Embed Size (px)
Citation preview

Parte 2 – Estimación puntual Prof. María B. Pintarelli
124
PARTE 2 - ESTADISTICA
7- Estimación puntual
7. 1 – Introducción
Supongamos la siguiente situación: en una fábrica se producen artículos, el interés está en la
producción de un día, específicamente, de todos los artículos producidos en un día nos interesa una
característica determinada, si el artículo es o no defectuoso. Sea p la proporción de artículos
defectuosos en la población, es decir en la producción de un día.
Tomamos una muestra de 25 artículos, podemos definir la v.a. X: “número de artículos defectuosos
en la muestra”, y podemos asumir que ),25(~ pBX .
En Probabilidades se conocían todos los datos sobre la v.a. X, es decir conocíamos p. De esa forma
podíamos responder preguntas como: ¿cuál es la probabilidad que entre los 25 artículos halla 5
defectuosos?. Si, por ejemplo, 1.0=p entonces calculábamos )5( =XP donde )1.0 ,25(~ BX .
En Estadística desconocemos las características de X total o parcialmente, y a partir de la muestra
de 25 artículos tratamos de inferir información sobre la distribución de X, o dicho de otra forma
tratamos de inferir información sobre la población.
Por ejemplo, en estadística sabremos que X tiene distribución binomial pero desconocemos p, y a
partir de la muestra de 25 artículos trataremos de hallar información sobre p.
En Estadística nos haremos preguntas tales como: si en la muestra de 25 artículos se encontraron 5
defectuosos, ¿ese hecho me permite inferir que el verdadero p es 0.1?.
El campo de la inferencia estadística está formado por los métodos utilizados para tomar decisiones
o para obtener conclusiones sobre el o los parámetros de una población. Estos métodos utilizan la
información contenida en una muestra de la población para obtener conclusiones.
La inferencia estadística puede dividirse en dos grandes áreas: estimación de parámetros y pruebas
de hipótesis.
7.2 – Muestreo aleatorio
En muchos problemas estadísticos es necesario utilizar una muestra de observaciones tomadas de la
población de interés con objeto de obtener conclusiones sobre ella. A continuación se presenta la
definición de algunos términos
En muchos problemas de inferencia estadística es poco práctico o imposible, observar toda la
población, en ese caso se toma una parte o subconjunto de la población
Para que las inferencias sean válidas, la muestra debe ser representativa de la población. Se
selecciona una muestra aleatoria como el resultado de un mecanismo aleatorio. En consecuencia, la
selección de una muestra es un experimento aleatorio, y cada observación de la muestra es el valor
observado de una variable aleatoria. Las observaciones en la población determinan la distribución de
probabilidad de la variable aleatoria.
Una población está formada por la totalidad de las observaciones en las cuales se tiene cierto
interés
Una muestra es un subconjunto de observaciones seleccionada de una población

Parte 2 – Estimación puntual Prof. María B. Pintarelli
125
Para definir muestra aleatoria, sea X la v.a. que representa el resultado de tomar una observación de
la población. Sea )(xf la f.d.p. de la v.a. X. supongamos que cada observación en la muestra se
obtiene de manera independiente, bajo las mismas condiciones. Es decir, las observaciones de la
muestra se obtienen al observar X de manera independiente bajo condiciones que no cambian,
digamos n veces.
Sea iX la variable aleatoria que representa la i-ésima observación. Entonces nXXX ,...,, 21
constituyen una muestra aleatoria, donde los valores numéricos obtenidos son nxxx ,...,, 21 . Las
variables aleatorias en una muestra aleatoria son independientes, con la misma distribución de
probabilidad f(x) debido a que cada observación se obtiene bajo las mismas condiciones. Es decir las
funciones de densidad marginales de nXXX ,...,, 21 son todas iguales a f(x) y por independencia, la
distribución de probabilidad conjunta de la muestra aleatoria es el producto de las marginales
)()...()( 21 nxfxfxf
El propósito de tomar una muestra aleatoria es obtener información sobre los parámetros
desconocidos de la población. Por ejemplo, se desea alcanzar una conclusión acerca de la proporción
de artículos defectuosos en la producción diaria de una fábrica. Sea p la proporción de artículos
defectuosos en la población, para hacer una inferencia con respecto a p, se selecciona una muestra
aleatoria (de un tamaño apropiado) y se utiliza la proporción observada de artículos defectuosos en
la muestra para estimar p.
La proporción de la muestra p se calcula dividiendo el número de artículos defectuosos en la
muestra por el número total de artículos de la muestra. Entonces p es una función de los valores
observados en la muestra aleatoria. Como es posible obtener muchas muestras aleatorias de una
población, el valor de p cambiará de una a otra. Es decir p es una variable aleatoria. Esta variable
aleatoria se conoce como estadístico.
Estadísticos usuales
Sea nXXX ,...,, 21 una muestra aleatoria de una v.a. X donde µ=)(XE y 2)( σ=XV
Si desconocemos µ un estadístico que se utiliza para estimar ese parámetro es la media o promedio
muestral ∑=
=n
i
iXn
X1
1
Análogamente si se desconoce 2σ un estadístico usado para tener alguna información sobre ese
parámetro es la varianza muestral que se define como ( )∑=
−−
=n
i
i XXn
S1
22
1
1
Otro estadístico es la desviación estándar muestral ( )∑=
−−
=n
i
i XXn
S1
2
1
1
Como un estadístico es una variable aleatoria, éste tiene una distribución de probabilidad, esperanza
y varianza.
Las variables aleatorias ( )nXXX ,...,, 21 constituyen una muestra aleatoria de tamaño n de una
v.a. X si nXXX ,...,, 21 son independientes idénticamente distribuidas
Un estadístico es cualquier función de la muestra aleatoria

Parte 2 – Estimación puntual Prof. María B. Pintarelli
126
Una aplicación de los estadísticos es obtener estimaciones puntuales de los parámetros
desconocidos de una distribución. Por ejemplo como se dijo antes se suelen estimar la media y la
varianza de una población.
Cuando un estadístico se utiliza para estimar un parámetro desconocido se lo llama estimador
puntual. Es habitual simbolizar en forma genérica a un parámetro con la letra θ y al estadístico que
se utiliza como estimador puntual de θ , simbolizarlo con Θ .
Por lo tanto Θ es una función de la muestra aleatoria: ( )nXXXh ,...,,ˆ21=Θ
Al medir la muestra aleatoria se obtienen nxxx ,...,, 21 , y entonces el valor que toma Θ es
( )nxxxh ,...,,ˆ21=θ y se denomina estimación puntual de θ
El objetivo de la estimación puntual es seleccionar un número, a partir de los valores de la muestra,
que sea el valor más probable de θ .
Por ejemplo, supongamos que 4321 ,,, XXXX es una muestra aleatoria de una v.a. X. Sabemos que X
tiene distribución normal pero desconocemos µ .
Tomamos como estimador de µ al promedio muestral X , es decir X=µ
Tomamos la muestra (medimos 4321 ,,, XXXX ) y obtenemos 32 ,27 ,30 ,24 4321 ==== xxxx
Entonces la estimación puntual de µ es 25.284
32273024=
+++=x
Si la varianza 2σ de X también es desconocida, un estimador puntual usual de 2σ es la varianza
muestral, es decir ( )∑=
−−
=n
i
i XXn
S1
22
1
1, para la muestra dada la estimación de 2σ es 12.25.
Otro parámetro que a menudo es necesario estimar es la proporción p de objetos de una población
que cumplen una determinada característica.
En este caso el estimador puntual de p sería ∑=
=n
i
iXn
p1
1ˆ donde
−
=contrariocaso
erésdeticacaracteríslatienenobservacióésimaílasi
X i 0
int1
ni ,...,2,1=
Por lo tanto ∑=
=n
i
iXn
p1
1ˆ es la proporción de objetos en la muestra cumplen la característica de
interés
Puede ocurrir que se tenga más de un estimador para un parámetro, por ejemplo para estimar la
media muestral se pueden considerar el promedio muestral, o también la semisuma entre 1X y nX ,
es decir 2
ˆ 1 nXX +=µ . En estos casos necesitamos de algún criterio para decidir cuál es mejor
estimador de µ .
7.3 – Criterios para evaluar estimadores puntuales
Lo que se desea de un estimador puntual es que tome valores “próximos” al verdadero parámetro.
Podemos exigir que el estimador Θ tenga una distribución cuya media sea θ .

Parte 2 – Estimación puntual Prof. María B. Pintarelli
127
Notar que si un estimador es insesgado entonces su sesgo es cero
Ejemplos:
1- Sea nXXX ,...,, 21 una muestra aleatoria de una v.a. X donde µ=)(XE y 2)( σ=XV
Si desconocemos µ un estadístico que se utiliza usualmente para estimar este parámetro es la media
o promedio muestral ∑=
=n
i
iXn
X1
1. Veamos si es un estimador insesgado de µ . Debemos ver si
( ) µ=XE .
Usamos las propiedades de la esperanza, particularmente la propiedad de linealidad.
( ) ( )∑∑∑===
=
=
=
n
i
i
n
i
i
n
i
i XEn
XEn
Xn
EXE111
111.
Pero, tratándose de las componentes de una muestra aleatoria es:
( ) ( ) n,...,,iµXEXE i 21=∀== . Luego:
( ) .µµnn
XE ==1
2- Sea X una variable aleatoria asociada con alguna característica de los individuos de una población
y sean ( ) µXE = y ( ) 2σXV = . Sea ( )2
1
2
1
1∑=
−−
=n
i
i XXn
S la varianza muestral (con
n/XXn
i
i
= ∑
=1
la esperanza muestral) para una muestra aleatoria de tamaño n, ( )nX,...,X,X 21 .
Entonces ( ) 22 σSE = es decir ( )2
1
2
1
1∑=
−−
=n
i
i XXn
S es un estimador insesgado de ( ) 2σXV =
pues:
( ) ( ) ( )
−
−=
−
−= ∑∑
==
2
1
2
1
2
1
1
1
1 n
i
i
n
i
i XXEn
XXn
ESE .
Reescribiremos la suma de una forma más conveniente. Sumamos y restamos µ y desarrollamos el
cuadrado:
( ) ( ) [ ] [ ]( ) =−+−=−+−=− ∑∑∑===
2
1
2
1
2
1
n
i
i
n
i
i
n
i
i XXXXXX µµµµ
[ ] [ ][ ] [ ]∑=
−+−−+−=n
iii XXXX
1
222 µµµµ [ ] [ ] [ ] [ ] =−+−−+−= ∑∑
==
2
11
22 XnXXX
n
i
i
n
i
i µµµµ
Se dice que el estimador puntual Θ es un estimador insesgado del parámetro θ si ( ) θ=ΘE
cualquiera sea el valor verdadero de θ
La deferencia ( ) θ−ΘE se conoce como sesgo de estimador Θ . Anotamos ( ) ( ) θ−Θ=Θ ˆˆ Eb

Parte 2 – Estimación puntual Prof. María B. Pintarelli
128
[ ] [ ] [ ] [ ]21
22 XnXnXX
n
ii −+−−+−= ∑
=µµµµ [ ] [ ] [ ]22
1
22 XµnXµnµX
n
i
i −+−−−= ∑=
.
Esto es:
( ) [ ] [ ]21
2
2
1
XµnµXXXn
i
i
n
i
i −−−=− ∑∑==
Entonces:
( ) ( ) [ ] [ ] =
−−−
−=
−
−= ∑∑
==
2
1
2
2
1
2
1
1
1
1XnXE
nXXE
nSE
n
i
i
n
i
i µµ
[ ] [ ] =
−−−
−= ∑
=
2
1
2
1
1µµ XnEXE
n
n
i
i
( ) ( )[ ] ( ) ( ) =
−
−=
−−
−= ∑∑
==
XnVXVn
XEXnEXVn
n
i
i
n
i
i
1
2
1 1
1
1
1
−
− nnn
n
22
1
1 σσ ,
donde en la última igualdad tuvimos en cuenta que ( ) ( ) n,...,,iσXVXV i 212 =∀== y que
( )n
σXV
2
= . Luego llegamos a lo que se deseaba demostrar: ( ) 22 σSE = .
3- Supongamos que tomamos como estimador de 2σ a ( )2
1
2 1ˆ ∑
=
−=n
i
i XXn
σ
Entonces notar que podemos escribir ( )( )
21
2
2
1
2 1
1
11ˆ S
n
n
n
XX
n
nXX
n
n
i
in
i
i
−=
−
−−
=−=∑
∑ =
=
σ
Por lo tanto ( ) ( ) 22222 111ˆ σσσ ≠
−=
−=
−=
n
nSE
n
nS
n
nEE
Es decir 2σ no es un estimador insesgado de 2σ , es sesgado, y su sesgo es
( ) ( ) 222222 11ˆˆ σσσσσσ
nn
nEb −=−
−=−=
Como el sesgo es negativo el estimador tiende a subestimar el valor de verdadero parámetro
En ocasiones hay más de un estimador insesgado de un parámetro θ
Por lo tanto necesitamos un método para seleccionar un estimador entre varios estimadores
insesgados.
Varianza y error cuadrático medio de un estimador puntual
Supongamos que 1Θ y 2Θ son dos estimadores insegados de un parámetro θ . Esto indica que la
distribución de cada estimador está centrada en el verdadero parámetro θ . Sin embargo las varianzas
de estas distribuciones pueden ser diferentes. La figura siguiente ilustra este hecho.

