Embed Size (px)
Citation preview

Discourse Structure:
Discourse Structure:Theory and Practice
Bonnie Webber1 Markus Egg2 Valia Kordoni3,4
1School of Informatics, University of Edinburgh (UK)
2Dept. of English and American Studies, Humboldt University Berlin (Germany)
3German Research Centre for Artificial Intelligence (DFKI GmbH, Germany)
4Dept. of Computational Linguistics, Saarland University (Germany)
July 4, 2011
B. Webber, et al Discourse Structure: 1
Discourse Structure:
Outline of Tutorial
1 Introduction
2 Computational approaches to discourse structure
3 Applications
4 Speculating about the future
B. Webber, et al Discourse Structure: 2
Discourse Structure:
Introduction
Outline of Part 1 (Introduction)
! What is discourse?
! What are discourse structures?
! What are the elements of discourse structures?
! What properties of these structures are relevant to LT?
B. Webber, et al Discourse Structure: 3
Discourse Structure:
Introduction
What is discourse?
Discourse and sentence sequences
Discourse usually involves a sequence of sentences.
But a discourse can be found even in a single sentence:
(1) If they’re drunkand they’re meant to be on paradeand you go to their roomand they’re lying in a pool of piss,
then you lock them up for a day.
[The Independent, 17 June 1997]
state + state + event + state ⇒ event
B. Webber, et al Discourse Structure: 4

Discourse Structure:
Introduction
What is discourse?
Discourse and sentence sequences
The patterns formed by the sentences in a discourse convey morethan each does individually.
(2) This parrot is no more.It has ceased to be.It’s expired and gone to meet its maker.This is a late parrot.It’s a stiff.Bereft of life, it rests in peace.If you hadn’t nailed it to the perch, it would be pushing upthe daisies.It’s rung down the curtain and joined the choir invisible.This is an ex-parrot. [Monty Python]
B. Webber, et al Discourse Structure: 5
Discourse Structure:
Introduction
What is discourse?
Discourse and language features
Discourse exploits language features that reveal that the speaker is
! still talking about the same thing(s).
Anaphoric expressions
(3) The police are not here to create disorder. They are here topreserve it. [Attributed to Yogi Berra]
Ellipsis
(4) Pope John XXIII was asked “How many people work in theVatican?”. He is said to have replied, “About half”.
B. Webber, et al Discourse Structure: 6
Discourse Structure:
Introduction
What is discourse?
Discourse and language features
Discourse exploits language features that reveal that the speaker is
! indicating relations that hold between states, events, beliefs,etc.
(5) Men have a tragic genetic flaw. As a result, they cannotsee dirt until there is enough of it to support agriculture.
[Paraphrasing Dave Barry, The Miami Herald - Nov. 23,2003]
B. Webber, et al Discourse Structure: 7
Discourse Structure:
Introduction
What is discourse?
Discourse and language features
Discourse exploits language features that reveal that the speaker is
! changing the topic or resuming an earlier topic.
(6) Man is now able to fly throught the air like a birdHe’s able to swim beneath the sea like a fishHe’s able to burrow beneath the ground like a moleNow if only he could walk the Earth like a man,This would be paradise.
[ Lyrics to This would be Paradise, Auf der Maur]
These are often called cue phrases or boundary features.
B. Webber, et al Discourse Structure: 8

Discourse Structure:
Introduction
What is discourse?
Discourse and language features
When these same features of language appear in a single sentence,
(7) When Pope John XXIII was asked “How many people workin the Vatican?”, he is said to have replied, “About half”.
(8) Everyone who assaults others, does so for their ownreasons.
they play the same role as they do across multiple clauses.
B. Webber, et al Discourse Structure: 9
Discourse Structure:
Introduction
What is discourse?
So what can we say about discourse?
So it’s reasonable to associate discourse with
! a sequence of sentences
! that convey more than its individual sentences through theirrelationships to one another, and
! that exploit special features of language that enable discourseto be more easily understood.
Discourse structure focuses on the second property.
B. Webber, et al Discourse Structure: 10
Discourse Structure:
Introduction
What are discourse structures?
What are discourse structures?
Discourse structures are the patterns one sees in multi-sentence(multi-clausal) texts.
Recognizing these pattern(s) and what they convey is essential toderiving intended information from the text.
Researchers in Language Technology (LT) are beginning to be ableto recognize and exploit these patterns for useful ends.
B. Webber, et al Discourse Structure: 11
Discourse Structure:
Introduction
What are the elements of discourse structures?
What are the elements of discourse structures?
At a high level,
! topics and their relationships compose structures ofexpository text;
! sentences serving particular roles compose functionalstructures;
! claims and evidence and their relationships composeargumentation structures;
! events and circumstances and their relationships composenarrative structures;
Feeding into these are low-level structures, variously calledcoherence relations, discourse relations, or rhetorical relations.
B. Webber, et al Discourse Structure: 12

Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
Properties of discourse structure relevant to LT
Properties ascribed to discourse structures have computationalimplications for LT:
! Are these structures hierarchical or flat?
! Are these structures trees or more complex graphs?
! Are these structures full or partial covers?
! Are the links of these structures symmetric or asymmetric?
B. Webber, et al Discourse Structure: 13
Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
Are DStructs hierarchical or flat?
Some discourse structures appear to have a hierarchical structure,like a sentence parse tree [Dal92, GS86, GS90, MT88, WSMP07]
For example, [Dal92] gives this recipe for Butter bean soup:
(9) Soak, drain and rinse the butter beans. Peel and chop theonion. Peel and chop the potato. Scrape and chop thecarrots. Slice the celery. Melt the butter. Add thevegetables. Saute them. Add the butter beans, the stockand the milk. Simmer. Liquidise the soup. Stir in the cream.Add the seasonings. Reheat.
For [Dal92], this has the structure on the next slide:
B. Webber, et al Discourse Structure: 14
Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
[Dale, 1992]
e
e1 e2
e3 e4 e5 e6
e10 e11 e12 e14 e16 e17
e23 e24 e25 e26 e27 e28
e7 e8 e9 e13 e15 e18 e19 e22e21e20
B. Webber, et al Discourse Structure: 15
Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
Are DStructs hierarchical or flat?
Other discourse structures appear to have a simpler linear structure[BL04, Hea97, MB06, Sib92] – e.g. Wikipedia articles:
Wisconsin Louisiana Vermont
1 Etymology Etymology Geography2 History Geography History3 Geography History Demographics4 Demographics Demographics Economy5 Law and government Economy Transportation6 Economy Law and government Media7 Municipalities Education Utilities8 ... ... ...
Linear segmentation is a less complex task than recovering anunderlying hierarchical structure.
B. Webber, et al Discourse Structure: 16

Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
Are DStructs trees or more complex graphs?
The syntactic structure of a sentence is kept a tree, in part byunderstanding more complex dependencies as semantic:
(10) Sue and John laughed and cried, respectively.
Viewed as syntactic structure:
NP and NP
NP
VP and VP
ADV
Sue John
respectively
criedlaughed
S
S
VP
S
B. Webber, et al Discourse Structure: 17
Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
Are DStructs trees or more complex graphs?
Viewed as semantic dependencies:S
NP
NPR
Suei
and NPR
Johnj
VP
V
laughedi
and V
criedj
ADV
respectively
B. Webber, et al Discourse Structure: 18
Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
Are DStructs trees or more complex graphs?
If all discourse dependencies are taken to be syntactic rather thansemantic, then discourse will indeed have a complex graphstructure.
What kind of dependencies lead to a complex graph structure, withcrossing edges and multiple directed edges into a node?
They include:
! attribution relations
! coreference relations to entities and events
B. Webber, et al Discourse Structure: 19
Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
Discourse Graph Bank [Wolf & Gibson, 2005]
(11) 1. “The administration should now state2. that3. if the February election is voided by the Sandinistas4. they should call for military aid,”5. said former Assistant Secretary of State Elliot Abrams.6. “In these circumstances, I think they’d win.” [wsj 0655]
attr
1 2 3 4 5 6
3−4
1−4
same cond attr
attr
evaluation−s
A complex graph structure makes the task of discourse parsingeven more complex.
B. Webber, et al Discourse Structure: 20

Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
Are DStructs full or partial covers?
The parse of a sentence fully covers its elements (words).
In contrast, the coherence relations in a discourse (its low-levelstructure) need not do so.
(12) “I’m sympathetic with workers who feel under the gun,”says Richard Barton of the Direct Marketing Association ofAmerica, which is lobbying strenuously against the Edwardsbeeper bill. “But the only way you can find out how yourpeople are doing is by listening.” [wsj 1058]
The coherence relation (concession) holds only between thehighlighted elements.
So recovering coherence relations (discourse chunking, Part 2.3)may be a less complex task than discourse parsing.
B. Webber, et al Discourse Structure: 21
Discourse Structure:
Introduction
What properties of discourse structures are relevant to LT?
Are the links in DStructs symmetric or asymmetric?
Rhetorical Structure Theory [MT88] takes certain discourserelations to be asymmetric, with one argument (the nucleus)more essential to the purpose of the communication than the other(the satellite).
So, Part 3.1 shows how RST-based extractive summarization takessatellites to be removable without harm [DM02].
Stede [Ste08b] argues that asymmetry in discourse has severalsources that should not be conflated: Other discourse relations aresimply symmetric.
This may be the source of problems noticed with RST-basedextractive summarization [Mar98].
B. Webber, et al Discourse Structure: 22
Discourse Structure:
Computational approaches to discourse structure
Outline of Part 2
! Recovering topic structure
! Recovering functional structure
! Recovering relational structure (Discourse Chunking)
! Recovering hierarchical structure (Discourse Parsing)
! Classifying unmarked relations
! Identifying entity structure
! Useful resources
B. Webber, et al Discourse Structure: 23
Discourse Structure:
Computational approaches to discourse structure
Recovering topic structure
Topic Structure
Expository text can be viewed as a sequence of topically coherentsegments, whose order may become conventionalized over time:
Wisconsin Louisiana Vermont
1 Etymology Etymology Geography2 History Geography History3 Geography History Demographics4 Demographics Demographics Economy5 Law and government Economy Transportation6 Economy Law and government Media7 Municipalities Education Utilities8 Education Sports Law and government9 Culture Culture Public Health10 ... ... ...
Wikipedia articles about US states
B. Webber, et al Discourse Structure: 24

