Embed Size (px)
Citation preview

9
O poder cognitivo das redes neurais artificiais modeloART1 na recuperação da informação
Resumo
O artigo relata um experimento de simulaçãocomputacional de um sistema de recuperação dainformação composto por uma base de índices textuaisde uma amostra de documentos, um software de redeneural artificial implementando conceitos da Teoria daRessonância Adaptativa, para automação do processode ordenação e apresentação de resultados, e umusuário humano interagindo com o sistema emprocessos de consulta. O objetivo do experimento foidemonstrar (i) a utilidade das redes neurais deCarpenter e Grossberg (1988) baseadas nessa teoriae (ii) o poder de resolução semântica com índicessintagmáticos da abordagem SiRILiCO proposta porGottschalg-Duque (2005), para o qual um sintagmanominal ou proposição é uma unidade linguísticaconstituda de sentido maior que o significado de umapalavra e menor que uma narrativa ou uma teoria.O experimento demonstrou a eficácia e a eficiência deum sistema de recuperação da informaçãocombinando esses recursos, concluindo-se que umambiente computacional dessa natureza terácapacidade de clusterização (agrupamento) variávelon-line com entradas e aprendizado contínuos nomodo não supervisionado, sem necessidade detreinamento em modo batch (off-line), para responder aconsultas de usuários em redes de computadores comdesempenho promissor.
Palavras-chave
Sistema de recuperação da informação. Sintagmanominal. Semântica. Indexação sintagmática.Mineração de textos. Redes neurais artificiais. Teoria daressonância adaptativa. Redes neurais ART. Simulaçãocomputacional. Inteligência artificial.
The cognitive power of artificial neuralnetworks model ART1 for informationretrieval
Abstract
This article reports an experiment with a computationalsimulation of an Information Retrieval Systemconstituted of a textual indexing base from a sample ofdocuments, an artificial neural network softwareimplementing Adaptive Resonance Theory conceptsfor the process of ordering and presenting outputs, anda human user interacting with the system in queryprocessing. The goal of the experiment was todemonstrate (i) the usefulness of Carpenter andGrossberg (1988) neural networks based on thattheory, and (ii) the power of semantic resolution basedon sintagmatic indexing of the SiRILiCO approachproposed by Gottschalg-Duque (2005), for whom anoun phrase or proposition is a linguistic unityconstituted of meaning larger than a word meaningand smaller than a story telling or a theory meaning.The experiment demonstrated the effectiveness andefficiency of an Information Retrieval System joiningtogether those resources, and the conclusion is thatsuch computational environment will be capable ofdynamic and on-line clustering with continuing inputsand learning in a non-supervised fashion, withoutbatch training needs (off-line), to answer user queriesin computer networks with promising performance.
Keywords
Information retrieval system. Noun phrase. Semantics.Syntagmatic indexing. Text mining. Artificial neuralnetworks. Adaptive resonance theory. ART neuralnetworks. Computational simulation. Artificialintelligence.
Ethel Airton CapuanoDoutorando em ciência da informação pela Universidade de Brasília (UnB). Mestre em gestão do conhecimento e da tecnologia daInformação pela Universidade Católica de Brasília (UCB).E-mail: [email protected]
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
ARTIGOS

10
INTRODUÇÃO
Este artigo relata um experimento de simulaçãocomputacional de um sistema de recuperação dainformação composto por uma base de índicestextuais sintagmáticos de uma amostra dedocumentos de apresentações ocorridas noseventos IA Summit (Encontros de Arquitetura daInformação) de 2005 a 2008, nos EUA, construídamanualmente por um especialista no tema, umsoftware de rede neural artificial implementandoconceitos da Teoria da Ressonância Adaptativa,de Helmholz, para automação do processo deordenação e apresentação de resultados, e umusuário humano interagindo com o sistema emprocessos de consulta (busca) em linguagemnatural. O objetivo do experimento é demonstrara utilidade de redes neurais artificiais baseadasnessa teoria, uma promissora tecnologia demineração de dados, em missões de recuperaçãoda informação textual.
Em ciência da informação o conceito de índice éamplo, consistindo do registro de valores de váriosatributos-chave de um texto referenciado com osquais se espera identificar e recuperar, futuramente,esse mesmo texto armazenado em alguma base deconteúdos informacionais (MEADOW et al.,2007). O uso de índices compostos por mais deum termo linguístico como metadados, em vez depalavras-chave, busca a redução da ambiguidade,conforme proposto por Gottschalg-Duque (2005).
O tema de pesquisa correlato, com esse tipo decomposição tecnológica utilizando inteligênciaartificial, é abordado na literatura brasileira daciência da informação por Ferneda (2006), queressalta, como vantagem da utilização de redesneurais em sistemas computacionais derecuperação da informação, os aspectos dinâmicosdessas redes de reconhecimento automático depadrões (aprendizado computacional). O usuáriodesse modelo de sistema de recuperação dainformação com redes neurais artificiais podeajustar os parâmetros de busca (consulta) na base
textual de acordo com o nível de relevância ougeneralização dos conceitos pretendidos,emprestando alguma capacidade de resoluçãosemântica ao processo de busca.
Os desafios metodológicos do experimento sãotambém interessantes no processo de indexaçãodevido à complexidade inerente e às implicaçõesepistemológicas da representação da informaçãocom índices textuais e codificação binária,problema abordado, por exemplo, por Meadowet al. (2007), Tsuruoka et al. (2007) e Yu, Wang eLai (2008). Os resultados esperados do experimentosão evidências do poder cognitivo computacionalde redes neurais artificiais modelo ART1, deCarpenter e Grossberg (1988), em contextos desistemas de recuperação de informação (SRI) combases textuais indexadas com sintagmas nominais.
CONCEITOS
Recuperação da informação
Contemporaneamente, Gottschalg-Duque (2005,p. 11), baseado em vários outros autores, apresentaa recuperação da informação como:
(...) o clássico problema da recuperação efetivae eficiente de documentos pertinentes extraídosde uma grande coleção (que nos dias de hojepode ser entendida como um armazém deinformação ou uma base de dados digital) deacordo com uma necessidade de informaçãoespecífica, consistindo de três processos: coleta,indexação e ordenação.
A coleta é um processo de identificação, avaliaçãoe armazenamento; a indexação, um processo decategorização com uso de palavras-chave pararepresentação de um documento; a ordenação, umprocesso de disponibilização de documentos aosusuários segundo critérios de representação quesatisfaçam suas necessidades.
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009

11
Semântica com sintagmas nominais
A construção de um sistema de recuperação dainformação1 que possa extrair, consistentemente,informações semânticas acuradas de todo tipo detexto nem sempre é possível (KONCHADY, 2006),constituindo um dos maiores problemasconceituais da recuperação da informação aambiguidade de termos linguísticos. Meadows etal. (2007) observam que:
(...) enquanto identificadores únicos sãoutilizados para algumas aplicações e indicadoresde classificação, em outros casos há incertezasobre valores ou significados, causandoconfusão ao leitor humano ou a um programade computador, ou ambos. E uma fonte deambiguidade é a semântica – o significado dossímbolos.
Gottschalg-Duque (2005, p. 29) apresenta umasolução metodológica para o problema propondoque se construam proposições (ou enunciados, namatriz aristotélica) para a interpretação semântica.Certamente, este autor define em seu framework derecuperação da informação que “uma proposiçãoé uma unidade constituída de sentido e que é maiorque o significado de uma palavra e menor que umanarrativa ou uma teoria”.
Considerando o significativo poder cognitivo sub-jacente à proposta de Gottschalg-Duque (2005)para solução do problema semântico, o experimen-to executado utilizou uma base de índices de tex-tos em linguagem natural representada por sintag-mas nominais, que são partes de uma sentençaconstituídas de substantivos geralmente apresen-tadas em estruturas sintáticas comoSUBSTANTIVO_PREPOSIÇÃO-SUBSTANTI-VO, SUBSTANTIVO_ADJETIVO, ADJETIVO_SUBSTANTIVO, SUBSTANTIVO_ PREPOSI-ÇÃO_ ARTIGO_ SUBSTANTIVO e SUBSTAN-TIVO_ SUBSTANTIVO. A base de índices de
textos em linguagem natural elaborada para o ex-perimento é composta, na maior parte, de estrutu-ras sintáticas estilo SUBSTANTIVO_ SUBSTAN-TIVO (ou NP_NP, no padrão inglês), SUBSTAN-TIVO_ PREPOSIÇÃO_ARTIGO_ SUBSTAN-TIVO (NP_PP_ART_NP) e ADJETIVO_ SUBS-TANTIVO (ADJ_NP).2 Como exemplos de sin-tagmas com essas estruturas sintáticas, encontram-se, na base textual utilizada, INFORMATIONSTRUCTURE (NP_NP), DATABASE-INTENSI-VE APPLICATION (ADJ_NP), FACETEDCLASSIFICATION (ADJ_NP). Observe-se que aestrutura sintática NP_NP é predominante nos sin-tagmas nominais do idioma inglês, equivalente, namaioria dos casos, à estrutura NP_PP_NP do idio-ma português, geralmente utilizadas para expres-sar substantivos compostos com relação de adjeti-vação de um termo sobre o outro no sintagma,como em Information Architecture (Arquitetura da In-formação) e User Needs (Necessidades do Usuá-rio). Outras estruturas sintáticas do idioma inglêstambém aparecem nos índices textuais, ainda quemenos frequentes, como ADJ_NP_NP (Faceted Bro-wse System), NP_PP_ART_NP (Metadata for theMasses) e NP_NP_NP (Desktop Data Integration).
Como vantagens desse método de indexação detextos, tem-se que:
a) um sintagma nominal é sempre mais poderoso,no sentido de redução da ambiguidade, que umtermo isolado;
b) dois ou mais sintagmas nominais correlatos emum texto podem contextualizar melhor os termossintáticos, do ponto de vista semântico, que apenasum sintagma nominal;
c) sintagmas nominais são estruturas de texto deextração relativamente fácil, atividade que podeser automatizada com uso de softwares deprocessamento de linguagem natural especializadosem etiquetação (tagging) e análise sintáticas (parsing),ou softwares de mineração de textos.
1 Utilizando-se, no caso, recuperação como um termo mais genérico,hiperônimo de extração. 2 NP: Noun Phrase; ADJ: Adjective; ART: Article; PP: Preposition.
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação

12
Mineração de textos
Os métodos e processos de descoberta deinformação (que alguns chamam, em certoscontextos, de conhecimento) relevantes em linguagemnatural, conhecidos como mineração de textos,constituem variantes do que se conhece comomineração de dados. Chauke-Nehme (2008), comojustificativa para os investimentos em pesquisa edesenvolvimento e o enorme interesse do mercadoem tecnologias dessa natureza, argumenta que umimportante desafio para os próximos dez anos é apreparação de um exército de Davi3 para tirarvantagem do volume de informações disponíveisexponencialmente crescente no mundo em favorde uma sociedade mais sábia, justa e igualitária emtermos de oportunidades para todos. Este autorobserva, em particular, que a mineração de textos,que constitui um dos tipos de tecnologias úteis parao tratamento adequado dessa inundação deinformações, tem apresentado significativaevolução na última década, desde o simplesprocessamento de palavras na segunda metade dadécada de 1990 até hoje, quando o processamentode conceitos (termos ontológicos), ou mesmo aextração de conhecimento de estruturaslinguísticas, tem se tornado possível.
Outros autores, como Do Prado e Ferneda (2008),definem mineração de textos como a aplicação demétodos e técnicas computacionais sobre dadostextuais com a finalidade de encontrar informaçõesintrinsecamente relevantes e conhecimento. Emrelação às origens da mineração de textos namodernidade, Penteado e Boutin (2008) recordamo estudo de textos estruturados para mensuraçãoda publicação científica, que surgiu e sedesenvolveu a partir dos esforços de pioneiros comoSolla Price, Small, van Raan, Swanson, Dou ePorter. Os autores mencionam que a mineração detextos estruturados é encontrada em campos doconhecimento tais como “bibliometria,
cientometria, informetria, midiametria,museometria e webmetria”, esclarecendo quenesses campos se estudam os diferentes aspectosda informação, inclusive sua qualidade, sendo aprincipal matéria-prima para esses estudos aspalavras nos textos.
Quanto às funções que podem ser desempenhadaspor sistemas de mineração de textos, Konchady(2006) observa que não há um conjunto padrãodefinido das funções desse tipo de tecnologia.O autor, no entanto, apresenta uma lista desoluções com uso (inclusive) de mineração de dadospara problemas comuns de gestão da informação:busca (search), extração de informação (busca depadrões de uso semântico), formação de clusters,categorização, construção de resumos(sumarização), monitoramento de informação,organização de perguntas e respostas (emaplicações de Frequent Asked Questions, por exemplo).O experimento relatado neste artigo pode serclassificado de modo abrangente, testando funçõescombinadas de busca de padrões semânticos eformação de clusters para ordenação de informaçãoao usuário de um sistema de recuperação dainformação.
Simulação computacional
Experimentos com uso de técnicas de simulaçãocomputacional em pesquisas na área de ciênciassociais não são comuns na literatura,caracterizando-se uma tendência histórica deprodução acadêmica mais intensa com esse tipode recurso metodológico nas denominadas ciênciasexatas e nas engenharias. Contudo, Pidd (1988)argumenta que métodos de simulaçãocomputacional têm se desenvolvido desde o iníciodos anos 1960, nos quais se incluem, talvez comoas ferramentas mais comumente utilizadas paratanto, as utilizadas na administração. O pesquisadorou analista que utiliza simulação computacionaldesenvolve um modelo do sistema de interesse queimita o problema real, escreve um programa decomputador que implementa esse modelo e utilizaum computador para emular o comportamento do
3 Como metáfora relacionada ao confronto bíblico entre Davi(representando os usuários de informações) e o gigante Golias(representando o enorme volume de informações disponíveis).
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009

13
sistema quando submetido a uma variedade depolíticas (ou situações) operacionais (PIDD, 1988).Como resultados observados das simulações, opesquisador ou analista terá dados para análise econdições de compor um modelo completo doproblema e da melhor solução possível, comparandoas implicações de adoção de uma solução ou outraem termos de desempenho.
O método que utiliza simulação pode serconsiderado um método experimental de pesquisacientífica à medida que testa um modelo conceitualde problema e solução, e Pidd (1988, p. 5-6)argumenta, no contexto da simulaçãocomputacional da administração, que:
O modelo é utilizado como um veículo paraexperimentação, frequentemente com tentativae erro, para demonstrar os prováveis efeitos devárias políticas. Então, aquelas que produzemos melhores resultados no modelo seriamimplementadas no sistema real.
A simulação computacional consome tempo e,geralmente, é uma tarefa bastante complexa, masapresenta também as seguintes vantagens (PIDD,1988):
a) custo: em geral é menor que um experimentoreal nas organizações;
b) tempo: após a modelagem e a construção doartefato computacional, as possibilidades deemulação de situações reais com simulação sãoilimitadas, podendo-se também simular períodosmaiores de operações reais em questão de segundosno computador;
c) possibilidade de replicação: um experimentosimulado pode ser replicado por outrospesquisadores, uma vez que as condiçõesambientais são modeladas e estruturadas de modointeligível, algo difícil de ocorrer em umexperimento real, pois as organizações e osambientes reais geralmente não se repetemnaturalmente de modo muito similar;
d) segurança: uma simulação geralmente nãoapresenta riscos para as organizações ou pessoas,o que nem sempre ocorre em experimentos reais(experiências reais malsucedidas podem acarretardanos ambientais ou prejuízos econômicos para asorganizações).
Redes neurais artificiais
As redes neurais artificiais são um paradigmaespecífico de inteligência artificial que representauma ruptura com os conceitos tradicionais nessaárea do conhecimento, estes centrados na lógicacomputacional e na heurística como meios de seintroduzir inteligência em um artefato. Com essasredes, uma corrente de cientistas da inteligênciaartificial buscou, no final dos anos 1950, aconstrução de artefatos inteligentes comcapacidade de aprendizado autônomo, semnecessidade de informação a priori de todos osdetalhes lógicos e heurísticos que o artefatointeligente deveria conter, em determinadascircunstâncias, para executar sua missão(FREEDMAN, 1995; FREEMAN; SKAPURA,1993).
O potencial uso de redes neurais artificiais emsistemas de recuperação da informação éapresentado, em literatura brasileira, por Ferneda(2006), comparando esse tipo de sistema a umarede neural de três camadas: a camada de termosde busca seria a camada de entrada de dados narede; a camada de documentos seria a saída; acamada de termos de indexação seria uma camadacentral. O experimento executado e relatado nopresente artigo segue essa arquitetura básica desistema; contudo, antes são apresentadas asprincipais características dos principais modelos deredes neurais artificiais.
Modelos e arquiteturas
Freeman e Skapura (1993) comentam que, quandoa única ferramenta que se dispõe é um martelo,todos os problemas que encontramos tendem a nosparecer como se fossem pregos. De fato, o mesmo
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação

14
vício ocorre entre os profissionais de tecnologiada informação: quem domina uma (e somente uma)tecnologia procura sempre implementar soluçõesque a utilizem, mesmo que existam outrastecnologias mais adequadas à disposição.Contribuindo para a superação desse hábitoprofissional, as redes neurais artificiais apresentamdiversas topologias, conceitos e vários algoritmosde aprendizado, sem falar nas aplicações bastantevariadas para cada tipo de rede. O desafio para oengenheiro do conhecimento responsável por um projetode mineração de dados é justamente empreender acorreta seleção de tecnologias e, tendo optado peloemprego de redes neurais artificiais, a corretaseleção do modelo e arquitetura da rede parasolucionar o problema que se apresenta.
O primeiro ponto a ser analisado no processo deseleção se refere ao modo de aprendizado, sesupervisionado, não supervisionado ou reforçado,e a decisão por um modo ou outro deve resultar doestudo cuidadoso do problema no contexto doecossistema informacional em que ele se insere.Como regra geral, o aspecto crucial é o grau deconhecimento que se tem dos padrões a seremreconhecidos pela rede, que se relaciona aoconhecimento que se tem dos dados disponíveispara mineração. Quando os padrões de saída darede, ou vetores-alvo, são previamente conhecidos,opta-se por redes com aprendizado supervisionado;neste caso, a rede opera com funções mais sensoriaisdo que cognitivas, pois os padrões a seremaprendidos já são conhecidos pelos usuários e otrabalho da rede se parece mais com classificaçãoque agrupamento (cluster).
As redes com aprendizado não supervisionado sãoespecialmente úteis quando se navega em umambiente de dados no qual o conhecimentoencontra-se oculto e não se sabe os conteúdos dasdescobertas – a rigor, o aprendizado nãosupervisionado representa a essênciaepistemológica da mineração de dados. Oexperimento objeto deste artigo mostra um meiode se transpor esse construto cognitivo paramineração de textos.
Topologias
Conforme Bigus (1996), as topologias básicas deredes neurais artificiais são de alimentaçãoprogressiva (feedforward), limitadamente recorrentese totalmente recorrentes (figura 1, a seguir). Osdados do fenômeno em estudo são introduzidosna camada de processamento da rede denominada“Entrada”, para que a rede realize as tarefas deaprendizado para as quais foi projetada na camada“Oculta” e, por fim, mostre os resultados aosusuários nas interfaces da camada “Saída”. Emredes com aprendizado supervisionado, os resul-tados devem mostrar quais dados de entrada seidentificam com quais padrões de saída esperados.
Como no conceito mais primitivo de caixa-pretade modelagem de sistemas, o modelo básico de trêscamadas é o modelo-padrão nas redes neurais,moldando sua topologia de modo explícito ouimplícito. Embora o modelo de três camadasclássico possa apresentar variantes, o que diferenciaum modelo topológico de rede de outro se relacionacom o método de aprendizagem, pois este é otrabalho das camadas intermediárias (ocultas).
Redes feedforward
As topologias de alimentação para frente(feedforward) são as mais comuns, sendo utilizadasem situações em que se introduzem todos os dadospara solução do problema, na camada deprocessamento de “Entrada”, de uma só vez. Nessetipo de topologia, os dados fluem através dascamadas de processamento na rede em um sósentido (daí sua denominação alimentação parafrente), sem reavaliações recursivas do processo deaprendizado, e a resposta é baseada somente noconjunto corrente de dados de entrada (BIGUS,1996).
A figura 1a mostra os blocos de construção de umarede neural artificial com alimentação para frentetípica, onde os dados entram na rede através dasunidades de entrada posicionadas à esquerda, sendosubmetidas a essas unidades como “valores deativação”. O trabalho da camada intermediária, em
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009

15
suma, será encontrar, mediante comparaçõesiterativas entre entradas e saídas, o melhorconjunto de pesos (números reais) que,multiplicados pelos valores dos dados de entrada,possam identificar semelhanças deste produto comos valores dos dados esperados na camada de“Saída”. A natureza computacional e heurística deuma rede neural, portanto, não é definida caso acaso, situação por situação, como nos algoritmosde inteligência artificial tradicional, mas sim comoum modelo cognitivo padrão de mais alto nível –alvo da crítica dos cientistas da corrente tradicional,porque essa vantagem cognitiva torna-se umadesvantagem lógica na medida em que não se podeexplicitar e formalizar, com precisão, osmecanismos de aprendizado do artefato.
Cada unidade de processamento combina todos ossinais de entrada ponderados com um valor limiar,e a soma dos sinais de entrada no “neurônio” ésubmetida a uma função de ativação, como nomodelo de ativação elétrica dos neurôniosbiológicos das redes neurais naturais, que determinaa saída atual da unidade da camada de
processamento de saída que, por sua vez, torna-seentrada para outra camada. A função matemáticade ativação mais utilizada é a sigmóide, queconverte um valor de entrada em uma saída comamplitude entre 0,0 e 1,0 (é uma função denormalização, portanto). Os valores dos dados quesaem das unidades de entrada são modulados pelospesos das conexões da rede e amplificados, se orespectivo peso da conexão for positivo e maiorque 1,0 (um), ou reduzidos, se o peso da conexãose encontra entre os valores 0,0 (zero) e 1,0 (um).O processo de aprendizado da rede consiste,portanto, no ajuste dos pesos de modo que asclassificações dos padrões de entrada sejamexecutadas corretamente.
As funções sigmóides têm a propriedade deapresentar resultados (variáveis dependentes)muito próximos a partir de certo limiar do valordos dados de entrada (variáveis independentes),razão de seu uso em redes neurais. Os produtosmatemáticos resultantes desses cálculos sãoutilizados como filtros para classificação dos dadosde entrada segundo os interesses dos usuários
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação
FIGURA 1Topologias de redes neurais

16
expressos na camada de dados de saída. O processode alimentação dos dados para frente, ou para acamada seguinte, é executado com base nos “sinaisde ativação” resultantes do processamento com ospesos, sendo o sinal positivo (geralmente, + 1)representativo da “aprovação” do sistema de pesosutilizado e o sinal negativo de sua “reprovação”(com sinal – 1). Ou seja, dados “aprovados” sãoclassificados em determinado padrão de saídaesperado e dados “reprovados” são desclassificadosnesse padrão, embora possam ser “aprovados” emoutro padrão de saída na rede.
Redes limitadamente recorrentes
Em uma rede neural artificial com topologialimitadamente recorrente (figura 1b), a sequênciadas entradas é importante e espera-se que a redearmazene, de algum modo, um registro das entradasanteriores (de “contexto”) e os fatores com os dadoscorrentes para produzir uma resposta. Nesse tipode rede, informações sobre entradas passadas sãoreintroduzidas e misturadas com as entradaspresentes através das conexões recorrentes ou deretroalimentação nas unidades das camadas ocultasou de saída. Dessa forma, a rede contém umamemória das entradas passadas a partir dasativações, incrementando o processo deaprendizado.
Redes limitadamente recorrentes estabelecem umcompromisso de equilíbrio entre a simplicidade daproposta feedforward e o poder de separação lógico-matemática não linear de redes totalmenterecorrentes e permitem a utilização do algoritmode treinamento de retropropagação(backpropagation). Com esse tipo de rede neural,pode-se operar, portanto, com um nível decomplexidade maior na classificação dos dados deentrada que as redes de alimentação para frente.
Redes totalmente recorrentes
Redes neurais com topologia totalmente recorrentepropiciam conexões de duas vias entre todas asunidades processadoras (figura 1c). Os dados deentrada fluem da primeira camada para todas as
demais camadas adjacentes e circulam para frentee para trás até que a ativação das unidades seestabilize. As ativações das camadas ocultas e desaída são, então, recomputadas até que toda a redese estabilize; nesse ponto, os valores de saídapodem ser lidos das unidades processadoras dacamada de saída.
Essas redes são sistemas muito complexos edinâmicos e exibem comportamento de sistemascaóticos (da Teoria do Caos). Apesar de seu altopoder de simulação de sistemas e soluçõescomplexas, o sistema revela alta instabilidade e,muitas vezes, não converge para uma única soluçãoou, quando converge, consome muito tempo comas iterações recorrentes entre os neurônios. Asmesmas características que trazem desvantagensapresentam também vantagens, e essas redes, porisso, são úteis para solução de problemas muitocomplexos que envolvem funções de otimização.
Paradigmas e algoritmos de aprendizado
Em termos de modelos completos de redes neuraisartificiais, assim definidos com base na topologiade conexões e no paradigma de aprendizado, asredes backpropagation (com retropropagação) eKohonen Feature Map (Mapa de Características deKohonen) são as mais populares para mineraçãode dados (BIGUS, 1996). Redes supervisionadascom aprendizado por retropropagação utilizamtopologia de alimentação progressiva, sendoresponsáveis pelo retorno do interesse pelas redesneurais na década de 1980, após as frustrações dadécada de 1960.
Essas redes tornaram-se populares graças aotrabalho de Rumelhart, Hinton e Williams esuperaram as críticas dos pesquisadores dainteligência artificial tradicional, como Minsky ePapert, do Massachusetts Institute of Technology.As principais vantagens das redes comretropropagação são a simplicidade do paradigmade aprendizado e seu ecletismo em termos deaplicações concretas, representando o ideal dainteligência artificial com base na natureza. Comodesvantagens, tem-se o tempo de resposta
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009

