Embed Size (px)
DESCRIPTION
Paradigma “Shared Address Space”. Algoritmos paralelos Glen Rodríguez. Plataformas de memoria compartida. En MPI: division de tareas y comunicación es explícita. En memoria compartida es semi-implícita. Además la comunicación es a través de la memoria común. - PowerPoint PPT Presentation
Citation preview

Paradigma “Shared Address Space”
Algoritmos paralelos
Glen Rodríguez

Plataformas de memoria compartida
En MPI: division de tareas y comunicación es explícita.
En memoria compartida es semi-implícita. Además la comunicación es a través de la memoria común.
Tecnologías: OpenMP, Parallel toolbox de Matlab

Hilos
Un hilo es un flujo de control individual en un programa.
Ej. Mult.matrices. for (row = 0; row < n; row++) for (column = 0; column < n; column++) c[row][column] = create_thread(dot_product(get_row(a, row),
get_col(b, col)));

Hilos o procesos accedena memoria compartida
Cada hilo puede tener variablesprivadas (stack)

Por qué hilos?
Portabilidad de software Memoria tiene menos latencia (ts=α) que
las redes. Además solo 1 hilo puede usar la red en un momento dado.
Scheduling y balance de carga semi-automático.
Facilidad de programar.

API de hilos de Posix
POSIX API : estándar IEEE 1003.1c-1995. Llamado Pthreads.
#include <pthread.h> int pthread_create ( pthread_t *thread_handle, const pthread_attr_t *attribute, void * (*thread_function)(void *), void *arg);

Ejemplo1 #include <pthread.h> 2 #include <stdlib.h> 3 4 #define MAX_THREADS 512 5 void *compute_pi (void *); 6 7 int total_hits, total_misses, hits[MAX_THREADS], 8 sample_points, sample_points_per_thread, num_threads; 9 10 main() { 11 int i; 12 pthread_t p_threads[MAX_THREADS]; 13 pthread_attr_t attr; 14 double computed_pi; 15 double time_start, time_end; 16 struct timeval tv; 17 struct timezone tz; 18 19 pthread_attr_init (&attr); 20 pthread_attr_setscope (&attr,PTHREAD_SCOPE_SYSTEM); 21 printf("Enter number of sample points: "); 22 scanf("%d", &sample_points); 23 printf("Enter number of threads: "); 24 scanf("%d", &num_threads);

Ejemplo26 gettimeofday(&tv, &tz); 27 time_start = (double)tv.tv_sec + 28 (double)tv.tv_usec / 1000000.0; 29 30 total_hits = 0; 31 sample_points_per_thread = sample_points / num_threads; 32 for (i=0; i< num_threads; i++) { 33 hits[i] = i; 34 pthread_create(&p_threads[i], &attr, compute_pi, 35 (void *) &hits[i]); 36 } 37 for (i=0; i< num_threads; i++) { 38 pthread_join(p_threads[i], NULL); 39 total_hits += hits[i]; 40 } 41 computed_pi = 4.0*(double) total_hits / 42 ((double)(sample_points)); 43 gettimeofday(&tv, &tz); 44 time_end = (double)tv.tv_sec + 45 (double)tv.tv_usec / 1000000.0; 46 47 printf("Computed PI = %lf\n", computed_pi); 48 printf(" %lf\n", time_end - time_start); 49 }

Ejemplo51 void *compute_pi (void *s) { 52 int seed, i, *hit_pointer; 53 double rand_no_x, rand_no_y; 54 int local_hits; 55 56 hit_pointer = (int *) s; 57 seed = *hit_pointer; 58 local_hits = 0; 59 for (i = 0; i < sample_points_per_thread; i++) { 60 rand_no_x =(double)(rand_r(&seed))/(double)((2<<14)-1); 61 rand_no_y =(double)(rand_r(&seed))/(double)((2<<14)-1); 62 if (((rand_no_x - 0.5) * (rand_no_x - 0.5) + 63 (rand_no_y - 0.5) * (rand_no_y - 0.5)) < 0.25) 64 local_hits ++; 65 seed *= i; 66 } 67 *hit_pointer = local_hits; 68 pthread_exit(0); 69 }

Primitivas de sincronización en Pthreads
Exclusión mutua para variables compartidas
Ej.: best_cost es compartida (=100 al inicio), my_cost es local (50 y 75)
1 /* each thread tries to update variable best_cost as follows */
2 if (my_cost < best_cost) 3 best_cost = my_cost;

Mutex-locks
El if y la asignación no son independientes: deberían ser una unidad. Además son una zona crítica (pedazo del programa donde solo 1 hilo debe correr a la vez).
Como soportar zona crítica y ops. atómicas: mutex-locks (locks de exclusión mutua)

Controlando atributos de Hilos y de Sincronización
Atributos de hilo: Tipo de scheduling Tamaño de stack
Atributos de mutez: tipo de mutex. Separo atributos del programa: más
fácil programar.

