhome>/pigoutput' using PigStorage();

Pig in Local: Examples
Word Count using Pig
$:~pig-*/bin/pig -x local wordcount.pig
myinput = LOAD ‘<myhome>/words.txt’ USING TextLoader() as (myword:chararray);
words = FOREACH myinput GENERATE FLATTEN(TOKENIZE(*));
grouped = GROUP words BY $0;
counts = FOREACH grouped GENERATE group, COUNT(words);
store counts into '<myhome>/pigoutput' using PigStorage();
wordcount.pig

Pig in Local: Examples
Word Count using Pig
myinput = LOAD ‘<myhome>/words.txt’ USING TextLoader() as (myword:chararray);
words = FOREACH myinput GENERATE FLATTEN(TOKENIZE(*));
grouped = GROUP words BY $0;
counts = FOREACH grouped GENERATE group, COUNT(words);
store counts into '<myhome>/pigoutput' using PigStorage();

Pig in Local: Examples
Word Count using Pig
myinput = LOAD ‘<myhome>/words.txt’ USING TextLoader() as (myword:chararray);
words = FOREACH myinput GENERATE FLATTEN(TOKENIZE(*));
grouped = GROUP words BY $0;
counts = FOREACH grouped GENERATE group, COUNT(words);
store counts into '<myhome>/pigoutput' using PigStorage();

Pig in Local: Examples
Word Count using Pig
myinput = LOAD ‘<myhome>/words.txt’ USING TextLoader() as (myword:chararray);
words = FOREACH myinput GENERATE FLATTEN(TOKENIZE(*));
grouped = GROUP words BY $0;
counts = FOREACH grouped GENERATE group, COUNT(words);
store counts into '<myhome>/pigoutput' using PigStorage();

Pig in Local: Examples
Word Count using Pig
myinput = LOAD ‘<myhome>/words.txt’ USING TextLoader() as (myword:chararray);
words = FOREACH myinput GENERATE FLATTEN(TOKENIZE(*));
grouped = GROUP words BY $0;
counts = FOREACH grouped GENERATE group, COUNT(words);
store counts into '<myhome>/pigoutput' using PigStorage();

Pig in Local: Examples
Word Count using Pig
myinput = LOAD ‘<myhome>/words.txt’ USING TextLoader() as (myword:chararray);
words = FOREACH myinput GENERATE FLATTEN(TOKENIZE(*));
grouped = GROUP words BY $0;
counts = FOREACH grouped GENERATE group, COUNT(words);
store counts into '<myhome>/pigoutput' using PigStorage();

Pig in Local: Examples
Word Count using Pig
myinput = LOAD ‘<myhome>/words.txt’ USING TextLoader() as (myword:chararray);
words = FOREACH myinput GENERATE FLATTEN(TOKENIZE(*));
grouped = GROUP words BY $0;
counts = FOREACH grouped GENERATE group, COUNT(words);
store counts into '<myhome>/pigoutput' using PigStorage();
the directory '<myhome>/pigoutput' has not to exist before the execution of the script

Pig in MapReduce: Examples
Word Count using Pig
$:~hadoop-*/bin/hadoop dfs -mkdir input
$:~hadoop-*/bin/hadoop dfs -copyFromLocal /tmp/words.txt input
$:~pig-*/bin/pig -x mapreduce wordcountMR.pig
myinput = LOAD ‘input/words.txt’ USING TextLoader() as (myword:chararray);
words = FOREACH myinput GENERATE FLATTEN(TOKENIZE(*));
grouped = GROUP words BY $0;
counts = FOREACH grouped GENERATE group, COUNT(words);
store counts into 'pigoutput' using PigStorage();
wordcountMR.pig

Pig in MapReduce: Examples
Word Count using Pig
hdfs:input
$:~pig-*/bin/pig -x mapreduce wordcountMR.pig

Pig in MapReduce: Examples
Word Count using Pig
hdfs:pigoutput
part-r-00000

Pig in Local: Examples
Computing average number of page visits by user
Basic idea:
Load the log file
Group based on the user field
Count the group
Calculate average for all users
Visualize result
visits.loguser url timeAmy www.cnn.com 8:00Amy www.crap.com 8:05Amy www.myblog.com 10:00Amy www.flickr.com 10:05Fred cnn.com/index.htm 12:00Fred cnn.com/index.htm 13:00
Logs of user visiting a webpage consists of (user,url,time)
Fields of the log are tab separated and in text format