Parte 2 – Estimación puntual Prof. María B. Pintarelli
129
-15 -10 -5 5 10 15
0.1
0.2
0.3
0.4
Como 1Θ tiene menor varianza que 2Θ , entonces es más probable que el estimador 1Θ produzca
una estimación más cercana al verdadero valor de θ . Por lo tanto si tenemos dos estimadores
insesgados se seleccionará aquel te tenga menor varianza.
Ejemplo: Sea nXXX ,...,, 21 una muestra aleatoria de una v.a. X donde µ=)(XE y 2)( σ=XV
Suponemos µ desconocido.
Estimamos al parámetro µ con la media o promedio muestral ∑=
=n
i
iXn
X1
1. Sabemos que es un
estimador insesgado de µ . Anotamos ∑=
==n
i
iXn
X1
1
1µ
Supongamos que tomamos otro estimador para µ , lo anotamos 2
ˆ 12
nXX +=µ
Entonces como
( ) ( ) ( )( ) ( ) µµµµµ ==+=+=
+= 2
2
1
2
1
2
1
2ˆ
211
2 XEXEXX
EE n ,
2ˆ 12
nXX +=µ es también un estimador insesgado de µ
¿Cuál de los dos estimadores es mejor?
Calculamos la varianza de cada uno utilizando las propiedades de la varianza.
Ya sabemos cuál es la varianza de ∑=
=n
i
iXn
X1
1 (se la halló para T.C.L.):
( )=XV ( ),XVn
XVn
Xn
Vn
i
i
n
i
i
n
i
i ∑∑∑===
=
=
12
12
1
111
donde en la última igualdad hemos tenido en cuenta que, por tratarse de una muestra aleatoria, las
iX con i=1,2,…,n son variables aleatorias independientes y, en consecuencia, la varianza de la suma
de ellas es la suma de las varianzas. Si tenemos en cuenta que además todas tienen la misma
distribución que X y por lo tanto la misma varianza:
( ) ( ) n,...,,iσXVXV i 212 =∀== , tenemos
( )=XV .n
σσn
n
22
2
1=
Distribución de 1Θ
Distribución de 2Θ
θ

Parte 2 – Estimación puntual Prof. María B. Pintarelli
130
Análogamente calculamos la varianza de 2
ˆ 12
nXX +=µ :
( ) ( ) ( )24
1)()(
4
1
2ˆ
222
211
2
σσσµ =+=+=
+= XVXV
XXVV n
Vemos que si 2>n entonces )ˆ()ˆ( 21 µµ VV < . Por lo tanto si 2>n es mejor estimador 1µ
Supongamos ahora que 1Θ y 2Θ son dos estimadores de un parámetro θ y alguno de ellos no es
insesgado.
A veces es necesario utilizar un estimador sesgado. En esos casos puede ser importante el error
cuadrático medio del estimador.
El error cuadrático medio puede escribirse de la siguiente forma:
( ) ( ) ( )( )2ˆˆˆ Θ+Θ=Θ bVECM
Dem.) Por definición ( ) ( )
−Θ=Θ
2ˆˆ θEECM . Sumamos y restamos el número ( )ΘE :
( ) ( ) ( )( )
−Θ+Θ−Θ=Θ
2ˆˆˆˆ θEEEECM , y desarrollamos el cuadrado:
( ) ( ) ( )( ) ( )( ) ( )( ) ( )( ) ( )( ) =
−ΘΘ−Θ+−Θ+Θ−Θ=
−Θ+Θ−Θ=Θ θθθ ˆˆˆ2ˆˆˆˆˆˆˆ 222
EEEEEEEEECM
Aplicamos propiedades de la esperanza:
( )( )( )
( )( )( )
( )( ) ( )( ) ( ) ( )( )20ˆ
2
ˆ
2 ˆˆˆˆˆ2ˆˆˆ
2
Θ+Θ=Θ−Θ−Θ+−Θ+
Θ−Θ=
ΘΘ
bVEEEEEE
bV
434214342144 344 21
θθ
El error cuadrático medio es un criterio importante para comparar estimadores.
Si la eficiencia relativa es menor que 1 entonces 1Θ tiene menor error cuadrático medio que 2Θ
Por lo tanto 1Θ es más eficiente que 2Θ
El error cuadrático medio de un estimador Θ de un parámetro θ está definido como
( ) ( )
−Θ=Θ
2ˆˆ θEECM
Si 1Θ y 2Θ son dos estimadores de un parámetro θ .
La eficiencia relativa de 2Θ con respecto a 1Θ se define como ( )( )2
1
ˆ
ˆ
Θ
Θ
ECM
ECM

Parte 2 – Estimación puntual Prof. María B. Pintarelli
131
Observaciones:
1- Si Θ es un estimador insesgado de θ , entonces ( ) ( )Θ=Θ ˆˆ VECM
2- A veces es preferible utilizar estimadores sesgados que estimadores insesgados, si es que tienen
un error cuadrático medio menor.
En el error cuadrático medio se consideran tanto la varianza como el sesgo del estimador.
Si 1Θ y 2Θ son dos estimadores de un parámetro θ , tales que ( ) θ=Θ1ˆE ; ( ) θ≠Θ2
ˆE y
( ) ( )12ˆˆ Θ<Θ VV , habría que calcular el error cuadrático medio de cada uno, y tomar el que tenga
menor error cuadrático medio. Pues puede ocurrir que 2Θ , aunque sea sesgado, al tener menor
varianza tome valores mas cercanos al verdadero parámetro que 1Θ
-7.5 -5 -2.5 2.5 5 7.5
0.1
0.2
0.3
0.4
Ejemplo:
Supóngase que 1Θ , 2Θ y 3Θ son dos estimadores de un parámetro θ , y que
( ) ( ) ;ˆˆ21 θ=Θ=Θ EE ( ) θ≠Θ3
ˆE , 10)ˆ( 1 =θV , 6)ˆ( 2 =ΘV y ( ) 4ˆ 2
3 =
−Θ θE . Haga una comparación
de estos estimadores. ¿Cuál prefiere y por qué?
Solución: Calculamos el error cuadrático medio de cada estimador
( ) ( ) 10ˆˆ11 =Θ=Θ VECM pues 1Θ es insesgado
( ) ( ) 6ˆˆ22 =Θ=Θ VECM pues 2Θ es insesgado
( ) ( ) 4ˆˆ 2
33 =
−Θ=Θ θEECM es dato
En consecuencia 3Θ es el mejor estimador de los tres dados porque tiene menor error cuadrático
medio.
Consistencia de estimadores puntuales
Distribución de 1Θ
Distribución de 2Θ
θ
Sea nΘ un estimador del parámetro θ , basado en una muestra aleatoria ( )nX,...,X,X 21 de
tamaño n. Se dice que nΘ es un estimador consistente de θ si
( ) 0ˆlim =≥−Θ∞→
εθnn
P para todo 0>ε

Parte 2 – Estimación puntual Prof. María B. Pintarelli
132
Observación:
Este tipo de convergencia, que involucra a una sucesión de variables aleatorias, se llama
convergencia en probabilidad y es la misma que consideramos en relación a la ley de los grandes
números Suele escribirse también θP
n →Θ .
Este tipo de convergencia debe distinguirse de la considerada en relación al teorema central del
límite. En este último caso teníamos una sucesión de distribuciones: ( ) ( )zZPzF nZ n≤= y se
considera el límite ( ) ( ) ( )zzZPlimzFlim nn
Zn n
Φ=≤=∞→∞→
.
Se habla, entonces, de convergencia en distribución y suele indicarse ZZd
n → ∼ ( )10,N .
Teorema. Sea nΘ un estimador del parámetro θ basado en una muestra aleatoria ( )nX,...,X,X 21 .
Si ( ) θ=Θ∞→ n
nE ˆlim y ( ) 0ˆlim =Θ
∞→ nn
V , entonces nΘ es un estimador consistente de θ .
Dem.)
Utilizamos la desigualdad de Chebyshev 0>∀ε :
( ) ( ) ( ) ( ) ( )
Θ+Θ=Θ=
−Θ≤≥−Θ
2
222
2
ˆˆ1ˆ1ˆˆ
nnnn
n bVECME
Pεεε
θεθ
Entonces, al tomar el límite ∞→n
lim y teniendo presente que ( ) θ=Θ∞→ n
nE ˆlim y ( ) 0ˆlim =Θ
∞→ nn
V , vemos que
( ) 0ˆlim =≥−Θ∞→
εθnn
P 0>∀ε , es decir nΘ es un estimador convergente de θ .
Ejemplo:
Sea X una variable aleatoria que describe alguna característica numérica de los individuos de una
población y sean ( )XEµ = y ( )XVσ =2 la esperanza poblacional y la varianza poblacional,
respectivamente. Sea ∑=
=n
i
iXn
X1
1 la esperanza muestral basada en una muestra aleatoria
( )nX,...,X,X 21 . Entonces X es un estimador consistente de la esperanza poblacional ( )XEµ = .
Sabemos que
a) ( ) ( )XEµXE == n∀
b) ( ) ( )n
XV
n
σXV ==
2
n∀
La propiedad a) ya me dice que X es un estimador insesgado de ( )XEµ = .
Por otra parte si a) vale para todo n, también vale en particular en el límite ∞→n :
( ) ( )XEµXElimn
==∞→
.
Además, de b) deducimos inmediatamente que
( ) 0=∞→
XVlimn
.
Por lo tanto vemos que X es un estimador consistente de ( )XEµ = .

Parte 2 – Estimación puntual Prof. María B. Pintarelli
133
7.4 – Métodos de estimación puntual
Los criterios anteriores establecen propiedades que es deseable que sean verificadas por los
estimadores. Entre dos estimadores posibles para un dado parámetro poblacional es razonable elegir
aquél que cumple la mayor cantidad de criterios o alguno en particular que se considera importante
para el problema que se esté analizando. Sin embargo estos criterios no nos enseñan por sí mismos a
construir los estimadores. Existen una serie de métodos para construir estimadores los cuales en
general se basan en principios básicos de razonabilidad. Entre éstos podemos mencionar:
- Método de los momentos
- Método de máxima verosimilitud
Método de los momentos
Se puede probar usando la desigualdad de Chebyshev el siguiente resultado:
Definimos los momentos de orden k de una variable aleatoria como:
( ) ( )∑∈
==Xi Rx
i
k
i
k
k xpxXEµ ( ),...,,k 210= Si X es discreta
( ) ( )∫+∞
∞−
== dxxfxXEµ kk
k ( ),...,,k 210= Si X es continua,
y definimos los correspondientes momentos muestrales de orden k como:
∑=
=n
i
k
ik Xn
M1
1 ( ),...,,k 210= ,
Entonces la ley débil de los grandes números se puede generalizar:
( ) 0lim =≥−∞→
εµkkn
MP ( ),...,,k 210= .
De acuerdo con esto parece razonable estimar los momentos poblacionales de orden k mediante los
momentos muestrales de orden k: kµ ∼ kM ( ),...,,k 210= .
Ley débil de los grandes números:
Sean ( )nX,...,X,X 21 n variables aleatorias independientes todas las cuales tienen la misma
esperanza ( )XEµ = y varianza ( )XVσ =2 . Sea ∑=
=n
i
iXn
X1
1. Entonces
( ) 0lim =≥−∞→
εµXPn
Decimos que X converge a µ en probabilidad y lo indicamos: µXp
→ .

Parte 2 – Estimación puntual Prof. María B. Pintarelli
134
Supongamos, entonces, una variable aleatoria X y supongamos que la distribución de X depende de r
parámetros rθθθ ,...,, 21 , esto es la fdp poblacional es ( )rixp θθθ ,...,,, 21 si X es discreta o
( )rxf θθθ ,...,,, 21 si es continua. Sean rµ,...,µ,µ 21 los primeros r momentos poblacionales:
( ) ( )∑∈
==Xi Rx
ri
k
i
k
k xpxXE θθθµ ,...,,, 21 ( )r,...,,k 21= Si X es discreta
( ) ( )∫+∞
∞−
== dxxfxXE r
kk
k θθθµ ,...,,, 21 ( )r,...,,k 21= Si X es continua,
y sean
∑=
=n
i
k
ik Xn
M1
1 ( )r,...,,k 21= los r primeros momentos maestrales para una muestra de tamaño n
( )nX,...,X,X 21 . Entonces el método de los momentos consiste en plantear el sistema de ecuaciones:
=
=
=
rr Mµ
Mµ
Mµ
MMM
22
11
Es decir
( )
( )
( )
=
=
=
∑∑
∑∑
∑∑
=∈
=∈
=∈
n
i
r
i
Rx
ri
r
i
n
i
i
Rx
rii
n
i
i
Rx
rii
Xn
xpx
Xn
xpx
Xn
xpx
Xi
Xi
Xi
1
21
1
2
21
2
1
1
21
1,...,,,
1,...,,,
1,...,,,
θθθ
θθθ
θθθ
MMM Si X es discreta,
o
( )
( )
( )
=
=
=
∑∫
∑∫
∑∫
=
∞+
∞−
=
∞+
∞−
=
+∞
∞−
n
i
r
ir
r
n
i
ir
n
i
ir
Xn
dxxfx
Xn
dxxfx
Xn
dxxxf
1
21
1
2
21
2
1
1
21
1,...,,,
1,...,,,
1,...,,,
θθθ
θθθ
θθθ
MMM Si X es continua.

