Embed Size (px)
Citation preview

People Centric Processing
Malcolm Slaney
Interval Research
Describing work by Malcolm Slaney, Michele Covell, Gerald McRoberts, Chris Bregler, Trevor Darrell, Gaile Gordon, Mike Harville, Dan Ellis, Scott Meredith, and
Electric Planet

Hard Problems
Honest Politician?
Traveling Salesman
Human Intelligence

Talk Goals
Better CHI with Signal ComputationRealistic human behavior
Recognition Synthesis

Outline
Recognition (BabyEars)
Improving Perception (Mach1, ASA)
Entertainment (Audio Morph, Mirror)
Synthesis (Video Rewrite)
What Works and What Doesn’t

Human Recognition
Speech RecognitionGesture RecognitionEmotion
At a distance Independent channel

BabyEars
Motivation Speech recognizers
Learn wordsIgnore prosody
Infants learn prosody!
Problem What can we tell about
the affective message? What do we do with this?

BabyEars Procedure
Data Collection Spontaneous
Labeling Approval Attention Prohibition Neutral (adult-directed)
Recognition

BabyEars Results
Strong ID Female Utterances
Global, Pitch Slope
Global, Pitch Range
-0.05 0 0.05
0.5
1
1.5
2
Strong ID Female Utterances
Global, Delta MFCC
Global, Energy Variance5 10 15
5
10
15
Strong AD/ID Female Utterances
Global, Pitch Slope
Global, Pitch Range
-0.05 0 0.05
0.5
1
1.5
2
2.5Strong AD/ID Female Utterances
Global, Delta MFCC
Global, Energy Variance5 10 15
5
10
15
Key Approval - White Attention - Blue Prohibition - Red Neutral -Green
(Adult)

BabyEars Results
Gender-dependent resultsStrengthMessage
Prohibitions
0 1 2 3 4 5 6 7 8
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
Classification versus Gender
All
Male
Female

BabyEars Successes
Recognition at human ratesAre these the right labels?Why it works
Broad classes Simple features Spontaneous data
What do we do with this?
1 2 3 4 5 6 7
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
Number of Features
Fraction Correct
Speaker Dependent Results
1 (f)
2 (f)
3 (m)
4 (f)
5 (f)
6 (m)
7 (f)
8 (m)
9 (f)
10 (m)
11 (m)
12 (m)

Human Perception
Algorithms to improve human performance
Speech PerceptionAuditory Scene Analysis
Middle Ear
Cochlea
Outer Ear
Auditory Nerve

Mach1
Speed up speechMaintain comprehensionModel human speaker
Compress fast speech less Compress unstressed speech more
Measure emphasis
Measure speaking rate
Modify rate
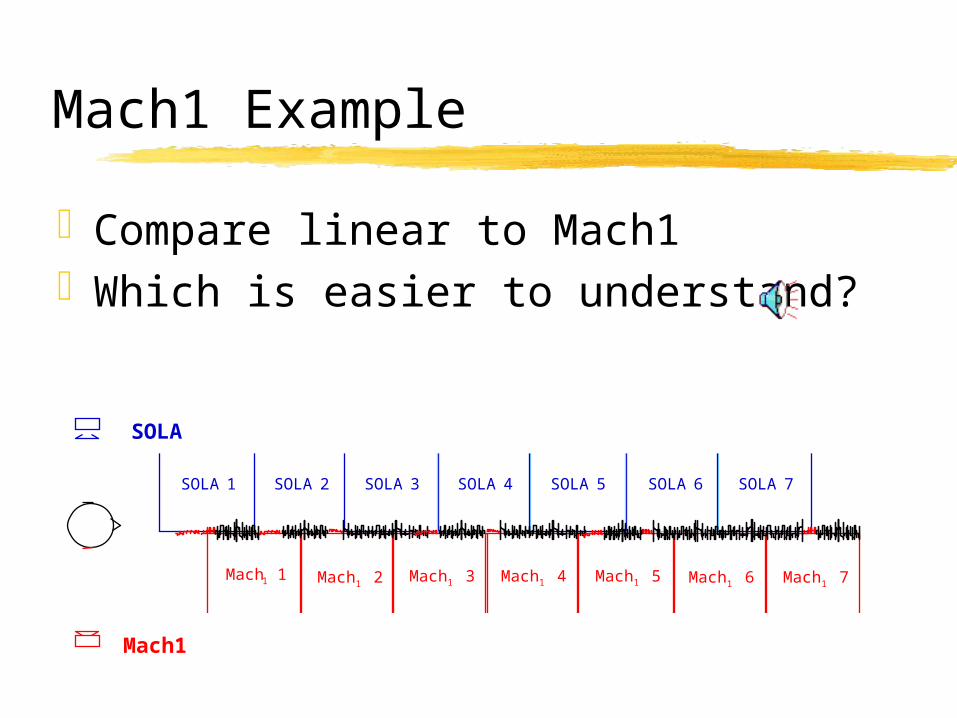
Mach1 Example
Compare linear to Mach1Which is easier to understand?
SOLA
Mach1
SOLA 1 SOLA 2 SOLA 3 SOLA 4 SOLA 5 SOLA 6 SOLA 7
Mach1 1 Mach1 2 Mach1 3 Mach1 4 Mach1 5 Mach1 6 Mach1 7

