Embed Size (px)
Citation preview

CLUSTERING DOKUMEN SKRIPSI BERDASARKAN
ABSTRAK DENGAN MENGGUNAKAN
BISECTING K-MEANS
NURUL ARIFIN SUBANDI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
INSTITUT PERTANIAN BOGOR
BOGOR
2014


PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Clustering Dokumen
Skripsi Berdasarkan Abstrak dengan Menggunakan Bisecting K-Means adalah
benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan
dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang
berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari
penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di
bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut
Pertanian Bogor.
Bogor, Juni 2014
Nurul Arifin Subandi
NIM G64114018

ABSTRAK
NURUL ARIFIN SUBANDI. Clustering Dokumen Skripsi Berdasarkan Abstrak
dengan Menggunakan Bisecting K-Means. Dibimbing oleh AHMAD RIDHA.
Kebutuhan terhadap pencarian data skripsi terus meningkat setiap tahunnya
seiring bertambahnya jumlah mahasiswa. Pencarian referensi dengan menelusuri
dokumen satu per satu memakan banyak waktu dan tenaga. Oleh sebab itu, sebuah
sistem yang mampu mengelompokkan dokumen secara otomatis dibutuhkan.
Penelitian ini mengembangkan sistem untuk melakukan clustering terhadap
dokumen skripsi secara otomatis berdasarkan abstrak yang ada dalam dokumen.
Metode yang digunakan adalah Bisecting K-Means untuk clustering data. Data
yang digunakan pada penelitian ini adalah skripsi Ilmu Komputer IPB yang terdiri
atas 78 dokumen abstrak berbahasa Indonesia dan 113 dokumen abstrak
berbahasa Inggris. Dari hasil yang diperoleh dapat disimpulkan bahwa clustering
dokumen dengan menggunakan Bisecting K-Means dapat dilakukan dengan nilai
threshold i (jarak internal cluster) terbaik untuk clustering abstrak bahasa
Indonesia adalah 0.67, yang menghasilkan rand index sebesar 0.867 dan nilai i
terbaik untuk clustering abstrak bahasa Inggris adalah 0.55 yang menghasilkan
rand index sebesar 0.862.
Kata kunci: abstrak, Bisecting K-Means, clustering.
ABSTRACT
NURUL ARIFIN SUBANDI. Skripsi Based Document Clustering Using Abstract
with Bisecting K-Means. Supervised by AHMAD RIDHA.
The need of thesis data searching increases every year along with the
increase in the number of students. Search of reference by tracing documents one
by one takes a lot of time. Therefore, a system that is capable of clustering
documents automatically is necessary. This study developed a system to perform
clustering of theses automatically based on their abstracts. It used bisecting K-
means method to cluster the data. The data in this research were from IPB’s
Computer Science bachelor theses, comprising 78 abstracts in Indonesian and 113
abstracts in English. The result showed that clustering the documents using
bisecting K-means could be done with the best value of i threshold (internal
cluster distance) of 0.67 for the Indonesian abstracts resulting in a rand index of
0.867, while the best i threshold value for the English abstracts was 0.55 resulting
in a rand index of 0.862.
Keywords: abstract, Bisecting K-Means, clustering.

Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
CLUSTERING DOKUMEN SKRIPSI BERDASARKAN
ABSTRAK DENGAN MENGGUNAKAN
BISECTING K-MEANS
NURUL ARIFIN SUBANDI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
INSTITUT PERTANIAN BOGOR
BOGOR
2014

Penguji:
Dr Ir Agus Buono, MSi MKom

Firman Ardiansyah, SKom MSi

Judul Skripsi : Clustering Dokumen Skripsi Berdasarkan Abstrak dengan
Menggunakan Bisecting K-Means
Nama : Nurul Arifin Subandi
NIM : G64114018
Disetujui oleh
Ahmad Ridha, SKom MS
Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom
Ketua Departemen
Tanggal Lulus:

PRAKATA
Puji dan syukur penulis kehadirat Allah subhanahu wata’ala atas segala
karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Shalawat berserta
salam juga penulis sampaikan kepada Nabi Muhammad shalallahu ’alaihi wa
sallam, berserta para keluarga, shahabat dan umatnya hingga akhir zaman.
Banyak pihak yang telah membantu penulis hingga terselesaikannya tugas
akhir ini. Oleh sebab itu, penulis ingin mengucapkan rasa terima kasih kepada:
1. Ayahanda Subandi dan Ibunda Suparti serta kakak penulis Arbyanto dan Ari
Nurita yang senantiasa mendoakan, memotivasi, dan memberikan kasih
sayangnya kepada penulis.
2. Bapak Ahmad Ridha, Skom MS selaku dosen pembimbing yang telah
membimbing dan mengarahkan penulis selama penelitian tugas akhir ini.
3. Bapak Dr Ir Agus Buono, MSi MKom dan Bapak Firman Ardiansyah, SKom
MSi selaku dosen penguji.
4. Keluarga besar Pondok Pesantren Nurul Imdad Bogor yang selalu mendidik,
mendoakan dan memotivasi penulis.
5. Seluruh teman-teman Ilkomerz atas ilmu, semangat, dan dukungannya,
khusunya : Selvya Rossalina, Niken Ratna Pertiwi, Suci Hitmawati, Mujahid
Hasan, Nana Suryana, Endrik Sugiyanto dan Catur Teguh Oktavian.
6. Keluarga besar BARAYA IPB, khususnya : Elinda Safitri, Ridiarsih, Cepi
Mangku Bumi, Fazmi Nawafi, Rahmi Amelinda, Abdul Haris Maulana dan
Astari Ratnadya.
Penulis menyadari bahwa masih terdapat kekurangan dalam penulisan
skripsi ini. Namun, penulis berharap dengan segala kekurangan yang ada semoga
tulisan ini bisa memberikan manfaat kelak di kemudian hari. Amin.
Bogor, Juni 2014
Nurul Arifin Subandi

DAFTAR ISI
DAFTAR TABEL v
DAFTAR GAMBAR v
DAFTAR LAMPIRAN v
PENDAHULUAN 10 Latar Belakang 10
Tujuan Penelitian 10 Ruang Lingkup Penelitian 10
METODE 2 Koleksi Dokumen 2 Praproses 2 Pemodelan Ruang Vektor 3 Clustering 5 Evaluasi 5 Lingkungan Pengembangan 6
HASIL DAN PEMBAHASAN 6 Pengambilan dan Pemilihan Data 6
Pengelompokan Manual 7 Praproses Data 7 Bisecting K-Means 7 Validasi Hasil Clustering 10
SIMPULAN DAN SARAN 10 Simpulan 10 Saran 10
DAFTAR PUSTAKA 10
LAMPIRAN 12
RIWAYAT HIDUP 19

DAFTAR TABEL
1 Jumlah term hasil dari tokenisasi 7
2 Serangkaian percobaan mencari posisi nilai i terbaik untuk kategori
kategori abstrak bahasa Indonesia 8
3 Serangkaian percobaan mencari posisi nilai i terbaik untuk kategori
abstrak bahasa Inggris 8
4 Hasil percobaan clustering pada kategori abstrak bahasa Indonesia 9
5 Hasil percobaan clustering pada kategori abstrak bahasa Inggris 9
DAFTAR GAMBAR
1 Skema Penelitian 2 2 Contoh dokumen abstrak bahasa Indonesia 3 3 Contoh dokumen abstrak bahasa Inggris 3 4 Ilustrasi kesamaan cosine similarity 5
DAFTAR LAMPIRAN
1 Contoh hasil ekstraksi data abstrak bahasa Indonesia 12 2 Contoh hasil ekstraksi data abstrak bahasa Inggris 13 3 Hasil pengelompokan manual untuk setiap kategori dokumen 14 4 Hasil percobaan clustering pada kategori abstrak bahasa Indonesia 15 5 Hasil percobaan clustering pada kategori abstrak bahasa Inggris 16 6 Contoh pasangan dokumen false positive bahasa Indonesia 17 7 Contoh pasangan dokumen false positive bahasa Inggris 18