Parte 2 – Estimación puntual Prof. María B. Pintarelli
135
Resolviendo estos sistema de ecuaciones para los parámetros desconocidos rθθθ ,...,, 21 en función de
la muestra aleatoria ( )nX,...,X,X 21 obtenemos los estimadores:
( )( )
( )
=Θ
=Θ
=Θ
nrr
n
n
XXXH
XXXH
XXXH
,...,,ˆ
,...,,ˆ
,...,,ˆ
21
2122
2111
M
Observación:
En la forma que presentamos aquí el método necesitamos conocer la forma de la fdp poblacional, por
lo tanto estamos frente a un caso de estimación puntual paramétrica.
Ejemplos:
1- Sea X una variable aleatoria. Supongamos que X tiene distribución gama con parámetros σ y λ :
X ∼ ( )λ,σΓ , es decir su fdp está dada por:
( )
>
=
−−
valoresdemás
xeσ
x
λσ)x(f
σ
xλ
0
01
1
Γ
con 0>σ ; 0>λ y ( ) ∫∞
−−=Γ0
1 dxexλ xλ .
Sea ( )nXXX ,...,, 21 una muestra aleatoria de tamaño n. Deseamos calcular los estimadores de σ y λ
dados por el método de los momentos.
Solución:
Como tenemos dos parámetros desconocidos a estimar, planteamos el sistema de ecuaciones:
=
=
22
11
Mµ
Mµ
Se puede probar que
σ.λµ =1
222
2 σ.λσ.λµ +=
Tenemos, entonces, el sistema de ecuaciones
=+
=
∑
∑
=
=n
i
i
n
i
i
Xn
σ.λσ.λ
Xn
σ.λ
1
2222
1
1
1
⇒
=+
=
∑=
n
i
iXn
X
1
2222 1..
.
σλσλ
σλ

Parte 2 – Estimación puntual Prof. María B. Pintarelli
136
Reemplazando en la segunda ecuación: ∑=
=+n
i
iXn
XX1
22 1σ ⇒
X
XXn
n
i
i∑=
−= 1
221
σ
Y despejando λ de la primera ecuación y reemplazando la expresión hallada para σ
( )
( )
−=
−=
∑
∑
=
=
Xn
XX
XX
Xn
n
i
i
n
i
i
1
2
1
2
2
ˆ
ˆ
σ
λ
2- Sea ( )nXXX ,...,, 21 una muestra aleatoria de tamaño n de una v.a. X donde [ ]θ,0~UX , θ
desconocido. Hallar el estimador de θ por el método de los momentos.
Solución:
Planteamos la ecuación: 11 M=µ
Sabemos que 22
0)(1
θθµ =
+== XE . Entonces X=
2
θ ⇒ X2ˆ =Θ
Observación: notar que el estimador X2ˆ =Θ es un estimador consistente de θ , pues
( ) ( ) ( ) θθ
====Θ2
222ˆ XEXEE y ( ) ( ) ( ) ( )0
312
0442ˆ
22
∞→→=
−===Θ
nnnXVXVV
θθ
3- Sea ( )nX,...,X,X 21 una muestra aleatoria de una v.a. X~ ),( 2σµN .
Encuentra los estimadores de µ y σ por el método de momentos.
Solución:
Planteamos las ecuaciones
=
=
22
11
Mµ
Mµ ⇒ ( )
=
=
∑=
n
i
iXn
XE
X
1
22 1
µ
pero en general es válido que 22 )()( µ−= XEXV ⇒ µ+= )()( 2 XVXE
Entonces las ecuaciones quedan
=+
=
∑=
n
i
iXn
X
1
222 1µσ
µ ⇒
−=
=
∑=
2
1
22 1ˆ
ˆ
XXn
Xn
i
iσ
µ
4- Sea ( )nX,...,X,X 21 una muestra aleatoria de una v.a. X~ ),0( 2σN .
Hallar un estimador por el método de los momentos de 2σ
Solución: en este caso no es conveniente plantear 11 M=µ pues quedaría

Parte 2 – Estimación puntual Prof. María B. Pintarelli
137
la ecuación X=0 que no conduce a nada.
Entonces podemos plantear 22 M=µ es decir
∑=
=n
i
iXn
XE1
22 1)( ⇒ ∑
=
=+n
i
iXn 1
22 10σ ⇒ ∑
=
=n
i
iXn 1
22 1σ
Observación: si Θ es un estimador por el método de los momentos de un parámetro θ , el estimador
de los momentos de ( )θg es ( )Θg , si )(xg es una función inyectiva.
Por ejemplo, en el ejemplo anterior un estimador de σ por el método de los momentos sería
∑=
==n
i
iXn 1
22 1ˆˆ σσ . Notar que xxg =)( es inyectiva para los reales positivos.
Método de máxima verosimilitud
Uno de los mejores métodos para obtener un estimador puntual de un parámetro es el método de
máxima verosimilitud.
La interpretación del método sería: el estimador de máxima verosimilitud es aquel valor del
parámetro que maximiza la probabilidad de ocurrencia de los valores muestrales
La adaptación para el caso en que X es una v.a. continua sería la siguiente
Notación: abreviamos estimador de máxima verosimilitud con EMV
Supongamos que X es una v.a. discreta con función de distribución de probabilidad ),( θxp ,
donde θ es un parámetro desconocido. Sean nxxx ,...,, 21 los valores observados de una muestra
aleatoria de tamaño n.
Se define la función de verosimilitud como la función de distribución conjunta de las
observaciones:
( ) ),().....,().,()()...()(,,...,, 21221121 θθθθ nnnn xpxpxpxXPxXPxXPxxxL =====
Notar que la función de verosimilitud es una función de θ .
El estimador de máxima verosimilitud de θ es aquel valor de θ que maximiza la función de
verosimilitud
Supongamos que X es una v.a. continua con función de densidad de probabilidad ),( θxf , donde
θ es un parámetro desconocido. Sean nxxx ,...,, 21 los valores observados de una muestra
aleatoria de tamaño n.
Se define la función de verosimilitud como la función de distribución conjunta de las
observaciones:
( ) ),().....,().,(,,...,, 2121 θθθθ nn xfxfxfxxxL =
La función de verosimilitud es una función de θ .
El estimador de máxima verosimilitud de θ es aquel valor de θ que maximiza la función de
verosimilitud

Parte 2 – Estimación puntual Prof. María B. Pintarelli
138
Ejemplos:
1- Sea ( )nX,...,X,X 21 una muestra aleatoria de una v.a. X~ ),1( pB
Por ejemplo, se eligen al azar n objetos de una línea de producción, y cada uno se clasifica como
defectuoso (en cuyo caso 1=ix ) o no defectuoso (en cuyo caso 0=ix ).
Entonces )1( == iXPp , es decir es la verdadera proporción de objetos defectuosos en la producción
total.
Queremos hallar el EMV de p
Solución:
Si X~ ),1( pB entonces kk ppk
kXP −−
== 1)1(
1)( 1,0=k
Planteamos la función de verosimilitud
( ) ( ) ( ) ( ) ( )[ ] ( )[ ] ( )[ ]nnxxxxxx
nn pppppppxppxppxppxxxL−−− −−−== 111
2121 1...11;...;;;,..,, 2211
Esto puede escribirse:
( ) ( ) ∑−∑
= == −
n
i
i
n
i
ixn
x
n pppxxxL 1
1 1;,...,, 21
Para maximizar la función de verosimilitud y facilitar los cálculos tomamos el logaritmo natural de L
Pues maximizar L es equivalente a maximizar ln(L) y al tomar logaritmos transformamos productos
en sumas.
Entonces
( )( ) ( )pxnpxpxxxLn
i
i
n
i
in −
−+
= ∑∑
==
1lnln;,...,,ln11
21
Y ahora podemos maximizar la función derivando e igualando a cero
( )
01
;,...,,ln 1121 =−
−−=
∂
∂ ∑∑==
p
xn
p
x
p
pxxxL
n
i
i
n
i
i
n
de donde despejando p
xn
x
p
n
i
i
==∑=1 la proporción de defectuosos en la muestra
Por lo tanto se toma como estimador a ∑=
==n
i
iXn
Xp1
1ˆ
2- El tiempo de fallar T de una componente tiene una distribución exponencial con parámetro λ :
T∼ ( )λExp , es decir la fdp es
( )
∞<≤=
−
valoresdemás
te
tf
t
0
0
;
λλλ
Recordemos que la esperanza y varianza son:

Parte 2 – Estimación puntual Prof. María B. Pintarelli
139
( ) λ1=TE y ( ) 2
1λ
=TV , respectivamente.
Se desea calcular el estimador de máxima verosimilitud del parámetro λ para una muestra de
tamaño n.
Solución:
La función de probabilidad es:
( ) ( ) ( ) ( ) [ ] [ ] [ ]nttt
nn eeetftftftttLλλλ λλλλλλλ −−− ×××== ...;...;;;,...,, 21
2121 ,
que puede escribirse:
( ) ( )∑
= =
−n
i
itn
n etttL 1;,...,, 21
λ
λλ
Nuevamente tomamos logaritmo natural
( ) ∑−==
n
iin tntttL
121 ln;,...,,ln λλσ
( )
01;,...,,ln
1
21 =∑−=∂
∂=
n
ii
n TntttL
λλλ
de donde podemos despejar λ :
t
t
nn
i
i
==
∑=1
λ , entonces el estimador de λ es
∑=
=n
i
iT
n
1
λ
El método de máxima verosimilitud presenta, algunas veces, dificultades para maximizar la función
de verosimilitud debido a que la ecuación obtenida a partir de 0)( =θθ
Ld
d no resulta fácil de
resolver. O también puede ocurrir que los métodos de cálculo para maximizar )(θL no son
aplicables.
Por ejemplo:
Sea ( )nXXX ,...,, 21 una muestra aleatoria de tamaño n de una v.a. X donde [ ]θ,0~UX , θ
desconocido. Hallar el estimador de θ por el método máxima verosimilitud.
Solución:
La f.d.p. de X es
<<=
contrariocaso
xsixf
0
01
)(θ
θ
Planteamos la función de verosimilitud

Parte 2 – Estimación puntual Prof. María B. Pintarelli
140
( )( )
<=
∀<<=
contrariocaso
xsi
contrariocaso
ixsixxxL
ii
nin
n0
max1
0
01
,,..., 21
θθ
θθθ
Si derivamos con respecto a θ obtenemos 1+
− −=n
n n
d
d
θθ
θ que es siempre menor que cero. Por lo
tanto la función de verosimilitud es una función decreciente para todos los ( )ii
xmax>θ
Si hacemos un gráfico de la función de verosimilitud
Vemos que donde la función tiene el máximo hay una discontinuidad no evitable.
Por lo tanto ( )ii
xmaxˆ =Θ
El método de máxima verosimilitud puede emplearse en el caso donde hay más de un parámetro
desconocido para estimar. En ese caso la función de verosimilitud es una función de varias variables.
Específicamente si tenemos para estimar k parámetros kθθθ ,..., 21 , entonces la función de
verosimilitud es una función de k variables ( )knxxxL θθθ ,...,,,...,, 2121 y los estimadores de máxima
verosimilitud kΘΘΘ ˆ,...ˆ,ˆ21 se obtienen al plantear ( si existen las derivadas parciales) y resolver el
sistema de k ecuaciones con k incógnitas kθθθ ,..., 21
( ) kixxxLd
dkn
i
,..2,10,...,,,...,, 2121 ==θθθθ
Ejemplo:
La variable aleatoria X tiene distribución ( )2σ,µN con µ y 2σ ambos parámetros desconocidos para
los cuales se desea encontrar los estimadores máxima verosimilitud. La fdp es
( )2
2
1
2
2
1
−−
= σ
µx
eσπ
σ,µ;xf ∞<<∞− x ,
La función de verosimilitud para una muestra aleatoria de tamaño n es
θ ( )ii
xmax
)(θL

