Embed Size (px)
Citation preview

8/4/2019 Paper-8_Clustering Analysis & Study on Deriving Concept Based User Profile From Search Engine Logs
http://slidepdf.com/reader/full/paper-8clustering-analysis-study-on-deriving-concept-based-user-profile 1/7
International Journal of Computational Intelligence and Information Security, August 2011 Vol. 2, No. 8
62
Clustering Analysis & Study on Deriving Concept Based
User Profile from Search Engine Logs
Name: NagaValli Susarla Name: B.Deepthi
Qualification: M.Tech Qualification:M.TechCollege: Varadhaman College of Engineering College: Jaya Prakesh NarayanEmail ID: [email protected]
Name:E.R.Aruna Name:B.V.Rama Krishna
Designation:Assoc Prof Designation:Assoc Prof College: Varadhaman College of Engineering College:VaradhamanCollege of Engineering
Abstract-The concept of user profiling is a fundamental component of any personalization applications. Most existing user
profiling strategies are based on objects that users are interested in i.e. positive preferences but not the objects that
users dislike i.e. negative preferences. In this paper, we focus on search engine personalization and implementation
of several concept-based user profiling methods that are based on both positive and negative preferences. Weanalyzed the proposed methods against our previously proposed personalized query clustering method. Our analysis
results show that profiles which capture and utilize both of the user’s positive and negative preferences perform the
best. An important result from our research is that profiles with negative preferences can increase the separation
between similar and dissimilar queries. The separation provides a clear threshold for an agglomerative clustering
algorithm to terminate and improve the overall quality of the resulting query clusters. Our works shows the effective
analysis compare to other and existing one.
Keywords – Search Engine, User Profile, Clustering, Positive & Negative Preferences
INTRODUCTION I
Information explosion on the internet has placed high demands on search engines. People are far from being satisfied with theperformance of the existing search engines, which often return thousands of documents in response to a user query. Many of thereturned documents are irrelevant to user’s need. The precision of current search engines is well under people’s expectations. To
find more precise answers to a query a new generation of search engines, question answering systems have appeared on the web(e.g http://www.askgoogle.com/). Unlike the traditional search engines that only use keywords to match documents, this newgeneration of system tries to match documents this new generation of systems tries to understand the users question and suggestsome similar questions that other people have often asked and for which the system has the correct answers. In fact the correct
answers have been prepared or checked by human editors in most cases then guarantee that if one of the suggested questions istruly similar to that of the user, the answers provided by the system will be relevant. The assumption behind such a system is thatmany people are interested in the same questions – the frequently asked.
User profiling strategy is an essential and fundamental component in search engine personalization. Most
personalization methods focused on the creation of one single profile for a user and applied the same profile to all of the user’squeries. We believe that different queries from a user should be handled differently because a user’s preferences may vary acrossqueries. For example, a user who prefers information about fruit on the query “orange” may prefer the information about AppleComputer for the query “apple.” Personalization strategies such as [1], [2] employed a single large user profile for each user in
the personalization process. To improve user’s search experience, most major commercial search engines provide querysuggestions to help users formulate more effective queries. When a user submits a query, a list of terms that are semanticallyrelated to the submitted query is provided to help the user identify terms that he/she really wants, hence improving the retrievaleffectiveness. Yahoo’s “Also Try” [6] and Google’s
“Searches related to” features provide related queries for narrowing search, while Ask Jeeves [1] suggests both more specific andmore general queries to the user. Unfortunately, these systems provide the same suggestions to the same query without
considering users’ specific interests.

