Embed Size (px)
Citation preview

Speaker name, TitleCompany/Organization Name
Join the Conversation #OpenPOWERSummit
OpenCAPI TechnologyMyron Slota
OpenCAPI Consortium

Industry Collaboration and Innovation

OpenCAPI Topics
Industry Background
Where/How OpenCAPI Technology is used
Technology Overview and Advantages
Demonstrations
OpenCAPI Consortium – Where it all Happens
Key Messages Throughout Open IO Standard
High Performance – No OS/Hypervisor/FW Overhead with Low Latency and High Bandwidth
Not tied to Power – Architecture Agnostic
Very Low Accelerator Design Overhead
Programing Ease
Ideal for Accelerated Computing and SCM
Supports heterogeneous environment – Use Cases
Optimized for within a single system node
Products exist today!
Computation Data Access

Industry Background that Defined OpenCAPIGrowing computational demand due to emerging workloads (e.g., AI, cognitive, etc.)Moore’s Law not being supported by traditional silicon scalingDriving increased dependence on Hardware Acceleration for performance
• Hyperscale Datacenters and HPC need much higher network bandwidth• 100 Gb/s -> 200 Gb/s -> 400Gb/s are emerging
• Deep learning and HPC require more bandwidth between accelerators and memory• Emerging memory/storage technologies are driving need for bandwidth with low latency
Hardware accelerators are defining the attributes of a high performance bus
• Growing demand for network performance and network offload• Introduction of device coherency requirements (IBM’s introduction in 2013)• Emergence of complex storage and memory solutions• Various form factors with no one able to address everything (e.g., GPUs, FPGAs, ASICs, etc.)
4
Computation Data Access
…all Relevant to Modern Data Centers

Use Cases - A True Heterogeneous Architecture Built Upon OpenCAPI
OpenCAPI 3.0
OpenCAPI 3.1
OpenCAPI specifications are downloadable from the websiteat www.opencapi.org- Register- Download

AcceleratedOpenCAPI Device
OpenCAPI Key Attributes
6
TL/DL 25Gb I/O
Any OpenCAPI Enabled Processor
U
Accelerated Function
TLx/DLx
1. Architecture agnostic bus – Applicable with any system/microprocessor architecture
2. Optimized for High Bandwidth and Low Latency
3. High performance 25Gbps PHY design with zero ‘overhead’
4. Coherency - Attached devices operate natively within application’s user space and coherently with host microprocessor
5. Virtual addressing enables low overhead with no Kernel, hypervisor or firmware involvement
6. Wide range of Use Cases and access semantics
7. CPU coherent device memory (Home Agent Memory)
8. Architected for both Classic Memory and emerging Advanced Storage Class Memory
9. Minimal OpenCAPI design overhead (FPGA less than 5%)
Caches
Application
Storage/Compute/Network etc ASIC/FPGA/FFSA FPGA, SOC, GPU Accelerator Load/Store or Block Access
Standard System Memory Advanced SCM Solutions
Bu
ffe
red
Sys
tem
Me
mo
ry
Op
en
CA
PIM
em
ory
Bu
ffe
rs
Device Memory
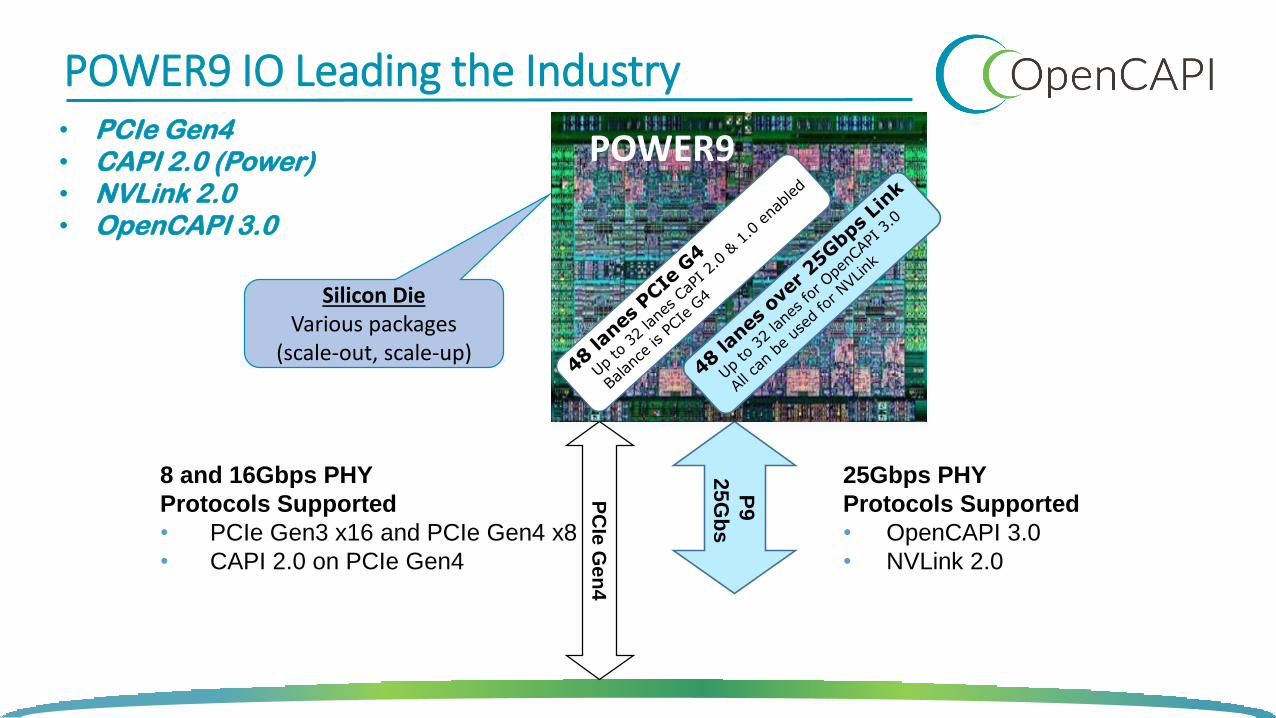
POWER9 IO Features
8 and 16Gbps PHY
Protocols Supported
• PCIe Gen3 x16 and PCIe Gen4 x8
• CAPI 2.0 on PCIe Gen4
PC
Ie G
en
4
P9
25
Gb
s
25Gbps PHY
Protocols Supported
• OpenCAPI 3.0
• NVLink 2.0
Silicon DieVarious packages
(scale-out, scale-up)
POWER9 IO Leading the Industry• PCIe Gen4• CAPI 2.0 (Power)• NVLink 2.0• OpenCAPI 3.0
POWER9