Discourse Structure:
Computational approaches to discourse structure
Recovering topic structure
Topic Structure
Being able to recognize topic structure was originally seen asbenefitting information retrieval [Hea97]
Recent interest comes from the potential use of topic structure insegmenting lectures, meetings or other speech events,making them more amenable to search [GMFLJ03, MB06].
B. Webber, et al Discourse Structure: 25
Discourse Structure:
Computational approaches to discourse structure
Recovering topic structure
Topic Structure
Computational work on topic structure and segmentation takes:
! the topic of each segment to relate only to the topic of thediscourse as a whole (eg, History of Vermont → Vermont).
! sequence to be the only relation holding between sistersegments, although certain sequences may be more commonthan others (cf. Wikipedia articles).
! the topic of each segment to differ from those of its adjacentsisters. (Adjacent spans that share a topic are taken to belongto the same segment.)
! topic to predict lexical choice, either of all words of a segmentor just its content words (ie, excluding “stop-words”).
B. Webber, et al Discourse Structure: 26
Discourse Structure:
Computational approaches to discourse structure
Recovering topic structure
Topic Structure
Making topic structure explicit (ie, topic segmentation) uses either
! semantic-relatedness, where words within a segment aretaken to relate to each other more than to words outside thesegment [Hea97, CWHM01, Bes06, GMFLJ03, MB06]
! topic models, where each segment is taken to be producedby a distinct, compact lexical distribution[CBBK09, EB08a, PGKT06]
See [Pur11] for an excellent overview and survey of this work.
B. Webber, et al Discourse Structure: 27
Discourse Structure:
Computational approaches to discourse structure
Recovering topic structure
Topic Segmentation through Semantic-relatedness
All computational models that use semantic-relatedness for topicsegmentation have:
1 a metric for assessing the semantic relatedness of termswithin a proposed segment;
2 a locality that specifies what units within the text areassessed for semantic relatedness;
3 a threshold for deciding how low relatedness can drop beforeit signals a shift to another topic.
B. Webber, et al Discourse Structure: 28
Discourse Structure:
Computational approaches to discourse structure
Recovering topic structure
TextTiling [Hearst 1997]
1 Metric: Cosine similarity, using a vector representation offixed-length spans (pseudo-sentences) in terms of frequency ofword stems (ie, words from which inflection has beenremoved)
2 Locality: Cosine similarity is computed between adjacentspans (and only adjacent spans)
3 Threshold: Empirically-determined in order to select where toplace segment boundaries.
B. Webber, et al Discourse Structure: 29
Discourse Structure:
Computational approaches to discourse structure
Recovering topic structure
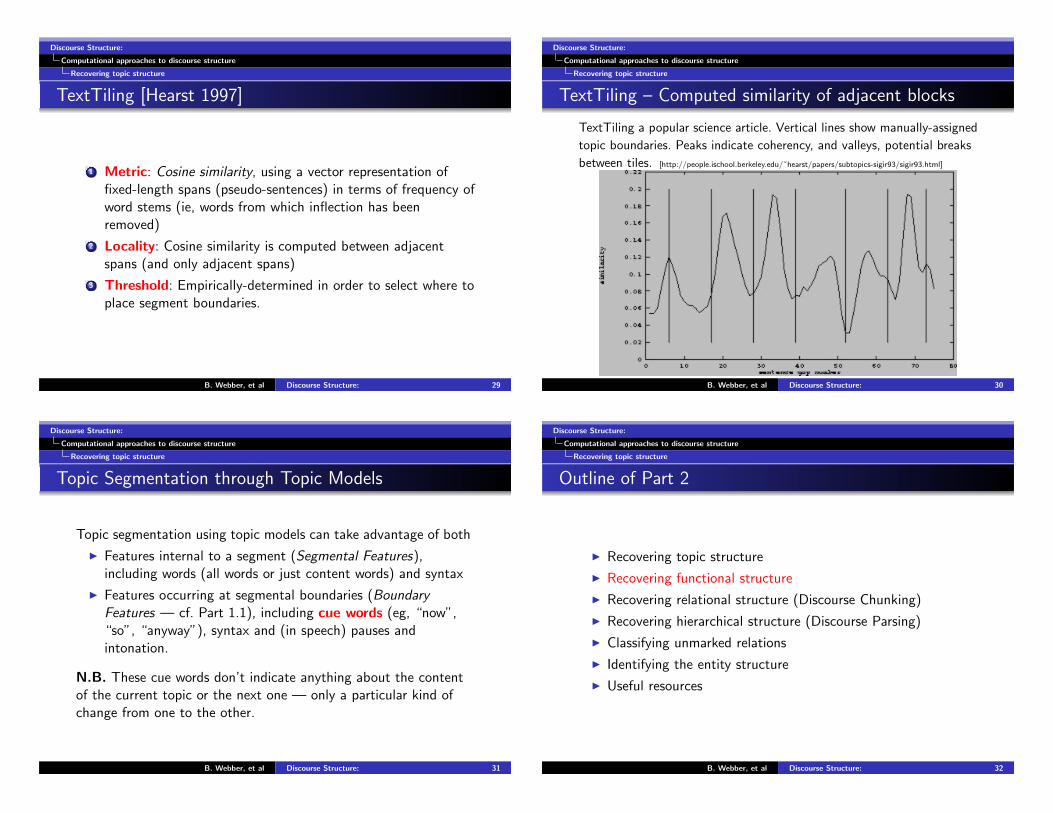
TextTiling – Computed similarity of adjacent blocks
TextTiling a popular science article. Vertical lines show manually-assigned
topic boundaries. Peaks indicate coherency, and valleys, potential breaks
between tiles. [http://people.ischool.berkeley.edu/˜hearst/papers/subtopics-sigir93/sigir93.html]
B. Webber, et al Discourse Structure: 30
Discourse Structure:
Computational approaches to discourse structure
Recovering topic structure
Topic Segmentation through Topic Models
Topic segmentation using topic models can take advantage of both
! Features internal to a segment (Segmental Features),including words (all words or just content words) and syntax
! Features occurring at segmental boundaries (BoundaryFeatures — cf. Part 1.1), including cue words (eg, “now”,“so”, “anyway”), syntax and (in speech) pauses andintonation.
N.B. These cue words don’t indicate anything about the contentof the current topic or the next one — only a particular kind ofchange from one to the other.
B. Webber, et al Discourse Structure: 31
Discourse Structure:
Computational approaches to discourse structure
Recovering topic structure
Outline of Part 2
! Recovering topic structure
! Recovering functional structure
! Recovering relational structure (Discourse Chunking)
! Recovering hierarchical structure (Discourse Parsing)
! Classifying unmarked relations
! Identifying the entity structure
! Useful resources
B. Webber, et al Discourse Structure: 32

Discourse Structure:
Computational approaches to discourse structure
Recovering functional structure
Functional discourse structure
Texts within a given genre – eg,
! news reports
! errata
! scientific papers
! letters to the editor of the New York Times
! . . .
generally share a similar structure, that is independent of topic (eg,sports, politics, disasters; or molecular genetics, radio astronomy,SMT), instead reflecting the function played by their parts.
B. Webber, et al Discourse Structure: 33
Discourse Structure:
Computational approaches to discourse structure
Recovering functional structure
Example: News Reports
Best known is the inverted pyramid structure of news reports:
! Headline
! Lead paragraph (sometimes spelled lede), conveying who isinvolved, what happened, when it happened, where ithappened, why it happened, and (optionally) how it happened
! Body, providing more detail about who, what, when, . . .
! Tail, containing less important information
This is why the first (ie, lead) paragraph is usually the bestextractive summary of a news report.
B. Webber, et al Discourse Structure: 34
Discourse Structure:
Computational approaches to discourse structure
Recovering functional structure
Example: Errata
Also recognizable are errata – declarations of errors made inprevious issue of a periodical and correct versions:
! Correct statement
! Description of error
(13) EMPIRE PENCIL, later called Empire-Berol, developedthe plastic pencil in 1973. Yesterday’s Centennial Journalmisstated the company’s name. [wsj 1751]
(14) PRINCE HENRI is the crown prince and hereditary grandduke of Luxembourg. An article in the World BusinessReport of Sept. 22 editions incorrectly referred to hisfather, Grand Duke Jean, as the crown prince. [wsj 1871]
B. Webber, et al Discourse Structure: 35
Discourse Structure:
Computational approaches to discourse structure
Recovering functional structure
Example: Scientific articles/abstracts
Well-known in academia is the multi-part structure of scientificpapers (and, more recently, their abstracts):
! Objective (aka Introduction, Background, Aim, Hypothesis)
! Methods (aka Method, Study Design, Methodology, etc.)
! Results or Outcomes
! Discussion
! Optionally, Conclusions
N.B. Not every sentence within a section need realise the samefunction: Fine-grained functional characterizations of scientificpapers show them serving a range of functions [LTSB10].
B. Webber, et al Discourse Structure: 36

Discourse Structure:
Computational approaches to discourse structure
Recovering functional structure
Functional Structure
Automatic annotation of functional structure is seen as benefitting:
! Information extraction: Certain types of information arelikely to be found in certain sections[MUD99, MUD00, Moe01]
! Extractive summarization: More “important” sentences aremore likely to be found in certain sections.
! Sentiment analysis: Words that have an objective sense inone section may have a subjective sense in another [TBS09]
! Citation analysis: A citation may serve different functions indifferent sections [Teu10]
B. Webber, et al Discourse Structure: 37
Discourse Structure:
Computational approaches to discourse structure
Recovering functional structure
Functional structure
Computational work on functional structure and segmentationassumes that:
! The function of a segment relates to the discourse as a whole.
! While relations may hold between sisters (eg, Methodsconstrain Results), only sequence has been used in modelling.
! Function predicts more than lexical choice:! indicative phrases such as “results show” (→ Results)! indicative stop-words such as “then” (→ Methods).
! Functional segments usually appear in a specific order, soeither sentence position is a feature in the models orsequential models are used.
B. Webber, et al Discourse Structure: 38
Discourse Structure:
Computational approaches to discourse structure
Recovering functional structure
Functional structure
Much computational work has ignored the internal structure ofsegments [Chu09, MS03, LKDFK06, RBC+07].
However, Hirohata et al [HOAI08] found that, within a segment:
! Properties of the first sentence differ from those of the othersentences (as in ’BIO’ approaches to Named EntityRecognition).
! Modelling this leads to improved performance in high-levelfunctional segmentation (ie, 94.3% per sentence accuracy vs.93.3%).
This accords with work in low-level (fine-grained) modelling offunctional structure [LTSB10].
B. Webber, et al Discourse Structure: 39
Discourse Structure:
Computational approaches to discourse structure
Recovering functional structure
Labelled biomedical abstracts
Functional segmentation takes biomedical abstracts with labelledsections as training data for segmenting unlabelled abstracts[Chu09, GKL+10, HOAI08, LTSB10, LKDFK06, MS03, RBC+07],
(15) BACKGROUND: Mutation impact extraction is a hithertounaccomplished task in state of the art mutation extraction systems.. . .RESULTS: We present the first rule-based approach for theextraction of mutation impacts on protein properties, categorizingtheir directionality as positive, negative or neutral.. . .CONCLUSION: . . . Our approaches show state of the art levels ofprecision and recall for Mutation Grounding and respectable level ofprecision but lower recall for the task of Mutant-Impact relationextraction. . . . [PMID 21143808]
Part 3.1 discusses segmentation of legal texts[MUD99, MUD00, Moe01] and student essays [BMAC01, BMK03]for Info Extraction.
B. Webber, et al Discourse Structure: 40

