Embed Size (px)
DESCRIPTION
Performance of a Heterogeneous Grid Partitioner for N-body Applications. Daniel J. Harvey Department of Computer Science Southern Oregon University E-mail: [email protected] Sajal K. Das Department of Computer Science and Engineering The University of Texas at Arlington - PowerPoint PPT Presentation
Citation preview

Performance of a Heterogeneous Grid Performance of a Heterogeneous Grid Partitioner for N-body ApplicationsPartitioner for N-body Applications
Daniel J. HarveyDaniel J. HarveyDepartment of Computer ScienceDepartment of Computer Science
Southern Oregon UniversitySouthern Oregon University
E-mail: E-mail: harveyd@[email protected]
Sajal K. DasSajal K. DasDepartment of Computer Science and EngineeringDepartment of Computer Science and Engineering
The University of Texas at ArlingtonThe University of Texas at Arlington
E-mail: E-mail: das@[email protected]
Rupak BiswasRupak BiswasNASA Ames Research CenterNASA Ames Research Center
E-mail: E-mail: rbiswasrbiswas@@nasnas..nasanasa..govgov

Presentation OverviewPresentation Overview
• The information power grid (IPG)The information power grid (IPG)• The MinEX partitionerThe MinEX partitioner• This paper’s contributionsThis paper’s contributions• MinEX refinementsMinEX refinements• The N-Body problemThe N-Body problem• Experimental studyExperimental study• Performance resultsPerformance results• Conclusions and on-going researchConclusions and on-going research

The Information Power Grid (IPG)The Information Power Grid (IPG)
• Harness power of geographically separated resourcesHarness power of geographically separated resources• Developed by NASA and other collaborative partnersDeveloped by NASA and other collaborative partners• Utilize geographically separated processors to solve Utilize geographically separated processors to solve
large-scale computational problemslarge-scale computational problems• CharacteristicsCharacteristics
– limited bandwidth and high latencylimited bandwidth and high latency– heterogeneous configurationsheterogeneous configurations
• Relevant applications identified by I-Way experimentRelevant applications identified by I-Way experiment– Remote access to large databases requiring high-end graphicsRemote access to large databases requiring high-end graphics– Remote virtual reality access to instrumentsRemote virtual reality access to instruments– Remote interactions with super-computer simulationsRemote interactions with super-computer simulations

The MinEX PartitionerThe MinEX Partitioner• We previously introduced a novel partitioner We previously introduced a novel partitioner
called MinEXcalled MinEX– Minex: A latency-tolerant dynamic partitioner for grid Minex: A latency-tolerant dynamic partitioner for grid
computing applications, FGCS, 18 (2002), pp. 477—489computing applications, FGCS, 18 (2002), pp. 477—489
• MinEX’s unique characterisitcs includeMinEX’s unique characterisitcs include– Environment: Environment: designed specifically for heterogeneous designed specifically for heterogeneous
geographically distributed environmentsgeographically distributed environments– Grid: Grid: maps configuration graph onto the partition graph; maps configuration graph onto the partition graph;
produces partitions reflecting the gridproduces partitions reflecting the grid– Goal: Goal: minimize runtime rather than balance processing minimize runtime rather than balance processing
workload and minimize edge cutworkload and minimize edge cut– Latency: Latency: accounts for latency tolerance during partitioningaccounts for latency tolerance during partitioning– Accounts for:Accounts for: data movement & communication overhead data movement & communication overhead

This Paper’s ContributionsThis Paper’s Contributions
• Evaluate MinEX performance with a wide range of Evaluate MinEX performance with a wide range of heterogeneous grid configurationsheterogeneous grid configurations– Compare MinEX to METIS, a popular state the art Compare MinEX to METIS, a popular state the art
partitionerpartitioner
– Run experiments using a real-life application solver Run experiments using a real-life application solver executing in simulated grid environmentsexecuting in simulated grid environments
• Introduce refinements to our initial algorithmIntroduce refinements to our initial algorithm• ResultsResults
– MinEX speed of execution is competitive with METISMinEX speed of execution is competitive with METIS
– MinEX produces superior grid-based partitions that MinEX produces superior grid-based partitions that reduce application runtime by up to a factor of 6reduce application runtime by up to a factor of 6