8/4/2019 Paper-8_Clustering Analysis & Study on Deriving Concept Based User Profile From Search Engine Logs
http://slidepdf.com/reader/full/paper-8clustering-analysis-study-on-deriving-concept-based-user-profile 2/7
International Journal of Computational Intelligence and Information Security, August 2011 Vol. 2, No. 8
63
SECTION II
2.1. What are Search Engines?The term “search engine” is often used generically to describe both crawler-based search engines and human-powered
directories. These two types of search engines gather their listings in radically different ways. Crawler-based search engines,such as Google, create their listings automatically. They crawl the web, and then people search through what they have found. If
there is any change on the web pages, crawler-based search engines eventually find these changes, and that can affect on thelisting. Some search engines also mine data available in news books, databases, or open directories. Unlike Web directories,which are maintained by human editors, search engines operate algorithmically or are a mixture of algorithmic and human input.2.2. How Search Engines Works? Crawler-based search engines [7] have three major elements. First one is spider or crawler.The spider visits a web page, reads it, and then follows links to other pages within the site. This is what it means when someonerefers to a site being “spidered” or “crawled.” The spider returns to the site on a regular basis, such as every month or two, tolook for changes. Everything the spider finds goes into the second part of the search engine, the index The index, sometimes
called the catalog, is like a giant book containing a copy of every web page that the spider finds. If a web page changes, then thisbook is updated with new information. Sometimes it can take a while for new pages or changes that the spider finds to be addedto the index. Thus, a web page may have been “spidered” but not yet “indexed.” Until it is indexed -- added to the index -- it isnot available to those searching with the search engine. Search engine software is the third part of a search engine. This is the
program that searches through the web pages recorded in the index to find matches to a search and then rank them in order of what it believes is most important.
2.3. How Search Engines Rank Web Pages ?
To Search for anything search engine use crawler-based search engine. Nearly instantly, the search engine will sort through the
millions of pages it knows about and present you with ones that match your topic [10]. The matches will even be ranked, so thatthe most relevant ones come first. Unfortunately, search engines [2] don’t have the ability to focus the search. They also can’trely on judgment and past experience to rank web pages, in the way humans can. So to determine relevancy they follow a set of rules, known as an algorithm. Exactly how a particular search engine’s algorithm works is a closely-kept trade secret. However,
all major search engines follow the general rules as mentioned below:
SECTION III3. Hierarchical clustering: Hierarchical models [8], [9] propose a better versatility as they do not require any priori definition of
the number of clusters to find. It is deterministic in nature and produces the same clustering each time. A perfect visualization of a dendrogram is provided. In hierarchical clustering, the data are not partitioned into a particular cluster in a single step. Therules [4] which govern between which points distances are measured to determine cluster membership include Complete-link (or
complete linkage) we merge in each step the two clusters whose merger has the smallest diameter (or the two clusters with the
smallest maximum pairwise distance).
dist(Ci, C j) = max {dist (oi, o j) | oi ε Ci , o j ε C j }Single-link (or single linkage) we merge in each step the two clusters whose two closest members have the smallest
distance (or the two clusters with the smallest minimum pairwise distance).
dist(Ci ,C j) = min {dist (oi, o j) | oi ε Ci , o j ε C j }
Average-link clustering merges in each iteration the pair of clusters with the average distance parameter. dist(C i ,C j) = mean{dist
(oi, o j) | oi ε Ci , o j ε C j }
Figure 1: Rules for member ship
Ward's method [8]: This method is distinct from all other methods because it uses an analysis of variance approach to evaluatethe distances between clusters. In short, this method attempts to minimize the Sum of Squares (SS) of any two (hypothetical)
clusters that can be formed at each step. In general, this method is regarded as very efficient, however, it tends to create clustersof small size.
A series of partitions takes place, which may run from a single cluster containing all objects to n clusters eachcontaining a single object and the Hierarchical clustering is based on the union between the two nearest clusters. Given a set of N
items to be clustered, and an N*N distance (or similarity) matrix. Hierarchical clustering is subdivided into agglomerativemethods, which proceed by series of fusions of the n objects into groups, and divisive methods, which separate n objects

8/4/2019 Paper-8_Clustering Analysis & Study on Deriving Concept Based User Profile From Search Engine Logs
http://slidepdf.com/reader/full/paper-8clustering-analysis-study-on-deriving-concept-based-user-profile 3/7
International Journal of Computational Intelligence and Information Security, August 2011 Vol. 2, No. 8
64
successively into finer groupings. For both the hierarchical methods, a hierarchy of tree-like structure is constructed which isknown as dendrogram or tree graph that is depicted for 2 clusters as shown in figure 2 below.