Cancelando hilos
Si un hilo ya no es necesario: int pthread_cancel (pthread_t thread); Un hilo se puede autocancelar, o
puede cancelar a otros.

Constructos compuestos de sincronización
Locks read-write Muchos hilos pueden leer una data a la
vez, pero sólo 1 puede escribir en ella. Y debería hacerlo sin reads a la vez.
Una vez que hay en cola un pedido de lock de escritura, ya no se aceptan más lecturas.
Barreras: similar a MPI

Diseñando programas asíncronos
Alt. 1: no importa el orden de los hilos Alt. 2: sí importa, en este caso hay que programar
explícitamente el orden con locks, mutexes, barreras, joins etc,
Setear los atributos, datos, mutexes, etc. al inicio de la vida del hilo.
Si hay hilo productor y consumidor, asegurarse que se produzca (y se ponga en memoria compartida) antes de que se consuma.
Si se puede, definir y usar sincronizaciones de grupo y replicación de data.

OpenMP ¿Qué es OpenMP? Regiones Paralelas Bloques de construcción para trabajo en
paralelo Alcance de los datos para proteger datos Sincronización Explícita Cláusulas de Planificación Otros bloques de construcción y cláusulas
útiles

¿Qué es OpenMP*?
Directivas del compilador para programación multihilos
Es fácil crear hilos en Fortran y C/C++ Soporta el modelo de paralelismo de datos Paralelismo incremental
Combina código serial y paralelo en un solo código fuente

¿Qué es OpenMP*?
omp_set_lock(lck)
#pragma omp parallel for private(A, B)
#pragma omp critical
C$OMP parallel do shared(a, b, c)
C$OMP PARALLEL REDUCTION (+: A, B)
call OMP_INIT_LOCK (ilok)
call omp_test_lock(jlok)
setenv OMP_SCHEDULE “dynamic”
CALL OMP_SET_NUM_THREADS(10)
C$OMP DO lastprivate(XX)
C$OMP ORDERED
C$OMP SINGLE PRIVATE(X)
C$OMP SECTIONS
C$OMP MASTER
C$OMP ATOMIC
C$OMP FLUSH
C$OMP PARALLEL DO ORDERED PRIVATE (A, B, C)
C$OMP THREADPRIVATE(/ABC/)
C$OMP PARALLEL COPYIN(/blk/)
Nthrds = OMP_GET_NUM_PROCS()
!$OMP BARRIER
http://www.openmp.orgLa especificación actual es OpenMP 2.5
250 Páginas
(C/C++ y Fortran)

Arquitectura OpenMP*
Modelo fork-join Bloques de construcción para trabajo en
paralelo Bloques de construcción para el ambiente
de datos Bloques de construcción para sincronización API (Application Program Interface)
extensiva para afinar el control

Modelo de programaciónParalelismo fork-join:
• El hilo maestro se divide en un equipo de hilos como sea necesario
• El Paralelismo se añade incrementalmente: el programa secuencial se convierte en un programa paralelo
Regiones paralelas
Hilo maestro

Sintaxis del Pragma OpenMP*
La mayoría de los bloques de construcción en OpenMP* son directivas de compilación o pragmas.
En C y C++, los pragmas toman la siguiente forma:
#pragma omp construct [clause [clause]…]

Regiones Paralelas
Define una región paralela sobre un bloque de código estructurado
Los hilos se crean como ‘parallel’
Los hilos se bloquean al final de la región
Los datos se comparten entre hilos al menos que se especifique otra cosa
#pragma omp parallel
Hilo
1Hilo
2Hilo
3
C/C++ : #pragma omp parallel
{ bloque
}

¿Cuántos hilos? Establecer una variable de ambiente para el
número de hilos. Ejemplo 4 hilos:
export OMP_NUM_THREADS=4
No hay un default estándar en esta variable En muchos sistemas: # de hilos = # de
procesadores