The MinEX PartitionerThe MinEX Partitioner
• Multi-level schemeMulti-level scheme– Collapse edges incrementallyCollapse edges incrementally– Partitions the contracted graphPartitions the contracted graph– Refines the graph in reverse Refines the graph in reverse
• Reassignments during refinement improves partition qualityReassignments during refinement improves partition quality
• Creates diffusive or from scratch partitionsCreates diffusive or from scratch partitions• User-supplied function estimates solver latency toleranceUser-supplied function estimates solver latency tolerance• Accounts for data redistribution cost during partitioningAccounts for data redistribution cost during partitioning

Metrics UtilizedMetrics Utilized
• Processing weight Processing weight Wgt = PWgtWgt = PWgtvv x Proc x Proccc
• Communication costCommunication costComm = Comm =
wwppCWgtCWgt(v,w) (v,w) x Connect(c,d)x Connect(c,d)
• Redistribution costRedistribution costRemap = Remap =
RWgtRWgtvv x Connect(c,d) if p x Connect(c,d) if p qq
• Weighted queue lengthWeighted queue length
QWgt(p) = QWgt(p) =
vvpp(Wgt + Comm + Remap )(Wgt + Comm + Remap )
• Heaviest load Heaviest load (MaxQWgt)(MaxQWgt)
• QlenQlenpp = Vertices = Vertices p p
• Average load Average load (WSysLL)(WSysLL)
• Total system loadTotal system load QWgtToT = QWgtToT = ppPPQWgt(p)QWgt(p)
• Imbalance factorImbalance factor LoadImb = LoadImb =
MaxQWgt/WSysLLMaxQWgt/WSysLL
v
p
v
p
v
p
v
p
p
v
p
v

MinVar, Gain andThroTTleMinVar, Gain andThroTTle
• Processor workload variance from WSysLLProcessor workload variance from WSysLL– Var = Var = pp(QWgt(p) - WSysLL)(QWgt(p) - WSysLL)22
– Var reflects the improvement in MinVar after a Var reflects the improvement in MinVar after a vertex reassignment. A positive value implies that vertex reassignment. A positive value implies that the Var value has increasedthe Var value has increased
• Gain is the change(Gain is the change(QWgtToT) to total system QWgtToT) to total system load resulting from a vertex reassignmentload resulting from a vertex reassignment
• ThroTTle is a user defined parameter. If Gain>0, ThroTTle is a user defined parameter. If Gain>0, Vertex moves that improve Vertex moves that improve Var are allowed if Var are allowed if GainGain22/-/-Var <= ThroTTleVar <= ThroTTle

MinEX Basic Partition CriteriaMinEX Basic Partition Criteria
• Minimize MaxQWgt rather than balance Minimize MaxQWgt rather than balance processor workloads.processor workloads.
• Move verticices from overloaded processors Move verticices from overloaded processors (QWgt(QWgtpp > WSysLL) to underloaded processors > WSysLL) to underloaded processors
(QWgt(QWgtpp < WSysLL) < WSysLL)

Reassignment Filter FunctionReassignment Filter Function GoalGoal: Minimize edge related processing; reject deleterious assignments: Minimize edge related processing; reject deleterious assignments
• Projects QwgtProjects Qwgtnewnew, , Var, Var, newGain newGain – Vertex totals used:Vertex totals used:
• Edge weights same Edge weights same cluster cluster
• Edge weights other Edge weights other clustersclusters
• Local Edge weightsLocal Edge weights– Total outgoing edge Total outgoing edge
weightweight– Relocation, Processing Relocation, Processing
weightsweights
IF (newQWgtIF (newQWgtfrom from > Qwgt> Qwgtfrom)from)
Reject AssignmentReject Assignment
IF (newQWgtIF (newQWgtto to < Qwgt< Qwgtto)to)
Reject AssignmentReject AssignmentIF (IF (var >= 0) var >= 0) Reject AssignmentReject AssignmentIF IF newGain>0 && newGain>0 &&
newGainnewGain22/-Dvar>ThroTTle/-Dvar>ThroTTle
Reject AssignmentReject Assignment
new=newQWgtnew=newQWgtfromfrom-newQWgt-newQWgttoto
old=QWgtold=QWgtfromfrom-QWgt-QWgtto)to)
IF fabs(Dnew)>abs(Dnew)IF fabs(Dnew)>abs(Dnew)
IF newQWgtIF newQWgtfromfrom<Qwgt<Qwgttoto
Reject AssignmentReject Assignment
IF newQWgtIF newQWgtto>to>QwgtQwgtfromfrom
Reject AssignmentReject AssignmentAssignment Passes FilterAssignment Passes Filter