Pig in Local: Examples
$:~pig-*/bin/pig -x local average_visits_log.pig
visits = LOAD ‘<myhome>/visits.log’ as (user,url,time);
user_visits = GROUP visits BY user;
user_cnts = FOREACH user_visits GENERATE group as user, COUNT(visits) as numvisits;
all_cnts = GROUP user_cnts all;
avg_cnt = FOREACH all_cnts GENERATE AVG(user_cnts.numvisits);
dump avg_cnt;
average_visits_log.pig
Computing average number of page visits by user

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user,url,time);
user_visits = GROUP visits BY user;
user_cnts = FOREACH user_visits GENERATE group as user, COUNT(visits) as numvisits;
all_cnts = GROUP user_cnts all;
avg_cnt = FOREACH all_cnts GENERATE AVG(user_cnts.numvisits);
dump avg_cnt;
Computing average number of page visits by user

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user,url,time);
user_visits = GROUP visits BY user;
user_cnts = FOREACH user_visits GENERATE group as user, COUNT(visits) as numvisits;
all_cnts = GROUP user_cnts all;
avg_cnt = FOREACH all_cnts GENERATE AVG(user_cnts.numvisits);
dump avg_cnt;
Computing average number of page visits by user

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user,url,time);
user_visits = GROUP visits BY user;
user_cnts = FOREACH user_visits GENERATE group as user, COUNT(visits) as numvisits;
all_cnts = GROUP user_cnts all;
avg_cnt = FOREACH all_cnts GENERATE AVG(user_cnts.numvisits);
dump avg_cnt;
Computing average number of page visits by user
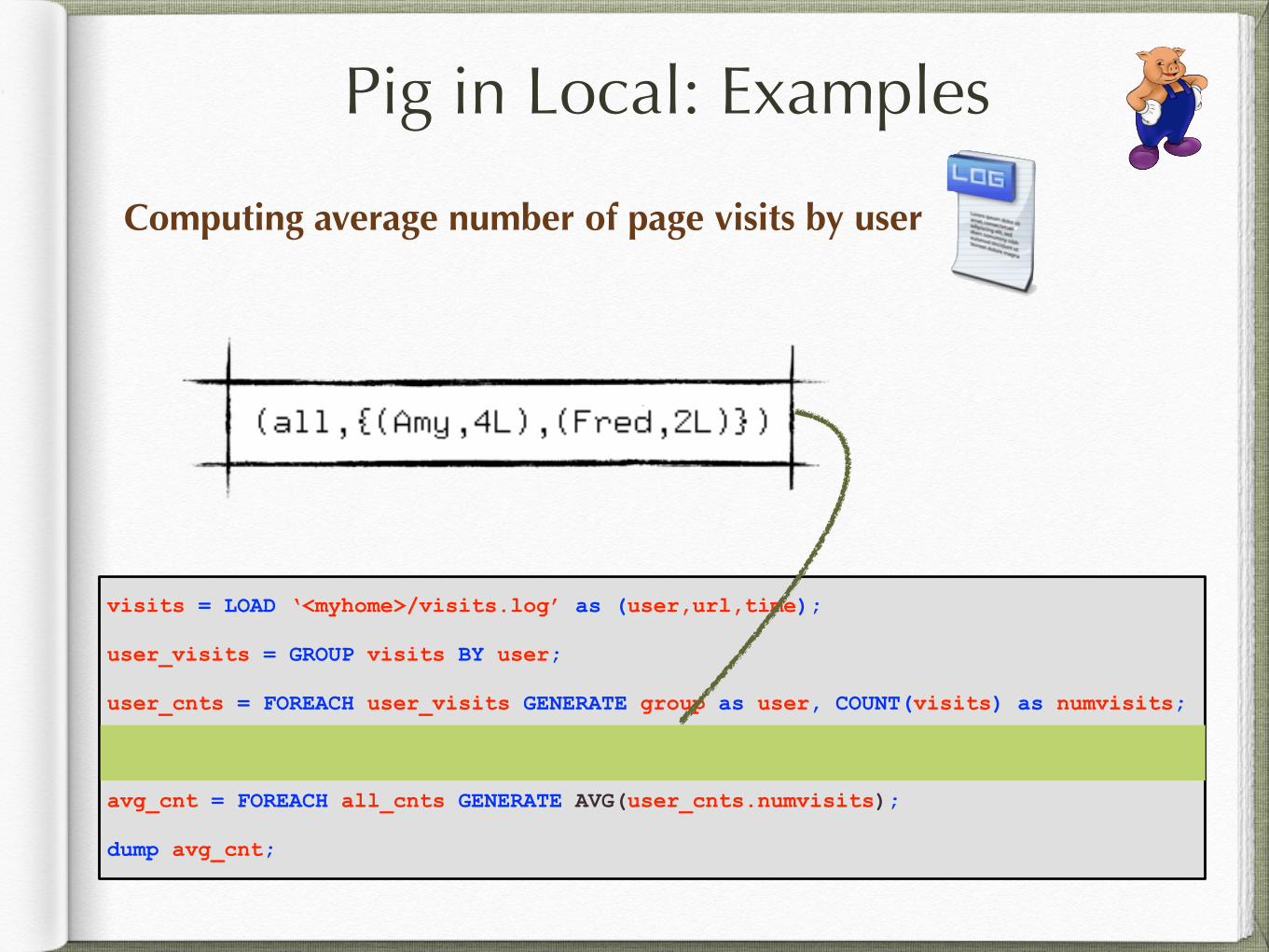
Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user,url,time);
user_visits = GROUP visits BY user;
user_cnts = FOREACH user_visits GENERATE group as user, COUNT(visits) as numvisits;
all_cnts = GROUP user_cnts all;
avg_cnt = FOREACH all_cnts GENERATE AVG(user_cnts.numvisits);
dump avg_cnt;
Computing average number of page visits by user

