Embed Size (px)
Citation preview

One Vector is Not Enough:Entity-Augmented Distributed Semantics for Discourse Relations
Yangfeng Ji and Jacob EisensteinSchool of Interactive ComputingGeorgia Institute of Technology
{jiyfeng, jacobe}@gatech.edu
Abstract
Discourse relations bind smaller linguisticunits into coherent texts. Automaticallyidentifying discourse relations is difficult,because it requires understanding the se-mantics of the linked arguments. A moresubtle challenge is that it is not enough torepresent the meaning of each argumentof a discourse relation, because the rela-tion may depend on links between lower-level components, such as entity mentions.Our solution computes distributed mean-ing representations for each discourse ar-gument by composition up the syntacticparse tree. We also perform a downwardcompositional pass to capture the mean-ing of coreferent entity mentions. Implicitdiscourse relations are then predicted fromthese two representations, obtaining sub-stantial improvements on the Penn Dis-course Treebank.
1 Introduction
The high-level organization of text can be char-acterized in terms of discourse relations betweenadjacent spans of text (Knott, 1996; Mann, 1984;Webber et al., 1999). Identifying these relationshas been shown to be relevant to tasks such assummarization (Louis et al., 2010a; Yoshida et al.,2014), sentiment analysis (Somasundaran et al.,2009), coherence evaluation (Lin et al., 2011), andquestion answering (Jansen et al., 2014). Whilethe Penn Discourse Treebank (PDTB) now pro-vides a large dataset annotated for discourse re-lations (Prasad et al., 2008), the automatic identi-fication of implicit relations is a difficult task, withstate-of-the-art performance at roughly 40% (Linet al., 2009).
One reason for this poor performance is that dis-course relations are rooted in semantics (Forbes-
u(`)0
Bob u(`)1
gave u(`)2
Tina u(`)3
the burger
u(r)0
She u(r)1
was hungry
(a) The distributed representations of burger and hungryare propagated up the parse tree, clarifying the implicitdiscourse relation between u(`)
0 and u(r)0 .
d(`)0
Bob d(`)1
gave d(`)2
Tina u(`)3
the burger
d(r)0
She u(r)1
was hungry
(b) Distributed representations for the coreferent men-tions Tina and she are computed from the parent and sib-ling nodes.
Figure 1: Distributed representations are com-puted through composition over the parse.
Riley et al., 2006), which can be difficult to re-cover from surface level features. Consider theimplicit discourse relation between the followingtwo sentences (also shown in Figure 1a):
(1) Bob gave Tina the burger.She was hungry.
While a connector like because seems appropriatehere, there is little surface information to signalthis relationship, unless the model has managed tolearn a bilexical relationship between burger andhungry. Learning all such relationships from an-notated data — including the relationship of hun-gry to knish, pierogie, pupusa etc — would requirefar more data than can possibly be annotated.

hungry
burger
Bob Tina
gave
shewas
thehe
Figure 2: t-SNE visualization (van der Maatenand Hinton, 2008) of word representations in thePDTB corpus.
We address this issue by applying adiscriminatively-trained model of composi-tional distributed semantics to discourse relationclassification (Socher et al., 2013; Baroni et al.,2014a). The meaning of each discourse argumentis represented as a vector (Turney and Pantel,2010), which is computed through a series ofbottom-up compositional operations over the syn-tactic parse tree. The discourse relation can thenbe predicted as a bilinear combination of thesevector representations. Both the prediction matrixand the compositional operator are trained in asupervised large-margin framework (Socher et al.,2011), ensuring that the learned compositionaloperation produces semantic representationsthat are useful for discourse. We show thatwhen combined with a small number of surfacefeatures, this approach outperforms prior work onthe classification of implicit discourse relations inthe PDTB.
Despite these positive results, we argue thatbottom-up vector-based representations of dis-course arguments are insufficient to capture theirrelations. To see why, consider what happens ifwe make a tiny change to example (1):
(2) Bob gave Tina the burger.He was hungry.
After changing the subject of the second sen-tence to Bob, the connective “because” no longerseems appropriate; a contrastive connector like al-though is preferred. But despite the radical dif-ference in meaning, the bottom-up distributed rep-resentation of the second sentence will be almostunchanged: the syntactic structure remains iden-tical, and the words he and she have very sim-ilar word representations (see Figure 2). If we
reduce each discourse argument span to a singlevector, built from the elements in the argument it-self, we cannot possibly capture the ways that dis-course relations are signaled by entities and theirroles (Cristea et al., 1998; Louis et al., 2010b).As Mooney (2014) puts it, “you can’t cram themeaning of a whole %&!$# sentence into a single$&!#* vector!”
We address this issue by computing vector rep-resentations not only for each discourse argu-ment, but also for each coreferent entity men-tion. These representations are meant to capturethe role played by the entity in the text, and sothey must take the entire span of text into account.We compute entity-role representations using afeed-forward compositional model, which com-bines “upward” and “downward” passes throughthe syntactic structure, shown in Figure 1b. In theexample, the downward representations for Tinaand she are computed from a combination of theparent and sibling nodes in the binarized parsetree. Representations for these coreferent men-tions are then combined in a bilinear product, andhelp to predict the implicit discourse relation. Inexample (2), we resolve he to Bob, and combinetheir vector representations instead, yielding a dif-ferent prediction about the discourse relation.
Our overall approach combines surface fea-tures, distributed representations of discourse ar-guments, and distributed representations of entitymentions. It achieves a 4% improvement in ac-curacy over the best previous work (Lin et al.,2009) on multiclass discourse relation classifica-tion, and also outperforms more recent work onbinary classification. The novel entity-augmenteddistributed representation improves accuracy overthe “upward” compositional model, showing theimportance of representing the meaning of coref-erent entity mentions.
2 Entity augmented distributedsemantics
We now formally define our approach to entity-augmented distributed semantics, using the nota-tion shown in Table 1. For clarity of exposition,we focus on discourse relations between pairs ofsentences. The extension to non-sentence argu-ments is discussed in Section 5.

Notation Explanation
`(i), r(i) left and right children of iρ(i), s(i) parent and sibling of iA(m,n) set of aligned entities between argu-
ments m and nY set of discourse relationsy∗ gold discourse relationψ(y) decision functionu upward vectord downward vectorAy classification parameter associated with
upward vectorsBy classification parameter associated with
downward vectorsU composition operator in upward com-
position procedureV composition operator in downward
composition procedureL(θ) objective function
Table 1: Table of notation
2.1 Upward pass: argument semanticsDistributed representations for discourse argu-ments are computed in a feed-forward “upward”pass: each non-terminal in the binarized syntacticparse tree has a K-dimensional vector represen-tation that is computed from the representations ofits children, bottoming out in pre-trained represen-tations of individual words.
We follow the Recursive Neural Network(RNN) model of Socher et al. (2011). For a givenparent node i, we denote the left child as `(i), andthe right child as r(i); we compose their represen-tations to obtain,
ui = tanh(U[u`(i);ur(i)]
), (1)
where tanh (·) is the element-wise hyperbolic tan-gent function (Pascanu et al., 2012), and U ∈RK×2K is the upward composition matrix. We ap-ply this compositional procedure from the bottomup, ultimately obtaining the argument-level repre-sentation u0. The base case is found at the leavesof the tree, which are set equal to pre-trained wordvector representations. For example, in the secondsentence of Figure 1, we combine the word repre-sentations of was and hungry to obtain u(r)
1 , andthen combine u(r)
1 with the word representation ofshe to obtain u(r)
0 . Note that the upward pass isfeedforward, meaning that there are no cycles andall nodes can be computed in linear time.
2.2 Downward pass: entity semanticsAs seen in the contrast between Examples 1 and 2,a model that uses a bottom-up vector representa-
tion for each discourse argument would find lit-tle to distinguish between she was hungry and hewas hungry. It would therefore almost certainlyfail to identify the correct discourse relation for atleast one of these cases, which requires trackingthe roles played by the entities that are coreferentin each pair of sentences. To address this issue,we augment the representation of each argumentwith additional vectors, representing the seman-tics of the role played by each coreferent entityin each argument. For example, in (1a), Tina gotthe burger, and in (1b), she was hungry. Ratherthan represent this information in a logical form— which would require robust parsing to a logi-cal representation — we represent it through addi-tional distributed vectors.
The role of a constituent i can be viewed as acombination of information from two neighboringnodes in the parse tree: its parent ρ(i), and its sib-ling s(i). We can make a downward pass, comput-ing the downward vector di from the downwardvector of the parent dρ(i), and the upward vectorof the sibling us(i):
di = tanh(V[dρ(i);us(i)]
), (2)
where V ∈ RK×2K is the downward compositionmatrix. The base case of this recursive procedureoccurs at the root of the parse tree, which is setequal to the upward representation, d0 , u0. Thisprocedure is illustrated in Figure 1b: for Tina, theparent node is d(`)2 , and the sibling is u(`)
3 .This up-down compositional algorithm propa-
gates sentence-level distributed semantics back toentity mentions. The representation of each men-tion’s role in the sentence is based on the corre-sponding role of the parent node in the parse tree,and on the internal meaning representation of thesibling node, which is computed by upward com-position. Note that this algorithm is designed tomaintain the feedforward nature of the neural net-work, so that we can efficiently compute all nodeswithout iterating. Each downward node di influ-ences only other downward nodes dj where j > i,meaning that the downward pass is feedforward.The upward node is also feedforward: each up-ward node ui influences only other upward nodesuj where j < i. Since the upward and down-ward passes are each feedforward, and the down-ward nodes do not influence any upward nodes,the combined up-down network is also feedfor-ward. This ensures that we can efficiently com-

