Embed Size (px)
Citation preview

4/28/11
1
Perceptron
Inner-product scalar Perceptron
Perceptron learning rule XOR problem
linear separable patterns Gradient descent Stochastic Approximation to gradient descent
LMS Adaline

4/28/11
2
Inner-product
A measure of the projection of one vector onto another
€
net =< w , x >=|| w || ⋅ || x || ⋅cos(θ)
€
net = wi ⋅ xii=1
n
∑
Example

4/28/11
3
Activation function
€
o = f (net) = f ( wi ⋅ xi)i=1
n
∑
€
f (x) := sgn(x) =1 if x ≥ 0−1 if x < 0
€
f (x) :=σ(x) =1
1+ e(−ax )
€
f (x) :=ϕ(x) =1 if x ≥ 00 if x < 0
sigmoid function €
f (x) :=ϕ(x) =
1 if x ≥ 0.5x if 0.5 > x > 0.50 if x ≤ −0.5

4/28/11
4
Graphical representation
Similarity to real neurons...

4/28/11
5
1040 Neurons 104-5 connections per neuron
Perceptron Linear threshold unit (LTU)
Σ
x1
x2
xn
. . .
w1
w2
wn
w0
X0=1
o
€
net = wi ⋅ xii= 0
n
∑
€
o = sgn(net) =1 if net ≥ 0−1 if net < 0
McCulloch-Pitts model of a neuron
The “bias”, a constant term that does not depend on any input value

4/28/11
6
The goal of a perceptron is to correctly classify the set of pattern D={x1,x2,..xm} into one of the classes C1 and C2
The output for class C1 is o=1 and fo C2 is o=-1
For n=2
Linearly separable patterns
€
o = sgn( wixii= 0
n
∑ )
€
wixii= 0
n
∑ > 0 for C0
wixii= 0
n
∑ ≤ 0 for C1
X0=1, bias...

4/28/11
7
Perceptron learning rule Consider linearly separable problems How to find appropriate weights Look if the output pattern o belongs to the
desired class, has the desired value d
η is called the learning rate 0 < η ≤ 1
€
wnew = wold + Δw
€
Δw =η(d − o)
In supervised learning the network has its output compared with known correct answers Supervised learning Learning with a teacher
(d-o) plays the role of the error signal

4/28/11
8
Perceptron The algorithm converges to the correct
classification if the training data is linearly separable and η is sufficiently small
When assigning a value to η we must keep in mind two conflicting requirements Averaging of past inputs to provide stable weights
estimates, which requires small η Fast adaptation with respect to real changes in the
underlying distribution of the process responsible for the generation of the input vector x, which requires large η
Several nodes
€
o1 = sgn( w1ixii= 0
n
∑ )
€
o2 = sgn( w2ixii= 0
n
∑ )

4/28/11
9
€
o j = sgn( w jixii= 0
n
∑ )
Constructions

4/28/11
10
Frank Rosenblatt
1928-1969

4/28/11
11

4/28/11
12
Rosenblatt's bitter rival and professional nemesis was Marvin Minsky of Carnegie Mellon University
Minsky despised Rosenblatt, hated the concept of the perceptron, and wrote several polemics against him
For years Minsky crusaded against Rosenblatt on a very nasty and personal level, including contacting every group who funded Rosenblatt's research to denounce him as a charlatan, hoping to ruin Rosenblatt professionally and to cut off all funding for his research in neural nets
XOR problem and Perceptron By Minsky and Papert in mid 1960