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user,url,time);
user_visits = GROUP visits BY user;
user_cnts = FOREACH user_visits GENERATE group as user, COUNT(visits) as numvisits;
all_cnts = GROUP user_cnts all;
avg_cnt = FOREACH all_cnts GENERATE AVG(user_cnts.numvisits);
dump avg_cnt;
Computing average number of page visits by user

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user,url,time);
user_visits = GROUP visits BY user;
user_cnts = FOREACH user_visits GENERATE group as user, COUNT(visits) as numvisits;
all_cnts = GROUP user_cnts all;
avg_cnt = FOREACH all_cnts GENERATE AVG(user_cnts.numvisits);
dump avg_cnt;
Computing average number of page visits by user

Pig in Local: ExamplesIdentify users who visit “Good Pages”
Good pages are those pages visited by users whose page rank is greater than 0.5
Basic idea:
Join table based on url
Group based on user
Calculate average page rank of user visited pages
Filter user who has average page rank greater than 0.5
Store the result
visits.loguser url timeAmy www.cnn.com 8:00Amy www.crap.com 8:05Amy www.myblog.com 10:00Amy www.flickr.com 10:05Fred cnn.com/index.htm 12:00Fred cnn.com/index.htm 13:00
pages.logurl pagerank
www.cnn.com 0.9
www.flickr.com 0.9
www.myblog.com 0.7
www.crap.com 0.2

Pig in Local: Examples
$:~pig-*/bin/pig -x local good_users.pig
visits = LOAD ‘<myhome>/visits.log’ as (user:chararray,url:chararray,time:chararray);
pages = LOAD ‘<myhome>/pages.log’ as (url:chararray,pagerank:float);
visits_pages = JOIN visits BY url, pages BY url;
user_visits = GROUP visits_pages BY user;
user_avgpr = FOREACH user_visits GENERATE group, AVG(visits_pages.pagerank) as avgpr;
good_users = FILTER user_avgpr BY avgpr > 0.5f;
store good_users into ‘<myhome>/pigoutput’;
good_users.pig
Identify users who visit “Good Pages”

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user:chararray,url:chararray,time:chararray);
pages = LOAD ‘<myhome>/pages.log’ as (url:chararray,pagerank:float);
visits_pages = JOIN visits BY url, pages BY url;
user_visits = GROUP visits_pages BY user;
user_avgpr = FOREACH user_visits GENERATE group, AVG(visits_pages.pagerank) as avgpr;
good_users = FILTER user_avgpr BY avgpr > 0.5f;
store good_users into ‘<myhome>/pigoutput’;
Identify users who visit “Good Pages”
Load files for processing with appropriate types

