Embed Size (px)
Citation preview


PERFORMANCE STUDY OF LUCENE IN PARALLEL
AND DISTRIBUTED ENVIRONMENTS
by
Kishore Sajja
A project
submitted in partial fulfillment
of the requirements for the degree of
Master of Science in Computer Science
Boise State University
December 2011


c© 2011Kishore Sajja
ALL RIGHTS RESERVED

The project presented by Kishore Sajja entitled Performance Study of Lucene inParallel and Distributed Environments is hereby approved.
Dr. Amit Jain, Advisor Date
Dr. Teresa Cole, Committee Member Date
Dr. Jyh-haw Yeh, Committee Member Date
John R. Pelton, Graduate Dean Date

ABSTRACT
Performance study is a common way to assess the usability of a component in
a software application. Lucene is a library for information retrieval. For this project,
we are going to study the performance of some available searching features of Lucene
in commonly available environments: serial, distributed and parallel. However there
is no information available as to how various features perform in these environments.
In this project we compare distributed searching versus parallel searching using
Lucene. Distributed searching is easily implemented with the Remote Method Invo-
cation hooks provided by Lucene. Parallel implementation requires more work. The
hypothesis was that if Lucene performs reasonably well in distributed mode then we
don’t need a parallel implementation.
We found that Lucene in distributed environments using the RMI hooks did not
perform reasonably as well as expected in our experiment setup. This is because
communication overhead dominates the actual searching time in the distributed en-
vironment. Next we experimented with Lucene in a parallel implementation. We
designed the experiment to keep the overhead from communication and other system
operations at a minimum. We got reasonably good speedups for this setup.
iv

TABLE OF CONTENTS
LIST OF FIGURES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vii
1 INTRODUCTION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Search, and its importance . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 About Lucene . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Lucene’s Wide Usage . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Organization of the writing document . . . . . . . . . . . . . . . . . . 4
2 RELATED WORK . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1 Case Studies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Previous Research . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 EXPERIMENTAL SETUP . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1 Testing Environments . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1.1 Serial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1.2 Distributed . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.1.3 Parallel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.2 Impact of JVM on experiment results . . . . . . . . . . . . . . . . . . 11
3.2.1 JVM, and how it works for us . . . . . . . . . . . . . . . . . . 11
3.2.2 JVM’s effect on the experiment . . . . . . . . . . . . . . . . . 11
3.3 Test Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.3.1 Hardware Environment . . . . . . . . . . . . . . . . . . . . . . 13
v

3.3.2 Software Environment . . . . . . . . . . . . . . . . . . . . . . 13
3.3.3 Network . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4 APPROACH . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.1 Framework development and running tests . . . . . . . . . . . . . . . 14
4.2 Test data setup across the cluster . . . . . . . . . . . . . . . . . . . . 15
5 RESULTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
5.1 Serial results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.2 RMI results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.3 Parallel results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
6 ANALYSIS OF RESULTS . . . . . . . . . . . . . . . . . . . . . . . . 23
6.1 Comparison of results with different search elements . . . . . . . . . . 23
6.2 Comparison of results with different sizes of data . . . . . . . . . . . 24
6.3 Comparison of results with different number of nodes . . . . . . . . . 26
7 CONCLUSIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
7.1 What have we done so far? . . . . . . . . . . . . . . . . . . . . . . . . 30
7.2 Future directions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
REFERENCES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
vi

LIST OF FIGURES
3.1 Serial experiment setup . . . . . . . . . . . . . . . . . . . . . . . . . . 73.2 Distributed experiment setup . . . . . . . . . . . . . . . . . . . . . . 93.3 Parallel experiment setup . . . . . . . . . . . . . . . . . . . . . . . . 10
5.1 Serial timing in milliseconds for various indices sizes . . . . . . . . . . 195.2 RMI results for different query types for different indices . . . . . . . 205.3 Parallel results for different query types for different indices . . . . . . 22
6.1 Serial results for different query types for different indices . . . . . . . 256.2 Serial results with different size of indices . . . . . . . . . . . . . . . . 286.3 Parallel speedups with different number of nodes . . . . . . . . . . . . 29
vii

1
Chapter 1
INTRODUCTION
1.1 Search, and its importance
Searching for “information” is a hot topic these days. Because of the exponential
growth in information storage, searching plays a key role in the design and develop-
ment of computer applications. The World Wide Web is a great source for information
and Internet databases like YouTubeTM, IMDb, Orkut, facebook and other informa-
tion sharing web sites are popular because they provide good means of information
retrieval. Being the key entity that drives the world of knowledge, data gathering
and information retrieval is a very profitable business on the Internet.
Incorporating search features with the existing computer applications is another
trend in information management. Most of the operating systems like Microsoft R©WindowsTM,
Apple R© Mac OS, Linux etc. have been exhibiting special interest in making search
as another key component in their desktop software and trying to decrease the search
cost as much as possible.
Business organizations that maintain their own e-commerce websites provide search
as a common feature for their customers to find out about their products with min-