pute all ui and di in time that is linear in thelength of the input. In Section 7.2, we compareour approach with recent related work on alterna-tive two-pass distributed compositional models.
Connection to the inside-outside algorithmIn the inside-outside algorithm for computingmarginal probabilities in a probabilistic context-free grammar (Lari and Young, 1990), the insidescores are constructed in a bottom-up fashion, likeour upward nodes; the outside score for node i isconstructed from a product of the outside scoreof the parent ρ(i) and the inside score of the sib-ling s(i), like our downward nodes. The stan-dard inside-outside algorithm sums over all pos-sible parse trees, but since the parse tree is ob-served in our case, a closer analogy would be tothe constrained version of the inside-outside algo-rithm for latent variable grammars (Petrov et al.,2006). Cohen et al. (2014) describe a tensor for-mulation of the constrained inside-outside algo-rithm; similarly, we could compute the downwardvectors by a tensor contraction of the parent andsibling vectors (Smolensky, 1990; Socher et al.,2014). However, this would involve K3 parame-ters, rather than the K2 parameters in our matrix-vector composition.
3 Predicting discourse relations
To predict the discourse relation between an argu-ment pair (m,n), the decision function is a sum ofbilinear products,
ψ(y) = (u(m)0 )>Ayu
(n)0
+∑
i,j∈A(m,n)
(d(m)i )>Byd
(n)j + by,
(3)
where Ay ∈ RK×K and By ∈ RK×K are the clas-sification parameters for relation y. A scalar by isused as the bias term for relation y, andA(m,n) isthe set of coreferent entity mentions shared by theargument pair (m,n). The decision value ψ(y) ofrelation y is therefore based on the upward vec-tors at the root, u(m)
0 and u(n)0 , as well as on
the downward vectors for each pair of aligned en-tity mentions. For the cases where there are nocoreferent entity mentions between two sentences,A(m,n) = ∅, the classification model considersonly the upward vectors at the root.
To avoid overfitting, we apply a low-dimensional approximation to each Ay,
Ay = ay,1a>y,2 + diag(ay,3). (4)
The same approximation is also applied to eachBy, reducing the number of classification parame-ters from 2×#|Y| ×K2 to 2×#|Y| × 3K.
Surface features Prior work has identified anumber of useful surface-level features (Lin et al.,2009), and the classification model can easily beextended to include them. Defining φ(m,n) as thevector of surface features extracted from the ar-gument pair (m,n), the corresponding decisionfunction is modified as,
ψ(y) = (u(m)0 )>Ayu
(n)0 +
∑i,j∈A(m,n)
(d(m)i )>Byd
(n)j
+ β>y φ(m,n) + by,
(5)where βy is the classification weight on surfacefeatures for relation y. We describe these featuresin Section 5.
4 Large-margin learning framework
There are two sets of parameters to belearned: the classification parametersθclass = {Ay,By,βy, by}y∈Y , and the com-position parameters θcomp = {U,V}. We usepre-trained word representations, and do notupdate them. While prior work shows that it canbe advantageous to retrain word representationsfor discourse analysis (Ji and Eisenstein, 2014),our preliminary experiments found that updatingthe word representations led to serious overfittingin this model.
Following Socher et al. (2011), we definea large margin objective, and use backpropa-gation to learn all parameters of the networkjointly (Goller and Kuchler, 1996). Learning isperformed using stochastic gradient descent (Bot-tou, 1998), so we present the learning problem fora single argument pair (m,n) with the gold dis-course relation y∗. The objective function for thistraining example is a regularized hinge loss,
L(θ) =∑
y′:y′ 6=y∗max
(0, 1− ψ(y∗) + ψ(y′)
)+ λ||θ||22
(6)where θ = θclass ∪ θcomp is the set of learningparameters. The regularization term λ||θ||22 indi-cates that the squared values of all parameters arepenalized by λ; this corresponds to penalizing the

squared Frobenius norm for the matrix parameters,and the squared Euclidean norm for the vector pa-rameters.
4.1 Learning the classification parametersIn Equation 6, L(θ) = 0, if for every y′ 6= y∗,ψ(y∗) − ψ(y′) ≥ 1 holds. Otherwise, the losswill be caused by any y′, where y′ 6= y∗ andψ(y∗) − ψ(y′) < 1. The gradient for the classi-fication parameters therefore depends on the mar-gin value between gold label and all other labels.Specifically, taking one component of Ay, ay,1,as an example, the derivative of the objective fory = y∗ is
∂L(θ)∂ay∗,1
= −∑
y′:y′ 6=y∗δ(ψ(y∗)−ψ(y′)<1) · u(m)
0 , (7)
where δ(·) is the delta function. The derivative fory′ 6= y∗ is
∂L(θ)∂ay′,1
= δ(ψ(y∗)−ψ(y′)<1) · u(m)0 (8)
During learning, the updating rule for Ay is
Ay ← Ay − η(∂L(θ)∂Ay
+ λAy) (9)
where η is the learning rate.Similarly, we can obtain the gradient in-
formation and updating rules for parameters{By,βy, by}y∈Y .
4.2 Learning the composition parametersThere are two composition matrices U and V,corresponding to the upward and downward com-position procedures respectively. Taking the up-ward composition parameter U as an example, thederivative of L(θ) with respect to U is
∂L(θ)∂U
=∑
y′:y′ 6=y∗δ(ψ(y∗)−ψ(y′)<1)
·(∂ψ(y′)
∂U− ∂ψ(y∗)
∂U
) (10)
As with the classification parameters, the deriva-tive depends on the margin between y′ and y∗.
For every y ∈ Y , we have the unified derivativeform,
∂ψ(y)
∂U=∂ψ(y)
∂u(m)0
∂u(m)0
∂U+∂ψ(y)
∂u(n)0
∂u(n)0
∂U
+∑
i,j∈A(m,n)
∂ψ(y)
∂d(m)i
∂d(m)i
∂U
+∑
i,j∈A(m,n)
∂ψ(y)
∂d(n)j
∂d(n)j
∂U,
(11)
The gradient of U also depends on the gradient ofψ(y) with respect to every downward vector d, asshown in the last two terms in Equation 11. This isbecause the computation of each downward vectordi includes the upward vector of the sibling node,us(i), as shown in Equation 2. For an example, seethe construction of the downward vectors for Tinaand she in Figure 1b.
The partial derivatives of the decision functionin Equation 11 are computed as,
∂ψ(y)
∂u(m)0
= Ayu(n)0 ,
∂ψ(y)
∂u(n)0
= A>y u(m)0 ,
∂ψ(y)
∂d(m)i
= Byd(n)j ,
∂ψ(y)
∂d(n)i
= B>y d(m)j , 〈i, j〉 ∈ A.
(12)
The partial derivatives of the upward and down-ward vectors with respect to the upward composi-tional operator are computed as,
∂u(m)i
∂U=
∑u
(m)k∈T (u
(m)i )
∂u(m)i
∂u(m)k
(u(m)k )> (13)
and
∂d(m)i
∂U=
∑u
(m)k∈T (d
(m)i )
∂d(m)i
∂u(m)k
(u(m)k )>, (14)
where T (um) is the set of all nodes in the upwardcomposition model that help to generate um. Forexample, in Figure 1a, the set T (u(`)
2 ) includesu(`)3 and the word representations for Tina, the,
and burger. The set T (dm,i) includes all the up-ward nodes involved in the downward composi-tion model generating d(m)
i . For example, in Fig-ure 1b, the set T (d(r)she) includes u(r)
1 and the wordrepresentations for was and hungry.
The derivative of the objective with respect tothe downward compositional operator V is com-puted in a similar fashion, but it depends only onthe downward nodes, d(m)
i .
5 Implementation
Our implementation will be made available onlineafter review. Training on the PDTB takes roughlythree hours to converge.1 Convergence is fasterif the surface feature weights β are trained sepa-rately first. We now describe some additional de-tails of our implementation.
1On Intel(R) Xeon(R) CPU 2.20GHz without parallelcomputing.