Ej. 1: Hello World
Modificar el código serial de “Hello, Worlds” para ejecutarse paralelamente usando OpenMP*
int main(){ saludo();}int saludo(){ int i;
for(i=0;i<10;i++) { printf(“Hola mundo desde el hilo principal\n”); sleep(1) }}

Bloques de construcción de trabajo en paralelo
Divide las iteraciones del ciclo en hilos Debe estar en la región paralela Debe preceder el ciclo
#pragma omp parallel#pragma omp for
for (i=0; i<N; i++){Do_Work(i);
}

Bloques de construcción de trabajo en paralelo
Los hilos se asignan a un conjunto de iteraciones independientes
Los hilos deben de esperar al final del bloque de construcción de trabajo en paralelo
#pragma omp parallel
#pragma omp for
Barrera implícita
i = 0
i = 1
i = 2
i = 3
i = 4
i = 5
i = 6
i = 7
i = 8
i = 9
i = 10
i = 11
#pragma omp parallel#pragma omp for for(i = 0; i < 12; i++) c[i] = a[i] + b[i]

Combinando pragmas Ambos segmentos de código son
equivalentes
#pragma omp parallel { #pragma omp for for (i=0; i< MAX; i++) { res[i] = huge(); } }
#pragma omp parallel for for (i=0; i< MAX; i++) { res[i] = huge(); }

Ambiente de datos
OpenMP usa un modelo de programación de memoria compartida
La mayoría de las variables por default son compartidas.
Las variables globales son compartidas entre hilo

Ambiente de datos
Pero, no todo es compartido... Las variables en el stack en funciones llamadas de
regiones paralelas son PRIVADAS
Las variables automáticas dentro de un bloque son PRIVADAS
Las variables de índices en ciclos son privadas (salvo excepciones) C/C+: La primera variable índice en el ciclo en ciclos anidados
después de un #pragma omp for

Atributos del alcance de datos
El estatus por default puede modificarsedefault (shared | none)
Clausulas del atributo de alcance
shared(varname,…)
private(varname,…)

La cláusula Private
Reproduce la variable por cada hilo Las variables no son inicializadas; en C++ el
objeto es construido por default Cualquier valor externo a la región paralela
es indefinido
void* work(float* c, int N) { float x, y; int i; #pragma omp parallel for private(x,y) for(i=0; i<N; i++) {
x = a[i]; y = b[i]; c[i] = x + y; }}

Ejemplo: producto puntofloat dot_prod(float* a, float* b, int N) { float sum = 0.0;#pragma omp parallel for shared(sum) for(int i=0; i<N; i++) { sum += a[i] * b[i]; } return sum;}
¿Qué es incorrecto?¿Qué es incorrecto?

Proteger datos compartidos
Debe proteger el acceso a los datos compartidos que son modificables
float dot_prod(float* a, float* b, int N) { float sum = 0.0;#pragma omp parallel for shared(sum) for(int i=0; i<N; i++) {#pragma omp critical sum += a[i] * b[i]; } return sum;}

#pragma omp critical [(lock_name)] Define una región crítica en un bloque estructurado
OpenMP* Bloques de construcción para regiones críticas
float R1, R2;#pragma omp parallel{ float A, B; #pragma omp for for(int i=0; i<niters; i++){ B = big_job(i);#pragma omp critical consum (B, &R1); A = bigger_job(i);#pragma omp critical consum (A, &R2); }}
Los hilos esperan su turno –en un momento, solo uno llama consum() protegiendo R1 y R2 de de condiciones de concurso.
Nombrar las regiones críticas es opcional, pero puede mejorar el rendimiento.
(R1_lock)
(R2_lock)

OpenMP* Cláusula de reducción
reduction (op : list) Las variables en “list” deben ser compartidas
dentro de la región paralela Adentro de parallel o el bloque de construcción
de trabajo en paralelo: Se crea una copia PRIVADA de cada variable de la lista y
se inicializa de acuerdo al “op”
Estas copias son actualizadas localmente por los hilos
Al final del bloque de construcción, las copias locales se combinan de acuerdo al “op” a un solo valor y se almacena en la variable COMPARTIDA original

Ejemplo de reducción
Una copia local de sum para cada hilo Todas las copias locales de sum se suman
y se almacenan en una variable “global”
#pragma omp parallel for reduction(+:sum) for(i=0; i<N; i++) { sum += a[i] * b[i]; }