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user:chararray,url:chararray,time:chararray);
pages = LOAD ‘<myhome>/pages.log’ as (url:chararray,pagerank:float);
visits_pages = JOIN visits BY url, pages BY url;
user_visits = GROUP visits_pages BY user;
user_avgpr = FOREACH user_visits GENERATE group, AVG(visits_pages.pagerank) as avgpr;
good_users = FILTER user_avgpr BY avgpr > 0.5f;
store good_users into ‘<myhome>/pigoutput’;
Identify users who visit “Good Pages”

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user:chararray,url:chararray,time:chararray);
pages = LOAD ‘<myhome>/pages.log’ as (url:chararray,pagerank:float);
visits_pages = JOIN visits BY url, pages BY url;
user_visits = GROUP visits_pages BY user;
user_avgpr = FOREACH user_visits GENERATE group, AVG(visits_pages.pagerank) as avgpr;
good_users = FILTER user_avgpr BY avgpr > 0.5f;
store good_users into ‘<myhome>/pigoutput’;
Identify users who visit “Good Pages”

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user:chararray,url:chararray,time:chararray);
pages = LOAD ‘<myhome>/pages.log’ as (url:chararray,pagerank:float);
visits_pages = JOIN visits BY url, pages BY url;
user_visits = GROUP visits_pages BY user;
user_avgpr = FOREACH user_visits GENERATE group, AVG(visits_pages.pagerank) as avgpr;
good_users = FILTER user_avgpr BY avgpr > 0.5f;
store good_users into ‘<myhome>/pigoutput’;
Identify users who visit “Good Pages”

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user:chararray,url:chararray,time:chararray);
pages = LOAD ‘<myhome>/pages.log’ as (url:chararray,pagerank:float);
visits_pages = JOIN visits BY url, pages BY url;
user_visits = GROUP visits_pages BY user;
user_avgpr = FOREACH user_visits GENERATE group, AVG(visits_pages.pagerank) as avgpr;
good_users = FILTER user_avgpr BY avgpr > 0.5f;
store good_users into ‘<myhome>/pigoutput’;
Identify users who visit “Good Pages”

Pig in Local: Examples
visits = LOAD ‘<myhome>/visits.log’ as (user:chararray,url:chararray,time:chararray);
pages = LOAD ‘<myhome>/pages.log’ as (url:chararray,pagerank:float);
visits_pages = JOIN visits BY url, pages BY url;
user_visits = GROUP visits_pages BY user;
user_avgpr = FOREACH user_visits GENERATE group, AVG(visits_pages.pagerank) as avgpr;
good_users = FILTER user_avgpr BY avgpr > 0.5f;
store good_users into ‘<myhome>/pigoutput’;
Identify users who visit “Good Pages”

Pig in Local with User Defined Functions: Examples
Find all planets similar and closed to Earth
Planets similar and closed to Earth are that with oxygen and whose distance from Earth is less than 5
Basic idea:
Define a User Defined Function (UDF)
Filter planets using UDF
planets.txt
planet, color, atmosphere, distanceFormEarth
gallifrey, blue, oxygen, 4.367 skaro, blue, phosphorus, 10.5 krypton, red, oxygen, 2.5 apokolips, white, unknown, 0 klendathu, orange, oxygen, 0.89 asgard, unknown, unknown, 0 mars, yellow, carbon dioxide, 0.00000589429108 thanagar, yellow, oxygen, 3.29 planet x, yellow, unknown, 0.78 warworld, red, phosphorus, 10.1 daxam, red, oxygen, 7.2 oa, blue white, nitrogen, 2.4 Gliese 667Cc, red dwarf, unknown, 22

package myudfs;import java.io.IOException;import org.apache.pig.FilterFunc;import org.apache.pig.data.Tuple;!public class DistanceFromEarth extends FilterFunc { public Boolean exec(Tuple input) throws IOException { if (input == null || input.size() == 0) return null; try { Object value = input.get(0); if (value instanceof Double) return ((Double)value) <5; } catch(Exception ee) { throw new IOException("Caught exception processing input row ", ee); } return null; }}
Find all planets similar and closed to Earth
DistanceFromEarth.java
Pig in Local with User Defined Functions: Examples

package myudfs;import java.io.IOException;import org.apache.pig.FilterFunc;import org.apache.pig.data.Tuple;!public class PlanetWithOxygen extends FilterFunc { public Boolean exec(Tuple input) throws IOException { if (input == null || input.size() == 0) return null; try { String value = (String)input.get(0); return (value.indexOf("oxygen") >=0); } catch(Exception ee) { throw new IOException("Caught exception processing input row ", ee); } }}
Find all planets similar and closed to Earth
PlanetWithOxygen.java
Pig in Local with User Defined Functions: Examples