Figure 2 is dendrogram
Hierarchical algorithms like AGNES, DIANA and MONA construct a hierarchy of clusters, with a number of clustersranging from one to the number of observations. The space complexity for hierarchical algorithm is O(n2), this is the spacerequired for the adjacency matrix. The space required for the dendrogram is O(Kn), which is much less than O(n2). The timecomplexity for hierarchical algorithms is O(kn2) because there is one iteration for each level in the dendrogram. Depending onthe specific algorithm this could actually be O(maxd n2) where maxd is the maximum distance between the points. Different
algorithms may actually merge the closest clusters from the next lowest level or creates new clusters at each level withprogressively larger distances.
3.1. Agglomerative Algorithm
Agglomerative algorithms [9], [8] start with an individual item in its own cluster and iteratively merge cluster until all
items belong to one cluster. All agglomerative approaches experience excess time and space constraints. The space required forthe adjacency matrix is O(n2) where there are n items to cluster. Agglomerative approaches are not incremental as when newelements are added or changed, the entire algorithm must be rerun.
Agglomerative Nesting (AGNES) [8]: The algorithm constructs a tree-like hierarchy which implicitly contains all values of k ,
starting with N clusters and proceeding by successive fusions until a single cluster is obtained with all the objects. It initializes nsub cluster with one vector each and computes the triangular distance matrix. This will be repeated n times. The smallest distanceof i and j are identified and the sub clusters i, j are merged into a new sub cluster (i, j).The new sub cluster is replaced with (i, j)and the matrix distance is changed which results in a hierarchical structure as shown in
Figure 3: Sub cluster merging
The sub cluster is merged by deleting the rows and columns i, j and adding a row for(i, j) with new distances. The distances can
be known by single, complete, average linkages.3.2. Divisive analysis (DIANA): With divisive clustering all items are initially placed in one cluster and clusters are repeatedlysplit in two until all items are in their own cluster. The idea is to split up clusters where some elements are not sufficiently close
to other elements. The method DIANA can be used for the same type of data as the method AGNES. Although AGNES and DIANA produce similar output, DIANA constructs its hierarchy in the opposite direction, starting with one large cluster
containing all objects. At each step, it splits up a cluster into two smaller ones, until all clusters contain only a single element.This means that for N objects, the hierarchy is built in N-1 steps. In the first step, the data are split into two clusters by makinguse of dissimilarities. In each subsequent step, the cluster with the largest diameter is split in the same way. After N-1 divisivesteps, all objects are apart.