PENDAHULUAN
Latar Belakang
Mengelola informasi dari sekumpulan dokumen teks yang jumlahnya sangat
besar tentunya bukan pekerjaan yang mudah karena butuh waktu lama dan tenaga
kerja yang tidak sedikit. Di sisi lain, setiap orang menginginkan waktu yang cepat
dalam memperoleh informasi yang diinginkan, sebagaimana yang diungkapkan
oleh Nah (2004). Bila ditinjau dari volume dokumen teks yang berada di internet,
perpustakaan digital, dan web intranet perusahaan yang sangat besar, suatu sistem
yang efisien diperlukan untuk mengekstraksi informasi agar waktu untuk
mendapatkan informasi menjadi lebih pendek.
Salah satu masalah yang terjadi dalam pengelolaan informasi adalah
pencarian data skripsi yang dilakukan oleh mahasiswa. Kebutuhan terhadap
pencarian data skripsi terus meningkat setiap tahunnya seiring bertambahnya
jumlah mahasiswa. Seringkali mahasiswa/orang yang mencari sumber referensi
kesulitan untuk mencari referensi terkait dengan topik penelitiannya. Tentu saja
ini dapat menghambat kinerja para mahasiswa dalam melakukan penelitian. Untuk
mengatasi permasalahan yang sering dialami mahasiswa, diperlukan sebuah
metode yang dapat mengorganisir dan mengklasifikasi dokumen secara otomatis
untuk mempermudah pencarian informasi yang relevan dengan kebutuhan.
Penelitian ini mengembangkan sistem untuk melakukan clustering terhadap
dokumen skripsi secara otomatis berdasarkan abstrak yang ada dalam dokumen.
Pada penelitian sebelumnya, Ramdani (2011) yang melakukan clustering
pada dokumen berita berbahasa Indonesia menggunakan Bisecting K-Means, dan
menemukan bahwa clustering berdasarkan dokumen berita dapat dilakukan dan
nilai akurasi mencapai 87.3%. Ramdani (2011) menggunakan data dokumen
dengan domain yang berbeda, sehingga tingkat perbedaan antar dokumen cukup
tinggi. Oleh karena itu, penelitian ini mencoba menggunakan metode Bisecting K-
Means untuk clustering data pada satu domain Ilmu Komputer yang memiliki
tingkat perbedaan yang rendah.
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan algoritme Bisecting K-Means
untuk mengelompokkan dokumen skripsi berdasarkan abstraknya.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini meliputi:
1 Data yang digunakan pada penelitian ini adalah skripsi Ilmu Komputer IPB
dengan format PDF.
2 Data yang digunakan dibagi atas 2 kategori, yaitu abstrak berbahasa Indonesia
dan abstrak berbahasa Inggris.

2
3 Penelitian ini menggunakan algoritme Bisecting K-means untuk clustering.
METODE
Penelitian ini dilakukan dengan beberapa tahap, seperti yang ditunjukan
pada Gambar 1. Data yang akan digunakan dalam penelitian ini adalah koleksi
abstrak dokumen skripsi. Selain koleksi abstrak, penelitian ini juga menggunakan
stopwords yang merupakan daftar kata buang yang akan digunakan pada
praproses. Setelah praproses, tahap selanjutnya adalah melakukan pemodelan
ruang vektor untuk pembobotan terhadap term dan merepresentasikan dokumen
ke dalam bentuk vektor. Hasil dari praproses adalah matriks document-concept
yang kemudian akan dikelompokkan menjadi K cluster. Pada tahap akhir,
dilakukan evaluasi menggunakan rand index terhadap hasil clustering.
Gambar 1 Skema Penelitian
Koleksi Dokumen
Koleksi dokumen yang digunakan dalam penelitian ini diperoleh dari
perpustakaan Ilmu Komputer IPB dengan jumlah 191 dokumen, yang terdiri dari
78 dokumen abstrak berbahasa Indonesia dan 113 dokumen abstrak berbahasa
Inggris. Dokumen yang masih dalam format PDF kemudian diekstrak menjadi
plain text dan diambil bagian abstraknya, setelah itu dibagi ke dalam 2 kategori,
yaitu abstrak berbahasa Indonesia dan abstrak berbahasa Inggris. Adapun contoh
abstrak berbahasa Indonesia dan abstrak berbahasa Inggris dapat dilihat pada
Gambar 2 dan Gambar 3.
Praproses
Pada tahap praproses dilakukan beberapa tahapan, yaitu lowercasing,
tokenisasi, dan pembuangan stopwords. Lowercasing adalah proses mengubah
semua huruf menjadi huruf kecil. Hal ini dilakukan agar setiap kata pada dokumen
menjadi case-sensitif pada saat pemrosesan teks dokumen.
Tokenisasi adalah proses untuk membagi teks input menjadi unit-unit kecil
yang disebut token (Manning et al. 2009). Token atau biasa disebut juga term bisa
berupa suatu kata, angka atau tanda baca. Pada penelitian ini tanda baca
dihilangkan sehingga tidak dianggap sebagai token.
Stopwords adalah daftar kata-kata yang dianggap tidak memiliki makna.
Kata yang tercantum dalam daftar ini dibuang dan tidak ikut diproses pada tahap
selanjutnya. Pada umumnya kata-kata yang masuk ke dalam stopwords memiliki
Dokumen Ekstraksi
Text Praproses
Pemodelan
Ruang Vektor Clustering Evaluasi
Stopwords

3
tingkat kemunculan yang tinggi di tiap dokumen sehingga kata tersebut tidak
dapat digunakan sebagai penciri suatu dokumen. Stopwords yang digunakan pada
penelitian ini sama seperti penelitian Ridha (2004), sedangkan stopwords untuk
abstrak bahasa Inggris diambil dari koleksi stopwords University of Glasglow
dengan alamat url http://ir.dcs.gla.ac.uk/resources/linguistic_utils/stop_words.
Gambar 2 Contoh dokumen abstrak bahasa Indonesia
Gambar 3 Contoh dokumen abstrak bahasa Inggris
Pemodelan Ruang Vektor
Model ruang vektor untuk koleksi dokumen mengandaikan dokumen d
sebagai sebuah vektor dalam term space. Clustering dokumen dipandang sebagai