Find all planets similar and closed to Earth
myudfs.jar
Pig in Local with User Defined Functions: Examples

$:~pig-*/bin/pig -x local planets.pig
REGISTER ‘<myhome>/myudfs.jar’;
planets = LOAD ‘<myhome>/planets.txt’ USING PigStorage(‘,') as
(planet:chararray,color:chararray,atmosphere:chararray,distance:double);
result = FILTER planets BY myudfs.PlanetWithOxygen(atmosphere) AND
myudfs.DistanceFromEarth(distance);
store result into ‘<myhome>/pigoutput’;
planets.pig
Find all planets similar and closed to Earth
Pig in Local with User Defined Functions: Examples

REGISTER ‘<myhome>/myudfs.jar’;
planets = LOAD ‘<myhome>/planets.txt’ USING PigStorage(‘,') as
(planet:chararray,color:chararray,atmosphere:chararray,distance:double);
result = FILTER planets BY myudfs.PlanetWithOxygen(atmosphere) AND
myudfs.DistanceFromEarth(distance);
store result into ‘<myhome>/pigoutput’;
Find all planets similar and closed to Earth
Pig in Local with User Defined Functions: Examples

Sort employees by department and by stack ranking.
Basic idea:
Define a User Defined Function (UDF)
order employees using UDF
employees.txt
name, stackrank, department
JohnS, 9.5, Accounting Bill, 6, Marketing Franklin, 7, Engineering Marci, 8, Exec Joe DeAngel, 4.5, Finance Steve Francis, 9, Accounting Sam Shade, 6.5, Engineering Sandi, 9, Exec Roderick Trevers, 7, Accounting Terri DeHaviland, 8.5, Exec Colin McCullers, 8, Marketing Fay LaMore, 9, Marketing
Pig in Local with User Defined Functions: Examples

#!/usr/bin/python @outputSchema("record: {(rank:int, name:chararray, stackrank:double, department:chararray)}") def enumerate_bag(input): output = [] for rank, item in enumerate(input): output.append(tuple([rank] + list(item))) return output
Sort employees by department and by stack ranking.
rankudf.py
Pig in Local with User Defined Functions: Examples

$:~pig-*/bin/pig -x local employee.pig
REGISTER ‘<myhome>/rankudf.py’;
employees = LOAD ‘<myhome>/employees.txt’ USING PigStorage(‘,') as
(name:chararray, stackrank:double, department:chararray);
employees_by_department = GROUP employees BY department;
result = FOREACH employees_by_department{
sorted = ORDER employees BY stackrank desc;
ranked = myudf.enumerate_bag(sorted);
generate flatten(ranked);
};
store result into ‘<myhome>/pigoutput’;
employee.pig
Sort employees by department and by stack ranking.
Pig in Local with User Defined Functions: Examples

REGISTER ‘<myhome>/rankudf.py’;
employees = LOAD ‘<myhome>/employees.txt’ USING PigStorage(‘,') as
(name:chararray, stackrank:double, department:chararray);
employees_by_department = GROUP employees BY department;
result = FOREACH employees_by_department{
sorted = ORDER employees BY stackrank desc;
ranked = myudf.enumerate_bag(sorted);
generate flatten(ranked);
};
store result into ‘<myhome>/pigoutput’;
Sort employees by department and by stack ranking.
Pig in Local with User Defined Functions: Examples

Hive Configuration
In the bash_profile export all needed environment variables

Hive ConfigurationTranslates HiveQL statements into a set of MapReduce jobs which are then executed on a Hadoop Cluster
HiveQL Hive
…
Execute on Hadoop Cluster
Monitor/Report
Client Machine Hadoop Cluster

Hive Configuration
Download a binary release of apache Hive:
hive-0.11.0-bin.tar.gz

Hive ConfigurationIn the conf directory of hive-home directory set hive-env.sh file
# Set HADOOP_HOME to point to a specific hadoop install directory HADOOP_HOME=/Users/mac/Documents/hadoop-1.2.1
set the HADOOP_HOME