Additional MinEX RefinementsAdditional MinEX Refinements
• Graph contraction phaseGraph contraction phase– Bucket sort vertices by processorBucket sort vertices by processor– Find edges to merge without searchingFind edges to merge without searching
• Defined user-defined latency tolerance Defined user-defined latency tolerance function function (called before each potential reassignment)(called before each potential reassignment)– Double MinEX(User *user, Ipg *ipg, Qtot *tot)Double MinEX(User *user, Ipg *ipg, Qtot *tot)– User = User options passed to the partitionerUser = User options passed to the partitioner– Ipg = Grid configuration graphIpg = Grid configuration graph
– tot contains Pproctot contains Pprocpp, Comm, Commpp, Remap, Remapp, p, QLenQLenpp

The N-Body ProblemThe N-Body ProblemClassical problem of simulating the movement of a set of bodiesClassical problem of simulating the movement of a set of bodies
• The Solution is based upon gravitational or The Solution is based upon gravitational or electrostatic forceselectrostatic forces
• The application Iterates over a series of time The application Iterates over a series of time stepssteps
• At each step for each bodyAt each step for each body– Compute forces from all other bodies using the Compute forces from all other bodies using the
gravitational lawsgravitational laws– Calculates Acceleration and integrates twice to Calculates Acceleration and integrates twice to
compute the position at the next time stepcompute the position at the next time step– Call the partitioner to balance the next-step Call the partitioner to balance the next-step
computations among the processors.computations among the processors.

Barnes & Hut Solution Barnes & Hut Solution (Framework for experiments)(Framework for experiments)
• Reduces computational complexity from O(nReduces computational complexity from O(n2) 2) to O(n lg n)to O(n lg n)– Clusters of bodies that are far from a cell are treated as a single body Clusters of bodies that are far from a cell are treated as a single body
using the total center of mass and the center of mass positionusing the total center of mass and the center of mass position– Cell CCell Cv v is considered far from Cell Cis considered far from Cell Cw w if the size of the cell divided by if the size of the cell divided by
the distance between cells is less than a constantthe distance between cells is less than a constant• Our implementationOur implementation
– InitializationInitialization
• Create the octtree of cellsCreate the octtree of cells• Form a graph graph using the cells of the octtreeForm a graph graph using the cells of the octtree
– Each time stepEach time step• Partition the graph, distribute cells to be relocated among Partition the graph, distribute cells to be relocated among
processorsprocessors• Run the solverRun the solver

The Partitioning GraphThe Partitioning GraphConstructed from the Barnes&Hut OctTreeConstructed from the Barnes&Hut OctTree
• One vertex per cell, COne vertex per cell, Cv v with |Cwith |Cvv| bodies| bodies
– Two associated weightsTwo associated weights• PWgtPWgtv v models the required computations models the required computations
PWgtPWgtv v = |C= |Cvv| x (|C| x (|Cvv|-|-
1+Close1+CloseBB+Far+Farvv+2)+2)
• RWgt models data distributionRWgt models data distributionRWgtRWgtvv = |C = |Cv|v|
– Edges model communication between close cellsEdges model communication between close cells• Each edge (v,w) relates to cells CEach edge (v,w) relates to cells Cv v and Cand Cww..
CWgtCWgt(v,w) (v,w) = |c= |cww| if C| if Cw w is close tois close to c cww; ;
else 0else 0

Graph ModificationsGraph Modifications
• N-Body graphN-Body graph
– CWgtCWgt(v,w) (v,w) can be different than CWgtcan be different than CWgt(w,v) (w,v) because |because |
CCvv| may not equal |c| may not equal |cww||
– CWgtCWgt(v,w) (v,w) can equal 0 if Ccan equal 0 if Cvv is close to c is close to cWW but C but Cww is far is far
from Cfrom Cvv..
• METIS LimitationsMETIS Limitations– Cannot operate on directed graphsCannot operate on directed graphs– Cannot tolerate edge weights of zeroCannot tolerate edge weights of zero
• For direct comparisons, experiments are run using For direct comparisons, experiments are run using – Original N-Body graph (Graph G)Original N-Body graph (Graph G)
– Modified Graph (Graph GModified Graph (Graph Gmm))