4
pengelompokan vektor berdasarkan suatu fungsi similarity antara dua vektor
tersebut. Dengan demikian koleksi dokumen dapat dituliskan sebagai matriks
kata-dokumen X sebagai berikut:
X = {xij } i = 1, 2,…, t ; j=1, 2, …, n
dengan xij adalah bobot term i dalam dokumen ke j.
Dalam pemodelan ruang vektor, pembobotan dasar dilakukan dengan
menghitung frekuensi kemunculan term dalam dokumen karena dipercaya bahwa
frekuensi kemunculan term (term frequency, tf) merupakan petunjuk sejauh mana
term tersebut mewakili isi dokumen. Hal ini berarti semakin banyak term tersebut
terdapat di dalam dokumen yang berbeda, maka nilainya semakin besar dan
memiliki pengaruh yang semakin besar pula pada clustering dokumen. Pada tahap
selanjutnya, dilakukan penhitungan jumlah dokumen dalam koleksi yang
mengandung term tertentu atau disebut dengan document frequency (df). Tahapan
terahir dalam pemodelan ruang vektor adalah menghitung nilai tf-idf, dengan idf
adalah invers document frequency menggunakan persamaan:
idft N/dft
Sedangkan untuk tf-idf menggunakan persamaan:
tf-idft,d = tfd,t * idft
N = Jumlah dokumen dalam koleksi
dft = Jumlah dokumen yang mengandung term yang bersangkutan
tfd,t = Frekuensi dari kemunculan sebuah term dalam dokumen yang
bersangkutan
Dari persamaan tersebut dapat dipahami bahwa tf-idft,d memberikan bobot
term t dalam dokumen d yang memiliki hubungan:
1 Bobot tinggi ketika kemunculan t dalam jumlah dokumen yang kecil.
2 Lebih rendah ketika kemunculan term sedikit dalam sebuah dokumen atau
muncul dalam banyak dokumen.
3 Paling rendah ketika muncul di hampir seluruh dokumen (Manning et al. 2009).
Penelitian ini menggunakan ukuran cosine similarity untuk pengukur jarak
antar vektor dokumen. Kesamaan cosine similarity memiliki sifat semakin besar
nilai persamaannya, semakin dekat jarak kedua vektor, dan berarti semakin mirip
kedua dokumen tersebut. Ilustrasi tentang hal ini dapat dilihat pada Gambar 4.
Perhitungan jarak antara 2 dokumen di dan dj adalah dengan menghitung
kesamaan cosine similarity dari representasi vektor dokumen 𝑉(di) dan 𝑉(dj).
Vektor dokumen merupakan term frequency yang merepresentasikan jumlah term
pada tiap dokumen. Kesamaan cosine similarity diformulasikan sebagai berikut:
Pembilang menunjukkan perkalian dalam atau dot product antara 2 vektor 𝑉(di)
dan 𝑉(dj). Penyebut menunjukkan perkalian panjang jarak masing-masing vektor
(Manning et al. 2009).

5
Gambar 4 Ilustrasi kesamaan cosine similarity
Clustering
Dalam model ruang vektor dikenal 2 pendekatan algoritme clustering, yaitu
hierarki dan partisi (Jain dan Dubes 1988). Algoritme hierarki memiliki dua
pendekatan, yaitu divisive dan aglomerative. Penelitian ini mengggunakan
algoritme Bisecting K-means untuk clustering, yang merupakan penggabungan
antara divisive clustering dan partitional clustering.
Bisecting K-means meiliki algoritme sebagai berikut:
1 Ambil satu cluster untuk dipecah dengan K-means (bisecting step).
2 Pilih satu dokumen yang akan dijadikan sebagai centroid awal.
3 Hitung jarak setiap dokumen terhadap centroid dengan menggunakan ukuran
cosine similarity. Dokumen yang memiliki jarak lebih besar dari threshold
akan berada dalam satu cluster dengan centroid, sedangkan yang lebih kecil
dari threshold akan membentuk cluster baru.
4 Ulangi langkah 1 sampai 3 sebanyak ITER kali, dan ambil hasil terbaik yang
memiliki overal similarity terbesar.
5 Ulangi langkah 1 sampai 4 sampai didapatkan K buah cluster.
Jumlah ITER yang digunakan dalam penelitian ini adalah 1 sehingga pembagian
menjadi dua (bisection) menggunakan K-Means hanya dilakukan satu kali untuk
setiap fase.
Evaluasi
Dalam proses clustering, dua dokumen ditempatkan ke dalam cluster yang
sama jika dan hanya jika kedua dokumen tersebut mirip. Evaluias hasil clustering
dilakukan untuk mengukur seberapa baik hasil clustering yang didapat. Evaluasi
dilakukan dengan membandingkan clusters hasil Bisecting K-means dengan
clusters hasil pengelompokan manual. Penelitian ini menggunakan pengukuran
akurasi Rand Index (RI) untuk evaluasi hasil clustering. RI merepresentasikan
hasil clustering sebagai kumpulan keputusan. Nilai akurasi RI adalah persentase
dari keputusan-keputusan yang benar (Manning et al. 2009).