2
imum effort and time. They can model the customer with some general interest
patterns and can optimize search that best suites the needs of a common customer.
But for organizations whose business is to search for best deals, it is very hard to
model the business patterns and to optimize their retrieval features to suit their cus-
tomers. Similar situations may rise in several other businesses, so providing a generic
search that returns good results is an important thing.
1.2 About Lucene
Lucene [1] is an “Information Retrieval” (IR) library, initially written in JavaTMas
an open source library [2], that can be used to incorporate search features into ap-
plications. It gives us flexibility for writing search based application by providing
indexing and searching functions so that the developer can focus mainly on applica-
tion logic. Due to Lucene’s wide usage, it has been ported to many languages, e.g.
.Net, Ruby, C++, Python etc. Lucene was originally implemented in JavaTMby Doug
Cutting. It has been adopted by Apache Software Foundation as a sub-project. It
has been used by many business organizations and non-profit organizations. A list
of users can be found at http://wiki.apache.org/lucene-java/PoweredBy. Lucene is
one of the top choices for a search API (Application Programming Interface) because
of its performance and scalability for large indices and its ability to handle multiple
searches concurrently on single index and to search more than one index in parallel.
With these capabilities Lucene is considered to be one of the best alternatives besides

3
developing one’s own search logic. Lucene’s customization ability allows us to adapt
the search process to our own application.
Search is going to be a must have feature in each and every information man-
agement system, as data is rapidly increasing in size and the performance of the
underlying hardware has also been rapidly increasing. In the past, the amount of
information saved was comparatively less. So most of the earlier developed applica-
tions often did not provide search. Today, search is one of the foremost features that
the customers look for in an application. Thus we need to provide user with good
searching features that will return relevant results.
1.3 Lucene’s Wide Usage
Since the launching of Lucene, it’s usage was grown a lot and features have also
improved steadily. Performance improvement has been a major area of concentration.
There are two steps in setting up a search feature for an application. The first
is indexing the data, which means making data more suitable for fast search and
making it small enough to search it fast. The Second, searching which is digging
into collected data and finding out relevant documents that match the search criteria
and present them to users in an appropriate manner. Indexing may be one time
or a periodic process whereas searching is a continuous, real-time process with the
collected data. So we thought we cannot do anything to the indexing process as it
may mess up the actual search protocols and search data structures which Lucene

4
uses for its operations. Instead we chose to study search features for our experiment.
But we did not find any studies about the performance of basic search elements which
are used collectively for searching the data.
1.4 Organization of the writing document
We split the writing into different chapters. The next chapter presents some related
work for this project. Chapter 3 elaborates about the experimental setup, we followed.
Chapter 4 describes about the approach we followed to do this experiment. Chapter 5
presents the results of the experiment. Chapter 6 explains the results analyzed by
taking different parameters into consideration. Chapter 7 concludes the writing and
gives some future directions for the project and related work.

5
Chapter 2
RELATED WORK
2.1 Case Studies
Here we will discuss some case-studies which investigated using Lucene [1] in custom-
designed environments. Most of these studies use Lucene as a supporting tool. We can
see the study of comparing the Lucene’s work with other information retrieval libraries
in “Logistic Regression Merging of Amberfish and Lucene Multisearch Results”, by
Christopher T. Fallen and Gregory B. Newby [10]. Several hardware benchmarks are
also available for Lucene [5]. Another study that discusses about the architecture
of the Lucene searching for better productivity is [7]. The architecture of Lucene
implementation of personalized records search is discussed in “A Case Study of Pol-
icy Decisions for Federated Search Across Digital Libraries”, by Andy Dong, Eric
Fixler and Alice Agogino [8]. Another study regarding recommendations for Lucene
architecture and JVM’s impact on Lucene is found in [11]. A case study of clustered
implementation based on Lucene and Nutch [3] can be found in “Scale-up x Scale-
out: A Case Study using Nutch/Lucene.” by Maged Michael, Jos E. Moreira, Doron
Shiloach, Robert W. Wisniewski [9].

6
2.2 Previous Research
Most of the Lucene usage and knowledge about performance comes from use in pro-
duction systems [1]. Most of the studies concentrate on hardware architecture and
no study is available to the best of our knowledge on the performance of particular
search features of Lucene. Current practice on Lucene systems depends on tuning the
Lucene’s features based on experience and avoiding some of the primitive Lucene con-
structs that can be time sinks because of lack of hardware support for them. This kind
of knowledge can only be gained by experienced organizations. Small organizations
do not have access to such experience.

7
Chapter 3
EXPERIMENTAL SETUP
3.1 Testing Environments
There are three searching environments: serial, distributed and parallel. The following
sections explain about them.
3.1.1 Serial
Figure 3.1. Serial experiment setup

8
We consider the following as the serial setup for our Lucene experiment.
Only one computing node is available with one or more computing cores. One hard
disk drive or multiple disks with a common file system are available. In serial en-
vironment the computing load is on one CPU and the peak rate of data transfer
depends on the transfer rate of the hard disk where the indexed data is stored. Other
programs that are running at the time of experiment may affect the results. Most of
the API is designed for serial systems with an assumption on availability of necessary
memory and disk space to hold the data in main memory and secondary memory.
See Figure 3.1.
3.1.2 Distributed
We consider the following as the Distributed setup for out Lucene experiment.
One or more co-operating computers are communicating over an unreliable channel.
Each has having individual disk space and there may or may not be a common file
system. The work is split across different nodes which needed to communicate in order
to balance load and share results. We need to consider the communication overhead
along with the size of data that has to be moved between different machines. The
storage needs are relatively less for each node as the work is going to be shared
by multiple nodes. Lucene has several API functions in order to shield user of the
API from handling all the complicated details of the network communications. See
Figure 3.2.

