Embed Size (px)
Citation preview

Multimedia Tools and Applications, 18, 31–54, 2002c© 2002 Kluwer Academic Publishers. Manufactured in The Netherlands.
Performance of a Scalable Multimedia Serverwith Shared-Storage Clusters∗
SIMON S.Y. SHIM [email protected] of Computer Engineering, San Jose State University, San Jose, CA, USA
TAI-SHENG CHANGGE Medical Systems, Chicago, IL, USA
DAVID H.C. DUDistributed Multimedia Research Center†and Department of Computer Science and Engineering,University of Minnesota, Minneapolis, MN, USA
JENWEI HSIEHHigh-End Server Development Group, Dell Computer Corporation, Austin, TX, USA
YUEWEI WANGIXMICRO, Inc. San Jose, CA, USA
Abstract. The existing SCSI parallel bus has been widely used in various multimedia applications. However,due to the unfair bus accesses the SCSI bus may not be able to fully utilize the potential aggregate throughputof disks. The number of disks that can be attached to the SCSI bus is limited, and link level fault tolerance isnot provided. The serial storage interfaces such as Serial Storage Architecture (SSA) provide high data band-width, fair accesses, long transmission distance between adjacent devices (disks or hosts) and link level faulttolerance. The fairness algorithm of SSA ensures a fraction of data bandwidth to be allocated to each device.In this paper we would like to know whether SSA is a better alternative in supporting continuous media thanSCSI. The scalability of a multimedia server is very important since the storage requirement may grow incre-mentally as more contents are created and stored. SSA in a shared-storage cluster environment also supportsconcurrent accesses by different hosts as long as their access paths are not overlapped. This feature is calledspatial reuse. Therefore, the effective bandwidth over an SSA can be higher than the raw data bandwidth and thespatial reuse feature is critical to the scalability of a multimedia server. This feature is also included in FC-AL3with a new mode called Multiple Circuit Mode (MCM). Using MCM, all devices can transfer data simultane-ously without collision. In this paper we have investigated the scalability of shared-stroage clusters over an SSAenvironment.
Keywords: shared storage, multimedia server, SSA, SCSI, scalability
∗This work is supported in part by the NSF under Grant CDA-9502979, CDA-9414015, CDA-9422044 and by agift from IBM.†Distributed Multimedia Research Center (DMRC) is sponsored by US WEST Communications, Honeywell, IVIPublishing, Computing Devices International and Network Systems Corporation.

32 SHIM ET AL.
1. Introduction
A multimedia server needs to support a variety of data media including video, audio, image,and text. Accessing and displaying continuous media such as video pose a challenge becauseof its large data size and real time constraint. If video frames are not delivered on time, delayjitters will occur during display. Continuous media are stored, retrieved and delivered tousers through broadband communication networks in real time. A server which is capableof processing many multimedia requests needs a large amount of memory and many disksto satisfy hundreds or thousands concurrent user requests.
There has been much research effort [1, 6, 17, 24, 25] on storage and retrieval of con-tinuous media. A multimedia server requires lots of resources and has to support manyusers. A multimedia server should guarantee continuous display of video without jitters byallocating adequate network bandwidth, memory, and storage resources. Anderson et al.[1] proposed the continuous media file system where it is guaranteed the minimal transferrate within a session. The authors examined issues on real-time constraints, data layout,admission tests for a new session, and disk scheduling in uncompressed audio data. Ranganet al. [17] discussed a mathematical model which includes storage granularity and scatter-ing parameters. They used the data pattern to store data in disks. Liu et al. [15] discussedthe issues involved when an experimental VOD server was implemented. They used theshared-memory multiprocessor machine with RAID-3 disk arrays. The authors discussedbuffer management and different data striping methods. A striping penalty was showedusing the experimental results. They showed the performance results in a large scale whena mass storage system was used in building a VOD server. There have been steady ef-forts in building multimedia servers such as Starlight [24] and IBM Tiger Shark [12].All of them use SCSI for I/O subsystems. Reddy and Wyllie [19] briefly explained theeffect of unfair SCSI bus contention for supporting multimedia applications using sim-ulation. Reddy et al. discussed that access fairness was important factor in supportingmultimedia applications. Du et al. [8] discussed the comparisons between SCSI, SSA, andFC-AL.
The existing SCSI parallel bus has been widely used in most storage subsystems. Sinceit is a commodity item, it is low in cost. It provides a good performance to legacy ap-plications. It supports a reasonable performance for a multimedia server. The traditionalSCSI bus uses a parallel interface which transfers data through many wires. Transmis-sions over parallel connections may cause problems in synchronization and signal integrityover longer distance. These difficulties limit the transmission distance and the numberof devices that can be attached on an SCSI bus. Parallel connections also require Widerand thicker cables. Serial interfaces eliminate these problems, and support longer distanceconnections with high transmission speed. One of the potential drawbacks of supportingmultimedia applications using an SCSI bus is the inherent nature of unfair accesses onthe bus. When load is high, the unfair accesses on an SCSI bus may hinder the real-timedelivering of multimedia information. In SCSI, priorities are based on the physical ad-dresses of devices. A high priority device wins an arbitration and transmits its data framesbefore low priority ones. As continuous media data are retrieved from disks on an SCSIbus, the response time may fluctuate depending on the priority of the disk in which data

A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 33
blocks are stored. A multimedia server also requires a high fault tolerance capability. SCSIdoes not offer fault tolerance against link and host failures. If a link fails in an SCSI bus,all disks on the bus may not be accessible. In order to provide fault tolerance againstlink and host failures, data mirroring may be used where redundant hosts and disks aremaintained for fail-over. However, the cost is high for supporting fault tolerance by datamirroring.
Recently several serial interface standards were developed. They include the Serial Stor-age Architecture (SSA) standard [3, 4, 8, 9], the Fibre Channel-Arbitrated Loop (FC-AL)standard [2, 8, 9], and the IEEE 1394 serial bus standard [14, 22]. SSA provides the aggre-gated data bandwidth of 80 MBytes/sec while fast-and-wide SCSI offers 20 MBytes/sec. Anode in SSA has four ports with two in and two out links. Each link supports 20 MBytes/secbandwidth. Hence a node can sustain 40 MBytes/sec for reads and 40 MBytes/sec forwrites. FC-AL was designed for high speed networks to provide low-cost storage attach-ments. FC-AL provides data bandwidth of 100 MB/s and fault tolerance with an optionalfairness algorithm. A configuration with dual loops and multiple hosts in FC-AL providesbandwidth of 200 MB/s and fault tolerance against link, host, and adapter failures. FC-AL also supports a bypass circuit which may be used to keep a loop operating when adevice on a loop is physically removed and failed. However, the cost of FC-AL is higherthan SSA, and the new standard FC-AL3 [11] does offer the spatial reuse feature with-out access fairness. The spatial reuse allows multiple concurrent transmissions as long asthe transmission paths are not overlapped. FC-AL3 supports a new mode called Multi-ple Circuit Mode (MCM). In this MCM mode, multiple circuits are active at the sametime and transfer data simultaneously without collision on the same medium. However,a downstream source may not be able to use its fair share of bandwidth since its sharedepends on upstream sources without access fairness. SSA is designed to take advantagesof this spatial reuse feature with the fairness algorithm and it can potential has a throughputrate higher than the raw data rate. Chen and Thapar presented results of a video serversimulation in which FC-AL and SCSI were used as storage interfaces [7]. They consid-ered these two interfaces in a video retrieval application using simulations. IEEE 1394 isdesigned for low cost PCs and consumer electronic interfaces [22]. Therefore, it is notthe best fit for server applications. Ultra SCSI is the next-generation parallel SCSI inter-faces. Clock speed is doubled in Ultra SCSI from the Fast and Wide SCSI-2 standards.Ultra2 SCSI supports data bandwidth of 80 MB/s. It also only allows a small numberof device attachments in a bus. The speeds of interfaces are increasing steadily. SSA-2supports link bandwidth of 40 MB/s, and Ultra2 SCSI provides 80 MB/s in a 12 meterbus with 16 devices. The next generation of each interface will be likely to double thespeed.
The speed of a bus is only one factor in the performance of a system. There are moreimportant characteristics than the bus speed. For instance, scalability is an important con-sideration for building a powerful and large scale multimedia server. In this paper, we focuson those issues that affects performance of a multimedia server rather than the speed of abus. SSA employs a fairness algorithm based on two quotas, and provides fault toleranceagainst link and interface failures.
The following is a summary of the advantages of SSA over SCSI.

