Embed Size (px)
Citation preview

OPTIMIZACIÓN DE REDES BAYESIANAS BASADO
EN TÉCNICAS DE APRENDIZAJE POR INDUCCIÓN
TESIS DE GRADO EN INGENIERÍA INFORMÁTICA
FACULTAD DE INGENIERÍA
UNIVERSIDAD DE BUENOS AIRES
TESISTA: Sr. Pablo Ezequiel FELGAER
DIRECTORES: Prof. Dr. Ramón GARCÍA-MARTÍNEZ
Prof. M. Ing. Paola BRITOS
Laboratorio de Sistemas Inteligentes
FEBRERO 2005


OPTIMIZACIÓN DE REDES BAYESIANAS BASADO EN TÉCNICAS
DE APRENDIZAJE POR INDUCCIÓN
TESIS DE GRADO EN INGENIERÍA INFORMÁTICA
Laboratorio de Sistemas Inteligentes
FACULTAD DE INGENIERÍA
UNIVERSIDAD DE BUENOS AIRES
Sr. Pablo Ezequiel Felgaer Prof. Dr. Ramón García-Martínez
Tesista Director
FEBRERO 2005


Resumen
Una red bayesiana es un grafo acíclico dirigido en el que cada nodo representa una
variable y cada arco una dependencia probabilística; son utilizadas para proveer : una forma
compacta de representar el conocimiento y métodos flexibles de razonamiento. El obtener
una red bayesiana a partir de datos es un proceso de aprendizaje que se divide en dos
etapas: el aprendizaje estructural y el aprendizaje paramétrico. En este trabajo se define un
método de aprendizaje automático que optimiza las redes bayesianas aplicadas a
clasificación mediante la utilización de un método de aprendizaje híbrido que combina las
ventajas de las técnicas de inducción de los árboles de decisión (TDIDT - C4.5) con las de
las redes bayesianas.
Palabras clave : Redes bayesianas. Aprendizaje por inducción. Clasificación. Sistemas
inteligentes híbridos.
Abstract
A bayesian network is a directed acyclic graph in which each node represents a
variable and each arc a probabilistic dependency; they are used to provide: a compact form
to represent the knowledge and flexible methods of reasoning. Obtaining a bayesian
network from data is a learning process that is divided in two steps: structural learning and
parametric learning. In this paper we define an automatic learning method that optimizes
the bayesian networks applied to classification using a hybrid method of learning that
combines the advantages of the induction techniques of the decision trees (TDIDT - C4.5)
with those of the bayesian networks.
Keywords : Bayesian networks. Induction learning. Classification. Hybrid intelligent
systems.


Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Índice Pablo Felgaer i
Índice
1. Introducción.................................................................................................................... 1
2. Estado del arte................................................................................................................. 5
2.1. Introducción............................................................................................................ 5
2.2. Redes bayesianas .................................................................................................... 7
2.2.1. Definición formal de las redes bayesianas...................................................... 8
2.2.2. Representación del conocimiento .................................................................11
2.2.3. Independencia condicional ...........................................................................12
2.2.4. Inferencia ......................................................................................................15
2.2.5. El aprendizaje en las redes bayesianas .........................................................28
2.2.6. Ventajas de las redes bayesianas ..................................................................36
2.3. Árboles de decisión – TDIDT...............................................................................39
2.3.1. Características de los árboles de decisión.....................................................39
2.3.2. Construcción de los árboles de decisión.......................................................39
2.3.3. Descripción general de los algoritmos..........................................................44
2.3.4. Presentación de los resultados ......................................................................53
2.4. Marco de la tesis ........................................................................................................54
3. Descripción del problema .............................................................................................55
4. Solución propuesta........................................................................................................57
4.1. Datos de entrada ...................................................................................................57
4.2. Sistema integrador ................................................................................................58
4.3. Otros abordajes .....................................................................................................60
5. Prueba experimental .....................................................................................................61
5.1. Descripción de los dominios.................................................................................61
5.1.1. Cáncer ...........................................................................................................62
5.1.2. Cardiología ...................................................................................................63
5.1.3. Dengue ..........................................................................................................64
5.1.4. Hongos ..........................................................................................................66
5.2. Metodología utilizada ...........................................................................................67
5.3. Análisis estadístico de los resultados....................................................................69

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
ii Pablo Felgaer Índice
5.3.1. Prueba de hipótesis estadísticas ....................................................................69
5.3.2. El test de Wilcoxon para la comparación de muestras apareadas ................71
5.3.3. Aplicación del test a los resultados...............................................................74
5.4. Resultados .............................................................................................................75
5.4.1. Cáncer ...........................................................................................................75
5.4.2. Cardiología ...................................................................................................77
5.4.3. Dengue ..........................................................................................................80
5.4.4. Hongos ..........................................................................................................82
6. Conclusiones .................................................................................................................85
Referencias ...........................................................................................................................87
A. Casos de uso .................................................................................................................95
A.1. Menú Archivo.......................................................................................................95
A.2. Menú Red..............................................................................................................96
A.3. Menú Nodo ...........................................................................................................97
A.4. Menú Herramientas ..............................................................................................98
A.5. Menú Configuración.............................................................................................99
A.6. Menú Ayuda ....................................................................................................... 100
B. Gestión de configuración............................................................................................ 103
B.1. Identificación de la configuración...................................................................... 103
B.2. Control de configuración.................................................................................... 103
B.3. Generación de informes de estado...................................................................... 105
C. Lote de prueba ............................................................................................................ 107
C.1. Plan de pruebas ................................................................................................... 107
C.2. Documento de diseño de la prueba..................................................................... 109
C.3. Especificación de los casos de prueba ................................................................ 110
C.4. Especificación del procedimiento de prueba ...................................................... 112
C.5. Informe de los casos de prueba ejecutados ......................................................... 113
C.6. Informe de la prueba ........................................................................................... 115
C.7. Anexo con documentación de las pruebas realizadas ......................................... 116
D. Manual del usuario ..................................................................................................... 125
D.1. Introducción........................................................................................................ 125

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Índice Pablo Felgaer iii
D.2. Estructuración del sistema .................................................................................. 125
D.2.1. Menú de opciones ....................................................................................... 126
D.2.2. Barra de herramientas ................................................................................. 127
D.2.3. Lista de nodos ............................................................................................. 128
D.2.4. Área de visualización.................................................................................. 128
D.2.5. Barra de estado ........................................................................................... 129
D.3. Abrir una red bayesiana ...................................................................................... 129
D.4. Guardar una red bayesiana .................................................................................. 130
D.5. Minería de datos ................................................................................................. 130
D.6. Trabajar con una red bayesiana .......................................................................... 134
D.6.1. Instanciar nodos .......................................................................................... 134
D.6.2. Información de la red .................................................................................. 135
D.6.3. Visualización de la red................................................................................ 137
D.7. Archivos externos ............................................................................................... 140
D.7.1. Archivos de redes ....................................................................................... 140
D.7.2. Archivos de datos ....................................................................................... 143
Índice de figuras
Figura 2.1: Ejemplo de red bayesiana...................................................................................13
Figura 2.2: Ejemplo de red bayesiana...................................................................................14
Figura 2.3: “The dog barking problem”. ..............................................................................22
Figura 2.4: “The dog barking problem” – Instanciación del nodo d ....................................25
Figura 2.5: “The dog barking problem” – Estado inicial......................................................26
Figura 2.6: “The dog barking problem” – Instanciación del nodo h ....................................26
Figura 2.7: “The dog barking problem” – Instanciación de los nodos h y f.........................27
Figura 2.8 “The dog barking problem” – Instanciación de los nodos h, f y d......................28
Figura 2.9: Tipos de conexiones en un grafo dirigido: (a) divergentes, (b) secuenciales y (c)
convergentes .................................................................................................................33
Figura 4.1: Esquema de obtención de redes bayesianas completas ......................................58

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
iv Pablo Felgaer Índice
Figura 4.2: Esquema de obtención de redes bayesianas C4.5 ..............................................59
Figura 4.3: Esquema del proceso de verificación del poder predictivo. ...............................60
Figura A.1: Casos de uso “Archivo”. ....................................................................................96
Figura A.2: Casos de uso “Red”. ..........................................................................................97
Figura A.3: Casos de uso “Nodo”.........................................................................................98
Figura A.4: Casos de uso “Herramientas”. ..........................................................................98
Figura A.5: Casos de uso “Configuración”. ....................................................................... 100
Figura A.6: Casos de uso “Ayuda”. .................................................................................... 101
Figura C.1: Abrir una red bayesiana (01) ........................................................................... 116
Figura C.2: Ver la tabla de probabilidades totales de una red bayesiana (04) .................... 117
Figura C.3: Ordenar la red bayesiana en la pantalla (05) ................................................... 117
Figura C.4: Instanciar un nodo de una red bayesiana (06) ................................................. 118
Figura C.5: Instanciar un nodo de una red bayesiana (07) ................................................. 118
Figura C.6: Desinstanciar un nodo de una red bayesiana (08) ........................................... 119
Figura C.7: Ver la tabla de probabilidades condicionales de un nodo de una red bayesiana
(09).............................................................................................................................. 119
Figura C.8: Ver la tabla de probabilidades totales de un nodo de una red bayesiana (10) . 120
Figura C.9: Ver las propiedades de un nodo de una red bayesiana (11) ............................ 120
Figura C.10: Proceso de Minería de Datos (12) ................................................................. 121
Figura C.11: Ocultar la barra de estado (13) ...................................................................... 121
Figura C.12: Ocultar la barra de herramientas (15) ............................................................ 122
Figura C.13; Mostrar los nodos de una red bayesiana por nombres (17) ........................... 122
Figura C.14: Mostrar los nodos de una red bayesiana por probabilidades (18) ................. 123
Figura C.15: Mostrar los nodos de una red bayesiana en los diferentes tamaños posibles
(19).............................................................................................................................. 123
Figura C.16: Ver las referencias respecto a los colores y las formas que se visualizan en el
sistema (20)................................................................................................................. 124
Figura D.1: Estructuración del sistema............................................................................... 125
Figura D.2: Abrir una red bayesiana................................................................................... 129
Figura D.3: Minería de datos – Presentación. ..................................................................... 130
Figura D.4: Minería de datos – Seleccionar archivo. ......................................................... 131

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Índice Pablo Felgaer v
Figura D.5: Minería de datos – Seleccionar archivo. ......................................................... 131
Figura D.6: Minería de datos – Seleccionar nodos raíz. ..................................................... 132
Figura D.7: Minería de datos – Seleccionar relaciones y restricciones.............................. 133
Figura D.8: Minería de datos – Realizando minería de datos. ............................................ 133
Figura D.9: Minería de datos – Definir direccionalidad de las relaciones. ........................ 134
Figura D.10: Instanciación de variables ............................................................................. 135
Figura D.11: Probabilidades totales de la red. .................................................................... 135
Figura D.12: Probabilidades condic ionales de un nodo. .................................................... 136
Figura D.13: Probabilidades totales de un nodo. ................................................................ 136
Figura D.14: Propiedades de un nodo................................................................................. 136
Figura D.15: Visualización por Número. ........................................................................... 137
Figura D.16 Visualización por Nombre. ............................................................................. 138
Figura D.17: Visualización por Probabilidad (tamaño grande). ......................................... 138
Figura D.18: Visualización por Probabilidad (tamaño pequeño). ...................................... 139
Figura D.19: Referencias de formas y colores del sistema................................................. 139
Índice de gráficos
Gráfico 5.1: Gráfico del poder predictivo para la base de datos “Cáncer”. ..........................75
Gráfico 5.2: Gráfico del poder predictivo para la base de datos “Cardiología”. ..................78
Gráfico 5.3: Gráfico del poder predic tivo para la base de datos “Dengue”. ........................80
Gráfico 5.4: Gráfico del poder predictivo para la base de datos “Hongos”. ........................83


Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Introducción Pablo Felgaer 1
1. Introducción
Una red bayesiana es un grafo acíclico dirigido en el que cada nodo representa una
variable y cada arco una dependencia probabilística; son utilizadas para proveer: una forma
compacta de representar el conocimiento y métodos flexibles de razonamiento. El obtener
una red bayesiana a partir de datos es un proceso de aprendizaje que se divide en dos
etapas: el aprendizaje estructural y el aprendizaje paramétrico. En este trabajo se define un
método de aprendizaje automático que optimiza las redes bayesianas aplicadas a
clasificación mediante la utilización de un método de aprendizaje híbrido que combina las
ventajas de las técnicas de inducción de los árboles de decisión (TDIDT - C4.5) con las de
las redes bayesianas.
Esta tesis se encuentra estructurada a lo largo de 6 capítulos principales y 4 capítulos
anexos.
El capítulo 2 describe el estado actual de los campos de estudio relacionados con esta
tesis. En la sección 2.1 se presenta una introducción general a la minería de datos, la
sección 2.2 presenta los conceptos y teorías importantes relativas a las redes bayesianas y a
lo largo de la sección 2.3 se presentan los árboles de decisión. En la sección 2.4 se presenta
el marco de investigación en el cual se desarrolló la presente tesis.
En el capítulo 3 se presenta el contexto de nuestro problema de interés.
En el capítulo 4 se presentan todos los aspectos relativos de la solución propuesta. En
la sección 4.1 se describen las características que deben cumplir los datos de entrada que
serán analizados y en la sección 4.2 se presenta la estructura del sistema integrador
utilizado. La sección 4.3 presenta antecedentes de otros abordajes para solucionar
problemas similares.
En el capítulo 5 se describen las pruebas que se realizaron para evaluar la efectividad
de la solución propuesta y se presentan los resultados obtenidos. En la sección 5.1 se realiza

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
2 Pablo Felgaer Introducción
una descripción de los dominios analizados, en la sección 5.2 se presenta la metodología
utilizada para llevar a cabo las pruebas experimentales, la sección 5.3 describe la teoría en
la que se basa el análisis estadístico de los resultados y, por último, en la sección 5.4 se
exponen los resultados obtenidos.
En el capítulo 6 se presentan las conclusiones extraídas a partir de la investigación
realizada y de los resultados obtenidos.
El anexo A describe los casos de uso analizados para llevar adelante el desarrollo del
sistema.
El anexo B presenta la gestión de configuración realizada para llevar a cabo el control
de cambios y modificaciones al sistema. La sección B.1 presenta las caracter ísticas
principales relativas al desarrollo del sistema, la sección B.2 indica la metodología utilizada
para llevar a cabo las correcciones de errores y gestión de cambios y, por último, la sección
B.3 muestra la generación de los informes de estado relativos al desarrollo del sistema.
El anexo C describe las pruebas realizadas para validar el correcto funcionamiento
del sistema. En la sección C.1 se presenta el plan de pruebas, la sección C.2 describe el
diseño de las pruebas, en la sección C.3 se presentan la especificación de los casos de
prueba a validar, en la sección C.4 se muestra el procedimiento de prueba para llevar a cabo
dicho control, la sección C.5 indica los resultados obtenidos para cada una de las pruebas
ejecutadas, en la sección C.6 se presenta el informe final con las conclusiones obtenidas
respecto al funcionamiento del sistema y, por último, la sección C.7 presenta
documentación anexa relativa a las pruebas realizadas.
En el anexo D se presenta el manual de usuario correspondiente al sistema de
“Minería de Datos mediante Redes Bayesianas” desarrollado. La sección D.1 presenta una
introducción, la sección D.2 describe la estructura general del sistema, la sección D.3
explica la operatoria para abrir redes bayesianas, la sección D.4 define la forma de guardar
las redes, la sección D.5 presenta la herramienta de minería de datos, la sección D.6 expone

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Introducción Pablo Felgaer 3
la manera de manipular las redes bayesianas a través del sistema y, finalmente, la sección
D.7 presenta los formatos de archivo de entrada y salida con los que el sistema interactúa.
También se presenta como anexo a este trabajo, un CD-ROM conteniendo el código
fuente del sistema desarrollado y las bases de datos de pruebas utilizadas.


Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 5
2. Estado del arte
2.1. Introducción
El aprendizaje puede ser definido como “cualquier proceso a través del cual un
sistema mejora su eficiencia” [Simon, 1983]. La habilidad de aprender es considerada como
una característica central de los “sistemas inteligentes” [Fritz et al., 1989; García-Martínez
& Borrajo, 2000] y es por esto que se ha invertido esfuerzo y dedicación en la investigación
y el desarrollo de esta área. El desarrollo de los sistemas basados en conocimientos motivó
la investigación en el área del aprendizaje con el fin de automatizar el proceso de
adquisición de conocimientos el cual se considera uno de los problemas principales en la
construcción de estos sistemas.
Un aspecto importante en el aprendizaje inductivo es el de obtener un modelo que
represente el dominio de conocimiento y que sea accesible para el usuario ; en particular
resulta importante obtener la información de dependencia entre las variables involucradas
en el fenómeno en los sistemas donde se desea predecir el comportamiento de algunas
variables desconocidas basados en otras conocidas; una representación del conocimiento
que es capaz de capturar esta información sobre las dependencias entre las variables son las
redes bayesianas [Cowell et al., 1990; Ramoni & Sebastiani, 1999].
Se denomina Minería de Datos al conjunto de técnicas y herr amientas aplicadas al
proceso no trivial de extraer y presentar conocimiento implícito, previamente desconocido,
potencialmente útil y humanamente comprensible, a partir de grandes conjuntos de datos,
con objeto de predecir de forma automatizada tendencias y comportamientos y describir de
forma automatizada modelos previamente desconocidos [Piatetski-Shapiro et al., 1991;
Chen et al., 1996; Mannila, 1997]. El término Minería de Datos Inteligente [Evangelos &
Han, 1996; Michalski et al., 1998] refiere específicamente a la aplicación de métodos de
aprendizaje automático [Michalski et al., 1983; Holsheimer & Siebes, 1991] para descubrir
y enumerar patrones presentes en los datos; para estos se desarrollaron un gran número de
métodos de análisis de datos basados en la estadística [Michalski et al., 1982]. En la medida

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
6 Pablo Felgaer Estado del arte
en que se incrementaba la cantidad de información almacenada en las bases de datos, estos
métodos empezaron a enfrentar problemas de eficiencia y escalabilidad y es aquí donde
aparece el concepto de minería de datos. Una de las diferencias entre al análisis de datos
tradicional y la minería de datos es que el primero supone que las hipótesis ya están
construidas y validadas contra los datos, mientras que el segundo supone que los patrones e
hipótesis son automáticamente extraídos de los datos [Hernández Orallo, 2000]. Las tareas
de la minería de datos se pueden clasificar en dos categorías: minería de datos descriptiva y
minería de datos predictiva [Piatetski-Shapiro et al., 1996; Han, 1999].
Una red bayesiana es un grafo acíclico dirigido en el que cada nodo representa una
variable y cada arco una dependencia probabilística en la cual se especifica la probabilidad
condicional de cada variable dados sus padres; la variable a la que apunta el arco es
dependiente (causa-efecto) de la que está en el origen de éste. La topología o estructura de
la red nos da información sobre las dependencias probabilísticas entre las variables pero
también sobre las independencias condicionales de una variable (o conjunto de variables)
dada otra u otras variables; dichas independencias simplifican la representación del
conocimiento (menos parámetros) y el razonamiento (propagación de las probabilidades).
El obtener una red bayesiana a partir de datos es un proceso de aprendizaje que se divide en
dos etapas: el aprendizaje estructural y el aprendizaje paramétrico [Pearl, 1988]. La primera
de ellas consiste en obtener la estructura de la red bayesiana, es decir, las relaciones de
dependencia e independencia entre las variables involucradas. La segunda etapa tiene como
finalidad obtener las probabilidades a priori y condicionales requeridas a partir de una
estructura dada.
Estas redes [Pearl, 1988] son utilizadas en diversas áreas de aplicación como por
ejemplo en medicina [Beinlinch et al., 1989], ciencia [Bickmore, 1994; Breese & Blake,
1995] y economía [Ezawa & Schuermann, 1995]. Las mismas proveen una forma compacta
de representar el conocimiento y métodos flexibles de razonamiento –basados en las teorías
probabilísticas– capaces de predecir el valor de variables no observadas y explicar las
observadas. Entre las características que poseen las redes bayesianas se puede destacar que
permiten aprender sobre relaciones de dependencia y causalidad, permiten combinar

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 7
conocimiento con datos [Heckerman et al., 1995; Díaz & Corchado, 1999] y pueden
manejar bases de datos incompletas [Heckerman, 1995; Heckerman & Chickering, 1996;
Ramoni & Sebastiani, 1996].
2.2. Redes bayesianas
Las redes bayesianas o probabilísticas se fundamentan en la teoría de la probabilidad
y combinan la potencia del teorema de Bayes con la expresividad semántica de los grafos
dirigidos; las mismas permiten representar un modelo causal por medio de una
representación gráfica de las independencias / dependencias entre las variables que forman
parte del dominio de aplicación [Pearl, 1988].
Una red bayesiana es un grafo acíclico dirigido –las uniones entre los nodos tienen
definidas una dirección– en el que los nodos representan variables aleatorias y las flechas
representan influencias causales; el que un nodo sea padre de otro implica que es causa
directa del mismo.
Se puede interpretar a una red bayesiana de dos formas:
1. Distribución de probabilidad: Representa la distribución de la probabilidad
conjunta de las variables representadas en la red.
2. Base de reglas: Cada arco representa un conjunto de reglas que asocian a las
variables involucradas. Dichas reglas están cuantificadas por las probabilidades
respectivas.
A continuación se describirán los fundamentos teóricos de las redes bayesianas y
distintos algoritmos de propagación.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
8 Pablo Felgaer Estado del arte
2.2.1. Definición formal de las redes bayesianas
Una red bayesiana es un grafo acíclico dirigido en el que los nodos representan
variables aleatorias que pueden ser continuas o discretas; en las siguientes definiciones se
utilizarán letras mayúsculas para denotar los nodos ( X ) y las correspondientes letras
minúsculas para designar sus posibles estados ( ix ).
Los estados que puede tener una variable deben cumplir con dos propiedades:
1. Ser mutuamente excluyentes, es decir, un nodo sólo puede encontrarse en uno de sus
estados en un momento dado.
2. Ser un conjunto exhaustivo, es decir, un nodo no puede tener ningún valor fuera de
ese conjunto.
A continuación se indican algunas definiciones y notaciones propias de la
terminología de las redes bayesianas:
• Nodo
Un nodo X es una variable aleatoria que puede tener varios estados ix . La
probabilidad de que el nodo X este en el estado x se denotará como
)()( xXPxP == .
• Arco
Es la unión entre dos nodos y representa la dependencia entre dos variables del
modelo. Un arco queda definido por un par ordenado de nodos ),( YX .
• Padre
El nodo X es un padre del nodo Y , si existe un arco ),( YX entre los dos nodos.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 9
• Hijo
El nodo Y es un hijo del nodo X , si existe un arco ),( YX entre los dos nodos.
• Probabilidad conjunta
Dado un conjunto de variables },,,{ ZYX K , la probabilidad conjunta especifica la
probabilidad de cada combinación posible de estados de cada variable
kjizyxP kji ,,,),,,( KK ∀ , de manera que se cumple que:
1),,,(,,
=∑kji
kji zyxPK
K
• Probabilidad condicional
Dadas dos variables X e Y , la probabilidad de que ocurra jy dado que ocurrió el
evento ix es la probabilidad condicional de Y dado X y se denota como )|( ij xyP .
La probabilidad condicional por definición es:
)(
),()|(
i
ijij xP
xyPxyP = , dado 0)( >ixP
Análogamente, si se intercambia el orden de las variables:
)(
),()|(
j
ijji yP
xyPyxP =
A partir de las dos fórmulas anteriores se obtiene:
)(
)|()()|(
i
jijij xP
yxPyPxyP =
esta expresión se conoce como el Teorema de Bayes que en su forma más general es:
∑=
j jji
jijij yPyxP
yxPyPxyP
)()|(
)|()()|(
al denominador se lo conoce como el Teorema de la Probabilidad Total.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
10 Pablo Felgaer Estado del arte
En las redes bayesianas el conjunto de valores que componen la probabilidad
condicional de un hijo dados sus padres, se representa en las llamadas tablas de
probabilidad condicional.
• Independencia
Dos variables X e Y son independientes si la ocurrencia de una no tiene que ver con
la ocurrencia de la otra. Por definición se cumple que Y es independiente de X si y
sólo si:
jixPyPxyP ijij ,)()(),( ∀=
Esto implica que:
jiyPxyP jij ,)()|( ∀=
jixPyxP iji ,)()|( ∀=
• Observación
Es la determinación del estado de un nodo ( xX = ) a partir de un dato obtenido en el
exterior del modelo.
• Evidencia
Es el conjunto de observaciones },,,{ zZyYxXe ==== K en un momento dado.
• Probabilidad a priori
Es la probabilidad de una variable en ausencia de evidencia.
• Probabilidad a posteriori
Es la probabilidad de una variable condicionada a la existencia de una determinada
evidencia ; la probabilidad a posteriori de X cuando se dispone de la evidencia e se
calcula como )|( eXP .