Learning During learning, we used AdaGrad(Duchi et al., 2011) to tune the learning rate ineach iteration. To avoid the exploding gradientproblem (Bengio et al., 1994), we used the normclipping trick proposed by Pascanu et al. (2012),fixing the norm threshold at τ = 5.0.
Hyperparameters Our model includes threetunable hyperparameters: the latent dimensionK for the distributed representation, the regu-larization parameter λ, and the initial learningrate η. All hyperparameters are tuned by ran-domly selecting a development set of 20% ofthe training data. We consider the values K ∈{20, 30, 40, 50, 60} for the latent dimensionality,λ ∈ {0.0002, 0.002, 0.02, 0.2} for the regular-ization (on each training instance), and η ∈{0.01, 0.03, 0.05, 0.09} for the learning rate. Weassign separate regularizers and learning rates tothe upward composition model, downward com-position model, feature model and the classifica-tion model with composition vectors.
Initialization All the classification parametersare initialized to 0. For the composition param-eters, we follow Bengio (2012) and initialize Uand V with uniform random values drawn fromthe range [−
√6/2K,
√6/2K].
Word representations We trained a word2vecmodel (Mikolov et al., 2013) on the PDTB corpus,standardizing the induced representations to zero-mean, unit-variance (LeCun et al., 2012). Exper-iments with pre-trained GloVe word vector repre-sentations (Pennington et al., 2014) gave broadlysimilar results.
Syntactic structure Our model requires that thesyntactic structure for each argument is repre-sented as a binary tree. We run the Stanfordparser (Klein and Manning, 2003) to obtain con-stituent parse trees of each sentence in the PDTB,and binarize all resulting parse trees. Argumentspans in the Penn Discourse Treebank need not besentences or syntactic constituents: they can in-clude multiple sentences, non-constituent spans,and even discontinuous spans (Prasad et al., 2008).In all cases, we identify the syntactic subtreeswithin the argument span, and unify them in a rightbranching superstructure.
Coreference The impact of entity semantics ondiscourse relation detection is inherently limitedby two factors: (1) the frequency with which the
Dataset Annotation Training (%) Test (%)
1. PDTB Automatic 27.4 29.12. PDTB∩Onto Automatic 26.2 32.33. PDTB∩Onto Gold 40.9 49.3
Table 2: Proportion of relations with coreferententities, according to automatic coreference reso-lution and gold coreference annotation.
arguments of a discourse relation share corefer-ent entity mentions, and (2) the ability of au-tomated coreference resolution systems to detectthese coreferent mentions. To extract entities andtheir mentions from the PDTB, we ran the Berke-ley coreference system (Durrett and Klein, 2013)on each document. For each argument pair, wesimply ignore the non-corefential entity mentions.Line 1 in Table 2 shows the proportion of the in-stances with shared entities in the PDTB trainingand test data, as detected by the Berkeley system.As the system does not detect coreferent mentionsin more than 70% of the cases, the performanceimprovements offered by distributed entity seman-tics are therefore limited. To determine whetherthis low rate of coreference is an intrinsic prop-erty of the data, or whether it is due to the qual-ity of state-of-the-art coreference resolution, wealso consider the gold coreference annotations inthe OntoNotes corpus (Pradhan et al., 2007), aportion of which intersects with the PDTB (597documents). Lines 2 and 3 of Table 2 give thestatistics for automatic and gold coreference onthis intersection. These results indicate that withperfect coreference resolution, the applicability ofdistributed entity semantics would reach 40% ofthe training set and nearly 50% of the test set.Thus, improvements in coreference resolution canbe expected to yield further improvements in theeffectiveness of distributed entity semantics fordiscourse relation detection.
Additional features We supplement our classi-fication model using additional surface featuresproposed by Lin et al. (2009). These include fourcategories: word pair features, constituent parsefeatures, dependency parse features, and contex-tual features. As done in this prior work, we usemutual information to select features in the firstthree categories, obtaining 500 word pair features,100 constituent features, and 100 dependency fea-tures. In addition, Rutherford and Xue (2014) dis-covered that replacing word pair with their Brown