34 SHIM ET AL.
• Bandwidth: Serial connections achieve higher speed than parallel ones. The aggregatethroughput of a 4-port SSA node is 80 MB/sec. In SSA2, it is 160 MB/sec. A fast andwide SCSI supports 20 MB/sec. In Ultra2 SCSI, it is 80 MB/sec.
• Fair access: SSA provides a fairness algorithm for fair accesses on a loop. SCSI usesdevice priorities for bus arbitration, thus results in unfair accesses.
• Fault tolerance: SSA is connected with two in and two out links. It provides a redundantpath when a link fails. A multiple host configuration in SSA offers fault tolerance againsthost, link, and adapter failures. SCSI does not provide any fault tolerance.
• Number of attachments: The maximum number of attachments in a fast-and-wide SCSIbus is 15 devices. On the other hand, maximum of 126 devices can be attached in an SSAloop.
A large scale multimedia server can be built using either a main frame computer or a largescale multiprocessor (usually a distributed memory multiprocessor with a special topology).However, the cost for such a system will be very high. Even though SCSI is lower in costthan SSA, the serial storage interfaces like SSA may offer a better alternative to build ascalable multimedia server. A multimedia server based on SSA can increase its capabilityby gradually adding more hosts and disks. It is important to know the effect of adding ahost or a disk to the system in a shared-storage environment. It is also important to identifythe performance bottleneck when multiple hosts or many disks are attached to a system.In a single host configuration, it is desirable to minimize the variations of access latenciesin supporting continuous media. SSA ensures fair accesses among devices using a fairnessalgorithm. Thus, it may minimize the variations of access latencies. Theoretically when thevariations of access latency are minimized, the number of video frames that can be supportedis increased. However, it is not clear to what degree the fair accesses to the loop can increasethe number of supported video streams. Even though the fairness algorithm of SSA willenforce the fairness up to a certain degree, it may not be totally fair to all the nodes sinceupstream nodes may be able to send more frames than downstream nodes. It is interesting tosee if the fairness algorithm which may not be totally fair will make a difference in supportingcontinuous media. Readers can find the detailed discussion on this in Sections 2 and 3. Thesimilar analysis can be made regarding the MCM mode of FC-AL3. However, the analysiswill be simpler since it does not support an access fairness algorithm. We want to investigatehow much improvement can be made by taking advantages of the spatial reuse featureoffered by SSA with shared storage. Our study is designed to answer these issues throughmathematical analysis and experiments. Hence, the contributions of this paper is two-fold:it shows the performance implications of the fairness algorithm in SSA, and analyze theperformance of shared storage clusters in supporting multimedia with real experiments.
The remainder of this paper is organized as the following. In Section 2, an overview of theSSA standards is presented. It includes fairness algorithm, spatial reuse, and fault tolerance.In Section 3, we analyzed the performance of a single host multimedia server based on SSAin terms of the number of video streams that can be supported. The scalability analysis withmultiple hosts on a loop for SSA is presented in Section 4. Experiment setup is describedin Section 5. Section 6 shows the results of comparison between SSA and SCSI. Section 7concludes the paper and outlines future work.

A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 35
Figure 1. Topology of an SSA loop.
2. Overview of serial storage architecture
SSA is based on a technology originally developed by IBM. It provides a high-speed(80 MB/sec aggregate bandwidth with 2-in and 2-out connections of 20 MB/s each to astorage device; 160 MB/sec aggregate bandwidth in the near future), full-duplex, and framemultiplexed communication interface with fault tolerance for the interconnection of storagedevices and host computers. It provides the capability to set up a flexible storage topologywith string, loop, or switched architectures. A typical topology for SSA is a loop. Multiplehosts can be connected to a loop to increase the performance of the whole system since eachhost can access any of the disks on the loop. SSA supports SCSI protocol to minimize thechanges when migrate the existing system from SCSI to SSA. A typical SSA configurationis shown in figure 1 where seven disks are connected by point-to-point links to form a loop.
2.1. Spatial reuse
SSA provides a spatial reuse feature which allows non-overlapping data transmissions tooccur simultaneously on the same loop. This is possible because each link in an SSA loopoperates independently. SSA is capable of supporting multiple simultaneous transmissionson the same loop. Figure 2 shows two concurrent data transmissions using spatial reuse.Host A receives data frames from Disk 3 while Host B receives data frames from Disk1. Since the communication paths are not overlapped, the total data bandwidth of a linkis reused. Therefore, the real aggregate link bandwidth can be greater than the one withoverlapped paths.
If four hosts are attached with ideal data distribution in disks, the aggregate link bandwidthcan be potentially increased four times. The performance can be potentially improvedmultiple folds without increasing link speed. When allocating data into disks, the dataplacement which can maximize the potential of spatial reuse can maximize the overallperformance. In order to be benefited from spatial reuse, SSA is designed to use very smallframes of 128 bytes. A large scale multimedia server can also be constructed by adding

36 SHIM ET AL.
Figure 2. Spatial reuse in an SSA loop.
more hosts and disks into the system. The detailed analysis of the scalability is presented inSection 4. Current implementation of an SSA loop supports up to eight hosts in a single loop.
2.2. Fairness algorithm
In order to enforce a fair sharing of the links among all the SSA nodes, a fairness algorithmbased on two predetermined quotas and a rotating token is defined. A token called SAT(SATisfied) is circulated in a loop in the opposite direction to the data flow (note that SSAalways has two loops). Since there are two data flows in SSA, two SAT tokens, one for eachdata flow, are operating independently on each direction. Figure 3 shows the SAT tokenrotations in an SSA loop.
During the configuration phase, all the nodes agree on two parameters, A quota and Bquota. In order to take advantages of spatial reuse, a node is allowed to transmit data framesoriginated from the node if there are no passing data frames from its upstream nodes.However, the passing data frames from upstream nodes have higher priority over the data
Figure 3. SAT token rotation in an SSA loop.