17
frequentemente moroso e sua inaplicabilidade deaprendizado em tempo real devido ao conhecidodilema entre a estabilidade necessária paraconvergência da solução com um conjunto depadrões de treinamento e a plasticidadeindispensável para que a rede possa aprender novospadrões sem esquecer os antigos.
Outros paradigmas de redes neurais artificiais sãoapresentados em Freeman (1993). Redes neuraiscom aprendizado baseado na Teoria da RessonânciaAdaptativa (Adaptive Resonance Theory, ou ART) sãoconsideradas uma família de redes recorrentes, comvariantes supervisionadas e não supervisionadas,úteis na mineração de dados para identificação declusters. O dilema estabilidade-plasticidade temmotivado pesquisas e desenvolvimentos demodelos de redes neurais artificiais que imitam deforma mais plausível o aprendizado cumulativo,contínuo e metamórfico do ser humano.O paradigma de aprendizado das redes ART, deGrossberg (1988), representa uma solução para oproblema.
TEORIA DA RESSONÂNCIA ADAPTATIVA
A Teoria da Ressonância Adaptativa é umparadigma de rede neural desenvolvido no Centrode Sistemas Adaptativos da Universidade deBoston (EUA) por Carpenter e Grossberg, tendocomo principal característica sua similaridade comos processos de aprendizado humano. Esseparadigma se contrapõe ao tradicional, baseado nalógica de primeira ordem e na heurísica, porquebusca na própria natureza os processos deaprendizado, entendendo que os seres vivossobrevivem porque aprendem a se adaptarcontinuamente ao ambiente mutante. Os artigosseminais desses pesquisadores pioneiros, quelançaram os fundamentos epistemológicos dessetipo de rede neural, foram publicadosoriginalmente em 1988 (GROSSBERG, 1988;CARPENTER; GROSSBERG, 1988) e 1991(CARPENTER; GROSSBERG; ROSEN, 1991),a partir dos quais se desenvolveu uma série devariantes do modelo original.
Com um trabalho de mais de quatro décadas emteorias sobre o funcionamento do cérebro einteligência artificial, Carpenter e Grossbergconstruíram, gradualmente, um conjunto demodelos de redes neurais que parecem explicaralguns dos mais desconcertantes problemas dopensamento e permitem simular sistemas deinteligência artificial que “veem, se movem eaprendem” da maneira humana (FREEDMAN,1995). A principal diferença entre o trabalho dessespesquisadores e a retropropagação ou outros tiposde redes neurais é que ele eliminou todas ascondições simplificadoras que lhes permitiamfuncionar. Com efeito, a maioria das redes neuraisartificiais funciona somente com informaçõesestacionárias e controle externo, ou seja, podemmanejar somente um conjunto de padrõesinvariável, introduzido na rede lentamente esupervisionado por um treinador, do mesmo modoque se executa um algoritmo computacional.
Grossberg insiste que uma rede neural artificialverdadeiramente semelhante à humana deveria ser“autônoma, de aprendizagem rápida e adaptável”;isso significa uma rede capaz de aprenderrapidamente como organizar e manejar um mundopleno de surpresas (FREEDMAN, 1995, p. 106).As redes ART, portanto, são inspiradas nainteligência artificial baseada na natureza, que épensada em termos de três princípios elementares(FREEDMAN, 1995, p. 27-95):
I. a melhor maneira de se compreender comofunciona a inteligência humana é estudar, antes,como funciona um modelo de inteligência maiselementar, como a inteligência animal;
II. a inteligência pode ser emergente, umapropriedade da interação complexa de elementosmais simples;
III. a inteligência é demasiadamente complexa paraque possa ser projetada a partir do zero.
Essa característica de autoaprendizagem das redesneurais modelo ART pode ser considerada comoum quarto princípio de aproximação à inteligência
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação

18
artificial baseada na natureza: não se pode inserira inteligência em um sistema, mas sim desenvolvê-la mediante interação desse sistema com o mundocircundante (FREEDMAN, 1995, p. 107).
EXPERIMENTO DE SIMULAÇÃOCOMPUTACIONAL
Objetivo e critérios de avaliação
O experimento de recuperação da informaçãotextual a partir de índices sintagmáticos com usode redes neurais modelo ART teve como principalobjetivo testar a utilidade desse tipo de tecnologiacombinada com os conceitos desenvolvidos porGottschalg-Duque (2005) no processamento desintagmas nominais para associação semântica determos. Ou seja, testar o framework conceitual derecuperação da informação sintagmática baseadona arquitetura de rede neural denominada ART1desenvolvida por Carpenter e Grossberg (1988).O conceito de sintagma nominal é explorado, noexperimento, pela sua promissora capacidade desuperação, ao menos parcial, do conhecidoproblema semântico inerente aos sistemastradicionais de recuperação da informação com usode técnicas estatísticas e sintáticas deprocessamento de termos da linguagem natural.
O critério de avaliação do experimento adotado éo da viabilidade funcional do framework no atualcontexto da recuperação da informação,subdividindo-se, do ponto de vista técnico, em (i)revocação e precisão (KENT et al., 1955), (ii)eficiência computacional e (iii) usabilidade. Define-se revocação como uma métrica de conjuntos quemostra a relação entre o número de documentos(ou registros) relevantes recuperados pelo sistemae o número de documentos relevantes existentesna base ou repositório de informação; precisão comoa relação entre o número de documentos relevantesrecuperados e o número total de documentosrecuperados. A eficiência computacional se refere,no caso, ao tempo de resposta do Sistema deRecuperação da Informação, ou seja, ao tempo deprocessamento dos dados de entrada no sistemaaté a apresentação dos resultados ao usuário.
A usabilidade é um conceito da ciência dacomputação que se refere à qualidade do softwaredo ponto de vista do usuário; no caso, avalia-secomo tal sistema poderia ser utilizado pelo usuáriosem que o mesmo tenha necessidade de se envolvercom a complexidade das redes neurais artificiais.
Esses três itens de avaliação que compõem ocritério de viabilidade adotado são discutidos aolongo deste capítulo, mostrando-se também, nocapítulo das conclusões, algumas questões emaberto para futuros experimentos.
Motivação
Conforme experiências anteriores de Chauke-Nehme (1996), Serrano-Gotarredona, Linares-Barranco e Andreou (1998), Capuano (2001),Capuano e Chauke-Nehme (2002) e outros, asredes neurais ART1, um modelo variante da famíliade redes ART, têm se mostrado eficientes noreconhecimento de padrões binários e flexíveis paraajustes de granularidade na formação de clusters.Contudo, sua capacidade de resposta não tem sidotestada com entradas textuais, ou seja, emcontextos de mineração de textos, com dadosrepresentativos de termos da linguagem natural,despertando curiosidade sobre seus resultadosnesse cenário funcional. E talvez uma de suasprincipais vantagens sobre outras tecnologias derecuperação da informação, mesmo outros modelosde redes neurais artificiais, seja a capacidade declusterização on-line com entradas contínuas nomodo não supervisionado, recursos que a habilitam,naturalmente, para implementação em sistemas derecuperação da informação para usuários em redesde computadores on-line operando em tempo real.
Os experimentos apresentados por Capuano (2001)e Capuano e Chauke-Nehme (2002), por exemplo,mostraram que o parâmetro de vigilância ρ das redesART1 podem ser ajustados a cada sessão (processode consulta computacional) de modo que a redeproduza clusters mais ou menos agrupados de acordocom a necessidade do usuário, demonstrando umacapacidade de clusterização que pode ser utilizadapara o agrupamento de termos mais específicos ou
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009