cluster assignments could give further improve-ments. In our implementation, we used the Brownword clusters provided by Turian et al. (2010), inwhich words from the Reuters Corpus (RCV1) aregrouped into 3,200 clusters. The feature selectionmethod of Lin et al. (2009) was then used to obtaina set of 600 Brown cluster features.
6 Experiments
We evaluate our approach on the Penn DiscourseTreebank (PDTB; Prasad et al., 2008), which pro-vides a discourse level annotation over the WallStreet Journal corpus. In the PDTB, each dis-course relation is annotated between two argu-ment spans. Identifying the argument spans of dis-course relations is a challenging task (Lin et al.,2012), which we do not attempt here; instead, weuse gold argument spans, as in most of the rele-vant prior work. PDTB relations may be explicit,meaning that they are signaled by discourse con-nectives (e.g., because); alternatively, they may beimplicit, meaning that the connective is absent.Pitler et al. (2008) show that most explicit connec-tives are unambiguous, so we focus on the prob-lem of classifying implicit discourse relations.
The PDTB provides a three-level hierarchy ofdiscourse relations. The first level consists offour major relation classes: TEMPORAL, CON-TINGENCY, COMPARISON and EXPANSION. Foreach class, a second level of types is defined toprovide finer semantic or pragmatic distinctions;there are sixteen such relation types. A third levelof subtypes is defined for only some types, speci-fying the semantic contribution of each argument.
There are two main approaches to evaluatingimplicit discourse relation classification. Multi-class classification requires identifying the dis-course relation from all possible choices. Thistask was explored by Lin et al. (2009), who fo-cus on second-level discourse relations. More re-cent work has emphasized binary classification,where the goal is to build and evaluate separate“one-versus-all” classifiers for each discourse re-lation (Pitler et al., 2009; Park and Cardie, 2012;Biran and McKeown, 2013). We primarily focuson multiclass classification, because it is more rel-evant for the ultimate goal of building a PDTBparser; however, to compare with recent priorwork, we also evaluate on binary relation classi-fication.
6.1 Multiclass classificationOur main evaluation involves predicting the cor-rect discourse relation for each argument pair,from among the second-level relation types. Thetraining and test set construction follows Lin et al.(2009) with a few changes:
• We use sections 2-20 of the PDTB as a train-ing set, sections 0-1 as a development set forparameter tuning, and sections 21-22 for test-ing.
• Five relation types have a combined total ofonly nine instances in the training set, and aretherefore excluded by Lin et al. (2009): CON-DITION, PRAGMATIC CONDITION, PRAG-MATIC CONTRAST, PRAGMATIC CONCES-SION and EXCEPTION. None of these rela-tions appear in the test or development data.We tried training with and without these rela-tion types in the training data, and found nodifference in the overall results.
• In the main multiclass experiment, we con-sider only the problem of distinguishing be-tween implicit relations. We perform an ad-ditional, reviewer-recommended experimentthat distinguishes implicit relations fromentity-based coherence relations, labeled EN-TREL. See below for more detail.
• Roughly 2% of the implicit relations in thePDTB are annotated with more than one type.During training, each argument pair that isannotated with two relation types is consid-ered as two training instances, each with onerelation type. During testing, if the classifierassigns either of the two types, it is consid-ered to be correct.
6.1.1 Baseline and competitive systemsMost common class The most common class is
CAUSE, accounting for 26.03% of the im-plicit discourse relations in the PDTB test set.
Additive word representations Blacoe and Lap-ata (2012) show that simply adding word vec-tors can perform surprisingly well at assess-ing the meaning of short phrases. In thisbaseline, we represent each argument as asum of its word representations, and estimatea bilinear prediction matrix.
Lin et al. (2009) To our knowledge, the best pub-lished accuracy on multiclass classification

Model +Entity semantics +Surface features K Accuracy(%)
Baseline models1. Most common class 26.032. Additive word representations 50 28.73
Prior work3. (Lin et al., 2009) X 40.2
Our work4. Surface features + Brown clusters X 40.66
5. DISCO2 50 36.986. DISCO2 X 50 37.63
7. DISCO2 X 50 43.75∗
8. DISCO2 X X 50 44.59∗∗ signficantly better than lines 3 and 4 with p < 0.05
Table 3: Experimental results on multiclass classification of level-2 discourse relations. The results ofLin et al. (2009) are shown in line 3. We reimplemented this system and added the Brown cluster featuresof Rutherford and Xue (2014), with results shown in line 4.
of second-level implicit discourse relations isfrom Lin et al. (2009), who apply feature se-lection to obtain a set of lexical and syntacticfeatures over the arguments.
Surface features + Brown clusters To get amore precise comparison, we reimplementedthe system of Lin et al. (2009). The majordifferences are (1) we apply our onlinelearning framework, rather than batch clas-sification, and (2) we include the Browncluster features described in Section 5 andoriginally proposed by Rutherford and Xue(2014).
Compositional Finally, we report results for themethod described in this paper. Since it isa distributional compositional approach todiscourse relations, we name it DISCO2.
6.1.2 Results
Table 3 presents results for multiclass identifica-tion of second-level PDTB relations. As shownin lines 7 and 8, DISCO2 outperforms both base-line systems and the prior state-of-the-art (line 3).The strongest performance is obtained by includ-ing the entity distributed semantics, with a 4.4%improvement over the accuracy reported by Lin etal. (2009) (p < .05 by a binomial test). We alsoobtain a significant improvement over the Sur-face Feature + Brown Cluster model. Becausewe have reimplemented this system, we can ob-
serve individual predictions, and can therefore usethe sign test for statistical significance, again find-ing that DISCO2 is significantly better (p < .05).Even without entity semantics, DISCO2 signifi-cantly outperforms these competitive models fromprior work. However, the surface features remainimportant, as the performance of DISCO2 is sub-stantially worse when only the distributed repre-sentation is included. The latent dimension K ischosen from a development set (see Section 5), asshown in Figure 3.
The multiclass evaluation introduced by Lin etal. (2009) focused on classification of implicit re-lations. Another question is whether it is possi-ble to identify entity-based coherence, annotatedin the PDTB as ENTREL, which is when a sharedentity is the only meaningful relation that holdsbetween two sentences (Prasad et al., 2008). Assuggested by a reviewer, we add ENTREL to theset of possible relations, and perform an additionalevaluation. Since this setting has not previouslybeen considered, we cannot evaluate against pub-lished results; instead, we retrain and evaluate thefollowing models:
• the surface feature baseline with Brown clus-ters, corresponding to line 4 of Table 3;
• DISCO2 with surface features but without en-tity semantics, corresponding to line 7 of Ta-ble 3;
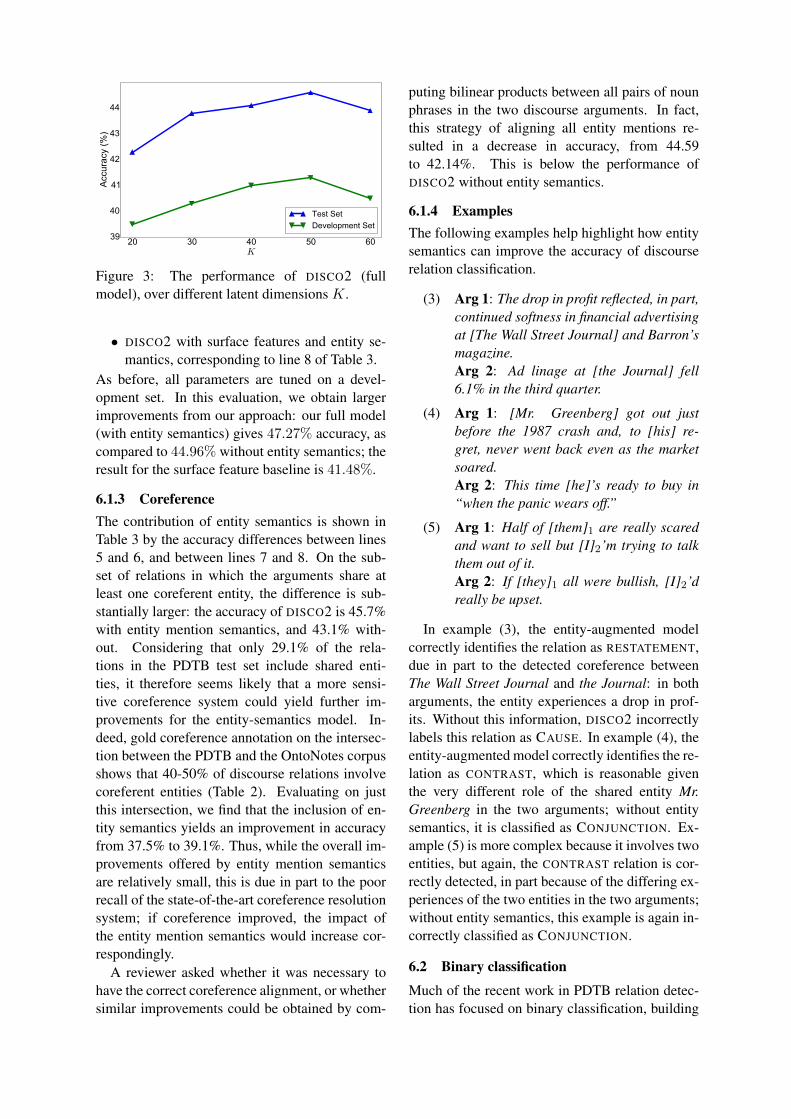
20 30 40 50 60K
39
40
41
42
43
44Ac
cura
cy (%
)
Test SetDevelopment Set
Figure 3: The performance of DISCO2 (fullmodel), over different latent dimensions K.
• DISCO2 with surface features and entity se-mantics, corresponding to line 8 of Table 3.
As before, all parameters are tuned on a devel-opment set. In this evaluation, we obtain largerimprovements from our approach: our full model(with entity semantics) gives 47.27% accuracy, ascompared to 44.96% without entity semantics; theresult for the surface feature baseline is 41.48%.
6.1.3 CoreferenceThe contribution of entity semantics is shown inTable 3 by the accuracy differences between lines5 and 6, and between lines 7 and 8. On the sub-set of relations in which the arguments share atleast one coreferent entity, the difference is sub-stantially larger: the accuracy of DISCO2 is 45.7%with entity mention semantics, and 43.1% with-out. Considering that only 29.1% of the rela-tions in the PDTB test set include shared enti-ties, it therefore seems likely that a more sensi-tive coreference system could yield further im-provements for the entity-semantics model. In-deed, gold coreference annotation on the intersec-tion between the PDTB and the OntoNotes corpusshows that 40-50% of discourse relations involvecoreferent entities (Table 2). Evaluating on justthis intersection, we find that the inclusion of en-tity semantics yields an improvement in accuracyfrom 37.5% to 39.1%. Thus, while the overall im-provements offered by entity mention semanticsare relatively small, this is due in part to the poorrecall of the state-of-the-art coreference resolutionsystem; if coreference improved, the impact ofthe entity mention semantics would increase cor-respondingly.
A reviewer asked whether it was necessary tohave the correct coreference alignment, or whethersimilar improvements could be obtained by com-
puting bilinear products between all pairs of nounphrases in the two discourse arguments. In fact,this strategy of aligning all entity mentions re-sulted in a decrease in accuracy, from 44.59to 42.14%. This is below the performance ofDISCO2 without entity semantics.
6.1.4 ExamplesThe following examples help highlight how entitysemantics can improve the accuracy of discourserelation classification.
(3) Arg 1: The drop in profit reflected, in part,continued softness in financial advertisingat [The Wall Street Journal] and Barron’smagazine.Arg 2: Ad linage at [the Journal] fell6.1% in the third quarter.
(4) Arg 1: [Mr. Greenberg] got out justbefore the 1987 crash and, to [his] re-gret, never went back even as the marketsoared.Arg 2: This time [he]’s ready to buy in“when the panic wears off.”
(5) Arg 1: Half of [them]1 are really scaredand want to sell but [I]2’m trying to talkthem out of it.Arg 2: If [they]1 all were bullish, [I]2’dreally be upset.
In example (3), the entity-augmented modelcorrectly identifies the relation as RESTATEMENT,due in part to the detected coreference betweenThe Wall Street Journal and the Journal: in botharguments, the entity experiences a drop in prof-its. Without this information, DISCO2 incorrectlylabels this relation as CAUSE. In example (4), theentity-augmented model correctly identifies the re-lation as CONTRAST, which is reasonable giventhe very different role of the shared entity Mr.Greenberg in the two arguments; without entitysemantics, it is classified as CONJUNCTION. Ex-ample (5) is more complex because it involves twoentities, but again, the CONTRAST relation is cor-rectly detected, in part because of the differing ex-periences of the two entities in the two arguments;without entity semantics, this example is again in-correctly classified as CONJUNCTION.
6.2 Binary classification
Much of the recent work in PDTB relation detec-tion has focused on binary classification, building