A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 37
frames originated by each node. That means a node must yield to the passing data frames.Therefore, an upstream node may have advantages over a downstream node (in terms of aparticular data flow). In order to ensure the fairness, each node is allowed to transmit up to Bquota data frames originated from itself between the arrival of two consecutive SAT tokensin this manner. When an SAT token arrives in a node, if the total number of data framestransmitted by the node after passing SAT token to the next node last time is less than Aquota and there are more data frames to send, the node can switch the priority betweenpassing frames and the frames originated by the node. That means the node can transmitup to A quota data frames originated by itself and temporarily block the transmission ofpassing frames before it passes the SAT token to the next node. If the number of data framestransmitted by a node after passing the SAT token to the next node last time is greater thanA quota, the node needs to pass the SAT token to the next node immediately. In general Aquota is less than or equal to B quota. Therefore, A quota can be considered as the minimumnumber of data frames a node is guaranteed to send and B quota is the maximum number ofdata frames that a node can possibly transmit between the passing of two consecutive SATtokens to the next node respectively.
Since a node can send up to B quota data frames when there are no passing data framesfrom upstream nodes, upstream nodes have a better chance to send more data frames thandown stream nodes if B quota is greater than A quota. This creates a potential unfair problemamong nodes based on the relative locations in the data flow path. Further details can befound in [3, 9].
2.3. Fault tolerance
Nodes in SSA are connected by dual ports. In a loop topology, two redundant paths areavailable between any two nodes. These redundant paths eliminate a single point of linkfailure. Figure 4 shows a link failure. Disk 2 and Disk 3 detect a link failure and notify anearby host. The host determines the location of the failure, and data frames are reroutedto an alternative path. The detailed error handling procedures are described in the SSA
Figure 4. Fault tolerance in an SSA loop.

38 SHIM ET AL.
standard [3, 4]. In a multiple host configuration, a host failure can be tolerated as shown infigure 4. When Host B fails, requests are forwarded to Host A because Host A can access allthe disks. A loop operates continuously even during host, link, or disk failure. Disk failurecan be tolerated by implementing Redundant Array of Independent Disks (RAID).
3. Performance analysis of a single server
We intend to analyze the performance of a single server in supporting continuous media inthis section. Continuous media are real-time data. The command latency to fetch a data blockis critical for determining the number of streams that can be supported. It is also importantto minimize the variations of command latencies to assure a consistent performance. Tominimize the variations, fair accesses to a loop may be important.
SCSI’s bus arbitration is based on the priority of a device. The highest priority devicewins an arbitration at any time. Hence, a low priority device may have to wait for a whilebefore it gets a chance to transmit because of the unfair arbitration policy. The streamsaccessing low priority disks are more likely to miss their deadlines. The number of streamsin supporting continuous media may not scale well as more disks are attached to an SCSIbus. However, smaller data block sizes may reduce the effect of unfair bus accesses. On theother hand, it may result in higher seek and rotational latency overhead as the data blocksize decreases.
SSA ensures fair accesses among devices using a fairness algorithm. In this section, weanalyzes the command latencies in SSA, and the effects of fair accesses when continuousmedia is supported (Table 1). Our goal is to find the maximum number of video streamsthat can be supported.
3.1. Serial storage architecture (SSA)
During retrieval of continuous media, there is a seek whenever a disk head moves fromone cylinder to the desired cylinder. After moving to the cylinder, the disk head may haveto wait for some time before the data block can be read. This waiting time is called latency.When the disk resumes fetching a block for a stream, it has to contend the bus to transferthe block. Hence, disk access time consists of disk seek, latency, and data transfer time.Both disk seek and latency times vary depending on the current disk head position and datalocation.
In order to reduce the possibility of experiencing a jitter, each stream should have sufficientdisplaying data in a buffer to cushion the maximum seek and latency times while retrievingthe next data block. This is given by Eq. (1) when a two-buffer scheme is used. In a two-buffer scheme, one buffer is used for retrieval of the next data block while the data in theother buffer is being delivered. When the display of current data block is over, the nextdata block should already be in the buffer. Therefore, the roles of the two buffers will beexchanged. Assume the following definitions. X is the number of video frames to be fetchedin a block. Tdisplay is the display duration of a video frame in seconds. T i
seek is the seek timeof diski in seconds. T i
latency is the latency time of diski in seconds. T itransfer is the time to
transfer a block of X frames in diski in seconds. To ensure no delay jitters, the following

A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 39
Table 1. Symbols and definitions.
Symbol Definition Units
X Number of video frames to be fetched as a block frames
Nstreams Number of continuous media streams supported from all disks stream
Ndisks Number of disks disk
Tdisplay Display duration of a video frame sec
T iseek Seek time of diski sec
T ilatency Latency time of diski sec
T itransfer Time to transfer a block of X frames in diski sec
T icommand latency Latency of a command sent to diski sec
T iqueue Queuing delay at the command queue of diski sec
T itoken rotation Time for one SAT token rotation sec
Scommand Size of a command bytes
SA quota Size of A quota bytes
SB quota Size of B quota bytes
Sframe Maximum data frame size bytes
Blink Link data bandwidth (20 MB/s) bytes/s
Rmpeg1 Bit rate of MPEG-1 movie (1.2 Mb/s) bytes/s
Tmin token holding Minimum token holding time sec
α Ratio of active nodes (transmiting nodes divided by the total numberof nodes)
equation should hold.
X × Tdisplay ≥ Ttransfer + Tseek + Tlatency (1)
In SSA, the size of a data frame is of 128 bytes and data frames are time divisionmultiplexed into one link. Each disk is allowed to transmit a minimum of A quota and amaximum of B quota frames during one SAT token rotation time as described in Section 2.2.In SSA, there are two different scenarios of data transfers depending on the size of acommand. The size of the requested data block is defined as a command Size. If A quota isgreater than the command size, each disk transmits the requested block to a host within asingle SAT rotation, thus ensuring fair accesses among disks. This is shown in Eq. (2) whenSAquota > Scommand. Assume Scommand and SA quota represent the size of a command and thesize of A quota, respectively. T i
command latency is the latency of a command sent to diski . T iqueue
is the queuing delay at the command queue of diski .
T icommand latency = T i
queue + T iseek + T i
latency + T itransfer (2)
In processing a read command, T itransfer consists of the time (t1) to transfer data from a disk
platter to a disk cache and the time (t2) to transfer from a disk cache to a host. Assumingthe command size is bigger than 512 bytes, in SSA as soon as the first block of 512 bytes