Mach1 Results
ToEFLComprehensionVary rateLinear vs.
Mach1Why it works
Mimics speakers No hard decisions

Auditory Scene Analysis
Foreground/backgroundSimilar to vision problem

ASA Results
Example by Dan Ellis
4.1 The original sound (10 seconds) 4.2 Background noise cloud ("Noise1") 4.3 Crash ("Noise2, Click1") 4.4 Horn1, Horn2, Horn3, Horn4, Horn5 ("Wefts1-4", "Weft5", "Wefts6,7", "Weft8", "Wefts9-12") 4.5 Complete reconstruction with all elements

Human Entertainment
Electric Planet videoMagic Morphin’ Mirror Audio Morphing

Audio Morphing
Interpolate between objectsVisual example

Morphing Sounds
Same pitch (/a/ to /i/)
Different pitch
Proper morph

Morphing Representations
Smooth spectrogram Encodes formants
(what was said)
Pitch spectrogram Encodes pitch
(how it was said) Encodes breath

Audio Morph Results
Corner to Morning Pitch changes Durations change Voicing changes Formants change
Why it works Perceptual representation

Magic Morphin’ Mirror

Mirror Magic
Real-time stereo depthSkin color detectionFace recognition and tracking

Mirror Results
VideoWhy it works
Uses multiple modalities Fuzzy boundaries Distortions are forgiving

Human Synthesis
Speech synthesisAudio-visual speech

Speech Synthesis
Words are easyProsody is hard
Pitch Duration Voice quality
Data driven prosody Original Repeat after me Courtesy of Scott Meredith (Microsoft)

Facial Animation
Graphical Model Data Driven
Polygons Image-based rendering
FM synthesis Wavetable synthesis
Formant synthesis Diphone concatenation
Diphone recognition HMM recognizers

Video Rewrite Approach
Data driven
Stitch
BackgroundVideoVideo
ModelAnalysis
Synthesis SelectLip Video
stage
stage Together

Video Rewrite–Model
Build video model of speakerUse speech recognition to label audio
/EH-B/
/IY-B/
/OW-B/
/AA-B/
Video ModelPhoneme
Recognition
Eigen-points
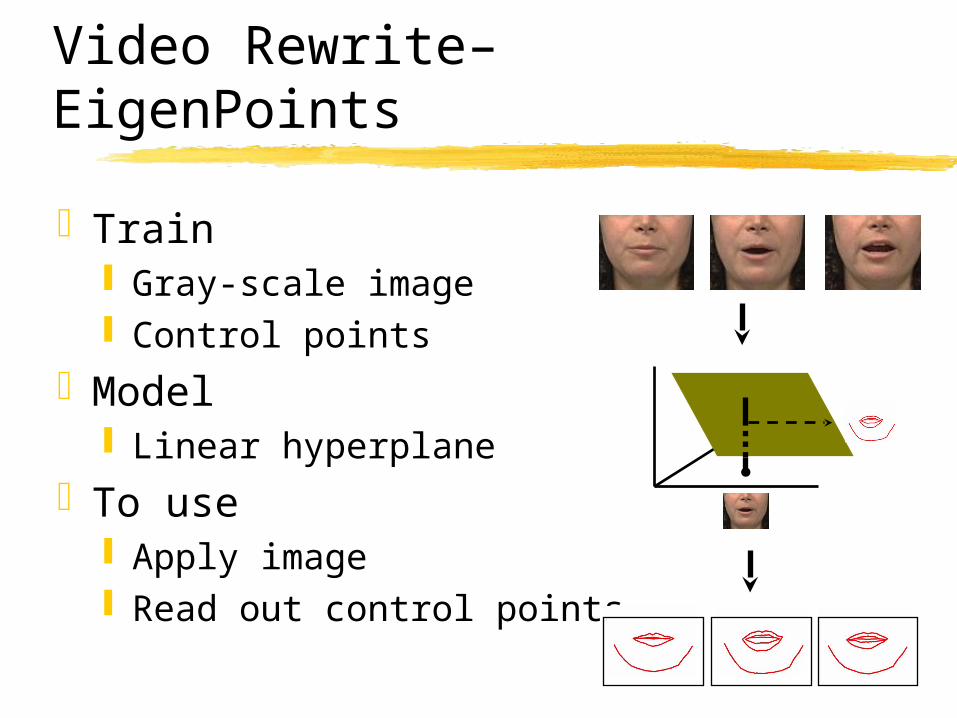
Video Rewrite–EigenPoints
Train Gray-scale image Control points
Model Linear hyperplane
To use Apply image Read out control points

Video Rewrite–Tracking
Find face Affine model Single reference image
Need for Database Placing Face
Subpixel accuracy necessary!

Video Rewrite–Results
Video database 8 minutes of Ellen 2 minutes of JFK
Only half usableHead rotation
Why it works Large amount of training data Prosody comes with audio

Intelligent CHI
Lots of possibilitiesDon’t expect perfectionUse lots of dataUse what we know of perception











![FOR THE EASTERN DISTRICT OF PENNSYLVANIA b/d/a …Plaintiff Home Line is a manufacturer, importer and distributor of home furnishings. (Testimony of David Bregler [“Bregler”],](https://img.dokumen.tips/doc/110x75/5e68be613397e11d7e051bcb/for-the-eastern-district-of-pennsylvania-bda-plaintiff-home-line-is-a-manufacturer.jpg)


