9
Figure 3.2. Distributed experiment setup
3.1.3 Parallel
We consider the following setup as the Parallel setup for our Lucene experiment.
Multiple computing systems whose common task is solely to execute the given tasks.
Data transfer over the wire is up to the user or an underlying library that makes
parallel calls easy. The data transfer is completely controlled by the user. We can
design our own parallel system where we can limit the data passage across the nodes
and data sharing across machines. User can choose wisely [sometimes heuristically]
how to do load balancing and other key aspects. The user may have secure, reliable
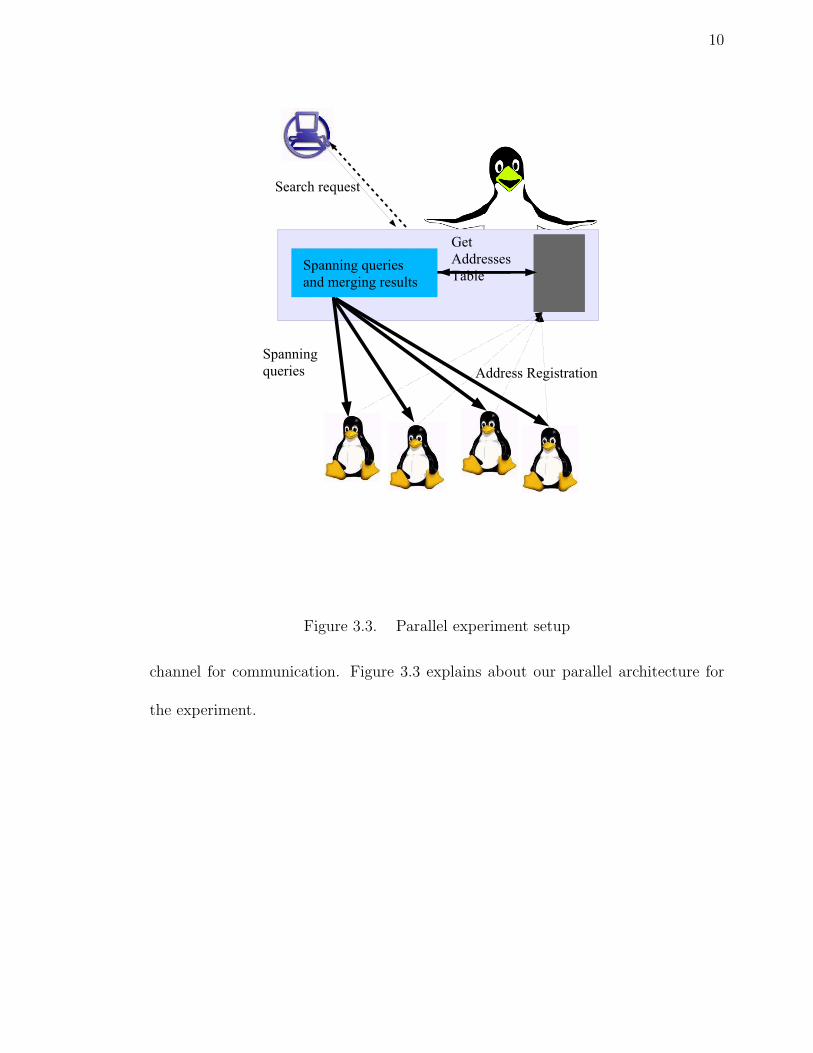
10
Figure 3.3. Parallel experiment setup
channel for communication. Figure 3.3 explains about our parallel architecture for
the experiment.

11
3.2 Impact of JVM on experiment results
3.2.1 JVM, and how it works for us
JVM[Java Virtual Machine] is a platform dependent software layer which abstracts
the complicated host dependent API and provides the assumed control for the func-
tion calls without affecting the security and integrity of the underlying machine.
JVMs have been implemented on almost all widely used proprietary and open source
platforms. Usually, JVM handles the communication with the underlying operating
system which provides rich API. Java Virtual Machine, which is a byte code inter-
preter, controls what the code does. JVM considers itself as the master process that
controls all other programs running on it, so it takes the responsibility to make native
calls in secure situations, handling disk data transfer in raw format, loading and un-
loading the required modules [classes here] based on the calls made to them. When
we invoke a Java method that needs to do a native call to the host machine, the
performance is lesser than making a direct native API call. Adding another layer of
abstraction comes at a cost. However the simplicity and power of the language and
its API are key items. Hence Lucene implementation in Java is justified.
3.2.2 JVM’s effect on the experiment
Caching:
Since the performance of accessing disk data is important in our project, file caching
mechanism is an important thing to consider. When we first run the test, it takes a

12
little longer time to search. Subsequent runs take less time due to caching. Caching is
also related to available memory, which obviously depends on the amount of memory
that JVM got started from the host operating system to run the full virtual machine.
Warm-up time:
Warm-up time includes the time to load the data structures and the class files and
making them available to run. Loading, unloading, allocating memory required for
data structures and holding whole data and making it available when needed by
program are some other things that will be affected by the warm-up time of the
JVM.
Memory constraints:
JVM is virtually a machine which has the same architecture as a hardware machine,
but is completely implemented in software. JVM itself has some guarding programs
running along with management, accounting programs etc. Memory available to load
and run the user programs will be affected, as the total loading and unloading the
required classes will be done dynamically.
Taking all these effects into consideration, we designed our test cases so as to
overcome these constraints and produce reasonable results.We considered the running
time of the queries only after the fourth or fifth query, allowing the JVM warm-up
time to be excluded from measurements when we run queries.