Un rango de operadores asociativos y conmutativos pueden usarse con la reducción
Los valores iniciales son aquellos que tienen sentido
C/C++ Operaciones de reducción
Operador Valor Inicial
+ 0
* 1
- 0
^ 0
Operador Valor Inicial
& ~0
| 0
&& 1
|| 0

Ejemplo de integración numérica4.0
2.0
1.00.0
4.0
(1+x2)f(x) =
4.0
(1+x2) dx = 0
1
X
static long num_steps=100000; double step, pi;
void main(){ int i; double x, sum = 0.0;
step = 1.0/(double) num_steps; for (i=0; i< num_steps; i++){ x = (i+0.5)*step; sum = sum + 4.0/(1.0 + x*x); } pi = step * sum; printf(“Pi = %f\n”,pi);}}

Calculando Pi Paralelize el código de
integración numérica usando OpenMP
¿Qué variables se pueden compartir?
¿Qué variables deben ser privadas?
¿Qué variables deberían considerarse para reducción?
static long num_steps=100000; double step, pi;
void main(){ int i; double x, sum = 0.0;
step = 1.0/(double) num_steps; for (i=0; i< num_steps; i++){ x = (i+0.5)*step; sum = sum + 4.0/(1.0 + x*x); } pi = step * sum; printf(“Pi = %f\n”,pi);}}

Asignando Iteraciones La cláusula schedule afecta en como las iteraciones
del ciclo se mapean a los hilos
schedule(static [,chunk]) Bloques de iteraciones de tamaño “chunk” a los hilos Distribución Round Robin
schedule(dynamic[,chunk]) Los hilos timan un fragmento (chunk) de iteraciones Cuando terminan las iteraciones, el hilo solicita el
siguiente fragmento

Asignando Iteracionesschedule(guided[,chunk])
Planificación dinámica comenzando desde el bloque más grande
El tamaño de los bloques se compacta; pero nunca más pequeño que “chunk”

Cláusula Schedule Cuando utilizar
STATIC Predecible y trabajo similar por iteración
DYNAMIC Impredecible, trabajo altamente variable por iteración
GUIDED Caso especial de dinámico para reducir la sobrecarga de planificación
Qué planificación utilizar
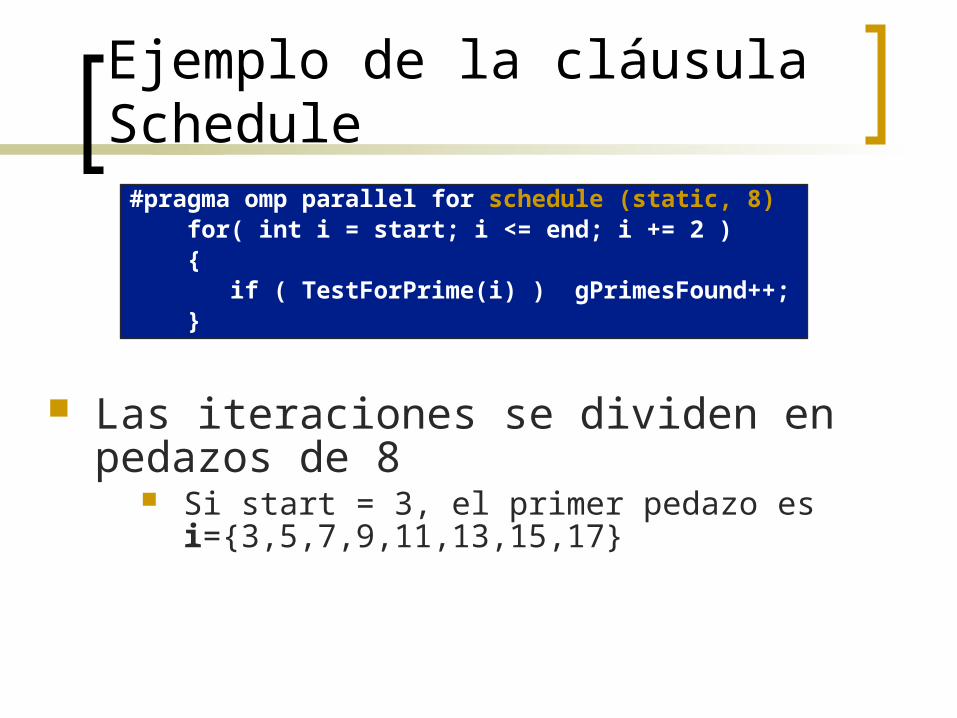
Ejemplo de la cláusula Schedule#pragma omp parallel for schedule (static, 8) for( int i = start; i <= end; i += 2 ) { if ( TestForPrime(i) ) gPrimesFound++; }
Las iteraciones se dividen en pedazos de 8 Si start = 3, el primer pedazo es
i={3,5,7,9,11,13,15,17}