Virtual Addressing and Benefits An OpenCAPI device operates in the virtual address spaces of the applications that it supports
• Eliminates kernel and device driver software overhead
• Allows device to operate on application memory without kernel-level data copies/pinned pages
• Simplifies programming effort to integrate accelerators into applications
• Improves accelerator performance
The Virtual-to-Physical Address Translation occurs in the host CPU
• Reduces design complexity of OpenCAPI-attached devices
• Makes it easier to ensure interoperability between OpenCAPI devices and different CPU architectures
• Security - Since the OpenCAPI device never has access to a physical address, this eliminates the possibility of a defective or malicious device accessing memory locations belonging to the kernel or other applications that it is not authorized to access

Acceleration Paradigms with Great Performance
9
Examples: Encryption, Compression, Erasure prior to
delivering data to the network or storage
Processor Chip
Acc
Data
Egress Transform
DLx/TLx
Processor Chip
Acc
Data
Bi-Directional Transform
Acc
DLx/TLx
Examples: NoSQL such as Neo4J with Graph Node Traversals, etc
Needle-in-a-haystack Engine
Examples: Machine or Deep Learning such as Natural Language processing,
sentiment analysis or other Actionable Intelligence using OpenCAPI attached memory
Memory Transform
Processor Chip
Acc
DataDLx/TLx
Example: Basic work offload
Processor Chip Acc
NeedlesDLx/TLx
Examples: Database searches, joins, intersections, merges
Only the Needles are sent to the processor
Ingress Transform
Processor Chip
Acc
DataDLx/TLx
Examples: Video Analytics, Network Security,
Deep Packet Inspection, Data Plane Accelerator,
Video Encoding (H.265), High Frequency Trading etc
Needle-In-A-Haystack Engine
Large
Haystack
Of Data
OpenCAPI is ideal for acceleration due
to Bandwidth to/from accelerators, best
of breed latency, and flexibility of an
Open architecture

Comparison of Memory Paradigms
Emerging Storage Class Memory
Processor ChipDLx/TLx
SCM
Data
OpenCAPI 3.1 Architecture
Ultra Low Latency ASIC buffer chip adding +5ns
on top of native DDR direct connect!!
Storage Class Memory tiered with traditional DDR
Memory all built upon OpenCAPI 3.1 & 3.0
architecture.
Still have the ability to use Load/Store Semantics
Storage Class Memories have the potential to be
the next disruptive technology…..
Examples include ReRAM, MRAM, Z-NAND……
All are racing to become the defacto
Main Memory
Processor ChipDLx/TLx
DD
R4
/5
Example: Basic DDR attach
Data
Tiered Memory
Processor ChipDLx/TLx
DD
R4
/5 DLx/TLx
SCM
Data Data
Common physical interface between non-memory and memory devicesOpenCAPI protocol was architected to minimize latency; excellent for classic DRAM memoryExtreme bandwidth beyond classical DDR memory interfaceAgnostic interface will handle evolving memory technologies in the future (e.g., compute-in-mem)Ability to handle a memory buffer to decouple raw memory and host interface to optimize power, cost, perf