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 11
2.2.2. Representación del conocimiento
Una red bayesiana representa relaciones causales en el dominio del conocimiento a
través de una estructura gráfica y las tablas de probabilidad condicional entre los nodos, por
lo tanto el conocimiento que representa la red está compuesto por los siguientes elementos:
1. Un conjunto de nodos }{ iX que representan cada una de las variables del modelo.
Cada una de ellas tiene un conjunto exhaustivo de estados }{ ix mutuamente
excluyentes.
2. Un conjunto de enlaces o arcos ),( ji XX entre aquellos nodos que tienen una
relación causal. De esta manera todas las relaciones están explícitamente
representadas en el grafo.
3. Una tabla de probabilidad condicional asociada a cada nodo iX indicando la
probabilidad de sus estados para cada combinación de los estados de sus padres. Si
un nodo no tiene padres se indican sus probabilidades a priori.
La estructura de una red bayesiana se puede determinar de la siguiente manera:
1. Se asigna un vértice o nodo a cada variable ( iX ) y se indica de qué otros vértices es
una causa directa; a ese conjunto de vértices “causa del nodo iX ” se lo denota como
el conjunto iXπ y se lo llamará “padres de iX ”.
2. Se une cada padre con sus hijos con flechas que parten de los padres y llegan a los
hijos.
3. A cada variable iX se le asigna una matriz )|(iXixP π que estima la probabilidad
condicional de un evento ii xX = dada una combinación de valores de los iXπ .
Una vez que se ha diseñado la estructura de la red y se han especificado todas la s
tablas de probabilidad condicional se está en condiciones de conocer la probabilidad de una
determinada variable dependiendo del estado de cualquier combinación del resto de

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
12 Pablo Felgaer Estado del arte
variables de la red; para ello se debe calcular la probabilidad a posteriori de cada variable
condicionada a la evidencia; estas probabilidades a posteriori se podrán obtener de forma
inmediata a partir de la probabilidad conjunta de todas las variables ),,,( 21 ixxxP K . A
continuación se indica cómo este proceso se ve simplificado al aplicar la propiedad de
independencia condicional que permite obtener la probabilidad conjunta a partir de las
probabilidades condicionales de cada nodo en función de sus padres.
2.2.3. Independencia condicional
Como se indicó anteriormente la topología o estructura de una red bayesiana no sólo
representa explícitamente dependencias probabilísticas entre variables, sino que también
describe implícitamente las independencias condicionales existentes entre ellas. La
siguiente definición muestra las condiciones que deben darse para que dos variables sean
condicionalmente independientes:
Una variable X es condicionalmente independiente de otra Y dada una tercer
variable Z , si el conocer Z hace que X e Y sean independientes. Es decir, si
conozco Z , Y no tiene influencia en X . Esto es: )|(),|( ZXPZYXP =
Esta definición se traduce a que cada variable es independiente de todos aquellos
nodos que no son sus “descendientes” una vez que se conocen sus propios nodos padres; a
lo largo de este trabajo se utilizarán las palabras “nodos” y “variables” como sinónimos.
Gráficamente se verifica en los casos en que los nodos X e Y están separados por Z en el
grafo. Esto implica que todos los caminos para ir de X a Y pasarán necesariamente por Z
[Pearl, 1988].
Por ejemplo, en la red bayesiana de la figura 2.1, }{E es condicionalmente
independiente de },,,,{ GFDCA dado }{B ; con lo cual )|(),,,,,|( BEPGFDCBAEP = ;
esto se conoce como Separación-D.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 13
Figura 2.1: Ejemp lo de red bayesiana.
En una red bayesiana todas las relaciones de independencia condicional representadas
en el grafo corresponden a relaciones de independencia en la distribución de probabilidad.
Si enumeramos los nodos de una red bayesiana, iXXX K,, 21 , de manera que se cumpla
que cada nodo aparece en la secuencia antes que cualquiera de sus hijos, dicha red
representa el siguiente aserto de independencia:
Cada variable iX es condicionalmente independiente de las variables del conjunto
},,,{ 121 −iXXX K conocidos los valores de sus padres.
Otra manera de expresarlo es:
Conociendo los padres de iX , éste se hace independiente del resto de sus
predecesores.
La regla de la cadena [Pearl, 1988] sostiene que la probabilidad conjunta puede ser
calculada como:
∏=
−=n
tttn xxxxPxxxP
112121 ),,|(),,,( KK
A B
D C E
G F

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
14 Pablo Felgaer Estado del arte
Los asertos de independencia condicional junto con las tablas de probabilidad
condicional nos permiten obtener la tabla de probabilidad conjunta de todas las variables a
partir de las tablas de probabilidad condicional de cada variable en función de sus padres;
de esta forma, aplicando la regla de la cadena conjuntamente con la propiedad de
independencia condicional se obtiene:
∏∏==
− ==n
txt
n
tttn t
xPxxxxPxxxP11
12121 )|(),,|(),,,( πKK
El siguiente ejemplo muestra el proceso para calcular la probabilidad conjunta de
varias variables conocida la estructura gráfica de la red y sus respectivas probabilidades
condicionales en función de sus padres:
Figura 2.2: Ejemplo de red bayesiana.
La figura 2.2 representa una red bayesiana que contiene el conjunto de nodos
},,,,,,{ gwsrhed ; si se elige una ordenación de los nodos de manera que se cumpla que
todo nodo aparece antes que sus hijos se obtiene, por ejemplo, el conjunto
},,,,,,{ gwdsreh ; aplicando la regla de la cadena y que cada nodo es independiente de sus
predecesores conocidos sus padres se obtiene que:
h e
s
w
r
g d

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 15
)|()|()|(),|()|()()(),,,,,,(
),,,,,|(),,,,,,(),,,,|(),,,|(),,|(),|()|()(),,,,,,(
sgPswPsdPehsPerPePhPgwdsrehP
wdsrehgPgwdsrehPdsrehwPsrehdPrehsPehrPhePhPgwdsrehP
=
==
KK
La expresión anterior calcula la probabilidad conjunta de todos los nodos que
componen la red a partir de las probabilidades condicionales de cada nodo en función de
sus nodos padres. Dichas independencias condicionales son importantes porque simplifican
la representación del conocimiento (menos parámetros) y el proceso de razonamiento o
inferencia (propagación de probabilidades).
2.2.4. Inferencia
2.2.4.1. Introducción
La inferencia es el proceso de introducir nuevas observaciones y calcular las nuevas
probabilidades que tendrán el resto de las variables; por lo tanto dicho proceso consiste en
calcular las probabilidades a posteriori )|( iyYXP = de un conjunto de variables X
después de obtener un conjunto de observaciones iyY = (donde Y es la lista de variables
observadas e iy es la lista correspondiente a los valores observados). El fundamento
matemático en el que se basan las redes probabilísticas para llevar a cabo la inferencia es el
Teorema de Bayes que como se indicó en la sección 2.2.1 se expresa como:
∑==
j jji
jij
i
jijij yPyxP
yxPyP
xP
yxPyPxyP
)()|(
)|()(
)(
)|()()|(
Las probabilidades a posteriori, )|( iyYXP = , se pueden obtener a partir de la
probabilidad marginal )|( YXP que a su vez puede obtenerse de la probabilidad conjunta
),,,( 21 ixxxP K sumando los valores para todas las variables que no pertenezcan al conjunto
YX ∪ . En la práctica, esto no es viable por el tiempo necesario para llevarlo a cabo ya que
incrementar el número de nodos de la red aumentaría exponencialmente el número de

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
16 Pablo Felgaer Estado del arte
sumas necesarias; por este motivo se han desarrollado varios algoritmos de propagación
que se citan a continuación.
2.2.4.2. Algoritmos de propagación
Una de las ventajas de disponer de una estructura gráfica de las relaciones entre las
variables es que se puede utilizar esta información para reducir el número de operaciones
necesarias para obtener las probabilidades a posteriori. Existen varios métodos
computacionales que aprovechan la estructura gráfica para propagar los efectos que las
observaciones del mundo real tienen sobre el resto de las variables de la red; las diferencias
entre ellos se basan principalmente en la precisión de los resultados y en el consumo de
recursos durante el tiempo de ejecución. Los algoritmos de propagación se dividen
inicialmente en “exactos” o “aproximados” según cómo calculen los valores de las
probabilidades. Los métodos exactos calculan los valores por medio del teorema de Bayes
mientras que los métodos aproximados utilizan técnicas iterativas de muestreo en las que
los valores se aproximarán más o menos a los exactos dependiendo del punto en que se
detenga el proceso.
Los algoritmos de propagación dependen de l tipo de estructura de la red bayesiana,
existiendo las siguientes tres topologías de red :
• Árboles (sección 2.2.4.2.1),
• Poliárboles (sección 2.2.4.2.2), y
• Redes multiconectadas (sección 2.2.4.2.3).
2.2.4.2.1. Propagación en árboles
Cada nodo corresponde a una variable discreta },,,{ 21 nAAAA K= con su respectiva
matriz de probabilidad condicional )|()|( ij ABPABP = . Dada cierta evidencia E

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 17
(representada por la instanciación de ciertas variables) la probabilidad posterior de
cualquier variable B es, por el teorema de Bayes:
)()()|(
)|(EP
BPBEPEBP ii
i =
ya que la estructura de la red es un árbol, el nodo B la separa en dos subárboles; de esta
manera podemos dividir la evidencia en dos grupos:
• −E : Datos en el árbol que cuya raíz es B .
• +E : Datos en el resto del árbol.
Entonces:
)()()|,(
)|(EP
BPBEEPEBP ii
i
+−
=
pero dado que ambos son independientes, se aplica nuevamente Bayes y se obtiene :
)|()|()|( iii BEPEBPEBP −+=α
donde α es una constante de normalización.
Esto separa la evidencia para actualizar la probabilidad de B ; además se observa que
no se requiere de la probabilidad a priori excepto en el caso de la raíz donde dado que dicho
nodo no posee padres se tiene que:
)()|( ii APEAP =+
Para simplificar el desarrollo se definen los siguientes términos:
)|()(
)|()(+
−
=
=
EBPB
BEPB
ii
ii
π
λ

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
18 Pablo Felgaer Estado del arte
Entonces:
)()()|( iii BBEBP λαπ=
Debido a que por la propiedad de independencia condicional (sección 2.2.3) los hijos
son condicionalmente independientes dado el padre:
∏∏ == −
kik
kiki BBEPB )()|()( λλ
donde −KE corresponde a la evidencia que proviene del hijo k de B denotado por kS .
Condicionando cada término en la ecuación anterior respecto de todos los posibles
valores de cada nodo hijo se obtiene:
∏ ∑
= −
k ji
kj
kjiki BSPSBEPB )|(),|()(λ
Dado que B es condicionalmente independiente de la evidencia bajo cada hijo dado
éste y usando la definición de λ :
∏ ∑
=
k
kj
ji
kji SBSPB )()|()( λλ
En forma análoga se obtiene una ecuación para π ; primero se la condiciona sobre
todos los posibles valores del padre:
∑ ++=j
jjii EAPAEBPB )|(),|()(π
Luego podemos eliminar +E del primer término dada independencia condicional. El
segundo término representa la probabilidad posterior de A sin contar la evidencia del
subárbol de B , por lo que podemos expresarla usando la ecuación para )|( EBP j y la
descomposición de λ .
∑ ∏
=
j kjkjjii AAABPB )()()|()( λαππ

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 19
donde k incluye a todos los hijos de A excepto B .
Mediante estas ecuaciones se integra un algoritmo de propagación de probabilidades
en árboles donde cada nodo guarda los valores de los vectores π y λ así como las matrices
de probabilidad P ; la propagación se hace por un mecanismo de paso de mensajes en
donde cada nodo envía los mensajes correspondientes a su padre e hijos:
Mensaje al padre (nodo B a su padre A ):
∑=j
jijiB BABPA )()|()( λλ
Mensaje a los hijos (nodo B a su hijo kS ):
∏≠
=kl
jljik BBB )()()( λαππ
Al instanciarse ciertos nodos, éstos envían mensajes a sus padres e hijos y se
propagan hasta llegar a la raíz u hojas o hasta encontrar un nodo instanciado; así que la
propagación se hace en un solo paso en un tiempo proporcional al diámetro de la red. Esto
se puede hacer en forma iterativa instanciando ciertas variables y propagando su efecto y
luego instanciando otras variables y propagando la nueva información combinando ambas
evidencias.
2.2.4.2.2. Propagación en poliárboles
Un poliárbol es una red en la que un nodo puede tener varios padres pero sin existir
múltiples trayectorias entre nodos (red conectada en forma sencilla – SCG). El algoritmo de
propagación es muy similar al de árboles; la principal diferencia es que se requiere de la
probabilidad conjunta de cada nodo dado todos sus padres:
),,|( 1 ni AABP K

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
20 Pablo Felgaer Estado del arte
En forma análoga al inciso anterior podemos deducir una expresión de la
probabilidad en un nodo cualquiera B en términos de sus padres e hijos:
)|()|(),,|()|( 11 iminii BEPBEPEEBPEBP −−++= LKα
A partir de esta ecuación se puede también obtener un mecanismo de propagación
local similar al de árboles con el mismo orden de complejidad.
2.2.4.2.3. Propagación en redes multiconectadas
Una red multiconectada es un grafo no conectado en forma sencilla, es decir, en el
que hay múltiples trayectorias entre nodos (MCG); en este tipo de red probabilística los
métodos anteriores ya no aplican pero existen otras técnicas alternativas que se detallan a
continuación:
• Condicionamiento : Al instanciar una variable de la red, ésta bloquea las trayectorias
de propagación lo cual implica que si se asumen valores para un grupo seleccionado
de variables, es posible descomponer la gráfica en un conjunto de SCG; este método
consiste en realizar el proceso de propagación de la evidencia para cada valor posible
de dichas variables y luego promediar las probabilidades ponderadas.
• Simulación estocástica: Se asignan valores aleatorios a las variables no instanciadas,
se calcula la distribución de probabilidad y se obtienen valores de cada variable
dando una muestra; se repite el procedimiento para obtener un número apreciable de
muestras y en base al número de ocurrencias de cada valor se determina la
probabilidad de dicha variable.
• Agrupamiento: El método de agrupamiento consiste en transformar la estructura de
la red para obtener un árbol mediante agrupación de nodos usando la teoría de grafos
[Lauritzen, 1988]. Para ello se parte de la gráfica original y se siguen los siguientes
pasos:
1. Se tr iangulariza el grafo agregando los arcos adicionales necesarios.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 21
2. Se identifican todos los conjuntos de nodos totalmente conectados (cliques).
3. Se ordenan los cliques de forma que todos los nodos comunes estén en un
solo clique anterior (su padre).
4. Se construye un nuevo grafo en que cada clique es un nodo formando un
árbol de cliques.
Para la propagación de probabilidades se utiliza este árbol de macro nodos (cliques)
obteniendo la probabilidad conjunta de cada claque, a partir de la cual se puede
obtener la probabilidad individual de cada variable en el clique. En general, la
propagación en una red probabilística con una estructura compleja es un problema de
complejidad NP-duro [Cooper, 1990]; sin embargo en muchas aplicaciones prácticas
la estructura de la red no es tan compleja y los tiempos de propagación son
razonables.
2.2.4.2.4. Ejemplo de propagación
A continuación se procederá a mostrar un ejemplo de aplicación del proceso de
propagación de probabilidades a través del algoritmo de paso de mensajes para redes
simplemente conectadas que de describió anteriormente.
Para ello se utilizará una red llamada “The dog barking problem” (figura 2.3) que
constituye uno de los ejemplos más utilizados al momento de analizar las redes bayesianas;
el mismo fue publicado originalmente por Charniak [Charniak, 1991].

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
22 Pablo Felgaer Estado del arte
Figura 2.3: “The dog barking problem”.
Todas las variables involucradas son binarias y en la siguiente tabla se describen las
probabilidades a priori y condicionales de las variables del dominio :
P(f) P(b) P(l|f) P(l|!f) P(d|f,b) P(d|f,!b) P(d|!f,b) P(d|!f,!b) P(h|d) P(h|!d)
Si 0.15 0.01 0.60 0.05 0.99 0.90 0.97 0.30 0.70 0.01
No 0.85 0.99 0.40 0.95 0.01 0.10 0.03 0.70 0.30 0.99
Tabla 2.1: Probabilidades condicionales de la red “The dog barking problem”
Propagación inicial
1. Todos los mensajes λ y π de cada nodo son inicializados en 1.
2. Las probabilidades de los estados de los nodos raíz son datos (ver tabla 2.1).
3. A continuación se esta en condiciones de calcular las probabilidades de los estados de
cada uno de los nodos que son hijos directos de los nodos raíz a partir de las matrices
de probabilidad condicional. Esto lo logramos propagando los mensajes π .
b f
d
h
l

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 23
La fórmula matemática para el mensaje π es:
Para un padre : mensaje π a c en el estado i con el padre p .
∑j
jji pPpcP )()|(
Para múltiples padres: mensaje π a c en el estado i con los padres na ,,K .
∑zkj
zkjzkji nPbPaPnbacP,,,
)()()(),,,|(K
LK
4. Luego la probabilidad para cada estado de los nodos es simplemente la suma
normalizada de los mensajes π .
En este ejemplo la probabilidad inicial de que el nodo l se encuentre en el estado i :
))()|()()|(()( 2211 fPflPfPflPoNormalizadlP iii +=
La probabilidad inicial de que el nodo d se encuentre en el estado i :
))()(),|()()(),|()()(),|()()(),|(()(
22221212
21211111
bPfPbfdPbPfPbfdPbPfPbfdPbPfPbfdPoNormalizaddP
ii
iii
++++=
5. A continuación se repite el proceso desde el paso (3) propagando hacia abajo por toda
la red de la misma manera hasta que todos los nodos hayan sido calculados
Una vez que se realizó la propagación inicial, la red bayesiana se encuentra en
condiciones de recibir nuevas observaciones y recalcular las probabilidades del resto de las
variables en función de dichos valores.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
24 Pablo Felgaer Estado del arte
Instanciación de nodos
Cuando un nodo es instanciado en alguno de sus valores:
1. A la evidencia lambda para dicho estado se le asigna el valor 1.
2. A la probabilidad para dicho estado se le asigna el valor 1.
3. A la probabilidad para cada uno de los estados restantes se les asigna el valor 0.
4. Los mensajes λ y π son enviados hacia sus padres e hijos respectivamente.
Los mensajes π son análogos a los expuestos en el proceso de propagación inicial.
La fórmula matemática para el mensaje λ es:
Para un padre : mensaje λ a p en el estado k desde el hijo c .
∑j
jkj cpcP )()|( λ
Observar que )( jcλ corresponde a la evidencia λ para el estado j del nodo c . En
los casos en que sean nodos instanciados, el valor será igual a 1 para el estado
instanciado y 0 para el resto de ellos.
Para múltiples padres: mensaje λ a p en el estado k desde el hijo c .
∑ ∑i j
jikjk cnapcPpP )(),,,|()( 1 λK
Observar que )( kpP corresponde a la evidencia π para el estado k del nodo p . En
los casos en que sean nodos instanciados, el valor será igual a 1 para el estado
instanciado y 0 para el resto de ellos.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 25
5. La propagación de los mensajes continúa como se indica en el paso (4) de manera
recursiva respetando las siguientes reglas.
Propagación de mensajes
• Los mensajes π no pueden propagarse a través de nodos instanciados.
Figura 2.4: “The dog barking problem” – Instanciación del nodo d
Por ejemplo se tiene la red con el nodo d instanciado (figura 2.4) y luego se
instancia el nodo b . Esta última instanciación propagará un mensaje π hacia el
nodo d pero no hacia h (ni a ninguno de sus otros hijos, si los tuviera).
• Los mensajes λ no son bloqueados por los nodos instanciados como se vio
anteriormente. Sin embargo son bloqueados por nodos convergentes que no
tienen evidencia lambda. Por ejemplo si el nodo d o un hijo de este no
estuvieran instanciados entonces no se enviaría ningún mensaje λ al nodo f .
b f
d
h
l
π π λ

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
26 Pablo Felgaer Estado del arte
Ejemplo de propagación completa
1. Inicialmente se propagan todos los mensajes π para inicializar la red (figura 2.5).
Figura 2.5: “The dog barking problem” – Estado inicial
• No se envían mensajes λ hacia los nodos d , b o f debido a que se encuentran
bloqueados por la falta de evidencia λ .
2. A continuación se procede a instanciar el nodo h (figura 2.6).
Figura 2.6: “The dog barking problem” – Instanciación del nodo h
b f
d
h
l
λ π λ
λ
b f
d
h
l
π π π
π

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 27
• Un mensaje λ es enviado del nodo h al nodo d .
• La probabilidad a posteriori del nodo d es recalculada a partir de la nueva
evidencia.
• Se envían mensaje a todas las relaciones del nodo d excepto de nuevo al nodo
h .
• Los nodos b y f recalculan sus probabilidades.
• El nodo f envía un mensaje π al nodo l pero nada devuelta al nodo d .
• El nodo l recalcula su probabilidad.
3. Ahora se procede a instanciar el nodo f (figura 2.7).
Figura 2.7: “The dog barking problem” – Instanciación de los nodos h y f
• El nodo f envía mensajes π a los nodos d y l .
• Los nodos d y l recalculan sus probabilidades.
• Dado que el nodo d tiene evidencia λ (proveniente del nodo h ) envía un
mensaje λ hacia el nodo b como así también un mensaje π al nodo h .
• Como el nodo h se encuentra instanciado no modifica su estado.
• El nodo b recalcula su probabilidad basado en el mensaje recibido del nodo d .
b f
d
h
l
λ π π
π

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
28 Pablo Felgaer Estado del arte
4. Finalmente se instancia el nodo d (figura 2.8).
Figura 2.8 “The dog barking problem” – Instanciación de los nodos h, f y d
• Mensajes λ son enviados a los nodos b y f mientras que un mensaje π se
envía al nodo h .
• Los nodos f y h se mantienen sin modificaciones pero el nodo b recalcula su
probabilidad.
• Dado que el nodo f se encuentra instanciado, éste no envía ningún mensaje π
al nodo l .
2.2.5. El aprendizaje en las redes bayesianas
El aprendizaje es una de las características que definen a los sistemas basados en
inteligencia artificia l porque siendo estrictos se puede afirmar que sin aprendizaje no hay
inteligencia; es difícil definir el término “aprendizaje”, pero la mayoría de las autoridades
en el campo coinciden en que es una de las características de los sistemas adaptativos que
son capaces de mejorar su comportamiento en función de su experiencia pasada, por
ejemplo al resolver problemas similares [Simon, 1983]. El aprendizaje suele ser
imprescindible en aquellos sistemas que deben trabajar en entornos desconocidos o zonas
de proceso poco frecuentes donde la adquisición de conocimiento de los expertos en una
b f
d
h
l
λ λ
π

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 29
tarea difícil o incluso imposible; los sistemas de aprendizaje son capaces de generar nuevo
conocimiento y de ajustar el conocimiento existente.
El aprendizaje en la redes bayesianas consiste en definir la red probabilística a partir
de datos almacenados en bases de datos en lugar de obtener el conocimiento del experto.
Este tipo de aprendizaje ofrece la posibilidad de inducir la estructura gráfica de la red a
partir de los datos observados y de definir las relaciones entre los nodos basándose también
en dichos casos; según Pearl [Pearl, 1988] a estas dos fases se las puede denominar
respectivamente aprendizaje estructural y aprendizaje paramétrico. A continuación se
resume cada una de estas dos fases:
• Aprendizaje estructural: obtiene la estructura de la red bayesiana a partir de bases
de datos, es decir, las relaciones de dependencia e independencia entre las variables
involucradas. Las técnicas de aprendizaje estructural dependen del tipo de estructura
o topología de la red (árboles, poliárboles o redes multiconectadas). Otra alternativa
es combinar conocimiento subjetivo del experto con aprendizaje, para lo cual se parte
de la estructura dada por el experto y se la valida y mejora utilizando datos
estadísticos.
• Aprendizaje paramétrico: dada una estructura y las bases de datos, obtiene las
probabilidades a priori y condicionales requeridas.
Uno de los principales trabajos en el campo del aprendizaje de redes bayesianas en el
de Herkovits y Copper [Herskovits & Copper, 1991]; el requisito principal para poder
realizar la tarea de aprendizaje de redes bayesianas a partir de datos es disponer de bases de
datos muy extensas en las que esté especificado el valor de cada variable en cada uno de los
casos.
El aprendizaje en redes bayesianas a partir de bases de datos incompletas
generalmente consiste en inferir de alguna manera los datos ausentes para completar la base
de datos; investigaciones al respecto [Ramoni & Sebastiani, 1997] estiman los límites del
conjunto de datos ausentes y obtienen un único punto de estimación que es modificado con

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
30 Pablo Felgaer Estado del arte
diferentes pesos dependiendo del patrón que supuestamente siguen dichos datos; finalmente
se construye una base de datos completa y se procede como se indicó anteriormente.
2.2.5.1. Aprendizaje paramétrico
El aprendizaje paramétrico consiste en encontrar los parámetros asociados a una
estructura dada de una red bayesiana. Dichos parámetros consisten en las probabilidades a
priori de los nodos raíz y las probabilidades condicionales de las demás variables dados sus
padres; si se conocen todas las variables es fácil obtener las probabilidades requeridas ya
que las probabilidades previas corresponden a las marginales de los nodos raíz y las
condicionales se obtienen de las conjuntas de cada nodo con su(s) padre(s). Para que se
actualicen las probabilidades con cada caso observado, éstas se pueden representar como
razones enteras y actualizarse con cada observación; en el caso de un árbol las fórmulas
para modificar las probabilidades correspondientes son:
Probabilidades previas:
kisaAP
kisaAP
ii
ii
≠+=
=++=
;)1()(
;)1()1()(
Probabilidades condicionales:
kiabABP
ljykiabABP
ljykiabABP
ijij
ijij
ijij
≠=
≠=+=
==++=
;)|(
;)1()|(
;)1()1()|(
donde:
• s corresponde al número de casos totales,
• ji, los índices de las variables, y
• lk , los índices de las variables observadas.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 31
El algoritmo anterior supone que las probabilidades tienen un valor preciso, es decir
que no hay incertidumbre en las probabilidades. Un enfoque más adecuado, pero un poco
más complejo, es utilizar una distribución de probabilidad para las probabilidades;
normalmente se utiliza para el caso de variables binarias la distribución Beta y para
variables mutivaluadas su generalización que es la distribución Dirichlet [Neapolitan,
1990]. Para fines prácticos se utiliza como estimado de la probabilidad el valor medio de
las distribuciones, el cual corresponde aproximadamente al que se obtiene en el algoritmo
anterior.
2.2.5.1.1. Variables no observadas
En algunos casos existen variables que son importantes para el modelo pero para las
cuales no se tienen datos; éstas se conocen como nodos no observables o escondidos. Si
algunos nodos no son observables, se pueden estimar de acuerdo a los observables y en
base a ello actualizar las probabilidades; para ello se aplica el siguiente algoritmo:
1. Instanciar todas las variables observables.
2. Propagar su efecto y obtener las probabilidades posteriores de las no observables.
3. Para las variables no observables, asumir el valor con probabilidad mayor como observado.
4. Actualizar las probabilidades previas y condicionales de acuerdo a las formulas anteriores.
5. Repetir (1) a (4) para cada observación.
El algoritmo anterior es la forma más simple de realizar aprendizaje de “nodos
escondidos”.
2.2.5.2. Aprendizaje estructural
2.2.5.2.1. Árboles
El método para aprendizaje estructural de árboles se basa en el algoritmo desarrollado
por Chow y Liu [Chow & Liu, 1968] para aproximar una distribución de probabilidad por

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
32 Pablo Felgaer Estado del arte
un producto de probabilidades de segundo orden (lo que corresponde a un árbol); la
probabilidad conjunta de n variables se puede representar como:
∏=
=n
iijin XXPXXXP
1)(21 )|(),,,( K
donde )( ijX es la causa o padre de iX .
Se plantea el problema de aprender la estructura de la red bayesiana a partir de datos
como uno de optimización y lo que se desea es obtener la estructura en forma de árbol que
más se aproxime a la distribución “real” para lo cual se utiliza una medida de la diferencia
de información entre la distribución real ( P ) y la aproximada ( *P ):
∑=x
XPXPXPPPI ))()(log()(),( **
Entonces el objetivo es minimizar I ; para ello se define una diferencia en función de
la información mutua entre pares de variables que se define como:
∑=x
jijijiji XPXPXXPXXPXXI ))()(),(log(),(),(
Chow [Chow, 1968] demuestra que la diferencia de información es una función del
negativo de la suma de las informaciones mutuas (pesos) de todos los pares de variables
que constituyen el árbol, por lo que encontrar el árbol más próximo equivale a encontrar el
árbol con mayor peso. Basado en lo anterior, el algoritmo para determinar la red bayesiana
óptima a partir de datos es el siguiente:
1. Calcular la información mutua entre todos los pares de variables (n(n-1)/2).
2. Ordenar las informaciones mutuas de mayor a menor.
3. Seleccionar la rama de mayor valor como árbol inicial.
4. Agregar la siguiente rama mientras no forme un ciclo, si es así, desechar.
5. Repetir (4) hasta que se cubran todas las variables (n-1ramas).