Parte 2 – Estimación puntual Prof. María B. Pintarelli
141
( )
( )2
1
22
2
2
1
2
1
22
2
1
2
1
2
1
2
21
2
2
1...
2
1
2
1,;,...,,
−−
−
−−
−−
−−
∑=
==
= σµ
σµ
σµ
σµ
πσ
σπσπσπσµ
in
i
n
xn
xxx
n
e
eeexxxL
Luego
( ) ( )2
1
22
212
12ln
2,;,...,,ln ∑
=
−−−=
n
i
in
xnxxxL
σµ
πσσµ
y el sistema de ecuaciones de verosimilitud queda:
( )
( ) ( )
=−
+−=∂
∂
=
−=
∂∂
∑
∑
=
=
02
1
2
,;,...,,ln
0,;,...,,ln
14
2
22
2
21
1
2
21
n
i
in
n
i
in
xnxxxL
xxxxL
σµ
σσσµ
σµ
µσµ
Resolvemos con respecto a µ y 2σ :
( ) ( )
−=−=
==
∑ ∑
∑
= =
=n
i
n
i
ii
n
i
i
xxn
xn
xxn
1 1
222
1
11
1
µσ
µ
Entonces los estimadores máxima verosimilitud de µ y 2σ son
( )
−=
==
∑
∑
=
=n
i
i
n
i
i
XXn
XXn
1
22
1
1ˆ
1ˆ
σ
µ
Propiedades de los estimadores máxima verosimilitud
1- Los EMV pueden ser sesgados, pero en general si Θ es el EMV de un parámetro θ basado en
una muestra de tamaño n, entonces θ=Θ∞→
)ˆ(limEn
, es decir son asintóticamente insesgados
2- Bajo condiciones bastantes generales se puede probar que los EMV son asintóticamente
consistentes
3- Bajo condiciones bastantes generales se puede probar que los EMV asintóticamente tienen
varianza mínima
4-Los EMV cumplen la propiedad de invarianza es decir:
si Θ es un EMV de un parámetro θ , el EMV de ( )θg es ( )Θg , si )(xg es una función inyectiva.
Ejemplos:
1- Si consideramos nuevamente la situación considerada en el Ejemplo 2, donde teníamos una v.a. T
cuya distribución es una exponencial: T∼ ( )λExp , entonces, si queremos el EMV de la varianza

Parte 2 – Estimación puntual Prof. María B. Pintarelli
142
poblacional, podemos calcularlo recordando que ( ) 21λ
=TV , es decir, ( ) ( ) 21λ
λ == gTV . Vimos
que T
T
nn
i
i
1ˆ
1
==
∑=
λ . Por lo tanto el EMV de la varianza es 2
2
ˆ
1ˆ
λσ = .
2- Sea nXXX ,........,, 21 una muestra aleatoria de una v.a. ),1( pB . Un EMV de p es ∑=
==n
i
iXn
Xp1
1ˆ
Se selecciona una muestra aleatoria de n cascos para ciclistas fabricados por cierta compañía.
Sea X : “ el número entre los n que tienen defectos” , y p = P(el casco tiene defecto).
Supongamos que solo se observa X ( el número de cascos con defectos).
Si n = 20 y x = 3, es la estimación de p es 20
3ˆ =p
El E.M.V. de la probabilidad (1-p)5, de que ninguno de los siguientes cinco cascos que se examinen
tenga defectos será ( )5ˆ1 p− y su estimación en este caso
5
20
31
−
8- Intervalos de confianza
8.1 – Introducción
Se ha visto como construir a partir de una muestra aleatoria un estimador puntual de un parámetro
desconocido. En esos casos necesitábamos dar algunas características del estimador, como por
ejemplo si era insesgado o su varianza.
A veces resulta más conveniente dar un intervalo de valores posibles del parámetro desconocido, de
manera tal que dicho intervalo contenga al verdadero parámetro con determinada probabilidad.
Específicamente, a partir de una muestra aleatoria se construye un intervalo ( )21ˆ,ˆ ΘΘ donde los
extremos 1Θ y 2Θ son dos estadísticos, tal que ( )( ) αθ −=ΘΘ∈ 1ˆ,ˆ21P donde θ es el parámetro
desconocido a estimar y α es un valor real entre cero y uno dado de antemano. Por ejemplo si
05.0=α , se quiere construir un intervalo ( )21ˆ,ˆ ΘΘ tal que ( )( ) 95.0ˆ,ˆ
21 =ΘΘ∈θP , o escrito de otra
forma ( ) 95.0ˆˆ21 =Θ≤≤Θ θP
Esta probabilidad tiene el siguiente significado: como 1Θ y 2Θ son estadísticos, los valores que
ellos toman varían con los valores de la muestra, es decir si nxxx ,...,, 21 son los valores medidos de
la muestra entonces el estadístico 1Θ tomará el valor 1θ y el estadístico 2Θ tomará el valor 2θ . Si
medimos nuevamente la muestra obtendremos ahora valores ,,
2
´,
1 ,...,, nxxx y por lo tanto 1Θ tomará
el valor ,
1θ y el estadístico 2Θ tomará el valor ,
2θ , diferentes en general de los anteriores. Esto
significa que si medimos la muestra 100 veces obtendremos 100 valores diferentes para 1Θ y 2Θ y
por lo tanto obtendremos 100 intervalos distintos, de los cuales aproximadamente 5 de ellos no
contendrán al verdadero parámetro.
Al valor α−1 se lo llama nivel de confianza del intervalo. También se suele definir como nivel de
confianza al ( ) %1001 α−
Parte 2 – Estimación puntual Prof. María B. Pintarelli
143
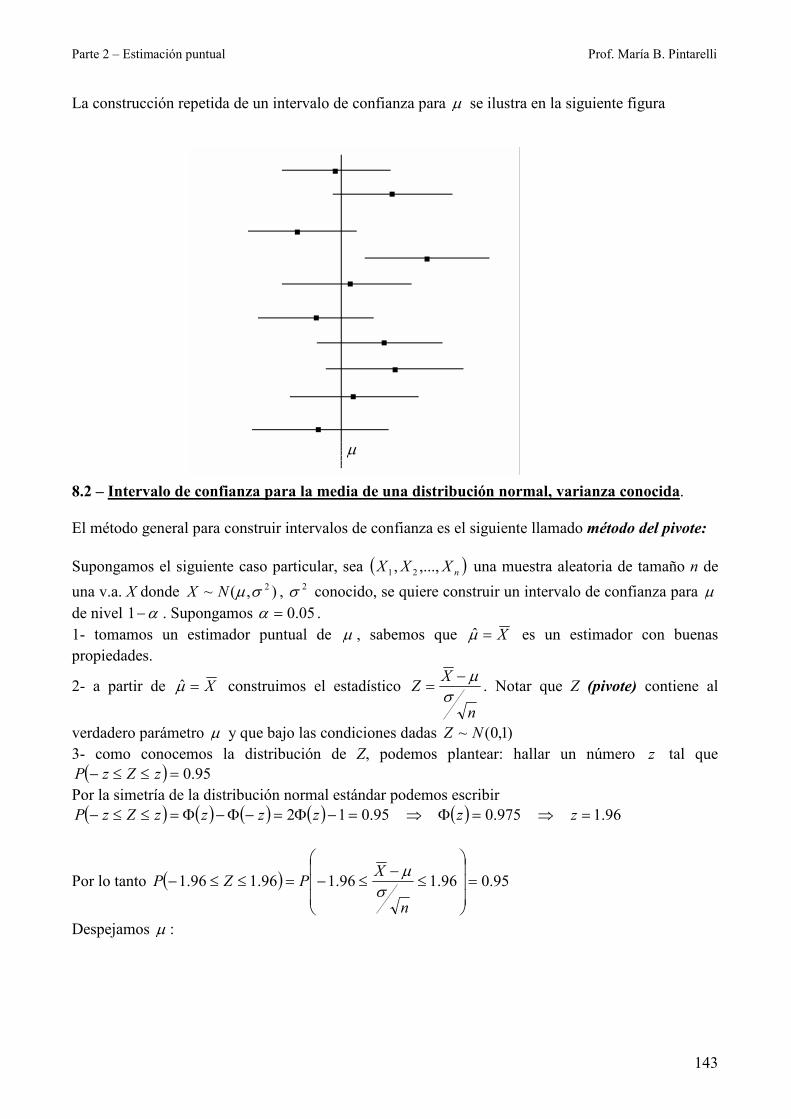
La construcción repetida de un intervalo de confianza para µ se ilustra en la siguiente figura
8.2 – Intervalo de confianza para la media de una distribución normal, varianza conocida.
El método general para construir intervalos de confianza es el siguiente llamado método del pivote:
Supongamos el siguiente caso particular, sea ( )nXXX ,...,, 21 una muestra aleatoria de tamaño n de
una v.a. X donde ),(~ 2σµNX , 2σ conocido, se quiere construir un intervalo de confianza para µ
de nivel α−1 . Supongamos 05.0=α .
1- tomamos un estimador puntual de µ , sabemos que X=µ es un estimador con buenas
propiedades.
2- a partir de X=µ construimos el estadístico
n
XZ
σµ−
= . Notar que Z (pivote) contiene al
verdadero parámetro µ y que bajo las condiciones dadas )1,0(~ NZ
3- como conocemos la distribución de Z, podemos plantear: hallar un número z tal que
( ) 95.0=≤≤− zZzP
Por la simetría de la distribución normal estándar podemos escribir
( ) ( ) ( ) ( ) 95.012 =−Φ=−Φ−Φ=≤≤− zzzzZzP ⇒ ( ) 975.0=Φ z ⇒ 96.1=z
Por lo tanto ( ) 95.096.196.196.196.1 =
≤−
≤−=≤≤−
n
XPZP
σµ
Despejamos µ :
µ

Parte 2 – Estimación puntual Prof. María B. Pintarelli
144
95.096.196.196.196.1
96.196.196.196.1
=
+≤≤−=
−≤−≤−−=
=
≤−≤−=
≤
−≤−
nX
nXPX
nX
nP
nX
nP
n
XP
σµ
σσµ
σ
σµ
σσ
µ
Entonces
95.096.1;96.196.196.1 =
+−∈=
+≤≤−
nX
nXP
nX
nXP
σσµ
σµ
σ
Es decir el intervalo de confianza para µ es
+−
nX
nX
σσ96.1;96.1 y tiene nivel de confianza
0.95 o 95%.
Aquí n
Xσ
96.1ˆ1 −=Θ y
nX
σ96.1ˆ
2 +=Θ
Repetimos el procedimiento anterior y construimos un intervalo de confianza para µ con nivel de
confianza α−1
1-Partimos de la esperanza muestral ∑=
=n
iXn
X11
1 para una muestra aleatoria ( )nX,...,X,X 21 de
tamaño n. Sabemos que es un estimador insesgado y consistente de µ .
2-Construimos el estadístico
N~n/σ
µXZ
−= (0,1)
La variable aleatoria Z cumple las condiciones necesarias de un pivote
Para construir un intervalo de confianza al nivel de confianza 1-α partiendo del pivote Z,
comenzamos por plantear la ecuación
( ) =≤≤− zZzP 1-α ,
donde la incógnita es el número real z.
Si reemplazamos la v.a. Z por su expresión tenemos:
=
+−≤−≤−−=
≤−≤−=
≤
−≤−
n
σzXµ
n
σzXP
n
σzµX
n
σzPz
n/σ
µXzP 1-α
Multiplicando todos los miembros de la desigualdad por -1 (el orden de los miembros se invierte)
llegamos a:
=
+≤≤−
n
σzXµ
n
σzXP 1-α
Evidentemente, si definimos

Parte 2 – Estimación puntual Prof. María B. Pintarelli
145
+=Θ
−=Θ
nzX
nzX
σ
σ
2
1
ˆ
ˆ
, hemos construido dos estadísticos 1Θ y 2Θ tales que ( )=Θ≤≤Θ 21ˆˆ µP 1-α ,
es decir hemos construido el intervalo de confianza bilateral deseado [ ]21ˆ,ˆ ΘΘ . Todos los elementos
que forman los estadísticos 1Θ y 2Θ son conocidos ya que el número z verifica la ecuación
anterior, es decir (ver figura):
( ) ( ) ( )zzzZzP −Φ−Φ=≤≤− =1-α donde ( )zΦ es la Fda para la v.a. N~Z (0,1)
Recordando que ( ) ( )zz Φ−=−Φ 1 , esta ecuación queda:
( ) ( )zz −Φ−Φ = ( ) 12 −Φ z =1-α , o bien (ver figura anterior),
( )2
1α
z −=Φ o de otra forma 2
)(α
=> zZP .
Al valor de z que verifica esta ecuación se lo suele indicar 2
αz . En consecuencia, el intervalo de
confianza bilateral al nivel de significación 1-α queda:
[ ]
+−=ΘΘ
nzX
nzX
σσαα22
21 ,ˆ,ˆ
En consecuencia:
Ejemplo:
Un ingeniero civil analiza la resistencia a la compresión del concreto. La resistencia está distribuida
aproximadamente de manera normal, con varianza 1000 (psi)2. Al tomar una muestra aleatoria de 12
especímenes, se tiene que 3250=x psi.
a) Construya un intervalo de confianza del 95% para la resistencia a la compresión promedio.
Si ( )nXXX ,...,, 21 una muestra aleatoria de tamaño n de una v.a. X donde ),(~ 2σµNX , 2σ
conocido, un intervalo de confianza para µ de nivel α−1 es
+−
nzX
nzX
σσαα22
, (8.1)
αz
2
αz 2
αz−
2
α
2
α
2
αzz =