CAPI and OpenCAPI Performance
11
CAPI 1.0
PCIE Gen3 x8
Measured BW @8Gb/s
CAPI 2.0
PCIE Gen4 x8
Measured BW @16Gb/s
OpenCAPI 3.0
25 Gb/s x8
Measured BW @25Gb/s
128B DMA Read
3.81 GB/s 12.57 GB/s 22.1 GB/s
128B DMA Write
4.16 GB/s 11.85 GB/s 21.6 GB/s
256B DMA Read
N/A 13.94 GB/s 22.1 GB/s
256B DMA Write
N/A 14.04 GB/s 22.0 GB/s
POWER8
Introduced
in 2013
POWER9
Second
Generation
POWER9
Open Architecture with a
Clean Slate Focused on
Bandwidth and Latency
POWER8 CAPI 1.0
POWER9 CAPI 2.0and OpenCAPI 3.0
Xilinx
KU60/VU3P FPGA

Latency Test Results
‡
‖
† § § §
‖

Latency Test
Simple workload created to simulate communication between system and attached FPGA
1. Copy 512B from host send buffer to FPGA
2. Host waits for 128 Byte cache injection from FPGA and polls for last 8 bytes
3. Reset last 8 bytes
4. Repeat Go TO 1.

OpenCAPI Enabled FPGA Cards
14
Mellanox Innova2 Accelerator Card Alpha Data 9v3 Accelerator Card
Typical eye diagram at 25Gb/s using these cards

Barrel Eye G2 System Demo
Actual Barrel Eye G2 demo system
Packet Classifier Demonstrationusing Alpha Data 9v3 Accelerator Card
(early classifier bringup at 20 Gb/s)

Barrel Eye G2 System Demo
Actual Barrel Eye G2 demo system
Packet Classifier Demonstrationusing Mellanox Innova2 Accelerator Card
(early classifier bringup at 20 Gb/s)

OpenCAPI Consortium
• Open forum founded by AMD, Google, IBM, Mellanox, and Micron• Manage the OpenCAPI specification, Establish enablement, Grow the ecosystem
• Currently over 35 members
• Consortium now established• Established Board of Directors (AMD, Google, IBM, Mellanox Technologies, Micron, NVIDIA, Western Digital, Xilinx)
• Governing Documents (Bylaws, IPR Policy, Membership) with established Membership Levels
• Website www.opencapi.org
• Technical Steering Committee with Work Group Process established
• Marketing/Communications Committee
• Work Groups• TL Specification, DL Specification, PHY Signaling, PHY Mechanical, Compliance, and Enablement
• Creation of additional work groups include: Memory, Software, Accelerator, and more
• OpenCAPI Specification available on web site, was contributed to consortium as starting point for the Work Groups
• Design enablement available today (reference designs, documentation, SIM environment, exercisers, etc.)5
Incorporated September 13, 2016 Announced October 14, 2016

OpenCAPI Design Enablement
18
Item Availability
OpenCAPI 3.0 TLx and DLx Reference Xilinx FPGA Designs (RTL and Specifications)
Today
Xilinx Vivado Project Build with Memcopy Exerciser Today
Device Discovery and Configuration Specification and RTL
Today
AFU Interface Specification Today
Reference Card Design Enablement Specification 2Q18
25Gbps PHY Signal Specification Today
25Gbps PHY Mechanical Specification Today
OpenCAPI Simulation Environment (OCSE) Tech Preview
Today
Memcopy and Memory Home Agent Exercisers Today
Reference Driver Available 2Q18

Membership Entitlement Details
Strategic level - $25K
• Draft and Final Specifications and enablement
• License for Product development
• Workgroup participation and voting
• TSC participation
• Vote on new Board Members
• Nominate and/or run for officer election
• Prominent listing in appropriate materials
Observing level - $5K
• Final Specifications and enablement
• License for Product development
Contributor level - $15K
• Draft and Final Specifications and enablement
• License for Product development
• Workgroup participation and voting
• TSC participation
• Submit proposals
Academic and Non-Profit level - Free
• Final Specifications and enablement
• Workgroup participation and voting

Current Members
20
Strategic Membership level
Contributor Membership level
Academic Membership Level
Observing Membership Level

Cross Industry Collaboration and Innovation
21
OpenCAPI Protocol
Welcoming new members in all areas of the ecosystem
Systems and Software
Accelerator SolutionsSW
Research &Academic
Products and Services
Deployment
SOC

OpenCAPI Consortium Next Steps
JOIN TODAY!
www.opencapi.org
Come see us in the Exhibit Hall
OpenCApI BOOth….
5







![Advanced Material Technology±MT[0-33-3].pdf · Material Technology Technology. Advanced Material Technology Advanced Material Technology. 3.4-16. Advanced Material Technology. Advanced](https://img.dokumen.tips/doc/110x75/5ebad08215a94a1265211c82/advanced-material-mt0-33-3pdf-material-technology-technology-advanced-material.jpg)





