40 SHIM ET AL.
is transferred, it is ready to be transmitted to a host. Hence, t1 and t2 may be overlappedwith each other. Depending on link load, T i
transfer is approximately equal to max(t1, t2). Inheavy load, t2 is the dominant one. Hence, t2 is assumed to compute the maximum numberof streams supported because we are interested in a heavy load scenario. Now the t2 is equalto Scommand/Blink where Blink represents the link data bandwidth.
Upstream nodes in relation to data flow can send more data than nodes in downstreambecause the upstream nodes have inherently higher priority over the downstream nodes.In heavy load, the nodes in downstream are allowed to transfer only up to A quota if theupstream nodes are sending frames continuously. On the other hand, the upstream nodessend the number of data frames up to B quota in one SAT token rotation time when B quotais greater than A quota. Equation (3) shows the latency of a command from a downstreamdisk when SAquota < Scommand. Assume that Disk j is a downstream node and T i
token rotationrepresents the time for one SAT token rotation.
T jcommand latency = T j
queue + T jseek + T j
latency + Scommand
Blink+
⌊Scommand
SA quota
⌋× Ttoken rotation
(3)
The token rotation time can be approximated as shown in Eq. (4) assuming α is the ratio ofthe number of transmitting nodes to the total number of nodes in a loop. Each station needsto keep the token for the minimum required time so that the token rotation time is above acertain threshold when all the nodes are idle. Tmin token holding represents the minimum tokenholding time. Hence, the token rotation time becomes the data transmission time plus theminimum token holding time for each node in the worst case.
Ttoken rotation =(
SA quota
Blink× α + Tmin token holding × (1 − α)
)× Ndisks (4)
Equation (5) shows command latency of a device in upstream. An upstream device maysend up to B quota at every token rotation time.
T jcommand latency = T j
queue + T jseek + T j
latency + Scommand
Blink+
⌊Scommand
SB quota
⌋× Ttoken rotation
(5)
From Eqs. (1) and (3), Eq. (6) is derived. It represents a case where a node transmits onlythe minimum number of frames at each SAT token rotation in high load. Hence Eq. (6) hasto be satisfied to support jitter free display.
X × Tdisplay ≥ T jqueue + T j
seek + T jlatency + Scommand
Blink+
⌊Scommand
SA quota
⌋× Ttoken rotation (6)
The number of streams supported from Ndisks is computed from the achievable databandwidth of a downstream disk because it is the bottleneck in supporting continuous me-dia. An upstream disk is capable of delivering data frames faster than a downstream disk.

A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 41
From Eq. (3), T jcommand latency is computed. The achievable data bandwidth from diski is com-
puted by Scommand/T jcommand latency. T j
queue is set to 0 because diski is processing commandscontinuously without any queuing delay. T j
queue is considered only when computing com-mand latency of an individual command. For a disk bandwidth perspective, Assuming loadis balanced among disks, each disk supports the same number of streams. Nstreams/Ndisks ×Rmpeg1 is the required data bandwidth from a single disk Rmpeg1 is the bit rate of MPEG-1movie.
Nstreams
Ndisks× Rmpeg1 = Scommand
T jcommand latency
(7)
Therefore, Eq. (7) has to be satisfied. Nstreams is computed from Eq. (8).
Nstreams = Scommand × Ndisks
T jcommand latency × Rmpeg1
(8)
Equation 8 in SSA was verified with the experimental results in Section 6.2. Latenciesin host processing is not considered in Eq. (8) such as operating system overhead. Eventhough the fairness algorithm does not enforce a perfect fair sharing among nodes in SSA.It guarantees that every node sends at least A quota frames within one token rotation time.Hence, SSA is better suited for supporting continuous media.
4. Performance analysis of shared storage clusters
As we discussed before, a large scale multimedia server can be formed by attaching multiplehosts to SSA loops with shared storage. The links in a SSA loop are shared among all thenodes. Hence, each host has to share link bandwidth with other hosts attached on the sameloop. The total throughput may not increase at some point even when more hosts are addedon the same loop. That is because most of link bandwidth is used by passing frames. Insuch a case, throughput can be improved if disks are divided into group of disks, whichis called domains, and a host accesses only the disks in a domain. This may reduce crosstraffic for some applications. However, this does not allow data sharing among hosts. Ifdata are not shared across different domains, the same data blocks may need to be dupli-cated into multiple domains. Data replication will take more disk space to store the samecontents. Hence, as more hosts are added, a configuration needs to be carefully examinedto achieve the optimal throughput. In this section, we study the throughput with the shareddata configuation.
A maximum of 127 devices including hosts and disks can be attached to an SSA loop. Inthis section we discuss the scalability of a multiple host configuration in SSA and identifythe performance bottleneck based on the disk throughput and the number of hosts on anSSA loop. Data frames are routed via a shortest path in SSA. Figure 5(a) shows a singlehost configuration with 8 disks. Disks 1, 2, 3, and 4 send frames to host A through link 1while Disks 5, 6, 7, and 8 send them through link 8 because they are the shortest paths to the

42 SHIM ET AL.
Figure 5. SSA configurations with multiple servers.
host. Half of the disks attached to a loop use one link, and the other half use the other link.Hence, there are no overlapped data paths in this configuration. Two links are used for reads.Each link provides 20 MB/s of link bandwidth. One host can potentially achieve 40 MB/sfrom the two incoming links for reads. Let us assume that the average disk bandwidth isBdisk with uniform accesses among disks. Link bandwidth (Blink) is 20 MB/s. If the numberof disks attached is Ndisks, the total disk throughput of an incoming link is Ndisks
2 × Bdisk.If Ndisks
2 × Bdisk ≥ Blink, a link becomes a bottleneck because the link is saturated. Hence,the maximum aggregate throughput of a host is 40 MB/s from the two incoming links.The maximum aggregate throughput is the total throughput which can be achieved from allhosts. If Ndisks
2 × Bdisk < Blink, the total disk throughput becomes the maximum aggregatethroughput of a host.
Assuming the load of each host is balanced, higher total throughput can be achieved byadding more hosts to a loop. In order to minimize link contention among hosts, the newhost should be added to the opposite side of the loop from the existing host as shown infigure 5(b). In a two host configuration, the links utilized by each host are different. Disk 1

A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 43
sends frames to Host 1 through the left directional links as shown in figure 5(b). On theother hand, frames from Disk 1 to Host 2 are routed via the right directional links (link 1).Since Diski sends frames in two different directions, each host can achieve the aggregatethroughput of 2×Blink (40 MB/s). Hence, two hosts achieves the aggregate link bandwidth of80 MB/s. The average disk throughput is divided by two hosts assuming uniform accesses. IfNdisks
2 × Bdisk ≥ Blink, the link is saturated. The maximum aggregate throughput is 80 MB/sin two host configuration. Otherwise, the total disk throughput becomes the maximumaggregate throughput.
The subsequent analysis assumed the uniform accesses on disks since each host accessesevery disk with equal probability. The analysis shows the throughput of a single link becausethe throughput of other links are symmetric with the link. That is because the uniformaccesses on disks are assumed. Figure 5(c) shows a configuration with four hosts. Eachhost uses Bdisk
4 of disk bandwidth from each disk. Host 1 reads data from Disk 9 to Disk 16through Link 16, and Host 2 fetches data from Disk 13 to Disk 16 through Link 16. The totaldisk traffic passing through Link 16 is (8 + 4) × Bdisk
Nhosts(= 3 × Bdisk). If 3 × Bdisk ≥ Blink, the
link bandwidth becomes a bottleneck. Otherwise, the total disk throughput through a linkdoes not saturate. The proportion of the bandwidth of Link 16 for Host 1 is 8/12 becauseit is also used by Host 2 to access disks from Disk 13 to Disk 16. Host 1 can achievethe total throughput of 26 MB/s (= 8
8+4 × 2(links) × Blink) from the two incoming links.The aggregate throughput is min (Nhosts × 26 MB/s, Ndisks × Bdisk). In other words, theaggregate throughput is the smaller value of either the total link throughput or the total diskthroughput. This is a theoretical bound. Using a similar argument, the bottleneck can beidentified in a configuration with eight hosts.
From figure 5(d), Host 1 receives data frames from Disk 9 to Disk 16 through Link 16.Host 2 receives data frames from Disk 11 to Disk 16 through Link 16. Host 3 receivesdata frames from Disk 13 to Disk 16 through Link 16. Host 4 receives data frame fromDisk 15 to Disk 16 through Link 16. Link 16 is shared by Host 1, Host 2, Host 3, andHost 4 in proportion to accesses frequencies from Disk 9 through Disk 16. The total diskthroughput of (8 + 6 + 4 + 2) × Bdisk
Nhosts(= 5 × Bdisk) is achieved through Link 16 on average.
If 5× Bdisk ≥ Blink, the link is saturated. With uniform accesses among disks, the proportionto the bandwidth of Link 16 from Host 1 is 8/20. In other words, a host can achieve the totalthroughput of 16 MB/s (= 8
8 + 6 + 4 + 2 × 2(links) × Blink) from the two incoming links. Theaggregate throughput from 8 hosts is min(16 MB/s × 8(hosts), Ndisks × Bdisk). The aboveanalysis can be generalized. If Nhosts is 2 × k and k is a positive integer, the throughputthrough a link in a host is computed by Eq. (10).
Throughputlink = Ndisks/2∑Nhosts/2i=1
NdisksNhosts
× i× Blink when
(9)Nhosts = 2 × k and k is a positive integer
Aggregate Link Throughput = Nhosts × Throughputlink × 2 (10)
The aggregate link throughput is the maximum link throughput that can be achievedthrough all links from all hosts. It can be computed from Eq. (10). Equation (10) analyzesonly link bandwidth under the assumption that there are enough attached disks to saturate