Parte 2 – Estimación puntual Prof. María B. Pintarelli
146
b) Construya un intervalo de confianza del 99% para la resistencia a la compresión promedio.
Compare el ancho de este intervalo de confianza con el ancho encontrado en el inciso a).
Solución:
La v. a. de interés es Xi: “resistencia a la compresión del concreto en un espécimen i”
Tenemos una muestra de 12=n especímenes.
Asumimos que ),(~ 2σµNX i para 12,...,3,2,1=i con 10002 =σ
a) Queremos un intervalo de confianza para µ de nivel 95%. Por lo tanto 05.0=α
El intervalo a utilizar es
+−
nzX
nzX
σσαα22
, .
Buscamos en la tabla de la normal estándar el valor de 96.1025.0
2
== zzα
Reemplazando:
=
×+×− 89227.3267,10773.3232
12
100096.13250,
12
100096.13250
b) repetimos lo anterior pero ahora 01.0=α
El intervalo a utilizar es
+−
nzX
nzX
σσαα22
, .
Buscamos en la tabla de la normal estándar el valor de 58.2005.0
2
== zzα
Reemplazando:
=
×+×− 55207.3273,44793.3226
12
100058.23250,
12
100058.23250
La longitud del intervalo encontrado en a) es: 35.78454
La longitud del intervalo encontrado en b) es: 47.10414
Notar que la seguridad de que el verdadero parámetro se encuentre en el intervalo hallado es mayor
en el intervalo b) que en el a), pero la longitud del intervalo b) es mayor que la del intervalo a).
Al aumentar el nivel de confianza se perdió precisión en la estimación, ya que a menor longitud hay
mayor precisión en la estimación.
En general la longitud del intervalo es n
zLσ
α2
2=
Notar que:
a) si n y σ están fijos, a medida que α disminuye tenemos que 2
αz aumenta, por lo tanto L
aumenta.
b) si α y σ están fijos, entonces a medida que n aumenta tenemos que L disminuye.
Podemos plantearnos la siguiente pregunta relacionada con el ejemplo anterior: ¿qué tamaño n de
muestra se necesita para que el intervalo tenga nivel de confianza 99% y longitud la mitad de la
longitud del intervalo hallado en a)?
Solución: el intervalo hallado en a) tiene longitud 35.78454, y queremos que el nuevo intervalo
tenga longitud 17.89227 aproximadamente. Planteamos:

Parte 2 – Estimación puntual Prof. María B. Pintarelli
147
89227.171000
58.2289227.1722
≤××⇒≤=nn
zLσ
α
Despejando n :
170.8389227.17
100058.22
2
≥⇒≤
×× nn
O sea, hay que tomar por lo menos 84 especímenes para que el intervalo tenga la longitud pedida.
Si estimamos puntualmente al parámetro µ con X estamos cometiendo un error en la estimación
menor o igual a n
zL σ
α2
2= , que se conoce como precisión del estimador
Ejemplo: Se estima que el tiempo de reacción a un estímulo de cierto dispositivo electrónico está
distribuido normalmente con desviación estándar de 0.05 segundos. ¿Cuál es el número de
mediciones temporales que deberá hacerse para que la confianza de que el error de la estimación de
la esperanza no exceda de 0.01 sea del 95%?
Nos piden calcular n tal que 01.02
2
<=n
zL σ
α con 05.0=α .
Por lo tanto
2
025.001.0
05.0
≥ zn .
Además 025,0z =1.96. Entonces ( ) 04965961010
050 2
2
9750 ...
.zn . =×=
≥ .
O sea hay que tomar por lo menos 97 mediciones temporales.
Ejemplo:
Supongamos que X representa la duración de una pieza de equipo y que se probaron 100 de esas
piezas dando una duración promedio de 501.2 horas. Se sabe que la desviación estándar poblacional
En general, si queremos hallar n tal que ln
zL ≤=σ
α2
2 , donde l es un valor dado, entonces
despejando n
2
2
2
≥l
z
n
σα
Para muestras tomadas de una población normal, o para muestras de tamaño 30≥n , de una
población cualquiera, el intervalo de confianza dado anteriormente en (8.1), proporciona buenos
resultados.
En el caso de que la población de la que se extrae la muestra no sea normal pero 30≥n , el nivel
de confianza del intervalo (8.1) es aproximadamente α−1 .
Pero para muestras pequeñas tomadas de poblaciones que no son normales no se puede garantizar
que el nivel de confianza sea α−1 si se utiliza (8.1).

Parte 2 – Estimación puntual Prof. María B. Pintarelli
148
es σ =4 horas. Se desea tener un intervalo del 95% de confianza para la esperanza poblacional
( ) µXE = .
Solución:
En este caso, si bien no conocemos cuál es la distribución de X tenemos que el tamaño de la muestra
es 30100 >=n (muestra grande) por lo tanto el intervalo buscado es
+−
nzX
nzX
σσαα22
,
Puesto que 1-α=0.95 025.02
05.095.01 =→=−=→α
α
De la tabla de la normal estandarizada obtenemos 025,0z =1.96. Entonces reemplazando:
+−
100
496.1,
100
496.1 XX
Para el valor particular x =501.2 tenemos el intervalo
=
+−=
+− 0.502,4.500
10
496.12.501,
10
496.12.501
496.1,
100
496.1
nxx .
Al establecer que
05024500 .,. es un intervalo al 95% de confianza de µ estamos diciendo que la
probabilidad de que el intervalo
05024500 .,. contenga a µ es 0.95. O, en otras palabras, la
probabilidad de que la muestra aleatoria ( )nX,...,X,X 21 tome valores tales que el intervalo aleatorio
+−
100
496.1,
100
496.1 XX defina un intervalo numérico que contenga al parámetro fijo
desconocido µ es 0.95.
8.2 - Intervalo de confianza para la media de una distribución normal, varianza desconocida
Nuevamente como se trata de encontrar un intervalo de confianza para µ nos basamos en la
esperanza muestral ∑=
=n
iXn
X11
1 que sabemos es un buen estimador de µ . Pero ahora no podemos
usar como pivote a
n/σ
µXZ
−=
porque desconocemos σ y una condición para ser pivote es que, excepto por el parámetro a estimar (
en este caso µ ), todos los parámetros que aparecen en él deben ser conocidos. Entonces proponemos
como pivote una variable aleatoria definida en forma parecida a Z pero reemplazando σ por un
estimador adecuado.
Ya vimos que la varianza muestral definida

Parte 2 – Estimación puntual Prof. María B. Pintarelli
149
( )2
11
2
1
1∑=
−−
=n
i XXn
S ,
donde X es la esperanza muestral, es un estimador insesgado de la varianza poblacional ( )XV , es
decir, ( ) ( ) 22 σXVSE == n∀ . Entonces estimamos σ con S y proponemos como pivote a la
variable aleatoria
n/S
µXT
−= .
Pero para poder usar a T como pivote debemos conocer su distribución.
Se puede probar que la distribución de T es una distribución llamada Student con parámetro n-1.
Nota: Una v.a. continua tiene distribución Student con k grados de libertad, si su f.d.p. es de la
forma
( )
∞<<∞−
+
Γ
+Γ
=+
x
k
xk
k
k
xfk
1
1
2
2
1
)(
2
1
2π
Notación: ktT ~
La gráfica de la f.d.p. de la distribución Student tiene forma de campana como la normal, pero tiende
a cero más lentamente. Se puede probar que cuando ∞→k la fdp de la Student tiende a la fdp de la
)1 ,0(N .
En la figura siguiente se grafica f(x) para diferentes valores de k
1=k
6=k
- - - - - ∞=k
Anotaremos kt ,α al cuantil de la Student con k grados de libertad que deja bajo la fdp a derecha un
área de α , y a su izquierda un área de α−1 .
-3 -2 -1 1 2 3
0.1
0.2
0.3
0.4

Parte 2 – Estimación puntual Prof. María B. Pintarelli
150
Luego, para construir el intervalo de confianza buscado a partir del pivote T procedemos como en
los casos anteriores:
Comenzamos por plantear la ecuación
( ) =≤≤− tTtP 1-α ,
donde la incógnita es el número real t.
Si reemplazamos la v.a. T por su expresión, tenemos sucesivamente (multiplicando por n/S y
restando X ):
=
+−≤−≤−−=
≤−≤−=
≤
−≤−
n
StXµ
n
StXP
n
StµX
n
StPt
n/S
µXtP 1-α
Multiplicando todos los miembros de la desigualdad por -1 (el orden de los miembros se invierte)
llegamos a:
=
+≤≤−
n
StXµ
n
StXP 1-α
Evidentemente, si definimos
+=Θ
−=Θ
n
StX
n
StX
2
1
ˆ
ˆ
, hemos construido dos estadísticos 1Θ y 2Θ tales que ( )=Θ≤≤Θ 21ˆˆ µP 1-α ,
veamos quien es el número t que verifica la ecuación, es decir (ver figura):
( ) ( ) ( )tFtFtTtP −−=≤≤− =1-α donde ( )tF es la Fda para la v.a. T ∼ 1−nt .
Por la simetría de la distribución t de Student se deduce fácilmente de la figura anterior que
( ) ( )tFtF −=− 1 , entonces:
( ) ( )tFtF −− = ( ) 12 −tF =1-α , o bien (ver figura anterior),
( )2
1α
tF −= .
2
αt− 2
αt
libertad de grados 4=k
2
α
2
α

Parte 2 – Estimación puntual Prof. María B. Pintarelli
151
Al valor de t que verifica esta ecuación se lo suele indicar 1,
2−n
tα . En consecuencia, el intervalo de
confianza bilateral al nivel de significación 1-α queda:
+−
−− n
StX
n
StX
nn 1,2
1,2
, αα con 2
11,
2
αα −=
−n
tF .
En consecuencia:
Ejemplo:
Se hicieron 10 mediciones sobre la resistencia de cierto tipo de alambre que dieron valores
1021 x,...,x,x tales que ∑=
==10
1
481010
1
i
i .xx ohms y ( )∑=
−=10
2
9
1
!i
i xxS = 1.36 ohms. Supóngase que
X~N(µ,σ2).
Se desea obtener un intervalo de confianza para la esperanza poblacional µ al 90 %.
Tenemos que →=− 9001 .α →= 10.α 05.02/ =α
De la Tabla de la t de Student tenemos que 8331.19,05.0 =t . Entonces el intervalo de confianza
buscado es:
+−=
+−
−− 10
36.18331.148.10,
10
36.18331.148.10,
1,2
1,2 n
StX
n
StX
nnαα
Esto es: [ ]27.11 ,69.9 .
8.3 – Intervalo de confianza para la diferencia de dos medias, varianzas conocidas
Supongamos que tenemos dos variables aleatorias independientes normalmente distribuidas:
Si ( )nXXX ,...,, 21 una muestra aleatoria de tamaño n de una v.a. X donde ),(~ 2σµNX , 2σ desconocido, un intervalo de confianza para µ de nivel α−1 es
+−
n
StX
n
StX
22
, αα (8.2)
Si la muestra aleatoria se toma de una distribución normal, σ2 es desconocido y el tamaño de la
muestra grande, entonces se puede probar que al reemplazar σ por S, el estadístico
( )10,Nn/S
µXZ ∼
−= aproximadamente
y puedo construir el intervalo para µ como antes:
+−
n
SzX
n
SzX
22
, αα , pero su nivel es aproximadamente α−1

Parte 2 – Estimación puntual Prof. María B. Pintarelli
152
( )( )
2
222
2
111
σ,µN~X
σ,µN~X y suponemos que las varianzas 2
1σ y 2
2σ son conocidas.
Sean además
( )111211 nX,...,X,X una muestra aleatoria de tamaño 1n de 1X
( )222221 nX,...,X,X una muestra aleatoria de tamaño 2n de 2X .
Deseamos construir un intervalo al nivel de confianza α−1 para la diferencia de esperanzas 21 µµ − .
Ya sabemos cuál es la distribución del promedio de variables aleatorias normales independientes:
=
=
∑
∑
=
=
2
1
1 2
2
222
2
2
1 1
2
111
1
1
1
1
n
i
i
n
i
i
n
σ,µN~X
nX
n
σ,µN~X
nX
Consideremos ahora la diferencia 21 XXY −= . Si 1X y 2X tienen distribución normal y son
independientes, su diferencia también es normal, con esperanza igual a la diferencia de las
esperanzas y la varianza es la suma de las varianzas:
+−−
2
2
2
1
2
12121 ,N~
nnXX
σσµµ .
Por lo tanto
( ) ( )1,0N~
2
2
2
1
2
1
2121
nn
XXZ
σσ
µµ
+
−−−= , es decir, tiene distribución normal estandarizada.
La v.a. Z cumple con toda las condiciones para servir de pivote y construiremos nuestro intervalo en
forma análoga a cómo hicimos en los casos anteriores:
Comenzamos por plantear la ecuación
( ) =≤≤− zZzP 1-α ,
donde la incógnita es el número real z.
Reemplazamos la v.a. Z por su expresión y tenemos sucesivamente (multiplicando por n/σ y
restando X ):
( ) ( )
( ) ( ) ( ) ασσ
µµσσ
σσµµ
σσ
σσ
µµ
−=
++−−≤−−≤+−−−=
=
+≤−−−≤+−=
≤
+
−−−≤−
12
2
2
1
2
12121
2
2
2
1
2
121
2
2
2
1
2
12121
2
2
2
1
2
1
2
2
2
1
2
1
2121
nnzXX
nnzXXP
nnzXX
nnzPz
nn
XXzP