13
3.3 Test Conditions
The complete experiment was conducted at Boise State University’s Linux cluster
laboratory, Onyx.
3.3.1 Hardware Environment
There were 32 nodes up and running continuously from several days. Each node is a
Pentium HT machine, with one GB RAM and 30 GB of scratch disk space.
3.3.2 Software Environment
All the nodes were running Linux Fedora Core 5. Each was installed with Network File
System(NFS). Each node has a local partition allocated for /tmp directory. Except
/tmp all other root directories are mounted on NFS and all nodes share common
directory structure served by the network server. Lucene 2.2 version files are placed
on user’s /mnt/ partition, including the data that has to be used. We used the
JavaTM1.6 version for programming and running the experiments.
3.3.3 Network
The whole cluster was connected by a Gigabit network. The network latency is
approximately 57 micro seconds.

14
Chapter 4
APPROACH
The approach we followed to implement this project was relatively straight forward.
We first learned about various Lucene features. Then we used Nutch, a JavaTMweb
crawler based on Lucene, along with its own plug-ins and filters to build Lucene indices
of various sizes. Once we had enough data for testing Lucene features, we developed
a framework to use in all three experiment environments: serial, distributed and
parallel.
4.1 Framework development and running tests
The basic idea behind developing a framework is to maintain consistency in comparing
results in various situations. We developed the framework keeping in mind that it
would be used in all three environments. We made common code blocks available so
that they could run in any of these setups. This approach reduced rewriting code.
To study the performance of Lucene, we identified a set of queries along with a set
of indices. Our framework was prepared to reuse the same code blocks over and
over again for different type of queries and indices. First we customized the code to
work in serial environment. We ran the experiments and gathered the results. After

15
that we customized the code to work with the RMI features provided by Lucene
to work in distributed mode. The ParallelMultiSearcher class is a part of the
RMI API of Lucene. It exposes a remote reachable object. When we search for the
ParallelMultiSearcher object in registry, virtually, we get all the IndexSearchers
and we can spawn queries all at once. Here the data would be split into different
indices which on combination will result in a unique linearly ordered index or less
in size(because of redundancies). The parallel setup required some modifications for
handling communication from application to the servers.
4.2 Test data setup across the cluster
Data collection was an important and time consuming part of the project. We needed
to collect Lucene-usable data for this experiment. The data is Lucene-usable in the
sense that indices that are going to be used by Lucene are prepared by the Lucene
indexing API. Lucene’s rich indexing API makes the attempt to collect data easier.
But indexing in principle tries to keep data to a minimum, as it is easier to search
and takes less time. The resulting Lucene index size is also small when compared to
the size of actual data that was indexed. Lucene can index any type of simple text
data, and it can index formatted data of any type provided we have an analyzer for
that format. So we can index virtually everything that can be saved electronically,
ranging from student records to complicated database files.
For our experiment, we have used the Nutch [3] web crawler to collect data and

16
build Lucene indices. We ran Nutch in parallel for four days to collect web data. We
used four dedicated nodes for indexing the web from randomly generated URLs from
URL database dmoz [4]. Collecting 20GB of data for four days on four nodes resulted
in generating a 1.6GB index. We used this data for serial searching experiments. After
some more crawls we got indices of different sizes about 1MB, 10MB, 50MB, 100MB,
200MB, 500MB, 750MB, 1.0GB, 1.6GB. Some of them were produced by merging
different data segments and other small indices. The exact size of indices vary by
±5% to ±10%. So the deviation could cause some discrepancies in the results, which
was taken care of in our analysis.
Distributed and Parallel experiments need to have a different set of data than serial
experiments use. In this case, we needed to run multiple crawl scripts targeted with
small amount of data. We split the data collection and created small indices of around
13MB. Then we merged them in various ways to get indices of 50MB,100MB,200MB,
400MB and 800MB for use with 1,2,4 and 8 processors. We copied the data to /tmp
folders of the corresponding machine when we were running the experiments across
several nodes so that the node can take advantage of local data access.

17
Chapter 5
RESULTS
In this chapter we will discuss the results of experiments. As was said before, the
complete experiment was definitely affected by the Java Virtual Machine’s execution
overhead. All experiments were conducted in situations where the load on the CPU
was less than 2% and disk I/O is almost zero and network overhead is not considered
as the data transferred over network is small for testing parallel design.
1. Directory
Lucene has two storage mechanisms. Those are:
—> FSDirectory.
A disk based implementation for holding documents to search.
—> RAMDirectory.
This is same as FSDirectory in every aspect expect holding documents in the main
memory for faster search.
2. Queries
Queries we tested in this experiment are:
—> TermQuery.
The basic element of search, on which all other queries depends. We take it a word