44 SHIM ET AL.
Table 2. Model parameters for IBM Ultrastar XP 4.51 GB (SSA) and Barracuda 4 4.29 GB (SCSI).
Parameter Ultrastar XP (SSA) Barracuda 4 (SCSI)
Capacity 4.51 GB 4.35 GB
Rotational speed 7202.7 RPM 7200 RPM
Average rotational latency 4.17 ms 4.17 ms
Seek times 0.5–16.5 ms 0.8–17 ms
Measured average transfer rate 5.5–7.3 MB/sec 4.0–6.5 MB/sec
the loops. In a configuration with multiple hosts, a host has to share the link bandwidthwith other hosts when data frames for other hosts may pass through its incoming links.In summary, the theoretical bound of the aggregate bandwidth is increased as more hostsare added in a loop. Hence, SSA provides a scalable architecture. As more capacity andthroughput are needed, more disks and hosts can be attached incrementally providing ascalable performance.
5. Experiment setup
To compare SSA and SCSI, a cluster of IBM RS/6000 Model 590 workstations wereused. The IBM RS/6000 workstations had fast-and-wide SCSI bus with data bandwidthof 20 MB/s. The IBM RS/6000 Model 590 workstations had 256 KB data cache, 32 KBinstruction cache, 256 MB of RAM, and 2 GB of scratch disk space.
Table 2 shows the summary of disk parameters used in the experiments. The detaileddisk parameters are given in [13], and [21]. The Ultrastar disks were attached to an SSAloop. The Barracuda disks were used in an SCSI bus. Both disks employ zone bit recording[20]. Cylinders of a disk are divided into many zones. The same recording density isused in each zone. Since outer zones are wider in space than inner zones, more data arestored in outer zones than inner zones. As a result, higher data transfer rate is obtainedin outer zones than in inner zones. Disk transfer rate in Table 2 is measured by reading1 MBytes blocks from the actual disks. The Ultrastar disks delivers higher transfer ratethan the Barracuda disks as shown in Table 2. However, sixteen frames of MPEG-1 issmaller than 1 MB. Using 128 KB block requests and limiting the data placement up to1.6 GB in outer zones, the average data transfer rates of Ultrastar and Barracuda weremeasured as 5.4 MB/s and 5.0 MB/s respectively. Hence, we used 1.6 GB in outer zones whenSSA and SCSI were compared in order to minimize the discrepancy in disk performance.However, the whole disk space (4.5 GB) was used when the throughput of an SSA loop wasmeasured.
Data bandwidth of fast-and-wide SCSI bus is 20 MB/s. In order to compare the perfor-mance of SSA and SCSI, the same data bandwidth in a link needs to be used in SSA. Onepath in the single direction in SSA is 20 MB/s. If data bandwidth of one direction in SSA isused, the data bandwidth of SSA and SCSI are equivalent. When SSA and SCSI were com-pared, disks on one side of a loop were used from a host. In SSA, frames are routed throughthe shortest path between a host and a disk. If the disks on one side of a loop are used from

A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 45
Figure 6. Single host configuration. For fair comparison, only 20 MB/s of one link is used for reads.
a host, those disks send data frames to the same direction (20 MB/sec). Figure 6 shows asingle host configuration with eight disks. A host sends commands to Disk 1 through Disk 4in one side. When SSA and SCSI were not compared, both directions (40 MB/s) were used.The MPEG-1 trace data used in the experiments requires roughly 1.2 Mbits/sec. It is en-coded as variable bit rate. The number of streams supported are measured when streams aresupported with the jitter ratio of less than 0.1 percent. Data blocks are striped over all disks.
6. Experimental results
6.1. Comparisons between SSA and SCSI
For a given configuration, the number of streams that can be supported is defined as themaximum number of stream with less than 0.1 percent delay jitters when accessed concur-rently. Video data are partitioned into blocks. Blocks are striped on all the disks. That meansall the blocks are allocated into all the disks in a round-robin manner. If small blocks areaccessed from disks, the overhead of disk seek and latency becomes large in proportion tothe size of data retrieved. On the other hand, if large blocks are used, buffer requirementsincrease to hold blocks in memory even though seek and latency overhead decrease. Hence,there exists tradeoffs between the block size and memory requirements. Figure 7 shows thenumber of streams supported with the varying block sizes. Using four frames in a block,SSA supports 26 streams in a four disk configuration. With eight frames per block, thenumber of streams supported are more than doubled from 26 to 61. However, increasingfrom 16 frames to 32 frames per block results in only fifteen percent increase in the numberof streams supported. As the block size increases, the proportion of seek and latency to totalcommand latency decreases. However, it translates into more buffer space to hold blocks inmemory. In summary, doubling the block size from four frames to eight frames results in130 percent increase in the number of streams supported. On the other hand, increasing 16frames to 32 frames results in only 15 percent increase in the number of streams supported.Hence, sixteen frames per block is used in the following experiments.