6
Berikut adalah persamaan Rand Index:
Keterangan:
RI = Rand Index
TP = True Positive / banyaknya pasangan dokumen yang berada pada cluster
yang sama dalam pengelompokan manual sekaligus pada pengelompokan
oleh sistem.
FP = False Positive / banyaknya pasangan dokumen yang berada pada cluster
yang berbeda dalam pengelompokan manual tetapi berada pada satu
cluster dalam pengelompokan oleh sistem.
TN = True Negative / banyaknya pasangan dokumen yang berada cluster yang
berbeda dalam pengelompokan manual sekaligus pada pengelompokan
oleh sistem.
FN = False Positive / banyaknya pasangan dokumen yang berada pada cluster
yang sama dalam pengelompokan manual tetapi berada pada cluster yang
berbeda dalam pengelompokan oleh sistem.
Pengelompokan yang dilakukan dengan cara manual dalam penelitian ini
merupakan pengelompokan dokumen yang telah dianggap benar.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk
penelitian ini adalah sebagai berikut:
Perangkat keras:
Processor Intel® CoreTM
i3
Memory 3 GB
Hard disk 320 GB
Perangkat lunak:
Sistem operasi Windows 7
Macromedia Dreamweaver 8
XAMPP
HASIL DAN PEMBAHASAN
Pengambilan dan Pemilihan Data
Data yang digunakan dalam penelitian ini diperoleh dari perpustakaan Ilmu
Komputer IPB dengan jumlah 191 dokumen, yang terdiri dari 78 dokumen abstrak
berbahasa Indonesia dan 113 dokumen abstrak berbahasa Inggris. Dokumen PDF
7
kemudian diekstrak menjadi plain text dan diambil bagian abstraknya, setelah itu
dibagi ke dalam 2 kategori, yaitu abstrak berbahasa Indonesia dan abstrak
berbahasa Inggris. Contoh data abstrak bahasa Indonesia pada penelitian ini dapat
dilihat pada Lampiran 1.
Pengelompokan Manual
Pengelompokkan manual dilakukan berdasarkan pada kesamaan topik
skripsi. Kesamaan topik antar-skripsi diketahui dengan cara membaca abstrak
pada setiap dokumen. Jika ditemukan topik skripsi yang tidak mempunyai
kelompok, pengelompokkan dilakukan dengan melihat dosen pembimbing pada
skripsi tersebut. Hal ini dilakukan dengan mengasumsikan bahwa seorang dosen
pembimbing akan membimbing mahasiswa pada satu domain topik. Hasil
pengelompokan manual untuk setiap kategori dokumen adalah 14 cluster untuk
setiap kategori bahasa Indonesia dan 12 cluster untuk kategori bahasa Inggris.
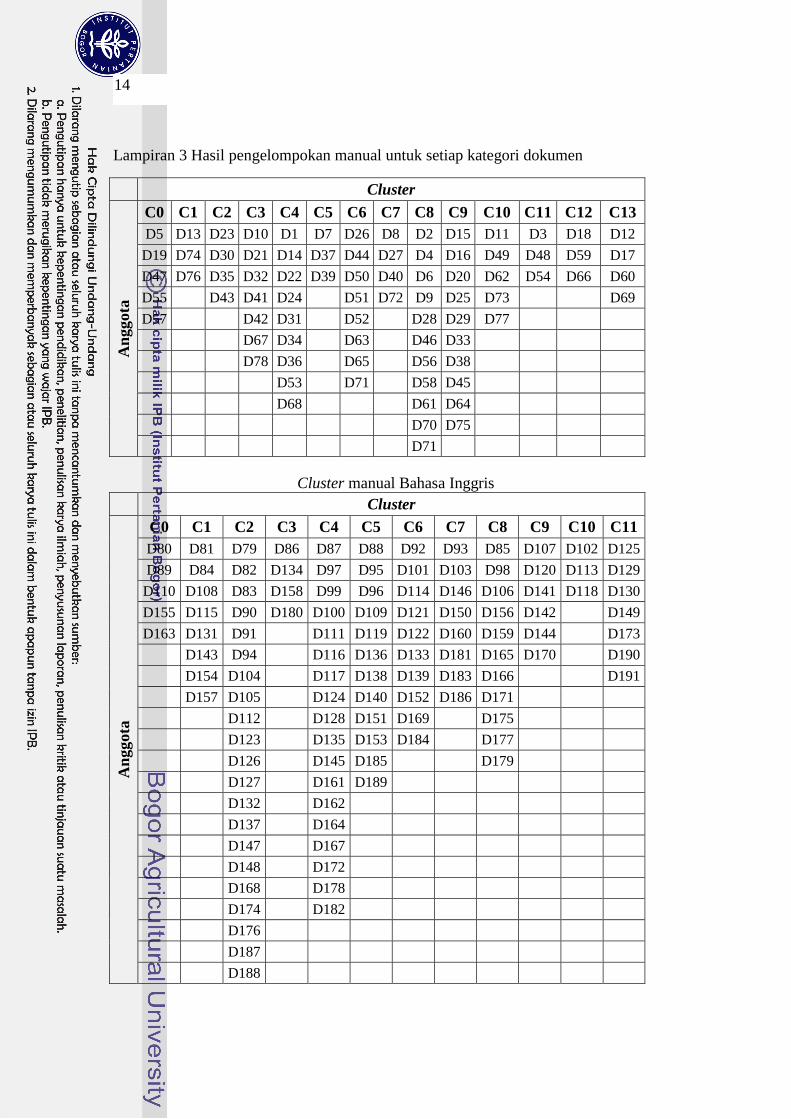
Adapun anggota untuk setiap cluster dapat dilihat pada Lampiran 2.
Praproses Data
Praproses data terbagi dalam beberapa tahapan, yaitu: lowercasing,
tokenisasi, dan pembuangan stopwords. Lowercasing dilakukan agar setiap kata
pada dokumen menjadi case-sensitif pada saat pemrosesan teks dokumen.
Tokenisasi menghasilkan suatu unit-unit kecil yang disebut token atau term.
Dalam proses tokenisasi, white space digunakan untuk melakukan pemecahan
token pada setiap dokumen, dalam penelitian ini term yang bertipe integer tidak
digunakan dalam proses clustering, sehingga pada saat tokeniasi term bertipe
tersebut dihapus. Jumlah term awal hasil dari tokenisasi memiliki jumlah yang
lebih besar dibandingkan setelah dilakukan pengurangan stopwords. Hal ini dapat
dilihat pada Tabel 2. Setelah term didapat, proses pembobotan dengan tf-idf
dilakukan. Hasil dari pembobotan tf-idf ini digunakan dalam proses clustering
dengan menggunakan Bisecting K-Means.
Tabel 1 Jumlah term hasil dari tokenisasi
Bahasa Indonesia Bahasa Inggris
Jumlah Dokumen 78 113
Total term awal 2941 3459
Total setelah penghapusan
stopwords
2629 3264
Bisecting K-Means
Proses clustering pada penelitian ini menggunakan algoritme Bisecting K-
means. Hasil dari clustering ini merupakan hasil akhir dari sistem yang
selanjutnya akan dievaluasi. Pengukuran keakuratan hasil clustering dilakukan
dengan menggunakan rand index.