Discourse Structure:
Computational approaches to discourse structure
Recovering functional structure
Outline of Part 2
! Recovering topic structure
! Recovering genre-specific structure
! Recovering relational structure (Discourse Chunking)
! Recovering hierarchical structure (Discourse Parsing)
! Classifying unmarked relations
! Identifying the entity structure
! Useful resources
B. Webber, et al Discourse Structure: 41
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
Elements of Discourse Chunking
Like “NP chunking”, discourse chunking is a lightweightapproximation to full discourse parsing.
It produces a flat structure of (possibly overlapping) coherencerelations relations”) by identifying
1 what is relating elements in a discourse;
2 what elements are being related;
3 what type(s) of relation hold(s) between them.
B. Webber, et al Discourse Structure: 42
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From discourse connectives to their arguments
The general problems are:
1 Given a language, what affixes, words, terms and/orconstructions can serve to relate elements in a discourse (ie,as its discourse connectives)?
2 Given a particular token in context, does it serve to relatediscourse elements?
3 Given such a token, what elements does it relate (ie, itsarguments)?
4 Given such a token and its arguments, what sense relation(s)hold between the arguments?
Examples are from the Penn Discourse TreeBank (PDTB)[PDL+08]. Part 2.7 will highlight other corpora.
B. Webber, et al Discourse Structure: 43
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From DConns to their Args: Problem 1
In English, both coordinating and subordinating conjunctionsindicate a relation between discourse elements.
! Coordinating conjunctions (on clauses or sentences)
(16) Finches eat seeds, and/but/or robins eat worms.
(17) Finches eat seeds. But today, I saw them eatinggrapes.
! Subordinating conjunctions
(18) While finches eat seeds, robins eat worms.
(19) Robins eat worms, just as finches eat seeds.
B. Webber, et al Discourse Structure: 44

Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From DConns to their Args: Problem 1
In other cases, only a subset of a given part-of-speech (PoS)indicates a relation between discourse elements
! eg, not all adverbials, just discourse adverbials
(20) Robins eat both worms and seeds. Consequently theyare omnivores. (discourse adverbial)
(21) Robins eat both worms and seeds. Fortunately theyprefer worms. (sentential adverbial)
B. Webber, et al Discourse Structure: 45
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From DConns to their Args: Problem 1
Constructions other than particular parts-of-speech regularly serveto indicate a discourse relation [PDL+08, PJW10b]:
! this/that <be> why/when/how <S>
! this/that <be> before/after/while/because/if/etc. <S>
! the reason/result <be> <S>
! what’s more <S>
Both bootstrapping and back translation have been used todiscover new instances of named entities and paraphrases.
Can these same techniques be used to identify otherconstructions that can indicate discourse relations?
B. Webber, et al Discourse Structure: 46
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From DConns to their Args: Problem 1
Syntactically constrained back translation [CB08] on EuroParltranslation pairs yields many phrases that were either notannotated as discourse connectives in the PDTB or don’t appearthere – eg,
Not annotated Doesn’t appearabove all as a consequenceafter all as an example
despite that by the same token... ...
But this doesn’t reveal instances with different syntactic structurethan their source phrase, without introducing extensive noise.
B. Webber, et al Discourse Structure: 47
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From DConns to their Args: Problem 2
It is hard to decide whether an individual token signals a coherencerelation because such tokens are often syntactically ambiguous[PN09]:
(22) Asbestos is harmful once it enters the lungs.(subordinating conjunction)
(23) Asbestos was once used in cigarette filters. (adverb)
PoS-tagging can often distinguish discourse from non-discourseuse.
Even without PoS-tagging, surface cues allow discourse andnon-discourse use to be distinguished with at least 94% accuracy[PN09].
B. Webber, et al Discourse Structure: 48

Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From DConns to their Args: Problem 3
Discourse relations in all languages analyzed so far relate twoarguments:
! Arg2 – argument syntactially bound to the relation! Arg1 – the other argument
With Arg2, the challenge is whether attribution is included.
(24) We pretty much have a policy of not commenting onrumors, and I think that falls in that category.[wsj 2314]
(25) Advocates said the 90-cent-an-hour rise, to $4.25an hour by April 1991, is too small for the workingpoor, while opponents argued that the increase willstill hurt small business and cost many thousands ofjobs. [wsj 0098]
B. Webber, et al Discourse Structure: 49
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From DConns to their Args: Problem 3
Identifying Arg1 is harder because it need not be adjacent to Arg2:
1. Discourse adverbials are anaphoric. Like pronouns, they mayrefer to an entity introduced earlier in the discourse.
(26) On a level site you can provide a cross pitch to the entireslab by raising one side of the form (step 5, p. 153),but for a 20-foot-wide drive this results in an awkward5-inch (20 x 1/4 inch) slant across the drive’s width.Instead, make the drive higher at the center.
B. Webber, et al Discourse Structure: 50
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From DConns to their Args: Problem 3
2. All parts of a text are not equally essential to an argument (cf.Part 1.4):
(27) Big buyers like Procter & Gamble say there are otherspots on the globe and in India, where the seedcould be grown. ”It’s not a crop that can’t be doubled ortripled,” says Mr. Krishnamurthy. But no one has madea serious effort to transplant the crop. [wsj 0515]
Here, the quote and its attribution are not essential to the relationheaded by But, so can be excluded from Arg1.
B. Webber, et al Discourse Structure: 51
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From Discourse Connectives to their Arguments
There is a growing amount of work on automatically identifyingdiscourse connectives and locating their arguments:
! Initial results [WP07] suggest that connective specificmodels might perform better than models that just considerthe type of connective (coordinating, subordination,adverbial).
! [EB08b] show that connective specific models significantlyimprove results for discourse adverbials: (67.5% vs. 49.0%).
! [PJW10a] show that for inter-sentential ’And’, ’But’ anddiscourse adverbials, performance is significantly higher forwithin-paragraph tokens, since 4301/4373 = 98% of thetime, Arg1 is in same paragraph, simplifying the problem.
B. Webber, et al Discourse Structure: 52

Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
From Discourse Connectives to their Arguments
[LNK10] demonstrate the first end-to-end processor for discoursechunking, identifying
1 Explicit connectives, their arguments and their senses;
2 Implicit relations and their senses (only top 11 sense types,given data sparcity);
3 Attribution.
F-score results on gold standard annotation (no error propagation):
! Similar to previous results for each type of explicit connective;
! 40% for implicit connects, dropping to around 25-26% witherror propagation.
B. Webber, et al Discourse Structure: 53
Discourse Structure:
Computational approaches to discourse structure
Recovering relational structure
Outline of Part 2
! Recovering topic structure
! Recovering genre-specific structure
! Recovering relational structure (Discourse Chunking)
! Recovering hierarchical structure (Discourse Parsing)
! Classifying unmarked relations
! Identifying entity structure
! Useful resources
B. Webber, et al Discourse Structure: 54
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discouse Parsing
Discourse parsing automatically constructs a discourse structure(usually, but not always, a tree) covering the entire input text.
Discourse Parsing is useful for:
! QA
! IE
! Text-to-Text Applications (Summarisation, Paraphrasing)
! Recognising Textual Entailment
! Modeling and Evaluating Text Coherence, etc.
History of discourse parsing:
! rule-based systems – either knowledge-rich or knowledge-poor;
! more recently, systems based on ML from corpora
B. Webber, et al Discourse Structure: 55
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Rule-based Approaches
Knowledge-rich models [HSAM93, KR93, AL03]
! logic-based
! explicit representation of world knowledge in knowledge base
! discourse meaning as an extension of sentence meaning (i.e.,the aim is to find the best logical form)
B. Webber, et al Discourse Structure: 56

Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Rule-based Approaches
Knowledge-poor models [Mar97, COCO98]
! input: syntactically analysed texts
! heuristics to compute discourse structure
! no extensive semantic knowledge (no knowledge base)
! surface form (syntactic structure, deixis, anaphora, cue words,etc.) provides cues for discourse structure
B. Webber, et al Discourse Structure: 57
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Corpus-based Approaches
Corpus-based approaches [Mar99, BL05]
! supervised machine learning
! training data: e.g., RST Discourse Treebank
! discourse parsing analogous to syntactic parsing
B. Webber, et al Discourse Structure: 58
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999)
Marcu automatically derives the discourse structure of texts. Twosubtasks:
1 Find boundaries between elementary discourse units (EDUs);
2 Find rhetorical relations that connect EDUs, buildingdiscourse trees.
Marcu’s approach:
! relies on manual annotation;
! based on Rhetorical Structure Theory (RST);
! uses decision-tree learning.
B. Webber, et al Discourse Structure: 59
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999) – Annotation
The data is extracted from the following corpora:
! MUC7 corpus (30 stories);
! Brown corpus (30 scientific texts);
! Wall Street (30 editorials).
The corpora are marked up:
! elementary discourse units (EDUs);
! discourse trees in the style of RST.
B. Webber, et al Discourse Structure: 60

Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999)
Task: process each lexeme (word or punctuation mark) andrecognize sentence and EDU boundaries and parenthetical units.To generate the learning cases:
! use the leaves of the manually built discourse trees;! associate each lexeme in the text with one learning case;! associate with each lexeme one of the following classes to be
learnt: sentence-break, EDU-break, start-paren, end-paren,none.
Approach: determine a set of features that will predict theseclasses, then:
! extract features from annotated text;! use decision-tree learning to combine features and perform
segmentation.
B. Webber, et al Discourse Structure: 61
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999) – Features
Local context features:
! POS tags preceding and following the lexeme (2 before, 2after);
! discourse connectives (because, and);
! abbreviations.
Global context features, pertaining to the boundary identificationprocess:
! discourse connectives that introduce expectations (e.g., on theone hand, although [CW97];
! commas or dashes before the estimated end of the sentence;
! verbs in unit of consideration.
B. Webber, et al Discourse Structure: 62
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999) – Results
Corpus B1 (%) B2 (%) DT (%)
MUC 91.28 93.1 96.24WSJ 92.39 94.6 97.14Brown 93.84 96.8 97.87
! B1: defaults to none;
! B2: defaults to sentence-break for every full-stop and noneotherwise;
! DT: decision tree classifier.
B. Webber, et al Discourse Structure: 63
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999) – Discourse Structure
Task: determine rhetorical relations and construct discourse treesas defined by RST.
Approach:
! exploit RST trees created by annotators;
! map tree structure onto shift/reduce operations;
! extract features for these operations;
! distinguish nuclei and satellites (following RST).
B. Webber, et al Discourse Structure: 64

Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999) – Discourse Structure
Operations:
! 1 shift operation;
! 3 reduce operations: relation-ns, relation-sn,relation-nn.
Rhetorical relations:
! taken from RST;
! 17 in total: contrast, purpose, evidence, example,elaboration, etc.
B. Webber, et al Discourse Structure: 65
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999) – Discourse StructureFeatures
Features used for decision tree classifier for operations:
! structural : rhetorical relations that link the immediate childrenof the link nodes;
! lexico-syntactic: discourse markers and their position;
! operational : last five operations;
! semantic: similarity between trees (bags of words).
B. Webber, et al Discourse Structure: 66
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999) – Discourse StructureResults
Corpus B3 (%) B4 (%) DT (%)
MUC 50.75 26.9 61.12WSJ 50.34 27.3 61.65Brown 50.18 28.1 61.81
! B3: defaults to shift;
! B4: chooses shift and reduce operations randomly;
! DT: decision tree classifier.
B. Webber, et al Discourse Structure: 67
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Marcu (1999) – Discourse StructureResults
Strengths:
! First fully automated system for parsing discourse structure.
Weaknesses:
! relies on manual annotation, which is time-consuming anddifficult.
Getting around manual annotation requires ability to automaticallyannotate both marked and unmarked discourse relations.
B. Webber, et al Discourse Structure: 68

Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Discourse Parsing: Summary
! knowledge-based systems:! few real implementations for small and well-defined domains
! heuristics-based systems:! relatively good for easy cases, with bad coverage, though, for
unmarked relations
! corpus-trained systems:! few annotated data available! accuracy approx. 60%
There may be many applications for which full discourse parsingmay not necessary.
B. Webber, et al Discourse Structure: 69
Discourse Structure:
Computational approaches to discourse structure
Recovering hierarchical structure
Outline of Part 2
! Recovering topic structure
! Recovering genre-specific structure
! Recovering relational structure (Discourse Chunking)
! Recovering hierarchical structure (Discourse Parsing)
! Classifying unmarked relations
! Identifying the entity structure
! Useful resources
B. Webber, et al Discourse Structure: 70
Discourse Structure:
Computational approaches to discourse structure
Classifying unmarked relations
Classifying Unmarked Relations
In both discourse chunking and discourse parsing, there may be nospecific cue (e.g., a discourse connective) of the relation that holdsbetween elements.
For otherwise unmarked relations, evidence for the relation may bederivable from other features.
(28) [ A car had broken down on an unmanned level crossingand was hit by a high speed train. ][ The train derailed. ]→ Result
(29) [ The damage to the train was substantial, ][ fortunately nobody was injured]→ Contrast
B. Webber, et al Discourse Structure: 71
Discourse Structure:
Computational approaches to discourse structure
Classifying unmarked relations
Classifying unmarked relations
To derive a classifier, considerable training data is needed (here,pairs of discourse elements annotated with the discourse relationsholding between them).
! start with manually annotated texts;
! perform active learning [NM01];
! automatically label training data [ME02].
B. Webber, et al Discourse Structure: 72

Discourse Structure:
Computational approaches to discourse structure
Classifying unmarked relations
Automatic Labeling of Data: Marcu and Echihabi (2002)
Data:
! 4 relations from RST [MT87]: contrast,cause-explanation-evidence, condition, elaboration;
! 2 non-relations: no-relation-same-text,no-relation-different-text;
! 900,000 to 4 million automatically labelled examples perrelation, derived from clauses connected by relativelyunambiguous subordinating or coordinating conjunctions.
Model:
! Naive Bayes! Word co-occurence features taken to predict the relation
indicated by the explicit conjunction found between theclauses.
B. Webber, et al Discourse Structure: 73
Discourse Structure:
Computational approaches to discourse structure
Classifying unmarked relations
Automatic Labeling of Data: Marcu and Echihabi (2002)
Results:
! test on automatically labelled data: 49.7% accuracy for 6-wayclassifier
! test on manually labelled examples from RST-DT (markedand unmarked) without removing discourse connectives fromtraining data and by using binary classifiers: 63% to 87%accuracy
! test on manually labelled, unmarked examples using binaryclassifiers (contrast vs. elaboration, andcause-explanation-evidence vs. elaboration): 69.5% recall forcontrast, 44.7% recall for cause-explanation-evidence
Subsequent work has used manually-labelled unmarked relationsfrom the PDTB and other corpora (cf. Part 2.7).
B. Webber, et al Discourse Structure: 74
Discourse Structure:
Computational approaches to discourse structure
Classifying unmarked relations
Outline of Part 2
! Recovering topic structure
! Recovering genre-specific structure
! Recovering relational structure (Discourse Chunking)
! Recovering hierarchical structure (Discourse Parsing)
! Classifying unmarked relations
! Identifying entity structure
! Useful resources
B. Webber, et al Discourse Structure: 75
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Coherence and entity structure
Coherence
! is a property of well-written texts;
! makes them easier to read and understand;
! ensures that sentences are meaningfully related.
The way entities are introduced and discussed influences coherence[GJW95].
By ignoring this, extractive summaries can appear incoherent.
B. Webber, et al Discourse Structure: 76

Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Coherence and entity structure
Summary A
Britain said!" #$he did not have
diplomatic immunity. TheSpanish authorities contend that!" #$Pinochet may have committedcrimes against Spanish citizens inChile.
!" #$Baltasar Garzon!" #$filed a request on Wednesday.Chile said, President!" #$Fidel Castro said Sunday hedisagreed with the arrest inLondon.
Summary B
Former Chilean dictator AugustoPinochet, was arrested in Londonon 14 October 1998. Pinochet,82, was recovering from surgery.The arrest was in response to anextradition warrant served by aSpanish judge. Pinochet wascharged with murderingthousands, including manySpaniards. Pinochet is awaiting ahearing, his fate in the balance.American scholars applauded thearrest.
B. Webber, et al Discourse Structure: 77
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Centering Theory
! Salience is associated (inter alia) with referring forms (headedNP or pronoun) and syntactic position (eg, subject, object,indirect object).
! Entities referred to in an utterance are ranked by salience.
! Each utterance has one center (topic or focus).
! Coherent discourse have utterances with common centers.
! Entity transitions capture degrees of coherence (e.g., inCentering theory continue > shift.)
B. Webber, et al Discourse Structure: 78
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Entity-based Local Coherence
John went to his favouritemusic store to buy a piano.
He had frequented the storefor many years.
He was excited that he couldfinally buy a piano.
He arrived just as the storewas closing for the day.
John went to his favouritemusic store to buy a piano.
It was a store John had fre-quented for many years.
He was excited that he couldfinally buy a piano.
It was closing just as Johnarrived.
B. Webber, et al Discourse Structure: 79
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
The Entity Grid
Can we compute entity structure automatically?
! Does it capture coherence characteristics?
! What linguistic information matters for coherence?
! Is it robust across domains and genres?
What is an appropriate coherence model?
! View coherence rating as a machine learning problem.
! Learn a ranking function without manual involvement.
! Apply to text-to-text generation tasks.
Inspired by Centering Theory, rather than a direct implementation.
B. Webber, et al Discourse Structure: 80

Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
The Entity Grid
1 Former Chilean dictator Augusto Pinochet, was arrested inLondon on 14 October 1998.
2 Pinochet, 82, was recovering from surgery.3 The arrest was in response to an extradition warrant served
by a Spanish judge.4 Pinochet was charged with murdering thousands, including
many Spaniards.5 He is awaiting a hearing, his fate in the balance.6 American scholars applauded the arrest.
B. Webber, et al Discourse Structure: 81
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
The Entity Grid
1!" #$Former Chilean dictator Augusto Pinochet S, was arrested
in!" #$London X on
!" #$14 October X 1998.
2!" #$Pinochet S, 82, was recovering from
%& '(surgery X.
3!" #$The arrest S was in
%& '(response X to!" #$an extradition warrant X
served by!" #$a Spanish judge S.
4!" #$Pinochet S was charged with murdering
!" #$thousands O, in-
cluding many!" #$Spaniards O.
5!" #$Pinochet S is awaiting
!" #$a hearing O,!" #$his fate X in!" #$the balance X.
6!" #$American scholars S applauded the
%& '(arrest O.
B. Webber, et al Discourse Structure: 82
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
The Entity Grid
1 PinochetS LondonX OctoberX2 PinochetS surgeryX
3 arrestS response X warrantX judgeO
4 PinochetS thousandsO SpaniardsO5 PinochetS hearingO PinochetX fateX balanceX
6 scholarsS arrestO
B. Webber, et al Discourse Structure: 83
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
The Entity Grid
Pin
oche
t
Lon
don
Oct
ober
Sur
gery
Arr
est
War
rant
Judg
e
Tho
usan
ds
Spa
niar
ds
Hea
ring
Fat
e
Bal
ance
Sch
olar
s
123456
B. Webber, et al Discourse Structure: 84

Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
The Entity Grid
S X X – – – – – – – – – – –S – – X – – – – – – – – – –– – – – S X X O – – – – – –S – – – – – – – O O – – – –S – – – – – – – – – O X X –– – – – O – – – – – – – – S
B. Webber, et al Discourse Structure: 85
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Entity Transitions
Definition A local entity transition is sequence {s, o, x, –}n thatrepresents entity occurrences and their syntactic roles in n adjacentsentences.
Feature Vector Notation Each grid xij for document di isrepresented by a feature vector:
Φ(xij) = (p1(xij), p2(xij), . . . , pm(xij))
m is the number of predefined entity transitionspt(xij) the probability of transition t in grid xij
B. Webber, et al Discourse Structure: 86
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Entity Transitions
Example (transitions of length
2)
SS
SO
SX
S–
OS
OO
OX
O–
XS
XO
XX
X–
–S
–O
–X
––
d1 0 0 0 .03 0 0 0 .02 .07 0 0 .12 .02 .02 .05 .25d2 0 0 0 .02 0 .07 0 .02 0 0 .06 .04 0 0 0 .36d3 .02 0 0 .03 0 0 0 .06 0 0 0 .05 .03 .07 .07 .29
B. Webber, et al Discourse Structure: 87
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Linguistic Dimensions
Salience: Are some entities more important than others?
! Discriminate between salient (frequent) entities and the rest.
! Collect statistics separately for each group.
Coreference: What is its contribution?
! Entities are coreferent if they have the same surface form.
! Coreference resolution tool [NC02].
Syntax: Does syntactic knowledge matter?
! Use four categories { S, O, X,– }.! Reduce categories to { X,– }.
B. Webber, et al Discourse Structure: 88

Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Learning a Ranking Function
Training Set:Ordered pairs (xij , xik), where xij and xik represent the samedocument di , and xij is more coherent than xik (assume j > k).
Goal:Find a parameter vector !w such that:
!w · (Φ(xij)− Φ(xik)) > 0 ∀j , i , k such that j > k
Support Vector Machines:Constraint optimization problem can be solved using the searchtechnique described in [Joa02]; see also [TMM04] for anapplication to parse selection.
B. Webber, et al Discourse Structure: 89
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Text Ordering
Motivation:
! Determine a sequence in which to present a set ofinformation-bearing items.
! Information-ordering is used to evaluate text structuringalgorithms.
! Essential step in generation applications.
Data:
! Source document and permutations of its sentences.
! Original order assumed coherent.
! Given k documents, with n permutations, we obtain k · npairwise rankings for training and testing.
! Two corpora, Earthquakes and Accidents, 100 texts each.
B. Webber, et al Discourse Structure: 90
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Text Ordering
Sentence 1Sentence 2Sentence 3Sentence 4
Sentence 2Sentence 3Sentence 4Sentence 1
Sentence 4Sentence 3Sentence 2Sentence 1
Sentence 2Sentence 1Sentence 4Sentence 3
B. Webber, et al Discourse Structure: 91
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Comparison with LSA Vector Model [FKL98]
! Meaning of individual words is represented in vector space.
! Sentence meaning is the mean of the vectors of its words.
! Average distance of adjacent sentences.
! Unsupervised, local, unlexicalised, domain independent.
B. Webber, et al Discourse Structure: 92

Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Comparison with HMM-based Model [BL04]
! Model topics and their order in text.
! Model is an HMM: states correspond to topics (sentences).
! Model selects sentence order with highest probability.
! Supervised, global, lexicalized, domain dependent.
B. Webber, et al Discourse Structure: 93
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Results
Model Earthquakes Accidents
Coreference+Syntax+Salience+ 87.2 90.4Coreference+Syntax+Salience− 88.3 90.1Coreference+Syntax−Salience+ 86.6 88.4∗∗
Coreference−Syntax+Salience+ 83.0∗∗ 89.9Coreference+Syntax−Salience− 86.1 89.2Coreference−Syntax+Salience− 82.3∗∗ 88.6∗
Coreference−Syntax−Salience+ 83.0∗∗ 86.5∗∗
Coreference−Syntax−Salience− 81.4∗∗ 86.0∗∗
HMM-based Content Models 88.0 75.8∗∗
Latent Semantic Analysis 81.0∗∗ 87.3∗∗
Evaluation metric: % correct ranks in test set.∗∗: significant different from Coreference+Syntax+Salience+
B. Webber, et al Discourse Structure: 94
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Results
! Omission of coreference causes performance drop.
! Linguistically poor model generally worse.
! Entity model is better than LSA.
! HMM-based content models exhibit high variability.
! Models seem to be complementary.
This appears a fruitful area, in which work is continuing.
B. Webber, et al Discourse Structure: 95
Discourse Structure:
Computational approaches to discourse structure
Identifying entity structure
Outline of Part 2
! Recovering topic structure
! Recovering genre-specific structure
! Recovering relational structure (Discourse Chunking)
! Recovering hierarchical structure (Discourse Parsing)
! Classifying unmarked relations
! Identifying the entity structure
! Useful resources
B. Webber, et al Discourse Structure: 96

Discourse Structure:
Computational approaches to discourse structure
Useful resources
Useful resources
English
! RST Discourse TreeBank [CMO03]http://www.ldc.upenn.edu, CatalogEntry=LDC2002T07
! Discourse Graph Bank [WG05]http://www.ldc.upenn.edu, CatalogEntry=LDC2005T08
! Penn Discourse TreeBank [PDL+07, PDL+08]http://www.ldc.upenn.edu, CatalogEntry=LDC2008T05
Dutch
! Discourse-annotated Dutch corpus [vdVBB+11]
German
! Potsdam Commentary Corpus [Ste04]
B. Webber, et al Discourse Structure: 97
Discourse Structure:
Computational approaches to discourse structure
Useful resources
Useful resources
Danish, English, German, Italian and Spanish
! Copenhagen Dependency TreeBank [BKrKeM09]Parallel treebanks (˜40K words per language)http://code.google.com/p/copenhagen-dependency-treebank/wiki/CDT
Turkish
! METU Turkish Discourse Resource[ZW08, ZTB+09, ZDSc+10]http://www.ii.metu.edu.tr/research group/metu-turkish-discourse-resource-project
B. Webber, et al Discourse Structure: 98
Discourse Structure:
Computational approaches to discourse structure
Useful resources
Useful resources
Hindi
! Hindi Discourse Relation Bank [OPK+09] 200K words corpusfrom the newspaper Amar Ujala
Arabic
! Leeds Arabic Discourse TreeBank [ASM10, ASM11]
B. Webber, et al Discourse Structure: 99
Discourse Structure:
Computational approaches to discourse structure
Useful resources
Multi-layer resources 1
Resources mentioned so far have one layer of discourse annotation.
! But annotating multiple discourse structures is revealing.
! e.g., the structure of condition coherence relations in (30)differs from its intentional structure in terms of motivation
(30) (a) Come home by five o’clock. (b) Then we can go to thehardware store. (c) That way we can finish thebookshelves tonight.
Informational Relations Intentional Relationscondition
condition
a b
c
motivation
a motivation
b c
B. Webber, et al Discourse Structure: 100

Discourse Structure:
Computational approaches to discourse structure
Useful resources
Multi-layer resources 2
Multi-level annotation [KOOM01, PSEH04] can handle this.
Multi-level annotation of discourse is not new.
! the Potsdam Commentary Corpus (PCC) [Ste04] annotatesboth coreference and discourse connectives and theirarguments
! Complementing the Penn Discourse Treebank (PDTB)[PDL+07, PDL+08] annotation of discourse relations is entitycoreference annotation in the OntoNotes project [HMP+06]
In multi-level discourse annotation, discourse structures themselvesform multiple layers.
B. Webber, et al Discourse Structure: 101
Discourse Structure:
Computational approaches to discourse structure
Useful resources
Multi-layer resources 3
The new PCC resource [Ste08a] distinguishes four layers
! conjunctive (aka coherence) relations: read off the text surface
! intentional structure: the speaker’s intention
! thematic structure: what the discourse and its parts are about
! referential structure: coreference relations
Typically, conjunctive relations link only parts of a discourse
! the majority of discourse relations is not signalled explicitly
B. Webber, et al Discourse Structure: 102
Discourse Structure:
Computational approaches to discourse structure
Useful resources
Multi-layer resources 4
The atomic segments of intentional structures are classified as‘speech acts’
! examples: ‘stating an option’, ‘making a suggestion’
These speech acts combine into larger units though relations like
! ‘encourage acting’ (≈ motivation in RST)
! ‘ease understanding’ (≈ background)
Segments can simultaneously enter conjunctive and intentionalrelations on different levels of the annotation.
B. Webber, et al Discourse Structure: 103
Discourse Structure:
Computational approaches to discourse structure
Useful resources
Multi-layer resources 5
The AMI meeting corpus (http://corpus.amiproject.org/) — richlyannotated with dialogue acts — has recently been annotated withrhetorical relations [PPB11], relating both semantic content andcommunicative function.
(31) B1: I’m afraid we have no time for that.B2: We’re supposed to finish this before twelve. [AMImeeting corpus ES2002a]
B2 has an Explanation relation to the Decline Request actin B1.
B. Webber, et al Discourse Structure: 104

Discourse Structure:
Applications
Outline of Part 3
! Summarization
! Information Extraction
! Essay analysis and scoring
! Sentiment analysis and opinion mining
B. Webber, et al Discourse Structure: 105
Discourse Structure:
Applications
Summarization
Summarization 1
Summarization is one of the earliest applications of discoursestructure analysis.
It motivated much research on theories of hierarchical discoursestructure (e.g., RST) [OSM94, Mar00a, TvdBPC04]
Discourse segmentation is also applied to summarization.
There are different types of summarizers:
! based on hierarchical or sequential discourse structure,
! designed for different kinds of documents,
! using different ways of identifying discourse structure.
B. Webber, et al Discourse Structure: 106
Discourse Structure:
Applications
Summarization
Summarization 2
Summarization based on hierarchical discourse structure
! This kind of summarization exploits the asymmetry of manydiscourse relations (slide 22).
! Information in nuclei is more central than the one in a satellite.
! Most satellites can be left out without diminishing thereadability of a text.
! From a hierarchical structure, one can derive a partial orderingof units according to importance.
! Advantage: cutoff points can be chosen freely, which makessummarisation scalable.
! Different ways of weighing units yield similar results [UPN10].
B. Webber, et al Discourse Structure: 107
Discourse Structure:
Applications
Summarization
Summarization 3
With its distant orbit (...), (C1) Mars experiences frigid weatherconditions. (C2) Surface temperatures typically average about -60degrees Celsius (-76 degrees Fahrenheit) at the equator (...). (C3)Only the midday sun at tropical latitudes is warm enough to thawice on occasion, (C4) but any liquid water formed in this waywould evaporate almost instantly (C5) because of the lowatmospheric pressure. (C6) Although the atmosphere holds a smallamount of water (...), (C7) most Martian weather involves blowingdust or carbon dioxide. (C8) Each winter, for example, a blizzard offrozen carbon dioxide rages over one pole (...). (C9) Yet even onthe summer pole (...) temperatures never warm enough to meltfrozen water. (C10)
(example from [Mar00b])
B. Webber, et al Discourse Structure: 108

Discourse Structure:
Applications
Summarization
Summarization 4
! The discourse structure tree of [Mar00b] for this example:
! The resulting equivalence classes for the segments:2 > 8 > 3, 10 > 1, 4, 5, 7, 9 > 6
B. Webber, et al Discourse Structure: 109
Discourse Structure:
Applications
Summarization
Summarization 5
Summarization based on hierarchical discourse structure (ctd)
! This approach instantiates extractive summarization, whichselects the most important sentences of a text.
! This is in contrast with sentence simplification systems, whichshorten (‘compress’) the individual sentences.
! It is used for summaries representing textual content [DM02].! There are other goals for summarization:
! Indicative summary: Is a text worth while reading? [BE97]! For scientific articles: highlight their contribution and relate it
to previous work [TM02].
! Bottleneck: automatic parsing of unrestricted discourse.
! Alleviation: underspecification of discourse structure [Sch02].
B. Webber, et al Discourse Structure: 110
Discourse Structure:
Applications
Summarization
Summarization 6
Summarization based on flat genre-specific discourse structure
! [TM02] use discourse segmentation (‘argumentative zoning’)for the summarization of scientific articles.
! They assume a structure of scientific papers comprising:! Aim (research goal),! Textual (outline of paper),! Own (own contribution; methods, results, discussion),! Other (presentation of other work).
! They classify sentences for membership in these classes.
! Summarization can then focus on specific parts of the paper.
B. Webber, et al Discourse Structure: 111
Discourse Structure:
Applications
Summarization
Summarization 7
Mostly, the types of documents to be summarized are news articlesor scientific articles.
Their structure is radically different - and so are ways ofapproaching their summarisation.
! The first sentences of news articles are often good summaries(due to their ‘inverted pyramid’ structure, see slide 34).
! For scientific articles, core sentences are more evenlydistributed.
Summarizers are optimized for one class of documents, e.g., theone of [Mar00a] targets essays and argumentative texts.
B. Webber, et al Discourse Structure: 112

Discourse Structure:
Applications
Summarization
Summarization 8
Discourse structure can be identified by cue phrases (e.g.,discourse markers) or punctuation [Mar00b].
[TM02]’s features include location in the document, length, andlexical and phrasal cue elements (e.g., along the lines of ).
[BE97, CL10] use lexical chains:
! They are useful for extraction and compression: identificationof summary-worthy sentences or key expressions.
! Strength of lexical chains is calculated in terms of chainlength/homogeneity or amount of units covered.
B. Webber, et al Discourse Structure: 113
Discourse Structure:
Applications
Summarization
Outline of Part 3
! Summarization
! Information Extraction
! Essay analysis and scoring
! Sentiment analysis and opinion mining
B. Webber, et al Discourse Structure: 114
Discourse Structure:
Applications
Information Extraction
Information Extraction 1
Information Extraction (IE) extracts from texts named entities andtheir roles in event descriptions.
! Named entities comprise persons, organizations, or locations.
IE systems focus on specific domains (e.g., terrorist incidents),searching only for information relevant to the domain.
Often, requests for information are described by templates:
Name: %MURDERED%Event Type: MURDERTriggerWord: murderedActivating Conditions: passive-verbSlots: VICTIM <subject>(human)
PERPETRATOR<prep-phrase, by>(human)INSTRUMENT<prep-phrase, with>(weapon)
B. Webber, et al Discourse Structure: 115
Discourse Structure:
Applications
Information Extraction
Information Extraction 2
Discourse structure is used to guide the selection of parts of adocument which are relevant for IE
This is part of a larger tendency towards a two-step IE
! identify relevant regions for a specific piece of information first
! then try to extract this piece of information from these regions
This boosts the overall performance of IE systems [PR07]:
! many fewer false multiple retrievals of fillers for the same slot,
! fewer false hits (often in irrelevant parts) ,
! a more confident search in the relevant parts.
B. Webber, et al Discourse Structure: 116