46 SHIM ET AL.
Figure 7. Comparison on the block size of SSA and SCSI. Four disks are attached to both SSA and SCSI. Theblock sizes used are 4, 8, 16, and 32 frames per block.
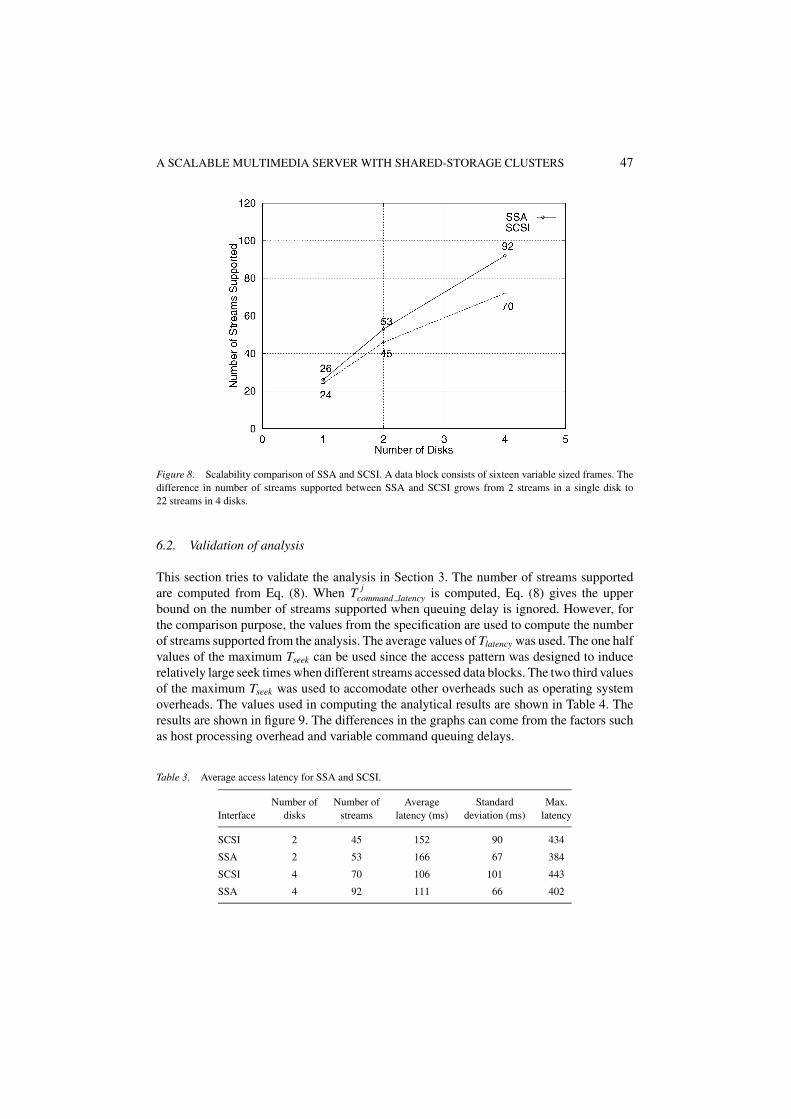
The number of streams supported has to scale up well as more disks are added. Themaximum number of disks attached in fast-and-wide SCSI and SSA is 15 and 127 respec-tively. Figure 8 shows the number of streams supported using different number of disks. Itshows the comparison in scalability of the performance in SSA and SCSI. The number ofstreams supported in a single disk are 26 for SSA and 24 for SCSI. The difference comesfrom the fact that the disks have different data transfer rates. Using 128 KB block size,the throughput of Ultrastar (SSA) and Barracuda (SCSI) was measured as 5.4 MB/s and5.0 MB/s respectively. The block size of 16 frames was used in the experiments. The ratiosof the number of streams supported between one disk and four disk setup in SCSI and SSAare 2.9 and 3.5 respectively. Doubling the number of disks in SSA results in a higher ratio.Hence, SSA provides better scalability in supporting continuous media. There are a numberof factors which contribute to the scalability. For example, a disk and an adapter throughputmay be different. However, an important factor is the fairness algorithm provided in SSA.The default values of Aquota and Bquota were 1 and 4 frames, respectively. The number ofstreams supported may increase if Aquota and Bquota are set to be the same value. However,in the current SSA setup, it is not allowed to change the values of Aquota and Bquota.
It is desirable to minimize the variations of access latencies in supporting continuousmedia. Table 3 shows the sample of average latencies when they were measured with twodisks and four disks. Even though the average latencies in SSA are larger, the standarddeviations in SSA are less than the ones in SCSI. The maximum latency is also smaller inSSA. Since each stream sends a read request as soon as one buffer is empty, the contentionon disks may be high. Hence, the maximum command latency for some streams tend tobe long as shown in Table 3. SSA ensures fair accesses among devices using the fairnessalgorithm. Thus, it minimizes the variations of access latencies.
A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 47
Figure 8. Scalability comparison of SSA and SCSI. A data block consists of sixteen variable sized frames. Thedifference in number of streams supported between SSA and SCSI grows from 2 streams in a single disk to22 streams in 4 disks.
6.2. Validation of analysis
This section tries to validate the analysis in Section 3. The number of streams supportedare computed from Eq. (8). When T j
command latency is computed, Eq. (8) gives the upperbound on the number of streams supported when queuing delay is ignored. However, forthe comparison purpose, the values from the specification are used to compute the numberof streams supported from the analysis. The average values of Tlatency was used. The one halfvalues of the maximum Tseek can be used since the access pattern was designed to inducerelatively large seek times when different streams accessed data blocks. The two third valuesof the maximum Tseek was used to accomodate other overheads such as operating systemoverheads. The values used in computing the analytical results are shown in Table 4. Theresults are shown in figure 9. The differences in the graphs can come from the factors suchas host processing overhead and variable command queuing delays.
Table 3. Average access latency for SSA and SCSI.
Number of Number of Average Standard Max.Interface disks streams latency (ms) deviation (ms) latency
SCSI 2 45 152 90 434
SSA 2 53 166 67 384
SCSI 4 70 106 101 443
SSA 4 92 111 66 402