and evaluating separate one-versus-all classifiersfor each relation type (Pitler et al., 2009; Park andCardie, 2012; Biran and McKeown, 2013). Thiswork has focused on recognition of the four first-level relations, grouping ENTREL with the EX-PANSION relation. We follow this evaluation ap-proach as closely as possible, using sections 2-20of the PDTB as a training set, sections 0-1 as a de-velopment set for parameter tuning, and sections21-22 for testing.
6.2.1 Classification method
We apply DISCO2 with entity-augmented seman-tics and the surface features listed in Section 5;this corresponds to the system reported in line 8 ofTable 3. However, instead of employing a multi-class classifier for all four relations, we train fourbinary classifiers, one for each first-level discourserelation. We optimize the hyperparametersK,λ, ηseparately for each classifier (see Section 5 for de-tails), by performing a grid search to optimize theF-measure on the development data. FollowingPitler et al. (2009), we obtain a balanced trainingset by resampling training instances in each classuntil the number of positive and negative instancesare equal.
6.2.2 Competitive systems
We compare against the published results fromseveral competitive systems, focusing on systemswhich use the predominant training / test split,with sections 2-20 for training and 21-22 for test-ing. This means we cannot compare with recentwork from Li and Nenkova (2014), who use sec-tions 20-24 for testing.
Pitler et al. (2009) present a classification modelusing linguistically-informed features, suchas polarity tags and Levin verb classes.
Zhou et al. (2010) predict discourse connectivewords, and then use these predicted connec-tives as features in a downstream model topredict relations.
Park and Cardie (2012) showed that the perfor-mance on each relation can be improved byselecting a locally-optimal feature set.
Biran and McKeown (2013) reweight word pairfeatures using distributional statistics fromthe Gigaword corpus, obtaining denser ag-gregated score features.
6.2.3 Experimental resultsTable 4 presents the performance of theDISCO2 model and the published results ofcompetitive systems. DISCO2 achieves the bestresults on most metrics, achieving F-measureimprovements of 4.14% on COMPARISON, 2.96%on CONTINGENCY, 0.8% on EXPANSION, and1.06% on TEMPORAL. These results are attainedwithout performing per-relation feature selection,as in prior work. While computing significanceover F-measures is challenging, we can computestatistical significance on the accuracy results byusing the binomial test. We find that DISCO2 issignificantly more accurate than all other systemson the CONTINGENCY and TEMPORAL relationsp � .001, not significantly more accurate onthe EXPANSION relation, and significantly lessaccurate than the Park and Cardie (2012) systemon the COMPARISON relation at p� .001.
7 Related Work
This paper draws on previous work in discourserelation detection and compositional distributedsemantics.
7.1 Discourse relations
Many models of discourse structure focus on re-lations between spans of text (Knott, 1996), in-cluding rhetorical structure theory (RST; Mannand Thompson, 1988), lexicalized tree-adjoininggrammar for discourse (D-LTAG; Webber, 2004),and even centering theory (Grosz et al., 1995),which posits relations such as CONTINUATION
and SMOOTH SHIFT between adjacent spans. Con-sequently, the automatic identification of dis-course relations has long been considered a keycomponent of discourse parsing (Marcu, 1999).We work within the D-LTAG framework, as an-notated in the Penn Discourse Treebank (PDTB;Prasad et al., 2008), with the task of identifyingimplicit discourse relations. The seminal work inthis task is from Pitler et al. (2009) and Lin etal. (2009). Pitler et al. (2009) focus on lexicalfeatures, including linguistically motivated wordgroupings such as Levin verb classes and polaritytags. Lin et al. (2009) identify four different fea-ture categories, based on the raw text, the context,and syntactic parse trees; the same feature sets areused in later work on end-to-end discourse pars-ing (Lin et al., 2012), which also includes compo-nents for identifying argument spans. Subsequent