Parte 2 – Estimación puntual Prof. María B. Pintarelli
153
Multiplicando todos los miembros de la desigualdad por -1 (el orden de los miembros se invierte)
llegamos a:
( ) ασσ
µµσσ
−=
++−≤−≤+−− 1
2
2
2
1
2
12121
2
2
2
1
2
121
nnzXX
nnzXXP
Evidentemente, si definimos
+−−=Θ
+−−=Θ
,ˆ
ˆ
2
2
2
1
2
1212
2
2
2
1
2
1211
nnzXX
nnzXX
σσ
σσ
habremos construido dos estadísticos 1Θ y 2Θ tales que ( )( )=Θ≤−≤Θ 2211ˆˆ µµP 1-α , es decir
habremos construido el intervalo de confianza bilateral deseado [ ]21 A,A . Todos los elementos que
forman los estadísticos 1Θ y 2Θ son conocidos ya que el número z verifica la ecuación anterior, es
decir:
( ) ( ) ( )zzzZzP −Φ−Φ=≤≤− =1-α donde ( )zΦ es la Fda para la v.a. N~Z (0,1)
o bien, según vimos:
( )2
1α
z −=Φ que anotamos 2
αz
En consecuencia, el intervalo de confianza bilateral al nivel de significación 1-α queda:
++−+−−
2
2
2
1
2
1
2
21
2
2
2
1
2
1
2
21 ,nn
zXXnn
zXXσσσσ
αα
Por lo tanto
Ejemplo:
Se utilizan dos máquinas para llenar botellas de plástico con detergente para máquinas lavaplatos. Se
sabe que las desviaciones estándar de volumen de llenado son 10.01 =σ onzas de líquido y
15.02 =σ onzas de líquido para las dos máquinas respectivamente. Se toman dos muestras
aleatorias, 121 =n botellas de la máquina 1 y 102 =n botellas de la máquina 2. Los volúmenes
promedio de llenado son 87.301 =x onzas de líquido y 68.302 =x onzas de líquido.
Si 1X y 2X son dos variables aleatorias independientes normalmente distribuidas:
( )2
111 ,N~ σµX , ( )2
222 ,N~ σµX y suponemos que las varianzas 2
1σ y 2
2σ son conocidas. Un
intervalo de confianza para la diferencia 21 µµ − de nivel α−1 es
++−+−−
2
2
2
1
2
1
2
21
2
2
2
1
2
1
2
21 ,nn
zXXnn
zXXσσσσ
αα
r (8.3)

Parte 2 – Estimación puntual Prof. María B. Pintarelli
154
Asumiendo que ambas muestras provienen de distribuciones normales
Construya un intervalo de confianza de nivel 90% para la diferencia entre las medias del volumen de
llenado.
Solución:
Como 90.01 =−α entonces 10.0=α
Por lo tanto 65.105.0
2
== zzα
El intervalo será ( ) ( )
++−+−−
10
15.0
12
10.065.168.3087.30;
10
15.0
12
10.065.168.3087.30
2222
O sea
281620.0;09837.0
Si se conocen las desviaciones estándar y los tamaños de las muestras son iguales (es decir
nnn == 21 ), entonces puede determinarse el tamaño requerido de la muestra de manera tal que la
longitud del intervalo sea menor que l
( )2
2
2
1
2
2
2
2
2
1
2
2
2 σσσσ α
α +
≥⇒≤+=l
z
nlnn
zL
Ejemplo:
Para muestras tomadas de dos poblaciones normales, o para muestras de tamaño 301 ≥n y
302 ≥n , de dos poblaciones cualesquiera, el intervalo de confianza dado anteriormente en (8.3),
proporciona buenos resultados.
En el caso de que la población de la que se extrae la muestra no sea normal pero 301 ≥n y
302 ≥n , el nivel de confianza del intervalo (8.3) es aproximadamente α−1 .
Si las muestras aleatorias se toma de una distribución normal, donde 1σ y 2σ son desconocidos,
301 ≥n y 302 ≥n , entonces se puede probar que al reemplazar 1σ por S1 y 2σ por S2, el
estadístico
)1,0()(
1
2
1
1
2
1
2121 N
n
S
n
S
XX≈
+
−−− µµ. aproximadamente
y puedo construir el intervalo para 21 µµ − como antes:
++−+−−
1
2
1
1
2
1
2
21
1
2
1
1
2
1
2
21 ,n
S
n
SzXX
n
S
n
SzXX αα , (8.4)
pero su nivel es aproximadamente α−1

Parte 2 – Estimación puntual Prof. María B. Pintarelli
155
De una muestra de 150 lámparas del fabricante A se obtuvo una vida media de 1400 hs y una
desviación típica de 120 hs. Mientras que de una muestra de 100 lámparas del fabricante B se obtuvo
una vida media de 1200 hs. y una desviación típica de 80 hs.
Halla los límites de confianza del 95% para la diferencia las vidas medias de las poblaciones A y B.
Solución:
Sean las variables aleatorias:
:1X “duración en horas de una lámpara del fabricante A”
:2X “duración en horas de una lámpara del fabricante B”
No se dice cuál es la distribución de estas variables, pero como 1501 =n y 1002 =n
podemos usar el intervalo dado en (8.4)
Tenemos que 14001 =x , 12002 =x , 1201 =s y 802 =s .
Además 95.01 =−α 1.96z z 0.025
2
==→ α
Entonces el intervalo es
=
+−−+−− 7922.224;2077.175100
80
150
12096.112001400;
100
80
150
12096.112001400
2222
Observación: como este intervalo no contiene al cero, podemos inferir que hay diferencia entre las
medias con probabilidad 0.95, es más, podemos inferir que la media del tiempo de duración de las
lámparas del fabricante A es mayor que la media del tiempo de duración de las lámparas del
fabricante B con probabilidad 0.95 .
8.4 – Intervalo de confianza para la diferencia de dos medias, varianzas desconocidas
Nuevamente supongamos que tenemos dos variables aleatorias independientes normalmente
distribuidas:
( )( )
2
222
2
111
σ,µN~X
σ,µN~X y suponemos que las varianzas 2
1σ y 2
2σ son desconocidas .
Sean además
( )111211 nX,...,X,X una muestra aleatoria de tamaño 1n de 1X
( )222221 nX,...,X,X una muestra aleatoria de tamaño 2n de 2X .
Pero ahora 1n o 2n no son mayores que 30
Supongamos que es razonable suponer que las varianzas desconocidas son iguales, es decir
σσσ == 21
Deseamos construir un intervalo al nivel de confianza α−1 para la diferencia de esperanzas 21 µµ −
Sean 1X y 2X las medias muestrales y 2
1S y 2
2S las varianzas muestrales. Como 2
1S y 2
2S son los
estimadores de la varianza común 2σ , entonces construimos un estimador combinado de 2σ . Este
estimador es
( ) ( )
2
11
21
2
22
2
112
−+
−+−=
nn
SnSnS p

Parte 2 – Estimación puntual Prof. María B. Pintarelli
156
Se puede comprobar que es un estimador insesgado de 2σ .
Se puede probar que el estadístico
( )
21
2121
11
nnS
XXT
p +
−−−=
µµr
tiene distribución Student con 221 −+ nn grados de libertad
Por lo tanto se plantea la ecuación
ααα −=
≤≤−
−+−+1
2,2
2,2
2121 nnnntTtP
o
( )
αµµ
αα −=
≤
+
−−−≤−
−+−+1
11 2,2
21
2121
2,2
2121 nn
p
nnt
nnS
XXtP
r
Despejamos 21 µµ − y queda la expresión
αµµ αα −=
+≤−≤+−−
−+−+1
1111
212,
2
21
212,
2
212121 nn
Stnn
StXXP pnn
pnn
Entonces
Ejemplo:
Se piensa que la concentración del ingrediente activo de un detergente líquido para ropa, es afectada
por el tipo de catalizador utilizado en el proceso de fabricación. Se sabe que la desviación estándar
de la concentración activa es de 3 g/l, sin importar el tipo de catalizador utilizado. Se realizan 10
observaciones con cada catalizador, y se obtienen los datos siguientes:
Catalizador 1: 57.9, 66.2, 65.4, 65.4, 65.2, 62.6, 67.6, 63.7, 67.2, 71.0
Catalizador 2: 66.4, 71.7, 70.3, 69.3, 64.8, 69.6, 68.6, 69.4, 65.3, 68.8
a) Encuentre un intervalo de confianza del 95% para la diferencia entre las medias de las
concentraciones activas para los dos catalizadores. Asumir que ambas muestras fueron extraídas de
poblaciones normales con varianzas iguales.
b) ¿Existe alguna evidencia que indique que las concentraciones activas medias dependen del
catalizador utilizado?
Si 1X y 2X son dos variables aleatorias independientes normalmente distribuidas:
( )2
111 ,N~ σµX , ( )2
222 ,N~ σµX y suponemos que las varianzas 2
1σ y 2
2σ son desconocidas e
iguales, es decir σσσ == 21
Un intervalo de confianza para la diferencia 21 µµ − de nivel α−1 es
21
2,2
21
212,
2
21
11;
11
2121 nnStXX
nnStXX p
nnp
nn+−−+−−
−+−+αα (8.5)

Parte 2 – Estimación puntual Prof. María B. Pintarelli
157
Solución:
Sean las variables aleatorias
:1X “ concentración del ingrediente activo con catalizador 1”
:2X “ concentración del ingrediente activo con catalizador 2”
Asumimos que ambas variables tienen distribución normal con varianzas iguales
Estamos e3n las condiciones para usar (8.5)
Tenemos que 22.651 =x , 42.682 =x , 444.31 =s , 224.22 =s , 1021 == nn
Calculamos ( ) ( )
4036.821010
224.29444.39
2
11 22
21
2
22
2
112 =−+×+×
=−+
−+−=
nn
SnSnS p
Por lo tanto 89890.24036.8 ==pS
Buscamos en la tabla de la Student 060.218,025.02,
221
==−+
ttnn
α
Entonces el intervalo es
[ ]52935.0;8706.5
10
1
10
189890.2060.242.6822.65;
10
1
10
189890.2060.242.6822.65
−−=
=
+×−−+×−−
b) Existe alguna evidencia que indique que las concentraciones activas medias dependen del
catalizador utilizado, pues el 0 no pertenece al intervalo.
En muchas ocasiones no es razonable suponer que las varianzas son iguales. Si no podemos
garantizar que las varianzas son iguales, para construir un intervalo de confianza de nivel α−1 para
21 µµ − utilizamos es estadístico
1
2
1
1
2
1
2121* )(
n
S
n
S
XXT
+
−−−=
µµ
Se puede probar que *T tiene aproximadamente una distribución Student con ν grados de libertad
donde
( )
( ) ( )11 2
2
2
2
2
1
2
1
1
1
2
2
2
21
2
1
−+
−
+=
n
nS
n
nS
nSnSν si ν no es entero, se toma el entero más próximo a ν
Por lo tanto planteamos la ecuación
αν
αν
α −=
≤≤− 1
,2
*
,2
tTtP
Y despejando 21 µµ − el intervalo es
++−+−−
2
2
2
1
2
1
,2
21
2
2
2
1
2
1
,2
21 ,n
S
n
StXX
n
S
n
StXX
να
να

Parte 2 – Estimación puntual Prof. María B. Pintarelli
158
Entonces
Ejemplo:
Una muestra de 6 soldaduras de un tipo tenía promedio de prueba final de resistencia de 83.2 ksi y
desviación estándar de 5.2. Y una muestra de 10 soldaduras de otro tipo tenía resistencia promedio
de 71.3 ksi y desviación estándar de 3.1. supongamos que ambos conjuntos de soldaduras son
muestras aleatorias de poblaciones normales. Se desea encontrar un intervalo de confianza de 95%
para la diferencia entre las medias de las resistencias de los dos tipos de soldaduras.
Solución:
Ambos tamaños muestrales son pequeños y las muestras provienen de poblaciones normales. No
podemos asumir igualdad de varianzas. Entonces aplicamos (8.6)
Tenemos que 2.831 =x , 3.712 =x , 2.51 =s , 1.32 =s , 10;6 21 == nn
Como 95.01 =−α entonces 025.02
=α
Además ( )
( ) ( ) ( ) ( )718.7
9
101.3
5
62.5
10
1.3
6
2.5
11
22
222
2
2
2
2
2
1
2
1
1
1
2
2
2
21
2
1 ≈=
+
+
=
−+
−
+=
n
nS
n
nS
nSnSν
Entonces buscamos en la tabla de la Student 365.27,025.0 =t
Por lo tanto el intervalo es
=
++−+−−=
=
++−+−−
43.17,37.610
1.3
6
2.5365.23.712.83;
10
1.3
6
2.5365.23.712.83
,
2222
2
2
2
1
2
1
,2
21
2
2
2
1
2
1
,2
21n
S
n
StXX
n
S
n
StXX
να
να
Si 1X y 2X son dos variables aleatorias independientes normalmente distribuidas:
( )2
111 ,N~ σµX , ( )2
222 ,N~ σµX y suponemos que las varianzas 2
1σ y 2
2σ son desconocidas y
distintas
Un intervalo de confianza para la diferencia 21 µµ − de nivel aproximadamente α−1 es
++−+−−
2
2
2
1
2
1
,2
21
2
2
2
1
2
1
,2
21 ,n
S
n
StXX
n
S
n
StXX
να
να (8.6)
Donde
( )
( ) ( )11 2
2
2
2
2
1
2
1
1
1
2
2
2
21
2
1
−+
−
+=
n
nS
n
nS
nSnSν