48 SHIM ET AL.
Table 4. Symbols and values used when computing analytical results.
Symbol Values used
T iseek 12 ms
T ilatency 4 ms
T itoken rotation ( 128
20 MB/s × α + 0.005 × (1 − α)) × Ndisks ms
Scommand 80 Kbytes
SA quota 128 bytes
Blink 20 MB/s
Rmpeg1 1.2 Mbit/s
Figure 9. Comparison between analytical and experimental results. The block size used is 16 frames per block.
Figure 9 shows the comparison between analytical and experimental results as the numberof disks varies. When queuing time is ignored, the analysis results should be considered asthe upper bound on the number of streams supported. The experimental results are differentfrom the results in the previous section because the whole disk space (4.5 GB) is used whenmovies are allocated.
6.3. Results of a multiple host configuration
The experiments in this section uses two directions of links from a host and the samenumber of disks (16 disks). Hence, the theoretical bandwidth of 40 MBytes/sec for readscan be achieved from a host. The number of streams supported represents the total numberof streams that can be supported from all hosts. The total data bandwidth is scalable as more
A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 49
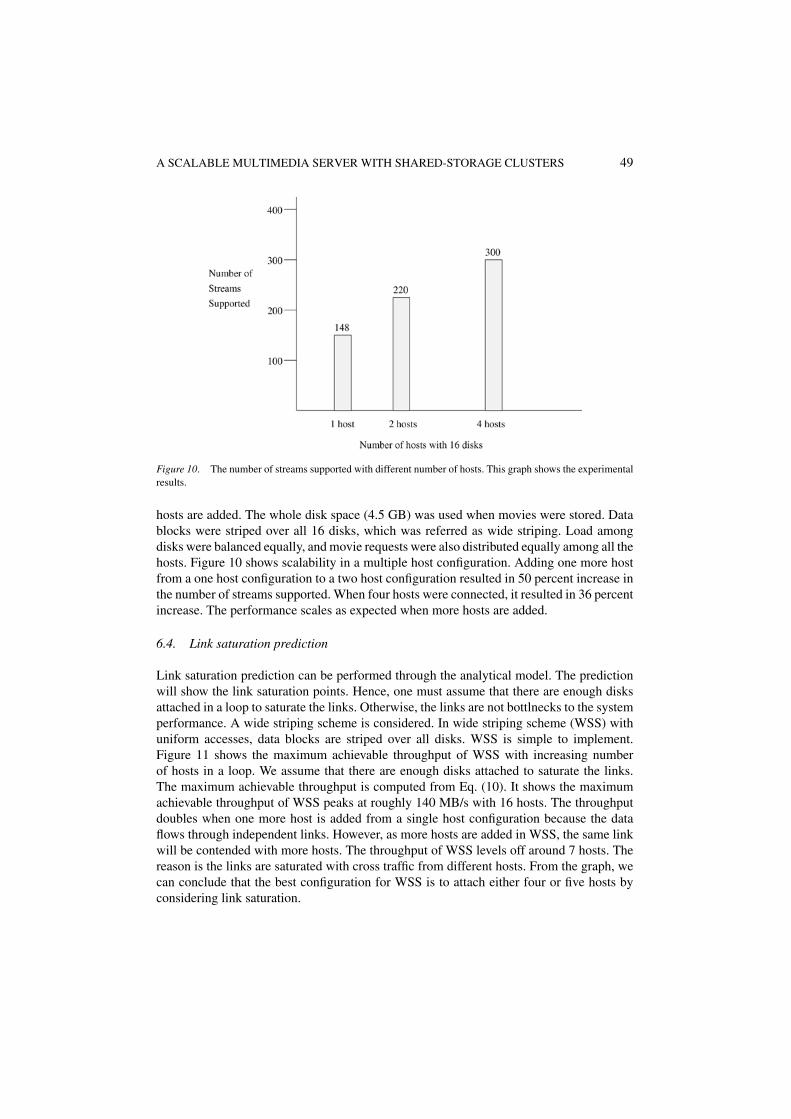
Figure 10. The number of streams supported with different number of hosts. This graph shows the experimentalresults.
hosts are added. The whole disk space (4.5 GB) was used when movies were stored. Datablocks were striped over all 16 disks, which was referred as wide striping. Load amongdisks were balanced equally, and movie requests were also distributed equally among all thehosts. Figure 10 shows scalability in a multiple host configuration. Adding one more hostfrom a one host configuration to a two host configuration resulted in 50 percent increase inthe number of streams supported. When four hosts were connected, it resulted in 36 percentincrease. The performance scales as expected when more hosts are added.
6.4. Link saturation prediction
Link saturation prediction can be performed through the analytical model. The predictionwill show the link saturation points. Hence, one must assume that there are enough disksattached in a loop to saturate the links. Otherwise, the links are not bottlnecks to the systemperformance. A wide striping scheme is considered. In wide striping scheme (WSS) withuniform accesses, data blocks are striped over all disks. WSS is simple to implement.Figure 11 shows the maximum achievable throughput of WSS with increasing numberof hosts in a loop. We assume that there are enough disks attached to saturate the links.The maximum achievable throughput is computed from Eq. (10). It shows the maximumachievable throughput of WSS peaks at roughly 140 MB/s with 16 hosts. The throughputdoubles when one more host is added from a single host configuration because the dataflows through independent links. However, as more hosts are added in WSS, the same linkwill be contended with more hosts. The throughput of WSS levels off around 7 hosts. Thereason is the links are saturated with cross traffic from different hosts. From the graph, wecan conclude that the best configuration for WSS is to attach either four or five hosts byconsidering link saturation.

50 SHIM ET AL.
Figure 11. Total throughput when increasing number of hosts are attached is computed from the analysis. It isassumed that there are enough disks attached to saturate the links.
6.5. Effects of quotas in the fairness algorithm
This section discusses the effect of the fairness algorithm in supporting continuous media.We are especially interested in the effects of two quotas of the fairness algorithm in SSA. Letus review the fairness algorithm briefly. A node can send the minimum number (Aquota)of frames and up to the maximum number (Bquota) of frames between one SAT tokenrotation. Since a node can generate up to Bquota when a link is idle, a node in upstream inthe direction of data flow can detect the idle link before a node in downstream does. Hence,an upstream node can potentially send more data frames than a downstream node whenAquota < Bquota.
This unequal accesses can be corrected by adjusting either Aquota or Bquota. Let us defineThroughputi is the data frames received from the i th node in bytes. When Aquota < Bquota,Throughputi ≤ Throughput j given that node j is upstream node from nodei . This may causethe unfairness in some degree. When the links are not saturated (Aquota < Bquota), thenumber of streams supported will not change based on the values of Aquota and Bquotabecause there are enough bandwidth for the downstream nodes to compensate while theupstream nodes are reading. On the other hand, when the links are saturated (Aquota <
Bquota), the downstream nodes are forced to send smaller amount of data than the upstreamnodes. In such a scenario, it is advantageous to set Aquota = Bquota so that the equalaccesses are guaranteed among all the nodes attached in the loop. This will force theupstream nodes to send the equal amount as the downstream nodes. It results in highernumber of streams supported.
Since we cannot change the values of Aquota and Bquota in the actual system, we studythe effects of different quotas using the simulation model. In the simulation, the disk models

A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 51
Figure 12. Number of streams supported with different values of Aquota and Bquota.
of Ultrastar XP is used as the specification is given in Table 2. The details of the simula-tion model is described in [9]. Figure 12 shows the simulation results on different valuesof Aquota and Bquota. The links are saturated when ten disks are attached on the loop.When eight disks are attached on the loop, different values of Aquota and Bquota do notmake difference on the number of streams supported as we discussed in the previous para-graph. However, as the link becomes saturates, it is advantageous to set Aquota = Bquota insupporting continuous media. The increase in the number of streams supported by settingAquota = Bquota is roughly one to six percent. Hence, it is desirable to set Aquota = Bquotain supporting continuous media. We would like to point out this conclusion may not be ap-plicable to other applications such as databases where the requirements are quite differentfrom a multimedia application. The number of streams supported in figure 12 is higher thanone from the acutal experiments because interface or operating system overheads were notcounted in the simulation model. Only the link propagation delay was incorporated in thesimulation model.
7. Conclusion
In this paper, we compared SSA and SCSI in supporting continuous media. We also pre-sented results of the experiments comparing the scalability of SSA and SCSI. SSA provideshigh data bandwidth, fault tolerance, and fair accesses. Those features are highly desirablein supporting continuous media. The results show that SSA achieves higher scalability andperformance in supporting continuous media than SCSI as more disks are added. A multiplehost configuration in SSA can take advantage of the spatial reuse feature. The number ofstreams supported increases 50 percent when one more host is added in a loop.