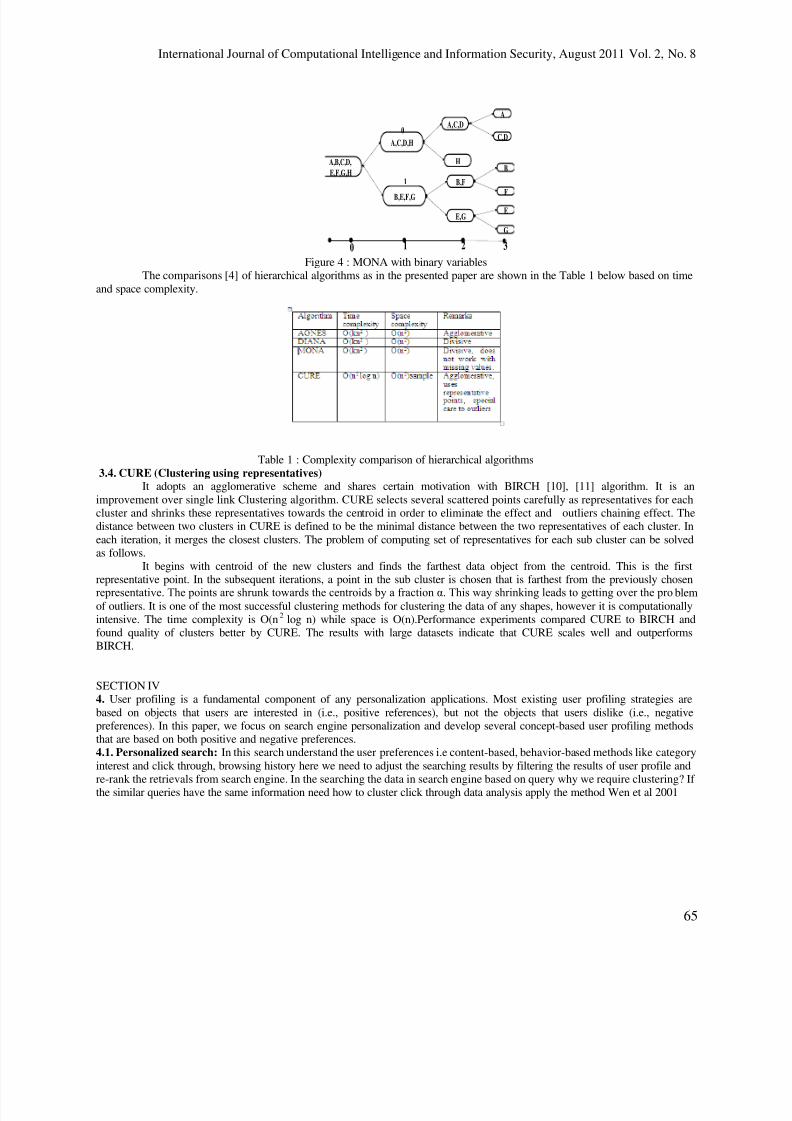
3.3. Monothetic Analysis (MONA)Most other hierarchical methods including AGNES and DIANA are polythetic. MONA operates on a data matrix with
binary variables. For each split MONA [8] uses a single variable for which it is called as Monothetic method. The MONA-algorithm constructs a hierarchy of clustering initially with a large one cluster. Clusters are divided until all observations in the
same cluster have identical values for all variables. At each stage, all clusters are divided according to the values of one variable.A cluster is divided into one cluster with all observations having value 1 for that variable, and another cluster with allobservations having value 0 for that variable as shown in figure 4. The variable used for splitting a cluster is the variable with themaximal total association to the other variables, according to the observations in the cluster to be splitted
8/4/2019 Paper-8_Clustering Analysis & Study on Deriving Concept Based User Profile From Search Engine Logs
http://slidepdf.com/reader/full/paper-8clustering-analysis-study-on-deriving-concept-based-user-profile 4/7
International Journal of Computational Intelligence and Information Security, August 2011 Vol. 2, No. 8
65
A,C,D,H
B,E,F,G
E,G
A,C,D
HA,B,C,D,
E,F,G,H
A
C,D
B
F
E
B,F
G
0 21 3
0
1
Figure 4 : MONA with binary variables
The comparisons [4] of hierarchical algorithms as in the presented paper are shown in the Table 1 below based on time
and space complexity.
Table 1 : Complexity comparison of hierarchical algorithms
3.4. CURE (Clustering using representatives) It adopts an agglomerative scheme and shares certain motivation with BIRCH [10], [11] algorithm. It is an
improvement over single link Clustering algorithm. CURE selects several scattered points carefully as representatives for eachcluster and shrinks these representatives towards the centroid in order to eliminate the effect and outliers chaining effect. Thedistance between two clusters in CURE is defined to be the minimal distance between the two representatives of each cluster. In
each iteration, it merges the closest clusters. The problem of computing set of representatives for each sub cluster can be solvedas follows.
It begins with centroid of the new clusters and finds the farthest data object from the centroid. This is the firstrepresentative point. In the subsequent iterations, a point in the sub cluster is chosen that is farthest from the previously chosen
representative. The points are shrunk towards the centroids by a fraction α. This way shrinking leads to getting over the pro blemof outliers. It is one of the most successful clustering methods for clustering the data of any shapes, however it is computationallyintensive. The time complexity is O(n2 log n) while space is O(n).Performance experiments compared CURE to BIRCH andfound quality of clusters better by CURE. The results with large datasets indicate that CURE scales well and outperformsBIRCH.