18
in the document as an example. e.g: Searching for “brown” in the documents.
—> BooleanQuery.
This is used for searching different terms connected with different boolean operators.
e.g: Searching for “cat” and “dog” not “mouse” in a document.
—> PhraseQuery.
This query is used to search for a complete phrase in a document. e.g: Searching for
“The quick brown fox jumped over the lazy dog”.
—> PrefixQuery.
This type of queries work on regular expressions. e.g: Searching for “trace” using
prefix query also searches for “traced”,“tracer” and “tracing” etc.
—> WildcardQuery.
This is a pure regular expression query. e.g: Searching for *pro* using WildcardQuery
returns all the searches related to “proton”,“protocol”, “wipro” and “MacBook Pro”
etc.
—> FuzzyQuery.
This is the one that is used to suggest something, if the user mistyped some search
string. e.g. searching “gogle” will also search for “google”,“googol”,“mingle” etc.
This uses Levenshtein’s edit distance algorithm [6].
—> QueryParser.
This is an optimized class to search based on clauses. This uses a plus (+) or a minus
(-) sign, indicating that the clause is required or prohibited respectively in query.

19
5.1 Serial results
Figure 5.1. Serial timing in milliseconds for various indices sizes
The serial results look interesting as they unveil more interesting facts about
the index organization of Lucene. We collected serial results mainly for two reasons.
First, they serve as base results to compare when we use multiple nodes in distributed
and parallel designs. Secondly, serial results reveal interesting facts about how the
index size affects the performance of Lucene, how the basic constructs perform, what
constructs consume more time in searching etc. We can see the timing for different
sizes of index sizes and different query types in Figure 5.1
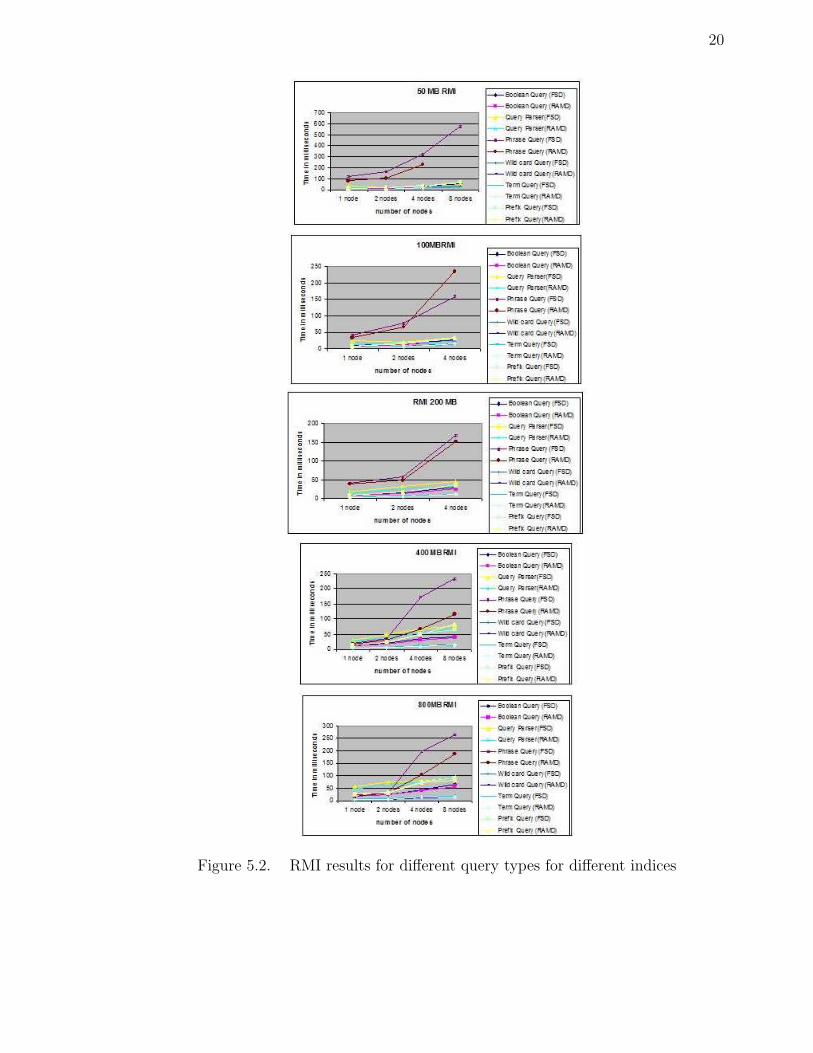
20
Figure 5.2. RMI results for different query types for different indices