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 33
Dicho algoritmo no provee la direccionalidad de los arcos, por lo que esta se puede
asignar en forma arbitraria o utilizando semántica externa (experto).
2.2.5.2.2. Poliárboles
Rebane y Pearl [Rebane & Pearl, 1989] extendieron el algoritmo de Chow y Liu para
poliárboles ; para ello parten del esqueleto (estructura sin direcciones) obtenido con el
algoritmo anterior y determinan las dirección de los arcos utilizando pruebas de
dependencia entre tripletas de variables; de esta forma se obtiene una red bayesiana en
forma de poliárbol, en cuyo caso la probabilidad conjunta es:
∏=
=n
iijmijiji XXXXPXP
1)()(2)(1 ),,,|()( K
donde },,,{ )()(2)(1 ijmijij XXX K es el conjunto de padres de la variable iX .
El algoritmo de Rebane y Pearl se basa en probar las relaciones de dependencia entre
todas las tripletas de variables en el esqueleto. Dadas tres variables existen tres casos
posibles:
• Arcos divergentes (figura 2.9-a),
• Arcos secuenciales (figura 2.9-b), y
• Arcos convergentes (figura 2.9-c).
Figura 2.9: Tipos de conexiones en un grafo dirigido: (a) divergentes, (b) secuenciales y (c) convergentes
A B C A
C
B
A
C
B
(a) (b) (c)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
34 Pablo Felgaer Estado del arte
Los primeros dos casos (arcos divergentes y secuenciales) son indistinguibles, pero el
tercero (arcos convergentes) es diferente, ya que las dos variables “padre” son
marginalmente independientes. Entonces el algoritmo consiste en:
1. Obtener el esqueleto utilizando el algoritmo de Chow y Liu.
2. Recorrer la red hasta encontrar una tripleta de nodos que sean convergentes (tercer caso) – nodo multipadre.
3. A partir de un nodo multipadre determinar las direcciones de los arcos utilizando la prueba de tripletas hasta donde sea posible (base causal).
4. Repetir (2) a (3) hasta que ya no se puedan descubrir más direcciones.
5. Si quedan arcos sin direccionar utilizar semántica externa para obtener su dirección.
El algoritmo está restringido a poliárboles y no garantiza obtener todas las
direcciones; desde el punto de vista práctico un problema es que generalmente no se
obtiene independencia absoluta (información mutua cero) por lo que habría que considerar
una cota empírica.
2.2.5.2.3. Redes multiconectadas
Al igual que en propagación, el caso de una red multiconectada es el más difícil para
aprendizaje estructural; una alternativa [Sucar & Pérez-Brito, 1995] es plantear el problema
nuevamente como uno de optimización buscando encontrar la estructura que de un
rendimiento deseable con el mínimo número de arcos, para lo cual se parte del algoritmo de
Chow-Liu para obtener un árbol inicial y se van agregando arcos hasta llegar al rendimiento
deseado o al máximo número permisible ; el algoritmo es el siguiente:
1. Obtener una estructura de árbol inicial mediante el algoritmo de Chow-Liu.
2. Hacer la variable hipótesis el nodo raíz y a partir de éste determinar la direccionalidad de los arcos.
3. Producir un ordenamiento de los nodos },,,{ 21 nXXX K a partir de la raíz y siguiendo el árbol de acuerdo a la información mutua entre variables.
4. Probar la capacidad predictiva del sistema:
(a) Si es satisfactoria terminar.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 35
(b) Sino, agregar un arco y regresar a 4. Seleccionar el arco de mayor información mutua basando su dirección en el ordenamiento anterior, de forma que su nodo inicial sea anterior al nodo final.
El algoritmo asume una variable hipótesis (sistemas predictivos) por lo que la
dirección de los arcos es arbitraria y no refleja necesariamente causalidad; esta es una área
de investigación actual en redes bayesianas y existen varias propuestas para aprendizaje
estructural en redes multiconectadas.
Las técnicas automáticas para aprendizaje estructural de redes bayesianas
multiconectadas consisten en dos aspectos principales:
1. Una medida de para evaluar que tan “buena” es cada estructura respecto a los datos.
2. Un método de búsqueda que genere diferentes es tructuras hasta encontrar la “óptima”
de acuerdo a la medida seleccionada.
Existen varias medidas de evaluar, entre las cuales se destacan las dos más utilizadas:
• Medida bayesiana : estima la probabilidad de la estructura dado los datos y se la trata
de maximizar.
• Longitud de descripción mínima (MDL): estima la longitud (tamaño en bits)
requerida para representar la probabilidad conjunta con cierta estructura; esta se
compone de dos partes:
1. Representación de la estructura.
2. Representación del error de la estructura respecto a los datos.
Aunque ambas medidas son semejantes, la segunda es un poco mejor ya que tiende a
preferir estructuras más simples.
El encontrar la estructura óptima es difícil ya que el espacio de búsqueda es muy
grande; por ejemplo hay más de 1040 diferentes estructuras para 10 variables. Por esto se
utilizan estrategias de búsqueda heurísticas que encuentran una solución aceptable pero,

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
36 Pablo Felgaer Estado del arte
generalmente, no óptima; otra alternativa es combinar los métodos automáticos con
conocimiento de expertos.
2.2.5.2.4. Mejora estructural
La mejora estructural combina el conocimiento de expertos con datos para encontrar
la estructura de una red bayesiana; un enfoque [Sucar, 1993] consiste en iniciar con una
estructura preliminar propuesta por un experto y utilizar datos para validarla y mejorar la
para lo cual asume que se tiene una estructura de tipo multiárbol o bosque (colección de
árboles) en donde se tienen una serie de subárboles, es decir, un nodo con varios hijos; en
cada subárbol los nodos hijo son independientes dado el padre, entonces la técnica consiste
en validar dicha independencia con los datos y modificar la estructura si no se cumple,
mediante los siguientes pasos:
1) Validar la estructura de cada subárbol de la red bayesiana:
a) Calcular la correlación entre cada par de nodos dado el padre:
i) Baja: es razonable asumir independencia, así que la estructura no se modifica.
Alta: no son independientes, modificar la estructura utilizando una de las siguientes estrategias:
(1) Eliminación de nodo.
(2) Combinación de nodos.
(3) Creación de nodo.
Otra alternativa es obtener una estructura inicial a partir de los datos (por ejemplo, un
árbol) y luego utilizar conocimiento del experto para alterar la estructura; repitiendo este
proceso en forma iterativa.
2.2.6. Ventajas de las redes bayesianas
El hecho de que las redes bayesianas constituyan una mezcla de técnicas estadísticas
y modelos gráficos les provee un serie de importantes ventajas. En primer lugar, el hecho
de que las redes guarden información sobre las dependencias e independencias existentes

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 37
entre las variables involucradas les permiten manejar situaciones donde exista
incertidumbre; por otro lado la presentación gráfica de la red facilita la interpretación y
obtención de conclusiones sobre el dominio en estudio por parte de la gente que lo analiza;
también, debido a que estas redes combinan relaciones causales con lógica probabilística,
permite combinar conocimiento experto con datos (dicho conocimiento experto
generalmente viene dado en forma de relaciones de causalidad).
Las redes bayesianas permiten definir modelos y utilizarlos tanto para hacer
razonamiento de diagnóstico (pues obtienen las causas más probables dado un conjunto de
síntomas), como para hacer razonamiento predictivo (obteniendo la probabilidad de
presentar un cierto síntoma suponiendo que existe una causa conocida). Una de las
características de las redes bayesianas es que un mismo nodo puede ser fuente de
información u objeto de predicción dependiendo de cuál sea la evidencia disponible. A
continuación se muestran cuáles son las características de estos dos tipos de inferencia
utilizando una red bayesiana :
• Predicción
Si se supone que es cierto un hecho del mundo real que está representado en la red
como un nodo padre, la red puede deducir cuáles serán sus efectos; para ello se debe
introducir esta hipótesis en el nodo correspondiente y propagar esta información hacia
el resto de los nodos. Este modo de razonamiento es de tipo predictivo y está regido
por una inferencia “deductiva” donde el conocimiento se puede expresar de la forma
“si a entonces b” y se cumple que el hecho conocido es “a” y el hecho deducido es
“b”.
• Interpretación de datos
Las mismas relaciones representadas en la red en forma causal permiten hacer
inferencias abductivas donde conocidos los síntomas se puede saber cuáles son sus
posibles causas. El conocimiento es el mismo que en el caso anterior: “si a entonces
b” pero ahora el hecho conocido es “b” y el hecho abducido es “es posible a”; este

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
38 Pablo Felgaer Estado del arte
modo de razonamiento es el que permite la interpretación de las causas que generan
determinados fenómenos.
Como se indicó anteriormente en este capítulo , las redes probabilísticas permiten
ejecutar simulaciones efectuando hipótesis sobre cualquiera de los datos e incluso
considerando ignorancia en alguna de las variables de entrada. En el caso de los
simuladores matemáticos sólo es posible establecer hipótesis sobre los datos de partida que
son introducidos en el modelo como las condiciones iniciales y además es imprescindible
que se introduzcan todas las variables de entrada del modelo para poder resolver las
ecuaciones.
Si un nodo de la red representa una variable correspondiente a la presencia de una
anomalía, se puede diagnosticar que ésta se encuentra presente cuando su probabilidad
excede un cierto umbral; con la llegada de nuevas evidencias, la probabilidad puede cruzar
el umbral varias veces dependiendo de que las nuevas evidencias ratifiquen o descarten la
presencia de esa anomalía; esto significa que cada nueva observación puede aumentar o
disminuir la estimación de una hipótesis ; por esta propiedad de las redes bayesianas se
puede afirmar que efectúan un razonamiento no monótono basado en la probabilidad y no
en la lógica. El siguiente ejemplo pretende clarificar en qué consiste el razonamiento no
monótono y permite apreciar que este tipo de razonamiento es imprescindible en muchos
dominios de aplicación:
Se supone que el síntoma “fiebre” puede ser causado por dos enfermedades distintas
“catarro” e “infección intestinal”. Si observamos que un paciente tienen fiebre
puede ser que tenga catarro o infección intestinal con unas ciertas probabilidades,
pero si por otro lado encontramos algún signo (ejemplo: diarrea) que nos ratifique
en la idea de que padece de infección intestinal, está claro que s imultáneamente debe
disminuir la probabilidad de que el paciente tenga catarro.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 39
2.3. Árboles de decisión – TDIDT
La familia de los Top Down Induction Trees (TDIDT) pertenece a los métodos
inductivos del aprendizaje automático que aprenden a partir de ejemplo s preclasificados; en
minería de datos, las mismas se utilizan para modelar las clasificaciones en los datos
mediante árboles de decisión.
2.3.1. Características de los árboles de decisión
Los árboles de decisión representan una estructura de datos que organiza eficazmente
los descriptores; dichos árboles son construidos de forma tal que en cada nodo se realiza
una prueba sobre el valor de los descriptores y de acuerdo con la respuesta se va
descendiendo en las ramas hasta llegar al final del camino donde se encuentra el valor del
clasificador. Se puede analizar un árbol de decisión como una caja negra en función de
cuyos parámetros (descriptores) se obtiene un cierto valor del clasificador; también puede
analizarse como una disyunción de conjunciones donde cada camino desde la raíz hasta las
hojas representa una conjunción y todos los caminos son alternativos, es decir, son
disyunciones.
2.3.2. Construcción de los árboles de decisión
Los árboles TDIDT, a los cuales pertenecen los generados por el ID3 y por el C4.5, se
construyen a partir del método de Hunt [Hunt et al., 1966]. El esqueleto de este método
para construir un árbol de decisión a partir de un conjunto T de datos de entrenamiento se
detalla a continuación; sean las clases },,,{ 21 kCCC K existen tres posibilidades:
1. T contiene uno o más casos, todos pertenecientes a una única clase jC :
El árbol de decisión para T es una hoja identificando la clase jC .
2. T no contiene ningún caso:

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
40 Pablo Felgaer Estado del arte
El árbol de decisión es una hoja, pero la clase asociada debe ser determinada por
información que no pertenece a T . Por ejemplo, una hoja puede escogerse de
acuerdo a conocimientos de base del dominio, como ser la clase mayoritaria.
3. T contiene casos pertenecientes a varias clases:
En este caso, la idea es refinar T en subconjuntos de casos que tiendan o parezcan
tender hacia una colección de casos pertenecientes a una única clase. Se elige una
prueba basada en una única variable que tiene uno o más resultados mutuamente
excluyentes },,,{ 21 nOOO K y T se particiona en los subconjuntos nTTT ,,, 21 K
donde iT contiene todos los casos de T que tienen el resultado iO para la prueba
elegida. El árbol de decisión para T consiste en un nodo de decisión identificando
la prueba con una rama para cada resultado posible. El mecanismo de
construcción del árbol se aplica recursivamente a cada subconjunto de datos de
entrenamientos para que la i-ésima rama lleve al árbol de decisión construido por
el subconjunto iT de datos de entrenamiento.
2.3.2.1. Cálculo de la ganancia de información
En los casos en los que el conjunto T contiene ejemplos pertenecientes a distintas
clases se realiza una prueba sobre las distintas variables y se realiza una pa rtición según la
“mejor” variable. Para encontrar la “mejor” variable se utiliza la teoría de la información
que sostiene que la información se maximiza cuando la entropía se minimiza (la entropía
determina la azarosidad o desestructuración de un conjunto). Si se supone que se tiene n
ejemplos positivos y negativos, la entropía del subconjunto iS , )( iSH puede calcularse
como:
−−++ −−= iiiii ppppSH log)(
donde +ip es la probabilidad de que un ejemplo tomado al azar de iS sea positivo. Esta
probabilidad puede calcularse como:
−+
++
+=
ii
ii nn
np

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 41
siendo +in la cantidad de ejemplos positivos de iS y −
in la cantidad de ejemplos negativos.
La probabilidad −ip se calcula en forma análoga a ? +
ip , reemplazando la cantidad de
ejemplos positivos por la cantidad de ejemplos negativos, y viceversa.
Generalizando la expresión anterior para cua lquier tipo de ejemplos, obtenemos la
fórmula general de la entropía:
∑=
−=n
iiii ppSH
1
log)(
En todos los cálculos relacionados con la entropía, definimos 00log0 = .
Si la variable at divide el conjunto S en los subconjuntos niSi ,,2,1, K= , entonces,
la entropía total del sistema de subconjuntos será:
∑=
⋅=n
iiii SHSPatSH
1
)()(),(
donde )( iSH es la entropía del subconjunto iS y )( iSP es la probabilidad de que un
ejemplo pertenezca a iS ; puede calcularse, utilizando los tamaños relativos de los
subconjuntos, como:
SS
SP ii =)(
La ganancia en información puede calcularse como la disminución en entropía. Es
decir:
),()(),( atSHSHatSI −=
donde )(SH es el valor de la entropía a priori antes de realizar la subdivisión y ),( atSH es
el valor de la entropía del sistema de subconjuntos generados por la partición según at .

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
42 Pablo Felgaer Estado del arte
2.3.2.2. Poda de los árboles generados
Existen varias razones para la poda de los árboles generados por los métodos de
TDIDT [Michalski et al., 1998]; entre ellas podemos nombrar la sobre-generalización, la
evaluación de variables poco importantes o significativas y el gran tamaño del árbol
obtenido. En el primer caso, un árbol puede haber sido construido a partir de ejemplos con
ruido, con lo cual algunas ramas del árbol pueden ser engañosas; en cuanto a la evaluación
de variables no relevantes, éstas deben podarse ya que sólo agregan niveles en el árbol y no
contribuyen a la ganancia de información. Por último, si el árbol obtenido es demasiado
profundo o demasiado frondoso se dificulta la interpretación por parte del usuario, con lo
cual hubiera sido lo mismo utilizar un método de caja negra.
Existen dos enfoques para podar los árboles: la pre-poda (preprunning) y la post-poda
(postprunning). En el primer caso se detiene el crecimiento del árbol cuando la ganancia de
información producida al dividir un conjunto no supera un umbral determinado; en la post-
poda se podan algunas ramas una vez que se ha terminado de construir el árbol. El primer
enfoque tiene la ventaja de que no se pierde tiempo en construir una estructura que luego
será simplificada en el árbol final; el método típico en estos casos es buscar la mejor
manera de partir el subconjunto y evaluar la partición desde el punto de vista estadístico
mediante la teoría de la ganancia de información, reducción de errores, etc. Si esta
evaluación es menor que un límite predeterminado la división se descarta y el árbol para el
subconjunto es simplemente la hoja más apropiada; sin embargo este tipo de método tiene
la contra de que no es fácil detener un particionamiento en el momento adecuado; un límite
muy alto puede terminar con la partición antes de que los beneficios de particiones
subsiguientes parezcan evidentes mientras que un límite demasiado bajo resulta en una
simplificación demasiado leve. El segundo enfoque utilizado por el ID3 y el C4.5 procede a
la simplificación una vez construido el árbol según los criterios propios de cada uno de los
algoritmos.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 43
2.3.2.3. El Principio de longitud de descripción mínima
El principio de longitud de descripción mínima (MDL) [Joachims et al., 1995;
Mitchell, 2000; Quinlan, 1993d; Quinlan, 1995; Quinlan & Cameron-Jones, 1995] sostiene
que la mejor teoría para un conjunto de datos es aquella que minimiza el tamaño de la
teoría y la cantidad de información necesaria para especificar las excepciones; desde el
punto de vista del aprendizaje automático esto significa que dado un conjunto de instancias
un sistema de aprendizaje infiere una teoría a partir de ellas; supóngase una analogía con el
campo de las comunicaciones: la teoría con las excepciones debe ser transmitida por un
canal perfecto. El MDL sostiene que la mejor generalización es aquella que requiere la
menor cantidad de bits para transmitir la generalización junto con los ejemplos a partir de la
cual fue generada. Esto evita las teorías que satisfacen los datos al extremo sobre-ajuste ya
que los ejemplos se transmiten también, y las teorías demasiado extensas serán penalizadas.
Por otro lado, también se puede transmitir la teoría nula que no ayuda en lo más mínimo al
transmitir los ejemplos. Entonces, pueden trans mitirse tanto las teorías simples como
aquellas muy complejas y el MDL provee una forma de medir la performance de los
algoritmos basándose en los datos de entrenamiento únicamente. Esta parece ser la solución
ideal al problema de medir la performance.
Veamos cómo se aplica el principio MDL. Supongamos que un sistema de
aprendizaje genera una teoría T , basada en un conjunto de entrenamiento E , y requiere
una cierta cantidad de bits [ ]TL para codificar la teoría. Dada la teoría, el conjunto de
entrenamiento puede codificarse en una cantidad [ ]TEL / de bits. [ ]TEL / está dada por la
función de ganancia de información sumando todos los miembros del conjunto de
entrenamiento. La longitud de descripción total de la teoría es [ ] [ ]TELEL /+ . El principio
MDL recomienda la teoría T que minimiza esta suma.
Hay que recordar que los algoritmos de la familia TDIDT realizan una búsqueda en el
espacio de hipótesis posibles constituido por todos los árboles de decisión posibles. Su
sesgo inductivo, siguiendo el principio de la Afeitadora de Occam , es una preferencia sobre
los árboles pequeños frente a los árboles más profundos y frondosos.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
44 Pablo Felgaer Estado del arte
2.3.3. Descripción general de los algoritmos
El algoritmo principal de los sistemas de la familia TDIDT, a la cual pertenecen el
ID3 y su descendiente el C4.5, es el proceso de generación de un árbol de decisión inicial a
partir de un conjunto de datos de entrenamiento. La idea original está basada en un trabajo
de Hoveland y Hunt de los años ‘50 culminado en el libro Experiments in Induction [Hunt
et al., 1966] que describe varios experimentos con varias implementaciones de sistemas de
aprendizaje de conceptos (Concept Learning Systems – CLS).
2.3.3.1. División de los datos
El método “divide y reinarás” realiza en cada paso una partición de los datos del
nodo según una prueba realizada sobre la “mejor ” variable. Cualquier prueba que divida a
T en una manera no trivial tal que al menos dos subconjuntos distintos }{ iT no estén
vacíos, eventualmente resultará en una partición de subconjuntos de una única clase aún
cuando la mayoría de los subconjuntos contengan un solo ejemplo. Sin embargo el proceso
de construcción del árbol no apunta meramente a encontrar cualquier partición de este tipo
sino a encontrar un árbol que revele una estructura del dominio y, por lo tanto, tenga poder
predictivo. Para ello se necesita un número importante de casos en cada hoja o, dicho de
otra manera, la partición debe tener la menor cantidad de clases posibles. En el caso ideal se
busca elegir en cada paso la prueba que genere el árbol más pequeño; es decir, se busca un
árbol de decisión compacto que sea consistente con los datos de entrenamiento. Para ello se
pueden explorar todos los árboles posibles y elegir el más simple pero desafortunadamente
un número exponencial de árboles debería ser analizado. El problema de encontrar el árbol
de decisión más pequeño consistente con un conjunto de entrenamiento es de complejidad
NP-completa.
La mayoría de los métodos de construcción de árboles de decisión (incluyendo el
C4.5 y el ID3) no permiten volver a estados anteriores, es decir, son algoritmos “golosos”
sin vuelta atrás. Una vez que se ha escogido una prueba para particionar el conjunto actual,
típicamente basándose en la maximización de alguna medida local de progreso, la partición