Experimental StudyExperimental StudySimulation of a Grid EnvironmentSimulation of a Grid Environment
• Simulated Grid Environment vs actual gridsSimulated Grid Environment vs actual grids– Low cost alternative to constructing a wide range heterogeneous Low cost alternative to constructing a wide range heterogeneous
configurationsconfigurations– Limited grid facilities are available in the field and are usually Limited grid facilities are available in the field and are usually
homogeneoushomogeneous
• MethodologyMethodology– Discrete time simulationDiscrete time simulation– Utilize configuration graph to model processing speed, Utilize configuration graph to model processing speed,
communication latency, and bandwidthcommunication latency, and bandwidth• ConfigurationsConfigurations ( (PProcessors=32,64,128; rocessors=32,64,128;
nterconnect slowdowns=10,100;nterconnect slowdowns=10,100;CClusters=4,8)lusters=4,8)– HO: Constant processing and intra-communication capabilityHO: Constant processing and intra-communication capability
UP: Faster processors have faster intra-communication capabilityUP: Faster processors have faster intra-communication capability– DN: Faster processors have slower intra-communication capabilityDN: Faster processors have slower intra-communication capability
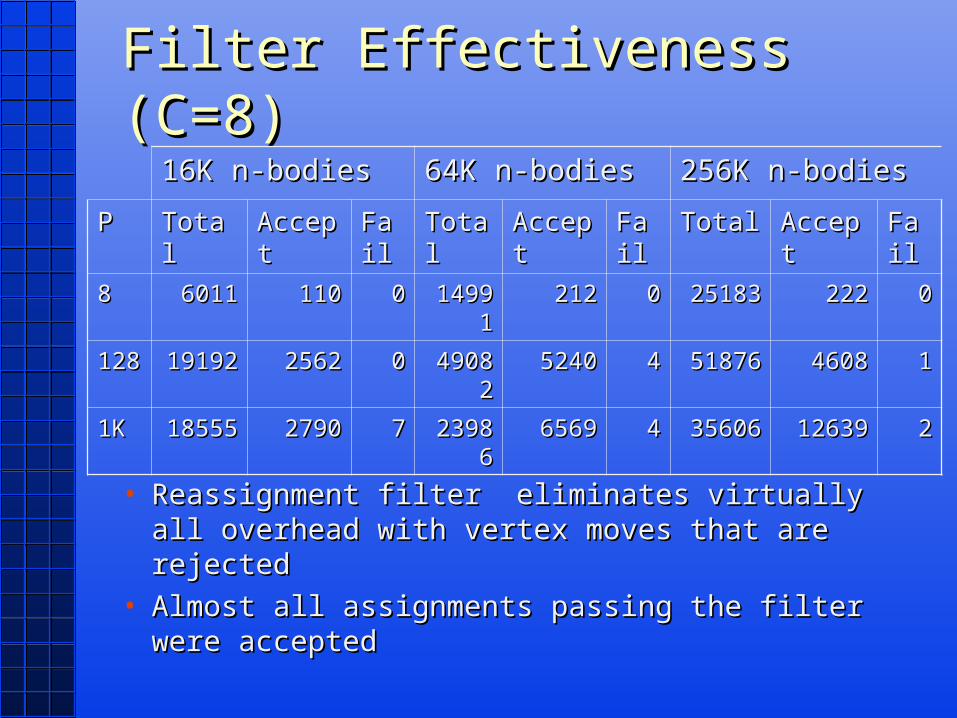
Filter Effectiveness (C=8)Filter Effectiveness (C=8)
• Reassignment filter eliminates virtually all Reassignment filter eliminates virtually all overhead with vertex moves that are rejectedoverhead with vertex moves that are rejected
• Almost all assignments passing the filter were Almost all assignments passing the filter were acceptedaccepted
16K n-bodies16K n-bodies 64K n-bodies64K n-bodies 256K n-bodies256K n-bodies
PP TotalTotal AcceptAccept FailFail TotalTotal AcceptAccept FailFail TotalTotal AcceptAccept FailFail
88 60116011 110110 00 1499114991 212212 00 2518325183 222222 00
128128 1919219192 25622562 00 4908249082 52405240 44 5187651876 46084608 11
1K1K 1855518555 27902790 77 2398623986 65696569 44 3560635606 1263912639 22