19
mais genéricos, assim como para a conexãosemântica (hierárquica ou facetada) de um grupode termos a outros com variados graus desimilaridade. Essa capacidade de clusterizaçãovariável é obtida de uma rede ART1 com relativafacilidade de manuseio, configurando-se ereconfigurando-se o parâmetro ρ como um dadode entrada no processamento computacional. Comisso, ART1 se mostra também uma tecnologia demaior usabilidade que outros modelos de redesneurais artificiais, na qual o próprio usuário finalde um serviço de recuperação da informaçãopoderia ajustar os parâmetros de granularidade desua consulta à base textual por meio de umainterface de software.
Metodologia
Codificação dos padrões textuais
Como mencionado anteriormente, os padrões deentrada em uma rede neural ART1 são vetores comcaracterísticas dimensionais representadas de for-ma binária (com zeros e uns). Consequentemente, odesafio metodológico inicialmente encontrado noexperimento se deveu à necessidade de represen-tação binária da informação dos sintagmas nomi-nais de indexação responsáveis pela expressivida-de semântica dos textos referenciados na base.
Os textos utilizados no experimento constituemuma amostra dos resumos das apresentações dosencontros IA Summit (nos EUA) de 2005 a 2008.O número de sintagmas nominais utilizados paraindexação de cada texto dessa base é três, pois comesse número pode-se obter significativo poder deresolução semântica no processo de recuperaçãoda informação sem pressionar demais a infra-estrutura computacional, como observado nasimulação executada. Com isso em mente e
sopesando-se os prós e contras de vários modelosde codificação baseados no padrão binário,escolheu-se um padrão simples de correlação entresinais gráficos do idioma inglês e números binários,decisão que teve como princípio norteador tambéma garantia de não colisão (ou ambiguidade) decódigos. Considerando que os índices sintagmáticosconstruídos para representação dos textos contêmapenas as 26 letras do alfabeto inglês mais o espaçoem branco (entre termos), o traço, a apóstrofe e ossinais de interrogação e exclamação, o códigocompleto precisa expressar 31 instâncias derepresentações diferentes de sinais gráficosidiomáticos. Optou-se, em função dessesrequisitos, por uma representação com 5 (cinco)bits por símbolo idiomático da linguagem natural(idioma inglês), que poderia, em um extremo,representar mais um símbolo que os 31 previstos.Ou seja, com cinco bits pode-se representar(mapear) até 32 símbolos diferentes (a figura 2, quemostra uma parte da planilha de codificação bináriaelaborada, ilustra como essa codificação foiimplementada).
Conhecendo-se a amostra de sintagmas deindexação produzidos na fase anterior aoexperimento, observou-se que seria necessária umastring (sequência de caracteres) padrão de nomínimo 30 símbolos léxicos de cinco bits cada,totalizando 150 bits por sintagma nominal. Comisso, um dos mais extensos sintagmas de indexaçãoproduzidos, information-processing devices, poderia terseus 30 símbolos léxicos codificados. Observe-se,no entanto, que em sintagmas mais curtos em bitssignificativos o preenchimento da string de 150 bits,na parte restante, dá-se com séries de bitscodificadas como 11010, que corresponde a umespaço em branco. O termo information architecture,por exemplo, é codificado nesse esquema como:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1601000 01101 00101 01110 10001 01100 00000 10011 01000 01110 01101 11010 00000 10001 00010 00111 I N F O R M A T I O N A R C H
17 18 19 20 21 22 23 24 25 26 27 28 29 3001000 10011 00100 00010 10011 10100 10001 00100 11010 11010 11010 11010 11010 11010 I T E C T U R E
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação
20
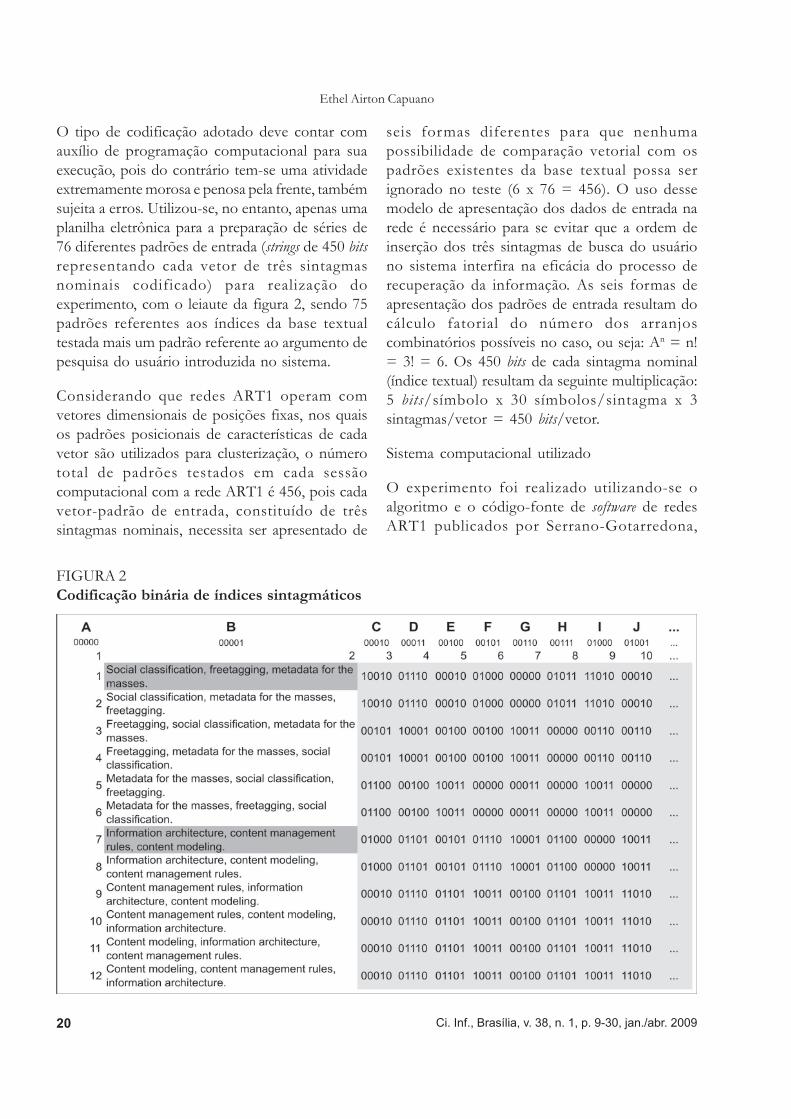
O tipo de codificação adotado deve contar comauxílio de programação computacional para suaexecução, pois do contrário tem-se uma atividadeextremamente morosa e penosa pela frente, tambémsujeita a erros. Utilizou-se, no entanto, apenas umaplanilha eletrônica para a preparação de séries de76 diferentes padrões de entrada (strings de 450 bitsrepresentando cada vetor de três sintagmasnominais codificado) para realização doexperimento, com o leiaute da figura 2, sendo 75padrões referentes aos índices da base textualtestada mais um padrão referente ao argumento depesquisa do usuário introduzida no sistema.
Considerando que redes ART1 operam comvetores dimensionais de posições fixas, nos quaisos padrões posicionais de características de cadavetor são utilizados para clusterização, o númerototal de padrões testados em cada sessãocomputacional com a rede ART1 é 456, pois cadavetor-padrão de entrada, constituído de trêssintagmas nominais, necessita ser apresentado de
FIGURA 2Codificação binária de índices sintagmáticos
seis formas diferentes para que nenhumapossibilidade de comparação vetorial com ospadrões existentes da base textual possa serignorado no teste (6 x 76 = 456). O uso dessemodelo de apresentação dos dados de entrada narede é necessário para se evitar que a ordem deinserção dos três sintagmas de busca do usuáriono sistema interfira na eficácia do processo derecuperação da informação. As seis formas deapresentação dos padrões de entrada resultam docálculo fatorial do número dos arranjoscombinatórios possíveis no caso, ou seja: An = n!= 3! = 6. Os 450 bits de cada sintagma nominal(índice textual) resultam da seguinte multiplicação:5 bits/símbolo x 30 símbolos/sintagma x 3sintagmas/vetor = 450 bits/vetor.
Sistema computacional utilizado
O experimento foi realizado utilizando-se oalgoritmo e o código-fonte de software de redesART1 publicados por Serrano-Gotarredona,
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009

21
Linares-Barranco e Andreou (1998), no modo decodificação complementar (vetores de entrada dedimensão dobrada), com algumas alteraçõesimplementadas por Capuano (2001) paraadequação de interfaces de entrada e saída dedados. Esse tipo de configuração dos padrões deentrada é necessário para se evitar inadequadaproliferação de clusters, como explicado porCarpenter, Grossberg e Rosen (1991) e Carpenteret al. (1992).
A linguagem de programação adotada foiMATLAB, uma linguagem de alto nível muitoutilizada nas engenharias para operações commatrizes, construída sobre bibliotecas de linguagensde programação de nível mais baixo. Omicrocomputador utilizado para processamento darede é um notebook HP Compaq nx9005, commicroprocessador mobile AMD Athlon XP2200+de 1,79 GHz, 1,0 GB de memória RAM, 40 GB dedisco rígido SATA e Sistema OperacionalMicrosoft Windows XP Pro, versão 2002 (ServicePack 2).
Organização dos dados e processamento
Os dados (padrões sintagmáticos) utilizados noexperimento foram organizados de modo arepresentar várias situações de um sistema derecuperação da informação no atendimento deconsultas de usuários. Simulou-se uma série de seisconsultas de usuários que teriam acesso ao sistemapor meio de uma tela de computador, quando omesmo precisaria informar ao sistema apenas osargumentos de busca constituídos por trêssintagmas nominais por consulta, que sugerem oconteúdo pesquisado, com alguma correlaçãosemântica entre si. Como exemplo dessassimulações, um usuário informaria, na tela deentrada dos parâmetros de pesquisa, os sintagmasseguintes (três campos de dados textuais):
[CAMPO 1]: Rich Internet Application[CAMPO 2]: Information Findability[CAMPO 3]: User Needs
Os sintagmas nominais simulados como dados dasseis consultas dos usuários ao sistema sãoapresentados a seguir:
• CONSULTA 1: Semantic Web; InformationRetrieval System; Digital Library;
• CONSULTA 2: Web Design; Vignette;Information Architects;
• CONSULTA 3: Rich Internet Application;Information Findability; User Needs;
• CONSULTA 4: Web Design; User Needs;Faceted Classification;
• CONSULTA 5: Findability; Search Engine;Google;
• CONSULTA 6: Information Findability;Information Architects; User Needs.
Conforme se pode comparar na lista de índicessintagmáticos que compuseram a base deinformações de referência do sistema, algumas dasconsultas (como a 1 e a 5) não deveriam produzirclusters com muito poder semântico em razão dapouca similaridade com os conteúdos da base,enquanto as demais (2, 3 e 4) poderiam se agruparem clusters mais interessantes (poderosos) do pontode vista semântico, com mais de um sintagmacoincidente entre a consulta e a base de dados dosistema. Essa variação dos padrões de consulta foiidealizada propositalmente para se testar os efeitosna rede ART1 do Sistema de Recuperação daInformação simulado. Com a consulta 6, noentanto, testou-se a capacidade de a redereconhecer um argumento de consulta totalmentecoincidente com um índice existente na basetextual.
Como recursos configuráveis de uma rede ART1,os parâmetros de precisão da busca também podemser informados pelo usuário, que poderá optar poruma busca mais genérica ou mais restrita(específica), algo que se implementou noexperimento simulado. Caso opte inicialmente poruma busca mais genérica, o usuário deveráconfigurar o parâmetro de vigilância (ρ) do sistemapara um valor adequado, geralmente entre 0,60 e0,75 (CAPUANO; CHAUKE-NEHME, 2002);
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação

22
caso opte, de imediato, por uma busca maisespecífica, tentando maior precisão, o usuáriodeverá informar um valor mais alto e próximo de1,0 para o parâmetro de vigilância (entre 0,75 e0,85). O parâmetro L da rede neural deverá serconfigurado pelos próprios administradores doaplicativo, pois sua melhor opção somente poderáser avaliada com testes na base de dados, algopouco recomendável para um ambientecomputacional on-line.
As dimensões do vetor de dados binários (n) e onúmero de padrões de entrada (np) a seremsubmetidos para processamento são parâmetros dopróprio sistema e deverão ser configurados peloadministrador do sistema de recuperação dainformação. O parâmetro np se relaciona com opróprio tamanho da base textual, sem limite teóricode quantidade de índices armazenados.
O esquema lógico de entradas, processamento esaídas desse sistema simulado com redes ART1 éesboçado na figura 3.
FIGURA 3Esquema lógico do SRI simulado
Resultados
O experimento simulado de um sistema derecuperação da informação baseado em redesneurais artificiais modelo ART1, com dados deentrada binários representando índices textuaiscompostos por sintagmas nominais, produziuresultados interessantes para a ampliação doconhecimento sobre esse tipo de tecnologia e seuuso potencial para desenvolvimento de soluçõespara o problema da semântica na recuperação dainformação. As tabelas 1 e 2, a seguir, mostram osresultados do processamento das seis consultas deusuários simuladas e seu significado em termos deutilidade no contexto. Os parâmetros ou argumen-tos de consulta (busca) do usuário aparecem nobloco de colunas à esquerda nas tabelas intituladoParâmetros de Consulta do Usuário Simulado, e osresultados da busca, no bloco da direita.
O usuário deve introduzir, nas interfaces do sistemasimulado, os sintagmas em linguagem natural(idioma inglês, no caso) que representam osconteúdos de interesse na busca textual e o
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009

23
parâmetro de vigilância da rede ART1 ρ, que regulao nível de generalização das respostas do sistema.Esse parâmetro necessitaria ser traduzido para umtermo mais próximo do senso comum, para queum usuário leigo nesse tipo de tecnologia possautilizar, conscientemente, o recurso de calibragemdo sistema – por exemplo, CAMPO 1: ConsultaAmpla e CAMPO 2: Consulta Restrita, onde oprimeiro nível de generalização da consultaimplicaria a parametrização de ρ com valores [0,6;0,65; 0,70] e o segundo nível com valores [0,75;0,80; 0,85].
O bloco Resultados mostra que o sistema devolve(i) um dado denominado npa, que corresponde aonúmero de clusters formados pela rede ART1, (ii)os números de identificação sequencial dos clustersformados que contenham, ainda que parcialmente,os sintagmas de busca introduzidos pelo usuário,(iii) os índices de textos da base (ou componentes)que foram considerados similares no respectivocluster enumerado e (iv) os textos, em linguagemnatural, dos próprios índices de textos recuperadospelo sistema, para que o usuário possa avaliar suautilidade no contexto. Certamente, desses dadosde saída, apenas os índices em linguagem naturalseriam mostrados ao usuário na tela do computador.
Análise da Consulta 1
Como se pode observar na tabela 1, a seguir, ossintagmas nominais introduzidos pelo usuáriosimulado na primeira consulta são os seguintes:Semantic Web; Information Retrieval System;Digital Library. Com o parâmetro de vigilância(ou de generalização) da sessão de busca ρ = 0,60,o usuário obteria como resultado um texto tendocomo índice sintagmático4 Wireframing;Customer Expectation; Web Development.Esse texto se encontraria indexado na base textualcom o número 449. O único fragmento de sintagma
que indica alguma similaridade entre o argumentode busca e o resultado, nesta sessão, é o termo Web(destacado na coluna Índices Sintagmáticos Recuperadosda tabela 1, a seguir). Os conteúdos semânticosdos demais sintagmas, ou fragmentos (termos) desintagmas, teriam de ser avaliados pelo usuário paraconcluir sobre sua utilidade.
Quando a rede ART1 executa a sessão declusterização, nessa mesma consulta, com oparâmetro de configuração ρ = 0,65, os resultadossão ampliados em números de textos recuperados,obtendo o usuário, como resposta do sistema, trêstextos recuperados com os seguintes índicessintagmáticos: IA Practices; InformationArchitects; Local IA Groups (número 426 na basetextual), Wireframe; Information Architect; IACommunity (número 427) e Consistency andIndexing; Information Retrieval; InformationArchitecture (número 436). Como destacado natabela 1, o termo Information e o sintagmanominal Information Retrieval é quecaracterizaram a similaridade sintática vetorial entreos argumentos de consulta e os índices textuais dereferência produzidos pela rede nesta sessão.
Observa-se, com o uso do parâmetro de vigilânciaρ = 0,65, um aumento do poder semântico dosíndices textuais referenciados resultantes da busca,pois Information Retrieval apresenta maior poder deesclarecimento semântico do texto referenciado doque simplesmente Information ou Web. Com ρ = 0,70a busca não melhorou em termos de resultados,retornando apenas o termo Information; poralgum motivo, a rede ART1, ao tentar especializarum pouco mais a clusterização, apresentou umresultado teoricamente pior que com ρ = 0,65.Como explicação para o caso, pode-se especularque nesta sessão os índices semanticamente maisbem obtidos na sessão anterior foram agregados aoutros clusters formados pela rede, concluindo-seque talvez o processamento de várias sessões com-putacionais, cada uma com um valor de ρ diferente,ampliando-se o conjunto dos sintagmas nominaisresultantes mediante a composição dos resultadosdas várias sessões, seja a solução mais adequadapara se evitarem problemas dessa natureza.
4 O sintagma apresentado na tabela é a variante original que serviucomo índice do texto na base e não, necessariamente, o sintagmavariante agregado ao cluster pela rede ART1. Como em ambos oscasos refere-se ao mesmo índice sintagmático, não há problema emse apresentarem os resultados dessa forma.
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação

24
TABELA 1Informações recuperadas nas consultas 1, 2 e 3
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009

25
Com valores de ρ mais altos, o sistema nãoproduziu nenhum resultado, pois a rede ART1 nãoencontrou padrões similares para clusterização depadrões de entrada e padrões da base textual nessesníveis de especialização maiores. Decerto, quandosubmetida a uma base de índices maior, commilhares ou dezenas de milhares de índices, umarede ART1 poderia encontrar mais padrõessimilares aos de entrada, com menor probabilidadede resultado nulo em uma consulta.
Análise da Consulta 2
Com os sintagmas nominais de busca Web Design,Vignette e Information Architects, o usuáriosimulado comandou a segunda consulta ao sistemaexperimental. Os três sintagmas nominaisintroduzidos no sistema nesta consulta apresentammaior similaridade com índices sintagmáticos dabase, esperando-se, portanto, resultados melhoresque no caso da consulta anterior.
A rede ART1 com ρ = 0,70 produziu comoresultados os seguintes índices sintagmáticos detextos: Information Architecture; CreativeDesign; Design Insights (177), InformationArchitects; Skills; Experience (197), DigitalLibrary; Museum; Collections (401), IAPractices; Information Architects; Local IAGroups (426), Wireframe; InformationArchitect; IA Community (432), Consistencyand Indexing; Information Retrieval;Information Architecture (437). O sintagmanominal Information Architects revelou-sepredominante como padrão de entrada,encontrando vários índices similares em váriosclusters formados pela rede. Os resultadosapresentados pelo sistema simulado possibilitamao usuário decidir se o conteúdo semântico quemais se aproxima de suas necessidades se encontraem um ou outro texto referenciado, ou se váriosdeles lhe serão úteis. Exemplos: (i) o usuário poderádecidir pela recuperação do texto com índicecomposto pelos sintagmas Information Architects,Skills, Experience, se o seu contexto de interesse foro que relaciona os profissionais Arquitetos da
Informação às habilidades (skills) e experiênciasdessa ocupação; ou (ii) decidir pela recuperaçãodos textos com índices IA Practices, InformationArchitects, Local IA Groups e Wireframe, InformationArchitect, IA Community, caso o interesse seja maispelo estudo de aspectos sociotécnicos da profissãode Arquiteto da Informação.
Os demais textos referenciados também poderãoser úteis, caso o usuário entenda que textosindexados com, inclusive, o sintagma InformationArchitecture apresentem possíveis conteúdos de seuinteresse no contexto, tais como Creative Design eDesign Insights, que aparecem no primeiro textorecuperado (mas que não contêm o sintagmaInformation Architects como índice).
Com esse tipo de consulta, demonstra-se que redesART1 também podem reconhecer, em uma basede dados textual referenciada, padrões próximosaos padrões de entrada, conferindo-lhe algunsrecursos (ainda que limitados) de processamentode linguagem natural conhecidos como lematização(redução de um termo flexionado a um termo maisprimitivo).
Os resultados dessa consulta com parâmetros ρ =0,75 e ρ = 0,80 se mostraram melhores ainda,quando o sistema recuperou referênciassemanticamente mais completas de textos da base.Com ρ = 0,75 o sistema recuperou os textosindexados com os sintagmas Web Design, SharedReferences, Information Architects (77), WebDesign, User Needs, Product Information (83),Information Findability, InformationArchitects, User Needs (96), InformationArchitects, Skills, Experience (195), EnterpriseWebsites, Intranets, Information Architects(224), IA Practices, Information Architects,Local IA Groups (424) e Wireframe,Information Architect, IA Community (429).Ou seja, além de ampliar o conteúdo semânticodos índices de textos recuperados apresentandoitens com mais de um sintagma ou termoidentificado com a consulta, a rede ART1 formouum conjunto de índices novos que incluiu também
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação

26
os obtidos na consulta na sessão anterior com ρ =0,70, demonstrando seu poder de clusterização comvários níveis de generalização taxonômica. A sessãode consulta com ρ = 0,80 especializou os conteúdosrecuperados, concentrando-se em apenas doistextos apresentados em sessões anteriores.
O texto recuperado que melhor deverá atender,teoricamente, às necessidades do usuário simulado,conforme os resultados desta consulta, é o de índicenúmero 77, coincidindo com o argumento daconsulta em dois dos três sintagmas do modelo deindexação: Web Design e Information Architects.
Análise das consultas 3, 4, 5 e 6
Os resultados das consultas 3, 4, 5 e 6(tabelas 1 e 2) apresentaram-se como nas consultasanteriores, demonstrando a capacidade de redesneurais artificiais ART1 na recuperação de padrõestextuais indexados e codificados com padrão derepresentação binária. Observou-se que os vetoresmais completos em termos de símbolossignificantes (padrões binários que representamtermos e não espaços em branco) produziram clustersa partir de valores de ρ mais baixos (0,65 nos casosdas consultas 3, 4 e 6), ao passo que o vetor maiscurto em termos de bits significantes (consulta 5)produziu um cluster útil somente com valor de ρbem mais alto (0,80, no caso). Como consequênciadessa inferência e com os resultados das sessõesde busca na consulta 4, por exemplo, resta evidenteque, com valores de ρ mais baixos, redes ART1podem reconhecer termos (ou fragmentos) desintagmas e com valores mais altos podemreconhecer sintagmas completos, como nos índicesYahoo, User Needs, Faceted Browse System e WebDesign, User Needs, Product Information.
A rede também reconhece, com precisão, padrõesde índices completos como o da consulta 6, na qualpropositalmente se realizou uma consulta de índiceexistente na base textual in totum, ou seja, um índicecom os três sintagmas idênticos à busca.
Revocação e precisão
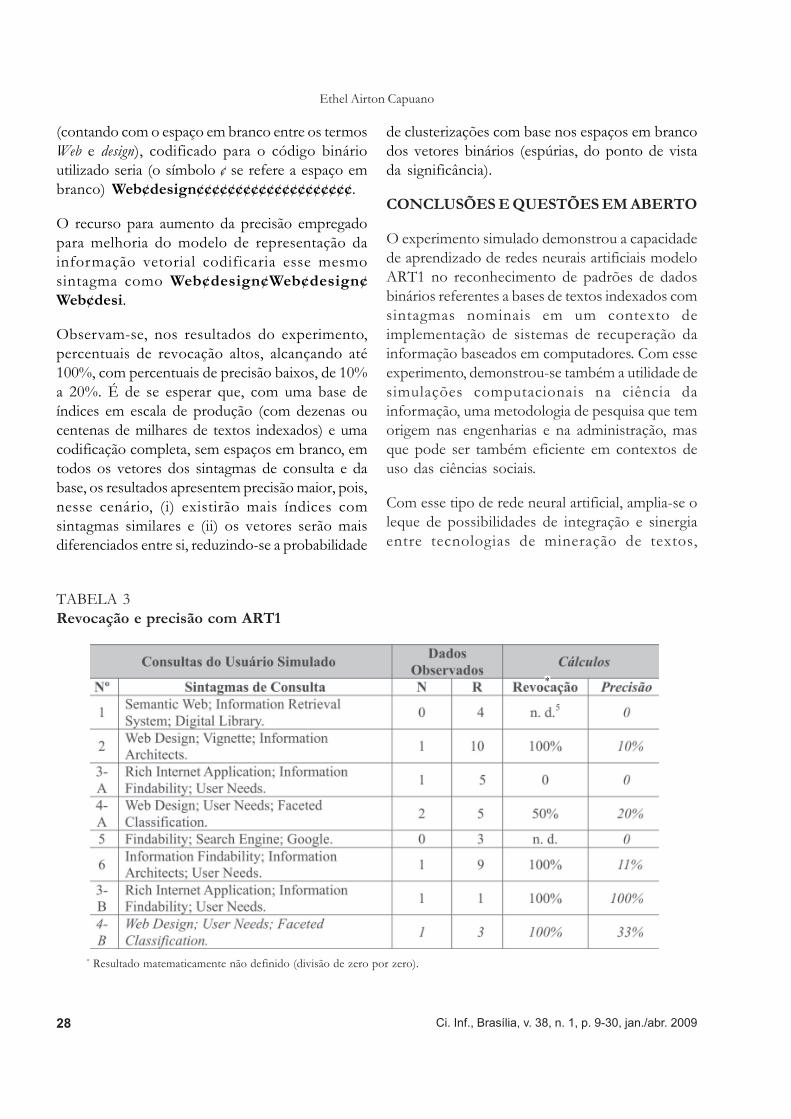
Define-se revocação como uma métrica de conjuntosque mostra a relação entre o número de documentos(ou registros) relevantes recuperados e o númerode documentos relevantes existentes na base ourepositório de informação. E precisão como a relaçãoentre o número de documentos relevantesrecuperados e o número total de documentosrecuperados. Os resultados do experimentoanotados segundo essas duas métricas sãoapresentados na tabela 3, a seguir.
É importante observar-se que em buscas comsintagmas nas quais a rede reconhece padrões poraproximação na forma vetorial, como é o caso deART1, a revocação é bem maior que a precisão,algo que, do ponto de vista de uma solução parabusca textual semântica, é natural. Observe-se,conforme os dados da tabela 3, que quanto maioro parâmetro de vigilância ρ, melhor o resultado emtermos de precisão e menor o resultado darevocação, tornando a busca mais específica.
O critério de cálculo de revocação e precisãoadotado no experimento assume que apenas osíndices recuperados da base textual com dois oumais sintagmas nominais coincidentes com ossintagmas da consulta serão considerados, emtermos de relevância (variável N na tabela 3), parauso nas fórmulas matemáticas de cálculo derevocação e precisão (R corresponde ao númerode documentos recuperados pela rede):
Revocação: | N ∩∩∩∩∩ R | / | N | ePrecisão: | N ∩∩∩∩∩ R | / | R |
As consultas 3-B e 4-B, na tabela 3, referem-se aosmesmos sintagmas das consultas 3-A e 4-A, mascom os espaços em branco para completar otamanho do vetor (30 símbolos de 5 bits cada, ou150 bits), tanto no padrão de entrada como norespectivo índice da base textual, preenchidos comos símbolos léxicos, mapeados para o códigobinário, dos mesmos sintagmas. O sintagma Webdesign, de apenas 10 símbolos significantes
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009

27
TABELA 2Informações recuperadas nas consultas 4, 5 e 6
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação
28
(contando com o espaço em branco entre os termosWeb e design), codificado para o código binárioutilizado seria (o símbolo ¢ se refere a espaço embranco) Web¢design¢¢¢¢¢¢¢¢¢¢¢¢¢¢¢¢¢¢¢¢.
O recurso para aumento da precisão empregadopara melhoria do modelo de representação dainformação vetorial codificaria esse mesmosintagma como Web¢design¢Web¢design¢Web¢desi.
Observam-se, nos resultados do experimento,percentuais de revocação altos, alcançando até100%, com percentuais de precisão baixos, de 10%a 20%. É de se esperar que, com uma base deíndices em escala de produção (com dezenas oucentenas de milhares de textos indexados) e umacodificação completa, sem espaços em branco, emtodos os vetores dos sintagmas de consulta e dabase, os resultados apresentem precisão maior, pois,nesse cenário, (i) existirão mais índices comsintagmas similares e (ii) os vetores serão maisdiferenciados entre si, reduzindo-se a probabilidade
TABELA 3Revocação e precisão com ART1
de clusterizações com base nos espaços em brancodos vetores binários (espúrias, do ponto de vistada significância).
CONCLUSÕES E QUESTÕES EM ABERTO
O experimento simulado demonstrou a capacidadede aprendizado de redes neurais artificiais modeloART1 no reconhecimento de padrões de dadosbinários referentes a bases de textos indexados comsintagmas nominais em um contexto deimplementação de sistemas de recuperação dainformação baseados em computadores. Com esseexperimento, demonstrou-se também a utilidade desimulações computacionais na ciência dainformação, uma metodologia de pesquisa que temorigem nas engenharias e na administração, masque pode ser também eficiente em contextos deuso das ciências sociais.
Com esse tipo de rede neural artificial, amplia-se oleque de possibilidades de integração e sinergiaentre tecnologias de mineração de textos,
* Resultado matematicamente não definido (divisão de zero por zero).
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
*