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 45
se concreta y las consecuencias de una elección alternativa no se exploran. Por este motivo
la elección debe ser bien realizada.
2.3.3.1.1. Elección del criterio de división
Para realizar la división de los datos en cada paso, Quinlan propone la utilización de
los métodos de la teoría de la información. En un principio el ID3 utilizaba la ganancia
como criterio de división, sin embargo a partir de numerosas pruebas se descubrió que este
criterio no era efectivo en todos los casos y se obtenían mejores resultados si se
normalizaba el criterio en cada paso, por lo tanto comenzó a utilizarse la proporción de
ganancia de información con mayor éxito ; a continuación se presentan ambos criterios.
2.3.3.1.1.1. Criterio de ganancia
La definición de ganancia se presenta de la siguiente forma: supongamos que
tenemos una prueba posible con n resultados que particionan al conjunto T de
entrenamiento en los subconjuntos nTTT ,,, 21 K . Si la prueba se realiza sin explorar las
divisiones subsiguientes de los subconjuntos iT , la única información disponible para
evaluar la partición es la distribución de clases en T y sus subconjuntos.
Consideremos una medida similar luego de que T ha sido particionado de acuerdo a
los n resultados de la prueba X . La información esperada (entropía) puede determinarse
como la suma ponderada de los subconjuntos, de la siguiente manera:
∑=
=n
ii
i TxHTT
XTH1
)(),(
La cantidad ),()(),( XTHTHXTI −= mide la información ganada al partir T de
acuerdo a la prueba X . El criterio de ganancia entonces selecciona la prueba que maximice
la ganancia de información, es decir, antes de particionar los datos en cada nodo se calcula
la ganancia que resultaría de particionar el conjunto de datos según cada uno de las
variables posibles y se realiza la partición que resulta en la mayor ganancia.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
46 Pablo Felgaer Estado del arte
2.3.3.1.1.2. Criterio de proporción de ganancia
El criterio de ganancia tiene un defecto muy serio y es que presenta una tendencia
muy fuerte a favorecer las pruebas con muchos resultados. Analicemos una prueba sobre
una variable que sea la clave primaria de un conjunto de datos en la cual obtendremos un
único subconjunto para cada caso y para cada subconjunto tendremos 0),( =XTI ; entonces
la ganancia de información será máxima. Desde el punto de vista de la predicción este tipo
de división no es útil.
Esta tendencia inherente al criterio de ganancia puede corregirse mediante una suerte
de normalización en la cual se ajusta la ganancia aparente atribuible a pruebas con muchos
resultados. Consideremos el contenido de información de un mensaje correspondiente a los
resultados de las pruebas. Por analogía a la definición de la )(SI tenemos:
∑=
−=
n
i
ii
T
Tx
T
TXdivisiónI
12log)(_
Esto representa la información potencial generada al dividir T en n subconjuntos,
mientras que la ganancia de información mide la información relevante a una clasificación
que nace de la misma división. Entonces:
)(_),(
)(__XdivisiónI
XTIXgananciadeproporción =
expresa la proporción útil de información generada en la partición. Si la partición es casi
trivial, la información de la división será pequeña y esta proporción se volverá inestable.
Para evitar este fenómeno el criterio de proporción de ganancia selecciona una prueba que
maximice la expresión anterior sujeta a la restricción de que la información de la división
sea grande, al menos tan grande como la ganancia promedio sobre todas las pruebas
realizadas.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 47
2.3.3.2. Construcción de árboles
2.3.3.2.1. ID3
El algoritmo ID3 diseñado en 1993 por J. Ross Quinlan [Quinlan, 1993a, Quinlan,
1993b] toma objetos de una clase conocida y los describe en términos de una colección fija
de propiedades o de variables produciendo un árbol de decisión sobre estas variables que
clasifica correctamente todos los objetos [Quinlan, 1993b]. Hay ciertas cualidades que
diferencian a este algoritmo de otros sistemas generales de inferencia. La primera se basa
en la forma en que el esfuerzo requerido para realizar una tarea de inducción crece con la
dificultad de la tarea. El ID3 fue diseñado específicamente para trabajar con masas de
objetos y el tiempo requerido para procesar los datos crece sólo linealmente con la
dificultad como producto de:
• La cantidad de objetos presentados como ejemplos.
• La cantidad de variables dadas para describir estos objetos.
• La complejidad del concepto a ser desarrollado (medido por la cantidad de nodos en
el árbol de decisión).
Esta linealidad se consigue a costa del poder descriptivo ya que los conceptos
desarrollados por el ID3 sólo toman la forma de árboles de decisión basados en las
variables dadas y este “lenguaje” es mucho más restrictivo que la lógica de primer orden o
la lógica multivaluada en la cual otros sistemas expresan sus conceptos [Quinlan, 1993b].
El ID3 fue presentado como descendiente del CLS creado por Hunt y, como
contrapartida de su antecesor, es un mecanismo mucho más simple para el descubrimiento
de una colección de objetos pertenecientes a dos o más clases. Cada objeto debe estar
descrito en términos de un conjunto fijo de variables, cada una de las cuales cuenta con su
conjunto de posibles valores. Por ejemplo la variable humedad puede tener los valores
{alta, baja} y la variable clima los valores {soleado, nublado, lluvioso}.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
48 Pablo Felgaer Estado del arte
Una regla de clasificación en la forma de un árbol de decisión puede construirse para
cualquier conjunto C de variables de esta forma [Quinlan, 1993b]:
• Si C está vacío, entonces se lo asocia arbitrariamente a cualquiera de las clases.
• SiC contiene los representantes de varias clases, se selecciona una variable y se
particiona C en conjuntos disjuntos nCCC ,,, 21 K , donde iC contiene aquellos
miembros de C que tienen el valor i para la variable seleccionada. Cada una de estos
subconjuntos se maneja con la misma estrategia.
El resultado es un árbol en el cual cada hoja contiene un nombre de clase y cada nodo
interior especifica una variable para ser testeada con una rama correspondiente al valor de
la variable.
2.3.3.2.1.1. Descripción del ID3
El objetivo del ID3 es crear una descripción eficiente de un conjunto de datos
mediante la utilización de un árbol de decisión. Dados datos consistentes, es decir, sin
contradicción entre ellos, el árbol resultante describirá el conjunto de entrada a la
perfección. Además, el árbol puede ser utilizado para predecir los valores de nuevos datos
asumiendo siempre que el conjunto de datos sobre el cual se trabaja es representativo de la
totalidad de los datos.
Dados:
• Un conjunto de datos.
• Un conjunto de descriptores de cada dato.
• Un clasificador/conjunto de clasificadores para cada objeto.
Se desea obtener un árbol de decisión simple basándose en la entropía, donde los
nodos pueden ser:

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 49
• Nodos intermedios : en donde se encuentran los descriptores escogidos según el
criterio de entropía que determinan cuál rama es la que debe tomarse.
• Hojas: estos nodos determinan el valor del clasificador.
Este procedimiento de formación de reglas funcionará siempre dado que no existen
dos objetos pertenecientes a distintas clases pero con idéntico valor para cada uno de sus
variables; si este caso llegara a presentarse, las variables son inadecuadas para el proceso de
clasificación.
Hay dos conceptos importantes a tener en cuenta en el algoritmo ID3 [Blurock,
1996]: la entropía y el árbol de decisión. La entropía se utiliza para encontrar el parámetro
más significativo en la caracterización de un clasificador. El árbol de decisión es un medio
eficiente e intuitivo para organizar los descriptores que pueden ser utilizados con funciones
predictivas.
2.3.3.2.1.2. Algoritmo ID3
A continuación se presenta el algoritmo del método ID3 para la construcción de
árboles de decisión en función de un conjunto de datos previamente clasificados.
Función ID3 (R: conjunto de atributos no clasificadores, C: atributo clasificador, S: conjunto de entrenamiento) devuelve un árbol de decisión;
Comienzo
Si S es tá vacío, Devolver un único nodo con Valor Falla;
Si todos los registros de S tienen el mismo valor para el atributo clasificador, Devolver un único nodo con dicho valor;
Si R está vacío, entonces Devolver un único nodo con el valor más frecuente del atributo clasificador en los registros de S [Nota: habrá errores, es decir, registros que no estarán bien clasificados en este caso];
Si R no está vacío, entonces D ß atributo con mayor Ganancia(D,S) entre los atributos de R; Sean {dj| j=1,2, .., m} los valores del atributo D; Sean {S j| j=1,2, .., m} los subconjuntos de S correspondientes a los valores de dj respectivamente;

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
50 Pablo Felgaer Estado del arte
Devolver un árbol con la raíz nombrada como D y con los arcos nombrados d1, d2,.., dm que van respectivamente a los árboles ID3(R-{D}, C, S1), ID3(R-{D}, C, S2), .., ID3(R-{D}, C, Sm);
Fin
2.3.3.2.1.3. Poda de los árboles de decisión
La poda de los árboles de decisión se realiza con el objetivo de que éstos sean más
comprensibles lo cual implica que tengan menos niveles y/o sean menos frondosos. La
poda aplicada en el ID3 se realiza una vez que el árbol ha sido generado y es un mecanismo
bastante simple: si de un nodo nacen muchas ramas las cuales terminan todas en la misma
clase, entonces se reemplaza dicho nodo por una hoja con la clase común, caso contrario se
analizan todos los nodos hijos.
2.3.3.2.1.4. Limitaciones al ID3
El ID3 puede aplicarse a cualquier conjunto de datos siempre y cuando las variables
sean discretas. Este sistema no cuenta con la facilidad de trabajar con variables continuas
ya que analiza la entropía sobre cada uno de los valores de una variable, por lo tanto
tomaría cada valor de una variable continua individualmente en el cálculo de la entropía lo
cual no es útil en muchos de los dominios. Cuando se trabaja con variables continuas,
generalmente se piensa en rangos de valores y no en valores particulares.
Existen varias maneras de solucionar este problema del ID3 como la agrupación de
valores presentada en [Gallion et al., 1993] o la discretización de los mismos explicada en
[Blurock, 1996; Quinlan, 1993d]. El C4.5 resolvió el problema de los atributos continuos
mediante la discretización.
2.3.3.2.2. C4.5
El C4.5 se basa en el ID3, por lo tanto, la estructura principal de ambos métodos es la
misma. El C4.5 construye un árbol de decisión mediante el algoritmo “divide y reinarás” y
evalúa la información en cada caso utilizando los criterios de entropía y ganancia o

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 51
proporción de ganancia, según sea el caso. A continuación, se explicarán las características
particulares de este método que lo diferencian de su antecesor.
2.3.3.2.2.1. Algoritmo C4.5
El algoritmo del método C4.5 para la construcción de árboles de decisión a grandes
rasgos muy similar al del ID3. Varía en la manera en que realiza las pruebas sobre las
variables, tal como se detalla en las secciones siguientes.
Función C4.5 (R: conjunto de atributos no clasificadores, C: atributo clasificador, S: conjunto de entrenamiento) devuelve un árbol de decisión;
Comienzo
Si S está vacío, Devolver un único nodo con Valor Falla;
Si todos los registros de S tienen el mismo valor para el atributo clasificador, Devolver un único nodo con dicho valor;
Si R está vacío, entonces Devolver un único nodo con el valor más frecuente del atributo clasificador en los registros de S [Nota: habrá errores, es decir, registros que no estarán bien clasificados en este caso];
Si R no está vacío, entonces D ß atributo con mayor Proporción de Ganancia(D,S) entre los atributos de R; Sean {dj| j=1,2, .., m} los valores del atributo D; Sean {S j| j=1,2, .., m} los subconjuntos de S correspo ndientes a los valores de dj respectivamente; Devolver un árbol con la raíz nombrada como D y con los arcos nombrados d1, d2,.., dm que van respectivamente a los árboles C4.5(R-{D}, C, S1), C4.5(R-{D}, C, S2), .., C4.5(R-{D}, C, Sm);
Fin
2.3.3.2.2.2. Características particulares del C4.5
En cada nodo, el sistema debe decidir cuál prueba escoge para dividir los datos. Los
tres tipos de pruebas posibles propuestas por el C4.5 son [Quinlan, 1993d]:
1. La prueba “estándar” para las variables discretas con un resultado y una rama para
cada valor posible de la variable.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
52 Pablo Felgaer Estado del arte
2. Una prueba más compleja, basada en una variable discreta, en donde los valores
posibles son asignados a un número variable de grupos con un resultado posible
para cada grupo en lugar de para cada valor.
3. Si una variable A tiene valores numéricos continuos se realiza una prueba binaria
con resultados ZA ≤ y ZA > para lo cual debe determinarse el valor límite Z .
Todas estas pruebas se evalúan de la misma manera, mirando el resultado de la
proporción de ganancia o alternativamente el de la ganancia resultante de la división que
producen. Ha sido útil agregar una restricción adicional: para cualquier división, al menos
dos de los subconjuntos iT deben contener un número razonable de casos. Esta restricción
que evita las subdivisiones casi triviales es tenida en cuenta solamente cuando el conjunto
T es pequeño.
2.3.3.2.2.3. Poda de los árboles de decisión
El método recursivo de particionamiento para construir los árboles de decisión
descripto anteriormente subdividirá el conjunto de entrenamiento hasta que la partición
contenga casos de una única clase o hasta que la prueba no ofrezca mejora alguna. Esto da
como resultado, generalmente, un árbol muy complejo que sobre-ajusta los datos al inferir
una estructura mayor que la requerida por los casos de entrenamiento [Mitchell, 2000;
Quinlan, 1995]. Además, el árbol inicial generalmente es extremadame nte complejo y tiene
una proporción de errores superior a la de un árbol más simple. Mientras que el aumento en
complejidad se comprende a simple vista, la mayor proporción de errores puede ser más
difícil de visualizar.
Para entender este problema supongamos que tenemos un conjunto de datos con dos
clases donde una proporción 5.0≥p de los casos pertenecen a la clase mayoritaria. Si un
clasificador asigna todos los casos con valores indeterminados a la clase mayoritaria, la
proporción esperada de error es claramente p−1 . Si en cambio el clasificador asigna un
caso a la clase mayoritaria con probabilidad p y a la otra clase con probabilidad p−1 , su
proporción esperada de error es la suma de:

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Estado del arte Pablo Felgaer 53
• La probabilidad de que un caso perteneciente a la clase mayoritaria sea asignado a la
otra clase, )1( pp − .
• La probabilidad de que un caso perteneciente a la otra clase sea asignado a la clase
mayoritaria, pp )1( − .
que da como resultado )1(2 pp − . Como p es al menos 0.5, esto es generalmente superior
a p−1 , entonces el segundo clasificador tendrá una mayor proporción de errores. Un árbol
de decisión complejo tiene una gran similitud con este segundo tipo de clasificador. Los
casos no se relacionan a una clase, entonces, el árbol manda cada caso al azar a alguna de
las hojas.
Un árbol de decisión no se simplifica borrando todo el árbol a favor de una rama sino
que se eliminan las partes del árbol que no contribuyen a la exactitud de la clasificación
para los nuevos casos, produciendo un árbol menos complejo y por lo tanto más
comprensible.
2.3.4. Presentación de los resultados
Tanto el ID3 como el C4.5 generan un clasificador de la forma de un árbol de
decisión cuya estructura es [Quinlan 1993d]:
• Una hoja indicando una clase, o
• Un nodo de decisión que especifica alguna prueba a ser realizada sobre un único
atributo con una rama y subárbol para cada valor posible de la prueba.
El árbol de decisión generado por el C4.5 cuenta con varias características
particulares, entre ellas cada hoja tiene asociados dos números que indican el número de
casos de entrenamientos cubiertos por cada hoja y la cantidad de ellos clasificados
erróneamente por la hoja; es en cierta manera un estimador del éxito del árbol sobre los
casos de entrenamiento. El ID3 en cambio no clasifica erróneamente a los datos de

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
54 Pablo Felgaer Estado del arte
entrenamiento, con lo cual no son necesarios este tipo de indicadores; es por ello que este
algoritmo, a diferencia del C4.5, corre el riesgo de caer en sobre-ajuste.
2.4. Marco de la tesis
Esta tesis se desarrolla en el marco de los proyectos “Minería de Datos basada en
Sistemas Inteligentes” (UBACYT 2003 código I605 Res.HCS N° 1022/03) y “Explotación
de Información basada en Sistemas Inteligentes” (UBACYT 2004-2007 código I050
Res.HCS N° 2706/04) que articulan una línea de trabajo en el área de sistemas de
aprendizaje automático iniciada en el año 1993 con el estudio de aprendizaje basado en
formación y ponderación de teorías [García-Martínez, 1993; 1995; 1997; García-Martínez y
Borrajo, 2000; García-Martínez et al., 2003] y sus aplicaciones a la explotación de
información en problemas abiertos de las ciencias aplicadas [Perichinsky y García-
Martínez, 2000; Perichinsky et al., 2000; 2001; 2003a; 2003b] y de la industria [Grosser et
al., 2005].

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Descripción del problema Pablo Felgaer 55
3. Descripción del problema
Las redes bayesianas están diseñadas para hallar las relaciones de dependencia e
independencia entre todas las variables que conforman el dominio de estudio; esto permite
realizar predicciones sobre el comportamiento de cualquiera de las variables desconocidas a
partir de los valores de las otras variables conocidas; esto presupone que cualquier variable
de la base de datos puede comportarse como incógnita o como evidencia según el caso.
Existen muchas tareas prácticas que pueden reducirse a problemas de clasificación:
diagnóstico médico y reconocimiento de patrones son sólo dos ejemplos de ellas; este tipo
de tareas tienen la finalidad de asignar objetos a categorías o clases determinadas según sus
propiedades Las redes bayesianas pueden realizar la tarea de clasificación, la cual es un
caso particular de la tarea de predicción, que se caracteriza por tener una sola de las
variables de la base de datos (clasificador) que se desea predecir mientras que todas las
otras son los datos propios del caso que se desea clasificar; pueden existir una gran cantidad
de variables en la base de datos, algunas de las cuales estarán directamente relacionadas
con la variable clasificadora que se quiere predecir pero también pueden existir otras
variables que no lo estén.
Al utilizar redes bayesianas en la tarea de clasificación, éstas se ven afectadas por una
serie de inconvenientes. En primer lugar los grafos correspondientes a las redes bayesianas
contienen un nodo por cada variable que compone el dominio de aplicación aún cuando
dicha variable no repercuta de manera directa sobre la tarea de clasificación; de este modo
los grafos obtenidos pueden presentar un grado de complejidad innecesario que dificulte la
representación e interpretación del conocimiento así como también la eficiencia del proceso
de inferencia. Por otro lado, las capacidades predictivas de las redes bayesianas están
orientadas a pronosticar el valor de cualquiera de las variables pertenecientes al dominio de
aplicación en lugar de intentar maximizar el poder clasificatorio.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
56 Pablo Felgaer Descripción del problema
En este contexto, el objetivo que se plantea este trabajo consiste en encontrar un método de
aprendizaje automático para favorecer la optimización de las redes bayesianas, en particular
las de tipo poliárbol, aplicadas a problemas de clasificación.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Solución propuesta Pablo Felgaer 57
4. Solución propuesta
Para solucionar los problemas de las redes bayesianas aplicadas a la tarea de
clasificación (ver capítulo 3), lo que se propone en este trabajo es utilizar un método de
aprendizaje híbrido que combine las ventajas de las técnicas de inducción de los árboles de
decisión (TDIDT – C4.5) con las de las redes bayesianas. Este método de aprendizaje
híbrido consiste de dos etapas principales: preselección de nodos y construcción de la red.
En la primer fase se elige, a partir de todas las variables del dominio, un subconjunto de
nodos con la finalidad de generar la red bayesiana para la tarea particular de clasificación y
de esta forma optimizar la performance y mejorar la capacidad predictiva de la red; dichos
nodos son seleccionados a partir de los árboles de decisión obtenidos mediante las técnicas
de inducción (TDIDT – C4.5). En la segunda fase se construye la red bayesiana a partir del
subconjunto de variables seleccionado en la etapa previa aplicando el método de
aprendizaje para poliárboles expuesto en la sección 2.2.5.
4.1. Datos de entrada
Dado que no todas las tareas de clasificación son apropiadas para el enfoque
inductivo que se presenta en este trabajo, a continuación se detallan los requerimientos
principales que deben cumplir los dominios a ser analizados mediante la metodología
propuesta:
• Descripciones de atributo-valor: los datos a ser analizados deben poder expresarse
como un archivo plano, es decir, toda la información de un objeto o caso debe poder
expresarse en términos de una colección fija de variables o atributos. Cada atributo
puede ser discreto o numérico pero los atributos utilizados para describir un caso no
pueden variar de un caso a otro; esto restringe los dominios de aplicación en los
cuales los objetos tienen inherentemente atributos variables.
• Clases predefinidas : las categorías a las cuales se asignan los casos deben estar
establecidas de antemano. Esto significa que los algoritmos se aplican sobre un
conjunto de datos de entrenamiento previamente clasificados del tipo

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
58 Pablo Felgaer Solución propuesta
{valor_atributo1, valor_atributo2, ..., valor_atributon, clasek}. En la terminología del
aprendizaje automático esto se conoce como aprendizaje supervisado, en
contraposición al aprendizaje no supervisado en el cual la agrupación de casos se
encuentra mediante y durante el análisis.
• Clases discretas y disjuntas : las clases a las cuales se asignan los casos deben ser
totalmente disjuntas; un caso pertenece o no pertenece a una clase pero no puede
pertenecer a dos clases a la vez. Además deben existir muchos más casos que clases
para que el modelo generado sea válido en el dominio analizado.
• Datos suficientes: los patrones generados por la generalización inductiva no serán
válidos si no se los pueden distinguir de las casualidades. Como esta diferenciación se
basa generalmente en pruebas estadísticas deben existir casos suficientes para que
dichas pruebas sean efectivas. La cantidad de datos requeridos está afectada por
factores como la cantidad de propiedades y clases, y la complejidad del modelo de
clasificación; a medida que estos se incrementan se necesitan más datos para
construir un modelo confiable.
4.2. Sistema integrador
Para estudiar la solución propuesta es este trabajo se desarrolló un sistema de
“Minería de Datos utilizando Redes Bayesianas” (ver Anexo D) el cual se acopló a un
programa preexistente que realiza la inducción de árboles de decisión (TDIDT – C4.5)
[Servente & García-Martínez, 2002]. A continuación se presentan los esquemas que
ilustran la metodología de obtención de las redes bayesianas completas y de las redes
bayesianas preprocesadas (C4.5).
Figura 4.1: Esquema de obtención de redes bayesianas completas
Datos de entrenamiento
Aprendiza-je
estructural
Estructura de la red
bayesiana
Aprendiza-je paramé-
trico
Red bayesiana Completa

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Solución propuesta Pablo Felgaer 59
Figura 4.2: Esquema de obtención de redes bayesianas C4.5
En la figura 4.1 se observa el proceso mediante el cual se obtienen las redes
bayesianas completas a partir de los datos de entrenamientos. Esto se logra mediante el uso
del sistema de “Minería de Datos utilizando Redes Bayesianas” cuyos componentes
principales son los procesos de aprendizaje estructural y aprendizaje paramétrico.
La figura 4.2 describe el proceso de obtención de las redes bayesianas C4.5 donde se
puede observar la etapa de preselección de variables. Los datos de entrenamiento son
introducidos al programa generador de árboles de decisión y una vez obtenido el árbol se
procede a la preselección; ésta consiste en armar un subconjunto que incluya solamente a
las variables del dominio que conforman el árbol inducido. Luego se procede a la obtención
de la red bayesiana C4.5 de forma análoga a como se presentó en la figura 4.1 pero
trabajando exclusivamente con el conjunto de variables preseleccionado anteriormente.
Una vez obtenidas las dos versiones de las redes bayesianas del dominio en estudio se
procede a la verificación del poder predictivo de las mismas. Como se observa en la figura
4.3 el proceso de verificación se nutre de la red bayesiana que se desea verificar y del
conjunto de datos de validación; a partir de esta información se procesa y se obtiene un
reporte detallado sobre el poder predictivo de la red investigada.
Generador árboles de decisión
Árbol de decisión
C4.5 Datos de
entrenamiento
Preselec-ción de
variables
Variables preselec-cionadas
Datos de entrenamiento
Variables preselec-cionadas
Aprendiza-je
estructural
Estructura de la red
bayesiana
Aprendiza-je paramé-
trico
Red bayesiana
C4.5