Discourse Structure:
Applications
Information Extraction
Information Extraction 3
Discourse structure information helps identify relevant parts ofdocuments with a strongly conventionalised structure.
Different kinds of discourse structure can be used for IE:
! a flat discourse structure based on [TM02]’s argumentativezoning (see slide 111) for biology articles [MKMC06],
! the top levels of a hierarchical discourse structure[MUD99, MUD00],
! the lower levels of a hierarchical discourse structure [MC07].
B. Webber, et al Discourse Structure: 117
Discourse Structure:
Applications
Information Extraction
Information Extraction 4
Example 1: extracting the novel contribution of a scientific paper.
! Discourse parts expressing results might report earlier work.
! Argumentative zoning identifies parts with novel contributions.
! [MKMC06] refine the Own class of [TM02] into Method ,Result, Insight, and Implication.
! Then they investigate the distribution of these subclassesacross the common fourfold division of scientific articles in:Introduction, Materials and methods, Results, and Discussion.
! Subclasses and divisions do not correlate perfectly:! high for Materials and methods vs. Method ,! low for Results vs. Result.
B. Webber, et al Discourse Structure: 118
Discourse Structure:
Applications
Information Extraction
Information Extraction 5
Example 2: extraction of offences and verdicts from criminal cases.
! The structure of this genre is highly conventionalized.
! Discourse parsing is used to identify the parts that convey thisinformation [MUD99, MUD00].
! The top part of the hierarchical discourse structure for legaltexts is follows a fixed order.
! This information is then the basis for short indicativesummaries.
B. Webber, et al Discourse Structure: 119
Discourse Structure:
Applications
Information Extraction
Outline of Part 3
! Summarization
! Information Extraction
! Essay analysis and scoring
! Sentiment analysis and opinion mining
B. Webber, et al Discourse Structure: 120

Discourse Structure:
Applications
Essay analysis and scoring
Essay analysis and scoring 1
Here, the overall goal is improving essay quality by giving feedbackon its organizational structure.
For this, specific discourse elements in an essay are identified.
The elements are part of a non-hierarchical genre-specificconventional discourse structure (slide 34).
First, thesis statements are automatically identifed [BMAC01]:
! They explicate purpose and/or main ideas of the essay.
! This can itself serve as feedback to the authors.
! Assessing essay structure centers around the thesis statement.
B. Webber, et al Discourse Structure: 121
Discourse Structure:
Applications
Essay analysis and scoring
Essay analysis and scoring 2
For the automatic identification of thesis statements, probabilisticclassifiers are trained on corpora of manually annotated essays.
Features include position in the essay and specific lexical items.
RST-based features (relation, nuclearity) are obtained fromdiscourse parsing [SM03].
This approach generalizes across essay topics.
B. Webber, et al Discourse Structure: 122
Discourse Structure:
Applications
Essay analysis and scoring
Essay analysis and scoring 3
This approach was extended to identify the main parts of anargumentative essay:
! introductory material,! thesis,! main idea [thesis + main idea(s) = thesis statement],! supporting ideas,! conclusion [BMK03].
(32) <Introductory material> I’ve seen many successfulpeople who are doctors, artists, teachers, designers, etc.</Introductory material> <Main point> In myopinion they were considered successful people becausethey were able to find what they enjoy doing and workedhard for it. </Main point>
B. Webber, et al Discourse Structure: 123
Discourse Structure:
Applications
Essay analysis and scoring
Essay analysis and scoring 4
Two kinds of discourse analysers are used to identify the mainparts of an argumentative essay:
! decision-based, with the features discourse structure markers(not parsing), syntactic structure, and position in the essay,
! stochastic, targeting sequences of segments (e.g., noconclusion at the beginning).
Combining the best analysers in a voting system optimizes results.
B. Webber, et al Discourse Structure: 124

Discourse Structure:
Applications
Essay analysis and scoring
Essay analysis and scoring 5
The next level is to assess the internal coherence of the essay.
This presupposes identification of the discourse units in an essay.
[HBMG04] define coherence in terms of relatedness of units:
! to the essay topic (in particular, for thesis statement,background, and conclusion),
! to thesis (especially for main ideas, background material, andconclusion),
! within units.
Relatedness is modelled as semantic similarity, i.e., the amount ofterms in the same semantic domain.
B. Webber, et al Discourse Structure: 125
Discourse Structure:
Applications
Essay analysis and scoring
Outline of Part 3
! Summarization
! Information Extraction
! Essay analysis and scoring
! Sentiment analysis and opinion mining
B. Webber, et al Discourse Structure: 126
Discourse Structure:
Applications
Sentiment analysis and opinion mining
Sentiment analysis and opinion mining 1
Its goal is to assess the overall opinion expressed in a review.
The impact of evaluative words in a text is rated and a score forthe text is calculated.
But this impact depends on their position in the discourse.
As a first approximation, evaluative words can get more weight atthe beginning and the end [PLV02] or only at the end [VT07].
As a second approximation, discourse markers can be used toweigh evaluative words [PZ04].
(33) Though Al is brilliant at math, he is a horrible teacher.
B. Webber, et al Discourse Structure: 127
Discourse Structure:
Applications
Sentiment analysis and opinion mining
Sentiment analysis and opinion mining 2
But such approaches will encounter problems in cases like (34):
(34) Aside from a couple of unnecessary scenes, The SixthSense is a low-key triumph of mood and menace; the mostshocking thing about it is how hushed and intimate it is,how softly and quietly it goes about its business ofcreeping us out. The movie is all of a piece, which isprobably why the scenes in the trailer, ripped out ofcontext, feel a bit cheesy.
B. Webber, et al Discourse Structure: 128

Discourse Structure:
Applications
Sentiment analysis and opinion mining
Sentiment analysis and opinion mining 3
The central statement in (34) is the second clause.
Its evaluative word triumph outweighs the majority of negativeevaluative words.
A related observation is that evaluative words in highly topicalsentences get higher weight [PL05, Tur02].
Appraisal Analysis [Mar00c] refines the notion of opinion bydistinguishing three components:
! affect (emotional),
! judgement (ethical),
! appreciation (aesthetic).
B. Webber, et al Discourse Structure: 129
Discourse Structure:
Applications
Sentiment analysis and opinion mining
Sentiment analysis and opinion mining 4
Movie reviews are also complicated because they are a mixture ofdescriptive and evaluative segments.
Evaluative words in descriptive segments do not count [PLV02].
(35) I love this movie
(36) The colonel’s wife (played by Deborah Kerr) loves thecolonel’s staff sergeant (played by Burt Lancaster).
This calls for a discourse analysis of evaluative texts.
! [TBS09] successfully include discourse-structure information ina system that classifies reviews as either positive or negative.
! Argumentative zoning works better here than discourseparsing [VT07, TBS09].
B. Webber, et al Discourse Structure: 130
Discourse Structure:
Speculating about the future
Outline of Part 4
In the next 5-10 years, we expect to see:
! Improved recognition of discourse structures
! New applications of discourse structures – in particular,Machine Translation
B. Webber, et al Discourse Structure: 131
Discourse Structure:
Speculating about the future
Improved recognition
Improved recognition of discourse structures
Theory: Better understanding of
! each type of discourse structure;
! relations between different types/layers of structure.
Practice: More training data through
! Easier, cheaper ways acquisition of manual annotation;
! More effective use of unlabelled data.
B. Webber, et al Discourse Structure: 132

Discourse Structure:
Speculating about the future
Improved recognition
New Applications
(Statistical) Machine Translation could draw benefits from threeaspects of discourse structure:
! Segments of topic structure and functional structure vary intheir syntactic and lexical features;
! Relational and hierarchical structure convey meaning throughstructure;
! With entity structure, reference is constrained throughstructure.
B. Webber, et al Discourse Structure: 133
Discourse Structure:
Speculating about the future
New applications
Topic Structure and Machine Translation (MT)
◦ Text heterogeneity across topic and functional structures can beexploited to improve translation.
⇒ Tailor sub-language models to sub-structure. Overcome lack ofa natural back-off strategy for gaps in data [FIK10].
◦ Propagation of corrections made in post-editting a document canalready improve translation to the rest [HE10].
◦ For highly structured documents such as patents, correctionsmade to near-by sentences provide more value than correctionsfurther away [HE10].⇒ Given a source text annotated with topic structure breaks, onecould focus correction propagation to all/only sentences within thesame segment of topic or functional structure.
B. Webber, et al Discourse Structure: 134
Discourse Structure:
Speculating about the future
New applications
Entity Structure and Statistical MT
Anaphors (pronouns and 0-anaphors) are constrained by theirantecedents in all languages, but in different ways.
! English: Pronoun gender reflects the referent of theantecedent.
! French, German, Czech: Pronoun gender reflects the form ofthe antecedent.
(37) a. Here’s a book. I wonder if it is new. (inanimate,neuter referent)
b. Voici un livre. Je me demande si il est nouveau.(masculine form)
B. Webber, et al Discourse Structure: 135
Discourse Structure:
Speculating about the future
New applications
Entity Structure and SMT
Phrase-based and syntax-based SMT just consider the localcontext - cf. Google translate
(38) I wonder if it is new.Google translate: Je me demande si elle est nouvelle.
(39) I wondered if it was new.Google translate: Je me demandais si il etait neuf.
B. Webber, et al Discourse Structure: 136

Discourse Structure:
Speculating about the future
New applications
Entity Structure and SMT
Recognizing entity structures in a source text links anaphors totheir antecedents, potentially allowing appropriate anaphoric formsto be projected into the target.
Preliminary work [NK10, HF10] is based on annotating source text:
! Identify the antecedent(s) of a source language pronounthrough anaphor resolution;
! Identify the gender of the target text aligned with thatantecedent;
! Annotate the source text pronoun with this gender, and usethe annotated text to produce a translation model;
! Annotate source text pronouns with their antecedents in testdata, to make use of this enriched translation model.
B. Webber, et al Discourse Structure: 137
Discourse Structure:
Speculating about the future
New applications
Relational structure and SMT
◦ Aspects of meaning are conveyed through relational structures,that can be marked by discourse connectives.
◦ Discourse connectives cover different senses in differentlanguages.
! Since in English can express either an explanation (likebecause) or a temporal relation (like after).
! Puisque in French expresses only the former sense, whiledepuis expresses only the latter.
⇒ Preliminary work [Mey11] suggests that recognizing andannotating relational structures in the source can allowappropriate discourse connectives to be selected in the target.
B. Webber, et al Discourse Structure: 138
Discourse Structure:
Speculating about the future
New applications
Relational structure and SMT
◦ Translators often make discourse connectives explicit in theirtarget translation that were implicit in the source [KO11]:
Connective Orig Frequency Trans Frequencytherefore 0.153% 0.287%nevertheless 0.019% 0.045%thus 0.015% 0.041%moreover 0.008% 0.035%
◦ This can produce source-target mis-alignments that produce badentries in the translation model.
B. Webber, et al Discourse Structure: 139
Discourse Structure:
Speculating about the future
New applications
Relational structure and SMT
◦ Using relational structure to explicitate implicit connectivesin source texts [PDL+08] should improve alignment and thus SMT.
E.g. Implicit therefore (114 tokens) and thus (179 tokens) inthe PDTB.
(40) Its valuation methodologies, she said, “are recognizedas some of the best on the Street.Implicit = therefore Not a lot was needed to bedone.” [wsj 0304]
(41) “In Asia, as in Europe, a new order is taking shape,”Mr. Baker said. Implicit = thus “The U.S., with itsregional friends, must play a crucial role in designingits architecture.” [wsj 0043]
B. Webber, et al Discourse Structure: 140