Scalability Test Scalability Test (Scales well to 128 processors)(Scales well to 128 processors)
P varied between 8 and 1024, C=8, Runtimes comparedP varied between 8 and 1024, C=8, Runtimes compared
050000
100000150000200000250000300000350000
16K MinEX-G
16K METIS-GM
64K MinEX-G
64K METIS-GM
256K MinEX-G
256K METIS-GM

ThroTTle Test (C=8)ThroTTle Test (C=8)(Initially Improves as throttle increases until curve flattens out)(Initially Improves as throttle increases until curve flattens out)
0
1000
2000
3000
4000
5000
60000 2 8
32
128
512
I=10,P=32
I=100,P=32
I=10,P=64
I=100,P=64
I=10,P=128
I=100,P=128

Multiple Time Step TestMultiple Time Step TestP=64, I=10, C=8, B=16KP=64, I=10, C=8, B=16K
• Multiple iterations have limited impactMultiple iterations have limited impact
• Subsequent experiments run a single time stepSubsequent experiments run a single time step
Single IterationSingle Iteration 50 Iterations50 Iterations
TypeType RunTimeRunTime LoadImbLoadImb RunTImeRunTIme LoadImbLoadImb
MinEX-GMinEX-G 401401 1.031.03 388388 1.011.01
MinEX-GmMinEX-Gm 413413 1.051.05 398398 1.021.02
METIS-GmMETIS-Gm 16301630 2.162.16 15341534 2.032.03