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
60 Pablo Felgaer Solución propuesta
Figura 4.3: Esquema del proceso de verificación del poder predictivo.
4.3. Otros abordajes
Existen antecedentes de otros trabajos que encaran el problema de optimizar
diferentes tipos de redes bayesianas aplicadas a la tarea de clasificación.
Langley y Sage [1994] propusieron un método para optimizar redes bayesianas de
tipo naive. El método define una etapa de preselección de variables donde se evalúa el
grado de correlación entre las mismas.
Singh y Provan propusieron dos métodos para optimizar redes bayesianas de tipo
multiconectadas. El K2-AS [Singh & Provan, 1995a] define una etapa de preselección de
variables donde se evalúa la capacidad predictiva de la red al incorporar cada atributo. El
Info-AS [Singh & Provan, 1995b] define una etapa de preselección de variables basada en
las métricas de información: ganancia, proporción de ganancia [Quinlan, 1986] y medida de
distancia [López de Mantaras, 1991]. El manejo de las redes bayesianas se realiza mediante
el sistema HUGIN [Andersen et al., 1989] y se utiliza el algoritmo de aprendizaje
estructural K2 [Cooper & Herskovits, 1992].
En este trabajo se propone un método para optimizar redes bayesianas de tipo
poliárbol. El método define una etapa de preselección de variables basada en árboles de
decisión TDIDT – C4.5 [Quinlan, 1993d]. El manejo de las redes bayesianas se realiza
mediante un sistema desarrollado como parte de esta tesis y se utiliza el algoritmo de
aprendizaje estructural de Rebane y Pearl [1989].
Datos de validación
Proceso verificador
Reporte del poder predictivo Red
bayesiana
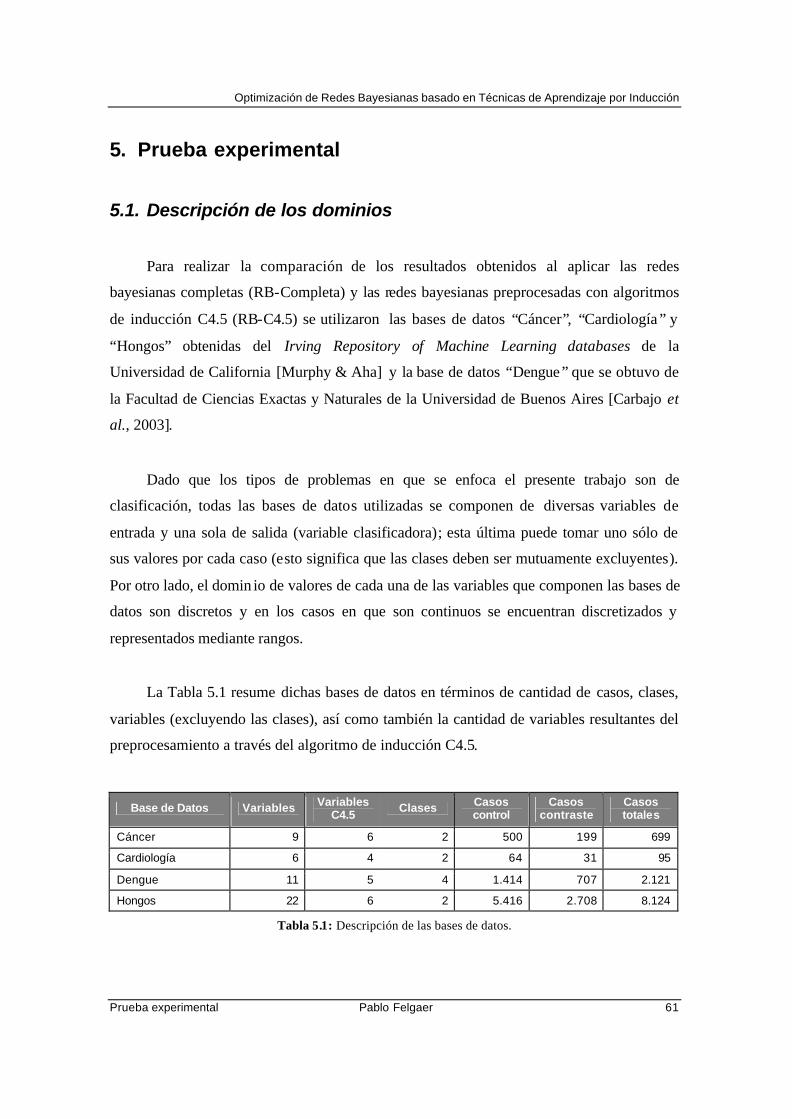
Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 61
5. Prueba experimental
5.1. Descripción de los dominios
Para realizar la comparación de los resultados obtenidos al aplicar las redes
bayesianas completas (RB-Completa) y las redes bayesianas preprocesadas con algoritmos
de inducción C4.5 (RB-C4.5) se utilizaron las bases de datos “Cáncer”, “Cardiología ” y
“Hongos” obtenidas del Irving Repository of Machine Learning databases de la
Universidad de California [Murphy & Aha] y la base de datos “Dengue” que se obtuvo de
la Facultad de Ciencias Exactas y Naturales de la Universidad de Buenos Aires [Carbajo et
al., 2003].
Dado que los tipos de problemas en que se enfoca el presente trabajo son de
clasificación, todas las bases de datos utilizadas se componen de diversas variables de
entrada y una sola de salida (variable clasificadora); esta última puede tomar uno sólo de
sus valores por cada caso (esto significa que las clases deben ser mutuamente excluyentes).
Por otro lado, el domin io de valores de cada una de las variables que componen las bases de
datos son discretos y en los casos en que son continuos se encuentran discretizados y
representados mediante rangos.
La Tabla 5.1 resume dichas bases de datos en términos de cantidad de casos, clases,
variables (excluyendo las clases), así como también la cantidad de variables resultantes del
preprocesamiento a través del algoritmo de inducción C4.5.
Base de Datos Variables Variables C4.5 Clases Casos
control Casos
contraste Casos totales
Cáncer 9 6 2 500 199 699
Cardiología 6 4 2 64 31 95
Dengue 11 5 4 1.414 707 2.121
Hongos 22 6 2 5.416 2.708 8.124
Tabla 5.1: Descripción de las bases de datos.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
62 Pablo Felgaer Prueba experimental
Donde la columna:
• Base de Datos indica el nombre descriptivo del conjunto de datos correspondiente.
• Variables indica la cantidad de variables que posee la base de datos original.
• Variables C4.5 muestra la cantidad de variables que posee la base de datos luego de
preprocesarla mediante el algoritmo C4.5 (ambas columnas excluyen a la variable
clasificadora).
• Clases indica cuantos valores puede tomar la variable clasificadora.
• Casos control representa la cantidad de registros que abarcan las bases de datos de
control.
• Casos contraste representa la cantidad de registros que abarcan las bases de datos de
contraste.
• Casos totales representa la cantidad de registros que abarcan las bases de datos de
totales.
A continuación se procederá a describir con mayor nivel de detalle cada una de las
bases de datos utilizadas. Para cada una de ellas se describe su dominio, las variables que
las componen con sus correspondientes valores posibles y las distribuciones de las clases
tanto en el conjunto de casos de control como así también en el de contraste.
5.1.1. Cáncer
a) Descripción
Esta base de datos de cáncer fue obtenida de la University of Wisconsin Hospitals,
Madison del Dr. William H. Wolberg. La misma posee registros de 699 casos donde para
cada uno de ellos se relevaron el valor de 9 variables y si el tumor encontrado resultó ser
benigno o maligno.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 63
b) Variables
Variable Valores
Clump thickness 1 – 10
Uniformity of cell size 1 – 10
Uniformity of cell shape 1 – 10
Marginal adhesion 1 – 10
Single epithelial cell size 1 – 10
Bare nuclei 1 – 10
Bland chromatin 1 – 10
Normal nucleoli 1 – 10
Mitoses 1 – 10
Clase Benigno, Maligno
Tabla 5.2: Variables de la base de datos “Cáncer”.
c) Cantidad de registros y distribución de las clases
Clase
Benigno Maligno Total
Casos control 328 172 500
Casos contraste 130 69 199
Total 458 241 699
Tabla 5.3: Distribución de las clases de la base de datos “Cáncer”.
5.1.2. Cardiología
a) Descripción
Los ejemplos planteados en este caso corresponden a la patología Infarto Agudo de
Miocardio [Montalvetti, 1995]. En este caso, todos los ejemplos responden a personas de
sexo masculino, entre 40 y 50 años, fumadores, con displidemia e hipertens ión arterial
presente. Pueden obtenerse dos diagnósticos de los ejemplos planteados: Si (es un infarto
agudo de miocardio) o No (no es un infarto agudo de miocardio). Aunque en medicina es

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
64 Pablo Felgaer Prueba experimental
difícil realizar un diagnóstico con una cantidad de variables reducidas, se determinó que las
variables planteadas en estos ejemplos alcanzaban para realizar un diagnóstico preliminar
de gran ayuda al experto.
b) Variables
Variable Valores
Dolor de pecho de angor Típico, Atípico, Ausente
Irradiación del angor Si, No
Duración del angor Menos de 30 minutos, Más de 30 minutos
Angor en relación Con esfuerzo, En reposo
Antigüedad del angor Reciente, Más de un mes
Respuesta vasodilatadora Positiva, Negativa
Clase Si, No
Tabla 5.4: Variables de la base de datos “Cardiología”.
c) Cantidad de registros y distribución de las clases
Clase
Si No Total
Casos control 18 46 64
Casos contraste 9 22 31
Total 27 68 95
Tabla 5.5: Distribución de las clases de la base de datos “Cardiología”.
5.1.3. Dengue
a) Descripción
En 1996 los primeros estudios sobre A. aegypti (el vector transmisor del Dengue) en
la Ciudad de Buenos Aires mostraron que se encontraba en toda la ciudad y que había
diferencias en su abundancia entre el centro de la ciudad y la periferia. A partir de 1998

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 65
comenzó un muestreo exhaustivo mediante ovitrampas 1 y búsqueda de larvas en domicilios
de la ciudad con el objetivo de dilucidar en mayor detalle la heterogeneidad espacial y
temporal de su distribución. La disponibilidad de capas de información de la ciudad muy
detalladas sobre demografía y urbanización permitieron relevar la distribución del vector y
el ambiente.
b) Variables
Variable Valores
Coherencia Si, No
Industrias [0..50], (50..150], (150..450], [>500]
Verde [0..1], (1..25], (25..50], [>50]
Casas [0..5], (5..10], (10..20], [>20]
Gente [0..80], (80..160], (160..320], [>320]
Departamentos [0..10], (10..30], (30..60], [>60]
TM 0, 2, 5
TP 1, 2, 5, 6
Altitud [0..10], (10..20], [>20]
Avenidas [0..30], (30..90], (90..270], [>270]
Estación Verano, Primavera, Otoño, Invierno
Positividad 0, 1, 2, 3
Tabla 5.6: Variables de la base de datos “Dengue”.
c) Cantidad de registros y distribución de las clases
Positividad 0 1 2 3 Total
Casos control 844 195 112 263 1.414
Casos contraste 410 107 47 143 707
Total 1.254 302 159 406 2.121
Tabla 5.7: Distribución de las clases de la base de datos “Dengue”.
1 Trampas donde el mosquito transmisor del Dengue deposita sus huevos.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
66 Pablo Felgaer Prueba experimental
5.1.4. Hongos
a) Descripción
Esta base de datos incluye las descripciones de muestras hipotéticas de 23 especies de
hongos de las familias Agaricus y Lepiota. Cada especie es identificada como apta para ser
ingerida, absolutamente venenosa, o de ingestión dudosa y ciertamente no recomendable.
Esta última clase fue combinada con la venenosa. La guía de donde se obtuvieron los datos
explica que no existe una regla simple para determinar si un hongo es ingerible o no.
b) Variables
Variable Valores
Forma sombrero Acampanada, Cónica, Convexa, Chata, Abotonada, Hundida
Superficie sombrero Fibrosa, Ranurada, Escamosa, Suave
Color sombrero Marrón, Piel, Canela, Gris, Verde, Rosa, Violeta, Rojo, Blanco, Amarillo
Magulladuras Si, No
Olor Almendra, Anís, Creosota, Pescado, Hediondo, Mohoso, Ninguno, Punzante, Especioso
Tipo membrana Adherida, Descendente, Libre, Muescada
Espaciado membrana Cercano, Poblado, Distante
Tamaño membrana Ancha, Fina
Color membrana Negra, Marrón, Piel, Chocolate, Gris, Verde, Naranja, Rosa, Violeta, Roja, Blanca, Amarilla
Forma tronco Abultada, Cónica
Raíz tronco Bulbosa, Agarrotada, Copa, Igual, Rizomorfa, Arraizada
Superficie tronco arriba anillo Fibrosa, Escamosa, Sedosa, Suave,
Superficie tronco debajo anillo Fibrosa, Escamosa, Sedosa, Suave
Color tronco arriba anillo Marrón, Piel, Canela, Gris, Naranja, Rosa, Rojo, Blanco, Amarillo
Color tronco debajo anillo Marrón, Piel, Canela, Gris, Naranja, Rosa, Rojo, Blanco, Amarillo
Tipo velo Parcial, Universal
Color velo Marrón, Naranja, Blanco, Amarillo
Cantidad anillos Ninguno, Uno, Dos
Tipo anillo Tejido, Evanescente, Resplandeciente, Grande, Ninguno, Pendiente, Cubierto, Zonal

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 67
Variable Valores
Color esporas Negro, Marrón, Piel, Chocolate, Verde, Naranja, Violeta, Blanca, Amarillo
Población Abundante, Agrupada, Numerosa, Dispersa, Varios, Solitaria
Hábitat Pastos, Hojas, Praderas, Caminos, Urbano, Basura, Bosque
Clase Ingerible, Venenoso
Tabla 5.8: Variables de la base de datos “Hongos”.
c) Cantidad de registros y distribución de las clases
Clase Ingerible Venenoso Total
Casos control 2.805 2.611 5.416
Casos contraste 1.403 1.305 2.708
Total 4.208 3.916 8.124
Tabla 5.9: Distribución de las clases de la base de datos “Hongos”.
5.2. Metodología utilizada
La metodología utilizada para llevar a cabo los experimentos con cada una de las
bases de datos evaluadas se detalla a continuación.
1. Dividir la base de datos en dos. Una de control o entrenamiento (aproximadamente 2/3 de la base total) y otra de contraste o validación (con los datos restantes)
2. Procesar la base de datos de control mediante el algoritmo de inducción C4.5 para obtener el subconjunto de variables que conformarán la red bayesiana C4.5
3. Repetir para el 10%, 20%, …, 100% de los datos de la base de control
3.1. Repetir 30 veces, por cada repetición
3.1.1. Tomar al azar el X% de la base de datos de control según el porcentaje que corresponda a la iteración
3.1.2. Mediante ese subconjunto de casos de la base de control, realizar el aprendizaje estructural y paramétrico de las redes bayesianas Completa y C4.5
3.1.3. Evaluar el poder predictivo de ambas redes utilizando la base de datos de contraste
3.2. Calcular el poder predictivo promedio (a partir de las 30 iteraciones)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
68 Pablo Felgaer Prueba experimental
4. Graficar el poder predictivo de ambas redes (Completa y C4.5) en función de los casos de
entrenamiento
El paso (1) del algoritmo hace referencia a la división de la base de datos en la de
control y la de contraste. En la mayoría de los casos las bases de datos obtenidas de los
repositorios antes citados ya se encontraban divididas.
Para la preselección de variables mediante algoritmos de inducción C4.5 del paso (2),
se introdujeron a un sistema generador de árboles de decisión TDIDT cada una de las bases
de datos de control. A partir de ahí, se obtuvieron los árboles de decisión que representan
cada uno de los dominios analizados. Las variables que componen dicha representación
pasaron a conformar el subconjunto de variables que fueron tenidas en cuenta para el
aprendizaje de las redes bayesianas preprocesadas.
A continuación (3) se inicia un bucle que itera diez veces; en cada una de estas
iteraciones se procesó el 10%, 20%,…, 100% de la base de datos de control para el
aprendizaje estructural y paramétrico de las redes. De esta forma se pudo analizar no sólo la
diferencia en la capacidad predictiva de las distintas redes obtenidas sino también cómo
evolucionó dicha capacidad en la medida en que se “aprendió” con mayor cantidad de
casos.
La estructura repetitiva del paso (3.1) tiene como objetivo minimizar los resultados
casuales que no se corresponden con la realidad del modelo en estudio. Se logra minimizar
este efecto tomando diferentes muestras de datos y finalmente promediando los valores
obtenidos.
En los pasos (3.1.x) se realiza el aprendizaje estructural y paramétrico de las redes
bayesianas completas y C4.5 partiendo de un subconjunto de los casos de control
disponibles (ambas redes se obtienen a partir del mismo subconjunto de datos). Una vez
logrado esto se procede a evaluar la capacidad predictiva de las redes mediante los casos de
contraste. Para ello se recorre esta base y por cada caso se instancian todas las variables de

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 69
entrada y se analiza si la clase inferida por la red se corresponde con la indicada en el
archivo. Dado que la red bayesiana no hace clasificaciones excluyentes (es decir que
predice para cada valor de la clase cual es su probabilidad de ocurrencia) se considera como
la clase inferida a la que tiene asociado el mayor valor de probabilidad. La capacidad
predictiva corresponde al porcentaje de casos clasificados correctamente respecto al total de
casos evaluados.
En el punto (3.2) se establece cual es el poder predictivo de la red simplemente
promediando los valores obtenidos a través de todas las iteraciones realizadas.
Finalmente, en el paso (4) se procede a graficar el poder predictivo promedio de
ambas redes bayesianas en función de la cantidad de casos de entrenamiento considerados.
5.3. Análisis estadístico de los resultados
A continuación se detalla el análisis estadístico que se aplicó sobre los resultados
experimentales obtenidos en este trabajo y que avalan las afirmaciones y conclusiones
realizadas. Las nociones teóricas de probabilidad y estadística fueron extraídas
principalmente de Canavos [Canavos, 1984].
5.3.1. Prueba de hipótesis estadísticas
En todas las ramas de la ciencia, cuando un investigador hace una afirmación con
respecto a un fenómeno (que puede estar basada en su intuición, o en algún desarrollo
teórico que parece demostrarla), debe luego probar la misma mediante la realización de
experimentos. La experimentación consiste en armar un ambiente de prueba en el que
ocurra el fenómeno (o buscarlo en el ambiente real) y tomar mediciones de las variables
involucradas. Luego, se realizan análisis estadísticos de los resultados para determinar si los
mismos confirman la afirmación realizada.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
70 Pablo Felgaer Prueba experimental
Una hipótesis estadística es una afirmación con respecto a una característica
desconocida de una población de interés. La esencia de probar una hipótesis estadística es
el decidir si la afirmación se encuentra apoyada por la evidencia experimental que se
obtiene a través de una muestra aleatoria. Supóngase, por ejemplo, que unos fabricantes de
tubos de luz marca ACME están teniendo problemas en el mercado debido a algunos casos
de mala calidad de sus productos. Para recuperar su prestigio hacen la siguiente afirmación:
“El promedio de vida útil de los tubos de luz marca ACME es de 500 horas”. Y encargan a
una firma independiente que haga una serie de experimentos para contrastar esta afirmación
con esta otra: “El promedio de vida útil de los tubos de luz marca ACME es menor a 500
horas”.
• A la afirmación “promedio = 500” se la llama hipótesis nula, y se escribe como:
H0: promedio = 500
• A la afirmación “promedio < 500” se la llama hipótesis alternativa, y se escribe
como:
H1: promedio < 500
La hipótesis nula debe considerarse verdadera a menos que exista suficiente evidencia
en su contra. Es decir, se rechazará la afirmación de que la vida útil promedio es de 500
horas sólo si la evidencia experimental se encuentra muy en contra de ésta afirmación. En
caso contrario, no se podrá rechazar la afirmación basándose en la evidencia experimental.
Debe notarse que no poder rechazar la afirmación no es lo mismo que aceptarla. El caso es
análogo al de un juicio donde hay un sospechoso acusado de un crimen: si la evidencia es
suficiente se lo declarará culpable. De lo contrario se dirá que la evidencia no alcanza para
demostrar su culpabilidad.
Existen entonces dos posibles decisiones con respecto a la hipótesis nula: rechazarla ó
no poder rechazarla. A su vez la hipótesis nula puede ser verdadera o falsa. Esto deja cuatro
posibles escenarios:

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 71
Se denomina α la probabilidad de cometer un error de tipo I y β a la probabilidad de
cometer un error de tipo II. Los valores de α y β son interdependientes. Para cada
experimento, al disminuir uno de ellos aumenta el otro. El error de tipo I se considera más
grave que el de tipo II (volviendo a la analogía con el juicio, se prefiere dejar ir a un
culpable y no condenar a un inocente) por lo que el procedimiento seguido habitualmente
consiste en fijar un valor pequeño para α (por ejemplo, 5%) y luego tratar de minimizar β
lo más que se pueda.
5.3.2. El test de Wilcoxon para la comparación de muestras apareadas
5.3.2.1. Introducción
Existen numerosos métodos para la prueba de hipótesis estadísticas. El hecho de que
cada uno de ellos pueda aplicarse a una situación en particular depende de los siguientes
factores:
• La cantidad de medic iones realizadas.
• La naturaleza de los valores a analizar (si son valores en un intervalo numérico, si son
categorías cualitativas, si son del tipo SI / NO, etc.).
• El grado de dependencia existente entre las mediciones.
Rechazar H0 No poder
rechazar H0
Cuando H0
es verdadera
(error Tipo I)
Cuando H0
es falsa
Cuando H0
es verdadera
Cuando H0
es falsa
(error Tipo II)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
72 Pablo Felgaer Prueba experimental
Los experimentos realizados para comparar las redes bayesianas completas con las
redes bayesianas preprocesadas con C4.5 son un caso que se denomina “de muestras
apareadas” en el cual se miden variables numéricas. Para estos casos el test de Wilcoxon es
el más apropiado [Canavos, 1984]. El término “muestras apareadas” se refiere a que las
mediciones realizadas no son independientes sino que son tomadas de a pares. Esto hace
que lo que deba analizarse sean las diferencias que existen en cada par de valores, que es
precisamente lo que hace el test de Wilcoxon.
5.3.2.2. Descripción del test
Los experimentos para comparar la calidad de predicción de los dos tipos de redes
obtenidas se realizan de la siguiente forma:
1. Se toman N muestras de datos.
2. Se realizar el proceso de aprendizaje estructural y paramétrico de las redes con ambos algoritmos.
3. Se mide el porcentaje de predicción para cada una de las redes.
Luego de la realización de los experimentos se confecciona una tabla que tiene la
siguiente forma (ejemplo para 4 muestras):
Muestra Algoritmo 1 Algoritmo 2 Diferencia (1 -2)
Ranking Ranking con signo
1 0,79 0,80 -0,01 1 -1
2 0,46 0,51 -0,05 4 -4
3 0,91 0,87 0,04 3 3
4 0,23 0,25 -0,02 2 -2
Tabla 5.10: Ejemplo de tabla para aplicar el test de Wilcoxon.
Como se ve, los valores pueden tener grandes variaciones de muestra a muestra pero
lo que importa es la diferencia entre los valores de cada algoritmo para cada muestra ya que
eso es lo que indicará el mejor o peor rendimiento de cada uno.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 73
La hipótesis nula que es puesta a prueba es que el promedio de los valores es igual
para los dos algoritmos (es decir, que la capacidad predictiva de ambas redes obtenidas es
equivalente). Se plantean dos hipótesis alternativas: una de ellas afirma que el promedio de
los valores es mayor para el algoritmo 1 y la otra que el promedio de los valores es mayor
para el algoritmo 2.
La metodología del test es la siguiente:
• Se calculan las diferencias de los valores para cada muestra.
• Luego se asigna a cada diferencia un valor en un ranking (de menor a mayor) en base
a su valor absoluto.
• Por último a cada valor del ranking se le asigna el signo de la diferencia que le dio
origen.
Se denomina +T a la suma de los valores positivos y −T a la suma de los negativos.
Si no hubiera diferencias entre los algoritmos es de esperar que +T resulte igual a −T (en
valor absoluto). Para muestras lo suficientemente grandes, la variable +T puede
aproximarse por medio de una distribución normal con media )( +TE y varianza )( +TVar ,
donde:
4)1(
)(+
=+NN
TE
24)12)(1(
)(++
=+NNN
TVar
Luego, si se define la transformación:
)()()(
++−+
=+TVar
TETzT
la variable +zT tiene una distribución normal estándar (media igual a 0 y varianza igual a
1). El valor del parámetro α determina los límites mínimo y máximo para el valor

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
74 Pablo Felgaer Prueba experimental
observado de +zT más allá de los cuales se rechaza la hipótesis nula. Si el valor de +zT
es superior al límite máximo se aceptará la hipótesis alternativa de que el promedio de
valores para el algoritmo 1 es mayor que para el algoritmo 2. Si el valor de +zT es inferior
al límite mínimo se aceptará la hipótesis alternativa de que el promedio de valores para el
algoritmo 2 es mayor que para el algoritmo 1.
5.3.3. Aplicación del test a los resultados
En el caso de los experimentos realizados en este trabajo se utilizaron diez
mediciones de la capacidad predictiva de la red para cada una de las dos redes que se
desean comparar por lo que 10=N . El valor de α utilizado es de 5%, 05.0=α . Esto
quiere decir que en los casos en que rechacemos la hipótesis nula y aceptemos alguna de las
hipótesis alternativa s, el test nos dará un 95% de confianza. Teniendo N y α quedan
definidos los límites mínimo y máximo para +zT , que son respectivamente -1,645 y 1,645.
A partir N también se puede calcular el valor de )( +TE y de )( +TVar mediante las
fórmulas antes citadas.
5,274
)110(104
)1()( =
+=
+=+
NNTE
25,9624
)1102)(110(1024
)12)(1()( =
++=
++=+
xNNNTVar
con lo cual la aplicación del test de Wilcoxon se reduce al armado de las tablas, calcular el
valor de +zT y compararlo contra los límites.
81,95,27)(
)()()( −+
=+
+−+=+
TTVar
TETzT
En la siguiente sección de resultados, para cada uno de los dominios en los que se
realizaron experimentos, se aplica el test de Wilcoxon para verificar y avalar las
conclusiones obtenidas.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 75
5.4. Resultados
A continuación se presentarán los resultados experimentales que surgen de aplicar la
metodología previamente citada a cada una de las bases de datos de prueba.
5.4.1. Cáncer
A continuación se presentan los resultados obtenidos sobre el dominio de datos
“Cáncer”.
5.4.1.1. Gráfico
Gráfico del poder predictivo de las RB-Completa y RB-C4.5 en función de la
cantidad de casos de aprendizaje para el dominio “Cáncer”.
Cáncer
66,00%
68,00%
70,00%
72,00%
74,00%
76,00%
78,00%
80,00%
82,00%
84,00%
50 100 150 200 250 300 350 400 450 500
Casos
Pre
dic
ció
n
RB-Completa RB-C4.5
Gráfico 5.1: Gráfico del poder predictivo para la base de datos “Cáncer”.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
76 Pablo Felgaer Prueba experimental
Completo C4.5 Registros
Casos OK Mal Predicción Casos OK Mal Predicción
10% 50 150 49 67,00% 50 163 37 74,00%
20% 100 135 64 67,84% 100 148 52 74,12%
30% 150 134 66 67,09% 150 150 49 75,25%
40% 200 141 58 70,73% 200 160 39 80,53%
50% 250 138 61 69,35% 250 160 39 80,53%
60% 300 141 58 70,73% 300 161 38 80,78%
70% 350 143 56 71,86% 350 164 35 82,29%
80% 400 143 56 71,73% 400 164 35 82,54%
90% 450 142 58 71,11% 450 164 35 82,41%
100% 500 143 56 71,86% 500 164 35 82,41%
Tabla 5.11: Tabla del poder predictivo para la base de datos “Cáncer”.
5.4.1.2. Test de Wilcoxon
Muestra Red Completa
Red C4.5
Diferencia Ranking Ranking con signo
1 67,00% 74,00% -7,00% 2 -2
2 67,84% 74,12% -6,28% 1 -1
3 67,09% 75,25% -8,17% 3 -3
4 70,73% 80,53% -9,80% 4 -4
5 69,35% 80,53% -11,18% 9 -9
6 70,73% 80,78% -10,05% 5 -5
7 71,86% 82,29% -10,43% 6 -6
8 71,73% 82,54% -10,80% 8 -8
9 71,11% 82,41% -11,31% 10 -10
10 71,86% 82,41% -10,55% 7 -7
Tabla 5.12: Tabla de aplicación del test de Wilcoxon para la base de datos “Cáncer”.
De la tabla surge que T+ = 0 y que T- = 55 con lo cual zT+ = -2,8. Por lo tanto debe
rechazarse la hipótesis nula y aceptarse la hipótesis alternativa que sostiene que los valores
para el algoritmo híbrido (RB-C4.5) son mayores que para el algoritmo puro (RB-
Completa).