8
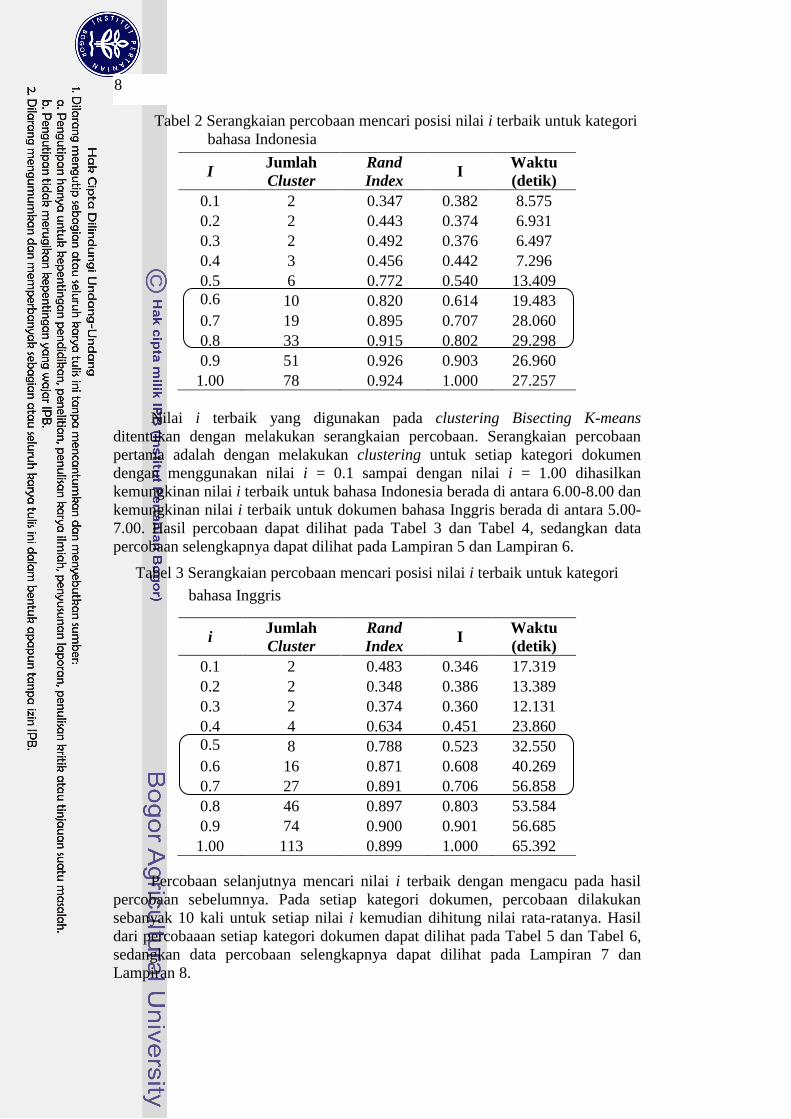
Tabel 2 Serangkaian percobaan mencari posisi nilai i terbaik untuk kategori
bahasa Indonesia
I Jumlah
Cluster
Rand
Index I
Waktu
(detik)
0.1 2 0.347 0.382 8.575
0.2 2 0.443 0.374 6.931
0.3 2 0.492 0.376 6.497
0.4 3 0.456 0.442 7.296
0.5 6 0.772 0.540 13.409
0.6 10 0.820 0.614 19.483
0.7 19 0.895 0.707 28.060
0.8 33 0.915 0.802 29.298
0.9 51 0.926 0.903 26.960
1.00 78 0.924 1.000 27.257
Nilai i terbaik yang digunakan pada clustering Bisecting K-means
ditentukan dengan melakukan serangkaian percobaan. Serangkaian percobaan
pertama adalah dengan melakukan clustering untuk setiap kategori dokumen
dengan menggunakan nilai i = 0.1 sampai dengan nilai i = 1.00 dihasilkan
kemungkinan nilai i terbaik untuk bahasa Indonesia berada di antara 6.00-8.00 dan
kemungkinan nilai i terbaik untuk dokumen bahasa Inggris berada di antara 5.00-
7.00. Hasil percobaan dapat dilihat pada Tabel 3 dan Tabel 4, sedangkan data
percobaan selengkapnya dapat dilihat pada Lampiran 5 dan Lampiran 6.
Tabel 3 Serangkaian percobaan mencari posisi nilai i terbaik untuk kategori
bahasa Inggris
i Jumlah
Cluster
Rand
Index I
Waktu
(detik)
0.1 2 0.483 0.346 17.319
0.2 2 0.348 0.386 13.389
0.3 2 0.374 0.360 12.131
0.4 4 0.634 0.451 23.860
0.5 8 0.788 0.523 32.550
0.6 16 0.871 0.608 40.269
0.7 27 0.891 0.706 56.858
0.8 46 0.897 0.803 53.584
0.9 74 0.900 0.901 56.685
1.00 113 0.899 1.000 65.392
Percobaan selanjutnya mencari nilai i terbaik dengan mengacu pada hasil
percobaan sebelumnya. Pada setiap kategori dokumen, percobaan dilakukan
sebanyak 10 kali untuk setiap nilai i kemudian dihitung nilai rata-ratanya. Hasil
dari percobaaan setiap kategori dokumen dapat dilihat pada Tabel 5 dan Tabel 6,
sedangkan data percobaan selengkapnya dapat dilihat pada Lampiran 7 dan
Lampiran 8.
9
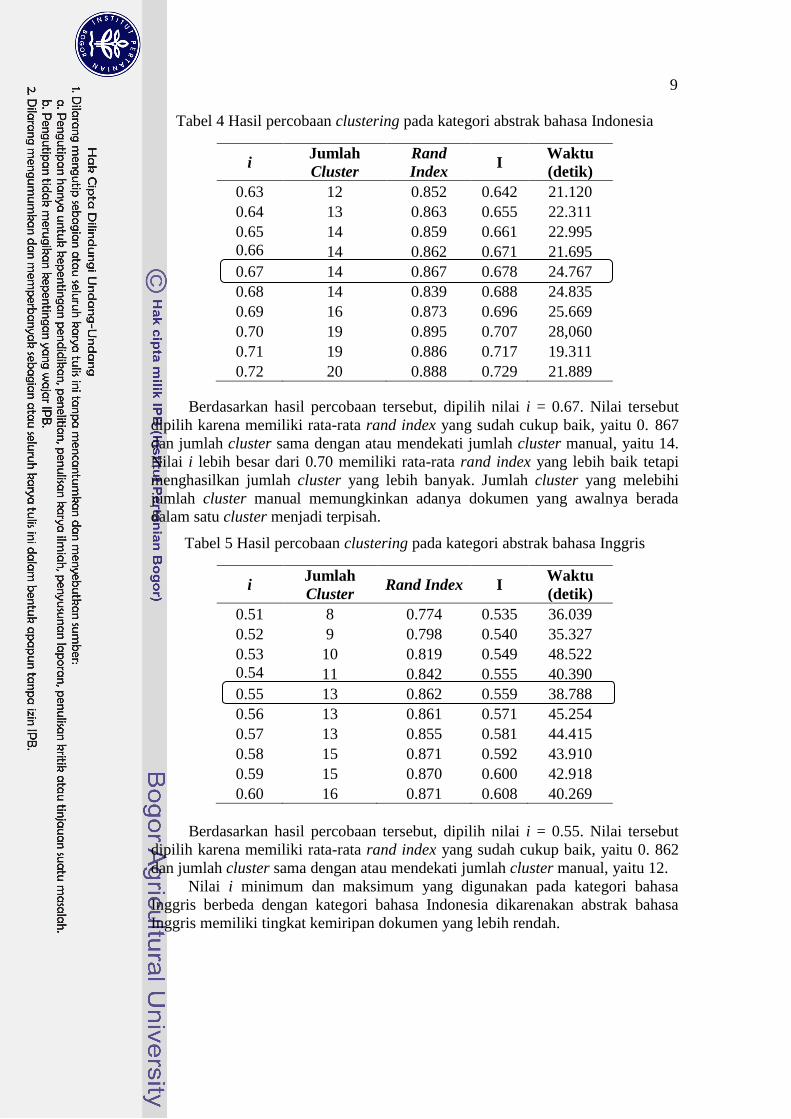
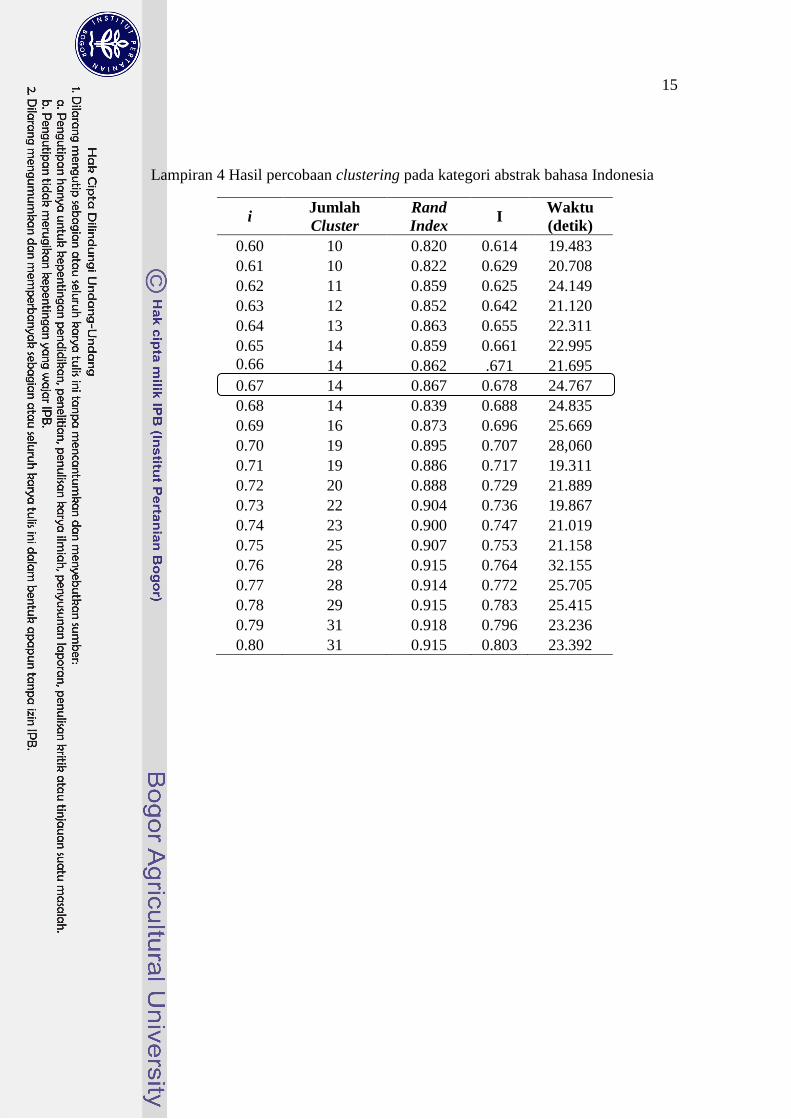
Tabel 4 Hasil percobaan clustering pada kategori abstrak bahasa Indonesia
i Jumlah
Cluster
Rand
Index I
Waktu
(detik)
0.63 12 0.852 0.642 21.120
0.64 13 0.863 0.655 22.311
0.65 14 0.859 0.661 22.995
0.66 14 0.862 0.671 21.695
0.67 14 0.867 0.678 24.767
0.68 14 0.839 0.688 24.835
0.69 16 0.873 0.696 25.669
0.70 19 0.895 0.707 28,060
0.71 19 0.886 0.717 19.311
0.72 20 0.888 0.729 21.889
Berdasarkan hasil percobaan tersebut, dipilih nilai i = 0.67. Nilai tersebut
dipilih karena memiliki rata-rata rand index yang sudah cukup baik, yaitu 0. 867 dan jumlah cluster sama dengan atau mendekati jumlah cluster manual, yaitu 14.
Nilai i lebih besar dari 0.70 memiliki rata-rata rand index yang lebih baik tetapi
menghasilkan jumlah cluster yang lebih banyak. Jumlah cluster yang melebihi
jumlah cluster manual memungkinkan adanya dokumen yang awalnya berada
dalam satu cluster menjadi terpisah.
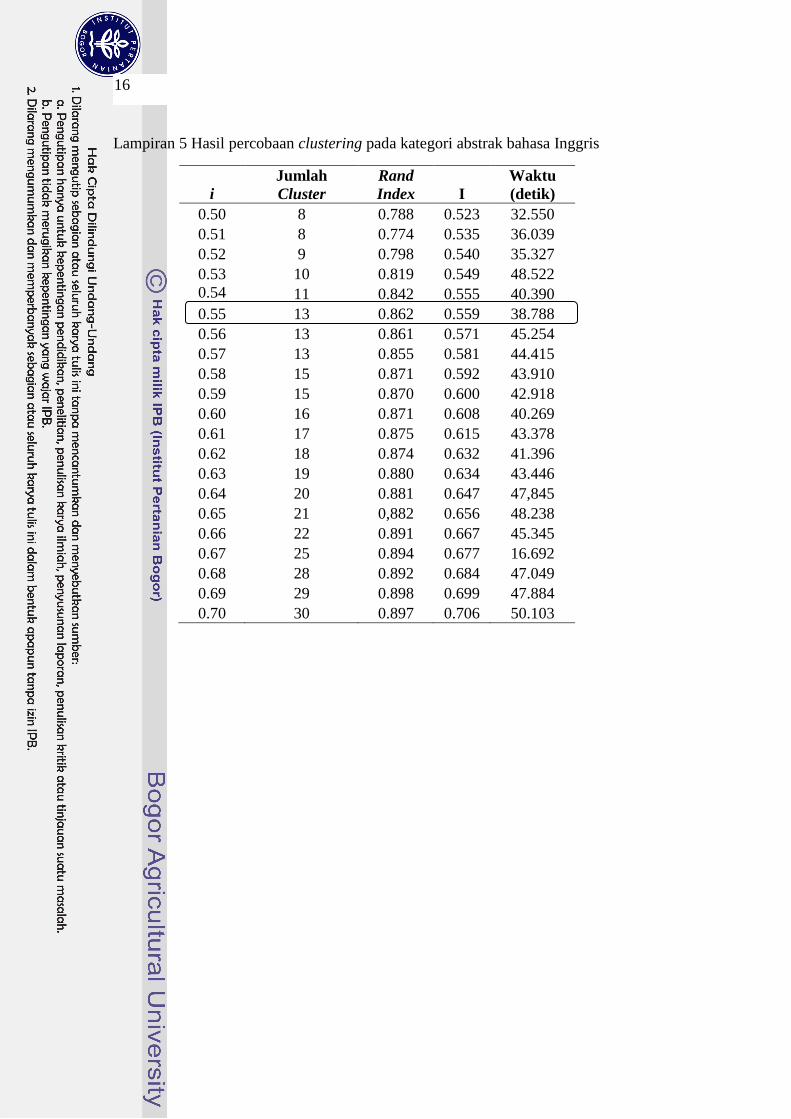
Tabel 5 Hasil percobaan clustering pada kategori abstrak bahasa Inggris
i Jumlah
Cluster Rand Index I
Waktu
(detik)
0.51 8 0.774 0.535 36.039
0.52 9 0.798 0.540 35.327
0.53 10 0.819 0.549 48.522
0.54 11 0.842 0.555 40.390
0.55 13 0.862 0.559 38.788
0.56 13 0.861 0.571 45.254
0.57 13 0.855 0.581 44.415
0.58 15 0.871 0.592 43.910
0.59 15 0.870 0.600 42.918
0.60 16 0.871 0.608 40.269
Berdasarkan hasil percobaan tersebut, dipilih nilai i = 0.55. Nilai tersebut
dipilih karena memiliki rata-rata rand index yang sudah cukup baik, yaitu 0. 862
dan jumlah cluster sama dengan atau mendekati jumlah cluster manual, yaitu 12.
Nilai i minimum dan maksimum yang digunakan pada kategori bahasa
Inggris berbeda dengan kategori bahasa Indonesia dikarenakan abstrak bahasa
Inggris memiliki tingkat kemiripan dokumen yang lebih rendah.