21
5.2 RMI results
The results in Figure 5.2 show that the time increases as the number of nodes in-
creases. The results may look disappointing, but the reason behind them is informa-
tive. When we use Lucene for performing searches in a distributed fashion, the com-
munication overhead for synchronization between nodes decreases the performance of
the whole searching. There will be a break even point, where the overhead becomes
comparatively smaller than the time for execution. Using this experiment we proved
that this point is not less than the maximum size of our experiment, that is, 800MB.
The result also depends on the number of nodes in the experiment. If the number of
nodes is more then the communication overhead is also more.
5.3 Parallel results
The results in Figure 5.3 show that the time to search decreases as the number of nodes
increase for parallel searches. We can see that there is a minimum time to search,
after which the time don’t get smaller: about 6 to 8 ms. This is very small and we can
ascribe it to JVM overhead for thread creation and starting up the communication
with other nodes.
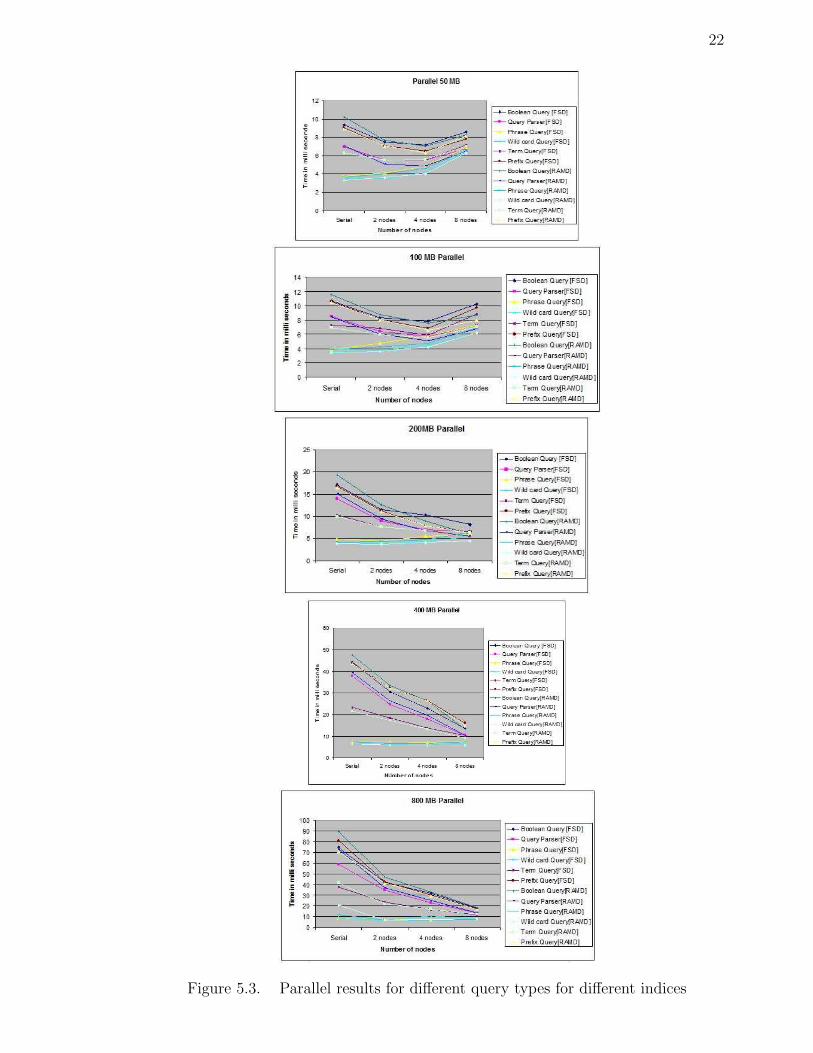
22
Figure 5.3. Parallel results for different query types for different indices

23
Chapter 6
ANALYSIS OF RESULTS
In this chapter, we try to analyze the results which we got through the experiments
conducted using different designs. The searching API uses mainly query objects to
pass to the IndexSearcher, which is a search element for a particular query and
particular type of directory.
6.1 Comparison of results with different search elements
First we like to compare the search results between FSDirectory and RAMDirectory.
As we know, FSDirectory is an object which we pass to the IndexSearcher for
searching across indices. FSDirectory is a disk based index accessing mechanism.
There is another type of directory called RAMDirectory that tries to keep all its data
in the main memory. When we are using RAMDirectory that is small enough to fit
into main memory we can get improved speed. All the queries that we studied here are
basic building blocks to form complex search functions. BooleanQuery is to search for
more than one term connected with a boolean operator and, or, not etc. PhraseQuery
is used to search relevant documents which consist of a given phrase. We can set the
allowable distance between different terms in a document, which is called slope.

24
Using different values for slope we can find varying number of documents. Another
one we studied here is a TermQuery, which is the basic element to search across an
index. All other Queries are formed by combining several TermQuery. PrefixQuery
is used when a user mistyped a search phrase or term to suggest some other queries
based on the term the user entered. FuzzyQuery also belongs to same category, but
we can set it to different levels of regular expression formations. All these queries
when operated with the directories return an object which is called Hits, which has
all the information regarding the found documents for the query. We use Hits object
to retrieve document information when user asks to retrieve data. The following set
of figures will explain different things about Lucene. We can deduce from the Figure:
?? that all query types regardless of which directory type will behave in same manner
as they increase or decrease in search time. We can see that the time taken for Prefix,
Fuzzy and Wildcard Queries is longer. We should keep the use of them to a minimum.
6.2 Comparison of results with different sizes of data
The previous section discussed the comparison between different basic elements. In
this section we see how different index sizes affect the timing of search on indices.
Index size is a key issue in search time. The primary concern in our project is to
study the performance of different searching elements when the index size is changed.
The time will change according to the change in the size. When we check the results