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 77
5.4.1.3. Análisis
Como puede observarse en el gráfico 5.1 (dominio “Cáncer”) el poder predictivo de
la RB-C4.5 es superior al de la RB-Completa a lo largo de todos sus puntos (esta
afirmación es avalada al aplicar el test de Wilcoxon). Asimismo, se puede observar como
dicha capacidad predictiva se ve incrementada, casi siempre, en la medida que se toman
mayor cantidad de casos de entrenamiento para generar las redes. Finalmente, se observa
que a partir de los 350 casos de entrenamiento el poder predictivo de las redes tiene a
estabilizarse alcanzando su punto máximo.
5.4.2. Cardiología
A continuación se presentan los resultados obtenidos sobre el dominio de datos
“Cardiología”.
5.4.2.1. Gráfico
Gráfico del poder predictivo de las RB-Completa y RB-C4.5 en función de la
cantidad de casos de aprendizaje para el dominio “Cardiología”.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
78 Pablo Felgaer Prueba experimental
Cardiología
60,00%
65,00%
70,00%
75,00%
80,00%
85,00%
90,00%
95,00%
6 12 18 24 30 36 42 48 54 60
Casos
Pre
dic
ció
n
RB-Completa RB-C4.5
Gráfico 5.2: Gráfico del poder predictivo para la base de datos “Cardiología”.
Completo C4.5 Registros Casos OK Mal Predicción Casos OK Mal Predicción
10% 6 20 11 64,27% 6 21 10 66,61%
20% 12 24 7 76,45% 12 25 6 79,60%
30% 19 26 5 83,31% 19 27 4 86,05%
40% 25 27 4 87,90% 25 28 3 90,32%
50% 32 28 3 90,89% 32 29 3 91,94%
60% 38 28 3 90,97% 38 29 2 92,66%
70% 44 29 2 92,18% 44 29 2 93,39%
80% 51 29 2 92,98% 51 29 2 93,47%
90% 57 29 2 93,79% 57 29 2 94,11%
100% 64 29 2 93,55% 64 29 2 93,55%
Tabla 5.13: Tabla del poder predictivo para la base de datos “Cardiología”.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 79
5.4.2.2. Test de Wilcoxon
Muestra Red Completa
Red C4.5
Diferencia Ranking Ranking con signo
1 64,27% 66,61% -2,34% 6 -6
2 76,45% 79,60% -3,15% 9 -9
3 83,31% 86,05% -2,74% 8 -8
4 87,90% 90,32% -2,42% 7 -7
5 90,89% 91,94% -1,05% 3 -3
6 90,97% 92,66% -1,69% 5 -5
7 92,18% 93,39% -1,21% 4 -4
8 92,98% 93,47% -0,48% 2 -2
9 93,79% 94,11% -0,32% 1 -1
10 93,55% 93,55% 0,00%
Tabla 5.14: Tabla de aplicación del test de Wilcoxon para la base de datos “Cardiología”.
De la tabla surge que T+ = 0 y que T- = 45 con lo cual zT+ = -1,8. Por lo tanto debe
rechazarse la hipótesis nula y aceptarse la hipótesis alternativa que sostiene que los valores
para el algoritmo híbrido (RB-C4.5) son mayores que para el algoritmo puro (RB-
Completa).
5.4.2.3. Análisis
Al analizar el gráfico 5.2 correspondiente a la base de datos “Cardiología” también se
puede observar una mejora por parte de la RB-C4.5 respecto de la RB-Completa. Si bien
las diferencias entre los valores obtenidos con ambas redes son menores que en el caso
anterior, el algoritmo híbrido presenta una mejor aproximación a la realidad que el otro.
Cabe destacar que en este caso el nivel de mejora va disminuyendo a medida que el
conjunto de casos utilizados para el aprendizaje se incrementa.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
80 Pablo Felgaer Prueba experimental
5.4.3. Dengue
A continuación se presentan los resultados obtenidos sobre el dominio de datos
“Dengue”.
5.4.3.1. Gráfico
Gráfico del poder predictivo de las RB-Completa y RB-C4.5 en función de la
cantidad de casos de aprendizaje para el dominio “Dengue”.
Dengue
57,00%
59,00%
61,00%
63,00%
65,00%
67,00%
69,00%
71,00%
141 282 423 564 705 846 987 1128 1269 1410
Casos
Pre
dic
ció
n
RB-Completa RB-C4.5
Gráfico 5.3: Gráfico del poder predictivo para la base de datos “Dengue”.
Completo C4.5 Registros
Casos OK Mal Predicción Casos OK Mal Predicción
10% 141 417 290 58,00% 141 484 224 68,00%
20% 282 412 295 58,40% 282 493 214 68,30%
30% 424 413 294 59,00% 424 493 214 68,40%
40% 565 410 297 58,70% 565 494 213 68,70%

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 81
Completo C4.5 Registros
Casos OK Mal Predicción Casos OK Mal Predicción
50% 707 410 297 60,00% 707 494 213 68,60%
60% 848 410 297 60,50% 848 493 214 68,80%
70% 989 410 297 61,00% 989 494 213 68,90%
80% 1131 410 297 60,70% 1131 494 213 69,00%
90% 1272 410 297 61,00% 1272 494 213 69,50%
100% 1414 410 297 61,30% 1414 494 213 69,87%
Tabla 5.15: Tabla del poder predictivo para la base de datos “Dengue”.
5.4.3.2. Test de Wilcoxon
Muestra Red Completa
Red C4.5 Diferencia Ranking Ranking con
signo
1 58,00% 68,00% -10,00% 9,5 -9,5
2 58,40% 68,30% -9,90% 8 -8
3 59,00% 68,40% -9,40% 7 -7
4 58,70% 68,70% -10,00% 9,5 -9,5
5 60,00% 68,60% -8,60% 6 -6
6 60,50% 68,80% -8,30% 2 -2
7 61,00% 68,90% -7,90% 1 -1
8 60,70% 69,00% -8,30% 3,5 -3,5
9 61,00% 69,50% -8,50% 3,5 -3,5
10 61,30% 69,87% -8,57% 5 -5
Tabla 5.16: Tabla de aplicación del test de Wilcoxon para la base de datos “Dengue”.
De la tabla surge que T+ = 0 y que T- = 55 con lo cual zT+ = -2,8. Por lo tanto debe
rechazarse la hipótesis nula y aceptarse la hipótesis alternativa que sostiene que los valores
para el algoritmo híbrido (RB-C4.5) son mayores que para el algoritmo puro (RB-
Completa).

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
82 Pablo Felgaer Prueba experimental
5.4.3.3. Análisis
Para la base de datos de “Dengue” correspondiente al gráfico 5.3 se observa una
mejoría en el poder predictivo de la red obtenida mediante al método propuesto. Como
puede observarse en el gráfico y sus respectivas tablas de valores, la RB-C4.5 logra realizar
la clasificación de los casos con una precisión entre 8% y 10% mayor que la obtenida
mediante la otra red.
5.4.4. Hongos
A continuación se presentan los resultados obtenidos sobre el dominio de datos
“Hongos”.
5.4.4.1. Gráfico
Gráfico del poder predictivo de las RB-Completa y RB-C4.5 en función de la
cantidad de casos de aprendizaje para el dominio “Hongos”.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Prueba experimental Pablo Felgaer 83
Hongos
97,20%
97,40%
97,60%
97,80%
98,00%
98,20%
98,40%
98,60%
541 1082 1623 2164 2705 3246 3787 4328 4869 5410
Casos
Pre
dic
ció
n
RB-Completa RB-C4.5
Gráfico 5.4: Gráfico del poder predictivo para la base de datos “Hongos”.
Completo C4.5 Registros Casos OK Mal Predicción Casos OK Mal Predicción
10% 541 2636 72 97,33% 541 2646 63 97,69%
20% 1083 2638 70 97,42% 1083 2648 60 97,78%
30% 1624 2640 68 97,49% 1624 2655 53 98,03%
40% 2166 2641 67 97,51% 2166 2656 52 98,07%
50% 2708 2641 67 97,52% 2708 2658 50 98,15%
60% 3249 2641 67 97,54% 3249 2659 49 98,19%
70% 3791 2642 66 97,58% 3791 2665 43 98,40%
80% 4332 2643 65 97,59% 4332 2662 46 98,29%
90% 4874 2643 65 97,60% 4874 2662 46 98,29%
100% 5416 2643 65 97,60% 5416 2668 40 98,52%
Tabla 5.17: Tabla del poder predictivo para la base de datos “Hongos”.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
84 Pablo Felgaer Prueba experimental
5.4.4.2. Test de Wilcoxon
Muestra Red Completa
Red C4.5
Diferencia Ranking Ranking con signo
1 97,33% 97,69% -0,36% 2 -2
2 97,42% 97,78% -0,35% 1 -1
3 97,49% 98,03% -0,54% 3 -3
4 97,51% 98,07% -0,56% 4 -4
5 97,52% 98,15% -0,64% 5 -5
6 97,54% 98,19% -0,65% 6 -6
7 97,58% 98,40% -0,82% 9 -9
8 97,59% 98,29% -0,69% 7,5 -7,5
9 97,60% 98,29% -0,69% 7,5 -7,5
10 97,60% 98,52% -0,92% 10 -10
Tabla 5.18: Tabla de aplicación del test de Wilcoxon para la base de datos “Hongos”.
De la tabla surge que T+ = 0 y que T- = 55 con lo cual zT+ = -2,8. Por lo tanto debe
rechazarse la hipótesis nula y aceptarse la hipótesis alternativa que sostiene que los valores
para el algoritmo híbrido (RB-C4.5) son mayores que para el algoritmo puro (RB-
Completa).
5.4.4.3. Análisis
Al evaluar los resultados obtenidos con las bases de datos de “Hongos” (gráfico 5.4)
se afianzan las afirmaciones citadas referentes a la mejora que produce el preprocesamiento
de las variables de la red aplicadas a los problemas de clasificación. En este caso también,
el poder predictivo se ve incrementado.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Conclusiones Pablo Felgaer 85
6. Conclusiones
Como se puede observar todas las gráficas que representan el poder predictivo en
función de la cantidad de casos de entrenamiento son crecientes. Este fenómeno se da
independientemente del dominio de datos utilizado y del método evaluado (RB-Completa o
RB-C4.5).
Del análisis de los resultados obtenidos en la experimentación podemos concluir que
el método híbrido de aprendizaje propuesto en esta tesis (RB-C4.5) genera una mejora en el
poder predictivo de la red respecto a la obtenida sin realizar el preprocesamiento de las
variables (RB-Completa).
En otro aspecto, las RB-C4.5 poseen una cantidad de variables menor (o a lo sumo
igual) que las RB-Completa; esta reducción de la cantidad de variables involucradas
produce una simplificación en la conceptualización del dominio analizado, la cual trae
aparejado dos importantes ventajas; por un lado, facilitan la representación e interpretación
del conocimiento eliminando parámetros que no repercuten de manera directa sobre el
objetivo buscado (tarea de clasificación). Por el otro lado, simplifica y optimiza la tarea de
razonamiento (propagación de las probabilidades) lo cual conlleva a la mejora de los
tiempos de procesamiento.
En suma, basándonos en los resultados experimentales obtenidos concluimos que el
método híbrido de aprendizaje propuesto en este trabajo optimiza las configuraciones de las
redes bayesianas de tipo poliárbol aplicadas a tareas de clasificación.


Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Referencias Pablo Felgaer 87
Referencias
Andersen, S.K., Olesen, K.G., Jensen, F. (1989). HUGIN – a Shell for Building Belief
Universes for Expert Systems. In Proc. IJCAI, pages 1080-1085.
Beinlich, I.A., Suermondt, H.J., Chavez, R.M., Cooper, G.F. (1989). The ALARM
monitoring system: A case study with two probabilistic inference techniques for
belief networks. In proceedings of the 2nd European Conference on Artificial
Intelligence in Medicine.
Bickmore, Timothy W. (1994). Real-Time Sensor Data Validation. NASA Contractor
Report 195295, National Aeronautics and Space Administration.
Blurock, Eduard S. (1996). The ID3 Algorithm. Research Institute for Symbolic
Computation, Austria.
Breese, John S., Blake, Russ (1995). Automating Computer Bottleneck Detection with
Belief Nets. Proceedings of the Conference on Uncertainty in Artificial Intelligence,
Morgan Kaufmann, San Francisco, CA, pp 36-45.
Canavos, G.C. (1984). Probabilidad y Estadística, Aplicaciones y Métodos. Mc.Graw-Hill.
Carbajo, A., Curto, S., Schweigmann, N. (2003). Distribución espacio-temporal de Aedes
aegypti (Diptera: Culicidae). Su relación con el ambiente urbano y el riesgo de
transmisión del virus dengue en la Ciudad de Buenos Aires. Departamento de
Ecología, Genética y Evolución. Facultad de Ciencias Exactas y Naturales.
Universidad de Buenos Aires.
Chen, M., Han, J., Yu, P. (1996). Data mining: An overview from database perspective.
IEEE Transactions on Knowledge and Data Eng.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
88 Pablo Felgaer Referencias
Cooper, G.F., Herskovits, E. (1992). A Bayesian Method for the Induction of Probabilistic
Networks from Data. In Machine Learning 9, pages 54-62, Kluwer.
Cowell, R., Dawid, A., Lauritzen, S., Spiegelhalter, D. (1990). Probabilistic Networks and
Expert Systems. Springer, New York, NY.
Diaz, F., Corchado, J.M. (1999). Rough sets bases learning for bayesian networks.
International workshop on objetive bayesian methodology, Valencia, Spain.
Díez Vegas, F.J. (1994). Sistema experto bayesiano para ecocardiografía . Tesis doctoral,
Universidad Nacional de Educación a Distancia.
Evangelos, S., Han, J. (1996). Proceedings of the Second International Conference on
Knowledge Discovery and Data Mining. Portland, EE.UU.
Ezawa, Kazuo J., Schuermann, Til (1995). Fraud/Uncollectible Debt Detection Using a
Bayesian Network Based Learning System: A Rare Binary Outcome with Mixed
Data Structures. Proceedings of the Conference on Uncertainty in Artificial
Intelligence, Morgan Kaufmann, San Francisco, CA, pp 157-166.
Felgaer, P., Britos, P., Sicre, J., Servetto, A., García-Martínez, R., Perichinsky, G. (2003).
Optimización de redes bayesianas basado en técnicas de aprendizaje por inducción.
IX Congreso Argentino de Ciencias de la Computación. La Plata. Octubre 6 al 10.
Fritz, W., García-Martínez, R., Rama, A., Blanqué, J., Adobatti, R., Sarno, M. (1989). The
Autonomous Intelligent System. Robotics and Autonomous Systems. Elsevier
Science Publishers. Holanda. Volumen 5. Número 2. Páginas 109-125.
Gallion, R., Clair, D., Sabharwal, C., Bond, W.E. (1993). Dynamic ID3: A Symbolic
Learning Algorithm for Many-Valued Attribute Domains. Engineering Education
Center, University of Missouri-Rolla, St. Luis, EE.UU.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Referencias Pablo Felgaer 89
García-Martínez, R. (1993). Aprendizaje Automático basado en Método Heurístico de
Formación y Ponderación de Teorías. Revista Tecnología. Brasil. Volumen 15.
Número 1-2. Páginas 159-182.
García-Martínez, R. (1995). Aprendizaje Automático. Enciclopedia Iberoamericana de
Psiquiatría. Volumen II (Ed. G. Vidal, R. Alarcón & F. Lolas). Páginas 824-828.
Editorial Médica Panamerica. ISBN 950-06-2311-0.
García-Martínez, R. (1997). Sistemas Autónomos. Aprendizaje Automático. 170 páginas.
Editorial Nueva Librería. ISBN 950-9088-84-6.
García-Martínez, R., Borrajo, D. (2000). An Integrated Approach of Learning, Planning
and Executing. Journal of Intelligent and Robotic Systems. Volumen 29, Número 1,
Páginas 47-78. Kluwer Academic Press.
García-Martínez, R., Servente, M., Pasquini, D. (2003). Sistemas Inteligentes. 347 páginas.
Editorial Nueva Librería. ISBN 987-1104-05-7.
Gowans, M. (2001). Bayesian Network Toolkit. Department of Computing, Imperial
College.
Grosser, H., Britos, P., García-Martínez, R. (2005). Detecting Fraud in Mobile Telephony
Using Neural Networks. Lecture Notes in Artificial Intelligence. Volumen 3533,
Páginas 613-615.
Han, J. (1999). Data Mining. Urban and Dasgupta (eds.), Encyclopedia of Distributed
Computing, Kluwer Academic Publishers.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
90 Pablo Felgaer Referencias
Harris, N., Siegelhalter, D.J., Bull, K., Franklin, R.C.G. (1990). Criticizing Conditional
Probabilities in Belief Networks. SCAMC 90, Proceedings of the 4th Annual
Symposium on Computer Applications in Medical Care. Pp. 805-809.
Heckerman, D., Chickering, M., Geiger, D. (1995). Learning bayesian networks, the
combination of knowledge and statistical data. Machine learning 20: 197-243
Heckerman, D. (1995). A tutorial on learning bayesian networks. Technical report MSR-
TR-95-06, Microsoft research, Redmond, WA.
Heckerman, D.E., Geiger, D., Chickering, D. (1995). Learning Bayesian networks: The
combination of knowledge and statistical data. Machine Learning, vol. 20, pp. 197-
243.
Heckerman, D., Chickering, M. (1996). Efficient approximation for the marginal likelihood
of incomplete data given a bayesian network . Technical report MSR-TR-96-08,
Microsoft Research, Microsoft Corporation.
Hernández Orallo, J. (2000). Extracción automática de conocimiento de bases de datos e
ingeniería de software. Programación declarativa e ingeniería de la programación.
Herskovits, E.H., Copper, G.F. (1991). Algorithms for Bayesian belief-networks
percomputation. Meth. Inf. Med., 30:81-9.
Holsheimer, M., Siebes, A. (1991). Data Mining: The Search for Knowledge in Databases.
Report CS-R9406, ISSN 0169-118X, Amersterdam, The Netherlands.
Hunt, E.B., Marin, J., Stone, P.J. (1966). Experiments in Induction. New York, Academic
Press, EE.UU.
Joachims, T., Freitag, D., Mitchell, T. (1995). Web Watcher: A Tour Guide for the World
Wide Web. School of Computer Science, Carnegie Mellon University, EE.UU.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Referencias Pablo Felgaer 91
López de Mantaras, R. (1991). A distance-based attribute selection measure for decision
tree induction. Machine Learning, 6, 81-92.
Murphy, P.M., Aha, D.W. UCI Repository of Machine Learning databases. Machine-
readable data repository, Department of Information and Computer Science,
University of California, Irvine.
Langley, P., Sage, S. (1994). Induction of selective Bayesian classifiers. In Proc. Conf. On
Uncertainly in AI, pages 399-406. Morgan Kaufmann.
Lauritzen, S.L., Spiegelhalter, D.J. (1988). Local computations with probabilities on
graphical structures and their applications to expert systems. Journal of the Royal
Statistical Society, series B; 50(2):157-224.
Mannila, H. (1997). Methods and problems in data mining. In Proc. of International
Conference on Database Theory, Delphi, Greece.
Michalski, R.S., Baskin, A.B., Spackman, K.A. (1982). A Logic-Based Approach to
Conceptual Database Analysis. Sixth Annual Symposium on Computer
Applications on Medical Care, George Washington University, Medical Center,
Washington, DC, EE.UU.
Michalski, R.S., Carbonell, J.G., Mitchell, T.M. (1983). Machine learning I: An AI
Approach. Morgan Kaufmann, Los Altos, CA.
Michalski, R.S., Bratko, I., Kubat, M. (1998). Machine Learning and Data Mining,
Methods and Applications. John Wiley & Sons Ltd, West Sussex, England.
Mitchell, T. (2000). Decision Trees. Cornell University, EE.UU.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
92 Pablo Felgaer Referencias
Montalvetti, M. (1995). Sistemas de adquisición automática de conocimientos. Tesis de
grado en ingeniería de computación. Universidad Católica de Santiago del Estero,
Argentina.
Pearl, J. (1988). Probabilistic reasoning in intelligent systems: networks of plausible
inference. San Mateo, California: Morgan Kaufmann.
Perichinsky, G., García-Martínez, R. (2000). A Data Mining Approach to Computational
Taxonomy. Proceedings del Workshop de Investigadores en Ciencias de la
Computación. Páginas 107-110. Editado por Departamento de Publicaciones de la
Facultad de Informática. Universidad Nacional de La Plata. Mayo.
Perichinsky, G., García-Martínez, R., Proto, A. (2000). Knowledge Discovery Based on
Computational Taxonomy And Intelligent Data Mining. CD del VI Congreso
Argentino de Ciencias de la Computación. (\cacic2k\cacic\sp\is-039\IS-039.htm).
Ushuaia. Octubre 2 al 6.
Perichinsky, G., García-Martínez, R., Proto, A., Sevetto, A, Grossi, D. (2001). Data
Mining: Supervised and Non-Supervised Intelligent Knowledge Discovery.
Proceedings del II Workshop de Investigadores en Cienc ias de la Computación.
Mayo. Editado por Universidad Nacional de San Luis en el CD
Wicc2001:\Wiccflash\Areas\IngSoft\Datamining.pdf
Perichinsky, G., Servetto, A., García-Martínez, R., Orellana, R., Plastino, A. (2003a).
Taxomic Evidence Applying Algorithms of Intelligent Data Minning Asteroid
Families. Proceedings de la International Conference on Computer Science,
Software Engineering, Information Technology, e-Bussines & Applications. Pág.
308-315. Río de Janeiro (Brasil). ISBN 0-9742059-3-7.
Perichinsky, G., Servente, M., Servetto, A., García-Martínez, R., Orellana, R., Plastino, A.
(2003b). Taxonomic Evidence and Robustness of the Classification Applying

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Referencias Pablo Felgaer 93
Intelligent Data Mining. Proceedings del VIII Congreso Argentino de Ciencias de la
Computación. Pág. 1797-1808.
Piatetski-Shapiro, G., Frawley, W.J., Matheus, C.J. (1991). Knowledge discovery in
databases: an overview . AAAI-MIT Press, Menlo Park, California.
Piatetsky-Shapiro, G., Fayyad, U.M., Smyth, P. (1996). From data mining to knowledge
discovery. AAAI Press/MIT Press, CA.
Quinlan, J.R. (1986). Induction of decision trees. Machine Learning, 1, 81-106.
Quinlan, J.R. (1993a). The effect of noise on concept learning. En R.S. Michalski, J.G.
Carbonell, & T.M. Mitchells (Eds.) Machine learning, the artificial intelligence
approach. Morgan Kaufmann, Vol. I, Capítulo 6, páginas 149-167. San Mateo, CA:
Morgan Kaufmann, EE.UU.
Quinlan, J.R. (1993b). Learning efficient Classification Procedures and Their Application
to Chess Games. En R.S. Michalski, J.G. Carbonell, & T.M. Mitchells (Eds.)
Machine learning, the artificial intelligence approach. Morgan Kaufmann, Vol. II,
Capítulo 15, páginas 463-482, EE.UU.
Quinlan, J.R. (1993c). Combining instance-based and model-based learning. Basser
department of computer science, University of science, Australia.
Quinlan, J.R. (1993d). C4.5: Programs for machine learning. Morgan Kaufmann
publishers, San Mateo, California, EE.UU.
Quinlan, J.R. (1995). MDL and categorical theories. Basser department of computer
science, University of science, Australia.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
94 Pablo Felgaer Referencias
Quinlan, J.R., Cameron-Jones, R.M. (1995). Oversearching and layered search in
empirical learning. Basser department of computer science, University of science,
Australia.
Ramoni, M., Sebastiani, P. (1996). Learning bayesian networks from incomplete databases.
Technical report KMI-TR-43, Knowledge Media Institute, The Open University.
Ramoni, M., Sebastiani, P. (1997). Efficient Parameter Learning in Bayesian Networks
from Incomplete Databases. Report KMI-TR-41, January 1997, Knowledge Media
Institute, The Open University.
Ramoni, M., Sebastiani, P. (1999). Bayesian methods in Intelligent Data Analysis. An
Introducction. Pages 129-166. Physica Verlag, Heidelberg.
Servente, M., García-Martínez, R. (2002). Algoritmos TDIDT Aplicados a la Minería
Inteligente. Revista del Instituto Tecnológico de Buenos Aires. Volumen 26.
Páginas 39-57.
Simon, H.A. (1983). Why should machines learn?. Machine Learning, Michalski et al.
(eds.) Palo Alto CA: Tioga.
Singh, M., Provan, G. (1995a). A Comparison of Induction Algorithms for Selective and
non-Selective Bayesian Classifiers. In Proceedings of the 12 th International
Conference on Machine Learning, 497-505. Morgan Kaufmann.
Singh, M., Provan, G. (1995b). Efficient Learning of Selective Bayesian Network
Classifiers. University of Pennsylvania.
Spiegelhalter, D.J., Lauritzen, S.L. (1990). Sequential updating of conditional probabilities
on directed graphs structures. Networks, 20, pp. 579-605.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Casos de uso Pablo Felgaer 95
A. Casos de uso
A continuación se presentan los casos de uso [Booch, Jacobson & Rumbaugh, 2000]
obtenidos durante el análisis del software a construir. Los mismos corresponden a la
interacción de los usuarios con el sistema de redes bayesianas.
En cada uno de estos casos de uso el usuario inicia una acción a partir de la selección
de opciones del menú del sistema.
A.1. Menú Archivo
El menú “Archivo” contiene las opciones relacionadas con los archivos externos al
sistema. Al seleccionar la opción “Nueva”, en caso de haber una red cargada se descarga y
se vuelve al estado inicial. La opción “Abrir” abre una red bayesiana en el sistema. Al
elegir “Guardar” se guardan las modificaciones sobre la red bayesiana abierta. Con
“Guardar como…” se guarda la red bayesiana abierta con otro nombre de archivo.
Finalmente la opción “Salir” cierra el sistema.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
96 Pablo Felgaer Casos de uso
Figura A.1: Casos de uso “Archivo ”.
A.2. Menú Red
El menú “Red” contiene las opciones relacionadas con la red bayesiana abierta en el
sistema. La opción “Probabilidades” muestra una tabla con las probabilidades totales de los
nodos de la red. La opción “Ordenar” realiza un ordenamiento automático de los nodos de
la red en la pantalla.
Usuario
Menú:
Archivo – Nueva
Menú:
Archivo – Abrir
Menú:
Archivo – Guardar
Menú:
Archivo – Guardar
como…
Menú:
Archivo – Salir