4/28/11
13
Gradient Descent To understand, consider simpler linear unit,
where
Let's learn wi that minimize the squared error, D={(x0,t0),(x1,t1),..,(xn,tn)}
• (t for target) • no bias any more
€
o = wi ⋅ xii= 0
n
∑
4/28/11
14
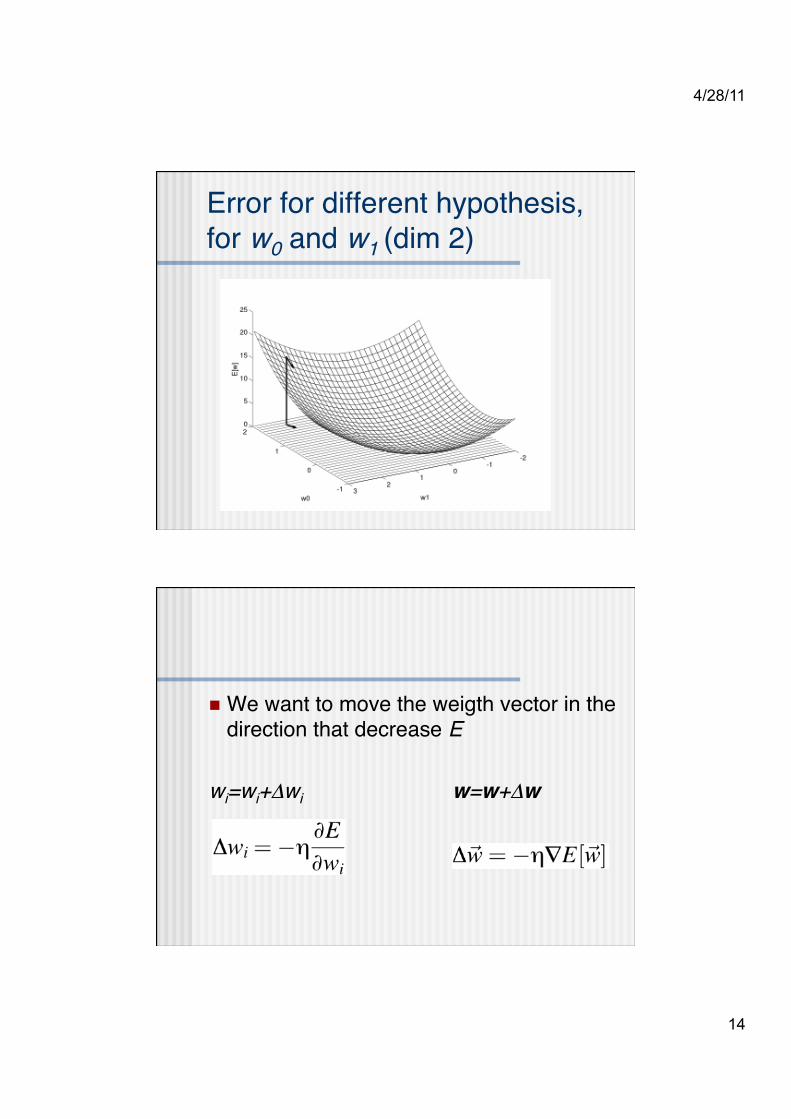
Error for different hypothesis, for w0 and w1 (dim 2)
We want to move the weigth vector in the direction that decrease E
wi=wi+Δwi w=w+Δw

4/28/11
15
The gradient
Differentiating E

4/28/11
16
Update rule for gradient decent
€
Δwi =η (tdd ∈D∑ − od )xid
Gradient Descent Gradient-Descent(training_examples, η) Each training example is a pair of the form <(x1,…xn),t> where (x1,…,xn) is the vector
of input values, and t is the target output value, η is the learning rate (e.g. 0.1) Initialize each wi to some small random value Until the termination condition is met, Do
Initialize each Δwi to zero For each <(x1,…xn),t> in training_examples Do
• Input the instance (x1,…,xn) to the linear unit and compute the output o • For each linear unit weight wi • Do
• Δwi= Δwi + η (t-o) xi For each linear unit weight wi Do
• wi=wi+Δwi €
Δwi =η (tdd ∈D∑ − od )xid

4/28/11
17
Stochastic Approximation to gradient descent
The gradient decent training rule updates summing over all the training examples D
Stochastic gradient approximates gradient decent by updating weights incrementally
Calculate error for each example Known as delta-rule or LMS (last mean-square)
weight update Adaline rule, used for adaptive filters Widroff and
Hoff (1960)
€
Δwi =η(t − o)xi

4/28/11
18
LMS Estimate of the weight vector No steepest decent No well defined trajectory in the weight space Instead a random trajectory (stochastic gradient
descent) Converge only asymptotically toward the
minimum error Can approximate gradient descent arbitrarily
closely if made small enough η
Summary Perceptron training rule guaranteed to succeed if
Training examples are linearly separable Sufficiently small learning rate η
Linear unit training rule uses gradient descent or LMS guaranteed to converge to hypothesis with minimum squared error Given sufficiently small learning rate η Even when training data contains noise Even when training data not separable by H

4/28/11
19
Inner-product scalar Perceptron
Perceptron learning rule XOR problem
linear separable patterns Gradient descent Stochastic Approximation to gradient descent
LMS Adaline
XOR?Multi-Layer Networks
input layer
hidden layer
output layer





