29
recuperação da informação e processamento dalinguagem natural. As redes ART1, fundamentadasna Teoria da Ressonância Adaptativa, apresentampropriedades que são características funcionaisúteis na construção de um sistema de recuperaçãoda informação, tais como aprendizado nãosupervisionado, controle do grau de generalizaçãodos conteúdos dos clusters, autoescalabilidade,autoestabilização com pequeno número deiterações computacionais, aprendizado on-line,captura de eventos raros, acesso direto a padrõesde entrada similares, acesso direto a subconjuntose padrões de subconjuntos e enviesamento da redepara formação de novas categorias. O aprendizadonão supervisionado é essencial nesse tipo deimplementação e talvez seja sua propriedade maisimportante, dispensando a necessidade de qualquerinteração do usuário com o sistema que não seja ainclusão dos argumentos (sintagmas nominais) debusca em linguagem natural e do nível degeneralização de conteúdos pretendido. Outrapropriedade bastante útil em contextos de sistemasde recuperação da informação é a capacidade deaprendizado on-line das redes ART1, podendo criarnovos padrões ou classificar padrões de entradaem padrões conhecidos (aprendidos anteriormente)sem necessidade de nova etapa de aprendizadoprévio com processamento off-line (batch).
Outra característica de redes ART1 observada emCapuano (2001) e confirmada no experimentoapresentado neste artigo é o reduzido número deiterações de seu algoritmo computacional(geralmente em torno de duas iterações), quepropicia um tempo de resposta relativamentereduzido (no pior caso, com valores de ρ mais altos,a rede consumiu apenas 45 segundos noprocessamento dos dados). Os experimentosanteriores com redes ART1 sugerem que esse tipode tecnologia de processamento paralelo é bastanteescalável, sendo mais sensível, em termos dedesempenho computacional, a operações declusterização mais específicas (com valores de ρmais próximos de 1,0) do que ao aumento donúmero de registros (vetores) na base de dados.
Embora não constitua um item de prova deconceito de uma grande implementação de sistemade recuperação da informação, os tempos derespostas parecem menores que os tempos deresposta observados em redes neurais com outrasarquiteturas, especialmente os modelos maispopulares conhecidos como backpropagation. Coma contínua redução histórica dos custos de hardwarecomputacional previstos na Lei de Moore, é de seesperar que sistemas de recuperação da informaçãocom esse tipo de tecnologia de rede neural setornem economicamente viáveis e possam serimplementados corporativamente, no modo deaprendizado on-line, possibilitando o acesso demilhares de usuários simultâneos.
Os possíveis esquemas de codificação binária,embora eficazes, podem se tornar mais eficientesà medida que os padrões vetoriais possam serrepresentados de modo mais discriminatório, semlacunas que necessitem de preenchimento comfragmentos de strings de bits comuns (como osespaços em branco após o término da partesignificativa dos padrões binários, por exemplo).
O modelo de representação da informação adotadono experimento revelou-se adequado paraatendimento dos requisitos enunciados em(MEADOW et al., 2007, p. 64): (i) capacidade dediscriminação entre padrões, (ii) capacidade deidentificação de similaridades entre padrões, (iii)acurácia e (iv) capacidade de redução deambiguidades. Entretanto, algumas questõespermanecem em aberto para estudos e pesquisasem torno de soluções mais otimizadas para oproblema da recuperação da informação textualcom agregação de conteúdos semânticos.A mineração de textos, com metodologias etecnologias par excellence nesse tipo de missãocomputacional, envolve modelos de representaçãoda linguagem natural que necessitam deaperfeiçoamentos, como sugerido na análise críticado presente experimento.
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009
O poder cognitivo das redes neurais artificiais modelo ART1 na recuperação da informação
Artigo submetido em 07/12/2008 e aceito em 08/04/2009.

30
REFERÊNCIAS
BIGUS, Joseph P. Data mining with neural networks: solving businessproblems from application development to decision support. [SãoPaulo]: McGraw-Hill, 1996.
CAPUANO, Ethel Airton. Mineração de dados com redes neurais não-supervisionadas modelo ART: parâmetros e aplicações. 2001.Dissertação (Mestrado) - Universidade Católica de Brasília, Brasília,2001.
_________; CHAUKE-NEHME, C. Exploring the parameter spaceof unsupervised ART neural networks for data mining. In:INTERNATIONAL CONFERENCE ON DATA MINING, 3.,2002. Proceedings… Southampton: WIT Press, 2002. p. 461-472.
CARPENTER, G. A. et al. Fuzzy-ARTMAP: a neural networkarchitecture for incremental supervised learning of analogmuldimensional maps. IEEE Transactions on Neural Networks, n. 3,p. 698-713, 1992.
_________; GROSSBERG, S.; ROSEN, D. B. Fuzzy ART: faststable learning and categorization of analog patterns by an adaptiveresonance system. Neural Networks, n. 4, p. 759-771, 1991.
_________. The ART of adaptive pattern recognition by a self-organizing neural network. IEEE, Mar. 1988.
CHAUKE-NEHME, Cláudio. Foreword. In: PRADO, HérculesAntonio do; FERNEDA, Edilson (Org.). Emerging technologies oftext mining: techniques and applications. Hershey: InformationScience Reference, 2008. p. 11.
_________. Modelo neurocomputacional de elementos centralizadores cominterações laterais aplicado ao reconhecimento de padrões temporais. 1996.Tese (Doutorado)- Universidade Federal do Rio de Janeiro, Rio deJaneiro, 1996.
FERNEDA, Edberto. Redes neurais e sua aplicação em sistemas derecuperação de informação. Ciência da Informação, Brasília, v. 35, n.1, p. 25-30, jan./abr. 2006.
FREEDMAN, David H. Los hacedores de cérebros: cómo loscientíficos están perfeccionando las computadoras, creando umrival del cerebro humano. [S. l.]: Andres Bello, 1995.
FREEMAN, James A.; SKAPURA, David M. Redes neuronales:algoritmos, aplicaciones y técnicas de programación. Wilmington,USA: Addison-Wesley Iberoamericana, 1993.
GOTTSCHALG-DUQUE, Cláudio. SiRILiCO: uma proposta paraum sistema de recuperação de informação baseado em teorias dalinguística computacional e ontologia. 2005. Tese (Doutorado)-Escola de Ciência da Informação da Universidade Federal de MinasGerais, Belo Horizonte, 2005.
GROSSBERG, Stephen. Non-linear neural networks: principles,mechanisms, and architectures. Neural Networks, v. 1, 1988.
KENT, A. et al. Machine literature searching VII: operationalcriteria for designing information retrieval systems. AmericanDocumentation, v. 6, n. 2, p. 93-101, 1955.
KONCHADY, Manu. Text mining application programming. Boston:Charles River Media, 2006.
MEADOW, Charles T. et al. Text information retrieval systems. 3rd ed.[S. l.]: Elsevier, 2007.
PENTEADO, Roberto; BOUTIN, Eric. Creating strategicinformation for organizations with structured text. In: PRADO,Hércules Antonio do; FERNEDA, Edilson (Org.). Emergingtechnologies of text mining: techniques and applications. Hershey:Information Science Reference, 2008. p. 34-53.
PIDD, Michael. Computer simulation in management science. 2nd ed.[S. l.]: John Wiley & Sons, 1988.
PRADO, Hércules Antonio do; FERNEDA, Edilson (Org.).Emerging technologies of text mining: techniques and applications.Hershey: Information Science Reference, 2008.
SERRANO-GOTARREDONA, Teresa; LINARES-BARRANCO,Bernabé; ANDREOU, Andreas G. Adaptive resonance theory microchips:circuit design techniques. Boston: Kluwer Academic, 1998.
TSURUOKA, Yoshimasa. et al. Learning string similarity measuresfor gene/protein name dictionary look-up using logistic regression.Bioinformatics Advance Access, p. 1-6, 12 ago. 2007.
YU, Lean; WANG, Shouyang; LAI, Kin Keung. A multi-agentneural network system for web text mining. In: PRADO, HérculesAntonio do; FERNEDA, Edilson (Org.). Emerging technologies oftext mining: techniques and applications. Hershey: InformationScience Reference, 2008. p. 162-183.
Ethel Airton Capuano
Ci. Inf., Brasília, v. 38, n. 1, p. 9-30, jan./abr. 2009





