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Casos de uso Pablo Felgaer 97
Figura A.2: Casos de uso “ Red”.
A.3. Menú Nodo
El menú “Nodo” contiene las opciones relacionadas con el nodo seleccionado de la
red bayesiana abierta. Al presionar “Instanciar – Estado <X>” se instancia el nodo en el
estado indicado. Al presionar “Instanciar – Ninguno” se desinstancia el nodo. La opción
“Probabilidades Condicionales” muestra una tabla con las probabilidades condicionales.
“Probabilidades Totales ” muestra una tabla con las probabilidades totales. Finalmente,
“Propiedades” muestra información relativa al nodo seleccionado
Usuario
Menú:
Red – Probabilidades
Menú:
Red – Ordenar

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
98 Pablo Felgaer Casos de uso
Figura A.3: Casos de uso “Nodo”.
A.4. Menú Herramientas
El menú “Herramientas” contiene las opciones relacionadas con herramientas de
valor agregado. En particular, “Minería de Datos” obtiene la red bayesiana a partir de
datos.
Figura A.4: Casos de uso “Herramientas”.
Usuario
Menú:
Herramientas – Minería
de datos
Usuario
Menú:
Nodo – Instanciar –
Estado <X>
Menú:
Nodo – Instanciar –
Ninguno
Menú:
Nodo – Probabilidades
condicionales
Menú:
Nodo – Probabilidades
totales
Menú:
Nodo – Propiedades

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Casos de uso Pablo Felgaer 99
A.5. Menú Configuración
El menú “Configuración” contiene las opciones relativas a la interfaz gráfica del
sistema. La opción “Barra de Herramientas ” muestra u oculta la barra de herramientas.
“Barra de Estado” muestra u oculta la barra de estado. La opción “Mostrar nodos por…”
permite visualizar gráficamente a los nodos por “Números” (muestra a los nodos por
número), “Nombres” (muestra a los nodos por nombre) o “Probabilidades” (muestra a los
nodos con los estados y las probabilidades). La opción “Zoom…” permite mostrar a los
nodos en diferentes tamaños (sólo en formato “Probabilidades”); ellos son “Tamaño
grande” o “Tamaño chico ”.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
100 Pablo Felgaer Casos de uso
Figura A.5: Casos de uso “Configuración”.
A.6. Menú Ayuda
El menú de “Ayuda” contiene las opciones relativas a la ayuda. “Referencias”
muestra el significado de las formas y colores dentro del sistema. “Acerca de…” muestra
información sobre el sistema.
Usuario
Menú:
Configuración – Barra de
herramientas
Menú:
Configuración – Barra de
estado
Menú:
Configuración – Mostrar
nodos por… – Números
Menú:
Configuración – Mostrar
por… – Nombres
Menú:
Configuración – Mostrar
por… – Probabilidades
Menú:
Configuración – Zoom –
Tamaño grande
Menú:
Configuración – Zoom –
Tamaño chico

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Casos de uso Pablo Felgaer 101
Figura A.6: Casos de uso “Ayuda”.
Usuario
Menú:
Ayuda – Referencias
Menú:
Ayuda – Acerca de…


Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Gestión de configuración Pablo Felgaer 103
B. Gestión de configuración
B.1. Identificación de la configuración
Nombre de la aplicación: “Minería de Datos mediante Redes Bayesianas”.
Objetivo de la aplicación: Obtener redes bayesianas a partir de bases de datos y permitir la
manipulación de las mismas para realizar predicciones de variables no observadas a partir
de otras observadas.
Ciclo de vida del software : Modelo en cascada.
Fases del ciclo de vida :
1. Relevamiento de necesidades (Capítulo 2 y Capítulo 3).
2. Análisis y diseño (Capítulo 2 y Capítulo 4).
3. Codificación (Ver CD-ROM).
4. Prueba y ajuste (Anexo C).
5. Implementación (Anexo D).
6. Mantenimiento (Anexo B).
Líneas bases establecidas : Para el desarrollo del presente trabajo se han acotado las líneas
base como los elementos de configuración definidos. En este caso el criterio es que dado
que es una sola persona (el tesista) quien realiza la documentación del proyecto y la
programación se ha definido una sola línea base para todo el proceso de desarrollo y
programación (“Línea base integral”).
B.2. Control de configuración
A continuación se presenta la metodología utilizada para realizar el control de
cambios:

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
104 Pablo Felgaer Gestión de configuración
• Generación de una solicitud de cambio
Ante el requerimiento de un cambio funcional o la detección de un error se realiza un
reporte del problema donde se detallan las cuestiones a solucionar.
• Ingreso de la solicitud a la base de datos de cambios
Una vez efectuado el reporte se lo archiva de manera de que quede asentada la
solicitud.
• Análisis de la solicitud de cambio
Cada uno de los reportes es analizado y se decide si se rechaza o se acepta el cambio.
• Evaluación de la solicitud de cambio
Si se decide la aceptación de la solicitud de cambio se debe realizar la evaluación
técnica de la misma emitiendo un informe en donde se exprese el esfuerzo requerido
para satisfacer el pedido, las repercusiones que dicho cambio genera en otros
elementos y el costo estimado.
• Generación de la orden de cambio
El informe generado durante la evaluación de la solicitud de cambio se analiza y se le
asigna una prioridad.
• Realización del cambio
Se realiza el cambio , se registra y se realiza el control de la modificación.
• Prueba e implementación del cambio
Se certifica que el cambio funciona correctamente y se procede a su implementación
a través de la modificació n de manuales y documentos que deban reflejar el cambio.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Gestión de configuración Pablo Felgaer 105
B.3. Generación de informes de estado
A continuación se detallan algunos de los informes que componen la “Gestión de
Configuración” y los datos relevantes de cada uno de ellos.
Registro de solicitudes de cambio
Sistema Minería de Datos mediante Redes Bayesianas Fecha dd/mm/aaaa
Resultado de la evaluación Aceptado Rechazado Nº Sol. 0001
Cambio solicitado
Se detectó un problema al visualizar la tabla de probabilidades condicionales de una variable con muchos “padres” ya que a veces el ancho de dicha tabla supera los límites de la pantalla
Solución propuesta
Para evitar este inconveniente, se propone que en los casos en que el ancho de la tabla de probabilidades supere los límites de la pantalla se adecue el tamaño de la misma a una medida coherente con las dimensiones del monitor y se muestre una barra de scroll horizontal análogamente a como esta programado para el alto de la tabla.
Elementos del producto software afectados por el cambio
Esta modificación impacta directamente en el código fuente del sistema.
Sistema Minería de Datos mediante Redes Bayesianas Fecha dd/mm/aaaa
Resultado de la evaluación Aceptado Rechazado Nº Sol 0002
Cambio solicitado
Se solicita agregarle al sistema una nueva funcionalidad para facilitar la tarea de experimentación en función de la metodología propuesta en la tesis (sección 5.2),
Solución propuesta
Para facilitar la prueba experimental, se propone desarrollar una nueva opción que permita procesar de manera paralela dos bases de datos (la Completa y la C4.5) e itere de manera automática tomando el 10%, 20%,…, 100% de la base de datos tal cual está estipulado en la metodología propuesta (sección 5.2) y genere dos archivos planos de salida con el porcentaje de predictividad obtenido en cada una de las iteraciones realizadas.
Elementos del producto software afectados por el cambio
Esta modificación impacta directamente en el código fuente del sistema.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
106 Pablo Felgaer Gestión de configuración
Informe de estado de cambios
Sistema Minería de Datos mediante Redes Bayesianas Fecha dd/mm/aaaa
Fecha desde dd/mm/aaaa Fecha hasta dd/mm/aaaa
Nº Sol. Fecha Descripción Estado
0001 dd/mm/aaaa Agregar una scrollbar horizontal en tabla de probabilidades condicionales.
Pendiente
0002 dd/mm/aaaa Proceso automático para realizar la prueba experimental. Finalizado

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Lote de prueba Pablo Felgaer 107
C. Lote de prueba
C.1. Plan de pruebas
Objetivo de la prueba
Determinar las fallas en el sistema de “Minería de Datos mediante Redes
Bayesianas”.
Objetos a probar
• Abrir una red bayesiana.
• Guardar una red bayesiana.
• Guardar una red bayesiana con otro nombre.
• Ver la tabla de probabilidades totales de una red bayesiana.
• Ordenar la red bayesiana en la pantalla.
• Instanciar un nodo de una red bayesiana.
• Desinstanciar un nodo de una red bayesiana.
• Ver la tabla de probabilidades condicionales de un nodo de una red bayesiana.
• Ver la tabla de probabilidades totales de un nodo de una red bayesiana.
• Ver las propiedades de un nodo de una red bayesiana.
• Proceso de minería de datos para la obtención de una red bayesiana.
• Mostrar y ocultar la barra de estado.
• Mostrar y ocultar la barra de herramientas.
• Mostrar los nodos de una red bayesiana en los diferentes formatos posibles.
• Mostrar los nodos de una red bayesiana en los diferentes tamaños posibles.
• Ver las referencias respecto a los colores y las formas que se visualizan en el sistema.
• Salir del sistema.
Características a probar
Funcionalidad de cada uno de los objetos a probar sobre una plataforma Microsoft
Windows XP.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
108 Pablo Felgaer Lote de prueba
Características a no probar
No se tendrá en cuenta otra plataforma que no sea Microsoft Windows XP así como
tampoco la velocidad en las operaciones realizadas por el sistema.
Cantidad de casos de prueba
El lote de prueba utilizado se compone de 21 casos.
Método de prueba a utilizar
Se utilizará el método de adivinación de errores.
Recursos a utilizar
Recursos tecnológicos
• Computadora: PC Pentium 4 de 2GHz, con HDD de 30GB, 256MB de RAM.
• Impresora: Hewlett Packard DeskJet 930C.
• Lenguaje de programación: Microsoft Visual Basic 6.0.
• Procesador de texto: Microsoft Word 2002.
Recursos humanos
• Dado que es una sola persona (el tesista) quien realiza el proyecto, tanto la
planificación de las pruebas como la programación han sido realizadas por la misma
persona.
Productos a generar durante el proceso de pruebas
• Plan de pruebas (sección C.1.).
• Documento de diseño de la prueba (sección C.2.).
• Especificación de los casos de prueba (sección C.3.).
• Especificación del procedimiento de prueba (sección C.4.).
• Informe de los casos de prueba ejecutados (sección C.5.).
• Informe de la prueba (sección C.6.).
• Anexo con documentación de las pruebas realizadas (sección C.7.).

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Lote de prueba Pablo Felgaer 109
C.2. Documento de diseño de la prueba
Procedimiento de pruebas
Las pruebas serán llevadas a cabo de acuerdo a lo descripto en la sección C.4
(Especificación del procedimiento de prueba) registrándose las anomalías planteadas.
Métodos de prueba a utilizar
Se utilizará el método de caja negra, adivinación de errores, para poder así determinar
las posibles fallas del sistema en cuanto a la funcionalidad.
Criterios para la aprobación de pruebas
Los criterios para la aprobación de las pruebas se realizarán de acuerdo a la siguiente
tabla:
• Excelente: cuando el resultado obtenido luego de realizada la prueba es idéntico al
resultado citado en la Especificación de pruebas.
• Muy bueno : cuando el resultado obtenido luego de realizada la prueba es parecido al
resultado citado en la Especificación de pruebas.
• Bueno : cuando el resultado obtenido luego de realizada la prueba no fue el resultado
citado en la Especificación de pruebas, pero no ha provocado anomalías en el
funcionamiento del programa.
• Regular: cuando el resultado obtenido luego de realizada la prueba no fue el
resultado citado en la Especificación de pruebas, y ha provocado anomalías en el
funcionamiento del programa.
• Malo: cuando el resultado obtenido luego de realizada la prueba no fue el resultado
citado en la Especificación de pruebas, y ha provocado anomalías en el
funcionamiento del programa tales como la salida del sistema o “colgarse”.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
110 Pablo Felgaer Lote de prueba
C.3. Especificación de los casos de prueba
Ítem Objetivo Acción Entrada Resultado esperado
01 Abrir una red bayesiana.
Seleccionar la opción “Archivo à Abrir”
Archivo: “DogProblem.xml”
Red bayesiana visualizada en el sistema.
02 Guardar una red bayesiana.
Seleccionar la opción “Archivo à Guardar”
----- Red bayesiana modificada guardada en el archivo.
03 Guardar una red bayesiana con otro nombre.
Seleccionar la opción “Archivo à Guardar como…”
Archivo: “DogProblem2.xml”
Red bayesiana modificada guardada en el nuevo archivo.
04
Ver la tabla de probabilidades totales de una red bayesiana.
Seleccionar la opción “Red à Probabilidades”
-----
Tabla con las probabilidades de todos los estados de cada variable.
05 Ordenar la red bayesiana en la pantalla.
Seleccionar la opción “Red à Ordenar”
-----
Red bayesiana distribuida en la pantalla de manera clara.
06 Instanciar un nodo de una red bayesiana.
Seleccionar la opción “Nodo à Instanciar à Estado <X>”
Nodo: “Dog out” Estado: “True”
Probabilidades de los estados de cada nodo actualizadas según nueva evidencia.
07 Instanciar un nodo de una red bayesiana.
Seleccionar la opción “Nodo à Instanciar à Estado <X>”
Nodo: “Lights on” Estado: “False”
Probabilidades de los estados de cada nodo actualizadas según nueva evidencia.
08 Desinstanciar un nodo de una red bayesiana.
Seleccionar la opción “Nodo à Instanciar à Ninguno”
Nodo: “Dog out” Estado: “True”
Probabilidades de los estados de cada nodo actualizadas según nueva evidencia.
09
Ver la tabla de probabilidades condicionales de un nodo de una red bayesiana.
Seleccionar la opción “Nodo à Probabilidades Condicionales”
Nodo “Dog out”
Tabla con las probabilidades condicionales del nodo seleccionado.
10
Ver la tabla de probabilidades totales de un nodo de una red bayesiana.
Seleccionar la opción “Nodo à Probabilidades Totales ”
Nodo: “Dog out”
Tabla con las probabilidades totales del nodo seleccionado.
11
Ver las propiedades de un nodo de una red bayesiana.
Seleccionar la opción “Nodo à Propiedades ”
Nodo: “Dog out” Tabla con las propiedades del nodo seleccionado.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Lote de prueba Pablo Felgaer 111
Ítem Objetivo Acción Entrada Resultado esperado
12
Proceso de minería de datos para la obtención de una red bayesiana.
Seleccionar la opción “Herramientas à Minería de Datos ”
Archivo: “MendelGenetic.txt”
Red bayesiana visualizada en el sistema.
13 Ocultar la barra de estado.
Seleccionar la opción “Configuración à Barra de Estado”
----- Barra de Estado oculta.
14 Mostrar la barra de estado.
Seleccionar la opción “Configuración à Barra de Estado”
----- Barra de Estado visible.
15 Ocultar la barra de herramientas.
Seleccionar la opción “Configuración à Barra de Herramientas ”
----- Barra de Herramientas oculta.
16 Mostrar la barra de herramientas.
Seleccionar la opción “Configuración à Barra de Herramientas ”
----- Barra de Herramientas visible.
17
Mostrar los nodos de una red bayesiana en el formato “Nombres”.
Seleccionar la opción “Configuración à Mostrar nodo por à Nombres ”
----- Red bayesiana visualizada por nombres.
18
Mostrar los nodos de una red bayesiana en el formato “Probabilidades”.
Seleccionar la opción “Configuración à Mostrar nodo por à Probabilidades ”
----- Red bayesiana visualizada por probabilidades.
19
Mostrar los nodos de una red bayesiana en el tamaño pequeño.
Seleccionar la opción “Configuración à Zoom à Tamaño chico”
----- Red bayesiana visualizada en tamaño chico.
20
Ver las referencias respecto a los colores y las formas que se visualizan en el sistema.
Seleccionar la opción “Ayuda à Referencias ”
----- Tabla de referencias en la pantalla.
21 Salir del sistema. Seleccionar la opción “Archivo à Salir”
----- Abandonar el sistema.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
112 Pablo Felgaer Lote de prueba
C.4. Especificación del procedimiento de prueba
Ítem Acción Entrada Resultado esperado
01 Seleccionar la opción “Archivo à Abrir” Archivo: “DogProblem.xml”
Red bayesiana visualizada en el sistema.
02 Seleccionar la opción “Archivo à Guardar” -----
Red bayesiana modificada guardada en el archivo.
03 Seleccionar la opción “Archivo à Guardar como…”
Archivo: “DogProblem2.xml”
Red bayesiana modificada guardada en el nuevo archivo.
04 Seleccionar la opción “Red à Probabilidades” -----
Tabla con las probabilidades de todos los estados de cada variable.
05 Seleccionar la opción “Red à Ordenar” -----
Red bayesiana distribuida en la pantalla de manera clara.
06 Seleccionar la opción “Nodo à Instanciar à Estado <X>”
Nodo: “Dog out” Estado: “True”
Probabilidades de los estados de cada nodo actualizadas según nueva evidencia.
07 Seleccionar la opción “Nodo à Instanciar à Estado <X>”
Nodo: “Lights on” Estado: “False”
Probabilidades de los estados de cada nodo actualizadas según nueva evidencia.
08 Seleccionar la opción “Nodo à Instanciar à Ninguno”
Nodo: “Dog out” Estado: “True”
Probabilidades de los estados de cada nodo actualizadas según nueva evidencia.
09 Seleccionar la opción “Nodo à Probabilidades Condicionales ” Nodo “Dog out”
Tabla con las probabilidades condicionales del nodo seleccionado.
10 Seleccionar la opción “Nodo à Probabilidades Totales”
Nodo: “Dog out”
Tabla con las probabilidades totales del nodo seleccionado.
11 Seleccionar la opción “Nodo à Propiedades ” Nodo: “Dog out”
Tabla con las propiedades del nodo seleccionado.
12 Seleccionar la opción “Herramientas à Minería de Datos”
Archivo: “MendelGenetic.txt”
Red bayesiana visualizada en el sistema.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Lote de prueba Pablo Felgaer 113
Ítem Acción Entrada Resultado esperado
13 Seleccionar la opción “Configuración à Barra de Estado”
----- Barra de Estado oculta.
14 Seleccionar la opción “Configuración à Barra de Estado”
----- Barra de Estado visible.
15 Seleccionar la opción “Configuración à Barra de Herramientas”
----- Barra de Herramientas oculta.
16 Seleccionar la opción “Configuración à Barra de Herramientas” ----- Barra de
Herramientas visible.
17 Seleccionar la opción “Configuración à Mostrar nodo por à Nombres” -----
Red bayesiana visualizada por nombres.
18 Seleccionar la opción “Configuración à Mostrar nodo por à Probabilidades” -----
Red bayesiana visualizada por probabilidades.
19 Seleccionar la opción “Configuración à Zoom à Tamaño chico”
----- Red bayesiana visualizada en tamaño chico.
20 Seleccionar la opción “Ayuda à Referencias”
----- Tabla de referencias en la pantalla.
21 Seleccionar la opción “Archivo à Salir” ----- Abandonar el sistema.
C.5. Informe de los casos de prueba ejecutados
Ítem Acción Entrada Resultado esperado Resultado obtenido
01 Seleccionar la opción “Archivo à Abrir”
Archivo: “DogProblem.xml”
Red bayesiana visualizada en el sistema.
Excelente.
02 Seleccionar la opción “Archivo à Guardar”
----- Red bayesiana modificada guardada en el archivo.
Excelente.
03
Seleccionar la opción “Archivo à Guardar como…”
Archivo: “DogProblem2.xml”
Red bayesiana modificada guardada en el nuevo archivo.
Excelente.
04 Seleccionar la opción “Red à Probabilidades”
-----
Tabla con las probabilidades de todos los estados de cada variable.
Excelente.
05 Seleccionar la opción “Red à Ordenar”
-----
Red bayesiana distribuida en la pantalla de manera clara.
Excelente.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
114 Pablo Felgaer Lote de prueba
Ítem Acción Entrada Resultado esperado Resultado obtenido
06
Seleccionar la opción “Nodo à Instanciar à Estado <X>”
Nodo: “Dog out” Estado: “True”
Probabilidades de los estados de cada nodo actualizadas según nueva evidencia.
Bueno. (Se detectó un problema visual ya que el puntero del mouse queda en estado “pensando” hasta que se desplaza fuera del área del nodo instanciado.)
07
Seleccionar la opción “Nodo à Instanciar à Estado <X>”
Nodo: “Lights on” Estado: “False”
Probabilidades de los estados de cada nodo actualizadas según nueva evidencia.
Bueno. (Se detectó un problema visual ya que el puntero del mouse queda en estado “pensando” hasta que se desplaza fuera del área del nodo instanciado.)
08
Seleccionar la opción “Nodo à Instanciar à Ninguno”
Nodo: “Dog out” Estado: “True”
Probabilidades de los estados de cada nodo actualizadas según nueva evidencia.
Bueno. (Se detectó un problema visual ya que el puntero del mouse queda en estado “pensando” hasta que se desplaza fuera del área del nodo instanciado.)
09
Seleccionar la opción “Nodo à Probabilidades Condicionales”
Nodo “Dog out”
Tabla con las probabilidades condicionales del nodo seleccionado.
Regular. (Se detectó un problema cuando la variable consultada tiene muchos “padres” ya que a veces el ancho de la tabla de probabilidades supera los límites de la pantalla.)
10
Seleccionar la opción “Nodo à Probabilidades Totales ”
Nodo: “Dog out”
Tabla con las probabilidades totales del nodo seleccionado.
Excelente.
11 Seleccionar la opción “Nodo à Propiedades ”
Nodo: “Dog out” Tabla con las propiedades del nodo seleccionado.
Excelente.
12
Seleccionar la opción “Herramientas à Minería de Datos”
Archivo: “MendelGenetic.txt”
Red bayesiana visualizada en el sistema.
Excelente.
13
Seleccionar la opción “Configuración à Barra de Estado”
----- Barra de Estado oculta. Excelente.
14
Seleccionar la opción “Configuración à Barra de Estado”
----- Barra de Estado visible. Excelente.
15
Seleccionar la opción “Configuración à Barra de Herramientas ”
----- Barra de Herramientas oculta. Excelente.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Lote de prueba Pablo Felgaer 115
Ítem Acción Entrada Resultado esperado Resultado obtenido
16
Seleccionar la opción “Configuración à Barra de Herramientas ”
----- Barra de Herramientas visible. Excelente.
17
Seleccionar la opción “Configuración à Mostrar nodo por à Nombres”
----- Red bayesiana visualizada por nombres.
Excelente.
18
Seleccionar la opción “Configuración à Mostrar nodo por à Probabilidades”
----- Red bayesiana visualizada por probabilidades.
Excelente.
19
Seleccionar la opción “Configuración à Zoom à Tamaño chico”
----- Red bayesiana visualizada en tamaño chico.
Excelente.
20 Seleccionar la opción “Ayuda à Referencias”
----- Tabla de referencias en la pantalla. Excelente.
21 Seleccionar la opción “Archivo à Salir”
----- Abandonar el sistema.
Regular. (Cuando se sale del programa haciendo click en la “X” de la ventana, el sistema no solicita confirmar si realmente se desea salir del sistema ni si se desean guardar los cambios realizados sobre la red bayesiana abierta.)
C.6. Informe de la prueba
Comentario de la prueba
El sistema funcionó de manera correcta en la mayoría de las oportunidades de
acuerdo a los casos de prueba analizados. Se detectaron algunas falencias, en su mayoría
relacionadas con la interfaz gráfica del sistema, las cuales fueron corregidas una vez
identificadas. Tanto las interfaces de usuario como los procesos internos del sistema
responden adecuadamente en función de los requerimientos impuestos.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
116 Pablo Felgaer Lote de prueba
Recomendaciones
Se recomienda dar por cumplimentada la fase de prueba y a continuación se adjunta
la documentación que constata las pruebas realizadas.
C.7. Anexo con documentación de las pruebas realizadas
Figura C.1: Abrir una red bayesiana (01)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Lote de prueba Pablo Felgaer 117
Figura C.2: Ver la tabla de probabilidades totales de una red bayesiana (04)
Figura C.3: Ordenar la red bayesiana en la pantalla (05)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
118 Pablo Felgaer Lote de prueba
Figura C.4: Instanciar un nodo de una red bayesiana (06)
Figura C.5: Instanciar un nodo de una red bayesiana (07)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Lote de prueba Pablo Felgaer 119
Figura C.6: Desinstanciar un nodo de una red bayesiana (08)
Figura C.7: Ver la tabla de probabilidades condicionales de un nodo de una red bayesiana (09)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
120 Pablo Felgaer Lote de prueba
Figura C.8: Ver la tabla de probabilidades totales de un nodo de una red bayesiana (10)
Figura C.9: Ver las propiedades de un nodo de una red bayesiana (11)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Lote de prueba Pablo Felgaer 121
Figura C.10: Proceso de Minería de Datos (12)
Figura C.11: Ocultar la barra de estado (13)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
122 Pablo Felgaer Lote de prueba
Figura C.12: Ocultar la barra de herramientas (15)
Figura C.13; Mostrar los nodos de una red bayesiana por nombres (17)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Lote de prueba Pablo Felgaer 123
Figura C.14: Mostrar los nodos de una red bayesiana por probabilidades (18)
Figura C.15: Mostrar los nodos de una red bayesiana en los diferentes tamaños posibles (19)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
124 Pablo Felgaer Lote de prueba
Figura C.16: Ver las referencias respecto a los colores y las formas que se visualizan en el sistema (20)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 125
D. Manual del usuario
D.1. Introducción
A lo largo de esta sección, se describirán las características y funcionalidades más
importantes del “Sistema de Minería de Datos mediante Redes Bayesianas” desarrollado.
D.2. Estructuración del sistema
En la figura D.1 se presenta una imagen del sistema en su estado inicial; todas las
pantallas del sistema se encuentran estructuradas de manera uniforme para facilitar su
comprensión y utilización.
Figura D.1: Estructuración del sistema.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
126 Pablo Felgaer Manual del usuario
Como puede observarse en la figura D.1 la interfaz gráfica del sistema se encuentra
estructurada en cinco áreas:
1. Menú de opciones.
2. Barra de herramientas.
3. Lista de nodos.
4. Área de visualización.
5. Barra de estado.
A continuación se expondrá una descripción más detallada de cada una de estas áreas.
D.2.1. Menú de opciones
El menú de opciones está compuesto por todas acciones que se pueden realizar
mediante el sistema; dichas acciones se encuentran organizadas en forma de árbol y se
enumeran a continuación acompañadas por una breve descripción de su funcionalidad.
1. Archivo: opciones relacionadas con los archivos externos al sistema.
1.1. Nueva: en caso de haber una red cargada, se descarga y se vuelve al estado inicial.
1.2. Abrir: abre una red bayesiana en el sistema.
1.3. Guardar: guarda las modificaciones sobre la red bayesiana abierta.
1.4. Guardar como…: guarda la red bayesiana abierta con otro nombre de archivo.
1.5. Salir: cierra el sistema.
2. Red: opciones relacionadas con la red bayesiana abierta en el sistema.
2.1. Probabilidades: muestra tabla con las probabilidades totales de los nodos de la red.
2.2. Ordenar: realiza un ordenamiento automático de los nodos de la red en la pantalla.
3. Nodo: opciones relacionadas con el nodo seleccionado de la red bayesiana abierta.
3.1. Instanciar: instancia o desinstancia el nodo.
3.1.1. Estado <X>: lo instancia en el estado <X>.
3.1.2. Ninguno: lo desinstancia.
3.2. Probabilidades Condicionales: muestra tabla con las probabilidades condicionales.
3.3. Probabilidades Totales: muestra tabla con las probabilidades totales.
3.4. Propiedades: muestra información relativa al nodo seleccionado