SECTION IV4. User profiling is a fundamental component of any personalization applications. Most existing user profiling strategies are
based on objects that users are interested in (i.e., positive references), but not the objects that users dislike (i.e., negativepreferences). In this paper, we focus on search engine personalization and develop several concept-based user profiling methodsthat are based on both positive and negative preferences.4.1. Personalized search: In this search understand the user preferences i.e content-based, behavior-based methods like category
interest and click through, browsing history here we need to adjust the searching results by filtering the results of user profile andre-rank the retrievals from search engine. In the searching the data in search engine based on query why we require clustering? If the similar queries have the same information need how to cluster click through data analysis apply the method Wen et al 2001

8/4/2019 Paper-8_Clustering Analysis & Study on Deriving Concept Based User Profile From Search Engine Logs
http://slidepdf.com/reader/full/paper-8clustering-analysis-study-on-deriving-concept-based-user-profile 5/7
International Journal of Computational Intelligence and Information Security, August 2011 Vol. 2, No. 8
66
Figure 5 shows the flow query processing in user profile search engine
Clustering algorithm is based on similarity function, the method is similarity function :Similarity = a * Simkeyword + b * Simfeedback
This cluster similarity work based on keyword type from query given by the user feedback is clicked documents set by query.The result of clustering is a global map which is a set of document pairs
Figure 6 shows the global set of documents
4.2. How to create group profileFirst choose N user profile, pick N1/2 profiles randomly as leader Compute similarity and choose the nearest leader adjustment,remove small one Problems not incremental initial N user profile choosing to identify the group for a user is calculate thedistance between the user and group which is nearest one.
4.3. Solution to our Proposed system: we address the our problem by proposing and studying seven concept-based user
profiling strategies that are capable of deriving both of the user’s positive and negative preferences. The entire user profilingstrategies is query-oriented, meaning that a profile is created for each of the user’s queries. The user profiling strategies areevaluated and compared with our previously proposed personalized query clustering method. Experimental results show that user
profiles which capture both the user’s positive and negative preferences perform the best among all of the profiling strategiesstudied. Moreover, we find that negative preferences improve the separation of similar and dissimilar queries, which facilitates anagglomerative clustering algorithm to decide if the optimal clusters have been obtained. We show by experiments that thetermination point and the resulting precision and recalls are very close to the optimal results.
SECTION V5.1. User profile: A user profile is simple profile when used in-context is a collection of personal data associated to a specific
user. A profile refers to the explicit digital representation of a person's identity. A user profile can also be considered as thecomputer representation of a user specific model.A profile can be used to store the description of the characteristics of person. This information can be exploited by systems takinginto account the persons' characteristics and preferences. For instance profiles can be used by hypermedia systems thatpersonalize the human computer interaction.
5.2. User profile extraction:
User profile extraction from query evaluation engineThe task of the Query Evaluation Engine (QE) is to determine the type of the user online and compute Recommendations basedon the recent actions of that user. The decision is based on the knowledge attained from the existing logs and page ranking as in
Fig .1.No user is attached to a particular outcome, as users are free to move from one locality to another. However, with carefullydesigned user profile extraction, the recommendation covers the majority of the user session. The pages are ranked using a Visalgorithm (1) [1]:

8/4/2019 Paper-8_Clustering Analysis & Study on Deriving Concept Based User Profile From Search Engine Logs
http://slidepdf.com/reader/full/paper-8clustering-analysis-study-on-deriving-concept-based-user-profile 6/7
International Journal of Computational Intelligence and Information Security, August 2011 Vol. 2, No. 8
67
Fig7. User Profile System
In the formula, Marks (i) represents total marks obtained by the student, Grade value (i) represents the number of hits for a pageduring Marks (i), p is a probability value between 0 and 1 and can be predefined. Thus, only the nearest past will play a crucialrole in ranking.
5.3. Comparative study on ClusteringHierarchical clustering [1] are computationally expensive, works on relatively small data sets and require much
memory space, though CURE is able to give good clustering results but it is costly in computation overhead. Nice visualization,because of dendrograms are possible. It is deterministic in nature and cannot correct early mistakes as split or merge leads to next
step. A major drawback of existing hierarchical scheme like CURE is that the merging decisions are based on static model of theclusters to be merged.