Hive ConfigurationHive uses Hadoop
In addition, you must create /tmp and /user/hive/warehouse and set them chmod g+w in HDFS before you can create a table in Hive.
Commands to perform this setup:
$:~$HADOOP_HOME/bin/hadoop dfs -mkdir /tmp
$:~$HADOOP_HOME/bin/hadoop dfs -mkdir /user/hive/warehouse
$:~$HADOOP_HOME/bin/hadoop dfs -chmod g+w /tmp
$:~$HADOOP_HOME/bin/hadoop dfs -chmod g+w /user/hive/warehouse

Hive RunningRunning Hive:
$:~hive-*/bin/hive <parameters>
Try the following command to acces to Hive shell:
Hive Shell
$:~hive-*/bin/hive
Logging initialized using configuration in jar:file:/Users/mac/Documents/hive-0.11.0-bin/lib/hive-common-0.11.0.jar!/hive-log4j.properties
Hive history file=/tmp/mac/[email protected]_201404091440_1786371657.txt
hive>

Hive RunningIn the Hive Shell you can call any HiveQL statement:
hive> CREATE TABLE pokes (foo INT, bar STRING);
OK
Time taken: 0.354 seconds
hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);
OK
Time taken: 0.051 seconds
create a table
hive> SHOW TABLES;
OK
invites
pokes
Time taken: 0.093 seconds, Fetched: 2 row(s)
browsing through Tables: lists all the tables

Hive Running
hive> SHOW TABLES ‘.*s’;
OK
invites
pokes
Time taken: 0.063 seconds, Fetched: 2 row(s)
browsing through Tables: lists all the tables that end with 's'.
hive> DESCRIBE invites;
OK
foo int None
bar string None
ds string None
# Partition Information
# col_name data_type comment
ds string None
Time taken: 0.191 seconds, Fetched: 8 row(s)
browsing through Tables: shows the list of columns of a table.

Hive Running
hive> ALTER TABLE events RENAME TO 3koobecaf;
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT);
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
hive> ALTER TABLE invites REPLACE COLUMNS (foo INT, bar STRING, baz INT
COMMENT 'baz replaces new_col2');
altering tables
hive> DROP TABLE pokes;
dropping Tables

Hive Running
hive> LOAD DATA LOCAL INPATH './examples/files/kv1.txt'
OVERWRITE INTO TABLE pokes;
DML operations
hive> SELECT * FROM pokes;
SQL query
hive> LOAD DATA INPATH ‘/user/hive/files/kv1.txt’
OVERWRITE INTO TABLE pokes;
takes file from local file system
takes file from HDFS file system

Hive Configuration on the Job Tracker of Hadoop
In the conf directory of hive-home directory you have to add and edit the hive-site.xml file
By default, Hive utilizes LocalJobRunner; Hive can use the JobTracker of Hadoop

In the conf directory of hive-home directory you have to add and edit the hive-site.xml file
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.exec.scratchdir</name>
<value>/Users/mac/Documents/hive-0.11.0-bin/scracth</value>
<description>Scratch space for Hive jobs</description>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
<description>Location of resourceManager so Hive knows where to execute mapReduce Jobs</description>
</property>
</configuration>
Hive Configuration on the Job Tracker of Hadoop

Hive RunningRunning Hive “One Shot” command:
$:~hive-*/bin/hive -e <command>
For instance:
Result
$:~hive-*/bin/hive -e “SELECT * FROM mytable LIMIT 3”
OK
name1 10
name2 20
name3 30

Hive RunningExecuting Hive queries from file:
$:~hive-*/bin/hive -f <file>
For instance:
query.hql
$:~hive-*/bin/hive -f query.hql
SELECT *
FROM mytable
LIMIT 3

Hive Running
Executing Hive queries from file inside the Hive Shell
$:~ cat /path/to/file/query.hql
SELECT * FROM mytable LIMIT 3
$:~hive-*/bin/hive
hive> SOURCE /path/to/file/query.hql;
…

Hive in Local: Examples
Word Count using Hive
words.txt
programprogrampigpigprogrampighadooppiglatinlatin
CREATE TABLE docs (line STRING);
LOAD DATA LOCAL INPATH ‘./exercise/data/words.txt'
OVERWRITE INTO TABLE docs;
CREATE TABLE word_counts AS
SELECT word, count(1) AS count FROM
(SELECT explode(split(line, '\s')) AS word FROM docs) w
GROUP BY word
ORDER BY word;
wordcounts.hql

Hive in Local: Examples
Word Count using Hive
words.txt
programprogrampigpigprogrampighadooppiglatinlatin
$:~hive-*/bin/hive -f wordcounts.hql