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 127
4. Herramientas: opciones relacionadas con herramientas de valor agregado.
4.1. Minería de Datos: obtiene la red bayesiana a partir de datos.
5. Configuración: opciones relativas a la interfaz gráfica del sistema.
5.1. Barra de Herramientas: muestra u oculta la barra de herramientas.
5.2. Barra de Estado: muestra u oculta la barra de estado.
5.3. Mostrar nodos por…: muestra a los nodos en diferentes formatos.
5.3.1. Números: muestra a los nodos por número.
5.3.2. Nombres: muestra a los nodos por nombre.
5.3.3. Probabilidades: muestra a los nodos con los estados y las probabilidades.
5.4. Zoom…: muestra a los nodos en diferentes tamaños (sólo en formato “Probabilidades”).
5.4.1. Tamaño grande : muestra a los nodos es tamaño grande.
5.4.2. Tamaño chico: muestra a los nodos en tamaño chico.
6. Ayuda : opciones relativas a la ayuda.
6.1. Referencias: muestra el significado de las formas y colores dentro del sistema.
6.2. Acerca de…: muestra información sobre el sistema.
D.2.2. Barra de herramientas
La barra de herramientas provee un acceso rápido y sencillo (con un sólo click) a la
mayoría de las opciones que se encuentran en el menú antes citado; a continuación se
presentan los íconos de la barra de herramientas y las equivalencias con las opciones del
menú correspondientes.
1. Archivo – 1.1. Nueva
1. Archivo – 1.2. Abrir
1. Archivo – 1.3. Guardar
2. Red – 2.1. Probabilidades
2. Red – 2.2. Ordenar
3. Nodo – 3.1. Instanciar
3. Nodo – 3.2. Probabilidades Condicionales
3. Nodo – 3.3. Probabilidades Totales
3. Nodo – 3.4. Propiedades
4. Herramientas – 4.1. Minería de Datos

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
128 Pablo Felgaer Manual del usuario
5. Configuración – 5.1. Barra de Herramientas
5. Configuración – 5.2. Barra de Estado
5. Configuración – 5.3. Mostrar nodos por…
5. Configuración – 5.4. Zoom… – 5.4.1. Tamaño grande
5. Configuración – 5.4. Zoom… – 5.4.2. Tamaño chico
6. Ayuda – 6.1. Referencias
1. Archivo – 1.5. Salir
D.2.3. Lista de nodos
En esta área de la pantalla se presenta una lista ordenada de todos los nodos
correspondientes a la red bayesiana abierta en el sistema; se muestra el nombre de las
variables y el número correspondiente asignado por el sistema (este número identifica de
forma unívoca a cada nodo de la red bayesiana). A través de esta lista se puede seleccionar
cualquiera de los nodos haciendo click sobre él; también se puede visualizar el conjunto de
estados del nodo seleccionado así como también las probabilidades totales asociadas a cada
uno de ellos y si hay algún estado instanciado.
D.2.4. Área de visualización
En esta área de la pantalla se visualiza una representación gráfica de la red bayesiana
abierta; las relaciones entre los nodos de la red se representan mediante flechas en cuyo
origen se encuentra el nodo padre y apunta en dirección al nodo hijo. Los nodos se
representan mediante diferentes formas y colores indicando el estado en que se encuentran
(ver sección D.6.3), pueden ser seleccionados haciendo doble click sobre ellos y, cuando se
están visualizando en formato “Probabilidades” (ver sección D.6.3), se puede instanciar
simplemente haciendo click sobre el estado deseado; haciendo click con el botón derecho
del mouse sobre un nodo de la red se despliega un menú de tipo pop-up con las opciones
correspondientes al menú de “Nodos” detallado anteriormente (ver sección D.2.1). La
disposición de los nodos en la pantalla puede ser manipulada realizando drag and drop.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 129
D.2.5. Barra de estado
La barra de estado provee información sobre las acciones que está tomando el sistema
a cada momento; en su parte derecha tiene información general como la fecha y la hora
mientras que la parte izquierda de la barra tiene un semáforo que indica si el sistema se
encuentra procesando o si está listo para recibir nuevas peticiones; estos estados quedan
representados por la luz roja o verde respectivamente y al lado del semáforo se muestra la
descripción del estado del sistema.
D.3. Abrir una red bayesiana
Este sistema ha sido diseñado para trabajar con redes bayesianas almacenadas en
archivos con formato .XML (ver sección D.7.1). La opción para abrir este tipo de archivos
se invoca a través del menú “Archivo – Abrir” o mediante el icono de la barra de
herramientas equivalente; una vez seleccionada esta opción se presenta la ventana de
selección del archivo (figura D.2) y al elegir un archivo con formato válido la red es
visualizada en la pantalla.
Figura D.2: Abrir una red bayesiana.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
130 Pablo Felgaer Manual del usuario
D.4. Guardar una red bayesiana
La opción para guardar redes bayesianas se invoca a través del menú “Archivo –
Guardar” o mediante el icono de la barra de herramientas correspondiente; una vez
seleccionada esta opción se presenta un mensaje para confirmar que realmente se deseen
guardar las modificaciones en el archivo; la opción “Archivo – Guardar como… ” permite
almacenar la red bayesiana abierta en un archivo .XML con nombre diferente.
D.5. Minería de datos
La opción de “Minería de datos” del menú “Herramientas” permite obtener redes
bayesianas a partir de datos. Al seleccionar esta opción se muestra la pantalla de
presentación expuesta en la figura D.3; en esta pantalla se presenta la herramienta de
minería de datos y se resume su funcionalidad. Esta utilidad está estructurada en varios
pasos secuenciales y en cada uno de ellos se van completando los requisitos necesarios para
llevar a cabo la tarea.
Figura D.3: Minería de datos – Presentación.
Lo primero que se necesita de finir para llevar a cabo la minería de datos es el archivo
que contiene los datos; este sistema está preparado para trabajar con archivos de texto que
cumplen un formato específico (ver sección D.7.2). En la figura D.4 se presenta la pantalla
que solicita seleccionar el archivo que contiene la fuente de datos.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 131
Figura D.4: Minería de datos – Seleccionar archivo.
Esta pantalla permite ingresar en forma directa la ruta del archivo a procesar o,
haciendo click en el botón que se encuentra a la derecha del campo de texto, se presenta
una ventana de navegación a partir de la cual se puede seleccionar el archivo (figura D.5).
Figura D.5: Minería de datos – Seleccionar archivo.
Una vez seleccionado el archivo de datos, el sistema verifica que el formato sea el
correcto y si todo está en orden se debe realizar el ingreso de información externa que el
sistema tendrá en cuenta al momento de realizar el aprendizaje de la red bayesiana; esta
información externa corresponde a conocimientos a priori que se tengan sobre el dominio
de datos que se está utilizando. La primera información que se debe ingresar es relativa a

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
132 Pablo Felgaer Manual del usuario
los nodos raíz de la red bayesiana que se está infiriendo; esto significa qué nodos son
totalmente independiente (figura D.6).
Figura D.6: Minería de datos – Seleccionar nodos raíz.
Una vez definidos los nodos raíz, el siguiente paso permite definir relaciones y/o
restricciones en forma explícita (figura D.7); para ello se deberá seleccionar de las listas
correspondientes el nodo padre y el nodo hijo y a continuación hacer click sobre el botón
que indica si lo que se desea especificar es una relación (>>) o una restricción (><); estas
reglas se verán reflejadas en la red bayesiana obtenida al final de este proceso. Si se desea
eliminar una o más de las reglas impuestas basta con seleccionarla de la lista de
“Relaciones y Restricciones” que aparece en la parte inferior de la pantalla y presionar la
tecla “Delete”. El sistema advertirá al usuario si intenta establecer reglas contradictorias
(por ejemplo una relación y una restricción entre el mismo par de variables) o si mediante
las relaciones indicadas establece un camino cíclico que viole la propiedad de grafo acíclico
dirigido que poseen las redes utilizadas por este sistema. Por último cabe mencionar que
dado que las redes son grafos dirigidos, no existe simetría en las relaciones ni en las
restricciones (es decir que A>>B es distinto a B>>A y que A><B es distinto a B><A).

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 133
Figura D.7: Minería de datos – Seleccionar relaciones y restricciones.
Una vez introducida toda esta información el sistema estará en condic iones de
come nzar el proceso de aprendizaje (figura D.8); este proceso comienza con el cálculo de
las métricas de las relaciones entre todas las variables que determinará cuales de ellas
tienen mayor preponderancia sobre las otras luego de lo cual se establecerá la topología de
la red (aprendizaje estructural).
Figura D.8: Minería de datos – Realizando minería de datos.
En este punto el sistema presentará una ventana identificando todas las relaciones
inferidas (figura D.9) y permitirá al usuario alterar la direccionalidad de las mismas en caso
de desearlo; una vez aceptado esto, el proceso culminará realizando el aprendizaje
paramétrico y efectuando la propagación inicial de probabilidades. Al terminar, la red

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
134 Pablo Felgaer Manual del usuario
bayesiana aprendida a partir del archivo de datos se visualizará en la pantalla y estará lista
para analizarla, manipularla y guardarla en un archivo.
Figura D.9: Minería de datos – Definir direccionalidad de las relaciones.
D.6. Trabajar con una red bayesiana
D.6.1. Instanciar nodos
Una vez que se dispone de una red bayesiana cargada en el sistema se puede proceder
a la instanciación de variables para analizar el comportamiento de la misma. Existen varias
alternativas para llevar a cabo el proceso de instanciación; uno de ellos consiste en
seleccionar el nodo correspondiente a la variable que se desee instanciar y realizarlo desde
el menú “Nodo – Instanciar” o desde el botón de la barra de herramientas equivalente;
dentro de esta opción del menú se mostrarán todos los estados que posee el nodo
seleccionado y también la opción “Ninguno” en caso de que lo que se desee sea
desinstanciarlo. Otra forma de realizar esta tarea consiste en hacer click derecho sobre el
nodo de la red y seleccionar el estado a instanciar de la lista expuesta en el menú
desplegado. Finalmente, en caso de que la forma de visualización de la red sea
“Probabilidades” se podrá instanciar una variable simplemente haciendo click sobre el
estado elegido (figura D.10). Al instanciar cualquiera de las variables, automáticamente se
procede a recalcular todas las probabilidades de la red y este resultado es presentado

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 135
instantáneamente en la pantalla. Los estados instanciados se presentan en color rojo y,
obviamente, con el 100% de probabilidad de ocurrencia.
Figura D.10: Instanciación de variables
D.6.2. Información de la red
Una vez que se tiene una red bayesiana abierta en el sistema, éste permite interactuar
y obtener una serie de informaciones relacionadas con ella. Seleccionando la opción
“Probabilidades” del menú “Red” se desplegará una ventana conteniendo una tabla con
todas las variables de la red bayesiana abierta y la probabilidad total de cada uno de los
estados (figura D.11).
Figura D.11: Probabilidades totales de la red.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
136 Pablo Felgaer Manual del usuario
Si lo que se desea obtener es la tabla de probabilidades condicionales de un nodo en
particular, se puede lograr seleccionándolo y accediendo a la opción “Probabilidades
Condicionales” del menú “Nodo” o accediendo a la misma opción del menú contextual
presionando el botón derecho del mouse sobre dicho nodo (figura D.12).
Figura D.12: Probabilidades condicionales de un nodo.
Las probabilidades totales de un nodo se obtienen de manera similar a través de la
opción “Probabilidades Totales” del menú “Nodo” (figura D.13).
Figura D.13: Probabilidades totales de un nodo.
Las propiedades de un nodo indican el nombre, número interno asignado, si se
encuentra seleccionado, si es un nodo raíz u hoja de la red y la lista de estado que
componen el dominio de valores que puede asumir; se puede acceder a esta información a
través de la opción “Propiedades” del menú “Nodo” (figura D.14).
Figura D.14: Propiedades de un nodo.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 137
D.6.3. Visualización de la red
El sistema permite varios formatos de visualización gráfica de la red bayesiana ; cada
uno de estos formatos difiere en la información que se muestra en la representación gráfica
del nodo y el tamaño que utiliza para hacerlo; esta visualización puede ser seleccionada a
través de la opción “Configuración – Ver nodos por…”. El formato más compacto pero que
menos información presenta es por “Números” (figura D.15); aquí se presentan los nodos
en forma de círculos conteniendo el número de nodo asignado por el sistema. En caso de
que el nodo se encuentre instanciado se presenta con forma de un cuadrado con las aristas
redondeadas.
Figura D.15: Visualización por Número.
La configuración por “Nombre” encuadra a cada una de las variables dentro de
elipses y en caso de encontrarse instanciada se presenta en forma de rectángulo (figura
D.16).

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
138 Pablo Felgaer Manual del usuario
Figura D.16 Visualización por Nombre.
La visualización por “Probabilidad” es sin duda la que más información revela ya
que presenta el nombre de la variable acompañada por la lista de todos sus estados, las
probabilidades asociadas a cada uno de ellos y también se destacan los estados instanciados
(figura D.17).
Figura D.17: Visualización por Probabilidad (tamaño grande).
Este formato de visualización se puede presentar en dos tamaños predeterminados:
grande o pequeño, y estas dimensiones se varían mediante la opción “Configuración –

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 139
Zoom”. En la figura D.17 se muestra el tamaño grande de visualización mientras que en la
figura D.18 se presenta la red en tamaño reducido.
Figura D.18: Visualización por Probabilidad (tamaño pequeño).
Los significados de las diferentes formas y colores con que se muestran las redes
bayesianas pueden ser consultados en el menú “Ayuda – Referencias” (figura D.19); allí se
puede observar como se diferencian los nodos ins tanciados de los que no lo están así como
también se distinguen mediante un código de colores el nodo seleccionado y sus
predecesores y sucesores inmediatos.
Figura D.19: Referencias de formas y colores del sistema.

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
140 Pablo Felgaer Manual del usuario
D.7. Archivos externos
Como se indicó anteriormente, este sistema interactúa con dos tipos de archivos
diferentes: por un lado están los archivos que contienen las redes bayesianas y, por el otro
lado, los archivos que contienen los datos a partir de las cuales se desean inferir las redes. A
continuación se procederá a brindar una descripción detallada de ambos formatos de
archivos.
D.7.1. Archivos de redes
Para manejar las redes bayesianas almacenadas en archivos externos se definió un
formato particular basado en el lenguaje XML (con lo cual “XML” debe ser la extensión de
estos archivos). A continuación se presenta a modo de ejemplo el archivo con la red
bayesiana “The dog barking problem ” analizada anteriormente (ver sección 2.2.4.2.4) y se
explicarán cada uno de sus componentes.
<NETWORK> <NODE>
<DESCRIPTION>Bowel problem</DESCRIP TION> <STATE>True</STATE> <STATE>False</STATE> <XPOSITION>500</XPOSITION> <YPOSITION>500</YPOSITION>
</NODE> <NODE>
<DESCRIPTION>Family out</DESCRIPTION> <STATE>True</STATE> <STATE>False</STATE> <XPOSITION>5360</XPOSITION> <YPOSITION>440</YPOSITION>
</NODE> <NODE>
<DESCRIPTION>Dog out</DESCRIPTION> <STATE>True</STATE> <STATE>False</STATE> <XPOSITION>2525</XPOSITION> <YPOSITION>2825</YPOSITION>
</NODE> <NODE>
<DESCRIPTION>Lights on</DESCRIPTION> <STATE>True</STATE> <STATE>False</STATE>

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 141
<XPOSITION>7835</XPOSITION> <YPOSITION>2825</YPOSITION>
</NODE> <NODE>
<DESCRIPTION>Hear bark</DESCRIPTION> <STATE>True</STATE> <STATE>False</STATE> <XPOSITION>2525</XPOSITION> <YPOSITION>5675</YPOSITION>
</NODE> <PROBABILITY>
<FOR>Bowel problem</FOR> <TABLE>0,01 0,99</TABLE>
</PROBABILITY> <PROBABILITY>
<FOR>Family out</FOR> <TABLE>0,15 0,85</TABLE>
</PROBABILITY> <PROBABILITY>
<FOR>Dog out</FOR> <PARENT>Family out</PARENT> <PARENT>Bowel problem</PARENT> <TABLE>0,99 0,90 0,97 0,30 0,01 0,10 0,03 0,70</TABLE>
</PROBABILITY> <PROBABILITY>
<FOR>Lights on</FOR> <PARENT>Family out</PARENT> <TABLE>0,60 0,05 0,40 0,95</TABLE>
</PROBABILITY> <PROBABILITY>
<FOR>Hear bark</FOR> <PARENT>Dog out</PARENT> <TABLE>0,70 0,01 0,30 0,99</TABLE>
</PROBABILITY> </NETWORK>
La información de la red bayesiana comienza con el delimitador <NETWORK> y
termina con el delimitador </NETWORK>. En términos generales todos los bloques de
información comienzan con un delimitador del tipo <X> y su finalización es indicada
incluyendo otro delimitador del tipo </X> con lo cual todo lo que quede entre estos
delimitadores indicará la información que lo describe. Observando el archivo expuesto
puede verse como la red bayesiana (NETWORK) tiene básicamente dos tipos de
componentes: los nodos (NODE) y las relaciones (PROBABILITY).

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
142 Pablo Felgaer Manual del usuario
D.7.1.1. Definición de los nodos
Cada uno de los nodos de la red bayesiana queda definido por la información
contenida entre los delimitadores <NODE> y </NODE>. Estos nodos se componen de una
descripción que indica el nombre de la variable que representan (DESCRIPTION), un
conjunto de estados que pueden asumir (STATE) y finalmente dos coordenadas que indican
la ubicación del nodo en la pantalla al momento de mostrarlo (XPOSITION e
YPOSITION).
D.7.1.2. Definición de las relaciones
Las relaciones de dependencia entre las variables de la red expresadas mediante los
delimitadores PROBABILITY están compuestas por el nodo hijo de la relación (FOR) y el
o los padres de ese nodo (PARENT). Una vez definida esta relación entre el hijo y los
padres de este se define la matriz de probabilidades condicionales (TABLE). Dentro de este
delimitador se incluirán los valores de las probabilidades para cada combinación distinta de
estados de los nodos participantes en la relación en cuestión separados por tabulaciones.
Para comprender de que manera se arma esta tabla analizaremos el caso del nodo “Dog
out” del ejemplo. El nodo “Dog out” ( d ) tiene dos padres: los nodos “Family out” ( f ) y
“Bowel problem” (b ). Cada uno de estos nodos son binarios pudiendo tomar los valores
“True” (1) o “False” (0 ). A partir de estos nodos y sus posibles estados se arma la
siguiente tabla:
d f b P(d|f,b)
1 1 1 0,99
1 1 0 0,90
1 0 1 0,97
1 0 0 0,30
0 1 1 0,01
0 1 0 0,10
0 0 1 0,03
0 0 0 0,70

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 143
La primer columna corresponde al nodo hijo, la segunda columna al primer padre y la
tercer columna al segundo padre (en caso de existir más padres se continua de manera
análoga). La primera fila de la tabla corresponde a la probabilidad de que el nodo hijo se
encuentre en su primer estado sabiendo que sus dos padres están también en sus respectivos
primeros estados. La segunda fila corresponde a la probabilidad de que el nodo hijo se
encuentre en su primer estado sabiendo que el primer padre está en su primer estado y el
segundo padre se encuentra en su segundo estado. La siguiente probabilidad corresponde a
la probabilidad de que el nodo hijo se encuentre en su primer estado sabiendo que el padre
número uno se encuentra en su segundo estado y el segundo padre en su estado número
uno. Se procede de manera análoga hasta conformar la tabla de probabilidades
condicionales completa.
D.7.2. Archivos de datos
Para el manejo de los archivos de datos a partir de lo s cuales se hace minería para
obtener las redes bayesianas también se definió un formato particular cuya extensión debe
ser “TXT”. A continuación se presenta a modo de ejemplo un archivo con una base de
datos y se explicarán cada uno de sus componentes.
-- Archivo de ejemplo 3 Sexo { Masculino {M} Femenino {F} } Tipo de carrera { Ingeniería {Informática, Electrónica, Industrial} Sociales {Historia, Filosofía } } Calificación { Reprobado [0, 4) Satisfactorio [4, 6) Muy bueno [6, 8)

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
144 Pablo Felgaer Manual del usuario
Sobresaliente [8, 10) } M Ingeniería Muy bueno F Sociales Satisfactorio M Ingeniería Reprobado M Ingeniería Sobresaliente …
El formato de los archivos de datos se divide en dos partes: la primer parte
(Encabezado) contiene la información sobre la estructura de la información y la segunda
parte (Datos) se compone de la base de datos propiamente dicha. Cualquier renglón del
archivo que comience con dos guiones (--) será considerado una línea de comentario y por
lo tanto no será procesada por el sistema; tampoco serán procesadas las líneas en blanco.
D.7.2.1. Definición del encabezado
El primer renglón del archivo que contenga información deberá indicar el número de
variables que conforman la base de datos (en el caso de este ejemplo: 3). A continuación se
deberán definir cada una de estas variables con sus respectivos estados. El sistema permite
definir dos tipos de variables: discretas y continuas. En la definición de las variables se
indica primero el nombre y luego, encerrado entre llaves, los estados. A su vez, cada uno de
estos estados puede agrupar a uno o más valores de la base de datos. En el ejemplo anterior,
la primer variables (“Sexo”) es discreta; bajo el nombre del estado “Masculino” se agrupan
a los datos de la base que tengan el valor “M” y bajo el título de “Femenino” a los que
tengan “F”. La siguiente variable que se define es “Tipo de carrera” y en este caso bajo un
mismo título se agrupan a más de un estado de la base de datos; por ejemplo “Ingeniería”
incluye a las carreras de “Informática”, “Electrónica” e “Industrial” mientras que
“Sociales” incluye a “Historia ” y “Filosofía”. La última variable definida (“Calificación”)
es de tipo continua; esta definición se realiza especificando los rangos que abarcan cada
título, por ejemplo “Reprobado” se considera a las calificaciones entre 0 y menos de 4
puntos (los símbolos “[“ y “]” indican inclusión y los símbolos “(“ y “)” indican exclusión),
“Satisfactorio” son las calificaciones entre 4 y menos de 6, “Muy bueno” son entre 6 y 8, y
“Sobresaliente” son las calificaciones superiores a 8 puntos. En este caso la variable se

Optimización de Redes Bayesianas basado en Técnicas de Aprendizaje por Inducción
Manual del usuario Pablo Felgaer 145
encuentra acotada tanto inferior como superiormente, pero en caso de no ser así la letra “X”
ubicada en el lugar del rango mínimo y/o máximo actúa como ∞− y ∞+ respectivamente.
D.7.2.2. Definición de los datos
Una vez que queda definida la sección del encabezado sólo resta incluir la sección de
datos que se compone de un renglón por registro y los valores de las variables separadas
por tabulaciones en el mismo orden en que se definieron en el encabezado.
D.7.2.3. Eliminación de variables
Este formato de datos también contempla la posibilidad de obviar variables al
momento de realizar la minería de datos; esto se logra simplemente agregando un asterisco
(*) antes del nombre de la variable que se desea eliminar. Esta funcionalidad resulta de
suma utilidad para analizar la importancia de determinadas variables dentro de la estructura
total de la red bayesiana y poder realizar comparaciones entre el poder predictivo de las
redes bayesianas obtenidas considerando todas las variables de la base de datos y las redes
obtenidas que utilizan sólo parte de estas variables.





