Discourse Structure:
Speculating about the future
New applications
Hierarchical structure and SMT
◦ Languages may differ in their common ways of expressingrelational and hierarchical structure [MCW00].
◦ Syntactic/dependency structure is beginning to be used as aninter-lingua so that features of the source conveyed throughsyntactic and/or dependency structure can be preserved intranslating to the target.
◦ In the same way, a hierarchical structure such as RST could beused as an inter-lingua for a larger unit of text.
◦ Here it would be features of the source expressed throughhierarchical structure that would be preserved, even if sentenceorder were violated [GBC01].
B. Webber, et al Discourse Structure: 141
Discourse Structure:
Conclusion
Conclusion
This tutorial has tried to introduce you to:! Ways in which discourse is structured;! Ways of recovering these structures from text;! Ways that discourse structures can support LT applications;! Discourse resources that will support new discoveries and
applications;! Opportunities for improving and exploiting discourse
structures in the future.
The future is in your hands.
Thank you!
Nicholas Asher and Alex Lascarides.
Logics of Conversation.Cambridge University Press, 2003.
Amal Al-Saif and Katja Markert.
The Leeds Arabic Discourse Treebank: Annotating discourse connectives for Arabic.In Proceedings of the 7th International Conference on Language Resources and Evaluation (LREC 2010),page 8 pages, Valletta, Malta, 2010.
Amal Al-Saif and Katja Markert.
Modelling discourse relations for Arabic.In EMNLP ’11: Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2011.
Regina Barzilay and Michael Elhadad.
Using lexical chains for text summarization.In Proceedings of the ACL Workshop on Intelligent Scalable Text Summarization, pages 10–17, 1997.
Yves Bestgen.
Improving text segmentation using Latent Semantic Analysis: A reanalysis of Choi, Wiemer-Hastings, andMoore (2001).Computational Linguistics, 32(1):5–12, 2006.
Matthias Buch-Kromann, Iørn Korzen, and Henrik Høeg Muller.
Uncovering the ‘lost’ structure of translations with parallel treebanks.In Fabio Alves, Susanne Gpferich, and Inger Mees, editors, Copenhagen Studies of Language: Methodology,Technology and Innovation in Translation Process Research, Copenhagen Studies of Language, vol. 38,pages 199–224. Copenhagen Business School, 2009.
Regina Barzilay and Lillian Lee.
Catching the drift: Probabilistic content models, with applications to generation and summarization.In Proceedings of the 2nd Human Language Technology Conference and Annual Meeting of the NorthAmerican Chapter, pages 113–120, 2004.
Jason Baldridge and Alex Lascarides.
Probabilistic Head-driven Parsing for Discourse Structure.In Proceedings of CoNNL’05, 2005.
Jill Burstein, Daniel Marcu, Slava Andreyev, and Martin Chodorow.
Towards automatic classification of discourse elements in essays.In Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics, pages 98–105,Toulouse, France, 2001. Association for Computational Linguistics.
Jill Burstein, Daniel Marcu, and Kevin Knight.
Finding the WRITE stuff: Automatic identification of discourse structure in student essays.IEEE Intelligent Systems: Special Issue on Advances in Natural Language Processing, 18:32–39, 2003.
Chris Callison-Birch.
Syntactic constraints on paraphrases extracted from parallel corpora.In Proceedings of EMNLP, 2008.
Harr Chen, S. R. K. Branavan, Regina Barzilay, and David Karger.
Global models of document structure using latent permutations.In NAACL ’09: Proceedings of Human Language Technologies: The 2009 Annual Conference of the NorthAmerican Chapter of the Association for Computational Linguistics, pages 371–379, 2009.
Grace Chung.
Sentence retrieval for abstracts of randomized controlled trials.BMC Medical Informatics and Decision Making, 10(9), February 2009.
James Clarke and Mirella Lapata.
Discourse constraints for document compression.Computational Linguistics, 36:411441, 2010.
Lynn Carlson, Daniel Marcu, and Mary Ellen Okurowski.
Building a discourse-tagged corpus in the framework of Rhetorical Structure Theory.In J. van Kuppevelt & R. Smith, editor, Current Directions in Discourse and Dialogue. Kluwer, New York,2003.
Simon Corston-Oliver and Simon H. Corston-Oliver.
Beyond string matching and cue phrases: Improving efficiency and coverage in discourse analysis.In The AAAI Spring Symposium on Intelligent Text Summarization, pages 9–15, 1998.
Dan Cristea and Bonnie Webber.
Expectations in incremental discourse processing.
In Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics(ACL97/EACL97), pages 88–95, Madrid, Spain, 1997.
Freddy Choi, Peter Wiemer-Hastings, and Johanna Moore.
Latent Semantic Analysis for text segmentation.In EMNLP ’01: Proceedings of the Conference on Empirical Methods in Natural Language Processing,pages 109–117, 2001.
Robert Dale.
Generating Referring Expressions.MIT Press, Cambridge MA, 1992.
Hal Daume III and Daniel Marcu.
A noisy-channel model for document compression.In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages449–456, Philadelphia PA, 2002.
Jacob Eisenstein and Regina Barzilay.
Bayesian unsupervised topic segmentation.In EMNLP ’08: Proceedings of the Conference on Empirical Methods in Natural Language Processing,pages 334–343, 2008.
Robert Elwell and Jason Baldridge.
Discourse connective argument identication with connective specic rankers.In Proceedings of the IEEE Conference on Semantic Computing (ICSC-08), Santa Clara CA, 2008.
George Foster, Pierre Isabelle, and Roland Kuhn.
Translating structured documents.In Proceedings of the 9th Conference of the Association for Machine Translation in the Americas, DenverCO, 2010.
Peter Foltz, Walter Kintsch, and Thomas Landauer.
The measurement of textual coherence with Latent Semantic Analysis.Discourse Processes, 25:285–307, 1998.
Hatem Ghorbel, Afzal Ballim, and Giovanni Coray.
Rosetta: Rhetorical and semantic environment for text alignment.In Proceedings of Corpus Linguistics 2001, page 224233, Lancaster, 2001.
Barbara Grosz, Aravind Joshi, and Scott Weinstein.
Centering: A framework for modeling the local coherence of discourse.Computational Linguistics, 21(2):203–225, 1995.
Yufan Guo, Anna Korhonen, Maria Liakata, Ilona Silins, Lin Sun, and Ulla Stenius.
Identifying the information structure of scientific abstracts: An investigation of three different schemes.In Proceedings of the 2010 Workshop on Biomedical Natural Language Processing, pages 99–107, Uppsala,Sweden, 2010.
Michel Galley, Kathleen McKeown, Eric Fosler-Lussier, and Hongyan Jing.
Discourse segmentation of multi-party conversation.In Proceedings of the 41st Annual Conference of the Association for Computational Linguistics, 2003.
Barbara Grosz and Candy Sidner.
Attention, intention and the structure of discourse.Computational Linguistics, 12(3):175–204, 1986.
Barbara Grosz and Candace Sidner.
Plans for discourse.In Philip Cohen, Jerry Morgan, and Martha Pollack, editors, Intentions in Communication, pages 417–444.MIT Press, Cambridge MA, 1990.
Derrick Higgins, Jill Burstein, Daniel Marcu, and Claudia Gentile.
Evaluating multiple aspects of coherence in student essays.In Proceedings of HLT-NAACL, pages 185–192, Boston MA, 2004. Association for ComputationalLinguistics.
Daniel Hardt and Jokob Elming.
Incremental re-training for post-editing SMT.In Proceedings of AMTA, 2010.
Marti Hearst.
TextTiling: Segmenting text into multi-paragraph subtopic passages.Computational Linguistics, 23(1):33–64, 1997.
Christian Hardmeier and Marcello Federico.
Modelling pronominal anaphora in Statistical Machine Translation.In Proceedings of the 7th International Workshop on Spoken Language Translation, Paris, 2010.
Eduard Hovy, Mitchell Marcus, Martha Palmer, Lance Ramshaw, and Ralph Weischedel.
OntoNotes: The 90% solution.In Proceedings of HLT-NAACL, pages 57–60, New York, 2006. Association for Computational Linguistics.
Kenji Hirohata, Naoki Okazaki, Sophia Ananiadou, and Mitsuru Ishizuka.
Identifying sections in scientific abstracts using conditional random fields.
In Proceedings of the 3rd International Joint Conference on Natural Language Processing, pages 381–388,2008.
Jerry R. Hobbs, Mark Stickel, Douglas Appelt, and Paul Martin.
Interpretation as abduction.Artificial Intelligence, 63(1-2):69–142, 1993.
Thorsten Joachims.
Learning to classify text using Support Vector Machines – methods, theory, and algorithms.Kluwer/Springer, 2002.
Moshe Koppel and Noam Ordan.
Translationese and its dialects.In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: HumanLanguage Techologies, pages 1318–1326, Portland, Oregon, 2011.
Alistair Knott, Jon Oberlander, Michael O’Donnell, and Chris Mellish.
Beyond elaboration: The interaction of relations and focus in coherent text.In Ted Sanders, Joost Schilperoord, and Wilbert Spooren, editors, Text representation: linguistic andpsycholinguistic aspects, pages 181–196. Benjamins, Amsterdam, 2001.
Hans Kamp and Uwe Reyle.
From Discourse to Logic.Kluwer Academic Publishers, 1993.
Jimmy Lin, Damianos Karakos, Dina Demner-Fushman, and Sanjeev Khudanpur.
Generative content models for structural analysis of medical abstracts.In Proceedings of the HLT-NAACL Workshop on BioNLP, pages 65–72, 2006.
Ziheng Lin, Hwee Tou Ng, and Min-Yen Kan.
A PDTB-styled end-to-end discourse parser.Technical report, Department of Computing, National University of Singapore, November 2010.http://arxiv.org/abs/1011.0835.
Maria Liakata, Simone Teufel, Advaith Siddharthan, and Colin Batchelor.
Corpora for the conceptualisation and zoning of scientific papers.In Proceedings of the 7th International Conference on Language Resources and Evaluation (LREC 2010),Valletta, Malta, 2010.
Daniel Marcu.
The Rhetorical Parsing of Natural Language Texts.In Proceedings of ACL/EACL 1997, 1997.
Daniel Marcu.
To build text summaries of high quality, nuclearity is not sufcient.In Proceedings of AAAI-98 Spring Symposium on Intelligent Text Summarization, 1998.
Daniel Marcu.
A decision-based approach to rhetorical parsing.In Proceedings of ACL’99, pages 365–372, 1999.
Daniel Marcu.
The rhetorical parsing of unrestricted texts: A surface-based approach.Computational Linguistics, 26:395–448, 2000.
Daniel Marcu.