Parte 2 – Estimación puntual Prof. María B. Pintarelli
159
8.5 – Intervalo de confianza para 21 µµ − para datos pareados
Hasta ahora se obtuvieron intervalos de confianza para la diferencia de medias donde se tomaban
dos muestras aleatorias independientes de dos poblaciones de interés. En ese caso se tomaban 1n
observaciones de una población y 2n observaciones de la otra población.
En muchas situaciones experimentales, existen solo n unidades experimentales diferentes y los datos
están recopilados por pares, esto es cada unidad experimental está formada por dos observaciones.
Por ejemplo, supongamos que se mide el tiempo en segundos que un individuo tarda en hacer una
maniobra de estacionamiento con dos automóviles diferentes en cuanto al tamaño de la llanta y la
relación de vueltas del volante. Notar que cada individuo es la unidad experimental y de esa unidad
experimental se toman dos observaciones que no serán independientes. Se desea obtener un
intervalo de confianza para la diferencia entre el tiempo medio para estacionar los dos automóviles.
En general, supongamos que tenemos los siguientes datos ( ) ( ) ( )nn XXXXXX 2122122111 ,;...;,;,1
.
Las variables aleatorias 1X y 2X tienen medias 1µ y 2µ respectivamente.
Sea jjj XXD 21 −= con nj ,...,2,1= .
Entonces
( ) ( ) ( ) ( )212121 µµ −=−=−= jjjjj XEXEXXEDE
y
( ) ( ) ( ) ( ) ( ) ( )21
2
2
2
1212121 ,2,2 XXCovXXCovXVXVXXVDV jjjjjjj −+=−+=−= σσ
Estimamos ( )21 µµ −=jDE con ( )
21
1
21
1
11XXXX
nD
nD
n
j
jj
n
j
j −=−== ∑∑==
En lugar de tratar de estimar la covarianza, estimamos la ( )jDV con ( )∑
=
−−
=n
j
jD DDn
S1
2
1
1
Anotamos 21 µµµ −=D y ( )jD DV=2σ
Asumimos que ( )2,N~ DDjD σµ con nj ,...,2,1=
Las variables aleatorias en pares diferentes son independientes, no lo son dentro de un mismo par.
Para construir el intervalo de confianza notar que
1/
−∼−
= n
D
D tnS
DT
µ
entonces al plantear la ecuación ( ) =≤≤− tTtP 1-α , deducimos que 1,
2−
=n
tt α
Por lo tanto el intervalo de confianza para 21 µµµ −=D de nivel α−1 se obtendrá al sustituir T en
la ecuación anterior y despejar 21 µµµ −=D
El intervalo resultante es
+−
−− n
StD
n
StD D
n
D
n 1,2
1,2
; αα
Entonces

Parte 2 – Estimación puntual Prof. María B. Pintarelli
160
Ejemplo:
Consideramos el ejemplo planteado al comienzo. Deseamos un intervalo de nivel 0.90
Sean las variables aleatorias
jX 1 : “tiempo en segundos que tarda el individuo j en estacionar automóvil 1” con nj ,...,2,1=
jX 2 : “tiempo en segundos que tarda el individuo j en estacionar automóvil 2” con nj ,...,2,1=
Medimos estas variables de manera que tenemos las siguientes observaciones
Automóvil 1 Automóvil 2 diferencia
sujeto (observación jx1 ) (observación jx2 ) jD
1 37.0 17.8 19.2
2 25.8 20.2 5.6
3 16.2 16.8 -0.6
4 24.2 41.4 -17.2
5 22.0 21.4 0.6
6 33.4 38.4 -5.0
7 23.8 16.8 7.0
8 58.2 32.2 26.0
9 33.6 27.8 5.8
10 24.4 23.2 1.2
11 23.4 29.6 -6.2
12 21.2 20.6 0.6
13 36.2 32.2 4.0
14 29.8 53.8 -24.0
A partir de la columna de diferencias observadas se calcula 21.1=D y 68.12=DS
Además 771.113,05.01,
2
==−
ttn
α , entonces el intervalo para la diferencia 21 µµµ −=D de nivel 0.90
es
−=
×+×− 21.7;79.4
14
68.12771.121.1;
14
68.12771.121.1
8.6 – Intervalo de confianza para la varianza de una distribución normal
Supongamos que se quiere hallar un intervalo de confianza para la varianza 2σ de una distribución
normal.
Sea ( )nX,...,X,X 21 una muestra aleatoria de una v.a. X, donde ),(~ 2σµNX .
Cuando las observaciones se dan de a pares ( ) ( ) ( )nn XXXXXX 2122122111 ,;...;,;,1
, y las diferencias
jjj XXD 21 −= son tales que ( )2,N~ DDjD σµ para nj ,...,2,1= , un intervalo de confianza de
nivel α−1 para 21 µµµ −=D es
+−
−− n
StD
n
StD D
n
D
n 1,2
1,2
; αα (8.7)

Parte 2 – Estimación puntual Prof. María B. Pintarelli
161
Tomamos como estimador puntual de 2σ a ( )2
11
2
1
1∑=
−−
=n
i XXn
S
Luego a partir de este estimador puntual construimos el estadístico ( )
2
21
σSn
X−
=
Este estadístico contiene al parámetro desconocido a estimar 2σ y tiene una distribución conocida,
se puede probar que X tiene una distribución llamada ji-cuadrado con n-1 grados de libertad
Observación: Si X es una v.a. continua se dice que tiene distribución ji-cuadrado con k grados de
libertad si su f.d.p. es
( )
0
22
1)( 2
12
2
>
Γ=
−−xex
kxf
xk
k
Notación: X~2
kχ
La distribución ji-cuadrdo es asimétrica. En la figura siguiente se grafica la densidad para diferentes
valores de k
10 20 30 40 50 60
0.02
0.04
0.06
0.08
0.1
0.12
Anotaremos k,2αχ al cuantil de la ji-cuadrado con k grados de libertad que deja bajo la fdp a derecha
un área de α , y a su izquierda un área de α−1 .
Propiedades:
1- Se puede probar que si nXXX ,...,, 21 son variables aleatorias independientes con distribución
)1,0(N entonces 22
2
2
1 ... nXXXZ +++= tiene distribución ji-cuadrado con n grados de libertad.
2- Si nXXX ,...,, 21 son variables aleatorias independientes tal que iX tiene distribución ji-cuadrado
con ik grados de libertad, entonces nXXXZ +++= ...21 tiene distribución ji-cuadrado con k
grados de libertad donde nkkkk +++= ...21
3- Si 2~ kX χ entonces para k grande
− 1,12~2 kNX aproximadamente.
Para desarrollar el intervalo de confianza planteamos hallar dos números a y b tales que
( ) α−=≤≤ 1bXaP es decir ( )
ασ
−=
≤
−≤ 1
12
2
bSn
aP
30
15
2
=
=
=
k
k
k

Parte 2 – Estimación puntual Prof. María B. Pintarelli
162
Se puede probar que la mejor elección de a y b es: 2
1,2
1 −−=
na αχ y 2
1,2
−=
nb αχ
Por lo tanto
( )
αχσ
χ αα −=
≤
−≤
−−−1
1 2
1,2
2
22
1,2
1 nn
SnP
y despejando 2σ se llega a
( ) ( )
αχ
σχ αα
−=
−
≤≤−
−−−
111
2
1,2
1
22
2
1,2
2
nn
SnSnP
Entonces
Observación: un intervalo de confianza para σ de nivel α−1 , es ( ) ( )
−−
−−−
2
1,2
1
2
2
1,2
2 1 ;
1
nn
SnSn
αα χχ
Ejemplo:
Un fabricante de detergente líquido está interesado en la uniformidad de la máquina utilizada para
llenar las botellas. De manera específica, es deseable que la desviación estándar σ del proceso de
llenado sea menor que 0.15 onzas de líquido; de otro modo, existe un porcentaje mayor del deseable
de botellas con un contenido menor de detergente. Supongamos que la distribución del volumen de
llenado es aproximadamente normal. Al tomar una muestra aleatoria de 20 botellas, se obtiene una
Si ( )nX,...,X,X 21 es una muestra aleatoria de una v.a. X, donde ),(~ 2σµNX , un intervalo de
confianza para 2σ de nivel α−1 es
( ) ( )
−−
−−−
2
1,2
1
2
2
1,2
2 1 ;
1
nn
SnSn
αα χχ (8.8)
2
α
α−1
2
1,2
1 −− nαχ 2
1,2
−nαχ
2
α
5=k

Parte 2 – Estimación puntual Prof. María B. Pintarelli
163
varianza muestral 0153.02 =S . Hallar un intervalo de confianza de nivel 0.95 para la verdadera
varianza del volumen de llenado.
Solución:
La v.a. de interés es X: “ volumen de llenado de una botella”
Se asume que ),(~ 2σµNX con σ desconocido.
Estamos en las condiciones para aplicar (8.8)
Tenemos que 95.01 =−α 05.0 =→ α → 91.82
19,975.0
2
1,2
1==
−−χχ α
n y 85.322
19,025.0
2
1,2
==−
χχαn
Además 0153.02 =S
Por lo tanto el intervalo es
( ) ( ) ( ) ( ) ( ).03260 ;00884.0
91.8
0153.0120 ;
85.32
0153.01201 ;
12
1,2
1
2
2
1,2
2
=
×−×−=
−−
−−− nn
SnSn
αα χχ
Y un intervalo para σ es ( ) ( )1805.0 ;09.00326.0 ;00884.0 =
Por lo tanto con un nivel de 0.95 los datos no apoyan la afirmación que 15.0<σ
8.7 – Intervalo de confianza para el cociente de varianzas de dos distribuciones normales
Supongamos que se tienen dos poblaciones normales e independientes con varianzas desconocidas 2
1σ y 2
2σ respectivamente. Se desea encontrar un intervalo de nivel α−1 para el cociente de las dos
varianzas 2
2
2
1
σσ
.
Se toma una muestra aleatoria de tamaño 1n de una de las poblaciones y una muestra de tamaño 2n
de la otra población. Sean 2
1S y 2
2S las dos varianzas muestrales.
Consideramos el estadístico
21
21
22
22
σ
σ
S
S
F =
Notar que F contiene al parámetro de interés 2
2
2
1
σσ
, pues 22
21
21
22
σ
σ
×
×=
S
SF
Se puede probar que F tiene una distribución llamada Fisher con 12 −n y 11 −n grados de libertad.