COMPARISON CONTINGENCY EXPANSION TEMPORAL
F1 Acc F1 Acc F1 Acc F1 Acc
Competitive systems1. (Pitler et al., 2009) 21.96 56.59 47.13 67.30 76.42 63.62 16.76 63.492. (Zhou et al., 2010) 31.79 58.22 47.16 48.96 70.11 54.54 20.30 55.483. (Park and Cardie, 2012) 31.32 74.66 49.82 72.09 79.22 69.14 26.57 79.324. (Biran and McKeown, 2013) 25.40 63.36 46.94 68.09 75.87 62.84 20.23 68.35Our work5. DISCO2 35.93 70.27 52.78 76.95 80.02 69.80 27.63 87.11
Table 4: Evaluation on the first-level discourse relation identification. The results of the competitivesystems are reprinted.
research has explored feature selection (Park andCardie, 2012; Lin et al., 2012), as well as combat-ing feature sparsity by aggregating features (Biranand McKeown, 2013). Our model includes sur-face features that are based on a reimplementationof the work of Lin et al. (2009), because they alsoundertake the task of multiclass relation classifica-tion; however, the techniques introduced in morerecent research may also be applicable and com-plementary to the distributed representation thatconstitutes the central contribution of this paper;if so, applying these techniques could further im-prove performance.
Our contribution of entity-augmented dis-tributed semantics is motivated by the intuitionthat entities play a central role in discourse struc-ture. Centering theory draws heavily on referringexpressions to entities over the discourse (Groszet al., 1995; Barzilay and Lapata, 2008); similarideas have been extended to rhetorical structuretheory (Corston-Oliver, 1998; Cristea et al., 1998).In the specific case of PDTB relations, Louis etal. (2010b) explore a number of entity-based fea-tures, including grammatical role, syntactic real-ization, and information status. Despite the solidlinguistic foundation for these features, they areshown to contribute little in comparison with moretraditional word-pair features. This suggests thatsyntax and information status may not be enough,and that it is crucial to capture the semanticsof each entity’s role in the discourse. Our ap-proach does this by propagating distributed se-mantics from throughout the sentence into the en-tity span, using our up-down compositional proce-dure. In recent work, Rutherford and Xue (2014)take an alternative approach, using features thatrepresent whether coreferent mentions are argu-
ments of similar predicates (using Brown clus-ters); they obtain nearly a 1% improvement onCONTINGENCY relations but no significant im-provement on the other three first-level relationtypes. Finally, Kehler and Rohde (2013) show thatinformation also flows in the opposite direction,from discourse relations to coreference: in somecases, knowing the discourse relation is crucial toresolving pronoun ambiguity. Future work shouldtherefore consider joint models of discourse anal-ysis and coreference resolution.
7.2 Compositional distributed semantics
Distributional semantics begins with the hypothe-sis that words and phrases that tend to appear inthe same contexts have the same meaning (Firth,1957). The current renaissance of interest in dis-tributional and distributed semantics can be at-tributed in part to the application of discrimina-tive techniques, which emphasize predictive mod-els (Bengio et al., 2006; Baroni et al., 2014b),rather than context-counting and matrix factoriza-tion (Landauer et al., 1998; Turney and Pantel,2010). Recent work has made practical the idea ofpropagating distributed information through lin-guistic structures (Smolensky, 1990; Collobert etal., 2011). In such models, the distributed rep-resentations and compositional operators can befine-tuned by backpropagating supervision fromtask-specific labels, enabling accurate and fastmodels for a wide range of language technolo-gies (Socher et al., 2011; Socher et al., 2013; Chenand Manning, 2014).
Of particular relevance is recent work on two-pass procedures for distributed compositional se-mantics. Paulus et al. (2014) perform targeted sen-timent analysis by propagating information from

the sentence level back to child non-terminals inthe parse tree. Their compositional procedure isdifferent from ours: in their work, the “down-ward” meaning of each non-terminal is recon-structed from the upward and downward mean-ings of its parents. Irsoy and Cardie (2013) pro-pose an alternative two-pass procedure, where thedownward representation for a node is computedfrom the downward representation of its parent,and from its own upward representation. A keydifference in our approach is that the siblings in aproduction are more directly connected: the up-ward representation of a given node is used tocompute the downward representation of its sib-ling, similar to the inside-outside algorithm. Inthe models of Paulus et al. (2014) and Irsoy andCardie (2013), the connection between siblingsnodes is less direct, as it is channeled through therepresentation of the parent node. From this per-spective, the most closely related prior work isthe Inside-Outside Recursive Neural Network (Leand Zuidema, 2014), published shortly before thispaper was submitted. The compositional proce-dure in this paper is identical, although the ap-plication is quite different: rather than inducingdistributed representations of entity mentions, thegoal of this work is to support an infinite-ordergenerative model of dependency parsing. WhileLe and Zuidema apply this idea as a generativereranker within a supervised dependency parsingframework, we are interested to explore whetherit could be employed to do unsupervised syntacticanalysis, which could substitute for the supervisedsyntactic parser in our system.
The application of distributional and distributedsemantics to discourse includes the use of la-tent semantic analysis for text segmentation (Choiet al., 2001) and coherence assessment (Foltzet al., 1998), as well as paraphrase detectionby the factorization of matrices of distributionalcounts (Kauchak and Barzilay, 2006; Mihalcea etal., 2006). These approaches essentially computea distributional representation in advance, andthen use it alongside other features. In contrast,our approach follows more recent work in whichthe distributed representation is driven by supervi-sion from discourse annotations. For example, Jiand Eisenstein (2014) show that RST parsing canbe performed by learning task-specific word repre-sentations, which perform considerably better thangeneric word2vec representations (Mikolov et al.,
2013). Li et al. (2014) propose a recursive neuralnetwork approach to RST parsing, which is sim-ilar to the upward pass in our model, and Kalch-brenner and Blunsom (2013) show how a recurrentneural network can be used to identify dialogueacts. However, prior work has not applied theseideas to the classification of implicit relations inthe PDTB, and does not consider the role of en-tities. As we argue in the introduction, a singlevector representation is insufficiently expressive,because it obliterates the entity chains that help totie discourse together.
More generally, our entity-augmented dis-tributed representation can be viewed in the con-text of recent literature on combining distributedand formal semantics: by representing entities,we are taking a small step away from purelyvectorial representations, and towards more tra-ditional logical representations of meaning. Inthis sense, our approach is “bottom-up”, as wetry to add a small amount of logical formalismto distributed representations; other approachesare “top-down”, softening purely logical repre-sentations by using distributional clustering (Poonand Domingos, 2009; Lewis and Steedman, 2013)or Bayesian non-parametrics (Titov and Klemen-tiev, 2011) to obtain types for entities and rela-tions. Still more ambitious would be to imple-ment logical semantics within a distributed com-positional framework (Clark et al., 2011; Grefen-stette, 2013). At present, these combinations oflogical and distributed semantics have been ex-plored only at the sentence level. In generalizingsuch approaches to multi-sentence discourse, weargue that it will not be sufficient to compute dis-tributed representations of sentences: a multitudeof other elements, such as entities, will also haveto represented.
8 Conclusion
Discourse relations are determined by the mean-ing of their arguments, and progress on discourseparsing therefore requires computing representa-tions of the argument semantics. We presenta compositional method for inducing distributedrepresentations not only of discourse arguments,but also of the entities that thread through the dis-course. In this approach, semantic compositionis applied up the syntactic parse tree to inducethe argument-level representation, and then downthe parse tree to induce representations of entity