25
Figure 6.1. Serial results for different query types for different indices

26
of the Serial experiment we can say one thing for sure: the order of increase in time
is not linear according to Figure: ?? below. The change is non-linear. The time to
search per document is gradually decreasing when the size of data increases. We can
take the optimization of index as a primary reason. That is also because of caching
of the data in the memory. When the data is cached in main memory, it obviously
should take less time. Due to JVM caching of disk data like files and indices, the
performance will increase as the size of data increase. That looks like the primary
reason, where as the optimization is secondary. We can assume that the size of data
is slightly irregular as we specified in the previous sections. But the deviation is not
much more than 5-7% as specified. Although the deviation makes a difference, the
data size may be more or less than the specified size. So we can ignore that difference
in our results.
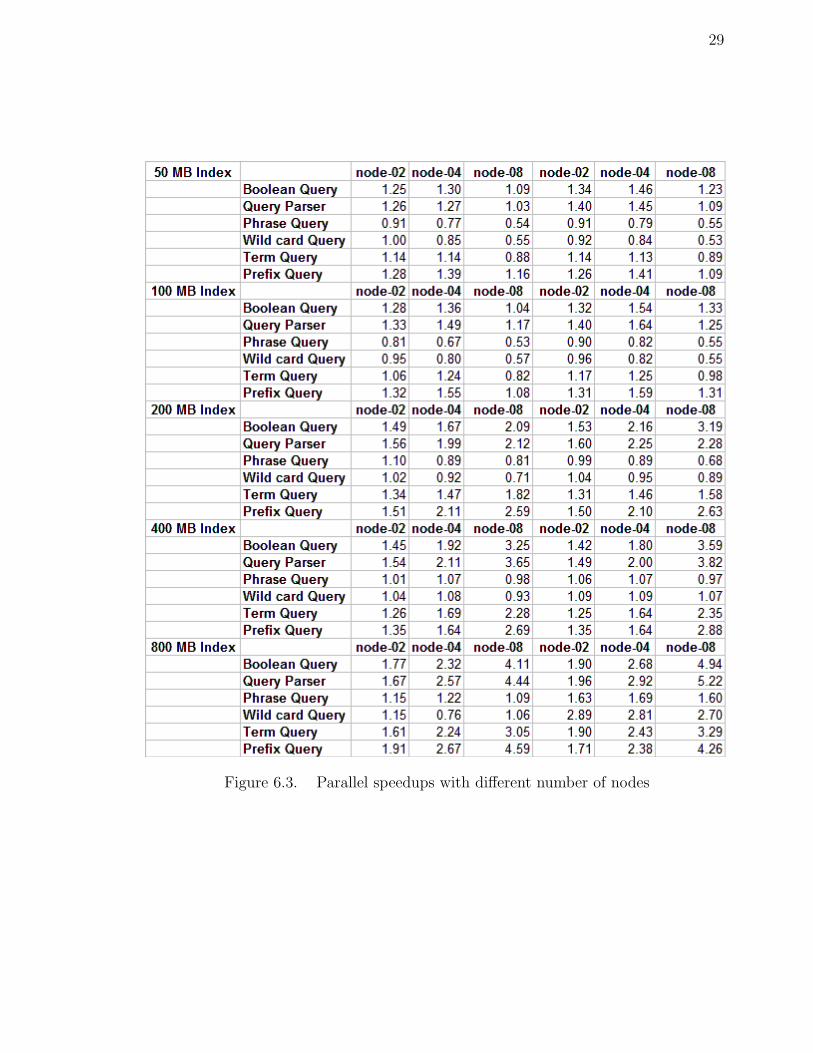
6.3 Comparison of results with different number of nodes
Using multiple nodes for searching is not a new trend in implementing dedicated
search servers. All the previous mentioned points also apply to this situation. Ac-
tually we decided to study the performance of RMI hooks provided by Lucene for
making distributed search servers. 800MB of index data is comparatively small. Ac-
tual production systems may have several gigabytes of data for searching. We decided
to study the performance with a reasonable amount of data. That is, of maximum
size 800MB. When we used RMI the time to do search increases with the number of