Partitioner Speed ComparisonsPartitioner Speed Comparisons
• MinEX has the advantage for P=32 and P=64MinEX has the advantage for P=32 and P=64
• METIS has the advantage for P=1kMETIS has the advantage for P=1k
• Overall, MinEX is competitiveOverall, MinEX is competitive
BB TypeType P=8P=8 P=16P=16 P=32P=32 P=64P=64 P=1hP=1h P=2hP=2h P=5hP=5h P=1kP=1k
16K16K MinEX-GMinEX-G .17.17 .20.20 .23.23 .33.33 .53.53 1.091.09 1.581.58 2.362.36
MinEx-GmMinEx-Gm .18.18 .20.20 .23.23 .32.32 .53.53 1.131.13 1.511.51 2.392.39
METIS-GmMETIS-Gm .16.16 .23.23 .35.35 1.021.02 1.051.05 1.461.46 1.811.81 2.882.88
64K64K MinEX-GMinEX-G .31.31 .33.33 .40.40 .59.59 1.001.00 1.931.93 3.093.09 4.934.93
MinEx-GmMinEx-Gm .35.35 .37.37 .39.39 .58.58 1.051.05 1.991.99 3.093.09 4.734.73
METIS-GmMETIS-Gm .21.21 .22.22 .45.45 .60.60 1.551.55 1.821.82 2.322.32 3.423.42
256K256K MinEX-GMinEX-G .48.48 .53.53 .57.57 .71.71 1.081.08 2.272.27 5.375.37 9.089.08
MinEx-GmMinEx-Gm .50.50 .55.55 .55.55 .69.69 1.081.08 2.302.30 5.885.88 9.179.17
METIS-GmMETIS-Gm .43.43 .49.49 .59.59 .76.76 1.201.20 2.572.57 3.183.18 4.184.18
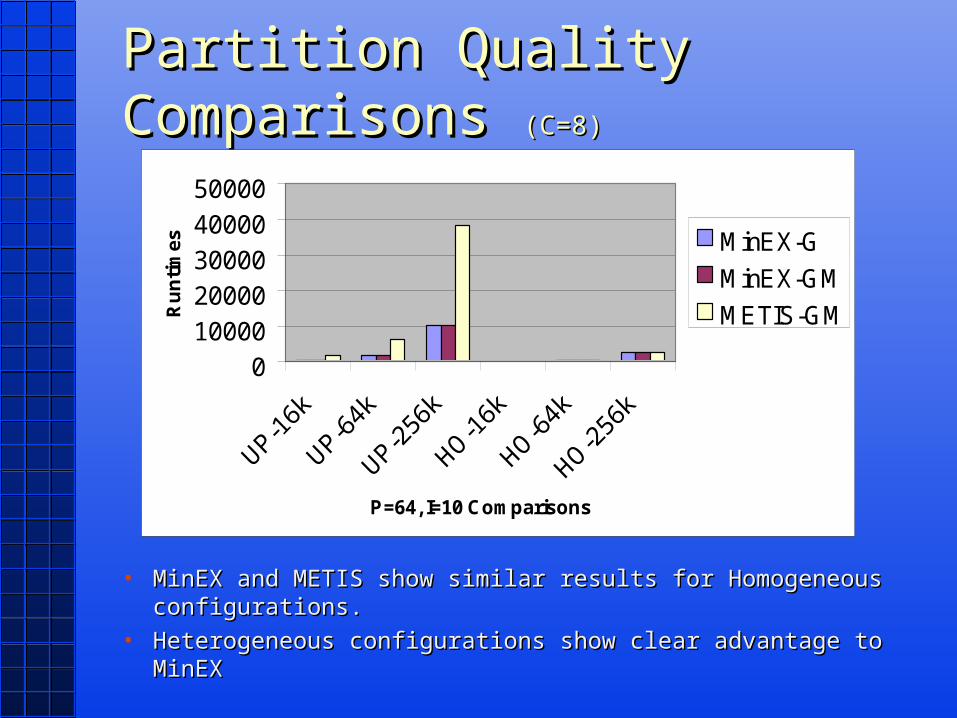
Partition Quality Comparisons Partition Quality Comparisons (C=8)(C=8)
• MinEX and METIS show similar results for Homogeneous MinEX and METIS show similar results for Homogeneous configurations. configurations.
• Heterogeneous configurations show clear advantage to MinEXHeterogeneous configurations show clear advantage to MinEX
01000020000300004000050000
P=64, I=10 Comparisons
Ru
ntim
es MinEX-G
MinEX-GM
METIS-GM
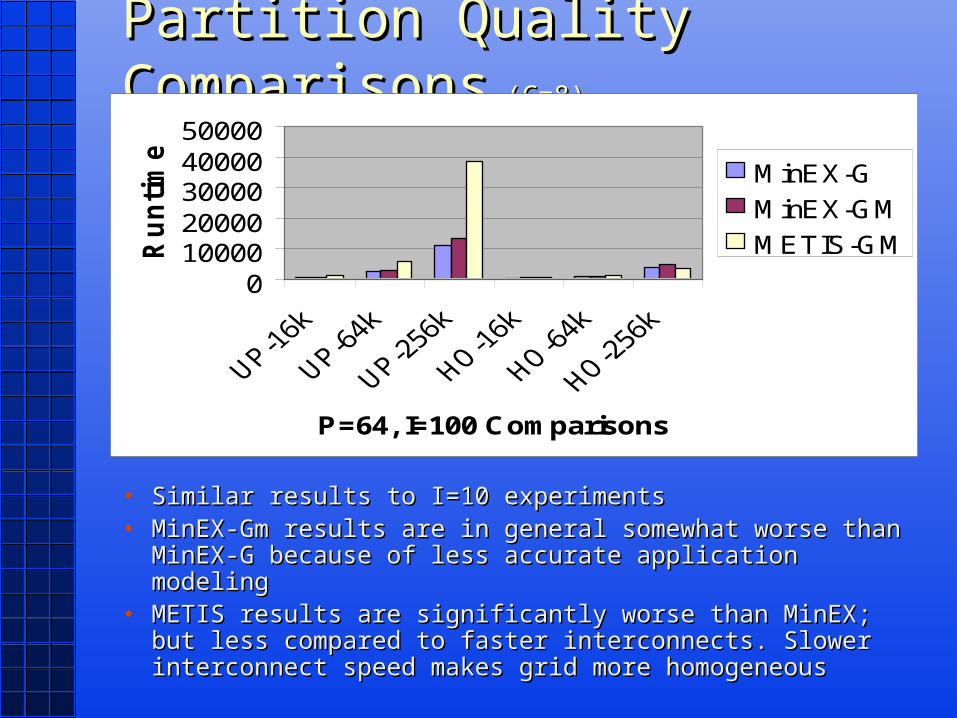
Partition Quality ComparisonsPartition Quality Comparisons (C=8) (C=8)
• Similar results to I=10 experimentsSimilar results to I=10 experiments• MinEX-Gm results are in general somewhat worse than MinEX-Gm results are in general somewhat worse than
MinEX-G because of less accurate application modelingMinEX-G because of less accurate application modeling• METIS results are significantly worse than MinEX; but METIS results are significantly worse than MinEX; but
less compared to faster interconnects. Slower less compared to faster interconnects. Slower interconnect speed makes grid more homogeneousinterconnect speed makes grid more homogeneous
01000020000300004000050000
P=64, I=100 Comparisons
Ru
ntim
es
MinEX-G
MinEX-GM
METIS-GM