Parte 2 – Estimación puntual Prof. María B. Pintarelli
164
Observación:
Sea X una variable aleatoria continua, se dice que tiene distribución Fisher con u grados de libertad
en el numerador y v grados de libertad en el denominador si su fdp es de la forma
∞<<
+
Γ
Γ
+Γ
=+
−
x
xv
uvu
xv
uvu
xfvu
uu
0
122
2)(
2
12
2
En particular si W e Y son variables aleatorias independientes ji-cuadrado con u y v grados de
libertad respectivamente, entonces el cociente
vY
uW
F =
Tiene una distribución Fisher con u grados de libertad en el numerador y v grados de libertad en el
denominador.
Notación: vuFF ,~
La gráfica de una distribución Fisher es similar a la de una ji-cuadrado, es asimétrica. Anotamos
vuf ,,α al cuantil que deja a su derecha un área de α bajo la curva de densidad.
Existe la siguiente relación entre los cuantiles de una vuF , y de una uvF ,
uv
vuf
f,,
,,1
1
αα =−
Planteamos la siguiente ecuación ( ) α−=≤≤ 1bFaP y se pede probar que la mejor elección de a
y b es: 1,1,
21 12 −−−
=nn
fa α y 1,1,
212 −−
=nn
fb α
20 ;15 == vu
α
vuf ,,α

Parte 2 – Estimación puntual Prof. María B. Pintarelli
165
Entonces ασσ
αα −=
≤≤
−−−−−1
1,1,2
2
1
2
1
2
2
2
2
1,1,2
1 1212 nnnnf
S
SfP
Despejando el cociente 2
2
2
1
σσ
queda :
ασσ
αα −=
≤≤
−−−−−1
1,1,2
2
2
2
1
2
2
2
1
1,1,2
12
2
2
1
1212 nnnnf
S
Sf
S
SP
Por lo tanto
Ejemplo:
Una compañía fabrica propulsores para uso en motores de turbina. Una de las operaciones consiste
en esmerilar el terminado de una superficie particular con una aleación de titanio. Pueden emplearse
dos procesos de esmerilado, y ambos pueden producir partes que tienen la misma rugosidad
superficial promedio. Interesaría seleccionar el proceso que tenga la menor variabilidad en la
rugosidad de la superficie. Para esto se toma una muestra de 12 partes del primer proceso, la cual
tiene una desviación estándar muestral 1.51 =S micropulgadas, y una muestra aleatoria de 15 partes
del segundo proceso, la cual tiene una desviación estándar muestral 7.42 =S micropulgadas. Se
desea encontrar un intervalo de confianza de nivel 90% para el cociente de las dos varianzas.
Suponer que los dos procesos son independientes y que la rugosidad de la superficie está distribuida
de manera normal.
Solución:
Estamos en las condiciones para aplicar (8.9)
20 ;15 == vu
2
α
2
α
1,1,2
1 12 −−− nnf α
1,1, 12 −− nnfα
Si se tienen dos poblaciones normales e independientes con varianzas desconocidas 2
1σ y 2
2σ
respectivamente, entonces un intervalo de nivel α−1 para el cociente de las dos varianzas 2
2
2
1
σσ
es
−−−−− 1,1,
2
2
2
2
1
1,1,2
12
2
2
1
1212
;nnnn
fS
Sf
S
Sαα (8.9)

Parte 2 – Estimación puntual Prof. María B. Pintarelli
166
Buscamos en la tabla de la Fisher 39.058.2
11
14,11,05.0
11,14,95.01,1,
21 12
====−−− f
ffnn
α
y 74.211,14,05.01,1,
212
==−−
ffnn
α
Entonces el intervalo es
[ ]23.3 ;46.0 2.747.4
1.5 ;39.0
7.4
1.52
2
2
2
=
Como este intervalo incluye al 1, no podemos afirmar que las desviaciones estándar de los dos
procesos sean diferentes con una confianza de 90%.
8.8 – Intervalo de confianza para una proporción
Sea una población de tamaño N (eventualmente puede ser infinito) de cuyos individuos nos interesa
cierta propiedad A. Supongamos que la probabilidad de que un individuo de la población verifique A
es ( )APp = .El significado del parámetro p es, en consecuencia, el de proporción de individuos de
la población que verifican la propiedad A. Podemos definir una variable
aleatoria iX que mide a los individuos de la población la ocurrencia o no de la propiedad A .
La variable aleatoria tendrá la distribución:
( )( ) ( )
( ) ( )
−===
====
,100
11
pXPp
pXPp
xp
i
i
es decir, Xi es una v.a. que toma sólo dos valores: 1 (si el individuo verifica A) con probabilidad p y
0 (cuando no verifica A) con probabilidad 1-p. Esto es equivalente a decir que Xi tiene una
distribución binomial con parámetros 1 y p: Xi ~ B(1,p).
Supongamos que consideramos una muestra aleatoria ( )nXXX ...,, 21 de tamaño n . Si formamos el
estadístico =X nXXX +++ ...21 , es evidente que esta v.a. mide el número de individuos de la
muestra de tamaño n que verifican la propiedad A. Por lo tanto por su significado X es una v.a. cuya
distribución es binomial con parámetros n y p: X~B(n,p). De acuerdo con esto, la variable aleatoria
P definida: n
XP = representa la proporción de individuos de la muestra que verifican la propiedad
A.
Observemos que siendo Xi ~ B(1,p) es ( ) pXE i = . Y, dado que X~B(n,p), también es
( ) ( ) pnpn
XEnn
XEPE ===
=11
, es decir P es un estimador insesgado de p . Esto es de esperar
pues ∑=
==n
i
iXnn
XP
1
1ˆ .
Pero además, es fácil ver que P es estimador consistente de p . En efecto, tenemos que ( ) pPE = ,
pero también es

Parte 2 – Estimación puntual Prof. María B. Pintarelli
167
( ) ( ) ( )n
pppnp
nn
XVPV
−=−=
=1
112
.
Deseamos construir un intervalo de confianza de p. Es razonable basarnos en el estimador insegado
P . Consideramos como pivote a la variable aleatoria
( )n
pp
pPZ
−
−=
1 cuya distribución es, para n suficientemente grande, aproximadamente N(0,1). En
efecto:
Siendo n
X
n
X
n
XP n+++= ...ˆ 21 , es ( ) ∑
=
=
=
n
i
i pn
XEPE
1
ˆ y ( ) ( )∑=
−=
=
n
i
i
n
pp
n
XVPV
1
1ˆ
Por lo tanto:
( )( )1,0~
1
ˆN
n
pp
pPZ
granden−
−= ,
El pivote puede ponerse en una forma más conveniente si tenemos en cuenta que, según vimos
recién, P es estimador consistente de p y en consecuencia, en el denominador reemplazamos el
parámetro desconocido p por su estimador P , y se puede probar que :
( )≈
−
−=
n
PP
pPZ
ˆ1ˆ
ˆN(0,1). aproximadamente si n es grande
Partiendo de este pivote podemos seguir los mismos pasos de los casos anteriores para llegar al
siguiente intervalo de confianza al nivel α−1 de p:
( ) ( )
−+
−−
n
PPzP
n
PPzP
ˆ1ˆˆ,ˆ1ˆˆ
22
αα con 2
12
αα −=
Φ z .
Entonces
Si P es la proporción de observaciones de una muestra aleatoria de tamaño n que verifican una
propiedad de interés, entonces un intervalo de confianza para la proporción p de la población que
cumple dicha propiedad de nivel aproximadamente α−1 es
( ) ( )
−+
−−
n
PPzP
n
PPzP
ˆ1ˆˆ ,ˆ1ˆˆ
22
αα (8.10)

Parte 2 – Estimación puntual Prof. María B. Pintarelli
168
Observaciones:
1- Este procedimiento depende de la aproximación normal a la distribución binomial. Por lo tanto el
intervalo (8.10) se puede utilizar si 10ˆ >Pn y 10)ˆ1( >− Pn , es decir, la muestra debe contener un
mínimo de diez éxitos y diez fracasos.
2- La longitud del intervalo es ( )
n
PPzL
ˆ1ˆ2
2
−= α , pero esta expresión está en función de P
Si nos interesa hallar un valor de n de manera tal que la longitud L sea menor que un valor
determinado, podemos hacer dos cosas:
a) tomar una muestra preliminar, con ella estimar p con P y de la expresión anterior despejar n, lo
que lleva a
( ) ( )PP
l
z
nln
PPzL ˆ1ˆ
2
ˆ1ˆ
2
2
2
2
−
≥⇒≤−
=α
α
b) si no tomamos una muestra preliminar, entonces acotamos ( ) ( )5.015.0ˆ1ˆ −×≤− PP , entonces
( ) ( )
2
2
22
5.015.0
2ˆ1ˆ
2
≥⇒≤−
≤−
=l
z
nln
zn
PPzL
α
αα
Ejemplo:
Un fabricante de componentes compra un lote de dispositivos de segunda mano y desea saber la
proporción de la población que están fallados. Con ese fin experimenta con 140 dispositivos elegidos
al azar y encuentra que 35 de ellos están fallados.
a) Calcular un intervalo de confianza del 99% para la proporción poblacional p.
b) ¿De qué tamaño deberá extraerse la muestra a fin de que la proporción muestral no difiera de la
proporción poblacional en más de 0.03 con un 95% de confianza?
Solución:
a) El tamaño de la muestra es 140=n (muestra grande)
La proporción muestral es 25.0140
35ˆ ==P
El nivel de confianza es 9901 .α =− → 010.α = → 00502
.α
= .
De la tabla de la normal estandarizada vemos que 58.2005.0 =z . Entonces el intervalo buscado es:
( ) ( ) [ ]34441.0 ,15558.0140
25.0125.058.225.0 ,
140
25.0125.058.225.0 =
−+
−−
b) Buscamos el tamaño n de la muestra tal que con un 95% de confianza la proporción muestral P
esté a una distancia 0.03 de la proporción poblacional p, es decir buscamos n tal que

Parte 2 – Estimación puntual Prof. María B. Pintarelli
169
03.02
≤L
, por lo tanto como 05.0=α → 025.02
=α
si tomamos la muestra anterior como
preliminar :
( ) ( ) 3333.80025.0125.003.02
96.12ˆ1ˆ
22
2
2 =−
××
=−
≥ PPl
z
n
α
Por lo tanto hay que tomar una muestra de tamaño por lo menos 801. como ya se tomó una muestra
de tamaño 140, hay que tomar otra adicional de tamaño 661140801 =−
Supongamos que no tomamos una muestra inicial, entonces directamente planteamos
1111.106703.02
96.12
2
2 =
×
=
≥l
z
n
α
Entonces hay que tomar una muestra de tamaño 1068 por lo menos.
8.9 – Intervalo de confianza para la diferencia entre dos proporciones
Supongamos que existen dos proporciones de interés 1p y 2p y es necesario obtener un intervalo de
confianza de nivel α−1 para la diferencia 21 pp − .
Supongamos que se toman dos muestras independientes de tamaños 1n y 2n respectivamente de dos
poblaciones.
Sean las variables aleatorias
:1X “número de observaciones en la primera muestra que tienen la propiedad de interés”
:2X “número de observaciones en la segunda muestra que tienen la propiedad de interés”
Entonces 1X y 2X son variables aleatorias independientes y X1~B(n1,p1) ; X2~B(n2,p2)
Además 1
11ˆ
n
XP = y
2
22ˆ
n
XP = son estimadores puntuales de 1p y 2p respectivamente.
Vemos que ( ) 2121ˆˆ ppPPE −=− y ( ) ( ) ( )
2
22
1
1121
11ˆˆn
pp
n
ppPPV
−+
−=−
Aplicando la aproximación normal a la binomial podemos decir que
( )( ) ( )
)1,0(11
ˆˆ
2
22
1
11
2121 N
n
pp
n
pp
ppPPZ ≈
−+
−
−−−= , y como en el caso de intervalo para una proporción estimamos
( ) ( )2
22
1
11 11
n
pp
n
pp −+
− con
( ) ( )2
22
1
11ˆ1ˆˆ1ˆ
n
PP
n
PP −+
− y entonces
( )( ) ( )
)1,0(ˆ1ˆˆ1ˆ
ˆˆ
2
22
1
11
2121 N
n
PP
n
PP
ppPPZ ≈
−+
−
−−−= aproximadamente.
Planteamos la ecuación ( ) ( ) ( )zzzZzP −Φ−Φ=≤≤− =1-α , lo que lleva a

Parte 2 – Estimación puntual Prof. María B. Pintarelli
170
2
αzz = , y con una deducción análoga a las anteriores se llega al intervalo
( ) ( ) ( ) ( )
−+
−+−
−+
−−−
2
22
1
11
2
21
2
22
1
11
2
21
ˆ1ˆˆ1ˆˆˆ ;
ˆ1ˆˆ1ˆˆˆ
n
PP
n
PPzPP
n
PP
n
PPzPP αα
Entonces
Ejemplo:
Se lleva a cabo un estudio para determinar la efectividad de una nueva vacuna contra la gripe. Se
administra la vacuna a una muestra aleatoria de 3000 sujetos, y de ese grupo 13 contraen gripe.
Como grupo de control se seleccionan al azar 2500 sujetos, a los cuales no se les administra la
vacuna, y de ese grupo 170 contraen gripe. Construya un intervalo de confianza de nivel 0.95 para la
diferencia entre las verdaderas proporciones de individuos que contraen gripe.
Solución:
Sean las variables aleatorias
:1X “número de personas que contraen gripe del grupo que recibió la vacuna”
:2X “número de personas que contraen gripe del grupo que no recibió la vacuna”
Entonces X1~B(n1,p1) ; X2~B(n2,p2) donde 30001 =n ; 25002 =n
Además 3000
13ˆ1 =P ;
2500
170ˆ2 =P
Y 96.195.01 025.0
2
==→=− zzαα
Entonces
( ) ( ) ( ) ( )
−−=
−+
−+−
−+
−−
−=
=
−+
−+−
−+
−−−
0535222.0;0738112.02500
2500
1701
2500
170
3000
3000
131
3000
13
96.12500
170
3000
13
;2500
2500
1701
2500
170
3000
3000
131
3000
13
96.12500
170
3000
13
ˆ1ˆˆ1ˆˆˆ ;
ˆ1ˆˆ1ˆˆˆ
2
22
1
11
2
21
2
22
1
11
2
21n
PP
n
PPzPP
n
PP
n
PPzPP αα
Si 1P y 2P son las proporciones muestrales de una observación de dos muestras aleatorias
independientes de tamaños 1n y 2n respectivamente que verifican la propiedad de interés,
entonces un intervalo de confianza de nivel α−1 aproximadamente es
( ) ( ) ( ) ( )
−+
−+−
−+
−−−
2
22
1
11
2
21
2
22
1
11
2
21
ˆ1ˆˆ1ˆˆˆ ;
ˆ1ˆˆ1ˆˆˆ
n
PP
n
PPzPP
n
PP
n
PPzPP αα (8.11)





