spans. Discourse arguments can then be com-pared in terms of their overall distributed represen-tation, as well as by the representations of coref-erent entity mentions. This enables the composi-tional operators to be learned by backpropagationfrom discourse annotations. In combination withtraditional surface features, this approach outper-forms previous work on classification of implicitdiscourse relations in the Penn Discourse Tree-bank. While the entity mention representationsoffer only a small improvement in overall perfor-mance, we show that this is limited by the recallof the coreference resolution system: when eval-uated on argument pairs for which coreference isdetected, the raw improvement from entity seman-tics is more than 2%. Future work will considerjoint models of discourse structure and corefer-ence, and consideration of coreference across theentire document. In the longer term, we hope to in-duce and exploit representations of other discourseelements, such as event coreference and shallowsemantics.
Acknowledgments This work was supported bya Google Faculty Research Award to the sec-ond author. Chris Dyer, Ray Mooney, and Bon-nie Webber provided helpful feedback, as did theanonymous reviewers and the editor. Thanks alsoto Te Rutherford, who both publicly released hiscode and helped us to use and understand it.
ReferencesMarco Baroni, Raffaella Bernardi, and Roberto Zam-
parelli. 2014a. Frege in space: A program forcompositional distributional semantics. LinguisticIssues in Language Technologies.
Marco Baroni, Georgiana Dinu, and GermanKruszewski. 2014b. Dont count, predict! asystematic comparison of context-counting vs.context-predicting semantic vectors. In Proceedingsof the Association for Computational Linguistics(ACL), Baltimore, MD.
Regina Barzilay and Mirella Lapata. 2008. Modelinglocal coherence: An Entity-Based approach. Com-putational Linguistics, 34(1):1–34, March.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.1994. Learning long-term dependencies with gra-dient descent is difficult. Neural Networks, IEEETransactions on, 5(2):157–166.
Yoshua Bengio, Holger Schwenk, Jean-SebastienSenecal, Frederic Morin, and Jean-Luc Gauvain.2006. Neural probabilistic language models. In
Innovations in Machine Learning, pages 137–186.Springer.
Yoshua Bengio. 2012. Practical recommendationsfor gradient-based training of deep architectures. InNeural Networks: Tricks of the Trade, pages 437–478. Springer.
Or Biran and Kathleen McKeown. 2013. Aggre-gated word pair features for implicit discourse re-lation disambiguation. In Proceedings of the Asso-ciation for Computational Linguistics (ACL), pages69–73, Sophia, Bulgaria.
William Blacoe and Mirella Lapata. 2012. A com-parison of vector-based representations for semanticcomposition. In Proceedings of Empirical Methodsfor Natural Language Processing (EMNLP), pages546–556.
Leon Bottou. 1998. Online learning and stochastic ap-proximations. On-line learning in neural networks,17:9.
Danqi Chen and Christopher D Manning. 2014. Afast and accurate dependency parser using neuralnetworks. In Proceedings of Empirical Methodsfor Natural Language Processing (EMNLP), pages740–750.
Freddy YY Choi, Peter Wiemer-Hastings, and JohannaMoore. 2001. Latent semantic analysis for text seg-mentation. In Proceedings of Empirical Methods forNatural Language Processing (EMNLP).
Stephen Clark, Bob Coecke, and MehrnooshSadrzadeh. 2011. Mathematical foundationsfor a compositional distributed model of meaning.Linguistic Analysis, 36(1-4):345–384.
Shay B Cohen, Karl Stratos, Michael Collins, Dean PFoster, and Lyle Ungar. 2014. Spectral learningof latent-variable PCFGs: Algorithms and samplecomplexity. Journal of Machine Learning Research,15:2399–2449.
R. Collobert, J. Weston, L. Bottou, M. Karlen,K. Kavukcuoglu, and P. Kuksa. 2011. Natural lan-guage processing (almost) from scratch. Journal ofMachine Learning Research, 12:2493–2537.
Simon Corston-Oliver. 1998. Beyond string matchingand cue phrases: Improving efficiency and coveragein discourse analysis. In The AAAI Spring Sympo-sium on Intelligent Text Summarization, pages 9–15.
Dan Cristea, Nancy Ide, and Laurent Romary. 1998.Veins theory: A model of global discourse cohe-sion and coherence. In Proceedings of the 36thAnnual Meeting of the Association for Computa-tional Linguistics and 17th International Conferenceon Computational Linguistics-Volume 1, pages 281–285. Association for Computational Linguistics.

John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. The Journal of Ma-chine Learning Research, 12:2121–2159.
Greg Durrett and Dan Klein. 2013. Easy victories anduphill battles in coreference resolution. In Proceed-ings of the Conference on Empirical Methods in Nat-ural Language Processing.
J. R. Firth. 1957. Papers in Linguistics 1934-1951.Oxford University Press.
Peter W Foltz, Walter Kintsch, and Thomas K Lan-dauer. 1998. The measurement of textual coherencewith latent semantic analysis. Discourse processes,25(2-3):285–307.
Katherine Forbes-Riley, Bonnie Webber, and AravindJoshi. 2006. Computing discourse semantics: Thepredicate-argument semantics of discourse connec-tives in d-ltag. Journal of Semantics, 23(1):55–106.
Christoph Goller and Andreas Kuchler. 1996. Learn-ing task-dependent distributed representations bybackpropagation through structure. In Neural Net-works, IEEE International Conference on, pages347–352. IEEE.
Edward Grefenstette. 2013. Towards a Formal Distri-butional Semantics: Simulating Logical Calculi withTensors, April.
Barbara J Grosz, Scott Weinstein, and Aravind K Joshi.1995. Centering: A framework for modeling the lo-cal coherence of discourse. Computational linguis-tics, 21(2):203–225.
Ozan Irsoy and Claire Cardie. 2013. Bidirectional re-cursive neural networks for token-level labeling withstructure. CoRR (presented at the 2013 NIPS Work-shop on Deep Learning), abs/1312.0493.
Peter Jansen, Mihai Surdeanu, and Peter Clark. 2014.Discourse complements lexical semantics for non-factoid answer reranking. In Proceedings of the As-sociation for Computational Linguistics (ACL), Bal-timore, MD.
Yangfeng Ji and Jacob Eisenstein. 2014. Represen-tation learning for text-level discourse parsing. InProceedings of the Association for ComputationalLinguistics (ACL), Baltimore, MD.
Nal Kalchbrenner and Phil Blunsom. 2013. Recurrentconvolutional neural networks for discourse compo-sitionality. In Proceedings of the Workshop on Con-tinuous Vector Space Models and their Composition-ality, pages 119–126, Sofia, Bulgaria, August. Asso-ciation for Computational Linguistics.
David Kauchak and Regina Barzilay. 2006. Para-phrasing for automatic evaluation. In Proceedingsof NAACL, pages 455–462. Association for Compu-tational Linguistics.
Andrew Kehler and Hannah Rohde. 2013. Aprobabilistic reconciliation of coherence-driven andcentering-driven theories of pronoun interpretation.Theoretical Linguistics, 39(1-2):1–37.
Dan Klein and Christopher D Manning. 2003. Ac-curate unlexicalized parsing. In Proceedings of theAssociation for Computational Linguistics (ACL),pages 423–430.
Alistair Knott. 1996. A data-driven methodology formotivating a set of coherence relations. Ph.D. the-sis, The University of Edinburgh.
Thomas Landauer, Peter W. Foltz, and Darrel Laham.1998. Introduction to Latent Semantic Analysis.Discource Processes, 25:259–284.
Karim Lari and Steve J Young. 1990. The estima-tion of stochastic context-free grammars using theinside-outside algorithm. Computer speech & lan-guage, 4(1):35–56.
Phong Le and Willem Zuidema. 2014. The inside-outside recursive neural network model for depen-dency parsing. In Proceedings of Empirical Meth-ods for Natural Language Processing (EMNLP),pages 729–739.
Yann A LeCun, Leon Bottou, Genevieve B Orr, andKlaus-Robert Muller. 2012. Efficient backprop. InNeural networks: Tricks of the trade, pages 9–48.Springer.
Mike Lewis and Mark Steedman. 2013. Combineddistributional and logical semantics. Transactionsof the Association for Computational Linguistics,1:179–192.
Junyi Jessy Li and Ani Nenkova. 2014. Reducing spar-sity improves the recognition of implicit discourserelations. In Proceedings of SIGDIAL, pages 199–207.
Jiwei Li, Rumeng Li, and Eduard Hovy. 2014. Recur-sive deep models for discourse parsing. In Proceed-ings of Empirical Methods for Natural LanguageProcessing (EMNLP).
Ziheng Lin, Min-Yen Kan, and Hwee Tou Ng. 2009.Recognizing implicit discourse relations in the penndiscourse treebank. In Proceedings of Empir-ical Methods for Natural Language Processing(EMNLP), pages 343–351, Singapore.
Ziheng Lin, Hwee Tou Ng, and Min-Yen Kan. 2011.Automatically Evaluating Text Coherence UsingDiscourse Relations. In Proceedings of the Asso-ciation for Computational Linguistics (ACL), pages997–1006, Portland, OR.
Ziheng Lin, Hwee T. Ng, and Min Y. Kan. 2012. APDTB-styled end-to-end discourse parser. NaturalLanguage Engineering, FirstView:1–34, November.