Partition Quality ComparisonsPartition Quality ComparisonsAdditional ObservationsAdditional Observations
• DN configuration results are similar to UP experiments with a DN configuration results are similar to UP experiments with a few exceptionsfew exceptions– DN runs are worse than the UP runs in a few cases DN runs are worse than the UP runs in a few cases
(998 vs 1489 if P=128, C=4, I=100, B=64K)(998 vs 1489 if P=128, C=4, I=100, B=64K)– The MinEX projected 975, but converged to 1489.The MinEX projected 975, but converged to 1489.– When Simulating a second input channel, the solver converges at When Simulating a second input channel, the solver converges at
975 for DN. No such improvement for METIS975 for DN. No such improvement for METIS
• HO runs with P=32 & 64, I=100, B=256K give METIS an HO runs with P=32 & 64, I=100, B=256K give METIS an advantage (7399 to 5199 and 4231 and 3334 respectively). advantage (7399 to 5199 and 4231 and 3334 respectively). – MinEX is converging tightly (LoadImb=1.0001) to a high valueMinEX is converging tightly (LoadImb=1.0001) to a high value– Perhaps the criteria for reassignments needs to be further refined.Perhaps the criteria for reassignments needs to be further refined.

ConclusionsConclusions• Direct comparisons between MinEX and METISDirect comparisons between MinEX and METIS
– An N-body solver on simulated grid environments form the basis An N-body solver on simulated grid environments form the basis for our experimentsfor our experiments
– MinEX produces partitions that reduce runtime by up to a factor of MinEX produces partitions that reduce runtime by up to a factor of 6 in highly-heterogeneous grids6 in highly-heterogeneous grids
– MinEX and METIS are competitive in homogeneous gridsMinEX and METIS are competitive in homogeneous grids– MinEX is competitive to METIS as far as speed of executionMinEX is competitive to METIS as far as speed of execution
• Implemented performance refinements to MinEXImplemented performance refinements to MinEX– The reassignment filter minimizes overhead associated with The reassignment filter minimizes overhead associated with
potential reassignments that are rejectedpotential reassignments that are rejected– Sorting processors by QWgt speed up partitioning decisionsSorting processors by QWgt speed up partitioning decisions– A bucket sort speeds up finding edges to collapseA bucket sort speeds up finding edges to collapse
• Minex can partition directed graphsMinex can partition directed graphs– Not commonly allowed by current partitionersNot commonly allowed by current partitioners
• Account for latency tolerance during partitioningAccount for latency tolerance during partitioning– Established the benefit and feasibility of this approachEstablished the benefit and feasibility of this approach

On-going ResearchOn-going Research
• MinEX RefinementsMinEX Refinements– Analyze effect of using multiple I/O channels and Analyze effect of using multiple I/O channels and
network dynamicsnetwork dynamics– Refine the method of selecting vertices for Refine the method of selecting vertices for
reassignmentreassignment• Refine the discrete time simulatorRefine the discrete time simulator
– Develop a general-purpose tool for simulating Develop a general-purpose tool for simulating heterogeneous gridsheterogeneous grids
– Establish the accuracy of the simulator by Establish the accuracy of the simulator by comparing its projections to the performance of comparing its projections to the performance of applications running on actual gridsapplications running on actual grids





