10
Validasi Hasil Clustering
Validasi hasil clustering pada penelititan ini dilakukan dengan
menggunakan ukuran akurasi rand index. Hasil clustering untuk setiap kategori
abstrak menghasilkan nilai rand index yang kurang dari 1.00. Hal ini
menunjukkan bahwa masih terdapat kesalahan clustering yang dilakukan oleh
sistem. Kesalahan ini terjadi bisa disebabkan oleh tingkat kemiripan antar
dokumen yang rendah sehingga dokumen tersebut dimasukkan ke dalan cluster
terdekat. Contoh pasangan dokumen false positive bahasa Indonesia dan bahasa
Inggris dapat dapat dilihat pada Lampiran 3 dan 4.
Lampiran 3 adalah pasangan dokumen D22 dan D24 seharusnya tidak
berada dalam satu cluster, karena dokumen D22 membahas masalah Perangkat
Lunak Pembelajaran, sedangkan dokumen D24 membahas tentang Kinerja
Interkoneksi IPv4 dan IPv6.
SIMPULAN DAN SARAN
Simpulan
Berdasarkan hasil yang diperoleh dapat disimpulkan bahwa clustering
dokumen dengan menggunakan Bisecting K-Means dapat dilakukan. Ditinjau dari
segi hasil, nilai i terbaik untuk clustering abstrak bahasa Indonesia adalah 0.67
yang menghasilkan rand index sebesar 0.867 dan nilai i terbaik untuk clustering
abstrak bahasa Inggris adalah 0.55 yang menghasilkan rand index sebesar 0. 862.
Saran
Penelitian ini menerapkan algoritme Bisecting K-Means untuk
mengelompokkan dokumen skripsi berdasarkan abstraknya dan belum
memberikan bobot untuk kata yang diambil dari judul skripsi dan kata kunci.
Untuk penelitian selanjutnya disarankan memberikan bobot tambahan untuk kata
yang diambil dari judul skripsi dan kata kunci dalam abstrak.
DAFTAR PUSTAKA
Jain AK, Dubes RC. 1988. Algorithm for Clustering Data. New Jersey (US) :
Prentice Hall.
Manning CD, Raghavan P, Schutze H. 2009. An Introduction to Information
Retrieval. Cambridge (OB) : Cambridge University Press.
Nah F. 2003. A study on tolerable waiting time: how long are web users willing to
wait? Di dalam: 9th Americas Conference on Information Systems, AMCIS
2003; 2003 Agustus 4-6; Florida. United States of America. Florida (US):
DBLP. hlm 153-163.