Hive in Local with User Defined Functions: Examples
Convert unixtime to a regular time date format
Basic idea:
Define a User Defined Function (UDF)
Convert time field using UDF
subscribers.txtname, department, email, time
Frank Black, 1001, [email protected], -72710640
Jolie Guerms, 1006, [email protected], 1262365200
Mossad Ali, 1001, [email protected], 1207818032
Chaka Kaan, 1006, [email protected], 1130758322
Verner von Kraus, 1007, [email protected], 1341646585
Lester Dooley, 1001, [email protected], 1300109650

package com.example.hive.udf;!import java.util.Date;import java.util.TimeZone;import java.text.SimpleDateFormat;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;!public class Unix2Date extends UDF{ public Text evaluate(Text text) { if(text == null) return null; long timestamp = Long.parseLong(text.toString()); // timestamp*1000 is to convert seconds to milliseconds Date date = new Date(timestamp*1000L); // the format of your date SimpleDateFormat sdf = new SimpleDateFormat("dd-MM-yyyy HH:mm:ss z"); sdf.setTimeZone(TimeZone.getTimeZone("GMT+2")); String formattedDate = sdf.format(date); return new Text(formattedDate); }}
Unix2Date.java
Hive in Local with User Defined Functions: Examples
Convert unixtime to a regular time date format

unix_date.jar
Hive in Local with User Defined Functions: Examples
Convert unixtime to a regular time date format

$:~hive-*/bin/hive -f time_conversion.hql
CREATE TABLE IF NOT EXISTS subscriber (
username STRING,
dept STRING,
email STRING,
provisioned STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
LOAD DATA LOCAL INPATH ‘./exercise/data/subscribers.txt' INTO TABLE subscriber;
add jar ./exercise/jar_files/unix_date.jar;
CREATE TEMPORARY FUNCTION unix_date AS 'com.example.hive.udf.Unix2Date';
SELECT username, unix_date(provisioned) FROM subscriber;
time_conversion.hql
Hive in Local with User Defined Functions: Examples
Convert unixtime to a regular time date format

$:~hive-*/bin/hive -f time_conversion.hql
Hive in Local with User Defined Functions: Examples
Convert unixtime to a regular time date format
Frank Black 12-09-1967 12:36:00 GMT+02:00
Jolie Guerms 01-01-2010 19:00:00 GMT+02:00
Mossad Ali 10-04-2008 11:00:32 GMT+02:00
Chaka Kaan 31-10-2005 13:32:02 GMT+02:00
Verner von Kraus 07-07-2012 09:36:25 GMT+02:00
Lester Dooley 14-03-2011 15:34:10 GMT+02:00
Time taken: 9.12 seconds, Fetched: 6 row(s)

Quickly Wrap Up
!Two ways of doing one
thing
OR !
One way of doing two things

Two ways of doing same thing
Both generate map-reduce jobs from a query written in higher level language.
Both frees users from knowing all the little secrets of Map-Reduce & HDFS.

Language
PigLatin: Procedural data-flow language
A = LOAD ‘mydata’;
dump A;
HiveQL: Declarative SQLish language
SELECT * FROM ‘mytable’;

Different languages = Different users
Pig: More popular among
programmers
researchers
Hive: More popular among
analysts

Different users = Different usage pattern
Pig:
programmers: Writing complex data pipelines
researchers: Doing ad-hoc analysis typically employing Machine Learning
Hive:
analysts: Generating daily reports

Different usage patternDifferent Usage Pattern
7
Data Collection
Data Factory Pig Pipelines Iterative Processing Research
Data Warehouse Hive
BI Tools Analysis
Different Usage Pattern
7
Data Collection
Data Factory Pig Pipelines Iterative Processing Research
Data Warehouse Hive
BI Tools Analysis
Different Usage Pattern
7
Data Collection
Data Factory Pig Pipelines Iterative Processing Research
Data Warehouse Hive
BI Tools Analysis
Data Collection Data Factory Data Warehouse
Pig
-Pipeline
-Iterative Processing
-Research
Hive
-BI tools
-Analysis

Different usage pattern = Different future directions
Pig is evolving towards a language of its own
Users are asking for better dev environment: debugger, linker, editor etc.
Hive is evolving towards Data-warehousing solution
Users are asking for better integration with other systems (O/JDBC)

Resources

Pig vs HiveBig Data 2014





