52 SHIM ET AL.
SSA is flexible and offers many desirable features in supporting continuous media. Thefairness algorithm in SSA can be improved if two quotas are carefully selected. Effectof different quotas needs to be studied further. We are also investigating Fibre ChannelArbitrated Loop (FC-AL) in supporting continuous media.
Acknowledgment
The authors would like to thank Paul Dokas for his help in setting up SSA subsystems.
References
1. D.P. Anderson, Y. Osawa, and R. Govindan, “A file system for continuous media,” ACM Transactions onComputer Systems, 1992.
2. ANSI X3.272-199x, “Fibre Channel—Arbitrated Loop (FC-AL), Revision 4.5,” American National StandardInstitute, Inc., June 1, 1995.
3. ANSI X3T10.1/0989D revision 10, “Information Technology—Serial Storage Architecture—Transport Layer1 (SSA-TL1) Draft Proposed American National Standard.” American National Standard Institute, Inc., April,1996.
4. ANSI X3T10.1/1121D revision 7, “Information Technology—Serial Storage Architecture—SCSI-2 Protocol(SSA-S2P) Draft Proposed American National Standard.” American National Standard Institute, Inc., April,1996.
5. T. Chang, S. Shim, and D. Du, “Scalability of serial storage interfaces based on spatial reuse,” in Fifth AnnualWorkshop on I/O in Parallel and Distributed Systems, Nov. 1997, pp. 93–101.
6. M. Chen, D. Kandlur, and P. Yu, “Optimization of the grouped sweeping scheduling (GSS) with heterogeneousmultimedia streams,” in Proceedings of the ACM Multimedia’93, Aug. 1993, pp. 235–242.
7. S. Chen and M. Thapar, “Fibre channel storage interface for video-on-demand servers,” in Proceedings ofMultimedia Computing and Networking 1996, San Jose, Jan. 1996.
8. D.H.C. Du, T. Chang, J. Hsieh, S. Shim, and Y. Wang, “Emerging serial interfaces,” Special Issue on DigitalLibraries for International Journal of Multimedia Tools and Applications, Vol. 10, Nos. 2/3, pp. 179–203,2000.
9. D.H.C. Du, J. Hsieh, T. Chang, Y. Wang, and S. Shim, “Interface comparisons: SSA versus FC-AL,” IEEEConcurrency, Vol. 6, No. 2, pp. 55–70, 1998.
10. FC-AL2 standard, “Fibre Channel—Arbitrated Loop 2, Revision 086v2,” www.t11.org, April 1999.11. FC-AL3 draft, “Fibre Channel—Arbitrated Loop 3 (FC-AL3),” www.t11.org, May 1999.12. R. Haskin, “The shark continuous media file server,” in Proceedings of 1993 Spring IEEE COMPCON, Feb.
1993, pp. 12–17.13. IBM Corporation, “Functional Specification, Ultrastar XP Models,” 1995.14. A. Kunzman and A. Wetzel, “1394 high performance serial bus: The digital interface for ATV,” IEEE Trans-
actions on Consumer Electronics, Vol. 41, No. 3, pp. 893–900, 1995.15. J. Liu, D. Du, and J. Schnepf, “Supporting random access on the retrieval of digital continuous media,” Journal
of Computer Communication, a special issue on multimedia storage and databases, Feb. 1995.16. J. Liu, D. Du, S. Shim, J. Hsieh, and M. Lin, “Design and evaluation of a generic software architecture for on-
demand servers,” IEEE Transactions on Knowledge and Data Engineering, Vol. 11, No. 3, pp. 406–424, 1999.17. P. Rangan, H. Vin, and S. Ramanathan, “Designing an on-demand multimedia service,” IEEE Communication
Magazine, Vol. 30, pp. 155–162, 1992.18. N. Reddy, “Disk scheduling in a multimedia I/O system,” in Proceedings of the ACM Multimedia’93, Aug.
1993, pp. 225–233.19. N. Reddy and J. Wyllie, “I/O issues in a multimedia system,” IEEE Computer, pp. 69–74, 1994.20. C. Ruemmler and J. Wilkes, “An introduction to disk drive modeling,” IEEE Computer, pp. 17–28, 1994.21. Seagate Technology, Inc. “Barracuda Family Specification, Barracuda 4,” 1995.22. C. Severance, “Linking computers and consumer electronics,” IEEE Computer, pp. 119–121, 1997.

A SCALABLE MULTIMEDIA SERVER WITH SHARED-STORAGE CLUSTERS 53
23. SSA Industry Association, “Serial storage architecture: A technology overview,” Version 3.0, 1995.24. F. Tobagi, J. Pang, R. Baird, and M. Gang, “Streaming raid(TM)—A disk array management system for
video files,” in Proceedings of the ACM Multimedia’93, Aug. 1993, pp. 393–400.25. H. Vin and V. Rangan, “Admission control algorithm for multimedia on-demand servers,” in Proceedings of
the Third International Workshop on Network and Operating System Support for Digital Audio and Video,Nov. 1992, pp. 56–69.
Simon S.Y. Shim is currently an associate professor at San Jose State University. He is a co-director of the InternetTechnology Laboratory which is supported by grants from Intel, Microsoft, Wytec and Informix Corporation. Hereceived the B.S. degree from the Rochester Institute of Technology, the M.S. degree from Rensselaer PolytechnicInstitute, and the Ph.D. degree from the University of Minnesota all in computer science. His research interestsinclude Internet computing, multimedia servers, and multimedia network.
Tai-Sheng Chang received a Ph.D. in Computer Science and Engineering at the University of Minnesota. He iscurrently working at Integrated Imaging Solutions of GE Medical Systems. He received the B.S. and M.S. degreefrom National Chengchi University, Taiwan in Mathematical Sciences.
David H.C. Du is a Professor in Computer Science and Engineering Department at University of Minnesota. Ex-pertise includes: research in multimedia computing and storage systems, high speed networking, high-performance

54 SHIM ET AL.
computing over clusters of workstations, database design, and CAD for VLSI circuits. He has authored and co-authored over 150 technical papers including 70 referred journal publications in his research area. He has graduated37 Ph.D. students in the last 15 years. His research in multimedia computing and storage systems include video-ondemand server architecture, video and audio synchronization techniques, multimedia storage systems, and multi-media authoring tools. His research in CAD area includes physical layout, timing verification and delay fault testfro high-speed circuits. His research in high-speed networking include heterogeneous high-performance comput-ing over high-speed networks, quality of services over ATM networks, communication configuration management,and high-performance computing over a cluster of workstations and PCs.
Dr. Du is an IEEE Fellow and was an Editor of IEEE Transactions on Computers from 1993 to 1997. He hasalso served as Conference Chair and Program Committee Chair to several conferences in multimedia and databaseareas. He holds a Ph.D. in Computer Science (1981) from University of Washington (Seattle), an M.S. in ComputerScience (1980) from University of Washington and a B.S. in Mathematics from National Tsing-Hua University inTaiwan.
Jenwei Hsieh is a Lead Scientist in the Scalable Systems Group at the Dell Computer Corporation. Currently, heis responsible for the architecture, design and deployment of the High Performance Computing Cluster solutions.His research interests include I/O subsystem support for clustering computing, high-speed networks, multimediacommunications, and high-speed interconnect support for distributed network computing. He has published morethan 30 technical papers in these areas. He also has more than a dozen patent disclosures. Jenwei received a BEdegree in Computer Science from Tamkang University in Taiwan; and his Ph.D. degree in computer science fromthe University of Minnesota.
Yuewei Wang received the B.E. degree in Computer Science and Engineering from Tsinghua University, Beijing,People’s Republic of China, the M.S. degree in Computer Science from the Pennsylvania State University,University Park, Pennsylvania, and the Ph.D. degree in Computer Science from University of Minnesota, TwinCities, Minnesota. He is currently associated with IXMICRO. His research interests include video servers, stream-ing technology and service, high-performance storage systems, Internet caching, quality of service, and visualprogramming systems.





