11
Ramdani H. 2011. Clustering konsep dokumen berbahasa Indonesia
menggunakan Bisecting K-Means [skripsi]. Bogor (ID) :Institut Pertanian
Bogor.
Ridha A. 2002. Pengindeksan otomatis dengan istilah tunggal untuk dokumen
berbahasa Indonesia [SNIKTI]. Bogor(ID): Institut Pertanian Bogor.

12
Lampiran 1 Contoh hasil ekstraksi data abstrak bahasa Indonesia
ARSANDA PRAWISDA. Pengembangan Data Warehouse Program Tracking
Stasiun TV di Indonesia. Dibimbing oleh WISNU ANANTA KUSUMA dan
HARI AGUNG ADRIANTO. Stasiun TV berusaha untuk meningkatkan rating,
share, dan jumlah penonton dengan memperhatikan biaya produksi yang
dikeluarkan. Data stasiun TV yang berisi rating, share, jumlah penonton, dan
biaya produksi adalah data program tracking. Data program tracking diterima
stasiun TV dari perusahaan penyedia data setiap minggu. Data acara tersebut
menjadi acuan dalam menganalisis potensi sebuah acara. Untuk memudahkan
proses analisis, maka dibuat data warehouse yang merupakan tempat
penyimpanan data yang terintegrasi, multidimensi, dan menampilkan data dalam
suatu bentuk yang diharapkan akan memudahkan proses analisis dalam
pembuatan keputusan. Hasil dari penelitian ini adalah suatu data warehouse untuk
data program tracking dan suatu OLAP browser yang mempunyai fasilitas untuk
menambah data yang datang setiap minggunya dan visualisasi berupa tabel pivot
dan diagram batang dalam menampilkan data numerik dan tabel relasional untuk
menampilkan data kategorik. Visualisasi ini dibuat untuk mempermudah
pengguna dalam melihat data dalam proses analisis. Kata Kunci : Data warehouse,
Multidimensi, Online Analytical Processing (OLAP), Skema bintang.

13
Lampiran 2 Contoh hasil ekstraksi data abstrak bahasa Inggris
DEVI DIAN PRAMANA PUTRA. Extended Boolean Model on Retrieval Using
P-Norm Model and Belief Revision. Supervised by JULIO ADISANTOSO.
Extended Boolean Model is introduced to intermediate between the Boolean
system of query processing and the vector-processing model. The query structure
inherent in the Boolean system is preserved, while at the same time weighted term
may be incorporated into both queries and stored documents. The retrieved output
can also be ranked in strict similarity order with the user queries. Belief Revision
is a logical framework in which documents and queries are represented by
propositional formulas. Disjunctive Normal Form (DNF) is used to represent
documents and queries in the Belief Revision. The purpose of this research is to
implement Extended Boolean Model using P-Norm Model and Belief Revision
for documents in Bahasa Indonesia. This testing used 30 queries from a thousand
agricultural documents and 13 queries from 93 medicinal plants documents. The
test result shows that the use of medicinal plants documents is better than
agricultural documents. This is due to agricultural documents which have a high
similarity between documents. The performance of information retrieval with P-
Norm Model and Belief Revision gave good result which is around 81% average
precision for medicinal plants documents and 54% for agricultural documents.
Keywords: Boolean Model, Extended Boolean Model, P-Norm Model, Belief
Revision.
14
Lampiran 3 Hasil pengelompokan manual untuk setiap kategori dokumen
Cluster
An
ggota
C0 C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13
D5 D13 D23 D10 D1 D7 D26 D8 D2 D15 D11 D3 D18 D12
D19 D74 D30 D21 D14 D37 D44 D27 D4 D16 D49 D48 D59 D17
D47 D76 D35 D32 D22 D39 D50 D40 D6 D20 D62 D54 D66 D60
D55 D43 D41 D24 D51 D72 D9 D25 D73 D69
D57 D42 D31 D52 D28 D29 D77
D67 D34 D63 D46 D33
D78 D36 D65 D56 D38
D53 D71 D58 D45
D68 D61 D64
D70 D75
D71
Cluster manual Bahasa Inggris
Cluster
An
ggota
C0 C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11
D80 D81 D79 D86 D87 D88 D92 D93 D85 D107 D102 D125
D89 D84 D82 D134 D97 D95 D101 D103 D98 D120 D113 D129
D110 D108 D83 D158 D99 D96 D114 D146 D106 D141 D118 D130
D155 D115 D90 D180 D100 D109 D121 D150 D156 D142 D149
D163 D131 D91 D111 D119 D122 D160 D159 D144 D173
D143 D94 D116 D136 D133 D181 D165 D170 D190
D154 D104 D117 D138 D139 D183 D166 D191
D157 D105 D124 D140 D152 D186 D171
D112 D128 D151 D169 D175
D123 D135 D153 D184 D177
D126 D145 D185 D179
D127 D161 D189
D132 D162
D137 D164
D147 D167
D148 D172
D168 D178
D174 D182
D176
D187
D188
15
Lampiran 4 Hasil percobaan clustering pada kategori abstrak bahasa Indonesia
i Jumlah
Cluster
Rand
Index I
Waktu
(detik)
0.60 10 0.820 0.614 19.483
0.61 10 0.822 0.629 20.708
0.62 11 0.859 0.625 24.149
0.63 12 0.852 0.642 21.120
0.64 13 0.863 0.655 22.311
0.65 14 0.859 0.661 22.995
0.66 14 0.862 .671 21.695
0.67 14 0.867 0.678 24.767
0.68 14 0.839 0.688 24.835
0.69 16 0.873 0.696 25.669
0.70 19 0.895 0.707 28,060
0.71 19 0.886 0.717 19.311
0.72 20 0.888 0.729 21.889
0.73 22 0.904 0.736 19.867
0.74 23 0.900 0.747 21.019
0.75 25 0.907 0.753 21.158
0.76 28 0.915 0.764 32.155
0.77 28 0.914 0.772 25.705
0.78 29 0.915 0.783 25.415
0.79 31 0.918 0.796 23.236
0.80 31 0.915 0.803 23.392
16
Lampiran 5 Hasil percobaan clustering pada kategori abstrak bahasa Inggris
i
Jumlah
Cluster
Rand
Index I
Waktu
(detik)
0.50 8 0.788 0.523 32.550
0.51 8 0.774 0.535 36.039
0.52 9 0.798 0.540 35.327
0.53 10 0.819 0.549 48.522
0.54 11 0.842 0.555 40.390
0.55 13 0.862 0.559 38.788
0.56 13 0.861 0.571 45.254
0.57 13 0.855 0.581 44.415
0.58 15 0.871 0.592 43.910
0.59 15 0.870 0.600 42.918
0.60 16 0.871 0.608 40.269
0.61 17 0.875 0.615 43.378
0.62 18 0.874 0.632 41.396
0.63 19 0.880 0.634 43.446
0.64 20 0.881 0.647 47,845
0.65 21 0,882 0.656 48.238
0.66 22 0.891 0.667 45.345
0.67 25 0.894 0.677 16.692
0.68 28 0.892 0.684 47.049
0.69 29 0.898 0.699 47.884
0.70 30 0.897 0.706 50.103