27
nodes. We expected the time to decrease when we increase nodes. When we analyzed
the reason for this, we have to think about communication overhead. In the process
of synchronizing and load balancing the ParallelMultiSearcher may communicate
multiple times with the BackServers. The time being taken to communicate is more
than the time taken for the actual search. So the search time increases when we
increase number of nodes to search. This is true for all index sizes.
Keeping all these things in mind, we designed a new parallel experiment based on
the same basic components we used for Serial experimenting. The design is pretty
simple: the SearchServer communicates with the BackServers that are ready to
search. SearchServer sends the search strings and type of query, directory that it
likes to use for search. The BackServers construct the query object and search it on
the directory, which will return a serialized Hits object to the SearchServer. This
design keeps the communication between different servers at a minimum. We got
almost linear speedup when we increased number of nodes. From this observation
we can say that the ParallelMultiSearcher is not optimized for smaller amount of
data. Figure 6.3 shows the results for the parallel setup.
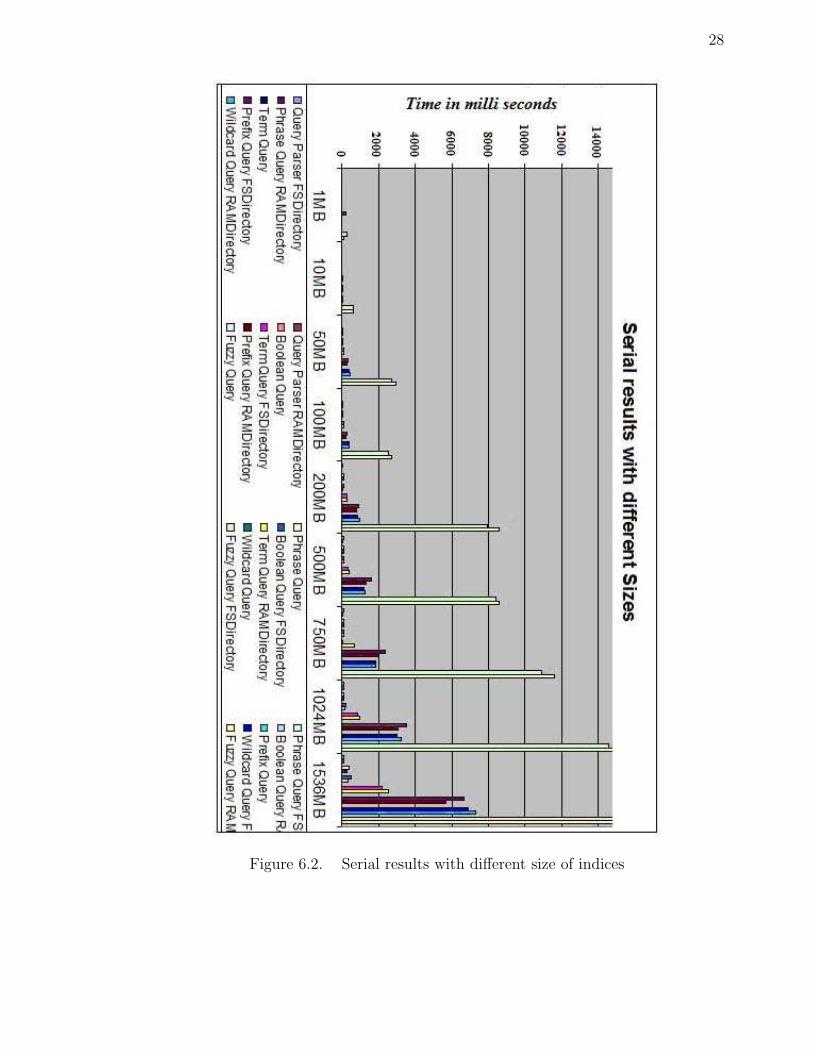
28
Figure 6.2. Serial results with different size of indices
29
Figure 6.3. Parallel speedups with different number of nodes

30
Chapter 7
CONCLUSIONS
7.1 What have we done so far?
The complete scope of this topic is very large. We committed to study a part of
the Lucene search library, which justifies the topics we selected to study. The re-
sults reveal some important things. Getting speedups when the timing is in millisec-
onds is very hard. Small things may change the results. Lucene’s multi searching
library is said to be good to use when we have enough data that supersedes the com-
munication overhead with the time to search. Our experiments show that Lucene
ParallelMultiSearcher library is good to use when it is important to make the
implementation simple and accessing different sets of data made easy without much
concern for search time and performance. When we wish to get good performance for
small amount of data, we must use our own parallel implementation. One approach
for parallel implementations was discussed in previous sections. This implementation
is able to achieve good speedups as we listed in previous sections. Our experimental
results show that we reached a minimum time in search. The minimum time we got
is small, close to the time for threading and communication overhead.

31
7.2 Future directions
At this time Lucene doesn’t have any parallel constructs to use. We can implement
some constructs which deal with using Lucene in parallel environments. We can
provide an API for giving user more control over data transfer and communication.
Experimenting with the same set of requirements with large amount of data may re-
veal more important things about the ParallelMultiSearcher and MultiSearcher.
We can try some more parallel designs for comparing and getting appropriate models
based on the situation for using Lucene.

32
REFERENCES
[1] Apache Website for Lucene. Documentation and Information about Lucene.http://lucene.apache.org/
[2] Open Source Initiative. Open Source home page.http://www.opensource.org/
[3] Apache Website for Nutch. Documentation and Information about Nutch.http://lucene.apache.org/nutch/
[4] URL Database. DMOZ URL Database.http://www.dmoz.org/
[5] Benchmarks. Hardware Benchmarks for Lucene.http://lucene.apache.org/java/docs/benchmarks.html
[6] Levenshtein distance. Levenshtein distance algorithm.http://en.wikipedia.org/wiki/Levenshtein distance
[7] Dong, A. and Agogino, A.M. “Designing an untethered digital library.”. J.Roschelle, T.-W. Chan, Kinshuk, & S.J.H. Yang (Eds.), The 2nd IEEE In-ternational Workshop on Wireless and Mobile Technologies in Education (pp.144-148). Jhongli, Taiwan, 2004.
[8] Andy Dong, Eric Fixler and Alice Agogino. “A Case Study of Policy Decisions forFederated Search Across Digital Libraries.” International Conference on DigitalLibraries,(Vol. 2, pp. 892-898), 2004.
[9] Maged Michael, Jos E. Moreira, Doron Shiloach, Robert W. Wisniewski. IBMThomas J. Watson Research Center. “Scale-up x Scale-out: A Case Study usingNutch/Lucene.” IIPDPS 2007: 1-8, 2007.
[10] Christopher T. Fallen and Gregory B. Newby. Arctic Region SupercomputingCenter “Logistic Regression Merging of Amberfish and Lucene Multisearch Re-sults.” Fourteenth Text REtrieval Conference, 2005.
[11] California Digital Library team, Appendix-E. The Melvyl Recommender Project:Final Report (Fourth edition), 2001.
[12] Otis Gospodnetic, Erik Hatcher. Lucene in Action. Manning Publications, 2004.






