The theory and practice of discourse parsing and summarization.MIT Press, 2000.
J. Martin.
Beyond exchange: Appraisal systems in English.In S. Hunston and G. Thompson, editors, Evaluation in Text: Authorial Distance and the Construction ofDiscourse, pages 142–175. Oxford University Press, Oxford, 2000.
Igor Malioutov and Regina Barzilay.
Minimum cut model for spoken lecture segmentation.In Proceedings of the 21st International Conference on Computational Linguistics and the 44th annualmeeting of the Association for Computational Linguistics, pages 25–32, 2006.
Mstislav Maslennikov and Tat-Seng Chua.
A multi-resolution framework for information extraction from free text.In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, pages 592–599,Prague, Czech Republic, 2007. Association for Computational Linguistics.
Daniel Marcu, Lynn Carlson, and Maki Watanabe.
The automatic translation of discourse structures.In Proceedings of the 1st Conference of the North American Chapter of the ACL, pages 9–17, 2000.
Daniel Marcu and Abdessamad Echihabi.
An unsupervised approach to recognizing discourse relations.In Proceedings of ACL’02, 2002.
Thomas Meyer.
Disambiguating temporal-contrastive connectives for machine translation.In Proceedings of the ACL 2011 Student Session, pages 46–51, Portland, OR, June 2011.
Yoko Mizuta, Anna Korhonen, Tony Mullen, and Nigel Collier.
Zone analysis in biology articles as a basis for information extraction.International Journal of Medical Informatics, 75:468487, 2006.
Marie-Francine Moens.
Innovative techniques for legal text retrieval.Artificial Intellicence and Law, 9:29–57, 2001.
Larry McKnight and Padmini Srinivasan.
Categorization of sentence types in medical abstracts.In Proceedings of the AMIA Annual Symposium, pages 440–444, 2003.
William C. Mann and Sandra A. Thompson.
Antithesis: A study in clause combining and discourse structure.In Language topics: Essays in Honour of Michael Halliday, pages 359–384, Amsterdam, 1987. JohnBenjamins.
William Mann and Sandra Thompson.
Rhetorical Structure Theory: Toward a functional theory of text organization.Text, 8(3):243–281, 1988.
Marie-Francine Moens, Caroline Uyttendaele, and Jos Dumortier.
Information extraction from legal texts: the potential of discourse analysis.International Journal of Human-Computer Studies, 51:1155–1171, 1999.
Marie-Francine Moens, Caroline Uyttendaele, and Jos Dumortier.
Intelligent information extraction from legal texts.Information & Communications Technology Law, 9:17–26, 2000.
Vincent Ng and Claire Cardie.
Identifying anaphoric and non-anaphoric noun phrases to improve coreference resolution.In Proceedings of COLING 2002, 2002.
Ronan Le Nagard and Philipp Koehn.
Aiding pronoun translation with co-reference resolution.In Proceedings of the Joint Workshop on Statistical Machine Translation and MetricsMATR, Uppsala,Sweden, 2010.
Tadashi Nomoto and Yuji Matsumoto.
A new approach to unsupervised text summarization.In SIGIR ’01: Proceedings of the 24th annual international ACM SIGIR conference on Research anddevelopment in information retrieval, pages 26–34, New York, NY, USA, 2001. ACM.
Umangi Oza, Rashmi Prasad, Sudheer Kolachina, Dipti Misra Sharma, and Aravind Joshi.
The hindi discourse relation bank.In Proc. 3rd ACL Language Annotation Workshop (LAW III), Singapore, 2009.
Kenji Ono, Kazuo Sumita, and Seiji Miike.
Abstract generation based on rhetorical structure extraction.In COLING, pages 344–348, 1994.
Rashmi Prasad, Nikhil Dinesh, Alan Lee, Aravind Joshi, and Bonnie Webber.
Attribution and its annotation in the Penn Discourse TreeBank.TAL (Traitement Automatique des Langues), 42(2), 2007.
Rashmi Prasad, Nikhil Dinesh, Alan Lee, Eleni Miltsakaki, and et al.
The Penn Discourse Treebank 2.0.In Proceedings of the 6th International Conference on Language Resources and Evaluation, Marrakech,Morocco, 2008.
Matthew Purver, Tom Griffiths, K.P. Kording, and Joshua Tenenbaum.
Unsupervised topic modelling for multi-party spoken discourse.In Proceedings of the 21st International Conf. on Computational Linguistics (COLING) and the 44th annualmeeting of the Association for Computational Linguistics, pages 17–24, 2006.
Rashmi Prasad, Aravind Joshi, and Bonnie Webber.
Exploiting scope for shallow discourse parsing.In Proceedings of the 7th International Conference on Language Resources and Evaluation (LREC 2010),page 8 pages, Valletta, Malta, 2010.
Rashmi Prasad, Aravind Joshi, and Bonnie Webber.
Realization of discourse relations by other means: Alternative lexicalizations.In Proceedings of COLING, page 9 pages, Beijing, China, 2010.
Bo Pang and Lillian Lee.
Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales.In Proceedings of the ACL, pages 115–124, 2005.
Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan.
Thumbs up? Sentiment classification using Machine Learning techniques.In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages79–86, Philadelphia, July 2002, 2002. Association for Computational Linguistics.
Emily Pitler and Ani Nenkova.
Using syntax to disambiguate explicit discourse connectives in text.In ACL-IJCNLP ’09: Proceedings of the 47th Meeting of the Association for Computational Linguistics andthe 4th International Joint Conference on Natural Language Processing, 2009.
Volha Petukhova, Laurent Prevot, and Harry Bunt.
Multi-level discourse relations between dialogue units.In Sixth Joint ACL - ISO Workshop on Interoperable Semantic Annotation (isa-6), pages 18–27, 2011.
S. Patwardhan and E. Riloff.
Effective information extraction with semantic affinity patterns and relevant regions.In Proceedings of the 2007 Conference on Empirical Methods in Natural Language Processing(EMNLP-07), 2007.
Massimo Poesio, Rosemary Stevenson, Barbara Di Eugenio, and Janet Hitzeman.
Centering: A parametric theory and its instantiations.Computational Linguistics, 30:309–363, 2004.
Matthew Purver.
Topic segmentation.In Gokhan Tur and Renato de Mori, editors, Spoken Language Understanding: Systems for ExtractingSemantic Information from Speech. Wiley, Hoboken NJ, 2011.
Livia Polanyi and Annie Zaenen.
Contextual valence shifters.In Proceedings of AAAI Spring Symposium on Attitude, page 10 pages, 2004.
Patrick Ruch, Celia Boyer, Christine Chichester, Imad Tbahriti, Antoine Geissbuhler, Paul Fabry, and et al.
Using argumentation to extract key sentences from biomedical abstracts.International Journal of Medical Informatics, 76(2–3):195–200, 2007.
Frank Schilder.
Robust discourse parsing via discourse markers, topicality and position.Natural Language Engineering, 8(3):235–255, 2002.
Penni Sibun.
Generating text without trees.Computational Intelligence, 8(1):102–122, 1992.
Radu Soricut and Daniel Marcu.
Sentence level discourse parsing using syntactic and lexical information.In Proceedings of NAACL 2003, 2003.
Manfred Stede.
The Potsdam Commentary Corpus.In ACL Workshop on Discourse Annotation, Barcelona, Spain, 2004.
Manfred Stede.
Disambiguating rhetorical structure.Research on Language and Computation, 6:311–332, 2008.
Manfred Stede.
RST revisited: Disentangling nuclearity.In Subordination versus Coordination in Sentence and Text. John Benjamins, Amsterdam, 2008.
Maite Taboada, J. Brooke, and Manfred Stede.
Genre-based paragraph classification for sentiment analysis.In Proceedings of the 10th Annual SIGDIAL Conference on Discourse and Dialogue, pages 62–70, London,2009.
Simone Teufel, editor.
The Structure of Scientific Articles.CSLI Publications, 2010.
Simone Teufel and Marc Moens.
Summarizing scientific articles - experiments with relevance and rhetorical status.Computational Linguistics, 28:409–445, 2002.
Kristina Toutanova, Penka Markova, and Christopher D. Manning.
The leaf path projection view of parse trees: Exploring string kernels for HPSG parse selection.In EMNLP’04, pages 166–173, 2004.
Peter Turney.
Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews.In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), pages417–424, Philadelphia, July 2002, 2002. Association for Computational Linguistics.
G. Thione, M. van den Berg, L. Polanyi, and C. Culy.
Hybrid text summarization: combining external relevance measures with structural analysis.In Proceedings of the ACL 2004 Workshop Text Summarization Branches Out, 2004.
Vinıcius Rodrigues Uzeda, Thiago Alexandre Salgueiro Pardo, and Maria Das Gracas Volpe Nunes.
A comprehensive comparative evaluation of RST-based summarization methods.ACM Transactions on Speech and Language Processing, 6:1–20, 2010.
Nynke van der Vliet, Ildiko Berzlanovich, Gosse Bouma, Markus Egg, and Gisela Redeker.
Building a discourse-annotated Dutch text corpus.In Beyond Semantics, page 9 pages, Gottingen, Germany, February 2011.
Kimberly Voll and Maite Taboada.
Not all words are created equal: Extracting semantic orientation as a function of adjective relevance.In Proceedings of the 20th Australian Joint Conference on Artificial Intelligence, pages 337–346, GoldCoast, Australia, 2007.
Florian Wolf and Edward Gibson.
Representing discourse coherence: A corpus-based study.Computational Linguistics, 31:249–287, 2005.
Ben Wellner and James Pustejovsky.
Automatically identifying the arguments of discourse connectives.In Proceedings of the 2007 Conference on Empirical Methods in Natural Language Processing(EMNLP-07), 2007.
Marilyn Walker, Amanda Stent, Francois Mairess, and Rashmi Prasad.
Individual and domain adaptation in sentence planning for dialogue.Journal of Artificial Intelligence Research, 30:413–456, 2007.
Deniz Zeyrek, Isın Demirsahin, Ayısıgı Sevdik-Callı, Hale Ogel Balaban, Ihsan Yalcınkaya, and Umut Deniz
Turan.The annotation scheme of the Turkish Discourse Bank and an evaluation of inconsistent annotations.In Proceedings of the 4th Linguistic Annotation Workshop (LAW III), Uppsala, Sweden, 2010.
Deniz Zeyrek, Umut Deniz Turan, Cem Bozsahin, Ruket Cakici, and et al.
Annotating Subordinators in the Turkish Discourse Bank.In Proceedings of the 3rd Linguistic Annotation Workshop (LAW III), Singapore, 2009.
Deniz Zeyrek and Bonnie Webber.
A discourse resource for Turkish: Annotating discourse connectives in the METU corpus.
In Proceedings of the 6th Workshop on Asian Language Resources (ALR6), Hyderabad, India, 2008.
B. Webber, et al Discourse Structure: 142





