17
Lampiran 6 Contoh pasangan dokumen false positive bahasa Indonesia
D22
DIAN WIRADARYA. INTEGRASI TEKS, GAMBAR, AUDIO DAN
VIDEO DALAM PERANGKAT LUNAK PEMBELAJARAN. Dibimbing oleh
Kudang Boro Seminar dan Panji Wasmana. Perangkat lunak pembelajaran saat ini
menggunakan multimedia. Hal ini mengubah paradigma belajar menjadi membaca,
melihat, mendengar, mengamati, dan mengerjakan. Tapi, pembuat perangkat
lunak pembelajaran ini haruslah orang yang memahami bahasa pemograman
karena tidak ada aplikasi khusus yang menyediakan template untuk membuat
perangkat lunak pembelajaran. Penelitian ini akan menganalisis, merancang dan
membuat prototipe perangkat lunak yang menampung template untuk membuat
perangkat lunak pembelajaran. Perangkat lunak yang dibangun merupakan
perangkat lunak yang mudah digunakan sehingga orang yang tidak paham bahasa
pemograman pun dapat menggunakannya. Aplikasi yang dibangun diberi nama
Perangkat Lunak Pembelajaran Institut Pertanian Bogor (PLPIPB) ), yaitu
PLPIPB EDITOR dan PLPIPB APLIKASI. Kedua aplikasi ini dapat dijalankan
terpisah dan memiliki fungsi yang berbeda. PLPIPB EDITOR digunakan untuk
melakukan integrasi objek multimedia dan PLPIPB APLIKASI digunakan untuk
menjalankan aplikasi hasil integrasi PLPIPB EDITOR. Dengan demikian, aplikasi
hasil integrasi tersebut dapat disebarluaskan tanpa bisa diedit. Kelebihan sistem
ini dari aplikasi yang telah ada adalah penggunaan bahasa Indonesia untuk fungsi-
fungsi yang dimiliki, besar program yang relatif kecil dan tingkat kompleksitas
penggunaan sistem yang relatif rendah.
D29
ANDRA RIZKI AQUARY. Analisis Kinerja Interkoneksi IPv4 dan IPv6
Menggunakan Mekanisme NAT-PT. Dibimbing oleh HERU SUKOCO dan
FIRMAN ARDIANSYAH. IPv6 adalah versi baru protokol Internet yang
dikembangkan untuk menggantikan IPv4. Alasan utama dikembangkannya IPv6
adalah untuk meningkatkan ruang alamat Internet sehingga mampu
mengakomodasi perkembangan jumlah pengguna Internet yang sangat cepat.
Penyebaran IPv6 membutuhkan banyak waktu dan usaha, sehingga terdapat suatu
masa transisi di mana IPv6 dan IPv4 berjalan bersamaan. Pada masa ini
dibutuhkan teknik-teknik yang dapat diimplementasikan oleh IPv6 untuk dapat
kompatibel dengan IPv4, teknik-teknik ini disebut mekanisme transisi. Salah satu
bentuk mekanisme transisi adalah penerjemahan protokol dari IPv4 ke IPv6
maupun sebaliknya. NAT-PT merupakan salah satu bentuk implementasi dari
penerjemahan protokol. Dengan NAT-PT dimungkinkan komunikasi dua arah
baik dari IPv6 ke IPv4 maupun sebaliknya. Dalam penelitian ini diamati kinerja
interkoneksi antara IPv6 dan IPv4, ukuran kinerjanya meliputi throughput, RTT,
utilisasi CPU, dan waktu resolusi nama. Interkoneksi dari IPv6 ke IPv4
memperoleh kinerja throuhgput yang lebih baik dibandingkan interkoneksi
dengan arah sebaliknya. Hasil sebaliknya terjadi pada pengujian RTT di mana
keunggulan dimiliki oleh interkoneksi IPv4 ke IPv6. Di lain pihak, untuk dua
pengujian lainnya, interkoneksi IPv6 ke IPv4 kembali memperoleh hasil lebih

18
baik. Hasil pengujian juga menunjukkan satu kelemahan NAT-PT, yaitu
ketidakmampuannya menangani paket-paket yang terfragmentasi.
Lampiran 7 Contoh pasangan dokumen false positive bahasa Inggris
D80
SUTANTO. Infrastructure Integration of VoIP Technology on Smartphone
(Android) and PABX in IPB Computer Network Environment. Under the
supervision of ENDANG PURNAMA GIRI. Voice over Internet Protocol (VoIP)
has become a widely used communication media. The increase of internet and
number of smartphone users has become important factors that supports the
broader use of VoIP technology. While on the other hand the number users of
Public Switched Telephone Network (PSTN) is still quite a lot, even in office
buildings are usually equipped with a device Private Automatic Branch eXchange
(PABX). The purposes of this research is to interconnect VoIP networks and
PABX network on IPB computer network and also develop a VoIP client
application for Android. In this research the use of Android smartphone is limited
on Wi-Fi network. The method used in this study consisted of: study of the
network topology of IPB, installation of VoIP server, interconnection between
VoIP network and PABX, interconnection VoIP server and server of Lightweight
Directory Access Protocol, and development of VoIP client application for
smartphones. Communication between VoIP and PABX on the IPB computer
network has been established, and a VoIP client application for smartphones has
been developed. The values of delay, jitter and packet loss are 43.74 ms, 14.76 ms,
and 0.81% respectively and the value of Mean Opinion Score (MOS) is between 4
and 4.3. It can be concluded that the quality of VoIP networks in IPB is good.
Keywords: VoIP, VoIP and PBX integration, VoIP Application for Android, VoIP
in Wi-Fi Network.
D99
ANDI RUSMIA SOFARI. Image Compression Using Embedded Zerotree
Wavelet. Under direction of Ahmad Ridha. High quality digital images need large
storage space. One solution to solve that is digital image compression techniques.
This research used Embedded Zerotree Wavelet (EZW) method to compress 24-
bit RGB images. EZW is very effective to quantize discrete wavelet coefficients
and to generate the bit stream in order of importance. This research used several
thresholds, i.e., 5, 10, 30, 50, and 70. The method is compared with JPEG and
JPEG2000 compression method using Peak Signal-to-Noise Ratio (PSNR) and
compression ratio as performance metrics. For JPEG compression, the image
quality level is set at low, medium, high, and maximum. At threshold 10, the
output quality of EZW compression approaches the low quality JPEG
compression, but the compression ratio of EZW is higher (13.769 versus 5.766).
Compression ratio of EZW at threshold 5 approaches the compression of medium
level JPEG compression, but output quality of EZW is better than output quality
JPEG (PSNR: 39.217 versus 36.537). For JPEG2000 compression, the image
quality level is set at 30, 50, 80, and 100. At threshold 10, the output quality of the
EZW compression approaches the output of the JPEG2000 compression at quality
level 50, but the compression ratio of EZW is higher (13.679 versus 5.796).
Compression ratio of EZW at threshold 5 approaches the compression of

19
JPEG2000 at quality level 50, but output quality of EZW is better than output
quality JPEG2000 (PSNR: 39,217 versus 36,289). Compression with EZW
method can offer better results than the method of JPEG and JPEG2000 on
condition adjacent to each other in quality of output or compression ratio.
Keywords: compression, discrete wavelet transform, embedded zerotree wavelet





