Partitional clustering run in linear time with better efficiency, tendency to result in local minimum, and dependency onthe input order. The clustering quality is however not good as that of hierarchical algorithm. They are computationally efficient
for large data sets. As they have predefined no. of clusters, optimization is difficult. Non-deterministic, should be run severaltimes. There is always room for iterative improvement. Creates cluster in one step as opposed to several steps in hierarchicalclustering.
CONCLUSION V
User profile can improve a search engine’s performance by identifying the information needs for individual users. Inthis paper, we proposed several user profiling strategies. The techniques make use of click through data to extract from Web-snippets to build concept-based user profiles automatically. We applied preference mining rules to infer not only users’ positivepreferences but also their negative preferences, and utilized both kinds of preferences in deriving users profiles. The userprofiling strategies were evaluated and compared with the personalized query clustering method that we proposed previously.
Our analysis show that profiles capturing both of the user’s positive and negative preferences perform the best among the userprofiling strategies studied. Apart from improving the quality of the resulting clusters, the negative preferences in the proposeduser profiles also help to separate similar and dissimilar queries into distant clusters, which helps to determine near optimalterminating points for our clustering algorithm.
Reference[1] Allan Borodin, Gareth O. Roberts, Jeffrey S. Rosenthal, Panayiotis Tsaparas. “Link Analysis Ranking: Algorithms,Theory and Experiments.” ACM Transactions on Internet
Technology (TOIT) 5:1 (2005), 231–297.[2] Franklin, Curt. “How Internet Search Engines Work”,
2002.[3] Rui Xu, , Donald Wunsch II , Survey of Clustering Algorithms, IEEE in Neural Networks 16(3) (2005)
[4] Combining Partitional and Hierarchical algorithms for robust and efficient data clustering with cohesion self merging IEEEtransactions on knowledge and data engineering 17(2) (2005) 145-159[5] Venkatesh Ganti,Johannes Gehrke,Raghu Ramakrishnan DEMON-Mining & monitoring evolving data IEEE transactions onknowledge and data engineering 13(1) (2001)
[6] Karl-Heinrich Anders, A Hierarchical Graph-Clustering Approach to find Groups of Objects, IEEE[7] J.Han and M.Kamber, Data Mining: Concepts and Techniques Morgar Kauffmann (2000) 21-25

8/4/2019 Paper-8_Clustering Analysis & Study on Deriving Concept Based User Profile From Search Engine Logs
http://slidepdf.com/reader/full/paper-8clustering-analysis-study-on-deriving-concept-based-user-profile 7/7
International Journal of Computational Intelligence and Information Security, August 2011 Vol. 2, No. 8
68
[8] Venkatesh Ganti,Johannes Gehrke,Raghu Ramakrishnan DEMON-Mining & monitoring evolving data IEEE transactions onknowledge and data engineering 13(1) (2001)[9] Lamia fhalthu ibrahim by Using of clustering approach for rural network planning third international conference on infotech
(2005)pp 1-5[10] J.Han and M.Kamber, Data Mining: Concepts and Techniques Morgar Kauffmann (2000) 21-25
[11] Kaufmann, L. & Rausseew clustering by means of k-medoids north holland Amsterdam (1987) 405-416
NagaValli Susarla pursuing M.Tech from Varadhaman College of Engineering her areas of interestinclude Networks, Semantic Web Data Mining & warehousing currently focusing on Clustering
E.R. Aruna Asso Prof from Varadhaman College of Engineering M.Tech from Padamavathi MahilaUniversity areas of include Data Mining & Warehousing
B.Deepthi pursuing M.Tech from Jaya Prakesh Narayan College of Engineering her areas of interest include Networks, Data mining & Warehousing
Mr B.V.Rama Krishna Assoc Prof M.Tech from Punjab University currently he is the head of
department at Ashok Institute of Technology, Hyderabad. His areas of interest include DataMining, Information Security.





