Secciones paralelas Secciones independientes
de código se pueden ejecutar concurrentemente
Serial Paralela
#pragma omp parallel sections
{
#pragma omp section
phase1();
#pragma omp section
phase2();
#pragma omp section
phase3();
}

Denota un bloque de código que será ejecutado por un solo hilo
El hilo seleccionado es dependiente de la implementación
Barrera implícita al final
Bloque de construcción Single
#pragma omp parallel{ DoManyThings();#pragma omp single { ExchangeBoundaries(); } // threads wait here for single DoManyMoreThings();}

Denota bloques de código que serán ejecutados solo por el hilo maestro
No hay barrera implícita al final
Bloque de construcción Master
#pragma omp parallel{ DoManyThings();#pragma omp master { // if not master skip to next stmt ExchangeBoundaries(); } DoManyMoreThings();}

Barreras implícitas
Varios bloques de construcción de OpenMP* tienen barreras implícitas
parallel for single
Barreras innecesarias deterioran el rendimiento Esperar hilos implica que no se trabaja!
Suprime barreras implícitas cuando sea seguro con la cláusula nowait.

Cláusula Nowait
Cuando los hilos esperarían entren cómputos independientes
#pragma single nowait
{ [...] }
#pragma omp for nowait
for(...)
{...};
#pragma omp for schedule(dynamic,1) nowait for(int i=0; i<n; i++) a[i] = bigFunc1(i);
#pragma omp for schedule(dynamic,1) for(int j=0; j<m; j++) b[j] = bigFunc2(j);

Barreras
Sincronización explícita de barreras Cada hilo espera hasta que todos
lleguen#pragma omp parallel shared (A, B, C) {
DoSomeWork(A,B);printf(“Processed A into B\n”);
#pragma omp barrier DoSomeWork(B,C);printf(“Processed B into C\n”);
}

Operaciones Atómicas
Caso especial de una sección crítica Aplica solo para la actualización de
una posición de memoria
#pragma omp parallel for shared(x, y, index, n) for (i = 0; i < n; i++) { #pragma omp atomic x[index[i]] += work1(i); y[i] += work2(i); }

API de OpenMP* Obtener el número de hilo dentro de un equipo
int omp_get_thread_num(void); Obtener el número de hilos en un equipo
int omp_get_num_threads(void); Usualmente no se requiere para códigos de
OpenMP Tiene usos específicos (debugging) Hay que incluir archivo de cabecera
#include <omp.h>

Problemas de rendimiento
Los hilos ociosos no hacen trabajo útil Divide el trabajo entre hilos lo más
equitativamente posible Los hilos deben terminar trabajos paralelos al
mismo tiempo
La sincronización puede ser necesaria Minimiza el tiempo de espera de recursos
protegidos

Cargas de trabajo no balanceadas
Cargas de trabajo desigual produce hilos ociosos y desperdicio de tiempo.
Ocupado Ocioso
#pragma omp parallel{
#pragma omp for for( ; ; ){
}
}
tiempo

#pragma omp parallel{
#pragma omp critical { ... } ...}
Sincronización
Tiempo perdido por locks
tiempo
Ocupado Ocioso En SC

Afinando el rendimiento
Los profilers usan muestreo para proveer datos sobre el rendimiento.
Los profilers tradicionales están limitados para usarse con códigos de OpenMP*:
Miden tiempo del CPU, no tiempo real No reportan contención de objetos de sincronización No pueden reportar carga de trabajo desbalanceada Muchos de ellos no tienen todo el soporte de OpenMP
Los programadores necesitan profilers específicamente diseñadas para OpenMP.

Planificación estática: Hacerlo por uno mismo
Debe conocerse: Número de hilos (Nthrds) Cada identificador ID de cada hilo (id)
Calcular iteraciones (start y end):
#pragma omp parallel{
int i, istart, iend;istart = id * N / Nthrds;iend = (id+1) * N / Nthrds;for(i=istart;i<iend;i++){ c[i] = a[i] + b[i];}
}





