Annie Louis, Aravind Joshi, and Ani Nenkova. 2010a.Discourse indicators for content selection in summa-rization. In Proceedings of the 11th Annual Meetingof the Special Interest Group on Discourse and Di-alogue, pages 147–156. Association for Computa-tional Linguistics.
Annie Louis, Aravind Joshi, Rashmi Prasad, and AniNenkova. 2010b. Using entity features to classifyimplicit discourse relations. In Proceedings of theSIGDIAL, pages 59–62, Tokyo, Japan, September.Association for Computational Linguistics.
William C Mann and Sandra A Thompson. 1988.Rhetorical structure theory: Toward a functional the-ory of text organization. Text, 8(3):243–281.
William Mann. 1984. Discourse structures for textgeneration. In Proceedings of the 10th InternationalConference on Computational Linguistics and 22ndannual meeting on Association for ComputationalLinguistics, pages 367–375. Association for Com-putational Linguistics.
Daniel Marcu. 1999. A decision-based approach torhetorical parsing. In Proceedings of the 37th an-nual meeting of the Association for ComputationalLinguistics on Computational Linguistics, pages365–372. Association for Computational Linguis-tics.
Rada Mihalcea, Courtney Corley, and Carlo Strappa-rava. 2006. Corpus-based and knowledge-basedmeasures of text semantic similarity. In AAAI.
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig.2013. Linguistic regularities in continuous spaceword representations. In Proceedings of the NorthAmerican Chapter of the Association for Com-putational Linguistics (NAACL), pages 746–751,Stroudsburg, Pennsylvania. Association for Compu-tational Linguistics.
Raymond J. Mooney. 2014. Semantic parsing: Past,present, and future. Presentation slides from theACL Workshop on Semantic Parsing.
Joonsuk Park and Claire Cardie. 2012. ImprovingImplicit Discourse Relation Recognition ThroughFeature Set Optimization. In Proceedings of the13th Annual Meeting of the Special Interest Groupon Discourse and Dialogue, pages 108–112, Seoul,South Korea, July. Association for ComputationalLinguistics.
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio.2012. On the difficulty of training recurrent neuralnetworks. arXiv preprint arXiv:1211.5063.
Romain Paulus, Richard Socher, and Christopher DManning. 2014. Global belief recursive neural net-works. In Neural Information Processing Systems(NIPS), pages 2888–2896, Montreal.
Jeffrey Pennington, Richard Socher, and ChristopherManning. 2014. Glove: Global vectors for wordrepresentation. In Proceedings of Empirical Meth-ods for Natural Language Processing (EMNLP),pages 1532–1543.
Slav Petrov, Leon Barrett, Romain Thibaux, and DanKlein. 2006. Learning accurate, compact, and in-terpretable tree annotation. In Proceedings of theAssociation for Computational Linguistics (ACL).
Emily Pitler, Mridhula Raghupathy, Hena Mehta, AniNenkova, Alan Lee, and Aravind Joshi. 2008. Eas-ily identifiable discourse relations. In Coling 2008:Companion volume: Posters, pages 87–90, Manch-ester, UK, August. Coling 2008 Organizing Com-mittee.
Emily Pitler, Annie Louis, and Ani Nenkova. 2009.Automatic Sense Prediction for Implicit DiscourseRelations in Text. In Proceedings of the 47th An-nual Meeting of the ACL and the 4th IJCNLP of theAFNLP .
Hoifung Poon and Pedro Domingos. 2009. Unsu-pervised semantic parsing. In Proceedings of Em-pirical Methods for Natural Language Processing(EMNLP), pages 1–10, Singapore.
Sameer S Pradhan, Eduard Hovy, Mitch Mar-cus, Martha Palmer, Lance Ramshaw, and RalphWeischedel. 2007. Ontonotes: A unified relationalsemantic representation. International Journal ofSemantic Computing, 1(04):405–419.
Rashmi Prasad, Nikhil Dinesh, Alan Lee, Eleni Milt-sakaki, Livio Robaldo, Aravind Joshi, and BonnieWebber. 2008. The penn discourse treebank 2.0. InProceedings of LREC.
Attapol T Rutherford and Nianwen Xue. 2014.Discovering Implicit Discourse Relations ThroughBrown Cluster Pair Representation and CoreferencePatterns. In Proceedings of the European Chap-ter of the Association for Computational Linguistics(EACL), Stroudsburg, Pennsylvania. Association forComputational Linguistics.
Paul Smolensky. 1990. Tensor product variable bind-ing and the representation of symbolic structuresin connectionist systems. Artificial intelligence,46(1):159–216.
Richard Socher, Cliff C. Lin, Andrew Y. Ng, andChristopher D. Manning. 2011. Parsing NaturalScenes and Natural Language with Recursive Neu-ral Networks. In Proceedings of the InternationalConference on Machine Learning (ICML), Seattle,WA.
Richard Socher, Alex Perelygin, Jean Y Wu, JasonChuang, Christopher D Manning, Andrew Y Ng,and Christopher Potts. 2013. Recursive deep mod-els for semantic compositionality over a sentimenttreebank. In Proceedings of Empirical Methods forNatural Language Processing (EMNLP).

Richard Socher, Danqi Chen, Christopher D. Manning,and Andrew Y. Ng. 2014. Reasoning With NeuralTensor Networks For Knowledge Base Completion.In Neural Information Processing Systems (NIPS).Lake Tahoe.
Swapna Somasundaran, Galileo Namata, JanyceWiebe, and Lise Getoor. 2009. Supervised andunsupervised methods in employing discourse rela-tions for improving opinion polarity classification.In Proceedings of EMNLP.
Ivan Titov and Alexandre Klementiev. 2011. Abayesian model for unsupervised semantic pars-ing. In Proceedings of the 49th Annual Meeting ofthe Association for Computational Linguistics: Hu-man Language Technologies-Volume 1, pages 1445–1455. Association for Computational Linguistics.
Joseph Turian, Lev Ratinov, and Yoshua Bengio.2010. Word Representation: A Simple and GeneralMethod for Semi-Supervised Learning. In Proceed-ings of the Association for Computational Linguis-tics (ACL), pages 384–394, Uppsala, Sweden.
Peter D. Turney and Patrick Pantel. 2010. From Fre-quency to Meaning: Vector Space Models of Seman-tics. JAIR, 37:141–188.
Laurens van der Maaten and Geoffrey Hinton. 2008.Visualizing Data using t-SNE. Journal of MachineLearning Research, 9:2759–2605, November.
Bonnie Webber, Alistair Knott, Matthew Stone, andAravind Joshi. 1999. Discourse relations: A struc-tural and presuppositional account using lexicalisedtag. In Proceedings of the Association for Computa-tional Linguistics (ACL), pages 41–48.
Bonnie Webber. 2004. D-LTAG: extending lexicalizedTAG to discourse. Cognitive Science, 28(5):751–779, September.
Yasuhisa Yoshida, Jun Suzuki, Tsutomu Hirao, andMasaaki Nagata. 2014. Dependency-based Dis-course Parser for Single-Document Summarization.In Proceedings of Empirical Methods for NaturalLanguage Processing (EMNLP).
Zhi-Min Zhou, Yu Xu, Zheng-Yu Niu, Man Lan, JianSu, and Chew Lim Tan. 2010. Predicting discourseconnectives for implicit discourse relation recogni-tion. In Proceedings of the 23rd International Con-ference on Computational Linguistics, pages 1507–1514.